optimizaciÓn estructural aplicaciÓn en losas …
TRANSCRIPT

OPTIMIZACIÓN ESTRUCTURAL APLICACIÓN EN LOSAS ESTRUCTURALES EN UNA
DIRECCIÓN
Carlos Felipe Santander
Director Mauricio Sánchez-Silva, Ph. D.

Optimización Estructural Aplicación en Losas Estructurales en una Dirección
ICIV 200410 43
Proyecto de Grado Presentado por
Carlos Felipe Santander F.
para optar al título de Ingeniero Civil
al
Departamento de Ingeniería Civil y Ambiental
Director
Mauricio Sánchez-Silva, Ph. D. Profesor Asociado
Universidad de Los Andes Bogotá, Colombia
Junio, 2004

Contenido Contenido i Índice de Tablas iii Índice de Figuras iv Introducción v Capítulo 1 - Confiabilidad Estructural 1
1.1 Introducción 1 1.2 Función de Estado Límite 2
1.2.1 Función de Estado Límite Básica 2 1.2.2 Función de Estado Límite Complejas y Conjunto de FELs 3
1.3 Índice de Confiabilidad β 4 1.3.1 Variables Reducidas 5 1.3.2 Espacio Reducido y Definición General del Índice de Confiabilidad 6
1.4 Análisis de Confiabilidad de Primer Orden (FORM) 8 1.4.1 Algoritmo de FORM [9] 8
1.5 Simulaciones de Monte Carlo 8 1.6 Conclusiones 9
Capítulo 2 - Función Objetivo 11 2.1 Introducción 11 2.2 Función Objetivo Básica 11 2.3 Modificaciones a la Función Objetivo Básica 12 2.4 Función Objetivo Definida por el Ciclo de Vida 12
2.4.1 Cargas Invariantes en el Tiempo 14 2.4.2 “Fallas cuya ocurrencia está descrita por un proceso de Poisson” [1] 14
2.5 Conclusiones 15 Capítulo 3 - Métodos de Optimización 16
3.1 Introducción 16 3.2 Tipos de Restricciones 16
3.2.1 Sistema sin Restricciones 17 3.2.2 Sistema con Restricciones de Igualdad 17 3.2.3 Sistema con Restricciones de Desigualdad 18
3.3 Método de Multiplicadores de Lagrange 20 3.3.1 Derivación Geométrica [3] 21 3.3.2 Derivación Algebraica [3] 23

ICIV 200410 43 Contenido
ii
3.4 Método del Gradiente Reducido 24 3.4.1 Algoritmo de Método de Gradiente Reducido (Adaptado de Bazaraa, [2]) 25
3.5 Programación Cuadrática 26 3.5.1 Problema Lineal Complementario 28
3.6 Programación Cuadrática Sucesiva (SQP) 30 3.6.1 Programación Cuadrática Sucesiva Rudimentaria 32 3.6.2 Programación Cuadrática Sucesiva Completa 32
3.7 Cálculo del Índice de Confiabilidad β por Medio de Técnicas de Optimización 34 3.7.1 Función moderadamente no lineal 34 3.7.2 Función muy no lineal 39
3.8 Conclusiones 40 Capítulo 4 - Ejemplo Práctico: Losa Armada en Una Dirección 42
4.1 Introducción 42 4.2 Losas Armadas en una Dirección 42 4.3 Variables Involucradas 46 4.4 Función de Costos 47
4.4.1 Función de Costos Rudimentaria 48 4.4.2 Función de Costos Compleja 50
4.5 Función Objetivo 50 4.5.1 Función objetivo de modelo 50 4.5.2 Restricciones 51
4.6 Optimización por Iteraciones Independientes para cada Variables 52 4.6.1 Cálculo de la probabilidad de falla 53 4.6.2 Proceso de optimización 54 4.6.3 Conclusiones del proceso iterativo 59
4.7 Optimización por Regresión Multivariable 59 4.7.1 Cálculo de Probabilidad de Falla 59 4.7.2 Ecuación de Probabilidad. Regresión Multivariable 63 4.7.3 Resultado 69 4.7.4 Conclusiones del proceso por Regresión Multivariable 69
Capítulo 5 - Conclusiones 73 Apéndice A - Cálculo de β en Mathcad con SQP multivariable 74 Apéndice B - Algoritmos de Mathcad para el Cálculo de pf de Losas 83 Apéndice C - Cálculo de β en Mathcad con FORM multivariable 87 Bibliografía 90

iii
Índice de Tablas
Tabla 3.1. Representación de la matriz A dependiendo de I1 26 Tabla 3.2. Modificación de la matriz A de acuerdo a I1 26 Tabla 3.3. Tabla Problema Lineal Complementario, antes de ser pivotada por la inicialización 29 Tabla 3.4. Medias y Desviaciones Estándar de los Parámetros de la ecuación de estado límite 34 Tabla 3.5. Resumen de las iteraciones para encontrar el índice de confiabilidad usando SQP 37 Tabla 3.6. Medias y Desviaciones Estándar de los Parámetros de la ecuación de estado límite 39 Tabla 5.1. Diseño tradicional de losas – Variables Geométricas. 44 Tabla 5.2. Avalúo de carga muerta para la losa del ejemplo. 44 Tabla 5.3. Valores de Desviación Estándar de las variables Probabilísticas 53 Tabla 5.4. Valores de las parámetros de diseño cada iteración. 58 Tabla 5.5. Cambio de las variables del diseño tradicional al diseño óptimo. 59 Tabla 5.5. Valores de la media de cada variable en el algoritmo para la optimización. 60 Tabla 5.6. Muestra de las probabilidad de falla contra 6 variables obtenida por Monte Carlo y ya filtrada. 63 Tabla 5.7. Variables y Combinaciones de Variables involucradas en la regresión. 65

iv
Índice de Figuras
Figura 1.1. Zona Segura y Zona de Falla: G(R,S) = 0 Adaptada de Sánchez-Silva [1]. 3 Figura 1.2. Probabilidad de falla en función de β. Aproximación en los valores típicos de β. 5 Figura 1.3. Probabilidad de falla en función de β. 7 Figura 2.1. Representación de la función Z y sus Dominios. 13 Figura 3.1 a) Restricciones h1 y h2 en un espacio tridimensional. b) Curva formada por la intersección de las restricciones. 21 Figura 3.2. Función objetivo y línea de restricción de los parámetro x, y. 35 Figura 3.3. Función de estado límite en el plano xy. Punto óptimo calculado por medio de SQP. 38 Figura 3.4. Seguimiento de los pasos del algoritmo hasta encontrar el punto óptimo. 39 Figura 3.5. Función de Estado Límite en el espacio transformado. 40 Figura 3.6. Función de Estado Límite proyectada en la Función Objetivo. 40 Figura 5.1. Esquema de la Losa del Ejemplo. Definición de las variables correspondientes a la geometría de la Losa. 43 Figura 5.2. Corte A – A de la Losa del Ejemplo. 43 Figura 5.3. Probabilidad de falla contra Número de Simulaciones. Convergencia. 54 Figura 5.4. Probabilidad de falla contra ASpos. 55 Figura 5.5. Función Objetivo (Z) contra ASpos. 55 Figura 5.6. Probabilidad de falla contra ASneg. 56 Figura 5.7. Función Objetivo (Z) contra ASneg. 56 Figura 5.8. Probabilidad de falla contra b. 57 Figura 5.9. Función Objetivo (Z) contra b. 57 Figura 5.10. Probabilidad de falla contra AV. Total independencia de esta variable. Área de acero por cada metro. 58 Figura 5.11. Influencia de ALpos y ALneg en la Probabilidad de Falla 61 Figura 5.12. Influencia de AV en la Probabilidad de Falla 62 Figura 5.13. Comportamiento de correlación entre hf y b. 63 Figura 5.14. Comportamiento de pf a lo largo de la muestra. 64 Figura 5.15. Probabilidad de Falla contra ASpos 66 Figura 5.16. Probabilidad de Falla contra ASneg 66 Figura 5.17. Probabilidad de Falla contra ALpos 67 Figura 5.18. Probabilidad de Falla contra s 68 Figura 5.19. Probabilidad de Falla contra h 68 Figura 5.20. Probabilidad de Falla contra b 69

Introducción
El diseño óptimo basado en confiabilidad tiene gran aplicación en la ingeniería civil y contribuye en el desarrollo de países como Colombia en los cuales el déficit de vivienda toma cifras astronómicas. Esta es la principal motivación para elaborar un proyecto que abra las puertas a este nuevo tipo de diseño y sobre todo ilustre como es posible optimizar las estructuras reduciendo costos que liberen recursos para ayudar al desarrollo del sector de la construcción. No objetivo de este trabajo criticar el diseño tradicional de estructuras que ha sido pilar de las sociedades y sus últimos aportes al cuidado no solo de la vida sino también del patrimonio. Sin embargo el diseño óptimo basado en confiabilidad es el futuro de esta profesión ya que cuenta con muchas ventajas sobre sus antecesores.
Los códigos o normas sismo resistentes que rigen la ingeniería estructural alrededor del mundo en ocasiones se convierten en una atadura para el calculista ya que para buenos niveles de confiabilidad agrupan cierto número de estructuras que a conveniencia económica podrían trabajarse de manera independiente. El diseño basado en confiabilidad como el que se describe en el Capítulo 4, independiza todas las estructuras y convierte el diseño en único. Es importante aclarar que este proceder está tipificado en las normas (ej. NSR 98 para el caso de Colombia) donde permiten realizar estudios independientes que no necesariamente tienen que coincidir a lo que ellas proponen.
Para grandes construcciones como preseas o viaductos los ingenieros hacen los estudios pertinentes pero hasta este momento ningún ingeniero en Colombia propone un análisis detallado para una pequeña estructura como una casa de vivienda de interés social. Es objetivo de este trabajo concienciar a los ingenieros en la práctica que un diseño detallado como el óptimo basado en confiabilidad puede ser aplicado a estructuras medianas o pequeñas produciendo un ahorro considerable.
Actualmente en la Universidad de Los Andes, como en muchas universidades en todos los continentes, tiene un grupo de personas dedicas a la investigación de optimización y confiabilidad cuyo principal propósito es encontrar la forma de incentivar el uso de la optimización a la hora de hacer diseños. Este es un proyecto a largo plazo que requiere gran trabajo como la elaboración de un software que mecanice los pasos expuestos en muchos ensayos, artículos y trabajos como el que se está presentando.
El trabajo se divide en tres partes. La primera parte a la que pertenecen los Capítulos 1 y 2 es acercamiento a la teoría que ha sido desarrollada en los últimos años acerca de la confiabilidad estructural (1) y la optimización estructural (2). De manera resumida se presenta el trabajo de personas como Rackwitz, Sánchez-Silva, Haldar, Mahadevan entre otros para lograr introducir un poco el procedimiento se utiliza en la última parte del trabajo.
La segunda parte del trabajo conformada exclusivamente por el Capítulo 3 es una descripción detallada de los métodos de programación no – lineal utilizados en este tipo de procedimientos. Se quiso dar un enfoque a esta parte en especial teniendo en cuenta que con este proyecto de grado se inicia una investigación que busca resultados más

ICIV 200410 43 Introducción
vi
concisos. Esta parte del proyecto es la más importante y es en donde los mayores esfuerzos de la investigación se han concentrado y concluye proponiendo un método de programación no – lineal para el cálculo de la probabilidad de falla. Este método denominado Programación Sucesiva de Cuadrados es el más completo de los estudiados en esta parte del trabajo.
Por último para dar sentido a las dos primeras partes, la tercera propone un ejemplo práctico del diseño óptimo basado en confiabilidad en el cual se obtienen conclusiones asombrosas que representan un enorme avance para continuar investigando acerca de este tema. El ejemplo seleccionado fue una losa estructural armada en una dirección por lo que en los artículos estudiados ningún ingeniero dedicado al tema reporto una optimización hecha en este tipo de estructuras.
Al final del trabajo se encuentran 3 Apéndices en los que se presentan los algoritmos utilizados a lo largo de todo el proyecto. Los algoritmos se encuentran programados en Mathcad; pero evitan el uso de funciones exclusivas del programa madre con el fin de facilitar la programación de FORTRAN o cualquier otro lenguaje de programación.
Independientemente de si los resultados obtenidos en el Capítulo 4 sean correctos o no las conclusiones son de gran utilidad para el grupo de investigación del área de confiabilidad estructural de la Universidad de Los Andes dirigido por el doctor Mauricio Sánchez-Silva también director de este proyecto de grado.

Capítulo 1 Confiabilidad Estructural
1.1 Introducción
El Diseño Optimo Basado en Confiabilidad1 tiene como objetivo encontrar los valores de los parámetros de diseño tales que representen el menor costo o el mayor beneficio al construir una obra. Problema que se puede desarrollar desde dos puntos de vista distintos [8]:
Minimizar: C(x)
Sujeto a: ff Pp ≤)(x (1.1)
Minimizar: pf(x)
Sujeto a: max)( CC ≤x (1.2)
Donde C es la función de costos, pf es la función de probabilidad de falla y x es el
vector de todos los parámetros que representan algún costo o están involucrados en la falla de un elemento o un sistema.
En ambos enfoques el cálculo de la probabilidad de falla no es tarea fácil por lo que intervienen en esta las posibles variaciones de todos los parámetros que intervienen en el diseño. La meta primordial de la confiabilidad estructural es encontrar la función pf(x) en términos de las cantidades de obra que se usan al evaluar la función de costos, o en algunos casos encontrar pf tal que pf = pf(x). La palabra confiabilidad, término complementario al riesgo (término más conocido por la gente), hace referencia a la garantía probabilística de que un sistema o u elemento cumpla con las funciones para las cuales fueron diseñado [9].
El termino “probabilidad” esta íntimamente ligado a la confiabilidad estructural por la incertidumbre involucrada en todos los análisis mecánicos. Por ejemplo, si varias varillas de acero idénticas son falladas en el laboratorio, todas fallaran a cargas distintas, y el valor de resistencia con el que se elabora el diseño es el promedio de las medidas [9]. Adicionalmente con las medidas suficientes se puede determinar la distribución de probabilidad que sigue este parámetro. Ahora bien, la incertidumbre no sólo se presenta en los valores relacionados a la resistencia sino que también se presenta en la solicitación.
Los ingenieros dedicados al diseño reconocen la existencia de esta incertidumbre en el análisis, sin embargo los procedimientos tradicionales de diseño simplifican el problema convirtiendo las variables de probabilísticas a determinísticas combatiendo la incertidumbre con una serie de factores de seguridad calibrados de manera empírica. 1 Ver Capítulo 2.

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
2
Haldar y Mahadevan [9] critican los factores de seguridad ya que aunque estos son obtenidos por referencia histórica, no garantizan un nivel de seguridad determinado. Adicional a esto, los factores de seguridad no proveen información acerca de cómo cada componente del sistema o elemento afecta la seguridad del mismo.
Se ha discutido de manera aproximada el significado de la confiabilidad estructural, para mayor información acerca de este tema se puede acudir a diferente bibliografía (ej. [1], [6], [7], [8], [9], [10])
1.2 Función de Estado Límite Para realizar un análisis de confiabilidad es necesario definir una función que separe
la situación de falla de la situación de no-falla. A esta función se le conoce como función de Estado Límite o función de desempeño [9]. En esta se presentan todas las variables que pueden verse involucradas en la falla de un sistema o elemento. Es una función En ℜ y generalmente se presenta igualándola a cero.
0)( =xG (1.3)
1.2.1 Función de Estado Límite Básica La función de estado límite debe marcar la frontera entre la zona de falla y la zona
segura. Esto quiere decir que esta función debe relacionar la solicitación que se le esta haciendo al sistema o elemento y su resistencia. Son estas dos variables las que entran en dicha función cuando se tiene la forma más básica.
SRSRG −=),( (1.4)
Si la solicitación (S) excede la resistencia, la función toma valores negativos por lo
que como se vio en (1.3), G(R,S) = 0 es la frontera entre las dos áreas.

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
3
Figura 1.1. Zona Segura y Zona de Falla: G(R,S) = 0 Adaptada de Sánchez-Silva [1].
Tanto la resistencia como la solicitación pueden ser variables deterministicas, pero
en la mayoría de casos, las dos siguen una función de probabilidad determinada. Es aquí donde entra en juego la confiabilidad estructural y el valor de la probabilidad de falla toma valores distintos de 0 y 1. R y S no necesariamente siguen la misma distribución, y no tienen nunca el mismo valor medio. En la Figura 1.1 se muestra como la probabilidad conjunta de no presenta su media sobre la función de estado límite pero la campana formada por esta si logra tocarla lo que garantiza que existe una probabilidad de falla. Más adelante se discutirá como estas distribuciones y la interacción entre las variables se utiliza para calcular en Índice de Confiabilidad y posteriormente la probabilidad de falla.
1.2.2 Función de Estado Límite Complejas y Conjunto de FELs La función de estado límite básica permite desarrollar las ecuaciones y
metodologías utilizadas en el análisis de confiabilidad, pero esta no tiene usos prácticos ya que la resistencia y solicitación son funciones de las variables de diseño. La función de estado límite no es una función bidimensional, es por el contrario multidimensional en la que como se indicó anteriormente entran todas las variables de diseño. Por ejemplo en el análisis de una vigueta de hormigón para una losa armada en una sola dirección la resistencia es función de la cantidad e acero y de las dimensiones, mientras que la solicitación es función de la separación entre viguetas.
Una vez analizado lo compleja que puede llegar a ser una función de estado límite es necesario discutir la necesidad, en algunas ocasiones, de implementar más de una función para describir la falla de un sistema o elemento. Es claro que la falla de un sistema debe ser descrita por el conjunto de las funciones de estado límite de cada uno de sus elementos, pero cada elemento individual puede tener su propio conjunto de funciones que indiquen la falla. Se puede tomar una viga de acero de alma llena como ejemplo. La viga puede fallar por cada uno de los esfuerzos a las que esta sometida, es decir:
1. Flexión Pura 2. Cortante Puro 3. Pandeo Local del Patín Superior 4. Pandeo Local del Patín Inferior (si está sometida a momento negativos) 5. Pandeo Lateral Torsional 6. Torsión Pura (por ejemplo un punte curvo) Cada uno de estos estados presenta su propia ecuación de estado límite que se
debe tener en cuenta al momento del análisis ya al violarse cualquiera de ellas el elemento falla. Adicional a los esfuerzos que se tienen, existen otras funciones que garantizan el buen servicio de una construcción que deben tenerse en cuenta. En una viga la deflexión máxima debe tener ciertos limitantes para que no afecte los muros divisorios y elementos no estructurales que te reposan en las vigas inferiores.
Una vez descritas el objetivo de la función de estado límite, se puede a partir de esta y las distribuciones probabilidad de cada una de las variables, se puede calcular la probabilidad de falla.

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
4
1.3 Índice de Confiabilidad β El índice de confiabilidad o índice β es el parámetro más utilizado para medir la
confiabilidad de un sistema. “Es una medida del número de desviaciones estándar entre el valor medio del margen de seguridad y el límite que define la región segura” [1]. Dada esta definición se puede calcular como:
G
Gσµ
β = (1.5)
Donde, como se vio en la sección anterior G es la función de estado límite. Para
calcular la media y desviación estándar de la función de estado límite, es necesario tener en cuenta las medias y desviaciones de todas las variables que hacen parte de esta y hacer las mismas operaciones aritméticas que se presentan en la ecuación. Para la función (1.4) se tendría que:
SRG µµµ −= (1.6)222SRG σσσ += (1.7)
El valor de β esta íntimamente ligado al valor de la probabilidad de falla2, y en
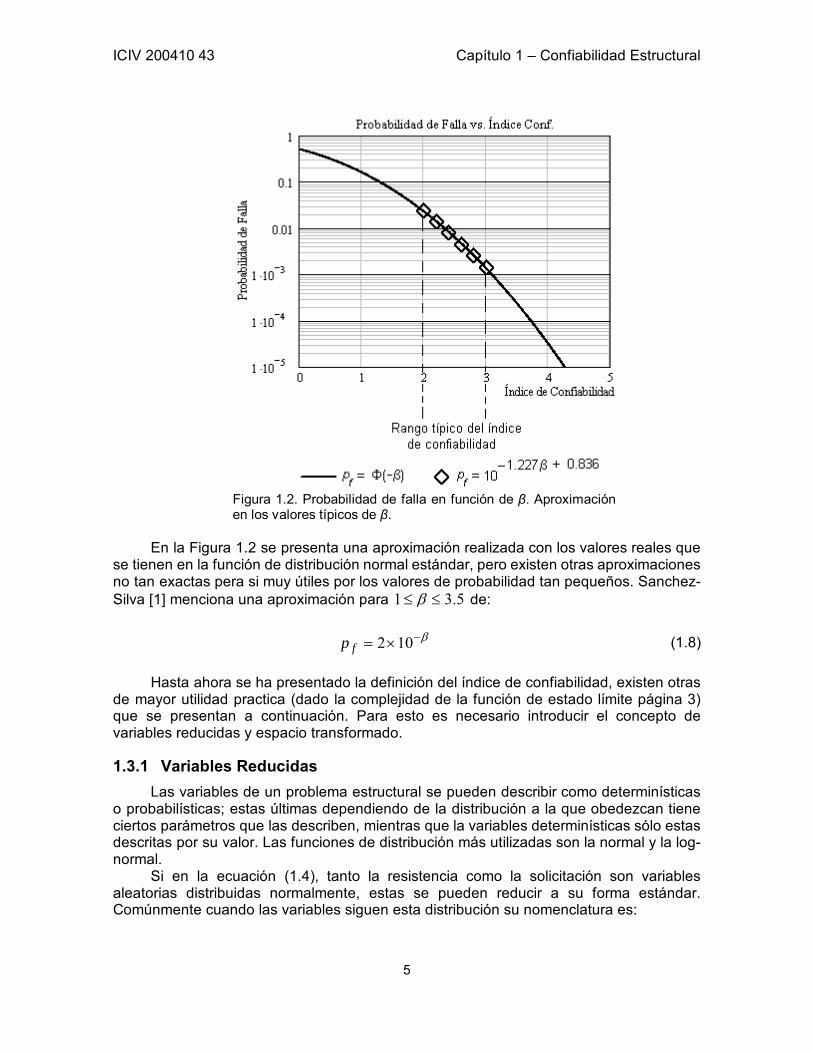
muchas ocasiones no se distinguen entre si. Como se puede ver en la Figura 1.2 entre los valores típicos la función que se tiene entre el logaritmo de la probabilidad de falla y el índice de confiabilidad es casi lineal.
2 pf esta dada por Φ(-β), donde Φ es la distribución normal de probabilidad.
ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
5
Figura 1.2. Probabilidad de falla en función de β. Aproximación en los valores típicos de β.
En la Figura 1.2 se presenta una aproximación realizada con los valores reales que
se tienen en la función de distribución normal estándar, pero existen otras aproximaciones no tan exactas pera si muy útiles por los valores de probabilidad tan pequeños. Sanchez-Silva [1] menciona una aproximación para 5.31 ≤≤ β de:
β−×= 102fp (1.8)
Hasta ahora se ha presentado la definición del índice de confiabilidad, existen otras
de mayor utilidad practica (dado la complejidad de la función de estado límite página 3) que se presentan a continuación. Para esto es necesario introducir el concepto de variables reducidas y espacio transformado.
1.3.1 Variables Reducidas Las variables de un problema estructural se pueden describir como determinísticas
o probabilísticas; estas últimas dependiendo de la distribución a la que obedezcan tiene ciertos parámetros que las describen, mientras que la variables determinísticas sólo estas descritas por su valor. Las funciones de distribución más utilizadas son la normal y la log-normal.
Si en la ecuación (1.4), tanto la resistencia como la solicitación son variables aleatorias distribuidas normalmente, estas se pueden reducir a su forma estándar. Comúnmente cuando las variables siguen esta distribución su nomenclatura es:

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
6
),(~ RRNR σµ ),(~ SSNS σµ
(1.9)
La forma estandarizada de una variable esta dada al resta al valor de la variable su
media y dividirla por la desviación estándar. Lo que se hace con esta transformación es ubicar las variables en un espacio en el que tiene media cero y desviación estándar 1. Para este caso, las nuevas variables reducidas, UR y US, serían:
R
RR
RUσ
µ−= (1.10)
S
SS
SU
σµ−
= (1.11)
Una vez teniendo las definiciones de las ecuaciones (1.10) y (1.11) se pueden
despejar las variables R y S y re-escribir la ecuación (1.4):
0)()(),( =⋅+−⋅+= SSSRRRSR UUUUG σµσµ (1.12)
1.3.2 Espacio Reducido y Definición General del Índice de Confiabilidad En la Figura 1.1 se muestra la función de estado límite en el espacio formado por R
y S, pero de esta misma manera se puede, al haber transformado las variables, trazar la función de estado límite (1.9) en el espacio UR y US. El espacio formado por las variables reducidas recibe el nombre de espacio reducido Figura 1.3.
Una vez establecido el espacio reducido de las variables se puede introducir una nueva definición para el índice de confiabilidad, como la distancia más corta entre el origen de este espacio y la curva G(UR,US) [10]. Esta definición fue introducida por Hasofer y Lind en 1974 y es pilar de los métodos para el cálculo de la probabilidad de falla que se expondrán más adelante.
Por geometría se puede calcular β como [10]:
22SR
QR
σσ
µµβ
+
−= (1.13)

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
7
Figura 1.3. Probabilidad de falla en función de β.
La ecuación (1.9) muestra una formula de cálculo exclusiva para la ecuación de
estado límite que se ha venido utilizando hasta ahora, pero se puede verificar que si existen más variables y la función de estado límite sigue siendo lineal, el valor de β se puede calcular como:
∑
∑
=
=+
=n
iUi
n
iUi
i
i
a
aa
2
2
10
)( σ
µβ (1.14)
Donde a0 es la constante de la ecuación lineal, ai son los respectivos coeficientes
de todas las n variables que entran en la ecuación. Se puede ver que el numerador de la ecuación (1.14) es la función de estado límite G(U). Por esta razón también es factible encontrar una ecuación generalizada para funciones lineales y no-lineales [10]:
iin
iUi
UGa
a
G
i
∂∂
==
∑=
donde
)(
)(
2
2σ
β µ
(1.15)
µ es el vector de medias de las variables involucradas. Esta ecuación logra minibar
la distancia entre el origen y la curva de la función de estado límite, según plantea la definición de Hasofer, en el Capítulo 3 se plantea la posibilidad de encontrar esta distancia por métodos de programación no lineal, cuya ventaja, como se verá más adelante, es la posibilidad de programar sus algoritmos para que funcionen en cualquier función.
La ecuación (1.14) es de fácil aplicación, no obstante la ecuación (1.15) se puede llegar a complicar si las derivadas parciales son difíciles de calcular. Para esto se han organizado distintos algoritmos para encontrar de manera simplificada el parámetro β y por consiguiente la probabilidad de falla de un sistema o un elemento.

