matem - torricelli.uvigo.es · estas notas son el resultado de varios a ... y mec ´ anica y...
TRANSCRIPT

Universidad de Vigo
Notas de Clase
de la asignatura
Matematicas de la Especialidad
(plan de 1981)
Curso 2001-02
Emilio Faro Rivas

Introducci on
La asignatura de Matematicas de la Especialidaden la titulacion de Ingeniero Industrial
Estas notas son el resultado de varios anos de experiencia docente con laasignatura de Matematicas de la Especialidad en la Escuela Superior deIngenieros Industriales de la Universidad de Vigo.
La asignatura forma parte del plan de estudios aprobado en la ordenministerial de 25 de noviembre de 1981 (B.O.E. de 5 de febrero de 1982),donde se establece como una asignatura del cuarto curso en las especialida-des de Electricidad (tanto en la intensificacion de Electrotecnia como en lade Regulacion Automatica y Electronica) y Mecanica y conlleva una cargadocente semanal de 3 horas de teorıa y 2 horas de problemas de acuerdo ala siguiente tabla:
1er cuat. 2o cuat.Asignatura
T P T P
Matematicas de la Especialidad 3 2 – –
Dicho plan de estudios no especifica descriptores para “Matematicasde la Especialidad”, pero por la posicion que esta asignatura ocupa en lacarrera (laultima asignatura de matematicas en las especialidades en quese imparte), debe considerarse como la culminacion de los estudios de ma-tematicas en dichas especialidades. Ası pues, a esta asignatura le corres-ponde el importante papel de consolidacion de los estudios matematicos enla formacion de los alumnos de ingenierıa a quienes va dirigida. Por tan-to, nos parece que en ella deben “recogerse los frutos” de todas las otras
3

4 Introduccion
asignaturas de matematicas de la carrera para ponerlos al servicio de lasnecesidades del ingeniero.
Dado que dichas necesidades son eminentemente necesidades practicasde calculo (incluyendo el analisis de datos, la resolucion numerica de pro-blemas y el analisis crıtico de las soluciones), a “Matematicas de la Especia-lidad” le corresponde ser una asignatura eminentemente practica, orientadahacia los metodos numericos. Esta orientacion de la asignatura es tanto masimportante y adecuada cuanto que ninguna otra de las asignaturas de ma-tematicas de esta titulacion (en el plan de estudios a que pertenece) incluyemetodos numericos en sus contenidos.
De lo dicho se desprende que la asignatura de Matematicas de la Espe-cialidad tiene la tarea de “completar” las otras asignaturas de matematicasde su plan de estudios, incluyendo los aspectos numericos fundamenta-les de cada una de ellas. Dichas otras asignaturas son: Calculo Infinitesi-mal; Algebra Lineal; Ampliacion de Calculo; y Ecuaciones Diferenciales.En ellas el alumno debe aprender a plantear y resolver (al menos a nivelteorico) problemas tales como sistemas de ecuaciones lineales, calculo dedeterminantes y valores propios de una matriz, calculo de derivadas y suaplicacion a problemas de extremos de funciones de una o varias variables,calculo de primitivas y de integrales, y resolucion de ecuaciones diferen-ciales ordinarias. Ademas dichas asignaturas deben poner al alumno ensituacion de comprender conceptos de aproximacion mediante polinomiosde Taylor, estimacion de valores lımite y asintoticos y las distintas formasdel teorema del valor medio que emanan de la formula del resto del poli-nomio de Taylor, conceptos que son fundamentales para el desarrollo de uncurso de calculo numerico.
Esperamos que esta asignatura sirva tambien para que los alumnos ad-quieran una perspectiva mas completa en otras asignaturas al ofrecer herra-mientas de calculo que, al fin y al cabo, deben ser utilizadas en la resolucionde muchos de los problemas que se plantean y estudian en esas otras asig-naturas. Al mismo tiempo, esas otras asignaturas son de gran utilidad paracomprender el contenido y desarrollo de la que nos ocupa, pues propor-cionan gran parte de la motivacion que hay tras muchos de los metodosnumericos que aquı estudiamos. Nos referimos especialmente a las asig-naturas de Fısica, Quımica, Dibujo tecnico, Mecanica, Campos y Ondas,Elasticidad y Resistencia de Materiales, Estadıstica, Termodinamica, Elec-trotecnia, Mecanica de Fluidos, Regulacion Automatica y Teorıa de las Es-tructuras.
Introduccion 5
Por ultimo hemos de decir una palabra sobre el uso de las nuevas tec-nologıas. Evidentemente es inconcebible plantear hoy dıa una asignaturacomo la que nos ocupa sin contemplar un laboratorio de practicas en quelos alumnos puedan realizar en el ordenador la programacion de los algo-ritmos y metodos estudiados en la asignatura. En consecuencia la Junta deTitulacion de esta Escuela decidio incluir como parte de esta asignatura larealizacion de unas practicas de laboratorio que sirvan para desarrollar losconocimientos basicos del uso del ordenador como herramienta de calculo.Ası, de las dos horas semanales de practicas se ha asignado una a “practicasde pizarra” y la otra a practicas de Laboratorio Informatico. En consecuen-cia, la distribucion de horas queda como sigue:
Clases de AulaClases de
Laboratorio
Teorıa Problemas
3 h/sem. 1 h/sem. 6 practicas de 2.5 h.
Total cuatrimestre 45 h. 15 h. 15 h.
Objetivos generales de la asignatura
El objetivo principal de esta asignatura es el de capacitar al alumno pa-ra obtener resultados numericos correctos dentro de lımites razonables ydeterminar, en cada caso, cuales son esos lımites razonables, es decir, laaceptabilidad de los resultados numericos obtenidos. Para ello se procu-rara dotar a los estudiantes de las herramientas computacionales basicasque les permitan hacer calculos numericos reales en la resolucion de losproblemas que se plantean en la Ingenierıa. Esto incluye: (1) el iniciarlesen las tecnicas de programacion de ordenadores digitales para la resolu-cion de problemas numericos, y (2) cristalizar sus conceptos de analisis deerrores, estudio y aceleracion de la convergencia de procesos iterativos, in-terpolacion y aproximacion, y analisis de Fourier. Creemos que las tecnicasestudiadas en esta asignatura tienen el suficiente caracter formativo comopara que, cuando los estudiantes terminen la carrera, esten preparados paraemprender por sı mismos la resolucion numerica de problemas nuevos quepuedan encontrar en su practica profesional.

6 Introduccion
La busqueda de dicho caracter formativo ha sido una de las guıas prin-cipales que hemos seguido a la hora de realizar la necesaria seleccion detemas a incluir en el programa. Ası, hemos preferido limitar el programaa unos contenidos que de forma realista puedan ser cubiertos en suficientedetalle y profundidad. Pensamos que una formacion solida y profunda, aun-que no sea muy extensa, es, a la larga, masutil que un curso con un apretadoprograma en que ningun tema se puede tratar con la suficiente profundidad.Estoultimo es, ademas, causa de desanimo en los estudiantes, mientras quede la otra forma, una vez que el alumno se ha visto capaz de dominar untema y que ha comprendido las ideas basicas de los metodos numericos ex-plicados, queda capacitado para poder abordar por sı mismo, en el futuro,el estudio de nuevos metodos que le puedan resultar necesarios. En suma,quizas se echen en falta en el programa que presentamos ciertos temas quese pueden considerar centrales al Analisis Numerico (como, por ejemplo,la teorıa de estabilidad de algunos metodos para ecuaciones diferenciales).Como justificacion hemos de decir que, dadas las restricciones de tiempoimpuestas por el hecho de ser una asignatura cuatrimestral, y dado el detalley profundidad que hemos querido dar a los temas tratados, no nos pareceapropiado incluir mas materia en un curso academico.
De hecho, estas notas incluyen mas materia de la que nos parece ade-cuado explicar en un solo curso. La razon de ello es que que estas notasquieren servir de guıa para dos (o, quizas tres) asignaturas distintas que seadapten mas especıficamente a las necesidades de cada una de las espe-cialidades (e incluso, a ser posible, de las intensificaciones) a las que vadirigida. Ası, para los alumnos de la especialidad de Electricidad (especial-mente en la intensificacion de¿Automatica y ElectronicaÀ) resulta esencialel tema de ecuaciones diferenciales, mientras que el de integracion es masimportante para los de la especialidad de Mecanica. Nuestra intencion alpresentar este material es, pues, que sirva de referencia general para extraerdeel los temarios apropiados a cada especialidad.
Otra meta importante de esta asignatura es la de esclarecer las dificul-tades que surgen en el calculo y resolucion numerica de ecuaciones ma-tematicas en relacion tanto con los errores inherentes a los datos como conlos errores de redondeo provinientes de la necesaria limitacion en la repre-sentacion decimal (o de “coma flotante”) de los numeros en el ordenador.Esta asignatura pondra en claro el justo valor de ciertos resultados teoricosque no son eficaces como metodos de calculo. Sin menospreciar la impor-tancia teorica de tales resultados, es necesario inculcar la idea de que con
Introduccion 7
ellos, aunque parecen ser la solucion de un problema, no se acaba el proble-ma sino que aun quedan importantes cuestiones practicas a considerar, lascuales con frecuencia incluso revelan nuevos aspectos teoricos de interes.
Finalmente, hemos de procurar proporcionar a los alumnos los criteriosnecesarios para que puedan apreciar tanto la mayor o menor credibilidad delas distintas soluciones que de un mismo problema nos dan metodos de re-solucion diferentes, como elcostecomputacional de los distintos metodos.Esto pondra a los alumnos en posicion de ser capaces de elegir y utilizarel metodo de calculo mas apropiado para cada problema y, en los casos enque varios metodos sean igualmente aplicables, saber valorar la aceptabili-dad de las distintas soluciones obtenidas.

Indice General
Introducci on 3
La asignatura de Matematicas de la Especialidad en la titu-lacion de Ingeniero Industrial. . . . . . . . . . . . . . . . 3
Objetivos generales de la asignatura. . . . . . . . . . . . 5
Indice General 9
1 La aritm etica en el ordenador 15
1.1 Representacion de los numeros enteros. . . . . . . . . . . 16
1.1.1 Origen de los sistemas de numeracion y del cero . 16
1.1.2 Cambio de sistema de numeracion . . . . . . . . . 16
1.2 Numeros fraccionarios. . . . . . . . . . . . . . . . . . . 19
1.3 Dos ejemplos de programacion . . . . . . . . . . . . . . . 20
1.3.1 Raıces de una ecuacion cuadratica . . . . . . . . . 20
1.3.2 Calculo de la raız cuadrada. . . . . . . . . . . . . 22
1.4 Aritmetica de coma flotante. . . . . . . . . . . . . . . . . 23
1.4.1 Precision y dıgitos significativos. . . . . . . . . . 24
1.4.2 Analisis de errores. . . . . . . . . . . . . . . . . 26
2 Resolucion de ecuaciones no lineales 31
2.1 Metodos generales. . . . . . . . . . . . . . . . . . . . . 32
9

10 INDICE GENERAL
2.1.1 Metodo de la biseccion . . . . . . . . . . . . . . . 32
2.1.2 Regula Falsi (falsa posicion) . . . . . . . . . . . . 34
2.1.3 Regula Falsi Modificada. . . . . . . . . . . . . . 36
2.1.4 Metodo de la Secante e idea del Metodo de Muller 37
2.2 Metodos iterativos. . . . . . . . . . . . . . . . . . . . . . 39
2.2.1 Metodo de Newton. . . . . . . . . . . . . . . . . 40
2.2.2 Propiedades generales de los metodos iterativos . . 44
2.2.3 Velocidad de convergencia. . . . . . . . . . . . . 47
2.2.4 Aceleracion de la convergencia. . . . . . . . . . 52
2.3 Ecuaciones polinomicas. . . . . . . . . . . . . . . . . . . 55
2.3.1 Introduccion . . . . . . . . . . . . . . . . . . . . 55
2.3.2 Propiedades generales de los polinomios. . . . . 56
2.3.3 Algoritmo de Newton para ecuaciones polinomicas 63
2.3.4 Ecuaciones polinomicas mal condicionadas. . . . 63
2.3.5 El metodo de Bernoulli. . . . . . . . . . . . . . . 65
2.4 El Metodo de Muller . . . . . . . . . . . . . . . . . . . . 67
3 Sistemas de Ecuaciones Lineales 73
3.1 Metodos directos. . . . . . . . . . . . . . . . . . . . . . 73
3.1.1 Eliminacion de Gauss . . . . . . . . . . . . . . . 73
3.1.2 Factorizacion triangular . . . . . . . . . . . . . . 80
3.1.3 Metodo de Gauss-Jordan. . . . . . . . . . . . . . 86
3.1.4 Otras tecnicas de pivotacion . . . . . . . . . . . . 87
3.2 Analisis de errores y Condicion . . . . . . . . . . . . . . . 89
3.2.1 Introduccion: Distintas medidas del error. . . . . 89
3.2.2 Mejora iterativa. . . . . . . . . . . . . . . . . . . 90
3.2.3 Normas de matrices. . . . . . . . . . . . . . . . . 94
3.2.4 Condicion de una matriz y acotacion de errores . . 97
3.2.5 Estimacion de la condicion de una matriz. . . . . 101
3.2.6 Condicion de las matrices ortogonales. . . . . . . 102
INDICE GENERAL 11
3.3 Metodos iterativos. . . . . . . . . . . . . . . . . . . . . . 103
3.3.1 Ejemplo introductorio del metodo iterativo . . . . 103
3.3.2 Esquema general del Metodo Iterativo. . . . . . . 105
3.3.3 Convergencia del metodo iterativo general. . . . . 106
3.3.4 Metodo de Jacobi. . . . . . . . . . . . . . . . . . 108
3.3.5 Aceleracion de la convergencia; metodo de Gauss-Seidel . . . . . . . . . . . . . . . . . . . . . . . . 111
3.3.6 Metodo de las relajaciones sucesivas. . . . . . . . 114
4 Vectores y valores propios 117
4.1 Metodo de la potencia. . . . . . . . . . . . . . . . . . . . 118
4.2 MetodoQRo de la factorizacion ortogonal . . . . . . . . 119
4.2.1 La Sucesion General del Metodo de la Factoriza-cion Ortogonal . . . . . . . . . . . . . . . . . . . 120
4.2.2 La factorizacion ortogonal de una matriz: Metodode las rotaciones planas. . . . . . . . . . . . . . . 121
4.2.3 Simplificacion que ocurre para las matrices tipo Hes-senberg . . . . . . . . . . . . . . . . . . . . . . . 124
4.2.4 Metodo de las reflexiones de Householder para elcalculo de una matriz Hessenberg semejante a unadada. . . . . . . . . . . . . . . . . . . . . . . . . 124
4.2.5 Simplificacion aplicable a matrices simetricas . . . 129
4.2.6 Algoritmo rapido para la factorizacion ortogonal dematrices Hessenberg. . . . . . . . . . . . . . . . 129
5 Interpolacion y Aproximacion 135
5.1 El problema general. . . . . . . . . . . . . . . . . . . . . 135
5.1.1 Introduccion . . . . . . . . . . . . . . . . . . . . 135
5.1.2 Interpolacion, aproximacion y ajuste de datos . . .136
5.2 Interpolacion polinomica . . . . . . . . . . . . . . . . . . 137
5.2.1 Existencia y unicidad del polinomio de interpolacion138

12 INDICE GENERAL
5.2.2 Formula de Lagrange para la interpolacion polinomica.Polinomios de Lagrange. . . . . . . . . . . . . . 140
5.2.3 Formula baricentrica para el polinomio de interpo-lacion . . . . . . . . . . . . . . . . . . . . . . . .142
5.2.4 Analisis de errores. . . . . . . . . . . . . . . . . 144
5.3 Metodo de Newton. . . . . . . . . . . . . . . . . . . . . 146
5.3.1 La formula de Newton. . . . . . . . . . . . . . . 147
5.3.2 Las diferencias divididas. . . . . . . . . . . . . . 148
5.3.3 Propiedades de simetrıa . . . . . . . . . . . . . . 151
5.3.4 Tabla de diferencias divididas. Adicion de nuevosnodos . . . . . . . . . . . . . . . . . . . . . . . . 152
5.4 El algoritmo de interpolacion de Aitken . . . . . . . . . . 153
5.5 Nodos igualmente espaciados. . . . . . . . . . . . . . . . 155
5.5.1 Problemas de la interpolacion con nodos igualmen-te espaciados. . . . . . . . . . . . . . . . . . . . 157
5.6 Varillas flexibles (splines) . . . . . . . . . . . . . . . . . . 158
5.6.1 Introduccion . . . . . . . . . . . . . . . . . . . . 158
5.6.2 Varillas flexibles cubicas . . . . . . . . . . . . . . 160
5.6.3 Un algoritmo para obtener varillas flexibles cubicasde extremos libres . . . . . . . . . . . . . . . . . 168
5.7 Interpolacion Optima . . . . . . . . . . . . . . . . . . . . 169
5.7.1 Introduccion y motivacion . . . . . . . . . . . . . 169
5.7.2 El concepto de interpolacion optima . . . . . . . . 170
5.7.3 Los polinomios de Chebyshev. . . . . . . . . . . 173
5.7.4 Teorema de los nodos de Chebyshev. . . . . . . . 174
5.7.5 Interpolacion optima en un intervalo arbitrario . .176
5.7.6 Ejemplo de la interpolacion de Chebyshev. . . . . 177
6 Integracion numerica 181
6.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . .181
6.2 Formulas Simples de Cuadratura. . . . . . . . . . . . . . 183
INDICE GENERAL 13
6.2.1 Formulas de cuadratura de Newton-Cotes. . . . . 184
6.3 Formulas compuestas del trapezoide y de Simpson. . . . 187
6.4 El algoritmo de Romberg. . . . . . . . . . . . . . . . . . 190
6.5 Integracion adaptativa. . . . . . . . . . . . . . . . . . . . 192
6.6 Integracion gaussiana. . . . . . . . . . . . . . . . . . . . 194
7 Ecuaciones diferenciales 197
7.1 Problemas de valores iniciales. . . . . . . . . . . . . . . 198
7.1.1 El algoritmo de Euler. . . . . . . . . . . . . . . . 198
7.1.2 Metodos de Taylor. . . . . . . . . . . . . . . . . 200
7.1.3 Metodos de Runge-Kutta. . . . . . . . . . . . . . 202
7.1.4 Error local y paso variable. . . . . . . . . . . . . 205
7.1.5 Metodos de paso multiple . . . . . . . . . . . . . 206
7.1.6 Sistemas de ecuaciones. . . . . . . . . . . . . . . 208
7.2 Problemas de valores en la frontera. . . . . . . . . . . . . 208
7.2.1 Metodos de tiro o disparo. . . . . . . . . . . . . 208
7.2.2 Problemas lineales: Metodo de las diferencias finitas210
7.2.3 Metodos de colocacion . . . . . . . . . . . . . . . 211
7.2.4 Tratamiento Variacional. . . . . . . . . . . . . . 212
7.2.5 Metodo de los elementos finitos. . . . . . . . . . 213
8 Analisis de Fourier 215
8.1 Funciones sinusoidales. . . . . . . . . . . . . . . . . . . 216
8.1.1 Tres definiciones equivalentes. . . . . . . . . . . 216
8.1.2 Las funciones trigonometricas Seno y Coseno . . .216
8.2 Superposicion de funciones periodicas . . . . . . . . . . . 217
8.3 El sistema trigonometrico y las series de Fourier. . . . . . 217
8.3.1 Forma compleja de la serie de Fourier. . . . . . . 219
8.4 Transformada de Fourier. . . . . . . . . . . . . . . . . . 220
8.5 Transformada rapida de Fourier. . . . . . . . . . . . . . . 222

14 INDICE GENERAL
Bibliograf ıa 225
A Ejercicios Complementarios 229
B Respuestas a ejercicios seleccionados 239
Respuestas Ejercicios Capıtulo 1 . . . . . . . . . . . . . . 239
Respuestas Ejercicios Capıtulo 2 . . . . . . . . . . . . . . 242
Respuestas Ejercicios Capıtulo 3 . . . . . . . . . . . . . . 246
Respuestas Ejercicios Capıtulo 4 . . . . . . . . . . . . . . 254
Respuestas Ejercicios Capıtulo 5 . . . . . . . . . . . . . . 255
Respuestas Ejercicios Capıtulo 6 . . . . . . . . . . . . . . 260
Respuestas Ejercicios Capıtulo 7 . . . . . . . . . . . . . . 260
Respuestas Ejercicios Capıtulo 8 . . . . . . . . . . . . . . 261
Respuestas Ejercicios Apendice A . . . . . . . . . . . . . 261
Indice Alfabetico 273
Capıtulo 1
La aritm etica en elordenador
El almacenamiento y manipulacion de datos en un ordenador digital se re-aliza en un dispositivo llamado con el nombre generico de memoria. Di-cha memoria consiste en una coleccion de unidades fısicas cuyo estado essiempre uno de dos estados posibles (“0” y “1”) y que puede ser cambia-do a voluntad. A la cantidad de informacion que es posible almacenar enuna de tales unidades se le llama universalmente con la palabra inglesabit(ingles, “poquito”). Todo dato almacenado en dicha memoria debera, pues,ser representado previamente como una serie de ceros y unos. Esto es es-pecialmenteutil para la representacion de numeros enteros ya que una seriede ceros y unos es la representacion de un numero natural en el sistema bi-nario. Por supuesto, todo otro tipo de informacion puede representarse pormedio de bits, ya sea informacion escrita, imagen, sonido o cualquier otrotipo de senal. El proceso por el que se realiza esta representacion se llamadigitalizacion. Pero aquı nosotros estamos principalmente interesados enla representacion binaria de los numeros y, en general en los sistemas derepresentacion generales de los numeros. Comenzaremos con la represen-tacion de los numeros enteros.
15

16 1. La aritmetica en el ordenador
1.1 Representacion de los numeros enteros
1.1.1 Origen de los sistemas de numeracion y del cero
La llamada representacion arabigade los numeros, cuyo origen se remon-ta miles de anos a la India Antigua, consistio originalmente en elegir una“pequena” coleccion de sımbolos (concretamentenueve) para representarotros tantos de los numeros naturales inicialesuno, dos, tres,etc. y usarsecuencias de sımbolos ordenadas de derecha a izquierda para representarnumeros mayores que el nueve de acuerdo a un sencillo convenio por el cualel valor inicial de un sımbolo queda multiplicado por diez tantas veces co-mo indica su posicion. Para poder representar todos los numeros naturaleses necesario que algunas “combinaciones” de sımbolos admitan espaciosvacıos y de la necesidad de indicar con claridad estos espacios vacıos nacioel dıgito 0, que en sus orıgenes fue una pequena marca o punto y mas tardetomo la forma de un pequeno cırculo.
1.1.2 Cambio de sistema de numeracion
El punto de vista moderno es solamente ligeramente distinto del que acaba-mos de describir. Las diferencias fundamentales son: (1) Hoy dıa se utili-zan diversasbases, y (2) Hoy se considera la serie de los numeros naturalescomenzando con el cardinal cero, correspondiente al conjunto vacıo.
Al elegir un sistema de numeracion se fija una base,β, que es el numerode sımbolos basicos correspondientes a losβ primeros numeros incluyendoel cero y mediante la notacion
(ak, . . . ,a0)β
se representa el numero
(ak, . . . ,a0)β =0∑
p=k
(ap)ββp = (ak)ββ
k + · · · + (a0)ββ0
omitiendose los parentesis y el subındiceβ solamente cuando se usa elsistema decimal o cuando se sobrentiende el sistema empleado.
Una importante dificultad con que se enfrentan algunos estudiantes para comprender los distin-tos sistemas de numeracion y los cambios de base es la frecuente, y en cierta medida necesaria
1.1. Representacion de los numeros enteros 17
con-fusion entre elnumeroy el sımboloque lo representa. Es necesario comprender que elnumero es algo que existe como consecuencia de la variedad de cosas, independientemente denuestro deseo o voluntad, mientras que los sımbolos que usamos para representar los numerosson artificio y eleccion humana. La confusion de que estamos hablando es tanto mas difıcil dedeshacer cuanto que en la mayorıa de los lenguajes humanos se nombran los numeros median-te un metodo que se basa en el sistema de numeracion decimal y los nombres de los sımboloso guarismos basicos del sistema de numeracion coinciden con los de los numeros que repre-sentan. Esto a pesar que a veces se procure distinguir entre ambos con expresiones tales como“el guarismo 2” y “el numero 2”.
Ejemplo: En el sistema decimal tenemos
(257)diez= (2)diez× diez2+ (5)diez× diez+ (7)diez
= dos× cien+ cinco× diez+ siete.
Mientras que
(257)ocho= (2)ocho× ocho2+ (5)ocho× ocho+ (7)ocho
= dos× (sesenta y cuatro)+ cinco× ocho+ siete.
Igualmente en el sistema binario tenemos
(101101)dos= 1× dos5 + 0× dos4 + 1× dos3 + 1× dos2 + 0× dos1 + 1× dos0
= 1× treinta y dos+ 1× ocho+ 1× cuatro+ 1
= cuarenta y cinco.
Como acabamos de ver, el valor del numeroN = (ak, . . . ,a0)β repre-sentado por el sımboloak, . . . ,a0 en baseβ, se halla evaluando en la base(es decir, enx = β) el polinomiop(x) =∑k
r=0(ar )βxr , cuyos coeficientesson (los numeros que corresponden a) los dıgitos que forman la represen-tacion del numero. Veremos a continuacion la forma mas eficaz de realizaresta evaluacion.
Evaluacion de polinomios : Metodo de Horner o de las multiplicacionesencajadas.
La forma mas eficaz de evaluar un polinomio es mediante el llamadometodode Hornero de lasmultiplicaciones encajadas. Con este metodo se reduceel numero de operaciones necesarias para la evaluacion de un polinomiogeneral de gradon a n multiplicaciones yn sumas (frente an(n + 1)/2

18 1. La aritmetica en el ordenador
multiplicaciones yn sumas necesarias en la evaluacion mas ingenua —la que realizarıa una maquina a la que se le manda evaluar la formulaanxn + · · · + a1x + a0— o frente a 2n − 1 multiplicaciones yn sumassi se van guardando los resultados de las potenciasx2, x3, etc.). El metodode evaluacion de las multiplicaciones encajadas corresponde a la represen-tacion del polinomio en la forma
p(x) = (· · · ((anx + an−1)x + an−2)x + · · · )x + a0 (1.1)
y puede llevarse a cabo mediante el siguiente proceso de calculo:
b0 = an
b1 = b0x + an−1
b2 = b1x + an−2
...
bn = bn−1x + a0
con lo que terminamos teniendop(x) = bn. Este calculo repetitivo sepuede llevar a cabo mediante el siguiente programa o algoritmo en el queno se guardan los resultados intermedios:
1. Suponemos almacenados los datos en las variablesn, a0, . . . ,an, x.
2. Asignamos:b = an e i = 0.
3. Si i = n entonces el valor dep(x) esb. PARAR.
4. Asignamosi = i + 1, y b = bx+ an−i .
5. Ir al paso3.
La expresion de un polinomio en la forma (1.1) ofrece la ventaja adicio-nal de indicar la forma de obtener la representacion de un numero enteroNen un sistema de numeracion dado, lo cual es inmediato en cuanto se conoz-can los coeficientes del polinomio cuyo valor en la base esN y cuyos co-eficientes son enteros no negativos menores queβ (pues los coeficientes secorresponden directamente con los dıgitos o sımbolos de la base del sistemade numeracion). Sabiendo quep(β) = N, los coeficientes dep quedan de-terminados (ya que cada uno de ellos ha de satisfacer 0≤ ak < β) como lasclases de restos moduloβ de los numerosb1 = N , b2 = ent(b1/β), . . . yen generalbk = ent(bk−1/β).
Lo que acabamos de decir es la clave para resolver el siguiente
1.2. Numeros fraccionarios 19
Ejercicio 1.1Hallar el polinomiop(x) cuyos coeficientes son enteros no negativos y queverifica
p(1) = 17 y p(18) = 5774458.
Demostrar que conocidosp(1) y p(p(1)+ 1) queda completamente deter-minado cualquier polinomiop de coeficientes enteros no negativos.
Sabiendo determinar un numero a partir de su representacion en unabase y sabiendo realizar el proceso inverso de hallar la representacion deun numero dado en una base dada es inmediato como transformar la re-presentacion de un numero de una base dada a otra cualquiera. La princi-pal dificultad que le aparece al principiante viene de la confusion entre losnumeros (cardinales en el caso de enteros no negativos que nos ocupa) ysus representaciones en algun sistema de numeracion.
Un caso especialmente sencillo de transformacion de la representacionde un numero en una base a la representacion de ese numero en otra esaquel en que una de las bases es una potencia de la otra, como ocurre conlas bases de los sistemas binario y octal. En este casoβ2 = β3
1 y por lo tantola transformacion del sistema binario al octal se puede realizar agrupandolos dıgitos de la representacion binaria de tres en tres y transformando aloctal cada uno de esos grupos independientemente.
Por ejemplo si sabemos que(010)2 = (a1)8, (110)2 = (a2)8, y (001)8 =(a3)8 entonces tendremos
(1010110110)2 = (a3a1a2a2)8 .
1.2 Representacion de numeros fraccionarios
La representacion decimal de los numeros fraccionarios mediante una comaque separa la parte entera de la parte decimal o fraccionaria tiene una gene-ralizacion inmediata a cualquier sistema de numeracion. Sia1,a2, . . . ,an
son sımbolos de la base de un sistema de numeracion conβ elementos,utilizamos la notacion
(0.a1a2 · · ·an)β = (a1)β β−1+ · · · + (an)β β
−n =n∑
k=1
(ak)β β−k

20 1. La aritmetica en el ordenador
La obtencion de tal representacion a partir de un numero dadox, quesuponemos entre 0 y 1, es aun mas sencilla que la de la representacion deun entero, pues no es necesario hallar clases de restos. Si se conoce el valory = p(1/β) de un polinomio de la formap(x) = c1x + c2x2 + · · · +cnxn, cuyos coeficientes verifican 0≤ ck < β estos se hallan facilmentemediante el siguiente algoritmo:
b1 = βy , c1 = ent(b1) , d1 = b1− c1
b2 = βd1 , c2 = ent(b2) , d2 = b2− c2
......
...
el cual termina en el momento en que se alcance undr = 0.
Por ejemplo, si queremos expresar el numeroy = (0.625)10 en el sis-tema binario calculamos lo siguiente:
b1 = 2y = 1.25, c1 = ent(1.25) = 1 , d1 = 1.25− 1= 0.25
b2 = 2× 0.25= 0.5 , c2 = ent(0.5) = 0 , d2 = 0.5− 0= 0.5
b3 = 2× 0.5= 1 , c3 = ent(1) = 1 , d3 = 1− 1= 0 − fin
de donde(0.625)10 = (0.c1c2c3)2 = (0.101)2
1.3 Dos ejemplos de programacion
1.3.1 Raıces de una ecuacion cuadratica
El siguiente ejemplo ilustra el hecho de que una solucion perfectamentevalida desde el punto de vista teorico no es laultima palabra a la hora deponerla en practica implementandola en el ordenador.
De todos es conocida la formula para las soluciones de una ecuacioncuadraticaax2+ bx+ c = 0,
x = −b±√b2− 4ac
2a.
1.3. Dos ejemplos de programacion 21
Aunque esta formula es exacta para cualesquiera coeficientes (siemprequea 6= 0), y a pesar de su gran utilidad teorica, no es la mejor expresionque podemos usar cuando necesitamos programarla en un ordenador digi-tal. La dificultad estriba en que admite la posibilidad de introducir erroresde redondeo evitables cuandob2 es mucho mas grande que|4ac|, caso enel que numerador se hace cercano a cero si se elige para la raız cuadradael signo igual al deb, es decir, cuando se busca la solucion de menor valorabsoluto.
Por ejemplo, tratemos de resolver la ecuacion
x2+ 111.11x + 1.2121= 0
usando aritmetica de coma flotante de cinco dıgitos. Calculamos
b2 = 12345
b2− 4ac= 12340√b2− 4ac= 111.09
x1 = −b+√b2− 4ac
2a= −0.01000
mientras que el valor correcto con cinco dıgitos (que no es lo mismo quecinco decimales) es
x1 = −0.010910.
Ha habido, pues, una perdida de precision.
La dificultad mencionada puede resolverse usando una formula alterna-tiva para la solucion de menor valor absoluto de una ecuacion cuadratica.Notese que
−b±√b2− 4ac
2a= −2c
b±√b2− 4ac.
Si utilizamos la segunda formula en el ejemplo anterior obtendremos elvalor correcto de la solucion de menor valor absoluto con aritmetica decoma flotante de cinco dıgitos. Un sencillo analisis nos lleva a expresar lassoluciones de una ecuacion cuadratica mediante las formulas:
x1 = −2c
b+ sign(b)√
b2− 4ac, x2 = b+ sign(b)
√b2− 4ac
−2a(1.2)

22 1. La aritmetica en el ordenador
que son las formulas mas adecuadas en programacion. La razon de elloes que en la evaluacion de la expresion b + sign(b)
√b2− 4ac se evita
la perdida de precision que ocurre al restar numeros muy proximos (verla seccion 1.4.2). Hay otras razones para preferir las formulas (1.2) a laformula clasica, por ejemplo: la primera de ellas es valida incluso en elcasoa = 0, en el que nuestra ecuacion se reduce a una ecuacion lineal o deprimer grado. Pero una razon de mas peso, que resultara de ayuda cuandoestudiemos el metodo de Muller (capıtulo 2) esta basada en el siguienteresultado:
Ejercicio 1.2Demostrar que si las dos soluciones de una ecuacion cuadraticaax2+bx+c = 0 no tienen el mismo valor absoluto entonces las formulas(1.2) nosdan respectivamente la solucion de menor valor y la de mayor valor abso-luto, es decir:
solucion de menor valor absoluto= −2c
b+ sign(b)√
b2− 4ac
solucion de mayor valor absoluto= b+ sign(b)√
b2− 4ac
−2a.
1.3.2 Un procedimiento iterativo: calculo de la raız cua-drada
Si queremos escribir un programa que calcule la raız cuadrada de un numero,podrıamos intentar programar el algoritmo “del colegio” que se usa parahallar una raız cuadrada a mano y con el que se van obteniendo sucesivosdıgitos exactos de la solucion como ocurre con el algoritmo de la division.Sin embargo dicho algoritmo no es recomendable por su complicacion ypor existir una alternativa sencilla basada en el siguiente resultado:
Ejercicio 1.3Demostrar que siN y x son dos numeros positivos el intervalo de extremosx y N/x acota (es decir, contiene) a
√N y para cualquier otro numero
positivoy, el intervalo de extremosx y N/x necesariamente contiene o estacontenido en el intervalo de extremosy y N/y, de manera que si elegimosun y cualquiera en el intervalo de extremosx y N/x entonces el intervalode extremosy y N/y acota a
√N mejor que el intervalo de extremosx y
N/x
1.4. Aritmetica de coma flotante 23
Segun esto podemos realizar un proceso iterativo tomando en cada pasoy igual al punto medio entrex y N/x, es deciry = 1
2(x+ N/x) y tomandocomo nuevo intervalo el de extremosy y N/y. Repitiendo este procesoobtenemos el siguiente metodo iterativo para acercarse a
√N.
1. Suponemos dadosN y x.
2. Calculamosy = 12
(x + N
x
).
3. Si |x − y| es suficientemente pequeno entonces PARAR.√
N ' y
4. Asignar ax el valor dey e ir al paso2.
Al aplicar este algoritmo los sucesivos valores dey se acercan rapidamentea la raız buscada.
1.4 Aritm etica de coma flotante
Evidentemente no podemos representar los numeros reales en el ordenadoren forma exacta ya que en general no habra espacio suficiente para almace-nar todos los dıgitos, cualquiera que sea el sistema de numeracion utilizado.En el diseno de un ordenador se fija el numero de dıgitos,n, que se usaranpara representar los numeros, la base,β, del sistema de numeracion y elrango [m,M ] de exponentes admitidos (usualmente conm = −M). Elnumeron se llamaprecisionde la maquina. Fijado esto, a cada numero re-al se le asocia unarepresentacion en coma flotantecuya forma normalizadaes
±0.d1d2 · · ·dn × βE
con E un entero en el intervalo [m,M ] y d1 6= 0 a menos que se trate delnumero 0.
Ejercicio 1.4Hallese el numero de distintas representaciones en coma flotante en baseβ,con precisionn y rango de exponentes[m,M ].
Dado un numero realx, para introducirlo en el ordenador es necesarioconvertirlo en su expresion en coma flotante, que denotaremos fl(x). Si x esun numero cuya expresion decimal en baseβ esx = (0.d1 · · ·dndn+1 · · · )ββE
entonces definimos su representacion en coma flotante conn dıgitos como

24 1. La aritmetica en el ordenador
la truncacion (0.d1 · · ·dn)ββE si 0 ≤ dn+1 < β/2, y en caso contrario
incrementaremos el dıgito dn en una unidad. Es decir:
fl(x) ={(0.d1 · · ·dn)ββ
E si 0≤ dn+1 < β/2
(0.d1 · · ·dn)ββE + βE−n si β/2≤ dn+1 < β .
Este metodo se conoce comoredondeo simetrico y tiene algunas ventajasrespecto a la simpletruncacion.
Ası pues, la mera introduccion de un numero en el ordenador produceun error de redondeoigual a fl(x)− x. Este error depende fuertemente dex y por ello conviene medirlo relativo ax, definiendo elerror relativo deredondeo, δ, (parax 6= 0) mediante
δ = fl(x)− x
xo bien fl(x) = x(1+ δ)
el cual, aunque aun depende dex, admite una acotacion independiente dex:
Ejercicio 1.5Demostrar que siβm ≤ |x| ≤ βM el error relativo de redondeo,δ, en larepresentacion dex en coma flotante conn dıgitos en baseβ satisface laacotacion
|δ| < 12β
1−n .
El maximo valor que puede alcanzar el error relativo de redondeo en unsistema de representacion de coma flotante se llama launidad de redondeoy lo denotamosu. Segun el anterior ejercicio, para un sistema de represen-tacion de coma flotante conn dıgitos y baseβ, en el que fl(x) se calculapor redondeo simetrico, tenemosu ≤ 1
2β1−n.
1.4.1 Precision y dıgitos significativos
Una de las fuentes de error que aparece con frecuencia y que suele serevitable cuando la prevemos anticipadamente es la perdida de precisionque ocurre al restar dos numeros proximos que coinciden en varios dıgitossignificativos. Para poder explicar este fenomeno en detalle necesitamosesclarecer el concepto de precision en una representacion de un numero.
1.4. Aritmetica de coma flotante 25
Definicion: Decimos quex∗ aproxima ax con una precision den dıgitossignificativos en baseβ si
|x − x∗| < 12β
s−n+1
dondes es el mayor entero tal queβs ≤ |x|
Ejercicio 1.6Demostrar que22
7 = 3.142857aproxima aπ = 3.14159265. . . con unaprecision de tres dıgitos decimales significativos. ¿Con cuantos dıgitos bi-narios significativos aproxima22
7 aπ?
Ejercicio 1.7Demostrar que el maximo numero de dıgitos significativos en baseβ conquex∗ aproxima ax puede calcularse mediante la formula:
n = ent
(ln |x|lnβ
)− ent
(ln(2|x − x∗|)
lnβ
)
Perdida de precision.–
Supongamos que queremos calcular la diferencia
z= x − y
para lo cual disponemos de aproximaciones
x∗ = 0.76545421× 10−2, y∗ = 0.76544200× 10−2
con precision de siete dıgitos decimales significativos. Debido a la proxi-midad dex e y, en la diferenciax∗ − y∗ ocurre una cancelacion de cuatrodıgitos, lo cual resulta en que esta diferencia solo aproxima az con unaprecision de tres dıgitos significativos. Por consiguiente, aunque el errorabsoluto mantiene su valor de±1
210−9, el error relativo enx∗ − y∗ es de±1
210−9/(x∗ − y∗) ' ±0.41×10−2, lo cual representa un aumento por unfactor de cerca de 63000.

26 1. La aritmetica en el ordenador
1.4.2 Analisis de errores
Al calcular en el ordenador el valor de una funcion f , el valor hallado esel resultadoy∗ = f ∗(x) = f (x)(1+ δ(x)) de aplicar ax una funcion f ∗ligeramente distinta def . Sin embargo tambien podemos interpretary∗como el resultado de evaluarf exactamente en un valor perturbadox∗ =x(1+ δ) dex para algun δ menor queu en valor absoluto.
Para ilustrar este hecho consideremos evaluacion de la funcion f (x) =x2n
. Una forma eficaz de evaluar esta funcion enx0 utilizando solamentela funcion “elevar al cuadrado” es mediante el algoritmo
x1 = x20 , x2 = x2
1 , . . . , xn = x2n−1 .
Con este algoritmo, lo que el ordenador realmente calcula son los numeros
x1 = x20(1+ δ1) , x2 = x2
1(1+ δ2) , . . . , xn = x2n−1(1+ δn) ,
de forma que
xn = x2n
0 (1+ δ1)2n−1(1+ δ2)2n−2 · · · (1+ δn)
donde cadaδi verifica|δi | ≤ u. Ahora bien,
Ejercicio 1.8Seanα1, . . . , αn numeros reales tales que|αi − 1| ≤ u dondeu es unnumero real positivo fijo menor que la unidad. La media geometricaα =n√α1α2 · · ·αn tambien verifica|α − 1| ≤ u. Asimismo, sib1, . . . ,bn son
numeros positivos entonces la media ponderada de losα1, . . . , αn con pe-sosb1, . . . ,bn, β = (b1α1 + · · · + b1αn)/(b1 + b2 + · · · + bn) tambienverifica|β − 1| ≤ u.
Esto implica que en nuestro ejemplo existe unδ menor o igual queu envalor absoluto tal que
xn = x2n
0 (1+ δ)2n−1(1+ δ)2n−2 · · · (1+ δ) = x2n
0 (1+ δ)2n
Luegoxn = f (x0(1+ δ)).En conclusion, tenemos que
Para estudiar el efecto que tiene el uso de la aritmetica de coma flo-tante en la precision del valor calculado de una funcion f (x) es suficienteestudiar el comportamiento def (x) frente a pequenas perturbaciones dex.
1.4. Aritmetica de coma flotante 27
Condicion de una funcion.–
La sensibilidad del valor de una funcion f a errores en la variable puedemedirse por un numero llamadocondicion de f , que es el maximo factorpor el que se multiplica el error relativo de la variable al evaluar la funcion,es decir, el numero que multiplicado por el error relativo enx nos da elerror relativo enf (x). Supongamos que queremos evaluarf (x) pero noconocemos el valor exacto dex, sino un valor aproximadox∗ de cuyo errorabsoluto solo sabemos que es menor queε. Entonces, de acuerdo con laanterior definicion, la evaluacion de f enx tiene la siguiente condicion:
condicion de f enx = max|x−x∗|<ε
{∣∣∣∣ f (x)− f (x∗)f (x)
∣∣∣∣ / ∣∣∣∣x − x∗
x
∣∣∣∣}= max|x−x∗|<ε
{∣∣∣∣ f (x)− f (x∗)x − x∗
x
f (x)
∣∣∣∣} .Puesto que el lımite de este numero paraε → 0 es
∣∣∣ f ′(x)xf (x)
∣∣∣, podemos tomar
este cociente como valor aproximado de la condicion y poner
condicion de f enx '∣∣∣∣ f ′(x)x
f (x)
∣∣∣∣ .Una funcion se dice que esta bien condicionada si tiene un valor pe-
queno de la condicion, es decir, si al evaluar la funcion el error relativo dela variable queda multiplicado por un factor pequeno.
Ejemplos.–
Consideremos la funcion f (x) = √x y hallemos su condicion. f ′(x) =1
2√
xluego, la condicion es aproximadamente∣∣∣∣∣∣
12√
xx
√x
∣∣∣∣∣∣ = 1
2
la condicion de√
x tiene un valor de12 independiente dex. Al evaluar estafuncion el posible error relativo de la variable se reduce a la mitad. Es unafuncion bien condicionada.

28 1. La aritmetica en el ordenador
Consideremos ahora la funcion f (x) = a− x dondea es fijo. f ′(x) =−1, luego, la condicion es aproximadamente∣∣∣∣−1 · x
a− x
∣∣∣∣ = ∣∣∣∣ x
a− x
∣∣∣∣que tiende a infinito parax → a. Luego esta funcion esta muy mal condi-cionada cerca dea.
Esteultimo ejemplo pone de manifiesto el origen de la dificultad queplantea la resta de dos numeros proximos mencionada antes.
Ejercicio 1.9Si definimos la condicion de f en x como el cociente
∣∣∣ f ′(x)xf (x)
∣∣∣ entonces la
condicion del producto o cociente de dos funciones es menor o igual que lasuma de sus condiciones
Estabilidad de un proceso de calculo.–
Un concepto analogo al de condicion de una funcion es el deestabilidadde un proceso de calculo. En tal proceso el error final es consecuencia delos errores cometidos en cada paso del proceso y la condicion de tal proce-so es igual a la de la funcion peor condicionada de las que intervienen enel. Puede ocurrir que para evaluar una funcion que esta bien condicionadaelijamos un proceso de calculo en el que intervienen una o mas funcionesmal condicionadas, lo cual tendra como consecuencia errores excesivos enel valor calculado. En consecuencia no basta con asegurarse de que la fun-cion a evaluar este bien condicionada; es necesario prestar atencion a cadauna de las funciones intermedias que se usan en el algoritmo o proceso decalculo.
Por ejemplo, la funcion f (x) = √x + 1−√x esta muy bien condicio-nada incluso para valores grandes dex:∣∣∣∣ f ′(x)x
f (x)
∣∣∣∣ = 1
2
∣∣1/√x + 1− 1/√
x∣∣ x√
x + 1−√x= 1
2
x√x + 1
√x= 1
2
√x
x + 1∼ 1
2,
pero intentemos calcular su valor parax = 0.1234× 108. El algoritmo
1.4. Aritmetica de coma flotante 29
sugerido por la formula es
x0 = 12340000
x1 = x0+ 1= 12340001
x2 = √x1 =√
12340001= 0.3512833756× 104
x3 = √x0 =√
12340000= 0.3512833614× 104
x4 = x2− x3 = 0.142× 10−3
mientras que el valor correcto es 0.142335× 10−3, luego hemos incurridoen un error relativo de ... El problema viene de laultima funcion usada en elalgoritmo, la cual esta mal condicionada parax2 cerca dex3. Concluimosque este algoritmo es una forma inestable de evaluarf (x). Un algoritmoestable serıa el siguiente:
x0 = 12340000
x1 = x0+ 1= 12340001
x2 = √x1 =√
12340001= 0.3512833756× 104
x3 = √x0 =√
12340000= 0.3512833614× 104
x4 = x2+ x3 = 0.7025667370× 104
x5 = 1/x4 = 0.142335× 10−3
que corresponde a expresarf mediante la formula f (x) = 1/(√
x + 1+√x).
Otro ejemplo. Se quiere calcular la funcion f (x) = 1 − cosx paravalores dex cercanos a cero. Esta funcion esta bien condicionada, sinembargo la evaluacion de f (x) mediante la formula indicada puede tenergran perdida de precision.
Esto es analogo a la dificultad que surge en el calculo de la solucionde menor valor absoluto de una ecuacion cuadratica por la formula usual.La solucion, al igual que en aquel caso, consiste en utilizar una formulaalternativa. En este caso podemos usar el hecho de que:
1− cosx = sen2 x
1+ cosx.

30 1. La aritmetica en el ordenador
En general siempre podremos usar los primeros terminos de la serie deTaylor cerca del valor que da problema.
Ejercicio 1.10Utilizando una calculadora que trabaje en aritmetica de coma flotante condoce dıgitos decimales evaluar la funcion
f (x) = 1− cosx
enx = 0.1234× 10−5 de las siguientes tres formas:
(1) Evaluando la expresion1− cosx.
(2) Evaluando la expresion equivalentesen2 x1+cosx .
(3) Evaluando el primer termino de la serie de Taylor,f (x) = 12x2− 1
24x4+· · · .¿Cual de ellas da el mejor resultado?
Capıtulo 2
Resolucion de ecuaciones nolineales
Uno de los primeros problemas de las matematicas ha sido el de la resolu-cion de ecuaciones. Pero, ¿que es una ecuacion?
El concepto general de ecuacion
El concepto mas general de ecuacion se obtiene al igualar dos funcionesf : X → A, g : Y → A cuyos valores pertenecen a un mismo rango.Resolver la ecuacion de f y g es, en tal situacion, hallar todos los pares(x, y) para los cuales se verifica la igualdad
f (x) = g(y). (2.1)
Pero nada se gana con tanta generalidad porque esta formulacion tan gene-ral es, curiosamente, equivalente a una simplificacion de uno de sus casosparticulares: a saber, el caso mas sencillo en que las dos funciones tienenel mismo dominio, es decir, son de la forma:
Xf//
g// A
y la solucion de la ecuacion de f y g esta formada por todos los elementosx ∈ X tales que
f (x) = g(x). (2.2)
Para convencerse de que saber resolver ecuaciones del tipo (2.2) es su-ficiente para resolver todas las del tipo (2.1) no hay mas que ver que el
31

32 2. Resolucion de ecuaciones no lineales
problema de (2.1) se puede reducir al de (2.2) utilizando el producto carte-siano,X × Y, de los dominios. Un razonamiento mas sutil (que utiliza ladiagonal1 : X→ X× X) muestra que saber resolver todos los problemasde tipo (2.1) es suficiente para resolver todos los del tipo (2.2).
En el planteamiento general que acabamos de presentar no hace faltasuponer quef y g sean funciones numericas. Sin embargo, en el caso deque lo sean, (2.2) es equivalente a la ecuacion f (x)− g(x) = 0. Este es elcaso que nos interesara en lo que sigue y por tanto podemos decir que lassoluciones de una ecuacion como (2.2) son loscerosde la funcion diferen-cia f − g. Ası, nuestro problema general sera el de resolver ecuaciones dela forma
f (x) = 0 , (2.3)
es decir, el de hallar ceros de funciones.
Tambien es posible plantear la resolucion de una ecuacion como el pro-blema de hallar lospuntos fijosde una funcion g, es decir, las solucionesde¿Que es un punto
fijo? g(x) = x.
Por ejemplo, dar una solucion de (2.3) es equivalente a dar un punto fijo decualquier funcion de la formag(x) = x + f (x)/λ conλ 6= 0 (entre otrasmuchas posibles). Planteado el problema de esta forma se puede sometera los metodos generales de resolucion de problemas de punto fijo, que sellamanmetodos iterativos.
Ası pues, estudiaremos dos tipos de metodos de resolucion de ecua-ciones:metodos generales(o busqueda de ceros) ymetodos iterativos(obusqueda de puntos fijos). Ademas de esto estudiaremos algunos metodosparticulares para las ecuaciones polinomicas, es decir para el caso en quela funcion f (x) en (2.3) sea un polinomio.
2.1 Metodos generales
2.1.1 Metodo de la biseccion
El metodo de la biseccion sirve para aproximarse tanto como se quiera aun cero de una funcion real de variable real continua y que toma valores designos opuestos en los extremos de un intervalo [a,b]. Suponemos, pues,que f es continua en [a,b] y que f (a) f (b) < 0. Esto implica quef
2.1. Metodos generales 33
tiene (al menos) un cero en [a,b]. El punto medio de [a,b], x0 = (a +b)/2, aproxima al cero con un error menor que|b − a|/2. Existen dosposibilidades: (1)f (x0) = 0, en cuyo caso ya hemos hallado el cero, y(2) f (x0) 6= 0, en cuyo caso, segun que el signo def (x0) sea opuesto delde f (a) o del de f (b), el intervalo [a, x0] o el [x0,b] tiene con certeza uncero. Si se da la posibilidad (2) hemos reducido la acotacion del cero a lamitad, de forma que si al principio conocıamos el cero con un error menorque(b− a)/2, despues de un paso de biseccion el error en el nuevo puntomedio es menor que(b−a)/22. Continuando el proceso vamos reduciendoel error a la mitad en cada paso. Ası, llegamos al siguiente algoritmo parael metodo de la biseccion. Enel se calcula el numeroN de pasos que hayque dar para garantizar que el error sea menor queε en base a la relacion(b− a)/2N+1 ≤ ε, que es equivalente aN ≥ (ln(b− a)− ln ε)/ ln 2− 1.
Algoritmo del Metodo de la Biseccion
1 Datos: f (la funcion de la que se quiere un cero), a, b (extremos delintervalo en quef (a) f (b) < 0), ε (precision deseada).
2 N = ent((ln(b− a)− ln ε)/ ln 2)
3 Si N = (ln(b− a)− ln ε)/ ln 2 entoncesN = N − 1
4 x = (a+ b)/2
5 Para i = 1 hasta N
Si f (x) = 0 entonces ir a 7Si f (x) f (a) < 0 entoncesb = x
Si f (x) f (a) > 0 entoncesa = x
x = (a+ b)/2
6 siguientei
7 Resultado: x (el valor del cero con error menor queε).
El principal inconveniente de este metodo es su lentitud. Esto es masde notar cuando es necesario aplicarlo repetidamente muchas veces y locomparamos con otros metodos que veremos a continuacion. Por otro lado,tiene la ventaja de ser un metodo sencillo, robusto y que ofrece un controlexcelente de la precision de la aproximacion y la posibilidad de calcularel numero exacto de pasos que hay que dar para aproximar la solucioncon un error inferior a un valor dado. Por estas razones este metodo es

34 2. Resolucion de ecuaciones no lineales
adecuado cuando necesitamos el calculo sencillo y esporadico de un cerode una funcion continua con una cierta precision dada.
Ejercicio 2.1Hallar el numero de pasos que se han de dar con el algoritmo de la biseccionpara hallar, con un error menor que una milesima, el cero de una funcionde la que se sabe que toma valores de signos opuestos en los extremos delintervalo[−1,1]. ¿Y si solo quisieramos que el error fuese menor que unoctavo?
2.1.2 Regula Falsi (falsa posicion)
El siguiente metodo es una variante del anterior en el que se pretende ace-lerar la convergencia utilizando un punto de corte del intervalo que tengamayor probabilidad de estar cerca del cero, a saber la posicion que tendrıael cero en caso de que la funcion fuese una lınea recta (pasando por lospuntos(a, f (a)) y (b, f (b))).
Ejercicio 2.2Demostrar que el punto de corte de la recta que pasa por los puntos(a, f (a))y (b, f (b)) con el ejex es
x0 = a− f (a)b− a
f (b)− f (a)= a f (b)− bf (a)
f (b)− f (a).
El siguiente ejercicio muestra que otra forma de describir el punto decorte es diciendo que es el promedio ponderado de los puntosa y b con lospesos| f (b)| y | f (a)|.
Ejercicio 2.3Demostrar que sif (a) f (b) < 0 entonces
a| f (b)| + b| f (a)|| f (b)| + | f (a)| =
a f (b)− bf (a)
f (b)− f (a).
Algoritmo de la Regula Falsi
1 Datos: f (la funcion de la que se quiere un cero), a, b (extremos delintervalo en quef (a) f (b) < 0), ε (precision deseada).
2.1. Metodos generales 35
2 x0 = (a f (b)− bf (a))/( f (b)− f (a))
3 x = x0
4 Si f (x) = 0 entonces ir a 105 Si f (x) f (a) < 0 entoncesb = x
6 Si f (x) f (a) > 0 entoncesa = x
7 x0 = (a f (b)− bf (a))/( f (b)− f (a))
8 Si |x − x0| < ε entonces ir a 109 Ir a 3
10 Resultado: x0.
Este algoritmo produce rapidamente un puntox donde| f (x)| ' 0,pero no produce un intervalo pequeno que contenga el cero. La razon esque en general va a acercarnos al cero por la derecha (manteniendo fijoel extremo inferior del intervalo) si la funcion es concava en el intervalo,o por la izquierda (manteniendo fijo el extremo superior del intervalo) sila funcion es convexa. Por ejemplo, en la siguiente figura (fig. 2.1) enque tenemos una funcion concava vemos que las aproximaciones se vanacercando al cero por la derecha.
a
b
Figura 2.1: Regula Falsi.
Este problema se evita en el metodo de laregula falsi modificada.

36 2. Resolucion de ecuaciones no lineales
2.1.3 Regula Falsi Modificada
Este metodo es una pequena variante de la regula falsi. Conel se intentaevitar el que sucesivas aproximaciones se mantengan del mismo lado delcero, de forma que ningun extremo del intervalo quede fijo todo el tiempo.De esta forma la longitud del intervalo de acotacion se va reduciendo hastahacerse tan pequeno como se quiera.
Para conseguir esta reduccion del intervalo de acotacion, si en un pasousamos la cuerda de extremos(a, f (a)) y (b, f (b)) para obtener la apro-ximacion x = (a f (b) − bf (a))/( f (b) − f (a)), antes del siguiente pasomiramos si el signo def (x) coincide con el def (a) o con el de f (b).Supongamos que coincide con el def (b) (como en la figura 2.2. —Sicoincidiese conf (a) se realizarıa el proceso analogo correspondiente—),entonces el siguiente punto se obtendra a partir del segmento de extremos(a, f (a)
2 ) y (x, f (x)) continuando de esta forma, cada vez reduciendo a lamitad la ordenada del extremo del segmento ena hasta que se obtenga unpunto en el que el valor def tenga el mismo signo quef (a). En ese mo-mento se vuelve a trazar una cuerda y se repite el proceso. Un algoritmosencillo para implementar este metodo se indica a continuacion
a
f (a)2q
bx
Figura 2.2: Regula Falsi Modificada.
2.1. Metodos generales 37
Algoritmo de la Regula Falsi Modificada
1 Datos: f (la funcion de la que se quiere un cero), a, b (extremos delintervalo en quef (a) f (b) < 0), ε (precision deseada).
2 F = f (a); G = f (b); x0 = a
3 x = (aG− bF)/(G− F)
4 Si f (a) f (x) < 0 entoncesb = x; G = f (x) en otro caso ir a 65 Si f (x) f (x0) > 0 entoncesF = F/2
6 Si f (x) f (a) > 0 entoncesa = x; F = f (x) en otro caso ir a 87 Si f (x) f (x0) > 0 entoncesG = G/2
8 Si f (x) = 0 entonces ir a 129 Si |b− a| < ε entonces ir a 12
10 x0 = x
11 Ir a 312 Resultado: x (el valor del cero con error menor queε).
2.1.4 Metodo de la Secante e idea del Metodo de Muller
El metodo de la secante puede considerarse como otra modificacion de laregula falsi porque al igual que en aquel metodo, en cada paso vamos a in-tersecar una secante a la grafica de nuestra funcion con el ejex. Sin embar-go ahora abandonamos el proposito de obtener intervalos que encierren a lasolucion en cada paso y simplemente construimos una sucesion que conver-ge a dicha solucion. Ası, en este metodo cada secante es la que correspondea los dosultimos puntos encontrados y por lo tantoxn+1 se obtiene al in-tersecar el ejex con la recta que pasa por los puntos(xn−1, f (xn−1)) y(xn, f (xn)),
xn+1 = xn−1 f (xn)− xn f (xn−1)
f (xn)− f (xn−1). (2.4)
La formula (2.4) es propensa a dar errores de perdida de precision cuan-do xn es proximo axn−1. Como alternativa es preferible usar la formulaequivalente
xn+1 = xn − f (xn)xn − xn−1
f (xn)− f (xn−1)(2.5)

38 2. Resolucion de ecuaciones no lineales
xn−2
xn-xnxn+
Figura 2.3: Metodo de la secante.
Cuando converge, el metodo de la secante nos acerca muy rapidamentea la solucion. El problema principal de este metodo es que necesita partirde dos estimaciones iniciales,x0 y x1, suficientemente cercanasal puntobuscado. Si las dos estimaciones iniciales no son suficientemente cercanasa la solucion es facil que el metodo no converja. En consecuencia estemetodo debe ir acompanado de alguna tecnica de acercamiento previo a lasolucion.
Un metodo parecido en su concepcion al metodo de la secante es elmetodo de Muller, que estudiamos mas detenidamente en la seccion 2.4.Aquı solo queremos recalcar la relacion que existe entre los dos metodos.La idea principal en el metodo de la secante es que, conocida la funcionen dos puntos cercanos a un cero, podemos aproximar ese cero por la raızdel polinomio de primer grado que coincide con la funcion en esos dospuntos. El metodo de Muller se obtiene al llevar esta idea un paso maslejos: aproximar el cero de nuestra funcion por una raız del polinomio desegundo grado que coincide con la funcion en tres puntos cercanos al cerobuscado.
2.2. Metodos iterativos 39
2.2 Metodos iterativos
Iterar una funcion es evaluarla en un punto que es resultado de haberla eva-luado previamente, es decir, hacer una evaluacion de la formaf ( f (x)). Unendomorfismoes una funcion f : A→ A cuyo dominio es igual a su codo-minio o rango. Tales funciones pueden iterarse repetida e indefinidamenteporque sus valores siempre perteneceran a su dominio (es decir, al conjun-to de los elementos en los quef se puede evaluar). Por tanto para una talfuncion todo elementox0 ∈ A define una sucesion enA que consiste en lassucesivas iteraciones def comenzando conx0: xn = f (· · · f ( f (x0)) · · · ),o xn = ( f ◦ · · · ◦ f )(x0) o
x0 ∈ A, xn+1 = f (xn).
Un importante concepto asociado con las funciones que son endomor-fismos es el depunto fijo. Decir que un puntox ∈ A es un punto fijo de lafuncion f : A→ A significa que
f (x) = x.
Por ejemplo, el numero 1 es un punto fijo de la funcion y = x2. Igualmentelo es el numero 0.Estos son lounicos puntos fijos de la funcion x2. Para lafuncion identidad,y = x, todo numero es un punto fijo.
Ejercicio 2.4Si f : A→ A es un endomorfismoidempotente(es decir, tal quef 2 = f )entonces los puntos fijos def son precisamente los valores def , es decirlos puntos de la formaa = f (x) para algun x ∈ A.
Ejercicio 2.5Si g es una funcion continua y{xn} es una sucesion de iteraciones deg queconverge, entonces su lımite ξ = lim{xn} es un punto fijo deg.
Basado en este resultado surge el metodo iterativo de resolucion de pro-blemas de punto fijo, que consiste en formar una sucesion de iteracionesque converja.
Recordemos que una condicion sencilla que garantiza la convergenciade una sucesion de iteraciones de una funcion g es la existencia de unametrica enA para la queg sea una funcioncontractiva(teorema de Banachdel punto fijo).

