co-procesador para cÁlculo de rmsd en esqueletos de proteÍnas
DESCRIPTION
CO-PROCESADOR PARA CÁLCULO DE RMSD EN ESQUELETOS DE PROTEÍNAS. MARTIN RAMIRO GIOIOSA. > INTRODUCCIÓN > RMSD. EL PLEGAMIENTO DE LAS PROTEÍNAS ES UN PROCESO POR EL CUAL LA MISMA VA ADQUIRIENDO ESTRUCTURA TRIDIMENSIONAL. SEGÚN SU PLEGAMIENTO SE PUEDE DETERMINAR SU FUNCIÓN BIOLÓGICA. - PowerPoint PPT PresentationTRANSCRIPT

CO-PROCESADOR PARA CÁLCULO DE RMSD EN ESQUELETOS DE PROTEÍNAS
MARTIN RAMIRO GIOIOSA

> INTRODUCCIÓN > RMSD
EL PLEGAMIENTO DE LAS PROTEÍNAS ES UN PROCESO POR EL CUAL LA MISMA VA ADQUIRIENDO ESTRUCTURA TRIDIMENSIONAL.SEGÚN SU PLEGAMIENTO SE PUEDE DETERMINAR SU FUNCIÓN BIOLÓGICA.
BASE DE DATOS(ESTRUCTURAS CONOCIDAS)COMPARACIÓN POR SECUENCIA
DE AMINOÁCIDOS
COMPARACIÓN FÍSICA(RMSD)
FUNCIÓN BIOLÓGICA

> INTRODUCCIÓN > RMSD
EL PROYECTO CONSISTE EN IMPLEMENTAR UN CO-PROCESADOR BASADO EN FPGA PARA ACELERAR EL PROCESO DE CÁLCULO QUE PERMITE OBTENER LA DIFERENCIA ARQUITECTURAL ENTRE ESTRUCTURAS DE PROTEÍNAS BASÁNDOSE EN SU FORMA Y CONFORMACIÓN TRIDIMENSIONAL.
EL VALOR DE RMSD (ROOT MEAN SQUARE DEVIATION) NOS INDICA EL GRADO DE SIMILITUD ENTRE DOS ESTRUCTURAS, ADQUIRIENDO VALORES PEQUEÑOS A MEDIDA QUE LAS MISMAS SE ASEMEJAN.

> INTRODUCCIÓN > RMSD
ENTONCES EL CÁLCULO DE RMSD ES UTILIZADO COMO MEDIO DE COMPARACIÓN PARA DETERMINAR LA FUNCIONALIDAD BIOLÓGICA DE LAS PROTEÍNAS.
DICHA EVALUACIÓN DE FUNCIONALIDAD BIOLÓGICA COMPLEMENTADO CON OTRAS APLICACIONES PERMITE:
ANÁLISIS DE IMPACTO PARA SUMINISTRO DE DROGAS DETERMINAR LA PENETRACIÓN DE VIRUS EN CÉLULAS TRATAMIENTO DE ENFERMEDADES EMERGENTES POR DEFORMACIÓN DE
DETERMINADAS PROTEÍNAS (MODIFICACIONES GENÉTICAS)

> INTRODUCCIÓN > FPGA
UN FPGA (FIELD PROGRAMMABLE GATE ARRAY) ESTÁ FORMADO POR ARREGLOS DE VARIOS BLOQUES PROGRAMABLES O BLOQUES LÓGICOS, ESTOS BLOQUES ESTÁN INTERCONECTADOS ENTRE SÍ POR MEDIO DE CANALES DE CONEXIÓN TANTO VERTICALES Y HORIZONTALES.
CAPACIDAD DE REPRODUCIR CUALQUIER CIRCUITO LÓGICO COMPUTACIONAL
PERMITE OPTIMIZAR TIEMPOS DE PROCESAMIENTO POR MEDIO DE EJECUCIONES LÓGICAS EN PARALELO Y GENERACIÓN DE PIPELINES.
FÁCIL PROTOTIPADO Y CORTO PLAZO EN IMPLEMENTACIÓN DEL DISEÑO.
GRAN VARIEDAD DE HERRAMIENTAS PARA EL DISEÑO Y TESTEO DE LOS PROTOTIPOS.