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
8
1.4 Análisis de Confiabilidad de Primer Orden (FORM) Como se muestra en la Figura 1.3, si β esta definido como la distancia más corta
entre el origen y la función de estado límite en el espacio transformado, y esta función es lineal, se puede calcular β de una manera relativamente sencilla. Lo que se busca con el análisis de confiabilidad de primer orden o FORM3, es aproximar la función a sus rectas tangentes para buscar la distancia entre el origen y la tangente, suponiendo que si la función es moderadamente no – lineal, no existen mucha diferencia entre esta distancia y la real.
1.4.1 Algoritmo de FORM [9] 1. Definir la función de estado límite 2. Asumir un valor inicial para el índice de confiabilidad. Entre más razonable sea el
valor menos iteraciones son necesarias. 3. Asumir los valores iniciales de diseño del punto x*. Si no se dispone de buena
información se puede asumir las medias como valores iniciales. 4. Transformar todas las variables que no tengan una distribución normal, a una
normal equivalente de acuerdo a sus medias y desviaciones estándar. 5. Evaluar todas las derivadas parciales en el punto x*. 6. Evaluar los cosenos directores en el punto x* de acuerdo con:
*2
1
*
∑=
⎟⎟⎠
⎞⎜⎜⎝
⎛⋅
∂∂
⋅⎟⎟⎠
⎞⎜⎜⎝
⎛∂∂
=n
i
Nx
i
Nx
ix
i
i
i
xG
xG
σ
σα (1.16)
7. Evaluar los nuevos valores de x* como:
Nxi
Nxi
iix σβαµ ⋅⋅−=* (1.17)
8. Repetir los pasos 4, 5, 6, y 7 hasta que los valores de los cosenos directores converjan a una tolerancia adecuada. Usualmente se usa una tolerancia de 0.005.
9. Evaluar el nuevo valor de β tal que se satisfaga la función de estado límite en el nuevo punto de control.
10. Volver al paso 3 hasta que el valor del índice de confiabilidad converja.
1.5 Simulaciones de Monte Carlo La simulación de Monte Carlo es utilizada en el mundo a partir de los estudios de
Von Newman durante la segunda guerra mundial [1], su nombre se debe a la capital del principado de Mónaco por su parecido con el azar que habita constantemente en los casinos de la ciudad. La sencillez del método es su principal cualidad por lo que en muchas ocasiones es más utilizado que FORM o SORM. Este método es una simulación
3 Se llama FORM por sus siglas en ingles: First Order Reliability Method

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
9
artificial del comportamiento de un sistema usando un muestreo aleatorio, y este incluye los siguientes pasos [1]:
1. “Definir la función Y que describe el problema, en términos de todas las variables
aleatorias. 2. Determinar la distribución de probabilidad y los parámetros de cada variable
aleatoria. 3. Generar valores aleatorios para cada una de las variables con base en su función
de distribución de probabilidad. 4. Evaluar la función Y determinísiticamente, utilizando las realizaciones de cada
variable, un numero N de veces suficientemente grande. 5. Determinar la eficiencia y la precisión de la simulación. 6. Extraer información probabilística y estadística del resultado.”
La función Y es la ecuación de estado límite que se tenga y las variables son los parámetros estructurales de los que depende esa falla. El generar valores aleatorios de acuerdo a una distribución especifica tampoco representada dificultad ya que muchos programas cuentan con funciones propias que tienen esta labor.
Elaborar un algoritmo en el que se utilicen los N valores generados es relativamente sencillo. En este, como lo indica el paso 4, se evalúa la función de estado límite llevando un contador que indique el número de veces que ocurre la falla: NF. Al final del procedimiento la probabilidad de falla se puede calcular como:
NN
p Ff ≈ (1.18)
El paso a continuación es determinar la eficiencia y precisión de la simulación. Un
número muy pequeño de realizaciones puede ocasionar una probabilidad de falla ficticia, pero un número demasiado grande puede ser inútil ya que la probabilidad de falla tiene a converger en cierto número de simulaciones y no varia si se aumentan las mismas. Esta probabilidad de falla es el correcto resultado del procedimiento de Monte Carlo y determinar el N necesario es una de las principales tareas. Existen varias maneras de determinar el número de ensayos correctos, pero se recomienda realizar una prueba de inspección ya que el resultado de esta siempre es exacto.
Para mayor información sobre los métodos de simulación todas sus pruebas y todo el procedimiento que este involucra se recomienda el Capítulo 7 de [1], de donde se obtuvo toda la información al respecto utilizada en este trabajo.
1.6 Conclusiones En este Capítulo se discutieron, de manera aproximada, los métodos que existen
para evaluar la probabilidad de falla de un sistema o un elemento. Cada método discutido es igualmente útil en todos los problemas de confiabilidad estructural como el tratado en este proyecto de grado. La selección de la metodología utilizada depende exclusivamente de la persona dedicada a la investigación y cuya decisión depende exclusivamente de la naturaleza del problema.
En un futuro, el desarrollo del diseño óptimo basado en confiabilidad necesita herramientas computacionales en las que se programen todos los métodos existentes

ICIV 200410 43 Capítulo 1 – Confiabilidad Estructural
10
para el cálculo de probabilidad y debe contar con algún tipo de inteligencia artificial para lograr seleccionar de manera adecuada el método necesario para cada problema.
Si bien el cálculo de la función de probabilidad teniendo en cuenta todas las variables involucradas es el procedimiento más complicado, el procedimiento de optimización puede llevar cierta dificultad. En los siguientes capítulos se hace una aproximación a la función objetivo de la optimización y de los métodos más utilizados para este análisis en los últimos años.

Capítulo 2 Función Objetivo
2.1 Introducción
El diseño en Ingeniería Civil consiste en encontrar los valores de los distintos parámetros estructurales para garantizar el funcionamiento y economía. El hombre a través de los años ha estudiado el comportamiento de materiales y sistemas determinando ecuaciones que relacionan los valores de los parámetros y niveles requeridos. Pero existe en torno a esta toma de decisiones por las que tiene que pasar todo ingeniero diseñador una discusión perpetua: “¿cuan seguro es suficientemente seguro?”. Se puede pensar que poner columnas de dimensiones colosales, capas de pavimentos extremadamente gruesas, o sobredimensionar estructuras hidráulicas puede garantizar la vida de sus ocupantes o personas pero existe otra consideración muy importante a la hora de evaluar un diseño, la economía. Esta es crucial a la hora de evaluar la viabilidad de una construcción. Ahora bien retomando el tema de que tan seguro es suficiente se puede replantear esta afirmación como que tan seguro es económicamente viable.
Los costos de un proyecto se pueden dividir en dos categorías principales, los costos directos donde se agrupa todos esos costos que implica la construcción, y los costos indirectos, que entre otros se encuentra los costos de daño y reconstrucción en caso de falla. Un análisis para verificar la factibilidad de un proyecto debe estar orientado al costo total, para no sobre diseñar una estructura o en el caso más critico entregar un diseño que no cumpla las exigencias de funcionalidad requeridas.
Los códigos, criticados por algunos y alabados por otros, tienen ventajas y desventajas. Una de las principales desventajas y por las cuales la ingeniería moderna ha enfocado sus esfuerzos en “el diseño óptimo basado en confiabilidad”, es el hecho que agrupa todas las estructuras en unos pocos grupos. Para lograr hacer esta agrupación garantizando el buen desempeño de todo el conjunto, en muchas ocasiones el diseño se realiza por el lado seguro, y aunque su construcción es factible, no resulta económicamente óptimo. Es entonces donde el concepto de diseño óptimo entra a jugar un papel muy importante. Los códigos llevan este concepto, junto con el de probabilidad de falla, muy ligado a sus recomendaciones, pero se ha comprobado que en algunos casos un análisis independiente a cada estructura sería una fuente de ahorro para el sector y para el país.
2.2 Función Objetivo Básica La función objetivo es una función que entra en un proceso de optimización. El
proceso consiste en modificar todas las variables involucradas de manera apropiada para encontrar el valor máximo o mínimo de dicha función teniendo en cuenta un grupo de restricciones. Para entrar a evaluar el diseño civil se han planteado en mucho artículos

ICIV 200410 43 Capítulo 2 – Función Objetivo
12
diversas funciones objetivo, pero todas parten de una función básica propuesta por Rosenblueth y Hasofer [6] en la década de los setenta. Si se agrupan todo los parámetros de cualquier diseño en un vector denominado p, se puede ver la función objetivo como una función de utilidad que se quiere maximizar [6].
)()()()( pppp DCBZ −−= (2.1)
B(p) es el beneficio de la construcción, C(p) son los costos directos y D(p) es el
costo esperado en caso de falla. Muchos investigadores utilizan la función (2.2) dado que el beneficio es constante:
)()()(* ppp DCZ += (2.2)
En el cual el objetivo de la optimización cambia, y ahora es necesario minimizar
Z*(p). Este cambio está argumentado en el hecho que el beneficio casi constante con la variación de cualquier parámetro en el vector p, y adicionalmente a esto, el beneficio es un valor económico de interés al dueño de la obra en el que el ingeniero diseñador no puede decidir.
Como se discutirá más adelante la función de costo puede descomponer de distintas maneras, por ejemplo (Rackwitz):
∑ ⋅+=i
ii pcCC 0)(p (2.3)
Donde C0 es independiente de p y ci es el costo relacionado a cada parámetro que
no depende de ningún otro.
2.3 Modificaciones a la Función Objetivo Básica Varios autores han propuesto sus propias modificaciones a la función objetivo
básica [1]. Un ejemplo de esto es la propuesta de Melchers, donde toma el costo de construcción y el costo en caso de falla y los expande a:
)(·)()()( 1 pCpCCCCpCpBpZ ffMINSCQA −−−−−−= (2.4)
“C1 es el costo inicial de construir el proyecto, CQA es el costo de implementar las
medidas de aseguramiento de calidad, CC es el costo de la respuesta a cada una de las medidas de aseguramiento de calidad, CINS es el costo de asegurar el proyecto, CM es el costo de mantenimiento, pf la probabilidad y Cf el costo asociado a la falla.” [1].
2.4 Función Objetivo Definida por el Ciclo de Vida El Profesor Rüdiger Rackwitz de la Universidad Técnica de Munich, Alemania, es
una de las personas que más ha investigado acerca del diseño óptimo basado en confiabilidad en Ingeniería Civil. En varios de sus artículos el profesor Rackwitz, discute ampliamente la función objetivo para optimizar sistemas estructurales, involucrando conceptos de costo beneficio y el índice de calidad de vida.

ICIV 200410 43 Capítulo 2 – Función Objetivo
13
El problema típico de optimización es en realidad en problema inverso de un análisis de confiabilidad estructural [7]. Encontrar los valores de p, que maximice el beneficio dentro de una función de estado límite que determina la frontera entro lo seguro y la falla dada cierta confiabilidad. La función objetivo debe partir siempre de la función básica presentada en las secciones anteriores, donde en esta para el análisis de Rackwitz se hace énfasis en que C y D deben ser diferenciables en cada uno de los componentes de p. La optimización se debe hacer enfocados en un punto de vista en especial ya que los costos pueden diferir entre los distintos participantes de un proyecto en Ingeniería. La función Z vista incluyendo el beneficio, solo tiene sentido si toma un valor positivo, y por otro lado un poco más específico sólo tiene sentido si el valor de la utilidad para el dueño, o para la parte evaluada, es mayor que en cualquier otro proyecto. En la Figura 2.1 se pueden ver que existe solo un rango en los parámetros de diseño donde la realización del proyecto es razonable [7].
Figura 2.1. Representación de la función Z y sus Dominios.
Una vez descritas las propiedades de la función, y el rango en el cual los
parámetros p son razonables, es necesario introducir el concepto de valor presente. Las estructuran pueden fallar a un tiempo aleatorio, relacionado con la probabilidad de falla, que claramente es distinto al instante en el cual se hacen los estudios de prefactibilidad y factibilidad. Por esta razón todos los costos involucrados con la falla deben ser pasados a valor presente. Aunque los costos D son los más lejanos al momento de toma de decisión los costos en C también tienen estas características, más aún si la obra no es de construcción inmediata. La tasa que Rackwitz propone en función del tiempo en [7] es:
)exp()( tt ⋅−=∂ γ (2.5)
Donde γ es la tasa de intereses. Esta se puede expresar en función de la tasa de
descuento γ’ como:

ICIV 200410 43 Capítulo 2 – Función Objetivo
14
)'1ln( γγ += (2.6)
A continuación se distinguen entre dos estrategias de reemplazo, la primera donde
la estructura es abandonada después de la primera falla y la segunda donde es remplazada sistemáticamente después de cada falla. Existen otras políticas que no se discutirán en el presente trabajo, se pueden consultar en: [1], [6] y [7]. Las dos estrategias consideradas pueden ocurrir ya sea por cargas invariantes en el tiempo o por fallas que obedezcan a procesos de Poisson.
2.4.1 Cargas Invariantes en el Tiempo Si la falla ocurre por las cargas invariantes en el tiempo (esencialmente carga
muerta) la función objetivo sería para la política de abandono después de la falla sería [1]:
)())(()()( pppp fpHCCBZ ⋅+−−= (2.7) Y para el caso de reconstrucción sistemática [1]:
)(1)(
))(()()(pp
pppf
f
pp
HCCBZ−
⋅+−−=γ
(2.8)
En donde puede estimarse como un porcentaje del costo básico. “H es el costo
económico en caso de falla, incluidos costos directos, los costos de demolición, los costos por pérdida de oportunidad entre otros. Estas dos ecuaciones se obtienen después de un análisis matemático detallado que incluyen las transformaciones de Laplace necesarias para independizar los términos del tiempo. Esta transformación es de suma importancia ya que simplifica el problema y evita que los ingenieros diseñadores que decidan implementar este tipo de práctica se enfrenten a complejos problemas de economía, una ciencia poco estudiada por la mayoría de ingenieros.
2.4.2 “Fallas cuya ocurrencia está descrita por un proceso de Poisson” [1] Si las fallas tienen una ocurrencia que obedece a un proceso de Poisson puede
darse por un proceso normal o por la influencia de cargas extremas como terremotos o terrorismo. Estas últimas de conocen como perturbaciones de Poisson. Para los dos casos se tienen los dos escenarios de reconstrucción. Para el proceso simple de Poisson con una ocurrencia de falla )(tλ la función objetivo con política de abandono una vez ocurrida la falla es [1]:
)()()(
)()(
ppp
pp
λγλ
λγ −⋅+−−
+= HCBZ (2.9)
Y para política de reconstrucción sistemática [1]:

ICIV 200410 43 Capítulo 2 – Función Objetivo
15
γλ
γ)())(()()( pppp ⋅+−−= HCCBZ (2.10)
En el caso de perturbaciones para el abandono y la reconstrucción sistemática
respectivamente las funciones objetivos son:
)()(
)()(
)(pp
pp
pf
f
f pp
HCp
BZ⋅−
⋅⋅+−−
⋅+=
λγλ
λγ (2.11)
γλ
γ)(
))(()()(p
ppp fpHCCBZ
⋅⋅+−−= (2.12)
La ecuación (2.12) es la más utilizada por los investigadores ya que representa un
escenario bastante frecuente en las estructuras alrededor del mundo. Es esta ecuación la utilizada en la optimización que se presenta en el Capítulo 4. Todas estas funciones cuentan con una amplia teoría para mayor referencia revisar [6].
2.5 Conclusiones Existen diversas formas de la función objetivo utilizada para el diseño óptimo
basado en confiabilidad, pero aquella presentada por el profesor Rackwitz y otros investigadores como el Dr. Sánchez – Silva en donde se introduce el ciclo de vida es de vital importancia para el futuro de la investigación. La inclusión del ciclo de vida aterriza el procedimiento de optimización a situaciones económicas que vive cada país. El uso de estas funciones en lugar de las funciones rudimentarias avala el valor futuro que puede tener la obra en el momento de la falla.
Por estas razones es recomendable el uso de las funciones de objetivo donde se incluya el ciclo de vida en el proceso de optimización de estructuras.

Capítulo 3 Métodos de Optimización
3.1 Introducción
Las técnicas de optimización se dividen en dos, de acuerdo con el sistema que se quiera evaluar. Un sistema consta de dos partes, la función objetivo que esta precedida del objetivo de la optimización (minimizar o maximizar) y las funciones de restricción. Si ambas partes del sistema están conformadas por funciones estrictamente lineales, se dice que el problema es de programación lineal. Si por el contrario, alguna de las partes no es lineal, el problema es de programación no-lineal. En general la optimización estructural no puede desconocer las propiedades mecánicas, la teoría de la elasticidad, o los métodos más modernos como los elementos finitos, en los que se basa el análisis estructural. La combinación de estos resultados, como resultado del análisis, arroja ecuaciones de orden superior a uno; por lo tanto la optimización estructural, debe recurrir usualmente a métodos de programación no-lineal.
Varios paquetes computacionales como MATLAB, MATHCAD, Microsoft Excel, entre otros, contienen bibliotecas o programas para resolver problemas de optimización no-lineales. Sin embargo en algunas ocasiones la ecuación objetivo es tan compleja que los programas de cómputo no son capaces de resolverlos; y es en estos casos que es necesario recurrir a los algoritmos de los métodos y de ser posible elaborar un programa que se adapte perfectamente al problema al que se esta enfrentando.
Los métodos utilizados varían mucho con respecto al grupo de investigación y al problema que se quiere tratar. Los más utilizados en problemas estrictamente de optimización basada en confiabilidad estructural, son:
• El método del Gradiente Reducido • Programación Sucesiva de Cuadrados ó Aproximación por Lagrangiano
Proyectado Cada uno de ellos se utiliza según el sistema que se quiere evaluar. El algoritmo de
estos se explica en las siguientes secciones.
3.2 Tipos de Restricciones Independientemente si las restricciones son de carácter lineal o no-lineal, estas se
pueden clasificar de acuerdo a si son restricciones de igualdad, desigualdad, o si no hay restricciones. Cada uno de estos casos presenta condiciones distintas que debe cumplir el punto óptimo. Las condiciones van desde las más simples, en sistemas sin restricciones, hasta las más complejas en problemas con todo tipo de restricciones ( jjii bhbg =≤ )(y )( xx ), recopiladas finalmente en las condiciones Karush-Kuhn-Tucker (KKT). Para propósitos del Diseño Optimo Basado en Confiabilidad, las restricciones más apropiadas son de desigualdad, pero se mencionan las condiciones necesarias para cualquier tipo, ya que algunos métodos eliminan estas condiciones agregando variables al

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
17
sistema y manejando sólo condiciones de igualdad. Adicionalmente a esto, algunos algoritmos de programación no-lineal como la programación cuadrática sucesiva, cuentan con un tipo de restricciones generalizada (desigualdad), para esto es necesario tener en cuenta que por medios de manipulación de las restricciones se puede llegar un sistema generalizado. Esto se explica en detalle más adelante.
3.2.1 Sistema sin Restricciones Los sistemas sin restricciones carecen de aplicaciones prácticas, pero las
condiciones que aquí se postulan son base para la solución de sistemas con restricciones de igualdad y sistemas con restricciones de desigualdad. En la optimización estructural tampoco se tienen aplicaciones prácticas, ya que por algunas restricciones técnicas como por ejemplo, la cuantía en elementos de concreto reforzado, obligan siempre a la aparición de restricciones.
La principal condición para que x , sea un máximo o un mínimo local de f(x) es que su vector gradiente1 sea igual al vector nulo (0), pero dependiendo de la forma de la función este punto puede ser un máximo, un mínimo o un punto de inflexión. Para verificar si en realidad el punto con 0)( =∇ xf es un punto óptimo se calcula la matriz Hessiana2. Para esto la función debe ser doblemente diferenciable en el punto x Si en este punto H esta definida positivamente, x , es estrictamente un mínimo, y si esa definida negativamente es un máximo.
3.2.2 Sistema con Restricciones de Igualdad Las restricciones de igualdad, de la forma gi(x) = bi actúan sólo como reductores de
dimensionamiento, pero no establecen fronteras al posible conjunto de posibles soluciones. Para ilustrar mejor esta afirmación se propone el siguiente ejemplo tomado de [2].
Minimizar: 2
322
21 xxx ++
Sujeto a: 10321 =++ xxx (3.1)
La restricción coloca todas las posibles soluciones en un plano pero estas en
realidad no están acotadas, puede ser cualquier punto dentro de este plano. En otras palabras, toda restricción de igualdad puede ser insertada de alguna manera en la función objetivo y convertir el problema una optimización sin restricciones, Entonces la ecuación (3.1) se puede reescribir como:
1 El vector gradiente de una función f∇ es el vector cuyas componentes son las derivadas parciales con respecto a cada una de las variables. 2 La matriz Hessiana de f es una matriz tal que sus componentes son las segundas derivadas de la función f. Suponga f = f(x,y). La Hessiana denotada con H es:
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
∂
∂∂∂
∂
∂∂∂
∂
∂
2
22
2
2
2
y
fxyf
yxf
x
f

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
18
Minimizar: 221
22
21 )10( xxxx −−++ (3.2)
Puesto que el nuevo problema no tiene restricciones, las condiciones necesarias
para encontrar el mínimo o máximo de una función son las mismas de un problema sin restricciones. La única diferencia radica en que el gradiente y la Hessiana a evaluar son los de la función que incluye las restricciones (el nuevo problema), como se explica más adelante en el Método de Multiplicadores de Lagrange [3].
3.2.3 Sistema con Restricciones de Desigualdad Un sistema con restricciones de desigualdad es la generalización de cualquier
problema de programación no – lineal. Para describir la solución del sistema se hace uso de las condiciones Karush – Kuhn – Tucker (KKT). Estas plantean que si se encuentra el punto optimo x*, no es posible encontrar una dirección en la que el valor de la función objetivo se incremente (para el caso de maximización), mientras se encuentre en la región factible acotada por las restricciones. Para introducir de manera matemática las condiciones KKT, es importante introducir primero la definición de dirección factible.
La dirección factible es cualquier vector d, que al encontrase en una solución viable la operación x + εd conduzca a otra solución viable para todos los ε suficientemente pequeños. El conjunto de direcciones factibles en cualquier punto x (siendo x viable) esta definido como [3]:
{ }Π∈+⇒≥≥>∃= dxdx εεσσ 0 que tal0 |)(D (3.3)
Donde Π es la región factible acotada por las restricciones. En otras palabras se
puede decir que duna dirección d dentro del conjunto D es aquella en la que se puede mover de x un pequeña distancia y se sigue estando en la región factible, en el caso sin restricciones D(x) = En.
El comportamiento hasta ahora descrito en D es general para todos los puntos dentro de ∏, pero existen un conjunto de x* en el cual se cumple la siguiente propiedad:
*)( 0*)( xddx Df t ∈∀≤∇ (3.4)
Los puntos x* maximizan o minimizan la función objetivo, por lo que se conocen
como óptimos. Las funciones la mayoría de veces tienen varios óptimos locales, por lo que se dice que x* es un conjunto de puntos y no uno solo. Vale la pena anotar que en los procesos de optimización se busca el punto más cercano a las condiciones iniciales que se plantean en el problema, es por esta razón que es importante prestar mucha atención a estas condiciones. Es fácilmente demostrable [3] que la ecuación (3.4) también se cumple en los límites de D(x*) (clousure3), a este conjunto se denota como )*(xD .
Ahora bien, en cualquier punto viable de la solución, las restricciones pueden dividir en dos tipos, las activas (igualdad) y las inactivas (desigualdad):
3 En inglés, clousure hace referencia al conjunto formado por los elementos que se encuentran en las fronteras de un conjunto mayor.