40 2. Resolucion de ecuaciones no lineales
Un metodo iterativo de resolucion de una ecuacion f (x) = 0 consiste,pues en los siguientes pasos:
1. Elegir una funcion g, continua, cuyos puntos fijos sean ceros def .
2. Formar una sucesion de iteraciones deg que sea convergente.
3. Hallar el lımite de dicha sucesion, que sera necesariamente la solu-cion de nuestra ecuacion.
Tal funcion g se llama unafuncion de iteracionpara la ecuacion f (x) = 0.El ejemplo mas famoso de funcion de iteracion es la que corresponde almetodo iterativo llamado metodo de Newton, que describimos a continua-cion.
2.2.1 Metodo de Newton
Dada una ecuacion f (x) = 0, donde f es una funcion diferenciable, elmetodo de Newton para aproximarse a un cero def es el metodo iterativocorrespondiente a la funcion de iteracion
g(x) = x − f (x)
f ′(x). (2.6)
Ejercicio 2.6Demostrar que todo punto fijo de la funcion definida en (2.6) es un cero def .
Ejercicio 2.7Demostrar que la interseccion del ejex con la recta que pasa por el punto(x, y) con pendientem tiene su abscisa igual ax− y/m. Como consecuen-cia la interseccion de la tangente a la grafica def en el punto(x, f (x)) conel ejex tiene su abscisa igual ax − f (x)/ f ′(x).
Segun esteultimo ejercicio, el metodo de Newton puede describirsegeometricamente como una variante del metodo de la secante: en lugar detrazar secantes a la grafica de nuestra funcion, trazamos rectas tangentes ypor lo demas procedemos igual que en el metodo de la secante (figura 2.4).
2.2. Metodos iterativos 41
ξ
x0a bx1x2
Figura 2.4: Metodo de Newton.
El metodo de Newton produce una sucesion en la que cada termino,xn+1, se obtiene del anterior por la formula
xn+1 = xn − f (xn)
f ′(xn).
Notese la semejanza entre esta formula y la del metodo de la secante en laforma (2.5). De hechoesta es el caso lımite de aquella paraxn−1 = xn, loque corresponde al hecho geometrico de que la recta tangente es la posicionlımite de rectas secantes cuyos dos puntos de corte se aproximan uno al otrohasta coincidir en el punto de tangencia.
Para aplicar el metodo de Newton se puede utilizar el siguiente algorit-mo:
Algoritmo del Metodo de Newton
1 Datos: f (la funcion de la que se quiere un cero), x (estimacioninicial de la solucion), M (numero maximo de pasos que queremosdar), ε (precision deseada).
2 Para i = 1 hasta M
3 x0 = x

42 2. Resolucion de ecuaciones no lineales
4 x = x − f (x)/ f ′(x)5 Si |x − x0| < ε entonces ir a 96 Siguientei
7 Imprimir “No hubo convergencia despues de”; M ; “pasos”
8 PARAR9 Resultado: x (con error menor queε)
Ejercicio 2.8Aplicar el metodo de Newton a la ecuacion x2 − N = 0 para obtener unalgoritmo para el calculo de la raız cuadrada de un numero positivoN.Disenar un algoritmo analogo para el calculo de la raız cubica.
Como veremos mas adelante, el metodo de Newton, cuando conver-ge, converge incluso mas rapido que el metodo de la secante. Sin em-bargo este metodo plantea varias dificultades. Una de ellas es la necesi-dad de evaluar la funcion derivadaf ′ muchas veces, lo cual puede llegara ser muy costoso. Para mitigar esta dificultad se han disenado varian-tes del metodo de Newton en las que se evalua la derivada un numeromenor de veces. La idea tras estos metodos es la siguiente: Suponga-mos que modificamos el metodo de Newton de forma que para calcularxn+1 con n par, en lugar de evaluar la derivada enxn utilizamos el valorf ′(xn−1) que habıamos calculado en el paso anterior, de forma quepara npar calculamosxn+1 = xn − f (xn)/ f ′(xn−1) y paran impar calculamosxn+1 = xn − f (xn)/ f ′(xn). Entonces, dado que (al menos paran grande)las pendientesf ′(xn) son todas proximas a su lımite f ′(ξ), obtendremosuna sucesion que diferira muy poco de la del metodo de Newton y conver-gera aξ casi tan rapidamente como aquella, pero con la mitad de evalua-ciones de la derivada. Llevando esto mas lejos podemos elegir un enteropositivo p y modificar el metodo de forma que se calculen solamente unaderivada de cadap terminos, o sea que definimos la sucesion de iteracionesde la siguiente forma:
xn+1 =
xn − f (xn)/ f ′(x0) si 0< n ≤ p− 1
xn − f (xn)/ f ′(xp) si p < n ≤ 2p− 1...
xn − f (xn)/ f ′(xrp) si rp < n ≤ (r + 1)p− 1...
2.2. Metodos iterativos 43
La otra dificultad basica del metodo de Newton consiste en la necesidadde conocer una estimacion inicial suficientemente proxima al cero buscado.El siguiente teorema nos da una idea precisa de lo que es “suficientementeproximo” en este contexto.
Teorema 1 (Convergencia del metodo de Newton)Supongamos quef esuna funcion continua en un intervalo[a,b], que tiene derivada segundacontinua en(a,b) y que satisface las siguientes condiciones:
1. f (a) f (b) < 0, es decir, los valores def en los extremos de[a,b]tienen distinto signo.
2. La derivada primera def no se anula en[a,b], es decir,f es estric-tamente monotona en[a,b].
3. La derivada segunda def no cambia de signo en[a,b], es decir, laconcavidad def no cambia en[a,b].
4. ∣∣∣∣ f (a)
f ′(a)
∣∣∣∣ < b− a y
∣∣∣∣ f (b)
f ′(b)
∣∣∣∣ < b− a,
(esto, supuestas las condiciones anteriores, equivale a que las tan-gentes a la grafica de f en(a, f (a)) y (b, f (b)) intersecan al ejexdentro del intervalo[a,b])
entoncesf tiene ununico cero,ξ , en[a,b] y el metodo de Newton convergea ξ para cualquier estimacion inicial x0 ∈ [a,b].
Demostracion: Por la continuidad def y las dos primeras condiciones,ftiene ununico cero,ξ , en [a,b]. Sin perder generalidad se puede suponerque f es convexa y creciente, es decir,f (a) < 0 y f ′′(x) ≥ 0 en(a,b)(como en la figura 2.4). Six0 6= ξ hay dos posibilidades:
1. ξ < x0. En este caso, por la convexidad def tendremosξ ≤ x1 ≤ x0y en generalξ ≤ xn+1 ≤ xn, es decir, la sucesion producida por elmetodo de Newton es monotona decreciente acotada inferiormente.En consecuencia converge siendo su lımite necesariamente el cero,ξ , de f .
2. x0 < ξ . En este caso tendremosx0 < ξ ≤ x1 ≤ b con lo que a partirdex1 estamos en la situacion del caso anterior, obteniendo la mismaconclusion.

44 2. Resolucion de ecuaciones no lineales
Los demas casos (segun la convexidad def y si es creciente o decreciente)se analizan de forma analoga, llegandose a las mismas conclusiones.
Ejemplo de aplicacion del metodo de Newton.–
Como ejemplo, supongamos que queremos hallar el menor cero positivo def (x) = e−x − senx. Vamos a buscar un intervalo que satisfaga las condi-ciones del teorema de convergencia del metodo de Newton. Comenzamoscalculando las derivadasf ′(x) = −e−x − cosx, f ′′(x) = e−x + senx.Vemos quef (0) = 1, f (1) ' −0.47. Ademas f ′(x) < 0 parax ∈ [0,1]
ξ 1
1
2 3π2
senx
π
e−x
y tambien f ′′(x) > 0 parax ∈ [0,1]. Solo nos falta estudiar laultimacondicion en [0,1]: Tenemos,f (0) = 1, f ′(0) = −2, | f (0)/ f ′(0)| = 1
2 <
b− a = 1; f (1) = −0.47, f ′(1) = −1.36, | f (1)/ f ′(1)| = 0.34< b− a.Luego las condiciones se satisfacen en el intervalo [0,1].
El metodo de Newton es uno de los metodos iterativos mas importantespero en ocasiones puede resultar mas apropiado utilizar un metodo iterativodistinto (basado en otra funcion de iteracion). A continuacion estudiamoslas propiedades generales de los metodos iterativos.
2.2.2 Propiedades generales de los metodos iterativos
Dada una ecuacion de la formaf (x) = 0 existen diversas funcionesg(x)cuyos puntos fijos son precisamente los ceros def . El ejemplo mas sen-cillo, mencionado mas arriba, esg(x) = x + f (x), pero en general habramuchas otras posibilidades como se ve en el siguiente ejercicio.
Ejercicio 2.9Demostrar que los puntos fijos de las cuatro funciones dadas a continuacion
2.2. Metodos iterativos 45
son solucion de la ecuacion x2− x − 2= 0:
g1(x) =√
2+ x , g2(x) = 1+ 2
x,
g3(x) = x − x2− x − 2
m(m 6= 0) , g4(x) = x2+ 2
2x − 1.
Ahora bien, no toda funcion cuyos puntos fijos sean solucion de nuestraecuacion sirve como funcion de iteracion. Es necesario que las sucesivasiteraciones de la funcion den una sucesion convergente. En general vamosa pedir a toda funcion de iteraciong que cumpla las siguientes condiciones:
Condiciones que ha de cumplir una funcion de iteracion.–
(a) Que exista un intervaloI = [a,b] en el queg este definida y en elqueg tome sus valores, es decir queg sea un endomorfismo deI ,
Ig−→ I ,
(b) Queg sea continua enI ,
(c) Queg sea diferenciable enI y exista una constantek < 1 tal quepara todox ∈ I se cumpla|g′(x)| ≤ k.
Notese que nos hemos permitido cierta redundancia en estas condicio-nes (por ejemplo (c)⇒ (b)). Lo mas importante de estas condiciones esque garantizan la existencia y unicidad de punto fijo y la convergencia dela sucesion de iteraciones. La existencia de punto fijo es una sencilla con-secuencia de (a) y (b), cuya demostracion proponemos como ejercicio:
Ejercicio 2.10Demostrar que toda funcion g que cumpla las propiedades (a) y (b) ante-riores tiene un punto fijo en el intervaloI .
(Sugerencia: Estudiar los cambios de signo de la funcion h(x) = g(x)− x.)
Ademas de esto tenemos:
Teorema 2 Si g es una funcion que satisface las condiciones (a), (b), (c)anteriores entoncesg tiene ununico punto fijo,ξ ∈ I y para cualquiervalor inicial x0 ∈ I , la sucesion de iteracionesxn+1 = g(xn), converge aξ .

46 2. Resolucion de ecuaciones no lineales
Demostracion: Sabemos por el ejercicio 2.10 que existe enI un puntoξque es punto fijo deg, es decir tal que,g(ξ) = ξ . Si demostramos quetoda sucesion de iteraciones converge aξ , la unicidad del punto fijo seraconsecuencia de la unicidad de lımite de una sucesion. Ahora bien, loserroresen = ξ − xn verifican
en = g(ξ)− g(xn−1) = g′(ηn)(ξ − xn−1) = g′(ηn)en−1
ya que segun el teorema del valor medio existe un numeroηn (entreξ yxn−1) tal queg′(ηn) = (g(ξ)−g(xn−1))/(ξ − xn−1). En consecuencia, porser|g′(x)| ≤ k para todox ∈ I , tenemos que para todon |en| ≤ k|en−1|,de donde
|en| ≤ k|en−1| ≤ k2|en−2| ≤ · · · ≤ kn|e0|y por tanto, al serk < 1,
limn→∞ |en| = |e0| lim
n→∞ kn = 0,
lo que significa que lim{xn} = ξ .
En aquellos casos en que sea difıcil comprobar la condicion (a), puedeser suficiente aplicar la siguiente version debil del teorema:
Corolario 1 Si g es una funcion continuamente diferenciable en algun in-tervalo abiertoI que contenga un punto fijoξ deg, y si |g′(ξ)| < 1, enton-ces existe un numeroε > 0 tal que para todo valor inicialx0 que diste deξ menos queε la sucesion de iteracionesxn+1 = g(xn), converge aξ .
Demostracion: Por ser|g′(ξ)| < 1 existek tal que|g′(ξ)| < k < 1, ypor serg′ continua enξ existe unε > 0 tal que para todox que diste deξ menos queε, |g′(x)| < k. Entonces se cumple la condicion (c) en elintervaloI = [ξ − ε, ξ + ε] (lo que implica la condicion (b)). Ademas paratodox ∈ I
|g(x)− ξ | = |g(x)− g(ξ)| = |g′(ξ)||x − ξ | ≤ kε ≤ ε ,luegog(x) ∈ I , de forma que tambien se cumple (a) enI y podemos aplicarel teorema al intervaloI .
Ejercicio 2.11Para cada una de las cuatro funciones del ejercicio 2.9 hallar un intervaloI , si existe, en el que se cumplan las condiciones (a), (b) y (c).
2.2. Metodos iterativos 47
2.2.3 Velocidad de convergencia
Definicion: Sea{xn} una sucesion convergente cuyo lımite esξ . Sea, pa-ra cada entero positivon, en = ξ − xn (el “error” del terminon-esimo).Decimos que{xn} tieneorden de convergenciaigual al numero realp si lasucesion {|en+1|/|en|p} es convergente y su lımite es distinto de cero.
A la vista de esta definicion quizas a uno le pueda quedar la duda de siel numero realp tiene que serunico si existe. Por lo tanto conviene hacerel siguiente ejercicio para disipar esa duda.
Ejercicio 2.12Demostrar que sip y q son dos numeros reales tales que
0< limn→∞
|en+1||en|p <∞
y
0< limn→∞
|en+1||en|q <∞
entoncesp = q.
Si {xn} tiene orden de convergencia igual ap la constante
c = limn→∞
|en+1||en|p
se llamaconstante de erroro constante de error asintotico de{xn}.Si una sucesion tiene orden de convergencia igual a 1 decimos que tiene
convergencia linealy si tiene orden de convergencia igual a 2 decimos quetieneconvergencia cuadratica.
Proposicion 1 Seag una funcion de iteracion continuamente diferenciablepara la que la sucesion de iteracionesxn+1 = g(xn) converge al punto fijoξ deg y para la queg′(ξ) 6= 0. Entonces la sucesion de iteraciones tieneconvergencia lineal y su constante de error es igual a|g′(ξ)|.
Demostracion: Al igual que en la demostracion del teorema 2, deduci-mos (aplicando el teorema del valor medio) que para cada entero posi-tivo n existe un numeroηn en el intervalo de extremosxn y ξ tal que

48 2. Resolucion de ecuaciones no lineales
|en+1| = |g′(ηn)||en|. Como evidentemente lim{ηn} = ξ ,
limn→∞
|en+1||en| = |g
′(ξ)| .
Igualmente, sig es una funcion de iteracion con derivada segunda con-tinua y con punto fijoξ , tal queg′(ξ) = 0 y g′′(ξ) 6= 0 entoncesen+1 =12g′′(ηn)e2
n de donde se deduce que la sucesion de iteraciones deg tieneconvergencia cuadratica y la constante de error asintotico es|12g′′(ξ)|. Engeneral tenemos lo siguiente
Ejercicio 2.13En las condiciones de la proposicion 1, si lasn − 1 primeras derivadas deg se anulan enξ y la derivadan-esima no se anula entonces la sucesion deiteraciones tiene orden de convergencia igual an. ¿Cuanto vale la constantede error?
Orden de convergencia del metodo de Newton.–
Podemos ahora justificar la ventaja del metodo de Newton respecto a suvelocidad de convergencia demostrando que, si la derivada def enξ no seanula, tiene convergencia cuadratica. Para ello calculamos la derivada de lafuncion de iteracion g(x) = x − f (x)/ f ′(x) obteniendo
g′(x) = 1− ( f ′(x)2− f (x) f ′′(x))/ f ′(x)2 = f (x) f ′′(x)/ f ′(x)2.
Ahora hemos de evaluar esta derivada en el puntoξ , en el quef (ξ) = 0.La forma de hacerlo es calculando el lımite
g′(ξ) = limx→ξ
f (x) f ′′(x)f ′(x)2
= 0.
Esto prueba que la convergencia es al menos cuadratica.
Para hallar la constante de error asintotico hemos de hallar la derivadasegunda deg y evaluarla enx = ξ . El resultado es el siguiente:
Ejercicio 2.14Si f ′(ξ), f ′′(ξ) 6= 0 entonces la constante de error asintotico del metodode Newton aplicado a la funcion f para hallar el ceroξ es igual a
1
2
∣∣∣∣ f ′′(ξ)f ′(ξ)
∣∣∣∣
2.2. Metodos iterativos 49
Ejercicio 2.15Si ξ es un cero def de orden dos, (es decir,f (ξ) = f ′(ξ) = 0 y f ′′(ξ) 6=0) entonces el metodo de Newton no converge cuadraticamente (probar queg′(ξ) = 1
2). En este caso se puede modificar el algoritmo de Newton usandola funcion de iteracion
g(x) = x − 2 f (x)
f ′(x)la cual, si f ′′′ es continua, da lugar a una convergencia cuadratica.(Sugerencia: Usar el hecho de que
limx→ξ
f (x) f ′′(x)f ′(x)2
= limx→ξ
f (x)
f ′(x)2lim
x→ξ f ′′(x)
junto con la regla de L’Hopital.)
El resultado de este ejercicio se puede generalizar:
Ejercicio 2.16Si ξ es un cero def de ordenm entonces la funcion de iteracion
g(x) = x −mf (x)
f ′(x)da lugar a una convergencia cuadratica.
Orden de convergencia del metodo de la secante.–
El metodo de la secante no es un metodo iterativo en el sentido que aquıentendemos. Sin embargo es un metodo que da lugar, igual que los metodositerativos a una sucesion de la que podemos estudiar la velocidad de conver-gencia siguiendo los conceptos generales vistos mas arriba. De este estudiose deduce que la convergencia es casi tan buena como la del metodo deNewton, ya que su orden de convergencia es cercano a 1.62.
Para hallar el orden de convergencia del metodo de la secante necesitamosestablecer primeramente la siguiente representacion de una funcion (lema1):
f (x) = f (α)+ f [α, β](x − α)+ f [α, β, x](x − α)(x − β) . (2.7)
La notacion usada en esta formula significa lo siguiente: en primer lugartenemos laprimera diferencia dividida,
f [a,b] ={
f (a)− f (b)a−b si a 6= b,
f ′(a) si a = b.

50 2. Resolucion de ecuaciones no lineales
En segundo lugar tenemos lasegunda diferencia dividida:
f [a,b, c] =
f [a,b]− f [a,c]
b−c si b 6= c,f [a,c]− f [b,c]
a−b si a 6= b,12 f ′′(a) si a = b = c.
Ejercicio 2.17Demostrar que con la notacion que acabamos de introducir, la sucesion ob-tenida por el metodo de la secante se puede expresar de la siguiente forma:
xn+1 = xn − f (xn)
f [xn, xn−1].
Ejercicio 2.18Demostrar que, suponiendoa 6= b y b 6= c,
f [a,b] − f [a, c]
b− c= f [a, c] − f [b, c]
a− b
y
limb→a
f [a,b] − f [a,a]
b− a= 1
2f ′′(a).
Estas diferencias divididas se estudiaran con mas detalle en el proximocapıtulo. De momento solo las necesitamos para establecer la formula(2.7):
Lema 1 Sea f una funcion con derivada segunda continua en un inter-valo I y seanα, β ∈ I . Entonces, para todox ∈ I se cumple
f (x) = f (α)+ f [α, β](x − α)+ f [α, β, x](x − α)(x − β) . (2.7)
Demostracion: Si x = α la formula no es mas que la identidadf (x) =f (x). Podemos suponer, pues,x 6= α. Si x = β esta formula no es mas queuna reescritura de la definicion del sımbolo f [α, β], mientras que six 6= βla formula es una reescritura de la definicion del sımbolo f [α, β, x].
Ahora usaremos la formula (2.7) para hallar el orden de convergenciadel metodo de la secante. Seaξ un cero de la funcion f . Poniendox = ξen (2.7) tenemos:
0= f (α)+ f [α, β](ξ − α)+ f [α, β, ξ ](ξ − α)(ξ − β)
2.2. Metodos iterativos 51
de donde
ξ = α − f (α)
f [α, β]− f [α, β, ξ ]
f [α, β](ξ − α)(ξ − β)
Supongamos ahora queβ y α son sucesivas aproximacionesβ = xn−1,α = xn obtenidas al aplicar el metodo de la secante a la funcion f parahallar el ceroξ . Entoncesξ − β = ξ − xn−1 y ξ − α = ξ − xn sonlos sucesivos erroresen−1 y en, mientras que, segun el ejercicio 2.17,α −
f (α)f [α,β] = xn− f (xn)
f [xn,xn−1] = xn+1, de donde deducimos la siguiente relacionentre tres errores consecutivos:
en+1 = − f [xn, xn−1, ξ ]
f [xn, xn−1]enen−1. (2.8)
De esta relacion junto con la hipotesis de que tanto la derivada primeracomo la derivada segunda def en ξ son distintas de cero deducimos in-mediatamente que el orden de convergencia del metodo de la secante esp = (1+√5)/2= 1.618. . . , debido al siguiente teorema:
Teorema 3 Sea{xn} una sucesion convergente al numeroξ para la quelos erroresen = ξ − xn verificanen+1 = cnenen−1 donde las constantescn convergen ac∞ = lim{cn}. Entonces{xn} tiene orden de convergenciap = (1 + √5)/2 ' 1.618 y tiene constante de error asintotico igual a
|c∞|1p .
Demostracion: Tenemos que hallar el valor dep tal que los cocientesyn = |en+1|/|en|p tengan lımite distinto de cero, es decir, tal que lim{yn} 6=0. Para conseguir esto buscamos el valor dep que hace queyn puedaexpresarse en terminos deyn−1. Supongamos que el valor dep es tal quepara algunα se cumple
yn = |cn||en|1−p|en−1| = |cn|(yn−1)α. (2.9)
Entonces la sucesion de cocientesyn satisfara la relacion
yn+1 = |cn|yαn ,y el lımite c = lim{yn} verificara c = (lim{|cn|})cα = |c∞|cα, es decir,
c = |c∞|1
1−α . Para calcularp y α solo hace falta escribir (2.9) en la forma
yn = |cn||en|1−p|en+1| = |cn|( |en||en+1|p
)α

52 2. Resolucion de ecuaciones no lineales
para deducir quep y α han de verificarαp = −1 y α = 1− p. De aquı se
deducec = |c∞|1p y p2− p− 1= 0, de dondep = (1+√5)/2.
Corolario 2 Supongamos queξ es un cero de primer orden de la funcionf y que la derivada segunda def enξ es distinta de cero. Entonces supo-niendo que el metodo de la secante aplicado af converge aξ , su orden deconvergencia esp = (1+√5)/2 y su constante de error asintotico es∣∣∣∣12 f ′′(ξ)
f ′(ξ)
∣∣∣∣ 1p
Demostracion: Segun el teorema anterior y la formula (2.8) solo nece-sitamos demostrar
limn→∞
f [xn, xn−1, ξ ]
f [xn, xn−1]6= 0.
Pero usando el resultado del ejercicio 2.18, es inmediato comprobar que
limn→∞
f [xn, xn−1, ξ ]
f [xn, xn−1]= f [ξ, ξ, ξ ]
f [ξ, ξ ]= 1
2
f ′′(ξ)f ′(ξ)
6= 0,
como querıamos demostrar.
2.2.4 Aceleracion de la convergencia
Como hemos visto, sig es una funcion de iteracion cuya sucesion de ite-raciones tiene convergencia lineal al lımite ξ entoncesg′(ξ) 6= 0. Ademaspara cadan existeηn en el intervalo de extremosξ y xn tal que
ξ − xn+1 = g′(ηn)(ξ − xn)
de donde
ξ(1− g′(ηn)
) = xn+1− g′(ηn)xn
= xn+1− g′(ηn)xn+1+ g′(ηn)xn+1− g′(ηn)xn
= (1− g′(ηn))xn+1+ g′(ηn)(xn+1− xn).
De aquı obtenemos la siguiente expresion para el lımite ξ :
ξ = xn+1+ g′(ηn)(xn+1− xn)
1− g′(ηn)= xn+1+ xn+1− xn
g′(ηn)−1− 1.
2.2. Metodos iterativos 53
En consecuencia, si podemos aproximarg′(ηn), podrıamos utilizar esa apro-ximacion en esta formula para obtener una aproximacion deξ de la que sepuede esperar que sea mas exacta quexn+1.
Aceleracion12 de Aitken.–
Una forma de aproximarg′(ηn) nos viene sugerida por el hecho de quepara todon el cociente(g(xn)− g(xn−1))/(xn − xn−1) es igual al valor dela derivada deg en algun puntoζn entrexn y xn−1. Este puntoζn estaranecesariamente proximo aηn (al menos para valores grandes den) ya queηn se encuentra entrexn y ξ y la sucesion {xn} converge aξ (vease la figura2.5). Ası pues, teniendo en cuenta queg(xn) = xn+1 podemos usar laaproximacion
g′(ηn) ≈ g′(ζn) = g(xn)− g(xn−1)
xn − xn−1= xn+1− xn
xn − xn−1
para aproximarξ mediante
xn = xn+1+ xn+1− xn
rn − 1(2.10)
con
rn = 1
g′(ζn)= xn − xn−1
xn+1− xn. (2.11)
Como se puede ver en la figura 2.5 esta correccion corresponde a unainterpolacion lineal deg en los puntosxn y xn−1. Este proceso de acele-racion se conoce como aceleracion12 de Aitken debido a que la formula(2.10) puede expresarse en terminos de los operadores de incremento1 y12 definidos de la siguiente forma:
1xn = xn+1− xn
12xn = 1(1xn) = 1xn+1−1xn = xn+2− 2xn+1+ xn.
Ejercicio 2.19Demostrar que la formula (2.10) es equivalente a
xn = xn+1− (1xn)2
12xn−1.

54 2. Resolucion de ecuaciones no lineales
qqqqq
������������
ξ xn−1xn ζnxn
Figura 2.5: Aceleracion12.
Se puede demostrar que al aplicar este proceso de aceleracion a unasucesion cualquiera que tenga convergencia lineal se obtiene otra que tieneun orden de convergencia mayor.
Iteraci on de Steffensen.–
Cuando aplicamos la aceleracion12 a la sucesion que resulta de un metodoiterativo con orden de convergencia lineal, una vez calculada la correccionxn, es mejor usar este valor en el siguiente paso de iteracion, en lugar deusarxn+1. De esta forma se llega al siguiente algoritmo que acelera unproceso iterativo lineal intercalando un paso de aceleracion entre cada dospasos de iteracion:
Algoritmo de Iteracion de Steffensen
1 Datos: g (la funcion de iteracion), x0 (estimacion inicial), M (numeromaximo de pasos que queremos dar), ε (precision deseada).
2 x = x0
3 Para i = 1 hasta M
x0 = x
x1 = g(x0); x2 = g(x1);d = 1x1 = x2− x1; r = 1x0/d = (x1− x0)/d
2.3. Ecuaciones polinomicas 55
x = x2+ d/(r − 1)
Si |d/(r − 1)| < ε entonces ir a 6
4 Siguientei
5 Imprimir “No hubo convergencia despues de”; M ; “pasos”y PA-RAR
6 Solucion: x.
2.3 Ecuaciones polinomicas
2.3.1 Introduccion
Las ecuaciones polinomicas son aquellas ecuacionesf (x) = g(x) en lasque ambas funciones,f y g, son polinomios. Como la diferenciaf − ges de nuevo un polinomio, la resolucion de las ecuaciones polinomicas sereduce al problema del calculo de las raıces de polinomios.
Las raıces de los polinomios de segundo grado se obtendran directa-mente mediante las conocidas formulas
solucion de menor valor absoluto= −2c
b+ sign(b)√
b2− 4ac,
solucion de mayor valor absoluto= b+ sign(b)√
b2− 4ac
−2a.
Existen tambien formulas para las raıces de los polinomios de tercer ycuarto grado. En el caso de la ecuacion cubica existe siempre una raız real,la cual puede hallarse de la siguiente forma:
Ecuacion cubica: x3+ a1x2+ a2x + a3 = 0
Se calculan primeramente las cantidades:
Q = 3a2− a21
9, R= 9a1a2− 27a3− 2a3
1
54, D = Q3+ R2.
y entonces:
1. Si D ≥ 0 una solucion real esx1 = 3√
R+√D+ 3√
R−√D− 13a1.

56 2. Resolucion de ecuaciones no lineales
2. Si D < 0 el calculo se puede hacer mediante trigonometrıa:
x1 = 2√−Q cos
[13 arccos
(R/√−Q3
)]− 13a1.
Una vez hallada la raız real x1 es facil reducir la cubica a una ecua-cion cuadratica para hallar las restantes raıces: no hay mas que dividir elpolinomio de tercer grado por el binomiox − x1.
La formula de las raıces de una ecuacion cuartica nos las da en funcionde las raıces de una de tercer grado:
Ecuacion cuartica: x4+ a1x3+ a2x2+ a3x + a4 = 0
SeaY una solucion real de la ecuacion cubica asociada
y3− a2y2+ (a1a3− 4a4)y+ (4a2a4− a23 − a2
1a4) = 0
Entonces las soluciones de la cuartica son las raıces de las dos ecuacionescuadraticas enz
z2+ 12
(a1±
√a2
1 − 4a2+ 4Y)
z+ 12
(Y ∓
√Y2− 4a4
)= 0 .
Un famoso trabajo de Galois demuestra que para los polinomios de gra-do superior al cuarto no existe ninguna formula algebraica que nos de susraıces y por lo tanto es imprescindible recurrir en esos casos a los metodosnumericos. Es mas, los metodos numericos son incluso preferibles parapolinomios de grado cuatro e incluso tres.
Por supuesto, las ecuaciones polinomicas pueden siempre resolversepor los metodos generales de resolucion de ecuaciones no lineales que he-mos visto hasta ahora. Sin embargo, para los polinomios existen metodosespeciales que nos permiten mayor flexibilidad y eficacia. Estos metodosse basan en las propiedades especiales de estas funciones.
2.3.2 Propiedades generales de los polinomios
Cuando nos enfrentamos con la tarea de hallar las raıces de un polinomioes con frecuencia posible deducir informacion util acerca de las raıces me-diante un breve estudio preliminar del polinomio dado. En este estudioconviene tener en cuenta resultados generales acerca de los polinomios co-mo son los siguientes:
2.3. Ecuaciones polinomicas 57
Evaluacion de un polinomio y de su derivada.–
El conocido algoritmo de la division de numeros puede efectuarse tambiencon polinomios y aplicarlo al caso particular de la division de un polinomiocualquierap(x) = anxn + · · · + a1x + a0 por un polinomio lineal de laformax − a.
La demostracion de que el resto de la division p(x)/(x − a) esp(a) sereduce facilmente al caso de binomios monicos:
Ejercicio 2.20Demostrar quexn−an es divisible porx−a siendo el cociente el polinomio
xn−1+ axn−2+ · · · + an−2x + an−1 .
Deducir de ello que para todo polinomiop(x) la diferenciap(x) − p(a)es divisible porx − a, lo que significa quep(a) es el resto al dividirp(x)entrex − a.
Una demostracion alternativa de este resultado es la siguiente. Seaq(x) = bn−1xn−1+ · · ·+b1x+b0 el cociente yr el resto de la division dep(x) entrex − a, de forma que
p(x) = (x − a)q(x)+ r . (2.12)
Queremos hallar los coeficientesbk y r . Realizando la multiplicacion obte-nemos
(x − a)q(x) = bn−1xn + · · · + b1x2+ b0x
− (abn−1xn−1+ · · · + ab1x + ab0)
= bn−1xn + (bn−2− abn−1)xn−1
+ · · · + (b0− ab1)x − ab0
Sumandor e igualando coeficientes con los dep(x)
bn−1 = an
bn−2− abn−1 = an−1
...
b0− ab1 = a1
r − ab0 = a0

58 2. Resolucion de ecuaciones no lineales
de lo que deducimos que los coeficientesbk satisfacen la relacion recursiva
bk = ak+1+ abk+1
(con la condicion inicialbn−1 = an) y el resto esr = a0+ ab0, que podrıaser llamadob−1. En consecuencia el resto puede considerarse como elresultado final de un proceso iterativo que va produciendo los coeficientesbk uno en cada paso. Por ejemplo, suponiendo que el grado esn = 4 elresto es
r = a0+ a(a1+ a
(a2+ a(a3+ aa4)
)).
¡Pero esto no es mas que la evaluacion dep(x) enx = a por el metodo deHorner o de las multiplicaciones encajadas! De esto se deduce que el restor es igual al valorp(a) que el polinomio toma ena.
Vemos pues que
Los resultados intermedios en el proceso de evaluacion de un polinomiop(x) ena por el metodo de las multiplicaciones encajadas son los coeficien-tes del polinomio obtenido al dividirp(x) entrex − a y el resultado final,el valor del polinomio ena, p(a), es el resto en dicha division.
Dichos resultados intermedios tienen una importancia adicional en laevaluacion de la derivada dep(x) en el puntoa. De la expresion (2.12)deducimos
p′(x) = q(x)+ (x − a)q′(x)
de dondep′(a) = q(a) .
Es decir,
El valorq(a) que toma ena el cocienteq(x) de dividir p(x) entrex−aes igual al valor que toma la derivada dep en el mismo punto.
Esto era de esperar ya que siendo
p(x)− p(a)
x − a= q(x),
por la definicion de derivada
p′(a) = limx→a
p(x)− p(a)
x − a= lim
x→aq(x) = q(a).
2.3. Ecuaciones polinomicas 59
La consecuencia mas importante de este resultado es que podemos ha-cer una sencilla modificacion del algoritmo de Horner para que nos evaluetanto el polinomio como su derivada en un punto dado:
Datos: a0, . . . ,an (coeficientes del polinomiop), a
c = an ; b = a · an + an−1
Para k = n− 2 hasta0 paso−1c = a · c+ b
b = a · b+ ak
siguientek
Resultados:b (el valor dep(a)), c (el valor dep′(a)).
Raıces o ceros de polinomios.–
Puesto que el resto de la division de un polinomiop(x) entre un polinomiolineal de la formax − a es la constantep(a) que resulta al evaluarp ena,se puede concluir lo siguiente:
Ejercicio 2.21Un numeroa es un cero o raız de un polinomiop(x) si y solo si el polino-mio x − a es un factor dep.
Un polinomioirreduciblees aquel que es distinto de cero y no es iguala un producto de polinomios de menor grado. Con este concepto podemosenunciar de forma precisa el teorema que tiene como corolario que, contan-do cada raız tantas veces como indica su multiplicidad, “todo polinomio degradon tienen raıces”:
Teorema 4 (Teorema fundamental delalgebra) En el campo de los numeroscomplejos los polinomios irreducibles son precisamente los no nulos degrado menor o igual que uno, o sea: los polinomios lineales y las constan-tes no nulas.
Notese que parte del contenido de este teorema es trivial, puesEn cual-quier campo de numeros los polinomios lineales y las constantes no nulasson irreducibles.
Si una potencia(x−a)k, k > 0, de un polinomio monico lineal aparececomo factor de un polinomiop(x) entonces el numeroa es una raız de p.

60 2. Resolucion de ecuaciones no lineales
Si (x− a)k es pero(x− a)k+1 no es un factor dep entonces se dice que lamultiplicidad del factorx − a en p esk y que la raız a tienemultiplicidadk. En consecuencia el teorema anterior nos dice que todo polinomio degradon con coeficientes complejos tienen raıces complejas contando sumultiplicidad.
Para polinomios con coeficientes reales conviene recordar que:
Lema 2 Los polinomios irreducibles en el campo de los numeros realesson los de grado uno y aquellos de grado dos que tienen discriminantenegativo.
Ejercicio 2.22Si p(x) es un polinomio con coeficientes reales entonces para todo numerocomplejoz, p(z) = p(z) (p evaluado en el conjugado dez es el conjugadode p(z)).
Corolario 3 Las raıces complejas no reales de un polinomio con coeficien-tes reales aparecen en pares conjugados. En otras palabras: siz= a+ bies raız de un polinomiop(x) con coeficientes reales entonces tambien suconjugado,z= a− bi , es raız dep.
De esto se deduce que todo polinomio de grado impar y con coeficientesreales tiene al menos una raız real. Es interesante comparar la demostra-cion de este hecho basada en los resultados anteriores (una demostracionpuramente “algebraica”) con una demostracion analıtica del mismo hechobasada en la continuidad de los polinomios y el cambio de signo que ocurreen los polinomios de grado impar (cuando se considera un intervalo sufi-cientemente grande) debido a que paran impar, limx→±∞ xn = ±∞.
Regla de los signos de Descartes.–
La regla de los signos de Descartes nos permite limitar y a veces determinarel numero de ceros reales positivos y el numero de ceros reales negativosde un polinomio de coeficientes reales. Dice lo siguiente:
El numero de raıces positivas de un polinomio de coeficientes realesrestado del numero de cambios de signo que ocurren en sus coeficientes daun numero par no negativo.
Una consecuencia evidente de esto es:
2.3. Ecuaciones polinomicas 61
Corolario 4 Para todo polinomio en el que ocurra exactamente un cambiode signo entre sus coeficientes el numero de raıces reales positivas es iguala uno.
Para estudiar las raıces reales negativas dep(x) basta estudiar el poli-nomio q(x) = p(−x) ya que es evidente que sia es un cero positivo deq(x) entonces−a es un cero negativo dep(x) de manera que el numero deraıces negativas dep(x) es igual al numero de raıces positivas deq(x).
Por ejemplo, consideremos el polinomio
p(x) = x4− x3− x2+ x − 1
Puesto que tiene tres cambios de signo, el numero de raıces positivas es unimpar menor o igual que tres, esto es, uno o tres. Por otro lado, el polinomio
q(x) = p(−x) = x4+ x3− x2− x − 1
solo tiene un cambio de signo, por lo quep(x) solo tiene una raız realnegativa. Por tanto este polinomio tiene o bien tres raıces reales positivas yuna negativa o bien una raız real positiva, dos complejas conjugadas y unareal negativa.
Acotaciones de las raıces.–
Existen varios teoremas que nos dan informacion acerca de la situacion delos ceros de polinomios en el plano complejo.
Teorema 5 Todos los ceros del polinomiop(x) = anxn + · · · + a1x + a0tienen modulo menor o igual que
r = 1+ max0≤k≤n−1
∣∣∣∣ak
an
∣∣∣∣es decir, todos se encuentran en el disco de centro cero y radior .
Por ejemplo, para el polinomio
p(x) = x3− x − 1

62 2. Resolucion de ecuaciones no lineales
tenemosa2a3= 0, a1
a3= −1, a0
a3= −1, luego
r = 1+ max0≤k≤n−1
∣∣∣∣ak
an
∣∣∣∣ = 2
por lo que toda raız x de p satisface|x| ≤ 2.
Teorema 6 Todo polinomiop(x) = anxn + · · · + a1x+ a0 tiene al menosun cero cuyo modulo es menor que cualquiera de los numeros
ρ1 = n
∣∣∣∣a0
a1
∣∣∣∣ , ρn =∣∣∣∣a0
an
∣∣∣∣ 1n
es decir,p tiene al menos un cero dentro del disco del plano complejo decentro cero y radiomin{ρ1, ρ2}.
Para el polinomio del ejemplo anterior,p(x) = x3− x − 1, tenemos
ρ1 = 3∣∣∣−1
−1
∣∣∣ = 3 y ρ3 =∣∣∣−1
1
∣∣∣ 13 = 1
por lo quep tiene al menos una raız x tal que|x| ≤ 1.
Finalmente tenemos un teorema debido a Cauchy:
Teorema 7 Dado un polinomiop(x) = anxn+· · ·+a1x+a0, si formamoslos polinomios
P(x) = |an|xn − · · · − |a1|x − |a0| ,Q(x) = |an|xn + · · · + |a1|x − |a0| ,
dado que ambos tienen exactamente un cambio de signo, cada uno de ellostiene exactamente un cero positivo y toda raız dep tiene su modulo com-prendido entre dichos ceros.
Reduccion de grado.–
Cuando se quieren hallar todos los ceros de un polinomiop(x) se puedeemplear la tecnica dereduccion de gradoque consiste en, hallada una raıza, obtener el polinomioq(x) = p(x)/(x − a). El grado deq es menorque el dep y sus raıces son las restantes raıces dep. A continuacion sebusca una raız deq, lo que permite una nueva reduccion de grado y asısucesivamente hasta llegar a un polinomio de segundo grado.
2.3. Ecuaciones polinomicas 63
2.3.3 Algoritmo de Newton para ecuaciones polinomicas
Veremos a continuacion un sencillo algoritmo en el que se adapta el metodode Newton para calculo de ceros de funciones al calculo de una raız de unpolinomio. El metodo de Newton consiste en iterar la funcion g(x) =x − f (x)/ f ′(x) a partir de una estimacion del cero, en consecuencia nosresultara util el algoritmo que hemos visto para la evaluacion de un polino-mio y de su derivada. Ası llegamos al siguiente:
Algoritmo de Newton para Polinomios
1 Datos: n (grado del polinomiop(x)); a0, . . . ,an (coeficientes delpolinomio p); a (estimacion inicial del cero);ε (tolerancia de error);M (maximo numero de iteraciones)
2 Para i = 1 hasta Mc = an ; b = a · an + an−1
Para k = n− 2 hasta0 paso−1c = a · c+ ak
b = a · b+ ak
Siguientek
d = b/c
Si |d| ≤ ε entonces ir a 5a = a− d
3 Siguientei
4 Imprimir “ No hubo convergencia despues de”; M ; “ pasos.” yPARAR
5 Imprimir “ Solucion es:”; a− d; “ .” y PARAR
2.3.4 Ecuaciones polinomicas mal condicionadas
En esta seccion vamos a estudiar como cambian las raıces de un polinomiopor el hecho de cometer pequenos errores en sus coeficientes. Suponga-mos quep(x) es un polinomio de gradon con coeficientes reales y conraıces simplesr1, . . . , rn. Vamos a suponer tambien que producimos unaalteracion en los coeficientes dep de la forma
P(x, ε) = p(x)+ εq(x)

64 2. Resolucion de ecuaciones no lineales
dondeq(x) es otro polinomio de gradon.
Seanz1(ε), . . . , zn(ε) las funciones que nos dan las raıces deP (comopolinomio enx) en funcion deε. Evidentemente para cadai = 1, . . . ,neszi (0) = ri . En estas condiciones puede demostrarse que estas funcio-neszi son funciones diferenciables (incluso analıticas) en algun entornodel origenε = 0 y en consecuencia paraε pequeno podemos aproximarzi (ε) ' zi (0)+ εz′i (0) = ri + εz′i (0) de donde podemos estimar el cambiosufrido por las raıces dep mediante:
|z(ε)− ri | ' |ε||z′i (0) (2.13)
Ası, solo nos falta determinar los valores de las derivadasz′i (0). Para ellohacemos lo siguiente: Sabemos que
0= P(zi (ε), ε) = p(zi (ε))+ εq(zi (ε))
de donde, derivando respecto aε,
0= p′(zi (ε))z′i (ε)+ q(zi (ε))+ εq′(zi (ε))z
′i (ε)
y despejandoz′i (ε),
z′i (ε) = −q(zi (ε))
p′(zi (ε))+ εq′(zi (ε)).
Por la hipotesis de que todas las raıces son simples, podemos evaluarestas derivadas enε = 0 con lo que obtenemos
z′i (0) = −q(ri )
p′(ri ).
En consecuencia, la estimacion (2.13) del cambio sufrido por las raıcesde p(x) nos da
|zi (ε)− ri | ' |εq(ri )||p′(ri )| .
De esta estimacion aprendemos dos cosas: Primeramente, como cabeesperar para funciones en general, cuando la derivada es pequena en valorabsoluto cerca o en un cero la busqueda de ese cero es un problema malcondicionado. La segunda cosa que aprendemos es que pequenos errores enun coeficiente de una potencia alta dex en p(x) puede afectar seriamenteel calculo de las raıces de valor absoluto grande (tomeseq(x) = xn ysupongamos queri tiene|ri | grande y se vera que|εq(ri )|/|p′(ri )| puedeser muy grande).
2.3. Ecuaciones polinomicas 65
2.3.5 El metodo de Bernoulli
Vamos a terminar este tema de raıces de polinomios con una breve referen-cia a un antiguo metodo atribuido a Daniel Bernoulli (de la famosa familiaBernoulli de matematicos) que (en su version mas sencilla) sirve para apro-ximar la raız real de mayor valor absoluto de un polinomio.
El estudiante conoce seguramente el metodo para obtener una formulapara el termino general de una sucesion {xn} que satisface una ecuacion derecurrencia de la formaa2xn + a1xn−1 + a0xn−2 = 0 (dondea2 6= 0).Claramente, paraa0,a1,a2 dados, el conjunto de tales sucesiones forma unespacio vectorial de dos dimensiones (pues cada sucesion esta completa-mente determinada por sus dos terminos inicialesx0, x1). En consecuenciala forma general de una tal sucesion esta dada por una combinacion linealde dos de ellas que sean linealmente independientes.
Por otro lado, supongamos que{xn} es una sucesion de ese espaciovectorial, es decir, que satisface la relacion de recurrencia dada. Entonceses muy facil de ver que en caso de que la sucesion de cocientes sucesivosyn = xn+1/xn converja, su lımite necesariamente sera una raız del poli-nomio a2x2 + a1x + a0. Este hecho es la base del metodo de Bernoulli,el cual consiste en construir de forma mas o menos arbitraria una sucesionque satisfaga la recurrencia e intentar calcular su lımite (con la esperanzade que exista). A continuacion veremos una situacion en que la existenciade dicho lımite esta garantizada.
Ejercicio 2.23Si z es una raız real del polinomioa2x2 + a1x + a0 entonces la sucesionxn = zn satisface la relacion de recurrenciaa2xn+a1xn−1+a0xn−2 = 0. Siz1, z2 son dos raıces reales no nulas distintas del mismo polinomio entonceslas dos sucesioneszn
1, zn2 (satisfacen aquella relacion de recurrencia y) son
linealmente independientes
Ejercicio 2.24Si el polinomioa2x2 + a1x + a0 tiene dos raıces reales distintasz1, z2entonces la forma general de las sucesiones que satisfacen la relacion derecurrenciaa2xn + a1xn−1+ a0xn−2 = 0 es
xn = c1zn1 + c2zn
2
dondec1 y c2 son dos constantes arbitrarias.

66 2. Resolucion de ecuaciones no lineales
La importancia del ejercicio 2.24 consiste en que deel se deduce losiguiente. Supongamos que|z1| > |z2|. Entonces podemos poner
xn+1
xn= c1zn+1
1 + c2zn+12
c1zn1 + c2zn
2
= zn+11
zn1
c1+ c2(z2/z1)n+1
c1+ c2(z2/z1)n= z1
c1+ c2(z2/z1)n+1
c1+ c2(z2/z1)n.
Esto implica (por ser limn→∞ (z2/z1)n = 0) que, sic1 6= 0, la sucesion
yn = xn+1/xn tiene como lımite la raız de a2x2 + a1x + a0 de mayorvalor absoluto. Y esto se cumple cualquiera que sea la sucesion {xn} quesatisface la relacion de recurrencia asociada con el polinomio cuadraticoa2x2+a1x+a0, con tal quex1/x0 no sea ya una raız. Pero es muy sencilloconstruir sucesiones que satisfacen dicha recurrencia; no hay mas que elegir“arbitrariamente” (pero juiciosamente tambien) los dos terminos inicialesy los demas quedan determinados por la propia relacion de recurrencia.Ası pues, llegamos al siguiente metodo de estimar la raız de mayor valorabsoluto de un polinomio cuadratico:
Proposicion 2 Si p(x) = a2x2+ a1x+ a0 es un polinomio de coeficientesreales con dos raıces reales distintasz1 y z2 y |z1| > |z2| entonces paracualesquiera valores inicialesx0, x1 tales quex1/x0 no es raız dep(x), lasucesion {xn} definida recurrentemente por
xn = −(a1xn−1+ a0xn−2)/a2
tiene la propiedad
limn→∞
xn+1
xn= z1
Todo lo que acabamos de decir para ecuaciones cuadraticas vale tam-bien para ecuaciones polinomicas de cualquier grado. Ademas no es nadamas difıcil demostrar el caso general:
Teorema 8 (Metodo de Bernoulli) Si z1, . . . , zm (ordenados por sus va-lores absolutos, es decir|z1| > · · · > |zm|) sonm raıces reales de un poli-nomio de gradomcon coeficientes realesa0, . . . ,am (es decir, si
∑mk=0 akzk
i =0) entonces la forma general de una sucesion{xn} que satisfaga la relacion
2.4. El Metodo de Muller 67
de recurrencia∑m
k=0 akxn+k−m = 0 esxn =∑m
i=1 ci zni y para cualquier
tal sucesion conc1 6= 0 se verifica
limn→∞
xn+1
xn= z1.
Una tal sucesion se puede obtener mediante la formula
xn =m−1∑k=0
akxn+k−m
y una eleccion juiciosa de losm terminos inicialesx0, . . . , xm−1.
El metodo de Bernoulli, como metodo general para hallar raıces de po-linomios tiene muchas dificultades, especialmente en su forma simple ex-plicada aquı. Incluso en los casos en los que es aplicable para hallar la raızde mayor valor absoluto, la sucesion de aproximaciones suele convergermuy despacio. Evidentemente es un metodo que tiene que ir acompanadode la tecnica de reduccion de grado explicada mas arriba. Con todo, cuan-do aplicable, es un metodo muy sencillo que se puede utilizar como pasoprevio a otro mas eficaz con la intencion de proporcionar una estimacioninicial de la raız buscada.
Hay que decir tambien que este metodo ha sido objeto de exhausti-vas investigaciones y con modificaciones apropiadas puede utilizarse in-cluso para estimar pares complejo-conjugados de raıces en algunos casos.Una variante moderna de este metodo (el algoritmo QD o decociente-diferencia) resuelve muchas de las dificultades del algoritmo de Bernoulli yproporciona estimaciones de todas las raıces simultaneamente (incluyendoraıces complejas).
2.4 El Metodo de Muller
Ya hemos indicado en la seccion 2.1.4 la idea que hay tras el metodo deMuller y su semejanza con el metodo de la secante. Como aquel, es unmetodo que no requiere la evaluacion de la derivada y que converge casicuadraticamente. Ademas tiene la ventaja de que no necesita una estima-cion inicial precisa, aunque sı es necesario elegir no dos sino tres valoresiniciales.

68 2. Resolucion de ecuaciones no lineales
Aunque en lo que sigue se supone tacitamente que buscamos un ceroreal y que las variables son todas reales, todo lo que se dice vale sin cambiospara el caso complejo. Esta es una de las ventajas que hacen del metodo deMuller una herramienta excelente a la hora de buscar ceros de funciones,pues no tenemos que preocuparnos a priori de si el cero buscado es real ocomplejo.
Dados tres puntosa,b, c en la recta real, comenzamos por calcular elpolinomio cuadratico,q(x), que coincide con la funcion dada,f , en esostres puntos, es decir, tal queq(a) = f (a), q(b) = f (b), q(c) = f (c).
Una vez hallado dicho polinomio cuadratico q(x) calculamos, de susdos raıces, aquella que mas se acerque al cero buscado. Esa raız sera elsiguiente termino de la sucesion que converge al cero buscado. Ası pues elmetodo de Muller progresa de la siguiente forma: Conocidos tres terminosconsecutivos de la sucesion,xn−2, xn−1, xn, el siguiente termino se obtienehaciendo lo siguiente:
1. Primeramente hacemosa = xn−2, b = xn−1, c = xn.
2. Calculamos el polinomioq(x) determinado porq(a) = f (a), q(b) =f (b), q(c) = f (c).
3. Hallamos el cero deq(x)mas cercano a la solucion buscada, sea estecerox, y ponemosxn+1 = x.
4. Porultimo preparamos los datos para el siguiente paso haciendoa =b, b = c, c = x y vamos al paso 2.
Para elegir cual de las dos posibles soluciones deq(x) = 0 nos interesa,razonamos ası: a medida que el metodo progresa los tres puntosa,b, cestaran mas y mas cerca del cero y por tanto mas cerca entre sı, lo queimplica que la parabola representada pory = q(x) se aproximara masy mas a una lınea recta que pasa cerca del cero buscado. Por lo tanto,mientras una raız deq(x) se acerca a la solucion buscada la otra tenderaa+∞ o a−∞. Esto nos dice que la raız deq(x) que debemos desechares la de mayor valor absoluto. Otra forma de plantear esto es buscar laecuacion cuadratica satisfecha por la diferenciax−xn, es decir, expresandola ecuacionq(x) = 0 en la formap(x− xn) = 0 (ecuacion (2.14)). En estecaso de nuevo buscarıamos la solucion de menor valor absoluto ya que amedida que progresa el metodo esta diferencia ira acercandose a cero.
2.4. El Metodo de Muller 69
Este proceso continua hasta que alcancemos un error (medido en terminosde las correcciones) menor que el maximo tolerado.
La forma mas sencilla de hallar el polinomioq(x) es expresandolo enla forma
q(x) = y3+ A(x − x3)+ B(x − x2)(x − x3)
ası se garantiza que pasa por(x3, y3) y solo tenemos que calcular dos coefi-cientes, los cuales se obtienen muy facilmente. Deq(x2) = y2 deducimosqueA vale
A = y2− y3
x2− x3
y deq(x1) = y1 deducimos
y1 = y3+ A(x1− x3)+ B(x1− x2)(x1− x3)
de donde
B =y1−y3x1−x3
− A
x1− x2.
Para hallar el cero que nos interesa expresaremosq(x) en la forma
q(x) = y3+ C(x − x3)+ D(x − x3)2 , (2.14)
cuyos coeficientes se determinan tambien facilmente. En primer lugar, porser igual al coeficiente principal, ha de serD = B. Por otro lado el coefi-cienteC ha de verificarC + (x − x3)B = A+ (x − x2)B, de donde
C = A+ B(x3− x2)
y la correccion que tenemos que hacer sobrex3 es
x − x3 = −2y3
C + sign(C)√
C2− 4y3B.
Como dijimos mas arriba, este metodo sirve para obtener tanto los cerosreales como los ceros complejos no reales de una funcion.
En el caso de que el cero buscado sea real, y a pesar de que todas las va-riables involucradas sean reales, los calculos intermedios pueden producir

70 2. Resolucion de ecuaciones no lineales
ocasionalmente valores complejos no reales por obtenerse un discriminantenegativo en la resolucion de la ecuacion cuadratica.
Esas salidas del eje real no influyen en la aproximacion al cero, peropuede ser conveniente evitarlas (en el caso de que el cero buscado se sepacon seguridad que es real) especialmente si se realizan los calculos en unlenguaje de programacion que no admite aritmetica compleja.
En tal situacion puede evitarse que aparezcan en los calculos cantida-des complejas no reales sin mas que evitar el calculo de la raız cuadrada√
C2− 4y3B cuandoC2− 4y3B < 0. Esta es la tecnica empleada en elsiguiente algoritmo que implementa el metodo de Muller para el calculo deceros reales usando solo aritmetica real.
Algoritmo del Metodo de Muller
(ceros reales)
1 Datos: x1, x2, x3 (valores iniciales), f (funcion de la que se deseaun cero), ε (tolerancia de error), M (maximo numero de pasos delalgoritmo).
2 h = x3− x2; y1 = f (x1); y2 = f (x2):3 Para k = 1,M
y3 = f (x3); A = (y3− y2)/h;B = y1−y3
x1−x3; B = B− A; B = B/(x1− x2);
C = A+ Bh; Q = C2− 4y3B
Si Q < 0 entoncesQ = 0
h = −2y3/(C + sign(C)√
Q);Si |h| < ε entonces ir a 6x1 = x2; x2 = x3; x3 = x3+ h; y1 = y2; y2 = y3;Imprimir x3
4 Siguientek
5 Imprimir “ No hubo convergencia despues de”; M ; “ pasos.” yPARAR
6 Imprimir “ Solucion es:”; x3; “ .” y PARAR
Naturalmente serıa necesario modificar este algoritmo para que encon-trase ceros complejos no reales. Para ello serıa suficiente eliminar la lınea
2.4. El Metodo de Muller 71
Si Q < 0 entoncesQ = 0
siempre y cuando se pudiesen realizar los calculos en aritmetica de numeroscomplejos. Si se quieren buscar ceros complejos usando solamente aritmeticareal serıa necesario hacer mas modificaciones; principalmente en el calculodeh = −2y3/(C + sign(C)
√Q). Dejamos este trabajo al estudiante tra-
bajador.
En el siguiente ejercicio se busca un cero complejo de la funcion Cose-no Integral de Fresnel, cuyounico cero real es el obviox = 0.
Ejercicio 2.25Utilizar el metodo de Muller para hallar el cero no nulo de menor modulode la funcion Coseno Integral de Fresnel:
C(x) =∞∑
n=0
(−1)n(π2 )2n
(2n)!(4n+ 1)x4n+1.
(Sugerencias: EvaluarC truncando su serie de potencias en un valor den par (por ejemplo,en n = 2 con lo cualC(x) ' a0x + a1x5 + a2x9). Con ello se evitara la aparicion deun cero real espurio. Dividir porx para obviar la solucion x = 0. Evaluar cada coeficienteak en terminos deak−1 para mejorar la precision, y evaluar el polinomio resultante por elmetodo de las multiplicaciones encajadas. Comenzar las iteraciones conx1 = 1.6, x2 = 1.7,y x3 = 1.8, lo cual permitira obtener dos dıgitos de precision en cinco o seis iteraciones. Iraumentando progresivamente el numero de terminos de la serie (siempre truncando enn par)para ir aumentando la precision de la solucion.)

Capıtulo 3
Resolucion de Sistemas deEcuaciones Lineales
3.1 Metodos directos
La regla de Crameres un metodo teorico de resolucion directa de sistemasde ecuaciones lineales, sin embargo no lo consideramos como un metodonumerico por la complejidad de calculo que conlleva. Para un sistema deordenn la regla de Cramer requiere el calculo den+1 determinantes de or-denn, lo que significa realizar(n+1)!(n−1)multiplicaciones: un numerode operaciones excesivamente grande comparado con el requerido por losmetodos que vamos a estudiar.
3.1.1 Eliminacion de Gauss
El metodo de eliminacion de Gauss es el metodo mas sencillo de resolucionde sistemas de ecuaciones lineales. Launica diferencia entre este metodoy lo que suele hacer un estudiante principiante esta en que el metodo deGauss es una formaordenada y sistematicade realizar la eliminacion de lasincognitas, lo que da lugar a un algoritmo sencillo y eficaz, que se puedeprogramar. Este algoritmo puede aplicarse tanto a sistemas sobredetermi-nados como a sistemas incompletos, pero en lo que sigue supondremos que
73

74 3. Sistemas de Ecuaciones Lineales
el sistema dado es no-singular y tiene tantas ecuaciones como incognitas.El algoritmo consta de dos partes: (1) laeliminacion propiamente dicha,que consiste en reducir el sistema a uno triangular superior (cuya matrizde coeficientes tiene todo ceros debajo de la diagonal); y (2)sustitucionu obtencion de la solucion por el metodo llamado desustitucion regresi-va. Veamos a continuacion cada una de estas dos partes ilustradas con unejemplo.
Eliminaci on.–
Supongamos que queremos resolver el siguiente sistema de ecuaciones li-neales:
10x − 7y = 7
−3x + 2y+ 6z= 4 (3.1)
5x − y + 5z= 6
El primer paso del metodo de eliminacion de Gauss es eliminar la pri-mera incognita de todas las ecuaciones que siguen a la primera, para locual se les resta sucesivamente la primera ecuacion multiplicada por el fac-tor adecuado a cada una (llamadomultiplicador). Para ello, en este caso,restamos de la segunda ecuacion la primera multiplicada por elmultiplica-dor − 3
10 y restamos de la tercera ecuacion la primera multiplicada por elmultiplicador 5
10 con lo que el sistema se convierte en uno equivalente dela forma
10x − 7y = 7
− 0.1y+ 6z= 6.1
2.5 y+ 5z= 2.5
El siguiente paso y sucesivos consisten en repetir el primer paso pero apli-cado al subsistema formado por las ecuaciones que hayan sido modificadasen el paso anterior. Ası pues, en nuestro ejemplo el paso siguiente es elimi-nar el termino eny de la tercera ecuacion para lo que le restamos la segundamultiplicada por 2.5/(−0.1) = −25, de forma que nos queda
10x − 7y = 7
− 0.1y+ 6z= 6.1
155z= 155.
3.1. Metodos directos 75
El resultado final (al cabo den − 1 pasos en un sistema de ordenn) eshaber transformado el sistema original en otro equivalente pero triangularsuperior.
Ejercicio 3.1Describir un algoritmo que efectue el proceso de eliminacion que acabamosde describir para un sistema den ecuaciones lineales conn incognitas (deforma que lo transforme en uno equivalente pero triangular superior).
Sustitucion regresiva.–
Despues de haberlo reducido a forma triangular es inmediato encontrar lasolucion del sistema dado empezando por laultima ecuacion y procedien-do hacia atras. Laultima ecuacion es ahora una ecuacion lineal en unaincognita que se resuelve de forma inmediata. Llevando esta solucion a laecuacion anterior podremos hallar la incognita anterior, y ası sucesivamentehasta hallar todas las incognitas. En nuestro ejemplo,
z= 1 ;y = 6.1− 6z
−0.1= 6.1− 6
−0.1= −1 ;
x = 7+ 7y+ 0z
10= 7+ 7(−1)
10= 0 .
Esta resolucion en escalada hacia atras se conoce comosustitucion regresi-va.
Ejercicio 3.2Describir un algoritmo que efectue el proceso de sustitucion regresiva en unsistema den ecuaciones lineales conn incognitas supuesto dado en formatriangular superior.
Ejercicio 3.3Hallar el numero de operaciones (contando solo multiplicaciones y divi-siones) que es necesario realizar para resolver un sistema den ecuacioneslineales conn incognitas por el metodo de eliminacion de Gauss.

