biometria clase 11
TRANSCRIPT

BIOMETRÍA
242203 242317
30 de mayo de 2012
Sergio Neira – Hugo Arancibia

• Hipótesis para muestras múltiples
• Introducción al análisis de varianza

Cuando las medidas de una variable vienen de dos muestras, usamos pruebas-t para dos muestras y/o para muestras pareadas. Sin embargo, los biólogos generalmente recolectan medidas de una variable como tres o más muestras, desde tres o más poblaciones. Para ello requerimos un análisis de muestras múltiples.

Existe la tentación de probar hipótesis de muestras múltiples aplicando una prueba prueba-t para dos muestras a todos los pares de muestras posibles. Por ejemplo podríamos probar la hipótesis H0 : µ1 = µ2 = µ3 Probando cada una de las siguientes hipótesis: H0 : µ1 = µ2 H0 : µ1 = µ3 H0 : µ2 = µ3

Sin embargo, el procedimiento de utilizar una serie de pruebas-t para dos muestras es inválido.
La prueba estadística t y el valor que encontramos en la Tabla t, están diseñados para probar si dos estadígrafos muestrales, media 1 y media 2, tienen la probabilidad de venir de la misma población (o desde dos poblaciones con medias idénticas).

Al aplicar correctamente la prueba para dos
muestras, podríamos arribar aleatoriamente a
dos medias muestrales desde la misma
población y concluir equivocadamente que
corresponden a estimados de dos medias
poblacionales distintas.
Sin embargo, sabemos que la probabilidad de
este error (el Error Tipo I) no será mayor a .

Consideremos que recolectamos tres muestras
desde una población.
Si realizamos las tres pruebas-t indicadas
anteriormente, con =0.05, la probabilidad de
concluir erróneamente que dos de las medias
estiman parámetros distintos es 14% (lo que es
> ).

Si probamos diferencia en cuatro medias, de
dos en dos con =0.05, usando la prueba-t,
existirán seis pares de Hipótesis nulas a ser
probadas.
En este caso con un 26% de probabilidades de
concluir erróneamente que existe diferencia
entre una o más de las medias.
¿Por qué?

Para cada prueba-t de dos muestras realizada al 5% de
nivel de significancia, existe un 95% de probabilidad de
que concluiremos correctamente no rechazar H0 cuando
las dos medias son iguales.
Para el conjunto de tres hipótesis, la probabilidad de
declinar correctamente rechazar todas ellas es:
P= 0.953 = 0.86
Esto significa que la probabilidad de rechazar
incorrectamente al menos una de las H0 es:
P= 1 - 0.953 = 0.86 = 0.14

A medida que el número de medias aumenta, se alcanza
la certidumbre que ejecutando todas las pruebas-t
posibles se concluirá que algunas de las medias
muestrales estiman distintos valores de µ, incluso
cuando provienen de la misma población.

Para probar la hipótesis
H0 : µ1 = µ2 = µ3 = µk
donde k es el número de grupos
experimentales, o muestras, necesitamos
familiarizarnos con el tópico de Análisis
de Varianza (ANOVA, ANOV, AOV)

ANOVA gran área de métodos
estadísticos, y debe su nombre a los
aportes de R.A. Fisher*.
Existen muchas ramificaciones de las
consideraciones del ANOVA, acá
discutiremos las aplicaciones más
comunes al ámbito de la biología.

¿Por qué llamamos análisis de varianza a
un procedimiento usado para probar
igualdad de medias?

Supongamos que deseamos probar si
cuatro tipos de alimento resultan en
diferentes pesos en un animal de
importancia comercial.
En este caso probaremos el efecto de un
factor (tipo de alimento) sobre la variable en
estudio (peso corporal), el término
apropiado es ANOVA de un factor (ANOVA
de una vía).

Además diremos que cada alimento es un
nivel del factor.
El diseño de este experimento debería
tener a cada animal experimental
asignado aleatoriamente* para recibir uno
de los cuatro tipos de alimento, con
aproximadamente igual número de
animales recibiendo cada tipo de alimento.

