biometria clase 10
TRANSCRIPT

BIOMETRÍA
242203 242317
23 de mayo de 2012
Sergio Neira – Hugo Arancibia

Test de hipótesis usando la distribución 2

1. números aleatorios Hemos usado números aleatorios en algunos prácticos, por ejemplo calculados en Excel. ¿Cuál es la propiedad subyacente en las secuencias de números aleatorios? Y ¿podemos probar si un determinado conjunto de números es aleatorio? Definición. Un conjunto de dígitos es una secuencia de dígitos aleatorios si cada posición en la secuencia es igualmente probable de ser ocupado por cualquier otro de los dígitos usados.

Entonces, si usamos todos los dígitos {0, 1, 2,…,9} cada posición tendrá una probabilidad de 1/10 de contener 0 ó 1/10 de contener 1, y así sucesivamente. Aún más, para satisfacer la definición, cada posición tiene que ser llenada independientemente de cualquier otra,. Entonces, es igualmente probable que un 0 sea seguido de un 0 ó de un 1 ó de un 2 y así sucesivamente. De hecho, definimos dígitos aleatorios diciendo que éstos deben formar un modelo estadístico particular: los dígitos aleatorios son observaciones tomadas desde una distribución discreta uniforme, cuya función de probabilidad es: Pr(r) =1/10 r=0, 1, 2,…, 9.

Es muy difícil producir una secuencia de números aleatorios escribiéndolos desde nuestra imaginación, porque tendemos a no repetir ningún dígito. Normalmente en una lista hecha de esta forma no existirán muchos 00s, 11s…, y los 000s y 111s serán incluso más raros. El test más simple para probar dígitos aleatorios es el de frecuencia, que toma series largas (una o más páginas) de dígitos y examina si cada dígito (0, 1, 2, …, 9) tiene igual frecuencia, dentro de límites estadísticos aceptables.

Una corrida de 1000 dígitos tiene las frecuencias siguientes
de 0, 1, 2,..., 9. ¿Es posible considerarlos aleatorios?
Dígito (r) 0 1 2 3 4 5 6 7 8 9 Total
Frecuencia
(fr)
106 88 97 101 92 103 96 112 114 91 1000

Las frecuencias fr no son exactamente iguales, pero ningún
estadístico espera que lo sean.
En muestras repetidas, cada muestra consistente de 1000 dígitos,
los conjuntos de frecuencias mostrarán (como el conjunto anterior)
variaciones desde la igualdad exacta, y también mostraran
variaciones entre ellos.
Lo que deseamos hacer es comparar las frecuencias observadas
con las esperadas si nuestro modelo estadístico es correcto.
Si los dígitos son una secuencia de dígitos aleatorios, entonces
están modelados por una distribución uniforme discreta.

Entonces, la hipótesis nula establece que:
Pr(r) =1/10 para cada r desde el 0 al 9.
Y en una muestra de N las frecuencias de r=0, 1, 2,…, 9
son todas iguales a:
NPr(r)=1/N (1000 en nuestro ejemplo).
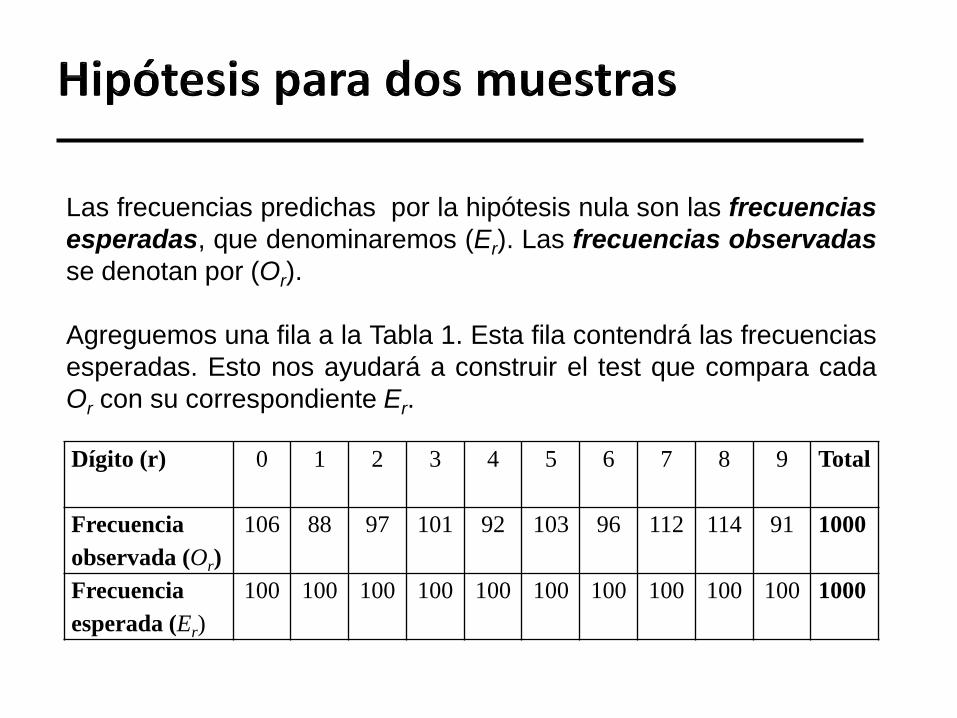
Las frecuencias predichas por la hipótesis nula son las frecuencias
esperadas, que denominaremos (Er). Las frecuencias observadas
se denotan por (Or).
Agreguemos una fila a la Tabla 1. Esta fila contendrá las frecuencias
esperadas. Esto nos ayudará a construir el test que compara cada
Or con su correspondiente Er.
Dígito (r) 0 1 2 3 4 5 6 7 8 9 Total
Frecuencia
observada (Or)
106 88 97 101 92 103 96 112 114 91 1000
Frecuencia
esperada (Er)
100 100 100 100 100 100 100 100 100 100 1000

