estadística simple
TRANSCRIPT

TEMA 1-2: ESTADÍSTICA DESCRIPTIVA Estadística descriptiva: organizar observaciones de forma cuantitativa. Tablas, gráficos, valores
numéricos… para estudiar relación o asociación.
Estadística inferencial: para inferir algo, basándose en los datos obtenidos de la descriptiva.
Población: conjunto de individuos sobre el que se quieren obtener conclusiones
Muestra: subconjunto de la población sobre el que se van a hacer las observaciones. Es
representativo, formado por n miembros. Un caso clínico n=1.
Poblaciones cerradas o cohortes: tamaño fijo, sin entradas ni salidas. Nacidos en 1982,
diagnósticos de angina de pecho en 1946…
Poblaciones dinámicas: n puede aumentar en el tiempo, permiten entradas y salidas. Población
del País Vasco
- En estado estacionario: n no cambia, por cada salida hay una entrada.
- Población de derecho: empadronados en un lugar donde ejercen sus derechos
- Población de hecho: no está empadronada, no hay intención de permanecer en un lugar
(lugares de vacaciones).
- Población flotante: se desplazan durante unas horas a un lugar pero su residencia está
en otro sitio (zonas de ocio, trabajo…)
Variables: características que son objeto de interés y estudio. En medicina son persona,
tiempo y lugar.
- Cualitativas – datos categóricos: se recoge la categoría, y se hace codificación numérica.
o Nominales: no hay referencia numérica. Género, color de ojos, profesión…
o Ordinales: hay un orden numérico, pero no de cifra. Orden de nacimiento,
estadio de la enfermedad…
o Dicotómica: si/no – hombre/mujer
- Cuantitativas – datos numéricos: recogida numérica, se puede codificar o categorizar.
o De Intervalo: no hay cero absoluto – la temperatura. ver ≠ entre 2 valore
o De razón: tiene un cero absoluto - ingresos
o Discretas: sin decimales, solo valores enteros – diagrama de barras
o Numéricas o continuas: escala de números reales – histograma y ojiva
Instrumentos de medida:
- Sensibilidad: más sensible cuanto más pequeña sea la cantidad que puede medir.
Umbral de sensibilidad – la menor división de la escala del aparato de medida. Depende
de la finalidad del aparato (balanza para personas no mide en mg sino en kg)
- Fidelidad: reproduce siempre el mismo valor, o muy próximo, al medir la misma
cantidad en las mismas condiciones. Dispersa poco las medidas.
- Precisión: los errores absolutos que se producen al usar el aparato son mínimos – se
desvía poco del valor verdadero. Aumenta si disminuye el error aleatorio.
Tipos de datos:
- Datos en bruto o simples
- Datos agrupados en Tablas de frecuencias

Medidas de localización o posición**: situación promedio de los valores de una
variable en una recta de números reales. Puede haber valores superiores o inferiores a dicho
valor central. *centralización (x afectan extremos – Me no afectan extremos) talla y peso niños.
1. *Mediana: Me – divide en dos partes iguales. 50% valores superiores y 50% inferiores.
2. **Percentiles: el p% de los individuos toman valores menores o iguales a él.
3. **Cuartiles: dividen n individuos en 4 partes iguales (**deciles, cuantiles…)
Q1 = P25 Q2 = P50 = Me Q3 = P75
4. *Moda: Mo – el que más se repite. Unimodal, bimodal, multimodal…
5. *Media o media aritmética – datos desagrupados:
6. Media ponderada – datos agrupados:
Medidas de dispersión: promedio de las distancias de cada dato con respecto del valor
central – a la media. Pueden ser desviaciones positivas o negativas. Evitar con | - | ó ( )2
1. Varianza: desviación cuadrática media s2 –
sensible a extremos
2. Desviación estándar: tiene la unidad de la
variable s. a una s de la media está más de la
mitad de la muestra(68%), a dos s casi
todas(95%).
3. Coeficiente de variación (CV): no tiene unidad, no lo calcula STATA. σ/x*100 para
comparar la dispersión en dos variables distintas o con diferentes unidades CV no
tiene unidades!¡
4. Rango (Re): diferencia entre el máximo y el mínimo (sensible a extremos).
5. Rango intercuartílico: diferencia entre Q3 y Q1.(no sens a extremos)
Medidas de forma:
1. Simetría: x(media) = Me = Mo (si unimodal)
a. Asimetría a la izquierda ó - : x<Me cola izda
b. Asimetría derecha ó + : x>Me cola dcha
2. Coeficiente de asimetría de Pearson:

3. Apuntamiento o Curtosis: coeficiente de asimetría de Fisher g2.
CAMBIOS DE LOCALIZACIÓN Y DE ESCALA EN EL PPT1
TEMA PPT GRÁFICOS 1.Para variables DISCRETAS: cualitativas codificadas – diagrama de barras, diagrama de sectores
2.Para variables CUANTITATIVAS – datos brutos: diagrama de tronco hojas
3.Para variables CONTINUAS – datos agrupados:
histograma: el área bajo el histograma indica la cantidad (% o frec) de individuos en el
intervalo).
polígono de frecuencias: une los puntos medios de cada columna del histograma, el área
bajo el polígono es igual al área del histograma
polígono de frecuencias acumuladas: ojiva
diagrama de cajas: resumen con 5 números – mínimo, cuartiles y máximo. La caja es el
RI – contiene al 50%. Los bigotes solo se pueden extender 1.5RI. más allá son out layers.
Las tablas de frecuencias y los gráficos son maneras equivalentes de presentar la información.
- Frecuencia absoluta: número de personas en un intervalo
- Frecuencia relativa: la proporción o porcentaje. Cuánta gente entre el total. Frec
Abs/total: Es el tanto por uno. Multiplicar le porcentaje por 100.
- Frecuencia acumulada: acumulación de las frecuencias relativas
TEMA 4: FRECUENCIA DE ENFERMEDAD
Razón: cociente dos valores que no tienen por qué estar relacionados entre s (IMC) 𝑹𝒂𝒛𝒐𝒏 =𝒙
𝒚·
𝟏𝟎𝒏 n=0 normalmente
Prevalencia de la enfermedad: porcentaje de diagnosticados de una enfermedad en un
momento dado.
Incidencia: fuerza de una enfermedad para generar nuevos casos, se mide en un periodo de
tiempo
Mortalidad: estudio de la incidencia de la muerte
Entre la prevalencia P[E] y la incidencia DI[E] de una
enfermedad [E] existe una relación matemática:

TEMA 2: ASOCIACIÓN DE VARIABLES CUANTITATIVAS
1. Diagrama de dispersión: nube de puntos –con centro de gravedad, donde se cruzan las
dos medias Para dos variables. Relación directa o positiva, relación inversa o negativa,
variables no relacionadas.
2. Coeficiente de correlación lineal de Pearson: Rxy=𝑆𝑥𝑦
𝑆𝑥·𝑆𝑦 . Va de -1 < r < +1. =0 no hay
relación. Si se acerca a +-1 si hay relación siendo ésos los máximos. Igual signo que
covarianza y coef. de regresión. Si =0 covarianza=0
3. Ecuación de regresión lineal: y = a + bx . A es una constante: el valor de y cuando x vale
0. B es el coeficiente de regresión o la pendiente, la variación de y por cada incremento
unitario de x.
4. Coeficiente de determinación R2: mide proporción de variabilidad (o varianza) de al
variable dependiente (y), explicada por la varianza de la variable independiente (x).
5. Coeficiente de regresión o pendiente (B): aumento que se
produce en y (a explicar) cuando la explicativa (x) aumenta
una unidad
6. Covarianza: no está acotada. Si X=Y;
Sxy=S2=var. El cambio de escala afecta a la
covarianza
Coeficiente Símbolo Fórmula Interpretación Valores
Correlación R Sxy/Sx·Sy Mide asociación [-1<R<+1]
Regresión B Sxy/S2x ó R·Sy/Sx
Variación de y, ∆x=1
(-∞<B<+∞)
Determinación R2 R2·100% Proporción de y explicada por x
0<R2<1
1) B (coef regresión) y R (coef correlacion lineal) tienen mismo signo
2) Da B, interpreta R
3) Da R, interpreta B
4) Dar R2, interpreta R
5) A partir de R2 no se puede calcular R
TEMA 3: ASOCIACIÓN DE VARIABLES CUALITATIVAS
Frecuencia observada: la que recojo en mi encuesta, la que me da STATA.
Frecuencia esperada: la que esperaría encontrar si las variables fuesen independientes.
Si los valores de la distribución conjunta son parecidos – independientes
Si los valores de la distribución conjunta son diferentes – no presentan independencia
Chi-cuadrado χ2: estandariza diferencia entre observado y esperado. Mas diferencia, menos
probabilidad de que sea al azar. Si es menor que 0.05 α – rechazo la hipótesis de independencia.
χ2= (𝐹.𝑂−𝐹.𝐸)
𝐹𝐸
2