ANOVA de un factor no requiere que las
muestras sean del mismo tamaño.
Sin embargo, el poder de la prueba se
fortalece al tener muestras de tamaño lo más
parecido posible.
El desempeño de la prueba también se potencia
si se selecciona animales experimentales lo
más similares posibles (misma camada, sexo
y edad, mantenidos a igual temperatura, etc.).
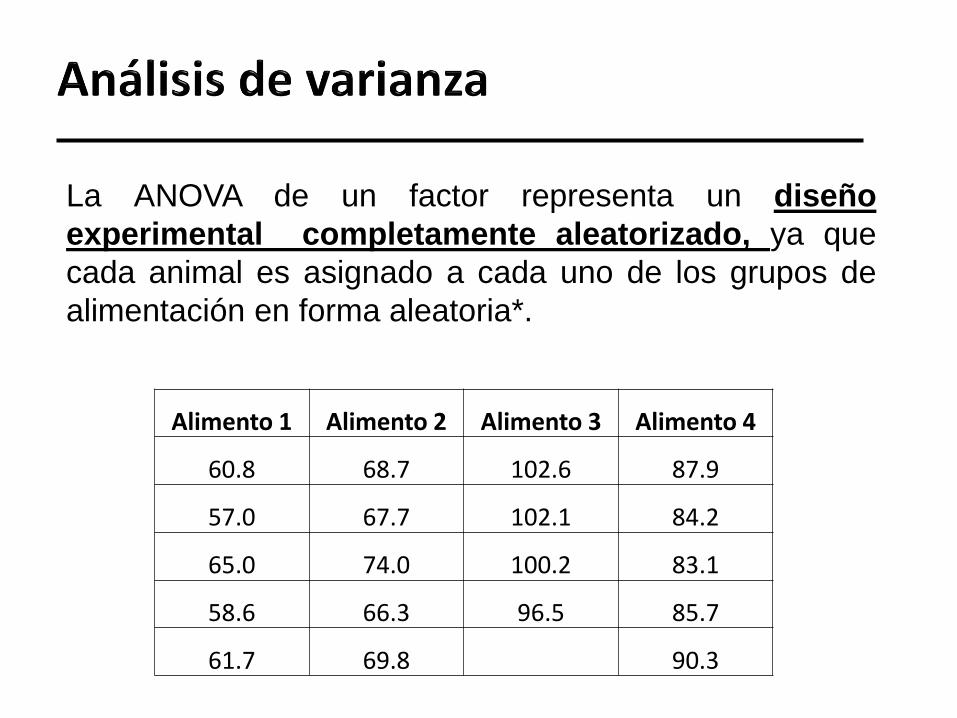
La ANOVA de un factor representa un diseño
experimental completamente aleatorizado, ya que
cada animal es asignado a cada uno de los grupos de
alimentación en forma aleatoria*.
Alimento 1 Alimento 2 Alimento 3 Alimento 4
60.8 68.7 102.6 87.9
57.0 67.7 102.1 84.2
65.0 74.0 100.2 83.1
58.6 66.3 96.5 85.7
61.7 69.8 90.3

Tal como en la prueba-t para dos muestras, en
ANOVA suponemos igualdad de varianzas de
las poblaciones muestreadas.
σ21 = σ2
2 = σ23 = σ2
4
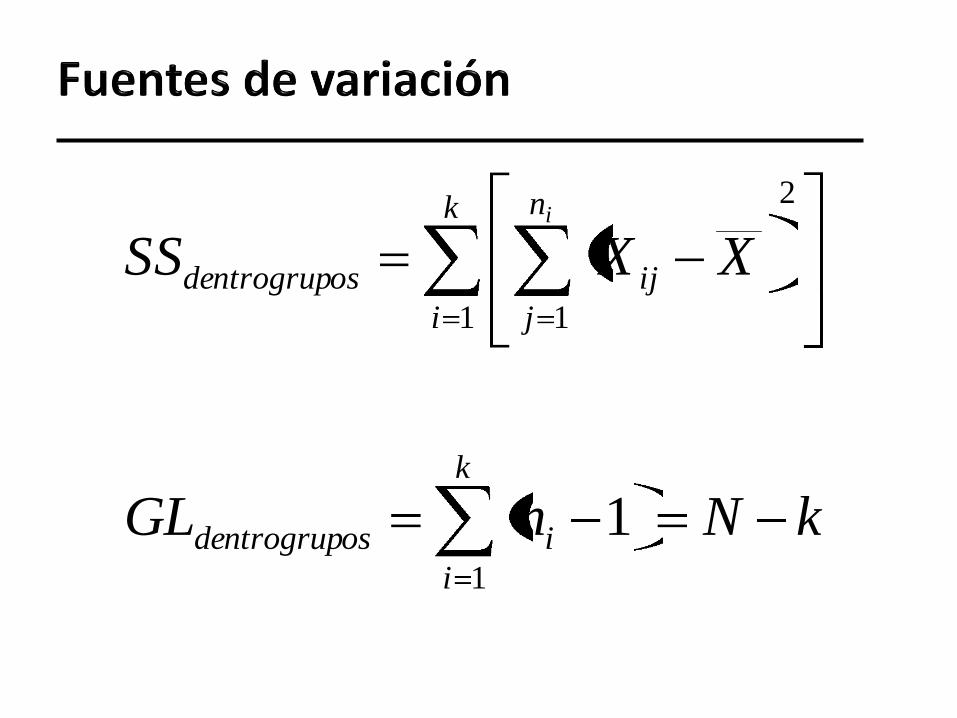
Y estimamos la varianza poblacional
(suponiendo que es igual para todos los grupos
k) mediante una varianza obtenida usando la
suma de cuadrados comunes y los grados de
libertad comunes.
k
i
n
j
ijosdentrogrup
i
XXSS1
2
1
k
i
iosdentrogrup kNnGL1
1

