modelo para la caracterización del delito en la ciudad de...
TRANSCRIPT

INVESTIGACIÓN X PROFUNDIZACIÓN ____
Modelo para la Caracterización del Delito en la Ciudad de Bogotá,
Aplicando Técnicas de Minería de Datos Espaciales.
AUTOR
ALFONSO PEÑA SUAREZ
TESIS PARA OBTENER EL GRADO DE
MAESTRIA EN CIENCIAS DE LAINFORMACIÓN Y COMUNICACIONES
DIRECTOR
ÁLVARO ENRIQUE ORTIZ DÁVILA
MAGISTER EN CIENCIAS DE LA INFORMACIÓN Y LAS COMUNICACIONES
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS
MAESTRÍA EN CIENCIAS DE LA INFORMACIÓN Y LAS COMUNICACIONES
ÉNFASIS EN SISTEMAS DE INFORMACIÓN
BOGOTÁ, COLOMBIA
JULIO DE 2017

1
Nota de aceptación
________________
________________
________________
________________
________________
Presidente del Jurado
________________
Jurado
_________________
Jurado
Ciudad y Fecha ________________________________

2
AGRADECIMIENTOS.
Agradezco a Dios por bendecirme con la vida y permitirme llegar hasta este momento
rodeado de gente extraordinaria.
Agradezco a mi esposa e hijos, por todo el apoyo que siempre me han brindado, me han
motivado para seguir adelante.
Agradezco de manera muy especial a mi director de tesis, Ms. Álvaro Ortiz Dávila, por todo
el apoyo y por haber tenido la paciencia necesaria para ayudarme; pero sobre todo por su
amistad.
También deseo agradecer a la profesora Ms. Luz Ángela Rocha y al profesor MS. Miguel
Alberto Melgarejo Rey por su colaboración y aportes a este trabajo.
Agradezco al personal administrativo de la Maestría en Ciencias de la Información y las
Comunicaciones en especial a Alison Rubiano por su valiosa ayuda en todos los trámites y
papeleos.
Agradezco a todas aquellas personas que me animaron y motivaron a finalizar este proyecto.

3
Contenido
Listado de Figuras ........................................................................................................................... 6
Listado de Tablas ............................................................................................................................ 8
Resumen .......................................................................................................................................... 9
Introducción .................................................................................................................................. 10
1. PLANTEAMIENTO DEL PROBLEMA .............................................................................. 13
Situación Problemática ................................................................................................... 13
Formulación del Problema ............................................................................................. 16
Justificación .................................................................................................................... 17
Objetivos ........................................................................................................................ 18
1.4.1 Objetivo General ..................................................................................................... 18
1.4.2 Objetivos Específicos.............................................................................................. 18
2. MARCO TEÓRICO .............................................................................................................. 19
Antecedentes .................................................................................................................. 19
2.1.1 Aplicativos y Herramientas de Software ................................................................ 19
2.1.2 Trabajos Publicados ................................................................................................ 23
2.1.3 Modelo a Desarrollar. ............................................................................................. 27
Bases Teóricas ................................................................................................................ 27
Marco Conceptual .......................................................................................................... 29

4
2.3.1 Bases de Datos Espaciales ...................................................................................... 29
2.3.2 Minería de Datos Espaciales ................................................................................... 32
2.3.3 Tareas de la Minería de Datos ................................................................................ 36
2.3.4 Técnicas de Minería de Datos ................................................................................. 38
2.3.5 Agrupamiento o Clustering ..................................................................................... 41
2.3.6 Técnicas de Clustering ............................................................................................ 43
2.3.7 Algoritmos de Clustering ........................................................................................ 47
3. HIPÓTESIS ........................................................................................................................... 52
4. METODOLOGÍA .................................................................................................................. 53
Población de Estudio ...................................................................................................... 53
Recolección de Información........................................................................................... 56
Identificación de Variables............................................................................................. 58
Desarrollo de la Investigación. ....................................................................................... 60
4.4.1 Proceso de Gestion de la Información .................................................................... 61
4.4.2 Tecnicas de Mineria de Datos ................................................................................. 65
Modelos. ......................................................................................................................... 66
Presentación de resultados ............................................................................................. 79
Discusión de Resultados................................................................................................. 86
5. CONCLUSIONES ................................................................................................................. 88
6. REFERENCIAS ................................................................................................................... 90

5
7. ANEXOS ............................................................................................................................... 95
Diccionario de Datos ...................................................................................................... 95
Anexo B Modelos........................................................................................................... 98

6
Listado de Figuras
FIGURA 1. DELITOS CONTRA EL PATRIMONIO POR LOCALIDAD AÑO 2015 ...................................... 15
FIGURA 2. SISTEMA IBM I2 COPLINK ............................................................................................ 20
FIGURA 3. SISTEMA EUROCOP PRED-CRIME ............................................................................. 21
FIGURA 4. SISTEMA CRIMEVIEW ................................................................................................... 23
FIGURA 5. EJEMPLO DE PREDICADOS ESPACIALES. ....................................................................... 31
FIGURA 6. PROCESO DE MINERÍA DE DATOS. ................................................................................. 34
FIGURA 7. TAREAS DE LA MINERÍA DE DATOS. .............................................................................. 36
FIGURA 8. ANÁLISIS DE CLÚSTER. ................................................................................................. 42
FIGURA 9. ALGORITMOS BÁSICOS DE CLUSTERING. ...................................................................... 44
FIGURA 10. CLUSTERING JERÁRQUICO .......................................................................................... 45
FIGURA 11. EJEMPLO CLUSTERING PARTICIONAL ......................................................................... 46
FIGURA 12. ALGORITMO K-MEANS ............................................................................................... 49
FIGURA 13. PUNTOS DE NÚCLEO, BORDE Y RUIDO ........................................................................ 51
FIGURA 14. HURTO A PERSONAS AÑOS 2013 – 2015 ...................................................................... 54
FIGURA 15. LOCALIDAD DE CHAPINERO ........................................................................................ 56
FIGURA 16. METODOLOGIA DE DESARROLLO DEL PROYECTO. ...................................................... 60
FIGURA 17. DISEÑO BASE DE DATOS ESPACIAL (MODELO ENTIDAD RELACIÓN) ......................... 62
FIGURA 18. ESTADISTICAS DEL USO DE ARMAS Y MODALIDAD DEL DELITO. ................................ 63
FIGURA 19. ESTADISTICAS DE DELITOS SEGÚN HORA Y DÍA DE LA SEMANA ................................. 64
FIGURA 20. ESTADISTICAS DE DELITOS POR MES. ......................................................................... 64
FIGURA 21. DELITOS PRESENTADOS POR BARRIO DE LA LLOCALIDAD DE CHAPINERO. ................ 65
FIGURA 22. MODELO CARACTERIZACIÓN DEL DELITO .................................................................. 66

7
FIGURA 23. DELITOS CONTRA PATRIMONIO LOCALIDAD DE CHAPINERO. ..................................... 67
FIGURA 24. ALGORITMO K-MEAS .................................................................................................. 69
FIGURA 25. ALGORITMOS K-MEANS SEGUDA ITERACIÓN .............................................................. 70
FIGURA 26. ALGORITMO K-MEANS TERCERA ITERACIÓN ............................................................. 71
FIGURA 27. RESULTADO OBTENIDO POR EL ALGORITMO K-MEAS ................................................. 72
FIGURA 28. ALGORITMO DBSCAN PRIMERA ITERACIÓN .............................................................. 75
FIGURA 29. ALGORITMO DBSCAN SEGUNDA ITERACIÓN ............................................................ 76
FIGURA 30. ALGORITMO DBSCAN TERCERA ITERACIÓN ............................................................ 77
FIGURA 31. RESULTADOS OBTENIDOS ALGORITMO DBSCAN ...................................................... 78
FIGURA 32. RESULTADOS OBTENIDOS K-MEANS Y DBSCAN ...................................................... 79
FIGURA 33. COMPARATIVO DELITOS POR MODALIDAD ................................................................. 81
FIGURA 34 COMPARATIVO TIPO ARMA UTILIZADA ....................................................................... 82
FIGURA 35. COMPARATIVO DELITOS POR RANGO DE HORA .......................................................... 83
FIGURA 36. COMPARATIVO DE DELITOS POR DÍA.......................................................................... 84
FIGURA 37. COMPARATIVO DE DELITOS POR MES DEL AÑO ......................................................... 85

8
Listado de Tablas
TABLA 1: CLASIFICACIÓN DE LAS TÉCNICAS DE MINERÍA DE DATOS .............................................. 38
TABLA 2 INFORMACIÓN DE DELITOS OCURRIDOS EN BOGOTÁ 01-01-2015 – 26-09-2015 ......... 57
TABLA 3. INFORMACIÓN DELITOS PATRIMONIO. ........................................................................... 58
TABLA 4. INFRAESTRUCTURA DE SEGURIDAD POLICIA NACIONAL. ............................................... 59
TABLA 5. INFORMACIÓN DE LA UBICACIÓN DEL DELITO. .............................................................. 59
TABLA 6. FECHA DE DELITO .......................................................................................................... 59
TABLA 7. VARIABLES DE IDENTIFICACIÓN DEL DELITO. ................................................................ 60

9
RESUMEN
La seguridad ciudadana y el combate a la delincuencia constituyen una de las mayores
preocupaciones sociales no sólo en Bogotá sino en todo el país. La reducción del índice delictivo
se puede lograr, mediante el uso de herramientas que permitan caracterizar el comportamiento del
delito.
La minería de datos espaciales se utiliza para extraer conocimiento. Sus métodos pueden ser
utilizados para explorar, descubrir relaciones entre datos espaciales y no espaciales, reorganizar
datos espaciales en bases de datos y determinar sus características generales de manera simple.
Existen diferentes métodos de minería de datos espaciales como: Métodos basados en
generalización, métodos de reconocimiento de patrones, métodos usando agrupamiento, métodos
explorando asociaciones espaciales. Aplicando técnicas de minería de datos espaciales, se pretende
caracterizar el comportamiento de los delitos contra el patrimonio que afectan a la ciudad de
Bogotá.
El objetivo de este trabajo es establecer un modelo para caracterizar el comportamiento del delito
para un sector de la ciudad de Bogotá D.C., aplicando técnicas de agrupamiento de minería de
datos espaciales.
Para lograr este objetivo se trabajará con la información obtenida de diferentes entidades como: la
Infraestructura de Datos Espaciales del Distrito Capital (IDECA), Cámara de Comercio de Bogotá,
el portal WEB de entidades oficiales como la Alcaldía Mayor de Bogotá y la Policía Metropolitana
de Bogotá entre otras.
Palabras Clave:
Minería de datos espaciales, delito, información espacial.

10
INTRODUCCIÓN
La seguridad ciudadana y el combate a la delincuencia constituyen una de las mayores
preocupaciones sociales no sólo en Bogotá sino en todo el país. De acuerdo con diversos informes
realizados por entidades oficiales y privadas como: El informe de calidad de vida del portal Bogotá
Como Vamos, El observatorio de seguridad de la Cámara de Comercio de Bogotá, informes de
seguridad y convivencia publicados por la Secretaria Distrital de Gobierno, e informes sobre
seguridad publicados por periódicos de circulación nacional como El Tiempo con información
suministrada por la Policía Metropolitana de Bogotá, se puede percibir, que además de los hechos
de violencia, el delito contra el patrimonio, es una realidad que ha venido afectando la tranquilidad
de los habitantes de la capital del país, para reducir los índices de estos hechos y la percepción de
inseguridad, es necesario contar con el apoyo de herramientas, que permitan analizar la actividad
delictiva y así concentrar la actividad logística y los recursos necesarios para combatir eficaz y
eficiente el delito.
El aporte de los avances tecnológicos, en el campo del análisis del delito incluye el diseño de
bases de datos espaciales, visualización de los hechos delictivos a través de mapas y la aplicación
de técnicas complejas de minería de datos.
El análisis de datos es una tarea que consiste en buscar o encontrar tendencias o variaciones
de comportamiento en los datos, de tal manera que esta información resulte de utilidad para los
usuarios finales. A estas tendencias o variaciones se le conocen como patrón. Si los patrones son
útiles y de relevancia para el dominio, entonces se le llama conocimiento (Olmos Pineda &
González Bernal, 2007). Para que el usuario pueda explorar, reorganizar y entender la información,

11
es necesario usar herramientas que permitan el almacenamiento, la gestión y el análisis de esta.
(Mariscal, Marbán, & Fernández, 2010).
Las bases de datos espaciales se utilizan, para almacenar, gestionar y operar datos temáticos y
espaciales, en este tipo de bases de datos es imprescindible establecer un sistema de referencia
espacial (SRS), para definir la localización y relación entre objetos. Los sistemas de referencia
espacial pueden ser de dos tipos: georreferenciados (carreteras, ciudades, suelo, altitudes), son los
que normalmente se utilizan, ya que es un dominio manipulable, perceptible y que sirve de
referencia y no georreferenciados (son sistemas que tienen valor físico, pero que pueden ser útiles
en determinadas situaciones). La información en estas bases de datos se almacena de dos formas,
vectorial y raster.
El modelo raster se utiliza habitualmente para representar fenómenos de la realidad que se
presentan de manera continua en el espacio. El modelo vectorial, representa los datos valiéndose
de primitivas geométricas, tales como puntos, líneas y polígonos. Junto con estas geometrías, se
encuentran los atributos temáticos de los fenómenos que representan. Por ejemplo: una ciudad, se
puede modelar a través de polígonos y puede contener atributos como el nombre, cantidad de
habitantes, temperatura, etc.
Las relaciones que existen, en una base de datos espacial, se pueden reconocer y analizar,
mediante relaciones topológicas, se entiende como topología a las relaciones espaciales entre los
diferentes elementos gráficos (topología de nodo/punto, topología de red/arco/línea, topología de
polígono) y su posición en el mapa (proximidad, inclusión, conectividad y vecindad) (Open
Geospatial Consortium Inc, 2011).

12
La consulta de datos espaciales, se hace mediante operaciones entre figuras geométricas; estas
operaciones se clasifican en tres grupos: Predicados espaciales, operaciones espaciales y otras
operaciones espaciales (Yáñez & González, 2005, págs. 41 - 49).
Los datos espaciales son fundamentales para promover el desarrollo económico, administrar
responsablemente los recursos naturales y proteger el medio ambiente, entre muchas otras
aplicaciones. La creciente necesidad del gobierno, empresas públicas y privadas y centros de
investigación de mejorar la toma de decisiones, aumentar su eficiencia, reducir costos en el proceso
de generación y mantenimiento de datos, evitar la duplicidad de información y los avances
tecnológicos han impulsado el desarrollo bases de datos espaciales bien sea a nivel corporativo,
local, regional, nacional y global. En estas bases de datos espaciales a menudo se esconde
información interesante que los sistemas convencionales y las clásicas técnicas de minería de datos
son incapaces de descubrir.
La minería de datos espacial crece con la incidencia e importancia del conjunto de datos geo-
espaciales, que permiten determinar estudios en diversas áreas como: los efectos climatológicos,
el uso del suelo, la cartografía del delito, los datos del censo, transporte, seguridad social, salud
pública y otras. Lo anterior trae como consecuencia la necesidad de nuevas herramientas de
administración y análisis que permitan manipular la gran cantidad de datos espaciales y espacio-
temporales para extraer patrones interesantes y útiles, y no triviales.
La minería de datos espacial se diferencia de la minería de datos tradicional en el tipo de
objetos a utilizar. Los objetos de tipo espacial manejan un componente descriptivo, y un
componente espacial. Otra diferencia está dada en el tipo de relaciones entre los objetos, las
relaciones entre los objetos de tipo tradicional son relaciones frecuentemente explícitas en la
entrada de los datos son del tipo: aritméticas, ordenamiento, subclases de y entre miembros, las

13
relaciones entre objetos con componente espacial se pueden diferenciar en: relaciones
topológicas que expresa las relaciones entre los objetos de forma cualitativa: conectividad,
contigüidad, proximidad, inclusión, etc., y relaciones geométricas (calculadas a partir de las
coordenadas de los objetos). (Shekhar, Wu, Ozesmi, & Chawla , 2001)
La complejidad de datos, relaciones y auto correlación espacial de los datos espaciales, hace
que la extracción de patrones en conjuntos de datos espaciales sea más compleja que en conjuntos
de datos tradicionales (datos numéricos). Para el tratamiento de datos espaciales se debe manejar
el análisis espacial y técnicas de optimización de búsquedas de tipo espacial. Las técnicas de
algoritmos a utilizar en la minería de datos espaciales son parecidas a las de minería de datos
tradicional, pero con el factor espacial como valor agregado. Entre ellas se encuentran la
generalización, la agrupación, la exploración de asociación espacial, entre otras (Mennis & Guo,
2009) (Shekhar, Zhang, Huang, & Raju, 2003).
1. PLANTEAMIENTO DEL PROBLEMA
Situación Problemática
La ciudad de Bogotá Distrito Capital ubicada en el centro del país, en la cordillera oriental,
tiene una extensión aproximada de 33 kilómetros de sur a norte y 16 kilómetros de oriente a
occidente y se encuentra situada en las siguientes coordenadas: Latitud Norte: 4° 35'56'' y Longitud
Oeste de Greenwich: 74°04'51'' (Alcaldía Mayor de Bogotá, 2015) , en la actualidad cuenta
aproximadamente con 8.098.043 habitantes (Secretaría Distrital de Planeación, 2013),

14
administrativamente el Distrito Capital se encuentra dividido en diecinueve localidades urbanas
y una localidad rural.
De acuerdo con diversos estudios realizados por entidades como: la Policía Metropolitana de
Bogotá, La Cámara de Comercio de Bogotá, el portal Bogotá Cómo Vamos, la Secretaria Distrital
de Planeación, la Veeduría Distrital y la DIJIN entre otras, se estima que la ciudad se ha visto
afectada por una creciente ola de delitos, la anterior afirmación se sustenta en la percepción de
inseguridad que tiene la ciudadanía, según la encuesta de percepción y victimización de la cámara
de comercio de Bogotá donde se manifiesta que el 46% de los encuestados percibe que la
inseguridad aumento, el 40% percibe que sigue igual y el 14% percibe que ha disminuido. En lo
que se refiere al tipo de delito, el hurto a personas con el 64%, el hurto a residencias con el 6% y
el hurto a establecimientos comerciales con el 3%, son los delitos que más afectan a los habitantes
de las diferentes localidades (Camara de Comercio de Bogotá, 2015) (Cámara de Comercio de
Bogotá, 2016, págs. 7, 20).
Al contrastar la anterior información con el Boletín Especial Delitos Contra el Patrimonio en
Bogotá Primer semestre 2016, publicado por el portal Bogotá Cómo Vamos, el cual presenta un
análisis de los delitos contra el patrimonio (hurto a personas, hurto a residencias y hurto a
establecimientos comerciales) por localidad (Bogotácómovamos, 2016) Figura 1, se puede
observar que no es solamente la percepción de los ciudadanos, sino que efectivamente estos delitos
son los que más se presentan. Esta situación no solo afecta el patrimonio y la integridad física de
las personas, sino también conlleva a un deterioro en el estado de derecho.

