unidad ii.‐ modelos de regresión con series de tiempo ... · con la base de datos okun.dta en...
TRANSCRIPT

Unidad II.‐ Modelos de regresión con series de tiempo: variables estacionarias
1.‐ El contexto dinámico y las series de tiempo
i) Modelo de rezago distribuido (DL)
(9.1)
ii) Modelo con variable dependiente rezagada (AR)
(9.2)
i) y ii) Modelo autorregresivo de rezagos distribuidos (ARDL)
(9.3)
iii) Correlación serial en el error
(9.4)
* Series de Tiempo en STATA
* Limpiar memoria
clear
* Preparar espacio para 100 observaciones
set obs 100
* Generar variable de fecha
generate date = tq(1961q1) + _n-1
* Desplegar listado primeras 5 observaciones
list date in 1/5
* Aplicar formato de fecha
format %tq date
* Desplegar listado primeras 5 observaciones
list date in 1/5
* Configurar variable etiqueta de tiempo
tsset date
* Guardar base de datos
save new.dta, replace
2.‐ Supuestos de mínimos cuadrados
En corte transversal, considerando el modelo niexy iii ,,1para
jjiiji yEyyEyEyy ,cov
jjjjiiii exEexexEexE
1( , )t t ty f y x
1 1 2( , , , )t t t t ty f y x x x
1 2( , , ,...)t t t ty f x x x
1( ) ( )t t t t ty f x e e f e
jjjjiiii eEexxeEexxE
0,cov jijijjii eeeeEeEeeEeE ji
jieeyy jiji para0,cov,cov
En series de tiempo, considerando el modelo Ttexy ttt ,,1para
ssttst yEyyEyEyy ,cov
sssstttt exEexexEexE
sssstttt eEexxeEexxE
0,cov ststsstt eeeeEeEeeEeE st
steeyy stst para0,cov,cov
El contexto dinámico de los modelos de series de tiempo (2), (3) y (4) implica correlación entre ty
y 1ty , por lo tanto, entre te y 1te : violación del supuesto de no autocorrelación.
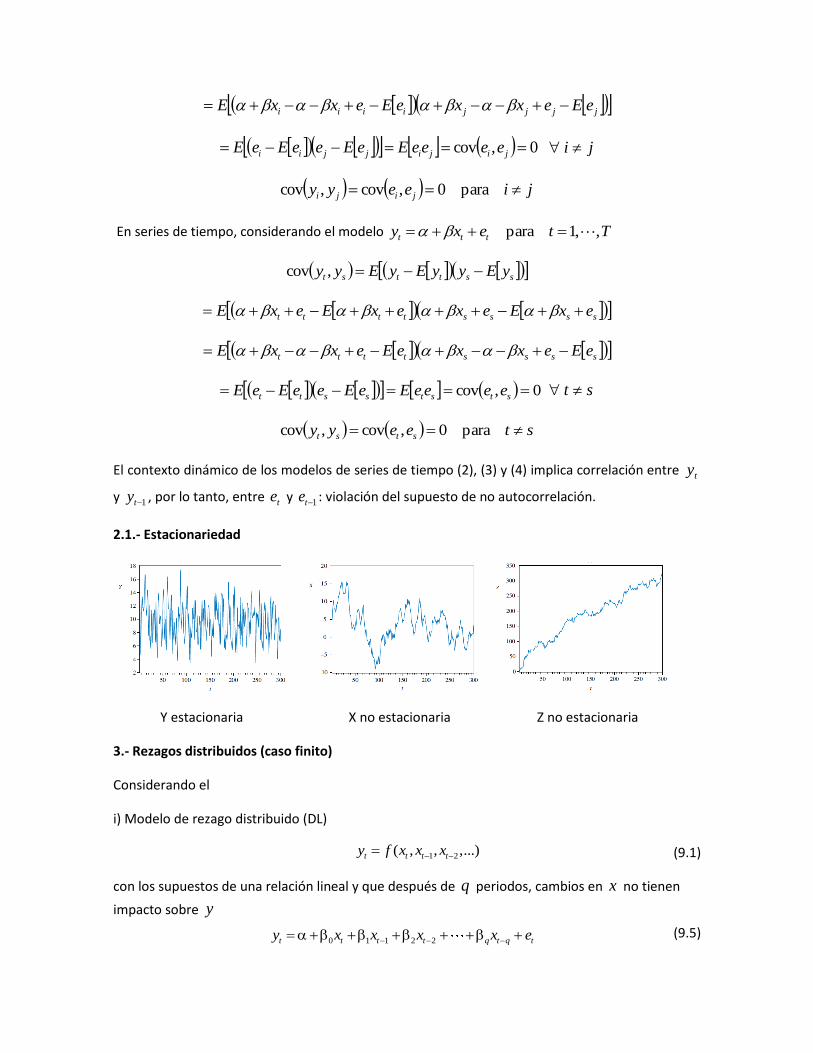
2.1.‐ Estacionariedad
Y estacionaria X no estacionaria Z no estacionaria
3.‐ Rezagos distribuidos (caso finito)
Considerando el
i) Modelo de rezago distribuido (DL)
(9.1)
con los supuestos de una relación lineal y que después de q periodos, cambios en x no tienen
impacto sobre y
(9.5) 0 1 1 2 2t t t t q t q ty x x x x e
1 2( , , ,...)t t t ty f x x x
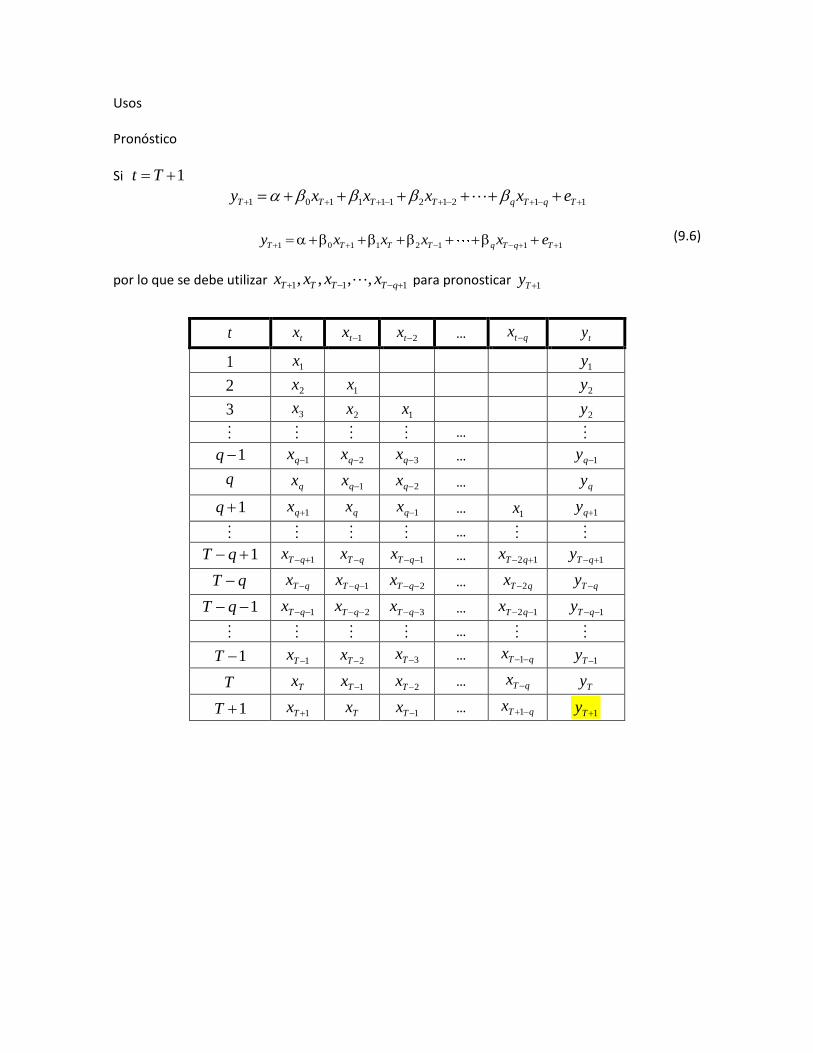
Usos Pronóstico
Si 1Tt
11212111101 TqTqTTTT exxxxy
(9.6)
por lo que se debe utilizar 111 ,,,, qTTTT xxxx para pronosticar 1Ty
t tx 1tx 2tx … qtx ty
1 1x 1y
2 2x 1x 2y
3 3x 2x 1x 2y
…
1q 1qx 2qx 3qx … 1qy
q qx 1qx 2qx … qy
1q 1qx qx 1qx … 1x 1qy
…
1 qT 1qTx qTx 1qTx … 12 qTx 1qTy
qT qTx 1qTx 2qTx … qTx 2 qTy
1 qT 1qTx 2qTx 3qTx … 12 qTx 1qTy
…
1T 1Tx 2Tx 3Tx … qTx 1 1Ty
T Tx 1Tx 2Tx … qTx Ty
1T 1Tx Tx 1Tx … qTx 1 1Ty
1 0 1 1 2 1 1 1T T T T q T q Ty x x x x e
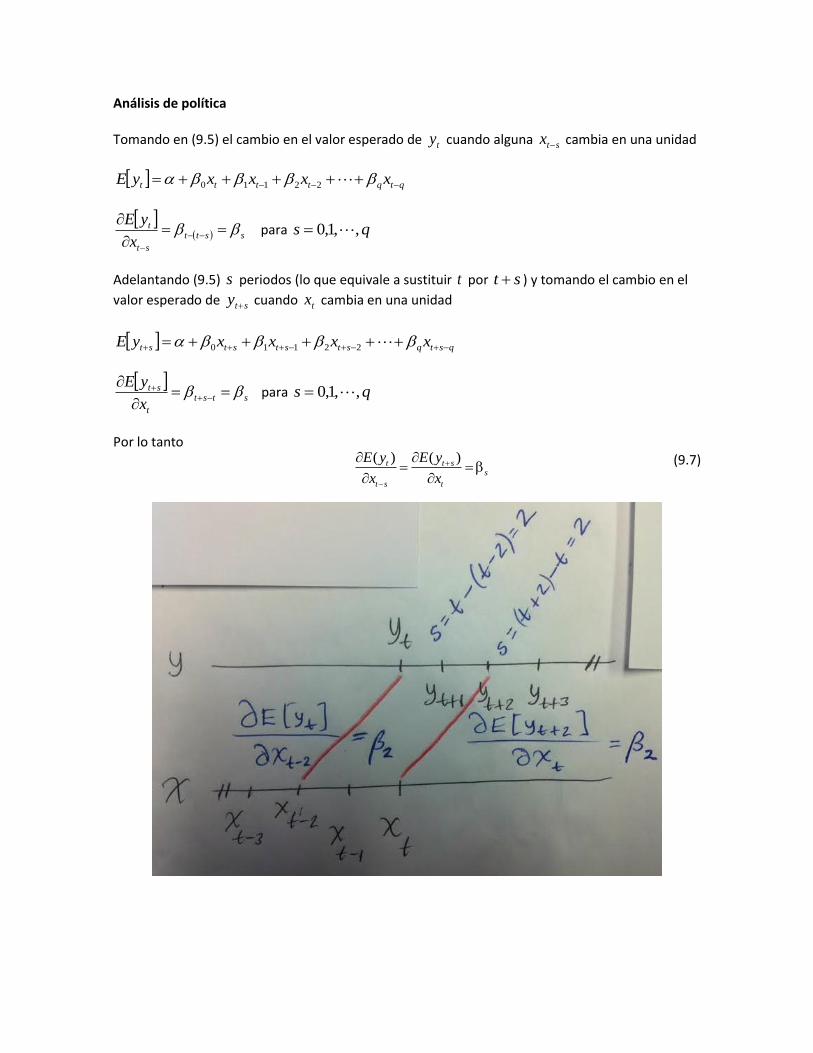
Análisis de política
Tomando en (9.5) el cambio en el valor esperado de ty cuando alguna stx cambia en una unidad
qtqtttt xxxxyE 22110
sstt
st
t
x
yE
para qs ,,1,0
Adelantando (9.5) s periodos (lo que equivale a sustituir t por st ) y tomando el cambio en el
valor esperado de sty cuando tx cambia en una unidad
qstqstststst xxxxyE 22110
stst
t
st
x
yE
para qs ,,1,0
Por lo tanto (9.7)
( ) ( )t t ss
t s t
E y E y
x x
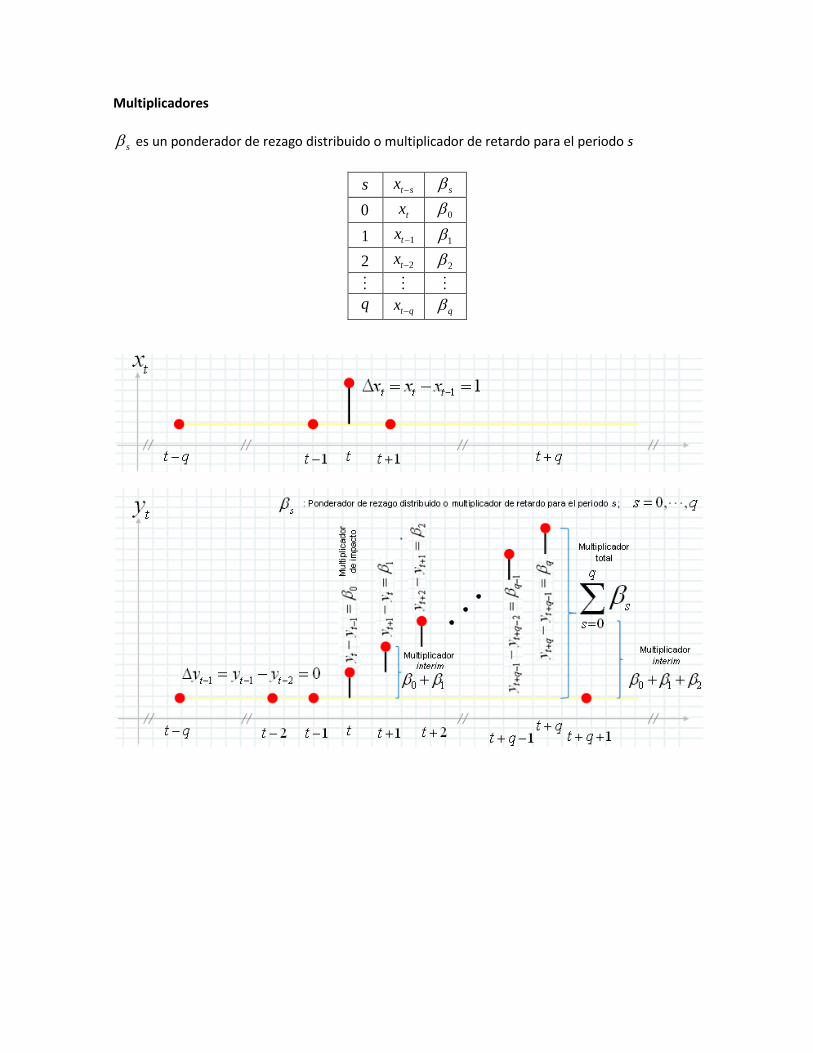
Multiplicadores
s es un ponderador de rezago distribuido o multiplicador de retardo para el periodo s
s stx s
0 tx 0
1 1tx 1
2 2tx 2
q qtx
q

Supuestos del modelo de rezagos distribuidos
TSMR1. 𝑦𝑡 =∝ +𝛽0𝑥𝑡 + 𝛽1𝑥𝑡−1 + 𝛽2𝑥𝑡−2 + ⋯ + 𝛽𝑞𝑥𝑡−𝑞 + 𝑒𝑡 para 𝑡 = 𝑞 + 1, … , 𝑇
TSMR2. 𝑦 y 𝑥 son variables aleatorias estacionarias, y 𝑒𝑡 es independiente de los valores
presentes, pasados y futuros de 𝑥.
TSMR3. 𝐸(𝑒𝑡) = 0
TSMR4. 𝑣𝑎𝑟(𝑒𝑡) = 𝜎2
TSMR5. 𝑐𝑜𝑣 (𝑒𝑡 , 𝑒𝑠) = 0 𝑡 ≠ 𝑠
TSMR6. 𝑒𝑡~𝑁(0, 𝜎2)

Aplicación: Ley de Okun
El cambio en la tasa de desempleo de un periodo al próximo, depende de la tasa de crecimiento
del producto en la economía.
𝑈𝑡 − 𝑈𝑡−1 = −𝛾(𝐺𝑡 − 𝐺𝑁) (9.8)
𝑈𝑡 : tasa de desempleo en el periodo t
𝐺𝑁 : tasa de crecimiento normal, necesaria para mantener una tasa de desempleo constante
Se espera 0 < 𝛾 < 1
Denotando el cambio en la tasa de desempleo como 𝐷𝑈𝑡 = ∆𝑈𝑡 = 𝑈𝑡 − 𝑈𝑡−1 y desarrollando el
lado derecho de (9.8)
𝐷𝑈𝑡 = 𝛾𝐺𝑁 − 𝛾𝐺𝑡
haciendo
𝛼 = 𝛾𝐺𝑁
y
𝛽0 = −𝛾
quedando la especificación econométrica de (9.8) como
𝐷𝑈𝑡 = 𝛼 + 𝛽0𝐺𝑡 + 𝑒𝑡 (9.9)
por lo que 𝛼, 𝛽0 y 𝛾 son los parámetros a estimar.
Además, conociendo �̂� y 𝛾 se puede estimar la tasa de crecimiento normal, necesaria para
mantener una tasa de desempleo constante, pues 𝐺𝑁 =�̂�
�̂�
Expandiendo (9.9) al incluir 𝑞 rezagos de 𝐺𝑡
𝐷𝑈𝑡 = 𝛼 + 𝛽0𝐺𝑡 + 𝛽1𝐺𝑡−1 + 𝛽2𝐺𝑡−2 + ⋯ + 𝛽𝑞𝐺𝑡−𝑞 + 𝑒𝑡 (9.10)
El crecimiento del producto se define como
𝐺𝑡 =𝐺𝐷𝑃𝑡−𝐺𝐷𝑃𝑡−1
𝐺𝐷𝑃𝑡−1 (9.11)
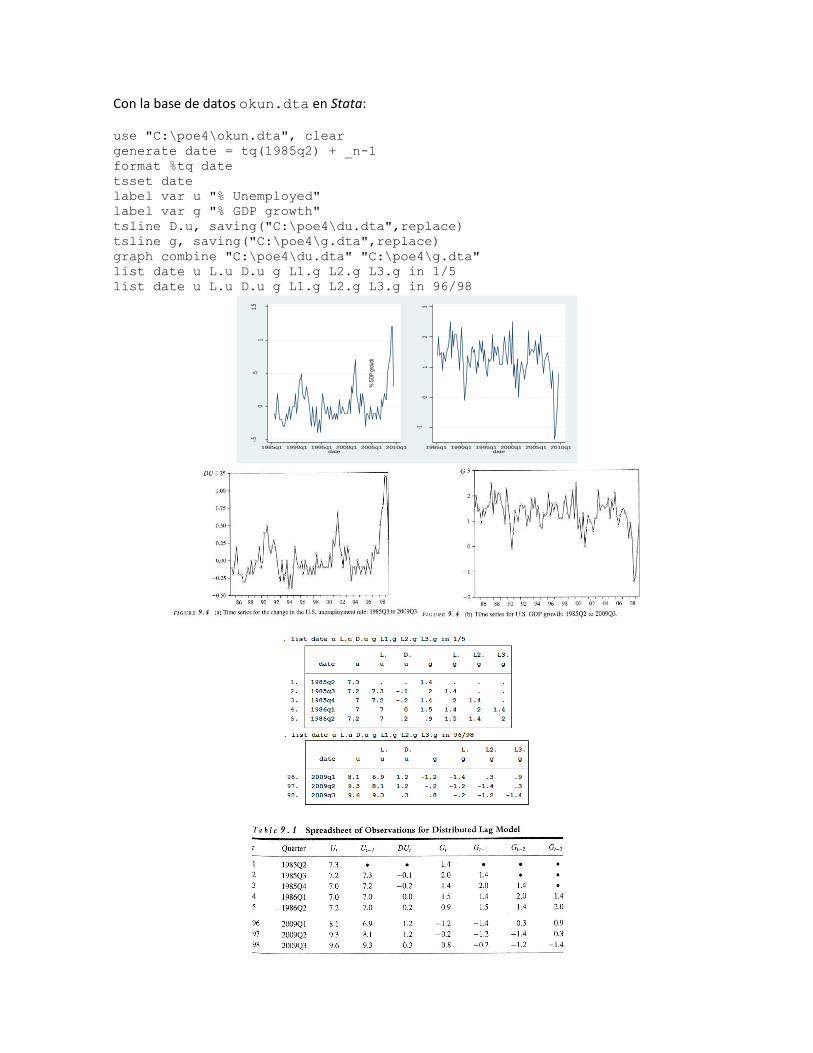
Con la base de datos okun.dta en Stata:
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
label var u "% Unemployed"
label var g "% GDP growth"
tsline D.u, saving("C:\poe4\du.dta",replace)
tsline g, saving("C:\poe4\g.dta",replace)
graph combine "C:\poe4\du.dta" "C:\poe4\g.dta"
list date u L.u D.u g L1.g L2.g L3.g in 1/5
list date u L.u D.u g L1.g L2.g L3.g in 96/98
-.50
.51
1.5
% U
nem
ploy
ed, D
1985q1 1990q1 1995q1 2000q1 2005q1 2010q1date
-10
12
3
% G
DP
grow
th
1985q1 1990q1 1995q1 2000q1 2005q1 2010q1date
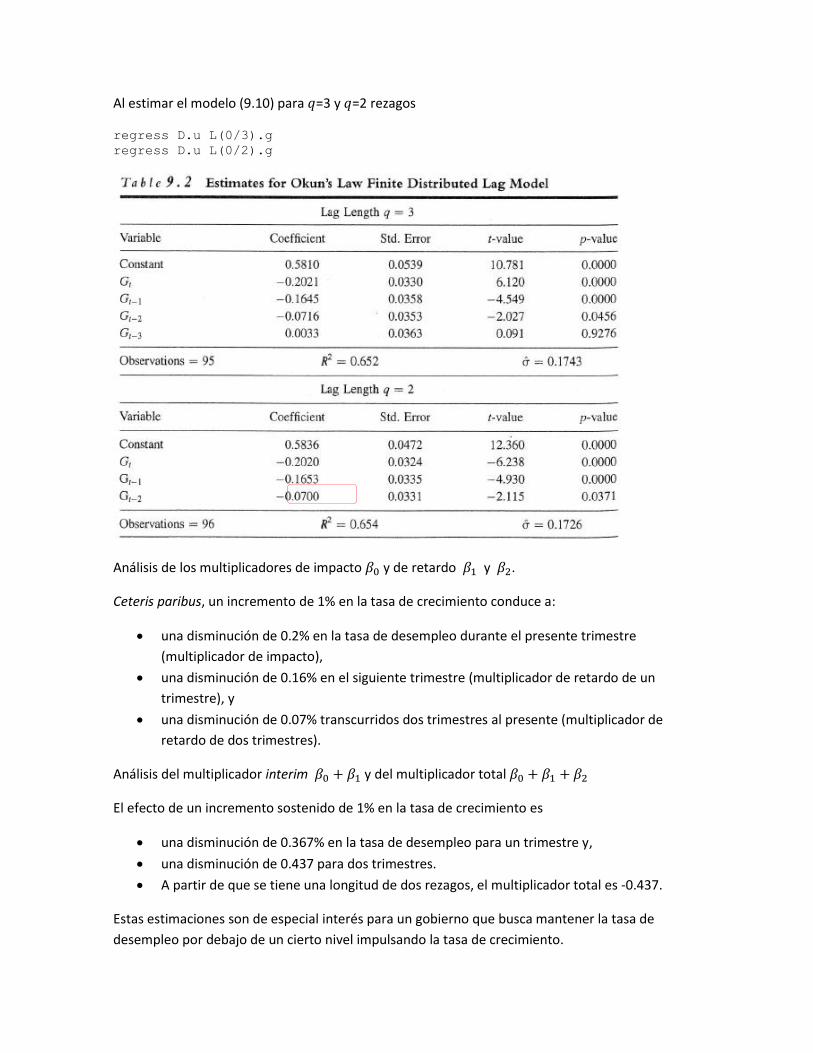
Al estimar el modelo (9.10) para 𝑞=3 y 𝑞=2 rezagos
regress D.u L(0/3).g
regress D.u L(0/2).g
Análisis de los multiplicadores de impacto 𝛽0 y de retardo 𝛽1 y 𝛽2.
Ceteris paribus, un incremento de 1% en la tasa de crecimiento conduce a:
una disminución de 0.2% en la tasa de desempleo durante el presente trimestre
(multiplicador de impacto),
una disminución de 0.16% en el siguiente trimestre (multiplicador de retardo de un
trimestre), y
una disminución de 0.07% transcurridos dos trimestres al presente (multiplicador de
retardo de dos trimestres).
Análisis del multiplicador interim 𝛽0 + 𝛽1 y del multiplicador total 𝛽0 + 𝛽1 + 𝛽2
El efecto de un incremento sostenido de 1% en la tasa de crecimiento es
una disminución de 0.367% en la tasa de desempleo para un trimestre y,
una disminución de 0.437 para dos trimestres.
A partir de que se tiene una longitud de dos rezagos, el multiplicador total es -0.437.
Estas estimaciones son de especial interés para un gobierno que busca mantener la tasa de
desempleo por debajo de un cierto nivel impulsando la tasa de crecimiento.
A partir de (9.8), el efecto total que tiene un cambio en el crecimiento del producto sobre el
desempleo, el cual se ha estimado en
𝛾 = − ∑ �̂�𝑠
2
𝑠=0
= −(�̂�0 + �̂�1 + �̂�2) = −(0.202 + .165 + 0.07) = 0.437
Por lo que el estimador de la tasa normal de crecimiento necesaria para mantener una tasa de
desempleo constante es
𝐺𝑁 =�̂�
�̂�=
0.5836
0.437= 1.3% trimestral
Correlación serial Función de autocorrelación Análisis de correlación serial en el crecimiento del producto
Las correlaciones entre una variable y sus rezagos se denominan autocorrelaciones.
Una exploración visual mediante la gráfica de dispersión de 𝐺𝑡 y 𝐺𝑡−1 sugiere que a altos valores
de 𝐺 en 𝑡 − 1 le siguen valores altos en 𝑡 y a bajos valores de 𝐺 en 𝑡 − 1 le siguen valores bajos
en 𝑡 , revelando una autocorrelación positiva entre las observaciones que distan un periodo de
tiempo, es decir, de orden uno.
summarize g
return list
scatter g L.g, xline(`r(mean)') yline(`r(mean)')
Calculando el coeficiente de correlación de 𝐺𝑡 y 𝐺𝑡−1, se verifica la relación directa entre dichas
series.
. correlate g L.g
(obs=97)
| L.
| g g
-------------+------------------
g |
--. | 1.0000
L1. | 0.4958 1.0000
-10
12
3
% G
DP
gro
wth
-1 0 1 2 3% GDP growth, L

En teoría, a partir de que la correlación poblacional entre dos variables x y y se define como
𝜌𝑥𝑦 =𝑐𝑜𝑣(𝑥, 𝑦)
√𝑣𝑎𝑟(𝑥)𝑣𝑎𝑟(𝑦)
Así, la correlación poblacional entre 𝐺𝑡 y 𝐺𝑡−1 es
𝜌1 =𝑐𝑜𝑣(𝐺𝑡,𝐺𝑡−1)
√𝑣𝑎𝑟(𝐺𝑡)𝑣𝑎𝑟(𝐺𝑡−1)=
𝑐𝑜𝑣(𝐺𝑡,𝐺𝑡−1)
𝑣𝑎𝑟(𝐺𝑡) (9.12)
notando que si la serie 𝐺𝑡 es estacionaria
𝑣𝑎𝑟(𝐺𝑡) = 𝑣𝑎𝑟(𝐺𝑡−1)
La covarianza muestral a estimar queda expresada como
𝑐𝑜𝑣(𝐺𝑡 , 𝐺𝑡−1) =̂1
𝑇 − 1∑(𝐺𝑡 − �̅�)(𝐺𝑡−1 − �̅�)
𝑇
𝑡=2
en tanto que, la varianza muestral a estimar es
𝑣𝑎𝑟(𝐺𝑡)̂ =1
𝑇 − 1∑(𝐺𝑡 − �̅�)2
𝑇
𝑡=1
donde �̅� es la media muestral
�̅� =1
𝑇∑ 𝐺𝑡
𝑇
𝑡=1
Con ello, la autocorrelación muestral de rezago uno para 𝐺𝑡 es
𝑟1 =𝑐𝑜𝑣(𝐺𝑡 , 𝐺𝑡−1)̂
𝑣𝑎𝑟(𝐺𝑡)̂=
1𝑇 − 1
∑ (𝐺𝑡 − �̅�)(𝐺𝑡−1 − �̅�)𝑇𝑡=2
1𝑇 − 1
∑ (𝐺𝑡 − �̅�)2𝑇𝑡=1
de lo que resulta
𝑟1 =∑ (𝐺𝑡−�̅�)(𝐺𝑡−1−�̅�)𝑇
𝑡=2
∑ (𝐺𝑡−�̅�)2𝑇𝑡=1
(9.13)
En general, la autocorrelación muestral de orden k para una serie y es la correlación muestral
entre las series separadas k periodos. Para las observaciones de la serie 𝑦𝑡 y las observaciones de
la serie 𝑦𝑡−𝑘, se calculará
𝑟𝐾 =∑ (𝑦𝑡−�̅�)(𝑦𝑡−𝑘−�̅�)𝑇
𝑡=𝑘+1
∑ (𝑦𝑡−�̅�)2𝑇𝑡=1
(9.14)

En estricto sentido se divide el numerador entre 𝑇 − 𝑘 observaciones y el denominador entre 𝑇
observaciones:
𝑟′𝐾 =1
𝑇−𝑘∑ (𝑦𝑡−�̅�)(𝑦𝑡−𝑘−�̅�)𝑇
𝑡=𝑘+11
𝑇∑ (𝑦𝑡−�̅�)2𝑇
𝑡=1
(9.15)
La expresión (9.14) es la que utilizan la mayoría de los paquetes, entre ellos Stata.
Aplicando (9.14) se obtienen las primeras cuatro autocorrelaciones de la serie 𝐺𝑡
clear
program drop _all
use "C:\poe4\okun.dta", clear
gen t=_n
tsset t
* Cálculo de autocovarianza de orden k=0
sum g
scalar n=_N
scalar m=r(mean)
gen dg=g-m
gen dg2=dg*dg
sum dg2
scalar c0=_N*_result(3)
* Cálculo de autocorrelación de orden k>0
program define autoc
gen dl`1'g=l`1'.g-m
gen prod`1'=dg*dl`1'g
sum prod`1'
scalar c`1'=(n-`1')*_result(3)
dis c`1'/c0
end
for num 1/4: autoc X
* Función de autocorrelación y correlograma
corrgram g, lags(4)
se obtiene
𝑟1 = 0.494 𝑟2 = 0.411 𝑟3 = 0.154 𝑟4 = 0.200 (9.16)
Ahora, ¿cómo probar si una autocorrelación es significativamente distinta de cero?
Se plantea el contraste de hipótesis 𝐻0 ∶ 𝜌𝑘 = 0 𝐻𝑎 ∶ 𝜌𝑘 ≠ 0
Bajo la hipótesis nula, la autocorrelación muestral 𝑟𝑘 sigue aproximadamente una distribución
normal con media cero y varianza 1
𝑇 , es decir
𝑟𝑘 ~ 𝑁 (0,1
𝑇)
por lo que el estadístico de prueba normal estándar es
𝑍 =𝑟𝑘 − 𝜌𝑘
𝑠𝑒(𝑟𝑘)

Bajo 𝐻0
𝑍𝑐𝑎𝑙𝑐. =𝑟𝑘−0
𝑠𝑒(𝑟𝑘)=
𝑟𝑘
√1
𝑇
= √𝑇𝑟𝑘 ~ 𝑁(0, 1) (9.17)
Al 5% de significancia, rechazamos 𝐻0 cuando el estadístico calculado sea mayor que el valor
teórico de 𝑍, es decir
En Stata, el valor teórico de 𝑍 lo obtenemos con la siguiente instrucción, dado el nivel de significancia
display invnormal(1-0.05/2)
1.959964
Para las autocorrelaciones de orden 1 a 4 calculadas
k 𝑟𝑘 𝑍𝑐𝑎𝑙𝑐. 𝑍𝑡𝑒ó𝑟𝑖𝑐𝑜 Decisión
1 𝑟1=0.494 √98 ∗0.494=4.89 1.96 Se rechaza 𝐻0: 𝜌1 = 0
2 𝑟2=0.411 √98 ∗0.411=4.07 1.96 Se rechaza 𝐻0: 𝜌2 = 0
3 𝑟3=0.154 √98 ∗0.154=1.53 1.96 No se rechaza 𝐻0: 𝜌3 = 0
4 𝑟4=0.200 √98 ∗0.200=1.98 1.96 Se rechaza 𝐻0: 𝜌4 = 0
Por lo que se concluye que la tasa de crecimiento trimestral del producto norteamericano muestra
correlación serial significativa en los primeros dos rezagos. El cuarto rezago resultó significativo en
el límite.

El correlograma
Para 12 rezagos, se obtiene la tabla de AC y la gráfica de dicha función de autocorrelación clear
program drop _all
use "C:\poe4\okun.dta", clear
gen t=_n
tsset t
* Cálculo de autocovarianza de orden k=0
sum g
scalar n=_N
scalar m=r(mean)
gen dg=g-m
gen dg2=dg*dg
sum dg2
scalar c0=_N*_result(3)
* Cálculo de autocorrelación de orden k>0
program define autoc
gen dl`1'g=l`1'.g-m
gen prod`1'=dg*dl`1'g
sum prod`1'
scalar c`1'=(n-`1')*_result(3)
dis c`1'/c0
end
for num 1/12: autoc X
* Correlograma con bandas de confianza
corrgram g, lags(12)
matrix r=r(AC)'
clear
svmat r
ren r1 r
gen t=_n
display invnormal(1-0.05/2)/sqrt(98)
graph bar r, over(t) yline(-.19798626 .19798626) ytitle("Autocorrelación")
k 𝑟𝑘 𝑍𝑐𝑎𝑙𝑐. 𝑍𝑡𝑒ó𝑟𝑖𝑐𝑜 Decisión
1 0.494 4.89 1.96 Se rechaza 𝐻0: 𝜌1 = 0
2 0.411 4.07 1.96 Se rechaza 𝐻0: 𝜌2 = 0
3 0.154 1.53 1.96 No se rechaza 𝐻0: 𝜌3 = 0
4 0.200 1.98 1.96 Se rechaza 𝐻0: 𝜌4 = 0
5 0.090 0.89 1.96 No se rechaza 𝐻0: 𝜌5 = 0
6 0.025 0.24 1.96 No se rechaza 𝐻0: 𝜌6 = 0
7 -0.030 -0.30 1.96 No se rechaza 𝐻0: 𝜌7 = 0
8 -0.082 -0.81 1.96 No se rechaza 𝐻0: 𝜌8 = 0
9 0.044 0.44 1.96 No se rechaza 𝐻0: 𝜌9 = 0
10 -0.021 -0.21 1.96 No se rechaza 𝐻0: 𝜌10 = 0
11 -0.087 -0.86 1.96 No se rechaza 𝐻0: 𝜌11 = 0
12 -0.204 -2.02 1.96 Se rechaza 𝐻0: 𝜌12 = 0
Al 5% de significancia
√𝑇𝑟𝑘 ≤ −1.96 o √𝑇𝑟𝑘 ≥ 1.96
lo que equivale a
𝑟𝑘 ≤ −1.96
√𝑇 o √𝑇𝑟𝑘 ≥
1.96
√𝑇

entonces, se rechaza 𝐻0 si la autocorrelación es mayor en valor absoluto que la banda de
significancia.
En este caso T=98 observaciones y se tiene el correlograma con las bandas de confianza.
Errores serialmente correlacionados La Curva de Phillips Relación entre inflación y desempleo
𝐼𝑁𝐹𝑡 = 𝐼𝑁𝐹𝑡𝐸 − 𝛾(𝑈𝑡 − 𝑈𝑡−1) (9.18)
La especificación econométrica del modelo asignando 𝛽1 = 𝐼𝑁𝐹𝑡𝐸 asumiendo que la expectativa
de inflación son contante en el tiempo y 𝛽2 = −𝛾 es
𝐼𝑁𝐹𝑡 = 𝛽1 + 𝛽2𝐷𝑈𝑡 + 𝑒𝑡 (9.19)
A partir del modelo estimado
𝐼𝑁𝐹�̂� = 𝑏1 + 𝑏2𝐷𝑈𝑡
los residuales de mínimos cuadrados ordinarios que se calcularán son
𝑒�̂� = 𝐼𝑁𝐹𝑡 − 𝐼𝑁𝐹�̂� = 𝐼𝑁𝐹𝑡 − (𝑏1 + 𝑏2𝐷𝑈𝑡) = 𝐼𝑁𝐹𝑡 − 𝑏1 − 𝑏2𝐷𝑈𝑡 (9.20)
Con estos residuales se pretende estimar el correlograma de los errores poblacionales para
evaluar si se viola o no el supuesto de no correlación entre los errores:
𝑐𝑜𝑣 (𝑒𝑡 , 𝑒𝑠) = 0 para 𝑡 ≠ 𝑠
Retomando conceptualmente la expresión (9.14) se construye la correspondiente a la
autocorrelación para los residuales
𝑟𝑘 =∑ (𝑒𝑡 − �̅�)(𝑒𝑡−𝑘 − �̅�)𝑇
𝑡=𝑘+1
∑ (𝑒𝑡 − �̅�)2𝑇𝑡=1
-.2
0.2
.4.6
Au
tocorr
ela
ció
n
1 2 3 4 5 6 7 8 9 10 11 12
de lo que resulta
𝑟𝑘 =∑ 𝑒𝑡𝑒𝑡−𝑘
𝑇𝑡=𝑘+1
∑ 𝑒𝑡2𝑇
𝑡=1 (9.21)
Con la base de datos phillips_aus.dta en Stata:
clear
program drop _all
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
tsline inf, saving("C:\poe4\inf.dta",replace)
tsline D.u, saving("C:\poe4\du.dta",replace) graph combine "C:\poe4\inf.dta" "C:\poe4\du.dta", saving("C:\poe4\fig97.dta",replace)
* Estimación del modelo de la Curva de Phillips
regress inf D.u
* Serie de residuales
predict ehat, residuals
* Correlograma con bandas de confianza
corrgram ehat, lags(12)
matrix r=r(AC)'
clear
svmat r
ren r1 r
gen t=_n
display invnormal(1-0.05/2)/sqrt(90)
graph bar r, over(t) yline(-.20659834 .20659834) ytitle("Autocorrelación")
Las gráficas de las series de inflación y cambio trimestral en el desdempleo en Australia son
El modelo estimado es
𝐼𝑁�̂� = 0.7776 − 0.5279𝐷𝑈
(𝑠𝑒) (0.0658) (0.2294) (9.22)
-10
12
3
Aus
tralia
n In
flatio
n R
ate
1985q1 1990q1 1995q1 2000q1 2005q1 2010q1date
-.50
.51
Aus
tralia
n U
nem
ploy
men
t Rat
e (S
easo
nally
adj
uste
d), D
1985q1 1990q1 1995q1 2000q1 2005q1 2010q1date

El correlograma
Se visualiza autocorrelación en la serie de los residuales. Los primeros seis y el octavo rezagos son,
al 5% de significancia, distintos de cero. Hay suficiente evidencia de que los errores en el modelo
de la curva de Phillips están serialmente correlacionados. Se viola el supuesto 𝑐𝑜𝑣 (𝑒𝑡 , 𝑒𝑠) = 0.
Otras pruebas para errores serialmente correlacionados Prueba del multiplicador de Lagrange
Una segunda prueba de correlación serial en los errores se deriva del principio general de
Lagrange que consiste en comparar estadísticamente el modelo sin autocorrelación con el modelo
con autocorrelación a través de una regresión auxiliar. El contraste de hipótesis está basado en el
estadístico denominado multiplicador de Lagrange (LM).
Si 𝑒𝑡 y 𝑒𝑡−1 están correlacionados, una forma simple de modelar esta relación es
𝑒𝑡 = 𝜌𝑒𝑡−1 + 𝑣𝑡 (9.23)
Si la regresión principal es
𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝑒𝑡
Al sustituir (9.23) para 𝑒𝑡 se tiene
𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝜌𝑒𝑡−1 + 𝑣𝑡 (9.24)
donde se suponen 𝑣𝑡 y 𝑒𝑡−1 independientes.
Se plantea, así, el contraste de hipótesis
𝐻0 ∶ 𝜌 = 0 𝐻𝑎 ∶ 𝜌 ≠ 0
pero 𝑒𝑡−1 es no observable, por lo que utilizamos los residuales rezagados e inferimos sobre el
parámetro 𝜌 en la ecuación
𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝜌�̂�𝑡−1 + 𝑣𝑡 (9.25)

Sustituyendo del lado izquierdo el modelo principal para 𝑦𝑡 con sus residuales en lugar del error
𝑏1 + 𝑏2𝑥𝑡 + �̂�𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝜌�̂�𝑡−1 + 𝑣𝑡
Reordenando términos, la regresión auxiliar queda
�̂�𝑡 = (𝛽1 − 𝑏1) + (𝛽2−𝑏2)𝑥𝑡 + 𝜌�̂�𝑡−1 + 𝑣𝑡
= 𝛾1 + 𝛾2𝑥𝑡 + 𝜌�̂�𝑡−1 + 𝑣𝑡 (9.26)
donde
𝛾1 = 𝛽1 − 𝑏1
𝛾2 = 𝛽2−𝑏2
Como están centrados alrededor de cero, el poder explicativo significativo de la regresión proviene
de �̂�𝑡−1.
Si 𝐻0 ∶ 𝜌 = 0 es verdadera, el estadístico de prueba LM a calcular es
𝐿𝑀 = 𝑇 × 𝑅2 ~ 𝜒1 𝑔.𝑙.2
Para 𝑘 > 1, si 𝐻0 ∶ 𝜌𝑘 = 0 es verdadera, el estadístico de prueba LM a calcular es
𝐿𝑀 = (𝑇 − 𝑘) × 𝑅2 ~ 𝜒𝑘 𝑔.𝑙.2

En la práctica, con los datos de la curva de Phillips para Australia
* PRUEBAS DE AUTOCORRELACIÓN
* Estimando (9.25)
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
* PRUEBAS DE SIGNIFICANCIA del coeficiente (coeficiente de autocorrelación rho)
* inciso i) alternativa 1
regress inf D.u
predict ehat, res
regress inf D.u L.ehat
test L.ehat
* inciso ii) alternativa 2. Reemplazando ehat(1) por cero y realizando la prueba
replace ehat = 0 in 1
regress inf D.u L.ehat
test L.ehat
(𝑖) 𝑡 = 6.219 𝐹 = 38.67 valor 𝑝 = 0.000 (𝑖𝑖) 𝑡 = 6.202 𝐹 = 38.47 valor 𝑝 = 0.000
* Estimando (9.26)
* PRUEBAS LM para AR(1)
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
* Pruebas LM para error AR(1)
* inciso iii) alternativa 1
regress inf D.u
predict ehat, res
regress ehat D.u L.ehat
display "Observaciones = " e(N) " y T*R2 = " e(N)*e(r2)
* inciso iv) alternativa 2
replace ehat = 0 in 1
regress ehat D.u L.ehat
display "Observaciones = " e(N) " y T*R2 = " e(N)*e(r2)
display "Valor teórico de la Chi-cuadrada 1 g.l. al 95% = ", invchi2(1,0.95)
(𝑖𝑖𝑖) 𝐿𝑀 = (𝑇 − 1) × 𝑅2 = 89 × 0.3102 = 27.61
(𝑖𝑣) 𝐿𝑀 = 𝑇 × 𝑅2 = 90 × 0.3066 = 27.59
Los estadísticos calculados 𝐿𝑀 = 27.61 y 𝐿𝑀 = 27.59 son mayores que el valor teórico al %5 de
significancia 𝜒1 2 =3.84. Se rechaza la hipótesis nula 𝐻0 ∶ 𝜌1 = 0.
* Probando autocorrelación para más de un rezago
* PRUEBAS LM para error AR(4)
* inciso iii) alternativa 1
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress inf D.u
predict ehat, res
regress ehat D.u L(1/4).ehat
display "Observaciones = " e(N) " and TR2 = " e(N)*e(r2)
* inciso iv) alternativa 2
gen ehat1=l.ehat
gen ehat2=ll.ehat
gen ehat3=lll.ehat
gen ehat4=llll.ehat
replace ehat=0 in 1
replace ehat1=0 in 1/2
replace ehat2=0 in 1/3
replace ehat3=0 in 1/4
replace ehat4=0 in 1/5
regress ehat D.u ehat1-ehat4
display "Observaciones = " e(N) " and TR2 = " e(N)*e(r2)
display "Valor teórico de la Chi-cuadrada 4 g.l. al 95% = ", invchi2(4,0.95)
(𝑖𝑖𝑖) 𝐿𝑀 = (𝑇 − 4) × 𝑅2 = 86 × 0.3882 = 33.4 (𝑖𝑣) 𝐿𝑀 = 𝑇 × 𝑅2 = 90 × 0.4075 = 36.7

Los estadísticos calculados 𝐿𝑀 = 33.4 y 𝐿𝑀 = 36.7 son mayores que el valor teórico al %5 de
significancia 𝜒4 2 =9.49. Se rechaza la hipótesis nula 𝐻0 ∶ 𝜌4 = 0.
Stata facilita la inferencia para el modelo con error AR(k) para cualquier número k de rezagos, mediante el siguiente procedimiento de Breusch-Godfrey para la prueba de autocorrelación basada en el multiplicador de Lagrange (LM):
* Prueba Breush-Godfrey
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress inf D.u
* Para error autorregresivo de orden 1 : AR(1)
estat bgodfrey, lags(1)
* Para error autorregresivo de orden 4 : AR(4)
estat bgodfrey, lags(4)
El estadístico calculado 𝐿𝑀 = 27.593 es mayor que el valor teórico al %5 de significancia
𝜒1 2 =3.84. Se rechaza la hipótesis nula 𝐻0 ∶ 𝜌1 = 0.
El estadístico calculado 𝐿𝑀 = 36.672 es mayor que el valor teórico al %5 de significancia
𝜒4 2 =9.49. Se rechaza la hipótesis nula 𝐻0 ∶ 𝜌4 = 0.
Prueba Durbin-Watson
Las pruebas de correlación serial basadas en el correlograma y el estadístico LM están diseñadas
para grandes muestras. Como alternativa se encuentra la prueba Durbin-Watson, la cual no está
basada en una aproximación a muestras grandes. En la actualidad se utiliza con menos frecuencia
porque se requiere examinar una cota inferior y una cota superior y su distribución no aplica
cuando la ecuación cuando el modelo contiene un rezago de la variable dependiente. Otra
limitante es su enfoque a probar correlación serial de primer orden.
Si suponemos que 𝑣𝑡 son errores aleatorios independientes con distribución 𝑁(0, 𝜎𝑣2) y que la
hipótesis alternativa es autocorrelación positiva en el modelo 𝑒𝑡 = 𝜌𝑒𝑡−1 + 𝑣𝑡 . Es decir,
𝐻0 ∶ 𝜌 = 0 𝐻𝑎 ∶ 𝜌 > 0

El estadístico de prueba Durbin-Watson que se utiliza para este contraste de hipótesis es
𝑑 =∑ (�̂�𝑡−�̂�𝑡−1)2𝑇
𝑡=2
∑ �̂�𝑡2𝑇
𝑡=1 (9A.1)
donde 𝑒𝑡 son los residuales de mínimos cuadrados ordinarios
�̂�𝑡 = 𝑦𝑡 − 𝑏1 − 𝑏2𝑥𝑡
Para ver por qué 𝑑 es un estadístico razonable para probar autocorrelación, se expande (9A.1),
desarrollando el binomio diferencia al cuadrado de los términos del numerador, como
𝑑 =∑ �̂�𝑡
2+∑ �̂�𝑡−12 −2 ∑ �̂�𝑡�̂�𝑡−1
𝑇𝑡=2
𝑇𝑡=2
𝑇𝑡=2
∑ �̂�𝑡2𝑇
𝑡=1=
∑ �̂�𝑡2𝑇
𝑡=2
∑ �̂�𝑡2𝑇
𝑡=1+
∑ �̂�𝑡−12𝑇
𝑡=2
∑ �̂�𝑡2𝑇
𝑡=1− 2
∑ �̂�𝑡�̂�𝑡−1𝑇𝑡=2
∑ �̂�𝑡2𝑇
𝑡=1≈ 1 + 1 − 2𝑟1 (9A.2)
así,
𝑑 = 2 − 2∑ �̂�𝑡�̂�𝑡−1
𝑇𝑡=2
∑ �̂�𝑡2𝑇
𝑡=1≈ 2(1 − 𝑟1) (9A.3)
Se observa que si 𝑟1 = 0, entonces 𝑑 ≈ 2, lo que indica que los errores en el modelo no están
autocorrelacionados. Un valor bajo del estadístico Durbin-Watson implica que los errores en el
modelo están correlacionados y 𝜌 > 0.
La pregunta relevante es ¿qué tan cerca de cero debe estar el valor del estadístico de prueba para
concluir que los errores están correlacionados? Es decir, cuál es el valor crítico 𝑑𝑐 (teórico a un
nivel de significancia dado) del estadístico de Durbin-Watson.
Los valores de 𝑓(𝑑) dependen de los valores de las variables explicativas que determinan a su vez
a los residuales con los que se calcula el estadístico 𝑑. Por lo tanto, no hay una distribución única
para dicho estadístico de prueba.