Normalmente se conoce estas dos cantidades
como la suma de cuadrados del error y los
grados de libertad del error, respectivamente.
Si dividimos el primero por el segundo (SSerror
/DFerror) es un estadígrafo que es el mejor
estimador de la varianza, σ2 , común a a todas
las k poblaciones.

La variabilidad entre los k grupos también es
importante en nuestra prueba de hipótesis, y la
denotamos como:
k
i
iiisentregrupo XXnSS1
2
1kGL sentregrupo

Al dividir SSgrupales o el SSerror por sus
respectivos grados de libertad, obtenemos una
varianza, que en la terminología ANOVA
conocemos como un cuadrado medio (se
abrevia MS). Entonces:
grupos
grupos
sentregrupoGL
SSMS
error
errorerrores
GL
SSMS

error
grupos
MS
MSF
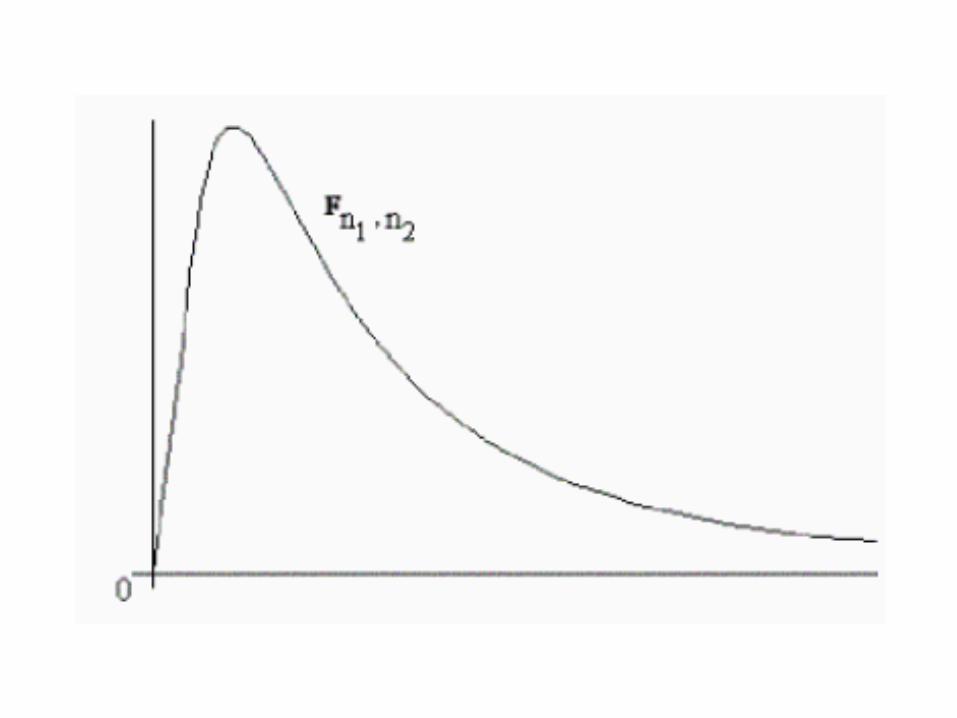

error
grupos
MS
MSF
F 0.05(1),3,15 = 3.29