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
19
Ψ∉>Ψ∈=
igig
i
i
0)( 0)(
xx
(3.5)
Donde Ψ es el conjunto de los índices pertenecientes a las restricciones activas. Se
puede entones definir un nuevo grupo de direcciones factibles como:
{ }Ψ∈∀≥∇=∆ itig 0)(|)( dxdx (3.6)
Este nuevo conjunto toma en cuenta solo las restricciones activas por lo que se
tiene un nuevo lema: )()( xx ∆⊂D . Desafortunadamente existen situaciones en las que direcciones incluidas en ∆ no se encuentran en D , sin embargo se ha demostrado que estas situaciones son puramente matemáticas y no tienen aplicaciones prácticas [3]. Esta pequeña perdida de generalidad se considera despreciable y para formular las condiciones KKT, se tiene que )()( xx ∆=D en especial para el punto óptimo:
*)(*)( xx ∆=D (3.7)
Teniendo esta igualdad, llamada en inglés “constraint qualification”, se puede
entonces a partir de (3.4) formular la siguiente expresión:
{ }*)( *)(|*)( 0*)( x0dxdxddx Ψ∈∀≥∇=∆∈∀≤∇ igf ti
t (3.8) Lo cual es equivalente a decir que existen una serie de multiplicadores
*)( ,0 xΨ∈≥ iiλ , tal que [3]:
∑Ψ∈
=∇+∇*)(
*)(*)(x
0xxi
ii gf λ (3.9)
En la próxima sección estos multiplicadores se conocerán como multiplicadores de
Lagrange, y sirven para formular el teorema Kuhn – Tucker. Si se tiene un problema de programación no lineal, P, definido de la siguiente manera:
],1[ 0)( :a Sujeto)( :Maximizar
migf
i ∈≥xx
(3.10)
Si x* es una solución óptima del problema P, y se asume que la “constraint
qualification” aplica, necesariamente se deben cumplir las siguientes condiciones: 1. x* es factible 2. Existen una serie de multiplicadores iλ para todo i tal que: 0*)( =⋅ xii gλ .
3. ∑=
=∇+∇m
iii gf
10*)(*)( xx λ

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
20
Este teorema con solo estas tres condiciones ha demostrado ser insuficiente en algunas ocasiones [3]. Por esta razón se cuenta con un teorema adicional que se conoce como el teorema de “suficiencia4”. Este agrega características especiales que deben tener las funciones en el problema P para que se cumplan las condiciones propuestas por el teorema KT. Tanto la función f como las funciones g’s deben ser diferenciables, adicionalmente la función objetivo, f, debe ser pseudo-cóncava y las restricciones, g’s, deben ser cuasi-cóncavas. Esto garantiza que la región factible Π sea convexa. Este teorema de condiciones necesarias extras que deben cumplir las función f y g’s hace que las condiciones tomen el tercer nombre y sean actualmente conocidas como Karush – Kuhn – Tucker [2].
Finalmente se debe tener en cuenta que las condiciones KKT pueden tener en cuenta las restricciones de igualdad explicadas en la sección anterior, para el caso se convertirían en restricciones activas en el punto óptimo. Si se modifica el problema P a:
],1[ 0)( :a Sujeto],1[ 0)( :a Sujeto
)( :Maximizar
lihmig
f
i
i
∈=∈≥
xxx
(3.11)
Las condiciones se pueden escribir de forma vectorial en las siguientes 3
ecuaciones [2]:
0λxgλ
0νxhλxg
≥=
=∇+∇+∇
0*)(
*)()(*)(t
tt*xf
(3.12)
Donde *)(xg∇ y *)(xh∇ son las matrices Jacobianas5 de las funciones de
restricciones de desigualdad e igualdad respectivamente, y los vectores λ y ν son los multiplicadores de Lagrange asociados a estas restricciones. El funcionamiento detallado de estos multiplicadores se explica con cierta profundidad en la siguiente sección.
3.3 Método de Multiplicadores de Lagrange El Método de Multiplicadores de Lagrange es un método generalizado de
programación lineal y no-lineal. Su aplicación se extiende a cualquier problema de optimización. La única desventaja es que no es un método fácilmente desarrollable. Para revisar como funcionan los multiplicadores de Lagrange, primero se toma restricciones de igualdad. Como se dijo anteriormente este tipo de restricciones pueden despejarse dentro la función objetivo y con técnicas convencionales de cálculo se puede encontrar el punto 4 “Suficiencia” por su traducción textual del inglés Sufficiency. 5 La matriz Jacobiana esta dada por:
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
∂∂
∂∂
∂∂
∂∂
n
n
n
n
xg
xg
xg
xg
L
MOM
L
1
111

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
21
máximo o mínimo. Sin embargo en algunas ocasiones cuando las funciones no son polinómicas (pueden ser exponenciales, logarítmicas entre otras) la solución analítica es difícil de encontrar. Además, cuando las restricciones son numerosas también complica de manera considerable el despeje.
La demostración de la metodología de los multiplicadores de Lagrange, puede hacerse de manera algebraica, o de manera geométrica, esta última limitando el espacio a 3 dimensiones, pero facilitando se compresión. Por esta razón se mencionan a continuación a las dos metodologías.
3.3.1 Derivación Geométrica [3] Sea el problema:
Minimizar: ),,( 321 xxxf
Sujeto a: 0),,( 3211 =xxxh
0),,( 3212 =xxxh
(3.13)
Si se supone que existe una solución factible para el problema (3.13), las superficies
formadas por las restricciones h1 y h2 forman una curva, C, en el espacio tridimensional. Curva que se puede ver en cualquier ejes coordenados, pero por conveniencia se muestra (Figura 3.1) proyectada en el plano de los ejes de x1 y x2. Se puede ver que al manejar restricciones de igualdad es necesario tener una restricción menos que el número total de variables que ya si se igualan, la intersección no sería una curva sino un punto, y la solución del problema estaría dada al resolver es sistema de ecuaciones planteadas en las restricciones.
Figura 3.1 a) Restricciones h1 y h2 en un espacio tridimensional. b) Curva formada por la intersección de las restricciones.
La solución del sistema (3.13), puede encontrase explorando los valores k, tal que
f(x1; x2; x3) = k, encontrando el punto optimo cuando el valor de k sea máximo. Es fácilmente demostrable que la superficie formada por f(x1; x2; x3) = kmax es tangente a la curva C, en P = (x1,opt,x2,opt). El vector gradiente de la función f es perpendicular a la

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
22
misma, y por la propiedad de tangencia que existe entre la curva C y esta función, también es perpendicular a C. Ahora bien, si se organiza el proceso comenzando por la intersección de las superficies formadas por f(x1; x2; x3) = k y cualquiera de las intersecciones se puede ver que el gradiente de las restricciones cumple a su vez la perpendicularidad con C y f. En otras palabras se dice que los vectores gradientes de las funciones involucradas en el sistema (3.13), son linealmente dependientes en P, por lo que existen α1, α2 y α3 pertenecientes a ℜ , no todos 0, tal que:[3]
0=∇+∇+∇ 23121 hhf ααα (3.14)
Dado que las dos superficies de las restricciones se interceptan para la formar la
curva C, sus gradientes también deben interceptarse por lo que no existe otro resultado que 0=∇+∇ 2312 hh αα [3], para satisfacer la ecuación (3.14) por lo que 1α necesariamente debe ser distinto de 0, y por lo tanto se puede dividir esta ecuación por este valor. Si se definen los multiplicadores de Lagrange como 121 /ααλ −= y
132 /ααλ −= , se puede volver a escribir la ecuación (3.14) como:
0=∇−∇−∇ 2211 hhf λλ (3.15)
Extendiendo el sistema vectorial a un sistema algebraico se obtiene un sistema de 3 ecuaciones con 5 incógnitas, x1opt, x2opt, x3opt, λ1, λ1.
01
22
1
11
1=
∂∂
⋅−∂∂
⋅−∂∂
xh
xh
xf λλ
02
22
2
11
2=
∂∂
⋅−∂∂
⋅−∂∂
xh
xh
xf λλ
03
22
3
11
3=
∂∂
⋅−∂∂
⋅−∂∂
xh
xh
xf λλ
(3.16)
Las ecuaciones de la restricciones del sistema (3.13), dan las otra dos ecuaciones
para completar el un sistema de 5 ecuaciones con 5 incógnitas. Si estas ecuaciones son lineales, se encuentra una única solución, pero si no son lineales se encuentran varias soluciones, entre ellas el máximo global o mínimo global, que se esta buscando. Para otras combinaciones de número de variables y número de restricciones no es necesario memorizarse las ecuaciones a resolver, para esto se cuenta con la función Lagrangiana, y el sistema esta dado por las derivadas parciales con respecto a los x y a los λ igualadas a cero, se obtienen todas las ecuaciones necesarias incluidas las restricciones.
)()(),( xxλx i
ii hfF ⋅−= ∑λ (3.17)

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
23
3.3.2 Derivación Algebraica [3] Aún cuando la derivación geométrica es muy clara, y puede aceptarse para
inclusión de más variables, las tratar con restricciones de desigualdad, es necesario revisar primero una derivación algebraica. Para comenzar se miran nuevamente el problema sin este tipo de restricciones, pero al final, una vez descrito el procedimiento, se extiende a cualquier tipo sistema que se quiera optimizar. Sea entonces:
Minimizar: )(xf
Sujeto a: [ ]mibxhi ,1 )( 1 ∈∀= (3.18)
Donde x, es un vector columna de n componentes, y necesariamente, como se
expuso en la sección anterior n > m. Al cumplirse esta relación se pueden escoger m variables (de x1 a xm) tales que la matriz Jacobiana de m restricciones, tiene una inversa evaluable en cualquier posible solución de (3.18). Al cumplirse esta condición, y todas las n – m funciones de restricción restantes, también tengan primera derivada continua, se pueden reemplazar las primeras m variables en término de las otras n – m [3]. Es decir
[ ]migx ii ,1 todapara )( ∈= x) y tnmm xxx ),,,( 21 K)
++=x , por lo que la función objetivo se puede ver como:
)),(),(),(()( 2 xxxxx ))L))mi hhhff = (3.19)
La cual es una función sin restricciones en el punto óptimo, ox
) , por lo que todas las derivadas parciales con respecto a estas n – m variables son iguales a cero. Si se extiende esta condición a la totalidad de las variables, haciendo uso de la regla de la cadena se tiene, en el punto óptimo que:
[ ]nmjxf
xg
xf
j
m
k j
k
k,1 0
1+∈∀=
∂∂
+⎟⎟⎠
⎞⎜⎜⎝
⎛
∂∂
⋅∂∂∑
= (3.20)
Así mismo las restricciones, que son funciones de las n variables se pueden
expresar en función del vector x) , y aplicando la misma metodología de la regla de la cadena que se uso con la función objetivo, se tiene (3.21) que a diferencia de su semejante con la función objetivo no solo se cumple en el punto óptimo, si no en sus vecindades.
[ ][ ]mi
nmjxg
xg
xh
j
im
k j
k
k
i,1
,1 0
1 ∈∀+∈∀
=∂∂
+⎟⎟⎠
⎞⎜⎜⎝
⎛
∂∂
⋅∂∂∑
= (3.21)
Igualando estas dos ecuaciones, teniendo en cuenta que existen un conjunto de
números reales (los multiplicadores de Lagrange) y remplazando las funciones que relacionaban unas variables con otras se encuentra la siguiente ecuación.

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
24
( ) ( ) [ ]nix
fx
h
j
om
i j
oii ,1
1∈∀
∂∂
=∂
∂∑=
xxλ (3.22)
Dado que desde el principio se definió la matriz Jacobina como invertible, se puede
demostrar que los valores de los distintos multiplicadores son iguales para todas las variables. Por ende se tiene nuevamente la función Lagrangiana como base para encontrar la solución óptima de cualquier sistema, ya sea lineal o no-lineal. Con la derivación algebraica se pueden incluir restricciones de desigualdad transformando las de igualdad al aumentar el número de variables. Es decir si una expresión necesariamente tiene que ser menor que cierto número dado, es equivalente a decir que esta expresión más nueva variable elevada al cuadrado es igual a dicho número. Como la explicación algebraica no nos obliga a quedarnos en un solo espacio, es factible hacer este cambio y plantear las derivadas parciales del Lagrangiano incluida la correspondiente a esta nueva variable y realizar todo el procedimiento.
3.4 Método del Gradiente Reducido El Método del Gradiente Reducido, desarrollado por primera vez en 1963 por Wolfe
para resolver problemas cuya ecuación objetivo fuera no-lineal, y sus restricciones lineales. En la actualidad se sigue utilizando este método exclusivamente para estas condiciones [Koskito, Ellingwood, 1997], aunque ya en su forma generalizada [Abadie, Carpentier, 1969] permite el manejo de restricciones no-lineales [2].
El Método del Gradiente Reducido de Wolfe, se explica a continuación, para mayor profundización dirigirse a [2]. Se formula entonces un problema de la siguiente manera:
Minimizar: )(xf
Sujeto a:
0xbAx
≥=
(3.23)
En donde A es una matriz de nm × con rango igual a m, b es un vector de m
componentes y f es una función tal que es continuamente derivable en el espacio n- dimensional. Se considera entonces, sin pérdida de generalidad, que la matriz tiene m columnas linealmente independientes, por lo que todo punto extremo de una solución viable tiene m componentes distintos de cero, y dadas las condiciones en (3.23), positivos. Las demás componentes (n – m) pueden tomar valores de cero. Es por esto que se puede descomponer la matriz A en [B, N], y la solución xt en [ t
NtB xx , ]. En donde B
es ahora una matriz cuadrada de mm× y por esto es invertible, por lo que se hace necesario que la primera parte en la que se descompuso el vector solución tiene componentes mayores a cero. Esta parte es conocida como el vector básico [2], y xN como el vector no básico. Siguiendo esta filosofía, el gradiente de la función objetivo ( tf )(x∇ ) también se descompone en la unión de dos vectores, un gradiente con respecto al vector básico y un gradiente con respecto al vector no básico.
Para llegar a la respuesta óptima de cualquier problema, es necesario tener una dirección adecuada, como se discutió anteriormente. Sea dt el vector de esta dirección, el cual también se puede descomponer en [ t
NtB dd , ], vector no – básico y básico

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
25
respectivamente. Nótese que la posición de los vectores en el vector total vario con respecto a la posición que se estaba llevando hasta el momento. Esto es porque el que define la posición de los vectores y las matrices B y N es el conjunto de índices de los m mayores partes de x, en cada posición de la parte básica y la parte no básica es la misma, pero esta varia al comenzar cada nuevo ciclo.
Antes de entrar al algoritmo es necesario definir un último vector denominado gradiente reducido, finalmente es el que le da nombre al método. El gradiente reducido es:
ABxxr ⋅⋅∇−∇= −1)()( t
Btt ff (3.24)
Es fácilmente demostrable [2] que, dada la definición de gradiente reducido, se
cumple NtN
tf drdx ⋅=⋅∇ )( , ecuación fundamental para la aplicación del algoritmo.
3.4.1 Algoritmo de Método de Gradiente Reducido (Adaptado de Bazaraa, [2])
1. Para empezar la convergencia, se debe tomar un vector xk, cuya única condición sea cumplir con las restricciones de la optimización, es decir A·xk = b, sea k = 1.
2. Se define Ik como el conjunto de m índices correspondientes a los m mayores componentes de xk. Hay que recordar que m es el rango de la matriz A.
3. La matriz B queda definida por los vectores columna de la matriz A, cuyos índices pertenecen a Ik, y la matriz N queda entonces definida por los vectores columna sobrantes.
4. Calcular r como se definió en (3.14).
5. Calcular dN de la siguiente manera: ⎭⎬⎫
⎩⎨⎧
>∉→⋅−≤∉→−
=0y
0y
jkjj
jkjj rIjrx
rIjrd
6. Calcular dB de la siguiente manera: NB dNBd ⋅⋅−= −1 7. Calcular dk como el vector compuesto por estas dos partes. Es importante recordar
que este vector debe ser armado de acuerdo a las posiciones en Ik y a dN y dB. 8. Si dk es igual al vector nulo, se ha llegado a la solución óptima6 y se para el
algoritmo. De no ser así, se debe proseguir al paso 9. 9. Encontrar la solución al siguiente sistema:
Minimizar: f(xk + λdk) Sujeto a: max0 λλ ≤≤
donde: ⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
≥→∞
<→⎟⎟⎠
⎞⎜⎜⎝
⎛>
−=
0d
0d
k
kjkjk
jk ddx
0:minmaxλ
Problema de optimización que se puede resolver con herramientas de cálculo diferencial, ya que el mínimo de f(xk + λd), función que solo depende de λ, se encuentra bien sea en los extremos del dominio o en los probables mínimos
6 La solución óptima corresponde al punto de las condiciones KKT.

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
26
locales. Se tiene ahora que xk+1 = xk + λdk, y se vuelve al segundo paso haciendo k = k + 1.
Nota sobre el algoritmo Si al empezar una nueva iteración uno o más elementos del Ik cambian con respecto
a Ik+1, se debe hacer un cambio en la matriz A para tener en cuenta las variables que dejan la base y las que entran a esta. Este cambio depende de la ubicación de las variables dentro de la matriz y dentro de la base. Para ilustrar como debe efectuarse este cambio en la matriz A, se hace uso del siguiente ejemplo:
Sea bxA =· en forma extendida:
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⋅⎥⎦
⎤⎢⎣
⎡
4
3
2
1
4
3
2
1
24232221
14131211
bbbb
xxxx
aaaaaaaa
(3.25)
Si I1 es igual a {2,3} se puede hacer una tabla que contenga la matriz A, y
representar la base de la siguiente manera:
Tabla 3.1. Representación de la matriz A dependiendo de I1 I1 = {2,3} x1 x2 x3 x4
x2 a11 a12 a13 a14
x3 a21 a22 a23 a24
Si es necesario cambiar de base, por ejemplo I2 = {1,3} se efectúan operaciones que
se conocen como operaciones de pivotaje para cambiar a la siguiente matriz A. La fila correspondiente a la variable que deja la variable que deja la base, se vuelve ahora la fila de la variable que entra dividiéndola por el valor que se encuentra en la columna correspondiente a la variable que entra. Las demás filas en la matriz se les resta la fila elaborada en el paso anterior multiplicada por la casilla de la columna de la variable que entra que se encuentra en la fila que se esta modificando. Para ilustrar mejor el ejemplo, la tabla se la segunda iteración sería:
Tabla 3.2. Modificación de la matriz A de acuerdo a I1
I2 = {1,3} x1 x2 x3 x4
x1 11
11aa
11
12aa
11
13aa
11
14aa
x3 11
112121 a
aaa −11
122122 a
aaa −11
132123 a
aaa −
11
142124 a
aaa −
3.5 Programación Cuadrática La Programación Cuadrática es la base para el Método de Programación Sucesiva
de Cuadrados, método que como se vio en la introducción de este Capítulo, es de gran

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
27
utilidad para resolver problemas en el Diseño Óptimo Basado en Confiabilidad. Los problemas con los que trabaja este tipo de programación se pueden describir de la siguiente manera:
Minimizar: ∑∑∑= ==
+n
j
n
kkjjk
n
jjj xxcxc
1 11
Sujeto a: [ ]
[ ]nijx
mibxa
j
n
jijij
,0
,1,1
∈∀≥
∈∀=∑=
(3.26)
donde aij, bij y cij ℜ∈ . La formulación de la función objetivo es tal, que esta incluye
los cuadrados de las n variables y las combinaciones cuadráticas entre ellas. Además se incluyen las variables en su forma lineal. El sistema (3.26) tiene n variables y m restricciones, y resulta general si se tiene en cuenta las siguientes variaciones [3]:
a. La minimización de una función puede verse como la maximización de la función multiplicada por -1.
))(min())(max( xx ff −= b. Restricciones de desigualdad, pueden incluirse al adicionar una variable no
negativa a la restricción en cuestión. 0≥∧=−⋅⇒≤⋅ yy 0xabxa
c. Si existen variables sin restricción de negatividad, estas se pueden remplazar por dos variables restringidas de tal modo la variable remplazada sea la resta de las nuevas variables.
00 :por remplaza Se
nrestricciósin
≥∧≥−=
→
iBiA
iBiAi
i
xxxxx
x
Haciendo uso del álgebra lineal y para comprimir un poco la expresión (3.26), esta se puede escribir de la siguiente manera:
Minimizar: xDxxc ⋅+ tt21
Sujeto a:
0xbxA
≥=⋅
(3.27)
Como en los métodos anteriores, x y b son vectores columna, y en este caso el
nuevo vector que contiene los coeficientes de las partes lineales, c, también lo es. Siguiendo esta filosofía, A es una matriz nm × y D es una matriz cuadrada de nn× que tiene la particularidad de ser simétrica. Si partimos de la segunda parte de la función objetivo en (3.26), la matriz D se puede organizar de la siguiente forma [3]:
kjcdd
kjcd
jkkjjk
jjjj
<∀==
=∀⋅=
2 (3.28)

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
28
Ahora bien, denotando el vector de los multiplicadores de Lagrange de las
restricciones de tipo A·x = b como λ y el vector de los multiplicadores de Lagrange de las restricciones x ≥ 0 como ν, y el vector de las variables adicionales para quitar las restricciones de desigualdad como y, las condiciones KKT se pueden escribir como:
0νλ,yx0yλ
0νx
cνλAxD
byxA
≥=
=
=+−−
=+
,,
·
·
t
t
t
(3.29)
Si consideramos las siguientes definiciones:
⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡ −=
xλ
zνy
wcb
qDAA0
M ;;;t (3.30)
Podemos plantear un problema lineal que nos lleve a la solución de la programación
cuadrática; este problema es:
0z)(w,0zwqMzw ≥==− ,, t (3.31)
y se llama problema lineal complementario y se discute en la siguiente sección.
3.5.1 Problema Lineal Complementario El problema lineal complementario consiste en encontrar dos vectores, w y z tales
que satisfagan:
[ ][ ]pijxw
pjz,w
jj
jj
,0
,100
∈∀=
∈∀≥≥=−
qMzw
(3.32)
Donde M es una matriz pp × y q es un vector de p componentes. Para encontrar
una solución al sistema (3.32), es conveniente adicionar una nueva variable z0 [2]. Si se nombra 1 al vector columna de p componentes todas iguales a la unidad, podemos modificar el problema lineal de la siguiente manera:

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
29
[ ][ ]
0
,0
,100
0
0
≥
∈∀=
∈∀≥≥=−−
z
pijxw
pjz,wz
jj
jj
q1Mzw
(3.33)
Si z = 0, w = q + 1z0 y z0 = max {-qi: 1 ≤ i ≤ p}, se tiene la solución de la primera
iteración del algoritmo que lleva a la variable ajena al sistema original a 0, y a satisfacer (3.32).
3.5.1.1 Algoritmo del Problema Lineal Complementario Aunque existen varias alternativas para resolver el problema lineal complementario,
(3.32), a continuación se presenta la solución propuesta por Lemke, esta es una adaptación de Bazzara [2].
1. Inicialización: Si q ≥ 0, se tiene la solución al problema dada por (w, z) = (q, 0). De lo contrario es necesario cambiar el sistema (3.32) por el sistema extendido (3.33) y organizar el sistema en una tabla como se muestra a continuación. Se define la fila s aquella que contenga el valor de qs, siendo este definido como:
{ }piqq is ≤≤−=− 1:max . Antes de ir a la primera iteración se pivota con respecto a la fila s y a la columna z0
7. Sea zs = zs.
Tabla 3.3. Tabla Problema Lineal Complementario, antes de ser pivotada por la inicialización
w1 · · · wp z1 · · · zp z0 RHS w1 1 0 0 0 0 -1
0 1 0 0 0 -1 0 0 1 0 0 -1
· · · 0 0 0 1 0 -1
wp 0 0 0 0 1
– M -1
q
2. Sea ds el vector columna correspondiente a la variable ys una vez actualizado, si todas las componentes de este son menores o iguales de 0, es necesario aplicar una “terminación de rayo”, esta es explicada en el paso 5. De no ser así, es necesario determinar el índice r por una prueba de mínima proporción.
⎭⎬⎫
⎩⎨⎧
>= 0:min isis
i
rs
r ddq
dq
(3.34)
Donde q es el vector de la derecha, bajo el nombre de RHS, una vez actualizada. Si la variable en la base (primera columna a la izquierda) de la fila r es z0 se sigue al paso 3, de no ser así se continua con el paso 4.
7 Este procedimiento se explica en la nota sobre el algoritmo del Método de Gradiente Reducido. Pagina 25.

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
30
3. Dado que la variable que entra a la base es ys y la variable que sale de la misma es z0 se pivota por última vez con respecto a la fila r y la columna s, produciendo la solución al sistema lineal complementario. Se detiene el algoritmo.
4. La variable que sale de la base corresponde a la fila r es un w o un z diferenta a la que corresponde a la fila ys, que precisamente es la variable que entra. Se pivota de acuerdo a la fila r y la columna s, y de define la nueva variable ys dependiendo de la variable que dejó la base. Si r correspondía a wk, ys = zk y si r correspondía a zk, ys = wk. Se vuelve al paso 2 con esta nueva variable.
5. El algoritmo para con una terminación rayo. Se debe encontrar un rayo ( ){ }0:,, 0 ≥+= λλdzw zR
tal que en cada punto de estos se satisfaga (3.33). Esta entonces es una solución quasi-complementaria asociada a la última tabla, y d es la dirección extrema teniendo un 1 en la fila correspondiente a ys.
3.6 Programación Cuadrática Sucesiva (SQP8) Como se anticipó en la introducción de este capítulo, el Método de Programación
Cuadrática Sucesiva es utilizado en toda clase de problemas no-lineales, sin importar la naturaleza de sus restricciones, ya sean estas de igualdad, o desigualdad; o bien lineales o no lineales. Para aclarar el funcionamiento del método, como se ha venido haciendo hasta ahora, inicialmente se descubre el problema utilizando restricciones de igualdad, pero más adelante este se extiende para incluir todo tipo de restricciones.
La Programación Cuadrática Sucesiva parte de resolver directamente las condiciones KKT, por lo que es necesario tener en cuenta el método de multiplicadores de Lagrange presentado anteriormente. Además, como su nombre lo indica, el algoritmo que aquí se presenta se apoya en la Programación Cuadrática expuesta en la sección anterior. Para llegar a una solución la principal condición es que todas las funciones presentadas en el sistema (3.35) sean continuas y doblemente derivables.
Dado el sistema:
Minimizar: )(xf Sujeto a: [ ] mihi ,10)( ∈∀=x
(3.35)
Por los multiplicadores de Lagrange se sabe que una solución de este sistema debe
cumplir:
[ ]mih
hf
i
l
iii
,10)(
)()(1
∈∀=
=∇+∇ ∑=
x
0xx λ (3.36)
Ahora bien, este sistema de ecuaciones se puede escribir de manera más compacta
como W(x, λ), por el método de Newton – raspón se puede minimizar una función en la cual (3.36) represente la condición de primer orden que iguale el gradiente a cero [2]. Por
8 A la programación cuadrática sucesiva se le llama SQP por las siglas del método en inglés: Sequential Quadratic Programming

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
31
lo tanto dada una solución de la primera iteración, (xk, λk), se puede encontrar la segunda iteración resolviendo la aproximación de primer orden:
0λλxx
λxWλxW =⎥⎦
⎤⎢⎣
⎡−−
∇+k
kkkkk ),(),( (3.37)
Donde W∇ es el Jacobiano de W, y la iteración (xk+1, λk+1) esta dada por la solución
(x, λ). Si a la matriz Hessiana del Lagragiano en el punto xk con multiplicadores de Lagrange λk se nombra )(2
kL x∇ , y h∇ es el Jacobiano de h cuyas filas constan de t
ih )(x∇ para [ ]mi ,1∈ , se puede calcular el Jacobiano de W como:
⎥⎥⎦
⎤
⎢⎢⎣
⎡
∇∇∇
=0xxxλxW
)()()(),(
2
k
tkk
kk hhL
(3.38)
Con la formulación de los multiplicadores de Lagrange presentada en (3.36), y la
expresión para el Jacobiano de W, y remplazando x – xk = d se puede escribir la aproximación de primer orden como:
)()()()()(2
kk
tkk
hfhL
xhdxxλxdx
−=∇−∇=∇+∇
(3.39)
Ahora bien, si existe la solución para el sistema planteado, este se puede resolver
para (d, λ) = (dk, λk+1), y hacer xk+1 = xk + dk. Se incrementa k hasta encontrar d = 0. Una vez estudiada la programación cuadrática en la sección anterior, se puede establecer u sub-programa que pueda resolver con esta clase de programación y cuyo mínimo represente las mismas condiciones de (3.39). Se identifica la programación cuadrática como QP, por sus siglas en inglés, para diferenciarlo del sistema original (3.35) [2].
QP(xk, λk):
Minimizar: dxddxx )(21)()( 2
ktt
kk Lff ∇+∇+
Sujeto a: [ ] mihh tii ,10)()( ∈∀=∇+ dxx
(3.40)
El primer término de la función objetivo no interviene a la hora de la evaluación ya
que este al ser evaluado en xk se convierte en una constante. Adicionalmente es importante aclarar que )(2
kL x∇ debe ser una matriz definida positivamente para que el método converja. Si se cumple esta condición, y la solución inicial se encuentra lo suficientemente cerca al punto óptimo, el algoritmo hasta aquí planteado tiene muy buenos resultados.