15
Figura 1. Delitos contra el patrimonio por localidad año 2015
Fuente: Elaboración propia con información del portal (Bogotácómovamos, 2016).
De acuerdo con los informes citados, la seguridad ciudadana y el combate a la delincuencia
constituyen una de las mayores preocupaciones sociales no sólo en Bogotá sino en todo el país. A
pesar de la cantidad de recursos, tanto humanos como materiales que se destinan, estos resultan
insuficientes, tanto para reducir el índice delictivo, como para disminuir la sensación de
inseguridad de los ciudadanos, por tal razón se requiere contar con herramientas que tornen más
eficaz y eficiente el trabajo de combatir el delito.
1 10 100 100010000
Usaquén
Chapinero
Santa Fe
San Cristóbal
Usme
Tunjuelito
Bosa
Kennedy
Fontibón
Engativá
Suba
Barrios Unidos
Teusaquillo
Los Mártires
Antonio Nariño
Puente Aranda
La candelaria
Rafael Uribe…
Ciudad Bolívar
Delitos Contra el Patrimonio
Hurto Personas
Hurto Residencias
Hurto
Establecimientos
Comerciales

16
Si se utilizan herramientas que permitan analizar la actividad delictiva, se lograría un beneficio
doble. Por una parte, sería posible concentrar los recursos y actividad logística necesarios para
combatir ese tipo de actividad en la zona y tiempo anticipados. Por otra parte, se podría establecer,
de manera dinámica, varios de los parámetros comunes del trabajo cotidiano en seguridad pública
como el diseño específico de patrullas de vigilancia, la distribución de fuerzas en espacio y tiempo,
la realización de operativos de seguridad e inclusive de campañas de información y prevención.
El aporte de la informática en el campo del análisis delictivo actualmente incluye el diseño de
bases de datos con información espacial, visualización de los hechos en mapas y el uso de técnicas
complejas de minería de datos.
De acuerdo con el escenario presentado, este proyecto diseña una base de datos espacial, con
información suministrada por entidades como la infraestructura de datos del Distrito Capital , que
en su portal WEB comparte información geográfica sobre temas como: catastro, entidad territorial
y transporte; y con información sobre los delitos que afectan al patrimonio de las personas como:
tipo, modalidad, uso de armas, y fecha entre otros, y aplica los algoritmos de agrupamiento de
minería de datos espaciales, K-means y Dbscan para caracterizar el delito en un sector de la ciudad
de Bogotá D. C.
Formulación del Problema
Según lo expuesto anteriormente, es necesario contar con un modelo de análisis delictivo, que
permita caracterizar las tendencias del delito contra el patrimonio en una zona piloto de Bogotá.

17
¿Cómo plantear e implementar un modelo de caracterización del comportamiento delictivo al
patrimonio mediante técnicas de minería de datos?
Justificación
La seguridad ciudadana y el combate a la delincuencia constituyen una de las mayores
preocupaciones sociales no sólo en Bogotá sino en todo el país. El análisis del delito es una
necesidad, ya que se trata de una labor fundamental y clave y, por lo mismo, decisiva para el éxito
de las estrategias de reducción del delito. El análisis de los registros de incidencia delictiva es
necesario para encontrar patrones delictivos que permitan la caracterización del delito.
A partir de la información disponible en las bases de datos, hoy se pueden emplear técnicas y
herramientas poderosas que desarrollan la habilidad para identificar relaciones, probar hipótesis y
analizar grandes volúmenes de datos, dentro de este proceso de análisis se pueden aplicar
diferentes métodos.
Una vez se analiza la información con la que se cuenta sobre el problema del delito,
comúnmente lo que se busca es caracterizar y/o describir cómo éste evolucionará. Si el interés es
resolver procesos administrativos o estratégicos, entonces pueden utilizarse los métodos de
pronóstico de manera efectiva para informar sobre una toma de decisión. Por otro lado, los
problemas operacionales y tácticos no se pueden abordar con efectividad mediante un pronóstico;
los métodos de predicción funcionarán mejor cuando la tarea es anticipar qué, dónde o cuándo
probablemente podrían repetirse incidentes delictivos.
El aporte de la informática en el campo del análisis delictivo actualmente incluye desde el
diseño de bases de datos espaciales, visualización de los hechos en un mapa hasta el uso de técnicas
complejas de minería de datos. Las bases de datos almacenan gran cantidad de información, y con

18
el paso del tiempo y gracias al avance tecnológico, se hacen cada vez más grandes, más robustas,
más importantes y por lo tanto más complejas, estos datos en bruto raramente son beneficiosos
directamente y su verdadero valor se basa en la habilidad para extraer información útil para la toma
de decisiones y descubrir conocimiento de este enorme volumen de datos es un reto.
A primera vista la solución a este problema es usar métodos de consultas para bases de datos,
pero estas herramientas no permiten analizar la totalidad de los datos, el porcentaje faltante
contiene información más importante y requiere la utilización de métodos más avanzados como la
aplicación de algoritmos de minería de datos.
Objetivos
1.4.1 Objetivo General
Diseño de un modelo de caracterización del delito contra el patrimonio que afecta a la ciudad
de Bogotá mediante técnicas de agrupamiento de minería de datos espaciales.
1.4.2 Objetivos Específicos
• Recolectar, analizar y clasificar información referente al comportamiento delictivo que
afecta el patrimonio.
• Diseñar e implementar de una base de datos espacial con información georreferenciada de
los eventos delictivos que afectan el patrimonio. Caso de estudio delitos al patrimonio en Bogotá.
• Aplicar a la información contenida en la base de datos espacial los algoritmos de
agrupamiento K-MEANS y DBSCAN de minería de datos para caracterizar el comportamiento de
los delitos al patrimonio (robo en sus diferentes modalidades).

19
• Generar nuevos escenarios con inclusión de diferentes niveles de información
(información de Estaciones, Cais, cuadrantes, sitios de interés) que permitan caracterizar el
comportamiento del delito en estos escenarios.
2. MARCO TEÓRICO
Antecedentes
A continuación, se relacionan aplicativos y herramientas de software, que han sido utilizadas
para describir y en algunos casos predecir el comportamiento del delito.
2.1.1 Aplicativos y Herramientas de Software
2.1.1.1. IBM Intelligent Operations Center for Emergency Management
IBM Intelligent Operations Center for Emergency Management (IBM), es un software
desarrollado y comercializado por International Business Machines. (IBM). Este producto de
software está diseñado para Integrar, correlacionar y analizar información operativa para crear
una imagen operativa común, geoespacial y dinámica, para la gestión de incidentes, emergencias
y la seguridad publica en organizaciones públicas y privadas, con la finalidad de acelerar la toma
de decisiones y mejorar los tiempos de respuesta.
Sus principales características son:
Visualización de datos en lista y mapas
Filtrado de datos en lista y mapas
Visualización de gráficos
Visualización de informes personalizados

20
Impresión de mapas y del contenido de informes
Creación de un análisis
Visualización de alertas
Análisis de los datos de delincuencia.
2.1.1.2. IBM i2 COPLINK
IBM i2 COPLINK (IBM, s.f.), es un software desarrollado y comercializado por International
Business Machines. (IBM). Es un software policial modular, que puede personalizarse con
herramientas adicionales a fin de cubrir las necesidades específicas del usuario y mejorar los
requerimientos de resolución de delitos. Cuenta con funcionalidades para consolidar datos de
diversas fuentes, facilitar la colaboración y generar pistas tácticas. Permite a los profesionales de
la policía generar sesiones de reconocimiento con fotografías, guardar su historial de búsquedas y
organizar investigaciones para crear fácilmente informes.
Figura 2. Sistema IBM i2 Coplink
Tomado de: WEB http://www-03.ibm.com/software/products/es/coplink
Características de IBM i2 Coplink:
Descubrir pistas de los casos investigados

21
Visualizar y analizar información en mapas
Centralizar varias bases de datos
Compartir información con otras organizaciones especializadas en seguridad.
Realizar búsquedas.
2.1.1.3. EuroCop PRED-CRIME (Sistema para la Predicción y Prevención del Delito)
EuroCop PRED-CRIME es un producto informático desarrollado por EuroCop Security
Systems una empresa española especializada en el desarrollo, integración y mantenimiento de
sistemas informáticos dirigidos a las fuerzas y cuerpos de seguridad, así como a empresas
relacionadas con la seguridad (EuroCop, Sa).
Se trata de un sistema integrado, de tratamiento de datos masivos vinculados a delitos; basado
en un modelo espacio-temporal e información geográfica de mapas de calor; que utiliza modelos
y algoritmos matemáticos y que permite la predicción y prevención de los delitos.
Figura 3. Sistema EuroCop PRED-CRIME
Fuente: http://www.eurocop.com/sistemas-de-eurocop/analisis-y-prediccion-del-delito/
Características de EuroCop PRED-CRIME

22
Algoritmos y modelos matemáticos para la predicción del delito, basados en información
(no sólo policial) y su análisis estadístico de series históricas de delitos y de delincuentes.
Integración de información en diferentes soportes: vídeo, imágenes, audio, texto: obtenida
de diferentes fuentes: Video Cámaras, Base Datos Policial, Juzgados, Protección civil,
Datos Socio-económicos, Urbanísticos, etc.
Análisis masivo de información basado en Espacio-Tiempo, en tiempo real y en continuo
para la elaboración de rutas de patrulla, modificación de las mismas o ampliar la cobertura
de seguridad en puntos y en momentos determinados.
Generación de mapas de calor con zonas propensas a la realización de un delito para
aumentar en eficacia y eficiencia la acción policial.
2.1.1.4 CrimeView
CrimeView es The Omega Group (THE OMEGA GROUP, s.f.). Es la herramienta de
cartografía y análisis criminal más utilizada en América del Norte. Cientos de agencias y analistas
de delitos utilizan CrimeView para investigaciones, administración de emergencias y reportes. Los
datos de Sistemas de Gestión de Registros y Asistencia Asistida por computador se importan
automáticamente en la plataforma de mapeo, lo que permite a los usuarios finales visualizar la
actividad delictiva geográficamente. CrimeView ofrece a los analistas de delitos una interfaz
sencilla que permite realizar análisis avanzados como la asignación de Hot Spot y la repetición de
llamadas.

23
Figura 4. Sistema CrimeView
Fuente: sitio WEB http://www.theomegagroup.com/police/crimeview_desktop.html
Características de CrimeView
Permite la búsqueda de hechos delictivos por categorías (tipo de delito, fecha y hora).
Encuentra áreas con problemas graves de delincuencia (hot spots) y crea mapas de
llamadas que ayudan a aislar las áreas problemáticas.
Automatiza las tareas repetitivas como la generación de informes periódicos.
Hace notificaciones cuando la delincuencia supera un nivel específico.
Realiza reportes detallados y resumidos de cualquier capa de la delincuencia y las clasifica
por numerosas categorías.
Crea tablas y gráficos por día de la semana, hora del día y mes del año.
2.1.2 Trabajos Publicados
A nivel de artículos relacionados con técnicas de minería de datos y análisis espacio temporal
aplicados a predicción y/o descripción de delitos, publicados en bases de datos científicas se
relacionan a continuación los siguientes:

24
2.1.2.1. Filtering Estimated Crime Series Based on Route Calculations on Spatio-temporal
Data
En este artículo (Boldt & Bala, 2017) , diseñan, implementan y evalúan un método de filtrado,
para identificar y filtrar crimines contra robos residenciales, utilizando dos conjuntos de datos de
robos a residencias: una serie de delitos con evidencias físicas, conocidos y recopilados por la
policía sueca, y otra serie de delitos estimados vinculados por evidencia suave (comportamiento
de los infractores).
Se diseñó un método de filtrado que utiliza las distancias y la duración del recorrido entre los
lugares del delito usando mapas de Google. Este filtrado se realiza en dos fases. La primera fase
se basa en las distancias y la segunda fase se basa en la duración del viaje. También se usó un
método trivial que usaba distancias lineales euclidianas entre puntos para representar el estado de
la técnica. Este método simplemente calcula la distancia en metros entre dos pares de coordenadas
de latitud y longitud que representan dos localizaciones de crimen.
En la validación se encontró que todas las series conocidas pasaron el método de filtrado
usando mapas de Google. Cuando se aplicó el mismo método en la serie estimada, solo se filtró el
4,4%. El método de filtrado propuesto se comparó con un método basado en las distancias lineales
euclidianas. En esta comparación, el método propuesto logró filtrar un 79% más de vínculos
delictivos erróneos. Por último, un análisis cronológico de las series de crímenes, incluyendo el
análisis de la ruta, indica que los ladrones tienen un promedio de hasta 15 minutos para realizar el
robo.

25
2.1.2.2. Spatio-Temporal Modeling of Criminal Incidents Using Geographic, Demographic,
and Twitter-derived Information.
Este trabajo realizado por (Wang, Brown, & Gerber, 2012), reúne dos enfoques previos a la
modelización de incidentes criminales. El primer enfoque Spatio-temporal Generalized Additive
Modeling (STGAM) usó características numéricas describiendo las propiedades geográficas y
demográficas de una región. El segundo enfoque utilizó información textual extraída de los
mensajes de Twitter. Evalúa el modelo híbrido usando datos reales de incidentes criminales para
Charlottesville, Virginia. Los resultados indican que el modelo híbrido exhibe un mejor
desempeño de predicción en comparación con el modelo STGAM estándar. El modelo híbrido
puede generalizarse a otras áreas de aplicación donde la información textual no estructurada
contiene indicadores relevantes para las propiedades espacio-temporales de los eventos. Además,
este trabajo ha descrito un nuevo algoritmo de selección de características. La prueba con datos
reales mostró que el algoritmo se desempeñó mejor que un modelo de regresión lineal penalizado
clásico. Este algoritmo puede aplicarse independientemente para elegir características para
modelos no lineales.
2.1.2.3. The CriLiM Methodology: Crime Linkage with a Fuzzy MCDM Approach.
En este artículo (Albertetti, Cotofrei, & Grossrieder, 2013), presentan la metodología CriLiM
para investigar tanto la criminalidad grave como de gran volumen. El trabajo consiste en
implementar un sistema de información de vinculación de delitos basado en un enfoque difuso
Multi-Criteria Decisión Making (MCDM) con el fin de combinar la información espacio-temporal,
conductual y forense. Como prueba de la implementación, las series de robos son examinadas a
partir de datos reales y comparadas con resultados de expertos.

