redes neuronales artificiales y mapas autooraganizados (2004, david martínez gonzález)
TRANSCRIPT

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
RREEDDEESS NNEEUURROONNAALLEESS
AARRTTIIFFIICCIIAALLEESS
YY
MMAAPPAASS AAUUTTOOOORRGGAANNIIZZAADDOOSS
David Martínez González
Sistemas Expertos e Inteligencia Artificial. 3º I.T.I.G.
Curso 2004-05. Universidad de Burgos.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Índice de Contenidos
1. REDES NEURONALES ARTIFICIALES 11.1. Introducción 11.2. Neuronas naturales 11.3. Neuronas artificiales 21.4. Representaciones dimensionales 31.5. Perceptrón 41.6. Ejemplo sobre un perceptrón con una única neurona 51.7. Perceptrón multicapa 61.8. Aprendizaje 7
1.9. Mecanismos de aprendizaje 81.9.1. Supervisado 81.9.2. Con Fortalecimiento 81.9.3. Estocástico 91.9.4. No Supervisado 9
1.9.4.1. Hebbiano 91.9.4.2. Competitivo 10
2. MAPAS AUTOORGANIZADOS (SOM) 122.1. Introducción 122.2. Arquitectura de las SOMs 132.3. Método de Aprendizaje (algoritmo winner-take-all) 14
2.4. Ejemplo sobre el algoritmo winner-take-all 162.5. Obtención de mapas. Función de vecindad. 182.6. Tipos de función de vecindad. 192.7. Variación de la función de vecindad y de la tasa de aprendizaje 202.8. Algoritmo de aprendizaje 212.9. Simulación mediante ordenador 222.10. Variaciones de las SOMs 232.11. Aplicaciones 242.12. Herramientas software de simulación de SOMs 24
3. EJEMPLO DE APLICACIÓN DE LAS SOMs: FACERET 273.1. Introducción 27
3.2. Funcionamiento de FACERET 273.3. Mapas Autoorganizados Arbóreos (TS-SOM) 293.4. Sistemas de selección 313.5. Simulaciones 31
4. BIBLIOGRAFIA Y OTROS RECURSOS 33

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Índice de Figuras
1 Estructura de una neurona natural 12 Similitudes entre neuronas naturales y artificiales 23 Estructura de una neurona artificial 24 Neurona reconociendo la función lógica AND. 45 Representación gráfica del ejemplo sobre el perceptrón 66 Función lógica XOR 77 Perceptrón multicapa 78 Mapa del córtex cerebral. 129 Mapa fonético del idioma finlandés reconocido por una SOM. 13
10 Arquitectura de una SOM 1411 Ejemplo Aprendizaje y sus fases 16
12 Ejemplo Proceso de aprendizaje 1813 SOM reconociendo los colores rojo, verde y azul. 1914 Tipos de función de vecindad 2015 Regiones delimitadas por una función rectangular o de tipo pipa 2016 Simulación por ordenador del algoritmo de aprendizaje. 2217 Estructura de FACERET 2818 Arquitectura de un mapa autoorganizado arbóreo o TS-SOM 2919 Ejemplo de ubicación ordenada de caras en el nivel más bajo de
una estructura TS-SOM30
20 Matriz de selección asociada a un nivel de la TS-SOM 3121 Simulación de una búsqueda en FACERET 32
Índice de Tablas
1 Funciones de activación 32 Ejemplo sobre perceptrón 53 Funcionamiento del aprendizaje hebbiano 104 Datos de entrada y salida esperada sobre el ejemplo del algoritmo
winner-take-all
16
5 Datos obtenidos al aplicar el algoritmo winner-take-all 17

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-1-
1. REDES NEURONALES ARTIFICIALES
1.1. Introducción
El estudio de las redes neuronales artificiales se engloba dentro de la rama subsimbólicade la inteligencia artificial, dicha rama se dedica al estudio y desarrollo de simulacionesde los elementos inteligentes de la naturaleza (cerebros) con el fin de que de formaespontánea estas simulaciones (redes neuronales) se comporten de forma inteligente.
Así pues partiendo del estudio biológico del cerebro humano o animal las redesneuronales intentan simular su estructura y funcionamiento. Si en un cerebro elelemento básico es la neurona, en una red neuronal el elemento básico es la neuronaartificial, debemos conocer el funcionamiento de la neurona natural para simularlo en laneurona artificial.
1.2. Neuronas naturales
La neurona natural está formada por tres partes:[4]• Soma o núcleo celular, es el núcleo de la célula que dirige la actividad de la
misma.• Axón, es una prolongación muy larga que permite transmitir el impulso eléctrico
producido por la soma a otras neuronas.• Dendritas, son pequeñas prolongaciones mediante las cuales se reciben los
impulsos eléctricos de otras neuronas.
Figura 1: Estructura de una neurona natural
La conexión entre axones y dendritas por la que se permite la comunicación entreneuronas se llama sinapsis. En una misma neurona puede haber sinapsis másdesarrolladas que otras, las dendritas con sinapsis más desarrolladas recibirán más vecesimpulsos eléctricos que las otras.
Una neurona es sometida a través de sus dendritas a muchos estímulos eléctricos,cuando la suma de todos los estímulos eléctricos recibidos de sus dendritas es losuficientemente grande se produce la activación de la neurona y su consiguiente emisióneléctrica a través de su axón.
De esta forma una neurona natural es un sistema que procesa varias entradas que lellegan a través de las dendritas, las suma y si la suma supera un umbral se activa y
produce una salida que la lleva al axón, y este a las siguientes neuronas.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-2-
1.3. Neuronas artificiales
Una vez estudiada en profundidad la estructura y funcionamiento de la neurona natural podemos simularla en un elemento de proceso que llamaremos neurona artificial(modelo de McCulloch-Pitts)[6] y que podemos definir como un dispositivo que a partir
de un conjunto de entradas xi, i=1,..n (o vector x), genera una única salida y (binaria).Cada entrada xi lleva asociada un peso wi que representa la importancia que le damos aesa entrada (el desarrollo de la sinapsis), por lo tanto también tenemos como entrada elvector w. Además necesitamos conocer el umbral Θ por el que se activará o no laneurona. Así tenemos como entradas:
• El vector x que representa las entradas.• El vector w que representa los pesos de las entradas• El umbral Θ de activación de la neurona
Se produce una única salida y como resultado de la siguiente fórmula:
y = f(x.w – Θ) = f (Σ xi.wi – Θ)
es decir, comparamos la suma de los productos de las entradas por sus pesos (suma ponderada) y la comparamos con el umbral de activación, si la resta da un resultado positivo la neurona se activa y si es negativo no se activa.
Figura 2. Similitudes entre neuronas naturales y artificiales
El umbral puede ser considerado como una entrada más, x0, en la que su peso w0 tienevalor -1, así la fórmula se simplifica de esta manera:
y = f(x.w) = f (Σ xi.wi)
Figura 3. Estructura de una neurona artificial
La salida y puede tomar diversos valores (según sus diversas funciones de activaciónf(x)):[6]
• Neurona de McCulloch-Pitts: tiene entradas binarias (1,0) y la función deactivación es el escalón definido entre 0 y 1. y = 1 si se supera el umbral (six>0), y = 0 si no se supera.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-3-
• En otros modelos puede tomar el valor 1 si se supera el umbral y -1 si no sesupera.
• Neurona sigmoidea: las entradas pueden ser de cualquier tipo, continuas odiscretas, pero la salida es continua con la función de activación de tiposigmoide:
axe
x f −+
=1
1)(
• Existe otra variante trigonométrica en el que la función de activación es unafunción trigonométrica como la tangente hiperbólica.
)tanh()( x x f =
• Por último también se puede utilizar la función identidad f(x)=x
f(x)=1 si x>0f(x)=0 si x<0
f(x)=1 si x>0f(x)=-1 si x<0
Sigmoidea Tangentehiperbólica
f(x)=x
Tabla 1. Funciones de activación
La red neuronal debe ser sometida a un proceso de aprendizaje antes de su utilización,en dicho proceso los pesos de cada una de sus neuronas se modifican para dar más
relevancia a unas entradas frente a otras y conseguir la especialización de cada neuronaque forma la red neuronal. Este ajuste de los pesos debe hacerse basándose en algunaregla de aprendizaje, que se plasma en un algoritmo de aprendizaje, el cual determina el
procedimiento numérico de ajuste de los pesos.
1.4. Representaciones dimensionales
Si en una neurona tenemos dos entradas x1 y x2, podemos representar el funcionamientoy la salida de la neurona en un plano con ejes de coordenadas x1 y x2 (dos dimensiones),
para cada combinación de valores de x1 y x2 podemos indicar la salida esperada y con(por ejemplo) un circulo relleno para indicar la salida afirmativa (activación de la
neurona, suele ser 1 pero depende de la función de activación) y circulo vacío paraindicar la salida negativa (neurona no activada, 0 o -1 dependiendo del modelo,consideramos que la salida es discreta).
Si en lugar de dos entradas tuviésemos tres entradas deberíamos representarlo en unosejes de coordenadas de tres dimensiones xyz
Volviendo a nuestro espacio de dos dimensiones y basándonos en la fórmula:
y = f(x.w – Θ) = f (Σ xi.wi – Θ)
desarrollando:

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-4-
x1w1 + x2w2 - Θ = 0
considerando x1 y x2 como incógnitas y w1, w2 y Θ como valores fijos tenemos laecuación de una recta en la que al modificar los pesos modificamos la inclinación de larecta y modificando el umbral movemos la recta acercándola o alejándola del centro del
eje de coordenadas
-2
-1
0
1
2
-2 -1 0 1 2
Figura 4. Neurona reconociendo la función lógica AND.
Esta recta nos determina el límite por el que la salida se considera correcta para unosvalores de las entradas, por ejemplo para cualquier combinación de entradas que den un
punto que se encuentre a la izquierda de la recta se considera que la salida es correcta, laneurona se activa, si el punto se encuentra a la derecha la neurona no se activa.
Si la recta divide el espacio dejando a un lado todos los círculos rellenos y a otro ladotodos los círculos vacíos, hemos hallado los pesos y el umbral correctos por lo que laneurona estará bien entrenada.
Si en lugar de tener un espacio de dos dimensiones (dos entradas) tenemos uno de tresdimensiones (tres entradas) en lugar de una recta tendremos un plano que dividirá elespacio en dos subespacios.
1.5. PerceptrónEs una aplicación práctica de las neuronas artificiales que permite el reconocimiento deimágenes y la resolución de problemas sencillos. En este modelo los pesos ya no estánrestringidos a valores 1 o -1, su valor se modifica a lo largo del aprendizaje a través dela fórmula:
∆wi = η.xi p (t p – o p)
Dondeη es el factor de aprendizaje, un número pequeño que se hace más pequeño a lo largo
del aprendizajet p es el vector que representa la salida esperada

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-5-
o p es el vector que representa la salida obtenida: o p = w.x xi
p es el vector entrada
La diferencia entre datos esperados y datos obtenidos representa el error que queremosminimizar, su decremento marca la convergencia hacia los datos esperados a través de
la modificación de los pesos en cada iteración.
wij(t) = wij(t-1) + ∆wij
Algoritmo de aprendizaje:• El experimento comienza con unos valores aleatorios para los pesos• Se selecciona un vector de entrada del que conocemos la salida deseada.• Se calcula la salida según los pesos actuales.• Si la salida es correcta se vuelve al paso 2, sino se modifican los pesos.
1.6. Ejemplo sobre un perceptrón con una única neurona
En una empresa se fabrican y venden 5 clases de productos (los numeramos del 1 al 5) a3 clases de clientes (A, B y C). Existen unas restricciones de forma que los clientes detipo A sólo pueden comprar productos de las clases 3, 4 y 5, los de tipo B sólo puedencomprar productos de las clases 4 y 5 y los de tipo C productos de clase 5. Es decir,tenemos como entrada el producto y el cliente y como salida la venta (si o no):
Producto (x1) Cliente (x2) Venta (salida)1 A NO2 A NO
3 A SI4 A SI5 A SI1 B NO2 B NO3 B NO4 B SI5 B SI1 C NO2 C NO3 C NO4 C NO5 C SI
Tabla 2. Ejemplo sobre perceptrón
La neurona se activará cuando la venta sea posible. Utilizamos los pesos y el umbral:w1 = 0.5w2 = 0.5Θ = 2.9y renombramos los tipos de clientes A, B y C por 3, 2 y 1 para poder operar con ellos,aplicamos la fórmula y = f(x.w) = f (Σ xi.wi) y obtenemos:
1*0.5 + 3*0.5 = 2 < 2.9
NO2*0.5 + 3*0.5 = 2.5 < 2.9 NO3*0.5 + 3*0.5 = 3 > 2.9 SI
5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-6-
4*0.5 + 3*0.5 = 3.5 > 2.9 SI5*0.5 + 3*0.5 = 4 > 2.9 SI
1*0.5 + 2*0.5 = 1.5 < 2.9 NO2*0.5 + 2*0.5 = 2 < 2.9 NO
3*0.5 + 2*0.5 = 2.5 < 2.9 NO4*0.5 + 2*0.5 = 3 > 2.9 SI5*0.5 + 2*0.5 = 3.5 > 2.9 SI
1*0.5 + 1*0.5 = 1 < 2.9 NO2*0.5 + 1*0.5 = 1.5 < 2.9 NO3*0.5 + 1*0.5 = 2 < 2.9 NO4*0.5 + 1*0.5 = 2.5 < 2.9 NO5*0.5 + 1*0.5 = 3 > 2.9 SI
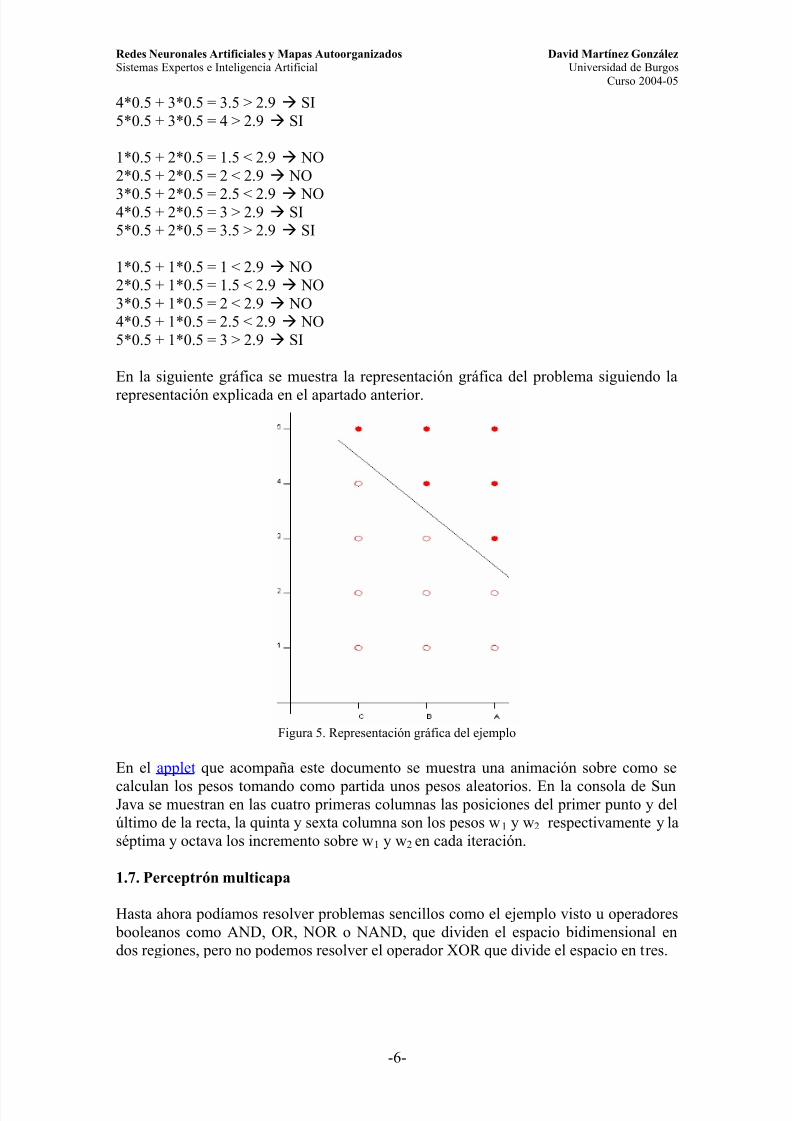
En la siguiente gráfica se muestra la representación gráfica del problema siguiendo la
representación explicada en el apartado anterior.
Figura 5. Representación gráfica del ejemplo
En el applet que acompaña este documento se muestra una animación sobre como se
calculan los pesos tomando como partida unos pesos aleatorios. En la consola de SunJava se muestran en las cuatro primeras columnas las posiciones del primer punto y delúltimo de la recta, la quinta y sexta columna son los pesos w1 y w2 respectivamente y laséptima y octava los incremento sobre w1 y w2 en cada iteración.
1.7. Perceptrón multicapa
Hasta ahora podíamos resolver problemas sencillos como el ejemplo visto u operadores booleanos como AND, OR, NOR o NAND, que dividen el espacio bidimensional endos regiones, pero no podemos resolver el operador XOR que divide el espacio en tres.
5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-7-
-2
-1
0
1
2
-2 -1 0 1 2
Figura 6. Función lógica XOR
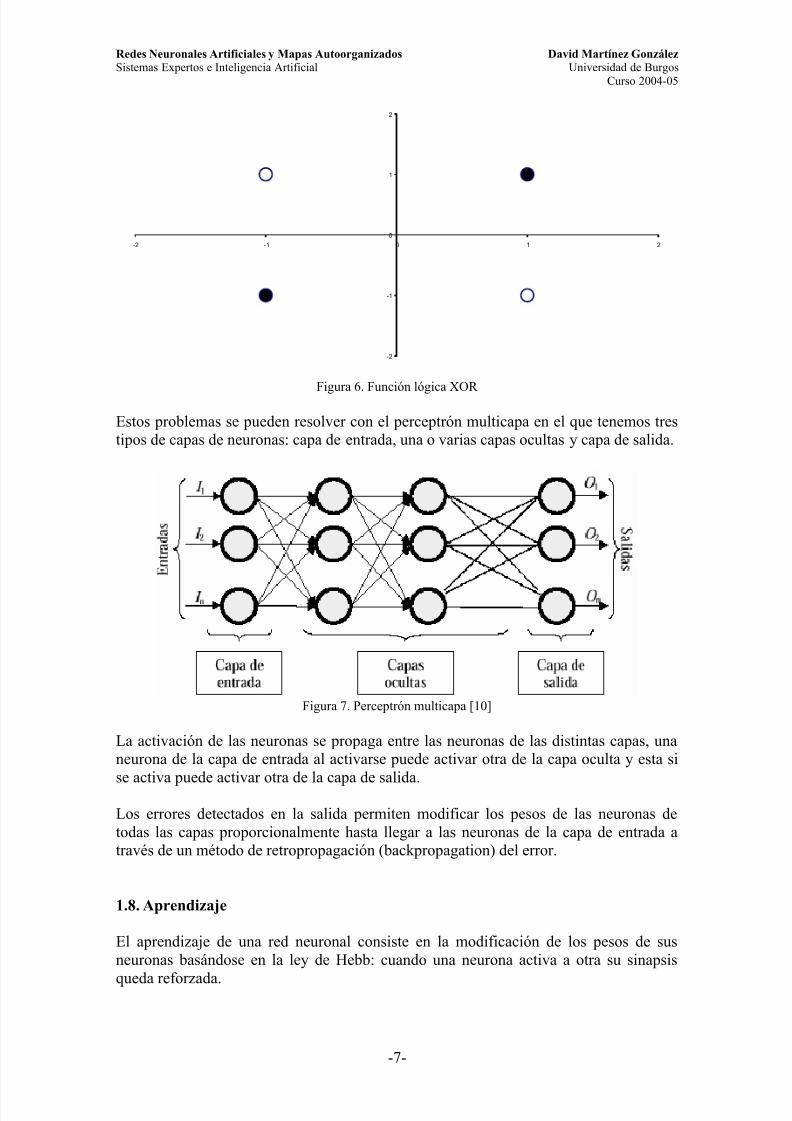
Estos problemas se pueden resolver con el perceptrón multicapa en el que tenemos trestipos de capas de neuronas: capa de entrada, una o varias capas ocultas y capa de salida.
Figura 7. Perceptrón multicapa [10]
La activación de las neuronas se propaga entre las neuronas de las distintas capas, unaneurona de la capa de entrada al activarse puede activar otra de la capa oculta y esta si
se activa puede activar otra de la capa de salida.Los errores detectados en la salida permiten modificar los pesos de las neuronas detodas las capas proporcionalmente hasta llegar a las neuronas de la capa de entrada através de un método de retropropagación (backpropagation) del error.
1.8. Aprendizaje
El aprendizaje de una red neuronal consiste en la modificación de los pesos de susneuronas basándose en la ley de Hebb: cuando una neurona activa a otra su sinapsis
queda reforzada.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-8-
Mediante la modificación de los pesos se produce la especialización de las neuronas detal forma que las redes neuronales adquieren facultades de clasificación e identificaciónde patrones.
Pero más relevante que esto es la capacidad de generalización, la red debe ser capaz al
finalizar su entrenamiento de generalizar sus resultados, lo que le faculta para identificar o clasificar cualquier cosa que sea similar al patrón aprendido, no sólo los objetos particulares con los que ha aprendido en la fase de entrenamiento.
Una vez entrenada, la red congela sus pesos y funcionará en modo de recuerdo oejecución: se le suministra una entrada y la red responde con una salida.
1.9. Mecanismos de Aprendizaje:
1.9.1. Supervisado
Se le suministra a la red un conjunto de datos de entrada y la respuesta esperada. Secomparan los datos obtenidos por el sistema con los datos de entrada aportados, con larespuesta esperada y se modifican los pesos en función del error obtenido.
El conjunto de datos utilizados en el proceso de aprendizaje se denomina conjunto deentrenamiento (training set). Si los vectores de entrada utilizados no contienen lainformación idónea la red puede llegar a no aprender.
La duración del proceso de aprendizaje no se conoce a priori, puede durar minutos omeses hasta que la red alcanza los resultados deseados.
Algunos modelos que implementan este tipo de aprendizaje son:• Perceptrón y perceptrón multicapa• RBF, BAM
Aplicaciones en problemas sobre:• Clasificación, reconocimiento de patrones• Predicción• Análisis de datos• Control
1.9.2. Con Fortalecimiento
En este método no se informa al sistema sobre el resultado esperado, sólo se le indica siel resultado es correcto o incorrecto (éxito = +1 o fracaso = -1), sin aportarle másinformación.
Si la red produce una respuesta incorrecta se produce el ajuste de los valores de los pesos basándose en un mecanismo de probabilidades.
Es un método de aprendizaje más lento que el aprendizaje supervisado.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-9-
1.9.3. Estocástico
Consiste básicamente en realizar cambios aleatorios en los valores de los pesos de lasconexiones de la red y evaluar su efecto a partir del objetivo deseado y de distribucionesde probabilidad.
En pocas palabras el aprendizaje consistiría en realizar un cambio aleatorio de losvalores de los pesos y determinar la energía de la red. Si la energía es menor después delcambio, es decir, si el comportamiento de la red se acerca al deseado, se acepta elcambio; si, por el contrario, la energía no es menor, se aceptaría el cambio en función deuna determinada y preestablecida distribución de probabilidades.
1.9.4. No supervisado
Sólo se aplica a la red neuronal los datos de entrada, sin indicarle la salida esperada.La red neuronal es capaz de reconocer algún tipo de estructura en el conjunto de datos
de entrada (normalmente redundancia de datos) y de esta forma se produce elautoaprendizaje.
Durante el proceso de aprendizaje la red autoorganizada debe descubrir por sí mismarasgos comunes, regularidades, correlaciones o categorías en los datos de entrada, eincorporarlos a su estructura interna de conexiones. Se dice, por tanto, que las neuronasdeben autoorganizarse en función de los estímulos (datos) procedentes del exterior.
Algunos modelos que implementan este tipo de aprendizaje son:• Mapas autoorganizados•
PCA• Redes de HopfieldAplicaciones en problemas sobre:
• Análisis y comprensión de datos• Agrupamiento• Memoria asociativa
En cuanto a los algoritmos de aprendizaje no supervisado, en general se suelenconsiderar dos tipos, que dan lugar a los siguientes aprendizajes:
• Aprendizaje hebbiano.
• Aprendizaje competitivo.
1.9.4.1. Hebbiano
Esta regla de aprendizaje es la base de muchas otras, la cual pretende medir lafamiliaridad o extraer características de los datos de entrada. El fundamento es unasuposición bastante simple: si dos neuronas Ni y Nj toman el mismo estadosimultáneamente (ambas activas o ambas inactivas), el peso de la conexión entre ambasse incrementa.
Las entradas y salidas permitidas a la neurona son: {-1, 1} o {0, 1} (neuronas binarias).Esto puede explicarse porque la regla de aprendizaje de Hebb se originó a partir de laneurona biológica clásica, que solamente puede tener dos estados: activa o inactiva.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-10-
Este aprendizaje se basa en una simulación matemática de la ley de Hebb: cuando unaneurona activa a otra su sinapsis queda reforzada. Veamos como funciona:Supongamos que dos neuronas i y j están conectadas de tal forma que la salida de i es laentrada de j. Definimos el ajuste de los pesos de esta conexión como: [2]
∆w=c*(oi*o j)
Donde c es el factor de aprendizaje y es constante, oi es el signo (positivo o negativo) dela salida de la neurona i y o j es el signo de la salida de la neurona j. En la siguiente tabla
podemos ver que cuando ambas son positivas o negativas ∆w es positivo y se produceel refortalecimiento de la sinapsis de ambas neuronas. Cuando ∆w es negativo se inhibela conexión entre las dos neuronas.
Oi Oj Oi*Oj+ + +
+ - -- + -- - +
Tabla 3. Funcionamiento del aprendizaje hebbiano
En general lo podemos expresar así:
∆wij = η*(x j*yi)
Siendo η el factor de aprendizaje e yi = Σ x j.wij
1.9.4.2. Competitivo
En la red neuronal tiene lugar una competición entre las neuronas de forma que laneurona que gana la competición se activará, las demás neuronas no se activan.
La competición la gana la neurona cuyo vector de pesos sea más parecido al vector entrada.
En el aprendizaje competitivo simple se encuentra una neurona ganadora y se actualizanlos pesos únicamente de esa neurona para hacer que tenga más posibilidades para ganar
la próxima vez que un vector de entrada similar sea mostrado a la red. De esta forma se produce su especialización en el reconocimiento de este tipo de entradas al activarseúnicamente ante una entrada similar.
Se puede presentar un problema en este tipo de aprendizaje: algunas neuronas puedenllegar a dominar el proceso y ganar siempre mientras otras neuronas no ganan nunca(neuronas muertas). Para evitar esto nos aseguramos de que los pesos son actualizados ynormalizados en cada iteración.
Este aprendizaje se suele presentar en las neuronas de la capa de salida, a este tipo deneuronas se las llama el-ganador-toma-todo (winner-take-all)

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-11-
Se produce una organización en función de la estructura de los datos de la entrada. Estemétodo intenta asegurar que los elementos que pertenecen al mismo grupo sean lo mássimilares posible entre sí y lo más diferentes posibles a elementos de otros grupos.
El objetivo de este tipo de aprendizaje es categorizar conjuntos de datos estudiando su
estructura y clasificándolo en grupos.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-12-
2. MAPAS AUTOORGANIZADOS (SOM)
2.1. Introducción
Los Mapas Autoorganizados o SOM (Self-Organizing Maps) fueron creados por TeuvoKohonen entre los años 1982 y 1990, y son (en su mayoría) una puesta en práctica delaprendizaje no supervisado y competitivo (de cuyo algoritmo winner-take-all fuecreador Kohonen en 1984). Existe una pequeña minoría de SOMs en las que en lugar del aprendizaje competitivo utilizan el hebbiano, descrito en el anterior apartado.
Los estudios sobre este tipo de redes están relacionados con los estudios sobre redes biológicas. Se ha observado que en el córtex cerebral de los animales superioresaparecen zonas donde las neuronas detectoras de rasgos similares se encuentrantopológicamente ordenadas; de forma que las informaciones captadas del entorno através de los órganos sensoriales, se representan internamente en forma de mapas
bidimensionales. [1] De esta forma existe una zona dedica al tratamiento de la visión,otra diferente para el oído, otra para las funciones motoras, etc. Incluso las neuronas quereciben señales de sensores que se encuentran próximos en la piel se sitúan también
próximas en el córtex, de manera que reproducen (de forma aproximada) el mapa de lasuperficie de la piel en una zona de la corteza cerebral, es decir se reproduce latopología observada.
Figura 8. Mapa del córtex cerebral. Podemos distinguir las siguientes áreas: motoras (4, 6, 8), visuales(17, 18, 19) y auditivas (41, 42) situadas de forma ordenada en el córtex cerebral. [3]
Aunque en gran medida esta organización neuronal está predeterminada genéticamente,es probable que parte de ella se origine mediante el aprendizaje. Esto sugiere, por tanto,que el cerebro podría poseer la capacidad inherente de formar mapas topológicos de lasinformaciones recibidas del exterior. [9]Por otra parte, también se ha observado que la influencia que una neurona ejerce sobre
las demás es función de la distancia entre ellas, siendo muy pequeña cuando están muyalejadas y muy grande cuando están muy cerca la una de la otra.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-13-
Basándose en estas ideas se desarrollaron los mapas autoorganizados, de forma quecuando un conjunto de datos de entrada se presenta a la red, los pesos de las neuronas seadaptan de forma que la clasificación presente en el espacio de entrada se preserva en lasalida.
Básicamente las SOMs pueden cumplir con dos funcionalidades:• Actuar como clasificadores, encontrando patrones en los datos de entrada y
clasificándolos en grupos según estos patrones.• Representar datos multidimensionales en espacios de mucha menor dimensión,
normalmente una o dos dimensiones, preservando la topología de la entrada.Esto es muy útil cuando se trabaja con espacios multidimensionales (más de tresdimensiones) que el ser humano no es capaz de representar, como por ejemploen problemas físicos en los que intervienen numerosas variables comotemperatura, presión, humedad, etc.
Un ejemplo de aplicación muy conocido es el reconocimiento de fonemas de unlenguaje (en este caso el finlandés). Tras el aprendizaje obtenemos un mapa fonético enel que cada neurona se ha especializado en reconocer un tipo de fonema, y en el quesonidos similares o pequeñas variaciones quedan representados sobre neuronas vecinas.
Figura 9. Mapa fonético del idioma finlandés reconocido por una SOM. [1]
De esta forma vemos como el mapa autoorganizado mimetiza con la especialización desus neuronas la realidad observada, el orden que existe entre los fonemas. Hay quedestacar, además, el parecido del mapa fonético con los mapas fonotópicos del córtextemporal del cerebro.
2.2. Arquitectura de las SOM
La arquitectura de una red neuronal determina qué posibles interconexiones entreneuronas son factibles entre las neuronas de la red.
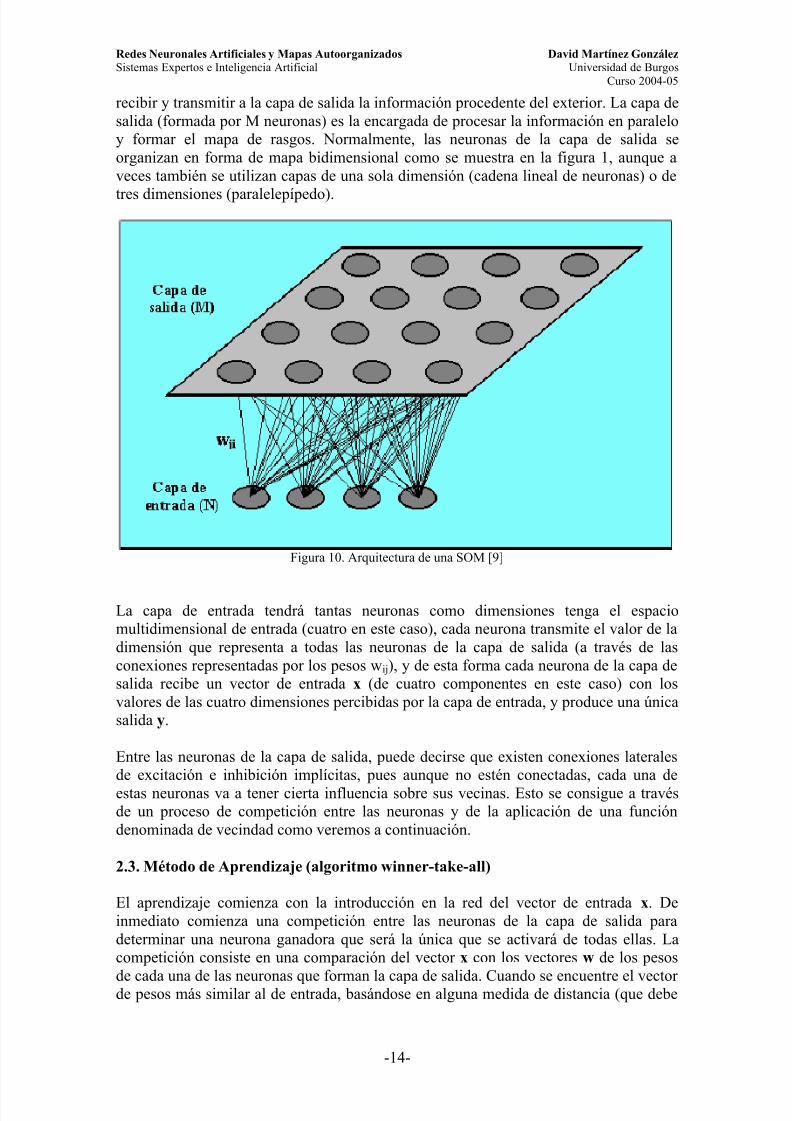
La arquitectura de una SOM está formada por dos capas de neuronas. La capa deentrada (formada por N neuronas, una por cada variable de entrada) se encarga de
5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-14-
recibir y transmitir a la capa de salida la información procedente del exterior. La capa desalida (formada por M neuronas) es la encargada de procesar la información en paraleloy formar el mapa de rasgos. Normalmente, las neuronas de la capa de salida seorganizan en forma de mapa bidimensional como se muestra en la figura 1, aunque aveces también se utilizan capas de una sola dimensión (cadena lineal de neuronas) o de
tres dimensiones (paralelepípedo).
Figura 10. Arquitectura de una SOM [9]
La capa de entrada tendrá tantas neuronas como dimensiones tenga el espaciomultidimensional de entrada (cuatro en este caso), cada neurona transmite el valor de ladimensión que representa a todas las neuronas de la capa de salida (a través de lasconexiones representadas por los pesos wij), y de esta forma cada neurona de la capa desalida recibe un vector de entrada x (de cuatro componentes en este caso) con losvalores de las cuatro dimensiones percibidas por la capa de entrada, y produce una únicasalida y.
Entre las neuronas de la capa de salida, puede decirse que existen conexiones lateralesde excitación e inhibición implícitas, pues aunque no estén conectadas, cada una deestas neuronas va a tener cierta influencia sobre sus vecinas. Esto se consigue a travésde un proceso de competición entre las neuronas y de la aplicación de una funcióndenominada de vecindad como veremos a continuación.
2.3. Método de Aprendizaje (algoritmo winner-take-all)
El aprendizaje comienza con la introducción en la red del vector de entrada x. Deinmediato comienza una competición entre las neuronas de la capa de salida paradeterminar una neurona ganadora que será la única que se activará de todas ellas. Lacompetición consiste en una comparación del vector x con los vectores w de los pesos
de cada una de las neuronas que forman la capa de salida. Cuando se encuentre el vector de pesos más similar al de entrada, basándose en alguna medida de distancia (que debe

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-15-
ser mínima), la neurona poseedora de esos pesos se declara neurona ganadora o BMU(Best Matching Unit).Para calcular las distancias entre x y w se utiliza: [6]
• Producto escalar o correlación (xwi donde i indica el nº de neurona), dosvectores serán más similares cuanto mayor sea su correlación. Costosa cuando el
tamaño de los vectores es grande.• Producto escalar normalizado (regla del coseno), medida independiente del
tamaño de los vectores.
),cos(|||||||| i
i
i w x xw
xw=
• Distancia euclídea, dos vectores serán más similares cuanto menor sea sudistancia.
2)(),( k
k
ik i xww x D −= ∑
• Distancia de Minkowsky (generalización de la euclídea para valores de
exponente y raíz diferentes de 2)
( ) ℜ∈
−= ∑ λ
λ λ ,),(
1
k
k ik i xww x D
• Distancia de Manhattan (caso concreto de la anterior para λ=1)||),( ∑ −=
k
k ik i xww x D
Al activarse únicamente la neurona BMU estamos potenciando que esa neuronaganadora se esté especializando en activarse cuando le lleguen entradas de ese tipo. Elvector de pesos asociado a la neurona vencedora se modifica de manera que se parezcaun poco más al vector de entrada. De este modo, ante el mismo patrón de entrada, dichaneurona responderá en el futuro todavía con más intensidad.
Así establecemos la siguiente regla de aprendizaje
∆wij = α * (x j – wij), para i=c
∆wij = 0, para i≠c
donde c indica la neurona BMU y α es una constante llamada tasa de aprendizaje que
tendrá un valor pequeño para que los pesos de la red no oscilen demasiado entreiteraciones.
Como: ∆wij = α * (x j – wij) = α * x j - α * wij
Podemos observar que en cada iteración se elimina un cierta fracción del antiguo vector de pesos w (lo que implica un cierto olvido), el cual es sustituido por una fracción delvector actual x, de modo que en cada paso el vector de pesos de la ganadora w se pareceun poco más al vector de entradas x que la hace ganar. [1]
∆wij para la neurona ganadora va a ser un valor muy pequeño porque la diferencia (x j –
wij) es la mínima posible de la red neuronal, de esta forma apenas variamos los pesos de

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-16-
la neurona ganadora. Si ∆wij tiene un valor grande supone que nuestra red no estáapenas entrenada y que es necesario hacer retoques importantes en la misma.
Este proceso se repite para numerosos patrones de entrada, de forma que al final cadaneurona se especializa en reconocer cada clase en las que está dividido el espacio de
entrada.
La siguiente interpretación geométrica (Masters, 1993) del proceso de aprendizaje puede resultar interesante para comprender la operación de la red SOM. [1] El efecto dela regla de aprendizaje no es otro que acercar de forma iterativa el vector de pesos de laneurona de mayor actividad (ganadora) al vector de entrada. En la figura se muestran enun espacio bidimensional tres clusters (grupos) correspondientes a tres neuronas quedeben terminar reconociendo cada uno su correspondiente cluster. Los límites de losclusters están dibujados en negro. Al principio del entrenamiento los vectores de pesosde las tres neuronas (representados por vectores de color rojo) son aleatorios y sedistribuyen por la circunferencia. Conforme avanza el aprendizaje, éstos se van
acercando progresivamente a las muestras procedentes del espacio de entrada, paraquedar finalmente estabilizados como centroides de los tres clusters.
Figura 11. Aprendizaje y sus fases. [1]
2.4. Ejemplo sobre el algoritmo winner-take-all [2]
Consideramos las entradas x1 y x2 y la salida esperada que se muestran a continuación:
x1 x2 Salida1.0 1.0 19.4 6.4 -12.5 2.1 18.0 7.7 -10.5 2.2 17.9 8.4 -17.0 7.0 -12.8 0.8 11.2 3.0 17.8 6.1 -1
Tabla 4. Datos de entrada y salida esperada.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-17-
Queremos entrenar una red neuronal sencilla formada por sólo dos neuronas (A y B)que van a recibir ambas las entradas x1 y x2. Inicializamos los vectores de pesos de cada neurona con los valores (7,2) y (2,9)correspondientes a los vectores w1 y w2 de las neuronas A y B respectivamente.
El entrenamiento comienza con la introducción en la red del primer par de datos.Utilizaremos la distancia euclídea como medida de la distancia entre los pesos de lasneuronas y la entrada para determinar la neurona ganadora. Calculamos la distanciarespecto de la neurona A:D((1,1),(7,2))=√((1-7)2+(1-2)2)=6.08respecto de la neurona B:D((1,1),(2,9))= √((1-2)2+(1-9)2)=8.06como podemos observar la distancia menor corresponde a la neurona A, esta neurona esla ganadora de la competición. Calculamos el incremento de pesos con el que vamos a
premiar a la neurona ganadora, aplicando la regla ∆wij = α * (x j – wij) donde tomamosun α = 0.5
∆w = 0.5((1,1)-(7,2))=(-3,-0.5)Actualizamos los pesos de la neurona A (los de la neurona B los dejamos como están):w(t) = w(t-1) + ∆w = (7,2) + (-3,-0.5) = (4,1.5)
Procesamos las restantes entradas de la misma manera y obtenemos la siguiente tabla:
x1 x2 D(x,A) D(x,B) BMU ∆wA ∆wB w(t)A w(t)B 9.4 6.4 7.29 7.75 A (2.7,2.5) 0 (6.7,4) (2,9)2.5 2.1 4.6 6.92 A (-2.1,-0.5) 0 (4.6,3.5) (2,9)8.0 7.7 5.4 6.14 A (1.7,2.1) 0 (6.3,5.6) (2,9)
0.5 2.2 6.72 6.96 A (-2.9,-1.7) 0 (3.4,3.9) (2,9)7.9 8.4 6.36 5.93 B 0 (2.9,-0.3) (3.4,3.9) (4.9,8.7)7.0 7.0 4.75 2.7 B 0 (1.05,-0.85) (3.4,3.9) (6,7.85)2.8 0.8 3.16 7.74 A (-0.3,-1.5) 0 (3.1,2.4) (6,7.85)1.2 3.0 2 6.82 A (-0.95,0.3) 0 (2.15,2.7) (6,7.85)7.8 6.1 6.6 2.5 B 0 (0.9,-0.87) (2.15,2.7) (6.9,7)
Tabla 5. Datos obtenidos al aplicar el algoritmo
Al final del proceso obtenemos los pesos:wA = (2.15,2.7)wB = (6.9,7)
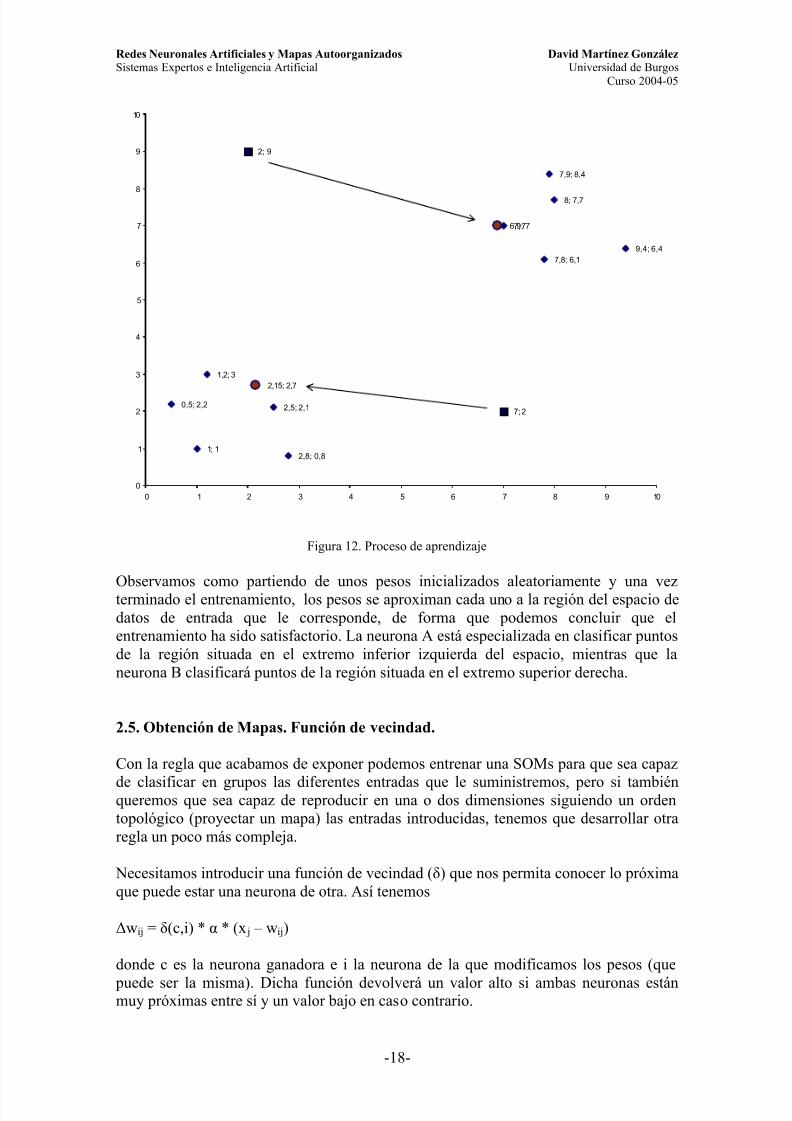
En el siguiente gráfico se representan los datos de entrada (con un rombo) junto con los pesos inicializados aleatoriamente (cuadrados) y los mismos pesos al finalizar elentrenamiento (círculos). Se puede observar como los datos de entrada se distribuyen endos regiones del espacio bidimensional, cada región representa una clase que nuestrared neuronal es capaz de reconocer a través de sus dos neuronas, una para cada clase.
5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-18-
1; 1
9,4; 6,4
2,5; 2,1
8; 7,7
0,5; 2,2
7,9; 8,4
7; 7
2,8; 0,8
1,2; 3
7,8; 6,1
7; 2
2; 9
2,15; 2,7
6,9; 7
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
Figura 12. Proceso de aprendizaje
Observamos como partiendo de unos pesos inicializados aleatoriamente y una vezterminado el entrenamiento, los pesos se aproximan cada uno a la región del espacio dedatos de entrada que le corresponde, de forma que podemos concluir que elentrenamiento ha sido satisfactorio. La neurona A está especializada en clasificar puntosde la región situada en el extremo inferior izquierda del espacio, mientras que laneurona B clasificará puntos de la región situada en el extremo superior derecha.
2.5. Obtención de Mapas. Función de vecindad.
Con la regla que acabamos de exponer podemos entrenar una SOMs para que sea capaz
de clasificar en grupos las diferentes entradas que le suministremos, pero si tambiénqueremos que sea capaz de reproducir en una o dos dimensiones siguiendo un ordentopológico (proyectar un mapa) las entradas introducidas, tenemos que desarrollar otraregla un poco más compleja.
Necesitamos introducir una función de vecindad (δ) que nos permita conocer lo próximaque puede estar una neurona de otra. Así tenemos
∆wij = δ(c,i) * α * (x j – wij)
donde c es la neurona ganadora e i la neurona de la que modificamos los pesos (que
puede ser la misma). Dicha función devolverá un valor alto si ambas neuronas estánmuy próximas entre sí y un valor bajo en caso contrario.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-19-
Esta fórmula se aplicará a todas las neuronas de la red y no sólo a la ganadora comoocurría antes. En este modelo seguiremos llamando neurona ganadora a la que tengamínima diferencia entre sus pesos y la entrada.
De esta forma los pesos de todas las neuronas se modificarán en función de su cercaníarespecto de la ganadora, los pesos de las neuronas más cercanas sufrirán un incrementomayor que los pesos de las neuronas más lejanas.
Figura 13. SOM reconociendo los colores rojo, verde y azul. A medida que nos acercamos a las neuronasganadoras de cada clase el color se vuelve más intenso.
Con esto conseguimos que los pesos de las neuronas cercanas a la ganadora sean muysimilares a los pesos de la ganadora y esta similitud irá disminuyendo progresivamentea medida que nos alejemos de la neurona BMU. Esto es lo que permite formar unaordenación topológica de la red neuronal dividiendo ésta en regiones y mimetizando asíla topología de la realidad de la que se toman los datos.
La utilización de la función de vecindad en el modelo de mapas autoorganizados aportarespecto del modelo competitivo sencillo dos ventajas adicionales: el ritmo efectivo deconvergencia se mejora y el sistema es más robusto frente a variaciones en los valoresiniciales de los pesos.
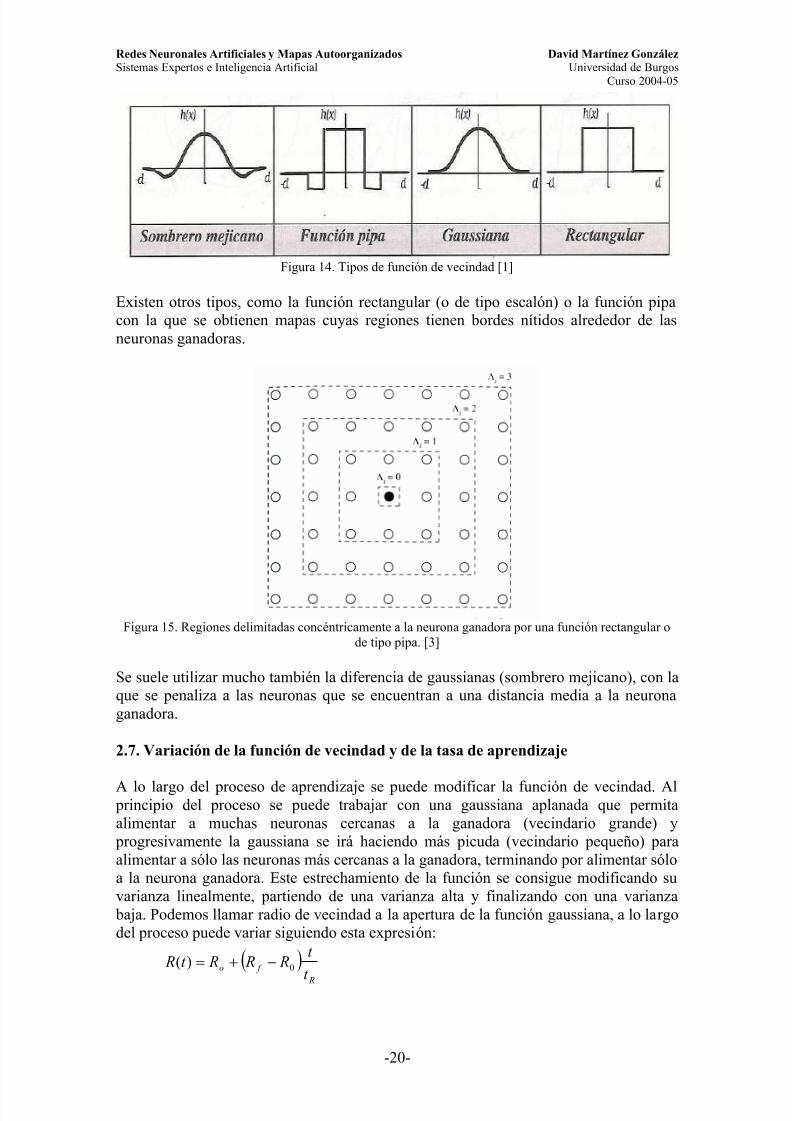
2.6. Tipos de función de vecindad
Normalmente la función de vecindad (δ) suele seguir una curva Gaussiana centrada enla posición de la neurona ganadora. Pero también puede tener otras formas:
5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-20-
Figura 14. Tipos de función de vecindad [1]
Existen otros tipos, como la función rectangular (o de tipo escalón) o la función pipacon la que se obtienen mapas cuyas regiones tienen bordes nítidos alrededor de lasneuronas ganadoras.
Figura 15. Regiones delimitadas concéntricamente a la neurona ganadora por una función rectangular ode tipo pipa. [3]
Se suele utilizar mucho también la diferencia de gaussianas (sombrero mejicano), con laque se penaliza a las neuronas que se encuentran a una distancia media a la neuronaganadora.
2.7. Variación de la función de vecindad y de la tasa de aprendizaje
A lo largo del proceso de aprendizaje se puede modificar la función de vecindad. Al principio del proceso se puede trabajar con una gaussiana aplanada que permitaalimentar a muchas neuronas cercanas a la ganadora (vecindario grande) y
progresivamente la gaussiana se irá haciendo más picuda (vecindario pequeño) paraalimentar a sólo las neuronas más cercanas a la ganadora, terminando por alimentar sóloa la neurona ganadora. Este estrechamiento de la función se consigue modificando suvarianza linealmente, partiendo de una varianza alta y finalizando con una varianza
baja. Podemos llamar radio de vecindad a la apertura de la función gaussiana, a lo largodel proceso puede variar siguiendo esta expresión:
( ) R
f o
t
t R R Rt R 0)( −+=

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-21-
donde R 0 representa el radio inicial y tiene un valor grande y R f el radio final y tiene unvalor igual a 1, t representa la iteración y tR el número de iteraciones para alcanzar R f
También suele variar a lo largo del proceso la tasa de aprendizaje (α) partiendo con unvalor alto (con el que la modificación de los pesos es mayor) y disminuyendo
linealmente hacia un valor bajo. A lo largo del proceso de aprendizaje modificamos encada iteración un poco menos los pesos respecto de la anterior.
Podemos aplicar la ecuación anterior a la tasa de aprendizaje obteniendo una funciónlineal de decrecimiento:
( )α
α α α α t
t t f o 0)( −+=
o bien podemos utilizar la siguiente función exponencial obteniendo un decrecimientomás rápido:
α
α
α
α α
t t
f
t
= 00)(
Con la variación de estos dos parámetros se consigue favorecer (y hacer más rápida) laconvergencia de los pesos creando así una SOM eficiente.
2.8. Algoritmo de Aprendizaje
El proceso de aprendizaje comprende dos fases fundamentales: una ordenación global,en la que se produce el despliegue del mapa y un ajuste fino, en el que las neuronas seespecializan.
En el proceso de aprendizaje para el despliegue del mapa se pueden seguir estos pasos:[5]
1. Los pesos de todas las neuronas se inicializan aleatoriamente con valores pequeños, para que todas las neuronas tengan similares posibilidades de ganar.
2. Se inicializa la tasa de aprendizaje (α) y la varianza inicial de la función devecindad (δ)
3. Se introduce en la red un vector de entrada con valores aleatorios.4. Se calcula la distancia entre los pesos de todas las neuronas y el vector de
entrada. A través de una competición (distancia mínima) se establece la neurona
ganadora para ese vector de entrada.5. Se calcula la vecindad de cada neurona respecto de la ganadora.6. Se aplica la regla de aprendizaje en todas las neuronas de la red, modificando
sus pesos.7. Se recalcula el valor de α y la varianza de δ para la siguiente iteración.8. Se repite el proceso desde el paso 3 hasta que los pesos converjan.
Se puede realizar a continuación una segunda fase en el aprendizaje, en la que se produce el ajuste fino del mapa, de modo que la distribución de los pesos sinápticos seajuste más a la de las entradas. El proceso es similar al anterior, tomando α constante eigual a un valor pequeño (por ejemplo 0.01), y radio de vecindad constante e igual auno.
5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-22-
2.9. Simulación mediante ordenador [3]
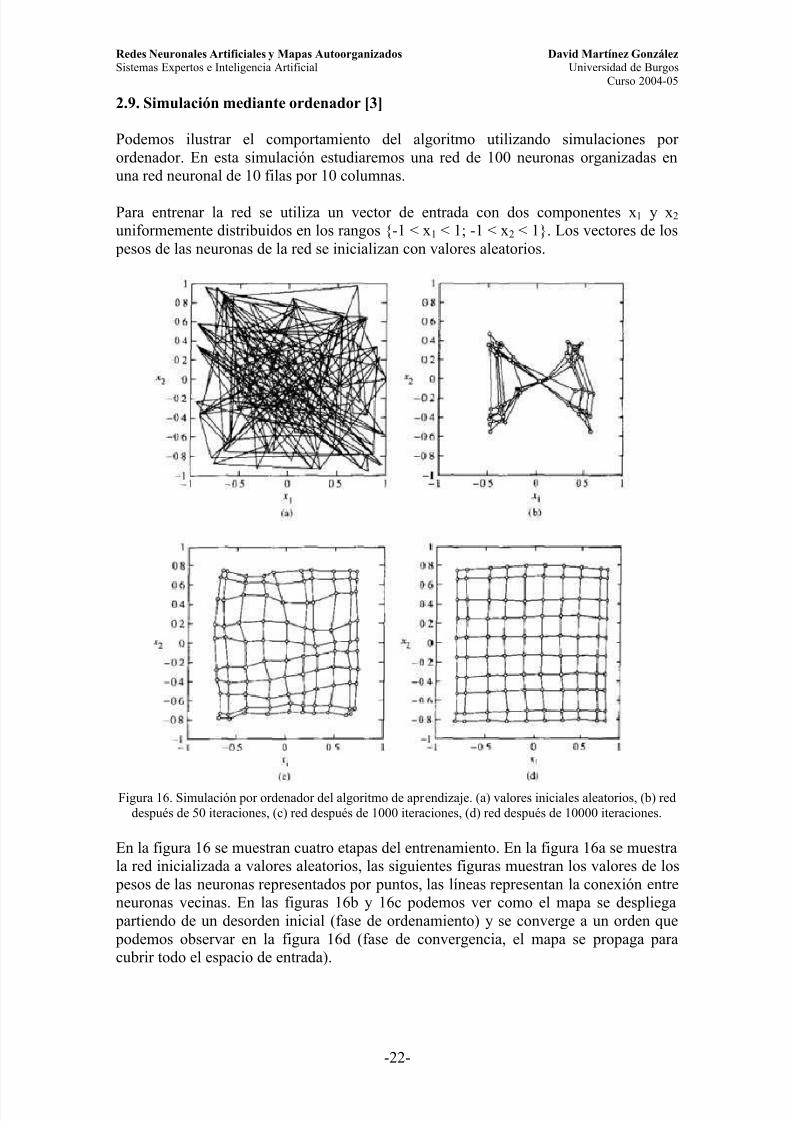
Podemos ilustrar el comportamiento del algoritmo utilizando simulaciones por ordenador. En esta simulación estudiaremos una red de 100 neuronas organizadas enuna red neuronal de 10 filas por 10 columnas.
Para entrenar la red se utiliza un vector de entrada con dos componentes x 1 y x2 uniformemente distribuidos en los rangos {-1 < x1 < 1; -1 < x2 < 1}. Los vectores de los
pesos de las neuronas de la red se inicializan con valores aleatorios.
Figura 16. Simulación por ordenador del algoritmo de aprendizaje. (a) valores iniciales aleatorios, (b) reddespués de 50 iteraciones, (c) red después de 1000 iteraciones, (d) red después de 10000 iteraciones.
En la figura 16 se muestran cuatro etapas del entrenamiento. En la figura 16a se muestrala red inicializada a valores aleatorios, las siguientes figuras muestran los valores de los
pesos de las neuronas representados por puntos, las líneas representan la conexión entreneuronas vecinas. En las figuras 16b y 16c podemos ver como el mapa se despliega
partiendo de un desorden inicial (fase de ordenamiento) y se converge a un orden que podemos observar en la figura 16d (fase de convergencia, el mapa se propaga paracubrir todo el espacio de entrada).

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-23-
Al finalizar el entrenamiento la distribución de las neuronas se aproxima al vector deentrada, exceptuando el efecto de los bordes (que veremos en el siguiente apartado).
2.10. Variantes de las SOMs
Sobre este modelo general que acabamos de exponer los investigadores han incorporadoalgunas modificaciones para mejorar su eficacia. [1]
Mapas autoorganizados crecientes.
Se parte de un mapa con pocas neuronas y en cada iteración se añaden nuevas neuronascuyos pesos se obtienen de la interpolación de los valores de los pesos de las neuronasvecinas.
Corrección del efecto de los bordes del mapa.
Las neuronas situadas en las orillas de mapa no aprenden de igual forma que el resto,debido a que tienen menos vecinas. Se presentan asimetrías entre las neuronas delinterior y las de los bordes.
Para corregir esto se puede someter a un ritmo de aprendizaje mayor a las neuronas delos bordes; o bien se puede cerrar el mapa, considerar que una neurona de un extremodel mapa es vecina de la neurona correspondiente del extremo opuesto, obteniendo asíuna superficie esferoidal o toroidal.
Introducción de un mecanismo de conciencia.
Durante el proceso de aprendizaje pueden existir neuronas que monopolicen el procesoganando iteración tras iteración. Para conseguir una equiprobabilidad de victoria entrelas neuronas se introduce un mecanismo de conciencia consistente en contabilizar durante el proceso el número de veces que cada neurona gana, y penalizar a aquellasque ganan en demasiadas ocasiones.
Redes de contrapropagación (counterpropagation) de Hetch-Nielsen.
En este modelo se parte de un mapa autoorganizado de aprendizaje no supervisado yuna vez realizado su entrenamiento se someten sus resultados a una red neuronal de
aprendizaje supervisado.Se trata pues de un modelo híbrido en el que, en su versión más simple, consta de trescapas neuronas: capa de entrada, capa oculta no supervisada (de tipo Kohonen) y capade salida supervisada (de tipo Grossberg). En esta red el aprendizaje queda dividido endos fases: [2]
• Fase no supervisada. Gradualmente se identifican características de los datos,estableciendo límites entre ellos y agrupándolos en clases.
• Fase supervisada. Un supervisor externo da nombres a las clases obtenidas ysomete a la clasificación a un ajuste más fino.
Las características de este modelo son comparables con las del perceptrón multicapa,mejorando su velocidad de convergencia pero con peor capacidad de generalización.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-24-
Red LVQ (Learning Vector Quantization)
Se trata de un modelo supervisado, compuesto por una capa simple de neuronas deKohonen sin relaciones de vecindad, que en ocasiones se emplea como procedimiento
supervisado de ajuste fino del mapa de Kohonen.
Este modelo, utilizado la clasificación de patrones, se basa en premiar a aquellasneuronas que clasifican correctamente un determinado patrón, y castigar a las querealizan una clasificación errónea, modificando sus pesos en sentido contrario.
2.11. Aplicaciones
Las aplicaciones de los mapas autoorganizados se dividen en dos grandes grupos:• Clasificación de datos en clases.• Visualización de datos multidimensionales a través de la reducción de la
dimensionalidad.
Con estos dos posibles usos de las SOMs tenemos las siguientes áreas de aplicación:• Análisis y minería de datos.• Bioinformática, análisis de secuencias genéticas.• Reconocimiento del habla, modelado del lenguaje natural.• Control industrial, monitorización y diagnosis de procesos y plantas industriales.• Aplicaciones médicas: diagnosis, creación de prótesis, modelado de perfiles de
pacientes.• Telecomunicaciones, distribución de recursos en la red, procesado de señales.
• Detección de intrusos en sistemas informáticos, clasificación de ataques en losSDI (Sistemas de Detección de Intrusos).• Clasificación de nubes en imágenes por satélite• Investigación sobre desordenes del sueño.• Análisis de señales eléctricas del cerebro.• Organización y recuperación de grandes colecciones de textos (WEBSOM)• Análisis y visualización de grandes colecciones de datos estadísticos.• Etc…
2.12. Herramientas software de simulación de SOMsExisten en el mercado una serie de herramientas software que permiten la simulacióndel funcionamiento de redes SOM. Algunas de las más conocidas son las siguientes:
• SOM_PAK (Helsinki University of Technology)[11]. Conjunto de programasescritos en C por Teuvo Kohonen y su equipo que permiten construir redesSOM. El formato de los ficheros en los que se almacenan datos de entrada conlos que se trabaja es el siguiente:
o Primera linea contiene la dimensión de los vectores.o Las siguientes lineas contienen los pesos separados por espacios.o Al final de cada una se puede tener una etiqueta adicional.o Las lineas que comienzan por # son comentarios

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-ma
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-25-
Algunos programas importantes del paquete:o lininit y randinit: inicializan los pesos del mapa.o vsom : realiza el entrenamiento de los mapas autoorganizados.o qerror: calcula el error cuantificado.o umat: genera una representación en postscript del mapa.o visual: devuelve las coordenadas de las neuronas BMU encontradas
Se suelen utilizar scripts para trabajar con las funciones el paquete.
• SOM ToolBox (Helsinki University of Technology)[11]. Constituye una libreríade funciones para Matlab que implementan procedimientos para crear ymanipular redes SOM. Utilizan la potencia de cálculo y facilidad de
programación de la herramienta matemática Matlab para la simulación deSOMs. Los datos de entrada para el entrenamiento de la SOM se puedenintroducir en un fichero de texto o directamente en la consola de Matlab.Algunas de las funciones más interesantes son:
o som_read_data: lee un fichero de datos ASCII en el formato definido para los ficheros de datos para SOM_PAK
o som_data_struct: genera una estructura de datos a partir de unos datos deentrenamiento.
o som_normalize: normaliza una estructura de datos.o som_randinit: inicializa una SOM con valores aleatorios.o som_make: crea, inicializa y entrena la SOM con valores por defecto que
consigue de otras funciones. Recibe como parámetro obligatorio elconjunto de datos necesario para realizar el entrenamiento.
o som_seqtrain y som_batchtrain: entrena una red SOM pasada por parámetro utilizando para ello un conjunto de datos también pasado por parámetro. La primera utiliza un algoritmo secuencial, mientras que lasegunda uno en modo batch.
o som_bmus: encuentra la neurona BMU. Recibe como parámetros la redSOM y los datos de entrada necesarios para la búsqueda
o som_show: visualiza una red SOM pasada por parámetro.En el modo de operar con SOM Toolbox se suelen seguir los siguientes pasos:
1. construir el conjunto o estructura de datos de entrenamiento2. normalizarlo3. crear y entrenar el mapa utilizando los datos normalizados4. visualizar el mapa
5. analizar los resultados
• NeuroSolutions [12]. Conjunto de herramientas para la simulación de redesneuronales en entorno visual. Además de otros tipos de redes (como
perceptrones multicapa), se pueden simular redes SOM. Herramientas:o NeuralBuilder: asistente que facilita la creación de un red SOM en unos
pocos pasos en los que se solicita al usuario: el fichero con los datos deentrenamiento y con los datos esperados, el error con el que elentrenamiento se parará, el número de capas ocultas de la red y susdimensiones (cantidad de neuronas), las reglas de aprendizaje y modosde propagación de las neuronas, el número máximo de iteraciones del
entrenamiento y el modo en el que se desea visualizar cada elemento delentrenamiento. A continuación construye la red neuronal y muestra en un

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-26-
gráfico su estructura. Apoyado en gráficos y hojas de datos se puedeobservar el entrenamiento.
o NeuroSolutions for Excel. Conjunto de funcionalidades integradas en lahoja de cálculo MS Excel que permiten desde dicho programa procesar yanalizar datos, además de crear gráficos y redes neuronales a partir de los
datos introducidos en la hoja de cálculo.o NeuralExpert. Asistente muy sencillo de manejar que permite seleccionar
entre resolver cuatro tipos de problemas: clasificación, aproximación, predicción y clustering de datos. Si seleccionamos clasificación podemoscrear una red neuronal en 8 sencillos pasos.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-27-
3. EJEMPLO DE APLICACIÓN DE LAS SOMs
FACERET: SISTEMA DE ADMINISTRACIÓN Y BÚSQUEDA INTELIGENTE DE CARAS EN
BASES DE DATOS DE IMÁGENES.
ADAPTADO Y RESUMIDO DE [13] Y [14]
INVESTIGACIÓN Y ARTICULOS ORIGINALES OBRA DE:
Javier Ruiz del SolarProfesor Asistente Depto. de Ingeniería Eléctrica, U. de Chile. Ingeniero CivilElectrónico, Universidad Técnica Federico Santa María. ChileDr. Engineer, Technical University of Berlin, GermanyPagina personal: http://www.cec.uchile.cl/~aabdie/jruizd/
Pablo Navarrete
Ingeniero Civil Electricista, Universidad de Chile
3.1. Introducción
El sistema FACERET (FACE RETrieval) es un sistema formado por una TS-SOM (queexplicaremos más adelante) y una base de datos donde almacenamos gran número defotografías de caras de personas. El sistema permite buscar y localizar la cara de una
persona dentro de una base de datos con muchas imágenes de caras, recorriendo elmínimo de imágenes posibles (mediante al uso de la TS-SOM).
Este sistema se puede aplicar en usos policiales en los que es necesario identificar el
sospechoso de un delito y en el que los testigos del delito no pueden recordar conexactitud los rasgos de la cara del delincuente, tan solo tienen un recuerdo, pero no unaimagen nítida.
El sistema presenta iterativamente al usuario una serie de caras, en cada iteración elusuario selecciona las caras que más parecido encuentra con la del delincuente, hastaque (si se produce convergencia) se le muestra la fotografía del presunto delincuente,finalizando la búsqueda con éxito. En cada nueva iteración la selección realizada por elusuario en la iteración anterior es relevante para determinar las imágenes a mostrar en laiteración. Este proceso de búsqueda se llama retroalimentación de relevancia ( Relevance Feedback ). Durante este proceso iterativo se descartan una gran cantidad deimágenes (el espacio de búsqueda disminuye en cada iteración) de forma que la
búsqueda se puede conseguir mucho más rápidamente que con una búsqueda secuencial.
3.2. Funcionamiento de FACERET
En el siguiente esquema se describe la estructura del sistema FACERET. Podemosdistinguir la base de datos, en la cual se almacenan todas las imágenes o fotografías delas caras, y la red TS-SOM, encargada de administrar en forma eficiente la base dedatos y la información de las caras contenidas en la misma.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-28-
Figura 17. Estructura de FACERET
El esquema de funcionamiento del sistema se puede resumir en este algoritmo:
1. FACERET escoge un conjunto al azar de imágenes de caras que son mostradas al usuario.
2. El usuario selecciona las caras mostradas por el sistema que encuentre parecidas a la cara que está buscando.
3. FACERET determina un nuevo conjunto de imágenes a partir de las imágenes que han sidoseleccionadas y no-seleccionadas por el usuario durante todas las consultas.
4. El usuario analiza las caras mostradas por el sistema:
4.a El usuario encuentra la cara buscada:SALIR.
4.b El usuario encuentra caras parecidas a la cara buscada:
IR A 2. 4.c El usuario no encuentra caras parecidas a la cara buscada:4.c.1 El usuario desiste de la búsqueda:
SALIR. 4.c.2 El usuario decide continuar la búsqueda. No selecciona ninguna de las caras
mostradas por el sistema:IR A 1.
La información que obtiene el sistema en cada iteración del usuario consiste en valores binarios, parecido o no parecido, asociados a cada cara mostrada al usuario. A partir deesta información el sistema debe determinar un nuevo grupo de fotografías a mostrar al
usuario, de forma que se reduzca el espacio de búsqueda y se asegure la convergencia ala cara buscada. Para conseguir esto es necesario:
• Comprender los criterios utilizados por los humanos para definir parecidos entrecaras. En este punto se utiliza el Análisis de Componentes Principales (PCA)
para obtener vectores de características (descriptores) de las imágenes de caras yel uso de Distancia Euclidiana como criterio de similitud entre estos vectores odescriptores.
• Un ordenamiento de la base de datos para seleccionar grupos de imágenessimilares a la cara buscada. Lo cual se consigue a través de las TS-SOM que
pasamos a exponer en el siguiente apartado.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-29-
3.3. Mapas Autoorganizados Arbóreos (TS-SOM)
Los mapas autoorganizados arbóreos suponen una variación arquitectónica de un mapaautoorganizado convencional.
El uso de TS-SOM (Tree Structured – SOM) permite disminuir considerablemente eltiempo de búsqueda de una neurona ganadora al introducir en la red un vector deentrada respecto al tiempo necesario en una red SOM convencional. Esto es debido a su
particular arquitectura, basada en una estructura piramidal dividida en niveles, en cadauno de los niveles se encuentra una red SOM.
Figura 18. Arquitectura de un mapa autoorganizado arbóreo o TS-SOM
A medida que se profundiza en la estructura del árbol las neuronas de cada nivel tieneuna especialización mayor en reconocer patrones que las del nivel anterior. De estaforma la neurona raíz tendrá unos pesos que permitirán su activación con suficientefacilidad, la activación de la neurona provocará la comunicación de esta con las delnivel inferior. Una o varias de estas neuronas se activarán en función de su
especialización. Cada una de estas neuronas gobierna una región de neuronas en el nivelsiguiente, de modo que su activación provoca la comunicación con la regióncorrespondiente, descartándose la comunicación con el resto de regiones. A medida quenos adentramos en la estructura del árbol se activan únicamente pequeñas regiones deneuronas de cada nivel, de cada una de las redes SOM que forman el árbol.
De este modo se descarta desde los primeros niveles del árbol el uso de muchasneuronas de la pirámide, reduciéndose considerablemente el espacio de búsqueda yacelerando el tiempo de búsqueda.
En la figura 18 se muestra un TS-SOM de tres niveles en el que cada neurona de cadanivel gobierna sobre cuatro neuronas del nivel inferior.
El espacio de búsqueda en niveles inferiores de la TS-SOM está restringido a una ciertazona del mapa correspondiente a las neuronas situadas debajo de la neurona máscercana del nivel anterior. Luego, la complejidad de las búsquedas en una estructura TS-SOM con unidades es , donde es el número de hijos por neurona. Lacomplejidad de una red SOM convencional es )(nO debido a que para determinar laneurona ganadora es necesario procesar todas las neuronas de la red. De esta forma sedemuestra que la velocidad de entrenamiento y de operación de una TS-SOM es mayor que en una SOM.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-30-
Para determinar los vectores de pesos en la red TS-SOM se debe seguir el siguientealgoritmo:
Paso 0: En el primer nivel (con una sola neurona) el vector de pesos es igual al vector promedio de toda la base de datos.
Paso 1: En los niveles bajo la raíz, el vector de pesos de cada neurona es inicializadocopiando el vector de pesos de la neurona padre (del nivel anterior).
Paso 2: Por cada neurona procedemos de la siguiente forma:Paso 2.1: Determinamos su neurona más cercana.Paso 2.2: Definimos grupo limitado de neuronas como el grupo de neuronasformado por las neuronas hijas del neurona más cercana y los neuronas hijas desus vecinasPaso 2.3: Definimos centroide como el promedio de los vectores de lasneuronas que forman el grupo limitado. Procedemos a su cálculo.
Paso 3: Los nuevos vectores de pesos se calculan como el promedio de los centroidesvecinos, ponderados por el número de vectores más cercanos (de cada neurona)
y por una función que asigna más importancia a los vecinos más cercanos(usualmente gaussiana).Paso 4: Si el vector de pesos no converge de acuerdo a algún criterio de variación entre
iteraciones, el procedimiento continúa con el siguiente nivel de la TS-SOM enel Paso 1. Si no es así, el procedimiento se repite desde el Paso 2.
En la Figura 19 se muestra la ubicación de un grupo de caras en el último nivel de la redTS-SOM entrenada usando las componentes PCA1 (que definen e identifican cada cara)comprobándose que existe consistencia con el parecido entre caras asociado a loshumanos.
Figura 19. Ejemplo de ubicación ordenada de caras en el nivel más bajo de una estructura TS-SOM
1 Para más información sobre la aplicación de PCA en este sistema consultar [14]

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-31-
3.4. Sistema de Selección
El sistema de búsqueda de caras está basado en el sistema PicSOM de búsqueda deimágenes en bases de datos. Se muestra al usuario en cada iteración un conjunto
pequeño (por ejemplo 6) de fotografías para que seleccione las que le parezcan más
cercanas a la persona buscada. El problema radica en determinar el siguiente conjuntode fotografías a mostrar al usuario en la siguiente iteración.
Para solucionar esto se utilizan matrices de selección. En cada nivel de la red TS-SOMse define una matriz de selección con las mismas dimensiones de la red SOMcorrespondiente (ver Figura 20). Cada posición de la matriz representa una neurona delnivel de la TS-SOM correspondiente.
(a) Mapa Auto-Organizativo.
(b) Matriz de Selección.
Figura 20. Matriz de selección asociada a un nivel de la TS-SOM
Cuando un usuario selecciona caras que considera parecidas a la cara buscada (dentrode las 6 mostradas), el sistema asigna valores positivos a las caras seleccionadas por elusuario y valores negativos a las caras no-seleccionadas. Los valores positivos ynegativos se normalizan tal que sumen cero. Estos valores se suman a la matriz deselección en las posiciones correspondientes a las caras mostradas según su posición enel nivel de la TS-SOM. Por último se distribuyen los valores de cada posición dentro lamatriz hacia sus vecinos aplicando un filtro paso-bajo. El resultado se puede observar enla figura 20b
El nuevo conjunto de caras que el sistema muestra al usuario corresponde a las carasubicadas en las neuronas con mayor valor en los elementos correspondientes de lamatriz de selección.
3.5. Simulaciones
Se han efectuado simulaciones sobre el sistema FACERET para comprobar su correctofuncionamiento sobre una base de datos FERET ( Facial Recognition Technology) que
puede almacenar 14.051 imágenes en escala de grises agrupadas en 1209 clases deindividuos, aunque para la simulación se utilizó 1196 imágenes de 1196 sujetosdistintos. Se entrenó una red TS-SOM con 6 niveles y 32×32 neuronas en el último
nivel.

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-32-
En la figura 21 se muestra una simulación en donde se buscó una cara dentro de la basede datos. En esta simulación se converge a la cara buscada después de 6 iteraciones, loque corresponde a mostrar entre un 3% y un 3,5% de la base de datos. Entre cada una delas iteraciones se muestran las 6 matrices de selección que indican cómo el sistemaconverge a una zona del mapa autoorganizativo donde se encuentra la cara buscada.
Figura 21. Simulación de una búsqueda
Es importante mencionar que hubo casos en que el sistema no logró converger en unnúmero razonable de iteraciones, debido a que se concentraba en zonas completamentedistintas a la zona donde se ubicó la cara buscada. Luego el resultado de lassimulaciones demostró que el sistema funciona eficientemente en la mayoría de loscasos, pero no asegura la convergencia de la búsqueda (en pocas iteraciones).

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-33-
4. BIBLIOGRAFIA Y OTROS RECURSOS
BIBLIOGRAFIA
[1] Redes Neuronales y Sistemas BorrososBonifacio Martín del Río, Alfredo Sanz MolinaRa-Ma 2001
[2] Artificial IntelligenceGeorge F. Luger, William A. StubblefieldAddison Wesley 1998
[3] Neural Networks. A comprehensive Foundation.Simon HaykinMacmillan College Publishing Company 1994
CONFERENCIAS
[4] Análisis de Componentes Principales y Redes NeuronalesCésar I. García Osorio (Universidad de Burgos)Curso de Verano “Inteligencia Artificial y sus Aplicaciones”. UBu. Julio 2003.
[5] Fundamentos y Aplicaciones de los Mapas AutoorganizadosJesús M. Maudes Raedo (Universidad de Burgos)Curso de Verano “Inteligencia Artificial y sus Aplicaciones”. UBu. Julio 2003.
[6] Reconocimiento y Clasificación con Redes NeuronalesLuis Alonso Romero (Universidad de Salamanca)Curso de Verano “Inteligencia Artificial y sus Aplicaciones”. UBu. Julio 2003.
[7] Aprendizaje CompetitivoEmilio S. Corchado Rodríguez (Universidad de Burgos)Curso de Verano “Inteligencia Artificial y sus Aplicaciones”. UBu. Julio 2003.
[8] Modelos Conexionistas aplicados a la seguridad SDI/SDAEmilio S. Corchado Rodríguez (Universidad de Burgos)Curso de Verano “Integración de Sistemas Operativos, Comunicaciones ySeguridad”. UBu. Julio 2004.
RECURSOS DE INTERNET
[9] Tutorial sobre Redes Neuronales Artificiales: Los Mapas Autoorganizados de
Kohonen Palmer, A., Montaño J.J. y Jiménez, R.Universitat de les Illes Balears
[10] Trabajo de Redes Neuronales y algoritmos de primer orden (INF 350-1) Universidad Católica de Valparaíso
[11] Página del Laboratorio de Computación y Ciencias de la información de laUniversidad Tecnológica de Helsinkihttp://www.cis.hut.fi/
[12] NeuroDimension, Inc.http://www.nd.com

5/12/2018 Redes Neuronales Artificiales y Mapas Autooraganizados (2004, David Mart ne...
http://slidepdf.com/reader/full/redes-neuronales-artificiales-y-mapas-autooraganizados-2004-david-mar
Redes Neuronales Artificiales y Mapas Autoorganizados David Martínez GonzálezSistemas Expertos e Inteligencia Artificial Universidad de Burgos
Curso 2004-05
-34-
SISTEMA FACERET
[13] Pontificia Universidad Católica de Chile http://www2.ing.puc.cl/~iing/ed437/Anales/
[14] Navarrete, P., and Ruiz-del-Solar, J. (2002). Interactive Face Retrieval using Self-
Organizing Maps. 2002 Int. Joint Conf. on Neural Networks – IJCNN 2002, May12-17, Honolulu, USAhttp://www.cec.uchile.cl/~aabdie/jruizd/papers/wcci2002a.pdf