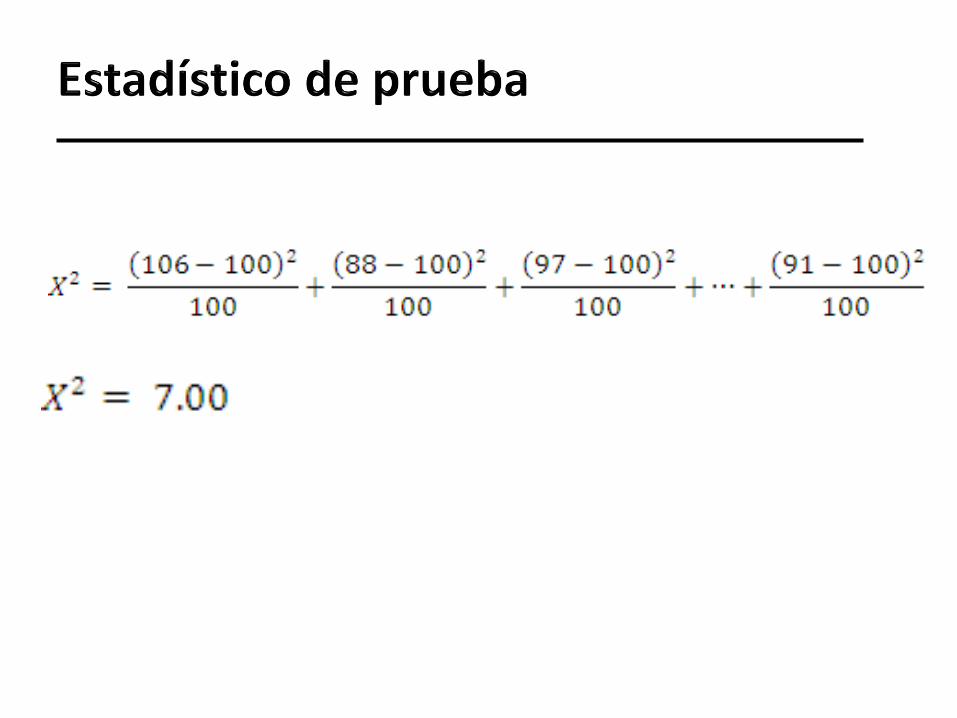
Es la base de este test y de muchos otros como este.
Para cada celda de la tabla (cada valor r en este caso) calculamos
(observado – esperado)2/esperado.
Todas estas contribuciones se suman, para todas las celdas de la
tabla. Entonces,

La distribución muestral de X2 es aproximadamente una distribución
2.
Nuestra hipótesis nula en el ejemplo es que todos los dígitos
ocurren con igual frecuencia.
Una alternativa es que todos los dígitos no ocurren con igual
frecuencia.
Mientras más cerca esté cada Or a su Er correspondiente, más
consistente será con la hipótesis nula.
Entonces, a menor valor de X2 menor evidencia para rechazar H0.

Sólo cuando X2 es muy grande la evidencia en las observaciones
apunta en contra de H0 y entonces la hipótesis alternativa entrega
una mejor explicación para las observaciones.
La regla para llevar a cabo el test de significancia es entonces
rechazar la hipótesis nula cuando el valor X2 es grande.

Del ejemplo 1.
X2 se distribuirá aproximadamente 2(9) si la hipótesis
nula es cierta.
El valor calculado de X2 fue 7.00.
Desde la tabla de valores vemos que ese valor no es
improbable para una variable aleatoria 2(9), y que no
podemos rechazar la hipótesis nula.
Considerando la evidencia de este test, es razonable
considerar como aleatorios el conjunto de 1000 dígitos.

1. Cincuenta lanzamientos de una moneda producen
30 caras; ¿esta evidencia es suficiente para
considerar que la moneda está cargada?

2. Un investigador espera ¾ de las plantas de una
especie particular tengan flores rojas, y el resto
blancas. El investigador planta 100 plantas y obtiene
15 con flores blancas. ¿Son correctas sus ideas
respecto de esta planta?

3. En 240 lanzamientos de un dado, hay
1 2 3 4 5 6
35 43 39 45 44 34
¿Está el dado cargado?

4. Una pareja de coballos produjo una descendencia
total de 60, de los cuales 30 son rojos, 5 negros y 25
blancos. Un genetista predice que, en un cruzamiento
de este tipo, la progenie debiera ocurrir siguiendo las
siguientes razones 9:3:4.
Use un test adecuado para determinar si la
descendencia está en acuerdo con la teoría.