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
32
3.6.1 Programación Cuadrática Sucesiva Rudimentaria El algoritmo de la programación cuadrática teniendo en cuenta las condiciones de la
matriz )(2kL x∇ y de la proximidad de la primera iteración, consta de tan solo dos pasos.
1. Sea k = 1, seleccionar una solución dual inicial. Dual hace referencia a que no es sólo seleccionara el vector xk sino que también es necesario seleccionar el vector de los multiplicadores de Lagrange. Se recomienda hacer λk = 0.
2. Resolver el subproblema QP(xk, λk), obteniendo así la solución dk y los multiplicadores de Lagrange de la siguiente iteración. Si dk = 0, se tiene la solución óptima en (xk, λk+1), si no es así, xk+1 = xk + dk se incrementa k en uno y se itera este paso.
Este algoritmo no se ve afectado al tener en cuenta las restricciones de tipo de desigualdad, si se separan los multiplicadores de Lagrange de las restricciones de igualdad y las restricciones de desigualdad, λ y ν, respectivamente, el sistema cuadrático complementario sería:
QP(xk, λk):
Minimizar: dxddxx )(21)()( 2
ktt
kk Lff ∇+∇+
Sujeto a: [ ] mihh tii ,10)()( ∈∀=∇+ dxx
[ ] ligg tii ,10)()( ∈∀≤∇+ dxx
(3.41)
La solución de este sistema es entonces dk, junto con los multiplicadores de
Lagrange λk+1, νk+1. El procedimiento del algoritmo rudimentario es igual a que si no se tuvieran desigualdades.
3.6.2 Programación Cuadrática Sucesiva Completa Como se mencionó anteriormente, para poder implementar la programación
cuadrática sucesiva rudimentaria con éxito, es necesario que la matriz Hessiana del Lagrangiano cumpla con ciertas propiedades y que la primera iteración este muy cerca de la solución. Condiciones que se vuelven complicadas cuando se tiene una cantidad considerable de variables y restricciones, ya que la solución de la primera iteración no solo incluye las variables sino también los multiplicadores de Lagrange para cada restricción. La primera desventaja que se resolverá será la correspondiente a la matriz Hessiana del Lagrangiano.
3.6.2.1 Aproximaciones “Quasi – Newton” Para que el algoritmo de la programación cuadrática sucesiva funciones es
necesario que )(2kL x∇ , este definida positiva. Una matriz es definida positiva cuando
sus eigenvalores son estrictamente positivos. En muchos casos de optimización, esta matriz tiene eigenvalores negativos o cero, lo que hace que no sea definida positivamente, para esto es importante antes de comenzar la k–esima iteración, hacer esta revisión y de ser necesario cambiar la matriz por una aproximación quasi-Newton definida positiva. Es decir teniendo una aproximación Bk de )(2
kL x∇ , se puede resolver

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
33
el algoritmo planteado anteriormente cambiando )(2kL x∇ por Bk. Siguiendo el
procedimiento se obtienen una única solución para, el problema cuadrático complementario: (dk, λk+1, νk+1). Haciendo uso de la fórmula Broyden-Fletcher-Goldfarb-Shanno (BFGS) se puede encontrar la matriz B para la siguiente iteración como:
kktk
kkkk
ktk
tkk
kkpBpBppB
pqqq
BB −+=+1
Donde: kkk xxp −= +1 )(')(' 1 kkk LL xxq ∇−∇= +
∑∑=
+=
+ ∇+∇+∇=∇l
iiik
m
iiik ghfL
1)1(
1)1( )()()()(' xxxx νλ
(3.42)
Una primera aproximación para la matriz B, se obtiene definiendo un parámetro δ >
0, y encontrar B = (εI + )(2kL x∇ )-1. Donde I es la matriz identidad y ε es el menor número
real mayor o igual a cero que hace los eigenvalores de (εI + )(2kL x∇ ) mayores o iguales
a δ. Esto garantiza que la matriz que entra en el algoritmo de la programación cuadrática sucesiva sea definida positiva.
3.6.2.2 Función de Ventaja Una vez resuelto el problema que se puede presentar en algunas ocasiones en la
matriz Hessiana requerida, solo falta por discutir la gran desventaja que se tienen cuando se empieza con un punto lejos del óptimo, el algoritmo no parece converger ya que es muy lento cuando se tienen cortas direcciones d. Para esto se introduce el concepto de la función de ventaja9[2]. Esta función ayuda a guiar cada iteración más cerca de la solución, sin importar que tan lejos este. En otras palabras hace que el algoritmo converja más rápido de lo normal. Como función de ventaja es popularmente usada la función de penalidad l1[2]. Para el problema planteado en (3.41) la función de ventaja sería [2]:
{ }⎥⎥⎦
⎤
⎢⎢⎣
⎡++= ∑ ∑
= =
l
i
m
iiiE hgfF
1 1)()(,0max)(()( xxxx µ
Donde: { }ml λλννµ ,,,,,max 11 LL≥
(3.43)
Donde υi y λi son los multiplicadores de Lagrange correspondientes a las
restricciones de desigualdad e igualdad respectivamente.
3.6.2.3 Algoritmo General de la Programación Cuadrática Sucesiva 1. Sea k = 1, seleccionar una solución factible inicial. Seleccionar una aproximación
Bk de la matriz Hessiana del Lagragiano, teniendo en cuenta que en la solución factible los multiplicadores de Lagrange asociados a las restricciones de
9 En inglés es llamada Merit Funtion o función mérito, pero la traducción más apropiada es ventaja y no mérito.

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
34
desigualdad deben ser iguales o mayores a cero. Nuevamente se recomienda que los multiplicadores escogidos para la primera iteración sean iguales a cero. La aproximación Bk, puede ser la misma )(2
kL x∇ .
2. Resolver el subproblema cuadrático remplazando )(2kL x∇ por Bk obteniendo la
solución (dk, λk+1, νk+1). Si el vector de direcciones es igual al vector nulo, se tiene que xk es el vector solución. De no ser así continuar con el siguiente paso.
3. Sea xk+1 = xk + αkdk. Donde αk minimiza FE(xk + αdk) sujeto a α ≥ 0. 4. Se actulaliza la matriz Bk a la matriz definida positiva Bk+1, donde esta matriz
puede ser la misma Bk o )( 12
+∇ kL x . Se incremente al contador k en uno y de vuelve al paso 2.
3.7 Cálculo del Índice de Confiabilidad β por Medio de Técnicas de Optimización El índice de confiabilidad o parámetro β, se puede calcular encontrando la distancia
más corta entre el origen y la curva o superficie que describe la función de estado límite. Si esta función es lineal encontrar esta distancia es trivial. En ocasiones esta función es no lineal o altamente no lineal, para esto se han establecido métodos como FORM (Capítulo 1) para encontrar es distancia o al menos una aproximación adecuada. Una vez estudiados los métodos de optimización no-lineal, se puede hacer uso de estos para encontrar esta distancia. La programación sucesiva de cuadrados al involucrar toda clase de sistemas de optimización es bastante útil para este ejercicio ya que tanto la función objetivo como las restricciones son no-lineales.
3.7.1 Función moderadamente no lineal Supongamos que la función de estado límite depende de dos parámetros
únicamente (X, Y), y esta dada por: h(X,Y) = Y3 + X2 + X·Y – 60·Y2 – 220·X + 1100·Y + 3900. Los dos parámetros siguen una distribución normal cuya media y desviación estándar aparecen en la siguiente tabla.
Tabla 3.4. Medias y Desviaciones Estándar de los Parámetros de la ecuación de estado límite
Parámetro Media Desviación Estándar X 100 1 Y 20 1
Haciendo la transformación vista en el Capítulo 1, se puede llegar a tener la función
de estado límite en el espacio reducido, si llamamos x y y las variables reducidas se tiene que 0100),( 23 =−⋅++= yxxyyxh . Esta sería la única restricción en el sistema a optimizar, y la función objetivo estaría dada por la función de distancia entre el origen y
cualquier punto, 22 yx + . Al ser la función raíz siempre creciente, maximizarla (o minimizar) tiene el mismo sentido que maximizar (o minimizar) la función interna. Para nuestro caso el sistema que se quiere representar, ilustrado en la Figura 3.2 es:
ICIV 200410 43 Capítulo 3 – Métodos de Optimización
35
Minimizar: 22),( yxyxf += Sujeto a: 0100),( 23 =−⋅++= yxxyyxh
(3.44)
Se observa en que la restricción de tipo igualdad no acota un espacio, la solución
puede estar cualquier zona de la línea oscura, es decir los valores de las variables x y y pueden ir desde –∞ a +∞. Es factible, como se dijo en la sección que describe este tipo de restricciones, encontrar la ecuación de esta parábola oscura )(xfy = y con herramientas del cálculo diferencial encontrar el valor de x para el cual la función toma su valor mínimo, luego con la restricción encontrar el valor de y. Este procedimiento es sencillo a la hora de evaluar funciones de estado límite sencillas, pero cuando estas se complican es mejor seguir el procedimiento de una programación cuadrática sucesiva que, como se verá más adelante, se simplifica para este tipo de problemas.
Figura 3.2. Función objetivo y línea de restricción de los parámetro x, y.
Antes de comenzar el algoritmo es conveniente encontrar la formulación de los
vectores gradientes y matrices Hessianas de las dos funciones.
Gradientes: ⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
yx
yxf22
),( ⎟⎟⎠
⎞⎜⎜⎝
⎛+
+=∇
xyyx
yxh 222
),(
Hessianas: ⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
2002
),(2 yxf ⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
yyxh
6112
),(2
Para este tipo de problemas, cálculo de β, se simplifica de manera considerable el
algoritmo, ya que la matriz Hessiana de f es siempre igual a la matriz identidad multiplicada por 2. El gradiente también tiene la misma forma sin importar el número de variables involucradas. El gradiente y la Hessiana que corresponden a la ecuación de estado límite no tienen ninguna forma definida, ya que esta podría ser cualquier función. Es por esto la dificultad de manejar el algoritmo en un lenguaje de programación radica exclusivamente en el cálculo por métodos numéricos de este vector y esta matriz. La matriz Hessiana del Lagrangiano, con un solo valor λ, por tener una sola restricción es:

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
36
⎟⎟⎠
⎞⎜⎜⎝
⎛+
+=∇
λλλλ
λ··62
22),,(2
yyxL
Para desarrollar este ejercicio, se creo una secuencia de funciones en Mathcad 11
donde se tienen, por comodidad al momento de pasar el código a otro lenguaje, las derivadas calculadas con métodos numéricos y por lo tanto el código es ejecutable sin importar el número de variable. Estas funciones se presentan en el Apéndice A, con todos los comentarios explicatorios. Para presentar estas funciones se pidieron resultados más particulares de todos los vectores, matrices y parámetros necesarios, pero el funcionamiento es exactamente el mismo que el presentado en el apéndice.
Primera Iteración La primera solución dual propuesta es: x1 = 0.50, y1 = 4.60 y λ1 = 0.00. Con esta se
puede calcular la matriz Hessiana del Lagrangiano, y sus eigenvalores:
⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
2002
),,( 1112 λyxL ⎟⎟
⎠
⎞⎜⎜⎝
⎛=∇
22
)( 2Leseigenvalor
Como los valores propios de la matriz, para esta iteración fueron positivos, la matriz
esta definida positiva, por lo que no es necesario aproximarla por métodos Quasi-Newton, o lo que es lo mismo se dice que B1 = ),,( 111
2 λyxL∇ . Para poder armar el sistema lineal complementario es necesario calcular los valores de los vectores gradientes de las dos funciones en este punto, y el resultado de la función h, este último se conoce de ante mano ya que es con esta restricción que se obtienen los valores de la primera iteración. h(x,y) = 0 para cualquier iteración .
⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
03.6460.5
),( 11 yxh ⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
20.900.1
),( 11 yxf
El problema lineal complementario definido por w – M·z = q, en este tipo de
problemas con los restricciones de igualdad y sin restricción alguna para los parámetros en z, tienen una solución particular. w es el vector unión de los vectores de las variables extras (restricciones de desigualdad) y los multiplicadores de Lagrange de las restricciones de no negatividad. Como este vector es nulo, la solución de z está dada por M-1·(-q). Donde la matriz M es siempre invertible dado su proveniencia. Para esta iteración se tiene la siguiente linealización para el problema cuadrático complementario.
QP1
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛ −=
2003.640260.503.6460.50
M⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛=
20.900.100.0
q ⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛=
000
w ⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛=
2
1
2
ddλ
z

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
37
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−−
=01.010.014.0
soluciónz
Tomando los valores correspondientes al algoritmo global de la programación
cuadrática sucesiva, el vector solución z se distribuye como: λ2 = –0.14, dx1 = –0.10 y dy1 = 0.01. Como el vector de la dirección encontrada no es 0, se encuentra otros valores para x y y continuando así con siguiente iteración, k = 2.
Segunda Iteración Con: x2 = 0:40, y2 = 4:61 y λ2 = –0.14, se calcula la matriz Hessiana del Lagrangiano
y sus valores propio. Es importante resaltar que en esta ocasión la función de ventaja no tuvo mayor implicación sobre los valores de la segunda iteración, estos resultaron siendo los valores de la iteración anterior sumados con las direcciones halladas.
⎟⎟⎠
⎞⎜⎜⎝
⎛−−−
=∇98.144.144.172.1
),,( 2222 λyxL ⎟⎟
⎠
⎞⎜⎜⎝
⎛−
=∇00.2
72.1)( 2Leseigenvalor
Como estos valores no son todos positivos es necesario hacer una aproximación B2
que en esta ocasión no es igual a ),,( 2222 λyxL∇ , para esto se sigue una aproximación
quasi – Newton (página 32). Esta matriz, junto con los otros valores necesarios se encuentran a continuación.
⎟⎟⎠
⎞⎜⎜⎝
⎛=
41.105.005.028.0
2B ⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
17.6442.5
),( 22 yxh ⎟⎟⎠
⎞⎜⎜⎝
⎛=∇
22.981.0
),( 22 yxf
Una vez armada la linealización del problema cuadrático complementario, de
acuerdo a lo explicado en la iteración anterior se puede calcular el resultado de esta: λ3 = –0.14, dx2 = –0.12 y dx2 = 0.01. Al no ser un vector dirección nulo, se sigue con la siguiente iteración k = 3. El procedimiento es igual al planteado en la esta iteración ya que de ahora en adelante hasta que converja es necesario usar la aproximación de la Hessiana. Esta se va a actualizar siguiendo la metodología planteada anteriormente y teniendo la aproximación anterior.
Finalización del Proceso Para terminar el proceso fueron necesarias 4 iteraciones, el resumen de estas se
encuentra en la siguiente tabla:
Tabla 3.5. Resumen de las iteraciones para encontrar el índice de confiabilidad usando SQP λk+1 dxk dyk xk+1 yk+1 1. -0.14 -0.10 0.01 0.40 4.61 2. -0.14 -0.12 0.01 0.38 4.61 3. -0.14 0.11 0.01 0.39 4.61 4. -0.14 0.00 0.00 - -
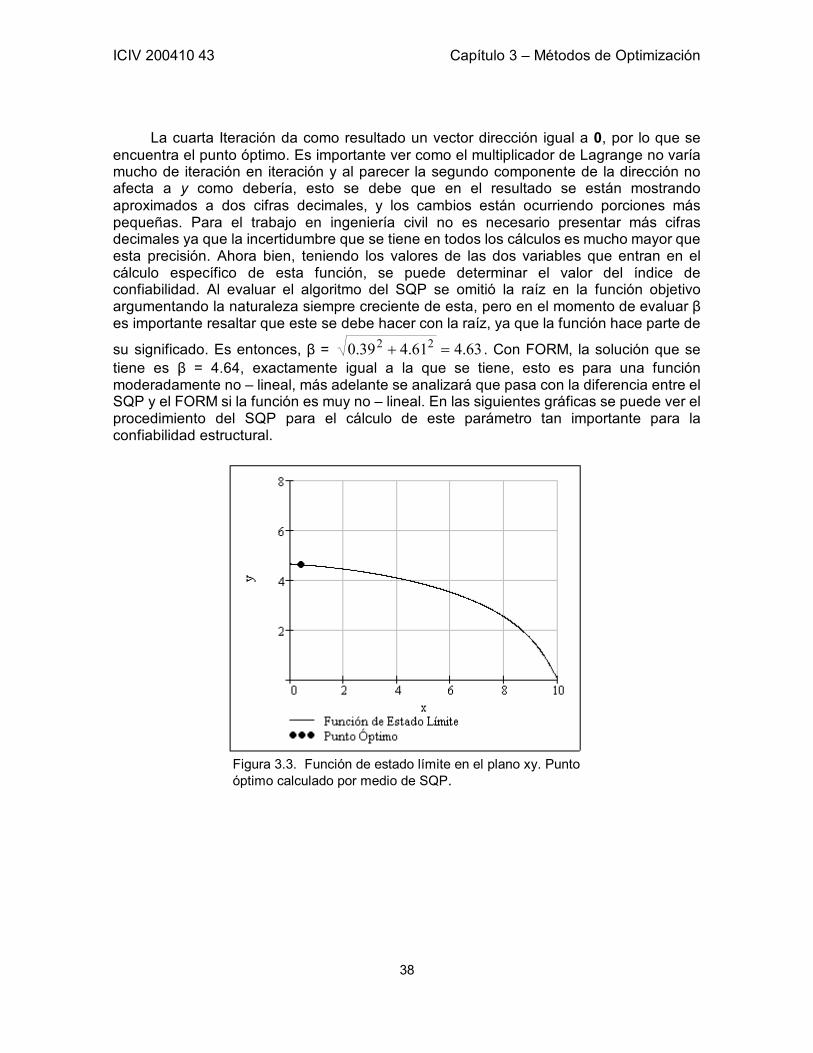
ICIV 200410 43 Capítulo 3 – Métodos de Optimización
38
La cuarta Iteración da como resultado un vector dirección igual a 0, por lo que se
encuentra el punto óptimo. Es importante ver como el multiplicador de Lagrange no varía mucho de iteración en iteración y al parecer la segundo componente de la dirección no afecta a y como debería, esto se debe que en el resultado se están mostrando aproximados a dos cifras decimales, y los cambios están ocurriendo porciones más pequeñas. Para el trabajo en ingeniería civil no es necesario presentar más cifras decimales ya que la incertidumbre que se tiene en todos los cálculos es mucho mayor que esta precisión. Ahora bien, teniendo los valores de las dos variables que entran en el cálculo específico de esta función, se puede determinar el valor del índice de confiabilidad. Al evaluar el algoritmo del SQP se omitió la raíz en la función objetivo argumentando la naturaleza siempre creciente de esta, pero en el momento de evaluar β es importante resaltar que este se debe hacer con la raíz, ya que la función hace parte de
su significado. Es entonces, β = 63.461.439.0 22 =+ . Con FORM, la solución que se tiene es β = 4.64, exactamente igual a la que se tiene, esto es para una función moderadamente no – lineal, más adelante se analizará que pasa con la diferencia entre el SQP y el FORM si la función es muy no – lineal. En las siguientes gráficas se puede ver el procedimiento del SQP para el cálculo de este parámetro tan importante para la confiabilidad estructural.
Figura 3.3. Función de estado límite en el plano xy. Punto óptimo calculado por medio de SQP.

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
39
Figura 3.4. Seguimiento de los pasos del algoritmo hasta encontrar el punto óptimo.
3.7.2 Función muy no lineal El método del FORM se basa en una aproximación lineal de la función de estado
límite, por esta razón es razonable pensar que entre menos lineal que sea la función FORM no debe poder calcular la probabilidad de falla y un algoritmo como el presentado, con base en SQP La función en el espacio real que se escogió fue X10 + Y3·X2 – 200 = 0 y las propiedades de cada variable se encuentran enunciadas a continuación:
Tabla 3.6. Medias y Desviaciones Estándar de los Parámetros de la ecuación de estado límite
Parámetro Media Desviación Estándar X 10 1 Y 2 0.02
Siguiendo el mismo procedimiento que para la función moderadamente no lineal,
haciendo uso del algoritmo del Apéndice A, y una vez habiendo transformado las variables al espacio reducido se encontró que el valor del índice de confiabilidad era de 3.36. Para encontrar este valor el programa necesitó de 9 iteraciones. La función objetivo en el espacio reducido se puede ver en la Figura 3.5 donde se ubica el punto que representa la distancia más corta entre el origen y la función. En la Figura 3.6 se puede ver como la función de estado límite restringe la función objetivo a una línea que esta vez no es una función sencilla. El resultado con FORM es poco alentador ya que este no alcanza a linealizar la función, posiblemente por el pico que esta presenta. En el algoritmo presentado en el Apéndice C el resultado fue β = -6.14. Este resultado daría una probabilidad de falla de uno, completamente errónea.
Una de las cosas que hace el algoritmo de SQP tan eficiente es que este puede manjar el echo que existan raíces imaginarias en la función de estado límite, FORM no es dotado con esta metodología y por esta razón puede colapsar en funciones altamente no lineales. Es recomendación de esta investigación el usar un SQP, que como se vio

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
40
anteriormente es fácilmente programable para el caso del cálculo del índice de confiabilidad, ya que este siempre proporciona resultados exactor.
Figura 3.5. Función de Estado Límite en el espacio transformado.
Figura 3.6. Función de Estado Límite proyectada en la Función Objetivo.
3.8 Conclusiones La Programación Cuadrática Sucesiva es el método de programación no – lineal
más completo ya que permite la solución de sistemas en las que tanto la función objetivo como las restricciones pueden ser funciones lineales o no. La gran conclusión que se

ICIV 200410 43 Capítulo 3 – Métodos de Optimización
41
obtiene del trabajo desarrollado en este capítulo es que siento el problema del cálculo del índice de confiabilidad un problema de optimización no – lineal, SQP puede convertirse en una gran solución que puede abarcar cualquier función de estado límite. Se pudo demostrar con un ejemplo numérico que al ser la función de estado límite extremamente no lineal FORM puede presentar errores de gran magnitud, mientras que el algoritmo de SQP no los presenta.
El estudio de los métodos de optimización no solo permitieron el avance de un algoritmo para un futuro programa que se enfrente a problemas de optimización sino que permitió descubrir una nueva técnica para el problema de confiabilidad no utilizado para este fin.