Stata calcula el valor de 𝑑 y de acuerdo con la regla de decisión:
Rechazar 𝐻0 ∶ 𝜌 = 0 si 𝑑 ≤ 𝑑𝑐
No rechazar 𝐻0 ∶ 𝜌 = 0 si 𝑑 > 𝑑𝑐
al 5% de significancia, buscamos una 𝑑𝑐 tal que
𝑃(𝑑 ≤ 𝑑𝑐) = 0.05
En la práctica,
* Prueba Durbin-Watson
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress inf D.u
estat dwatson
Una vez estimado el modelo de la curva de Phillips para Australia
𝐼𝑁�̂� = 0.7776 − 0.5279𝐷𝑈
(𝑠𝑒) (0.0658) (0.2294) (9.22)
se obtiene el estadístico calculado Durbin-Watson dadas 90 observaciones para 2 regresores (incluido el intercepto), a partir de los residuales de la ecuación anterior
Ahora, se requiere examinar una cota inferior y una cota superior. Los valores inferior y superior de la 𝑑𝑐 de acuerdo con la siguiente tabla de valores críticos DW al 5% son 𝑑𝐿𝑐 =1.635 y 𝑑𝑈𝑐 =1.679
http://web.stanford.edu/~clint/bench/dw05a.htm

Finalmente, se toma la decisión de
Rechazar 𝐻0 ∶ 𝜌 = 0 si 𝑑 < 𝑑𝐿𝑐
No rechazar 𝐻0 ∶ 𝜌 = 0 si 𝑑 > 𝑑𝑈𝑐
Indecisión si 𝑑𝐿𝑐 < 𝑑 < 𝑑𝐿𝑐 .
El estadístico calculado 𝑑=0.8873 es menor que la cota inferior del valor crítico 𝑑𝐿𝑐 =1.635, por lo que se concluye que 𝑑 < 𝑑𝑐 , entonces se rechaza 𝐻0 ∶ 𝜌 = 0. Hay evidencia que sugiere que los errores en el modelo de la curva de Phillips australiana están serialmente correlacionados.

Tres métodos de estimación con errores serialmente correlacionados
Hemos visto que en los modelos de series de tiempo generalmente se rechaza la hipótesis de no
autocorrelación en los errores. Se viola el supuesto de que los errores no están correlacionados:
𝑐𝑜𝑣 (𝑒𝑡 , 𝑒𝑠) = 0 para 𝑡 ≠ 𝑠
Por lo que se requiere estimar un modelo que capture la dinámica todas las fuentes explicativas de
𝑦𝑡, tales como los rezagos de 𝑥, los rezagos de 𝑦 y el error serial.
Antes de considerar los siguientes 3 métodos, es necesario relajar el supuesto
TSMR2. 𝑦 y 𝑥 son variables aleatorias estacionarias, y 𝑒𝑡 es independiente de los valores
presentes, pasados y futuros de 𝑥.
Consideremos el modelo
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + 𝛿0𝑥𝑡 + 𝛿1𝑥𝑡−1 + 𝑣𝑡
Bajo este supuesto, el error no estaría correlacionado con los valores presentes, pasados y futuros
de 𝑦𝑡−1, 𝑥𝑡 y 𝑥𝑡−1. En virtud de que 𝑦𝑡 es un valor futuro de 𝑦𝑡−1 y 𝑦𝑡 depende directamente del
error, se viola el supuesto. Por lo tanto, debemos reemplazarlo por este otro, que aplica para
modelos con variable dependiente rezagada
TSMR2. En el modelo de regresión múltiple 𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡2 + ⋯ + 𝛽𝐾𝑥𝑡𝐾 + 𝑣𝑡 donde
algunas de las 𝑥𝑡𝑘 pueden ser valores rezagados de 𝑦, 𝑣 no está correlacionado
con todas las 𝑥𝑡𝑘 y sus valores pasados.
Los siguientes 3 métodos contemplan modelos a estimar con este último supuesto.
1) Mínimos cuadrados ordinarios con autocorrelación
A partir de que el estimador 𝑏2 del modelo 𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝑒𝑡 es
𝑏2 =∑ (𝑥𝑡 − �̅�)(𝑦𝑡 − �̅�)𝑇
𝑡=1
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
=∑ (𝑥𝑡 − �̅�)𝑦𝑡 − �̅� ∑ (𝑥𝑡 − �̅�)𝑇
𝑡=1𝑇𝑡=1
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
=∑ (𝑥𝑡 − �̅�)𝑦𝑡
𝑇𝑡=1
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
−�̅�𝑇�̅� + �̅�𝑇�̅�
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
= ∑𝑥𝑡 − �̅�
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
𝑦𝑡
𝑇
𝑡=1
= ∑ 𝑤𝑡𝑦𝑡
𝑇
𝑡=1
donde se observa que ∑ 𝑤𝑡𝑇𝑡=1 = 0, pues
∑𝑥𝑡 − �̅�
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
𝑇
𝑡=1
=∑ 𝑥𝑡
𝑇𝑡=1
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
−∑ �̅�𝑇
𝑡=1
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
=𝑇�̅�
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
−𝑇�̅�
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
= 0
así, 𝑏2 es un estimador lineal.
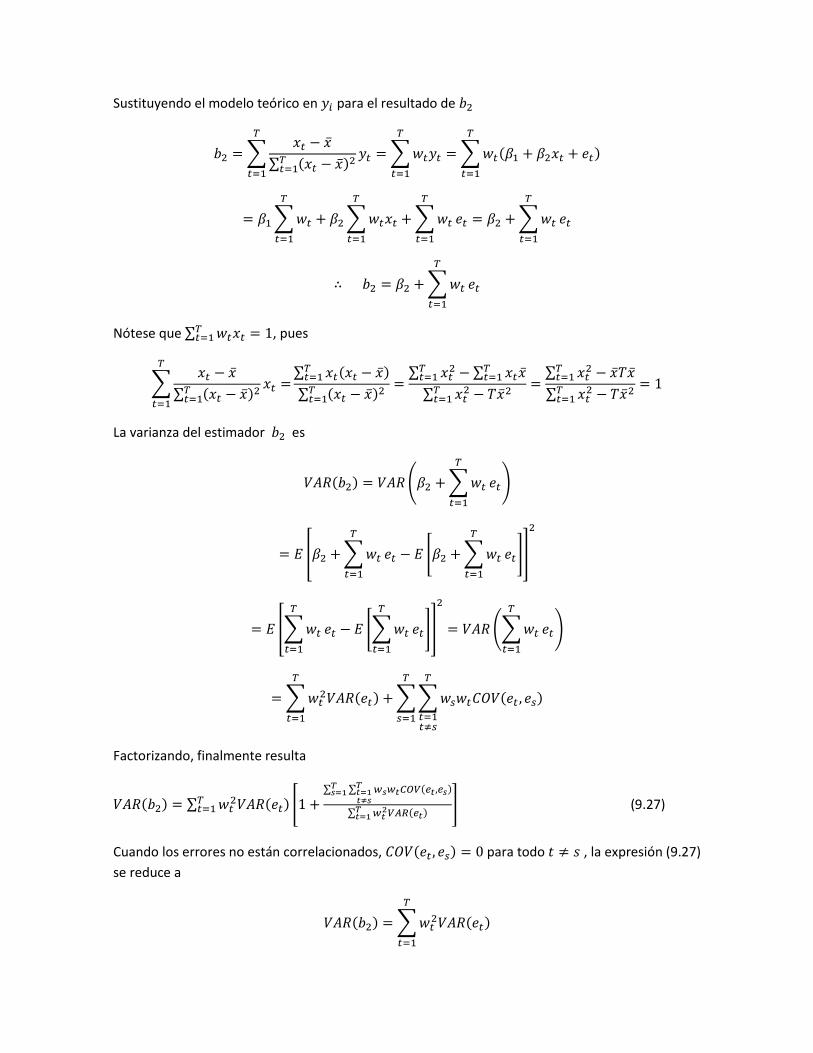
Sustituyendo el modelo teórico en 𝑦𝑖 para el resultado de 𝑏2
𝑏2 = ∑𝑥𝑡 − �̅�
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
𝑦𝑡
𝑇
𝑡=1
= ∑ 𝑤𝑡𝑦𝑡
𝑇
𝑡=1
= ∑ 𝑤𝑡(𝛽1 + 𝛽2𝑥𝑡 + 𝑒𝑡)
𝑇
𝑡=1
= 𝛽1 ∑ 𝑤𝑡
𝑇
𝑡=1
+ 𝛽2 ∑ 𝑤𝑡𝑥𝑡
𝑇
𝑡=1
+ ∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡 = 𝛽2 + ∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡
∴ 𝑏2 = 𝛽2 + ∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡
Nótese que ∑ 𝑤𝑡𝑥𝑡𝑇𝑡=1 = 1, pues
∑𝑥𝑡 − �̅�
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
𝑥𝑡 =
𝑇
𝑡=1
∑ 𝑥𝑡(𝑥𝑡 − �̅�)𝑇𝑡=1
∑ (𝑥𝑡 − �̅�)2𝑇𝑡=1
=∑ 𝑥𝑡
2𝑇𝑡=1 − ∑ 𝑥𝑡�̅�𝑇
𝑡=1
∑ 𝑥𝑡2𝑇
𝑡=1 − 𝑇�̅�2=
∑ 𝑥𝑡2𝑇
𝑡=1 − �̅�𝑇�̅�
∑ 𝑥𝑡2𝑇
𝑡=1 − 𝑇�̅�2= 1
La varianza del estimador 𝑏2 es
𝑉𝐴𝑅(𝑏2) = 𝑉𝐴𝑅 (𝛽2 + ∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡)
= 𝐸 [𝛽2 + ∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡 − 𝐸 [𝛽2 + ∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡]]
2
= 𝐸 [∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡 − 𝐸 [∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡]]
2
= 𝑉𝐴𝑅 (∑ 𝑤𝑡
𝑇
𝑡=1
𝑒𝑡)
= ∑ 𝑤𝑡2𝑉𝐴𝑅(𝑒𝑡)
𝑇
𝑡=1
+ ∑ ∑ 𝑤𝑠𝑤𝑡𝐶𝑂𝑉(𝑒𝑡 , 𝑒𝑠)
𝑇
𝑡=1𝑡≠𝑠
𝑇
𝑠=1
Factorizando, finalmente resulta
𝑉𝐴𝑅(𝑏2) = ∑ 𝑤𝑡2𝑉𝐴𝑅(𝑒𝑡)𝑇
𝑡=1 [1 +∑ ∑ 𝑤𝑠𝑤𝑡𝐶𝑂𝑉(𝑒𝑡,𝑒𝑠)𝑇
𝑡=1𝑡≠𝑠
𝑇𝑠=1
∑ 𝑤𝑡2𝑉𝐴𝑅(𝑒𝑡)𝑇
𝑡=1] (9.27)
Cuando los errores no están correlacionados, 𝐶𝑂𝑉(𝑒𝑡 , 𝑒𝑠) = 0 para todo 𝑡 ≠ 𝑠 , la expresión (9.27)
se reduce a
𝑉𝐴𝑅(𝑏2) = ∑ 𝑤𝑡2𝑉𝐴𝑅(𝑒𝑡)
𝑇
𝑡=1

que se utiliza para encontrar los errores estándar consistentes con heteroscedasticidad (HC).
Cuando los errores están correlacionados, 𝐶𝑂𝑉(𝑒𝑡 , 𝑒𝑠) ≠ 0 para todo 𝑡 ≠ 𝑠 , la relación entre los
dos estimadores de varianzas a partir de la expresión (9.27) se expresa como
𝑉𝐴𝑅𝐻𝐴𝐶(𝑏2)̂ = 𝑉𝐴𝑅𝐻𝐶(𝑏2)̂ × 𝑔 (9.28)
donde 𝑔 es el término entre paréntesis rectangulares que se estima para obtener los errores
estándar consistentes con heteroscedasticidad y autocorrelación (HAC).
Por lo tanto, el estimador de varianza HAC es igual al estimador de varianza HC multiplicado por
un término que depende de la correlación serial en los errores.
Ejemplo:
Para el modelo estimado de la curva de Phillips se obtendrán los errores estándar incorrectos (HC),
al ignorar la autocorrelación, y los correctos que reconocen la autocorrelación (HAC).
En Stata
* Estimación por MCO, con errores estándar HC
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
scalar B = round(4*(e(N)/100)^(2/9))
scalar list B
regress inf D.u
estimates store Wrong_SE
* Estimación con errores estándar HAC, reconociendo autocorrelación de orden 3
newey inf D.u, lag(3)
estimates store HAC_3
* Cuadro comparativo
esttab Wrong_SE HAC_3, compress se(%12.3f) b(%12.5f) gaps scalars(r2_a rss aic)
title("Variable Dependiente: inf") mtitles("LS" "HAC(3)")
Así, la curva de Phillips estimada con errores estándar sin autocorrelación (HC) y con errores
estándar con autocorrelación (HAC) es
𝐼𝑁�̂� = 0.7776 − 0.5279𝐷𝑈 (0.0658) (0.2294) errores estándar incorrectos (9.29) (0.1030) (0.3127) errores estándar HAC

Los errores estándar HAC de Newey-West son más grandes que los HC obtenidos por mínimos
cuadrados ordinarios, lo que implica que si ignoráramos la autocorrelación estaríamos
sobreestimando la confiabilidad de los estimadores MCO. Los estadísticos 𝑡 y valores 𝑝 de la
prueba 𝐻0 ∶ 𝛽2 = 0 son:
𝑡 = − 0.5279 0.2294⁄ = −2.301 𝑝 = 0.0238 bajo errores estándar HC por MCO
𝑡 = − 0.5279 0.3127⁄ = −1.688 𝑝 = 0.0950 bajo errores estándar HAC
Bajo errores estándar HC por MCO, el valor 𝑝 es menor al 5%, por lo tanto para la prueba de dos
colas, al 5% de significancia, se rechaza la hipótesis nula 𝐻0 ∶ 𝛽2 = 0. En tanto que, bajo errores
estándar HAC de Newey-West, el valor 𝑝 es mayor al 5%, por lo tanto para la prueba de dos colas,
al 5% de significancia, no se rechaza la hipótesis nula 𝐻0 ∶ 𝛽2 = 0. Así, se observa que al emplear
errores estándar incorrectos se obtienen resultados que no son confiables.
Los intervalos de confianza, con el valor 𝑡 crítico al 95%,
son, bajo errores estándar HC por MCO
𝑃[�̂�2 − 𝑡0.975,88𝑠𝑒𝐻𝐶(�̂�2) < 𝛽2 < �̂�2 + 𝑡0.975,88𝑠𝑒𝐻𝐶(�̂�2)] = 0.95
𝑃[−0.5278 − 1.9873 ∗ 0.2294 < 𝛽2 < −0.5278 + 1.9873 ∗ 0.2294] = 0.95
𝑃[−0.984 < 𝛽2 < −0.072] = 0.95
y, bajo errores estándar HAC de Newey-West
𝑃[�̂�2 − 𝑡0.975,88𝑠𝑒𝐻𝐴𝐶(�̂�2) < 𝛽2 < �̂�2 + 𝑡0.975,88𝑠𝑒𝐻𝐴𝐶(�̂�2)] = 0.95
𝑃[−0.5278 − 1.9873 ∗ 0.3127 < 𝛽2 < −0.5278 + 1.9873 ∗ 0.3127] = 0.95
𝑃[−1.149 < 𝛽2 < −0.094] = 0.95
El intervalo estimado para el estimador 𝛽2 bajo MCO es más estrecho que el correspondiente bajo
errores estándar HAC de Newey-West. La conclusión sobre la confiabilidad de la estimación HC es
exagerada con respecto a la estimación HAC.
2) Modelo de error AR(1)

Con la metodología anterior (errores HAC) no se logra obtener estimadores con menor varianza
que los estimadores de MCO, por lo que otro método es derivar un estimador compatible con el
supuesto de errores autocorrelacionados.
El modelo autorregresivo de primer orden, AR(1), para el error es
𝑒𝑡 = 𝜌𝑒𝑡−1 + 𝑣𝑡 (9.30)
Con los siguientes supuestos sobre 𝑣
𝐸(𝑣𝑡) = 0 𝑉𝐴𝑅(𝑣𝑡) = 𝜎𝑣2 𝐶𝑂𝑉(𝑣𝑡 , 𝑣𝑠) = 0 para 𝑡 ≠ 𝑠 (9.31)
Propiedades del error AR(1)
Otro supuesto es que el proceso de 𝑒𝑡 es estacionario, lo que implica
−1 < 𝜌 < 1 (9.32)
Ahora, calculamos la media y la varianza de 𝑒𝑡
Media de 𝑒𝑡
Al rezagar el proceso AR(1) un periodo
𝑒𝑡−1 = 𝜌𝑒𝑡−2 + 𝑣𝑡−1
Sustituyendo en (9.30)
𝑒𝑡 = 𝜌(𝜌𝑒𝑡−2 + 𝑣𝑡−1) + 𝑣𝑡
𝑒𝑡 = 𝜌2𝑒𝑡−2 + 𝜌𝑣𝑡−1 + 𝑣𝑡 (9B.1)
Al rezagar el proceso AR(1) dos periodos
𝑒𝑡−2 = 𝜌𝑒𝑡−3 + 𝑣𝑡−2
Sustituyendo en (9B.1)
𝑒𝑡 = 𝜌2(𝜌𝑒𝑡−3 + 𝑣𝑡−2) + 𝜌𝑣𝑡−1 + 𝑣𝑡
𝑒𝑡 = 𝜌3𝑒𝑡−3 + 𝜌2𝑣𝑡−2 + 𝜌𝑣𝑡−1 + 𝑣𝑡 (9B.2)
Repitiendo este procedimiento 𝑘 veces
𝑒𝑡 = 𝜌𝑘𝑒𝑡−𝑘 + 𝜌𝑘−1𝑣𝑡−(𝑘−1) + ⋯ + 𝜌2𝑣𝑡−2 + 𝜌𝑣𝑡−1 + 𝑣𝑡
reordenando los rezagos de 𝑣 se obtiene
𝑒𝑡 = 𝜌𝑘𝑒𝑡−𝑘 + 𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + ⋯ + 𝜌𝑘−1𝑣𝑡−𝑘+1 (9B.3)

Cuando 𝑘 → ∞, el primero y último términos de la expresión anterior se van a cero, debido a que
−1 < 𝜌 < 1, el resultado es
𝑒𝑡 = 𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ (9B.4)
Así, el error de regresión 𝑒𝑡 puede ser expresado como una suma ponderada de los valores
presente y pasados del error no correlacionado 𝑣𝑡. La importancia de este resultado radica en que
todos los valores pasados de 𝑣𝑡 tienen un impacto sobre el error 𝑒𝑡 y este se transmite a 𝑦 a
través de la ecuación de regresión. Los ponderadores de 𝑣 decrecen geométricamente cuanto
más distantes se encuentran del periodo presente. Eventualmente se vuelven despreciables.
El valor esperado de 𝑒𝑡
𝐸[𝑒𝑡] = 𝐸[𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ ]
= 𝐸[𝑣𝑡] + 𝐸[𝜌𝑣𝑡−1] + 𝐸[𝜌2𝑣𝑡−2] + 𝐸[𝜌3𝑣𝑡−3] + ⋯
= 𝐸[𝑣𝑡] + 𝜌𝐸[𝑣𝑡−1] + 𝜌2𝐸[𝑣𝑡−2] + 𝜌3𝐸[𝑣𝑡−3] + ⋯ = 0
= 0 + 𝜌 × 0 + 𝜌2 × 0 + 𝜌3 × 0 + ⋯ = 0
Varianza de 𝑒𝑡
𝑉𝐴𝑅[𝑒𝑡] = 𝐸[𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ − 𝐸[𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ ]]2
= 𝐸[𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ ]2
= 𝐸[𝑣𝑡2 + 𝜌2𝑣𝑡−1
2 + 𝜌4𝑣𝑡−22 + 𝜌6𝑣𝑡−3
2 + ⋯ ]
= 𝐸[𝑣𝑡2] + 𝐸[𝜌2𝑣𝑡−1
2 ] + 𝐸[𝜌4𝑣𝑡−22 ] + 𝐸[𝜌6𝑣𝑡−3
2 ] + ⋯
= 𝐸[𝑣𝑡2] + 𝜌2𝐸[𝑣𝑡−1
2 ] + 𝜌4𝐸[𝑣𝑡−22 ] + 𝜌6𝐸[𝑣𝑡−3
2 ] + ⋯
= 𝑉𝐴𝑅[𝑣𝑡] + 𝜌2𝑉𝐴𝑅[𝑣𝑡−1] + 𝜌4𝑉𝐴𝑅[𝑣𝑡−2] + 𝜌6𝑉𝐴𝑅[𝑣𝑡−3] + ⋯
= 𝜎𝑣2 + 𝜌2𝜎𝑣
2 + 𝜌4𝜎𝑣2 + 𝜌6𝜎𝑣
2 + ⋯
= 𝜎𝑣2(1 + 𝜌2 + 𝜌4 + 𝜌6 + ⋯ )
= 𝜎𝑣2
1
1 − 𝜌2=
𝜎𝑣2
1 − 𝜌2
Este último paso se justifica por el resultado de la siguiente suma infinita de términos
Sea 𝑆 = 1 + 𝑎 + 𝑎2 + ⋯ + 𝑎𝑛−1 (1) donde −1 < 𝑎 < 1. Multiplicando (1) por 𝑎 𝑎𝑆 = 𝑎 + 𝑎2 + ⋯ + 𝑎𝑛−1 + 𝑎𝑛 (2) Restando (2) de (1) se tiene 𝑆 − 𝑎𝑆 = 1 − 𝑎𝑛

de donde 𝑆 =1−𝑎𝑛
1−𝑎.
Tomando el límite de 𝑆 cuando 𝑛 → ∞
lim𝑛→∞
𝑆 =1 − lim
𝑛→∞𝑎𝑛
1 − 𝑎=
1
1 − 𝑎
Con lo que se demuestra que la media y la varianza del error 𝑒𝑡 son
𝐸(𝑒𝑡) = 0 𝑉𝐴𝑅(𝑒𝑡) = 𝜎𝑒2 =
𝜎𝑣2
1−𝜌2 (9.33)
La covarianza entre dos errores 𝑒𝑡 y 𝑒𝑡−1 que están distantes 1 periodo es
𝐶𝑂𝑉[𝑒𝑡 , 𝑒𝑡−1] = 𝐸[(𝑒𝑡 − 𝐸[𝑒𝑡])(𝑒𝑡−1 − 𝐸[𝑒𝑡−1])] = 𝐸[𝑒𝑡𝑒𝑡−1]
Sustituyendo (9B.4) y el rezago de (9B.4)
= 𝐸[(𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ )(𝑣𝑡−1+𝜌𝑣𝑡−2 + 𝜌2𝑣𝑡−3 + 𝜌3𝑣𝑡−4 + ⋯ )]
Los términos cruzados de 𝑣 originarán términos de covarianza entre 𝑣𝑡 y 𝑣𝑠 que serán cero, de
acuerdo con el supuesto 𝐶𝑂𝑉(𝑣𝑡, 𝑣𝑠) = 0 para 𝑡 ≠ 𝑠 hecho en (9.31). Así, el resultado anterior se
simplifica a
= 𝐸[𝜌𝑣𝑡−12 + 𝜌3𝑣𝑡−2
2 + 𝜌5𝑣𝑡−32 + ⋯ ]
= 𝐸[𝜌𝑣𝑡−12 ] + 𝐸[𝜌3𝑣𝑡−2
2 ] + 𝐸[𝜌5𝑣𝑡−32 ] + ⋯
= 𝜌𝐸[𝑣𝑡−12 ] + 𝜌3𝐸[𝑣𝑡−2
2 ] + 𝜌5𝐸[𝑣𝑡−32 ] + ⋯
= 𝜌𝜎𝑣2 + 𝜌3𝜎𝑣
2 + 𝜌5𝜎𝑣2 + ⋯ = 𝜌𝜎𝑣
2(1 + 𝜌2 + 𝜌4 + ⋯ )
= 𝜌𝜎𝑣2
1
1 − 𝜌2=
𝜌𝜎𝑣2
1 − 𝜌2
La covarianza entre dos errores 𝑒𝑡 y 𝑒𝑡−2 que están distantes 2 periodos es
𝐶𝑂𝑉[𝑒𝑡 , 𝑒𝑡−2] = 𝐸[(𝑒𝑡 − 𝐸[𝑒𝑡])(𝑒𝑡−2 − 𝐸[𝑒𝑡−2])] = 𝐸[𝑒𝑡𝑒𝑡−2]
Sustituyendo (9B.4) y el rezago a dos periodos de (9B.4)
= 𝐸[(𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ )(𝑣𝑡−2+𝜌𝑣𝑡−3 + 𝜌2𝑣𝑡−4 + 𝜌3𝑣𝑡−5 + ⋯ )]
Los términos cruzados de 𝑣 originarán términos de covarianza entre 𝑣𝑡 y 𝑣𝑠 que serán cero, de
acuerdo con el supuesto 𝐶𝑂𝑉(𝑣𝑡, 𝑣𝑠) = 0 para 𝑡 ≠ 𝑠 hecho en (9.31). Así, el resultado anterior se
simplifica a
= 𝐸[𝜌2𝑣𝑡−22 + 𝜌4𝑣𝑡−3
2 + 𝜌6𝑣𝑡−42 + ⋯ ]
= 𝐸[𝜌2𝑣𝑡−22 ] + 𝐸[𝜌4𝑣𝑡−3
2 ] + 𝐸[𝜌6𝑣𝑡−42 ] + ⋯
= 𝜌2𝐸[𝑣𝑡−22 ] + 𝜌4𝐸[𝑣𝑡−3
2 ] + 𝜌6𝐸[𝑣𝑡−42 ] + ⋯
= 𝜌2𝜎𝑣2 + 𝜌4𝜎𝑣
2 + 𝜌6𝜎𝑣2 + ⋯ = 𝜌2𝜎𝑣
2(1 + 𝜌2 + 𝜌4 + ⋯ )