76 3. Sistemas de Ecuaciones Lineales
Dificultades que pueden surgir en la eliminacion.–
Veamos ahora dos tipos de dificultades que pueden surgir en la aplicaciondel metodo de eliminacion.
En primer lugar puede ocurrir que al comienzo de alguno de los pasosel coeficiente por el que tenemos que dividir los demas de su columna parahallar los multiplicadores de ese paso sea cero, con lo cual no podremoscontinuar la eliminacion. Por ejemplo, esto ocurre ya en el primer paso enel sistema
− 7y+ 10z= 7
6x + 2y− 3z = 4
5x − y + 5z = 6
sin embargo es evidente que, a menos que el sistema sea singular, no pue-den ser cero todos los coeficientes de la primera columna, con lo cual siem-pre podremos intercambiar la ecuacion cuyo primer coeficiente es cero conuna ecuacion posterior cuyo primer coeficiente no sea cero (intercambioque evidentemente no afecta en nada a la solucion). Este mecanismo de in-tercambio de ecuaciones en la busqueda de un coeficiente adecuado para serusado como divisor en el calculo de los multiplicadores de un cierto pasode eliminacion se llamapivotacion y el coeficiente encontrado (que pasaraa ocupar la posicion (1,1) del subsistema sobre el que vamos a trabajar enese paso) se llama elpivotede ese paso. Existen diversas estrategias pararealizar la pivotacion. La que acabamos de describir consiste en buscar elprimer coeficiente no nulo en la primera columna del subsistema, estrategiaconocida comopivotacion simple. Segun lo dicho,
Teorema 9 Todo sistema no singular den ecuaciones lineales conn incognitaspuede resolverse por el metodo de eliminacion de Gauss con pivotacionsimple.
Asimismo se conoce una caracterizacion de los sistemas que se puedenresolver por el metodo de eliminacion de Gauss sin necesidad de realizarpivotacion alguna. Esta propiedad, evidentemente, es simplemente una pro-piedad del orden en que decidimos tomar las ecuaciones del sistema duranteel proceso de eliminacion. Recordemos que losmenores principalesde unamatriz son las submatrices cuadradas que se obtienen al eliminar todas lasfilas y columnasa partir de la columnak y de la filak para un mismok fijo.
3.1. Metodos directos 77
Ası, el menor principal de ordenk de una matrizA = (ai j ) puede definirsecomo la matriz cuadrada cuyos elementos son todos losai j con 1≤ i ≤ ky 1≤ j ≤ k. Dicho esto podemos enunciar:
Teorema 10 Un sistema den ecuaciones lineales conn incognitas puederesolverse por el metodo de eliminacion de Gauss sin pivotacion alguna siy solo si en la matriz de coeficientes todos los menores principales son nosingulares.
Demostracion: Primeramente hay que observar que las operaciones ele-mentales realizadas sobre la matriz de coeficientes durante el proceso deeliminacion no cambian los valores de los determinantes de los menoresprincipales. Denotemosa(k)i j los elementos obtenidos al realizar el pasok − 1 de eliminacion. Si se puede realizar la eliminacion sin pivotacionentonces los elementos
a11, a(2)22 , a(3)33 , . . . ,a(n)nn
son todos distintos de cero. Ademas, para todor ∈ {1, . . . ,n} el menorprincipal de ordenr , Arr , tiene determinante dado por
det(Arr ) = a11 · a(2)22 · a(3)33 · · ·a(r )rr ,
luego todos los menores principales son no singulares.
Supongamos ahora que algun menor principal sea singular. Sear elmenor de losordenes de los menores principales que sean singulares. En-tonces podemos realizarr − 1 pasos de eliminacion sin pivotacion y loselementos
a11, a(2)22 , a(3)33 , . . . ,a(r−1)r−1r−1
son todos distintos de cero, pero el elementoa(r )rr obtenido en el pasor − 1sera necesariamente igual a cero y en consecuencia la eliminacion no puedeproseguir sin pivotacion.
Evidentemente la propiedad de un sistema de ecuaciones lineales men-cionada en este teorema (de poder ser resuelto por eliminacion sin pivota-cion) no es una propiedad del sistema como tal, sino que es una propiedaddel orden en que estan dadas las ecuaciones. En todo sistema no singularpueden reordenarse las ecuaciones de tal forma que el sistema tenga dichapropiedad.

78 3. Sistemas de Ecuaciones Lineales
La segunda dificultad que puede surjir durante la eliminacion es un pocomas sutil y es debida al hecho de que los calculos necesarios para obtenerla solucion se realicen en aritmetica de coma flotante con una precisionprefijada. Como consecuencia de esto puede ocurrir que al comienzo dealguno de los pasos el coeficiente por el que tenemos que dividir los demasde su columna para hallar los multiplicadores de ese paso, sin ser cero, sea,en valor absoluto, tan pequeno en relacion a los demas coeficientes queproduzca uno o varios multiplicadores con valor absoluto excesivamentegrande, resultando en graves errores de redondeo. Esto puede dar lugar auna solucion completamente inaceptable como en el siguiente ejemplo enque los coeficientes y terminos independientes estan dados con una preci-sion de cuatro dıgitos decimales y se usa aritmetica de coma flotante concuatro dıgitos:
0.0003x + 1.566 y = 1.569
0.3454x − 2.436 y = 1.018.
El primer (yunico) multiplicador es0.34540.0003= 1151, luego en el primer paso
de eliminacion obtenemos
0.0003x + 1.566 y = 1.569
− 1804y = −1805,
de donde
y = −1805/1804= 1.001
x = 1.569− 1.566× 1.001
0.0003= 3.333.
mientras que la solucion exacta esx = 10, y = 1.
Una sencilla solucion de esta dificultad, que simultaneamente resuel-ve la primera mencionada, consiste en incluir en la fase de eliminacion lallamadapivotacion parcial.
Pivotacion parcial.–
El metodo de pivotacion parcial consiste en elegir comopivote en cadapaso de la eliminacion el coeficiente de mayor valor absoluto de la primera
3.1. Metodos directos 79
columna del subsistema correspondiente a ese paso. Por ejemplo, en el casodel sistema
− 7y+ 10z= 7
6x + 2y− 3z = 4
5x − y + 5z = 6
en el primer paso queremos eliminar lax. La ecuacion que tiene el coefi-ciente dex con maximo valor absoluto es la segunda, luego el pivote eneste paso es 6 y comenzamos el primer paso intercambiando las ecuacionesprimera y segunda quedando el sistema en la forma:
6x + 2y− 3z = 4
− 7y+ 10z= 7
5x − y + 5z = 6
Con este metodo el calculo de los multiplicadores a utilizar en cada pasose realiza mediante una division por el divisor de mayor valor absoluto quees posible tener sin permutar las variables, lo que resuelve en gran medidalas dificultades mencionadas. Notese que el pivote necesariamente sera nonulo en cada paso si el sistema es no-singular. Este metodo nos ofrece,pues, un test de singularidad.
Algoritmo del metodo de eliminacion de Gauss con pivotacion parcial.–
Lo que hemos dicho hasta ahora queda reflejado en el siguiente pseudocodigo para resolver un sistema de ecuaciones lineales:
Suponemos dados: n, el orden del sistema,
A(i, j), la matriz de coeficientes y
B(i), la matriz de terminos independientes.
La solucion sera X(i).
********* BUCLE DE ELIMINACION *********
para k = 1 hasta n-1
********* BUSQUEDA DEL pivote *********
c = abs(A(k, k)); p = k
para i = k+1 hasta n
si abs(A(i, k)) > c entonces c = abs(A(i, k)) y p = i
siguiente i

80 3. Sistemas de Ecuaciones Lineales
si c = 0 entonces imprimir ‘SISTEMA SINGULAR’ y parar
********* INTERCAMBIO DE LA ECUACION k CON LA p *********
para j = k hasta n
t = A(p, j); A(p, j) = A(k, j); A(k, j) = t
siguiente j
t = B(p); B(p) = B(k); B(k) = t
********* PASO k DE LA ELIMINACION *********
para i = k+1 hasta n
m = A(i, k)/A(k, k); A(i, k) = 0
para j = k+1 hasta n
A(i, j) = A(i, j) - m*A(k, j)
siguiente j
B(i) = B(i) - m*B(k)
siguiente i
siguiente k
********* SUSTITUCION REGRESIVA *********
si A(n, n) = 0 entonces imprimir ‘SISTEMA SINGULAR’ y parar
X(n) = B(n)/A(n, n)
para k = n-1 hasta 1 incremento -1
s = 0
para j = k+1 hasta n
s = s + A(k, j)*X(j)
siguiente j
X(k) = (B(k) - s)/A(k, k)
siguiente k
3.1.2 La factorizacion triangular realizada por la elimi-nacion de Gauss
El proceso de transformacion a que se somete un sistema de ecuacionesal resolverlo por el metodo de eliminacion consiste en una serie deope-raciones elementalesrealizadas sobre las filas de la matriz de coeficientesampliada por la columna de terminos independientes.
Recordemos que el resultado de realizar una serie de operaciones ele-mentales sobre las filas de una matriz cualquiera es el mismo que si (1) re-alizamos dichas operaciones elementales sobre (las filas de) la matriz iden-tidad que tiene el mismo numero de filas que la dada y (2) multiplicamos lamatriz resultante (por la izquierda) por la matriz dada.
Por ejemplo, la eliminacion que hemos realizado en el sistema (3.1)
3.1. Metodos directos 81
consiste en las operaciones elementales:
1. Restar de la segunda fila la primera multiplicada por− 310,
2. Restar de la tercera fila la primera multiplicada por510,
3. Restar de la tercera fila la segunda multiplicada por−25.
Efectuando estas operaciones sobre la matriz identidad de orden 3estase convierte sucesivamente en
1 0 0310 1 0
0 0 1
,
1 0 0310 1 0
−510 0 1
,
1 0 0310 1 0
25×3−510 25 1
=
1 0 0310 1 0
7 25 1
.
Multiplicando ahora la matriz resultante por la matriz de coeficientesobtenemos 1 0 0
310 1 0
7 25 1
10 −7 0
− 3 2 6
5 −1 5
=10 −7 0
0 −0.1 6
0 0 155
que es la matriz de coeficientes del sistema reducido, es decir, del obteni-do tras la eliminacion. Analogamente, si multiplicamos por la matriz determinos independientes obtendremos los terminos independientes del sis-tema reducido: 1 0 0
310 1 0
7 25 1
7
4
6
= 7
6.1
155
La consecuencia mas importante de todo esto es que el proceso de eli-
minacion puede considerarse como la construccion de la matrizM quemultiplicada por la matriz de coeficientes,A, nos da una matriz triangu-lar superiorU
M · A = U.
La matrizU resultante es la matriz de los coeficientes del nuevo sistema deecuaciones yM es la matriz que se obtiene al aplicar las operaciones ele-mentales de eliminacion a la matriz identidad. Ası pues una forma sencillade obtener la matrizM es realizando el proceso de eliminacion sobre lamatriz de coeficientes ampliada con la matriz identidad (igual que hacemos

82 3. Sistemas de Ecuaciones Lineales
en el calculo de la matriz inversa). Cuando la matriz de coeficientes se hapuesto en forma triangular (A 7→ U ), la matriz identidad se ha convertidoen la matrizM (I 7→ M).
Una caracterıstica importante de la matrizM de las transformacioneselementales realizadas durante la eliminacion es que si, como ocurre en elejemplo, durante la eliminacion no ha habido ninguna pivotacion entoncesM es una matriz triangular inferior con unos en la diagonal. En este casosu inversa,L = M−1 nos proporciona la factorizacion triangular de lamatriz de coeficientes del sistema:A = LU . Ademas esta inversa,L,tiene la propiedad de ser tambien una matriz triangular inferior con unosen la diagonal pero que ademas sus elementos bajo la diagonal son losmultiplicadores utilizados en la eliminacion.
El proceso de eliminacion de Gauss nos proporciona, en caso de poderlorealizar sin pivotacion alguna como en nuestro ejemplo, la factorizaciontriangular (o factorizacion LU ) de una matriz sin mas que hallarL = M−1.En nuestro ejemplo,
A =
10 −7 0
− 3 2 6
5 −1 5
= 1 0 0
310 1 0
7 25 1
−110 −7 0
0 −0.1 6
0 0 155
es decir,
L =
1 0 0310 1 0
7 25 1
−1
, U =
10 −7 0
0 −0.1 6
0 0 155
.
Notese queL resultara ser (suponiendo que no ha habido pivotaciones) lainversa de una matriz triangular inferior con unos en la diagonal, lo quejustifica que ella misma es triangular inferior con unos en la diagonal.
Pero esto no es todo. El proceso de eliminacion de Gauss nos propor-ciona directamente la matrizL sin necesidad de calcular ninguna inversa.La razon de esto es queL es la inversa de un producto de matrices elementa-les y por tanto se puede obtener ella misma como resultado de operacioneselementales sobre las filas de la matriz identidad. Lounico que necesi-tamos es realizar las inversas de las operaciones elementales usadas en laeliminacion y en el orden inverso. Es decir, en nuestro ejemplo,
3.1. Metodos directos 83
1. Sumar a la tercera fila la segunda multiplicada por−25.
2. Sumar a la tercera fila la primera multiplicada por510,
3. Sumar a la segunda fila la primera multiplicada por− 310,
que efectuadas sucesivamente sobre la matriz identidad de orden 3 dan lu-gar a
1 0 0
0 1 0
0 −25 1
,
1 0 0
0 1 0510 −25 1
,
1 0 0−310 1 0510 −25 1
= L .
Ejercicio 3.4Comprobar que
1 0 0−310 1 0510 −25 1
= 1 0 0
310 1 0
7 25 1
−1
.
Ası pues, la factorizacion LU de nuestra matriz de coeficientes es:
10 −7 0
− 3 2 6
5 −1 5
=
1 0 0−310 1 0510 −25 1
10 −7 0
0 −0.1 6
0 0 155
.
Vemos que los elementos de la matrizL bajo la diagonal son precisa-mente los multiplicadores utilizados en la eliminacion. Esto es un resultadogeneral:
El proceso de eliminacion de Gauss (sin pivotacion) lleva a cabo unafactorizacion de la matriz de coeficientes en una matriz (L) triangular in-ferior con unos en la diagonal y una matriz (U ) triangular superior. Loselementos de la matrizL (bajo la diagonal) son los multiplicadores utiliza-dos durante la eliminacion mientras que los deU son los coeficientes delsistema reducido.

84 3. Sistemas de Ecuaciones Lineales
Efecto de la pivotacion.–
En lo que precede hemos supuesto explıcitamente que en el proceso deeliminacion no se realizaba ninguna reordenacion de filas, es decir, se re-alizaba sin pivotacion. ¿Como se altera lo dicho en el caso de realizar laeliminacion con algun tipo de pivotacion?
Para contestar a esta pregunta supongamos que llevamos a cabo un pro-ceso de eliminacion con pivotacion sobre un sistema de ecuaciones linea-les. Esto significa que algunas de las operaciones elementales realizadasdurante la eliminacion pueden ser intercambios de filas. Por ejemplo, ennuestro ejemplo pivotacion parcial darıa lugar a las siguientes operacioneselementales:
1. Restar de la segunda fila la primera multiplicada por− 310,
2. Restar de la tercera fila la primera multiplicada por510,
3. Intercambiar la segunda fila con la tercera,
4. Restar de la tercera fila la segunda multiplicada por(−1/25).
Ahora bien, el intercambio de filas (o pivotacion) realizado antes delpasok de la eliminacion puede realizarse inmediatamente antes de realizarel pasok − 1 sin afectar en nada al proceso (ya que es un intercambio dedos ecuacionesposterioresa lak − 1, que es la ecuacion pivote en el pasok − 1). Podemos luego, para cada ecuacion, calcular su multiplicador, quees independiente del orden que ocupa (aunque esto implica una “reordena-cion” de los multiplicadores, pero que se realiza automaticamente). Comoconsecuencia se tiene que todos los intercambios de ecuaciones necesariosen un proceso de eliminacion con pivotacion pueden realizarse juntos (perosin alterar su orden) antes de comenzar la eliminacion. En nuestro ejemplo,la eliminacion puede realizarse mediante los pasos (notese el intercambiode los dos primeros multiplicadores):
1. Intercambiar la segunda fila con la tercera,
2. Restar de la segunda fila la primera multiplicada por510,
3. Restar de la tercera fila la primera multiplicada por− 310,
4. Restar de la tercera fila la segunda multiplicada por(−1/25).
La consecuencia de lo que acabamos de decir es que la eliminacion deGauss con pivotacion es equivalente a la eliminacion sin pivotacion perorealizada despues de una reordenacion de las ecuaciones del sistema. Esta
3.1. Metodos directos 85
reordenacion puede realizarse sobre la matriz de coeficientes,A, (ası comosobre la matriz de terminos independientes,B), mediante la multiplicacion(por la izquierda) por una matriz de permutacion P que se ha obtenidosometiendo la matriz identidad a los sucesivos intercambios de filas que sehan de realizar sobreA. Ası pues, el proceso de eliminacion con pivotaciones equivalente a la transformacion de la matrizA en la forma
M P A= U
dondeP es una matriz de permutacion.
Como consecuencia de todo lo dicho tenemos:
Teorema 11 (Factorizacion triangular) Para toda matriz cuadrada no sin-gular A se puede hallar una permutacion P tal queP A admite una facto-rizacion triangular, es decir, de la forma
P A= LU
dondeL una matriz triangular inferior con unos en la diagonal yU unamatriz triangular superior. Las matricesL y U estan completamente de-terminadas porA y P. Ademas, se podra elegir P = 1 (matriz identidad)si y solo si todos los menores principales deA son no singulares.
Ademas sabemos como encontrarP ası como los elementos deL y Umediante el proceso de eliminacion de Gauss con pivotacion parcial,
Ejercicio 3.5Adaptar el algoritmo de eliminacion de Gauss con pivotacion parcial paraconvertirlo en un algoritmo que efectue la factorizacion triangular de unamatriz no singular dada, es decir, que a partir de una matrizA encuentre lasmatricesP, L, y U del teorema anterior.
Uso de la factorizacion triangular en la resolucion de sistemas de ecua-ciones lineales.–
El mayor interes de obtener la factorizacion triangular mencionada masarriba esta en el hecho de que permite resolver cualquier sistema de ecua-ciones lineales con la misma matriz de coeficientesA mediante una susti-tucion progresiva seguida de una sustitucion regresiva. Esto es: del sistema

86 3. Sistemas de Ecuaciones Lineales
Ax = b pasamos aP Ax = Pb, o sea,LU x = b′. Esto significa que sihemos realizado la eliminacion enA obteniendoP, L y U , la resolucion deun sistemaAx = b se reduce a estos pasos:
1. Obtener el vectorb′ = Pb.
2. ResolverLy = b′ mediante una sustitucion progresiva.
3. ResolverU x = y mediante una sustitucion regresiva.
Esto es especialmenteutil cuando necesitamos resolver varios sistemasde ecuaciones que tienen la misma matriz de coeficientes.
Segun se ha visto, al resolver un sistema de ecuaciones lineales me-diante el proceso de eliminacion de Gauss con pivotacion parcial se lleva acabo en realidad una factorizacion triangularP A = LU de una permuta-cion de la matriz de coeficientes ası como una sustitucion progresiva y unasustitucion regresiva. En la parte de factorizacion no interviene la columnade terminos independientes, sino solamente la matriz de coeficientes. Estoabre la posibilidad de separar las dos partes del proceso, de forma que sinecesitamos resolver varios sistemas de ecuaciones lineales en los que solodifieren los terminos independientes, solo tengamos que realizar la parte defactorizacion una vez. Puesto que esa parte es la mas costosa (en terminosdel numero de operaciones a realizar), esta estrategia redundara en una ma-yor eficacia del metodo.
Una de las aplicaciones de este metodo es el calculo de la matriz in-versa. Este calculo es claramente equivalente a la resolucion den sistemasde ecuaciones lineales todos ellos con la matriz dada como matriz de coefi-cientes y teniendo como columnas de terminos independientes las columnasde la matriz identidad. Es interesante observar que el calculo de la matrizinversa de una matrizA de ordenn por este metodo requiere realizar elmismo numero de operaciones que el calculo deA2.
Otra aplicacion de este metodo es el algoritmo de la mejora iterativa delas soluciones aproximadas que explicamos mas adelante (pagina 90).
3.1.3 Metodo de Gauss-Jordan
Si en cada paso del proceso de eliminacion
(ecuacion i ) = (ecuacion i )−mi × (ecuacionk) i = k+ 1, . . .n
3.1. Metodos directos 87
aplicamos la eliminacion no solo a las ecuaciones siguientes a la ecuacionk, sino tambien a las ecuaciones anteriores entonces estaremos convirtiendonuestro sistema en uno diagonal, no solo triangular. Es decir si en el pasok realizamos
(ecuacion i ) = (ecuacion i )−mi × (ecuacionk)
parai = 1, . . . , k − 1, k + 1, . . .n, nuestro sistema queda convertido enuno den ecuaciones con una incognita, para cuya solucion no es necesarioel proceso de sustitucion regresiva. Solamente necesitaremosn divisionesadicionales. Este metodo se conoce con el nombre demetodo de Gauss-Jordan
Ejercicio 3.6Hallar el numero de operaciones (contando solo multiplicaciones y divi-siones) que es necesario realizar para resolver un sistema den ecuacioneslineales conn incognitas por el metodo de eliminacion de Gauss-Jordan.
3.1.4 Otras tecnicas de pivotacion
Una tecnica de pivotacion es un criterio para la eleccion de la fila o ecua-cion pivoteen cada paso del proceso de eliminacion. Hasta ahora hemosencontrado dos tecnicas de pivotacion: pivotacion simple y pivotacion par-cial, pero existen muchas otras posibilidades. Lo ideal serıa descubrir unatecnica sencilla de pivotacion que nos asegurase que hacemos las operacio-nes en el ordenoptimo en el sentido de que se minimizan tanto la perdidade precision como los errores de redondeo. En ausencia de esa tecnica idealhemos de guiarnos por la experiencia y por consideraciones generales talescomo la citada mas arriba. Veremos a continuacion dos tecnicas adicionalesque suelen dar resultados adecuados.
Pivotacion parcial escalada.–
Para algunos sistemas podemos obtener algun aumento en la precision si alelegir la fila pivote tenemos en cuenta de alguna manera no tanto el tamanodel elemento pivote como su tamano relativo a los demas elementos de sufila. De esta forma el proceso no quedarıa afectado si se re-escala algunade las ecuaciones del sistema, es decir, si se multiplica por un numero todauna ecuacion (lo cual, en principio no deberıa afectar a la solucion).

88 3. Sistemas de Ecuaciones Lineales
Ası pues, realizaremos unapivotacion parcial escaladacuando en cadapaso de la eliminacion elijamos como pivote aquel candidato cuyo cocientepor el tamano de su fila sea maximo. Por “tamano” de una fila se puede en-tender alguna norma vectorial conveniente tal como la norma del maximo,la cual se calcula con poco esfuerzo.
Para realizar la pivotacion parcial escalada de forma eficaz calculare-mos los tamanos de todas las filas antes de comenzar el primer paso de laeliminacion,
di = max1≤ j≤n
|ai j |
Despues, al comienzo del pasok parak = 1, . . . ,n− 1, si los posibles pi-votes sonakk, . . . ,ank, elegimos como pivote aquel para el que el cociente|aik |/di sea maximo.
Ejercicio 3.7Modificar el algoritmo de eliminacion de Gauss para que realice pivotacionparcial escalada en lugar de mera pivotacion parcial.
Pivotacion total.–
La tecnica de pivotacion total es considerada como la que da mejores re-sultados en general, aunque su uso es bastante limitado debido al costeadicional de programacion que supone. Esta tecnica es una variante de lapivotacion parcial en la que no solo se barajan las ecuaciones restantes enla busqueda del pivote sino que en cada paso se busca la incognita masadecuada a eliminar en ese paso. Ası, no solo nos permitimos permutar lasecuaciones, sino que tambien nos permitimos permutar las incognitas.
Al comienzo del pasok se elegira como pivote aquel elemento de ma-yor valor absoluto en la submatriz de coeficientes con que se trabajara enese paso. En consecuencia un algoritmo que lleve a cabo pivotacion totalrealizara en cada paso tanto una permutacion de filas (o ecuaciones) comouna permutacion de columnas (o variables).
3.2. Analisis de errores y Condicion 89
3.2 Analisis de errores y Condicion de un siste-ma de ecuaciones lineales
3.2.1 Introduccion: Distintas medidas del error
En la practica del calculo cientıfico raramente se conocen con exactitud loscoeficientes y terminos independientes del sistema de ecuaciones linealesque se quiere resolver. En general, esos coeficientes se calculan a partir deobservaciones experimentales sujetas como mınimo a errores que vienende la limitada precision de los aparatos de medida. En consecuencia seplantea la cuestion de laconfianzaque podemos tener en los resultados denuestros calculos sabiendo que los propios datos estan sujetos a error. Enotras palabras, nos preguntamos en que medida nuestros calculos puedenhaber amplificado el error inherente a los datos y sieste se habra mantenidodentro de lımites razonables.
Normalmente la confianza que podemos tener en la solucion dependeradel sistema de que se trate: distintas matrices de coeficientes daran lugara distintos comportamientos respecto a la propagacion y amplificacion deerrores. Nuestro objetivo es poder determinar a priori el tipo de comporta-miento que una matriz dada va a tener. Para ello comenzaremos repasandovarias formas de medir la exactitud o precision de una solucion aproximada,x, de un sistema de ecuaciones linealesAx = b.
La primera forma es mediante elerror absoluto o diferenciae= x− xentre la solucion exacta y la solucion aproximada. Obviamente esto esnormalmente desconocido. Otra forma de medir la exactitud dex comosolucion de Ax = b es mediante elerror residual , que mide cuan lejosesta x de satisfacer el sistema de ecuaciones lineales. El error residual dexes
r = Ax− Ax = Ae,
lo cual puede calcularse sin dificultad, pues es igual a la diferenciab− Axentre el vector de terminos independientes dado y el calculado a partir de lasolucion aproximada.
En general el error residual no sera el vector cero, aunque podemosesperar que su tamano sea pequeno. Al hablar del “tamano” de vectoresen Rn nos referimos a una norma particular fija que suponemos elegidade antemano. Que norma se use no tiene demasiada importancia mientrasuno se atenga a usar siempre esa norma. Una norma muy en uso es la

90 3. Sistemas de Ecuaciones Lineales
“norma infinito” o del maximo ya que se calcula con muy poco esfuerzo(no requiere operaciones aritmeticas). En general se puede suponer que lanorma usada es una “normap”, para algun realp ≥ 1, definida por
‖x‖p =(|x1|p + · · · + |xn|p
)1/p.
De estas la norma del maximo es el caso lımite parap → ∞. Los casosmas utilizados sonp = 1,2,∞.
El tamano del error residual esta relacionado con el tamano del error ab-soluto. Al multiplicar la matrizA por un vector columnau la norma deestepuede variar mucho, pero hay que observar, sin embargo, que el cambiore-lativo o factor por el que ha cambiado la norma (el cociente‖Au‖/‖u‖) nopuede ser arbitrario. Necesariamente permanecera dentro de ciertos lımitesque dependen de la matrizA. Concretamente‖Au‖/‖u‖ sera necesaria-mente menor o igual que elmaximo factorpor el queA multiplica las nor-mas de los vectores. Veremos a continuacion que debido a esto elerrorresidual relativo ‖b− Ax‖
‖b‖ = ‖r ‖‖b‖ =‖Ae‖‖Ax‖
es un buen indicador, no del errore, sino delerror relativo
‖x − x‖‖x‖ = ‖e‖‖x‖ .
(ver formula (3.3)).
3.2.2 Mejora iterativa
Algunos ordenadores y lenguajes de programacion admiten realizar aritme-tica de coma flotante en dos modos distintos de precision: sencilla y doble,de los que el segundo modo cuesta aproximadamente el doble de tiempo-maquina que el primero pero permite reducir los errores (especialmentelos de perdida de precision) al realizar las operaciones con aritmetica decoma flotante con el doble de dıgitos de precision que en el modo de pre-cision sencilla. Cuando se dispone de esta posibilidad se puede reducirnotablemente el error en la solucion de sistemas de ecuaciones lineales sinun coste excesivo (como el que implicarıa el realizar todos los calculos condoble precision). La tecnica que permite realizar esta reduccion de error seconoce comomejora iterativay consiste en lo siguiente:
3.2. Analisis de errores y Condicion 91
Supongamos que hemos utilizado el metodo de la factorizacion trian-gular (con precision sencilla) para hallar la solucion de un sistema de ecua-ciones linealesAx = b tal como0.20000 0.16667 0.14286
0.16667 0.14286 0.125000.14286 0.12500 0.11111
xyz
=0.50953
0.434530.37897
.O sea, suponemos que ya hemos obtenido una factorizacion A = PLU dela matriz de coeficientes, que en nuestro ejemplo es
L = 1 0 0
0.83335 1 00.71430 0.89673 1
, U =0.20000 0.16667 0.14286
0 0.00397 0.005950 0 0.00015
,sin realizar permutaciones, o sea queP es la identidad, y hemos obtenidola solucion
x(1) =x
yz
= 1.0384
0.896731.0667
,realizando las operaciones con aritmetica de coma flotante con precision decinco dıgitos. Este resultado puede mejorarse de la siguiente forma:
Primeramente calculamos el error residualr (1) = b − Ax(1) utilizan-do aritmetica de doble precision. Esto significa realizar para cadai ∈{1, . . . ,n} las siguientes(n − 1) multiplicaciones yn sumas con dobleprecision:
r (1)i = b−n∑
k=1
aik x(1)k ,
lo que en nuestro ejemplo da
Ax(1) =0.5095324653
0.43451905930.3789619207
y r (1) =−0.24653
1.09410.80793
10−5
Obtenida esta aproximacion del vector de error residual la utilizamospara calcular una estimacion e(1) del error absolutoe resolviendo la ecua-cion Ae= r . Esta ecuacion representa un sistema de ecuaciones linealesque solo se diferencia del dado en los terminos independientes. En con-secuencia, como ya disponemos de la factorizacion de la matriz de coefi-cientes la nueva resolucion tendra un coste mucho menor ya que se reduce

92 3. Sistemas de Ecuaciones Lineales
a una sustitucion progresiva y una sustitucion regresiva como las que nosllevaron deb a x(1), pero esta vez utilizandor (1) en lugar deb como vectorde terminos independientes. De esta forma obtenemos el vectore(1), quesumado ax(1) resultara en la mejora
x(2) = x(1) + e(1) .
En nuestro ejemplo obtenemos
e(1) =−0.03709
0.09955−0.06424
y x(2) = x(1) + e(1) = 1.0014
0.996281.0024
Repitiendo este proceso hallarıamos el restor (2) asociado conx(2) utili-
zando doble precision, despues hallarıamos el ‘error’e(2) mediante la reso-lucion deAe(2) = r (2) y obtendrıamos una nueva mejorax(3) = x(2)+e(2),que en nuestro ejemplo es
x(3) = 1.0001
0.999861.0001
.Continuando de este modo se obtiene una sucesion de vectores
{x(1), x(2), . . . }
que son sucesivas mejoras que bajo hipotesis bastante razonables conver-geran a la solucion exactax (en el ejemplo la solucion exacta es
x =1
11
como se comprueba facilmente).
Resumiendo, tenemos el siguiente algoritmo para la mejora iterativa dela solucion de un sistema de ecuaciones lineales:
Algoritmo de la Mejora Iterativa
1 Factorizacion triangularA = PLU.
3.2. Analisis de errores y Condicion 93
2 Utilizar dos sustituciones a partir deP, L , U y b para obtenerx.
3 Con doble precision calcular el resto dex, r = b− Ax.
4 Utilizar dos sustituciones a partir deP, L , U y r para obtenere.
5 Sumare al viejo x para obtener el nuevox.
6 Ir al paso3.
La unica condicion que se ha de cumplir para poder garantizar que estealgoritmo converge a la solucion exacta es que el proceso de resolucion (unasustitucion progresiva y una regresiva basadas en la factorizacion PLU dela matriz de coeficientes) sea equivalente a aplicar una matrizC “suficiente-mente cercana” a la inversa de la matriz de coeficientes, como se demuestraen el siguiente teorema:
Teorema 12 (Convergencia del metodo de mejora iterativa) Seax(1) unvector cualquiera y seaC una matriz cercana a la inversa deA en el sen-tido de que
‖I − C A‖ < 1 .
Entonces la sucesion de vectores{x(n)} definida inductivamente por
x(n+1) = x(n) + C(b− Ax(n))
converge a la solucion x del sistema de ecuaciones linealesAx = b.
Demostracion: Basta demostrar que limn→∞‖x
(n) − x‖ = 0. Ahora bien,
‖x(n) − x‖ = ‖x(n−1) + C(b− Ax(n−1))− x‖= ‖x(n−1) − x + C(Ax− Ax(n−1))‖= ‖x(n−1) − x − C A(x(n−1) − x)‖= ‖(I − C A)(x(n−1) − x)‖ ≤ ‖I − C A‖ · ‖x(n−1) − x‖
y continuando ası se llega a
‖x(n) − x‖ ≤ ‖I − C A‖n−1 · ‖x(1) − x‖de donde
0≤ limn→∞‖x
(n)− x‖ ≤ ‖x(1)− x‖ limn→∞‖I −C A‖n−1 = ‖x(1)− x‖ ·0= 0
ya que por ser‖I − C A‖ < 1, obviamente limn→∞ ‖I − C A‖n−1 = 0.

94 3. Sistemas de Ecuaciones Lineales
Detencion del algoritmo.–
Para implementar cualquier algoritmo iterativo es necesario establecer uncriterio de detencion, es decir, establecer una norma a seguir para deter-minar en que paso conviene detener los calculos. Un posible criterio (enocasiones elunico) es realizar un numero fijo de pasos determinado a prio-ri. Por supuesto el criterio mejor serıa poder decidir cual es el error absolutoque estamos dispuestos a aceptar y detener el algoritmo justo cuando se al-cance un error inferior al que vamos a aceptar. Esto se complica por elhecho de que el error absoluto es desconocido, sin embargo en el algoritmode la mejora iterativa que acabamos de estudiar el error absoluto puede seracotado en terminos de las sucesivascorreccionescomo indica el siguienteresultado,
Ejercicio 3.8En el proceso de mejora iterativa definido por
x(n+1) = x(n) + C(b− Ax(n))
el tamano del errorx(n) − x se puede acotar en cada paso por el siguientemultiplo de la correccion x(n+1) − x(n) a realizar en ese paso:
‖x(n) − x‖ ≤ ‖(C A)−1‖‖x(n+1) − x(n)‖ .
Como la matrizC A (y por tanto tambien(C A)−1) es cercana a la identi-dad, el factorα = ‖(C A)−1‖ sera cercano a la unidad, por lo que podemosutilizar como criterio de detencion el tamano de las sucesivas correccio-nes‖x(n+1) − x(n)‖, es decir, detener el algoritmo cuando la correccionrealizada tenga un tamano menor que el error maximo admisible.
3.2.3 Normas de matrices
El maximo factor por el queA multiplica las normas de los vectores sellama lanorma de la matrizA (relativa a la norma vectorial empleada). Esdecir, definimos la norma de la matrizA como
‖A‖ = maxx 6=0
‖Ax‖‖x‖ (3.2)
3.2. Analisis de errores y Condicion 95
y en consecuencia se verifica evidentemente para todou 6= 0,
‖Au‖‖u‖ ≤ ‖A‖,
y por lo tanto, suponiendo queA es no-singular, tambien
‖v‖‖Av‖ ≤ ‖A
−1‖,
para todov 6= 0.
Ejercicio 3.9Multiplicando esas dos desigualdades deducir que para cualquier matrizcuadrada no-singularA y cualesquiera dos vectores no nulosu, v se verifica
‖Au‖‖u‖ ≤ ‖A‖‖A
−1‖ · ‖Av‖‖v‖ .
Concluir que el numero‖A‖ · ‖A−1‖ es siempre mayor o igual que1.
La primera consecuencia de nuestra definicion de norma de una ma-triz es la siguiente acotacion del tamano del error absoluto en terminos deltamano del error residual:
‖r ‖‖A‖ ≤ ‖e‖ ≤ ‖A
−1‖‖r ‖ .
Ejercicio 3.10Del resultado del ejercicio A.11 se deduce que siA es una matriz cuadradano-singular cualquiera se verifica
1
‖A‖‖A−1‖ ·‖Av‖‖Au‖ ≤
‖v‖‖u‖ ≤ ‖A‖‖A
−1‖ · ‖Av‖‖Au‖para cualesquiera vectores no nulosu, v.
Ejercicio 3.11Demostrar que la definicion (3.2) de norma de una matriz es equivalente a
‖A‖ = max‖x‖=1
‖Ax‖,
y tambien a la conjuncion de(∀x‖Ax‖ ≤ ‖A‖‖x‖) y ∃x 6= 0 | ‖Ax‖ ≥ ‖A‖‖x‖.

96 3. Sistemas de Ecuaciones Lineales
Ejercicio 3.12Demostrar que el concepto de norma de matrices definido antes satisfacelos axiomas usuales de normas y dos axiomas adicionales: (1) Para todamatriz identidad,I , ‖I ‖ = 1, y (2) Si A y B son matrices cuadradas delmismo orden,‖AB‖ ≤ ‖A‖ · ‖B‖. Usar estas dos propiedades para probarque siA es inversible,‖A‖‖A−1‖ ≥ 1.
Calculo de algunas normas de matrices.–
El calculo de la norma de una matriz asociada a una norma vectorial dadapuede llegar a ser bastante engorroso. Un caso especial por su sencillez noslo da la norma del maximo o “norma infinito”. Observese que para todox,
‖Ax‖∞ = max1≤i≤n
∣∣∣ n∑j=1
ai j x j
∣∣∣ ≤ max1≤i≤n
n∑j=1
|ai j ||xj |
≤ max1≤i≤n
((max
1≤ j≤n|xj |
) n∑j=1
|ai j |)= ‖x‖∞ max
1≤i≤n
n∑j=1
|ai j |
lo cual demuestra que‖A‖∞ ≤ max1≤i≤n∑n
j=1 |ai j |. Por otro lado esfacil dar un vectorx tal que‖Ax‖∞ ≥ ‖x‖∞max1≤i≤n
∑nj=1 |ai j |. Para
ello seai0 la fila deA para la que la suma∑n
j=1 |ai j | es maxima, es decir,tal que
n∑j=1
|ai0 j | = max1≤i≤n
n∑j=1
|ai j |
Eligiendox de forma quexj = signo(ai0 j ), tendremos (suponiendoA 6= 0)‖x‖∞ = 1 y
‖Ax‖∞ = max1≤i≤n
∣∣∣ n∑j=1
ai j x j
∣∣∣ ≥ ∣∣∣ n∑j=1
ai0 j x j
∣∣∣=
n∑j=1
|ai0 j | = ‖x‖∞ max1≤i≤n
n∑j=1
|ai j |
En conclusion tenemos que para toda matriz cuadradaA = (ai j ),
‖A‖∞ = max1≤i≤n
n∑j=1
|ai j | .
3.2. Analisis de errores y Condicion 97
Por ejemplo, en el sistema de ecuaciones
0.0003x + 1.566 y = 1.569
0.3454x − 2.436 y = 1.018.
la matriz de coeficientes
A =(
0.0003 1.5660.3454 −2.436
)tiene norma-infinito
‖A‖∞ = max{|0.0003| + |1.566| , |0.3454| + | − 2.436|} = 2.781.
Al extremo opuesto de la norma infinito esta la norma uno que, curio-samente, su calculo cuesta lo mismo que el de la norma infinito ya que
Ejercicio 3.13Para toda matriz cuadradaA, su norma-uno es igual a la norma-infinito desu traspuesta
‖A‖1 = ‖At‖∞ ,
es decir,‖A‖1 = max1≤ j≤n
n∑i=1
|ai j |.
3.2.4 Condicion de una matriz y acotacion de errores
Acotacion del error relativo.–
Volviendo a nuestro sistema de ecuaciones linealesAx = b y a los erroresabsoluto,e= x − x, y residual,r = b− Ax = Ae, podemos interpretar elresultado del ejercicio 3.10 como estableciendo la siguiente acotacion delerror relativo‖e‖/‖x‖ en terminos del error residual relativo‖r ‖/‖b‖ y delnumeroc(A) = ‖A‖ · ‖A−1‖,
1
c(A)· ‖r ‖‖b‖ ≤
‖e‖‖x‖ ≤ c(A) · ‖r ‖‖b‖ . (3.3)
Este numeroc(A) = ‖A‖‖A−1‖,

98 3. Sistemas de Ecuaciones Lineales
que podemos asociar con cada matriz no singularA una vez elegida unanorma, se llamacondicion de la matrizA (relativo a la norma elegida).Segun laultima parte del ejercicio A.11 la condicion de una matriz verifica
c(A) ≥ 1.
Por ejemplo, para la matriz del ejemplo anterior, con precision de cuatrodıgitos,
A−1 = 1
detA
( −2.436 −1.566−0.3454 0.0003
)=(
4.498 2.8910.6377 −5.539× 10−4
)y por tanto
‖A−1‖∞ = max{|4.498| + |2.891| , |0.6377| + | − 0.0006|}= 7.389,
de donde obtenemos
c∞(A) = ‖A‖∞‖A−1‖∞ = 2.781× 7.389= 20.55
indicando un pobre condicionamiento de la matriz en cuestion.
Condicion en terminos de operadores lineales.–
Hay que acentuar el hecho de que la condicion de una matriz esta definidasolamente si se ha especificado una norma vectorial, aunque algunas ma-trices (como por ejemplo las que son un multiplo de la identidad) tienenla misma condicion relativa a cualquier norma. En realidad el concepto decondicion que acabamos de definir pertenece, rigurosamente hablando, alos operadores lineales en espacios normados. Cuando se habla de normade una matriz se esta identificando esa matriz con el operador lineal enRn
que la tiene por matriz en la base canonica. El siguiente ejercicio nos in-dica el significado geometrico de la condicion de un operador lineal en unespacio normado: es una medida de la distorsion que el operador produceen las bolas.
Ejercicio 3.14La condicion de un operador lineal en un espacio normado es igual al co-ciente del radio maximo al radio mınimo de la imagen de la bola unitaria.
3.2. Analisis de errores y Condicion 99
Ejercicio 3.15La condicion de una matrizA es igual a1 si y solo si (el operador linealrepresentado por)A conserva las bolas, lo cual es decir que multiplica lasnormas de todos los vectores por el mismo factor.
Dado que la condicion de una matriz depende de la norma vectorialcon que se calcula, se plantea la cuestion de si un sistema de ecuacioneslineales puede parecer bien condicionado en terminos de una norma y malcondicionado en terminos de otra distinta. Como respuesta parcial a estacuestion tenemos:
Ejercicio 3.16Si A es una matriz cuadrada real no singular que esta bien condicionadarespecto a unap-norma entonces tambien estara bien condicionada respec-to a cualquier otrap-norma. Ademas, si la condicion deA es igual a1 enrelacion a unap-norma parap 6= 2 entonces la condicion deA tambien esigual a1 en relacion a cualquier otrap-norma. (Demuestrese en el caso dematrices de orden2.)
Errores en los terminos independientes.–
La condicion de una matrizA nos sirve para estimar, mediante las des-igualdades (3.3) el error relativo de una solucion aproximada de cualquiersistema de ecuaciones lineales cuya matriz de coeficientes seaA. Peroademas la condicion deA es un indicador de la sensibilidad de la solucionde dicho sistema de ecuaciones lineales a errores en el vector de terminosindependientes ya que las desigualdades (3.3) pueden interpretarse tambiende la siguiente forma: Supongamos que existe un error1b en el vectorbde terminos independientes lo cual produce un error1x en la solucion, esdecir, tenemosA(x + 1x) = b + 1b dondex es la solucion exacta deAx = b. EntoncesA1x = 1b, e= 1x y resultar = Ae= 1b en (3.3),y tenemos la siguiente acotacion del error relativo resultante de los erroresen los terminos independientes:
1
c(A)· ‖1b‖‖b‖ ≤
‖1x‖‖x‖ ≤ c(A) · ‖1b‖
‖b‖ .
Ası pues, el condicionamiento de un sistema de ecuaciones lineales estaindicado por la condicion de la matriz de coeficientes. Si este numero escercano a la unidad el sistema esta bien condicionado porque pequenos

100 3. Sistemas de Ecuaciones Lineales
errores (relativos) en los datos (terminos independientes) no pueden darlugar a grandes errores (relativos) en la solucion.
Errores en los coeficientes del sistema.–
Nos interesa tambien estudiar el efecto que tienen los errores que puedahaber en los coeficientes del sistema.
Supongamos primeramente queA y B son dos matrices de las queAes inversible y queu, v son dos vectores tales queAu = Bv. Entoncesu = A−1Bv y por tanto
‖u‖ = ‖A−1Bv‖ ≤ ‖A−1‖‖Bv‖ ≤ ‖A−1‖‖B‖‖v‖de donde deducimos, suponiendov 6= 0,
‖B‖‖v‖‖u‖ ≥1
‖A−1‖ o bien‖u‖‖v‖ ≤ c(A)
‖B‖‖A‖ . (3.4)
Esta acotacion puede aplicarse al caso de un sistema de ecuaciones li-neales en el que los coeficientes se conozcan solo aproximadamente como,por ejemplo, cuando se han obtenido como resultado de medidas experi-mentales. Tal situacion es la de un sistemaAx = b del que en lugar de lamatriz A solo disponemos de la matrizA = A+ E dondeE es una matrizde error. Si resolvemos exactamente el sistemaAx = b, ¿Cual sera el errorrelativo en que hemos incurrido?
Nuestra situacion es la de tenerAx = b = Ax = (A−E)x = Ax−Ex,de dondeA(x− x) = Ex y por tanto la acotacion que acabamos de ver nosproporciona una acotacion del error relativo en terminos de algo que esaproximadamente el error relativo de los coeficientes,
‖x − x‖‖x‖ ≤ c(A)
‖E‖‖A‖ .
Alternativamente podemos poner(A+ E)x = Ax para escribirA(x −x) = Ex de donde el error relativo en los coeficientes nos da una acota-cion de una cantidad que es aproximadamente igual al error relativo en lasolucion,
‖x − x‖‖x‖ ≤ c(A)
‖E‖‖A‖ .
3.2. Analisis de errores y Condicion 101
3.2.5 Estimacion de la condicion de una matriz
El calculo de la condicion de una matrizA tiene la dificultad de requerircalcular la matriz inversa,A−1, lo cual es, en general, demasiado costoso.Resulta, pues, importante encontrar metodos de estimacion o acotacion dela condicion. Uno de tales metodos se basa en el siguiente teorema que sededuce facilmente de (3.4),
Teorema 13 Si A es una matriz inversible entonces para cualquier matrizsingular E se verifica
‖A+ E‖ ≥ 1
‖A−1‖ y por tanto c(A) ≥ ‖A‖‖A+ E‖ .
Demostracion: Por serE singular existe un vector no nulox tal queEx =0. Entonces para este vector,(A+ E)x = Ax y la conclusion se deduce de(3.4) conB = A+ E y u = v = x.
Ejercicio 3.17Usar el resultado de este teorema para demostrar que toda matriz condia-gonal estrictamente dominantees inversible, es decir, no singular.
Corolario 5 (Condicion de matrices triangulares) Si A = (ai j ) es unamatriz triangular inversible entonces para cualquier elementoaii de sudiagonal se verifica
c∞(A) ≥ ‖A‖∞|aii | ,
en particular,
c∞(A) ≥ ‖A‖∞min
1≤i≤n|aii | .
Demostracion: SeaE la matriz que resulta al sustituir el elementoaj j de Apor cero. EntoncesE es obviamente singular y por tanto
c∞(A) ≥ ‖A‖∞‖A− E‖∞ =
‖A‖∞|aj j | .
Ejercicio 3.18Demostrar que las conclusiones de este corolario siguen siendo ciertas sise sustituye la norma infinito por la norma uno, obteniendose una formula

102 3. Sistemas de Ecuaciones Lineales
de acotacion de la condicion, relativa a la norma uno, de cualquier matriztriangular.
Corolario 6 (Estimacion de la condicion de cualquier matriz) Si A = (ai j )
es una matriz inversible de ordenn entonces para cualquierj ∈ {1, . . . ,n}se verifica
c∞(A) ≥ ‖A‖∞max
1≤i≤n|ai j |
y en particular,
c∞(A) ≥ ‖A‖∞min
1≤ j≤n
(max
1≤i≤n|ai j |
) .Demostracion: SeaE la matriz obtenida al sustituir todos los elementosde la columnaj de la matrizA por cero. ObviamenteE es una matrizsingular y la matrizA− E es una matriz todos cuyos elementos son ceroexcepto que la columnaj es igual a la columnaj de A. Por tanto tenemos‖A− E‖∞ = max
1≤i≤n|ai j |. En consecuencia, segun el teorema 13,
c∞(A) ≥ ‖A‖∞max
1≤i≤n|ai j | .
Ejercicio 3.19Establecer, por analogıa con el resultado anterior, una formula de acotacionde la condicion de cualquier matriz relativa a la norma uno.
3.2.6 Condicion de las matrices ortogonales y sus multiplos
Las matrices ortogonales tienen condicion optima para la norma euclıdeaya que conservan esta norma y por tanto conservan sus bolas, lo cual, segunel ejercicio 3.15, implica que el numero de condicion es 1. Pero asimismo,cualquier multiplo de una matriz ortogonal conservara las bolas de la normaeuclıdea por lo que tambien tendra condicion 1 en esa norma.
3.3. Metodos iterativos 103
3.3 Metodos iterativos
Los sistemas de ecuaciones lineales que surgen de ciertos problemas (prin-cipalmente en la resolucion de ecuaciones diferenciales por metodos dediferencias finitas) tienen la caracterıstica de ser deordenes excesivamenteelevados para su tratamiento por metodos directos de resolucion, los cualesexigirıan la utilizacion de gran cantidad de memoria para almacenar todoslos elementos de la matriz de los coeficientes del sistema. Por otro lado loscoeficientes de tales sistemas suelen venir dados por una formula sencilla,de forma que pueden ser generados cuando se necesiten. Estoultimo ocurretambien con las matricesescasasen las que una gran mayorıa de elementosson cero. Tales sistemas suelen cumplir las condiciones de convergencia demetodos iterativos como los utilizados en la determinacion del punto fijode un operador (vease (19)), metodos que se pueden aplicar sin necesidadde tener todos los coeficientes del sistema almacenados. Ası pues, para laresolucion de algunos sistemas de ecuaciones lineales resultan mas conve-nientes los metodos iterativos como los que estudiamos a continuacion.
3.3.1 Ejemplo introductorio del metodo iterativo
Supongamos que nos dan el sistema de ecuaciones lineales
10x + 2y− 3z = 5
2x + 8y+ z = 6 (3.5)
3x − y + 15z= 12
Ahora “despejamos”x de la primera ecuacion, y de la segunda yz de latercera obteniendo
x = 5− 2y+ 3z
10,
y = 6− 2x − z
8,
z= 12− 3x + y
15.
Esto obviamente no nos proporciona una solucion; es simplemente una re-formulacion del sistema de ecuaciones lineales dado, que ha tomado la for-ma general
x = f (x) (3.6)

104 3. Sistemas de Ecuaciones Lineales
para f dada porf (x) = Gx+ d donde
G =
0 − 2
10310
−28 0 −1
8
− 315
115 0
y d =
510681215
.
La reformulacion (3.6) indica que la solucion del sistema (3.5) es un puntofijo de la funcion f . ¿Que ocurrira si aplicamosf a un vectorx arbitra-rio? Supongamos que elegimos una estimacion inicial arbitraria como porejemplo
x(0) = 0.5 , y(0) = 1 , z(0) = 1 .
Aplicando f a este vector obtenemos otro vectorx(1) = f (x(0)) = Cx(0)+d cuyas coordenadas son
x(1) = 0.6 , y(1) = 0.5 , z(1) = 0.76.
Si ahora aplicamosf al resultado que acabamos de obtener llegamos a unvectorx(2) dado por
x(2) = 0.63, y(2) = 0.504, z(2) = 0.7133,
y continuando de esta forma en la octava iteracion se obtiene
x(8) = 0.611831, y(8) = 0.508104, z(8) = 0.711507,
lo cual esta muy cerca de la solucion del sistema.
Este es el procedimiento basico de los metodos iterativos: construiruna funcion contractiva cuyo punto fijo es la solucion buscada eiterar re-petidamente dicha funcion hasta acercarnos suficientemente al punto fijo.Decimos que seitera una funcion cuando se evaluaesta en el resultado dehaberla evaluado previamente, es decir, la evaluacion de f ( f (x)). Si seempieza con un valorx(0) las sucesivas iteraciones def se obtienen siem-pre evaluandof en distintos valores, pero producen los mismos resultadosque si aplicamos sucesivamente las funcionesf , f 2, f 3, etc. ax(0).
Reformulado un sistema de ecuaciones lineales como un problema depunto fijo de una funcion contractiva (llamadafuncion de iteracion), porla teorıa general de las funciones contractivas sabemos que sucesivas ite-raciones de la funcion empezando con cualquier vector dara lugar a unasucesion que converge a la solucion del sistema. Veamos a continuacionun metodo general de obtener una funcion de iteracion para un sistema deecuaciones lineales dado para la cual es relativamente sencillo determinarsi es contractiva o no.
3.3. Metodos iterativos 105
3.3.2 Esquema general del Metodo Iterativo
No es difıcil inventar formas de asociar a un sistema de ecuaciones linealesuna funcion para la que la solucion del sistema sea un punto fijo. Menostrivial es hacerlo de forma que la funcion obtenida sea contractiva. El si-guiente metodo general tiene la ventaja de que permite confirmar de formasencilla si la funcion asociada al sistema es contractiva y por tanto si elmetodo iterativo converge.
SeaAx = b nuestro sistema de ecuaciones. SeaA = A1 + A2 unadescomposicion de la matriz de coeficientesA como suma de dos matricesde forma tal queA1 es inversible.
Ejercicio 3.20Si calculamos
G = −A−11 A2 y d = A−1
1 b
entonces el sistemaAx = b es equivalente a
x = Gx+ d .
En consecuencia tenemos,
Si A = A1 + A2 y G = −A−11 A2, d = A−1
1 b entonces cada soluciondel sistemaAx = b es un punto fijo de la funcion
f (x) = Gx+ d
y viceversa.
El metodo general descrito en el ejercicio 3.20 da lugar a muchos metodosparticulares cuando se eligen diversas formas de descomponer la matriz decoeficientesA como suma de dos matrices una de las cuales es inversible.Una de las formas mas sencillas de hacer esto es llamada el metodo deJacobi, que estudiaremos en breve.
Ejercicio 3.21Indicar tres formas diferentes de descomponer una matriz cuadradaA sinceros en la diagonal como suma de dos matrices una de las cuales es inver-sible. Describir el metodo iterativo de resolucion de sistemas de ecuacioneslineales a que cada una de esas formas de descomposicion da lugar.

106 3. Sistemas de Ecuaciones Lineales
3.3.3 Convergencia del metodo iterativo general
SeaAx = b un sistema de ecuaciones lineales y supongamos que tenemosuna descomposicion A = A1 + A2 de la matriz de coeficientes tal queA1es inversible, de modo que el sistema original es equivalente al problemade punto fijox = Gx+ d dondeG = −A−1
1 A2 y d = A−11 b. Nos interesa
saber bajo que condiciones se puede resolver el problema de punto fijomediante iteraciones de la funcion f (x) = Gx+ d, es decir, nos interesaconocer las condiciones que garantizan que dado un vectorx(0), la sucesion
{x(k)} = { f (x(0)), f ( f (x(0))), . . . , f k(x(0)), . . . } (3.7)
converge al punto fijo def . Pero notese que si dicha sucesion converge aun vectorx, la continuidad def implica
x = limk→∞
x(k) = limk→∞
f (x(k−1)) = f ( limk→∞
x(k−1)) = f (x),
o sea,x es un punto fijo def . O sea, que basta saber que la sucesion deiteraciones converge, pues si lo hace el lımite es necesariamente la solucionde nuestro sistema.
Supongamos, que{x(k)} converge y que su lımite esx. Entonces lasucesion de “errores”{x(k) − x} converge a cero, pero teniendo en cuentaque
x(k) − x = G(x(k−1))+ d − (G(x)+ d) = G(x(k−1) − x) = · · ·= Gk(x(0) − x)
vemos quelim
k→∞Gk(x(0) − x) = 0.
De esto se deduce que si la sucesion (3.7) converge para cualquier elecciondel vector inicialx(0) entonces la sucesion de potencias de la matrizGtiende a la matriz cero. Trivialmente se cumple tambien el recıproco (hayque recordar quef tieneun punto fijo por hipotesis), de forma que tenemos:
Teorema 14 Un metodo iterativox = Gx+d de resolucion de un sistemade ecuaciones lineales converge para toda eleccion del vector inicialx(0)
si y solo si Gn→ 0, o sea, si y solo si la sucesion de potencias de la matrizG tiende a la matriz cero.
3.3. Metodos iterativos 107
Una forma trivial de comprobar queGn → 0 serıa el comprobar quepara alguna norma se verifica‖G‖ < 1 ya que en tal caso‖Gn‖ ≤ ‖G‖n→0. Por tanto es evidente que una sencilla condicion suficiente de convergen-cia es:
Condicion suficiente de convergencia de un metodo iterativo. Si‖G‖∞ <
1 entonces el metodo iterativox = Gx+d converge para toda eleccion delvector inicialx(0).
En realidad no cuesta demasiado esfuerzo adicional el dar una visioncompleta de la situacion demostrando el siguiente teorema que da las doscondiciones necesarias y suficientes fundamentales para la convergenciadel metodo iterativo general:
Teorema 15 (Condiciones necesarias y suficientes)Cada una de las con-diciones enunciadas a continuacion es necesaria y suficiente para que unmetodo iterativo,x = Gx+ d, de resolucion de un sistema de ecuacioneslineales converja para toda eleccion del vector inicialx(0):
1. Que exista una norma para la que se verifique‖G‖ < 1,
2. Que todo autovalor deG tenga valor absoluto menor que1.
Demostracion: Como ya hemos observado mas arriba, la condicion 1es suficiente. Por otro lado es inmediato que la condicion 2 es necesaria yaque siG tiene un autovalor,λ, cuyo valor absoluto es|λ| ≥ 1, este autovalortendra un autovectory (para el cualGky = λky) que hace imposible que
Gk → 0 (ya que para todok, ‖Gk‖ ≥ ‖Gk y‖‖y‖ = |λ|k ≥ 1). Ası pues, la
demostracion del teorema queda completa con el siguiente lema:
Lema 3 Si todo autovalor deG tiene valor absoluto menor que1 entoncesexiste una norma para la que se verifica‖G‖ < 1.
Demostracion: Si todo autovalor deG tiene valor absoluto menor que1 entonces el radio espectral,ρ(G), de G (el maximo de los valores ab-solutos de los autovalores deG) es menor que 1, por lo tanto existe unnumero real,ε, tal que 0< ε < 1 − ρ(G). SeaD la matriz diagonalD = diag(1, ε−1, ε−2, ..., ε1−m). SeaJ la forma canonica de Jordan deG y S la matriz de semejanza tal queJ = SGS−1. Para toda matrizXdefinimos
‖X‖T = ‖T XT−1‖∞

108 3. Sistemas de Ecuaciones Lineales
dondeT = DS. Basta demostrar dos cosas: (1) que‖ · ‖T es una norma,y (2) que‖G‖T < ρ(G) + ε. La primera se deduce de que‖ · ‖T es lanorma matricial asociada a la norma vectorial‖x‖ = ‖T x‖∞, y la segundase comprueba con un sencillo calculo teniendo en cuenta que enDJ D−1
en cada bloque de Jordan quedan sustituidos los unos porε.
Veamos ahora un criterio para la detencion de las iteraciones. ¿Cuandopodemos considerar que ya hemos realizado suficientes iteraciones? Parapoder detener las iteraciones de una forma eficaz es necesario poder estimarel error. El resultado siguiente nos permite hallar una cota superior de lamagnitud del error en cada paso en terminos de la correccion realizada enese paso:
Proposicion 3 Seax(k+1) = Gx(k) + d un metodo iterativo dado. Paracualquier norma se verifica que en cada paso de iteracion
‖x(k) − x‖ ≤ ‖G‖1− ‖G‖‖x
(k) − x(k−1)‖ .
Por lo tanto, si existe alguna norma para la que‖G‖ < 12 entonces el error
en cada paso (medido con esa norma) esta acotado superiormente por lacorreccion realizada en ese paso.
Demostracion: Dado quex(k) − x = −G(x(k) − x(k−1)) + G(x(k) − x),tomando normas obtenemos,
‖x(k) − x‖ ≤ ‖G‖‖x(k) − x(k−1)‖ + ‖G‖‖x(k) − x‖
y despejando‖x(k) − x‖ obtenemos
‖x(k) − x‖ ≤ ‖G‖1− ‖G‖‖x
(k) − x(k−1)‖ ,
como querıamos demostrar.
3.3.4 Metodo de Jacobi
Estamos ahora en situacion de volver al ejemplo ilustrativo de los metodositerativos explicado al principio y analizarlo de forma un poco mas teorica.
3.3. Metodos iterativos 109
Descrito en forma general, el metodo en que se basaba aquel ejemplo es elsiguiente:
Dado un sistema de ecuaciones linealesAx = b, la ecuacion i puedeescribirse
n∑j=1
ai j x j = bi .
Supongamos que los elementos diagonales deA sean todos distintos de ce-ro. Entonces podemos despejar la primera incognita de la primera ecuacion,la segunda incognita de la segunda ecuacion, y ası hasta despejar laultimaincognita de laultima ecuacion de forma que el sistema queda re-escritocomo
xi =(bi −
n∑j=1j 6=i
ai j x j
)/aii . (3.8)
Esto lo podemos expresar facilmente en forma matricial si observamos que
n∑j=1j 6=i
ai j x j =
0 a12 · · · · · · a1n
a21 0. . .
......
. . .. . .
. . ....
.... . . 0 an−1n
an1 · · · · · · an n−1 0
x1x2...
xn
= A2x ,
dondeA2 es la matriz obtenida a partir deA al hacer cero todos sus ele-mentos diagonales. Ademas, siA1 es “la diagonal deA”, es decir, tal queA = A1 + A2, entonces el vector de coordenadasbi /aii es simplementeA−1
1 b y el vector de coordenadas(∑n
j=1j 6=i
ai j x j)/aii (parai = 1, . . . ,n) es
simplementeA−11 A2x, de forma que la expresion (3.8) en forma matricial
esx = A−1
1 b− A−11 A2x ,
es decir, la expresion (3.8) tiene la forma
x = Gx+ d con G = −A−11 A2 , y d = A−1
1 b .
Esta eleccion de descomposicion de la matriz de coeficientes de un sis-tema de ecuaciones lineales en “diagonal” mas “el resto” para resolverlo

110 3. Sistemas de Ecuaciones Lineales
por el metodo iterativo, se conoce con el nombre deMetodo de Jacobio delosdesplazamientos simultaneos. Resumiendo,
Supongamos que la matriz de coeficientesA de nuestro sistema de ecua-ciones lineales no tiene ningun cero en la diagonal. En tal situacion, la ma-triz A1 cuya diagonal es igual a la deA y cuyos otros elementos son cero esinversible y el metodo iterativo basado en la descomposicion A = A1+ A2se conoce como metodo de Jacobi.
Convergencia del metodo de Jacobi.–
Segun la condicion suficiente de convergencia establecida justo antes delteorema 15, el metodo de Jacobi sera aplicable siempre que la matrizAde los coeficientes del sistema de ecuaciones lineales tenga la propiedadde que‖D−1(A − D)‖∞ = ‖D−1A − I ‖∞ < 1 dondeD es la matriz“diagonal deA”. Ahora bien,
‖D−1A− I ‖∞ = max1≤i≤n
{( n∑j=1j 6=i
|ai j |)/|aii |
}
luego una condicion suficiente para la convergencia del metodo de Jacobies:
max1≤i≤n
{( n∑j=1j 6=i
|ai j |)/|aii |
}< 1 o , (∀i )1≤i≤n |aii | >
n∑j=1j 6=i
|ai j | .
Expresando esta condicion con palabras:
Condicion suficiente para la convergencia del metodo de Jacobi es quecada elemento de la diagonal de la matriz de coeficientes tenga un valor ab-soluto mayor que la suma de los valores absolutos de los demas elementosde su fila.
Las matrices descritas en la condicion suficiente anterior se llamanma-trices de diagonal estrictamente dominante (por filas). Concluimos, pues,que el metodo de Jacobi es aplicable a cualquier sistema cuya matriz decoeficientes tiene la diagonal estrictamente dominante (por filas).
Observese que toda matriz de diagonal estrictamente dominante (lo queimplica que es no singular segun el ejercicio 3.17) necesariamente tiene
3.3. Metodos iterativos 111
todos los elementos de la diagonal distintos de cero y por tanto tiene sentidoel plantearse usar el metodo de Jacobi.
3.3.5 Aceleracion de la convergencia; metodo de Gauss-Seidel
La principal dificultad que plantean los metodos iterativos tales como el dedesplazamientos simultaneos (o de Jacobi) es su lentitud en la convergen-cia. Por ello es necesario disenar metodos de aceleracion de la convergen-cia, El primero que estudiaremos es el dedesplazamientos sucesivos(o deGauss-Seidel). Mas tarde estudiaremos los llamados metodos derelajacionpor su origen en el estudio de problemas mecanicos. Libros aconsejados:(17), (38) y (21).
El metodo de Jacobi se puede describir como basado en las ecuaciones(3.8), que nos dan las siguientes ecuaciones de iteracion:
x(k+1)i =
(bi −
n∑j=1j 6=i
ai j x(k)j
)/aii .
Segun estas ecuaciones cada coordenada del pasok + 1 se halla mediantelas coordenadas del pasok. Pero observese que habiendo calculadox(k+1)
1 ,
y dado que en principiox(k+1)1 esta mas cerca de la solucion exacta que
x(k)1 , parece logico pensar que serıa mas provechoso usarx(k+1)1 quex(k)1
en el calculo dex(k+1)2 . Asimismo serıa mas ventajoso usarx(k+1)
1 y x(k+1)2
en lugar dex(k)1 y x(k)2 en el calculo dex(k+1)3 y ası sucesivamente. Esto
sugiere el sustituir las ecuaciones de iteracion anteriores por estas otras
x(k+1)i =
(bi −
i−1∑j=1
ai j x(k+1)j −
n∑j=i+1
ai j x(k)j
)/aii . (3.9)
en las que en cada paso se usan para cada coordenada su estimacion masactual.
Este metodo se conoce con el nombre deMetodo de Gauss-Seidelypuede llegar a aumentar la velocidad de convergencia en algunos casos amas del doble (respecto al metodo de Jacobi).

112 3. Sistemas de Ecuaciones Lineales
Las ecuaciones (3.9) pueden expresarse en forma matricial para descu-brir a que corresponden en el esquema general del metodo iterativo y poderası estudiar su convergencia basados en el teorema 15. Pasando todos losterminos que hay en (3.9) con coordenadas del pasok+1 al miembro de laizquierda despues de haber multiplicado poraii las ecuaciones (3.9) quedan
i∑j=1
ai j x(k+1)j = bi −
n∑j=i+1
ai j x(k)j ,
pero teniendo en cuenta que
i∑j=1
ai j x(k+1)j =
a11 0 · · · · · · 0
a21 a22. . .
......
. . .. . .
...... an−1n−1 0
an1 · · · · · · an n−1 an n
x(k+1)
1x(k+1)
2...
x(k+1)n
y
n∑j=i+1
ai j x(k)j =
0 a12 · · · · · · a1n
0 0. . .
......
. . .. . .
...... 0 an−1n
0 · · · · · · 0 0
x(k)1x(k)2...
x(k)n
podemos escribir las ecuaciones anteriores como
A1x(k+1) = b− A2x(k) o x(k+1) = Gx(k) + d
dondeA1 es la matriz obtenida al hacer cero todos los elementos deA sobrela diagonal, yA2 = A− A1. En otras palabras, el metodo de Gauss-Seidelencaja en el esquema general de los metodos iterativos como el metodoobtenido con la descomposicion
A =
a11 0 · · · · · · 0
a21 a22. . .
......
. . .. . .
...... an−1n−1 0
an1 · · · · · · an n−1 an n
+
0 a12 · · · · · · a1n
0 0. . .
......
. . .. . .
...... 0 an−1n
0 · · · · · · 0 0
.
3.3. Metodos iterativos 113
Convergencia del metodo de Gauss-Seidel.–
Del teorema general de convergencia del metodo iterativo se deduce la si-guiente condicion suficiente de convergencia:
Teorema 16 (Convergencia del metodo de Gauss-Seidel)El metodo ite-rativo de Gauss-Seidel para la resolucion de un sistema de ecuacioneslineales converge para cualquier vector inicial siempre que la matriz decoeficientes del sistema sea de diagonal estrictamente dominante.
Demostracion: SeaA = L + D + U la descomposicion de la matriz decoeficientes en elementos bajo la diagonal (matrizL), elementos diagona-les (matrizD) y elementos sobre la diagonal, de forma que la matriz de lafuncion de iteracion del metodo de Gauss-Seidel esG = −(L + D)−1Uy la matriz de la funcion de iteracion del metodo de Jacobi esGJ =−D−1(L + U ), cumpliendose‖GJ‖∞ < 1. El teorema quedara demos-trado si demostramos que‖G‖∞ ≤ ‖GJ‖∞. Para ello basta demostrar quepara cualquier vectorx se cumple‖Gx‖∞ ≤ ‖GJ‖∞‖x‖∞ o equivalen-temente que cada componenteyk del vectory = Gx = −(L + D)−1U xverifica
|yk| ≤n∑
j=1j 6=i
|ai j ||aii | ‖x‖∞. (3.10)
Esto lo demostramos por induccion completa en las componentes. Prime-ramente, y teniendo en cuenta que(L+D)y = −U x, expresamos el vectory en la formay = D−1(−Ly−U x) de donde se obtienen para las coorde-nadas dey formulas analogas a (3.9), a saber:
yi =(−
i−1∑j=1
ai j yj −n∑
j=i+1
ai j x j
)/aii .
De aquı se deduce (3.10) parai = 1 (¡ejercicio!). Supongamos ahora quei > 1 y que se cumple la hipotesis de induccion (3.10) para todoyj con j <i . Entonces cada una de estasyj tambien verifica|yj | ≤ ‖G‖∞‖x‖∞ <

114 3. Sistemas de Ecuaciones Lineales
‖x‖∞ y por lo tanto tenemos:
|yi | ≤( i−1∑
j=1
|ai j ||yj | +n∑
j=i+1
|ai j ||xj |)/|aii |
≤( i−1∑
j=1
|ai j ‖x‖∞ +n∑
j=i+1
|ai j |‖x‖∞)/|aii |
≤( i−1∑
j=1
|ai j | +n∑
j=i+1
|ai j |)‖x‖∞
/|aii |
≤n∑
j=1j 6=i
|ai j ||aii | ‖x‖∞
con lo que se completa la demostracion.
Es interesante observar el hecho de que hay matrices (que necesaria-mente no son de diagonal estrictamente dominante ni por filas ni por co-lumnas) para las que el metodo de Jacobi converge pero el de Gauss-Seidelno; y tambien hay matrices para las que el metodo de Gauss-Seidel conver-ge pero el de Jacobi no.
3.3.6 Metodo de las relajaciones sucesivas
En los metodos iterativos que estamos estudiando, y en particular en el deGauss-Seidel, cada paso de iteracion puede considerarse como la realiza-cion de una correccion (tambien llamadarelajacion) a una aproximacion dela solucion. Visto desde este punto de vista podemos preguntarnos cualesson las correcciones empleadas en cada paso del metodo de Gauss-Seidely si hay alguna forma de mejorarlas. Evidentemente las correcciones sonlas diferenciasx(k+1)
i − x(k)i , que se encuentran facilmente a partir de lasformulas de iteracion (3.9). De allı con poco esfuerzo se obtiene:
x(k+1)i − x(k)i =
(bi −
i−1∑j=1
ai j x(k+1)j −
n∑j=i
ai j x(k)j
)/aii
(notese que elındice inferior del segundo sumatorio ha cambiado dei + 1a i ). Ahora bien, el hecho de que estas correcciones no proporcionen de in-mediato la solucion exacta indica que son (en valor absoluto) insuficientes
3.3. Metodos iterativos 115
(caso de una convergencia monotona) o excesivas (caso de una convergen-cia alternada), y que la correccion exacta serıa de la forma
ci = ω(bi −
i−1∑j=1
ai j x(k+1)j −
n∑j=i
ai j x(k)j
)/aii
para algun factorω cercano a la unidad, que serıa mayor o menor que launidad segun multiplicase a una correccion insuficiente o excesiva. Estefactor se llamacoeficiente de relajacion. Si acertamos a elegir un valorapropiado paraω entonces el uso de las nuevas correcciones nos da lasecuaciones de iteracion
x(k+1)i = x(k)i + ω
(bi −
i−1∑j=1
ai j x(k+1)j −
n∑j=i
ai j x(k)j
)/aii
que pueden converger mas rapidamente que (3.9). Este metodo de acelera-cion se conoce comoMetodo de las relajaciones sucesivas.
El uso del terminorelajacion surge del hecho de que gran parte de lostrabajos iniciales sobre metodos para la solucion iterativa de sistema deecuaciones lineales estaban enfocados a la determinacion de las fuerzas ymomentos en estructuras mecanicas. Si se usan valores incorrectos de esascantidades desconocidas, entonces es necesario aplicar en cada nodo de laestructura fuerzas restrictivas artificiales. A medida que uno se acerca a lasolucion correcta, esas fuerzas pueden ser “relajadas”. Vease (17) p.92.
Ejercicio 3.22Indicar la descomposicion A = A1 + A2 con A1 inversible que es nece-sario utilizar para que el esquema general de los metodos iterativos,G =−A−1
1 A2, d = A−11 b, de lugar, con esta descomposicion, al metodo de las
relajaciones sucesivas, es decir, que se obtenga
G = (D + ωL)−1[(1− ω)D − ωU ] y d = ω(D + ωL)−1b
dondeA = L + D +U es la obvia descomposicion en parte inferior, partediagonal y parte superior.
La dificultad principal para poner en practica el metodo de las relaja-ciones sucesivas consiste en realizar la eleccion adecuada del coeficienteω. El valor optimo de este coeficiente puede hallarse analıticamente solo

116 3. Sistemas de Ecuaciones Lineales
en casos muy especiales y en general ha de hallarse a base de ensayos. Sinembargo es facil demostrar, apoyados en el teorema 15 y en la expresionparaG dada en el ejercicio 3.22, que losunicos valores deω que puedendar lugar a un metodo convergente son aquellos valores positivos menoresque 2.
Proposicion 4 Para la matrizGω = (D+ωL)−1[(1−ω)D−ωU ], dondeD es diagonal yL, U son respectivamente triangulares inferior y superiorcon diagonal cero, se verifica que su radio espectral es mayor o igual que|1− ω| y en consecuencia para que un metodo iterativo de la forma
x(k+1) = Gωx(k) + d
converja para cualquier valor inicial es condicion necesaria que|1−ω| <1, es decir,0< ω < 2.
Demostracion: Seanλ1, λ2, . . . , λn los autovalores deGω, entonces
λ1 · · · λn = detGω = detD−1 det[(1− ω)D]
= (1− ω)n detD−1 detD = (1− ω)n
de esto se deduce que|1− ω| ≤ maxi |λi |. Como se querıa demostrar.
Capıtulo 4
Calculo de vectores yvalores propios
El problema general de encontrar todos los valores y vectores propios deuna matriz cuadrada es bastante amplio y su estudio podrıa llenar facilmenteun trimestre completo. En este capıtulo haremos solamente una mera intro-duccion al tema. Veremos elmetodo de la potenciapara el calculo delautovalor de mayor valor absoluto de una matriz que tenga un autovalordominante y, tras explicar la transformacion, mediante matrices de House-holder, de una matriz en otra semejante a ella pero de tipo Hessenberg, seexplicara el llamado metodo de lafactorizacion ortogonal(o metodoQR),el cual es el metodo general mas eficaz y de mayor uso para el calculo detodos los valores propios de una matriz arbitraria. Este metodo, descubiertopor J. G. F. Francis y publicado en 1961, ofrece ciertas dificultades compu-tacionales que se pueden reducir si se prepara previamente la matriz dadaA reduciendola a una forma de tipoHessenberg, proceso que, por conser-var la simetrıa, da lugar a una matriz tridiagonal semejante aA si esta essimetrica.
117

118 4. Vectores y valores propios
4.1 Metodo de la potencia
El metodo de la potencia es un metodo iterativo de calculo del autovalorde maximo valor absoluto de una matriz diagonalizable. Esta basado en lasiguiente observacion:
Supongamos queA es una matriz diagonalizable de ordenn, x(0) unvector arbitrario y
{x(k)
}la sucesion de vectores definida recurrentemente
por:x(k) = Ax(k−1) = Akx(0).
Por la hipotesis de queA es diagonalizable existe una base, que denota-remos{u1,u2, . . . ,un}, formada por vectores propios deA, que podemossuponer dados en orden decreciente de magnitud de autovalores, es decir,si λi es el autovalor correspondiente al vector propioui ,
|λ1| ≥ |λ2| ≥ · · · ≥ |λn|.
Entonces, six(0) = α1u1 + · · · + αnun, el termino general de la sucesionanterior tiene la siguiente expresion en la base{ui } de vectores propios deA:
x(k) = Ak(α1u1+ α2u2+ · · · + αnun)
= α1λk1u1+ α2λ
k2u2+ · · · + αnλ
knun
= λk1
(α1u1+ α2
(λ2λ1
)ku2+ · · · + αn
(λnλ1
)kun
).
Supongamos ahora por un momento que el vectorx(0) no es arbitrariocomo hemos dicho sino que tiene la propiedad de queα1 6= 0 1. Si, ademas,la matriz A es tal que tiene unautovalor dominante(es decir,λ1 6= λ2,o sea, la desigualdad|λ1| ≥ |λ2| es estricta de modo que|λ1| > |λ2|)entonces tenemos
limk→∞
1
λk1
x(k) = α1u1,
1Esta hipotesis no se puede comprobar de antemano porque se desconocen los vectoresui .Sin embargo no es una hipotesis demasiado restrictiva porque, por un lado, la probabilidad deque un vector elegido al azar tengaα1 = 0 es cero y, por otro lado, aunque fueseα1 = 0, alo largo de los calculos los errores de redondeo acabarıan por introducir una componente nonula en la direccion deu1.
4.2. MetodoQRo de la factorizacion ortogonal 119
y por lo tanto para cualquierındicei ∈ {1, . . . ,n},
1= limk→∞
( 1
λk1
x(k)i
)/( 1
λk−11
x(k−1)i
)= 1
λ1lim
k→∞x(k)i
x(k−1)i
,
de donde,
limk→∞
x(k)i
x(k−1)i
= λ1 ,
con lo que tenemos una sucesion que converge al autovalor dominante dela matrizA.
Si ya conocemos el signo del autovalor buscado (o su argumento, en ca-so de que sea complejo) solo necesitamos hallar su valor absoluto. Para estopodemos obtener una sucesion que tiene mejor velocidad de convergenciaque la anterior ya que
limk→∞
‖Akx(0)‖‖Ak−1x(0)‖ = lim
k→∞‖x(k)‖‖x(k−1)‖ = |λ1| .
Lo que acabamos de decir significa que siA es una matriz cuadradade ordenn con un autovalor dominante,este se puede hallar mediante elsiguiente proceso iterativo:
Algoritmo del Metodo de la Potencia
1 Elegir un vector inicialv 6= 0 y una tolerancia de errorT . Ademas,inicializar la variableλ0 = 0.
2 Calcular el productoy = Av.
3 Hallar j tal que|yj | = max1≤i≤n |yi |.4 AsignarS= |yj |; λ = yj /v j ; v = y/S.
5 Si |λ0− λ| ≤ T entonces PARAR.
6 Asignarλ0 = λ e ir al paso2.
4.2 Metodo QRo de la factorizacion ortogonal
Cuando se desean conocer todos los autovalores de una matriz de ordengrande, el calculo de su polinomio caracterıstico y subsiguiente estimacion

120 4. Vectores y valores propios
de raıces no es siempre el metodo mas sencillo o eficaz. El metodo reco-mendado en general es el metodo de la factorizacion ortogonal que se basaen los siguientes teoremas:
Teorema 17 (Exist. y unicid. de la factorizacion ortogonal) Para toda ma-triz real A existen matricesQ, ortogonal, yR, triangular superior, talesque A = QR. Ademas, si A es no singular entonces estas matrices estanunıvocamente determinadas porA excepto en el signo de los elementos.
Demostracion: Existencia: Esto se demostrara en la seccion siguiente en laque se da un metodo de construccion de las matricesQ y R.Unicidad: En primer lugar, la matriz identidad no admite mas factorizacionortogonalI = QR que la trivial, o sea, aquella conQ = I = R ya queQ−1 = R nos dice queR es una matriz ortogonal triangular, lo que implicaque es la identidad salvo, quizas por los signos de los elementos diagonales.En segundo lugar, siA = QR = Q′R′ entoncesI = Q−1Q′R′R−1, dedondeR′R−1 = S, una matriz de signos, que solo difiere de la identidad enlos signos de sus elementos y por tantoS= S−1 = Q−1Q′ lo que implicaR′ = SRy Q′ = QS.
4.2.1 La Sucesion General del Metodo de la FactorizacionOrtogonal
Una vez que determinemos un metodo de construir una factorizacion orto-gonal de una matriz cuadrada cualquiera, podemos utilizarlo para construirla siguiente sucesion definida recursivamente a partir de una matriz cuadra-da cualquieraA:
A(0) = A, A(k+1) = R(k)Q(k)
dondeR(k) y Q(k) se obtienen mediante la factorizacion ortogonal
A(k) = Q(k)R(k)
de la matrizA(k)
Llamaremos a esta sucesion la sucesion general del metodo de la fac-torizacion ortogonal determinada porA. Esta sucesion goza de algunaspropiedades evidentes pero de gran importancia:
4.2. MetodoQRo de la factorizacion ortogonal 121
1. Dado que dos terminos consecutivos estan relacionados por:
A(k+1) = (Q(k))−1A(k)Q(k),
Todas las matrices de esta sucesion son semejantes entre sı y portanto todas tienen los mismos autovalores yestos son tambien losautovalores de su lımite
2. Dado que la inversa de una matriz ortogonal es su traspuesta, tenemos(A(k+1))t = (Q(k))t(A(k))t Q(k),
y por tantosi una matriz de esta sucesion es simetrica entonces todaslo son.
Visto esto podemos enunciar el teorema en el que se basa el metodo dela factorizacion ortogonal:
Teorema 18 (Metodo QRpara calculo de autovalores)Sea A una ma-triz real cuadrada no singular entre cuyos autovalores no hay dos con elmismo valor absoluto, es decir, que verifican
|λ1| > |λ2| > · · · > |λn| > 0.
Entonces la sucesion general del metodo de la factorizacion ortogonaldeterminada porA converge a una matriz triangular. Si la matrizA essimetrica, el lımite es una matriz diagonal.
Ası pues, para una matrizA cuyos autovalores tengan todos distintovalor absoluto, estos son los elementos diagonales lımite de lasucesiongeneral del metodo de la factorizacion ortogonaldeterminada porA.
Ejercicio 4.1Demostrar que lasucesion general del metodo de la factorizacion ortogonaldeterminada porA = ( 0 1
1 0
)no converge a una matriz triangular. ¿Cual de
las hipotesis del teorema anterior no cumple esta matriz?
4.2.2 La factorizacion ortogonal de una matriz: Metodode las rotaciones planas
La factorizacion ortogonal de una matriz puede realizarse por un metodoque es formalmente parecido al metodo de eliminacion de Gauss utilizado

122 4. Vectores y valores propios
para realizar la factorizacion triangular. Al igual que en aquel la idea esaplicar sucesivas transformaciones a la matriz de partida para ir haciendocero los elementos bajo la diagonal de forma que al final quede transfor-mada en una matriz triangular superior. La diferencia es que si allı se uti-lizaban transformaciones elementales (que combinadas resultaban en unamatriz triangular inferior con unos en la diagonal), aquı se utilizaran trans-formaciones ortogonales (concretamente rotaciones planas) que combina-das daran lugar a una matriz ortogonal.
Una rotacion plana en el espacion-dimensional queda determinada porel plano de rotacion y el angulo de rotacion. Si el plano de rotacion es eldeterminado por los ejes de coordenadas 1 y 2 y elangulo de rotacion esαentonces la matriz de rotacion tiene la forma
Pα(1,2) =
cosα − senαsenα cosα 0
1
0. . .
1
y en general una rotacion sobre el plano de los ejesi y j (con i > j ) tieneuna matriz de la forma (escribiendo solo los elementos no nulos)
1. . .
1fila j → c · · · −s
1...
. . ....
1fila i → s · · · c
1. . .
1
= Pα(i, j )
dondec y s son los cosenos directores de la rotacion, es decir, el coseno yseno respectivamente delanguloα de rotacion.
Si queremos hallar los cosenos directoresc, s de la matrizP(i, j ) parahacer cero el elemento(i, j ) de la matrizA = (ai, j ) no tenemos mas que
4.2. MetodoQRo de la factorizacion ortogonal 123
considerar la ecuacion obtenida al multiplicarP(i, j ) por la columnaj deA, es decir,
1. . .
1j → c · · · −s
1...
. . ....
1i → s · · · c
1. . .
1
a1 j...
aj j...
ai j...
anj
=
a1 j...
aj−1 jcaj j − sai j
aj+1 j...
ai−1 jsaj j + cai j
ai+1 j...
anj
,
de donde se deduce que los cosenos directoresc, s han de verificar
c2+ s2 = 1 y saj j + cai j = 0,
y una posible solucion de esto es
c = aj j√a2
j j + a2i j
, s= −ai j√a2
j j + a2i j
(4.1)
Teniendo en cuenta lo que acabamos de decir el proceso de elimina-cion para la factorizacion ortogonal de una matrizA se lleva a cabo dela siguiente forma: En un primer paso se hacen cero los elementos de laprimera columna bajo la diagonal mediante multiplicacion sucesiva de lamatriz A por matrices de rotacion plana sobre los ejes(1,2), (1,3), . . . .Es decir obtenemosQ1A donde Q1 = P(1,n)P(1,n − 1) · · · P(1,2).Despues se hacen cero los elementos de la segunda columna bajo la dia-gonal multiplicando la matrizQ1A por matrices de rotacion plana sobrelos ejes(2,3), (2,4), . . . . Ası obtenemos una matrizQ2Q1A dondeQ2 =P(2,n)P(2,n− 1) · · · P(2,3). Continuando de esta forma se obtiene unamatriz triangular superior
R= Qn−1 · · · Q1A
donde todas las matricesQi son matrices ortogonales por ser producto dematrices ortogonales. Con esto queda demostrada la existencia de la facto-rizacion ortogonal.

124 4. Vectores y valores propios
Ejercicio 4.2Hallar el numero de matrices de rotacion plana que es necesario multiplicarpara hallar la factorizacion de una matriz arbitraria de ordenn.
4.2.3 Simplificacion que ocurre para las matrices tipo Hes-senberg
Supongamos que la matrizA es de tipo Hessenberg, es decir tiene cerosbajo la subdiagonal. Entonces su factorizacion ortogonal puede llevarse acabo con solamenten − 1 rotaciones planas. LasQi constan cada una deuna sola rotacion. Ademas:
Lema 4 Si Res una matriz triangular superior y para cadai ∈ {1, . . . ,n−1} Qi = P(i, i + 1) (una rotacion sobre el plano de los ejesi e i + 1)entonces la matrizRQ1 · · · Qn−1 es una matriz tipo Hessenberg.
Demostracion: Por induccion.
La consecuencia de este lema es que si el algoritmoQR es aplicado auna matriz Hessenberg entonces todas las matrices de la sucesion obtenidason de tipo Hessenberg. Veremos ahora como podemos transformar porsemejanza una matriz arbitraria en otra de tipo Hessenberg.
El resultado del ejercicio 4.2 muestra el enorme coste que tendrıa laaplicacion del metodo QR a una matriz arbitraria. Afortunadamente esposible reducir drasticamente ese coste gracias a dos cosas: (1) Segun aca-bamos de ver, el algoritmoQRconserva la forma Hessenberg de una matriz(es decir, el tener ceros bajo la subdiagonal), y (2) Toda matriz puede trans-formarse por semejanza en otra tipo Hessenberg. Veremos cada uno deestos dos hechos a continuacion.
4.2.4 Metodo de las reflexiones de Householder para elcalculo de una matriz Hessenberg semejante a unadada
En esta seccion haremos uso del producto interior natural enRn. Si repre-sentamos los vectores en una base ortonormal mediante matrices columna,el producto interior dex e y, normalmente denotadox · y o 〈x, y〉, es igualal producto de matricesxty y tambien igual aytx.
4.2. MetodoQRo de la factorizacion ortogonal 125
Un vector unitariow determina un subespacio ortogonal ael y, para Si un vector unitariow lorepresentamos como un“vector columna”, la matriz
wwt representa laaplicacion lineal‘proyeccion ortogonal sobrela recta de direccionw, o“componente longitudinalen la direccionw”.La matriz I − wwtrepresenta entonces la“componente transversalala direccionw”.
cada vectorx podemos calcular su componente en la direccion dew comoxw = (x · w)w. Este vector (como matriz columna) es igual al productodel escalarxtw por el vectorw. Esto se puede expresar como el produc-to de matricesw(xtw) que se puede reescribir comow(wtx), y usando lapropiedad asociativa,
xw = (wwt )x .
Si a un vectorx le restamos su componente en la direccion de un vectorw, obtenemos la proyeccion ortogonal dex sobre el hiperplano ortogonala w. Si a esta proyeccion le restamos una vez mas la componente dex enla direccion dew, obtenemos la reflexion, Pwx, de x sobre el hiperplanoortogonal aw. En consecuencia tenemos
Pwx = x− 2xw = x− 2(wwt )x = (I − 2wwt )x
de esta forma llegamos a la expresion general de la matriz de la reflexionsobre el hiperplano ortogonal a un vector unitariow:
Pw = I − 2wwt .
A partir de esta formula es sencillo demostrar que las matrices de reflexionson ortogonales:
Ejercicio 4.3Toda matriz de la formaPw = I − 2wwt conw unitario (matriz de una re-flexion referida a una base ortonormal) es simetrica (Pt
w = Pw) e involutiva(P2
w = I ), por lo cual es una matriz ortogonal.
Ahora observamos el hecho fundamental que nos permitira llegar alalgoritmo de Householder, esto es: que toda reflexion sobre un hiperplanoqueda completamente determinada por la imagen de un vector (que no estecontenido en el hiperplano de reflexion), en otras palabras:
Proposicion 5 Para cualesquiera vectoresx, y no nulos y de igual normaexiste unaunica reflexion P tal quePx = y.
Demostracion: Primero veamos la unicidad. Esto es consecuencia de que,para toda reflexion P, la direccion w de (el hiperplano de) reflexion estadeterminada porP porque es la misma que la del vectorx− Px para cual-quier x tal quex 6= Px. Por tanto si dos reflexiones coinciden en un tal

126 4. Vectores y valores propios
vector, son reflexiones sobre el mismo hiperplano y por tanto son la mismareflexion. Ahora la existencia: Dados dos vectores distintosx e y de igualnorma, seaP la reflexion sobre el hiperplano ortogonal a la direccion delvector diferenciax − y (6= 0) y seaw = (x − y)/‖x − y‖ la direccion deese hiperplano. Como(x − y)/2 = 1
2‖x − y‖w es el centro del rombo deverticesx,−y, x− y y el origen, el producto escalarwtx o componente dex en la direccionw es igual a la norma de(x− y)/2, por tanto
Pwx = (I − 2wwt )x = x− 2wwtx = x− 2w‖(x− y)/2‖= x− x− y
‖x− y‖‖x− y‖ = x− (x− y) = y .
como querıamos demostrar.
La consecuencia de esto es que six es un vector no nulo de coordenadasx1, . . . , xn, y si k ∈ {1, . . . ,n}, eligiendo el numeroS de forma tal que elvector y de coordenadasx1, . . . , xk,−S,0, . . . ,0 tenga la misma normaquex (es decir, eligiendoS tal queS2 = x2
k+1+, . . . ,+x2n), existira una
(unica) reflexion P tal quePx = y. Esta es la reflexion de direccion
w = (x − y)/‖x − y‖ = 1
R
0...
0xk+1+ S
xk+2...
xn
donde
R= ‖x − y‖ =√(xk+1+ S)2+ x2
k+2+ · · · + x2n
=√(xk+1+ S)2+ S2− x2
k+1
=√
2(xk+1+ S)S
Para evitar una perdida de precision en estos calculos conviene elegir elsigno deSde tal forma que al sumarlexk+1 se sumen sus valores absolutos.Esto significa elegir paraSel mismo signo que tengaxk+1, de forma que laformula deSes:
S= sgn(xk+1)
√x2
k+1+ · · · + x2n .
4.2. MetodoQRo de la factorizacion ortogonal 127
Con lo dicho hasta aquı estamos preparados para demostrar el siguiente
Teorema 19 Para toda matriz cuadradaA existe una matriz ortogonalPtal que el productoP APt es una matriz tipo Hessenberg.
Demostracion: Empezamos construyendo una matriz de reflexion, Pw1 quehaga cero todos los elementos bajo la subdiagonal deA en la primera co-lumna. Para ello aplicamos lo dicho mas arriba al caso de que el vectorxes la primera columna deA. Entonces tendremos
w1 = 1
R1
0
a21+ S1a31...
an1
El productoPw1 A tendra todo ceros bajo la subdiagonal en la primera co-lumna. A continuacion multiplicamos por la derecha de esta matriz la inver-sa dePw1 (que es ella misma) para obtener la matrizPw1 APw1, semejantea A. Ahora bien, comow1 tiene un cero como primer elemento, la matrizw1w1
t tiene todo ceros tanto en la primera fila como en la primera columna,lo que implica que la matrizPw1 es de la forma
Pw1 = I − 2w1w1t =
1 0 · · · 00 × · · · ×...
......
0 × · · · ×
Esto implica que al multiplicar(Pw1 A) por Pw1 no se altera la primeracolumna dePw1 A con lo cual la matrizPw1 APw1 sigue teniendo todo ce-ros bajo la subdiagonal en la primera columna. Similarmente construimosuna matriz de reflexion, Pw2 que haga cero todos los elementos bajo lasubdiagonal dePw1 APw1 en la segunda columna y hallamos el productoPw2 Pw1 APw1 Pw2. Continuando de esta forma, en el pasok, puesto que las

128 4. Vectores y valores propios
primerask componentes dewk son cero, usamos una reflexion de la forma
Pwk = I − 2wkwkt =
1. . . 0
1× · · · ×
0...
...
× · · · ×
por lo cual al multiplicar
Pwk(Pwk−1 · · · Pw1 APw1 · · · Pwk−1)Pwk
no se alteran lask primeras columnas de
Pwk(Pwk−1 · · · Pw1 APw1 · · · Pwk−1),
las cuales tienen todo ceros bajo la subdiagonal.
En consecuencia este proceso produce una matriz ortogonalP = Pwn−2 · · · Pw1
tal queP APt es de tipo Hessenberg.
Para implementar de forma eficaz el algoritmo de Householder, en cadapaso del cual se efectua un producto de la formaPw APw, conviene teneren cuenta que dicho producto se puede realizar de la siguiente forma:
Proposicion 6 Si A es una matriz cuadrada yw es un vector unitario en-tonces siv = Aw, zt = wt A, y λ = wtv
Pw APw = A+ 2(qwt + wr t )
dondeq = λw− v y r t = λwt − zt .
Demostracion: Solo hay que calcular el productoPw APw = (I−2wwt )A(I−2wwt ):
Pw APw = (I − 2wwt )(A− 2Awwt )
= (I − 2wwt )(A− 2vwt )
= A− 2vwt − 2wwt A+ 4w(wtv)wt
= A− 2vwt − 2wzt + 4λwwt
= A+ 2λwwt − 2vwt + 2λwwt − 2wzt
= A+ 2(λw− v)wt + 2w(λwt − zt )
= A+ 2qwt + 2wr t ,
4.2. MetodoQRo de la factorizacion ortogonal 129
que da el resultado requerido.
Ejercicio 4.4Usar el resultado anterior para demostrar que siw es un vector unitario, elproductoPw APt
w puede calcularse mediante el siguiente algoritmo:
1. Para cadai ∈ {1, . . . ,n} hallarvi =∑
j ai jw j y zi =∑
j aj iw j .2. Hallarλ =∑i wi vi .3. Para cadai ∈ {1, . . . ,n} y cada j ∈ {1, . . . ,n} hallar
a′i j = ai j + 2(2λwiw j − w j vi − wi zj ) .
Ejercicio 4.5Usando los resultados anteriores escribir un programa que transforme unamatriz dada en otra semejante a ella pero de tipo Hessenberg.
4.2.5 Simplificacion aplicable a matrices simetricas
En el caso de que queramos transformar una matriz simetrica a forma Hes-senberg, esutil observar dos cosas. En primer lugar cada paso del algorit-mo de Householder produce una matriz simetrica ya que siA es una matrizsimetrica tambien lo esPw APw por serloPw. Esto implica que en este ca-so el resultado es una matriztridiagonal. En segundo lugar, los calculos decada paso del algoritmo pueden simplificarse ya que
Proposicion 7 Si A es una matriz simetrica yw es un vector unitario en-tonces siv = Aw y λ = wtv,
Pw APw = A+ 2(qwt + wqt )
dondeq = λw− v.
Demostracion: Esto es consecuencia directa del resultado de la proposicion6 teniendo en cuenta que siA es simetrica entonceszt = wt A = vt con loquer t = λwt − zt = λwt − vt = qt .
4.2.6 Algoritmo rapido para la factorizacion ortogonal dematrices Hessenberg
SeaA una matriz de tipo Hessenberg de ordenn. Para hallar su factoriza-cion ortogonal por medio de rotaciones planas son necesariasn rotaciones,

130 4. Vectores y valores propios
Q1, . . . Qn, cada una de las cuales anulara un elemento de la subdiagonalde A. Para eliminar el primer elemento usamos la rotacion sobre el planode los ejes(1,2) dada por
Qt1 =
c1 −s1s1 c1 0
1
0. . .
1
donde los cosenos directores de la rotacion, c1 y s1, estan determinados,como ya hemos visto en las formulas (4.1) por
c1 = a11√a2
11+ a221
, s1 = −a21√a2
11+ a221
.
Al multiplicar Qt1 por A obtenemos una matriz que difiere deA a lo
sumo en las dos primeras filas y cuyo elemento en posicion(2,2) ess1a12+c1a22. De esta matriz eliminaremos el segundo elemento de la subdiagonalmultiplicandola por
Qt2 =
1c2 −s2s2 c2
1. . .
1
lo cual claramente no altera la primera columna. Continuando de esta ma-nera llegaremos a obtener la matriz triangular superiorR como el producto
R= Qtn−1 · · · Qt
2Qt1A
lo que implicaA = QR
donde (teniendo en cuenta queQti = Q−1
i por ser ortogonal)
Q = Q1Q2 · · · Qn−1 .
4.2. MetodoQRo de la factorizacion ortogonal 131
Nos proponemos ahora describir un algoritmo que nos permite calcu-lar la matrizQ en la forma mas compacta posible. Para ello estudiamosla estructura de las matrices obtenidas al calcular los sucesivos productosQ0 = I , Q1, Q1 · Q2, . . . de los cuales eln-esimo es la propia matrizQ.Las primeras dos matrices (aparte deQ0) son:
Q1 =
c1 s1
−s1 c1 01
0. . .
1
, Q1Q2 =
c1 s1c2 s1s2
−s1 c1c2 c1s2 00 −s2 c2
1
0. . .
1
.
Ejercicio 4.6Comprobar que c1 s1 0
−s1 c1 00 0 1
1 0 00 c2 s20 −s2 c2
= c1 s1c2 s1s2−s1 c1c2 c1s20 −s2 c2
En esta sucesion la matrizi -esima (es decir el productoQ1 · · · Qi ) para
i = 1, . . .n se puede obtener de la anterior (el productoQ1 · · · Qi−1) y delos coeficientesci , si aplicando los siguientes pasos: (Parai = 1 partimosde Q0 que tomamos siempre igual a la matriz identidad.)
1. Hacer la columnai + 1 igual a la columnai multiplicada porsi .
2. Multiplicar la columnai porci .
3. Hacer los elementos de la filai+1 en posicion(i+1, i ) e(i+1, i+1)(elemento a la derecha de la diagonal y en la diagonal) iguales a−siy ci respectivamente.
Ejercicio 4.7Comprobar que mediante aplicacion de los pasos anteriores se obtiene latransformacion (coni = 3):
c1 s1c2 s1s2−s1 c1c2 c1s20 −s2 c2
1
7→
c1 s1c2 s1s2c3 s1s2s3−s1 c1c2 c1s2c3 c1s2s30 −s2 c2c3 c2s30 0 −s3 c3
y que el resultado es precisamenteQ1Q2Q3.

132 4. Vectores y valores propios
Ejercicio 4.8Hallar el numero de multiplicaciones necesarias para obtener la matrizQ(de ordenn) mediante iteracion de los pasos indicados mas arriba a partirde los valores (supuestos conocidos)(c1, s1), . . . ,(cn−1, sn−1).
Estas observaciones nos llevan al siguiente algoritmo compacto pararealizar la factorizacion ortogonal de una matriz tipo Hessenberg:
Algoritmo de factorizacion ortogonal de matrices Hessenberg
1 SeaA la matriz dada. Declaramos las variablesQ y R como matricesdel mismo orden queA.
2 Inicializamos las matricesQ = I y R= 0.
3 Inicializamos el contadork = 0.
4 Incrementamos el contadork = k+ 1.
5 Hallamos el valor provisional de la columnak de R:Para i = 1, . . . , k hacemosrik =
∑kj=1 qji ajk .
Hallamos rk+1k = ak+1k.6 Calculamos los cosenos directores de este paso:
c = rkk/
√r 2kk+ r 2
k+1k s= −ak+1k/
√r 2kk+ r 2
k+1k .
7 Corregimos la columnak de R:
rkk = crkk− srk+1k y rk+1k = 0.
8 Calculamos la nuevaQ haciendoPara j = 1, . . . , k hacemosqj k+1 = sqjk , qjk = cqjk .Hecho esoqk+1k+1 = c , qk+1k = −s.
9 Si k < n− 1 ir al paso4.
10 Si k = n− 1 calculamos laultima columna deR:Para i = 1, . . . ,n hacemosrin =
∑nj=1 qji ajn .
Notese que este algoritmo admite una pequena simplificacion ya que elvalor derk+1k es inicialmente cero y finalmente tambien cero (paso 7). Esevalor solo se usa en los pasos 6 y 7 ypodemos evitar su introduccion usandodirectamenteak+1k en esos pasos. Ademas debe notarse que el valor derkk
calculado en el paso 7 es igual al denominador usado en el paso 6. Ası pueslos pasos 5 a 7pueden sustituirse por los siguientes mas eficaces:
4.2. MetodoQRo de la factorizacion ortogonal 133
5′. Hallamos el valor provisional de la columnak de R:
Parai = 1, . . . , k hacemosrik =∑k
j=1 qji ajk .
6′. Calculamos los cosenos directores de este paso:
t =√
r 2kk+ a2
k+1k c = rkk/t s= −ak+1k/t .
7′. Corregimos la columnak de R: rkk = t .

Capıtulo 5
Teorıa de la Interpolacion yAproximaci on
5.1 El problema general de interpolacion
5.1.1 Introduccion
Antes de la gran difusion que los ordenadores personales y las calculadorasdigitales tuvieron en elultimo tercio del siglo XX, los calculos necesariospara resolver los problemas de ingenierıa y otras ciencias aplicadas se reali-zaban principalmente con la ayuda de tablas de funciones. No hace muchoaun se ensenaba en el bachillerato el uso de lastablas trigonometricas ylogarıtmicasen que se listan los valores (cuidadosamente calculados) quetoma en ciertos puntos una funcion particular, como puede ser el seno oel logaritmo. Naturalmente las tablas no pueden contener todos los puntosque se puedan necesitar. Para los puntos no tabulados es necesario realizarunainterpolacion basada en los puntos de la tabla que sean mas proximosal dado. Por ejemplo, como nos ensenaban en el bachillerato, si necesita-mos el valor de la funcion f en el puntox y en nuestra tabla de la funcionf aparecenx1 y x2 como puntos mas cercanos ax, tendremos
f (x)− f (x2) ≈ (x − x2)f (x1)− f (x2)
x1− x2
135

136 5. Interpolacion y Aproximacion
de donde se obtiene el valor interpolado def enx.
Lo que acabamos de ver es un ejemplo de interpolacion lineal. Consisteen hallar el polinomio lineal o de primer grado que “pasa” por los puntos(x1, f (x1)) y (x2, f (x2)) y tomar paraf (x) el valor de ese polinomio enx. Si este polinomio lineal es una aproximacion suficientemente buena dela funcion f en el intervalo [x1, x2] entonces sus valores ahı podran sertomados por los def . Ası pues, el problema general de interpolacion estamuy relacionado con la teorıa de aproximacion.
La esencia del problema de interpolacion ha de ser entendida como labusqueda de un criterio de como debe comportarse una funcion razonableentre los puntos dados. Despues de todo, se puede usar un numero infinitode curvas distintas para interpolar unos datos y debemos tener, en cadacaso, un criterio para elegir entre ellas. Normalmente ese criterio incluyesencillez y minimizar la curvatura.
5.1.2 Interpolacion, aproximacion y ajuste de datos
La diferencia entre el problema de interpolacion y el problema de apro-ximacion de funciones es principalmente de enfoque. En el problema deaproximacion se busca una funcion (de entre las de una cierta clase) quesea lo mas parecida posible (en un sentido a definir en cada problema) auna funcion dada. En el problema de interpolacion lo que nos interesa esla estimacion delvalor en un punto o unos puntos concretos de una cier-ta funcion que solo es conocida de forma mas o menos exacta en ciertosotros puntos. Por supuesto, este problema puede resolverse a veces si seencuentra una funcion que aproxime a la dada suficientemente bien en elintervalo de interes, pero tambien puede resolverse por otros metodos es-peciales adaptados al problema particular de interpolacion.
Otro problema parecido y relacionado con el problema de interpolaciones el de ajuste de una funcion a unos datos. En ambos casos se trata depoder hallar valores de una funcion en “puntos intermedios” a los de unatabla dada{(xi , yi )}i=1,...,n. Pero en el problema de interpolacion los datosson considerados exactos, y se requerira que la funcion de interpolacionpase exactamente por cada uno de los puntos(xi , yi ), mientras que en elproblema de ajuste lo que se considera correcto es la clase de funciones en-tre las que buscamos la nuestra, mientras que los datos se consideran comoresultados aproximados de la evaluacion de la funcion (ya sea mediante el
5.2. Interpolacion polinomica 137
calculo o como resultados de medidas experimentales), por lo que no sepide que la funcion pase exactamente por ellos (lo que, por otra parte notendrıa normalmente solucion).
5.2 Interpolacion polinomica
Entre las distintas clases de funciones que se usan en la practica para lainterpolacion y aproximacion ocupa un lugar destacado por su sencillez,facilidad de evaluacion y por su gran numero de aplicaciones la clase delas funciones polinomicas. Debe recordarse que toda funcion diferenciablede clasek en un puntox0 puede aproximarse en un entorno dex0 por supolinomio de Taylor en torno a ese punto y que toda funcion continua puedeaproximarse tanto como se quiera mediante polinomios en el sentido delfamoso teorema de Weierstrass:
Teorema 20 (Teorema de Weierstrass)Dada una funcion f continua enun intervalo[a,b] seaEn( f ), para cada entero positivon, el ınfimo de losvalores que toma la cantidad‖ f − p‖∞ = supa≤x≤b | f (x)− p(x)| cuandop recorre el conjuntoPn de los polinomios de grado menor o igual quen,es decir,
En( f ) = infp∈Pn
(sup
a≤x≤b| f (x)− p(x)|
).
Entonceslim
n→∞ En( f ) = 0.
Ası pues, los polinomios son las primeras funciones que se usaran enlas tecnicas de interpolacion, lo cual nos lleva a la teorıa de lainterpolacionpolinomica. Para hacer una interpolacion polinomica de una funcion f enunos puntos dadosx0, . . . , xn, llamados losnodos de interpolacion, es ne-cesario conocer los valores exactosyk = f (xk), k = 0, . . . ,n que f tomaen esos puntos. Entonces interpolar polinomicamentef en un puntox delintervalo que contiene a losx0, . . . , xn es evaluar enx el polinomio delmenor grado posible que coincida conf en los nodosx0, . . . , xn. Tal po-linomio se llamapolinomio de interpolacion de f en los nodosx0, . . . , xn
o tambien polinomio de interpolacion en los puntos(x0, y0), . . . , (xn, yn).Veremos que el valor que el polinomio de interpolacion toma en el puntox

138 5. Interpolacion y Aproximacion
se podra considerar, bajo condiciones adecuadas, como una buena aproxi-macion del valor def en ese punto.
5.2.1 Existencia y unicidad del polinomio de interpola-cion
Dado que un polinomio de grado menor o igual quen esta determinadopor susn+ 1 coeficientes, quedara completamente determinado porn+ 1condiciones como son, por ejemplo, que tome valores prescritos enn + 1puntos distintos. Seana0, . . . ,an los n + 1 coeficientes desconocidos delpolinomio p(x) = anxn+· · ·+a1x+a0. Para quep(x) pase por losn+1puntos(x0, y0), ..., (xn, yn) dichos coeficientes deben satisfacer el sistemaden+ 1 ecuaciones lineales en lasn+ 1 incognitasa0, . . . ,an,
anxn0 + · · · + a1x0+ a0 = y0
... (5.1)
anxnn + · · · + a1xn + a0 = yn .
La matriz de coeficientes de este sistema es la matriz de Vandermonde
M =
xn
0 xn−10 · · · x0 1
xn1 xn−1
1 · · · x1 1...
... · · · ......
xnn xn−1
n · · · xn 1
cuyo determinante es
Ejercicio 5.1
detM =∏
0≤i< j≤n
(xi − xj )
(Sugerencia: tomese la abscisaxn como una variable,t . Entonces la funcion p(t) = det(M(t)
)es un polinomio de gradon cuyas raices son las otras abscisas.)
Este determinante es ciertamente distinto de cero si y solo si xi 6= xj
siempre quei 6= j . En consecuencia el sistema (B.1) tiene solucion unicapara cualesquieran + 1 puntos condistintasabscisasx0, . . . , xn. Hemospues demostrado
5.2. Interpolacion polinomica 139
Teorema 21 Dadosn+1 puntos del plano(x0, y0), ...,(xn, yn) con distin-tas abscisasx0, . . . , xn, existe ununico polinomio de grado menor o igualque n,p(x) que pase por todos ellos, es decir tal que
p(xk) = yk. (k = 0,1, . . . ,n)
En base a este teorema podemos dar la siguiente:
Definicion: Dadosn+ 1 puntos del plano(x0, y0), ..., (xn, yn) con distin-tas abscisasx0, . . . , xn, el unico polinomio de grado menor o igual quen,p(x) que pase por todos ellos se llama elpolinomio de interpolacionde di-chos puntos. Dada una funcion real de variable realf , y abscisas distintasx0, . . . , xn el unico polinomio de grado≤ n que toma el mismo valor quef en los nodosx0, . . . , xn se llama elpolinomio de interpolacion de f enx0, . . . , xn.
Ejercicio 5.2¿Que condicion deben cumplir losn+ 1 puntos{(xk, yk)}0≤k≤n) para queen la solucion de(B.1) resultean = 0?
Ejercicio 5.3¿Cual es el grado del polinomio de interpolacion para los puntos(x0, y0),..., (xn, yn) si estos verificanyk = xk para cadak?
La demostracion de unicidad del polinomio de interpolacion tambienpuede hacerse con el siguiente razonamiento: Supongamos queP(x) yQ(x) son dos polinomios de grado≤ n que coinciden conf en losn + 1puntosx0, . . . , xn. EntoncesP(x) − Q(x) es un polinomio de grado≤ nque se anula en losn+ 1 puntosx0, . . . , xn, es decir, que tienen+ 1 ceros.Esto solo es posible si es el polinomio cero, es decir, siP(x) = Q(x).
De lo dicho se deduce la siguiente importante consecuencia:
Si la funcion f es un polinomio de grado menor o igual quen, el polino-mio de interpolacion de f enn+1 puntos es la propia funcion f . En conse-cuencia, el polinomio de interpolacion paran+1nodos(x0, y0), . . . , (xn, yn)
que tengan las mismas ordenadas,y0 = y1 = · · · = yn = y, es el polino-mio constante (de grado cero) igual ay.

140 5. Interpolacion y Aproximacion
5.2.2 Formula de Lagrange para la interpolacion polinomica.Polinomios de Lagrange
El calculo del polinomio de interpolacion de una funcion en unos puntos da-dos puede hacerse de varias maneras. Despues de lo dicho mas arriba quizaslo primero que se le ocurrirıa a uno serıa resolver el sistema (B.1), sin em-bargo con ello estarıamos calculando mas de lo necesario porque en generalsolo necesitamos evaluar el polinomio de interpolacion en un punto o dos,para lo cual no es necesario evaluar sus coeficientes explıcitamente. A con-tinuacion veremos un metodo de calculo que lleva el nombre deformulade Lagrangeel cual tiene importantes aplicaciones en variasareas de lasmatematicas.
Suponemos dadosn+1 nodos de interpolacion,x0, . . . , xn, todos ellosdistintos entre sı y en cada uno de los cuales se conoce el valor de la fun-cion a interpolar. Para cadak ∈ {0, . . . ,n} formamos el polinomioqk(x)definido como el polinomiomonico(coeficiente principal 1) de gradon quese anula en todos los nodos excepto enxk, es decir, queqk(x) viene dadopor la formula
qk(x) = (x − x0) · · · (x − xk−1)(x − xk+1) · · · (x − xn) =n∏
j=0j 6=k
(x − xj ).
Podemos hacer que esteqk(x) tome el mismo valor quef enxk si lo multi-plicamos porf (xk)/qk(xk). Repitiendo lo mismo para cada nodo y suman-do los resultados obtenemos un polinomio
p(x) = f (x0)
q0(x0)q0(x)+ · · · + f (xn)
qn(xn)qn(x)
que tiene grado≤ n por ser suma de polinomios de gradon y que clara-mente coincide conf en todos los nodos.Este es, pues, el polinomio deinterpolacion de f en los nodosx0, . . . , xn.
Ejercicio 5.4Usar el hecho de que los polinomiosqk(x) son todos monicos de gradonpara deducir que el coeficiente del termino de gradon del polinomio deinterpolacion de f en los nodosx0, . . . , xn es
f (x0)
q0(x0)+ · · · + f (xn)
qn(xn)(5.2)
5.2. Interpolacion polinomica 141
Si definimos los polinomios
Lk(x) = qk(x)
qk(xk)
el polinomio de interpolacion puede expresarse de la siguiente forma lla-madaformula de Lagrange:
p(x) = f (x0)L0(x)+ · · · + f (xn)Ln(x) =n∑
k=0
f (xk)Lk(x) . (5.3)
Los polinomiosLk(x) se llamanpolinomios de Lagrangerelativos a losnodosx0, . . . , xn.
Los polinomios de Lagrange tienen (entre otras propiedades algebrai-cas de interes) la ventaja de ser independientes de la funcion a interpolar;dependenunicamente de los nodos, no de los valoresyk = f (xk) de la fun-cion. Por tanto una vez calculados para unos nodos determinados puedenser utilizados para interpolar cualquier funcion en esos nodos.
Ejemplo de interpolacion usando los polinomios de Lagrange.–
Supongamos que queremos estimar el valor de ciertas funcionesf , g en elpuntox = 2.12 para lo cual disponemos de los valores dados en la siguientetabla:
x f (x) g(x)
2.0 0.69315 0.56931
2.1 0.74194 0.57884
2.2 0.78846 0.67419
entonces procedemos de la siguiente forma: primero evaluamos los po-linomios de Lagrange en los nodos, lo cual puede hacerse directamenteescribiendo solamente:
L0(2.12) = (2.12− 2.1)(2.12− 2.2)
(2.0− 2.1)(2.0− 2.2)= (0.02)(−0.08)
(−0.1)(−0.2)= −0.08
L1(2.12) = (2.12− 2.0)(2.12− 2.2)
(2.1− 2.0)(2.1− 2.2)= (0.12)(−0.08)
(0.1)(−0.1)= 0.96
L2(2.12) = (2.12− 2.0)(2.12− 2.1)
(2.2− 2.0)(2.2− 2.1)= (0.12)(0.02)
(0.2)(0.1)= 0.12

142 5. Interpolacion y Aproximacion
(Observacion: L0(2.12)+ L1(2.12)+ L2(2.12) = 1. ¿Casualidad?)
y ahora es inmediato calcular el valor estimado def (x):
f (2.12) ' p2(2.12)
= 0.69315× (−0.08)+ 0.74194× 0.96+ 0.78846× 0.12
= 0.75142,
y el valor estimado deg(x):
g(2.12) ' q2(2.12)
= 0.56931× (−0.08)+ 0.57884× 0.96+ 0.67419× 0.12
= 0.59104.
5.2.3 Formula baric entrica para el polinomio de interpo-lacion
El calculo de un punto de interpolacion mediante la formula de Lagran-ge es excesivamente costoso si se compara con el numero de operacionesnecesarias para evaluar un polinomio de gradon (a saber,n sumas yn mul-tiplicaciones).
Ejercicio 5.5La evaluacion de un punto de interpolacion mediante la formula de Lagran-ge del polinomio de interpolacion paran+ 1 puntos requiere
n(2n+ 3) sumas (on(n+ 2) si se guardan
los resultados intermedios)
(n+ 1)(2n− 1) multiplicaciones
n+ 1 divisiones
lo cual representa un numero de operaciones del orden de4n2 (o 3n2 si seguardan resultados intermedios).
Por supuesto, al aplicar la formula de Lagrange no solo estamos eva-luando el polinomio de interpolacion sino que tambien estamos, de algunamanera y hasta cierto punto, hallando ese polinomio. Esto nos indica quesi necesitamos hacer varias interpolaciones con los mismos nodos estare-mos de alguna forma repitiendo innecesariamente algunos calculos. Ası
5.2. Interpolacion polinomica 143
pues podemos preguntarnos si existe alguna forma de disponer los calculospara reducir al maximo el numero de operaciones que hemos de realizaro para ahorrar trabajo en el caso de que necesitemos interpolar en variospuntos. La formula baricentrica es una forma de escribir el polinomio deinterpolacion que da una solucion parcial a esta cuestion.
En primer lugar notemos que losn+ 1 polinomios de LagrangeLk(x)estan relacionados por el hecho de que su suma vale 1 en cualquier punto.Esto es consecuencia del hecho observado mas arriba de que el polinomiode interpolacion de la funcion constantef (x) = 1 es ella misma y por lotanto
1=n∑
k=0
Lk(x).
Ademas de esto si definimos el polinomio de gradon+ 1
q(x) = (x − x0) · · · (x − xn),
entonces para todok ∈ {0, . . . ,n} tenemosqk(x) = q(x)/(x − xk) lo cualpermite escribir el polinomio de interpolacion como
p(x) = q(x) f (x0)
(x − x0)q0(x0)+ · · · + q(x) f (xn)
(x − xn)qn(xn)
= q(x)n∑
k=0
f (xk)
(x − xk)qk(xk). (5.4)
Ejercicio 5.6Demostrar que el polinomioq(x) definido mas arriba tiene la propiedad deque para todok ∈ {0, . . . ,n} su derivada verificaq′(xk) = qk(xk).
Sugerencia:Derivarq(x) = qk(x)(x − xk) respecto ax.
Ejercicio 5.7De la relacion 1 = ∑n
k=0 Lk(x) se deduce que el polinomioq(x) puedeexpresarse como
q(x) = 1n∑
k=0
1
(x − xk)qk(xk)
. (5.5)

144 5. Interpolacion y Aproximacion
Como consecuencia de estos resultados, se llega a la formula baricentricadel polinomio de interpolacion:
Teorema 22 (Formula baric entrica) Dadosn+1puntos(x0, y0), ...,(xn, yn)
y definidas las cantidades
ak = 1
qk(xk),
el valor enx del polinomio de interpolacion para los puntos(x0, y0), ...,(xn, yn) es el promedio ponderado o baricentro de las ordenadasyk conpesos ak
(x−xk), es decir,
p(x) =a0
(x−x0)y0+ · · · + an
(x−xn)yn
a0(x−x0)
+ · · · + an(x−xn)
Demostracion: Esto no es mas que la formula (5.4) en la que se ha expre-sadoq(x) segun (5.5).
En consecuencia si se evalua el polinomio de interpolacion medianteesta formula y se guardan los valores de las cantidadesak, ası como los delas cantidadesbk = akyk, posteriores evaluaciones para distintos valores dex solo cuestan 3n+ 1 sumas y 2(n+ 1)+ 1= 2n+ 3 divisiones, es decir,del orden de 5n operaciones.
5.2.4 Analisis de errores
Nos proponemos ahora estimar el error que se comete al realizar una inter-polacion polinomica. SeaPn(x) el polinomio de interpolacion de f (x) enlos puntosx0, . . . , xn y seaRn(x) el restoo error cometido al tomarPn(x)por f (x), Rn(x) = f (x) − Pn(x). EvidentementeRn es una funcion quese anula en losn+ 1 puntosx0, . . . , xn por lo que podemos poner
Rn(x) = C(x)(x − x0) · · · (x − xn).
Fijamos ahora el puntox ∈ [x0, xn], distinto de cualquiera de los nodosx0, . . . , xn, y definimos, para estex fijo, la funcion
F(t) = f (t)− Pn(t)− C(x)(t − x0) · · · (t − xn).
5.2. Interpolacion polinomica 145
Esta funcion se anula parat = x0, . . . , xn y tambien parat = x, luegotienen+ 2 ceros distintos en el intervalo [x0, xn]. En consecuencia, segunel teorema de Rolle, su derivada tienen+1 ceros distintos en [x0, xn]. Por lamisma razon la derivada segundaF ′′(t) tienen ceros distintos en [x0, xn]y siguiendo de esta forma llegamos a que la derivadan + 1, F (n+1)(t),tiene un cero en [x0, xn] que denotaremosη. Pero, teniendo en cuenta que
la derivadan + 1 de un polinomio de gradon es cero y quedn+1
dtn+1 {(t −x0) · · · (t − xn)} = dn+1
dtn+1 tn = (n+ 1)!, tenemos
F (n+1)(t) = f (n+1)(t)− P(n+1)n (t)− C(x)
dn+1
dtn+1
{(t − x0) · · · (t − xn)
}= f (n+1)(t)− C(x)(n+ 1)!,
en consecuencia
f (n+1)(η)− C(x)(n+ 1)! = 0
de donde deducimos
C(x) = f (n+1)(η)
(n+ 1)!.
Con esto la formula del resto queda
Rn(x) = f (n+1)(η)
(n+ 1)!(x − x0) · · · (x − xn) (5.6)
para algunη ∈ [x0, xn]. Notese la semejanza de esta formula con la formuladel resto del polinomio de Taylor (vease, por ejemplo (5.16)).
El valor de f (n+1)(η) que aparece en la formula (5.6) es desconocido(entre otras razones porque el puntoη es desconocido). Sin embargo, confrecuencia es posible dar una acotacion de f (n+1) en el intervalo [x0, xn]donde sabemos se encuentraη. En tal caso podemos utilizar la formula delresto (5.6) para estimar el error de interpolacion como ilustramos con elsiguiente ejemplo:
Supongamos que estimamos el valor de log10 7 mediante interpolacion

146 5. Interpolacion y Aproximacion
en la siguiente tablax log10(x)
5 0.69897
6 0.77815
8 0.90309
9 0.95424
10 1
El error es
R4(7) = C(7)(7− 5)(7− 6)(7− 8)(7− 9)(7− 10) = −12C(7)
dondeC(7) = 15!
d5 log10(x)dx5
∣∣x=η = 1
5!1
ln 104!η5 = 1
5 ln 10η5 . Ahora bien, como
η > 5, 1η5 <
155 y por tanto
|R4(7)| = | − 12C(7)| = 12
5 ln 10η5<
12
56 ln 10' 0.000334.
Este resultado nos indica que podemos esperar tres decimales exactos en elvalor de log10 7 hallado por interpolacion.
5.3 Metodo de Newton para simplificar el anadirnuevos puntos
Hemos visto que la formula baricentrica representa una economıa de ope-raciones respecto a la formula de Lagrange, especialmente si necesitamosinterpolar la misma funcion en varios puntos con los mismos nodos. Sinembargo en ocasiones uno desearıa hacer una interpolacion de una mismafuncion en un mismo punto pero con unos nodos diferentes. Por ejemplo,podemos encontrarnos en la situacion de poder elegir entre unos nodos uotros, o, en caso de trabajar con una tabla en la que los nodos son fijos, po-demos haber calculado una interpolacion basandonos en ciertos puntos dela tabla y desear repetir la interpolacion usando algun valor adicional conla intencion de aumentar la exactitud. En este segundo caso ¿serıa necesa-rio repetir los calculos desde el principio otra vez? ¿Podremos aprovecharparte de los calculos ya realizados? Newton observo que se puede expre-sar el polinomio de interpolacion, Pn, den+ 1 puntos, como una suma de
5.3. Metodo de Newton 147
terminos tal que elultimo termino sea igual aPn − Pn−1. De esta forma,al anadir mas puntos de interpolacion no es necesario recalcular todos losterminos, sino simplemente anadir unos nuevos.
5.3.1 La formula de Newton
SeaPn(x) el polinomio de interpolacion de losn+ 1 puntos
(x0, y0), . . . , (xn, yn).
El calculo de este polinomio puede hacerse con un mınimo de operacionesadicionales si se conoce ya el polinomioPn−1(x) de interpolacion paralos n puntos(x0, y0), . . . , (xn−1, yn−1). Para ver lo que hemos de anadira Pn−1(x) para obtenerPn(x) estudiemos la diferenciaPn(x) − Pn−1(x).Claramente esta diferencia es un polinomio de grado menor o igual quenque se anula en losn puntosx0, . . . , xn−1 por lo tanto es de la forma
Pn(x)− Pn−1(x) = An(x − x0) · · · (x − xn−1)
para alguna constanteAn que hemos de determinar a partir de los datos(x0, y0), . . . , (xn, yn).
Ejercicio 5.8Demostrar que la constanteAn es igual al coeficiente del termino de gradon del polinomioPn(x). Usar el resultado del ejercicio 5.4 para deducir laformula
An = y0
q0(x0)+ · · · + yn
qn(xn)(5.7)
Ası pues, dados los puntos(x0, y0), . . . , (xn, yn), para cadak ∈ {0, . . . ,n}podemos calcular la constanteAk la cual es, por definicion, el coeficienteprincipal del polinomio de interpolacion de gradok en los puntos(x0, y0),. . . , (xk, yk). Estas constantes tienen una importancia especial y reciben unnombre que indica una forma alternativa de calcularlas:
Definicion: Las constantesA1, A2, . . . , An se denominandiferencias di-vididas de los puntos(x0, y0), . . . , (xn, yn). Cuando losyk se obtienencomo los valores de una funcion f en losxk, estas diferencias divididas serepresentan con la notacion
Ak = f [x0, . . . , xk] .

148 5. Interpolacion y Aproximacion
Evidentemente esta definicion implica la siguientes expresiones paralos sucesivos polinomios de interpolacion:
P0(x) = f (x0)
P1(x) = f (x0)+ f [x0, x1](x − x0)
P2(x) = f (x0)+ f [x0, x1](x − x0)+ f [x0, x1, x2](x − x0)(x − x1)
.
.
.
Pn(x) = f (x0)+ f [x0, x1](x − x0)+ · · · + f [x0, . . . , xn](x − x0) · · · (x − xn−1)
Esta forma de expresar los polinomios de interpolacion se conoce comoformula de Newton. Podemos expresarla en forma mas compacta ası:
Pn(x) =n∑
i=0
f [x0, . . . , xi ]i−1∏j=0
(x − xj ) (5.8)
Ejercicio 5.9Utilizar el resultado del ejercicio 5.8 para establecer la formula
f [x0, . . . , xn] = 1
n!
dn Pn(x)
dxn(5.9)
Vamos ahora a estudiar la forma mas eficaz de calcular las diferenciasdivididas f [x0, . . . , xi ] que aparecen en la formula de Newton.
5.3.2 Las diferencias divididas
Dando ax los valoresx0, . . . , xn en la formula de Newton obtenemos
y0 = f (x0)
y1 = y0 + f [x0, x1](x1 − x0)
y2 = y0 + f [x0, x1](x2 − x0)+ f [x0, x1, x2](x2 − x0)(x2 − x1)
.
.
.
yn = y0 + f [x0, x1](xn − x0)+ · · · + f [x0, . . . , xn](xn − x0) · · · (xn − xn−1)
5.3. Metodo de Newton 149
De esto, suponiendo que los nodos son distintos dos a dos, deducimos:
f [x0, x1] = y1− y0
x1− x0
f [x0, x1, x2] =y2−y0x2−x0
− f [x0, x1]
x2− x1= f [x0, x2] − f [x0, x1]
x2− x1,
y continuando de esta manera se puede llegar a establecer en general:
f [x0, . . . , xk+1] = f [x0, . . . , xk−1, xk+1] − f [x0, . . . , xk−1, xk]
xk+1− xk(5.10)
que es la formula que expresaf [x0, . . . , xk+1] como diferencia dividida.Sin embargo esta formula puede demostrarse mucho mas sencillamente dela siguiente forma:
Ejercicio 5.10Seanx0, . . . , xk+1 nodos de interpolacion distintos entre si. Sip(x) es elpolinomio de interpolacion de f en x0, . . . , xk−1, xk+1, y q(x) es el poli-nomio de interpolacion de f enx0, . . . , xk, entonces el polinomio
x − xk
xk+1− xkp(x)+ xk+1− x
xk+1− xkq(x)
tiene grado≤ k + 1 y coincide conf enx0, . . . , xk+1 (y por lo tanto es elpolinomio de interpolacion de f en los puntosx0, . . . , xk+1).
Sugerencia:Ver la demostracion del Lema de Aitken.
Utilizando el resultado de este ejercicio se llega facilmente al siguienteresultado:
Ejercicio 5.11Seanf [x0, . . . , xk−1, xk+1] y f [x0, . . . , xk] los coeficientes del termino degradok de los polinomiosp y q del ejercicio 5.10. Entonces, suponiendoquexk+1 6= xk, el coeficiente del termino de gradok+ 1 del polinomio deinterpolacion de f enx0, . . . , xk+1 es igual a
f [x0, . . . , xk−1, xk+1] − f [x0, . . . , xk−1, xk]
xk+1− xk.

150 5. Interpolacion y Aproximacion
En realidad, la formula (5.10) es solo una de las posibles formulas delas diferencias divididas. Todas esas formulas pueden deducirse a la vez aldemostrar, con un razonamiento analogo al de los ejercicios 5.10 y 5.11, elsiguiente teorema,
Teorema 23 Si los nodos de interpolacion son todos distintos entre si, en-tonces lan-esima diferencia divididaf [x0, . . . , xn] puede calcularse, paracualesquierai, j ∈ {0, . . . ,n} con i 6= j , mediante
f [x0, . . . , xn] = f [x0, . . . , xi , . . . , xn] − f [x0, . . . , x j , . . . , xn]
xj − xi(5.11)
donde el circunflejo indica una variable que no se considera incluida en lalista, por ejemplo,
f [x0, . . . , xi , . . . , xn] = f [x0, . . . , xi−1, xi+1, . . . , xn].
El caso particular de la formula (5.11) mas utilizado es el que resulta altomari = 0 y j = n, es decir
f [x0, . . . , xn] = f [x1, . . . , xn] − f [x0, . . . , xn−1]
xn − x0. (5.12)
Este teorema se deduce (con un razonamiento analogo al que nos llevadel ejercicio 5.10 al ejercicio 5.11) de un teorema conocido con el nombredeLema de Aitken.
Teorema 24 (Lema de Aitken) Sea f una funcion continua en un inter-valo I y sean{x0, . . . , xn} ∈ I . Para cada subconjuntoS⊂ {x0, . . . , xn}denotemosPS(x) el polinomio de interpolacion de f en los nodos que sonelementos deS. Sixi , xj ∈ Sy xi 6= xj entonces
PS(x) =(x − xj )PS−{x j }(x)− (x − xi )PS−{xi }(x)
xi − xj.
Demostracion: Seam+ 1 el numero de elementos deS. Lo que hay queprobar es quePS tiene grado≤ m y que coincide conf en los elementosde S. Lo ultimo es evidente paraxi y paraxj porque lo cumplenPS−{xi }
5.3. Metodo de Newton 151
y PS−{x j }. Para unxk ∈ S distinto dexi y de xj , dado quePS−{xi }(xk) =f (xk) y PS−{x j }(xk) = f (xk), tenemos
PS(xk) = (xk − xj ) f (xk)+ (xi − xk) f (xk)
xi − xj
= −xj f (xk)+ xi f (xk)
xi − xj= f (xk).
Solo falta demostrar quePS tiene grado≤ m. Por ser polinomios de in-terpolacion enm nodos tantoPS−{xi } comoPS−{x j } tienen grado≤ m− 1y al multiplicarlos por polinomios de primer grado se obtienen polinomiosde grado≤ m, por lo quePS tiene grado≤ m. En consecuenciaPS es elpolinomio de interpolacion en los nodos que son elementos deS.
5.3.3 Propiedades de simetrıa
Una propiedad importante de las diferencias divididas de un conjunto depuntos es el ser independientes del orden en que los puntos esten dados.
Teorema 25 (Propiedad de simetrıa de las diferencias divididas)Dadosn+ 1 numerosx0, . . . , xn en el dominio de una funcion f , para cualquierpermutacionσ : {0, . . . ,n} → {0, . . . ,n} de losındices{0, . . . ,n} se veri-fica
f [x0, . . . , xn] = f [xσ(0), . . . , xσ(n)]
Demostracion: Una demostracion inmediata se basa en la formula (5.7)en la que una reordenacion de los puntosx0, . . . , xn solo cambia el ordende los sumandos. Otra demostracion puede hacerse por induccion en elnumero de puntos. La simetrıa es trivial para el caso de un punto (n = 0) yes evidente en el caso de dos puntos:
f [x0, x1] = f (x1)− f (x0)
x1− x0= f (x0)− f (x1)
x0− x1= f [x1, x0].
Supongamos que se cumple para el caso den puntos y consideremos losn+1 puntosx0, . . . , xn y la permutacion σ : {0, . . . ,n} → {0, . . . ,n}. Seani = σ(0), j = σ(n), entonces (por la hipotesis de induccion) f [x0, . . . , xi , . . . , xn] =f [xσ(1), . . . , xσ(n)] e igualmentef [x0, . . . , x j , . . . , xn] = f [xσ(0), . . . , xσ(n−1)]

152 5. Interpolacion y Aproximacion
donde el circunflejo sobre una variable indica que esa variable no se consi-dera incluida en la lista. Entonces, segun las formulas (5.11) y (5.12),
f [x0, . . . , xn] = f [x0, . . . , xi , . . . , xn] − f [x0, . . . , x j , . . . , xn]
xj − xi
= f [xσ(1), . . . , xσ(n)] − f [xσ(1), . . . , xσ(n−1)]
xσ(n) − xσ(0)= f [xσ(0), . . . , xσ(n)]
con lo que queda demostrado el teorema.
5.3.4 La tabla de diferencias divididas y adicion de nue-vos nodos
Si calculamos las diferencias divididas de una funcion f en los puntosx0, . . . , xn mediante (5.12) podemos disponerlas en una tabla de la siguien-te forma:
x0 f [x0]f [x0, x1]
x1 f [x1] f [x0, x1, x2]f [x1, x2] f [x0, x1, x2, x3]
x2 f [x2] f [x1, x2, x3] f [x0, x1, x2, x3, x4]f [x2, x3] f [x1, x2, x3, x4]
x3 f [x3] f [x2, x3, x4]f [x3, x4]
x4 f [x4]
Esta tabla nos indica la forma de calcular cada diferencia dividida: ladiferencia de las dos que estan a su izquierda dividida entre la correspon-diente diferencia de lasx. Por ejemplo, la tabla de diferencias divididaspara los datos
x f (x)
1 1.5709
4 1.5727
6 1.5751
es1 1.5709
0.00064 1.5727 0.00012
0.00126 1.5751
5.4. El algoritmo de interpolacion de Aitken 153
Supongamos ahora que nos dan el punto(0,1.5708) como informacionadicional. Entonces solo tenemos que hacer un poco mas de trabajo paracompletar la tabla
1 1.57090.0006
4 1.5727 0.000120.0012 −0.000001
6 1.5751 0.0001210.000717
0 1.5708
5.4 El algoritmo de interpolacion de Aitken
Gran parte del error cometido al hacer una interpolacion proviene del re-dondeo en las operaciones aritmeticas realizadas. Veremos a continuacionun algoritmo para la evaluacion del polinomio de interpolacion, que estaespecialmente adaptado para reducir los errores de calculo.
Antes de introducir dicho algoritmo, llamado elalgoritmo de Aitken,vamos a introducir la siguiente notacion para los polinomios de interpola-cion. Denotaremos porP0,...,n el polinomio de interpolacion de una funcionf en los nodosx0, . . . , xn. Es decir, usamos como subındices en el poli-nomio de interpolacion el conjunto deındices correspondientes a los nodosde interpolacion. De acuerdo con esto tenemos:
P0,1 = f (x0)x − x1
x0− x1+ f (x1)
x − x0
x1− x0, (Lagrange)
P0,1 = f (x0)+ f (x1)− f (x0)
x1− x0(x − x0), (Newton)
P0,1 = (x − x0) f (x1)− (x − x1) f (x0)
x1− x0(Aitken)
= (x − x0)P1(x)− (x − x1)P0(x)
x1− x0.
Para tres puntos la formula de Aitken es
P0,1,2(x) = (x − x1)P0,2(x)− (x − x2)P0,1(x)
x2− x1

154 5. Interpolacion y Aproximacion
y en general, de acuerdo con la formula del lema de Aitken, tenemos
P0,...,k+1(x) = (x − xk)P0,...,k−1,k+1(x)− (x − xk+1)P0,...,k(x)
xk+1− xk.
Esta formula es la base del algoritmo de Aitken:
Algoritmo de interpolacion de Aitken
1 Datos: n (numero de intervalos o segmentos), x0, . . . , xn (nodos de interpolacion),y0, . . . , yn (ordenadas en los nodos), x (punto en el que se desea interpolar la fun-cion).
2 Para k = 0,n
A(k,0) = yk;D(k) = x − xk;
3 Siguientek
4 Para i = 1,n
Para j = 1, iA(i, j ) = [D( j − 1)A(i, j − 1)− D(i )A( j − 1, j − 1)]/(xi − x j−1);
Siguiente j
5 Imprimir A(i, i )
6 Siguientei
7 Imprimir “ Solucion es:”; A(n,n); “ .” y PARAR
En este algoritmo se imprimen todos los valores intermedios,A(i, i ),con el objetivo de tener una idea de la convergencia. Dichos valores de ladiagonal deA forman una sucesion de aproximaciones al valor deseado.Si esta sucesion se acerca a un valor fijo podemos tomar ese valor comoel valor de la interpolacion deseado. Normalmente dichos valores parecenconverger al cabo de unos pocos pasos y llegados a un punto empiezan a di-verger con un empeoramiento de la estimacion. Esto nos indica que pasadocierto punto no se gana precision al utilizar mas nodos de interpolacion.
Cuando se hacen calculos con una calculadora de bolsillo, se puedensistematizar los calculos segun un esquema sencillo facil de memorizar.Por ejemplo, el calculo deP0,1,2 = [(x−x1)P0,2− (x−x2)P0,1]/(x2−x1)
es como el de un determinante 2×2 dividido porx2− x1. En esta situacionconviene disponer los calculos en una tabla de la siguiente forma:
5.5. Nodos igualmente espaciados 155
xi x − xi f (xi )
x0 x − x0 P0
x1 x − x1 P1 P0,1
x2 x − x2 P2 P0,2 P0,1,2
x3 x − x3 P3 P0,3 P0,1,3 P0,1,2,3
Ejercicio 5.12Comprobar la siguiente tabla de interpolaciones de la funcion f en el puntox = 4.5,
xi x − xi f (xi )
4.0 0.5 0.60206
4.2 0.3 0.62325 0.65504
4.4 0.1 0.64345 0.65380 0.65318
4.6 −0.1 0.66276 0.65264 0.65324 0.65321
4.8 −0.3 0.68124 0.65155 0.65330 0.65321 0.65321
5.5 Interpolacion con nodos igualmente espacia-dos
Vamos a suponer ahora que los nodos de interpolacion estan igualmenteespaciados, es decir (suponiendo los nodos dados en orden creciente,x0 <
· · · < xn), las diferenciasxi+1 − xi son todas iguales a un valor fijo quedenotamosh. Entonces, sia = x0 y b = xn, tenemosh = (b− a)/n.
Dado un puntox definimos la variables = (x − x0)/h, de forma quex = x0 + sh. Con este cambio de variable los nodos corresponden a losvalores enteros no negativos des, s = 0, . . . ,n y podemos aplicar estecambio de variable a la funcion f para obtener la funcion de variable enteraF tal que para valores correspondientes dex y s, F(s) = f (x) = f (x0 +sh) = fs.
Ahora definimos los incrementos deordenes sucesivos,
11 fs = fs+1− fs = F(s+ 1)− F(s)
12 fs = 11 fs+1−11 fs

156 5. Interpolacion y Aproximacion
y, en general
1i+1 fs = 1i fs+1−1i fs.
Estos incrementos se llamandiferencias progresivasy se pueden calcu-lar para cualquier conjunto de puntos(xi , yi ) en los que las abscisas estenigualmente espaciadas. En base a estas diferencias progresivas se puedencalcular facilmente las diferencias divididas correspondientes a los nodosdados mediante la formula que se establece en el siguiente teorema:
Teorema 26 Si las abscisas de los puntos(xi , f (xi )) estan igualmente es-paciadas siendo el espaciamientoh = xi+1− xi , entonces
f [xk, . . . , xk+n] = 1n fkn!hn
Demostracion: Por induccion. Sin = 0, f [xk] = f (xk) = 10 fk/h0 = fk.Tambien se puede comprobar inmediatamente que la formula es valida paran = 1. Supongamos el resultado cierto para cierton. Entonces
f [xk, . . . , xk+n+1] = f [xk+1, . . . , xk+n+1] − f [xk, . . . , xk+n]
xk+n+1− xk
=1
n!hn1n fk+1− 1
n!hn1n fk
(n+ 1)h
= 1n fk+1−1n fk(n+ 1)!hn+1
= 1n+1 fk(n+ 1)!hn+1
con lo que se completa la demostracion.
Corolario 7 Si Pn es el polinomio de interpolacion de f en nodos igual-mente espaciadosx0, . . . , xn conxk = x0+ kh entonces
dn Pn(x)
dxn= 1n f0
hn
Demostracion:
Segun la formula (5.9) que aparece en el ejercicio 5.9, tenemosf [x0, . . . , xn] =1n! d
n Pn(x)/dxn. Ahora bien, segun el teorema anterior
f [x0, . . . , xn] = 1
n!1n f0/h
n,
5.5. Nodos igualmente espaciados 157
por tanto, igualando terminos y cancelando el factorial se obtiene la formuladel corolario.
Vamos a ver ahora la forma que adopta la formula de Newton del po-linomio de interpolacion para nodos igualmente espaciados con espacia-miento igual ah = (xn − x0)/n. Utilizando la expresion de las diferenciasdivididas dada en el teorema anterior, la formula de Newton queda
Pn(x) = f (x0)+ 11 f0h
(x − x0)+ · · · + 1n f0
n!hn(x − x0) · · · (x − xn−1)
y teniendo en cuenta que para cadak, x−xk = (s−k)h (usando la variables definida pors= (x − x0)/h), podemos poner
Pn(x) = f0+ s11 f0+s(s− 1)
2!12 f0+ · · · +
s(s− 1) · · · (s− n+ 1)
n!1n f0.
Ahora bien, podemos definir los numeros combinatorios(sk
)paras no ne-
cesariamente entero mediante(s
k
)= s(s− 1) · · · (s− k+ 1)
k!,
con lo cual el polinomio de interpolacion queda
Pn(x) = f0+(
s
1
)11 f0+
(s
2
)12 f0+ · · · +
(s
n
)1n f0,
o en forma mas compacta
Pn(x) = Pn(x0+ sh) =n∑
k=0
(s
k
)1k f0.
5.5.1 Problemas de la interpolacion con nodos igualmenteespaciados
Si nos fijamos en la funcion q(x) = (x − x0) · · · (x − xn) que determinael comportamiento del error de interpolacion, nos encontramos con unafuncion que, para nodos igualmente espaciados, tiene grandes oscilacioneshacia los extremos del intervalo de interpolacion. Como ejemplo observeseel comportamiento deq(x) para las abscisas obtenidas al dividir el intervalo[−1,1] en 9 subintervalos iguales:
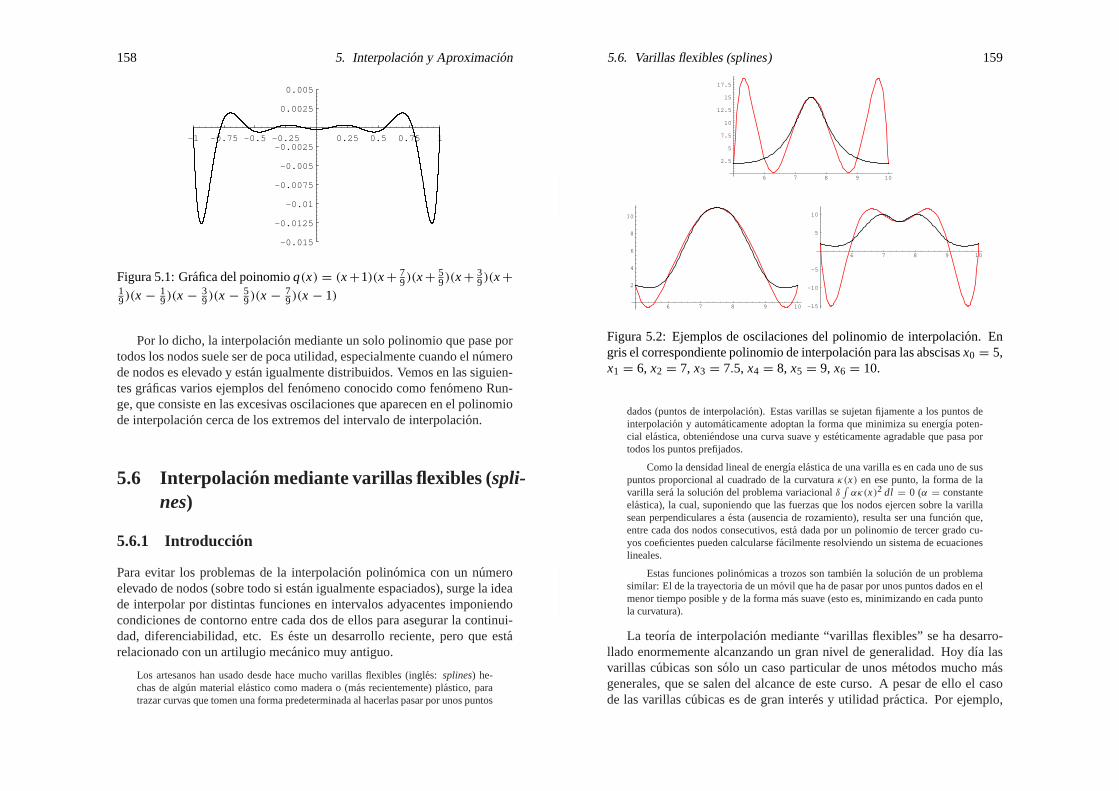
-1 -0.75 -0.5 -0.25 0.25 0.5 0.75 1
-0.015
-0.0125
-0.01
-0.0075
-0.005
-0.0025
0.0025
0.005
6 7 8 9 10
2.5
5
7.5
10
12.5
15
17.5
6 7 8 9 10
2
4
6
8
10
6 7 8 9 10
-15
-10
-5
5
10
158 5. Interpolacion y Aproximacion
Figura 5.1: Grafica del poinomioq(x) = (x+1)(x+ 79)(x+ 5
9)(x+ 39)(x+
19)(x − 1
9)(x − 39)(x − 5
9)(x − 79)(x − 1)
Por lo dicho, la interpolacion mediante un solo polinomio que pase portodos los nodos suele ser de poca utilidad, especialmente cuando el numerode nodos es elevado y estan igualmente distribuidos. Vemos en las siguien-tes graficas varios ejemplos del fenomeno conocido como fenomeno Run-ge, que consiste en las excesivas oscilaciones que aparecen en el polinomiode interpolacion cerca de los extremos del intervalo de interpolacion.
5.6 Interpolacion mediante varillas flexibles (spli-nes)
5.6.1 Introduccion
Para evitar los problemas de la interpolacion polinomica con un numeroelevado de nodos (sobre todo si estan igualmente espaciados), surge la ideade interpolar por distintas funciones en intervalos adyacentes imponiendocondiciones de contorno entre cada dos de ellos para asegurar la continui-dad, diferenciabilidad, etc. Eseste un desarrollo reciente, pero que estarelacionado con un artilugio mecanico muy antiguo.
Los artesanos han usado desde hace mucho varillas flexibles (ingles: splines) he-chas de algun material elastico como madera o (mas recientemente) plastico, paratrazar curvas que tomen una forma predeterminada al hacerlas pasar por unos puntos
5.6. Varillas flexibles (splines) 159
Figura 5.2: Ejemplos de oscilaciones del polinomio de interpolacion. Engris el correspondiente polinomio de interpolacion para las abscisasx0 = 5,x1 = 6, x2 = 7, x3 = 7.5, x4 = 8, x5 = 9, x6 = 10.
dados (puntos de interpolacion). Estas varillas se sujetan fijamente a los puntos deinterpolacion y automaticamente adoptan la forma que minimiza su energıa poten-cial elastica, obteniendose una curva suave y esteticamente agradable que pasa portodos los puntos prefijados.
Como la densidad lineal de energıa elastica de una varilla es en cada uno de suspuntos proporcional al cuadrado de la curvaturaκ(x) en ese punto, la forma de lavarilla sera la solucion del problema variacionalδ
∫ακ(x)2 dl = 0 (α = constante
elastica), la cual, suponiendo que las fuerzas que los nodos ejercen sobre la varillasean perpendiculares aesta (ausencia de rozamiento), resulta ser una funcion que,entre cada dos nodos consecutivos, esta dada por un polinomio de tercer grado cu-yos coeficientes pueden calcularse facilmente resolviendo un sistema de ecuacioneslineales.
Estas funciones polinomicas a trozos son tambien la solucion de un problemasimilar: El de la trayectoria de un movil que ha de pasar por unos puntos dados en elmenor tiempo posible y de la forma mas suave (esto es, minimizando en cada puntola curvatura).
La teorıa de interpolacion mediante “varillas flexibles” se ha desarro-llado enormemente alcanzando un gran nivel de generalidad. Hoy dıa lasvarillas cubicas son solo un caso particular de unos metodos mucho masgenerales, que se salen del alcance de este curso. A pesar de ello el casode las varillas cubicas es de gran interes y utilidad practica. Por ejemplo,
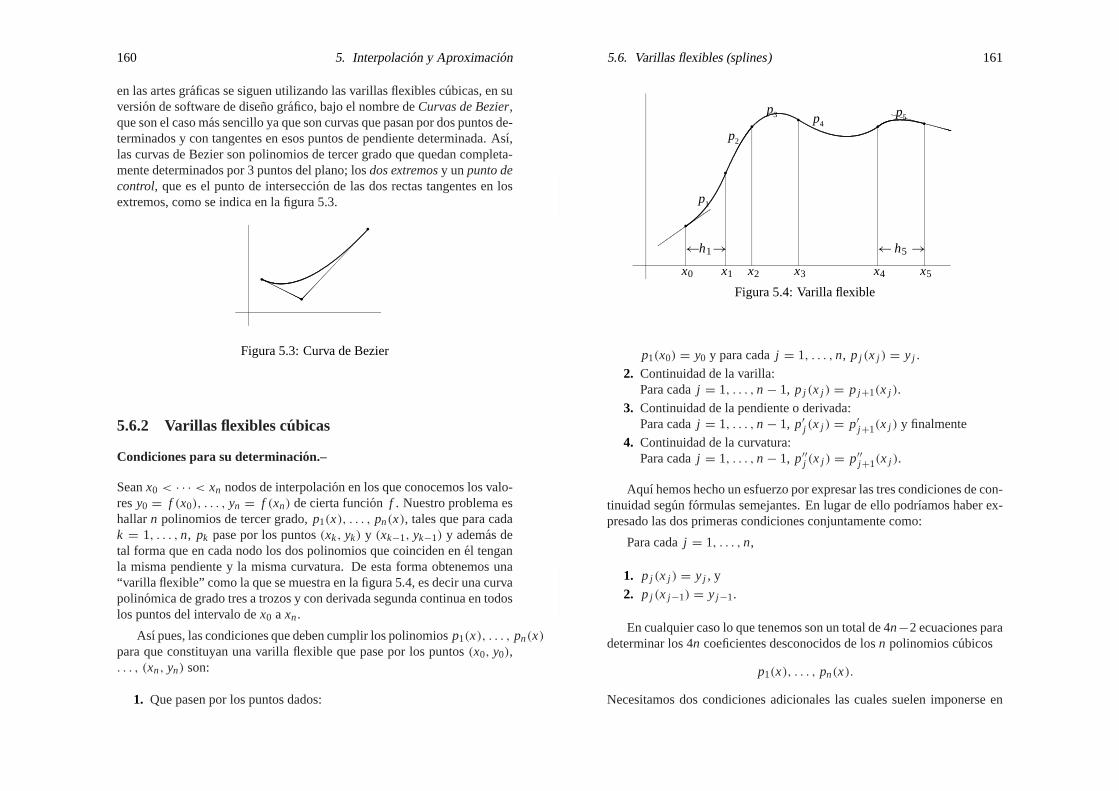
160 5. Interpolacion y Aproximacion
en las artes graficas se siguen utilizando las varillas flexibles cubicas, en suversion de software de diseno grafico, bajo el nombre deCurvas de Bezier,que son el caso mas sencillo ya que son curvas que pasan por dos puntos de-terminados y con tangentes en esos puntos de pendiente determinada. Ası,las curvas de Bezier son polinomios de tercer grado que quedan completa-mente determinados por 3 puntos del plano; losdos extremosy unpunto decontrol, que es el punto de interseccion de las dos rectas tangentes en losextremos, como se indica en la figura 5.3.
qFigura 5.3: Curva de Bezier
5.6.2 Varillas flexibles cubicas
Condiciones para su determinacion.–
Seanx0 < · · · < xn nodos de interpolacion en los que conocemos los valo-resy0 = f (x0), . . . , yn = f (xn) de cierta funcion f . Nuestro problema eshallarn polinomios de tercer grado,p1(x), . . . , pn(x), tales que para cadak = 1, . . . ,n, pk pase por los puntos(xk, yk) y (xk−1, yk−1) y ademas detal forma que en cada nodo los dos polinomios que coinciden enel tenganla misma pendiente y la misma curvatura. De esta forma obtenemos una“varilla flexible” como la que se muestra en la figura 5.4, es decir una curvapolinomica de grado tres a trozos y con derivada segunda continua en todoslos puntos del intervalo dex0 a xn.
Ası pues, las condiciones que deben cumplir los polinomiosp1(x), . . . , pn(x)para que constituyan una varilla flexible que pase por los puntos(x0, y0),. . . , (xn, yn) son:
1. Que pasen por los puntos dados:
5.6. Varillas flexibles (splines) 161
qqq q q q
x0 x1 x2 x3 x4 x5
h1← → h5← →
p1
p2
p3 p4p5
Figura 5.4: Varilla flexible
p1(x0) = y0 y para cadaj = 1, . . . ,n, pj (xj ) = yj .
2. Continuidad de la varilla:Para cadaj = 1, . . . ,n− 1, pj (xj ) = pj+1(xj ).
3. Continuidad de la pendiente o derivada:Para cadaj = 1, . . . ,n− 1, p′j (xj ) = p′j+1(xj ) y finalmente
4. Continuidad de la curvatura:Para cadaj = 1, . . . ,n− 1, p′′j (xj ) = p′′j+1(xj ).
Aquı hemos hecho un esfuerzo por expresar las tres condiciones de con-tinuidad segun formulas semejantes. En lugar de ello podrıamos haber ex-presado las dos primeras condiciones conjuntamente como:
Para cadaj = 1, . . . ,n,
1. pj (xj ) = yj , y
2. pj (xj−1) = yj−1.
En cualquier caso lo que tenemos son un total de 4n−2 ecuaciones paradeterminar los 4n coeficientes desconocidos de losn polinomios cubicos
p1(x), . . . , pn(x).
Necesitamos dos condiciones adicionales las cuales suelen imponerse en

162 5. Interpolacion y Aproximacion
los extremosx0, xn de la varilla. Estas condiciones adicionales pueden im-ponerse de varias maneras, dependiendo del contexto de nuestro problema.
Una de las condiciones mas naturales, satisfecha por una varilla fısicaque solo esta restringida a pasar sin rozamiento por los nodos (lo que da lu-gar al nombre decondicion de extremos libres), consiste en tener curvaturacero en los extremos. Puesto que la curvatura es un multiplo de la derivadasegunda esta condicion es equivalente a
p′′1(x0) = 0 y p′′n(xn) = 0.
Una segunda condicion utilizada con frecuencia consiste en imponeren cada uno de los extremos la misma derivada segunda que en su nodoadyacente, es decir:
p′′1(x0) = p′′1(x1) y p′′n(xn) = p′′n(xn−1).
Porultimo veremos una condicion en los extremos consistente en asig-nar en ellos una pendiente predeterminada a la curva, es decir, imponer unvalor predeterminado a las derivadas
p′1(x0) = y′0 y p′n(xn) = y′n.
Aunque estas tres condiciones son las mas comunes, en modo algunoson lasunicas posibles. Segun las necesidades se pueden emplear distintascombinaciones de estas u otras condiciones.
Calculo de las varillas flexibles cubicas.–
Para el calculo eficaz de los polinomiosp1, . . . , pn que componen la varillaflexible los expresaremos en la formapk(x) = ak(x−xk)
3+bk(x−xk)2+
ck(x−xk)+dk de manera que las condicionespk(x) = yk nos proporcionanautomaticamente el valor de los coeficientes de grado cero:dk = yk, conlo cual nos queda
pk(x) = ak(x − xk)3+ bk(x − xk)
2+ ck(x − xk)+ yk
y solo necesitamos determinar tres coeficientes en cada polinomio.
En lo que sigue utilizaremos frecuentemente los valores de las distan-cias entre nodos consecutivos, las cuales denotaremos medianteh1, . . . , hn,definidas por
hk = xk − xk−1.
5.6. Varillas flexibles (splines) 163
En terminos de estas cantidades las condiciones de continuidad de la varilla(a saber:pk(xk−1) = yk−1 parak = 2, . . . ,n) dan lugar a las ecuaciones
ak(xk−1− xk)3+ bk(xk−1− xk)
2+ ck(xk−1− xk)+ yk = yk−1,
es decir:akh3
k − bkh2k + ckhk = yk − yk−1 (5.13)
parak = 1, . . . ,n.
Nuestro objetivo ahora es expresar cada uno de los coeficientes incognitaak,bk, ck en terminos de una misma variable o parametro,sk, para reducirnuestro problema a un sistema den+ 1 ecuaciones en lasn+ 1 incognitass0, s1, . . . , sn. Estas nuevas incognitas seran las derivadas segundas de lospolinomiospk en los nodos, es decir, definimos
sk = p′′k(xk),
parak = 1, . . . ,n, y ademas, el parametros0 que es igual a la derivadasegunda dep1 enx0, esto es,
s0 = p′′1(x0). (5.14)
Teniendo en cuenta que las dos primeras derivadas de lospk son
p′k(x) = 3ak(x − xk)2+ 2bk(x − xk)+ ck
p′′k(x) = 6ak(x − xk)+ 2bk
la definicion anterior implica
bk = 12sk
parak = 1, . . . ,n. Ademas,
Ejercicio 5.13Las condiciones de continuidad de la curvatura (expresadas en terminos delassk), junto con la definicion des0 dada por la formula(5.14)implican
ak = sk − sk−1
6hk
parak = 1, . . . ,n.

164 5. Interpolacion y Aproximacion
Ejercicio 5.14Sustituyendo en las ecuaciones(5.13) la expresion de los coeficientesak
dada en el ejercicio 5.13, ası como las expresiones de los coeficientesbk,obtenemos
ck = yk − yk−1
hk+ 1
6(sk−1+ 2sk)hk
parak = 1, . . . ,n.
Con las expresiones dadas en estos dos ejercicios podemos obtener loscoeficientes de los polinomiosp1, . . . , pn una vez conocidos los parametrossk. Para hallarestos usamos la condicion de continuidad de la derivada,segun la cual parak = 1, . . . ,n−1, p′k(xk) = p′k+1(xk), es decir, 3ak(xk−xk)
2+2bk(xk− xk)+ck = 3ak+1(xk− xk+1)2+2bk+1(xk− xk+1)+ck+1,
lo que nos da
ck = 3ak+1h2k+1− 2bk+1hk+1+ ck+1.
Introduciendo en esta ecuacion las expresiones de los coeficientesak,bk, ck
en terminos de los parametrossk obtenemos las siguientesn−1 ecuacioneslineales en lasn+ 1 incognitass0, . . . , sn
yk − yk−1
hk+ 1
6(sk−1+ 2sk)hk
= 12(sk+1− sk)hk+1− sk+1hk+1+ yk+1− yk
hk+1+ 1
6(sk + 2sk+1)hk+1
y ordenando segun lossk,
hksk−1+ 2(hk + hk+1)sk + hk+1sk+1 = bk, (5.15)
donde hemos introducido los terminos independientes
bk = 6( yk+1− yk
hk+1− yk − yk−1
hk
).
En forma matricial las ecuaciones anteriores son:
5.6. Varillas flexibles (splines) 165
h1 2(h1+ h2) h2
h2 2(h2+ h3) h3. . .
hn−1 2(hn−1+ hn) hn
s0
s1...
sn−1
sn
=
b1...
bn−1
.
Necesitamos dos ecuaciones adicionales, las cuales, como hemos dicho,se obtienen generalmente de las condiciones en los extremos. Nosotros nosvamos a limitar a tres posibles conjuntos de condiciones:
Varillas de extremos libres.–
Este es el caso en el que se imponen las dos condiciones adicionaless0 = 0y sn = 0. Entonces en nuestro sistema de ecuaciones se eliminan la primera(s0) y ultima (sn) incognitas (lo que conlleva eliminar la primera yultimacolumnas de la matriz de coeficientes) y queda
2(h1 + h2) h2
h2 2(h2 + h3) h3. . .
hn−2 2(hn−2 + hn−1) hn−1
hn−1 2(hn−1 + hn)
s1
s2...
sn−2
sn−1
=
b1...
bn−1
Notese que el sistema que resulta tiene una matriz de coeficientes simetrica,de tipo Hessenberg y con diagonal dominante. Estoultimo por sı solo ga-rantiza la existencia de solucion unica.
Varillas de extremos con pendiente prefijada.–
Supongamos que se quiere imponer un valor determinado a la pendiente dela varilla flexible en los extremosx0 y xn: p′1(x0) = y′0 y p′n(xn) = y′n. Estonos proporciona dos ecuaciones adicionales que podemos utilizar en lugarde las condiciones de extremos libres y el problema tendra una solucion queen general sera distinta de la de extremos libres. Solo se obtendra la misma

166 5. Interpolacion y Aproximacion
solucion si los valores dey′0 e y′n son precisamente losp′1(x0) y p′n(xn) dela varilla de extremos libres. En todo caso esta claro que las varillas deextremos libres pueden considerarse un caso particular de la situacion masgeneral de varillas con pendiente prefijada en los extremos.
Por otro lado, se da la circunstancia de que este caso aparentemente masgeneral de varillas flexibles puede obtenerse como un caso particular delas varillas de extremos libres. Una justificacion geometrica de este hechose basa en lo siguiente: Consideremos dos abscisas accesorias adicionalesque denotamosx−1 y xn+1 y que haremos variar segun los valores de unparametro positivoε del siguiente modo:x−1 = x0 − ε y xn+1 = xn +ε. Asociada a cada una de estas abscisas consideramos la ordenada quenos da el punto sobre la recta que pasa por(x0, y0) con pendientey′0 (o,en el extremo opuesto, que pasa por(xn, yn) con pendientey′n), es decir,consideramos las ordenadasy−1 = y0− y′0ε e yn+1 = yn + y′nε.
Ejercicio 5.15La varilla de extremos libres que pasa por los puntos descritos mas arriba
(x−1, y−1), (x0, y0), . . . , (xn, yn), (xn+1, yn+1)
tiene como posicion lımite cuandoε tiende a cero la de la varilla que pasapor (x0, y0), . . . , (xn, yn) con pendientesy′0 e y′n respectivamente en losextremosx0 y xn.
Teniendo en cuenta que los parametros asociados con la varilla de ex-tremos libres correspondiente a un ciertoε son:
h0 = ε, hn+1 = ε,
b0 = 6( y1− y0
h1− y′0
), bn = 6
(y′n −
yn − yn−1
hn
)podemos concluir que el sistema de ecuaciones que determina la varillaflexible con pendiente prefijada en los extremos es
5.6. Varillas flexibles (splines) 167
2h1 h1
h1 2(h1+ h2) h2
h2 2(h2+ h3) h3. . .
hn−1 2(hn−1+ hn) hn
hn 2hn
s0
s1...
sn−1
sn
=
b0...
bn
.
Naturalmente el mismo resultado se puede justificar algebraicamente apartir de las ecuaciones adicionales impuestas por las pendientes asignadasa los extremos, las cuales son,
3a1h21− 2b1h1+ c1 = y′0 y cn = y′n
en las que hemos de expresar los coeficientes en terminos de lossk. Ha-ciendo esto se obtienen las ecuaciones
12(s1− s0)h1− s1h1+ y1− y0
h1+ 1
6(s0+ 2s1)h1 = y′0
yyn − yn−1
hn+ 1
6(sn−1+ 2sn)hn = y′n,
que despues de reordenar sus terminos se pueden escribir como
2h1s0+ h1s1 = 6( y1− y0
h1− y′0
)≡ b0
y
hnsn−1+ 2hnsn = 6(
y′n −yn − yn−1
hn
)≡ bn.
Unidasestas a las (5.15) se llega al sistema den + 1 ecuaciones linea-les en lasn + 1 incognitass0, . . . , sn que obtuvimos por el razonamientogeometrico.
Varillas con s0 = s1 y sn = sn−1.–
Al utilizar esta condicion el sistema de ecuaciones (5.15) toma la forma

168 5. Interpolacion y Aproximacion
3h1 + 2h2 h2
h2 2(h2 + h3) h3. . .
hn−2 2(hn−2 + hn−1) hn−1
hn−1 2hn−1 + 3hn
s1
s2...
sn−2
sn−1
=
b1...
bn−1
.
La matriz de coeficientes sigue siendo simetrica, de tipo Hessenberg ycon diagonal dominante.
5.6.3 Un algoritmo para obtener varillas flexibles cubicasde extremos libres
Para terminar esta seccion sobre aproximacion mediante varillas flexiblesvamos a dar un algoritmo que evalua varillas flexibles de extremos libres.
Algoritmo para evaluar varillas flexibles de extremos libres
1 Datos: n (numero de intervalos o segmentos), x0, . . . , xn (abscisas de los nodos),y0, . . . , yn (ordenadas de los nodos), x (punto en el que se desea evaluar la varillaflexible).
2 s0 = 0; sn = 0;3 Para k = 1,n
hk = xk − xk−1;
4 Siguientek
5 Para k = 1,n− 1
A(k, k) = 2(hk + hk+1);A(k, k+ 1) = hk+1;A(k+ 1, k) = hk+1;
bk = 6[(yk+1 − yk)/hk+1 − (yk − yk−1)/hk];
6 Siguientek
7 Para i = 2,n− 1
m= A(i, i − 1)/A(i − 1, i − 1);A(i, i ) = A(i, i )−m A(i − 1, i );bi = bi −mbi−1;
8 Siguientei
9 Para k = n− 1,1 incremento−1
sk = (bk − A(k, k+ 1)sk+1)/A(k, k);
10 Siguientek
5.7. Interpolacion Optima 169
11 Para k = 1,nak = (sk − sk−1)/(6hk);bk = sk/2;ck = (yk − yk−1)/hk + (sk−1 + 2sk)hk/6;
12 Siguientek
13 Si x < x0 entonces ir a 1614 Para k = 1,n
Si x ≤ xk entonces ir a 17
15 Siguientek
16 Imprimir “ x no esta contenido en el intervalo de interpolacion.” y PARAR17 h = x − xk
18 y = yk + h(ck + h(bk + hak))
19 Imprimir “ Solucion es:”; y; “ .” y PARAR
5.7 Interpolacion Optima y Polinomios de Chebys-hev
5.7.1 Introduccion y motivacion
Estudiamos ahora un problema relacionado con el problema de interpola-cion polinomica pero planteado desde el punto ligeramente distinto de lateorıa de la aproximacion. Queremos poder evaluar una funcion dada,f ,en cualquier punto de un intervalo [a,b] contenido en su dominio de defi-nicion. En general no disponemos de una formula algebraica sencilla paraevaluar una funcion dada a menos queesta sea de un tipo muy especial.Por “formula sencilla” nos referimos a una formula que involucre solamen-te las operaciones aritmeticas (como en los polinomios), lo cual descartatodas las funciones trascendentes.
Una posible idea es la de representar la funcion dada (supuesta diferen-ciable de orden suficientemente alto) mediante su polinomio de Taylor decierto grado en torno a algun punto del intervalo de interes:
f (x) = f (x0)+ f ′(x0)(x − x0)+ · · · + 1
n!f (n)(x0)(x − x0)
n + Rn
donde el restoRn esta dado por
Rn = f (n+1)(η)
(n+ 1)!(x − x0)
n+1 (5.16)

170 5. Interpolacion y Aproximacion
para algunη que dista dex0 menos quex. Ya que los polinomios son fun-ciones que se pueden evaluar facilmente, el polinomio de Taylor nos ofreceuna forma sencilla de evaluar aproximadamentef en cualquier punto cercade x0 siempre que podamos obtener con suficiente precision el valor defy el de sus derivadas enx0.
El problema de este metodo es que, en general, el error aumenta rapidamentea medida que nos alejamos dex0. Esto se deduce de la formula del error(5.16) que nos proporciona la formula de acotacion
|Rn| ≤ M
(n+ 1)!|x − x0|n+1
dondeM = maxa≤η≤b | f (n+1)(η)|.Intuitivamente este aumento del error se comprende facilmente al pen-
sar que el polinomio de Taylor de grado 1 representa la recta tangente a lagrafica de f en el punto de abscisax0 y como esta aproxima en generalpeor y peor af a medida que nos alejamos dex0.
Como ilustracion consideremos la evaluacion de la funcion senome-diante su polinomio de Taylor de grado tres en torno al origen
senx ' x − x3
3!= x
(1− x2
6
).
Los resultados se muestran en la tabla 5.1, donde se ve que el error aumentamuy rapidamente a medida que nos alejamos dex = 0.
Se plantea, pues, la cuestion de hallar un polinomio que aproxime unafuncion dada en un intervalo [a,b] con mas uniformidad que el polinomiode Taylor. Una posible idea es utilizar un polinomio de interpolacion. Paraello necesitamos elegir los nodos de interpolacion y evaluar la funcion dadaen esos nodos.
5.7.2 El concepto de interpolacion optima
Surge, pues, la cuestion de como elegir los nodos de interpolacion y de sihabra algun criterio segun el cual una eleccion es mejor que otra. Si apro-ximamos la funcion f mediante un polinomio de interpolacion de gradoprefijado, digamosn, el error cometido en un puntox esta dado por una
5.7. Interpolacion Optima 171
x p3(x) senx Error
0.1 0.0998333 0.0998334 0.0000001
0.2 0.1986667 0.1986693 0.0000027
0.3 0.2955000 0.2955202 0.0000202
0.4 0.3893333 0.3894183 0.0000850
0.5 0.4791667 0.4794255 0.0002589
0.6 0.5640000 0.5646425 0.0006425
0.7 0.6428333 0.6442177 0.0013844
0.8 0.7146667 0.7173561 0.0026894
0.9 0.7785000 0.7833269 0.0048269
Tabla 5.1: Aproximacion de Taylor de grado 3,p3(x) = x − x3/6.
expresion parecida a (5.16):
| f (x)− Pn(x)| =∣∣∣∣∣ f (n+1)(η)
(n+ 1)!(x − x0) · · · (x − xn)
∣∣∣∣∣dondex0, . . . , xn son los nodos de interpolacion y η es algun punto delintervalo de interpolacion. Supongamos que la derivadan+1 de la funcionf esta acotada en el intervalo de interes, o sea, que existe un numeroMtal que para todox ∈ [a,b], se cumple| f n+1(x)| ≤ M . Entonces el errorcometido al interpolarf en los nodosx0, . . . , xn esta acotado por
| f (x)− Pn(x)| ≤ M
(n+ 1)!max
a≤x≤b|(x − x0) · · · (x − xn)|
y nuestra mejor estrategia es elegir los nodosxk ∈ [a,b] de tal forma quela cantidad
maxa≤x≤b
|(x − x0) · · · (x − xn)| (5.17)
sea lo mas pequena posible. Losn+1 puntos del intervalo [a,b], x0, . . . , xn,que minimizan la cantidad (5.17) seran llamados losnodos de interpolacionoptima de gradon en [a,b]. Dado que la condicion que define los nodosde interpolacion optima no depende de la funcion a aproximar, una vez ha-llados,estos serviran para interpolar de formaoptima cualquier funcion enel intervalo [a,b].

0.2 0.4 0.6 0.8 1
-0.002
-0.0015
-0.001
-0.0005
0
0.0005
0.001
0.0015
0.002
172 5. Interpolacion y Aproximacion
sen(x)− p3(x)
Figura 5.5: Error en la aproximacion de la funcion seno mediante el poli-nomio de Taylor de grado 3,p3(x) = x − x3/6.
Podemos replantear nuestro problema como el problema de hallar unpolinomio monico de gradon+ 1, cuyos ceros esten en un intervalo dado[a,b] y cuyo maximo valor absoluto en [a,b] sea lo mas pequeno posible.
Se puede reducir el problema de hallar los nodos de interpolacionoptimaen un intervalo arbitrario [a,b] al mismo problema en el intervalo [−1,1].Los resultados se pueden trasladar despues al intervalo [a,b] mediantela transformacion compuesta de la homotecia que convierte la longituddel intervalo [−1,1] en la longitud del intervalo [a,b] (es decir, la razonr = (b − a)/2), seguida de la traslacion que lleva el origen al centro delintervalo [a,b] (o sea, “sumarh = (a+b)/2”), en resumen, la transforma-cion:
t (x) = r x + h = b− a
2x + b+ a
2.
Ası pues, el problema toma ahora la siguiente forma: encontrarn + 1puntosx0, , . . . , xn ∈ [−1,1] tales que la cantidad
max−1≤x≤1
|(x − x0) · · · (x − xn)|
tenga el menor valor posible. Equivalentemente: encontrar el polinomiomonico de gradon + 1 (que denotaremosTn+1(x)) cuya norma∞ en elintervalo [−1,1] sea lo mas pequena posible. No es difıcil descubrir cualesson dichos polinomios para valores pequenos den comon = 0, n = 1, eincluson = 2. En el caso general los polinomios de interpolacion optima
5.7. Interpolacion Optima 173
estan directamente relacionados con los llamadospolinomios de Chebyshevque estudiamos a continuacion.
5.7.3 Los polinomios de Chebyshev
¿Que son los polinomios de Chebyshev? Pensemos por un momento en elsiguiente hecho conocido:
Ejercicio 5.16Paran = 0,1, . . . el coseno denα puede expresarse como combinacionlineal de las potencias
(cosα)0, . . . , (cosα)n.
Definicion: El polinomio de Chebyshevde gradon, Tn(x), es el polinomiocuyos coeficientes son los de las potencias(cost)k en la expresion de cosnten terminos de cost . Es decir,Tn(x) esta definido por la propiedad
Tn(cosθ) = cosnθ.
Ejemplos:
T0(x) = 1; T1(x) = x; T2(x) = 2x2− 1
ya que cos 0θ = 1; cosθ = cosθ ; y cos 2θ = 2 cos2 θ − 1.
La importancia de los polinomios de Chebyshev para nuestro problemaradica en el siguiente resultado:
Teorema 27 (Nodos de Chebyshev)Los nodos de interpolacion optimade gradon en el intervalo[−1,1] son losn + 1 ceros del polinomio deChebyshev de gradon+ 1, Tn+1(x).
Es decir, los nodos de Chebyshev para el gradon son los puntosxk = cosθkdondeθ0, . . . , θn son losangulos tales que
cos[(n+ 1)θk] = 0
o sea,
θ0 = 1n+1 · π2 , θ1 = 3
n+1 · π2 , . . . , θk = 2k+1n+1 · π2 , . . . , θn = 2n+1
n+1 · π2

174 5. Interpolacion y Aproximacion
θ0
θ1
θ2
θ3
rrrrrrr
x0x1x2x3
Figura 5.6: Nodos de Chebyshev no negativos para interpolar con polino-mio de gradon = 7.
con lo que los nodos de interpolacion optima son
xk = cos
((2k+ 1)π
2(n+ 1)
).
Notese que estos puntos son las abscisas de los puntos del cırculo unitariodeterminados por losangulosθk. Dicho de otra forma, losxk son las partesreales de los numeros complejos unitariosei θk . En consecuencia pueden di-bujarse facilmente sin mas que dividir la semicircunferencia cuyo diametroes el intervalo [−1,1] enn+ 1 arcos iguales y hallando las abscisas de lospuntos medios de dichos arcos. En realidad, habida cuenta de la simetrıa,es suficiente hallar los nodos correspondientes a la parte positiva como semuestra en la figura 5.6.
5.7.4 Demostracion del teorema de los nodos de Chebys-hev
Para demostrar el teorema 27 observemos primero lo siguiente:
Proposicion 8 Supongamos queT(x) es un polinomio monico de gradonque tienen raıces reales en el intervalo[a,b] y tal que todos sus extremosen[a,b] tienen el mismo valor absoluto. Entonces sus raıces son los nodosde interpolacion optima en[a,b].
5.7. Interpolacion Optima 175
Demostracion: Tenemos que demostrar que todo otro polinomio monico degradon alcanza en [a,b] valores (absolutos) mayores quem= maxa≤x≤b T(x).Sea, pues,P(x) un polinomio monico de gradon distinto deT(x). Eviden-temente la diferencia
Q(x) = T(x)− P(x)
es un polinomio de grado estrictamente menor quen. Supongamos que entodo puntox ∈ [a,b] fuese|P(x)| ≤ m, entonces, tanto en los puntoscrıticos deT como en los extremosa, b del intervalo el signo deQ(x)es igual al signo deT(x). En consecuenciaQ(x) tiene al menos tantoscambios de signo comoT(x) y por tanto tiene tambien al menos tantasraıces comoT , esto es,n. Pero comoQ(x) tiene grado menor quen, esnecesariamente el polinomio nulo; esto es,P(x) es igual aT(x).
El siguiente es un simple ejercicio de maximos y mınimos. Conel seestablece el hecho de que en el intervalo [−1,1] todo polinomio de Chebys-hev toma sus valores entre−1 y 1. Este es un importante resultado que seutilizara en la demostracion del teorema de los nodos de Chebyshev.
Ejercicio 5.17EvaluarTn(x) parax = ±1 y usar el resultado para demostrar que
maxx∈[−1,1]
|Tn(x)| = 1.
Ejercicio 5.18Demostrar que los extremos relativos del polinomio de Chebyshev de gradon son los numeros de la formaxk = cos(kπ/n) parak ∈ {1, . . . ,n − 1}.Ademas tambien son extremos los puntosa = −1 y b = 1, que se obtienende la formula de losxk parak = 0 y k = n. Por lo tanto podemos decirque los extremos son losxk parak ∈ {0, . . . ,n}, pero cuidado: parak = 0y k = n T′n(xk) 6= 0 (demuestrese).
Estamos ahora en condiciones de demostrar nuestro teorema. La de-mostracion es muy sencilla; solo necesitamos demostrar lo siguiente:
Proposicion 9 El maximo valor de| 12n−1 Tn(x)| en [−1,1] es 1
2n−1 y paratodo otro polinomio monico de gradon, Pn(x), su valor absoluto alcanza,en alguno de los puntosxk = cos(kπ/n), valores≥ 1
2n−1 .

176 5. Interpolacion y Aproximacion
Demostracion: Por reduccion al absurdo. Supongamos que para todok ∈{0, . . . ,n} se verifica|Pn(xk)| < 1
2n−1 . Esto es lo mismo que decir que elpolinomio
Q(x) = 1
2n−1Tn(x)− Pn(x)
tiene en cadaxk el mismo signo queTn (esto es,(−1)k —ejercicio (5.18)).Vamos a ver que bajo la suposicion hecha el polinomioQ(x) tendrıa gradomenor quen y, al mismo tiempo,n cambios de signo en [−1,1], lo cual esabsurdo ya que“el n umero total de cambios de signo de un polinomio degradon es menor o igual quen” . El polinomio Q(x) no es cero y, por serdiferencia de dos polinomios monicos de gradon, su grado es menor quen. Por otra parte
Q(xk) = 1
2n−1Tn(xk)− Pn(xk) = (−1)k
2n−1− Pn(xk)
y el signo de la diferencia es el mismo que el del minuendo porque, porhipotesis, el sustraendo tiene menor valor absoluto. En consecuenciaQ(x)tienen cambios de signo en [−1,1] y por ser una funcion continua ha detenern ceros en [−1,1]. Pero es un polinomio no nulo de grado menor quen. Contradiccion. Luego para algun xk ∈ [−1,1] se verifica|Pn(xk)| ≥
12n−1 .
Con esto queda establecida la formula de los nodos de Chebyshev onodos de interpolacion optima en el intervalo [−1,1]. Nuestra tarea ahoraes obtener las formulas correspondientes para un intervalo arbitrario.
5.7.5 Interpolacion optima en un intervalo arbitrario
Si necesitamos aproximar una funcion f (x) en un intervalo [a,b] distintode [−1,1] hemos de trasladar los nodos de Chebyshev
xk = cos(2k+ 1)π
2(n+ 1)
del intervalo [−1,1] al intervalo [a,b]. El resultado es:
Ejercicio 5.19Demostrar que los nodos de interpolacionoptima de gradon en un intervalo[a,b] son
yk = b− a
2cos
((2k+ 1)π
2(n+ 1)
)+ b+ a
2
5.7. Interpolacion Optima 177
x P3(x) senx Error
0.1 0.0999441 0.0998334 −0.0001107
0.2 0.1987851 0.1986693 −0.0001158
0.3 0.2955310 0.2955202 −0.0000108
0.4 0.3893151 0.3894183 0.0001033
0.5 0.4792708 0.4794255 0.0001548
0.6 0.5645314 0.5646425 0.0001111
0.7 0.6442302 0.6442177 −0.0000125
0.8 0.7175005 0.7173561 −0.0001444
0.9 0.7834758 0.7833269 −0.0001489
Tabla 5.2: Interpolacion de Chebyshev de grado 3
Notese que, como dijimos mas arriba, el resultado no es mas que el deaplicar al intervalo [−1,1] la homotecia que cambia su longitud de ser 2 aser la del intervalo [a,b] y despues aplicar una traslacion al resultado paraque sus extremos coincidan con los del intervalo [a,b], es decir, despuesde la homotecia, trasladar el origen al punto medio del intervalo [a,b]. Enconsecuencia, dado que las homotecias y las traslaciones convierten circun-ferencias en circunferencias y rectas en rectas, la construccion geometricadada para los nodos de Chebyshev puede aplicarse a cualquier intervalo.
Ejercicio 5.20Demostrar que para una funcion f (x) cuya derivadan+ 1 esta acotada enel intervalo[a,b] por la constanteM , el error cometido en la aproximacionde Chebyshev de gradon en el intervalo[a,b], Pn(x), esta acotado por
| f (x)− Pn(x)| ≤ 2M
(n+ 1)!
(b− a
4
)n+1
.
5.7.6 Ejemplo de la interpolacion de Chebyshev
Vamos a comparar el resultado de aproximar la funcion senoen [0,1] porel metodo de Chebyshev con un polinomio de grado tres que interpole enlos nodosoptimos con la aproximacion de la misma funcion en el mismointervalo por el polinomio de Taylor de grado cinco hecha al principio deesta leccion.

0.2 0.4 0.6 0.8 1
-0.002
-0.0015
-0.001
-0.0005
0
0.0005
0.001
0.0015
0.002
178 5. Interpolacion y Aproximacion
Los cuatro nodos en el intervalo [0,1] estan dados porxk = 12 cos(2k+1)π
8 +12, o sea que son:
x0 = 0.5(1+ cos
π
8
)= 0.9619398, x1 = 0.5
(1+ cos
3π
8
)= 0.6913417
x2 = 0.5(1+ cos
5π
8
)= 0.3086583, x3 = 0.5
(1+ cos
7π
8
)= 0.0380602
Para hallar el polinomio de interpolacion calculamos las diferencias di-vididas
x senx
0.9619398 0.82030250.6752862
0.6913417 0.6375714 −0.30147990.8722374 −0.1444449
0.3086583 0.3037806 −0.16803020.9820084
0.0380602 0.0380510
con lo que el polinomio de interpolacion es
P3(x) = 0.8203025+ (x − 0.9619398)[0.6752862
+ (x − 0.6913417)(−0.3014799− 0.1444449(x − 0.3086583))]
= −0.1444449x3 − 0.01808759x2 + 1.003947x − 0.0001252498
= [−(0.1444449x + 0.01808759)x + 1.003947]x − 0.0001252498.
Podemos ahora evaluar este polinomio en varios puntos del intervalo[0,1] para comparar los resultados con los valores exactos de la funcionsenoen esos puntos. El resultado se muestra en la tabla 5.2. Comparesecon la tabla 5.1.
Ejercicio 5.21Utilizar la formula del error dada en el ejercicio 5.20 para estimar la cotadel error correspondiente a la aproximacion de Chebyshev de grado 3 de lafuncion senoen el intervalo[0,1]. Comprobar que los errores obtenidos enla tabla 5.2 concuerdan con la cota de error estimada. ¿Cual serıa la cotadel error si se usase el polinomio de grado 5?
sen(x)− P3(x)
Figura 5.7: Error en la aproximacion de Chebyshev de grado 3 de la funcionseno.

180 5. Interpolacion y Aproximacion
Capıtulo 6
Integracion numerica
En este tema estudiaremos, desde el punto de vista del calculo numerico,el problema de evaluar integrales de funciones reales de variable real. Eltema incluye la idea general de integracion interpolatoria y las formulas decuadratura de Newton-Cotes, formulas compuestas trapezoidal y de Simp-son, la idea de integracion adaptativa ilustrada con un sencillo algoritmo, yel algoritmo de integracion de Romberg.
6.1 Introduccion
¿Por que es necesario el analisis numerico en el calculo de integrales? Mu-chos estudiantes creen que la razon es que “hay muchas integrales que nose pueden hacer”. Nada menos cierto. Esta idea viene del error (desgracia-damente demasiado comun) de identificar “integrar” con “aplicar la reglade Barrow”. Supongamos que queremos hallar la integral
∫ 60 f (x)dx de la
funcion constante definida por la grafica
2
2
4 6
f (x)
181

182 6. Integracion numerica
Segun la definicion de integral, la respuesta correcta e inmediata es:∫ 6
0f (x)dx = area= 6× 2= 12.
ya que “integral” esarea.
El calculo∫ 6
0f (x)dx =
∫ 6
02dx = [2x]60 = 2× 6− 2× 0= 12− 0= 12
no es la definicion de integral, y contestar de esta forma a la pregunta esdesvirtuar el problema con una deformacion conceptual, que tiene otrasconsecuencias que sı son temibles.
Es cierto que los estudiantes de calculo se enfrentan antes o despuescon la cuestion de las integrales que “se pueden hacer” y las que “no sepueden hacer”. Evidentemente es necesario matizar esta cuestion para po-der darle un significado preciso. El significado de la expresion “integralesque se pueden hacer” es simplemente “funciones que tienen una primitivaelemental”. Las funciones que no son elementales se llaman funciones es-peciales, y la problematica de las integrales que “no se pueden hacer” surjeen los cursos elementales de calculo debido al hecho de que hay algunasfunciones especiales cuya derivada es elemental. Por ejemplo, la funcionelıptica de segunda especie
E 12(x)
es unafuncion especialcuya derivada es la funcion elemental
E′12(x) = 1
2
√4− sen2 x.
En consecuencia, se dice que “la integral∫ √4− sen2 x dx
no se puede hacer”, a pesar de que sabemos que (por definicion)∫ √4− sen2 x dx= 2E 1
2(x)+ C.
Es necesario, pues, replantear el problema de calcular integrales “queno se pueden hacer” y ver la necesidad de los metodos numericos al menos
6.2. Formulas Simples de Cuadratura 183
para ellas. Sin embargo, no podemos limitarnos a esto, pues ¿que criterionos dice que las funciones circulares e hiperbolicas son elementales mien-tras que las funciones elıpticas son especiales? ¿Que diferencia hay entreunas tablas de logaritmos y unas tablas de funciones elıpticas? Launicadiferencia es el grado de familiaridad que tenemos con ellas, pero ambas sehan obtenido del mismo modo: mediante metodos numericos. Los metodosnumericos son fundamentales para el calculo de todo tipo de funciones, ypuesto que el metodo fundamental por el que se han encontrado las funcio-nes que se manejan en las Ciencias Exactas es a traves de las ecuacionesdiferenciales de que son solucion, decir “calculo de funciones” es, en granmedida, decir “calculo de integrales”. La distincion entre integrales “que sepueden hacer” y “que no se pueden hacer” es, desde un punto de vista fun-damental, completamente artificial e irrelevante para el calculo numerico.Es una distincion analoga a la que hay entre “funciones ya tabuladas” y“funciones por tabular”.
6.2 Formulas Simples de Cuadratura
La estrategia general que vamos a seguir para la evaluacion de una inte-gral es la siguiente: Primero, division del intervalo de integracion en cier-to numero de subintervalos (normalmente iguales, pero que no siempre loseran). Entonces se aproxima la integral en cada subintervalo medianteunaformula de cuadratura“simple”. Esta formula de cuadratura “simple”estara basada en general en la integracion exacta de un polinomio de inter-polacion de la funcion a integrar en el subintervalo correspondiente. Por lotanto, cada cuadratura “simple” implica a su vez la eleccion de unos nodosde interpolacion en cada uno de los subintervalos en que se ha dividido elintervalo total de integracion. El uso de polinomios de interpolacion nospermite dar formulas de acotacion del error cometido en cada subinterva-lo. Para obtener estas formulas de la forma mas directa, expresaremos lafuncion a integrar en terminos de su polinomio de interpolacion y del co-rrespondiente error, segun la formula
f (x) = pn(x)+ f [x0, . . . , xn, x](x − x0) · · · (x − xn). (6.1)
Ası pues, una cuadratura ‘simple” incluye siempre una regla:∫ b
af (x)dx ' I ( f ) =
∫ b
apn(x)dx

184 6. Integracion numerica
y una formula de error,E( f ), que se obtiene por aproximacion de∫ b
af [x0, . . . , xn, x](x − x0) · · · (x − xn)dx.
La suma de los resultados obtenidos en cada subintervalo da lugar a laformula compuestadel metodo empleado, la cual vendra acompanada dela correspondiente formula de acotacion del error obtenida a partir de lasfomulas de error de los subintervalos.
6.2.1 Formulas de cuadratura de Newton-Cotes
Las formulas de cuadratura de Newton-Cotes son la familia de formulas“simples” que se obtienen al utilizar en un intervalo un polinomio de inter-polacion con nodos igualmente espaciados. Sin es el grado del polinomiode interpolacion que vamos a utilizar en el intervalo [a,b], dividimos eseintervalo enn partes iguales mediante los siguientesn+ 1 nodos:
x0 = a, x1 = a+ h, . . . xk = a+ kh, . . . xn = a+ nh,
dondeh = (b − a)/n si n 6= 0 (si n = 0 entoncesh no esta definido nifalta que hace). Naturalmente, sin 6= 0 entoncesxn = b. Detallamos acontinuacion los casosn = 0,1,2, que dan lugara las formulas llamadas“del rectangulo”, “del trapezoide”, y “de Simpson”.
El caso mas sencillo esn = 0. La formula de Newton-Cotes correspon-diente a este caso se llamaregla del rectanguloy se obtiene a partir de lasiguiente expresion de f (x) en terminos de su polinomio de interpolacionde grado cero en el nodox0 = a:
f (x) = f (a)+ f [x0, x](x − x0)
Ejercicio 6.1Deducir la regla del rectangulo (simple):
I R( f ) = (b− a) f (a).
La fomula del error en la regla del rectangulo se halla de la siguienteforma. Comenzamos simplificando la integral que da el error mediante el
6.2. Formulas Simples de Cuadratura 185
uso del teorema del valor medio y la hipotesis de diferenciabilidad def (x):
ER( f ) =∫ b
af [x0, x](x − a)dx = f [x0, ξ ]
∫ b
a(x − a)dx
= f ′(ξ)(b− a)2
2.
Si elegimos interpolar con un polinomio de grado 1, podemos partir dela expresion
f (x) = f (a)+ f [a,b](x − a)+ f [a,b, x](x − a)(x − b)
para obtener lo siguiente:
Ejercicio 6.2Deducir las formulas de la regla del trapezoide (simple):
I T ( f ) = (b− a)f (a)+ f (b)
2, ET = − 1
12f ′′(ξ)(b− a)3.
Finalmente, la regla de Simpson se obtiene al interpolar mediante unpolinomio de grado 2. Los nodos de interpolacion sonx0 = a, x1 = (a+b)/2, x2 = b. En este caso los calculos son un poco mas laboriosos queen los casos anteriores. La formula de cuadratura se obtiene integrandoel polinomio de interpolacion en esos nodos, que conviene expresar en laforma:
p2(x) = f (a)+ f [a,b](x − a)+ f [a,b,a+ b
2](x − a)(x + b)
Ejercicio 6.3Utilizar la expresion anterior para demostrar:∫ b
ap2(x)dx = f (a)(b−a)+ f [a,b](b−a)2/2− f [a, a+b
2 ,b](b−a)3/6.
La fomula que se obtiene en el ejercicio anterior es bastante inmane-jable, pero afortunadamente se puede simplificar considerablemente y unollega a la formula de cuadratura de Simpson:

186 6. Integracion numerica
Ejercicio 6.4Simplificar la expresion obtenida en el ejercicio anterior para obtener:
I S = (b− a)
6
[f (a)+ 4 f
(a+b2
)+ f (b)].
El resto de esta seccion esta dedicado a obtener la formula del errorcorrespondiente a la formula de Simpson. Para ello es necesario calcular laintegral ∫ b
af[a, a+b
2 ,b, x]ϕ2(x)dx
dondeϕ2(x) = (x − a)(x − a+b2 )(x − b). Ahora bien, no es dificil probar
que
Ejercicio 6.5
∫ b
aϕ2(x)dx =
∫ b
a(x − a)(x − a+b
2 )(x − b)dx = 0,
y esto, junto con la formula
f[a, a+b
2 ,b, x] = f
[a, a+b
2 ,b, a+b2
]+ f[a, a+b
2 ,b, a+b2 , x
](x − a+b
2 )
tiene como consecuencia que
Ejercicio 6.6
∫ b
af[a, a+b
2 ,b, x]ϕ2(x)dx =
∫ b
af[a, a+b
2 ,b, a+b2 , x
]ϕ3(x)dx.
donde
ϕ3(x) = (x − a)(x − a+b2 )(x − b)(x − a+b
2 ) = (x − a)(x − a+b2 )2(x − b)
La ventaja de expresar el error de la formula de Simpson segun el re-sultado del ejercicio anterior, es decir mediante
ES( f ) =∫ b
af[a, a+b
2 ,b, a+b2 , x
]ϕ3(x)dx,
6.3. Formulas compuestas del trapezoide y de Simpson 187
es queϕ3(x) tiene signo constante en el intervalo [a,b] y por lo tanto po-demos aplicar el teorema del valor medio para obtener:
ES( f ) = 1
4!f (4)(ξ)
∫ b
aϕ3(x)dx,
para algun puntoξ ∈ [a,b].
Ejercicio 6.7Calcular
∫ b
aϕ3(x)dx =
∫ b
a(x − a)(x − a+b
2 )2(x − b)dx = − 4
15
(b− a
2
)5
Llegamos, pues, finalmente a la formula del error de la formula deSimpson (simple):
ES( f ) = − 1
4!f (4)(ξ)
4
15
(b− a
2
)5
= − 1
90f (4)(ξ)
(b− a
2
)5
.
6.3 Formulas compuestas del trapezoide y deSimpson
Denotemos ahora por [a,b] el intervalo total de integracion (no simple-mente uno de sus subintervalos como hacıamos en la seccion anterior). Su-pongamos que dividimos este intervalo [a,b] en N subintervalos iguales delongitudh = (b− a)/N. Los nodos de integracion son los puntos del in-tervalo [a,b] que determinan los subintervalos. Denotamos esos nodos porxk = a + kh. Si para cadak = 1, . . . , N aplicamos en [xk−1, xk] la regladel trapezoide, con su termino de error, obtendremos laregla trapezoidalcompuestajunto con su error, llamadoerror de discretizacion (obtenido alsumar los errores correspondientes a cada subintervalo). Puesto que∫ xk
xk−1
f (x)dx ' (xk − xk−1)f (xk−1)+ f (xk)
2= h
2[ f (xk−1)+ f (xk)]

188 6. Integracion numerica
tendremos, para la integral,
I TN ( f ) =
N∑k=1
∫ xk
xk−1
f (x)dx
= h2[ f (x0)+ 2 f (x1)+ · · · + 2 f (xN−1)+ f (xN)]
= h(
f (x1)+ · · · + f (xN−1))+ h
f (a)+ f (b)
2,
y para el error de discretizacion,
ETN( f ) = −h3
12
N∑k=1
f ′′(ξk)
= −h2
12(b− a)
f ′′(ξ1)+ · · · + f ′′(ξN)
N
= −h2
12(b− a) f ′′(ξ).
Resumiendo, laformula trapezoidal compuestaes:
TN( f ) = hN−1∑k=1
f (xk)+ hf (a)+ f (b)
2− h2
12(b− a) f ′′(ξ)
Igualmente, aplicando la regla de Simpson en cada subintervalo obten-dremos laregla de Simpson compuestajunto con su correspondiente errorde discretizacion.
I SN( f ) =
N∑k=1
∫ xk
xk−1
f (x)dx
= h
6
N∑k=1
[f (xk−1)+ 4 f
(xk−1+xk
2
)+ f (xk)
]= h
6
[f (a)+ f (b)+ 2
N−1∑k=1
f (xk)+ 4N∑
k=1
f(
xk−1+xk2
)],
6.3. Formulas compuestas del trapezoide y de Simpson 189
y, suponiendo la continuidad def (4), el error es
ESN( f ) = − 1
90
(h
2
)5 N∑k=1
f (4)(ξk)
= − 190
(h
2
)4 b− a
2
f (4)(ξ1)+ · · · + f (4)(ξN)
N
= − 1
180
(h
2
)4
(b− a) f (4)(ξ).
Ejercicio 6.8Se desea estimar
∫ ba f (x)dx mediante la formula de Simpson compuesta.
Se pide dar una formula para hallar el numeroN de subintervalos en quese debe dividir el intervalo[a,b] para garantizar que la estimacion tieneun error menor queε, sabiendounicamente que la derivada cuarta de lafuncion f (x) esta acotada superiormente en valor absoluto, en el intervalo[a,b], por la constanteM .
Es natural preguntarse a la hora de calcular numericamente una inte-gral, que formula nos conviene usar. Para poder contestar adecuadamente aesta cuestion es necesario conocer otros metodos ademas de los vistos hastaaquı, pero es ahora un momento adecuado para llamar la atencion sobre unfactor que es necesario tener en cuenta si se quiere comparar la eficacia dela formula de Simpson con la del trapezoide o la del rectangulo. El numerode subintervalos,N, que aparece en las correspondientes formulas de errora traves de la longitudh de cada subintervalo en que se aplica una formulasimple, no es la cantidad adecuada a comparar. La cantidad a comparardebe serel numero de evaluaciones del integrando que es necesario reali-zar. Evidentemente en la formula del trapezoide compuesta este numero esN + 1, mientras que en la formula de Simpson compuesta es 2N + 1.
Cambiando a otro orden de ideas, en el proximo apartado veremoscomo podemos mejorar la precision que nos ofrecen las formulas que he-mos visto hasta aquı. En particular veremos una tecnica de mejora de laprecision basada en el hecho de que se puede estimar el error de discreti-zacion mediante la comparacion del resultado de estimar la integral con unnumeroN de subintervalos con el resultado obtenido al usar el doble de su-bintervalos. Concretamente, como el error de discretizacion en el metodode Simpson es aproximadamente proporcional a 1/N4, al doblar el numero

190 6. Integracion numerica
de subintervalos ese error queda dividido por 16. Por tanto, la igualdadSN + EN = S2N + E2N junto conEN ≈ 16E2N nos dice que
S2N − SN ≈ 15E2N o E2N ≈ S2N − SN
15.
Este tipo de ideas son las que se encuentran a la base de un algoritmo co-nocido comoalgoritmo de Romberg, que discutimos con mas detalle (parael caso de la formula trapezoidal) a continuacion.
6.4 El algoritmo de Romberg
La estimacion de error estudiada en la seccion anterior puede utilizarse paramejorar la estimacion de la integral a partir de estimaciones conN y con 2Npuntos. Por ejemplo, usando la formula trapezoidal compuesta, dado queen este caso el error de discretizacion es aproximadamente proporcional a1/N2, al doblar el numero de puntos el error queda dividido por 4. Portanto la igualdadTN + EN = T2N + E2N junto conEN ≈ 4E2N nos diceque
T2N − TN ≈ 3E2N
de donde
E2N ≈ T2N − TN
3
y por lo tanto podemos esperar que el valor
T (1)2N = T2N + T2N − TN
3= 4T2N − TN
3(6.2)
se aproxime mas queT2N al valor de la integral. Este proceso de mejorapuede continuarse mediante una estimacion analoga del error cometido enT (1)2N . Para ello es necesario utilizar el siguiente hecho
Lema 5 Si f es suficientemente diferenciable en el intervalo de integra-cion [a,b] entonces el error en la estimacion TN de la integral
∫ ba f (x)dx
por la formula trapezoidal compuesta deN puntos es de la forma
A11
N2+ A2
1
N4+ · · · + Ak
1
N2k+ o
(1
N2k+2
).
6.4. El algoritmo de Romberg 191
Basandonos en este resultado podemos demostrar facilmente que el errorcometido enT (1)2N es aproximadamente proporcional a 1/N4. Ası, si calcu-
lamosT4N , podemos obtener la correspondiente mejoraT (1)4N de modo que
la igualdadT (1)2N + E(1)2N = T (1)4N + E(1)4N junto conE(1)2N ≈ 16E(1)4N nos diceque
T (1)4N − T (1)2N ≈ 15E(1)4N
lo cual nos permite dar la siguiente mejora como
T (2)4N =16T (1)4N − T (1)2N
15
Continuando de esta forma obtenemos la siguientetabla de Romberg
TN
T2N T (1)2N
T4N T (1)4N T (2)4N
T4N T (1)8N T (2)8N T (3)8N . . .
en la que el termino general es
T (m)2k =4mT (m−1)
2k − T (m−1)k
4m− 1
Este algoritmo se puede usar como practica de programacion esperandosede los alumnos que escriban un programa similar al siguiente:
Algoritmo de integracion de Romberg
Datos: a,b (lımites de integracion), δ (tolerancia de error), N (numerode subintervalos, que elegiremos par).k = 1;
T (0)N2= TN
2; T (0)N = TN ; T (1)N = (4T (0)N − T (0)N
2)/3
1 T = T (k)N ; N = 2N; k = k+ 1;
T (0)N = TN

192 6. Integracion numerica
Para m= 1, k
T (m)N =4mT (m−1)
N − T (m−1)N/2
4m− 1
Si |T (k)N − T | < δ entonces ir a 2Ir a 1
2 Imprimir “ Solucion es:”; T (k)N .
6.5 Integracion adaptativa
Para comprender el objetivo y la idea fundamental tras los metodos de inte-gracion adaptativos, consideremos el siguiente ejemplo numerico concreto:estimar la integral
∫ 30.5 dx/x2 (cuyo valor exacto es 5/3 = 1.6666. . . ).
Nos propoemos la estimacion de esta integral por la formula de Simpsoncompuesta, con un error menor que una milesima. Despues de hacer elejercicio 6.8 es inmediato encontrar que necesitamos una division del inter-valo [0.5,3] en N = 24 subintervalos (cada uno de los cuales Simpson vaa dividir en dos, o sea que en la practica estamos usando 48 subintervalos)para alcanzar la precision deseada.
Calculemos ahora dicha integral usando la formula de Simpson simpleen cada uno de los cuatro subintervalos de [a,b] = [0.5,3] en que lo di-viden las abscisas 0.6, 0.7, 0.9, 1.1, 1.3, 1.7, y 2.1, es decir, estimamosla formula de Simpson en los intervalos [0.5,0.6], [0.6,0.7], [0.7,0.9],[0.9,1.1], [1.1,1.3], [1.3,1.7], [1.7,2.1], y [2.1,3]. El error es ahoramenor que una milesima. Esta forma de calcular la integral, utilizando in-tervalos mas pequenos allı donde el error de la formula de cuadratura tiendea ser mayor e intervalos de mayor tamano donde el error tiende a ser menor,es lo que se conoce como integracion adaptativa.
Para cada formula de cuadratura elegida es necesario comprender lasrazones que pueden hacer en general que una eleccion apropiada de los no-dos permita obtener mayor precision con menos operaciones. Ademas esnecesario disenar un procedimiento automatico para realizar la eleccion delos nodos, el cual presumiblemente debera proporcionar mas nodos (o unpaso de integracion menor) allı donde el error tienda a ser comparativamen-te mayor.
El siguiente es un algoritmo sencillo (pero que tiene un uso bastante
6.5. Integracion adaptativa 193
difundido en la practica), que sirve como ejemplo de tecnica adaptativa. Laidea es ir dividiendo el intervalo de integracion en dos subintervalos iguales,en cada uno de los cuales se pide que el error no sobrepase la mitad de latolerancia de error en el intervalo total. La estimacion del error se hacemediante la formula
E2N ≈ S2N − SN
15
deducida en la seccion A.30.
Algoritmo de integracion adaptativa
Datos: a,b (lımites de integracion), δ (tolerancia de error), f (inte-grando).x0 = a; x2 = b; I = 0; k = 0;h = (x2 − x0)/2; x1 = (x0 + x2)/2; y0 = f (x0); y1 = f (x1);y2 = f (x2); S1 = h(y0+ 4y1+ y2)/3;
1 x3 = x0+ h/2; x4 = x0+ 3h/2; y3 = f (x3); y4 = f (x4);S21 = h(y0+ 4y3+ y1); S21 = h(y0+ 4y3+ y1); S2 = S21+ S22;Si |S2− S1| < δ entonces ir a 2k = k+ 1;Si k < 10entonces ir a 3Imprimir “ Demasiadas iteraciones”;Ir a 2
3 Ak = x1; Bk = x2; fk = y1; gk = y2; hk = y4; ek = δ; SK = S22;x2 = x1; δ = δ/2; h = (x2 − x0)/2; x1 = (x0 + x2)/2; y2 = y1;y1 = y3;Ir a 1
2 I = I + S2;Si x2 ≥ b entonces ir a 4x0 = Ak; x2 = Bk; δ = ek; y0 = fk; y2 = gk; y1 = hk; S1 = Sk;k = k− 1;Ir a 1
4 Imprimir “ Solucion es:”; I .

194 6. Integracion numerica
6.6 Integracion gaussiana
Nos planteamos ahora la siguiente cuestion: ¿cual es el mınimo numerode subintervalos,n, en que hemos de subdividir el intervalo de integracionpara poder tener unareglade cuadratura de la forma∫ b
af (x)dx =
n∑k=0
wk f (xk)
que de el valor exacto para todos los polinomios de gradom? Este plantea-miento da lugar am+1 ecuaciones para las 2(n+1) incognitas constituidaspor losn+ 1 pesosw0, . . . , wn y losn+ 1 nodosx0, . . . , xn, por tanto, dela relacionm+ 1= 2(n+ 1) concluimos que debe ser posible disenar unaformula de cuadratura conn+ 1 nodos que sea exacta para polinomios degrado hasta 2n+ 1.
Una posible forma de hallar dicha formula de cuadratura serıa resolverlas ecuaciones satisfechas por los nodos y los pesos. Esta forma nos lleva acalculos que conviene simplificar de varias maneras. En primer lugar obser-vamos que, al igual que en el problema de interpolacion optima, medianteun cambio de variable, se puede reducir el problema de integracion en unintervalo general [a,b] al de integracion en el intervalo [−1,1]. Ademaspodemos hacer uso de las propiedades de simetrıa de la integracion paradeducir que tanto los nodos como los pesos deben estar simetricamentedistribuidos respecto al origen (six es un nodo tambien lo es−x y ambosdeben tener el mismo peso). Con esto reducimos el numero de incognitasa la mitad. Porultimo, conocemos la relacion entre los nodos y los pesospor los resultados generales de integracion interpolatoria, que nos muestrancomo hallar los pesos que corresponden a unos nodos dados (integrando loscorrespondientes polinomios de Lagrange).
Ejercicio 6.9Aplicar las ideas anteriores a la resolucion de los casosn = 1 y n = 2.
En la resolucion del ejercicio 6.9 se perciben las dificultades de calculocon que nos encontraremos en los casos de valores elevados den. Afortu-nadamente existe otro enfoque de este problema con el que se simplificanlos calculos grandemente. Sif (x) es un polinomio de grado menor o igualque 2n + 1 y Pn(x) es el polinomio de interpolacion de f en n + 1 no-dosx0, . . . , xn entonces el resto de esta interpolacion es una funcion de la
6.6. Integracion gaussiana 195
formaf (x)− Pn(x) = g(x)(x − x0) · · · (x − xn)
donde necesariamenteg(x) es un polinomio de grado menor o igual quen.Ademas, decir que dichos nodos proporcionan una formula de cuadraturaque es exacta para todo polinomio de grado menor o igual que 2n + 1 esequivalente a decir que para todo polinomiog(x) de grado menor o igualquen se verifica ∫ 1
−1g(x)(x − x0) · · · (x − xn) = 0
esto es, el polinomio de gradon + 1 (x − x0) · · · (x − xn) es ortogonal atodos los polinomios de grado menor o igual quen, lo que nos dice que po-demos hallarlo aplicando el proceso de ortogonalizacion de Gram-Schmidta la base canonica de polinomios{1, x, x2, . . . }. De esta forma, dicho poli-nomio queda identificado como un polinomio de Legendre y los nodos parala integracion gaussiana en [−1,1] quedan identificados como los ceros delos polinomios de Legendre.

Capıtulo 7
Resolucion de ecuacionesdiferenciales ordinarias
Las ecuaciones iferenciales ordinarias (esto es, las que no contienen de-rivadas parciales) de orden superior siempre se pueden reducir a sistemasde ecuaciones diferenciales de primer orden. Para hacer esto no hay masque dar nombre a las sucesivas derivadas de la incognita (por ejemplo,u(x) = f ′(x), v(x) = f ′′(x), w(x) = f ′′′(x), etc.), de forma que laderivada mas alta pasa a ser una derivada primera. Despues solo quedaexpresar estas igualdades en terminos de derivadas primeras solamente (esdecir: u(x) = f ′(x), v(x) = u′(x), w(x) = v′(x), etc.), y utilizar esosnombres en lugar de las correspondientes derivadas de la incognita en laecuacion dada. Ası, una ecuacion tal como
2(y′′)2− 5 sen(y′)+ xyy′′′ = 0
se sustituiria por el sistema
2v2− 5 senu+ xyv′ = 0
u = y′
v = u′.
Esto justifica la suficiencia de estudiar los metodos de resolucion deecuaciones de primer orden. En este curso nos limitaremos a los metodos
197

198 7. Ecuaciones diferenciales
de resolucion de una sola ecuacion diferenciable de primer orden, pero sedebe comprender queestos se pueden adaptar facilmente a la resolucion desistemas.
Una importante cuestion asociada con los problemas de ecuaciones di-ferenciales es la relativa a las condiciones de contorno. Los metodos deresolucion dependen fuertemente de si estas condiciones se imponen en ununico punto (problemas de valores iniciales) o en varios puntos (problemasde valores en la frontera). En este tema estudiaremos principalmente lasnociones fundamentales de los metodos numericos para problemas de va-lores iniciales, dedicando al final una breve seccion a las ideas generales detres tipos de metodos elementales para problemas de valores en la frontera(el de lasdiferencias finitas, el dedisparoy los decolocacion).
7.1 Problemas de valores iniciales
El problema de valores iniciales para las ecuaciones diferenciales ordinariasde primer orden consiste en evaluar en un intervalo dado [a,b] funcionesy(x) que verifican
y′(x) = f (x, y(x)) , y(x0) = y0 (7.1)
donde f es una funcion real de dos variables reales. Observese que lasolucion de (7.1) tiene la propiedad
y(x) = y0+∫ x
x0
f (t, y(t))dt , (7.2)
expresion que debe considerarse como una formulacion equivalente delproblema de valores iniciales (7.1). En lo que sigue supondremosx0 = a.
7.1.1 El algoritmo de Euler
El metodo numerico mas sencillo para resolver un problema de valoresiniciales como (7.1) es el algoritmo de Euler.Este se basa en la formula
y(x + h) = y(x)+ hy′(x)+ 12h2y′′(ξ)
7.1. Problemas de valores iniciales 199
en base a la cual, elegido un numeroh suficientemente pequeno como paraqueh2 sea despreciable, formamos las sucesiones
xi+1 = xi + h , yi+1 = yi + h f (xi , yi ). (7.3)
Esto se puede conseguir mediante el siguiente algoritmo
Algoritmo de Euler
Datos: x0,b (extremos del intervalo), h (longitud del paso), y0 (valorinicial).
1 y0 = y0+ h f (x0, y0); x0 = x0+ h;Imprimir x0, y0;Si x0 < b entonces ir al paso 1;Stop.
Para poder hacer un uso eficaz de un metodo numerico comoeste, es ne-cesario calcular tambien la cota del error que se comete en cada paso. Estopuede hacerse de varias maneras, dependiendo de la cantidad que queramostomar como indicativa del error. El error en que quizas se piense primeroes la diferenciay(xi ) − yi entre el valor exacto de la funcion incognita encada nodo y el valor estimado en ese nodo. Esta cantidad se llamaerrorglobal. Es sencillo demostrar que para el metodo de Euler,
Ejercicio 7.1Supongamos que aplicamos el metodo de Euler al problema(7.1) y quef (x, y) y fy = ∂ f/∂y son funciones continuas en el rectangulox0 < x <b, c < y < d y la solucion de(7.1) satisface para todox0 < x < b quec < y(x) < d. Si M es una cota superior de|y′′| y L una cota superiorde fy(x, y(x)) en x0 < x < b entonces la sucesion de errores globales,Ek = |y(xk)− yk|, satisface:
Ek+1 ≤ (1+ hL)Ek + 12 Mh2
Para el metodo de Euler el error global tiene una cota superior dada porel siguiente teorema:
Teorema 28 Si f (x, y) y fy = ∂ f/∂y son funciones continuas en el rectangulox0 < x < b, c < y < d y la solucion de (7.1) satisface para todo

200 7. Ecuaciones diferenciales
x0 < x < b quec < y(x) < d entonces el error global en la sucesionyn de(7.3) tiene la siguiente cota superior en valor absoluto,
En = |y(xn)− yn| < M
2Lh((1+ hL)n − 1
) ≈ M
2Lh(e(xn−x0)L − 1)
dondeM es una cota superior de|y′′| y L una cota superior defy(x, y(x))enx0 < x < xn.
7.1.2 Metodos de Taylor
Los problemas asociados con el algoritmo de Euler sugieren llevar maslejos la aproximacion mediante serie de Taylor
y(x + h) = y(x)+ hy′(x)+ 1
2h2y′′(x)+ 1
3!h3y′′′(x)+ · · · (7.4)
Si esta aproximacion tiene una aplicacion practica a la resolucion de(7.1) esto es debido a que (suponiendo quef es suficientemente diferen-ciable)todas las derivadas dey(x) pueden calcularse en terminos def ysus derivadas parciales. Por ejemplo, diferenciandoy′(x) = f (x, y(x))se obtieney′′(x) = fx + f fy. Ası obtenemos una nueva funcion de dosvariables
f (1)(x, y) = fx(x, y)+ f (x, y) fy(x, y)
que, al igual que ocurre conf (x, y) respecto dey′(x), para cadax, y′′(x) =f (1)(x, y(x)) Analogamente,
Ejercicio 7.2Demostrar (suponiendo quef pueda diferenciarse tanto como sea necesa-rio) que siy′(x) = f (x, y(x)) y definimos
f (2) = fxx + 2 f fxy+ f 2 fyy+ fx fy + f ( fy)2
entonces
y′′′(x) = f (2)(x, y(x))
= fxx(x, y(x))+ 2 f (x, y(x)) fxy(x, y(x))+ f 2(x, y(x)) fyy(x, y(x))
+ fx(x, y(x)) fy(x, y(x))+ f (x, y(x))( fy(x, y(x)))2.
7.1. Problemas de valores iniciales 201
Si definimos el “polinomio de Taylor de ordenp” asociado af median-te
Tp(x, y, h) = f (x, y)+ h
2!f (1)(x, y)+ · · · + hp−1
p!f (p−1)(x, y);
entonces (7.4) se reduce a
y(x1) = y0+ hTp(x0, y0, h)+ hp+1
(p+ 1)!y(p+1)(ξ)
y en general, paraxk = x0+ kh, definimos el algoritmo de Taylor de ordenp mediante
y(xk+1) = yk + hTp(xk, yk, h) , con y0 = y(x0).
Ejercicio 7.3Demostrar que el algoritmo de Taylor de orden 1 es precisamente el algo-ritmo de Euler.
En la practica, por su complicacion, no se usan los algoritmos de Taylorde orden superior al 2. Pero esutil conocer en detalle el caso de orden dos.En este caso tenemos
y(xk+1) = yk + hT2(xk, yk, h)
= yk + h(
f (xk, yk)+ h
2!
(fx(xk, yk)+ f (xk, yk) fy(xk, yk)
))lo cual da lugar al siguiente algoritmo:
Algoritmo de Taylor de orden 2
Datos: x0,b (extremos del intervalo), h (longitud del paso), y0 (valorinicial). Funciones predefinidas:f (x, y), fx(x, y), fy(x, y).
1 f0 = f (x0, y0); f1 = fx(x0, y0)+ f0 fy(x0, y0);T2+ f0+ 0.5h f1; y0 = y0+ hT2; x0 = x0+ h;Imprimir x0, y0;Si x0 < b entonces ir al paso 1;Stop.

202 7. Ecuaciones diferenciales
La principal ventaja de los metodos de Taylor es su potencial para ob-tener una precision muy alta en los resultados sin necesidad de utilizar unnumero demasiado grande de pasos (es decir, sin necesidad de elegir unpaso de longitud excesivamente pequena). Pero, por otro lado, para alcan-zar esa precision es necesario disponer de las derivadas parciales def , elcalculo de las cuales pueden requerir un gran numero de operaciones.Estees uno de los inconvenientes de estos metodos. Otro inconveniente mas se-rio es la necesidad de llevar a cabo el trabajo preliminar de analisis (calculode las derivadas) y programacion (para la evaluacion de dichas derivadas).Este inconveniente puede resolverse hoy dıa (al menos para cierta clase defunciones) mediante el uso de programas de calculo simbolico que automa-tizan el calculo de derivadas de expresiones complejas. Algunos de estosprogramas se encuentran disponibles en calculadoras simbolicas modernastales como la HP48 deHewlett-Packard.
A pesar de lo dicho, los metodos de Taylor rara vez se usan en lapractica. Su principal interes es de tipo teorico porque la mayorıa de losmetodos practicos intentan alcanzar la misma precision que un metodo deTaylor del mismo orden sin la desventaja de tener que calcular las derivadassuperiores. Esto nos lleva a los metodos de Runge-Kutta.
7.1.3 Metodos de Runge-Kutta
Segun lo dicho mas arriba, la motivacion principal de los metodos de Runge-Kutta es el intento de imitar la precision de los metodos de Taylor evitandorealizar las derivadas de orden superior de la funcion f . La forma massencilla e intuitiva de introducir los metodos de Runge-Kutta es comenzarcon el caso particular conocido comometodo de Heun((28), p. 515, (9), p.541) ometodo de Euler mejorado((38), p. 421), el cual puede plantearsecomo un metodo de aceleracion del metodo de Euler.
Consideremos la siguiente idea: el valor def (xn, yn) aproxima la pen-diente dey(x) enxn y esto nos permite estimaryn+1 comoyn+h f (xn, yn).Pero al disponer de este valor estimado podemos usarlo a su vez para esti-mar la pendiente dey(x) enxn+1 como
y′(xn+1) ≈ f (xn+1, yn+1)
y a partir de esta estimacion realizar una correccion enyn+1, recalculandoloen base a los valores estimados de las pendientes enxn y enxn+1 y aproxi-mandoy(x) en [xn, xn + h] por una parabola. De esta forma se obtiene el
7.1. Problemas de valores iniciales 203
algoritmo del metodo de Heun,
yn+1 = yn + h
2
(f (xn, yn)+ f
(xn + h, yn + h f (xn, yn)
)).
xn
yn
xn+1
yn+1
Es interesante tambien observar que el valor final de la pendiente enxn+1 es la media aritmetica de las pendientesf (xn, yn) y f
(xn + h, yn +
h f (xn, yn))
inicialmente estimadas enxn y xn+1. Esto no debe sorprenderporque la pendiente de la parabola varıa linealmente.
La idea general de los metodos de Runge-Kutta de orden 2, es utilizaruna formula de iteracion de la forma:
yn+1 = yn + h(a1 f (xn, yn)+ a2 f (xn + b1h, yn + b2h f (xn, yn))
)donde las constantesa1,a2,b1,b2 han de determinarse de tal forma que
yn+1 = yn + hT2(xn, yn, h)+ O(3)
Ejercicio 7.4Demostrar que la restriccion impuesta a las constantesa1,a2,b1,b2 implicaqueestas deben verificara1 + a2 = 1, a2b1 = 1
2, a2b2 = 12 cona2 > 0 y
que por tanto un metodo de Runge-Kutta de orden 2 esta determinado porla constantea = a2 y tiene la forma
yn+1 = yn + (1− a)h f (xn, yn)+ ah f(xn + h2a , yn + h
2a f (xn, yn))
De esta forma general es inmediato ver que

204 7. Ecuaciones diferenciales
Ejercicio 7.5El metodo de Heun es el caso particular de los metodos de Runge-Kuttade orden 2 que se obtiene al tomara = 1
2 en la formula que aparece en elejercicio(7.4).
Por otro lado, resulta interesante que el metodo original desarrolladopor RUNGE hace mas de un siglo (1895) era el caso particular paraa = 1.Este caso tambien se conoce con el nombre demetodo de Euler modificadoy se reduce a la ecuacion de iteracion siguiente:
yn+1 = yn + h f (xn + 12h, yn + 1
2h f (xn, yn)).
En la practica de programacion de los algoritmos de los metodos deRunge-Kutta es comun y util ordenar y efectuar los calculos mediante lascantidades
k1 = h f (xn, yn)
k2 = h f (xn + 12ah, yn + 1
2ak1)
yn+1 = yn + (1− a)k1+ ak2
Estos calculos se pueden implementar con el siguiente algoritmo:
Algoritmo de Runge-Kutta de orden 2
Datos: x0,b (extremos del intervalo), h (longitud del paso), y0 (valorinicial), c (constante del metodo, Runge-Kutta original esc = 1
2a =12). Funcion predefinida:f (x, y).
1 k1 = h f (xn, yn);k2 = h f (xn + ch, yn + ck1)− k1;y0 = y0+ k1+ 2ck2; x0 = x0+ h;Imprimir x0, y0;Si x0 < b entonces ir al paso 1;Stop.
A continuacion explicamos la forma de obtener metodos de Runge-Kutta deordenes superiores por un metodo analogo al utilizado para obte-ner la formula general de los metodos de orden 2. Sin entrar en los detalles
7.1. Problemas de valores iniciales 205
de calculo, el metodo usual de orden 4 (utilizado por KUTTA en 1905), esel siguiente,
yn+1 = yn + 16(k1+ 2k2+ 2k3+ k4)
donde
k1 = h f (xn, yn)
k2 = h f(xn + 1
2h, yn + 12k1
)k3 = h f
(xn + 1
2h, yn + 12k2
)k4 = h f (xn + h, yn + k3).
Este metodo requiere cuatro evaluaciones de la derivaday′(x) en cadapaso de iteracion, frente a las dos evaluaciones necesarias con los metodosde orden 2. Puesto que el orden de exactitud de este metodo es mayor queel de aquel, lo dicho significa que el metodo sera superior si podemos usarun paso de longitudal menos dobleque el necesario en el metodo de orden2 para obtener la misma precision. Este es importante para evitar caer enla creencia ciega en la superioridad del metodo de Runge-Kutta de cuartoorden frente al de segundo orden. Ciertamente el metodo de cuarto orden essuperior en la mayorıa de los casos, pero no es una propiedad del metodosino de los problemas a los que se suele aplicar. Igual comentario puedehacerse sobre la superioridad del metodo de cuarto orden frente a los deorden superior. ((39), p.604.)
7.1.4 Error local y paso variable
Una consideracion que debe quedar clara respecto al uso de los metodos deRunge-Kutta es la referente al tamano del paso empleado en cada iteracion,es decir, el hecho de que no hay razon por la cual se deba mantener fijala longitudh del paso. Hecha esta consideracion se abre la posibilidad deajustar el paso de cada iteracion al error maximo que se quiere tolerar. Estonos llevara a la cuestion de estimar el error local (ver CONTE y DE BOOR
(14), p. 366).
Nos limitaremos a uno de los metodos conocidos de estimacion delerror local, a saber, el que se basa en dividir los intervalos en dos partesiguales. Explicaremos la idea de este metodo suponiendo que utilizamos unmetodo de Runge-Kutta de ordenp e indicando que el caso mas corrientees p = 4. La idea es muy sencilla: integrar una vez dexn a xn+1 = xn + h

206 7. Ecuaciones diferenciales
y despues hacer dos integraciones de pasoh/2 a partir dexn. De estaforma se obtienen dos estimacionesyh(xn+1) e yh/2(xn+1) mediante cuyacomparacion podemos estimar el error local como
Dn = |yh/2(xn+1)− yh(xn+1)|2p − 1
.
Ahora podemos describir la forma de controlar el paso. Para ello esnecesario fijar una tolerancia de error local,ε, con la cual limitaremos elerror localpor unidad de paso, es decir:Dn ≤ hε. A partir de la toleranciade error local calcularemos la cota inferior del error localε′ = ε/2p+1, pordebajo de la cual consideraremos que la precision es excesiva. Con estoestablecemos el siguiente criterio de actuacion:
(a) Si ε′ <Dn
h< ε nos quedamos con el valor obtenido deyh/2(xn+1)
y continuamos integrando a partir dexn+1 con el mismo pasoh.
(b) Si ε <Dn
hreducimosh a la mitad y repetimos los calculos desdexn.
(c) SiDn
h< ε′ nos quedamos conyh/2(xn+1) pero cambiamosh al
doble antes de seguir integrando a partir dexn+1.
7.1.5 Metodos de paso multiple
La idea de los metodos de paso multiple es muy simple y natural. Para in-troducir un caso sencillo que ilustre la idea general utilizaremos la formulasiguiente
Ejercicio 7.6Si y es una funcion con derivada tercera continua, entonces para algun ξ ∈(a− h,a+ h)
y′(a) = y(a+ h)− y(a− h)
2h+ 1
6h2y′′′(ξ)
a partir de la cual es sencillo deducir el metodo
yn+1 = yn−1+ 2h f (xn, yn).
7.1. Problemas de valores iniciales 207
El error local de truncacion en este metodo es de la formaτn+1(h) =13 y′′′(ξn)h2 y por tanto es un metodo de segundo orden. Compararemos estemetodo con los metodos de Runge-Kutta de orden 2, destacando la ventajaque aquı tenemos por la gran simplicidad de los calculos.
A continuacion introduciremos la idea de utilizar la informacion dadapor los puntos ya calculados,(x0, y0), . . . , (xn, yn), para aproximarf (x, y(x))mediante interpolacion en algunos de dichos puntos (losm ultimos) y usaresta aproximacion en la version integral,
yn+1 = yn +∫ xn+1
xn
f (x, y(x))dx
de nuestra ecuacion diferencial. Ası, llegamos a las formulas de Adams-Bashforth. Estas se pueden escribir bien en terminos de diferencias o enterminos de ordenadas, de las cuales preferiremos la segunda forma. Ası,en el casom = 3 obtendremos la formula (usando la abreviacion fn =f (xn, yn))
yn+1 = yn + 124h
(55 fn − 59 fn−1+ 37 fn−2− 9 fn−3
),
cuya formula del error local se deduce integrando la formula del error deinterpolacion y da
E = h4y(5)(ξ)251720.
Otras formulas de paso multiple se deducen de la misma idea aplicadaa la integracion de f (x, y(x)) en intervalos distintos del [xn, xn+1], porejemplo, integrando desdexn−1 hastaxn+1. En general, estas formulasse obtienen integrando desdexn−p hastaxn+1 para algun valor dep ∈{0, . . . ,n}. Ası se obtienen, por ejemplo (casosm = 1, p = 1 y m = 3,p = 3) las formulas
yn+1 = yn−1+ 2h f (xn, yn) , E = 13 y′′′(ξ)h2
yn+1 = yn−3+ 43h( fn − fn−1+ 2 fn−2) , E = 14
45y(5)(ξ)h4
entre las cuales reconocemos las del metodo presentado al principio de esteapartado.
Porultimo mencionaremos una dificultad de que adolecen las formulasde paso multiple: requieren conocer varios valores iniciales de la funcionf(x, y(x)
)para poder comenzar los calculos. Estos valores iniciales de-
ben ser provistos por otro metodo, y es necesario asegurarse de que sonsuficientemente precisos para la precision total requerida.

208 7. Ecuaciones diferenciales
7.1.6 Sistemas de ecuaciones
En este apartado indicaremos brevemente la forma de adaptar los metodosque hemos estudiado al caso de sistemas de ecuaciones. Para ello estudiare-mos en detalle la reformulacion de los metodos de Euler y de Heun para lossistemas que provienen de problemas de valores iniciales para una ecuacionde segundo orden, es decir, para problemas de la forma
y′1 = y2 , y1(a) = A
y′2 = f (x, y1(x), y2(x)) , y2(a) = B
que seran utilizados en la siguiente seccion.
7.2 Problemas de valores en la frontera
7.2.1 Metodos de tiro o disparo
Comenzamos esta seccion recordando la forma general de los problemasunidimensionales de valores en la frontera, y como se reducen a un sistemade ecuaciones diferenciales de primer orden. Explicaremos las dificultadesinherentes a los problemas de valores en la frontera dando una idea generaldel procedimiento a seguir en los metodos de disparo. En especial indicare-mos la necesidad de utilizar una version multidimensional de algun metodode resolucion numerica de ecuaciones no-lineales tal como (por ejemplo)el metodo de la secante o el de Newton-Raphson.
A continuacion indicaremos el tipo particular de problema con que ilus-traremos los metodos de resolucion de disparo, asegurandonos de que elalumno comprenda la posibilidad de modificar los metodos explicados pa-ra aplicarlos a problemas mas generales.
El problema particular que estudiaremos es el problema de segundoorden de dos puntos frontera, es decir el problema de evaluar una funciony(x) que satisface
y′′(x) = f (x, y(x), y′(x)) , y(a) = A , y(b) = B
que reformularemos como el sistema
y′1 = y2 , y1(a) = A
y′2 = f (x, y1(x), y2(x)) , y1(b) = B.
7.2. Problemas de valores en la frontera 209
Para explicar conceptualmente el proceso de resolucion del metodo deldisparo plantearemos considerar una funcion T : R → R que a cadanumero realα (quizas restringido a cierto dominio) le asocia el valor enb de la funcion y1 solucion del sistema
y′1 = y2 , y1(a) = A
y′2 = f (x, y1(x), y2(x)) , y2(a) = α,es decir,T es la funcion que se puede representar de la forma
α@A BCT
OO//{
y′1 = y2 , y1(a) = A
y′2 = f (x, y1(x), y2(x)) , y2(a) = α
}R-K // y1(b)
Nuestro problema es equivalente al de hallar el numeroα tal que
T(α) = B.
Este problema lo resolvemos por alguno de los metodos de resolucionnumerica de ecuaciones no lineales, por ejemplo por el metodo de la se-cante. Con ese metodo tenemos que realizar las iteraciones
αn+1 = αn −(T(αn)− B
)(αn − αn−1)
T(αn)− T(αn−1)
en cada una de las cuales hay que realizar una nueva evaluacion deT , lo quesignifica una aplicacion de un metodo numerico para problemas de valoresiniciales tal como, por ejemplo, el usual de Runge-Kutta de cuarto orden.
Para terminar este apartado sobre metodos de disparo comentaremosbrevemente la variante llamada deldisparo a un punto intermedio, que re-sulta necesaria cuando el problema es de tal naturaleza o la estimacion ini-cial α0 esta tan apartada de su valor correcto que los “disparos” iniciales noson capaces de atravesar todo el dominio de integracion. En estos casos,y en aquellos en que los extremos del intervalo de integracion son puntossingulares de la ecuacion diferencial de partida, suele ser ventajoso, en lu-gar de integrar desde un extremo del intervalo [a,b] hasta el otro, elegirun punto intermediox0 y realizar dos integraciones, una desdea hastax0y otro desdeb hastax0. En lugar de la ecuacion no lineal a resolver quetenıamos antes (T(α) = B), ahora tendremos (en el caso unidimensional

210 7. Ecuaciones diferenciales
de segundo orden que hemos tomado como ejemplo) un sistema de dosecuaciones no lineales de la forma
Ta(α) = Tb(β)
Sa(α) = Sb(β)
de las que la primera expresa la igualdad de los dos valores obtenidos paray(x) en x0 y la segunda expresa la igualdad de los dos valores obtenidospara la derivaday′(x) enx0.
7.2.2 Problemas lineales: Metodo de las diferencias fini-tas
En este apartado explicaremos el metodo de las diferencias finitas para pro-blemas lineales de valores en la frontera. De nuevo, nos restringiremos aproblemas unidimensionales de segundo orden. Este caso lo usaremos pa-ra ilustrar el procedimiento general: elegir unamalla de puntos (x0 = a,con xn = x0 + nh, h = (b − a)/N) en el intervalo del problema y sus-tituir la ecuacion diferencial por su aproximacion mediante una ecuacionen diferencias finitas resultante de sustituir las derivadas que aparecen enla ecuacion diferencial por sus aproximaciones en terminos dediferenciascentrales, es decir, realizando las aproximaciones
y′(x) ≈ y(x + h)− y(x − h)
2h
y′′(x) ≈ y(x + h)− 2y(x)+ y(x − h)
h2
y′′′(x) ≈ y(x + 2h)− 3y(x + h)+ 3y(x − h)− y(x − 2h)
h3
...
De esta forma pasamos del problema
y′′(x)+ f (x)y′(x)+ g(x)y(x) = q(x) , y(a) = α , y(b) = βa su aproximacion en diferencias finitas, es decir, al sistema deN−1 ecua-ciones lineales enN − 1 incognitas:(
1− 12h fn
)yn−1+
(− 2+ h2gn)yn +
(1+ 1
2h fn)yn+1 = h2qn
7.2. Problemas de valores en la frontera 211
donden = 1, . . . , N − 1.
Observaremos que la matriz de coeficientes de este sistema siempreresulta ser tridiagonal, con lo cual el sistema es susceptible de ser resueltopor los metodos especiales descritos en el tema de metodos numericos parael algebra lineal.
7.2.3 Metodos de colocacion
Haremos una breve mencion a los metodos decolocacion, cuya idea generalse aplica a cualquier ecuacion funcional lineal
Ly = f
y por tanto a las ecuaciones diferenciales lineales.
La idea es muy sencilla. Se comienza eligiendo una malla de puntosque denotamosa = x0, x1, . . . , xN, xN+1 = b y, ademas, se eligenNfunciones basicasϕ1, . . . , ϕN que supuestamente sirven para aproximar lasolucion mediante una combinacion lineal de la forma
y(x) ≈ c1ϕ1(x)+ · · · + ϕN(x).
Debido a la linealidad del operadorL, la condicion de que dicha aproxima-cion seaexactaen losN puntosinterioresde la malla (puntos decoloca-cion) nos lleva a un sistema deN ecuaciones lineales en lasN incognitasc1, . . . , cN . Ademas, si las condiciones de contorno son homogeneas, bas-tara elegir las funcionesϕi de forma que satisfagan dichas condiciones decontorno para que cualquier combinacion lineal de ellas tambien las satis-faga. Esto hace que este metodo sea muy apropiado para los problemas deSturm-Liouville con condiciones de contorno homogeneas.
Cuando las condiciones de contorno no son homogeneas tenemos queimponerlas sobre la combinacion linealc1ϕ1(x) + · · · + ϕN(x) y reducircorrespondientemente el numero de puntos de colocacion para seguir te-niendo un sistema determinado.
No insistiremos mas en este metodo salvo para indicar que un conjuntode funciones basicas de gran utilidad nos las ofrecen las varillas flexibles(splines) adaptadas a las condiciones de contorno de nuestro problema. Enparticular son de interes las varillas flexibles cubicas que hemos estudiadoen un tema anterior.

212 7. Ecuaciones diferenciales
Muy probablemente los problemas de contorno han aparecido ya en va-rias asignaturas de los tres primeros anos de ingenierıa. Los metodos pararesolver estos problemas son en general muy distintos de los metodos pa-ra resolver problemas de valores iniciales, sin embargo estudiaremos aquıun metodo sencillo (llamadometodo del disparo) que reduce el problemade contorno a una serie de problemas de valores iniciales. Consiste estemetodo en la busqueda iterativa de condiciones iniciales tales que la solu-cion determinada por ellas satisfaga las condiciones de contorno dadas.
7.2.4 Tratamiento Variacional
El metodo variacional o de la energıa reduce la resolucion de problemaselıpticos de contorno a la de un problema variacional. Una clase de proble-mas unidimensionales que pueden tratarse por este metodo es la de aque-llos que sean equivalentes a las ecuaciones del movimiento de un siste-ma mecanico en que las fuerzas que actuan provengan de una funcion deenergıa potencialV . Entonces se puede demostrar que existe unafuncionlagrangianaL (la diferencia entre la energıa cinetica y la energıa potencial)tal que el movimiento del sistema, para cualesquiera condiciones iniciales,minimiza laaccion
∫L dt, es decir, es la solucion del problema variacional
δ∫
L dt = 0. El teorema fundamental del calculo de variaciones estableceque una funcion x(t) da un valor extremo a una integral de la forma∫ t2
t1L(x, x, t)dt,
si y solo si es solucion de la ecuacion diferencial de Euler asociada al pro-blema variacional:
∂L
∂x− d
dt
∂L
∂ x= 0.
Si x es un vector conn dimensiones se obtendrann ecuaciones de Euler,pero los razonamientos son enteramente iguales al caso unidimensional enque concentraremos nuestra atencion. Una clase bastante general de pro-blemas a los que se pueden aplicar estos metodos son los que se expresanmediante una ecuacion diferencial de la forma
x + f (t)x = g(t) (7.5)
la cual puede obtenerse como ecuacion de Euler de un problema variacionaltomando como lagrangiana (entre otras posibles) la funcion L(x, x, t) =
7.2. Problemas de valores en la frontera 213
x2 − f (t)x2 + 2g(t)x. Una funcion lagrangiana que da lugar a problemasno lineales paraa 6= 0 esL(x, x, t) = (ax+ b)x2− f (t)x2+ 2g(t)x.
Un metodo eficaz para la resolucion numerica de problemas variacio-nales es elmetodo de los elementos finitosque en realidad se aplica a casosde varias dimensiones (siendot en la ecuacion (7.5) un vector) pero cuyaaplicacion ilustraremos solamente en el caso unidimensional descrito.
7.2.5 Metodo de los elementos finitos
Para hallar numericamente una funcion x(t) definida en el intervalo(t1, t2)que minimize la integral
I =∫ t2
t1
(x2− f (t)x2+ 2g(t)x
)dt
se procedera como sigue: Comenzamos dividiendo el intervalo de integra-cion en subintervalos (oelementos, de donde el nombre del metodo). Encada elemento se aproxima la solucion mediante una funcion polinomica degrado pre-especificado y los coeficientes de todos esos polinomios se some-ten a las condiciones de continuidad, diferenciabilidad y contorno apropia-das y se evalua en terminos de ellos la integralI . Esta resultara ser necesa-riamente una funcion lineal de los coeficientes y cuadratica en los valoresquex toma en los nodos de los elementos. En consecuencia la condicion deextremo de la integral conduce a un sistema de ecuaciones lineales con ma-triz de coeficientes simetrica y definida positiva. La solucion de ese sistemasera la solucion aproximada de nuestra ecuacion diferencial.

Capıtulo 8
Analisis de Fourier
Los trabajos de Fourier sobre analisis de ondas en terminos de ondas sinu-soidales opurascausaron el asombro de sus contemporaneos. Muy prontola teorıa del analisis de Fourier se desarrollo y fue encontrando multiplesaplicaciones que sobrepasan el uso que le dio Fourier en la resolucion de laecuacion del calor. No solo se encuentra esta teorıa en la base de resultadostan fundamentales como los principios de incertidumbre de la MecanicaCuantica sino que abrio las puertas paraareas tan importantes como lateorıa de espectroscopıa y ha llegado a formar la base de una importanterama de las matematicas que se conoce como Analisis Armonico.
El tema del Analisis de Fourier es de gran importancia para la inge-nierıa, contandose entre sus aplicaciones las tecnicas de analisis espec-troscopico (Espectroscopıa Raman, Espectroscopıa Infrarroja), el diseno yanalisis de osciladores electronicos e incluso el analisis de las vibracionesde las estructuras mecanicas.
Aunque el analisis de Fourier ha alcanzado un enorme nivel de gene-ralizacion y abstraccion, en este curso vamos a darle la presentacion masintuitiva posible recorriendo de cerca su desarrollo historico y conservandosu interpretacion fısica en terminos de senales y sus espectros.
215

216 8. Analisis de Fourier
8.1 Funciones sinusoidales
8.1.1 Tres definiciones equivalentes
Una funcion sinusoidal es un funcion cuya grafica es de la forma
¿Pero que ae entiende por esto. Intentemos hacerlo mas preciso.
(1) las funciones que representan los movimientos de oscilacion armonicasimple, es decir, aquellos que se obtienen al proyectar ortogonalmente unmovimiento circular uniforme sobre una recta.
(2) las soluciones de las ecuaciones armonicasy′′ = −ω2y para distin-tos valores deω.
Estas definiciones son equivalentes y hacen destacar las caracterısticasprincipales de las funciones sinusoidales. Ademas nos permiten justificar,por su significado fısico, la terminologıa usada para los distintos parametrosasociados con ellas (amplitud, perıodo, frecuencia, frecuencia angular, fa-se) ya que relacionan las funciones sinusoidales con los fenomenos fısicosondulatorios o vibratorios y con la funcion exponencialeiαt .
8.1.2 Las funciones trigonometricas Seno y Coseno
A partir de aquı es sencillo ver que las funciones seno y coseno puedendefinirse como casos particulares de funciones sinusoidales1,
Ejercicio 8.1Demostrar que las funciones Seno y Coseno son las componentes respecti-vamente vertical y horizontal del movimiento circular uniforme de frecuen-cia angular unidad, amplitud unidad y posicion inicial (1,0).
y que toda funcion sinusoidal admite unaunica representacion en terminosde estas dos.
1Esto es evidente en el enfoque del movimiento circular y, de hecho, es la forma de defi-nirlas en el bachillerato cuando se definen como los cocientes de los catetos a la hipotenusa.La unica diferencia es que aquı admitimosangulos variables (con velocidad constante).
8.2. Superposicion de funciones periodicas 217
Ejercicio 8.2Demostrar que siy(t) es una funcion real tal quey′′ = −ω2y, entoncesexisten constantes realesa y b tales quey(y) = a cosωt + bsenωt .
8.2 Superposicion de funciones periodicas
En este apartado repasamos el concepto de funcion periodica demostrandoque las funciones sinusoidales son periodicas. Nuestro objetivo es plantearla idea de superposicion de funciones periodicas y demostrar que el resul-tado es de nuevo una funcion periodica si y solo si las de partida tenıanperıodos conmensurables y deducir la formula del perıodo de la funcionresultante.
De esta forma el alumno comprendera sin dificultad que las frecuenciasque pueden entrar a “formar parte” de una funcion periodica son precisa-mente aquellas que son multiplos enteros de la frecuencia (fundamental)de esa funcion periodica. Con esto quedara establecido quetoda superpo-sicion de funciones sinusoidales cuyas frecuencias sean todas multiplos deun valor fijoν dara lugar a una funcion periodica de frecuenciaν. Esto ser-vira de motivacion para plantear el teorema de Fourier como una especiede recıproco de lo anterior y permitira comprender su importancia para elanalisis y sıntesis de senales periodicas.
8.3 El sistema trigonometrico y las series de Fou-rier
Las funciones sinusoidales basicas de frecuencias naturales, a saberfn(t) =cos(2πnt), y gn(t) = sen(2πnt), paran = 0,1,2, ... (excluyendo la fun-cion nulag0), constituyen lo que se llamael sistema trigonometrico. Elcontenido esencial del teorema de Fourier puede enunciarse diciendo queel sistema trigonometrico es un sistemaortogonaly completorespecto alproducto interior
〈 f, g〉 =∫ a+T
af (t)g(t)dt

218 8. Analisis de Fourier
en un espacio vectorial de funciones periodicas de perıodoT .2
Aunque la demostracion de este teorema se sale de los objetivos delos estudios de ingenierıa (al menos en los dos primeros ciclos), no nosparece conveniente enunciar un teorema de la importancia deeste sin daralgun tipo de justificacion. Parte de este resultado (la ortogonalidad) puededemostrarse directamente3 y seguramente es un ejercicio que muchos delos alumnos han realizado en algun curso anterior. Sin embargo, creemosmas adecuado justificar el resultado entero utilizando algunos resultadosque forman parte del curso de Ecuaciones Diferenciales y que, dada suimportancia repasaremos brevemente.
Veremos primero que el sistema trigonometrico esta constituido por elsistema de autofunciones del siguiente problema de autovalores con condi-ciones de contorno periodicas (ver PERAL (2)):
y′′ = −ω2y
y(−π) = y(π)
y′(−π) = y′(π)
el cual es un problema autoadjunto. La demostracion de esto es trivial y,desde cierto punto de vista no hay nada que demostrar, pues, como hemosindicado, el sistema trigonometrico puede definirse como el sistema de au-tofunciones de dicho problema autoadjunto de autovalores.
A continuacion aplicaremos al caso anterior el siguiente resultado ge-neral de la teorıa general de las ecuaciones diferenciales:todo conjuntode autofunciones de un problema de autovalores definido por un operadordiferencial autoadjunto y con condiciones de contorno ya sean separadaso periodicas, constituye un sistema ortogonal completo en el espacio defunciones sobre las que actua el operador.(ver PERAL (2), p. 150.)
2Para lo que nos interesa aquı no es necesario dar una descripcion exacta de ese espaciode funciones, pero podemos decir que incluye todas las funciones periodicas de perıodo Tque tienen norma finita segun el producto interior citado. Esto incluye todas las funcionesperiodicas de perıodo T que solo tienen un numero finito de discontinuidades yestas sondiscontinuidades de salto finito.
3Dicha demostracion directa suele plantearse como un ejercicio de integracion de funcio-nes trigonometricas del tipo
∫senmxcosnx dx, estudiando separadamente los casosm 6= n y
m= n. Sin embargo, es mucho mas sencillo realizar los calculos si se plantea el problema enterminos de la funcion exponencial, con lo cual obtenemos integrales del tipo
∫eimxeinx dx,
que son inmediatas.
8.3. El sistema trigonometrico y las series de Fourier 219
Esto nos permite concluir que el sistema trigonometrico es ortogonal ycompleto debido a que es el conjunto de autofunciones de un problema deautovalores autoadjunto.
Ademas, recordaremos que el que un conjunto de funciones{φk}k=0,1,...de un espacio con producto interior〈 , 〉 sea un sistema ortogonal completosignifica que toda funcion f de ese espacio puede expresarse como una se-rie que converge uniformemente af , de forma que se obtiene una formulade la forma
f (x) =∞∑
k=0
akφk(x).
Con esa informacion es inmediato obtener las formulas de representa-cion de funciones periodicas (de perıodoT) mediante series de Fourier
f (t) = a0+∞∑
n=1
an cos(2πn
Tt)+∞∑
n=1
bn sen(2πn
Tt).
8.3.1 Forma compleja de la serie de Fourier
Conviene explicar en cierto detalle la reformulacion de la serie de Fourieren terminos de la forma exponencial compleja del sistema trigonometrico,es decir, en terminos de las funciones{eint ,e−int }n=0,1,... = {eint }n∈Z , ydeducir las expresion
f (t) =∞∑
n=−∞A( n
T )ei ·2πnt/T ,
donde
A( nT ) =
1
T
∫ T2
− T2
f (t)e−i ·2πNt/T dt ,
y la interpretacion fısica de los terminos que en ellas aparecen. De particu-lar importancia por su significado fısico es la identidad de Parseval
1
T
∫ a+T
a| f (t)|2 dt =
∞∑n=−∞
|A(n)|2
que nos dice que la energıa total (por ciclo) de una onda periodica es iguala la suma de las energıas de las ondas sinusoidales que la constituyen (oque entran a formar parte de su espectro).

220 8. Analisis de Fourier
8.4 Transformada de Fourier o espectro conti-nuo de una senal
Las senales realesf (t) rara vez son funciones rigurosamente periodicas yaque evidentemente no existen para todo valor del tiempot . Esto planteael problema matematico de realizar un analisis (en terminos de funcionessinusoidales) de funciones que no son periodicas y de averiguar que tipo de“espectro” pueden tener tales funciones.
Explicaremos aquı que para considerar la funcion f en toda la recta reales necesario pasar de la expansion en serie de Fourier def en el intervalo[−T
2 ,T2 ] a la representacion integral
f (t) =∫ ∞−∞
f (ν)ei ·2πνt dν donde f (ν) =∫ ∞−∞
f (t)e−i ·2πνt dt .
Esta representacion se puede concebir y obtener como un paso al lımitede la expansion en serie cuando el perıodoT tiende a infinito. La funcionque asigna a cada posible frecuenciaν la amplitud f (ν) con que intervieneen f se llama la transformada de Fourier def y debido a que (bajo cier-tas condiciones) una funcion y su transformada se determinan mutuamente,ambas suelen ser consideradas como representaciones distintas (una desdeel punto de vista de valores temporales y la otra desde el de amplitudesdefinidas en el “espacio” de frecuencias) de un mismo ente que es la senal.La transformada de Fourier de una funcion real de variable real es una fun-cion simetrica cuyo significado fısico es el de unadensidad de amplituddeondas sinusoidales razon por la cual tambien recibe el nombre deespectrocontinuo.
El espectro continuo debe ser considerado como la representacion fielde una senal real, f (t). El analisis deesta pasa por una observacion enun intervalo finito, que en el mejor de los casos es una truncacion g de f ,limitada a un intervalo de interes [a,a+ T ]. Esto da lugar a una aproxima-cion del espectro (continuo) def por un espectro discreto, formado por loscoeficientes de Fourier deg (es decir, de la extension periodica deg). Esteespectro discreto se llama unatransformada discretade f . En lo que siguesupondremos que el intervalo de observacion es [0,2π ].
El espectro discreto def en dicho intervalo esta dado por la integral
f (n) = 1
2π
∫ 2π
0f (t)e−int dt
8.4. Transformada de Fourier 221
la cual debemos calcular mediante alguna formula de integracion numerica.Vamos a elegir aquı la formula trapezoidal compuesta, la cual, al dividir elintervalo de integracion enN subintervalos iguales nos da
f (n) = 1
2π
(∫ 2π
0f (t)e−int dt
)
≈ 1
2π
(2π
N
N−1∑k=0
f (2πk/N)e−in·2πk/N
)= fN(n).
es decir, aproximamos el espectro def mediante
fN(n) = 1
N
N−1∑k=0
f (tk)e−intk
donde los puntostk = 2πk/N son los puntos o nodos demuestreoy losvalores f (tk) son los valores de muestreo.
A continuacion estudiaremos la cuestion de cuan precisos son los valo-res fN(n) ası obtenidos como aproximacion de los coeficientesf (n). Paraello demostraremos el hecho crucial de que cada aproximacion fN(n) re-sulta ser igual a la suma de todos aquellos coeficientesf (k) tales quek escongruente conn modulo N, es decir
fN(n) =∞∑
k=0
f (n+ kN).
Esta superposicion de armonicos puede “explicarse” por el hecho deque parak ≡ n mod N la simple evaluacion en los nodos de muestreotk no puede distinguir entre las funcioneseikt y eint . Un efecto notable ybien conocido que es consecuencia de esta identificacion es el fenomenoque se observa al mirar una rueda que gira de “ver” mover los radios a unavelocidad distinta de la de la rueda, en ocasiones viendose inmoviles o gi-rando en sentido contrario. En este ejemplo el ojo muestrea un movimientoperiodico a intervalos de aproximadamente una vigesima de segundo y elcerebro interpreta esos datos identificandolos con el movimientomas lentocompatible con la observacion (ver CONTE (14)).
Porultimo explicaremos que la importancia que tiene para nosotros di-cha identificacion es el hecho de que nos impide observar el comportamien-to periodico que pudiera haber en la funcion f (t) con frecuencias mayores

222 8. Analisis de Fourier
que 12
N2π y por lo tanto,si queremos observar un fenomeno periodico de
frecuenciaν debemos muestrear como mınimo con una frecuencia de2ν,esto es, utilizar un numero de nodosN ≥ 4πν. Equivalentemente, aunquefN(n) es una aproximacion de f (n) para todon, usaremos estas aproxima-ciones solamente para valores den tales que|n| ≤ N/2. Indicaremos tam-bien la enorme importancia que estas observaciones tienen en el proceso dedigitalizacion de una senal (analogica), pueseste es un tipo de muestreo4
que de no ser adecuadamente planeado (segun el tipo de senal de que setrate) puede dar lugar a la perdida de aquellas frecuencias que tenıan mayorinteres.
8.5 Transformada rapida de Fourier
Dado un conjunto den datosz0, z1, ..., zn−1 que suponemos ser el muestreoa intervalos regulares de una senal, la transformada discreta de Fourier deesos datos consiste en losn valoresw0, w1, ..., wn−1 tales que
zt =n−1∑k=0
wkei ·2πkt/n.
Estos valores se calculan por medio de la formula de inversion:
wk = 1
n
n−1∑t=0
zte−i ·2πkt/n .
En este punto hemos de aclarar, para que el alumno pueda apreciar ensu justo valor la importancia del algoritmo de transformada rapida, que nohay ninguna dificultad en evaluar dichos coeficientes por el metodo directode las multiplicaciones encajadas. La dificultad comienza solamente cuan-do, para ciertas aplicaciones (por ejemplo, en telecomunicaciones, analisisde series temporales, etc.), tenemos que realizar millones de calculos deese tipo, con grandes valores den, y queremos realizarlos “en tiempo re-al”, esto es, a medida que se va registrando una senal queremos calcularsu espectro sin demora. Un calculo sencillo mostrara que, llamando “ope-racion” a una multiplicacion junto con una suma de numeros complejos,
4Llamadomuestreo analogico, para distinguirlo delmuestreo discretoque se puede reali-zar sobre una senal ya digitalizada.
8.5. Transformada rapida de Fourier 223
se necesitann2 operaciones para cada evaluacion de una transformada, loque daba cantidades prohibitivas de operaciones a realizar antes de la di-fusion del algoritmo de Cooley-Tukey (hacia mitad de los anos 60). Condicho algoritmo se necesitan solamenten(r1 + · · · + r p) operaciones sinse puede factorizar comon = r1 · · · r p. Ası, incluso para un caso modestocomon = 27 = 128, casi queda dividido por 10 el numero de operacionesnecesarias.
Con dichas razones esperamos que el alumno comprenda el completocambio de actitud, que tuvo lugar con el advenimiento del algoritmo dela transformada rapida, hacia lo que se puede hacer usando metodos deFourier en un ordenador.
La idea basica tras el algoritmo de Cooley-Tukey es muy sencilla ysurge al plantear la evaluacion de una transformada den puntos como laevaluacion en una raız n-esima de la unidad,x = e−i ·2π/n, den polinomiosde la forma
p1(x) = a0+ a1+ a2+ · · · + an−1 =n−1∑k=0
ak
p2(x) = a0+ a1x + a1x2+ · · · + an−1xn−1 =n−1∑k=0
akxk
p3(x) = a0+ a1x2+ a1x4+ · · · + an−1x2(n−1) =n−1∑k=0
akx2k
...
pn(x) = a0+ a1xn−1+ · · · + an−1x(n−1)(n−1) =n−1∑k=0
akx(n−1)k
lo cual se puede expresar con notacion matricial admirablemente adaptadaal problema en la forma:

224 8. Analisis de Fourier
p1
p2
p3...
pn
=
1 1 1 · · · 1
1 x x2 · · · xn−1
1 x2 x4 · · · x2(n−1)
......
......
1 xn−1 x2(n−1) · · · x(n−1)2
a0
a2
a3...
an−1
.
Estudiaremos primeramente el caso particular en quen se descomponecomo producto de dos factores,n = pq mostrando como, al considerarel vector de coordenadas(z1, . . . , zn) como una matrizp × q, z(i, j ), sepuede reducir el calculo de una transformada den puntos al calculo deptransformadas deq puntos seguidas deq transformadas dep puntos. Cadauna de estasultimas se puede calcular con un algoritmo de la forma
x = 1; ωn = e−i ·2π/n;Para i = 1 hasta p
Para j = 1 hastaqz0( j, i ) = z1( j, p);Para k = p− 1 hasta1 incremento−1
z0( j, i ) = z1( j, k)+ x · z0( j, i );siguientek
x = x · ωn
siguiente j
x = x · ωn
siguientei
en el cual el numero de operaciones que se realizan es del orden deqp2. Unalgoritmo analogo nos permitira calcular lasp transformadas deq puntos.Ası pues, el coste total es depq2+ qp2 = n(p+ q) operaciones. Tambiendiscutiremos el casooptimo en quen es una potencia de 2, en que el calculode la transformada discreta se puede realizar con un coste de solo 2n log2 noperaciones.
Bibliograf ıa
[1] Abramowitz and Stegun.Handbook of Mathematical Functions, Gra-phs, and Mathematical Tables. Dover, 1965.
[2] Ireneo Peral Alonso.Primer Curso de Ecuaciones en Derivadas Par-ciales. Addison-Wesley Iberoamericana, S.A., 1995.
[3] Larry C. Andrews.Special Functions of Mathematics for Engineers.McGraw-Hill, second edition, 1992.
[4] Kendall E. Atkinson. An introduction to Numerical Analysis. JohnWiley & Sons, 1978.
[5] N. Bakhvalov.Metodos numericos. Paraninfo, 1980.
[6] Richard Barret and Others.Templates for the Solution of Linear Sys-tems: Building Blocks for Iterative Methods. SIAM, 1994.
[7] Ronald N. Bracewell.The Fourier Transform and its Applications.McGraw-Hill, 2 edition, 1986.
[8] Brice Carnahan, H. A. Luther, and James O. Wilkes.CalculoNumerico Metodos, Aplicaciones. Editorial Rueda, Madrid, 1979.
[9] Steven C. Chapra and Raymond P. Canale.Metodos Numericos paraIngenieros. McGraw-Hill, 1985.
[10] Ciarlet. Introduction a l’analyse numerique matricielle eta l’optimi-sation. Masson, 1982.
[11] P. G. Ciarlet and J. L. Lions, editors.Handbook of Numerical Analy-sis, volume I, II, III, IV. North-Holland, 1994.
225

226 BIBLIOGRAFIA
[12] A. M. Cohen, J. F. Cutts, R. Fielder, D. E. Jones, J. Ribbans, and E.Stuart.Analisis Numerico. Editorial Reverte, 1977.
[13] S. D. Conte and C. De Boor.Analisis Numerico Elemental. LibrosMcGraw-Hill de Mexico, segunda edition, 1974.
[14] Samuel Daniel Conte and Carl De Boor.Elementary NumericalAnalysis. McGraw-Hill, third edition, 1981.
[15] Crouzeix and Mignot. Analyse numerique des equationsdifferentielles. Masson, 1983.
[16] Dahlquist and Bjorck.Numerical Methods. Prentice-Hall, 1974.
[17] Graham De Vahl Davis. Numerical Methods in Engineering andScience. Chapman and Hall, second edition, 1986.
[18] Deuflhard and Hohmann.Numerical Analysis. Walter de Gruyter,1995.
[19] Forsythe, Malcom, and Moler.Computer Methods for MathematicalComputations. Prentice-Hall, 1977.
[20] Gene Golub and James M. Ortega.Scientific Computing. An introduc-tion to Parallel Computing. Academic Press, Inc., 1993.
[21] Hammerlin and Hoffmann.Numerical Mathematics. Springer UTM,1991.
[22] Peter Henrici.Elements of Numerical Analysis. John Wiley & Sons,5 edition, 1964.
[23] Nicholas J. Higham.Accuracy and Stability of Numerical Algorithms.Siam, 1996.
[24] Joe D. Hoffman. Numerical Methods for Engineers and Scientists.McGraw-Hill, 1992.
[25] Isaacson and Keller.Analysis of Numerical Methods. Wiley, 1966.
[26] Eugene Jahnke and Fritz Emde.Tables of Functions with formulaeand curves. Dover, 5 edition, 1945.
[27] Jain, Iyengar, and Jain.Numerical Methods for Scientific and Engi-neering Computation. Wiley Eastern, 1993.
BIBLIOGRAFIA 227
[28] David Kinkaid and Ward Cheney.Analisis Numerico. Addison-Wesley Iberoamericana, 1994.
[29] P. Lascaux and R. Theodor.Analyse numerique matricielle appliqueea l’art de l’ingenieur, volume 1. Masson, 1986.
[30] Charles Van Loan.Computational Frameworks for the Fast FourierTransform. SIAM, 1992.
[31] Luenberger.Optimization by vector space methods. Wiley, 1969.
[32] F. Marcellan, L. Casasus, and A. Zarzo.Ecuaciones Diferenciales.McGraw-Hill, Madrid, 1990.
[33] John H. Mathews.Metodos Numericos para Matematicas, Ciencia eIngenierıa. Dover, 2 edition, 1945.
[34] John H. Mathews.Numerical Methods for Mathematics, Science, andEngineering. Prentice-Hall, second edition, 1992.
[35] A. V. Oppenheim and A. S. Willski.Senales y Sistemas. Prentice-HallHispanoamericana, 1994. Traducido de la segunda edicion inglesa.
[36] Alan V. Oppenheim and Alan S. Willski. Signals and Systems.Prentice-Hall, second edition, 1983.
[37] James M. Ortega.Numerical Analysis: a second course. SIAM, 1990.
[38] Benjamin F. Plybon.An Introduction to Applied Numerical Analysis.PWS-KENT, 1992.
[39] William H. Press, Saul A. Teukolsky, William T. Vetterling, and BrianP. Flannery.Numerical Recipies in Fortran. Cambridge UniversityPress, second edition, 1994.
[40] Robert W. Ramirez.The FFT Fundamentals and Concepts. Prentice-Hall, 1985.
[41] H. R. Schwarz.Numerical Analysis, A Comprehensive Introduction.Wiley, 1989.
[42] Murray R. Spiegel.Mathematical Handbook of Formulas and Tables.Schaum’s Outline Series in Mathematics. McGraw-Hill, 1968.

228 BIBLIOGRAFIA
[43] J. Stoer and R. Bulirsch.Introduction to Numerical Analysis. Texts inApplied Mathematics, 12. Springer TAM, 2 edition, 1993.
[44] R. Theodor.Initiation a l’Analyse numerique. Masson, 2emeedition,1986.
[45] John Todd.Basic Numerical Mathematics, volume 2 (Numerical Al-gebra) ofInternational Series in Numerical Mathematics, 22. Aca-demic Press, 1977.
[46] John Todd. Basic Numerical Mathematics, volume 1 (NumericalAnalysis) ofInternational Series in Numerical Mathematics, 14. Aca-demic Press, 1979.
[47] William T. Vetterling, Saul A. Teukolsky, William H. Press, and BrianP. Flannery.Numerical Recipies Example Book [Fortran]. CambridgeUniversity Press, second edition, 1995.
[48] Norbert Wiener.The Fourier Integral and certain of its Applications.Cambridge University Press, 1933.
[49] Stephen Wolfram.Mathematica: A System for Doing Mathematics byComputer. Addison-Wesley, 3 edition, 1996.
Apendice A
EjerciciosComplementarios
Ejercicio A.1Para cada una de las funciones dadas abajo, comprobar que toma valoresde signos opuestos en los extremos del intervalo[0,1]. ¿Que valor lımitese obtiene al aplicar el algoritmo de la biseccion? ¿Es ese valor un cero def (x)?
f (x) = 1
3x − 1, f (x) = cos 10x.
Ejercicio A.2Prueba que la ecuacionex−4x2 = 0 tiene una solucion en el intervalo[4,5]y otra en[0,1]. ¿Que relacion hay entre las soluciones de dicha ecuaciony las deex/2 − 2x = 0? Supon que se quiere usarg(x) = 1
2ex/2 comofuncion de iteracion para hallar las soluciones de la primera ecuacion.
(a) Demuestra que, a menos que de la casualidad de quex0 sea ya el ceroen[4,5], las iteraciones deg no pueden converger a este cero.
(b) Demuestra que six0 ∈ [0,1], entonces las iteraciones deg convergenal cero en[0,1].
(c) Halla una funcion de iteracion que sirva para calcular el cero en[4,5].
229

230 A. Ejercicios Complementarios
Ejercicio A.3 (Feb 2001)Demuestra que el orden de convergencia de una sucesion es un numero realbien definido, es decir, que sip > 0 es un numero real tal que
0< limn→∞
|en+1||en|p <∞
entonces para0< q < p
limn→∞
|en+1||en|q = 0,
y paraq > p
limn→∞
|en+1||en|q = ∞.
Ejercicio A.4Sabemos que sig(x) es una funcion de iteracion tal que en su punto fijog′ se anula yg′′ es continua entonces las iteracionesxn+1 = g(xn) conver-gen cuadraticamente. Enuncia condiciones que garanticen la convergenciacubica de las iteraciones.
Ejercicio A.5Esta es una pregunta sobre la regla de los signos de Descartes. Para entraren materia, recuerda que la regla de los signos de Descartes es una reglasencilla que nos da alguna informacion sobre el numero de ceros positivos
de un polinomio de coeficientes...(escribe la palabra adecuada)
, sin mas que mirar los
signos de sus coeficientes. Las preguntas son: (1) ¿Que dice la regla delos signos de Descartes? (2) ¿Que consecuencia importante tiene esta reglapara los polinomios entre cuyos coeficientes solo hay un cambio de signo?(3) ¿Como puede usarse la regla de los signos para averiguar algo sobreel numero de raices negativas de un polinomio? (4) Fıjate en el polinomiop(x) = 2x4− 7x3− 3x2+ 5x− 1 y di si el numero de raices positivas quetiene es par o impar. (5) Escribe un polinomio tal que aplicandole la reglade los signos obtendremos informacion sobre el numero de raices negativasde p(x). (6) Sabiendo que todas las raices del polinomiop(x) dado antesson reales, ¿cuantas de sus raices son positivas y cuantas son negativas?
231
Ejercicio A.6Aplica la idea de las multiplicaciones encajadas para encontrar una formaeficaz de evaluar las siguientes series (supuesto que se truncan para un valorn = N dado).
ex =∞∑
n=0
xn/n!
ln x = 2∞∑
n=0
1
2n+ 1
(x − 1
x + 1
)2n+1
arcsenx = x + 1
2
x3
3+ · · · =
∞∑n=0
1 · 3 · · · (2n− 1)
2 · 4 · · ·2n
(x2n+1
2n+ 1
).
Ejercicio A.7 (Feb 2001)Aplica la idea de las multiplicaciones encajadas para encontrar una formaeficaz de evaluar la siguiente serie (supuesto que se trunca para un valorn = N dado).
ln x = 2∞∑
n=0
1
2n+ 1
(x − 1
x + 1
)2n+1
.
Escribe, en tu propio pseudocodigo, un algoritmo que tome como datosN y x y evalue ln x mediante dicha serie truncada enn = N, aplicando laidea que hayas descrito.
Ejercicio A.8Demostrar que en una factorizacion triangularA = LU de una matrizsimetrica A, la matriz triangular superiorU se puede expresar comoU =DLt dondeD es una matriz diagonal yLt es la traspuesta deL. JustificarqueD sera necesariamente la diagonal deU .
Sugerencia:Considerese la factorizacion triangular deUt .
Ejercicio A.9Explica como se realiza lamejora iterativade la solucion de un sistema deecuaciones lineales. ¿En que parte de los calculos se saca ventaja de operaren modo de doble precision?

232 A. Ejercicios Complementarios
Ejercicio A.10(a) ¿Como se calcula la condicion, en la norma infinito, de una matriz
2× 2 comoesta: (a b
c d
)?
(b) Explica como encontrar cotas superior e inferior del error relativode una solucion aproximada de un sistema de ecuaciones lineales enterminos de su resto y de la condicion de su matriz de coeficientes.
Ejercicio A.11(a) ¿Que utilidad tiene conocer la condicion de la matriz de coeficientes
de un sistema de ecuaciones lineales?
(b) ¿Cual es la condicion, en la norma infinito, de la matriz de coeficien-tes del siguiente sistema de ecuaciones lineales:
0,0003x + 1,566 y = 1,569
0,3454x − 2,436 y = 1,018
(c) Halla el resto de la siguiente solucion aproximada del sistema ante-rior: x = 8, y = 1. Acota superior e inferiormente el error relativoen esta solucion utilizando la norma infinito.
Ejercicio A.12Calcular la norma euclıdea (es decir, la norma matricial correspondiente a
la norma vectorial‖x‖2 =√
x2+ y2) de la matriz
A =(
3 −5
6 1
).
Ejercicio A.13Sabemos que sig(x) es una funcion de iteracion tal que en su punto fijog′ se anula yg′′ es continua entonces las iteracionesxn+1 = g(xn) conver-gen cuadraticamente. Enuncia condiciones que garanticen la convergenciacubica de las iteraciones.
Ejercicio A.14Supon que la funcion f (x) es un polinomio de gradon. Demuestra que elpolinomio de interpolacion de f (x) enn+ 1 puntos distintos cualesquieraes la propia funcion f (x).
233
Ejercicio A.15 (Feb 2001)Una forma Teorica de hallar un polinomio de interpolacion para unos da-tos(x0, y0), ..., (xn, yn) es resolver un sistema de ecuaciones lineales cuyamatriz de coeficientes es de Vandermonde. Explica como el hecho de queconozcamos otras formas de hallar un polinomio de interpolacion nos pro-porciona tambien una forma de hallar la inversa de una matriz de Vander-monde cualquiera.
Pista:Polinomios de Lagrange.
Ejercicio A.16Usa los polinomios de Lagrange para hallar la inversa de la matriz de Van-dermonde
1 1 1 1
1 2 4 8
1 3 9 27
1 5 25 125
.
Pista:Hacer primero el ejercicio A.15.
Ejercicio A.17Se desea expresar el polinomio19− 34x + 19x2− 3x3 en la forma
A0+ A1(x + 1)+ A2(x + 1)(x + 2)+ A3(x + 1)(x + 2)(x + 3).
Teniendo en cuenta que los coeficientesAk pueden considerarse como di-ferencias divididas, calculense sus valores evaluando el polinomio dado enlos puntosx = 1, x = 2, x = 3, y x = 4, y construyendo la correspondien-te tabla de diferencias divididas.
Ejercicio A.18Teniendo en cuenta que la diferencia divididaf [x0, . . . , xn] es el coefi-ciente del termino de gradon en el polinomio de interpolacion de f en lospuntosx0, . . . , xn, demuestra que la forma de Lagrange del polinomio deinterpolacion nos proporciona la siguiente formula para las diferencias divi-didas, donde aparece la derivada del polinomioq(x) = (x−x0) · · · (x−xn):
f [x0, . . . , xn] =n∑
i=0
f (xi )
q′(xi ).

234 A. Ejercicios Complementarios
Ejercicio A.19Usando la siguiente formula para las diferencias divididas:
f [x0, . . . , xn] =n∑
i=0
f (xi )
q′(xi ),
(dondeq(x) = (x − x0) · · · (x − xn)) calcular el lımite de f [x0, x1, x2]cuandox2→ x1 mientras quex0 y x1 permanecen fijos.
Ejercicio A.20Se desea construir una tabla de la funcion seno en el intervalo[0, π/2] aintervalos igualmente espaciados con la que se pueda evaluarsen(x) con 5dıgitos de precision realizando a lo sumo interpolaciones lineales. ¿Cuantosvalores debe contener la tabla?
Ayuda: La precision deseada equivale a un error menor que0.5× 10−5.
Ejercicio A.21Usa la formula del error de interpolacion,
En(x) = f (x)− pn(x) = f (n+1)(ξ)
(n+ 1)!(x − x0) · · · (x − xn)
para dar una cotasuperiordel error al estimar el valor deln(32) mediante
interpolacion cubica deln x en los puntosx0 = 1, x1 = 43, x2 = 5
3, x3 = 2.
Ejercicio A.22Demostrar que la derivadap′(x) de la parabolap(x) que interpola af (x)en los puntosx0 < x1 < x2 es la recta que toma valoresf [xi−1, xi ] enlos puntosxi−1+xi
2 para i = 1,2. Generalizar este resultado al caso delpolinomio de interpolacion pn(x) de f (x) en los puntosx0 < · · · < xn
para describirp′n(x) como la interpolante de los datos(ξi , f [xi , xi+1]),para valores apropiados deξi ∈ [xi , xi+1].
Ejercicio A.23Discutir las condiciones en que se puede o no se puede esperar que se pue-da realizar una interpolacion inversa, es decir, el obtener de una tabla devalores de una funcion f (x) el valor x = x0 en que la funcion f toma undeterminado valory0.
235
Ejercicio A.24Se desea construir una tabla de la funcion coseno en el intervalo[0, π/2]a intervalos igualmente espaciados con la que se pueda evaluarcos(x)con seis dıgitos de precision realizando a lo sumo interpolaciones lineales.¿Cuantos valores debe contener la tabla?
Ayuda: Seis dıgitos de precision es un error menor que0.5× 10−6.
Ejercicio A.25Usa la definicion trigonometrica de los polinomios de ChebyshevTn(x)para demostrar que para todon, estos verifican
max−1≤x≤1|Tn(x)| = 1
Ejercicio A.26Describe el problema de interpolacion optima en un intervalo dado y ex-plica la propiedad que tienen los polinomios de Chebyshev en relacion conese problema.
Ejercicio A.27Supon que se te presenta un programa FORTRAN, “FUNCTON F(X)”, sete dice que es una rutina que evalua el polinomio conocidop(x) (de grado= r ) y te propones verificar esa afirmacion. Al examinar el codigo dela rutina encuentras que, efectivamente, no contiene mas operaciones quesumas, restas y multiplicaciones, y que la variableX no aparece nunca comofactor mas der veces, lo cual prueba que la rutina evalua algun polinomiode grado≤ r . ¿En cuantos puntos sera necesario y suficiente evaluar larutina para confirmar que representa ap(x)?
Ejercicio A.28(a) ¿Que condiciones deben cumplir tres polinomios de grado≤ 3, p1(x),
p2(x), p3(x) para que constituyan la varilla flexible (spline) cubicade extremos libres que pasa por los puntos(x0, y0), (x1, y1), (x2, y2),(x3, y3).
(b) Verificar si los tres polinomios
p1(x) =1+ (12/23) (x−1)− (33/46) (x−1)2− (11/46) (x−1)3,
p2(x) =1− (15/46) (x − 2)− (3/23) (x − 2)2+ (9/46) (x − 2)3,
p3(x) =−(27/46) (x − 4)+ (1/46) (x − 4)3

236 A. Ejercicios Complementarios
constituyen o no la varilla flexible cubica de extremos libres que pasapor los puntos
(0,0), (1,1), (2,1) y (4,0)
Ejercicio A.29Se desea estimar la integral ∫ 3
1xe−x dx
con un error menor que una diezmilesima mediante la formula del trapezoi-de compuesta. ¿En cuantos subintervalos iguales (en cada uno de los cualesse aplicara la formula del trapezoide simple) se debe dividir el intervalo deintegracion?
Ejercicio A.30Se desea estimar la integral∫ 1
2
0
√1− x2 dx
con un error menor que una diezmilesima mediante la formula de Simpsoncompuesta. ¿En cuantos subintervalos iguales (en cada uno de los cualesse aplicara la formula de Simpson simple) se debe dividir el intervalo deintegracion?
Ejercicio A.31Se desea estimar la integral ∫ 2
1xe−x dx
con un error menor que una cienmilesima mediante la formula de Simpsoncompuesta. ¿En cuantos subintervalos iguales se debe dividir el intervalode integracion?
Ejercicio A.32Demuestra que en el algoritmo de integracion de Romberg, el primer valor
obtenido,T (1)2N , segun la formula
T (1)2N = T2N + T2N − TN
3= 4T2N − TN
3,
237
es igual al valorI SN proporcionado por la formula de Simpson compuesta
con N subintervalos.
Ejercicio A.33El metodo de Euler es un metodo sencillo de resolucion numerica de pro-blemas de valores iniciales en las ecuaciones diferenciales ordinarias deprimer orden. ¿En que idea se basa? Escribe la ecuacion de iteracion dedicho metodo aplicada al siguiente problema de valores iniciales:
y′ = x + y , y(0) = 1,
y efectua los calculos del primer paso de integracion con una longitud depasoh = 0.01.
Ejercicio A.34El metodo de Heun o metodo de Euler mejorado es un metodo sencillo deresolucion numerica de problemas de valores iniciales en las ecuacionesdiferenciales ordinarias de primer orden. ¿En que idea se basa? Escribe laecuacion de iteracion de dicho metodo y muestra que se trata de un metodode segundo orden.
Ejercicio A.35 (Feb 2001)La ecuacion
yn+1 = yn−1+ 2h f (xn, yn)
constituye un sencillo metodo multipaso de grado 1 para la resolucionnumerica de problemas de valores iniciales en las ecuaciones diferencialesordinarias de primer orden. Deduce dicha ecuacion, junto con su formuladel error, a partir del polinomio de Taylor de orden 2 con resto paray(a+h)e y(a− h).
Aplica dicho metodo al siguiente problema de valores iniciales:
y′ = x + y , y(0) = 1,
de la siguiente forma: efectua los calculos del primer paso de integraciondel metodo de Euler con una longitud de pasoh = 0.01. Con el y1 asıobtenido y el valor inicial dado,y0, efectua los calculos del primer paso deintegracion del metodo multipaso dado arriba para obtenery2 con la mismalongitud de pasoh.

238 A. Ejercicios Complementarios
Ejercicio A.36La ecuacion
yn+1 = yn−1+ 2h f (xn, yn)
constituye un sencillo metodo multipaso de grado 1 para la resolucionnumerica de problemas de valores iniciales en las ecuaciones diferencialesordinarias de primer orden. Deduce dicha ecuacion, junto con su formuladel error, a partir del polinomio de Taylor de orden 2 con resto paray(a+h)e y(a− h).
Aplica dicho metodo al siguiente problema de valores iniciales:
y′ = (x + y)2 , y(1) = 0,
de la siguiente forma: efectua los calculos del primer paso de integraciondel metodo de Euler con una longitud de pasoh = 0.1. Con el y1 asıobtenido y el valor inicial dado,y0, efectua los calculos del primer paso deintegracion del metodo multipaso dado arriba para obtenery2 con la mismalongitud de pasoh.
Apendice B
Respuestas a ejerciciosseleccionados
Respuestas a Algunos Ejercicios del Capıtulo 1
Ejercicio 1.1 Como el polinomio tiene todos los coeficientes no negativosy p(1) = 17 es la suma de esos coeficientes, sabemos que cada coeficientees menor que 18. Por tanto el termino independiente es la clase de restos deN0 = p(18) = 5774458 modulo 18, es decira0 = mod (5774458,18) =4. Los restantes coeficientes son los coeficientes del polinomio(p(x) −a0)/x del que podemos calcular su valor enx = 18: N1 = (p(18) −a0)/18= (5774458−4)/18= 320803. Repitiendo el mismo razonamientoobtenemos sucesivamente:
a1 = mod (N1,18) = mod (320803,18) = 7 ,
N2 = (N1− a1)/18= (320803− 7)/18= 17822
a2 = mod (N2,18) = mod (17822,18) = 2 ,
N3 = (N2− a2)/18= (17822− 2)/18= 990
239

240 B. Respuestas a ejercicios seleccionados
a3 = mod (N3,18) = mod (990,18) = 0 ,
N4 = (N3− a3)/18= (990− 0)/18= 55
a4 = mod (N4,18) = mod (55,18) = 1 ,
N5 = (N4− a4)/18= (55− 1)/18= 3
a5 = mod (N5,18) = mod (3,18) = 3 ,
N6 = (N5− a5)/18= (3− 3)/18= 0
ası que el polinomio erap(x) = 3x5+ x4+ 2x2+ 7x + 4
Ejercicio 1.2 La hipotesis nos dice queb2 − 4ac > 0 pues en otro casoo son raıces reales coincidentes o son complejas conjugadas y en amboscasos tendrıan el mimo valor absoluto. Los valores absolutos de las raicesson:
|x1| = 2|c||b| + √b2− 4ac
, |x2| = |b| +√
b2− 4ac
2|a|
y tenemos que demostrar|x2| − |x1| > 0. Pero|x2| − |x1| =((|b| +
√b2− 4ac)2 − 4|ac|
)/2|a|(|b| + √b2− 4ac), luego todo se reduce a de-
mostrar que
2b2+ 2|b|√
b2− 4ac− 4ac− 4|ac| > 0.
Si ac ≤ 0 esto es obvio. Siac > 0 tenemos(|x2| − |x1|
)· 2|a|(|b| +√
b2− 4ac) = 2b2+2|b|√b2− 4ac−8ac= 2(b2−4ac+2|b|√b2− 4ac),
que es mayor que cero por serb2−4ac> 0. Otra demostracion, quizas massencilla, se obtiene al reducir las dos formulas a fracciones con el mismodenominador:
x1 = −2c
b+ sign(b)√
b2− 4ac= b− sign(b)
√b2− 4ac
−2a
x2 = b+ sign(b)√
b2− 4ac
−2a,
y ver que los valores absolutos de los numeradores son claramente el dex1menor que el dex2.
Respuestas Ejercicios del Capıtulo 1 241
Ejercicio 1.3 Es indiferente que seax < N/x o N/x < x ya que ambas
situaciones son simetricas por serN
(N/x)= x). Consideremosx variable.
Cuandox toma el valor√
N el intervalo de extremosx y N/x se reduce a[√
N,√
N], es decir, al punto√
N. Por otro lado, mientrasx varıa de√
N
a 0,N/x varıa de√
N a+∞, es decir, limx→0+N
x= +∞. Ademas, como
la funcion f (x) = N/x es monotona, dados dos numeros positivos cuales-quierax e y el intervalo de extremosx y N/x necesariamente contiene oesta contenido en el intervalo de extremosy y N/y.
Ejercicio 1.4 Contando el cero separadamente, para el primer dıgito dela mantisa hayβ − 1 posibles valores ya que no puede ser cero. Para cadauno de los demas hayβ, luego el numero de posibles mantisas (sin contar elsigno) es(β−1)βn−1. Para el exponente hayM−m+1 posibilidades, luegohay(β−1)βn−1(M+m+1) representaciones positivas. Teniendo en cuentael signo y contando el cero, la respuesta es 1+ 2(β − 1)βn−1(M −m+ 1).
Ejercicio 1.5 Podemos suponer sin perdida de generalidad quex > 0.Ası pues, seax = (0.d1 · · ·dndn+1 · · · )ββE. Si dn+1 < β/2 entonces
|δ| =∣∣∣∣ fl(x)− x
x
∣∣∣∣ =∣∣∣∣∣ (0.d1 · · ·dn)ββ
E − (0.d1 · · ·dndn+1 · · · )ββE
(0.d1 · · ·dndn+1 · · · )ββE
∣∣∣∣∣= (0.0 · · ·0dn+1 · · · )ββE
(0.d1 · · ·dndn+1 · · · )ββE= (0.0 · · ·0dn+1 · · · )β(0.d1 · · ·dn)β + (0.0 · · ·0dn+1 · · · )β
<(0.0 · · ·0dn+1 · · · )β(0.d1 · · ·dn)β
= (dn+1.dn+2 · · · )ββ−(n+1)
(0.d1 · · ·dn)β<
β2β−n−1
(0.1)β= 1
2β1−n
Por otro lado, sidn+1 ≥ β/2 y fijamosd1, . . . ,dn mientras variamosx,el valor de| fl(x) − x| = fl(x) − x disminuira cuandox aumenta y enconsecuencia|δ| disminuye cuandox aumenta, de forma que el mayor valorde |δ| ocurre paradn+1 = β/2 y 0 = dn+2 = dn+3 = · · · , o sea, parax = ((0.d1 · · ·dn)β + 1
2β−n)βE. Por lo tanto, sidn+1 ≥ β/2
|δ| ≤(β−n − 1
2β−n)βE
x=
12β−n
(0.d1 · · ·dn)β + 12β−n≤
12β−n
(0.1)β + 12β−n
= 1
2βnβ−1+ 1<
1
2βnβ−1= 1
2β1−n .

242 B. Respuestas a ejercicios seleccionados
Ejercicio 1.6 Podemos usar la formula dada en el siguiente ejercicio. Enel caso de dıgitos binarios obtenemos
n = ent
(ln |π |ln 2
)− ent
(ln(2|π − 22
7 |)ln 2
)= 10.
Ejercicio 1.7 Segun la definicion, x∗ aproxima ax conn dıgitos signifi-cativos en baseβ si y solo si ln(2|x− x∗|) ≤ (s−n+1) lnβ, es decir,n ≤s+1− ln(2|x−x∗|)
lnβ ≤ s+1−[ent
(ln(2|x−x∗|)
lnβ
)+ 1
]≤ s−ent
(ln(2|x−x∗|)
lnβ
).
Por lo tanto el maximo valor den esn = s− ent(
ln(2|x−x∗|)lnβ
). Aquı s es el
mayor entero tal ques lnβ ≤ ln |x|. En consecuencias = ent(ln |x|/ lnβ)con lo que la formula queda demostrada.
Ejercicio 1.8 Es suficiente demostrar que siα1 ≤ · · · ≤ αn entonces lamedia geometrica,α, y cualquier media aritmetica ponderadaβ verifican
α1 ≤ α ≤ αn y α1 ≤ β ≤ αn .
Tenemos, pues que demostrar estas cuatro desigualdades. Todas se de-muestran con el mismo tipo de razonamiento. Por ejemplo, para demostrarα1 ≤ α: si todos losαi los hacemos iguales aα1 su media quedarıa reduci-da. Pero entonces es media serıa igual aα1, luegoα1 es menor o igual queα.
Ejercicio 1.9∣∣∣ ( f g)′x
f g
∣∣∣ = ∣∣∣ ( f ′g+ f g′)xf g
∣∣∣ = ∣∣∣ f ′xf + g′x
g
∣∣∣ ≤ ∣∣∣ f ′xf
∣∣∣+ ∣∣∣ g′xg
∣∣∣ y un
calculo analogo lo demuestra para el cociente.
Ejercicio 1.10
Respuestas a Algunos Ejercicios del Capıtulo 2
Ejercicio 2.1 (Esto esta hecho para otros datos.) ConN pasos a partir deun intervalo de longitudl se obtiene un intervalo de longitudl/2N . El puntomedio de este intervalo tendra un error menor que el radio, o sea, menor que12l/2N (el error no puede ser igual al radio porque eso significarıa que elcero es uno de los extremos, lo que habrıa sido detectado por el algoritmoy se hubiera hallado el cero exacto). Para que dicho error sea menor queε
necesitamos que el numero de pasos,N, sea tal que 2N ≥ 12l/ε, es decirN
Respuestas Ejercicios del Capıtulo 2 243
mayor o igual que log(l/2ε)/ log 2= log(l/ε)/ log 2− 1, que es lo mismoque decir
N =ent(log(l/ε)/ log 2) si frc(log(l/ε)/ log 2) 6= 0
log(l/ε)/ log 2− 1 si frc(log(l/ε)/ log 2) = 0.
En nuestro caso (l = 20 yε = 10−6) log(l/ε)/ log 2= log(2·107)/ log 2=1+ 7/ log 2= 24.25. . . luegoN = 24.
Ejercicio 2.2 La pendiente de la recta esf (a)a−x0= f (b)− f (a)
b−a . despejandox0 se obtiene
x0 = a− f (a)b− a
f (b)− f (a)= a f (b)− bf (a)
f (b)− f (a).
Ejercicio 2.3 En realidad dicho promedio ponderado es tambien iguala −a f (b)+bf (a)− f (b)+ f (a) . Ambas expresiones se obtienen al tener en cuenta que
f (a) f (b) < 0 lo cual implica que o bien| f (a)| = f (a) y | f (b)| = − f (b)o bien| f (a)| = − f (a) y | f (b)| = f (b).
Ejercicio 2.4 Seaa = f (x). Calculemosf (a). f (a) = f ( f (x)) =f 2(x) = f (x) = a. Luegoa es un punto fijo. Recıprocamente, seaa unpunto fijo de f . Entonces tomandox = a se verifica quea = f (x)
Ejercicio 2.5 ξ = lim{xn} = lim{g(xn−1)} = g(lim{xn−1}) = g(ξ).
Ejercicio 2.6 Seaξ el punto fijo, entoncesξ = g(ξ) = ξ − f (ξ)f ′(ξ) . Esto
implica f (ξ) = 0.
Ejercicio 2.7 Seaa dicha abscisa. Entoncesf ′(x) = f (x)/(x − a), dedonde se deduce inmediatamente la formula dada.
Ejercicio 2.8 Como f (x) = x2− N y f ′(x) = 2x la funcion de iteracion
del metodo de Newton esg(x) = x − x2−N2x = x − x
2 + N2x = 1
2(x + Nx ).
Para la ecuacion x3 − N = 0, f ′(x) = 3x2 y la funcion de iteracion es
g(x) = x − x3−N3x2 = x − 2x
3 + N3x2 = 1
3(2x + Nx2 ). Luego el algoritmo es:
xn+1 = 13(2xn + N/x2
n).
Ejercicio 2.9 (a) Parag1: si x = √2+ x entoncesx2 = 2+ x, que es laecuacion dada. (b) Parag2: si x = 1+ 2
x entoncesx2 = x + 2, que es la
ecuacion dada. (c) Parag3: si x = x − x2−x−2m entonces 0= − x2−x−2
m , de
donde 0+ x2 − x − 2 que es la ecuacion dada. (d) Parag4: si x = x2+22x−1

244 B. Respuestas a ejercicios seleccionados
entoncesx(2x−1) = x2+2, de donde 2x2− x = x+2, que es equivalentea la ecuacion dada.
Ejercicio 2.10 Si g(a) = a o g(b) = b ya tenemos un punto fijo. En caso
contrario, puesto queIg−→ I , tenemosa < g(a) < b, y a < g(b) < b,
lo que implica que la funcion h(x) = g(x) − x es positiva ena y negativaenb, ademas de ser continua en I. En consecuenciah tiene un cero enI elcual es un punto fijo deg.
Ejercicio 2.11 Como g′(x) = 1/(2√
2+ x), para x > 0 se cumple|g′(x)| < 1/
√8 < 1, luego la condicion (c) se cumple para todox > 0.
Comog es creciente, para que la condicion (a) se cumpla en [a,b] bastaque seag(a) ≥ a y g(b) ≤ b. Lo primero se cumple paraa = 0 y losegundo es
√2+ b ≤ b o 2+ b ≤ b2 o b ≥ 2. Luego podemos tomar
I = [0,3].
Ejercicio 2.12
Ejercicio 2.13 La constante de error es igual a
1
n!|g(n)(ξ)| .
Ejercicio 2.14 La derivada segunda deg es(
f ′(x)2 f ′′(x)+ f (x) f ′′′(x)−2 f (x) f ′′(x)2
)/ f ′(x)3. De aquı, teniendo en cuenta quef (ξ) = 0, se ob-
tieneg′′(ξ) = f ′′(ξ)/ f ′(ξ).Ejercicio 2.15 (a)
g′(ξ) = limx→ξ
f (x) f ′′(x)f ′(x)2
= limx→ξ
f (x)
f ′(x)2limx→ξ
f ′′(x)
= f ′′(ξ) limx→ξ
f ′(x)2 f ′(x) f ′′(x)
= f ′′(ξ)1
2 f ′′(ξ)= 1
2.
(b) g′(x) = 1 − 2[ f ′(x)]2− f (x) f ′′(x)[ f ′(x)]2 = 1 − 2[ f ′(x)]2
[ f ′(x)]2 + 2 f (x) f ′′(x)[ f ′(x)]2 =
−1+ 2 f (x) f ′′(x)[ f ′(x)]2 . Para hallarg′(ξ) calculamos el lımite
limx→ξg
′(x) = −1+ 2 limx→ξ
f (x) f ′′(x)[ f ′(x)]2
= −1+ 2 limx→ξ
f (x)
[ f ′(x)]2lim
x→ξ f ′′(x)
= −1+ 2
(lim
x→ξf (x)
[ f ′(x)]2
)f ′′(ξ) = −1+ 2
(lim
x→ξf ′(x)
2 f ′(x) f ′′(x)
)f ′′(ξ)
= −1+ 2
(lim
x→ξ1
2 f ′′(x)
)f ′′(ξ) = −1+ 2
1
2 f ′′(ξ) f ′′(ξ) = 0
Respuestas Ejercicios del Capıtulo 2 245
de donde efectivamenteg′(ξ) = 0. Ahora tenemos que demostrar queg′′es continua enx = ξ . Para ello hemos de ver que limx→ξg′′(x) es finito.Primero hallamos
g′′ =(−1+ 2
f f ′′
[ f ′]2
)′= 2
( f ′ f ′′ + f f ′′′) f ′ − 2 f f ′′ f ′′
[ f ′]3
= 2[ f ′]2 f ′′ + f f ′′′ f ′ − 2 f [ f ′′]2
[ f ′]3= 2
([ f ′]2− 2 f f ′′) f ′′ + f f ′′′ f ′
[ f ′]3
= 2([ f ′]2− 2 f f ′′)
[ f ′]3f ′′ + 2
f
[ f ′]2f ′′′
y ahora, aplicando la regla de l’Hopital y el hecho de que
limx→ξ
f (x)
[ f ′(x)]2= lim
x→ξf ′(x)
2 f ′(x) f ′′(x)= 1
2 f ′′(ξ),
obtenemos,
limx→ξ g′′(x) = 2 lim
x→ξ([ f ′(x)]2− 2 f (x) f ′′(x))′
3 f ′(x)2 f ′′(x)lim
x→ξ f ′′(x)+ 2f ′′′(ξ)
2 f ′′(ξ)
= 2 limx→ξ
2 f ′(x) f ′′(x)− 2 f ′(x) f ′′(x)− 2 f (x) f ′′′(x)3 f ′(x)2
+ f ′′′(ξ)f ′′(ξ)
= f ′′′(ξ)f ′′(ξ) −
43 f ′′′(ξ) lim
x→ξf (x)
[ f ′(x)]2= f ′′′(ξ)
f ′′(ξ) −23
f ′′′(ξ)f ′′(ξ) =
13
f ′′′(ξ)f ′′(ξ)
Ejercicio 2.16
Ejercicio 2.17
Ejercicio 2.18 Supongamos primeramente quea = c. Entonces:
f [a,b] − f [a, c]
b− c= f [a, c] − f [a,b]
c− b= f [a, c] − f [c,b]
a− b= f [a, c] − f [b, c]
a− b
donde hemos usado la propiedad obviaf [c,b] = f [b, c]. Supongamosahora quea 6= c. Tenemos que demostrar
( f [a,b] − f [a, c])(a− b) = ( f [a, c] − f [b, c])(b− c),
que es equivalente a
f (a)− f (b)− f [a, c]a+ f [a, c]b = f [a, c]b− f [a, c]c− f (b)+ f (c)

246 B. Respuestas a ejercicios seleccionados
y cancelando el termino− f (b)+ f [a, c]b y operando, el problema quedareducido a probar
f (a)− f [a, c]a = − f [a, c]c+ f (c),
lo cual no es mas que una reescritura de la definicion del sımbolo f [a, c].
Ejercicio 2.19 Esto es un simple calculo:
xn = xn+1+ xn+1− xnxn−xn−1xn+1−xn
− 1= xn+1+ (xn+1− xn)
2
xn − xn−1− (xn+1− xn)
= xn+1+ (1xn)2
xn − xn−1− xn+1+ xn= xn+1− (1xn)
2
xn−1+ xn+1− 2xn
= xn+1− (1xn)2
12xn−1.
Ejercicio 2.20
Ejercicio 2.21 Si a es una raız dep entonces al dividirp(x) entrex−a elresto esp(a) = 0 y por lo tantox−a es un factor dep(x). Por otro lado, esevidente que six−a es un factor dep, p(x) = (x−a)q(x) para algun otropolinomioq(x) y entoncesa es un cero dep: p(a) = (a− a)q(a) = 0.
Ejercicio 2.22 p(z) = anzn+· · ·+a1z+a0 = anzn+· · ·+a2z2+a1z+a0.Teniendo en cuenta que los coeficientes son reales y por tanto verificanak = ak deducimos
p(z) = anzn + · · · + a1z+ a0 = p(z) .
Ejercicio 2.23 La satisfaccion de la relacion de recurrencia es una com-probacion inmediata. La independencia lineal de{zn
1} y {zn2} se reduce a la
no singularidad de la matriz (1 z1
1 z2
),
la cual es equivalente az1 6= z2.
Ejercicio 2.24
Ejercicio 2.25 z= 1.7437+ 0.3057i
Respuestas Ejercicios del Capıtulo 3 247
Respuestas a Algunos Ejercicios del Capıtulo 3
Ejercicio 3.1 Sin preocuparnos de posibles divisiones por cero, la basedel algoritmo de eliminacion es la siguienteDatos: n, el orden del sistema,A(i, j), la matriz de coeficientes yB(i), la matriz de terminos independientes.para k = 1 hasta n-1para i = k+1 hasta nm = A(i, k)/A(k, k)para j = k hasta nA(i, j) = A(i, j) - m*A(k, j)siguiente jB(i) = B(i) - m*B(k)siguiente isiguiente k
Notese que podemos ahorrarnos algunas operaciones en el bucle internosi evitamos calcular los ceros que se obtienen paraj = k. Estos se puedenintroducir “manualmente” como en
para k = 1 hasta n-1para i = k+1 hasta nm = A(i, k)/A(k, k)A(i, k) = 0para j = k+1 hasta nA(i, j) = A(i, j) - m*A(k, j)siguiente jB(i) = B(i) - m*B(k)siguiente isiguiente k
Ejercicio 3.2 La sustitucion regresiva se puede realizar mediante el si-guiente algoritmo que se puede aplicar a sistemas singulares ya que detectadicha condicion.
si A(n, n) = 0 entoncesimprimir ‘SISTEMA SINGULAR’ y pararX(n) = B(n)/A(n, n)para k = n-1 hasta 1 incremento -1

248 B. Respuestas a ejercicios seleccionados
si A(k, k) = 0 entoncesimprimir ‘SISTEMA SINGULAR’ y parar
s = 0para j = k+1 hasta ns = s + A(k, j)*X(j)
siguiente jX(k) = (B(k) - s)/A(k, k)siguiente k
Ejercicio 3.3 En el metodo de eliminacion de Gauss hay dos partes: (1)Eliminacion de los elementos bajo la diagonal y (2) sustitucion regresiva.
En la primera parte, para eliminar el elemento en posicion(k, l ) es nece-saria una division para calcular el multiplicador y, si el sistema es de ordenn, n − l + 1 multiplicaciones para multiplicar cada uno de los elementosak l+1,ak l+2, . . . ,ak n,bk por el multiplicador. Totaln− l + 2 operacio-nes para el elemento(k, l ). Ası pues, el numero total de operaciones en estaparte es
n−1∑l=1
n∑k=l+1
(n− l + 2) =n−1∑l=1
(n− l )(n− l + 2)
= (n− 1)(n+ 1)+ (n− 2)n+ (n− 3)(n− 1)+ · · · + 1 · 3= 1 · (2+ 1)+ 2 · (2+ 2)+ · · · + (n− 1)(2+ n− 1)
= 2(1+ 2+ · · · + (n− 1))+ (12+ 22+ · · · + (n− 1)2)
= 2n(n− 1)
2+ 1
6(n− 1)n(2(n− 1)+ 1)
= n2− n+ 16(n
2− n)(2n− 1)
= n2− n+ 16(2n3− 3n2− n)
= 13n3+ 1
2n2− 56n.
a esto hay que sumarle las operaciones realizadas durante la sustitucionregresiva, que son: una division para laultima ecuacion, y en general unadivision y k multiplicaciones para la ecuacion n− k (k = 0, . . . ,n− 1), o
sea∑n−1
k=0(k+ 1) = 12n(n+ 1) = n2
2 + n2. Ası pues:
Operaciones en Eliminacion de Gauss:13n3+ n2− 13n .
Este mismo resultado puede obtenerse de forma mucho menos trabajosasi se sabe que la funcion que buscamos es un polinomio enn de tercergrado, es decir de la formaf (n) = an3+ bn2+ cn+ d. Entonces lounicoque tenemos que hacer para averiguar los coeficientesa, b, c, d es resolver
Respuestas Ejercicios del Capıtulo 3 249
un sistema de cuatro ecuaciones y cuatro incognitas que resulta al evaluarf respectivamente en 0, 1, 2, y 3:f (0) = 0, f (1) = 1, f (2) = 6, f (3) =17, (esto se halla contando directamente el numero de multiplicaciones ydivisiones necesarios para resolver los sistemas deordenes cero, uno, dos ytres) lo cual nos da el sistema de ecuaciones
0 0 0 1
1 1 1 1
8 4 2 1
27 9 3 1
a
b
c
d
=
0
1
6
17
cuya solucion esa = 1
3, b = 1, c = −13, d = 0. Otra observacion util
para este problema es que la funcion f (n) puede definirse recursivamente apartir del valor inicial f (0) = 0 por f (n) = f (n− 1)+ (n2+ n− 1). Coneste metodo el computo se simplifica al reducirse a contar las operacionesnecesarias para eliminar la primera columna y para elultimo paso de lasustitucion regresiva (lo que nos da el sumando(n2+ n− 1) de la formulade f (n)).
Ejercicio 3.4Ejercicio 3.5 El siguiente algoritmo efectua la descomposicion triangularde una matriz. Suponemos dados:n, el orden del sistema, yA(i, j ), lamatriz de coeficientes. La solucion se almacenara en las variablesp(i ),L(i, j ), y U (i, j ). Empezamos haciendoU igual aA y L igual a la matrizidentidad.
para i = 1 hasta n
para j = 1 hasta n
U(i, j) = A(i, j); L(i, j) = 0
si i = j entonces L(i, j) = 1
siguiente j
siguiente i
para k = 1 hasta n-1
c = abs(U(k, k)); p(k) = k
para i = k+1 hasta n
si abs(U(i, k)) > c entonces c = abs(U(i, k)) y p(k) = i
siguiente i
si c = 0 entonces imprimir ‘MATRIZ SINGULAR’ y parar
para j = k hasta n
t = U(p(k), j); U(p(k), j) = U(k, j); U(k, j) = t
siguiente j

250 B. Respuestas a ejercicios seleccionados
para i = k+1 hasta n
L(i, k) = U(i, k)/U(k, k); U(i, k) = 0
para j = k+1 hasta n
U(i, j) = U(i, j) - L(i, k)*U(k, j)
siguiente j
siguiente i
siguiente k
si U(n, n) = 0 entonces imprimir ‘MATRIZ SINGULAR’
Ejercicio 3.6 En el metodo de Gauss-Jordan hay una parte de eliminaciony una parte de sustitucion. La segunda consta solamente den divisionesmientras que en la primera se usann− l + 2 operaciones para eliminar elelemento(k, l ) dondek toman − 1 valores yl varıa desde la columna 1hasta lan. Ası pues, el numero total de operaciones en esta parte es
n∑l=1
(n− 1)(n− l + 2) = (n− 1)n∑
l=1
(n− l + 2)
= (n− 1)[(n+ 1)+ n+ (n− 1)+ · · · + 2]
= (n− 1)(12(n+ 1)(n+ 2)− 1)
= (n− 1)(12n2+ 3
2n+ 1− 1) = 12n3+ n2− 3
2n.
y sumando aestas lasn operaciones de la segunda parte, tenemos:
Operaciones en Eliminacion de Gauss-Jordan:12n3+ n2− 12n .
De nuevo, al mismo resultado se llega resolviendo el sistema de ecua-ciones
0 0 0 1
1 1 1 1
8 4 2 1
27 9 3 1
a
b
c
d
=
0
1
7
21
satisfecho por los coeficientes deg(n) = an3+ bn2+ cn+ d.
Ejercicio 3.7Ejercicio 3.8 A partir dex(n+1) = x(n)+C(b− Ax(n)) = x(n)+C A(x−x(n)) se deduce(C A)−1(x(n+1) − x(n)) = x − x(n), de donde
‖x(n) − x‖ ≤ ‖(C A)−1‖‖x(n+1) − x(n)‖ .Ejercicio 3.9 Evidente. Laultima conclusion se obtiene tomandou =v 6= 0.
Respuestas Ejercicios del Capıtulo 3 251
Ejercicio 3.10 La desigualdad de la derecha es consecuencia inmediatade la del ejercicio anterior. La desigualdad de la izquierda se obtiene de lade la derecha intercambiandou y v y tomando inversos.
Ejercicio 3.11 Si A es un operador lineal en un espacio normado, la obviainclusion de conjuntos de numeros
E = {‖Ax‖ | ‖x‖ = 1} ⊂{‖Ax‖‖x‖ | x 6= 0
}= F
es en realidad una igualdad ya que six 6= 0 entonces tomandoy = kx conk = 1/‖x‖, su norma es‖y‖ = 1 y por lo tanto
‖Ax‖‖x‖ = k‖Ax‖ = ‖k · Ax‖ = ‖A(kx)‖ = ‖Ay‖ ∈ E,
o seaF ⊂ E. Ası puesE = F , de donde
maxx 6=0
‖Ax‖‖x‖ = maxF = maxE = max
‖x‖=1‖Ax‖.
De las dos formulas dadas a continuacion, la formula de la izquierda di-ce que‖A‖ es mayor o igual que el maximo deE, mientras que la de laderecha dice que es menor o igual que ese maximo.
Ejercicio 3.12 ‖I ‖ = maxx 6=0‖I x‖‖x‖ = maxx 6=0
‖x‖‖x‖ = 1. Por ejemplo el
otro axioma adicional es consecuencia de que para todox,
‖ABx‖ ≤ ‖A‖‖Bx‖ ≤ ‖A‖‖B‖‖x‖ .Usando estas dos propiedades, 1= ‖I ‖ = ‖AA−1‖ ≤ ‖A‖‖A−1‖.Ejercicio 3.13 Primeramente tenemos para todo vectorx,
‖Ax‖1 =n∑
i=1
∣∣∣ n∑j=1
ai j x j
∣∣∣ ≤ n∑i=1
n∑j=1
|ai j ||xj | =n∑
j=1
( n∑i=1
|ai j |)|xj |
≤(
max1≤ j≤n
n∑i=1
|ai j |)‖x‖1 .
Por otro lado, seak una columna deA para la que la suma de los valoresabsolutos de sus elementos es maxima, es decir que
max1≤ j≤n
n∑i=1
|ai j | =n∑
i=1
|aik |.