Capítulo 4 Ejemplo Práctico: Losa Armada en Una Dirección
4.1 Introducción
La estructura o “súper estructura” como es llamada en el caso de los puentes, es el esqueleto de las edificaciones. Esta puede estar constituida por concreto reforzado, metal, madera, mampostería o combinaciones entre ellas. Cuando un ingeniero diseña la estructura toma la decisión acerca de que material usar de acuerdo no solo al diseño arquitectónico sino a la economía de la obra. Por esta razón se puede ver más edificaciones hechas en acero estructural en países productores del material como Estados Unidos o el norte de Europa y más edificios en concreto reforzado en países como Colombia y en general todo Suramérica. Varios autores que se han dedicado a análisis y diseño óptimo basado en confiabilidad han trabajado en estos sistemas principales, pero pocos se han dedicado a las “sub estructuras” o estructuras secundarias.
Una de las partes de una edificación donde más material es utilizado es en el sistema de entre pisos, por esta razón es posible afirmar que optimizar las losas estructurales puede constituir una gran fuente de ahorro en todo el diseño. En este trabajo se ha escogido optimizar una losa estructural armada en una dirección para ver como se puede comparar el diseño tradicional de este tipo de sub estructuras, con un diseño basado en confiabilidad estructural. Cómo función objetivo de la optimización fue escogida la propuesta de Rackwitz presentada en el Capítulo 2.
Para poder realizar el cálculo de la ecuación de probabilidad de falla, necesario para la ecuación de Rackwitz (2.12), se hizo una secuencia de algoritmos en Mathcad, donde se utilizaron simulaciones de Monte Carlo para el cálculo de esta variando sólo una variable o variando todas las variables. Con el cálculo individual de cada se hicieron iteraciones en para encontrar la respuesta a la optimización. Posteriormente con una buena base de datos (cálculo variando todas las variables) se analizaron las distintas variables para ver cuales de ellas tiene trascendencia en la probabilidad de falla. Una vez depurada un poco la base de datos, se usó el programa SPSS para Windows, para realizar una regresión múltiple y encontrar la ecuación pf(p).
La optimización se realizó con los métodos estudiados en el Capítulo 3, y por último se analizaron los resultados y se compararon con el diseño que se obtiene tradicionalmente. En las siguientes secciones se explica a mayor detalle cada paso del procedimiento.
4.2 Losas Armadas en una Dirección Las losas armadas en una dirección de concreto reforzado es uno de los sistemas
de entre piso más utilizado en Colombia. El diseño de estas losas esta regido por el título B de la Norma Sismo-Resistente [13]. Para ilustrar el diseño basado en confiabilidad estructural se toma una losa estructural con las siguientes características: La losa

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
43
mostrada en la Figura 4.1 hace parte de un sistema de entre piso que tiene paneles iguales al mostrado en ambos sentidos en un número suficiente para poder asegurar que tanto vigas principales como viguetas se encuentran empotradas. Ya sea por diseño arquitectónico, por ubicación de la estructura principal del edificio o por cualquier otro motivo las distancias B y H no hacen parte de la optimización y son constantes. Más adelante se presentarán todos los parámetros y sus características. Como se muestra en la figura B es la longitud de la losa paralela a las viguetas y H es la medida perpendicular a las mismas. Esta nomenclatura es puramente ilustrativa para este ejemplo y en algunos de los casos puede variar con la utilizada en la práctica. Los valores utilizados son:
m58m
==
HB
(4.1)
Figura 4.1. Esquema de la Losa del Ejemplo. Definición de las variables correspondientes a la geometría de la Losa.
Figura 4.2. Corte A – A de la Losa del Ejemplo.
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
44
El diseño basado en confiabilidad estructural necesita un punto de partida para lograr calcular la confiabilidad de falla por simulaciones de Monte Carlo para esto es conveniente estar cerca al punto óptimo. Por esta razón y argumentando que los códigos de construcción usados alrededor del mundo usan la optimización y confiabilidad en alguna medida para sus cálculos, el punto de diseño tradicional debe estar cerca al óptimo y se convierte en el punto de partida de este nuevo tipo de diseño.
De acuerdo con la NSR98 las variables geométricas mostradas en la Figura 4.2 serían:
Tabla 4.1. Diseño tradicional de losas – Variables Geométricas.
Parámetro Dimensión Procedencia h 57 cm Tabla C.9-1(a) Para losas con nervios
armadas en una dirección ambos apoyos continuos.
s 80 cm Diseño típico para este tipo de losas. hf 5 cm Tabla C.9.1(a) Para losas macizas con ambos
apoyos continuos y l = s. b 15 cm Diseño típico para este tipo de losas.
Una vez tenida la geometría de la losa es necesario ver que solicitaciones tiene.
Normalmente las losas no hacen parte del sistema estructural de una edificación su función es soportar el sistema de entre piso y lograr garantizar diafragma rígido. Para este caso no se va a tener en cuenta las restricciones que se generan para garantizar este tipo de diafragma, suponiendo que el diseño del esqueleto estructural puede también ser diseñado con dia-fragma flexible o semi-rígido. Por último en las propiedades geométricas se deja un recubrimiento de 7 cm.
En el diseño de losas estructurales no actúan fuerzas horizontales, por lo que sólo recibe solicitaciones de carga viva y carga muerta. La losa hace parte de una edificación tipo vivienda, y solo tiene como carga muerta los acabados, los muros divisorios y el peso propio. Un avalúo preliminar que se acomoda a los objetivos de este trabajo sería:
Tabla 4.2. Avalúo de carga muerta para la losa del ejemplo.
CARGA MUERTA Acabados NSR98 sin análisis detallado 150 kgf/m2
Muros Divisorios Según NSR98 Bloque de Arcilla Hueco 300 kgf/m2
Carga Muerta Sin Peso Propio 450 kgf/m2
Peso Losa 2.4 tonf/m3 · hf (5 cm) 120 kgf/m2
Peso Propio Vigueta 2.4 tonf/m3 · (h – hf) · b / s 234 kgf/m2
Carga Muerta Total 804 kgf/m2
Se un presenta el subtotal de la carga muerta incluyendo solo los muros divisorios y
acabados ya que estas dos cargas no entran en el análisis de confiabilidad, no dependen de la geometría. El algoritmo que se presenta más adelante para obtener la regresión de la ecuación de la probabilidad de falla calcula la carga muerta independiente para cada iteración. Por otro lado, la carga viva que se tiene para el diseño es de 180 kgf/m2 nuevamente siguiendo las especificaciones de la NSR98 y las propiedades del proyecto de construcción. La única combinación de cargas que se tiene para el análisis por esfuerzos últimos para las losas es:

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
45
DLLL 1.4 1.7 + (4.2)
Por lo que para este ejemplo es:
1.7 (180 kgf/m2) + 1.4 (804 kgf/m2) = 1432 kgf/m2 (4.3) Para calcular las áreas de acero que se utilizan en el diseño tradicional tanto para el
momento positivo máximo y el momento negativo máximo se utilizó una resistencia del concreto de 210 kgf/cm2 y de acero de 4200 kgf/cm2. Al considerar que las viguetas se encuentran doblemente empotradas, el momento máximo posivo se puede calcular como:
24
2w·LM =+ (4.4)
Donde w esta dado por la carga última multiplicada por la separación de viguetas. Para esta carga, el área de acero a utilizar es:
ASpos = 1.66 cm2 (4.5)
El área de acero negativa se puede calcular utilizando el mismo procedimiento, esta vez el momento considerando empotramiento absoluto es:
12
2w·LM =− (4.6)
ASneg = 3.42 cm2 (4.7)
El refuerzo por cortante se supone la fuerza cortante igual a la reacción en uno de
los apoyos, es decir:
2w·LV = (4.8)
Con este valor de cortante el concreto alcanza a resistir toda la fuerza que se
produce, por lo que se pone área de acero mínima. Cada 25 cm se pone un fleje número 3 en forma de S. Es decir:
AV = 2.84 cm2 / m (4.9)
Con este mismo procedimiento, calculado los valores por metro de ancho se puede
definir el área inicial del acero de refuerzo de la losa.
ALpos = ALneg = 0.84 cm2 (4.10)

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
46
Con este diseño como el punto de inicio ahora es necesario describir el comportamiento de las variables que finalmente van a determinar la probabilidad de falla y punto óptimo de diseño.
4.3 Variables Involucradas El primer paso que se debe seguir en el diseño óptimo basado en confiabilidad es
identificar todas las variables involucradas. Para un diseño en el que la economía es lo más importante las variables involucradas no son sólo aquellas que controlan el comportamiento físico de la estructura, en este caso la losa, sino en todas las que representan algún costo. Si se compara con el diseño tradicional, las variables involucradas en este fueron: el área de acero que se utilice a lo largo de las viguetas, en los estribos y en el refuerzo de la losa, además las dimensiones geométricas de viguetas y torta superior. En este nuevo diseño además de estas variables que involucran la cantidad de material y por consiguiente costos, se involucran parámetros como la altura a la que se construye la losa, ya que el costo de subir un metro cúbico de concreto comparado con el de subir una tonelada de acero puede representar un cambio en las proporciones de estos materiales que se vayan a usar.
Para el ejemplo que se presenta a continuación, se han escogido los parámetros de diseño más relevantes a la hora de calcular la probabilidad de falla, y se escogió la función de costo rudimentaria (4.18), que hace solo referencia a los costos directos debidos a la cantidad de los materiales. Si bien para la función objetivo Z(p) entran todas estas variables que influyen en los costos, es necesario reducir al máximo la cantidad de estas para que el análisis no sea exceda las capacidades computacionales con las que se disponen. Un claro ejemplo de esto que se puede suponer es que el valor óptimo de acero en la posición de la vigueta donde el momento es máximo optimizará la totalidad del refuerzo positivo. Lo mismo sucede con el refuerzo negativo.
Existe una clara diferencia hasta ahora planteada de las variables que entran a formar parte del sistema a optimizar (ver Capítulo 2) y las variables que entran a evaluar la probabilidad de falla (Capítulo 1). Cada una de estas, cuenta con propias características que las describen. Para la optimización de la losa (Figura 4.1) se usaron 15 variables divididas en los siguientes grupos. Constantes
- Longitud de la losa paralela a las viguetas (B) - Longitud de la losa perpendicular a las viguetas (L) - Recubrimiento (R)
Probabilísticas de Diseño - Altura total de la losa (h) - Altura torta Superior de la losa (hf) - Separación entre centroides de las viguetas (s)
Determinísticas de Diseño - Área de acero viguetas, refuerzo positivo (ASpos) - Área de acero viguetas, refuerzo negativo (ASneg) - Área de acero flejes viguetas (por metro lineal) (AV) - Área de acero torta superior refuerzo positivo
(por metro de ancho) (ALpos) - Área de acero torta superior refuerzo negativo
(por metro de ancho) (ALneg)

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
47
Probabilísticas fijas (no hacen parte del diseño) - Resistencia máxima permitida del concreto (fc) - Resistencia máxima permitida del acero (fy) - Carga muerta (por metro cuadrado) (DL) - Carga viva (por metro cuadrado) (LL)
Las variables fueron clasificadas en estos grupos de acuerdo a su influencia en el diseño. Dos de las constantes enuncian el problema (B y H), el recubrimiento por otro lado también se considera constante ya que su incertidumbre se asocia a otra variable, la altura total de la losa. Con este último cambio se tiene una sola variable probabilística en lugar de dos, lo que significa un gran avance a la hora de programar el algoritmo. Por otro lado todas las áreas de acero involucradas han sido consideradas determinísticas aún cuando pueden tener una naturaleza probabilística. Existen dos razones para llegar a esta conjetura: 1. Los procesos industrializados en los que se elaboran las varillas de refuerzo, son absolutamente estrictos y actualmente estos productos son casi exactos. 2. Sea cual sea el resultado del diseño basado en confiabilidad o el diseño tradicional es poco probable que el área de acero resultante se consiga de manera exacta con el refuerzo comercial, por lo general se coloca un poco más de área que es sustancialmente mayor a la poca desviación estándar que se tendría.
Los grupos de variables pueden dividirse en dos grandes categoría. Diseño, que quiere decir que el objetivo de las simulaciones y la optimización es encontrar los valores a utilizar y fijas, que aunque ya se tiene su media establecida para el diseño, su incertidumbre hace que sea necesario involúcralas como variables probabilísticas a la hora de calcular la probabilidad de falla.
4.4 Función de Costos Como se ha discutido hasta el momento, la función que describe la probabilidad de
falla en función de todos los parámetros involucrados en su cálculo, representa la mayor dificultad a la hora de evaluar la función Z(p) para la optimización de cualquier sistema estructural. Sin embargo existe otra función, que aunque no represente una dificultad matemática, si representa una amplia complejidad conceptual. La función de costo, C(p), de cualquier estructura puede calcularse de tal manera que cuya dependencia sea de los parámetros que se utilizan en el análisis de confiabilidad, pero en realidad esta función no depende directamente de de estos. En la ecuación (2.3) se presenta la función de costo como un costo inicial más la sumatoria de cada parámetro por su respectivo costo. Esta ecuación se puede ampliar a:
∑∑ +⋅+⋅+=i
iii
ii MOptpcCC )()(` 0 pp (4.11)
Donde esta vez ci es el costo directo del insumo, ti es el costo de transporte de cada
variable y MO es la mano de obra que depende de todos los parámetros del vector p. Tanto el transporte y la mano de obra se deben tener en cuenta a la hora de optimizar ya que pueden representar diferencia sustancial a la hora de escoger las cantidades de obra. Por ejemplo, en una viga de concreto reforzado pude resultar más económico aumentar la sección bruta de concreto colocando menos área de acero, manteniendo la probabilidad de falla igual; pero si esta viga se encuentra en un décimo piso y el transporte no se esta teniendo en cuenta se puede llegar a cometer un error en la optimización ya que llevar acero a diez pisos de altura puede ser más económico que transportar concreto. Con la

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
48
mano de obra sucede lo mismo. En este mismo ejemplo, si se es tenido en cuenta el transporte y no la mano de obra puede volver a presentarse el mismo problema ya que para armar el refuerzo se necesita mano de obra más calificada, y por ende más costosa, que para vaciar los metros cúbicos extra de concreto.
4.4.1 Función de Costos Rudimentaria Se puede llamar función de costos rudimentaria aquella basada sólo en los costos
fijos de la construcción y en el costo directo del material. Esta función estaría conformada sólo por los primeros dos términos de la ecuación (4.11) y es en si la función que se usa en el Capítulo 2. Es importante diferenciar la función de costos rudimentaria de la función de costos compleja ya que esta da una aproximación bastante buena del costo de la estructura en las etapas de pre-diseño y diseño. Actualmente los ingenieros diseñadores calculan las cantidades de obra y los precios unitarios para calcular el valor del diseño, esto no es otra cosa que usar la función de costos rudimentaria.
Para el caso de una losa estructural armada en una dirección, esta función de costos puede ser bastante elaborada ya que se debe tener en cuenta tanto el material utilizado en las viguetas como el que se usa en la torta superior. Como las variables que se utilizan para definir esta función son las mismas utilizadas en el análisis de confiabilidad, es necesario tener una consistencia en la manera como se nombran. Todas las variables que se utilizan se encuentran listadas en la página 46.
Para mantener un orden que garantice no repetir material, es conveniente comenzar a evaluar el costo de la losa y luego el de las viguetas. La losa tiene como único parámetro que controla el volumen del concreto la altura de esta, ya que el área que cubre la losa no es motivo de optimización, va definida por diseño arquitectónico o por conveniencia. El volumen de concreto utilizado en la losa esta dado por:
hfHBVconcretoLosa ⋅⋅= (4.12)
Donde B y H son las dimensiones de la losa y hf su altura. La losa también cuenta
con un acero de refuerzo que es idéntico para el momento positivo como para el momento negativo ya que para la mayoría de losas este refuerzo se coloca en la mitad. Como se tiene que tener en cuenta las ecuaciones de diseño de losas es conveniente tratar este acero como área por metro lineal de losa. Para evaluar cuanto pesa1 el acero correspondiente a toda la losa es necesario primero multiplicarlo por la dimensión de la losa que hace referencia a la totalidad de metros que debe cubrir el acero, por otro lado es necesario multiplicar este valor por la longitud que van a tener las varillas, es decir la otra dimensión de la losa. Este resultado da el valor del volumen total de acero utilizado en la torta superior, que multiplicado por la densidad refuerzo se obtiene el peso. La ecuación para este cálculo es:
33
cmkg108.7 −×⋅⋅⋅= ALposHBWaceroLosa (4.13)
Es necesario multiplicar la ecuación por un factor de 10-3 ya que para toda la función
objetivo de la optimización, el valor de las áreas de acero se tiene en cm2 y no en m2.
1 El peso de acero utilizado es lo que finalmente determina su costo.

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
49
Teniendo ya las cantidades de obra de la torta ahora se puede calcular las correspondientes a una vigueta teniendo en cuenta de no repetir el volumen de concreto donde se unen estos dos elementos. Para cada vigueta se tiene un volumen de concreto igual a:
)( hfhbBVconcretoVigueta −⋅⋅= (4.14)
A la altura total de la placa (h) es necesario restarle la altura ya usada en (4.12). El
cálculo del acero de las viguetas es el más complejo dentro de la función de costos rudimentaria. Una estimación de cantidades de obra elaborada tendría en cuenta los cambios en el refuerzo que se pueden llegar a tener a lo largo el eje de la viga. Como esta función de uso exclusivo en la optimización se puede suponer que los costos varían exclusivamente con el refuerzo donde la solicitación es máxima. Es decir se tiene en cuenta que si el acero en donde se presenta el momento positivo máximo crece, todo el acero a lo largo de la viga también crece. Esto mismo ocurre con el momento negativo máximo y el máximo cortante. Siguiendo esta suposición la función que calcula el peso de los refuerzos longitudinal es:
33
cmkg108.7)( −×⋅+⋅= ASnegASposBWacero alLongitudin (4.15)
Para definir el peso del acero de refuerzo transversal es necesario tener en cuenta
la altura de la vigueta y su recubrimiento. Existe además una dimensión en los ganchos que se debe aproximar teniendo en cuenta que para viguetas se usan flejas S de un solo ramal. Si el recubrimiento se denomina como R y la longitud del gancho se aproxima a 4 cm en cada extremo se tiene que el peso esta definido por:
33
cmkg108.78cm)2-( −×⋅+⋅⋅⋅= RhAVBWacero lTransversa (4.16)
El área de acero transversal se expresa por cada metro de viga, por lo que
suponiendo que se tiene el mismo refuerzo a lo largo de toda la viga, este se multiplica por B. Una vez se tiene todas las cantidades de obra teóricas por cada vigueta es necesario determinar el número de viguetas que cubre la losa.
1−=sHNViguetas (4.17)
Para complementar la función de costos rudimentaria es necesario contar con los
precios unitarios del momento en el que se planea comprar los materiales. Para este ejemplo se tomaron los precios presentados por la Gobernación del Valle en el decreto 523 de abril 1 de 2004. El concreto de las especificaciones deseadas tiene un costo de 169.910 pesos por metro cúbico, y el acero de refuerzo 2.910 pesos por kilo. En el caso del refuerzo de la losa se utiliza refuerzo elaborado en mallas electro soldadas este tiene un incremento del costo en 21 por ciento. Esta diferenciación se hacer para contar con un solo precio base en la función de costo. Con los costos y las ecuaciones de (4.13) a

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
50
(4.17) se tiene la ecuación de costos rudimentaria para la losa del ejemplo propuesto en este trabajo.
169910)(
2910))((1.2)(
⋅×++
+⋅++×=
ViguetasViguetasLosa
lTransversaalLongitudinViguetasLosa
VconcretoNVconcreto
WaceroWaceroNWaceroC p(4.18)
4.4.2 Función de Costos Compleja La función de costos compleja es una ampliación de la función de costos
rudimentaria. Esta ampliación consiste en los dos últimos términos de la ecuación (4.11). Varios ingenieros dedicados al área de la construcción han desarrollado innumerables técnicas para el avaluó de funciones de costos complejas para distintos tipos de estructura. Todas estas investigaciones coinciden en que la experiencia, más exactamente, el registro histórico constituye el pilar para este tipo de ecuaciones.
Uno de estos investigadores es el profesor Surinder Singh quien en 1990 publicó un artículo con procedimiento interactivo basado en computador para encontrar los costos exactos de vigas y losas en concreto reforzado [15]. El objetivo principal del profesor Singh era elaborar un modelo que incluyera todas las variables involucradas en el diseño y mostrara su efecto en el costo de los componentes en construcciones de concreto. El modelo se basa en una regresión programada en un algoritmo computacional que determina según la entrada (características de la losa o viga) cual es el costo.
Lo importante del avance de este artículo es que tenía en cuenta variables como tipo de edificación (comercial, residencial, hospitalaria, industrial) y la altura a la que se va construir la losa agrupando los costos desde 5 hasta 50 pisos en grupos de 5. En el algoritmo presentado tiene en cuenta costos individuales de cada recurso y es bastante completo.
La función de costos presentada por Singh no es explicita, por lo que es necesario correr el programa cada vez que se tiene una losa distinta. Es por esta razón la necesidad de utilizar una regresión multivariable para acercarse a la solución. No es propósito de este trabajo presentar los algoritmos completos para la evaluación de costos complejos, pero es importante aclarar que el diseño óptimo basado en confiabilidad debe hacer este análisis ya que la mano de obra o el transporte de cierto material puede constituirse en la razón para utilizarlo en gran cantidad o tratar de evitarlo. Para el modelo desarrollado en las siguientes secciones se escogió la función de costos rudimentaria.
4.5 Función Objetivo
4.5.1 Función objetivo de modelo La función objetivo de la optimización está casi completa. Se tiene la función de
costo (en esta ocasión función de costos rudimentaria) y la función de probabilidad de falla. Como se discutió en el Capítulo 2 las mejores funciones objetivos que se han desarrollado hasta el momento son las propuestas por Rackwitz en [7]. Si se tiene en cuenta que las fallas tienen origen en cargas extremas (terremotos, terrorismo, etc.) con una ocurrencia que está descrita por un proceso de Poisson y existe una política de reconstrucción sistemática cada vez que ocurra la falla se tiene que la ecuación a maximizar es [1]:

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
51
γλ
γ)(
))(()()(p
ppp fpHCCbZ
⋅+−−= (4.19)
Como maximizar utilidades es equivalente a minimizar costos se tiene que esta
ecuación se transforma en Z* para un sistema cuyo objetivo es la minimización.
γλ )(
))(()()(*p
ppp fpHCCZ
⋅++= (4.20)
Los parámetros involucrados en (4.20) ya han sido discutidos en Capítulo 2
necesario para este ejemplo redefinirlos con valores prácticos. Para el modelo que condujo a esta función objetivo H fue planteada como independiente de la función de costos, para este ejemplo no es absurdo plantear H como un porcentaje del costo ya que se está utilizando una función de costos rudimentaria. El costo de reparación de una losa depende exclusivamente su estado después de la falla, si se considera que la falla deja la losa completamente inservible se debe ver el escenario en el que quedó la estructura completa que requiere una atención primordial. Por esta razón se justifica optimizar el diseño de las losas de entrepiso teniendo en cuenta fallas mediana y menores, es concepto se ve reflejado en considerar el costo de la falla en sólo el 20 por ciento del costo original.
)(20.0 pCH ×= (4.21)
La tasa de descuento γ se toma igual a 0.05 adecuada para la situación actual del
país. Se aclara que es pertinente al aplicar este procedimiento a la práctica hacer un estudio económico del entorno social y revisar las proyecciones de entidades como CAMACOL, el Banco de La Republica y Planeación Nacional para escoger la tasa más adecuada según el tipo de construcción que se vaya a realizar. Por otro lado la tasa de falla promedio en el proceso de Poisson se puede suponer como 0.1.
4.5.2 Restricciones Para este tipo de problemas se sugiere que las restricciones se dividan en tres
grupos. Las primeras restricciones son aquellas que aparecen en las etapas anteriores del procedimiento en este caso la (4.22) que relaciona b con hf. Dado que esta relación no tiene ninguna explicación en el comportamiento mecánico de la losa y que la variable hf fue omitida de la función de costos se decide no poner esta dentro de la lista de restricciones.
El segundo gran grupo de restricciones son aquellas que impone el código. Estas son de gran importancia porque tienen su origen en el comportamiento físico, en el laboratorio. En este grupo además se podrían concentrar las restricciones de servicio (también enunciadas en el código) como la máxima deformación permisible para no afectar las actividades sobre y debajo de la losa. Para no ampliar el problema de los

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
52
recursos computacionales y congestionados2 se omitieron las restricciones debidas al servicio. Las demás propuestas por el código se enumeran a continuación3.
1. Cuantía Positiva Mínima: 0033.0R)-(hb
ASpos≥
⋅
2. Cuantía Positiva Máxima: 016.0R)-(hb
ASpos≤
⋅
3. Cuantía Negativa Mínima: 0033.0R)-(hb
ASneg≥
⋅
4. Cuantía Negativa Máxima: 016.0R)-(hb
ASneg≤
⋅
El tercer grupo de restricciones son aquellas presunciones que se pueden obtener
de la experiencia. No es estrictamente necesario la inclusión de estas restricciones, con un ecuación de probabilidad de falla que se ajuste exactamente a las variables el proceso de optimización debe ajustarse a valores similares a los que se encuentran en la práctica. Desafortunadamente en esta ocasión el coeficiente de correlación (R2) que se tuvo después de la regresión fue de 0.884, un poco bajo para que el proceso de optimización trabaje sólo sobre algunas variables. Las restricciones que se recomiendan para este caso son:
5. Espaciamiento mínimo: cm 50s ≥ 6. Espaciamiento máximo: cm 501s ≤
7. Ancho de vigueta mínimo: cm 01b ≥
4.6 Optimización por Iteraciones Independientes para cada Variables El procedimiento que se describe a continuación a sido frecuentemente ya que evita
análisis multivariable, que como se verá más adelante, puede constituir en un problema de difícil solución dado todos los recursos que consume. Las iteraciones individuales para cada variable se hacen modificando el algoritmo presentado en el Apéndice B para que solo se varíe una variable al calcular por el método de Monte Carlo la probabilidad de falla. Al ser una regresión de una sola variable se puede encontrar una regresión para obtener la probabilidad de falla en función de esta única variable.
Para tener el análisis de esta función de probabilidad se opto por aproximaciones lineales, es decir se aproximó la función a N – 1 segmentos de recta, donde N es el número de puntos que se analizaron con la simulación. Este procedimiento permite el 2 Ver 4.7.4.2 3 Las cuantías de acero para la torta superior es de la misma forma que las presentadas para las viguetas, el área de acero a evaluar es ALpos y ALneg, el ancho es de 100 cm y la altura es la mitad de la altura total de la losa.

