revisiÓn del estado del arte en el anÁlisis de series de ... · cambios de los precios de una...
TRANSCRIPT

REVISIÓN DEL ESTADO DEL ARTE EN EL ANÁLISIS DE SERIES DE TIEMPO
Por:
Hernán Camilo Yate Támara
Director:
Mat. Leonardo Jiménez Moscovitz
Investigador Grupo de Investigación PROMENTE
KONRAD LORENZ-FUNDACIÓN UNIVERSITARIA FACULTAD DE MATEMÁTICAS E INGENIERÍAS
PROGRAMA DE MATEMÁTICAS JUNIO DE 2011

Nota:
Este trabajo nace de la confluencia entre el interés del estudiante Hernán Camilo Yate
Támara y los intereses académicos del grupo de investigación PROMENTE, alrededor del
análisis de series de tiempo utilizando el software libre R, y consta de dos partes: la primera
desarrollada como parte del trabajo del Grado y la otra desarrollada dentro de la práctica
investigativa, la cual se anexa al final de este documento.

A mi madre
La que nunca me niega sus manos tan tibias
La que seca mis lágrimas y entrega caricias
La que ampara tristezas y regala sonrisas
La que con dulces palabras alienta mis días
La que me dio la vida y me ha enseñado a vivirla

iv

Índice general
Introducción ix
Objetivos xi
Alcance y Limitaciones xiii
1. Preliminares 1
1.1. Espacio de Probabilidad . . . . . . . . . . . . . . . . . . . . . . . 11.1.1. Espacio Muestral de Eventos . . . . . . . . . . . . . . . . 11.1.2. Álgebra de Eventos . . . . . . . . . . . . . . . . . . . . . . 21.1.3. Función de Probabilidad . . . . . . . . . . . . . . . . . . . 2
1.2. Variables Aleatorias . . . . . . . . . . . . . . . . . . . . . . . . . 31.2.1. Valor Esperado de una Variable Aleatoria . . . . . . . . . 31.2.2. Varianza de una Variable Aleatoria . . . . . . . . . . . . . 3
1.3. Vectores Aleatorios . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3.1. Valor esperado de un Vector Aleatorio . . . . . . . . . . . 51.3.2. Varianza de un Vector Aleatorio . . . . . . . . . . . . . . 51.3.3. Función Generadora de Momentos Conjunta . . . . . . . . 61.3.4. Covarianza y Coeciente de Correlación . . . . . . . . . . 61.3.5. Esperanza Condicional . . . . . . . . . . . . . . . . . . . . 71.3.6. Variables Aleatorias Independientes . . . . . . . . . . . . 8
1.4. Distribución Normal . . . . . . . . . . . . . . . . . . . . . . . . . 8
2. Conceptos Fundamentales 9
2.1. Antecedentes Históricos . . . . . . . . . . . . . . . . . . . . . . . 92.1.1. Observación, medición y generalización . . . . . . . . . . 92.1.2. Formalización . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2. Series de Tiempo y Procesos Estocásticos . . . . . . . . . . . . . 102.3. Medias, Varianzas y Covarianzas . . . . . . . . . . . . . . . . . . 11
2.3.1. La "Caminata Aleatoria" (Random Walk) . . . . . . . . . 122.3.2. Promedios Móviles . . . . . . . . . . . . . . . . . . . . . . 13
2.4. Estacionariedad . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.4.1. Ruido Blanco (White Noise) . . . . . . . . . . . . . . . . 15
v

vi ÍNDICE GENERAL
3. Tendencias 17
3.1. Tendencias Determinísticas contra Tendencias Estocásticas . . . 173.2. Estimación de la Media Constante . . . . . . . . . . . . . . . . . 173.3. Métodos de Regresión . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3.1. Tendencias Lineales y Cuadráticas . . . . . . . . . . . . . 193.3.2. Tendencias cíclicas. . . . . . . . . . . . . . . . . . . . . . . 203.3.3. Tendencias del Coseno . . . . . . . . . . . . . . . . . . . . 20
3.4. Conabilidad y Eciencia de las Estimaciones de la Regresión . . 213.5. Análisis de Residuales . . . . . . . . . . . . . . . . . . . . . . . . 23
3.5.1. Función de Autocorrelación Muestral . . . . . . . . . . . . 23
4. Modelos para Series de Tiempo Estacionarias 25
4.1. Procesos Generales Lineales . . . . . . . . . . . . . . . . . . . . . 254.2. Procesos de Promedios Móviles . . . . . . . . . . . . . . . . . . . 27
4.2.1. Procesos de Promedios Móviles de Primer Orden . . . . . 274.2.2. Procesos de Promedios Móviles de Segundo Orden . . . . 284.2.3. Procesos de Promedios Móviles de Orden q . . . . . . . . 29
4.3. Procesos Autorregresivos . . . . . . . . . . . . . . . . . . . . . . . 294.3.1. Procesos Autorregresivos de Primer Orden . . . . . . . . 29
4.3.1.1. Versión General Lineal de un Modelo AR (1) . . 304.3.1.2. Estacionariedad de un Proceso AR (1) . . . . . . 31
4.3.2. Procesos Autorregresivos de Segundo Orden . . . . . . . . 314.3.2.1. Estacionariedad de un Proceso AR (2) . . . . . . 314.3.2.2. La Función de Autocorrelación del Proceso AR (2) 33
4.3.3. Varianza del Modelo AR (2) . . . . . . . . . . . . . . . . . 334.3.4. Proceso Autorregresivo General . . . . . . . . . . . . . . . 34
4.4. Modelos Mixtos Autorregresivos de Promedios Móviles . . . . . . 354.4.1. El modelo ARMA (1, 1) . . . . . . . . . . . . . . . . . . . 354.4.2. La Función de Autocorrelación para un ProcesoARMA (p, q)
Cryer and Chan [2008] . . . . . . . . . . . . . . . . . . . . 364.4.3. Invertibilidad . . . . . . . . . . . . . . . . . . . . . . . . . 37
5. Modelos para Series de Tiempo No Estacionarias 39
5.1. Estacionariedad a través de los Operadores Diferencia . . . . . . 395.2. Modelos Integrados Autorregresivos de Promedios Móviles . . . . 42
5.2.1. El Modelo IMA (1, 1) . . . . . . . . . . . . . . . . . . . . 435.2.2. El Modelo IMA (2, 2) . . . . . . . . . . . . . . . . . . . . 445.2.3. El Modelo ARI (1, 1) . . . . . . . . . . . . . . . . . . . . . 445.2.4. Términos Constantes en modelos ARIMA . . . . . . . . . 455.2.5. Otras Transformaciones . . . . . . . . . . . . . . . . . . . 46
5.2.5.1. Cambios de Porcentajes y Logaritmos . . . . . . 475.2.5.2. Transformaciones de Potencia . . . . . . . . . . 47

ÍNDICE GENERAL vii
6. Construcción del Modelo 496.1. Especicación del Modelo . . . . . . . . . . . . . . . . . . . . . . 49
6.1.1. Propiedades de la Función de Autocorrelación Muestral . 506.1.2. La Función de Autocorrelación Parcial y la Función de
Autocorrelación Extendida . . . . . . . . . . . . . . . . . 526.1.2.1. La Función de Autocorrelación Parcial Muestral 546.1.2.2. Modelos Mixtos y la Función de Autocorrelación
Extendida . . . . . . . . . . . . . . . . . . . . . 556.1.3. Especicación para Modelos No Estacionarios . . . . . . . 56
6.1.3.1. El problemas de la Sobrediferenciación . . . . . 576.1.3.2. La prueba de la raíz unitaria de Dickey Fuller . 57
6.1.4. Otros Métodos de Especicación . . . . . . . . . . . . . . 586.1.4.1. Criterio de la Información de Akaike . . . . . . 586.1.4.2. Criterio de la Información Bayesiano . . . . . . 58
6.2. Estimación de Parámetros . . . . . . . . . . . . . . . . . . . . . . 596.2.1. El Método de los Momentos . . . . . . . . . . . . . . . . . 59
6.2.1.1. Modelos Autorregresivos . . . . . . . . . . . . . 596.2.1.2. Modelos de Promedios Móviles . . . . . . . . . . 606.2.1.3. Modelos Mixtos . . . . . . . . . . . . . . . . . . 616.2.1.4. Estimación de la Varianza del Ruido . . . . . . . 61
6.2.2. Estimación por Mínimos Cuadrados . . . . . . . . . . . . 626.2.2.1. Modelos Autorregresivos . . . . . . . . . . . . . 626.2.2.2. Modelos de Promedios Móviles . . . . . . . . . . 646.2.2.3. Modelos Mixtos . . . . . . . . . . . . . . . . . . 65
6.2.3. Estimaciones de Máxima Verosimilitud y Mínimos Cua-drados Incondicionales . . . . . . . . . . . . . . . . . . . . 666.2.3.1. Estimación de Máxima Verosimilitud . . . . . . 666.2.3.2. Mínimos Cuadrados Incondicionales . . . . . . . 68
6.2.4. Propiedades de las Estimaciones . . . . . . . . . . . . . . 686.3. Diagnóstico del Modelo . . . . . . . . . . . . . . . . . . . . . . . 69
6.3.1. Análisis de residuales . . . . . . . . . . . . . . . . . . . . . 696.3.1.1. Autocorrelación de los Residuales . . . . . . . . 70
6.3.2. Sobreajuste y Redundancia de Parámetros . . . . . . . . . 71
7. Pronósticos 737.0.3. Pronóstico por el Método de Error Cuadrático Medio . . 737.0.4. Tendencias Determinísticas . . . . . . . . . . . . . . . . . 767.0.5. Pronósticos de modelos ARIMA . . . . . . . . . . . . . . 76
7.0.5.1. AR (1) . . . . . . . . . . . . . . . . . . . . . . . 777.0.5.2. MA (1) . . . . . . . . . . . . . . . . . . . . . . . 797.0.5.3. ARMA (p, q) . . . . . . . . . . . . . . . . . . . . 80
7.0.6. Modelos no Estacionarios . . . . . . . . . . . . . . . . . . 827.0.7. Límites de la Predicción . . . . . . . . . . . . . . . . . . . 83
7.0.7.1. Tendencias Determinísticas . . . . . . . . . . . . 847.0.7.2. Modelos ARIMA . . . . . . . . . . . . . . . . . 84
7.0.8. Actualización de los Pronósticos ARIMA . . . . . . . . . 85

viii ÍNDICE GENERAL
7.0.9. Pesos de Pronósticos y Promedios Móviles Exponencial-mente Ponderados. . . . . . . . . . . . . . . . . . . . . . . 85
7.0.10. Pronósticos de Series de Tiempo Transformadas . . . . . 877.0.10.1. Operador Diferencia . . . . . . . . . . . . . . . . 877.0.10.2. Transformaciones Logarítmicas . . . . . . . . . . 87
8. Modelos de Estado y Espacio y el Filtro Kalman 898.1. Evaluación de la Función de Verosimilitud y el Filtro Kalman . . 908.2. Estado Inicial de la Matriz de Covarianzas . . . . . . . . . . . . . 92
Conclusiones 95
Bibliografía 97

Introducción
Los datos obtenidos de observaciones secuenciales a través del tiempo sonmuy comunes en diferentes disciplinas. Por ejemplo, en nanzas, se observancambios de los precios de una acción en un día, índices de precios en un mes,inaciones anuales, etc. En meteorología, se observan uctuaciones de tempera-tura diaria, precipitaciones anuales, estados de los suelos, entre otros. La listade disciplinas en las que se estudian series de tiempo, prácticamente no tiene n,por lo que el análisis de las series cronológicas ha tomado gran importancia. Dehecho la teoría matemática en la que se basa el análisis de series de tiempo hasido, quizá, una de las áreas con mayor actividad, en los últimos años, convir-tiéndose así en una herramienta de mucho peso a la hora de resolver problemassin importar en la disciplina que se esté usando.
Sin embargo, la aplicación de los métodos inherentes a los problemas deseries de tiempo requiere un trasfondo estadístico fuerte. En el presente textose describirá la teoría básica para el análisis de series de tiempo, abarcando,desde los conceptos fundamentales de probabilidad hasta llegar a los modelosde mayor estudio (AR, MA, ARMA, ARIMA), con el n de poder pronosticarestadísticamente los valores de la serie de tiempo de estudio.
La revisión de la teoría propia de las series cronológicas es de gran importan-cia para los lectores de este texto, ya que tendrán la oportunidad de poseer untexto teórico recopilado de las más importantes fuentes bibliográcas, teniendoen cuenta la fundamentación matemática de ciertos algoritmos y métodos. Esdecir, un texto que recopila los conceptos y métodos de mayor frecuencia de usoen el análisis de series temporales, teniendo en cuenta la rigurosidad matemáticarequerida.
ix

x INTRODUCCIÓN

Objetivos
Objetivo General
El objetivo general del presente documento es presentar la teoría referente alestudio de las series cronológicas, y establecer un documento teórico base parafuturas investigaciones.
Objetivos Especícos
1. Recopilar y presentar la teoría de viarios textos reconocidos en el área delanálisis de series de tiempo.
2. Reseñar una de las más importantes aplicaciones de la matemática a pro-blemas que se presentan en diferentes campos del conocimiento.
3. Construir un texto el cual haga las veces de texto introductorio al análisisde series de tiempo.
xi

xii OBJETIVOS

Alcance y Limitaciones
El trabajo pretende presentar las familias de modelos de mayor utilización,como lo son los modelos autorregresivos (AR), modelos de promedios móviles(MA), modelos autorregresivos mixtos de promedios móviles (ARMA ) y losmodelos autorregresivos integrados de promedios móviles (ARIMA), además delos modelos de estado y espacio y el ltro Kalman. Todos los temas mencionadosanteriormente se constituyen como la base teórica para cualquier desarrollo detrabajos de series de tiempo.
Aunque una de las pretensiones más importantes del trabajo es describir unnúmero signicativo de métodos y modelos, solo se tendrán en cuenta el casounivariado, paramétrico es decir se excluirán por ejemplo la familia de modelosAutorregresivos de Umbral (TAR), la familia de modelos Vectoriales Autorre-gresivos (VAR), entre otros y algunos métodos de estimaciones de tendenciascomo la regresión usando Splines, el Filtro de Smirnov entre otros.
xiii

xiv ALCANCE Y LIMITACIONES

Capítulo 1
Preliminares
1.1. Espacio de Probabilidad
La probabilidad es un marco conceptual que permite analizar la ocurrenciade sucesos aleatorios, es decir, facilita el estudio de sucesos en los cuales no esposible predecir con exactitud el resultado de un experimento. La construccióndel marco conceptual de la probabilidad se inicia con el de espacio de probabi-lidad (Ω;A; p) asociado a un experimento E. Con este objetivo, se desarrollanlos siguientes temas:
Experimento.
Espacio Muestral.
Álgebra de Eventos.
Función de Probabilidad.
1.1.1. Espacio Muestral de Eventos
Denición 1 Un experimento E es la realización de una tarea bien denida yde la cual se ha establecido la codicación o forma de tabulación de los posiblesresultados. El experimento se dice aleatorio cuando el resultado no es predeciblecon exactitud.
Denición 2 Al conjunto de todos los posibles resultados obtenidos al realizarun experimento se denomina espacio muestral de eventos y se denota por Ω. Loselementos a ∈ Ω se denominan puntos muestrales.Rincón [2011]
Denición 3 Un espacio muestral Ω se denomina discreto si es nito o enu-merable, en tal caso E se dice experimento discreto. Rincón [2011]
1

2 CAPÍTULO 1. PRELIMINARES
1.1.2. Álgebra de Eventos
En un experimento E, cada punto muestral en el espacio muestral Ω sedenomina evento simple y al evento resultante de la unión, intersección u otraoperación de conjuntos denida en el conjunto de eventos simples se denominaevento compuesto.
Denición 4 Para E un experimento discreto y Ω su espacio muestral de even-tos se dene un álgebra de eventos a cualquier colección de conjuntos A quesatisfaga las siguientes propiedades Rincón [2011]:
Ω ∈ A.
Si A ∈ A entonces Ac ∈ A
Si A ∈ A y B ∈ A entonces A∪ B ∈ A.
1.1.3. Función de Probabilidad
Denición 5 Sea E un experimento discreto, Ω su espacio muestral de posiblesresultados y A un álgebra de eventos denida para Ω, una función p : A → [0; 1]es una función de probabilidad si satisface los siguientes axiomasCanavos [1998]:
p(B) ≥ 0, Para todo B ∈ A
P (Ω) = 1
Si A1, A2, . . . , An es una colección de conjuntos mutuamente disyuntos yk⋃i=1
Ai ∈ A entonces
p
(k⋃i=1
Ai
)=
k∑i=1
p(Ai) Para todo k ≤ n
Denición 6 Un espacio de probabilidad para un experimento E está confor-mado por la tripleta (Ω;A; p) Rincón [2011]
Interesa construir el espacio de probabilidad para un experimento E con elálgebra de eventos A = ℘(Ω) y una función de probabilidad p denida sobresus eventos simples. La función de probabilidad p se dene sobre los eventossimples y para ello existen varias posibilidades que generan diferentes espaciosde probabilidad. La más frecuente es conocida como probabilidad clásica, en ellalos eventos simples son equiprobables, la probabilidad de cada evento simple está
dada por1
η(Ω),donde η(Ω) es el cardinal del espacio muestral, y en este caso el
espacio de probabilidad se denomina espacio de probabilidad laplaciano.

1.2. VARIABLES ALEATORIAS 3
1.2. Variables Aleatorias
A continuación se mostrarán elementos del modelo de distribución de pro-babilidad para una variable aleatoria, que bien puede se discreta o continua, Xdenida en (Ω;A; p)
Denición 7 En un espacio de probabilidad (Ω;A; p) una función X : A −→ Res una variable aleatoria si para cualquier valor de r ∈ R el conjuntoAr = W ×W ≤ r pertenece a A. X se dice discreta si su rango RX es con-table y continua en caso contrario. Rincón [2011]
La denición de una variable aleatoria X en un espacio de probabilidad(Ω;A; p), permite caracterizar todos los eventos del experimento, en expresionesmatemáticas en función de los valores de X
1.2.1. Valor Esperado de una Variable Aleatoria
A continuación se presentarán las deniciones de valor esperado o esperanzamatemática para una variable aleatoria, tanto discreta como continua.
Denición 8 Para una variable aleatoria discreta X, el valor esperado E (X),se dene comoWalpole et al. [1998]
E (X) = µx =∑x∈Rx
xp(X)
En general, el valor esperado X de una variable aleatoria discreta X esel promedio de X ponderado con los valores de p(x), se interpreta igual que elpromedio ponderado aritmético y es el valor referente para calcular la dispersiónde los datos y para caracterizar la asimetría de la distribución de probabilidad.
Denición 9 Para una variable aleatoria continua X, el valor esperado E (X),se dene como Walpole et al. [1998]
E (X) = µx =
∞
−∞
xf (x) dx
Donde la función f (x) es conocida como la función de densidad de probabi-lidad.
1.2.2. Varianza de una Variable Aleatoria
De la misma manera que con el valor esperado, se presentarán las denicionesde varianza y desviación estándar para variables aleatorias discretas y continuas
Denición 10 La varianza σ2X , para X variable aleatoria discreta se dene
como Walpole et al. [1998]
V (X) = σ2X =
∑x∈Rx
(x− µx)2p (x)

4 CAPÍTULO 1. PRELIMINARES
Denición 11 La varianza σ2X , para X variable aleatoria continua se dene
como Walpole et al. [1998]
V (X) = σ2X =
∞
−∞
(x− µx)2f (x) dx
Denición 12 La desviación estándar σX , para X una variable aleatoria, biensea, discreta o continua se dene como la raíz cuadrada positiva de la varianzaσ2X . Walpole et al. [1998]
1.3. Vectores Aleatorios
Un vector aleatorio se origina cuando en el mismo espacio de probabilidad(Ω;A; p) se denen X1, X2, ..., Xn variables aleatorias, e interesa observar yanalizar su comportamiento probabilístico conjunto.
Denición 13 Sean X1, X2, ..., Xn variables aleatorias discretas denidas en(Ω;A; p), al vector X = X1, X2, ..., Xn se denomina vector aleatorio de di-mensión n. El rango o conjunto de valores del vector X está contenido en elconjunto Rincón [2011]
R = RX1×RX2
× · · · ×RX1
con RXi el rango de Xi para i = 1, 2, ..., n.
Se dice que el vector aleatorio es discreto si cada Xi es una variable aleatoriadiscreta y se dice vector aleatorio continuo si cada Xi es na variable aleatoriacontinua.
Denición 14 Dado un vector aleatorio X = X1, X2, ..., Xn con p(x1, x2, ...xn)la función de probabilidad conjunta, para cada variable Xi existe la función deprobabilidad marginal p (x) denida comoRincón [2011]
p (x) =
∑x1∈Rx1
∑x2∈Rx2
· · ·∑
x2∈Rx2
p(x1, x2, ...xn) Si Xes discreto
∞
−∞
∞
−∞
· · ·∞
−∞
p(x1, x2, ...xn)dΩ Si Xes continuo
DondedΩ = dx1dx2 · · · dxi−1dxi+1 · · · dxn
Denición 15 Sea X = X1, X2, ..., Xn un vector aleatorio denido en (Ω;A; p)y p(x1, x2, ...xn) la función de probabilidad conjunta. La función de probabilidadacumulada de X está dada por Rincón [2011]

1.3. VECTORES ALEATORIOS 5
F (x) =
∑A
p(k1, k2, ...kn) Si Xes discreto
ˆ
A
p(k1, k2, ...kn)dΩ Si Xes continuo
dondeA = x1, x2, ...xn : x1 ≤ k1;x2 ≤ k2; ...;xn ≤ kn
ydΩ = dx1dx · · · dxn
1.3.1. Valor esperado de un Vector Aleatorio
Teniendo denidas las funciones de probabilidad conjunta es posible denirel valor esperado de una vector aleatorio discreto o continuo, según sea el caso.
Denición 16 Sea X = X1, X2, ..., Xn un vector aleatorio denido en (Ω;A; p)y p(x1, x2, ...xn) la función de probabilidad conjunta. El vector de medias de Xes el vector de los valores esperados de las variables Xi, i = 1, 2, ..., n y estádado por Canavos [1998]
E (X) = µX = (µX1, µX2
, ...µXn)
donde
µXi =
∑x1∈Rx1
xpXi (x) i = 1, 2, ...n Si Xes discreto
∞
−∞
xpXi (x) dx i = 1, 2, ...n Si Xes continuo
1.3.2. Varianza de un Vector Aleatorio
Denición 17 Sea X = X1, X2, ..., Xn un vector aleatorio denido en (Ω;A; p)y p(x1, x2, ...xn) la función de probabilidad conjunta. El vector de varianzas deX es el vector de varianzas de las variables Xi i = 1, 2, ...n y está dado porCanavos [1998]
V (X) = σ2X =
(σ2X1, σ2X2, ...σ2
Xn
)donde
Denición 18
σ2Xi =
∑x1∈Rx1
(x− µXi)2pXi (x) i = 1, 2, ...n Si Xes discreto
∞
−∞
(x− µXi)2pXi (x) dx i = 1, 2, ...n Si Xes continuo

6 CAPÍTULO 1. PRELIMINARES
1.3.3. Función Generadora de Momentos Conjunta
Denición 19 Sea X = X1, X2, . . . , Xn un vector aleatorio denido en (Ω;A; p)con probabilidad conjunta p (x1, x2, ..., xn) . La función generadora de momentosconjunta de X está dada por Rincón [2011]
Mx (t) = E(etX)
Para t ∈ RLa función generadora de momentos recibe su nombre gracias a que sus
derivada calculadas en cero generan los momentos de vector X, es decir
M ′x (0) = M1 = µx
M ′′x (0) = M2 = µ2x
...
1.3.4. Covarianza y Coeciente de Correlación
Denición 20 [Covarianza]Sea (X,Y ) un vector aleatorio denido en (Ω;A; p)y p (x, y) la función de probabilidad conjunta. La covarianza de X y Y está dadapor: Koopman [1964]
Cov (X,Y ) =∑x,y
(x− µx) (y − µy) p (x, y) = σ2XY
Denición 21 Sea X = X1, X2, ...Xn un vector aleatorio denido en (Ω;A; p)y p (x1, x2, ..., xn) la función de probabilidad conjunta. La matriz de varianzas ycovarianzas está dada por Koopman [1964]
∑XY =
σ2X1
σ2X1X2
· · · σ2X1Xn
σ2X2X1
σ2X2
· · · σ2X2Xn
......
. . ....
σ2XnX1
σ2XnX2
· · · σ2Xn
Denición 22 [Coeciente de Correlación]Sea (X,Y ) un vector aleatorio de-nido en (Ω;A; p) y p(x, y) la función de probabilidad conjunta. el coeciente decorrelación de X y Y está dado por: Koopman [1964]
ρXY =Cov (X,Y )
σXσY
Denición 23 Sea X = X1, X2, ...Xn un vector aleatorio denido en (Ω;A; p)y p (x1, x2, ..., xn) la función de probabilidad conjunta. La matriz de de correla-ciones de X está dada por Koopman [1964]
RXY =
1 ρ
X1X2· · · ρ
X1Xn
ρX2X1
1 · · · ρX2Xn
......
. . ....
ρXnX1
ρXnX2
· · · 1

1.3. VECTORES ALEATORIOS 7
1.3.5. Esperanza Condicional
Sean X y Y vectores aleatorios
Denición 24 Si X y Y tienen función de probabilidad conjunta f (x, y) , ysea f (x) la función de probabilidad marginal de X. La función de probabilidadcondicional de Y dado X = x, es Koopman [1964]
f (y | x) =f (x, y)
f (x)
Para un valor dado de x, la función de probabildad condicional tiene todas laspropiedades usuales de una función de densidad de probabilidad. En particular,
Denición 25 La esperanza condicional de Y dado x = x es denida comoKoopman [1964]
E (Y | X = x) =
∑y∈Ry
yf (y | x) Si Xy Y son discretos
∞
−∞
yf (y | x) dy Si Xy Y son continuos
Como un valor esperado, la esperanza condicional goza de todas las propie-dades usuales. Por ejemplo
E (aY + bZ + c | X = x) = aE (Y | X = x) + bE (Z | X = x) (1.1)
y
E [h (Y ) | X = x] =
∑x∈Rx
yf (y | x) Si Xy Y son discretos
∞
−∞
yf (y | x) dx Si Xy Y son continuos(1.2)
AdemásE [h (x) | X = x] = h (x) (1.3)
Es decir que, dado X = x la variable aleatoria h (x) puede ser tratada comouna constante. En general
E [h (X,Y ) | X = x] = E [h (x, Y ) | X = x] (1.4)
Sea E (Y | X = x) = g (x) , entonces g (x) es una variable aleatoria y sepuede considerar E [g (x)] , donde
E [g (x)] = E (Y )
Lo que usualmente se escribe como
E [E (Y | X)] = E (Y ) (1.5)

8 CAPÍTULO 1. PRELIMINARES
1.3.6. Variables Aleatorias Independientes
Sea X = X1, X2, . . . , Xn un vector aleatorio denido en (Ω;A; p) conprobabilidad conjunta p (x1, x2, ..., xn) Xi se dicen mutuamente independientessi cumple alguna de las siguientes condiciones Rincón [2011]
p (Xi | Xj) = pxi ∀i 6= j
p (x1, x2, ..., xn) =
n∏i=1
pxi (xi)
F (x1, x2, ..., xn) =
n∏i=1
Fxi (xi)
1.4. Distribución Normal
Denición 26 Una variable continua X con Rx = (−∞,∞) se tiene distribu-ción normal con parámetros
(µ, σ2
), si su función de densidad de probabilidad
está dada por Canavos [1998]
f(x, µ, σ2
)=
1√2πσ
e−12
(x−µσ
)2La distribución normal es quizá la más importante en la teoría estadística
ya que muchos desarrollos teóricos se construyen sobre este supuesto. Se denotapor X ∼ N
(µ, σ2
)y se utiliza cuando el polígono de frecuencias de los valores
de X tiene forma acampanada, con X = µX como eje de simetría. También esimportante señalar las siguientes características de la distribución normal.
µx se denomina parámetro de localización y la función de densidad essimétrica en X = µx es decir p (X ≤ µX) = p (X ≥ µX) = 0,5.
σ2X se denomina parámetro de escala y establece la dispersión de los valores
de X con respecto a µx.
Denición 27 Cuando X se distribuye normal con parámetros (0, 1) , se deno-mina normal estándar, se denota por Z ∼ N (0, 1) y su función de densidad deprobabildad está dada por Canavos [1998]
f (z) =1√2πe
z2
2

Capítulo 2
Conceptos Fundamentales
En este capítulo se describirán los conceptos fundamentales en la teoría refe-rente a la series de tiempo. Particularmente se tratarán los conceptos de procesoestocástico, funciones de media y covarianza, procesos estacionarios, y las fun-ciones de autocorrelación, así como una breve descripción histórica.
2.1. Antecedentes Históricos
La historia de las series de tiempo se puede dividir en dos épocas (Ob-servación, Medición y Generalización y Formalización) teniendo en cuenta losmétodos para abordar los diferentes fenómenos que motivaron el estudio delcomportamiento de ciertos elementos respecto al tiempo.
2.1.1. Observación, medición y generalización
El antecedente más antiguo de las series de tiempo se remonta a 1846 cuandoel astrónomo Heinrich Schwabe, observó la actividad periódica de las manchassolares (sunspots). Seguido de décadas de investigación, no solo en la físicasolar sino en el magnetismo terrestre, meteorología e incluso economía, dondese examinaban las series para comprobar si su periodicidad coincidía con losdiferentes fenómenos anteriormente mencionados, por ejemplo, Simon Laplacey Jacques Quetelet, habían analizado datos meteorológicos y William Herschelhabía escrito un libro al respecto. Todos estudios basados en la observaciónempírica.
Las técnicas en uso variaban desde las más simples, como la tabla de BuysBallot, la cual permitía conocer la disposición de los centros de alta y bajapresión respecto de la dirección en que sopla el viento, a formas más sosticadascomo el análisis armónico, es el caso del físico Arthur Schuster quien introdujoen 1889 el periodograma, el cual permite calcular la densidad espectral de unaseñal.
9

10 CAPÍTULO 2. CONCEPTOS FUNDAMENTALES
Sin embargo, por ese entonces, una forma rival del análisis de series tempo-rales, basada en la correlación y promovida por Pearson, Yule, Hooker y otros,fue tomando forma.
2.1.2. Formalización
El análisis estadístico de las series de tiempo tienen sus inicios formales conel texto escrito por George Udny Yule en 1927 llamado On a Method of In-vestigating Periodicities in Disturbed Series, with Special Reference to Wolfer'sSunspot Numbers, donde, basado en el concepto de correlación intenta explicarlas manchas solares con otros fenómenos astronómicos.
A pesar de los avances propuestos por varios estadísticos inuyentes de lasprimeras décadas del siglo XX, no fue sino hasta 1970, con la publicación de"Time Series Analysis: Forecasting and Control" por Box y Jenkins en 1970, quese constituyó una herramienta bibliográca, que permitía aplicar los métodosde series de tiempo de manera sistemática, y además logro unicar el objetivode investigación.
Es importante mencionar que, el desarrollo teórico y práctico del análisis deseries de tiempo está estrechamente relacionado con el desarrollo informático,ya que este, provee las herramientas necesarias para los extensos cálculos quedemandan los métodos inherentes al análisis de series de tiempo. Uno de los masimportantes consiste en la parametrización de los modelos de estado y espacioy el ltro Kalman desarrollados en su mayoría en el nal de la década de 1970.1
2.2. Series de Tiempo y Procesos Estocásticos
La secuencia de variables aleatorias Yt : t = 0,±1,±2,±3, ... se conoce co-mo proceso estocástico, y sirve como modelo para una serie de tiempo observada.Se sabe que la estructura probabilística de dicho proceso es determinado por elconjunto de las distribuciones de todas las colecciones nitas de Xi. Sin embar-go, la mayoría de información de las funciones de probabilidad conjunta puedeser descrita en términos de sus medias, varianzas y covarianzas. Por lo cualdichos parámetros (primer y segundo momento) serán el objetivo principal (Silas distribuciones de X son distribuciones normales multivariadas, el primer ysegundo momento determinan completamente toda la distribución conjunta)
1Cada uno de los métodos mencionados en este apartado serán ampliados, mientras se
desarrollan los conceptos.

