unlock-apuntes identificación 5ed(julio2014)
DESCRIPTION
Un sistema puede ser definido como un objeto o una colección de objetos cuyas propiedades queremos estudiar. Ejemplos de sistemas son por ejemplo, el sistema solar, una planta fabricadora de papel, un circuito RC (Resistencia-Condensador),..., etc.TRANSCRIPT
APUNTES DE
IDENTIFICACIÓN DE SISTEMAS
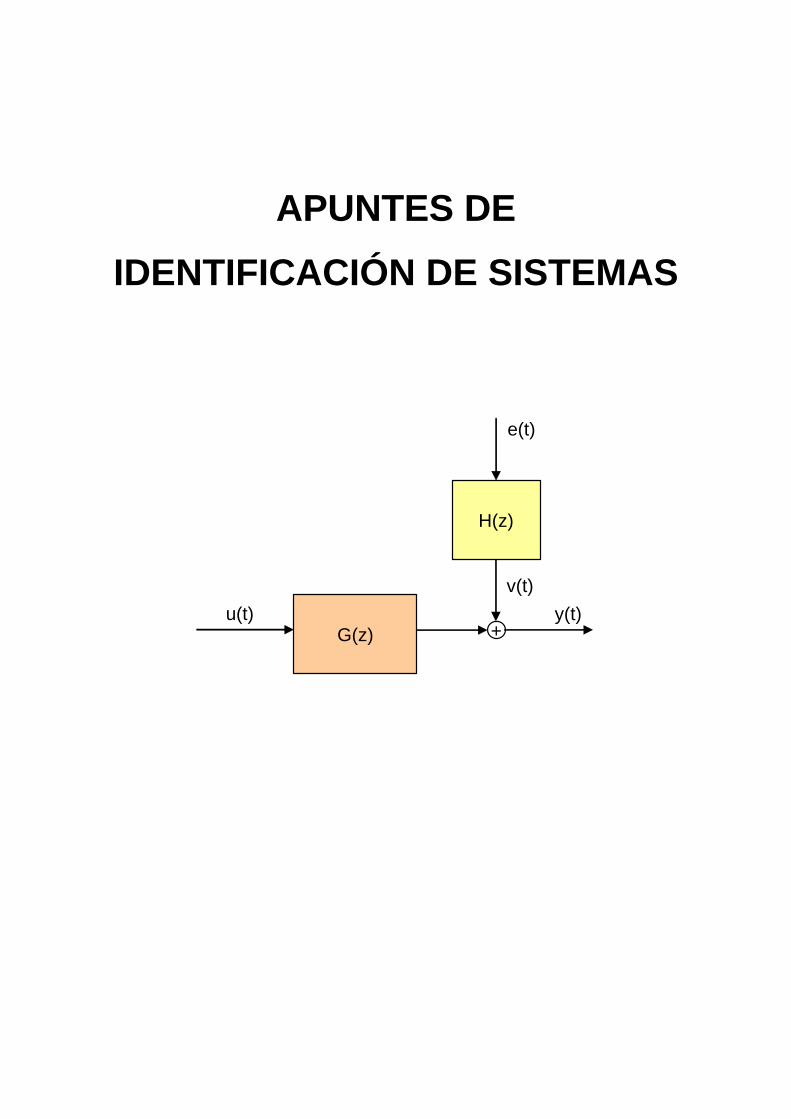
G(z)u(t)
v(t)
y(t)+
H(z)
e(t)

ÍNDICE
TEMA 1: MODELOS DE SISTEMAS CONTINUOS Y DISCRETOS
1.1 INTRODUCCIÓN ............................................................................................................ 1-1
1.2 MODELADO DE SISTEMAS CONTINUOS .................................................................... 1-3
1.2.1 Ecuaciones diferenciales ......................................................................................... 1-3
1.2.2 Modelo en el espacio de estados ............................................................................ 1-5
1.2.3 Función de transferencia ....................................................................................... 1-11
1.3 MODELADO DE SISTEMAS DISCRETOS ................................................................... 1-16
1.3.1 Secuencias ............................................................................................................ 1-16
1.3.2 La transformada Z de una secuencia .................................................................... 1-18
1.3.3 Ecuaciones en diferencias ..................................................................................... 1-21
1.3.4 Modelo en el espacio de estados .......................................................................... 1-24
1.3.5 Función de transferencia ....................................................................................... 1-24
1.4 CONSIDERACIONES BÁSICAS SOBRE LA RESPUESTA TEMPORAL Y
FRECUENCIAL DE UN SISTEMA LINEAL ................................................................... 1-25
1.4.1 Sistemas de primer orden ...................................................................................... 1-25
1.4.2 Integrador .............................................................................................................. 1-30
1.4.3 Efecto de un cero en la respuesta temporal de un sistema de primer orden ........ 1-31
1.4.4 Respuesta temporal de un sistema de segundo orden ......................................... 1-33
1.4.5 Efecto de un cero en la respuesta temporal de un sistema de segundo orden..... 1-37
1.4.6 Respuesta temporal de un sistema lineal con ganancia negativa ......................... 1-40
1.4.7 Respuesta temporal de un sistema lineal con ceros en el semiplano derecho ..... 1-41
1.4.8 Respuesta temporal de un sistema lineal con retardo........................................... 1-42
1.4.9 Especificaciones de la respuesta temporal de un sistema lineal .......................... 1-44
1.5 CONSIDERACIONES BÁSICAS SOBRE LA RESPUESTA FRECUENCIAL DE UN
SISTEMA LINEAL ......................................................................................................... 1-46
1.5.1 Definición de respuesta en frecuencia de un sistema lineal .................................. 1-46
1.5.2 Representación gráfica de la respuesta en frecuencia de un sistema .................. 1-48
1.5.3 Respuesta frecuencial de un sistema lineal genérico continuo ............................. 1-51
1.5.4 Respuesta frecuencial de una constante .............................................................. 1-52
1.5.5 Respuesta frecuencial de un integrador ................................................................ 1-52

Indice
1.5.6 Respuesta frecuencial de un derivador ................................................................. 1-54
1.5.7 Respuesta frecuencial de un elemento de retardo ................................................ 1-55
1.5.8 Respuesta frecuencial de un polo real: sistema de primer orden.......................... 1-56
1.5.9 Respuesta frecuencial de un cero real .................................................................. 1-57
1.5.10 Respuesta frecuencial de un par de polos complejos conjugados: sistema de
segundo orden .................................................................................................... 1-58
1.5.11 Respuesta frecuencial de un par de ceros complejos conjugados ..................... 1-61
1.5.12 Efecto de un cero en la respuesta frecuencial de un sistema de primer orden ... 1-62
1.5.13 Efecto de un cero en la respuesta frecuencial de un sistema de segundo orden1-63
BIBLIOGRAFÍA ................................................................................................................... 1-64
TEMA 2: MODELOS DE PERTURBACIONES
2.1 INTRODUCCIÓN ............................................................................................................ 2-1
2.2 CARÁCTER DE LAS PERTURBACIONES ..................................................................... 2-3
2.3 REDUCCION DE LOS EFECTOS DE LAS PERTURBACIONES .................................. 2-4
2.3.1 Reducción en la fuente ............................................................................................ 2-4
2.3.2 Reducción mediante realimentación local ............................................................... 2-4
2.3.3 Reducción mediante feedforward ............................................................................ 2-5
2.3.4 Reducción mediante predicción .............................................................................. 2-6
2.4 MODELOS DETERMINISTAS DE LAS PERTURBACIONES ........................................ 2-6
2.5 CONCEPTOS BÁSICOS DE LA TEORÍA DE PROCESOS ESTOCÁSTICOS ............... 2-8
2.5.1 Variables aleatorias ................................................................................................. 2-8
2.5.2 Procesos estocásticos ........................................................................................... 2-14
2.6 MODELOS DE PROCESOS ESTOCÁSTICOS ............................................................ 2-24
2.6.1 Ruido blanco .......................................................................................................... 2-24
2.6.2 Procesos AR .......................................................................................................... 2-27
2.6.3 Procesos MA ......................................................................................................... 2-32
2.6.4 Procesos ARMA .................................................................................................... 2-34
2.6.5 Procesos ARIMA ................................................................................................... 2-36
2.6.6 Identificación del tipo de modelo estocástico a utilizar a partir de una serie
temporal ............................................................................................................... 2-39
2.7 FILTRADO DE PROCESOS ESTOCÁSTICOS ESTACIONARIOS .............................. 2-48
BIBLIOGRAFÍA ................................................................................................................... 2-51

Indice
TEMA 3: CONSIDERACIONES GENERALES SOBRE LA IDENTIFICACIÓN DE
SISTEMAS
3.1 INTRODUCCIÓN ............................................................................................................ 3-1
3.2 PROCEDIMIENTO GENERAL DE IDENTIFICACIÓN DE SISTEMAS ........................... 3-3
3.3 HERRAMIENTAS SOFTWARE PARA IDENTIFICACIÓN DE SISTEMAS ..................... 3-6
3.3.1 SITB, la toolbox para identificación de sistemas de MATLAB ................................. 3-6
3.3.2 ITSIE, una herramienta interactiva para la enseñanza de la identificación de
sistemas .................................................................................................................. 3-9
BIBLIOGRAFÍA ................................................................................................................... 3-12
TEMA 4: DISEÑO DE EXPERIMENTOS Y TRATAMIENTO DE DATOS
4.1 INTRODUCCIÓN ............................................................................................................ 4-1
4.2 CONSIDERACIONES GENERALES SOBRE LA ELECCIÓN DE LA SEÑAL DE
ENTRADA ............................................................................................................................. 4-2
4.2.1 Excitación persistente .............................................................................................. 4-2
4.2.2 Características deseables en teoría para la entrada ............................................... 4-2
4.2.3 Características deseables en la práctica para la entrada: entradas “amigables” con
la planta. .................................................................................................................. 4-4
4.2.4 Índices para establecer el grado de amigabilidad de una entrada. ......................... 4-5
4.3 TIPOS DE SEÑALES DE ENTRADA .............................................................................. 4-7
4.3.1 Señal escalón .......................................................................................................... 4-7
4.3.2 Señal pulso simple .................................................................................................. 4-8
4.3.3 Señal pulso doble .................................................................................................. 4-10
4.3.4 Ruido blanco .......................................................................................................... 4-11
4.3.5 Señal binaria aleatoria (RBS) ................................................................................ 4-12
4.3.6 Señal binaria psedoaleatoria (PRBS) .................................................................... 4-14
4.3.7 Señal multiseno ..................................................................................................... 4-18
4.3.8 Conclusiones ......................................................................................................... 4-24
4.4 ELECCIÓN DEL PERIODO DE MUESTREO ............................................................... 4-24
4.5 TRATAMIENTO DE LOS DATOS ................................................................................. 4-27
4.5.1 Filtrado de las señales ........................................................................................... 4-28
4.5.2 Eliminación de valores medios .............................................................................. 4-31
4.5.3 Detección de outliers ............................................................................................. 4-33
BIBLIOGRAFÍA ................................................................................................................... 4-34

Indice
TEMA 5: IDENTIFICACIÓN DE MODELOS NO PARAMÉTRICOS
5.1 INTRODUCCIÓN ............................................................................................................ 5-1
5.2 ANÁLISIS DEL TRANSITORIO ....................................................................................... 5-4
5.3 ANÁLISIS DE CORRELACIÓN ....................................................................................... 5-6
5.4 ANALISIS DE FRECUENCIA ........................................................................................ 5-11
5.5 ANÁLISIS DE FOURIER ............................................................................................... 5-13
5.6 ANALISIS ESPECTRAL ................................................................................................ 5-16
5.6.1 Periodograma ........................................................................................................ 5-16
5.6.2 Periodograma promedio: Método de Welch .......................................................... 5-19
5.6.3 Suavizado del periodograma: El método de Blackman - Tukey ............................ 5-19
5.6.4 Estimación de la densidad espectral cruzada ....................................................... 5-23
5.6.5 Estima de la función de frecuencia usando análisis espectral .............................. 5-24
5.6.6 Resumen de las características básicas del análisis espectral ............................. 5-28
BIBLIOGRAFÍA ................................................................................................................... 5-28
TEMA 6: IDENTIFICACIÓN DE MODELOS PARAMÉTRICOS DISCRETOS
6.1 INTRODUCCIÓN ............................................................................................................ 6-1
6.2 MODELOS PARAMÉTRICOS BASADOS EN EL ERROR DE PREDICCIÓN ................ 6-2
6.2.1 Definición ................................................................................................................. 6-2
6.2.2 Tipos de modelos PEM ............................................................................................ 6-4
6.3 ESTIMACIÓN DE LOS PARÁMETROS DE UN MODELO PEM .................................... 6-8
6.3.1 Planteamiento general del problema ....................................................................... 6-8
6.3.2 Cálculo de la estima cuando el modelo PEM se puede expresar como una regresión
lineal ...................................................................................................................... 6-10
6.3.3 Cálculo de la estima cuando el modelo PEM no se puede expresar como una
regresión lineal ...................................................................................................... 6-14
6.4 PROPIEDADES DEL MODELO PEM ESTIMADO ....................................................... 6-16
6.4.1 Calidad del modelo ................................................................................................ 6-16
6.4.2 Errores existentes en un modelo ........................................................................... 6-16
6.4.3 Error de sesgo ....................................................................................................... 6-17
6.4.4 Error de varianza ................................................................................................... 6-22
6.4.5 Compromiso entre el error de sesgo y el error de varianza .................................. 6-25
6.5 CONSIDERACIONES SOBRE LA ELECCIÓN DEL TIPO Y LA ESTRUCTURA DEL
MODELO PEM ............................................................................................................. 6-27
6.5.1 Elección del tipo de modelo ................................................................................... 6-27

Indice
6.5.2 Elección de la estructura del modelo ..................................................................... 6-28
6.6 VALIDACIÓN DEL MODELO ESTIMADO .................................................................... 6-32
6.6.1 Verificación del comportamiento de entrada-salida ............................................... 6-37
6.6.2 Análisis de los residuos ......................................................................................... 6-34
6.7 REDUCCIÓN DEL MODELO ........................................................................................ 6-37
6.8 ALGUNAS DIRECTRICES PARA OBTENER EL MODELO PEM MAS APROPIADO . 6-38
BIBLIOGRAFÍA ................................................................................................................... 6-39
TEMA 7: IDENTIFICACIÓN DE MODELOS PARAMÉTRICOS CONTINUOS
7.1 INTRODUCCIÓN ............................................................................................................ 7-1
7.2 OBTENCIÓN A PARTIR DE LA TRANSFORMACIÓN DEL MODELO DISCRETO
IDENTIFICADO .............................................................................................................. 7-1
7.3 ESTIMACIÓN A PARTIR DE DATOS DE ENTRADA-SALIDA TEMPORALES .............. 7-7
7.4 ESTIMACIÓN A PARTIR DE DATOS EN EL DOMINIO DE LA FRECUENCIA ........... 7-11
7.4.1 Estimación a partir de las transformadas de Fourier de la entrada y de la salida. 7-11
7.4.2 Estimación a partir de datos obtenidos del análisis en frecuencia. ....................... 7-12
BIBLIOGRAFÍA ................................................................................................................... 7-15
TEMA 8: IDENTIFICACIÓN EN LAZO CERRADO
8.1 INTRODUCCIÓN ............................................................................................................ 8-1
8.2 PROBLEMAS QUE PRESENTA LA IDENTIFICACIÓN EN LAZO CERRADO .............. 8-2
8.3 IDENTIFICACIÓN EN LAZO CERRADO MEDIANTE APROXIMACIÓN DIRECTA ....... 8-7
8.3.1 Consideraciones generales ..................................................................................... 8-7
8.3.2 Consideraciones sobre el error de sesgo ................................................................ 8-9
8.3.3 Selección del punto de aplicación de la señal de excitación ................................. 8-10
8.3.4 Consideraciones sobre el error de varianza .......................................................... 8-14
8.4 CONCLUSIONES .......................................................................................................... 8-15
BIBLIOGRAFÍA ................................................................................................................... 8-16
TEMA 9: IDENTIFICACIÓN RELEVANTE PARA EL CONTROL
9.1 INTRODUCCIÓN ............................................................................................................ 9-1
9.2 RELACIÓN ENTRE EL MODELO IDENTIFICADO Y EL DISEÑO DEL
CONTROLADOR .................................................................................................... 9-2
9.3 IDENTIFICACIÓN DE MODELOS APROXIMADOS ....................................................... 9-5
9.3.1 Identificación basada en el error de predicción ....................................................... 9-5

Indice
9.3.2 Desajuste modelo - proceso en lazo cerrado .......................................................... 9-6
9.3.3 Criterio de identificación relevante para control ...................................................... 9-8
9.3.4 Identificación a partir de datos obtenidos en lazo cerrado ...................................... 9-9
9.4 IDENTIFICACIÓN Y CONTROL ITERATIVOS ............................................................. 9-12
9.5 PREFILTRADO RELEVANTE PARA CONTROL .......................................................... 9-16
9.5.1 Estimación de parámetros relevantes para control ............................................... 9-16
9.5.2 Efecto del prefiltrado en la estimación de parámetros........................................... 9-17
9.5.3 Obtención de un prefiltro relevante para control.................................................... 9-18
9.5.4 Algoritmo para la implementación de un prefiltro relevante para control ............... 9-23
9.6 CONCLUSIONES .......................................................................................................... 9-25
BIBLIOGRAFÍA .................................................................................................................. 9-26
TEMA 10: IDENTIFICACIÓN DE SISTEMAS MULTIVARIABLES
10.1 INTRODUCCIÓN ........................................................................................................ 10-1
10.2 DESCRIPCIÓN DE UN SISTEMA MULTIVARIABLE ................................................. 10-2
10.3 DISEÑO DE ENTRADAS PARA SISTEMAS MULTIVARIABLES .............................. 10-4
10.3.1 Diseño de señales RBS multientrada .................................................................. 10-4
10.3.2 Diseño de señales PRBS multientrada ................................................................ 10-4
10.3.3 Diseño de señales multiseno multientrada .......................................................... 10-6
10.4 ESTIMACIÓN DE MODELOS MULTIVARIABLES ..................................................... 10-8
BIBLIOGRAFÍA ................................................................................................................. 10-20
TEMA 11: IDENTIFICACIÓN DE SISTEMAS NO LINEALES
11.1 INTRODUCCIÓN ........................................................................................................ 11-1
11.2 ALGUNAS CONSIDERACIONES SOBRE LA NECESIDAD DE IDENTIFICAR
MODELOS NO LINEALES ........................................................................................... 11-1
11.3 COMPROBACIÓN DE LA NO LINEALIDAD DE UN SISTEMA .................................. 11-2
11.3.1 Test en el dominio del tiempo basado en la respuesta a escalones. .................. 11-2
11.3.2 Test basado en las funciones de correlación de orden más alto. ....................... 11-3
11.4 DISEÑO DE LA SEÑAL DE ENTRADA ...................................................................... 11-4
11.5 MODELOS NO LINEALES MÁS USUALES ............................................................... 11-5
11.5.1 Modelo de Hammerstein- Weiner ........................................................................ 11-5
11.5.2 Modelo NARMAX ................................................................................................. 11-8
11.5.3 Modelo NARX ...................................................................................................... 11-9
11.5.4 Modelo de Volterra ............................................................................................ 11-11

Indice
11.6 CONSIDERACIONES ADICIONALES SOBRE LA IDENTIFICACIÓN DE SISTEMAS
NO LINEALES .............................................................................................................. 11-11
11.6.1 Prefiltrado .......................................................................................................... 11-11
11.6.2 Análisis de los residuos ..................................................................................... 11-12
BIBLIOGRAFÍA ................................................................................................................. 11-13


TEMA 1
MODELOS DE SISTEMAS CONTINUOS Y DISCRETOS
1.1 INTRODUCCIÓN
Un sistema puede ser definido como un objeto o una colección de objetos cuyas
propiedades queremos estudiar. Ejemplos de sistemas son por ejemplo, el sistema solar,
una planta fabricadora de papel, un circuito RC (Resistencia-Condensador),..., etc.
Unas veces la curiosidad y otras la necesidad nos hace buscar respuestas a muchas
preguntas sobre las propiedades de los sistemas. Por ejemplo: ¿Cómo se podría ajustar la
planta para obtener papel de mejor calidad?, ¿qué ocurre si disminuyo la capacidad del
condensador?, ¿cuándo tendrá lugar el próximo eclipse total de sol?, etc.
La respuesta a alguna de estas preguntas se puede encontrar mediante
experimentación. Por ejemplo, se puede conectar el condensador a la resistencia y ver qué
ocurre. Sin embargo, muchas veces no es posible experimentar directamente con el sistema
ya que resulta demasiado caro, es demasiado peligroso o el sistema todavía no ha sido
construido.
En los casos anteriores resulta muy útil disponer de un modelo del sistema. Un modelo
es una idealización del sistema físico, usado para reducir el esfuerzo de cálculo en el
análisis y diseño del sistema. El modelo se desarrolla de forma que represente
adecuadamente al sistema.
Al desarrollar un modelo para un sistema físico, ciertos parámetros y variables del
sistema o relaciones entre sus componentes se pueden despreciar. Sin embargo, se debe
de tener cuidado de no despreciar parámetros o relaciones que son cruciales para la
precisión del modelo. Esto implica que un sistema físico pueda tener modelos diferentes
dependiendo de la aplicación del modelo. Por ejemplo, un transistor tiene diferentes

TEMA 1: Modelos de sistemas continuos y discretos
1-2
modelos dependiendo de la amplitud y frecuencia de la señal aplicada. Generalmente, se
elige un modelo que resulte simple y que, al mismo tiempo, describa adecuadamente la
conducta del sistema.
Los modelos se pueden dar en varias formas y con diferentes grados de formalismo
matemático dependiendo del grado de sofisticación necesario. Así, se pueden usar modelos
mentales, como los usados en la vida diaria, sin ningún formalismo matemático. Por ejemplo
este es el caso del modelo usado cuando se conduce un automóvil (“al girar el volante el
automóvil gira” o “al pisar el freno el automóvil reduce la velocidad”).
Para ciertas aplicaciones, la descripción del sistema se puede hacer mediante modelos
gráficos y tablas numéricas. Por ejemplo, un sistema lineal se puede describir mediante su
diagrama de Bode o las gráficas de respuesta a un impulso o a un escalón.
Para aplicaciones más avanzadas se necesitan modelos que describan las relaciones
entre sus variables y componentes en términos de expresiones matemáticas como
ecuaciones diferenciales o en diferencias, es decir, usar modelos matemáticos.
Dependiendo del tipo de ecuaciones diferenciales o en diferencias usadas, estos modelos
matemáticos serán continuos o discretos, lineales o no lineales, deterministas o
estocásticos, etc.
Un sistema (ver Figura 1.1) se puede representar como uno o varios bloques que
reciben una o varias señales de entrada predeterminadas u(t) y genera una o varias señales
de salida y(t). Además el sistema puede estar sometido a una o varias perturbaciones w(t),
que generalmente son señales de tipo aleatorio.
Sistemau(t)
w(t)
y(t)
Figura 1.1. Entradas, salidas y perturbaciones de un sistema.
Si el sistema posee m entradas, r perturbaciones y p salidas u(t), w(t) e y(t) son
vectores:

Identificación de sistemas
1-3
)(
:
)(
)(
)(
)(
:
)(
)(
)(
)(
:
)(
)(
)(2
1
2
1
2
1
ty
ty
ty
ty
tw
tw
tw
tw
tu
tu
tu
tu
prm
(1.1)
Si la magnitud de las entradas, salidas y perturbaciones puede cambiar en cualquier
instante de tiempo t [0,] el sistema es de tiempo continuo o simplemente continuo. Por
otro lado si la magnitud de las entradas, salidas y perturbaciones sólo puede cambiar en
instante discretos de tiempo t={t1, t2, ...., tN} el sistema es de tiempo discreto o simplemente
discreto.
En este tema se describen los modelos matemáticos de sistemas continuos y de
sistemas discretos. En ambas casos, por simplificar la exposición se considerará que no
existen perturbaciones. Éstas son estudiadas en detalle en el Tema 2. También en este
tema se incluyen las características básicas de la respuesta temporal y de la respuesta
frecuencial de un sistema lineal.
1.2 MODELADO DE SISTEMAS CONTINUOS
1.2.1 Ecuaciones diferenciales
De forma general un sistema dinámico continuo se puede modelar matemáticamente
usando una ecuación diferencial de la forma
0))(),(),...,(),(),(),(),....,(),(( )1()()1()( tututututytytytyg mmnn (1.2)
donde
)()();()( )()( tudt
dtuty
dt
dty
k
kk
k
kk (1.3)
y g() es una función no lineal arbitraria y vector-valuada.
Ejemplo 1.1:
Considérese un tanque de agua con una sección de A(m2) y un orificio de salida con un área de
a(m2). La altura o nivel del líquido en el tanque es h(m), el caudal de entrada es u(m3/s) y el caudal de
salida es q(m3/s). Se desea construir un modelo matemático que refleje como el caudal de salida
depende del caudal de entrada.

TEMA 1: Modelos de sistemas continuos y discretos
1-4
De acuerdo con la ley de Bernoulli la velocidad del caudal de salida en (m/s) es:
)(··2)( thgtv (1)
Donde g es la aceleración de la gravedad.
La relación entre el caudal de salida y su velocidad es por definición:
)(·)( tvatq (2)
El volumen del líquido en el tanque en el instante t es obviamente A·h(t) (m3), y cambia debido a la
diferencia entre el caudal de entrada y el caudal de salida:
)()()(· tqtuthAdt
d (3)
A la ecuación anterior se le denomina como balance de masa, ya que la densidad es constante.
Sustituyendo (1) y (2) en (3) se obtiene la siguiente ecuación diferencial no lineal:
)(·1
)(·2·
)( tuA
thA
gath
dt
d (4)
Conocidas a, A y u(t), mediante (4) se puede obtener la altura h(t). Conocida ésta el caudal de salida
es:
)(·2·)( thgatq (5)
Si se introducen n variables internas xi(t) con i=1,...,n la ecuación diferencial (1.2) se
puede descomponer en un sistema de n ecuaciones diferenciales de primer orden
))(),....,(),(),...,(()(
:
))(),....,(),(),...,(()(
))(),....,(),(),...,(()(
11
1122
1111
tututxtxftx
tututxtxftx
tututxtxftx
mnnn
mn
mn
(1.4)
Equivalentemente las ecuaciones anteriores se pueden escribir de forma más compacta
usando la siguiente notación:

Identificación de sistemas
1-5
))(),(()( tutxftx (1.5)
donde
),(
:
),(
),(
),(,
)(
:
)(
)(
)( 2
1
2
1
uxf
uxf
uxf
uxf
tx
tx
tx
tx
nn
(1.6)
Las salidas del modelo se pueden calcular a partir de las variables internas xi(t) y de las
entradas ui(t) usando las siguientes ecuaciones:
))(),....,(),(),...,(()(
:
))(),....,(),(),...,(()(
))(),....,(),(),...,(()(
11
1122
1111
tututxtxhty
tututxtxhty
tututxtxhty
mnnp
mn
mn
(1.7)
Equivalentemente las ecuaciones anteriores se pueden escribir de forma más compacta
usando la siguiente notación:
))(),(()( tutxhty (1.8)
1.2.2 Modelo en el espacio de estados
La salida de un sistema dinámico depende no sólo del valor actual de la entrada sino de
todos sus valores anteriores. En consecuencia no es suficiente con conocer u(t) para tt0
para poder calcular y(t) para tt0 también es necesario tener información del sistema. Dicha
información es el estado del sistema dinámico que es un conjunto de cantidades físicas,
cuyas especificaciones (en ausencia de excitación externa) determina completamente la
evolución del sistema.
La noción de estado de un sistema dinámico es una noción fundamental en Física. La
premisa básica de la dinámica newtoniana es que la evolución futura de un proceso
dinámico está completamente determinada por su estado actual.
Considérese un sistema general de ecuaciones diferenciales de primer orden de la
forma (1.5) con la salida dada en la forma (1.8)

TEMA 1: Modelos de sistemas continuos y discretos
1-6
))(),(()(
))(),(()(
tutxhty
tutxftx
(1.9)
Para este sistema el vector x(t0) define el estado del sistema en el instante t0. Si f(x,u)
es continuamente diferenciable y u es continua a trozos la ecuación diferencial (1.9) con
x(t0)=x0 tiene una solución única para tt0.
En consecuencia se ha establecido que las variables internas xi(t) i=1,..,n determinan el
estado del sistema en el instante t. Las ecuaciones (1.9) definen el modelo en el espacio de
estados, el vector x(t) es el vector de estado y sus componentes xi(t) son las variables de
estado. El orden del modelo queda definida por la dimensión del vector x(t), que recordemos
es n.
El modelo en el espacio de estados (1.9) se dice que es lineal si f(x,u) y h(x,u) son
funciones lineales de x y u:
uDxCty
uBxAtx
··)(
··)(
(1.10)
En la expresión anterior A, B, C y D son matrices de dimensiones n x n, n x m, p x n y
p x m, respectivamente. Usualmente D=0. Si u e y son escalares (m=p=1), B es entonces un
vector columna y C es un vector fila.
Si las matrices A, B, C y D son independientes del tiempo el modelo se dice que es
lineal e invariante en el tiempo o LTI (Linear Time Invariant).
Ejemplo 1.2:
Sobre un móvil (ver Figura 1.2) que se mueve con una aceleración u(t) se sitúa una masa m sujeta a
la pared del móvil por un muelle de constante de elasticidad k y un amortiguador de coeficiente de
amortiguación b.
)(tu
)(tym
b
k
Figura 1.2: Masa con resorte y amortiguamiento sobre móvil

Identificación de sistemas
1-7
Para este sistema la variable de entrada es la aceleración u(t) y la variable de salida es el
desplazamiento y(t). La ecuación del movimiento de este sistema se obtiene aplicando la segunda ley
de Newton:
amF ·
Donde F es la suma de todas las fuerzas aplicadas sobre la masa m y a es el vector aceleración del
cuerpo.
En este sistema las fuerzas que están actuando son las correspondientes al muelle y al amortiguador,
que actúan en la dirección horizontal:
dt
dybykF ··
La aceleración total es:
)()(
2
2
tudt
tyda
Con lo que la ecuación del movimiento es:
)()(·)(
·)(
·2
2
tmutykdt
tdyb
dt
tydm
Si se definen las siguientes variables de estado:
dt
dyxyx 21
Entonces la ecuación de estado que describe las dinámicas del sistema es:
)(·1
0
)(
)(·
10
)(
)(
2
1
2
1 tutx
tx
m
b
m
ktx
tx
Y la ecuación de salida es:
)(
)(·01)(
2
1
tx
txty

TEMA 1: Modelos de sistemas continuos y discretos
1-8
Ejemplo 1.3:
Se considera la red eléctrica RLC de la Figura 1.3. La variable de entrada es la tensión aplicada u=vs
y la de salida es la intensidad de corriente por la resistencia R, es decir, y=i1. Como variables de
estado se pueden elegir la caída de tensión x1 =vc en el condensador C y la corriente x2=i2 a través de
la inductancia L.
+-+-)(tvs
)(tvcC
R
L
)(1 ti )(2 ti
Figura 1.3: Red eléctrica RLC
Aplicando las leyes de Kirchoff a este circuito se obtienen las siguientes expresiones:
dt
diLv
iidt
dvC
viRv
c
c
cs
2
21
1
·
·
·
Operando sobre estas expresiones se obtienen las ecuaciones de estado:
c
scc
vLdt
di
vCR
iC
vCRdt
dv
·1
·
11
·
1
2
2
En forma matricial:
uRCx
x
L
CCRx
x·
0
1·
01
1
·
1
2
1
2
1
La ecuación de salida es:

Identificación de sistemas
1-9
1
11x
Ru
Ry
Ejemplo 1.4:
)(tea
)(tTr
aR
)(tia
aL
)(ti f
fL
fR
)(teb
)(t
cJ ,
Figura 1.4: Diagrama esquemático del motor de corriente continua excitado por separado
En la Figura 1.4 se representa un diagrama esquemático de un motor de corriente continua. En dicha
figura Ra y La representan la resistencia y la inductancia de la armadura. eb(t) representa la fuerza
contra-electromotriz debida a la rotación de los conductores de la armadura en el campo magnético.
Análogamente, Rf y Lf indican la resistencia y la inductancia de la bobina del campo. Las
no-linealidades y la dependencia de los parámetros con el tiempo de estas bobinas se han
despreciado.
Se supone que la bobina del campo (el estator) está conectada a una fuente de voltaje constante y la
bobina de la armadura (el rotor) está conectada a una fuente de voltaje variable v(t). De esta forma, la
intensidad de campo ef se puede considerar constante. El voltaje ea(t) puede variar para cambiar la
velocidad angular (t) del rotor.
El flujo magnético de la bobina del campo es una constante cuando if se supone constante. El torque
Tr con el eje del motor es proporcional a ia por una constante Km del motor.
amr iKT ·

TEMA 1: Modelos de sistemas continuos y discretos
1-10
El voltaje eb(t) generado como resultado de la rotación, es proporcional a la velocidad de rotación del
eje , por una constante Kg1 del generador:
)(·)( tKte gb
Aplicando las leyes de Kirchoff al circuito de la armadura se obtiene:
)()(·)(
·)( tetiRdt
tdiLte baa
aaa
El torque del rotor Tr(t) y la velocidad angular están relacionados mediante la segunda ley de Newton
de la dinámica:
)(·)(
·)()( tcdt
tdJtTtT dr
Donde Td(t) es el torque de la carga en el eje del rotor, c es la constante de rozamiento viscoso y J es
el momento de inercia de la carga.
Combinando estas ecuaciones se obtiene el siguiente sistema de ecuaciones diferenciales con
coeficientes constantes:
)(1
)()()(
)(1
)()()(
tTJ
tJ
cti
J
K
dt
td
teL
tL
Kti
L
R
dt
tdi
dam
aaa
ga
a
aa
Estas ecuaciones se pueden escribir en la forma matricial de ecuaciones de estado:
)(
)(·
10
01
)(
)(·
)(
)(
tT
te
J
Lt
ti
J
c
J
KL
K
L
R
dt
tddt
tdi
d
aaa
m
a
g
a
aa
Si se considera como salida del sistema la velocidad de rotación del motor, entonces la ecuación de
salida es:
)(
)(·10
t
tiy a
1 En unidades consistentes, Km es igual a Kg, pero en algunos casos la constante motor-torsión viene dada en otras unidades, como onzas-pulgadas por amperes, y la constante del generador debe de expresarse en unidades de voltios por 1000 rpm.

Identificación de sistemas
1-11
Si las variables de salida son el torque desarrollado por el eje del rotor y la velocidad de rotación,
entonces se tiene como ecuación de salida:
)(
)(·
10
0
t
tiKy am
1.2.3 Función de transferencia
La transformada de Laplace es un método operativo que se usa para resolver
ecuaciones diferenciales lineales. Mediante su uso es posible convertir muchas funciones
comunes, tales como funciones sinusoidales, sinusoidales amortiguadas y exponenciales,
en funciones algebraicas de una variable compleja s=+j·.
Considérese una función del tiempo f(t), la transformada de Laplace de f(t) se define
como:
0
·)·()()]([ dtetfsFtfL st (1.11)
El proceso inverso de encontrar la función del tiempo f(t) a partir de la transformada de
Laplace F(s) se realiza tomando la transformada inversa de Laplace.
1 1( ) [ ( )] ( )
2
jst
j
f t L F s F s e dsj
(1.12)
Puesto que F(s) es una función racional, si descompone en fracciones simples es
posible usando una tabla de transformadas de Laplace obtener la expresión de f(t). En la
Tabla 1.1 se recogen las transformadas de Laplace de algunas de las funciones más
habituales.
Una de las propiedades más interesantes de la transformada de Laplace es la
posibilidad de aplicarla sobre la derivada de orden k de la función f(t)
)0(...)0()0()(·)]([ )1(21 kkkkk
k
ffsfssFstfdt
dL (1.13)
Así en el caso de la primera (k=1) y segunda (k=2) derivada se obtienen,
respectivamente, las siguientes expresiones:

TEMA 1: Modelos de sistemas continuos y discretos
1-12
)0()(·)]([ fsFstfdt
dL (1.14)
)0()0()(·)]([ 22
2
fsfsFstfdt
dL (1.15)
Otras propiedades bastante útiles de la transformada de Laplace son las siguientes:
Teorema del valor final.
0lim ( ) lim ( )s t
sF s f t
(1.16)
Teorema del valor inicial.
0lim ( ) lim ( )s t
sF s f t
(1.17)
Teorema de traslación en el tiempo
1[ ( ) ( )] ( )asL f t a u t a e F s (1.18)
Donde a es número real positivo y 1( )u t es la función escalón unidad.
Supóngase el modelo de estados (1.10) de un sistema LTI con condiciones iniciales
nulas. Sean U(s) e Y(s) las transformadas de Laplace del vector de entradas u(t) y del vector
de salidas y(t) del sistema, respectivamente. Ambas se relacionan mediante la siguiente
expresión:
)()·()( sUsGsY (1.19)
donde G es una matriz de dimensión p x m que de denomina función de transferencia.
Se puede demostrar que la función de transferencia se relaciona con las matrices A, B,
C y D del modelo de estados a través de la siguiente relación:
DBAIsCsG 1··)( (1.20)
Si u e y son escalares (p=m=1), entonces G(s) es una función racional:
nnnn
nnmm
asasas
bsbsbsb
sU
sY
11
1
11
10
...
...
)(
)( (1.21)

Identificación de sistemas
1-13
f(t) F(s)
00
0)(
tsi
tsit
1
0( )
0 0
A si tf t
si t
A
s
0( )
0 0
At si tf t
si t
2
A
s
( 0)nAt t 1
· !n
A n
s
· ( 0)a te t
as 1
cos( · ) ( 0)t t 2 2
s
s
( · ) ( 0)sen t t 2 2s
·· ( 0)a tt e t 2)(
1
as
· · ( · ) ( 0)a te cos t t 22)(
as
as
· · ( · ) ( 0)a te sen t t 22)(
as
Tabla 1.1. Transformadas de Laplace de algunas funciones
El grado n del denominador debe ser mayor o igual que el grado m del numerador para
garantizar la causalidad del sistema y que el modelo tenga sentido físico, en caso contrario
la salida del modelo en el instante actual dependería del futuro.
Al denominador de la función de transferencia se le denomina polinomio característico y
sus raíces son los polos de sistema. Normalmente los polos son idénticos a los autovalores
de la matriz A de la ecuación (1.10). Algunos autovalores puede, sin embargo, corresponder
a dinámicas que no pueden ser excitadas u observadas a partir del comportamiento entrada-
salida. Estos autovalores no se incluyen entre los polos.
Por su parte las raíces del numerador constituyen los ceros del sistema. Los polos y los
ceros de una función de transferencia se representan en un plano complejo denominado
plano s que en el eje de abcisas contiene la parte real de los polos o ceros (). y en el eje de
ordenadas la parte imaginaria (j·).

TEMA 1: Modelos de sistemas continuos y discretos
1-14
Si un sistema posee algún polo o par de polos complejos conjugados con su parte real
positiva, entonces el sistema es inestable, en el caso contrario se dice que el sistema es
estable. Por otra parte, si un sistema posee algún cero o par de ceros complejos conjugados
con su parte real positiva, se dice que el sistema es de fase no mínima (n.m.p) 2. En caso
contrario, se dice que el sistema es de fase mínima (m.p) 3.
Ejemplo 1.5:
Para el sistema de masa con resorte y amortiguamiento sobre móvil del Ejemplo 1.2 la ecuación del
movimiento era
)()(·)(
·)(
·2
2
tmutykdt
tdyb
dt
tydm
Tomando la transformada de Laplace con condiciones iniciales nulas sobre la ecuación anterior
)()(·)(·)(· 2 smUsYkssYbsYsm
y reordenando términos se obtiene que la función de transferencia del sistema es:
m
ks
m
bsksbsm
m
sU
sYsG
·
1
··)(
)()(
22
Si se aplica la ecuación (1.26) se obtiene el mismo resultado.
Ejemplo 1.6:
Para la red eléctrica RLC del Ejemplo 1.3 aplicando la ecuación (1.26) se obtiene la siguiente función
de transferencia
CLs
CRs
LCRs
RRRC
sL
CRCs
RsG
1
·
1··
111
0
1·
1
11
·01
)(2
21
2 n.m.p es el acrónimo derivado del término inglés non-minimum phase. 3 m.p es el acrónimo derivado del término inglés minimum phase.

Identificación de sistemas
1-15
Ejemplo 1.7:
Para el motor de corriente continua del Ejemplo 1.4 aplicando la ecuación (1.26)
·1
0
01
10
0)(
1
J
L
J
cs
J
KL
K
L
RsK
sG a
m
a
g
a
a
m
se obtiene que la función de transferencia es:
a
a
a
m
a
gm
a
m
a
gm
a
a
L
Rs
JLJ
KLJ
KK
J
cs
L
K
LJ
KK
J
cs
L
Rs
sG·
1
·
·
··
·
·
·1
)(
A la transformada inversa de Laplace de la función de transferencia G(s)
1 1( ) [ ( )] ( )
2
jst
j
g t L G s G s e dsj
(1.22)
se le denomina función de respuesta a un impulso del sistema. Se puede demostrar que la
salida del sistema en un instante de tiempo t se puede expresar en términos de la función de
respuesta a un impulso y de la señal de entrada u(t) del sistema de la siguiente forma:
0
( ) ( ) ( )t
y t g v u t v dv (1.23)
A esta expresión se le denomina integral de convolución. La convolución es una
operación compleja sobre funciones definida por la integral de las dos funciones
multiplicadas entre sí y desplazadas en el tiempo.
Nótese que si la entrada fuese un impulso u(t)=(t) entonces
0
( ) ( ) ( ) ( )t
y t g v t v dv g t (1.24)
con lo que se demuestra así que g(t) es la respuesta a un impulso del sistema.

TEMA 1: Modelos de sistemas continuos y discretos
1-16
Se observa que la salida puede ser obtenida como una suma ponderada de valores
pasados de la entrada, es decir, la salida es una convolución de la entrada en instantes
anteriores con la función peso g(v).
La función peso g(v) caracteriza completamente el comportamiento del sistema, de la
misma forma que lo hace su ecuación diferencial.
1.3 MODELADO DE SISTEMAS DISCRETOS
1.3.1 Secuencias
Las señales discretas se pueden modelar como secuencias, que son conjuntos
ordenados de valores. El orden se indica mediante un subíndice k que es número entero y
se representan por: {y0, y1, y2,.., }, o de forma abreviada por {yk}.
Una forma alternativa de definir una señal discreta es mediante la posible función que
define el término genérico de la secuencia. Por ejemplo: yk=1+0.5k-0.32k define la secuencia
{1,1.41,1.242,...} cuando k=0, 1, 2, ...
Las operaciones básicas que se pueden realizar con una secuencia son:
Suma o resta:
,...},,{}{}{}{ 221100 uyuyuyuyx kkk
Multiplicación por un escalar:
,...}·,·,·{}·{}{ 210 yyyyx kk
Retraso de una secuencia:
,...},,,0,...,0,0{}{}{ 21010 yyyyx ddkk
Estas secuencias se pueden obtener como valores que a lo largo del tiempo y
normalmente en instantes de tiempo igualmente espaciados por un periodo de muestreo T
va tomando una variable determinada. Para estos tipos de secuencias obtenidas a partir del
muestreo con periodo T de una señal continua es corriente usar la siguiente notación:
,...2,1,0),...·2(),(),0()·( kTyTyyTky
Si el periodo es T=1 s, entonces:
Identificación de sistemas
1-17
,...2,1,0),...2(),1(),0()( kyyyky
que es equivalente a la notación:
,...2,1,0,...,,)( 210 kyyyyky k
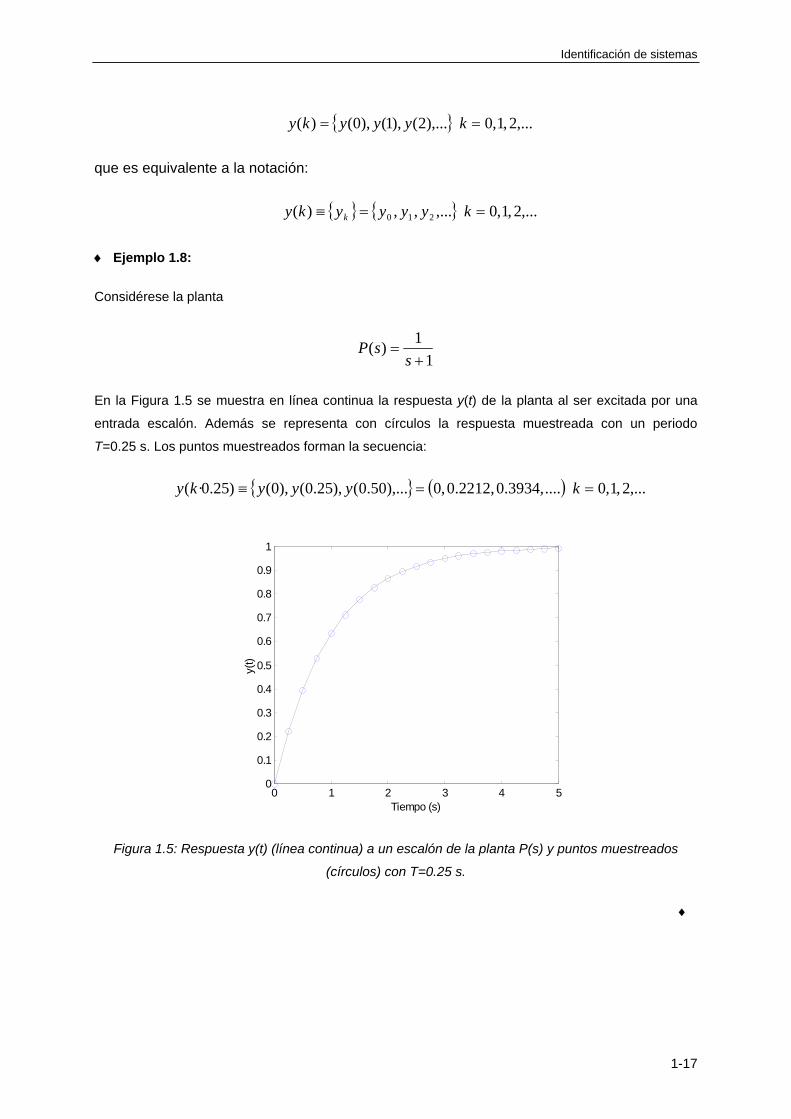
Ejemplo 1.8:
Considérese la planta
1
1)(
ssP
En la Figura 1.5 se muestra en línea continua la respuesta y(t) de la planta al ser excitada por una
entrada escalón. Además se representa con círculos la respuesta muestreada con un periodo
T=0.25 s. Los puntos muestreados forman la secuencia:
,...2,1,0....,3934.0,2212.0,0),...50.0(),25.0(),0()25.0·( kyyyky
0 1 2 3 4 50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Tiempo (s)
y(t)
Figura 1.5: Respuesta y(t) (línea continua) a un escalón de la planta P(s) y puntos muestreados
(círculos) con T=0.25 s.

TEMA 1: Modelos de sistemas continuos y discretos
1-18
1.3.2 La transformada Z de una secuencia
Trabajar con secuencias no parece lo más apropiado para obtener las características
dinámicas y estáticas de los sistemas discretos. Por este motivo, se introduce la
transformada Z que facilita el análisis matemático de las secuencias. La transformada Z en
sistemas de control en tiempo discreto juega el mismo papel que la transformada de Laplace
en los sistemas de control en tiempo continuo.
Dada una secuencia {yk} su transformada Z se define mediante la siguiente ecuación:
...···] }{y[)( 22
110
0k
zyzyyzyZzYi
ii (1.25)
La transformada Z de una función del tiempo y(t) que ha sido muestreada con un
periodo T obteniéndose la secuencia de valores y(k·T) con k=0,1,2,... se define mediante la
siguiente ecuación:
...)··2()·()0()··(y] )·(y[] )(y[)( 21
0
zTyzTyyzTkTkZtZzYk
k (1.26)
Algunas de sus propiedades más importantes son:
Multiplicación por una constante.
)(·] }{y[·] }{y·[ kk zYaZaaZ
Carácter lineal de la transformación.
)(·)(·] }{u[·] }{y[·] }b{u}{y·[ kkkk zUbzYaZbZaaZ
Desplazamiento temporal:
)(·}{ zYzyZ ddk
(1.27)
111
0 ·...··)(·}{
dddd
dk yzyzyzzYzyZ (1.28)
Teorema del valor final. Permite el cálculo del valor límite de la secuencia, si éste
existe (todos los polos de X(z) se encuentran dentro del círculo unitario con la
posible excepción de un solo polo en z=1), a partir del conocimiento de la función
transformada, según la expresión:

Identificación de sistemas
1-19
)()·1(lim}{lim 1
1zYzy
zk
k
(1.29)
Ejemplo 1.9:
Sea la función escalón unitario:
00
01)(
t
tty
Se trata de una función continua en el tiempo. Si dicha señal se muestrea con un periodo T se
obtendría la siguiente secuencia:
,...2,1,0,,...1,1,1 kyk
La transformada Z se calcula aplicando la ecuación (1.31):
11
1...1·] }{y[)(
1321
0k
z
z
zzzzzyZzY
i
ii
Ejemplo 1.10:
Sea la función rampa unitaria:
00
0)(
t
ttty
Se trata de una función continua en el tiempo. Si dicha señal se muestrea con un periodo T se
obtendría la siguiente secuencia:
,...2,1,0,,...,·2,,0 kTTyk
La transformada Z se calcula aplicando la ecuación (1.31):
221
1
321321
0k
1
·
1·
·3·2·...··3··2·0·] }{y[)(
z
zT
z
zT
zzzTzTzTzTzyZzYi
ii

TEMA 1: Modelos de sistemas continuos y discretos
1-20
Tabla 1.2. Transformada z de algunas funciones elementales
La transformación en Z es biunívoca, pudiendo pasar a su secuencia asociada de forma
inmediata. Así dada la transformada Z de una secuencia es posible obtener la secuencia
original aplicando la transformada Z inversa, que se denota mediante Z-1. Es decir,
kykyzYZ )()]([1 (1.30)
Si Y(z) viene expresada de forma racional existen diferentes métodos para obtener la
transformada Z inversa, por ejemplo:

Identificación de sistemas
1-21
1) Método de expansión en fracciones simples. Se descompone en fracciones simples a
Y(z) y se utiliza una tabla de transformadas elementales (Ver Tabla 1.2) para obtener
la transformada Z inversa de cada uno de las fracciones.
2) Método de la división directa. Se divide el numerador de Y(z) entre el denominador
de Y(z), el cociente que se va obteniendo es la expansión de Y(z) en una serie
infinita de potencias de z-1. Los coeficientes de cada una de las potencias z-1 son de
acuerdo con (1.1) los elementos de la secuencia {y0, y1, y2,...}. Con este método rara
vez es posible obtener la expresión para el término general {yk}.
1.3.3 Ecuaciones en diferencias
Una ecuación en diferencias da el valor de la salida actual yk en función de los valores
de las salidas anteriores yk-1,yk-2,... y de las entradas actual uk y anteriores uk-1,uk-2....
),...,,,,...,,( 211 nkkkmkkkk yyyuuufy
La ecuación en diferencias permite representar el modelo con un número finito de
términos. Si el sistema es LTI la ecuación en diferencias toma la siguiente forma:
n
iiki
m
iikik yauby
10
·· (1.31)
O de forma equivalente:
)(·...)1(·)(·)(·...)1(·)( 101 mkubkubkubnkyakyaky mn (1.32)
Si se define el operador retardo q-1 como
)1()(·
)1()(·1
kykyq
kykyq
entonces la ecuación (1.37) se puede expresar como:
)()()()( 11 kuqBkyqA
donde
mm
nn
qbqbqB
qaqaqA
·...·1)(
·...·1)(1
11
11
1

TEMA 1: Modelos de sistemas continuos y discretos
1-22
Ejemplo 1.11:
Se desea resolver la siguiente ecuación en diferencias:
)()2()1(·2)(·2 kukykyky
donde y(k)=0 para k<0 y
00
2,1,01)(
k
kku
Los valores de la secuencia y(k) se obtienen a partir de la ecuación en diferencias:
2
)()2()1(·2)(
kukykyky
Los primeros valores de la secuencia son:
5.02
)0()2()1(·2)0(
uyyy
12
105.0·2
2
)1()1()0(·2)1(
uyyy
25.12
15.01·2
2
)2()0()1(·2)2(
uyyy
Se va a resolver la ecuación en diferencias tomando la transformada Z:
121
1
1)()(·2)(·2
zzYzzYzzY
Despejando Y(z):
)1·22)(1()·22(
1·
)1(
1)(
2
3
211
zzz
z
zzzzY
Expandiendo Y(z) en fracciones simples:
21
1
12
2
·22
1
1
1
1·221)(
zz
z
zzz
zz
z
zzY

Identificación de sistemas
1-23
Nótese que los polos involucrados en el último término cuadrático de Y(z) son complejos conjugados.
Por lo tanto Y(z) se puede reescribir de la siguiente forma:
21
1
21
1
1 ·5.01
·5.0·
2
1
·5.01
·5.01·
2
1
1
1)(
zz
z
zz
z
zzY
Si se acude a una tabla de transformadas z, se encuentra que:
)··(·)(·)···cos(·21
)·(··)( ··
2··21·
1·
TksenekxzezTe
TsenzezX Tka
TaTa
Ta
y que
)···cos()(·)···cos(·21
)··cos(·1)( ··
2··21·
1·
TkekxzezTe
TzezX Tka
TaTa
Ta
Para Y(z) se identifica que
2
1)·cos(
5.0··2
T
e Ta
Luego, se obtiene que
2
1)·(
4·
Tsen
T
Entonces la transformada Z inversa de Y(z) se puede escribir como:
)··(··2
1)···cos(·
2
11)( ···· TkseneTkeky TkaTka
Y sustituyendo valores:
...2,1,04
··
2
1·
2
1
4
··cos
2
1·
2
11)(
k
ksen
kky
kk
Conviene comprobar que el término general obtenido es el correcto, para ello se van calcular los
primeros valores de la secuencia:

TEMA 1: Modelos de sistemas continuos y discretos
1-24
25.12
·2
1·
2
1
2·cos
2
1·
2
11)2(
14
·2
1·
2
1
4·cos
2
1·
2
11)1(
5.00·2
1·
2
10·cos
2
1·
2
11)0(
22
00
seny
seny
seny
1.3.4 Modelo en el espacio de estados
Para sistemas de tiempo discreto, el modelo en el espacio de estados es:
),(
),(1
kkk
kkk
uxgy
uxfx
(1.33)
En el caso de sistemas lineales el modelo en el espacio de estados toma la siguiente
forma:
kkkkk
kkkkk
uDxCy
uMxFx
··
··1
(1.34)
En la expresión anterior Fk, Mk, Ck y Dk son matrices de dimensiones n x n, n x m, p x n
y p x m, respectivamente. La presencia del subíndice en las matrices indica que éstas varían
con el tiempo. En el caso de un sistema LTI estas matrices son constantes, por lo que el
subíndice desaparece.
1.3.5 Función de transferencia
Supóngase el modelo de estado de un sistema LTI en tiempo discreto con condiciones
iniciales nulas. Sean U(z) e Y(z) las transformadas z del vector de entradas uk y del vector
de salidas yk del sistema, respectivamente. Ambas se relacionan mediante la siguiente
expresión:
)()·()( zUzHzY (1.35)
donde H es una matriz de dimensión p x m que de denomina función de transferencia en
tiempo discreto.

Identificación de sistemas
1-25
Se puede demostrar que la función de transferencia H se relaciona con las matrices F,
M, C y D del modelo de estados a través de la siguiente relación:
DMFIzCzH 1··)( (1.36)
Si u e y son escalares (p=m=1), entonces H(z) es una función racional:
nnnn
nnmm
azazaz
bzbzbzb
zU
zYzH
11
1
11
10
...
...
)(
)()( (1.37)
Si todos los polos de H(z) se encuentran dentro del círculo unidad el sistema es estable.
La función de transferencia H(z) de un sistema en tiempo discreto también se define
como
0
·)(k
kk zhzH (1.38)
donde hk es la respuesta (supuesto condiciones iniciales nulas) de un sistema en tiempo
discreto a un impulso:
00
01
k
kk (1.39)
Transformando (1.38) al dominio del tiempo, se obtiene la siguiente expresión:
0
·r
rkrk uhy (1.40)
Que permite obtener la respuesta del sistema a cualquier entrada, si se conoce la
respuesta de un sistema en tiempo discreto a un impulso.
1.4 CONSIDERACIONES BÁSICAS SOBRE LA RESPUESTA TEMPORAL Y FRECUENCIAL DE UN SISTEMA LINEAL
1.4.1 Sistemas de primer orden
Supóngase un sistema lineal continuo de primer orden de la forma:
( )( ) ( )
dy ty t Ku t
dt (1.41)

TEMA 1: Modelos de sistemas continuos y discretos
1-26
donde u(t) e y(t) son la entrada y la salida del sistema, respectivamente. Tomando la
transformada de Laplace con condiciones iniciales nulas se obtiene la siguiente función de
transferencia:
( )( )
( ) 1
Y s KG s
U s s
(1.42)
Este sistema de primer orden queda caracterizado por dos parámetros: su ganancia
estática K y su constante de tiempo . El sistema tiene un polo situado en s=-1/.
Si se excita al sistema de primer orden (1.42) con una entrada impulso (u(t)=(t) o
U(s)=1) la salida en el dominio de Laplace es:
( ) ( )· ( )1
KY s G s U s
s
Tomando la transformada inversa de Laplace sobre la expresión anterior, de acuerdo
con la Tabla 1.1, se obtiene la respuesta temporal del sistema a un impulso:
( ) · 0tK
y t e t
(1.43)
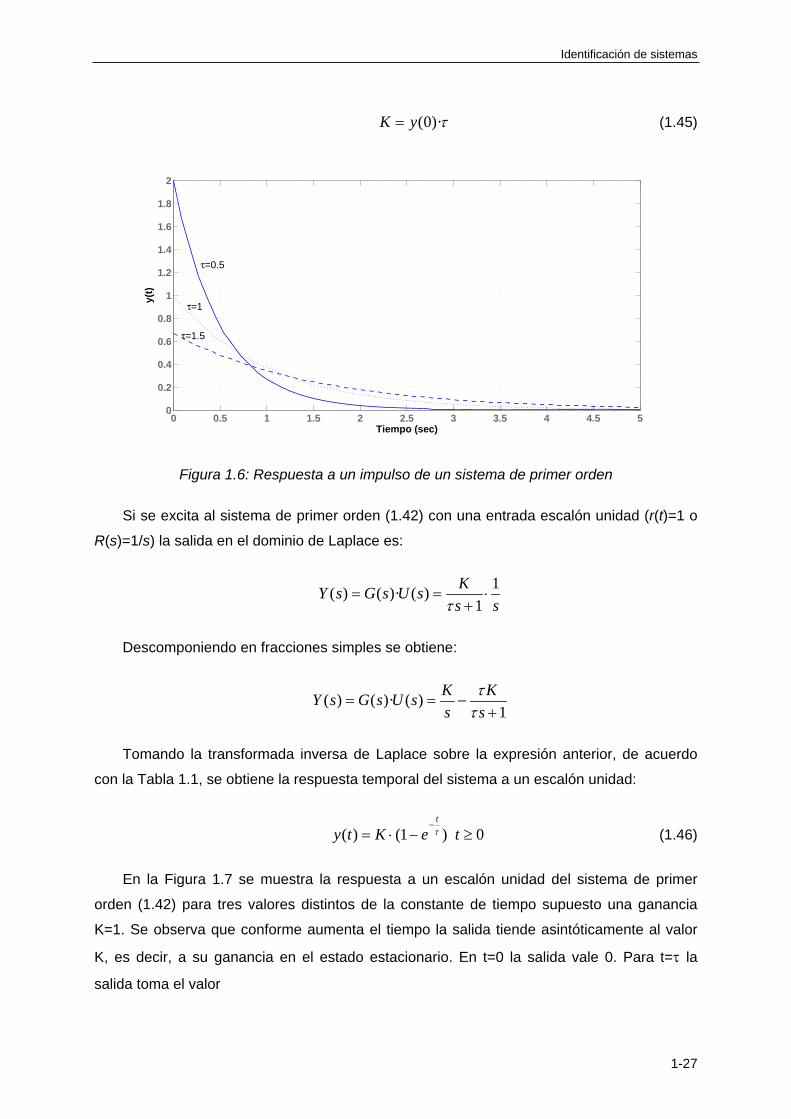
En la Figura 1.6 se muestra la respuesta a un impulso del sistema de primer orden
(1.42) para tres valores distintos de la constante de tiempo supuesto una ganancia K=1. Se
observa que el valor máximo de la respuesta es K/ el cual se alcanza cuando t=0. Si t= la
salida toma el valor
1( ) · 0.37·K K
y e
(1.44)
Es decir es aproximadamente el 37% de su valor inicial. Además conforme t aumenta la
salida tiende asintóticamente al valor 0.
Si se dispone de la salida a un impulso de un sistema de primer orden de la forma
(1.42) cuyos parámetros K y son desconocidos es posible estimar estos parámetros. La
constante de tiempo es el instante de tiempo en que la salida toma el 37% de su valor
inicial. Por su parte la ganancia K se obtiene a partir del valor inicial de la salida y de la
constante de tiempo que se relacionan mediante la siguiente expresión:
Identificación de sistemas
1-27
(0)·K y (1.45)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Tiempo (sec)
y(t)
τ=0.5
τ=1
τ=1.5
Figura 1.6: Respuesta a un impulso de un sistema de primer orden
Si se excita al sistema de primer orden (1.42) con una entrada escalón unidad (r(t)=1 o
R(s)=1/s) la salida en el dominio de Laplace es:
1( ) ( )· ( )
1
KY s G s U s
s s
Descomponiendo en fracciones simples se obtiene:
( ) ( )· ( )1
K KY s G s U s
s s
Tomando la transformada inversa de Laplace sobre la expresión anterior, de acuerdo
con la Tabla 1.1, se obtiene la respuesta temporal del sistema a un escalón unidad:
( ) (1 ) 0t
y t K e t
(1.46)
En la Figura 1.7 se muestra la respuesta a un escalón unidad del sistema de primer
orden (1.42) para tres valores distintos de la constante de tiempo supuesto una ganancia
K=1. Se observa que conforme aumenta el tiempo la salida tiende asintóticamente al valor
K, es decir, a su ganancia en el estado estacionario. En t=0 la salida vale 0. Para t= la
salida toma el valor

TEMA 1: Modelos de sistemas continuos y discretos
1-28
1( ) (1 ) 0.63·y K e K
Es decir, es aproximadamente el 63% de su valor final.
0 1 2 3 4 5 6 7 8 90
0.2
0.4
0.6
0.8
1
Tiempo (sec)
y(t)
τ=0.5
τ=1
τ=1.5
Figura 1.7. Respuesta a un escalón unidad de un sistema de primer orden
Para t=3 la salida toma el valor
(3 ) 0.95·y K
Es decir es aproximadamente el 95% de su valor final.
Para t=4 la salida toma el valor
(4 ) 0.98·y K
Es decir, es aproximadamente el 98% de su valor final. Al instante t=4 se le considera
el tiempo de asentamiento para sistemas de primer orden, es decir, el instante de tiempo a
partir del cual la respuesta a un escalón unidad permanece dentro de una banda del 2% de
su valor final. Aunque de acuerdo con (1.50) el estado estacionario se alcanza en tiempo
infinito, en la práctica se considera que se alcanza el valor estacionario cuando se alcanza
el 98 % del valor final, es decir, transcurrido un tiempo igual a cuatro constantes de tiempo.
Otra característica importante de la respuesta a un escalón unidad del sistema de
primer orden (1.42) es que su pendiente en t=0 es igual a:

Identificación de sistemas
1-29
(0)K
y
(1.47)
Luego la abcisa del punto de la intersección de la recta tangente al valor inicial con la
recta horizontal de valor K, es precisamente la constante de tiempo . Recuérdese que la
constante de tiempo también se puede estimar como el instante de tiempo en que la
respuesta a un escalón unidad alcanza el 63 % de su valor final. En la Figura 1.8 se
resumen los dos métodos para obtener la constante de tiempo de un sistema de primer
orden.
0 1 2 3 4 5 6 7 8 90
0.2
0.4
0.6
0.8
1
Tiempo (sec)
y(t)
τ
Figura 1.8. Determinación de la constante de tiempo de un sistema de primer orden
Supóngase que la salida del sistema de primer orden (1.42) se encuentra en un valor
estado estacionario y1 al que ha llegado tras ser excitado con una entrada escalón de
amplitud u1 Si en un cierto instante posterior es excitado con una entrada escalón de
amplitud u=u2-u1, el valor de su salida cuando alcance el estacionario será y2. A partir de
esta información se pueden estimar los parámetros de la función de transferencia del
sistema (1.42) de la siguiente forma:
2 1
2 1
y y yK
u u u
(1.48)
0.632· ·K u (1.49)

TEMA 1: Modelos de sistemas continuos y discretos
1-30
Las expresiones (1.48) y (1.49) permiten establecer el comportamiento del sistema de
primer orden (1.42) en función del valor de su constante de tiempo:
Si la constante de tiempo es positiva >0 entonces la salida está acotada. Por lo
tanto el sistema es estable. Nótese que en este caso el polo s=-1/ se encuentra
ubicado en el semiplano izquierdo del plano s.
Si la constante de tiempo es negativa <0 entonces la salida no está acotada y el
sistema es inestable. Nótese que en este caso el polo s=-1/ se encuentra ubicado
en el semiplano derecho del plano s.
Si la constante de tiempo fuese cero, entonces el sistema no sería dinámico, y la
relación entre la entrada y la salida vendría dada por la ganancia K.
Se observa que cuanto mayor es el valor de la constante de tiempo más dura la
respuesta transitoria y la respuesta tarda más en alcanzar su valor final, es decir, su valor en
el estado estacionario. En conclusión la constante de tiempo es un indicador de la rapidez
de la respuesta transitoria del sistema.
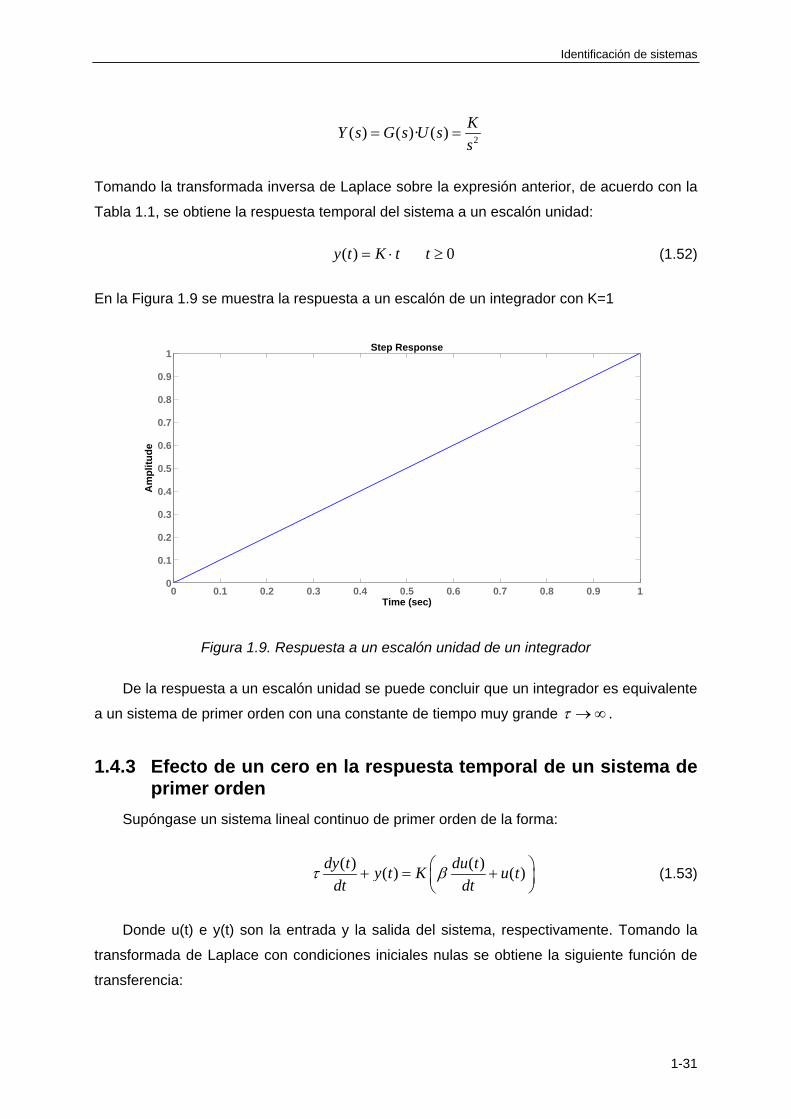
1.4.2 Integrador
Supóngase un sistema lineal continuo de primer orden de la forma:
( )( )
dy tKu t
dt (1.50)
Donde u(t) e y(t) son la entrada y la salida del sistema, respectivamente. Puesto que la
salida se obtiene integrando la entrada, a este sistema se le denomina integrador.
Tomando la transformada de Laplace con condiciones iniciales nulas se obtiene la
siguiente función de transferencia:
( )( )
( )
Y s KG s
U s s (1.51)
El sistema tiene un polo situado en el origen del plano s, es decir, en s=0. A este
elemento se le denomina integrador.
Si se excita (1.51) con una entrada escalón unidad (r(t)=1 o R(s)=1/s) la salida en el
dominio de Laplace es:
Identificación de sistemas
1-31
2( ) ( )· ( )
KY s G s U s
s
Tomando la transformada inversa de Laplace sobre la expresión anterior, de acuerdo con la
Tabla 1.1, se obtiene la respuesta temporal del sistema a un escalón unidad:
( ) 0y t K t t (1.52)
En la Figura 1.9 se muestra la respuesta a un escalón de un integrador con K=1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Step Response
Time (sec)
Am
plit
ud
e
Figura 1.9. Respuesta a un escalón unidad de un integrador
De la respuesta a un escalón unidad se puede concluir que un integrador es equivalente
a un sistema de primer orden con una constante de tiempo muy grande .
1.4.3 Efecto de un cero en la respuesta temporal de un sistema de primer orden
Supóngase un sistema lineal continuo de primer orden de la forma:
( ) ( )( ) ( )
dy t du ty t K u t
dt dt
(1.53)
Donde u(t) e y(t) son la entrada y la salida del sistema, respectivamente. Tomando la
transformada de Laplace con condiciones iniciales nulas se obtiene la siguiente función de
transferencia:

TEMA 1: Modelos de sistemas continuos y discretos
1-32
( ) 1( )
( ) 1
Y s sG s K
U s s
(1.54)
El sistema tiene un polo situado en s=-1/ y un cero situado en s=-1/. La aparición de
este cero es consecuencia de la existencia en la ecuación diferencial de la derivada de la
entrada.
Si se excita (1.54) con una entrada escalón unidad (r(t)=1 o R(s)=1/s) la salida en el
dominio de Laplace es:
1 1( ) ( )· ( )
1
sY s G s U s K
s s
Descomponiendo en fracciones simples se obtiene:
( )( ) ( )· ( )
1
K KY s G s U s
s s
Tomando la transformada inversa de Laplace sobre la expresión anterior, de acuerdo
con la Tabla 1.1, se obtiene la respuesta temporal del sistema a un escalón unidad:
( ) 1 1 0t
y t K e t
(1.55)
Se observa que si >0 conforme t aumenta la salida tiende asintóticamente al valor K,
es decir, a su ganancia en el estado estacionario. La presencia del cero no afecta a este
valor. Tampoco afecta a la estabilidad del sistema ya que no aparece en el término
exponencial.
En t=0 la salida toma el valor
·(0)
Ky
(1.56)
A diferencia del valor 0 que tomaba el sistema de primer orden cuando no existía un
cero. Esto es debido a que el sistema no es estrictamente causal, es decir, el orden del
denominador es igual que el orden del numerador de la función de transferencia.
Si <0, el valor inicial de la salida tiene signo contrario al valor que toma en el
estacionario. Este tipo de respuesta se denomina respuesta de fase no mínima o respuesta
Identificación de sistemas
1-33
inversa. Nótese que en este caso el cero se encuentra situado en el semiplano derecho del
plano s, se dice que se tiene un cero de fase no mínima.
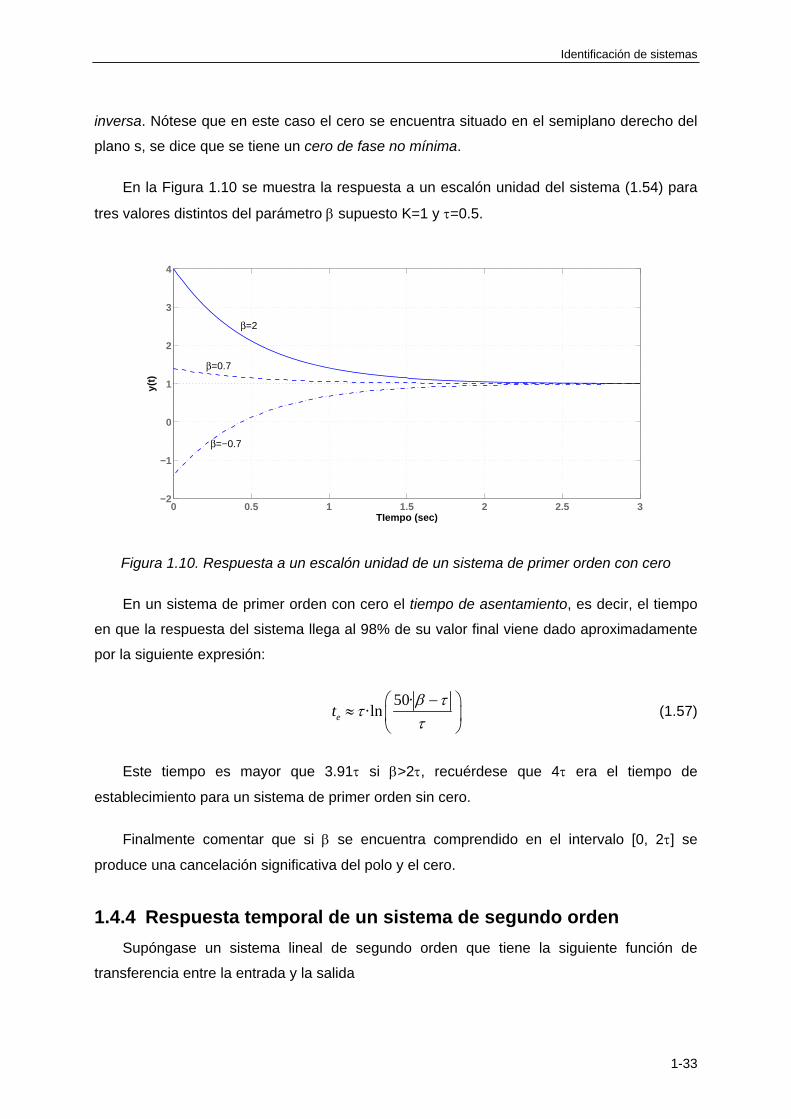
En la Figura 1.10 se muestra la respuesta a un escalón unidad del sistema (1.54) para
tres valores distintos del parámetro supuesto K=1 y =0.5.
0 0.5 1 1.5 2 2.5 3−2
−1
0
1
2
3
4
TIempo (sec)
y(t)
β=2
β=0.7
β=−0.7
Figura 1.10. Respuesta a un escalón unidad de un sistema de primer orden con cero
En un sistema de primer orden con cero el tiempo de asentamiento, es decir, el tiempo
en que la respuesta del sistema llega al 98% de su valor final viene dado aproximadamente
por la siguiente expresión:
50··lnet
(1.57)
Este tiempo es mayor que 3.91 si >2, recuérdese que 4 era el tiempo de
establecimiento para un sistema de primer orden sin cero.
Finalmente comentar que si se encuentra comprendido en el intervalo [0, 2] se
produce una cancelación significativa del polo y el cero.
1.4.4 Respuesta temporal de un sistema de segundo orden
Supóngase un sistema lineal de segundo orden que tiene la siguiente función de
transferencia entre la entrada y la salida

TEMA 1: Modelos de sistemas continuos y discretos
1-34
2
2 2
( ) ·( )
( ) 2· · ·n
n n
Y s KG s
R s s s
(1.58)
En la expresión anterior K es la ganancia estática, es el factor o coeficiente de
amortiguamiento (adimensional) y n es la frecuencia natural no amortiguada (rad/s). Este
sistema se puede expresar equivalentemente en la forma
)·()(
2
d
n
jssG
(1.59)
donde es la razón de amortiguamiento y d es la frecuencia amortiguada.
x
x
n
dj·
0
Imag
Real
Par de polos complejos conjugados
Figura 1.11. Representación en el plano complejo de un par de polos complejos conjugados
De acuerdo con la Figura 1.11 se establece la siguiente relación entre d, n y :
22d
2n (1.60)
Además el factor de amortiguamiento se relaciona con y con n mediante la expresión
n
cos (1.61)
Luego
n · (1.62)
Con lo que
Identificación de sistemas
1-35
2nd 1 (1.63)
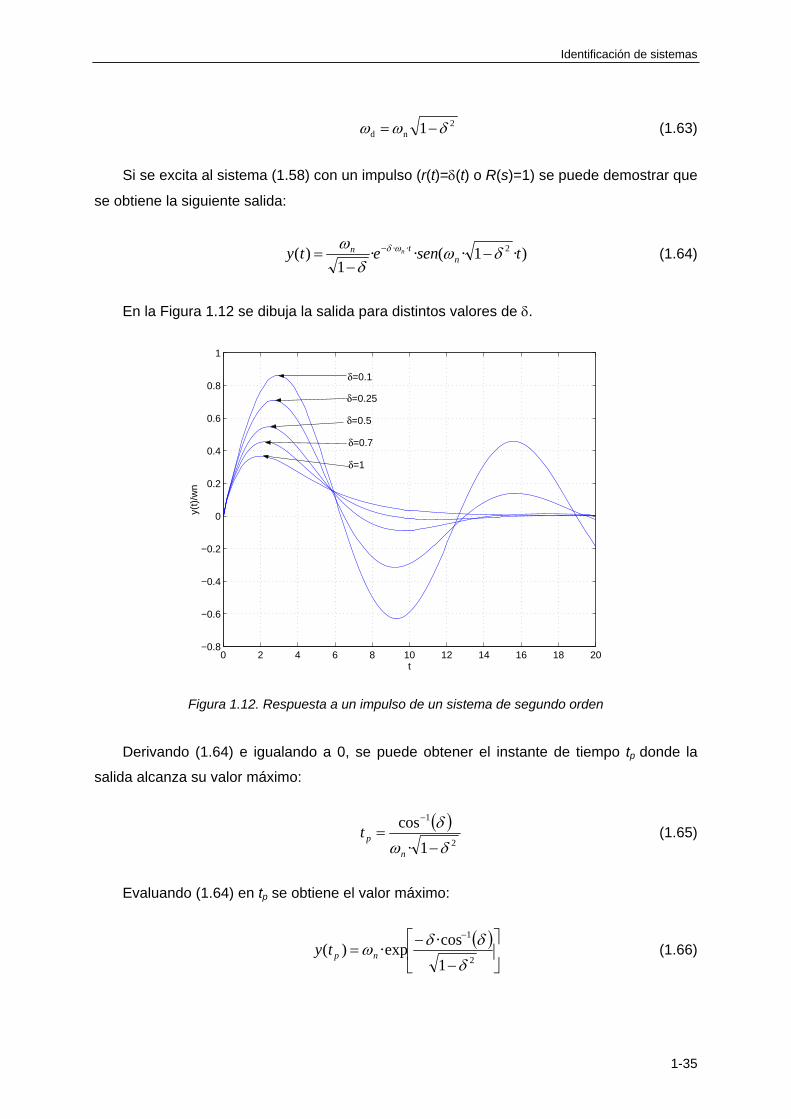
Si se excita al sistema (1.58) con un impulso (r(t)=(t) o R(s)=1) se puede demostrar que
se obtiene la siguiente salida:
)·1·(··1
)( 2·· tsenety ntn n
(1.64)
En la Figura 1.12 se dibuja la salida para distintos valores de .
0 2 4 6 8 10 12 14 16 18 20−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
t
y(t)
/wn
δ=0.7
δ=1
δ=0.1
δ=0.5
δ=0.25
Figura 1.12. Respuesta a un impulso de un sistema de segundo orden
Derivando (1.64) e igualando a 0, se puede obtener el instante de tiempo tp donde la
salida alcanza su valor máximo:
2
1
1·
cos
n
pt (1.65)
Evaluando (1.64) en tp se obtiene el valor máximo:
2
1
1
·cos·exp)(
npty (1.66)
TEMA 1: Modelos de sistemas continuos y discretos
1-36
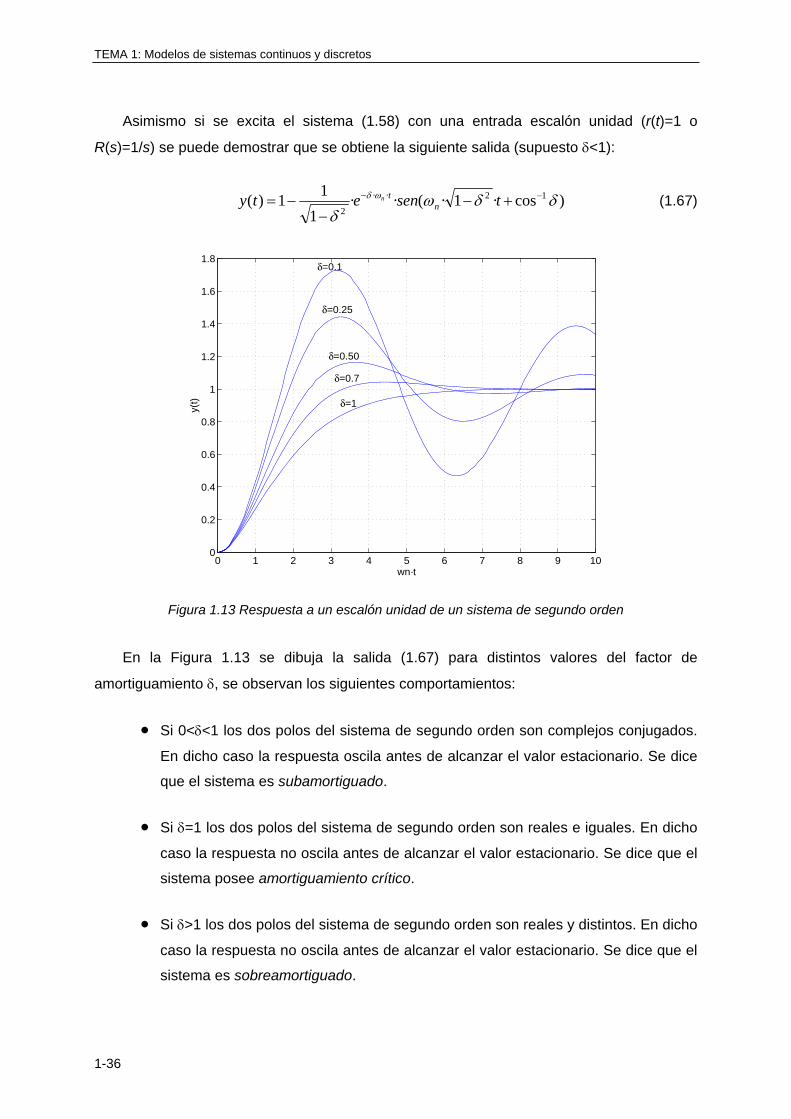
Asimismo si se excita el sistema (1.58) con una entrada escalón unidad (r(t)=1 o
R(s)=1/s) se puede demostrar que se obtiene la siguiente salida (supuesto <1):
)cos·1·(··1
11)( 12··
2
tsenety n
tn (1.67)
0 1 2 3 4 5 6 7 8 9 100
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
wn·t
y(t)
δ=0.50
δ=1
δ=0.25
δ=0.7
δ=0.1
Figura 1.13 Respuesta a un escalón unidad de un sistema de segundo orden
En la Figura 1.13 se dibuja la salida (1.67) para distintos valores del factor de
amortiguamiento , se observan los siguientes comportamientos:
Si 0<<1 los dos polos del sistema de segundo orden son complejos conjugados.
En dicho caso la respuesta oscila antes de alcanzar el valor estacionario. Se dice
que el sistema es subamortiguado.
Si =1 los dos polos del sistema de segundo orden son reales e iguales. En dicho
caso la respuesta no oscila antes de alcanzar el valor estacionario. Se dice que el
sistema posee amortiguamiento crítico.
Si >1 los dos polos del sistema de segundo orden son reales y distintos. En dicho
caso la respuesta no oscila antes de alcanzar el valor estacionario. Se dice que el
sistema es sobreamortiguado.

Identificación de sistemas
1-37
Si =0, los dos polos del sistema de segundo orden son complejos conjugados y
no poseen parte real. En dicho caso la respuesta oscila con una amplitud
constante y nunca alcanza el valor estacionario. Se dice que el sistema es
oscilante.
Si <0, el sistema es inestable y la respuesta es oscilante con oscilaciones de
amplitud cada vez mayor.
Si se deriva (1.67) y se iguala a 0 se puede obtener el instante de tiempo tp donde la
salida alcanza su valor máximo:
21·
n
pt (1.68)
Sustituyendo tp en (1.67) se obtiene el valor máximo o máxima sobrelongación de la
salida:
21
·exp1)(
ppp Myty (1.69)
Se define la sobreelongación relativa M0 como:
ss
ssp
y
yyM
0 (1.70)
Siendo yss el valor que la salida alcanza en el estado estacionario.
1.4.5 Efecto de un cero en la respuesta temporal de un sistema de segundo orden
Supóngase un sistema lineal de segundo orden que tiene la siguiente función de
transferencia entre la entrada y la salida
2
2 2
( ) · ( 1)( )
( ) 2· · ·n
n n
Y s K sG s
U s s s
(1.71)
En la expresión anterior K es la ganancia estática, es el factor o coeficiente de
amortiguamiento (adimensional), n es la frecuencia natural no amortiguada (rad/s) y es la
constante de tiempo del cero s=-1/.

TEMA 1: Modelos de sistemas continuos y discretos
1-38
Este sistema se puede expresar equivalentemente en la forma
2 2( ) ( ) ( )G s G s sG s (1.72)
Donde
2
2 2 2
·( )
2· · ·n
n n
KG s
s s
(1.73)
Si se excita (1.71) con una entrada escalón unidad (r(t)=1 o R(s)=1/s) la salida en el
dominio de Laplace es:
2 2 2 2
1 1( ) ( )· ( ) ( ) ( ) ( ) ( )Y s G s U s G s sG s Y s sY s
s s
Donde
2 2
1( ) ( )Y s G s
s
Es decir, Y2(s) es la transformada de Laplace de y2(t) que es la respuesta a un escalón
unidad de un sistema de segundo orden sin cero. Aplicando la transformada inversa de
Laplace con condiciones iniciales nulas se obtiene que la respuesta a un escalón unidad del
sistema de segundo orden con cero (1.71) es:
22
( )( ) ( )
dy ty t y t
dt
Luego se observa que dicha respuesta es igual a la respuesta del sistema de segundo
orden sin cero más la derivada de esta señal ponderada por la constante de tiempo del
cero.
Si el sistema es sobreamortiguado, la función de transferencia pasa a tener la siguiente
forma:
2
1 2
( ) · ( 1)( )
( ) ( 1)( 1)nY s K s
G sU s s s
(1.74)
Donde 1 y 2 son las constantes de tiempo de los dos polos reales. En este caso la
respuesta a un escalón se verá afectada por la posición relativa del cero con respecto a los

Identificación de sistemas
1-39
polos. Señalar que si un cero se sitúa cerca de un polo se cancelan en gran medida los
efectos de los dos elementos en la respuesta.
Tanto si se tiene un sistema sobreamortiguado como subamortiguado, la derivada de la
salida no es nula en t=0, al contrario de lo que sucede en un sistema de segundo orden sin
cero.
La respuesta de un sistema de segundo orden con cero se clasifica en dos tipos
atendiendo al signo de la constante de tiempo del cero:
Si >0 el cero s=-1/ se encuentra situado en el semiplano izquierdo del plano s
y el sistema se dice que es de fase mínima. En este caso la respuesta temporal
se verá afectada en forma de un aumento en la rapidez de la respuesta y en la
sobreoscilación. Se distinguen los siguientes casos:
1. Si >2>1. La respuesta presenta una sobreoscilación tanto más
acusada cuanto más se acerca el cero al origen respecto a la posición de
los polos.
2. Si 2>>1. La respuesta se puede aproximar a la de un sistema de
primer orden con polo s=-1/1, aunque debido a la cancelación del cero y
el polo se produce un transitorio de pequeña magnitud que produce una
deriva lenta de la salida hacia su situación en estado estacionario.
3. Si 2>>1. La presencia del cero tiende a acelerar la respuesta respecto
al caso sin cero. Si el cero está cerca del polo más alejado del origen, la
respuesta cada vez más se aproximará más a la de un sistema de primer
orden con constante de tiempo 2. En este caso no se produce una
deriva lenta de la salida hacia su estado estacionario porque la dinámica
despreciada se anula rápidamente.
4. Si 2>1>. Al alejar el cero del origen del plano complejo (y de los polos),
la respuesta tiende a la que tendría el sistema de segundo orden con los
mismos polos pero sin el cero.
Si <0 el cero s=-1/ se encuentra situado en el semiplano derecho del plano s y
el sistema se dice que es de fase no mínima. En este caso en la respuesta
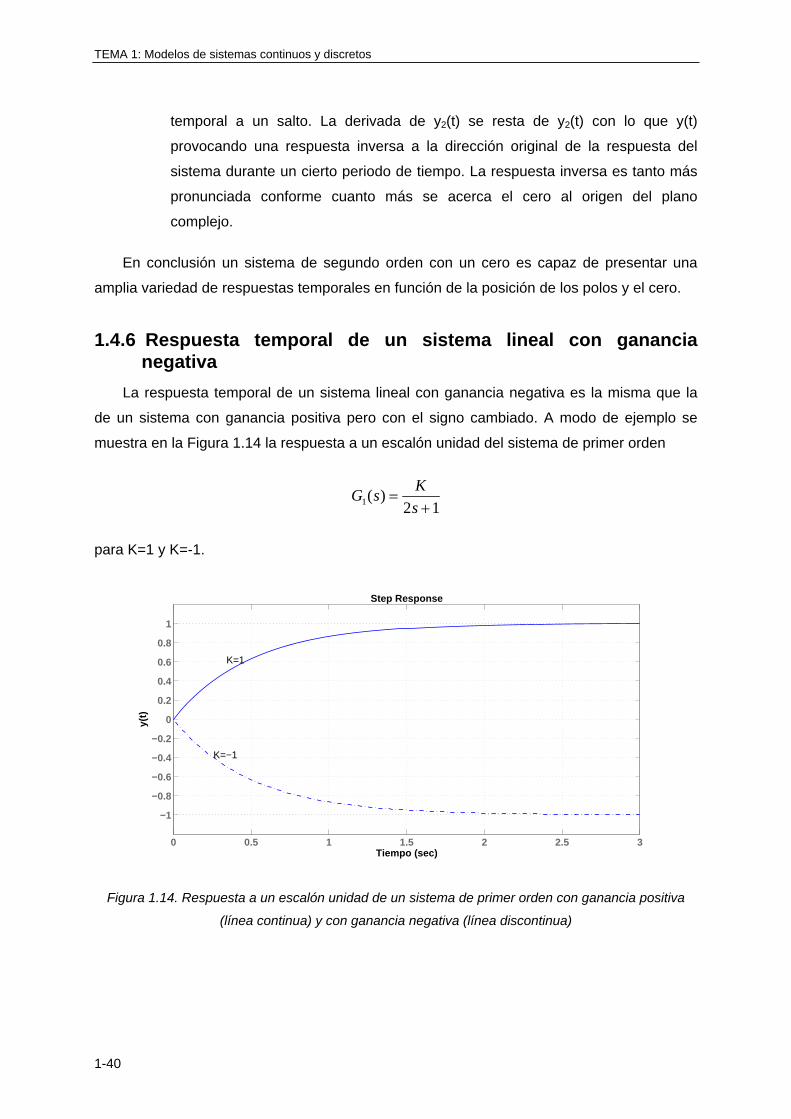
TEMA 1: Modelos de sistemas continuos y discretos
1-40
temporal a un salto. La derivada de y2(t) se resta de y2(t) con lo que y(t)
provocando una respuesta inversa a la dirección original de la respuesta del
sistema durante un cierto periodo de tiempo. La respuesta inversa es tanto más
pronunciada conforme cuanto más se acerca el cero al origen del plano
complejo.
En conclusión un sistema de segundo orden con un cero es capaz de presentar una
amplia variedad de respuestas temporales en función de la posición de los polos y el cero.
1.4.6 Respuesta temporal de un sistema lineal con ganancia negativa
La respuesta temporal de un sistema lineal con ganancia negativa es la misma que la
de un sistema con ganancia positiva pero con el signo cambiado. A modo de ejemplo se
muestra en la Figura 1.14 la respuesta a un escalón unidad del sistema de primer orden
1( )2 1
KG s
s
para K=1 y K=-1.
0 0.5 1 1.5 2 2.5 3
−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Step Response
Tiempo (sec)
y(t)
K=1
K=−1
Figura 1.14. Respuesta a un escalón unidad de un sistema de primer orden con ganancia positiva
(línea continua) y con ganancia negativa (línea discontinua)
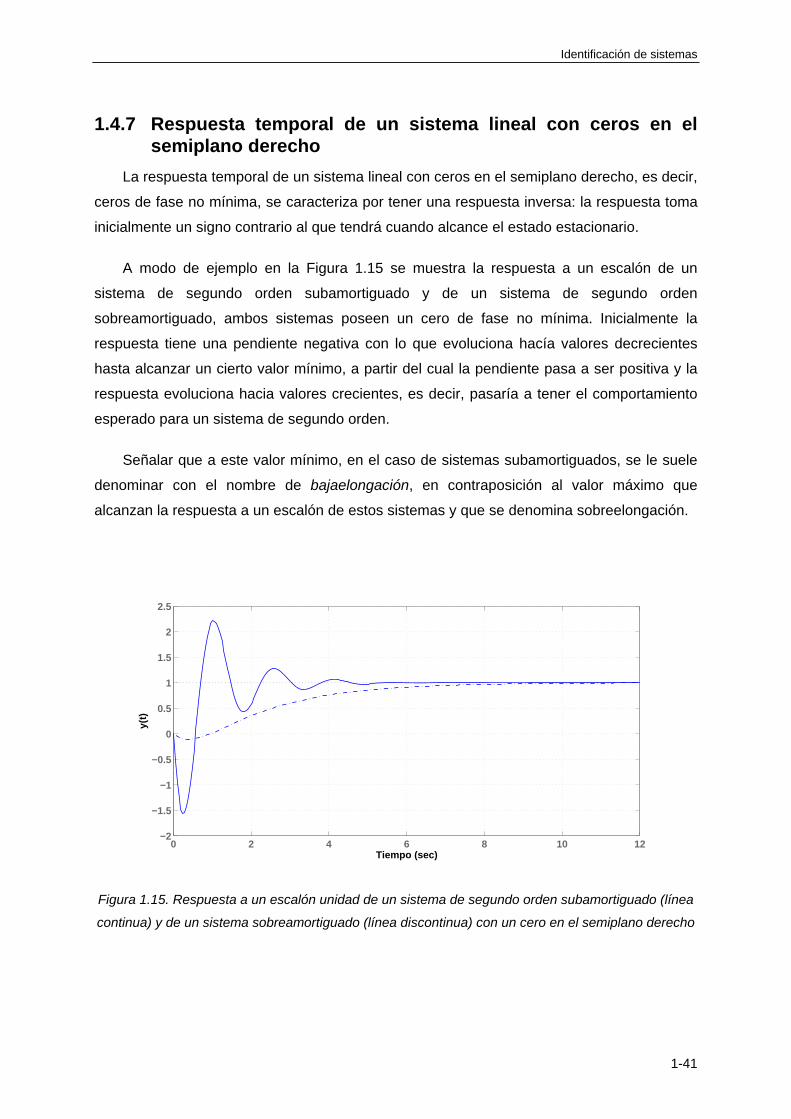
Identificación de sistemas
1-41
1.4.7 Respuesta temporal de un sistema lineal con ceros en el semiplano derecho
La respuesta temporal de un sistema lineal con ceros en el semiplano derecho, es decir,
ceros de fase no mínima, se caracteriza por tener una respuesta inversa: la respuesta toma
inicialmente un signo contrario al que tendrá cuando alcance el estado estacionario.
A modo de ejemplo en la Figura 1.15 se muestra la respuesta a un escalón de un
sistema de segundo orden subamortiguado y de un sistema de segundo orden
sobreamortiguado, ambos sistemas poseen un cero de fase no mínima. Inicialmente la
respuesta tiene una pendiente negativa con lo que evoluciona hacía valores decrecientes
hasta alcanzar un cierto valor mínimo, a partir del cual la pendiente pasa a ser positiva y la
respuesta evoluciona hacia valores crecientes, es decir, pasaría a tener el comportamiento
esperado para un sistema de segundo orden.
Señalar que a este valor mínimo, en el caso de sistemas subamortiguados, se le suele
denominar con el nombre de bajaelongación, en contraposición al valor máximo que
alcanzan la respuesta a un escalón de estos sistemas y que se denomina sobreelongación.
Tiempo (sec)
y(t)
0 2 4 6 8 10 12−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
2.5
Figura 1.15. Respuesta a un escalón unidad de un sistema de segundo orden subamortiguado (línea
continua) y de un sistema sobreamortiguado (línea discontinua) con un cero en el semiplano derecho

TEMA 1: Modelos de sistemas continuos y discretos
1-42
1.4.8 Respuesta temporal de un sistema lineal con retardo
Se dice que un sistema de una entrada y una salida posee un retardo (delay), también
denominado tiempo muerto (dead time) o retraso de transporte (transport lag) td si al ser
excitado en el instante t0 en su entrada el sistema comienza a generar una salida a partir del
instante t0+ td.
Muchos procesos en la industria, así como en otras áreas, presentan retardos en su
comportamiento dinámico. Los retardos son causados principalmente por fenómenos de
transporte de información, energía o masa.
Los retardos tienen una gran influencia (generalmente negativa) en la estabilidad de los
sistemas en lazo cerrado. Además la existencia de retardos dificulta el diseño y análisis de
controladores ya que cada acción realizada por la señal de control sobre la variable
manipulada del proceso solo comenzará a afectar a la variable controlada cuando haya
transcurrido el tiempo de retardo.
La respuesta temporal de un sistema lineal con retardo es la misma que la respuesta
temporal del sistema si no existiera retardo pero retrasada un tiempo td. Se va ilustrar este
hecho con un sistema lineal continuo de primer orden de la forma:
( )( ) ( )d
dy ty t Ku t t
dt (1.75)
donde u(t) e y(t) son la entrada y la salida del sistema, respectivamente. Además K es la
ganancia estática, la constante de tiempo, y td el tiempo que tarda el sistema en responder
a la entrada o tiempo de retardo. Tomando la transformada de Laplace con condiciones
iniciales nulas se obtiene:
( ) ( ) ( )dt ssY s Y s Ke U s (1.76)
Reorganizando se obtiene la siguiente función de transferencia:
( )( )
( ) 1dt sY s K
G s eU s s
(1.77)
Si se compara esta función de transferencia con la función de transferencia (1.42) se
observa que la existencia de un tiempo de retardo td introduce el término exponencial dt se .
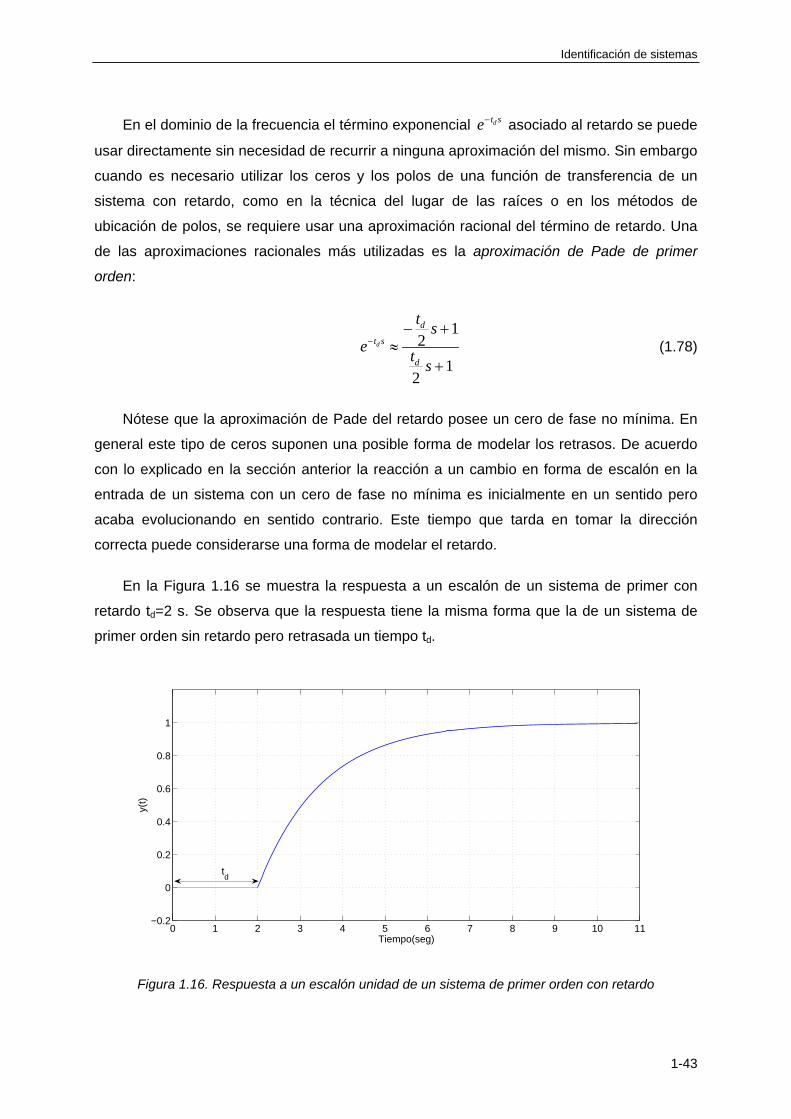
Identificación de sistemas
1-43
En el dominio de la frecuencia el término exponencial dt se asociado al retardo se puede
usar directamente sin necesidad de recurrir a ninguna aproximación del mismo. Sin embargo
cuando es necesario utilizar los ceros y los polos de una función de transferencia de un
sistema con retardo, como en la técnica del lugar de las raíces o en los métodos de
ubicación de polos, se requiere usar una aproximación racional del término de retardo. Una
de las aproximaciones racionales más utilizadas es la aproximación de Pade de primer
orden:
12
12
d
d
t s
d
ts
et
s
(1.78)
Nótese que la aproximación de Pade del retardo posee un cero de fase no mínima. En
general este tipo de ceros suponen una posible forma de modelar los retrasos. De acuerdo
con lo explicado en la sección anterior la reacción a un cambio en forma de escalón en la
entrada de un sistema con un cero de fase no mínima es inicialmente en un sentido pero
acaba evolucionando en sentido contrario. Este tiempo que tarda en tomar la dirección
correcta puede considerarse una forma de modelar el retardo.
En la Figura 1.16 se muestra la respuesta a un escalón de un sistema de primer con
retardo td=2 s. Se observa que la respuesta tiene la misma forma que la de un sistema de
primer orden sin retardo pero retrasada un tiempo td.
0 1 2 3 4 5 6 7 8 9 10 11−0.2
0
0.2
0.4
0.6
0.8
1
Tiempo(seg)
y(t)
td
Figura 1.16. Respuesta a un escalón unidad de un sistema de primer orden con retardo
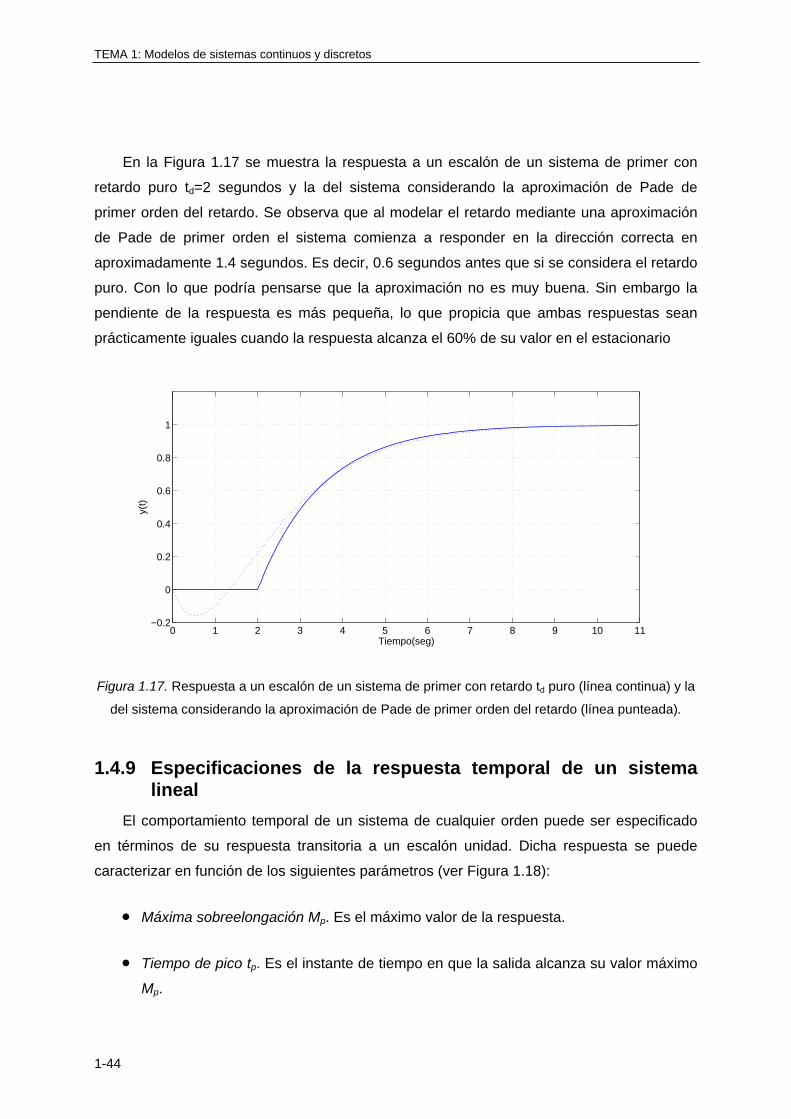
TEMA 1: Modelos de sistemas continuos y discretos
1-44
En la Figura 1.17 se muestra la respuesta a un escalón de un sistema de primer con
retardo puro td=2 segundos y la del sistema considerando la aproximación de Pade de
primer orden del retardo. Se observa que al modelar el retardo mediante una aproximación
de Pade de primer orden el sistema comienza a responder en la dirección correcta en
aproximadamente 1.4 segundos. Es decir, 0.6 segundos antes que si se considera el retardo
puro. Con lo que podría pensarse que la aproximación no es muy buena. Sin embargo la
pendiente de la respuesta es más pequeña, lo que propicia que ambas respuestas sean
prácticamente iguales cuando la respuesta alcanza el 60% de su valor en el estacionario
0 1 2 3 4 5 6 7 8 9 10 11−0.2
0
0.2
0.4
0.6
0.8
1
Tiempo(seg)
y(t)
Figura 1.17. Respuesta a un escalón de un sistema de primer con retardo td puro (línea continua) y la
del sistema considerando la aproximación de Pade de primer orden del retardo (línea punteada).
1.4.9 Especificaciones de la respuesta temporal de un sistema lineal
El comportamiento temporal de un sistema de cualquier orden puede ser especificado
en términos de su respuesta transitoria a un escalón unidad. Dicha respuesta se puede
caracterizar en función de los siguientes parámetros (ver Figura 1.18):
Máxima sobreelongación Mp. Es el máximo valor de la respuesta.
Tiempo de pico tp. Es el instante de tiempo en que la salida alcanza su valor máximo
Mp.
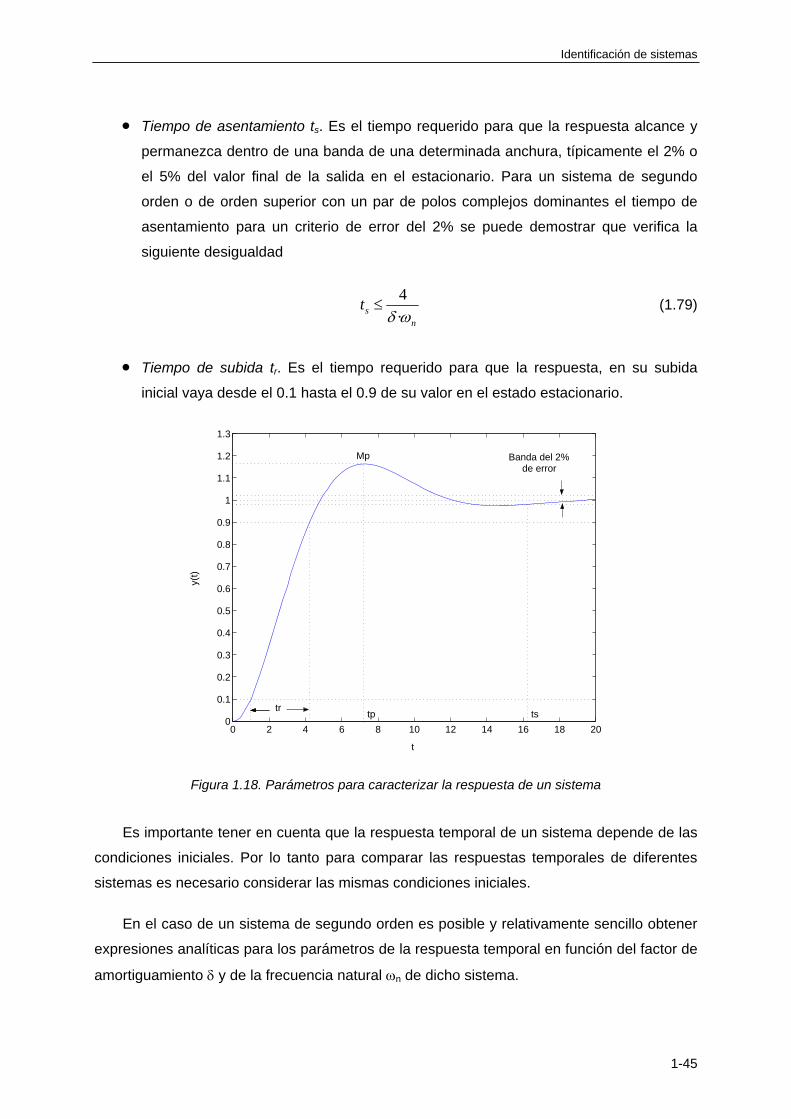
Identificación de sistemas
1-45
Tiempo de asentamiento ts. Es el tiempo requerido para que la respuesta alcance y
permanezca dentro de una banda de una determinada anchura, típicamente el 2% o
el 5% del valor final de la salida en el estacionario. Para un sistema de segundo
orden o de orden superior con un par de polos complejos dominantes el tiempo de
asentamiento para un criterio de error del 2% se puede demostrar que verifica la
siguiente desigualdad
nst ·
4 (1.79)
Tiempo de subida tr. Es el tiempo requerido para que la respuesta, en su subida
inicial vaya desde el 0.1 hasta el 0.9 de su valor en el estado estacionario.
0 2 4 6 8 10 12 14 16 18 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
t
y(t)
tr ts tp
Banda del 2% de error
Mp
Figura 1.18. Parámetros para caracterizar la respuesta de un sistema
Es importante tener en cuenta que la respuesta temporal de un sistema depende de las
condiciones iniciales. Por lo tanto para comparar las respuestas temporales de diferentes
sistemas es necesario considerar las mismas condiciones iniciales.
En el caso de un sistema de segundo orden es posible y relativamente sencillo obtener
expresiones analíticas para los parámetros de la respuesta temporal en función del factor de
amortiguamiento y de la frecuencia natural n de dicho sistema.

TEMA 1: Modelos de sistemas continuos y discretos
1-46
En sistemas de orden superior a dos su obtención es más tediosa. Sin embargo si un
sistema G(s) de orden superior a dos posee un par de polos complejos dominantes, que son
aquellos cuya parte real se encuentra situada más cerca del eje imaginario que la del resto
de polos del sistema, entonces su respuesta puede ser aproximada por la de un sistema con
función de transferencia Gr(s) que contiene exclusivamente dichos polos dominantes y con
ganancia igual a la del sistema original G(s).
En consecuencia si un sistema tiene uno o dos polos dominantes, su respuesta a un
escalón puede determinarse a partir de los resultados analizados en las secciones
anteriores para sistemas de primer y segundo orden. Obviamente para realizar la
aproximación se debe tener en cuenta la presencia de ceros que estén a una distancia del
eje imaginario comparable, o inferior, a la de los polos dominantes.
Si el sistema tiene un par de polos dominantes con comportamiento subamortiguado es
posible estimar el factor de amortiguamiento y la frecuencia natural n de estos polos si se
dispone de los valores de la sobreelongación Mp y tiempo de asentamiento ts de la respuesta
a un escalón del sistema mediante las siguientes expresiones:
22
2
)1ln(
)1ln(
p
p
M
M (1.80)
4
·nst
(1.81)
1.5 CONSIDERACIONES BÁSICAS SOBRE LA RESPUESTA FRECUENCIAL DE UN SISTEMA LINEAL
1.5.1 Definición de respuesta en frecuencia de un sistema lineal
Se denomina función de transferencia en el dominio de la frecuencia o más
abreviadamente función de frecuencia o respuesta en frecuencia del sistema a la función
G(j) que se obtiene sustituyendo s por j en la función de transferencia del sistema.
G(j) es una función compleja que puede descomponerse en la suma de su parte real
(Re) y su parte imaginaria (Im).
( ) Re[ ( )] Im[ ( )]G j G j j G j (1.82)
De forma equivalente G(j) puede expresarse de la siguiente forma:

Identificación de sistemas
1-47
arg ( )( ) ( )· j G jG j G j e (1.83)
donde:
2 2( ) (Re[ ( )]) (Im[ ( )])G j G j G j (1.84)
Im[ ( )]arg ( ) arctan
Re[ ( )]
G jG j
G j
(1.85)
( )G j es el módulo, amplitud o magnitud y arg ( )G j es el argumento o fase.
Para un sistema lineal G(s) con una entrada u(t) y una salida y(t), se cumple que
( ) ( )· ( )Y s G s U s (1.86)
Haciendo s=j se obtiene
( ) ( )· ( )Y j G j U j (1.87)
Que se puede expresar equivalentemente en la forma:
arg ( ) arg ( ) arg ( )( )· ( )· ( )·j Y j j G j j U jY j e G j e U j e
De la que se deducen las siguientes expresiones para la magnitud y la fase de G(j):
( )( )
( )
Y jG j
U j
arg ( ) arg ( ) arg ( )G j Y j U j
Es decir | ( ) |G j se determina como el cociente entre la amplitud de la señal de salida
y la amplitud de la señal de entrada. Mientras que la fase arg ( )G j se determina como la
diferencia entre la fase de la señal de salida menos la fase de la señal de entrada.

TEMA 1: Modelos de sistemas continuos y discretos
1-48
1.5.2 Representación gráfica de la respuesta en frecuencia de un sistema
1.5.2.1 Magnitud logarítmica
La magnitud logarítmica (logarithmic magnitude (Lm)) se define de la siguiente forma:
)(·log20))(( 10 jGjGLm (1.88)
y sus unidades son los decibelios (dB).
Algunas propiedades útiles de la magnitud logarítmica son:
El valor en decibelios de números recíprocos difieren sólo en un signo. Por
ejemplo Lm(2)= 6.02 dB y Lm (½ )= -6.02 dB.
Cuando un número se duplica su valor en dB aumenta en 6 dB. Por ejemplo,
como Lm(0.5)= -6.02 dB entonces Lm(2·0.5)= Lm(2)+Lm(0.5)=6.02 -6.02= 0 dB
Cuando un número se multiplica en un factor de 10 su valor en dB se incrementa
en 20 dB. Por ejemplo, como Lm(10)= 20 dB entonces
Lm(10*10)=Lm(10)+Lm(10)=20+20= 40 dB.
1.5.2.2 Octava y década
Se dice que el rango o banda de frecuencias [f1, f2] posee una anchura de una octava si
se verifica que f2/f1=2. Por ejemplo la banda de frecuencia [1, 2] (Hz) posee una anchura de
una octava en anchura, al igual que la banda [17.4, 34.8] (Hz). El número de octavas en el
rango de frecuencia [f1, f2] es
1
210
10
1210 ·log32.32log
)/(log
f
fff octavas (1.89)
Se dice que el rango o banda de frecuencias [f1, f2] posee una anchura de una década si
se verifica que f2/f1=10. Por ejemplo la banda de frecuencia [1, 10] (Hz) posee una anchura
de una década en anchura, al igual que la banda [2.5, 25] (Hz). El número de décadas en el
rango de frecuencia [f1, f2] es
1
210log
f
f décadas (1.90)

Identificación de sistemas
1-49
1.5.2.3 Tipos de diagramas en el dominio de la frecuencia
La función de transferencia en el dominio de la frecuencia de un sistema se suele
representar, principalmente, en tres tipos de diagramas:
Diagrama de Nyquist o diagrama polar. En el eje de abscisas se representa la parte
real de G(j) y en el eje de ordenadas se representa su parte imaginaria. A este
plano se le denomina también plano complejo.
Diagrama de Bode. Consta de dos gráficas. La primera gráfica representa la
magnitud logarítmica Lm(G(j)) en función de la frecuencia . En el eje de abscisas
se usa escala logarítmica y en el eje de ordenadas escala lineal. La segunda gráfica
representa la fase arg(G(j)) expresada en grados en función de la frecuencia .
Tanto en el eje de abscisas como en el de ordenadas se usa escala lineal.
Diagrama de Nichols. En el eje de abscisas se representa la fase arg(G(j)) en
grados y en el eje de ordenadas se representa la magnitud logarítmica Lm(G(j)).
Tanto en el eje de abscisas como en el de ordenadas se usa escala lineal.
1.5.2.4 Conceptos importantes asociados a las representaciones de la respuesta en frecuencia
Existen varios conceptos importantes asociados a las representaciones de la respuesta
del sistema en el dominio de la frecuencia:
Frecuencia de corte c (rad/s). Para sistemas cuya amplitud a bajas frecuencias
es un valor constante no nulo, es decir, el sistema no tiene en ni polos ni ceros en
el origen, la frecuencia de corte se define como la frecuencia a partir de la cual la
amplitud del sistema se reduce en 3 dB (70.7 %) respecto a la amplitud en =0.
1( · ) ( ·0)
2cG j G j
10 10
10 10
1( ( · )) 20 log ( · ) 20 log ( ·0)
2
120 log 20 log ( ·0)
23.0103 ( ( ·0))
c cLm G j G j G j
G j
Lm G j

TEMA 1: Modelos de sistemas continuos y discretos
1-50
Frecuencia esquina e (rad/s). Es aquella frecuencia o frecuencias en las que la
aproximación asintótica de la respuesta en frecuencia de un polo o un cero
cambia de pendiente.
Ancho de banda o banda pasante. Es el rango de frecuencias por debajo de la
frecuencia de corte:
0 c
Para sistemas con un comportamiento de filtro pasa-baja, es decir, que dejan
pasar las bajas frecuencias y atenúan las altas frecuencias, su ganancia a bajas
frecuencias será un valor constante distinto de cero. Para dichos sistemas el
ancho de banda coincide con la frecuencia de corte.
Para sistemas con un comportamiento de filtro pasa-alta, es decir, que dejan
pasar las altas frecuencias y atenúan las bajas frecuencias, la ganancia de
referencia para calcular el ancho de banda es la ganancia a alta frecuencia.
Para sistemas con un comportamiento de filtro pasa-banda, es decir, que dejan
pasar una banda de frecuencia pero atenúan las bajas y las altas frecuencias, el
ancho de banda es la diferencia entras las frecuencias en las que su atenuación al
pasar a través del sistema se mantiene igual o inferior a 3 dB comparada con la
frecuencia principal, que se suele tomar como la central de la banda.
El ancho de banda de un sistema da una indicación de las propiedades de la
respuesta transitoria de un sistema de control, así como de las características al
filtrado de ruido.
El ancho de banda es una medida de la posibilidad que tiene el sistema de
reproducir fielmente una señal de entrada. Generalmente la respuesta del sistema
para valores de frecuencia superiores al ancho de banda estará atenuada.
El ancho de banda es además una medida directa de la sensibilidad del sistema al
ruido (un ancho de banda muy grande indica que el sistema es muy sensible a los
ruidos de alta frecuencia).

Identificación de sistemas
1-51
1.5.3 Respuesta frecuencial de un sistema lineal genérico continuo
La función de transferencia de un sistema lineal en tiempo continuo puede expresarse
de la siguiente forma general:
2
21 1
2
21 1
2( 1) 1
( )2
( 1) 1
d
q rl
ll l t snl nl
p hN i
ii i ni ni
s sK s
G s es s
s s
(1.91)
Se observa que esta función de transferencia posee los siguientes factores individuales:
una ganancia K, q ceros reales, r pares de ceros complejos conjugados, N polos en el origen
(integradores), p polos reales, h pares de polos complejos conjugados y un tiempo de
retardo td.
Sustituyendo s por j en (1.91) se obtiene lo siguiente:
2
1 1
2
1 1
2( 1) 1
( )2
( ) ( 1) 1
d
q rl
ll l nl nl t j
p hN i
ii i ni ni
jK j j
G j ej
j j j
(1.92)
La magnitud logarítmica de G(j) se obtiene como la suma de las magnitudes
logarítmicas de cada uno de los factores individuales de que consta la función de
transferencia:
2
1 1
2
1 1
2( ( )) ( ) ( 1) 1
2(( ) ) ( 1) 1
q rl
ll l nl nl
p hN i
ii i ni ni
jLm G j Lm K Lm j Lm j
jLm j Lm j Lm j
(1.93)
Por su parte la fase de G(j) expresada en grados se obtiene como la suma de las
fases de cada uno de los factores individuales de que consta la función de transferencia:

TEMA 1: Modelos de sistemas continuos y discretos
1-52
2
1 1
2
1 1
2arg( ( )) arg( 1) arg 1 arg(( ) )
2arg( 1) arg 1 arg( )d
q rNl
ll l nl nl
p hj ti
ii i ni ni
jG j j j j
jj j e
(1.94)
Se concluye por tanto que el diagrama de Bode de un sistema genérico se puede
obtener sumando la gráfica debida a cada factor individual.
En las siguientes secciones se describe la respuesta frecuencial de cada uno de los
posibles factores que pueden formar parte de una función de transferencia: ganancia,
integrador, derivador, elemento de retardo, polo real, cero real, par de polos complejos
conjugados y par de ceros complejos conjugados.
1.5.4 Respuesta frecuencial de una constante
Supóngase una constante:
K (1.95)
La magnitud logarítmica y la fase de una constante son:
1020·logLmK K (1.96)
0 0arg
180º 0
KK
K
(1.97)
Se observa que tanto la magnitud logarítmica como la fase son independientes de la
frecuencia. En consecuencia el diagrama de Bode de una constante es una línea horizontal
en la curva de magnitud y otra línea horizontal en la curva de fase.
1.5.5 Respuesta frecuencial de un integrador
Supóngase N polos en el origen o integradores:
1Ns
(1.98)
Sustituyendo s por j se obtiene la respuesta en frecuencia:
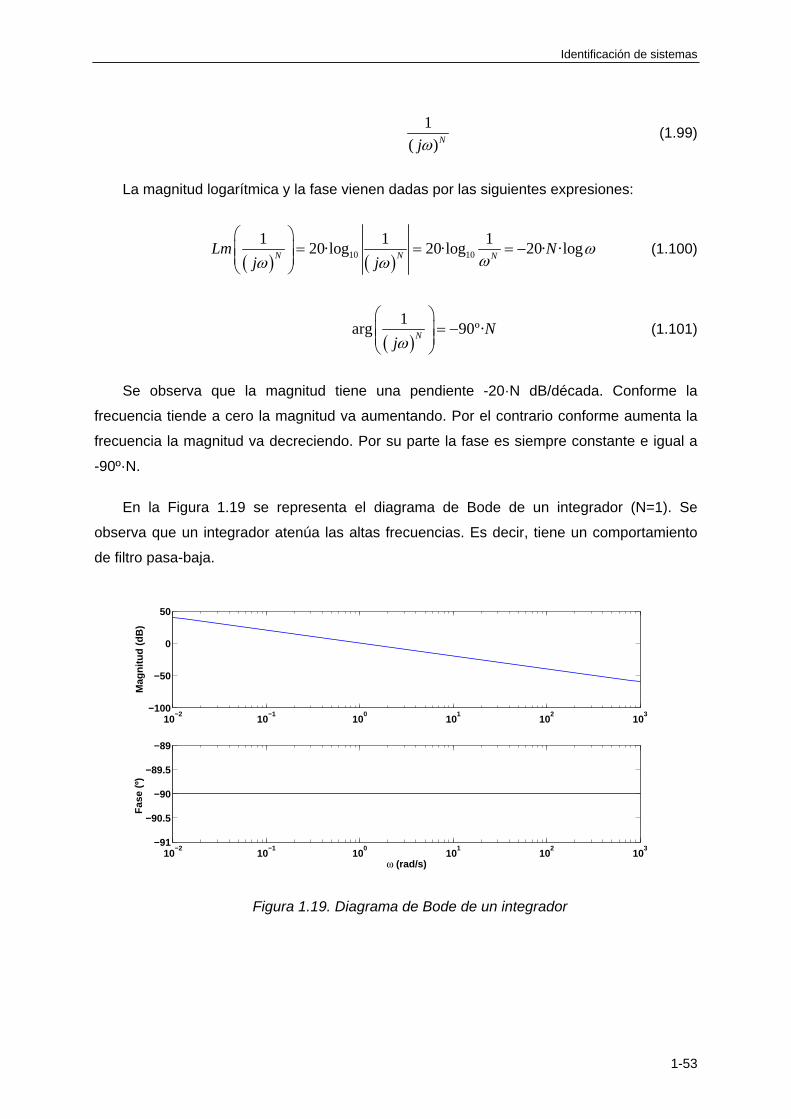
Identificación de sistemas
1-53
1
( )Nj (1.99)
La magnitud logarítmica y la fase vienen dadas por las siguientes expresiones:
10 10
1 1 120·log 20·log 20· ·logN N N
Lm Nj j
(1.100)
1
arg 90º·N Nj
(1.101)
Se observa que la magnitud tiene una pendiente -20·N dB/década. Conforme la
frecuencia tiende a cero la magnitud va aumentando. Por el contrario conforme aumenta la
frecuencia la magnitud va decreciendo. Por su parte la fase es siempre constante e igual a
-90º·N.
En la Figura 1.19 se representa el diagrama de Bode de un integrador (N=1). Se
observa que un integrador atenúa las altas frecuencias. Es decir, tiene un comportamiento
de filtro pasa-baja.
10−2
10−1
100
101
102
103
−100
−50
0
50
Mag
nit
ud
(d
B)
10−2
10−1
100
101
102
103
−91
−90.5
−90
−89.5
−89
ω (rad/s)
Fas
e (º
)
Figura 1.19. Diagrama de Bode de un integrador
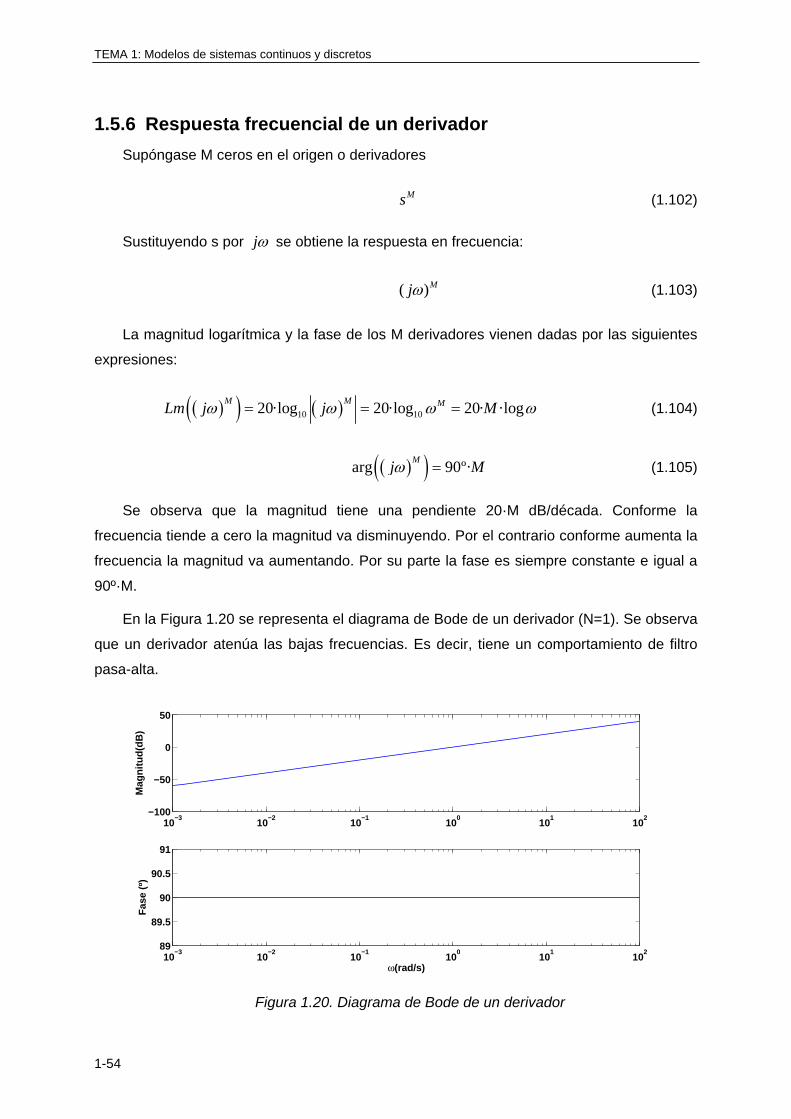
TEMA 1: Modelos de sistemas continuos y discretos
1-54
1.5.6 Respuesta frecuencial de un derivador
Supóngase M ceros en el origen o derivadores
Ms (1.102)
Sustituyendo s por j se obtiene la respuesta en frecuencia:
( )Mj (1.103)
La magnitud logarítmica y la fase de los M derivadores vienen dadas por las siguientes
expresiones:
10 1020·log 20·log 20· ·logM M MLm j j M (1.104)
arg 90º·M
j M (1.105)
Se observa que la magnitud tiene una pendiente 20·M dB/década. Conforme la
frecuencia tiende a cero la magnitud va disminuyendo. Por el contrario conforme aumenta la
frecuencia la magnitud va aumentando. Por su parte la fase es siempre constante e igual a
90º·M.
En la Figura 1.20 se representa el diagrama de Bode de un derivador (N=1). Se observa
que un derivador atenúa las bajas frecuencias. Es decir, tiene un comportamiento de filtro
pasa-alta.
10−3
10−2
10−1
100
101
102
−100
−50
0
50
Mag
nit
ud
(dB
)
10−3
10−2
10−1
100
101
102
89
89.5
90
90.5
91
ω(rad/s)
Fas
e (º
)
Figura 1.20. Diagrama de Bode de un derivador

Identificación de sistemas
1-55
1.5.7 Respuesta frecuencial de un elemento de retardo
Supóngase un retardo puro td
dste (1.106)
Sustituyendo s por j se obtiene la respuesta en frecuencia:
dj te (1.107)
La magnitud logarítmica y la fase del elemento de retardo vienen dadas por las
siguientes expresiones:
10 1020·log 20·log 1 0dj t j tdLm e e (1.108)
arg dj tde t (1.109)
Se observa que un elemento de retardo no contribuye a la magnitud de un sistema pues
tienen magnitud 1 (0 dB) pero introduce un desfase lineal con la frecuencia.
En la Figura 1.21 se representa el diagrama de Bode de un elemento de retardo con
td=2.
10−2
10−1
100
101
102
−1
0
1
Mag
nit
ud
(d
B)
10−2
10−1
100
101
102
−15000
−10000
−5000
0
ω (rad/s)
Fas
e (º
)
Figura 1.21. Diagrama de Bode de un elemento de retardo con td=2
Los tiempos de retardo tienen una gran influencia en la respuesta en frecuencia de un
sistema, puesto que constituyen un elemento de fase no mínima, que contribuye con un
decremento extra de la fase el cual puede causar inestabilidad

TEMA 1: Modelos de sistemas continuos y discretos
1-56
1.5.8 Respuesta frecuencial de un polo real: sistema de primer orden
Considérese un polo real:
1
· 1s (1.110)
Sustituyendo s por j se obtiene la respuesta en frecuencia:
1
· 1j (1.111)
La magnitud logarítmica y la fase vienen dadas por las siguientes expresiones:
10 10 2 2
2 210
1 1 120log 20log
1 1 1
10log ( 1)
Lmj j
(1.112)
1arg arctan( )
1j
(1.113)
Se observa que a bajas frecuencias, es decir, para 0 la magnitud logarítmica
tiende al valor de 0 dB. Por su parte la fase tiende a 0º.
Conforme aumenta la frecuencia la magnitud logarítmica se va haciendo cada vez más
negativa con una pendiente asintótica de -20 dB/década. Por su parte la fase tiende a -90º.
Señalar que si el polo fuese inestable <0 entonces la fase tiende a 90º, es decir, se
comporta como un cero real.
En definitiva un polo real tiene un comportamiento de filtro pasa baja, por lo que el
ancho de banda de este sistema de primer orden es:
0 c
Aplicando su definición y operando se puede demostrar que la frecuencia de corte es:
1c (1.114)
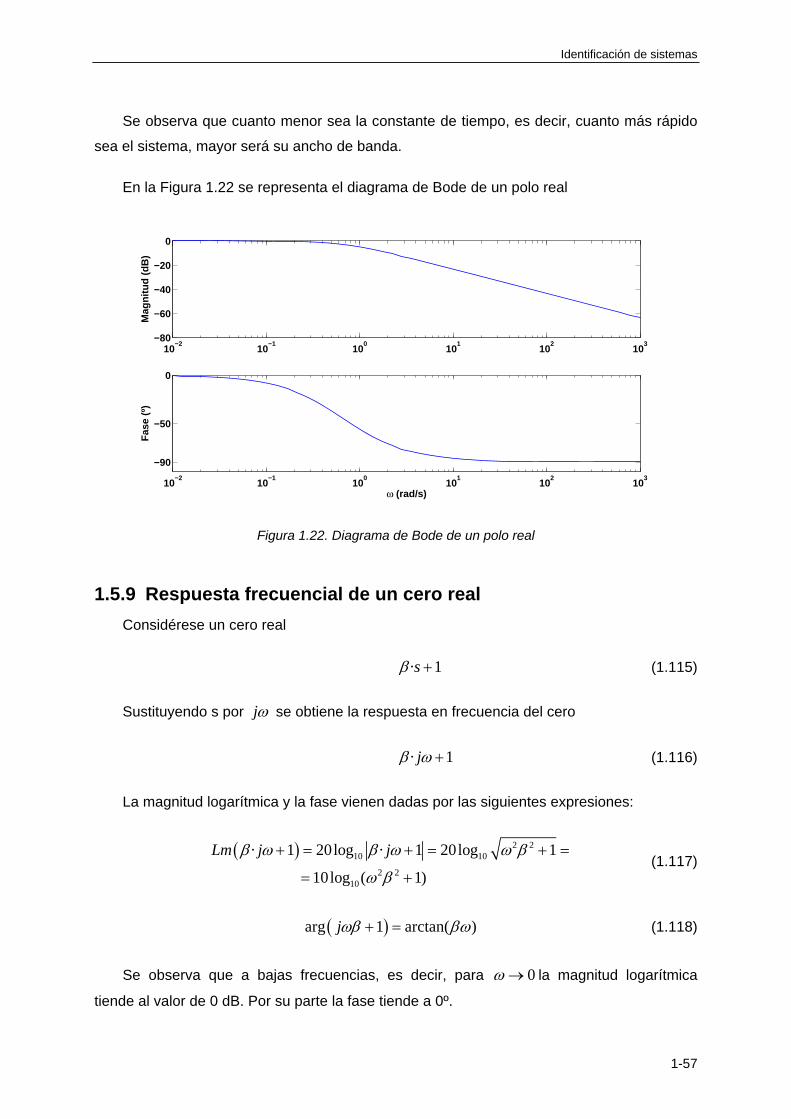
Identificación de sistemas
1-57
Se observa que cuanto menor sea la constante de tiempo, es decir, cuanto más rápido
sea el sistema, mayor será su ancho de banda.
En la Figura 1.22 se representa el diagrama de Bode de un polo real
10−2
10−1
100
101
102
103
−80
−60
−40
−20
0
Mag
nit
ud
(d
B)
10−2
10−1
100
101
102
103
−50
0
−90
ω (rad/s)
Fas
e (º
)
Figura 1.22. Diagrama de Bode de un polo real
1.5.9 Respuesta frecuencial de un cero real
Considérese un cero real
· 1s (1.115)
Sustituyendo s por j se obtiene la respuesta en frecuencia del cero
· 1j (1.116)
La magnitud logarítmica y la fase vienen dadas por las siguientes expresiones:
2 210 10
2 210
· 1 20log · 1 20log 1
10log ( 1)
Lm j j
(1.117)
arg 1 arctan( )j (1.118)
Se observa que a bajas frecuencias, es decir, para 0 la magnitud logarítmica
tiende al valor de 0 dB. Por su parte la fase tiende a 0º.
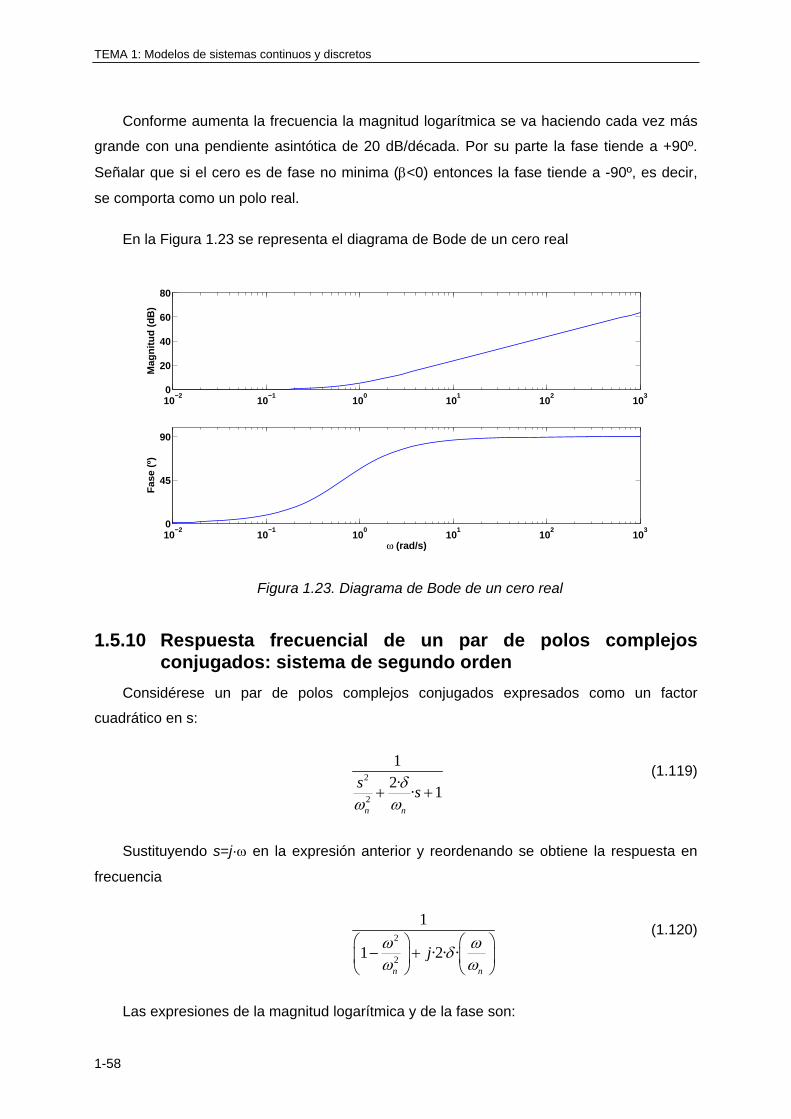
TEMA 1: Modelos de sistemas continuos y discretos
1-58
Conforme aumenta la frecuencia la magnitud logarítmica se va haciendo cada vez más
grande con una pendiente asintótica de 20 dB/década. Por su parte la fase tiende a +90º.
Señalar que si el cero es de fase no minima (<0) entonces la fase tiende a -90º, es decir,
se comporta como un polo real.
En la Figura 1.23 se representa el diagrama de Bode de un cero real
10−2
10−1
100
101
102
103
0
20
40
60
80
Mag
nit
ud
(d
B)
10−2
10−1
100
101
102
103
0
45
90
ω (rad/s)
Fas
e (º
)
Figura 1.23. Diagrama de Bode de un cero real
1.5.10 Respuesta frecuencial de un par de polos complejos conjugados: sistema de segundo orden
Considérese un par de polos complejos conjugados expresados como un factor
cuadrático en s:
2
2
12·
· 1n n
ss
(1.119)
Sustituyendo s=j· en la expresión anterior y reordenando se obtiene la respuesta en
frecuencia
2
2
1
1 ·2· ·n n
j
(1.120)
Las expresiones de la magnitud logarítmica y de la fase son:

Identificación de sistemas
1-59
22 22
10 2 22
2
110·log 1 4· ·
1 ·2· · n n
n n
Lm
j
(1.121)
22
22
1 2· · /arg arctan
11 ·2· ·
n
nn n
j
(1.122)
Se observa que a bajas frecuencias la magnitud tiende a 1, es decir a 0 dB y la fase a
0º. Mientras que para altas frecuencias la magnitud tiende a 0, es decir, la magnitud
logarítmica se va haciendo cada vez más negativa con una pendiente asintótica de -40
dB/década. Por su parte, si el par de polos complejos es estable, es decir, se encuentran
ubicados en el semiplano izquierdo del plano complejo entonces, la fase tiende a -180º. En
caso contrario si los polos son inestables, entonces la fase tiende a 180º, es decir, se
comporta como un par de ceros complejos conjugados estables.
Si el par de polos complejos es subamortiguado entonces la representación gráfica de
la magnitud en el diagrama de Bode presenta un pico de resonancia en =r que es la
frecuencia de resonancia que está cerca de n.
Derivando e igualando a 0 la expresión de la magnitud de un par de polos complejos
conjugados se puede encontrar la frecuencia de resonancia r para la que se obtiene el
valor máximo en la magnitud Mr
2· 1 2·r n (1.123)
Sustituyendo este valor en (1.83) se obtiene
2
1
2· · 1rM
(1.124)
En la Figura 1.24 se representa la magnitud logaritmica para distintos valores de .

TEMA 1: Modelos de sistemas continuos y discretos
1-60
10−1
100
−15
−10
−5
0
5
10
15
w (rad/s)
|G| (
dB)
δ=0.7
δ=1
δ=0.25
δ=0.5
δ=0.1
Figura 1.24. Amplitud de un sistema de polo complejo con n=0.5 rad/s y distintos valores de
Señalar que la magnitud del pico Mr solo depende de . Conforme tiende a 0,
r n y rM . Para >0.707 no hay pico de resonancia y Mr=1
El ancho de banda viene dado por la siguiente expresión
2 2 41 2 2 4 4nAB (1.125)
Cuando varía entre 0 y 1, el ancho de banda es directamente proporcional a la
frecuencia natural n y varía entre 1.55 n y 0.64 n . Para =0.707, nAB
Si los polos son reales, es decir, el sistema es sobreamoriguado, entonces el diagrama
de Bode se construye a partir de los dos sistemas de primer orden que lo forman.
Si un sistema G(s) de orden superior a dos posee un par de polos complejos
dominantes, que son aquellos cuya parte real se encuentra situada más cerca del eje
imaginario que la del resto de polos del sistema, entonces una aproximación de una función
de transferencia de alto orden que contenga sus polos dominantes tiende a reproducir la
dinámica lenta del sistema, pasando por alto la rápida. En consecuencia la respuesta en
frecuencia de la aproximación con polos dominantes no difiere mucho de la del sistema
original a bajas frecuencias. Luego la aproximación con polos dominantes representa un
modelo a baja frecuencia del sistema. Esto es algo esperable ya que los polos o ceros

Identificación de sistemas
1-61
rápidos (constantes de tiempo pequeñas o frecuencias naturales elevadas) contribuyen muy
poco para valores bajos de la frecuencia.
1.5.11 Respuesta frecuencial de un par de ceros complejos conjugados
Considérese un par de polos complejos conjugados expresados como un factor
cuadrático en s:
2
2
2·· 1
n n
ss
(1.126)
Sustituyendo s=j· en la expresión anterior y reordenando se obtiene la respuesta en
frecuencia
2
21 ·2· ·
n n
j
(1.127)
Las expresiones de la magnitud logarítmica y de la fase son:
22 2 22
102 2 21 ·2· · 10·log 1 4· ·
n n n n
Lm j
(1.128)
2
22
2
2· · /arg 1 ·2· · arctan
1
n
n n
n
j
(1.129)
Se observa que a bajas frecuencias la magnitud tiende a 1, es decir a 0 dB y la fase a
0º. Mientras que para altas frecuencias la magnitud tiende a infinito, es decir, la magnitud
logarítmica se va haciendo cada vez más positiva con una pendiente asintótica de 40
dB/década. Por su parte, si el par de ceros complejos es estable, es decir, se encuentran
ubicados en el semiplano izquierdo del plano complejo entonces, la fase tiende a 180º. En
caso contrario si los polos son inestables, entonces la fase tiende a -180º, es decir, se
comporta como un par de polos complejos conjugados estables.

TEMA 1: Modelos de sistemas continuos y discretos
1-62
Si el par de polos complejos es subamortiguado entonces la representación gráfica de
la magnitud en el diagrama de Bode presenta un pico de resonancia en =r que es la
frecuencia de resonancia que está cerca de n
1.5.12 Efecto de un cero en la respuesta frecuencial de un sistema de primer orden
Considérese el siguiente sistema de primer orden con un cero:
( ) 1( )
( ) 1
Y s sG s K
U s s
(1.130)
La forma de su respuesta en frecuencia dependerá de la posición relativa del polo
s=-1/ con respecto al cero s=-1/, es decir de los valores de las constantes de tiempo
características y .
Si > , con > 0 y > 0, el cero se encuentra a la izquierda del polo y ambos se
encuentran en el semiplano izquierdo del plano s, al sistema se le denomina controlador, red
o compensador de retraso de fase. En este caso si se representa el diagrama de Bode (ver
Figura 1.25) se puede observar que la magnitud presenta un valor constante a baja
frecuencia y otro valor constante a alta frecuencia. La transición entre ambos valores se
realiza con una pendiente -20 dB/década entre =1/ y =1/.
Si < , con > 0 y > 0, el cero se encuentra a la derecha del polo y ambos se
encuentran en el semiplano izquierdo del plano s, al sistema se le denomina controlador, red
o compensador de adelanto de fase. En este caso si se representa el diagrama de Bode
(ver Figura 1.25) se puede observar que la magnitud presenta un valor constante a baja
frecuencia y otro valor constante a alta frecuencia. La transición entre ambos valores se
realiza con una pendiente 20 dB/década entre =1/ y =1/.
Si el cero o/y el polo se encuentran en el semiplano derecho del plano complejo, se
tiene un sistema de fase no mínima. En este caso la magnitud será similar a la explicada en
los párrafos anteriores, pero la fase cambiará en función de la posición del polo y/o del cero
en el semiplano derecho del plano complejo, así como de sus posición relativa. Se pueden
llegar a introducir desfases de hasta 360º en función del cero.
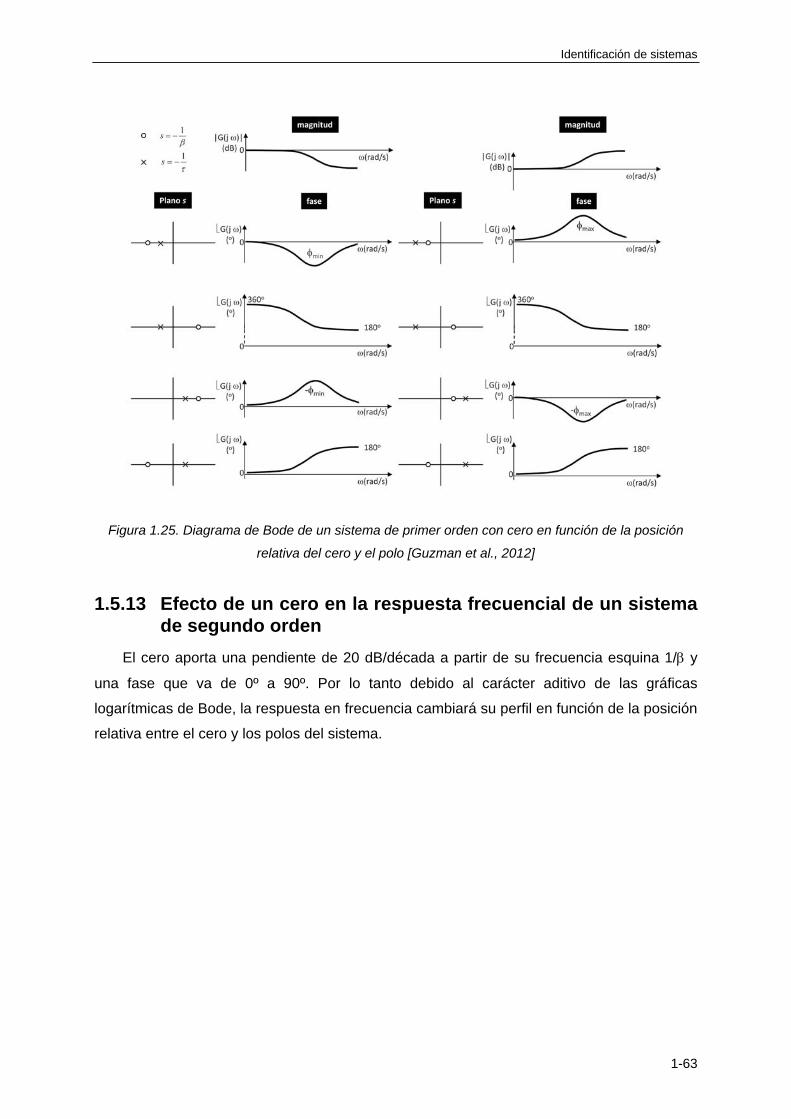
Identificación de sistemas
1-63
Figura 1.25. Diagrama de Bode de un sistema de primer orden con cero en función de la posición
relativa del cero y el polo [Guzman et al., 2012]
1.5.13 Efecto de un cero en la respuesta frecuencial de un sistema de segundo orden
El cero aporta una pendiente de 20 dB/década a partir de su frecuencia esquina 1/ y
una fase que va de 0º a 90º. Por lo tanto debido al carácter aditivo de las gráficas
logarítmicas de Bode, la respuesta en frecuencia cambiará su perfil en función de la posición
relativa entre el cero y los polos del sistema.

TEMA 1: Modelos de sistemas continuos y discretos
1-64
BIBLIOGRAFÍA
[Aström, K. J. y Wittenmark, 1984] K. J. Aström, y B. Wittenmark. Computer Controlled Systems.
Prentice-Hall, 1984.
[D’Azzo y Houpis, 1981] J. J. D’Azzo, y C. H. Houpis. Linear control system analysis
and design. McGraw-Hill. 1981.
[Dorf y Bishop, 2005] R. C. Dorf, y R. H. Bishop. Sistemas de control moderno.
10ª Edición. Pearson- Prentice Hall. 2005.
[Dormido, 2004] S. Dormido. Apuntes de la asignatura Control Digital.
UNED 2004.
[Guzman et al., 2012] J. L. Guzmán, R. Costa, M. Berenguel y S. Dormido. Control
automático con herramientas interactivas.
Pearson-UNED. 2012.
[Ogata, 1996] K. Ogata. Sistemas de Control en Tiempo Discreto. Prentice
Hall.1996.
[Ogata, 1998] K. Ogata. Ingeniería de Control Moderna. Prentice Hall.1998.

TEMA 2
MODELOS DE PERTURBACIONES
2-1
2.1 INTRODUCCIÓN
Una perturbación es una señal externa que afecta al comportamiento del sistema y cuyo
valor no puede ser elegido o controlado, como por ejemplo el ruido que afecta a los
sensores de medida o las ráfagas de viento y las turbulencias que afectan al vuelo de un
avión. En consecuencia si se quiere disponer de un modelo realista de un sistema se hace
necesario modelar también las perturbaciones que le afectan.
La construcción de modelos para las perturbaciones de un sistema depende en gran
medida de si se conoce la fuente o fuentes que originan las perturbaciones y de si son
medibles o no. En el mejor de los casos las perturbaciones w(t) que afectan al sistema son
perturbaciones medibles de origen conocido. Por ejemplo, en un panel solar la intensidad
del sol en un determinado instante de tiempo es una señal de perturbación ya que su valor
no puede ser elegido o controlado. Sin embargo, es perfectamente medible y su origen es
conocido.
Para este tipo de perturbaciones es posible construir modelos a partir de medición
directa. En estos casos se pueden obtener modelos continuos del sistema de la forma:
))(),(),(()(
))(),(),(()(
twtutxhty
twtutxftx
O modelos discretos
),,(
),,(1
kkkk
kkkk
wuxhy
wuxfx

TEMA 2: Modelos de perturbaciones
2-2
Por otra parte una situación bastante común es que al examinar las variables de un
sistema se observa que el comportamiento de las mismas se desvía del teóricamente
previsto. Esta desviación es producida por perturbaciones de origen conocido (por ejemplo,
el ruido de un sensor) o desconocido que no pueden ser medidas de forma directa. En
consecuencia la presencia de estas perturbaciones se detecta debido a que influyen sobre
otras variables del sistema que sí pueden ser medidas. Una forma bastante común de tratar
estas perturbaciones no medibles es agruparlas en un término de perturbación w(t) que se
añade a la salida del sistema y(t):
)()()( twtzty
donde z(t) es la salida sin perturbar. Se tiene por tanto el sistema que se muestra en la
Figura 2.1.
Sistemau(t)
w(t)
y(t)+
z(t)
Figura 2.1: Sistema con perturbación añadida a la salida
Las perturbaciones w(t) pueden ser modeladas como señales deterministas o como
señales aleatorias (procesos estocásticos). Usualmente las entradas u(t) del sistema son
señales deterministas por lo que si w(t) es una señal determinista entonces la salida y(t)
también será determinista. Por el contrario si w(t) es un proceso estocástico entonces la
salida y(t) también será un proceso estocástico.
Este tema está dedicado al estudio de los posibles modelos que se pueden utilizar para
las perturbaciones que afectan a un sistema. En primer lugar se realiza una clasificación de
las perturbaciones atendiendo a su carácter. En segundo lugar se comenta cómo es posible
reducir los efectos de las perturbaciones. En tercer lugar se describen los modelos
deterministas de las perturbaciones. En cuarto lugar se incluyen los conceptos básicos de la
teoría de procesos estocásticos. En quinto lugar se definen y caracterizan los modelos de
procesos estocásticos. Dichos modelos resultan útiles para describir tanto a las
perturbaciones como a las salidas del sistema. La parte final del tema se dedica al filtrado de
procesos estocásticos estacionarios y a la factorización espectral.

Identificación de sistemas
2-3
2.2 CARÁCTER DE LAS PERTURBACIONES
Comúnmente, atendiendo a su carácter, se distinguen tres tipos diferentes de
perturbaciones:
Perturbaciones en la carga. Este tipo de perturbaciones influyen sobre las
variables del proceso. En general este tipo de perturbaciones varían lentamente, y
pueden ser periódicas. En sistemas mecánicos las perturbaciones en la carga se
representan por fuerzas de perturbación, por ejemplo las ráfagas de viento sobre
una antena estabilizada, las olas sobre un barco, la carga en un motor. En
sistemas térmicos las perturbaciones en la carga podrían ser variaciones en la
temperatura del medio ambiente.
Errores de medida. Este tipo de perturbaciones se introducen en los sensores de
medida. Pueden existir errores estacionarios en algunos sensores debido a
errores de calibración. Sin embargo, los errores de medida típicamente poseen
componentes de alta frecuencia. Estos errores pueden poseer una cierta dinámica
debido a la dinámica de los sensores. Un ejemplo típico es el termopar, que posee
una contante de tiempo de entre 10 y 50 s dependiendo de su encapsulado. Por
otra parte, pueden existir complicadas interacciones dinámicas entre los sensores
y el proceso. Un ejemplo típico son las medidas de los giróscopos y las medidas
del nivel de líquido en los reactores nucleares.
En algunos casos no es posible medir la variable controlada directamente,
entonces su valor es deducido a partir de las medidas de otras variables. La
relación existente entre estas variables y la variable controlada puede ser bastante
compleja. Una situación muy común es que un instrumento dé una rápida
indicación con errores bastante grandes y otro instrumento dé una medida muy
precisa pero a costa de un alto retardo.
Variaciones en los parámetros. Cuando se consideran sistemas lineales, la
perturbación en la carga y el ruido de medida se introducen en el sistema de una
forma aditiva. Los sistemas reales son, en la mayoría de los casos, no lineales,
esto significa que las perturbaciones se introducirán en el sistema de una forma
mucho más complicada. Puesto que los sistemas lineales son obtenidos mediante
linealización de modelos no lineales, algunas perturbaciones aparecen entonces
como variaciones en los parámetros del modelo lineal.

TEMA 2: Modelos de perturbaciones
2-4
2.3 REDUCCION DE LOS EFECTOS DE LAS PERTURBACIONES
Las perturbaciones pueden ser reducidas actuando sobre su fuente, usando
realimentación local o usando feedforward. Por otra parte técnicas de predicción pueden ser
usadas para estimar perturbaciones no medibles.
2.3.1 Reducción en la fuente
La forma más obvia de reducir los efectos de las perturbaciones es intentar actuar sobre
la fuente que origina dichas perturbaciones. Esta aproximación está estrechamente ligada a
la etapa de diseño del proceso. Algunos ejemplos típicos son:
Reducir las fuerzas de fricción en un servo usando cojinetes mejores.
Ubicar un sensor en una posición donde las perturbaciones sean más pequeñas.
Modificar la electrónica del sensor para que se vea afectado por menos ruido.
Sustituir un sensor por otro que posea una respuesta más rápida.
Cambiar el periodo de muestreo para obtener una representación mejor de las
características de los procesos.
2.3.2 Reducción mediante realimentación local
Si las perturbaciones no se pueden atenuar en su fuente, se puede intentar entonces su
reducción mediante realimentación local (ver Figura 2.2). Para usar esta aproximación es
necesario que las perturbaciones se introduzcan en el sistema en una o varias posiciones
bien definidas. También es necesario tener acceso a la variable medida que es resultado de
la perturbación. Además es necesario tener acceso a la variable de control que entra al
sistema en la vecindad de la perturbación. Las dinámicas que relacionan la variable medida
con la variable de control deberían ser tales que se pueda utilizar un lazo de control de
ganancia elevada.
El uso de la realimentación es a menudo fácil y efectivo ya que no es necesario tener
información detallada de las características de los procesos, siempre que una alta ganancia
pueda ser utilizada en el lazo. En caso contrario, se necesitará un lazo extra de
realimentación. Algunos ejemplos de realimentación local son:
En sistemas hidráulicos, la reducción en las variaciones en el suministro de
presión en válvulas, instrumentos y reguladores mediante el uso de un regulador
de presión.

Identificación de sistemas
2-5
En sistemas térmicos, la reducción de las variaciones en el control de temperatura
mediante la estabilización del suministro de voltaje.
Realimentaciónlocal
+u
+y
ónPerturbaci
A B
ocesoPr
Figura 2.2: Reducción de perturbaciones mediante el uso de realimentación local. La perturbación se
introduce en el sistema entre los puntos A y B. Las dinámicas entre estos dos puntos deben ser tales
que sea posible usar una alta ganancia en el lazo.
2.3.3 Reducción mediante feedforward
Las perturbaciones que sean medibles pueden ser reducidas usando una estructura de
tipo feedforward. El principio genérico de esta estructura se ilustra en la Figura 2.3. Se mide
la perturbación y se aplica al sistema una señal de control que intenta contrarrestarla.
+ Hp +
Hw
Hff
ocesoPr
yu
medidaónPerturbaci
Figura 2.3: Reducción de perturbaciones mediante el uso de una estructura feedforward
Si la funciones de transferencia que relacionan la salida y a la perturbación w y al
control u son Hw y Hp, respectivamente, entonces la función de transferencia Hff del
compensador feedforward idealmente sería:
wpff HHH ·1

TEMA 2: Modelos de perturbaciones
2-6
Si la función de transferencia Hff es inestable o no realizable (mayor número de ceros
que de polos) se debe seleccionar alguna aproximación adecuada. El diseño de un
compensador feedforward se basa a menudo en un simple modelo estático, es decir, Hff es
una ganancia. La estructura feedforward es especialmente útil para perturbaciones
generadas por cambios en la señal de referencia.
2.3.4 Reducción mediante predicción
La reducción de perturbaciones mediante predicción es una extensión de la técnica de
feedforward que puede utilizarse cuando las perturbaciones no pueden ser medidas.
Consiste en predecir la perturbación a partir de la medida de señales. La señal de
feedforward se genera a partir de la perturbación predicha.
Es importante observar que no es necesario predecir la propia perturbación en si misma
sino que es suficiente con modelar una señal que represente el efecto de la perturbación
sobre las variables del proceso más importantes.
2.4 MODELOS DETERMINISTAS DE LAS PERTURBACIONES
En algunas ocasiones una perturbación se puede modelar como una señal temporal
determinista. Entre las señales más frecuentemente utilizadas para representar a una
perturbación (ver Figura 2.4) se encuentran:
El impulso y el pulso. Son realizaciones simples de perturbaciones inesperadas de
duración muy corta. Pueden representar tanto a perturbaciones en la carga como
a errores de medida. Para sistemas continuos la perturbación es modelada como
un impulso:
00
0)()(
tsi
tsittuw
Para sistemas discretos se modela como un pulso con amplitud unidad y una
duración de un periodo de muestreo.
00
01
ksi
ksiu kwk
El pulso y el impulso son también importantes por motivos teóricos ya que la
respuesta de un sistema lineal continuo en el tiempo está completamente

Identificación de sistemas
2-7
especificada por su respuesta a un impulso, mientras que la de un sistema
discreto está determinada por su respuesta a un pulso.
El escalón. Se usa típicamente para representar una perturbación en la carga o un
offset en una medida. Tiene la siguiente definición en tiempo continuo
00
01)(
t
ttuw
La rampa. Es una señal que se utiliza para representar la deriva en los errores de
medida así como a perturbaciones que de repente comienzan a desplazarse. En
la práctica estas perturbaciones se encuentran acotadas, sin embargo el uso de
una señal rampa suele ser una útil idealización. Tiene la siguiente definición en
tiempo continuo
00
0)(
t
ttty
La sinusoide. Es el prototipo de una perturbación periódica. La posibilidad de
seleccionar su frecuencia la hace idónea para representar tanto a las
perturbaciones en la carga (de baja frecuencia) como al ruido de medida (de alta
frecuencia). Tiene la siguiente definición en tiempo continuo
00
0)·(·)(
t
ttsenAty
Pulso Escalón Rampa Sinusoide
Figura 2.4: Modelos deterministas de perturbaciones

TEMA 2: Modelos de perturbaciones
2-8
2.5 CONCEPTOS BÁSICOS DE LA TEORÍA DE PROCESOS ESTOCÁSTICOS
Si las perturbaciones que afectan a un sistema tienen un carácter aleatorio, entonces
deben ser modeladas usando modelos de procesos estocásticos o aleatorios. En esta
sección se incluyen los conceptos básicos de la teoría de procesos estocásticos.
2.5.1 Variables aleatorias
Una variable aleatoria x(k) es una variable que puede tomar valores aleatorios en
función de los resultados de algún experimento aleatorio. Es decir, los resultados aleatorios
de un experimento se pueden representar por un número real x(k), llamado variable
aleatoria.
Para un experimento aleatorio, los posibles resultados se denominan espacio de
muestra. Una variable aleatoria x(k) es una función definida para los k puntos del espacio de
muestra, que toma valores reales en el rango [-,+] asociados a cada uno de los k puntos
que pueden ocurrir.
La forma de especificar la probabilidad con que la variable aleatoria toma diferentes
valores es mediante la función de distribución de probabilidad F(x), definida de la siguiente
forma:
))(()( xkxPxF
Es decir, es la probabilidad de que la variable aleatoria x(k) tome valores menores o
iguales a x. La función de distribución de probabilidad cumple las siguientes propiedades:
1)(
0)(
)()(
F
F
basibFaF
Si la variable aleatoria tiene un rango continuo de valores, entonces se puede definir la
función densidad de probabilidad f(x):
x
xxkxxPxf
x
)(lim)(
0
Se verifica que:

Identificación de sistemas
2-9
0)( xf
1)(
dxxf
dx
xdFxf
)()(
La probabilidad de que x(k) tome un valor entre x y x+dx es f(x)·dx.
En el caso de que x(k) tome valores discretos xi con probabilidades pi distintas de cero,
entonces la función f(x) se puede expresar como una serie de funciones de Dirac por las
probabilidades correspondientes:
i
ii xxpxf )(·)(
Si se conoce la función de distribución de probabilidad o la función de densidad de
probabilidad de una variable aleatoria x(k) es posible calcular la probabilidad de que la
variable aleatoria tome un valor comprendido en un rango [x1,x2]. En ocasiones no es posible
determinar estas funciones exactamente, sin embargo es posible caracterizar la distribución
de probabilidad mediante el valor medio y la varianza de la variable aleatoria.
El valor medio de una variable aleatoria escalar x(k), también denominado valor
esperado o primer momento se define de la siguiente forma:
E x(k) · ( )x x f x dx
(2.1)
El valor medio es el centro de gravedad de la función de densidad de probabilidad de la
variable aleatoria x.
El valor cuadrático medio o segundo momento de x(k) se obtiene mediante la expresión
dxxfxx
)((k)xE 222 (2.2)
Si x no es un escalar entonces

TEMA 2: Modelos de perturbaciones
2-10
dxxfx
)((k)x(k)·x(k)x(k)·xE T2T
Un parámetro que se utiliza en lugar del valor cuadrático medio es la raíz cuadrada
positiva del mismo, conocido por su terminología anglosajona como rms de “root-mean
squared”.
La varianza de la variable aleatoria x(k) se define como
2 2 2 2 2x xVar[x(k)]=E (x(k)- ) (x(k)- ) ( )x x xf x dx
(2.3)
Si x no es un escalar:
22xx
2xx )()-(x(k))·-(x(k))-(x(k))-(x(k)E xx
Tx
T dxxf
La raíz cuadrada de la varianza, x, es por definición la desviación estándar de la
variable aleatoria. Si el valor medio es nulo, entonces la desviación estándar coincide con el
valor rms.
La varianza es una medida de la variabilidad o dispersión del valor de la variable
aleatoria con respecto a su valor medio. En consecuencia describe la extensión de la
función de densidad de probabilidad de la variable aleatoria.
Ejemplo 2.1: Distribución Gaussiana o Normal
Una variable aleatoria x(k) tiene una distribución gaussiana o normal (ver Figura 2.5) si su función
densidad de probabilidad está dada por la siguiente expresión:
2
2
2
)(
·2
1)( b
ax
eb
xf
Se puede comprobar que a y b se corresponden con el valor medio y la desviación estándar de la
variable aleatoria x(k)
2222 )()(]))([(
)()]([
bdxxfaxakxE
adxxxfkxE
x
x
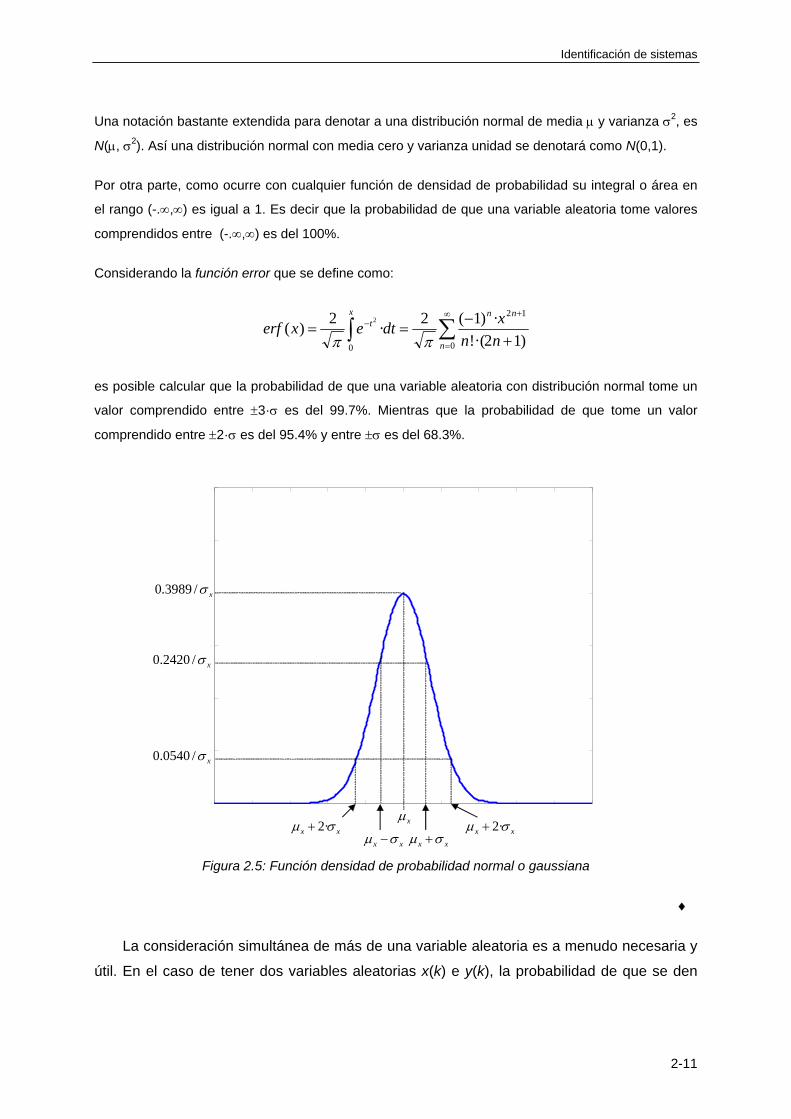
Identificación de sistemas
2-11
Una notación bastante extendida para denotar a una distribución normal de media y varianza 2, es
N(, 2). Así una distribución normal con media cero y varianza unidad se denotará como N(0,1).
Por otra parte, como ocurre con cualquier función de densidad de probabilidad su integral o área en
el rango (-.,) es igual a 1. Es decir que la probabilidad de que una variable aleatoria tome valores
comprendidos entre (-.,) es del 100%.
Considerando la función error que se define como:
0
12
0 )12!·(
·)1(2·
2)(
2
n
nnxt
nn
xdtexerf
es posible calcular que la probabilidad de que una variable aleatoria con distribución normal tome un
valor comprendido entre 3· es del 99.7%. Mientras que la probabilidad de que tome un valor
comprendido entre 2· es del 95.4% y entre es del 68.3%.
0 1 2 3 4 5 6 7 8 9 100
0.05
0.1
0.15
0.2
0.25
0.3
0 1 2 3 4 5 6 7 8 9 100
0.05
0.1
0.15
0.2
0.25
0.3
x
xx xx ·2
xx xx ·2
x/3989.0
x/2420.0
x/0540.0
Figura 2.5: Función densidad de probabilidad normal o gaussiana
La consideración simultánea de más de una variable aleatoria es a menudo necesaria y
útil. En el caso de tener dos variables aleatorias x(k) e y(k), la probabilidad de que se den

TEMA 2: Modelos de perturbaciones
2-12
pares de valores en un determinado rango de valores está dada por la función de
distribución de probabilidad conjunta F2(x, y).
ykyxkxPyxF )(&)(),(2
La correspondiente función de densidad de probabilidad conjunta se define como:
yx
yykyyPxxkxxPyxf
yx
)(&)(lim),(
00
2
que verifica las siguientes propiedades:
0),(2 yxf
yx
yxFyxf
),(
),( 22
2
1),(2
dxdyyxf
Sean fx y fy las funciones de densidad de probabilidad de las variables aleatorias x(k) e
y(k), si se verifica que
)()·(),(2 yfxfyxf yx
entonces las dos variables son estadísticamente independientes. Es decir, el suceso x(k) x
es independiente del suceso y(k) y.
Una medida de la dependencia líneal de dos variables aleatorias x(k) e y(k) viene dada
por la covarianza que se define de la siguiente forma:
xy x y x y 2Cov[x(k),y(k)] r E (x(k)- )(y(k)- ) (x- )(y- ) ( , )f x y dxdy
(2.4)
Que se puede expresar de forma equivalente como:
y(k)E·x(k)Ex(k)y(k)Ex(k)y(k)-x(k)y(k)E)-)(y(k)-(x(k)E yxyxyx
La covarianza cumple las siguientes propiedades:

Identificación de sistemas
2-13
Cov[x(k),y(k)]=Cov[y(k),x(k)]
Cov[x(k),x(k)] Var[x(k)]
Por otra parte si x(k) e y(k) son estadísticamente independientes entonces
x y x yCov[x(k),y(k)]=E (x(k)- )(y(k)- ) E x(k)- ·E y(k)- 0
Para simplificar el estudio de la covarianza, ésta se suele normalizar dividiéndola por las
desviación estándar de cada variable. A la covarianza normalizada se le denomina
coeficiente de correlación:
yx
xyxy
r
(2.5)
Se verifica que
11 xy
El coeficiente de correlación proporciona una medida del grado de dependencia lineal
entre las variables aleatorias x(k) e y(k). Si x(k) e y(k) son independientes entre si entonces
xy=0, y se dice que las variables aleatorias x(k) e y(k) no están correlacionadas.
Si la distribución de probabilidad conjunta es normal y xy=0 entonces x(k) e y(k) son
independientes. Si la distribución no es normal y xy=0 entonces x(k) e y(k) no están
correlacionados aunque no necesariamente son independientes.
Si xy=1 entonces
( ) · ( )y k a b x k
Mientras que si xy=-1 entonces
( ) · ( )y k a b x k
Conforme xy se acerca al valor 1 los valores de y(k) con respecto a x(k) se van
concentrando en las cercanías de una línea recta de pendiente positiva. Mientras que
conforme xy se acerca al valor -1 los valores de y(k) con respecto a x(k) se van
concentrando en las cercanías de una línea recta de pendiente negativa.
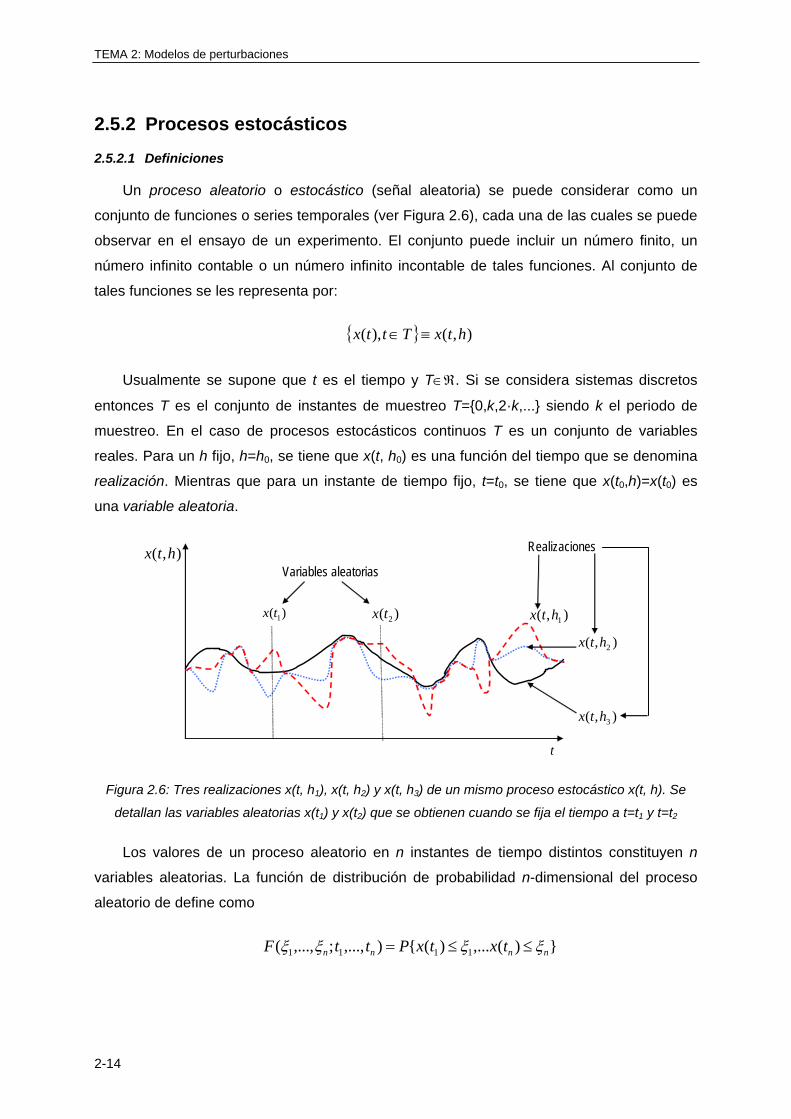
TEMA 2: Modelos de perturbaciones
2-14
2.5.2 Procesos estocásticos
2.5.2.1 Definiciones
Un proceso aleatorio o estocástico (señal aleatoria) se puede considerar como un
conjunto de funciones o series temporales (ver Figura 2.6), cada una de las cuales se puede
observar en el ensayo de un experimento. El conjunto puede incluir un número finito, un
número infinito contable o un número infinito incontable de tales funciones. Al conjunto de
tales funciones se les representa por:
),(),( htxTttx
Usualmente se supone que t es el tiempo y T. Si se considera sistemas discretos
entonces T es el conjunto de instantes de muestreo T={0,k,2·k,...} siendo k el periodo de
muestreo. En el caso de procesos estocásticos continuos T es un conjunto de variables
reales. Para un h fijo, h=h0, se tiene que x(t, h0) es una función del tiempo que se denomina
realización. Mientras que para un instante de tiempo fijo, t=t0, se tiene que x(t0,h)=x(t0) es
una variable aleatoria.
)( 1tx )( 2tx
Realizaciones
Variables aleatorias
t
),( 1htx
),( 2htx
),( 3htx
),( htx
Figura 2.6: Tres realizaciones x(t, h1), x(t, h2) y x(t, h3) de un mismo proceso estocástico x(t, h). Se
detallan las variables aleatorias x(t1) y x(t2) que se obtienen cuando se fija el tiempo a t=t1 y t=t2
Los valores de un proceso aleatorio en n instantes de tiempo distintos constituyen n
variables aleatorias. La función de distribución de probabilidad n-dimensional del proceso
aleatorio de define como
})(,...)({),...,;,...,( 1111 nnnn txtxPttF

Identificación de sistemas
2-15
Un proceso aleatorio se denomina Gausiano o normal si todas las distribuciones de
dimensión finita son normales.
Para n=1 la función de distribución de probabilidad es:
])([),( txPtF
La función de densidad de probabilidad correspondiente se define
d
tdFtf
),(),(
La función valor medio de un proceso aleatorio x se define como:
dtfx ),(·(t)E(t)
(2.6)
La función varianza de un proceso aleatorio x se define como:
2 (t) Var[x(t)]=E ( ) ( ) ( ) ( ) ( ) ( ) · ( , )T T
x t t x t t t t f t d
(2.7)
La varianza da información del tamaño de las fluctuaciones del proceso con respecto a
su valor medio. A la raíz cuadrada de la varianza se le denomina desviación estándar.
Nótese que tanto el valor medio como la varianza son funciones del tiempo.
La función de covarianza de un proceso aleatorio x se define como:
1 2 1 2 1 1 2 2
1 1 2 2 1 2 1 2 1 2
, cov ( ), ( ) E ( ) ( ) ( ) ( )
( ) ( ) · ( , ; , ) ·
T
xx
T
t t x t x t x t t x t t
t t f t t d d
(2.8)
La función de covarianza cruzada de dos procesos aleatorios x e y se puede definir de
forma similar a la función de covarianza:
1 2 1 2 1 1 2 2, cov ( ), ( ) E ( ) ( ) ( ) ( )T
xy x yt t x t y t x t t y t t (2.9)
Un proceso aleatorio o estocástico se denomina estacionario si su distribución de
probabilidad n-dimensional para x(t1), x(t2),..., x(tn) es idéntica a la distribución de x(t1+),

TEMA 2: Modelos de perturbaciones
2-16
x(t2+),..., x(tn+) para todo , n, t1,..., tn. La función valor medio de un proceso aleatorio
estacionario es constante. La función de covarianza o autocovarianza de un proceso
aleatorio estacionario es función del desplazamiento o retraso (lag) considerado:
1 1cov ( ), ( ) cov ( ), ( )x xx x t x t x t x t (2.10)
Nótese que el valor de la función de covarianza en el origen 0x es la varianza del
proceso.
La función de covarianza cruzada de procesos aleatorios estacionarios también es
función de :
cov ( ), ( ) [( ( ) )( ( ) )]xy x yx t y t E x t y t (2.11)
Se cumple que
xy yx
Si la función de covarianza o autocovarianza es normaliza por 0x se obtiene la
función de correlación o autocorrelación, que se define de la siguiente forma:
2
( )0
x xx
x x
(2.12)
Aplicando la desigualdad de Schwartz
0xx rr
se obtiene que
1)( x
Es decir, la magnitud de la función de correlación es menor que la unidad.
El valor de x() da idea de la magnitud de la correlación existente entre dos puntos del
proceso distanciados unidades de tiempo. Valores de x() cercanos a uno significan que
existe una fuerte correlación positiva. Mientras que valores de x() cercanos a menos uno
significan que existe una fuerte correlación negativa. Asimismo, si x()=0 entonces no existe
correlación.

Identificación de sistemas
2-17
De forma análoga puede definirse la función de correlación cruzada entre dos procesos
x e y:
( )
·0 · 0
xy xyxy
x yx y
(2.13)
que cumple las siguientes propiedades:
( ) 1xy
( ) ( )xy yx
Si ( ) ( ) 0xy yx entonces no existe correlación cruzada entre los procesos x e y,
se dice entonces que los procesos no están correlacionados o que son estadísticamente
independientes.
La función de densidad espectral o espectro de potencia de un proceso aleatorio
estacionario permite conocer la distribución en frecuencia del proceso, se define como la
transformada de Fourier de su función de covarianza
1( ) ( )
2ik
xx xxk
k e
(2.14)
Si se toma la transforma inversa de Fourier del espectro de potencia del proceso se
obtendría la función de covarianza del proceso
( ) ( )ikxx xxk e d
(2.15)
La densidad espectral cruzada de dos procesos aleatorios estacionarios x e y se define
como la transformada de Fourier de su función de covarianza cruzada:
1( ) ( )
2ik
xy xyk
k e
(2.16)
Si se toma la transforma inversa de Fourier de densidad espectral cruzada se obtendría
la función de covarianza cruzada

TEMA 2: Modelos de perturbaciones
2-18
( ) ( )ikxy xyk e d
(2.17)
En el caso de procesos aleatorios continuos se tiene:
1( ) ( )
2it
xx xx t e dt
(2.18)
1( ) ( )
2it
xy xy t e dt
(2.19)
( ) ( )itxx xxt e d
(2.20)
( ) ( )itxy xyt e d
(2.21)
Un proceso estocástico estacionario puede ser descrito por su valor medio, varianza y
función de autocorrelación o función de densidad espectral. Nótese que si se conoce la
función de densidad espectral se puede calcular la función de autocorrelación y viceversa.
2.5.2.2 Interpretación de la función de covarianza y de la densidad espectral
Los valores de un proceso aleatorio x en n instantes de tiempo {t1, t2,..., tn} distintos
constituyen n variables aleatorias x(t1), x(t2),...,x(tn). Supuesto que los n instantes de tiempo
están equiespaciados un valor , es decir, ti+1-ti= i=1,...,n-1 y tomando el instante t1 como
origen de referencia, entonces las n variables aleatorias se pueden denotar como x(0),
x(),x(2),...,x((n-1)·). Obsérvese que si se tomase t2 como origen entonces las variables
aleatorias se denotarían como x(-),x(0),...,x((n-2)·). En el caso de un proceso estocástico
estacionario, se puede tomar cualquier instante como origen.
La función de covarianza o autocovarianza de un proceso estocástico permite analizar
la relación que existen entre los valores o variables aleatorias de dicho proceso. Es decir,
como influye el valor de un proceso en un instante de tiempo en el valor de dicho proceso en
los restantes instantes de tiempo, o equivalentemente como influye una variable aleatoria
del proceso en las restantes variables aleatorias de dicho proceso. En consecuencia,
analizar la forma de la función de covarianza aporta información sobre las interdependencias
temporales del proceso (ver Figura 2.7).
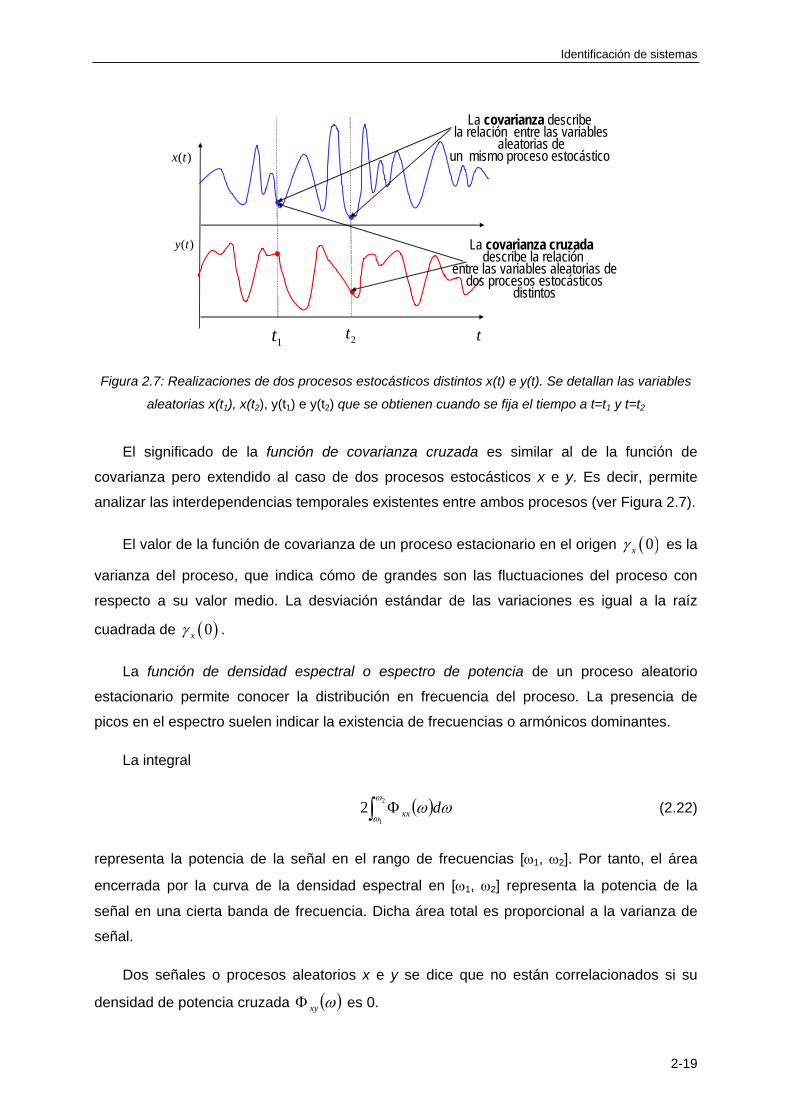
Identificación de sistemas
2-19
1t 2t
)(tx
)(ty
t
La covarianza describela relación entre las variables
aleatorias deun mismo proceso estocástico
La covarianza cruzadadescribe la relación
entre las variables aleatorias dedos procesos estocásticos
distintos
Figura 2.7: Realizaciones de dos procesos estocásticos distintos x(t) e y(t). Se detallan las variables
aleatorias x(t1), x(t2), y(t1) e y(t2) que se obtienen cuando se fija el tiempo a t=t1 y t=t2
El significado de la función de covarianza cruzada es similar al de la función de
covarianza pero extendido al caso de dos procesos estocásticos x e y. Es decir, permite
analizar las interdependencias temporales existentes entre ambos procesos (ver Figura 2.7).
El valor de la función de covarianza de un proceso estacionario en el origen 0x es la
varianza del proceso, que indica cómo de grandes son las fluctuaciones del proceso con
respecto a su valor medio. La desviación estándar de las variaciones es igual a la raíz
cuadrada de 0x .
La función de densidad espectral o espectro de potencia de un proceso aleatorio
estacionario permite conocer la distribución en frecuencia del proceso. La presencia de
picos en el espectro suelen indicar la existencia de frecuencias o armónicos dominantes.
La integral
2
1
2
dxx (2.22)
representa la potencia de la señal en el rango de frecuencias [1, 2]. Por tanto, el área
encerrada por la curva de la densidad espectral en [1, 2] representa la potencia de la
señal en una cierta banda de frecuencia. Dicha área total es proporcional a la varianza de
señal.
Dos señales o procesos aleatorios x e y se dice que no están correlacionados si su
densidad de potencia cruzada xy es 0.

TEMA 2: Modelos de perturbaciones
2-20
2.5.2.3 Estimación del valor medio, covarianza y densidad espectral
Usualmente se suele disponer de N valores muestreados de una cierta realización de
un proceso aleatorio estacionario x(t), en dicho caso la función valor medio, la función de
covarianza o autocovarianza y la función de autocorrelación se estiman a través de las
siguientes expresiones (también es habitual usar el símbolo k en lugar de para referirse al
desplazamiento o retardo (lag)):
N
t
txN
x1
)(1
(2.23)
1
1ˆ( ) ( ) ( ( ) )·( ( ) )
N
xx xxt
c x t x x t xN
(2.24)
( )ˆ( ) ( )
(0)xx
xx xxxx
cr
c
(2.25)
Asimismo si también se dispone de N valores muestreados de otro proceso aleatorio
estacionario y(t), la función de covarianza cruzada y la función de correlación cruzada entre
x e y se estima con las siguientes expresiones:
1
1
1( ( ) )·( ( ) ) 0,1,2...
ˆ( ) ( )1
( ( ) )·( ( ) ) 1, 2,...
N
txy xy N
t
x t x y t yN
c
y t y x t xN
(2.26)
( )ˆ( ) ( )
(0)· (0)
xyxy xy
xx yy
cr
c c
(2.27)
Por último la función densidad espectral o espectro de potencia se estima con la
siguiente expresión:
ˆ ( ) ( )· ( )M
ix x M
M
c W e
(2.28)
donde WM() se denomina ventana de retardo (lag window) siendo M un entero positivo
denominado anchura de la ventana o parámetro de truncación. La ventana de retardo es
una función que sirve para enfatizar las componentes de frecuencia más importantes y
despreciar las menos relevantes, de esta forma se logra suavizar la forma del espectro de

Identificación de sistemas
2-21
potencia. Una de las ventanas de retardo más utilizadas es la conocida como ventana de
Hamming que tiene la siguiente expresión:
M
MMWM
0
·cos1·
2
1)( (2.29)
A las funciones estimadas a partir de N datos en la literatura inglesa también se les
denomina con el término sample (muestra), donde este término hace referencia a la muestra
de datos observados, así se habla del valor medio de la muestra (sample mean),
autocovarianza de la muestra (sample autocovariance), etc.
2.5.2.4 Error de las estimas
La estima F de una función F asociada a una señal aleatoria obtenida a partir de N
valores muestreados de una realización de dichas señal posee un cierto error F-F cuya
magnitud se encontrará comprendida dentro de un cierto intervalo 1 2(L , L ) con una
probabilidad del P%.
En consecuencia el valor real de la función se encontrará dentro del intervalo
1 2ˆ ˆ(F-l , F+l )
con una probabilidad del P %. A dicho intervalo se le denomina intervalo de confianza del
P%.
Supuesto que la señal aleatoria tiene una distribución de probabilidad normal el
intervalo de confianza del P% viene dado por la siguiente expresión:
ˆ ˆˆ ˆ(F- · , F+ · )n n
donde n=1, 2,3, … y es una estima del error o desviación estándar. En este caso al
intervalo de confianza del P% también se le denomina intervalo de confianza n· . De
acuerdo con el Ejemplo 2.1 un intervalo de confianza 2 sería equivalente a un intervalo de
confianza del 95.4% y un intervalo de confianza 3 sería equivalente a un intervalo de
confianza del 99.7%.

TEMA 2: Modelos de perturbaciones
2-22
Se puede demostrar [Box and Jenkins, 1976] que si supone que el proceso x(t) es de
tipo ruido blanco (ver sección 2.6.1) entonces una estima del error o desviación estándar
existente en el estimador de la función de autocorrelación (2.25) viene dada por la siguiente
expresión
1ˆ
N (2.30)
Asimismo se puede demostrar [Box and Jenkins, 1976] que supuesto que los procesos
x(t) e y(t) no están correlacionados y que uno de ellos es ruido blanco entonces una estima
del error o desviación estándar del estimador de la función de correlación cruzada (2.27)
viene dada por la siguiente expresión:
1ˆ
N
(2.31)
2.5.2.5 Procesos estocásticos no estacionarios
Un proceso estocástico no estacionario se caracteriza porque sus propiedades
estadísticas varían con el tiempo. Existen infinitas formas de no estacionaridad, por ejemplo
si se consideran únicamente los dos primeros momentos de un proceso estocástico se
tendrían las siguientes formas de no estacionaridad: valor medio variable con el tiempo y
varianza constante, valor medio constante y varianza variable con el tiempo, y valor medio y
varianza variables con el tiempo.
El análisis de la representación gráfica de una serie temporal (realización) de un
proceso estocástico permite detectar en muchas ocasiones la no estacionaridad del
proceso. Si la serie temporal presenta derivas (drifts) y/o tendencias (trends) en su valor
medio o/y en su pendiente el proceso será no estacionario.
Ejemplo 2.2
En la Figura 2.8 se representa un ejemplo de una serie temporal que presenta un comportamiento no
estacionario en su valor medio (también denominado nivel). Se observa que esta serie presenta tres
valores medios o niveles locales los cuales se han representado con rectas de trazo discontinuo.
En la Figura 2.9 se representa un ejemplo de una serie temporal que presenta un comportamiento no
estacionario en su valor medio y en su pendiente. Se observa que esta serie presenta tres tendencias
locales de tipo lineal, las cuales se han representado con rectas de trazo discontinuo
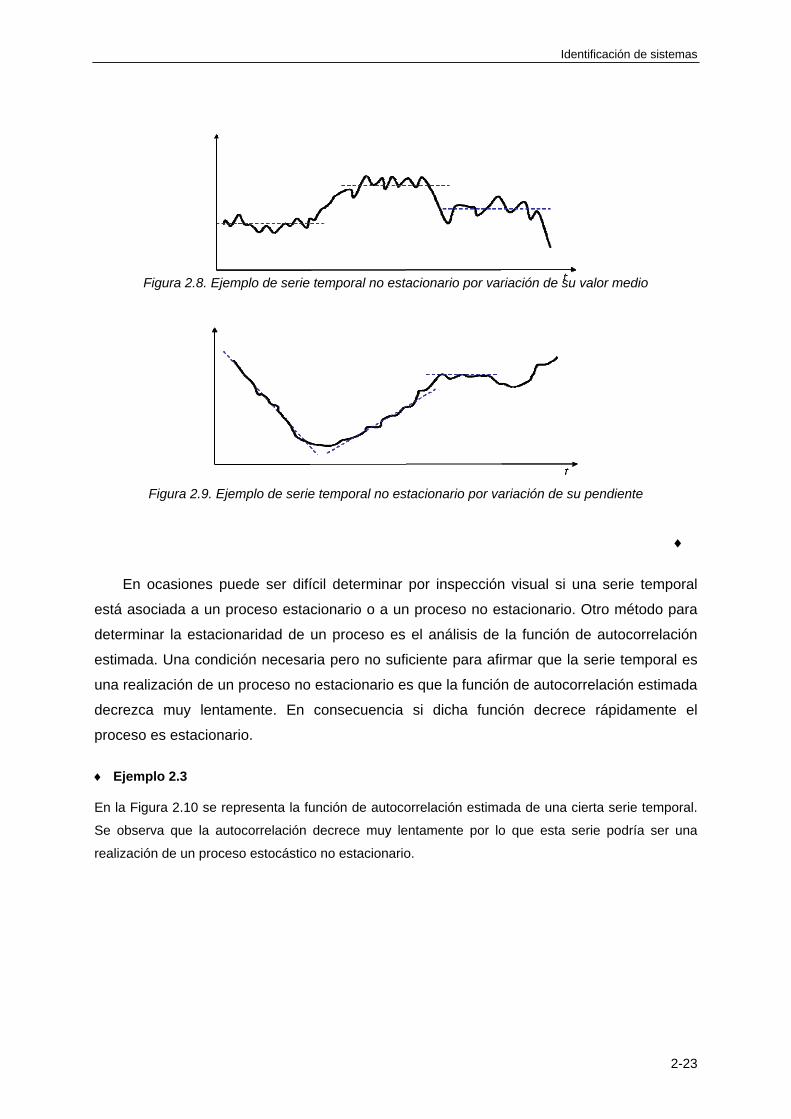
Identificación de sistemas
2-23
Figura 2.8. Ejemplo de serie temporal no estacionario por variación de su valor medio
Figura 2.9. Ejemplo de serie temporal no estacionario por variación de su pendiente
En ocasiones puede ser difícil determinar por inspección visual si una serie temporal
está asociada a un proceso estacionario o a un proceso no estacionario. Otro método para
determinar la estacionaridad de un proceso es el análisis de la función de autocorrelación
estimada. Una condición necesaria pero no suficiente para afirmar que la serie temporal es
una realización de un proceso no estacionario es que la función de autocorrelación estimada
decrezca muy lentamente. En consecuencia si dicha función decrece rápidamente el
proceso es estacionario.
Ejemplo 2.3
En la Figura 2.10 se representa la función de autocorrelación estimada de una cierta serie temporal.
Se observa que la autocorrelación decrece muy lentamente por lo que esta serie podría ser una
realización de un proceso estocástico no estacionario.
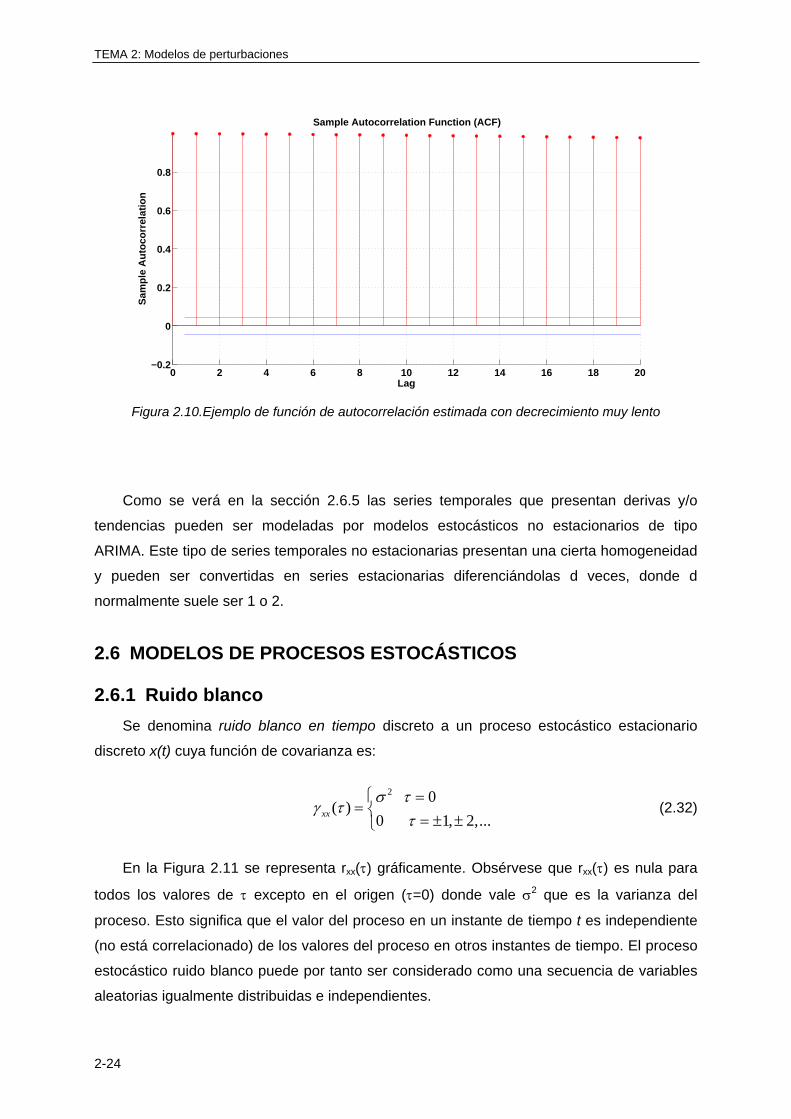
TEMA 2: Modelos de perturbaciones
2-24
0 2 4 6 8 10 12 14 16 18 20−0.2
0
0.2
0.4
0.6
0.8
Lag
Sam
ple
Au
toco
rrel
atio
n
Sample Autocorrelation Function (ACF)
Figura 2.10.Ejemplo de función de autocorrelación estimada con decrecimiento muy lento
Como se verá en la sección 2.6.5 las series temporales que presentan derivas y/o
tendencias pueden ser modeladas por modelos estocásticos no estacionarios de tipo
ARIMA. Este tipo de series temporales no estacionarias presentan una cierta homogeneidad
y pueden ser convertidas en series estacionarias diferenciándolas d veces, donde d
normalmente suele ser 1 o 2.
2.6 MODELOS DE PROCESOS ESTOCÁSTICOS
2.6.1 Ruido blanco
Se denomina ruido blanco en tiempo discreto a un proceso estocástico estacionario
discreto x(t) cuya función de covarianza es:
2 0( )
0 1, 2,...xx
(2.32)
En la Figura 2.11 se representa rxx() gráficamente. Obsérvese que rxx() es nula para
todos los valores de excepto en el origen (=0) donde vale 2 que es la varianza del
proceso. Esto significa que el valor del proceso en un instante de tiempo t es independiente
(no está correlacionado) de los valores del proceso en otros instantes de tiempo. El proceso
estocástico ruido blanco puede por tanto ser considerado como una secuencia de variables
aleatorias igualmente distribuidas e independientes.
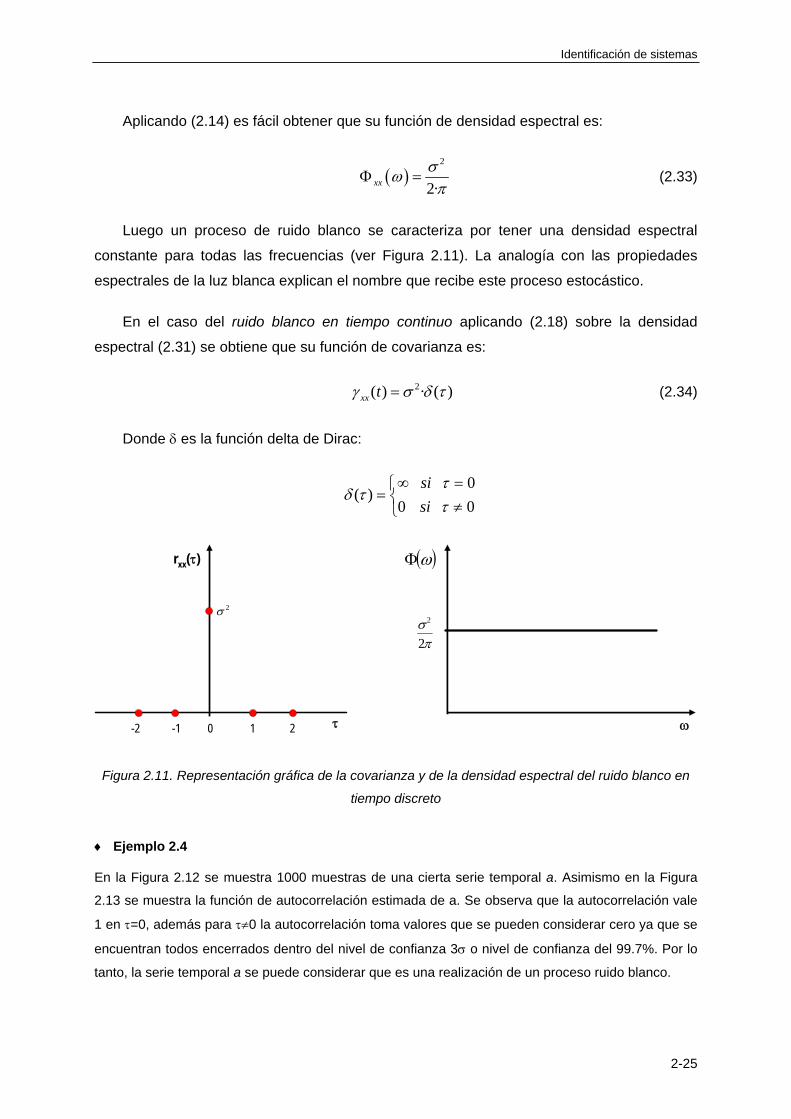
Identificación de sistemas
2-25
Aplicando (2.14) es fácil obtener que su función de densidad espectral es:
2
2·xx
(2.33)
Luego un proceso de ruido blanco se caracteriza por tener una densidad espectral
constante para todas las frecuencias (ver Figura 2.11). La analogía con las propiedades
espectrales de la luz blanca explican el nombre que recibe este proceso estocástico.
En el caso del ruido blanco en tiempo continuo aplicando (2.18) sobre la densidad
espectral (2.31) se obtiene que su función de covarianza es:
2( ) · ( )xx t (2.34)
Donde es la función delta de Dirac:
00
0)(
si
si
0 1-1 2
rxx()
2
-2
2
2
Figura 2.11. Representación gráfica de la covarianza y de la densidad espectral del ruido blanco en
tiempo discreto
Ejemplo 2.4
En la Figura 2.12 se muestra 1000 muestras de una cierta serie temporal a. Asimismo en la Figura
2.13 se muestra la función de autocorrelación estimada de a. Se observa que la autocorrelación vale
1 en =0, además para 0 la autocorrelación toma valores que se pueden considerar cero ya que se
encuentran todos encerrados dentro del nivel de confianza 3 o nivel de confianza del 99.7%. Por lo
tanto, la serie temporal a se puede considerar que es una realización de un proceso ruido blanco.
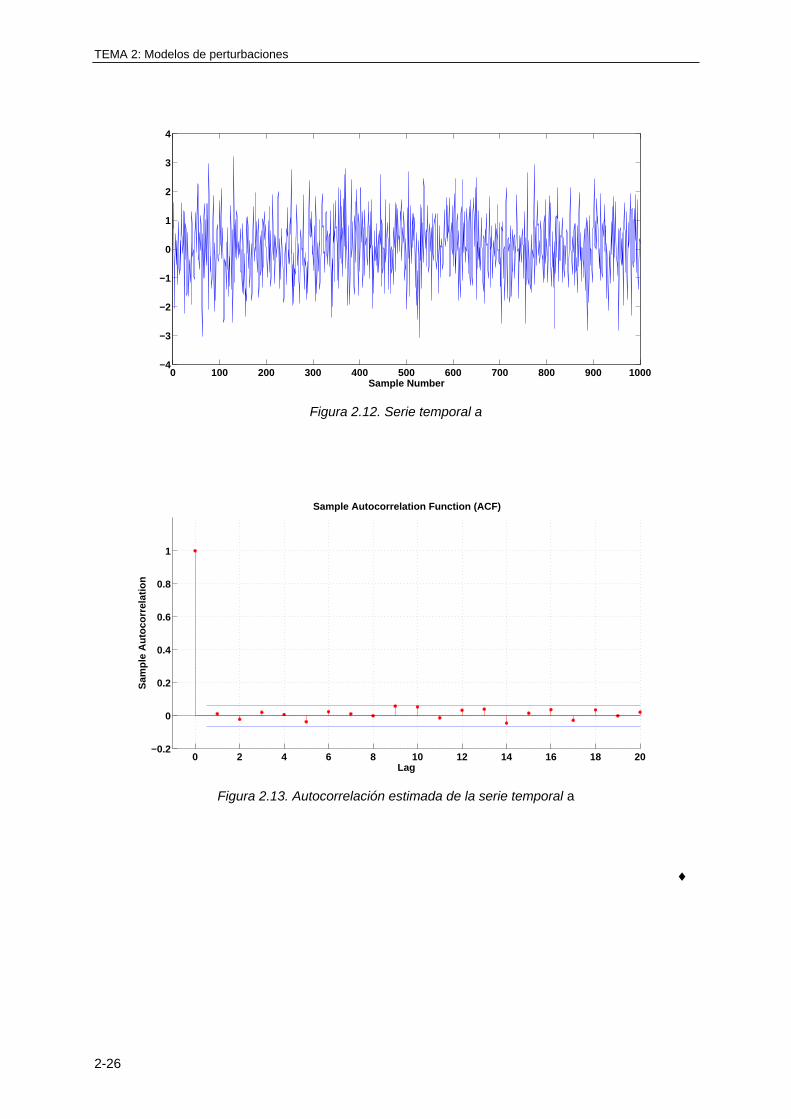
TEMA 2: Modelos de perturbaciones
2-26
0 100 200 300 400 500 600 700 800 900 1000−4
−3
−2
−1
0
1
2
3
4
Sample Number
Figura 2.12. Serie temporal a
0 2 4 6 8 10 12 14 16 18 20−0.2
0
0.2
0.4
0.6
0.8
1
Lag
Sam
ple
Au
toco
rrel
atio
n
Sample Autocorrelation Function (ACF)
Figura 2.13. Autocorrelación estimada de la serie temporal a

Identificación de sistemas
2-27
2.6.2 Procesos AR
Considérese un proceso estocástico zt, la desviación de este proceso con respecto a un
cierto origen, o con respecto a su media si el proceso es estacionario, es:
t tz z (2.35)
Considérese además el proceso de ruido blanco at con media E[at]=0 y varianza
var[at]=2a
Si el proceso estocástico tz es generado mediante una ecuación en diferencias de la
forma
1 1 ...t t n t n tz z z a (2.36)
donde 1( ,..., )n son parámetros reales, entonces se dice que tz es un proceso
autoregresivo de orden n o más abreviadamente un proceso AR(n).
Considerando el operador retardo q-1
11· t tq y y (2.37)
este proceso se puede escribir equivalentemente de la siguiente forma:
111 ... n
n t tq q z a (2.38)
o
1( ) t tq z a (2.39)
donde
1 11( ) 1 ... n
nq q q (2.40)
Por lo tanto
1
1
( )t tz aq
(2.41)

TEMA 2: Modelos de perturbaciones
2-28
El proceso autoregresivo tz se puede considerar la salida de un filtro con función de
transferencia 1
1
( )qque es excitado con una entrada de ruido blanco.
A la ecuación 1( ) 0q se le denomina ecuación característica del proceso y puede
expresarse de la siguiente forma:
1 1 1 11 2( ) (1 )(1 ) (1 ) 0nq p q p q p q (2.42)
Donde 1 1 11 2, , , np p p son las raíces de 1( ) 0q . Nótese que las raíces de
1( ) 0q son las reciprocas del polinomio
11( ) ... 0n n
nq q q (2.43)
Por lo tanto si 1 1 11 2, , , np p p son las raíces de 1( ) 0q entonces
1 2, , , np p p son las raíces de ( ) 0q .
Para que el proceso sea estacionario todas las raíces 1 1 11 2, , , np p p de la ecuación
característica 1( ) 0q deben encontrarse fuera del círculo unidad. O equivalentemente
las raíces 1 2, , , np p p de ( ) 0q deben encontrarse dentro del círculo unidad:
1 1,2,...,ip i n (2.44)
Se puede demostrar [Box and Jenkins, 1976] que la función de autocorrelación de un
proceso AR(n) estacionario se puede calcular a partir de la siguiente ecuación en
diferencias:
1 1 2 2 ... 0n n (2.45)
cuya solución general es:
1 1 2 2 ... n nA p A p A p
(2.46)
Donde 1 1 11 2, , , np p p son las raíces de la ecuación característica 1( ) 0q del
proceso AR(n).

Identificación de sistemas
2-29
Para que el proceso sea estacionario 1 1,2,...,ip i n . Con lo que si ip es una raíz
real entonces el término i iA p tiende a 0 geométricamente cuando aumenta, es decir, se
comporta como una exponencial amortiguada. Mientras que si ip y jp son raíces complejas
conjugadas entonces contribuyen con un término
(2 )D sen f F
en la función de autocorrelación, que se corresponde con una oscilación sinusoidal
amortiguada con factor de amortiguamiento i jD p p y frecuencia
12 cos Re( ) /if p D
.
En general, un proceso AR(n) estacionario se caracteriza por tener una función de
autocorrelación cuyo valor absoluto va decreciendo conforme aumenta el desplazamiento
como una suma de exponenciales amortiguadas y oscilaciones sinusoidales amortiguadas.
Cuanto más alejadas se encuentren las raíces 1 1 11 2, , , np p p del círculo unidad más
rápido será el decrecimiento, y viceversa, cuanto más próximas se encuentren al círculo
unidad más lento será el decrecimiento, es decir, más se acerca a un comportamiento no
estacionario.
Ejemplo 2.5
Considérese el proceso AR(1):
1t t tx x a
Donde at es ruido blanco 2(0, )aN . Este proceso es estacionario si 1 1 .
Se puede demostrar que su varianza y su función de autocorrelación son:
22
21a
x
( ) 0xx
Supóngase que 0.9 y 2a =1. En la Figura 2.14 se representa una realización de este proceso
AR(1). En la Figura 2.15 se representa la función de autocorrelación de este proceso AR(1). Se
observa que según aumenta el desplazamiento la autocorrelación disminuye de forma exponencial.

TEMA 2: Modelos de perturbaciones
2-30
0 100 200 300 400 500 600 700 800 900 1000−8
−6
−4
−2
0
2
4
6
8
Sample Number
Figura 2.14. Una realización de un proceso AR(1) con 0.9
0 2 4 6 8 10 12 14 16 18 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Lag τ
ρ(τ)
Theorical Autocorrelation Function
Figura 2.15. Función de autocorrelación de un proceso AR(1) con 0.9
Se va a considerar ahora que 0.9 y 2a =1. En la Figura 2.16 se representa una realización del
proceso AR(1). En la Figura 2.17 se representa la función de autocorrelación de este proceso AR(1).
Se observa que según aumenta el desplazamiento el valor absoluto de la autocorrelación
disminuye.

Identificación de sistemas
2-31
0 100 200 300 400 500 600 700 800 900 1000−8
−6
−4
−2
0
2
4
6
8
Sample Number
Figura 2.16. Una realización de un proceso AR(1) con 0.9
0 2 4 6 8 10 12 14 16 18 20−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Lag τ
ρ(τ)
Theorical Autocorrelation Function
Figura 2.17. Función de autocorrelación de un proceso AR(1) con 0.9

TEMA 2: Modelos de perturbaciones
2-32
2.6.3 Procesos MA
Si el proceso estocástico tz (ver sección anterior) es generado mediante una ecuación
en diferencias de la forma
1 1 ...t t t m t mz a a a (2.47)
donde 1( ,..., )m son parámetros reales, entonces se dice que tz es un proceso de media
móvil (moving average) de orden m o más abreviadamente un proceso MA(m).
Considerando el operador retardo q-1 este proceso se puede escribir equivalentemente
de la siguiente forma:
111 ... m
t m tz q q a (2.48)
o
1( )·t tz q a (2.49)
donde
1 11( ) 1 ... m
mq q q (2.50)
El proceso de media móvil tz se puede considerar la salida de un filtro con función de
transferencia 1( )q que es excitado con una entrada de ruido blanco.
Un proceso MA(m) es siempre estacionario. Además su función de autocorrelación es
distinta de cero únicamente en m puntos, sin considerar el lag =0.
Ejemplo 2.6
Considérese el proceso MA(1):
1t t tx a a
Donde at es ruido blanco 2(0, )aN . Este proceso es siempre estacionario independientemente del
valor de
Se puede demostrar que su varianza y su función de autocorrelación son:
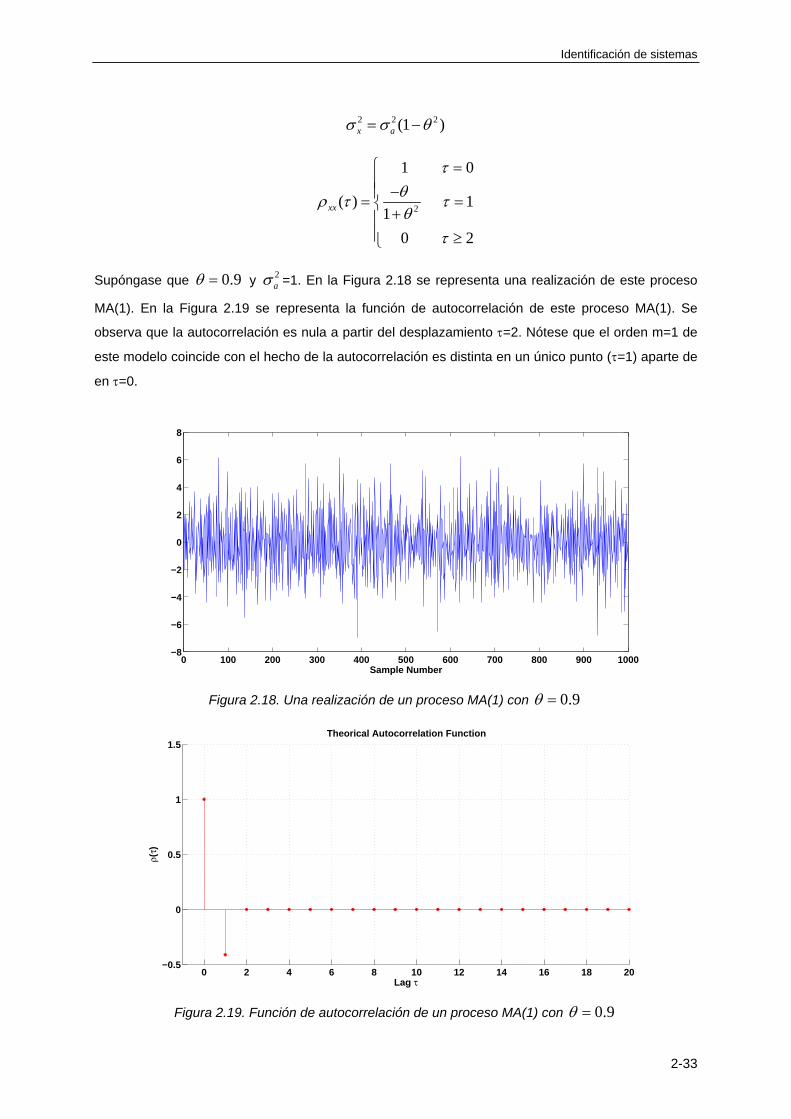
Identificación de sistemas
2-33
2 2 2(1 )x a
2
1 0
( ) 11
0 2
xx
Supóngase que 0.9 y 2a =1. En la Figura 2.18 se representa una realización de este proceso
MA(1). En la Figura 2.19 se representa la función de autocorrelación de este proceso MA(1). Se
observa que la autocorrelación es nula a partir del desplazamiento =2. Nótese que el orden m=1 de
este modelo coincide con el hecho de la autocorrelación es distinta en un único punto (=1) aparte de
en =0.
0 100 200 300 400 500 600 700 800 900 1000−8
−6
−4
−2
0
2
4
6
8
Sample Number
Figura 2.18. Una realización de un proceso MA(1) con 0.9
0 2 4 6 8 10 12 14 16 18 20−0.5
0
0.5
1
1.5
Lag τ
ρ(τ)
Theorical Autocorrelation Function
Figura 2.19. Función de autocorrelación de un proceso MA(1) con 0.9

TEMA 2: Modelos de perturbaciones
2-34
2.6.4 Procesos ARMA
Si el proceso estocástico tz (ver sección 2.6.2) es generado mediante una ecuación en
diferencias de la forma
1 1 1 1... ...t t n t n t t m t mz z z a a a (2.51)
entonces se dice que tz es un proceso autoregresivo de media móvil o más abreviadamente
un proceso ARMA(n,m).
Considerando el operador retardo q-1 este proceso se puede escribir equivalentemente
de la siguiente forma:
1 11 11 ... · 1 ... ·n m
n t m tq q z q q a (2.52)
o
1 1( )· ( )·t tq z q a (2.53)
Donde
1 11( ) 1 ... n
nq q q (2.54)
1 11( ) 1 ... m
mq q q (2.55)
Por lo tanto
1
1
( )
( )t t
qz a
q
(2.56)
El proceso de autoregresivo de media móvil tz se puede considerar la salida de un filtro
con función de transferencia 1
1
( )
( )
q
q
que es excitado con una entrada de ruido blanco.
Un proceso ARMA(n,m) es estacionario si las raíces de 1( ) 0q se encuentran fuera
del círculo unidad. Además se caracteriza por tener una función de autocorrelación con un
comportamiento similar al de un proceso AR.
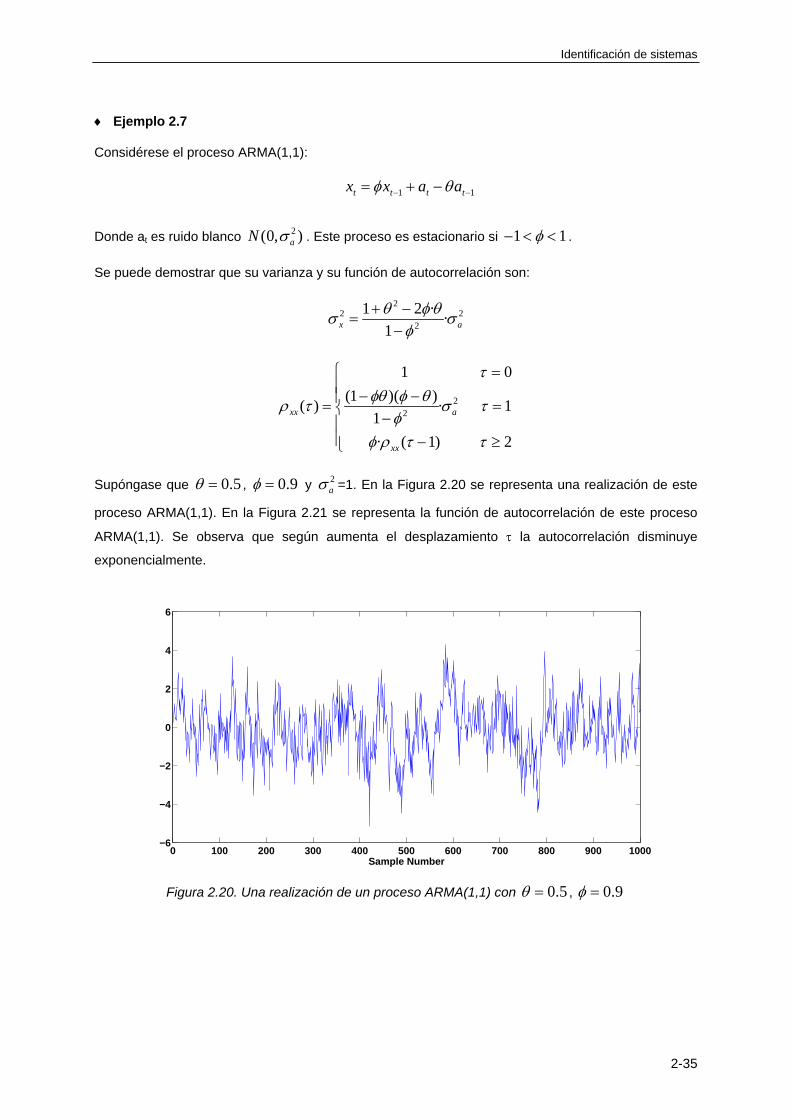
Identificación de sistemas
2-35
Ejemplo 2.7
Considérese el proceso ARMA(1,1):
1 1t t t tx x a a
Donde at es ruido blanco 2(0, )aN . Este proceso es estacionario si 1 1 .
Se puede demostrar que su varianza y su función de autocorrelación son:
22 2
2
1 2 ··
1x a
22
1 0
(1 )( )( ) · 1
1
· ( 1) 2
xx a
xx
Supóngase que 0.5 , 0.9 y 2a =1. En la Figura 2.20 se representa una realización de este
proceso ARMA(1,1). En la Figura 2.21 se representa la función de autocorrelación de este proceso
ARMA(1,1). Se observa que según aumenta el desplazamiento la autocorrelación disminuye
exponencialmente.
0 100 200 300 400 500 600 700 800 900 1000−6
−4
−2
0
2
4
6
Sample Number
Figura 2.20. Una realización de un proceso ARMA(1,1) con 0.5 , 0.9
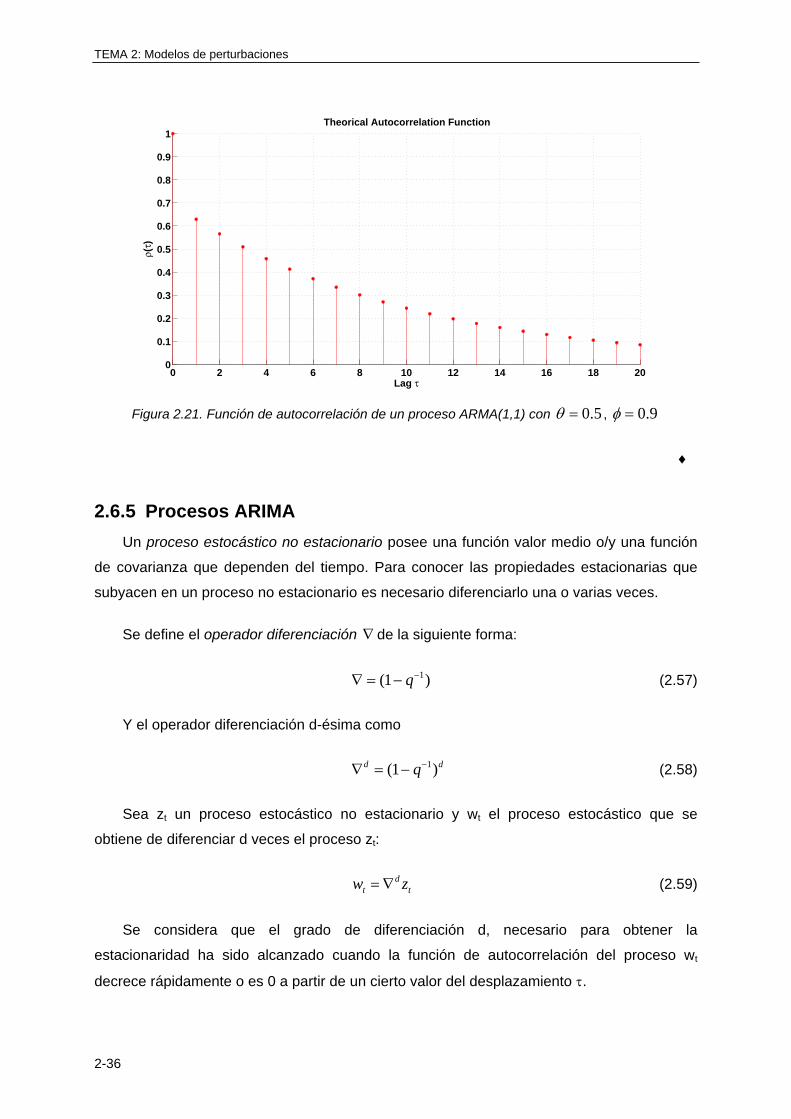
TEMA 2: Modelos de perturbaciones
2-36
0 2 4 6 8 10 12 14 16 18 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Lag τ
ρ(τ)
Theorical Autocorrelation Function
Figura 2.21. Función de autocorrelación de un proceso ARMA(1,1) con 0.5 , 0.9
2.6.5 Procesos ARIMA
Un proceso estocástico no estacionario posee una función valor medio o/y una función
de covarianza que dependen del tiempo. Para conocer las propiedades estacionarias que
subyacen en un proceso no estacionario es necesario diferenciarlo una o varias veces.
Se define el operador diferenciación de la siguiente forma:
1(1 )q (2.57)
Y el operador diferenciación d-ésima como
1(1 )d dq (2.58)
Sea zt un proceso estocástico no estacionario y wt el proceso estocástico que se
obtiene de diferenciar d veces el proceso zt:
dt tw z (2.59)
Se considera que el grado de diferenciación d, necesario para obtener la
estacionaridad ha sido alcanzado cuando la función de autocorrelación del proceso wt
decrece rápidamente o es 0 a partir de un cierto valor del desplazamiento .

Identificación de sistemas
2-37
La consideración de este operador permite definir los procesos autoregresivos
integrados de media móvil o procesos ARIMA(n,d,m) como aquellos generados por la
siguiente ecuación:
1 1( )· ( )·dt tq z q a (2.60)
Equivalentemente un proceso ARIMA tz puede considerarse la salida de un filtro con la
siguiente función de transferencia que es excitado con una entrada de ruido blanco ta :
11
1 11
1 ...·
(1 ) ·(1 ... )
mm
t td nn
q qz a
q q q
(2.61)
Un proceso ARIMA(n,d,m) es una extensión de un proceso ARMA(n,m) al caso de
procesos estocásticos no estacionarios. Obsérvese, de hecho, que si en la ecuación anterior
se sustituye tz por tz entonces un proceso ARIMA(n,0,m) es un proceso ARMA(n,m).
Nótese también que un proceso ARIMA(0,0,0) es un proceso ruido blanco, un proceso
ARIMA(0,0,m) es un proceso MA(m) y que un proceso ARIMA(n,0,0) es un proceso AR(n).
Ejemplo 2.8
El ejemplo más sencillo de proceso aleatorio no estacionario es el denominado como paseo aleatorio
(random walk) que se obtiene mediante la siguiente ecuación en diferencias
1t t tx x a
donde at es ruido blanco 2(0, )aN .
Si se resuelve la ecuación de diferencias que representa un proceso paseo aleatorio se obtiene la
siguiente solución:
01
t
t ii
x x a
A partir de esta expresión se puede demostrar la varianza y la función de autocorrelación de un
proceso paseo aleatorio son:
2 2[ ] [( [ ]) ] ·t t t aVar x E x E x t
( ) 1 0xx
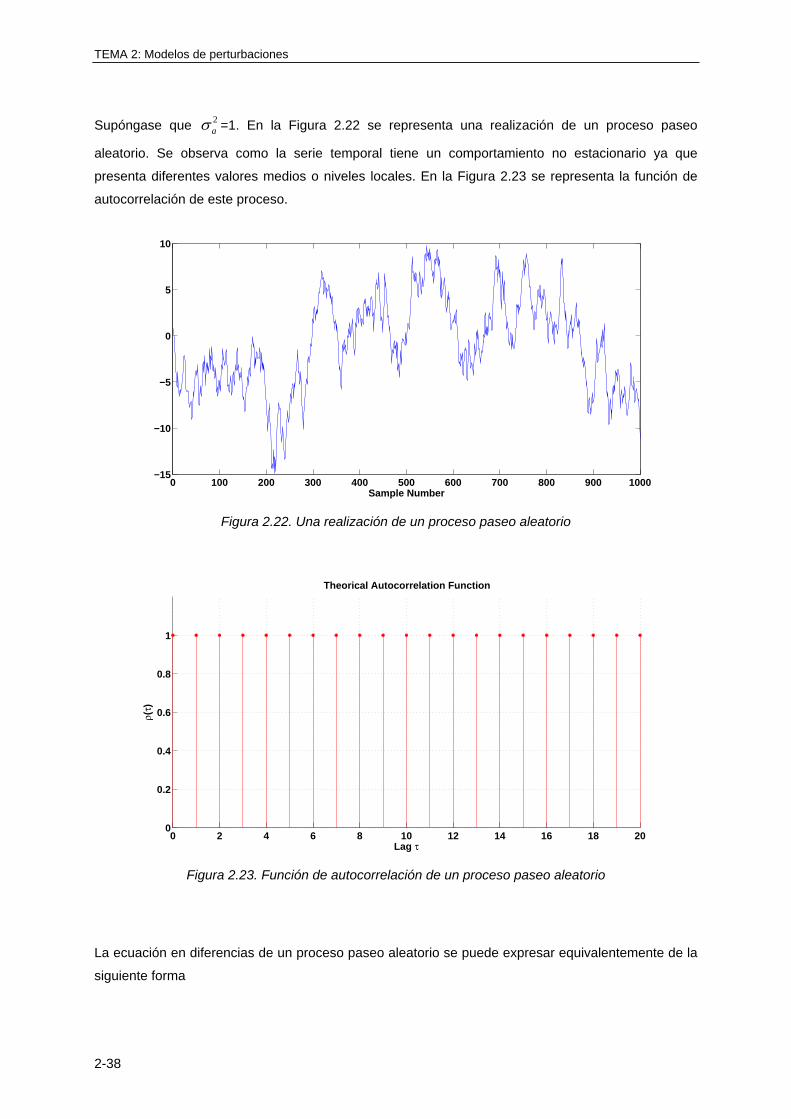
TEMA 2: Modelos de perturbaciones
2-38
Supóngase que 2a =1. En la Figura 2.22 se representa una realización de un proceso paseo
aleatorio. Se observa como la serie temporal tiene un comportamiento no estacionario ya que
presenta diferentes valores medios o niveles locales. En la Figura 2.23 se representa la función de
autocorrelación de este proceso.
0 100 200 300 400 500 600 700 800 900 1000−15
−10
−5
0
5
10
Sample Number
Figura 2.22. Una realización de un proceso paseo aleatorio
0 2 4 6 8 10 12 14 16 18 200
0.2
0.4
0.6
0.8
1
Lag τ
ρ(τ)
Theorical Autocorrelation Function
Figura 2.23. Función de autocorrelación de un proceso paseo aleatorio
La ecuación en diferencias de un proceso paseo aleatorio se puede expresar equivalentemente de la
siguiente forma

Identificación de sistemas
2-39
1(1 )· t tq x a
De la que se deduce que un proceso paseo aleatorio es un proceso ARIMA(0,1,0). Nótese que la
ecuación anterior se puede expresar también en la forma
1
1
1t tx aq
Con lo que un proceso paseo aleatorio se puede considerar la salida de un filtro con función de
transferencia 1
1
1 q que es excitado con una entrada de ruido blanco. Esta función de tranferencia
corresponde a la de un integrador en tiempo discreto. Luego un proceso paseo aleatorio se obtiene
integrando ruido blanco.
Nótese que si se diferenciara una vez la salida de este filtro se eliminarían los efectos de la
integración y se obtendría como resultado la entrada del filtro: ruido blanco, que es una señal
estacionaria. Es decir, se habría eliminado la no estacionaridad de la serie temporal introducida por el
integrador.
2.6.6 Identificación del tipo de modelo estocástico a utilizar a partir de una serie temporal
2.6.6.1 Función de autocorrelación parcial
La función de autocorrelación parcial kk es un instrumento matemático [Box and
Jenkins, 1976] que permite determinar junto con la función de autocorrelación qué tipo de
proceso estocástico básico (ruido blanco, AR, MA, ARMA o ARIMA) ha podido generar una
determinada serie temporal. La función de autocorrelación parcial puede ser estimada
ajustando por mínimos cuadrados los datos de la serie temporal a modelos AR(k) de
órdenes k crecientes 1,2,3,...k De esta forma el coeficiente k del modelo AR(k) es
precisamente el valor estimado kk del coeficiente k de la función de autocorrelación parcial.
El error o desviación estándar existente en la función de autocorrelación parcial
estimada puede ser estimado a través de la siguiente ecuación [Box and Jenkins, 1976]:
1/2
1ˆˆ[ ]kk k pN
(21)

TEMA 2: Modelos de perturbaciones
2-40
bajo la hipótesis de que se tiene una realización de un proceso AR(p).
En los procesos estocásticos básicos la función de autocorrelación parcial presenta el
siguiente comportamiento:
Ruido blanco. La función de autocorrelación parcial se comporta como la función de
autocorrelación del ruido blanco, es decir, tiene un único valor distinto de cero en el
lag =0.
AR(p). La función de autocorrelación parcial se comporta como la función de
autocorrelación de un proceso MA(p), es decir, todos sus puntos son cero excepto en
p además de en =0.
MA(q). La función de autocorrelación parcial se comporta como la función de
autocorrelación de un proceso AR(q), es decir, decrece conforme aumenta el número
de lags como una suma de exponenciales amortiguadas y sinusoides
amortiguadas.
ARMA(p,q). La función de autocorrelación parcial se comporta como la función de
autocorrelación de un proceso AR(q).
2.6.6.2 Procedimiento de análisis
Supóngase que se dispone de N datos de una cierta serie temporal y se desea
determinar el tipo de modelo estocástico básico que permite generarla, para posteriormente
poder estimar sus parámetros (ver Tema 6). Una forma de determinarlo es analizar la
representación de la serie temporal, su función de autocorrelación estimada y su función de
autocorrelación parcial estimada.
En primer lugar mediante el estudio de la representación de la serie temporal y de su
función de autocorrelación estimada se debe determinar si la serie es estacionaria o no
estacionaria (ver sección 2.5.2.4). Si la serie es no estacionaria entonces debe ser
diferenciada el número de veces necesarias hasta conseguir que sea estacionaria. Nótese
que el número de veces que se diferencie la serie estará fijando el valor del orden d de un
modelo ARIMA(n,d,m).
Una vez que ha conseguido que la serie temporal sea estacionaria se debe analizar su
función de autocorrelación estimada (AE) y su función de autocorrelación parcial estimada
(APE). En dichas funciones se debe dibujar el intervalo de confianza 2 o 3 calculados con

Identificación de sistemas
2-41
la hipótesis de que la serie ha sido generada por un proceso ruido blanco, de tal forma que
si un valor de dicha función se encuentra dentro, sobre o ligeramente por encima del
intervalo puede considerarse que su valor es nulo bajo dicha hipótesis. Se pueden dar los
siguientes casos:
Si la AE tiene todos sus valores dentro del intervalo de confianza, exceptuando
el punto en el lag =0, entonces se puede modelar con un proceso de ruido
blanco.
Si la AE tiene m valores fuera del intervalo de confianza, exceptuando el punto
en el lag =0, se puede modelar con un proceso MA(m).
Si el valor absoluto de la AE decrece como una suma de exponenciales
amortiguadas y sinosuides amortiguadas conforme aumenta entonces se
puede modelar con un modelo AR(n) o ARMA(n,m). Para discriminar si se trata
de un modelo AR(n) o ARMA(n,m) se debe analizar la APE. Si se tratara de un
proceso AR(n) la APE tendría n valores fuera del intervalo de confianza,
exceptuando el punto en el lag =0.
Con respecto a la elección de los órdenes del modelo se debe tener en cuenta lo
siguiente:
La mayoría de series temporales aleatorias se pueden modelar mediante un
modelo estocástico de primer o segundo orden. Esto implica que n=1, 2 y m=1,
2
El grado de diferenciación típicamente suele ser d=1 o d=2. Recuérdese que se
considera que el grado de diferenciación d, necesario para obtener la
estacionaridad ha sido alcanzado cuando la función de autocorrelación estimada
de la señal diferenciada decrece rápidamente o se encuentra dentro del intervalo
de confianza a partir de un cierto valor del desplazamiento . En este último caso
el grado m del modelo ARIMA se determina como los m valores fuera del
intervalo de confianza, exceptuando a =0,
Además a la hora de analizar la función de autocorrelación estimada conviene tener
presente lo siguiente:

TEMA 2: Modelos de perturbaciones
2-42
Para considerar como válidos los resultados se debe dispone de una serie
temporal con un número de muestras N igual o mayor a 50.
Es suficiente con considerar un número de desplazamientos no superior a N/4.
En la práctica es suficiente con inspeccionar los primeros 20 desplazamientos:
=1, 2,…,20.
La función de autocorrelación estimada (AE) puede tener una alta varianza, lo
que implica que puede diferir de la función de autocorrelación teórica (AT) que
se puede calcular directamente si se conoce el modelo estocástico. Por ejemplo,
la AE puede tener valores altos cuando en la AT correspondería valores
pequeños ya que se estaría atenuando. También la AE puede tener rizados y
tendencias que no aparecen en la AT. Para evitar estos problemas se debe
disminuir la varianza, lo cual se consigue disponiendo de series temporales de
mayor longitud N. Lo mismo se aplica a la función de correlación cruzada
estimada.
Ejemplo 2.9
Considérese un cierto sistema 1 que es excitado con una señal de ruido blanco at de tipo N(0,1), la
salida del sistema es una señal aleatoria yt. Se dispone de N=1000 datos de la entrada y de la salida.
En la Figura 2.24 se representa la salida yt. Se observa que la señal presenta un comportamiento
estacionario, por lo que no es necesario diferenciarla. Esta conclusión se comprueba calculando su
función de autocorrelación estimada (ver Figura 2.25). Puesto que todos sus valores se encuentran
dentro del intervalo de confianza del 99.7%, excepto en =0 y =1, la señal es estacionaria además
se podría usar un modelo MA(1) para modelar el sistema.
Supóngase que el sistema 1 es excitado con otra señal distinta de ruido blanco et de tipo N(0,1), la
salida del sistema es la señal aleatoria zt. En la Figura 2.26 se representa su función de
autocorrelación estimada. Se observa que aparte de los puntos =0 y =1 como ya sucedía en la
anterior realización, también sobrepasan el intervalo de confianza del 99.7%, los puntos =2 , =10 y
=11. La existencia del punto =2 fuera del intervalo de confianza (o si estuviera muy próximo al
límite) podría llevar a pensar en utilizar un modelo MA(2), aunque también podría atribuirse a la
varianza existente en la serie temporal y considerar un modelo MA(1). La existencia de los puntos
=10 y =11 fuera del intervalo de confianza debe atribuirse a la varianza existente en la serie
temporal.
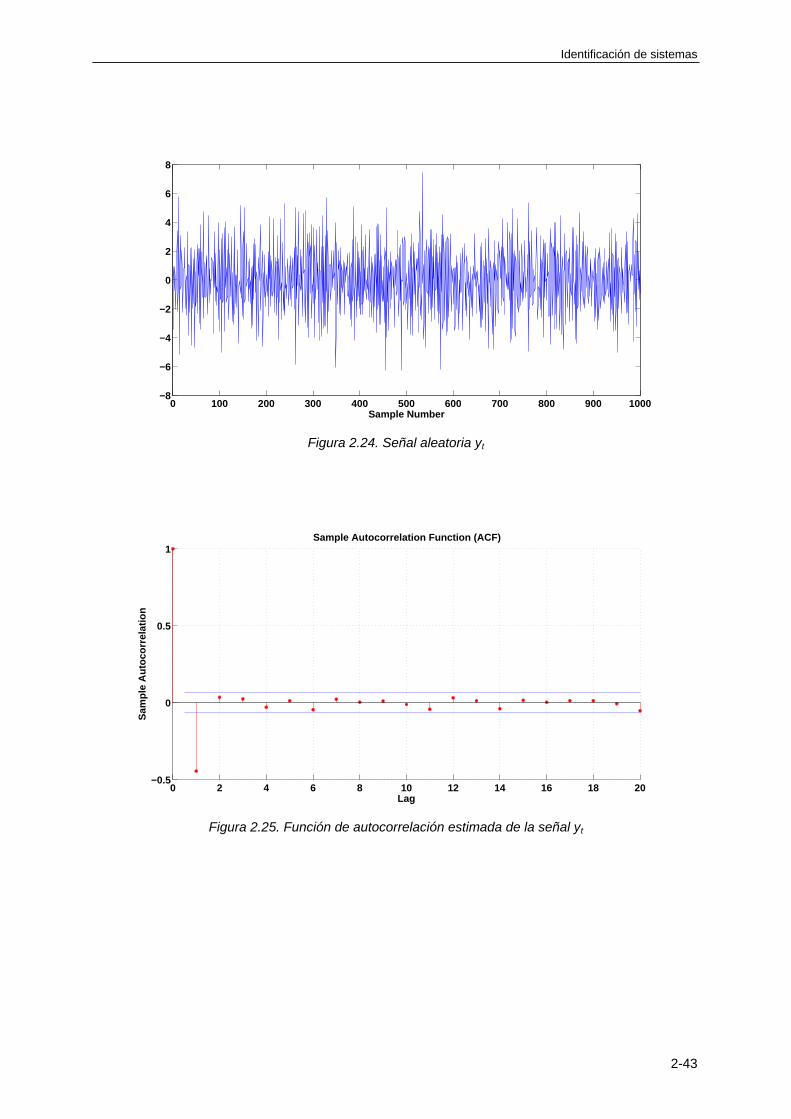
Identificación de sistemas
2-43
0 100 200 300 400 500 600 700 800 900 1000−8
−6
−4
−2
0
2
4
6
8
Sample Number
Figura 2.24. Señal aleatoria yt
0 2 4 6 8 10 12 14 16 18 20−0.5
0
0.5
1
Lag
Sam
ple
Au
toco
rrel
atio
n
Sample Autocorrelation Function (ACF)
Figura 2.25. Función de autocorrelación estimada de la señal yt
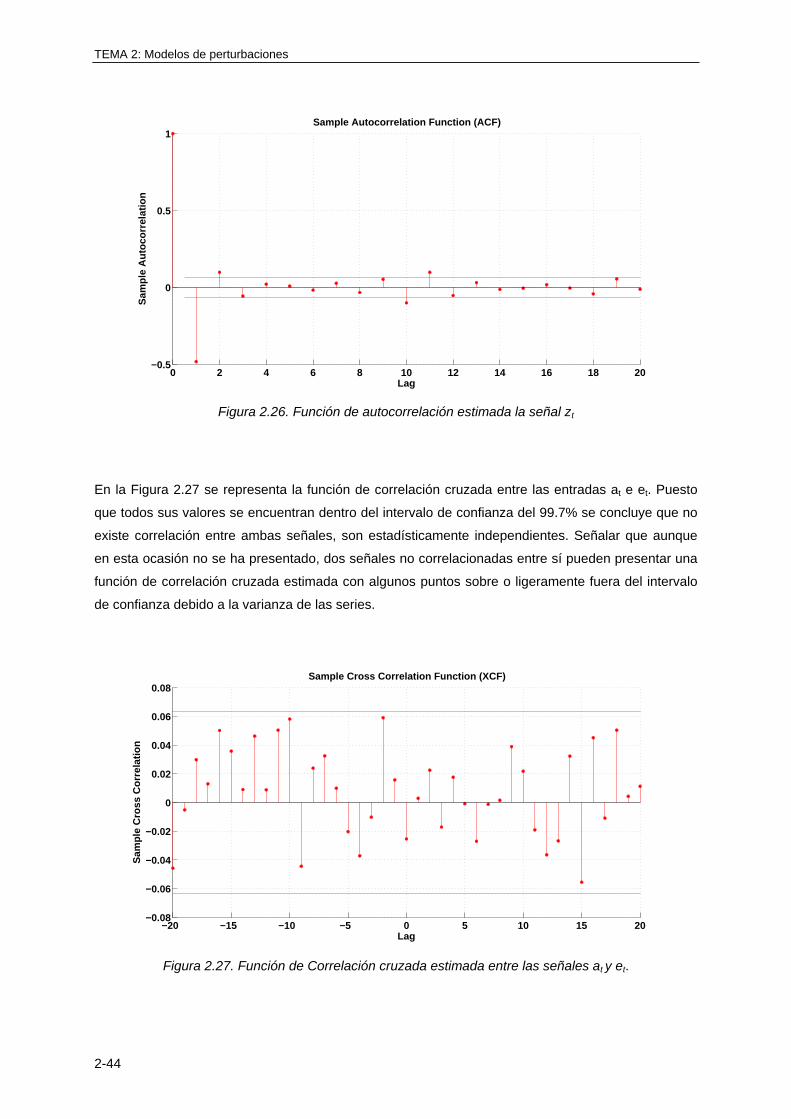
TEMA 2: Modelos de perturbaciones
2-44
0 2 4 6 8 10 12 14 16 18 20−0.5
0
0.5
1
Lag
Sam
ple
Au
toco
rrel
atio
n
Sample Autocorrelation Function (ACF)
Figura 2.26. Función de autocorrelación estimada la señal zt
En la Figura 2.27 se representa la función de correlación cruzada entre las entradas at e et. Puesto
que todos sus valores se encuentran dentro del intervalo de confianza del 99.7% se concluye que no
existe correlación entre ambas señales, son estadísticamente independientes. Señalar que aunque
en esta ocasión no se ha presentado, dos señales no correlacionadas entre sí pueden presentar una
función de correlación cruzada estimada con algunos puntos sobre o ligeramente fuera del intervalo
de confianza debido a la varianza de las series.
−20 −15 −10 −5 0 5 10 15 20−0.08
−0.06
−0.04
−0.02
0
0.02
0.04
0.06
0.08
Lag
Sam
ple
Cro
ss C
orr
elat
ion
Sample Cross Correlation Function (XCF)
Figura 2.27. Función de Correlación cruzada estimada entre las señales at y et.
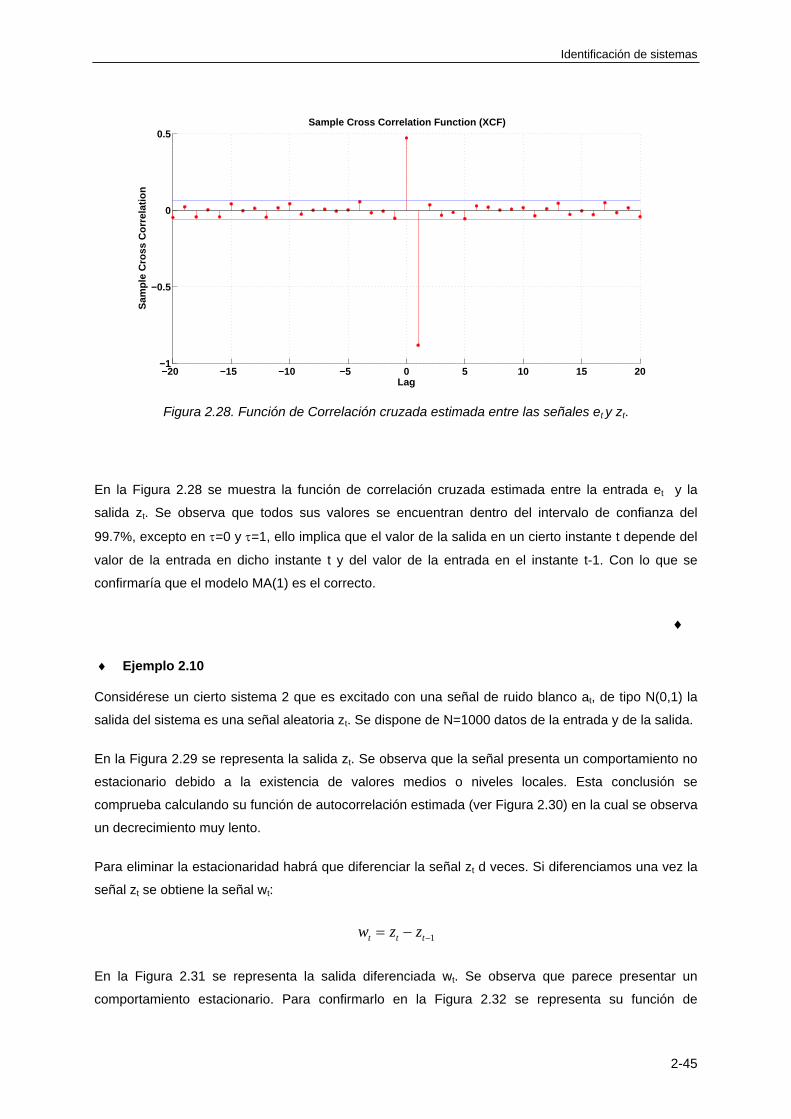
Identificación de sistemas
2-45
−20 −15 −10 −5 0 5 10 15 20−1
−0.5
0
0.5
Lag
Sam
ple
Cro
ss C
orr
elat
ion
Sample Cross Correlation Function (XCF)
Figura 2.28. Función de Correlación cruzada estimada entre las señales et y zt.
En la Figura 2.28 se muestra la función de correlación cruzada estimada entre la entrada et y la
salida zt. Se observa que todos sus valores se encuentran dentro del intervalo de confianza del
99.7%, excepto en =0 y =1, ello implica que el valor de la salida en un cierto instante t depende del
valor de la entrada en dicho instante t y del valor de la entrada en el instante t-1. Con lo que se
confirmaría que el modelo MA(1) es el correcto.
Ejemplo 2.10
Considérese un cierto sistema 2 que es excitado con una señal de ruido blanco at, de tipo N(0,1) la
salida del sistema es una señal aleatoria zt. Se dispone de N=1000 datos de la entrada y de la salida.
En la Figura 2.29 se representa la salida zt. Se observa que la señal presenta un comportamiento no
estacionario debido a la existencia de valores medios o niveles locales. Esta conclusión se
comprueba calculando su función de autocorrelación estimada (ver Figura 2.30) en la cual se observa
un decrecimiento muy lento.
Para eliminar la estacionaridad habrá que diferenciar la señal zt d veces. Si diferenciamos una vez la
señal zt se obtiene la señal wt:
1t t tw z z
En la Figura 2.31 se representa la salida diferenciada wt. Se observa que parece presentar un
comportamiento estacionario. Para confirmarlo en la Figura 2.32 se representa su función de
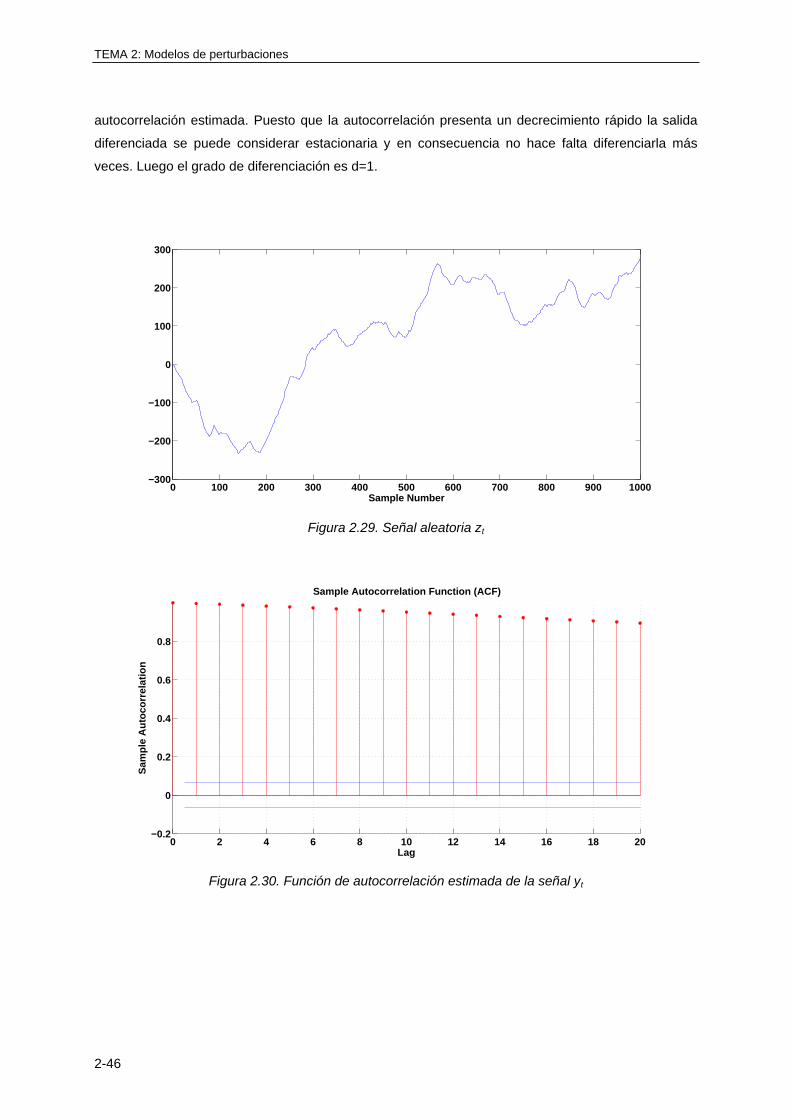
TEMA 2: Modelos de perturbaciones
2-46
autocorrelación estimada. Puesto que la autocorrelación presenta un decrecimiento rápido la salida
diferenciada se puede considerar estacionaria y en consecuencia no hace falta diferenciarla más
veces. Luego el grado de diferenciación es d=1.
0 100 200 300 400 500 600 700 800 900 1000−300
−200
−100
0
100
200
300
Sample Number
Figura 2.29. Señal aleatoria zt
0 2 4 6 8 10 12 14 16 18 20−0.2
0
0.2
0.4
0.6
0.8
Lag
Sam
ple
Au
toco
rrel
atio
n
Sample Autocorrelation Function (ACF)
Figura 2.30. Función de autocorrelación estimada de la señal yt

Identificación de sistemas
2-47
0 100 200 300 400 500 600 700 800 900 1000−10
−8
−6
−4
−2
0
2
4
6
8
Sample Number
Figura 2.31. Salida diferenciada wt
0 2 4 6 8 10 12 14 16 18 20−0.2
0
0.2
0.4
0.6
0.8
Lag
Sam
ple
Au
toco
rrel
atio
n
Sample Autocorrelation Function (ACF)
Figura 2.32. Función de autocorrelación estimada de la salida diferenciada wt
Figura 2.33. Función de autocorrelación parcial estimada de la salida diferenciada wt

TEMA 2: Modelos de perturbaciones
2-48
Por otra parte, este decrecimiento exponencial de la función de autocorrelación estimada indica que
la salida diferenciada wt puede ser generada por un proceso AR(n) o ARMA(n,m). Para discriminar
qué tipo de proceso la genera se ha calculado la función de autocorrelación parcial estimada (ver
Figura 2.33) Se observa que todos sus valores se encuentran dentro del intervalo de confianza
excepto en =0, =1 y =2, luego se trataría de un proceso AR(2).
En conclusión el sistema 2 podría modelarse como un modelo ARIMA(2,1,0).
2.7 FILTRADO DE PROCESOS ESTOCÁSTICOS ESTACIONARIOS
Considérese un sistema dinámico de tiempo discreto estacionario con periodo de
muestreo T=1 (ver Figura 2.34) y función de transferencia pulso H(z). Sea la señal de
entrada u un proceso estocástico estacionario con media mu y densidad espectral u. Si el
sistema es estable, entonces la salida y es también un proceso estacionario con media
)()·1()( kmHkm uy (2.62)
y densidad espectral
)()·()·()( iTu
iy eHeH (2.63)
Además la densidad espectral cruzada entre la entrada y la salida está dada por la
expresión
)()·()( · u
iyu eH (2.64)
Este resultado tiene una sencilla interpretación física. El número )( ieH es la amplitud
en el estado estacionario de la respuesta del sistema a una señal seno de frecuencia . El
valor de la densidad espectral de la salida es entonces el producto de la ganancia de la
potencia 2
)( ieH y la densidad espectral de la entrada u().
H(z)u y
Figura 2.34. Sistema discreto estacionario

Identificación de sistemas
2-49
Por otra parte, la ecuación (2.64) indica que la densidad espectral cruzada es igual a la
función de transferencia del sistema si la entrada es ruido blanco con densidad espectral
unidad. Este resultado puede ser utilizado para determinar la función de transferencia pulso
del sistema.
Se va considerar ahora un sistema en tiempo continuo estable invariante en el tiempo
con respuesta a impulso g. La relación entre la entrada y la salida de dicho sistema viene
dada por:
0
)()·()()·()( dsstusgdssustgtyt
(2.65)
Sea la señal de entrada u a un proceso estocástico con función valor medio mu y
función de covarianza ru. El siguiente teorema es análogo al Teorema 3.3 enunciado para
sistemas en tiempo discreto.
Considérese un sistema lineal estacionario con función de transferencia G. Sea la señal
de entrada un proceso estocástico estacionario en tiempo continuo con valor medio mu y
densidad espectral u. Si el sistema es estable, entonces la salida es también un proceso
estacionario con valor medio
uy mGm )·0( (2.66)
y densidad espectral
)()·()·()( iGiG Tuy (2.67)
La densidad espectral cruzada entre la entrada y la salida está dada por
)()·()( uyu iG (2.68)
Se denomina factorización espectral al problema de obtener el sistema lineal H(z)
)(
)(
)(
)(·)(
zA
zB
pz
zzKzH
i
i
estacionario que al ser excitado por ruido blanco de covarianza unidad genera una salida
cuya densidad espectral y(), racional en cos , es conocida de antemano.

TEMA 2: Modelos de perturbaciones
2-50
Como la entrada es ruido blanco su densidad espectral es
·2
1)( u
Además como
iez
entonces por la ecuación (2.63) se tiene que:
11( ) · ( )· ( )
2·T
y H z H z
Teorema de factorización espectral. Dada una densidad espectral (), que sea una
función racional en cos , existe un sistema lineal con función de transferencia pulso
)(
)()(
zA
zBzH (2.69)
tal que la salida que se obtiene, cuando la entrada del sistema es ruido blanco, es un
proceso aleatorio estacionario con densidad espectral . El polinomio A(z) tiene todos sus
ceros dentro del círculo unidad. El polinomio B tiene todos sus ceros dentro del disco unidad
o sobre el circulo unidad.
De acuerdo con el teorema de factorización espectral es posible generar cualquier
proceso aleatorio estacionario con densidad espectral racional como la salida de un sistema
lineal estable al cual se le excita con ruido blanco. Por tanto es suficiente con estudiar cómo
se comportan los sistemas cuando son excitados por ruido blanco. Todos los otros procesos
estacionarios con densidad espectral racional pueden ser generados mediante el filtrado
adecuado del ruido blanco.

Identificación de sistemas
2-51
BIBLIOGRAFÍA
[Aström and Wittenmark, 1984] K. J. Aström. Y B. Wittenmark. Computer Controlled
Systems. Prentice-Hall, 1984.
[Bendat and Piersol, 1971] J. S. Bendat y A.G. Piersol. Random Data: Analysis and
Measurement Procedures. John Wiley & Sons, 1971.
[Box and Jenkins, 1976] G. E. P. Box y G. M. Jenkins. Time Series Analysis:
Forecasting and Control. Holden-Day. 1976.
[Jenkins and Watts, 1968] G. M. Jenkins y D. G. Watts. Spectral Analysis and Its
Applications. Holden-Day. 1968.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.


TEMA 3
CONSIDERACIONES GENERALES SOBRE LA IDENTIFICACION DE SISTEMAS
3-1
3.1 INTRODUCCIÓN
El modelo matemático de un sistema se puede utilizar para calcular o decidir cómo se
comporta el sistema. Una posible forma de realizar esto es resolviendo analíticamente las
ecuaciones matemáticas que describen el sistema y analizando el resultado. Sin embargo,
en muchas ocasiones no es posible encontrar una solución analítica, o ésta es tan
complicada que no permite extraer conclusiones claras. En dichos casos las ecuaciones del
modelo se deben resolver numéricamente con ayuda de un computador. Éste es
precisamente el fundamento de la simulación de sistemas, que permiten realizar
experimentos numéricos sobre el modelo de un sistema. Obviamente su principal desventaja
es que los resultados de la simulación dependen de la calidad del modelo del sistema
utilizado.
De forma general los modelos matemáticos se pueden obtener de dos formas distintas:
Modelización matemática. Es un método analítico que usa las leyes físicas (como
las leyes de Newton o las leyes de Kirchoff) para describir la conducta dinámica
del proceso. El modelado depende totalmente de la aplicación y a menudo tiene
sus raíces en la tradición y en las técnicas específicas del área de aplicación.
Generalmente, supone considerar el sistema dividido en subsistemas cuyas
propiedades son conocidas de experiencias anteriores y de los que se tienen
modelos matemáticos. El modelo del sistema completo se obtiene uniendo
matemáticamente los modelos de los subsistemas considerados.
Identificación de sistemas. Se trata de un método empírico, es decir, requiere de
la realización de varios experimentos para obtener datos de entrada-salida del
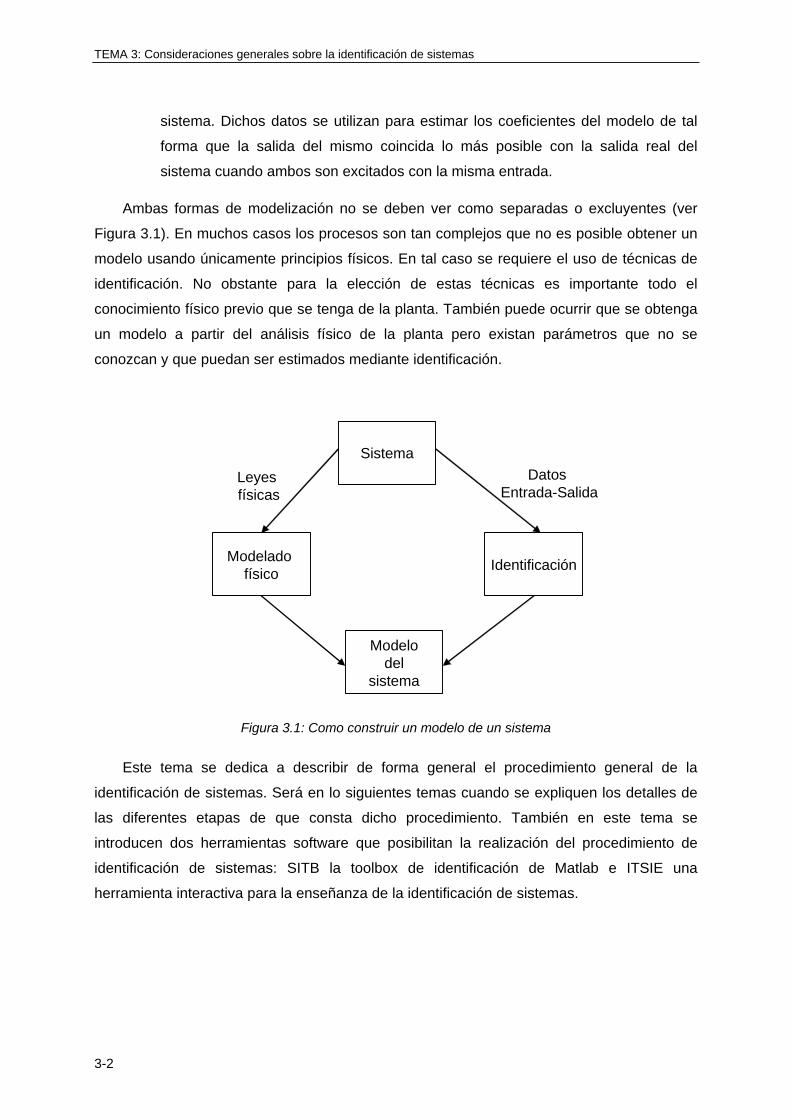
TEMA 3: Consideraciones generales sobre la identificación de sistemas
3-2
sistema. Dichos datos se utilizan para estimar los coeficientes del modelo de tal
forma que la salida del mismo coincida lo más posible con la salida real del
sistema cuando ambos son excitados con la misma entrada.
Ambas formas de modelización no se deben ver como separadas o excluyentes (ver
Figura 3.1). En muchos casos los procesos son tan complejos que no es posible obtener un
modelo usando únicamente principios físicos. En tal caso se requiere el uso de técnicas de
identificación. No obstante para la elección de estas técnicas es importante todo el
conocimiento físico previo que se tenga de la planta. También puede ocurrir que se obtenga
un modelo a partir del análisis físico de la planta pero existan parámetros que no se
conozcan y que puedan ser estimados mediante identificación.
Sistema
Modelado físico
Identificación
Leyes físicas
Datos Entrada-Salida
Modelodel
sistema
Figura 3.1: Como construir un modelo de un sistema
Este tema se dedica a describir de forma general el procedimiento general de la
identificación de sistemas. Será en lo siguientes temas cuando se expliquen los detalles de
las diferentes etapas de que consta dicho procedimiento. También en este tema se
introducen dos herramientas software que posibilitan la realización del procedimiento de
identificación de sistemas: SITB la toolbox de identificación de Matlab e ITSIE una
herramienta interactiva para la enseñanza de la identificación de sistemas.

Identificación de sistemas
3-3
3.2 PROCEDIMIENTO GENERAL DE IDENTIFICACIÓN DE SISTEMAS
En la Figura 3.2 se muestra un esquema del procedimiento general de la identificación
de sistemas. En primer lugar hay que diseñar el experimento o experimentos a los que se va
a someter al sistema. En dicho diseño resulta muy útil todo el conocimiento a priori que se
tenga del sistema. El conocimiento a priori del proceso se basa, por ejemplo, en la
comprensión general del proceso, en leyes físicas a las que éste obedece y en medidas
previas. Todo ello permite disponer de una idea sobre el grado de linealidad del proceso, su
varianza o invarianza con el tiempo, comportamiento integral o proporcional, constantes de
tiempo dominantes, retardos, características del ruido, rango de algunos parámetros, valor
de algunos de ellos, limitaciones de la estructura del modelo, etc.
Además, en el diseño del experimento hay que seleccionar, entre otros aspectos, la
señal de entrada (tipo, espectro y amplitud), el periodo de muestreo y la duración del
experimento (número de medidas).
Respecto a la selección de la señal de entrada que debe “excitar” al sistema, debe ser
seleccionada para que genere información en el rango de frecuencias de interés. Dos tipos
de entrada bastante utilizadas son las señales pseudoaleatorias binarias (PRBS) y las
señales multiseno. Estas señales de entrada serán objeto de estudio en el Tema 4.
Hay que tener en cuenta que pueden existir limitaciones físicas y económicas sobre la
máxima variación de las señales de entrada y salida durante la realización del experimento.
Por otro lado el aumento de la amplitud de la señal de entrada aumenta la relación entre la
señal y el ruido del sistema, lo que hace que mejore la identificación.
Respecto a la elección del periodo de muestreo, se debe seleccionar de acuerdo a las
constantes de tiempo del sistema. Utilizar un periodo de muestreo muy pequeño supone
tener una redundancia en los datos, con poco aporte de información en puntos nuevos. Por
otro lado, utilizar un periodo de muestreo muy grande implica una mayor dificultad en la
determinación de los parámetros que describen la dinámica del sistema. Una regla práctica
es utilizar una frecuencia de muestreo alrededor de diez veces la anchura de banda de
interés en el modelado.

TEMA 3: Consideraciones generales sobre la identificación de sistemas
3-4
Diseñode experimentos
Adquisicióny
tratamiento de datos
Selección del tipo y de laestructura del modelo
Estimación de losparámetros del modelo
Validación del modelo
¿Modelo adecuado?
Fin
Inicio
SiNo
Conocimientoa priori
del sistema
Figura 3.2: Procedimiento general de identificación de sistemas
Una vez realizado el experimento los datos de entrada y salida registrados deben ser
tratados matemáticamente antes de poder ser utilizados en el proceso de estimación de los
parámetros del modelo. Por ejemplo si los datos son series temporales estacionarias
entonces se les debe eliminar los valores medios. Si las series son no estacionarias, a las
series temporales se les debe eliminar las tendencias o las perturbaciones de baja
frecuencias que motivan la no estacionaridad. Una posible forma de eliminarlas es filtrar las
series temporales usando un filtro pasa-alta.
Por otra parte los datos experimentales, siempre que se disponga de suficientes datos,
se dividen en dos partes: una se utiliza para identificar el modelo (datos para identificación) y
otra para validarlo (datos para validación).
A continuación se debe escoger un determinado tipo de modelo y proceder a su
obtención usando los datos experimentales. Existen principalmente dos categorías de
modelos: no paramétricos y paramétricos.

Identificación de sistemas
3-5
Los modelos no paramétricos vienen expresados como curvas o tablas que no pueden
ser caracterizadas usando funciones con un número de parámetros finito. Algunos de los
modelos no paramétricos más usuales son los obtenidos mediante:
Análisis de correlación. Genera la respuesta a un impulso o a un escalón del sistema
a partir de los datos de entrada-salida disponibles. De la representación gráfica de
estas respuestas se pueden estimar los posibles retardos del sistema, el tipo de
respuesta (oscilatoria, amortiguada, etc) y la ganancia estática.
Análisis espectral. Genera una estima de la función de la frecuencia del sistema y del
espectro del ruido. A partir de la función de la frecuencia del sistema se puede
deducir que frecuencias atenúa o amplifica el sistema y en que rango (filtro pasa-
baja, pasa-banda o pasa-alta). Por su parte del estudio del espectro del ruido se
puede deducir si las perturbaciones que afectan al sistema se pueden modelar como
ruido blanco o se debe obtener un modelo específico para las mismas.
Los modelos paramétricos quedan definidos por un conjunto finito de parámetros. Los
parámetros del modelo se obtienen usando algún método de estimación o calibración de
parámetros como el método de los mínimos cuadrados que se basa en la minimización del
error de predicción, es decir, la diferencia entre la salida real medida y la salida generada
por el modelo.
Cuando se desea obtener modelos paramétricos una de las principales decisiones que
se deben tomar es que tipo de modelo utilizar. Normalmente se desean identificar modelos
lineales, algunos de los tipos de modelos discretos lineales más usuales son: ARX, ARMAX,
OE y BJ. Siempre se suele elegir en primer lugar un modelo ARX ya que es el más sencillo
de estimar.
Una vez elegido el tipo de modelo, otra decisión que se debe tomar es decidir cuál es la
estructura del mismo, es decir, los órdenes de los polinomios que definen el modelo. Lo más
normal es estimar varios modelos distintos, es decir, trabajar con diferentes estructuras, y
escoger el mejor modelo utilizando algún criterio de selección o información que también
debe ser especificado. En general se debe escoger el modelo que con la menor complejidad
(número de parámetros) resulte adecuado para el uso que se va hacer del mismo (control,
simulación, predicción,...)
Por último el modelo seleccionado debe ser validado. Entre los tests de validación más
utilizados se encuentran los siguientes:

TEMA 3: Consideraciones generales sobre la identificación de sistemas
3-6
Comparación de la salida del modelo con la salida real del sistema usando la misma
entrada. Siempre que sea posible, se debe realizar una validación cruzada, que
consiste en utilizar para realizar la validación un conjunto de datos de entrada-salida
distinto al que se ha utilizado para estimar los parámetros del modelo.
Comparación de la respuesta en frecuencia del modelo con la respuesta en
frecuencia estimada en el análisis espectral.
Análisis de los residuos. Los residuos son las diferencias entre la salida del modelo y
la salida real del sistema. Consiste en calcular la autocorrelación de los residuos y la
autocorrelación cruzada de los residuos y la entrada.
Si el resultado de la validación es negativo se debe considerar la opción de utilizar otras
estructuras y otros tipos de modelos. Si de esta forma tampoco se consiguen buenos
resultados habrá que plantearse la realización de nuevos experimentos sobre el sistema que
permitan generar datos de entrada-salida que contengan un grado de información mayor. En
consecuencia, tal y como se muestra en la Figura 3.2, el procedimiento de identificación es
iterativo.
En general la identificación de sistemas resulta muy útil para obtener un modelo de un
sistema cuando se dispone de poco o de ningún conocimiento a priori del mismo. En dicho
caso al sistema se le considera como una caja negra. En la identificación de modelos de
caja negra no suele importar tanto la estructura del modelo sino que el modelo genere una
salida que se ajuste lo más posible a la salida medida experimentalmente.
Por otra parte, la identificación también resulta útil cuando a partir del modelado físico
se ha obtenido un determinado modelo cuyos parámetros hay que estimar. En este caso al
sistema se le considera como una caja gris. En la identificación de modelos de caja gris lo
importante es estimar los parámetros de un modelo predeterminado de tal forma que la
salida del mismo se ajuste lo más posible a la salida del sistema medida experimentalmente.
3.3 HERRAMIENTAS SOFTWARE PARA IDENTIFICACIÓN DE SISTEMAS
3.3.1 SITB, la toolbox para identificación de sistemas de MATLAB
MATLAB® es un aplicación software bastante potente que soporta un lenguaje de
computación técnico de alto nivel y dispone de un entorno interactivo para el desarrollo de
algoritmos, visualización de datos, análisis de datos y cálculos numéricos.

Identificación de sistemas
3-7
MATLAB puede ser utilizado en un amplio rango de aplicaciones de ingeniería y ciencia,
como el procesamiento de señales y de imágenes, control, simulación, etc. La posibilidad de
escribir en el lenguaje nativo de MATLAB librerías de funciones (denominadas toolboxes)
permiten extender el uso de MATLAB a la resolución de toda clase de problemas en
distintas áreas de aplicación.
En 1987 Lennard Ljung, profesor del Departamento de Ingeniería Eléctrica de la
Universidad de Linköpings (Suecia), escribió una toolbox de funciones de MATLAB para la
identificación de sistemas denominada abreviadamente SIT o SITB acrónimo derivados de
System Identification Toolbox. La última versión disponible de esta toolbox, en el momento
de escribir estos apuntes, es la Versión 8.2 que se distribuye conjuntamente con la versión
R2013a de MATLAB: (http://www.mathworks.es/products/sysid/).
Obviamente cada nueva versión de SITB ha ido añadiendo nuevas funciones y mejoras
a la toolbox. Aunque no es necesario disponer de la última versión de SIT para poder aplicar
el procedimiento de identificación de sistemas a un problema real. En estos apuntes los
ejemplos se han realizado con la versión 6.0.1 de SITB (Matlab 7.0). Es importante recordar
los problemas de compatibilidad que presentan las diferentes versiones de MATLAB, así un
script desarrollado para una determinada versión no tiene asegurado que se pueda ejecutar
completamente sin generar errores en otra versión distinta.
La toolbox SITB contiene funciones para poder realizar todos los pasos del
procedimiento general de identificación de sistemas, excepto la etapa de diseño de
experimentos. Si se teclea en la línea de comandos de MATLAB la orden
>>help ident
aparece un listado con el nombre y la utilidad de todas las funciones de SITB. Para
conseguir información detallado sobre el uso y la sintaxis de una función en particular de
STIB se puede teclear el comando
>>help [nombre de la funcion]
Existe un manual de ayuda de SITB en formato HTML que puede ser invocado desde la
propia ventana de MATLAB. También existe una versión en PDF del manual de STIB
(http://www.mathworks.es/help/toolbox/ident/).
Las funciones disponibles en SITB pueden agruparse, entre otras, en las siguientes
categorías:

TEMA 3: Consideraciones generales sobre la identificación de sistemas
3-8
Presentación y tratamiento de datos. En esta categoría se engloban aquellas
funciones que permiten representar las series temporales de los datos de entrada
- salida, seleccionar rango de datos, modificar el periodo de muestreo, eliminar
valores medios y filtrar los datos
Estimación de modelos no paramétricos. Dentro de esta categoría se engloban
aquellas funciones que permiten realizar análisis de correlación y análisis
espectral.
Estimación de modelos paramétricos. En esta categoría se engloban aquellas
funciones que permiten estimar por diferentes métodos los parámetros de
diferentes tipos de modelos (ARX, ARMAX, OE, BJ,...). Así como generar familias
de modelos con diferentes estructuras y seleccionar la más adecuada según
diferentes criterios de información o selección.
Simulación y validación de modelos. En esta categoría se engloban aquellas
funciones que permiten simular la salida de un modelo ante diferentes entradas y
compararla con los datos de la salida real, realizar análisis de los residuos y
estudiar las posibles cancelaciones de ceros y polos que permitan reducir la
complejidad del modelo.
SITB emplea varios tipos de estructuras de datos en forma matricial que permiten
representar los distintos elementos con los que trabaja. También SITB dispone de las
funciones necesarias para la manipulación de estas estructuras de datos: creación de
nuevas estructuras, extracción y modificación de valores almacenados, representación
gráfica. Además dispone de funciones para convertir, cuando es posible, un tipo de
estructura a otro tipo distinto.
Aparte de poder invocar las funciones de SITB desde la línea de comandos de Matlab o
desde un script, SITB también dispone de una interfaz gráfica de usuario (GUI) atractiva y
sencillo que internamente invoca a las funciones de la toolbox pero sin que el usuario sea
consciente de ello, ya que únicamente tiene que operar con el ratón sobre la interfaz gráfica.
Al GUI de SITB (ver Figura 3.3) se le invoca con la siguiente orden:
>>ident

Identificación de sistemas
3-9
Figura 3.3. El interfaz gráfico de usuario de STIB
3.3.2 ITSIE, una herramienta interactiva para la enseñanza de la identificación de sistemas
En el año 2009 J.L. Guzman, profesor del Dpto. de Lenguajes y Computación de la
Universidad de Almería, desarrolló junto con otros profesores, la herramienta software
interactiva ITSIE (Interactive Tool for System Identification Education) para la enseñanza de
la identificación de sistemas que se distribuye (http://aer.ual.es/ITSIE/) de forma
gratuita.
Obviamente ITSIE es mucho menos flexible y limitada que la toolbox SITB. Sin
embargo, permite aprender fácilmente los fundamentos de la identificación de sistema y da
soporte al diseño de experimentos (configuración de la señal de entrada), algo de lo que
carece SITB.
ITSIE está desarrollada en Sysquake (http://www.calerga.com/index.html), un
lenguaje parecido al de MATLAB que posibilita de forma sencilla la creación de gráficos
interactivos. ITSIE se distribuye gratuitamente como un fichero autoejecutable por lo que no
requiere que se tenga instalado en el computador Sysquake.
ITSIE presenta un interfaz gráfico de una única ventana (ver Figura 3.4) que incluye
todas las etapas del procedimiento de identificación. El usuario interactúa sobre los
elementos presentes en la ventana con el uso del ratón o del teclado. Cualquier modificación
sobre algún elemento de la ventana se refleja inmediatamente sobre el resto de elementos.
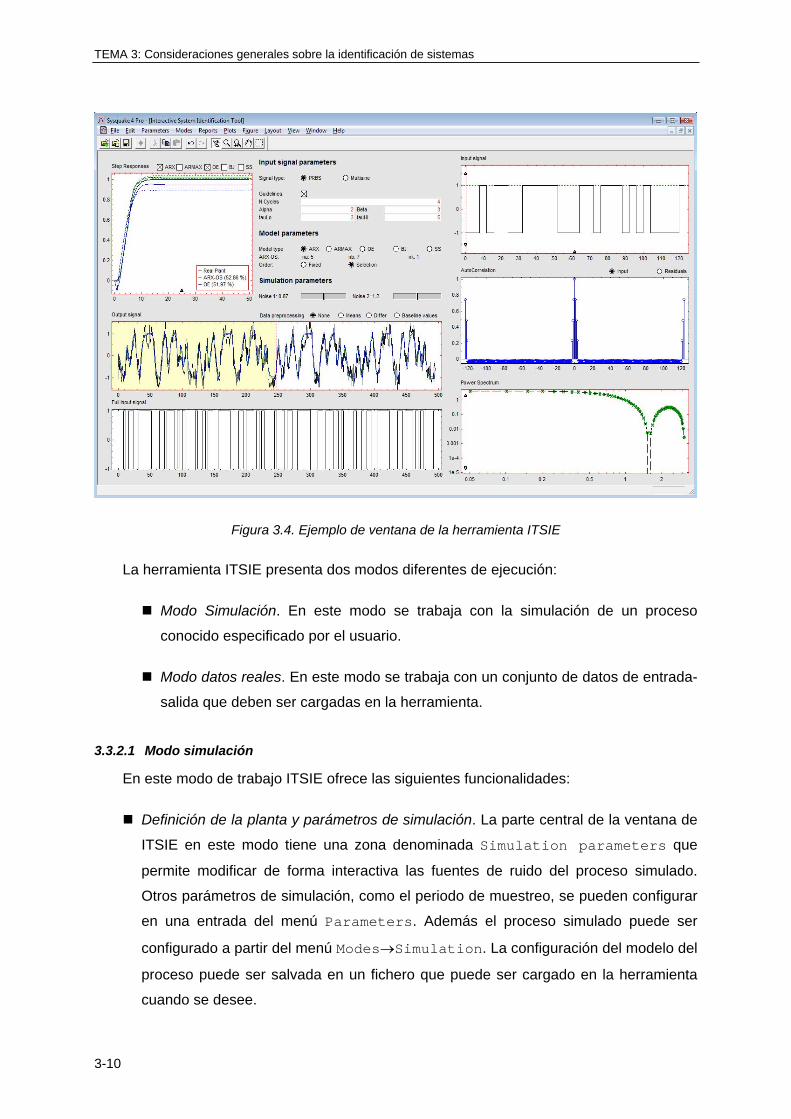
TEMA 3: Consideraciones generales sobre la identificación de sistemas
3-10
Figura 3.4. Ejemplo de ventana de la herramienta ITSIE
La herramienta ITSIE presenta dos modos diferentes de ejecución:
Modo Simulación. En este modo se trabaja con la simulación de un proceso
conocido especificado por el usuario.
Modo datos reales. En este modo se trabaja con un conjunto de datos de entrada-
salida que deben ser cargadas en la herramienta.
3.3.2.1 Modo simulación
En este modo de trabajo ITSIE ofrece las siguientes funcionalidades:
Definición de la planta y parámetros de simulación. La parte central de la ventana de
ITSIE en este modo tiene una zona denominada Simulation parameters que
permite modificar de forma interactiva las fuentes de ruido del proceso simulado.
Otros parámetros de simulación, como el periodo de muestreo, se pueden configurar
en una entrada del menú Parameters. Además el proceso simulado puede ser
configurado a partir del menú ModesSimulation. La configuración del modelo del
proceso puede ser salvada en un fichero que puede ser cargado en la herramienta
cuando se desee.

Identificación de sistemas
3-11
Diseño de la entrada. Existe una zona de definición de los parámetros de la entrada
con la que se excita el sistema denominada Input signal parameters, que se
encuentra localizada en la parte central superior de la ventana de ITSIE. En ella el
usuario puede elegir el tipo de señal de entrada (PRBS o multiseno) y si desea
especificar la señales directamente o seguir unas guías de diseño. En el primer caso
los parámetros de la señal de entrada pueden ser modificados interactivamente
mediante el uso de sliders o arrastrando en algunas de las figuras relacionadas a la
entrada: Input Signal que muestra la representación temporal,
Autocorrelation que muestra la representación gráfica de la autocorrelación y
Power Spectrum que muestra la representación gráfica de su espectro de
potencia. En la figura Full Input Signal se muestra la representación temporal
de la señal de entrada completa, es decir, con todos los ciclos que se hayan
especificado.
Selección del tipo y estructura del modelo y estimación de parámetros. En la central
de la ventana de ITSIE existen una zona con unas casillas que permiten seleccionar
el tipo del modelo (ARX, ARMAX, OE, BJ, CRA) y unos deslizadores para
seleccionar de forma manual la estructura del modelo. En el caso de un modelo ARX
también es posible dejar que sea la herramienta quien elija la mejor estructura dentro
de un rango de valores predeterminados el cual se especifica a través de una
entrada del menú Parameters. La señal de entrada completa es la que es aplicada
al proceso cargado en ITSIE para obtener la salida del proceso que se muestra en
color negro en la figura Output signal. Estos son los datos de entrada-salida que
se utilizan para estimar los parámetros del modelo seleccionado. En la Figura
Output signal existe una línea vertical de color magenta que permite especificar
el rango de datos de entrada-salida que se van usar para estimación (ocupan una
zona sombreada con amarillo claro situada a la izquierda de la línea) y los que se
van usar para validación (los situados a la derecha de la línea).
Validación del modelo. Se muestra en tres figuras diferentes: Step responses que
incluye la representación gráfica de la respuesta a un escalón del proceso cargado
en ITSIE y del modelo seleccionado, Correlation function of residuals
que incluye la representación gráfica de la función de correlación de los residuos y
Cross correlation function between input and prediction error
que incluye la representación gráfica de la función de correlación cruzada entre la
entrada y el error de predicción.

TEMA 3: Consideraciones generales sobre la identificación de sistemas
3-12
3.3.2.2 Modo datos reales
Los datos de entrada salida se cargan mediante el menú ModesReal data. Los
datos deben encontrarse en un fichero ASCII o en fichero .mat de MATLAB. En el caso de
que se encuentren en un fichero ASCII los datos se deben organizar en tres columnas:
tiempo, salida, entrada. Si se utiliza el formato MATLAB, el fichero .mat debe contener las
variables t (tiempo), y (salida) y u (entrada).
En este modo de trabajo el contenido de la ventana de ITSIE varía parcialmente con
respecto al modo simulación. Las zonas que antes estaban dedicadas a configurar los
parámetros de la señal de entrada y los parámetros de simulación ahora desaparecen.
Ahora aparecen zonas que permiten configurar las estructuras de diferentes tipos de
modelos.
BIBLIOGRAFÍA
[Guzman et al., 2009] J. L. Guzman, D. E. Rivera, S. Dormido y M. Berenguel.
ITSIE: An interactive Software tool for system identification
education. Proceeding of 15th IFAC Symposium on System
Identification (SYSID 2009). 2009.
[Guzman et al., 2009b] J. L. Guzman, D. E. Rivera, S. Dormido y M. Berenguel.
ITSIE: Teaching system identification through interactivity.
Proceeding of 8th IFAC Symposium on Advances in Control
Education. 2009.
[Ljung y Glad, 1994] L. Ljung y T. Glad. Modelling of dynamic systems. Prentice
Hall. 1994.
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.
[Schoukens y Pintelon, 1991] J. Schoukens, R. Pintelon. Identification of linear systems.
Pergamon Press. 1991.
[Söderström y Stoica, 1989] T. Söderström y P. Stoica, System Identification. Prentice
Hall. 1989.

TEMA 4
DISEÑO DE EXPERIMENTOS Y
TRATAMIENTO DE DATOS
4-1
4.1 INTRODUCCIÓN El éxito del procedimiento de identificación depende en gran medida de la calidad de los
datos de entrada-salida que se adquieran del sistema. Para obtener datos que contengan la
máxima información resulta fundamental realizar un diseño adecuado del experimento o
experimentos a los que se va a someter el sistema. Dicho diseño debe contemplar aspectos
tales como la selección del tipo y de las características (magnitud y duración) de la señal de
entrada con que se va a “excitar” el sistema. Así como la elección del periodo de muestreo.
También se debe procurar que los experimentos que se diseñen sean “amigables” con la
planta o sistema a identificar, es decir, que no perturben en exceso su actividad normal ni
puedan provocar la rotura de los actuadores.
Una vez realizados los experimentos, los datos de entrada-salida deben ser
representados gráficamente. A partir de dichas representaciones es posible detectar la
existencia de comportamientos no estacionarios (derivas y/o tendencias en el valor medio y
en la pendiente), la existencia de perturbaciones de alta frecuencia y la existencia de datos
erróneos (outliers). Antes de poder ser utilizados para la estimación de modelos los datos
deben ser tratados matemáticamente para eliminar las anomalías detectadas. Básicamente
dicho tratamiento incluye la eliminación de valores medios y tendencias de las series
temporales de entrada-salida. Así como el filtrado (si fuese necesario) de los datos para
eliminar las perturbaciones de baja (derivas) y alta frecuencia, o para enfatizar un
determinado rango de frecuencia de interés.
En este tema en primer lugar se realizan unas consideraciones generales sobre la
elección de la señal de entrada. En segundo lugar se describen las características de los
principales tipos de señales de entrada. A continuación se realizan unas consideraciones
sobre la elección del periodo de muestreo. Finalmente se describe el tratamiento

TEMA 4: Diseño de experimentos y tratamiento de datos
4-2
matemático que hay que realizar sobre los datos de entrada-salida obtenidos
experimentalmente antes de poder utilizarlos en el proceso de identificación.
4.2 CONSIDERACIONES GENERALES SOBRE LA ELECCIÓN DE LA SEÑAL DE ENTRADA
4.2.1 Excitación persistente Una señal de entrada u(t) estacionaria o cuasi-estacionaria con un espectro de potencia
u() se dice de excitación persistente (EP) de orden o grado n si para todos los filtros de la
forma
nn zmzmzM ·...·)( 1
1n (4.1)
la relación
0)(·)( 2
n u
jeM (4.2)
implica que
0)( n jeM (4.3)
En conclusión, una entrada u(t) es de EP de orden n si su espectro u() es distinto de
cero en al menos n puntos del intervalo -< <.
En general si se desea identificar un sistema de N parámetros se debe excitar con una
entrada de EP de grado n N. Si la señal de entrada fuese de EP de grado n < N no estaría
excitando suficientemente al sistema para identificar todos sus parámetros.
Asimismo, para un sistema dinámico con ruido no correlacionado la estima es
consistente (ver sección 6.4.3) si la señal de entrada es de EP de grado N, es decir, coincide
con el número de parámetros que posee el modelo.
4.2.2 Características deseables en teoría para la entrada
De forma general se puede utiliza el siguiente modelo lineal para modelar un sistema
(Ver Figura 4.1):
)()()·()( tvtuzGty (4.4)

Identificación de sistemas
4-3
G(z) es el modelo de la planta o sistema, u(t) es la entrada, v(t) es la perturbación e y(t)
es la salida. De acuerdo con el teorema de factorización espectral (ver sección 2.7) la
perturbación v(t) se puede considerar la salida de un filtro H(z) que es excitado por una
señal de ruido blanco a(t):
)()·()( tazHtv (4.5)
Luego el modelo del sistema se puede expresar de la siguiente forma:
)()·()()·()( tazHtuzGty (4.6)
G(z)u(t)
v(t)
y(t)+
H(z)
a(t)
Figura 4.1. Modelo lineal de un sistema
En general la perturbación v(t) es una señal aleatoria autocorrelacionada, por lo que la
salida y(t) también será una señal aleatoria autocorrelacionada. La entrada u(t) puede ser
determinista (PRBS, multiseno,...) o aleatoria, pero debe tener las siguientes características:
Debe poseer tanta potencia como sea posible, es decir, debe tener una EP de grado
elevado para excitar el mayor número posible de frecuencias del sistema y conseguir
que la salida contenga la máxima información posible.
Su duración debe ser lo mayor posible ya que, como se pondrá de manifiesto en
sección 6.4.4, cuanto mayor es el número N de datos de entrada-salida que se
recojan menor será la varianza de los parámetros del modelo del sistema que se
estimen.
Su amplitud debe ser lo mayor posible ya que así aumenta la relación señal-ruido
con lo se minimiza el efecto de la presencia de ruido en los sensores de medida.

TEMA 4: Diseño de experimentos y tratamiento de datos
4-4
No debe estar correlacionada con la perturbación. Es decir, no debe existir
realimentación de la salida sobre la entrada (operación en lazo cerrado). Esta
característica no siempre es requerida por todos los métodos de estimación de
parámetros pero siempre es deseable.
Si el modelo corresponde a una linealización de un sistema no lineal, su validez
estará limitada a un determinado rango de operación del sistema. Por lo que no se
debe escoger la señal de entrada de modo que saque al sistema fuera de la zona de
validez del modelo. No obstante, tras la identificación del modelo puede resultar
interesante realizar otro experimento con una amplitud mayor para determinar la
zona de validez de éste.
4.2.3 Características deseables en la práctica para la entrada: entradas “amigables” con la planta.
El término “amigable con la planta” (plant-friendly) proviene de la comunidad de control
de procesos químicos y está motivado por el deseo de que los experimentos para
identificación que se realicen sobre la planta o sistema no perturben en exceso el
funcionamiento normal de la planta.
Un experimento amigable con la planta es aquél que permite obtener, en un periodo de
tiempo razonable, datos de entrada-salida para identificar un modelo adecuado de la planta
manteniendo la magnitud de las entradas y las salidas dentro de unos rangos de valores
predefinidos por el usuario.
Una entrada amigable con la planta debería tener las siguientes características:
Tener una duración tan corta como sea posible. Con ello se consigue minimizar la
cantidad de producto que genera la planta no utilizable para su venta debido a
estar operando en condiciones fuera de las usuales. Además también se reduce
el coste a la mano de obra cualificada que se debe encargar de realizar los test de
identificación (lo que se conoce como coste de ingeniería).
No saturar los actuadores o exceder las limitaciones de movimiento de los
mismos.
Producir la mínima perturbación de las variables controladas, es decir, introducir
en las mismas una varianza baja y desviaciones pequeñas del punto de consigna.

Identificación de sistemas
4-5
De esta forma se consigue minimizar la variabilidad en la calidad del producto que
genera la salida de la planta.
Se observa que las características que debe reunir una entrada en la práctica para ser
amigable con la planta están en contraposición con las características deseables en teoría.
Por ejemplo en teoría la entrada debe tener una duración lo mas larga posible para así
disminuir el error de varianza de las estimas del modelo. Sin embargo en la práctica lo
recomendable es que su duración sea lo menor posible para minimizar la cantidad de
producto no utilizable y reducir costes.
En consecuencia, a la hora de diseñar la señal de entrada hay que llegar a un
compromiso entre los requerimientos prácticos (amigables con la planta) y los teóricos
(hostiles con la planta).
4.2.4 Índices para establecer el grado de amigabilidad de una entrada.
Existen diversos índices para medir el grado de amigabilidad de una entrada. Entre ellos
destacan: el índice de amigabilidad, el índice de comportamiento para señales de
perturbación y el factor de cresta.
4.2.4.1 Índice de amigabilidad
En [Doyle et al., 1999] definieron el índice de amigabilidad f de una secuencia de
entrada arbitraria uk, k=1,...,N de la siguiente forma
11100(%)
N
nf T (4.7)
donde N es la longitud de la secuencia de entrada y nT es el número de transiciones (es
decir, situaciones donde ukuk+1) de la señal de entrada. Nótese que el factor de
amigabilidad es un porcentaje. Una entrada se considera más amigable con la planta cuanto
mayor es el valor de f. Una secuencia de entrada constante es una entrada “100% amigable
con la planta”, mientras que una secuencia de entrada cuyo valor cambia en cada instante
de tiempo es “0% amigable con la planta”.
4.2.4.2 Índice de comportamiento para señales de perturbación
En [Godfrey et al., 1999] definieron el índice de comportamiento para señales de
perturbación PIPS( Performance Index for Perturbation Signals)

TEMA 4: Diseño de experimentos y tratamiento de datos
4-6
minmax
222100(%)
uu
uuPIPS meanrms
(4.8)
donde urms es la raíz cuadrada del valor cuadrático medio (root mean squared (rms)) de la
secuencia u, umean es su valor medio, umax es su valor máximo y umin es su valor mínimo.
Nótese que PIPS es un porcentaje y sus valores caen por tanto entre el 0% y el 100%, lo
cual lo hacen fácil de interpretar. Cuanto mayor es el valor de PIPS más amigable se
considera la señal de entrada.
4.2.4.3 Factor de cresta
El factor de cresta o CF (Crest Factor) de una señal se define [Guillaume et al., 1991]
como el cociente entre la norma infinito o norma de Chebyshev )(ul de la señal y la norma
dos )(2 ul de la señal:
)(
)(F(u)
2 ul
ulC (4.9)
La norma general pl se define en tiempo continuo de la siguiente forma:
pNp
p dttuN
ul
/1
0
·|)(|·1
)(
(4.10)
Mientras que en tiempo discreto se puede definir de la siguiente forma:
pN
k
pkp u
Nul
/1
1
||·1
)(
(4.11)
Y la norma infinito se define como
|)(|max)( txxlt
(4.12)
El factor de cresta es un valor comprendido entre 1 e infinito que proporciona una
medida de la distribución de los valores de la señal a lo largo de su rango posible de valores
(span). Un factor de cresta pequeño significa que la mayoría de los valores de la secuencia
de entrada caen cerca de los valores máximos y mínimos de la secuencia. Como
consecuencia la entrada es amigable con la planta.
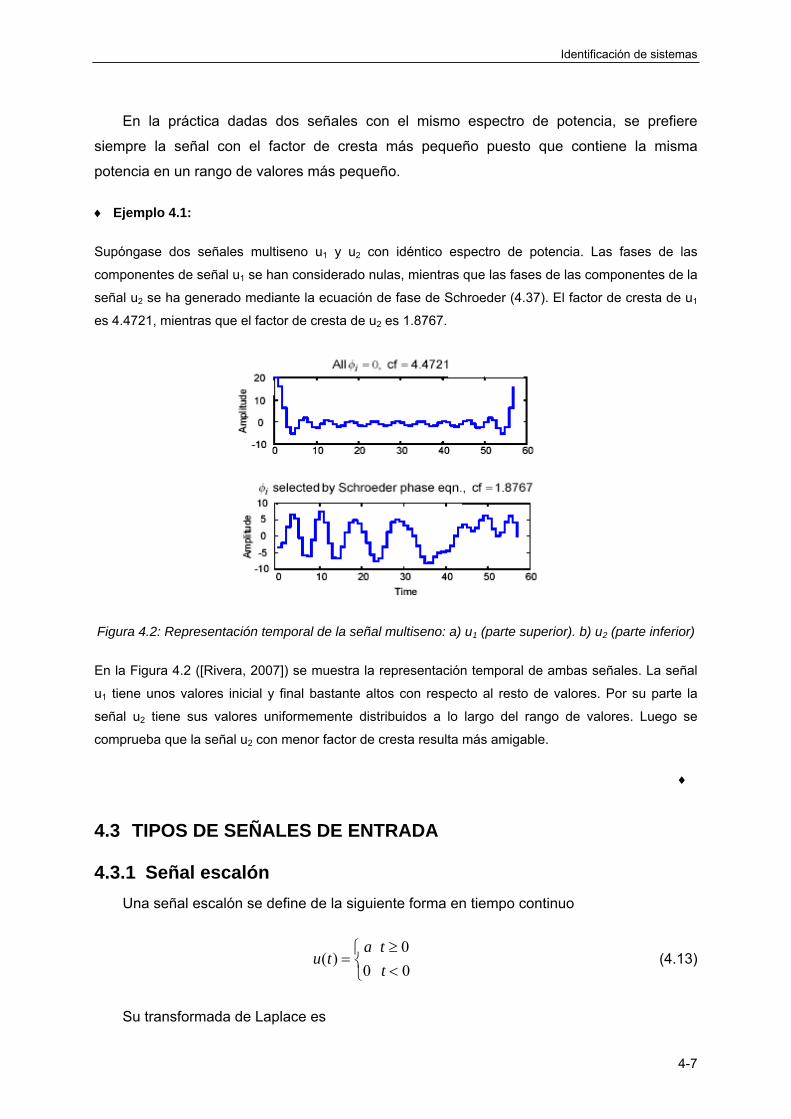
Identificación de sistemas
4-7
En la práctica dadas dos señales con el mismo espectro de potencia, se prefiere
siempre la señal con el factor de cresta más pequeño puesto que contiene la misma
potencia en un rango de valores más pequeño.
Ejemplo 4.1:
Supóngase dos señales multiseno u1 y u2 con idéntico espectro de potencia. Las fases de las
componentes de señal u1 se han considerado nulas, mientras que las fases de las componentes de la
señal u2 se ha generado mediante la ecuación de fase de Schroeder (4.37). El factor de cresta de u1
es 4.4721, mientras que el factor de cresta de u2 es 1.8767.
Figura 4.2: Representación temporal de la señal multiseno: a) u1 (parte superior). b) u2 (parte inferior)
En la Figura 4.2 ([Rivera, 2007]) se muestra la representación temporal de ambas señales. La señal
u1 tiene unos valores inicial y final bastante altos con respecto al resto de valores. Por su parte la
señal u2 tiene sus valores uniformemente distribuidos a lo largo del rango de valores. Luego se
comprueba que la señal u2 con menor factor de cresta resulta más amigable.
4.3 TIPOS DE SEÑALES DE ENTRADA
4.3.1 Señal escalón
Una señal escalón se define de la siguiente forma en tiempo continuo
0( )
0 0
a tu t
t
(4.13)
Su transformada de Laplace es
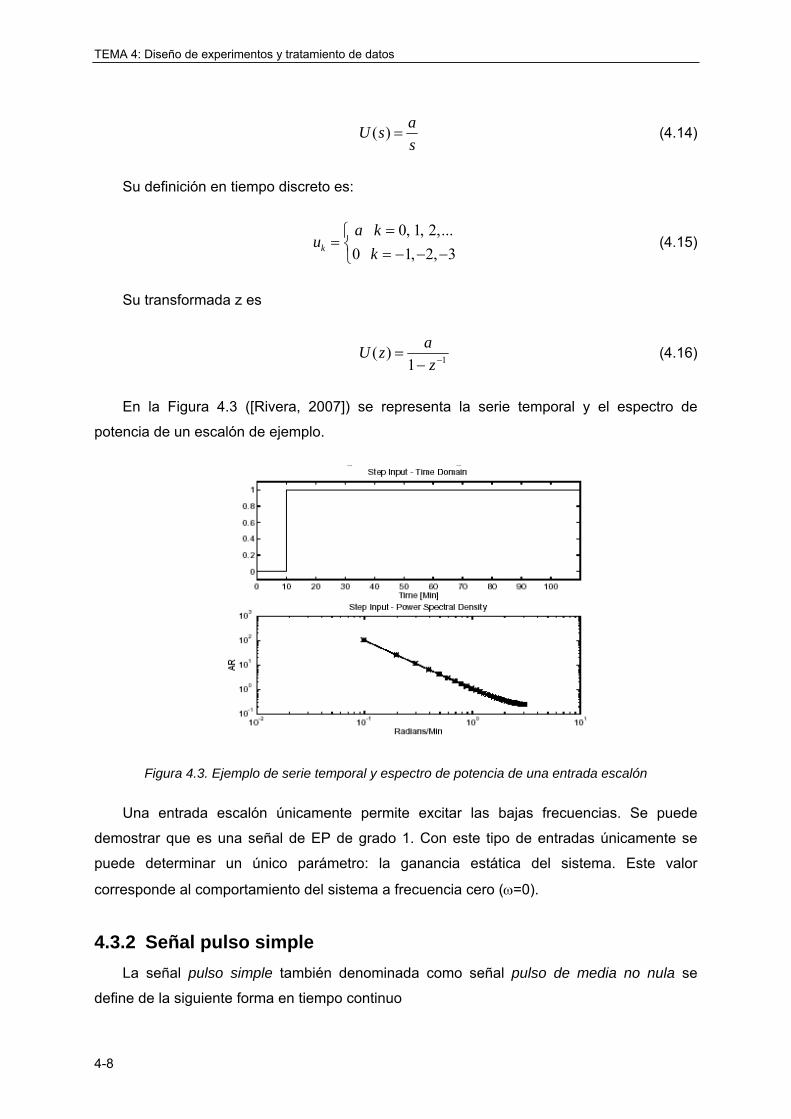
TEMA 4: Diseño de experimentos y tratamiento de datos
4-8
s
asU )( (4.14)
Su definición en tiempo discreto es:
0, 1, 2,...
0 1, 2, 3k
a ku
k
(4.15)
Su transformada z es
11)(
z
azU (4.16)
En la Figura 4.3 ([Rivera, 2007]) se representa la serie temporal y el espectro de
potencia de un escalón de ejemplo.
Figura 4.3. Ejemplo de serie temporal y espectro de potencia de una entrada escalón
Una entrada escalón únicamente permite excitar las bajas frecuencias. Se puede
demostrar que es una señal de EP de grado 1. Con este tipo de entradas únicamente se
puede determinar un único parámetro: la ganancia estática del sistema. Este valor
corresponde al comportamiento del sistema a frecuencia cero (=0).
4.3.2 Señal pulso simple
La señal pulso simple también denominada como señal pulso de media no nula se
define de la siguiente forma en tiempo continuo

Identificación de sistemas
4-9
tt
tta
t
tu
0
0
00
)( (4.17)
Su transformada de Laplace es
s
easU
st )1·()(
· (4.18)
Su definición en tiempo discreto es:
0 1, 2,...
0, 1, 2,...., /
0 1, 2,..k
k
u a k N N t T
k N N
(4.19)
Su transformada z es
TtNz
zazU
N
/1
)1·()(
1
(4.20)
En la Figura 4.3 ([Rivera, 2007]) se representa la serie temporal y el espectro de
potencia de un pulso simple de ejemplo.
Figura 4.3. Ejemplo de serie temporal y espectro de potencia de una entrada pulso simple
Una señal pulso a diferencia de una señal escalón consigue excitar algo al sistema en
un rango intermedio de frecuencia. Si se estrecha la anchura y se aumenta la amplitud de la
señal pulso, ésta se puede aproximar a un impulso. Mientras que si se aumenta su anchura
del pulso, éste se asemeja a la señal escalón.
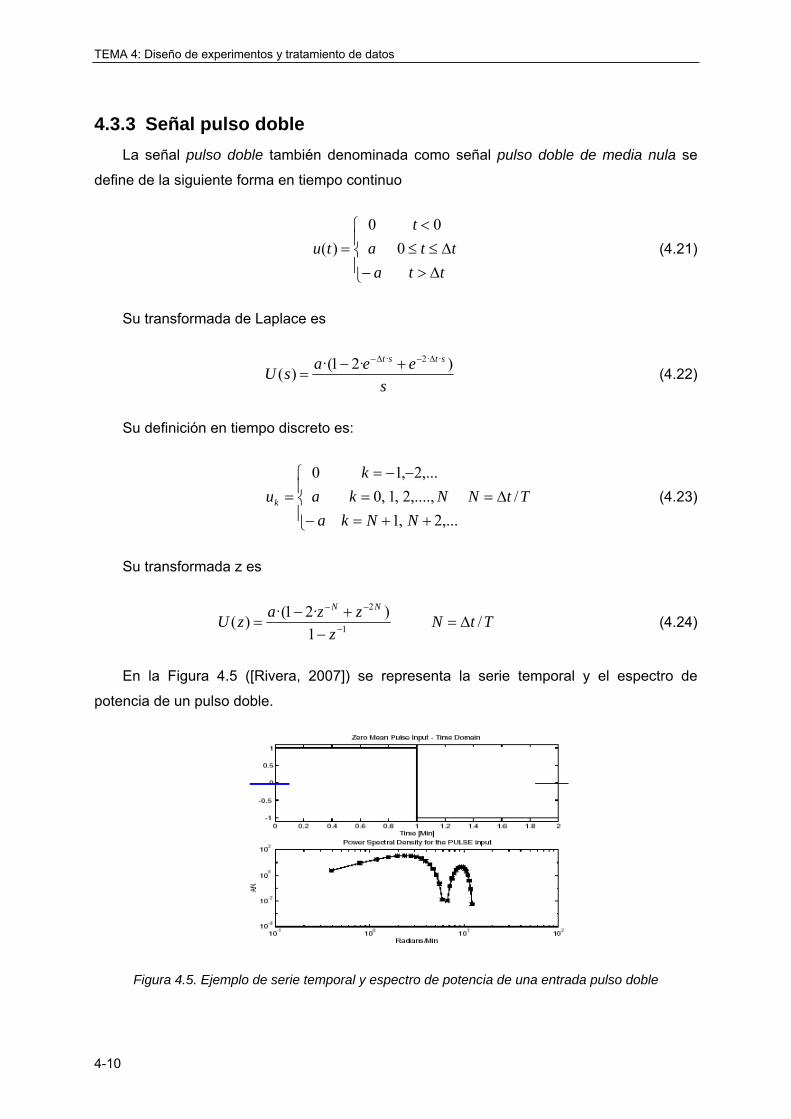
TEMA 4: Diseño de experimentos y tratamiento de datos
4-10
4.3.3 Señal pulso doble
La señal pulso doble también denominada como señal pulso doble de media nula se
define de la siguiente forma en tiempo continuo
tta
tta
t
tu 0
00
)( (4.21)
Su transformada de Laplace es
s
eeasU
stst )·21·()(
··2· (4.22)
Su definición en tiempo discreto es:
TtN
NNka
Nka
k
uk /
,...2,1
,....,2,1,0
,...2,10
(4.23)
Su transformada z es
TtNz
zzazU
NN
/1
)·21·()(
1
2
(4.24)
En la Figura 4.5 ([Rivera, 2007]) se representa la serie temporal y el espectro de
potencia de un pulso doble.
Figura 4.5. Ejemplo de serie temporal y espectro de potencia de una entrada pulso doble

Identificación de sistemas
4-11
Una señal pulso doble también consigue excitar algo al sistema en un rango intermedio
de frecuencia. Sin embargo atenúa las bajas frecuencias, lo cual puede suponer un
problema si la anchura del pulso t no es lo suficiente grande.
4.3.4 Ruido blanco
Se denomina ruido blanco en tiempo discreto a un proceso estocástico estacionario
discreto x(t) cuya función de covarianza es:
,...2,10
0)(
2
xxr (4.25)
En la Figura 4.6 se representa rxx() gráficamente. Obsérvese que rxx() es nula para
todos los valores de excepto en el origen (=0) donde vale 2 que es la varianza del
proceso. Esto significa que el valor del proceso en un instante de tiempo t es independiente
(no está correlacionado) de los valores del proceso en otros instantes de tiempo. El proceso
estocástico ruido blanco puede por tanto ser considerado como una secuencia de variables
aleatorias igualmente distribuidas e independientes.
0 1-1 2
rxx()
2
-2
2
2
Figura 4.6: Representación gráfica de la covarianza y de la densidad espectral del ruido blanco en
tiempo discreto
Su función de densidad espectral es:
·2
2
(4.26)

TEMA 4: Diseño de experimentos y tratamiento de datos
4-12
Luego un proceso de ruido blanco se caracteriza por tener una densidad espectral
constante para todas las frecuencias. La analogía con las propiedades espectrales de la luz
blanca explican el nombre que recibe este proceso estocástico.
En el caso del ruido blanco en tiempo continuo su función de covarianza es:
)(·)( 2 trxx (4.27)
Donde es la función delta de Dirac:
00
0)(
si
si
El ruido blanco es una señal de EP de grado infinito y eso es así porque dispone de
todas las frecuencias. En consecuencia es la señal de entrada idónea en teoría para
identificar un sistema. Desafortunadamente, no es una señal que resulte amigable con la
planta. Es por ello que se suele recurrir a señales cuyo espectro se puede aproximar en un
cierto rango de frecuencias al ruido blanco, es decir, señales cuyo espectro es
prácticamente constante en un cierto rango y que son más amigables con la planta. Las dos
aproximaciones más utilizadas son la señal aleatoria binaria o señal RBS (Random Binary
Signal) y la señal pseudoaleatoria binaria o señal PRBS (Pseudo-Random Binary Signal).
4.3.5 Señal binaria aleatoria (RBS)
Una señal binaria aleatoria o señal RBS discreta es una señal que conmuta con una
probabilidad p entre dos valores –a y a en instantes de tiempo equiespaciados t=h·Tsw
donde h=0,1,2,… y Tsw es el periodo de conmutación. Obviamente los parámetros de diseño
de esta señal son su amplitud a, su periodo de conmutación Tsw y la probabilidad de
conmutación p. En la Figura 4.7 ([Rivera, 2007]) se muestra una posible realización de una
señal RBS y su espectro de potencia.
Se puede demostrar ([Davies, 1970], [Godfrey, 1993]) que la expresión asintótica del
espectro de una señal RBS con p=0.5 es:
2
22
u )2/·(
)2/·(sin··)(
sw
swsw T
TTa
(4.28)
En la Figura 4.8 ([Rivera, 2007]) se muestra el espectro de potencia asintótico de una
señal RBS con p=0.5, se observa que es prácticamente constante en el rango de
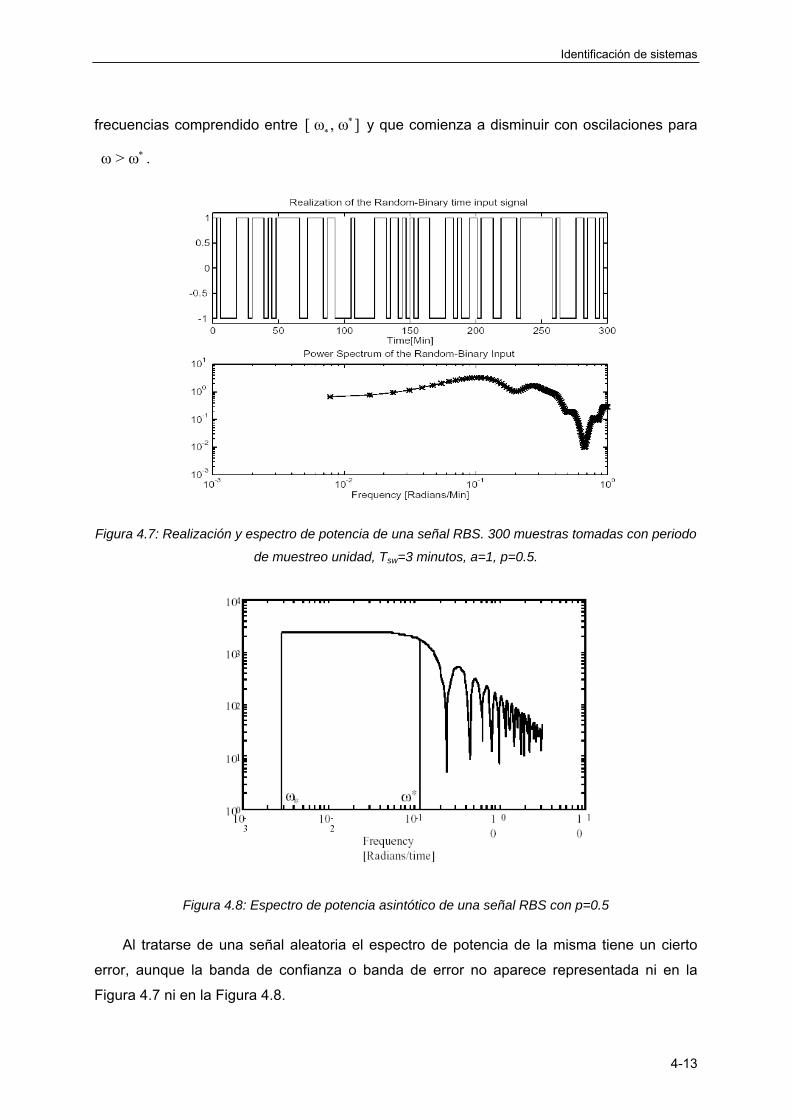
Identificación de sistemas
4-13
frecuencias comprendido entre [ ω , ω ] y que comienza a disminuir con oscilaciones para
ω > ω .
Figura 4.7: Realización y espectro de potencia de una señal RBS. 300 muestras tomadas con periodo
de muestreo unidad, Tsw=3 minutos, a=1, p=0.5.
Figura 4.8: Espectro de potencia asintótico de una señal RBS con p=0.5
Al tratarse de una señal aleatoria el espectro de potencia de la misma tiene un cierto
error, aunque la banda de confianza o banda de error no aparece representada ni en la
Figura 4.7 ni en la Figura 4.8.

TEMA 4: Diseño de experimentos y tratamiento de datos
4-14
4.3.6 Señal binaria psedoaleatoria (PRBS)
Una señal PRBS es una entrada periódica y determinista que se puede generar
utilizando registros de desplazamiento y algebra Boolena (ver Figura 4.9 ([Rivera, 2007])).
Figura 4.9: Generación de una señal PRBS utilizando un registro de desplazamiento de nr bits y una
puerta lógica XOR (OR-exclusiva).
Una señal PRBS posee las siguientes propiedades:
Tiene dos niveles ±a y puede cambiar de uno a otro sólo en ciertos intervalos de
tiempo t=0, Tsw, 2 Tsw, 3 Tsw,… A Tsw se le conoce como tiempo de reloj o de
conmutación.
Si se va a producir o no el cambio de la señal en un determinado intervalo está
"predeterminado". Luego la señal PRBS es determinista y los experimentos se
pueden repetir.
Es periódica con periodo T0=N Tsw, siendo N un número entero impar.
Posee un grado N de excitación persistente.
Su rango de frecuencia es configurable por el usuario.
Las señales PRBS más utilizadas son las que se basan en secuencias de longitud
máximas, para las cuales N=2nr-1 siendo nr la capacidad del registro de
desplazamiento.
La función de autocovarianza de una señal PRBS es periódica y se asemeja a la
del ruido blanco (ver Figura 4.10 ([Rivera, 2007])).
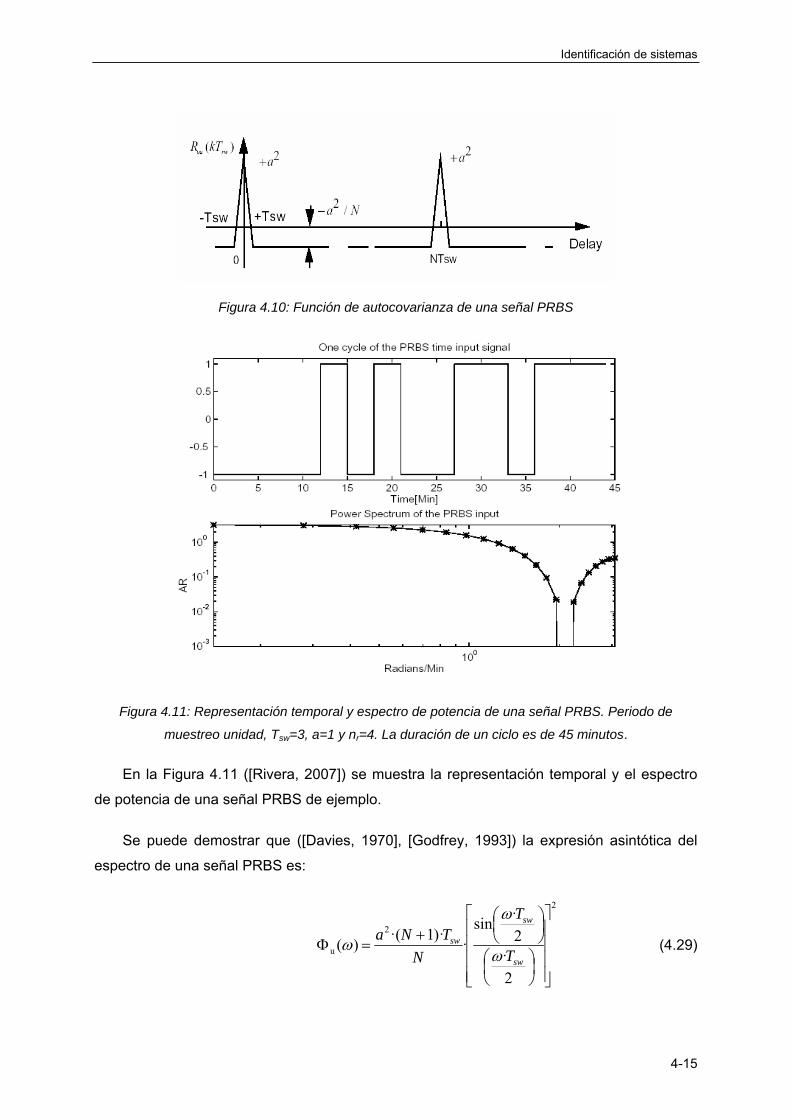
Identificación de sistemas
4-15
Figura 4.10: Función de autocovarianza de una señal PRBS
Figura 4.11: Representación temporal y espectro de potencia de una señal PRBS. Periodo de
muestreo unidad, Tsw=3, a=1 y nr=4. La duración de un ciclo es de 45 minutos.
En la Figura 4.11 ([Rivera, 2007]) se muestra la representación temporal y el espectro
de potencia de una señal PRBS de ejemplo.
Se puede demostrar que ([Davies, 1970], [Godfrey, 1993]) la expresión asintótica del
espectro de una señal PRBS es:
2
2
u
2
·2
·sin
·)·1·(
)(
sw
sw
sw
T
T
N
TNa
(4.29)
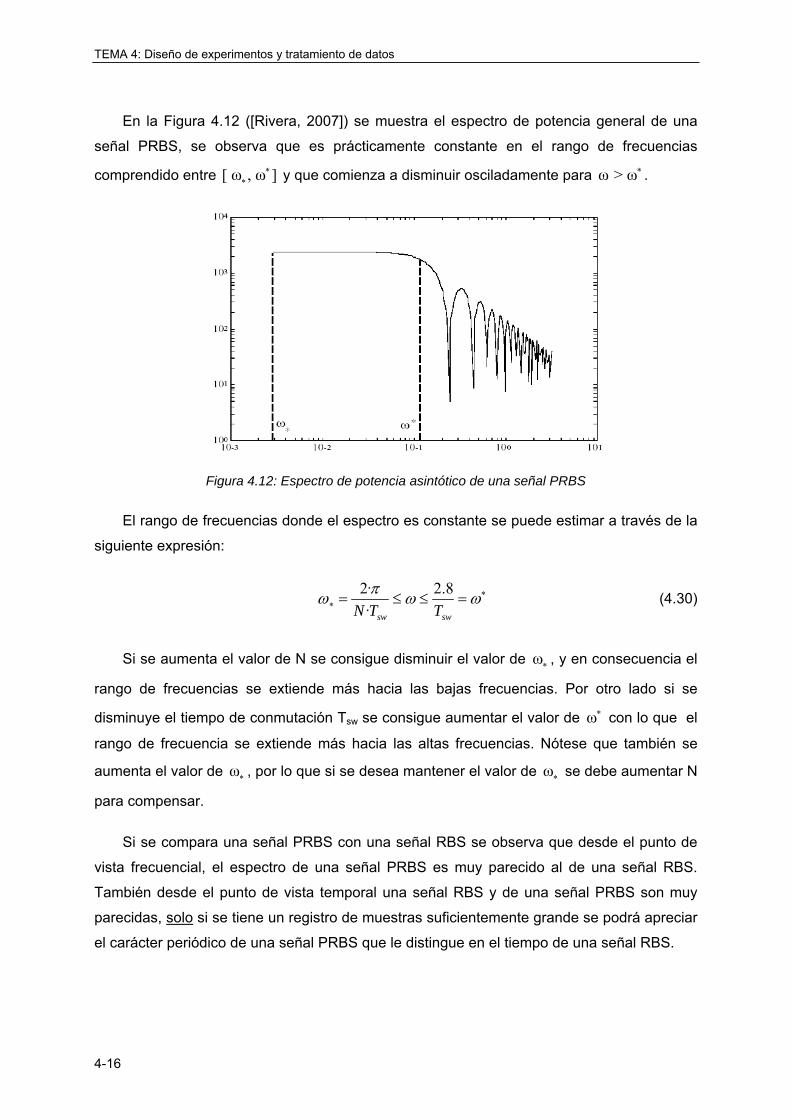
TEMA 4: Diseño de experimentos y tratamiento de datos
4-16
En la Figura 4.12 ([Rivera, 2007]) se muestra el espectro de potencia general de una
señal PRBS, se observa que es prácticamente constante en el rango de frecuencias
comprendido entre [ ω , ω ] y que comienza a disminuir osciladamente para ω > ω .
Figura 4.12: Espectro de potencia asintótico de una señal PRBS
El rango de frecuencias donde el espectro es constante se puede estimar a través de la
siguiente expresión:
2· 2.8
· sw swN T T
(4.30)
Si se aumenta el valor de N se consigue disminuir el valor de ω , y en consecuencia el
rango de frecuencias se extiende más hacia las bajas frecuencias. Por otro lado si se
disminuye el tiempo de conmutación Tsw se consigue aumentar el valor de ω con lo que el
rango de frecuencia se extiende más hacia las altas frecuencias. Nótese que también se
aumenta el valor de ω , por lo que si se desea mantener el valor de ω se debe aumentar N
para compensar.
Si se compara una señal PRBS con una señal RBS se observa que desde el punto de
vista frecuencial, el espectro de una señal PRBS es muy parecido al de una señal RBS.
También desde el punto de vista temporal una señal RBS y de una señal PRBS son muy
parecidas, solo si se tiene un registro de muestras suficientemente grande se podrá apreciar
el carácter periódico de una señal PRBS que le distingue en el tiempo de una señal RBS.

Identificación de sistemas
4-17
La principal diferencia entre ambos tipos de señales es que una señal PRBS es
determinista y por lo tanto reproducible experimentalmente, por eso siempre es preferible
utilizar una señal PRBS a una señal RBS.
Los parámetros de diseño de una señal PRBS son su amplitud a, el periodo de
conmutación Tsw y la longitud nr del registro de desplazamiento. En [Rivera, 1992] se dan
las siguientes expresiones como guías para ayudar a diseñar una señal PRBS:
2.8·
Ldom
sws
T
(4.31)
2· · · 2 1r
Hn s dom
sw
NT
(4.32)
Tanto Tsw como N son números enteros positivos. Además Tsw debe ser un múltiplo
entero del tiempo de muestreo T.
El significado de los parámetros que aparecen en las expresiones (4.31) y (4.32) es el
siguiente:
Ldom y H
dom son las estimas inferior y superior, respectivamente, de la constante
de tiempo dominante del proceso.
s es un factor entero positivo que permite especificar el valor de ω , es decir,
cuanta información de baja frecuencia estará presente en la entrada. Cuánto
mayor sea el valor de s más pequeño será el valor de ω y más información
de baja frecuencia contendrá la entrada. También s es un factor que representa
el tiempo de asentamiento del proceso. Por ejemplo, un valor s=3 especifica el
límite inferior de frecuencia ω usando el 95% del tiempo de asentamiento del
proceso, s=4 el 98% y s=5 el 99%.
s es un factor entero positivo que permite especificar el valor de ω , es decir,
cuanta información de alta frecuencia estará presente en la entrada. Cuánto
mayor sea el valor de s más grande será el valor de ω y más información de
alta frecuencia contendrá la entrada. También s es un factor que representa la
velocidad de la respuesta en lazo cerrado del proceso, expresada como un

TEMA 4: Diseño de experimentos y tratamiento de datos
4-18
múltiplo del tiempo de respuesta en lazo abierto. Por ejemplo si s=2, el
diseñador espera que la constante de tiempo del sistema en lazo cerrado sea la
mitad que la del sistema en lazo abierto (es decir, dos veces más rápido) y ello
requiere un mayor contenido de alta frecuencia en la entrada.
Considerando los parámetros anteriores el rango de frecuencias donde el espectro es
constante se puede estimar a través de la siguiente expresión
1
·s
H Ls dom dom
(4.33)
Nótese que si se aumenta s y s el rango de frecuencias se amplia y se incrementa la
resolución del espectro de la señal de entrada.
4.3.7 Señal multiseno
Una señal suma de sinusoides, también denominada como señal multiseno, es una
señal determinística periódica que puede expresarse, por ejemplo, de la siguiente forma:
sn
iiiis Tkku
1
)···cos(·2·)( (4.34)
En la expresión anterior T es el tiempo de muestreo, ns es el número de sinusoides (es
decir de armónicos) y i es la potencia relativa de una sinusoide (i>0 i=1,...,ns). Se verifica
que
11
sn
ii
Por otra parte, es un factor de escala para asegurar que la amplitud de la señal se
encuentra entre los valores ±usat.
La frecuencia de cada componente sinusoidal se calcula a través de la siguiente
expresión:
2· ·
·i
i
N T
(4.35)
donde N es la longitud de la secuencia. Se verifica que

Identificación de sistemas
4-19
2s
Nn (4.36)
La fase de cada componente sinusoidal se puede calcular, por ejemplo, usando la
ecuación de fase de Schroeder [Schroeder, 1970]:
i
jji j
1
···2 (4.37)
Lo que minimiza la aparición de picos pronunciados en la serie temporal. En dicho caso
a la señal multiseno, también se la denomina como señal de fase de Schroeder.
Una sinusoide es una señal de EP de grado 2, con esta entrada se puede determinar la
respuesta de un sistema a una determinada frecuencia, es decir, la amplitud con que se
modifica la señal al pasar por el sistema y el desfase que se introduce. Por lo tanto, una
señal formada por la suma de ns sinusoides es de EP de orden 2ns.
A modo de ejemplo, en la Figura 4.13 se muestra el espectro de potencia de una señal
suma m de sinusoides diseñada como filtro pasa-baja, se observa que posee una parte
constante (i0) en el rango de frecuencias comprendido entre [ ω , ω ] y es nulo (i=0) en
el rango [ ω , π/T] .
TNs·
·2*
*
T
0i
0i
Figura 4.13: Espectro de potencia de una señal suma de sinusoides diseñada como filtro pasa-baja.
En consecuencia el espectro de potencia de una señal multiseno está directamente
especificado mediante la selección del factor de escalado , los coeficientes de Fourier i, el
número de armónicos ns y la longitud de la señal N. En [Rivera et al., 1993] se dan las
siguientes expresiones como guías para ayudar a diseñar una señal multiseno:
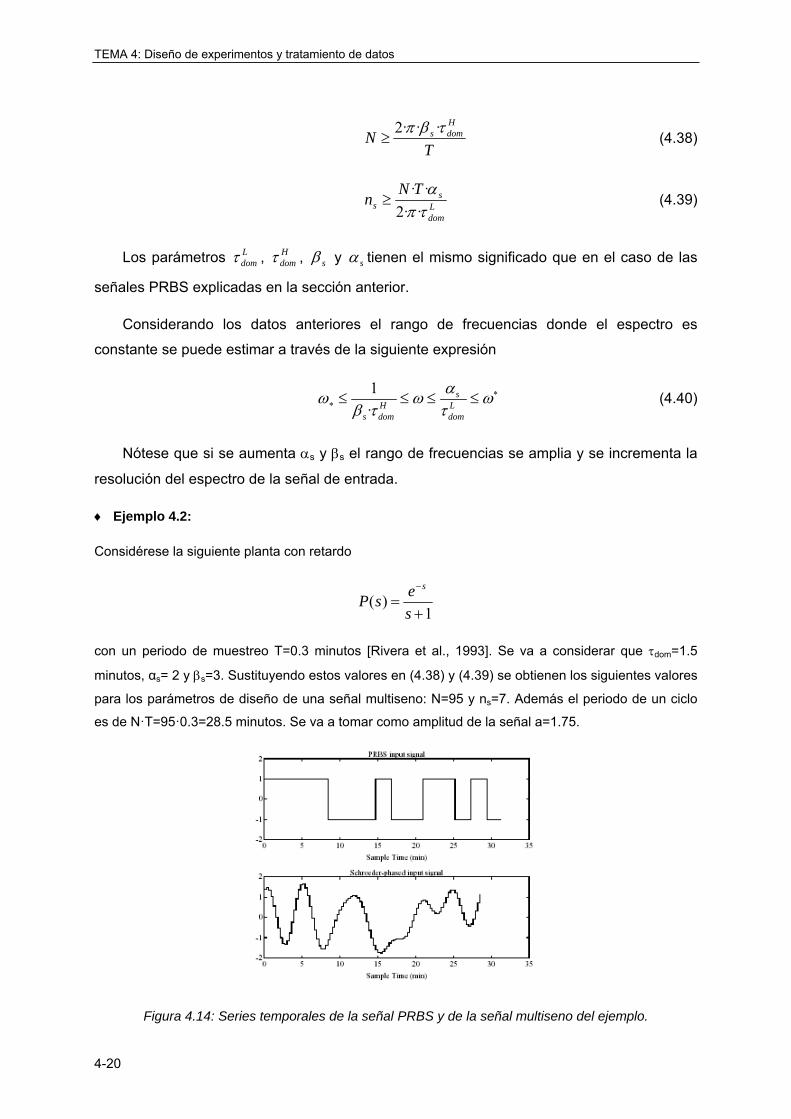
TEMA 4: Diseño de experimentos y tratamiento de datos
4-20
TN
Hdoms ···2
(4.38)
Ldom
ss
TNn
··2
·· (4.39)
Los parámetros Ldom , H
dom , s y s tienen el mismo significado que en el caso de las
señales PRBS explicadas en la sección anterior.
Considerando los datos anteriores el rango de frecuencias donde el espectro es
constante se puede estimar a través de la siguiente expresión
1
·s
H Ls dom dom
(4.40)
Nótese que si se aumenta s y s el rango de frecuencias se amplia y se incrementa la
resolución del espectro de la señal de entrada.
Ejemplo 4.2:
Considérese la siguiente planta con retardo
1)(
s
esP
s
con un periodo de muestreo T=0.3 minutos [Rivera et al., 1993]. Se va a considerar que dom=1.5
minutos, αs= 2 y s=3. Sustituyendo estos valores en (4.38) y (4.39) se obtienen los siguientes valores
para los parámetros de diseño de una señal multiseno: N=95 y ns=7. Además el periodo de un ciclo
es de N·T=95·0.3=28.5 minutos. Se va a tomar como amplitud de la señal a=1.75.
Figura 4.14: Series temporales de la señal PRBS y de la señal multiseno del ejemplo.
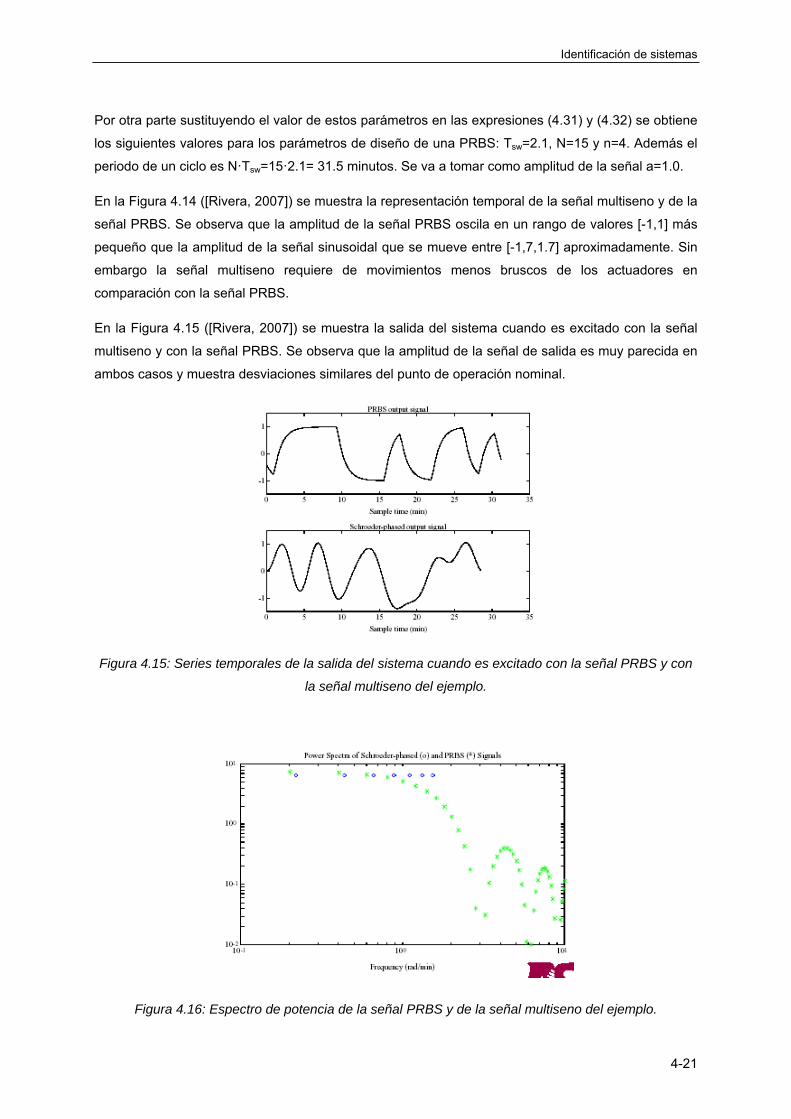
Identificación de sistemas
4-21
Por otra parte sustituyendo el valor de estos parámetros en las expresiones (4.31) y (4.32) se obtiene
los siguientes valores para los parámetros de diseño de una PRBS: Tsw=2.1, N=15 y n=4. Además el
periodo de un ciclo es N·Tsw=15·2.1= 31.5 minutos. Se va a tomar como amplitud de la señal a=1.0.
En la Figura 4.14 ([Rivera, 2007]) se muestra la representación temporal de la señal multiseno y de la
señal PRBS. Se observa que la amplitud de la señal PRBS oscila en un rango de valores [-1,1] más
pequeño que la amplitud de la señal sinusoidal que se mueve entre [-1,7,1.7] aproximadamente. Sin
embargo la señal multiseno requiere de movimientos menos bruscos de los actuadores en
comparación con la señal PRBS.
En la Figura 4.15 ([Rivera, 2007]) se muestra la salida del sistema cuando es excitado con la señal
multiseno y con la señal PRBS. Se observa que la amplitud de la señal de salida es muy parecida en
ambos casos y muestra desviaciones similares del punto de operación nominal.
Figura 4.15: Series temporales de la salida del sistema cuando es excitado con la señal PRBS y con
la señal multiseno del ejemplo.
Figura 4.16: Espectro de potencia de la señal PRBS y de la señal multiseno del ejemplo.
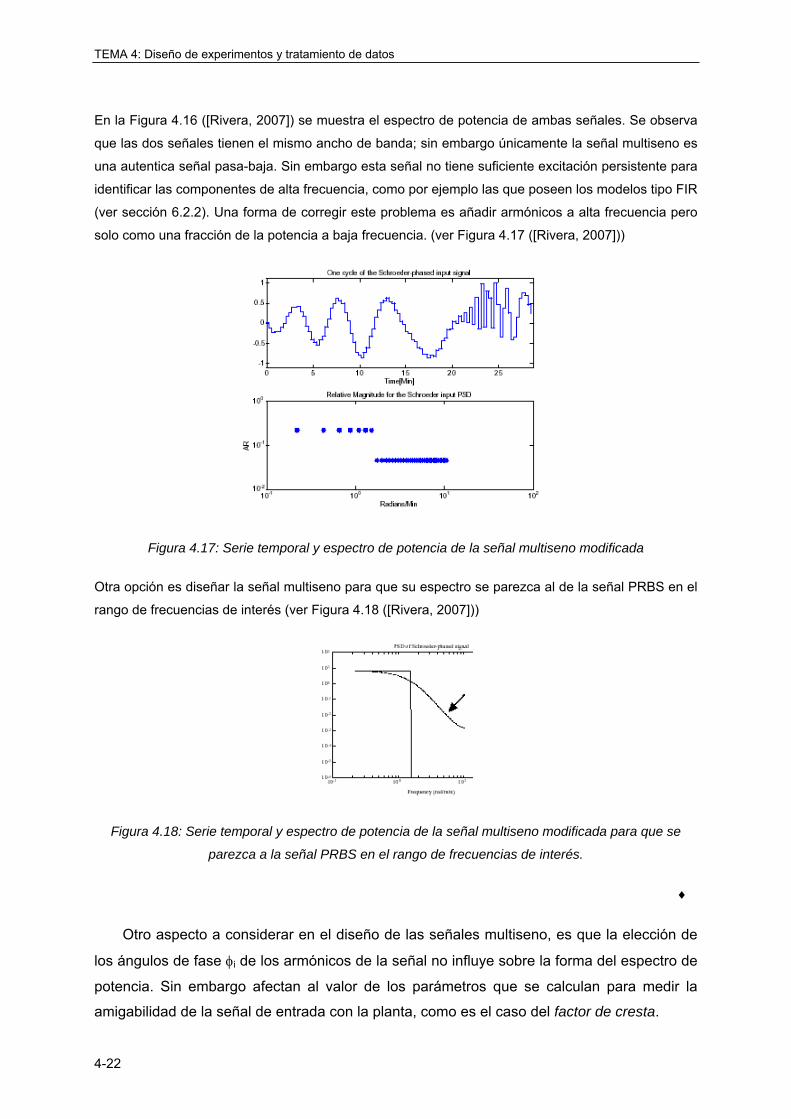
TEMA 4: Diseño de experimentos y tratamiento de datos
4-22
En la Figura 4.16 ([Rivera, 2007]) se muestra el espectro de potencia de ambas señales. Se observa
que las dos señales tienen el mismo ancho de banda; sin embargo únicamente la señal multiseno es
una autentica señal pasa-baja. Sin embargo esta señal no tiene suficiente excitación persistente para
identificar las componentes de alta frecuencia, como por ejemplo las que poseen los modelos tipo FIR
(ver sección 6.2.2). Una forma de corregir este problema es añadir armónicos a alta frecuencia pero
solo como una fracción de la potencia a baja frecuencia. (ver Figura 4.17 ([Rivera, 2007]))
Figura 4.17: Serie temporal y espectro de potencia de la señal multiseno modificada
Otra opción es diseñar la señal multiseno para que su espectro se parezca al de la señal PRBS en el
rango de frecuencias de interés (ver Figura 4.18 ([Rivera, 2007]))
Figura 4.18: Serie temporal y espectro de potencia de la señal multiseno modificada para que se
parezca a la señal PRBS en el rango de frecuencias de interés.
Otro aspecto a considerar en el diseño de las señales multiseno, es que la elección de
los ángulos de fase i de los armónicos de la señal no influye sobre la forma del espectro de
potencia. Sin embargo afectan al valor de los parámetros que se calculan para medir la
amigabilidad de la señal de entrada con la planta, como es el caso del factor de cresta.

Identificación de sistemas
4-23
Eligiendo adecuadamente los valores i de cada componente sinusoidal es posible
diseñar una señal multiseno con un espectro de potencia determinado y con un factor de
cresta lo más pequeño posible. Para ello hay que resolver un problema de optimización no
lineal que se puede enunciar de la siguiente forma: “Dada la siguiente estructura de señal
multiseno
sn
iiiis Tkku
1
)···cos(·2·)( (4.41)
y una densidad de potencia espectral (definida por los coeficientes de Fourier i ·2·
i=1,..,,ns de cada uno de los componentes sinusoidales) obtener el vector de fases de las
componentes sinusoidales óptimo
ns ...,,, 21p (4.42)
que minimiza el factor de cresta CF(us).”
La resolución de este problema no se puede hacer de forma directa (derivando e
igualando a cero) ya que la norma )(ul incluida en la definición del factor de cresta es no
diferenciable. Además la función objetivo es no convexa.
Guillaume et al. (1991) propusieron aproximar la minimización de )(ul por la
minimización secuencial de normas )(ul p donde p=4, 8, 16,.... Esta aproximación se basa en
el algoritmo de Pólya que afirma que
pp p
plim
Donde p es la solución minimax. Puesto que la norma )(2 ul permanece invariante
con respecto a las fases i, este método efectivamente aproxima la minimización del factor
de cresta. El vector de fases p es inicializado con las fases producidas por la ecuación de
Schroeder (4.37).
Aunque el algoritmo de Guillaume et al. (1991) no garantiza alcanzar el mínimo global,
si permite evitar muchos mínimos locales y produce en la práctica resultados bastante
buenos.

TEMA 4: Diseño de experimentos y tratamiento de datos
4-24
Nótese que a la formulación original del problema de optimización también se le podrían
añadir restricciones sobre los valores mínimos y máximos permitidos en la entrada [Rivera et
al., 2007]. Así como restricciones sobre el valor máximo permitido en las transiciones desde
un valor uk al siguiente uk+1 de la entrada.
4.3.8 Conclusiones
Con vistas a la reproducibilidad del experimento es conveniente usar una señal
determinista que una aleatoria. Si se conoce el rango de frecuencias del sistema que se
desea identificar entonces se puede elegir como señal de entrada una suma de sinusoides
distribuidas de forma regular sobre dicho rango. Si no se conoce el rango lo mejor es utilizar
una señal RBS o una señal PRBS.
4.4 ELECCIÓN DEL PERIODO DE MUESTREO
El teorema del muestreo de Shannon afirma que si una señal x(t) en tiempo continuo es
muestreada con un periodo de muestreo T, ésta podrá ser reconstruida a partir de la señal
muestreada x*(t)=x(tk) tk=k·T k=1, 2, ..,N si se cumple la siguiente relación:
1·2 s (4.43)
Siendo 1 es la componente de más alta frecuencia presente en la señal de tiempo
continuo x(t) y s es la frecuencia de muestreo
Ts
·2 (4.44)
En la práctica normalmente el periodo de muestreo se suele elegir para que se cumpla
la relación
1·10 s (4.45)
La elección del periodo de muestreo en el proceso de toma de datos de entrada/salida
del sistema a identificar está ligada a las constantes de tiempo de dicho sistema. Además se
deben tener en cuenta los siguientes aspectos:
La existencia de un intervalo de tiempo fijo para el experimento. Como el
periodo de muestreo no puede disminuirse una vez realizado el registro de los

Identificación de sistemas
4-25
datos conviene muestrear a una velocidad rápida y realizar después la
estimación considerando valores dobles, triples, etc del valor de muestreo.
El número total de datos a registrar fijo. El periodo de muestreo se debe elegir
entonces como un compromiso. Si es muy grande los datos contendrán poca
información sobre la dinámica de alta frecuencia del sistema. Si el periodo es
pequeño las perturbaciones pueden tener una influencia excesiva en el modelo
y, además, puede haber poca información del comportamiento a baja
frecuencia.
El objetivo final de la aplicación. Para los sistemas en lazo abierto se aconseja
tomar entre 2 y 4 muestras en el tiempo de subida. Para sistemas en lazo
cerrado se aconseja también ese número de muestras en el tiempo de subida
del sistema en lazo cerrado o bien entre 8 y 16 muestras en una oscilación
amortiguada del sistema. Otro valor que se suele indicar es el de realizar entre
5 y 16 muestras en el tiempo de asentamiento al 95% de la respuesta del
sistema en lazo cerrado a un escalón de entrada.
La fiabilidad del modelo resultante. El uso de periodos de muestreo muy
pequeños puede llevar a problemas prácticos, ya que los polos tienen a
agruparse en torno al punto z=1 del plano complejo y la determinación del
modelo se hace muy sensible a errores y perturbaciones, pudiendo resultar que
pequeños errores en los parámetros tengan una influencia importante sobre las
propiedades de entrada-salida del modelo. Además un muestreo muy rápido
lleva a que el modelo sea de fase no mínima lo que puede causar problemas a
la hora de diseñar la ley de control.
Ejemplo 4.3:
Se tiene la siguiente expresión para la función de transferencia de una planta que posee a su entrada
un retenedor de orden cero.
4;2;3;7;10;1
)1)(1)(1(
)1·()(
4321
321
4
d
sT
TTTTTK
sTsTsT
esTKsG
d
El modelo discreto equivalente que se obtiene considerando un periodo de muestreo T es:

TEMA 4: Diseño de experimentos y tratamiento de datos
4-26
)1(
)()(
33
22
11
33
22
110
zazaza
zbzbzbbzzG nk
La ganancia es
Kb
ai
i
1
En la Tabla 4.1 se muestran los valores de los coeficientes de G(z) en función del periodo de
muestreo T.
Cuando el periodo de muestreo disminuye las magnitudes de los parámetros a se incrementan y la de
los parámetros b disminuyen. Para un periodo de muestreo pequeño, por ejemplo T=1 s, se tiene
b a b a ai i i i i y 1
Se observa que pequeños errores en los parámetros pueden tener una influencia significativa en el
comportamiento entrada-salida del modelo, ya que, por ejemplo, el valor de bi depende
fuertemente de los valores de las cifras decimales cuarta y quinta.
T=1 T=4 T=8 T=16
a1 -2.48824 -1.49836 -0.83771 -0.30842
a2 2.05387 0.70409 0.19667 0.02200
a3 -0.56203 -0.09978 -0.00995 -0.00010
b0 0 0 0.06525 0.37590
b1 0.00462 0.06525 0.25598 0.32992
b2 0.00169 0.04793 -0.02850 0.00767
b3 -0.00273 -0.00750 -0.00074 -0.00001
bi 0.00358 0.10568 0.34899 0.71348
1+ai 0.00358 0.10568 0.34899 0.71348
Tabla 4.1: Coeficientes de G(z) en función del periodo de muestreo.
Por otra parte la elección de un periodo de muestreo muy grande puede llevar a una simplificación
excesiva del modelo dando este una descripción muy pobre de su comportamiento dinámico. En el
ejemplo se ve que para T=8 s. el modelo se reduce prácticamente a un sistema de segundo orden,
porque

Identificación de sistemas
4-27
a a b bi i3 31<< y <<
Para T=16 s el modelo se reduce prácticamente a uno de primer orden.
La elección del periodo de muestreo T determina también el valor de la frecuencia de
Nyquist N la cual se define de la siguiente forma:
2S
N T
(4.46)
La frecuencia de Nyquist establece la frecuencia más alta que puede contener una
señal antes de que aparezca el fenómeno del aliasing. Este fenómeno consiste en el
plegamiento de la función de densidad espectral de la señal para frecuencias mayores que
la frecuencia de Nyquist. Es decir, que debido al fenómeno del aliasing las frecuencias en la
señal más altas que la frecuencia de Nyquist son consideradas erróneamente como
frecuencias más bajas.
Para evitar el aliasing se recomienda usar un filtro antialiasing antes de muestrear la
salida del proceso (ver Figura 4.19). Un filtro antialiasing es un filtro analógico de tipo
pasabajas cuya frecuencia de corte se fija en la frecuencia de Nyquist.
Figura 4.19: Localización del filtro antialiasing
Obviamente si se utiliza un filtro antialiasing el modelo que se identifique a partir de los
datos de entrada {u(k)} e {y(k)} incluirá también la dinámica del filtro.
4.5 TRATAMIENTO DE LOS DATOS
Antes de iniciar el proceso de identificación es necesario realizar un tratamiento de los
datos de entrada-salida medidos experimentalmente. Dicho tratamiento consta de las
siguientes acciones: filtrado, eliminación de valores medios y detección de outliers.

TEMA 4: Diseño de experimentos y tratamiento de datos
4-28
Siempre hay que analizar si es necesario llevar a cabo cada una de estas acciones.
Dependiendo de la calidad de los datos de que se dispongan pueden ser necesario realizar
todas, alguna o ninguna de estas acciones.
4.5.1 Filtrado de los datos
El filtrado de los datos de entrada-salida (u(t), y(t)) consiste en diseñar un filtro digital
L(q) que puede ser un polinomio o una función racional del operador desplazamiento q que
se aplica tanto a los datos de entrada u(t) como a los de salida y(t) (ver Figura 4.20):
)()·()(
)()·()(
tuqLtu
tyqLty
F
F
(4.47)
Los datos de entrada-salida filtrados (uF(t), yF(t)) son los que se utilizan para identificar
el modelo.
Figura 4.20: Filtrado de los datos de entrada-salida
Señalar que en la literatura L(q) recibe el nombre de prefiltro y a (uF(t), yF(t)) se les
denomina datos prefiltrados. Asimismo a la operación de filtrar los datos de entrada/salida a
través del filtro L(q) se le denomina operación de prefiltrado de datos.
El diseño del filtro L(q) se realiza con el objetivo de conseguir uno o varios de los
siguientes objetivos:
Eliminación del comportamiento no estacionario.
Eliminación de las perturbaciones de alta frecuencia.
Enfatizar el rango de frecuencias donde se desea que el ajuste del modelo a los
datos experimentales sea mejor.

Identificación de sistemas
4-29
En las siguientes subsecciones se describe el diseño de un prefiltro para la consecución
de cada uno de los objetivos enumerados. Se deja para la sección 6.4.3 la descripción del
efecto que tiene el uso de un prefiltro sobre el espectro del error de predicción filtrado.
Además en la sección 9.5 se describirá el diseño de un prefiltro para la identificación
relevante para control.
4.5.1.1 Eliminación del comportamiento no estacionario
Las derivas y/o tendencias en el valor medio o/y en la pendiente características de una
serie temporal no estacionaria aparecen en el dominio de la frecuencia como componentes
de baja frecuencia. En consecuencia si los datos presentan un comportamiento no
estacionario, éste se puede eliminar filtrando los datos con un filtro pasa-alta, el cual atenúa
las componentes de baja frecuencia existente en los datos.
El filtro pasa-alta más simple es el diferenciador. Por ello la no estacionaridad de una
serie temporal se puede eliminar diferenciando la señal d veces, tal y como se describió en
la sección 2.6.5. En el caso de los datos de entrada-salida la diferenciación se realiza de la
siguiente forma:
1
1
( ) ( ) ( 1) (1 ) ( )
( ) ( ) ( 1) (1 ) ( )
F
F
y t y t y t q y t
u t u t u t q u t
(4.48)
Luego el filtro L(q) que implementa la operación de diferenciación toma la forma:
1( ) (1 )L q q (4.49)
Que se puede expresar equivalentemente en la forma:
1( )
zL z
z
(4.49)
Si se representa su diagrama de Bode puede comprobarse que L(z) tiene un
comportamiento de filtro pasa-alta.
En Matlab existen varias funciones que dados los coeficientes del filtro realizan el
filtrado de una señal. Este es el caso por ejemplo de la función filter de la toolbox de
procesamiento de señales.

TEMA 4: Diseño de experimentos y tratamiento de datos
4-30
Ejemplo 4.4:
La función filter de Matlab presenta la siguiente sintaxis:
v=filter(B,A,x);
Donde x es la señal a filtrar, v es la señal filtrada, A y B son los coeficientes del filtro L(q) de acuerdo
a la siguiente ecuación:
nannannbnnbnnn vavaxbxbxbva ·...··...··· 11211211
Por ejemplo, para diferenciar una vez los datos de entrada y salida habría que ejecutar los siguientes
comandos:
yf=filter([1 -1],1,y);
uf=filter([1 -1],1,u);
4.5.1.2 Eliminación de las perturbaciones de alta frecuencia
Si el filtro antialiasing no ha sido diseñado correctamente o el periodo de muestreo no
se ha elegido bien, entonces los datos pueden presentar ruido de alta frecuencia. Para
eliminarlo se puede diseñar un filtro L(q) de tipo pasa-baja que atenúa las componentes de
alta frecuencia.
4.5.1.3 Enfatizar el rango de frecuencias donde se desea que el ajuste del modelo a los datos experimentales sea mejor
Para enfatizar el rango de frecuencias donde se desea que el modelo presente un mejor
ajuste se debe usar un filtro pasa-banda. Usando un filtro de este tipo se consigue también
eliminar el comportamiento no estacionario asociado a componentes de baja frecuencia y el
ruido de alta frecuencia.
La función idfilt de la toolbox SITB permite implementar el filtrado de datos a través
de filtros pasabanda de tipo Butterworth, de orden 5 por defecto.
Ejemplo 4.5
La función idfilt de Matlab presenta la siguiente sintaxis:
zf=idfilt(z,filter);

Identificación de sistemas
4-31
Donde zf son los datos filtrados, z los datos de entrada-salida y filter es la especificación del
filtro la cual puede hacerse de diferentes formas. Por ejemplo, para implementar un filtro pasa-banda
en el rango de frecuencias [7.5, 22.5] (rad/s) se debería ejecutar el siguiente comando
zf= idfilt(z,[7.5, 22.5]);
Ejemplo 4.6
Como se estudiará en el Tema 6 un modelo paramétrico de tipo ARX se ajusta con un énfasis en el
comportamiento de alta frecuencia presente en los datos de entrada-salida, lo cual no es deseable en
general. Este efecto puede ser compensado prefiltrando los datos con un prefiltro L(q) de tipo pasa-
baja o pasa-banda.
Un método bastante útil y sencillo para diseñar este prefiltro consiste en obtener un modelo ARX
usando los datos originales (u(t),y(t)). Supóngase que el modelo ARX identificado es
1 1( ) ( ) ( ) ( ) ( )A q y t B q u t nk e t
El prefiltro se define entonces como:
1
1( )
( )L q
A q
4.5.2 Eliminación de valores medios
En la identificación de sistemas lineales, los valores medios en los datos de entrada
salida deben ser eliminados ya que pueden contribuir al error de sesgo en las estimas de los
parámetros (ver sección 6.4.3). No sucede así en la identificación de sistemas no lineales
donde los valores medios son importantes y no deben ser eliminados, ya que de lo contrario
se introduce error de sesgo.
Una forma de eliminar los valores medios de los datos de entrada/salida es fijar una
tendencia polinomial a la entrada y la salida mediante regresión lineal
y t m m t m t
u t n n t n tr
r
ss
*
*
( ) ...
( ) ...
0 1
0 1
y después calcular los datos eliminando las tendencias:
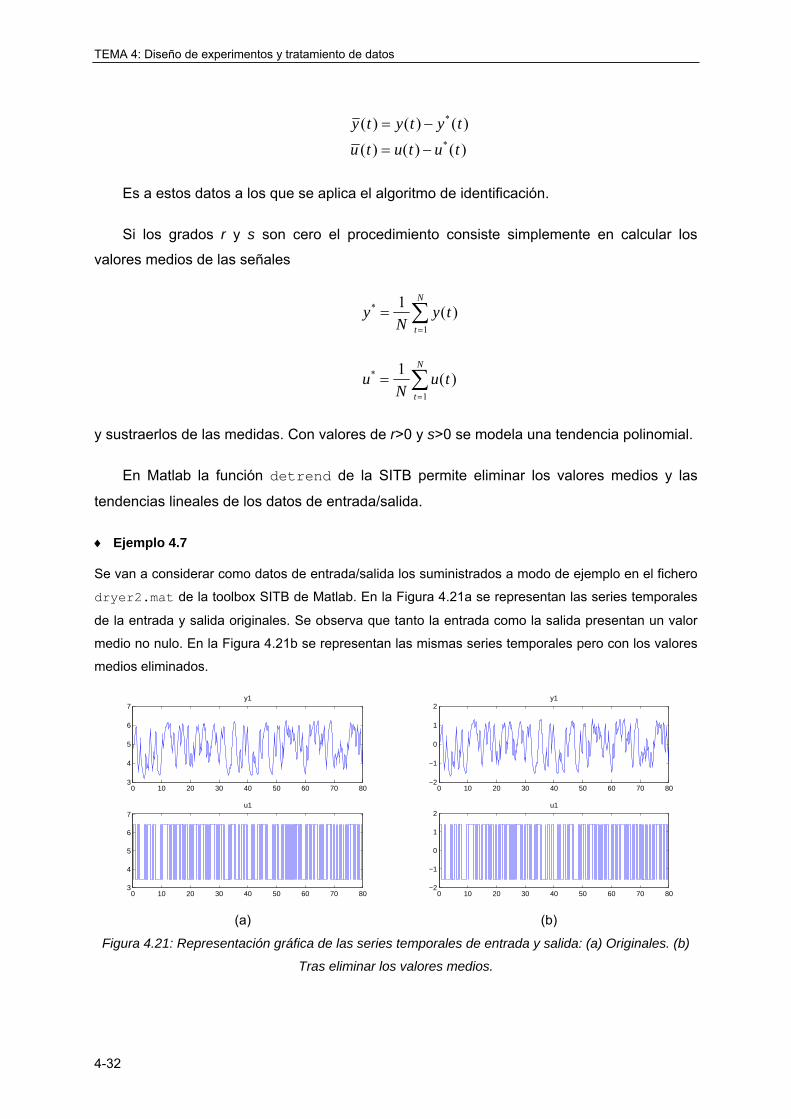
TEMA 4: Diseño de experimentos y tratamiento de datos
4-32
y t y t y t
u t u t u t
( ) ( ) ( )
( ) ( ) ( )
*
*
Es a estos datos a los que se aplica el algoritmo de identificación.
Si los grados r y s son cero el procedimiento consiste simplemente en calcular los
valores medios de las señales
yN
y tt
N* ( )
1
1
uN
u tt
N* ( )
1
1
y sustraerlos de las medidas. Con valores de r>0 y s>0 se modela una tendencia polinomial.
En Matlab la función detrend de la SITB permite eliminar los valores medios y las
tendencias lineales de los datos de entrada/salida.
Ejemplo 4.7
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SITB de Matlab. En la Figura 4.21a se representan las series temporales
de la entrada y salida originales. Se observa que tanto la entrada como la salida presentan un valor
medio no nulo. En la Figura 4.21b se representan las mismas series temporales pero con los valores
medios eliminados.
0 10 20 30 40 50 60 70 803
4
5
6
7y1
0 10 20 30 40 50 60 70 803
4
5
6
7u1
(a)
0 10 20 30 40 50 60 70 80−2
−1
0
1
2y1
0 10 20 30 40 50 60 70 80−2
−1
0
1
2u1
(b)
Figura 4.21: Representación gráfica de las series temporales de entrada y salida: (a) Originales. (b)
Tras eliminar los valores medios.

Identificación de sistemas
4-33
La secuencia de comandos de Matlab necesaria para obtener estas figuras es la siguiente:
load dryer2 Ts=0.08; %Periodo de muestreo datos0 = iddata(y2,u2,Ts); figure(1) plot(datos0) datos1=detrend(datos0); figure(2) plot(datos1)
También se observa que la entrada es una señal RBS o PRBS (sólo puede saberse si es una PRBS
si se tiene un registro suficientemente largo de datos donde pueda observar su periodicidad) y que no
parece existir ruido de alta frecuencia ya que ni la entrada ni la salida poseen fluctuaciones pequeñas
y rápidas en sus valores temporales.
Señalar que con este método se pueden eliminar tanto valores medios como tendencias
de tipo polinomial, por lo que si una señal no estacionaria presenta tendencias de este tipo
pueden ser eliminadas usando este método sin necesidad de diferenciarla previamente.
4.5.3 Detección de outliers
Cuando se realizan los experimentos ocurre a veces que hay grandes errores en las
medidas. Estos errores, denominados outliers, pueden estar causados por perturbaciones,
errores en las transmisiones de datos, fallos en la conversión, etc. Es importante detectar y
eliminar esos errores antes de analizar los datos, ya que su influencia cambiará en gran
medida los resultados de la identificación.
Los outliers aparecen como picos en la secuencia de errores de predicción o residuos,
que como se estudiará en el Tema 6, se definen como la diferencia entre la salida y medida
experimental y la salida estimada y por el modelo:
Nkyy kkk ,...,1ˆ
Una forma bastante usual de tratar los outliers es hacer un test de presencia de outliers
y ajustar los datos erróneos. En este caso se obtiene un modelo ajustando los datos sin
prestar atención a los outliers. Después se obtienen los residuos k y se representan
gráficamente. Se detecta la existencia de posibles picos en la secuencia k . Si por ejemplo

TEMA 4: Diseño de experimentos y tratamiento de datos
4-34
algún valor | k | para algún cierto valor j es anormalmente grande entonces el dato j de la
salida medida experimental yj se modifica. Una modificación sencilla es tomar
11·5.0 jjj yyy
Otra posibilidad es tomar como valor yj el valor estimado:
jj yy ˆ
La secuencia de valores obtenida haciendo las sustituciones anteriores se utiliza para
obtener un nuevo modelo.
BIBLIOGRAFÍA
[Davies, 1970] W. D. T. Davies. System Identification For Self-Adaptative
Control. Wiley Interscience. 1970.
[Godfrey, 1993] K. Godfrey. Perturbation Signals For System Identification.
Prentice Hall. 1993.
[Godfrey et al., 1999] K. Godfrey, H. A Barker, A. J. Tucker. Comparison of
perturbation signals for linear system identification in the
frequency domain. IEE Proceedings of Control Theory and
Applications. Vol. 146 , No. 6, pp. 535 – 548. 1999.
[Guillaume et al, 1991] P. Guillaume, J. Schoukens, R. Pintelon, I. Kollar. Crest-
factor minimization using nonlinear Chebyshev
approximation methods. IEEE Transactions on
Instrumentation and Measurement, Vol: 40 , No 6, pp. 982-
989. 1991.
[Ljung y Glad, 1994] L. Ljung y T. Glad. Modelling of dynamic systems. Prentice
Hall. 1994.
[Ljung, 1999] L. Ljung. System Identification: Theory for the user. 2nd
Edition. Prentice Hall.1999.
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.

Identificación de sistemas
4-35
[Rivera, 1992] D. E. Rivera. Monitoring tools for PRBS testing in system
identification. Paper 131d, AIChE Nationa Meeting, Miami
Beach. 1992.
[Rivera et al., 1993] D. E Rivera, X. Cheng, D. S. Bayard. Experimental design for
robust process control using Schroeder-phased input signals.
Proceeding of American Control Conference 1993. Pp. 895
– 899. 1993.
[Rivera et al., 2003] D. E Rivera, L. Hyunjin, W. B. Martin, H. Mittelmann. “Plant-
Friendly” system identification : a challenge for the process
industries. Proceeding of 13th IFAC Symposium on System
Identification (SYSID 2003). 2003.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.
[Rivera et al., 2007] D. E. Rivera, H. Lee, H. D Mittelmann, M. W. Braun. High-
purity distillation using plant-friendly multisine signals to
identify a strongly interactive process. Control Systems
Magazine, IEEE Vol. 27 ,No : 5 pp.72-89. 2007.
[Schroeder, 1970] M. Schroeder. Synthesis of low-peak-factor signals and
binary sequences with low autocorrelation (Corresp.), IEEE
Transactions on Information Theory. Vol. 16. No.1.pp. 85 -
89. 1970.


TEMA 5
IDENTIFICACIÓN DE MODELOS NO PARAMÉTRICOS
5-1
5.1 INTRODUCCIÓN
Un modelo de un sistema se considera no paramétrico si viene expresado en forma de
tabla o gráfica. Este tipo de modelos no pueden ser usados de forma directa para
simulación. Pese a esta limitación los modelos no paramétricos pueden aportar información
importante sobre las características temporales o frecuenciales del sistema que puede ser
utilizada en la etapa de estimación o validación de modelos paramétricos.
Considérese el sistema representado en la Figura 5.1, que posee una entrada u(t), una
salida y(t) y está sometido a una perturbación v(t).
Figura 5.1: Sistema a identificar
Supóngase que se disponen de N muestras (con periodo de muestreo T unidad) de la
señal de entrada {u(t)} t=1,2,...,N y de la señal de salida {y(t)}. Si se supone que el sistema
es lineal e invariante en el tiempo discreto de forma general dicho sistema se puede
expresar mediante la siguiente ecuación:

TEMA 5: Identificación de modelos no paramétricos
5-2
)()()·()( tvtuqGty (5.1)
donde G(q) es la función de transferencia del sistema
1
)·()(k
kqkgqG (5.2)
expresada en términos del operador desplazamiento q
)1()(·1 tutuq (5.3)
Los números {g(k)} son denominados la respuesta a un impulso del sistema.
Obviamente, g(k) es la salida del sistema en el instante k si la salida es un impulso (pulso)
en el instante cero. A partir de la respuesta a un impulso se puede obtener la respuesta a un
escalón.
Por otra parte, la función de transferencia evaluada sobre el circulo unidad (q=ei)
genera la función de la frecuencia
)( ieG (5.4)
En (5.1) el término v(t) es una perturbación estocástica no medible (ruido). Sus
propiedades pueden ser expresadas mediante su espectro de potencia
)(v (5.5)
que se define mediante
tivv eR ··)·()( (5.6)
donde Rv() es la función de covarianza de v(t):
)]()·([)( tvtvERv (5.7)
Alternativamente, se puede considerar que la perturbación v(t) se obtiene filtrando ruido
blanco e(t) de media nula y varianza a través de un filtro H(q)
)()·()( teqHtv (5.8)

Identificación de sistemas
5-3
En ese caso el espectro de potencia de v(t) toma la siguiente forma (ver sección 2.7):
2)(·)( i
v eH (5.9)
Si se sustituye (5.8) en (5.1) se obtiene
)()·()()·()( teqHtuqGty (5.10)
Esta ecuación da la descripción en el dominio temporal del sistema mientras que G(ei)
y v() constituyen su descripción en el dominio frecuencial.
Tanto la respuesta a un impulso {g(k)} (o a un escalón) como la función de frecuencia
del sistema G(ei) son una colección de puntos que pueden ser representados en una
gráfica o recopilados en una tabla. Se trata por lo tanto de modelos no paramétricos del
sistema. Lo mismo ocurre con el espectro de la perturbación del sistema v().
La respuesta a un impulso {g(k)} (o a un escalón) de un sistema permite obtener
información sobre la constante de tiempo y el retardo del sistema. Así como sobre la
ganancia en el estado estacionario. Los dos métodos más utilizados para obtener una
estima de la respuesta a un impulso de un sistema son:
Análisis del transitorio. Se trata de un método empírico que consiste en excitar al
sistema con un impulso (o pulso) o un escalón y registrar la respuesta que es la
que se estudia para obtener la información deseada.
Análisis de correlación. Consiste en obtener una estima de la respuesta a un
impulso del sistema usando las estimas de las funciones de correlación cruzada
calculada a partir de los datos de entrada-salida del sistema.
La función de frecuencia G(ej) del sistema proporciona información sobre el
comportamiento en frecuencia del sistema: si amplifica o atenúa, filtrado de frecuencias,
rango de frecuencias de interés, etc. Los tres métodos más utilizados para obtener una
estima de la respuesta en frecuencia del sistema son:
Análisis de frecuencia. Se trata de un método empírico que consiste en excitar al
sistema con una sinusoide pura a diferentes frecuencias. Supuesto que el sistema
también es lineal la salida será otra sinusoide desfasada. A partir de los datos de
la magnitud y la fase de la entrada y de la salida a una determinada frecuencia se

TEMA 5: Identificación de modelos no paramétricos
5-4
puede obtener la magnitud y la fase de la función de frecuencia a dicha
frecuencia.
Análisis de Fourier. Consiste en generar una estima de la función de frecuencia
del sistema a partir de las transformadas de Fourier de la entrada y de la salida
del sistema. A la estima obtenida de esta forma se le denomina estima de la
función de frecuencia empírica o ETFE (Empirical Transfer Function Estimate).
Análisis espectral. Consiste en generar una estima de la función de frecuencia del
sistema a partir del cálculo de las estimas de los espectros de potencia de la
entrada y la salida, y del espectro de potencia cruzada entre la entrada y la salida.
Dicho espectros se estiman a su vez a partir de las funciones de correlación
asociadas que se calculan a partir de los datos de entrada-salida. Este método
también permite obtener una estima del espectro de potencia de la perturbación.
Este tema está dedicado a describir las características básicas de los principales
métodos utilizados para obtener una estima de la respuesta a un impulso y de la función de
frecuencia de un sistema, que son modelos no paramétricos del sistema. En primer lugar se
describen los métodos para obtener una estima de la respuesta a un impulso: el análisis del
transitorio y el análisis de correlación. A continuación se describen los métodos para obtener
una estima de la función de frecuencia del sistema: el análisis de frecuencia, el análisis de
Fourier y el análisis espectral.
5.2 ANÁLISIS DEL TRANSITORIO
Se denomina análisis del transitorio al estudio de la respuesta de un sistema excitado
con una entrada impulso (o pulso) o una entrada escalón. De dicho análisis se puede
obtener la siguiente información:
Variables del sistema afectadas por la entrada. Esto simplifica la obtención de
diagramas de bloques del sistema y la decisión sobre que influencias pueden ser
despreciadas.
Constante de tiempo dominante del sistema. Lo que posibilita decidir que relaciones
en el modelo pueden ser descritas como estáticas, es decir, tienen constantes de
tiempo significativamente más rápidas que la escala de tiempo con la que estemos
trabajando.
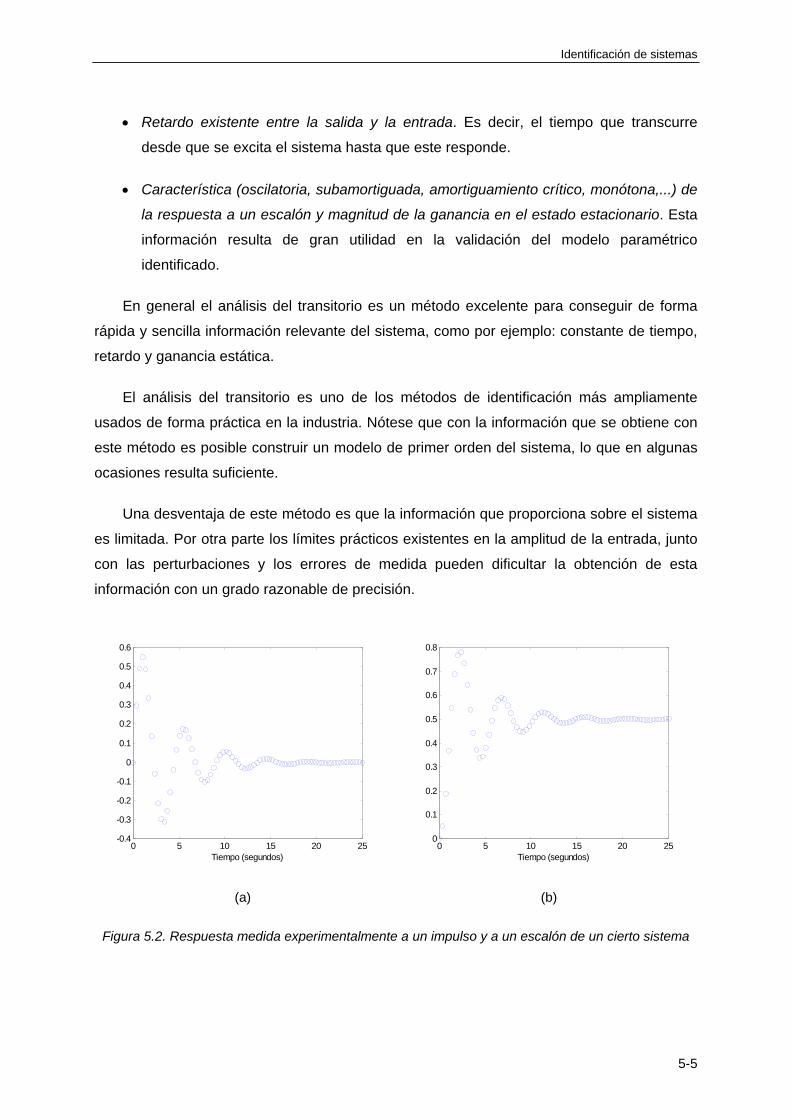
Identificación de sistemas
5-5
Retardo existente entre la salida y la entrada. Es decir, el tiempo que transcurre
desde que se excita el sistema hasta que este responde.
Característica (oscilatoria, subamortiguada, amortiguamiento crítico, monótona,...) de
la respuesta a un escalón y magnitud de la ganancia en el estado estacionario. Esta
información resulta de gran utilidad en la validación del modelo paramétrico
identificado.
En general el análisis del transitorio es un método excelente para conseguir de forma
rápida y sencilla información relevante del sistema, como por ejemplo: constante de tiempo,
retardo y ganancia estática.
El análisis del transitorio es uno de los métodos de identificación más ampliamente
usados de forma práctica en la industria. Nótese que con la información que se obtiene con
este método es posible construir un modelo de primer orden del sistema, lo que en algunas
ocasiones resulta suficiente.
Una desventaja de este método es que la información que proporciona sobre el sistema
es limitada. Por otra parte los límites prácticos existentes en la amplitud de la entrada, junto
con las perturbaciones y los errores de medida pueden dificultar la obtención de esta
información con un grado razonable de precisión.
0 5 10 15 20 25-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
Tiempo (segundos)
(a)
0 5 10 15 20 250
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Tiempo (segundos)
(b)
Figura 5.2. Respuesta medida experimentalmente a un impulso y a un escalón de un cierto sistema

TEMA 5: Identificación de modelos no paramétricos
5-6
Ejemplo 5.1:
En la Figura 5.2 se muestra la respuesta de un sistema medida experimentalmente a un impulso y a
un escalón. Del análisis de las mismas se puede deducir que no parece existir retardo entre la
entrada y la salida. Se observa que la respuesta es subamortiguada, por lo que podría probarse a
modelar el sistema con un modelo de segundo orden.
Además se observa que la ganancia en el estacionario tiende a 0.5. También podrían estimarse otros
parámetros del sistema como el tiempo de subida o el tiempo de asentamiento.
5.3 ANÁLISIS DE CORRELACIÓN
No es necesario usar un impulso como entrada para estimar directamente la respuesta
a un impulso de un sistema. Supóngase un sistema en tiempo discreto cuya respuesta a un
impulso {gk} viene dada por la siguiente expresión:
0
)()(·)(k
k tvktugty (5.11)
Sea {u(t)} una señal que es una realización de un proceso estocástico con valor medio
cero y función de covarianza Ru():
)]()·([)( tutuERu (5.12)
Supóngase que {u(t)} y {v(t)} no están correlacionadas, lo que implica que el sistema
está en lazo abierto. La función de covarianza cruzada entre la entrada u y la salida y se
determina de la siguiente forma:
)]()·([)( tutyERyu (5.13)
Sustituyendo (5.11) en (5.13) y desarrollando se obtiene la siguiente expresión:
00
)(·)]()·([)]()·([·)(k
ukk
kyu kRgtutvEtuktuEgR (5.14)
Si la entrada u(t) es ruido blanco entonces su función de covarianza es:
00
0)(
si
siRu

Identificación de sistemas
5-7
donde es la varianza. Además la función de covarianza cruzada (5.14) entre la entrada y la
salida es
gRyu ·)( (5.15)
Se observa que la función de covarianza cruzada es proporcional a la respuesta a un
impulso. Por supuesto esta función no es conocida, pero puede ser estimada a partir de los
datos experimentales de la entrada y la salida del sistema mediante la siguiente expresión:
N
t
Nyu tuty
NR
1
)()·(·1
)(ˆ (5.16)
Usando este estimador y de acuerdo con la expresión (5.15), es posible obtener la
siguiente estima para la respuesta a un impulso
)(ˆ·1
ˆ
Nyu
N Rg (5.17)
Si la entrada u(t) no es ruido blanco, se puede filtrar la secuencia de datos de la entrada
usando un filtro de blanqueo L(q) tal que la secuencia filtrada (ver sección 4.5.1):
)()·()( tuqLtuF (5.18)
se pueda considerar aproximadamente ruido blanco.
El filtro de blanqueo L(q) a menudo se calcula describiendo u(t) como un proceso AR
)()()·( tetuqA
Nótese que L(q)=A(q). Este polinomio se estima usando el método de los mínimos
cuadrados (se explica en el Tema 6).
Si se filtra la señal de entrada a través de L(q), entonces también hay que filtrar la
secuencia de salida y
)()·()( tyqLtyF (5.19)
De esta forma la estima de la función de covarianza cruzada se calcula usando los
datos filtrados

TEMA 5: Identificación de modelos no paramétricos
5-8
N
tFF
Nuy tuty
NR
FF1
)()·(·1
)(ˆ (5.20)
Calculando además la estima de la varianza de la entrada:
N
tFN tu
N 1
2 )(·1 (5.21)
la estima para la respuesta a un impulso usando la expresión se calcula mediante la
siguiente expresión
N
NuyN FF
Rg
ˆ
)(ˆˆ (5.22)
Dados unos datos de entrada u(k) y salida y(k), k=1,...,N, cuyos valores medios han sido
eliminados:
;)(1
)()(;)(1
)()(11
N
t
N
t
tuN
kukutyN
kyky
1. Filtrar las señales usando un filtro de blanqueo.
);()·()();()·()( tuqLkutyqLky FF
2. Calcular la estima de la función de covarianza entre la entrada y la salida.
N
tFF
Nuy tuty
NR
FF1
)()·(·1
)(ˆ
3. Calcular la estima de la varianza de la entrada.
N
tFN tu
N 1
2 )(·1
4. Calcular la estima de la respuesta a un impulso.
N
NuyN FF
Rg
ˆ
)(ˆˆ
Cuadro 5.1. Pasos del análisis de correlación
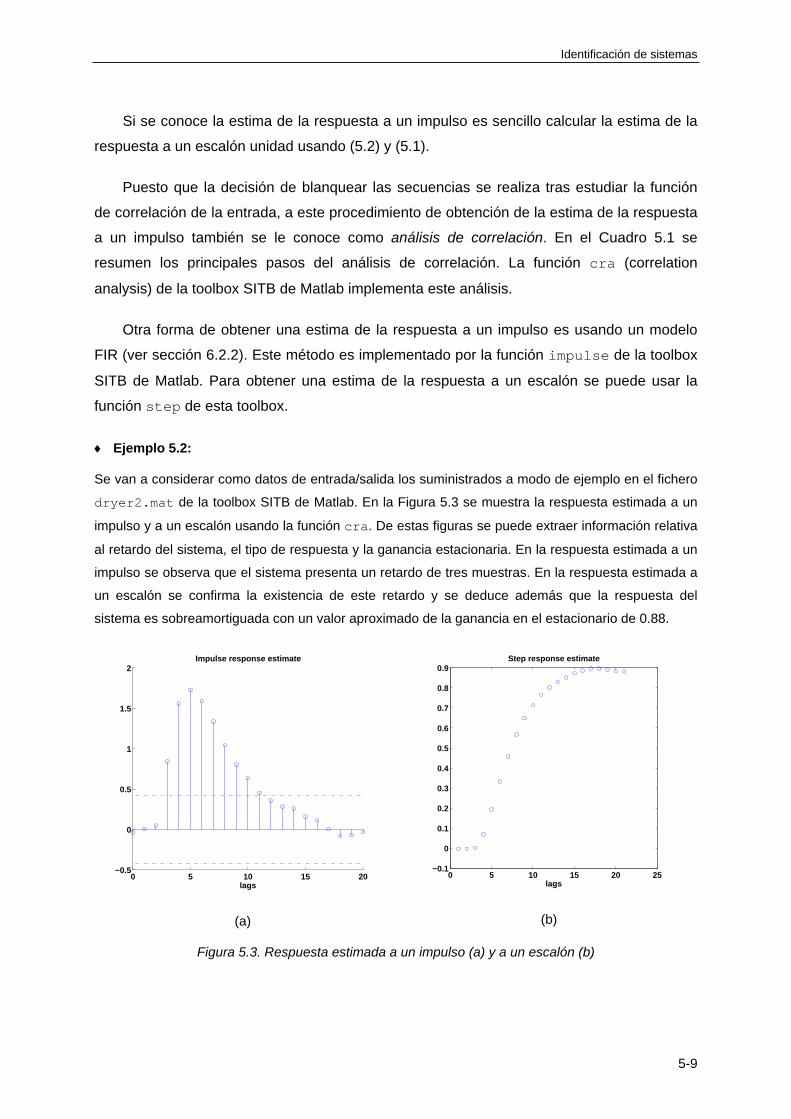
Identificación de sistemas
5-9
Si se conoce la estima de la respuesta a un impulso es sencillo calcular la estima de la
respuesta a un escalón unidad usando (5.2) y (5.1).
Puesto que la decisión de blanquear las secuencias se realiza tras estudiar la función
de correlación de la entrada, a este procedimiento de obtención de la estima de la respuesta
a un impulso también se le conoce como análisis de correlación. En el Cuadro 5.1 se
resumen los principales pasos del análisis de correlación. La función cra (correlation
analysis) de la toolbox SITB de Matlab implementa este análisis.
Otra forma de obtener una estima de la respuesta a un impulso es usando un modelo
FIR (ver sección 6.2.2). Este método es implementado por la función impulse de la toolbox
SITB de Matlab. Para obtener una estima de la respuesta a un escalón se puede usar la
función step de esta toolbox.
Ejemplo 5.2:
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SITB de Matlab. En la Figura 5.3 se muestra la respuesta estimada a un
impulso y a un escalón usando la función cra. De estas figuras se puede extraer información relativa
al retardo del sistema, el tipo de respuesta y la ganancia estacionaria. En la respuesta estimada a un
impulso se observa que el sistema presenta un retardo de tres muestras. En la respuesta estimada a
un escalón se confirma la existencia de este retardo y se deduce además que la respuesta del
sistema es sobreamortiguada con un valor aproximado de la ganancia en el estacionario de 0.88.
0 5 10 15 20−0.5
0
0.5
1
1.5
2Impulse response estimate
lags
(a)
0 5 10 15 20 25−0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
lags
Step response estimate
(b)
Figura 5.3. Respuesta estimada a un impulso (a) y a un escalón (b)

TEMA 5: Identificación de modelos no paramétricos
5-10
La secuencia de comandos de Matlab utilizada para obtener estas figuras es la siguiente:
load dryer2 Ts=0.08; %Periodo de muestreo datos0 = iddata(y2,u2,Ts); %Eliminación de valores medios datos1=detrend(datos0); %Seleccionar los primeros 500 puntos para estimar. d_est=datos1(1:500); %Estimar la respuesta a un impulso mediante análisis de correlación figure(1) ir=cra(d_est,20,10,1); %Calcular la respuesta a un escalón a partir de la respuesta a un impulso figure(2) sr=cumsum(ir); plot(sr,'o'); xlabel('lags'); title('Step response estimate');
Las propiedades básicas del análisis de correlación se pueden resumir en los siguientes
puntos:
El resultado del análisis de correlación son modelos no paramétricos que no se
pueden utilizar para simulación directamente.
Al igual que sucedía con el análisis del transitorio permite estimar de forma rápida las
constantes de tiempo, los retardos o las ganancias estacionarias del sistema.
Para su realización no es necesario disponer de datos de entrada- salida del sistema
obtenidos con una entrada con un alto grado de excitación (PRBS, multiseno,...). De
hecho se pueden utilizar incluso señales con una razón señal-ruido pequeña siempre
y cuando se disponga de un número de puntos N suficientemente grande.
El análisis de correlación, como se describe aquí, presupone que la entrada no está
correlacionada con las perturbaciones. Esto significa que este análisis no funcionará
correctamente cuando los datos son tomados de un sistema en lazo cerrado, es
decir, con realimentación de su salida.
Permite detectar la existencia de realimentaciones en los datos (ver sección 6.6.2).

Identificación de sistemas
5-11
5.4 ANÁLISIS DE FRECUENCIA
Un sistema lineal queda determinado de forma única por su respuesta a un impulso o
por su respuesta en frecuencia G(i) (la transformada de Laplace de la respuesta a un
impulso evaluada en s=i) o G(ej) si el sistema ha sido muestreado. Una posible forma de
estimar la respuesta en frecuencia G(i) es usando el método del análisis en frecuencia que
se describe a continuación
Si un sistema lineal con función de transferencia G(s) se excita con una entrada de tipo
sinusoidal (o cosenoidal)
)··cos()( 0 tutu (5.23)
entonces la salida en el estacionario es también de tipo sinusoidal
)··cos()( 0 tyty (5.24)
donde
00 ·)( uiGy (5.25)
)(arg iG (5.26)
Excitando al sistema con una entrada sinusoidal de amplitud u0 a diferentes frecuencias
i i=1,...,N y midiendo las fases i y las amplitudes yi de la salida es posible obtener la
magnitud |G(ji)| y la fase argG(ji) del sistema a las diferentes frecuencias i usando las
expresiones anteriores. Se puede construir así una tabla [i, |G(ji)|, argG(ji)] o
representaciones gráficas del modulo y de la fase de G frente a la frecuencia. Se tiene por lo
tanto una estima en forma de tabla o gráfica de la función G(j). Al método descrito de
obtención de una estima de la función G(j) se le conoce como análisis de frecuencia.
Ejemplo 5.3
En la Figura 5.4 se muestran representados en un diagrama de Bode los puntos de magnitud (en
decibelios) y de fase (en grados) a catorce frecuencias de la función de transferencia de un cierto
sistema que han sido estimados mediante análisis de frecuencia.
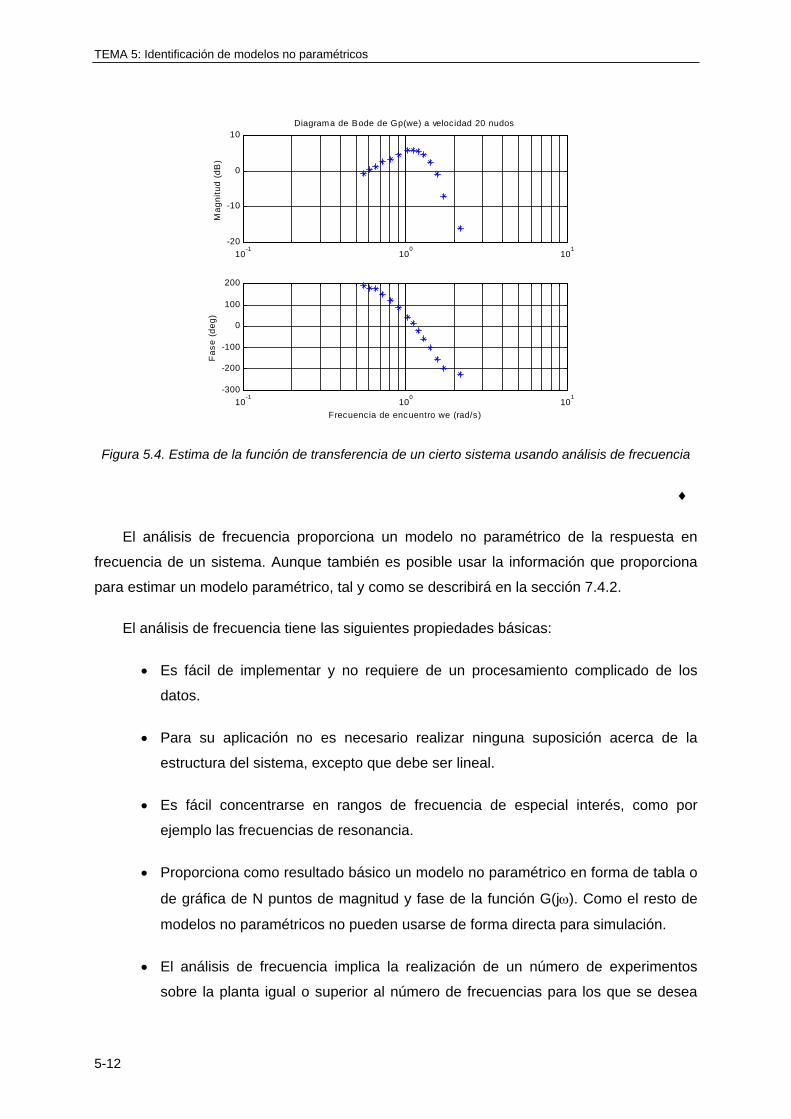
TEMA 5: Identificación de modelos no paramétricos
5-12
10-1
100
101
-20
-10
0
10Diagrama de Bode de Gp(we) a velocidad 20 nudos
Ma
gn
itu
d (
dB
)
10-1
100
101
-300
-200
-100
0
100
200
Fa
se
(d
eg
)
Frecuencia de encuentro we (rad/s)
Figura 5.4. Estima de la función de transferencia de un cierto sistema usando análisis de frecuencia
El análisis de frecuencia proporciona un modelo no paramétrico de la respuesta en
frecuencia de un sistema. Aunque también es posible usar la información que proporciona
para estimar un modelo paramétrico, tal y como se describirá en la sección 7.4.2.
El análisis de frecuencia tiene las siguientes propiedades básicas:
Es fácil de implementar y no requiere de un procesamiento complicado de los
datos.
Para su aplicación no es necesario realizar ninguna suposición acerca de la
estructura del sistema, excepto que debe ser lineal.
Es fácil concentrarse en rangos de frecuencia de especial interés, como por
ejemplo las frecuencias de resonancia.
Proporciona como resultado básico un modelo no paramétrico en forma de tabla o
de gráfica de N puntos de magnitud y fase de la función G(j). Como el resto de
modelos no paramétricos no pueden usarse de forma directa para simulación.
El análisis de frecuencia implica la realización de un número de experimentos
sobre la planta igual o superior al número de frecuencias para los que se desea

Identificación de sistemas
5-13
estimar G(j). Debe recordarse (ver sección 4.2.3) que muchos sistemas,
especialmente los usados en la industria de procesos, no pueden ser usados
libremente para la realización de cualquier tipo de experimentos.
5.5 ANÁLISIS DE FOURIER
Sea un sistema lineal que puede ser descrito mediante la función de transferencia G(s).
Si la entrada tiene energía finita, entonces se cumple la siguiente relación entre la entrada y
la salida del sistema:
)()·()( UiGY (5.27)
Donde Y() y U() son las transformadas de Fourier de la entrada y la salida,
respectivamente.
Si se conocieran Y() y U() entonces la función G(i) podría ser calculada
despejándola de la expresión anterior:
)(
)()(
U
YiG (5.28)
Normalmente, se dispone de información sobre la entrada u(t) y la salida y(t) durante un
intervalo finito de tiempo 0 t S. Las transformadas de Fourier de la entrada y la salida en
dicho intervalo se pueden calcular a través de las siguientes expresiones:
0 0
( ) ( )· · ( ) ( )· ·S S
i t i tS SY y t e dt U u t e dt (5.29)
Con lo que se puede construir la siguiente estima de la función de frecuencia:
( )ˆ ( )( )
NN
N
YG j
U
(5.30)
A (5.30) se le denomina estima de la función de transferencia empírica o ETFE
(Empirical Transfer Function Estimate) ya que se construye directamente a partir de los
datos experimentales sin ninguna otra suposición sobre el sistema salvo que es lineal.
Si la entrada es
)·cos()( *0 tutu (5.31)

TEMA 5: Identificación de modelos no paramétricos
5-14
de acuerdo con (5.29) su transformada de Fourier es
0
*
· ·( ) ; 1, 2,...
2S
u S kU S k
(5.32)
Aplicando (5.30) se obtiene la siguiente expresión para la ETFE:
SS
S dttsentyjdtttySu
jG0
*
0
*0
* )··()·()··)·cos((·
2)(
ˆ (5.33)
Si únicamente se dispone de valores muestreados de la entrada u y la salida y,
(u(kT),y(KT)), k=1,...,N, lo cual suele ser lo habitual, entonces se utilizan las siguientes
aproximaciones para las transformadas de Fourier de la entrada y la salida:
1 1
1 1( ) · ( )· , ( ) · ( )·
N Ni kT i kT
N Nk k
Y y kT e U u kT eN N
(5.34)
donde T es el periodo de muestreo y S=N·T. Nótese que estas expresiones pueden ser
calculadas eficientemente en =r·2/N, r=0,...,N-1, usando la transformada rápida de Fourier
o FFT (Fast Fourier Fransform). N se ajusta para que sea una potencia de 2.
Se puede demostrar [Ljung y Glad, 1994] que una cota para el error existente en la
ETFE respecto a la G(i) real viene dada por la siguiente expresión:
|)(|
|)(|
|)(|
··2|)()(
ˆ|
S
S
S
guS U
V
U
ccjGjG (5.35)
donde VS() es la transformada de Fourier de la perturbación v(t) sobre el intervalo [0,S].
Además se debe cumplir que:
uctu )(
0
·)( gcdg
Para una señal con energía infinita la transformada de Fourier típicamente tiene la
siguiente magnitud
constSU S ·|)(|

Identificación de sistemas
5-15
En el caso de un sinusoide pura con frecuencia 0 entonces
constSU S ·|)(| 0
Analizando la expresión (5.35) se concluye que si la entrada contiene sinusoides puras
(y la señal de perturbación no) la función de transferencia puede ser estimada a través de la
ETFE con una precisión arbitraria en las frecuencias de las sinusoides, cuando el intervalo
de tiempo tiende a infinito.
Para entradas que no contienen sinusoides puras, la ETFE tiene un error para S
grandes que es igual a la razón VS()/US() entre el ruido y la señal para la frecuencia en
cuestión.
Además el hecho de que en la práctica se usan señales en tiempo discreto en vez de
señales en tiempo continuo introduce discrepancias adicionales entre la ETFE y la función
de transferencia real además del error que indica la expresión (5.35). Para periodos de
muestreo T pequeños en comparación con la dinámica del sistema, estas discrepancias
adicionales suelen ser pequeñas.
El análisis de Fourier tiene las siguientes propiedades básicas:
Es fácil y eficiente de usar (especialmente si se utiliza la FFT).
La ETFE es una estima bastante buena de la función de frecuencia G(j) si se
usan sinusoides puras como entradas. En caso contrario, la ETFE fluctúa
bastante, con lo que únicamente proporciona una aproximación bastante grosera
de la función real.
El comando etfe de la toolbox SIT de Matlab permite calcular la ETFE a partir de los
datos de entrada-salida de un sistema.
Ejemplo 5.4
En la Figura 5.5 se muestra el diagrama de Bode (en línea punteada) de la función de transferencia
G(i) real de un cierto sistema y la ETFE (en línea continua) construida a partir de datos de entrada-
salida del sistema. Se observa como la ETFE supone una estima bastante razonable de la función de
transferencia G(i) hasta aproximadamente =0.8 rad/s. Por encima de este valor oscila bastante y
no es una estima fiable.

TEMA 5: Identificación de modelos no paramétricos
5-16
10−2
10−1
100
101
10−2
100
Am
plitu
de
From u1 to y1
10−2
10−1
100
101
−1500
−1000
−500
0
Pha
se (
degr
ees)
Frequency (rad/s)
Figura 5.5. Función de transferencia real (línea punteada) de un cierto sistema y ETFE (línea
continua)
5.6 ANALISIS ESPECTRAL
5.6.1 Periodograma
Basándose en la definición del espectro de potencia o función de densidad espectral de
una señal u dada en la sección 2.5.4 una estima natural del mismo es la siguiente:
21 2· ·ˆ ( ) ·| ( ) | , , 1, 2,...,Nu N
kU k N
N N
(5.36)
donde
1
( ) ( )N
i kN
k
U u k e
(5.37)
A la estima )(ˆ N de la función de densidad espectral de una señal se le denomina
periodograma.
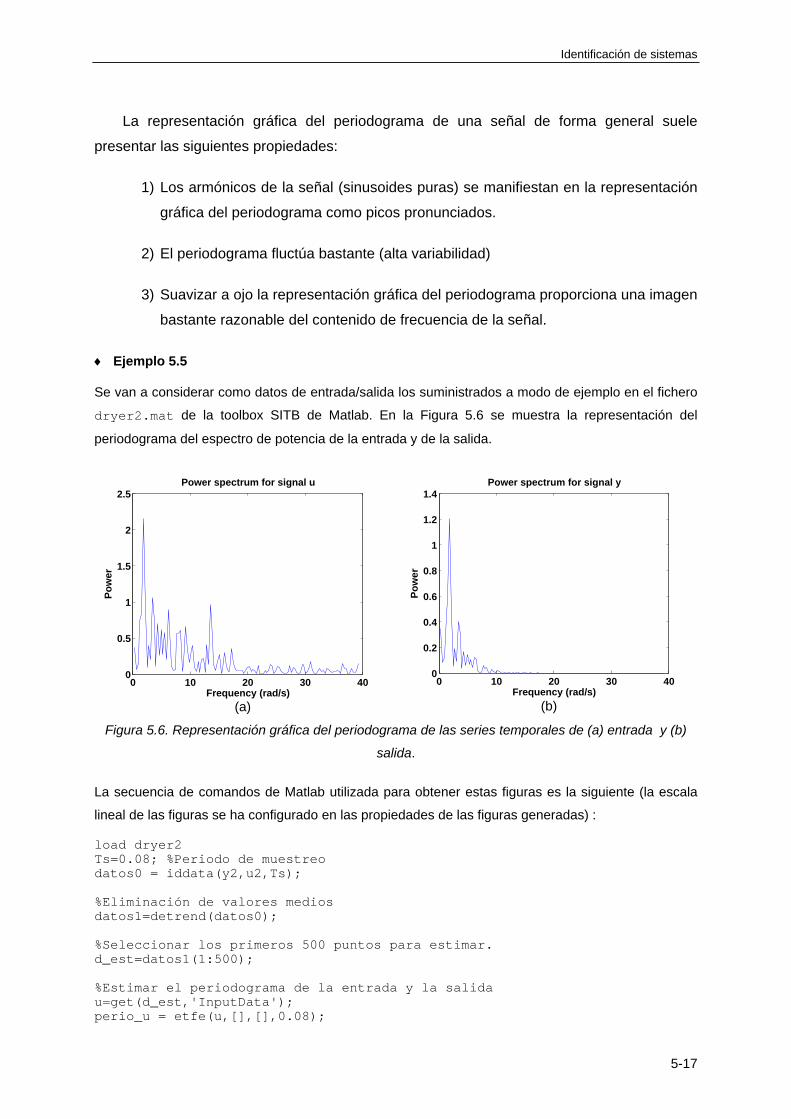
Identificación de sistemas
5-17
La representación gráfica del periodograma de una señal de forma general suele
presentar las siguientes propiedades:
1) Los armónicos de la señal (sinusoides puras) se manifiestan en la representación
gráfica del periodograma como picos pronunciados.
2) El periodograma fluctúa bastante (alta variabilidad)
3) Suavizar a ojo la representación gráfica del periodograma proporciona una imagen
bastante razonable del contenido de frecuencia de la señal.
Ejemplo 5.5
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SITB de Matlab. En la Figura 5.6 se muestra la representación del
periodograma del espectro de potencia de la entrada y de la salida.
0 10 20 30 400
0.5
1
1.5
2
2.5
Frequency (rad/s)
Po
wer
Power spectrum for signal u
(a)
0 10 20 30 400
0.2
0.4
0.6
0.8
1
1.2
1.4
Frequency (rad/s)
Po
wer
Power spectrum for signal y
(b)
Figura 5.6. Representación gráfica del periodograma de las series temporales de (a) entrada y (b)
salida.
La secuencia de comandos de Matlab utilizada para obtener estas figuras es la siguiente (la escala
lineal de las figuras se ha configurado en las propiedades de las figuras generadas) :
load dryer2 Ts=0.08; %Periodo de muestreo datos0 = iddata(y2,u2,Ts); %Eliminación de valores medios datos1=detrend(datos0); %Seleccionar los primeros 500 puntos para estimar. d_est=datos1(1:500); %Estimar el periodograma de la entrada y la salida u=get(d_est,'InputData'); perio_u = etfe(u,[],[],0.08);

TEMA 5: Identificación de modelos no paramétricos
5-18
y=get(d_est,'OutputData'); perio_y = etfe(y,[],[],0.08); figure(1) bode(perio_u) figure(2)
bode(perio_y)
Estas representaciones permiten visualizar las componentes de frecuencia existentes en la entrada y
la salida. Por lo que además de identificar los armónicos dominantes de la señales se puede saber si
existen perturbaciones de baja frecuencia o de alta frecuencia y en consecuencia si es necesario
filtrar las señales. También de estas representaciones es posible deducir el comportamiento del
sistema, es decir, si es pasa baja, pasa alta o pasa banda y si atenúa o amplifica la entrada.
Para este ejemplo de la representación gráfica del espectro de potencia estimado de las series
temporales de entrada y salida, se puede deducir que el sistema posee un comportamiento pasa baja
y que atenúa la entrada. Además como no aparecen en la salida componentes a frecuencias distintas
de las excitadas por la entrada eso indica también que no existen perturbaciones ni de baja ni de alta
frecuencia.
Otro aspecto importante a considerar a la hora de valorar la bondad de la estima de un
espectro es el de la resolución en frecuencia que proporciona. La resolución en frecuencia
de la estima de un espectro hace referencia a la capacidad para poder distinguir en el
espectro componentes de frecuencia de la señal muy cercanas entre si. Si existe una buena
resolución de frecuencia las componentes de frecuencia que están cerca pueden ser
separadas.
En el caso del periodograma obtenido para una señal de la que se dispone de N datos
la resolución de frecuencia es bastante buena y toma el valor 2/N (radianes/unidad de
tiempo). Este resultado se deduce del hecho de que la expresión (5.37) con que se
construye el periodograma proporciona la transforma de Fourier discreta a las frecuencias
=2h/N, h=1,...,N. Entre estas frecuencias la transformada de Fourier consiste de valores
interpolados trigonométricamente.
En resumen la principal ventaja del periodograma de una señal es que su resolución en
frecuencia es bastante buena. Por contra su principal inconveniente es su alto grado de
fluctuación o variabilidad.

Identificación de sistemas
5-19
En las siguientes secciones se examinan diferentes métodos para reducir la varianza de
la estima del espectro de potencia. El precio que se paga por esta reducción de la varianza
es un empeoramiento de la resolución de frecuencia.
5.6.2 Periodograma promedio: Método de Welch
Una forma clásica de reducir la varianza de una estima es utilizar el método de Welch
que consiste en tomar como estima el valor promedio de un determinado número de estimas
independientes. En este caso, la señal se divide en R segmentos de longitud M y se
construye el periodograma de cada uno de los R segmentos: ( ) ( )kN
, k=1,...,R.
La estima del espectro es el valor promedio de estos periodogramas:
1
1( ) ( )
R
N MkR
(5.38)
Seleccionando la longitud de los segmentos como una potencia de 2, el cálculo del
periodograma puede realizarse eficientemente usando la transformada rápida de Fourier.
Puesto que los R periodogramas están no correlacionados (si no existe solapamiento) la
varianza de la estima )(ˆ N se reduce en un factor R. Sin embargo, el precio a pagar por
esta reducción de la varianza es que se empeora la resolución de frecuencia en la estima,
que aumenta de 1/N (radianes/unidad de tiempo) (N es la longitud original de los datos) a
1/M=R/N (radianes/unidad de tiempo) (M=N/R es la longitud de los segmentos no
superpuestos). El acuerdo entre la varianza y la resolución de frecuencia está por lo tanto
determinado por el número de segmentos R que se consideren. A mayor número R de
segmentos menor varianza pero peor resolución.
5.6.3 Suavizado del periodograma: El método de Blackman - Tukey
5.6.3.1 Descripción del procedimiento
Otro procedimiento para suavizar un periodograma es promediando sobre un cierto
número de frecuencias vecinas:
( ) ( )· ( )N M NW d
(5.39)

TEMA 5: Identificación de modelos no paramétricos
5-20
En la expresión anterior )(MW es una función denominada función ventana o ventana
frecuencial que sirve para enfatizar las componentes de frecuencia más importantes y
despreciar las menos relevantes. De esta forma se logra suavizar la forma del espectro de
potencia que proporciona el periodograma que recordemos tiene un alto grado de
variabilidad.
La función de ventana cumple la siguiente propiedad
1·)(
dWM (5.40)
Normalmente )(MW suele estar centrada entorno a =0. El parámetro M, a veces
denominado como parámetro de truncación, describe la anchura de la ventana de
frecuencia, ya que M es inversamente proporcional a la anchura de la ventana.
Por ejemplo, una ventana rectangular de anchura 1/M viene descrita por la siguiente
función
Msi
MsiM
WM
2
1||0
2
1||
)(
(5.41)
1. Elegir la ventana temporal wM().
2. Elegir el tamaño de ventana M.
3. Calcular la estima de la covarianza de la señal para =0,...,M.
N
t
Nu tutu
NR
1
)()·(1
)(ˆ
4. Calcular la estima de Blackman-Tukey
ˆ( ) ( ) ( )·M
N iN M u
M
w R e
Cuadro 5.2: Pasos para construir la estima de Blackman-Tukey del espectro de potencia de una señal

Identificación de sistemas
5-21
La anchura de la ventana se corresponde con la resolución en frecuencia de la estima
suavizada ( )N
. Normalmente, se utilizan otros tipos de ventanas distintas de la
rectangular con lo que es posible dar más peso a los valores centrales de frecuencia.
Se puede demostrar [Ljung y Glad, 1994] que la expresión (5.39) puede ser escrita
equivalentemente de la siguiente forma:
ˆ( ) ( ) ( )·M
N iN M u
M
w R e
(5.42)
En la expresión anterior wM() es la función ventana expresada en el dominio del tiempo.
A esta función también se le denomina como ventana temporal o ventana de retardo (lag
window).
( ) ( )· iM Mw W e d
(5.43)
Mientras que )(ˆ NuR es la estima de la función de covarianza de la entrada:
N
t
Nu tutu
NR
1
)()·(1
)(ˆ (5.44)
A la estima del espectro de potencia dada por la ecuación (5.42) se le conoce como
estima de Blackman-Tukey. En el Cuadro 5.2 se resume el procedimiento para poder
obtener la estima de Blackman-Tukey.
En las expresiones anteriores se supone que wM() ha sido elegida para ser cero si
||>M. Esto implica que existen requerimientos especiales a la hora de escoger la ventana
WM() (una ventana rectangular no sería válida). Además en (5.44) se ha supuesto que
u(t)=0 cuando t se encuentra fuera del intervalo [1,N].
5.6.3.2 Elección de la función de ventana
El par de transformadas de Fourier wM() WM() determina las propiedades de la
estima de Blackman-Tukey del espectro de potencia de una señal. Para una anchura M
dada de la ventana temporal wM() es deseable tener una función de frecuencia WM/) tan
alta y estrecha como sea posible. No existe una solución óptima para este problema. Una
ventana muy utilizada es la conocida como ventana de Hamming (ver Figura 5.10) que tiene
la siguiente expresión:

TEMA 5: Identificación de modelos no paramétricos
5-22
M
MMwM
0
·cos1·
2
1)( (5.45)
Su transformada de Fourier es:
)()(
4
1)(
2
1)(
MD
MDDW MMMM
(5.46)
donde
)2/sin(
)·2
1(sin
)(
M
DM
La anchura efectiva de la ventana frecuencial A(M) (ver Figura 5.7) que da la resolución
de frecuencia puede ser calculada a través de la siguiente expresión:
2/1
2 ·)(·)(
dWMMA M (5.47)
En el caso de la ventana de Hamming se obtiene que
MMA
·
2
1)( (5.48)
Se observa que es inversamente proporcional a la anchura M de la ventana temporal.
Puede demostrarse [Ljung y Glad, 1994] que la resolución de frecuencia de la estima
del espectro de frecuencia de Blackman-Tukey es aproximadamente igual a
2M
(5.49)
Además la varianza de la estima del espectro de frecuencia de Blackman-Tukey es
aproximadamente igual a
2))(·(·2 uN
M (5.50)
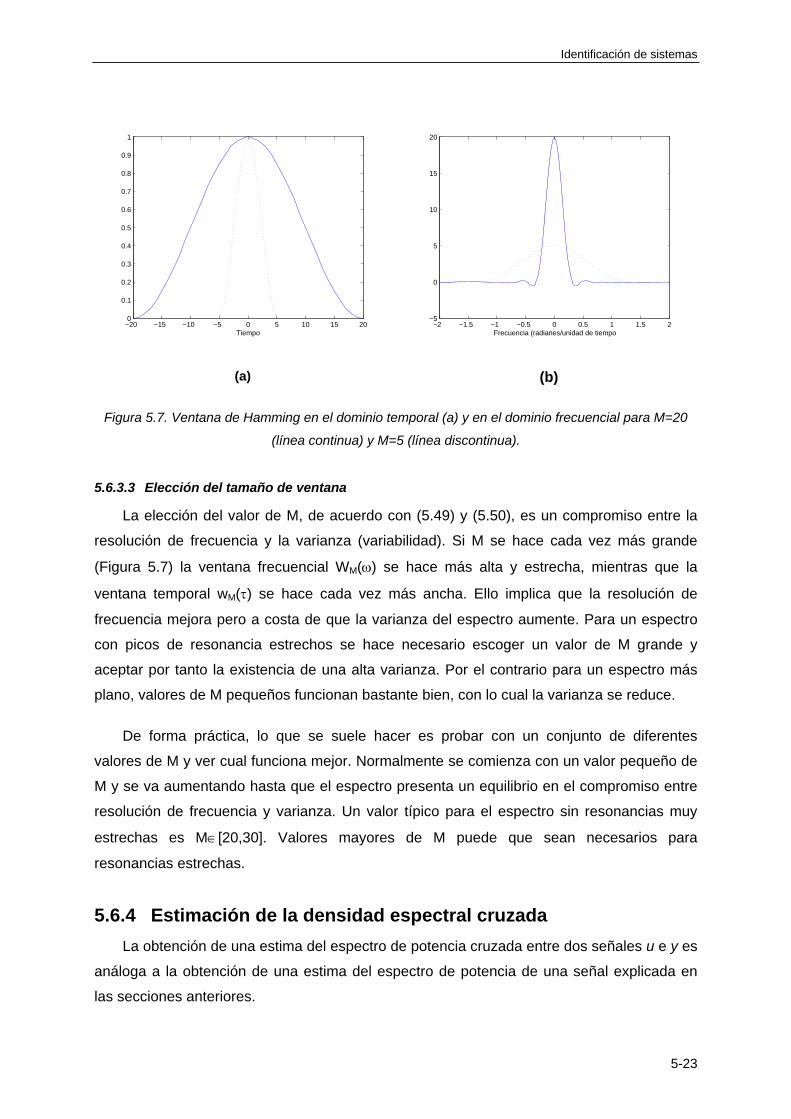
Identificación de sistemas
5-23
−20 −15 −10 −5 0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Tiempo
(a)
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2−5
0
5
10
15
20
Frecuencia (radianes/unidad de tiempo
(b)
Figura 5.7. Ventana de Hamming en el dominio temporal (a) y en el dominio frecuencial para M=20
(línea continua) y M=5 (línea discontinua).
5.6.3.3 Elección del tamaño de ventana
La elección del valor de M, de acuerdo con (5.49) y (5.50), es un compromiso entre la
resolución de frecuencia y la varianza (variabilidad). Si M se hace cada vez más grande
(Figura 5.7) la ventana frecuencial WM() se hace más alta y estrecha, mientras que la
ventana temporal wM() se hace cada vez más ancha. Ello implica que la resolución de
frecuencia mejora pero a costa de que la varianza del espectro aumente. Para un espectro
con picos de resonancia estrechos se hace necesario escoger un valor de M grande y
aceptar por tanto la existencia de una alta varianza. Por el contrario para un espectro más
plano, valores de M pequeños funcionan bastante bien, con lo cual la varianza se reduce.
De forma práctica, lo que se suele hacer es probar con un conjunto de diferentes
valores de M y ver cual funciona mejor. Normalmente se comienza con un valor pequeño de
M y se va aumentando hasta que el espectro presenta un equilibrio en el compromiso entre
resolución de frecuencia y varianza. Un valor típico para el espectro sin resonancias muy
estrechas es M[20,30]. Valores mayores de M puede que sean necesarios para
resonancias estrechas.
5.6.4 Estimación de la densidad espectral cruzada
La obtención de una estima del espectro de potencia cruzada entre dos señales u e y es
análoga a la obtención de una estima del espectro de potencia de una señal explicada en
las secciones anteriores.

TEMA 5: Identificación de modelos no paramétricos
5-24
A partir de los valores muestreados y(k) e u(k) k=1,...,N la función de covarianza
cruzada se estima a través de la siguiente expresión:
N
t
Nyu tuty
NR
1
)()·(1
)(ˆ (5.51)
Y el espectro de potencia cruzada se estima mediante la siguiente expresión:
M
M
iNyuM
Nyu eRw
)·(ˆ)()(ˆ (5.52)
La función de ventana wM() es la misma que la utilizada en la expresión (5.42) y las
mismas consideraciones sobre como elegirla realizadas en la sección anterior son
aplicables en este caso.
5.6.5 Estima de la función de frecuencia usando análisis espectral
Considérese el sistema dado por la siguiente expresión:
)()()·()( tvtuqGty (5.53)
donde y(t) es la salida, u(t) la entrada y v(t) la perturbación.
Si la entrada u(t) es independiente de la perturbación v(t), entonces el espectro de
potencia la salida es
)()(·)()(2
vu
iy eG (5.54)
Y el espectro de potencia cruzada entre la entrada y la salida es:
)()·()( u
iyu eG (5.55)
A partir de las estimas de los espectros (5.42) y (5.52) es posible obtener una estima de
la función de frecuencia G(ejT) del sistema:
)(ˆ)(ˆ
)(ˆ
Nu
NyuTj
N eG
(5.56)
Además también es posible obtener una estima del espectro de la perturbación v():

Identificación de sistemas
5-25
1. Elegir la ventana temporal wM().
2. Elegir el tamaño de ventana M.
3. Calcular )(ˆ)(ˆ),(ˆ Nyu
Nu
Ny RyRR para |k|M.
N
t
Nu tutu
NR
1
)()·(1
)(ˆ
N
t
Nyu tuty
NR
1
)()·(1
)(ˆ
N
t
Nv tvtv
NR
1
)()·(1
)(ˆ
4. Calcular la estima del espectro de u e y, así como la estima del espectro cruzado entre
y e u:
ˆ( ) ( ) ( )·M
N N ju M u
M
w R e
M
M
iNyM
Ny eRw
)·(ˆ)()(ˆ
ˆ( ) ( ) ( )·M
N N iyu M yu
M
w R e
5. Obtener la estima de la función de frecuencia y del espectro de la perturbación
)(ˆ)(ˆ
)(ˆ
Nu
NyuTi
N eG
)(
)()()(
2
Nu
NyuN
yNv
Cuadro 5.3. Obtención de una estima de la función de frecuencia y del espectro de la perturbación
mediante análisis espectral.

TEMA 5: Identificación de modelos no paramétricos
5-26
)(
)()()(
2
Nu
NyuN
yNv
(5.57)
A este procedimiento de cálculo de las estimas de la función de la frecuencia y del
espectro se le conoce como análisis espectral y se resume en el Cuadro 5.3. La función spa
(spectral analysis) de la toolbox SIT de Matlab implementa el análisis espectral del Cuadro
5.3.
La función de frecuencia estimada a partir de datos muestreados GT(ejT) no difiere
mucho de la función de frecuencia estimada continua G(j) en la región de frecuencias de
interés. Además la experiencia muestra que la estima de G(j) es poco fiable a altas
frecuencias.
Ejemplo 5.6:
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SITB de Matlab. En la Figura 5.8 se muestra la representación de la
estima de la función de la frecuencia y de la estima del espectro del ruido, considerando un valor de
M=30. La secuencia de comandos de Matlab utilizada para obtener estas figuras es la siguiente:
load dryer2 Ts=0.08; %Periodo de muestreo datos0 = iddata(y2,u2,Ts); %Eliminación de valores medios datos1=detrend(datos0); %Seleccionar los primeros 500 puntos para estimar. d_est=datos1(1:500); %Estima mediante análisis espectral de la función de frecuencia %y del espectro del ruido [Gspa,phiVspa]=spa(d_est); figure(1) bode(Gspa) figure(2) bode(phiVspa)
En la representación de la estima de la respuesta de la frecuencia se observa que el sistema
presenta un comportamiento de filtro pasa-baja. También se deduce que el sistema presenta un
comportamiento atenuador ya que la magnitud se encuentra por debajo de la línea de 0 dB. Además
se observa que aumenta el desfase conforme aumenta la frecuencia.
En la representación del espectro del ruido se observa que a bajas frecuencias presenta una
magnitud constante y que a partir de 0.2 rad/s comienza a disminuir. Por lo que en dicho rango podría
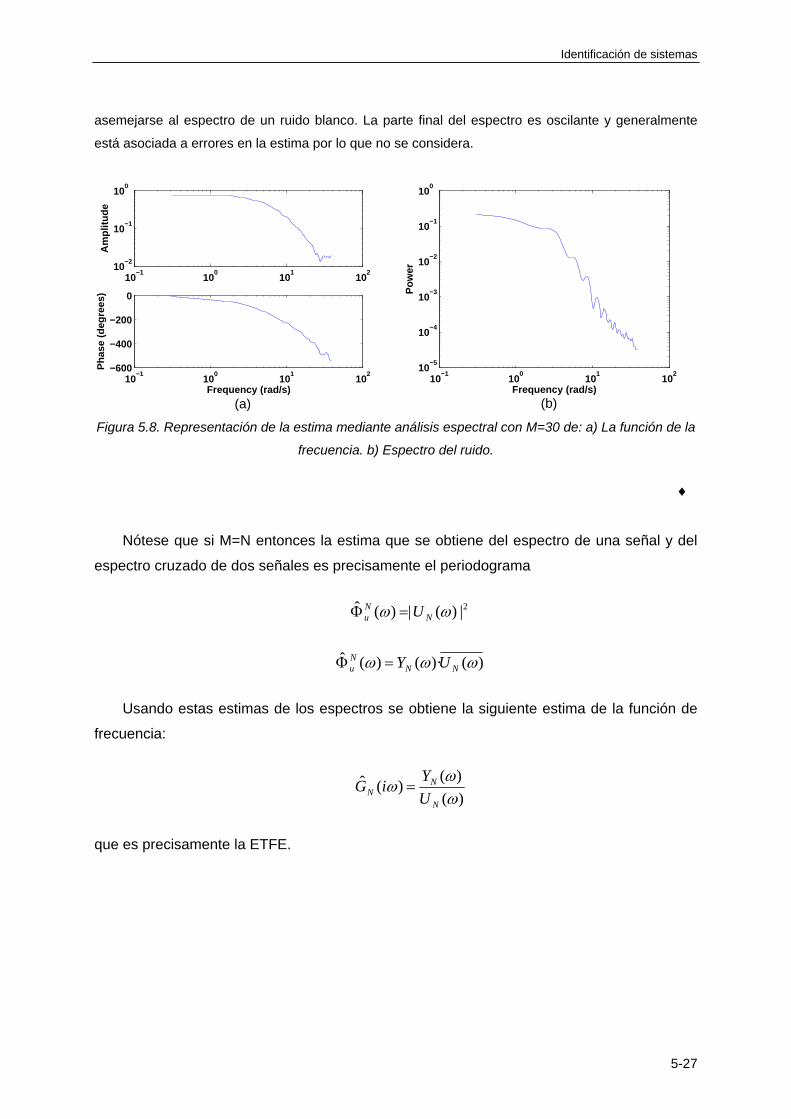
Identificación de sistemas
5-27
asemejarse al espectro de un ruido blanco. La parte final del espectro es oscilante y generalmente
está asociada a errores en la estima por lo que no se considera.
10−1
100
101
102
10−2
10−1
100
Am
plit
ud
e
10−1
100
101
102
−600
−400
−200
0
Ph
ase
(deg
rees
)
Frequency (rad/s)
(a)
10−1
100
101
102
10−5
10−4
10−3
10−2
10−1
100
Frequency (rad/s)
Po
wer
(b)
Figura 5.8. Representación de la estima mediante análisis espectral con M=30 de: a) La función de la
frecuencia. b) Espectro del ruido.
Nótese que si M=N entonces la estima que se obtiene del espectro de una señal y del
espectro cruzado de dos señales es precisamente el periodograma
2|)(|)(ˆ NNu U
)()·()(ˆ NNNu UY
Usando estas estimas de los espectros se obtiene la siguiente estima de la función de
frecuencia:
)(
)()(ˆ
N
NN U
YiG
que es precisamente la ETFE.

TEMA 5: Identificación de modelos no paramétricos
5-28
5.6.6 Resumen de las características básicas del análisis espectral
Las características básicas del análisis espectral que han ido apareciendo en las
secciones anteriores se pueden resumir en los siguientes puntos:
El análisis espectral es un método muy común para obtener estimas del espectro
de señales, del espectro cruzado entre señales y de la función de frecuencia
Tras realizar un ajuste adecuado del tamaño M de la ventana, es usualmente
posible obtener una buena representación gráfica de las propiedades
frecuenciales del sistema y de sus señales. Proporciona como resultado básico un
modelo no paramétrico en forma de tabla o de gráfica de N puntos de magnitud y
fase de la función de frecuencia G(j) o del espectro de la perturbación. Como el
resto de modelos no paramétricos no pueden usarse de forma directa para
simulación.
Es un método general, cuya única hipótesis de partida es que el sistema es lineal,
y no requiere de señales de entrada específicas.
El análisis espectral no se puede aplicar a sistema que operan en lazo cerrado. El
motivo es que la suposición de que la entrada u y la perturbación v no estén
correlacionadas no se cumple en dicho caso.
BIBLIOGRAFÍA
[Jenkins and Watts, 1968] G. M. Jenkins y D. G. Watts. Spectral Analysis and Its
Applications. Holden-Day. 1968.
[Ljung y Glad, 1994] L. Ljung y T. Glad. Modelling of dynamic systems. Prentice
Hall. 1994.
[Ljung, 1999] L. Ljung. System Identification: Theory for the user. 2nd
Edition. Prentice Hall.1999.
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.

TEMA 6
IDENTIFICACIÓN DE MODELOS PARAMÉTRICOS DISCRETOS
6-1
6.1 INTRODUCCIÓN
En el tema anterior se estudió la identificación de modelos no paramétricos. Aunque
estos modelos proporcionan información relevante del sistema, al ser tablas o gráficas no
pueden usarse para simular, controlar o predecir el comportamiento de un sistema. Para
poder lograr estos objetivos se hace necesario disponer de un modelo matemático del
sistema, el cual queda definido mediante un conjunto de parámetros.
De hecho el objetivo final de la metodología de identificación de sistemas es estimar un
modelo paramétrico que describa lo mejor posible al sistema de acuerdo con el uso final al
que se vaya a destinar el modelo, ya sea simulación, control o predicción del sistema.
Este tema está dedicado a explicar la estimación de modelos paramétricos en tiempo
discreto. Se deja para el próximo tema la explicación del caso de tiempo continuo. En primer
lugar se define la clase de modelos que se van a considerar, que típicamente son modelos
basados en la minimización del error de predicción o más abreviadamente denominados
modelos PEM (Prediction error model). En segundo lugar se explica cómo se estiman los
parámetros de un modelo PEM. A continuación se explican las principales propiedades del
modelo estimado: el error de sesgo y el error de varianza. Posteriormente se realizan
algunas consideraciones sobre la elección del tipo y la estructura del modelo. Finalmente se
explican las técnicas que se utilizan para validar el modelo estimado y se incluyen algunas
directrices para obtener el modelo PEM más apropiado.

TEMA 6: Identificación de modelos paramétricos discretos
6-2
6.2 MODELOS PARAMÉTRICOS BASADOS EN EL ERROR DE
PREDICCIÓN
6.2.1 Definición
Considérese un sistema lineal invariante en el tiempo descrito por la siguiente ecuación
en diferencias (ver Figura 6.1):
)()()·()( 0 tvtuqGty (6.1)
G0(q) es la función de transferencia de la planta, u(t) es la entrada, v(t) es la
perturbación e y(t) es la salida. Además q es el operador retardo q-1·u(t)=u(t-1) De forma
general la entrada puede ser una señal aleatoria o determinista. Por su parte la perturbación
será una señal aleatoria autocorrelacionada. En consecuencia la señal de salida también
será una señal aleatoria autocorrelacionada.
G0(q)u(t)
v(t)
y(t)+
H0(q)
a(t)
Figura 6.1. Sistema lineal a identificar
De acuerdo con el teorema de factorización espectral (ver sección 2.7) la perturbación
v(t) se puede considerar la salida de un filtro H0(q) que es excitado por una señal de ruido
blanco a(t):
)()·()( 0 taqHtv (6.2)
Luego la ecuación del sistema se puede expresar de la siguiente forma:
)()·()()·()( 00 taqHtuqGty (6.3)
Se desea identificar un modelo lineal que se aproxime lo mejor posible al sistema real.
La ecuación del modelo a identificar se puede escribir de la siguiente forma:

Identificación de sistemas
6-3
)()·()()·()( teqHtuqGty (6.4)
La variable e(t) es el error de predicción a un paso:
)1|(ˆ)()( ttytyte (6.5)
En la ecuación anterior y(t) es la salida real medida en el instante t e )1|(ˆ tty es la
salida estimada en el instante t usando el modelo y los datos disponibles de la salida en el
intervalo [0, t-1]. A )1|(ˆ tty se le denomina predictor a un paso de y o salida predicha a un
paso. La variable e(t) representa la parte de la salida y(t) que no puede ser predicha a partir
de los datos pasados. Se trata de ruido blanco que es independiente de todos los datos
anteriores. Despejando e(t) de (6.4) se obtiene la ecuación del error
)]()·()()·[()( 1 tuqGtyqHte (6.6)
Igualando con (6.5) y despejando )1|(ˆ tty se obtiene la siguiente expresión para el
predictor a un paso de la salida:
)())·(1()()·()·()1|(ˆ 11 tyqHtuqGqHtty (6.7)
Si no se considera un modelo del ruido ( ( ) 1H q ), el error de predicción se reduce al
error de la salida o residuo:
)()·()()(~)()( tuqGtytvtete resid (6.8)
Al modelo dado por (6.4) se le denomina modelo basado en el error de predicción o
modelo PEM (Prediction-Error Model). Las funciones G(q) y H(q) son funciones racionales
que quedan especificadas por los coeficientes de su numerador y denominador. En
consecuencia un modelo PEM es un modelo paramétrico ya que queda definido mediante
un número finito de parámetros: los coeficientes del numerador y del denominador.
Un modelo PEM se puede expresar de forma general mediante la siguiente ecuación:
)(·)()·(
)()(·
)()·(
)()( te
qDqA
qCnktu
qFqA
qBty (6.9)

TEMA 6: Identificación de modelos paramétricos discretos
6-4
El parámetro nk es el número de muestras que transcurren desde que se introduce una
entrada en el sistema hasta que genera una salida, es decir, representa el retardo del
sistema.
Igualando con (6.4) se deduce que:
)()·(
)()(·
)()·(
)()(
qDqA
qCqHq
qFqA
qBqG nk (6.10)
También se puede expresar en la forma:
)(·)(
)()(·
)(
)()()·( te
qD
qCnktu
qF
qBtyqA (6.11)
En las expresiones anteriores A(q), B(q), C(q), D(q) y F(q) son polinomios:
11
1 11 2
11
11
11
( ) 1 · ... ·
( ) · ... ·
( ) 1 · ... ·
( ) 1 · ... ·
( ) 1 · ... ·
nana
nbnb
ncnc
ndnd
nfnf
A q a q a q
B q b b q b q
C q c q c q
D q d q d q
F q f q f q
(6.12)
La estructura de un modelo PEM queda definida por los valores de los ordenes de sus
polinomios, es decir (na,nb,nc,nd,nf) y del retardo nk.
6.2.2 Tipos de modelos PEM
El tipo de modelo PEM queda establecido por el número de polinomios distintos a la
unidad. Se distinguen en consecuencia 32 posibles tipos de modelos PEM. Entre los
modelos PEM más utilizados se encuentran los siguientes (ver Tabla 6.1):
Modelo ARX. Se define mediante la siguiente ecuación en diferencias
)()()()()( tenktuqBtyqA (6.13)
con
1121
11
·...·)(
·...·1)(
nb
nb
nana
qbqbbqB
qaqaqA (6.14)

Identificación de sistemas
6-5
El nombre ARX (AutoRegressive with eXternal input) que se le da a este tipo de
modelo es porque A(q)·y(t) es una autoregresión. Mientras que B(q)·u(t-nk)
representa la contribución de la entrada externa. El problema de estimación de los
coeficientes de los polinomios A(q) y B(q) requiere resolver un problema de
regresión lineal.
La estructura de un modelo ARX queda definida por la tripleta de números
(na,nb,nk). Si se consideran valores muy altos para na y nb las estimas de los
coeficientes son más consistentes (ver sección 6.4.3) pero puede producir
problemas de varianza en presencia de una perturbación significativa. Por el
contrario si se consideran valores muy pequeños para na y nb las estimas son
problemáticas si existe una perturbación significativa o cuando la estructura del
modelo es incorrecta.
Señalar que un modelo ARX utiliza un modelo para el ruido de la forma:
1( )
( )H q
A q
En consecuencia el espectro del error de predicción filtrado (ver sección 6.4.3)
tendrá en su término asociado a la potencia de la señal de entrada el factor
2( )iA e en el numerador, lo que le confiere típicamente un claro comportamiento
de tipo pasa-alta. Esto implica que el modelo ARX se ajusta con un énfasis en el
comportamiento de alta frecuencia presente en los datos de entrada-salida, lo cual
no es deseable en general. Para evitarlo se recomienda prefiltrar los datos con un
filtro pasa-baja o pasa-banda (ver sección 4.5.1.3).
Modelo FIR (Finite Impulse Response). Se define mediante la siguiente ecuación
en diferencias
)()()()( tenktuqBty (6.15)
con
1121 ·...·)( nb
nb qbqbbqB (6.16)

TEMA 6: Identificación de modelos paramétricos discretos
6-6
Un modelo FIR se obtiene de un modelo ARX haciendo A(q)=1. El problema de
estimación de los coeficientes del polinomio B(q) requiere resolver un problema de
regresión lineal.
La estructura de un modelo FIR queda definido por la dupla (nb,nk). En general nb
suele ser grande: igual o superior a 20. El número de parámetros necesarios es
función del tiempo de asentamiento y de la constante de tiempo dominante.
Un modelo FIR es otra forma adicional de obtener la respuesta a un impulso de un
sistema. Recuérdese que la otra forma de estimar la respuesta a un impulso es
mediante análisis de correlación.
De acuerdo con (6.10) cuando se obtiene un modelo FIR no se estima un modelo
autocorrelacionado del ruido ya que 1)( qH .
Modelo ARMAX. Se define mediante la siguiente ecuación en diferencias
)()·()()()()( teqCnktuqBtyqA (6.17)
con
ncnc
nbnb
nana
qcqcqC
qbqbbqB
qaqaqA
·...·1)(
·...·)(
·...·1)(
11
1121
11
(6.18)
El nombre ARMAX (AutoRegressive Moving Average with eXtra Input) que se le
da a este tipo de modelo es por que A(q)·y(t) es una autoregresión (AR), C(q)·e(t)
es un ruido blanco de media móvil (MA) y B(q)·u(t-nk) representa la contribución
de la entrada externa. El problema de estimación de los coeficientes de los
polinomios A(q), B(q) y C(q) requiere resolver un problema de regresión no lineal.
La estructura de un modelo ARMAX queda definida por (na,nb,nc,nk).
Normalmente se escogen valores bajos de na, nb y nc. La presencia de un
polinomio autoregresivo (A(q)) puede conducir a problemas de sesgo (ver sección
6.4) en presencia de ruido significativo y/o a desajuste con la estructura del
modelo. Sin embargo el polinomio de media móvil (C(q)) a veces contrarresta
estos efectos.

Identificación de sistemas
6-7
Modelo OE (Output-Error). Se define mediante la siguiente ecuación en
diferencias
)()()(
)()( tenktu
qF
qBty (6.19)
con
nfnf
nbnb
qfqfqF
qbqbbqB
·...·1)(
·...·)(1
1
1121
(6.20)
El nombre OE (Output-Error) deriva del hecho de que la fuente del ruido del
modelo e(t) coincide con la perturbación v(t), luego será la diferencia (error) entre
la salida actual y la salida libre de ruido. El problema de estimación de los
coeficientes de los polinomios B(q) y F(q) requiere resolver un problema de
regresión no lineal.
La estructura de un modelo OE queda definida por (nb,nf,nk). Normalmente se
escogen valores bajos de nb y nf.
De acuerdo con (6.10) cuando se obtiene un modelo OE no se estima un modelo
autocorrelacionado del ruido ya que ( ) 1H z .
Modelo BJ (Box-Jenkins). Se define mediante la siguiente ecuación en diferencias
)()(
)()(
)(
)()( te
qD
qCnktu
qF
qBty (6.21)
con
nfnf
ndnd
ncnc
nbnb
qfqfqF
qdqdqD
qcqcqC
qbqbbqB
·...·1)(
·...·1)(
·...·1)(
·...·)(
11
11
11
1121
(6.22)
El problema de estimación de los coeficientes de los polinomios B(q), C(q), D(q) y
F(q) requiere resolver un problema de regresión no lineal. La estructura de un
modelo BJ queda definida por (nb,nc,nd,nf,nk). Normalmente se escogen valores
bajos de nb, nc, nd y nf.
TEMA 6: Identificación de modelos paramétricos discretos
6-8
Un modelo BJ proporciona funciones de transferencia independientes para la
parte determinista y la estocástica del modelo. Los modelos BJ son difíciles de
estimar ya que requieren de muchas iteraciones (computacionalmente costoso) y
de una mayor toma de decisiones por parte del diseñador.
Tipo modelo PEM Polinomios unidad )(zG )(zH
ARX C=1, D=1, F=1 nkz
zA
zB ·)(
)(
)(
1
zA
ARMAX D=1, F=1 nkz
zA
zB ·)(
)(
)(
)(
zA
zC
FIR A=1, C=1, D=1, F=1 nkzzB )·( 1
Box-Jenkins A=1 nkz
zF
zB ·)(
)(
)(
)(
zD
zC
Output Error A=1, C=1, D=1 nkz
zF
zB ·)(
)(
1
Tabla 6.1. Tipos de modelos PEM más utilizados
Supóngase que se dispone de un conjunto de N muestras de la entrada u(t) y la salida
y(t) t=1,...,N de un sistema real el problema que se desea resolver es el de obtener el
modelo PEM que mejor represente al sistema real. Es decir, que la salida que genere el
modelo sea lo más parecida posible a la salida real del sistema medida experimentalmente.
Obtener el mejor modelo PEM implica seleccionar un tipo de modelo, fijar una estructura
y estimar los coeficientes de los polinomios que definen el modelo.
6.3 ESTIMACIÓN DE LOS PARÁMETROS DE UN MODELO PEM
6.3.1 Planteamiento general del problema
Seleccionado el tipo y la estructura [na,nb,nc,nd,nf,nk] de un modelo PEM, la estimación
de los coeficientes de los polinomios de dicho modelo se realiza resolviendo un problema de
regresión lineal o no lineal.
Para un modelo general PEM la ecuación del error de predicción a un paso se puede
expresar de la siguiente forma:
)()]·()·()()[()()·()·()|(ˆ)()·( tyqAqDqCqFnktuqBqDtyqFqC (6.23)

Identificación de sistemas
6-9
La expresión anterior puede ser escrita equivalentemente en la forma de una regresión
“pseudolineal”:
)|()|(ˆ tty T (6.24)
donde
Td
cf
bkka
ntvtv
ntetentwtw
nntuntuntytyt
)]|(),...,|1(
)|(),...,|1(),|(),...,|1(
),1(),...,(),(),...,1([)|(
(6.25)
Tndncnfnbna ddccffbbaa ],....,,,....,,,....,,,....,,,...,[ 11111 (6.26)
Al vector columna se le denomina vector de parámetros ya que contiene los
parámetros del modelo que hay que estimar. Nótese que la dimensión del vector de
parámetros coincide con el número de parámetros que definen al modelo, también
denominado como orden del modelo. Salvo que se indique lo contrario se va denotar con la
letra d al número de parámetros de que consta un modelo:
d na nb nf nc nd
Nótese que cuanto mayor sea el valor de d, mayor será la complejidad del modelo.
Por su parte al vector columna )|( t se le denomina vector de regresión ya que
contiene los valores pasados de las salidas y las entradas medidas del sistema. Además
contiene los valores anteriores de las variables auxiliares w, v y e que dependen tanto de los
parámetros del modelo como de los datos (de ahí proviene el término de “pseudolineal”):
)(·)(
)()|( tu
qF
qBtw (6.27)
)|()()·()|( twtyqAtv (6.28)
)|(·)(
)()|(ˆ)()|( tv
qC
qDtytyte (6.29)
Para determinar se puede usar la siguiente función de coste o función objetivo

TEMA 6: Identificación de modelos paramétricos discretos
6-10
N
t
TN
tN ty
Nte
NV
1
2
1
2 )]|([1
)|(1
)( (6.30)
El objetivo o criterio de identificación es encontrar aquel vector de parámetros N que
minimice la función de coste:
NN Vminargˆ (6.31)
Nótese que la función de coste es la suma de los cuadrados de los errores. Por ello a la
estima N se le denomina estima de mínimos cuadrados. Este procedimiento de estimación
fue propuesto por Gauss en el siglo XVIII. Se trata en consecuencia de un problema de
optimización que puede ser resuelto usando algún método de búsqueda.
Aunque no van a ser tratados en estos apuntes, conviene saber que aparte de los
métodos de mínimos cuadrados existen otros métodos para estimar los parámetros del
modelo basándose en el error de predicción como el método de la variable instrumental y el
método de máxima verosimilitud. Asimismo existen otros métodos de estimación con una
filosofía diferente como los métodos basados en subespacios.
6.3.2 Cálculo de la estima cuando el modelo PEM se puede expresar como una regresión lineal
En el caso de un modelo PEM tipo ARX o FIR se puede demostrar que la estima de sus
parámetros se reduce a un problema de regresión lineal por lo que se puede obtener una
expresión analítica a través de la cual obtener la estima de mínimos cuadrados .
Desarrollando (6.30) la función de coste se puede escribir de la siguiente forma:
N
t
TTN
t
TN
tN tt
Ntyt
Nty
NV
111
2 )()(1
)()(21
)(1
)( (6.32)
O equivalentemente como
NT
NT
N
tN Rfty
NV
2)(1
)(1
2 (6.33)
Donde

Identificación de sistemas
6-11
N
tN tyt
Nf
1
)()(1 (6.34)
N
t
TN tt
NR
1
)()(1 (6.35)
Nótese que fN es un vector columna de dimensión d x 1 y RN es una matriz cuadrada de
dimensión d x d que se denomina matriz de covarianza de las estimas.
Si la matriz RN es invertible entonces la función de coste se puede escribir de la
siguiente forma:
)·()·(··)(1
)( 111
1
2NNN
TNNNN
TN
N
tN fRRfRfRfty
NV
(6.36)
El último término de la ecuación anterior es siempre cero ya que la matriz RN es
semidefinida positiva. El valor mínimo de VN() se obtiene cuando este término es cero, es
decir, cuando
NNN fR ·ˆ 1 (6.37)
Por lo tanto la estima de mínimos cuadrados N se calcula entonces mediante la
siguiente expresión:
N
t
N
t
TNNN tyt
Ntt
NfR
1
1
1
1 )()(1
)()·(1
·ˆ (6.38)
En la práctica para evitar problemas numéricos que pueden encontrarse al invertir una
matriz la estima N se calcula resolviendo el sistema de ecuaciones lineales dado por la
ecuación:
NNN fR · (6.39)
Ejemplo 6.1:
Considérese un modelo ARX:
)()()()()( tenktuqBtyqA

TEMA 6: Identificación de modelos paramétricos discretos
6-12
El predictor a un paso de la salida que proporciona este modelo es
)1(·...)(·)(·...)1(·)1|( 11 nbnktubnktubnatyatyatty nbna
Dicho predictor puede ser expresado en la forma de una regresión lineal
)·()1|(ˆ ttty T
Donde el vector de regresión y el vector de parámetros tienen la siguiente expresión:
Tbkka nntuntuntyty )]1(),...,(),(),...,1([
Tnbna bbaa ],....,,,...,[ 11
Para determinar se usa la siguiente función de coste o función objetivo
N
t
TN
tN ty
Nte
NV
1
2
1
2 )]|([1
)|(1
)( (6.40)
El objetivo es encontrar aquel vector de parámetros N que minimice la función de coste. Puesto que
se trata de una regresión lineal la estima de mínimos cuadrados se puede obtener de forma directa
resolviendo el siguiente sistema de ecuaciones
NNN fR ·
donde
N
tN tyt
Nf
1
)()(1
N
t
TN tt
NR
1
)()(1
Nótese que los elementos del vector fN y de la matriz RN para un modelo ARX son sumas de la forma:
N
t
N
t
N
t
ktujtuN
ktyjtyN
ktujtyN 111
)()(1
)()(1
)()(1
Luego la estima N es construida usando las estimas de las funciones de covarianza de la entrada y
la salida.
Por ejemplo supóngase el siguiente modelo ARX
)()1()1()( tetbutayty (e5)

Identificación de sistemas
6-13
En este caso:
b
aθ,
)1(
)1()(
tu
tyt
y
N
t
N
tN
tN
tutyN
tytyNtyt
Nf
1
1
1 )1()·(1
)1()·(1
)()(1
N
t
N
t
N
t
N
tN
t
TN
tuN
tutyN
tutyN
tyNtt
NR
1
2
1
11
2
1 )1(1
)1()·1(1
)1()·1(1
)1(1
)()(1
Luego el sistema de ecuaciones a resolver para encontrar la estima de mínimos cuadrados es
N
t
N
tN
t
N
t
N
t
N
t
tutyN
tytyN
b
a
tuN
tutyN
tutyN
tyN
1
1
1
2
1
11
2
)1()·(1
)1()·(1
)1(1
)1()·1(1
)1()·1(1
)1(1
Resolviendo se obtiene
2
11
2
1
2
1111
2
)1()·1()1(·)1(
)1()·(·)1()·1()1()·(·)1(
N
t
N
t
N
t
N
t
N
t
N
t
N
t
tutytuty
tutytutytytytu
a
2
11
2
1
2
11
2
11
)1()·1()1(·)1(
)1()·(·)1()1()·(·)1()·1(
N
t
N
t
n
t
N
t
N
t
N
t
N
t
tutytuty
tutytytytytuty
b

TEMA 6: Identificación de modelos paramétricos discretos
6-14
6.3.3 Cálculo de la estima cuando el modelo PEM no se puede expresar como una regresión lineal
Para otros tipos de modelos PEM como los modelos ARMAX, OE y BJ la función de
coste (6.30) es una función no lineal de por lo que la obtención de la estima del vector de
parámetros N que minimiza la función de coste debe realizarse usando algún método
numérico de búsqueda iterativa como el método de Newton-Raphson o el de Gauss-Newton
La base de todos estos métodos es la necesidad de encontrar una regla para iterar
sobre el vector de parámetros:
)()()1( ·ˆˆ iii f (6.41)
En la expresión anterior f(i) es la dirección de búsqueda determinada en base a los
valores de la función de coste de las iteraciones anteriores, sus gradientes (primeras
derivadas) y sus hessianos (segundas derivadas). Asimismo es una constante positiva
cuyo valor se debe fijar para obtener una apropiada disminución del valor de la función de
coste.
Por ejemplo, el método de Newton-Raphson permite resolver numéricamente la
ecuación
0)( xg
Para ello va buscando valores para x de forma iterativa:
)()](·[ )(1)()()1( iiii xgxgxx (6.42)
En la expresión anterior g’ es la derivada de g con respecto a x, y es un parámetro
denominado longitud del paso que permite garantizar que x(i+1) será mejor x(i).
El método Newton-Raphson puede ser utilizado para buscar el mínimo de la función de
coste (6.30), para ello hay que encontrar las soluciones de la ecuación
0)(
d
dVN (6.43)
Aplicando (6.41) se obtiene
)ˆ(·)]ˆ(·[ˆˆ )(1)()()()1( iN
iN
iii VV (6.44)

Identificación de sistemas
6-15
Nótese que puesto que es un vector columna de dimensión d x1. El gradiente (primera
derivada) NV () de la función de coste VN es también un vector columna de la misma
dimensión. Por su parte NV () el Hessiano (segunda derivada) de VN es una matriz
cuadrada de dimensión d x d. La longitud del paso (i) es determinada para que
)ˆ()ˆ( )()1( iN
iN VV .
La toolbox SIT de Matlab contiene funciones (arx, armax, oe , bj, pem, ...) que
permiten estimar los parámetros de un modelo PEM. Por ejemplo la función arx permite
estimar los parámetros de un modelo ARX, mientras que la función armax estima un modelo
ARMAX. En ambos casos es necesario obviamente especificar la estructura del modelo a
estimar, es decir, los valores [na,nb,nk] en el caso de un modelo ARX y los valores
[na,nb,nc,nk] en el caso de un modelo ARMAX.
Ejemplo 6.2:
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SIT de Matlab, donde el periodo de muestreo era T=0.08 s. Una vez
eliminados los valores medios se van a utilizar los primeros 500 datos para estimar un modelo ARX
con na=1, nb=1 y nk=2.
La secuencia de comandos necesarios para estimar dicho modelo ARX y mostrar información sobre
el mismo es la siguiente:
load dryer2 Ts=0.08; %Periodo de muestreo datos0 = iddata(y2,u2,Ts); %Eliminación de valores medios datos1=detrend(datos0); %Seleccionar los primeros 500 puntos para estimar d_est=datos1(1:500); %Estimar el modelo ARX (1,1,2) arx112=arx(d_est,[1,1,2]); %Presentar la infomración del modelo present(arx112)
En pantalla aparece lo siguiente:
Discrete-time IDPOLY model: A(q)y(t) = B(q)u(t) + e(t) A(q) = 1 - 0.9444 (+-0.009375) q^-1 B(q) = 0.06944 (+-0.005256) q^-2

TEMA 6: Identificación de modelos paramétricos discretos
6-16
Estimated using ARX from data set d_est Loss function 0.0290152 and FPE 0.0292483 Sampling interval: 0.08
Es decir, se muestra el polinomio A(q) y B(q) estimado. Así como información sobre el valor de la
función de coste (loss function) y del criterio de información FPE utilizado (que se explicará en la
sección 6.5.2).
6.4 PROPIEDADES DEL MODELO PEM ESTIMADO
6.4.1 Calidad del modelo
Tres son los aspectos que se pueden considerar para evaluar la calidad del modelo
estimado:
Uso final de modelo. Un modelo de un sistema puede ser excelente para poder
realizar un control del sistema pero resultar inadecuado para realizar simulación.
Habilidad del modelo para reproducir el comportamiento del sistema. Es decir, que la
salida que produce el modelo se parezca lo máximo posible a la salida real del
sistema cuando ambos son excitados por la misma entrada.
Estabilidad del modelo. Hace referencia a como de bien el modelo puede ser
reproducido a partir de diferentes segmentos de datos de entrada-salida del sistema
real. Obviamente habrá que cuestionarse el modelo resultante si varía mucho en
función de los segmentos de datos a partir de los cuales fue estimado.
6.4.2 Errores existentes en un modelo
De forma general el modelo estimado para un cierto sistema incluye dos tipos de
errores que evitan que pueda reproducir fielmente al sistema real:
Error de varianza. Engloba a los errores del modelo que surgen a causa del ruido
que influye sobre las medidas y el sistema. Si un experimento se repite usando la
misma entrada, la salida que se medirá no será exactamente la misma ya que el
ruido al ser aleatorio no puede ser reproducido. A causa de este ruido el modelo que
se estime será diferente. El error de varianza se puede disminuir si se aumenta el
número N de datos recogidos, es decir la duración de los experimentos. También

Identificación de sistemas
6-17
disminuye si aumenta la razón señal-ruido. Por el contrario aumenta conforme mayor
es el número d de parámetros del modelo (orden del modelo).
Error de sesgo (bias). Engloba a los errores sistemáticos que contiene el modelo
estimado debido a la estructura de modelo elegida. Si la estructura elegida para el
modelo no es adecuada, éste no será capaz de reproducir el comportamiento del
sistema real. Los errores de sesgo se manifiestan como variaciones en los
parámetros del modelo cuando son estimados con datos que han sido medidos en
diferentes condiciones (incluso aunque los intervalos de medida sean
suficientemente grandes para hacer el error de varianza insignificante). El motivo es
que según sean las condiciones del experimento (punto de operación,
características de la entrada y modo de operación (lazo abierto o cerrado)) los datos
contendrán ciertas propiedades del sistema y ocultarán otras. El modelo se ajusta
entonces únicamente a los aspectos dominantes de las propiedades del sistema
recogidas por los datos.
6.4.3 Error de sesgo
Considérese la estima del vector de parámetros N que minimiza la función de coste
N
tN te
NV
1
2 )|(1
)(
Supuesto que el número N de datos medidos tiende a infinito, el error de varianza será
despreciable y el único error que tendrá la estima será el asociado al error de sesgo.
Si el ruido que afecta al sistema puede ser descrito como un proceso estocástico
estacionario, entonces el error de predicción e(t|) para cada valor de es un proceso
estacionario. La varianza del error de predicción es:
)()]|([ 2 VteE (6.45)
Si e(t|) es una secuencia de variables estocásticas independientes, es decir, ruido
blanco, entonces cuando N la función de coste V() tiende a la varianza del error de
predicción )(V :
)()]|([)|(1 2
1
2 VteEteN N
N
t
(6.46)

TEMA 6: Identificación de modelos paramétricos discretos
6-18
La convergencia ocurre con una probabilidad 1. La convergencia es también uniforme
en el parámetro , esto implica que
)(minarg)(minargˆ * VVNNN (6.47)
Es decir, la estima del vector de parámetros N converge al valor que minimiza la
varianza del error de predicción. Este resultado es completamente general y contiene toda la
información del error de sesgo.
Si no se puede conseguir un modelo exacto se puede conseguir al menos la mejor
aproximación disponible dentro del modelo parametrizado, aquella que minimiza la varianza
del error de predicción. Esta es una importante propiedad de robustez de la estima.
En el caso de modelos lineales este resultado se interpreta mejor en el dominio de la
frecuencia. Considérese el siguiente sistema lineal
)()·()()·()()()·()( 000 taqHtuqGtvtuqGty (6.48)
Supóngase que se ha estimado el siguiente modelo del sistema
)()·()()·()( teqHtuqGty (6.49)
El error de predicción es
)()·()()]·()()·[(
)()·()·()()·()()·()·(
)]()·()()()·()·[(
)]()·()()·[()1|()()(
10
1
110
1
01
1
tvqHtuqGqGqH
tuqGqHtvqHtuqGqH
tuqGtvtuqGqH
tuqGtyqHttytyte
(6.50)
De acuerdo con el teorema de factorización espectral (ver sección 2.7) y supuesto que
la entrada es independiente de la perturbación, el espectro del error de predicción es
222
0 |)(|
)(
|)(|
)(·|)()(|
j
vj
ujje eHeH
eGeG
(6.51)
Considerando la fórmula de Parseval
dteE e )·|(·
·2
1)]|([ 2 (6.52)

Identificación de sistemas
6-19
se llega al siguiente resultado [Ljung y Glad, 1994]:
d
eHeGeG
jujj
NN
·|)(|
)(·|)()(|minargˆlim
22
0* (6.53)
Nótese que en esta expresión no aparece el último término de (6.51) ya que es
independiente de .
Por lo tanto la estima converge al valor *, el cual hace a la función de transferencia
),( *jeG del modelo tan cercana como sea posible a la función de transferencia de la
planta real )(0jeG medida en una norma de frecuencia cuadrática con una función de peso
2|)(|
)(
j
u
eH
(6.54)
En el caso de que los datos de la entrada y la salida hayan tenido que ser prefiltrados,
usando un prefiltro L(z), es decir,
)()·()()()·()( tyzLtytuzLtu FF
entonces la norma de frecuencia cuadrática pasa a ser:
22
|)(|
)(·|)(|
j
uj
eHeL
Nótese que seleccionando adecuadamente el prefiltro L, el espectro de potencia de la
entrada u y el modelo de la perturbación )( jeH es posible controlar los rangos de
frecuencia donde el ajuste entre el modelo y el sistema puede ser mejor. Este resultado
ilustra el hecho de como el error de sesgo depende de las condiciones del experimento, en
este caso el espectro de la entrada.
Expresando el espectro del error de predicción filtrado de la siguiente forma
22 * 2 2
0 0 0 02
| |( ) [| | · 2·Re(( )· ( )· ) | ( ) | · ]
| |F
i ie u ua a
LG G G G H e H e
H (6.55)
es posible deducir las principales fuentes del error de sesgo:

TEMA 6: Identificación de modelos paramétricos discretos
6-20
Potencia de la señal de entrada u. La señal de entrada debe tener suficiente
potencia en el rango de frecuencias de excitación del sistema. Es decir, debe
tener excitación persistente suficiente.
Elección del prefiltro L(z). El prefiltro actúa en el problema de estimación como un
peso dependiente de la frecuencia que se debe utilizar para mejorar la bondad del
ajuste en ciertas porciones de la respuesta del modelo.
Estructura del modelo G. Aumentar el número d de parámetros del modelo
disminuye el sesgo, aunque aumenta el error de varianza.
Estructura del modelo de la perturbación H. Actúa como un peso similar al
prefiltro. Los términos de autoregresión (A(z) y D(z)) enfatizan el ajuste a altas
frecuencias.
Espectro del ruido 2 20| ( ) | ·i
aH e . Si la dinámica del ruido difiere substancialmente
de la dinámica de la planta, un acuerdo entre el ajuste de 0H y H se producirá
siempre que A(z)1.
Espectro cruzado ua. Si la entrada está correlacionada con la perturbación
(debido a operación en lazo cerrado) puede producir sesgo.
Ajustando adecuadamente las fuentes anteriores es posible disminuir el error de sesgo
en los rangos de frecuencia de interés.
Se dice que la estima de mínimos cuadrados es consistente (libre de errores de sesgo)(
es decir converge a la planta real con probabilidad uno) si cuando N se cumple que
)()()()(
)·(2
1lim)(
1lim
00
2
1
2
zHzHzGzG
dteN ae
N
N
tF
N F
(6.56)
Es decir, la única fuente de error entre el modelo y el sistema real es la perturbación.
Nótese que la estima consistente se obtiene cuando se cumplen las siguientes
condiciones:
1) La estructura del modelo de la planta G y del ruido H describe al sistema real (G0
y H0). Es decir, sus órdenes son adecuados.

Identificación de sistemas
6-21
2) La entrada u posee excitación persistente de grado adecuado. Es decir el
espectro de la entrada debe ser distinto de cero en un rango de frecuencia
adecuado.
La teoría no exige que la entrada u y el ruido a tenga que ser secuencias
independientes, no correlacionadas (es decir 0)(ua ), es decir, que la operación
se realice en lazo abierto. Sin embargo, es un requisito deseable en la práctica ya que se
simplifica el proceso de identificación.
Si existiera un valor 0 tal que
)(),( 0 jj eGeG
entonces de (6.53) 0* independientemente de u () y )( jeH si u () es diferente de
cero para un número suficiente de frecuencias.
Otro resultado general que también se deduce directamente de (6.47) es el siguiente.
Supuesto que en el caso general, que existe un valor 0 tal que el error de predicción
)()|(ˆ)(),( 00 tatytyte (6.57)
sea ruido blanco a de varianza , entonces de (6.53) se obtiene lo siguiente:
]))|(ˆ)|(ˆ[(
]))|(ˆ)|(ˆ)([(]))|(ˆ)([()],([)(2
0
20
22
tytyE
tytytaEtytyEteEV (6.58)
ya que a(t) es independiente de todos los datos.
En consecuencia se observa que 0* minimiza la varianza )(V . De lo que se
deduce el siguiente resultado
0ˆ NN (6.59)
El resultado anterior es valido bajo la siguiente condición:
00 )|(ˆ)|(ˆ tyty (6.60)

TEMA 6: Identificación de modelos paramétricos discretos
6-22
6.4.4 Error de varianza
Sea N la estima que minimiza la función de coste (6.30) y sea 0 la estima tal que el
error de predicción sea ruido blanco a de varianza . Se puede demostrar que el error de
varianza de la estima se puede aproximar por la siguiente expresión [Ljung y Glag, 1994]:
100 ·])ˆ)·(ˆ[( R
NEP T
NNN
(6.61)
donde R· es la matriz de covarianza de las estimas cuando N.
Ejemplo 6.3:
Considérese un sistema descrito por la siguiente ecuación
)()1()1(·9.0)( tetutyty
La entrada u es ruido blanco de varianza y el ruido {e(t)} es ruido blanco de varianza .
Supóngase que se usa para identificar el sistema el siguiente modelo ARX
)()1(·)1()( tetubtayty
El predictor a un paso de la salida que proporciona este modelo es
)1(·)1()|(ˆ tubtayty
En este caso el vector de regresión y el vector de parámetros son:
b
aθ,
)1(
)1()(
tu
tyt
Además la matriz de covarianza es
N
t
N
t
N
t
N
tN
t
TN
tuN
tutyN
tutyN
tyNtt
NR
1
2
1
11
2
1 )1(1
)1()·1(1
)1()·1(1
)1(1
)()(1
Supuesto que

Identificación de sistemas
6-23
N
t
N
t
txN
txN 1
2
1
2 )(·1
)1(·1
y que N entonces la matriz de covarianza toma la siguiente forma:
)0()0(
)0()0(
)]([)]()·([
)]()·([)]([2
2
yyu
yuy
RR
RR
tuEtutyE
tutyEtyER
Hay que calcular los valores esperados de diferentes magnitudes. Como la entrada u y el ruido e son
independientes se cumple:
0)]()·([
0)]1()·([
0)]1()·([
tuteE
tutuE
teteE
Por otra parte las varianzas de la entrada y el ruido son
])([
])([2
2
iuE
ieE
Además como el valor el valor pasado de la salida y es independiente del valor actual de e o de u, se
cumple:
0)]()·1([
0)]()·1([
tetyE
tutyE
Elevando al cuadrado los dos miembros de la expresión del sistema y tomando el valor esperado E[
], se obtiene la siguiente ecuación
)1(·8.1)0()·81.01( yy RR
Multiplicando la ecuación del sistema por u(t) e tomando el valor esperado se obtiene
0)]()·([)0( tutyERyu
Ya que u(t) es independiente de y(t-1), u(t-1) y e(t).
Multiplicando la ecuación del sistema por y(t-1) y tomando el valor esperado se obtiene
0)0(·9.0)1( yy RR

TEMA 6: Identificación de modelos paramétricos discretos
6-24
Por lo tanto
19.0)0(
yR
Luego la matriz de covarianza toma la siguiente forma:
0
019.0R
De acuerdo con (6.61) la varianza en la estima Na del parámetro a es:
·19.0·
1)ˆ(
NaVar N
Mientras que la varianza en la estima de Nb del parámetro b es
·1
)ˆ(N
bVar N
Se observa como la varianza de la entrada influye en la precisión de la estima. Nótese además que
si N el error de varianza se hace nulo.
A partir de (6.61) es posible estimar la varianza del modelo estimado para la planta
)( jeG y para la perturbación )( jeH .Sea d el número de parámetros que contiene el
modelo y N el número de datos de entrada-salida disponibles. Si d y N son suficientemente
grandes la covarianza asintótica para la estima del modelo es [Ljung y Glag, 1994]:
1
)(
)()()·(·
)(
)(
au
uauvj
j
N
d
eH
eGCov (6.62)
Donde )(u es el espectro de potencia de la entrada, 220 ·|)(|)( a
iv eH es el
espectro de potencia de la perturbación y )()( * auua es el espectro de potencia
cruzada entre la entrada u(t) y el ruido blanco a(t).

Identificación de sistemas
6-25
En el caso de operar en lazo abierto ( 0)( ua ) la covarianza para la estima del
modelo toma la siguiente forma:
)(
)(·)(
u
vj
N
deGCov
(6.63)
2|)(·|)(
·)(
ivj eH
N
d
N
deHCov
(6.64)
Se observa que la covarianza de la estima del modelo, o lo que es lo mismo el error de
varianza, depende del número d de parámetros del modelo, del número N de datos y de la
relación ruido-señal. En consecuencia el error de varianza se puede disminuir si se reduce el
número de parámetros d del modelo, se aumenta el número N de datos o se aumenta la
potencia de la señal de entrada.
6.4.5 Compromiso entre el error de sesgo y el error de varianza
En la Figura 6.2 se representa el valor del error de sesgo y del error de varianza de un
cierto modelo en función del número de parámetros d del modelo que define la complejidad
de un modelo. Se puede observar como el error de sesgo disminuye cuando d aumenta. Por
su parte el error de varianza aumenta linealmente cuando d aumenta, lo cual era esperado
de acuerdo con (6.63).
En consecuencia a la hora de fijar la estructura de un modelo que define el número de
parámetros d que contendrá el mismo, hay que llegar a un compromiso entre el error de
sesgo y el error de varianza. Para ello se debe escoger el valor de d que minimice el error
total, es decir la suma del error de sesgo y del error de varianza (ver Figura 6.3).
Si se calculara el error del modelo con el conjunto de datos usados para estimar los
parámetros del modelo, no se podría detectar el error de varianza (ver Figura 6.4). Por ello
la validación de un modelo, como se explicará en la próxima sección, siempre es deseable
realizarla, si es posible, con un conjunto de datos (datos para validar) diferente al conjunto
de datos usados para estimar el modelo.
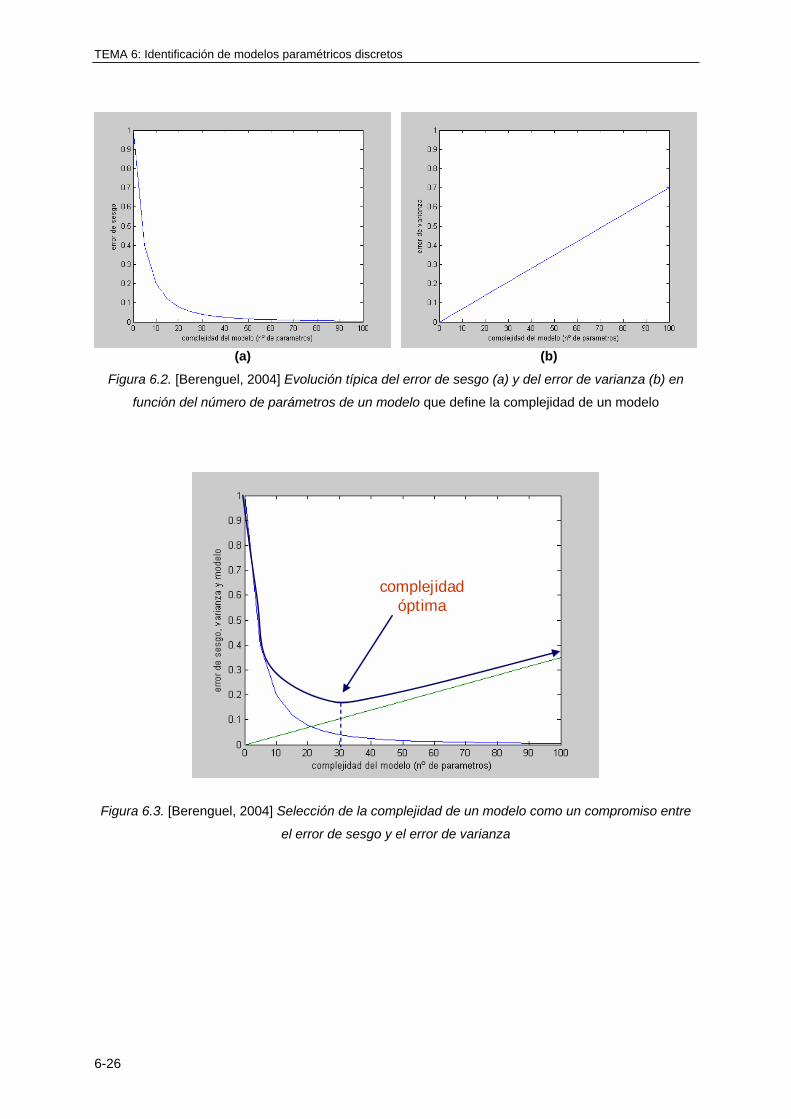
TEMA 6: Identificación de modelos paramétricos discretos
6-26
(a) (b)
Figura 6.2. [Berenguel, 2004] Evolución típica del error de sesgo (a) y del error de varianza (b) en
función del número de parámetros de un modelo que define la complejidad de un modelo
modelo
sesgo
varianza
Complejidad óptima
modelo
sesgo
varianza
Complejidad óptimacomplejidad
óptima
Figura 6.3. [Berenguel, 2004] Selección de la complejidad de un modelo como un compromiso entre
el error de sesgo y el error de varianza

Identificación de sistemas
6-27
error con datos para validación
error con datos para estimación
complejidad óptima
Figura 6.4. [Berenguel, 2004] Error de un modelo en función del número de parámetros del modelo
calculado con los datos usados para estimar y con los datos usados para validar
En general, los errores de sesgo y varianza no son conocidos, de modo que se suelen
estimar varios modelos de diferente complejidad y se comparan los errores evaluados sobre
el conjunto de datos usados para validar.
6.5 CONSIDERACIONES SOBRE LA ELECCIÓN DEL TIPO Y LA ESTRUCTURA DEL MODELO PEM
6.5.1 Elección del tipo de modelo
De acuerdo con el principio de parsimonia puesto que los modelos ARX son los más
fáciles de estimar, siempre se recomienda su utilización como modelo de partida de
cualquier problema de identificación de sistemas. La principal desventaja de un modelo ARX
es que el modelo de la perturbación )(/1)( qAqH comparte los mismos polos que el
modelo de la planta )(/)()( qAqBqG . En consecuencia es posible tener una estima
incorrecta de la dinámica del sistema porque el polinomio A(q) también describe las
propiedades de la perturbación. Puede ser necesario que los grados na y nb de los
polinomios A y B sean altos. Si la razón señal-ruido es adecuada, esta desventaja es menos
importante.

TEMA 6: Identificación de modelos paramétricos discretos
6-28
Un modelo ARX con los órdenes adecuados es capaz de proporcionar una estima
consistente. Esto órdenes pueden ser altos, por lo que quizás sea necesario reducir el
modelo obtenido
En el caso de no obtener buenos resultados con modelos ARX se debe pasar a utilizar
modelos ARMAX que presentan una mayor flexibilidad para tratar las perturbaciones,
gracias al polinomio C(q) que poseen que genera un modelo de ruido correlacionado.
El uso de los modelos OE se recomienda cuando las propiedades de las señales de
perturbación no necesitan ser modeladas, es decir, H=1. Permiten obtener una descripción
correcta de la función de transferencia determinista G sin importar la forma de las
perturbaciones.
Sólo cuando no se obtiene buenos resultados con modelos ARX, ARMAX y OE se
puede probar a usar modelos BJ, que permiten obtener funciones de transferencia
independientes para la parte determinista y la estocástica del modelo. Los modelos BJ son
difíciles de estimar ya requieren de muchas iteraciones (computacionalmente costoso) y de
una mayor toma de decisiones por parte del diseñador.
Los modelos ARX y ARMAX tienen dinámicas comunes (mismos polos) para el ruido
a(t) y la entrada u(t). Esto resulta adecuado cuando la perturbación dominante entra “antes”
en el proceso, por ejemplo en la entrada. Por otra parte, un modelo BJ es preferible cuando
las perturbaciones modeladas entran “después” en el proceso, por ejemplo, como ruido
medido en la salida.
6.5.2 Elección de la estructura del modelo
Una vez seleccionada la familia o tipo de modelos con la que se va identificar, se deben
estimar modelos con distintos órdenes de los polinomios (estructuras) y seleccionar aquel
que presenta un menor valor de la función de coste (6.30) al ser evaluada sobre un conjunto
de datos (datos de validación) distinto al conjunto de datos utilizados para estimar los
modelos (datos de estimación).
En ocasiones el número de datos disponibles es pequeño por lo que no es posible
reservar un conjunto de datos para validar, es decir, los datos que se usan para estimar los
modelos se deben usar también para validarlos. En este caso aparece el fenómeno
conocido como sobreestimación o sobreparametrización que consiste en que el modelo que
minimiza la función de coste (6.30) es siempre aquel que tiene un mayor número de
parámetros. A medida que aumenta el número de parámetros de un modelo se suele

Identificación de sistemas
6-29
obtener un valor más pequeño para la función de coste. Ya que se calcula minimizando
sobre un mayor número de parámetros. Si se dibujan los valores de la función de coste
como función del número de parámetros se obtiene una curva estrictamente decreciente. El
valor de la función de coste disminuye porque el modelo está incluyendo cada vez más
propiedades relevantes del sistema real. Sin embargo, aún después de que un orden
correcto del modelo ha sido alcanzado la función de coste continúa disminuyendo.
Un modelo sobreparametrizado contiene más parámetros de los realmente necesarios,
estos parámetros adicionales se utilizan para ajustar el modelo a las señales de
perturbación específicas presentes en las series temporales de los datos. El poseer un
modelo sobrestimado no sirve para ningún propósito práctico ya que el modelo será utilizado
con otras perturbaciones, puesto que éstas suelen tener una naturaleza estocástica.
La sobreestimación puede ser evitada utilizando funciones de coste que incluyan un
factor f(d,N) que penalice la utilización de un número de parámetros d excesivo.
N
1i
2
θd,θ)(i,ε)(min d,Nf (6.65)
A estas funciones de coste modificadas se las conoce como criterios de información.
Los más utilizados son los siguientes:
Error final de predicción de Akaike (FPE)
N
1i
2
d,θθ)(i,ε
1
1
1min
NNdNd
FPE (6.66)
Criterio teórico de información de Akaike (AIC)
N
1i
2
θd,θ)(i,ε
21min
N
dAIC (6.67)
Longitud mínima de la descripción de Rissanen (MDL)
N
1i
2
d,θθ)(i,ε)log(
21min N
N
dMDL (6.68)

TEMA 6: Identificación de modelos paramétricos discretos
6-30
Ejemplo 6.4
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SIT de Matlab. Se van a usar los 500 primeros datos para estimar y los
500 restantes para validar. Se desea obtener el modelo ARX que mejor se ajusta, es decir, minimiza
la función de coste (6.30) dentro del rango de estructuras na=1,…,10, nb=1,…,10 y nk=1,…,10.
La secuencia de comandos de Matlab necesaria para obtener el mejor modelo es la siguiente:
load dryer2 Ts=0.08; datos0 = iddata(y2,u2,Ts); datos1=detrend(datos0); d_est=datos1(1:500); d_val=datos1(501:1000); NN=struc(1:10,1:10,1:10); V=arxstruc(d_est,d_val,NN); NNmin=selstruc(V,0) arxsel=arx(d_est,NNmin); present(arxsel)
En la pantalla se mostraría lo siguiente:
NNmin = 6 9 2 Discrete-time IDPOLY model: A(q)y(t) = B(q)u(t) + e(t) A(q) = 1 - 0.9563 (+-0.04574) q^-1 + 0.02774 (+-0.06338) q^-2 - 0.09131 (+-0.06303) q^-3 + 0.09325 (+-0.06298) q^-4 + 0.001598 (+-0.06072) q^-5 + 0.02927 (+-0.03302) q^-6 B(q) = 0.004215 (+-0.001528) q^-2 + 0.0644 (+-0.001842) q^-3 + 0.0627 (+-0.003486) q^-4 + 0.02005 (+-0.00447) q^-5 - 0.007039 (+-0.004435) q^-6 - 0.01739 (+-0.004395) q^-7 - 0.01571 (+-0.004053) q^-8 - 0.009152 (+-0.003461) q^-9 - 0.005082 (+-0.00261) q^-10 Estimated using ARX from data set d_est Loss function 0.00140836 and FPE 0.00149548 Sampling interval: 0.08
Luego el modelo ARX que minimiza la función de coste es aquel con una estructura
(na,nb,nk)=(6,9,2)

Identificación de sistemas
6-31
Ejemplo 6.5
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SIT de Matlab. Se van a usar los 500 primeros datos para estimar y
también para validar. Considerando el conjunto de modelos ARX con estructuras na=1,…,10,
nb=1,…,10 y nk=1,…,10, se pide : a) Obtener el modelo ARX que minimiza la función de coste (6.30).
b) Obtener el modelo ARX según el criterio de información AIC.
a) La secuencia de comandos de Matlab necesaria para obtener el mejor modelo es la siguiente:
load dryer2 Ts=0.08; datos0 = iddata(y2,u2,Ts); datos1=detrend(datos0); d_est=datos1(1:500); NN=struc(1:10,1:10,1:10); V=arxstruc(d_est,d_est,NN); NNmin=selstruc(V,0) arxsel=arx(d_est,NNmin);
En la pantalla se mostraría lo siguiente:
NNmin = 10 10 2
Luego el modelo ARX que minimiza la función de coste es aquel con una estructura
(na,nb,nk)=(10,10,2). Se observa que al usar el mismo conjunto de datos para estimar y para validar
la estructura seleccionada es aquella que presenta el mayor número de parámetros (na=10 y nb=10).
Puede comprobarse que si se aumentase el espacio de estructuras a otras de mayor orden, siempre
el modelo ARX que minimizaría la función de coste sería aquella con mayor número de parámetros.
Es decir, existe el problema de la sobreestimación.
b) Los comandos necesarios para obtener el mejor modelo ARX según el criterio de información AIC
es (supuesto que se han escrito ya los del apartado anterior):
NNmin=selstruc(V,’aic’) arxselb=arx(d_est,NNmin);
En la pantalla se mostraría lo siguiente:
NNmin = 6 10 2

TEMA 6: Identificación de modelos paramétricos discretos
6-32
Luego el modelo ARX que minimiza la función de coste es aquel con una estructura
(na,nb,nk)=(6,10,2). Nótese lo próximo que está este modelo al obtenido como mejor modelo en el
Ejemplo 6.4.
6.6 VALIDACIÓN DEL MODELO ESTIMADO
Es muy importante tener en cuenta que en el proceso de selección y validación de los
modelos se debe usar, siempre que sea posible, un conjunto de datos distinto (datos de
validación) a los usados para estimar el modelo (datos de estimación), ya que de lo contrario
no se ve reflejado el error de varianza. A la validación del modelo con datos distintos a los
usados para estimarlo se le denomina en la literatura como validación cruzada.
Para analizar la validez del modelo estimado es conveniente realizar los siguientes
estudios: verificación del comportamiento de entrada-salida y análisis de los residuos.
6.6.1 Verificación del comportamiento de entrada-salida
Para validar el comportamiento de entrada-salida del modelo estimado se deben hacer
los siguientes test:
Comparar la respuesta temporal medida con la estimada por el modelo. Para ello
se debe utilizar la misma entrada usada en la identificación, así como otras
entradas no usadas en la identificación.
Comparar la respuesta a un impulso y a un escalón que proporciona el modelo
identificado con la respuesta a un impulso y a un escalón estimada mediante
análisis de correlación.
Comparar la respuesta en frecuencia obtenida por el modelo identificado con la
calculada mediante análisis espectral.
Puede suceder que un modelo presente un buen comportamiento de entrada-salida pero
que sin embargo el análisis de sus residuos indique que no se trata de un buen modelo.
Pese al desacuerdo entre ambas validaciones, dependiendo del uso final que se le vaya a
dar al modelo (simulación, control, predicción, filtrado,…), quizás el modelo no tenga por qué
ser rechazado.
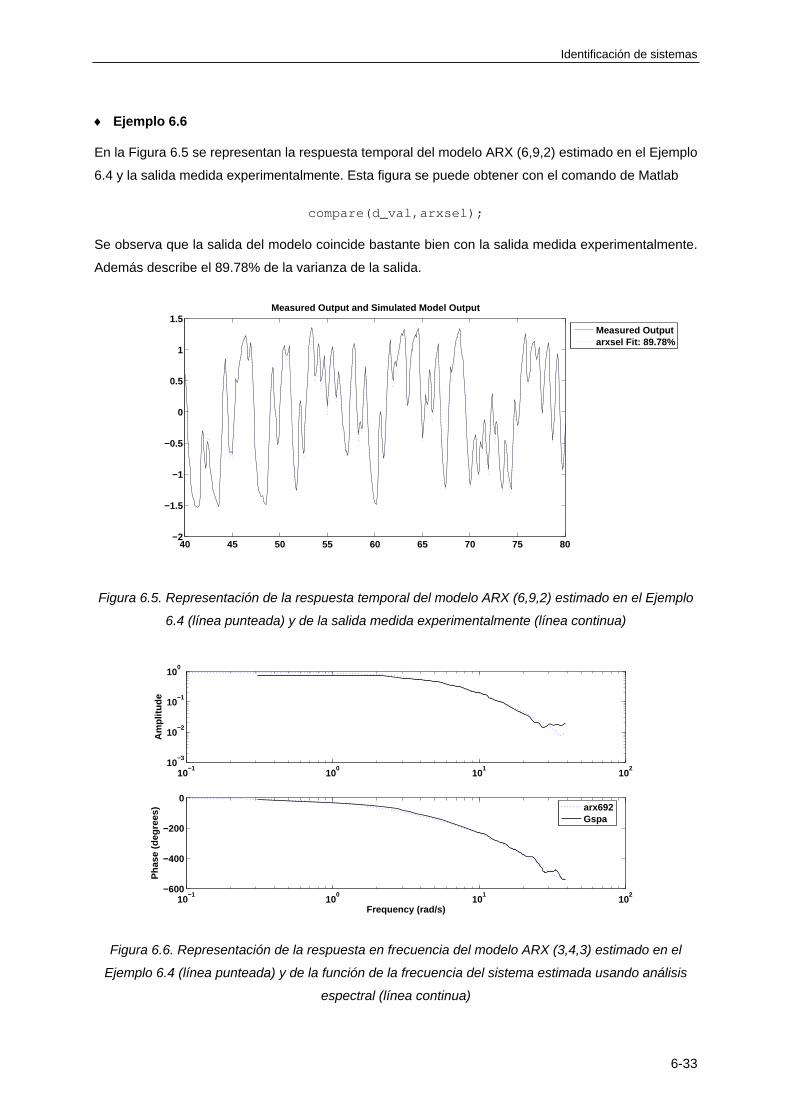
Identificación de sistemas
6-33
Ejemplo 6.6
En la Figura 6.5 se representan la respuesta temporal del modelo ARX (6,9,2) estimado en el Ejemplo
6.4 y la salida medida experimentalmente. Esta figura se puede obtener con el comando de Matlab
compare(d_val,arxsel);
Se observa que la salida del modelo coincide bastante bien con la salida medida experimentalmente.
Además describe el 89.78% de la varianza de la salida.
40 45 50 55 60 65 70 75 80−2
−1.5
−1
−0.5
0
0.5
1
1.5Measured Output and Simulated Model Output
Measured Outputarxsel Fit: 89.78%
Figura 6.5. Representación de la respuesta temporal del modelo ARX (6,9,2) estimado en el Ejemplo
6.4 (línea punteada) y de la salida medida experimentalmente (línea continua)
10−1
100
101
102
10−3
10−2
10−1
100
Am
plit
ud
e
10−1
100
101
102
−600
−400
−200
0
Ph
ase
(deg
rees
)
Frequency (rad/s)
arx692Gspa
Figura 6.6. Representación de la respuesta en frecuencia del modelo ARX (3,4,3) estimado en el
Ejemplo 6.4 (línea punteada) y de la función de la frecuencia del sistema estimada usando análisis
espectral (línea continua)

TEMA 6: Identificación de modelos paramétricos discretos
6-34
En la Figura 6.6 se representan la respuesta en frecuencia del modelo ARX (6,9,2) estimado en el
Ejemplo 6.4 y la función de la frecuencia del sistema estimada mediante análisis espectral. Esta
Figura se puede obtener con los siguientes comandos de Matlab.
[Gspa,phiVspa]=spa(d_est); bode(arxsel,Gspa) legend('arx692','Gspa')
Se observa que la respuesta en frecuencia del modelo ARX (6,9,2) es bastante parecida a la función
de frecuencia estimada para el sistema, aunque discrepa ligeramente en cuanto al valor de la
ganancia a baja frecuencia y en su comportamiento de alta frecuencia.
6.6.2 Análisis de los residuos
El error de predicción que produce el modelo estimado para t=1,...,N se calcula de la
siguiente forma:
)ˆ|(ˆ)()( Ntytyte (6.69)
El estudio del error de predicción (que se denominan residuos si el modelo del ruido es
igual a la unidad) que produce el modelo estimado puede aportar la siguiente información
sobre el modelo:
Existencia de dinámicas no modeladas. El modelo no recoge todas las dinámicas
del sistema.
Existencia de realimentaciones de la salida en la entrada. Lo que indica que los
datos utilizados han sido adquiridos en lazo cerrado.
Validez del modelo de la perturbación estimado. En el caso de que se requiera
obtener aparte un modelo de la planta también un modelo de las perturbaciones,
entonces se debe exigir que los residuos sean mutuamente independientes.
Básicamente el estudio del error de predicción se realiza a partir de la representación
gráfica de la estima de la función de correlación cruzada entre la entrada y el error de
predicción, y de la representación gráfica de la estima de la función de autocorrelación de
los residuos.
La función de correlación cruzada entre la entrada y el error de predicción se calcula
mediante la siguiente expresión:

Identificación de sistemas
6-35
MtuteN
RN
teu
||)()(1
)(ˆ1
Se puede demostrar que si {e(t)} y {u(t)} son realmente independientes, entonces la
estima de la función de correlación cruzada cuando N es grande está distribuida
normalmente, con valor medio cero y varianza
k
uer kRkRN
P )()·(1
donde Re(k) y Ru(k) son las funciones de covarianza de e y u, respectivamente.
La estima de la función de covarianza cruzada se suele representar gráficamente junto
con la representación de las líneas horizontales
rP·3
que definen el intervalo de confianza del 99.7%.
Si algún valor de )(ˆ euR sale fuera del intervalo de confianza entonces eso indica que
e(t+) y u(t) probablemente son dependientes para dicho valor de .
Si >0 entonces el modelo puede que esté incompleto, es decir, pueden existir
dinámicas no modeladas. Por ejemplo si se ha utilizado un modelo ARX y )(ˆ euR es
significativamente distinto de cero en =0, esto indica que el término u(t-0) debería ser
incluido en el modelo. Lo cual sirve de guía para seleccionar una mejor estructura ARX, en
concreto para elegir los órdenes nk y nb. Si no se consigue mejorar habrá que plantearse
otros tipos de modelos como un ARMAX.
Si hay correlación para valores negativos de , es decir e(t) influye en valores de la
entrada u(s) con s>t, entonces ello indica la existencia de realimentación de la salida en la
entrada, no que el modelo esté incompleto.
La función de autocorrelación de los residuos se define de la siguiente forma:
MteteN
RN
te
||)()(1
)(ˆ1

TEMA 6: Identificación de modelos paramétricos discretos
6-36
En el caso de que se requiera obtener un modelo de las perturbaciones, entonces se
debe exigir que los residuos sean mutuamente independientes, es decir, tengan una
distribución similar al ruido blanco. Si los residuos son ruido blanco la función de
autocorrelación deberá ser aproximadamente cero (estar dentro del intervalo de confianza)
en todos los puntos salvo en el origen. En caso contrario significará que las perturbaciones
no están bien modeladas.
En general en el análisis de los residuos se puede seguir la siguiente regla: si la
representación de la función de autocorrelación de los residuos y la representación de la
función de correlación cruzada entre los residuos y la entrada (hay que fijarse en los valores
positivos de de la función de correlación cruzada) cruzan significativamente sus
respectivos intervalos de confianza entonces el modelo no puede ser aceptado como una
buena descripción del sistema. Pese a ello si la verificación del comportamiento de entrada-
salida ha sido satisfactoria, dependiendo del uso final del modelo éste podría ser
considerado como válido.
Si se está interesado principalmente en identificar la parte determinista G del modelo,
como ocurre con los modelos OE, entonces habrá que concentrarse en conseguir la
independencia de los residuos frente a la entrada más que en la blancura de los residuos.
Ejemplo 6.7
Se van a analizar los residuos del modelo ARX (6,9,2) estimado en el Ejemplo 6.4. En la Figura 6.7
se representan la autocorrelación de los residuos y la correlación cruzada entre los residuos y la
entrada. Esta Figura se ha obtenido usando el comando de Matlab
resid(arxsel,d_val)
Se observa que la autocorrelación de los residuos se asemeja a la del ruido blanco por lo que el
modelo en cuanto a la modelización de las perturbaciones del sistema es correcto.
Por otra parte, la función de correlación cruzada entre los residuos y la entrada no cruza
significativamente la región de confianza del 99.7% en desplazamientos (lags) positivos , lo que
indica que no existen dinámicas no modeladas. Tampoco la cruza en desplazamientos negativos lo
que indica que no existe realimentación de la perturbación en la entrada, es decir, que el sistema
durante la adquisición de los datos ha estado operando en lazo abierto.

Identificación de sistemas
6-37
0 5 10 15 20 25−0.5
0
0.5
1Correlation function of residuals. Output y1
lag
−25 −20 −15 −10 −5 0 5 10 15 20 25−0.2
−0.1
0
0.1
0.2Cross corr. function between input u1 and residuals from output y1
lag
Figura 6.7. Análisis de los residuos del modelo ARX (6,9,2) estimado en el Ejemplo 6.4
6.7 REDUCCIÓN DEL MODELO Si el modelo identificado presenta unos órdenes en sus polinomios elevados, se puede
intentar simplificarlo buscando cancelaciones de polos y ceros. Si el modelo identificado es
de orden (por ejemplo n) mayor que el real (por ejemplo n0) entonces aparecerán n-n0 pares
de ceros-polos que se cancelan entre sí de forma aproximada. En dicho caso puede
probarse a estimar un modelo con una estructura de orden reducida en el número de
cancelaciones que se hayan producido.
También otra forma de conseguir un modelo de órdenes más reducidos es usando los
criterios de información que penalizan el uso de un número de parámetros excesivos.
Obviamente si se valida el modelo reducido se obtendrán peores resultados que con el
modelo original. Si el empeoramiento producido no es excesivo el modelo reducido podrá
considerarse como válido.
Ejemplo 6.8
En la Figura 6.8 se representa el diagrama de polos y ceros del modelo ARX (6,9,2) estimado en el
Ejemplo 6_4. Se muestran además los intervalos de confianza del 99.7% para la posición de los
ceros y los polos. Esta Figura se puede obtener con el comando de Matlab.
zpplot(arxsel,1)
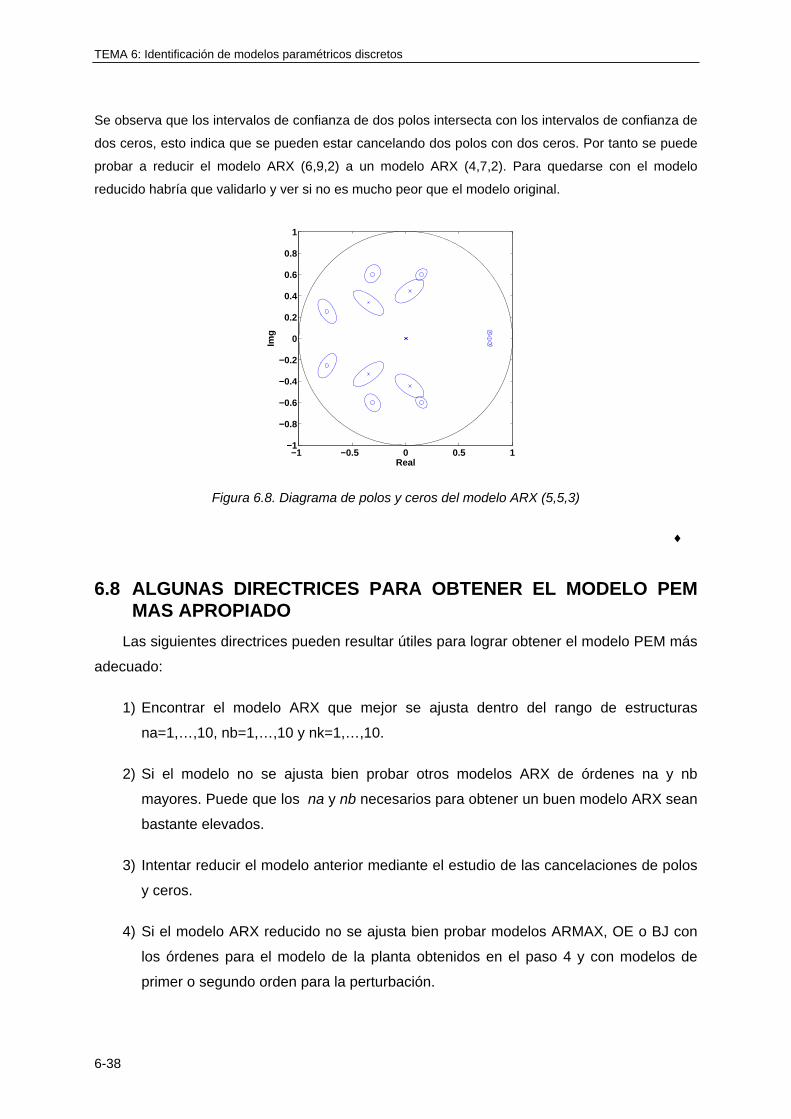
TEMA 6: Identificación de modelos paramétricos discretos
6-38
Se observa que los intervalos de confianza de dos polos intersecta con los intervalos de confianza de
dos ceros, esto indica que se pueden estar cancelando dos polos con dos ceros. Por tanto se puede
probar a reducir el modelo ARX (6,9,2) a un modelo ARX (4,7,2). Para quedarse con el modelo
reducido habría que validarlo y ver si no es mucho peor que el modelo original.
−1 −0.5 0 0.5 1−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
Real
Img
Figura 6.8. Diagrama de polos y ceros del modelo ARX (5,5,3)
6.8 ALGUNAS DIRECTRICES PARA OBTENER EL MODELO PEM MAS APROPIADO
Las siguientes directrices pueden resultar útiles para lograr obtener el modelo PEM más
adecuado:
1) Encontrar el modelo ARX que mejor se ajusta dentro del rango de estructuras
na=1,…,10, nb=1,…,10 y nk=1,…,10.
2) Si el modelo no se ajusta bien probar otros modelos ARX de órdenes na y nb
mayores. Puede que los na y nb necesarios para obtener un buen modelo ARX sean
bastante elevados.
3) Intentar reducir el modelo anterior mediante el estudio de las cancelaciones de polos
y ceros.
4) Si el modelo ARX reducido no se ajusta bien probar modelos ARMAX, OE o BJ con
los órdenes para el modelo de la planta obtenidos en el paso 4 y con modelos de
primer o segundo orden para la perturbación.

Identificación de sistemas
6-39
5) Si el modelo obtenido en el paso anterior no resulta adecuado, intentar descubrir si
existen entradas adicionales en el sistema que están afectando a la salida. Si pueden
ser medidas incluirlas en el modelo.
6) Si se sigue sin obtener un buen modelo utilizar el modelado semifísico, es decir
basándose en las leyes físicas que sigue el sistema y en el sentido común probar
alguna transformación no lineal sobre los datos de entrada-salida y aplicar sobre los
datos transformados la metodología de identificación.
Obviamente se presupone que se dispone de datos de entrada - salida de la calidad
suficiente, es decir, que el sistema ha sido excitado con una entrada con un grado de
excitación adecuado.
BIBLIOGRAFÍA
[Ljung y Glad, 1994] L. Ljung y T. Glad. Modelling of dynamic systems. Prentice
Hall. 1994.
[Ljung, 1999] L. Ljung. System Identification: Theory for the user. 2nd
Edition. Prentice Hall.1999.
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.
[Schoukens y Pintelon, 1991] J. Schoukens, R. Pintelon. Identification of linear systems.
Pergamon Press. 1991.
[Söderström y Stoica, 1989] T. Söderström y P. Stoica, System Identification. Prentice
Hall. 1989.


TEMA 7
IDENTIFICACIÓN DE MODELOS PARAMÉTRICOS CONTINUOS
7-1
7.1 INTRODUCCIÓN
Las propiedades de un modelo paramétrico en tiempo discreto dependen del periodo de
muestreo T que se haya utilizado para muestrear los datos de la entrada y la salida del
sistema utilizados para estimar el modelo. Si cambia el periodo de muestreo también
cambiarán los polos y ceros del modelo estimado y en consecuencia las características de la
respuesta del mismo. Un modelo en tiempo continuo es más general y no sufre de este
problema. Por ello resulta más útil, siempre que sea posible, disponer de un modelo
continuo del sistema que de uno discreto.
En este tema se describen las principales técnicas utilizadas, dentro del marco de la
identificación de sistemas, para obtener un modelo continuo de un sistema: obtención a
partir de la transformación del modelo discreto identificado, estimación a partir de datos
muestreados de las series temporales de la entrada y la salida, y estimación a partir de los
datos en el dominio de la frecuencia.
7.2 OBTENCIÓN A PARTIR DE LA TRANSFORMACIÓN DEL
MODELO DISCRETO IDENTIFICADO
Supóngase que se ha identificado un modelo paramétrico en tiempo discreto ( )(ˆ zG ,
)(ˆ zH ) de un cierto sistema usando datos de entrada-salida muestreados con un cierto
periodo T. A partir de este modelo discreto es posible obtener un modelo en tiempo continuo
equivalente ( )(ˆ sG y )(ˆ sH ).

TEMA 7: Identificación de modelos paramétricos continuos
7-2
Por simplificar en lo que resta de sección se utilizará la siguiente notación: G(z) es la
función de transferencia en tiempo discreto dada y G(s) es la función de transferencia en
tiempo continuo que se deriva de G(z).
La planta de un proceso real es un proceso en tiempo continuo controlada
generalmente por un controlador digital. La señal digital del controlador se pasa de digital a
analógico (ver Figura 7.1) usando típicamente un retenedor de orden cero o ZOH (zero order
hold) que convierte una señal muestreada u*(t) en una señal en tiempo continuo u(t).
Además la salida de la planta y(t) es muestreada para obtener la señal digital y*(t) que es
realimentada al controlador.
Figura 7.1. Relación entre G(z) y G(s) usando un ZOH
El circuito ZOH puede ser representado como un integrador que es automáticamente
inicializado a cero después de cada periodo de muestreo. Tal sistema tiene la siguiente
función de transferencia
s
esG
Ts
zoh
1)( (7.1)
Usando un ZOH las funciones G(z) y G(s) se relacionan de la siguiente forma:
s
sGZzsG
s
eZsGsGZzG
Ts
zoh
)()·1()(·
1)]()·([)( 1 (7.2)
Aplicando la transformada Z inversa se obtiene:
11
1
)()(
z
zGZ
s
sG (7.3)
expresión a partir de la cual sería posible obtener la función G(s) exacta siempre y cuando
no existan polos sobre el eje real negativo, sino sólo se puede obtener una aproximación a
la misma.

Identificación de sistemas
7-3
Ejemplo 7.1:
Supóngase que utilizando los datos de entrada-salida de una cierto sistema muestreado con un
periodo de muestreo T=0.1 s se ha identificado el siguiente modelo discreto para la planta:
3679.0
6321.0)(
zzG
Se desea obtener la función G(s) equivalente. Si se utiliza un ZOH de acuerdo con (7.2) se tiene la
siguiente relación entre G(z) y G(s):
)3679.01(
6321.0
1
1
1
)()(1
1
11
11
z
z
zZ
z
zGZ
s
sG
En este caso sencillo usando por ejemplo una tabla de equivalencias entre transformadas z y s se
puede encontrar que la transformada de Laplace de
)1)·(1(
)1()(
11
1
zez
zezH
aT
aT
es
)·()(
ass
asH
En este caso se tiene que a=10. Luego
)10(
10)(
sss
sG
Con lo que finalmente se obtiene que la función G(s) equivalente es:
)10(
10)(
ssG
Otra forma de pasar una función de transferencia discreta G(z) a continua G(s) es usar
alguna transformación matemática. La variable z de un modelo discreto se relaciona con la
variable s de un modelo continuo mediante la siguiente expresión:

TEMA 7: Identificación de modelos paramétricos continuos
7-4
sTez (7.4)
Dos aproximaciones utilizadas para esta expresión que derivan de su expansión en
serie son:
sTez sT 1 (7.5)
sTez sT
1
1 (7.6)
La expresión (7.5) procede de la aplicación del método de Euler que consiste en
aproximar la derivada de una señal x(t) en el instante t por la diferencia entre el valor
muestreado en el instante (t+T) y el instante t, a esta diferencia se le denomina diferencia
hacia delante (forward difference):
)(1)()()(
)( txT
q
T
txTtx
dt
tdxtpx
(7.7)
En la expresión anterior q es el operador desplazamiento y p es el operador
diferenciación.
Desde el punto de vista de las transformadas s y z, el método de Euler proporciona la
siguiente transformación
T
zs
1'
(7.8)
Nótese que se ha utilizado la notación s’ para enfatizar el hecho de que no se obtiene a
partir de la variable z la variable s exacta sino una aproximación a la misma. Despejando z
de la expresión anterior se obtiene (7.5).
Por su parte la expresión (7.6) procede de aproximar la derivada de una señal x(t) en el
instante t por la diferencia entre el valor muestreado en el instante (t) y el instante (t-T), a
esta diferencia se le denomina diferencia hacia atrás (Backward difference):
)(··
1)()()()( tx
Tq
q
T
TtxTx
dt
tdxtpx
(7.9)
Con lo que

Identificación de sistemas
7-5
zT
zs
1'
(7.10)
Despejando z de la expresión anterior se obtiene (7.6).
Otra aproximación posible que derivada del método trapezoidal de integración numérica
es la denominada como aproximación bilineal o aproximación de Tustin:
2/'1
2/'1
2/1
2/1
Ts
Ts
sT
sTez sT
(7.11)
De las tres aproximaciones propuestas la que más se utiliza es la aproximación de
Tustin ya que permite transformar el plano s dentro del círculo unidad del plano z. Con la
aproximación (7.5) obtenida por el método de Euler el semiplano izquierdo del plano s es
transformado en el semiplano Real[z] <1. En consecuencia una función de transferencia en
tiempo continuo todavía seguirá siendo estable si se utiliza la aproximación de Tustin para
obtener la función de transferencia discreta, mientras que puede que ésta sea inestable si
se usa la aproximación basada en el método de Euler.
El principal problema que presenta la aproximación de Tustin es que deforma la escala
de frecuencias ya que transforma el plano z en el plano s’ no en el plano s verdadero. Sea v
la frecuencia en el plano s’ y la frecuencia en el plano s. Pues bien el intervalo de
frecuencias ss ·5.0 en el plano s corresponde al intervalo ss v en el
plano s’. Se puede demostrar que se cumple la siguiente relación entre ambas:
2
··tan
2 T
Tv
(7.12)
Nótese que si T es pequeño entonces v es prácticamente igual a . Luego si se utiliza
un periodo de muestreo muy pequeño v es prácticamente igual a en un mayor rango de
frecuencias.
Por otra parte, es posible modificar la transformación de Tustin para eliminar la
distorsión en una frecuencia determinada 1
'·2
·tan
'·2
·tan
11
11
sT
sT
z
(7.13)

TEMA 7: Identificación de modelos paramétricos continuos
7-6
La toolbox Control de Matlab dispone de la función d2c para pasar a una función de
transferencia discreta a continuo usando entre otros métodos, un ZOH y la aproximación de
Tustin.
Ejemplo 7.2:
Supóngase que utilizando los datos de entrada-salida de una cierto sistema muestreado con un
periodo de muestreo T=0.1 s se ha identificado el siguiente modelo para la planta:
3679.0
6321.0)(
zzG
Se desea obtener el modelo continuo equivalente. Usando el método ZOH se obtiene
10
10)(
ssG
Por otro lado si se utiliza la aproximación de Tustin se obtiene
242.9
242.9·4621.0)(
s
ssG
En la Figura 7.2 se puede observar el error que posee la G(s) obtenida con la aproximación de Tustin
con respecto a la G(s) obtenida con un ZOH.
Frequency (rad/sec)
Pha
se (
deg)
; M
agni
tude
(dB
)
Bode Diagrams
-25
-20
-15
-10
-5
0From: U(1)
100
101
102
-200
-150
-100
-50
0
To:
Y(1
)
Figura 7.2: G(s) usando un ZOH (línea continua) y usando la aproximación de Tustin (línea
discontinua).

Identificación de sistemas
7-7
La secuencia de comandos de Matlab que permite obtener estos resultados es la siguiente:
num=0.6321;
den=[1 -0.3679];
G=tf(num,den,0.1);
Gc_zoh=d2c(G,'zoh')
Gc_tustin=d2c(G,'tustin')
bode(Gc_zoh, Gc_tustin)
7.3 ESTIMACIÓN A PARTIR DE DATOS DE ENTRADA-SALIDA
TEMPORALES
En el control de procesos industriales, los modelos más utilizados para la planta son
modelos continuos simples del tipo
dsT
p
esT
KsG
11)( (7.14)
Es decir un modelo de primer orden donde hay que estimar la ganancia en el
estacionario K, la constante de tiempo Tp1 y el retardo Td.
Entre las variantes de este modelo se encuentran el modelo sin retardo (Td=0)
11)(
psT
KsG
(7.15)
y el modelo con integrador
dsT
p
esTs
KsG
)1·()(
1
(7.16)
Además, se pueden considerar dos polos con o sin un cero:
dsT
pp
z esTsTs
sTKsG
)1)·(1·(
)1()(
21
(7.17)
Otra posibilidad adicional es permitir polos resonantes (modelos subamortiguados)

TEMA 7: Identificación de modelos paramétricos continuos
7-8
dsT
rr
z esTsT
sTKsG
2)(··21
)1()(
(7.18)
Pueden encontrarse en la literatura varios artículos y libros que discuten como estimar
modelos continuos de los tipos comentados a partir de datos de entrada-salida
muestreados, por ejemplo [Aström y Hägglund, 1995], [Rake, 1980] y [Ziegler et al., 1943].
La mayoría de los métodos clásicos son de tipo gráfico o semigráfico, como por ejemplo:
encontrar la tangente más inclinada a la respuesta a un escalón y calcular la intersección
con el eje de tiempo, calcular el área que encierra la curva de respuesta, etc.
En el marco de la identificación de sistemas estándar, la estimación de modelos de
procesos del tipo (7.14) a (7.18) no difiere de la estimación de cualquier modelo lineal
parametrizado discreto. Cualquiera de los modelos (7.14) a (7.18) pueden ser escritos en la
forma:
),( sG (7.19)
donde es el vector que contiene a los parámetros (K, Td, Tp1,...) del modelo.
Para estimar los parámetros usualmente se dispone de un conjunto de N datos
muestreados de la entrada u(t) y la salida y(t) t=1,...,N.
Supóngase que el periodo de muestreo es constante e igual a T, el modelo (7.19) es
muestreado también con este periodo de muestreo obteniéndose el siguiente modelo de
tiempo discreto
),( qGT (7.20)
La salida que proporciona este modelo es la siguiente:
NttuqGty T ,...,1),()·,()|(ˆ (7.21)
Los parámetros pueden entonces ser estimados obteniendo el vector de parámetros N
que minimice la función de coste del cuadrado de los errores de predicción:
N
tN tyty
1
2)]|(ˆ)([minargˆ
(7.22)
También es sencillo incluir ruido aditivo en el modelo continuo del sistema:

Identificación de sistemas
7-9
)()·,()()·,()( tepHtupGty (7.23)
donde p denota el operador diferenciación (sustituyendo a s):
dt
dp (7.24)
Simplemente hay que determinando el predictor muestreado adecuado del modelo (7.23) y
minimizar el error de la salida predicha por el mismo. Nótese que si se los datos de entrada
y salida son filtrados con un filtro de blanqueo L entonces ),( pH =1.
Las propiedades asintóticas del modelo estimado son bien conocidas. Supóngase que
la función de transferencia discreta de la planta del sistema es )( iT eG . Entonces para H=1,
se puede demostrar que
deLeGeG i
ui
Ti
TN ·)()·(|)(),(|minargˆ 220 (7.25)
donde )(u es el espectro de potencia de la entrada. La expresión anterior describe
exactamente en que forma un modelo continuo describe al sistema real.
A partir de la versión 6 de la toolbox SIT de Matlab 7.0 es posible estimar modelos
continuos simples del tipo (7.14)-(7.18). La forma de referirse a ellos es a través de un
acrónimo construido a partir de los siguientes símbolos básicos:
‘P’ significa modelo del proceso (Process Model) .
Un número entero denota el número de polos, sin incluir el integrador.
‘D’ significa que el modelo incluye un tiempo de retardo (time Delay).
‘I’ significa que el modelo incluye un integrador (Integrator).
‘Z’ significa que el modelo incluye un cero (zero).
‘U’ significa que el modelo incluye un polo subamortiguado (under-damped).
De acuerdo con lo anterior (7.14) se denotaría como P1D, (7.15) como P1, (7.16) como
P1ID, (7.17) como P2ZD y (7.18) como P2ZU.
Para crear un modelo de cualquiera de los tipos anteriores se utiliza el comando
idproc y para estimar sus parámetros a partir de un conjunto de datos de entrada-salida

TEMA 7: Identificación de modelos paramétricos continuos
7-10
hay que usar el comando pem. Con estos comandos también es posible incluir condiciones
iniciales, modelos de ruido aditivo, fijar el valor de algún parámetro, y establecer cotas
superiores inferiores y superiores para los valores de los parámetros. La estimación de
modelos continuos simples también se puede realizar desde el GUI de la SIT, en concreto
seleccionado la entrada Process Model dentro del menú Estimate.
Ejemplo 7.3:
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SITB 6.0 de Matlab 7.0, donde el periodo de muestreo era T=0.08 s. Una
vez eliminados los valores medios se van a utilizar los primeros 300 datos para estimar un modelo
continuo del tipo
dsT
p
esT
KsP
11)(
La secuencia de comandos necesarios para realizar estas acciones es la siguiente:
load dryer2.mat z2=[y2(1:300),u2(1:300)]; z2=dtrend(z2); y=z2(1:300,1); u=z2(1:300,2); data=iddata(y2,u2,0.08); m0=idproc('P1D'); m=pem(data,'P1D') m0=m;
En pantalla aparece lo siguiente
Process model with transfer function K G(s) = ---------- * exp(-Td*s) 1+Tp1*s with K = 0.9789 Tp1 = 0.3789 Td = 0.22071 Estimated using PEM from data set data
Loss function 0.0149167 and FPE 0.0150064
Nótese que como sucedía en el caso discreto después de estimar el modelo continuo hay que
validarlo para comprobar si es aceptable o debe ser rechazo. Los test de validación a utilizar son los
mismos que en el caso discreto (ver sección 6.6).

Identificación de sistemas
7-11
7.4 ESTIMACIÓN A PARTIR DE DATOS EN EL DOMINIO DE LA
FRECUENCIA
7.4.1 Estimación a partir de las transformadas de Fourier de la entrada y de la salida.
Supóngase que se disponen de N datos muestreados de la entrada u(t) y de la salida
y(t) del sistema a identificar. Si se aplica la transformada de Fourier discreta sobre la entrada
y la salida
NkNhkjhuUN
h
1)/)1(*)1·(·2·)·exp(()(1
(7.26)
NkNhkjhyYN
h
1)/)1(*)1·(·2·)·exp(()(1
(7.27)
es posible estimar directamente usando la aproximación del error de predicción un modelo
OE continuo G(s):
nbnbnfnf
nbnbnb
fsfsfs
bsbsbsG
11
1
11
1
...·
...·)( (7.28)
La estructura de este modelo queda definida por los órdenes del numerador y del
denominador [nb,nf].
Ejemplo 7.4:
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
dryer2.mat de la toolbox SITB 6.0 de Matlab 7.0, donde el periodo de muestreo era T=0.08 s. Una
vez eliminados los valores medios se van a utilizar los primeros 300 datos para estimar un modelo
OE continuo con estructura [2, 4], es decir
412
23
14
21
···
·)(
fsfsfsfs
bsbsG
La secuencia de comandos necesarios para realizar estas acciones es la siguiente:
load dryer2.mat z2=[y2(1:300),u2(1:300)]; z2=dtrend(z2); y=z2(1:300,1); u=z2(1:300,2); data=iddata(y2,u2,0.08);

TEMA 7: Identificación de modelos paramétricos continuos
7-12
df=fft(data); %Transformada de Fourier discreta df.ts=0; % Se fija el tiempo de muestreo a 0 para tratar los datos en %tiempo continuo nb=2;nf=4; m=oe(df,[nb nf])
En pantalla aparece lo siguiente
Continuous-time IDPOLY model: y(t) = [B(s)/F(s)]u(t) + e(t) B(s) = -8.051e006 s + 9.937e007 F(s) = s^4 + 7.272e005 s^3 + 8.232e006 s^2 + 5.574e007 s + 1.015e008 Estimated using OE from data set df Loss function 0.0100484 and FPE 0.0103338
Nótese que como sucedía en el caso discreto después de estimar el modelo continuo hay que
validarlo para comprobar si es aceptable o debe ser rechazo. Los test de validación a utilizar son los
mismos que en el caso discreto (ver sección 6.6).
Si los datos son muestreados con un periodo de muestreo muy pequeño, suele ser una buena idea
aplicar algún filtro pasa baja antes de hacer el ajuste. Por ejemplo si sólo interesa que el modelo este
bien ajustado en el rango de frecuencias entre 0 y 10 rad/s entonces el comando OE se debe escribir
de la siguiente forma
m=oe(df,[nb nf],'focus',[0, 10])
En pantalla se muestre el siguiente resultado:
Continuous-time IDPOLY model: y(t) = [B(s)/F(s)]u(t) + e(t) B(s) = -349.6 s + 5637 F(s) = s^4 + 46.96 s^3 + 517.9 s^2 + 3194 s + 5695 Estimated using OE from data set df Loss function 0.00610681 and FPE 0.00628023
7.4.2 Estimación a partir de datos obtenidos del análisis en frecuencia.
Si un sistema lineal con función de transferencia G(s) se excita con una entrada de tipo
sinusoidal (o cosenoidal)
)··cos()( 0 tutu (7.29)
entonces la salida en el estacionario es también de tipo sinusoidal
)··cos()( 0 tyty (7.30)
donde
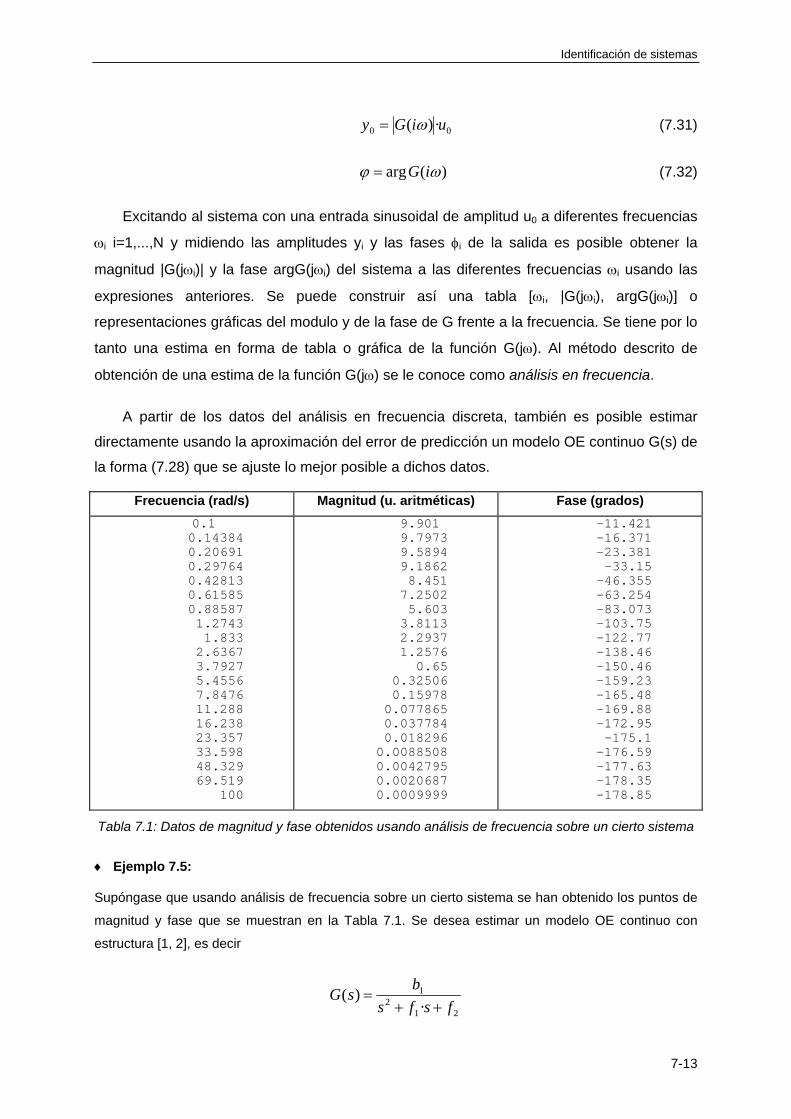
Identificación de sistemas
7-13
00 ·)( uiGy (7.31)
)(arg iG (7.32)
Excitando al sistema con una entrada sinusoidal de amplitud u0 a diferentes frecuencias
i i=1,...,N y midiendo las amplitudes yi y las fases i de la salida es posible obtener la
magnitud |G(ji)| y la fase argG(ji) del sistema a las diferentes frecuencias i usando las
expresiones anteriores. Se puede construir así una tabla [i, |G(ji), argG(ji)] o
representaciones gráficas del modulo y de la fase de G frente a la frecuencia. Se tiene por lo
tanto una estima en forma de tabla o gráfica de la función G(j). Al método descrito de
obtención de una estima de la función G(j) se le conoce como análisis en frecuencia.
A partir de los datos del análisis en frecuencia discreta, también es posible estimar
directamente usando la aproximación del error de predicción un modelo OE continuo G(s) de
la forma (7.28) que se ajuste lo mejor posible a dichos datos.
Frecuencia (rad/s) Magnitud (u. aritméticas) Fase (grados)
0.1 0.14384 0.20691 0.29764 0.42813 0.61585 0.88587 1.2743 1.833 2.6367 3.7927 5.4556 7.8476 11.288 16.238 23.357 33.598 48.329 69.519 100
9.901 9.7973 9.5894 9.1862 8.451 7.2502 5.603 3.8113 2.2937 1.2576 0.65 0.32506 0.15978 0.077865 0.037784 0.018296 0.0088508 0.0042795 0.0020687 0.0009999
-11.421 -16.371 -23.381 -33.15 -46.355 -63.254 -83.073 -103.75 -122.77 -138.46 -150.46 -159.23 -165.48 -169.88 -172.95 -175.1 -176.59 -177.63 -178.35 -178.85
Tabla 7.1: Datos de magnitud y fase obtenidos usando análisis de frecuencia sobre un cierto sistema
Ejemplo 7.5:
Supóngase que usando análisis de frecuencia sobre un cierto sistema se han obtenido los puntos de
magnitud y fase que se muestran en la Tabla 7.1. Se desea estimar un modelo OE continuo con
estructura [1, 2], es decir
212
1
·)(
fsfs
bsG
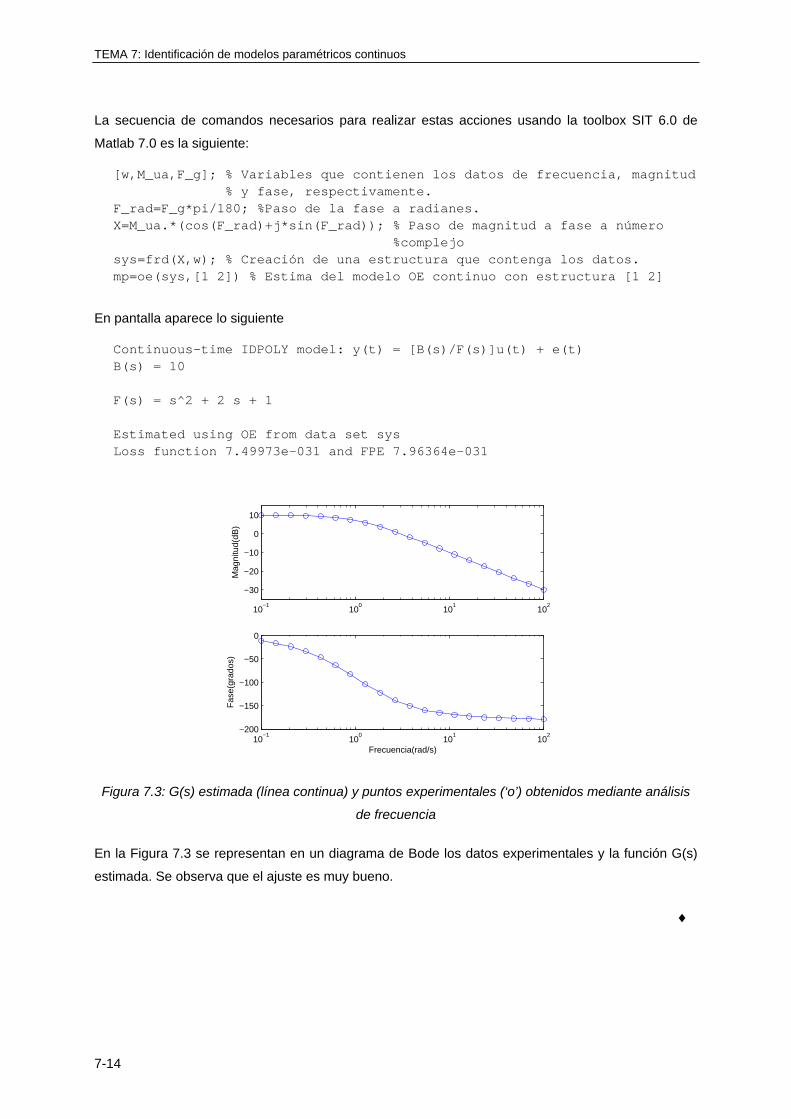
TEMA 7: Identificación de modelos paramétricos continuos
7-14
La secuencia de comandos necesarios para realizar estas acciones usando la toolbox SIT 6.0 de
Matlab 7.0 es la siguiente:
[w,M_ua,F_g]; % Variables que contienen los datos de frecuencia, magnitud % y fase, respectivamente. F_rad=F_g*pi/180; %Paso de la fase a radianes. X=M_ua.*(cos(F_rad)+j*sin(F_rad)); % Paso de magnitud a fase a número %complejo sys=frd(X,w); % Creación de una estructura que contenga los datos. mp=oe(sys,[1 2]) % Estima del modelo OE continuo con estructura [1 2]
En pantalla aparece lo siguiente
Continuous-time IDPOLY model: y(t) = [B(s)/F(s)]u(t) + e(t) B(s) = 10 F(s) = s^2 + 2 s + 1 Estimated using OE from data set sys Loss function 7.49973e-031 and FPE 7.96364e-031
10−1
100
101
102
−30
−20
−10
0
10
Mag
nitu
d(dB
)
10−1
100
101
102
−200
−150
−100
−50
0
Fas
e(gr
ados
)
Frecuencia(rad/s)
Figura 7.3: G(s) estimada (línea continua) y puntos experimentales (‘o’) obtenidos mediante análisis
de frecuencia
En la Figura 7.3 se representan en un diagrama de Bode los datos experimentales y la función G(s)
estimada. Se observa que el ajuste es muy bueno.

Identificación de sistemas
7-15
BIBLIOGRAFÍA
[Ljung y Glad, 1994] L. Ljung y T. Glad. Modelling of dynamic systems. Prentice
Hall. 1994.
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.
[Ogata, 1996] K. Ogata. Sistemas de Control en Tiempo Discreto. Prentice
Hall.1996.


TEMA 8
IDENTIFICACIÓN EN LAZO CERRADO
8-1
8.1 INTRODUCCIÓN
Muchos sistemas y procesos trabajan habitualmente en lazo cerrado (ver Figura 8.5), es
decir, usando un controlador realimentado con los valores de las salidas, en función de las
cuales y según una determinada ley de control genera los valores de las entradas.
Algunos sistemas son inestables en lazo abierto por lo que no es posible realizar ningún
experimento de identificación sobre ellos. Razones de seguridad o de tipo económico son el
principal argumento para operar con el sistema en lazo cerrado.
La realización de la identificación en lazo cerrado presenta varias ventajas:
Elimina la necesidad de poner el lazo de control en modo manual durante los
experimentos de identificación.
Permite mantener a la planta dentro de los límites habituales de operación.
Posibilita la realización de una identificación “amigable con la planta” de sistemas
que en lazo abierto son inestables.
Es importante saber si es posible identificar el sistema en lazo abierto a partir de datos
obtenidos operando en lazo cerrado. En general la existencia de realimentación introduce
diversos problemas que dificultan la identificación del sistema en lazo abierto, pero éstos
pueden ser tratados oportunamente. El principal objetivo de la identificación en lazo cerrado
es obtener buenos modelos del sistema en lazo abierto a pesar de la realimentación.
Existen diferentes métodos de identificación en lazo cerrado, los cuales se pueden
clasificar en dos grandes grupos:

TEMA 8: Identificación en lazo cerrado
8-2
Métodos basados en la aproximación directa. Ignoran la existencia de
realimentación e identifican el sistema en lazo abierto usando medidas de la
entrada u(t) y la salida y(t). Para obtener estas medidas el sistema es excitado
introduciendo una entrada externa ya diseñada (PRBS, multiseno,..) en el punto
de consigna r o en la entrada de la planta ud.
Métodos basados en la aproximación Indirecta. Identifican el sistema en lazo
cerrado usando medidas de la señal de referencia r y la salida y. Después
utilizan esta estima para obtener los parámetros del sistema en lazo abierto
supuesto que se conoce exactamente el modelo matemático del controlador.
Los métodos de identificación en lazo cerrado basados en la aproximación directa
producen mejores resultados que los basados en la aproximación indirecta. Esto es así
porque en la aproximación indirecta se requiere de un conocimiento exacto del controlador,
el problema es que en la realidad los controladores más simples, como por ejemplo un PID,
pueden no comportarse de acuerdo a su modelo matemático.
En este tema en primer lugar se comentan los problemas que presenta la identificación
en lazo cerrado. A continuación se describen las características y propiedades de los
métodos de identificación en lazo cerrado basados en la aproximación directa. El tema
finaliza con una recopilación de las principales conclusiones sobre la identificación en lazo
cerrado.
8.2 PROBLEMAS QUE PRESENTA LA IDENTIFICACIÓN EN LAZO
CERRADO
A menudo resulta peligroso o caro realizar experimentos sobre el sistema del cual se
desea obtener un modelo, por este motivo los datos tienen que ser obtenidos durante las
condiciones normales de operación del sistema. Usualmente esto significa que el proceso
está controlado, es decir opera en lazo cerrado, con lo que la entrada es determinada
parcialmente mediante la realimentación de la salida.
El principal problema que presenta la identificación en lazo cerrado según palabras de
L. Ljung es el siguiente: “el objetivo de la realimentación es hacer que la función de
sensibilidad del sistema sea pequeña, especialmente en aquellas frecuencias con presencia
de perturbaciones y con un pobre conocimiento del sistema. La realimentación, por lo tanto,
empeora la información que los datos medidos contienen sobre el sistema a dichas
frecuencias”.

Identificación de sistemas
8-3
En resumen la información sobre el sistema que contienen los datos que se obtienen en
lazo cerrado es menor que si se obtienen en lazo abierto. Sería posible aumentar la cantidad
de información de los datos medidos en lazo cerrado pero a costa de empeorar el
comportamiento del control (su sintonía) del sistema en lazo cerrado. En definitiva cuando
se realiza identificación en lazo cerrado se debe llegar a un compromiso entre el
comportamiento del control y el grado de información que contienen los datos.
Además otros problemas que presenta la identificación en lazo cerrado son los
siguientes:
La realimentación introduce correlación entre la entrada u y la perturbación v. Este el
motivo por el que algunos métodos de identificación como los no-paramétricos o la
aproximación de subespacios, que funcionan bien en lazo abierto, fallan cuando se
aplican sobre datos obtenidos en lazo cerrado, excepto si se toman unas medidas
especiales.
La acción de control distorsiona la señal de entrada, lo que introduce un error de
sesgo adicional al “comerse” parte de la excitación de la señal de entrada.
Ejemplo 8.1:
Considérese el siguiente sistema real
)()1()1(·)( 00 tetubtyaty (1)
Supóngase que el sistema opera en lazo cerrado usando el siguiente regulador proporcional
)(·)( tyftu (2)
Supóngase que a partir de datos obtenidos de este sistema se desea estimar los parámetros del
siguiente modelo ARX:
)()1(·)1(·)( tetubtyaty
El predictor de la salida es por lo tanto:
)1()··()1(·)1(·)|(ˆ tyafbtubtyaty
Todos las estimas )ˆ,ˆ( ba de los parámetros del modelo tal que afb ˆ·ˆ sea un cierto número dado
producirán por lo tanto idénticas predicciones con la realimentación existente. En consecuencia
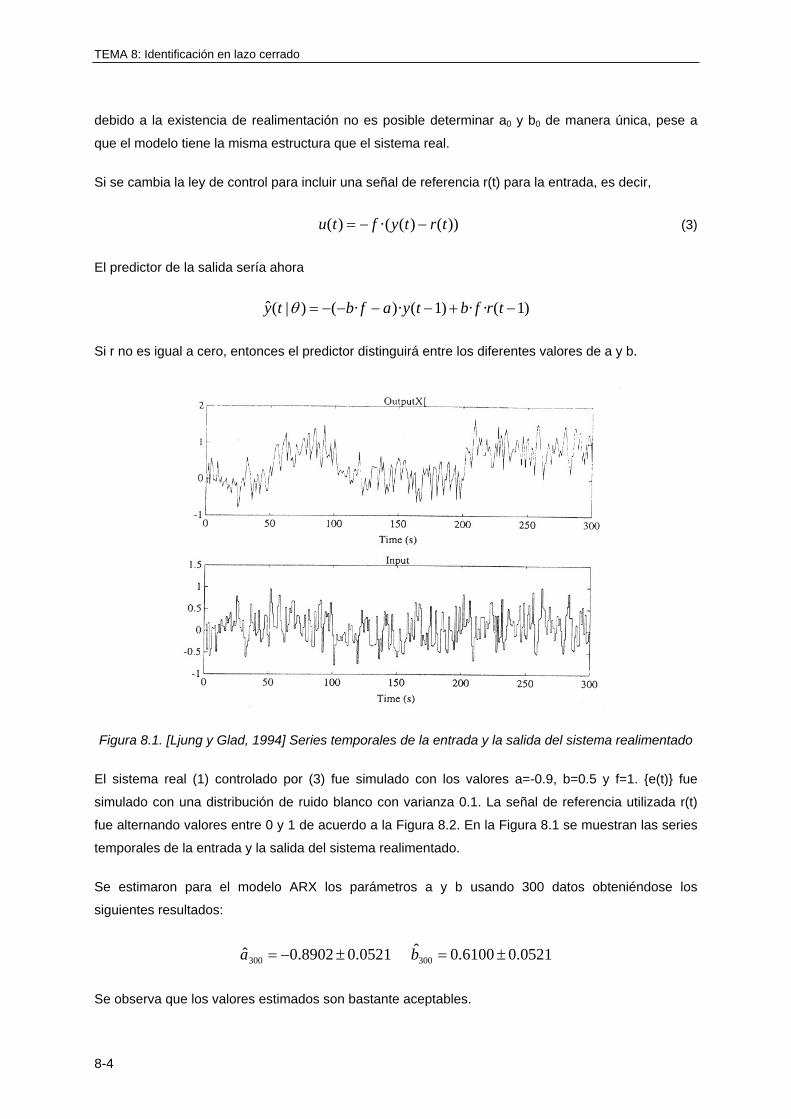
TEMA 8: Identificación en lazo cerrado
8-4
debido a la existencia de realimentación no es posible determinar a0 y b0 de manera única, pese a
que el modelo tiene la misma estructura que el sistema real.
Si se cambia la ley de control para incluir una señal de referencia r(t) para la entrada, es decir,
))()(·()( trtyftu (3)
El predictor de la salida sería ahora
)1(··)1()··()|(ˆ trfbtyafbty
Si r no es igual a cero, entonces el predictor distinguirá entre los diferentes valores de a y b.
Figura 8.1. [Ljung y Glad, 1994] Series temporales de la entrada y la salida del sistema realimentado
El sistema real (1) controlado por (3) fue simulado con los valores a=-0.9, b=0.5 y f=1. {e(t)} fue
simulado con una distribución de ruido blanco con varianza 0.1. La señal de referencia utilizada r(t)
fue alternando valores entre 0 y 1 de acuerdo a la Figura 8.2. En la Figura 8.1 se muestran las series
temporales de la entrada y la salida del sistema realimentado.
Se estimaron para el modelo ARX los parámetros a y b usando 300 datos obteniéndose los
siguientes resultados:
0521.06100.0ˆ0521.08902.0ˆ 300300 ba
Se observa que los valores estimados son bastante aceptables.
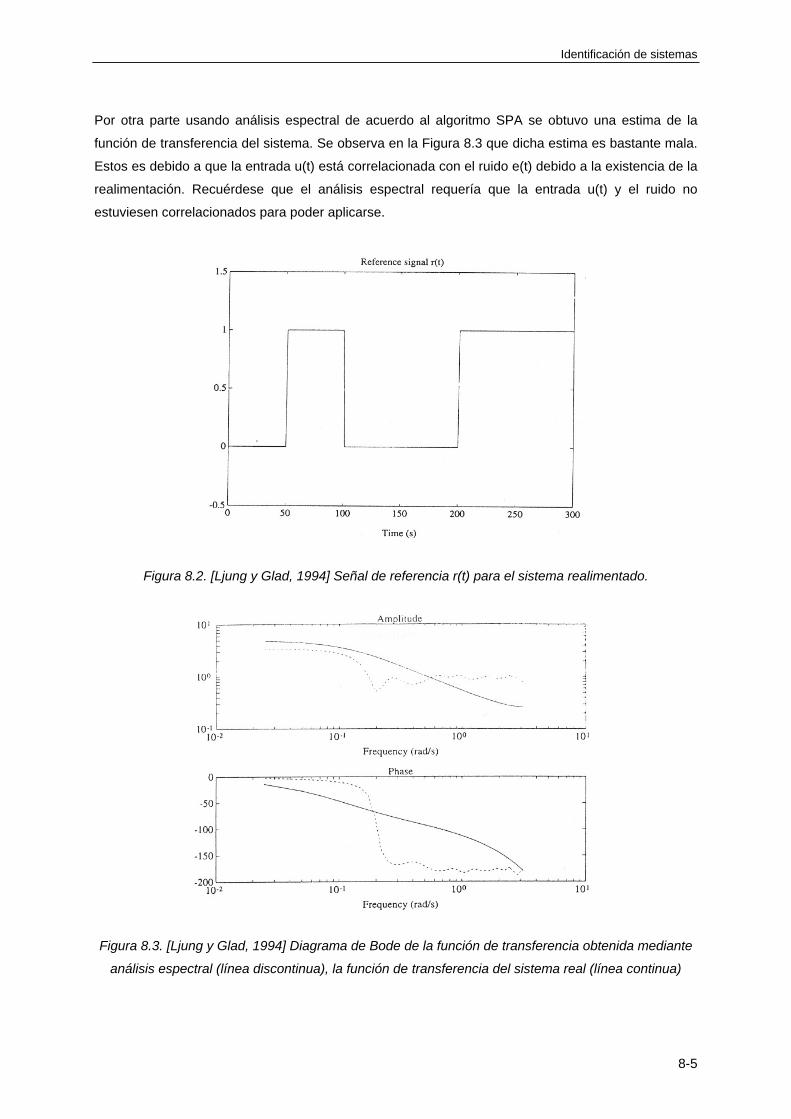
Identificación de sistemas
8-5
Por otra parte usando análisis espectral de acuerdo al algoritmo SPA se obtuvo una estima de la
función de transferencia del sistema. Se observa en la Figura 8.3 que dicha estima es bastante mala.
Estos es debido a que la entrada u(t) está correlacionada con el ruido e(t) debido a la existencia de la
realimentación. Recuérdese que el análisis espectral requería que la entrada u(t) y el ruido no
estuviesen correlacionados para poder aplicarse.
Figura 8.2. [Ljung y Glad, 1994] Señal de referencia r(t) para el sistema realimentado.
Figura 8.3. [Ljung y Glad, 1994] Diagrama de Bode de la función de transferencia obtenida mediante
análisis espectral (línea discontinua), la función de transferencia del sistema real (línea continua)
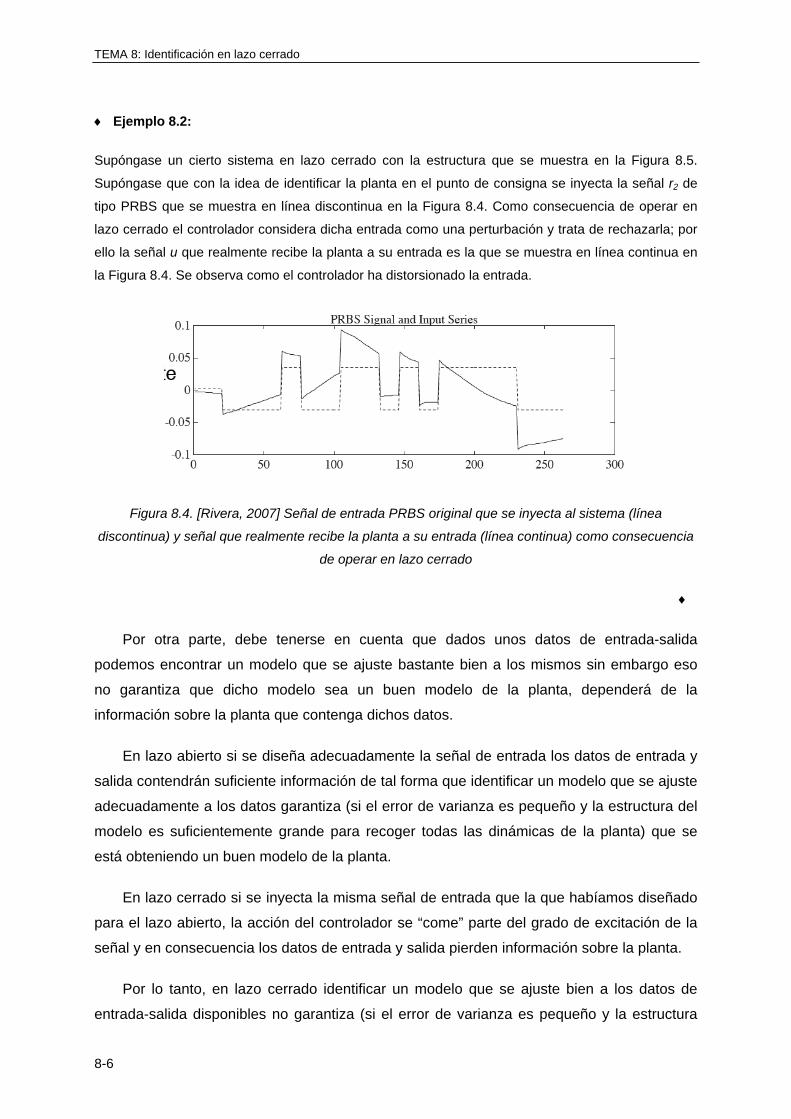
TEMA 8: Identificación en lazo cerrado
8-6
Ejemplo 8.2:
Supóngase un cierto sistema en lazo cerrado con la estructura que se muestra en la Figura 8.5.
Supóngase que con la idea de identificar la planta en el punto de consigna se inyecta la señal r2 de
tipo PRBS que se muestra en línea discontinua en la Figura 8.4. Como consecuencia de operar en
lazo cerrado el controlador considera dicha entrada como una perturbación y trata de rechazarla; por
ello la señal u que realmente recibe la planta a su entrada es la que se muestra en línea continua en
la Figura 8.4. Se observa como el controlador ha distorsionado la entrada.
Figura 8.4. [Rivera, 2007] Señal de entrada PRBS original que se inyecta al sistema (línea
discontinua) y señal que realmente recibe la planta a su entrada (línea continua) como consecuencia
de operar en lazo cerrado
Por otra parte, debe tenerse en cuenta que dados unos datos de entrada-salida
podemos encontrar un modelo que se ajuste bastante bien a los mismos sin embargo eso
no garantiza que dicho modelo sea un buen modelo de la planta, dependerá de la
información sobre la planta que contenga dichos datos.
En lazo abierto si se diseña adecuadamente la señal de entrada los datos de entrada y
salida contendrán suficiente información de tal forma que identificar un modelo que se ajuste
adecuadamente a los datos garantiza (si el error de varianza es pequeño y la estructura del
modelo es suficientemente grande para recoger todas las dinámicas de la planta) que se
está obteniendo un buen modelo de la planta.
En lazo cerrado si se inyecta la misma señal de entrada que la que habíamos diseñado
para el lazo abierto, la acción del controlador se “come” parte del grado de excitación de la
señal y en consecuencia los datos de entrada y salida pierden información sobre la planta.
Por lo tanto, en lazo cerrado identificar un modelo que se ajuste bien a los datos de
entrada-salida disponibles no garantiza (si el error de varianza es pequeño y la estructura

Identificación de sistemas
8-7
del modelo es suficientemente grande para recoger todas las dinámicas de la planta) que se
esté obteniendo un buen modelo de la planta, dependerá del grado de información sobre la
planta que contenga los datos. Dicho grado de información depende de la distorsión que
haya introducido el controlador a la señal de entrada inyectada. Cuanto más rápida sea la
velocidad de respuesta del controlador mayor será la distorsión de la señal de entrada y
menos información contendrán los datos de entrada-salida.
8.3 IDENTIFICACIÓN EN LAZO CERRADO MEDIANTE
APROXIMACIÓN DIRECTA
8.3.1 Consideraciones generales
Considérese el sistema en lazo cerrado de la Figura 8.5 donde C es el controlador, G0
es la planta, r es una señal de referencia o punto de consigna, ud es una señal de excitación
externa, u es la entrada de la planta, y es la salida del sistema y v una perturbación
aleatoria.
Figura 8.5. Sistema en lazo cerrado
El sistema real en lazo abierto es:
0 0 0( ) ( )· ( ) ( ) ( )· ( ) ( )· ( )y t G q u t v t G q u t H q a t (8.1)
donde {a(t)} es ruido blanco con varianza 2a . En lazo cerrado la entrada de la planta es:
( ) ( ) ( )·( ( ) ( ))du t u t C q r t y t (8.2)
El sistema en lazo cerrado se puede escribir de la siguiente forma (supuesto ud=0):
0 0( ) ( ) ( ) ( ) ( )y t T q r t S q v t (8.3)
donde S0(q) es la función de sensibilidad de la salida y a la perturbación v:

TEMA 8: Identificación en lazo cerrado
8-8
00
1( )
1 ( ) ( )S q
G q C q
(8.4)
Y T0(q) es la función de sensibilidad complementaria:
00 0
0
( ) ( )( ) 1 ( )
1 ( ) ( )
G q C qT q S q
G q C q
(8.5)
La identificación en lazo cerrado mediante aproximación directa consiste en:
1. Excitar al sistema en lazo cerrado con una señal de entrada (típicamente PRBS
o multiseno bien diseñada) que se inyecta en el punto de consigna (señal de
referencia r(t)) o en la entrada de la planta (señal ud(t)).
2. Recoger los datos de la entrada u(t) y la salida y(t).
3. A partir de los datos de entrada-salida medidos obtener un modelo del sistema
real en lazo abierto mediante algún método de identificación.
Generalmente se suelen obtener modelos basados en la minimización del error de
predicción (modelos PEM) cuyas propiedades y obtención fue descrita en el Tema 6 de
estos apuntes. Se trabaja con modelos de la forma
)()·,()()·,()( teqHtuqGty (8.6)
El predictor a un paso de la salida es
)())·,(1()()·,()·,()|(ˆ 11 tyqHtuqGqHty (8.7)
El error de predicción para este modelo viene dado por
))()·,()()·(,()|(ˆ)(),( 1 tuqGtyqHtytyt (8.8)
En general, la estima óptima se obtiene de la siguiente forma:
)(minargˆ NN V (8.9)
donde

Identificación de sistemas
8-9
N
tFN t
NV
1
2 ),(·2
11)( (8.10)
),()·,(),( tqLtF (8.11)
Siendo L algún prefiltro estable que se puede utilizar para realzar ciertos rangos de
frecuencia. Con lo que el error de predicción prefiltrado es:
))()·,()()·(,()·,(),( 1 tuqGtyqHqLtF (8.12)
El efecto del prefiltro L puede ser incluido dentro del modelo del ruido y es posible
suponer que L(q,)=1 sin pérdida de generalidad.
8.3.2 Consideraciones sobre al error de sesgo
Si el número de datos N tiende a infinito, el error de varianza será despreciable, y se
puede demostrar (ver sección 6.4.3) que el espectro del error de predicción prefiltrado es:
22 * 2 2
0 0 0 02
| |( ) [| | · 2·Re(( )· ( )· ) | ( ) | · ]
| |F
i ie u ua a
LG G G G H e H e
H (8.13)
En la expresión anterior se encuentran presentes todas las fuentes que contribuyen al
error de sesgo. Nótese que en lazo cerrado existe correlación cruzada entre la entrada u y la
perturbación a debido a la realimentación de la salida sobre la entrada y por ello el término
ua del espectro cruzado entre la entrada y la perturbación a es distinto de cero y contribuye
al error de sesgo.
Si el número de datos N tiende a infinito se puede obtener una estima consistente, es
decir, que las estimas de las funciones de transferencia de la planta y del ruido coincidan
con las del sistema real
0( ) ( )G q G q
0( ) ( )H q H q
Para ello se tienen que cumplir las siguientes condiciones:

TEMA 8: Identificación en lazo cerrado
8-10
1) La estructura de los modelos G y H de la planta y del ruido describe adecuadamente
a la planta G0 y al ruido H0 del sistema real. Es decir, se ha tenido que elegir
estructuras adecuadas para dichos modelos.
2) La entrada u(t) posee excitación persistente de orden adecuado. Es decir, el espectro
de potencia de la entrada debe ser distinto de cero en un rango de frecuencias
adecuado.
Nótese que estas dos condiciones para conseguir una estima consistente son
independientes del modo de operación del sistema (lazo abierto o lazo cerrado), es decir, no
requieren que la entrada u(t) y el ruido a(t) no estén correlacionados ( ua =0). Sin embargo,
en lazo abierto ( ua =0) se puede obtener una estima consistente G de la planta G0 aunque
el modelo del ruido no sea muy bueno. Por el contrario, en lazo cerrado, para obtener una
estima consistente G de la planta G0 se requiere disponer tanto de un buen modelo G de la
planta como de un buen modelo H del ruido. Por ello en lazo cerrado modelos PEM que no
consideran el ruido como los modelos OE no dan buenos resultados.
8.3.3 Selección del punto de aplicación de la señal de excitación
Puede demostrarse que en lazo cerrado la expresión del espectro del error de
predicción prefiltrado cuando el número de datos N tiende a infinito toma la siguiente forma:
2
2 1 2 2 2 20 0 0 0 02
| |( ) | | | | | | |1 | | | ]
| |F de r u v
LG G G T S GC S
H (8.14)
Analizando la expresión anterior se obtienen las siguientes conclusiones:
Para aquellas frecuencias donde el espectro del ruido v predomine, el
espectro del error de predicción se puede minimizar 0Fe cuando el modelo
de la planta es igual a la inversa del controlador:
1G
C
Para aquellas frecuencias donde / 1du v o / 1r v es posible obtener
una estimación sin error de sesgo de la planta, es decir, G=G0.
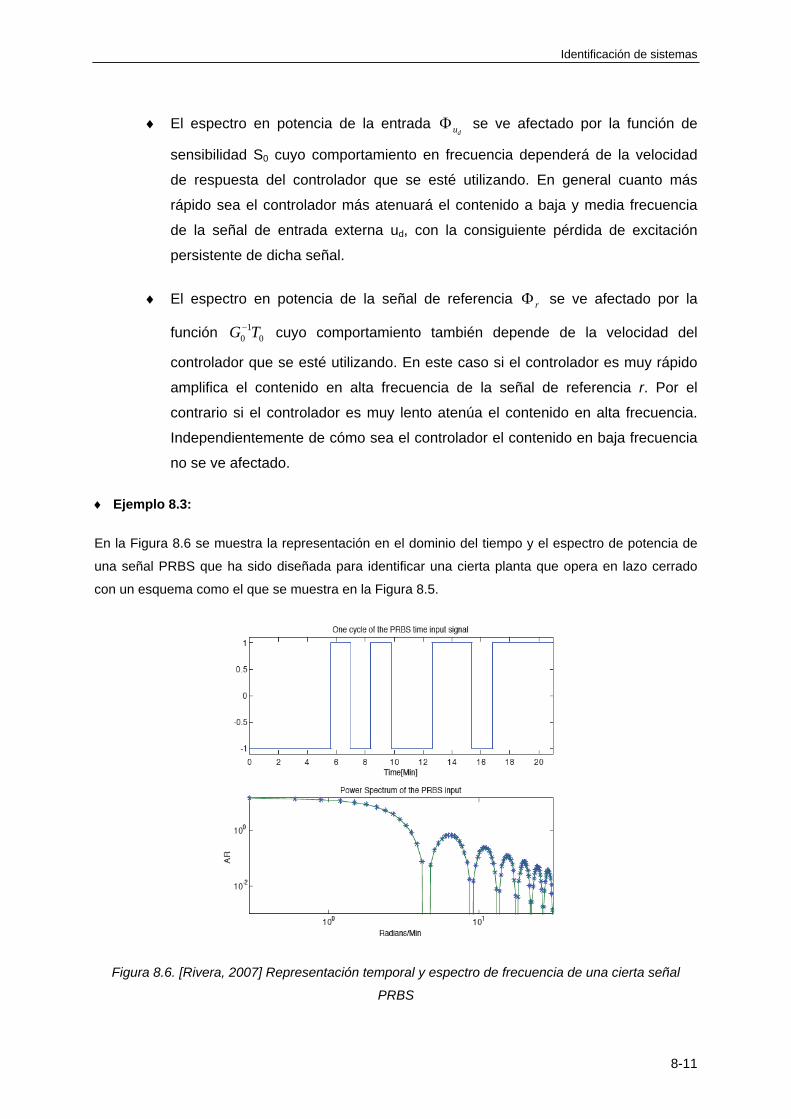
Identificación de sistemas
8-11
El espectro en potencia de la entrada du se ve afectado por la función de
sensibilidad S0 cuyo comportamiento en frecuencia dependerá de la velocidad
de respuesta del controlador que se esté utilizando. En general cuanto más
rápido sea el controlador más atenuará el contenido a baja y media frecuencia
de la señal de entrada externa ud, con la consiguiente pérdida de excitación
persistente de dicha señal.
El espectro en potencia de la señal de referencia r se ve afectado por la
función 10 0G T cuyo comportamiento también depende de la velocidad del
controlador que se esté utilizando. En este caso si el controlador es muy rápido
amplifica el contenido en alta frecuencia de la señal de referencia r. Por el
contrario si el controlador es muy lento atenúa el contenido en alta frecuencia.
Independientemente de cómo sea el controlador el contenido en baja frecuencia
no se ve afectado.
Ejemplo 8.3:
En la Figura 8.6 se muestra la representación en el dominio del tiempo y el espectro de potencia de
una señal PRBS que ha sido diseñada para identificar una cierta planta que opera en lazo cerrado
con un esquema como el que se muestra en la Figura 8.5.
Figura 8.6. [Rivera, 2007] Representación temporal y espectro de frecuencia de una cierta señal
PRBS
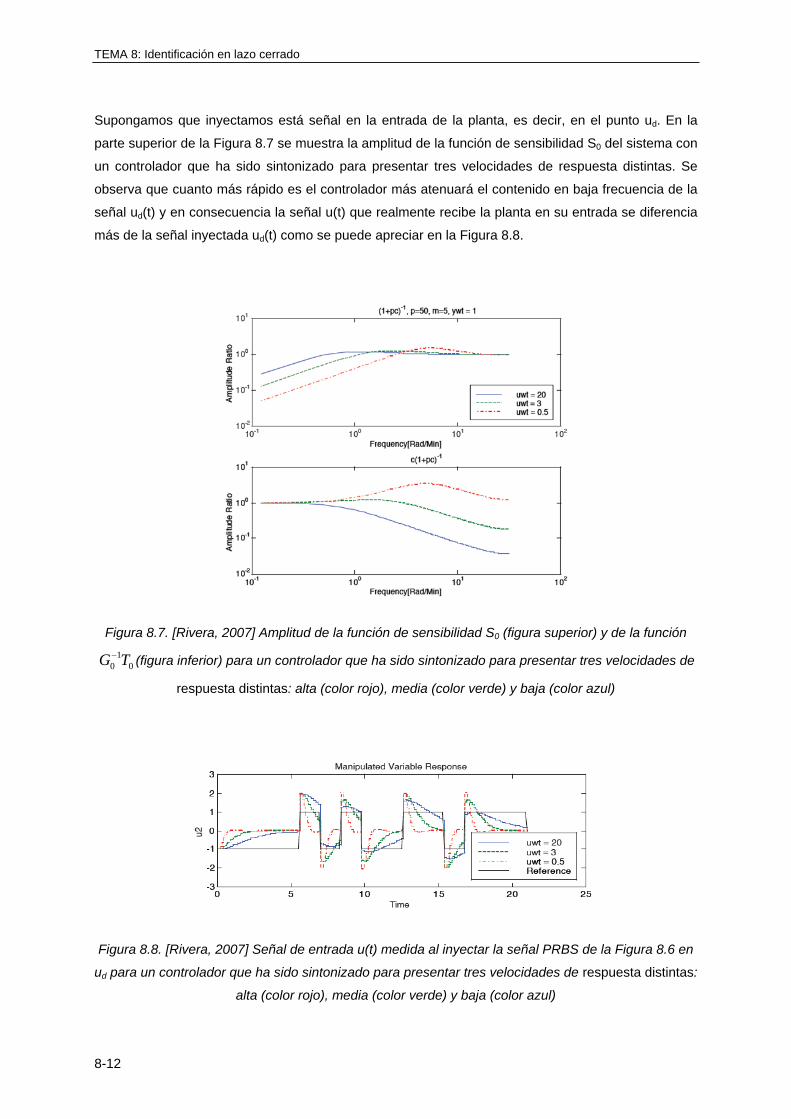
TEMA 8: Identificación en lazo cerrado
8-12
Supongamos que inyectamos está señal en la entrada de la planta, es decir, en el punto ud. En la
parte superior de la Figura 8.7 se muestra la amplitud de la función de sensibilidad S0 del sistema con
un controlador que ha sido sintonizado para presentar tres velocidades de respuesta distintas. Se
observa que cuanto más rápido es el controlador más atenuará el contenido en baja frecuencia de la
señal ud(t) y en consecuencia la señal u(t) que realmente recibe la planta en su entrada se diferencia
más de la señal inyectada ud(t) como se puede apreciar en la Figura 8.8.
Figura 8.7. [Rivera, 2007] Amplitud de la función de sensibilidad S0 (figura superior) y de la función
10 0G T (figura inferior) para un controlador que ha sido sintonizado para presentar tres velocidades de
respuesta distintas: alta (color rojo), media (color verde) y baja (color azul)
Figura 8.8. [Rivera, 2007] Señal de entrada u(t) medida al inyectar la señal PRBS de la Figura 8.6 en
ud para un controlador que ha sido sintonizado para presentar tres velocidades de respuesta distintas:
alta (color rojo), media (color verde) y baja (color azul)
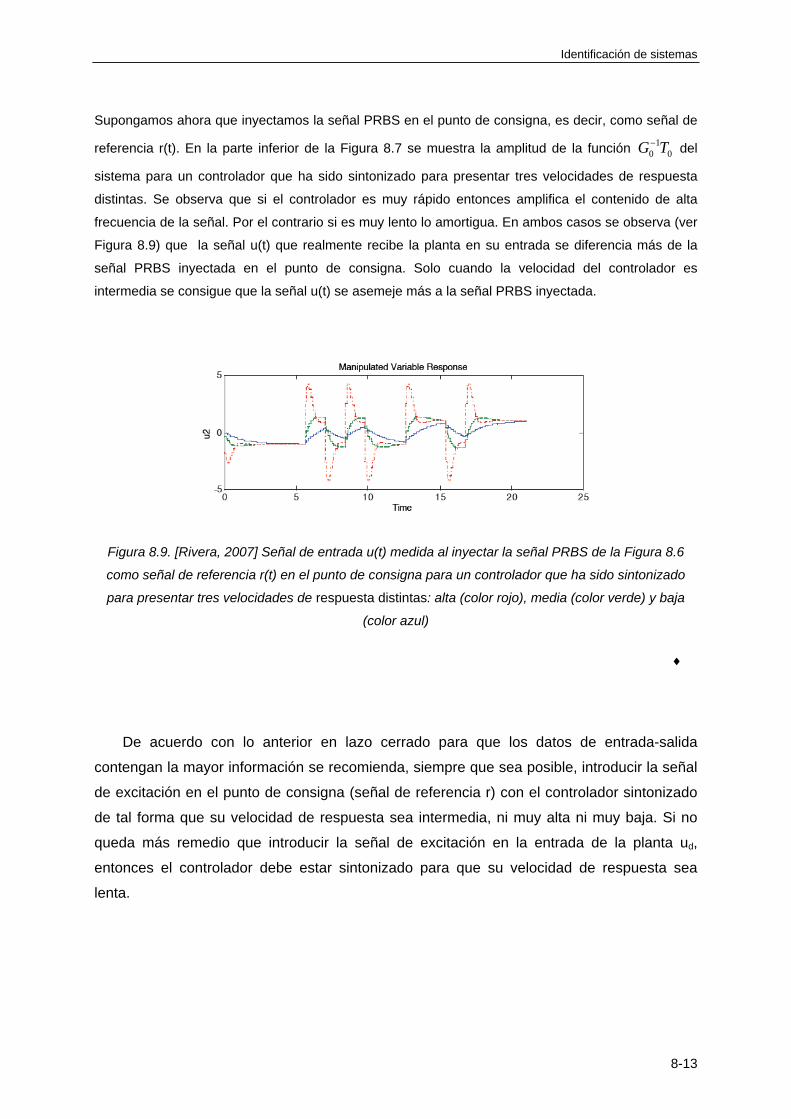
Identificación de sistemas
8-13
Supongamos ahora que inyectamos la señal PRBS en el punto de consigna, es decir, como señal de
referencia r(t). En la parte inferior de la Figura 8.7 se muestra la amplitud de la función 10 0G T del
sistema para un controlador que ha sido sintonizado para presentar tres velocidades de respuesta
distintas. Se observa que si el controlador es muy rápido entonces amplifica el contenido de alta
frecuencia de la señal. Por el contrario si es muy lento lo amortigua. En ambos casos se observa (ver
Figura 8.9) que la señal u(t) que realmente recibe la planta en su entrada se diferencia más de la
señal PRBS inyectada en el punto de consigna. Solo cuando la velocidad del controlador es
intermedia se consigue que la señal u(t) se asemeje más a la señal PRBS inyectada.
Figura 8.9. [Rivera, 2007] Señal de entrada u(t) medida al inyectar la señal PRBS de la Figura 8.6
como señal de referencia r(t) en el punto de consigna para un controlador que ha sido sintonizado
para presentar tres velocidades de respuesta distintas: alta (color rojo), media (color verde) y baja
(color azul)
De acuerdo con lo anterior en lazo cerrado para que los datos de entrada-salida
contengan la mayor información se recomienda, siempre que sea posible, introducir la señal
de excitación en el punto de consigna (señal de referencia r) con el controlador sintonizado
de tal forma que su velocidad de respuesta sea intermedia, ni muy alta ni muy baja. Si no
queda más remedio que introducir la señal de excitación en la entrada de la planta ud,
entonces el controlador debe estar sintonizado para que su velocidad de respuesta sea
lenta.

TEMA 8: Identificación en lazo cerrado
8-14
8.3.4 Consideraciones sobre el error de varianza
En la sección 6.4.4 se obtuvo la siguiente expresión para LA covarianza asintótica del
modelo estimado para la planta )( jeG y para la perturbación )( jeH , supuesto que el
número de parámetros d que contiene el modelo y N el número de datos de entrada-salida
disponibles es suficientemente grande:
1
2
( ) ( )( )· ( )·
( )( )
ju ua
vjau a
G e dCov
NH e
(8.15)
Donde )(u es el espectro de potencia de la entrada, 220 ·|)(|)( a
iv eH es el
espectro de potencia de la perturbación y )()( * auua es el espectro de potencia
cruzada entre la entrada u(t) y el ruido blanco a(t).
Si se opera con el elemento (1,1) de (8.15) se obtiene la siguiente expresión:
2
22[ ( )] · ( )·
( ) ( )j a
v
a u ua
dCov G e
N
(8.16)
Para el caso de considerar en lazo cerrado las entradas externas (ext) r y ud, las cuales
se suponen que no están correlacionadas con la perturbación v, se obtiene la siguiente
expresión:
1 2 20 0 0
( ) ( )[ ( )] · ·
( ) | | | |d
j v vextu r u
d dCov G e
N N G T S
(8.17)
En lazo cerrado el error de varianza en la estima de la planta depende, al igual que
sucedía en lazo abierto, de la relación señal ruido ( )
( )v
extu
. Sin embargo en lazo cerrado la
potencia de la señal de entrada se ve influenciada por la acción de control.
Si se compara el espectro de la salida en lazo cerrado
2 20 0( ) | |ext
y u vG S (8.18)
con el espectro de la salida en lazo abierto

Identificación de sistemas
8-15
2
0 ( )y u vG (8.19)
Se observa que cabe la posibilidad de generar datos en lazo cerrado que reduzcan la
varianza de la señal de salida sin incrementar la varianza de G. Para conseguirlo se
necesitará usar en lazo cerrado una señal de entrada externa con una magnitud mayor que
la que se necesitaría si se operara en lazo abierto.
8.4 CONCLUSIONES
Las principales conclusiones que se pueden extraer sobre la identificación en lazo
cerrado son:
El principal problema que produce la existencia de realimentación es que la
información que contienen los datos de entrada-salida es menor que en el caso de
operar en lazo abierto.
La existencia de realimentación también introduce correlación entre las medidas y
afecta al contenido en frecuencia de la señal de entrada, lo que influye en el error de
sesgo y en el error de varianza de la estima.
Para identificar en lazo cerrado se requiere usar una señal de excitación externa que
se recomienda inyectar en el punto de consigna (r(t)) sintonizando el controlador de
tal forma que su velocidad de respuesta sea intermedia.
Los métodos de identificación en lazo cerrado basados en la aproximación directa
proporcionan en la práctica mejores resultados que los métodos basados en la
aproximación indirecta.
Si se usa la aproximación directa los métodos basados en el error de predicción con
un modelo del ruido que pueda describir las propiedades del ruido que afecta al
sistema real pueden proporcionar estimas consistentes de una precisión arbitraria.
Varios métodos que dan estimas consistentes cuando se aplican a datos obtenidos
en lazo abierto pueden fallar en lazo cerrado si se utiliza la aproximación directa.
Entre estos métodos se encuentran los métodos no paramétricos, el método de la
variable instrumental, los métodos basados en subespacios y el uso de modelos OE
con un modelo incorrecto del ruido.

TEMA 8: Identificación en lazo cerrado
8-16
BIBLIOGRAFÍA
[Forssell and Ljung, 1997] U. Forsell, L. Ljung L. Issues in closed-loop identification.
Informe Técnico LiTH-ISY-R-1940. Department of Electrical
Engineering, Linköping University (Sweeden). 1997.
[Forssell and Ljung, 1999] U. Forsell, L. Ljung, Closed-loop identification Revisited.
Automatica, Vol 35, pp 1215-1241, 1999.
[Ljung y Glad, 1994] L. Ljung y T. Glad. Modelling of dynamic systems. Prentice
Hall. 1994.
[Ljung, 1999] L. Ljung. System Identification: Theory for the user. 2nd
Edition. Prentice Hall.1999.
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.
[Schoukens y Pintelon, 1991] J. Schoukens, R. Pintelon. Identification of linear systems.
Pergamon Press. 1991.
[Söderström y Stoica, 1989] T. Söderström y P. Stoica, System Identification. Prentice
Hall. 1989.
[Van Den Hof y Schrama, 1995] P. Van Den Hof y R. Schrama, R. Identification and control :
closed-loop issues. Automatica. Vol. 31. No. 12. Pp. 1751-
1770, 1995.

TEMA 9
IDENTIFICACIÓN RELEVANTE PARA EL CONTROL
9-1
9.1 INTRODUCCIÓN
Los controladores o reguladores son diseñados generalmente basándose en un modelo
paramétrico y cuantitativo del sistema dinámico o planta que va a ser controlada. Cuando se
identifican modelos de la planta con este fin se debe poner especial cuidado en que el
modelo identificado sea particularmente preciso en aquellos aspectos que son más
relevantes para el control.
Por un lado, para diseñar controladores de complejidad manejable suele ser
recomendable que el modelo de la planta sea de un determinado orden limitado. Este
requisito obliga a identificar modelos de órdenes reducidos que sean relevantes para el
control. Para la identificación de tales modelos, los experimentos en lazo cerrado tienen
ventajas particulares. Adicionalmente, la interrelación entre la identificación y el control a ha
conducido a una amplia variedad de métodos iterativos en los cuales, la identificación
relevante para el control se entrelaza con el diseño y análisis del control, con el objetivo de
conseguir una mejora gradual en el comportamiento del controlador.
Este tema está dedicado a describir los aspectos básicos de la identificación relevante
para control. En primer lugar se analiza la relación existente entre el modelo identificado y el
diseño del controlador. En segundo lugar se describe la identificación de modelos
aproximados relevantes para control. A continuación se propone un esquema iterativo de
identificación y control. Finalmente se describe la realización del proceso de prefiltrado de
datos con el objetivo de que el modelo se ajuste a los datos experimentales en aquellas
frecuencias que resultan más relevantes para el control.

TEMA 9: Identificación relevante para el control
9-2
9.2 RELACIÓN ENTRE EL MODELO IDENTIFICADO Y EL DISEÑO
DEL CONTROLADOR
Cuando se diseña un sistema de control realimentado para un proceso dinámico, la
información que contiene el modelo sobre el proceso juega un papel fundamental. El
sistema de control es básicamente diseñado y analizado sobre la base del modelo del
proceso utilizado. Dependiendo de cada estrategia de control en particular, la información
que debe aportar el modelo es distinta. Por ejemplo los métodos de sintonía de
controladores PID y los métodos de ajuste de la función de lazo en el dominio de la
frecuencia se basan generalmente en representaciones no paramétricas (gráficas) como la
respuesta a un escalón, la respuesta en frecuencia, el espectro de la perturbación, etc. No
obstante otras estrategias de control más avanzadas, las cuales típicamente se utilizan en
sistemas con múltiples entradas y múltiples salidas, requieren un modelo dinámico
paramétrico del proceso, además de un modelo de las perturbaciones que están actuando
sobre las señales medidas.
En el problema de identificación el proceso es sometido a diversos experimentos, los
datos de la entrada y la salida del proceso son utilizados para identificar un modelo del
mismo. En la etapa de diseño del control, el modelo identificado es utilizado para diseñar un
sistema de control realimentado según una determinada estrategia o metodología de control
que cumpla con unos determinados requisitos de comportamiento como estabilidad, rechazo
de perturbaciones, seguimiento de una señal de referencia, etc.
Cuando se considera la cuestión de que modelo identificado sería el más conveniente
para servir como base para el posterior diseño del control, existe una respuesta obvia. Si el
modelo representa exactamente al proceso bajo consideración, incluyendo las
perturbaciones que actúan sobre el proceso, entonces este modelo será el óptimo para
todos los posibles usos que se hagan del modelo, incluido el diseño de controladores
basados en modelos. Este principio de equivalencia segura que requiere que se construya
un modelo exacto y después usarlo para diseño de control, es difícil de justificar cuando el
modelo tiene que ser identificado a partir de datos medidos, ya que en este caso el modelo
contendrá incertidumbres debidas a las perturbaciones actuando sobre los sensores, tiempo
de observación finito, excitación limitada de las señales de entrada, el tipo de modelo
considerado, etc. Recuérdese que el modelo contiene un error de sesgo y un error de
varianza.

Identificación de sistemas
9-3
En la práctica suele ser imposible caracterizar todos los fenómenos que describen el
comportamiento dinámico del proceso. Por lo tanto, los modelos serán necesariamente
aproximados. Además, muchos métodos de diseño de control proporcionan controladores
cuyos órdenes están esencialmente determinados por el orden del modelo del proceso
considerado. De esta forma, un modelo del proceso de alto orden conducirá a un controlador
de orden alto, lo cual puede no resultar factible desde el punto de vista de su
implementación. Por lo tanto, para el diseño del control se necesitan modelos aproximados
del proceso de orden bajo.
Por otra parte, muchos procesos industriales complejos son controlados
satisfactoriamente por controladores de orden bajo como por ejemplo los PID. Esto sugiere
que los modelos del proceso de orden bajo son suficientes cuando sirven como base para el
diseño del control. Para identificar modelos de órdenes bajos que sean relevantes para el
diseño del control, es necesario seleccionar adecuadamente tanto los experimentos a
realizar como el método de identificación a utilizar.
Los modelos que describen con precisión la respuesta en lazo abierto del proceso no
son necesariamente buenos para el control. Asimismo los modelos que parecen ser malos
desde el punto de vista de la respuesta en frecuencia en lazo abierto pueden ser buenos
como base para el diseño del control. Esto es así ya que errores que pueden parecer
pequeños en lazo abierto pueden conducir a grandes errores en el comportamiento en lazo
cerrado. Por otra parte errores que pueden parecer grandes en lazo abierto pueden no
siempre conducir a un mal comportamiento en lazo cerrado. En consecuencia son los
requerimientos del control los que dictan la precisión que se requiere para el modelo que se
identifique, no al revés.
Ejemplo 9.1:
En la Figura 9.1 se muestra (en negro) la respuesta en frecuencia de un proceso dinámico, junto con
dos posibles modelos del proceso modelo 1(rojo) y modelo 2 (azul). El modelo 2 (azul) es muy exacto
en el rango de frecuencias bajas (<0.2 rad/s) pero se desvía en el rango de altas frecuencias. Por
su parte el modelo 1 (rojo) es bastante malo en el rango de frecuencias 0.2 rad/s 1 rad/s. La
pobre calidad del modelo 1 se pone también de manifiesto en la Figura 9.2a donde se muestra la
respuesta a un escalón del proceso real y de los dos modelos propuestos.
Cuando se evalúan las propiedades del proceso y los modelos en una configuración en lazo cerrado
con un determinado control que consigue un ancho de banda en lazo cerrado de 0.7 rad/s se
observa (ver Figura 9.2b) que la respuesta a un escalón en lazo cerrado del modelo 1 es muy
parecida a la del proceso real, mientras que la del modelo 2 se desvía bastante.
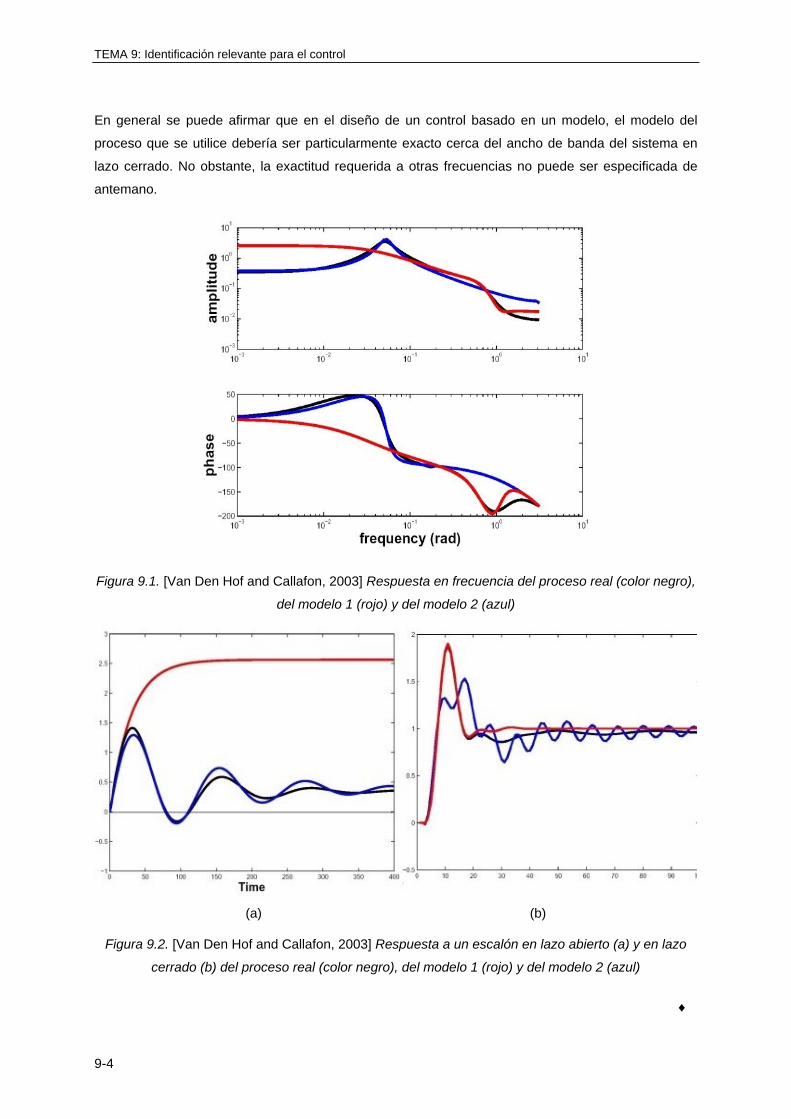
TEMA 9: Identificación relevante para el control
9-4
En general se puede afirmar que en el diseño de un control basado en un modelo, el modelo del
proceso que se utilice debería ser particularmente exacto cerca del ancho de banda del sistema en
lazo cerrado. No obstante, la exactitud requerida a otras frecuencias no puede ser especificada de
antemano.
Figura 9.1. [Van Den Hof and Callafon, 2003] Respuesta en frecuencia del proceso real (color negro),
del modelo 1 (rojo) y del modelo 2 (azul)
(a) (b)
Figura 9.2. [Van Den Hof and Callafon, 2003] Respuesta a un escalón en lazo abierto (a) y en lazo
cerrado (b) del proceso real (color negro), del modelo 1 (rojo) y del modelo 2 (azul)

Identificación de sistemas
9-5
9.3 IDENTIFICACIÓN DE MODELOS APROXIMADOS
9.3.1 Identificación basada en el error de predicción
Considérese el siguiente sistema o proceso real (ver Figura 9.3) descrito por las
siguientes ecuaciones:
)()·()(
)()()·()(
0
0
teqHtv
tvtuqGty
(9.1)
donde G0 y H0 representa dos sistemas lineales invariantes en el tiempo, u(t) e y(t) son la
entrada y la salida del proceso, {e(t)} es una secuencia de ruido blanco y q denota el
operador desplazamiento q-1u(t)=u(t-1). La representación H0 es utilizada para caracterizar la
distribución de potencia espectral del ruido aditivo v.
Figura 9.3. [Van Den Hof and Callafon, 2003] Sistema real a identificar
Para un modelo parametrizado {G(q,), H(q,)} con un vector de parámetros , el error
de predicción a un paso filtrado tiene la siguiente expresión:
)]()·,()(·[),()·(),( 1 tuqGtyqHqLtF (9.2)
que es utilizado como base para estimar el vector de parámetros, empleando un criterio de
identificación (mínimos cuadrados) el cual es construido con los datos de la entrada u(t) y de
la salida y(t) t=1,...,N del proceso obtenidos experimentalmente. El prefiltro L(q) es una
variable de diseño adicional que debe ser elegida por el usuario (ver sección 9.5).
Bajo condiciones suaves la estima converge (para N tendiendo a infinito) a una estima
límite, la cual para estructuras del modelo con un modelo de ruido fijo, es decir, H(q,)=H(q),
y para u y v no correlacionadas, se puede demostrar que viene dada por la siguiente
expresión:

TEMA 9: Identificación relevante para el control
9-6
d
eH
eLeGeG
i
iuii
2
22
0*
|)(|
|)()·|(·|),()(|
2
1minarg (9.3)
Que pone de manifiesto que en esta configuración el modelo del proceso ),()(ˆ *qGqG es
obtenido como resultado de la minimización del error cuadrático integrado entre G0 y G,
pesado con una función de peso particular determinada mediante el espectro de la entrada,
el prefiltro y el modelo del ruido.
9.3.2 Desajuste modelo - proceso en lazo cerrado
En el caso en que el modelo G del proceso vaya a ser utilizado para el diseño de un
control basado en un modelo, la aproximación a G0 dada por G no debería estar basada en
consideraciones en lazo abierto. De hecho la aproximación debería ser dirigida hacia un
ajuste en lazo cerrado en el modelo y el proceso, teniendo en cuenta el controlador C(q) que
va a ser diseñado.
Cuando un controlador G
C ˆ es diseñado sobre la base de un modelo G , el ajuste
deseado entre el sistema y el modelo queda verificado mediante la similitud entre los lazos
cerrados del proceso controlado (lazo conseguido) y el del modelo controlado (lazo de
diseño) tal y como se muestra en la Figura 9.4.
Figura 9.4. [Van Den Hof and Callafon, 2003] Lazo cerrado obtenido (superior) y lazo cerrado de
diseño (inferior).

Identificación de sistemas
9-7
Las funciones de sensibilidad de cada uno de estos lazos son:
1ˆ00 ]·1[
GCGS (9.4)
1ˆ ]·ˆ1[ˆ
GCGS (9.5)
Mientras que el error entre la salida real y la salida del modelo (ambos en lazo cerrado)
es:
WGGSSCGGCG
CG
CG
CGyy
G
G
G
G
G )·ˆ(ˆ··)·ˆ(·ˆ1
·ˆ
·1
·ˆ 00ˆ0
ˆ
ˆ
ˆ0
ˆ0
(9.6)
donde
SSCWG
ˆ·· 0ˆ (9.7)
La expresión anterior pone de manifiesto que desde una perspectiva en lazo cerrado, el
desajuste relevante entre el modelo y el proceso no debería ser considerado en una forma
aditiva simple, sino que el error aditivo debería ser pesado con una función de peso W.
Como consecuencia directa de lo anterior, el modelo del proceso G debería ser preciso en
la región de frecuencia donde la función de peso W es grande.
Un ejemplo típico es cuando el controlador diseñado G
C ˆ contiene una acción integral, lo
que implica que a bajas frecuencias 1|)(| ˆ iG
eC . En este caso la función de peso verifica
la siguiente relación
11ˆ··
1||
0ˆ
GGC
WG
(9.8)
Esto implica que el error del modelo )(ˆ)(0 qGqG en la región de baja frecuencia no
tiene casi influencia en las propiedades en lazo cerrado del modelo. Lo cual ya se puso de
manifiesto en el Ejemplo 9.1.

TEMA 9: Identificación relevante para el control
9-8
9.3.3 Criterio de identificación relevante para control
El criterio de comportamiento del control realimentado dado por la ecuación (9.6)
sugiere el siguiente criterio de identificación para la identificación del modelo G :
d
eGeCeGeC
eCeGeG
iiii
iii
22
0
20
*
),()·(1
1·
)()·(1
)(·|),()(|
2
1minarg (9.9)
Si se compara este criterio de identificación con el criterio dado por la ecuación (9.3)
usado en los métodos de identificación basados en la minimización del error de predicción,
es posible hacerlos equivalentes si se considera la siguiente configuración de identificación:
2
0 )()·(1
)()(
ii
i
ueGeC
eC
(9.10)
),()·(1
1)(
qGqCqL
(9.11)
1)( qH (9.12)
En esta configuración, el espectro de la señal de entrada deseada es generado
mediante u=C·S0·r. Este espectro se consigue haciendo experimentos con una señal de
referencia que tenga una función de densidad espectral plana ( 1)( r ) mientras el
proceso es controlado con el controlador C. El prefiltro L que se requiere depende de los
parámetros del modelo y puede ser implementado mediante adaptación iterativa de la
estimación del modelo. La elección H(q)=1 indica que se debe usar un modelo OE.
La configuración de identificación descrita generará datos experimentales y un modelo
identificado resultante que por construcción tiene propiedades que refleja aspectos
relevantes para el control del proceso.
Nótese que el experimento óptimo bajo el cual el proceso debería ser identificado, es
igual a la situación bajo la cual el modelo es utilizado. En consecuencia, en el caso de un
modelo que vaya a ser utilizado para control, el experimento de identificación óptimo es un
experimento en lazo cerrado usando el controlador G
C ˆ . Este controlador todavía tiene que
ser diseñado, luego es desconocido. Ello sugiere un esquema de identificación y de diseño
de control de tipo iterativo. Dicho esquema será explicado en la sección 9.4.

Identificación de sistemas
9-9
9.3.4 Identificación a partir de datos obtenidos en lazo cerrado
El problema típico de la identificación en lazo cerrado es el hecho de que la entrada u
de la planta está correlacionada con la perturbación v, a diferencia de lo que sucedía en los
experimentos en lazo abierto.
En los métodos de identificación basados en la aproximación directa (tal y como se
comentó en la sección 8.3.7), simplemente se aplica el procedimiento de identificación
estándar (error de predicción) sin tomar especiales medidas debido a la presencia de un
controlador realimentado. Una estima de los parámetros es obtenida de forma similar al
caso en lazo abierto. El criterio de identificación asintótico en el dominio de la frecuencia en
este caso viene dado por el espectro del error:
022
2
0
2
0
2
2
0
2
0 ·)(·)(
··
)(
)(·
SH
SH
H
GGSr
(9.13)
donde S(q,)=(1+C·G(q,))-1 es la función de sensibilidad del modelo parametrizado. Esta
expresión se obtiene simplemente combinando la ecuación (9.1) y (9.2) con la ecuación del
controlador u=C·(r-y). Si G0 puede ser modelado exactamente dentro del conjunto de
modelos elegido, es decir G0 G, el primer termino del espectro del error se puede hacer
cero; pero esto no es necesariamente una solución mínima debido a la presencia de G() en
el segundo término, cualquier desajuste en este término debido a H(q,) será compensado a
través de G(q,) en S(q,).
La aproximación directa puede proporcionar buenas estimas cuando se es capaz de
identificar modelos del orden que sea necesario tanto para la dinámica de la planta como
para la dinámica del ruido. En el caso de identificar modelos aproximados o cuando no se
considera el modelado de la dinámica del ruido completa, G0 no es identificado
consistentemente, y el criterio que gobierna la identificación aproximada de G0 no es
ajustable explícitamente por el usuario. Es decir, no tomará una forma simple como la dada
por (9.3) con el error aditivo en G0 ponderado con una función de peso conocida.
Para conseguir en una identificación en lazo cerrado un desacoplo entre G0 y H0 se
pueden usar otros aproximaciones a la identificación en lazo cerrado como la aproximación
indirecta o la aproximación de entrada-salida conjunta.
En los métodos basados en la aproximación indirecta se identifica el siguiente sistema
en lazo cerrado

TEMA 9: Identificación relevante para el control
9-10
)()·()()·()( teqWtrqTty (9.14)
a partir de las medidas de r(t) e y(t). Se obtienen por tanto los modelos )(ˆ qT y )(ˆ qW .
Supuesto además que el controlador C es conocido es posible obtener los modelos G y H
en lazo abierto a través de la siguiente expresión:
)(ˆ)·(1
)(ˆ)·()(ˆ
qGqC
qGqCqT
(9.15)
)(ˆ)·(1
)()(ˆ
qGqC
qHqW
(9.16)
En los métodos basados en la aproximación de entrada-salida conjunta, como por
ejemplo el método de las dos etapas, en primer lugar se identifica el siguiente sistema:
)()·()()·()( teqNtrqMtu (9.17)
a partir de las medidas de u(t) y r(t). Se obtienen por tanto los modelos M y N . A
continuación se construye la siguiente entrada para la planta libre de ruido:
)()·(ˆ)(ˆ trqMtu r (9.18)
La cual es utilizada en una segunda etapa para identificar el sistema
)()·()·()()·()( 000 teqSqHtuqGty r (9.19)
donde la señal de entrada libre de ruido ur=C(q)·S0(q)·r(t) que es no medible es sustituida
por su estima )(ˆ tu r . Nótese que en este método no es necesario ningún conocimiento
explícito sobre el controlador.
Los métodos anteriores basados en la aproximación indirecta o en la aproximación de
entrada-salida conjunta permiten la identificación separada de modelos para la planta y el
ruido. Cuando dichos modelos son parametrizados de forma independiente (o usando un
modelo de ruido fijo *W ) el criterio de identificación asintótica para la estimación de G0 toma
la siguiente forma en el caso de la aproximación indirecta:

Identificación de sistemas
9-11
d
W
eSeSeCeGeG
riii
ii
2*
2
020
*
||
)(·),()·()·(·|),()(|
2
1minarg (9.20)
el cual se ajusta perfectamente al criterio requerido formulado en (9.9) (en el caso del
método de las dos etapas la expresión de este criterio varia ligeramente). Esto implica que
en el caso con una elección aproximada de r y *W el criterio, que es requerido desde el
punto de vista de relevancia para el control, puede ser realizado exactamente mediante la
aplicación de un método de identificación en lazo cerrado basado en la aproximación
indirecta. En el caso particular de señales de excitación periódicas, la identificación
separada de G0 y H0 puede ser conseguida mediante la estimación de modelos del ruido no
paramétricos.
Las consideraciones realizadas hasta ahora han sido sobre las propiedades asintóticas
de las estimas. Esto se refiere a las propiedades de sesgo asintóticas de los modelos
identificados. Para analizar la varianza asintótica de las funciones de transferencia
estimadas, es conocido que cuando el orden n (número de parámetros) del modelo y el
número de datos N tienden a infinito se obtiene:
1
0)(
)()()·(·
)(ˆ)(ˆ
cov
ue
euuvi
i
N
n
eH
eG (9.21)
Que conduce a
ru
eu
ru
vru
v
N
n
N
nG 1···ˆcov (9.22)
ru
euv
ru
uv
N
n
N
nH 1····ˆcov
00 (9.23)
Siendo ru la densidad espectral de ur, y e
u la densidad espectral de ue=- C·S0·v, es
decir, la parte de la señal de entrada que se origina a partir de e. Estas expresiones de la
varianza se mantienen para todos los métodos de identificación en lazo cerrado
independiente de la aproximación usada.
Estas expresiones muestran que sólo la parte libre de ruido ur de la señal de entrada
contribuye a la reducción de la varianza de las funciones de transferencia. Nótese que si se

TEMA 9: Identificación relevante para el control
9-12
hace ur =u (ue=0) se obtienen los resultados correspondientes al caso en que el sistema
hubiese sido identificado en lazo abierto.
En el caso en que el espectro de la señal de entrada es limitado, se observa que sólo
parte de dicha potencia de entrada puede ser utilizada para reducir la varianza. Este hecho
conduce a los siguientes resultados:
Si la potencia de entrada es ilimitada y el controlador es diseñado sólo en base a
G y no de H , el experimento de identificación óptima para minimizar el coste de
la varianza del comportamiento del control es un experimento en lazo abierto con
un espectro de entrada que es proporcional a la función de sensibilidad del
sistema en lazo cerrado que vaya a ser diseñado.
Si durante los experimentos de identificación la potencia de la salida está limitada,
entonces los experimentos en lazo cerrado son entonces los óptimos.
Si el controlador es diseñado en base tanto G y de H , entonces los experimentos
en lazo cerrado son entonces los óptimos.
9.4 IDENTIFICACIÓN Y CONTROL ITERATIVOS
La situación descrita en las secciones anteriores muestra que los modelos relevantes
para el control son obtenidos cuando la identificación tiene lugar bajo condiciones
experimentales en lazo cerrado con el controlador (que aún tiene que ser diseñado)
GC ˆ siendo implementado sobre el proceso. Como este controlador es desconocido antes
que el modelo sea identificado se requiere un esquema iterativo para llegar a la situación
deseada:
Paso 1. Realizar un experimento de identificación con el proceso siendo
controlado por un controlador de estabilización inicial C.
Paso 2. Identificar un modelo G con un criterio relevante para control.
Paso 3. Diseñar un controlador G
C ˆ usando el modelo obtenido en el paso 2.
Paso 4. Usar el controlador diseñado en el paso 3 sobre el proceso y volver al
paso 1 usando este nuevo controlador.
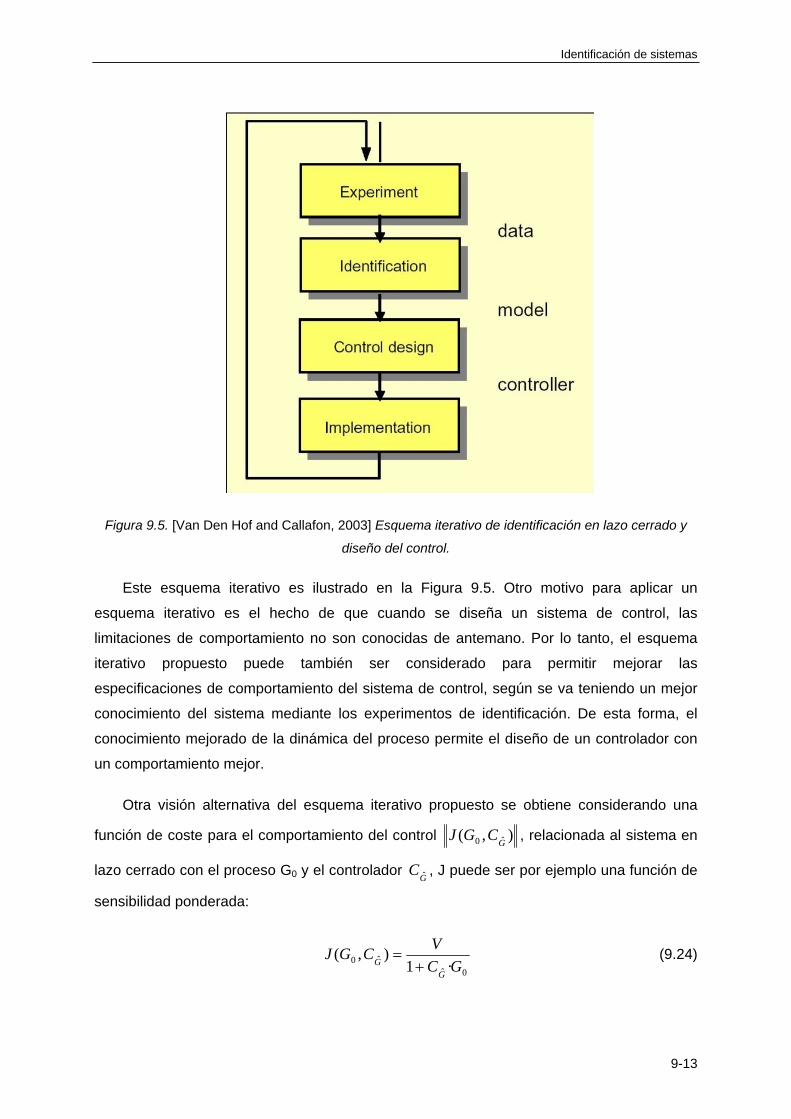
Identificación de sistemas
9-13
Figura 9.5. [Van Den Hof and Callafon, 2003] Esquema iterativo de identificación en lazo cerrado y
diseño del control.
Este esquema iterativo es ilustrado en la Figura 9.5. Otro motivo para aplicar un
esquema iterativo es el hecho de que cuando se diseña un sistema de control, las
limitaciones de comportamiento no son conocidas de antemano. Por lo tanto, el esquema
iterativo propuesto puede también ser considerado para permitir mejorar las
especificaciones de comportamiento del sistema de control, según se va teniendo un mejor
conocimiento del sistema mediante los experimentos de identificación. De esta forma, el
conocimiento mejorado de la dinámica del proceso permite el diseño de un controlador con
un comportamiento mejor.
Otra visión alternativa del esquema iterativo propuesto se obtiene considerando una
función de coste para el comportamiento del control ),( ˆ0 GCGJ , relacionada al sistema en
lazo cerrado con el proceso G0 y el controlador G
C ˆ , J puede ser por ejemplo una función de
sensibilidad ponderada:
0ˆˆ0 ·1),(
GC
VCGJ
GG
(9.24)

TEMA 9: Identificación relevante para el control
9-14
que tiene como objetivo a un sistema de control que satisfaga la especificación: |S0(ei)| <
|V(ei)|-1, elecciones alternativas para J incluyen un criterio LQ/LQG, control con referencia a
una modelo, optimización robusta y esquemas de control H.
En esta notación se presupone que el controlador C puede ser también una función del
modelo del ruido H . La meta del sistema de control es conseguir un valor mínimo de
),( ˆ0 GCGJ mediante la elección apropiada de G y
GC ˆ . La siguiente desigualdad triangular
es de gran ayuda para estudiar este problema:
),ˆ(),(),ˆ(),ˆ(),(),ˆ( ˆˆ0ˆˆˆ0ˆ GGGGGGCGJCGJCGJCGJCGJCGJ (9.25)
En ella se observan tres términos diferentes:
),( ˆ0 GCGJ , el comportamiento conseguido.
),ˆ(G
CGJ , el comportamiento diseñado.
),ˆ(),( ˆˆ0 GGCGJCGJ , la degradación del comportamiento.
Tomando como punto de partida que hay que obtener un comportamiento de diseño
que hay que satisfacer, dos requerimientos pueden ser formulados para conseguir un alto
comportamiento de la planta controlada:
1) Comportamiento nominal alto. Se consigue si ),ˆ(G
CGJ es pequeño.
2) Comportamiento robusto. Se consigue si ),ˆ(),ˆ(),( ˆˆˆ0 GGGCGJCGJCGJ .
Nótese que si se cumple este requerimiento, entonces la diferencia entre la función
de comportamiento diseñada ),ˆ(G
CGJ y la función de comportamiento conseguida
),( ˆ0 GCGJ es relativamente pequeña.
En la aproximación iterativa ambos requerimientos son incorporados como pasos
separados: minimizando el coste de comportamiento diseñado ),ˆ( CGJ sobre C para un
modelo fijo G (diseño del control), y minimizando el término de degradación del

Identificación de sistemas
9-15
comportamiento ),ˆ(),( ˆˆ0 GGCGJCGJ sobre G para un controlador fijo C (identificación
relevante para el control). En este caso, el término de degradación puede ser interpretado
como un criterio de modelado inducido por el comportamiento del control:
),(),(minargˆ0 CGJCGJG
G (9.26)
Si se considera la elección de J dada por (9.24) el criterio anterior toma la siguiente
forma:
)·1)·(·1(
)··(minargˆ
0
0
GCGC
CGGVG
G
(9.27)
Nótese que para una norma-2 este criterio tiene la misma expresión que la expresión
del sesgo para los métodos de identificación en lazo cerrado dada por (9.9).
Mediante la minimización del término de degradación del comportamiento, y haciéndolo
mucho más pequeño que el coste diseñado ),ˆ(G
CGJ , se sigue a partir de la desigualdad
triangular (9.25) que el comportamiento obtenido es forzado a estar cerca del
comportamiento diseñado, es decir,
),(),ˆ( ˆ0ˆ GGCGJCGJ
Esto es exactamente lo que el ingeniero que diseña el control intenta conseguir: diseñar
un controlador basado en un modelo que (después de ser implementado sobre el sistema
real) presente un coste del comportamiento que sea similar al comportamiento del modelo
controlado.
En general los esquemas iterativos tal y como han sido descritos no garantizan la
convergencia hacia un mejor modelo y un mejor controlador, aunque se pueden construir
esquemas robustos que sí la garantizan.
El esquema iterativo propuesto podría asemejarse con el control adaptativo donde
recursivamente en cada paso de tiempo un modelo actualizado es identificado y un nuevo
controlador es diseñado. Sin embargo en este esquema, no hay ninguna necesidad de
actualizar el modelo diseñado y el controlador en cada paso de tiempo, sino únicamente
después de la realización de experimentos separados. En consecuencia sería un control
adaptativo “extremadamente lento”.

TEMA 9: Identificación relevante para el control
9-16
9.5 PREFILTRADO RELEVANTE PARA CONTROL
Cuando se desea identificar modelos relevantes para el control, todas las etapas de la
metodología de identificación (diseño de la señal de entrada, selección de la estructura del
modelo, estimación de parámetros y validación del modelo) se deben considerar desde el
punto de vista relevante para control. En esta sección nos vamos a concentrar en la etapa
de estimación de parámetros usando métodos basados en el error de predicción, en
particular en el desarrollo de un prefiltro relevante para control. El prefiltrado actúa como un
peso dentro de la función de coste utilizada para estimación, y es por tanto una de las
variables de diseño mas importantes para selectivamente enfatizar la bondad del ajuste en
la identificación. El propósito del prefiltrado relevante para el control es enfatizar aquella
información contenida en los datos de entrada-salida que resulta más importante para
propósitos de control.
9.5.1 Estimación de parámetros relevantes para control
Las especificaciones de control pueden estrechar las regiones de tiempo y frecuencia
sobre las cuales un ajuste adecuado del modelo es necesario. Por lo tanto, si las
especificaciones de control son incorporadas dentro del problema de estimación de
parámetros, es posible obtener modelos mejorados sobre la banda de frecuencia que es
importante para el problema de control. Este es el objetivo del problema de estimación de
parámetros relevantes para el control (PEPRC). En el sentido matemático más general el
PEPRC es un problema de optimización que requiere minimizar un funcional del error
ponderado entre el modelo de la planta verdadero y el modelo estimado:
),(minmod
errorpesofPEPRCelo
(9.28)
El PEPRC lleva al tema de sistemáticamente seleccionar la descripción del funcional, el
peso y el error para ajustar el problema de control a mano.
En las siguientes secciones se mostrará como el prefiltrado actúa como un peso
dependiente de la frecuencia en el problema de estimación de parámetros. A continuación
se derivará un prefiltro relevante para el control a partir de la norma-2 de una función
objetivo en lazo cerrado.

Identificación de sistemas
9-17
9.5.2 Efecto del prefiltrado en la estimación de parámetros
El objetivo es conseguir una estimación tal que las propiedades importantes de la planta
con respecto al control deseado estén retenidas en el modelo. Se va a suponer que la planta
es descrita por el siguiente modelo lineal:
)()·()(
)()()·()(
0
0
teqHtv
tvtuqGty
(9.29)
donde v(t) es una secuencia de ruido estacionaria con potencia espectral v . Se desea
estimar un modelo para la planta de la siguiente forma:
)()·()()·()( teqHtuqGty (9.30)
Aplicando el prefiltro L(q) tanto a la entrada como a la salida se obtiene:
)()·()(
)()·()(
tuqLtu
tyqLty
F
F
(9.31)
Con lo que el error de predicción filtrado toma la siguiente forma:
)]()())·()()·[(()·()( 01 tvtuqGqGqHqLteF (9.32)
La función objetivo o función de coste para la estimación de los parámetros es:
N
tF te
NV
1
2)]([1
(9.33)
Esta función se puede escribir de la siguiente forma cuando N:
deH
eLeGeGV
i
i
vuii
N·
|)(|
|)(|·)()(·|)()(|
·2
1lim
2
22
0
(9.34)
Esta expresión pone de manifiesto algunas fuentes de error de sesgo en el problema de
estimación: la densidad espectral de la señal de entrada u , la elección del prefiltro L(q), la
estructura de G y H, y la densidad espectral de la señal de perturbación v .
Esta expresión también pone de manifiesto que L(z) actúa como un peso dependiente
de la frecuencia sobre el espectro de potencia del error de predicción, por lo tanto permite al

TEMA 9: Identificación relevante para el control
9-18
diseñador enfatizar selectivamente en que rango de frecuencias desea que la estimación de
los parámetros sea más precisa. Este conocimiento, sin embargo, resulta de poca utilidad
para el diseñador del control si no dispone de unas directrices claras sobre como diseñar L
(q).
9.5.3 Obtención de un prefiltro relevante para control
La identificación relevante para control requiere que se conozca el problema de control
(ver Figura 9.6) para el cual se desea obtener un modelo de la planta. Aparte de la
estructura del modelo, se debe especificar de antemano el tipo de modelo a ser identificado
(planta o perturbación), la estructura del controlador (realimentado, feedforward, PID, ...) y el
carácter de la respuesta (constantes de tiempo en lazo cerrado, porcentaje de
sobreelongación, etc). Esta información es normalmente conocida para el ingeniero en el
momento en que se va a realizar la estimación de parámetros.
u
d
y+G0C
r
-
+ e
Figura 9.6. Sistema de control realimentado clásico
Supóngase que se desea realizar la estimación relevante para el control de la planta
G0(z) que va a ser utilizada en un sistema de control realimentado con un único grado de
libertad. El objetivo de control es minimizar la norma-2 del error de control eC=r-y:
2/1
0
2
2)(
kCC kee (9.35)
Considérese el modelo estimado )(ˆ zG el cual ha sido obtenido a partir del ajuste sobre
los datos de entrada-salida del sistema verdadero G0(z). Se va suponer un controlador
realimentado C(z) diseñado con )(ˆ zG :
)()·()( teqCtu (9.36)
Se tienen, por tanto, las siguientes funciones de sensibilidad y de sensibilidad
complementaria para la respuesta nominal en lazo cerrado:

Identificación de sistemas
9-19
1)]()·(ˆ1[)( zCzGzS (9.37)
1)]()·(ˆ1)·[()·(ˆ)(1)( zCzGzCzGzSzT (9.38)
Cuando C(z) es implementado sobre la planta verdadera G0(z) el deterioro resultante en
el comportamiento del control causado por el desajuste entre el modelo y la planta se puede
representar de la siguiente forma:
)()()·(1
)()( dr
zezT
zSze
mC
(9.39)
donde
)(ˆ))(ˆ)(()( 10 zGzGzGzem
(9.40)
es el error multiplicativo entre la planta verdadera y el modelo estimado.
La estabilidad de C sobre )(ˆ zG , el modelo estimado, no asegura la estabilidad con
respecto a G0(z), la planta verdadera. La estabilidad del sistema de control es mucho más
rigurosamente determinada usando el criterio de estabilidad de Nyquist sobre T(z)·em(z). Un
requerimiento de estabilidad computacionalmente más simple es usar el teorema de
ganancia pequeña:
1|)()·(| jm
j eeeT (9.41)
Si dicho teorema se cumple entonces es posible desarrollar eC en serie de Taylor:
)....)()·(·1·()( 2 dreTeTSze mmC (9.42)
Truncando en el segundo termino se obtiene la siguiente aproximación:
))(·1·()( dreTSze mC (9.43)
Esta aproximación es especialmente válida cuando 1|)()·(| jm
j eeeT sobre el ancho
de banda definido mediante S·(r-d). Sustituyendo la aproximación en (9.35) se obtiene una
expresión aproximada para la función objetivo la cual puede ser escrita en el dominio de la
frecuencia usando el teorema de Parseval:

TEMA 9: Identificación relevante para el control
9-20
2/1
222
2·|||·1·|||
·2
1
ddreTSe mC (9.44)
2/1
222
2/1
22
2·|·||·|·||
·2
1·||·||
·2
1
ddreTSddrSe mC (9.45)
La expresión anterior tiene dos términos, uno está basado en las propiedades
nominales de la respuesta en lazo cerrado supuesto que )()(ˆ0 zGzG , y el otro basado en
la reducción del error multiplicativo em. El planteamiento del PEPRC se obtiene minimizando
la contribución que surge del error de identificación
2/1
2222
ˆ|)(·||·||)(·||)(|
·2
1min
deedreTeS jm
jj
G (9.46)
De la expresión anterior que define el PEPRC se pueden deducir las siguientes
conclusiones importantes:
Es un problema de error multiplicativo ponderado, al contrario del error aditivo no
ponderado ea=G-G0 que se utiliza habitualmente en la literatura de control.
La función de peso |S·T·(r-d)| incorpora explícitamente la respuesta en lazo
cerrado deseada y la descripción referencia/perturbación del problema.
La definición del prefiltro es obtenida comparando las expresiones (9.34) y (9.46).
Supuesto que la entrada u es ruido blanco (con lo que 1u ) y despreciando el término
asociado con la perturbación v(t) se obtiene la siguiente expresión para el prefiltro:
))()()·(()·()·(ˆ)·(ˆ)( 1 zdzrzTzSzGzHzL (9.47)
Se observa que el prefiltro L(z) consta de cuatro componentes:
Las funciones de sensibilidad S(z) y de sensibilidad complementaria T(z), que
definen la respuesta en lazo cerrado de la planta. Cuanto más rápida sea la
velocidad de respuesta deseada, mayor será el rango de frecuencia en que debe
coincidir el modelo estimado con el sistema real, y por lo tanto mayor será la

Identificación de sistemas
9-21
necesidad para obtener un buen modelo. Por otro lado, si se desea una respuesta
lenta, un modelo simple podría resultar adecuado.
La descripción referencia/perturbación r - d. Si el sistema de control es diseñado
para rechazar escalones, rampas, o perturbaciones estacionarías influirá en los
requerimientos del ajuste.
El modelo estimado de la planta )(ˆ zG . La estimación de parámetros relevantes
para el control requiere la minimización de error multiplicativo ponderado em. Los
métodos basados en el error de predicción, sin embargo, minimizan el error aditivo
ponderado ea. Por lo tanto, la inversa del modelo identificado debe ser incluida en
el prefiltro. Puesto que )(ˆ zG es desconocido inicialmente, la implementación del
prefiltro es inherentemente iterativa.
El modelo estimado del ruido )(ˆ zH . El modelo del ruido actúa como un peso en el
problema de estimación lo cual podría producir un error de sesgo nocivo. Para
eliminarlo, el modelo del ruido es incluido en la definición del prefiltro.
Ejemplo 9.2:
Considérese un modelo estimado de primer orden de tipo OE definido mediante la siguiente
expresión:
1)(ˆ;904.0
096.0)(ˆ
zH
zz
kzG
(1)
Esta planta tiene una constante de tiempo de 10 minutos y es muestreada con un periodo T=1
minuto. Supuesto que la constante de tiempo deseada en lazo cerrado es de 5 minutos, representada
por la siguiente expresión de primer orden:
818.0
1813.0)1()(
zz
zT
(2)
Donde =exp(-T/cl) y cl es la constante de tiempo en lazo cerrado.
Un controlador PI adecuadamente sintonizado podría conseguir esta respuesta en lazo cerrado.
Supóngase adicionalmente, que el sistema está sujeto a perturbaciones de tipo escalón a su salida:

TEMA 9: Identificación relevante para el control
9-22
1)(
z
zzT (3)
Usando (9.47), el prefiltro que se obtiene para este sistema es:
22 )818.0(
)904.0·(·89.1
)(
)(·
1)(
z
zz
z
zz
kzL
(4)
Por otra parte, si la constante de tiempo deseada en lazo cerrado fuera de 10 minutos entonces la
expresión del prefiltro sería:
2)904.0(·89.1)(
z
zzL (5)
Obsérvese que tanto (4) como (5) son esencialmente filtros pasa-baja con un ancho de banda
definido por la velocidad de respuesta del sistema en lazo cerrado. Esto significa que el énfasis de la
estimación está situado en preservar un buen ajuste en el rango de bajas frecuencias, las cuales son
las que tienen más impacto en el problema de control, mientras que ignora el comportamiento de alta-
frecuencia el cual no tiene un efecto significativo en la respuesta en lazo cerrado. Puesto que el
prefiltro (4) demanda una velocidad de respuesta más rápida que el prefiltro (5), su ancho de banda
es mayor.
Si el objetivo de control es cambiado de perturbaciones escalón a rechazar perturbaciones
estacionarias tales como una perturbación de primer orden de constante de tiempo de 7 minutos:
867.0
·133.0·)(
z
z
z
zzd
(6)
Entonces, el prefiltro relevante para control es de la forma:
)867.0·()818.0(
)1)·(904.0·(·251.0
)()(
)1)((·
)·1()(
22
zz
zzz
zz
zzz
kzL
(7)
Este prefiltro es un filtro pasabanda o filtro notch. La atenuación de las bajas frecuencias por el
prefiltro es por tanto esperada, como físicamente por las perturbaciones estacionarias, la acción
integral en el sistema de control no es necesaria, por lo tanto se elimina la necesidad de un buen
ajuste del modelo a bajas frecuencias.

Identificación de sistemas
9-23
9.5.4 Algoritmo para la implementación de un prefiltro relevante para control
Puesto que el prefiltro relevante para el control requiere tanto del modelo estimado para
la planta como del modelo estimado para el ruido, lo cuales son inicialmente desconocidos,
su implementación más rigurosa es iterativa. En [Rivera et al. 1992] se puede encontrar un
algoritmo iterativo para la implementación de un prefiltro relevante para control. En esta
sección se incluye el algoritmo no iterativo propuesto por [Rivera et al. 1992] que funciona
bastante bien en numerosos casos y que requiere que el usuario disponga de estimas
razonables de la constante de tiempo dominante de la planta y de la velocidad de respuesta
en lazo cerrado deseada.
El algoritmo no iterativo de [Rivera et al. 1992] se basa en el uso de la expresión (9.47)
para el prefiltro usando conjuntamente algunas hipótesis y simplificaciones. En primer lugar
se sugiere utilizar la siguiente estructura para T(z):
)(·)( zfzzT nk (9.48)
donde el orden de f(z) es dictado por el procedimiento del diseño del control y su ancho de
banda se elige para incluir las limitaciones al comportamiento en lazo cerrado que se puede
obtener creado mediante las restricciones de la velocidad de respuesta de las variables
controladas y manipuladas. Además, se supone el conocimiento de la constante de tiempo
de la planta con el objetivo de usar la siguiente aproximación para G :
z
zzG
nk 1
)(ˆ (9.49)
donde =exp(-T/dom) y dom es la constante de tiempo dominante del sistema. Una estima de
la ganancia en estado estacionario no es necesaria ya que la ganancia simplemente
aparece como una constante en (9.47). Para modelos del tipo OE o FIR, se tiene que 1ˆ H ,
lo cual conduce a la siguiente definición del prefiltro:
))()()·((·))(·1)(()( 1 zdzrzfzzfzzzL nk (9.50)
Siendo f(z) un filtro pasa-baja usado para suministrar robustez y atenuar los
movimientos de la variable manipulada. Una elección bastante común es considerar un filtro
de primer orden:

TEMA 9: Identificación relevante para el control
9-24
z
zzf
)·1()( (9.51)
donde =exp(-T/cl) y cl es la constante de tiempo o velocidad de respuesta en lazo cerrado.
Para modelos de tipo ARX se puede aproximar el modelo del ruido H con la misma
constante de tiempo dominante utilizada en G :
z
zzH )(ˆ (9.52)
con lo que se obtiene la siguiente expresión para el prefiltro:
))()()·(())·(·1()( zdzrzfzfzzL nk (9.53)
Nótese que en esta expresión se evita la necesidad de especificar dom lo cual sugiere
que la estimación ARX prefiltrada debería ser más fácil y más fiable que los otros métodos.
Se debe tener en cuanta que la estimación de los parámetros autoregresivos del modelo
ARX requieren un compromiso entre ajustar G y ajustar H , y por lo tanto un modelo
adecuado quizás no sea obtenido si la magnitud del ruido, especificada por v , es
significante.
Ejemplo 9.3:
Considérese el siguiente modelo estimado para una planta
z
KzG )(ˆ
que será controlada usando control predictivo vía QDMC (Quadratic Dynamic Matrix Control). La
estructura resultante para T(z) es de segundo orden, con lo que se va a definir f(z) de la siguiente
forma:
clTez
zzf
/555.1
2
22
)(
·)1()(
Se va suponer un cambio en la señal de referencia de tipo escalón. El prefiltro resultante para la
estimación FIR y OE es:

Identificación de sistemas
9-25
4
222
)(
))(·(·)1()(
z
zzzzL
Para modelos ARX se obtiene:
4
232
)(
)·(·)1()(
z
zzzL
En conclusión habiendo definido una estructura del modelo y la naturaleza del problema
de diseño del control, la elección del prefiltro queda reducida a simplemente especificar la
velocidad de respuesta en lazo cerrado (CL) y la constante de tiempo dominante en lazo
abierto (dom). Esta información puede ser fácilmente obtenida en la mayoría de las
situaciones a las que se enfrentan los ingenieros de control de procesos.
9.6 CONCLUSIONES
Es posible diseñar una configuración de identificación de tal forma que los modelos
resultantes automáticamente reflejen aquellos aspectos del proceso real que son más
relevantes para el subsiguiente diseño del control basado en el modelo. Desde el punto de
vista del error de sesgo, los experimentos en lazo cerrado son óptimos; desde el punto de
vista del error de varianza depende de si la potencia de la entrada y de la salida están
limitadas durante la realización de los experimentos y de si el controlador es diseñado en
base tanto a la dinámica de la planta como a la dinámica del ruido.
La optimización del diseño del control y de la identificación puede ser conseguida
mediante iteración entre la estimación del modelo y el diseño e implementación del
controlador. Este procedimiento iterativo se basa en el principio de aprendizaje, donde los
experimentos subsiguientes posibilitan un mejor entendimiento de las dinámicas del proceso
más relevantes y el diseño de controladores con un comportamiento que gradualmente se
va mejorando.
Por otra parte es posible diseñar un prefiltro que al ser aplicado sobre los datos
garantice el ajuste del modelo en aquellos rangos de frecuencia que son más relevantes
para el control.

TEMA 9: Identificación relevante para el control
9-26
BIBLIOGRAFÍA
[Rivera et al., 1992] D. E. Rivera, J. F. Pollard, C. García. Control-relevant
prefiltering : A systematic design approach and case study.
IEEE Transactions on Automatic Control. Vol. 37. Nº 7, July
1992.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.
[Van Den Hof and Callafon, 2003] P. Van Den Hof, R. Callafon. Identification for control.
Control Systems, Robotics and Automation, edited by H.
Unbehauen, in Encyclopedia of Life Support Systems
(EOLSS), Developed under the auspices of the UNESCO,
Eolss Publishers, Oxford, UK. 2003.

TEMA 10
IDENTIFICACIÓN DE SISTEMAS MULTIVARIABLES
10-1
10.1 INTRODUCCIÓN
En los temas anteriores se han considerado principalmente sistemas con una entrada y
una salida, es decir, sistemas SISO (Single-Input Single-Output). Sin embargo, los procesos
reales suelen ser sistemas multivariables con múltiples entradas y múltiples salidas (ver
Figura 10.1), es decir, son sistemas MIMO (Multiple Input - Multiple Output).
La principal dificultad que presenta un sistema MIMO no viene dada por la existencia de
un número excesivo de variables (entradas y salidas) sino por el grado de interacción
existente entre ellas, es decir, a como una determinada salida yj del sistema se verá
afectada por una o varias entradas uk. Una fuerte interacción puede dificultar la identificación
y control del sistema. El grado de interacción existente entre las variables de un sistema
MIMO puede ser medido. Existen de hecho diferentes medidas de la interacción, entre las
más utilizadas se encuentran [Skogestad y Postlethwaite, 96]: la matriz de ganancias
relativas o RGA, los vectores singulares y el número de condición. Nótese que el estudio de
la interacción de las variables de un sistema MIMO resulta de gran utilidad para poder saber
si es posible simplificar el modelo MIMO usando en su lugar varios modelos SISO o varios
modelos MISO (Multiple Input - Single Output).
Proceso
u1u2
um
y1y2
yp
Figura 10.1. Proceso multivariable

TEMA 10: Identificación de sistemas multivariables
10-2
La identificación de un sistema MIMO se realiza con la misma metodología comentada
en los temas anteriores para el caso de sistemas SISO. Simplemente el carácter
multivariable complica la realización de las diferentes etapas. Además si el grado de
interacción de las variables es elevado se deben tomar medidas y estrategias adicionales,
las cuales han dado lugar a multitud de publicaciones.
El objetivo de este tema es dar una sencilla y breve introducción de aquellos aspectos
de la identificación de sistemas multivariables que resultan menos complejos de entender en
una primera aproximación. Así en primer lugar se realiza una descripción de los sistemas
multivariables. A continuación se realizan varias consideraciones sobre el diseño de las
señales de entrada que se van a utilizar en los experimentos de identificación para excitar el
sistema. Finalmente se describe la estimación de los parámetros de un modelo
multivariable.
10.2 DESCRIPCIÓN DE UN SISTEMA MULTIVARIABLE
Supóngase un sistema multivariable con m entradas y p salidas que puede ser descrito
por el siguiente modelo discreto
)()·()(
)()()·()(
teqHtv
tvtuqGty
(10.1)
En la expresión y(t) es el vector de salidas de dimensión p x 1, u(t) es el vector de
entradas de dimensión m x 1, v(t) es el vector de perturbaciones de dimensión p x 1 (cada
salida tiene una perturbación asociada), y e(t) es un vector de secuencias de ruido blanco de
dimensión p x 1, de media nula y matriz de covarianza )]()·([ teteE T .
Además G(q) es una matriz de funciones de transferencia de dimensión p x m. Siendo q
el operador desplazamiento. En consecuencia el elemento Gij(q) de la matriz G(q) será la
función de transferencia que relaciona la salida yi con la entrada uj. Por su parte H(q) es una
matriz de funciones de transferencia cuadrada de dimensión p x p.
Otra forma de describir un sistema dinámico, que resulta especialmente cómoda cuando
éste es multivariable, es la representación en variables de estado:
0)0(
)()(·)(·)(
)(·)(·)(·)(
xx
kTekTuDkTxCkTy
kTeKkTuBkTxATkTx
(10.2)

Identificación de sistemas
10-3
donde T es el periodo de muestreo, u(kT) es la entrada en el instante kT, e y(kT) es la salida
en el instante KT. Nótese que el modelo queda descrito por las matrices A, B, K, C y D que
habría que estimar, pero los elementos de estas matrices son números reales en vez de
funciones racionales en q como sucede en G(q) y H(q).
A partir de las matrices A, B, K, C y D es posible obtener las matrices de funciones de
transferencia G(q) y H(q):
nynx
nx
IKAIqCqH
DBAIqCqG
·)··()(
·)··()(1
1
(10.3)
En la expresión anterior Inx es la matriz identidad nx x nx, siendo nx la dimensión del
vector x. Asimismo Iny es la matriz identidad ny x ny, siendo ny=p la dimensión del vector y (y
del vector e).
Además cuando se trabaja con un sistema multivariable hay que tener en cuenta lo
siguiente:
Las respuestas a un impulso g(k) y h(k) son matrices de dimensión p x m y p x p,
respectivamente, con la siguiente norma:
2/1
,
2||)(
jiijgkg (10.4)
Las covarianzas son matrices y se definen de la siguiente forma:
)()]()·([ sT RtstsE (10.5)
)()]()·([ swT RtwtsE (10.6)
El espectro de las salidas se obtiene de la siguiente forma
)(·)·()()·()·()( iTiiTu
iy eHeHeGeG (10.7)
Nótese que la definición de espectro sobre un vector de señales define
implícitamente el espectro cruzado entre las componentes de la señal.

TEMA 10: Identificación de sistemas multivariables
10-4
El teorema de factorización espectral ahora se enuncia de la siguiente forma:
supóngase que )(v es una matriz p x p definida positiva para toda y cuyas
entradas son funciones racionales de cos o (ei). Entonces existe una matriz H(z)
mónica de dimensión p x p cuyas entradas son funciones racionales de z ( o z-1) tales
que la función racional dada por el determinante de H no tiene ningún polo y ningún
cero sobre o fuera del circulo unidad.
10.3 DISEÑO DE ENTRADAS PARA SISTEMAS MULTIVARIABLES
A cada una de las entradas disponibles en un sistema multivariable se le denomina
canal de entrada o simplemente canal. Para obtener datos de las entradas-salidas del
modelo con los que poder identificar un modelo del sistema multivariable se debe inyectar
en cada canal de entrada una señal que sea independiente (no esté correlacionada) de las
señales inyectadas en los restantes canales. Obviamente, como sucedía en el caso SISO,
las señales de entrada que se elijan deben ser dentro de los posible amigables con la
planta.
Supóngase un sistema MIMO con m entradas habría que diseñar por tanto m señales
de entrada, usualmente las señales usadas son todas del mismo tipo, por ello al conjunto de
las m señales se las suele denominar de forma conjunta como señal [tipo] multientrada. En
las siguiente secciones se comenta como diseñar una señal RBS multientrada, una señal
PRBS multientrada y una señal multiseno multientrada.
10.3.1 Diseño de señales RBS multientrada
Para conseguir señales RBS independientes no correlacionados en cada canal de un
sistema multivariable se puede usar una semilla distinta en el generador de números para
cada señal RBS que se desee generar.
10.3.2 Diseño de señales PRBS multientrada
En la sección 4.3.6 se comentó que las principales variables de diseño de una señal
PRBS son el tiempo de conmutación Tsw, el tamaño n del registro de desplazamiento y la
amplitud de la señal.
En el caso de un sistema con múltiples entradas, el valor inicial del registro de
desplazamiento debe ser seleccionado para que la señal PRBS que se inyecte en un canal
no esté correlacionada con la de los restantes canales. Esta inicialización se consigue
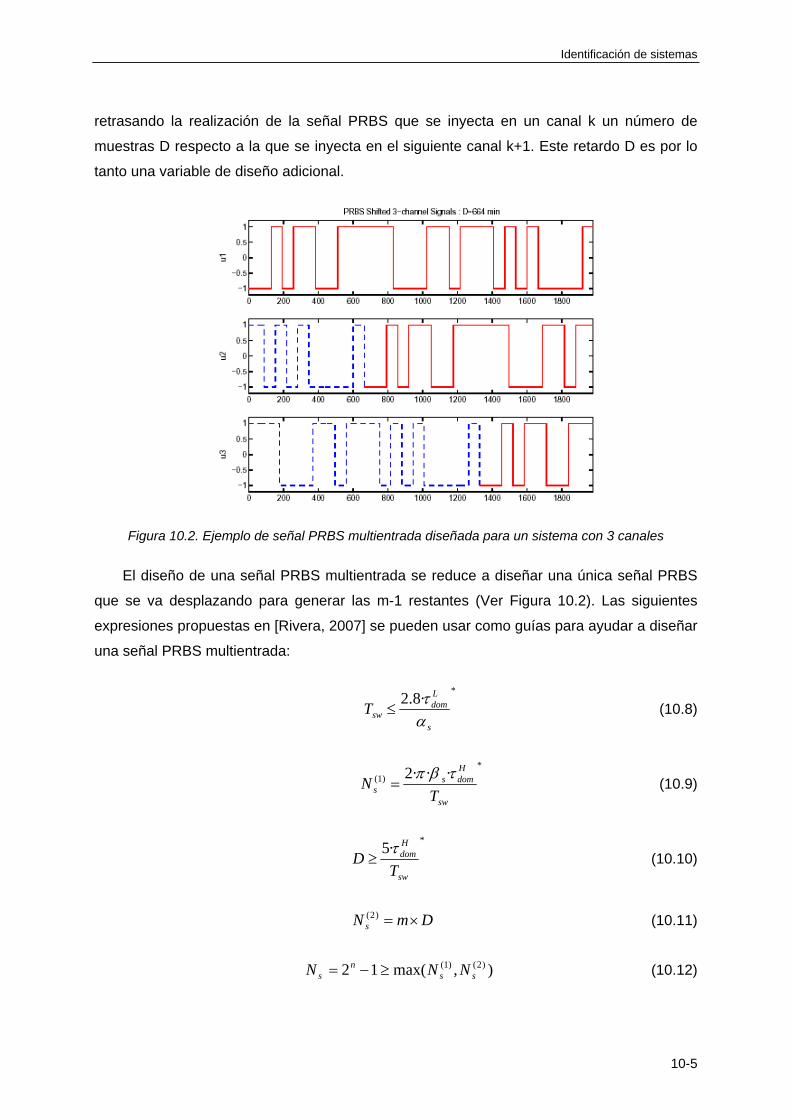
Identificación de sistemas
10-5
retrasando la realización de la señal PRBS que se inyecta en un canal k un número de
muestras D respecto a la que se inyecta en el siguiente canal k+1. Este retardo D es por lo
tanto una variable de diseño adicional.
Figura 10.2. Ejemplo de señal PRBS multientrada diseñada para un sistema con 3 canales
El diseño de una señal PRBS multientrada se reduce a diseñar una única señal PRBS
que se va desplazando para generar las m-1 restantes (Ver Figura 10.2). Las siguientes
expresiones propuestas en [Rivera, 2007] se pueden usar como guías para ayudar a diseñar
una señal PRBS multientrada:
*·8.2
s
Ldom
swT
(10.8)
*
)1( ···2
sw
Hdoms
s TN
(10.9)
*·5
sw
Hdom
TD
(10.10)
DmNs )2( (10.11)
),max(12 )2()1(ss
ns NNN (10.12)

TEMA 10: Identificación de sistemas multivariables
10-6
En las expresiones anteriores Ldom y H
dom son las estimas inferior y superior,
respectivamente, de la constante de tiempo dominante del sistema o planta. s es el factor
de representación del tiempo de asentamiento de la planta y s es el factor de
representación de la velocidad en lazo cerrado expresado como un múltiplo del tiempo de
respuesta en lazo abierto.
Además n y N deben ser valores enteros. Así como Tsw y D, que deben ser múltiplos
enteros del periodo de muestreo T y del periodo de conmutación Tsw.
10.3.3 Diseño de señales multiseno multientrada
Una señal multiseno es una señal determinista periódica que se genera como la suma
de múltiples sinusoides. Cada sinusoide especifica un armónico a una determinada
frecuencia.
Si se desea diseñar una señal multiseno multientrada un método consiste en diseñar
una señal multiseno base que se inyecta en cada canal desplazada (retardada) con respecto
a los restantes. El principal problema que presenta este método es que supuesto que se ha
empezado a excitar en el canal 1, la duración del ciclo de la señal inyectada en el canal k+1
es menor que la señal inyectada en el canal k, es decir, la duración del ciclo de la señal va
disminuyendo conforme se va inyectando en los diferentes canales.
Para evitar este problema y disponer de una duración de ciclo más larga en la señal
sinusoidal inyectada en cada canal k, se puede diseñar una señal multiseno en cremallera
(zippered). Se trata de una señal multiseno cuyo contenido en frecuencia se desglosa en m
señales multiseno. El desglose de dicho contenido en frecuencia se realiza de forma alterna
o en cremallera (zippered) entre los diversos canales. En la Figura 10.3 se muestra el
espectro en frecuencia de una señal multiseno en cremallera para un sistema con dos
canales. Se observa que los armónicos impares de la señal multiseno en cremallera
(representados con un cuadrado) se usan para formar la señal multiseno que se inyectará
en el canal 1. Mientras que los armónicos pares de la señal multiseno en cremallera
(representados con un círculo) se usan para formar la señal multiseno que se inyectará en el
canal 2.
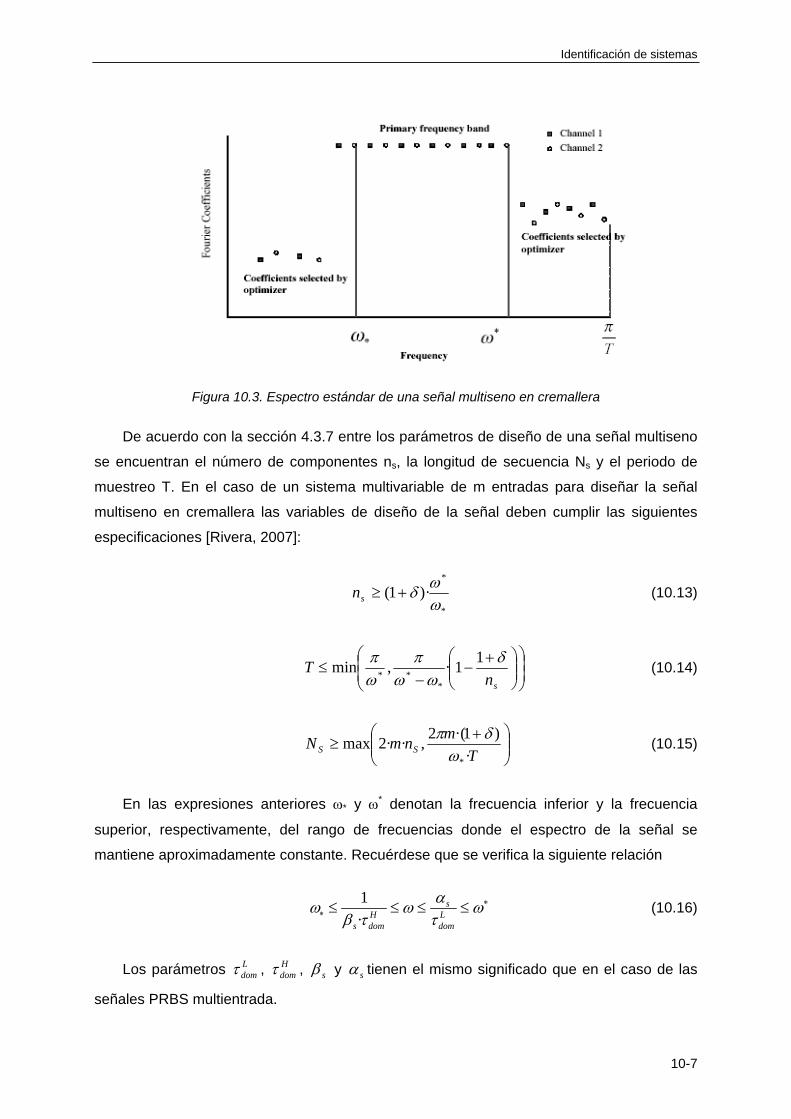
Identificación de sistemas
10-7
Figura 10.3. Espectro estándar de una señal multiseno en cremallera
De acuerdo con la sección 4.3.7 entre los parámetros de diseño de una señal multiseno
se encuentran el número de componentes ns, la longitud de secuencia Ns y el periodo de
muestreo T. En el caso de un sistema multivariable de m entradas para diseñar la señal
multiseno en cremallera las variables de diseño de la señal deben cumplir las siguientes
especificaciones [Rivera, 2007]:
*
*
)·1(sn (10.13)
snT
1
1·,min*
** (10.14)
T
mnmN SS ·
)1·(2,··2max
*
(10.15)
En las expresiones anteriores * y * denotan la frecuencia inferior y la frecuencia
superior, respectivamente, del rango de frecuencias donde el espectro de la señal se
mantiene aproximadamente constante. Recuérdese que se verifica la siguiente relación
1
·s
H Ls dom dom
(10.16)
Los parámetros Ldom , H
dom , s y s tienen el mismo significado que en el caso de las
señales PRBS multientrada.

TEMA 10: Identificación de sistemas multivariables
10-8
Por otra parte es un parámetro definido por el usuario. Los valores de los parámetros
finalmente determinados (que se van a denotar con el superíndice “d”) deberían satisfacer la
siguiente desigualdad:
m
NnNN
m
dsd
sdd
s ·2)1(··
··2
)( **
(10.17)
10.4 ESTIMACIÓN DE MODELOS MULTIVARIABLES
Supóngase que se dispone de N datos de cada una de las m entradas y de las p salidas
de un sistema MIMO. Se desea obtener una estima del vector de parámetros del siguiente
modelo del sistema multivariable
)()·,()()·,()( teqHtuqGty (10.18)
Donde recuérdese que G(q,) y H(q,) son matrices de dimensión p x m y p x p,
respectivamente, cuyos elementos son funciones de transferencia. Además y, e y u son
vectores de dimensión p x1, p x 1 y m x 1, respectivamente. Además t=1,2,,..,N
Ejemplo 10.1:
Considérese la ecuación de un modelo ARX
)()()·()()·( tetuzBtyzA (1)
En el caso de un sistema MIMO con p salidas y n entradas, y(t) sería un vector de dimensión p x 1,
u(t) sería un vector de dimensión m x 1 y e(t) sería un vector de dimensión p x 1. En consecuencia
A(z) debe ser una matriz de dimensión p x p donde cada uno de sus elementos aij(z) será un
polinomio de orden naij
naijnaijijijij
ppp
ij
p
zazaza
zaza
za
zaza
zA
...1)(
)(...)(
:)(:
)(...)(
)(
11
1
111
Por su parte B(z) es una matriz de dimensión p x m donde cada uno de sus elementos bij(z) será un
polinomio de orden nbij.

Identificación de sistemas
10-9
nbijnbijijijijij
pmp
ij
m
zbzbbzb
zazb
zb
zbzb
zB
...)(
)(...)(
:)(:
)(...)(
)(
110
1
111
En consecuencia para especificar la estructura de un modelo ARX MIMO m x p se deben especificar
los órdenes de los elementos de la matriz A y de la matriz B:
ppp
ij
p
nana
na
nana
NA
...
::
...
1
111
(1)
pmp
ij
m
nbnb
nb
nbnb
NB
...
::
...
1
111
(1)
Además habría que especificar los retardos en las salidas con respecto a las entradas:
pmp
ij
m
nknk
nk
nknk
NK
...
::
...
1
111
(1)
Multiplicando con A-1 por la izquierda de los dos miembros de (1) se obtiene:
)()·()()·()()( 11 tezAtuzBzAty (1)
Con lo que
)(),(
)()(),(1
1
zAqH
zBzAqG
(1)
Nótese que si se tuviese un sistema MISO de m entradas y una salida entonces la matriz A(z)
constaría de un único elemento a(s), por lo que NA=na. Mientras que la matriz B sería un vector fila
de m elementos, al igual que las matrices de ordenes NB y NK.

TEMA 10: Identificación de sistemas multivariables
10-10
El predictor de la salida a un paso es un vector de dimensión p x 1:
)())·,(()()·,()·,()|(ˆ 11 tyqHItuqGqHty (10.19)
En la expresión anterior I es la matriz identidad de dimensión p x p.
El error de predicción es también un vector de dimensión p x 1:
)]()·,()()·[,()|(ˆ)(),( 1 tuqGtyqHtytyte (10.20)
Si se usa un prefiltro L(q) sobre el error para enfatizar determinadas zonas de
frecuencia se tendrá el error de predicción filtrado:
),()·(),( teqLteF (10.21)
Se desea encontrar la estima N que miminiza la siguiente función de coste:
N
yF
TFN tete
NV
1
),()·,(·1
)( (10.22)
Es decir, el problema a resolver es el siguiente:
)(minargˆ NN V (10.23)
También en el caso multivariable se suele usar dentro de la función de coste una matriz
de peso W de dimensión p x p para dar más o menos importancia a minimización de los
errores de ciertas salidas en particular
N
yF
TFN teWte
NV
1
1 ),(·)·,(·1
)( (10.24)
La toolbox SIT de Matlab a partir de su versión 6.0 (Matlab 7.0) soporta la estimación de
modelos MIMO en variables de estado de la forma (10.2) a través del comando pem. Nótese
que una vez estimadas las matrices A, B, K, C y D del modelo en variables de estado, es
posible a través de la ecuación (10.3) obtener las matrices de funciones de transferencia
G(q,) y H(q,). Con el comando pem no se pueden obtener directamente modelos ARX,
ARMAX, OE y BJ para sistemas MIMO, pero si para sistemas MISO.

Identificación de sistemas
10-11
También es posible obtener modelos ARX MIMO a través del comando arx. Nótese
que hay que especificar las matrices de órdenes NA, NB y NK.
Ejemplo 10.2:
Se van a considerar como datos de entrada/salida los suministrados a modo de ejemplo en el fichero
SteamEng.mat de la toolbox SITB de Matlab 7.0. Se trata de los datos de un motor de vapor que es
un sistema MIMO con dos entradas (m=2) y con dos salidas (p=2). Las entradas son la presión del
vapor (normalmente aire comprimido) después del control de la válvula y el voltaje de magnetización
sobre el generador conectado al eje de salida. Las salidas son el voltaje generado y la velocidad
rotacional del generador (frecuencia del voltaje AC generado). El periodo de muestreo es T=50 ms.
En primer lugar se van a recoger las entradas y las salidas dentro de un objeto iddata de nombre
steam. Además se va a poner nombre a las entradas y a las salidas:
load SteamEng steam = iddata([GenVolt,Speed],[Pressure,MagVolt],0.05); steam.InputName = {'Pressure';'MagVolt'}; steam.OutputName = {'GenVolt';'Speed'};
A continuación se van a representar las series temporales de las entradas y las salidas los datos
disponibles (ver Figura 10.4):
plot(steam(:,1,1)) plot(steam(:,1,2)) plot(steam(:,2,1)) plot(steam(:,2,2))
Para tener una idea de la dinámica del sistema se va a estimar las respuestas a escalones (Ver
Figura 10.5) y a impulsos (ver Figura 10.6) del sistema a partir de los datos de entrada-salida
disponibles:
ms=step(steam); step(steam) impulse(ms,'sd',3)
Se observa que la entrada voltaje de magnetización no parece afectar mucho a la velocidad. Además
la dinámica de la salida voltaje del generador debido a la entrada voltaje de magnetización no tiene
mucha dinámica, sólo un retardo.
Se va a estimar un modelo en variables de estado de la forma (10.2) usando el comando pem con
sus valores por defecto y usando los primeros 250 datos para estimar
>> mp = pem(steam(1:250))
TEMA 10: Identificación de sistemas multivariables
10-12
(a) (b)
(c) (d)
Figura 10.4. Representación temporal de los datos de entrada-salida del motor de vapor: a) Entrada:
presión, salida: voltaje generado. b) Entrada: voltaje de magnetización, salida: voltaje generado. c)
Entrada: presión, salida: velocidad. d) Entrada: voltaje de magnetización, salida: velocidad.
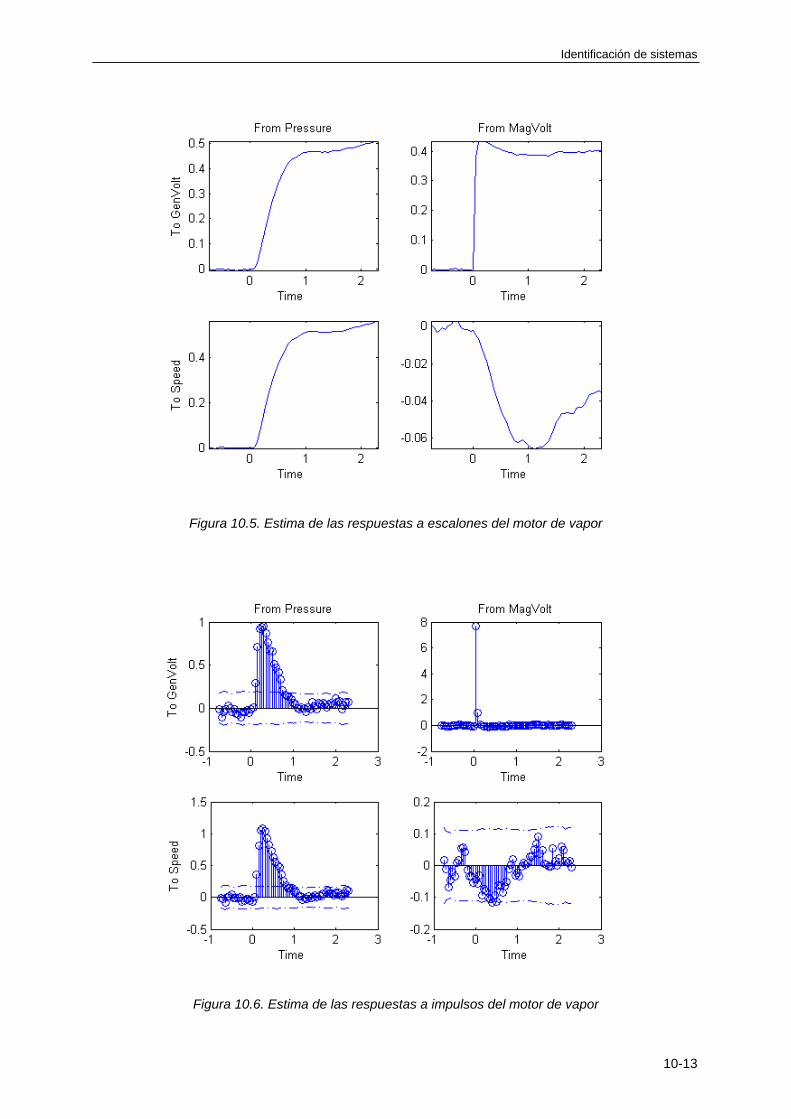
Identificación de sistemas
10-13
Figura 10.5. Estima de las respuestas a escalones del motor de vapor
Figura 10.6. Estima de las respuestas a impulsos del motor de vapor

TEMA 10: Identificación de sistemas multivariables
10-14
State-space model: x(t+Ts) = A x(t) + B u(t) + K e(t) y(t) = C x(t) + D u(t) + e(t) A = x1 x2 x1 0.15043 0.084359 x2 0.15893 0.93787 B = Pressure MagVolt x1 -0.00043924 0.034544 x2 -0.00082436 -0.007428 C = x1 x2 GenVolt 10.367 -3.9245 Speed -0.6629 -3.0046 D = Pressure MagVolt GenVolt 0 0 Speed 0 0 K = GenVolt Speed x1 -0.008793 -0.038367 x2 -0.098116 -0.31591 x(0) = x1 0 x2 0 Estimated using PEM from data set z Loss function 1.34188e-005 and FPE 1.47719e-005 Sampling interval: 0.05
Se va a comparar (ver Figura 10.7) las respuestas a escalones del modelo y las estimadas, para ello
se usará el siguiente comando
step(ms,'b:',mp,'r',3)
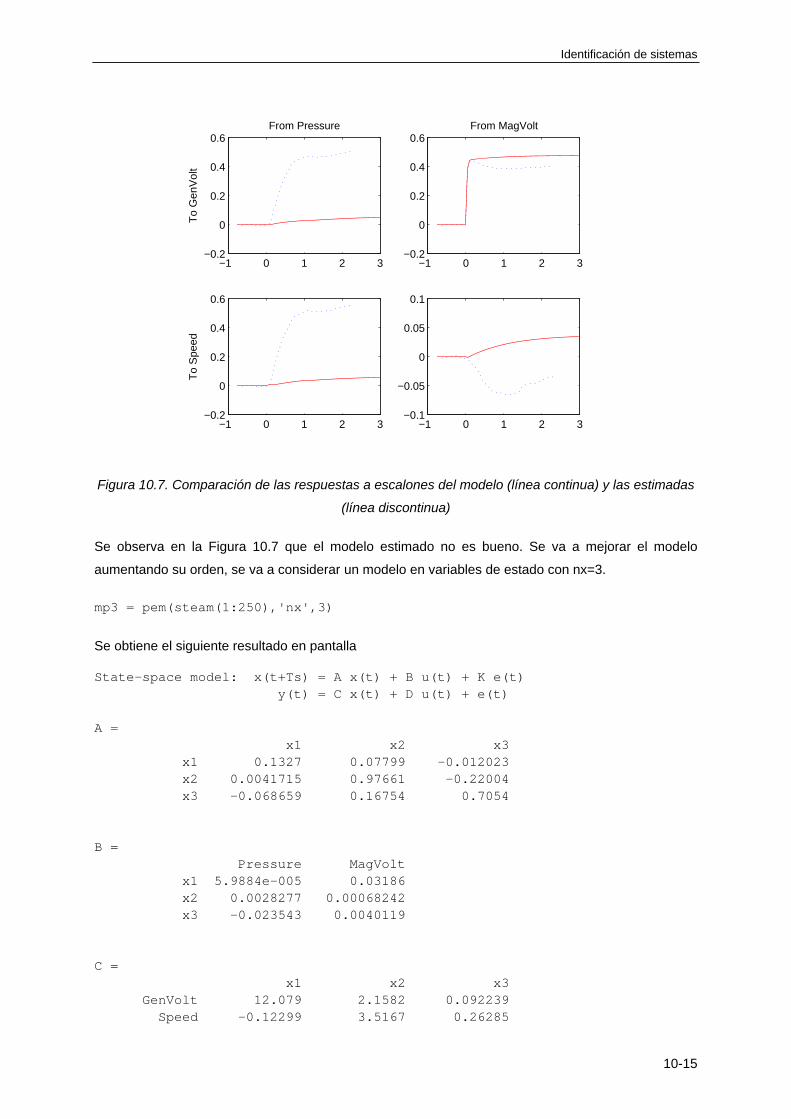
Identificación de sistemas
10-15
−1 0 1 2 3−0.2
0
0.2
0.4
0.6From Pressure
To
Gen
Vol
t
−1 0 1 2 3−0.2
0
0.2
0.4
0.6From MagVolt
−1 0 1 2 3−0.2
0
0.2
0.4
0.6
To
Spe
ed
−1 0 1 2 3−0.1
−0.05
0
0.05
0.1
Figura 10.7. Comparación de las respuestas a escalones del modelo (línea continua) y las estimadas
(línea discontinua)
Se observa en la Figura 10.7 que el modelo estimado no es bueno. Se va a mejorar el modelo
aumentando su orden, se va a considerar un modelo en variables de estado con nx=3.
mp3 = pem(steam(1:250),'nx',3)
Se obtiene el siguiente resultado en pantalla
State-space model: x(t+Ts) = A x(t) + B u(t) + K e(t) y(t) = C x(t) + D u(t) + e(t) A = x1 x2 x3 x1 0.1327 0.07799 -0.012023 x2 0.0041715 0.97661 -0.22004 x3 -0.068659 0.16754 0.7054 B = Pressure MagVolt x1 5.9884e-005 0.03186 x2 0.0028277 0.00068242 x3 -0.023543 0.0040119 C = x1 x2 x3 GenVolt 12.079 2.1582 0.092239 Speed -0.12299 3.5167 0.26285

TEMA 10: Identificación de sistemas multivariables
10-16
D = Pressure MagVolt GenVolt 0 0 Speed 0 0 K = GenVolt Speed x1 0.0055432 0.010936 x2 0.034068 0.17572 x3 0.1318 0.039441 x(0) = x1 0 x2 0 x3 0 Estimated using PEM from data set z Loss function 6.70722e-006 and FPE 7.748e-006 Sampling interval: 0.05:
Se va a comparar las respuestas a escalones del modelo y las estimadas, para ello se usará el
siguiente comando
step(ms,'b:',mp3,'r',3)
La representación gráfica que se obtiene se muestra en la Figura 10.8. Se observa que nuevo modelo
ahora ofrece mejores resultados que el modelo anterior excepto en el caso de la velocidad frente al
voltaje magnético, que también era muy malo entonces. Aunque tampoco importa ya que la influencia
de esta entrada sobre esta salida tampoco es significativa.
Se va a comparar las respuestas temporales del modelo frente a las respuestas medidas usando los
datos 251:400 para validar
compare(steam(251:450),mp3)
En la Figura 10.9 se muestran la representación gráfica que se obtiene. El modelo es muy bueno en
reproducir el voltaje generado y no va mal para reproducir la velocidad.

Identificación de sistemas
10-17
−1 0 1 2 3−0.2
0
0.2
0.4
0.6From Pressure
To
Gen
Vol
t
−1 0 1 2 3−0.2
0
0.2
0.4
0.6From MagVolt
−1 0 1 2 3−0.2
0
0.2
0.4
0.6
To
Spe
ed
−1 0 1 2 3−0.08
−0.06
−0.04
−0.02
0
0.02
Figura 10.8. Comparación de las respuestas a escalones del modelo en variables de estado de orden
nx=3 (línea continua) y las estimadas (línea discontinua)
12 14 16 18 20 22 24−2
−1
0
1
2
Gen
Vol
t
Measured Output and Simulated Model Output
12 14 16 18 20 22 24−0.6
−0.4
−0.2
0
0.2
0.4
Spe
ed
Measured Outputmp3 Fit: 89.54%
Measured Outputmp3 Fit: 47.62%
Figura 10.9. Comparación de las respuestas del modelo (línea continua) y las medidas
experimentalmente (línea discontinua)
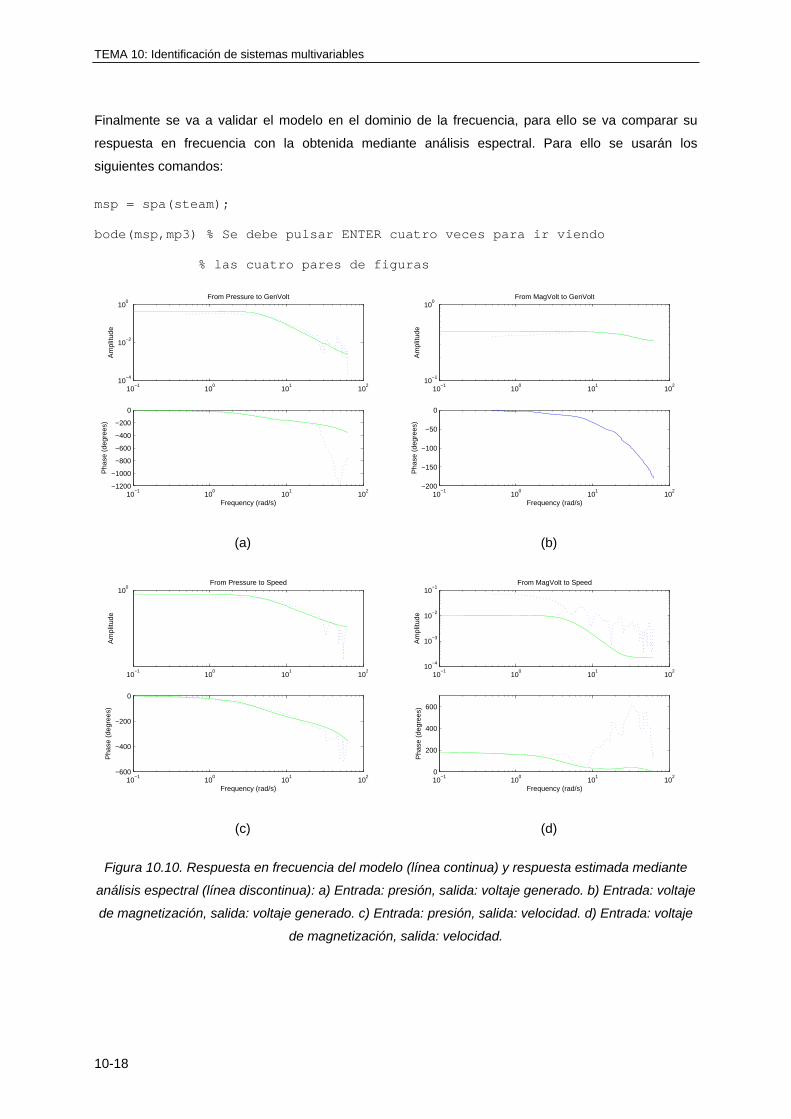
TEMA 10: Identificación de sistemas multivariables
10-18
Finalmente se va a validar el modelo en el dominio de la frecuencia, para ello se va comparar su
respuesta en frecuencia con la obtenida mediante análisis espectral. Para ello se usarán los
siguientes comandos:
msp = spa(steam);
bode(msp,mp3) % Se debe pulsar ENTER cuatro veces para ir viendo
% las cuatro pares de figuras
10−1
100
101
102
10−4
10−2
100
Am
plitu
de
From Pressure to GenVolt
10−1
100
101
102
−1200
−1000
−800
−600
−400
−200
0
Pha
se (
degr
ees)
Frequency (rad/s)
(a)
10−1
100
101
102
10−1
100
Am
plitu
de
From MagVolt to GenVolt
10−1
100
101
102
−200
−150
−100
−50
0P
hase
(de
gree
s)
Frequency (rad/s)
(b)
10−1
100
101
102
100
Am
plitu
de
From Pressure to Speed
10−1
100
101
102
−600
−400
−200
0
Pha
se (
degr
ees)
Frequency (rad/s)
(c)
10−1
100
101
102
10−4
10−3
10−2
10−1
Am
plitu
de
From MagVolt to Speed
10−1
100
101
102
0
200
400
600
Pha
se (
degr
ees)
Frequency (rad/s)
(d)
Figura 10.10. Respuesta en frecuencia del modelo (línea continua) y respuesta estimada mediante
análisis espectral (línea discontinua): a) Entrada: presión, salida: voltaje generado. b) Entrada: voltaje
de magnetización, salida: voltaje generado. c) Entrada: presión, salida: velocidad. d) Entrada: voltaje
de magnetización, salida: velocidad.

Identificación de sistemas
10-19
Se observa en la Figura 10.10 que el modelo es bastante aceptable excepto en el caso de la
velocidad frente al voltaje magnético. Aunque tampoco importa ya que la influencia de esta entrada
sobre esta salida tampoco es significativa.
Afortunadamente se ha obtenido rápidamente un modelo MIMO aceptable. En otros casos esto no se
será posible y habrá que plantearse despreciar interacciones y modelar independientemente los
canales con modelos SISO o MISO.
Ejemplo 10.3:
Considérese los datos del motor de vapor del ejemplo anterior, se desea estimar un modelo ARX
MIMO. Se van a considerar los siguientes órdenes para el modelo:
NA=[4 4; 4 4], NB=[4 4;4 4], NK=[1 1; 1 1]
El modelo se estima usando el siguiente comando:
arx441=arx(steam(1:250),'na',NA,'nb',NB,'nk',NK)
En la pantalla se muestra el siguiente resultado:
Multivariable ARX model A0*y(t)+A1*y(t-T)+ ... + An*y(t-nT) = B0*u(t)+B1*u(t-T)+ ... +Bm*u(t-mT) + e(t) A0: 1 0 0 1 A1: -0.19295 -0.6796 -0.26254 -0.65077 A2: 0.054257 -0.15973 0.066238 -0.22465 A3: -0.037682 0.17015 0.072165 0.046203 A4: -0.0026903 0.0048563 -0.011025 0.055283

TEMA 10: Identificación de sistemas multivariables
10-20
B0: 0 0 0 0 B1: 0.0047785 0.38658 0.0054493 -0.0012769 B2: 0.014671 -0.022031 0.01617 -0.10054 B3: 0.021951 0.015004 0.02188 0.010344 B4: 0.0086785 -0.010176 0.011904 0.030536 Estimated using ARX from data set data Loss function 4.00318e-006 and FPE 5.17842e-006 Sampling interval: 0.05
Se puede comprobar usando los test comentados en el ejemplo anterior que el modelo ARX MIMO
estimado produce unos resultados parecidos a los del modelo en variables de estado obtenido en el
ejemplo anterior.
BIBLIOGRAFÍA
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.
[Skogestad y Postlethwaite, 1996] S. Skogestad, I. Postlethwaite. Multivariable feedback
control. analysis and design. John Wiley & Sons. 1996

TEMA 11
IDENTIFICACIÓN DE SISTEMAS NO LINEALES
11-1
11.1 INTRODUCCIÓN
La mayoría de los sistemas y procesos industriales son sistemas no lineales, en
consecuencia modelar tales sistemas usando modelos lineales introduce un cierto grado de
aproximación. Mientras que dicha aproximación puede ser considerada aceptable en
muchas aplicaciones, en ciertos casos no producirá los resultados deseados y habrá que
plantearse la identificación de un modelo no lineal, la cual resulta en general mucho más
laboriosa que la identificación de sistemas lineales sobre todo en las etapas de la selección
de la estructura adecuada y estimación de los parámetros del modelo.
En este tema se realiza una pequeña introducción a la identificación de sistemas no
lineales. En primer lugar se analiza cuando es necesario identificar un modelo no lineal. En
segundo lugar se describen varios test para detectar si el sistema bajo consideración es no
lineal. En tercer lugar se describen los modelos no lineales más comunes. Finalmente se
realizan varias consideraciones sobre el prefiltrado y el análisis de los residuos cuando se
realiza identificación de sistemas no lineales.
11.2 ALGUNAS CONSIDERACIONES SOBRE LA NECESIDAD DE IDENTIFICAR MODELOS NO LINEALES
Un modelo lineal resulta a menudo suficiente para describir adecuadamente la dinámica
de un sistema. En consecuencia en la mayoría de los casos antes de plantearse identificar
un modelo no lineal conviene usar modelos lineales. Si la salida del modelo lineal elegido no
reproduce adecuadamente los datos reales del sistema medidos experimentalmente,
entonces quizás habrá que identificar un modelo no lineal.

TEMA 11: Identificación de sistemas no lineales
11-2
Antes de construir un modelo no lineal conviene verificar si realmente el sistema es no
lineal realizando sobre el mismo algunos test (ver sección 11.3). Si el sistema es no lineal
conviene probar a transformar las variables de entrada y de salida de tal forma que la
relación entre las variables transformadas sea lineal. Por ejemplo, considérese un
calentador que tiene como entradas una intensidad de corriente y un voltaje y como salida la
temperatura del líquido calentado. La salida depende de las entradas a través de la potencia
del calentador, la cual es igual al producto de la corriente y el voltaje. En vez de construir un
modelo no lineal para este sistema de dos entradas y una salida, se puede crear una nueva
variable de entrada tomando el producto de la intensidad y el voltaje, y después construir un
modelo que describa la relación entre la potencia y la temperatura.
En el caso de que no se encuentre ninguna transformación sobre las variables de
entrada y salida que permita relacionarlas linealmente, entonces habrá que usar un modelo
no lineal.
11.3 COMPROBACIÓN DE LA NO LINEALIDAD DE UN SISTEMA
Antes de plantearse la identificación de un modelo no lineal conviene asegurarse de que
el sistema real es realmente no lineal, para ello se pueden realizar diferentes test sobre el
sistema. Entre los más usuales se encuentra el estudio de la respuesta a un escalón y el
estudio de las funciones de correlación de órdenes más altos.
11.3.1 Test en el dominio del tiempo basado en la respuesta a escalones.
Se puede verificar la no linealidad de un sistema estudiando la respuesta del sistema a
una determinada entrada. Si se observa que la salida difiere dependiendo del nivel o del
signo de la entrada, entonces eso es un signo de no linealidad.
Supóngase que el sistema está operando en un cierto nivel estacionario [u0(t),yo(t)],
entonces se aplica un cambio escalón en la señal de entrada (u0(t)+u1) al proceso y se
mide la señal de salida y1(t). A continuación, cuando la planta vuelva a su nivel de operación
normal, se aplica un segundo escalón al proceso (u0(t)+u2) con
12 · uu (11.1)
Siendo una constante mayor que uno, es decir, u2 es veces mayor que u1. Se
debe medir la señal de salida y2(t) y construir la siguiente razón:

Identificación de sistemas
11-3
01
02
)(
)()(
yty
ytyt
(11.2)
Si (t) es constante e igual a entonces el sistema es lineal. Obviamente, para explotar
completamente este test se deberían aplicar escalones positivos y negativos. Puesto que las
medidas experimentales se ven afectadas por el ruido de los sensores, este test se debe
repetir varias veces y a las señales de salida se les deben eliminar sus valores medios.
Este test está especialmente recomendado para aquellos procesos en los que es
posible perturbar su actividad normal.
11.3.2 Test basado en las funciones de correlación de orden más alto.
Para aquellos sistemas sobre los que no es posible perturbar su actividad normal o si ya
se dispone de un determinado conjunto de datos de entrada-salida de la planta, entonces se
recomienda usar un test basado en las funciones de correlación de órdenes más altos.
Para poder aplicar este test se debe verificar que la entrada u(t) y el ruido e(t) son
independientes y de media nula. Además todos los momentos impares de u(t) y e(t) son
nulos. Además los momentos pares existen.
Básicamente el test se realiza de la siguiente forma: aplicar la entrada u(t)+b, donde b
es un nivel de continua, al proceso y medir la señal de salida y(t). Eliminar cualquier nivel
medio de la respuesta del proceso:
)]([)()( tyEtyty (11.3)
Calcular la función de correlación de orden más alto:
]))()·(([)( 22 tytyE
yy (11.4)
Se puede demostrar que 0)(2yy si y solo si el proceso es lineal. Nótese que el
nivel b de continua es añadido a la entrada para asegurarse que todos los términos que
reflejan la no linealidad del sistema contribuyen a )(2 yy
.

TEMA 11: Identificación de sistemas no lineales
11-4
11.4 DISEÑO DE LA SEÑAL DE ENTRADA
Cuando se realiza la identificación de un sistema no lineal conviene tener presentes las
siguientes consideraciones a la hora de diseñar la señal de entrada con que se va a excitar
al sistema:
Las señales de entrada de tipo binario pueden no resultar adecuadas para identificar
ciertos tipos de sistemas no lineales.
El uso de señales de entrada con una determinada frecuencia no garantiza que la
señal de salida vaya a tener la misma frecuencia.
Ejemplo 11.1:
Supóngase que un cierto sistema no lineal se puede describir por la siguiente ecuación
)(·)( 2 tukty
Si la señal de entrada fuese una señal de tipo binario PRBS o RBS con amplitud comprendida entre
-1 y 1, la salida del sistema sería
kty )(
Es decir, debida a la presencia de una no linealidad cuadrática, la salida es siempre una señal
constante, de la que no se puede extraer mucha información sobre el sistema.
Por otra parte si la entrada fuese la señal sinusoidal
)·()( 0 tsentu
la salida sería
2
)··2cos(1·)·(·)( 0
02 t
ktsenktu
Es decir, la señal de salida es de tipo sinusoidal con una frecuencia distinta (2·0) a la frecuencia (0)
de la señal de entrada.
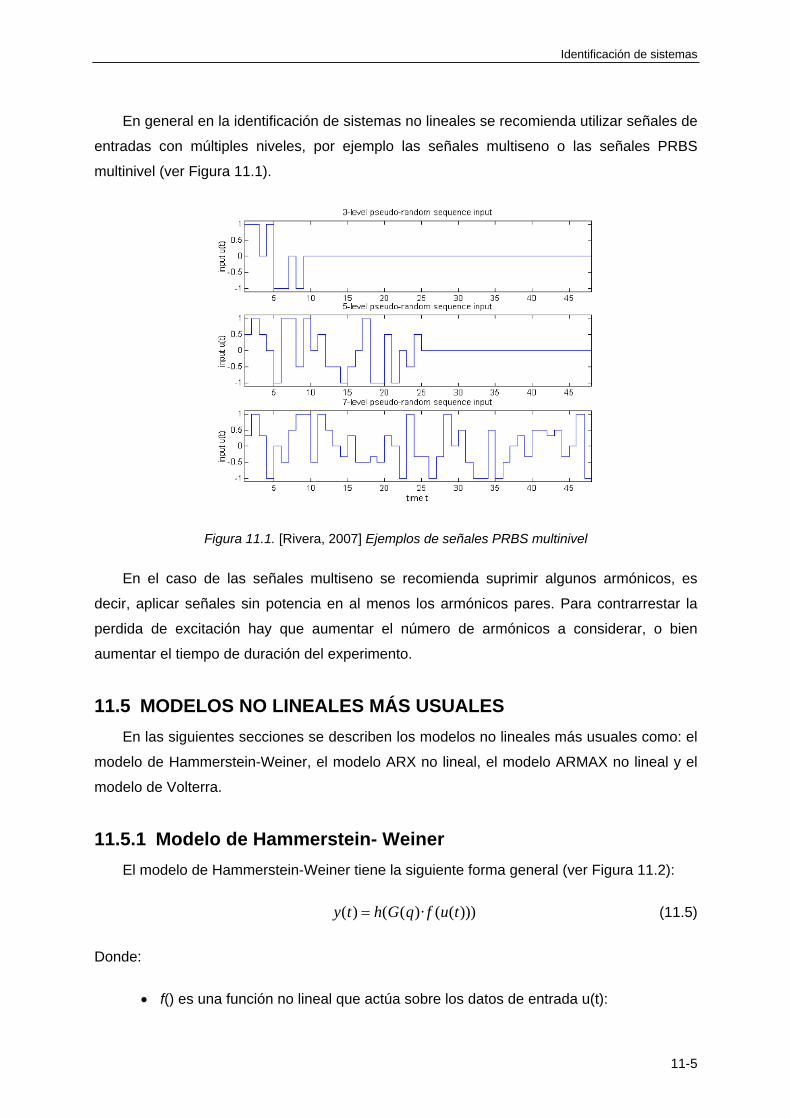
Identificación de sistemas
11-5
En general en la identificación de sistemas no lineales se recomienda utilizar señales de
entradas con múltiples niveles, por ejemplo las señales multiseno o las señales PRBS
multinivel (ver Figura 11.1).
Figura 11.1. [Rivera, 2007] Ejemplos de señales PRBS multinivel
En el caso de las señales multiseno se recomienda suprimir algunos armónicos, es
decir, aplicar señales sin potencia en al menos los armónicos pares. Para contrarrestar la
perdida de excitación hay que aumentar el número de armónicos a considerar, o bien
aumentar el tiempo de duración del experimento.
11.5 MODELOS NO LINEALES MÁS USUALES
En las siguientes secciones se describen los modelos no lineales más usuales como: el
modelo de Hammerstein-Weiner, el modelo ARX no lineal, el modelo ARMAX no lineal y el
modelo de Volterra.
11.5.1 Modelo de Hammerstein- Weiner
El modelo de Hammerstein-Weiner tiene la siguiente forma general (ver Figura 11.2):
)))(()·(()( tufqGhty (11.5)
Donde:
f() es una función no lineal que actúa sobre los datos de entrada u(t):

TEMA 11: Identificación de sistemas no lineales
11-6
))(()( tuftw (11.6)
G(q) es una función de transferencia lineal:
)(
)()(
qF
qBqG (11.7)
h() es una función no lineal que actúa sobre la salida x(t) del bloque lineal para
generar la salida del sistema y(t)
))(()( txhty (11.8)
En el modelo w(t) y x(t) son variables internas que definen la entrada y la salida del
bloque lineal. Ambas son de la misma dimensión que la entrada u(t) y la salida y(t) del
sistema.
G(q)f( ) h( )u(t) w(t) x(t) y(t)
No lineal Lineal No lineal
Figura 11.2. Estructura de un modelo de Hammerstein-Weiner
Tanto f como h son funciones estáticas sin memoria, es decir, que el valor que generan
en un instante t depende únicamente del valor de sus entradas en dicho instante t. Por
ejemplo: ...)(·)(·)( 2210 turturrtw . Si h=1 entonces se dice que se tiene un modelo de
Hammerstein. Asimismo si g=1, se dice que se tiene un modelo de Weiner.
En el caso de un sistema MIMO de m entradas y p salidas habría que diseñar m
funciones f y p funciones h. Además G(q) sería una matriz de funciones de transferencia.
Un modelo de Hammerstein-Wiener calcula la salida y en tres etapas:
1) Calculo de w(t)=f(u(t)).
2) Calculo de la salida del bloque lineal: x(t)=G(q) w(t)= (B(q)/F(q))·w(t).
3) Calculo de la salida del modelo mediante la transformación de la salida del bloque
lineal x(t) usando la función no lineal h: y(t)=h(x(t).

Identificación de sistemas
11-7
En general el principal problema que presenta el uso de un modelo no lineal reside en
encontrar la estructura más adecuada para el tipo de modelo no lineal elegido, ya que hay
más grados de libertad y el usuario tiene que tomar más decisiones.
La estructura de un modelo de Hammerstein-Weiner queda definida por la funciones no
lineales f y h que se elijan, así como por los ordenes de los polinomios B(q) y F(q). Luego el
diseñador debe tomar varias decisiones.
Elegida una determinada estructura el vector de parámetros de un modelo de
Hammerstein-Weiner está compuesto por los parámetros de la función f, los parámetros de
los polinomios B(q) y F(q), y los parámetros de la función h.
La estima de mínimos cuadrados se obtiene resolviendo el siguiente problema de
optimización:
2
2)(ˆ)(minargˆ tytyN
(11.9)
Siendo )(ˆ ty el predictor a un paso de la salida
Para resolver este problema se puede seguir el siguiente esquema iterativo:
1) Resolver (11.9) dando unos valores iniciales a los parámetros de las funciones no
lineales f y h. Se determina de este modo los parámetros del modelo lineal G(q)
2) Resolver (11.9) fijando los parámetros de G(q) con el valor obtenido en el paso 1.
Se determinan los parámetros de las funciones no lineales f y h.
3) Repetir el paso 1 con los valores para los parámetros de las funciones no lineales
f y h obtenidos en el paso 2.
4) Repetir el paso 3 con los valores de los parámetros del filtro lineal G(q) obtenidos
en el paso 3.
5) Repetir los pasos 3 y 4 hasta obtener valores convergentes.
La toolbox SIT de Matlab a partir de su versión 7.0 (Matlab R2007a) soporta la
estimación de modelos de Hammerstein-Weiner mediante el uso del comando nlhw.

TEMA 11: Identificación de sistemas no lineales
11-8
11.5.2 Modelo NARMAX
El modelo ARMAX no lineal o NARMAX (Nonlinear ARMAX) tiene la siguiente forma
general:
)())(),...,1(),(),...,1(),(,...,),1(()( tentetentutuntytyfty euy (11.10)
donde y(t) denota la salida, u(t) la entrada y {e(t)} es una secuencia de ruido blanco. Por su
parte f(.) es una función no lineal.
Expandiendo f(.) como un polinomio de grado L (donde L representa el grado de no
linealidad) se obtiene la siguiente representación:
n
iii tetxty
1
)()(·)( (11.11)
donde
L
iinn
0
(11.12)
con
10 n (11.13)
Liiinnnnn euyii ,...,1/)1·(1 (11.14)
Además i es el parámetro del modelo i-ésimo, x1(t)=1, y
eemuukyyj
r
mem
q
kuk
p
jyji
nnnnnn
Lrqprqpni
ntentuntytx
111
1;0,,;,...,2
)(·)()·()(111
(11.15)
La expansión polinomial de f(.) produce una ecuación de diferencias no lineal que es
lineal en los parámetros. Los componentes del modelo son funciones polinomiales lineales y
no lineales de la entrada y de la salida.
La estructura de un modelo NARMAX queda definida por los valores de nu, ny, ne y L.
Mientras que el vector de parámetros tiene por lo tanto la siguiente forma:

Identificación de sistemas
11-9
n ,...,1 (11.16)
Una vez fijada la estructura la estimación de los parámetros del modelo NARMAX puede
ser formulado y resuelto como un problema estándar de mínimos cuadrados (11.9).
Obviamente lo complicado es seleccionar la estructura correcta. Se puede comenzar fijando
una estructura sencilla e ir gradualmente incrementando nu, ny, ne y L hasta conseguir la
precisión deseada. No obstante esta forma de proceder suele conducir a modelos de
órdenes elevados sobreparametrizados y además el procedimiento de estimación estará mal
condicionado.
Podría pensarse por otro parte en ir estimando los parámetros para todas las posibles
estructuras y seleccionar la mejor de acuerdo con algún criterio de información como por
ejemplo el criterio de información de Akaike (AIC). Sin embargo este método no resulta
válido debido al gran número de estructuras a probar, incluso aunque el orden L de la
expansión polinomial sea pequeño.
Afortunadamente se han desarrollado diferentes algoritmos, como por ejemplo el
propuesto en [Thomson et al., 1996], para seleccionar la estructura de un modelo NARMAX
más adecuada, es decir con la complejidad mínima para reproducir adecuadamente la
dinámica del sistema no lineal.
11.5.3 Modelo NARX
El modelo ARX no lineal o NARX (Nonlinear ARX) tiene la siguiente forma general:
)())(),...,1(),(,...,),1(()( tentutuntytyfty uy (11.17)
donde y(t) denota la salida, u(t) la entrada y {e(t)} es una secuencia de ruido blanco. Por su
parte f(.) es una función no lineal. Al igual que sucedía con los modelos NARMAX la función
f() de un modelo NARX puede expandirse como un polinomio de grado L.
La toolbox SIT de Matlab a partir de su versión 7.0 (Matlab R2007a) soporta la estimación
de modelos NARX mediante el uso del comando nlarx. Este comando considera la
estructura para un modelo NARX que se muestra en la Figura 11.2. Dicho modelo calcula la
salida y en dos etapas:
1) Calculo de los regresores a partir del valor actual de la entrada y de los valores
pasados de la entrada y la salida.

TEMA 11: Identificación de sistemas no lineales
11-10
2) El estimador de la no linealidad genera la salida y del modelo usando una combinación
de funciones lineales y no lineales sobre los regresores
En el caso más simple se usan regresores estándar, es decir, las entrada y la salida en
los instantes pasados, como por ejemplo y(t-3) y u(t-1). Aunque el comando nlarx también
permite especificar regresores no lineales como por ejemplo, tan(u(t-1)) o u(t-1)*y(t-3). Por
defecto todos los regresores son utilizados como entradas para las funciones lineales y no
lineales del estimador de la no linealidad.
Regresoresu(t), u(t-1), y(t-1),…
u
Estimador de la no linealidad
Funciónno lineal
Funciónlineal
y
Figura 11.2. Estructura de un modelo NARX
También es posible seleccionar el tipo de estimador de la no linealidad a utilizar por el
comando nlarx, como por ejemplo, redes de partición en árbol (tree-partition), redes de
wavelet y redes neurales multicapa. Además es posible excluir o el bloque de la función
lineal o el bloque de la función no lineal del estimador de la no linealidad.
El bloque de estimación de la no linealidad también puede incluir bloques lineales y no
lineales en paralelo. Por ejemplo
))(()()( rxQgdrxLxF T (11.18)
donde, x es un vector de regresores, LT(x-r) + d es la salida del bloque de la función lineal y
es afín cuando d0, d es un escalar, g(Q(x-r) representa la salida del bloque de la función no
lineal, r es la media del vector de regresores x, y Q es una matriz de proyección que hace
que los cálculos estén bien condicionados. La forma exacta de F(x) depende de la elección
que se realice del estimador de la no linealidad.
La estimación de un modelo NARX mediante el comando nlarx, calcula los valores de
los parámetros del modelo, tales como L, r, d, Q y otros parámetros específicos de g(.)

Identificación de sistemas
11-11
11.5.4 Modelo de Volterra
El modelo de Volterra tiene la siguiente forma general:
N
n
nM tvty
10 )()( (11.19)
donde
M
i
M
i
M
innnn
nM ituituituiiitv
01 02 02121 )()·...·()·()·,...,,(...)( (11.20)
Fijado el valor de M y de N se obtiene una clase de modelos de Volterra que es un
conjunto de posibles modelos de media móvil. Por ejemplo entre los modelos contenidos en
la clase de modelos de Volterra V(N=2, M=1) se encuentran los siguientes:
Modelo FIR: )1()()( tutuky
Modelo de Hammerstein: )1()()1()()( 22 tutututuky
Modelo de Weiner: )1()·(·2)1()()1()()( 22 tutututututuky
Modelo de Robinson’s Volterra: )1()·(·2)1()()( tutututuky
11.6 CONSIDERACIONES ADICIONALES SOBRE LA IDENTIFICACIÓN DE SISTEMAS NO LINEALES
11.6.1 Prefiltrado
El prefiltrado de los datos de entrada-salida permite en la identificación de sistemas
lineales establecer en que rangos de frecuencia se desea que el modelo se ajuste mejor a
los datos experimentales. El prefiltro ejercía dentro del criterio de identificación expresado en
el dominio de la frecuencia el papel de función de peso configurable. Este comportamiento
del prefiltro no se obtiene sin embargo en el caso de los sistemas no lineales, donde el
prefiltrado de los datos puede introducir un error de sesgo no deseado.
Por otra parte en los sistemas no lineales no es equivalente el prefiltrado de los datos y
el prefiltrado del error de predicción. Mientras que el prefiltrado de los datos puede introducir
error de sesgo, el prefiltrado del error puede tener efectos positivos sobre el ajuste de los
modelos de tipo serie de Volterra a los datos.

TEMA 11: Identificación de sistemas no lineales
11-12
11.6.2 Análisis de los residuos
Los test clásicos de análisis de los residuos (ver sección 6.6.2) consistentes en el
estudio de la función de autocorrelación de los residuos y en el estudio de la función de
correlación cruzada entre los residuos y las entradas, no son suficientes para el caso de
sistemas no lineales. En este caso se requiere el estudio de las funciones de correlación de
órdenes más altos para detectar la presencia de términos lineales o no lineales no
modelados. Las funciones de correlación que hay que estudiar son las siguientes [Sriniwas
et al., 1995]:
0)](·))([()( 2
)( 2 ttuEu
(11.21)
0)](·))([()( 22
)( 22 ttuEu
(11.22)
0)]()·([)( ttE uu (11.23)
0)]()·([)( ttuE uu (11.24)
)()( t (11.25)
donde
)]([)()( txEtxtx (11.26)
N
k
N
k
N
kxy
ykyxkx
ykyxkx
22 ))((·))((
))()·()(()( (11.27)
N
k
N
k
N
k
ukuk
ukukkN
u
22 ))((·)(
))()·(1()·()( (11.28)
Es decir, habrá que estudiar la representación gráfica de cada una de las funciones de
correlación anteriores y comprobar que se son cercanas a 0 (se encuentran dentro del
intervalo de confianza seleccionado).

Identificación de sistemas
11-13
Se puede demostrar [Sriniwas et al., 1995] que los residuos no contienen términos
lineales o no lineales no modelados con un nivel de confianza del 95% si el valor absoluto
de cada una de las anteriores funciones de correlación es menor que N/96.1 .
BIBLIOGRAFÍA
[Ljung, 2010] L. Ljung. System Identification Toolbox 7. The Mathworks.
2010.
[Nelles, 2001] Nelles, O. (2001). Nonlinear System Identification. Springer-
Verlag.
[Rivera, 2007] D. E. Rivera. Introducción a la Identificación de Sistemas.
Curso impartido en el Dpto. de Informática y Automática de
la UNED del 17-28 de septiembre de 2007.
[Spinelli et al, 2005] W. Spinelli, L. Piroddi, M. Lovera M. On the role of prefiltering
in nonlinear system identification. IEEE Transactions on
Automatic Control, Vol.50, No.10, pp.1597-1602. 2005.
[Sriniwas et al., 1995] G. R. Sriniwas; Y. Arkun, I, L. Chien; B. A Ogunnaike. (1995).
Nonlinear identification and control of a high-purity distillation
column: a case study. Journal of Process Control, Vol. 5, No.
3, pp. 149-162. 1995
[Thomson et al., 1996] M. Thomson, S. P. Schooling, M. Soufian. The practical
application of a nonlinear identification methodology. Control
Engineering in Practice. Vol.4, No.3, pp. 295-306. 1996.
[Zhang et al., 2005] L. F. Zhang, Q. M. Zhu; A. Longden. Nonlinear model
validation using novel correlation tests. Proceedings of 2005
IEEE International Conference on Systems, Man and
Cybernetics. Volume : 3. Pp. 2879 - 2884. 2005.