> INTRODUCCIÓN > FPGA
EL BLOQUE LÓGICO ES CAPAZ DE PROPORCIONAR UNA FUNCIÓN LÓGICA EN GENERAL Y PROGRAMABLE.
LAS TABLAS DE LOOK-UP (LUT) SON MEMORIAS EN DONDE SE CARGAN DATOS. AL APLICARLE LOS DATOS DE ENTRADA A LA FUNCIÓN BOOLEANA LA MEMORIA DEVUELVE UN DATO CORRESPONDIENTE CON LA SALIDA REQUERIDA.
RECURSOS DE INTERCONEXIÓN
CÉLULAS DE E/S
BLOQUES LÓGICOS
SLICECELDA LÓGICA
CELDA LÓGICA
SLICECELDA LÓGICA
CELDA LÓGICA

> INTRODUCCIÓN > FPGA
HARDWARE EMBEBIDO EN LAS FPGA:
RAM EN BLOQUE SUMADORES, MULTIPLICADORES HARDCORES (PROCESADORES, PERIFERICOS …)

> INTRODUCCIÓN > FPGA
IPCORES RELEVANTES EN LOS DISEÑOS (XILINX)
PROCESADORES - MICROBLAZE (32 bit) - PICOBLAZE (8 bits)
BUSES DE COMUNICACIONES (SE UTILIZA LA FAMILIA DE BUSES CROSSCONNECT DESARROLLADA POR
IBM) - PROCESSOR LOCAL BUS (PLB) - DEVICE CONTROL REGISTER BUS (DCR) - ON-CHIP PERIPHERAL BUS (OPB) - FABRIC COPROCESSOR BUS (FCB) - FAST SIMPLEX LINK (FSL) - ON-CHIP MEMORY (OCM)

> INTRODUCCIÓN > FPGA
EJEMPLO DE SISTEMA BASADO EN HARDCORE:
SOURCE: XILINX

> INTRODUCCIÓN > FPGA
EJEMPLO DE SISTEMA BASADO EN SOFTCORE:
SOURCE: XILINX

> INTRODUCCIÓN > FPGA
DISEÑO EN FPGA: PLATAFORMA DE DESARROLLO QUE PROVEE EL FABRICANTE
UTILIZACIÓN DE IPCORES (INTELLECTUAL PROPERTY CORE) PREFABRICADOS.
IPCORES SON LOS COMPONENTES PREFABRICADOS LISTOS PARA SER INCORPORADOS DENTRO DE UNA FPGA. LA PLATAFORMA DEL FABRICANTE PROVEE ALGUNOS Y ADEMÁS PUEDEN CONSEGUIRSE DESDE INTERNET.
DISEÑO DE COMPONENTES UTILIZANDO : LENGUAJES HDL (HARWARE DESCRIPTOR LANGUAGE) - VHDL - VERILOG UTILIZACIÓN DE HERRAMIENTAS ESL (ELECTRONIC SYSTEM LEVEL) - ImpulseC

> HARDWARE UTILIZADO
DENTRO DE LA FPGA DISPONEMOS DE:
HARDWARE EMBEBIDO: PROCESADOR POWERPC Y CONTROLADOR ETHERNET
BLOQUES DE LÓGICA CONFIGURABLE

> HARDWARE UTILIZADO > FPGA VIRTEX-4
LOGIC CELLS: 12312
SLICES: 5472 (4 POR CADA BLOQUE LÓGICO)
BLOCK RAM
DCMs: 4
MAX DISTRIBUTED RAM: 86 Kb
ARRAY (ROW X COL): 64 x 40
MAX BLOCK RAM: 648 Kb
18Kb BLOCKS: 36

> ESQUEMA DE IMPLEMENTACIÓN
SERVIDOR (AVNET FX12 MINIMODULE)
FPGA VIRTEX-4 FX12
TRIMODEETHERNETMEDIAACCESS
CONTROLLER
POWERPC 405
EMACCOMPONENT
E ACELERADO
R
PHYETHERNET
FCB
COMUNICACIÓN ENTRE CLIENTE - SERVIDOR: SOCKETS TCP
COMUNICACIÓN ENTRE PROCESADOR POWERPC Y COMPONENTE ACELERADOR: POR MEDIO DEL BUS FCB (FABRIC CO-PROCESSOR BUS).
CLIENTE:APLICACIÓN CLIENTE ENVÍA
LAS ESTRUCTURAS DE PROTEÍNAS A COMPARAR
SERVIDOR (PLATAFORMA LINUX):APLICACIÓN SERVIDORA RECIBE EL PEDIDO Y DELEGA EL PROCESO DE
CÁLCULO AL COMPONENTE ACELERADOR
COMPONENTE ACELERADOR