2.3. MEDIAS, VARIANZAS Y COVARIANZAS 11
2.3. Medias, Varianzas y Covarianzas
Denición 28 (Función de la Media) Para un proceso estocásticoYt : t = 0,±1,±2,±3, ... la función de la media se dene como Fuller [1996]
µt = E (Yt) Para t = 0,±1,±2, ... (2.1)
Es decir que el valor de µt, es simplemente el valor esperado del proceso enel tiempo t. En general el valor de µt puede diferir para cada tiempo t.
Denición 29 (Función de Autocovarianza)La función γt,sse dene como:
γt,s = Cov (Yt, Ys) Para t, s = 0,±1,±2, ... (2.2)
Fuller [1996]
Donde Cov (Yt, Yt) está contemplada en la denición 20. La función ρt,s estádada por:
Denición 30
ρt,s = Corr (Yt, Ys) Para t, s = 0,±1,±2, ... (2.3)
Fuller [1996]
Donde según la denición 22 se puede concluir que:
Corr (Yt, Ys) =γt,s√γt,tγs,s
(2.4)
Teniendo en cuenta que tanto la covarianza y la correlación son medidas dedependencia lineal entre dos variables aleatorias, se enunciaran las siguientespropiedades que serán se gran utilidad a lo largo del desarrollo del tema.
γt,t = V ar (Yt) ρt,t = 1γt,s = γs,t ρt,s = ρs,t
|γt,s| =√γt,tγs,s |ρt,s| ≤ 1
(2.5)
Es importante recordar que valores de ρt,s cercanos a ±1 indican una fuertedependencia lineal, por otra parte valores cercanos a 0 indican dependencialineal débil, y si ρt,s = 0 se dice que Yt y Ys no están correlacionadas.
Con el n de investigar las propiedades de la covarianza de varios modelosde series de tiempo, el siguiente resultado Cryer and Chan [2008] será usadorepetidamete: Si c1, c2, , cm y d1, d2, , dn son constates y t1, t2, , tm y s1, s2, , snson puntos temporales entonces
Cov
m∑i=1
ciYti ,
m∑j=1
djYsj
=
m∑i=1
m∑j=1
cidiCov(Yti , Ysj
)(2.6)
Como caso especial se obtiene
V ar
[n∑i=1
ciYti
]=
n∑i=1
c2iV ar (Yti) + 2
n∑i=2
i−1∑j=1
cicjCov(Yti , Ytj
)(2.7)

12 CAPÍTULO 2. CONCEPTOS FUNDAMENTALES
2.3.1. La "Caminata Aleatoria" (Random Walk)
Sean e1, e2, ... una secuencia de variables aleatorias idénticamente distribui-das cada una con media cero y varianza σ2
e . Se construye la serie de tiempoYt : t = 1, 2, ... de la siguiente manera
Y1 = e1 (2.8)
Y2 = e1 + e2
...
Y = e1 + e2 + · · ·+ et
De forma alternativa se puede escribir
Yt = Yt−1 + et
Con la condición inicial Y1 = e1. Si ei es considerado como el tamaño delos "pasos" dados a lo largo de la recta numérica (bien sea hacia adelante oatrás). Entonces Yt es la posición del Caminante aleatorio en el tiempo t . Dela ecuación 2.8 se puede deducir la función de la media:
µt = E (Yt) = E (e1 + e2 + · · ·+ et) = E (e1) + E (e2) + ...E (et)
= 0 + 0 + · · ·+ 0
Entoncesµt = 0 Para todo t
También, se considera
V ar (Yt) = V ar (e1 + e2 + · · ·+ et) = V ar (e1) + V ar (e2) + ...V ar (et)
= σ2e + σ2
e + · · ·+ σ2e
EntoncesV ar (Yt) = tσ2
e (2.9)
Para calcular la función de covarianza, se asume que 1 ≤ t ≤ s Entonces
γt,s = Cov (Yt, Ys) = Cov (e1 + e2 + · · · et, e1 + e2 + · · ·+ et + et+1 + · · · es)
Por propiedades de la covarianza se arma que:
γt,s =
s∑i=j
t∑j=1
Cov (ei, ej)
Sin embargo, estas covarianzas son cero menos cuando i = j, y en ese casoV ar (ei) = σ2
e y existen exactamente t casos de dicha igualdad, luego γt,s = tσ2e .
y debido a que γt,s = γs,t es posible escribir la función de covarianza de lasiguiente manera:
γt,s = tσ2e Para 1 ≤ t ≤ s (2.10)

2.3. MEDIAS, VARIANZAS Y COVARIANZAS 13
La función de autocorrelación para la caminata aleatoria se obtiene de lasiguiente manera
ρt,s =γt,s√γt,tγs,s
=
√t
sPara 1 ≤ t ≤ s (2.11)
2.3.2. Promedios Móviles
Suponga que Yt es construido como
Yt =et + et−1
2(2.12)
Debido a que ei se asumen como variables aleatorias idénticamente distri-buidas con media cero y varianza σ2
e , entonces
µt = E (Yt) = E
[et + et−1
2
]=E (et) + E (et−1)
2
= 0
y
V ar (Yt) = V ar
[et + et−1
2
]=V ar (et) + V ar (et−1)
4
= 0,5σ2e
También
Cov (Yt, Yt−1) = Cov
[et + et−1
2,et−1 + et−2
2
]=Cov (et, et−1) + Cov (et, et−2) + Cov (et−1, et−1) + Cov (et−1, et−2)
4
=Cov (et−1, et−1)
4
= 0,25σ2e
oγt,t−1 = 0,25σ2
e Para todo t (2.13)
Además
Cov (Yt, Yt−2) = Cov
[et + et−1
2,et−1 + et−2
2
]= 0 Por ser e independientes
Del mismo modo, Cov (Yt − Yt−k) = 0 para k > 1 entonces se generaliza dela siguiente manera
γt,s =
0,25σ2e Para |t− s| = 0
0,5σ2e Para |t− s| = 1
0 Para |t− s| > 1

14 CAPÍTULO 2. CONCEPTOS FUNDAMENTALES
Para la función de autocorrelación, aplicando la ecuación 2.4 se obtiene
ρt,s =
1 Para |t− s| = 00,5 Para |t− s| = 10 Para |t− s| > 1
Es de gran importancia notar que ρ2,1 = ρ3,2 = ρ5,6 = ρ9,8 = 0,5. Es decirque valores de Y separados por una unidad de tiempo tiene la misma correlación.Más aún ρ3,1 = ρ5,3 = ρt,t−2 y más general ρt,t−k es el mismo para todo valorde t. Este hecho conduce al importante concepto de estacionariedad
2.4. Estacionariedad
Con el n de inferir acerca de la estructura de un proceso estocástico ba-sado en datos observados, se debe, usualmente, asumir ciertas condiciones quesimplican el proceso. El más importante de dichos supuestos es el de la esta-cionariedad. La idea principal de la estacionariedad consiste en que las reglasde probabilidad que rigen el proceso no cambian respecto al tiempo.
Denición 31 Especícamente, un proceso Yt, se dice que es estrictamente
estacionario si la distribución conjunta de Yt1 , Yt2 , . . . , Ytn es la misma que ladistribución conjunta de Yt1−k, Yt2−k, . . . , Ytn−k, para cada elección de puntost1, t2, ..., tn y todo rezago de tiempo k. Cryer and Chan [2008]
Una denición similar a la estrictamente estacional pero matemáticamentemas débil es la siguiente:
Denición 32 Un proceso Yt, se dice que es débilmente estacionario oestacionario de segundo orden si Cryer and Chan [2008]
1. La función de la media es constante a través del tiempo, y
2. γt,t−k = γ0,k para todo tiempo t y todo rezago k
Denición 33 Para procesos estacionarios usualmente se considera k ≥ 0.
Teorema 34 Sea Yi una serie de tiempo estacionaria con función de auto-
covarianza γk =1
n
n∑k=t
Yt pruebe que:
V ar(Y ) =γ0
n+
2
n
n−1∑k=1
(1 +
k
n
)γk
=1
n
n−1∑k=−n+1
(1− k
n
)γk

2.4. ESTACIONARIEDAD 15
2.4.1. Ruido Blanco (White Noise)
Un ejemplo bastante importante de lo que es un proceso estacional es lo quecomúnmente se conoce como ruidoblanco Montgomery et al. [2008].
Denición 35 El ruido blanco (White Noise) se dene como una secuencia devariables aleatorias, independientes idénticamente distribuidas et
La importancia del ruido blanco radica en el hecho de que muchos procesosútiles pueden ser construidos a partir de ruido blanco.
El término ruido blanco se basa en el hecho que en un análisis de frecuenciadel modelo muestral, en analogía con la luz blanca, todas las frecuencias entranal modelo equivalentemente. Usualmente se tiene que asumir que los procesosde ruido blanco tienen media igual a cero y varianza σ2
e .
Teorema 36 Sea Yi una serie de tiempo estacionaria con función de auto-
covarianza γk =1
n
n∑k=t
Yt pruebe que:
V ar(Y ) =γ0
n+
2
n
n−1∑k=1
(1 +
k
n
)γk
=1
n
n−1∑k=−n+1
(1− k
n
)γk

16 CAPÍTULO 2. CONCEPTOS FUNDAMENTALES

Capítulo 3
Tendencias
En una serie de tiempo general, la función de la media es una función ar-bitraria respecto al tiempo. En una serie de tiempo estacional, la función dela media debe ser constante a través del tiempo Cryer and Chan [2008]. Fre-cuentemente se debe establecer un punto medio entre las dos series de tiempo yconsiderar funciones de la media relativamente simples (no constantes) a travésdel tiempo. Esas tendencias serán tratadas en el siguiente capítulo.
3.1. Tendencias Determinísticas contra Tenden-
cias Estocásticas
Las tendencias en una serie de tiempo pueden ser subjetivas, dependiendodel punto de vista del investigador. De hecho, en diferentes simulaciones de lamisma variable aleatoria las tendencias pueden variar; a este tipo de tendenciasse les denomina tendencias estocásticas, teniendo en cuenta que esta deniciónno ha sido generalmente aceptada.
Por otro lado, para una serie de tiempo con parámetro cíclico determinísticose dice que la tendencia es determinística y su modelamiento se estudiará eneste capítulo.
3.2. Estimación de la Media Constante
Como primera medida se considerará la situación donde se asume una fun-ción de la media constante, entonces el modelo estaría dado por:
Yt = µ+Xt (3.1)
Donde E (Xt) = 0 para todo t. Se desea estimar µ con base en la serie detiempo observada Y1, Y2, ..., Yn . La estimación más común de µ es la media
17

18 CAPÍTULO 3. TENDENCIAS
muestral denida como
Y =1
n
n∑t=1
Yt (3.2)
Bajo el supuesto de la ecuación 3.1, se puede concluir que E(Y)
= µ; por lotanto Y es una estimación imparcial de µ. Para obtener la precisión de Y comoestimador de µ, es necesario hacer supuestos respecto a Xt.
Supóngase que Yt es una serie de tiempo estacionaria con función de au-tocorrelación ρk. Entonces por el teorema 20 se tiene Cryer and Chan [2008]
V ar(Y ) =γ0
n
[n−1∑
k=−n+1
(1 +|k|n
)ρk
](3.3)
=γ0
n
[1 + 2
n−1∑k=−n+1
(1− k
n
)ρk
]
Si la serie de tiempo Xt de la ecuación 3.1 es simplemente ruido blanco,
entonces, ρk = 0 para k > 0 y V ar(Y)se reduce simplemente a
γ0
n.
En el modelo estacionario de promedios móviles Yt =et − et−1
2, se encuentra
que ρ1 = −0,4 y ρk = 0 para k > 1 en este caso se obtiene
V ar(Y ) =γ0
n
[1 + 2
(1− 1
n
)(−0,4)
]=γ0
n
[1− 0,8
(n− 1
n
)]
Para valores de n, usualmente mayores que 50 el factor,
(n− 1
n
)es cercano
a 1, entonces
V ar(Y ) ≈ 0,2γ0
n
De esto se puede concluir que la correlación negativa en el rezago k, hamejorado la estimación de la media, comparada con la estimación obtenida enel modelo de ruido blanco (muestra aleatoria). Debido a que la serie tiende aoscilar alrededor de la media, la media muestral obtenida es más precisa.
Por otra parte, si ρk ≥ 0 para todo k ≥ 1, se puede observar, gracias a la
ecuación 3.3, que V ar(Y ) >γ0
n. En estos casos la correlación positiva hace que
la estimación de la media se haga más complicada que con los modelos de ruidoblanco. En general la ecuación 3.3 debe ser usada para evaluar el efecto en laserie de tiempo.
Para muchos procesos estacionarios, la función de autocorrelación, decrecelo sucientemente rápido, con rezagos crecientes tal que
∞∑k=0
|ρk| <∞ (3.4)

3.3. MÉTODOS DE REGRESIÓN 19
Teniendo en cuenta el supuesto de la ecuación 3.4, y teniendo una valorde n signicativamente alto, la ecuación 3.3 puede aproximarse de la siguientemanera Cryer and Chan [2008]
V ar(Y ) ≈ γ0
n
[ ∞∑k=−∞
ρk Para n sucientemente grande
](3.5)
Para procesos no estacionarios (pero con media constante), la precisión dela media muestral como una estimación de µ puede ser sorprendentemente di-ferente. Por ejemplo, supóngase que la variable Xt en la ecuación 3.1 es unproceso de caminata aleatoria luego utilizando la ecuación 2.8.
V ar(Y ) =1
n2V ar
[n∑i=1
Yi
]
=1
n2V ar
n∑i=j
i∑j=1
ej
=
1
n2V ar (e1 + 2e2 + 3e3 + · · ·nen)
=σ2e
n2
n∑K=1
k2
luego
V ar(Y ) = σ2e (2n+ 1)
(n+ 1)
6n
Se concluye que este es un caso especial, la varianza de la estimación dela media aumenta cuando el tamaño de la muestra también lo hace, lo queimplica que se necesita considerar otro método de estimación para series noestacionarias.
3.3. Métodos de Regresión
Los métodos estadísticos clásicos de regresión brindan una herramienta desuma importancia para estimar los parámetros de los modelos con tendenciamedia variable, en el desarrollo de este apartado, se consideraran los más útiles:lineal, cuadrática, medias estacionales, y tendencias del coseno.
3.3.1. Tendencias Lineales y Cuadráticas
Considérese la tendencia determinística expresada como
µt = β0 + β1t (3.6)

20 CAPÍTULO 3. TENDENCIAS
Donde la pendiente y el intercepto β1 y β0 respectivamente, son paráme-tros desconocidos. El método clásico de mínimos cuadrados consiste en elegirestimaciones de β1 y β0 tales que minimicen
Q (β0, β1) =
n∑t=1
[Yt − (β0 + β1t)]2
De esta forma, después de derivar parcialmente e igualar a cero, se obtiene:
β1 =
n∑t=1
(Yt − Y
)(t− t)
n∑t=1
(t− t)2(3.7)
β0 = Y − β1t
donde t =(n+ 1)
2es el promedio de 1, 2, ...n. Cryer and Chan [2008]
3.3.2. Tendencias cíclicas.
Se considerarán, a continuación, el modelamiento de tendencias estaciona-les, por ejemplo, la temperatura mensual. Se asumirá que la serie de tiempoobservada se puede escribir como
Yt = µt +Xt
Donde E (Xt) = 0 Para todo t.El supuesto más general para µt con datos estacionales mensuales, es que
existen 12 constantes o parámetros β1, β2, ..., β12, y teniendo el promedio espe-rado de temperatura para cada uno de los meses se puede escribir
µt =
β1 Para t = 1, 13, 25, ...β2 Para t = 2, 14, 26, ......
β12, Para t = 12, 24, 36, ...
(3.8)
Cryer and Chan [2008]
3.3.3. Tendencias del Coseno
Las medias estacionales del modelo para datos mensuales consiste 12 pará-metros independientes, y no tiene en cuenta la forma de la tendencia estacional.Por ejemplo, el hecho de que las medias de Marzo y Abril son similares no sereejan elmente en el modelo. En algunos casos, las tendencias estacionalespueden ser modeladas con cosenos , que proporcionan una curva suave entre unperiodo y otro, conservando la estacionariedad.

3.4. CONFIABILIDAD Y EFICIENCIA DE LAS ESTIMACIONES DE LA REGRESIÓN21
Considérese la curva con la ecuación:
µt = β cos (2πft+ Φ) (3.9)
Se le llama a β > 0 la amplitud, a f la frecuencia, y Φ la fase de la curva.Debido a que t varía, la curva oscila entre un máximo de β y un minimo de
−β. Debido a que la curva se repite a sí misma cada1
funidades de tiempo.
1
fes conocido como el periodo de la curva. Asimismo Φ es útil para establecer elorigen arbitrario en el eje del tiempo.
La ecuación 3.9 no es muy conveniente para efectos de las estimaciones, yaque, los parámetros β y Φ, no intereren en la fórmula de una manera lineal.Afortunadamente, usando una identidad trigonométrica la ecuación 3.9 puedeser escrita de la siguiente manera:
β cos (2πft+ Φ) = β1 cos (2πft) + β2sen (2πft)
Donde
β =√β2
1 + β22 , Φ = a tan
(−β2
β1
)y
β1 = β cos (Φ) , β2 = βsen (Φ)
Para estimar los parámetros β1 y β2 con técnicas de regresión, simplementese usa cos (2πft) y sen (2πft) como variables regresoras. El modelo más sencillo,teniendo en cuenta la tendencia, es el siguiente
µt = β0 + β1 cos (2πft) + β2sen (2πft) (3.10)
En este caso la constante, β0, puede ser pensada como un coseno con fre-cuencia igual a cero. Cryer and Chan [2008]
3.4. Conabilidad y Eciencia de las Estimacio-
nes de la Regresión
Asúmase que la serie de tiempo es representada por Yt = µt +Xt, donde µtes una tendencia determinística y Xt es un proceso estacionario de media cerocon funciones de autocovarianza y autocorrelación γk y ρk respectivamente.
Para medias estacionales, las estimaciones por mínimos cuadrados de lasmedias estacionales son, simplemente promedios estacionales, entonces, si setiene N años de datos mensuales se puede escribir la estimación para la mediaen la temporada j como
βj =1
N
N−1∑i=0
Yi + 12i

22 CAPÍTULO 3. TENDENCIAS
Ya que βj es un promedio como Y excepto que solo usa cada doceava obser-vación. La ecuación 3.3 puede ser modicada para obtener la varianza de βj . Sereemplaza n por N y ρk por ρ12k para obtener
V ar(βj
)=γ0
N
[1 + 2
N−1∑k=0
(1− k
n
)ρ12k
]Para j = 1, 2, ..., 12 (3.11)
Se pude notar que si Xt es un proceso de ruido blanco, V ar(βj
)=
γ0N .Además si varios ρk son diferentes de cero pero ρ12k = 0 entonces V ar
(βj
)=
γ0N . En cualquier caso, solo las correlaciones estacionales ρ12,ρ24, ... serán utili-zadas en la ecuación 3.11.
Para las tendencias del coseno expresadas en la ecuación 3.10. Para cualquierfrecuencia de la forma f = m
n donde m es un entero que satisface 1 ≤ m ≤ n2 ,
se pueden usar expresiones explicitas para los valores de las estimaciones β1 yβ2.
β1 =2
n
n∑t=1
[cos
(2πmt
n
)Yt
], β2 =
2
n
n∑t=1
[sen
(2πmt
n
)Yt
](3.12)
Ya que las anteriores ecuaciones son ecuaciones lineales de Yt , se evaluaránsus varianzas usando la ecuación 2.6, y teniendo en cuenta que Cryer and Chan[2008]
n∑t=1
=
[cos
(2πmt
n
)]2
=n
2
se obtiene
V ar(β1
)=
2γ0
n
[1 +
4
n
n∑s=2
s−1∑t=1
cos
(2πmt
n
)cos
(2πms
n
)ρs−t
]y
V ar(β1
)=
2γ0
n
[1 +
4
n
n∑s=2
s−1∑t=1
sen
(2πmt
n
)sen
(2πms
n
)ρs−t
]
Si Xt es un proceso de ruido blanco, se obtiene implemente 2γ0n . Si ρ1 6= 0,
ρk = 0 para k > 1 y mn = 1
12 la varianza se reduce a Cryer and Chan [2008]
V ar(β1
)=
2γ0
n
[1 +
4ρ1
n
n−1∑t=1
cos
(πt
6
)cos
(πt+ 1
6
)ρs−t
](3.13)
Para las tendencias lineales es más conveniente utilizar una formula alterna-tiva a la ecuación 3.7 para calcular β1. Según Cryer and Chan [2008] la estima-ción de la pendiente por medio de mínimos cuadrados puede ser escrita de la

3.5. ANÁLISIS DE RESIDUALES 23
siguiente manera
β1 =
n∑t=1
(t− t)Yt
n∑t=1
(t− t)2
(3.14)
Ya que la estimación, β1, es una combinación lineal de los valores de Y, yusando
n∑t=1
(t− t)2=n(n2 − 1
)12
la varianza se puede escribir como
V ar(β1
)=
12γ0
n (n2 − 1)
n∑s=2
s−1∑t=1
(t− t) (s− t) ρs−t (3.15)
3.5. Análisis de Residuales
Como ya se ha descrito anteriormente, la componente estocástica Xt puedeser estimada mediante el residual
Xt = Yt − µt
Se conoce a Xt como el residual correspondiente a la t − esima observa-ción Brillinger [2001]. Si el modelo de la tendencia es razonablemente correcto,entonces los residuales deberían comportarse como un componente estocásticoy se pueden establecer varios supuestos. Si el componente estocástico es ruidoblanco, entonces los residuales deberían comportarse como variables aleatoriasindependientes normalmente distribuidas con media cero y desviación estándars. Debido a que al ajuste mediante mínimos cuadrados de cualquier tenden-cia con términos constantes producen residuales con media cero, es importanteestandarizar los residuales como X t
s.Teniendo los residuales estandarizados, el
paso a seguir es comparar los residuales con la tendencia correspondiente delvalor ajustado y por medio de software especializado vericar las característicasdel proceso estocástico (normalidad, independencia, etc.) (Véase Yate [2011]).
3.5.1. Función de Autocorrelación Muestral
Una importante herramienta con la cual se puede examinar la dependenciaes la función de autocorrelación muestral. Considérese una secuencia de da-tos Y1, Y2, . . . , Yn (bien sea residuales, datos originales o datos transformados).Asumiendo tentativamente estacionariedad, se desea estimar la función de auto-correlación ρk para una variedad de rezagos k = 1, 2, . . . . La forma más evidentede realizar dicho cálculo, es calcular la función de correlación muestral entre ca-da par de datos (Y1, Y1+k) , (Y2, Y2+k) , . . . , (Yn−k, Yn) . Sin embargo, teniendo

24 CAPÍTULO 3. TENDENCIAS
en cuenta el supuesto de la estacionariedad, la cual implica una media y unavarianza común para la serie de tiempo. La función de autocorrelación muestralde la siguiente manera Cryer and Chan [2008]
Denición 37 La función de autocorrelación muestral, rk en el rezago k es
rk =
n∑t=k+1
(Yt − Y
) (Yt−k − Y
)n∑t=1
(Yt − Y
)2 (3.16)

Capítulo 4
Modelos para Series deTiempo Estacionarias
En el siguiente capítulo se discutirán los conceptos básicos de una ampliagama de modelos de series de tiempo paramétricas conocidas como modelosautorregresivos de promedios móviles o ARMA, debido a sus siglas en inglés.Cabe notar que este tipo de modelos tiene una gran importancia en los procesosde la vida cotidiana, en varios campos del conocimiento.
4.1. Procesos Generales Lineales
Hasta el momento, siempre se ha considerado a Yt cómo la serie de tiempoobservada. A partir de este capítulo, también se denotará a et como un ruidoblanco no observado, es decir, una secuencia de variables aleatorias, idéntica-mente distribuidas con media cero. También, en muchos casos, el supuesto deindependencia puede ser sustituido por el supuesto (más débil) que et, es unasecuencia de variables aleatorias no correlacionadas.
Denición 38 Un proceso general lineal Yt, es aquel que puede ser represen-tado como una combinación lineal ponderada, de los términos del pasado y delpresente de un proceso de ruido blanco de la siguiente manera.
Yt = et + ψ1et−1 + ψ2et−2 + · · · (4.1)
Cryer and Chan [2008]
Si la expresión de la derecha es ciertamente una serie innita, deben esta-blecerce condiciones sobre los pesos ψ, con el n de que dicha expresión tengasentido, matemáticamente hablando. Es suciente asumir que:
∞∑i=1
ψ2i <∞ (4.2)
25

26CAPÍTULO 4. MODELOS PARA SERIES DE TIEMPO ESTACIONARIAS
También debe notarse que dado que et es un proceso de ruido blanco noobservable, no se pierde la generalidad de la ecuación 4.2; si se asume que elcoeciente de et es 1; efectivamente ψ0 = 1.
Un ejemplo de suma importancia en el desarrollo del texto, es la caso en elcual los ψ forman una secuencia exponencialmente decreciente
ψj = φj
Donde −1 ≤ φ ≤ 1, entonces
Yt = et + φet−1 + φ2et−2 + · · ·
Para este ejemplo
E (Yt) = E(et + φet−1 + φ2et−2 + · · ·
)= 0
es decir que Yt tiene una media constante igual a cero. También
V ar (Yt) = V ar(et + φet−1 + φ2et−2 + · · ·
)= V ar (et) + φ2V ar (et−1) + φ4V ar (et−2) + · · ·= σ2
e
(1 + φ2 + φ4 + · · ·
)=
σ2e
1− φ2(Sumando la serie geométrica)
Además
Cov (Yt, Yt−1) = Cov(et + φet−1 + φ2et−2 + · · · , et−1 + φet−2 + φ2et−3 + · · ·
)= Cov (φet−1, et−1) + Cov
(φ2et−2, φet−2
)+ · · ·
= φσ2e + φ3σ2
e + φ5σ2e + · · ·
= φσ2e
(1 + φ2 + φ4 + · · ·
)=
φσ2e
1− φ2(Sumando la serie geométrica)
Entonces
Corr (Yt, Yt−1) =
[φσ2
e
1− φ2
][
σ2e
1− φ2
] = φ
De manera análoga, se puede calcular
Cov (Yt, Yt−k) =φkσ2
e
1− φ2
por lo tantoCorr (Yt, Yt−k) = φk (4.3)

4.2. PROCESOS DE PROMEDIOS MÓVILES 27
Es importante señalar que el proceso es estacionario, ya que la autocovarian-za depende solamente del rezago de tiempo y no del tiempo absoluto. Para unproceso general lineal
Yt = et + ψ1et−1 + ψ2et−2 + · · ·
se sigue un procedimiento análogo al anteriormente realizado para obtener
E (Yt) = 0 γk = Cov (Yt, Yt−k) = σ2e
∞∑i=0
ψiψi+k k ≥ 0 (4.4)
con ψ0 = 1. Un proceso con media, diferente de cero, µ puede ser obtenidoañadiendo el término µ a la parte derecha de la ecuación 4.1. Debido a que lamedia no afecta las propiedades de la covarianza, se sumirá que la media es cero,hasta que se ajusten modelos a una serie de datos
4.2. Procesos de Promedios Móviles
En el caso, donde solo existe un número nito de pesos ψ diferentes de cero,se tiene lo que se conoce como un proceso de promedios móviles
Denición 39 Una proceso Yt se dice que es promedios móviles cuando existeun número nito de pesos θ, y tiene la siguiente forma:
Yt = et − θ1et−1 − θ2et−2 − · · · − θqet−q (4.5)
La ecuación 4.5 se conoce como una serie de promedios móviles de orden qy se abrevia con las siglas MA(q). Box and Jenkins [1976]
El término Promedios Móviles se basa en el hecho que Yt se obtiene aplican-do los pesos 1,−θ1,−θ2, · · · ,−θq a las variables et, et−1, et−2, · · · , et−q y luegose mueven los pesos y se aplican a las variables et + 1, et, et−1, · · · , et−q+1 conn de obtener Yt+1.
4.2.1. Procesos de Promedios Móviles de Primer Orden
A continuación se considerará, el más simple, de los modelos, sin dejar deser importante. El proceso de promedios móviles de orden 1, es decir, MA(1).Según la ecuación 4.5 el modelos es de la forma:
Yt = et − θet−1
Es importante aclarar que para los modelos de primer orden θ1 se suele notarsimplemente como θ.
Claramente E (Y1) = 0 y V ar (Yt) = σ2e
(1 + θ2
), Además
Cov (Yt, Yt−1) = Cov (et − θet−1, θet−1 − θet−2)
= Cov (−θet−1, et−1) = −θσ2e

28CAPÍTULO 4. MODELOS PARA SERIES DE TIEMPO ESTACIONARIAS
y
Cov (Yt, Yt−2) = Cov (et − θet−1, θet−2 − θet−3)
= 0
Debido a que no existen variables e comunes entre Yt y Yt−2, Cov (Yt, Yt−k) =0 siempre y cuando k ≥ 2, es decir que el proceso no tiene correlación pararezagos mayores a 1.
En resumen, para un modelo MA (1) Y = et − θet−1
E (Yt) = 0 (4.6)
γ0 = V ar (Yt) = σ2e
(1 + θ2
)γ1 = −θσ2
e
ρ1 =−θ
(1 + θ2)
γk = ρk = 0 Para k ≥ 2
4.2.2. Procesos de Promedios Móviles de Segundo Orden
Según la ecuación 4.5 una serie de tiempo de promedios móviles de ordendos es de la forma:
Yt = et − θ1et−1 − θ2et−2
En este Caso
γ0 = V ar (Yt) = V ar (et − θ1et−1 − θ2et−2) =(1 + θ2
1 + θ22
)σ2e
γ1 = Cov (Yt, Yt−1) = Cov (et − θ1et−1 − θ2et−2, et−1 − θ1et−2 − θ2et−3)
= Cov (−θ1et−1, et−1) + Cov (−θ1et−2,−θ2et−2)
= [−θ1 + (−θ1) (−θ2)]σ2e
= (−θ1 + θ1θ2)σ2e
y
γ1 = Cov (Yt, Yt−2) = Cov (et − θ1et−1 − θ2et−2, et−2 − θ1et−3 − θ2et−4)
= Cov (−θ2et−2, et−2)
= −θ2σ2e
Entonces, para un modelo MA (2)
ρ1 =−θ1 + θ1θ2
1 + θ21 + θ2
2
ρ2 =−θ2
1 + θ21 + θ2
2
(4.7)
ρk = 0 Para k = 3, 4, ...