= 𝜌2𝜎𝑣2
1
1 − 𝜌2=
𝜌2𝜎𝑣2
1 − 𝜌2
La covarianza entre dos errores 𝑒𝑡 y 𝑒𝑡−𝑘 que están distantes 𝑘 periodos es
𝐶𝑂𝑉[𝑒𝑡 , 𝑒𝑡−𝑘] = 𝐸[(𝑒𝑡 − 𝐸[𝑒𝑡])(𝑒𝑡−𝑘 − 𝐸[𝑒𝑡−𝑘])] = 𝐸[𝑒𝑡𝑒𝑡−𝑘]
Sustituyendo (9B.4) y el rezago a 𝑘 periodos de (9B.4)
= 𝐸[(𝑣𝑡+𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ + 𝜌𝑘−1𝑣𝑡−(𝑘−1) + 𝜌𝑘𝑣𝑡−𝑘 + 𝜌𝑘+1𝑣𝑡−(𝑘+1)
+ 𝜌𝑘+2𝑣𝑡−(𝑘+2) + 𝜌𝑘+3𝑣𝑡−(𝑘+3) + ⋯ )(𝑣𝑡−𝑘+𝜌𝑣𝑡−(𝑘+1) + 𝜌2𝑣𝑡−(𝑘+2)
+ 𝜌3𝑣𝑡−(𝑘+3) + ⋯ )]
Los términos cruzados de 𝑣 originarán términos de covarianza entre 𝑣𝑡 y 𝑣𝑠 que serán cero, de
acuerdo con el supuesto 𝐶𝑂𝑉(𝑣𝑡, 𝑣𝑠) = 0 para 𝑡 ≠ 𝑠 hecho en (9.31). Así, el resultado anterior se
simplifica a
= 𝐸[𝜌𝑘𝑣𝑡−𝑘2 + 𝜌𝑘+2𝑣𝑡−(𝑘+1)
2 + 𝜌𝑘+4𝑣𝑡−(𝑘+2)2 + ⋯ ]
= 𝐸[𝜌𝑘𝑣𝑡−𝑘2 ] + 𝐸[𝜌𝑘+2𝑣𝑡−(𝑘+1)
2 ] + 𝐸[𝜌𝑘+4𝑣𝑡−(𝑘+2)2 ] + ⋯
= 𝜌𝑘𝐸[𝑣𝑡−𝑘2 ] + 𝜌𝑘+2𝐸[𝑣𝑡−(𝑘+1)
2 ] + 𝜌𝑘+4𝐸[𝑣𝑡−(𝑘+2)2 ] + ⋯
= 𝜌𝑘𝜎𝑣2 + 𝜌𝑘+2𝜎𝑣
2 + 𝜌𝑘+4𝜎𝑣2 + ⋯ = 𝜌𝑘𝜎𝑣
2(1 + 𝜌2 + 𝜌4 + ⋯ )
= 𝜌𝑘𝜎𝑣2
1
1 − 𝜌2=
𝜌𝑘𝜎𝑣2
1 − 𝜌2
𝐶𝑂𝑉(𝑒𝑡 , 𝑒𝑡−𝑘) =𝜌𝑘𝜎𝑣
2
1−𝜌2 para 𝑘 > 0 (9.34)
Ahora, la covarianza distinta de cero se explica por la existencia de una relación de rezago entre
los errores provenientes de distintos periodos de tiempo.
Es usual describir la correlación entre 𝑒𝑡 y 𝑒𝑡−𝑘 empleando los resultados obtenidos en (9.33) y
(9.34)
𝜌𝑘 = 𝐶𝑂𝑅𝑅(𝑒𝑡 , 𝑒𝑡−𝑘) =𝐶𝑂𝑉(𝑒𝑡,𝑒𝑡−𝑘)
√𝑉𝐴𝑅(𝑒𝑡)𝑉𝐴𝑅(𝑒𝑡−𝑘)=
𝐶𝑂𝑉(𝑒𝑡,𝑒𝑡−𝑘)
𝑉𝐴𝑅(𝑒𝑡)=
𝜌𝑘𝜎𝑣2 (1−𝜌2)⁄
𝜎𝑣2 (1−𝜌2)⁄
= 𝜌𝑘 (9.35)
Así, la autocorrelación de primer orden, es decir para 𝑘 = 1, es
𝜌1 = 𝑐𝑜𝑟𝑟(𝑒𝑡, 𝑒𝑡−1) = 𝜌 (9.36)
El modelo de error AR(1) contiene un sólo rezago de 𝑒, sin embargo, en la práctica encontramos
autocorrelaciones para rezagos mayores que uno, aunque decrecientes, pero distintas de cero.

La correlación persiste en virtud de que 𝑒𝑡 depende de todos los valores pasados de los errores
𝑣𝑡 , 𝑣𝑡−1, 𝑣𝑡−2, 𝑣𝑡−3, … en la ecuación (9B.4) expresada como sigue
𝑒𝑡 = 𝑣𝑡 + 𝜌𝑣𝑡−1 + 𝜌2𝑣𝑡−2 + 𝜌3𝑣𝑡−3 + ⋯ (9.37)
A continuación relacionamos estos resultados con la estimación de la curva de Phillips. Para los
primeros cinco rezagos se tiene
En Stata
* Correlograma de error en la curva de Phillips
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress inf D.u
predict e, resid
corrgram e, lags(5)
k 𝑟𝑘 �̂�𝑘 = �̂�𝑘
1 0.5487 0.5487
2 0.4557 0.3011
3 0.4332 0.1652
4 0.4205 0.0906
5 0.3390 0.0497
Como se observa en el cuadro anterior, los valores �̂�𝑘 de las autocorrelaciones de orden mayor
que 1 que resultan al imponer la estructura del modelo AR(1) son considerablemente menores
que las estimaciones no restringidas, 𝑟𝑘 , reportadas por el correlograma. Esto sugiere que el
supuesto AR(1) no es el adecuado para los errores de la curva de Phillips.
3) Mínimos cuadrados no lineales con error AR(1)
Ahora consideremos el modelo y supuestos siguientes
𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝑒𝑡 con 𝑒𝑡 = 𝜌𝑒𝑡−1 + 𝑣𝑡 , −1 < 𝜌 < 1 (9.38)
𝐸(𝑣𝑡) = 0 𝑉𝐴𝑅(𝑣𝑡) = 𝜎𝑣2 𝐶𝑂𝑉(𝑣𝑡 , 𝑣𝑠) = 0 para 𝑡 ≠ 𝑠 (9.39)
Sustituyendo la expresión de 𝑒𝑡 en 𝑦𝑡
𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝜌𝑒𝑡−1 + 𝑣𝑡 (9.40)
Despejando el error en el modelo de regresión
𝑒𝑡 = 𝑦𝑡 − 𝛽1 − 𝛽2𝑥𝑡
y rezagando un periodo
𝑒𝑡−1 = 𝑦𝑡−1 − 𝛽1 − 𝛽2𝑥𝑡−1 (9.41)
Multiplicando (9.41) por 𝜌

𝜌𝑒𝑡−1 = 𝜌𝑦𝑡−1 − 𝜌𝛽1 − 𝜌𝛽2𝑥𝑡−1 (9.42)
Sustituyendo (9.42) en (9.40)
𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝜌𝑦𝑡−1 − 𝜌𝛽1 − 𝜌𝛽2𝑥𝑡−1 + 𝑣𝑡
Agrupando términos semejantes
𝑦𝑡 = 𝛽1(1 − 𝜌) + 𝛽2𝑥𝑡 + 𝜌𝑦𝑡−1 − 𝜌𝛽2𝑥𝑡−1 + 𝑣𝑡 (9.43)
El modelo (9.43) es una transformación del modelo (9.38). Es lineal en las variables 𝑥𝑡 , 𝑥𝑡−1 y
𝑦𝑡−1 , pero no lineal en los parámetros 𝛽1 , 𝛽2 y 𝜌.
Estimar (9.38) por MCO conduce a estimadores que no son MELI y errors estándar incorrectos,
dado que los errores están correlacionados. Estimar (9.43) por MCNL , al minimizar la suma de
cuadrados de errores no correlacionados, conduce a estimadores que guardan las propiedades
deseables en grandes muestras.
El problema de MCNL se plantea como sigue
min�̂�1,�̂�2,�̂�
𝑆𝐶𝑅 = min�̂�1,�̂�2,�̂�
∑ 𝑣𝑡2
𝑇
𝑡=2
= min�̂�1,�̂�2,�̂�
∑[𝑦𝑡 − �̂�1(1 − �̂�) − �̂�2𝑥𝑡 − �̂�𝑦𝑡−1 + �̂��̂�2𝑥𝑡−1]2
𝑇
𝑡=2
Las condiciones de primer orden (C.P.O.) son
𝜕𝑆𝐶𝑅
𝜕�̂�1
= −2 ∑[𝑦𝑡 − �̂�1(1 − �̂�) − �̂�2𝑥𝑡 − �̂�𝑦𝑡−1 + �̂��̂�2𝑥𝑡−1]
𝑇
𝑡=2
(1 − �̂�) = 0
𝜕𝑆𝐶𝑅
𝜕�̂�2
= −2 ∑[𝑦𝑡 − �̂�1(1 − �̂�) − �̂�2𝑥𝑡 − �̂�𝑦𝑡−1 + �̂��̂�2𝑥𝑡−1]
𝑇
𝑡=2
(𝑥𝑡 − �̂�𝑥𝑡−1) = 0
𝜕𝑆𝐶𝑅
𝜕�̂�= −2 ∑[𝑦𝑡 − �̂�1(1 − �̂�) − �̂�2𝑥𝑡 − �̂�𝑦𝑡−1 + �̂��̂�2𝑥𝑡−1]
𝑇
𝑡=2
(𝑦𝑡−1 − �̂�1 − �̂�2𝑥𝑡−1) = 0
Analíticamente, no es posible obtener una solución explícita de los estimadores de MCNL, por lo
que se recurre a los métodos numéricos para resolver el sistema de ecuaciones normales no
lineales.
Stata permite estimar por MCNL la curva de Phillips mediante la ecuación (9.43) y reportar el
modelo (9.38) como sigue
𝐼𝑁𝐹𝑡 = 𝛽1(1 − 𝜌) + 𝛽2𝐷𝑈𝑡 + 𝜌𝐼𝑁𝐹𝑡−1 − 𝜌𝛽2𝐷𝑈𝑡−1 + 𝑣𝑡 (9.44)
En Stata
* Estimación por MCNL
use "C:\poe4\phillips_aus.dta", clear

generate date = tq(1987q1) + _n-1
format %tq date
tsset date
nl (inf = {b1}*(1-{rho}) + {b2}*D.u + {rho}*L.inf - {rho}*{b2}*(L.D.u)), variables(inf D.u
L.inf L.D.u)
𝐼𝑁�̂� = 0.7609 − 0.6944𝐷𝑈 𝑒𝑡 = 0.557𝑒𝑡−1 + 𝑣𝑡
(𝑠𝑒) (0.1245) (0.2479) (0.090) (9.45)
Comparando esta estimación con las obtenidas bajo los enfoques HC y HAC en (9.29) se encuentra
una magnitud similar para 𝛽1 y un valor negativo más grande para 𝛽2 , lo que sugiere un mayor
impacto del desempleo sobre la inflación.
El error estándar de 𝛽2 bajo MCNL es menor que el obtenido en HAC, lo que sugiere una
estimación más confiable, en tanto que el error estándar para 𝛽1 es inesperadamente mayor. El
estimador de 𝜌 en MCNL, �̂� = 0.557, es muy similar a 𝑟1 = 0.549 que es la correlación entre los
residuales de MCO distantes un trimestre.
3a) Mínimos Cuadrados Generalizados
Se puede demostrar que la estimación por MCNL es equivalente a usar un estimador iterativo
generalizado de mínimos cuadrados bajo el procedimiento de Cochrane-Orcutt.
Considerando el modelo expresado en (9.38), el objetivo es obtener los estimadores de mínimos
cuadrados generalizados para 𝛽1 y 𝛽2 transformando el modelo de manera que tenga un nuevo
término de error homoscedástico no correlacionado. Para especificar el modelo transformado a
partir de la expresión previa a (9.43) que es
𝑦𝑡 = 𝛽1 + 𝛽2𝑥𝑡 + 𝜌𝑦𝑡−1 − 𝜌𝛽1 − 𝜌𝛽2𝑥𝑡−1 + 𝑣𝑡 (9C.1)
reordenando términos

𝑦𝑡 − 𝜌𝑦𝑡−1 = 𝛽1(1 − 𝜌) + 𝛽2(𝑥𝑡 − 𝜌𝑥𝑡−1) + 𝑣𝑡 (9C.2)
definiendo las siguientes variables transformadas
𝑦𝑡∗ = 𝑦𝑡 − 𝜌𝑦𝑡−1 𝑥𝑡2
∗ = 𝑥𝑡 − 𝜌𝑥𝑡−1 𝑥𝑡1∗ = (1 − 𝜌)
el modelo queda reexpresado como
𝑦𝑡∗ = 𝛽1 𝑥𝑡1
∗ + 𝛽2𝑥𝑡2∗ + 𝑣𝑡 (9C.3)
Este modelo de variables transformadas contiene un término de error 𝑣 que no está
correlacionado con 𝑒. La distribución de vt es (0, σv2). Se espera que al aplicar mínimos cuadrados
ordinarios al modelo transformado (9C.3) los estimadores de 𝛽1 y 𝛽2 sean MELI.
Hay dos problemas adicionales por resolver:
1.- Dados los rezagos que se tienen de 𝑦𝑡 y 𝑥𝑡, sólo T − 1 nuevas observaciones son generadas
con la transformación. Se tienen (𝑦𝑡∗, 𝑥𝑡1
∗ , 𝑥𝑡2∗ ) para t = 2,3, … , T, pero no (𝑦1
∗, 𝑥11∗ , 𝑥12
∗ ).
2.- El valor del parámetro autorregresivo 𝜌 es desconocido. A partir de que (𝑦𝑡∗, 𝑥𝑡1
∗ , 𝑥𝑡2∗ )
dependen de 𝜌, no podemos calcular estas observaciones sin estimar 𝜌 .
Considerando primero el segundo problema, podemos usar la correlación muestral definida en
(9.21) como un estimador de . Alternativamente (9C.1) puede ser expresada como
𝑦𝑡 − 𝛽1 − 𝛽2𝑥𝑡 = 𝜌(𝑦𝑡−1 − 𝛽1 − 𝛽2𝑥𝑡−1) + 𝑣𝑡 (9C.4)
que es equivalente a
𝑒𝑡 = 𝜌𝑒𝑡−1 + 𝑣𝑡
Después de reemplazar 𝛽1 y 𝛽2 por los estimadores de mínimos cuadrados obtenidos �̂�1 y �̂�2 , se aplican de nuevo MCO a (9C.4) para estimar 𝜌 . Las ecuaciones (9C.3) y (9C.4) pueden ser estimadas iterativamente. Esto es, usamos �̂� a partir de (9C.4) para estimar 𝛽1 y 𝛽2 en (9C.3). Luego entonces, usamos estos nuevos estimadores para 𝛽1 y 𝛽2 en (9C.4) para reestimar 𝜌, el cual usaremos otra vez en (9C.3) para reestimar 𝛽1 y 𝛽2 y así sucesivamente. Este procedimiento iterativo es conocido como estimador de Cochrane-Orcutt. En la convergencia es idéntico al estimador de MCNL. Qué hay sobre el problema de tener 𝑇 − 1 en lugar de 𝑇 observaciones transformadas. Una forma es resolver este problema es ignorar esto y proceder con la estimación sobre la base de las 𝑇 − 1 observaciones. Esta estrategia es la de primera mano, la cual es razonable si 𝑇 es grande. Sin embargo, si buscamos mejorar la eficiencia al incluir una transformación de la primera observación, necesitamos crear un error transformado que tenga la misma varianza que los errores (𝑣2, 𝑣3, … , 𝑣𝑇). La primera observación en el modelo de regresión (9.38) es

𝑦1 = 𝛽1 + 𝛽2𝑥1 + 𝑒1 con varianza del error
𝑉𝐴𝑅(𝑒1) = 𝜎𝑣2
1
1 − 𝜌2=
𝜎𝑣2
1 − 𝜌2
La transformación que propicia una varianza del error de 𝜎𝑣2 es la multiplicación por √1 − 𝜌2.
El resultado es
√1 − 𝜌2𝑦1 = √1 − 𝜌2𝛽1 + √1 − 𝜌2𝛽2𝑥1 + √1 − 𝜌2𝑒1 que puede reexpresarse como
𝑦1∗ = 𝛽1𝑥11
∗ + 𝛽2𝑥12∗ + 𝑒1
∗ (9C.5)
donde
𝑦1∗ = √1 − 𝜌2𝑦1
𝑥11∗ = √1 − 𝜌2 (9C.6)
𝑥12∗ = √1 − 𝜌2𝑥1
𝑒1∗ = √1 − 𝜌2𝑒1
Para confirmar que la varianza de 𝑒1∗ es la misma que la de los errores (𝑣2, 𝑣3, … , 𝑣𝑇) debe
notarse que
𝑉𝐴𝑅(𝑒1∗) = (1 − 𝜌2)𝑉𝐴𝑅(𝑒1) = (1 − 𝜌2)
𝜎𝑣2
1 − 𝜌2= 𝜎𝑣
2
También se requiere que 𝑒1∗ no esté correlacionado con (𝑣2, 𝑣3, … , 𝑣𝑇). Este resultado se
mantiene porque cada uno de los 𝑣𝑡 no depende de cualesquiera valor pasado de 𝑒𝑡. La primera observación transformada en (9C.5) puede ser utilizada con las restantes observaciones transformadas en (9C.3) para obtener estimadores de mínimos cuadrados generalizados empleando todas las 𝑇 observaciones. Este procedimiento es denominado estimador de Prais-Winsten. A continuación su implementación en Stata con los datos de la curva de Phillips * Estimador de Prais-Winsten
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
prais inf D.u, twostep
estimates store _2step
prais inf D.u
estimates store Iterate
esttab _2step Iterate, compress se(%12.3f) b(%12.5f) gaps scalars(rss rho) mtitle("2-step"
"Iterated") title("Dependent Variable: inf")
3b) Un modelo más general: ARDL
Los resultados de (9.45) se obtuvieron al estimar el modelo de error AR(1) expresado en forma
transformada
𝑦𝑡 = 𝛽1(1 − 𝜌) + 𝜌𝑦𝑡−1 + 𝛽2𝑥𝑡 − 𝜌𝛽2𝑥𝑡−1 + 𝑣𝑡 (9.46)
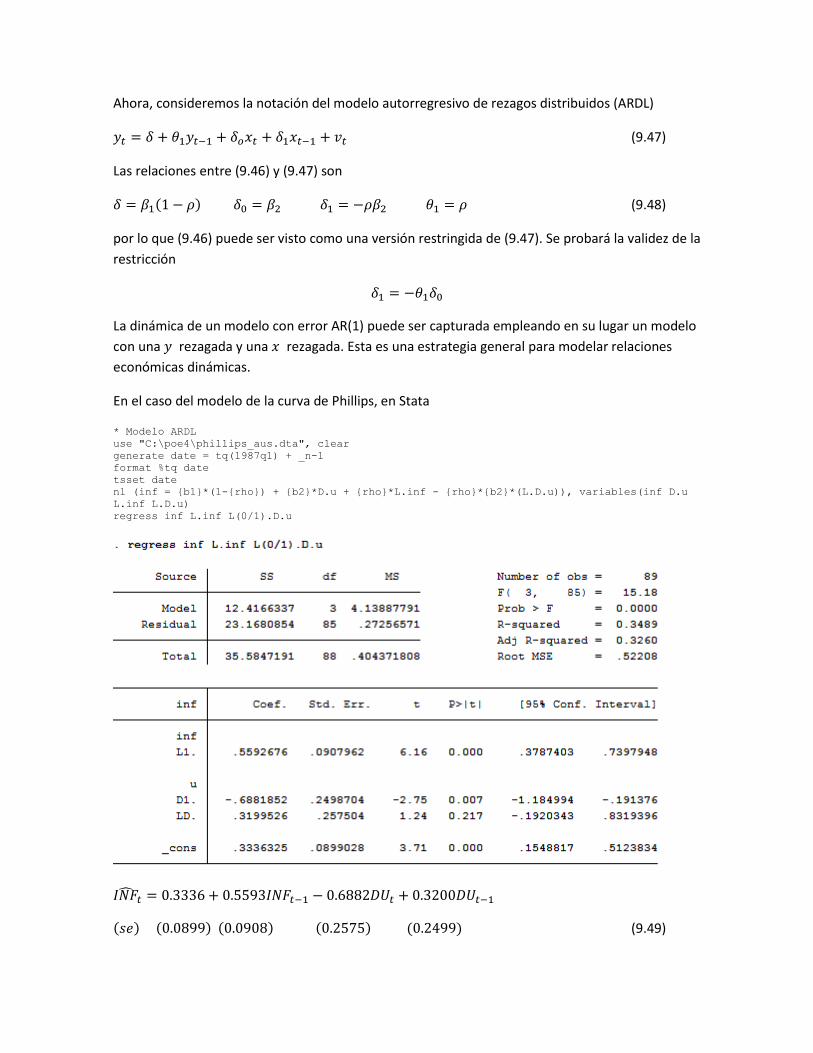
Ahora, consideremos la notación del modelo autorregresivo de rezagos distribuidos (ARDL)
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + 𝛿𝑜𝑥𝑡 + 𝛿1𝑥𝑡−1 + 𝑣𝑡 (9.47)
Las relaciones entre (9.46) y (9.47) son
𝛿 = 𝛽1(1 − 𝜌) 𝛿0 = 𝛽2 𝛿1 = −𝜌𝛽2 𝜃1 = 𝜌 (9.48)
por lo que (9.46) puede ser visto como una versión restringida de (9.47). Se probará la validez de la
restricción
𝛿1 = −𝜃1𝛿0
La dinámica de un modelo con error AR(1) puede ser capturada empleando en su lugar un modelo
con una 𝑦 rezagada y una 𝑥 rezagada. Esta es una estrategia general para modelar relaciones
económicas dinámicas.
En el caso del modelo de la curva de Phillips, en Stata
* Modelo ARDL
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
nl (inf = {b1}*(1-{rho}) + {b2}*D.u + {rho}*L.inf - {rho}*{b2}*(L.D.u)), variables(inf D.u
L.inf L.D.u)
regress inf L.inf L(0/1).D.u
𝐼𝑁�̂�𝑡 = 0.3336 + 0.5593𝐼𝑁𝐹𝑡−1 − 0.6882𝐷𝑈𝑡 + 0.3200𝐷𝑈𝑡−1
(𝑠𝑒) (0.0899) (0.0908) (0.2575) (0.2499) (9.49)

