nociones básicas de métodos cuantitativos para lingüistas
DESCRIPTION
IUOG, Seminario de Metodología, 28 marzo 2006. Nociones básicas de métodos cuantitativos para lingüistas. Crist óbal Lozano Universidad Autónoma de Madrid http://www.uam.es/cristobal.lozano. Objetivos del seminario. NO estudiaremos hoy: Cómo hacer estadística. Cómo diseñar un experimento. - PowerPoint PPT PresentationTRANSCRIPT

1
Nociones básicas de métodos cuantitativos
para lingüistas
Cristóbal Lozano
Universidad Autónoma de Madrid
http://www.uam.es/cristobal.lozano
IUOG, Seminario de Metodología, 28 marzo 2006

2
Objetivos del seminario
NO estudiaremos hoy: Cómo hacer estadística. Cómo diseñar un experimento. Cómo analizar datos en SPSS.
SÍ estudiaremos hoy: Conceptos y métodos básicos en investigación
cuantitativa. Principios básicos antes de comenzar estudio
cuantitativo qué hay que tener en cuenta.

3
Escoger tema de investigación Error del principiante: investigarlo “todo” Solución restringir el objeto de estudio
ERROR: quiero investigar la adquisición de pronombres en español L1
SOLUCIÓN: restringir: Pronombres personales: caso Pronombres personales accusativo: persona Pronombres personales acusativo 3ª: singular vs. plural.
►PREGUNTA ¿Necesitamos restringir estos temas de investigación?:
• Adquisición: El “periodo crítico” en la adquisición de español L2.
• Psicolingüística: La representación mental de los morfemas en pacientes con síndrome de Alzheimer.
• Corpus: la distribución de los sujetos postverbales con verbos inacusativos en dos corpus nativos: corpus español de la RAE y el British National Corpus.

4
Datos: Tipos ¿Qué/cómo son los datos lingüísticos?
Sintagmas Palabras Tiempo de reacción ante ciertas estructuras Nº de sujetos nulos Morfemas Grado de aceptabilidad ante una estructura/elemento. Edad de aprendizaje de L2 Nivel de competencia gramatical
Tipos de datos: Cualitativos:
Nominales: cada dato es una etiqueta, un nombre, sin valor numérico real: SN / SV. Hombre/mujer. L1 inglés / L1 español.
Ordinales: cada dato está ordenado según un criterio (mayormenor): Clase social (baja/media/alta) Tipología (S>OD>OI)
Cuantitativos: Continuos: cada dato es un número resultado de una medida, no hay “saltos”.
Milisegundos Edad cronológica (en meses)
Discretos: cada dato es un número resultado de contar (¿cuántas veces tanto?), hay “saltos” Nº de SN en un corpus Nº de producción de morfemas verbales
5
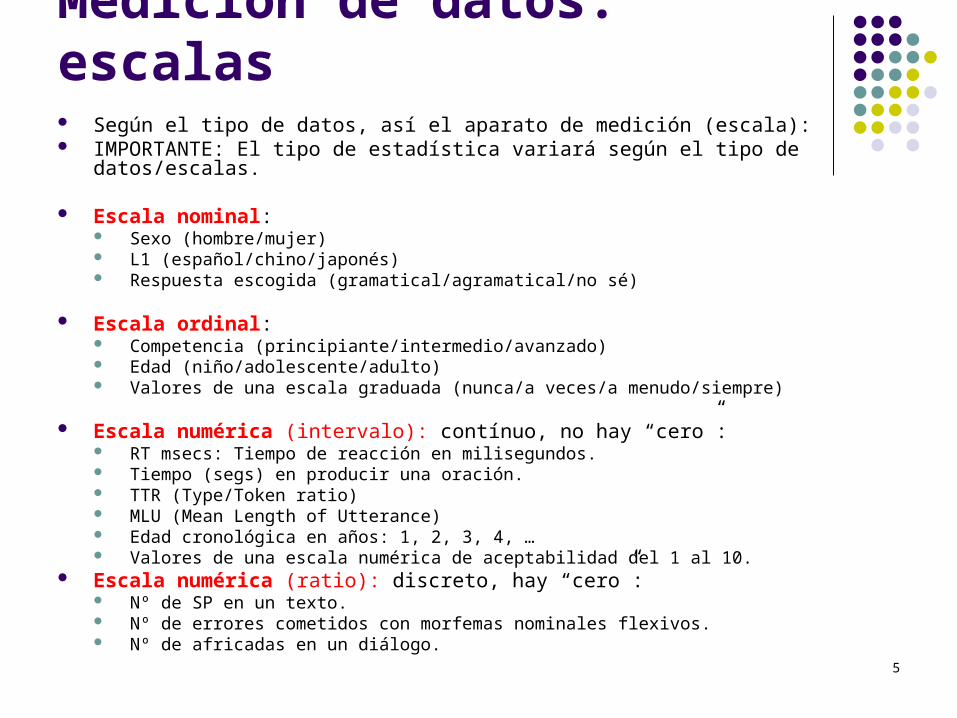
Medición de datos: escalas Según el tipo de datos, así el aparato de medición (escala): IMPORTANTE: El tipo de estadística variará según el tipo de datos/escalas.
Escala nominal: Sexo (hombre/mujer) L1 (español/chino/japonés) Respuesta escogida (gramatical/agramatical/no sé)
Escala ordinal: Competencia (principiante/intermedio/avanzado) Edad (niño/adolescente/adulto) Valores de una escala graduada (nunca/a veces/a menudo/siempre)
Escala numérica (intervalo): contínuo, no hay “cero”: RT msecs: Tiempo de reacción en milisegundos. Tiempo (segs) en producir una oración. TTR (Type/Token ratio) MLU (Mean Length of Utterance) Edad cronológica en años: 1, 2, 3, 4, … Valores de una escala numérica de aceptabilidad del 1 al 10.
Escala numérica (ratio): discreto, hay “cero”: Nº de SP en un texto. Nº de errores cometidos con morfemas nominales flexivos. Nº de africadas en un diálogo.
6
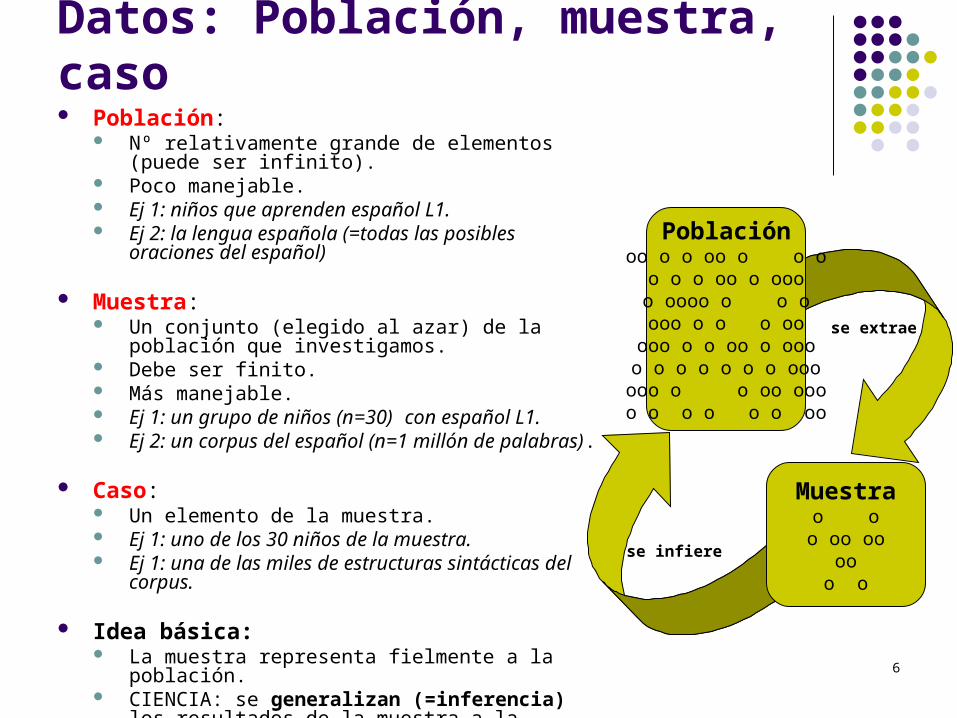
Datos: Población, muestra, caso Población:
Nº relativamente grande de elementos (puede ser infinito).
Poco manejable. Ej 1: niños que aprenden español L1. Ej 2: la lengua española (=todas las posibles
oraciones del español)
Muestra: Un conjunto (elegido al azar) de la población que
investigamos. Debe ser finito. Más manejable. Ej 1: un grupo de niños (n=30) con español L1. Ej 2: un corpus del español (n=1 millón de palabras).
Caso: Un elemento de la muestra. Ej 1: uno de los 30 niños de la muestra. Ej 1: una de las miles de estructuras sintácticas del
corpus.
Idea básica: La muestra representa fielmente a la población. CIENCIA: se generalizan (=inferencia) los
resultados de la muestra a la población en general.
Poblaciónoo o o oo o o o
o o o oo o oooo oooo o o oooo o o o oo
ooo o o oo o oooo o o o o o o oooooo o o oo oooo o o o o o oo
Muestrao o
o oo oooo
o o
se extrae
se infiere