4.3. PROCESOS AUTORREGRESIVOS 29
4.2.3. Procesos de Promedios Móviles de Orden q
Para el proceso general MA (q)
Yt = et − θ1et−1 − θ2et−2 − · · · − θqet−q
Siguiendo un proceso análogo al de los procesosMA (1) yMA (2) se obtiene
γ0 = V ar (Yt) =(1 + θ2
1 + θ22 + · · ·+ θ2
q
)σ2e (4.8)
y
ρk =
−θk+1 + θ1θk+1 + θ2θk+2 + · · ·+ θq−kθq
1 + θ21 + θ2
2 + · · ·+ θ2q
Para k = 1, 2, ..., q
0 Para k > q(4.9)
Box and Jenkins [1976]
4.3. Procesos Autorregresivos
Denición 40 Un proceso Autorregresivo Yt de orden p satisface la ecuaciónBox and Jenkins [1976]
Yt = φ1Yt−1 + φ1Yt−2 + · · ·+ φpYt−p + et (4.10)
El valor actual de la serie Yt es una combinación lineal del valor pasadomás reciente de p mas un término de innovación et, el cual incorpora todo loque no es explicado por las variables pasadas en la serie en el tiempo t. Por lotanto, se asume que cada t es independiente a Yt−1, Yt−2, Yt−3, ..
4.3.1. Procesos Autorregresivos de Primer Orden
El proceso autorregresivo de primer orden AR (1) , teniendo en cuenta laecuación 4.10, es de la forma
Yt = φYt−1 + et (4.11)
Como es usual, se asume que la media del proceso, ha sido extraída, luegola media de la serie es cero.
Teniendo en cuenta el procedimiento propuesto por Cryer and Chan [2008]Como primera medida se evaluará la varianza. Tomando la ecuación 4.11 ysacando la varianza a ambos lados de la igualdad se obtiene
γ0 = φ2γ0 + σ2e
Luego
γ0 = φ
(σ2e
1− φ2
)

30CAPÍTULO 4. MODELOS PARA SERIES DE TIEMPO ESTACIONARIAS
De los cual se puede concluir que φ2 < 1 o lo que es equivalente |φ| < 1.Ahora tomando la ecuación 4.11 y multiplicando ambos lados de la igualdadpor Yt−k con k = 1, 2, ..., y tomando el valor esperado se obtiene:
E (Yt−kYt) = φ2E (Yt−kYt−1) + E (etYt−k)
oγk = φγk−1 + E (etYt−k) = 0
Debido a que la serie se ha supuesto estacionaria con media cero, y teniendoen cuenta que et es independiente de Yt−k se obtiene:
E (etYt−k) = E (et)E (Yt−k) = 0
Entoncesγk = φγk−1
Sustituyendo k = 1 se obtiene γ1 = φγ0 es decir
γ1 =σ2e
1− φ2
Sustituyendo k = 2 se obtiene
γ2 =φ2σ2
e
1− φ2
Luego se puede concluir que en general
γk = φkσ2e
1− φ2
Por consiguiente
ρk =γkγ0
= φk Para k = 1, 2, 3, ...
Como |φ| < 1, la magnitud de la función de correlación decrece exponencial-mente según aumenta el número de rezagos k
4.3.1.1. Versión General Lineal de un Modelo AR (1)
La denición recursiva del modelo AR (1) dada en la ecuación 4.11 es de granutilidad para la interpretación del modelo. Sin embargo, para otros propósitos,es conveniente expresar el modelo AR (1) como un proceso general lineal comoen la ecuación 4.1. La denición recursiva es válida para todo t. Si se usa laecuación reemplazando t por t− 1, se tiene Yt−1 = φYt−2 + et−1. Sustituyendoen la ecuación general se obtiene
Yt = φ (φYt−2 + et−1) + et
= et + φet−1 + φ2Yt−2

4.3. PROCESOS AUTORREGRESIVOS 31
Si se repite el proceso hacia el pasado, k − 1 veces, se obtiene
Yt = et + φet−1 + φ2et−2 + +φk−1et−k+1 + φkYt−k (4.12)
Asumiendo que |φ| < 1, y permitiendo que k crezca, se obtiene la represen-tación innita:
Yt = et + φet−1 + φ2et−2 + φ3et−3 + · · · (4.13)
Box and Jenkins [1976]
4.3.1.2. Estacionariedad de un Proceso AR (1)
Sujeto a las restricciones que et es independiente a Yt−1, Yt−2, Yt−3, .. y queσ2e > 0, la solución de la recursividad del modelo AR (1)
Yt = φYt−1 + et
es estacional si y solo si |φ| < 1. Este requisito generalmente se conoce comola Condición de estacionariedad (Box and Jenkins [1976] p. 54)
4.3.2. Procesos Autorregresivos de Segundo Orden
Considérese la serie que satisface la siguiente ecuación
Yt = φ1Yt−1 + φ2Yt−2 + et (4.14)
Donde, como es usual, se asume que et es independiente de Yt−1, Yt−2, Yt−3, ... Paratener en cuenta la estacionariedad se introduce el Polinomio CaracterísticoAR
φ (x) = 1− φ1x− φ2x2
Y su respectiva Ecuación Característica AR
1− φ1x− φ2x2 = 0
Teniendo en cuenta que una ecuación cuadrática tiene dos raíces, posible-mente complejas.
4.3.2.1. Estacionariedad de un Proceso AR (2)
Sujeto a la condición que et es independiente de Yt−1, Yt−2, Yt−3, ...Una so-lución estacionaria a la ecuación 4.14, existe, si y solo si las raíces de la ecuacióncaracterística AR, son mayores que 1 en valor absoluto, o eventualmente se di-ce que las raíces están en el exterior del circulo unitario en el plano complejo(Box, Jenkins, and Reinsel, 1994,p. 54). Este concepto se generaliza a modelosde orden p sin cambio alguno. Lo que siguiere el siguiente teorema:

32CAPÍTULO 4. MODELOS PARA SERIES DE TIEMPO ESTACIONARIAS
Teorema 41 Cryer and Chan [2008] En el caso del modelo de segundo ordenAR(2) , las raíces de la ecuación característica son de la forma
φ1 ±√φ2
1 − 4φ2
−2φ2
Un modelo AR (2) es estacionario si y solo si se satisfacen las siguientes con-diciones
φ1 + φ2 < 1 φ2 − φ1 < 1 |φ2| < 1
Demostración Sean G1 y G2 los números recíprocos de las raíces de laecuación característica AR, entonces
G1 =2φ2
−φ1 −√φ2
1 + 4φ2
Racionalizando
G1 =2φ2
(−φ1 +
√φ2
1 + 4φ2
)−φ2
1 − (φ21 + 4φ2)
G1 =−φ1 −
√φ2
1 + 4φ2
2Del mismo modo
G2 =φ1 +
√φ2
1 + 4φ2
2Ahora, teniendo en cuenta el discriminante de una función cuadrática se
puede concluir que
La raíz es real si y solo si φ21 + 4φ2 ≥ 0
|Gi| < 1 para i = 1 y 2 si y solo si
−1 <φ1 −
√φ2
1 + 4φ2
2<φ1 +
√φ2
1 + 4φ2
2< 1
o2 < φ1 −
√φ2
1 + 4φ2 < φ1 +√φ2
1 + 4φ2 < 2
Tomando la primera parte de la desigualdad.2 < φ1 −
√φ2
1 + 4φ2 si y solo si√φ2
1 + 4φ2 < φ1 + 2 si y solo siφ2
1 + 4φ2 < φ21 + 4φ1 + 4 si y solo si
φ2 < φ1 + 1 oφ2 − φ1 < 1Análogamente la segunda desigualdad φ1 +
√φ2
1 + 4φ2 < 2 nos lleva aφ2 + φ1 < 1
La raíz es compleja si y solo si φ21 + 4φ2 < 0
Donde G1 y G2 son complejas conjugadas y|G1| = |G2| < 1
|G1|2 =φ2
1 +(−φ2
1 − 4φ2
)4
= −φ2

4.3. PROCESOS AUTORREGRESIVOS 33
φ2 > −1Eso junto con la desigualdad φ2
1 + 4φ2 < 0 nos lleva a|φ2| < 1 Cryer and Chan [2008]
4.3.2.2. La Función de Autocorrelación del Proceso AR (2)
Para calcular la función de autocorrelación para los modelos AR (2) se tomala ecuación 4.14 se multiplican ambos lados por Yt−k, y se toman los valoresesperados. Asumiendo estacionariedad, medias iguales a cero y la independenciade et respecto a Yt−1, Yt−2, Yt−3, .... Lo que conduce a
γk = φ1γk + φ2γk−2 Para k = 1, 2, 3, ... (4.15)
o dividiendo por γ0
ρk = φ1ρk−1 + φ2ρk−2 Para k = 1, 2, 3, ... (4.16)
Las ecuaciones 4.15 y 4.16 son conocidas como las ecuaciones Yule-Walker,especialmente el conjunto de dos ecuaciones obtenidas cuando k = 1 y k = 2.Haciendo k = 1 usando a ρ0 = 1 y ρ−1 = ρ1, se obtiene ρ1 = φ1 + φ2ρ1, luego
ρ1 =φ1
1− φ2
usando los valores conocidos de ρ1, se usa la ecuación 4.16 con k = 2 paraobtener
ρ2 = φ2ρ2 + φ2ρ2
=φ2 (1− φ2) + φ2
1
1− φ2
Y de una manera análoga y sucesiva se podría calcular ρk
4.3.3. Varianza del Modelo AR (2)
La varianza γ0 puede ser expresada en términos de los parámetros del modeloφ1 , φ2 y σ2
e de la siguiente manera: Tomando la ecuación 4.14 y evaluando lavarianza a ambos lados de la igualdad se obtiene
γ0 =(φ2
1 + φ22
)γ0 + 2φ1φ2γ1 + σ2
e (4.17)
Evaluando la ecuación 4.15 con k = 1 se obtiene una ecuación lineal para γ0
y γ1
γ1 = φ1γ0 + φ2γ1
la cual se puede resolver simultaneamente con la ecuación 4.17 para obtener
γ0 =(1− φ2)σ2
e
(1− φ2) (1− φ21 − φ2
2)− 2φ2φ21
=
(1− φ2
1 + φ2
)σ2e
(1− φ2)2 − φ2
1
(4.18)

34CAPÍTULO 4. MODELOS PARA SERIES DE TIEMPO ESTACIONARIAS
4.3.4. Proceso Autorregresivo General
Considere el modelo autorregresivo de orden p
Yt = φ1Yt−1 + φ1Yt−2 + · · ·+ φpYt−p + et (4.19)
Con su polinomio característico AR
φ (x) = 1− φ1x− φ2x2 − · · · − φpxp (4.20)
Y su respectiva ecuación característica
1− φ1x− φ2x2 − · · · − φpxp = 0 (4.21)
Como se mencionó antes, asumiendo que et es independiente de Yt−1, Yt−2, Yt−3, ...una solución estacionaria a la ecuación 4.21 existe si y solo si las p raíces de laecuación son mayores que 1 en valor absoluto.
Del mismo modo, asumiendo la estacionariedad y que las medias son igualesa cero, se puede multiplicar la ecuación 4.19 para obtener la siguiente ecuaciónrecursiva.
ρk = φ1ρk−1 + φ2ρk−2 + φ3ρk−3 + · · ·+ φpρk−p Para k ≥ 1 (4.22)
Deniendo k = 1, 2, ... y valores de p en la ecuación , y usando ρ0 = 1 yρ−k = ρk se obtienen las ecuaciones generales de Yule-Walker
ρ1 = φ1 + φ2ρ1 + φ3ρ2 + · · ·+ φpρp−1 (4.23)
ρ2 = φ1ρ1 + φ2 + φ3ρ1 + · · ·+ φpρp−2 (4.24)
...
ρp = φ1ρp−1 + φp−2 + φ3ρp−3 + · · ·+ φp
Además, considerando que
E (etYt) = E [et (φ1Yt−1 + φ2Yt−2 + · · ·+ φpYt−p + et)] = E(e2t
)= σ2
e
se puede multiplicar la ecuación 4.19 por Yt tomar valores esperados y ob-tener
γ0 = φ1γ1 + φ2γ2 + · · ·+ φpγp + σ2e
Que tomando a ρk =γkγ0
puede ser escrita de la siguiente manera Box and
Jenkins [1976]
γ0 =σ2e
1− φ1ρ1 − φ2ρ2 − · · · − φpρp(4.25)
Ecuación que expresa la varianza γ0 en términos de σ2e , φ1, φ2, ..., φp y los
valores conocidos de ρ1, ρ2, ..., ρp.

4.4. MODELOSMIXTOS AUTORREGRESIVOS DE PROMEDIOSMÓVILES35
4.4. Modelos Mixtos Autorregresivos de Prome-
dios Móviles
Si se asume que la serie de tiempo es parcialmente autorregresiva y parcial-mente de promedios móviles se puede obtener lo siguiente.
Denición 42 Una serie Yt se dice que es un proceso mezclado autorregre-sivo de promedios móviles de ordenes p y q, si satisface la siguiente ecuación
Yt = φ1Yt−1 +φ2Yt−2 + · · ·+φpYt−p+et−θ1et−1−θ2et−2−· · ·−θqet−q (4.26)
Con el n de abreviar, se utilizará la notación ARMA (p, q) . Asumiendoque en los modelo mixtos no existen factores comunes en los polinomios, tantoautorregresivos como de promedios móviles. Es claro que si existieran se podríancancelar y en ese caso el orden del modelo disminuiría Box and Jenkins [1976]
4.4.1. El modelo ARMA (1, 1)
Según la ecuación 4.26 el modelo ARMA (1, 1) se puede escribir de la si-guiente manera
Yt = φYt−1 + et − θet−1 (4.27)
Con el n de obtener las ecuaciones de Yule-Walker, primero:
E (et, Yt) = E [et (φYt−1 + et − θet−1)]
= σ2e
y
E (et−1Yt) = E [et−1 (φYt−1 + et − θet−1)]
= φσ2e − θσ2
e
= (φ− θ)σ2e
Si se multiplica la ecuación 4.27 por Yt−k y se calcula el valor esperado seobtiene el siguiente sistema de ecuaciones
γ0 = φγ0 + [1− θ (φ− θ)]σ2e
γ1 = φγ0 − θσ2e (4.28)
γk = φγk−1 Para k ≥ 2
Resolviendo las dos primeras ecuaciones
γ0 =
(1− φθ + θ2
)1 + φ2
σ2e (4.29)
Solucionando la ecuación recursiva
ρk =(1− θφ) (φ− θ)
1− θφ+ θ2φk−1 Para k ≥ 1 (4.30)

36CAPÍTULO 4. MODELOS PARA SERIES DE TIEMPO ESTACIONARIAS
Se puede concluir que la función de autocorrelación decrece a medida quelos rezagos k crecen.
La forma del proceso lineal general del modelo puede ser obtenida de lamisma manera que la obtenida gracias a la ecuación 4.13
Yr = et + (φ− θ)∞∑j=1
φj−1et−j (4.31)
Es decirψj = (φ− θ)φj−1 Para j ≥ 1
Donde la condición de estacionariedad |φ| < 1 se tiene que cumplir.
4.4.2. La Función de Autocorrelación para un ProcesoARMA (p, q) Cryer and Chan [2008]
Para un modelo general ARMA (p, q) , teniendo en cuenta que et es inde-pendiente de Yt−1, Yt−2, Yt−3, . . . , una solución estacionaria a la ecuación 4.26existe si y solo si todas las raíces en valor absoluto de la ecuación característicaAR son mayores que 1.
Si la condición de estacionariedad se satisface, el modelo puede ser escritocomo un proceso general lineal con ψ coecientes determinados gracias a
ψ0 = 1 (4.32)
ψ1 = −θ1 + φ1
ψ2 = −θ2 + φ2 + φ1ψ1
...
ψj = −θj + φpψj−p + φp−1ψj−p+1 + · · ·+ φ1ψj−1
donde, por practicidad se toma ψj = 0 para j < 0 y θj = 0 para j > q.Teniendo en cuenta la condición de estacionariedad, la función de autoco-
rrelación satisface
ρk = φ1ρk−1 + φ2ρk−2 + +φpρk−p Para k > q (4.33)
Además, sea Yt un proceso ARMA (p, q) invertible, teniendo en cuentaque dicho proceso se puede escribir en una forma general lineal de la siguienteforma
Yt =
∞∑j=0
ψjet−j (4.34)
donde los pesos ψ pueden ser obtenidos recursivamente gracias a la ecuación4.32, luego
E (Yt+ket) = E
∞∑j=0
ψjet+k−jet
= ψkσ2e Para k ≥ 0 (4.35)

4.4. MODELOSMIXTOS AUTORREGRESIVOS DE PROMEDIOSMÓVILES37
Entonces la autocovarianza debe satisfacer
γk = E (Yt+kYt) = E
p∑j=1
φjYt+k−j −q∑j=0
θjet+k−j
Yt
(4.36)
=
p∑j=1
φjγk−j − σ2e
q∑j=0
θψj−k
Donde θ0 = 1 y la ultima suma se cancela si k > q. Si se establece k =0, 1, , p y γ−k = γk se puede concluir que existen p + 1 ecuaciones lineales enγ0, γ1, . . . , γp.
γ0 = φ1γ1 + φ2γ2 + · · ·+ φpγp − σ2e (θ0 + θ1ψ1 + · · ·+ θ1ψ1)
γ1 = φ1γ0 + φ2γ1 + · · ·+ φpγp−1 − σ2e (θ1 + θ2ψ1 + · · ·+ θqψq−1)
...γp = φ1γp−1 + φ2γp−2 + · · ·+ φpγ0 − σ2
e (θp + θp+1ψ1 + · · ·+ θqψq−p)
(4.37)
donde θj = 0 si j > q.Para un conjunto dado de parámetros σ2
e , φ y θ (y por ende ψ) se puedensolucionar las ecuaciones con el n de obtener γ0, γ1, . . . , γp. Los valores de γkpara k > p pueden ser evaluados en la ecuación recursiva 4.33. Finalmente ρkes obtenido por medio de la ecuación.
ρk =γkγ0
4.4.3. Invertibilidad
Anteriormente se ha expuesto que para un proceso MA (1) se obtiene exac-tamente la misma función de correlación si θ es reemplazado por 1
θ . La faltade unicidad de los modelos MA, dada su función de autocorrelación, debe sertenida en cuenta antes de intentar inferir los valores de los parámetros con baseen la serie de tiempo observada.
Un proceso autorregresivo puede ser expresado como un proceso lineal ge-neral por medio de los coecientes ψ, es decir que un proceso AR puede serpensado como un proceso de promedios móviles MA de orden innito.
Considérese un modelo MA (1)
Yt = et − θet−1 (4.38)
Reescribiendo la ecuación 4.38 de la forma et = Yt + θet−1, reemplazando tpor t− 1 y sustituyendo por et−1 se obtiene
et = Yt + θ (Yt−1 + θet−2)
= Yt + θYt−1 + θ2et−2

38CAPÍTULO 4. MODELOS PARA SERIES DE TIEMPO ESTACIONARIAS
Si |θ| < 1, se puede continuar la anterior sustitución innitamente con el nde obtener la siguiente ecuación
et = Yt + θYt−1 + θ2Yt−2 + · · ·
oYt =
(−θYt−1 − θ2Yt−2 − θ3Yt−3 − · · ·
)+ et (4.39)
Si |θ| < 1, se puede ver que el modelo MA (1) puede ser invertido en unmodelo autorregresivo de orden innito. Es decir, se dice que el modelo MA (1)es invertible si y solo si |θ| < 1.
Para un proceso general MA (q) o ARMA (p, q) , se dene el polinomio ca-racterístico como
θ (x) = 1− θ1x− θ2x2 − θ3x
3 − · · · − θqxq (4.40)
y la correspondiente ecuación característica MA
1− θ1x− θ2x2 − θ3x
3 − · · · − θqxq = 0 (4.41)
Entonces el modelo MA (q) es invertible Box and Jenkins [1976]; es decir,existen coecientes πj tales que
Yt = π1Yt−1 + π2Yt−2 + π3Yt−3 + · · ·+ et (4.42)
Si y solo si las raíces de la ecuación característica son mayores, en valorabsoluto, a 1.

Capítulo 5
Modelos para Series deTiempo No Estacionarias
En el siguiente capítulo se introducirá el concepto de diferenciación u opera-dor diferencia de orden p, con el n de inducir la estacionariedad de una serie detiempo no estacionaria. Teniendo este concepto, es posible llegar al importanteconcepto de los modelos integrados autorregresivos de promedios móviles.
Además, se explorarán otro tipo de transformaciones que tienen el mismoobjetivo, tales transformaciones son los cambios de porcentaje, logaritmos y deforma más general las transformaciones de potencia o transformaciones Box-Cox.
5.1. Estacionariedad a través de los Operadores
Diferencia
Considérese el modelo AR (1)
Yt = φYt−1 + et (5.1)
Se ha dicho en los capítulos anteriores, que si et no esta correlacionada conYt−1, Yt−2, ..., se tiene que tener |φ| < 1. Sin embargo surge la pregunta: ¾Quépodría pasar si dicha condición no se cumple?.
Considérese la siguiente ecuación
Yt = 3Yt−1 + et (5.2)
Iterando respecto al pasado, como ya se ha hecho en capítulos anteriores, seobtiene:
Yt = et + 3et−1 + 32et−2 + · · ·+ 3t−1ei + 3tY0 (5.3)
Se puede observar que la inuencia de los valores distantes del pasado de Yty et, no se anula, de hecho, los pesos aplicados a Y0 y e1 crecen de una maneraexponencial.
39

40CAPÍTULO 5. MODELOS PARA SERIES DE TIEMPONO ESTACIONARIAS
Este fenómeno también se reeja en las funciones de varianza y covarianza,como se muestra a continuación
V ar (Yt) =1
8
(9t − 1
)σ2e (5.4)
y
Cov (Yt, Yt−k) =3k
8
(9t−k − 1
)σ2e (5.5)
De la misma manera
Corr (Yt, Yt−k) = 3k(
9t−k − 1
9t − 1
)≈ 1
Cuando t tiende a innito, y cuando los valores de k son moderadosEste mismo fenómeno de crecimiento exponencial o Comportamiento Ex-
plosivo (cite: Cryer) ocurrirá para cualquier φ tal que |φ| > 1.Otro tipo de modelos no estacionarios son los que cumplen con la condición
|φ| = 1. Un modelo de dichas características es de la forma:
Yt = Yt−1 + et (5.6)
Dicha ecuación se puede escribir de una forma alternativa:
∇Yt = et (5.7)
Donde ∇Yt = Yt − Yt−1 se conoce como la primera diferencia de Yt, uoperador diferencia de primer orden Guerrero [1998].
De esta denición se pueden hacer supuestos acerca de los modelos cuyosoperadores diferencia son modelos estacionarios. Por ejemplo, supóngase
Yt = Mt +Xt (5.8)
DondeMt es una serie cambiante respecto al tiempo. En este casoMt puedeser, bien sea, estocástica, o determinística. Si se supone que Mt es aproximada-mente constante en dos puntos consecutivos de tiempo, se podría estimar Mt sise elige un β0 de tal forma que Cryer and Chan [2008]
1∑j=0
(Yt−j − β0,t)2
Se minimice, con lo que se obtiene
Mt =1
2(Yt + Yt−1)
y la serie de tiempo sin tendencia en el tiempo t es:
Yt − Mt = Yt −1
2(Yt + Yt−1) =
1
2(Yt − Yt−1) =
1
2∇Yt

5.1. ESTACIONARIEDADA TRAVÉS DE LOS OPERADORES DIFERENCIA41
Es decir una constante múltiple del operador diferencia ∇Yt.Otro supuesto de gran importancia es queMt en la ecuación 5.8 es un proceso
estocástico, condicionado por un proceso de "caminata aleatoria", suponga porejemplo que:
Yt = Mt + et con Mt = Mt−1 + εt (5.9)
Donde et y εt son series de tiempo de ruido blanco independientes,entonces
∇Yt = ∇Mt +∇et= εt + et − et−1
La cual tendría la función de autocorrelación de un modelo MA (1) con
ρ1 = −
1
2 +(σ2ε
σ2e
) (5.10)
en cualquiera de estas situaciones, se tiene que estudiar el operador diferencia∇Yt como un proceso estacionario.
La suposición que conduce a un hecho bastante importante, es en la que te-niendo en cuenta la ecuación 5.8, y asumiendo, en este caso queMt es de carácterlineal en tres puntos de tiempo consecutivos. En este caso se puede estimar Mt
en el punto de tiempo medio t eligiendo β0,t y β1,t, tales que minimicen
1∑j=−1
(Yt−j − (β0,t + jβ1,t))2
Obteniendo
Mt =1
3(Yt+1 + Yt + Yt−1)
Por consiguiente la serie de tiempo sin tendencia es
Yt − Mt = Yt −(Yt+1 + Yt + Yt−1
3
)= −1
3(Yt+1 − 2Yt + Yt−1)
=
(−1
3
)∇2 (Yt+1)
Una múltiple constante del operador diferencia centrado de segundo ordende Yt. Nótese que se ha aplicado la diferencia dos veces, pero, ambas diferenciasen el rezago 1. del mismo modo es posible asumir que Cryer and Chan [2008]
Yt = Mt+et, Donde Mt = Mt−1+Wt y Wt = Wt−1+εt (5.11)

42CAPÍTULO 5. MODELOS PARA SERIES DE TIEMPONO ESTACIONARIAS
Con et y εt series de tiempo independientes de ruido blanco. En estecaso la tendencia Mt es aquella cuya "tasa de cambio" ∇Mt, está cambiandocon respecto al tiempo lentamente. Entonces
∇Yt = ∇Mt +∇et = Wt +∇et
y
∇2Yt = ∇Wt +∇2et
= εt + (et − et−1)− (et−1 − et−2)
= εt + et − 2et−1 + et−2
La cual, tiene la función de autocorrelación de un proceso MA (2) . Lo im-portante es el hecho que el operador diferencia de segundo orden de un procesono estacionario Yt es estacionario. Este hecho permite denir los modelosintegrados autorregresivos de promedios móviles.
5.2. Modelos Integrados Autorregresivos de Pro-
medios Móviles
Denición 43 Una serie de tiempo Yt se dice que sigue un modelo integradoautorregresivo de promedios móviles ARIMA si el operador diferencia de or-den d Wt = ∇dYt es un proceso ARMA estacionario. Si Wt es un procesoARMA (p, q) , se dice que Yt es un modelo ARIMA (p, d, q) . Box and Jenkins[1976]
Afortunadamente, para efectos prácticos, se puede tomar d = 1 o la sumo 2.Considérese un proceso ARIMA (p, 1, q) con Wt = Yt − Yt−1 entonces:
Wt = φ1Wt−1+φ2Wt−2+· · ·+φpWt−p+et−θ1et−1−θ2et−2−· · ·−θqet−q (5.12)
Lo que en términos de la serie de tiempo observada equivale a:
Yt − Yt−1 = φ1 (Yt−1 − Yt−2) + φ2 (Yt−2 − Yt−3) + · · ·+ φp (Yt−p − Yt−p−1)
+ et − θ1et−1 − θ2et−2 − · · · − θqet−q (5.13)
Lo cual se puede escribir:
Yt = (1 + φ1)Yt−1 + (φ2 − φ1)Yt−2 + (φ3 − φ2)Yt−3 + · · · (5.14)
+ (φp − φp−1)Yt−p − φpYt−p−1 + et − θ1et−1 − θ2et−2 − · · · − θqet−q
Esta última ecuación se conoce como la forma de la ecuación diferencia delmodelo. Box and Jenkins [1976]
Las representaciones explícitas de la serie de tiempo observada, bien sea,en términos de Wt o en términos del proceso de ruido blanco, son mucho máscomplicados que en los procesos estacionarios. Esto se debe a que los procesos

5.2. MODELOS INTEGRADOS AUTORREGRESIVOS DE PROMEDIOSMÓVILES43
no estacionarios no están en un "equilibrio estadístico", no se puede asumir laserie tiene, por decirlo de alguna manera, un pasado innito. Sin embargo, sepuede asumir que las series comienzan en un t = −m.
Por conveniencia, se tomarán Yt = 0 para t < −m. La ecuación del operadordiferencia Yt − Yt−1 = Wt, se puede solucionar sumando desde t = −m hastat = t para obtener:
Yt =
t∑j=−m
Wj (5.15)
Para el proceso ARIMA (p, 1, q) .
El proceso ARIMA (p, 2, q) puede ser resuelto similarmente, sumando dosveces para obtener la representación
Yt =
t∑j=−m
j∑i=−m
Wi (5.16)
=t+m∑j=0
(j + 1)Wt−j
Aunque estas representaciones tiene usos limitados, pueden ser usados paraobtener las propiedades de la covarianza del modelo ARIMA y también paraexpresar Yt en términos de la serie de ruido blanco et .
Si el proceso contiene términos no autorregresivos, se le llamará un modelointegrado de promedios móviles y se abreviará IMA (d, q) . Por otro lado si laserie no tiene términos de promedios móviles se le denomina ARI (p, d) .
5.2.1. El Modelo IMA (1, 1)
El modelo simple IMA (1, 1) , satisfactoriamente, representa numerosas se-ries de tiempo, especícamente, aquellas que surgen en problemas económicosGuerrero [1998]. En la forma de la ecuación diferencia el modelo tiene la forma:
Yt = Yt−1 + et − θet−1 (5.17)
Con el n de escribir Yt explícitamentemente, como una función de valoresdel ruido blanco tanto del futuro como del presente, se usará la ecuación 5.15 yel hecho que Wt = et − θet−1. En este caso, se puede escribir
Yt = et + (1− θ) et−1 + (1− θ) et−2 + · · ·+ (1− θ) e−m − θe−m−1 (5.18)
En contraste a los modelos estacionarios ARMA, los pesos de los términosdel ruido blanco, permanecen, sin importar que se tomen valores del pasado.Debido a que se asumió que −m < 1 y 0 < t, se debe pensar a Yt comouna acumulación igualmente ponderada de un gran número de valores de ruidoblanco.

44CAPÍTULO 5. MODELOS PARA SERIES DE TIEMPONO ESTACIONARIAS
De la ecuación 5.18 se pueden calcular las varianzas y las correlaciones de lasiguiente manera
V ar (Yt) =[1 + θ2 + (1− θ)2
(t+m)]σ2e (5.19)
y
Corr (Yt, Yt−k) =1− θ + θ2 + (1− θ)2
(t+m− k)√V ar (Yt)V ar (Yt−k)
≈√t+m− kt+m
(5.20)
Se puede notar que conforme que t aumenta, V ar (Yt) aumenta. También lacorrelación entre Yt y Yt−k será fuertemente positiva para los rezagos k = 1, 2, ...
5.2.2. El Modelo IMA (2, 2)
Los supuestos de la ecuación 5.11, conduce a un modelo IMA (2, 2) . En laforma de la ecuación diferencia el modelo tiene la forma:
∇2Yt = et − θ1et−1 − θ2et−2
oYt = 2Yt−1 − Yt−2 + et − θ1et−1 − θ2et−2 (5.21)
La representación de la ecuación 5.16 puede ser usada para expresar Yt entérminos de et, et−1, ... de la siguiente forma:
Yt = et +
t+m∑j=1
ψjet−j − [(t+m+ 1) θ1 + (t+m) θ2] e−m−1 (5.22)
− (t+m+ 1) θ2e−m−2
Donde ψ = 1 + θ2 + (1− θ1 − θ2) j para j = 1, 2, 3, .., t+m, donde los pesosψ permanecen y forman una función lineal de j.
5.2.3. El Modelo ARI (1, 1)
El proceso ARI (1, 1) satisface la siguiente ecuación Fuller [1996]
Yt − Yt−1 = φ (Yt−1 − Yt−2) + et (5.23)
oYt = (1 + φ)Yt−1 − φYt−2 + et (5.24)
Donde |φ| < 1Para encontrar los pesos ψ se usará una técnica que se puede generalizar a
cualquier modelo ARIMA,

5.2. MODELOS INTEGRADOS AUTORREGRESIVOS DE PROMEDIOSMÓVILES45
Los pesos ψ pueden ser obtenidos igualando las potencias de x en la identidad(1− φ1x− φ2x
2 − · · · − φpxp)
(1− x)d (
1 + ψ1x+ ψ2x2 + ψ3x
3 + · · ·)(5.25)
=(1− θ1x− θ2x
2 − θ3x3 − · · · − θqxq
)En el caso del modelo ARI (1, 1) la relación se reduce a:
(1− φx) (1− x)(1 + ψ1x+ ψ2x
2 + ψ3x3 + · · ·
)= 1
o [1− (1 + φ)x+ φx2
] (1 + ψ1x+ ψ2x
2 + ψ3x3 + · · ·
)= 1
Igualando las potencias semejantes a ambas partes de la igualdad, se obtiene
− (i+ φ) + ψ = 0
φ− (1 + φ)ψ1 + ψ2 = 0
y en general
ψk = (1 + φ)ψk−1 − φψk−2 Para k ≥ 2 (5.26)
Con ψ0 = 1 y ψ1 = 1 + φ. Esta función recursiva permite calcular tantospesos ψ como sea necesario.
5.2.4. Términos Constantes en modelos ARIMA
Para un modelo ARIMA (p, d, q) ,∇dYt = Wt es un proceso ARMA (p, q) es-tacionario, teniendo en cuenta el supuesto que un modelo estacionario tiene me-dia igual a cero, es decir que se trabajará con desviaciones de las media constan-tes. Una media diferente de cero constante µ, en un modelo ARMA estacionarioWt puede ser acomodado en cualquiera de los dos casos. Se puede asumir queBox and Jenkins [1976]:
Wt−µ = φ1 (Wt−1 − µ) + φ2 (Wt−2 − µ) + · · ·+ φp (Wt−p − µ)
+ et − θ1et−1 − θ2et−2 − · · · − θqet−q
Alternativamente, se puede introducir un término constante θ0 en el modelode la siguiente manera
Wt = θ0 + φ1Wt−1 + φ2Wt−2 + · · ·+ φpWt−p
+ et − θ1et−1 − θ2et−2 − · · · − θqet−q
Tomando los valores esperados en ambas partes de la igualdad
µ = θ0 + (φ1 + φ2 + · · ·+ φn)µ
Entonces
µ =θ0
1− φ1 − φ2 − · · · − φp(5.27)

46CAPÍTULO 5. MODELOS PARA SERIES DE TIEMPONO ESTACIONARIAS
o
θ0 = µ (1− φ1 − φ2 − · · · − φp) (5.28)
A continuación se evaluará el caso de una media diferente de cero.Considere el modelo IMA (1, 1) con un término constante, entonces se tiene
Yt = Yt−1 + θ0 + et − θet−1
o
Wt = θ0 + et − θet−1
Sustituyendo en la ecuación 5.14 de la página 42 se puede concluir que
Yt = et + (1− θ) et−1 + et + (1− θ) et−2 + · · ·+ et + (1− θ) e−m − e−m−1
(5.29)
+ (t+m+ 1) θ0
5.2.5. Otras Transformaciones
Hasta el momento se ha descrito como el operador diferencia, puede ser unaútil transformación para obtener estacionariedad. Sin embargo, la transforma-ción por logaritmo también es muy útil en algunos casos. Frecuentemente sepueden encontrar series de tiempo donde, el incremento de la dispersión pareceestar asociada a altos niveles de la serie, lo que implica mayor dispersión en elnivel Cryer and Chan [2008].
Especícamente suponga que Yt > 0 para todo t y que
E (Yt) = µt y√V ar (Yt) = µtσ (5.30)
Entonces
E [log (Yt)] ≈ log (µt) y V ar [log (Yt)] ≈ σ2 (5.31)
El siguiente resultado se obtiene tomando valores esperados y varianzas aambos lados de la expansión de Taylor
log (Yt) = log (µt) +Yt − µtµt
Es decir, que si la desviación estándar de la serie de tiempo es proporcional alnivel de la serie, la transformación logarítmica producirá una serie con varianzaaproximadamente constante a lo largo del tiempo. Además, si el nivel de la seriecambia exponencialmente, la serie log-transformada tendrá una tendencia lineal,por lo que se utilizará el operador diferencia de primer orden.

5.2. MODELOS INTEGRADOS AUTORREGRESIVOS DE PROMEDIOSMÓVILES47
5.2.5.1. Cambios de Porcentajes y Logaritmos
Supóngase que Yt tiende a tener un porcentaje de cambios relativamenteestable de un periodo de tiempo al siguiente. Especícamente se asume que:
Yt = (1 +Xt)Yt−1
Donde 100Xt es el porcentaje de cambio de Yt−1 a Yt entonces
log (Yt)− log (Yt−1) = log
(YtYt−1
)= log (1 +Xt)
Si se restringe Xt a |Xt| < 0,2 (es decir, que el porcentaje de cambios son a lomás±20 %) para una buena aproximación log (1 +Xt) ≈ Xt. Consecuentemente
∇ [log (Yt)] ≈ Xt
Será relativamente estable y lo más probable es que sea un proceso estacio-nario bien modelado Box and Jenkins [1976].
5.2.5.2. Transformaciones de Potencia
Denición 44 Para un parámetro dado λ, la transformación se dene comoBox and Jenkins [1976]
g (x) =xλ−1λ Para λ 6= 0
log x Para λ = 0
Las transformaciones de potencias solo se pueden aplicar a datos mayoresa cero. Si alguno de los valores no cumple la condición anterior, se tiene quesumar una constante positiva a todos los valores de la serie, con el n de hacerlospositivos antes de hacer la transformación. Dicho cambio, generalmente, se hacede manera arbitraria.
Se puede considerar a λ como un parámetro adicional en el modelo, que tieneque ser estimado. Sin embargo, una estimación precisa de λ no está usualmentegarantizada, y para dichos efectos los software estadísticos ofrecen una ampliorango de posibilidades para efectuar dicha estimación.

48CAPÍTULO 5. MODELOS PARA SERIES DE TIEMPONO ESTACIONARIAS

Capítulo 6
Construcción del Modelo
En los capítulos anteriores se han desarrollado modelos paramétricos, tantoestacionarios como no estacionarios para series de tiempo, los modelos ARIMA.En este capítulo se estudiarán y se implementarán los métodos para hacer in-ferencia estadística sobre dichos modelos, teniendo en cuenta los siguientes as-pectos.
1. La manera de escoger valores apropiados para p, d y q para una serie detiempo dada.
2. la manera de estimar los parámetros de un modelo ARIMA (p, d, q) .
3. La manera de vericar si un modelo es apropiado, o mejorarlo en caso deser necesario.
La estrategia general a tener en cuenta consiste, en primera medida, en elegirvalores tentativos pero razonables para p, d y q. Luego, se estimaran los paráme-tros φ, θ y σe más ecientes para el modelo. Por último, se vericara el modeloobtenido, con el n de comprobar su ecacia. Si el modelo parece ser inadecuadoen algún sentido, se considerará a dicho modelo como una base para elegir unnuevo modelo más adecuado, y repetir el proceso.
Con unas cuantas iteraciones de esta estrategia para la construcción delmodelo, se espera, que se llegue al mejor modelo posible para una serie detiempo dada. Gran parte de la literatura inherente a las series de tiempo llamana esta estrategia el método "Box-Jenkins" Box and Jenkins [1976]
6.1. Especicación del Modelo
En primera medida, y con el n de establecer los mejores valores para p, d yq se estudiarán las propiedades de la función de autocorrelación
49

50 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
6.1.1. Propiedades de la Función de Autocorrelación Mues-tral
Teniendo en cuanta la denición de la función de autocorrelación muestralo estimada para una serie observaba Y1, Y2, ...Yn de la página 24, se tiene:
rk =
n∑t=k+1
(Yt − Y
) (Yt−k − Y
)n∑t=1
(Yt − Y
)2 (6.1)
El objetivo principal es reconocer, comportamientos de rk que son carac-terísticos de los comportamientos conocidos de ρf para modelos ARMA. Porejemplo, ya se ha discutido que ρk = 0 para k > q
en un modelo MA (q) . Sin embargo, como rk es una estimación de ρk, sedeben enunciar las propiedades muestrales con el n de facilitar la comparaciónde las correlaciones estimadas con las correlaciones teóricas.
Teniendo en cuenta que según la denición de rk, rk es una familia de ecuacio-nes cuadráticas, de variables posiblemente dependientes, las propiedades mues-trales de rk no son sencillas de estimar, de modo que se tendrán en cuenta losresultados generales de una muestra numerosa y considerar sus implicaciones encasos especiales Brillinger [2001], además, se tendrá en cuenta un resultado másgeneral tomado de Shumway and Stoer [2006] (página 519)
Supóngase que:
Yt = µ+
∞∑j=0
ψjet−j
Donde et son variables aleatorias idénticamente distribuidas con media iguala cero y varianzas nitas diferentes de cero. Además se asume que:
∞∑j=0
|ψj | <∞ y
∞∑j=0
jψ2j <∞
(Condiciones que se satisfacen en un modelo ARMA estacionario)Entonces, para cualquier m jo, la distribución conjunta de
√n (r1 − ρ1) ,
√n (r2 − ρ2) , ...,
√n (rm − ρm)
Se aproxima, cuando n tiende a innito, a una distribución normal con mediacero, varianzas cjj , y covarianzas cij donde
cij =
∞∑k=−∞
(ρk + iρk+j + ρk−iρk+j − 2ρiρkρk+j − 2ρjρkρk+i + 2ρiρjρ
2k
)(6.2)
Para tamaños de muestra n signicativamente grandes, se puede decir que rksigue una distribución aproximadamente normal con media ρk y varianza ckk
n .

6.1. ESPECIFICACIÓN DEL MODELO 51
Además, Corr (rk, rj) ≈ ckj√ckkcjj
. Teniendo en cuenta que la varianza aproxima-da de rk es inversamente proporcional al tamaño de la muestra, Sin embargo,Corr (rk, rj) es aproximadamente constante para tamaños de muestra grandes.
Dado que la interpretación de la ecuación 6.2 es complicada, se consideraránalgunos casos especiales con el n de simplicar la expresión.
Supóngase, en primera medida, que Yt es un proceso de ruido blanco.Entonces, la ecuación 6.2, se reduce considerablemente a:
V ar ≈ 1
ny Corr (rk, rj) ≈ 0 Para k 6= j (6.3)
Ahora, supóngase que Yt es generado por un proceso AR (1) con ρk = φk
para k > 0. la ecuación 6.2 conduce a.
V ar (rk) ≈ 1
n
[(1 + φ2
) (1− φ2k
)1− φ2
− 2kφ2k
](6.4)
En particular
V ar (r1) ≈ 1− φ2
n(6.5)
Nótese que, cuando φ es cercano a ±1, la estimación de ρ = φ es más precisa.Para grandes rezagos k, los términos de la ecuación 6.4 los φk pueden ser
ignorados, entonces
V ar (rk) ≈ 1
n
[1 + φ2
1− φ2
]Para grandes rezagos k (6.6)
En contraste con la ecuación 6.5, si φ es cercano a ±1 la varianza de rkcrece, por lo que no se considera conveniente esperar estimaciones precisas deρk = φk ≈ 0, para rezagos grandes como se esperan para rezagos pequeños.
Para el modelo AR (1) la ecuación 6.2, también puede ser simplicada para0 < i < j de la siguiente manera.
cij =
(φj−i − φj+i
) (1 + φ2
)1− φ2
+ (j − i)φj−i − (j + i)φj+i (6.7)
Particularmente se encuentra que:
Corr (r1, r2) ≈ 2φ
√1− φ2
1 + 2φ2 − 3φ4(6.8)
Para el caso MA (1) la ecuación 6.2 puede ser simplicada de la siguientemanera
c11 = 1− 3ρ21 + 4ρ4
1 y ckk = 1 + 2ρ21 Para k > 1 (6.9)
Ademásc12 = 2ρ
(1− ρ2
1
)(6.10)

52 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
para un proceso general MA (q) la ecuación 6.2 se reduce a
ckk = 1 + 2
q∑j=1
ρ2j Para k > q
entonces
V ar =1
n
1 + 2
q∑j=1
ρ2j
Para k > q (6.11)
Para una serie de tiempo observada, se puede reemplazar ρ por r, tomarla raíz cuadrada y obtener una desviación estándar de rk, es decir, el errorestándar de rk para rezagos k grandes.
6.1.2. La Función de Autocorrelación Parcial y la Funciónde Autocorrelación Extendida
Teniendo en cuenta que para los modelosMA (q) , la función de autocorrela-ción es cero para rezagos mayores que q, la función de autocorrelación muestrales un buen indicador del orden del proceso. sin embargo las autocorrelacionesde un proceso AR(p), no se convierten en cero, sino después de un número signi-cativo de rezagos. Por eso es necesario denir una función diferente, que ayudea determinar el orden de los modelos autorregresivos.
Denición 45 Una función denida como la correlación entre Yt y Yt−k, des-pués de remover el efecto de las variables Yt−1, Yt−2, Yt−3, ..., Yt−k−1.se conocecomo la correlación parcial en el rezago k y será denotado por φkk Cryer andChan [2008]
Existen varias formas de hacer dicha denición precisa.Si Yt es una serie de tiempo normalmente distribuida
φkk = Corr (Yt, Yt−k | Yt−1, Yt−2, ..., Yt−k+1) (6.12)
Un acercamiento que no necesita el concepto de normalidad es el siguiente.Supóngase que se necesita predecir Yt basándose en una función lineal de lasvariables Yt−1, Yt−2, ..., Yt−k+1, es decir β1Yt−1 + βYt−2 + · · ·+ βk−1Yt−k+1 concada uno de los β escogidos para minimizar el error cuadrático medio de lapredicción. Se puede concluir, basándose en el concepto de estacionariedad queel "mejor predictor" de Yt−k basado en Yt−1, Yt−2, ..., Yt−k+1, será β1Yt−1 +βYt−2 + · · · + βk−1Yt−k+1. Estas consideraciones nos conducen a la siguientedenición.
Denición 46 La función de autocorrelación parcial en el rezago k es denidacomo la correlación entre los errores de la predicción, es decir Cryer and Chan[2008]
φkk = Corr(Yt − β1Yt−1 − βYt−2 −−βk − 1Yt−2, (6.13)
Yt−k − β1Yt−k+1 − β2Yt−k+2 −−βk−1Yt−1

6.1. ESPECIFICACIÓN DEL MODELO 53
Por ejemplo, considérese φ22, de acuerdo con la ecuación 6.13
φ22 = Cov (Yt − ρ1Yt−1, Yt−2 − ρ1Yt−1) = γ0
(ρ2 − ρ2
1 − ρ21 + ρ2
1
)= γ0
(ρ2 − ρ2
1
)ya que
V ar (Yt − ρ1Yt−1) = V ar (Yt−2 − ρ1Yt−1)
= γ0
(1 + ρ2
1 − 2ρ21
)= γ0
(1− ρ2
1
)Se tiene que, para cualquier proceso estacionario, la función de autocorre-
lación parcial para un rezago de k = 2 puede ser expresada de la siguientemanera
φ22 =ρ2 − ρ2
1
1− ρ21
(6.14)
Considérese ahora el modelo AR (1) , teniendo en cuenta que ρk = φk
φ22 =φ2 − φ2
1− φ2= 0
Considérese ahora el modelo general AR (p) , teniendo en cuanta que el mejorpredictor lineal de Yt basado en una función lineal de variables Yt−1, Yt−2, . . . , Yp, . . . , Yt−k+1
para k > p es φ1Yt−1 +φ2Yt−2 + . . .+φpYp. También el mejor predictor lineal deYt−k es una función de Yt−1, Yt−2, . . . , Yp, . . . , Yt−k+1, llámese h (Yt−1, Yt−2, . . . , Yp, . . . , Yt−k+1) .Entonces la covarianza entre dos errores de la predicción es Cryer and Chan[2008].
Cov(Yt − φ1Yt−1 − φ2Yt−2 −−φpYt−p, Yt−k − h (Yt−k+1, Yt−k+2, . . . , Yt−1))
= Cov (et, Yt−k − h (Yt−k+1, Yt−k+2, . . . , Yt−1))
= 0
Debido a que et es independiente a Yt−k,t−k+1 , Yt−k+2, . . . , Yt−1. Es decirque para un modelo AR (p)Cryer and Chan [2008]
φkk = 0 Para k > p (6.15)
Para un modelo MA (1) la ecuación 6.14 se puede escribir como Cryer andChan [2008]
φ22 =−θ2
1 + θ2 + θ4(6.16)
Además
φkk = −θk(1− θ2
)1− θ2(k−1)
Para k ≥ 1
Nótese que la correlación parcial de un modelo MA(1) nunca es cero, sinembargo, tiende a cero de forma exponencial conforme el rezago k aumenta.

54 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
Un método general para encontrar la función de autocorrelación parcial, paraun proceso estacionario con función de autocorrelación ρk es el siguiente Fuller[1976]:
Para un rezago dado k, se puede mostrar que φkk satisface las ecuaciones deYule-Walker (Capítulo 4, página 33)
ρj = φk1ρj−1 + φk2ρj−2 + φk3ρj−3, . . .+ φkkρj−k Para j = 1, 2, . . . , k (6.17)
De manera más explícita, se pueden escribir las k ecuaciones lineales de lasiguiente manera
φk1 + ρ1φk2 + ρ2φk3 + · · ·+ ρk−1φkk = ρ1 (6.18)
ρ1φk1 + φk2 + ρ1φk3 + · · ·+ ρk−2φkk = ρk
...
ρk−1φk1 + ρk−2φk2 + ρk−3φk3 + · · ·+ φkk = ρk
Estas ecuaciones permiten calcular φkk en cualquier proceso estacionario.Sin embargo si el proceso es, de hecho, AR (p) , entonces, debido a que k = p,las ecuaciones 6.18 no son más sino ecuaciones de Yule-Walker que el modeloAR (p) satisface, se debería tener que φpp = φp. Además, teniendo en cuentael cálculo alternativo de φkk = 0 para k > p, se puede concluir que la funciónde correlación parcial efectivamente, muestra el orden correcto de un procesoautorregresivo, como el máximo rezago k antes que φkk sea cero.
6.1.2.1. La Función de Autocorrelación Parcial Muestral
Para una serie de tiempo observada, se debe ser capaz de estimar la fun-ción de autocorrelación parcial en diferentes rezagos k. Dada la relación en laecuación 6.18, un método obvio, consiste en estimar los ρ, con las autocorre-laciones muestrales, los correspondientes r y luego resolver la ecuación linealpara k = 1, 2, 3, · · · para obtener el estimado de φkk, se le conoce a dicho méto-do como la función estimada de la función de autocorrelación parcial muestral(FACP muestral) y se denotará con φkk
Durbin [1960] (1960) expuso un método eciente para obtener las solucionesde las ecuaciones 6.18, para funciones de autocorrelación, bien sean teóricas omuestrales. Además, mostraron que la ecuación 6.18 puede ser evaluada recur-sivamente de la siguiente manera.
φkk =
ρk −k−1∑j=1
φk−1,j ρk−j
1−k−1∑j=1
φk−1,jρj
(6.19)
Donde
φk,j = φk−1,j − φkkφk−1,k−j Para j = 1, 2, . . . k − 1

6.1. ESPECIFICACIÓN DEL MODELO 55
Por ejemplo, usando φ11 = ρ1, se tiene
φ22 =ρ2 − φ11ρ1
1− φ11ρ1=ρ2 − ρ2
1
1− ρ21
Con φ21 = φ11 − φ22 − φ22φ11, entonces
φ33 =ρ3 − φ21ρ2 − φ22ρ1
1− φ21ρ1 − φ22ρ2
Estas ecuaciones recursivas dan como resultado las autocorrelaciones par-ciales teóricas Sin embargo, si se reemplaza ρ por r se obtiene la función deautocorrelación parcial muestral.
6.1.2.2. Modelos Mixtos y la Función de Autocorrelación Extendida
La función de autocorrelación muestral y la función de autocorrelación par-cial, se erigen como poderosas herramientas para identicar modelos AR(p) oMA(q). Sin embargo, para un modelo mixto ARMA, sus funciones de auto-correlación teórica y función de autocorrelación parcial, tienen innitos valoresdiferentes de cero, generando serias dicultades a la hora de identicar un mo-delo partiendo de la función de autocorrelación y su función de autocorrelaciónparcial. Varias herramientas grácas, son recomendadas en la literatura, con eln de facilitar el proceso de identicación de los modelos ARMA, por ejemplo,El método de la Esquina (Becuin 1980), el método de Autocorrelación Exten-dida (EACF ) (Tsay and Tiao, 1984) y el método de La mínima correlacióncanónica (SCAN), entre otros.
A continuación se describirá el método de autocorrelación extendida, el cualcuenta con propiedades muestrales importantes, para tamaños de muestra rela-tivamente grandes Chan [1999].
El método EACF usa el hecho que si la parte autorregresiva de un modelomixto ARMA es conocida, esta se ltra de la serie de tiempo observada y siresulta en un proceso puramente de promedios móviles que goza de la propiedadde truncamiento en su función de autocorrelación. Los coecientes autorregresi-vos pueden ser estimados por una secuencia nita de regresiones. A continuaciónse ilustrará el método EACF cuando el modelo es uno de tipo ARMA (1, 1) :
Yt = φYt−1 + et − θet−1
En este caso una simple regresión lineal de Yt sobre Yt−1, resulta en unestimador inconsistente de φ, incluso con datos innitos. De hecho, el coecientede regresión teórico
ρ1 =(φ− θ) (1− φθ)
1− 2φθ + θ26= φ
Sin embrago, la forma de los residuales contienen información acerca del pro-ceso del error et . Una segunda regresión múltiple consiste en la regresión deYt sobre Yt−1 y sobre el rezago k = 1 de los residuales de la primera regresión.

56 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
El coeciente de Yt−1 en la segunda regresión, denotado por φ, resulta ser unestimador consistente de φ. Se dene Wt = Yt − φYt−1, el cual es aproximada-mente un proceso MA (1) . Para un modelo ARMA (1, 2), una tercera regresiónde Yt sobre su rezago 1, el rezago 1 de los residuales de la segunda regresión, yel rezago 2 de la forma de los residuales de las primera regresión, permite llegaral coeciente de Yt−1, siendo este un estimador consistente de φ. Del mismomodo, los coecientes autorregresivos de un proceso ARMA (p, q) pueden serconsistentemente estimados por medio de una secuencia de q regresiones.
Debido a que el orden de los modelos AR y MA, se requiere un procesoiterativo. Sea
Wt,k,j = Yt − φ1Yt−1 − · · · − φkYt−k (6.20)
los residuales autorregresivos, denidos con los coecientes autorregresivosestimados iterativamente asumiendo que el orden del modelo AR es k y el ordendel modeloMA es j. Las autocorrelaciones muestrales deWt,k,j se pueden referircomo las autocorrelaciones extendidas muestrales. Para k = p y j ≥ q, Wt,k,jes aproximadamente un modelo MA (q) , es decir, que sus correlaciones teóricasde rezago k ≥ q + 1 son iguales a cero. Para el caso k > p, ocurre un problemade "sobreajuste" lo que incrementa el orden de los promedios móviles para elprocesoW, por el mínimo de k−p y j−q. Tsay and Tiao (1984) sugirieron reunirla información en la función de autocorrelación extendida muestral por medio deuna tabla, con el elemento en la k-ésima la y la j-ésima columna con el símboloX, si la correlación muestral de Wt,k,jen el rezago j + 1, es signicativamentediferente de cero (es decir, si su magnitud es mayor que 1,96√
n−j−kdebido a que laautocorrelación de la muestra es asintóticamente normalmente distribuida conmedia cero y desviación estándar 1
n−k−j ) si Wi con i = 1, 2, 3, .. son aproxima-damente un proceso MA (J) , y cero en otro caso. En dicha tabla un procesoMA (p, q) tendría, teóricamente hablando, un patrón triangular de ceros, con elmargen superior izquierdo correspondiente al orden del modelo ARMA.
6.1.3. Especicación para Modelos No Estacionarios
Como se mencionó en el capítulo 5 muchas series de tiempo muestran unano-estacionariedad que puede ser explicada por los modelos integrados autorre-gresivos de promedios móviles.
La función de autocorrelación muestral calculada para series no estaciona-rias usualmente, indicarán la no-estacionariedad. La denición de la función deautocorrelación implícitamente asume la estacionariedad; por ejemplo, se hanusado productos rezagados de las desviaciones de la media general, y el deno-minador asume una varianza constante a lo largo del tiempo. Por lo tanto noestá del todo claro que función de autocorrelación muestral se estima para unproceso no estacionario. Cabe notar que los valores de rk no necesariamentetiene que ser valores grandes, incluso para pequeños rezagos, pero generalmentelo son.

6.1. ESPECIFICACIÓN DEL MODELO 57
6.1.3.1. El problemas de la Sobrediferenciación
Se sabe que la diferencia de cualquier proceso estacionario, es también, es-tacionaria. Sin embargo, sobrediferenciar introduce correlaciones innecesarias auna serie de tiempo lo que complicaría el proceso de modelamiento.
Por ejemplo, supóngase una serie de tiempo observada Yt, dicha serie esde hecho un proceso de caminata aleatoria, entonces su operador diferencia deprimer orden, conducirá a un modelo de ruido blanco simple
∇Yt = Yt − Yt−1 = et
Sin embargo, si se aplica el operador diferencia una vez más se obtiene
∇2Yt = et − et−1
El cual es un modelo MA (1) con θ = 1. Si se toman dos diferencias, in-necesariamente, sería necesario estimar el valor desconocido de θ. Es decir unmodelo IMA (2, 1) no seria el más apropiado en este caso. El modelo de cami-nata aleatoria, el cual puede ser pensado como un modelo IMA (1, 1) con θ = 0es el modelo correcto.
La sobrediferenciación además genera un modelo no invertibe lo cual , di-cultara el trabajo de la estimación de sus parámetros.
Con el n de evitar la sobrediferenciación, se recomienda evaluar cuidadosa-mente cada diferencia para tener en cuenta el principio de parsimonia siemprepresente, "Los modelos deben ser simples, pero no muy simples" Cryer and Chan[2008]
6.1.3.2. La prueba de la raíz unitaria de Dickey Fuller
Mientras que el decrecimiento de la función de autocorrelación muestral esgeneralmente tomada como un síntoma de no estacionariedad y que se requiereaplicar el operador diferencia, es de gran utilidad cuanticar la evidencia de deno estacionariedad en el mecanismo de generación de datos. Este método decuanticación se hace por medio de una prueba de hipótesis Cryer and Chan[2008]. Considérese el modelo
Yt = αYt−1 +X Para t = 1, 2, . . .
donde Xt es un proceso estacionario. El proceso Yt es no estacionario siel coeciente α = 1, pero es estacionario si |α| < 1. Supóngase que Xt es unproceso AR (k) : Xt = φ1Xt−1 + · · · + φkXt−k + et. Bajo la hipótesis nula queα = 1, Xt = Yt − Yt−1. Sea a = α− 1, se obtiene:
Yt − Yt−1 = (α− 1)Yt−1 +Xt (6.21)
= aYt−1 + φ1Xt−1 + · · ·+ φkXt−k + et
= aYt−1 + φ1 (Yt−1 − Yt−2) + · · ·+ φk (Yt−k − Yt−k−1) + et
donde a = 0 bajo la hipótesis que el operador diferencia de Yt es no esta-cionaria. Por otra parte, si Yt es estacional, es decir, −1 < α < 1, entonces

58 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
Yt satisface una ecuación similar a la anteriormente mencionada, pero con coe-cientes diferentes. Por ejemplo,
a = (1− φ1 − · · · − φk) (1− α) < 0
entonces Yt es un proceso AR (k + 1) cuya ecuación característica estápor Φ (x) (1− αx) = 0 donde Φ (x) = 1 − φ1x − −φkxk. Entonces, la hipótesisnula corresponde al caso en el cual el polinomio característico del proceso ARtiene una raíz unitarias y la hipótesis alternativa corresponde a que no existenraíces unitarias.
Es decir que el proceso en no estacionario pero se convierte en un mode-lo estacionario después de aplicar el operador diferencia de primer orden. Lahipótesis alternativa a < 0 quiere decir que Yt es un proceso estacionario.
6.1.4. Otros Métodos de Especicación
6.1.4.1. Criterio de la Información de Akaike
El criterio de información de Akaike Akaike [1974] se basa en elegir el modeloque minimice
AIC = −2 log (Máxima Verosimilitud) + 2k (6.22)
Donde
k =
p+ k + 1 Si el moelo contiene un término constantep+ q En otro caso
El estimador de máxima verosimilitud de describirá en el capítulo 7. Laadición del término 2k hace las veces de una función penalizadora, con el n deasegurar el modelo más parsimonioso.
El criterio de información de Akaike estima E[D(p, qθ
)], donde θ es el
estimador de máxima verosimilitud del vector de parámetros θ. Sin embargo,el criterio de información de Akaike es un estimador sesgado, y dicho sesgopuede ser signicativo para una cantidad de parámetros alta. Según (cite Tsay1989) el sesgo puede ser aproximadamente eliminado, añadiendo un termino noestocástico de penalización, lo que conduce al criterio de información de Akaikecorregido, denotado por AICc, denido por la siguiente fórmula
AICc = AIC +2 (k + 1) (k + 2)
n− k − 2(6.23)
Donde n es el tamaño de la muestra y k es el número total de parámetrosexcluyendo el ruido de la varianza.
6.1.4.2. Criterio de la Información Bayesiano
Otro acercamiento para determinar el orden de un proceso ARMA es selec-cionar un modelo que minimice el Criterio de la Información Bayesiano (BIC)denido de la siguiente manera Cryer and Chan [2008]
BIC = −2 log (Máxima Verosimilitud) + k log n (6.24)

6.2. ESTIMACIÓN DE PARÁMETROS 59
Si el proceso verdadero sigue un modelo ARMA (p, q) , entonces, se sabe,que los ordenes obtenidos minimizando el BIC son consistentes, es decir, seaproximan a los ordenes verdaderos en la misma medida que el tamaño de lamuestra aumenta. Sin embargo, si el proceso verdadero no es un modeloARIMAde orden nito, aplicando el criterio de información de Akaike entre modelosARIMA de tamaño creciente, se goza de la propiedad que dicha minimizaciónconducirá un modelo ARMA óptimo
6.2. Estimación de Parámetros
A continuación, se investigará el problema de estimar los parámetros deun modelo ARIMA, basado en una serie de tiempo observada Y1, Y2, . . . , Yn. Seasume que el modelo ya está especicado, y que el modelo es estacionario (inclu-so a través del operador diferencia). En la práctica, se trabajará con la d-ésimadiferencia de la serie de tiempo original, a la cual se le estimarán los paráme-tros. Para efectos prácticos se denotará por Y1, Y2, . . . Yn el proceso estacionarioobservado.
6.2.1. El Método de los Momentos
El método de los momentos, consiste en igualar los momentos muestralescon los momentos teóricos, y resolver la ecuación con el n de estimar cualquierparámetro desconocido Box and Jenkins [1976]. El ejemplo más simple de estemétodo es en el que se estima la media de un proceso estacionario con una mediamuestral.
6.2.1.1. Modelos Autorregresivos
Considérese, en primera medida el modelo AR (1) . Para este proceso se tienela relación ρ1 = φ. En el método de los momentos ρ1 es igualado a r1, el rezago1 de la autocorrelación muestral, es decir que se puede estimar φ con:
φ = r1
Ahora, considérese el modelo AR (2) . Las relaciones entre los parámetrosφ1 y φ2 y varios momentos son dados por las ecuaciones de Yule-Walker (4.16página 33).
ρ1 = φ1 + ρ1φ2 y ρ2 = ρ1φ1 + φ2
El método de los momento, reemplaza ρ1 por r1 y ρ2 por r2 para obtener
r1 = φ1 + r1φ2 y r2 = r1φ1 + φ2
Las cuales son resueltas para obtener
φ1 =r1 (1− r2)
1− r21
y φ2 =r2 − r2
1
1− r21
(6.25)

60 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
Para el modelo general AR (p) , se procede de la misma manera, reempla-zando ρk por rk y a través de las ecuaciones de Yule-Walker (4.16 página 33).se obtiene
φ1 + r1φ2 + r2φ3 + · · ·+ rp−1φp = rp (6.26)
r1φ1 + φ2 + r1φ3 + · · ·+ rp−2φp = rp
...
rp−1φ1 + rp−2φ2 + rp−3φ3 + · · ·+ φp = rp
Estas ecuaciones lineales se solucionan para obtener los valores de φ1, φ2, . . . , φp.Las estimaciones obtenidas por este medio se conocen como estimaciones deYule-Walker
6.2.1.2. Modelos de Promedios Móviles
Lastimosamente el método de los momentos no es lo sucientemente conve-niente cuando se aplican a modelos de promedios móviles. Considérese el modeloMA(1) de la ecuación 4.6 (página 28), se sabe que
ρ1 = − θ
1 + θ2
Igualando ρ1 a r1 se tiene que resolver la ecuación cuadrática en θ
− θ
1 + θ2= r1
si |r1| < 0,5 las raíces reales son de la forma
− 1
2r1±
√1
4r21
− 1
Teniendo en cuenta, que el producto de las dos soluciones es igual a 1, solouna de las soluciones satisface la condición de la invertibilidad |θ| < 1. Es decir,la estimación del parámetro θ es de la forma
θ =−1 +
√1− 4r2
1
2r1(6.27)
Si r1 = ±0,5 existe una única solución real,±1, pero ninguna de las dosposibilidades cumplen la condición de invertibilidad. Si |r1| > 0,5, no existensoluciones reales, y el método de estimación por momentos no puede dar unaestimación del parámetro θ. Sin embargo si |r1| > 0,5, la especicación de unmodelo MA (1) estaría en duda.
Para modelos de promedios móviles de mayor orden el método de los momen-tos es bastante complicado, se pueden usar las ecuaciones 4.9 en la pagina 29 yreemplazar ρk por k = 1, 2, . . . , q para obtener las q ecuaciones con q incógnitasφ1, φ2, . . . , φq. Las ecuaciones no serian de tipo lineal, con múltiples solucionespor lo que no se describirá el proceso de solución.

6.2. ESTIMACIÓN DE PARÁMETROS 61
6.2.1.3. Modelos Mixtos
Para los modelos mixtos solo se considerará el modelo ARIMA (1, 1) , te-niendo en cuenta la ecuación 4.30
ρk =(1− θφ) (φ− θ)
1− 2θφ+ θ2φk−1 Para k ≥ 1
Teniendo en cuenta que ρ2ρ1
= φ se puede estimar φ de la siguiente manera
φ =r2
r1(6.28)
Entonces
r1 =
(1− θφ
)(φ− θ
)1− 2θφ+ θ2
(6.29)
6.2.1.4. Estimación de la Varianza del Ruido
El parámetro nal que debe ser estimado es la varianza del ruido σ2e . Box
and Jenkins [1976] En todos los casos, se puede estimar ,el proceso de varianzaγ0 = V ar (Yt) por la varianza muestral
s2 =1
n− 1
n∑t=1
(Yt − Y
)2(6.30)
y las relaciones establecidas en el capítulo 4 entre γ0, σ2e y los θ y φ para
estimar σ2e .
Para los modelos AR (p) la ecuación 4.25 conduce a
σ2e =
(1− φ1r1 − φ2r2 − · · · − φprp
)s2 (6.31)
En particular para un proceso AR (1)
σ2e =
(1− r2
1
)s2
ya que φ = r1.Para el caso MA (q) , usando la ecuación 4.8 conduce a
σ2e =
s2
1 + φ21 + φ2
2 + · · ·+ φ2q
(6.32)
Para el caso del modelo ARMA (1, 1) la ecuación 4.29 conduce a
σ2e =
1− φ2
1− 2φθ + θ2s2 (6.33)

62 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
6.2.2. Estimación por Mínimos Cuadrados
Para el método de estimación por mínimos cuadrados es necesario introduciral modelo estacionario una media posiblemente diferente de cero µ y considerarlacomo un nuevo parámetro que será estimado por el método.
6.2.2.1. Modelos Autorregresivos
Considérese el caso de primer orden donde
Yt − µ = φ (Yt−1 − µ) + et
se puede notar que lo anterior es un modelo de regresión para la variableYt explicada por la variable Yt−1. El método de mínimos cuadrados consiste enminimizar la suma de los cuadrados de las diferencias
et = (Yt − µ)− φ (Yt−1 − µ)
Debido a que en la serie de tiempo observada solo se tienen los valores deY1, Y2, . . . , Yn, solo se pude sumar desde t = 2 a t = n. Sea
Sc (φ, µ) =
n∑t=2
[(Yt − µ)− φ (Yt−1 − µ)]2 (6.34)
La ecuación 6.34 es usualmente llamada la función condicional de la sumade los cuadrados Cryer and Chan [2008]. De a cuerdo con el principio de míni-mos cuadrados, se estiman los valores de φ y µ con los respectivos valores queminimicen Sc (φ, µ) dados los valores observados de Y1, Y2, . . . , Yn.
Considérese la ecuación ∂Sc∂µ = 0, entonces
∂Sc∂µ
=
n∑t=2
2 [(Yt − µ)− φ (Yt−1 − µ)] (−1 + φ) = 0
Simplicando, y despejando el valor de µ
µ =1
(n− 1) (1− φ)
[n∑t=2
Yt − φn∑t=2
Yt−1
](6.35)
Para tamaños de muestra grandes se tiene
1
n− 1
n∑t=2
Yt ≈1
n− 1
n∑t=2
Yt−1 ≈ Y
Es decir que la ecuación 6.35 se reduce a
µ ≈ 1
1− φ(Y − φY
)= Y (6.36)

6.2. ESTIMACIÓN DE PARÁMETROS 63
Es decir que para efectos prácticos µ = Y .
Considérese ahora, la minimización de Sc (φ, µ) con respecto a φ
∂Sc (φ, µ)
∂φ=
n∑t=2
2[(Yt − Y
)− φ
(Yt−1 − Y
)] (Yt−1 − Y
)= 0
Resolviendo la ecuación para φ
φ =
n∑t=2
(Yt − Y
) (Yt−1 − Y
)n∑t=2
(Yt−1 − Y
)2Excepto por un término faltante en el denominador,
(Yn − Y
)2, la ecuación
anterior es la misma ecuación que r1. El término faltante no es necesario paraseries estacionarias, por lo que se puede concluir que el método de mínimoscuadrados y el método de estimación por momentos son prácticamente idénticos,en especial para tamaños de muestras grandes.
Para el proceso general AR (p) los métodos utilizados para obtener las ecua-ciones 6.35 y 6.36 representan el procedimiento análogo para llegar a la conclu-sión que
µ = Y (6.37)
Cryer and Chan [2008]Con el n de generalizar la estimación de φ, se considerará el modelo de
segundo orden. Siguiendo un proceso análogo al modelo de primer orden seobtiene
Sc(φ1, φ2, Y
)=
n∑t=3
[(Yt − Y
)− φ1
(Yt−1 − Y
)− φ2
(Yt−2 − Y
)]2(6.38)
Calculando ∂Sc∂φ1
= 0
−2
n∑t=3
[(Yt − Y
)− φ1
(Yt−1 − Y
)− φ2
(Yt−2 − Y
)] (Yt−1 − Y
)= 0 (6.39)
Lo cual se puede simplicar de la siguiente manera
n∑t=3
(Yt − Y
) (Yt−1 − Y
)=
(n∑t=3
(Yt−1 − Y
)2)φ1 (6.40)
+
(n∑t=3
(Yt−1 − Y
) (Yt−2 − Y
))φ2

64 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
La suma de los productos rezagadosn∑t=3
(Yt − Y
) (Yt−1 − Y
)es cercana al
numerador de r1 excepto que falta el término(Y2 − Y
) (Y1 − Y
)del mismo mo-
do en la suman∑t=3
(Yt−1 − Y
) (Yt−2 − Y
)hace falta el término
(Yn − Y
) (Yn−1 − Y
).
Si se dividen ambas partes de la igualad de la ecuación 6.40 porn∑t=3
(Yt − Y
)2,
y suponiendo la estacionariedad del proceso se obtiene
r1 = φ1 + r1φ2 (6.41)
Realizando el mismo proceso con la ecuación ∂Sc∂φ2
= 0 se obtiene
r2 = r1φ1 + φ2 (6.42)
Sin embargo las ecuaciones 6.41 y 6.42 son las ecuaciones muestrales deYule-Walker para un modelo AR (2) .
De una manera enteramente análoga, para un modelo AR (p) , las estima-ciones condicionales de mínimos cuadrados de los valores de φ, se obtienen uti-lizando las ecuaciones muestrales de Yule-Walker
6.2.2.2. Modelos de Promedios Móviles
Considérese la estimación por mínimos cuadrados para θ en un modeloMA (1)
Yt = et − θet−1 (6.43)
A primera vista, no es evidente como una regresión de mínimos cuadradosse puede aplicar a estos modelos. Sin embargo gracias a la ecuación 4.6 se puededecir que los modelos invertibles MA (1) se pueden expresar como
Yt = −θYt−1 − θ2Yt−2 − θ3Yt−3 − · · ·+ et
un modelo autorregresivo de orden nito. Entonces el método de mínimoscuadrados consiste en elegir un valor de θ que minimice Box and Jenkins [1976]
Sc =∑
(et)2
=∑[
Yt + θYt−1 + θ2Yt−2 + θ3Yt−3 + · · ·]
(6.44)
Donde et = et (θ) es una función de la serie de tiempo observada y el pará-metro desconocido θ
Es claro, teniendo en cuenta la ecuación 6.44, que el problema de mínimoscuadrados es un problema no lineal, por lo cual no se podrá minimizar Sc (θ) ,derivando e igualando a cero. Es decir que incluso para el modelo simpleMA (1) ,es necesario utilizar técnicas de optimización numérica. Además, no se han es-tablecido limites en las sumas de la ecuación 6.44 y no se ha descrito un métodopara manipular series innitas.
Para lidiar con dichos problemas, se supone que Sc (θ) se evalúa para unsolo valor dado de θ. Los únicos valores de Y disponibles, son los de la serie

6.2. ESTIMACIÓN DE PARÁMETROS 65
observada Y1, Y2. . . . , Yn. Entonces se puede reescribir la ecuación 6.43 de lasiguiente manera Cryer and Chan [2008]
et = Yt + θet−1 (6.45)
Usando esta ecuación e1,e2, . . . , en pueden ser calculados recursivamente, sise tiene el valor inicial e0, usualmente se aproxima e0 = 0 (Se aproxima a su valoresperado). Entonces, teniendo en cuenta la condición sobre e0 = 0 se obtiene
e1 = Y1 (6.46)
e2 = Y2 + θe1
e3 = Y3 + θe2
...
en = Yn + θen−1
Y luego calcular Sc (θ) =∑
(et)2 dado que e0 = 0, para dicho único valor
de θPara modelos de promedios móviles de orden superior, las ideas son total-
mente análogas pero la dicultad se incrementa considerablemente. Se calculaet = et (θ1, θ2, . . . , θq) recursivamente de
et = Yt + θ1et−1 + θ2et−2 + · · ·+ θqet−q (6.47)
Con e0 = e−1 = · · · = e−q = 0. La suma de los cuadrados es minimizadaconjuntamente en θ1, θ2, . . . , θq usando un método numérico multivariado.
6.2.2.3. Modelos Mixtos
Considérese el modelo ARMA (1, 1)
Yt = φYt,1 + et − θet−1 (6.48)
Como en el caso MA se considera et = et (φ, θ) , y se minimiza Sc (φ, θ) =∑e2t . Se puede escribir la ecuación 6.48 de la siguiente manera
et = Yt − φYt−1 + θet−1 (6.49)
Con el n de obtener e1, surge un problema adicional Y0. Una forma de evitarel problema es establecer a Y0 = 0 o Y0 = Y si el modelo contiene una mediadiferente de cero. Sin embargo, una mejor solución al problema es comenzar elprocedimiento recursivo en t = 0 con el n de evitar Y0.
Sc (φ, θ) =n∑t=2
e2t
Para el modelo general ARMA (p, q) se calcula
et = Yt−φ1Yt−1−φ2Yt−2−· · ·−φpYt−p+θ1et−1 +θ2et−2 + · · ·+θqet−q (6.50)
con ep = ep−1 = · · · = ep+1−q = 0 y luego se minimiza Sc (φ1, φ2, . . . , φp, θ1, θ2, . . . θq)numéricamente para obtener las estimaciones por el método de mínimos cua-drados condicionales para todos los parámetros

66 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
6.2.3. Estimaciones de Máxima Verosimilitud y MínimosCuadrados Incondicionales
Para series de tiempo de un número moderado de datos las variables ini-ciales ep = ep−1 = · · · = ep+1−q = 0 tendrán un efecto importante sobre lasestimaciones nales, por lo cual es de vital importancia considerar el problemade la estimación de máxima verosimilitud. La ventaja del método de máximaverosimilitud es que toda la información que los datos ofrecen se usa, en lugarde solo usar el primer y el segundo momento, como es el caso de los métodosmencionados anteriormente. Otra ventaja, es que muchos resultados se puedenconocer bajo pocas condiciones. Sin embargo, el método de estimación de má-xima verosimilitud, tiene la desventaja, de que en primera instancia, se debetrabajar con la función de probabilidad conjunta del proceso.
6.2.3.1. Estimación de Máxima Verosimilitud
Denición 47 Para cualquier conjunto de observaciones Y1,Y2, . . . , Yn, biensea de una serie de tiempo o no, la función de verosimilitud L es denida comola densidad de la probabilidad conjunta, obtenida de los datos observados. Boxand Jenkins [1976]
Sin embargo, se considera como una función de los parámetros desconocidosen un modelo con los datos observados jos. Para modelos ARIMA, L sería lafunción de φ, θ, µ y σ2
e dadas las observaciones Y1,Y2, . . . , Yn.
Denición 48 El estimador de máxima verosimilitud es entonces denido co-mo aquellos valores de los parámetros para los cuales los datos observados sonmás probables, es decir los valores que maximizan la función de verosimilitud.Box and Jenkins [1976]
Para el caso del modelo AR (1) , se asume, como es usual que los términos deruido blanco son variables aleatorias independientes normalmente distribuidascon medias iguales a cero y desviación estándar común σe. Entonces la función,de densidad de probabilidad de cada et es
(2πσ2
e
)− 12 e
− e2t
2σ2e
Para −∞ < et <∞
Y por independencia la función de densidad de probabilidad conjunta parae2, e3, . . . , en es
(2πσ2
e
)−n−12 e
− 1
2σ2e
n∑t=2
e2t
(6.51)

6.2. ESTIMACIÓN DE PARÁMETROS 67
Ahora, considérese
Y2 − µ = φ (Y1 − µ) + e2 (6.52)
Y3 − µ = φ (Y2 − µ) + e3
...
Yn − µ = φ (Yn−1 − µ) + en
Si se condiciona Y1 = y1, la ecuación 6.52 dene una transformación linealentre e2, e3, . . . , en y Y2,Y3, . . . , Yn. Entonces la función de densidad de proba-bilidad conjunta de Y2,Y3, . . . , Yn dado Y1 = y1 se puede obtener usando laecuación 6.52 para sustituir los términos de ruido blanco en términos de losvalores de Y en la ecuación 6.51, entonces se obtiene Cryer and Chan [2008]
f (y2, y3, . . . , yn | y1) =(2πσ2
e
)−n−12 e
− 1
2σ2e
n∑t=2
[(yt−µ)−φ(yt−1−µ)]2
(6.53)
Ahora, considérese la distribución marginal de Y1. Teniendo en cuenta larepresentación lineal del proceso AR (1) (Ecuación 4.13, Página 31) se puede
decir que Y1 tendrá una distribución normal con media µ y varianza σ2e
1−φ2 .Multiplicando la función de densidad de probabilidad en la ecuación 6.53 porla función de densidad de probabilidad marginal de Y1, da como resultado lafunción de densidad de probabilidad de Y1, Y2, . . . , Yn, la cual es la función deverosimilitud. Interpretada como función de los parámetros φ, µ y σ2
e la funciónde verosimilitud para un modelo AR (1) está dada por Cryer and Chan [2008]:
L(φ, µ, σ2
e
)=(2πσ2
e
)−n2(1− φ2
) 12 e
[−
1
2σ2e
S(φ,µ)
](6.54)
Donde
S (φ, µ) =
n∑t=2
[(Yt − µ)− φ (Yt−1 − µ)]2
+(1− φ2
)(Y1 − µ) (6.55)
La función S (φ, µ) es llamada la función de la suma de los cuadradosincondicional Cryer and Chan [2008]
Como una convención general, resulta más sencillo trabajar con el logaritmode la función verosimilitud que con la función de verosimilitud Box and Jen-kins [1976]. Para el caso AR (1) la función de log-verosimilitud denotada por`(φ, µ, σ2
e
)está dada por
`(φ, µ, σ2
e
)= −n
2log (2π)− n
2log(σ2e
)+
1
2log(1− φ2
)− 1
2σ2e
S (φ, µ) (6.56)
Para valores dados de φ y µ, `(φ, µ, σ2
e
)puede ser maximizada analítica-
mente con respecto a σ2e en términos de los estimadores de φ y µ, para obtener
σ2e =
S(φ, µ
)n
(6.57)

68 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
Como en muchos contextos similares se divide usualmente por n− 2 (ya quese están estimando dos parámetros, φ y µ) para obtener un estimador con menossesgo
Considérese la estimación de φ y µ. Una comparación de la función de lasuma de los cuadrados condicional Sc (φ, µ) de la ecuación 6.34 revela una simplediferencia
S (φ, µ) = Sc (φ, µ) +(1− φ2
)(Y1 − µ)
2 (6.58)
Ya que Sc (φ, µ) se basa en la suma de n − 1 componentes, por otro lado(1− φ2
)(Y1 − µ)
2 no involucra a n. Se establecerá que S (φ, µ) ≈ Sc (φ, µ) .Entonces, los valores de φ y µ que minimizan S (φ, µ) o Sc (φ, µ) deberían sermuy similares, al menos para tamaños de muestra signicativos.
6.2.3.2. Mínimos Cuadrados Incondicionales
Existe una asociación entre las estimaciones condicionales por mínimos cua-drados y la estimación por máxima verosimilitud, se debería considerar obtenerlas estimaciones de mínimos cuadrados, es decir, minimizar S (φ, µ) . Infortu-nadamente, el término
(1− φ2
)(Y1 − µ)
2 provoca que las ecuaciones ∂S∂φ = 0 y
∂S∂µ = 0 sean no lineales y por ende el procedimiento de minimización debe serejecutado por algún método numérico. Las estimaciones resultantes son cono-cidas como las estimaciones incondicionales por mínimos cuadrados Cryer andChan [2008].
6.2.4. Propiedades de las Estimaciones
Las propiedades de los estimadores de máxima verosimilitud y mínimos cua-drados (condicionales o no condicionales) para muestras de tamaño considera-ble, son idénticas y pueden ser obtenidos modicando la teoría estándar delconcepto de máxima verosimilitud Shumway and Stoer [2006]. A continuaciónse describirán los resultados y sus implicaciones para modelos ARIMA simples.
Para un tamaño de muestra n grande, los estimadores son aproximadamen-te insesgados y normalmente distribuidos. Las varianzas y correlaciones estándescritas a continuación.
AR (1) : V ar(φ)≈ 1− φ2
n(6.59)
AR (2) :
V ar
(φ1
)≈ V ar
(φ2
)≈ 1− φ2
2
n
Corr(φ1, φ2
)≈ − φ1
1− φ2= −ρ1
(6.60)
MA (1) : V ar(θ)≈ 1− θ2
n(6.61)
MA (2) :
V ar
(θ1
)≈ V ar
(θ2
)≈ 1− θ2
2
n
Corr(θ1, θ2
)≈ − θ1
1− θ2
(6.62)

6.3. DIAGNÓSTICO DEL MODELO 69
ARMA (1, 1) :
V ar(φ)≈[
1− φ2
n
] [1− φθφ− θ
]2
V ar(θ)≈[
1− θ2
n
] [1− φθφ− θ
]2
Corr(φ, θ)≈√
(1− φ2) (1− θ2)
1− φθ
(6.63)
Nótese que, en el caso AR (1) la varianza del estimador φ decrece en el casoque φ se acerque a ±1. También, es importante señalar que aunque un modeloAR (1) es un caso especial de un modelo AR (2) la varianza de φ1 expuesta enla ecuación 6.60, muestra que la estimación de φ1 generalmente sufrirá si sele ajusta un modelo AR (2) cuando, de hecho, φ2 = 0. Estas observaciones sonsimilares en el contexto en el que se ajuste un modeloMA (2) cuando un modeloMA (1) hubiese sido suciente, o ajustar un modelo ARMA (1, 1) cuando unmodelos AR (1) o MA (1) hubiese sido adecuado.
Para el caso del modelo ARMA (1, 1) nótese el denominador de φ− θ en lasecuaciones de la varianza (ecuación 6.63) Si φ y θ son aproximadamente iguales,la variabilidad de los estimadores φ y θ pude ser considerablemente extensa.
Nótese que, en todos los modelos de dos parámetros, los estimadores puedenestar altamente correlacionados, incluso para muestras grandes.
Para modelos estacionarios autorregresivos, el método de los momentos pro-vee estimadores equivalentes a los estimadores de máxima verosimilitud y losestimadores por mínimos cuadrados, al menos para muestras signicativas. Pa-ra los modelos que contienen términos de promedios móviles lo anterior no secumple.
6.3. Diagnóstico del Modelo
Hasta ahora se han descrito métodos para la especicación y la estimacióneciente de los parámetros de cierto modelo. El diagnóstico del modelo, consisteen evaluar la bondad o el ajuste de un modelo, y si el ajuste es pobre sugerirposibles modicaciones Box and Jenkins [1976]. En esta sección se presentarándos acercamientos complementarios: el análisis de residuales de un modelo ajus-tado y el análisis de modelos sobreparametrizados, es decir modelos que son másgenerales que un modelo propuesto pero que lo contiene
6.3.1. Análisis de residuales
Considérese el modelo AR (2) con un término constante
Yt = φ1Yt−1 + φ2Yt−2 + θ0 + et (6.64)
Habiendo estimado φ1, φ2 y θ0 los residuales se denen como
et = Yt − φ1Yt−q − φ2Yt−2 − θ0 (6.65)

70 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
Para modelos ARMA generales, que contienen términos de promedios mó-viles, se usará la forma innita autorregresiva inversa para denir los residuales.Para efectos prácticos se asumirá que θ0 = 0. Del modelo inverso (ecuación4.42), se tiene
Yt = π1Yt−1 + π2Yt−2 + π3Yt−3 + · · ·+ et
Entonces los residuales de denen de la siguiente manera
et = Yt − π1Yt−1 − π2Yt−2 − π3Yt−3 − · · · (6.66)
Donde cada uno de los valores de π no son estimados directamente, sino demanera implícita a través de las funciones de φ y θ. De hecho los residuales no secalculan usando la ecuación anterior, sino como un producto de las estimacionesde φ y θ
Si el modelo está correctamente especicado y los parámetros estimadosson cercanos a los valores verdaderos, entonces los residuales deberían tenerlas propiedades del proceso de ruido blanco. Es decir, se deberían comportarcomo variables aleatorias normales idénticamente distribuidas con medias ceroy desviaciones estándar comunes, alteraciones de dichas propiedades puedenayudar a obtener un mejor modelo. Aunque varios paquetes estadísticos ofrecenla posibilidad de realizar algunas pruebas con el n de vericar las propiedadesde los residuales (Véase Yate [2011]), existen algunas técnicas teóricas que serándescritas a continuación.
6.3.1.1. Autocorrelación de los Residuales
Con el n de vericar la independencia de los términos de ruido en el modelo,se considera la función de autocorrelación muestral de los residuales, denotadapor rk. De la ecuación 6.3 (página 51), se sabe que para procesos de ruido blancoy tamaños de muestra signicativos, las funciones de autocorrelación son apro-ximadamente no correlacionadas y normalmente distribuidas con medias ceroy varianzas 1
n . Infortunadamente, incluso los residuales de un modelo correcta-mente especicado con estimaciones de parámetros ecientes, tienen propiedadesdiferentes.
Generalmente, los residuales son aproximadamente normalmente distribui-dos con medias cero, sin embargo, para pequeños rezagos k y j, la varianzade rk puede ser signicativamente menor que 1
n y las estimaciones de rk y rjpueden estar altamente correlacionadas. Para rezagos mayores, la aproximaciónde la varianza a 1
n , no aplica y rk y rj están prácticamente no correlacionados.Por ejemplo, si se considera un modelo AR (1) , correctamente especicado yestimado se tiene que Box and Jenkins [1976]
V ar (rk) ≈ φ2
n(6.67)
V ar (rk) ≈1−
(1− φ2
)φ2k−2
nPara k > 1 (6.68)

6.3. DIAGNÓSTICO DEL MODELO 71
Corr (rk, rj) ≈ −Σ (φ)
(1− φ2
)φk−2
1− (1− φ2)φ2k−2Para k > 1 (6.69)
Donde
Σ (φ) =1 Si φ > 00 Si φ = 0−1 Si φ < 0
6.3.2. Sobreajuste y Redundancia de Parámetros
La segunda herramienta importante es la herramienta de sobreajuste. Des-pués de especicar y ajustar lo que se puede creer un modelo adecuado, seajusta un modelo más general, es decir un modelo que contenga el modelo ori-ginal. Por ejemplo, si un modelo AR (2) parece apropiado, se sobreajustaria unmodelo AR (3). El modelo original AR (2) seria conrmado si:
1. La estimación del parámetro adicional φ3, no es signicativamente dife-rente de cero.
2. La estimaciones de los parámetros en común φ1 y φ2 no cambian signi-cativamente, respecto a sus estimaciones originales.
Además, como se ha dicho anteriormente, cualquier modelo ARMA (p, q) puedeser considerado como un caso especial de un modelo ARMA más general con losparámetros adicionales iguales a cero. Sin embargo, cuando se generalizan mode-los ARMA, se debe tener especial cuidado con el problema de la redundanciade parámetros o falta de identicabilidad Cryer and Chan [2008].
Para aclarar, considérese un modelo ARMA (1, 2) :
Yt = φYt−1 + et − θ1et−1 − θ2et−2 (6.70)
Reemplazando t por t,1 se tiene
Yt−1 = φYt−2 + et−1 − θ1et−2 − θ2et−3 (6.71)
Si se multiplican ambos lados de la igualdad en la ecuación 6.71 por unaconstante c y luego se sustrae de la ecuación 6.70, después de simplicar seobtiene
Yt − (φ+ c)Yt−1 + φcYt−2 = et − (θ1 + c) et−1 − (θ2 − θ1c) et−2 + cθ2et−3
Lo que aparentemente dene un proceso ARMA (2, 3) . Nótese que existenfactorizaciones
1− (φ+ c)x+ φcx2 = (1− φx) (1− cx)
y
1− (θ1 + c)x− (θ2 − cθ1)x2 + cθ2x3 =
(1− θ1x− θ2x
2)
(1− cx)
Entonces los polinomios característicos de los modelos AR y MA en el pro-ceso ARMA (2, 3) tienen un factor en común (1− cx) . Incluso Yt no satisface el

72 CAPÍTULO 6. CONSTRUCCIÓN DEL MODELO
modelo ARMA (2, 3) , claramente los parámetros en dicho modelo no son úni-cos ya que la constante c es arbitraria. Entonces se dice que el modelo tieneparámetros redundantes en el modelo ARMA (2, 3) .
Las implicaciones de ajustar y sobre ajustar modelos son las siguientes Cryerand Chan [2008]
1. Especicar el modelo original cautelosamente, si un modelo simple pa-rece adecuado es necesario vericarlo antes de intentar un modelo máscomplicado.
2. Cuando se sobreajuste un modelo, no es aconsejable incrementar el ordende ambas partes del modelo AR y MA simultaneamente.
3. Es importante extender el modelo en la forma sugerida por el análisisde residuales. Por ejemplo, si después de ajustar un modelo MA (1), lacorrelación permanece en el rezago 2, es mejor ajustar un modelo MA (2)en lugar de un ARMA (1, 1) .

Capítulo 7
Pronósticos
Uno de los primeros objetivos al modelar una serie de tiempo, es tener la ca-pacidad de predecir los valores de la serie en el futuro. En el presente capítulo, sedescribirán los cálculos mediante los cuales se pueden predecir sus propiedades.Para la mayoría de los casos, se asumirá que el modelo se conoce, en su totali-dad, incluyendo los valores especícos para todos los parámetros. Sin embargo,en la práctica esto nunca ocurre, no obstante, el uso de los parámetros estimadospara tamaños de muestra considerablemente grandes no afectan drásticamentelos resultados.
7.0.3. Pronóstico por el Método de Error Cuadrático Me-dio
Suponga que Y es una variable aleatoria con media µY y varianza σ2Y . Si
el objetivo principal es predecir Y usando una constante c, se dene un crite-rio común y conveniente el cual consiste en elegir c tal que minimice el errorcuadrático medio de la predicción, es decir que minimice Box and Jenkins [1976]
g (c) = E[(Y − c)2
]= E
(Y 2)− 2cE (Y ) + c2
Luego minimizando g′ (c) = 0
g′ (c) = −2E (Y ) + 2c
Luegoc = E (Y ) = µ (7.1)
Nótese también que
mın−∞<c<∞
= E (Y − µ)2
= σ2Y (7.2)
73

74 CAPÍTULO 7. PRONÓSTICOS
Ahora, considérese la situación donde exista una segunda variable aleato-ria X y se desea usar la X observada para ayudara a predecir Y. Sea ρ =Corr (X,Y ).
En primera medida, se supone, por simplicidad, que solo se pueden usar enla predicción funciones lineales de la forma a + bX. Cryer and Chan [2008] Elerror cuadrático medio es entonces
g (a, b) = E (Y − a− bX)2
= E(Y 2)
+ a2 + b2E(X2)− 2aE (Y ) + 2abE (X)− 2bE (XY )
Luego resolviendo las ecuaciones ∂g(a,b)∂a = 0 y ∂g(a,b)
∂b = 0
∂g (a, b)
∂a= 2a− 2E (Y ) + 2bE (X) = 0
∂g (a, b)
∂b= 2bE
(X2)
+ 2aE (X)− 2E (XY ) = 0
entonces
a+ E (X) b = E (Y )
E (X) a+ E(X2)b = E (XY )
Multiplicando la primera ecuación por E (X) y restando, se obtiene
b =E (XY )− E (X)E (Y )
E (X2)− [E (X)]2 =
Cov (X,Y )
V ar (X)= ρ
σYσX
(7.3)
Luego
a = E (Y )− bE (X) = µY − ρσYσX
µX (7.4)
Sea Y la predicción por error cuadrático medio de Y con base en la funciónde X, entonces se puede escribir
Y =
[µY − ρ
σYσX
µX
]+
[ρσYσX
µX
]X (7.5)
oY − µYσY
= ρ
[X − µXσX
](7.6)
En términos de variables estandarizadas Y ∗ y X∗, se tiene que Y ∗ = ρX∗.Cryerand Chan [2008]
De la misma forma usando las ecuaciones 7.3 y 7.4 se obtiene
mın g (a, b) = σ2Y
(1− ρ2
)(7.7)
Lo cual otorga la prueba que −1 ≤ ρ ≤ 1 ya que g (a, b) ≥ 0.

75
Comparando la ecuación 7.7 con la ecuación 7.2, se concluye que el mínimoerror cuadrático medio que se obtiene cuando se usa una función lineal X con eln de predecir Y se reduce solamente en un factor 1− ρ2Cryer and Chan [2008]
Ahora considérese el problema general, en el cual se desea predecir Y conuna función arbitraria de X. De nuevo el procedimiento a seguir consiste enminimizar el error cuadrático medio de la predicción. Se elige una función h (X),tal que minimice
E [Y − h (X)]2 (7.8)
Usando le ecuación 1.5
E [Y − h (X)]2
= E(E
[Y − h (X)]2 | X
)(7.9)
Usando la ecuación 1.4 la esperanza interna se puede escribir como
E
[Y − h (X)]2 | X
= E
[Y − h (X)]
2 | X = x
(7.10)
Para cada valor de x, h (X) es una constante, y se puede aplicar el resultadode la ecuación 7.1, Entonces, para cada x, la mejor elección de h (X) es
h (x) = E (Y | X = x) (7.11)
Ya que h (x) minimiza la ecuación 7.9 también debe minimizar la ecuación7.8, entonces
h (X) = E (Y | X) (7.12)
es la mejor predicción de Y de todas las funciones de X.Cryer and Chan[2008]
Si X y Y tienen distribuciones normales bivariadas, se sabe que Cryer andChan [2008]
E (Y | X) = µY + ρσYσX
(X − µX)
Entonces las soluciones de las ecuaciones 7.5 y 7.12 coinciden Cryer and Chan[2008]. En este caso , el predictor lineal es el mejor para todas las funciones.
De manera más general si Y necesita ser predicha por una función deX1, X2, . . . , Xn
el predictor por error mínimo cuadrático, está dado porCryer and Chan [2008]
E (Y | X1, X2, . . . , Xn) (7.13)
Basado en la historia de la serie hasta el tiempo t, Yt−1, Y2, . . . , Yt−1, Yt, sedesea pronosticar el valor de Yt+` el cual ocurrirá ` unidades de tiempo en elfuturo. Se le conoce a t como el origen del pronóstico y a ` como el "plazo" parael pronóstico Cryer and Chan [2008], se denota el pronóstico como Yt (`)
El mínimo error cuadrático medio es, teniendo en cuenta la ecuación 7.13,de la forma
Yt (`) = E (Yt+` | Y1, Y2, . . . , Yt) (7.14)

76 CAPÍTULO 7. PRONÓSTICOS
7.0.4. Tendencias Determinísticas
Considérese el modelo de tendencia determinística
Yt = µt +Xt (7.15)
Donde la componente estocástica, Xt, tiene media cero. Para nes prácticosde esta sección, se asumirá que Xt es de hecho ruido blanco con varianza γ0.Para el modelo en la ecuación 7.15, se tiene
Yt (`) = E (µt+` +Xt+` | Y1, Y2, . . . , Yt)
= E (µt+` | Y1, Y2, . . . , Yt) + E (Xt+` | Y1, Y2, . . . , Yt)
= µt+` + E (Xt+`)
oYt (`) = µt+`
Ya que para ` ≥ 1, Xt+` es independiente de Y1, Y2, . . . , Yt−1, Yt y tienevalor esperado cero. Entonces, en este caso, pronosticar consiste en extrapolarla tendencia determinística en el futuro Box et al. [1994].
Para el caso de la tendencia lineal, µt = β0 + β1t, el pronóstico es:
Yt (`) = β0 + β1 (t+ `) (7.16)
En este modelo, se asume que la misma tendencia lineal persiste en el futuro.El error del pronóstico et (`) esta dado por
et (`) = Yt+` − Yt (`)
= µt+` +Xt+` − µt+`= Xt+`
EntoncesE (et (`)) = E (Xt+`) = 0
Luego, se dice que el pronóstico es insesgado. También
V ar (et (`)) = V ar (Xt+`) = γ0 (7.17)
Lo que corresponde a la varianza del error de la predicción para todo plazo`.
7.0.5. Pronósticos de modelos ARIMA
Para los modelos ARIMA, los pronósticos pueden ser expresados de muchasmaneras. Cada expresión contribuye al entendimiento del procedimiento generalcon respecto al cálculo, a la actualización, al incremento de la precisión o alcomportamiento a largo plazo del pronóstico.

77
7.0.5.1. AR (1)
En primera instancia se ilustrarán las ideas que afectan al modelo AR (1)con media cero, el cual satisface
Yt − µ = φ (Yt−1 − µ) + et (7.18)
Considérese el problema de pronosticar una unidad de tiempo en el futuro.Luego la ecuación 7.18 se puede escribir de la siguiente manera
Yt+1 − µ = φ (Yt − µ) + et+1 (7.19)
Dados Y1,Y2, . . . , Yt−1, Yt, se toman las esperanzas condicionales a ambaspartes de la igualdad de la ecuación 7.19, con el n de obtener
Yt (1)− µ = φ [E (Yt | Y1,Y2, . . . , Yt)− µ] + E (et+1 | Y1,Y2, . . . , Yt) (7.20)
Teniendo en cuenta, la propiedad de los valores esperados condicionales setiene
E (Yt | Y1,Y2, . . . , Yt) = Yt (7.21)
También, ya que et+1 es independiente de Y1,Y2, . . . , Yt, se obtiene
E (et+1 | Y1,Y2, . . . , Yt) = E (et+1) = 0 (7.22)
Entonces, la ecuación 7.20 se puede escribir de la siguiente forma
Yt (1) = µ+ φ (Yt − µ) (7.23)
Es decir, que una proporción φ de la desviación de la media del proceso seañade al proceso de la media con el n de pronosticar el valor del siguienteproceso.
Ahora considérese el plazo `. Reemplazando t por t + ` en la ecuación 7.18y tomando los valores esperados a ambas partes de la igualdad se obtiene
Yt (`) = µ+ φ[Yt (`− 1)− µ
]Para ` ≥ 1 (7.24)
Dado que E (Yt+` | Y1,Y2, . . . , Yt) = Yt (`− 1) y para ` ≥ 1, et+` es indepen-diente de Y1,Y2, . . . , Yt.
La ecuación recursiva 7.24 en el plazo `, muestra que el pronostico en cual-quier ` puede ser construido a partir de pronósticos para tiempos más cortosempezando con el pronóstico inicial Yt (1) calculado usando la ecuación 7.23 ysucesivamente hasta llegar al pronóstico Yt (`). La ecuación 7.24 y sus genera-lizaciones para otros modelos ARIMA es muy conveniente para efectos de loscálculos de los pronósticos. La ecuación 7.24 es, en algunas ocasiones, conocidacomo la forma de ecuación diferencia del pronóstico Cryer and Chan [2008].

78 CAPÍTULO 7. PRONÓSTICOS
Sin embargo, la ecuación 7.24 puede ser resuelta para obtener una expresiónexplicita para las predicciones en términos de la historia de la serie observada.Iterando ` en la ecuación 7.24, se tiene
Yt (`) = φ[Yt (`− 1)− µ
]+ µ
= φφ[Yt (`− 2)− µ
]+ µ
...
= φ`−1[Yt (1)− µ
]+ µ
oYt (`) = µ+ φ` (Yt−µ) (7.25)
La desviación de la media actual se descuenta por un factor φ`, cuya mag-nitud es inversamente proporcional al valor `. Esta desviación descontada, esluego añadida a la media del proceso con el n de producir el pronostico en elplazo `
En general, debido a que |φ| < 1, la ecuación 7.25 se puede aproximar de lasiguiente manera
Yt (`) ≈ µ Cuando `→∞ (7.26)
Considérese, el error del pronóstico de un paso adelante et (1) de las ecua-ciones 7.19 y 7.23 se tiene
et (1) = Yt+1 − Yt (1)
= [φ (Yt − µ) + µ+ et+1]− [φ (Yt − µ) + µ]
oet (1) = et+1 (7.27)
El proceso de ruido et puede ser reinterpretado como la secuencia de erro-res de pronóstico de un paso hacia adelante. Nótese que la ecuación 7.27 implicaque el error et (1) es independiente de la historia del proceso Y1, Y2, . . . , Yt−1, Ythasta el tiempo t. Si esto no fuera de esta forma, la dependencia podría serusada para mejorar el pronóstico.
A partir de la ecuación 7.27, se puede inferir que la varianza de los erroresdel pronóstico de un paso está dada por
V ar (et (1)) = σ2e (7.28)
Para obtener las propiedades de los errores de los pronósticos para plazosmayores, es conveniente expresar el modelo AR (1) de la forma de un modelogeneral lineal, MA (∞) de la ecuación 4.13 se tiene que
Yt = et + φet−1 + φ2et−2 + φ3et−3 + · · · (7.29)

79
Luego las ecuaciones 7.25 y 7.29 conducen a
et (`) = Yt−` − µ− φ` (Yt − µ)
= et+` + φet+`−1 + · · ·+ φ`−1et+1 + φ`et
+ · · · − φ` (et + φet−1 + · · · )
Tal queet (`) = et+` + φet+`−1 + · · ·+ φ`−1et+1 (7.30)
La cual puede ser escrita de la siguiente manera
et (`) = et+` + ψ1et+`−1 + ψ2et+`−2 + · · ·+ ψ`−1et+1 (7.31)
La cual se mostrará (Ecuación 7.53) que se cumple para todos los modelosARIMA.
Nótese que E (et (`)) = 0, por lo tanto los pronósticos son insesgados. Ade-más, de la ecuación 7.31 se obtiene
V ar (et (`)) = σ2e
(1 + ψ2
1 + ψ22 + · · ·+ ψ2
`−1
)(7.32)
Se puede ver que la varianza del error de pronóstico es proporcional a losincrementos `. En particular para el caso AR (1)
V ar (et (`)) = σ2e
[1− φ2`
1− φ2
](7.33)
La cual se obtiene con la suma de la serie geométrica nita.Además,
V ar (et (`)) ≈ σ2e
1− φ2Cuando `→∞
oV ar (et (`)) ≈ V ar (Yt) = γ0 Cuando `→∞ (7.34)
Más adelante se mostrará que la ecuación 7.34 es válida para todos los mo-delos estacionarios ARMA. (Ecuación 7.50)
7.0.5.2. MA (1)
Para ilustrar como resolver los problemas que surgen en los pronósticos delos modelos de promedios móviles o de los modelos mixtos. Considérese el casoMA (1) con media diferente de cero
Yt = µ+ et − θet−1
Reemplazando t por t+ 1, y tomando valores esperados en ambas partes dela igualdad se obtiene
Yt (1) = µ− θE (et | Y1, Y2, . . . , Yt) (7.35)

80 CAPÍTULO 7. PRONÓSTICOS
Sin embargo, para un modelo invertible la ecuación 4.39 (Página 38) muestraque et es una función de Y1, Y2, . . . , Yt y entonces
E (et | Y1, Y2, . . . , Yt) = et (7.36)
De hecho una aproximación está involucrada en esta ecuación ya que se estácondicionando el valor de Et con una serie nita, y no con la historia innita delproceso. Sin embargo, si t es lo sucientemente grande y el modelo es invertible,el error en la aproximación será mínimo.
Usando las ecuaciones 7.35 y 7.36 se tendría el pronóstico de un paso haciaadelante para un modelo invertible MA (1) expresado de la siguiente manera
Yt (1) = µ− θet (7.37)
El cálculo de et será un producto de las estimaciones de los parámetros enel modelo. De nuevo el error del pronóstico de un paso es
et (1) = Yt+1 − Yt (1)
= (µ+ et+1 − θet)− (µ− θet)= et+1
Luego, para plazos de tiempo mayores, se tiene
Yt (`) = µ+ E (et+` | Y1, Y2, . . . , Yt)− θE (et+`−1 | Y1, Y2, . . . , Yt)
Pero para ` > 1, ambos et+` y et+`−1 son independientes de Y1, Y2, . . . , Yt.Consecuentemente los valores esperados condicionales son valores incondiciona-les y se tiene
E[Yt (`)] = Yt(`) = µ Para ` > 1 (7.38)
7.0.5.3. ARMA (p, q)
Para el modelo general estacionario ARMA (p, q) , la forma de ecuación di-ferencia para al cálculo de los pronósticos está dada por Box et al. [1994]
Yt (`) = φ1Yt (`− 1) + φ2Yt (`− 2) + +φpYt (`− p) + θ0− (7.39)
θ1E (et+`−1 | Y1, Y2, . . . , Yt)− θ2E (et+`−2 | Y1, Y2, . . . , Yt)
− · · · − θqE (et+`−q | Y1, Y2, . . . , Yq)
Donde
E (et+j | Y1, Y2, . . . , Yt) =0 Para j > 0et+j Para j ≤ 0
(7.40)
Se puede notar que Yt (j) es un pronóstico verdadero para j > 0, pero,para j ≤ 0 Yt (j) = Yt+j . Al igual que antes, la ecuación 7.40 involucra ciertaaproximación. Para un modelo invertible, la ecuación 4.42 muestra que usandolos pesos π, et puede ser expresado como una combinación lineal de la secuencia

81
innita Yt, Yt−1, Yt−2, . . . . Sin embargo, los pesos π, decrecen exponencialmenterápido, y la aproximación asume que πj es irrelevante para j > t− q.
Como ejemplo, considérese el modelo ARMA (1, 1)
Yt = φYt + θ0 − θet (7.41)
conYt (2) = φYt (1) + θ0
Y de forma más general
Yt (`) = φYt (`− 1) + θ0 Para ` ≥ 2 (7.42)
Usando la ecuación 7.41 para comenzar la ecuación recursiva.Las ecuaciones 7.41 y 7.42 pueden ser reescritas en términos de la media del
proceso y luego solucionada iterando para obtener la expresión alternativa
Yt (`) = µ+ φ` (Yt − µ)− φ`−1et Para ` ≥ 1 (7.43)
Como lo indican las ecuaciones 7.39 y 7.40, los términos del ruido et−(q−1), . . . , et−1, etaparecen directamente en el cálculo de los pronósticos para plazos ` = 1, 2, . . . , q.Sin embargo, para ` > q, la porción autorregresiva de la ecuación diferencia sehace cargo, y de esa forma se obtiene
Yt (`) = φ1Yt (`− 1) + φ2Yt (`− 2) + +φpYt (`− p) + θ0 Para ` > q (7.44)
Es decir, la naturaleza del pronóstico para plazos extensos será determinadopor los parámetros autorregresivos φ1,φ2, . . . , φp y el término constante, θ0, quees relacionado con la media del proceso.
Teniendo en cuenta la ecuación 5.28 (Página 46) θ0 = µ (1− φ1 − φ2 − . . .− φp) ,se puede escribir la ecuación 7.44 en términos de es desviaciones respecto a lamedia µ de la siguiente manera
Yt (`)− µ = φ1
[Yt (`− 1)− µ
]+ φ2
[Yt (`− 2)− µ
]+ · · ·+ φp
[Yt (`− p)− µ
](7.45)
Para ` > q.Como función de `, Yt (`) − µ sigue las mismas condiciones de la función
ρk respecto a las ecuaciones de Yule-Walker 4.33 (Página en la página 36), porlo cual, las raíces de la ecuación característica determinará el comportamientogeneral de Yt (`)− µ, para ` extensos.
Entonces, para un modelo ARMA estacionario, Yt (`) − µ es inversamenteproporcional a `, y el pronóstico a largo plazo es simplemente la media delproceso µ como fue descrito en la ecuación 7.26. Esto es conforme a la ideaintuitiva de que en un modelo estacionario ARMA la dependencia decrece a laproporción que los espacios de tiempo entre las observaciones aumentan.
Con el n de validar la ecuación 7.32 para et (`), es necesario considerar unanueva representación para los procesos ARIMA. Usualmente de dice que un

82 CAPÍTULO 7. PRONÓSTICOS
modelo ARIMA puede ser expresado como un proceso lineal truncado Cryerand Chan [2008] de la siguiente manera
Yt+` = Ct (`) + It (`) Para ` > 1 (7.46)
Donde Ct (`) es una función de Yt, Yt−1,... y
It (`) = et+` + ψ1et+`−1 + ψ2et+`−2 + · · ·+ ψ`−1et+1 Para ` ≥ 1 (7.47)
Además para modelos invertibles con t razonablemente grande, Ct (`) escierta función de la historia nita Yt, Yt−1, . . . , Y1, entonces se tiene
Yt (`) = E (Ct (`) | Yt, Yt−1, . . . , Y1) + E (It (`) | Yt, Yt−1, . . . , Y1)
= Ct (`)
Finalmente
et (`) = Yt−` − Yt (`)
= [Ct (`) + It (`)]− Ct (`)
= It (`)
= et+` + ψ1et+`−1 + ψ2et+`−2 + · · ·+ ψ`−1et+1
Entonces, para un modelo invertible general ARIMA
E [et (`)] = 0 Para ` ≥ 1 (7.48)
y
V ar (et (`)) = σ2e
`−1∑j=0
ψ2j Para ` ≥ 1 (7.49)
Teniendo en cuenta las ecuaciones 4.4 y 7.49, se ve que para plazos extensosen procesos ARMA, se tiene
V ar (et (`)) ≈ σ2e
∞∑j=0
ψ2j
oV ar (et (`)) ≈ γ0 Para `→∞ (7.50)
7.0.6. Modelos no Estacionarios
Los pronósticos para modelos ARIMA no estacionales son muy similares alos pronósticos para modelos estacionales ARMA, excepto por ciertas diferen-cias. Teniendo en cuenta la ecuación 5.14 (Página 42) que permite escribir un mo-delo ARIMA (p, 1, q) como un modelo no estacionario ARMA (p+ 1, q) .Cryerand Chan [2008]
Yt = ϕ1Yt−1 + ϕ2Yt−2 + ϕ3Yt−3 + · · ·+ ϕpYt−p + ϕp+1Yt−p−1 (7.51)
+ et − θ1et−1 − θ2et−2 − · · · − θqet−q

83
Donde los coecientes ϕ están directamente relacionados con los coecientesde bloque φ. En particular
ϕ1 = 1 + φ1, φj = φj − φj−1 Para j = 1, 2, . . . , pyϕp+1 = −φp
Para un orden general de diferencia d, se tendrían p+d coecientes ϕ. Cryer
and Chan [2008]De dicha representación, se pueden extender las relaciones establecidas en
las ecuaciones 7.39, 7.40 y 7.42 con el n de cubrir los casos no estacionariosreemplazando p por p+ d y φj por ϕj .Cryer and Chan [2008]
Como ejemplo, considérese el caso ARIMA (1, 1, 1)
Yt − Yt−1 = φ (Yt−1 − Yt−2) + θ0 + et − θet−1
entoncesYt = (1 + φ)Yt−1 − φYt−2 + θ0 + et − θet−1
LuegoYt (1) = (1 + φ)Yt − φYt−1 + θ0 − θetYt (2) = (1 + φ) Yt (1)− φYt + θ0
yYt (`) = (1 + φ) Yt (`− 1)− φYt (`− 2) + θ0
(7.52)
Para el modelo general invertible ARIMA, la representación lineal truncadadel proceso dado en las ecuaciones 7.46 y 7.47 y los cálculos inherentes a dichasecuaciones se puede escribir
et (`) = et+` + ψ1et+`−1 + ψ2et+`−2 + · · ·+ ψ`−1et+1 Para ` ≥ 1 (7.53)
y entoncesE (et (`)) = 0 Para ` ≥ 1 (7.54)
y
V ar (et (`)) = σ2e
`−1∑j=0
ψ2j Para ` ≥ 1 (7.55)
Sin embargo, para series no estacionarias, los pesos ψ no decrecen mientrasj aumenta. Entonces, para un modelo no estacionario, la ecuación 7.55, mues-tra que el error del pronostico crecerá sin limite cuando el plazo ` crece. Estehecho también sigue el pensamiento intuitivo ya que en una serie de tiempo noestacionaria el futuro distante es muy incierto.
7.0.7. Límites de la Predicción
Como en la mayoría de los métodos estadísticos, en la predicción, aparte depronosticar los valores desconocidos de Yt+`, es importante estimar la precisiónde dichas predicciones.

84 CAPÍTULO 7. PRONÓSTICOS
7.0.7.1. Tendencias Determinísticas
Para el modelo de tendencia determinística con un componente estocásticode ruido blanco Xt, se tiene que
Yt (`) = µt+`
y
V ar (et (`)) = V ar (Xt+`) = γ0
Si la componente estocástica está normalmente distribuida, entonces el errordel pronóstico es
et (`) = Yt+` − Yt (`) = Xt+Yt(`)(7.56)
También está normalmente distribuida, entonces para para un nivel de con-anza 1− α, se puede usar un percentil z1−α2 con el n de decir
P
[−z1−α2 <
Yt+` − Yt (`)√V ar (et (`))
< z1−α2
]= 1− α
o equivalentemente
P[Yt (`)− z1−α2
√V ar (et (`)) < Yt+` < Yt (`) + z1−α2
√V ar (et (`))
]= 1− α
Entonces, se tiene una certeza de (1− α) 100 % que la observación futuraYt+` estará contenida en los límites de predicción Box and Jenkins [1976]
Yt (`)± z1−α2
√V ar (et (`)) (7.57)
7.0.7.2. Modelos ARIMA
Si los términos del ruido blanco et en un modelo ARIMA general surgenindependientemente de una distribución normal. De la forma de la ecuación7.53 se puede asegurar que el error del pronóstico et (`) , también tendrá unadistribución normal y los pasos realizados anteriormente tendrán validez. Sinembargo, en contraste con el modelo de tendencia determinística
V ar (et (`)) = σ2e
`−1∑j=0
ψ2j
En la práctica, σ2e no es conocido y debe ser estimado partiendo de la serie
observada. Los pesos ψ, son también desconocidos, ya que son funciones quedependen de los valores desconocidos de φ y θ. Estas estimaciones tendrán unmínimo efecto en los limites de la predicción nombrados anteriormente.

85
7.0.8. Actualización de los Pronósticos ARIMA
Supóngase que se desea estimar una serie de tiempo mensual. La última ob-servación es Febrero, y se pronosticaron los valores para Marzo, Abril y Mayo.Conforme al tiempo transcurre, los verdaderos valores de Marzo están disponi-bles. Con este valor nuevo en la serie observada, se desea actualizar o revisar(en el mejor de los casos mejorar), los pronósticos para Abril y Mayo.
En general, para un pronóstico original t y un plazo ` + 1, el pronósticooriginal Yt (`+ 1) una vez que la observación en el tiempo t+ 1 esté disponible,se busca actualizar el valor del pronóstico como Yt+1 (`). Las ecuaciones 7.46 y7.47 conducen a Cryer and Chan [2008]
Yt+`+1 = Ct (`+ 1) + et+`+1 + ψ1et+` + ψ2et+`−1 + · · ·+ ψ`et+1
Ya que Ct (`+ 1) y et+1 son funciones de Yt+1, Yt, . . . , donde et+`+1, et+`, . . . , et+2
son independientes de Yt+1, Yt, . . . , se obtiene la expresión
Yt+1 (`) = Ct (`+ 1) + ψ` + ψ`et+1
Sin embargo, Yt+1 (`+ 1) = Ct (`+ 1) y et+1 = Yt+1 − Yt (1) . Por lo tantola ecuación general de actualización está dada por Cryer and Chan [2008]
Yt+1 (`) = Yt+1 (`+ 1) + ψ`
[Yt+1 − Yt (1)
](7.58)
Donde[Yt+1 − Yt (1)
]es el error del pronóstico en el tiempo t + 1 una vez
que Yt+1 ha sido observado.
7.0.9. Pesos de Pronósticos y Promedios Móviles Expo-nencialmente Ponderados.
Para los modelos ARIMA que no contengan términos de promedios móviles,es claro como los pronósticos son explícitamente determinados a partir de la serieYt, Yt−1, . . . , Y1. Sin embargo, para cualquier modelo con q > 0, los términos delruido aparecen en el pronóstico y la naturaleza de los pronósticos explícitamenteen términos de Yt, Yt−1, . . . , Y1 está oculta. Para sacar a relucir dicho aspecto delos pronósticos se revisara el modelo inverso de un proceso ARIMA invertible
Yt = π1Yt−1 + π2Yt−2 + π3Yt−3 + · · ·+ et
Entonces, Yt+1 se puede escribir de la siguiente manera
Yt+1 = π1Yt + π2Yt−1 + π3Yt−2 + · · ·+ et+1
Tomando los valores esperados en ambas partes de la igualdad, dado Yt,Yt−1, . . . , Y1
se obtieneYt (1) = π1Yt + π2Yt−1 + π3Yt−2 + · · · (7.59)

86 CAPÍTULO 7. PRONÓSTICOS
De nuevo se asume que el valor de t es lo sucientemente grande o que losvalores de los pesos π se desvanescan lo sucientemente rápido de forma queπt, πt+1, .. son irrelevantes.
Para cualquier modelo ARIMA invertible, los pesos π pueden ser calculadosrecursivamente de las expresionesBox et al. [1994]
πj =
mın(j,q)∑i=1
θiπj−1 + ϕj Para 1 ≤ j ≤ p+ d
mın(j,q)∑i=1
θiπj−1 Para j > p+ d
(7.60)
Con el valor inicial π0 = −1Considérese, en particular el modelo no estacionario IMA (1, 1)
Yt = Yt−1 + et − θet−1
En este caso p = 0, d = 1, q = 1, con ϕ1 = 1, entonces
π1 = θπ0 + 1 = 1− θπ2 = θπ1 = θ (1− θ)
y de manera general
π2 = θπj−1 Para j > 1
Explícitamenteπj = (1− θ) θj−1 Para j ≥ 1
Así la ecuación 7.59 permite escribir
Yt (1) = (1− θ)Yt + (1− θ) θYt−1 + (1− θ) θ2Yt−2 + · · · (7.61)
En este caso los pesos π decrecen de forma exponencial, y además∞∑j=1
πj = (1− θ)∞∑j=1
θj−1 =1− θ1− θ
= 1
A Yt (1) se le conoce como promedios móviles exponencialmente ponderados(EWMA por sus siglas en inglés) Cryer and Chan [2008]. Donde Yt (1) se puedeescribir como Box et al. [1994]
Yt (1) = (1− θ)Yt + θYt−1 (1) (7.62)
y
Yt (1) = Yt−1 (1) + (1− θ)[Yt − Yt−1 (1)
](7.63)
Las ecuaciones 7.62 y 7.63 muestran la manera de actualizar los pronósticosdel tiempo de origen t − 1 al tiempo t, y expresan los resultados como unacombinación lineal de la nueva observación y el pronóstico antiguo en términosdel pronóstico antiguo y del ultimo error de pronóstico observado.
El parámetro 1 − θ es conocido como la constante de suavizamiento y suestimación es a menudo arbitraria.

87
7.0.10. Pronósticos de Series de Tiempo Transformadas
7.0.10.1. Operador Diferencia
Supóngase que interesa pronosticar una serie de tiempo, cuyo modelo involu-cra un primera diferencia con el n de obtener estacionariedad. A continuaciónse describirán dos métodos con los cuales se puede obtener el pronostico ante-riormente dicho Guerrero [1998].
1. Pronosticar la serie de tiempo no estacionaria original.
2. Pronosticar la serie diferenciada Wt = Yt−Yt−1 y luego volver a los datosoriginales sumando nuevamente los valores previamente substraídos
Sin embargo se mostrará que ambos métodos proveen el mismo resultado. Estose debe esencialmente a que el operador diferencia es un operador lineal, yporque la esperanza condicional de una combinación lineal es la combinaciónlineal de las esperanzas condicionales Box et al. [1994]
Considérese, en particular, el modelo IMA (1, 1) . Pronosticando basados enla serie no estacionaria
Yt (1) = Yt − θet (7.64)
yYt (`) = Yt (`− 1) Para ` > 1 (7.65)
Considérese ahora el modelo diferenciado estacionario MA (1) Wt = Yt −Yt−1. Se pronosticará Wt+` como
Wt (1) = −θet
yWt (`) = 0 Para ` > 1 (7.66)
Sin embargo Wt (1) = Yt (1)−Yt; por lo tanto Wt (1) = −θet es equivalente aYt (1) = Yt−θet. Similarmente Wt (`) = Yt (`)− Yt (`− 1) , y la ecuación 7.66 seconvierte en le ecuación 7.65 con lo que se muestra que la consideración anteriores cierta.
El mismo resultado se aplica para cualquier modelo que involucre diferenciasde cualquier orden y para cualquier tipo de transformación lineal con coecientesconstantes.
7.0.10.2. Transformaciones Logarítmicas
Sea Yt la serie de tiempo original y sea Zt = log (Yt) .
E (Yt+` | Yt, Yt−1, . . . , Y1) ≥ e[E(Zt+`|Zt,Zt−1,...,Z1)]
Entonces, el pronóstico e[Zt(`)], no es el pronóstico de mínimo error cuadráti-co medio, de Yt+`. Para evaluar el pronóstico de mínimo error cuadrático medioen términos de la serie original, se tiene que tener en cuenta el siguiente hecho

88 CAPÍTULO 7. PRONÓSTICOS
Box et al. [1994]: Si X tiene distribución normal con media µ y varianza σ2,entonces
E[eX]
= e
[µ+σ2
2
]Donde para efectos del caso particular presentado anteriormente se tiene que
Box et al. [1994]µ = E (Zt+` | Zt, Zt−1, . . . , Z1)
y
σ2 = V ar (Zt+` | Zt, Zt−1, . . . , Z1)
= V ar [et (`) + Ct (`) | Zt, Zt−1, . . . , Z1]
= V ar [et (`) | Zt, Zt−1, . . . , Z1] + V ar [Ct (`) | Zt, Zt−1, . . . , Z1]
= V ar [et (`) | Zt, Zt−1, . . . , Z1]
= V ar [et (`)]
El resultado anterior se debe a los resultados de las ecuaciones 7.46 y 7.47 yal hecho que Ct (`) es una función de Zt, Zt−1, . . . , donde et (`) es independientede Zt, Zt−1, . . . . Entonces el pronóstico de mínimo error cuadrático medio de laserie original está dado por Box et al. [1994]
e
Zt(`)+
1
2V ar[et(`)]
(7.67)
A través de la descripción del método de pronósticos para series de tiempolog-transformadas, se ha asumido que el mínimo error cuadrático medio es elcriterio idóneo para la elección del pronostico. Para variables aleatorias nor-malmente distribuidas el criterio de mínimo error cuadrático medio es el mejorcriterio. Sin embargo si Zt tiene una distribución normal, entonces Yt = eZt
tiene una distribución log-normal, por lo cual se necesita un criterio diferente.En particular, ya que la distribución log-normal es asimétrica y tiene una coladerecha pesada, un criterio basado en el error absoluto de la media puede sermás apropiado. Para este criterio, el pronóstico óptimo es la mediana de la dis-tribución condicional de Zt+` sobre Zt, Zt−1, . . . , Z. Teniendo en cuenta que latransformación logarítmica preserva el valor de la mediana, y ya que para unadistribución normal, la media y la mediana son iguales, el pronóstico
e[Zt (`)
]es el pronóstico óptimo para Yt+`, en el sentido que minimiza el error absoluto
del pronóstico de la media Cryer and Chan [2008].

Capítulo 8
Modelos de Estado y Espacioy el Filtro Kalman
La teoría del control es un campo que trata con el comportamiento de siste-mas dinámicos, es decir sistemas que cambian su estado a medida que el tiempotranscurre, debido a que la denición es bastante amplia los modelos de esta-do y espacio pueden ser aplicados a diferentes problemas de la vida diaria. Unejemplo de su gran importancia es, por ejemplo, su utilización el los algoritmosdel piloto automático de una nave, razón por la cual el hombre fue capaz dellegar a la luna.
Esta teoría ha sido satisfactoriamente desarrollada y ha sido llamada modelosde estado y espacio y Filtro Kalman desde que Kalman publico su trabajo en1960.
Denición 49 Considérese un proceso ARMA (p, q) invertible Zt . Sea m =max (p, q + 1), se dene el estado del proceso en el tiempo t como el vectorcolumna Z (t) de longitud m cuyo j − esimo elemento es el pronóstico Z (j)para j = 0, 1, 2, . . . ,m − 1, basado en Zt, Zt−1, . . . . Teniendo en cuenta que elelemento de pronostico de Z (t) es simplemente Z (0) = Zt
Usando la ecuación de actualización (Ecuación 7.58, Página 85), la cual enel contexto actual puede ser escrita como
Zt+1 (`) = Zt (`+ 1) + ψ`et+1 (8.1)
Dicha expresión se usará directamente apara ` = 0, 1, 2, . . . ,m − 2. Para` = m− 1, se tiene
Zt+1 (m− 1) = Zt (m) + ψm−1et+1 (8.2)
= φ1Zt+1 (m− 1) + φ2Zt (m− 2) + · · ·+ φpZt (m− p) + ψm−1et+1
Donde la última expresión se deduce de la ecuación 7.39 con µ = 0.
89

90CAPÍTULO 8. MODELOS DE ESTADOY ESPACIO Y EL FILTROKALMAN
La formulación matricial de las ecuaciones 8.1 y 8.2 relacionando Z (t+ 1)con Z (t) y et+1, llamadas las ecuaciones de estado (o Representación Marko-viana de Akaike)Box et al. [1994] está dada por
Z (t+ 1) = FZ (t) +Get+1 (8.3)
donde
F =
0 1 0 0 · · · 00 0 1 0 · · · 00 0 0 1 · · · 0...
......
.... . .
...0 0 0 0 · · · 1φm φm−1 φm−2 φm−3 · · · φ1
(8.4)
y
G =
1ψ1
ψ2
...ψm−1
(8.5)
Con φj = 0 para j > p. Nótese que la simplicidad de la ecuación 8.3 se debea la utilización de los procesos de cada uno de los valores de los vectores. Debidoa que la formulación de estado y espacio permite medir el error, usualmente,no se observa Zt directamente sino que se observa Yt, a través de la ecuaciónobservacional
Yt = HZ (t) + ε (8.6)
DondeH = [1, 0, 0, . . . , 0] y εt es un proceso de ruido blanco con media ceroindependiente de et. El caso especial donde no se toma en cuenta el error demedida, se obtiene estableciendo εt = 0 en la ecuación. Equivalentemente, estecaso se obtiene tomando σ2
ε = 0. Los modelos de estado espacio más generalespermiten que F,G y H sean mas generales e incluso posiblemente dependientesdel tiempo.
8.1. Evaluación de la Función de Verosimilitud y
el Filtro Kalman
Como primera medida se recuerda la denición de la matriz de covarianzas(Denición 21) además del siguiente teorema Cryer and Chan [2008]
Teorema 50 Si Y = AX + B, la matriz de covarianzas para Y es AV AT ,donde V es la matriz de covarianzas de X y el superíndice T denota la matriztranspuesta.

8.1. EVALUACIÓN DE LA FUNCIÓN DE VEROSIMILITUD Y EL FILTROKALMAN91
Sea Z (t+ 1 | t) el vector de dimensión m × 1 cuya j − esima componente
es E[Zt+1 (j) | Yt, Yt−1, . . . , Y1
]para j = 0, 1, 2, . . . ,m− 1. De la misma forma,
sea Z (t | t) el vector cuya j− esima componente es E[Zt (j) | Yt, Yt−1, . . . , Y1
]para j = 0, 1, 2, . . . ,m− 1.
Entonces, teniendo en cuenta que et+1 es independiente de Zt, Zt−1, . . . , ypor ende, también es independiente de Yt, Yt−1, . . . , Y1, gracias a la ecuación 8.3se puede concluir que
Z (t+ 1 | t) = FZ (t | t) (8.7)
De la misma manera, sea P (t+ 1 | t) la matriz de covarianzas para el errordel pronóstico Z (t− 1) − Z (t+ 1 | t) y P (t | t) la matriz de covarianzas delerror del pronóstico Z (t)− Z (t | t) , gracias a la ecuación 8.3 se puede escribir
P (t+ 1 | t) = F [P (t | t)]FT + σ2eGG
T (8.8)
Teniendo en cuenta la ecuación observacional 8.6 y reemplazando t+ 1 port se obtiene
Y (t+ 1 | t) = HZ (t+ 1 | t) (8.9)
donde Y (t+ 1 | t) = E (Yt+1 | Yt, Yt−1, . . . , Y1)Según Cryer and Chan [2008] la siguiente relación se cumple
Z (t+ 1 | t+ 1) = Z (t+ 1 | t) +K (t+ 1) [Yt+1 − Y (t+ 1 | t)] (8.10)
donde
K (t+ 1) = P (t+ 1 | t)HT[HP (t+ 1 | t)HT + σ2
ε
]−1(8.11)
y
P (t+ 1 | t+ 1) = P (t+ 1 | t)−K (t+ 1)HP (t+ 1 | t) (8.12)
Colectivamente las ecuaciones 8.10, 8.11 y 8.12 son llamadas las ecuacionesdel ltro KalmanBox et al. [1994]. La cantidad
errt+1 = Yt+1 − Y (t+ 1 | t) (8.13)
en la ecuación 8.10 es el error de la predicción y es independiente (o al menosno esta correlacionado) de las observaciones del pasado Yt, Yt−1, . . . . Debido aque se está permitiendo la medida del error errt+1 es, en general, diferente deet+1Box et al. [1994]
De las ecuaciones 8.13 y 8.6 se obtiene
vt+1 = V ar (errt+1) = HP (t+ 1 | t)HT + σ2ε (8.14)
Ahora se considera la función de verosimilitud para la serie de tiempo ob-servada Y1, Y2, , Yn, de la denición de la función condicional de densidad deprobabilidad se obtiene
f (y1, y2, . . . , yn) = f (yn | y1, y2, . . . , yn−1) f (y1, y2, . . . , yn−1)

92CAPÍTULO 8. MODELOS DE ESTADOY ESPACIO Y EL FILTROKALMAN
Tomando logaritmos
log f (y1, y2, . . . , yn) = log f (y1, y2, . . . , yn−1) + log f (yn | y1, y2, . . . , yn−1)(8.15)
Ahora, se asume que se está trabajando con distribuciones normales, es decirque et y εt son proceso de ruido blanco normalmente distribuidos.Luegose sabe que la distribución de Yn dado Y1 = y1, Y2 = y2, . . . , Yn−1 = y1, estambién una distribución normal con media y (n | n− 1) y varianza vn. Entoncesel segundo término de la parte derecha de la igualdad de la ecuación 8.15 sepuede escribir de la siguiente manera
log f (yn | y1, y2, . . . , yn−1) = −1
2log (2π)− 1
2log (vn)− 1
2
[yn − y (n | n− 1)]2
vn
Además, el primer término de la parte derecha de la igualdad de la ecuación8.15 puede ser descompuesto una y otra vez hasta obtener
log f (y1, y2, . . . , yn) =
n∑t=2
log f (yt | y1, y2, . . . , yt−1) + log f (y1) (8.16)
El cual se convierte en el error de predicción de la composición de la verosi-militud Box et al. [1994]
log f (y1, y2, . . . , yn) = −n2
log (2π)− 1
2
n∑t=1
vt−1
2
n∑t=1
[yn − y (n | n− 1)]2
vn(8.17)
con y (1 | 0) = 0 y v1 = V ar (Y1)− .La estrategia general usada para calcular la verosimilitud para un conjunto
dado de parámetros es usar las ecuaciones del ltro Kalman con el n de generarrecursivamente los errores de predicción y sus varianzas y luego usar el error depredicción de la composición de la verosimilitud. En este punto solo faltan losvalores iniciales Z (0 | 0) y P (0 | 0) para iniciar las ecuaciones recursivas.
8.2. Estado Inicial de la Matriz de Covarianzas
El vector de estado inicial Z (0 | 0) será un vector nulo para un procesocon media igual a cero, y P (0 | 0) es la matriz de covarianzas para Z (0) −Z (0 | 0) = Z (0) . Debido a que Z (0) es el vector columna con elementos[Z0, Z0 (1) , . . . , Z0 (m− 1)
], es necesario evaluar
Cov(Z0 (i) , Z0 (j)
)Para i, j = 0, 1, . . . ,m− 1
Para los procesos lineales truncados, (Ecuación 7.46) con Ct (`) = Zt (`) , sepuede escribir, para j > 0
Zj = Z0 (j) +
−1∑k=−j
ψj+ke−k (8.18)

8.2. ESTADO INICIAL DE LA MATRIZ DE COVARIANZAS 93
Multiplicando la ecuación 8.18 por Z0 y tomando valores esperados se obtiene
γj = E (Z0Zj) = E[Z0 (0)
(Z0 (j)
)]Para j ≥ 0 (8.19)
Elevando la ecuación 8.18 al cuadrado, tomando valores esperados, teniendoen cuenta que e es independiente de Z y asumiendo que 0 < i ≤ j se obtiene
γj−1 = Cov[Z0 (i) , Z0 (j)
]+ σ2
e
i−1∑k=0
ψkψk+j−1 (8.20)
Combinando las ecuaciones 8.19 y 8.18, se obtiene
Cov[Z0 (i) , Z0 (j)
]=
γi 0 = i ≤ j ≤ m− 1
γj−1 − σ2e
i−1∑k=0
ψkψk+j−1 1 ≤ i ≤ j ≤ m− 1
(8.21)donde los pesos ψ son obtenidos por medio de la ecuación recursiva 4.32 (Pá-
gina 36), y γk, la función de autocovarianza para el proceso Zt , se obtiene dela misma manera que la función de autocovarianza de un procese ARMA (p, q) .Cryer and Chan [2008]
La varianza σ2e puede ser removida dividiendo σ2
ε por σ2e . La varianza del
error de la predicción vt es reemplazada por σ2evt en la función de log-verosimilitud
de la ecuación 8.17 y igualando σ2e = 1 en la ecuación 8.8. se obtiene una nueva
ecuación de log-verosimilitud
` =
n∑t=1
log(σ2
2vt)
+[yt− y (t | t− 1)]
2
vt
(8.22)
La cual puede ser minimizada con respecto a σ2e . obteniendo
σ2e =
n∑t=1
[yt − y (t | t− 1)]
2
σ2evt
(8.23)
Sustituyendo este resultado en la ecuación 8.22 se obtiene
` =
n∑t=1
log (vt) + n log
n∑t=1
[yt − y (t | t− 1)]2
vt(8.24)
La cual es conocida como la función de log-verosimilitud concentrada.Box et al. [1994]

94CAPÍTULO 8. MODELOS DE ESTADOY ESPACIO Y EL FILTROKALMAN

Conclusiones
Se espera que el anterior texto haya desarrollado las deniciones, teoremasy métodos básicos para la construcción del concepto de serie de tiempo deuna manera clara y concreta, sirviendo como una referencia teórica básica detema. Sin embargo el tema desarrollado anteriormente no es la décima partede toda la teoría y metodología inherente a las series de tiempo, ya que lasseries cronológicas ha sido quizás el tema de mayor expansión y transversalidaden múltiples áreas del conocimiento las ultimas décadas. Razón por la cual seinvita al lector a ahondar en el tema y profundizar la investigación de este temaque es y será de gran utilidad en diferentes disciplinas.
1
1Para consultar la parte practica de toda la teoria vista en el documento vease Yate
95

96 CONCLUSIONES

Bibliografía
H. Akaike. Maximum likelihood identication of Gaussian autoregressive movingaverage models. Biometrika, 60:255265, 1973.
H. Akaike. A new look at the statistical model identication. IEEE Transactionson Automatic Control, 19:716723, 1974.
G. E. P. Box and G. M. Jenkins. Time Series Analysis. Holden-Day, SanFrancisco, 1976.
George E. Box, Gwilym M Jenkins, and Gregory C Reinsel. Time Series Analy-sis, Forecasting and Control. Prentice-Hall, Londres, 1994.
David R. Brillinger. Time Series, Data Analysis and Theory. SIAM, Londres,2001.
George Canavos. Probabilidad y Estadística, Aplicaciones y Métodos. McGrawHill, México, 1998.
Kung-Sik Chan. TSA: Time Series Analysis, 2010. URLhttp://CRAN.R-project.org/package=TSA. R package version 0.98.
W.S. Chan. A comparison of some pattern identication methods for orderdetermination of mixed arma models. Statistics and Probability Letters,, 85:413426, 1999.
C. Chateld. The Analysis of Time Series, An Introduction. Chapman & Hall,London, UK, 1982.
Chris Chateld. The Analysis of Time Series An Introduction. Chapman &Hall, 2005.
Jonathan Cryer and Kung-Sik Chan. Time Series Analysis With Aplications inR. Springer, Iowa, 2008.
Peter J. Brockwell Richard A. Davis. Time Series: Theory and Methods. Spriger,Nueva York, 1987.
F.M Dekking, C Kraaikamp, H.P Lopuhaa, and L.E Meester. Probabilidad yEstadística. Springer, 2005.
97

98 BIBLIOGRAFÍA
J. Durbin. The tting of time series models. Review of the International Stati-sical Institute, 28:233243, 1960. Cited in ?.
W. Feller. An Introduction to Probability Theory and its Applications, volume 2.John Wiley & Sons, New York, 1971. Second Edition.
W. Fuller. Introduction to statistical time series. Wiley, New York, 1976.
Wayne A. Fuller. Introduction to Statistical Time Series. Wiley Series in Pro-bability and Statistics, 1996.
V. Gmurman. Teoria de las Probabilidades y Estadística Matemática. MoscúEditorial, 1974.
Victor M. Guerrero. Análisis Estadístico de Series de Tiempo Económicas.Thomson, México, 1998.
James D Hamilton. Time Series Analysis. Princeton University Press, 1994.
Genshiro Kitagawa. Introduction to Time Series Modeling. CRC Press, 2010.
B. O. Koopman. The Bases of Probability. John Wiley and Sons, New York,1964.
J.K. Lindsey. Statistical Analysis of Stochastic Processes in Time. Cambridge,2004.
Douglas C. Montgomery, Cheryl L. Jennings, and Murat Kulahaci. Introductionto Tme Series and Forecasting. Wiley Series in Probability and Statistics,2008.
Daniel Peña and George E. Box. Identifying a simpliying structure in timeseries. Jorunal of the American Statistical Association, 82:836843, 1987.
Fredy O. Pérez. Introducción a las Series de Tiempo, Métodos Paramétricos.Universidad de Medellin, 2007.
R Development Core Team. R: A Language and Environment for StatisticalComputing. R Foundation for Statistical Computing, Vienna, Austria, 2010.URL http://www.R-project.org/. ISBN 3-900051-07-0.
Luis Fransisco Rincón. Texto guia de probabilidad. Universidad Santo Tomás,Bogotá, 2011.
Robert Shumway and David Stoer. Time Series Analysis and Its Applications:With R Examples. Springer, 2006.
Murray R Spiegel. Teoria y Problemas de Probabilidad y Estadística. McGrawHill, 1976.
R. E. Walpole, R. H. Myers, and S. L. Myers. Probability and Statistics forEngineers and Scientists. Prentice-Hall, Inc., New Jersey, sixth edition, 1998.

BIBLIOGRAFÍA 99
Camilo Yate. Implementación de los métodos estocásticos en el análisis de seriesde tiempo mediante el software libre r.
Camilo Yate. Revisión del estado del arte del análisis de series de tiempo. 2011.
Víctor Yohai. Notas de probabilidad y estadística.

Implementación de los Métodos Estocásticos en
el Análisis de Series de Tiempo Mediante el
Software Libre R
Hernán Camilo Yate Támara
2011


A mi familia
Quienes del bien del mal, de lo justo de lo cruel, me han diferenciado
De quienes nunca recibiré una desilusión o una negativa

Índice general
1. Introducción a R 7
1.1. El entorno R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2. Datos en R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2.1. Precipitaciones en la Cuidad de Los Ángeles . . . . . . . . 81.2.2. Serie de Tiempo de un Proceso Industrial . . . . . . . . . 91.2.3. Abundancia de la Liebre Canadiense . . . . . . . . . . . . 101.2.4. Promedio de la Temperatura Mensual en Dubuque, Iowa . 111.2.5. Venta Mensual de Barriles de Petróleo . . . . . . . . . . . 11
2. Construcción del Modelo 12
2.1. Especicación del Modelo . . . . . . . . . . . . . . . . . . . . . . 122.1.1. Precipitaciones en la Cuidad de Los Ángeles . . . . . . . . 122.1.2. Serie de Tiempo de un Proceso Industrial . . . . . . . . . 132.1.3. Abundancia de la Liebre Canadiense . . . . . . . . . . . . 142.1.4. Venta Mensual de Barriles de Petróleo . . . . . . . . . . . 16
2.2. Estimación de Parámetros . . . . . . . . . . . . . . . . . . . . . . 182.2.1. Serie de Tiempo de un Proceso Industrial . . . . . . . . . 192.2.2. Abundancia de la Liebre Canadiense . . . . . . . . . . . . 192.2.3. Venta Mensual de Barriles de Petróleo . . . . . . . . . . . 20
2.3. Diagnóstico del Modelo . . . . . . . . . . . . . . . . . . . . . . . 202.3.1. Serie de Tiempo de un Proceso Industrial . . . . . . . . . 20
2.3.1.1. Gráco de Residuales . . . . . . . . . . . . . . . 202.3.1.2. Normalidad en los Residuales . . . . . . . . . . . 212.3.1.3. Autocorrelación en los Residuales . . . . . . . . 212.3.1.4. Resumen del Diagnóstico . . . . . . . . . . . . . 22
2.3.2. Abundancia de la Liebre Canadiense . . . . . . . . . . . . 232.3.2.1. Gráco de Residuales . . . . . . . . . . . . . . . 232.3.2.2. Normalidad en los Residuales . . . . . . . . . . . 232.3.2.3. Autocorrelación en los Residuales . . . . . . . . 24
2.3.3. Venta Mensual de Barriles de Petróleo . . . . . . . . . . . 242.3.3.1. Gráco de Residuales . . . . . . . . . . . . . . . 242.3.3.2. Normalidad en los Residuales . . . . . . . . . . . 25
3

ÍNDICE GENERAL 4
3. Pronósticos 26
3.1. Promedio de la Temperatura Mensual en Dubuque, Iowa . . . . . 263.2. Serie de Tiempo de un Proceso Industrial . . . . . . . . . . . . . 273.3. Abundancia de la Liebre Canadiense . . . . . . . . . . . . . . . . 28
4. Filtrado 29
4.1. Serie de Tiempo de un Proceso Industrial . . . . . . . . . . . . . 294.2. Abundancia de la Liebre Canadiense . . . . . . . . . . . . . . . . 29
5. Conclusiones 30

Introducción
El análisis de las series de tiempo no ha sido ajeno al gran avance informáticoque se ha vivido en las últimas décadas. Gracias a esto se ha logrado acceder atodos los métodos inherentes a las series de tiempo de una forma mucho efectivay amigable. El desarrollo de este documento se deberá casi en su totalidad alsoftware libre R, el cual ofrece una gran cantidad de funciones de suma utilidadpara los objetivos del trabajo. Estas herramientas abarcan, por ejemplo, la im-plementación de los modelos más usados en el análisis de series de tiempo (AR,MA, ARMA, ARIMA).
5

Objetivos
Objetivo General
El obejetivo general del presente trabajo consiste en exponer la forma me-diante la cual se implementa la teoria inherente a las series de tiempo en elsoftware libre R
Objetivos Especicos
1. Realizar pruebas asistidas por el software libre R que permitan deter-minar la optimalidad un modelo determinado.
2. Describir el proceso de análisis de series de tiempo con la ayuda del paqueteestadístico R
3. Establecer diferencias entre los métodos de estimacion y predicción paradiferentes seres de tiempo
4. Evaluar cuál método estocástico provee las mejores estimaciones, y pro-nósticos para una serie temporal.
6

Capítulo 1
Introducción a R
R puede denirse como una nueva implementación del lenguaje S desarro-llado en AT&T por Rick Becker, John Chambers y Allan Wilks. Muchos de loslibros y manuales sobre S son útiles para R. La referencia básica es The NewS Language: A Programming Environment for Data Analysis and Graphics deRichard A. Becker, John M. Chambers and Allan R. Wilks. Las característicasde la versión de agosto de 1991 de S están recogidas en Statistical Models in Seditado por John M. Chambers y Trevor J. Hastie.
1.1. El entorno R
R es un conjunto integrado de programas para manipulación de datos, cálculoy grácos. Entre otras características dispone de:
Almacenamiento y manipulación efectiva de datos, operadores para calculosobre variables indexadas (Arrays), en particular matrices, una amplia, cohe-rente e integrada colección de herramientas para análisis de datos, posibilidadesgrácas para análisis de datos, que funcionan directamente sobre pantalla o im-presora, y un lenguaje de programación bien desarrollado, simple y efectivo,que incluye condicionales, ciclos, funciones recursivas y posibilidad de entradasy salidas.
El término entorno lo caracteriza como un sistema completamente dise-ñado y coherente, antes que como una agregación incremental de herramientasmuy especicas e inexibles, como ocurre frecuentemente con otros programasde análisis de datos. R es en gran parte un vehículo para el desarrollo de nue-vos métodos de análisis interactivo de datos. Como tal es muy dinámico y lasdiferentes versiones no siempre son totalmente compatibles con las anteriores.
1.2. Datos en R
Para los efectos del trabajo se trabajan con bases de datos de diferentescaracterísticas. Estas bases de datos las ofrece el paquete TSA, descargado desde
7
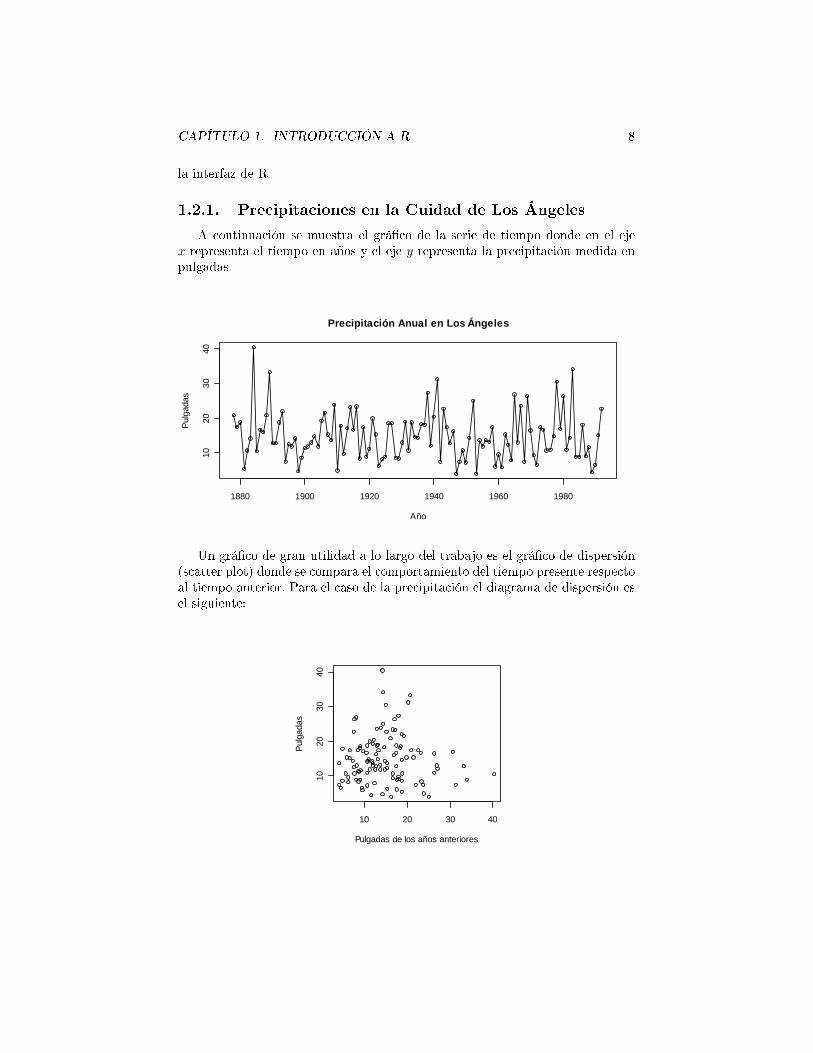
CAPÍTULO 1. INTRODUCCIÓN A R 8
la interfaz de R
1.2.1. Precipitaciones en la Cuidad de Los Ángeles
A continuación se muestra el gráco de la serie de tiempo donde en el ejex representa el tiempo en años y el eje y representa la precipitación medida enpulgadas
Precipitación Anual en Los Ángeles
Año
Pul
gada
s
1880 1900 1920 1940 1960 1980
1020
3040
Un gráco de gran utilidad a lo largo del trabajo es el gráco de dispersión(scatter plot) donde se compara el comportamiento del tiempo presente respectoal tiempo anterior. Para el caso de la precipitación el diagrama de dispersión esel siguiente:
10 20 30 40
1020
3040
Pulgadas de los años anteriores
Pul
gada
s

CAPÍTULO 1. INTRODUCCIÓN A R 9
1.2.2. Serie de Tiempo de un Proceso Industrial
En la siguiente serie de tiempo se muestra la medición de una propiedadreferente al color de cierto lote de productos dentro de un proceso industrial lagráca de la serie de tiempo está dada por:
Propiedad del Color de cierto proceso Industrial
Lote
Pro
pied
ad d
el C
olor
0 5 10 15 20 25 30 35
6570
7580
85
Además de su respectivo diagrama de dispersión:
65 70 75 80 85
6570
7580
85
Propiedad del Color del Lote Anterior
Pro
pied
ad d
el C
olor
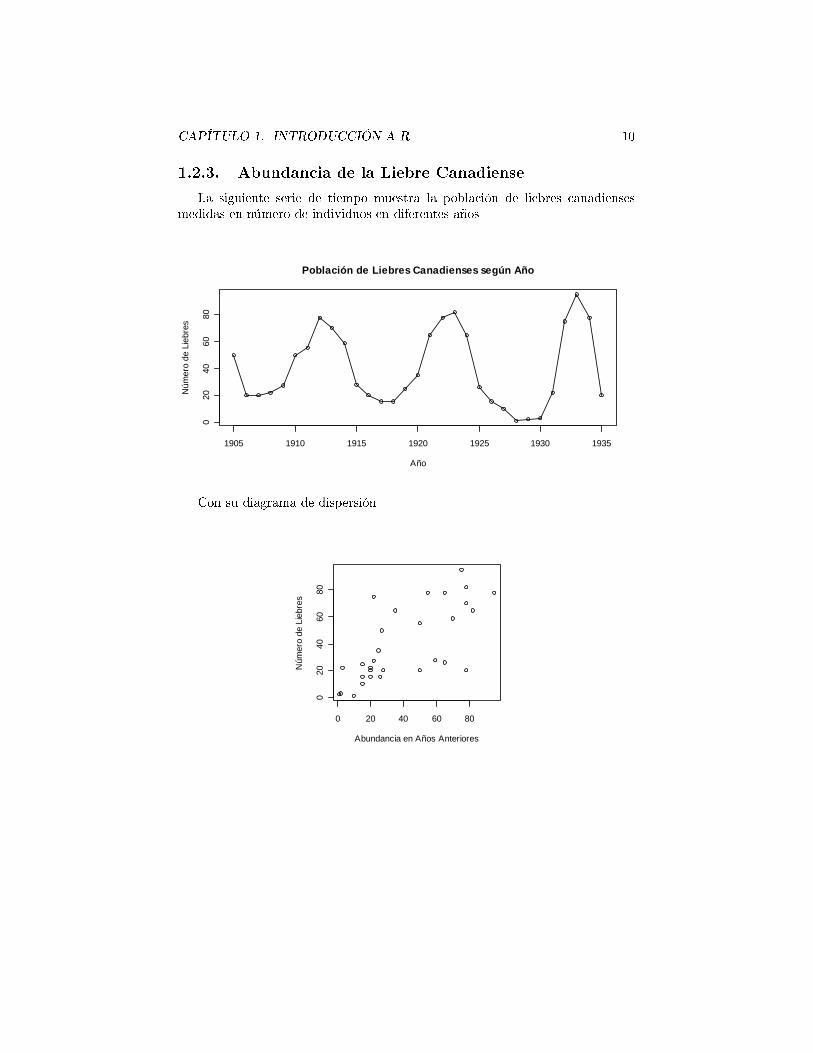
CAPÍTULO 1. INTRODUCCIÓN A R 10
1.2.3. Abundancia de la Liebre Canadiense
La siguiente serie de tiempo muestra la población de liebres canadiensesmedidas en número de individuos en diferentes años
Población de Liebres Canadienses según Año
Año
Núm
ero
de L
iebr
es
1905 1910 1915 1920 1925 1930 1935
020
4060
80
Con su diagrama de dispersión
0 20 40 60 80
020
4060
80
Abundancia en Años Anteriores
Núm
ero
de L
iebr
es
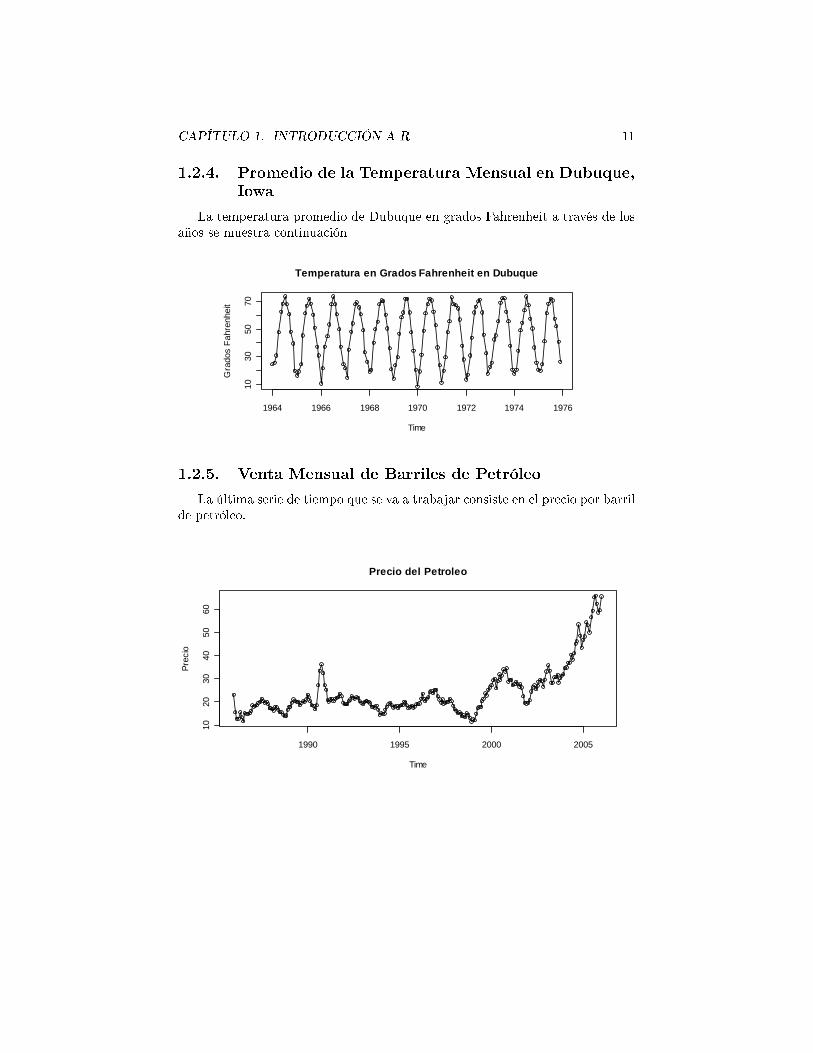
CAPÍTULO 1. INTRODUCCIÓN A R 11
1.2.4. Promedio de la Temperatura Mensual en Dubuque,Iowa
La temperatura promedio de Dubuque en grados Fahrenheit a través de losaños se muestra continuación
Temperatura en Grados Fahrenheit en Dubuque
Time
Gra
dos
Fah
renh
eit
1964 1966 1968 1970 1972 1974 1976
1030
5070
1.2.5. Venta Mensual de Barriles de Petróleo
La última serie de tiempo que se va a trabajar consiste en el precio por barrilde petróleo.
Precio del Petroleo
Time
Pre
cio
1990 1995 2000 2005
1020
3040
5060
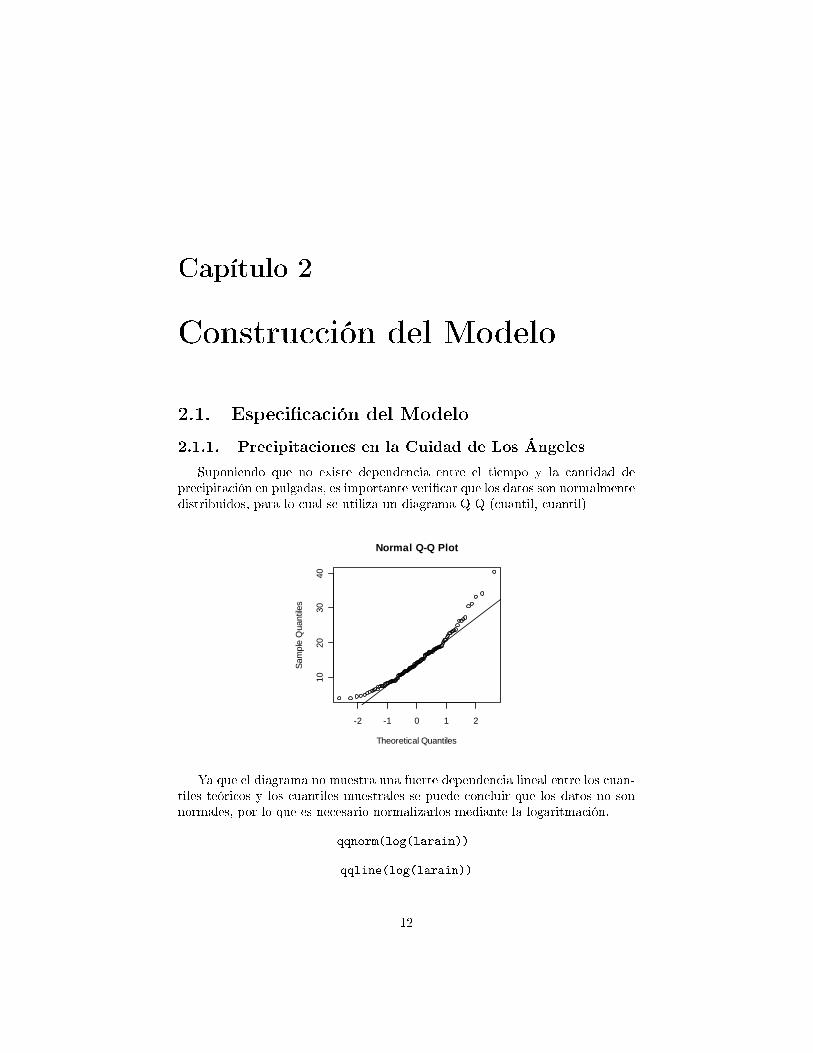
Capítulo 2
Construcción del Modelo
2.1. Especicación del Modelo
2.1.1. Precipitaciones en la Cuidad de Los Ángeles
Suponiendo que no existe dependencia entre el tiempo y la cantidad deprecipitación en pulgadas, es importante vericar que los datos son normalmentedistribuidos, para lo cual se utiliza un diagrama Q-Q (cuantil, cuantil)
-2 -1 0 1 2
1020
3040
Normal Q-Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Ya que el diagrama no muestra una fuerte dependencia lineal entre los cuan-tiles teóricos y los cuantiles muestrales se puede concluir que los datos no sonnormales, por lo que es necesario normalizarlos mediante la logaritmación.
qqnorm(log(larain))
qqline(log(larain))
12

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 13
-2 -1 0 1 2
1.5
2.0
2.5
3.0
3.5
Normal Q-Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
A continuación se muestra el gráco de la función de autocorrelación
2 4 6 8 10 12 14 16 18 20
-0.2
-0.1
0.0
0.1
Lag
AC
F
Función de Autocorrelación de la Precipitacuón Anua l en Los Ängles
Teniendo en cuenta el anterior gráco se puede concluir que la transfor-mación logarítmica ha mejorado notablemente la normalidad de los datos. Sinembargo, no existe evidencia de dependencia en la serie de tiempo. Es decir quela serie de tiempo se tiempo transformada logarítmicamente se puede modelarcomo variables aleatorias normalmente distribuidas con media 2.58 y desvia-ción estándar 0.478, teniendo en cuanta que ambas son el logaritmo de la serieoriginal.
2.1.2. Serie de Tiempo de un Proceso Industrial
El proceso industrial del color muestra un modelamiento más interesantedebido a dependencia de lotes sucesivos, la siguiente gráca de la función deautocorrelación muestral, puede sugerir a primera vista un modelo de promedios

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 14
móviles de primer orden MA(1), debido a que el únicamente la autocorrelacióndel rezago 1 es signicativamente diferente de cero.
2 4 6 8 10 12 14
-0.4
-0.2
0.0
0.2
0.4
Lag
AC
F
Función de Autocorrelación de las Propiedades del C olor
Sin embargo el comportamiento sinuosidad, obliga a examinar la función deautocorrelación parcial.
2 4 6 8 10 12 14
-0.2
0.0
0.2
0.4
Lag
Par
tial A
CF
Funcion de Autocorrelación Parcial
Teniendo en cuanta el gráco anterior se podría concluir que el modelo apro-piado sería el modelo autorregresivo de primer orden AR(1)
2.1.3. Abundancia de la Liebre Canadiense
La serie de tiempo de la cantidad de liebres en Canadá muestra, según su dia-grama de dispersión, una fuerte dependencia entre cada observación. Se sugiere

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 15
en la literatura que este tipo de datos debe pasar primero por una transfor-mación Box et al. [1994]. A continuación se muestra el estimador de máximaverosimilitud logarítmica como una función del parámetro de potencia λ
-2 -1 0 1 2
-50
050
λ
Log
Like
lihoo
d 95%
Se puede ver que el máximo de la función de máxima verosimilitud está enλ = 0,4. Sin embargo el valor de λ = 0,5 está dentro del intervalo de conanzapor lo que se transformará la variable tomando su raíz cuadrada. A continuaciónse muestra al función de autocorrelación de la variable transformada
2 4 6 8 10 12 14
-0.6
-0.2
0.2
0.4
0.6
Lag
AC
F
Función deAutocorrelacion de la Variable Trasformad a
De nuevo se puede apreciar un comportamiento sinuosidad lo que obliga aexaminar la gráca de la función de autocorrelación parcial

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 16
2 4 6 8 10 12 14
-0.4
0.0
0.2
0.4
0.6
Lag
Par
tial A
CF
Función de Autocorrelacion Parcial de la Variable T rasformada
Teniendo en cuanta la anterior gráca, se puede concluir que la función deautocorrelación parcial sugiere que el mejor modelo para la serie de tiempocorresponde a un modelo AR(2) o posiblemente un modelo AR(3).
2.1.4. Venta Mensual de Barriles de Petróleo
Como primera medida es importante observar la serie del precio del petróleo.Grácamente se puede asegurar que la diferencia de la serie transformada loga-rítmicamente puede ser considerablemente estacionaria. Sin embargo un métodoestadístico, el Test de la raíz unitaria de Dickey-Fuller aplicado al logaritmo dela serie original conlleva a la los valores de -1.1119 con un p-valor de 0.9189.Con la estacionariedad como hipótesis alternativa, se puede concluir con unagran certeza que la serie es no estacionaria y de allí la importancia de aplicar eloperador diferencia de los logaritmos.
Time
Cam
bios
en
el P
reci
o m
edia
nte
Loga
rtm
os
1990 1995 2000 2005
-0.4
-0.2
0.0
0.2
0.4

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 17
A continuación se muestra la tabla de la Función de Autocorrelación Exten-dida para la serie de tiempo del precio de petróleo por barril
La anterior tabla sugiere que los parámetros del modelo son p = 01 y q = 1.A continuación se muestran los posibles subconjuntos del modelo ARMA
BIC
(Int
erce
pt)
test
-lag1
test
-lag2
test
-lag3
test
-lag4
test
-lag5
test
-lag6
test
-lag7
erro
r-la
g1
erro
r-la
g2
erro
r-la
g3
erro
r-la
g4
erro
r-la
g5
erro
r-la
g6
erro
r-la
g718
13
8.8
5.2
2.5
-0.91
-3
-3.4
Este gráco sugiere que Yt = log(Oilt) debe ser modelado en términos deYt−1 y Yt−4. A continuación se presentarán las grácas de las funciones deautocorrelación general y parcial.

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 18
2 4 6 8 10 12 14 16 18 20 22
-0.1
0.0
0.1
0.2
Lag
AC
FFunción de Autocorrelación del Precio Transformado
2 4 6 8 10 12 14 16 18 20 22
-0.1
0.0
0.1
0.2
Lag
Par
tial A
CF
Función de Autocorrelación Parcial del Precio Trans formado
La gráca de la autocorrelación sugiere que se debe especicar un modeloMA(1) parta las diferencias logarítmicas del precio del petróleo y la función deautocorrelación parcial sugiere considerar un modelo AR(2) (ignorando algunospicos signicativos en los rezagos 15, 16 y 20)
2.2. Estimación de Parámetros
Para la estimación de parámetros, el paquete TSA (cite TSA) ofrece lasherramientas necesarias para ejecutar los procedimientos teóricos (véase Yate[2011])

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 19
2.2.1. Serie de Tiempo de un Proceso Industrial
Parámetro Momentos. Cuadrados Cond. Máx. Verosimilitud n
φ 0.5282 0.5549 0.5703 35
Donde el error estándar de las estimaciones es, aproximadamente:√V ar(φ) ≈
√1−(0,57)2
35 ≈ 0,14
2.2.2. Abundancia de la Liebre Canadiense
Para la estimación de los parámetros de la serie de tiempo de la cantidad deliebres en Canadá, hay que tener en cuenta que la serie se ha transformado. Acontinuación se mostrará la estimación de los parámetros de un modelo AR(3)por medio del método de la estimación de máxima verosimilitud otorgado porel paquete TSA Chan [2010]
Coecientes ar1 ar2 ar3 Intercepto
1.0519 -0.2292 -0.3931 5.6923E.S 0.1877 0.2942 0.1915 0.3371
Se puede notar que φ1 = 1,0519, φ2 = −0,2292 y φ3 = −0,3930 y la va-rianza del ruido es σ2
e = 1,066. Teniendo en cuenta los errores estándares, lasestimaciones del rezago 1 y del rezago 3, los coecientes autorregresivos sonsignicativamente diferentes de cero, al igual que la estimación del intercepto(estimación de la media del proceso µ) y la estimación del parámetro en el re-zago 2 no es signicativa. Entonces el modelo estimado puede ser escrito de lasiguiente manera
√Yt − 5,6923 = 1,0519
(√Yt−1 − 5,6923
)− 0,2292
(√Yt−2 − 5,6923
)−
0,3931(√
Yt−1 − 5,6923)+ et
o
√Yt = 3,25 + 1,0519
√Yt−1 − 0,2292
√Yt−1 − 0,3931
√Yt−1 + et
Donde Yt es la abundancia de liebres en el año t es términos de la serieoriginal. Y teniendo en cuenta que φ2 no es signicativa el modelo se puedeescribir:
√Yt = 3,483 + 0,919
√Yt−1 − 0,5313
√Yt−1 + et

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 20
2.2.3. Venta Mensual de Barriles de Petróleo
Teniendo en cuenta que la función de autocorrelación sugiere un modeloMA(1) para las diferencias de los logarítmos de los precios, a continuación semuestran las estimaciones para θpor medio varios métodos de estimación. Esimportante recordar que el método de estimación por máxima verosimilituddiere un poco respecto a los otros métodos.
Parámetro Momentos. Cuadrados Cond. Máx. Verosimilitud n
θ -0.2225 -0.2731 -0.2956 241
2.3. Diagnóstico del Modelo
R y el paquete TSA proveen herramientas mediante las cuales se puedevericar la bondad del modelo ajustado. A continuación de evaluarán dichasherramientas con la series anteriormente trabajadas.
2.3.1. Serie de Tiempo de un Proceso Industrial
2.3.1.1. Gráco de Residuales
Tiempo
Res
idua
les
Est
anda
rizad
os
0 5 10 15 20 25 30 35
-2-1
01
2
Ya que los residuales estandarizados se pueden acotar en el intervalo (−2, 2)se dice que el gráco de residuales soporta el modelo, ya que o existen tendenciaspresentes.
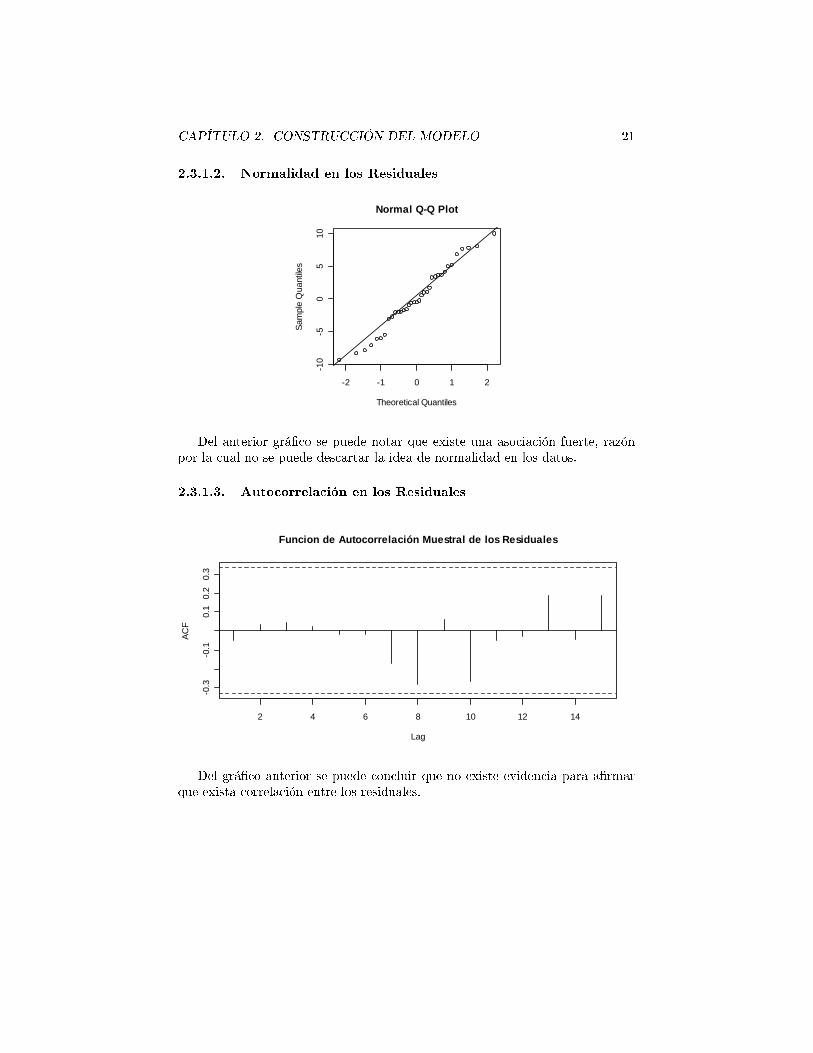
CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 21
2.3.1.2. Normalidad en los Residuales
-2 -1 0 1 2
-10
-50
510
Normal Q-Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Del anterior gráco se puede notar que existe una asociación fuerte, razónpor la cual no se puede descartar la idea de normalidad en los datos.
2.3.1.3. Autocorrelación en los Residuales
2 4 6 8 10 12 14
-0.3
-0.1
0.1
0.2
0.3
Lag
AC
F
Funcion de Autocorrelación Muestral de los Residual es
Del gráco anterior se puede concluir que no existe evidencia para armarque exista correlación entre los residuales.

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 22
2.3.1.4. Resumen del Diagnóstico
A continuación se muestra un gráco donde se resumen las herramientas dediagnóstico adicionando los p-valores del Test de Ljung-Box (cite Yate)
Sta
ndar
dize
d R
esid
uals
0 5 10 15 20 25 30 35
-20
12
2 4 6 8 10 12 14
-0.3
0.0
0.3
AC
F o
f Res
idua
ls
2 4 6 8 10 12 14
0.0
0.4
0.8
P-v
alue
s
Este resumen provee las herramientas para concluir que el modelo se ajustade una buena manera a la serie de tiempo.

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 23
2.3.2. Abundancia de la Liebre Canadiense
2.3.2.1. Gráco de Residuales
Tiempo
Res
idua
les
Est
anda
rizad
os
1905 1910 1915 1920 1925 1930 1935
-2-1
01
Se puede notar que los residuales tienen poca variación en el medio de laserie, sin embargo la gran variación al nal de la serie sugiere que el modelo noes el óptimo para ajustar la serie.
2.3.2.2. Normalidad en los Residuales
-2 -1 0 1 2
-2-1
01
Normal Q-Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Aunque los valores extremos de la serie no siguen la asociación lineal, se pue-de decir que no existe suciente evidencia pera rechazar la hipótesis que los datossean normales debido a que el tamaño de la muestra no es lo sucientementegrande.
CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 24
2.3.2.3. Autocorrelación en los Residuales
2 4 6 8 10 12 14
-0.3
-0.1
0.1
0.3
Lag
AC
F
Funcion de Autocorrelación Muestral de los Residual es
Teniendo en cuenta los grandes picos en los rezagos 1 y 4, se puede concluirque no existe suciente evidencia estadística de autocorrelación diferente decero.
2.3.3. Venta Mensual de Barriles de Petróleo
2.3.3.1. Gráco de Residuales
Tiempo
Res
idua
les
Est
anda
rizad
os
1990 1995 2000 2005
-4-2
02
4
Se puede notar que existen por lo menos tres residuales al inicio de la seriecuyas magnitudes son mayores de 3, hecho que es poco usual en distribucionesnormales. Es importante vericar si existe efectos externos que hayan podidoalterara el precio en esos momentos.

CAPÍTULO 2. CONSTRUCCIÓN DEL MODELO 25
2.3.3.2. Normalidad en los Residuales
-3 -2 -1 0 1 2 3
-0.4
-0.2
0.0
0.2
Normal Q-Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
El gráco anterior muestra la presencia de outliers en la serie, razón por lacual el modelo se puede descartar ya que este no es un comportamiento típicode una variable aleatoria normalmente distribuida.

Capítulo 3
Pronósticos
3.1. Promedio de la Temperatura Mensual en Du-
buque, Iowa
Para la predicción de la temperatura en Dubuque, Iowa se utilizo el siguientecódigo en R:
# Añadir 2 años de datos faltantes ya que se quiere predecir dos años
data(tempdub)
tempdub1=ts(c(tempdub,rep(NA,24)),start=start(tempdub),freq=frequency(tempdub))
#Crear las funciones armónicas y crear un modelo
har.=harmonic(tempdub,1)
m5.tempdub=arima(tempdub,order=c(0,0,0),xreg=har.)
m5.tempdub har.=harmonic(tempdub,1)
model4=lm(tempdub~har.) summary(model4)
#Crear las funciones en el periodo que se quiere predecir
newhar.=harmonic(ts(rep(1,24), start=c(1976,1),freq=12),1)
# Calcular y graficar las predicciones
win.graph(width=6, height=3,pointsize=8)
plot(m5.tempdub,n.ahead=24,n1=c(1972,1),newxreg=newhar.,type='b',
ylab='Temperatura',xlab='Año',main="Temperatura de Dubuque, Iowa")
Entonces la gráca que representa el pronóstico es:
26

CAPÍTULO 3. PRONÓSTICOS 27
Temperatura de Dubuque, Iowa
Año
Tem
pera
tura
1972 1973 1974 1975 1976 1977 1978
1020
3040
5060
7080
Debido a que el modelo se ajusta bastante bien a la serie de tiempo con unavarianza del error relativamente baja, los límites de la predicción son bastantecercanos a la tendencia del pronóstico.
3.2. Serie de Tiempo de un Proceso Industrial
Se usará la serie del color del proceso industrial como primera ilustración delpronóstico para una serie ARIMA.
Tiempo
Pro
pied
ad d
el C
olor
0 10 20 30 40
6065
7075
8085
La gráca anterior muestra la serie original junto con el pronóstico paraun plazo de 12 años. Además con unos límites de predicción del 95% tanto porencima como por debajo. Además una linea horizontal que pasa por la estimaciónde la media. Nótese como los pronósticos se aproximan exponencialmente a lamedia a medida que el tiempo aumenta, también, nótese como los limites depredicción también aumentan en su ancho.

CAPÍTULO 3. PRONÓSTICOS 28
3.3. Abundancia de la Liebre Canadiense
La serie de la abundancia de la libre canadiense fue ajustada tomando laraíz cuadrada de la serie original, y luego ajustada mediante un modelo AR(3).
Año
Rai
z de
l núm
ero
de L
iebr
es
1910 1920 1930 1940 1950 1960
05
10
Se puede notar como el pronóstico imita al ciclo aproximado de la serieoriginal incluso cuando se hace el pronóstico de la serie con un plazo de 25 años

Capítulo 4
Filtrado
El procedimiento mediante el cual el ltro Kalman sirve como herramientapara pronosticas es otorgado por una familia de funciones de R llamas Kalman-Like. A continuación se muestra el código mediante el cual se puede predecir lplazos de tiempo.
4.1. Serie de Tiempo de un Proceso Industrial
l=15
m1.color=arima(color,order=c(1,0,0))
attributes(m1.color)
m1.color$model
colorfc=KalmanForecast(n.ahead=l, mod=m1.color$model)
colorfc
4.2. Abundancia de la Liebre Canadiense
l=15
m2.hare=arima(sqrt(hare),order=c(3,0,0),fixed=c(NA,0,NA,NA))
attributes(m2.hare)
m2.hare$model
harefc=KalmanForecast(n.ahead=l, mod=m2.hare$model)
harefc
29

Capítulo 5
Conclusiones
Después de realizar todo el trabajo referente al análisis de series de tiempo,con gran soporte en el software R se puede concluir que este software ofrecebastantes alternativas para el desarrollo de los diferentes métodos que se men-cionan en el texto. Es decir, las limitaciones del trabajo no tienen nada que vercon las limitaciones de R, ya que este software prácticamente ofrece todas lasherramientas proporcionadas por estudiosas de los diferentes temas para que enlos diferentes niveles del aprendizaje R se erija como una herramienta de granrobustez y solidez.
30

Bibliografía
H. Akaike. Maximum likelihood identication of Gaussian autoregressive movingaverage models. Biometrika, 60:255265, 1973.
H. Akaike. A new look at the statistical model identication. IEEE Transactions
on Automatic Control, 19:716723, 1974.
G. E. P. Box and G. M. Jenkins. Time Series Analysis. Holden-Day, SanFrancisco, 1976.
George E. Box, Gwilym M Jenkins, and Gregory C Reinsel. Time Series Analy-
sis, Forecasting and Control. Prentice-Hall, Londres, 1994.
David R. Brillinger. Time Series, Data Analysis and Theory. SIAM, Londres,2001.
George Canavos. Probabilidad y Estadística, Aplicaciones y Métodos. McGrawHill, México, 1998.
Kung-Sik Chan. TSA: Time Series Analysis, 2010. URLhttp://CRAN.R-project.org/package=TSA. R package version 0.98.
W.S. Chan. A comparison of some pattern identication methods for orderdetermination of mixed arma models. Statistics and Probability Letters,, 85:413426, 1999.
C. Chateld. The Analysis of Time Series, An Introduction. Chapman & Hall,London, UK, 1982.
Chris Chateld. The Analysis of Time Series An Introduction. Chapman &Hall, 2005.
Jonathan Cryer and Kung-Sik Chan. Time Series Analysis With Aplications in
R. Springer, Iowa, 2008.
Peter J. Brockwell Richard A. Davis. Time Series: Theory and Methods. Spriger,Nueva York, 1987.
F.M Dekking, C Kraaikamp, H.P Lopuhaa, and L.E Meester. Probabilidad y
Estadística. Springer, 2005.
31

BIBLIOGRAFÍA 32
J. Durbin. The tting of time series models. Review of the International Stati-
sical Institute, 28:233243, 1960. Cited in ?.
W. Feller. An Introduction to Probability Theory and its Applications, volume 2.John Wiley & Sons, New York, 1971. Second Edition.
W. Fuller. Introduction to statistical time series. Wiley, New York, 1976.
Wayne A. Fuller. Introduction to Statistical Time Series. Wiley Series in Pro-bability and Statistics, 1996.
V. Gmurman. Teoria de las Probabilidades y Estadística Matemática. MoscúEditorial, 1974.
Victor M. Guerrero. Análisis Estadístico de Series de Tiempo Económicas.Thomson, México, 1998.
James D Hamilton. Time Series Analysis. Princeton University Press, 1994.
Genshiro Kitagawa. Introduction to Time Series Modeling. CRC Press, 2010.
B. O. Koopman. The Bases of Probability. John Wiley and Sons, New York,1964.
J.K. Lindsey. Statistical Analysis of Stochastic Processes in Time. Cambridge,2004.
Douglas C. Montgomery, Cheryl L. Jennings, and Murat Kulahaci. Introductionto Tme Series and Forecasting. Wiley Series in Probability and Statistics,2008.
Daniel Peña and George E. Box. Identifying a simpliying structure in timeseries. Jorunal of the American Statistical Association, 82:836843, 1987.
Fredy O. Pérez. Introducción a las Series de Tiempo, Métodos Paramétricos.Universidad de Medellin, 2007.
R Development Core Team. R: A Language and Environment for Statistical
Computing. R Foundation for Statistical Computing, Vienna, Austria, 2010.URL http://www.R-project.org/. ISBN 3-900051-07-0.
Luis Fransisco Rincón. Texto guia de probabilidad. Universidad Santo Tomás,Bogotá, 2011.
Robert Shumway and David Stoer. Time Series Analysis and Its Applications:
With R Examples. Springer, 2006.
Murray R Spiegel. Teoria y Problemas de Probabilidad y Estadística. McGrawHill, 1976.
R. E. Walpole, R. H. Myers, and S. L. Myers. Probability and Statistics for
Engineers and Scientists. Prentice-Hall, Inc., New Jersey, sixth edition, 1998.

BIBLIOGRAFÍA 33
Camilo Yate. Implementación de los métodos estocásticos en el análisis de seriesde tiempo mediante el software libre r.
Camilo Yate. Revisión del estado del arte del análisis de series de tiempo. 2011.
Víctor Yohai. Notas de probabilidad y estadística.