universidad tecnologica de pereira...09/02/2015 1 muestreo estadistico técnicas muestreo...
TRANSCRIPT
09/02/2015 1
Muestreo Estadistico
Técnicas
Muestreo Probabilistico
Muestreo No probabilistico
Población
Muestra
Inferir sobre los parámetros
Tomar decisiones precisas
UNIVERSIDAD TECNOLÓGICA DE PEREIRA FACULTAD DE INGENIERIA INDUSTRIAL Estadística III-Material 1-2012 Revisión y Cambios y Ampliación: Ing. José Alejandro Marín Fuente Primaria: Ing. César Augusto Zapata Urquijo
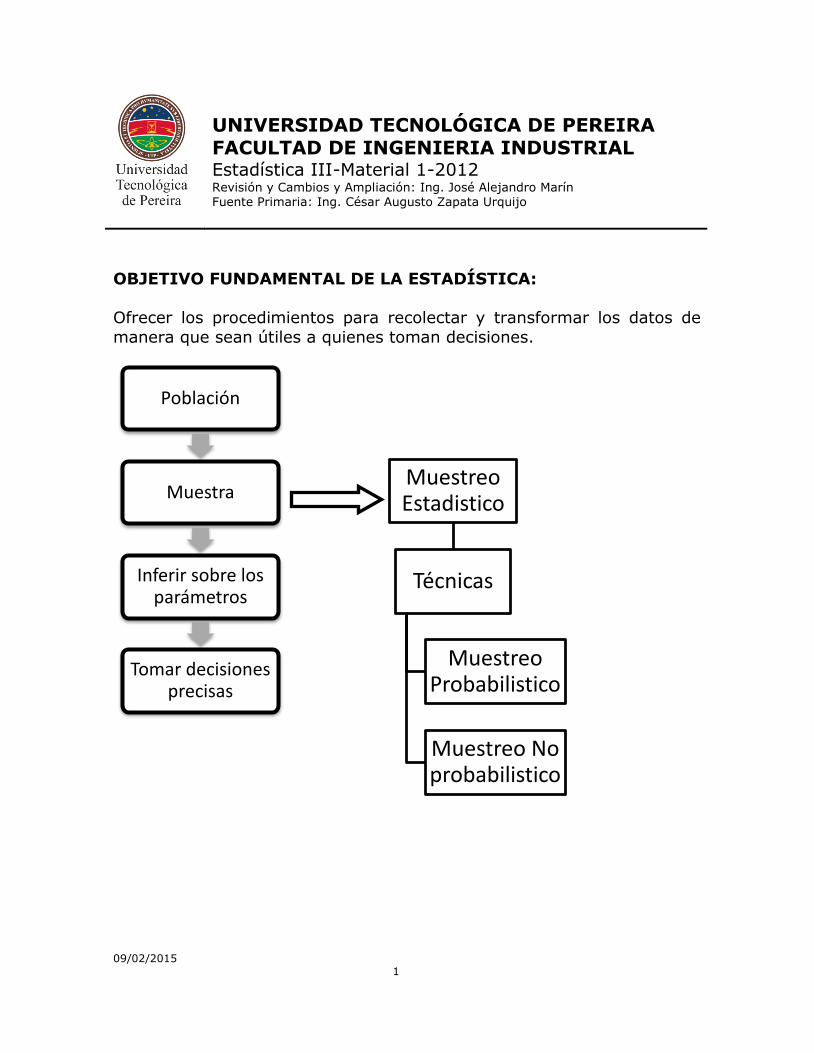
OBJETIVO FUNDAMENTAL DE LA ESTADÍSTICA:
Ofrecer los procedimientos para recolectar y transformar los datos de
manera que sean útiles a quienes toman decisiones.