TEMA 4: PROBABILIDAD
Suceso elemental: cualquier acontecimiento que puede verificarse como aleatorio. Hay que
delimitarlos y definirlos bien. P(A)>=0 siempre, y está entre 0 y 1.
-suceso seguro P(A)=1 -suceso imposible P(A)=0
P(A)= 𝑠𝑢𝑐𝑒𝑠𝑜𝑠 𝑝𝑟𝑜𝑏𝑎𝑏𝑙𝑒𝑠
𝑠𝑢𝑐𝑒𝑠𝑜𝑠 𝑝𝑜𝑠𝑖𝑏𝑙𝑒𝑠 P(A)= 1-P(A)
Combinación de sucesos:
- Unión: U ocurre uno u otro suceso P (AUB) = P(A) + P(B) – P(A∩B) – si los sucesos son
mutuamente excluyentes o incompatibles: P(A∩B) = 0
- Intersección: ∩ se verifican ambos sucesos P(A∩B)= P(A)·P(B|A) – dependientes. Si P(A)
es independiente de B, entonces P(B)=P(B|A) P(A)·P(B)
- Condicionada/Teorema de Bayes: 𝑃(𝐵|𝐴) =𝑃(𝐴∩B)
P(A) y 𝑃(𝐴|𝐵) =
𝑃(B∩A)
P(B)
Es la probabilidad de B sabiendo que ocurre A, o la probabilidad de A sabiendo que ocurre B.
- Teorema de la
probabilidad total:
TEST DIAGNÓSTICOS
P(E)=prevalencia
P(+|E) = probabilidad de + sabiendo que está enfermo sensibilidad (s)
P(+|noE) = probabilidad de – sabiendo que está sano especificidad (e)
P(-|E) = probabilidad de – sabiendo que está enfermo falsos negativos (1-s)
P(+|noE) = probabilidad de + sabiendo que está sano falsos positivos (1-e)
P(E|+) = valor predictivo positivo (VP+) de que esté enfermo sabiendo que da +
P(noE|-) = valor predictivo negativo (VP-) de que esté sano sabiendo que da -.

La prevalencia no influye en la sensibilidad (s), ni en la especificidad, como tampoco influye
en los FP y FN.
Si se
conoce una de las marginales y la distribución
condicionada a la misma, se puede calcular la P condicionada a la otra marginal mediante el
teorema de Bayes. Si se conoce s y e, la prevalencia se puede calcular, y VP+ y VP-, usando Bayes
y la probabilidad total.
- La prevalencia si influye en el VP+: a mayor prevalencia mayor VP+ (pero no solo de eso)
- E, s, 1-e, 1-s no dependen de la prevalencia
o x FP depende de la especificidad
o x FN depende de la sensibilidad
- VP+, VP* dependen de la prevalencia y de e, s, 1-e y 1-s
- La prevalencia la tiene que dar de manera explícita el enunciado
TEMA 7: DISTRIBUCIONES – MODELOS TEÓRICOS DE PROBABILIDAD
Media o esperanza matemática el valor esperado para una variable E[X]=μ
La varianza: Var[X]