> MAPA DE DESARROLLO
ETAPA DE INICIO:SE CUENTA CON EL ALGORITMO DE CÁLCULO DE RMSD IMPLEMENTADO EN C++
ETAPA DE DESARROLLO:1)MIGRAR LA ACTUAL APLICACIÓN A LENGUAJE C2)APLICAR ARITMÉTICA DE PUNTO FIJO EN REEMPLAZO DE PUNTO FLOTANTE.3)GENERAR APLICACIÓN CLIENTE-SERVIDOR EN PC Y COMUNICACIÓN POR SOCKETS.4)SIMULACIONES EN PC.5)GENERAR LA PLATAFORMA SERVIDORA SOBRE LA FPGA6)MIGRAR LA APLICACIÓN SERVIDORA A LA PLACA.7)MIGRAR PARTE DEL CÁLCULO AL COMPONENTE ACELERADOR.8)OPTIMIZAR EL COMPONENTE ACELERADOR.

RED
.
> DESARROLLO > APLICACIONES CLIENTE-SERVIDOR
SERVIDOR
HTON
NTOH
CLIENTE
HTON
NTOH
CARGA DE COORDENADAS
DE ESTRUCTURASA COMPARAR RMSD ENTRE
C/U DE LAS ESTRUCTURAS
RECEPCIÓN DEL PEDIDO
UTILIZACIÓN DE: SOCKETS CONVERSION DE ENDIANNESS ARITMÉTICA DE PUNTO FIJO
HTON (HOST TO NETWORK) = ENDIAN HOST -> BIG ENDIANNTOH (NETWORK TO HOST) = BIG ENDIAN -> ENDIAN HOST

SOPORTE A LOS COMPONENTES DE HARWARE
> DESARROLLO > PLATAFORMA SERVIDORA

KERNEL LINUX COMPILADO PARA LA ARQUITECTURA DEL PROCESADOR DE LA FPGA (POWERPC) HABILITADA LA INTERFAZ APU (AUXILIARY PROCESSOR UNIT) DEL POWERPC PARA CONECTARSE CON EL COMPONENTE ACELERADOR.
> DESARROLLO > PLATAFORMA SERVIDORA
POWERPC
INSTRUCCIÓN
CONTROLADOR APU
UNIDADEJECUCIÓN
CO-PROCESADOR
DECODER
RESULTADO
UNIDADEJECUCIÓN
DECODER

> INTRODUCCIÓN > COMPONENTE ACELERADOR (INTRODUCCIÓN)
ImpulseC:
PERMITE ABSTRAERSE DE LA PROGRAMACIÓN DE BAJO NIVEL (USA ANSI C)
REALIZAR OPTIMIZACIONES A NIVEL IMPLEMENTACIÓN: A) LOOP UNROLLING: CONSISTE EN REPLICAR EN HARDWARE EL CUERPO DEL LOOP TANTAS VECES COMO ITERACIONES SE REALIZA SOBRE EL MISMO. B) GENERACIÓN DE PIPELINES: CONSISTE EN IR TRANSFORMANDO UN FLUJO DE DATOS EN UN PROCESO COMPRENDIDO POR VARIAS FASES SECUENCIALES, SIENDO LA ENTRADA DE CADA UNA LA SALIDA DE LA ANTERIOR.
INCORPORA MÉTODOS DE COMUNICACIÓN

> INTRODUCCIÓN > COMPONENTE ACELERADOR (INTRODUCCIÓN)LOOP UNROLLING:
ES EQUIVALENTE A:
DIAGRAMA DE NIVELES (OPTIMIZADO):
for (i = 0; i < 3; ++i){ #pragma CO UNROLL
arrayA[i] = arrayB[i];}
arrayA[0] = arrayB[0];arrayA[1] = arrayB[1];arrayA[2] = arrayB[2];
DIAGRAMA DE NIVELES (ITERATIVO):

> INTRODUCCIÓN > COMPONENTE ACELERADOR (INTRODUCCIÓN)PIPELINE:
LATENCY: 4RATE (CYCLES/RESULT): 1MAX. UNIT DELAY: 64EFFECTIVE RATE: 64
acum = 0;for (i = 0; i < 3; ++i){ #pragma CO PIPELINE #pragma CO SET STAGEDELAY 64
sum = arrayA[i] + arrayB[i]; square = sum * sum; acum += square;}
DIAGRAMA DE NIVELES:
1
2
3
4

> INTRODUCCIÓN > COMPONENTE ACELERADOR (INTRODUCCIÓN)POSIBLES CANALES DE COMUNICACIÓN ENTRE EL SOFTWARE Y EL COMPONENTE ACELERADOR:
MEDIANTE CONTROLADOR APU (AUXILIARY PROCESSOR UNIT) PROVEE MECANISMOS DE SINCRONIZACIÓN Y COMUNICACIÓN ENTRE EL PROCESADOR POWERPC Y EL COMPONENTE ACELERADOR. SE USA EL BUS “FCB” DE ALTA VELOCIDAD Y PERMITE ENVIAR HASTA 32 BITS.
REGISTROS MAPEADOS EN MEMORIA ES UNA FORMA TÍPICA DE COMUNICACIÓN DE DATOS. ES NECESARIO DRIVERS DEL LADO DEL SOFTWARE PARA EL ACCESO A ESTA MEMORIA.

> INTRODUCCIÓN > COMPONENTE ACELERADOR (INTRODUCCIÓN)
PROYECTO ImpulseC
APLICACIÓN EN ANSI C
REFACTORIZADAGENERACIÓN DE
HARDWARE ACELERADOR
GENERACIÓN DE INTERFAZ DE HARDWARE
GENERACIÓN DE INTERFAZ DE SOFTWARE
DESCRIPCIÓN DE HARDWARE
SOFTWARE (COMUNICACIÓN)
FPGA VIRTEX-4
COMPONENTE ACELERADOR
PROCESADOR POWERPCBUS

EL CÁLCULO DE INTEGRAL DE RMSD CONSTA DE: 1- HACER COINCIDIR LOS CENTROS GEOMÉTRICOS ENTRE ESTRUCTURAS 2- ROTAR UNA CON RESPECTO A LA OTRA Y CONSEGUIR SUPERPOSICIÓN ÓPTIMA 3- CALCULAR EL RMSD ENTRE AMBAS
EL PUNTO 3, FUÉ MIGRADO AL COMPONENTE ACELERADOR
SE UTILIZÓ LA TÉCNICA DE EJECUCIÓN POR PIPELINES COMO OPTIMIZACIÓN
> DESARROLLO > COMPONENTE ACELERADOR

> DESARROLLO > COMPONENTE ACELERADORfor (i = 0; i < CANT_COORD_POR_ESTRUCTURA; ++i){ co_stream_read(input, &dato_entrada, sizeof(FloatType)); firstx[i] = dato_entrada; co_stream_read(input, &dato_entrada, sizeof(FloatType)); firsty[i] = dato_entrada; co_stream_read(input, &dato_entrada, sizeof(FloatType)); firstz[i] = dato_entrada;}for (i = 0; i < CANT_COORD_POR_ESTRUCTURA; ++i){ co_stream_read(input, &dato_entrada, sizeof(FloatType)); secondx[i] = dato_entrada; co_stream_read(input, &dato_entrada, sizeof(FloatType)); secondy[i] = dato_entrada; co_stream_read(input, &dato_entrada, sizeof(FloatType)); secondz[i] = dato_entrada;}
ret = constant_f_0_0;for (k = 0; k < CANT_COORD_POR_ESTRUCTURA; ++k){ #pragma CO PIPELINE #pragma CO SET STAGEDELAY 64
assign_add(ret, add3(square(sub(firstx[k], secondx[k])), square(sub(firsty[k], secondy[k])), square(sub(firstz[k], secondz[k]))));}
ret = square_root(divide(ret, to_current(CANT_COORD_POR_ESTRUCTURA)));
co_stream_write(output, &ret, sizeof(FloatType));
CÁLCULO DE RMSD
LECTURA STREAM DE ENTRADA
ESCRITURA STREAM DE SALIDA
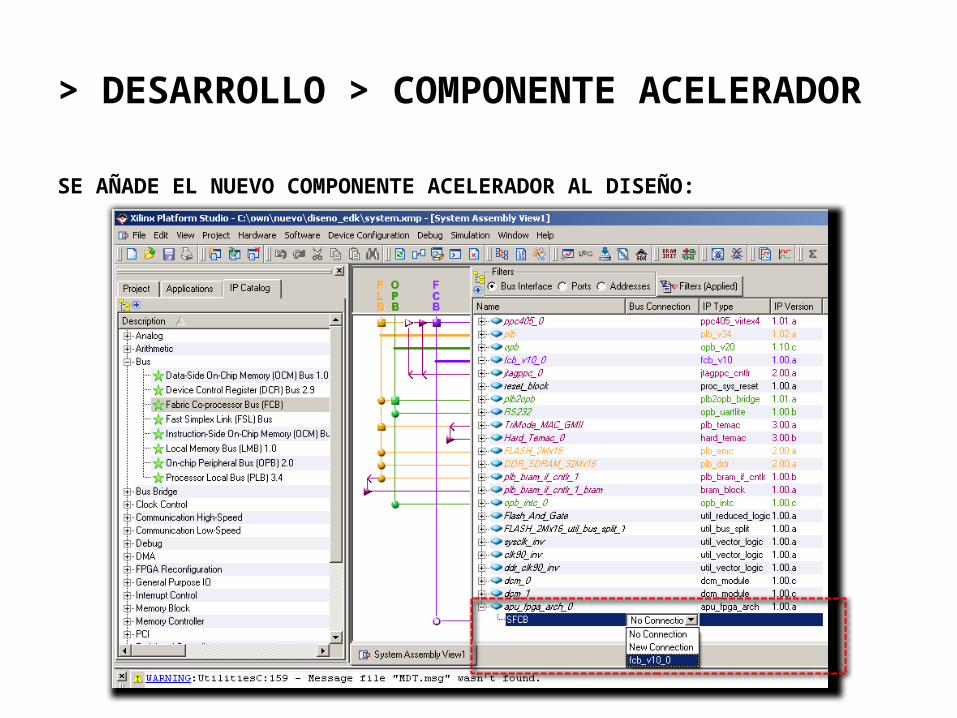
SE AÑADE EL NUEVO COMPONENTE ACELERADOR AL DISEÑO:
> DESARROLLO > COMPONENTE ACELERADOR

> DESARROLLO > UTILIZACIÓN DEL COMPONENTE ACELERADOR
FloatType rmsd_to(Coord3d* first, const Coord3d* second, const size_t num_coords){ FloatType ret = constant_f_0_0; rotalign_to(first, second, num_coords); size_t i; for (i = 0; i < num_coords; ++i) assign_add(ret, add3(square(sub(first[i].x, second[i].x)), square(sub(first[i].y, second[i].y)), square(sub(first[i].z, second[i].z)))); ret = square_root(divide(ret, to_current(num_coords))); return ret;}
FloatType rmsd_to(Coord3d* first, const Coord3d* second, const size_t num_coords){ FloatType ret = constant_f_0_0; rotalign_to(first, second, num_coords); co_processor_call(first, second, &ret); return ret;}
COMUNICACIÓN Y USO DEL COMPONENTE ACELERADOR DESDE LA APLICACIÓN SERVIDORA

> LLAMADA AL SERVIDOR

> MERCADO > FABRICANTES DE FPGAs
QUICKLOGIC
ALTERA
XILINX
CYPRESS SEMICONDUCTOR
LATTICE SEMICONDUCTOR
ATMEL
ACTEL

> MERCADO > ASPECTO ECONÓMICO
COSTO ELEVADO (LA UTILIZADA EN ESTE PROYECTO RONDA LOS 200 U$S)
PLATAFORMA DE DESARROLLO UTILIZABLE: - SOLO LA DEL FABRICANTE (COMPRA DE LICENCIAS)
IPCORES: - EL FABRICANTE EN SU PLATAFORMA DE DESARROLLO PROVEE ALGUNOS PAGOS Y OTROS LIBRES. - EN INTERNET EXISTEN IPCORES LIBERADOS.
GENERAR UNA PLATAFORMA EN UN SOLO INTEGRADO
IMPLEMENTAR DISEÑOS Y PROTOTIPOS DE MANERA FLEXIBLE Y RÁPIDA.