252 B. Respuestas a ejercicios seleccionados
Entonces para cualquier vectorx = (0, . . . ,0, xk,0, . . . ,0) todas cuyascomponentes sean cero excepto la del lugark, se verifica (ya que‖x‖1 =|xk|)
‖Ax‖1 =n∑
i=1
|aik xk| =( n∑
i=1
|aik |)|xk| =
(max
1≤ j≤n
n∑i=1
|ai j |)‖x‖1 .
En consecuencia
‖A‖1 = max1≤ j≤n
n∑i=1
|ai j | .
Ejercicio 3.14 Sabemos quec(A) = ‖A‖‖A−1‖. Por otro lado, segun elejercicio 3.11,‖A‖ = max‖x‖=1‖Ax‖, y analogamente
‖A−1‖ = maxy6=0
‖A−1y‖‖y‖ = max
x 6=0
‖x‖‖Ax‖ =
1
minx 6=0‖Ax‖‖x‖= 1
min‖x‖=1‖Ax‖
por lo tanto
c(A) = max‖x‖=1‖Ax‖min‖x‖=1‖Ax‖
Ejercicio 3.15 c(A) = 1 significa que
max‖x‖=1
‖Ax‖ = min‖x‖=1
‖Ax‖
y por lo tanto‖Ax‖ = const. para‖x‖ = 1. En otras palabras,A conservalas bolas de la norma en cuestion, lo cual es decir que conserva la normasalvo un factor constante.
Ejercicio 3.16 Si nos situamos en el plano es geometricamente evidenteque las matricesA que conservan unap-norma parap 6= 2 son precisa-mente las matrices del grupo de simetrıas del cuadrado y sip = 2 las delgrupo de simetrıas del cırculo.
Por otro lado, siA tiene condicionamiento 1 respecto a la norma eu-clıdea entonces puede no conservar lasp-normas parap 6= 2, pero la ima-gen de la bola unitaria de unap-norma siempre estara contenida dentro delcırculo de radio
√2 y contendra al cırculo de radio1
2
√2. En consecuencia,
para cualquierx tal que‖x‖p = 1 tendremos12√
2 ≤ ‖Ax‖p ≤√
2 y por
lo tanto la condicion deA relativa a la normap verificacp(A) ≤√
212
√2= 2.
Respuestas Ejercicios del Capıtulo 3 253
Ejercicio 3.17 Sea A una matriz cuadrada y seaD la matriz diagonalcuya diagonal es igual a la diagonal deA. Suponemos que los elementosde esa diagonal son todos no nulos (en caso contrarioA no puede ser dediagonal estrictamente dominante). Dividiendo cada elemento deA por elvalor absoluto del elemento diagonal de su fila obtenemos una matrizB queesB = D−1A, es decir,A = DB. Basta demostrar que siA es de diagonalestrictamente dominante entoncesB es inversible. Pero decir queA es dediagonal estrictamente dominante es equivalente a decir que‖B− I ‖∞ < 1,lo cual, por el teorema 13 implica que−B no es singular.
Ejercicio 3.18
Ejercicio 3.19
Ejercicio 3.20 Gx+ d = −A−11 A2x + A−1
1 b = −A−11 (A2x − b) luego
x = Gx+d es equivalente a−A1x = A2x−b, que a su vez es equivalenteab = A1x + A2x = Ax.
Ejercicio 3.21 Una descomposicion que siempre es posible se obtiene alelegir A1 = I (identidad). En el caso de una matriz sin ceros en la diagonaltambien A1 = D = diag(A) es inversible, ası como la matriz triangularobtenida al hacer cero enA los elementos que estan encima (o debajo) dela diagonal.Cada una de las descomposiciones anteriores da lugar a un metodo iterativo:
1. En este casoG = −I −1(A− I ) = I − A y d = I −1b = b, luego elmetodo iterativo para resolverAx = b asociado con esta descompo-sicion es hallar un punto fijo de la funcion(I −A)x+b = x−Ax+b.Efectivamente tal punto fijo verificax = x − Ax+ b que es equiva-lente aAx = b.
2. En el segundo caso tenemos el metodo de Jacobi.
3. En el tercer caso tenemos el metodo de Gauss-Seidel.
Ejercicio 3.22 Si tomasemosA1 = −(D+ωL) y A2 = (1−ω)D−ωUtendrıamos
A1+A2 = −(D+ωL)+(1−ω)D−ωU = −D−ωL+D−ωD−ωU = −ωA
mientras que lo que queremos esA1 + A2 = A. Por tanto tenemos quedividir los valores que habıamos dado aA1 y a A2 por −ω y entoncestomaremos
A1 = (D + ωL)/ω = L + 1ω
D

254 B. Respuestas a ejercicios seleccionados
yA2 = −[(1− ω)D − ωU ]/ω = U − (1−ω
ω
)D .
De esta forma tenemos−A−11 A2 = −ω(D + ωL)−1(U − (1−ω
ω
)D) =
−(D + ωL)−1(ωU − (1− ω)D) = G, y A1+ A2 = A. por lo tanto
d = A−11 b = ω(D + ωL)−1b .
Respuestas a Algunos Ejercicios del Capıtulo 4
Ejercicio 4.1 Su sucesion asociada es (por ejemplo) la sucesion constanteigual aA porqueA es ortogonal. No cumple la hipotesis de los autovaloresporque sus autovalores son 1 y−1 (igual valor absoluto). Evidentementeninguna matriz ortogonal cumple las hipotesis del teorema.
Ejercicio 4.2 Tantas como elementos hay bajo la diagonal, es decir lamitad del numero total,n2, menos losn de la diagonal:n(n− 1)/2 .
Ejercicio 4.3 SeaPw = I − 2wwt . EntoncesPtw = I t − 2(wwt )t =
I − 2(wt )twt = I − 2wwt = Pw, luegoPw es simetrica. Ademas P2w =
(I − 2wwt )2 = I − 2I 2wwt + (2wwt )2 = I − 4wwt + 4w(wtw)wt =I − 4wwt + 4wwt = I donde se usa que(wtw) = 1 por serw un vectorunitario.
Ejercicio 4.4 La respuesta es un mero e inmediato calculo.
Ejercicio 4.5 El siguiente algoritmo transforma una matriz cualquiera enotra Hessenberg. Suponemos dados:n, el orden de la matriz, yA(i, j ), lamatriz dada. La solucion se almacenara en la misma variableA.para k = 1 hasta n-2
********* CALCULAMOS LA DIRECCION DE REFLEXION *********
S = 0
para i = k+1 hasta n
S = S + A(i, k)^2
siguiente i
S = SGN(A(k+1, k))*SQRT(S)
R = SQRT(2*(A(k+1, k)+S)*S)
para j = 1 hasta k
w(j) = 0
Respuestas Ejercicios del Capıtulo 4 255
siguiente j
w(k+1) = (A(k+1, k)+S)/R
para j = k+2 hasta n
w(j) = A(j, k)/R
siguiente j
********* CALCULAMOS LOS VECTORES v Y z *********
para i = 1 hasta n
v(i) = 0; z(i) = 0
para j = 1 hasta n
v(i) = v(i) + A(i, j)*w(j)
z(i) = z(i) + A(j, i)*w(j)
siguiente j
siguiente i
********* CALCULAMOS EL ESCALAR lambda *********
lambda = 0
para j = 1 hasta n
lambda = lambda + v(j)*w(j)
siguiente j
********* CALCULAMOS LA NUEVA MATRIZ A *********
para i = 1 hasta n
para j = 1 hasta n
t = 2*lambda*w(i)*w(j) - v(i)*w(j) - w(i)*z(j)
A(i, j) = A(i, j) + 2*t
siguiente j
siguiente i
siguiente k
Ejercicio 4.6
Ejercicio 4.7
Ejercicio 4.8 Las dos comprobaciones son rutinarias. El numero de ope-raciones es la suma de las operaciones realizadas en cada paso. En el pasok, en el que se pasa de una matriz(k− 1)× (k− 1) a unak× k se realizan2(k− 1) multiplicaciones (supuestok ≥ 3) y por tanto el numero total es
n∑k=3
2(k− 1) = 2(2+ · · · + (n− 1)) = n(n− 1)− 2= n2− n− 2
que da el valor (correcto) 0 para el menor valor posible den (a saber:n =2).

256 B. Respuestas a ejercicios seleccionados
Respuestas a Algunos Ejercicios del Capıtulo 5
Ejercicio 5.1 Esto se puede hacer por induccion enn con ayuda de la
sugerencia dada. Paran = 1 se cumple det(
x0 1x1 1
)= x0 − x1. Supuesto
cierto paran puntos (distintos)x0, ..., xn−1, y anadamos aestos un nuevopunto variablet , de forma que obtenemos una matriz variable
M(t) =
xn
0 xn−10 · · · x0 1
...... · · · ...
...
xnn−1 xn−1
n−1 · · · xn−1 1
tn tn−1 · · · t 1
y nos preguntamos que tipo de funcion es la definida porp(t) = detM(t).Evidentemente es un polinomio ent . Su grado esn, tiene a cada una de lasx0, . . . , xn−1 como raiz (por lo que, dado su grado, no tiene mas raices queesas) y su coeficiente principal es
(−1)n det
xn−1
0 · · · x0 1... · · · ...
...
xn−1n−1 · · · xn−1 1
= (−1)n∏
0≤i< j≤n−1
(xi − xj )
Todo esto determina completamente el polinomiop(t) como
p(t) = (coef. ppal)× (t − x0) · · · (t − xn−1)
= (−1)n∏
0≤i< j≤n−1
(xi − xj )× (t − x0) · · · (t − xn−1),
y por tantodetM(xn) = p(xn) =
∏0≤i< j≤n
(xi − xj ).
Ejercicio 5.2 Que esten sobre la grafica de un polinomio de grado menorquen.
Ejercicio 5.3 Uno.
Ejercicio 5.4 Segun la formula
p(x) = f (x0)
q0(x0)q0(x)+ · · · + f (xn)
qn(xn)qn(x)
Respuestas Ejercicios del Capıtulo 5 257
el coeficiente del termino de gradon de p es la suma de los coeficientes delos terminos de gradon de los sumandos, es decir, suma de losf (xk)
qk(xk)ya
que losqk(x) son polinomios monicos de gradon.
Ejercicio 5.5
Ejercicio 5.6 Usando la formula de Leibnitz para la derivada de un pro-ducto se obtieneq′(x) = ∑n
k=0 qk(x) de dondeq′(xk) = qk(xk). Alter-nativamente el resultado se obtiene de forma inmediata derivandoq(x) =qk(x)(x − xk) y evaluando el resultado enxk.
Ejercicio 5.7 Es evidente que los polinomios de Lagrange son
Lk(x) = q(x)
(x − xk)qk(xk),
de lo cual se deduce inmediatamente la formula dada.
Ejercicio 5.8 EvidentementeAn es el coeficiente del termino de gradon del polinomio An(x − x0) · · · (x − xn−1), que es el polinomio diferen-cia Pn(x) − Pn−1(x). Pero esta diferencia tiene el mismo coeficiente deltermino de gradon que Pn(x) ya quePn−1(x) tiene grado estrictamentemenor quen. La formula dada no es mas que una reescritura de (5.2).
Ejercicio 5.9 Para todo polinomiop(x) = anxn + · · · de grado menoro igual quen la derivadan-esima dep es la constantedn p/dxn = n!an.Si p tuviese grado menor quen la derivadan-esima dep serıa cero. Encualquier caso1
n! dn p/dxn es igual al coeficiente del termino de gradon de
p.
Ejercicio 5.10 Evidentemente es un polinomio de grado≤ k+1 ya quepy q tienen grado≤ k y van multiplicados por polinomios de grado 1. Quecoincide conf en xk y en xk+1 es inmediato porquep coincide conf enxk+1 y q enxk. En los demas puntosxi ∈ {x0, . . . , xk−1} tenemos
xi − xk
xk+1− xkp(xi )+ xk+1− xi
xk+1− xkq(xi ) = xi − xk
xk+1− xkf (xi )+ xk+1− xi
xk+1− xkf (xi )
=(
xi − xk
xk+1− xk+ xk+1− xi
xk+1− xk
)f (xi ) = f (xi ).
Ejercicio 5.11 Usando la forma
x − xk
xk+1− xkp(x)+ xk+1− x
xk+1− xkq(x)

258 B. Respuestas a ejercicios seleccionados
del polinomio de interpolacion de f enx0, . . . , xk+1 (ver ejercicio 5.10) ysustituyendo los coeficientes del termino de gradok en p y enq, se obtie-ne inmediatamente la expresion dada para el termino de gradok + 1 delpolinomio de interpolacion enx0, . . . , xk+1.
Ejercicio 5.12
0.65504= 0.5×0.62325−0.3×0.602060.5−0.3 , 0.65380= 0.5×0.64345−0.1×0.60206
0.5−0.1
0.65264= 0.5×0.66276+0.1×0.602060.5+0.1 , 0.65155= 0.5×0.68124+0.3×0.60206
0.5+0.3
0.65318= 0.3×0.65380−0.1×0.655040.5−0.3 , 0.65324= 0.3×0.65264+0.3×0.65504
0.5−0.3
0.65330= 0.3×0.65155−0.3×0.655040.5−0.3 , 0.65321= 0.1×0.65324+0.1×0.65318
0.1+0.1
0.65321= 0.1×0.65330+0.3×0.653180.1+0.3 ,
y dado que los dosultimos coinciden, el siguiente debe ser tambien igual aellos.
Ejercicio 5.13 Segun la definicion de lossk, p′′k(x) = 6ak(x − xk) +sk. Por tanto, la condicion de continuidad de la curvatura,p′′k+1(xk) =p′′k(xk), (k = 1, . . . ,n− 1) implica que 6ak+1(xk− xk+1)+ sk+1 = sk, dedondesk+1− sk = 6ak+1hk+1 parak = 1, . . . ,n−1, lo que es equivalentea la formula dada.
Ejercicio 5.14 Las ecuaciones (5.13) sonakh3k−bkh2
k+ckhk = yk− yk−1
parak = 2, . . . ,n. Poniendo en ellasak = (sk − sk−1)/6hk y bk = 12sk
obtenemos((sk − sk−1)/6hk)h3k − 1
2skh2k + ckhk = yk − yk−1, de donde
16(sk − sk−1)hk − 1
2skhk + ck = (yk − yk−1)/hk y despejandock, ck =(yk − yk−1)/hk − 1
6(sk − sk−1)hk + 36skhk.
Ejercicio 5.15
Ejercicio 5.16 Esto puede hacerse facilmente por induccion. Es clara-mente cierto paran = 0,1. Si lo es paran− 1 y paran entonces
cos((n+ 1)α
) = cos((nα + α)
= cosnα cosα + sennα senα
= 2 cosnα cosα − ( cosnα cosα − sennα senα)
= 2 cosnα cosα − cos((n− 1)α
).
Ejercicio 5.17 Sabemos que maxx∈[−1,1] |Tn(x)| ≤ 1 porque en ese in-
Respuestas Ejercicios del Capıtulo 5 259
tervalox es el coseno de unangulo y por lo tantoTn tambien. Evaluando,Tn(1) = Tn(cos 0) = cosn0 = 1, Tn(−1) = Tn(cosπ) = cosnπ =(−1)n. En consecuencia maxx∈[−1,1] |Tn(x)| = 1.
Ejercicio 5.18 No hay mas que derivarTn(x) e igualar a cero para ob-tener que la condicion de extremo es sen(nθ)/ senθ = 0, de dondex =cosθ con θ 6= mπ y sennθ = 0 y por tantoxk = cos(kπ/n) parak ∈ {1, . . . ,n − 1}. En estos puntos tenemosTn(coskπ
n ) = cos(nkπn ) =
coskπ = (−1)k. Ademas, en los extremos del intervalo [−1,1] tenemosTn(1) = Tn(cos 0) = cos 0= 1 y Tn(−1) = Tn(cosπ) = cosnπ = (−1)n
y por tanto el maximo valor absoluto deTn(x) parax en el intervalo [−1,1]es 1.
Ejercicio 5.19 La transformacion linealy = px+ q que lleva−1 ena y1 enb esy = b−a
2 x + b+a2 , con lo que se obtiene la formula dada.
Ejercicio 5.20 Sabemos que el error del polinomio de interpolacion en losnodosy0, . . . , yn esta acotado por:
| f (x)− Pn(x)| ≤ M
(n+ 1)!|(x − y0) · · · (x − yn)|
en nuestro caso los nodos son, segun el ejercicio 5.19,yk = pxk+q dondexk son los correspondientes nodos de Chebyshev,p = (b − a)/2 y q =(b+ a)/2. Entonces
x − yk = x − (pxk + q) = x − q − pxk = p(x − q
p− xk
)luego
|(x − y0) · · · (x − yn)| =∣∣∣pn+1
( x − q
p− x0
)· · ·( x − q
p− xn
)∣∣∣=∣∣∣pn+1 1
2n Tn+1
( x − q
p
)∣∣∣ = pn+1 1
2n
∣∣∣Tn+1
( x − q
p
)∣∣∣≤ pn+1 1
2n =(b− a
2
)n+1 1
2n = 2(b− a
4
)n+1
donde hemos usado que parax ∈ [a,b] se cumplex−qp ∈ [−1,1] y por lo
tanto|Tn+1(x−q
p )| ≤ 1. Ası pues,
| f (x)− Pn(x)| ≤ 2M
(n+ 1)!
(b− a
4
)n+1.

260 B. Respuestas a ejercicios seleccionados
Ejercicio 5.21 El error estara acotado en valor absoluto por
2M
4!
(1
4
)4
= M
3× 45= sen 1
3072= 0.84147
3072= 0.000274 ,
donde hemos acotado la funcion d4 sen(x)/dx4 = senx por su valor enx = 1. Si interpolamos con grado 5, tenemos que acotar la funciond6 sen(x)/dx6 =− senx para la cual nos sirve la misma cota que en el caso anterior. La cotadel error es
2M
6!
(1
4
)6
= M
90× 47 =0.84147
1474560= 0.000000571.
Respuestas a Algunos Ejercicios del Capıtulo 6
Ejercicio 6.1
Ejercicio 6.2
Ejercicio 6.3
Ejercicio 6.4
Ejercicio 6.5
Ejercicio 6.6
Ejercicio 6.7
Ejercicio 6.8
N = menor entero mayor queb− a
24
√M(b− a)
180ε
Ejercicio 6.9
Respuestas a Algunos Ejercicios del Capıtulo 7
Ejercicio 7.1 Ver Plybon, pp. 409–410.
Ejercicio 7.2
Ejercicio 7.3
Respuestas Ejercicios del Capıtulo 8 261
Ejercicio 7.4 Ver Plybon, p. 420.
Ejercicio 7.5
Ejercicio 7.6 Si aplicamos la formula de Taylor de orden 2 con resto ay(a+ h) y a y(a− h), y restamos, nos queda
y(a+ h)− y(a− h) = 2hy′(a)+ 13h3 y′′′(η1)+ y′′′(η2)
2.
Pero la semisuma que aparece aquı es claramente (suponiendo y”’ conti-nua) igual ay′′′(ξ) para algun ξ ∈ (a− h,a+ h).
Respuestas a Algunos Ejercicios del Capıtulo 8
Ejercicio 8.1
Ejercicio 8.2
Respuestas a Algunos Ejercicios del Apendice A
Ejercicio A.1
Ejercicio A.3 Hay que suponer que limn→∞ en = 01. Casoq > p.En este casoq = p+ a cona > 0, luego podemos poner
‖en+1‖‖en‖q =
‖en+1‖‖en‖p
1
‖en‖a .
Como‖en‖a→ 0, 1‖en‖a →∞ y por tanto el producto‖en+1‖
‖en‖p1‖en‖a tambien.
2. Caso 0< q < p.Analogo. En este casoq = p− a cona positivo y sale
‖en+1‖‖en‖q =
‖en+1‖‖en‖p
‖en‖a.
Ejercicio A.5 coeficientes... reales(escribe la palabra adecuada)
.
(1) El numero de raices positivas de un polinomio de coeficientes re-ales es menor o igual que el numero de cambios de signo que ocurren en

262 B. Respuestas a ejercicios seleccionados
sus coeficientes (ordenados segun las potencias decrecientes dex) y ambosnumeros tienen la misma paridad.
(2) Que tiene exactamente una raiz real positiva.(3) Si queremos saber cuantas raices reales negativas tienep(x) no hay
mas que contar las raices reales positivas dep(−x).(4) impar.(5) 2x4+ 7x3− 3x2− 5x − 1.(6) 3 positivas y una negativa.
Ejercicio A.7 El problema es evaluar:
2N∑
n=0
1
2n+ 1
(x − 1
x + 1
)2n+1
.
Esto es igual a:
2
(x − 1
x + 1
)[1+ 1
3
(x − 1
x + 1
)2+ 1
5
(x − 1
x + 1
)4+ · · · + 1
2N + 1
(x − 1
x + 1
)2N].
y aplicando la idea de las multiplicaciones encajadas:
2
(x − 1
x + 1
)[1+ 1
3
(x − 1
x + 1
)2+ 1
5
(x − 1
x + 1
)4+ · · · + 1
2N + 1
(x − 1
x + 1
)2N]= 2
(x − 1
x + 1
)[1+
(x − 1
x + 1
)2[1
3+ 1
5
(x − 1
x + 1
)2+ · · · + 1
2N + 1
(x − 1
x + 1
)2N−2]]= 2
(x − 1
x + 1
)[1+
(x − 1
x + 1
)2[1
3+(
x − 1
x + 1
)2[1
5+ · · · + 1
2N + 1
(x − 1
x + 1
)2N−4]]]= . . . .
La evaluacion debe comenzar por el parentesis mas interior, es decir:(x − 1
x + 1
)2[ 1
2N − 1+ 1
2N + 1
(x − 1
x + 1
)2],
ası que podemos realizar los calculos con la siguiente rutina:Suponemos dados: N, X. La solucion sera S.
U = ( X - 1 )/( X + 1 )
V = U*U
S = 1/( 2*N + 1 )
para n = 1 hasta N
S = S*V + 1/( 2*(N - n) + 1 )
siguiente n
S = 2*U*S
Respuestas Ejercicios del Apendice A 263
Ejercicio A.8
Ejercicio A.9 Primeramente calculamos el error residualr (1) = b−Ax(1)
utilizando aritmetica de doble precision. Esto significa realizar para cadai ∈ {1, . . . ,n} las siguientes(n− 1) multiplicaciones yn sumas con dobleprecision:
r (1)i = b−n∑
k=1
aik x(1)k ,
Obtenida esta aproximacion del vector de error residual la utilizamospara calcular una estimacion e(1) del error absolutoe resolviendo la ecua-cion Ae= r . Esta ecuacion representa un sistema de ecuaciones linealesque solo se diferencia del dado en los terminos independientes. En con-secuencia, como ya disponemos de la factorizacion de la matriz de coefi-cientes la nueva resolucion tendra un coste mucho menor ya que se reducea una sustitucion progresiva y una sustitucion regresiva como las que nosllevaron deb a x(1), pero esta vez utilizandor (1) en lugar deb como vectorde terminos independientes. De esta forma obtenemos el vectore(1), quesumado ax(1) resultara en la mejora
x(2) = x(1) + e(1) .
Repitiendo este proceso hallarıamos el restor (2) asociado conx(2) utili-zando doble precision, despues hallarıamos el ‘error’e(2) mediante la reso-lucion deAe(2) = r (2) y obtendrıamos una nueva mejorax(3) = x(2)+e(2).Continuando de este modo se obtiene una sucesion de vectores
{x(1), x(2), . . . }
que son sucesivas mejoras de la solucion.Resumiendo, la mejora iterativa de la solucion de un sistema de ecua-
ciones lineales se realiza mediante el siguiente algoritmo (por simplicidadsuponemos que la factorizacion triangular puede hacerse sin permutacio-nes):
Algoritmo de la Mejora Iterativa
1. Factorizacion triangular de la matriz de coeficientes:A = LU .
2. Utilizar dos sustituciones a partir deL , U y b para obtenerx.
3. Con doble precision calcular el resto dex, r = b− Ax.

264 B. Respuestas a ejercicios seleccionados
4. Utilizar dos sustituciones a partir deP, L , U y r para obtenere.
5. Sumare al viejo x para obtener el nuevox.
6. Ir al paso 3.
La doble precision se usa en el calculo del error residual.
Ejercicio A.11
(a) Nos permite acotar superior e inferiormente el error relativo de unasolucion aproximada.
(b) Usando la formula c∞(A) = ‖A‖∞‖A−1‖∞, primero calculamos‖A‖∞ = |0,3454| + | − 2,436| = 2,7814.
A−1 =(
0,0003 1,566
0,3454 −2,436
)−1
=(
4,4976 2,8913
0,6377 −0,00055
)
‖A−1‖∞ =∥∥∥∥∥(
4,4976 2,8913
0,6377 −0,00055
)∥∥∥∥∥∞= |4,4976| + |2,8913|
= 7,3889
c∞(A) = 2,7814× 7,3889= 20,5513.
(c) El resto es
r = b− Ax =(
0,0006
0,6908
), ‖r‖∞ = 0,6908.
Usando las relaciones
1
c∞(A)‖r‖‖b‖ ≤
‖e‖‖x‖ ≤ c∞(A)
‖r‖‖b‖ ,
obtenemos:
Cota inferior: 1c∞(A)
‖r‖‖b‖ = 0,02142.
Cota superior:c∞(A) ‖r‖‖b‖ = 9,04835.
Respuestas Ejercicios del Apendice A 265
Ejercicio A.12 Hay que hallar el maximo valor de‖Ax‖2 parax = (x, y)satisfaciendo 1= ‖x‖2 =
√x2+ y2. Evidentemente la restriccion es equi-
valente ax2+ y2 = 1. Ası pues, el maximo de f (x, y) = ‖(3x− 5y,6x+y)‖2, que es la raiz cuadrada del maximo de
(3x − 5y)2+ (6x + y)2
puede hallarse bien parametrizando el cırculo unitario:x = cost , y = sento mediante multiplicadores de Lagrange. Por esteultimo metodo tenemos:
3(3x − 5y)+ 6(6x + y) = λx
−5(3x − 5y)+ (6x + y) = λy
x2+ y2 = 1
3(3x − 5y)y+ 6(6x + y)y = λxy
−5(3x − 5y)x + (6x + y)x = λxy
3(3x − 5y)y+ 6(6x + y)y = −5(3x − 5y)x + (6x + y)x
9xy− 15y2+ 36xy+ 6y2 = −15x2+ 25xy+ 6x2+ xy
−9y2+ 45xy= −9x2− 24xy
−9y2+ 19xy+ 9x2 = 0
9(y
x)2− 19
y
x− 9= 0
y
x= (19±
√685)/18' 2.51,−0.40
Ejercicio A.14 Si pn(x) es el polinomio de interpolacion, la diferenciaf (x)− pn(x) es un polinomio de grado≤ n que se anula enn+ 1 puntos,por tanto es el polinomio cero.
Ejercicio A.15 Los coeficientesa0, . . . , an del polinomio de interpola-cion para unos datos(x0, y0), ..., (xn, yn) son las soluciones del sistema deecuaciones lineales de Vandermonde (en lasn+ 1 incognitasa0, . . . ,an),
anxn0 + · · · + a1x0+ a0 = y0
... (B.1)
anxnn + · · · + a1xn + a0 = yn .

266 B. Respuestas a ejercicios seleccionados
y recıprocamente, toda solucion de un sistema de ecuaciones lineales deVandermonde esta constituida por los coeficientes de un polinomio de in-terpolacion para unos datos determinados por los coeficientes y terminosindependientes del sistema. En consecuencia, las tecnicas de interpolacionnos permiten resolver sistemas de ecuaciones lineales de Vandermonde.
Para hallar una matriz inversa de ordenn tenemos que resolvern siste-mas de ecuaciones todos ellos con matriz de coeficientes igual a la dada ycon vectores de terminos independientes que son las columnas de la matrizidentidad. Si la matriz de la que queremos hallar la inversa es de Vander-monde, esosn sistemas seran de Vandermonde y se podran resolver por lastecnicas de interpolacion antes mencionadas. Pero como los terminos inde-pendientes son precisamente las columnas de la identidad, los polinomiosde interpolacion resultantes son precisamente los polinomios de Lagrangede las abscisas que forman la matriz de Vandermonde.
Ası pues llegamos a quelas columnas de la inversa de una matriz deVandermonde determinada por las abscisasx0, . . . , xn estan constituidaspor los coeficientes de los polinomios de Lagrange de dichas abscisas.
Ejercicio A.17Evaluacion enx = 1: 19− 34+ 19− 3= 1Evaluacion enx = 2: 19− 34× 2+ 19× 22− 3× 23 = 3Evaluacion enx = 3: 19− 34× 3+ 19× 32− 3× 33 = 7Evaluacion enx = 4: 19− 34× 4+ 19× 42− 3× 43 = −5Tabla de diferencias divididas:
1 12
2 3 14 −3
3 7 −8−12
4 −5
Luego los coeficientes son:
A0 = 1 , A1 = 2 , A2 = 1 , A3 = −3 .
Ejercicio A.18 Ver los ejercicios 5.6 y 5.8.
Ejercicio A.20 LlamemosN al numero de valores que contiene la tabla.Esto significa utilizar un pasoh ≤ π/2
N−1, o sea,N ≥ π2h + 1. Para calcular
Respuestas Ejercicios del Apendice A 267
el paso usamos la formula del error:
error≤ | 12!
f ′′(η)(x − x0)(x − x0− h)|
donde se supone que el punto en que queremos evaluar,x, esta entrex0 yx0+ h.
El maximo de|(x − x0)(x − x0 − h)| parax entrex0 y x0 + h ocurreenx0+ h
2 y es igual a(h/2)2.f ′′(η) = − senη y su valor absoluto es menor o igual a 1. Por lo tanto,
0.5× 10−5 = error≤ 1
2!(h/2)2 = h2
8
de donde obtenemos que un error menor que 0.5× 10−5 quedara garanti-zado si
h2
8≤ 0.5× 10−5,
o sea, si el paso es:
h ≤ 2
105/2
El numero de valores que debe contener la tabla es, pues:
N ≥ 1+ π4
105/2.
Esto es aproximadamente cerca de 300 valores.
Ejercicio A.25Sabemos que el maximo en−1 ≤ x ≤ 1 es menor o igual a 1 porque
en ese intervalo todoTn esta dado por un coseno. Ademas el valor 1 sealcanza enx = 1:
Tn(1) = Tn(cos 0) = cos(n · 0) = cos 0= 1.
Ejercicio A.27 Siendor el grado dep(x) es necesario y suficiente com-probar la coincidencia enr + 1 puntos.
Ejercicio A.28
(a) Las condiciones son:
1. Deben pasar por los puntos dados:p1(x0) = y0, p2(x1) = y1,p3(x2) = y2, p3(x3) = y3.

268 B. Respuestas a ejercicios seleccionados
2. Deben formar una curva continua:p1(x1) = p2(x1), p2(x2) = p3(x2).
3. Deben formar una curva diferenciable:p′1(x1) = p′2(x1), p′2(x2) =p′3(x2).
4. Deben formar una curva con curvatura continua:p′′1(x1) = p′′2(x1),p′′2(x2) = p′′3(x2).
5. Deben satisfacer la condicion de extremos libres:p′′1(x0) = 0, p′′3(x3) =0.
(b) Con que una sola de las cinco condiciones anteriores deje de cumplir-se, la respuesta serıa que no. En caso contrario sı lo serıa. Veamoslas condiciones una a una:
1. p1(x0) = y0, p2(x1) = y1, p3(x2) = y2, p3(x3) = y3. Estoes,p1(0) = 0, p2(1) = 1, p3(2) = 1, p3(4) = 0. Calculemos,p1(0) =1−(12/23) (−1)−(33/46) (−1)2−(11/46) (−1)3 =1+ (12/23)− (33/46)+ (11/46) = 0p2(1) =1−(15/46) (1−2)−(3/23) (1−2)2+(9/46) (1−2)3 =1+ (15/46)− (3/23)− (9/46) = 1
2. p1(x1) = p2(x1), p2(x2) = p3(x2). Esto es,p1(x1) = y1,p2(x2) = y2 =. Por simple inspeccion se ve claramente queesto se cumple.
3. p′1(x1) = p′2(x1), p′2(x2) = p′3(x2).
4. p′′1(x1) = p′′2(x1), p′′2(x2) = p′′3(x2).
5. p′′1(x0) = 0, p′′3(x3) = 0.
Ejercicio A.29 El error en la formula del trapezoide compuesta con unnumeroN de subintervalos en el intervalo [a,b] es
E = −b− a
180f (4)(ξ)h4
dondeh = (b − a)/N. En nuestro casoa = 1, b = 3, f (x) = xe−x,f ′(x) = e−x − xe−x = −e−x(x − 1), f ′′(x) = e−x(x − 2), f ′′′(x) =−e−x(x − 3),
f (4)(x) = e−x(x − 4)
Puesto que es una funcion creciente, podemos acotar la cuarta derivada porsu valor absoluto enx = 1:
max1≤x≤3
| f (4)(x)| = | f (4)(1)| = 3
e= 1,1036.
Respuestas Ejercicios del Apendice A 269
En consecuencia queremos
|E| ≤ 2
1801,1036h4 ≤ 1
10000o sea
h4 ≤ 90
11036; h ≤ 0,3005
de donde
N = b− a
h≥ 2
0,3005= 6,6554. . .
y por tanto podemos tomarN = 7 .
Ejercicio A.30 El error en la formula de Simpson compuesta con unnumeroN de subintervalos en el intervalo [a,b] es
E = −b− a
180f (4)(ξ)h4
dondeh = (b− a)/N. En nuestro casoa =, b = 1/2, f (x) = √1− x2,f ′(x) = −x/
√1− x2,
Ejercicio A.31 En la division de un intervalo de integracion en subin-tervalos iguales para aplicar la formula de Simpson compuesta hay quedistinguir entre el numero total de subintervalos en que queda dividido elintervalo inicial (= numero de evaluaciones que hay que hacer del integran-do−1) y el numero de subintervalos en cada uno de los cuales se aplicala formula de Simpson simple. El primero es el doble del segundo y esrelevante en la comparacion de la regla de Simpson con otras reglas. Elsegundo es el que calcularemos y que denotamosN. El error en la formulade Simpson compuesta con un numeroN de subintervalos en el intervalo[a,b] es
E = b− a
180| f (4)(ξ)|(h/2)4
dondeh = (b − a)/N. En nuestro casoa = 1, b = 2, f (x) = xe−x,f ′(x) = e−x − xe−x = −e−x(x − 1), f ′′(x) = e−x(x − 2), f ′′′(x) =−e−x(x − 3),
f (4)(x) = e−x(x − 4)
Puesto que, parax < 4, el valor absoluto de la cuarta derivada es unafuncion decreciente, podemos acotarlo por su valor enx = 1:
max1≤x≤3
| f (4)(x)| = | f (4)(1)| = 3
e= 1,103638.

270 B. Respuestas a ejercicios seleccionados
En consecuencia queremos
E ≤ 2− 1
1801,103638h4 ≤ 1
100000
o sea
h4 ≤ 180
110363.8; h ≤ 0,20096
de donde
N = b− a
h≥ 1
0,20096= 4,97609. . .
y por tanto podemos tomarN = 6 .
Ejercicio A.32 Seah = (b− a)/N y xk = a+ kh parak = 0,1, . . . , N.Entonces las formulas trapezoidal y de Simpson en [a,b] con N subinter-valos son:
TN = h
2
[f (a)+ f (b)+ 2
N−1∑k=1
f (xk)
]
I SN =
h
6
[f (a)+ f (b)+ 2
N−1∑k=1
f (xk)+ 4N∑
k=1
f(
xk−1+xk2
)].
Por otro lado, seaxk = a + k h2 parak = 0,1, . . . ,2N, de manera que
x2k = xk y x2k−1 = xk−1+xk2 parak = 0,1, . . . , N. Entonces la formula
trapezoidal en [a,b] con 2N subintervalos es:
T2N = h
4
[f (a)+ f (b)+ 2
2N−1∑k=1
f (xk)
].
Ahora no hay mas que tener en cuenta que
2N−1∑k=1
f (xk) =2N−2∑k=par
f (xk)+2N−1∑
k=impar
f (xk)
=N−1∑k=1
f (x2k)+N∑
k=1
f (x2k−1)
=N−1∑k=1
f (xk)+N∑
k=1
f (xk−1+ xk
2),
Respuestas Ejercicios del Apendice A 271
e inmediatamente se obtiene que
4T2N − TN
3= I S
N .
Ejercicio A.35 La formula del polinomio de Taylor dey(x) en torno aade orden dos con resto nos da lo siguiente:
y(a+ h) = y(a)+ y′(a)h+ 1
2y′′(a)h2+ 1
3!y′′′(ξ1)h3
y(a− h) = y(a)− y′(a)h+ 1
2y′′(a)h2− 1
3!y′′′(ξ2)h3
de donde, restando miembro a miembro,
y(a+h)−y(a−h) = 2y′(a)h+13
y′′′(ξ1)+ y′′′(ξ2)2
h3 = 2y′(a)h+13 y′′′(ξ)h3.
Ası,y(a+ h) = y(a− h)+ 2y′(a)h
con error igual a13 y′′′(ξ)h3
para algun ξ ∈ [a− h,a+ h].Para aplicar dicha formula a la ecuacion diferencial dada, comenzamos
aplicando el metodo de Euler,yn+1 = yn + h f (xn, yn). Con h = 0.01tenemos,
x0 = 0
y0 = 1
x1 = 0.01
y1 = y0+ h f (x0, y0) = 1+ 0.01(x0+ y0) = 1+ 0.01(0+ 1) = 1.01
y ahora aplicamos el metodo multipaso dado:
y2 = y0+ 2h f (x1, y1)
= 1+ 2× 0.01(x1+ y1)
= 1+ 0.02(0.01+ 1.01)
= 1.0204 .

272 B. Respuestas a ejercicios seleccionados
Ejercicio A.36 La formula del polinomio de Taylor dey(x) en torno aade orden dos con resto nos da lo siguiente:
y(a+ h) = y(a)+ y′(a)h+ 1
2y′′(a)h2+ 1
3!y′′′(ξ1)h3
y(a− h) = y(a)− y′(a)h+ 1
2y′′(a)h2− 1
3!y′′′(ξ2)h3
de donde, restando miembro a miembro,
y(a+h)−y(a−h) = 2y′(a)h+13
y′′′(ξ1)+ y′′′(ξ2)2
h3 = 2y′(a)h+13 y′′′(ξ)h3.
Ası,y(a+ h) = y(a− h)+ 2y′(a)h
con error igual a13 y′′′(ξ)h3
para algun ξ ∈ [a− h,a+ h].Para aplicar dicha formula a la ecuacion diferencial dada, comenzamos
aplicando el metodo de Euler,yn+1 = yn + h f (xn, yn). Con h = 0.1tenemos,
x0 = 1
y0 = 0
x1 = 1.1
y1 = y0+ h f (x0, y0) = 0+ 0.1(x0+ y0)2 = 0.1(1+ 0)2 = 0.1
y ahora aplicamos el metodo multipaso dado:
y2 = y0+ 2h f (x1, y1)
= 0+ 2× 0.1(x1+ y1)2
= 0.2(1.1+ 0.1)2
= 0.288 .
Indice Alfabetico
Aabandonamos, 31abierto, 40abscisa, 34, 223absoluto, 58–62, 72, 73, 85, 88, 89, 91, 101,104, 111–113, 115, 232absolutos, 60, 104, 120, 231acabamos, 26, 44, 60acelera, 48aceleracion, 47, 48, 105, 109acelerar, 28acercandose, 62acercarnos, 29acotacion, 27, 30, 89, 93, 94acotada, 37acotado, 88, 102acotar, 88adecuada, 82, 109adecuado, 28, 68, 70adelante, 36adicional, 52admite, 64afectar, 58algoritmo, 27–30, 36, 43, 48, 51, 53, 57, 61,64, 67–69, 79, 80, 82, 86, 88, 118, 119, 122,123, 125, 126, 222, 223, 226, 227, 229, 234alteracion, 57ampliada, 74, 75amplificacion, 83amplificado, 83analıtica, 54analıticamente, 109analizan, 38analogıa, 96angulo, 116
anula, 37, 42anulan, 42aplicable, 61aplicacion, 70, 80, 119, 125aplicar, 35, 40, 45, 48, 75, 87, 109aplicarse, 67, 94aproxima, 27aproximacion, 27, 47, 64, 85aproximaciones, 29, 30, 61aproximada, 83, 93aproximadamente, 84, 94aproximan, 35aproximar, 27, 32, 47, 58, 59aproximara, 62argumento, 113aritmetica, 64, 65, 72, 84, 85aritmetica de coma flotante, 17aritmetica de coma flotante
efecto en la precision, 20artificiales, 109asintotico, 41, 42, 45, 46asociada, 90, 102, 234asociado, 86, 233asociar, 92, 99asociativa, 119aumentar, 105aumento, 81autovalor, 101, 111–113autovector, 101axioma, 231
Bbasadas, 87basado, 104, 105, 112basados, 106
273

274 Indice Alfabetico
base, 92, 110, 112, 118, 119, 226Bezier
curvas de, 154binomio, 50binomios, 51biseccion, 27, 28biseccion
algoritmo, 27inconveniente, 27ventajas, 27
bola, 92, 232bolas, 92, 93, 96, 232bucle, 226busqueda, 26, 58
Cc, 228calcula, 27, 82calculada, 48calculado, 36, 105, 126calculamos, 85, 99, 126calculan, 83calcular, 27, 36, 45, 59, 62, 63, 78, 87, 119,122, 125, 227calcularemos, 82calcularse, 83, 123calculo, 67, 70, 73, 76, 80, 83, 90, 95, 102,105, 111, 112, 115calculos, 72, 83, 84, 88, 112, 120, 123campo, 53, 54candidato, 82canonica, 101cantidad, 94, 97cantidades, 64caracterıstica, 76, 97caracterıstico, 113caracterizacion, 70cartesiano, 26centro, 55, 56, 120cercana, 87, 88cercano, 88, 109cero, 26–32, 34, 37, 38, 41–46, 53, 55–58,62–65, 70–72, 83, 95–97, 100, 103–106, 110,112, 116, 117, 121, 126, 222, 226, 228, 231,233ceros, 26, 34, 38, 54–57, 62–64, 68, 99, 118,121, 122, 226, 233cientıfico, 83cinco, 65
cociente, 51, 52, 82, 92codigo, 73codominio, 33coeficiente, 58, 63, 65, 70, 72, 73, 109coeficientes, 51, 52, 54, 55, 57, 60, 63, 68,70–72, 75–77, 79, 80, 82, 83, 85, 87, 91,93, 94, 97, 99, 100, 103, 104, 107, 125, 226,228–230coincidir, 35columna, 70, 72–74, 80, 84, 96, 117, 118,121, 124–127, 229, 231columnas, 80, 122combinacion, 59compacta, 125compacto, 126comparamos, 27compleja, 64complejas, 54, 55, 64complejidad, 67complejo, 54–56, 62, 65complejos, 53, 63–65componente, 107, 112, 119, 120componentes, 107, 122, 231comprobar, 40, 46computacionales, 111concava, 29concavidad, 37concepto, 90, 92condicion, 33, 38, 40, 87, 92, 93, 95, 96, 101,104, 107condicionada, 93condicionado, 58, 93condicionamiento, 92, 93, 232condiciones, 100, 101Condicion
de una funcion, 21confirmar, 99conjugadas, 55conjugado, 54conjuncion, 89conjunto, 33, 59conjuntos, 230conservar, 111, 232constante, 39, 41, 42, 45, 46, 53, 223, 270constante de error, 41construir, 59, 60contador, 126continua, 26, 28, 33, 34, 37, 39, 40, 42–44,223, 224
Indice Alfabetico 275
continua, 63continuidad, 37, 54contractiva, 98, 99contractivas, 98control
punto de, 154control, 27converge, 31–33, 36, 37, 39–41, 43, 46, 47,61, 62, 87, 98, 100, 101, 107, 108, 113, 115convergen, 45convergencia
cuadratica, 41lineal, 41
convergencia, 28, 33, 36, 38, 39, 41–46, 48,49, 57, 64, 97, 101, 104–107, 109, 113convergente, 39, 41, 45, 110converger, 61, 109convergera, 36convergeran, 86converja, 32, 101, 110convexa, 29, 37convexidad, 37, 38coordenada, 105coordenadas, 98, 103, 106, 107, 116, 120corolario, 95correccion, 47, 48, 63, 88, 102, 108, 109correcciones, 108, 109corte, 28, 35coste, 82, 84, 85, 118costosa, 80costoso, 36cota, 102creciente, 37, 38, 223criterio, 81, 88, 102cuadrada, 64, 71, 79, 89–91, 93, 99, 111,113–115, 121, 122, 232cuadradas, 70, 90cuadrado, 232cuadratica, 42, 50, 62, 64cuadraticamente, 43cuadraticas, 50, 60cuadratico, 60, 62cuartica, 50cubica, 50cuerda, 30Curvas de Bezier, 154
Ddatos, 62
debil, 40decreciente, 37, 112deducir, 89definicion, 89definido, 88, 90definimos, 101definirse, 71, 228demostracion, 39, 41, 51, 54, 101demostrada, 117demostrado, 107demostramos, 107demostrando, 101demostrar, 87, 95, 102, 107, 110, 119, 121,123, 233demuestra, 87, 90derivada, 36, 37, 42, 44–47, 52, 53, 57, 58,61, 224derivadas, 42, 58derivando, 58descomponer, 99descomposicion, 99, 103, 104, 107, 109descomposiciones, 233desconocido, 83desechar, 62desigualdad, 112, 230desigualdades, 89despejar, 103desplazamientos, 104detecta, 227detencion, 88, 102detener, 88, 102determina, 119determinacion, 109determinada, 114, 115determinadas, 79, 114determinado, 88, 116determinante, 71determinantes, 71determinar, 83, 88, 98diagonal, 26, 76, 77, 81, 95, 99, 103, 104,106, 107, 109, 110, 116, 117, 125, 227, 232–234diagonales, 103, 107, 114, 115diagonalizable, 112diferencia, 67, 83, 85, 116diferenciable, 34, 39–41diferenciables, 58diferenciales, 97diferencias, 44

276 Indice Alfabetico
difıcil, 40, 60dificultad, 36, 37, 72, 83, 95, 105, 109dificultades, 70, 111difiere, 114, 124difieren, 80dıgitos, 65, 85, 92dimensiones, 59direccion, 112, 119, 120directores, 116, 117, 124, 126, 127disco, 55, 56discriminante, 54, 64divididas, 44dividir, 50–52, 70, 72, 225, 233divisible, 51division, 51, 53, 73divisor, 70, 73doble, 84–87dominante, 104, 108, 111, 113dominio, 25, 33dominios, 26dos, 25–27, 32, 35, 37, 41, 43, 48, 54, 55,58–63, 65
Eecuacion, 25, 26, 34, 36, 38, 39, 49, 50, 59,62, 64, 68–70, 73, 78, 85, 97, 103ecuaciones, 67–71, 73–75, 78, 80–87, 91, 93,94, 97–100, 103–106, 109, 228ecuacion cuadratica
solucion de menor valor absoluto, 15efecto, 94efectuadas, 77efectue, 69, 79eficacia, 50, 80eficaz, 61, 67, 82, 102, 111, 114, 122ejemplo, 68–70, 72–74, 76, 78, 85, 86, 91,92, 94, 102, 103ejercicio, 89, 91, 92, 99, 110, 118, 230ejes, 116–118eleccion, 81, 100, 101, 103, 109elegida, 83, 92elegido, 112elegimos, 82elegir, 72, 79, 81, 109, 120, 233elegira, 82elementales, 71, 74–76, 78, 116elemento, 71, 82, 95, 116, 121, 124, 227, 229,232elementos, 71, 76, 77, 79, 81, 96, 97, 103–
107, 114–117, 121, 125, 227, 231–234elevados, 97eligen, 99eligiendo, 120elijamos, 82eliminacion, 67–72, 74–82, 115, 117eliminacion de Gauss, 67eliminacion de Gauss
dificultades, 70numero de operaciones, 69
eliminar, 64, 68, 73, 82, 124, 227, 229encajadas, 52, 65endomorfismo, 33, 39endomorfismos, 33engorroso, 90ensayos, 110entender, 82entero, 36, 41entonces, 71, 76, 81, 93, 95, 96, 99–103, 109,112–116, 118, 119, 122, 123, 231, 233entorno, 58enunciadas, 101enunciar, 115equivalente, 68, 69, 78, 80, 87, 89, 99, 100,233error
asintotico, constante de, 41error, 27, 28, 31, 36, 41, 42, 45, 46, 63, 83–85, 88, 89, 91, 93, 94, 102, 113, 222, 223errores, 31, 45, 57, 58, 72, 81, 83, 84, 91, 93,94, 112escalada, 69, 82escalar, 119, 120espacio, 92, 116, 230espectral, 110espurio, 65estimacion, 37, 57, 58, 61, 85, 95, 98, 105,113estimaciones, 32estimar, 58, 60, 61, 93, 102estrategia, 70estrategias, 70estrictamente, 104, 107, 108, 232estructura, 125estructuras, 109estudiamos, 97, 125estudiar, 67, 94, 106estudiaremos, 99, 105estudio, 105, 111
Indice Alfabetico 277
euclıdea, 96evalua, 98evaluacion, 52, 57, 61, 98evaluado, 33, 54evaluando, 98evaluar, 36, 42, 53, 58, 65, 228evidente, 70, 101, 232evitamos, 226evitar, 120, 126exacta, 72, 86, 87, 93, 105, 108exactamente, 94exactitud, 83exacto, 27excepto, 114, 231excesivamente, 67, 72excesivas, 109excesivo, 84exhaustivas, 61exista, 101existe, 93, 95, 101, 112, 119, 121existen, 81, 114existencia, 117existira, 120experiencia, 81experimentales, 83, 94extremo, 91
Ffacil, 90facilmente, 95, 103, 108, 111factor, 68, 84, 88, 93, 109, 232factorizacion, 76, 77, 79, 80, 85, 87, 111,114–118factorizacion
triangular, 79Factorizacion
triangularteorema, 79
falsi, 29–31fase, 72fija, 83fijo, 26, 29, 33, 34, 39, 40, 42, 70, 88, 97–100, 223, 233fijos, 33, 34, 38, 39fila, 70, 75, 77, 78, 81, 82, 90, 121, 125, 232filas, 70, 74, 76, 78, 82, 108, 124flotante, 72, 84, 85forma, 68, 69, 71, 75, 79–83, 86, 90, 97–103,106–109, 111, 116–123, 125, 228, 233
formada, 112formado, 68formas, 83, 99formula, 95–97, 119formula baricentrica, 137, 138formula de Lagrange, 134, 135formulas, 107, 108, 124fuerzas, 109funcion, 26–29, 31–40, 42–46, 48, 50, 58, 65,98, 99, 107funcion de iteracion, 34, 41funciones, 25, 26, 33, 38, 40, 49, 57, 58, 62,98fundamental, 119fundamentales, 101
Ggarantizar, 87generados, 97general, 82–84, 95, 97–99, 103, 106, 107,109–112, 114–116, 119, 228geometrico, 92goza, 114grado, 32, 49, 50, 52–54, 56–58, 61, 228grafica, 31, 34gran, 73, 97, 109grande, 72, 113graves, 72grupo, 232
Hherramienta, 62hiperplano, 119, 120hipotesis, 45, 58, 86, 112, 115
Iidea, 32, 36, 37, 61, 116idempotente, 33identidad, 33, 44, 74–77, 79, 80, 85, 88, 90,114identificando, 92igual, 71, 83, 84, 89, 91–94, 96, 104, 110,116, 118–120, 125, 126, 229, 231, 232, 234igualdad, 231iguales, 125imagen, 92, 119, 232impar, 36, 54, 55importancia, 83importante, 75, 76, 95

278 Indice Alfabetico
imposible, 101inaceptable, 72incognita, 69, 81, 82, 103incognitas, 67–71, 81incompletos, 67incorrectos, 109independiente, 78independientes, 72, 75, 79, 80, 83, 85, 86, 93indica, 88, 92, 98, 108indicador, 84, 93indicados, 126induccion, 107inferior, 76, 79, 88, 108, 110infinito, 91, 95informacion, 55inherente, 83inicial, 35, 37, 40, 57, 61, 98, 100, 101, 107,110, 113iniciales, 32, 59–61, 109inicialmente, 126inmediata, 69, 230inmediatamente, 78inmediato, 69, 101, 108, 234insuficiente, 109insuficientes, 108intercalando, 48intercambiando, 73, 230intercambiar, 70intercambio, 70, 78intercambios, 78, 79interes, 79interesa, 94, 100interesante, 80, 108interior, 118interno, 226interpolacion, 47, 129interpolacion polinomica, 131interpretarse, 93intersecan, 37intersecar, 31interseccion, 34intervalo, 26–31, 37–41, 44, 46, 54, 222intervalos, 31interviene, 80inventar, 99inversa, 76, 80, 87, 95, 115, 121inversas, 76inversible, 90, 94–96, 99, 104, 109, 233inverso, 76
involucradas, 63irreducible, 53irreducibles, 53, 54iteracion, 34, 39, 42, 46, 48, 98, 102, 105,107, 108, 126iteraciones, 33, 34, 36, 39–41, 65, 98, 100,102Iterar, 33iterar, 57iterarse, 33iterativa, 80, 86, 88, 109iterativo, 34, 38, 43, 48, 52, 88, 99–102, 104,106, 107, 110, 112, 233iterativos, 38, 43, 97, 105, 106, 108, 109izquierda, 106, 230, 231
Jjuiciosa, 61justifica, 76justo, 88, 104
LLagrange
formula de, 135polinomios de, 135
lema, 118Lema de Aitken, 144lenguajes, 84lentitud, 27, 105limitada, 83limitado, 82lımite, 34–37, 40, 41, 45, 46, 59, 60, 100, 115lımites, 83, 84lınea, 28, 62, 64lineal, 41, 46–48, 51, 53, 59, 69, 92, 93, 119,226, 230lineales, 53, 67, 69–71, 79, 83, 85, 92, 97,103linealmente, 59logico, 105longitud, 30, 222
Mmagnitud, 102, 112matematicas, 25matrices, 76, 79, 83, 90, 92, 93, 96, 97, 99,104, 108, 111, 114, 115, 117–119, 125, 126,232matricial, 103, 106
Indice Alfabetico 279
matriz, 68, 70, 71, 74–77, 79, 80, 84, 85, 87–97, 99–101, 103, 104, 107, 110–119, 121–126, 226, 229, 232–234maxima, 90maximo, 35, 48, 82, 84, 88, 90, 92, 101mecanicas, 109mecanicos, 105medida, 62, 73, 83, 92, 109medidas, 94medio, 27, 123, 222medir, 83mejor, 113mejora, 80, 86, 88mejorar, 65mejorarlas, 108mejorarse, 85mejoras, 86memoria, 97menor, 71, 84, 85, 88, 101, 109, 231, 235menores, 71, 79metodo, 27–32, 34–38, 42–46, 52, 57, 59–65,67–74, 80, 81, 85, 99–112, 114, 115, 118metodo de la biseccion, 26metodo de la secante, 61metodo de la secante, 31metodo de Muller, 31, 32, 61metodo de Newton
dificultades, 36metodo iterativo, 33, 34metodos, 26, 27, 32, 36, 38, 43, 50, 67, 95,97, 98, 105, 106, 108, 109metodos generales, 26metodos iterativos, 26metrica, 33minimizan, 81mınimo, 92mitad, 27, 30, 36modo, 84, 86, 100, 112modos, 84modulo, 55, 56, 65momento, 112monico, 53monotona, 37muestra, 118multiplica, 81, 88multiplicacion, 79, 117multiplicaciones, 52, 65, 69, 81, 85, 126, 228,235multiplicada, 68, 75, 77, 78, 125
multiplicado, 106multiplicador, 68, 72, 227multiplicadores, 70, 72, 73, 76–78multiplicamos, 74, 75, 121multiplicando, 117multiplicar, 84, 117, 118, 121, 124, 227multiplicase, 109multiplicidad, 53, 54multiplo, 88, 92, 96
Nnatural, 118nodo, 109nodos de interpolacion, 131norma, 82–84, 88–93, 95, 96, 101, 102, 119,120, 231, 232normado, 92, 230normas, 84, 88, 93notacion, 43, 44nula, 112nulo, 70, 73, 95, 120nulos, 89, 119, 232numero, 67, 69, 80, 81, 88, 91, 93, 96, 118,120, 126numeros fraccionarios, 13
Oobjetivo, 83observaciones, 83, 126octava, 98operaciones, 67, 69, 71, 74–76, 78, 80, 81,84, 85, 226–230, 235operador, 92, 97, 230operadores, 47, 92optima, 96optimo, 81, 109opuesto, 91orden, 67, 69–71, 75–78, 81, 90, 93, 96, 112,113, 118, 123, 126, 227, 229, 234ordenadores, 84orden de convergencia, 41ortogonal, 96, 114–122, 126, 234ortogonales, 96, 117ortonormal, 118
Pparabola, 62parcial, 78–80, 82, 93pares, 25, 61

280 Indice Alfabetico
paso, 68, 70–73, 78, 80–82, 87, 88, 102, 105,108, 113, 117, 121–123, 126, 229, 235pasos, 69–72, 88, 125, 126pendiente, 34, 222pensar, 105permutacion, 80, 82permutaciones, 85permutar, 73, 82pivotacion, 70, 71, 76, 78–82pivotacion parcial, 72, 81pivotacion simple, 70, 81Pivotacion
parcial escalada, 81total, 82
pivotebusqueda, 73
pivote, 73, 78, 81, 82plana, 116–118planas, 118, 123plano, 55, 56, 116, 118, 124, 232pobre, 92polinomicas, 26, 49, 50, 60polinomio, 32, 49–60, 62, 63, 113, 226, 228polinomio de interpolacion, 131polinomio de interpolacion
definicion, 133existencia y unicidad, 132unicidad, 133
polinomiosevaluacion, 11
polinomios, 49–51, 53–55, 59, 61polinomios de Lagrange, 135ponderado, 222posicion, 28, 35positiva, 55, 223positivas, 54, 55positivo, 36, 38, 41, 55, 56positivos, 54potencia, 53, 58, 112potencias, 65, 100precision, 27, 28, 31, 65, 72, 81, 83–87, 92,120preliminar, 50premutacion, 79primera diferencia dividida, 43principal, 71, 105, 109principales, 71, 79principio, 81, 102, 105probabilidad, 28, 112
procedimiento, 98proceso, 30, 47, 48, 52, 63, 69–71, 74–81,86–88, 113, 117, 122producto, 26, 53programa, 123programacion, 64, 84programar, 67progresa, 62progresiva, 80, 86progresivamente, 65promedio, 222promedio ponderado, 28propagacion, 83propiedad, 70, 71, 76, 104, 112, 119propio, 112propios, 111proposicion, 123proyeccion, 119pseudo, 73pudiesen, 65punto, 26–30, 32–35, 39, 40, 42, 47, 52, 53,222, 223punto de control, 154punto fijo, 33punto fijo, 26, 41puntos, 26, 28, 31–35, 38, 39, 62
Rradio, 55, 222raıces, 49, 50, 54–62, 114raız, 32, 36, 49, 50, 53–57, 59–62, 64rango, 33rapidamente, 109rapido, 36razon, 29, 76real, 26, 41, 49, 50, 54, 55, 59, 62–65, 84, 93,114, 115reales, 41, 54, 55, 57, 59, 60, 62–64, 226recomendado, 114recta, 28, 31, 34, 35, 62, 222recurrencia, 59–61, 226recursiva, 52recursivamente, 228redondeo, 72, 81reescritura, 44, 225reflejado, 73reflexion, 119–122reflexiones, 119, 120reformulacion, 98
Indice Alfabetico 281
regla, 43, 54, 67, 224regla de Cramer
numero de multiplicaciones, 67regla de Cramer, 67regresiva, 79, 80, 86, 87, 227–229regula, 30, 31Regula Falsi, 28
algoritmo, 28Regula Falsi Modificada, 30relacion, 72, 93relacionado, 84relacionados, 115relajaciones, 109reordenacion, 78, 79residual, 83–85, 91resolucion, 67, 69, 80, 85–87, 97, 99–101,107resolvemos, 94resolver, 68–70, 73, 79–81, 83, 100, 228, 233resolverlo, 103resolviendo, 85, 230restamos, 68, 119restantes, 82resto, 86, 87robusto, 27rombo, 120rotacion, 116–118, 124rotaciones, 116, 118, 123
Ssatisface, 90secante, 31, 32, 34, 35, 43, 45, 46secantes, 34, 35seccion, 57segmento, 30seis, 65semejante, 111, 121, 123semejanza, 35, 61, 101, 118sencilla, 72, 75, 81, 84, 97, 99, 101sencillas, 99sencillez, 90sencillo, 67, 98, 102, 114, 119sensibilidad, 93sentido, 81, 87, 105separar, 80serie, 65, 74significa, 67, 78, 80, 85, 113, 232significado, 92signo, 27, 30, 37, 39, 54–56, 113, 114, 120
signos, 114simetrıa, 111simetrica, 115, 119, 123simple, 61, 225simplificacion, 126simplificarse, 123simultaneamente, 72simultaneos, 105singular, 70, 71, 79, 93, 95, 96, 104, 115singulares, 71, 227singularidad, 226sistema, 68–71, 73–75, 77–81, 83, 85–87, 91,93, 94, 97–101, 103, 104, 107, 109, 227–230sistemas, 67, 70, 80, 81, 97, 99, 227, 228situacion, 94, 101, 102, 104sobredeterminados, 67solucion, 25–27, 31, 32, 34, 39, 49, 50, 62subdiagonal, 121, 124submatrices, 70submatriz, 82subsistema, 68, 70sucesion, 87, 100, 112–115, 118, 125sucesion de iteraciones, 33sucesiones, 59, 60sucesivamente, 68, 69, 77, 98, 105sucesivas, 86, 88, 109, 116sucesivos, 68, 79, 125suficiente, 101, 104, 107suficientemente, 98suficientes, 101, 102suma, 90, 99, 104, 231, 235sumado, 86sumando, 229, 230sumarle, 120, 228sumas, 85sumatorio, 108sumen, 120superior, 29, 50, 75, 77, 79, 102, 110, 114,116–118, 124superiormente, 102sustitucion, 79–81, 86sustituciones, 87sustitucion regresiva, 68, 69sustituidos, 102sustituir, 95, 96, 105sustituirse, 126sutil, 72

282 Indice Alfabetico
Ttangente, 35tangentes, 34, 37tecnica, 81, 82tecnicas, 81teorema, 37, 38, 40, 41, 46, 53, 54, 56, 71,79, 95, 96, 101, 106, 107, 110, 115teorıa, 98teorico, 67termino, 109, 112terminos, 74, 75, 80, 83, 85, 88, 89, 91, 93,102, 106, 115tiende, 100tipo, 78, 83, 111, 118, 121–123, 126tipos, 70tolerancia, 113total, 82, 227, 230, 234, 235trabajar, 70trabajara, 82trabajosa, 228transforma, 234transformacion, 74, 79, 111transformaciones, 76, 116transformada, 116transformar, 118, 123transformarse, 118transforme, 69, 123traspuesta, 115tratamiento, 97trazar, 30, 34tres, 32, 45, 50, 55, 62triangular, 69, 75–77, 79–81, 85, 86, 95, 114–118, 124, 229, 233triangulares, 110triangular superior, 68, 69tridiagonal, 111trivial, 99, 101, 114truncando, 65
Uultima, 69, 92, 126unica, 67, 87unicidad, 119unico, 76unicos, 110unidad, 88, 93, 109unitaria, 232unitario, 119, 122, 123
Vvalor, 27, 30, 31, 36, 39–41, 45, 47–49, 52,53, 58–62, 65valores, 25, 26, 28, 33, 37, 39, 47, 58, 60, 64variable, 26, 113, 234variables, 62, 63, 73, 126, 229variante, 28, 30, 34, 61, 82variantes, 36variar, 84vector, 80, 83–87, 90, 93, 95, 98, 100, 101,103, 107, 112, 113, 119–123, 231, 234vectore, 120vectores, 83, 84, 87–89, 93, 94, 111, 112,118, 119vectorial, 59, 82, 88, 90, 92, 93, 102velocidad, 42, 43, 105, 113ventaja, 42, 61, 99ventajas, 62ventajoso, 105verifica, 89, 92, 95, 96, 101, 102, 107, 110,231–233verifican, 115verificar, 117verifique, 101vertices, 120viejo, 87