7
Variables ►¿Qué es una var? ¿Es importante para la investigación? Variable:
Propiedad/aspecto que varía entre las personas/animales/objetos o cualquier otra unidad de análisis.
Su valor depende del azar (aleatorio). Existen Modelos de Probabilidad que describen el comportamiento de las vars, p. ej.,
Modelo distribución Normal, distribución Chi-cuadrado, distribución t, distrib Binominal , etc. Longitud corporal, peso de los gatos, talla del pie, número de infracciones de tráfico,
sexo (hombre/mujer), clase social, nº de SSNN en un texto, nº de errores cometidos en L2, etc.
Variable Independiente (VI): variable “predictora”, la manipula el investigador, predice lo que le ocurrirá a una segunda variable que depende de ella. [predictor, factor]
Variable Dependiente (VD): variable de “respuesta”, el resultado, lo que se mide.►EJEMPLO: adquisición: El investigador quiere descubrir si el nivel de proficiencia en L2 (Principiante vs. Avanzado) influye en la detección de errores de concordancia Sujeto-Verbo (*Pedro comes manzanas).
•VI: nivel de competencia (principiante/avanzado)
•VD: nº de detecciones de errores de concordancia Sujeto-Verbo
►PREGUNTA ¿Cuál es la VD y la VI?:
• Adquisición: El inglés es una lengua con sujetos obligatorios (*John believes that is intelligent), al igual que el francés pero a diferencia del español. El investigador predice que en la adquisición de inglés L2, nivel principiante, los francófonos producirán menos errores que los hispanófonos.

8
Niveles de la VI Niveles de la VI:
Competencia: principiante/intermedio/avanzado [3 niveles] Sexo: hombre/mujer [2 niveles] Lengua materna: español/japonés/chino [3 niveles] Modalidad del estímulo: auditivo/visual [2 niveles]
►PREGUNTA ¿Cuál es la VD y la VI? ¿Cuántos niveles de la VI?
• Adquisición: Ionin & Wexler (2002:95): Adquisición de morfología verbal en inglés L1 con verbos temáticos (no acescenso) vs. verbo “be” (ascenso): “A grammaticality judgement task of English tense/agreement morphology similarly shows that the child L2 English learners are significantly more sensitive to the “be” paradigm than to inflection on thematic verbs”.
•VI: flexión verbal: verbo temático vs. verbo “be” (2 niveles)
•VD: resultados (=puntuación) obtenidos en el juicio de gramaticalidad.
►PREGUNTA ¿Cuál es la VD y la VI? ¿Cuántos niveles de la VI?
• Psicolingüística: El investigador quiere saber el tiempo que se tarda (en milisegundos) en reaccionar a una violación sintáctica (ascenso verbal: *John eats often pasta) frente a una oración gramatical (no ascenso verbal: John often eats pasta).

9
“Confounding” variables Hay que controlar las variables que dan lugar a
confusión. El investigador quiere que los resultados (VD) se
expliquen por una causa específica que se ha controlado (VI) y no por otras causas irrelevantes.
►EJEMPLO: adquisición: Violaciones en la extracción de elementos wh- en inglés L2: *Who do you say that killed the president?
3 grupos de aprendices de inglés L2:
•Nativos de alemán (nivel principiante)
•Nativos de griego (nivel principiante)
•Nativos de griego (nivel avanzado)
Problema: ¿A qué se deben los resultados? ¿Al nivel: principiante vs. avanzado? ¿O a la lengua materna: griego vs. alemán).
Solución: VI: lengua materna (alemán/griego)
Descartar variable de confusión: nivel avanzado (griego).

10
Constantes
Las posibles variables de confusión hay que mantenerlas constantes (=una constante no varía, permanece fija, así que NO es una var).
►EJEMPLO ANTERIOR: Violaciones en la extracción de elementos wh- en inglés L2: *Who do you say that killed the president?
Solución: VI: lengua materna (alemán/griego)
Constante: nivel (avanzado sólo)
Constante: edad (sólo adolescentes)
Constante: tipo de instrucción (sólo contextos naturalistas)
11
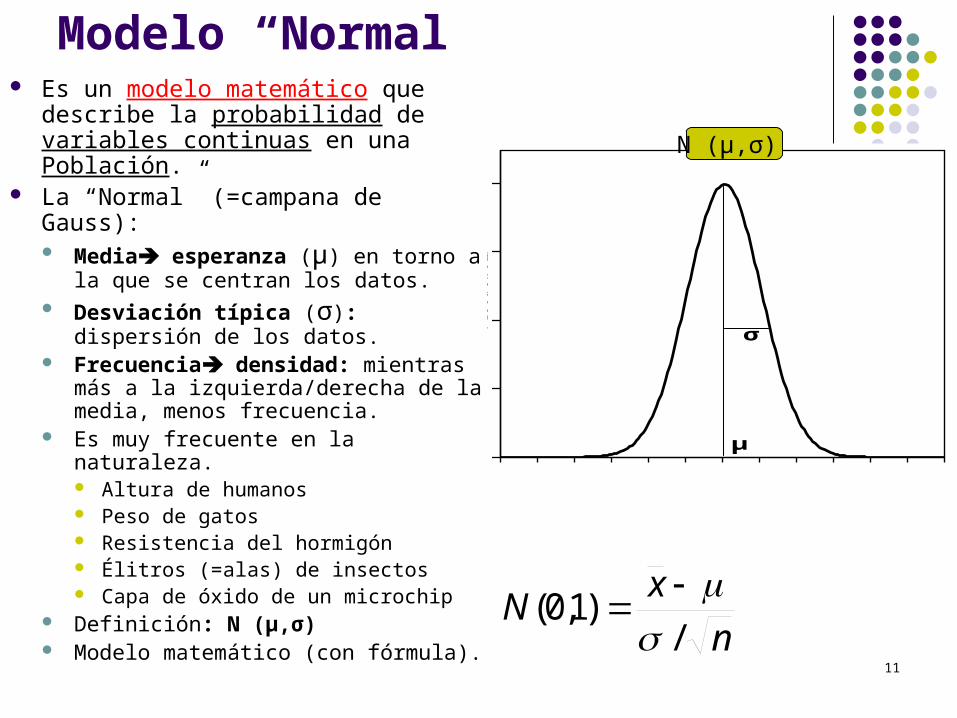
Modelo “Normal” Es un modelo matemático que
describe la probabilidad de variables continuas en una Población.
La “Normal” (=campana de Gauss): Media esperanza (μ) en torno a la
que se centran los datos. Desviación típica (σ): dispersión de
los datos. Frecuencia densidad: mientras
más a la izquierda/derecha de la media, menos frecuencia.
Es muy frecuente en la naturaleza. Altura de humanos Peso de gatos Resistencia del hormigón Élitros (=alas) de insectos Capa de óxido de un microchip
Definición: N (μ,σ) Modelo matemático (con fórmula).
Fre
cu
en
cia
μ
σ
N (μ,σ)
n
xN
/)1,0(
12
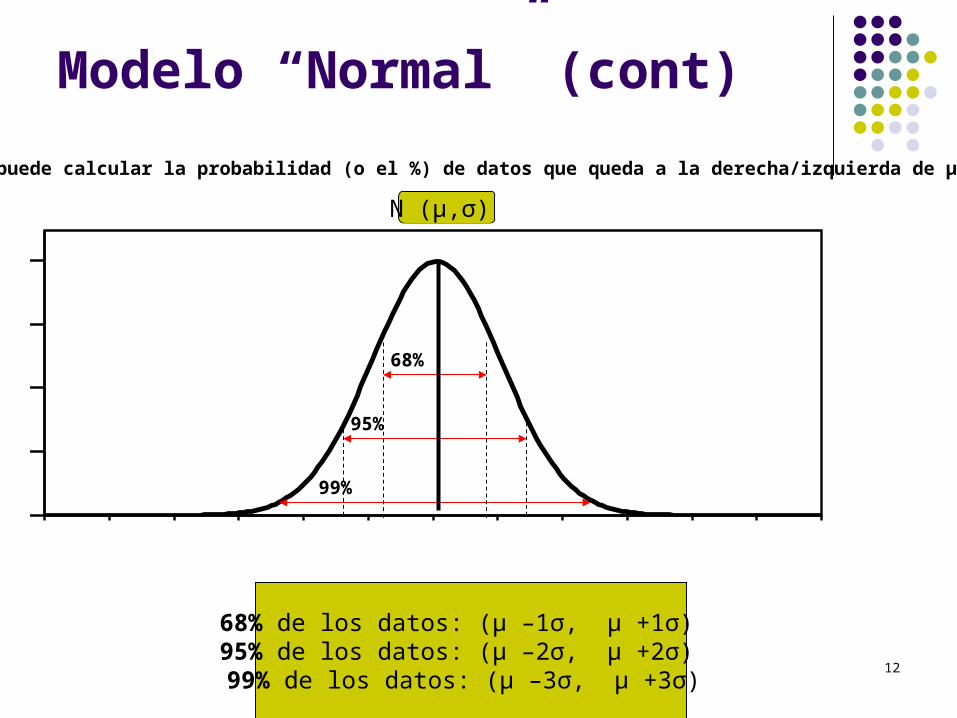
Modelo “Normal” (cont)
N (μ,σ)
68% de los datos: (μ –1σ, μ +1σ) 95% de los datos: (μ –2σ, μ +2σ) 99% de los datos: (μ –3σ, μ +3σ)
Se puede calcular la probabilidad (o el %) de datos que queda a la derecha/izquierda de μ.
Frecu
en
cia
68%
95%
99%
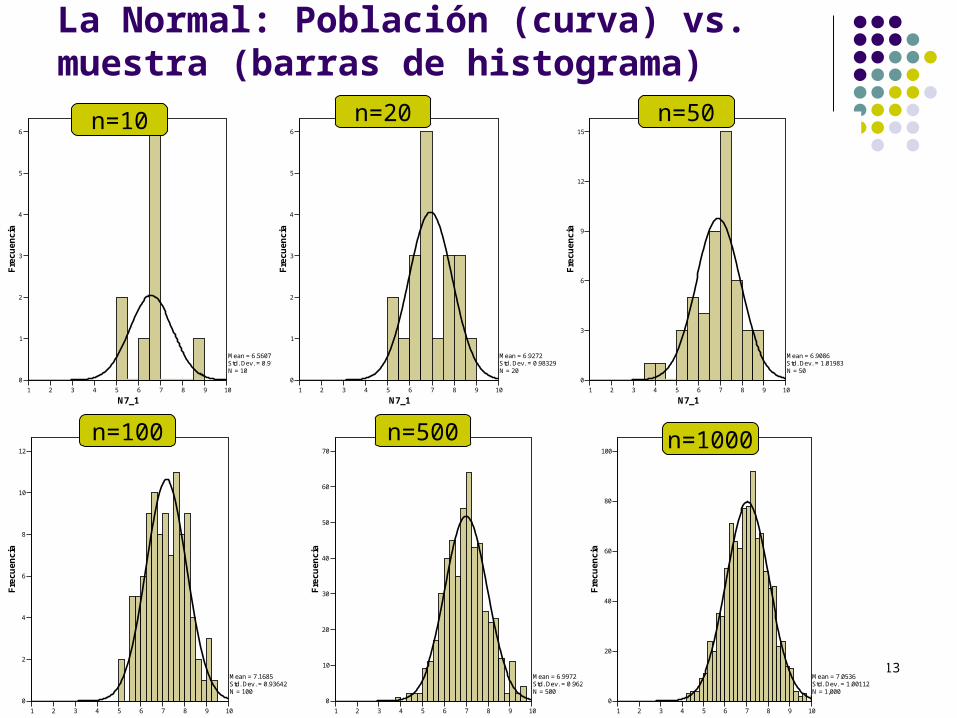
13
1 2 3 4 5 6 7 8 9 10
N7_1
0
1
2
3
4
5
6
Fre
cuen
cia
Mean = 6.5607Std. Dev. = 0.97628N = 10
La Normal: Población (curva) vs. muestra (barras de histograma)
1 2 3 4 5 6 7 8 9 10
N7_1
0
1
2
3
4
5
6
Fre
cuen
cia
Mean = 6.9272Std. Dev. = 0.98329N = 20
n=20
1 2 3 4 5 6 7 8 9 10
N7_1
0
3
6
9
12
15
Fre
cuen
cia
Mean = 6.9086Std. Dev. = 1.01983N = 50
n=50
1 2 3 4 5 6 7 8 9 10
N7_1
0
2
4
6
8
10
12
Fre
cue
nc
ia
Mean = 7.1685Std. Dev. = 0.93642N = 100
n=100
n=10
1 2 3 4 5 6 7 8 9 10
N7_1
0
10
20
30
40
50
60
70
Fre
cue
nc
ia
Mean = 6.9972Std. Dev. = 0.96272N = 500
n=500
1 2 3 4 5 6 7 8 9 10
N7_1
0
20
40
60
80
100
Fre
cue
nc
ia
Mean = 7.0536Std. Dev. = 1.00112N = 1,000
n=1000