26
2.1.2.4. Crime Prediction and Forecasting in Tamilnadu using Clustering Approaches
El análisis del crimen es una forma sistemática de detectar e investigar patrones y tendencias
en la delincuencia. En este trabajo (Sivaranjani, Sivakumari, & Aasha, 2017), utilizan varios
enfoques de agrupación de minería de datos para analizar los datos de delincuencia de Tamilnadu.
Los datos sobre delitos se extraen del National Crime Records Bureau (NCRB) de la India.
El objetivo de este trabajo es predecir la delincuencia en seis ciudades de Tamilnadu mediante
el uso de métodos de agrupamiento e identificar a los criminales mediante el uso de métodos de
clasificación. Para ello utilizan la clasificación KNN, el agrupamiento de K-Means, el
agrupamiento jerárquico aglomerativo y los algoritmos de agrupamiento DBSCAN
2.1.2.5. Spatial Patterns of Crimes in India using Data Mining Techniques.
En este artículo se estudia la influencia de la tasa de delincuencia de estados vecinos con el
estado de referencia mediante técnicas de minería de datos espaciales. En el estudio (Shafeeq,
Binu, & Binu, 2014), toman el PIB, la tasa de alfabetización, la tasa policial, la tasa de empleo y
varios delitos como el asesinato y disturbios, en los estados de la India como datos de localización.
El objetivo del trabajo es comprobar la correlación entre varios delitos. Todo el trabajo se
divide en dos partes: 1) para comprobar la auto correlación espacial entre los distintos delitos 2)
comparar varios clústeres de atributos y su relación. La distribución espacial de varios crímenes
en los estados de la India y también la correlación entre los atributos mencionados y los crímenes
en 2012 se analizaron utilizando métodos exploratorios de análisis espacial. El resultado del
estudio revela que los crímenes de los estados indios "tiene correlación espacial positiva entre los
estados y también encontró la disparidad espacial en la distribución del crimen entre los estados

27
locales. Los estados con mayor tasa de empleo son más afectados por los crímenes. La agrupación
se utiliza para identificar los patrones con diferentes densidades de delincuencia, empleo y
distribución de la fuerza de policía.
2.1.3 Modelo a Desarrollar.
Para el presente trabajo, según lo expuesto por (Epstein, 2008), el modelo a desarrollar es un
modelo explicativo y no predictivo, es un modelo explicito, sus resultados serán valorados por
otros, posteriormente a su implementación.
La intención de este modelo es explicar y no predecir. La caracterización del delito,
seguramente explicará el comportamiento de este en cuanto a su ubicación, fecha y hora de
ocurrencia, modalidad, etc., pero no es posible predecir el momento y lugar de su ocurrencia.
Primero se recopilan los datos y luego mediante la aplicación de técnicas de minería de datos
se analizan y encuentran patrones de comportamiento del delito. Al aplicar técnicas de minería de
datos, se puede encontrar información oculta y puede dar lugar a formular nuevas preguntas, que
son las que hacen que el modelo evolucione.
Los procesos utilizados para el análisis de datos espaciales, figura 22, pueden ser utilizados
análogamente en otras aplicaciones como: el procesamiento de imágenes, cómputo y multimedia,
análisis médico, economía, bioinformática y biometría entre otras.
Bases Teóricas
Una base de datos constituye un sistema que permite un manejo adecuado de los datos,
garantizando la seguridad e integridad de estos y permitiendo el acceso a distintos usuarios de

28
forma transparente. La base de datos está formada por los datos en sí, organizados de forma
estructurada, mientras que las operaciones las provee el sistema gestor de base de datos (SGBD).
Existen diversos modelos para el almacenamiento de datos, siendo el modelo relacional uno
de los modelos más utilizados. En el modelo relacional la información se organiza en tablas
relacionadas entre sí. Cada fila de una base de datos conforma una tupla, que contiene la
información correspondiente a una entidad dada.
El diseño de la base de datos es de gran importancia, y conlleva el diseño de un modelo
conceptual, el diseño de un modelo físico, la implementación y el mantenimiento. Herramientas
como los diagramas entidad relación (E - R) son de ayuda en las fases de diseño, cuyo principal
objetivo es crear una estructura de la base de datos que facilite la interpretación de la información
contenida y permita sacar el máximo rendimiento de esta (Silberschatz , Korrth, & Sudarshan,
2002).
En lo que a los sistemas de información geográfica (SIG) respecta, las bases de datos se han
ido incorporando a la gestión de los datos espaciales. Los sistemas gestores de bases de datos, han
venido integrándose en los SIG de diversas formas. En la actualidad, se utilizan bases de datos
relacionales, para almacenar, gestionar y operar datos temáticos y espaciales.
El volumen cada vez mayor y la diversidad de los datos geográficos sobrepasan fácilmente las
principales técnicas de análisis espacial que se orientan hacia la obtención de información escasa
a partir de conjuntos de datos pequeños y homogéneos. Los métodos estadísticos tradicionales, en
particular las estadísticas espaciales, tienen cargas computacionales elevadas. Estas técnicas son
confirmatorias y requieren que el investigador tenga hipótesis a priori. Por lo tanto, las técnicas
analíticas espaciales tradicionales no pueden descubrir fácilmente patrones, tendencias y

29
relaciones nuevas e inesperadas que pueden estar ocultas dentro de conjuntos de datos geográficos
muy grandes y diversos.
En respuesta a esta necesidad surge la minería de datos espaciales, como el proceso de análisis
automático, mediante la implementación de algoritmos, que ofrece la opción de buscar
correlaciones no evidentes y potencialmente útiles entre objetos espaciales. La aplicación de
minería de datos espacial conduce al descubrimiento de tendencias o variaciones de
comportamiento en los datos, de tal manera que esta información resulte de utilidad para los
usuarios finales. A estas tendencias o variaciones se le conocen como patrón (Mariscal, Marbán,
& Fernández, 2010). Si los patrones son útiles y de relevancia para el dominio, entonces se le llama
conocimiento.
Marco Conceptual
2.3.1 Bases de Datos Espaciales
Las bases datos espaciales, son un sistema administrador de bases de datos que maneja datos
existentes en un espacio o datos espaciales. Estas bases de datos incluyen datos geográficos,
imágenes médicas, redes de transporte o información de tráfico, etc., donde las relaciones
espaciales son muy relevantes (Hernández, Ramírez , & Ferri, 2007, pág. 9). En este tipo de bases
de datos es imprescindible establecer un cuadro de referencia (un SRE, Sistema de Referencia
Espacial) para definir la localización y relación entre objetos, ya que los datos tratados en este tipo
de bases de datos tienen un valor relativo, no es un valor absoluto. Los sistemas de referencia
espacial pueden ser de dos tipos: georreferenciados (carreteras, ciudades, suelo, altitudes), son los
que normalmente se utilizan, ya que es un dominio manipulable, perceptible y que sirve de

30
referencia y no georreferenciados (son sistemas que tienen valor físico, pero que pueden ser útiles
en determinadas situaciones), estos se almacena de dos formas: vectorial y raster.
El modelo raster se utiliza habitualmente para representar fenómenos de la realidad que se
presentan de manera continua en el espacio. En este caso el espacio se suele dividir en celdas
regulares, donde cada una de estas celdas presenta un valor. Los rasgos del territorio se reconocer
al analizar en conjunto dichos elementos, como sucede al visualizar una fotografía aérea
compuesta de una infinidad de píxeles, o una grilla que representa las precipitaciones caídas a lo
largo de un año.
Este modelo fue el primero en ser utilizado, y está representado principalmente por el uso de
imágenes proveniente de satélites o fotografías aéreas digitales.
El modelo vectorial, representa los datos valiéndose de primitivas geométricas, tales como
puntos (se utilizan para las entidades geográficas que mejor pueden ser expresadas por un único
punto de referencia), líneas (son usadas para rasgos lineales como ríos, caminos, ferrocarriles,
rastros, líneas topográficas o curvas de nivel) y polígonos (se utilizan para representar elementos
geográficos que cubren un área particular de la superficie de la tierra. Estas entidades pueden
representar lagos, parques naturales, ciudades). Junto con estas geometrías, se encuentran los
atributos temáticos de los fenómenos que representan. Por ejemplo, una ciudad, se puede modelar
a través de polígonos, se pueden encontrar atributos como el nombre, cantidad de habitantes,
temperatura, etc.
Una base de datos espacial puede reconocer y analizar las relaciones espaciales que existen en
la información geográfica almacenada, mediante relaciones topológicas. Estas relaciones permiten
construir modelos y análisis espaciales complejos. En los sistemas de información geográfica se
entiende como topología a las relaciones espaciales entre los diferentes elementos gráficos

31
(topología de nodo/punto, topología de red/arco/línea, topología de polígono) y su posición en el
mapa (proximidad, inclusión, conectividad y vecindad). Estas relaciones, que pueden ser obvias a
simple vista, se deben establecer mediante un lenguaje y unas reglas de geometría matemática.
La consulta de datos espaciales, se hace mediante operaciones entre figuras geométricas que
se clasifican en tres grupos: Predicados espaciales, operaciones espaciales y otras operaciones
espaciales (Yáñezs & González , 2005, págs. 41 - 49).
Predicados Espaciales: Se aplican a una o varias figuras geométricas y devuelven un valor
booleano: verdadero o falso. Los predicados espaciales permiten comprobar la relación topológica
que existe entre dos figuras geométricas de cualquier tipo figura 5.
Figura 5. Ejemplo de Predicados Espaciales.
Fuente: Tomado de Wikipediahttps://es.wikipedia.org/wiki/Topolog%C3%ADa_geoespacial, Consultado el 25
de mayo 2017.
La figura 5, identifica las relaciones topológicas: disjunto, toca, cruza, solapa y dentro, entre
figuras geométricas.

32
Las operaciones espaciales, se aplican a una o varias figuras geométricas y devuelven como
resultado una o varias figuras geométricas. Ejemplo la unión, intersección y diferencia entre dos
figuras geométricas dadas o el complemento, borde, centroide de una figura geométrica.
Las mediciones y otras operaciones espaciales, permiten obtener un valor numérico a partir de
una o varias figuras geométricas. Por ejemplo las coordenadas de un punto, el área de una
superficie, la pendiente una recta o transformar entre varios formatos de intercambio de datos
(Yang, , Bai, & Gong,, 2008, págs. 541 - 544), (Open Geospatial Consortium Inc, 2011)
2.3.2 Minería de Datos Espaciales
La identificación de patrones comunes, asociaciones, reglas generales y nuevo conocimiento
es una actividad investigativa de gran interés, a este proceso se le denomina también
descubrimiento de conocimiento en bases de datos (Knowledge Discovery in Data bases, KDD).
La minería de datos y la minería de datos espaciales son el núcleo matemático del proceso
KDD son técnicas que hacen parte de este proceso, que comprende los algoritmos que exploran
los datos, desarrollan modelos matemáticos y descubren patrones significativos (implícita o
explícita), los cuales son la esencia del conocimiento útil (Rokach & Maimon, 2010). Se les
denomina patrones a las relaciones que existen entre los elementos de los datos analizados. Los
patrones son de interés, si son confiables, novedosos y útiles respecto al conocimiento que generan
y el acoplamiento con los objetivos del análisis.
La minería de datos se define como “La técnica de extraer conocimiento útil y comprensible,
previamente desconocido desde grandes cantidades de datos almacenados en distintos formatos.
Es decir, la tarea fundamental de la minería de datos es encontrar modelos inteligibles a partir de
los datos” (Witten, Frank, Hall, & Pal, 2016). Técnicamente, la minería de datos es el proceso de
encontrar correlación o patrones entre la información almacenada en bases de datos relacionales.

33
El crecimiento de los datos espaciales y el uso generalizado de las bases de datos espaciales
requieren de procesos automáticos que identifiquen patrones válidos. La minería de datos
espaciales es la técnica de encontrar a través de diferentes métodos y herramientas patrones
interesantes y previamente desconocidos, pero potencialmente útiles en bases de datos espaciales;
este tipo de bases de datos no almacenan explícitamente patrones o reglas que determinan las
relaciones espaciales entre los objetos y algunas características no espaciales (Shekhar, Wu,
Ozesmi, & Chawla , 2001). La complejidad de los datos espaciales y las relaciones espaciales
intrínsecas limita la utilidad de las técnicas convencionales de minería de datos.
Inicialmente se podría pensar que la minería de datos espacial comparte los mismos métodos
utilizados en la minería de datos tradicional, sin embargo, debido a la complejidad de los datos
espaciales, ya que los objetos espaciales están compuestos no sólo de atributos generales
representados en forma numérica o de texto, sino también de atributos espaciales, tales como su
geometría e información topológica
Aunque las técnicas y algoritmos de la minería de datos tradicional y espacial son similares,
hay que recalcar que los últimos deben manejar características especiales debido a la complejidad
de los datos (Yang, , Bai, & Gong,, 2008), las técnicas que se utilizan deben ser en completa
concordancia con el problema a tratar; el enfoque tradicional difiere al enfoque espacial, por
factores como: i) el hecho que la primera asume características como la independencia existente
en la distribución de los datos, que viola la primera ley de la geografía enunciada por Tobler W. R
(1970) (Rengert & Lockwood, 2009) todo se encuentra relacionado con todo lo demás, pero los
objetos cercanos se encuentran mayormente relacionados que los objetos distantes), (ii) los tipos
de datos complejos y (iii) la existencia de correlación entre características espaciales . Igualmente
se debe tratar con información que ha sido almacenada cronológicamente en periodos de tiempos

34
constantes, o bien, presenta información que puede ser considerada como una secuencia de
eventos, como por ejemplo la ocurrencia de un delito en un determinado rango de horas o días de
la semana.
Un proceso de minería de datos espaciales es semejante al proceso de minería de datos
tradicional figura 6.
Figura 6. Proceso de minería de datos.
Fuente: Tomado de (Olmos Pineda & González Bernal, 2007)
Un proceso típico de minería de datos consta de los siguientes pasos generales (Hernández,
Ramírez , & Ferri, 2007):
Selección del conjunto de datos, tanto en lo que se refiere a las variables objetivo (aquellas
que se quiere predecir, calcular o inferir), como a las variables independientes (las que sirven para
hacer el cálculo o proceso), como posiblemente al muestreo de los registros disponibles.
Preparación de los datos, en especial los histogramas, diagramas de dispersión, presencia
de valores atípicos y ausencia de datos (valores nulos).

35
Transformación del conjunto de datos de entrada, se realizará de diversas formas en
función del análisis previo, con el objetivo de prepararlo para aplicar la técnica de minería de datos
que mejor se adapte a los datos y al problema, a este paso también se le conoce como pre
procesamiento de los datos.
Seleccionar y aplicar la técnica de minería de datos, se construye el modelo descriptivo
o predictivo, de clasificación o segmentación.
Extracción de conocimiento, mediante una técnica de minería de datos, se obtiene un
modelo de conocimiento, que representa patrones de comportamiento observados en los valores
de las variables del problema o relaciones de asociación entre dichas variables. También pueden
usarse varias técnicas a la vez para generar distintos modelos, aunque generalmente cada técnica
obliga a un pre procesado diferente de los datos.
Interpretación y evaluación de patrones, una vez obtenido el modelo, se debe proceder
a su validación comprobando que las conclusiones que arroja son válidas y suficientemente
satisfactorias. En el caso de haber obtenido varios modelos mediante el uso de distintas técnicas,
se deben comparar los modelos en busca de aquel que se ajuste mejor al problema. Si ninguno de
los modelos alcanza los resultados esperados, debe alterarse alguno de los pasos anteriores para
generar nuevos modelos.

36
2.3.3 Tareas de la Minería de Datos
Las tareas de minería de datos se dividen en dos categorías, como se muestra en la
Figura 7.
Figura 7. Tareas de la Minería de Datos.
Elaboración: Propia
2.3.3.1. Predictiva
El objetivo de este tipo de minería, es predecir el valor particular de un atributo basado en
otros atributos. El atributo a predecir es comúnmente llamado “clase” o variable dependiente,
mientras que los atributos usados para hacer la predicción se llaman variables independientes
Permite predecir valores de variables desconocidas (variable dependiente o variable objetivo)
a partir de otros atributos de la base de datos (variables independientes) (Weiis & Indurkhya,
1998).
Clasificación: El objetivo de esta tarea es la clasificación de un dato dentro de las
clases definidas del dominio que se está modelando. Permite la clasificación de los registros
que tienen clase desconocida en categorías o clases ya definidas en la base de datos (Tan ,
Steinbach , & Kumar , 2006).
Regresión: Predice un valor de una variable de valor continúo dado en base a los
valores de las otras variables, suponiendo un modelo lineal o no lineal de dependencia. El
objetivo es predecir los valores de una variable continua a partir de la evolución sobre otra

37
variable continua, generalmente el tiempo. Ejemplo, se intenta predecir el número de clientes o
pacientes, los ingresos, llamadas, ganancias, costos, etc. a partir de los resultados de semanas,
meses o años anteriores (Hernández, Ramírez , & Ferri, 2007).
2.3.3.2. Descriptiva
El objetivo de este tipo de minería, es encontrar patrones (correlaciones, tendencias, grupos,
trayectorias y anomalías) que resuman relaciones en los datos Se encarga de identificar patrones
para la descripción de los datos existentes (Han, Pei, & Kamber, 2011).
Agrupamiento: Permite obtener grupos o conjuntos en donde se incorpore elementos
similares extraídos de las clases del dominio dado (Riquelme, Ruiz, & Gilbert, 2006). Permite la
segmentación en grupos excluyentes entre sí y cercanos dentro del grupo.
Reglas de Asociación: Una asociación entre dos atributos ocurre cuando la frecuencia de
que se den dos valores determinados de cada uno conjuntamente es relativamente alta. Ejemplo,
en un supermercado se analiza si los pañales y la leche del bebe se compran conjuntamente
(Hernández, Ramírez , & Ferri, 2007). Encuentra relaciones entre dos o más atributos que ocurren
con mayor frecuencia.
Secuenciación: Es un conjunto de objetos dado, con cada objeto asociado con su propia
línea de tiempo de eventos, encuentra reglas que predicen fuertes dependencias secuenciales entre
los diferentes eventos. Las reglas se forman descubriendo primero patrones. Las ocurrencias de
eventos en los patrones se rigen por restricciones de temporización (Hernández, Ramírez , & Ferri,
2007).

38
2.3.4 Técnicas de Minería de Datos
Las técnicas de minería de datos permiten llevar a cabo las tareas predictivas y descriptivas
haciendo uso de algoritmos de minería de datos. Según el objetivo del análisis de los datos,
algoritmos utilizados se clasifican en supervisados y no supervisados (Weiis & Indurkhya,
Aprendizaje supervisado (o predictivo): Predicen el valor de un atributo (etiqueta)
de un conjunto de datos, desconocido a priori, a partir de otros atributos conocidos (atributos
descriptivos). A partir de datos cuya etiqueta se conoce se induce una relación entre dicha
etiqueta y otra serie de atributos. Esas relaciones sirven para realizar la predicción en datos
cuya etiqueta es desconocida. Esta forma de trabajar se conoce como aprendizaje supervisado
y se desarrolla en dos fases: Entrenamiento (construcción de un modelo usando un subconjunto
de datos con etiqueta conocida) y prueba (prueba del modelo sobre el resto de los datos).
Aprendizaje no supervisado (o del descubrimiento del conocimiento): Se
descubren patrones y tendencias en los datos. El descubrimiento de esa información sirve para
llevar a cabo acciones y obtener un beneficio (científico o de negocios) de ellas. En la Tabla
1, se muestra algunas de las técnicas de minería de datos.
Tabla 1: Clasificación de las técnicas de minería de datos
Supervisados No supervisados
Arboles de decisión Detección de desviaciones
Inducción neuronal Segmentación
Regresión Agrupamiento (clustering)
Series Temporales Reglas de Asociación
Patrones Secuenciales

39
A continuación, se hace una breve descripción de un conjunto seleccionado de tareas y
métodos relacionados, incluyendo reglas de asociación, clasificación (aprendizaje supervisado),
geo visualización multivariado y posteriormente se enfatiza en las técnicas de agrupamiento o
clustering (clasificación no supervisada).
2.3.4.1 Reglas de Asociación Espacial: Aunque en la minería de datos espacial las reglas de
asociación tienen muchos beneficios, existen dificultades en la definición de predicados espacial
y el establecimiento de valores a varios niveles de las reglas de asociación. También puede tener
diferentes resultados de acuerdo a los métodos de entrada de los atributos no espaciales. Al igual
que la extracción de reglas de asociación en bases de datos relacionales, las reglas de asociación
espaciales pueden ser extraídas en bases de datos espaciales teniendo en cuenta las propiedades
espaciales y predicados (Ding, Ding, & Perrizo, 2008).
Un algoritmo usado en reglas de asociación es el PARM, se basa en el algoritmo clásico
Apriori. El algoritmo A priori utiliza un enfoque levelwise (nivel acertado) para generar toda la
frecuencia de conjuntos de elementos, comenzando con frecuencia 1 de conjuntos de elementos.
En base a el hecho que, si un conjunto de elementos es frecuente, todo su subgrupo también debe
ser frecuente, el algoritmo Apriori genera candidato (k + 1) los conjuntos de elementos frecuentes
de k-conjuntos de elementos y luego calcula el soporte para cada candidato (k + 1)-conjunto de
elementos para formar frecuentes (k + 1)-conjuntos de elementos.
2.3.4.2 Clasificación Espacial. Por lo general, en la clasificación espacial, los objetos son
clasificados teniendo en cuenta los atributos espaciales y no espaciales. La clasificación espacial
también utiliza árboles de decisión (Koperski & Han, 1998).