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
53
manejo individual de cada variable, procedimiento mucho más sencillo que aquel que maneja todas las variables simultáneamente.
4.6.1 Cálculo de la probabilidad de falla Para el análisis por iteraciones independientes para cada variable, el proceso de
optimización y cálculo de probabilidad de falla se realiza en numerosas ocasiones variable por variable. La probabilidad se calcula elaborando una tabla de 20 filas con todas las variables constantes a excepción de una. Las variables que permanecen constantes toman, en primera estancia, los valores del diseño tradicional. El parámetro que toma los 20 valores distintos varía entre el 10 por ciento del valor del diseño tradicional y 200 por ciento. Una vez completado el proceso de optimización de un parámetro este nuevo valor entra en el cálculo de probabilidad con respecto a la siguiente variable por lo que iteración tras iteración va variando el diseño hasta converger.
Todas las variables se tomaron como normalmente distribuidas para hacer simplificar este primer acercamiento a un procedimiento que pueda ser llevado a la práctica. La desviación estándar, segundo parámetro que define este tipo de distribución fue tomado como un porcentaje de la media. Probablemente en algunas ocasiones esta suposición no es completamente cierta, se recomienda siempre tener ensayos de laboratorios o mediciones para tener un mejor acercamiento al valor real de estas desviaciones. En la siguiente tabla se puede ver los valores que se tomo para cada variable, introduciendo dos variables hasta ahora no tratadas CM y CV4. Tanto la carga muerta como la carga viva tienen una distribución de probabilidad que debe ser tratada como mucho detenimiento.
Tabla 4.3. Valores de Desviación Estándar de las variables Probabilísticas
Variable Desviación Estándar (% de la media)
fc 5 s 0.5 h 0.75 b 0.5 hf 0.5 fy 5
CM 5 CV 5
Todas las variables geométricas tienen una desviación relativamente baja, tan sólo
el 0.5 %. Esto se debe a que con las técnicas de construcción con las que se cuenta actualmente se pueden conseguir mediciones casi exactas en las formaletas y por ende en las variables geométricas de diseño. La única variable que tiene una desviación estándar un poco mayor es la altura de la vigueta. Como se anticipó esta variable no tiene involucrada sólo sus características de incertidumbre sino que también computa la incertidumbre del recubrimiento que se fijo como constante.
Aunque los recursos computacionales que consume la simulación por Monte Carlo son altos, se consideró que este era el mejor método para un acercamiento a la
4 CM: Carga Muerta. CV: Carga Viva.
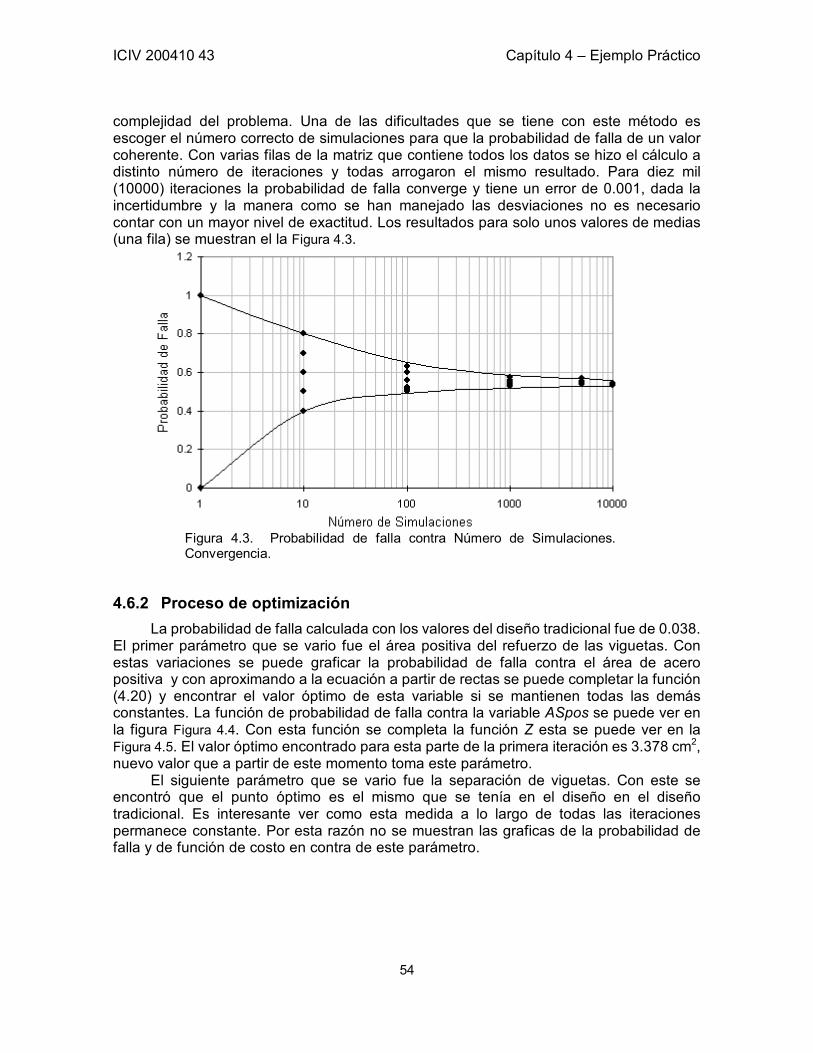
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
54
complejidad del problema. Una de las dificultades que se tiene con este método es escoger el número correcto de simulaciones para que la probabilidad de falla de un valor coherente. Con varias filas de la matriz que contiene todos los datos se hizo el cálculo a distinto número de iteraciones y todas arrogaron el mismo resultado. Para diez mil (10000) iteraciones la probabilidad de falla converge y tiene un error de 0.001, dada la incertidumbre y la manera como se han manejado las desviaciones no es necesario contar con un mayor nivel de exactitud. Los resultados para solo unos valores de medias (una fila) se muestran el la Figura 4.3.
Figura 4.3. Probabilidad de falla contra Número de Simulaciones. Convergencia.
4.6.2 Proceso de optimización La probabilidad de falla calculada con los valores del diseño tradicional fue de 0.038.
El primer parámetro que se vario fue el área positiva del refuerzo de las viguetas. Con estas variaciones se puede graficar la probabilidad de falla contra el área de acero positiva y con aproximando a la ecuación a partir de rectas se puede completar la función (4.20) y encontrar el valor óptimo de esta variable si se mantienen todas las demás constantes. La función de probabilidad de falla contra la variable ASpos se puede ver en la figura Figura 4.4. Con esta función se completa la función Z esta se puede ver en la Figura 4.5. El valor óptimo encontrado para esta parte de la primera iteración es 3.378 cm2, nuevo valor que a partir de este momento toma este parámetro.
El siguiente parámetro que se vario fue la separación de viguetas. Con este se encontró que el punto óptimo es el mismo que se tenía en el diseño en el diseño tradicional. Es interesante ver como esta medida a lo largo de todas las iteraciones permanece constante. Por esta razón no se muestran las graficas de la probabilidad de falla y de función de costo en contra de este parámetro.
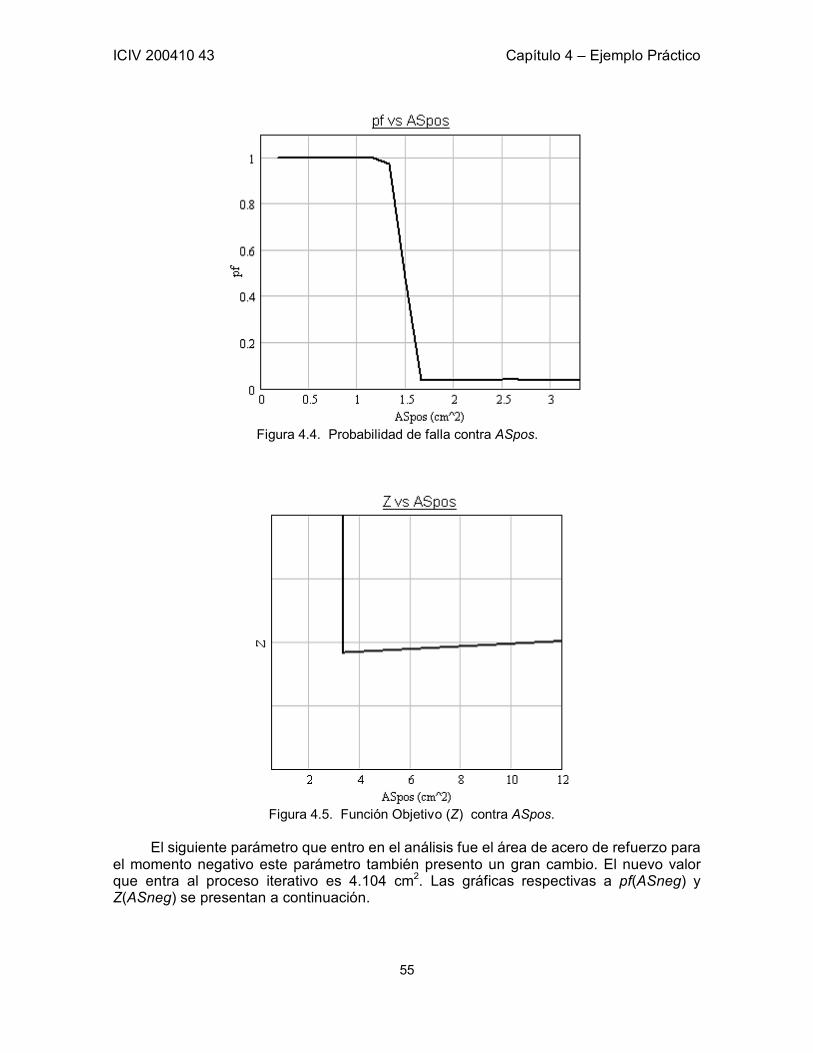
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
55
Figura 4.4. Probabilidad de falla contra ASpos.
Figura 4.5. Función Objetivo (Z) contra ASpos.
El siguiente parámetro que entro en el análisis fue el área de acero de refuerzo para el momento negativo este parámetro también presento un gran cambio. El nuevo valor que entra al proceso iterativo es 4.104 cm2. Las gráficas respectivas a pf(ASneg) y Z(ASneg) se presentan a continuación.
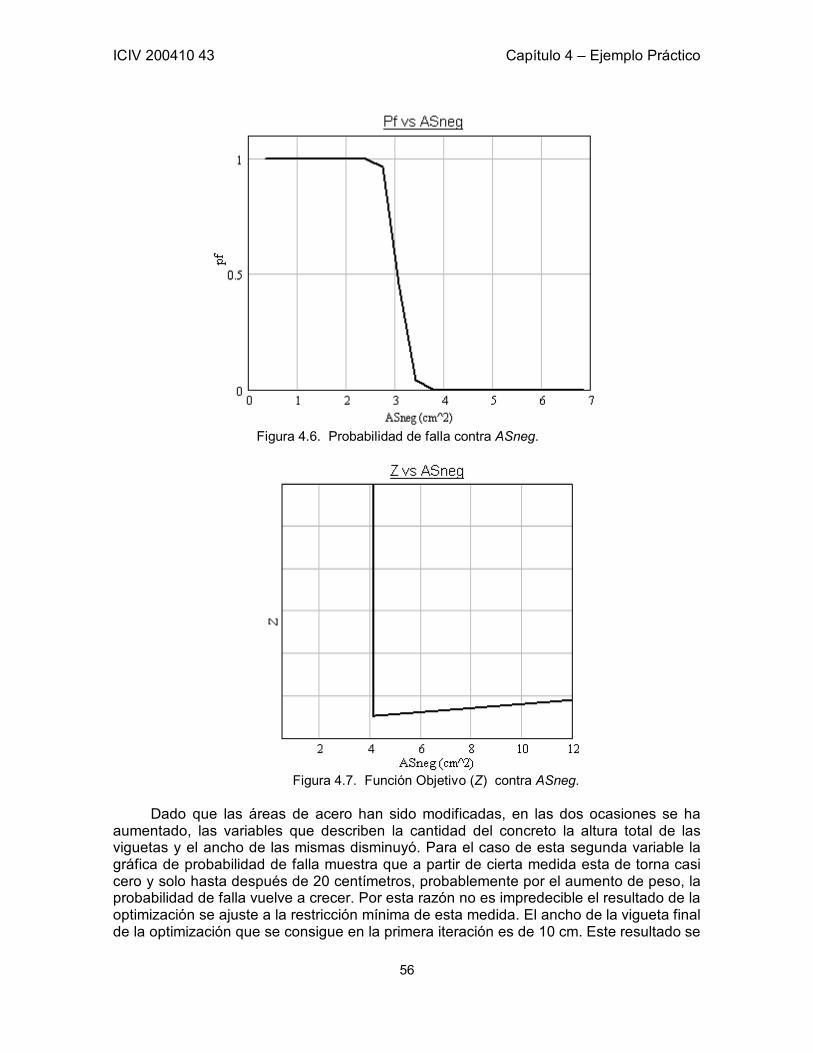
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
56
Figura 4.6. Probabilidad de falla contra ASneg.
Figura 4.7. Función Objetivo (Z) contra ASneg.
Dado que las áreas de acero han sido modificadas, en las dos ocasiones se ha
aumentado, las variables que describen la cantidad del concreto la altura total de las viguetas y el ancho de las mismas disminuyó. Para el caso de esta segunda variable la gráfica de probabilidad de falla muestra que a partir de cierta medida esta de torna casi cero y solo hasta después de 20 centímetros, probablemente por el aumento de peso, la probabilidad de falla vuelve a crecer. Por esta razón no es impredecible el resultado de la optimización se ajuste a la restricción mínima de esta medida. El ancho de la vigueta final de la optimización que se consigue en la primera iteración es de 10 cm. Este resultado se
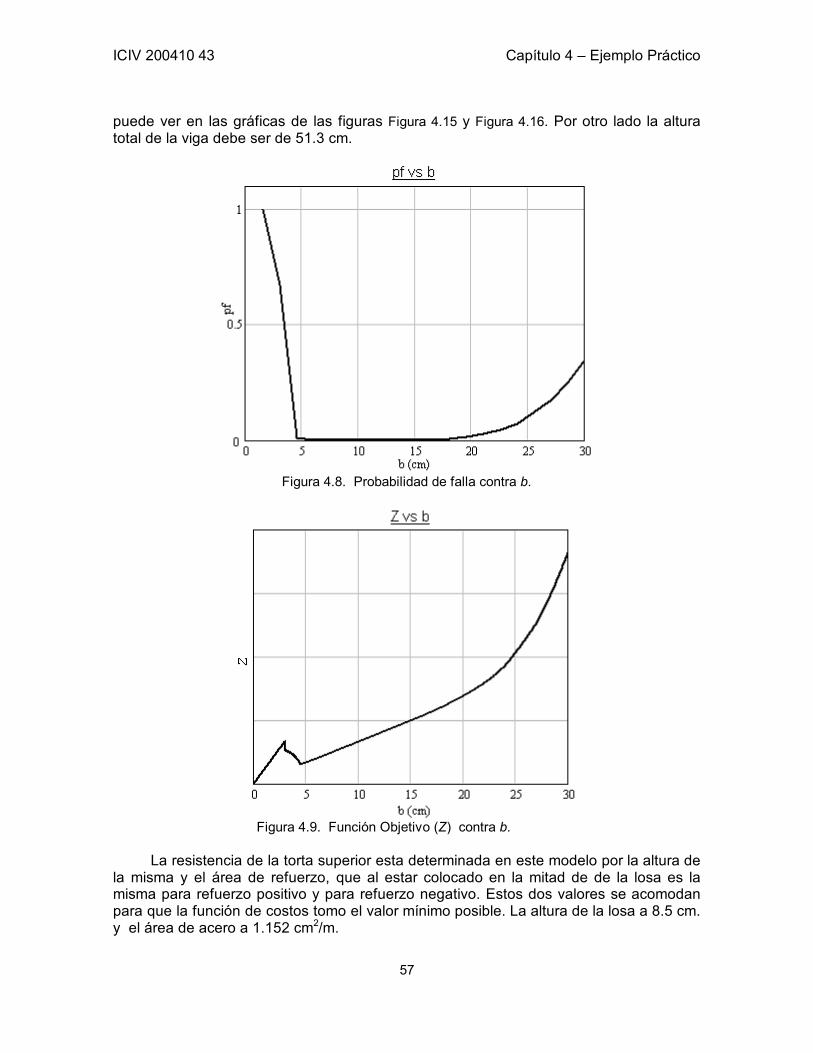
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
57
puede ver en las gráficas de las figuras Figura 4.15 y Figura 4.16. Por otro lado la altura total de la viga debe ser de 51.3 cm.
Figura 4.8. Probabilidad de falla contra b.
Figura 4.9. Función Objetivo (Z) contra b.
La resistencia de la torta superior esta determinada en este modelo por la altura de
la misma y el área de refuerzo, que al estar colocado en la mitad de de la losa es la misma para refuerzo positivo y para refuerzo negativo. Estos dos valores se acomodan para que la función de costos tomo el valor mínimo posible. La altura de la losa a 8.5 cm. y el área de acero a 1.152 cm2/m.

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
58
Por otro lado el refuerzo transversal de las viguetas no representa ningún efecto en el análisis de optimización por confiabilidad y es necesario siempre poner el mínimo refuerzo establecido por la norma.
Figura 4.10. Probabilidad de falla contra AV. Total independencia de esta variable. Área de acero por cada metro.
Todos los valores de las variables en las diferentes iteraciones se muestran en la
Tabla 4.4 y en la tabla tal se puede ver como varía el valor de las variables con respecto al diseño tradicional.
Tabla 4.4. Valores de las parámetros de diseño cada iteración.
ASpos s ASneg h b hf ALpos ALneg AV Trad. 1.66 80 3.42 57 15 5 0.84 0.84 2.84
3.378 4.104 5.13 10 8.5 P
rimer
a
Itera
ción
1.152 1.152 2.702
4.925 46.17
Seg
unda
Ite
raci
ón
9.164 3.783
5.91
Terc
era
Ite
raci
ón
43.94 FINAL 3.405 80 3.42 43.94 10 9.164 1.152 1.152

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
59
No existe cambio.
Tabla 4.5. Cambio de las variables del diseño tradicional al diseño óptimo.
Diseño Tradicional
Diseño Optimo Diferencia
ASpos 1.66 3.405 -1.745 s 80 80 0
ASneg 3.42 5.91 -2.49 h 57 43.94 13.06 b 15 10 5 hf 5 9.164 -4.164
ALpos 0.84 1.512 -0.672 ALneg 0.84 1.512 -0.672
AV 2.84 2.84 0 Mientras que la probabilidad de falla del diseño tradicional es de 0.038, con los
valores del diseño óptimo esta se reduce. Lo interesante es ver que no solo el costo directo (C) se reduce sino que la probabilidad falla se vuelve casi nula. El costo de la función rudimentaria propuesta para este modelo se reduce en un 44% con respecto al resultado del diseño tradicional.
4.6.3 Conclusiones del proceso iterativo El proceso de optimización hecho por iteraciones sucesivas facilita en gran medida
el diseño basado en optimización. Esto es de gran importancia a la hora facilitar el diseño a las distintas empresas dedicadas a esta labor. Por otro lado el gran inconveniente que se tiene es el hecho que no analiza la interacción que puede existir entre cada variable. Al variar un solo parámetro por iteración se mide el comportamiento de la probabilidad de falla de acuerdo a este, pero manteniendo las demás constantes. En realidad lo que se debe medir es el cambio de la probabilidad de falla mientras varían todos los parámetros toman los valores adecuados para realizar un buen análisis.
Independientemente si el análisis es completamente confiable o no, los resultados son sorprendentes al reducir los costos directos en un 44% de los costos que se tienen en un diseño tradicional. Este costo puede representar un ahorro suficiente para, en el caso de vivienda de interés social, pensar en la construcción de otra vivienda ayudando así a solucionar el déficit habitacional del país ya que la tasa de construcción se duplicaria.
4.7 Optimización por Regresión Multivariable La optimización por regresión multivariable toma en cuenta el efecto conjunto de
todas las variables. Por esta razón se constituye en el futuro del diseño óptimo basado en confiabilidad. Este tipo de optimización no está al alcance de este proyecto, pero su procedimiento se explica a continuación.
4.7.1 Cálculo de Probabilidad de Falla Para lograr crear una matriz donde se varíen los parámetros que hacen parte de los
dos grupos de diseño se programo un algoritmo cuyo propósito era crear en más de
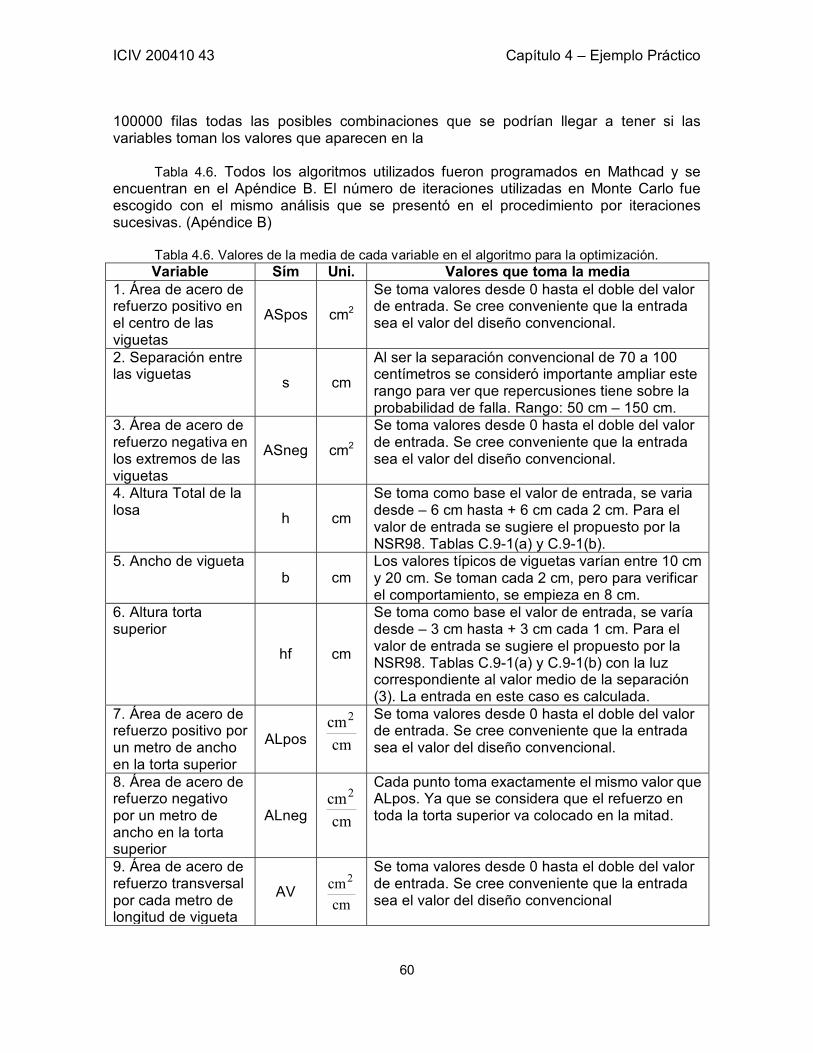
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
60
100000 filas todas las posibles combinaciones que se podrían llegar a tener si las variables toman los valores que aparecen en la
Tabla 4.6. Todos los algoritmos utilizados fueron programados en Mathcad y se
encuentran en el Apéndice B. El número de iteraciones utilizadas en Monte Carlo fue escogido con el mismo análisis que se presentó en el procedimiento por iteraciones sucesivas. (Apéndice B)
Tabla 4.6. Valores de la media de cada variable en el algoritmo para la optimización. Variable Sím Uni. Valores que toma la media
1. Área de acero de refuerzo positivo en el centro de las viguetas
ASpos cm2
Se toma valores desde 0 hasta el doble del valor de entrada. Se cree conveniente que la entrada sea el valor del diseño convencional.
2. Separación entre las viguetas s cm
Al ser la separación convencional de 70 a 100 centímetros se consideró importante ampliar este rango para ver que repercusiones tiene sobre la probabilidad de falla. Rango: 50 cm – 150 cm.
3. Área de acero de refuerzo negativa en los extremos de las viguetas
ASneg cm2
Se toma valores desde 0 hasta el doble del valor de entrada. Se cree conveniente que la entrada sea el valor del diseño convencional.
4. Altura Total de la losa h cm
Se toma como base el valor de entrada, se varia desde – 6 cm hasta + 6 cm cada 2 cm. Para el valor de entrada se sugiere el propuesto por la NSR98. Tablas C.9-1(a) y C.9-1(b).
5. Ancho de vigueta b cm
Los valores típicos de viguetas varían entre 10 cm y 20 cm. Se toman cada 2 cm, pero para verificar el comportamiento, se empieza en 8 cm.
6. Altura torta superior
hf cm
Se toma como base el valor de entrada, se varía desde – 3 cm hasta + 3 cm cada 1 cm. Para el valor de entrada se sugiere el propuesto por la NSR98. Tablas C.9-1(a) y C.9-1(b) con la luz correspondiente al valor medio de la separación (3). La entrada en este caso es calculada.
7. Área de acero de refuerzo positivo por un metro de ancho en la torta superior
ALpos cmcm2
Se toma valores desde 0 hasta el doble del valor de entrada. Se cree conveniente que la entrada sea el valor del diseño convencional.
8. Área de acero de refuerzo negativo por un metro de ancho en la torta superior
ALneg cmcm2
Cada punto toma exactamente el mismo valor que ALpos. Ya que se considera que el refuerzo en toda la torta superior va colocado en la mitad.
9. Área de acero de refuerzo transversal por cada metro de longitud de vigueta
AV cm
cm2
Se toma valores desde 0 hasta el doble del valor de entrada. Se cree conveniente que la entrada sea el valor del diseño convencional

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
61
en el extremo de la misma.
Una vez completa la matriz con los datos de las medias de las variables de diseño y
todas las posibles combinaciones de estas de acuerdo con la Tabla 4.6 se debía calcular la probabilidad de falla.
Con 10000 iteraciones por cada combinación de medias y exactamente 101376 combinaciones el algoritmo presentado en el Apéndice B, con el que se calcularon igual número de probabilidades de falla el programa demoró aproximadamente 15 horas en correr. Desafortunadamente los recursos computacionales con los que se contaba no lograban correr la totalidad de simulaciones (10000 x 101376) simultáneamente por lo que las 15 horas se tornaron en una semana y media dedica a este paso del proceso. Como se discutirá más adelante este es uno de los mayores problemas de llevar el diseño optimo basado en confiabilidad a la práctica.
De los 101376 datos ya completos (con su respectiva probabilidad de falla) no todos eran competentes para elaborar un análisis de regresión y ajustar la función pf(p). La gran mayoría de datos presentaban valores de pf inútiles tal como 1 o 0. Se descartaron todos los valores mayores a 0.9 y los valores menores a 0.01. Se sabe que el punto óptimo de de diseño no se encuentra en los rangos omitidos. Adicional a esto se redujo el tamaño de la muestra a 2887 líneas lo que garantizaba que el programa utilizado en la regresión no presentara problemas a la hora de manejar tal cantidad de datos.
Con la muestra ya filtrada se procedió a verificar si todas las variables utilizadas tienen influencia en la probabilidad de falla. Por ejemplo para ALpos – ALneg los resultados igualando una sola serie de datos mostraba independencia pero al verificar con otras dos series se concluyo que si había una dependencia. Igualar una serie de datos hacer referencia a dejar todos los demás parámetros iguales y ver como varia el parámetro que se esta evaluando. Los resultaos para el área de acero de refuerzo de la torta superior se muestran en la siguiente gráfica.
Figura 4.11. Influencia de ALpos y ALneg en la Probabilidad de Falla