09/02/2015 2
El propósito es encaminar al ingeniero en:
Conocer el aparato conceptual necesario desde el punto de vista
estadístico para emprender de forma sólida y científica una
investigación. Mostrar algunas de las formas científicas de obtener una muestra.
Tipo de muestreo a utilizar según el interés del profesional. Como determinar el tamaño de muestra necesario para el desarrollo
de la investigación.
1. CONCEPTOS GENERALES:
Dentro de esa gama de conceptos primarios tenemos los siguientes:
Elemento o unidad de estudio
Es el objeto del cual se toman las observaciones y es indivisible.
Unidad de muestreo
Es divisible y se compone de elementos de observación, sin embargo, de acuerdo al tipo de muestreo o a la población objetivo, el elemento
puede ser la misma unidad.
Para que una muestra sea representativa de la población tiene que cumplir con el cálculo del tamaño de la muestra y la técnica de
muestreo, este segundo procedimiento implica la elección de los elementos que conforman la población para construir nuestra
muestra, pero no se elige a las unidades de estudio sino a las unidades de muestreo, esto quiere decir que unidad de estudio no es
sinónimo de unidad de muestreo de hecho, en todo trabajo de investigación hay solamente una unidad de estudio, pero pueden
haber varias unidades de muestreo, tantas como etapas tenga un
muestreo polietápico.
1. Unidades de muestro propias En la mayoría de los casos la unidad de estudio es la que se
muestrea, y en estos casos la unidad de estudio se convierte en unidad de muestreo, este es el caso más frecuente y también es el
más exacto, haciendo referencia al muestreo aleatorio simple, pero no siempre es factible desde el punto de vista de los costos poner en
práctica este tipo de muestreo, si queremos conocer la existencia de

09/02/2015 3
ansiedad previa al examen de admisión en una institución
universitaria que cuenta con mil alumnos. Los alumnos son las unidades de estudio y también son las unidades de muestreo si
someten a aleatorización, a estos elementos para confirmar la
muestra.
2. Unidades de muestreo conjuntas Se trata de un conjunto de unidades de estudio donde las
características del grupo representan proporcionalmente a las características de la población, por tanto estos grupos podrían
considerarse como “mini-poblaciones” porque tienen toda la variabilidad que se observa en la población, en este caso, lo que se
muestrea son estos conjuntos. Por ejemplo, En un estudio sobre la satisfacción laboral de los trabajadores del Ministerio de la Salud a
nivel de la atención primaria, las unidades de estudio son los trabajadores de la salud pero las unidades de muestreo son los
centros y puestos de salud; estos conjuntos de unidades de estudio que tienen la variabilidad que se expresa en la población esto
corresponde al muestreo por conglomerados o clúster.
3. Unidades de muestreo identificadoras
Si la unidad de estudio es un conjunto de individuos y la característica en estudio pertenece al grupo y no individualmente a sus elementos,
es preciso ubicar a uno de sus elementos que nos permita identificar la unidad de estudio a fin de poder ejecutar el muestreo. Véase, en
un estudio para conocer la relación médico-paciente, se evalúa a cada médico y luego a un conjunto de sus pacientes. Las unidades de
estudio son el binomio médico-paciente, pero lo que se somete a aleatorización son los médicos, de nada servirá evaluar a los
pacientes si no pudimos evaluar al médico, esto es coincidente con el muestro por cuotas, el médico es al unidad de muestreo
identificadora.
4. Unidades de muestreo contenedoras
Son secciones censales, así los denominan los investigadores de las ciencias sociales o áreas geográficas que contiene a la unidad de
estudio. Es propio del muestro bietápico estratificado por conglomerados, las unidades muéstrales de primera línea son por
ejemplo las viviendas familiares y a través de ellas se logra acceder a las unidades de estudio. Un ejemplo, en un estudio de preferencias
políticas las unidades de estudio son los votantes, pero se muestrean las viviendas en cuyo interior se ubica a la unidad de estudio, la

09/02/2015 4
unidad de muestreo es la vivienda y la unidad de estudio es el
votante, esto es observable en el muestreo polietapico.
Más sobre unidades de estudio…
Población
No es más que aquel conjunto de individuos o elementos que le
podemos observar, medir una característica o atributo. "El universo o población puede estar constituido por personas, animales, registros
médicos, los nacimientos, las muestras de laboratorio, los accidentes viales entre otros". (PINEDA et al 1994:108)
Ejemplos de población:
El conjunto formado por todos los estudiantes universitarios en
Colombia. El conjunto de todos los estudiantes de la Universidad Tecnológica
de Pereira.
El conjunto de personas fumadoras de una región. El conjunto de personas expuestas al virus del Chikungunya.
El conjunto de tigres de bengala de los parques protegidos en la India.
Son características medibles u observables de cada elemento por
ejemplo, su estatura, su peso, edad, sexo, etc.