40
La técnica utiliza los predicados sobre la relación entre los objetos espaciales, como
criterios de decisión. En el primer paso, los atributos espaciales se representan como
predicados espaciales y, a continuación, la posible utilidad de los predicados se extrae con el
algoritmo RELIEF. Para la segunda etapa, el árbol de decisión es construido con los predicados
(Koperski & Han, 1998).
Las ventajas de esta técnica son las siguientes:
o El árbol de decisión se construye después de descartar predicados ineficaces, el
costo de la construcción del árbol se reduce considerablemente.
o Se puede hacer clasificación rápida y correcta a través de uso de reglas simples
mediante la construcción de un árbol de decisión binaria y se minimiza el coste computacional
de podar con el algoritmo RELIEF.
2.3.4.3 Caracterización Espacial: Caracterización espacial extrae un esquema global de
clases de datos para una región espacial mediante el uso de objetos espaciales de la región. Se
da simple y clara información abstracta de la región (Ester, Kriegel, & Sander, 2001).
La caracterización espacial evalúa si dadas las características de los objetos espaciales se
expanden a cerca de la región. Para hacer esto, los objetos se definen como un vecino de otro
considerando su distancia o dirección. La información del vecino es lograda mediante el uso
de la tabla de vecinos. La región manejada por la caracterización espacial se puede ampliar
con un algoritmo de expansión espacial utilizando tablas de vecino (Guo & Gahegan, 2006).
2.3.4.4 Geo visualización: Se refiere al desarrollo de la teoría y el método para facilitar
la construcción del conocimiento a través de la exploración visual y el análisis de los datos
geoespaciales y la implementación de herramientas visuales para la posterior recuperación del
conocimiento, síntesis, comunicación y uso (Jia & Liu, 2009). Como un dominio emergente,

41
geo visualización ha elaborado a partir de los intereses de los diversos campos afines del
conocimiento y ha evolucionado a lo largo de un conjunto diverso de direcciones de investigación
investigación (Guo & Gahegan, 2006)
La principal diferencia entre la cartografía tradicional y geo visualización es que, la primera
se centra en el diseño y uso de mapas para la comunicación de la información y el consumo
público, mientras que el segundo hace hincapié en el desarrollo de mapas interactivos y
herramientas asociadas para exploración de datos, generación de hipótesis y la construcción
del conocimiento (Guo 2006).
2.3.5 Agrupamiento o Clustering
El análisis clúster es un conjunto de técnicas multivariantes utilizadas para clasificar a un
conjunto de individuos en grupos homogéneos. El análisis de clúster se aplica cuando no se conoce
a que grupo pertenecen los datos y se quiere encontrar dichos grupos, esta técnica agrupa objetos
basados solamente en la información encontrada en los datos que describen a los objetos y sus
relaciones. El objetivo es que los elementos dentro de un grupo sean similares (o relacionados)
entre sí y diferentes de (o no relacionados con) los elementos en otros grupos. A mayor similitud
(u homogeneidad) dentro de un grupo y a mayor diferencia entre grupos, más distinto es el
agrupamiento (Pascual, Pla, & Sánchez, 2007).
En la figura 9, existen tres grupos, en el cual los elementos pertenecientes a cada grupo son
similares entre si y diferentes o no relacionados con los elementos de otros grupos.

42
Figura 8. Análisis de Clúster.
Fuente: Tomado de (Tan , Steinbach , & Kumar , 2006)
El agrupamiento o Clustering es una de las técnicas más útiles para encontrar
conocimiento oculto en un conjunto de datos. En la actualidad el análisis de clustering en
minería de datos se utiliza en una amplia variedad de áreas tales como: reconocimiento de
patrones, análisis de datos espaciales, procesamiento de imágenes, cómputo y multimedia,
análisis médico, economía, bioinformática y biometría principalmente (Han, Pei, & Kamber,
2011).
La actividad de clustering implica los siguientes pasos (Jain 1999, Hernández, 2006).
Representación de patrones: Se refiere al número de clases, número de patrones
disponibles, y el número, tipo y tamaño de las características disponibles para el algoritmo de
clustering.
Definición de proximidad: La proximidad de los patrones es usualmente medida por
una función distancia definida; esta función utiliza medidas de distancia como: euclidiana,
manhattan, chebyshev y minkowski. (Gibert & Nonell, 2005).

43
Clustering o agrupamiento: Puede ser realizado en un gran número de formas. Se pueden
utilizar algoritmos de clustering jerárquicos, particionales y otras técnicas que abarcan métodos
probabilísticos o de teoría de grafos.
Abstracción de datos: Es el proceso de extraer una representación simple y compacta del
conjunto de datos.
Verificación de resultados: Consiste en validar el análisis de clustering realizado
evaluando los resultados obtenidos.
2.3.6 Técnicas de Clustering
Los algoritmos de clustering varían entre sí por las reglas heurísticas que utilizan y el tipo de
aplicación para el cual fueron diseñados. La mayoría de ellos se basa en el empleo sistemático de
distancias entre vectores (objetos a agrupar) así como entre grupos que se van formando durante
el clustering. Las características básicas por las que los algoritmos de clustering pueden ser
clasificados son en función de (Hernández, 2006):
El tipo de dato que manejan (numérico, categórico y/o mixto).
El criterio utilizado para medir la similitud entre los puntos.
Los conceptos y técnicas de clustering empleadas (ej. lógica difusa, estadísticas).
En la literatura existen una gran cantidad de técnicas de clustering que varían de acuerdo a la
arquitectura que utilizan (Jain, Murty, & Flynn, 1999). Una clasificación general divide los
algoritmos en: clustering jerárquico, clustering particional y clustering basado en densidad, Figura
9.

44
Figura 9. Algoritmos Básicos de Clustering.
Fuente: Elaboración Propia.
2.3.6.1. Clustering jerárquico
Un conjunto de clústeres anidados organizados como un árbol jerárquico (Tan, Steinbach,
2006). Un método jerárquico crea una descomposición jerárquica de un conjunto de datos,
formando un dendrograma (árbol) que divide recursivamente el conjunto de datos en conjuntos
cada vez más pequeños (Jain, 1999). Un método jerárquico puede ser clasificado como
aglomerativo o divisivo, basado en cómo se forma la descomposición jerárquica (Han, Pei, &
Kamber, 2011).
Aglomerativo, llamado también bottom-up, comienza con cada objeto formando un
grupo separado. Sucesivamente los objetos o grupos cercanos uno al otro se une, hasta que
todos los grupos se combinan en uno (el nivel más alto de la jerarquía) o hasta que se cumpla
alguna condición de terminación.
Divisivo, llamado también top-down, comienza con todos los objetos del mismo
cluster. En cada iteración sucesiva, un cluster se divide en grupos más pequeños, hasta que
cada objeto este en un clúster, o se cumpla la condición de terminación.

45
Figura 10. Clustering Jerárquico
Tomado de: (Tan , Steinbach , & Kumar , 2006)
El clustering jerárquico no es recomendable para bases de datos grandes con millones de
registros ya que la cantidad de distancias a calcular sería mayor, y la construcción del endrograma
sería compleja.
2.3.6.2. Clustering particional
Clustering particional es una división de objetos de datos en subconjuntos que no se
superponen (clúster) de tal manera que cada objeto de datos está exactamente en un subconjunto
(Tan , Steinbach , & Kumar , 2006), figura 11.

46
Figura 11. Ejemplo Clustering Particional
Tomado de: Tan, Steinbach y Kumar, 2006
Dado un conjunto de n objetos, un método de partición construye k particiones de los
datos, donde cada partición representa un clúster y k≤ N; es decir, divide los datos en k grupos
de manera que cada grupo debe contener al menos un objeto. En otras palabras, los métodos
de partición realizan un nivel de partición en conjuntos de datos. Los métodos de partición
básicos adoptan típicamente la separación de clúster exclusiva; es decir, cada objeto debe
pertenecer exactamente a un grupo (Han, Kamber y Pei, 2011).
El clustering particional se puede utilizar para grandes cantidades de datos, encuentra
clúster mutuamente exclusivos de forma circular y está basado en la distancia.
2.3.6.3. Clustering basado en densidad
Un grupo es una región densa de puntos, que está separada por regiones de baja densidad,
de otras regiones de alta densidad. Se utiliza cuando los grupos son irregulares o entrelazados,
y cuando hay ruido presente (Tan , Steinbach , & Kumar , 2006)
La mayoría de los métodos de clustering agrupan objetos basados en la distancia entre
objetos. Tales métodos pueden encontrar solamente clúster de forma esférica y encuentran
dificultades para descubrir clúster de formas arbitrarias.

47
Otros métodos de agrupamiento han sido desarrollados basados en la noción de densidad. Su
idea general es continuar creciendo un cluster dado, siempre y cuando la densidad (número de
objetos o puntos de datos) en el “vecindario” supere algún umbral. Por ejemplo, para cada punto
de datos dentro de un grupo dado, la vecindad de un radio dado debe contener al menos un número
mínimo de puntos. Este método puede usarse para filtrar el ruido uoutliers y descubrir clusters de
forma arbitraria (Han, Kamber y Pei, 2011).
2.3.7 Algoritmos de Clustering
2.3.7.1. Clustering jerárquico aglomerativo
El algoritmo de clustering aglomerativo es la técnica de clustering jerárquico más popular. Los
algoritmos jerárquicos tradicionales utilizan una matriz de similitud o distancia (Tan, Steinbach y
Kumar, 2006).
Este enfoque de clustering se refiere a una colección de técnicas de agrupamiento
estrechamente relacionadas que producen un agrupamiento jerárquico comenzando con cada punto
como un clúster con un solo elemento e iterativamente lo agrupa con los dos clúster más cercanos
hasta que un único clúster que abarca a los todos los demás permanece (Flores, 2014). Los
algoritmos de clustering jerárquicos no son recomendables para grandes cantidades de datos ya
que son costosos en términos de sus requerimientos computacionales y de almacenamiento. El
hecho de que todos los clústeres terminen finalmente unidos también puede causar problemas para
datos ruidosos o de alta dimensionalidad (Flores, 2014).
El algoritmo básico es sencillo:

48
Algoritmo de Clustering Aglomerativo
1. Calcular la matriz de proximidad
2. Dejar que cada punto de datos sea un clúster
3. Repeat
4. Combinar los dos clústeres más cercanos
5. Actualizar la matriz de proximidad
6. Until solamente queda un solo clúster
Tomado de : (Tan, Steinbach y Kumar, 2006).
2.3.7.2. K-means
Esta técnica está basada en el clustering particional que intenta encontrar un número de
clúster (K) especificados por el usuario, los cuales son representados por sus centroides. El
algoritmo básico se describe a continuación:
Primero se eligen K centroides iniciales, donde K es un parámetro especificado por el
usuario y corresponde al número de clúster deseados.
Cada punto es asignado a su centroide más cercano y cada colección de puntos asignado
a un centroide representa un clúster. El centroide de cada clúster se actualiza basado en la
asignación de puntos al clúster.
Se repiten los pasos de asignación y actualización hasta que los puntos dentro del clúster
no cambien, o equivalentemente, hasta que los centroides dejen de cambiar (Flores, 2014).
El algoritmo básico de K-means consta de los siguientes pasos (Tan, Steinbach y Kumar,
2006):
1. Seleccionar K puntos iniciales como centroides
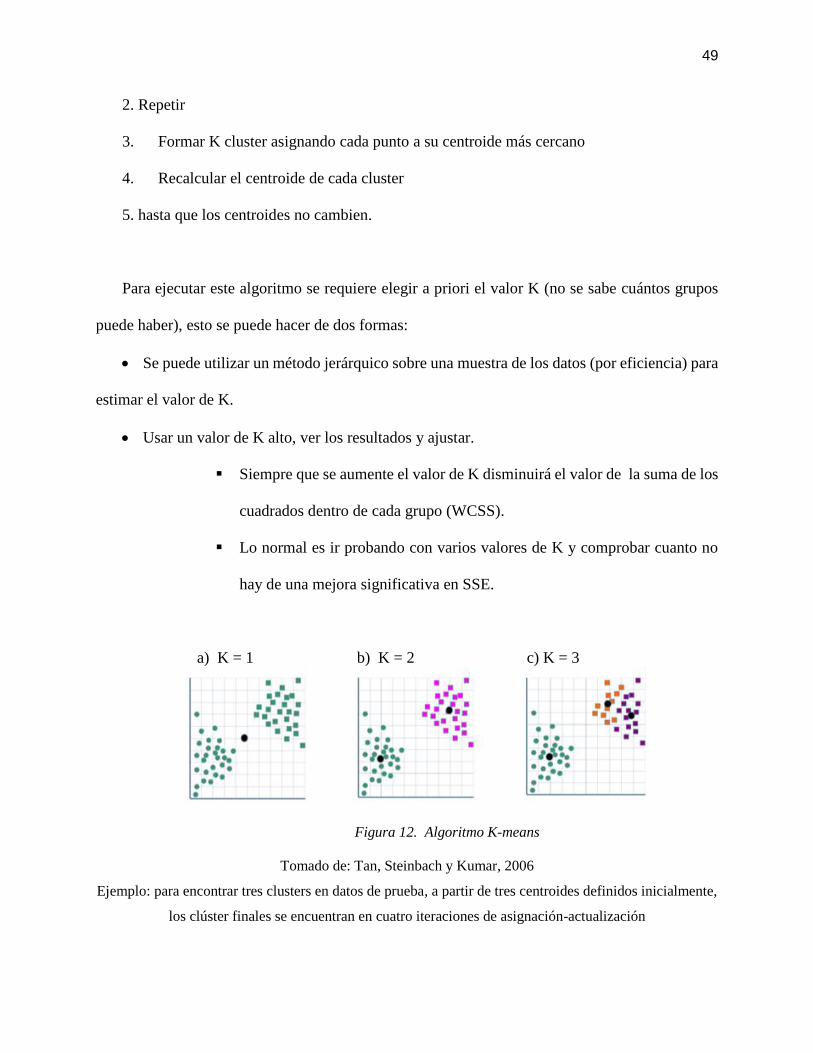
49
2. Repetir
3. Formar K cluster asignando cada punto a su centroide más cercano
4. Recalcular el centroide de cada cluster
5. hasta que los centroides no cambien.
Para ejecutar este algoritmo se requiere elegir a priori el valor K (no se sabe cuántos grupos
puede haber), esto se puede hacer de dos formas:
Se puede utilizar un método jerárquico sobre una muestra de los datos (por eficiencia) para
estimar el valor de K.
Usar un valor de K alto, ver los resultados y ajustar.
Siempre que se aumente el valor de K disminuirá el valor de la suma de los
cuadrados dentro de cada grupo (WCSS).
Lo normal es ir probando con varios valores de K y comprobar cuanto no
hay de una mejora significativa en SSE.
a) K = 1 b) K = 2 c) K = 3
Figura 12. Algoritmo K-means
Tomado de: Tan, Steinbach y Kumar, 2006
Ejemplo: para encontrar tres clusters en datos de prueba, a partir de tres centroides definidos inicialmente,
los clúster finales se encuentran en cuatro iteraciones de asignación-actualización

50
Las limitaciones de K-means según (Tan, Steinbach y Kumar, 2006) son:
K-means tiene problemas cuando los clúster son de diferente tamaño, densidades, que
no tengan forma esférica.
K-means tiene problemas cuando los datos contienen outliers.
La ventaja de K-means es ser un algoritmo simple, efectivo para pequeñas y medianas
cantidades de datos. Utiliza el promedio para representar los centros de los clusters.
2.3.7.3. DBSCAN:
Es un método de clustering basado en densidad. La idea es hacer crecer un clúster siempre
y cuando la densidad en el entorno del objeto exceda de un umbral. Este tipo de método
permite la detección de clusteres de forma arbitraria, sirviendo además para filtrar datos
ruidosos.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) encuentra
objetos núcleo, es decir, objetos que tienen vecinos denso-alcanzables. Conecta objetos
núcleos y sus vecinos para formar regiones densas como clusters (Han, Kamber y Pei, 2011).
Es un algoritmo de clustering basado en densidad que produce un clustering particional, en el
cual el número de cluster es determinado automáticamente por el algoritmo. Los puntos con
baja densidad son clasificados como ruido y son omitidos, por lo que el algoritmo no produce
un clustering completo (Tan, Steinbach y Kumar, 2006).
Este algoritmo opera en un enfoque de densidad en base a centros, la densidad es estimada
para un punto en particular contando el número mínimo de puntos (MinPts), requeridos para
formar un cluster que se encuentra al interior de un radio máximo de la vecindad (Eps). Permite
clasificar los puntos como aquellos que se encuentran al interior de una región densa (puntos

51
de núcleo), aquellos en el borde de una región densa (puntos de borde) y aquellos que se encuentran
dispersos (puntos de ruido o de fondo) (Tan, Steinbach y Kumar, 2006) (Flores, 2014).
Puntos de núcleo (core): Puntos que tienen más de MinPts vecinos dentro de su vecindario
de Radio Eps.
Puntos de borde (border): Son los puntos que tienen menos de MinPts vecinos dentro de
su vecindario de radio Eps, pero están en la vecindad de un punto de núcleo.
Puntos de ruido (noise): Son aquellos puntos que no caen en ninguna de las dos categorías
anteriores.
Figura 13. Puntos de Núcleo, Borde y Ruido
(Considerando un Eps de valor 1 y un MinPts de valor 4.
Fuente: (Tan, Steinbach y Kumar, 2006). Adaptación: propia. )
El algoritmo comienza seleccionando un punto p arbitrario, si p es un punto central, se
comienza a construir un grupo y se ubican en su grupo todos los objetos denso-alcanzables desde
p. Si p no es un punto central se visita otro objeto del conjunto de datos. El proceso continúa hasta
que todos los objetos han sido procesados. Los puntos que quedan fuera de los grupos formados

52
se llaman puntos ruido, los puntos que no son ni ruido ni centrales se llaman punto borde
(Pascual, Pla, & Sánchez, 2007).
Cualquier par de puntos de núcleo que estén lo suficientemente cerca (menor a una
distancia Eps) son asignados a un mismo clúster. Así mismo, cualquier punto de borde que
este lo suficientemente cerca de un punto de núcleo es puesto en el mismo clúster que el punto
de núcleo, los puntos de ruido se descartan (Tan, Steinbach y Kumar, 2006).
El algoritmo DBSCAN se describe como sigue:
Algoritmo DBSCAN (Tan, Steinbach y Kumar, 2006)
1. Etiquetar todos los puntos como núcleo, borde o ruido
2. Eliminar puntos de ruido
3. Poner un borde entre todos los puntos de núcleo que están dentro de Eps de cada uno
de otros
4. Convierta cada grupo de puntos centrales conectados en un clúster separado
5. Asignar cada punto de borde a uno de los clusters de sus puntos de núcleo asociados.
DBSCAN puede encontrar clusters de forma arbitraria; pero a veces no produce un
clustering completo ya que los puntos con baja densidad son considerados como ruidos y
omitidos.
3. HIPÓTESIS
Al aplicar técnicas de minería de datos espaciales a la información de delitos al patrimonio
en la ciudad de Bogotá, caracterizando el comportamiento delictivo, se crean escenarios de
ocurrencia de delitos.

53
4. METODOLOGÍA
A continuación, se realiza la explicación de la selección de la zona de estudio, los datos y
registros usados para la elaboración de la base de datos y las fuentes de donde se obtuvo dicha
información, además de la metodología planteada y seguida para la elaboración del estudio.
Población de Estudio
Bogotá está ubicada en el Centro del país, en la cordillera oriental, la capital del país tiene una
extensión aproximada de 33 kilómetros de sur a norte y 16 kilómetros de oriente a occidente. “La
orientación general de la ciudad, está determinada porque sus carreras son orientadas de sur a norte
y sus calles de oriente a occidente” (Alcaldía Mayor de Bogotá, 2015).
“La capital de Colombia cuenta con una división administrativa de 20 localidades o distritos
para ofrecer a los ciudadanos redes de servicios públicos como infraestructura vial, entretenimiento
y abastecimiento de productos” (Alcaldía Mayor de Bogota D. C., 2015).
De acuerdo con los estudios presentados por organizaciones como: El Centro de Estudio y
Análisis en Convivencia y Seguridad Ciudadana (CEACSC) de la Alcaldía Mayor de Bogotá, la
Cámara de Comercio de Bogotá, entre otras entidades, donde se analiza el comportamiento de
los delitos de mayor impacto en Bogotá, con el fin de mejorar las condiciones de seguridad de
la ciudad. En la edición número 49, del Observatorio de Seguridad en Bogotá, publicado por la
Cámara de Comercio, se analiza el comportamiento de los delitos de mayor impacto que afectaron
a las diferentes localidades en el primer semestre del 2015, donde se destaca que “En el primer
semestre de 2015, se denunciaron 14.539 hurtos a personas y las localidades de Suba, Usaquén,
Kennedy y Chapinero concentraron, el 41% de las denuncias por este delito “ (Camara

54
de Comercio de Bogotá, 2015). Al contrastar la anterior información con el Boletín Especial
Delitos Contra el Patrimonio en Bogotá Primer semestre 2016, publicado por el portal Bogotá
Cómo Vamos, el cual presenta las estadísticas de los años 2013 – 2015, del delito hurto a personas
por localidad (Bogotá cómo vamos, 2016), efectivamente las localidades que presentan mayor
índice de denuncias de este delito son las localidades de Suba, Kennedy, Usaquén y Chapinero,
figura 14.
Figura 14. Hurto a Personas años 2013 – 2015
Fuente: Elaboración Propia, Datos tomados de: (Bogotácómovamos, 2016)
Luego de analizar las estadísticas de percepción de inseguridad y el índice de delitos
presentados contra el patrimonio en las localidades de Bogotá, y si a este indicador se le añade
que la localidad de Chapinero está ubicada en una zona central de la ciudad, de alta influencia
comercial, cultural y de entretenimiento, en la actualidad cuenta con aproximadamente 166.000

55
habitantes y una población flotante (personas que residen temporal o permanentemente en la
localidad, aun no estando oficialmente inscritas en el censo de población,) de más de 500.000
personas (Secretaría Distrital de Planeación, 2013), estas características permiten considerar a la
localidad de chapinero como una zona factible para el estudio.
La localidad de Chapinero figura 15, es la número 2 de Bogotá, está ubicada en el centro-
oriente de la ciudad y limita, al norte, con la calle 100 y la vía a La Calera, vías que la separan de
la localidad de Usaquén; por el occidente, el eje vial Autopista Norte-Avenida Caracas que la
separa de las localidades de Barrios Unidos y Teusaquillo; en el oriente, las estribaciones del
páramo de Cruz Verde, la Piedra de la Ballena, el Pan de Azúcar y el cerro de la Moya, crean el
límite entre la localidad y los municipios de La Calera y Choachí. El río Arzobispo (calle 39)
define el límite de la localidad al sur, con la localidad de Santa Fe. Chapinero tiene una extensión
total de 3.898,96 hectáreas con un área rural de 2.664,25 ha (68%) y un área urbana de 1.234,71
ha (32%),
La localidad cuenta con cinco UPZ: Chapinero, San Isidro Patios, Pardo Rubio, El Refugio,
Chicó Lago. La Localidad de Chapinero está compuesta por 50 barrios.
El Refugio: Chicó Reservado, Bellavista, Chicó Alto, El Nogal, El Refugio, La Cabrera,
Los Rosales, Seminario y Toscana; San Isidro Patios: La Esperanza Nororiental, La Sureña, San
Isidro y San Luis Altos del Cabo; Pardo Rubio: Bosque Calderón, Bosque Calderón Tejada;
Chapinero Alto, El Castillo, El Paraíso, Emaus, Granada, Ingemar, Juan XXIII, La Salle, Las
Acacias, Los Olivos, María Cristina, Mariscal Sucre, Nueva Granada, Palomar, Pardo Rubio, San
Martín de Porres, Villa Anita y Villa del Cerro; Chicó Lago: Antiguo Country, Chicó Norte, Chicó
Norte II, Chicó Norte III, Chicó Occidental, El Chicó, El Retiro, Espartillal, La Cabrera, Lago

56
Gaitán, Porciúncula y Quinta Camacho; Gran Chapinero: Cataluña, Chapinero Central, Chapinero
Norte, Marly y Sucre (Secretaría Distrital de Cultura, Recreación y Deportes, 2008).
Figura 15. Localidad de Chapinero
Fuente: Elaboración Propia.
Recolección de Información
Para la recolección de los datos se utilizaron diferentes fuentes, tales como:
Estadísticas de los estudios de percepción ciudadana.
Resultados publicados directamente por parte de la DIJIN.
Boletines de seguridad de la Secretaría Distrital de Planeación.

57
Observatorio Nacional de Seguridad de Bogotá de la Cámara de Comercio.
Informes de Seguridad de la Veeduría Distrital.
Revista Criminalidad de la Policía Metropolitana de Bogotá.
La tabla 2, esta relacionada la información de los delitos ocurridos en la ciudad de Bogotá
entre los meses de enero a setiembre de 2015, la cual se almacena en un archivo (libro) en excel y
se encuentra organizada por hojasde acuerdo con el tipo de delito.
Tabla 2 Información de delitos ocurridos en Bogotá 01-01-2015 – 26-09-2015
Hoja Registros
Vida 14.622
Vehículos hurtados 4.017
Patrimonio 27.606
Terrorismo 10
Secuestro 10
Extorsión 399
Abigeato 15
Total: 46.660
Elaboracion: Propia
Para el desarrollo del presente trabajo se seleccionan los delitos que afectan el patrimonio en
sus diferentes modalidades (atraco, raponazo, cosquilleo entre otros), del total de 27.606 registros,
se toma como muestra 2101 registros que son los que corresponden a la localidad de Chapinero.
La información que contiene este archivo se relaciona en la tabla 3.
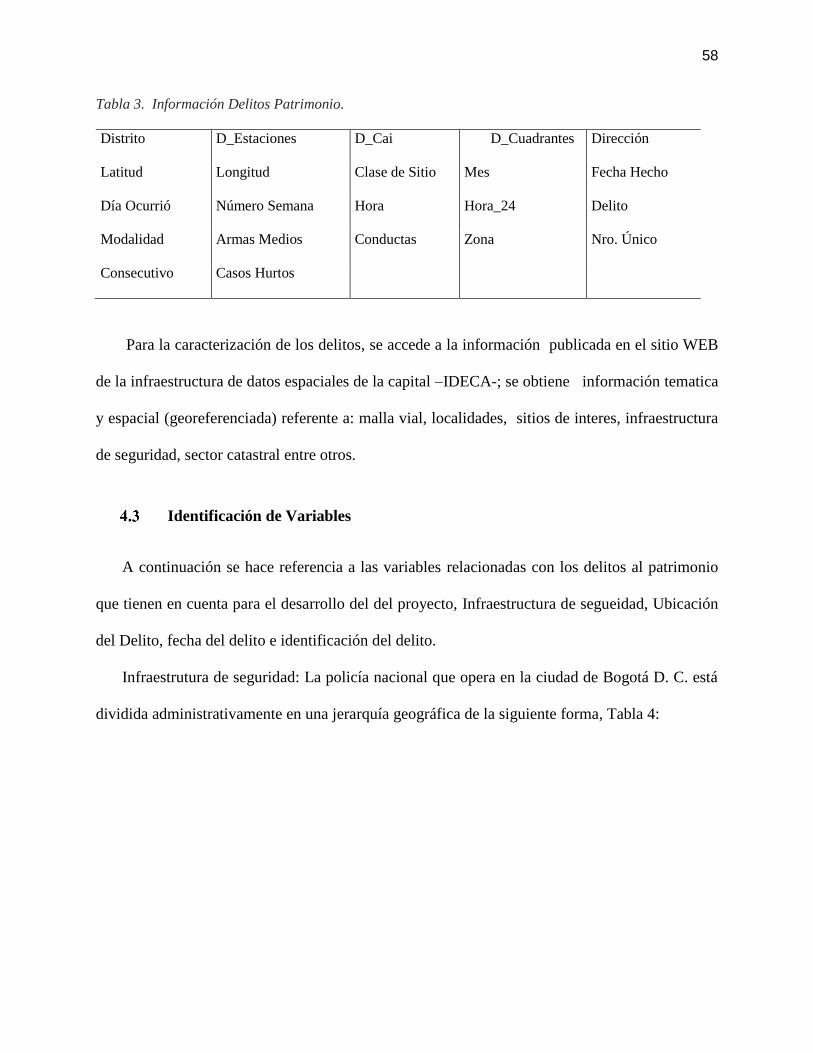
58
Tabla 3. Información Delitos Patrimonio.
Distrito D_Estaciones D_Cai D_Cuadrantes Dirección
Latitud Longitud Clase de Sitio Mes Fecha Hecho
Día Ocurrió Número Semana Hora Hora_24 Delito
Modalidad Armas Medios Conductas Zona Nro. Único
Consecutivo Casos Hurtos
Para la caracterización de los delitos, se accede a la información publicada en el sitio WEB
de la infraestructura de datos espaciales de la capital –IDECA-; se obtiene información tematica
y espacial (georeferenciada) referente a: malla vial, localidades, sitios de interes, infraestructura
de seguridad, sector catastral entre otros.
Identificación de Variables
A continuación se hace referencia a las variables relacionadas con los delitos al patrimonio
que tienen en cuenta para el desarrollo del del proyecto, Infraestructura de segueidad, Ubicación
del Delito, fecha del delito e identificación del delito.
Infraestrutura de seguridad: La policía nacional que opera en la ciudad de Bogotá D. C. está
dividida administrativamente en una jerarquía geográfica de la siguiente forma, Tabla 4:

59
Tabla 4. Infraestructura de Seguridad Policia Nacional.
Nombre Variable Descripcion
d_distrito Comandos de Seguridad Ciudadana
d_estacion Estación de Policía
d_cai Comando de Atención Inmediata
d_cuadrant Cuadrante
Ubicación del delito: El delito se ubica meniante dirección o coordenadas geograficas (latitud
y longitud).
Tabla 5. Información de la Ubicación del Delito.
Nombre Variable Descripcion
Clase_de_s Tipo de sitio donde ocurrio el hecho
Dirección Ubicación del sitio
Zona Corresponde a zona urbana o rural
Scanombre Nombre del barrio del barrio donde se perpetra el delito
Referente al instante de ocurrencia del delito: Esta variables sitúan en el tiempo, el hecho
delictivo ocurrido.
Tabla 6. Fecha de Delito
Nombre Variable Descripción
numero_sem Número de la semana del año, en la que ocurrió el hecho
mes Nombre del mes, en el que ocurrió el hecho
fecha_hech Fecha en la cual ocurrió el hecho
dia_ocurri Día de la semana
hora Hora del hecho delictivo
rago_h Rango de agrupado por cada tres horas

60
Referente al Delito: Variables que permiten identificar la modalidad del delito y el tipo de
arma utilizado.
Tabla 7. Variables de Identificación del Delito.
Nombre
Variable
Descripcion
modalidad Hace referencia a la modalidad del delito (atraco, raponazo,
cosquilleo, factor de oportunidad, engaño)
arma Arma utilizada para perpetrar el delito (arma blanca, arma de
fuego, sin uso de armas, cortopunzante)
Desarrollo de la Investigación.
Deacuerdo con la metodologia planteada en la figura 16, se desarrolla el proyecto de acuerdo
con las siguientes fases:
Figura 16. Metodologia De desarrollo del Proyecto.
Fuente: Elaboración Propia

61
4.4.1 Proceso de Gestion de la Información
Dentro del proceso de gestión de la información, se realizan las siguientes actividades:
Tecnicas de Recolección de Datos. Para la recoleccion de los datos, se hace una observación
directa mediante la captacion de personas alrededor del autor, igualmente se hace una
recuperacion, analisis e interpretación de documentos obtenidos por diferentes medios (internet,
periosicos, revistas e informes y otros documentos), aunque se concreto una entrevista con
personal de la Dirección de Investigación Criminal e Interpol de la Policía Nacional (DIJIN)
Bogotá, debido al tipo de información requerida no existio interes por parte de esta institución para
facilitar el acceso a la información.
Analisis y Clasificación. Una vez se recolecta la información esta se analiza y clasifica, se
descartan aquellos datos que son irrelevantes o innecesarios, se trata la presencia de datos faltantes
o perdidos y se detecta la presencia de valores que no se ajustan al comportaniento general de los
datos.
Otra actividad que se realiza dentro de esta fase es georeferenciar (localización espacial) las
coordenadas geograficas (latitud y longitud), de la ubicación de los delitos al patrimionio.
Diseño de la Base de Datos. Una vez se ha recopilado la información, se diseña el modelo
entidad relación de la base de datos. Figura 17.

62
Figura 17. Diseño Base de Datos Espacial (Modelo Entidad Relación)
Fuente: Elaboración Propia
Nota: La información completa de los atributos de las tablas se encuenta detallada en el anexo A.
En el diseño del modelo conceptual de la base de datos se identifican las entidades, sus
atributos y relaciones. El modelo conceptual se compone de las siguientes entidades:
Entidades Espaciales:
Delitos. Su geometría es punto.
Delitos (gid, fecha, modalidad, arma, localidad, hora, geom).
Localidad: su geometría es polígono.
Localidad (código, nombre, área, geom).
Sector catastral, su geometría es polígono.
Sec_catast (gid, area, tipo, geom)

63
Entidades no espaciales:
Tipo de delito que contiene información de la modalidad del delito: cosquilleo, atraco,
raponazo, engaño y factor de oportunidad: tipo_ delito (código, nombre).
Armas, que contiene información del tipo de arma utilizada para llevar a cabo el delito:
armas blancas, de fuego, contundentes, otras y sin empleo de armas: armas (código, nombre).
En la siguiente actividad se diseñan consultas a la base de datos, con respecto a las variables:
ubicación del delito, fecha del delito e identificación del delito (4.3 Identificación de Variables),
para establecer el estado inicial de la información referente a la localidad de chapinero.
Al observar la modalidad del delito y el uso de armas utilizada en la ejecución de este figura
18, el uso de armas blancas y objetos contudentes son equivalentes, mientras que en la mayoria de
los casos no se utiliza armas para cometer el delito, el factor de oportunidad menos frecuente es el
raponazo.
Figura 18. Estadisticas del Uso de Armas y Modalidad del Delito.
Fuente: Elaboración Propia.
En cuanto a la temporalidad del delito figura 19, en lo referente a delitos por rango de hora y
delitos por día de la semana se puede observar que el porcentaje mas alto de delitos se presenta en
0
500
1000
1500
Uso de Armas
otras Arma Fuego Contudente
Arma Blanca Sin Armas
0
200
400
600
800
1000
1200
1
Modalidad Delito
Raponazo Cosquilleo
Atraco Factor Oportunidad

64
el horario comprendido entre las 4 pm. y las 12 de la noche; los dias de mayor actividad delictiva
son los viernes y martes, mientar el domingo esta actividad se reduce lo mas probable por que el
comercio y universidades del sector registran una baja actividad.
Figura 19. Estadisticas de Delitos según hora y Día de la Semana
En cuanto a los delitos por mes figura 20, a partir del mes de junio los hecho delictivos
comienzan a disminuir.
Figura 20. Estadisticas de Delitos por Mes.
Elaboración Propia.
0
50
100
150
200
250
300
350
400
450
Delitos por Dia de la Semana
0
50
100
150
200
250
300
Delitos Por Mes

65
En lo referente a la ubicación de la actividad delictiva por barrio la figura 21, relaciona los los
diez barrios donde se concentra el 58% de la actividad delictiva en la localidad, destacadose que
los sectores de marly y chapinero occidental, son los barrios que presentan mayor actividad
delictiva
Barrio Núm. Delitos
MARLY 216
CHAPINERO CENTRAL 207
PORCIUNCULA 133
QUINTA CAMACHO 113
CHICO NORTE 107
SUCRE 102
PARDO RUBIO 97
LAGO GAITAN 86
EL RETIRO 82
CHAPINERO NORTE 80
Figura 21. Delitos Presentados por Barrio de la LLocalidad de Chapinero.
Fuente Propia
4.4.2 Tecnicas de Mineria de Datos
El objetivo de analizar datos mediante mineria de datos es extraer conocimiento, el cual puede
ser en forma de relaciones, patrones o reglas de inferidas de los datos y y previamente
desconocidos, o bien en forma de una descripcion más concisa. Estas relaciones o resumenes
constituyen el modelo de los datos analizados.
Dado que el modelo a desarrollar es un modelo descrptivo, para realizar la tarea de
agrupamiento de datos espaciales se hace uso de los algoritmos K-means y DBscan.
0 50 100 150 200 250
MARLY
CHAPINERO CENTRAL
PORCIUNCULA
QUINTA CAMACHO
CHICO NORTE
SUCRE
PARDO RUBIO
LAGO GAITAN
EL RETIRO
CHAPINERO NORTE
Delitos por Barrio

66
Modelos.
De acuerdo con la definición del tipo de modelo página (26) la figura 22, identifica las fases
de desarrollo del modelo de caracterización de los delitos contra el patrimonio que afectan a la
ciudad de Bogotá.
Figura 22. Modelo Caracterización del Delito
Elaboración: Propia

67
El modelo a desarrolar debe ubicar los sectores donde hay una cocentración mayor de hechos
delictivos y caracterizar el delito de acuerdo con las siguientes variables:
¿ Cuál es la Ubicación del delito ?
¿ Cuál es la modalidad mas frecuente ?
¿ Qué armas son las mas utilizadas?
¿ Cuál día de la semana se presentan mas hechos delictivos?
¿Cuál es el rango horario en el que se presentan mas hechos delictivos?
¿Cuál es el mes de mayor ocurrencia de delitos?
Con la información almacenada en una base de datos en postgresql (sistema administrador
de bases de datos), y utizando Quantum GIS (sistema de información geográfica) como
herramienta para visualizar los datos, se procede a realizar el proceso de minería de datos.
La figura 23, se aprecia la localidad de chapinero; los puntos representan los delitos contra el
patrimonio.
Figura 23. Delitos contra patrimonio Localidad de Chapinero.
Elaboración Propia.

68
En el proceso de mineria de datos se aplican los algoritmos: K-means y DBScan.
Algoritmo K-means, Básicamente, es un algoritmo de aprendizaje no supervisado con varias
aplicaciones de análisis de datos, ampliamente utilizado para la minería de datos y fines de
aprendizaje de máquina, Su complejidad computaciona es de orden polinomial, El objetivo
principal es particionar datos en K clusters (para un K dado).
Para aplicar el algoritmo se debe ingresar como parametro de entrada la cantidad de
particiones (K). Para efectos de este proyecto se tiene en cuenta que la mayoria de delitos, son
cometidos en el area urbana de la localidad figura 23, la cual se encuentra ubicada, entre las calles
39 y 100 y entre la carrera 14 con la diagonal 3 y tiene una extensión de 1.234.71 ha. Para
calcular la cantidad de particiones, se experimenta con K igual a: 3, 8 y 5 particiones, buscando
proporción entre la cantidad de particiones y cantidad de objetos por patición, figura 24.

69
Primer Modelo, K = 3
Segundo Modelo, K = 8
Tercer Modelo, K = 5
Figura 24. Algoritmo K-meas
Elaboración: Propia
Las estrellas negras en cada modelo representan los centroides calculados por el algoritmo,
cada una de las particiones se representa mediante un color, el valor entre paréntesis, hace
referencia a la cantidad de objetos agrupados en cada partición o clúster. (Para un mejor detalle
consultar anexo B)

70
Al analizar el comportamiento del algoritmo k-means en los tres modelos, se observa que se
intersectan en la zona donde se agrupa la mayor cantidad de puntos por partición: en el primer
modelo el grupo conformado por los puntos amarillos (grupo 0), es la de mayor cantidad de
puntos, y se ubicada entre las calle 38 y calle 70, en el segundo modelo el grupo conformado por
los puntos de color verde (grupo 2), esta ubicado la calles 40 y 65 y en el tercer modelo el grupo
conformado por los puntos de color azul (grupo 0), esta ubicado entre las calles 38 y 55.
Los tres modelos se intersectan entre las calles 38 y 55, para hacer una aproximación exacta
del sector donde ocurren mas delitos, se toma como muestra para aplicar una segunda iteración
del algoritmo, el grupo correspondiente al tercer modelo, por coincidir exactamente con la
intersección de los tres modelos.
Para la segunda iteración se experimenta con K igual a: 7 y 5, figura 25.
Cuarto Modelo K = 7
Quinto modelo Modelo K = 5
Figura 25. Algoritmos K-means Seguda Iteración
Elaboración Propia

71
Al analizar el comportamiento del algoritmo en la segunda iteración figura 25. Se observa que en el
cuarto modelo, el grupo conformado por los puntos de color verde (grupo 4), se intersecta con los
puntos de color morado (grupo 0) del quinto modelo, esta intersección esta ubicada entre las calles
50 y 55. Luego de esta iteración se quiere tener una referencia mas exacta sobre la ubicación del
delito en el sector. Se realiza una tercera iteración del algoritmo, tomando como muestra, el grupo
conformado por los puntos morados (GRUPO 0) del quinto modelo, ya que agrupa la mayor
cantidad de puntos (170), entre los grupos que conforman los dos modelos.
Para esta tercera iteración del algoritmo se experimenta K igual a 5, figura 26.
Modelo Final, K= 5
Figura 26. Algoritmo K-means Tercera Iteración
En la tercera iteración, de los cinco grupos generados al aplicar el algoritmo, el grupo
conformado por los puntos de color fucsia (grupo 1) es el que contiene más puntos (63), y se
encuentra ubicado entre las calles 52 y 54, pero la mayor cantidad de puntos están ubicados entre
las calles 52 a 53 y entre las carreras 14 y 10 Figura 27.

72
Igualmente se puede observar que alrededor de ese sector se encuentran tres puesto de policía
(circulo azul): Estos puestos están distanciados con respecto al centroide de cada grupo, del
siguiente modo: El CAI de Chapinero está ubicado a 640 metros lineales, la estación de Policía de
Chapinero está ubicada a 810 metros lineales y el CAI Borde de Choachi se encuentra ubicado a
820 metro lineales.
Figura 27. Resultado Obtenido por el algoritmo K-meas

73
BSCAN: Hace referencia a “Density based spatial clustering of applications with noise”, es
un algoritmo que agrupa los registros por clústeres teniendo en cuenta los elementos ruido y
modelando la densidad de puntos. El algoritmo DBSCAN requiere dos parámetros de entrada ε,
Minpts; el primero define la distancia máxima entre dos elementos para considerarlos vecinos, y
el segundo define el mínimo número de elementos que deben ser vecinos para formar un clúster .
El algoritmo comienza por un punto arbitrario que no haya sido visitado. La e-vecindad de este
punto es visitada, y si contiene suficientes puntos, se inicia un clúster sobre el mismo. De lo
contrario, el punto es etiquetado como ruido. Si un punto se incluye en la parte densa de un clúster,
su e-vecindad también forma parte del clúster. Así, todos los puntos de dicha vecindad se añaden
al clúster, al igual que las e-vecindad de estos puntos que sean lo suficientemente densas. Este
proceso continúa hasta construir completamente un clúster densamente conectado. Entonces, un
nuevo punto no visitado se visita y procesa con el objetivo de descubrir otro clúster o ruido. Puede
encontrar clusters de formas arbitrarias, es robusto al ruido, tiene una complejidad computacional
de O(n log n).
Para aplicar el algoritmo, se estima como parametros de entrade para ε: 100, 200 y 300
metros y como cantidad para Minpts 40, estos valores se estiman despues de experimentar
con diferentes valores y observar el compotamiento del algoritmo; si el parametro ε es muy grade
los objetos pueden quedar agrupados en un solo grupo, igualmente debido al tamaño de la muestras
si el parametro Minpts es muy pequeño, esto puede generar un numero grande cluster. Se
aplicaron pruebas, combinando aleatoriamente la distancia entre puntos y la cantidad minima de
puntos por grupo, con los siguientes pares de valores se obtiene mejores resultados: (ε = 100 m ,
Minpts = 40), (ε = 200 m, Minpts = 40) y (Minpts = 300 m , 40),de estos valores el que mejor

74
comportamiento presento fue el par (ε = 200, Minpts, = 40), por ser el modelo que menor cantidad
de puntos marca como ruido.
El algoritmo DBScan, tiene un comportamiento diferente, ya que puede encontrar clusters con
formas geométricas arbitrarias. Puede incluso hallar un cluster completamente rodeado (pero no
conectado) de otro cluster distinto. en el momento de construir los grupos
En el primer modelo genera cinco grupos con un total de 197 objetos agrupados entre los
diferentes grupos y marca como ruido a 1.903 puntos; en el segudo modelo construye un grupo
con 310 puntos y marca como ruido a 1.791 puntos, y en el tercer modelo genera cuatro grupos
con un total 1.431 puntos agrupados entre los diferentes grupos y marca como ruido 669 puntos.
Como se puede observar el tercer modelo es donde menos puntos marca como ruido, el grupo
conformado por los puntos verdes (grupo es el que contiene mayor cantidad de puntos (872),
teniendo en cuenta los grupos que conforman cada modelo.
Como lo que se pretende es encontrar el sector con mayor densidad de puntos, a nivel de la
localidad, se hace una segunda iteración; para esta iteración se toma como muestra, el grupo que
conforman los puntos de color verde (grupo 1) del tercer modelo figura 28.

75
Primer Modelo, ε = 100, Minpts 40
Segundo Modelo, ε = 300, Minpts 40
Tercer Modelo, ε = 200, Minpts 40
Figura 28. Algoritmo DBSCAN Primera Iteración

76
Para aplicar la segunda iteración, se toma como parametros de entrada: (ε = 100 m, Minpts 10)
y (ε = 100, Minpts 20), figura 24, al observar los resultados de esta segunda iteración. En el
cuarto modelo, el grupo compuesto por puntos verdes (grupo 7), ubicado entrelas calles 43 y 47,
queda incluido dentro del grupo conformado por los puntos morados (grupo 0), ubicado entre las
calles 38 y 54 del tercer modelo.
Para poder establecer el sector con mayor densidad de puntos en la zona de estudio, se aplica
una tercera iteración del algoritmo, tomando como muestra el grupo 0 del tercer modelo, por ser
el mayor cantidad de puntos (530) que tiene agrupados.
Tercer Modelo, ε = 100, Minpts 10
Cuarto Modelo, ε = 100, Minpts 20
Figura 29. Algoritmo DBSCAN Segunda Iteración
Para aplicar la tercera iteración del algoritmo, se define como parametros de entrada : (ε =
50 m, Minpts 10) figura 29. Como resultado de la tercera iteración se obtienen cinco grupos, de
los cuales el grupo compuesto de puntos verdes (grupo 0) y el grupo compuesto de puntos azules

77
(grupo 3), contienen la mayor cantidad de puntos (34 c/u), con respecto a los demás grupos,
igualmente marca 395 puntos como ruido.
Quinto Modelo, ε = 50, Minpts 10
Figura 30. Algoritmo DBSCAN Tercera Iteración
Elaboración Propia
El grupo 3 se ubica entre las calles 44 y 45 y entre la avenida caracas y la carrera 13, y el grupo
0 se ubica entre las calles 44 y 45 y entre la carrera 8 y carrera 6, figura 30. Llama la atención que
los dos grupos se ubican practicamente sobre la misma calle y separdos por escazas dos cuadras,
En cuanto a estaciones de policia, circulo azul en la figura 31, los puestos de policia mas cercanos
mas cercanos son: la estación de policia de teusaquillo a 543 metros lineales del grupo cero (0) y
a 531 metros lineales del grupo tres (3); el CAI Borde de Choachi esta ubicado a 950 metros lineles
del grupo cero (0) y a 700 metros lineales del grupo tres (3).

78
Figura 31. Resultados obtenidos Algoritmo DBSCAN

79
Presentación de resultados
Una vez realizado el proceso de minería de datos para la caracterización del delito, se detalla
a continuación los resultados obtenidos:
Figura 32A
Figura 32B
Figura 32. Resultados Obtenidos K-means y DBScan
¿Cuál es la Ubicación del delito? Al unir los resultados de los modelos desarrollados con los
dos algoritmos se pueden establecer, tres focos o grupos delictivos:
El primer punto se obtiene al aplicar el algoritmo DBSCAN y comprende el sector entre la
calle cuarenta y tres y la calle cuarenta y cinco y entre la carrera sexta y carrera octava, la estación
de policía más cercana es la Estación de Teusaquillo ubicada a 480 metros lineales.

80
El segundo punto se obtiene al aplicar el Algoritmo DBSCAN y comprende el sector entre la
calle cuarenta y tres y la calle cuarenta y cinco y entre la carrera trece y la avenida caracas, la
estación de policía más cercana es la Estación de Teusaquillo ubicada a 535 metros lineales.
El tercer punto se obtiene al aplicar el algoritmo K-MEANS y comprende el sector entre la
calle cincuenta y dos y la calle cincuenta y cinco y entre la carrera novena y la avenida caracas, la
estación de policía más cercana es la Estación de Chapinero ubicada a 607 metros lineales, figura
32A.
En este sector se encuentran ubicados sitios como: centros educativos, clínicas, hospitales,
hoteles, supermercados, entidades financieras, la Alcaldía de Chapinero, entre otros, lo cual
conlleva a una alta afluencia de personas, figura 32B.
A continuación, se caracteriza el delito, de acuerdo con variables como: la modalidad, el uso
o empleo de armas, el rango horario, los días de la semana y los meses del período objeto de estudio
y se cruzan con el análisis realizado a la información de los delitos antes de aplicar los respectivos
algoritmos (página 54).
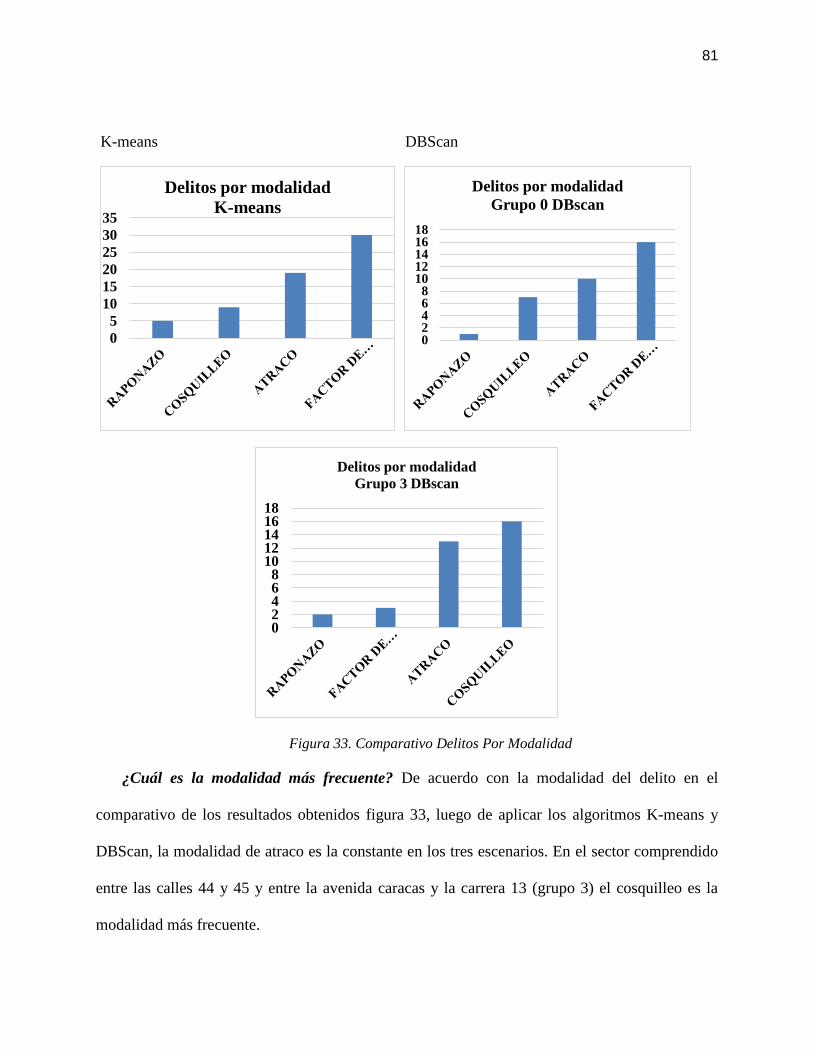
81
K-means
DBScan
Figura 33. Comparativo Delitos Por Modalidad
¿Cuál es la modalidad más frecuente? De acuerdo con la modalidad del delito en el
comparativo de los resultados obtenidos figura 33, luego de aplicar los algoritmos K-means y
DBScan, la modalidad de atraco es la constante en los tres escenarios. En el sector comprendido
entre las calles 44 y 45 y entre la avenida caracas y la carrera 13 (grupo 3) el cosquilleo es la
modalidad más frecuente.
0
5
10
15
20
25
30
35
Delitos por modalidad
K-means
02468
1012141618
Delitos por modalidad
Grupo 0 DBscan
02468
1012141618
Delitos por modalidad
Grupo 3 DBscan

82
Figura 34 Comparativo Tipo Arma Utilizada
Elaboración Propia
¿Qué armas son las más utilizadas? En relación del tipo de arma utilizada, el uso de armas
blancas para cometer el delito, es el arma más utilizada en los tres sectores.
05
10152025303540
Tipo de arma utilizada
K-means
0
5
10
15
20
25
OTRAS ARMA DE
FUEGO
ARMA
BLANCA
SIN
EMPLEO
DE ARMAS
Tipo de arma utilizada
Grupo 0 DBscan
0
5
10
15
20
25
Tipo de arma utilizada
Grupo 3 DBscan

83
Figura 35. Comparativo Delitos por Rango de Hora
¿Cuál es el rango horario en el que se presentan más hechos delictivos? En lo referente al
rango horario para K-means y el grupo 3 de DBScan, la tendencia de los hechos delictivos es el
horario entre las 10 am., y las 3 pm. Estos dos sectores están ubicados entre la carrera 13 y la
avenida caracas y entre las calles 44 y 55, están separados por más o menos cuatro cuadras.
0
2
4
6
8
10
12
14
16
01 -
03
04 -
06
22 -
00
07 -
09
16 -
18
19 -
21
10 -
12
13 -
15
Delitos por Hora
K-means
0
2
4
6
8
10
12
04 -
06
01 -
03
07 -
09
22 -
00
10 -
12
16 -
18
19 -
21
13 -
15
Delitos por rango de hora
Grupo 0 DBscan
0
2
4
6
8
10
04 -
06
22 -
00
07 -
09
19 -
21
16 -
18
13 -
15
10 -
12
Delitos por rango de hora
Grupo 3 DBscan

84
Figura 36. Comparativo de Delitos por Día
¿Cuál día de la semana se presentan más hechos delictivos? Los días donde se presentan
más hechos delictivos, son los jueves y martes para el grupo 3 de DBScan y el grupo de K-means,
coincidiendo los jueves con el grupo 0 de DBScan.
0
5
10
15
20
Delitos por día
K-means
02468
10
Delitos por día
Grupo 0 DBscan
0
2
4
6
8
10
12
14 Delitos por día
Grupo 3 DBscan

85
Figura 37. Comparativo de Delitos por Mes del Año
¿Cuál es el mes de mayor ocurrencia de delitos? En cuanto a los meses en los cuales se
presentan más delitos, el grupo 0 y el grupo 3 generados por el algoritmo DBscan coinciden en el
mes de marzo, mientras que para K-means el mes de mayo la actividad delictiva fue el mes de
septiembre.
Como se puede observar al unir los resultados, muchos de los delitos ocurren en sectores de
alta afluencia de público, las estaciones de policía están ubicadas a una distancia mayor de 400
metros lineales a cada uno puntos delictivos, causando demoras en la atención de una emergencia
y falta de presencia en las zonas más peligrosas, permitiendo así que el accionar delictivo siga
tranquilamente.
02468
1012
Delitos por mes
K-means
0
2
4
6
8
Delitos por mes
Grupo 0 DBscan
0
2
4
6
8
10
Delitos por mes
Grupo 3

86
Con estos resultados y dada su interpretación y la relevancia de los modelos obtenidos, se
establecen los siguientes criterios: Los sectores de la localidad donde se presenta la mayor cantidad
de hecho delictivos, son sectores de alta afluencia publica y escaza presencia de la Policía, esto los
convierte en campo de acción para el hurto a personas. Igualmente, entre más alejado de una
estación de Policía se encuentre el delincuente, es más fácil efectuar el hurto. La ubicación de las
estaciones de policía deja muchas zonas alejadas y sin presencia Policial. Los lugares cercanos a
centros educativos, supermercados y clínicas son también zonas para el actuar delictivo, estos son
puntos con gran afluencia de personas y en los alrededores los delincuentes están atentos para
actuar. Una zona a más de 400 metros lineales de una estación de Policía, ya es un punto en donde
fácilmente el delincuente puede actuar, los delincuentes prefieren actuar entre las diez de la
mañana y tres de la tarde, los días más en los que se presentan más hechos delictivos son los jueves
y martes, la modalidad más frecuente es el cosquilleó y debido a esta situación en la mayoría de
los hechos no hay uso de armas.
Cada uno de los mapas delictivos contribuyó para poder establecer estos criterios, la unión de
estos factores permite conocer y caracterizar el hurto a personas en la localidad de Chapinero,
además establecer posibles zonas de riesgo con características similares a las encontradas mediante
la minería de datos espaciales.
Discusión de Resultados.
En esta sección se discuten los siguientes elementos:
¿Qué se aprendió? Organizar y administrar la información espacial, en bases de datos
espaciales de acuerdo con sus características (representación, relaciones y operaciones).

87
Igualmente, en estas bases de datos se puede realizar el proceso de preparar y transformar el
conjunto de datos de entrada, para posteriormente aplicar las técnicas de minería de datos.
La minería de datos y la minería de datos espaciales son técnicas que hacen parte del proceso
de descubrir conocimiento oculto en bases de datos (Knowledge Discovery in Data bases, KDD),
mediante algoritmos que exploran los datos y descubren patrones significativos. Estos algoritmos
de clasifican de acuerdo con la tarea de minería de datos a realizar (descriptiva o preventiva).
Los algoritmos de agrupamiento k_menas y DBscan, operan de una forma diferente mientras
en K-means se especifica la cantidad de grupos o particiones a obtener y calcula aleatoriamente la
distancia entre los objetos de cada grupo, en DBscan se debe especificar un radio de distancia entre
los objetos y la cantidad mínima de objetos por cada grupo. Allí se comprendió la utilidad de los
algoritmos de agrupamiento y la funcionalidad y aporte para este estudio, ya que permiten
precisamente analizar espacialmente elementos aleatorios sin un patrón en común.
¿Cuál es la validez del modelo de caracterización? Caracterizar información referente a los
delitos al patrimonio afectan la localidad de Chapinero de la ciudad de Bogotá, generando
descripciones de la tendencia delictiva y este conocimiento puede ser utilizado por autoridades,
empresarios y comunidad en general.
¿Qué implicaciones tienen los resultados obtenidos? El aporte específico es la
implementación de técnicas de minería de datos espaciales en la caracterización del delito. Obtener
resultados que no son un índice, un porcentaje, un valor o un número resultado de un proceso
estadístico; sino un resultado que implica visualización del componente espacial a través de mapas.
esto es un aporte tanto para este estudio como para estudios similares futuros.

88
¿Cuáles son las ventajas y limitaciones de este proyecto? Una de las principales limitaciones
fue el acceso a los datos de los delitos al patrimonio. La Policía Metropolitana de Bogotá tiene una
gran cantidad de información de todos los delitos denunciados, pero desafortunadamente no son
de acceso público y a pesar que se logró una entrevista con personal de la institución, no fue posible
tener acceso a esta información, así su uso fuera para fines académicos o investigativos. Así que
finalmente se trabajó con los datos obtenidos por otras fuentes.
En cuanto a ventajas el uso del componente espacial, permite obtener resultados que facilitan
su interpretación, análisis y son soporte para la toma de decisiones.
5. CONCLUSIONES
1. Los resultados obtenidos, demuestran que al aplicar técnicas de agrupamiento de minería
de datos espacial a la información del delito contra el patrimonio que afecta a la ciudad de Bogotá,
fue posible desarrollar un modelo para caracterizar el comportamiento delictivo en un sector de la
localidad de Chapinero.
2. Las técnicas de minería de datos espacial, pese a ser de carácter dependiente, se pueden
aplicar y obtener buenos resultados sobre objetos geográficos almacenados.
3. Aunque los algoritmos K-means y DBscan, utilizan técnicas diferentes para agrupar los
objetos; al ser aplicados a la información de delitos al patrimonio, coincidieron al agrupar los
objetos, en un sector cercano separado aproximadamente por seis calles.

89
4. Los algoritmos K-Means (agrupamiento particional) y DBscan (agrupamiento basado en
localidades), demostraron ser eficientes sobre objetos espaciales, si bien son diferentes en cuanto
a la técnica de agrupación, se ajustan más a circunstancias espaciales de agrupamiento. En el caso
práctico del trabajo de investigación los resultados fueron parecidos, pero el orden de complejidad
de los algoritmos es diferente, siendo más efectivo el tiempo computacional de DBscan que es O(n
log n) usando los índices en la base de datos.
5. En total se manejaron 2.100 registros de delitos al patrimonio, ocurridos en la localidad de
Chapinero de la ciudad de Bogotá del periodo comprendido de 1 enero de 2015 al 26 de septiembre
de 2015, Es posible mejorar y afinar los escenarios presentados, si se contara con la colaboración
de las entidades que administran la información de la actividad delictiva que afecta a la ciudad.
6. Se recomiendo hace análisis temporales (por mes y trimestre) a fin de determinar
comportamientos por épocas del año, y compararlas con información de otros años para analizar
si hay aumentos o desplazamientos de zonas de influencia de delito por época o tipos de delito.
7. La metodología presentada y los algoritmos usados se pueden implementar
independientemente de la cantidad de datos, y no solamente para analizar los delitos al patrimonio,
sino para cualquier estudio que implique minería de datos espaciales mediante algoritmos de
agrupamiento.

90
6. REFERENCIAS
Albertetti, F., Cotofrei, P., & Grossrieder, L. (Noviembre de 2013). The CriLiM Methodology:
Crime Linkage with a Fuzzy MCDM Approach. IEEE Xplore Digital Library.
doi:10.1109/EISIC.2013.17
Alcaldía Mayor de Bogotá. (07 de octtuibre de 2015). Ubicación de la Ciudad. Obtenido de
Alcaldía Mayor de Bogotá: http://www.bogota.gov.co/ciudad/ubicacion
Alcaldía Mayor de Bogota D. C. (2015). Alcaldía Mayor de Bogota D. C. Obtenido de Secretaría
de Cultura Recreacón y Deporte: http://www.culturarecreacionydeporte.gov.co/
Bala , J., & Boldt, M. (2016). Filtering Estimated Crime Series Based on Route Calculations on
Spatio-temporal Data. In Intelligence and Security Informatics Conference (EISIC) IEEE,
92-95.
Bogotácómovamos. (9 de Septiembre de 2016). Cifras de seguridad en Bogotá – Boletín
especial. Obtenido de Bogotácómovamos:
http://www.bogotacomovamos.org/documentos/delitos-contra-el-patrimonio-boletin-
especial/
Boldt, M., & Bala, J. (Marzo de 2017). Filtering Estimated Crime Series Based on Route
Calculations on Spatio-temporal Data. IEEE Xplore Digital Library.
doi:10.1109/EISIC.2016.024
Camara de Comercio de Bogotá. (Noviembre de 2015). Delitos Contra el Patrimonio.
Observatorio de Seguridad en Bogotá(49), 38 - 45. Obtenido de
http://bibliotecadigital.ccb.org.co/bitstream/handle/11520/14055/14%20Observatorio%20
de%20seguridad%20en%20Bogota%20No%2049.pdf?sequence=1&isAllowed=y
Cámara de Comercio de Bogotá. (sd de Abril de 2016). Cámara de Comercio de Bogotá.
Obtenido de Encuesta de Percepción y Victimización en Bogotá, segundo semestre de
2015: http://bibliotecadigital.ccb.org.co/handle/11520/14864

91
Ding, Q., Ding, Q., & Perrizo, W. (2008). PARM—An efficient algorithm to mine association
rules from spatial data. IEEE Transactions on Systems, Man, and Cybernetics, 1513-
1524.
Epstein, J. (2008). Why Model? Journal of Artificial Societies and Social Simulation, 11(4).
Recuperado el 10 de Julio de 2017, de http://jasss.soc.surrey.ac.uk/11/4/12.html
Ester, M., Kriegel, H.-P., & Sander, J. (2001). Algorithms and applications for spatial data
mining. Geographic Data Mining and Knowledge Discovery, 5(6), 25.
EuroCop. (Sd de Sm de Sa). EuroCop. Recuperado el 20 de Agosto de 2016, de Eurocop Pred-
Crime Sistemas para la Predicción y Prevención del Delito:
http://www.eurocop.com/catedra-eurocop/proyectos-en-marcha/eurocop-pred-crime-
sistemas-para-la-prediccion-y-prevencion-del-delito/
Gibert, K., & Nonell, R. (2005). Knowledge discovery with clustering: Impact of metrics and
reporting phase by using klass. Neural Network World, 15(4), 319.
Guo, D., & Gahegan, M. (2006). Spatial ordering and encoding for geographic data mining and
visualization. Journal of Intelligent Information Systems, 27(3), 243-266.
Han, J., Pei, J., & Kamber, M. (2011). Data mining: concepts and techniques. Elsevier.
Hernández, J., Ramírez , J., & Ferri, C. (2007). Introducción a la Minería de Datos. Madeid,
España: Pearson Prentice Hall.
IBM. (s.f.). IBM. Recuperado el 20 de Agosto de 2016, de IBM Intelligent Operations Center for
Emergency Management: http://www-03.ibm.com/software/products/es/ioc-emergency-
management
IBM. (s.f.). IBM i2 COPLINK. Recuperado el 20 de Agosto de 2016, de IBM i2 COPLINK:
http://www-03.ibm.com/software/products/es/coplink
Jain, A. K., Murty, N., & Flynn, P. J. (1999). Data clustering: a review. ACM computing surveys
(CSUR), 31(3), 264-323.

92
Jaiwei, H., & Kamber, M. (2006). Data mining: concepts and techniques. San Francisco,
California: Morgan Kaufmann.
Jia, Z., & Liu, Y. (2009). Visualized geology spatial data classifying based on integrated
techniques between GIS and SDM. First International Workshop on. IEEE, 165-169.
Koperski, K., & Han, J. (1998). An efficient two-step method for classification of spatial data. In
proceedings of International Symposium on Spatial Data Handling (SDH’98), 45-54.
Mariscal, G., Marbán, Ó., & Fernández, C. (2010). A survey of data mining and knowledge
discovery process models and methodologies. The Knowledge Engineering Review, 137 -
166.
Mennis, J., & Guo, D. (Noviembre de 2009). Spatial data mining and geographic knowledge
discovery—An introduction. Computers, Environment and Urban Systems, 33(6), 403 -
408. Recuperado el 15 de Marzo de 2013, de
http://www.sciencedirect.com/science/article/pii/S0198971509000817
Olmos Pineda, I., & González Bernal, J. A. (2007). Minería de Datos. Semana de la Informatica.
Puebla, Mexico.
Open Geospatial Consortium Inc. (28 de Mayo de 2011). Implementation Standard for
Geographic information - Simple feature access - Part 1: Common architecture. (J. R.
Herring, Editor) Recuperado el 8 de Julio de 2016, de Open Geospatial Consortium Inc:
http://www.opengeospatial.org/standards/sfa
Pascual, D., Pla, F., & Sánchez, S. (2007). Algoritmos de agrupamiento. Método Informáticos
Avanzados, 164 - 174.
Rengert, G. F., & Lockwood, B. (2009). Geographical Units of Analysis and the Analysis of
Crime. En B. W. Weisburd D., Putting Crime in its Place (págs. 109 - 122). New York:
Spring Link. doi: 10.1007/978-0-387-09688-9_5

93
Riquelme, J. C., Ruiz, R., & Gilbert, K. (2006). Mineria de Datos: Conceptos y tendencias
Inteligencia artificial. Iberoamericana de Inteligencia Artificial, 10 (29), 11 - 18.
Recuperado el 25 de Mayo de 2017
Rokach, L., & Maimon, O. (2010). Supervised learning. Data Mining and Knowledge Discovery
Handbook. Springer Link.
Secretaría Distrital de Cultura, Recreación y Deportes. (2008). Localidad de Chapinero Ficha
Básica. Bogotá. Obtenido de
http://www.culturarecreacionydeporte.gov.co/observatorio/documentos/localidades/chapi
nero.pdf
Secretaría Distrital de Planeación. (20 de Julio de 2013). Reloj de Población. Obtenido de Portal
Secretaría Distrital de Planeación:
http://www.sdp.gov.co/portal/page/portal/PortalSDP/InformacionTomaDecisiones/Estadi
sticas/RelojDePoblacion
Shafeeq, A., Binu, V., & Binu, V. (2014). Spatial Patterns of Crimes in India using Data Mining
Techniques. International Journal of Engineering and Innovative Technology (IJEIT),
3(11), 291-295. Recuperado el 20 de Mayo de 2017, de
https://www.researchgate.net/profile/Ahamed_Shafeeq/publication/286301649_Spatial_P
atterns_of_Crimes_in_India_using_Data_Mining_Techniques/links/5667abc608ae34c89a
025e51.pdf
Shekhar, S., Wu, W., Ozesmi, U., & Chawla , S. (2001). Modeling Spatial Dependencies for
Mining Geospatial Data. SIAM International Conference on Data Mining, 1 - 17.
Shekhar, S., Zhang, P., Huang, Y., & Raju, R. (19 de Septiembre de 2003). Spatial Data Mining.
Obtenido de http://citeseerx.ist.psu.edu: www-users.cs.umn.edu]
Silberschatz , A., Korrth, H. F., & Sudarshan, S. (2002). Fundamentos de Bases de Datos.
Madrid, España: McGraw-Hii/Interamericana de España.

94
Sivaranjani, S., Sivakumari, S., & Aasha, M. (2017). Crime prediction and forecasting in
Tamilnadu using clustering approaches. IEEE Xplore Digital Library.
doi:10.1109/ICETT.2016.7873764
Tan , P.-N., Steinbach , M., & Kumar , V. (2006). Classification: basic concepts, decision trees,
and model evaluation. Introduction to data mining.
THE OMEGA GROUP. (s.f.). THE OMEGA GROUP. Obtenido de CrimeView:
http://www.theomegagroup.com/police/crimeview_desktop.html
Wang, X., Brown, D. E., & Gerber, M. S. (2012). Spatio-temporal modeling of criminal
incidents using geographic, demographic, and twitter-derived information. IEEE Xplore
Digital Library. doi:10.1109/ISI.2012.6284088
Weiis, S., & Indurkhya, N. (1998). Predictive data mining: a practical guide. San Francisco,
California: Morgan Kaufmann.
Witten, I. H., Frank, E., Hall, M., & Pal, C. (2016). Data Mining: Practical machine learning
tools and techniques. Morgan Kaufmann.
Yang, , T., Bai, P., & Gong,, Y. (2008). Spatial Data Mining Features Between General Data
Mining. Ettandgrs. In Proceedings of International Workshop on Education Technology
and Training & International Workshop on Geoscience and Remote Sensing, 541 - 544.
Yáñezs, J. M., & González , J. Á. (2005). Sistemas de información medioambiental. España:
Netbiblo S. L.
95
7. ANEXOS
Diccionario de Datos
Tabla Delitos Chapinero
Columns
Name Data type
Not
Null?
Primary
key? Default Comment
d_distrito
character
varying(50) No No
d_estacion
character
varying(50) No No
d_cai
character
varying(60) No No
d_cuadrant
character
varying(50) No No
clase_de_s
character
varying(70) No No
numero_sem numeric(10) No No
mes
character
varying(20) No No
fecha_hech date No No
dia_ocurri
character
varying(20) No No
hora
character
varying(254) No No
rago_h smallint No No
modalidad smallint No No
arma smallint No No
locarea numeric No No
shape_leng numeric No No
shape_area numeric No No
geom geometry No No
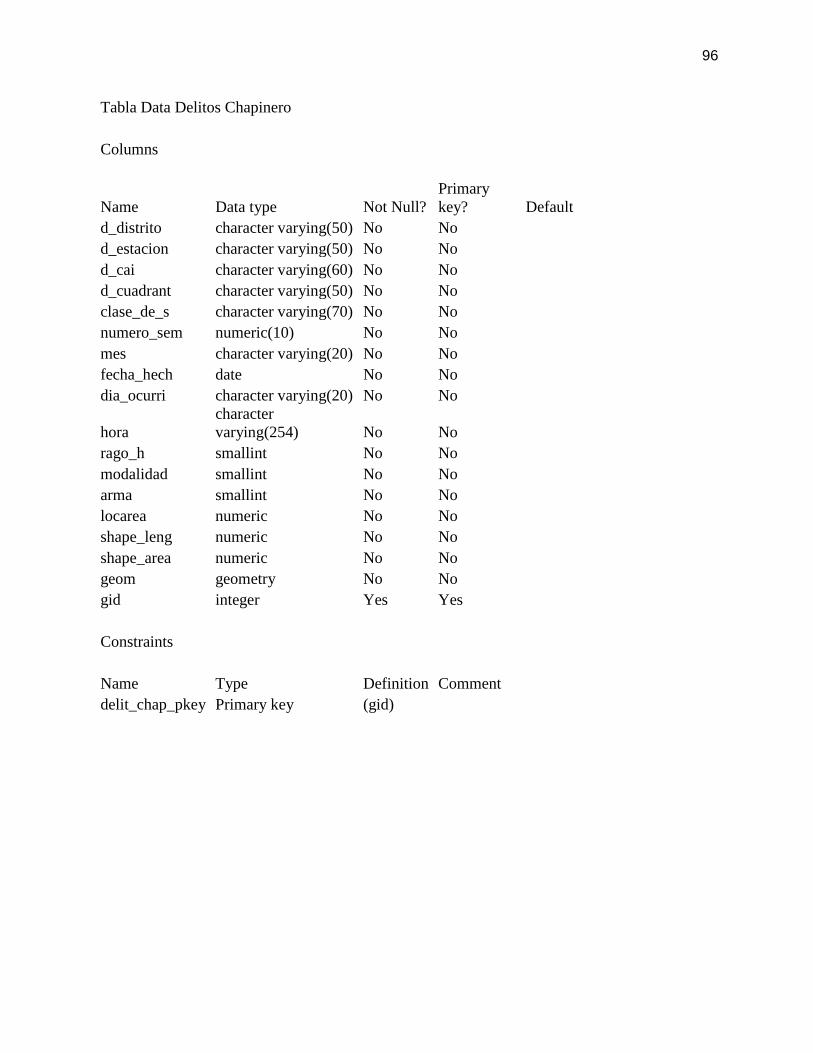
96
Tabla Data Delitos Chapinero
Columns
Name Data type Not Null?
Primary
key? Default
d_distrito character varying(50) No No d_estacion character varying(50) No No d_cai character varying(60) No No d_cuadrant character varying(50) No No clase_de_s character varying(70) No No numero_sem numeric(10) No No mes character varying(20) No No fecha_hech date No No dia_ocurri character varying(20) No No
hora
character
varying(254) No No rago_h smallint No No modalidad smallint No No arma smallint No No locarea numeric No No shape_leng numeric No No shape_area numeric No No geom geometry No No gid integer Yes Yes
Constraints
Name Type Definition Comment delit_chap_pkey Primary key (gid)

97
Tabla - infrseg_chap
Columns
Name Data type Not Null? Primary key? Default
nombre character varying(254) No No
geom geometry(797699) No No gid integer Yes Yes
Constraints
Name Type Definition Comment infrseg_chap_pkey Primary key (gid)
Tabla Tipo de Arma
Columns
Name Data type Not
Null?
Primary
key? Default Comment
id smallint Yes Yes
nombre character varying(20) No No
Constraints
Name Type Definition Comment
arma_pkey Primary key (id)

98
Anexo B Modelos
Primer Modelo K-means

99
Segundo Modelo K-means
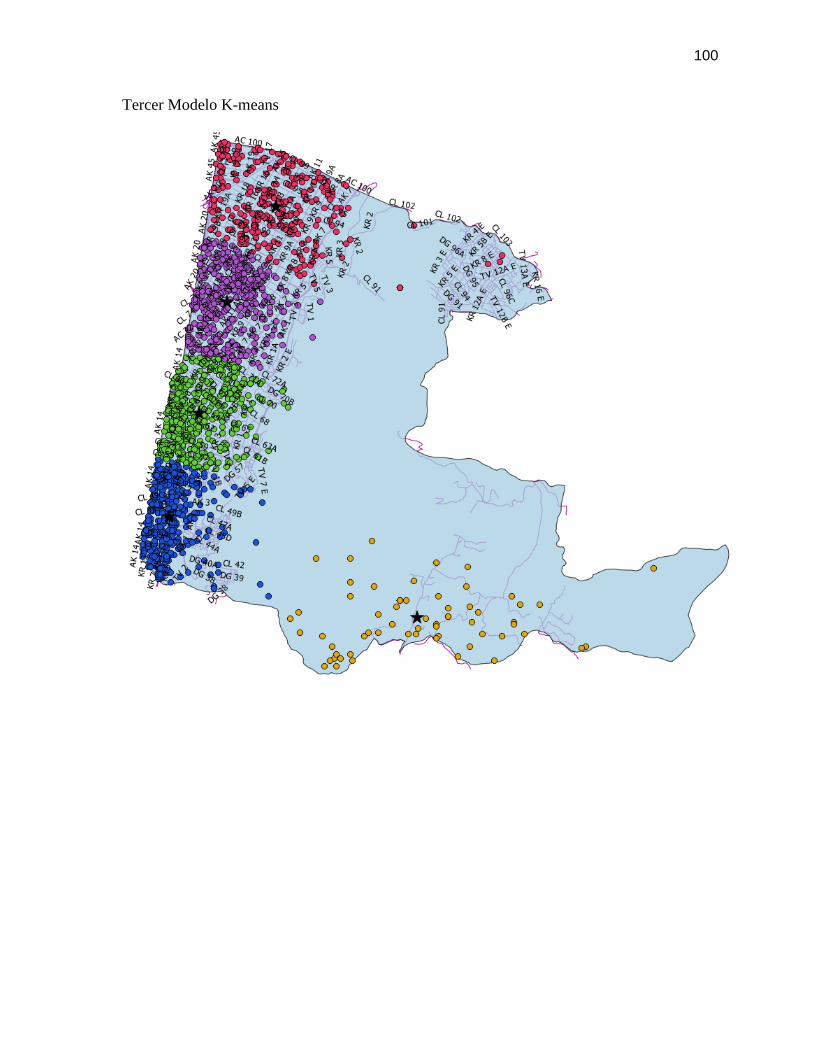
100
Tercer Modelo K-means

101
Quinto Modelo K-means
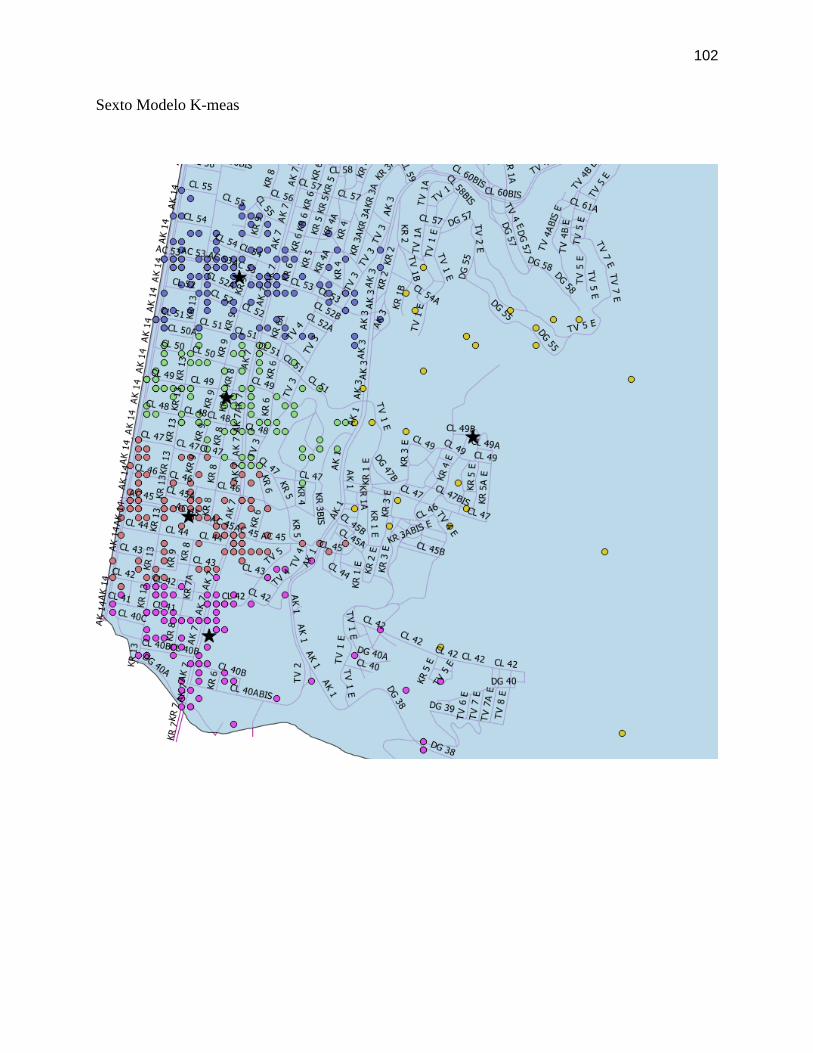
102
Sexto Modelo K-meas

103
Modelo Final Kmeans.

104
Primer Modelo DBscan

105
Segundo Modelo DBscan
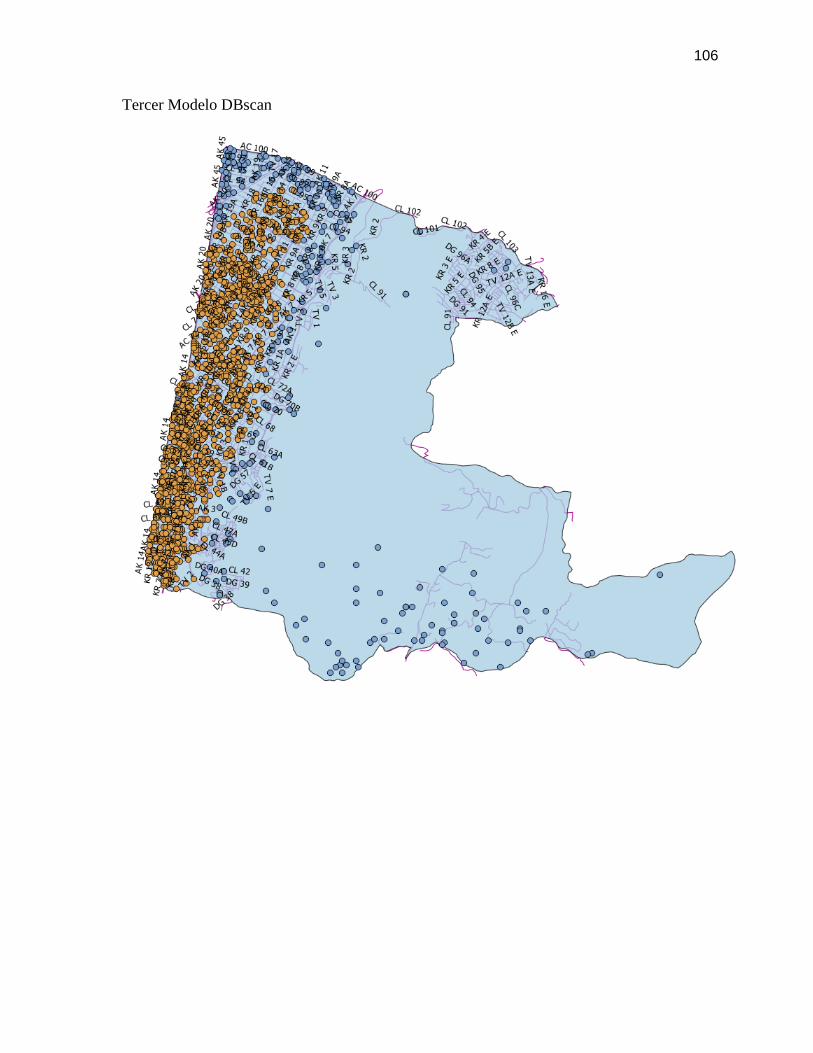
106
Tercer Modelo DBscan
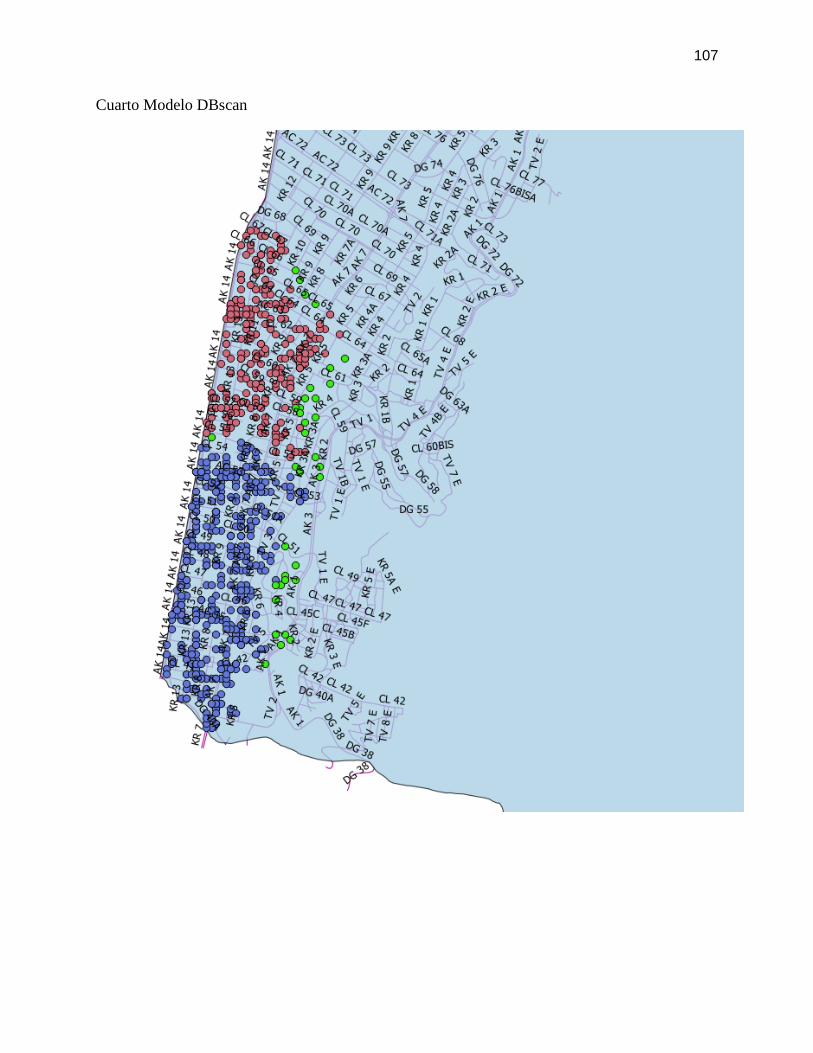
107
Cuarto Modelo DBscan

108
Quinto Modelo DBscan

109
Modelo Final Resultados Obtenidos K-mean, DBscan

110