redes neuronales artificiales para predicción en series...
TRANSCRIPT

Redes Neuronales Artificiales para predicción en series temporales
– Alba Martín Lázaro– José Miguel Martínez Romera– Pablo Morales Mombiela

Contenidos
1. Redes Neuronales Artificiales2. RNA para predicción en series temporales3. Resultados Experimentales
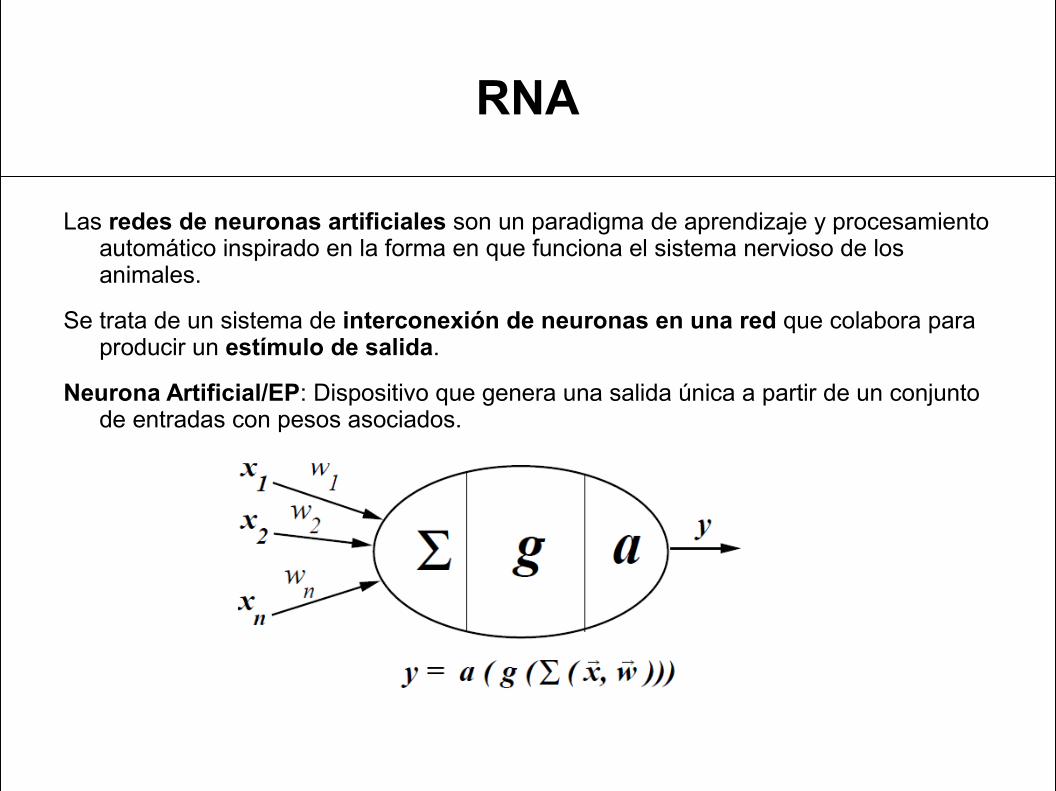
RNA
Las redes de neuronas artificiales son un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso de los animales.
Se trata de un sistema de interconexión de neuronas en una red que colabora para producir un estímulo de salida.
Neurona Artificial/EP: Dispositivo que genera una salida única a partir de un conjunto de entradas con pesos asociados.

Características
1. Función de transferencia (): Calcula la entrada al EP. Combina valores de pesos y entradas
2. Función de activación (g): Calcula estado de activación de la neurona en función de las entradas y, opcionalmente, del estado de activación actual.
3. Función de salida (a): Genera la salida de la neurona en función del estado de activación. Normalmente, función identidad, a(g(x)) = g(x).
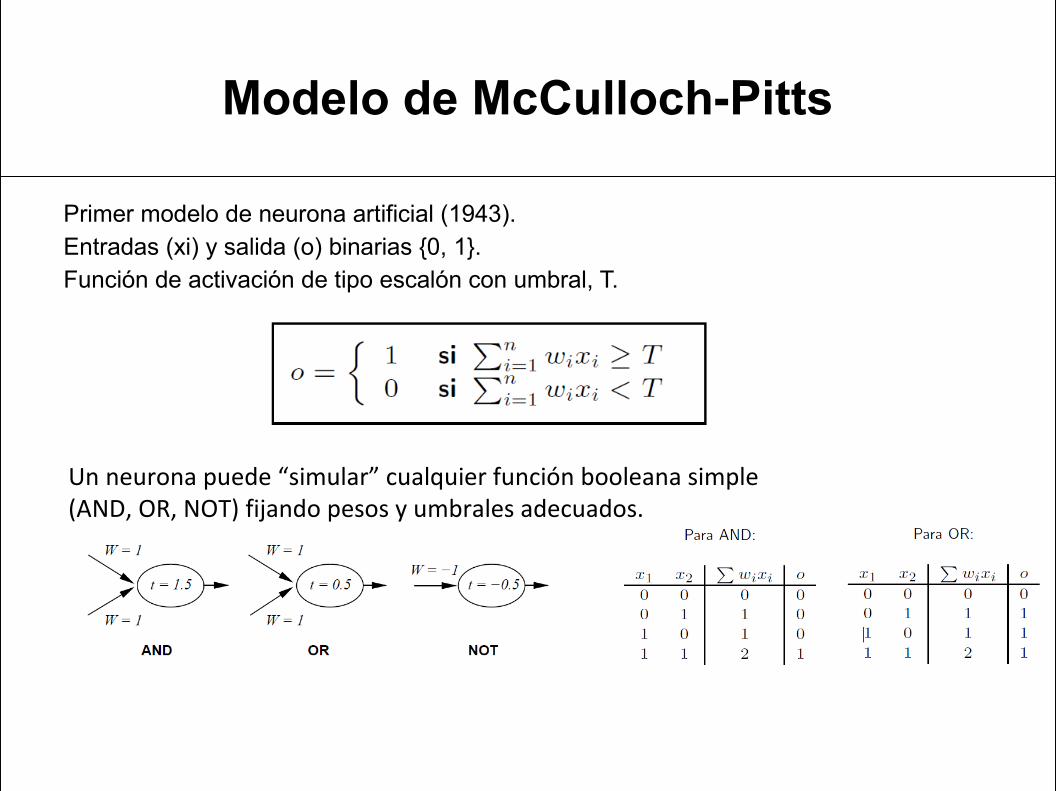
Modelo de McCulloch-Pitts
Primer modelo de neurona artificial (1943).Entradas (xi) y salida (o) binarias {0, 1}.Función de activación de tipo escalón con umbral, T.
Un neurona puede “simular” cualquier función booleana simple(AND, OR, NOT) fijando pesos y umbrales adecuados.
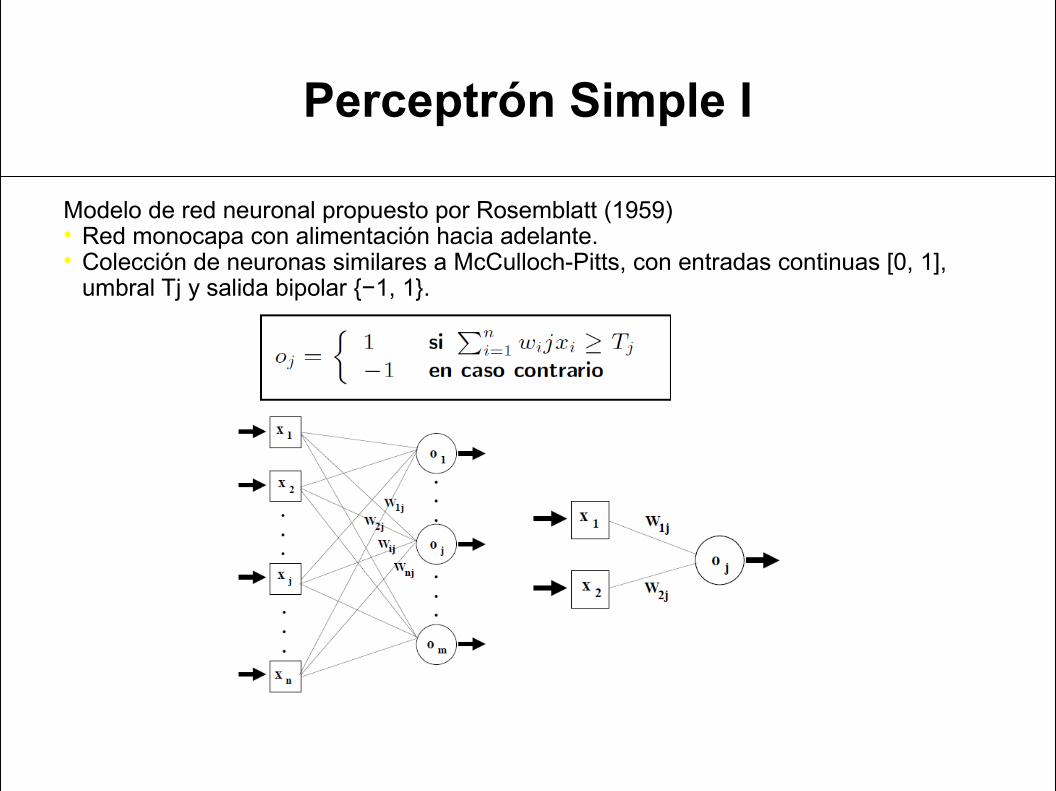
Perceptrón Simple I
Modelo de red neuronal propuesto por Rosemblatt (1959)• Red monocapa con alimentación hacia adelante.• Colección de neuronas similares a McCulloch-Pitts, con entradas continuas [0, 1],
umbral Tj y salida bipolar {−1, 1}.

Perceptrón Simple II
Capaz de aprender a clasificar patrones linealmente separables.• Salida +1 si pertenece a la clase, −1 si no pertenece• Pesos determinan zonas de clasificación separadas por un hiperplano (en el caso de 2 entradas, la separación será una línea)• Ejemplo: con dos entradas:
Minsky y Papert (1969) mostraron esta limitación del perceptrón para representar/aprender funciones no separables linealmente (ejemplo: XOR no separable linealmente, necesita mas de 1 capa)

Teorema de aproximación universal I
“Sea ϕ(.) una función continua no constante, acotada y monótonamente. Sea In el hipercubo unitario n-dimensional [0,1]n. Sea C(In) el espacio de funciones continuas definidas en In .Entonces, dada cualquier función g en C(In) y cualquier ε>0, existe unentero h y unos conjuntos de constantes reales αi, θi y wi donde i=1,...,h yj=1,...,n tales que la función f definida por:
es una realización aproximada de la función g(.), de tal modo que:
para todo (x1,...,xn) en ln.”