BERNOULLI
Sólo dos resultados posibles estar enfermo/sano. P= prevalencia de la enfermedad o P de que
un individuo se cure.
X=1 éxito p X=0 fracaso q p + q = 1
μ = 𝑝 σ=√𝑝 · 𝑞
BINOMIAL Bi(n,p)
Repetimos el experimento n veces. n=número de pruebas independientes # p probabilidad de
éxito en cada prueba. 0 ≤ 𝑋 ≤ 𝑛 Si tengo n, p y x busco en las tablas de la binomial. Cuando
pide una probabilidad, me tiene que dar n.
μ = 𝑛 · 𝑝 σ=√𝑛 · 𝑝 · 𝑞
Binomial si n>10, p<=0.1 poisson (λ); si λ>=10 normal N(np, √𝑛𝑝𝑞)
Bin N si: n>30, n*p>5, n*q>5
POISSON Po(λ)
Calcular probabilidades de sucesos raros P muy baja. Cuando P es muy pequeña n tiende a
ser grande. Necesitamos conocer λ. Sacamos λ y buscamos en las tablas. λ =nºsucesos/tiempo
λ = n(tiempo) · p(casos) λ=0 P=0 siempre
- Si dan un número medio de veces que ocurre algo en un periodo de tiempo, el periodo
de tiempo será siempre λ.
NORMAL N(μ,σ)
Probabilidad para variables continuas. Simétrica, mesocúrtica y asintótica. Estándar: N(0,1).
Para estandarizar: N(μ,σ) N (0,1)
Z=X−μ
σ X Z
f(x) es siempre positiva, el área bajo f(x)=1, la probabilidad entre los puntos a y b es el área bajo
f(x) entre ambos puntos
¿Cuándo se estandariza? Variable aleatoria continua.
TEMA 8: ESTADÍSTICA INFERENCIAL – DISTRIBUCIÓN MUESTRAL Y ERROR TÍPICO
Parámetro: constante de interés, que suele ser grande. La muestra debe ser
representativa, individuos con P no nula, si P=0 muestra sesgada (Sesgo de selección).
- La distribución del estadístico es normal.
- La media de la distribución muestral coincide con la media poblacional.
- El error típico (desviación típica de la distribución muestral del estadístico) no coincide
con la desviación típica de la población es más pequeño siempre.

Muestra representativa: no está sesgada; extracciones aleatorias – tablas de números
aleatorios. Si no hay sesgo o error sistemático validez.
Si hay sesgo población en estudio – si no coincide con la población objetivo hay sesgo o
error sistemático.
Muestreo: Para evitar los sesgos (errores sistemáticos) muestreo probabilístico
- Aleatorio simple con reemplazamiento o sin reemplazamiento (sobre poblaciones
grandes)
- Sistemático
- Seudoaleatorio: itinerarios
- Estratificado: muestreo de individuos dentro de estratos
- Por conglomerados o grupos.
Inferencia: para conocer las características de una determinada población objetivo,
controlando el error aleatorio muestras extraídas por muestreos adecuados que no sesgan y
producen una muestra representativa de la población objetivo.
Errores aleatorios ε: se evalúan mediante probabilidades
Estadísticos – estimación puntual del parámetro
- Insesgado: su esperanza debe ser el parámetro que se va a estimar
- Mínima varianza
- Distribución condicionada y conocida
Error estándar o típico de la media 𝜎𝑥 =𝜎
√𝑛
Error típico de la proporción 𝜎𝑝 = √𝑝·𝑞
𝑛
Teorema del límite central
Error aleatorio: diferencia entre estimación puntual de la muestra y el parámetro que
queremos estimar.
Int. Confianza
Test de Hipótesis