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
62
La única variable con la que la probabilidad de falla mostró total independencia fue el área de acero de refuerzo transversal de las viguetas En esta ocasión se probaron todas las series que existían en la muestra y se obtuvo el mismo resultado. En la Figura 4.12 se muestran 4 de estas series y se ve como el comportamiento de pf es constante independientemente del valor que tome AV mientras los otros valores permanezcan constantes. Esta variable fue excluida de la regresión y se ajusta a la práctica ya que generalmente este tipo de viguetas lleva refuerzo transversal mínimo.
Por otro lado una vez reducida la muestra se encontró una relación estrecha entre la altura de la torta y el ancho de las viguetas. Teóricamente no existe motivo para que estas variables estén relacionadas, pero cuando una de las variables tomaba un valor determinado la otra tenía un y solo un valor y cualquiera de las dos cambia la otra hacia lo propio. En general como tal hf y b se comportaban como se muestra en la Figura 4.13. Pensando que el ancho de la vigueta podría significar un mayor ahorro en el costo de la vigueta se dejó esta variable excluyendo la altura de la torta de la regresión con la posibilidad de asumirla como restricción de tipo igualdad (4.22) en la optimización.
hf = 0.2 x b + 2 (4.22)
Figura 4.12. Influencia de AV en la Probabilidad de Falla
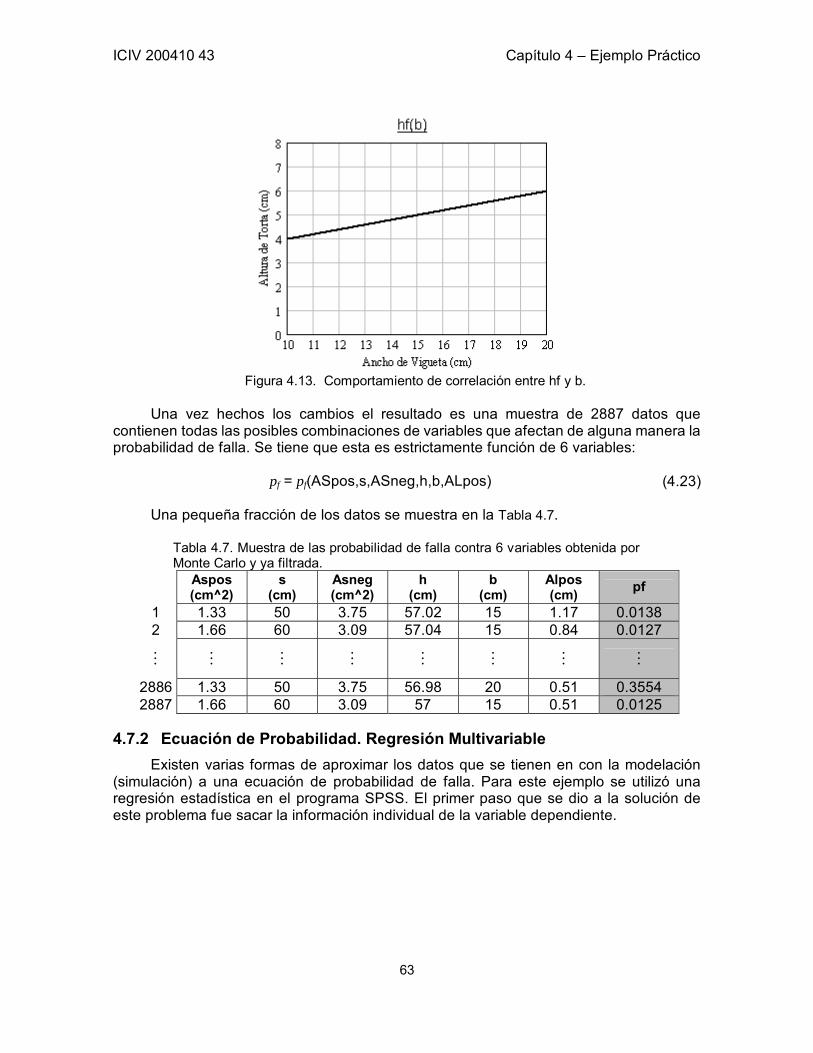
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
63
Figura 4.13. Comportamiento de correlación entre hf y b.
Una vez hechos los cambios el resultado es una muestra de 2887 datos que
contienen todas las posibles combinaciones de variables que afectan de alguna manera la probabilidad de falla. Se tiene que esta es estrictamente función de 6 variables:
pf = pf(ASpos,s,ASneg,h,b,ALpos) (4.23)
Una pequeña fracción de los datos se muestra en la Tabla 4.7.
Tabla 4.7. Muestra de las probabilidad de falla contra 6 variables obtenida por Monte Carlo y ya filtrada.
Aspos (cm^2)
s (cm)
Asneg (cm^2)
h (cm)
b (cm)
Alpos (cm) pf
1 1.33 50 3.75 57.02 15 1.17 0.0138 2 1.66 60 3.09 57.04 15 0.84 0.0127
M M M M M M M M
2886 1.33 50 3.75 56.98 20 0.51 0.3554 2887 1.66 60 3.09 57 15 0.51 0.0125
4.7.2 Ecuación de Probabilidad. Regresión Multivariable Existen varias formas de aproximar los datos que se tienen en con la modelación
(simulación) a una ecuación de probabilidad de falla. Para este ejemplo se utilizó una regresión estadística en el programa SPSS. El primer paso que se dio a la solución de este problema fue sacar la información individual de la variable dependiente.
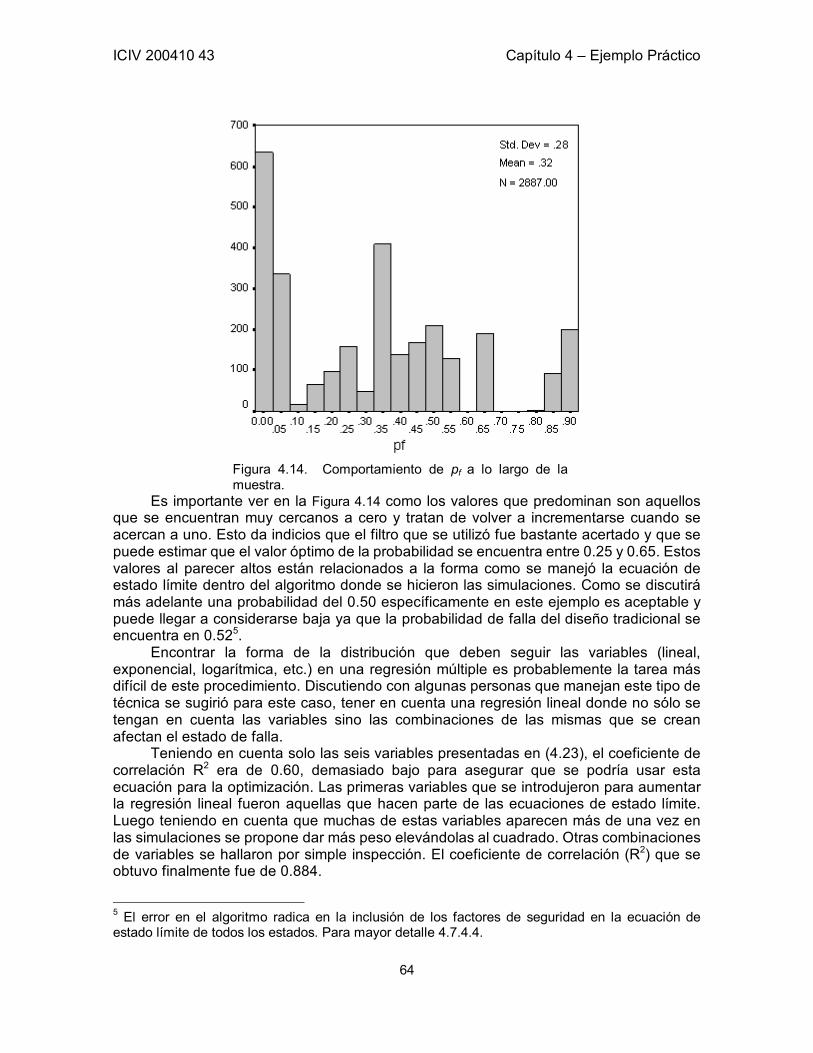
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
64
Figura 4.14. Comportamiento de pf a lo largo de la muestra.
Es importante ver en la Figura 4.14 como los valores que predominan son aquellos que se encuentran muy cercanos a cero y tratan de volver a incrementarse cuando se acercan a uno. Esto da indicios que el filtro que se utilizó fue bastante acertado y que se puede estimar que el valor óptimo de la probabilidad se encuentra entre 0.25 y 0.65. Estos valores al parecer altos están relacionados a la forma como se manejó la ecuación de estado límite dentro del algoritmo donde se hicieron las simulaciones. Como se discutirá más adelante una probabilidad del 0.50 específicamente en este ejemplo es aceptable y puede llegar a considerarse baja ya que la probabilidad de falla del diseño tradicional se encuentra en 0.525.
Encontrar la forma de la distribución que deben seguir las variables (lineal, exponencial, logarítmica, etc.) en una regresión múltiple es probablemente la tarea más difícil de este procedimiento. Discutiendo con algunas personas que manejan este tipo de técnica se sugirió para este caso, tener en cuenta una regresión lineal donde no sólo se tengan en cuenta las variables sino las combinaciones de las mismas que se crean afectan el estado de falla.
Teniendo en cuenta solo las seis variables presentadas en (4.23), el coeficiente de correlación R2 era de 0.60, demasiado bajo para asegurar que se podría usar esta ecuación para la optimización. Las primeras variables que se introdujeron para aumentar la regresión lineal fueron aquellas que hacen parte de las ecuaciones de estado límite. Luego teniendo en cuenta que muchas de estas variables aparecen más de una vez en las simulaciones se propone dar más peso elevándolas al cuadrado. Otras combinaciones de variables se hallaron por simple inspección. El coeficiente de correlación (R2) que se obtuvo finalmente fue de 0.884.
5 El error en el algoritmo radica en la inclusión de los factores de seguridad en la ecuación de estado límite de todos los estados. Para mayor detalle 4.7.4.4.
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
65
Algunas de las combinaciones más importantes fueron las cuantías (positiva y negativa) calculadas con la altura total y no con la altura efectiva6. Una lista completa de las variables y combinaciones se presenta a continuación.
Tabla 4.8. Variables y Combinaciones de Variables involucradas en la regresión.
1 ASpos 6 hb
ALpos⋅
11 b
ASpos2 16 2ASpos 21 2ALpos
2 s 7 bh2 12 2
hbASneg
⎟⎠⎞
⎜⎝⎛
⋅ 17 22hb
ASnegASpos ⋅ 22 sASpos ⋅
3 ASneg 8 2s 13 2ASneg 182
sbh
⎟⎠⎞
⎜⎝⎛ ⋅
23 sASneg ⋅
4 h 9 hb
ASpos⋅
14 ALpos
ASnegASpos ⋅⋅19 sALpos ⋅ 24
2
hbASpos
⎟⎠⎞
⎜⎝⎛
⋅
5 ALpos 10 hb
ASneg⋅
15 ASnegASpos ⋅ 202
sALpos
⎟⎠⎞
⎜⎝⎛ 25 hsb ⋅⋅
El orden de las variables y combinaciones presentadas en la Tabla 4.8 es
exactamente igual al utilizado en el programa de la regresión, orden que se eligió para facilitar la presentación de la ecuación en forma vectorial. Es importante resaltar como el programa SPSS automáticamente excluye la variable b (ancho de viguetas) porque no es representativa al momento de relacionar la variable dependiente, pero sus combinaciones si lo son y por esto permanece la variable b implícita.
Para mostrar la ecuación en forma vectorial se toma las variables y combinaciones, se organizan en un vector columna en el cual se ponen las columnas de la Tabla 4.8 una debajo de la otra. Este vector se nombra va. Por otro lado se tiene un vector similar con todos los coeficientes que multiplican estas combinaciones, este es llamado coef. La ecuación que describe la probabilidad de falla es:
pf(ASpos,s,ASneg,h,b,ALpos) = coef · va + 6.003 (4.24)
El coeficiente 6.003 es la constante que ajusta la regresión. En esta ocasión se
presenta con solo 3 cifras decimales pero en el momento utilizar esta ecuación en la optimización tanto la constante como los componente de coef deben tener todas las cifras decimales posibles ya que una aproximación de estas significa un cambio notable en el resultado. Con la ecuación (4.24) se puede ver como es el comportamiento de la probabilidad de falla dependiendo de cada variable y ver si el resultado que arrojó el modelo se ajusta a lo esperado. Graficando la probabilidad de falla contra el área de acero de refuerzo para momento positivo (Figura 4.15) se observa un comportamiento esperado. La probabilidad de falla disminuye a medida que aumente el refuerzo. Esto mismo pasa para los otros tipos de refuerzo que finalmente entraron al cálculo y 6 La altura efectiva se obtiene restándole a la altura total una constante, el recubrimiento. Como se dijo anteriormente este problema fusionaba dos incertidumbres y por esta razón en el procedimiento nunca se elaboran cálculos con la altura efectiva.
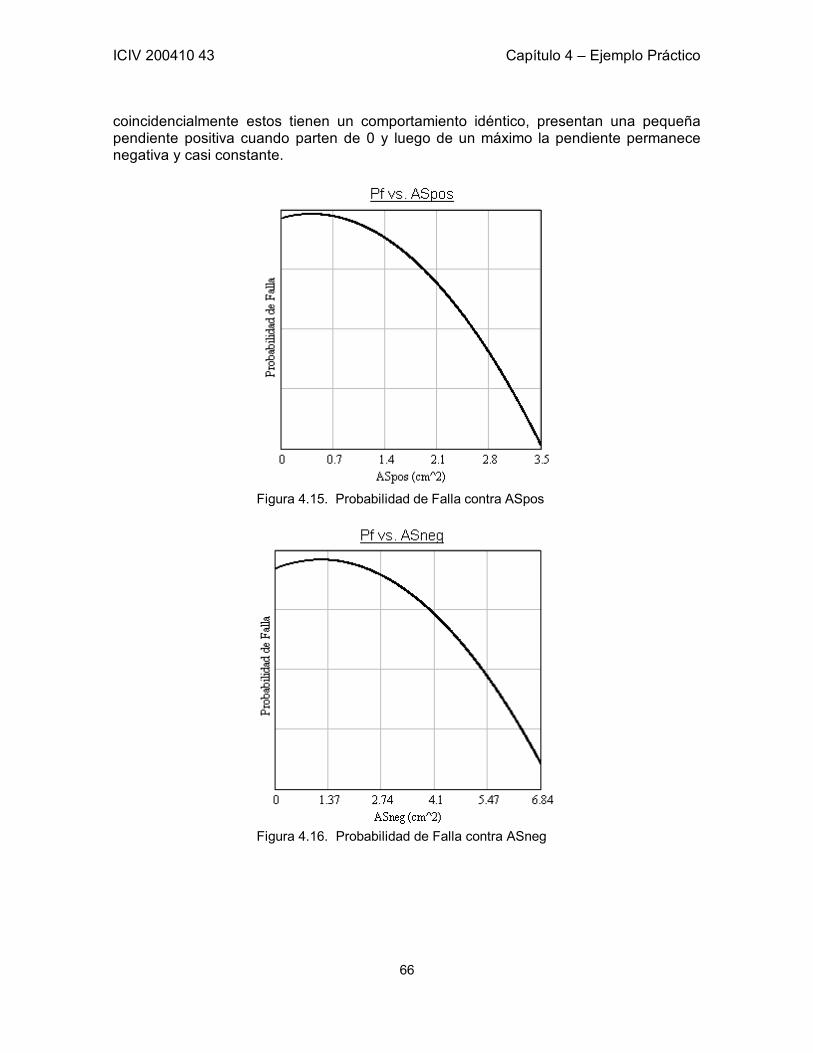
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
66
coincidencialmente estos tienen un comportamiento idéntico, presentan una pequeña pendiente positiva cuando parten de 0 y luego de un máximo la pendiente permanece negativa y casi constante.
Figura 4.15. Probabilidad de Falla contra ASpos
Figura 4.16. Probabilidad de Falla contra ASneg
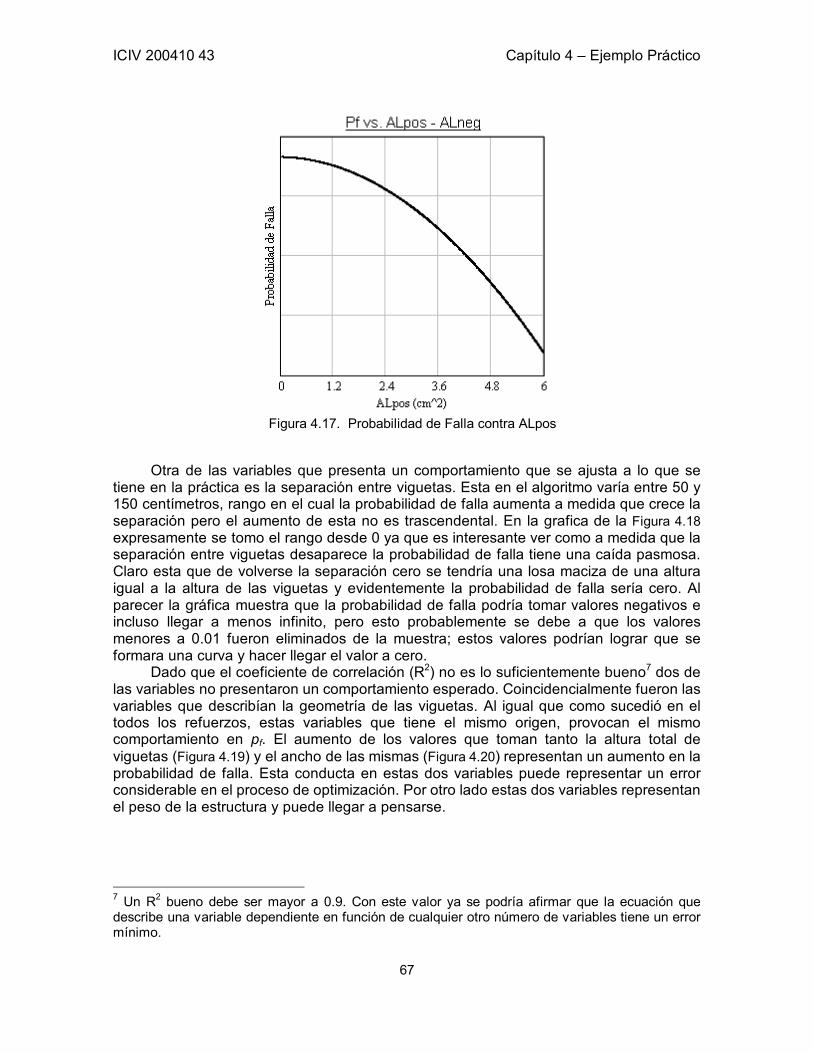
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
67
Figura 4.17. Probabilidad de Falla contra ALpos
Otra de las variables que presenta un comportamiento que se ajusta a lo que se
tiene en la práctica es la separación entre viguetas. Esta en el algoritmo varía entre 50 y 150 centímetros, rango en el cual la probabilidad de falla aumenta a medida que crece la separación pero el aumento de esta no es trascendental. En la grafica de la Figura 4.18 expresamente se tomo el rango desde 0 ya que es interesante ver como a medida que la separación entre viguetas desaparece la probabilidad de falla tiene una caída pasmosa. Claro esta que de volverse la separación cero se tendría una losa maciza de una altura igual a la altura de las viguetas y evidentemente la probabilidad de falla sería cero. Al parecer la gráfica muestra que la probabilidad de falla podría tomar valores negativos e incluso llegar a menos infinito, pero esto probablemente se debe a que los valores menores a 0.01 fueron eliminados de la muestra; estos valores podrían lograr que se formara una curva y hacer llegar el valor a cero.
Dado que el coeficiente de correlación (R2) no es lo suficientemente bueno7 dos de las variables no presentaron un comportamiento esperado. Coincidencialmente fueron las variables que describían la geometría de las viguetas. Al igual que como sucedió en el todos los refuerzos, estas variables que tiene el mismo origen, provocan el mismo comportamiento en pf. El aumento de los valores que toman tanto la altura total de viguetas (Figura 4.19) y el ancho de las mismas (Figura 4.20) representan un aumento en la probabilidad de falla. Esta conducta en estas dos variables puede representar un error considerable en el proceso de optimización. Por otro lado estas dos variables representan el peso de la estructura y puede llegar a pensarse.
7 Un R2 bueno debe ser mayor a 0.9. Con este valor ya se podría afirmar que la ecuación que describe una variable dependiente en función de cualquier otro número de variables tiene un error mínimo.
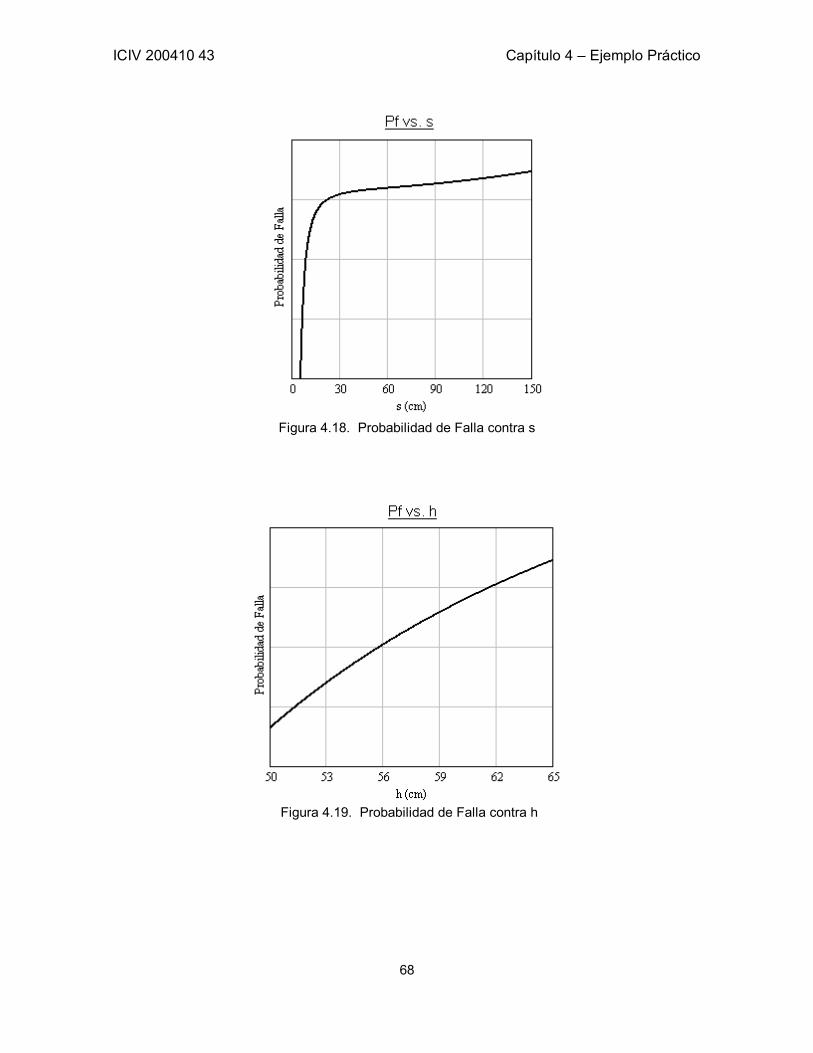
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
68
Figura 4.18. Probabilidad de Falla contra s
Figura 4.19. Probabilidad de Falla contra h
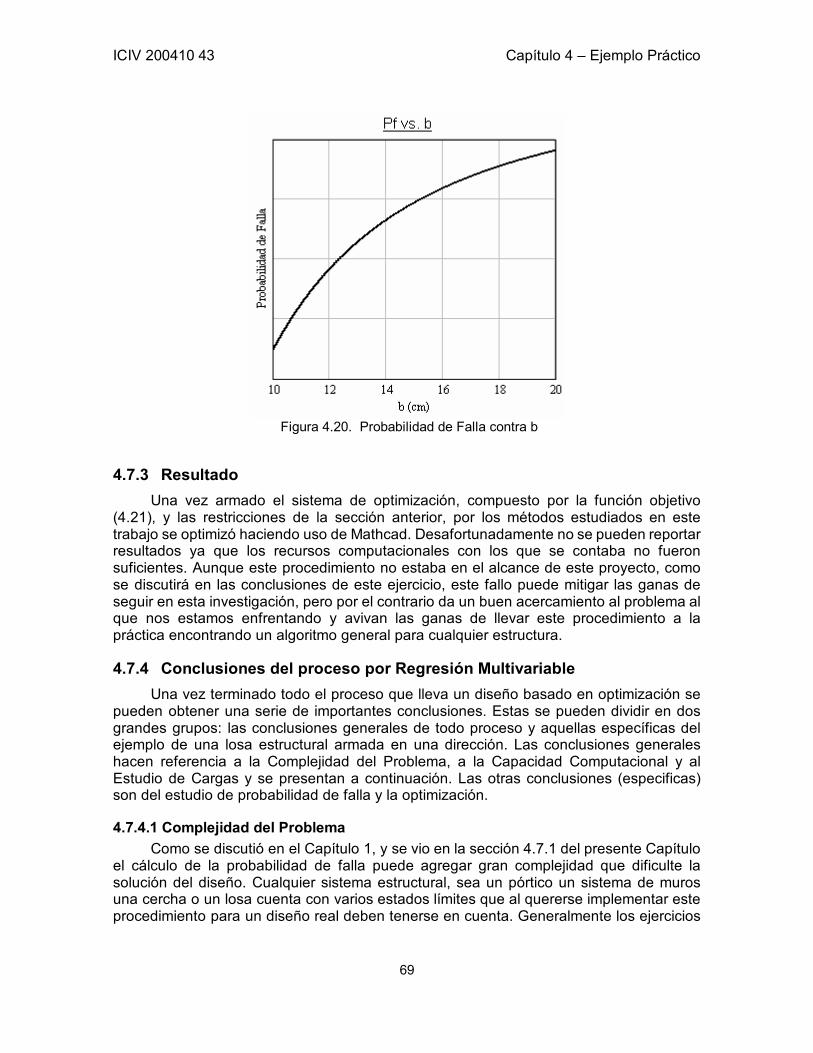
ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
69
Figura 4.20. Probabilidad de Falla contra b
4.7.3 Resultado Una vez armado el sistema de optimización, compuesto por la función objetivo
(4.21), y las restricciones de la sección anterior, por los métodos estudiados en este trabajo se optimizó haciendo uso de Mathcad. Desafortunadamente no se pueden reportar resultados ya que los recursos computacionales con los que se contaba no fueron suficientes. Aunque este procedimiento no estaba en el alcance de este proyecto, como se discutirá en las conclusiones de este ejercicio, este fallo puede mitigar las ganas de seguir en esta investigación, pero por el contrario da un buen acercamiento al problema al que nos estamos enfrentando y avivan las ganas de llevar este procedimiento a la práctica encontrando un algoritmo general para cualquier estructura.
4.7.4 Conclusiones del proceso por Regresión Multivariable Una vez terminado todo el proceso que lleva un diseño basado en optimización se
pueden obtener una serie de importantes conclusiones. Estas se pueden dividir en dos grandes grupos: las conclusiones generales de todo proceso y aquellas específicas del ejemplo de una losa estructural armada en una dirección. Las conclusiones generales hacen referencia a la Complejidad del Problema, a la Capacidad Computacional y al Estudio de Cargas y se presentan a continuación. Las otras conclusiones (especificas) son del estudio de probabilidad de falla y la optimización.
4.7.4.1 Complejidad del Problema Como se discutió en el Capítulo 1, y se vio en la sección 4.7.1 del presente Capítulo
el cálculo de la probabilidad de falla puede agregar gran complejidad que dificulte la solución del diseño. Cualquier sistema estructural, sea un pórtico un sistema de muros una cercha o un losa cuenta con varios estados límites que al quererse implementar este procedimiento para un diseño real deben tenerse en cuenta. Generalmente los ejercicios

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
70
teóricos presentados en los salones de clase y en artículos sobre el tema tienen en cuenta uno o dos estados límites y adicional a esto aproximan la probabilidad de falla total a la suma de probabilidades parciales. En este procedimiento se tuvo en cuenta todos los posibles orígenes de ruptura y la probabilidad de falla se calculó de forma conjunta en un solo algoritmo de Monte Carlo (ver Apéndice B).
La función de costos también tiene su complejidad sobre todo si se tiene en cuenta una función de costos avanzada donde se tengan en cuenta transporte, desperdicio y en general todas las variables que implique un costo. La función objetivo en si incrementa el trabajo de los diseñadores al tener que contar con un economista en el equipo de diseño para encontrar la tasa de descuento que mejor se ajuste. Este ajuste como todo el procedimiento debe ser individual para cada proyecto ya que dependerá de la naturaleza del mismo.
La complejidad del problema es evidente. Un diseño tradicional puede ser más sencillo y por esta razón elaborarse en un menor tiempo. Este problema es el principal enemigo de este tipo de diseños innovadores y es aquí donde tiene que radicar toda investigación de los próximos años. La teoría de la optimización y confiabilidad estructural esta muy bien desarrollada pero el paso a la practica en países como Colombia esta muy retrasado. Colombia necesita ahorro y extender sus inversiones en todos los sectores y es concluyente que el diseño óptimo es una gran herramienta para esto.
4.7.4.2 Capacidad Computacional Otro gran obstáculo en la implementación del diseño óptimo basado en confiabilidad
es el recurso computacional. Este proyecto de grado se corrió en Mathcad en un computador con un procesador AMD Athlon de 1.2 Ghz en una tarjeta madre DFI, con una memoria física de 512 MB. Estas características son iguales o superiores a las que se encuentran en las oficinas de los diseñadores donde se corren programas como SAP2000. Si a este rendimiento computacional colapsó el diseño de una losa es de esperarse que colapse en el diseño de otras estructuras y al no haber recursos computacionales disponibles los ingenieros en la práctica no aprobaran la entrada de un nuevo procedimiento.
El problema del colapso puede ser consecuencia de muchos factores cuya solución puede ser relativamente sencilla. Es necesario concentrarse en este software ya que una vez desarrollado la implementación del diseño óptimo basado en confiabilidad sería un hecho. Entre estos problemas se encuentran el procedimiento desordenado que seguramente tenía el algoritmo. Este no solo mejoraría la parte de optimización sino que su vez agilizaría el cálculo de la probabilidad de falla que para este ejemplo tomo más de 5 días (un diseñador no aceptaría todo este tiempo para un diseño tan simple). Otro problema es el uso de Mathcad como programa madre. Este programa ya cuenta con sus recursos y procesos propios que ocupan abundante memoria. Programar en FORTRAN o en cualquier otro lenguaje un programa dedicado a puede mejorar el proceso computacional.
Asociado a las restricciones del ordenador que se utiliza para elaborar el procedimiento existe otro un poco más difícil de solucionar. En varias etapas del procedimiento es determinante algunas decisiones que hasta ahora los programas de computador no están en la capacidad de hacer. Un ejemplo claro de esta afirmación es la regresión que es necesaria para tener un acercamiento acertado a la probabilidad de falla. Si bien es cierto que en la actualidad existen numerosos programas para realizar este tipo de oficios ninguno de ellos es lo suficientemente “inteligente” para descifrar o decidir que

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
71
tipo de variables se deben introducir o como se deben combinar las mismas. De este trabajo se puede ver la necesidad de estudiar el tema con detenimiento para poder determinar la estructura de la ecuación pf(p) para cada caso (losas, pórticos, muros, etc.) y enfocar los algoritmos en la búsqueda de las constantes de estos modelos y no de todo el modelo. Es necesario aclarar que se ya se han implementado varias metodologías para evitar esta disfuncionalidad como el “response surface approach”.
4.7.4.3 Estudio de Cargas Para la realización de este estudio se utilizaron cargas estipuladas en el código
colombiano NSR-98. Se puede concluir que para un análisis basado en confiabilidad el uso de estas cargas puede resultar incorrecto ya que, por ejemplo para la carga viva, estas ya tienen un análisis estadístico y estas se encuentran siempre en la zona segura. Es necesario hacer un estudio más detallado para ver cual es el valor real de la media que se debe tener para cada caso. En otras palabras se puede decir que la carga viva o de acabados es muy distinta en una oficina de ingenieros y una de comerciantes. La NSR-98 no diferencia entre los tipos de oficinas ni los tipos de acabados aunque si abre la posibilidad de hacer un estudio detallado.
El problema con la media de estas cargas importante pero fácilmente solucionable con un estudio detallado. Otros dos problemas de igual importancia no tienen esta misma cualidad. El tipo de distribución que sigue cada carga y su desviación estándar son mucho más complicados de medir. Esto dificulta más el diseño basado en confiabilidad porque es en estos dos parámetros que radica la probabilidad de falla. Si las cargas fueran medidas determinísticas la probabilidad de falla dependería únicamente de la resistencia y no de la solicitación, afirmación que es completamente falsa si se tiene en cuenta que los que más incertidumbre tiene en este vinculo R – S es precisamente la solicitación.
4.7.4.4 Sobre la Probabilidad de Falla El procedimiento con el que se calculó la probabilidad de falla tuvo varios errores
que sirvieron para mejorar todo futuro procedimiento. Sánchez-Silva [1] explica que el índice de confiabilidad y por ende la probabilidad de falla es “el principal criterio para la definición de los factores de carga y resistencia utilizados en los códigos de diseño”. Desafortunadamente a la hora de programar el algoritmo de la simulación de Monte Carlo la ecuaciones de estado límite quedaron tanto con los factores de carga como con los de resistencia, esto hacia que el diseño tradicional la falla fuera de 53 por ciento en lugar de menos del 5 por ciento como debería. Se analizó este problema y su incidencia en el resultado no era de preocuparse ya que se solucionaba asumiendo que la probabilidad de falla máxima permitida se acercaba al 55 por ciento. Claro esta que es recomendable evitar este error que aunque no sean evidentes puede traer efector en la regresión y evitar la “doble” seguridad en la que incurre.
Por otro lado la base de datos sufrió de un filtro que dejó como datos útiles menos del 3 por ciento del total de datos que se tenían. Aparte de los datos que se debieron ignorar por la inclusión de los factores de carga y resistencia hubo mucho que no cumplían por las áreas de refuerzo seleccionadas. Se debió restringir el área de acero entre la cuantía máxima y la cuantía mínima en lugar del doble del área y cero. Este cambio probablemente aprovecha de mejor medida los 101376 datos.
El procedimiento matemático arrojó la necesidad de omitir varias variables en la regresión. No queda claro que comportamiento físico de la estructura permite hacer algunas de estas exclusiones. El área de acero del refuerzo transversal en viguetas es

ICIV 200410 43 Capítulo 4 – Ejemplo Práctico
72
posible por la posibilidad de que se requiera, para el ejemplo, refuerzo mínimo pero la exclusión de la altura de la torta por su dependencia con el ancho de la vigueta no es clara. No existen hipótesis del comportamiento estructural de una losa que expliquen esta dependencia por lo que probablemente se deba al error de los factores.
La regresión múltiple, aunque es el método más exacto para encontrar la ecuación de probabilidad de falla, si no se encuentra una correlación del 90 por ciento mínimo, puede dar resultados muy inexactos. El error máximo que se tenía entre la probabilidad de la simulación y la encontrada por medio de la ecuación de la regresión era de 0.2. Este es bastante amplio si ya que el nivel de exactitud trabajado es de 0.01. Así mismo la regresión que se tuvo presentaba comportamientos erróneos en dos de las variables. La regresión utilizó la altura total de la losa y el ancho de las viguetas para ajustarse y no representaba la realidad. De presentarse este error máximo en la zona cerca al óptimo el proceso de optimización no sería confiable pero si demuestra que los errores de cierta importancia ocurren fuera la zona de influencia del punto óptimo el procedimiento es completamente válido.
4.7.4.5 Sobre la Optimización Para ahorrar recursos computacionales se dejaron restricciones de lado, una de las
más importantes son aquellas pertinentes a las deformaciones máximas admitidas para que muros divisorios no tengan ningún tipo de daño. Estas ecuaciones podrían llegar a tratarse como ecuaciones de estado límite adicionales, pero dado que su naturaleza es distinta es conveniente ubicarlas como restricciones del sistema de optimización. Como estas ecuaciones existen muchas que se omiten en los ejemplos encontrados en la literatura y en este ejemplo. Una valiosa conclusión que se obtuvo al terminar esta investigación, es que para que el diseño basado en confiabilidad sea eficiente y consiga desplazar al diseño tradicional es necesario involucrar todas las restricciones y condiciones del problema incluyendo la función de costos completa. Los recursos computacionales, nuevamente, se convierten en el limitante de este diseño, claro esta que puede tener solución si la investigación continúa.

Capítulo 5 Conclusiones
• La confiabilidad puede representar ahorres importantes en la construcción,
estimulando el desarrollo de más construcciones y mejorando la calidad de vida de muchas personas.
• El paso a seguir en la investigación concerniente al diseño basado en confiabilidad es la creación de programas computacionales que agilicen el proceso de análisis y desarrollo de estos diseños. Actualmente un proceso completo como el cálculo de la probabilidad de falla por regresión múltiple ocupa mucho recurso computacional, este proceso necesita ser depurado para garantizar la eficiencia del mismo.
• La optimización estructural cuenta con varios procedimientos que llevan a resultados parecidos pero no exactos, es labor del diseñador escoger el procedimiento que mejor se ajusta a cada problema. Este tema puede ser el de mayor complejidad a la hora de utilizar el diseño basado en confiabilidad.
• Aunque la mayor meta en de los investigadores en este tema es lograr traspasar las fronteras de la práctica, la investigación teórica tiene mucho campo por descubrir. Un ejemplo de esto es el uso de SQQ, un método de optimización no – lineal para calcular el índice de confiabilidad y por ende la probabilidad de falla de un elemento o un sistema.

Apéndice A Cálculo de β en Mathcad con SQP multivariable
Calcular el índice de confiabilidad con un conjunto de subrutinas o funciones es
relativamente sencillo si se cuenta con todas las herramientas del cálculo numérico para calcular derivadas. Una vez elaborado el algoritmo de todas estas subrutinas, se puede escribir el código en un lenguaje de programación para poder compilar una aplicación que tenga este ejercicio. En este apéndice se presenta el código escrito en Mathcad para este problema, claro esta que se evita usar las funciones propias del programa (derivadas), y as{i se facilita la trascripción del código a cualquier lenguaje. Claro esta que en algunas ocasiones, como se explicará cuando sea debido, el código todavía se apoya en funciones propias de Mathcad, por lo que es necesario encontrar formas de pasar de estas funciones a un algoritmo general. Constantes Necesarias Para garantizar la convergencia del programa es necesario contar con la tolerancia que de quiere tener en el momento de la solución. Para mayor explicación al respecto dirigirse a 3.7. La otra constante necesaria es el límite de variables que puede llegar a tener la función de estado límite. Existe una subrutina que determina cuantas variables se están usando, pero es necesario que esta función recorra un número determinado de posibles variables: 1 – LIMITEVAR
Función de Estado Límite Esta sería la única entrada del usuario, a menos que se quiera definir las constantes anteriores también como entradas. La función de estado límite se puede ver como una subrutina en la que entra un vector y devuelve un número. Por ahora este código se apoya en la interfase de Mathcad para ser leída, pero es posible crear un algoritmo que entrada una función, con los nombres de variables cualquiera, transforme esta en el tipo de función que se necesita. Para ilustrar el procedimiento de muestra ahora una función, pero esta puede ser cambiada por el usuario.
Número de Variables La función a continuación lee el número de variables que entran en la función. Con esta no es necesario pedir al usuario la cantidad de variables que se están usando. Para Mathcad, queda en N este número y se puede solicitar desde cualquier otra rutina.

ICIV 200410 43 Apéndice A – Cálculo β con SQP
75
Función Objetivo Dado que la función objetivo tiene la misma forma para cualquier número de variables, es posible armarla de acuerdo al resultado de la función que identifica el número de variables.
Vectores Gradientes de las Funciones f(x) y h(x) Para definir en Mathcad los vectores gradientes de las funciones es necesario usar el cálculo numérico. Estas subrutinas quedan listas para ser usadas en Fortran 90 o cualquier otro lenguaje. Se puede ver que las funciones son iguales lo único que cambia es la función interna que se usa para evaluar la integral. Existe la posibilidad de crear una función como variable de entrada tenga otra función, pero para este caso del índice de confiabilidad con SQP, al ser solo dos gradientes es más eficiente definir los dos gradientes por separado.

ICIV 200410 43 Apéndice A – Cálculo β con SQP
76
Matriz Hessiana de la Función de Estado Límite La matriz Hessiana de la función de estado límite se convierte en la función más elaborada para realizar. Tratando de no utilizar las funciones internas de Mathcad, para lograr pasar el código luego a Fortran 90 o cualquier lenguaje. Para esto es necesario tener uno vectores x evaluadas en las distintas variables en x + h y x – h, y tener combinado un vector donde sean dos x distintos los que cambian. Para esto se usan dos matrices, una con la suma y otra con las restas. Las columnas contiene el vector correspondiente a la variación de a variable cuyo número coincida con la columna. Para esto se crea una función independiente, adicional a otra función encargada de combinar dos de estos vectores cuando sea necesario. La tercera función adicional escoge de la matriz armada con los vectores cambiados el vector que se necesita usar en cada iteración.

ICIV 200410 43 Apéndice A – Cálculo β con SQP
77
Matriz Hessiana de la Función Objetivo La matriz Hessiana de la función objetivo es siempre la matriz Identidad de N variables multiplicada por 2. Esta función solo arma esta matriz.

ICIV 200410 43 Apéndice A – Cálculo β con SQP
78
Hessiana del Lagrangiano Puede parecer una línea de comando de Mathcad pero en realidad se puede ver como una función de una sola línea de código.
Primera Iteración Una caracteristica de ls función h(x) (función de estado limite) es que se encuentra igualada a cero, por lo que por el método de Newton – Raphson se puede encontrar la primera iteración del algoritmo.

ICIV 200410 43 Apéndice A – Cálculo β con SQP
79
Matriz M del Problema Lineal Complementario Esta función se apoya en que todos los lenguajes de programación tienen incluidas las funciones que aumentan matrices, por lo que no es necesario armar estas funciones. Cuando se pase el Algoritmo a otro lenguaje es necesario solo cambiar los nombres de estas dos funciones ya que aquí se presentan con los nombres de Mathcad.
Valores Propios Esta función analiza si los valores propios de una matriz son positivos o no. Devuelve 1 si lo son y 0 de lo contrario. La función funciona sin importar el número de variables, pero depende de la existencia en la biblioteca matemática del lenguaje de una función que calcule los eigenvalores.
Aproximación B Al igual que la función anterior, la función que tiene la primera aproximación cuando los valores propios de la matriz original son distintos de cero, depende de una función en el lenguaje que calcule los eigenvalores. La función que actualiza la matriz para las siguientes iteraciones no tiene este problema.

ICIV 200410 43 Apéndice A – Cálculo β con SQP
80
Función de Ventaja Aunque esta función funcione perfectamente en un programa multi – variable, es la única función que todavía usa funciones propias de Mathcad ya que no se ha podido ver como se calcula con cálculo numérico la derivada involucrada.
Cuerpo del Programa El cuerpo del programa incluye 5 subrutinas encargadas de organizar los resultados en tablas para guardar las iteraciones, y encargadas de leer una iteración anterior cuando sea necesario para actualizar la matriz B. La función principal SQP, devuelve una tabla en la cual las filas son las distintas iteraciones, y las columnas son las N variables. Las seis funciones que pertenecen exclusivamente al cuerpo funcionan perfectamente sin importar el número de variables.
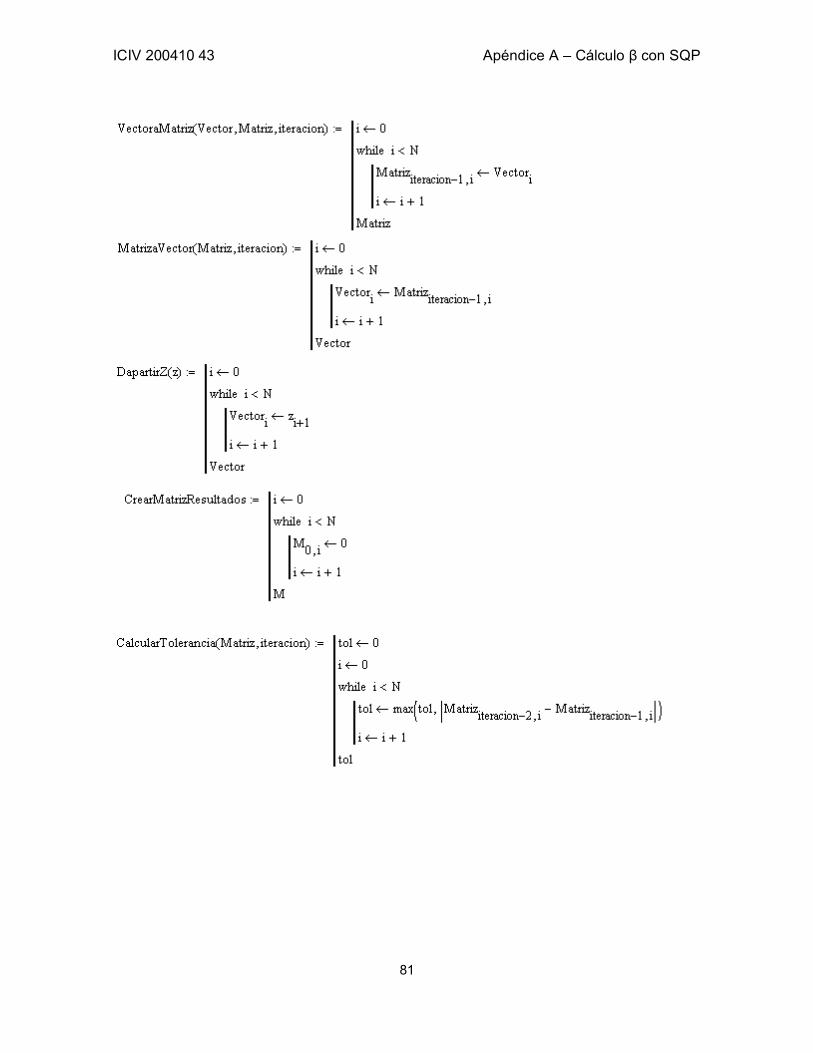
ICIV 200410 43 Apéndice A – Cálculo β con SQP
81

ICIV 200410 43 Apéndice A – Cálculo β con SQP
82

Apéndice B Algoritmos de Mathcad para el Cálculo de pf de Losas
Funciones de Estado Límite Se programaron todas las funciones de estado límite consideradas.

ICIV 200410 43 Apéndice B – Cálculo pf: Monte Carlo
84
Matriz de Datos La siguiente función tiene solo como objetivo llenar una matriz P con todas las posibles combinaciones de variables que se van a evaluar para el cálculo de la probabilidad de falla. Esta matriz contiene más de 100000 filas pero puede modificarse para las necesidades del problema.

ICIV 200410 43 Apéndice B – Cálculo pf: Monte Carlo
85
Cálculo de Probabilidad Esta función recibe como datos de entrada los índices de la matriz P de las líneas que se quieran evaluar devolviendo un vector con el mismo número de líneas donde se

ICIV 200410 43 Apéndice B – Cálculo pf: Monte Carlo
86
encuentran archivadas las probabilidades de falla. Usa anidadamente las funciones de estado límite definidas con anterioridad.

Apéndice C Cálculo de β en Mathcad con FORM multivariable
El algoritmo programado en Mathcad, al igual que el presentado en el Apéndice A,
es multivarible, donde las variables hacen parte de un vector x. También se consideran que existen dos vectores un con las medias de las variables y otro con las desviaciones. Estos vectores se llaman µ y σ respectivamente.
Cálculo del Vector G
Solución de la Última Variable Esta función calcula el valor de una variable dependiendo de la función de estado límite y los valores de N – 1 variables. Se programó para que la variable calculada fuera la útlima en el arreglo.

ICIV 200410 43 Apéndice C – Cálculo β con FORM
88
Cuerpo del Programa Esta función da como resultado una matriz con los datos de todas las iteraciones entre ellos Z’s y α’s. Este resultado después es organizado en una tabla con la ayuda de un componente de Excel.
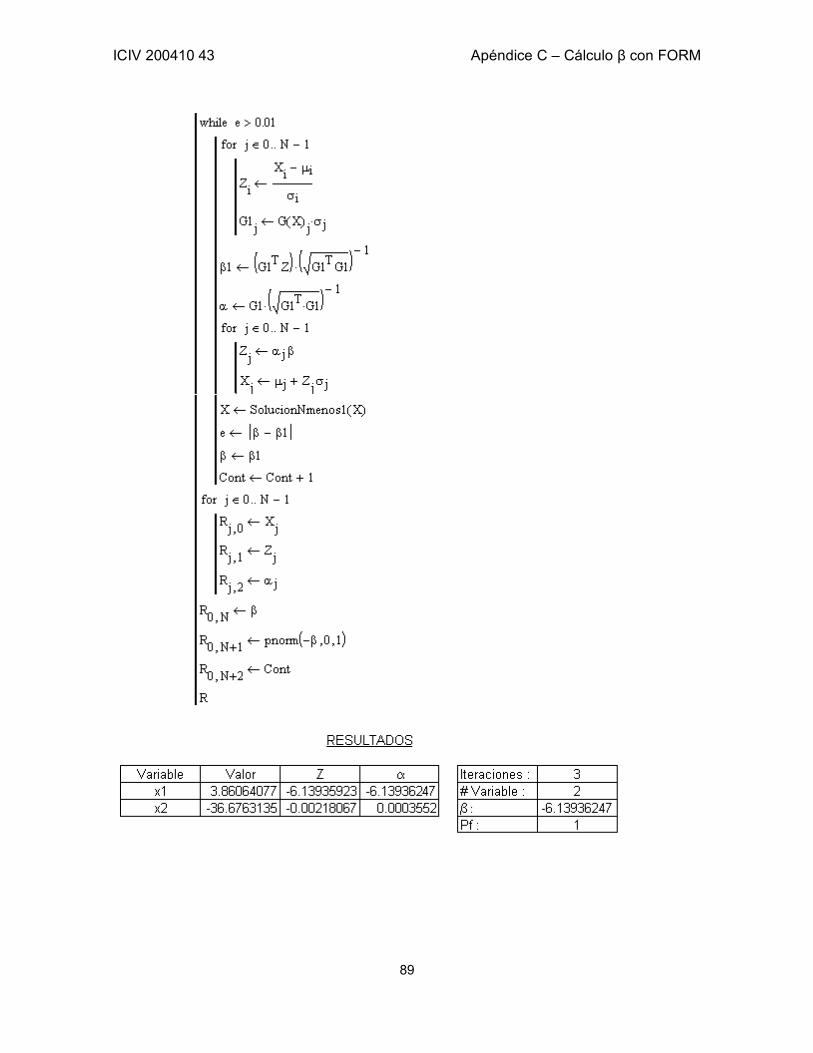
ICIV 200410 43 Apéndice C – Cálculo β con FORM
89

Bibliografía
[1] Sánchez-Silva, Mauricio. Introducción a la Evaluación de Riesgos: Teoría y
aplicaciones en Ingeniería. Notas de Clase. Departamento de Ingeniería Civil y Ambiental. Universidad de los Andes. 2002
[2] Bazaraa, M. Sherali, H. Shetty C. Nonlinear Programming: Theory and Algorithms. Segunda Edición. John Wiley & Sons, Inc. 1993.
[3] Simmons, Donald M. Nonlinear Programing for Operations Researsh. Prentice-Hall Internacional Series in Management. 1995.
[4] Künzi, H. Krelle, W. Nonlinear Programming. Blaisdell Publishing Company.1966.
[5] Grossman, Stanley I. Álgebra lineal. Quinta Edición. McGrawHill. 1996.
[6] Rackwitz, Rüdiger. Optimization – the basis of code-making and reliability verification. Structural Safety. Volumen 22. Año 2000. Páginas 27 – 60.
[7] Rackwitz, Rudiger. Risk Control and Optimization for Structural Facilities. Presentado en: 20th IFIP TC7 on “System Modelling and Optimization”, Julio 23 – 27, 2001, Trier, Alemania.
[8] Marti, Kurt. Stocckl. Gerald. Optimal Design of Trusses by Stochastic Linear Programming with Recourse. Lecture Presented at the VII International Conference on Stochastic Programming, 1998, Vancouver/Canada.
[9] Haldar, Achintya. Mahadevan, Sankaran. Probability, Reliability and Statical Methods in Engineering Design. John Wiley & Sons, Inc. 2000.
[10] Nowak, Andrzej. Collins, Kevin. Reliability of Structures. McGrawHill. 2000.
[11] Nilson, Arthur. Diseño de Estructuras de Concreto. Duodécima edición. McGrawHill. 1999.
[12] Uribe, Jairo. Análisis de Estructuras. Segunda edición. Editorial Escuela Colombiana de Ingeniería. ECOE Ediciones. 2000.
[13] Normas Colombianas de Diseño y Construcción Sismo – Resistente NSR-98. Edición: Temas Jurídicos, 3R Editores. 2002.
[14] Gobernación del Valle del Cauca. Listado de Precios Unitarios Oficiales de referencia para la Contratación de Obras Directas de Infraestructura. Decreto 523 de abril 1 de 2004. http://www.elvalle.com.co. En línea. Última visita: 22 de junio 2004.
[15] Singh, Surinder. Cost Model for Reinforced Concrete Beam and Slab Structura in Buildings. Journal of Construction Engineering and Management. Vol. 116, No. 1 American Society of Civil Engineering ASCE. Marzo de 1990.