Teorema de aproximación universal II
Este teorema puede aplicarse directamente al Perceptrón de n entradas y una salida, con una única capa oculta compuesta por h neuronas de función de activación sigmoidal o hiperbólica (ambas cumplen las condiciones impuestas a ()), y función ϕde activación identidad
La Ecuación
da la función de transferencia del correspondiente Perceptrón, donde las constantes wij y θi se refieren a los pesos de la capa oculta y las αi a los de la capa de salida.

Teorema de aproximación universal III
Conclusión:Las Redes Neuronales Artificiales (RNAs) se pueden considerar una familia de
“aproximación universal” (Hornik et al, 1989; Cybenko, 1989), lo cual implica que una red neuronal puede aproximar cualquier función continua hasta cualquier nivel de exactitud.
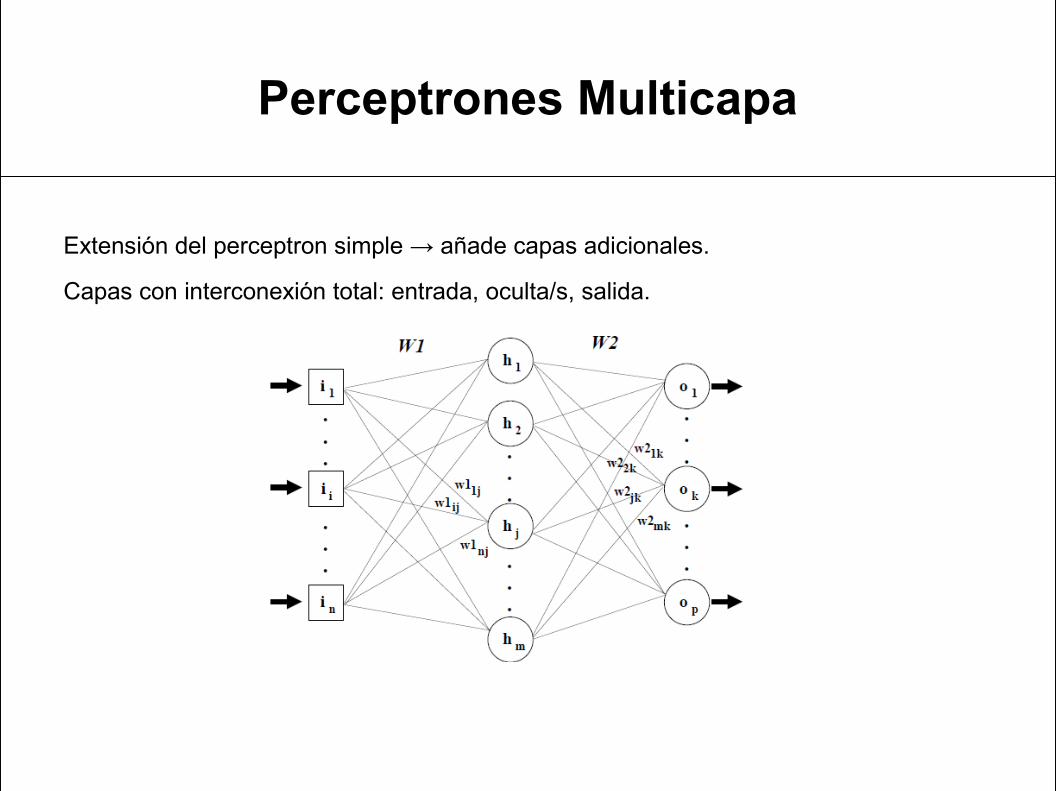
Perceptrones Multicapa
Extensión del perceptron simple → añade capas adicionales.
Capas con interconexión total: entrada, oculta/s, salida.

Propagación hacia adelante I
• Patrones de entrada se presentan en capa de entrada.• Se propagan hasta generar salida.
Función activación neuronas: sigmoidal.
Entradas y salidas continuas [0, 1]Pesos de conexión determinan una función que relaciona entradascon salidas.
• Sin capa oculta: funciones linealmente separables (perceptron simple)
• Una capa oculta: resuelve el problema del XOR (regiones triangulares)
• Dos capas ocultas: resuelve cualquier región poligonal
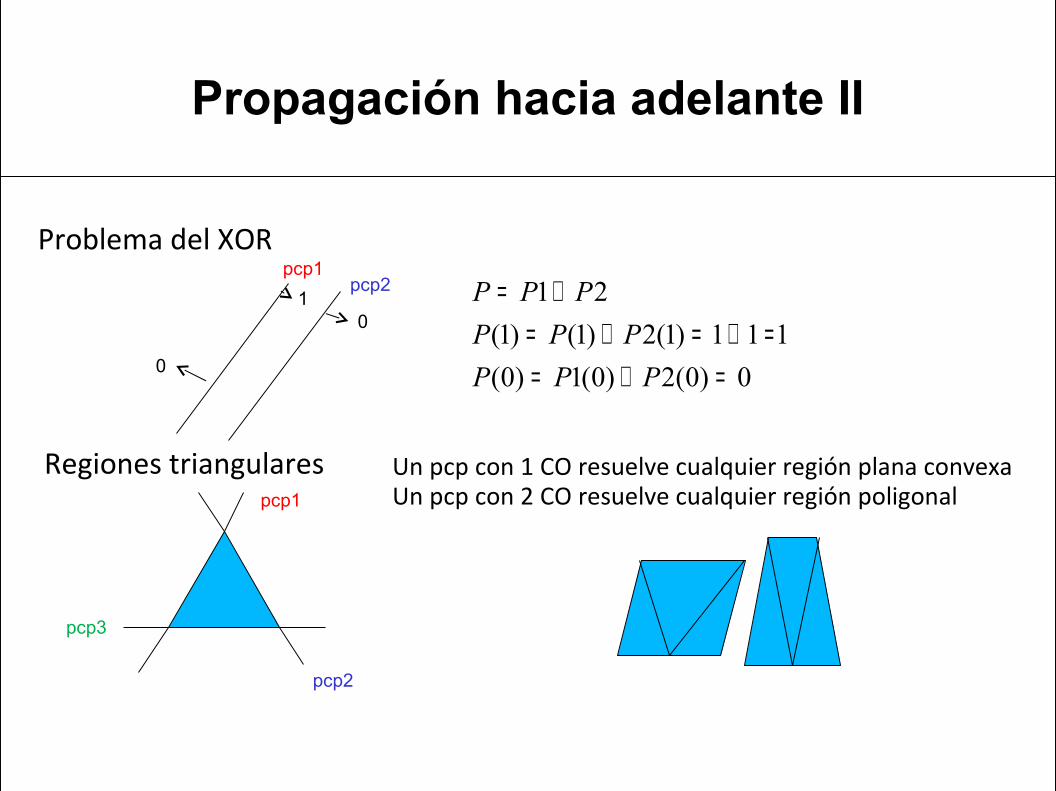
Propagación hacia adelante II
1
1 0
0
Problema del XOR pcp1
pcp2
0
01
Regiones triangularespcp1
pcp2
pcp3
Un pcp con 1 CO resuelve cualquier región plana convexaUn pcp con 2 CO resuelve cualquier región poligonal
0)0(2)0(1)0(111)1(2)1()1(
21
=∧==∧=∧=
∨=
PPPPPP
PPP

Retropropagación I
Propuesto por Rumelhart (1984).Objetivo: ajustar pesos para reducir el error cuadrático de las salidas (problema de
optimización).Funcionamiento aprendizaje:
Inicializar pesos aleatoriamenteRepetir hasta tener salidas "suficientemente" correctas (EPOCH)
Para cada patrón de entrenamiento (E,T)Propagar E por la red para obtener salida actual (O)Comparar con salida deseada (T-O)Actualizar pesos hacia atrás, capa a capa.
Exige función de activación (g) continua y derivable. La función sigmoidal se puede derivar de manera eficiente:

Retropropagación II
(1) Ajuste pesos CAPA SALIDA
Nuevos pesos para neurona de salida ok:
Idea base: ”Repartir” error obtenido para cada neurona de salida (k) entre los pesos de sus conexiones de forma proporcional a la intensidad de la entrada recibida (hj).

Retropropagación III
(2) Ajuste pesos CAPA/S OCULTA/S
Nuevos pesos para neurona oculta hj:Problema: Cuantificar error en las capas ocultas (j).Idea: Propagar la parte proporcional del error en la capa de salida (k) del cual es ”responsable” cada neurona oculta hj.
Estimación del error en neurona oculta hj:

Retropropagación IV
Aprendizaje retropropag. ≈ búsqueda por descenso de gradiente.Espacio de búsqueda = conjunto de posibles valores de pesosMétrica de evaluación = error cuadrático (en función de pesos)
En cada ejemplo de entrenamiento:• A partir del error calculado→ se definen los pesos de la nueva red.•Se ajustan pesos en la dirección de mayor pendiente.Uso de la derivada g en el ajuste pesos.′•Objetivo: Minimizar valor de la función de error. En realidad se pretende hacer que su derivada (E (red)) sea 0.′ Se buscan unos pesos para los que esa función tenga un mínimo (E (pesos) = 0)′
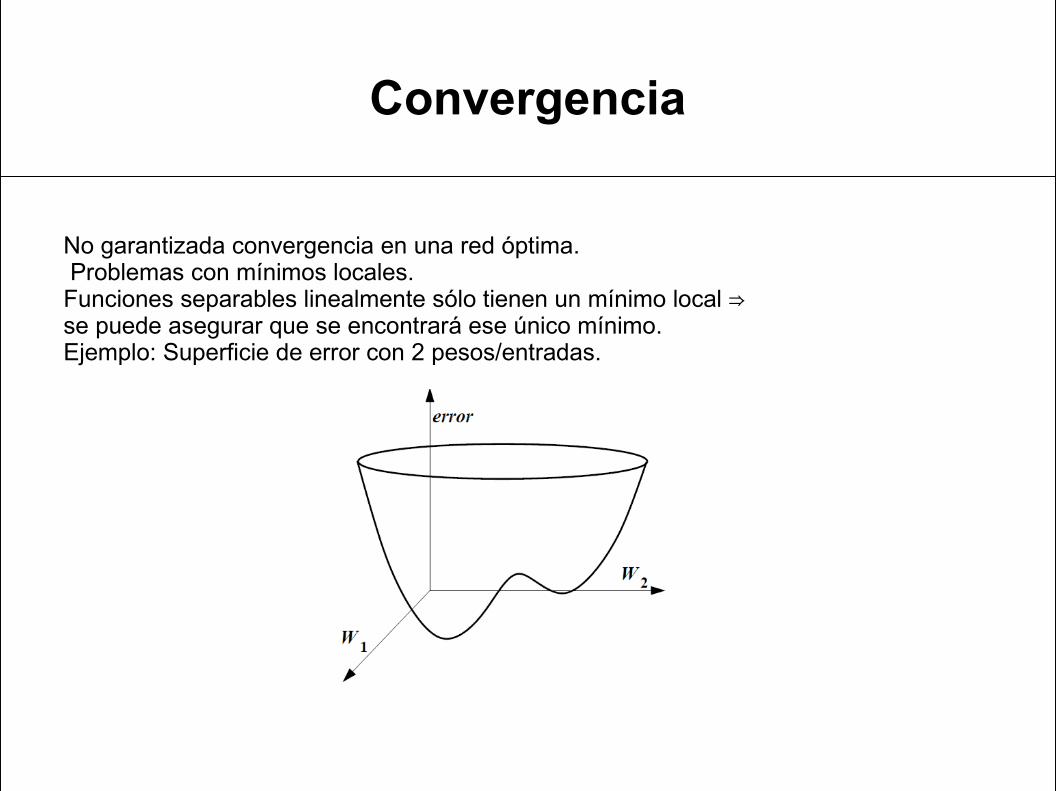
Convergencia
No garantizada convergencia en una red óptima. Problemas con mínimos locales.Funciones separables linealmente sólo tienen un mínimo local ⇒se puede asegurar que se encontrará ese único mínimo.Ejemplo: Superficie de error con 2 pesos/entradas.