14
Hipótesis Son predicciones que se aceptarán o rechazarán DESPUÉS del
análisis de datos. Hipótesis nula (H0): hipótesis por defecto, no predice diferencias,
X=Y, la VI no influye. Hipótesis alternativa (H1): predice diferencias, X≠Y, causadas por
la VI. Idea básica:
Rechazar H0 para así poder aceptar H1 (con un margen de confianza alto). Así, el investigador tentrá la certeza (con un margen de error bajo) de que los
resultados se deben a manipulación de IV (lengua materna) y no a otros factores o al azar.
¿Por qué margen de error? Porque trabajamos sobre la muestra, que es un conjunto incompleto de la población.
Idea “matemática”: H0: μx = μy
H1: μx ≠ μy►EJEMPLO ANTERIOR: Violaciones en la extracción de elementos wh- en inglés L2: *Who do you say that killed the president?
H0: No se observarán diferencias entre ambos grupos de principiantes (griego vs. alemán) en el nº
de detecciones de violaciones –wh.
H1: Habrá una diferencia entre los dos grupos de principiantes (griego vs. alemán) en el nº de detecciones de violaciones de elementos –wh.

15
Dirección de las hipótesis Ejemplo anterior: hipótesis bidireccional
(=dos colas): Grupo alemán > grupo griego Grupo alemán < grupo griego
Posibilidad de cometer error en predicción es doble.
Hipótesis unidireccional (=una cola): Grupo alemán > grupo griego
Posibilidad de cometer error en predicción es la mitad (α/2).
►EJEMPLO : Corpus: material sintáctico que interviene entre el Verbo y el Sujeto postverbal: V X S.
Basándose en teorías lingüísticas, el investigador asume que la proporción de material sintáctico será mayor en un corpus nativo de español que en otro de italiano.
¿Cuáles son H0 y H1 ? ¿Unidireccional o bidireccional?

16
3 diseños experimentales básicos Diseño: cómo se interrelacionan los grupos de datos y las variables. 3 tipos de preguntas/hipótesis básicas en cualquier ciencia:
¿Hay diferencias entre varX y varY? ¿Hay diferencias entre varX y varY? ¿Existe una relación entre varX y varY?
3 tipos de diseños básicos: Inter-grupos [between-group design, unrelated design]: Se comparan dos
grupos diferentes de sujetos/muestras: Psicolingüística: Los inmigrantes con árabe L1 que llegan a España antes del periodo
crítico (14 años) alcanzan un nivel de competencia mayor que aquellos que llegan después del periodo crítico 2 GRUPOS DIFERENTES (PREPUBESCENTE vs POSTPUBESCENTE)
Intra-grupos [within-group design, related design]: Se comparan dos elementos del mismo grupo/muestra: Psicolingüística: Los inmigrantes con árabe L1 que llegan a España después del
periodo crítico producen más regularizaciones morfológicas con participios de la tercera conjugación (*escribido) que con los de la segunda (*ponido) 1 GRUPO, MISMOS SUJETOS, SE TOMAN MUESTRAS REPETIDAS.
Correlacional: relación entre dos variables: Psicolingüística: El nivel de competencia lingüístico disminuye conforme la edad de
llegada al país de destino aumenta (=a más edad, menos competencia). RELACIÓN ENTRE 2 VAR (EDAD Y COMPETENCIA)

17
Ejemplo: inter-grupos vs. intra-grupos
* SVAO French #1 8 French #2 10 French #3 7 French #4 5 French #5 7 Chinese #1 6 Chinese #2 3 Chinese #3 2 Chinese #4 2 Chinese #5 4
Ascenso verbal en inglés L2: SAVO: John often eats pasta. SVAO: *John eats often pasta
2 grupos: Francés Chino
Método: juicios de aceptabilidad: escala del 0 (inaceptable) al 10 (aceptable).
¿Cuál podría ser H1? ¿Y H0? ¿Cuál es la VI? Y la ¿VD? ¿Cuántos niveles tiene VI? Observando a simple vista los datos, ¿podemos rechazar H0?
SAVO * SVAO French #1 9 8 French #2 8 9 French #3 8 7 French #4 9 5 French #5 10 7
Inter grupos Intra grupo

18
Ejemplo: correlacional Español L1 Producción de dos elementos:
Flexión con verbos finitos (limpio, limpias, limpia) vs. formas verbales por defecto (“limpá”)
Sujetos pronominales plenos (yo, tú, él) vs. nulos (pro) Predicción: H1: la producción de flexión verbal se correlaciona con la
producción de sujetos plenos a más flexión verbal, menos sujetos nulos.
Month/ age of sampling
Production of finite verbal
inflection (% )
Production of null subjects (% )
mar 10 92 apr 21 84 may 38 75 jun 50 52 jul 69 32 aug 77 25 sep 91 15 oct 95 12 nov 96 3 dec 99 2

19
2 tipos de estadística
Estadística descriptiva: Describe la muestra. Proporciona un “resumen” de los datos de la muestra:
Centralidad: ¿qué datos son los más representativos? Frecuencia: ¿cuántas veces aparece X? Dispersión: ¿cuán dispersos son los datos?
Estadística inferencial: Basándonos en la muestra, se infiere algo sobre la
población. Dice si las diferencias o las correlaciones entre las VI son
significativas.

20
Descriptiva: tendencias de centralidad
Centralidad: información sobre el comportamiento más típico de los casos. Media: (promedio): la suma de todos los valores
observados divididos por el nº de datos. Moda: valor más frecuente (puede haber más de
una moda). Mediana: valor que divide la muestra en dos
grupos (la mitad está por debajo de la mediana, la otra mitad por encima).

21
Ejemplo centralidad Investigador: quiere comprobar una teoría lingüística (Hipótesis
Incusativa). Hipótesis Inacusativa:
Inergativos como ‘llorar’: SV Inacusativos como ‘venir’: VS
Contextos neutros: la info es desconocida y ningún constituyente es Foco (info nueva): A: ¿Qué pasó? B: Un niño vino (SV) / Vino un niño (VS) B’: Un niño lloró (SV) / Lloró un niño (VS)
Método: Test de juicios de aceptabilidad pareados: Ayer, mientras estabas en el banco, un ladrón entró a robar. Hoy, tu amigo
José ha escuchado en la radio una noticia sobre el banco, pero no sabe qué paso. Así que José te llama por teléfono y te pregunta: “¿Qué pasó ayer en el banco?”. Tú respondes: Un ladrón entró -2 -1 0 +1 +2 Entró un ladrón -2 -1 0 +1 +2
22
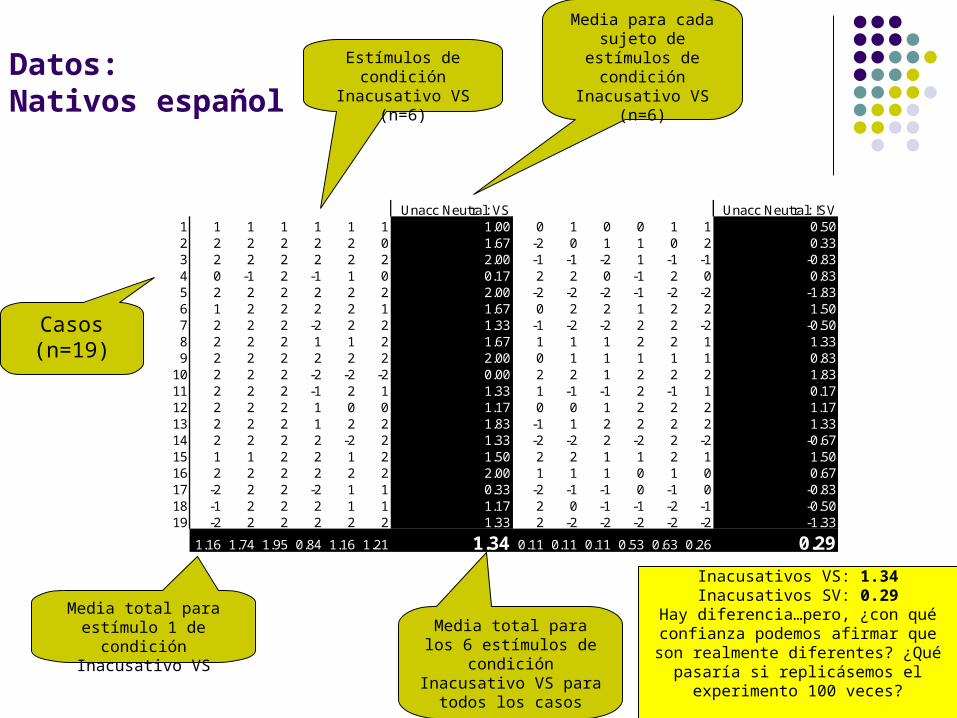
Datos:Nativos español
Casos(n=19)
Estímulos de condición Inacusativo VS
(n=6)
Media para cada sujeto de estímulos de condición Inacusativo
VS(n=6)
Media total para estímulo 1 de condición Inacusativo VS
Media total para los 6 estímulos de condición
Inacusativo VS para todos los casos
Unacc Neutral: VS Unacc Neutral: !SV1 1 1 1 1 1 1 1.00 0 1 0 0 1 1 0.502 2 2 2 2 2 0 1.67 -2 0 1 1 0 2 0.333 2 2 2 2 2 2 2.00 -1 -1 -2 1 -1 -1 -0.834 0 -1 2 -1 1 0 0.17 2 2 0 -1 2 0 0.835 2 2 2 2 2 2 2.00 -2 -2 -2 -1 -2 -2 -1.836 1 2 2 2 2 1 1.67 0 2 2 1 2 2 1.507 2 2 2 -2 2 2 1.33 -1 -2 -2 2 2 -2 -0.508 2 2 2 1 1 2 1.67 1 1 1 2 2 1 1.339 2 2 2 2 2 2 2.00 0 1 1 1 1 1 0.83
10 2 2 2 -2 -2 -2 0.00 2 2 1 2 2 2 1.8311 2 2 2 -1 2 1 1.33 1 -1 -1 2 -1 1 0.1712 2 2 2 1 0 0 1.17 0 0 1 2 2 2 1.1713 2 2 2 1 2 2 1.83 -1 1 2 2 2 2 1.3314 2 2 2 2 -2 2 1.33 -2 -2 2 -2 2 -2 -0.6715 1 1 2 2 1 2 1.50 2 2 1 1 2 1 1.5016 2 2 2 2 2 2 2.00 1 1 1 0 1 0 0.6717 -2 2 2 -2 1 1 0.33 -2 -1 -1 0 -1 0 -0.8318 -1 2 2 2 1 1 1.17 2 0 -1 -1 -2 -1 -0.5019 -2 2 2 2 2 2 1.33 2 -2 -2 -2 -2 -2 -1.33
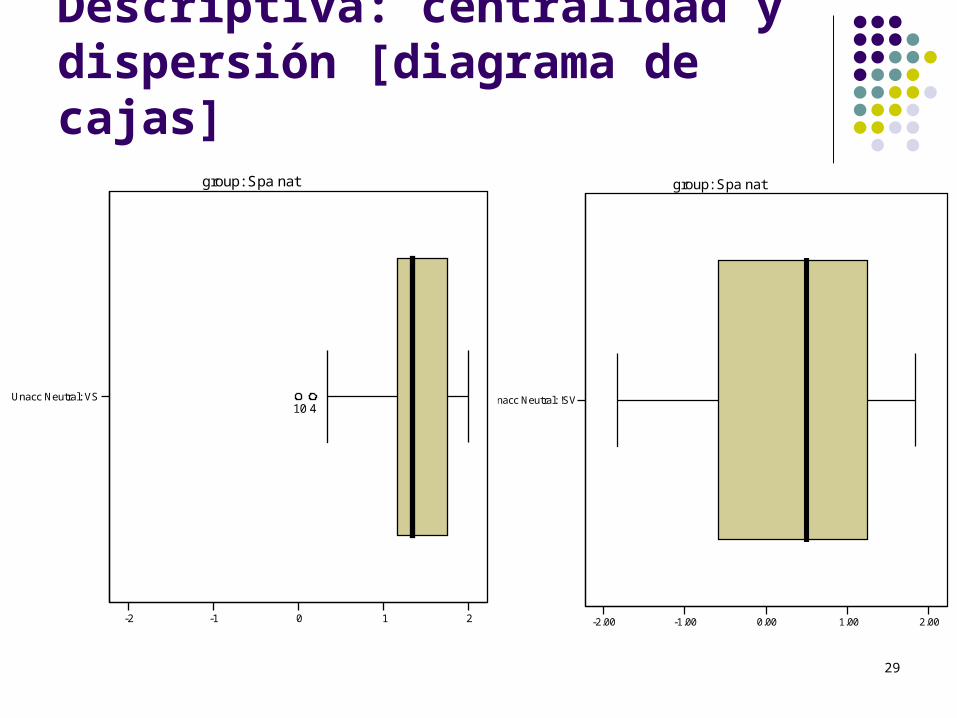
1.16 1.74 1.95 0.84 1.16 1.21 1.34 0.11 0.11 0.11 0.53 0.63 0.26 0.29
Inacusativos VS: 1.34Inacusativos SV: 0.29
Hay diferencia…pero, ¿con qué confianza podemos afirmar que son realmente
diferentes? ¿Qué pasaría si replicásemos el experimento 100 veces?

23
¿Qué hacer con los datos? 1º. Explorar y resumir [estadística descriptiva]:
Tablas (detallado pero poco intuitivo) Gráficos (menos detallado pero visualmente intuitivo)
2º. Inferir y generalizar [estadística inferencial] Test(s) relevante(s): t-test, chi-cuadrado, ANOVA, etc… Comprobar si las diferencias son significativas (o no). Ver si H0 es rechazada o aceptada. Generalizar/inferir de la muestra a la población.
3º. Interpretar Implicaciones teóricas/lingüísticas

24
Frecuencias (absolutas): tablas
Unacc Neutral: VSa
1
1
1
1
2
4
1
3
1
4
19
.00
.17
.33
1.00
1.17
1.33
1.50
1.67
1.83
2.00
Total
VálidosFrecuencia
group = Spa nata.
Unacc Neutral: !SVa
1
1
2
1
2
1
1
1
1
2
1
2
2
1
19
-1.83
-1.33
-.83
-.67
-.50
.17
.33
.50
.67
.83
1.17
1.33
1.50
1.83
Total
VálidosFrecuencia
group = Spa nata.
25
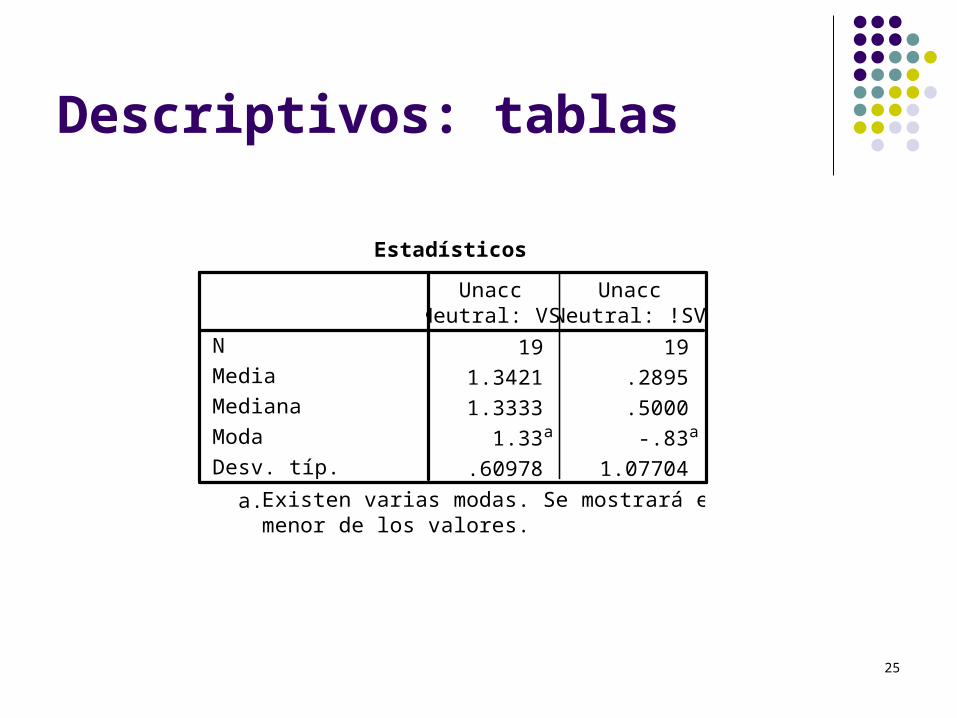
Descriptivos: tablas
Estadísticos
19 19
1.3421 .2895
1.3333 .5000
1.33a -.83a
.60978 1.07704
N
Media
Mediana
Moda
Desv. típ.
UnaccNeutral: VS
UnaccNeutral: !SV
Existen varias modas. Se mostrará elmenor de los valores.
a.

26
Descriptivos: medias
Hay diferencia… pero ¿con qué confianza podemos decir que la diferencia es real? ¿Podemos rechazar H0 (para aceptar H1)?
1.34
0.29
-2
-1
0
1
2
Natives
Mea
n ac
cept
abilit
y ra
te
Unac Neut VS
Unac Neut #SV
n
xx i
datos nº
datos de sumatorio

27
Descriptiva: dispersión Desviación típica [inglés standard deviation]
La desviación de los datos con respecto a la media. Desviación típica baja: datos homogéneos. Desviación típica alta: datos heterogéneos.
Inacusativos VS: 0.61 Inacusativos SV: 1.08
Rango: diferencia entre valor más alto y más bajo. Inacusativos VS: valor más bajo (0), valor más alto (+2)
rango: 2 Inacusativos SV: valor más bajo (-1.83), valor más alto
(+1.83) rango: 3.66
n
xxs i )(
datos nº
residuos de sumatorio
28
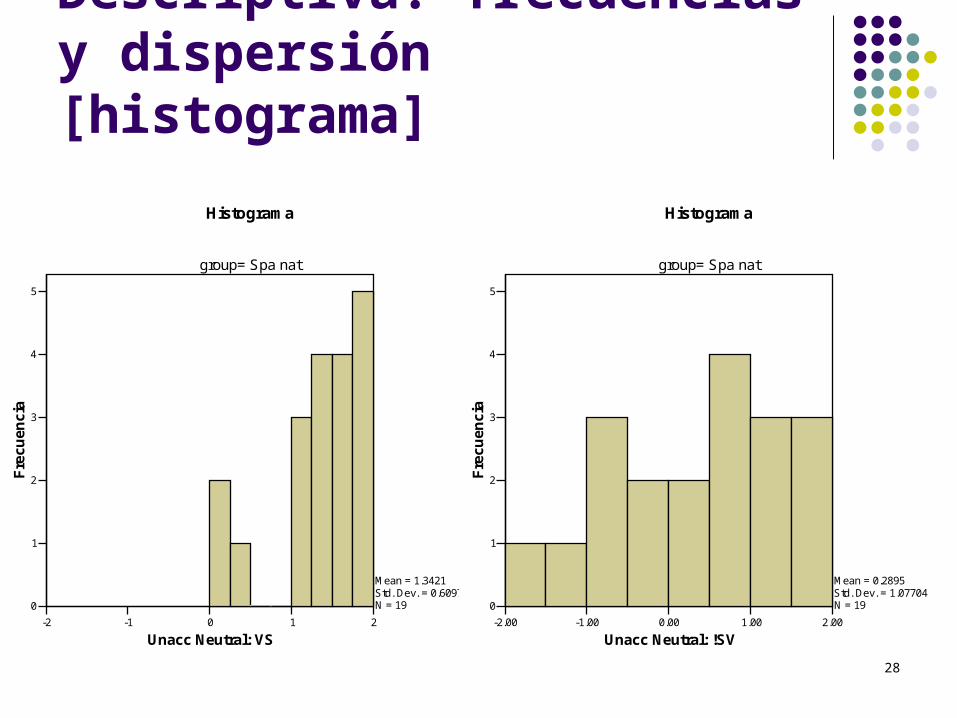
Descriptiva: frecuencias y dispersión [histograma]
-2 -1 0 1 2
Unacc Neutral: VS
0
1
2
3
4
5
Fre
cuen
cia
Mean = 1.3421Std. Dev. = 0.60978N = 19
group= Spa nat
Histograma
-2.00 -1.00 0.00 1.00 2.00
Unacc Neutral: !SV
0
1
2
3
4
5
Fre
cuen
cia
Mean = 0.2895Std. Dev. = 1.07704N = 19
group= Spa nat
Histograma
29
Descriptiva: centralidad y dispersión [diagrama de cajas]
Unacc Neutral: !SV
-2.00 -1.00 0.00 1.00 2.00
group: Spa nat
Unacc Neutral: VS
-2 -1 0 1 2
10 4
group: Spa nat

30
Inferencial: Nivel de significación ¿Con qué margen de confianza podemos rechazar H0 (para así aceptar H1)?
Investigador establece el nivel de significación α: α=0.05 posibilidad de error del 5% (confianza del 95%) lingüística, psicología α=0.01 posibilidad de error del 1% (confianza del 99%) medicina, farmacología
El test estadístico (SPSS) arroja el valor p, que varía entre 0 y 1. p=0.03 implica:
La probabilidad matemática (de 0 a 1) de que H0 sea cierta: 0.03 = 3%. Podemos rechazar H0 con una confianza de p=0.97 = 97%. La diferencia (o correlación) entre X e Y es estadísticamente sig porque p<α. La probabilidad de que la diferencia (o correlación) se deba al azar es 3%. Podemos estar 97% seguros de que nuestros resultados no se deben al azar. Podemos estar 97% seguros de que la diferencia (o correlación) de nuestra muestra se
puede aplicar a la población en general. p=0.60 implica:
La probabilidad matemática (de 0 a 1) de que H0 sea cierta: 0.60 = 60%. Podemos rechazar H0 con una confianza del p=0.40= 40%. La diferencia (o correlación) entre X e Y NO es estadísticamente sig porque p>α. La probabilidad de que la diferencia (o correlación) se deba al azar es 60%. Podemos estar 40% seguros de que nuestros resultados no se deben al azar. Podemos estar 40% seguros de que la diferencia (o correlación) de nuestra muestra se
puede aplicar a la población en general.
RESUMEN: p<0.05 diferencias sig p>0.05 diferencias n.s.

31
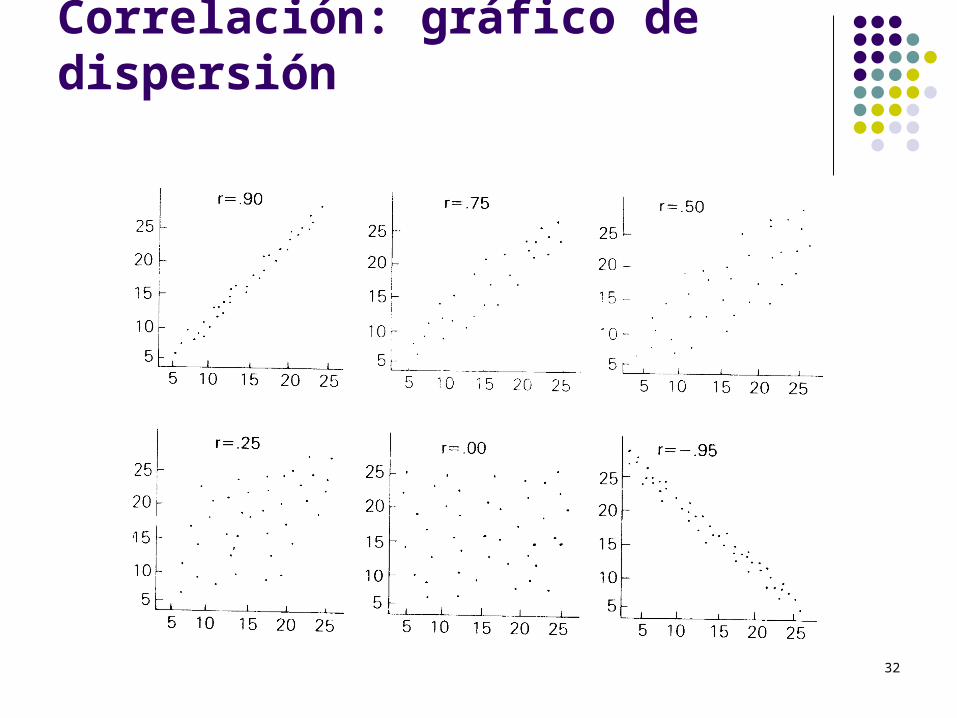
Asociación: Correlación
Correlación: mide el grado de relación entre dos variables: X e Y. Covarianza: mide relación lineal entre X e Y.
Coeficiente de correlación r
Medición de vars: escála numérica. Datos cuantitativos
Correlación positiva: Mientras más A, más B.
A más horas de instrucción en una L2, más nivel de competencia. Correlación negativa:
Mientras más A, menos B. Mientras más tarde se aprenda una L2, menor será el nivel de
competencia.
yxss
YXCOV ),(
Y típicadesvpor X típicadesv
Y)(X, de covarianza
n
yyxxYXCOV ii
))((
datos nº
Y residuospor X residuos sumatorio),(
32
Correlación: gráfico de dispersión

33
Ejemplo: correlación Vida cotidiana: a más altura, más peso. Adquisición: Español L1, Inglés L2 H1: a más producción de concordancia S-V
(walk-s, sing-s), más producción de pronombres plenos (he walks, she sings).
Learner Production of overt pronominal subjects
(% )
Production of finite inflection -s
(% )
#1 70 80 #2 90 84 #3 73 75 #4 48 52 #5 48 32 #6 20 25 #7 22 25 #8 8 12 #9 7 3 #10 7 2
34
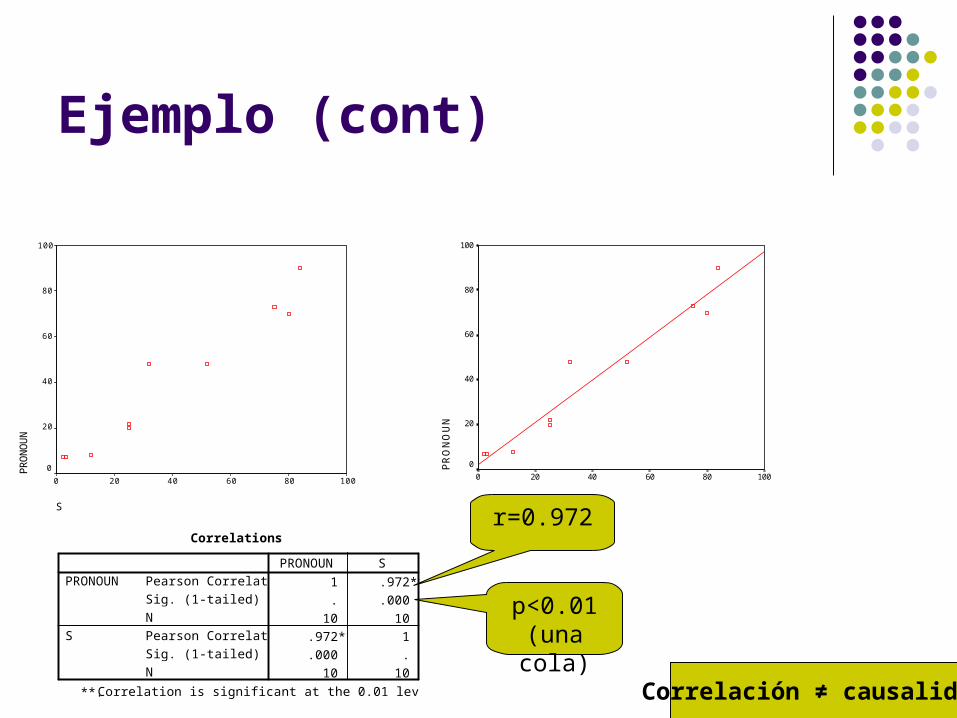
Ejemplo (cont)
S
100806040200
PR
ON
OU
N
100
80
60
40
20
0
S
100806040200
PR
ON
OU
N
100
80
60
40
20
0
Correlations
1 .972**
. .000
10 10
.972** 1
.000 .
10 10
Pearson Correlation
Sig. (1-tailed)
N
Pearson Correlation
Sig. (1-tailed)
N
PRONOUN
S
PRONOUN S
Correlation is significant at the 0.01 level (1-tailed).**. Correlación ≠ causalidad
r=0.972
p<0.01 (una cola)

35
Asociación: Chi cuadrado χ2
Mide la asociación/relación entre dos var nominales. Compara las frecuencias observadas con el
modelo teórico-matemático “Chi cuadrado” (=frecuencias esperadas).
Medición: escala nominal (datos cualitativos): sí/no SN/SV/SP nunca/a veces/siempre L1 inglés / L1 alemán
Cada caso (=persona) es contado sólo 1 vez.
E
E) - (O
esperadas freq
esperadas) - observadas (freq 222

36
Ejemplo chi cuadrado Investigador: relación/asociación entre…?
Lengua materna (L1): holandés / griego Nivel de pronunciación en L2: suena como un nativo / NO suena
como un nativo Hipótesis de trabajo: ¿Está la lengua materna asociada al nivel
de pronunciación en L2? SÍ. Por ejemplo, si la L1 y la L2 son fonológicamente similares, el nivel de pronunciación en L2 será mayor.
H1: hay diferencias entre L1 holandés y L1 griego. En concreto, la proporción aprendices clasificados como “suena nativo” será significativamente más alta en el grupo holandés que en el griego.
Método: fonólogo evalúa como nativo/no nativo grabaciones orales de los aprendices.

37
Datos chi-cuadrado

38
Resultados chi-cuadradoGROUP * ATTAINME Crosstabulation
Count
18 7 25
6 15 21
24 22 46
Dutch
Greek
GROUP
Total
Native-likeNon
native-like
ATTAINME
Total
18 holandeses fueron
clasificados como “nativo”
Chi-Square Tests
8.626b 1 .003
6.974 1 .008
8.908 1 .003
.007 .004
8.439 1 .004
46
Pearson Chi-Square
Continuity Correctiona
Likelihood Ratio
Fisher's Exact Test
Linear-by-LinearAssociation
N of Valid Cases
Value dfAsymp. Sig.
(2-sided)Exact Sig.(2-sided)
Exact Sig.(1-sided)
Computed only for a 2x2 tablea.
0 cells (.0%) have expected count less than 5. The minimum expected count is10.04.
b.
p=0.003 (dos colas)p=0.003/2 (una cola)
¿Podemos rechazar H0 (no hay relación entre L1 y nivel de pronunciación)?P=0.003/2=0.0015 (una cola)
¿Es p menor que α? 0.0015<0.05 SÍEntonces, rechazamos H0 y aceptamos H1
Conclusión: existe una relación significativa entre L1 y nivel de pronunciación en L2 … o la L1 influye más en el nivel de pronunciación de L2 mientras más cercanas estén
fonológicamente

39
Diferencias: test t de Student
Modelo matemático:
Compara si dos medias son significativamente diferentes.
Tipos: Test t para muestra independientes (inter grupos):
Dos grupos diferentes, p. ej., L1 griego, L1 español Test t para muestras relacionadas (intra grupos):
Un mismo grupo (L1 español) se mide dos veces con verbos inacusativos: orden SV y luego orden VS.
Medición: escala (datos cuantitativos).
ns
xtn
/ˆ1
40
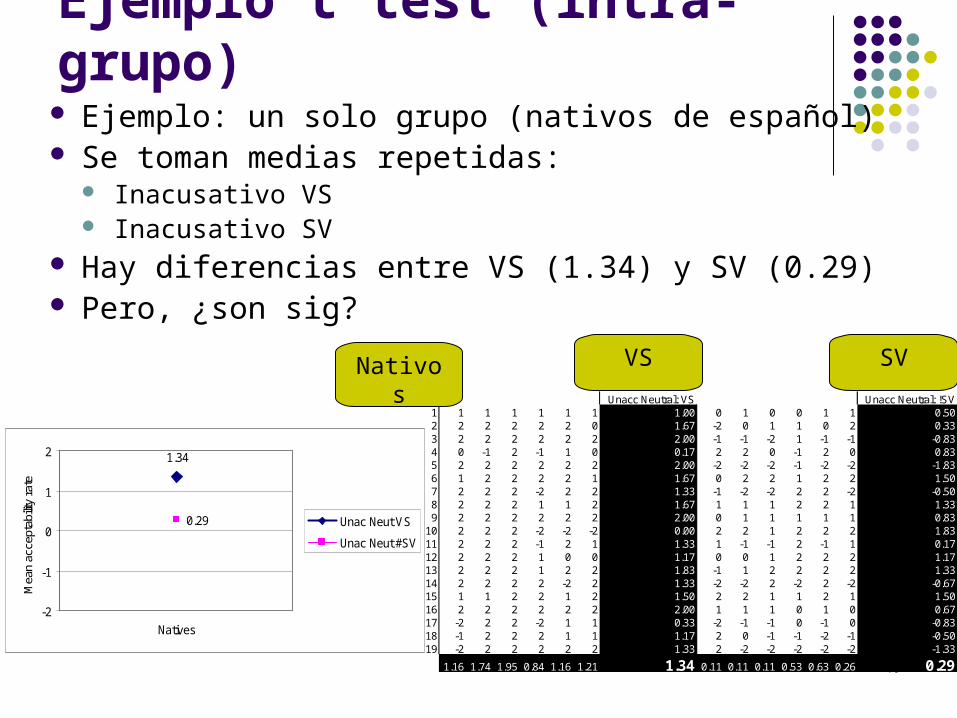
Ejemplo t test (intra-grupo) Ejemplo: un solo grupo (nativos de español) Se toman medias repetidas:
Inacusativo VS Inacusativo SV
Hay diferencias entre VS (1.34) y SV (0.29) Pero, ¿son sig?
Unacc Neutral: VS Unacc Neutral: !SV1 1 1 1 1 1 1 1.00 0 1 0 0 1 1 0.502 2 2 2 2 2 0 1.67 -2 0 1 1 0 2 0.333 2 2 2 2 2 2 2.00 -1 -1 -2 1 -1 -1 -0.834 0 -1 2 -1 1 0 0.17 2 2 0 -1 2 0 0.835 2 2 2 2 2 2 2.00 -2 -2 -2 -1 -2 -2 -1.836 1 2 2 2 2 1 1.67 0 2 2 1 2 2 1.507 2 2 2 -2 2 2 1.33 -1 -2 -2 2 2 -2 -0.508 2 2 2 1 1 2 1.67 1 1 1 2 2 1 1.339 2 2 2 2 2 2 2.00 0 1 1 1 1 1 0.83
10 2 2 2 -2 -2 -2 0.00 2 2 1 2 2 2 1.8311 2 2 2 -1 2 1 1.33 1 -1 -1 2 -1 1 0.1712 2 2 2 1 0 0 1.17 0 0 1 2 2 2 1.1713 2 2 2 1 2 2 1.83 -1 1 2 2 2 2 1.3314 2 2 2 2 -2 2 1.33 -2 -2 2 -2 2 -2 -0.6715 1 1 2 2 1 2 1.50 2 2 1 1 2 1 1.5016 2 2 2 2 2 2 2.00 1 1 1 0 1 0 0.6717 -2 2 2 -2 1 1 0.33 -2 -1 -1 0 -1 0 -0.8318 -1 2 2 2 1 1 1.17 2 0 -1 -1 -2 -1 -0.5019 -2 2 2 2 2 2 1.33 2 -2 -2 -2 -2 -2 -1.33
1.16 1.74 1.95 0.84 1.16 1.21 1.34 0.11 0.11 0.11 0.53 0.63 0.26 0.29
Nativos VS SV
1.34
0.29
-2
-1
0
1
2
Natives
Mea
n ac
cept
abilit
y ra
te
Unac Neut VS
Unac Neut #SV
41
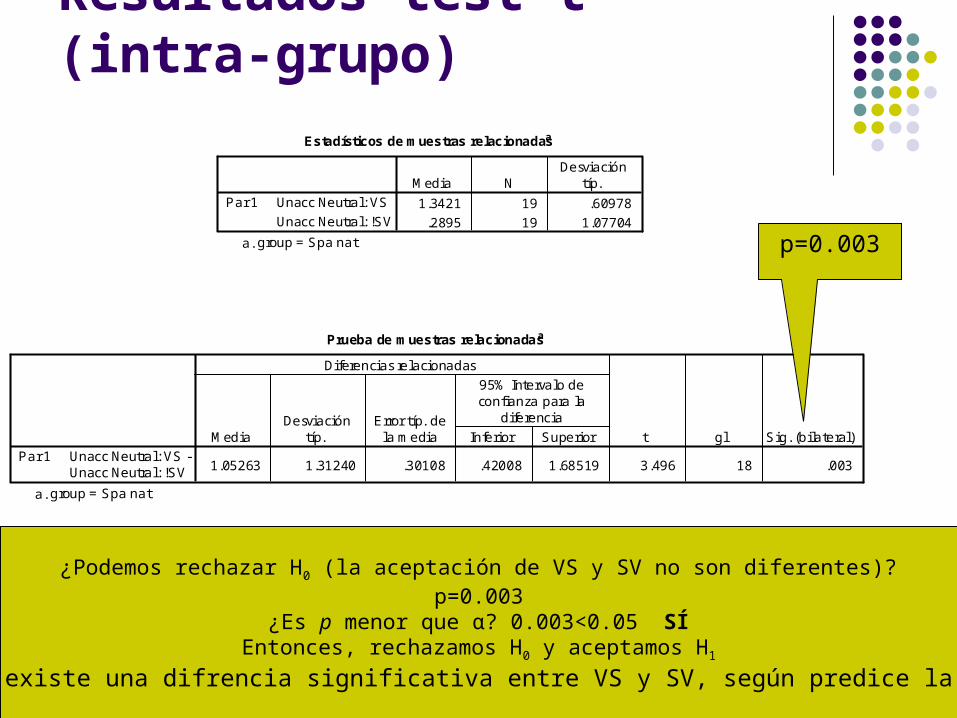
Resultados test t (intra-grupo)Estadísticos de muestras relacionadasa
1.3421 19 .60978
.2895 19 1.07704
Unacc Neutral: VS
Unacc Neutral: !SV
Par 1Media N
Desviacióntíp.
group = Spa nata.
Prueba de muestras relacionadasa
1.05263 1.31240 .30108 .42008 1.68519 3.496 18 .003Unacc Neutral: VS -Unacc Neutral: !SV
Par 1Media
Desviacióntíp.
Error típ. dela media Inferior Superior
95% Intervalo deconfianza para la
diferencia
Diferencias relacionadas
t gl Sig. (bilateral)
group = Spa nata.
p=0.003
¿Podemos rechazar H0 (la aceptación de VS y SV no son diferentes)?p=0.003
¿Es p menor que α? 0.003<0.05 SÍEntonces, rechazamos H0 y aceptamos H1
Conclusión: existe una difrencia significativa entre VS y SV, según predice la Hipo. Inac.

42
Ejemplo: test t (inter-grupos)
1 2 2 2 2 2 2 2.002 2 2 2 2 1 1 1.673 1 2 2 2 2 1 1.674 2 1 1 0 1 1 1.005 2 2 2 2 2 2 2.006 2 2 2 -1 1 2 1.337 -2 2 2 2 -2 -2 0.008 2 2 2 2 2 2 2.009 -1 2 2 -2 0 -1 0.00
10 2 2 2 2 2 2 2.0011 2 2 2 2 2 2 2.0012 2 2 2 2 2 2 2.0013 2 2 1 1 2 1 1.5014 1 1 2 -2 2 1 0.8315 -1 2 2 2 2 2 1.5016 2 2 2 2 2 2 2.0017 2 2 2 -2 2 2 1.3318 1 1 2 2 2 1 1.5019 0 1 -2 0 1 0 0.0020 2 2 2 2 2 2 2.0021 1 2 2 2 2 2 1.8322 2 2 0 2 0 1 1.1723 2 2 2 2 1 1 1.67
24 2 1 2 2 1 1 1.50
1.44
Inacusativos: orden VS 2 grupos:
Nativos de español Griegos aprendices de español L2 (nivel avanzado bajo)
Nativos
Griegos
Hay diferencias entre los nativos y los griegos: 1.34 vs. 1.44
PREGUNTA: ¿Es la diferencia realmente significativa?
1 1 1 1 1 1 1 1.002 2 2 2 2 2 0 1.673 2 2 2 2 2 2 2.004 0 -1 2 -1 1 0 0.175 2 2 2 2 2 2 2.006 1 2 2 2 2 1 1.677 2 2 2 -2 2 2 1.338 2 2 2 1 1 2 1.679 2 2 2 2 2 2 2.00
10 2 2 2 -2 -2 -2 0.0011 2 2 2 -1 2 1 1.3312 2 2 2 1 0 0 1.1713 2 2 2 1 2 2 1.8314 2 2 2 2 -2 2 1.3315 1 1 2 2 1 2 1.5016 2 2 2 2 2 2 2.0017 -2 2 2 -2 1 1 0.3318 -1 2 2 2 1 1 1.1719 -2 2 2 2 2 2 1.33
1.34
Unac Neut VS
1.44 1.34
-2
-1
0
1
2
Gk Low adv Natives
Mea
n ac
cept
abilit
y ra
te
Unac Neut VS
43
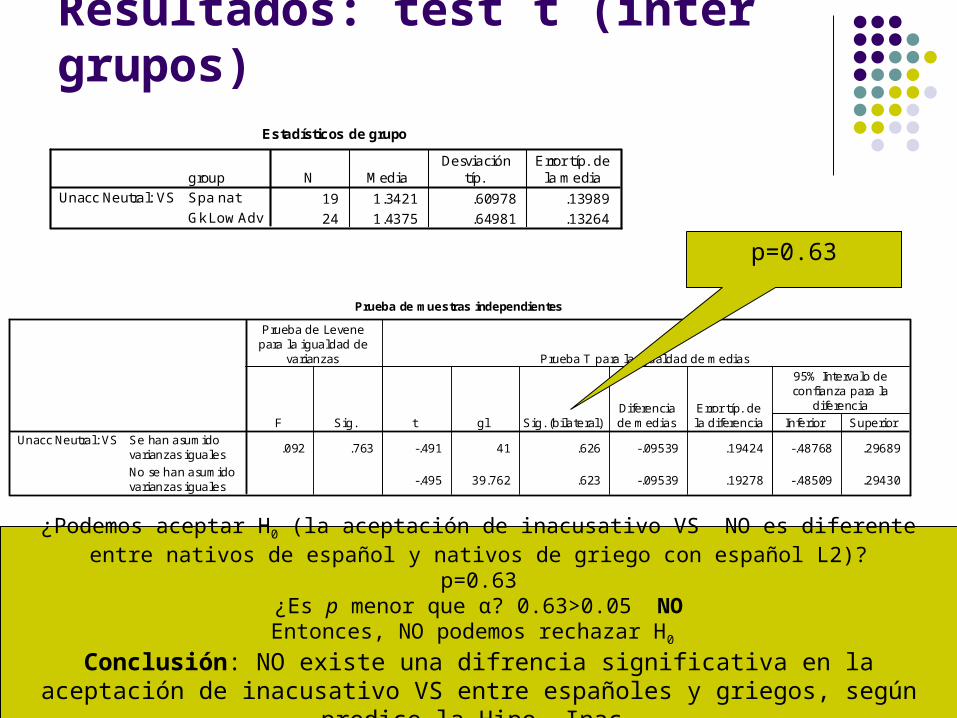
Resultados: test t (inter grupos)Estadísticos de grupo
19 1.3421 .60978 .13989
24 1.4375 .64981 .13264
groupSpa nat
Gk Low Adv
Unacc Neutral: VSN Media
Desviacióntíp.
Error típ. dela media
Prueba de muestras independientes
.092 .763 -.491 41 .626 -.09539 .19424 -.48768 .29689
-.495 39.762 .623 -.09539 .19278 -.48509 .29430
Se han asumidovarianzas iguales
No se han asumidovarianzas iguales
Unacc Neutral: VSF Sig.
Prueba de Levenepara la igualdad de
varianzas
t gl Sig. (bi lateral)Diferenciade medias
Error típ. dela diferencia Inferior Superior
95% Intervalo deconfianza para la
diferencia
Prueba T para la igualdad de medias
p=0.63
¿Podemos aceptar H0 (la aceptación de inacusativo VS NO es diferente entre nativos de español y nativos de griego con español L2)?
p=0.63¿Es p menor que α? 0.63>0.05 NOEntonces, NO podemos rechazar H0
Conclusión: NO existe una difrencia significativa en la aceptación de inacusativo VS entre españoles y griegos, según predice la Hipo. Inac.

44
Differences between conditions?
Correlation between scores?
Counting categories?
Spearman rho (r) coefficient
1 IV or 2 (or more) IVs?
yes
yes
how many conditions/ levels?
1 IV 2(+) IVs
same or different subjects?
same or different subjects?
same or different subjects?
t-test repeated measures (within groups)
t-test independ. groups (between groups)
same different
1-way ANOVA repeated measures (within groups)
1-way ANOVA independent groups (between groups)
2-way ANOVA repeated measures (within groups)
2-way ANOVA mixed
same different same
2 levels 3(+) levels
Adapted from Greene and D’Oliveira (1999)
Diagrama de flujo:¿En qué consiste el estudio?

45
Bibliografía Brace, N., Kemp, R., Snelgar, R., 2000. SPSS for Psychologists. Basingstoke: Palgrave.
Christie, K. and Lantolf, J. The ontological status of learner grammaticality judgments in UG approaches to L2 acquisition. Rassegna Italiana di Linguistica Applicata 24[3], 31-57. 1992.
Cowart, W., 1997. Experimental syntax: Applying Objective Methods to Sentence Judgments. Thousand Oaks, CA.: Sage.
Crain, S., Thornton, R., 1998. Investigations in Universal Grammar: A guide to Experiments on the Acquisition of Syntax and Semantics. Cambridge, MA.: MIT Press.
Dörnyei, Z., 2003. Questionnaires in Second Language Research: Construction, Administration and Processing. Mahwah, NJ: LEA.
Faer, C and Casper, G. Introspection in Second Language Research. 1987.
Graham, A., 1995. Statistics: An Introduction. London: Hodder & Stoughton.
Greene, J., D'Oliveira, M., 1999. Learning to Use Statistical Tests in Psychology (2nd edition). Buckingham: Open University Press.
Greer, B., Mulhern, G., 2002. Making sense of data and statistics in psychology. Basingstoke: Palgrave.
Mackey, A., Gass, S.M., 2005. Second Language Research: Methodology and Design. Mahwah, NJ: Lawrence Erlbaum.
Mandell, P.B., 1999. On the reliability of grammaticality judgement tests in second language acquisition research. Second Language Research 15, 73-99.
Marinis, T., 2003. Psycholinguistic techniques in second language acquisition research. Second Language Research 19, 144-161.
McDaniel, D, McKee, C, and Cairns, H. S. Methods for assessing children's syntax. 1996. 1998, MIT Press.
Menn, L., Ratner, N.B., 2000. Methods for studying language production. Mahwah, NJ: Lawrence Erlbaum.
Oakes, M.P., 1998. Statistics for Corpus Linguistics. Edinburgh: Edinburgh University Press.
Porte, G.K., 2002. Appraising Research in Second Language Learning: A Practical Approach to Critical Analysis of Quantitative Research. Amsterdam: John Benjamins.
Prideaux, G.D., 1984. Psycholinguistics: The Experimental Study of Language. London: Croom Helm.
Rietveld, T., van Hout, R., 2005. Statistics in Language Research: Analysis of Variance. Mouton de Gruyter.
Scholfield, P., 1995. Quantifying language : a researcher's and teacher's guide to gathering language data and reducing it to figures. Clevedon: Multilingual Matters.
Schütze, C.T., 1996. The Empirical Base of Linguistics: Grammaticality Judgments and Linguistic Methodology. Chicago: The University of Chicago Press.
Seliger, H.W., Shohamy, E., 1989. Second Language Research Methods. Oxford: Oxford University Press.
Sorace, A., 1996. The use of acceptability judgments in second language acquisition research. In: Ritchtie, W.C., Bhatia, T.K. (eds.), Handbook of Second Language Acquisition London: Academic Press.