cuyo modelo teórico es
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + 𝛿𝑜𝑥𝑡 + 𝛿1𝑥𝑡−1 + 𝑣𝑡 (9.47)
Comparemos estos resultados con los obtenidos bajo MCNL. Sustituyendo los resultados
obtenidos en (9.45) en las relaciones indicadas en (9.48)
𝛿 = �̂�1(1 − �̂�) = 0.7609 × (1 − 0.5574) = 0.3368 que es similar a 0.3336
𝜃1 = �̂� = 0.5574 que es similar a 0.5593
𝛿0 = �̂�2 = −0.6944 que es similar a −0.6882
𝛿1 = −�̂��̂�2 = −0.5574 × (−0.6944) = 0.3871 que es diferente de 0.3200
La diferencia en el valor de estimación y el error estándar grande en el coeficiente 𝐷𝑈𝑡−1 sugiere
probar la restricción 𝐻0 ∶ 𝛿1 = −𝜃1𝛿0
testnl _b[L.D.u]=-_b[L.inf]*_b[D.u]
Formalmente, la prueba Chi-cuadrada de Wald es
El valor 𝑝 es mayor que 0.05, por lo que no se rechaza la hipótesis nula. El modelo de error AR(1)
no es restrictivo.
La especificación y la estimación de un modelo más general tiene sus ventajas, entre ellas la forma
explícita de la dependencia entre 𝑦𝑡 y su rezago, así como 𝑥𝑡 y 𝑥𝑡−1, lo que ofrece una
interpretación económica más útil. Retomando la primer especificación hecha en (9.18) del
modelo de la curva de Phillips
𝐼𝑁𝐹𝑡 = 𝐼𝑁𝐹𝑡𝐸 − 𝛾(𝑈𝑡 − 𝑈𝑡−1) (9.50)
el término de expectativas inflacionarias en la expresión (9.49) es
𝐼𝑁𝐹𝑡𝐸 = 0.3336 + 0.5593𝐼𝑁𝐹𝑡−1
Las expectativas de inflación en el trimestre corriente son 0.33% más 0.56 veces la tasa de
inflación del trimestre anterior. El efecto del desempleo en (9.49) es -0.6882(𝑈𝑡 − 𝑈𝑡−1) +
0.3200(𝑈𝑡−1 − 𝑈𝑡−2) cuya dinámica es más compleja que la del término de la especificación
original −𝛾(𝑈𝑡 − 𝑈𝑡−1).
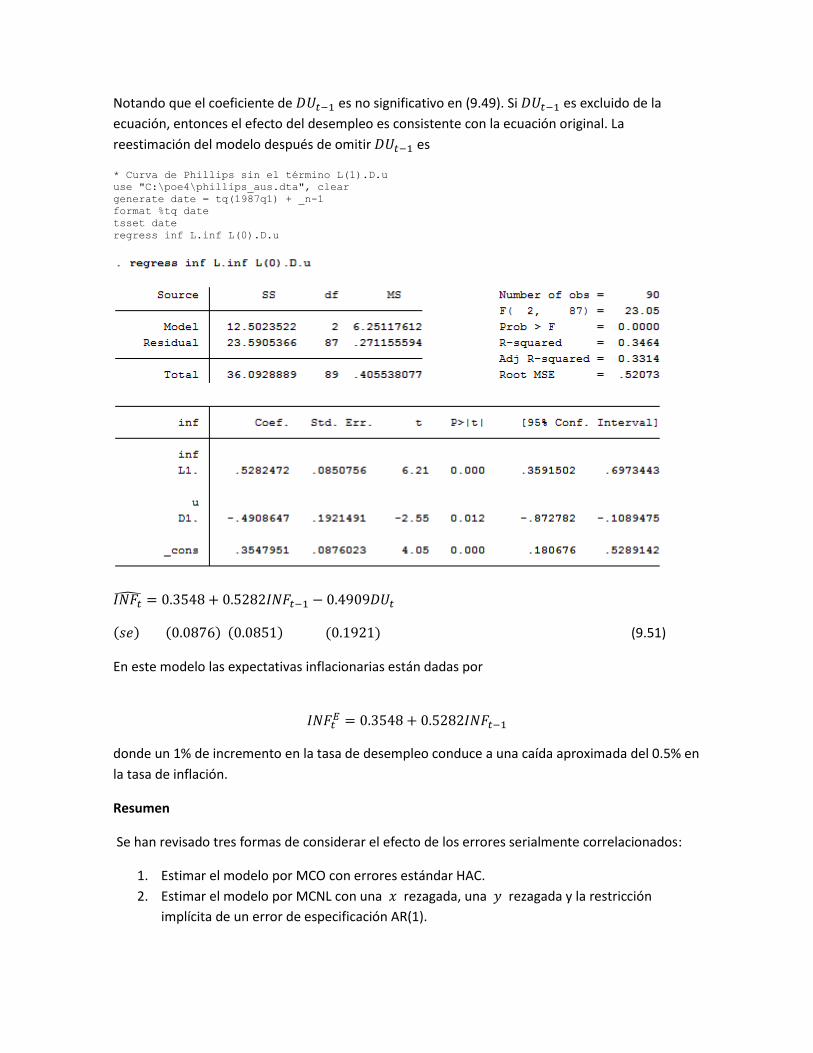
Notando que el coeficiente de 𝐷𝑈𝑡−1 es no significativo en (9.49). Si 𝐷𝑈𝑡−1 es excluido de la
ecuación, entonces el efecto del desempleo es consistente con la ecuación original. La
reestimación del modelo después de omitir 𝐷𝑈𝑡−1 es
* Curva de Phillips sin el término L(1).D.u
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress inf L.inf L(0).D.u
𝐼𝑁𝐹�̂� = 0.3548 + 0.5282𝐼𝑁𝐹𝑡−1 − 0.4909𝐷𝑈𝑡
(𝑠𝑒) (0.0876) (0.0851) (0.1921) (9.51)
En este modelo las expectativas inflacionarias están dadas por
𝐼𝑁𝐹𝑡𝐸 = 0.3548 + 0.5282𝐼𝑁𝐹𝑡−1
donde un 1% de incremento en la tasa de desempleo conduce a una caída aproximada del 0.5% en
la tasa de inflación.
Resumen
Se han revisado tres formas de considerar el efecto de los errores serialmente correlacionados:
1. Estimar el modelo por MCO con errores estándar HAC.
2. Estimar el modelo por MCNL con una 𝑥 rezagada, una 𝑦 rezagada y la restricción
implícita de un error de especificación AR(1).

3. Estimar por MCO con una 𝑥 rezagada, una 𝑦 rezagada, pero sin la restricción implícita de
un error de especificación AR(1).
Actualmente el tercer método es más preferido por los econometristas, al ser menos restrictivo
que el modelo de error AR(1). El modelo con rezagos es útil para la interpretación económica y
puede ser empleado para corregir formas más generales de correlación serial que la del error
AR(1).
Modelos ARDL(p,q)
El modelo ARDL con 𝑝 rezagos en 𝑦 y 𝑞 rezagos en 𝑥 se expresa
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + ⋯ + 𝜃𝑝𝑦𝑡−𝑝 + 𝛿0𝑥𝑡 + 𝛿1𝑥𝑡−1 + ⋯ + 𝛿𝑞𝑥𝑡−𝑞 + 𝑣𝑡 (9.52)
El componente AR proviene de la regresión de 𝑦 sobre sus rezagos. El componente DL proviene del
efecto de rezago distribuido de las 𝑥‘s. Las expresiones (9.50) y (9.51) son dos ejemplos claros:
𝐴𝑅𝐷𝐿(1,1): 𝐼𝑁�̂�𝑡 = 0.3336 + 0.5593𝐼𝑁𝐹𝑡−1 − 0.6882𝐷𝑈𝑡 + 0.3200𝐷𝑈𝑡−1
𝐴𝑅𝐷𝐿(1,0): 𝐼𝑁�̂�𝑡 = 0.3548 + 0.5282𝐼𝑁𝐹𝑡−1 − 0.4909𝐷𝑈𝑡
El modelo ARDL tiene muchas ventajas. Captura la dinámica de efectos de las 𝑥‘s y las 𝑦‘s
rezagadas y al incluir un número suficiente de rezagos de 𝑦 y 𝑥 , podemos eliminar correlación
serial en los errores.
Más aún, un modelo ARDL puede ser transformado en uno con 𝑥‘s rezagadas hasta un pasado
infinito (modelo de rezago distribuido infinito)
𝑦𝑡 = 𝛼 + 𝛽0𝑥𝑡 + 𝛽1𝑥𝑡−1 + 𝛽2𝑥𝑡−2 + 𝛽3𝑥𝑡−3 + ⋯ + 𝑒𝑡 (9.53)
= 𝛼 + ∑ 𝛽𝑠𝑥𝑡−𝑠
∞
𝑠=0
+ 𝑒𝑡
Los dos principales usos de los modelos ARDL son para pronósticos y análisis de multiplicadores. A
continuación cuatro criterios posibles, que no necesariamente conducen a la elección de 𝑝 y 𝑞:
1. ¿Ha sido eliminada la correlación serial en el modelo? Si no, entonces MCO originará sesgo
tanto en pequeñas y como en grandes muestras. Es importante incluir suficientes rezagos,
especialmente en 𝑦, para asegurar que no persista la correlación serial. Esto puede ser
probado usando el correlograma o las pruebas del multiplicador de Lagrange.
2. ¿Son los signos y magnitudes de las estimaciones consistentes con lo que esperamos a
partir de la teoría económica? Las estimaciones son pobres en el sentido de que pueden
ser consecuencia de elecciones pobres de 𝑝 y 𝑞, pero estas pueden ser también
sintomáticas de un problema más general de modelado.
3. ¿Son las estimaciones significativamente distintas de cero, particularmente aquéllas que
corresponden a los rezagos más alejados?

4. Qué valores de 𝑝 y 𝑞 minimizan el criterio de información tales como el AIC y el SC? En el
contexto del modelo ARDL estos criterios entrañan la elección de 𝑝 y 𝑞 tales que
minimizan la suma de cuadrados de los residuales (SCR) sujeta a una penalización que se
incrementa conforme el número de parámetros aumenta.La creciente longitud de los
rezagos incrementa el número de parámetros y, usando el mismo número de
observaciones en cada caso, reduce la suma de cuadrados de los residuales; los términos
de penalización son incluidos con el fin de capturar los efectos esenciales de los rezagos
sin introducir un excesivo número de parámetros. El criterio de información de Akaike
(AIC) está dado por
𝐴𝐼𝐶 = ln (𝑆𝐶𝑅
𝑇) +
2𝐾
𝑇 (9.54)
donde 𝐾 = 𝑝 + 𝑞 + 2 es el número de coeficientes que son estimados. El criterio de
información de Schwarz (SC) está dado por
𝑆𝐶 = ln (𝑆𝐶𝑅
𝑇) +
𝐾 𝑙𝑛(𝑇)
𝑇 (9.55)
Dado que 𝐾 𝑙𝑛(𝑇)
𝑇>
2𝐾
𝑇 para 𝑇 ≥ 8, SC penaliza los rezagos adicionales más que AIC.
Enseguida se mostrarán ejemplos de aplicación de los criterios de información AIC y SC, para valorar
en qué medida es posible mejorar las especificaciones anteriormente vistas.

Curva de Phillips
En (9.51) se estimó el siguiente modelo ARDL(1,0)
𝐼𝑁𝐹�̂� = 0.3548 − 0.5282𝐼𝑁𝐹𝑡−1 − 0.4909𝐷𝑈𝑡, 𝑜𝑏𝑠 = 90
(𝑠𝑒) (0.0876) (0.0851) (0.1921) (9.56)
Se elegirá este modelo sobre el ARDL(1,1) debido a que el coeficiente de 𝐷𝑈𝑡−1 no fue
significativamente distinto de cero. Para evitar alguna confusión a partir de que estamos
considerando modelos con distinto número de rezagos, se indica que se están usando 90
observaciones en la estimación.
Para detectar si los errores en (9.56) están serialmente correlacionados, se obtiene el
correlograma de los residuales que revela al 5% no autocorrelación (valores 𝑝 de la prueba 𝑄
mayores a 0.05). Con la prueba del multiplicador de Lagrange se detecta al 5% autocorrelación de
órdenes uno, cuatro y cinco (valores 𝑝 de la prueba 𝜒2 menores a 0.05).
* Selección del modelo de la Curva de Phillips
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress inf L.inf D.u
predict ehat, res
ac ehat, lags(12) saving("C:\poe4\phil_ac_ehat.gph",replace)
corrgram ehat, lags(12)
matrix r=r(AC)'
estat bgodfrey, lags(1 2 3 4 5)
drop ehat
clear
svmat r
ren r1 r
gen t=_n
display invnormal(1-0.05/2)/sqrt(91)
graph bar r, over(t) yline(-.20546005 .20546005) ylabel(-0.3(0.1)0.3)
ytitle("Autocorrelación") saving("C:\poe4\phil_corrgram_ehat.gph",replace)
graph combine "C:\poe4\phil_ac_ehat.gph"
"C:\poe4\phil_corrgram_ehat.gph",saving("C:\poe4\phil_accg_ehat.gph",replace)

El conjunto de resultados anteriores proporciona alguna evidencia de autocorrelación. La variable
dependiente rezagada un periodo no ha sido suficiente para eliminar autocorrelación. Al agregar
rezagos adicionales de INF y DU, se encuentra que
1. Los coeficientes de rezagos extra de DU no son significativamente distintos de cero al 5%
de significancia.
2. Para 𝑝 = 2 y 𝑞 = 0, los coeficientes de 𝐼𝑁𝐹𝑡−1 e 𝐼𝑁𝐹𝑡−2 son significativamente distintos
de cero al 5% de significancia; para 𝑝 = 3 y 𝑞 = 0, los coeficientes de 𝐼𝑁𝐹𝑡−1 e 𝐼𝑁𝐹𝑡−3 son
significativos; y para 𝑝 = 4 y 𝑞 = 0, los coeficientes de 𝐼𝑁𝐹𝑡−1 e 𝐼𝑁𝐹𝑡−4 son significativos.
Coeficientes para rezagos mayores que 4 (𝑝 ≥ 5) no son significativos. Más aún, para 𝑝 =
2 y 𝑝 = 3, la prueba LM continua sugiriendo que hay correlación serial en los errores. Para
𝑝 = 4 no persiste la correlación.
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress L(0/2).inf L(0/0).D.u if date >= tq(1987q3)
estat bgodfrey, lags(1 2 3 4 5)
regress L(0/3).inf L(0/0).D.u if date >= tq(1987q4)
-0.2
0-0
.10
0.0
00.1
00.2
0
Auto
corr
ela
tions o
f eha
t
0 5 10 15Lag
Bartlett's formula for MA(q) 95% confidence bands
-.3
-.2
-.1
0.1
.2.3
Auto
corr
ela
ció
n
1 2 3 4 5 6 7 8 9 10 11 12
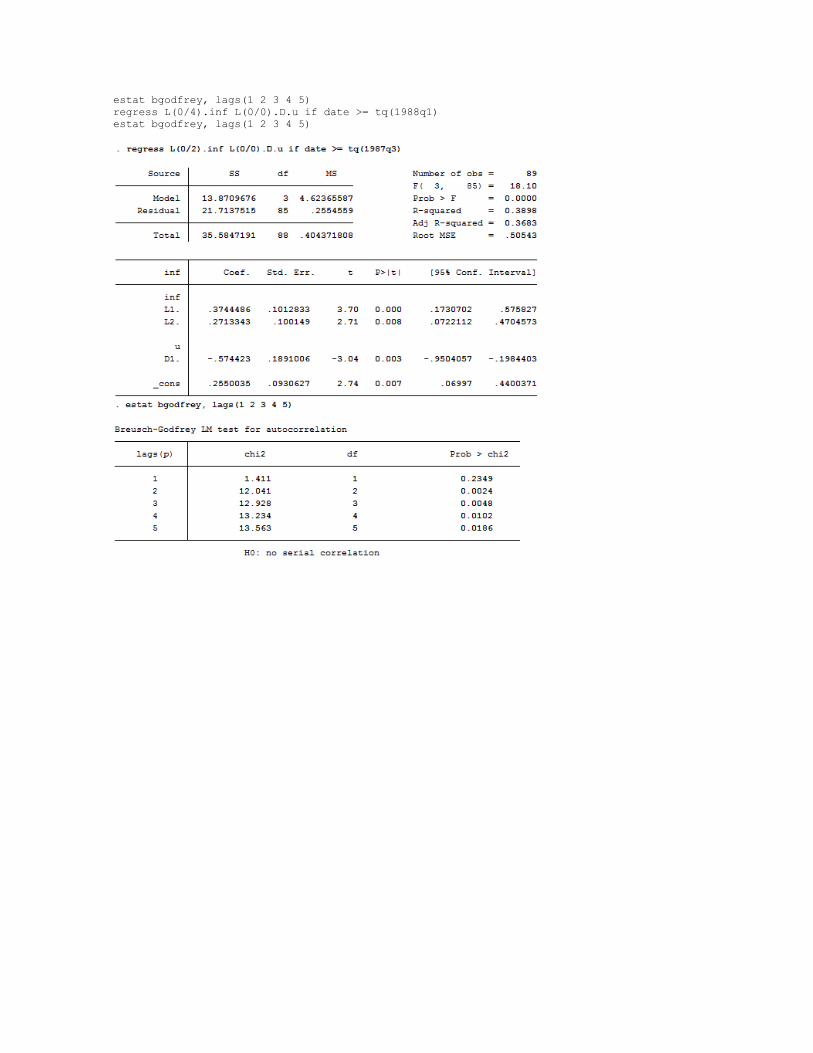
estat bgodfrey, lags(1 2 3 4 5)
regress L(0/4).inf L(0/0).D.u if date >= tq(1988q1)
estat bgodfrey, lags(1 2 3 4 5)
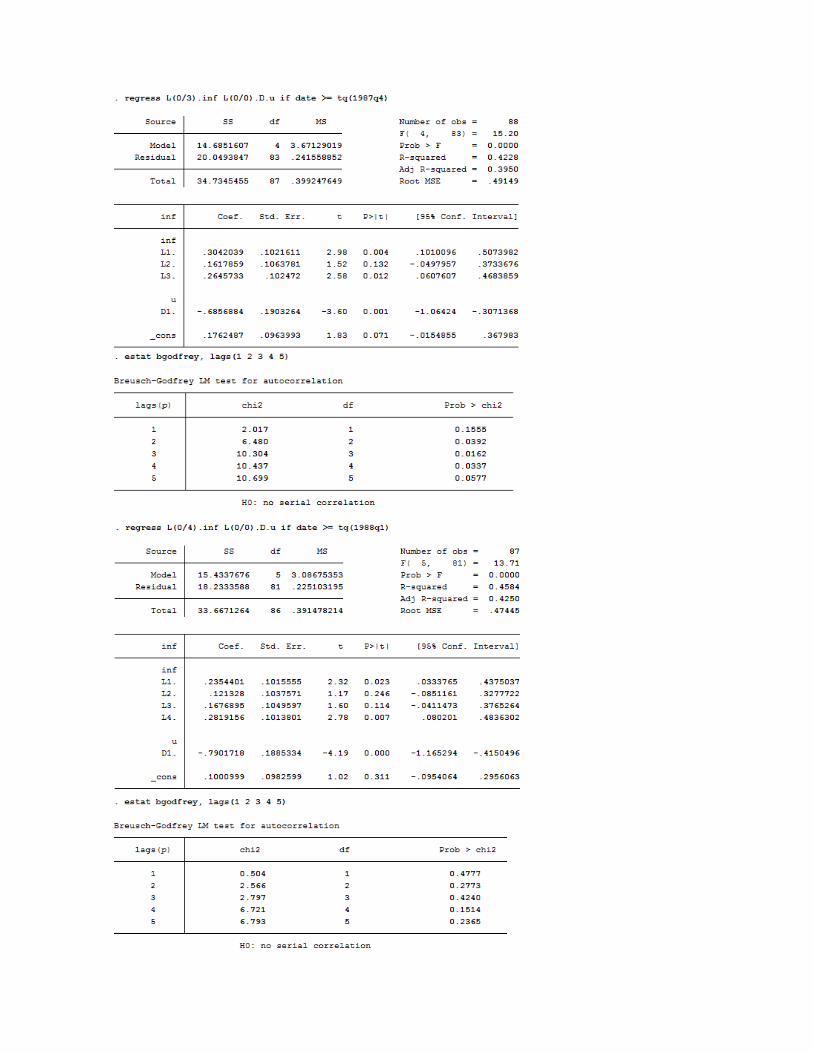

Por lo tanto, empleando la significancia de los coeficientes y la eliminación de correlación serial en
los errores como criterio de selección de rezagos, se elige el modelo ARDL(4,0)
𝐼𝑁𝐹�̂� = 0.1001 + 0.2354𝐼𝑁𝐹𝑡−1 + 0.1213𝐼𝑁𝐹𝑡−2 + 0.1677𝐼𝑁𝐹𝑡−3 + 0.2819𝐼𝑁𝐹𝑡−4 − 0.7902𝐷𝑈𝑡 (9.57)
(𝑠𝑒) (0.0983) (0.1016) (0.1038) (0.1050) (0.1014) (0.1885) obs = 87
En este modelo, las expectativas inflacionarias están dadas por
𝐼𝑁𝐹𝑡𝐸 = 0.1001 + 0.2354𝐼𝑁𝐹𝑡−1 + 0.1213𝐼𝑁𝐹𝑡−2 + 0.1677𝐼𝑁𝐹𝑡−3 + 0.2819𝐼𝑁𝐹𝑡−4
Un ponderador relativamente grande que está dado a la inflación corriente en el trimestre
correspondiente del año anterior (𝑡 − 4). El efecto del desempleo sobre la inflación es mayor en
este modelo. Un 1% de incremento en el desempleo reduce la inflación en aproximadamente
0.8%.
A continuación se desarrolla el algoritmo, en Stata, para estimar y seleccionar el modelo de la
curva de Phillips bajo los criterios AIC y SC, para 𝑝 = 1 a 6 y 𝑞 = 0, 1. Para ello, se utilizan 𝑇 −
max (𝑝, 𝑞)=91- max (6,1)=91-6=85 observaciones en todos los casos, comenzando con la
observación del tercer trimestre de 1988.
Los valores de 𝑝 y 𝑞 tales que minimizan los criterios de información AIC y SC son 𝑝 = 4 y 𝑞 = 0, lo
que soporta la elección del modelo ARDL(4,0) dado en la expresión (9.57).
* Selección del modelo de la Curva de Phillips (criterios AIC y SC)
program drop _all
matrix drop _all
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
for num 0/1: matrix selqX=J(6,5,0)
program define loop_q
regress L(0/`1').inf L(0/`2').D.u if date >= tq(1988q3)
matrix selq`2'[`1',1]= `1'
matrix selq`2'[`1',2]= `2'
matrix selq`2'[`1',3]= ln(e(rss)/e(N))+2*e(rank)/e(N)
matrix selq`2'[`1',4]= ln(e(rss)/e(N))+e(rank)*ln(e(N))/e(N)
matrix selq`2'[`1',5]= e(N)
end
program define loop_p
for num 0/1: loop_q `1' X
end
for num 1/6: loop_p X
program define loopv
clear
svmat selq`1', names(selq)
rename selq1 p
rename selq2 q
rename selq3 aic
rename selq4 sc
rename selq5 obs
save "C:\poe4\selq`1'.dta", replace
end
for num 0/1: loopv X
use "C:\poe4\selq0.dta",clear
append using "C:\poe4\selq1.dta"
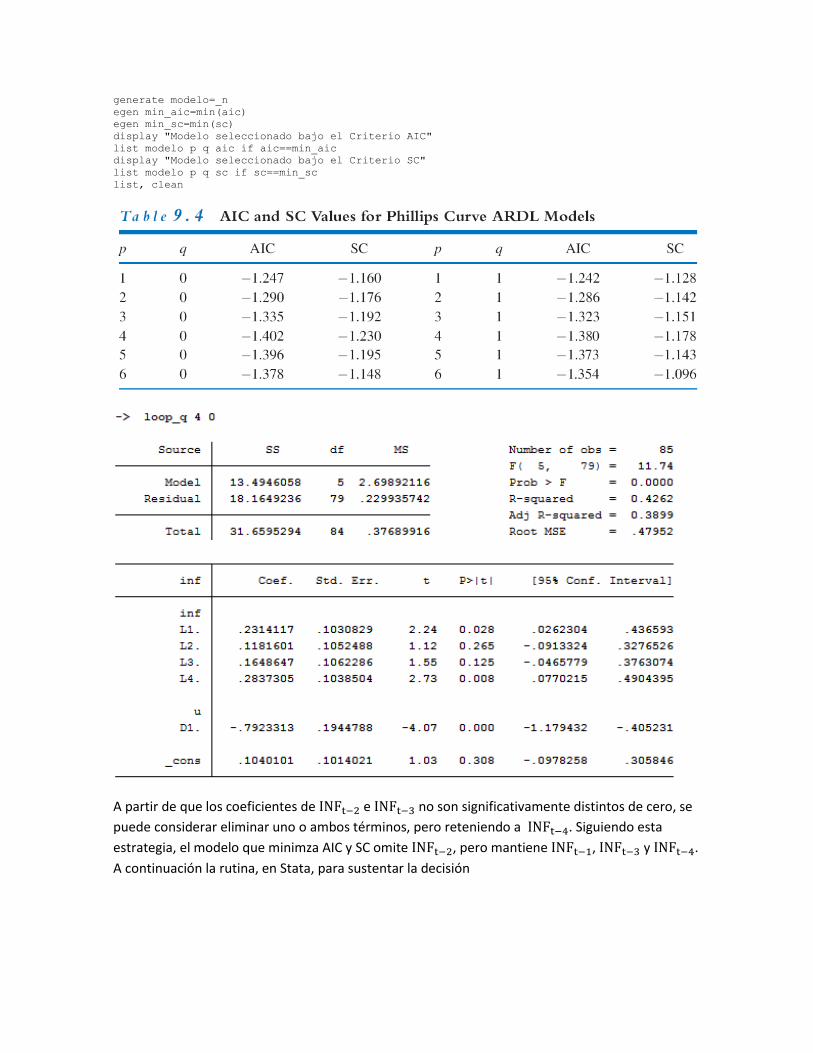
generate modelo=_n
egen min_aic=min(aic)
egen min_sc=min(sc)
display "Modelo seleccionado bajo el Criterio AIC"
list modelo p q aic if aic==min_aic
display "Modelo seleccionado bajo el Criterio SC"
list modelo p q sc if sc==min_sc
list, clean
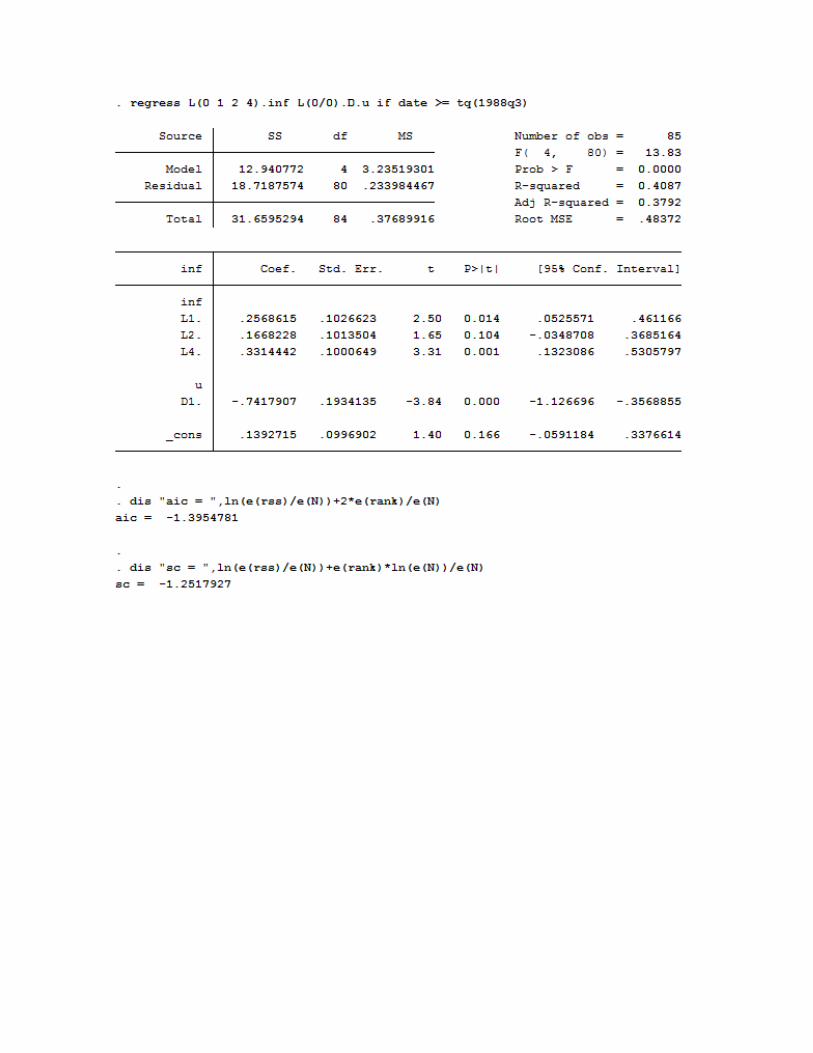
A partir de que los coeficientes de INFt−2 e INFt−3 no son significativamente distintos de cero, se
puede considerar eliminar uno o ambos términos, pero reteniendo a INFt−4. Siguiendo esta
estrategia, el modelo que minimza AIC y SC omite INFt−2, pero mantiene INFt−1, INFt−3 y INFt−4.
A continuación la rutina, en Stata, para sustentar la decisión
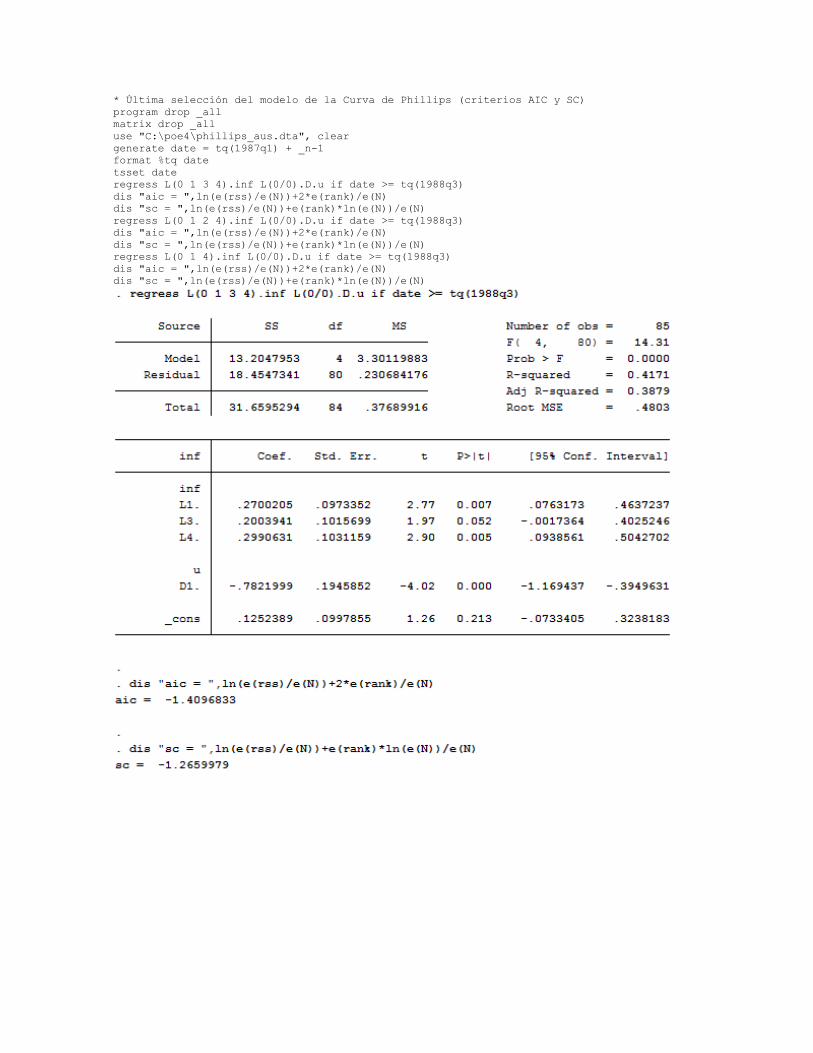
* Última selección del modelo de la Curva de Phillips (criterios AIC y SC)
program drop _all
matrix drop _all
use "C:\poe4\phillips_aus.dta", clear
generate date = tq(1987q1) + _n-1
format %tq date
tsset date
regress L(0 1 3 4).inf L(0/0).D.u if date >= tq(1988q3)
dis "aic = ",ln(e(rss)/e(N))+2*e(rank)/e(N)
dis "sc = ",ln(e(rss)/e(N))+e(rank)*ln(e(N))/e(N)
regress L(0 1 2 4).inf L(0/0).D.u if date >= tq(1988q3)
dis "aic = ",ln(e(rss)/e(N))+2*e(rank)/e(N)
dis "sc = ",ln(e(rss)/e(N))+e(rank)*ln(e(N))/e(N)
regress L(0 1 4).inf L(0/0).D.u if date >= tq(1988q3)
dis "aic = ",ln(e(rss)/e(N))+2*e(rank)/e(N)
dis "sc = ",ln(e(rss)/e(N))+e(rank)*ln(e(N))/e(N)
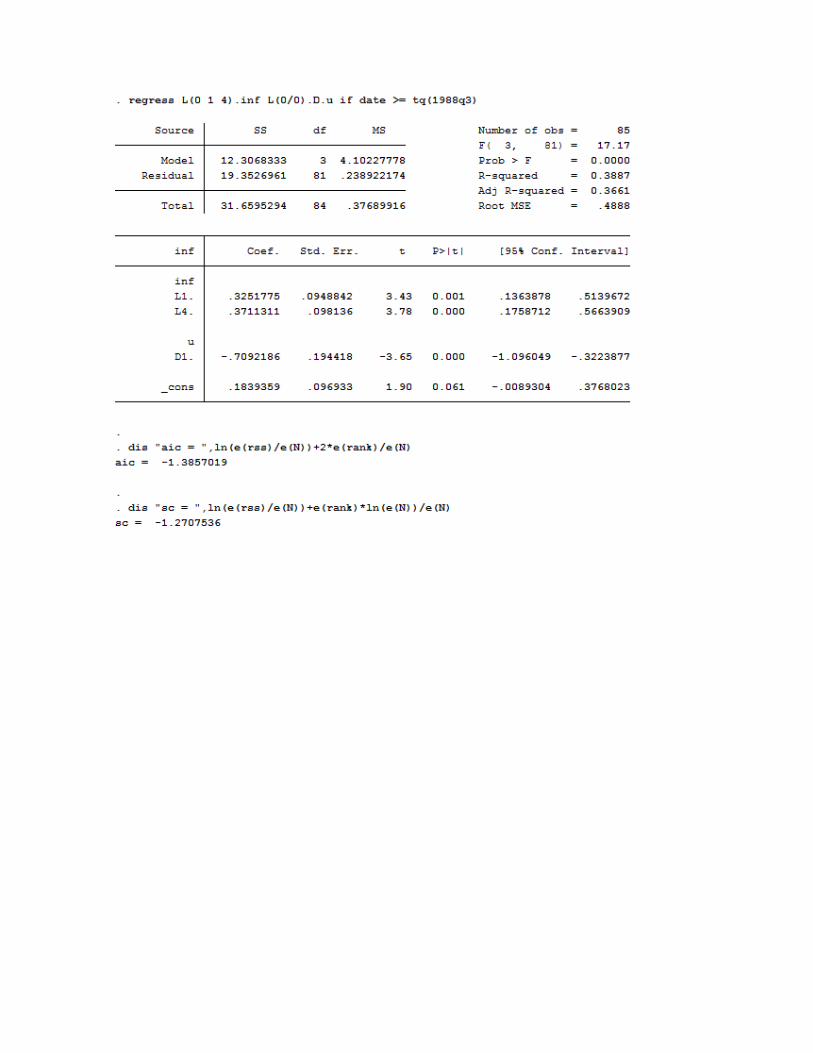

Ley de Okun
Anteriormente, se estimó el modelo sin rezagos en 𝐷𝑈 y con dos rezagos en 𝐺
𝐷𝑈𝑡̂ = 0.5836 − 0.2020𝐺𝑡 − 0.1653𝐺𝑡−1 − 0.0700𝐺𝑡−2 𝑜𝑏𝑠 = 96
(𝑠𝑒) (0.0472) (0.0324) (0.0335) (0.0331) (9.58)
Se detecta autocorrelación mediante el correlograma de los errores (autocorrelación significativa
de orden uno e insignificante en orden superior) y la prueba LM (valor 𝑝 igual a 0.0004 para
autocorrelación de primer orden)
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
regress D.u L(0/2).g
predict ehat, res
ac ehat, lags(12) saving("C:\poe4\okun_ac_ehat.gph",replace)
corrgram ehat, lags(12)
matrix r=r(AC)'
estat bgodfrey, lags(1 2 3 4 5)
clear
svmat r
ren r1 r
gen t=_n
display invnormal(1-0.05/2)/sqrt(98)
graph bar r, over(t) yline(-.19798626 .19798626) ylabel(-0.4(0.1)0.4)
ytitle("Autocorrelación") saving("C:\poe4\okun_corrgram_ehat.gph ",replace)
graph combine "C:\poe4\okun_ac_ehat.gph"
"C:\poe4\okun_corrgram_ehat.gph",saving("C:\poe4\okun_ac_cg_ehat.gph",replace)
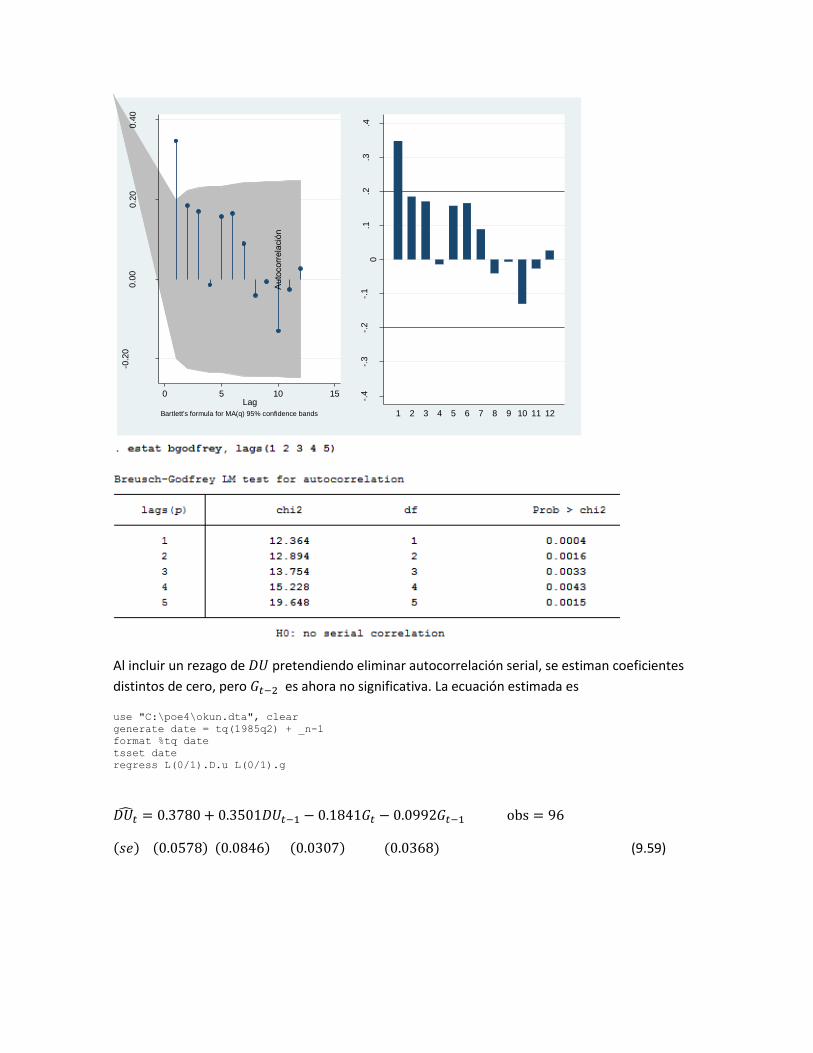
Al incluir un rezago de 𝐷𝑈 pretendiendo eliminar autocorrelación serial, se estiman coeficientes
distintos de cero, pero 𝐺𝑡−2 es ahora no significativa. La ecuación estimada es
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
regress L(0/1).D.u L(0/1).g
𝐷𝑈𝑡̂ = 0.3780 + 0.3501𝐷𝑈𝑡−1 − 0.1841𝐺𝑡 − 0.0992𝐺𝑡−1 obs = 96
(𝑠𝑒) (0.0578) (0.0846) (0.0307) (0.0368) (9.59)
-0.2
00.0
00.2
00.4
0
Auto
corr
ela
tions o
f eha
t
0 5 10 15Lag
Bartlett's formula for MA(q) 95% confidence bands
-.4
-.3
-.2
-.1
0.1
.2.3
.4
Auto
corr
ela
ció
n
1 2 3 4 5 6 7 8 9 10 11 12
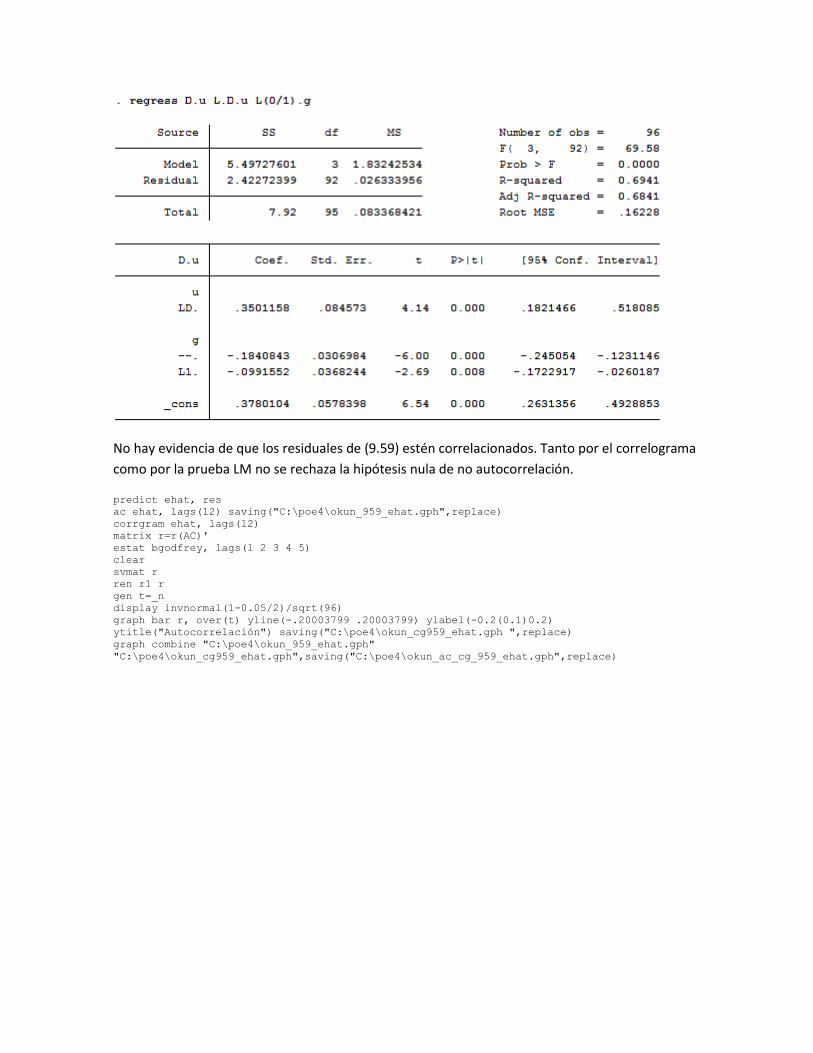
No hay evidencia de que los residuales de (9.59) estén correlacionados. Tanto por el correlograma
como por la prueba LM no se rechaza la hipótesis nula de no autocorrelación.
predict ehat, res
ac ehat, lags(12) saving("C:\poe4\okun_959_ehat.gph",replace)
corrgram ehat, lags(12)
matrix r=r(AC)'
estat bgodfrey, lags(1 2 3 4 5)
clear
svmat r
ren r1 r
gen t=_n
display invnormal(1-0.05/2)/sqrt(96)
graph bar r, over(t) yline(-.20003799 .20003799) ylabel(-0.2(0.1)0.2)
ytitle("Autocorrelación") saving("C:\poe4\okun_cg959_ehat.gph ",replace)
graph combine "C:\poe4\okun_959_ehat.gph"
"C:\poe4\okun_cg959_ehat.gph",saving("C:\poe4\okun_ac_cg_959_ehat.gph",replace)
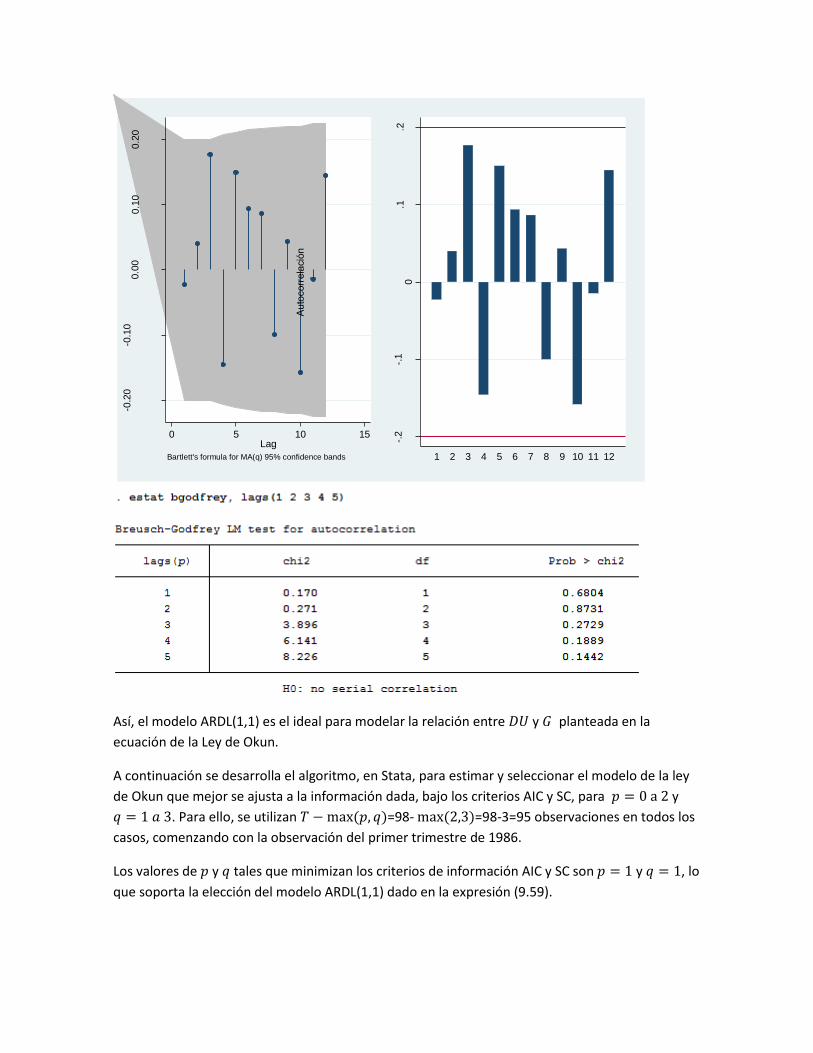
Así, el modelo ARDL(1,1) es el ideal para modelar la relación entre 𝐷𝑈 y 𝐺 planteada en la
ecuación de la Ley de Okun.
A continuación se desarrolla el algoritmo, en Stata, para estimar y seleccionar el modelo de la ley
de Okun que mejor se ajusta a la información dada, bajo los criterios AIC y SC, para 𝑝 = 0 a 2 y
𝑞 = 1 𝑎 3. Para ello, se utilizan 𝑇 − max (𝑝, 𝑞)=98- max (2,3)=98-3=95 observaciones en todos los
casos, comenzando con la observación del primer trimestre de 1986.
Los valores de 𝑝 y 𝑞 tales que minimizan los criterios de información AIC y SC son 𝑝 = 1 y 𝑞 = 1, lo
que soporta la elección del modelo ARDL(1,1) dado en la expresión (9.59).
-0.2
0-0
.10
0.0
00.1
00.2
0
Auto
corr
ela
tions o
f eha
t
0 5 10 15Lag
Bartlett's formula for MA(q) 95% confidence bands
-.2
-.1
0.1
.2
Auto
corr
ela
ció
n
1 2 3 4 5 6 7 8 9 10 11 12

* Selección del modelo de la Ley de Okun (criterios AIC y SC)
program drop _all
matrix drop _all
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
for num 1/3: matrix selqX=J(3,5,0)
program define loop_q
regress L(0/`1').D.u L(0/`2').g if date >= tq(1986q1)
matrix selq`2'[`1'+1,1]= `1'
matrix selq`2'[`1'+1,2]= `2'
matrix selq`2'[`1'+1,3]= ln(e(rss)/e(N))+2*e(rank)/e(N)
matrix selq`2'[`1'+1,4]= ln(e(rss)/e(N))+e(rank)*ln(e(N))/e(N)
matrix selq`2'[`1'+1,5]= e(N)
end
program define loop_p
for num 1/3: loop_q `1' X
end
for num 0/2: loop_p X
program define loopv
clear
svmat selq`1', names(selq)
rename selq1 p
rename selq2 q
rename selq3 aic
rename selq4 sc
rename selq5 obs
save "C:\poe4\selq`1'.dta", replace
end
for num 1/3: loopv X
use "C:\poe4\selq1.dta",clear
append using "C:\poe4\selq2.dta"
append using "C:\poe4\selq3.dta"
generate modelo=_n
egen min_aic=min(aic)
egen min_sc=min(sc)
display "Modelo seleccionado bajo el Criterio AIC"
list modelo p q aic if aic==min_aic
display "Modelo seleccionado bajo el Criterio SC"
list modelo p q sc if sc==min_sc
list, clean

Modelos autorregresivos
Los modelos ARDL vistos tienen un componente autorregresivo (los valores rezagados de la
variable dependiente) y un componente de rezago distribuido (una variable explicativa y sus
rezagos). Los modelos AR(p) son un caso particular de los modelos ARDL(p,q), en general
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + 𝜃2𝑦𝑡−2 + ⋯ + +𝜃𝑝𝑦𝑡−𝑝 + 𝑣𝑡 (9.60)
Cuando (9.60) es empleada para ponosticar, se están empleando los valores corriente y pasados
de una variable para pronosticar su valor futuro.
Como ejemplo consideremos los datos sobre el crecimiento del producto en Estados Unidos del
segundo trimestre de 1985 al tercer trimestre de 2009, en la base okun.dta
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
corrgram g, lags(12)
rezago autocorrelación Gt , Gt-k
k rk ρk = ρk
1 0.494 0.494
2 0.411 0.244
3 0.154 0.121
4 0.200 0.060
5 0.090 0.030
6 0.025 0.015
7 -0.030 0.007
8 -0.082 0.004
9 0.044 0.002
10 -0.021 0.001
11 -0.087 0.000
12 -0.204 0.000
Para que el modelo AR(1) para 𝐺 sea el adecuado, las diferencias entre la autocorrelación
muestral y la teórica deben ser pequeñas, sin embargo se observa que para el segundo rezago
0.244 es mucho menor que 0.411, por lo que hay autocorrelación extra que puede ser capturada
por un modelo AR(2), cuya estimación es
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
regress L(0/2).g
predict ehat, resid
corrgram ehat, lags(12)
matrix r=r(AC)'
clear
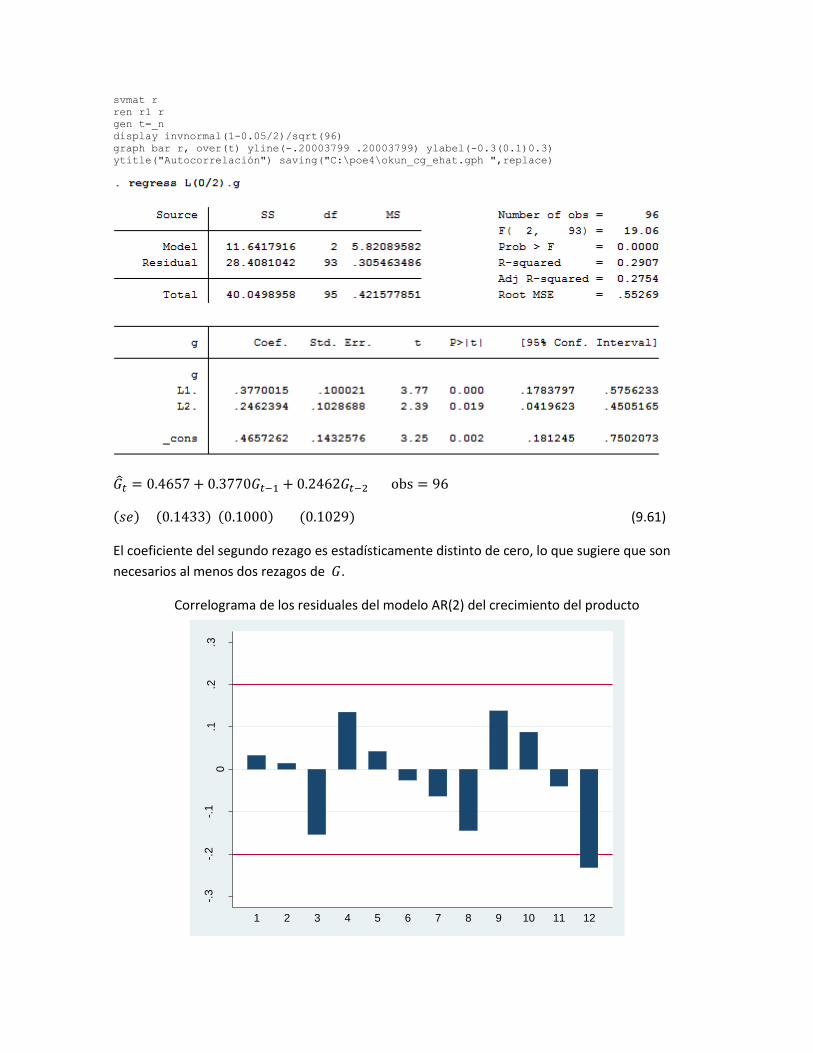
svmat r
ren r1 r
gen t=_n
display invnormal(1-0.05/2)/sqrt(96)
graph bar r, over(t) yline(-.20003799 .20003799) ylabel(-0.3(0.1)0.3)
ytitle("Autocorrelación") saving("C:\poe4\okun_cg_ehat.gph ",replace)
𝐺𝑡 = 0.4657 + 0.3770𝐺𝑡−1 + 0.2462𝐺𝑡−2 obs = 96
(𝑠𝑒) (0.1433) (0.1000) (0.1029) (9.61)
El coeficiente del segundo rezago es estadísticamente distinto de cero, lo que sugiere que son
necesarios al menos dos rezagos de 𝐺.
Correlograma de los residuales del modelo AR(2) del crecimiento del producto
-.3
-.2
-.1
0.1
.2.3
Au
tocorr
ela
ció
n
1 2 3 4 5 6 7 8 9 10 11 12

A continuación se desarrolla el algoritmo, en Stata, para estimar y seleccionar el modelo de la tasa
de crecimiento del producto norteamericano que mejor se ajusta a la información dada, bajo los
criterios AIC y SC, para 𝑝 = 1 a 5. Para ello, se utilizan 𝑇 − 𝑝=98-5=93 observaciones en todos los
casos, comenzando con la observación del tercer trimestre de 1986.
El valor de 𝑝 tal que minimiza el criterio de información AIC es 𝑝 = 4 y bajo el criterio de
información SC es 𝑝 = 2. Este último es más robusto al penalizar el uso de más rezagos, lo que
soporta la elección del modelo AR(2) de la expresión (9.61).
* Selección del modelo de crecimiento del producto (criterios AIC y SC)
program drop _all
matrix drop _all
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
matrix sel=J(5,4,0)
program define loop_p
regress L(0/`1').g if date >= tq(1986q3)
matrix sel[`1',1]= `1'
matrix sel[`1',2]= ln(e(rss)/e(N))+2*e(rank)/e(N)
matrix sel[`1',3]= ln(e(rss)/e(N))+e(rank)*ln(e(N))/e(N)
matrix sel[`1',4]= e(N)
end
for num 1/5: loop_p X
clear
svmat sel, names(sel)
rename sel1 p
rename sel2 aic
rename sel3 sc
rename sel4 obs
save "C:\poe4\sel.dta", replace
generate modelo=_n
egen min_aic=min(aic)
egen min_sc=min(sc)
display "Modelo seleccionado bajo el Criterio AIC"
list modelo p aic if aic==min_aic
display "Modelo seleccionado bajo el Criterio SC"
list modelo p sc if sc==min_sc
list, clean

Pronósticos
Pronosticar valores de variables económicas es una de las actividades más importantes en muchas
instituciones, incluyendo empresas, bancos, gobiernos e individuos. Los pronósticos precisos son
importantes para la toma de decisiones en política económica gubernamental, estrategias de
inversión, la oferta de bienes a distribuidores y una multitud de acciones que afectan nuestra vida
diaria. A continuación se considerarán pronósticos para tres tipos de modelos: AR, ARDL y
suavizamiento exponencial. El enfoque de pronósticos de corto plazo considera hasta tres
periodos en el futuro.
Pronósticos con un modelo AR
Suponiendo que es el tercer trimestre de 2009, con el modelo AR(2) estimado en (9.61) se desea
pronosticar el crecimiento del producto para los siguientes 3 trimestres.
¿Cómo usar el modelo AR(2) estimado para obtener dichos pronósticos?
¿Cómo calcular los errores estándar de los pronósticos?
¿Cómo elaborar los intervalos de confianza para tales pronósticos?
Los pasos son los siguientes:
1. Escribimos el modelo AR(2) en términos de coeficientes desconocidos (modelo teórico)
𝐺𝑡 = 𝛿 + 𝜃1𝐺𝑡−1 + 𝜃2𝐺𝑡−2 + 𝑣𝑡 (9.62)
2. Denotando como 𝐺𝑇 a la última observación de la variable en cuestión, se pretende
pronosticar 𝐺𝑇+1, 𝐺𝑇+2 y 𝐺𝑇+3. Usando (9.62) obtenemos la ecuación que genera 𝐺𝑇+1
sustituyendo el subíndice de tiempo 𝑡 por 𝑇 + 1, se obtiene
𝐺𝑇+1 = 𝛿 + 𝜃1𝐺(𝑇+1)−1 + 𝜃2𝐺(𝑇+1)−2 + 𝑣𝑇+1
por lo que, al simplificar los subíndices, la ecuación requerida para 𝐺𝑇+1 es
𝐺𝑇+1 = 𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1 + 𝑣𝑇+1
Análogamente,para 𝐺𝑇+2 y 𝐺𝑇+3
𝐺𝑇+2 = 𝛿 + 𝜃1𝐺𝑇+1 + 𝜃2𝐺𝑇 + 𝑣𝑇+2
𝐺𝑇+3 = 𝛿 + 𝜃1𝐺𝑇+2 + 𝜃2𝐺𝑇+1 + 𝑣𝑇+3
3. Escribimos el modelo AR(2) en términos de los coeficientes estimados (modelo ajustado)
𝐺𝑡 = 𝛿 + 𝜃1𝐺𝑡−1 + 𝜃2𝐺𝑡−2

4. Usamos la ecuación anterior para generar 𝐺𝑇+1 sustituyendo el subíndice de tiempo 𝑡 por
𝑇 + 1, se obtiene
𝐺𝑇+1 = 𝛿 + 𝜃1𝐺(𝑇+1)−1 + 𝜃2𝐺(𝑇+1)−2
por lo que, al simplificar los subíndices, la ecuación requerida es
�̂�𝑇+1 = 𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1
Análogamente, para 𝐺𝑇+2 y 𝐺𝑇+3
�̂�𝑇+2 = 𝛿 + 𝜃1�̂�𝑇+1 + 𝜃2𝐺𝑇
𝐺𝑇+3 = 𝛿 + 𝜃1�̂�𝑇+2 + 𝜃2�̂�𝑇+1
La información necesaria es
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
regress L(0/2).g
list date g in -2/-1
En este contexto, se tiene el siguiente cuadro
Trimestre Periodo t 𝐺𝑡
2009q2 T-1 𝐺𝑇−1 = -0.2
2009q3 T 𝐺𝑇 = 0.8
2009q4 T+1 𝐺𝑇+1
2010q1 T+2 𝐺𝑇+2
2010q2 T+3 𝐺𝑇+3
Calculamos los pronósticos requeridos, en Stata,
set obs 101
for num 99/101: replace date = date[X-1] + 1 in X
list date g in -5/-1
for num 99/101: replace g=_b[_cons]+_b[L.g]*g[X-1]+_b[L2.g]*g[X-2] in X
list date g in -5/-1
Manualmente,
𝐺𝑇+1 = 0.46573 + 0.37700 × 0.8 + 0.24624 × (−0.2) = 0.7181 (9.63)

�̂�𝑇+2 = �̂� + 𝜃1�̂�𝑇+1 + 𝜃2𝐺𝑇 = 0.46573 + 0.37700 × 0.71808 + 0.24624 × 0.8 = 0.9334 (9.64)
�̂�𝑇+3 = �̂� + 𝜃1�̂�𝑇+2 + 𝜃2�̂�𝑇+1 = 0.46573 + 0.37700 × 0.93343 + 0.24624 × 0.71808 = 0.9945 (9.65)
Con los anteriores cálculos, completamos el cuadro
Trimestre Periodo t 𝐺𝑡
2009q2 T-1 𝐺𝑇−1 = -0.2
2009q3 T 𝐺𝑇 = 0.8
2009q4 T+1 𝐺𝑇+1 = 0.71808
2010q1 T+2 𝐺𝑇+2 = 0.93343
2010q2 T+3 𝐺𝑇+3 = 0.99445
Las tasas de crecimiento pronosticadas para 2009q4, 2010q1 y 2010q2 son aproximadamente
0.72%, 0.93% y 0.99%, respectivamente.
Para obtener los errores estándar, partimos de que el primer error de pronóstico ocurre en el
periodo T+1, el cuál es la diferencia entre lo observado y lo pronosticado, esto es
𝑢1 = 𝐺𝑇+1 − 𝐺𝑇+1 = 𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1 + 𝑣𝑇+1 − (𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1)
= (𝛿 − 𝛿) + (𝜃1 − 𝜃1)𝐺𝑇 + (𝜃2 − 𝜃2)𝐺𝑇−1 + 𝑣𝑇+1
Si los estimadores son insesgados, el error de pronóstico un trimestre después es
𝑢1 = 𝑣𝑇+1 (9.66)
Para dos trimestres después, el error de pronóstico es
𝑢2 = 𝐺𝑇+2 − 𝐺𝑇+2 = 𝛿 + 𝜃1𝐺𝑇+1 + 𝜃2𝐺𝑇 + 𝑣𝑇+2 − (𝛿 + 𝜃1�̂�𝑇+1 + 𝜃2𝐺𝑇)
= 𝛿 + 𝜃1(𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1 + 𝑣𝑇+1) + 𝜃2𝐺𝑇 + 𝑣𝑇+2 − 𝛿−𝜃1(𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1) − 𝜃2𝐺𝑇
= (𝛿 − 𝛿) + (𝜃1𝛿−𝜃1�̂�) + (𝜃12 − 𝜃1
2)𝐺𝑇 + (𝜃1𝜃2−𝜃1�̂�2)𝐺𝑇−1 + 𝜃1𝑣𝑇+1 + (𝜃2 − 𝜃2)𝐺𝑇 + 𝑣𝑇+2
Si los estimadores son insesgados, el error de pronóstico dos trimestres después es
𝑢2 = 𝜃1𝑣𝑇+1 + 𝑣𝑇+2 (9.67)
Para tres trimestres después, el error de pronóstico es
𝑢3 = 𝐺𝑇+3 − 𝐺𝑇+3 = 𝛿 + 𝜃1𝐺𝑇+2 + 𝜃2𝐺𝑇+1 + 𝑣𝑇+3 − (𝛿 + 𝜃1�̂�𝑇+2 + 𝜃2�̂�𝑇+1)

= 𝛿 + 𝜃1(𝛿 + 𝜃1𝐺𝑇+1 + 𝜃2𝐺𝑇 + 𝑣𝑇+2) + 𝜃2(𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1 + 𝑣𝑇+1) + 𝑣𝑇+3 − 𝛿
− 𝜃1(𝛿 + 𝜃1�̂�𝑇+1 + 𝜃2𝐺𝑇) − 𝜃2(�̂� + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1)
= 𝛿 + 𝜃1𝛿 + 𝜃12𝐺𝑇+1 + 𝜃1𝜃2𝐺𝑇 + 𝜃1𝑣𝑇+2 + 𝜃2𝛿 + 𝜃1𝜃2𝐺𝑇 + 𝜃2
2𝐺𝑇−1 + 𝜃2𝑣𝑇+1 + 𝑣𝑇+3 − 𝛿
− 𝜃1�̂� − 𝜃12�̂�𝑇+1 − 𝜃1�̂�2𝐺𝑇 − 𝜃2�̂� − 𝜃1𝜃2𝐺𝑇 − 𝜃2
2𝐺𝑇−1
= 𝛿 + 𝜃1𝛿 + 𝜃12(𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1 + 𝑣𝑇+1) + 𝜃1𝜃2𝐺𝑇 + 𝜃1𝑣𝑇+2 + 𝜃2𝛿 + 𝜃1𝜃2𝐺𝑇 + 𝜃2
2𝐺𝑇−1
+ 𝜃2𝑣𝑇+1 + 𝑣𝑇+3 − 𝛿 − 𝜃1�̂� − 𝜃12(𝛿 + 𝜃1𝐺𝑇 + 𝜃2𝐺𝑇−1) − 𝜃1𝜃2𝐺𝑇 − 𝜃2�̂�
− 𝜃1�̂�2𝐺𝑇 − 𝜃22𝐺𝑇−1
= 𝛿 + 𝜃1𝛿 + 𝜃12𝛿 + 𝜃1
3𝐺𝑇 + 𝜃12𝜃2𝐺𝑇−1 + 𝜃1
2𝑣𝑇+1 + 𝜃1𝜃2𝐺𝑇 + 𝜃1𝑣𝑇+2 + 𝜃2𝛿 + 𝜃1𝜃2𝐺𝑇
+ 𝜃22𝐺𝑇−1 + 𝜃2𝑣𝑇+1 + 𝑣𝑇+3 − 𝛿 − 𝜃1�̂� − 𝜃1
2�̂� − 𝜃13𝐺𝑇 − 𝜃1
2𝜃2𝐺𝑇−1 − 𝜃1�̂�2𝐺𝑇
− 𝜃2�̂� − 𝜃1�̂�2𝐺𝑇 − 𝜃22𝐺𝑇−1
= (𝛿 − 𝛿) + (𝜃1𝛿 − 𝜃1�̂�) + (𝜃12𝛿 − 𝜃1
2�̂�) + (𝜃13 − 𝜃1
3)𝐺𝑇 + (𝜃12𝜃2 − 𝜃1
2�̂�2)𝐺𝑇−1 + 𝜃12𝑣𝑇+1
+ (𝜃1𝜃2 − 𝜃1𝜃2)𝐺𝑇 + 𝜃1𝑣𝑇+2 + (𝜃2𝛿 − 𝜃2�̂�) + (𝜃1𝜃2 − 𝜃1�̂�2)𝐺𝑇
+ (𝜃22 − 𝜃2
2)𝐺𝑇−1 + 𝜃2𝑣𝑇+1 + 𝑣𝑇+3
Si los estimadores son insesgados, el error de pronóstico dos trimestres después es
𝑢3 = (𝜃12 + 𝜃2)𝑣𝑇+1 + 𝜃1𝑣𝑇+2 + 𝑣𝑇+3 (9.68)
La varianza del error de pronóstico en cada periodo futuro es
𝜎12 = 𝑉𝐴𝑅(𝑢1) = 𝑉𝐴𝑅[𝑣𝑇+1] = 𝜎𝑣
2
𝜎22 = 𝑉𝐴𝑅(𝑢2) = 𝑉𝐴𝑅[𝜃1𝑣𝑇+1 + 𝑣𝑇+2] = 𝜃1
2𝑉𝐴𝑅(𝑣𝑇+1) + 𝑉𝐴𝑅(𝑣𝑇+2) = 𝜎𝑣2(1 + 𝜃1
2)
𝜎32 = 𝑉𝐴𝑅(𝑢3) = 𝑉𝐴𝑅[(𝜃1
2 + 𝜃2)𝑣𝑇+1 + 𝜃1𝑣𝑇+2 + 𝑣𝑇+3]
= (𝜃12 + 𝜃2)2𝑉𝐴𝑅(𝑣𝑇+1) + 𝜃1
2𝑉𝐴𝑅(𝑣𝑇+2) + 𝑉𝐴𝑅(𝑣𝑇+3) = 𝜎𝑣2((𝜃1
2 + 𝜃2)2 + 𝜃12 + 1)
Usando los resultados de (9.61)
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
regress L(0/2).g
tsappend, add(3)
for num 99/101: replace date = date[X-1] + 1 in X
list date g in -5/-1
for num 99/101: replace g=_b[_cons]+_b[L.g]*g[X-1]+_b[L2.g]*g[X-2] in X
list date g in -5/-1
�̂�𝑣 = 0.55269
𝜃1 = 0.37700

𝜃2 = 0.24624
El error estándar del error de pronóstico es la raíz cuadrada de la varianza del error estimada, para
cada periodo de pronóstico se tiene
scalar se1 = e(rmse)
scalar se2 = e(rmse)*sqrt(1+_b[L.g]^2)
scalar se3 = e(rmse)*sqrt((_b[L.g]^2+_b[L2.g])^2+_b[L.g]^2+1)
display se1, se2, se3
�̂�1 = 𝑆�̂�(𝑢1) = √�̂�𝑣2 =�̂�𝑣 = 0.55269
�̂�2 = 𝑆�̂�(𝑢2) = √�̂�𝑣2(1 + 𝜃1
2) = �̂�𝑣 √1 + 𝜃12 = 0.55269√1 + 0.3772 = 0.59066
�̂�3 = 𝑆�̂�(𝑢3) = �̂�𝑣√(�̂�12 + �̂�2)
2+ �̂�1
2 + 1 = 0.55269√(0.3772 + 0.24624)2 + 0.3772 + 1 = 0.62845
Los intervalos al 95% de confianza, y 93 grados de libertad para el estadístico 𝑡 de Student, son
Para el pronóstico de 𝐺𝑇+1
display "P[",g[99]-invt(93,0.975)*se1,"< G T+1 <", g[99]+invt(93,0.975)*se1,"] = 0.95"
𝑃[�̂�𝑇+1 − 𝑡0.975,93𝑆�̂�(𝑢1) < 𝐺𝑇+1 < 𝐺𝑇+1 + 𝑡0.975,93𝑆�̂�(𝑢1)] = 0.95
𝑃[0.71808 − 1.9858 x 0.55269 < 𝐺𝑇+1 < 0.71808 + 1.9858 x 0.55269] = 0.95
𝑃[−0.379 < 𝐺𝑇+1 < 1.816] = 0.95
Para el pronóstico de 𝐺𝑇+2
display "P[",g[100]-invt(93,0.975)*se2,"< G T+2 <", g[100]+invt(93,0.975)*se2,"] = 0.95"
𝑃[�̂�𝑇+2 − 𝑡0.975,93𝑆�̂�(𝑢2) < 𝐺𝑇+2 < 𝐺𝑇+2 + 𝑡0.975,93𝑆�̂�(𝑢2)] = 0.95
𝑃[0.93343 − 1.9858 x 0.59066 < 𝐺𝑇+1 < 0.93343 + 1.9858 x 0.59066] = 0.95
𝑃[−0.239 < 𝐺𝑇+1 < 2.106] = 0.95
Para el pronóstico de 𝐺𝑇+3
display "P[",g[101]-invt(93,0.975)*se3,"< G T+3 <", g[101]+invt(93,0.975)*se3,"] = 0.95"
𝑃[�̂�𝑇+3 − 𝑡0.975,93𝑆�̂�(𝑢3) < 𝐺𝑇+3 < 𝐺𝑇+3 + 𝑡0.975,93𝑆�̂�(𝑢3)] = 0.95
𝑃[0.99445 − 1.9858 x 0.62845 < 𝐺𝑇+1 < 0.99445 + 1.9858 x 0.62845] = 0.95
𝑃[−0.254 < 𝐺𝑇+1 < 2.242] = 0.95

Pronósticos con un modelo ARDL
Como ejemplo, si se desea pronosticar el desempleo futuro utilizando el modelo ARDL(1,1) para la
Ley de Okun estimado en (9.59)
𝐷𝑈𝑡 = 𝛿 + 𝜃1𝐷𝑈𝑡−1 + 𝛿0𝐺𝑡 + 𝛿1𝐺𝑡−1 + 𝑣𝑡 (9.69)
A diferencia del pronóstico con el modelo AR(p) puro visto arriba, el pronóstico bajo el modelo
ARDL(p,q) requiere valores futuros de la variable independiente. El valor de 𝐷𝑈 en el primer
periodo post-muestra es
𝐷𝑈𝑇+1 = 𝛿 + 𝜃1𝐷𝑈𝑇 + 𝛿0𝐺𝑇+1 + 𝛿1𝐺𝑇 + 𝑣𝑇+1 (9.70)
Antes de usar esta ecuación para pronosticar 𝐷𝑈𝑇+1, se requiere un valor para 𝐺𝑇+1. Pronosticar
para valores futuros de 𝐷𝑈 requerirá de más valores futuros de 𝐺. Estos valores pueden ser
pronósticos independientes. El procedimiento para obtener los errores estándar e intervalos de
confianza es el ya visto.
Una característica especial del modelo ARDL, como el planteado en (9.69), a partir de que la
variable dependiente es el cambio en el desempleo 𝐷𝑈𝑡 = 𝑈𝑡 − 𝑈𝑡−1, la implicación para
pronosticar el nivel de desempleo al reescribir (9.70) como
𝑈𝑇+1 − 𝑈𝑇 = 𝛿 + 𝜃1(𝑈𝑇 − 𝑈𝑇−1) + 𝛿0𝐺𝑇+1 + 𝛿1𝐺𝑇 + 𝑣𝑇+1
despejando 𝑈𝑇+1
𝑈𝑇+1 = 𝛿 + (𝜃1 + 1)𝑈𝑇 − 𝜃1𝑈𝑇−1 + 𝛿0𝐺𝑇+1 + 𝛿1𝐺𝑇 + 𝑣𝑇+1
= 𝛿 + 𝜃1∗𝑈𝑇 + 𝜃2
∗𝑈𝑇−1 + 𝛿0𝐺𝑇+1 + 𝛿1𝐺𝑇 + 𝑣𝑇+1 (9.71)
donde
𝜃1∗ = 𝜃1 + 1
𝜃2∗ = −𝜃1
es que, para propósitos de calcular los pronósticos puntual y de intervalo, el modelo ARDL(1,1)
para un cambio en desempleo puede ser expresado como un modelo ARDL(2,1) para el nivel de
desempleo con parámetros 𝜃1∗ y 𝜃2
∗. Este resultado no sólo se mantiene para los modelos ARDL en
los que la variable dependiente esté medida en terminos de un cambio o diferencia, sino también
para modelos AR puros que involucren tales variables. Esto es particularmente relevante cuando
las variables no estacionarias son diferenciadas para lograr estacionariedad, una transformación
que se verá más adelante.
Finalmente, para un modelo de rezagos distribuidos DL(q), es decir, sin componente AR(p), el
pronóstico se efectúa en el contexto de predicción usual vista en los modelos de corte transversal.

Suavizamiento exponencial
Al igual que en el pronóstico de modelos AR(p), este método no requiere información de alguna
otra variable. Sólo requiere las observaciones pasadas de la variable a pronosticar 𝑦.
Consideremos la muestra de observaciones (𝑦1, 𝑦2, ⋯ , 𝑦𝑇−1, 𝑦𝑇) y el objetivo es pronosticar 𝑦𝑇+1.
Promediando las últimas 𝑘 = 3 observaciones
�̂�𝑇+1 =𝑦𝑇 + 𝑦𝑇−1 + 𝑦𝑇−2
3
Esta regla de pronóstico es ejemplo de un modelo de promedio móvil simple (con ponderadores
iguales) con 𝑘 = 3. Nótese que cuando 𝑘 = 3, todos el peso del ponderador se ubica en el la
observación más reciente y el pronóstico es
�̂�𝑇+1 = 𝑦𝑇.
Ahora, considerando ponderadores que den mayor peso a la información reciente y declinando
conforme el pasado es más alejado se tiene la forma de suavizamiento exponencial
�̂�𝑇+1 = 𝛼𝑦𝑇 + 𝛼(1 − 𝛼)1𝑦𝑇−1 + 𝛼(1 − 𝛼)2𝑦𝑇−2 + ⋯ (9.72)
El ponderador de 𝑦𝑇−𝑠 es (1 − 𝛼)𝑠 con 0 < 𝛼 ≤ 1. Se tiene la suma infinita de la progresión
geomérica
∑ 𝛼(1 − 𝛼)𝑠 = 𝛼 ∑(1 − 𝛼)𝑠 = 𝛼1
1 − (1 − 𝛼)
∞
𝑠=0
= 1
∞
𝑠=0
Usar la información del pasado infinito no es conveniente para pronosticar. Reconociendo que
(1 − 𝛼)�̂�𝑇 = 𝛼(1 − 𝛼)𝑦𝑇−1 + 𝛼(1 − 𝛼)2𝑦𝑇−2 + 𝛼(1 − 𝛼)3𝑦𝑇−3 + ⋯ (9.73)
Los términos a la derecha de (9.73) son los mismos que los de la derecha de (9.72), por lo tanto al
sustituir (9.73) en (9.72) se tiene
�̂�𝑇+1 = 𝛼𝑦𝑇 + (1 − 𝛼)�̂�𝑇 (9.74)
Esto es, el pronóstico del siguiente periodo es un promedio ponderado del valor realizado en el
periodo corriente y el pronóstico para el periodo corriente.
Se requiere un valor del parámetro de suavizamiento 𝛼 tal que minimice la suma de cuadrados de
los errores de pronóstico en una etapa, estimando los pronósticos dentro de la muestra a partir de
la información histórica, mediante
�̂�𝑡 = 𝛼𝑦𝑡−1 + (1 − 𝛼)�̂�𝑡−1 𝑡 = 2,3, … , 𝑇 (9.75)
Los errores de pronóstico son
𝑣𝑡 = 𝑦𝑡 − �̂�𝑡 = 𝑦𝑡 − (𝛼𝑦𝑡−1 + (1 − 𝛼)�̂�𝑡−1) (9.76)
El problema
min𝛼
∑ 𝑣𝑡2
𝑇
𝑡=2
= min𝛼
∑(𝑦𝑡 − �̂�𝑡)2
𝑇
𝑡=2
= min𝛼
∑(𝑦𝑡 − [𝛼𝑦𝑡−1 + (1 − 𝛼)�̂�𝑡−1])2
𝑇
𝑡=2
Para calcular la suma de cuadrados de residuales se requiere un valor inicial para �̂�1. Una opción
es fijar �̂�1 = 𝑦1, otra es fijar �̂�1 igual al promedio de las primeras 𝑇+1
2 observaciones de 𝑦.
Los pronósticos para 2009Q4 para cada valor de 𝛼 son:
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
tsappend, add(1)
* alfa = 0.38
tssmooth exponential sm1=g, parms(0.38)
scalar f1 = 0.38*g[98]+(1-0.38)*sm1[98]
scalar list f1
list sm1 in 99
tsline g sm1, legend(lab (1 "G") lab(2 "Ghat")) title(alpha=0.38) lpattern(solid dash)
saving("C:\poe4\g9_11.gph",replace)
* alfa = 0.8
tssmooth exponential sm2=g, parms(0.8)
scalar f2 = 0.8*g[98]+(1-0.8)*sm2[98]
scalar list f2
list sm2 in 99
tsline g sm2, legend(lab (1 "G") lab(2 "Ghat")) title(alpha=0.8) lpattern(solid dash)
saving("C:\poe4\g9_12.gph",replace)
graph combine "C:\poe4\g9_11.gph" "C:\poe4\g9_12.gph", title("Pronóstico con suavizamiento
exponencial") saving("C:\poe4\g9.gph",replace)
𝛼 = 0.38: 𝐺𝑇+1 = 𝛼𝐺𝑇 + (1 − 𝛼)𝐺𝑇 = 0.38 × 0.8 + (1 − 0.38) × (−0.403921) = 0.0536
𝛼 = 0.8: �̂�𝑇+1 = 𝛼𝐺𝑇 + (1 − 𝛼)𝐺𝑇 = 0.8 × 0.8 + (1 − 0.8) × (−0.393578) = 0.5613
-10
12
3
1985q1 1990q1 1995q1 2000q1 2005q1 2010q1date
G Ghat
alpha=0.38
-10
12
3
1985q1 1990q1 1995q1 2000q1 2005q1 2010q1date
G Ghat
alpha=0.8
Pronóstico con suavizamiento exponencial
* alfa óptima
tssmooth exponential sm3=g
scalar f3 = r(alpha)*g[98]+(1-r(alpha))*sm3[98]
scalar list f3
list sm3 in 99
tsline g sm3, legend(lab (1 "G") lab(2 "Ghat")) title(alpha=0.3803) lpattern(solid dash)
saving("C:\poe4\g9_13.gph",replace)
Análisis de multiplicadores
Los conceptos de multiplicadores de impacto, retardo, interim y total fueron introducidos con el
modelo DL finito. Ahora se revisarán los propios en el caso de los modelos ARDL(p,q) de la forma
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + ⋯ + 𝜃𝑝𝑦𝑡−𝑝 + 𝛿0𝑥𝑡 + 𝛿1𝑥𝑡−1 + ⋯ + 𝛿𝑞𝑥𝑡−𝑞 + 𝑣𝑡 (9.77)
el cual se transforma en un modelo DL infinito
𝑦𝑡 = 𝛼 + 𝛽0𝑥𝑡 + 𝛽1𝑥𝑡−1 + 𝛽2𝑥𝑡−2 + 𝛽3𝑥𝑡−3 + ⋯ + 𝑒𝑡 (9.78)
Los multiplicadores son similares a los del modelo DL finito. Específicamente
𝛽𝑠 =𝜕𝑦𝑡
𝜕𝑥𝑡−𝑠= 𝑠 multiplicador de retardo de 𝑠 periodos
∑ 𝛽𝑗 = 𝑠𝑠𝑗=0 multiplicador intermedio de 𝑠 periodos
∑ 𝛽𝑗∞𝑗=0 multiplicador total
Al estimar un modelo ARDL(p,q) se obtienen estimadores de 𝜃’s y 𝛿’s en (9.77). Para obtener los
multiplicadores que están expresados en términos de 𝛽’s, necesitamos ser capaces de calcular los
estimadores de 𝛽’s a partir de los de 𝜃’s y 𝛿’s.
-10
12
3
1985q1 1990q1 1995q1 2000q1 2005q1 2010q1date
G Ghat
alpha=0.3803

Se utilizará el operador de rezago que se define como
𝐿𝑦𝑡 = 𝑦𝑡−1
Para rezagar una variable dos veces
𝐿(𝐿𝑦𝑡) = 𝐿𝑦𝑡−1 = 𝑦𝑡−2
la cual podemos escribir como 𝐿2𝑦𝑡 = 𝑦𝑡−2. En general, el rezago de 𝑦, 𝑠 veces se denota
𝐿𝑠𝑦𝑡 = 𝑦𝑡−𝑠
Ahora, expresemos el modelo ARDL(p,q) en la notación de los operadores de rezagos, a partir de
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + ⋯ + 𝜃𝑝𝑦𝑡−𝑝 + 𝛿0𝑥𝑡 + 𝛿1𝑥𝑡−1 + ⋯ + 𝛿𝑞𝑥𝑡−𝑞 + 𝑣𝑡 (9.77)
con la notación del operador de rezago, se tiene
𝑦𝑡 = 𝛿 + 𝜃1𝐿𝑦𝑡+𝜃2𝐿2𝑦𝑡 + ⋯ + 𝜃𝑝𝐿𝑝𝑦𝑡 + 𝛿0𝑥𝑡 + 𝛿1𝐿𝑥𝑡 + 𝛿2𝐿2𝑥𝑡 + ⋯ + 𝛿𝑞𝐿𝑞𝑥𝑡 + 𝑣𝑡 (9.79)
Agrupando y factorizando
(1 − 𝜃1𝐿 − 𝜃2𝐿2 − ⋯ − 𝜃𝑝𝐿𝑝)𝑦𝑡 = 𝛿 + (𝛿0 + 𝛿1𝐿 + 𝛿2𝐿2 + ⋯ + 𝛿𝑞𝐿𝑞)𝑥𝑡 + 𝑣𝑡 (9.80)
Para facilitar el álgebra, retomemos el modelo ARDL(1,1) de la Ley de Okun visto así
𝐷𝑈𝑡 = 𝛿 + 𝜃1𝐷𝑈𝑡−1 + 𝛿0𝐺𝑡 + 𝛿1𝐺𝑡−1 + 𝑣𝑡 (9.81)
Podemos escribirlo como
𝐷𝑈𝑡 = 𝛿 + 𝜃1𝐿𝐷𝑈𝑡 + 𝛿0𝐺𝑡 + 𝛿1𝐿𝐺𝑡 + 𝑣𝑡
𝐷𝑈𝑡 − 𝜃1𝐿𝐷𝑈𝑡 = 𝛿 + 𝛿0𝐺𝑡 + 𝛿1𝐿𝐺𝑡 + 𝑣𝑡
(1 − 𝜃1𝐿)𝐷𝑈𝑡 = 𝛿 + (𝛿0 + 𝛿1𝐿)𝐺𝑡 + 𝑣𝑡 (9.82)
Ahora, suponemos que es posible definir la inversa de (1 − 𝜃1𝐿), que puede escribirse como
(1 − 𝜃1𝐿)−1, tal que
(1 − 𝜃1𝐿)−1(1 − 𝜃1𝐿) = 1
Por lo que multiplicando ambos lados de (9.82) por (1 − 𝜃1𝐿)−1 se tiene
𝐷𝑈𝑡 = (1 − 𝜃1𝐿)−1𝛿 + (1 − 𝜃1𝐿)−1(𝛿0 + 𝛿1𝐿)𝐺𝑡 + (1 − 𝜃1𝐿)−1𝑣𝑡 (9.83)
Esta representación puede igualarse con la del modelo DL infinito de (9.78)
𝐷𝑈𝑡 = 𝛼 + 𝛽0𝐺𝑡 + 𝛽1𝐺𝑡−1 + 𝛽2𝐺𝑡−2 + 𝛽3𝐺𝑡−3 + ⋯ + 𝑒𝑡
= 𝛼 + (𝛽0 + 𝛽1𝐿 + 𝛽2𝐿2 + 𝛽3𝐿3 + ⋯ )𝐺𝑡 + 𝑒𝑡 (9.84)

Para que (9.83) y (9.84) sean idénticas debe cumplirse que
𝛼 = (1 − 𝜃1𝐿)−1𝛿 (9.85)
𝛽0 + 𝛽1𝐿 + 𝛽2𝐿2 + 𝛽3𝐿3 + ⋯ = (1 − 𝜃1𝐿)−1(𝛿0 + 𝛿1𝐿) (9.86)
𝑒𝑡 = (1 − 𝜃1𝐿)−1𝑣𝑡 (9.87)
Resolviendo (9.85) para 𝛼
(1 − 𝜃1𝐿)𝛼 = (1 − 𝜃1𝐿)(1 − 𝜃1𝐿)−1𝛿
𝛼 − 𝜃1𝐿𝛼 = 𝛿
el rezago de una constante es la misma constante
(1 − 𝜃1)𝛼 = 𝛿
despejando 𝛼
𝛼 =𝛿
1 − 𝜃1
Resolviendo (9.86) para las 𝛽’s
(1 − 𝜃1𝐿)(1 − 𝜃1𝐿)−1(𝛿0 + 𝛿1𝐿) = (1 − 𝜃1𝐿)(𝛽0 + 𝛽1𝐿 + 𝛽2𝐿2 + 𝛽3𝐿3 + ⋯ )
𝛿0 + 𝛿1𝐿 = (1 − 𝜃1𝐿)( 𝛽0 + 𝛽1𝐿 + 𝛽2𝐿2 + 𝛽3𝐿3 + ⋯ )
desarrollando el lado derecho
𝛿0 + 𝛿1𝐿 = 𝛽0 + 𝛽1𝐿 + 𝛽2𝐿2 + 𝛽3𝐿3 + ⋯ − 𝛽0𝜃1𝐿 − 𝛽1𝜃1𝐿2 − 𝛽2𝜃1𝐿3 − ⋯
agrupando para las 𝐿’s
𝛿0 + 𝛿1𝐿 = 𝛽0 + (𝛽1 − 𝛽0𝜃1)𝐿 + (𝛽2 − 𝛽1𝜃1)𝐿2 + (𝛽3 − 𝛽2𝜃1)𝐿3 + ⋯ (9.88)
Igualando coeficientes de las mismas potencias de 𝐿
𝛿0 + 𝛿1𝐿 + 0𝐿2 + 0𝐿3 = 𝛽0 + (𝛽1 − 𝛽0𝜃1)𝐿 + (𝛽2 − 𝛽1𝜃1)𝐿2 + (𝛽3 − 𝛽2𝜃1)𝐿3 + ⋯ (9.89)
se tiene
𝛿0 = 𝛽0
𝛿1 = 𝛽1 − 𝛽0𝜃1
0 = 𝛽2 − 𝛽1𝜃1
0 = 𝛽3 − 𝛽2𝜃1

y así. Finalmente se resuelven recursivamente estas ecuaciones para las 𝛽’s en términos de las 𝜃’s
y las 𝛿’s. Esto es
𝛽0 = 𝛿0
𝛽1 = 𝛿1 + 𝛽0𝜃1 (9.90)
𝛽𝑗 = 𝛽𝑗−1𝜃1 𝑗 ≥ 2
Dados los valores de 𝑝 y 𝑞, la forma general del modelo ARDL en la notación de (9.88) es
𝛿0 + 𝛿1𝐿 + 𝛿2𝐿2 + ⋯ + 𝛿𝑞𝐿𝑞 = (1 − 𝜃1𝐿 − 𝜃2𝐿2 − ⋯ − 𝜃𝑝𝐿𝑝) × (𝛽0 + 𝛽1𝑙 + 𝛽2𝐿2 + 𝛽3𝐿3 + ⋯ )
(9.91)
por lo que luego de desarrollar el lado derecho, se igualan los coeficientes por potencias de 𝐿 y se
resuelven recursivamente estas ecuaciones para las 𝛽’s en términos de las 𝜃’s y las 𝛿’s.
En el contexto del modelo de la Ley de Okun estimado en (9.59), bajo la notación teórica de (9.52),
el algoritmo en Stata para obtener los valores de los multiplicadores es
use "C:\poe4\okun.dta", clear
generate date = tq(1985q2) + _n-1
format %tq date
tsset date
regress L(0/1).D.u L(0/1).g
matrix beta=J(8,1,0)
matrix beta[1,1]=_b[g]
matrix beta[2,1]=_b[L.g]+_b[g]*_b[LD.u]
for num 3/8:matrix beta[X,1]= beta[X-1,1]*_b[LD.u]
matrix list beta
display "Multiplicador Total = ", _b[g]+(_b[L.g]+_b[g]*_b[LD.u])/(1-_b[LD.u])
clear
svmat beta
gen lag=_n-1
rename beta1 beta
label var beta "Multiplicador"
label var lag "Rezago"
line beta lag, xlabel(0(1)7) ylabel(-0.20(0.02)0.00) title("Multiplicadores de retardo")
subtitle("Modelo ARDL(1,1) de la Ley de Okun")
𝐷�̂�𝑡 = 0.3780 + 0.3501𝐷𝑈𝑡−1 − 0.1841𝐺𝑡 − 0.0992𝐺𝑡−1
𝑦𝑡 = 𝛿 + 𝜃1𝑦𝑡−1 + ⋯ + 𝜃𝑝𝑦𝑡−𝑝 + 𝛿0𝑥𝑡 + 𝛿1𝑥𝑡−1 + ⋯ + 𝛿𝑞𝑥𝑡−𝑞 + 𝑣𝑡
�̂�0 = 𝛿0 = −0.1841
�̂�1 = 𝛿1 + �̂�0�̂�1 = 𝛿1 + 𝛿0𝜃1 = −0.0991552 − 0.1840843 × 0.3501158 = −0.1636
�̂�2 = �̂�1𝜃1 = −0.16360602 × 0.3501158 = −0.0573
�̂�3 = �̂�2𝜃1 = −0.05728105 × 0.3501158 = −0.0201
�̂�4 = �̂�3𝜃1 = −0.020055 × 0.3501158 = −0.0070
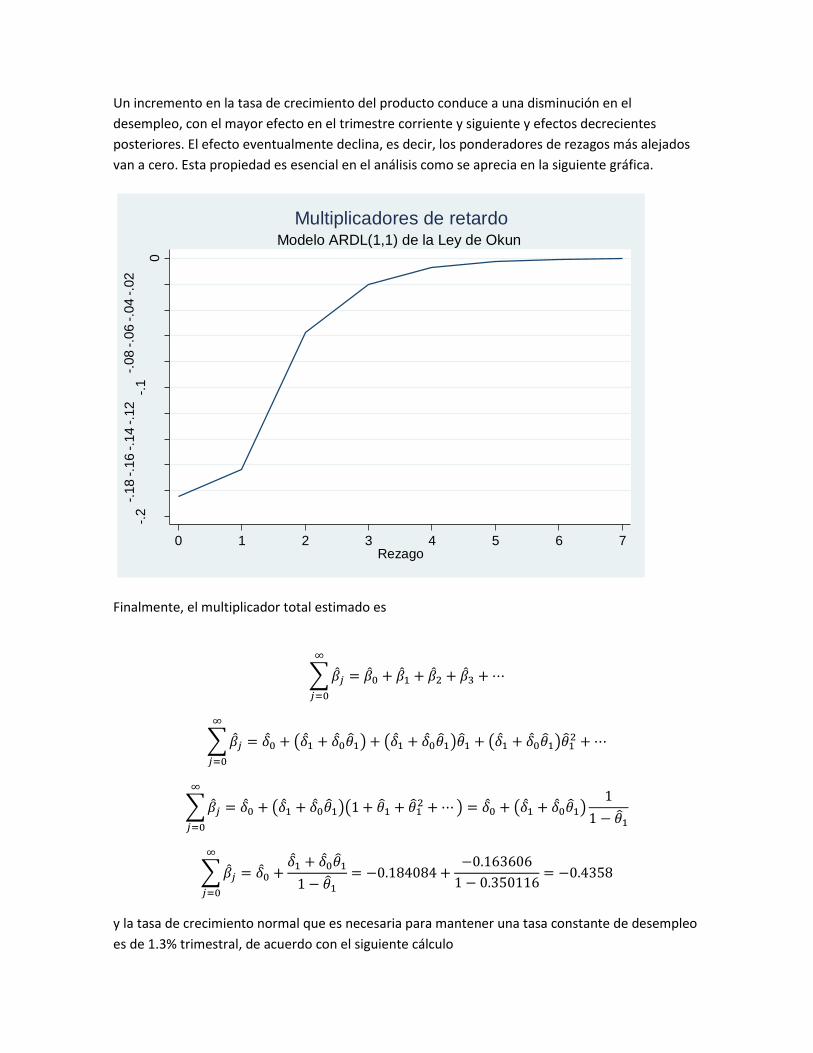
Un incremento en la tasa de crecimiento del producto conduce a una disminución en el
desempleo, con el mayor efecto en el trimestre corriente y siguiente y efectos decrecientes
posteriores. El efecto eventualmente declina, es decir, los ponderadores de rezagos más alejados
van a cero. Esta propiedad es esencial en el análisis como se aprecia en la siguiente gráfica.
Finalmente, el multiplicador total estimado es
∑ �̂�𝑗
∞
𝑗=0
= �̂�0 + �̂�1 + �̂�2 + �̂�3 + ⋯
∑ �̂�𝑗
∞
𝑗=0
= 𝛿0 + (𝛿1 + 𝛿0𝜃1) + (𝛿1 + 𝛿0𝜃1)�̂�1 + (𝛿1 + 𝛿0𝜃1)�̂�12 + ⋯
∑ �̂�𝑗
∞
𝑗=0
= 𝛿0 + (𝛿1 + 𝛿0𝜃1)(1 + 𝜃1 + 𝜃12 + ⋯ ) = 𝛿0 + (𝛿1 + 𝛿0𝜃1)
1
1 − 𝜃1
∑ �̂�𝑗
∞
𝑗=0
= 𝛿0 +𝛿1 + 𝛿0𝜃1
1 − 𝜃1
= −0.184084 +−0.163606
1 − 0.350116= −0.4358
y la tasa de crecimiento normal que es necesaria para mantener una tasa constante de desempleo
es de 1.3% trimestral, de acuerdo con el siguiente cálculo
-.2
-.18
-.16
-.14
-.12
-.1
-.08
-.06
-.04
-.02
0
Mu
ltip
licad
or
0 1 2 3 4 5 6 7Rezago
Modelo ARDL(1,1) de la Ley de Okun
Multiplicadores de retardo

𝐺𝑁 =−�̂�
∑ �̂�𝑗∞𝑗=0
=
−𝛿
1 − 𝜃1
∑ �̂�𝑗∞𝑗=0
=−
0.37801041 − 0.350116
−0.43583068= 1.3%
Estos resultados son consistentes con los vistos al inicio para el modelo DL(q) finito, en el que se
obtuvo un multiplicador total de -0.437 y 𝐺𝑁 = 1.3%.