Actualización de Pesos
• On-line: los parámetros del modelo se ajustan tras cada evaluación de la función de coste.
Requiere aleatorización en el orden de las muestras para garantizar la convergencia.
• Batch: los gradientes se acumulan tras cada evaluación y solo se actualiza el modelo tras procesar toda la muestra.
Tarda más en converger.

Aprendizaje Supervisado
Aprendizaje supervisadoEn general, no se garantiza convergencia.En la práctica, es posible entrenamiento adecuado para problemas reales. Entrenamiento lento. Puede requerir muchos ciclos de entrenamiento (epoch). Se suele usar: conj. entrenamiento + conj. validación. Verificar si realmente ha aprendido y puede generalizar.Criterios de parada: Número fijo de ciclos de entrenamiento (epochs)Umbral de error sobre conjunto entrenamiento.Umbral de error sobre conjunto de validación.

Problemas del Aprendizaje
• ¿Cuál es la topología de red adecuada?:Pocas neuronas/capas → incapaz de aprender función.Muchas neuronas/capas → posibilidad de sobreajuste.Además: ¿Qué funciones activación usar?, ¿Cómo codificar entradas/salidas?, etc,...
• Mala Generalización por Sobre Ajuste:Error pequeño conj. entrenamiento, grande conj. validación.Demasiados ciclos entrenamiento Pérdida capacidad generalización.⇒Red demasiado compleja Se ajusta a cualquier función.⇒Se memorizan patrones, no se generaliza con otros nuevos.
• Mínimos locales: Si se inicializa la red con diferentes pesos aleatorios se pueden encontrar mínimos
mejores.
Redes Neuronales Artificiales para predicción de series temporales

Tipos de Modelos
Paramétricos:− ARMA− GARCH
No Paramétricos:− RNA− SVM Kernel

Características de las RNA utilizadas
Familia de Aproximación universalSi se aplican configuraciones especiales:
- Se reducen el número de parámetros.- El modelo puede si ser paramétrico.- Mejora el interpretación.
Métodos generales de obtención de parámetros mediante optimización (retropropagación).

Metodología
1.Transformaciones necesarias para que la serie transformada sea estacionaria.
2.Separar conjunto de test1 y test2.3.Elegir función de coste y criterio de parada.4.Elegir topología de la red.5.Entrenar la red.6.Calcular el error de predicción en el conjunto de
test1.7.Calcular error honesto mediante el grupo de test2.

Formulación de la Predicción
El predictor basado en minimización del error cuadrático medio es la media condicional (para ruido y gaussiano):
En la práctica lo que se utiliza es la aproximación con número finito de muestras:
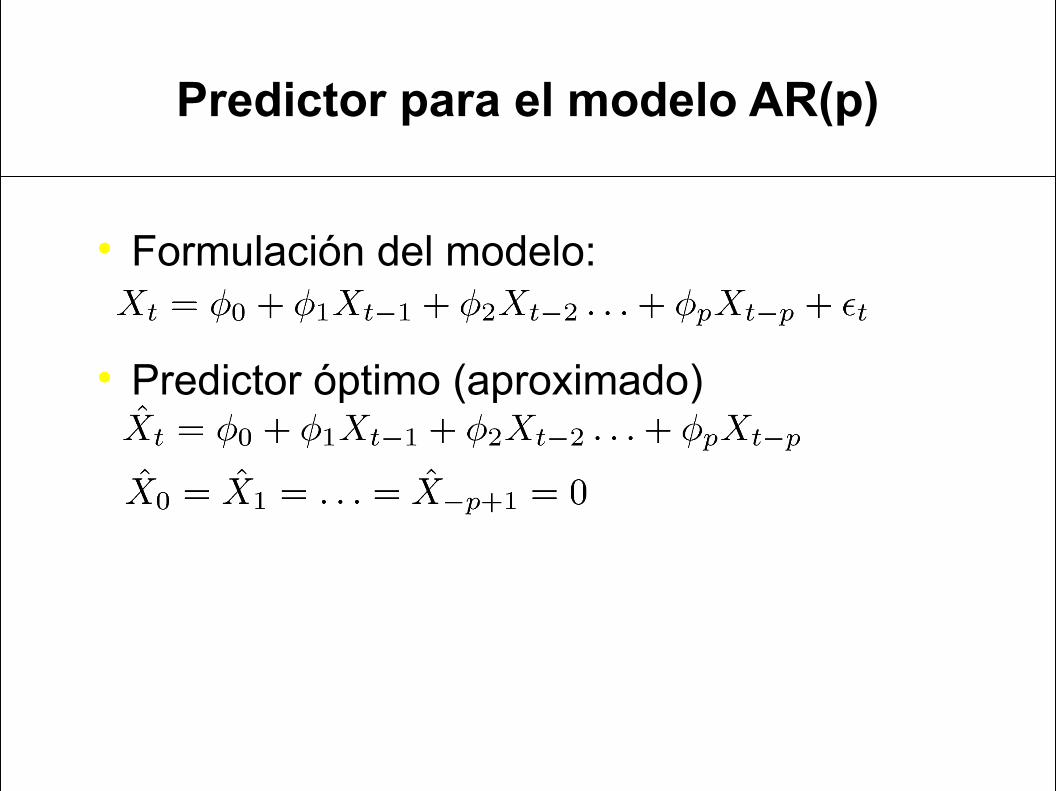
Predictor para el modelo AR(p)
Formulación del modelo:
Predictor óptimo (aproximado)
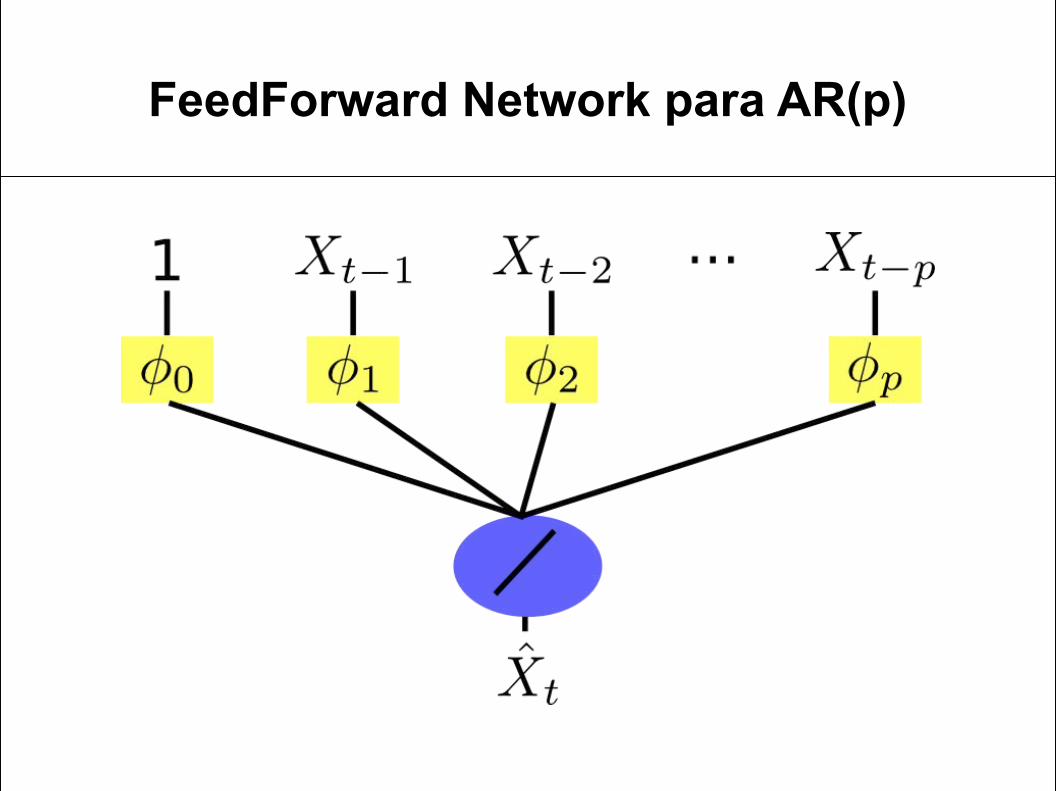
FeedForward Network para AR(p)
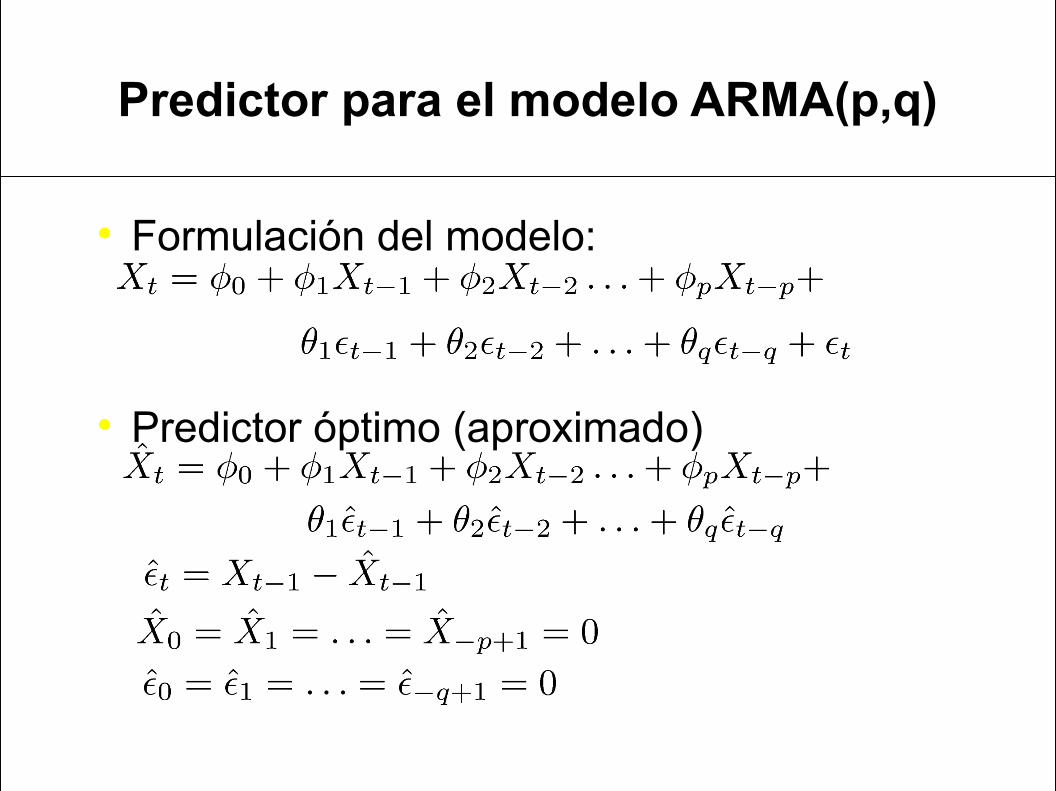
Predictor para el modelo ARMA(p,q)
Formulación del modelo:
Predictor óptimo (aproximado)
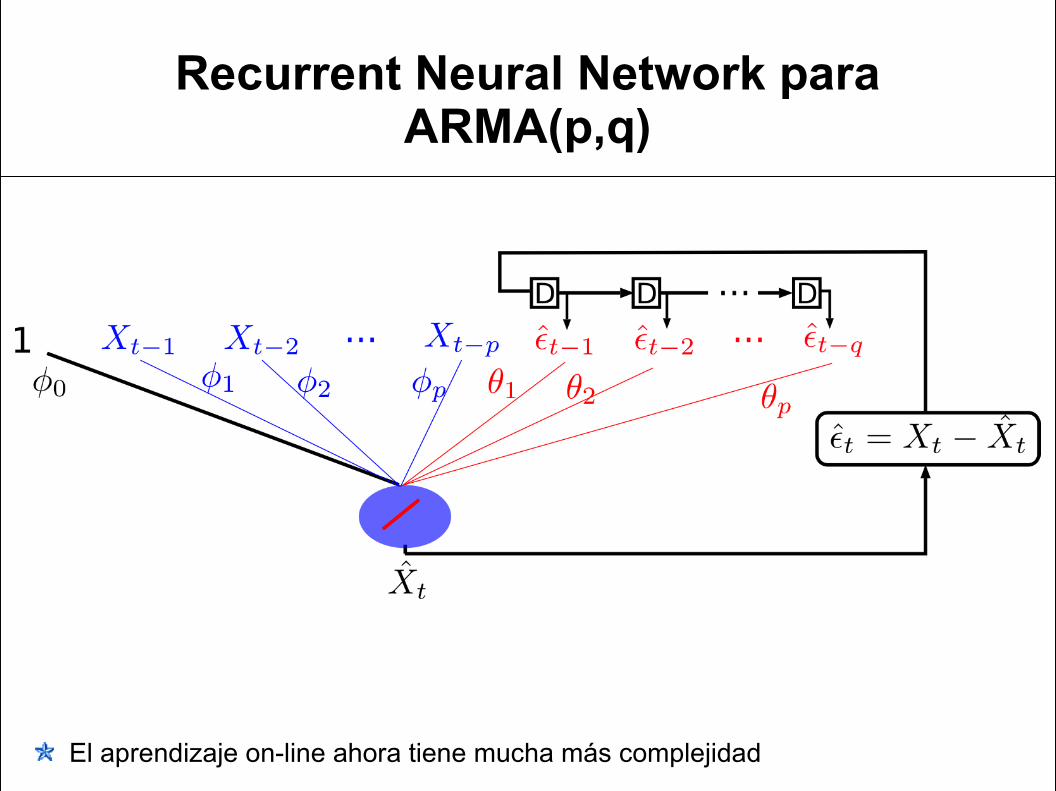
Recurrent Neural Network para ARMA(p,q)
El aprendizaje on-line ahora tiene mucha más complejidad
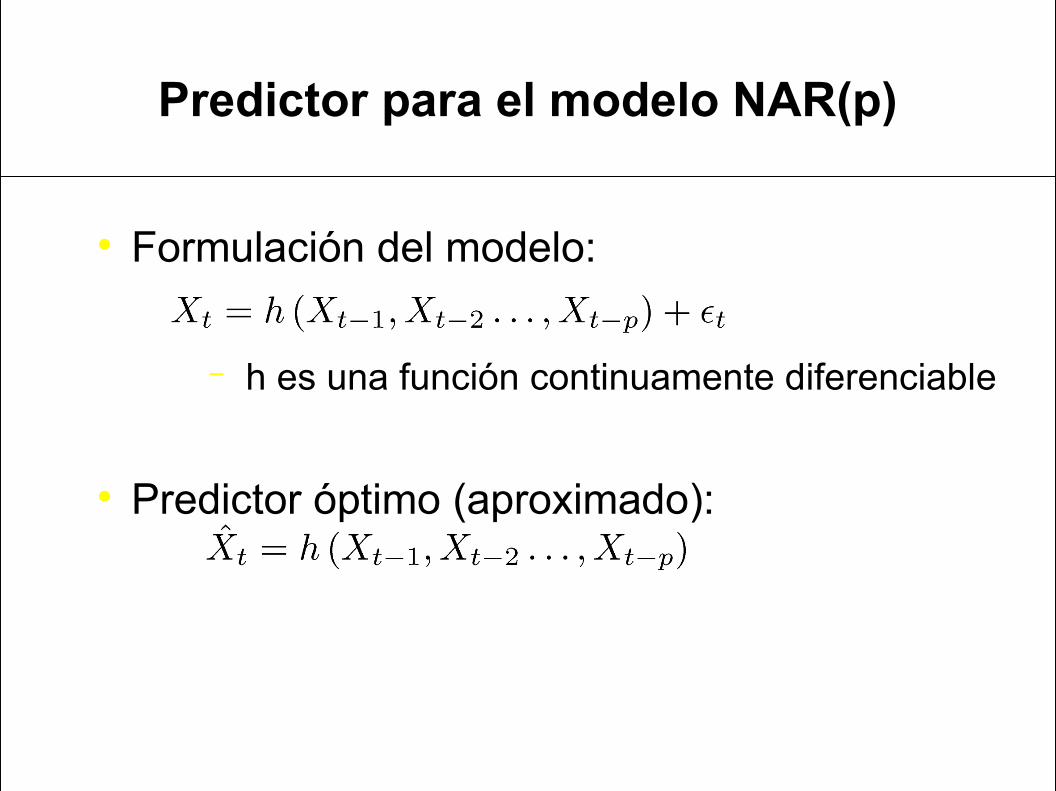
Predictor para el modelo NAR(p)
Formulación del modelo:
− h es una función continuamente diferenciable
Predictor óptimo (aproximado):
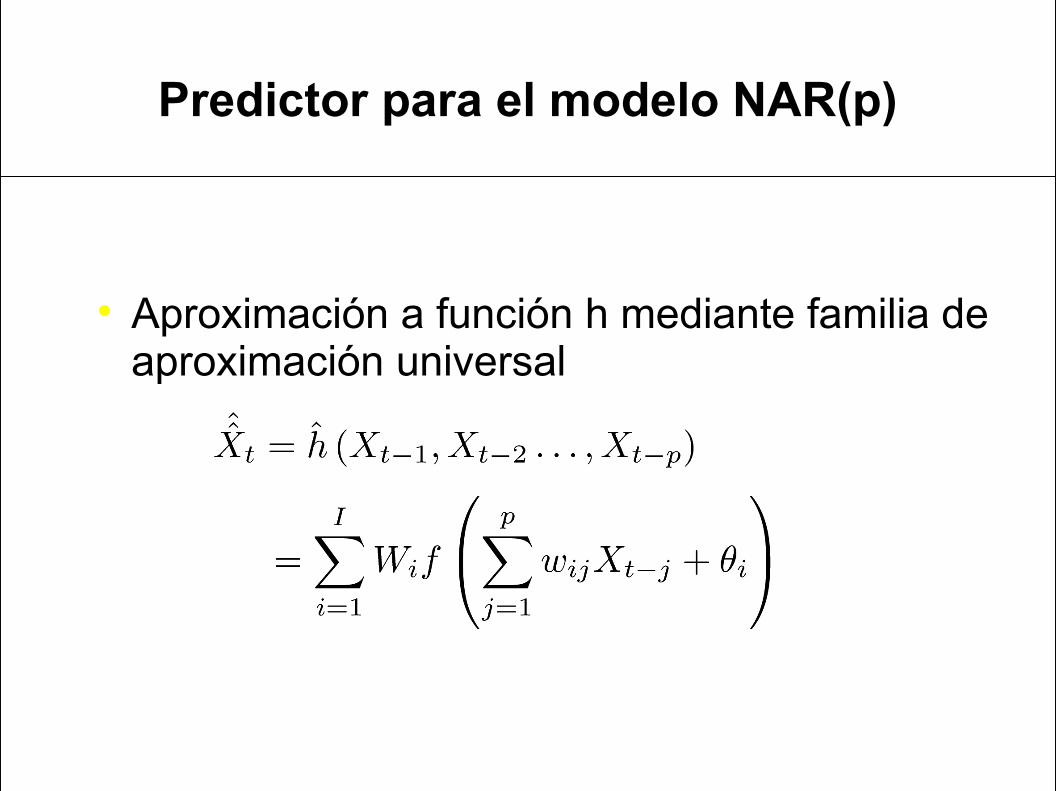
Predictor para el modelo NAR(p)
Aproximación a función h mediante familia de aproximación universal
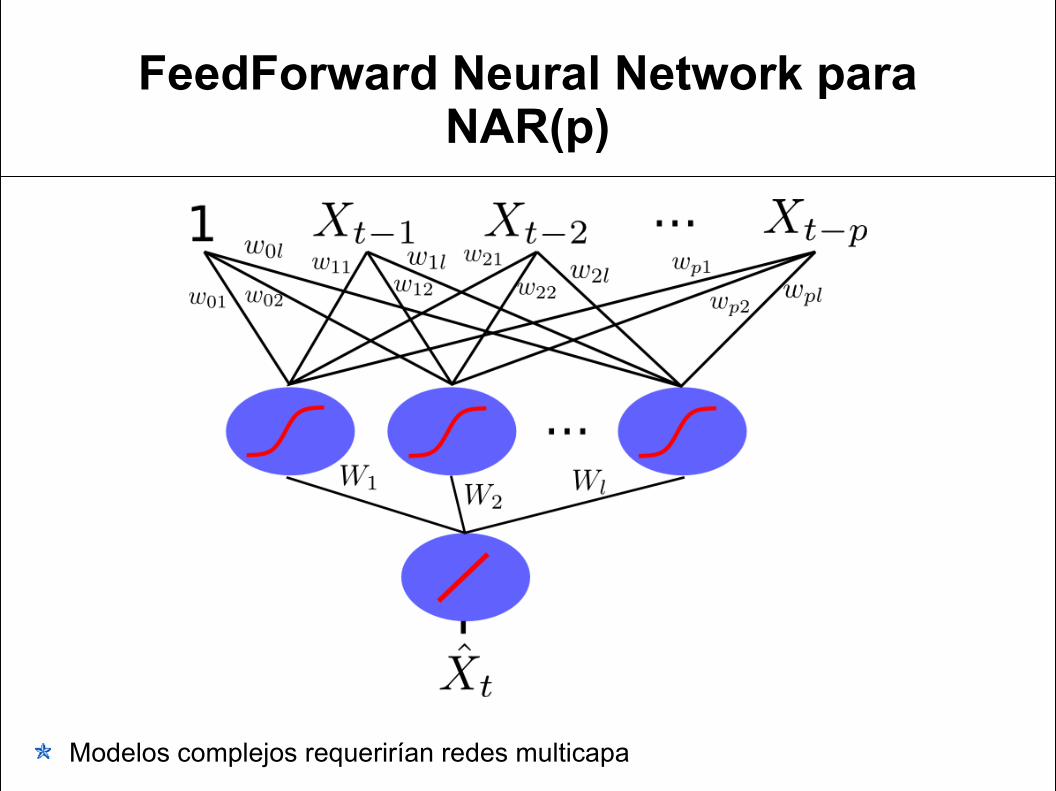
FeedForward Neural Network para NAR(p)
Modelos complejos requerirían redes multicapa

Configuración de la red neuronal
Capa de Presentación: activación lineal Capas ocultas: función sigmoidal:
Función de coste: suma de residuos cuadrados:
Optimización: descenso por gradiente o método de segundo orden.
Sin conexiones directas a la capa de presentación
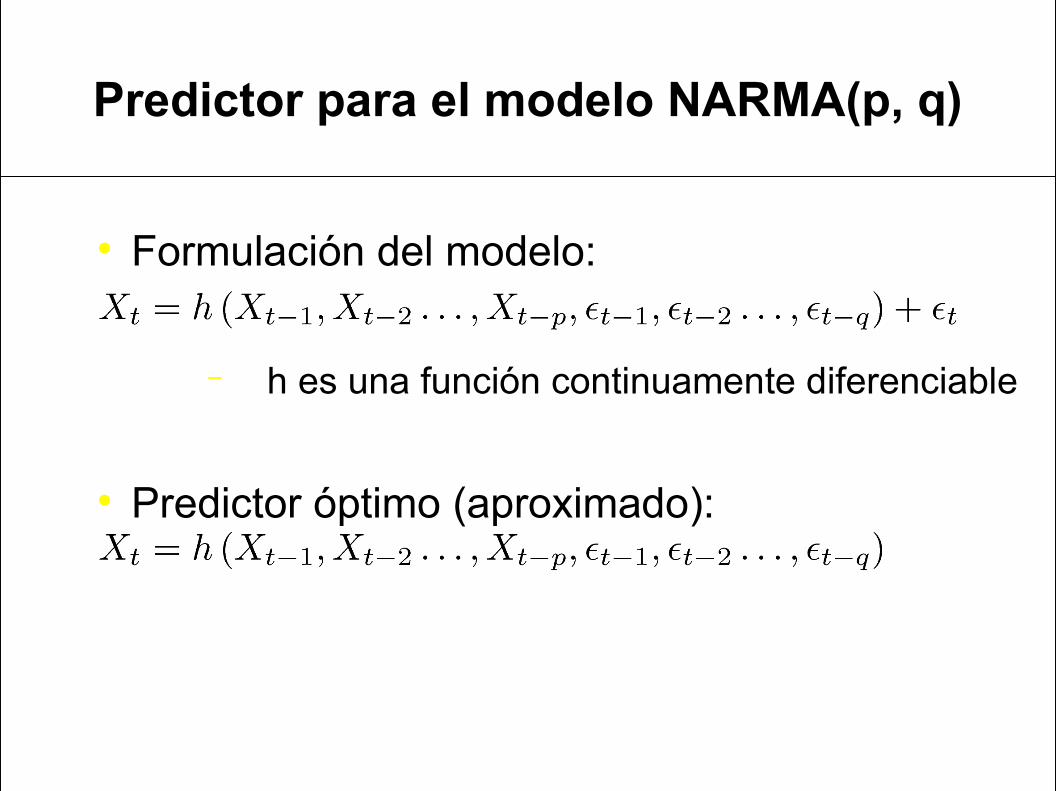
Predictor para el modelo NARMA(p, q)
Formulación del modelo:
− h es una función continuamente diferenciable
Predictor óptimo (aproximado):

Predictor para el modelo NARMA(p, q)
Aproximación a función h mediante familia de aproximación universal
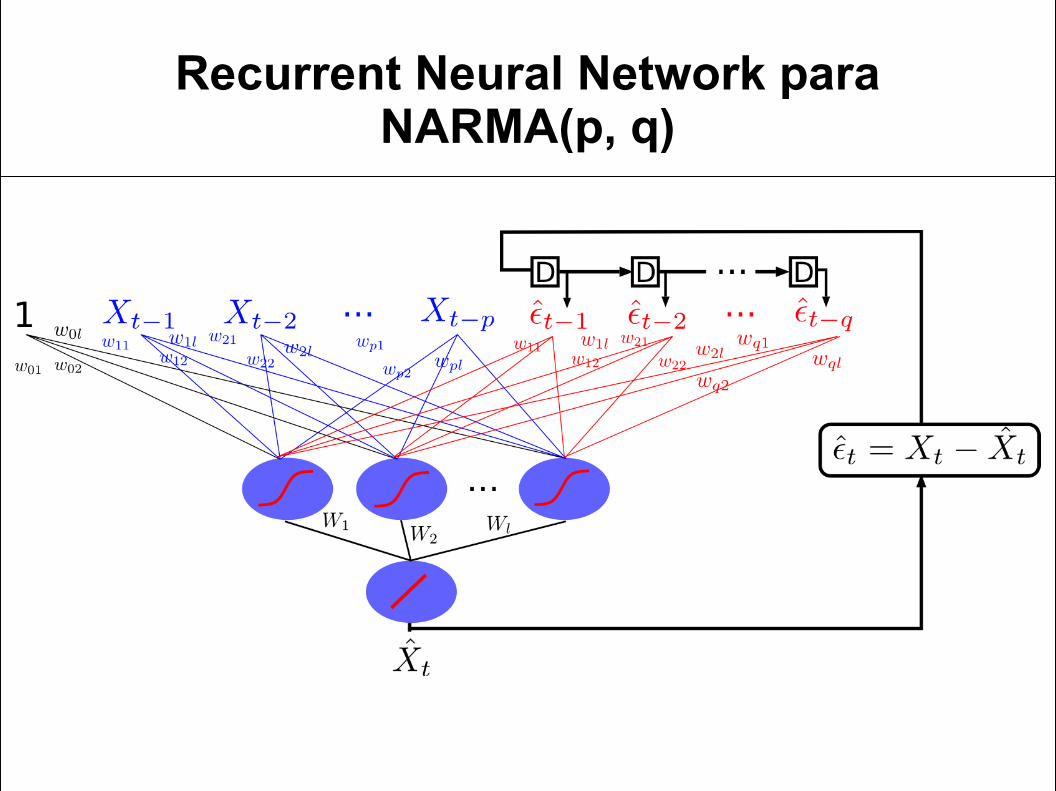
Recurrent Neural Network para NARMA(p, q)
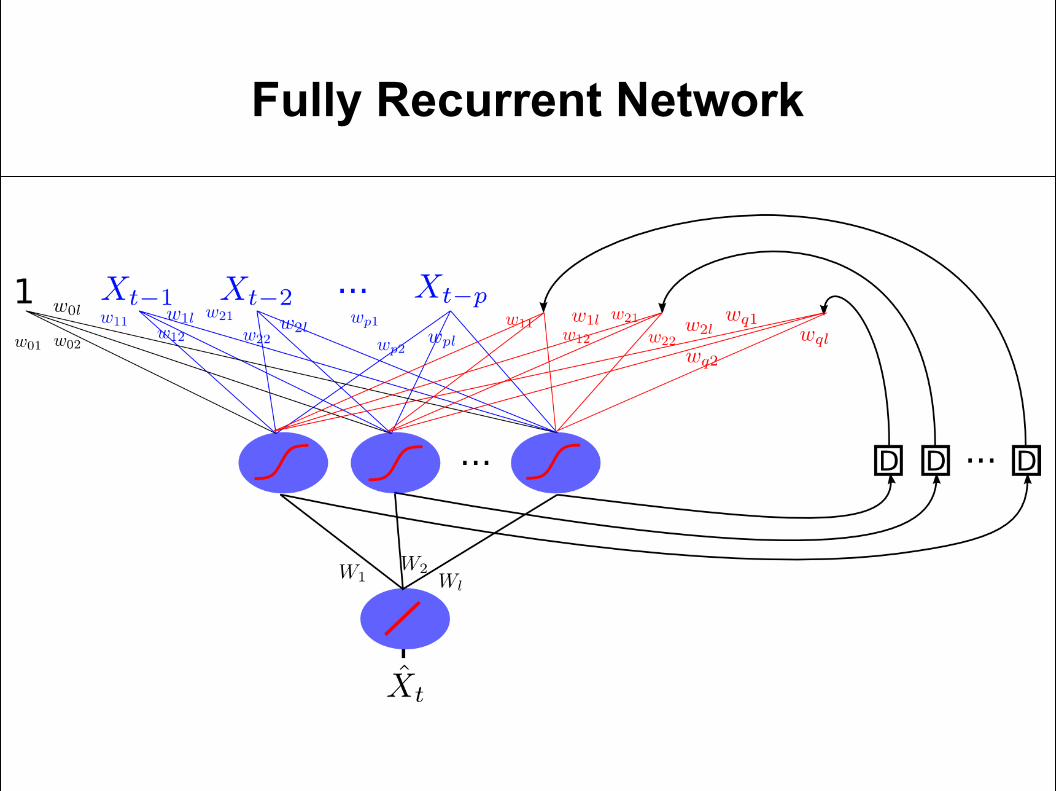
Fully Recurrent Network
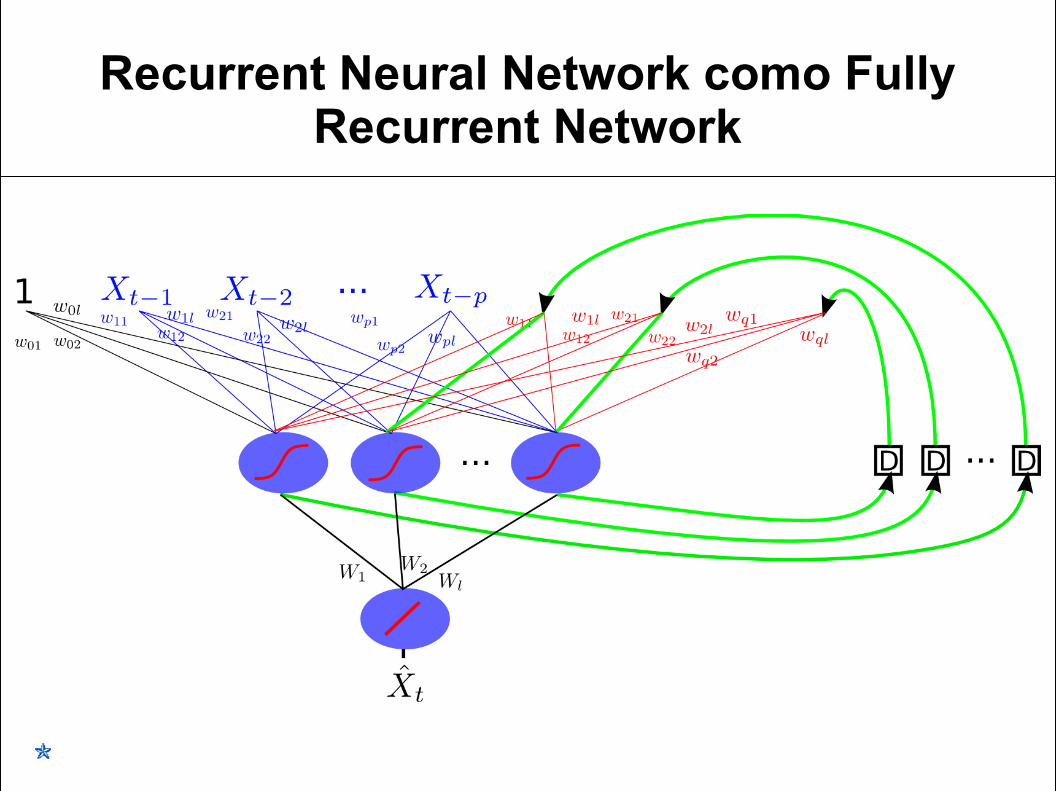
Recurrent Neural Network como Fully Recurrent Network
Requiere muchos más parámetros
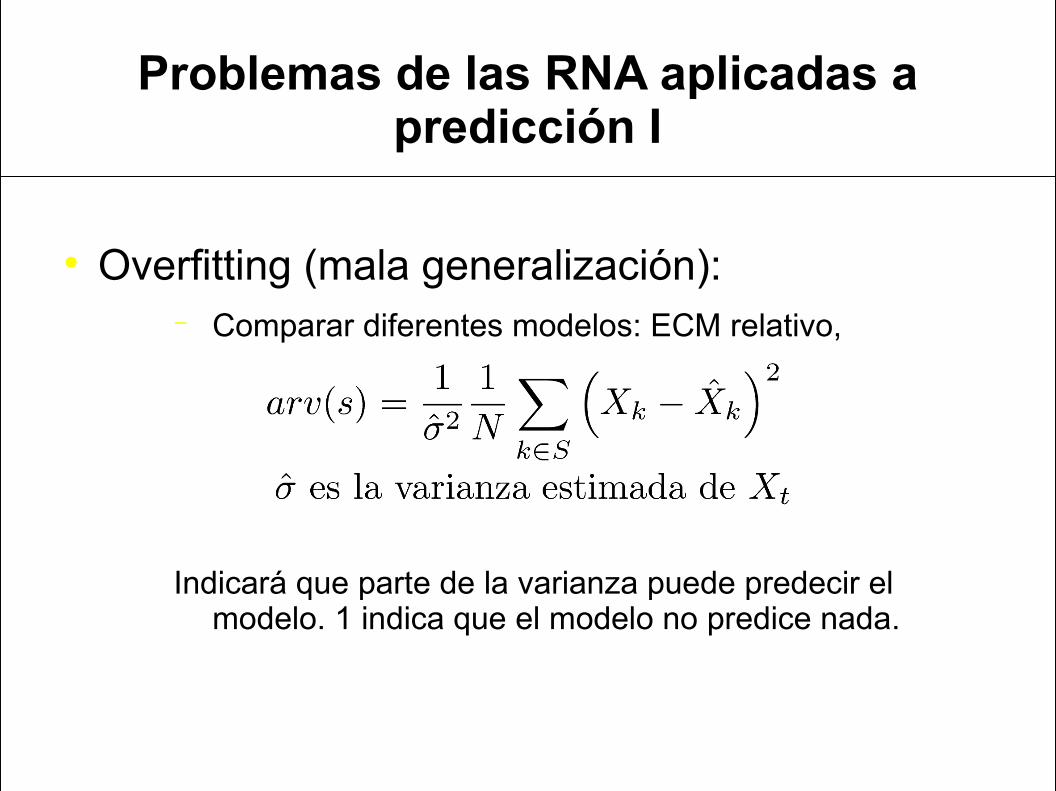
Problemas de las RNA aplicadas a predicción I
Overfitting (mala generalización):− Comparar diferentes modelos: ECM relativo,
Indicará que parte de la varianza puede predecir el modelo. 1 indica que el modelo no predice nada.
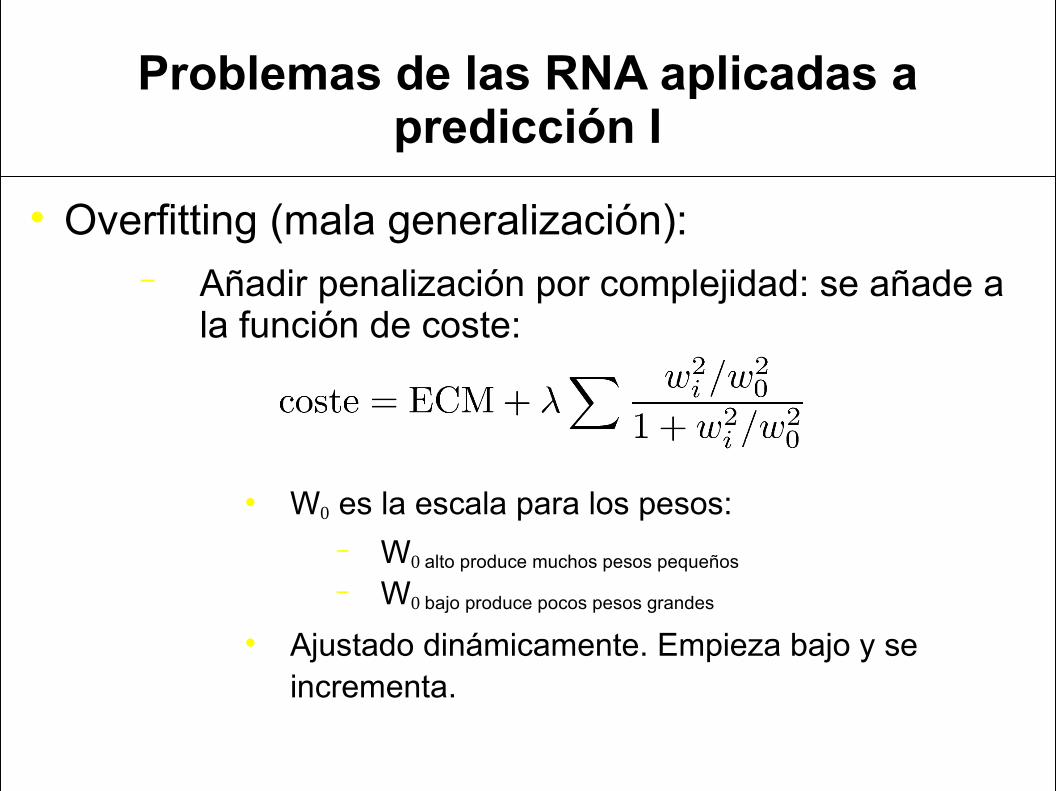
Problemas de las RNA aplicadas a predicción I
Overfitting (mala generalización):− Añadir penalización por complejidad: se añade a
la función de coste:
W0 es la escala para los pesos:− W0 alto produce muchos pesos pequeños
− W0 bajo produce pocos pesos grandes
Ajustado dinámicamente. Empieza bajo y se incrementa.

Problemas de las RNA aplicadas a predicción II
Overfitting (mala generalización):− Parada Temprana:
Usando un conjunto de validación (early test). Mezclas de expertos: se crean variaos
subconjuntos aleatorios de la muestra mediante remuestreo. Con cada conjunto se entrena una red. Luego se calcula la predicción en función de las salidas de cada red neuronal.

Problemas de las RNA aplicadas a predicción III
Parámetros libres Outliers : filtrado Interpretar el modelo:
− Orden del modelo relacionado con entradas.− Valor de Predicción.− Intervalo de Confianza mediante bootstrap
sobre conjunto de test (late test).− Residuo del modelo

Resultados Experimentales
Experimentos: Resultados y Conclusiones

Experimentos
1. Datos simulados• AR(1)• MA(1)• NARMA(1,1)
2. Datos reales • Predicción de series de tipo de cambio • Predicción de manchas solares

Simulación AR(1)
Proceso Gaussiano AR(1) I Modelo:
Entrenamiento: primeras 500 muestras. Test: 10.000 muestras. Criterio de parada: validación cruzada.

Resultados AR(1)
Red p q l M.S.E. Conjunto
de entrenamiento
M.S.E. Conjunto de Test
Feedforward
NAR
1
2
3
4
5
0
0
0
0
0
3
3
2
3
3
1.00
1.03
1.00
0.99
0.98
1.02
1.08
1.03
1.06
1.09NARMA
Recurrente
0
1
1
1
4
3
2.03
0.99
2.12
1.01Fully Recurrent 1 - 5 1.01 1.04

Simulación MA(1)
• Proceso Gaussiano MA(1) • Modelo:
• Test: 500 muestras.• Entrenamiento: 10.000 muestras.• Criterio de parada: validación cruzada.
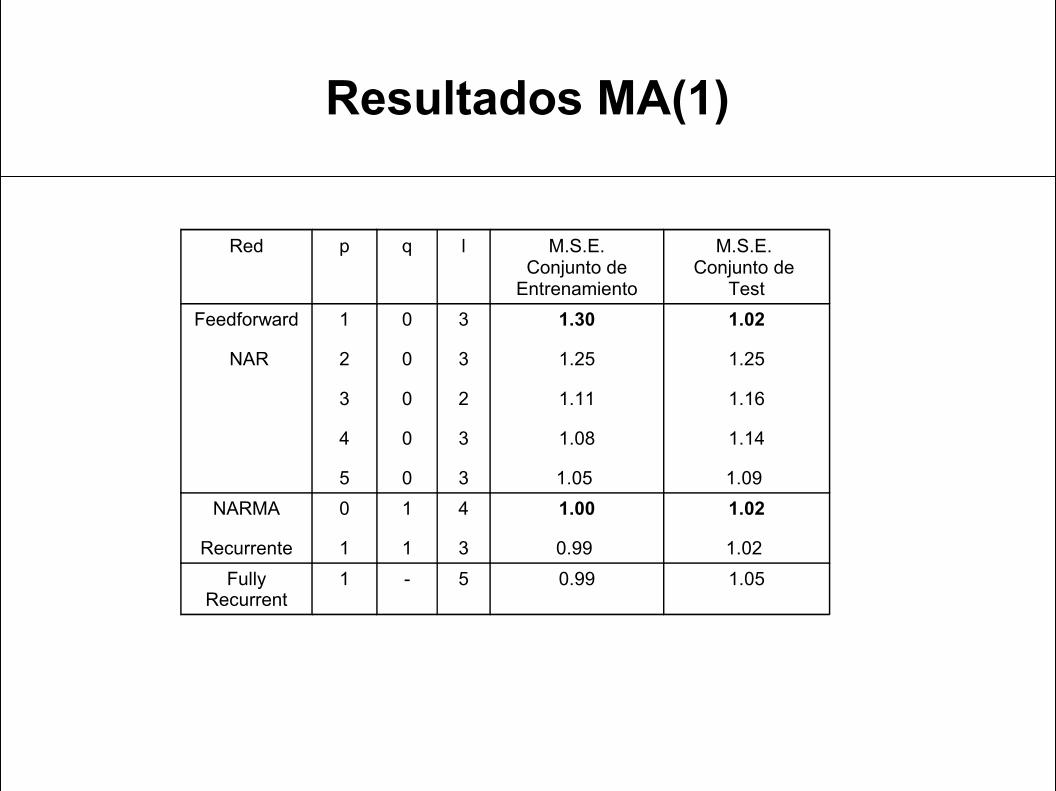
Resultados MA(1)
Red p q l M.S.E. Conjunto de Entrenamiento
M.S.E. Conjunto de
TestFeedforward
NAR
1
2
3
4
5
0
0
0
0
0
3
3
2
3
3
1.30
1.25
1.11
1.08
1.05
1.02
1.25
1.16
1.14
1.09 NARMA
Recurrente
0
1
1
1
4
3
1.00
0.99
1.02
1.02 Fully
Recurrent1 - 5 0.99 1.05

Simulación NARMA(1,1)
Proceso bilineal NARMA(1,1) Modelo:
Entrenamiento: 500 muestras. Test: 10.000 muestras. Criterio de parada: validación cruzada.
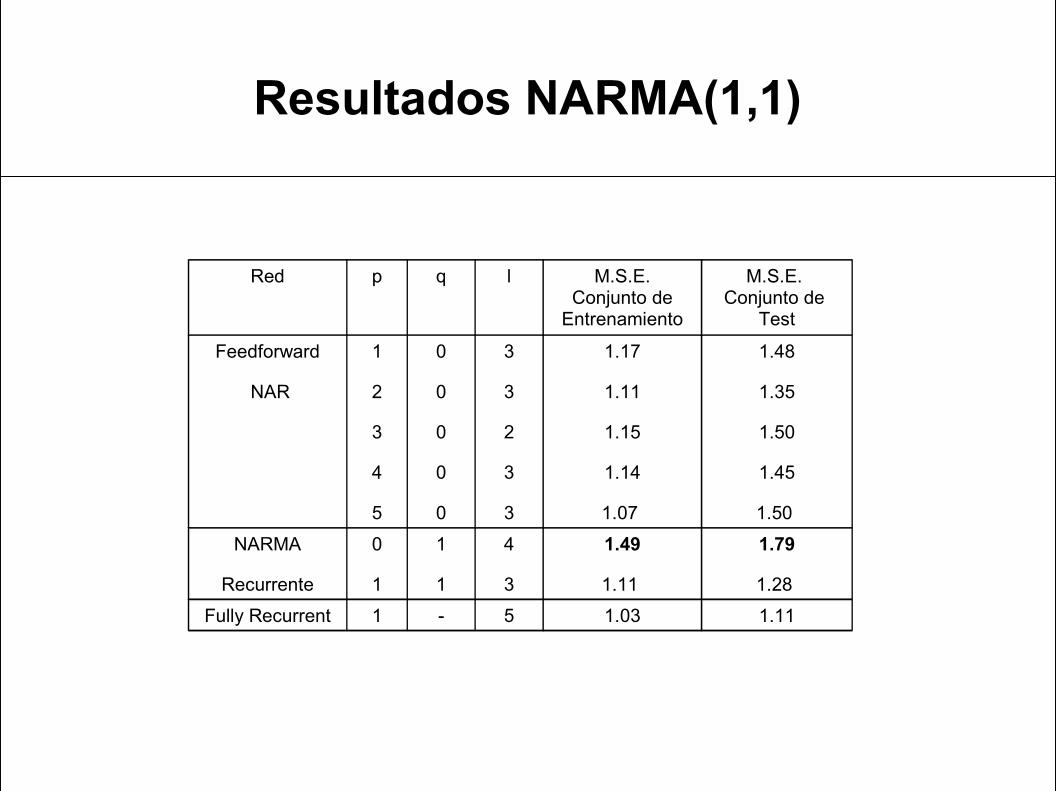
Resultados NARMA(1,1)
Red p q l M.S.E. Conjunto de
Entrenamiento
M.S.E. Conjunto de
Test
Feedforward
NAR
1
2
3
4
5
0
0
0
0
0
3
3
2
3
3
1.17
1.11
1.15
1.14
1.07
1.48
1.35
1.50
1.45
1.50 NARMA
Recurrente
0
1
1
1
4
3
1.49
1.11
1.79
1.28 Fully Recurrent 1 - 5 1.03 1.11

Datos Reales

Series de Tipo de Cambio I
Serie que se estima:• Retornos logarítmicos
Para cambios pequeños, el retorno es la diferencia hasta el día anterior normalizada por el precio pt-1

Series de Tipo de Cambio II
Funciones útiles:• Day Trend
• Volatility
Aunque la red neuronal sería capaz de calcular estas funciones se quiere orientar a la red en este sentido.
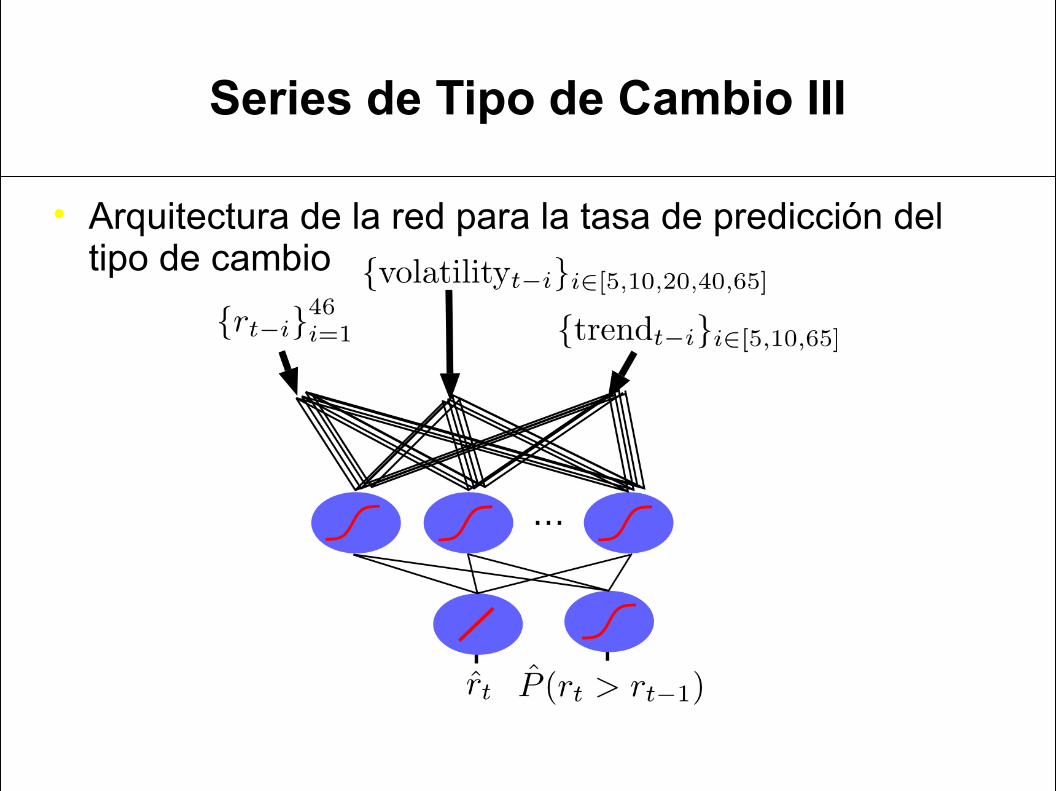
Series de Tipo de Cambio III
• Arquitectura de la red para la tasa de predicción del tipo de cambio
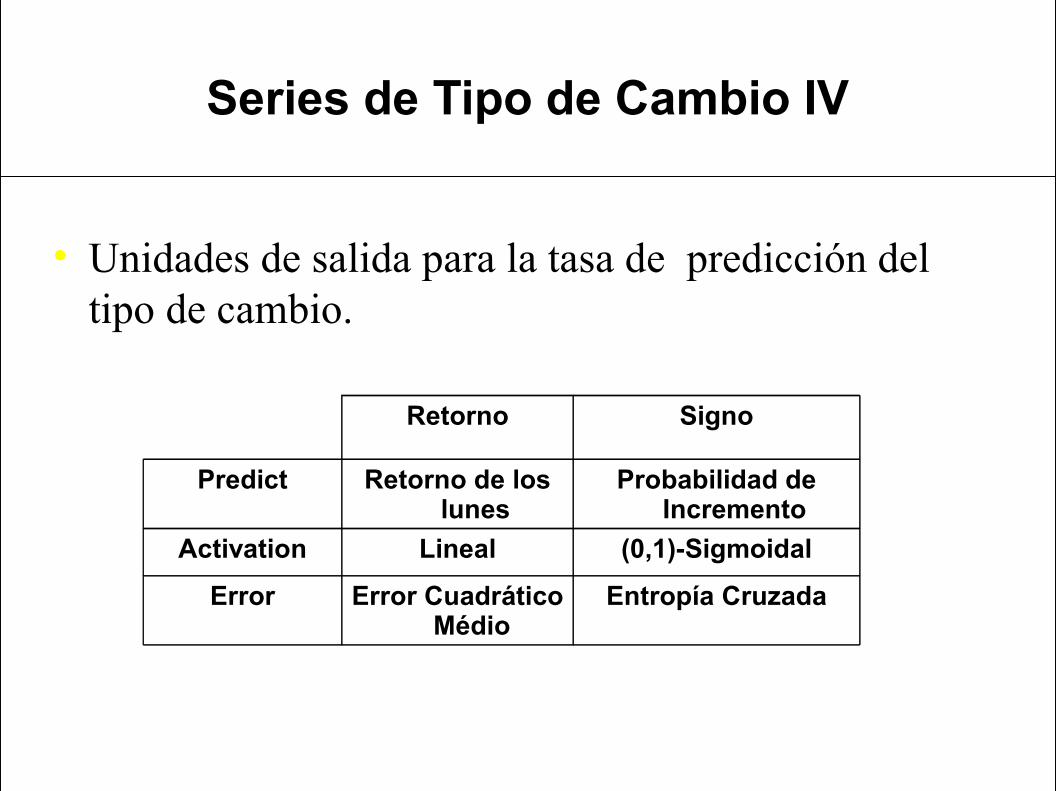
Series de Tipo de Cambio IV
• Unidades de salida para la tasa de predicción del tipo de cambio.
Retorno Signo
Predict Retorno de los lunes
Probabilidad de Incremento
Activation Lineal (0,1)-Sigmoidal
Error Error Cuadrático Médio
Entropía Cruzada
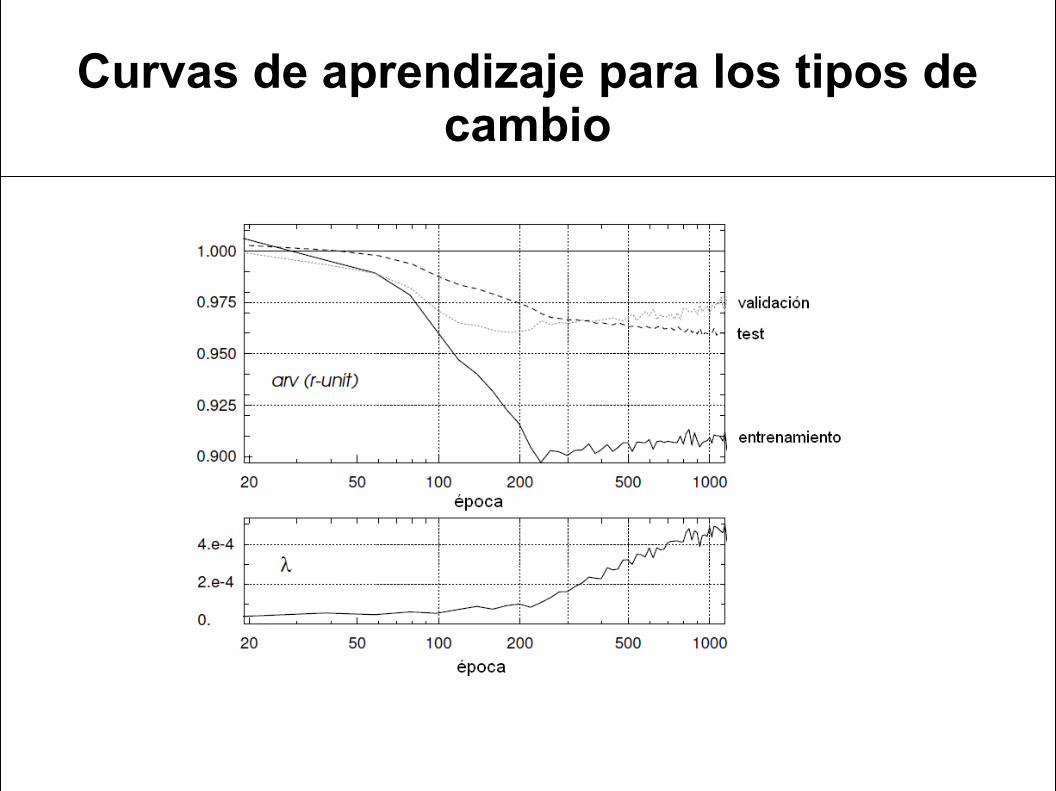
Curvas de aprendizaje para los tipos de cambio

Predicción de Manchas Solares: Introducción
Mancha solar: región central oscura, llamada "umbra", rodeada por una "penumbra" más clara. Una sola mancha puede llegar a medir hasta 12 000 km (casi tan grande como el diámetro de la Tierra), pero un grupo de manchas puede alcanzar 120 000 km de extensión e incluso algunas veces más. Número de manchas = k(10g + f),
k = factor de escala g = número de grupos de manchas f = número de manchas individuales
• Esta serie ha servido como Benchmark (referencia) en la literatura estadística.

Predicción de Manchas Solares
• Predicciones y observaciones de las manchas solares desde 1700 a 1979.

Configuración de la Red
• Activación sigmoidal• Una Capa oculta• Función de error: Error Cuadrático Medio.

Técnicas de parada evaluadas
1. Validación interna2. Eliminación de Pesos
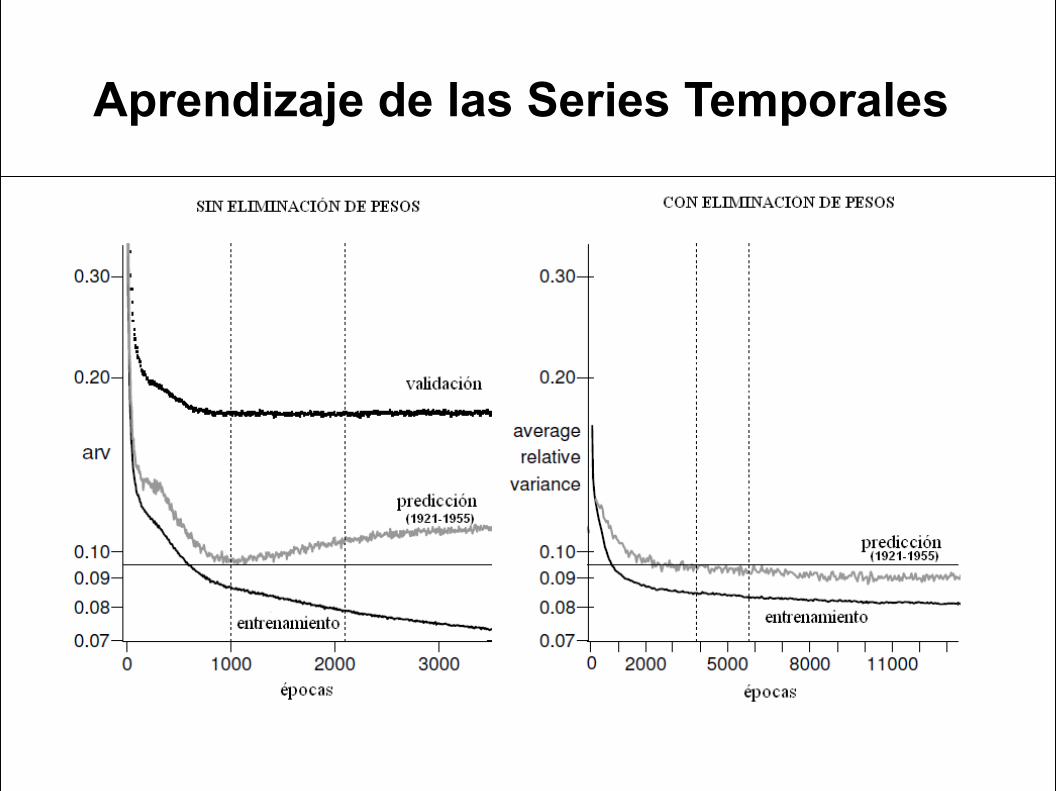
Aprendizaje de las Series Temporales
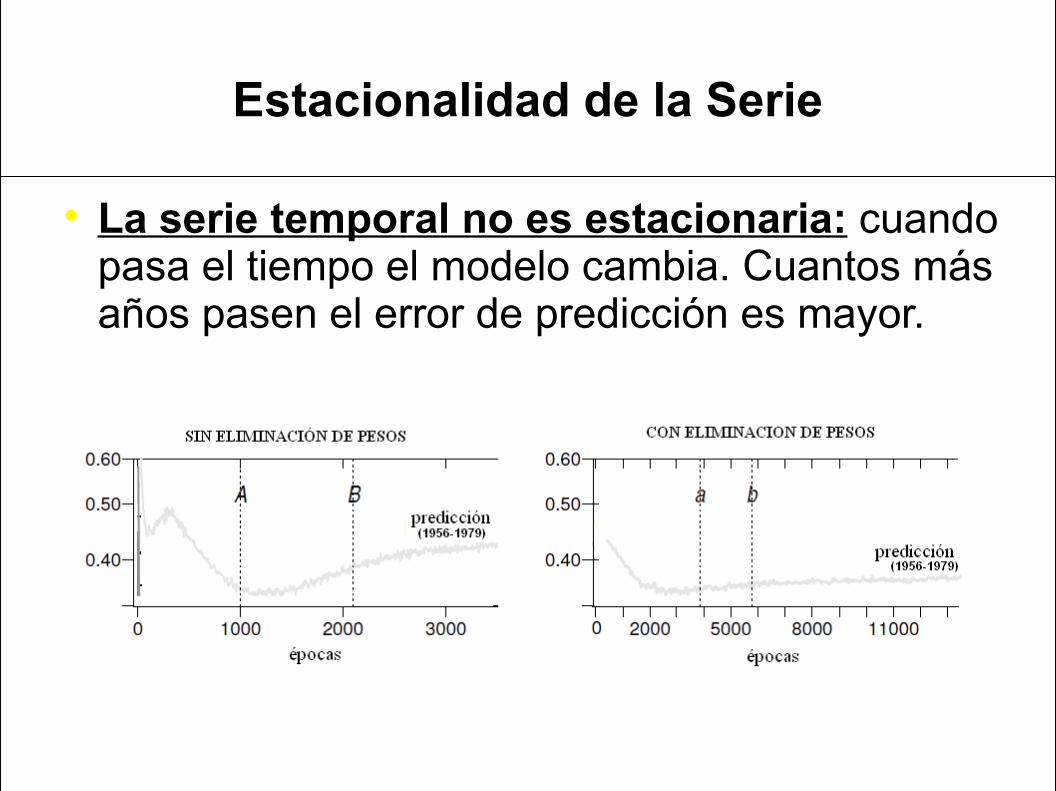
Estacionalidad de la Serie
La serie temporal no es estacionaria: cuando pasa el tiempo el modelo cambia. Cuantos más años pasen el error de predicción es mayor.

Variando la dimensión de las entradas
Se pasa de 1 unidad de entrada a 41. El error se vuelve prácticamente constante al
aumentar el número de unidades de entrada. Si el número de entradas excede a las
necesarias la red ignora las que sean irrelevantes, por ello el rendimiento no se ve afectado por la dimensión de las entradas (ventaja sobre otros métodos de predicción).

Referencias
• Recurrent Neural Networks and Robust Time Series Prediction, Jerome T.Connot, R. Douglas Martin
• Predicting Sunspots And Exchange Rates With Connectionist Networks, Andreas S.Weigend Bernardo A.Huberman David E. Rumelhart
• Predicting Daily Probability Distributions, Andres S.Weigend, Shanming Shi
• SVM Kernels for Time Series Analysis, Stefan Ruping
• Neural Networks for Pattern Recognition, Christopher M.Bishop