TEMA 10: ESTIMACIÓN
Nivel de confianza: (1-α) probabilidad de que el parámetro esté entre los valores que
estimo – siendo α el nivel de significación
Error aleatorio o máximo (ε): diferencia entre el parámetro poblacional y el estadístico
muestral.
- |μ-x| lo que nos equivocamos aplicado a la media
- |P-Pm| error aleatorio de la proporción
Estimación puntual: ofrecer como valor esperado el parámetro del estadístico muestral
- μ media poblacional // x media muestral μ=x estimación puntual de media muestral
- P proporción poblacional // Pm proporción muestral P^=Pm est punt prp poblacional
Cuando los grados de libertad >30 T de Student se convierte en normal
Fórmulas de CI
Iμ1-α
Conozco σ 𝑥 ± 𝑧 ·𝑞
√𝑛
No conozco σ 𝑥 ± 𝑡(𝑛 − 1) ·𝑠
√𝑛
Ip1-α 𝑃𝑚 ± 𝑧 · √
𝑝𝑚 · 𝑞𝑛
𝑛
Diferencia significativa
Si reducimos el nivel de confianza disminuye el error aleatorio
El error aleatorio disminuye si la variabilidad disminuye
Cuando aumenta n disminuye el error aleatorio (el único manipulable)
Disminuye la probabilidad de error tipo II aumentando n
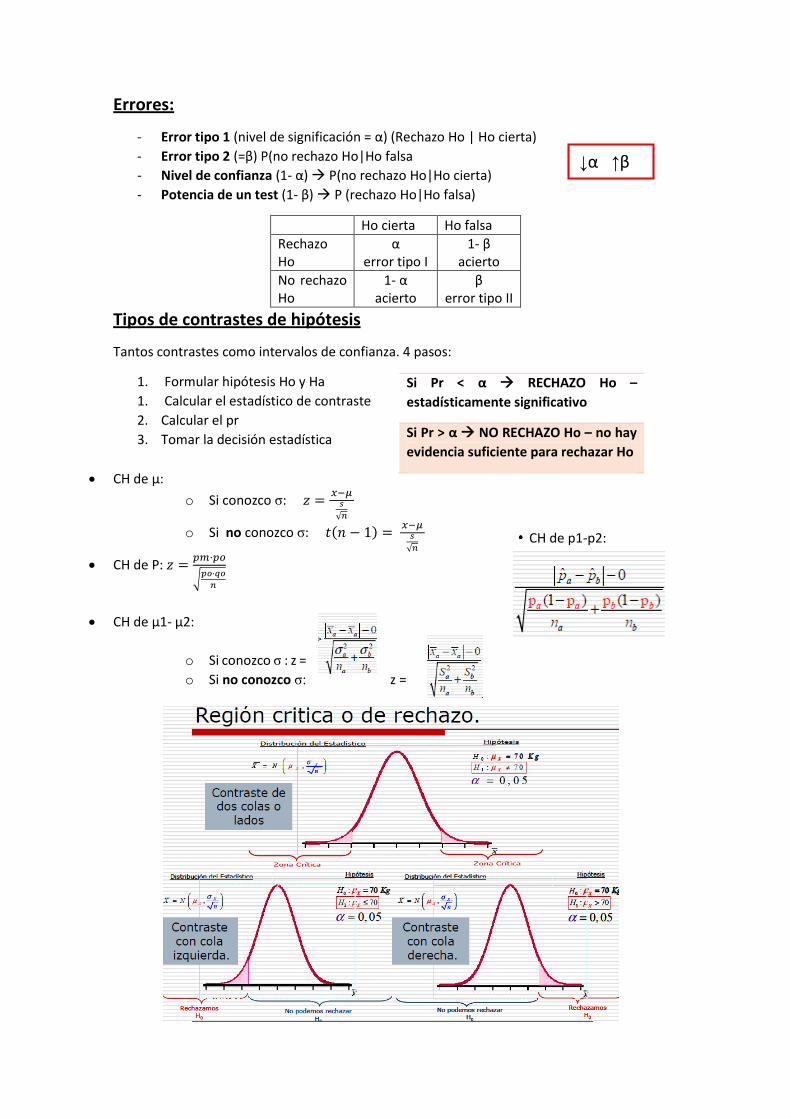
TEMA 10: CONTRASTE DE HIPÓTESIS
Ho: hipótesis nula – afirma que no hay diferencia entre el dato observado en la muestra y el
parámetro esperado
Ha: hipótesis alternativa
Nivel de significación de los datos: p-valor – probabilidad de encontrarnos el resultado
muestral asumiendo como cierta Ho. p es un valor entre 0 y 1
1- α 90% 95% 99%
Z 1.64 1.96 2.58
Errores:
- Error tipo 1 (nivel de significación = α) (Rechazo Ho | Ho cierta)
- Error tipo 2 (=β) P(no rechazo Ho|Ho falsa
- Nivel de confianza (1- α) P(no rechazo Ho|Ho cierta)
- Potencia de un test (1- β) P (rechazo Ho|Ho falsa)
Ho cierta Ho falsa
Rechazo Ho
α error tipo I
1- β acierto
No rechazo Ho
1- α acierto
β error tipo II
Tipos de contrastes de hipótesis
Tantos contrastes como intervalos de confianza. 4 pasos:
1. Formular hipótesis Ho y Ha
1. Calcular el estadístico de contraste
2. Calcular el pr
3. Tomar la decisión estadística
CH de μ:
o Si conozco σ: 𝑧 =𝑥−𝜇
𝑠
√𝑛
o Si no conozco σ: 𝑡(𝑛 − 1) = 𝑥−𝜇
𝑠
√𝑛
CH de P: 𝑧 =𝑝𝑚·𝑝𝑜
√𝑝𝑜·𝑞𝑜
𝑛
CH de μ1- μ2:
o Si conozco σ : z =
o Si no conozco σ: z =
Si Pr < α RECHAZO Ho –
estadísticamente significativo
Si Pr > α NO RECHAZO Ho – no hay
evidencia suficiente para rechazar Ho
↓α ↑β
CH de p1-p2: