web profunda. acceso a información de calidad: sitios y
TRANSCRIPT

Web Profunda. Acceso a información de calidad: sitios y herramientas
Lic. Adrián Curti
IRICE (CONICET/UNR)
Introducción
Este documento es una recopilación de conceptos sobre web profunda o internet
invisible para dar a conocer, someramente, en qué consiste. Se adjunta, también, una
presentación en PowerPoint con ejemplos de sitios y aplicaciones características de la
web profunda de interés para los gestores de información en bibliotecas y centros de
documentación.
Definición
“La web profunda, también conocida como deep web o invisible es el grupo de
sitios web que no están indexados por los buscadores que habitualmente se usan:
google, bing, yahoo. Esto significa que cuando uno busca con un buscador, los
resultados que nos aparecen son aquellos que los buscadores ya han indexado. Hay otra
información que la gente ha puesto en Internet y que, sin embargo, como no ha sido
indexada (analizada, clasificada) por los buscadores, no se encuentra. Es toda la
información, en todos los formatos posibles a los que, además del tema de los
buscadores, no se puede acceder ya sea por estar cifrada o por estar alojadas en base de
datos, formularios, o porque necesitan una contraseña de usuario. No se puede entrar en
la web profunda con ninguno de los navegadores habituales porque las páginas están
cifradas. Las direcciones o Urls son diferentes a las que estamos acostumbrados y que
terminan con «.htm» o «.html». Las direcciones de las páginas de la deep web terminan
con la extensión «.onion»” (Lippenholtz, 2016).
Clasificación antigua
Sherman y Price (2001) categorizaron cuatro tipos de invisibilidad: la web opaca
(opaque web), la web privada (private web), la web propietaria (proprietary web) y la
web realmente invisible (truly invisible web)

Imagen N°1
a) La web opaca
Páginas que pueden ser indexadas, pero no son incluidas en los buscadores. Los
motivos para que los buscadores "decidan" no incluirlas pueden ser:
- Profundidad de exploración: los sitios tienen "profundidad". La home page o página
principal es el primer nivel; ahí llegan todos los buscadores. De ahí se linkean a páginas
internas del sitio, ése sería el segundo nivel, al que no llegan los Directorios y algunos
motores de búsqueda. Esas páginas, a su vez, enlazan con páginas "más" internas, que
no estaban en la home page. A este nivel llegan muy pocos buscadores. Cuanto más
profundo sea el nivel, menos buscadores lo indexarán.
- Frecuencia de exploración: un sitio puede cambiar todos los días, pero muchos de los
robots de los buscadores que exploran los sitios los visitan una vez por mes o menos por
una cuestión de costos. Todos los cambios entre una visita y otra no figuran en los
buscadores.
- Supera el número máximo de resultados: cada buscador define qué cantidad de
páginas de un sitio mostrará. Si un sitio tiene más páginas que las que el buscador
incluye, las restantes quedarán sin indexar.
- Errores de exploración: puede haber un problema en el sitio o en el robot del buscador
(o en la compatibilidad entre ambos) que impida que una página (o hasta un sitio
completo) sea incluida en la base de datos del buscador.
b) La web privada
Sitios completos o páginas individuales que son técnicamente indexables por el
buscador, pero que fueron excluidos por el dueño del sitio. Se trata de información no
pública (bases de datos de una empresa para exclusivo uso interno, discos virtuales,
intranets, etc.). Eligieron la web como medio por todas sus ventajas, pero no tienen

ningún interés en que la información que allí almacenan se haga pública. En esos casos
se dice que es un sitio cerrado.
Técnicas de protección: Alguien puede no mandar su sitio a un buscador para ser
indizado y el buscador puede indizarlo igual. Por eso, los sitios se valen de diferentes
técnicas de protección para que ni los buscadores, ni los usuarios no registrados puedan
acceder a información protegida. Entre las técnicas de protección de la información, las
siguientes son las tres más frecuentes:
- Password: el sitio está cerrado y sólo puede consultarlo aquél que tenga nombre de
usuario y contraseña.
- Robots.txt: es un archivo de texto que elabora cada sitio que le indica a cada buscador
que páginas debe indexar y cuáles no.
- Noindex metatag: similar al anterior, pero es un comando que se pone en cada página
que no se quiere indexar. Si el buscador la detecta, no la incorpora en su base de datos.
c) La web propietaria
Sitios accesibles solo para aquellos que se registran: muchos foros o redes
sociales y otros sitios similares permiten el acceso sólo a los usuarios registrados. En
esos casos se dice que es un sitio semiabierto. Como los robots de los buscadores no
pueden (ni quieren) "llenar un formulario de registro" para acceder a la información, no
es incorporada en los buscadores.
En buena parte de la web propietaria los contenidos se cierran con una finalidad
económica: hay que pagar una tarifa por tiempo (día, año) o por contenido (artículo,
ejemplar de un diario) para acceder a la información.
Tanto en la web propietaria como en la privada los sitios protegidos no son
indexados por los buscadores, pero en la web propietaria se puede acceder a esta
información por otras vías (registrándonos, pagando), mientras que en la privada no.
d) La web realmente invisible
Este contenido no puede ser indexado por los buscadores por razones técnicas.
Los documentos pueden estar en un formato que los robots no reconozcan (música,
videos) o por páginas generadas dinámicamente (la página se autodiseña, no hay ningún
diseñador humano de por medio, se genera sola). Ese tipo de páginas (foros de
discusión, sitios de remates, catálogos, diccionarios, etc.) no son tenidas en cuenta por
los buscadores.
También elaboraron una lista de categorías de recursos de la web invisible; algunas de
éstas son:

- Documentos de entidades
públicas
- Guías telefónicas
- Patentes
- Libros inéditos
- Catálogos de bibliotecas
- Cotizaciones de valores
- Códigos postales
- Información demográfica
- Colecciones de arte
- Datos del clima
El número que describe la relación entre lo indexado y lo no indexado es el de
un 20% y un 80%. Lo más llamativo es que ese 80% es la información que se
desconoce, que no se ve, es el porcentaje de la web profunda (Lippenholtz, 2016).
También hay estimaciones similares con una relación 16%-84%. Pero por su
propia naturaleza, el tamaño de la web invisible es difícil de calcular (Deep Web Sites,
2016)
Clasificación actual
Lo más común es utilizar la imagen del mar para explicar el porcentaje de
diferencia.
La Web profunda también se puede clasificar en: web profunda, propiamente
dicha (información académica, repositorios, archivos médicos y legales, etc. y web
oscura (información ilegal, sitios de tráfico de drogas ilegales, hackers, asesinos a
sueldo, pedofilia, comunicaciones privadas encriptadas)
Imagen N° 2

También se puede dividir por seis niveles de profundidad; siendo el nivel 1 la
web superficial y desde allí hasta el 6 el más profundo, denominado “Islas Marianas”.
Cuanto más profundo el nivel, los sitios son más privados, de navegación más segura,
anónima y encriptada.
Imagen N° 3

Sitios y herramientas para el acceso a la información
Para ejemplificar la web profunda que nos incumbe como gestores de la
información, nos vamos a situar en la sub-división “Web Profunda” que se ve en la
imagen N°2 y que se corresponde (aproximadamente) a los niveles 2 y 3 de la imagen
N° 3.
Están presentados de acuerdo a los siguientes tipos:
• Repositorios digitales
• Sitios gubernamentales
• Sitios de descarga de archivos
• Bibliotecas y OPACs
• Grupos y Foros
• Páginas en redes sociales
• Gestores de referencias bibliográficas
• Gestores de favoritos
• Aplicaciones móviles (Android/AppStore)
Los sitios tomados como ejemplo en la presentación adjunta (PowerPoint)
tienen en común (la gran mayoría) la característica de su origen cooperativo o
colaborativo, donde mucha gente del ámbito académico, profesional y bibliotecológico
comparte información muy valiosa en diferentes sitios y a través de muchas
herramientas vía web que son de difícil acceso por medio de los buscadores
tradicionales.

Bibliografía citada y consultada
Sherman, Chris and Price, Gary (2001). The invisible Web. CyberAge Books
Disponible en: http://eds.b.ebscohost.com
Lippenholtz, Betina (2016). Hablamos de … Web profunda (o invisible).
Disponible en:
https://www.educ.ar/sitios/educar/noticias/ver?id=129603&referente=docent
es
Deep Web Sites (2016). Disponible en: https://www.deepweb-sites.com/
La Deep Web (Documental). Disponible en:
https://www.youtube.com/watch?v=EDS5ybh4uu8
Bergman, Michael K (2001). The Deep Web: Surfacing Hidden Value. Disponible
en: http://quod.lib.umich.edu/j/jep/3336451.0007.104?view=text;rgn=main

La Web Profunda y el acceso a
información de calidad
Lic. Adrián N. Curti Bibliotecario
Instituto Rosario de Investigaciones en Ciencias de la Educación (IRICE)
CONICET/UNR
49ª Reunión Nacional de Bibliotecarios
“Bibliotecas, el ágora de los hallazgos"
25 al 27 de abril de 2017

Qué es la WEB PROFUNDA?
Es toda la información a la que no
acceden los
buscadores tradicionales y su
calidad es varias veces superior a
la de la web superficial.

WEB OPACA
Páginas que pueden ser indexadas, pero no son incluidas en los buscadores.
WEB PRIVADA
Sitios completos o páginas individuales que son técnicamente indexables por
el buscador, pero que fueron excluidos por el dueño del sitio.
WEB PROPIETARIA
Sitios accesibles solo para aquellos que se registran.
WEB REALMENTE INVISIBLE
Este contenido no puede ser indexado por los buscadores por razones
técnicas.
Clasificación “antigua” de la Web Profunda

Nueva clasificación de la Web Profunda

Fuente: http://www.deepwebtech.com/
Clasificación de la Web Profunda

Características de la Web Profunda

Herramientas y sitios de la Web Profunda
•Sitios de descarga de archivos
•Grupos y Foros
•Páginas en redes sociales
•Repositorios digitales
•Sitios gubernamentales
•Intranets institucionales
•Bibliotecas y catálogos
•Bases de datos
•Gestores de referencias bibliográficas
•Gestores de favoritos
•Aplicaciones móviles (Android/AppStore)
•Extensiones/complementos de navegadores (Chrome/Firefox)

Herramientas para el acceso a la información “invisible”

Fuente: http://sci-hub.cc/

http://www.ares.com.es/

Fuente: https://mega.nz/#

Navegador invisible y anónimo. https://www.torproject.org/

Fuente: https://archive.org/index.php
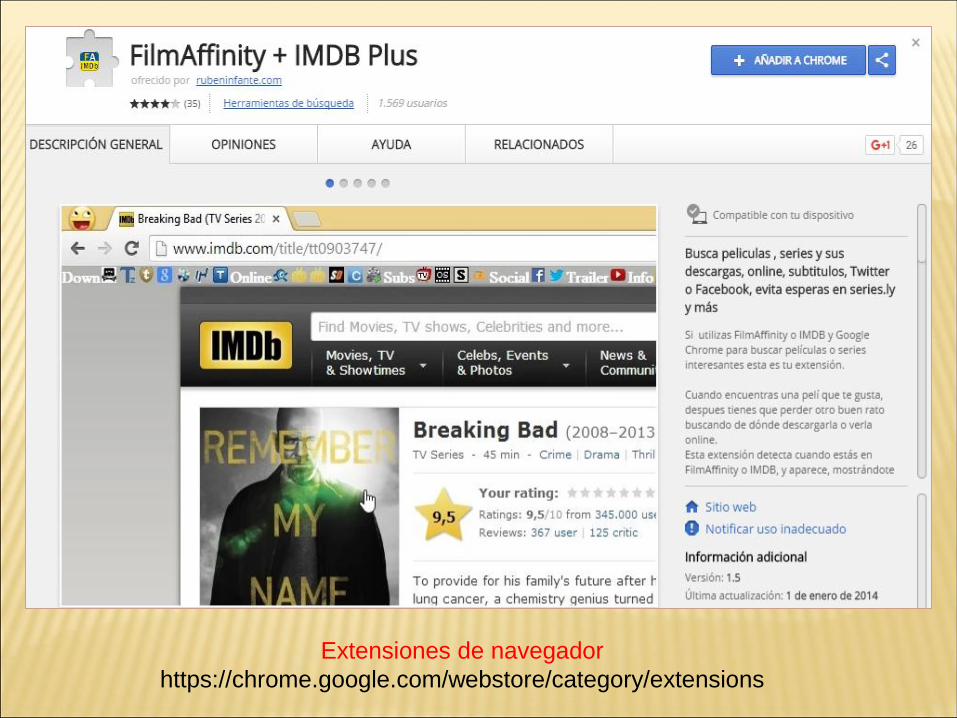
Extensiones de navegador
https://chrome.google.com/webstore/category/extensions

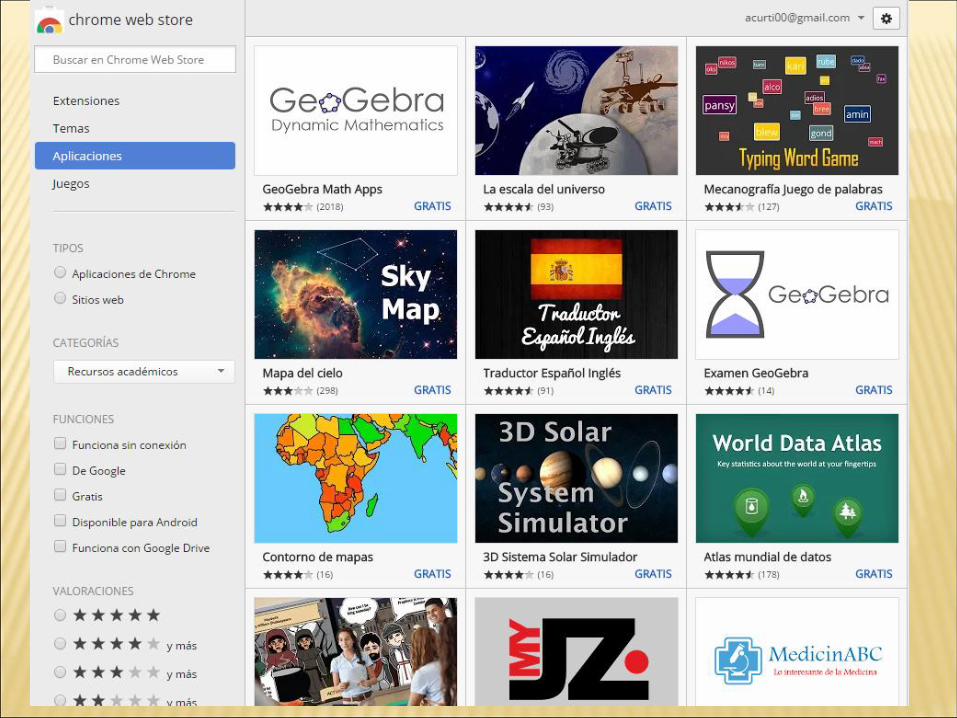
Extensiones de navegador
https://chrome.google.com/webstore/category/extensions

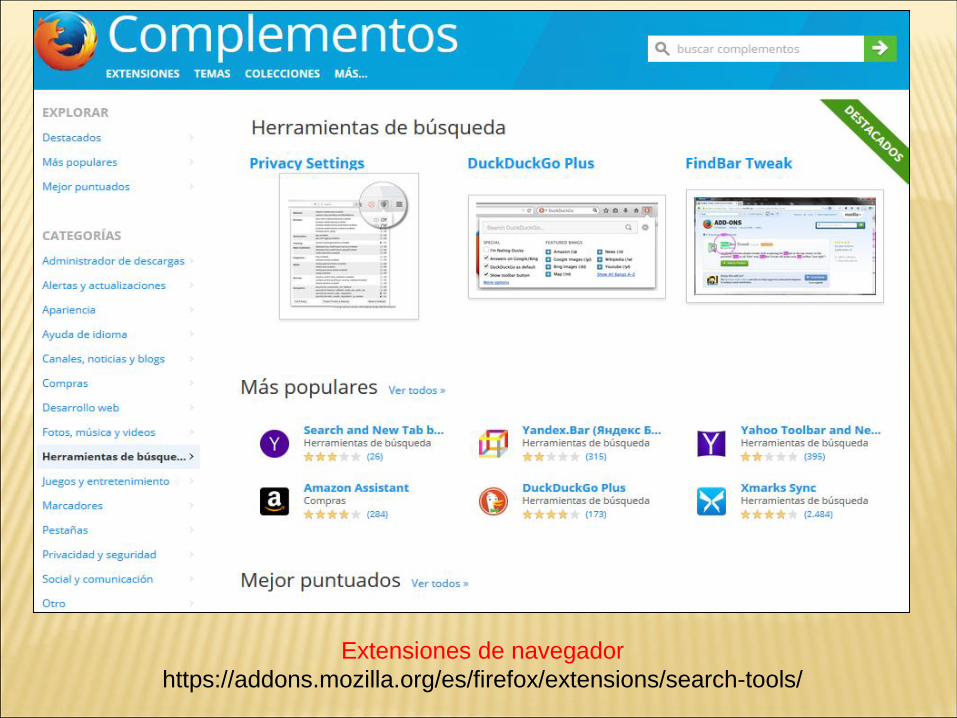
Extensiones de navegador
https://addons.mozilla.org/es/firefox/extensions/search-tools/
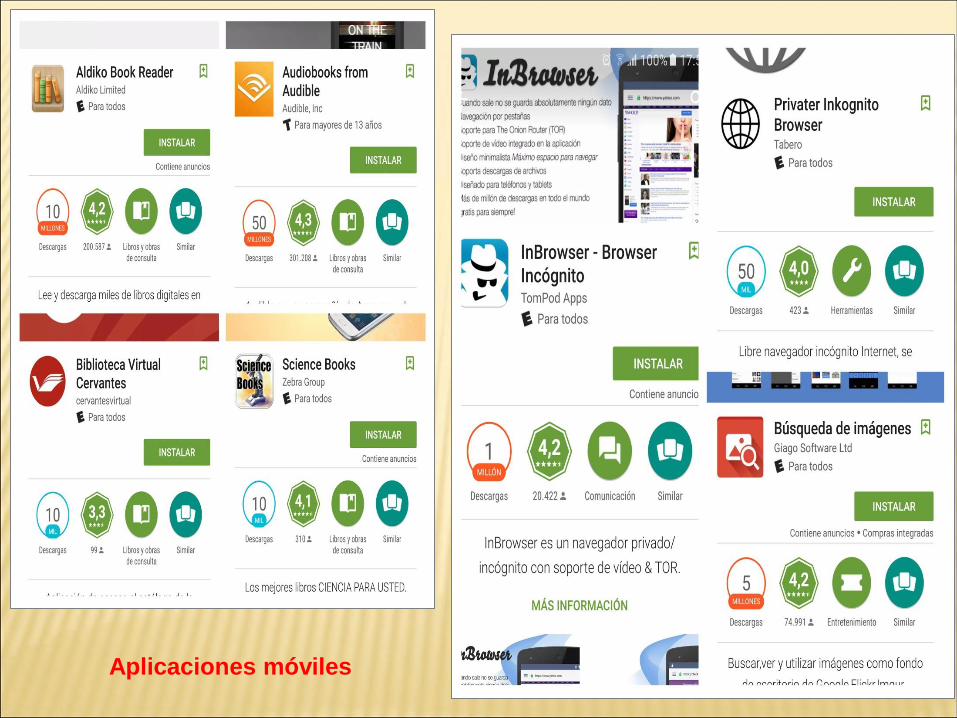
Aplicaciones móviles


Aplicaciones móviles

Repositorios de Acceso Abierto - http://roar.eprints.org/

http://repositorio.educacion.gov.ar/

http://www.datos.gob.ar/
http://www.senado.gov.ar/
http://www.rosario.gov.ar/
http://www.abc.gov.ar/
http://www.anses.gob.ar/
Sitios gubernamentales

Intranets institucionales

Intranets institucionales

Grupos-Foros https://groups.google.com

https://es.groups.yahoo.com

Grupos y Páginas en redes sociales - https://www.facebook.com/search/all/

Listas de correo

http://www.biblioteca.mincyt.gob.ar/

http://catalogo.bibliotecas.gob.ar

Bases de datos: http://guides.lib.uw.edu/az.php ------ https://www.base-search.net/

https://wikileaks.org/

http://www.citeulike.org/
https://www.zotero.org/
https://www.refworks.com
Gestores de Referencias Bibliográficas

Fuente: https://www.mendeley.com/

Gestor de Favoritos - http://symbalooedu.es/

Gestor de Favoritos - https://stash.ai

Estrategias para buscar en la Web Profunda
1. Buscar portales y directorios.
2. Buscar fundaciones, institutos de investigación, organismos de
gobierno.
3. Universidades: Cuentan con excelentes portales de información.
4. Piensa globalmente, actúa localmente: la mejor fuente de
información no siempre está en los grandes portales o buscadores.
5. Pregunte a un experto: la mayor parte de la información de esta guía
ha sido puesta en la web por expertos.
Extraído y adaptado de: http://guides.lib.uw.edu/c.php?g=342031&p=2300192
h t t p : / / w w w . l i b . w a s h i n g t o n . e d u /

Conclusiones
- La Web profunda o invisible contiene un inmenso volumen de información a
sólo unos “clics” o “toques”.
- L@s bibliotecari@s: consumidores y productores de dicha información.
- Confiable y de acceso libre.
Recomendaciones
- Investigar la web profunda para identificar sitios de interés para la
gestión de la información.
- Elaborar recopilaciones, listados y análisis de estos sitios. Publicar el
documento resultante en acceso abierto y compartirlo en redes sociales.
- Usar, recomendar y fomentar la utilización de esta parte de la web.