09/02/2015 5
Ejemplo
Supongamos que nos interesa conocer el peso promedio de la población formada por los estudiantes de una universidad. Si la universidad tiene
5376 alumnos, bastaría pesar cada estudiante, sumar los 5376 pesos (kgs) y dividirlo por 5376. Pero este proceso puede presenta
dificultades dentro de las que podemos mencionar:
localizar y pesar con precisión cada estudiante: escribir todos los datos sin equivocaciones en una lista:
efectuar los cálculos.
Las dificultades son mayores si en número de elementos de la población
es infinito, si los elementos se destruyen, si sufren daños al ser medidos o están muy dispersos, si el costo para realizar el trabajo es
muy costoso.
Una solución a este problema consiste en medir solo una parte de la población que llamaremos muestra y tomar el peso medio en la
muestra como una aproximación del verdadero valor del peso medio de la población.
El tamaño de la población es la cantidad de elementos de esta y el
tamaño de la muestra es la cantidad de elementos de la muestra. Las
poblaciones pueden ser finitas e infinitas.
Los datos obtenidos de una población pueden contener toda la información que se desee de ella. De lo que se trata es de “extraerle”
esa información a la muestra, es decir a los datos muéstrales obtener toda la información de la población.
Marco muestral
Es una lista que contiene las unidades de la población. Por ejemplo, los
estudiantes matriculados de la UTP en el primer semestre de 2011; el listado de votantes registrados en una zona puede servir de marco para
una encuesta de opinión pública. Nótese que este marco no incluye todos los elementos de la población, porque actualizar la lista
diariamente es imposible.

09/02/2015 6
Muestra
Es una colección de unidades o elementos seleccionados del marco
muestral mediante alguna técnica estadística, sobre esta se realiza la inferencia respectiva para la toma de decisiones. La muestra es una
parte representativa de la población.
La muestra debe obtener toda la información deseada para tener la posibilidad de extraerla, esto sólo se puede lograr con una buena
selección de la muestra y un trabajo muy cuidadosos y de alta calidad en la recogida de los datos.
Es bueno señalar que en un momento una población puede ser muestra
en una investigación y una muestra puede ser población, esto está dado por el objetivo del investigación, por ejemplo en el caso de determinar
la estatura media de los estudiantes universitarios en Cuba una muestra podía ser escoger algunas universidades del país y realizar el trabajo, si
por el contrario se quiere saber la estatura promedio de los estudiantes
de una universidad en especifico en Cuba, entonces el conjunto formado por todos los estudiantes de esta universidad sería la población y la
muestra estaría dada por los grupos, carreras o años seleccionado para realzar el experimento.
Parámetro
Son las medidas o datos que se obtienen sobre la distribución de
probabilidades de la población, tales como la media, la varianza, la proporción, etc.
Estadístico
Los datos o medidas que se obtienen sobre una muestra y por lo tanto
una estimación de los parámetros.
Error muestral, de estimación o standard.
Es la diferencia entre un estadístico y su parámetro correspondiente. Es
una medida de la variabilidad de las estimaciones de muestras repetidas en torno al valor de la población, nos da una noción clara de hasta dónde
y con qué probabilidad una estimación basada en una muestra se aleja del valor que se hubiera obtenido por medio de un censo completo.

09/02/2015 7
Siempre se comete un error, pero la naturaleza de la investigación nos
indicará hasta qué medida podemos cometerlo (los resultados se someten a error muestral e intervalos de confianza que varían muestra a
muestra). Varía según se calcule al principio o al final. Un estadístico
será más preciso en cuanto y tanto su error es más pequeño. Podríamos decir que es la desviación de la distribución muestral de un estadístico y
su fiabilidad.
Nivel de confianza
Probabilidad de que la estimación efectuada se ajuste a la realidad. Cualquier información que queremos recoger está distribuida según una
ley de probabilidad (Gauss o Student), así llamamos nivel de confianza a la probabilidad de que el intervalo construido en torno a un estadístico
capte el verdadero valor del parámetro.
Varianza poblacional
Corresponde a la variabilidad de las mediciones en una población.
Cuando una población es más homogénea la varianza es menor y el número de entrevistas necesarias para construir un modelo reducido del
universo, o de la población, será más pequeño. Generalmente es un valor desconocido y hay que estimarlo a partir de datos de estudios
previos.
Inferencia estadística
Trata el problema de la extracción de la información sobre la población contenida en las muestras.
Para que los resultados obtenidos de los datos muestrales se puedan
extender a la población, la muestra debe ser representativa de la población en lo que se refiere a la característica en estudio, o sea, la
distribución de la característica en la muestra debe ser
aproximadamente igual a la distribución de la característica en la población.
La representatividad en estadística se logra con el tipo de muestreo
adecuado que siempre incluye la aleatoriedad en la selección de los elementos de la población que formaran la muestra. No obstante, tales
métodos solo nos garantizan una representatividad muy probable pero no completamente segura.

09/02/2015 8
¿Por qué muestrear?
Muestrear es una forma de evaluar la calidad de un producto, la opinión
de los consumidores, la eficacia de un medicamento o de un
tratamiento. Muestra es una parte de la población. Población es el total de resultados de un experimento. Hacer una conclusión sobre el grupo
entero (población) basados en información estadística obtenida de un pequeño grupo (muestra) es hacer una inferencia estadística.
A menudo no es factible estudiar la población entera. Algunas de las
razones por lo que es necesario muestrear son:
1. La naturaleza destructiva de algunas pruebas 2. La imposibilidad física de revisar todos los elementos de la
población. 3. El costo de estudiar a toda la población es muy alto.
4. El resultado de la muestra es muy similar al resultado de la población.
5. El tiempo para contactar a toda la población es inviable.
2. REPASO ESTADISTICA DESCRIPTIVA
El propósito de los procedimientos de la estadística descriptiva es explicar de forma breve una amplia colección de medidas, con unos
cuantos valores fundamentales. El resumen más común se obtiene al promediar los valores. En estadística, el proceso de promediar
usualmente se logra al calcular la media, lo cual implica sumar todos los valores y dividirlos entre el número de valores.
La media de la muestra (con barra) se calcula utilizando la ecuación 2.1.
�̅�= ∑ X
𝑛 (2.1)
Donde
�̅� = media de la muestra X
∑ X = suma de todos los valores de la muestra
n = tamaño de la muestra
Para simplificar los cálculos en este texto, se utilizan algunas
notaciones abreviadas. En la notación simplificada para sumar todos los valores de X (vea la ecuación 2.1), se entiende que las

09/02/2015 9
sumatorias se extienden desde uno hasta n. Una notación más
formal para este procedimiento es:
∑ 𝑋𝑖
n
i=1
donde el subíndice i variará su valor inicial de 1 hasta n en
incrementos de uno. Dado que casi todas las sumas van desde 1 hasta n, los índices del principio y el final (n) se omitirán y se
utilizará la notación más simple, excepto donde sea necesaria la
notación más completa por cuestiones de claridad.
Además de medir la tendencia central de un grupo de valores mediante el cálculo de la media, la medida en la cual los valores se
dispersan alrededor de la media es, a menudo, de interés. La desviación estándar se puede concebir como una manera de medir la
dispersión de los datos en torno a la media. La ecuación 2.2 es la fórmula para la desviación estándar:
𝑆 = √𝛴(𝑋−�̅�)2
𝑛−1= √𝛴𝑋2−
(𝛴𝑋)2
𝑛
𝑛−1 (2.2.)
donde el numerador representa la suma de las diferencias al cuadrado entre los valores medidos y su media.
Muchos procedimientos estadísticos utilizan la varianza muestral, la
cual se define como el cuadrado de la desviación estándar de un conjunto de medidas. Así que la varianza de la muestra (S2) se
calcula como:
𝑆2 = 𝛴(𝑋−�̅�)2
𝑛−1=
𝛴𝑋2−(𝛴𝑋)2
𝑛
𝑛−1 (2.3.)
Ejemplo 1
Considere la siguiente colección de edades de personas:
22, 37, 41, 24, 59, 54, 49, 41, 30, 38

09/02/2015 10
Para esta muestra, n = 10 y ΣXi = X1 + X2 + X3 + ⋯ + X10 = 22 + 37 + 41 + ⋯ + 38 = 395
�̅�= ∑ X
𝑛=
395
10= 39.5
𝑆2 = 𝛴(𝑋 − �̅�)2
𝑛 − 1=
(22 − 39.5)2 + ⋯ + (38 − 39.5)2
𝑛 − 1=
1330.5
9= 147,8
𝑆 = √𝑆2 = √147,8 = 12.1
El término grados de libertad se utiliza para indicar el número de datos que son independientes unos de otros, en el sentido de que no
pueden calcularse a partir de los demás y, por lo tanto, llevan piezas únicas de información. Por ejemplo, suponga que se hacen las
siguientes tres declaraciones:
Estoy pensando en el número 4. Estoy pensando en el número 6.
La suma de los dos números en mi mente es 10.
A primera vista, se presentan tres piezas de información. Sin embargo, si se conocen dos de estas afirmaciones, se puede
determinar la otra. Podría decirse que sólo hay dos piezas únicas de información en las tres declaraciones o, para usar el término
estadístico, nada más hay dos grados de libertad puesto que sólo dos de los valores tienen libertad para variar, el tercero no.
Los grados de libertad se refieren al número de datos que son independientes unos de otros y que son piezas únicas de
información.
En el ejemplo que se presentó anteriormente, las edades de 10 personas constituyen una muestra con 10 grados de libertad. La
edad de cualquiera de ellas pudo haberse incluido en la muestra y, por lo tanto, cada una de las edades tiene libertad para variar.
Cuando la media se calcula, las diez edades se utilizan para explicar
una edad media total de 39.5 años.
El cálculo de la desviación estándar de la muestra es diferente. Cuando se calcula la desviación estándar de la muestra, se utiliza un
valor estimado de la media de la población (la media de la muestra X). Al utilizar la media de la muestra como valor estimado de la

09/02/2015 11
media de la población en los cálculos, por lo general se obtendrá una
desviación estándar más pequeña que la desviación estándar de la población. Sin embargo, este problema puede corregirse si se divide
el valor 𝛴(𝑋 − �̅�)2 entre los grados de libertad adecuados. Una vez
que se ha calculado la media de la muestra en este ejemplo, sólo se requieren nueve de las desviaciones (𝑋 − �̅�) para calcular la
desviación estándar de la muestra. Dadas nueve de las desviaciones,
la última desviación, la número 10, es fija debido a que 𝛴(𝑋 − �̅�) debe
ser igual a cero. En consecuencia, se dice que la desviación estándar
de la muestra (o varianza de la muestra) tiene nueve grados de libertad. En general, siempre que se utilice un estadístico de muestra
como estimado de un parámetro de la población en un cálculo, se pierde un grado de libertad.
Las estadísticas descriptivas pueden definirse para las poblaciones. A fin de distinguir las estadísticas de población de las estadísticas de la
muestra, se usa una notación diferente. La tabla 2.2 muestra los símbolos utilizados tanto para estadísticas de población como de
muestra.
Tabla -1. Notación para estadísticas de población y de muestra Estadística Símbolo
de la población
Símbolo
de la muestra
Media μ �̅�
Varianza 𝜎2 𝑆2
Desviación estándar
𝜎 𝑆
La media y la desviación estándar son las formas más comunes de
describir, de forma breve y significativa, los datos de muestras. Sin embargo, en ocasiones también se utilizan otras estadísticas
descriptivas. En ocasiones, la mediana se utiliza para indicar un valor central en una colección de datos. La mediana es aquel valor en el
que la mitad de los valores en la colección es mayor que ella y la otra
mitad es menor.

09/02/2015 12
3. TIPOS DE MUESTREO
Muestreo No probabilístico:
Se utiliza cuando no existe o es muy difícil de conseguir un marco muestral bien definido o cuando se requiere una gran rapidez en los
resultados.
Muestreo por conveniencia: Es aquel en el que el investigador reúne una cantidad de elementos con base a un resultado
especifico.
Muestreo por juicio: Los elementos seleccionados son expertos en el objeto de la investigación.
Muestreo probabilístico:
Para este se debe obtener o crear un marco muestral tratando que
contenga la mayor parte de los elementos que conforman la población y se debe aplicar el principio de aleatoriedad para la conformación de la
muestra. A continuación se mencionan y se explican brevemente cada uno de los muestreos probabilísticos.
3.1. Muestreo Aleatorio
Para comenzar, empezaremos distinguiendo entre las dos clases de poblaciones, Poblaciones finitas y poblaciones infinitas.
Una población es finita si consta de un número finito o fijo de
elementos, medidas u observaciones. Por ejemplo los pesos netos de 2000 latas de atún, las calificaciones de todos los estudiantes de la
universidad...
A diferencia de las poblaciones finitas, las poblaciones infinitas contienen
una infinidad de elementos. Este es el caso de cuando observamos una variable continua y hay una infinidad de resultados distintos. También es
el caso del lanzamiento indefinido de dos dados,...
Para ver la idea de muestreo aleatorio en una población finita de tamaño N, primero veamos cuantas muestras distintas se pueden tomar de

09/02/2015 13
tamaño n. El número de muestras distintas es N
n
Por ejemplo si N=12
y n= 2:
12
2
12 11
266
•
! Muestras distintas.
Con base en el resultado de que hay N
n
muestras distintas de tamaño n
de una población finita de tamaño N, podemos definir como muestra
aleatoria o muestra aleatoria simple de una población finita:
“Una muestra de tamaño n de una población finita de tamaño N es una
variable aleatoria si se selecciona de manera tal que cada una de las N
n
muestras posibles tienen la misma probabilidad 1
N
n
de ser seleccionada”
Por ejemplo si una población consistente en lo N= 5 elementos a,e,i, o,
u (que podrían ser los ingresos anuales de cinco personas, los pesos de
5 vacas,.....) hay 5
310
muestras posibles de tamaño n = 3 . Estas
constan de los elementos:
aei aeo aeu aio aiu aou eio eiu eou iou
si seleccionamos una de esas muestras de forma que esta muestra tenga probabilidad 1/10 de ser elegida, decimos que dicha muestra es
aleatoria.
En la práctica el describir todas las posibles muestras sería complicado si N y n son grandes. Por ejemplo si n=4 y N=200 tendríamos 64,684,950
muestras distintas.
Por suerte podemos realizar una muestra aleatoria, sin necesidad de describirlas todas. Basta con numerar los N elementos de la población y
retirar una a una hasta completar los n-elementos de la muestra. Este
procedimiento también da una probabilidad de 1
N
n
de ser seleccionada
la muestra por los que sería aleatoria.

09/02/2015 14
Ahora bien si la población es infinita: diremos que:
Una muestra de tamaño n de una población infinita es aleatoria si
consta de valores de variables aleatorias independientes que tienen la misma distribución.
Por ejemplo si lanzamos un dado 12 veces y obtenemos 2, 5, 5, 3, 3, 3,
5, 1, 6, 1,4, 1. Estos números constituyen una variable aleatoria si son valores aleatoria independientes que tienen la misma distribución de
probabilidad f(x) = 1/6 para x= 1, 2, 3, 4, 5, 6.
3.2. Muestreo sistemático
En algunos casos la manera más práctica de realizar un muestreo
consiste en seleccionar, un primer elemento al azar y luego ir cogiendo cada x-término de una lista, o dejar pasar a x- individuos y preguntar al
que sigue y así sucesivamente. Aunque un muestreo sistemático puede no ser aleatorio de acuerdo con la definición, a menudos es razonable
tratar las muestras sistemáticas como si fueran aleatorias.
El riesgo de los muestreos sistemáticos es el de las periodicidades
ocultas. Supongamos que queremos testar el funcionamiento de una máquina, para lo cual vamos a seleccionar una de cada 15 piezas
producidas. Si ocurriera la desgracia de que justamente 1 de cada 15 piezas fuese defectuosa y el error de la máquina fuera defectuoso
periódicamente, tendríamos dos posibles resultados muestrales:
- Que falla siempre - Que no falla nunca.
3.3. Muestreo estratificado
Si tenemos información a cerca de una población (es decir de su composición) y esta es importante para nuestra investigación, podemos
mejorar el muestreo aleatorio por medio de la estratificación. Este es
un procedimiento que consiste en estratificar o dividir la población en un número de sub-poblaciones o estratos. Y seleccionamos de cada
estrato una muestra aleatoria.
Este procedimiento se conoce como muestreo aleatorio (simple) estratificado.

09/02/2015 15
3.4. Muestreo por conglomerados
Para ilustrar esta clase de muestreo, supongamos que una gran empresa quiere estudiar los patrones variables de los gastos familiares
de una ciudad como Sevilla. Al intentar elaborar los programas de
gastos de una muestra de 1200 familias, nos encontramos con la dificultad de realizar un muestreo aleatorio simple, (es complicado tener
una lista actualizada de todos los habitantes de una ciudad). Una manera de tomar una muestra en esta situación es dividir el área total
(Sevilla en este caso) en áreas más pequeñas que no se solapen (Por ejemplo Distritos postales, manzanas, etc..) En este caso
seleccionaríamos algunas áreas al azar y todas las familias (o muestras de éstas) que residen en estos distritos postales o manzanas,
constituirían la muestra definitiva.
En este tipo de muestreo, llamado muestreo por conglomerados, se divide la población total en un número determinado de subdivisiones
relativamente pequeñas y se seleccionan al azar algunas de estas subdivisiones o conglomerados, para incluirlos en la muestra total. Si
estos conglomerados coinciden con áreas geográficas, este muestreo se
llama también muestreo por áreas.
Aunque las estimaciones basadas en el muestreo por conglomerados, por lo general no son tan fiables como las obtenidas por muestreos
aleatorios simples del mismo tamaño, son más baratas. Volviendo al ejemplo anterior, es mucho más económico visitar a familias que viven
en el mismo vecindario, que ir visitando a familias que viven en un área muy extensa.
En la práctica se pueden combinar el uso de varios de los métodos de
muestreo que hemos analizados para un mismo estudio.

09/02/2015 16
ANEXOS
Más sobre unidades de estudio
Condiciones básicas en la definición, registro y medición de variables
Al registrar los valores de una variable, existen al menos dos
características que la variable definida debe poseer. En primer lugar, una variable debe ser exhaustiva, debe considerar
todas las posibles alternativas u opciones de respuesta. Si al aplicar un cuestionario e indagar acerca de las características del nivel
socioeconómico como es: tipo de empleo, previamente categorizado; de no incluirse todas las posibles opciones se corre el riesgo de una errónea
clasificación u omisión del dato.
Simultáneamente los atributos de una variable deben ser mutuamente excluyentes, lo que significa que un sujeto no debiera identificarse con
más de una categoría al ser encuestado. En el caso de indagar, por
ejemplo, acerca de la situación laboral se pueden dar las siguientes opciones:
Empleado
Desempleado Buscando empleo