autor: javier seco benso madrid, septiembre de 2009 · proyecto fin de carrera extracción de...
TRANSCRIPT

PROYECTO FIN DE CARRERA
Extracción de conocimiento mediante técnicas
de minería de datos y grid computing
AUTOR: Javier Seco Benso
MADRID, Septiembre de 2009
UNIVERSIDAD PONTIFICIA COMILLAS
ESCUELA TÉCNICA SUPERIOR DE INGENIERÍA (ICAI)
INGENIERO SUPERIOR EN INFORMÁTICA

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
Autorizada la entrega del proyecto del alumno/a:
Javier Seco Benso
EL DIRECTOR DEL PROYECTO
Eugenio Fco. Sánchez Úbeda
Fdo: ………………………. Fecha: ……/ ……/ …………..
Rafael Palacios Hielscher
Fdo: ………………………. Fecha: ……/ ……/ …………..
V° B° del Coordinador de Proyectos
David Contreras Bárcera
Fdo: ………………………. Fecha: ……/ ……/ …………..

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
I
RESUMEN

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
II
Los árboles de regresión son un tipo de técnica de aprendizaje automático inductivo en
la que la salida es modelada como un conjunto de hiperplanos sin solape. Estos modelos
de regresión se crean utilizando algoritmos de ajuste estándar basados en el paradigma
divide y vencerás. Aunque este enfoque de aprendizaje puede ser fácilmente
paralelizado, la mayoría de las herramientas de análisis de datos emplean
implementaciones para un único procesador.
Estas implementaciones para un único procesador se han venido utilizando durante las
últimas décadas debido a la habilidad de las mismas para generar buenos resultados en
tiempos razonables utilizando ordenadores estándar. Sin embargo, el tamaño de los
problemas de aprendizaje a resolver crece continuamente, requiriendo cada vez más
recursos computacionales para crear los modelos de aprendizaje automático.
Hoy en día la tecnología GRID ha alcanzado el nivel requerido para poder considerarse
como una solución alternativa al enfoque mono-procesador. Es más, herramientas
existentes como BOINC o Netsolve proporcionan entornos de desarrollo estables y
sencillos de utilizar.
En este proyecto se han desarrollado utilizando BOINC dos implementaciones paralelas
del algoritmo de inducción top-down de árboles de regresión. La primera descompone
el problema utilizando un recorrido en anchura, mientras que la segunda utiliza un
recorrido en profundidad para descomponer el problema. Estos dos enfoques se han
probado utilizando un pequeño grid y dos problemas de aprendizaje sintéticos de gran
tamaño. Después de un análisis detallado de los resultados obtenidos, se ha propuesto y
validado un nuevo algoritmo que combina ambas estrategias.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
III
ABSTRACT

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
IV
Regression trees are a type of inductive automatic learning technique where the output
is modeled as a set of non-overlapping hyper-planes. These regression models are
created by applying standard learning algorithms based on the divide-and-conquer
paradigm. Although this learning approach can be easily parallelized, most of the
existing data analysis tools use single-processor implementations.
These single-processor implementations have been used during last decades due to their
ability to provide good results using standard PCs in reasonable CPU-time. However,
the size of the learning problems to be solved is increasing continuously, requiring more
computational resources in order to build the automatic learning models.
Nowadays the GRID technology has reached the required state to be considered as an
alternative solution to one single processor approaches. Furthermore, existing software
tools as BOINC or Netsolve provide stable user-friendly developing environments.
In this project two main parallel implementations of the top-down induction of
regression trees have been developed using BOINC. The first one decomposes the
problem using a breadth first search approach, whereas the second one uses a depth first
search strategy. These two approaches have been tested using a small grid and two
different large-scale synthetic learning problems. After a detailed analysis of the
obtained results, a new algorithm that combines both strategies has been proposed and
tested.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
V
ÍNDICE

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
VI
1 INTRODUCCIÓN ................................................................................................ 1
1.1 CONSIDERACIONES GENERALES SOBRE EL PROYECTO ................ 1
1.1.1 Árboles de Regresión ............................................................................... 1
1.1.1.1 APRENDIZAJE AUTOMÁTICO ..................................................... 1
1.1.1.2 APRENDIZAJE INDUCTIVO .......................................................... 4
1.1.1.3 ÁRBOLES DE DECISIÓN ............................................................... 6
1.1.1.4 ÁRBOLES DE REGRESIÓN ......................................................... 10
1.1.2 Computación Voluntaria ........................................................................ 11
1.1.3 Computación Voluntaria vs GRID ......................................................... 12
2 METODOLOGÍA ............................................................................................... 13
2.1 MODELO LINEAL ..................................................................................... 13
3 PLANIFICACIÓN DEL PROYECTO ............................................................... 18
4 PRESUPUESTO ................................................................................................. 20
5 IDENTIFICACIÓN DE NECESIDADES ......................................................... 23
5.1 OBJETIVOS DEL SISTEMA ...................................................................... 23
5.2 ALCANCE DEL SISTEMA ........................................................................ 23
5.3 TIPOLOGÍA DE USUARIOS FINALES .................................................... 24
5.4 RESTRICCIONES ....................................................................................... 24
5.5 ORGANIZACIÓN DEL PROYECTO ........................................................ 25
6 ANÁLISIS REQUISITOS .................................................................................. 28
6.1 DIAGRAMA DE PRESENTACIÓN........................................................... 28
6.2 LISTA DE REQUISITOS ............................................................................ 28
7 ESTUDIO DE ARQUITECTURA ..................................................................... 41
7.1 SISTEMA DISTRIBUIDO .......................................................................... 41
7.2 ESTRATEGIAS ........................................................................................... 41

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
VII
7.2.1 Estrategia A ............................................................................................ 42
7.2.2 Arquitectura Estrategia A ....................................................................... 44
7.2.3 Estrategia B ............................................................................................ 45
7.2.4 Arquitectura Estrategia B ....................................................................... 47
8 ARQUITECTURA BOINC ................................................................................ 49
8.1 INTRODUCCIÓN ....................................................................................... 49
8.2 ARQUITECTURA ....................................................................................... 50
8.2.1 Servidores ............................................................................................... 50
8.2.2 Clientes ................................................................................................... 50
8.2.3 Esquema general de la arquitectura ........................................................ 51
8.2.4 Forma de trabajo Cliente-Servidor ......................................................... 54
9 MODELO LÓGICO DEL SISTEMA ............................................................... 58
DFD-0 Diagrama de Contexto .............................................................................. 58
DFD-1 Diagrama Conceptual ............................................................................... 60
DFD-1.1 Crear Árbol ............................................................................................ 62
DFD-1.1.1 Establecer Parámetros Iniciales .......................................................... 64
DFD-1.1.2 Construir Árbol .................................................................................. 67
DFD-1.1.3 Crear Tareas ....................................................................................... 70
DFD-1.1.4 Obtener Árbol Completo .................................................................... 73
DFD-1.2 Generar Tiempos ................................................................................... 76
DFD-1.3 Crear Gráfica ......................................................................................... 79
10 MODELO FÍSICO DEL SISTEMA .................................................................. 81
DFD-0 Diagrama de Contexto .............................................................................. 81
DFD-1 Diagrama Conceptual ............................................................................... 83
DFD-1.1 Crear Árbol ............................................................................................ 86
DFD-1.1.1 Establecer Parámetros Iniciales .......................................................... 88

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
VIII
DFD-1.1.2 Construir Árbol .................................................................................. 91
DFD-1.1.3 Generar Informe Árbol ....................................................................... 94
DFD-1.2 Generar WU .......................................................................................... 97
DFD-1.3 Generar Análisis GRID ....................................................................... 100
DFD-1.4 Crear Gráfica ....................................................................................... 104
11 DESARROLLO DE ALGORITMOS .............................................................. 106
11.1 SUBSISTEMA 1: CREACIÓN DEL ÁRBOL .................................... 106
11.1.1 Código Multiuso .............................................................................. 107
11.1.2 Código Modular .............................................................................. 111
11.1.3 Recursividad .................................................................................... 113
11.1.4 Vectores Dinámicos ........................................................................ 116
12 PRUEBAS ........................................................................................................ 117
12.1 CONJUNTO DE PRUEBAS DESEQUILIBRADO ............................ 117
12.2 CONJUNTO DE PRUEBAS EQUILIBRADO ................................... 118
12.3 PLANIFICACIÓN ............................................................................... 119
12.3.1 Conjunto de Pruebas Desequilibrado ................................................... 120
12.3.2 Conjunto de Pruebas Equilibrado ......................................................... 121
12.4 RESULTADOS .................................................................................... 122
12.4.1 Conjunto de Pruebas Desequilibrado ................................................... 123
12.4.2 Conjunto de Pruebas Equilibrado ......................................................... 124
13 ANÁLISIS ........................................................................................................ 125
13.1 CONJUNTO DE PRUEBAS DESEQUILIBRADO ............................ 128
13.1.1 Monotarea ............................................................................................. 129
13.1.2 Estrategia A .......................................................................................... 131
13.1.3 Estrategia B .......................................................................................... 136
13.2 CONJUNTO DE PRUEBAS EQUILIBRADO ................................... 151

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
IX
13.2.1 Monotarea ............................................................................................. 152
13.2.2 Estrategia A .......................................................................................... 154
13.2.3 Estrategia B .......................................................................................... 159
14 ESTRATEGIA ÓPTIMA ................................................................................. 173
15 CONCLUSIONES ............................................................................................ 183
16 TRABAJOS FUTUROS ................................................................................... 184
17 BIBLIOGRAFÍA .............................................................................................. 185
Apéndice I MANUAL DE USUARIO .................................................................. 186
Apéndice II MANUAL INSTALACIÓN .............................................................. 197

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
1
1 INTRODUCCIÓN
1.1 CONSIDERACIONES GENERALES SOBRE EL PROYECTO
En este apartado se describen brevemente los dos aspectos que se pretenden solapar en
este proyecto: qué son y de dónde provienen los Árboles de Regresión y la
Computación Voluntaria.
1.1.1 Árboles de Regresión
Para explicar qué es un Árbol de Regresión, primeramente se deben describir una serie
de campos de la Inteligencia Artificial de los cuales procede. Estos campos son el
Aprendizaje Automático, el Aprendizaje Inductivo y los Árboles de decisión, que se
procede a describir a continuación:
1.1.1.1 APRENDIZAJE AUTOMÁTICO
Dentro de la Inteligencia Artificial existe una rama que se denomina Aprendizaje
Automático y cuyo objetivo consiste en desarrollar técnicas que permitan aprender a las
computadoras.
El Aprendizaje Automático trata de construir sistemas informáticos que optimicen un
criterio de rendimiento utilizando datos o experiencia previa. Además estos sistemas se
caracterizan por tener un propósito general gracias a que transforman los datos en
conocimiento, siendo capaces de adaptarse a las circunstancias.
Se trata, en definitiva, de un proceso de inducción de conocimiento que consiste en la
creación de sistemas informáticos capaces de generalizar comportamientos a partir de
una información no estructurada suministrada en forma de ejemplos.
Hay diversas utilidades que podemos dar al aprendizaje en los programas de
Inteligencia Artificial, entre ellas podemos citar tres esenciales:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
2
Tareas difíciles de programar:
Existen muchas tareas que por su complejidad es prácticamente imposible desarrollar
un programa capaz de resolverlas.
Por ejemplo, si queremos crear un sistema de visión capaz de reconocer un conjunto
de caras sería imposible programar a mano ese reconocimiento. El aprendizaje
automático nos permitiría construir un modelo a partir de un conjunto de ejemplos
que nos haría la tarea de reconocimiento. Otras tareas de este tipo lo constituirían
ciertos tipos de sistemas basados en el conocimiento (sobre todo los de análisis), en
los que a partir de ejemplos dados por expertos podríamos crear un modelo que
realizara su tarea.
Aplicaciones auto adaptables:
Muchos sistemas realizan mejor su labor si son capaces de adaptarse a las
circunstancias.
Por ejemplo, podemos tener una aplicación que adapte su interfaz a la experiencia
del usuario, como es el caso de los gestores de correo electrónico, que son capaces de
aprender a distinguir entre el correo no deseado y el correo normal.
Minería de datos/Descubrimiento de conocimiento:
El aprendizaje puede servir para ayudar a analizar información, extrayendo de
manera automática conocimiento a partir de conjuntos de ejemplos (usualmente
millones) y descubriendo patrones complejos.
Entre las muchas aplicaciones exitosas pueden citarse el reconocimiento del habla o de
lenguaje escrito, la navegación autónoma de robots, los motores de búsqueda, la
recuperación de información documental, los sistemas de diagnóstico médico o el
análisis del mercado de valores.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
3
El área del Aprendizaje Automático es relativamente amplia, dando lugar a varias
técnicas o paradigmas diferentes de aprendizaje:
Aprendizaje inductivo:
Se pretenden crear modelos de conceptos a partir de la generalización de conjuntos
de ejemplos. Buscamos descripciones simples que expliquen las características
comunes de esos ejemplos.
Los Árboles de Decisión, y más concretamente los Árboles de Regresión, pertenecen
a este paradigma, por eso profundizaremos un poco más en él en apartados
posteriores.
Aprendizaje analítico o deductivo:
Aplicamos la deducción para obtener descripciones generales a partir de un ejemplo
de concepto y su explicación. Esta generalización puede ser memorizada para ser
utilizada en ocasiones en las que nos encontremos con una situación parecida a la del
ejemplo.
Aprendizaje genético:
Aplica algoritmos inspirados en la teoría de la evolución para encontrar
descripciones generales a conjuntos de ejemplos. La exploración que realizan los
algoritmos genéticos permite encontrar la descripción mas ajustada a un conjunto de
ejemplos.
Aprendizaje conexionista:
Busca descripciones generales mediante el uso de la capacidad de adaptación de
redes de neuronas artificiales. Una red neuronal esta compuesta de elementos simples
interconectados que poseen estado. Tras un proceso de entrenamiento, el estado en el
que quedan las neuronas de la red representa el concepto aprendido.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
4
1.1.1.2 APRENDIZAJE INDUCTIVO
Un proceso de inducción es aquel que a partir de casos particulares trata de llegar a la
obtención de un concepto general (generalización).
El Aprendizaje Automático por Inducción consiste en obtener la definición de un
concepto a partir de ejemplos que lo afirman y contraejemplos que lo niegan. El
concepto obtenido debe de ser compatible con todos los ejemplos que lo afirman y no
contener ninguno de los contraejemplos.
Un ejemplo sencillo es el problema del aprendizaje del concepto arco, popularizado por
Winston: “Un arco está compuesto de dos bloques de pie, separados, en cuya parte
superior se coloca otro bloque”.
Ejemplos de arco Ejemplos de no-arco
La representación del concepto obtenido podría ser:
no_tocando
derecha_de
ARCO
izquierda_de
soportado_por
es_parte es_parte
es_parte
Bloque
3
Bloque
1
Bloque
2

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
5
El proceso de inducción consta de los siguientes pasos:
1. Se parte con el valor inicial del concepto, que ha de coincidir con la descripción
de un ejemplo positivo.
2. El concepto es comparado con el siguiente ejemplo positivo, modificándose de
forma que el nuevo concepto cubra los dos ejemplos. Así se consigue ignorar
atributos irrelevantes.
3. El procedimiento continúa hasta cubrir todos los ejemplos positivos, obteniendo el
concepto más general posible.
4. Al mismo tiempo los ejemplos negativos son utilizados para eliminar alternativas
al concepto no adecuadas.
Los elementos requeridos en un proceso de Aprendizaje Automático por Inducción son
los siguientes:
Un conjunto de entrenamiento.
Un algoritmo de aprendizaje.
Una representación simbólica del conocimiento.
Un esquema de valoración.
El conjunto de entrenamiento está formado por el conjunto de ejemplos, tanto positivos
como negativos, junto a la decisión tomada en cada caso. Este conjunto se divide,
usando una parte de los ejemplos para extraer los conceptos que encierran los mismos y
la otra parte como test para validar los conceptos extraídos.
Los ejemplos se definen en base a una serie de rasgos o atributos. Además, los ejemplos
llevan también asociada la solución o decisión tomada (clase a la que pertenecen). Los
atributos y clases pueden expresarse como tres tipos de variables diferentes:
a) Binarias: dos valores posibles. Normalmente indican la presencia o ausencia de un
atributo.
b) Continuas: pueden tomar cualquier valor fraccional dentro de un intervalo.
c) Categóricas: pueden tomar un valor dentro de un conjunto finito de posibilidades.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
6
Atributo 1 Atributo 2 … Atributo M CLASE
Ejemplo 1
Ejemplo 2
…
Ejemplo N
En cuanto al número de ejemplos y de atributos a emplear ha de tenerse en cuenta los
siguientes criterios:
Un número de ejemplos reducido puede no ser suficientemente significativo y dar
lugar a falsas definiciones de conceptos.
Definir ejemplos con demasiados atributos puede dar lugar a un proceso de
aprendizaje más largo y requerir más ejemplos para cubrir el espacio de entrada.
Los ejemplos deben estar definidos mediante un número suficiente de atributos
que permitan diferenciarlos entre sí.
1.1.1.3 ÁRBOLES DE DECISIÓN
Es una técnica de Aprendizaje Automático por Inducción que permite identificar
conceptos (clases de objetos) a partir de las características de un conjunto de ejemplos
que los representan. La información extraída queda organizada jerárquicamente en
forma de árbol.
Esta técnica plantea el aprendizaje de un concepto como el averiguar cuál es el conjunto
mínimo de preguntas que hacen falta para distinguirlo de otros. El conjunto de todas
estas preguntas sirve para caracterizar dicho concepto.
Un árbol se representa por un gráfico dirigido que consta de un nodo raíz, nodos
intermedios y hojas (nodos terminales).

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
7
Cada nodo tiene asociado un separador que formula una pregunta o realiza un test
acerca de la existencia o no de una característica en cada caso ejemplo. Esto permite
clasificar los ejemplos y determinar cuáles serían los nodos sucesores.
Las hojas del árbol corresponden con la clase a la que pertenecen los ejemplos que
tienen como respuestas todas las existentes en el camino entre la raíz y la hoja. La clase
de la hoja se asigna por el criterio de a la que pertenezcan la mayoría de los ejemplos en
ella.
El hecho de que las diferentes opciones de clasificación (respuestas a las preguntas) son
excluyentes entre sí, hace que a partir de un caso desconocido y siguiendo el árbol
adecuadamente, se llegue a una única conclusión o decisión a tomar. Así, dicho ejemplo
desconocido será representante de la clase en donde caiga recorriendo el árbol
desarrollado desde la raíz a las hojas.
A continuación se muestra un ejemplo sencillo de un Árbol de Decisión que clasifique
el siguiente conjunto de animales:
E1 Gallina: vive en la superficie, alimentación vegetariana, tiene plumas.
E2 Oso: vive en la superficie, alimentación omnívora, tiene pelo.
E3 Tiburón: vive en el agua, alimentación carnívora, tiene aletas.
E4 Vaca: vive en la superficie, alimentación vegetariana, tiene pelo.
E5 Ballena: vive en el agua, alimentación vegetariana, tiene aletas.
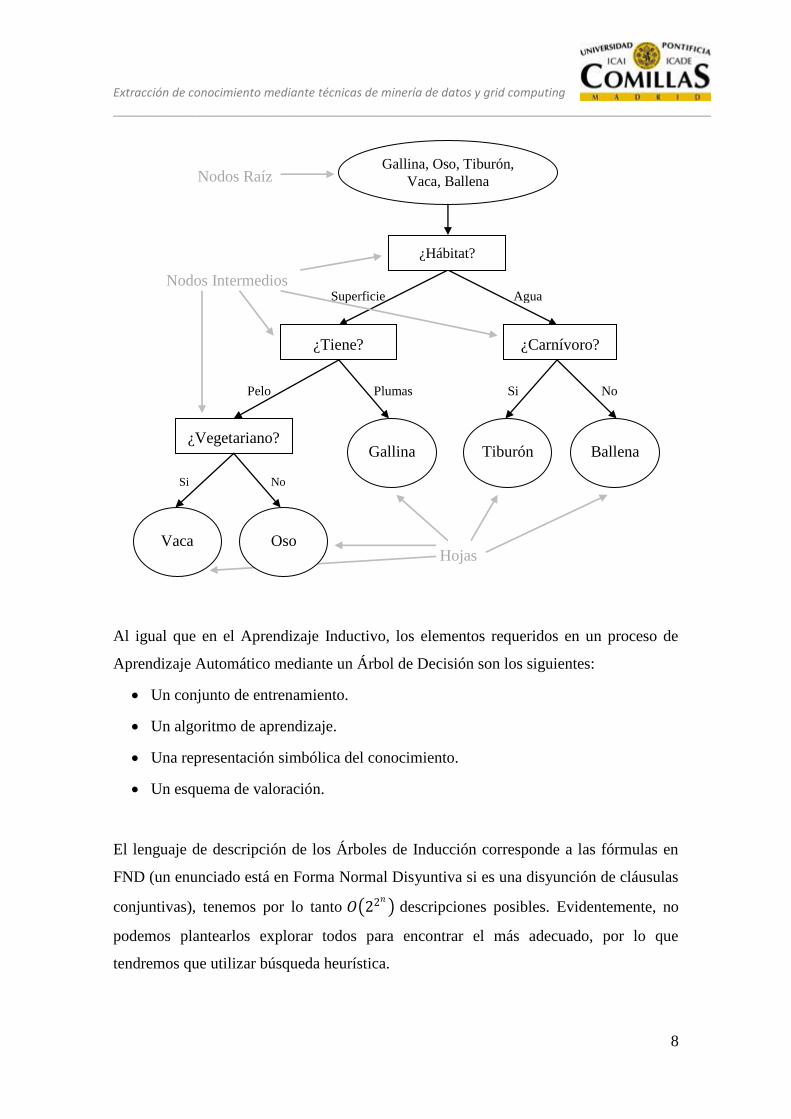
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
8
Al igual que en el Aprendizaje Inductivo, los elementos requeridos en un proceso de
Aprendizaje Automático mediante un Árbol de Decisión son los siguientes:
Un conjunto de entrenamiento.
Un algoritmo de aprendizaje.
Una representación simbólica del conocimiento.
Un esquema de valoración.
El lenguaje de descripción de los Árboles de Inducción corresponde a las fórmulas en
FND (un enunciado está en Forma Normal Disyuntiva si es una disyunción de cláusulas
conjuntivas), tenemos por lo tanto 𝑂 22𝑛 descripciones posibles. Evidentemente, no
podemos plantearlos explorar todos para encontrar el más adecuado, por lo que
tendremos que utilizar búsqueda heurística.
Hojas
Si No
Pelo Plumas Si No
Agua Superficie
¿Vegetariano?
Vaca Oso
Gallina Tiburón Ballena
Gallina, Oso, Tiburón,
Vaca, Ballena
¿Tiene? ¿Carnívoro?
¿Hábitat?
Nodos Intermedios
Nodos Raíz

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
9
Los algoritmos de construcción de árboles de inducción siguen una estrategia Hill-
Climbing. Se parte de un árbol vacío y se va particionando el conjunto de ejemplos
eligiendo a cada paso el atributo que mejor discrimina entre las clases. El operador de
cambio de estado es la elección de este atributo. La función heurística será la que
determine que atributo es el mejor, esta elección es irrevocable, por lo que no tenemos
garantía de que sea la óptima. La ventaja de utilizar esta estrategia es que el coste
computacional es bastante reducido.
La función heurística ha de poder garantizarnos que el atributo elegido minimiza el
tamaño del árbol. Si la función heurística es buena el árbol resultante será cercano al
óptimo.
El proceso de creación de un árbol consta de los siguientes pasos:
1. Se parte del conjunto de entrenamiento.
2. Se usa un criterio para seleccionar un atributo “separador” capaz de dividir el
conjunto de entrenamiento.
3. El conjunto de entrenamiento es subdividido progresivamente usando los
separadores seleccionados como nodos. Los ejemplos caen en las hojas del árbol.
El criterio de selección del rasgo separador debe ser un test restringido a una función de
solamente un atributo de los que definen los ejemplos. Entre las razones para esta
restricción podemos destacar las expuestas a continuación:
Es difícil definir un adecuado criterio de selección de rasgos a base de grupos de
atributos tomados a la vez.
Una combinación de variables considerada como separador en un nodo provocaría
un importante número de hijos.
Puesto que los árboles de decisión son construidos examinando todos los posibles
tests en cada etapa, aumentando el número de fórmulas a ser exploradas
conduciría a un significativo incremento del coste de cálculo.
El árbol de decisión resultante sería mucho más difícil de entender si cada test es
una función compleja, y por tanto más difícil de usar en aprendizaje.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
10
El uso de árboles de decisión tiene las siguientes ventajas:
Son fáciles de interpretar.
Las ramas del árbol simulan bastante bien el proceso humano para la toma de
decisiones.
Las ramas del árbol definen directamente las reglas de asignación. Los resultados
son operativos de forma inmediata.
Minimizan el pretratamiento, pueden trabajar con un cierto nivel de ruido y datos
ausentes.
Detectan de forma automática estructuras complejas entre variables.
Son computacionalmente eficientes.
1.1.1.4 ÁRBOLES DE REGRESIÓN
Cuando la clase a predecir es numérica existen dos variantes:
Árboles de regresión: guardan el valor promedio de los valores en las hojas.
Árboles de modelos: utilizan una regresión lineal para predecir los valores de las
clases.
Los dos tipos de árboles se construyen de forma muy parecida a los árboles de decisión.
En lugar de usar la ganancia de información obtenida al disminuir la entropía de los
subconjuntos obtenidos tras la aplicación de un separador, seleccionan el atributo que
maximiza el decremento de la varianza (como medida de desorden) del nodo.
El criterio se basa en tratar la desviación estándar en el nodo como una medida de
dispersión del mismo y calcular la reducción esperada de error (SDR) como resultado
de probar cada atributo en ese nodo:
𝑆𝐷𝑅 = destd T − TiT×
i
destd(Ti)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
11
Donde 𝑇1,𝑇2 … son los conjuntos que resultan de dividir al nodo de acuerdo al atributo
seleccionado y destd es desviación estándar:
𝑑𝑒𝑠𝑡𝑑 = 𝜒 𝑖 − 𝜇 2 𝑛 − 1 𝑛
𝑖, 𝜇 = 𝜒 𝑖 𝑛
𝑛
𝑖
El proceso termina o cuando se tienen muy pocas instancias en el nodo o cuando la
desviación estándar es una pequeña fracción (5%) de la desviación estándar original de
los datos.
El árbol de regresión segmenta la población en tantos grupos como nodos terminales. A
cada individuo de un nodo terminal se le asigna el valor medio de la variable de
respuesta en ese nodo.
1.1.2 Computación Voluntaria
La Computación Voluntaria se basa en la cesión gratuita y voluntaria de recursos
computacionales a un determinado proyecto.
Los proyectos pueden ser de cualquier tipo, siendo los más habituales los académicos
(proyectos universitarios) o los dedicados a la investigación científica.
Cualquier persona u organización puede ser parte del grupo de voluntarios de un
determinado proyecto, siendo la gran mayoría propietarios de un ordenador de uso
doméstico con conexión a Internet.
La Computación Voluntaria se basa en un vínculo de confianza entre el voluntario y el
proyecto al que se adhiere:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
12
Debido al anonimato de los voluntarios, si uno de ellos actúa maliciosamente,
como por ejemplo devolviendo resultados manipulados, el proyecto no puede
enjuiciar o disciplinar a dicho voluntario. Aunque para ello cuenta con
herramientas para la validación de la integridad de los resultados.
Así mismo, los voluntarios han de confiar en el proyecto al que ayudan. Esta
confianza es mucho más ciega, por así decirlo, ya que en este caso no hay medios
que “validen” la buena intención por parte del proyecto. Los aspectos a tener en
cuenta son los siguientes:
o Confiar en que las aplicaciones proporcionadas no dañen el equipo o
invadan la intimidad.
o Confiar en que el proyecto sea sincero en los objetivos y en el trabajo que
están desarrollando sus aplicaciones y el buen uso intelectual de los
resultados obtenidos.
o Confiar en que el proyecto emplee medidas de seguridad adecuadas, y así
evitar que algún hacker emplee el proyecto con otros propósitos.
1.1.3 Computación Voluntaria vs GRID
Existen ciertas diferencias importantes entre la Computación Voluntaria y la
Computación GRID. Las distinciones más importantes son las que se presentan a
continuación:
1. Mientras que en Computación Voluntaria hay que cerciorarse de que los
resultados no hayan sido manipulados maliciosamente, en GRID se puede asumir
la integridad de los resultados.
2. Mientras que en Computación Voluntaria es necesario dotar a cada estación
cliente de una herramienta para la visualización de gráficos y de un mecanismo de
control de la carga computacional que se desea prestar; en GRID esta necesidad es
inexistente, ya que todo el proceso está centralizado y es totalmente invisible para
los usuarios.
3. En GRID todo el proceso de los clientes está normalmente automatizado.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
13
2 METODOLOGÍA
Se ha decidido seguir la metodología lineal o en cascada. Ésta metodología se
caracteriza por tener un conjunto de etapas bien definidas de antemano, no
comenzándose una etapa sin tener finalizada y validada la etapa anterior.
2.1 MODELO LINEAL
En este modelo se ordenan rigurosamente las etapas del ciclo de vida del software, de
forma tal que no se inicia una etapa o fase hasta que se completa la anterior. Este
modelo es perfecto para proyectos en los que están muy bien definidos los
requerimientos y en los que se conozca la herramienta a utilizar.
Como inconveniente principal está el hecho de que no se suele disponer de requisitos
concisos y detallados inicialmente, sino que se van modelando a lo largo del ciclo.
Además los cambios en el desarrollo son difícilmente asumibles y los resultados no se
ven hasta muy avanzado el desarrollo.
El modelo lineal seguido se representa en el siguiente diagrama:
1Identificación Necesidades
2Análisis
Requisitos
3Estudio
Arquitectura
4Diseño Externo
5Diseño Interno
6Desarrollo
Núcleo
7Validación
Núcleo
8Desarrollo
Estrategia A
9Validación
Estrategia A
10Desarrollo
Estrategia B
11Validación
Estrategia B
12Simulaciones
13Análisis
Resultados
14Desarrollo
Estra. Óptima
15Validación
Estra. Óptima

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
14
A continuación se procede a describir cada una de las etapas realizadas a lo largo del
proyecto para su mayor entendimiento:
1. Identificación de Necesidades
En esta etapa, se debe conseguir identificar cuales son los objetivos y necesidades que
se desean satisfacer a través del proyecto a desarrollar, así se definirán los siguientes
apartados:
Objetivos del sistema: Se trata de objetivos de tipo empresarial y no de tipo
informático.
Alcance del sistema: Funciones de negocio a considerar dentro del alcance.
Tipología de usuarios finales: Perfil de personas al que va dirigido el producto
final a obtener.
Restricciones: Se deben identificar y considerar aquellas restricciones que pueden
afectar al plan de proyecto y a su desarrollo.
Organización del proyecto: Perfil de los participantes en el equipo de trabajo
asignado al proyecto y su organización.
2. Análisis de Requisitos
Se analizarán las necesidades de los usuarios finales del software para determinar qué
objetivos se deben cubrir. De esta fase surgirá una especificación completa de lo que
debe hacer el sistema sin entrar en detalles internos.
3. Estudio de Arquitectura
Los objetivos de esta etapa son los siguientes:
Definir el conjunto de posibles soluciones software, hardware y de
comunicaciones que se adapten a las restricciones y requisitos sobre el sistema.
Escoger entre las soluciones estudiadas la óptima para el proyecto, validada por el
cliente.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
15
Para alcanzar estos objetivos es necesario un estudio sobre tecnologías hardware,
software y de comunicaciones para cada solución propuesta.
4. Diseño Externo
En esta etapa se establecerá el modelo de procesos lógicos y físicos definidos en la
etapa de análisis de requisitos con la solución tecnológica escogida en el anterior
apartado.
Como resultado se obtendrá el modelo físico del sistema.
5. Diseño Interno
En esta etapa se identificarán y diseñarán los componentes software de cada subsistema,
especificando cada uno de los programas a desarrollar.
Se debe definir completamente la estructura de los ficheros intermedios implicados en
cada proceso del sistema, a diferencia de las entradas y salidas obtenidas en la etapa
anterior.
6. Desarrollo del Núcleo Uniproceso
Esta etapa contempla el desarrollo del algoritmo de resolución uniproceso diseñado en
la etapa anterior.
Además, se debe elaborar el manual de usuario adecuado para el correcto aprendizaje de
los usuarios y la descripción de las características y peculiaridades del interfaz
implementado.
7. Validación del Núcleo
Una vez desarrollado el núcleo uniproceso, se procederá a su validación y refinamiento
del código.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
16
8. Desarrollo de la Estrategia A
Tras la validación del núcleo uniproceso, se procederá a su adaptación para su
funcionamiento en GRID, según la estrategia A de resolución y bajo la arquitectura
GRID escogida.
Además, se debe elaborar el manual de usuario adecuado para el correcto aprendizaje de
los usuarios y la descripción de las características y peculiaridades del interfaz
implementado.
9. Validación de la Estrategia A
Una vez desarrollada la estrategia A, se procederá a su validación y refinamiento del
código.
10. Desarrollo de la Estrategia B
Esta etapa comprende la adaptación del código validado en el paso anterior para que
soporte también la estrategia B de resolución.
Además, se debe elaborar el manual de usuario adecuado para el correcto aprendizaje de
los usuarios y la descripción de las características y peculiaridades del nuevo interfaz
implementado.
11. Validación de la Estrategia B
Una vez desarrollada la estrategia B, se procederá a su validación y refinamiento del
código.
12. Simulaciones
En esta etapa se realizarán las simulaciones con las diferentes estrategias y criterios de
configuración determinantes, siguiendo un esquema de pruebas previamente
planificado.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
17
13. Análisis de Resultados
Una vez terminadas las simulaciones, se procederá a analizar los resultados obtenidos
en éstas.
Para ello será necesaria la generación de gráficas que faciliten el estudio.
14. Desarrollo de la Estrategia Óptima
Tras analizar las simulaciones y obtener las conclusiones finales, se contará con la
información necesaria para proponer y desarrollar una nueva estrategia de resolución
más óptima.
Esta etapa contempla el desarrollo de un nuevo algoritmo de resolución que implemente
esta nueva estrategia óptima.
Además, se debe elaborar el manual de usuario adecuado para el correcto aprendizaje de
los usuarios y la descripción de las características y peculiaridades del interfaz
implementado.
15. Validación de la Estrategia Óptima
Una vez desarrollada la estrategia óptima se procederá a su validación y refinamiento
del código.
Además, se realizará un conjunto de simulaciones y se expondrán los resultados
obtenidos.
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
18
3 PLANIFICACIÓN DEL PROYECTO
La planificación temporal del proyecto ha sido elaborada sobre las etapas del mismo
definidas en anteriores apartados y según las restricciones temporales descritas en el
apartado 5.4 Restricciones de Tiempo, debiéndose entregar antes del 3 de septiembre de
2009. A continuación se muestra una tabla simplificada con los días de cada etapa y el
porcentaje que representa sobre el total.
ETAPA DESCRIPCIÓN DÍAS COMPARTIDOS DÍAS COMPLETOS %
E1 Identificación necesidades 0 5 1,64%
E2 Análisis requisitos 0 5 1,64%
E3 Estudio arquitectura 0 4 1,32%
E4 Diseño interno 0 11 3,62%
E5 Diseño externo 0 12 3,95%
E6 Desarrollo núcleo uniproceso
21
38,5 12,66%
E7 Validación núcleo 26,5 8,72%
E8 Desarrollo estrategia A
29
54.5 17,93%
E9 Validación estrategia A 50,5 16,61%
E10 Desarrollo estrategia B
27
32,5 10,69%
E11 Validación estrategia B 28,5 9,38%
E12 Simulaciones
25
17,5 5,76%
E13 Análisis resultados 15,5 5,10%
E14 Desarrollo estrategia óptima
2
1,5 0,49%
E15 Validación estrategia óptima 1,5 0,49%
304 100%
En la siguiente página se muestra el diagrama de Gantt de la planificación temporal
seguida.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
___________________________________________________________________________________________________________________________________________
19
Id. Nombre de tarea Comienzo Fin Duracióndic 2008 mar 2009 jun 2009ene 2009 abr 2009nov 2008 may 2009 jul 2009feb 2009oct 2008
11/19/11 8/3 15/321/12 19/714/61/2 7/68/2 10/529/3 21/65/416/11 18/1 24/54/123/115/10 26/412/419/10 12/71/315/212/10 25/1 28/63/526/10 19/422/22/11 7/12 22/3 5/728/12 31/530/11 26/714/12 17/5
6 49d25/12/200807/11/2008Desarrollo núcleo uniproceso
7 37d10/01/200905/12/2008Validación núcleo
8 69d20/03/200911/01/2009Desarrollo Estrategia A
9 65d25/04/200920/02/2009Validación estrategia A
10 46d10/06/200926/04/2009Desarrollo Estrategia B
11 42d25/06/200915/05/2009Validación estrategia B
12 30d25/07/200926/06/2009Simulaciones
13 28d28/07/200901/07/2009Análisis resultados
1 5d05/10/200801/10/2008Identificación necesidades
2 5d10/10/200806/10/2008Análisis requisitos
3 4d14/10/200811/10/2008Estudio arquitectura
4 11d25/10/200815/10/2008Diseño interno
5 12d06/11/200826/10/2008Diseño externo
14
15
2d30/07/200929/07/2009Desarrollo estrategia óptima
2d31/07/200930/07/2009Validación estrategia óptima
2/8
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
20
4 PRESUPUESTO
En la primera tabla se expone, por cada etapa definida en apartados anteriores, el coste
en horas/hombre de cada perfil implicado en la realización del proyecto.
Para ello se mostrará primeramente una tabla cuyas filas representan todas las etapas del
proyecto y su asignación en horas para cada perfil. Los totales de horas corresponden
por paquete y perfil al final de cada fila y columna. Además, se representa el porcentaje
de la duración de cada paquete respecto al total, dato que ayuda a cuantificar el esfuerzo
que representa cada etapa del proyecto.
ETAPA DESCRIPCIÓN DP1 DP2 JP An Pr TOTAL %
E1 Identificación necesidades 3 3 12 30 0 48 2,26%
E2 Análisis requisitos 3 3 12 30 0 48 2,26%
E3 Estudio arquitectura 0 0 9 24 0 33 1,55%
E4 Diseño interno 0 0 20 30 30 80 3,77%
E5 Diseño externo 0 0 24 35 35 94 4,43%
E6 Desarrollo núcleo uniproceso 0 0 45 19 231 295 13,89%
E7 Validación núcleo 12 12 90 0 41 155 7,30%
E8 Desarrollo estrategia A 0 0 55 27 327 409 19,26%
E9 Validación estrategia A 20 20 150 0 95 285 13,42%
E10 Desarrollo estrategia B 0 0 36 16 195 247 11,63%
E11 Validación estrategia B 13 13 96 0 44 166 7,82%
E12 Simulaciones 19 19 102 0 0 140 6,59%
E13 Análisis resultados 20 20 60 0 0 100 4,71%
E14 Desarrollo estrategia óptima 0 0 3 2 7 12 0,56%
E15 Validación estrategia óptima 1 1 7 0 3 12 0,56%
91 91 721 213 1008 2124 100%

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
21
El resultado de horas total invertidas en el proyecto en todos los perfiles asciende a
2124 horas.
Una vez realizado el coste en horas/hombre, se explica el presupuesto económico del
proyecto, definiendo en primer lugar una tarifa para cada perfil que haya participado en
la estimación del coste.
PERFIL DESCRIPCIÓN €/hora
DP Director de Proyecto 80
JP Jefe de Proyecto 60
An Analista 50
Pr Programador 50
Para calcular el coste económico del proyecto se multiplican las horas invertidas de
cada perfil por su tarifa correspondiente.
Señalar que sólo se tiene en cuenta el coste monetario del tiempo dedicado por cada
participante, no existiendo otros costes de licencias o pruebas ya que el cliente dispone
de todas las herramientas necesarias para el correcto funcionamiento.
PERFIL DESCRIPCIÓN HORAS TARIFA TOTAL %
DP1 Director de Proyecto 91 80 7280 6,12%
DP2 Director de Proyecto 91 80 7280 6,12%
JP Jefe de Proyecto 721 60 43260 36,39%
An Analista 213 50 10650 8,96%
PR Programador 1008 50 50400 42,40%
2124 55,965 118870 100%
Para obtener una mejor perspectiva del coste económico, se expone a continuación el
coste ligado a cada una de las etapas del proyecto.
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
22
ETAPA DESCRIPCIÓN HORAS TARIFA MEDIA TOTAL %
E1 Identificación necesidades 48 56,25 2700 2,27%
E2 Análisis requisitos 48 56,25 2700 2,27%
E3 Estudio arquitectura 33 52,73 1740 1,46%
E4 Diseño interno 80 52.5 4200 3,53%
E5 Diseño externo 94 52,55 4940 4,16%
E6 Desarrollo núcleo uniproceso 295 51,53 15200 12,79%
E7 Validación núcleo 155 60,45 9370 7,88%
E8 Desarrollo estrategia A 409 51,34 21000 17,67%
E9 Validación estrategia A 285 59,47 16950 14,26%
E10 Desarrollo estrategia B 247 51,46 12710 10,69%
E11 Validación estrategia B 166 60,48 10040 8,45%
E12 Simulaciones 140 65,43 9160 7,71%
E13 Análisis resultados 100 68 6800 5,72%
E14 Desarrollo estrategia óptima 12 52,5 630 0,53%
E15 Validación estrategia óptima 12 60,83 730 0,61%
2124 55,965 118870 100%
Como se puede observar en ambas tablas de estimación, el coste económico total
obtenido es de 118870 euros.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
23
5 IDENTIFICACIÓN DE NECESIDADES
En esta etapa, se debe conseguir identificar cuales son los objetivos y necesidades que
se desean satisfacer a través del proyecto a desarrollar.
5.1 OBJETIVOS DEL SISTEMA
Dentro de la Minería de Datos, existe un tipo de modelos de aprendizaje supervisado
que por sus características se adaptan especialmente para su ajuste en un GRID de
ordenadores.
En este proyecto se pretende desarrollar un algoritmo de ajuste especialmente diseñado
para explotar las ventajas de un GRID en la construcción de un modelo jerárquico
novedoso basado en los árboles de regresión.
Para ello será necesario diseñar y desarrollar una aplicación informática que implemente
dicha estrategia de ajuste en un GRID.
Finalmente se realizará un estudio de rendimiento de la utilización del GRID en la
construcción del modelo jerárquico.
5.2 ALCANCE DEL SISTEMA
La construcción del sistema implica la realización de las siguientes funciones que se
determinan a continuación:
1. Crear el algoritmo de ajuste
Tiene como objetivo el diseño y desarrollo de una aplicación que implemente la
estrategia de creación de árboles de regresión. Dicha aplicación será uniproceso, es
decir, se ejecutará en una sola máquina. Se incluirán mecanismos para el control de
tiempo del tiempo de cálculo del algoritmo.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
24
2. Adaptar el algoritmo al GRID
Tiene como objetivo la adaptación del código desarrollado para su uso en un GRID
de ordenadores.
3. Simular y analizar resultados
Tiene como objetivo la realización de una serie de simulaciones planificadas y su
posterior análisis de rendimiento, para ello será necesaria la obtención de gráficas de
tiempos de cálculo de las simulaciones realizadas.
5.3 TIPOLOGÍA DE USUARIOS FINALES
El grupo de usuarios a los que la aplicación final y el estudio están destinados
corresponde al personal del IIT de la Universidad que crea oportuno su uso en estudios
futuros.
Esta serie de usuarios cuentan con un amplio conocimiento teórico en el campo de los
árboles de regresión y están ampliamente familiarizados con todo tipo de resultados
derivados de estudios de índole investigativa.
Sin embargo se espera que su capacidad sobre conocimiento de las herramientas
empleadas en este estudio sea limitada, por lo que se acompaña a este documento de un
manual de usuarios muy detallado.
5.4 RESTRICCIONES
En este apartado se lista la serie de restricciones impuestas sobre el proyecto tanto por el
cliente (IIT) como por la Universidad (Comillas). Estas restricciones responden a varias
tipologías:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
25
1. RESTRICCIONES DE TIEMPO:
Entrega del Proyecto
El plazo de realización del proyecto impuesto por la Universidad, que comprende la
fecha mínima de inicio correspondiente a 1 de Octubre del 2008 (inicio del curso
académico) y la fecha límite máxima de entrega el 3 de septiembre de 2009, para su
evaluación por el coordinador de proyecto.
2. RESTRICCIONES GEOGRÁFICAS:
IIT (GRID)
Los recursos hardware que se van a emplear en la mayoría de las etapas
de desarrollo se encuentran en el IIT de la universidad, por lo que habrá que acogerse
al calendario y al horario de apertura y cierre de la universidad.
3. RESTRICCIONES DE TIPO ORGANIZATIVO:
Disponibilidad de los directores
La disponibilidad de los directores de proyecto, aunque alta, no es total, pudiendo
quedar suspendido durante un corto espacio de tiempo a causa de este motivo.
Compartición de recursos hardware
Los recursos hardware que se van a emplear en el desarrollo del proyecto son usados
para el desarrollo de otros proyectos de alumnos de la universidad, por lo que su
disponibilidad tampoco será total.
5.5 ORGANIZACIÓN DEL PROYECTO
Existirán cinco perfiles que participan en el equipo de trabajo designado al proyecto,
como se representa en el siguiente organigrama:
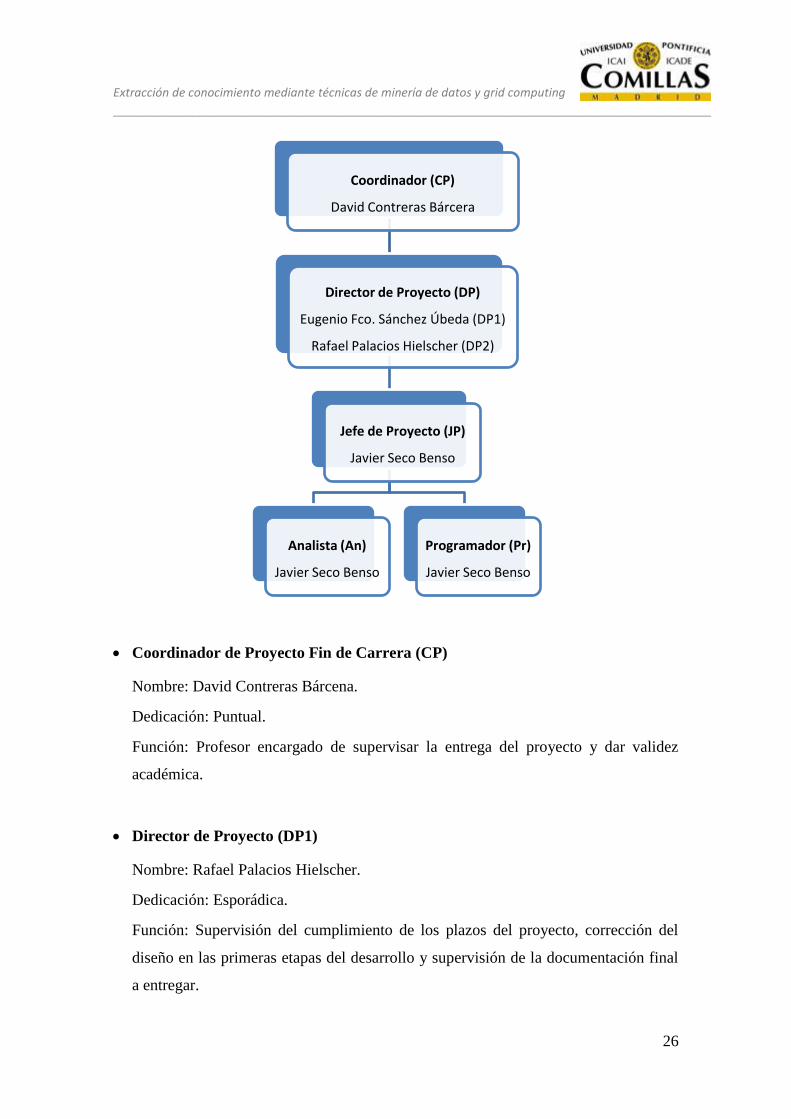
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
26
Coordinador de Proyecto Fin de Carrera (CP)
Nombre: David Contreras Bárcena.
Dedicación: Puntual.
Función: Profesor encargado de supervisar la entrega del proyecto y dar validez
académica.
Director de Proyecto (DP1)
Nombre: Rafael Palacios Hielscher.
Dedicación: Esporádica.
Función: Supervisión del cumplimiento de los plazos del proyecto, corrección del
diseño en las primeras etapas del desarrollo y supervisión de la documentación final
a entregar.
Coordinador (CP)
David Contreras Bárcera
Director de Proyecto (DP)
Eugenio Fco. Sánchez Úbeda (DP1)
Rafael Palacios Hielscher (DP2)
Jefe de Proyecto (JP)
Javier Seco Benso
Analista (An)
Javier Seco Benso
Programador (Pr)
Javier Seco Benso

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
27
Director de Proyecto (DP2)
Nombre: Eugenio Fco. Sánchez Úbeda.
Dedicación: Esporádica.
Función: Supervisión del cumplimiento de los plazos del proyecto, corrección del
diseño en las primeras etapas del desarrollo y supervisión de la documentación final
a entregar.
Jefe de Proyecto (JP)
Nombre: Javier Seco Benso.
Dedicación: Parcial.
Función: Supervisión de las partes de diseño y análisis en todas las fases del
proyecto.
Analista (An)
Nombre: Javier Seco Benso.
Dedicación: Total.
Función: Encargado de la realización de la identificación de necesidades, análisis de
requisitos, diseño interno y externo.
Programador (Pr)
Nombre: Javier Seco Benso.
Dedicación: Total.
Función: Encargado del implementar la solución adoptada.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
28
6 ANÁLISIS REQUISITOS
En esta etapa se analizarán las necesidades de los usuarios finales del software para
determinar qué objetivos se deben cubrir. De esta fase surgirá una especificación
completa de lo que debe hacer el sistema sin entrar en detalles internos.
6.1 DIAGRAMA DE PRESENTACIÓN
A continuación se expone el diagrama que representa el contexto general del sistema
que se desea desarrollar:
Ficheros de datos: Conjuntos de ejemplos (reales o sintéticos) para la realización
de simulaciones.
Sistema: Se encarga de generar el árbol de regresión a partir de unos datos de
entrada
Gráficas de Resultados: Conjunto de gráficas de los procesos de creación de los
árboles de regresión para su estudio de rendimiento.
6.2 LISTA DE REQUISITOS
A continuación se expone la lista de los distintos tipos de requisitos asociados al
desarrollo del nuevo sistema:
Sistema
Gráficas
Resultados
Ficheros
Datos

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
29
Requisitos Funcionales
La aplicación permitirá la creación de Árboles de Regresión a partir de una matriz
de datos.
El algoritmo de creación de árboles de regresión deberá ser diseñada para ser
capaz de trabajar en modo uniproceso y ser fácilmente adaptable a GRID.
Para la resolución en GRID se deberá seleccionar una de las plataformas GRID ya
existentes que mejor se adapte a la solución elegida.
Es de vital importancia la implementación de un mecanismo que controle y
guarde los tiempos de creación del árbol.
Para facilitar el estudio de los tiempos de creación de árboles, será preciso el
dibujo de gráficas a partir de los resultados obtenidos.
Requisitos Operativos
Los tiempos de medición de las etapas del proceso de generación de los árboles
deberán ser lo más precisos posibles, siendo deseable que la precisión de éstos no
sea superior a los milisegundos.
Requisitos de Rendimiento
La creación de árboles de regresión requiere grandes cantidades de tiempo y
espacio, por tanto se deberá optimizar lo máximo posible los algoritmos y
estructuras usadas. (memoria dinámica)
Requisitos de Prestaciones
El algoritmo de creación de árboles de regresión se podrá adaptar fácilmente a
distintos tipos de estrategias de ajuste.
El algoritmo de creación de árboles de regresión deberá soportar todo tipo de
variables de entrada: discretas, categóricas y continuas.
El usuario decidirá si desea obtener un fichero de Log donde se muestren los
resultados de cada una de las etapas de la construcción del árbol, incluyendo el
dibujo del árbol obtenido.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
30
El usuario podrá determinar los siguientes aspectos de configuración de la
creación del árbol:
o Variables de entrada que se desean usar.
o Variable de salida del árbol.
o Se podrá determinar una profundidad máxima para el árbol.
o Determinar los parámetros de parada del árbol: mínimo número de ejemplos
y mínimo MSE de un nodo.
Requisitos de Fiabilidad
Es muy importante que los árboles generados sean reales, por lo que deberá hacer
hincapié en la validación de los algoritmos de resolución generados.
A continuación se pasa a describir todos estos requisitos en más detalle:
REQUISITO
Título: Datos de entrada con estructura matricial.
Categoría: Funcional
Descripción: La aplicación permitirá la creación de un árbol de regresión a
partir de una matriz de datos de entrada.
MEDICIÓN
Los datos de entrada se darán ordenados en una estructura matricial. Debido a
las grandes cantidades de información que se manejan actualmente, dicha
matriz podrá tener un tamaño considerable, del orden de miles o millones de
ejemplos (filas).
Además, es muy frecuente que no se quiera emplear todas las variables
(columnas) en el estudio, por tanto, será preciso que el usuario sea capaz de
seleccionar aquella información que se desea ser sometida a estudio.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
31
BENEFICIOS
Debido al cuantioso número de datos con el que el algoritmo deberá trabajar,
cobra gran importancia el diseño de las estructuras donde se va a guardar dicha
información. De esta manera, se hace indispensable establecer unos criterios de
presentación de los datos de entrada, para que el algoritmo sea capaz de leerlas
y general sus propias estructuras de una forma rápida y eficaz.
COMENTARIOS / SOLUCIONES SUGERIDAS
La aplicación contará con un archivo de configuración donde se podrá
especificar, entre otras opciones, qué variables se desea ser sometidas a
estudio.
El algoritmo de creación del árbol contará con una primera etapa de carga de la
información de entrada a memoria.
REQUISITO
Título: Algoritmo fácilmente adaptable a GRID.
Categoría: Funcional
Descripción: El algoritmo de creación de árboles de regresión deberá ser
diseñado para ser capaz de trabajar en modo uniproceso y ser fácilmente
adaptable a GRID.
MEDICIÓN
El código del algoritmo de creación de árboles de regresión será capaz de
funcionar en modo uniproceso o GRID dependiendo de unas variables de
entrada, y sin necesidad de reescribir funciones del código.
BENEFICIOS
El diseño, desde un principio, de un algoritmo modular y recursivo, nos

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
32
permitirá una adaptación mucho más sencilla al funcionamiento en GRID,
donde la creación de un árbol se reparte entre varias estaciones.
COMENTARIOS / SOLUCIONES SUGERIDAS
Se hará hincapié en el diseño modular de las funciones del algoritmo de
creación de árboles de regresión, estudiando cada una de las etapas del proceso
y haciéndola lo más independiente posible del resto.
El algoritmo de creación del árbol deberá ser un algoritmo de tipo recursivo, de
forma que cada iteración siga los siguientes pasos:
1. Lectura de los datos de entrada del nodo.
2. Expansión del nodo.
3. Creación de los datos de salida del nodo.
De esta manera el algoritmo será capaz de resolver un árbol desde un nodo
inicial o bien de resolver tan solo una rama de éste.
REQUISITO
Título: Selección de la plataforma GRID.
Categoría: Funcional
Descripción: Para la resolución en GRID se deberá seleccionar una de las
plataformas GRID ya existentes que mejor se adapte a la estrategia escogida.
MEDICIÓN
El algoritmo de resolución de árboles de regresión deberá ser fácilmente
adaptable a la plataforma GRID elegida, sin tener que hacer grandes
modificaciones en su estructura.
BENEFICIOS
La elección de la plataforma GRID que mejor se adapte a la estrategia GRID

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
33
escogida será fundamental para un rendimiento de la aplicación sea óptimo y
unos resultados lo fiables.
COMENTARIOS / SOLUCIONES SUGERIDAS
Primero se realizará un estudio de las diferentes estrategias posibles para la
resolución de un árbol de regresión en un GRID, y se elegirá la mejor
candidata.
A continuación se realizará un estudio de diferentes plataformas GRID ya
existentes para analizar cuál de ellas se adecúa mejor a la estrategia
seleccionada.
REQUISITO
Título: Control de tiempos de creación del árbol.
Categoría: Funcional
Descripción: Es de vital importancia la implementación de un mecanismo que
controle y guarde los tiempos de creación del árbol.
MEDICIÓN
La precisión de los tiempos obtenidos no será superior al orden de las
centésimas de segundo.
Los puntos de medición se tomarán tras la finalización de cada una de las
etapas de creación del árbol. Estas etapas presentaran una estructura parecida a
la siguiente: recepción de datos, carga de datos, cálculo del árbol, generación
de resultados, envío de resultados.
BENEFICIOS
Para un análisis preciso de los rendimientos obtenidos con cada una de las
configuraciones que serán sometidas a estudio, se hace necesaria una medición

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
34
precisa en la toma de tiempos de cada una de las etapas del proceso de
obtención del árbol.
COMENTARIOS / SOLUCIONES SUGERIDAS
Para la obtención de mediciones del orden de las centésimas será preciso el uso
de un lenguaje de programación que posea herramientas para tal efecto.
Asimismo, se deberá estudiar la plataforma GRID escogida para ver si ofrece
funciones de ayuda en el control de tiempos de asignación y recepción de
tareas, o en su defecto, obtener los tiempos a través del protocolo utilizado de
envío y recepción de datos en la red.
REQUISITO
Título: Generación de gráficas de resultados.
Categoría: Funcional
Descripción: Para facilitar el estudio de los tiempos de creación de árboles,
será preciso el dibujo de gráficas a partir de los resultados obtenidos
MEDICIÓN
Las gráficas obtenidas deberán ser lo suficientemente claras para diferencial
visualmente cada una de las etapas del proceso de creación del árbol.
BENEFICIOS
La obtención de gráficas facilitará en gran medida un primer análisis de los
resultados de un caso, y ayudará a comprender el modelo de rendimiento
global comparando varios resultados de distintas configuraciones.
COMENTARIOS / SOLUCIONES SUGERIDAS
Será necesaria la creación de un nuevo algoritmo que recabe los tiempos

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
35
concernientes al proceso de creación del árbol y, cuando se emplee el GRID,
también aquellos tiempos concernientes al los tiempos de envío y recepción de
información por la red. El modo de obtención de la información relativa a estos
últimos tiempos dependerá de la plataforma GRID escogida.
Para la generación de las gráficas será preciso que el nuevo algoritmo genere
una matriz de tiempos que sirva como entrada para alguna de las aplicaciones
ya existentes para la generación de gráficas (por ejemplo Matlab).
REQUISITO
Título: Precisión de mediciones.
Categoría: Operativo
Descripción: Los tiempos de medición de las etapas del proceso de generación de
los árboles deberán ser lo más precisos posibles.
MEDICIÓN
Es deseable que la precisión de las mediciones no sea superior a los
milisegundos.
BENEFICIOS
Con unas mediciones precisas se obtendrán unos resultados más realistas.
COMENTARIOS / SOLUCIONES SUGERIDAS
Se hará uso de funciones de medición de tiempos precisas con el lenguaje de
programación escogido y se consultarán las bases de datos y ficheros de log
generados en las simulaciones.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
36
REQUISITO
Título: Optimizar el manejo de la información.
Categoría: Rendimiento
Descripción: La creación de árboles de regresión requiere grandes cantidades
de tiempo y espacio, por tanto se deberá optimizar al máximo posible los
algoritmos y estructuras usadas.
MEDICIÓN
La resolución de los árboles de regresión deberá obtenerse en un espacio de
tiempo razonable.
BENEFICIOS
El uso de unas estructuras de datos bien diseñadas reducirá de forma notable el
tiempo y los recursos necesarios para la obtención del árbol de regresión.
COMENTARIOS / SOLUCIONES SUGERIDAS
Se hará hincapié en el diseño de las estructuras de datos en las que se cargará la
información de entrada del árbol.
Además se gestionará cuidadosamente la memoria empleada por la aplicación.
REQUISITO
Título: Algoritmo adaptable a varias estrategias de resolución.
Categoría: Prestación
Descripción: El algoritmo de creación de árboles de regresión se podrá adaptar
fácilmente a distintos tipos de estrategias de ajuste.
MEDICIÓN

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
37
El sistema generado debe ser capaz de generar el mismo árbol de regresión con
las distintas estrategias de resolución posibles.
BENEFICIOS
Con el cumplimento de éste requisito se desea analizar los pros y contras de
cada estrategia de resolución.
COMENTARIOS / SOLUCIONES SUGERIDAS
Una buena modularización del algoritmo de resolución generado permitirá la
ejecución de las distintas estrategias posibles.
REQUISITO
Título: Conjuntos de ejemplos heterogéneos.
Categoría: Prestación
Descripción: El algoritmo de creación de árboles de regresión deberá soportar
todo tipo de variables de entrada: discretas, categóricas y continuas.
MEDICIÓN
La aplicación será capaz de crear el árbol de regresión dados unos datos de
entradas formados por cualquier tipo de variables.
BENEFICIOS
Se tendrá la posibilidad de emplear el algoritmo de creación de árboles de
regresión en un mayor abanico de ejemplos.
También se conseguirá una mayor reutilización del código creado para otros
proyectos o estudios que requieran de la creación de un árbol de regresión.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
38
COMENTARIOS / SOLUCIONES SUGERIDAS
Se deberá usar estructuras dinámicas para poder soportar todo tipo de variables
de entrada.
REQUISITO
Título: Generación de Log
Categoría: Prestación
Descripción: El usuario decidirá si desea obtener un fichero de Log donde se
muestren los resultados de cada una de las etapas de la construcción del árbol,
incluyendo el dibujo del árbol obtenido.
MEDICIÓN
El fichero de LOG será lo suficientemente claro para que el usuario pueda ver
cuáles fueron todos los pasos y decisiones llevadas a cabo por el algoritmo para
la determinación del árbol de regresión.
Además, el fichero mostrará un esquema del árbol obtenido.
BENEFICIOS
Servirá como herramienta de verificación durante la etapa de desarrollo del
código.
Así mismo, es muy posible que el usuario necesite obtener un dibujo del árbol
creado, así como de los pasos realizados para su obtención.
COMENTARIOS / SOLUCIONES SUGERIDAS
La aplicación contará con un archivo de configuración donde se podrá
especificar, entre otras opciones, si se desea obtener el fichero de LOG. Habrá
que tener en cuenta que para el análisis de tiempo esta opción se recomienda

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
39
que esté desactivada, ya que incrementaría considerablemente la carga a
realizar por la estación.
REQUISITO
Título: Configuración de usuario.
Categoría: Prestación
Descripción: El usuario podrá determinar los siguientes aspectos de
configuración de la creación del árbol:
Variables de entrada que se desean usar.
Variable de salida del árbol.
Se podrá determinar una profundidad máxima para el árbol.
Determinar los parámetros de parada del árbol: mínimo número de
ejemplos y mínimo MSE de un nodo.
MEDICIÓN
El algoritmo de creación del árbol de regresión tomará como condiciones de
creación del árbol aquellas descritas por el usuario en el fichero de
configuración.
BENEFICIOS
La construcción de un árbol de regresión implica una serie de condiciones
iniciales que deben ser tenidas en cuenta por el algoritmo. Es indispensable
desarrollar un mecanismo que permita al algoritmo conocer dichas
condiciones.
Asimismo, el poder acotar la profundidad en la creación del árbol también será
de gran ayuda a la hora de repartir tareas cuando se resuelva a través del GRID.
COMENTARIOS / SOLUCIONES SUGERIDAS

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
40
La aplicación contará con un archivo de configuración donde el usuario podrá
especificar todas las condiciones iniciales.
REQUISITO
Título: Generación fiable de árboles de regresión.
Categoría: Prestación
Descripción: Es muy importante que los árboles generados sean reales, por lo que
deberá hacer hincapié en la validación de los algoritmos de resolución generados.
MEDICIÓN
Se realizará un exhaustivo proceso de validación de los algoritmos de resolución
generados.
BENEFICIOS
Dado el carácter de investigación de este proyecto, es esencial poder asegurar
que los resultados obtenidos por el sistema son totalmente realistas.
COMENTARIOS / SOLUCIONES SUGERIDAS
Tras el desarrollo de la solución a cada una de las estrategias de resolución se
llevarán a cabo una serie de simulaciones con conjuntos de pruebas simples, de
los que pueda saberse de antemano qué resultados deben obtenerse.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
41
7 ESTUDIO DE ARQUITECTURA
Los objetivos de esta etapa son los siguientes:
Definir el conjunto de posibles soluciones software, hardware y de
comunicaciones que se adapten a las restricciones y requisitos sobre el sistema.
Escoger entre las soluciones estudiadas la óptima para el proyecto, validada por el
cliente.
Para alcanzar estos objetivos es necesario un estudio sobre tecnologías hardware,
software y de comunicaciones para cada solución propuesta.
7.1 SISTEMA DISTRIBUIDO
Para la realización del cálculo distribuido del árbol de regresión se propone el uso de
una de las arquitecturas Middleware GRID existentes.
No hay que confundir Middleware GRID con un GRID. Un Middleware GRID
(Plataforma Software) se usa para construir un GRID concreto.
Estas arquitecturas proporcionan el middleware que sirve de puente entre los sistemas
de escritorio con interfaces estándar de programación y la rica oferta de servicios
soportados por la arquitectura GRID.
Entre las arquitecturas más populares podemos citar las siguientes: Alchemi, BOINC,
Condor, G-Farm, Globus Toolkit, Netsolve/Gridsolve, Nimrod, Ninf y PVM.
7.2 ESTRATEGIAS
Una vez analizadas las arquitecturas, y partiendo de las dos estrategias propuestas para
la repartición del trabajo en el GRID, se han seleccionado dos arquitecturas a tener en
cuenta.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
42
7.2.1 Estrategia A
Se trata de una estrategia centralizada, basándose en el uso de una estación “servidora”
y de otras estaciones “clientes” con una asignación estática de tareas.
La estación servidora se encarga de ajustar el árbol de regresión hasta cierta altura
indicada por el usuario, obteniéndose así N nodos finales pendientes de resolución.
Cada uno de estos nodos será enviado al GRID y resuelto por una estación cliente libre
de trabajo. Finalmente, las estaciones clientes devuelven los resultados obtenidos a la
estación servidora.
El objetivo es construir el árbol hasta generar un número suficiente de tareas para ser
resueltas paralelamente en el GRID. Para las simulaciones planificadas, se dispone de 5
ordenadores con doble procesador, por tanto el número de tareas que más se ajusta a esa
configuración es de 23 = 8. Para esto, la estación servidora deberá ajustar el árbol hasta
el nivel 4 de profundidad.
Ventajas:
Simplicidad en la gestión del GRID. Las tareas a despachar quedan definidas
por el usuario durante la primera etapa.
Mínima cantidad de tareas generadas: Se genera el menor número de tareas
posibles para llenar el GRID.
Poca carga media en la red. Al no haber asignación dinámica de tareas, la red no
se satura durante todo el proceso de cálculo, concentrándose la carga durante el
proceso inicial de asignación de tareas a las estaciones clientes.
Simplicidad en el control del GRID: la asignación estática de tareas permite
llevar un mejor control del trabajo realizado por cada elemento del GRID, tanto a
la hora de analizarlo como de solventar posibles fallos.
Desventajas:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
43
Posibilidad de infrautilización del GRID. Si se da el caso de que todos los
nodos se encuentran ya asignados, aquellas estaciones clientes que estén libres
permanecerán infrautilizadas. De ahí que el usuario tenga un peso importante para
el rendimiento final obtenido a la hora de decidir cuántas tareas se van a crear en
la estación servidora.
Posible saturación en la red. Como ya se ha comentado, la mayor parte de la
carga que va a soportar la red se concentra durante la primera etapa de asignación
de tareas a las estaciones clientes.
A continuación se muestra un ejemplo de una posible resolución siguiendo esta
estrategia en un GRID de cuatro estaciones: G1, G2, G3 y G4:
1. La estación servidora (G1) realiza el cálculo hasta el nivel 3 del árbol de
regresión.
Nótese que durante este proceso el resto de estaciones del GRID está en desuso,
por lo que éste no debe ser muy costoso para que el rendimiento global no decaiga
demasiado.
2. Los nodos pendientes de resolución son enviados a las estaciones cliente que se
encuentren libres (G2, G3 y G4).
Las estaciones clientes se encargan de resolver su nodo asignado.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
44
3. Las estaciones clientes envían los resultados obtenidos a la estación servidora
(G1) y pasan a estar de nuevo libres, por si hubiera más nodos que resolver.
Tal es el caso de la estación G4, que al ser la primera en acabar su cometido, es
asignada de nuevo para resolver el último nodo pendiente.
7.2.2 Arquitectura Estrategia A
Para el desarrollo de esta estrategia se ha decidido que la arquitectura más indicada es la
ofrecida por BOINC. Las razones por las que se ha seleccionado esta opción son las
expuestas a continuación:
La arquitectura BOINC está pensada para una distribución estática de tareas
paralelizables en el GRID.
La arquitectura BOINC permite el uso de aplicaciones en lenguajes tan comunes
como C, C++ y Fortran (pronto soportará Java) con tan solo un mínimo de
modificaciones en el código.
Presenta las herramientas necesarias para la obtención de la información necesaria
para el análisis que se pretende realizar.
Ofrece una buena seguridad frente a distintos tipos de ataques.
Soporta aplicaciones que pueden producir o consumir grandes cantidades de datos
y recursos.
Disponible para varias plataformas: Windows, Unix, Linux y Mac OS X.
El director del proyecto cuenta con experiencia previa en el uso de esta
arquitectura.
Es posiblemente la más conocida de las arquitecturas y cuenta con la aceptación
de la comunidad.
Software libre con licencia GNU LGPL. La principal diferencia entre la GPL y la
LGPL es que la última puede enlazarse contra (en el caso de una biblioteca, 'ser
utilizada por') un programa no-GPL, que puede ser software libre o software no
libre.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
45
7.2.3 Estrategia B
Se trata también de una estrategia centralizada, basándose igualmente en el uso de una
estación “servidora” y de otras estaciones “clientes”, pero con una asignación dinámica
de tareas.
La estación servidora, al igual que en la estrategia anterior, se encarga de resolver el
árbol de regresión hasta cierta altura indicada por el usuario, obteniéndose así N nodos
finales pendientes de resolución.
Cada uno de estos nodos será enviado a distintas estaciones clientes del GRID para ser
resueltos no en su totalidad, sino hasta cierto nivel de profundidad indicado previamente
por el usuario. Una vez desarrollado uno de estos nodos, la estación cliente devuelve los
resultados obtenidos a la servidora junto con los nodos hijos que no han sido totalmente
resueltos.
La estación servidora vuelve a enviar estos nodos hijos a las estaciones clientes hasta
que todo el árbol quede resuelto.
El objetivo de esta estrategia es llenar el GRID lo antes posible, con la intención de
hacer uso de los recursos computacionales disponibles desde el principio.
Ventajas:
Utilización óptima del GRID. La utilización de las estaciones del GRID es muy
alta ya que el número de tareas lanzadas a éste es muy elevado durante todo el
proceso, quedando una escasa o nula cantidad de estaciones libres e
infrautilizadas.
Rápida utilización de los recursos computacionales: Se hace uso de todos los
recursos computacionales disponibles lo antes posible.
Evita picos de saturación en la red. La carga de la red no se concentra en ningún
punto del proceso, sino que se mantiene estable a lo largo del mismo.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
46
El usuario se desentiende de la estructura del GRID. El usuario no tiene que
decidir, según la estructura del GRID, cuántas tareas se deben crear para una
utilización adecuada del mismo.
Desventajas:
Complejidad en la gestión del GRID. La asignación dinámica de tareas requiere
de una gestión más compleja del GRID.
Complejidad en el control del GRID: la asignación dinámica de tareas dificulta
el seguimiento del proceso realizado por el GRID ya una estación no resuelve una
parte significativa del problema, sino pequeñas porciones inconexas de mismo.
Esto afecta tanto a la hora de analizar el proceso como de solventar posibles
fallos.
Alta carga de la red del GRID. El continuo trasiego de información a través del
GRID durante todo el proceso provoca una alta carga de la red empleada.
Retrasos por envío de tareas. Cada tarea lanzada al GRID requiere de una serie
de pasos (búsqueda y asignación de una estación libre, envío y recepción de
información a través de la red…) que, aunque poco relevantes individualmente, en
conjunto pueden incrementar significativamente el tiempo total empleado en
resolver el problema.
A continuación se muestra un ejemplo de una posible resolución siguiendo esta
estrategia en un GRID de cinco estaciones: G1, G2, G3, G4 y G5:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
47
1. La estación servidora (G1) realiza el cálculo hasta el nivel 3 del árbol de
regresión.
Nótese que durante este proceso el resto de estaciones del GRID está en desuso,
por lo que éste no debe ser muy costoso para que el rendimiento global no decaiga
demasiado.
2. Los nodos pendientes de resolución son enviados a las estaciones cliente que se
encuentren libres (G2, G3, G4 y G5).
Las estaciones clientes se encargan de resolver dos niveles de su nodo asignado.
3. Las estaciones clientes envían los resultados obtenidos a la estación servidora
(G1), junto con los nodos hijos que no han podido ser totalmente resueltos. Acto
seguido pasan a estar de nuevo libres, por si hubiera más nodos que resolver.
4. Se vuelve al paso 2, hasta que todo el árbol se resuelve completamente.
7.2.4 Arquitectura Estrategia B
Para el desarrollo de esta estrategia la arquitectura más indicada es la ofrecida por
NETSOLVE/GRIDSOLVE, debido a las siguientes razones expuestas a continuación:
La arquitectura NETSOLVE/GRIDSOLVE está orientada para una distribución
dinámica de tareas paralelizables.
Facilidad de uso e implantación.
Acceso muy sencillo al GRID desde diferentes entornos: a bajo nivel, desde
lenguaje C o Fortran, y a alto nivel con sistemas de cálculo matemático como
Matlab, Mathematica u Octave.
Presenta las herramientas necesarias para la obtención de la información necesaria
para el análisis que se pretende realizar.
Disponible para plataformas Windows y la mayor parte de las variantes de Unix.
Eficiente balanceo en la asignación del trabajo entre las estaciones del GRID.
Ofrece una buena seguridad.
Software gratuito.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
48
El director del proyecto cuenta con experiencia previa en el uso de esta
arquitectura.
Debido a restricciones de tiempo se ha decidido implementar esta estrategia con la
misma arquitectura que la primera: una arquitectura BOINC que, aunque no tan eficaz
como sería el empleo de Netsolve/Gridsolve, permitirá obtener los resultados deseados.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
49
8 ARQUITECTURA BOINC
BOINC (Berkeley Open Infrastructure for Network Computing) es una infraestructura
orientada a la computación distribuida, desarrollada originalmente para el conocido
proyecto SETI@home, pero que se ha ido extendiendo a diversos campos como física,
medicina nuclear, climatología, etc.
8.1 INTRODUCCIÓN
Actualmente, BOINC es desarrollado por un grupo con sede en Berkeley, en la
Universidad de California, y dirigido por David Anderson, director del proyecto
SETI@home. La plataforma es considerada como un cuasi-superordenador,
disponiendo de unos 485.000 ordenadores activos en todo el mundo y con un
rendimiento medio de 1,28 TFLOPS en diciembre de 2008. Esto hace superar en
rendimiento al mayor superordenador del mundo, Blue Gene.
El objetivo principal es obtener una capacidad de computación muy elevada utilizando
para ello las ventajas que ofrece la Computación Voluntaria.
La Computación Voluntaria es un acuerdo en el que personas o entidades donan sus
recursos computacionales a proyectos de investigación de su interés; los cuales utilizan
dichos recursos para realizar computación y/o almacenamiento distribuido.
Los proyectos BOINC se benefician de los ciclos muertos de CPU de sus donantes,
consiguiendo realizar en conjunto trabajos que requieren de una enorme capacidad de
cálculo.
Esta plataforma de software está desarrollada con la filosofía de código abierto, bajo
licencia GNU LGPL, y se encuentra disponible en varias plataformas incluyendo
Windows, Unix, Linux, FreeBSD o Mac OS X.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
50
8.2 ARQUITECTURA
Boinc está basado en la arquitectura Cliente-Servidor, conectados mediante RPCs, en la
que los servidores registran y reparten los trabajos y los clientes ejecutan los ejecutan;
todo ello de una forma transparente para los usuarios. A continuación se explicará con
más detalle el funcionamiento de ambas partes:
8.2.1 Servidores
La mayor parte de los proyectos incluyen un servidor remoto, que puede ejecutarse en
una o más máquinas para permitirle a BOINC escalar a proyectos de cualquier
envergadura.
Los servidores de BOINC funcionan bajo una plataforma Linux y utilizan Apache, Php
y MySQL como base para sus sistemas web y de base de datos.
Una vez que los ordenadores de los usuarios realizan los cálculos científicos, los
resultados obtenidos son enviados a los servidores para ser analizados, una vez hayan
sido validados, y transferidos desde el software BOINC hacia la base de datos de los
investigadores y científicos.
Los servidores BOINC también están provistos de herramientas avanzadas, incluyendo
redundancia homogénea (envío de paquetes de cálculos exclusivamente a ordenadores
de la misma plataforma), truncamiento de unidad de trabajo (envío de información al
servidor antes de que el proceso de una unidad de trabajo esté completado), y
segmentación localizada (envío de unidades de trabajo a ordenadores que ya contenían
los archivos necesarios, creando trabajo por demanda).
8.2.2 Clientes
La estructura del cliente consiste en una pequeña aplicación que gestiona el trabajo de
los ordenadores donde se encuentra el software BOINC.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
51
Cualquier ordenador puede suscribirse a cuantos proyectos BOINC desee, pudiendo así
participar en múltiples tipos de investigaciones.
El cliente BOINC se encarga automáticamente de la descarga y subida de trabajo.
Además, se ocupa también de dividir el tiempo de trabajo en cada proyecto de acuerdo a
las preferencias del usuario, pero no es capaz de auto actualizarse dadas razones de
seguridad. Sin embargo, las aplicaciones científicas se descargan de manera automática
y son actualizadas cuando un ordenador está suscrito a un proyecto. Esto permite a los
científicos distribuir fácilmente nuevo software a los participantes sin su intervención.
8.2.3 Esquema general de la arquitectura
A continuación se muestra el esquema general de una arquitectura Cliente-Servidor
BOINC:
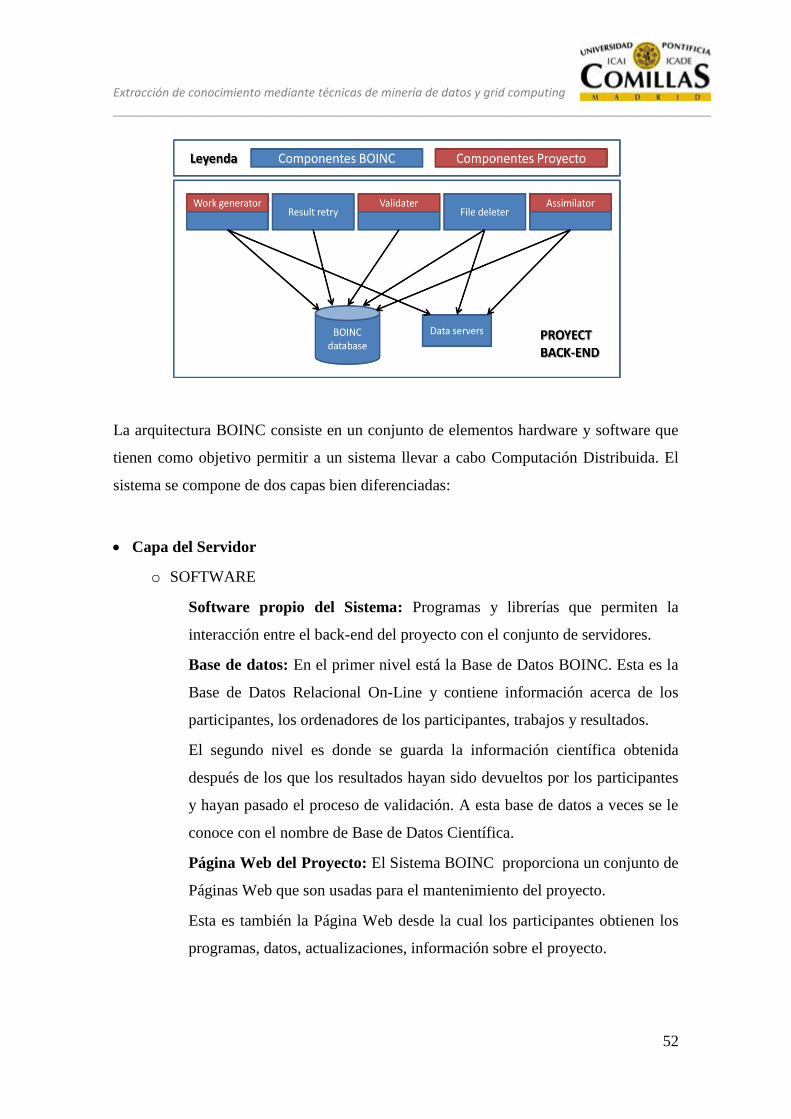
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
52
La arquitectura BOINC consiste en un conjunto de elementos hardware y software que
tienen como objetivo permitir a un sistema llevar a cabo Computación Distribuida. El
sistema se compone de dos capas bien diferenciadas:
Capa del Servidor
o SOFTWARE
Software propio del Sistema: Programas y librerías que permiten la
interacción entre el back-end del proyecto con el conjunto de servidores.
Base de datos: En el primer nivel está la Base de Datos BOINC. Esta es la
Base de Datos Relacional On-Line y contiene información acerca de los
participantes, los ordenadores de los participantes, trabajos y resultados.
El segundo nivel es donde se guarda la información científica obtenida
después de los que los resultados hayan sido devueltos por los participantes
y hayan pasado el proceso de validación. A esta base de datos a veces se le
conoce con el nombre de Base de Datos Científica.
Página Web del Proyecto: El Sistema BOINC proporciona un conjunto de
Páginas Web que son usadas para el mantenimiento del proyecto.
Esta es también la Página Web desde la cual los participantes obtienen los
programas, datos, actualizaciones, información sobre el proyecto.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
53
o HARDWARE
Servidores: Conjunto de servidores formado por el Servidor de Datos, el
Servidor de Planificación y el Servidor Web.
Capa del Cliente
o SOFTWARE
Núcleo: Es el núcleo de la aplicación BOINC cliente. Se comunica con los
servidores externos a través del protocolo http para solicitar y devolver
trabajos.
Manager BOINC: Es el responsable de controlar en el uso de los recursos
de disco, red y procesamiento en el ordenador del cliente. Normalmente se
inicia automáticamente durante el arranque del sistema.
Dispone de una interfaz gráfica que permite que la gestión la realice
directamente el usuario.
Se comunica con el núcleo a través de conexiones TCP locales.
Demonio BOINC: Se trata de un programa en ejecución continua que
controla la ejecución de las Aplicaciones Científicas y recibe órdenes desde
el interfaz gráfico del Manager BOINC.
Otras funciones gestionadas por el demonio incluyen la carga de trabajo
realizado y la gestión del trabajo en el Work Buffer mediante el Planificador
de Trabajo.
Aplicaciones científicas: Aplicación o conjunto de aplicaciones con los
cálculos científicos que van ejecutarse en el cliente.
Las aplicaciones hacen uso de la API BOINC, con la que se consiguen
adaptar aplicaciones científicas ya creadas sin tener que reescribir
componentes que ya hayan sido desarrollados, testeados y depurados.
o HARDWARE
PC del participante.
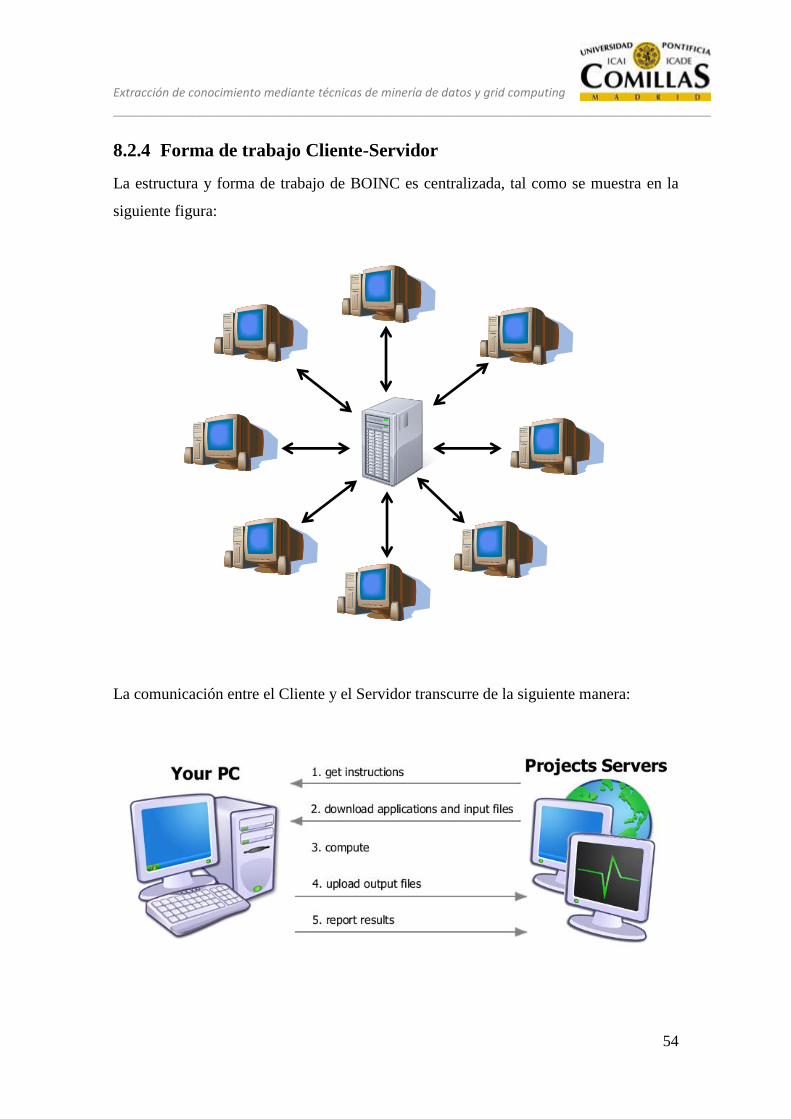
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
54
8.2.4 Forma de trabajo Cliente-Servidor
La estructura y forma de trabajo de BOINC es centralizada, tal como se muestra en la
siguiente figura:
La comunicación entre el Cliente y el Servidor transcurre de la siguiente manera:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
55
1. El cliente obtiene una serie de tareas del servidor de planificación (scheduling server)
del proyecto. Las tareas dependen del ordenador del cliente: por ejemplo, el servidor
no asignará tareas que requieran más RAM de la que posee. Los proyectos pueden
soportar varias aplicaciones, y el servidor puede enviar tareas de cualquiera de ellas.
2. El cliente descarga el ejecutable y los ficheros de entrada del servidor de datos del
proyecto. Si el proyecto realiza nuevas versiones de sus aplicaciones, los ejecutables
se descargan automáticamente al cliente.
3. El cliente ejecuta los programas de la aplicación, produciendo los ficheros de salida.
4. El cliente envía los ficheros de salida al servidor de datos.
5. Más tarde (hasta varios días después, dependiendo de la configuración) el cliente
informa de las tareas terminadas al servidor de planificación, y obtiene más tareas.
Este ciclo se repite indefinidamente. BOINC realiza este proceso automáticamente, de
una forma transparente para el cliente.
1) PLATAFORMAS
Servidor
Linux OS.
Cliente
La aplicación cliente BOINC permite una amplia gama de sistemas operativos y
arquitecturas hardware.
Los sistemas operativos compatibles son Microsoft Window (98 o posterior), Linux,
Max OS y Solaris.
Entre las CPU compatibles con la aplicación se encuentra una amplia gama de
procesadores Intel (32 ó 64 bits), AMD (32 ó 64 bits), Motorola PowerPC y SPARC;
todos ellos tanto en sus versiones de 32 o 64 bits.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
56
2) ALMACENAMIENTO
BOINC almacena la información en una base de datos MySQL. Las principales tablas
son las expuestas a continuación:
Platform: Targets de compilación del núcleo del cliente BOINC y/o las
aplicaciones.
App: Aplicaciones. El núcleo del cliente BOINC se trata como una aplicación más,
llamada "core_client".
App_version: Versiones de las aplicaciones. Cada registro incluye la URL desde la
que descargar el fichero ejecutable, y el hash MD5 del mismo.
User: Describe los usuarios, incluyendo sus direcciones de email, nombres,
contraseña web y autentificador.
Preferences: Describe las opciones de configuración. La información concreta sobre
la configuración se almacena en un documento XML.
Host: Describe la máquina cliente.
Workunit: Describe las unidades de trabajo. Las descripciones de los ficheros de
entrada se almacenan en un documento XML dentro de un campo binario. Incluye la
cuenta del número de resultados asociados a esta unidad de trabajo, el número de
resultados transmitidos, el número de éxitos y el número de fallos.
Result: Describe los resultados. Incluye un "estado" (si el resultado se ha transmitido
o no). Almacena algunos elementos que sólo tienen significado después de haber
entregado el resultado: el tiempo de CPU, el estado de salida y el estado de
validación.
3) SEGURIDAD
Boinc cuenta con una serie de medidas de seguridad para prevenir los siguientes
incidentes:
Falsificación de resultados.
Falsificación de créditos.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
57
Aplicaciones maliciosas.
Desbordamiento del servidor de información.
Robo de cuenta cliente por ataque al servidor.
Robo de una cuenta cliente por ataque de red.
Robo de archivos del proyecto.
Abuso intencionado de hosts por el proyecto.
Abuso accidental de hosts por el proyecto.
4) CONFIGURACIÓN DEL GRID USADO
El GRID empleado está compuesto por los siguientes componentes:
Seis ordenadores
Doble núcleo 2,0 GHz
1 GB RAM
S.O. Ubuntu 9.0
Un Switch
100 Mbps Ethernet Network.
Sincronización con el servidor de hora: hora.upcomillas.es.
GRID 1 GRID 2 GRID 3 GRID 4 GRID 5 GRID 6
(Servidor)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
58
9 MODELO LÓGICO DEL SISTEMA
DFD-0 Diagrama de Contexto
Problema
1
SistemaInvestigador
Matriz Datos
Gráfica tiempos
Configuración
inicial
Informe árbol
Informe tiempos
Cliente
Configuración
tarea
pendiente
Estructura
tarea
pendiente
Matriz
tarea
pendiente
Informe
tarea
pendiente
Servidor
Configuración
tarea
solicitada
Estructura
tarea
solicitada
Matriz
tarea
solicitada
Informe
tarea
solicitada
DIAGRAMA DE FLUJO DE DATOS: DFD-0-DIAGRAMA_CONTEXTO
El Sistema se encarga de ajustar el árbol de regresión expuesto en un Problema.
Su funcionamiento puede ser en modo uniproceso o en GRID, en cuyo caso
trabajará como servidor o como cliente del GRID. Por último, el Sistema
proporciona al Investigador los resultados obtenidos para su estudio.
ENTIDAD EXTERNA: EE-PROBLEMA
Enunciado del problema que se desea resolver. Incluye los datos de aprendizaje y
los parámetros de configuración del algoritmo de ajuste del árbol.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
59
ENTIDAD EXTERNA: EE-CLIENTE
Unidad externa, parte del GRID, a la que el Sistema le encarga la resolución de
una parte del árbol.
ENTIDAD EXTERNA: EE-SERVIDOR
Unidad externa, parte del GRID, que actúa como servidor y solicita al Sistema la
resolución de una parte del árbol.
ENTIDAD EXTERNA:EE- INVESTIGADOR
Usuario final del Sistema que requiere de los resultados de éste para su posterior
análisis.
PROCESO: PR-1-SISTEMA
EXPLOSIONA EN: DFD-1-DIAGRAMA_CONCEPTUAL
La resolución uniproceso o GRID de un árbol de regresión y la presentación de
unos informes y gráficas relativas a los tiempos de creación, requieren de un
proceso complejo de cálculo y tratamiento de información.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
60
DFD-1 Diagrama Conceptual
Informe
tarea pendiente 1.1
Crear árbol
1.2
Generar tiempos
1.3
Crear gráfica
Estructura árbol
Matriz tiempos
Gráfica tiemposInforme tiempos
Informe
tarea solicitada
Configuración
inicialConfiguración
tarea solicitadaMatriz
datos
Matriz tarea
solicitada
Estructura
tarea solicitada
Informe árbol
Estructura
tarea pendiente
Configuración
tarea pendiente
Matriz
tarea pendiente
DIAGRAMA DE FLUJO DE DATOS: DFD-1-DIAGRAMA_CONCEPTUAL
La obtención de los resultados requeridos por el usuario final consta de tres etapas
o procesos bien diferenciados:
1. Crear el árbol de regresión.
2. Recabar información sobre los tiempos empleados en la creación del árbol.
3. Generar la gráfica que represente dichos tiempos.
PROCESO: PR-1.1-CREAR_ÁRBOL
EXPLOSIONA EN: DFD-1.1-CREAR_ÁRBOL

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
61
Todo proceso de creación de un árbol de regresión, ya sea total o parcial, requiere
de dos tipos de entradas: unos datos con los que trabajar y una configuración del
árbol que se desea obtener con ellos.
Como resultado debe obtenerse la estructura del árbol creado junto con un
informe que lo describa.
PROCESO: PR-1.2-GENERAR_TIEMPOS
EXPLOSIONA EN: DFD-1.2-GENERAR_TIEMPOS
Una vez obtenido el árbol de regresión, es necesaria la recopilación de
información relativa a los tiempos empleados durante el proceso.
Como resultado de la recopilación se obtiene un informe y una matriz de los
tiempos empleados.
PROCESO: PR-1.3-CREAR_GRÁFICA
EXPLOSIONA EN: DFD-1.3-CREAR_GRÁFICA
La representación de una gráfica de tiempos requiere de unos datos de entrada que
son suministrados mediante una matriz de tiempos.
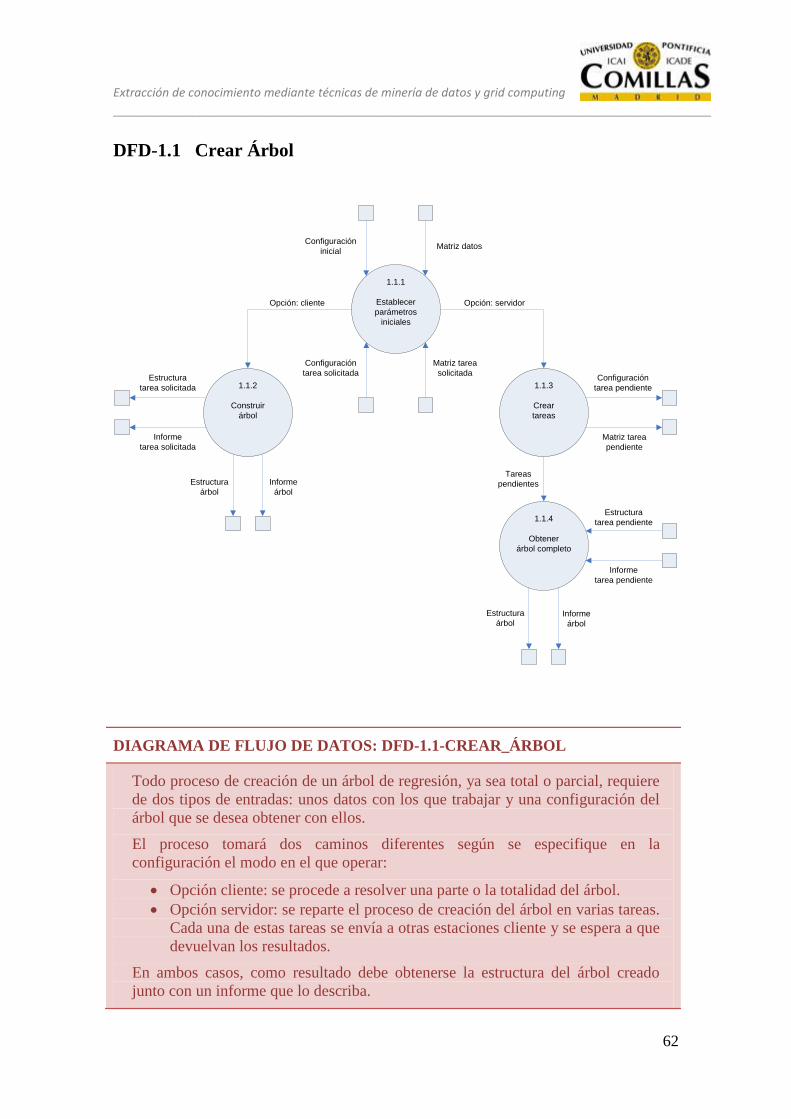
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
62
DFD-1.1 Crear Árbol
1.1.1
Establecer
parámetros
iniciales
1.1.2
Construir
árbol
1.1.3
Crear
tareas
Opción: cliente Opción: servidor
1.1.4
Obtener
árbol completo
Tareas
pendientes
Configuración
inicial
Estructura
árbol
Configuración
tarea solicitada
Informe
árbol
Estructura
árbol
Informe
árbol
Configuración
tarea pendiente
Estructura
tarea pendiente
Matriz tarea
pendiente
Matriz datos
Estructura
tarea solicitada
Matriz tarea
solicitada
Informe
tarea pendiente
Informe
tarea solicitada
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1-CREAR_ÁRBOL
Todo proceso de creación de un árbol de regresión, ya sea total o parcial, requiere
de dos tipos de entradas: unos datos con los que trabajar y una configuración del
árbol que se desea obtener con ellos.
El proceso tomará dos caminos diferentes según se especifique en la
configuración el modo en el que operar:
Opción cliente: se procede a resolver una parte o la totalidad del árbol.
Opción servidor: se reparte el proceso de creación del árbol en varias tareas.
Cada una de estas tareas se envía a otras estaciones cliente y se espera a que
devuelvan los resultados.
En ambos casos, como resultado debe obtenerse la estructura del árbol creado
junto con un informe que lo describa.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
63
PROCESO: PR-1.1.1-ESTABLECER_PARÁMETROS_INICIALES
EXPLOSIONA EN: DFD-1.1.1-ESTABLECER_PARÁMETROS_INICIALES
El primer paso para la creación del árbol consiste en obtener los datos con los que
trabajar y las especificaciones del problema descritas en la configuración.
La configuración dictará el siguiente proceso a seguir: resolver el árbol o repartir
el trabajo en el GRID.
PROCESO: PR-1.1.2-CONSTRUIR ÁRBOL
EXPLOSIONA EN: DFD-1.1.2-CONSTRUIR_ÁRBOL
Se aplica el algoritmo de resolución de árboles de regresión. Los resultados se
envían a distintas fuentes según quién los halla solicitado:
Problema: se envía el informe del árbol obtenido al Investigador. La
estructura del árbol es enviada al proceso Generar Tiempos (1.2) para el
estudio de los tiempos de creación.
Servidor: se le devuelven al mismo los resultados obtenidos.
PROCESO: PR-1.1.3-CREAR_TAREAS
EXPLOSIONA EN: DFD-1.1.3-CREAR_TAREAS
Se aplica la estrategia de repartición de tareas en el GRID escogida. Una vez
creadas las tareas, cada una de ellas será enviada a un Cliente para su resolución.
A su vez, la lista de estas tareas pendientes de resolución es enviada al siguiente
proceso del diagrama.
PROCESO: PR-1.1.4-OBTENER_ÁRBOL_COMPLETO
EXPLOSIONA EN: DFD-1.1.4-OBTENER_ÁRBOL_COMPLETO
El proceso recibe la lista de tareas que están pendientes de resolución. Espera a
recibir todos los resultados para conformar el informe y la estructura del árbol
completo, para ser enviados al Investigador y al siguiente proceso del nivel
superior (1.2) respectivamente.
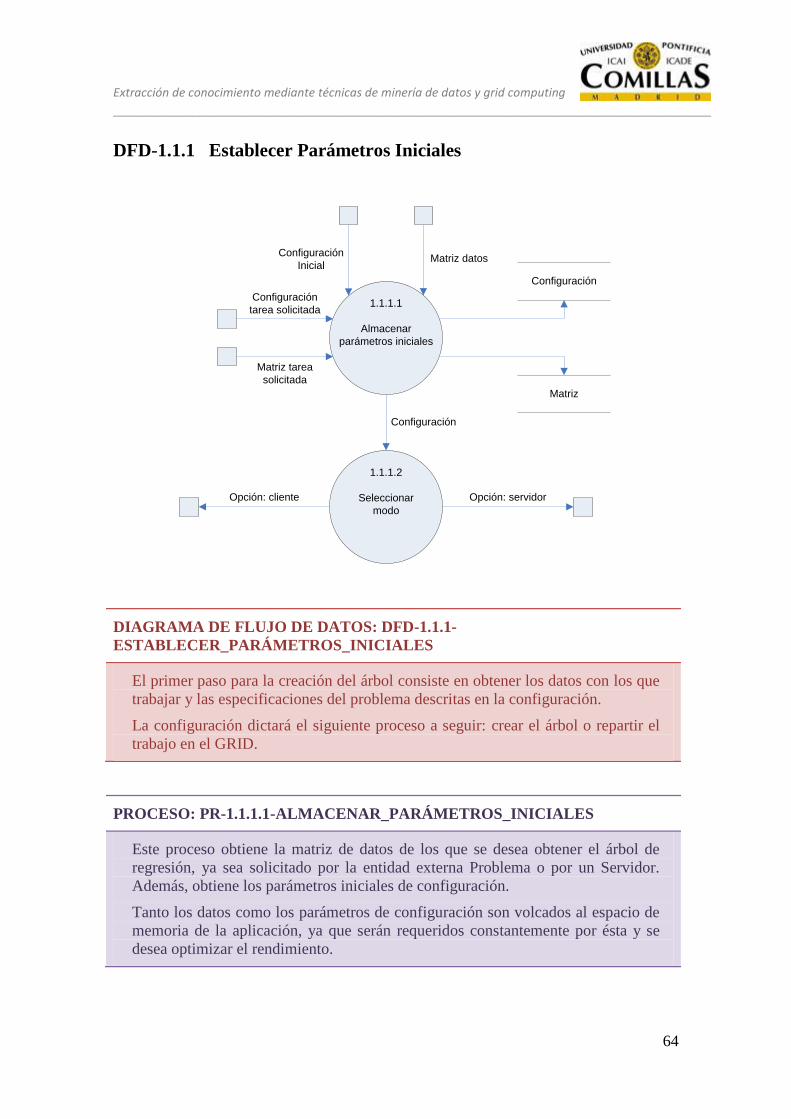
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
64
DFD-1.1.1 Establecer Parámetros Iniciales
1.1.1.1
Almacenar
parámetros iniciales
Configuración
Inicial
Configuración
tarea solicitada
Matriz datos
Matriz tarea
solicitada
Configuración
1.1.1.2
Seleccionar
modo
Configuración
Matriz
Opción: cliente Opción: servidor
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1.1-
ESTABLECER_PARÁMETROS_INICIALES
El primer paso para la creación del árbol consiste en obtener los datos con los que
trabajar y las especificaciones del problema descritas en la configuración.
La configuración dictará el siguiente proceso a seguir: crear el árbol o repartir el
trabajo en el GRID.
PROCESO: PR-1.1.1.1-ALMACENAR_PARÁMETROS_INICIALES
Este proceso obtiene la matriz de datos de los que se desea obtener el árbol de
regresión, ya sea solicitado por la entidad externa Problema o por un Servidor.
Además, obtiene los parámetros iniciales de configuración.
Tanto los datos como los parámetros de configuración son volcados al espacio de
memoria de la aplicación, ya que serán requeridos constantemente por ésta y se
desea optimizar el rendimiento.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
65
PROCESO: PR-1.1.1.2-SELECCIONAR_MODO
Este proceso capta el modo en el que debe funcionar la aplicación: modo cliente o
modo servidor. Escogiendo cuál es el siguiente paso a seguir dentro del Sistema.
FLUJO DE DATOS: FD-CONFIGURACIÓN_INICIAL
Parámetros iniciales de configuración del árbol solicitado por la entidad externa
Problema. Los parámetros de los que consta son los siguientes:
Variables de entrada a tener en cuenta
Variable de salida
Profundidad a la que construir el árbol
Constantes del criterio de parada: mínimo número de elementos por nodo y
MSE mínimo.
Modo de trabajo: cliente o servidor.
Entidad que solicita el árbol: entidad externa Problema o Servidor.
FLUJO DE DATOS: FD-MATRIZ_DATOS
Matriz con las variables y los ejemplos con los que se desea construir el árbol de
regresión solicitado por la entidad externa Problema.
FLUJO DE DATOS: FD-CONFIGURACIÓN_TAREA_SOLICITADA
Parámetros iniciales de configuración de la porción del árbol de regresión
solicitado por un Servidor. Los parámetros de los que consta son los siguientes:
Variables de entrada a tener en cuenta
Variable de salida
Profundidad a la que construir el árbol
Constantes del criterio de parada: mínimo número de elementos por nodo y
MSE mínimo.
Modo de trabajo: cliente o servidor.
Entidad que solicita el árbol: entidad externa Problema o Servidor.
FLUJO DE DATOS: FD-MATRIZ_TAREA_SOLICITADA
Matriz con las variables y los ejemplos con los que se desea construir la porción
del árbol de regresión solicitado por un Servidor.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
66
FLUJO DE DATOS: FD-CONFIGURACIÓN
Parámetro inicial de configuración quién es el solicitante del árbol de regresión: la
entidad externa Problema o un Servidor.
FLUJO DE DATOS: FD-OPCIÓN_CLIENTE
Parámetro que informa que la manera de operar de la aplicación es en modo
cliente.
FLUJO DE DATOS: FD-OPCIÓN_SERVIDOR
Parámetro que informa que la manera de operar de la aplicación es en modo
servidor.
ALMACÉN: AL-CONFIGURACIÓN
Espacio de memoria donde se vuelcan los parámetros iniciales de configuración.
ALMACÉN: AL-MATRIZ
Espacio de memoria donde se vuelca la matriz de datos.
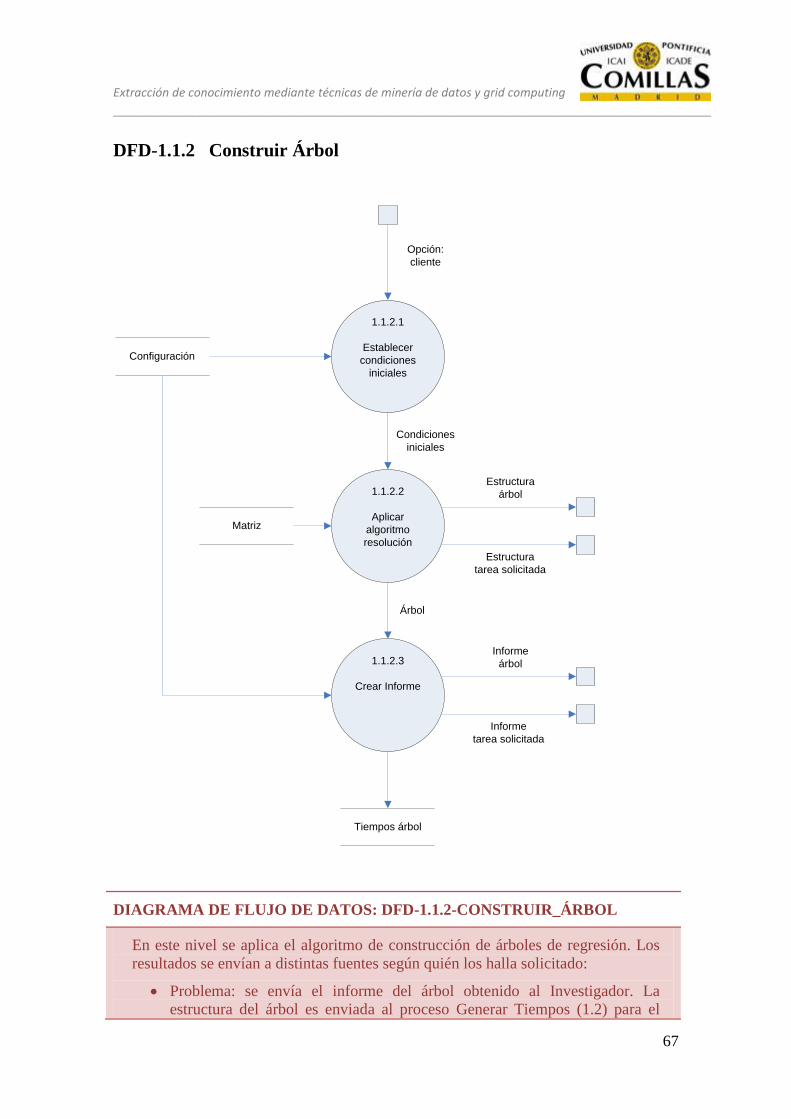
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
67
DFD-1.1.2 Construir Árbol
1.1.2.1
Establecer
condiciones
iniciales
Informe
árbol
Informe
tarea solicitada
Opción:
cliente
Configuración
Matriz
1.1.2.2
Aplicar
algoritmo
resolución
Condiciones
iniciales
1.1.2.3
Crear Informe
Árbol
Estructura
árbol
Estructura
tarea solicitada
Tiempos árbol
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1.2-CONSTRUIR_ÁRBOL
En este nivel se aplica el algoritmo de construcción de árboles de regresión. Los
resultados se envían a distintas fuentes según quién los halla solicitado:
Problema: se envía el informe del árbol obtenido al Investigador. La
estructura del árbol es enviada al proceso Generar Tiempos (1.2) para el

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
68
estudio de los tiempos de creación.
Servidor: se le devuelven al mismo los resultados obtenidos.
PROCESO: PR-1.1.2.1-ESTABLECER_CONDICIONES_INICIALES
Se inicializan las variables del algoritmo de resolución según los parámetros de
configuración establecidos.
PROCESO: PR-1.1.2.2-APLICAR-ALGORITMO_RESOLUCIÓN
Se ejecuta el algoritmo de resolución de árboles de regresión sobre la matriz de
datos y siguiendo los parámetros de configuración establecidos.
Como resultado se obtendrá el árbol de regresión y su estructura.
PROCESO: PR-1.1.2.3-CREAR_INFORME
Una vez resuelto el árbol se procede a realizar un informe detallado de todo el
proceso de creación: pasos seguidos durante el proceso, decisiones tomadas y una
representación del árbol creado.
Además, se guardan todos los tiempos de establecimiento de condiciones iniciales
(1.1.2.1), de creación del árbol (1.1.2.2) y de creación del informe (1.1.2.3), para
su análisis en procesos futuros.
FLUJO DE DATOS: FD-OPCIÓN_CLIENTE
Parámetro que informa que la manera de operar de la aplicación es en modo
cliente.
FLUJO DE DATOS: FD-CONDICIONES_INICIALES
Variables inicializadas según los parámetros de configuración establecidos.
FLUJO DE DATOS: FD-ESTRUCTURA_ÁRBOL
Estructura del árbol obtenido.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
69
FLUJO DE DATOS: FD-ESTRUCTURA_TAREA_SOLICITADA
Estructura de la parte del árbol solicitada por el servidor.
FLUJO DE DATOS: FD-ÁRBOL
Árbol obtenido tras aplicar el algoritmo de resolución, junto con los parámetros de
configuración, a la matriz de datos.
FLUJO DE DATOS: FD-INFORME_ÁRBOL
Informe detallado de todo el proceso de creación del árbol: pasos seguidos durante
el proceso, decisiones tomadas y una representación del árbol creado.
FLUJO DE DATOS: FD-INFORME_TAREA_SOLICITADA
Informe detallado de todo el proceso de creación de la parte del árbol solicitada
por el servidor: pasos seguidos durante el proceso, decisiones tomadas y una
representación del árbol creado.
ALMACÉN: AL-CONFIGURACIÓN
Espacio de memoria donde se vuelcan los parámetros iniciales de configuración.
ALMACÉN: AL-MATRIZ
Espacio de memoria donde se vuelca la matriz de datos.
ALMACÉN: AL-TIEMPOS_ÁRBOL
Almacén donde se guardan los tiempos de establecimiento de condiciones
iniciales (1.1.2.1), de creación del árbol (1.1.2.2) y de creación del informe
(1.1.2.3), para su análisis en procesos futuros.
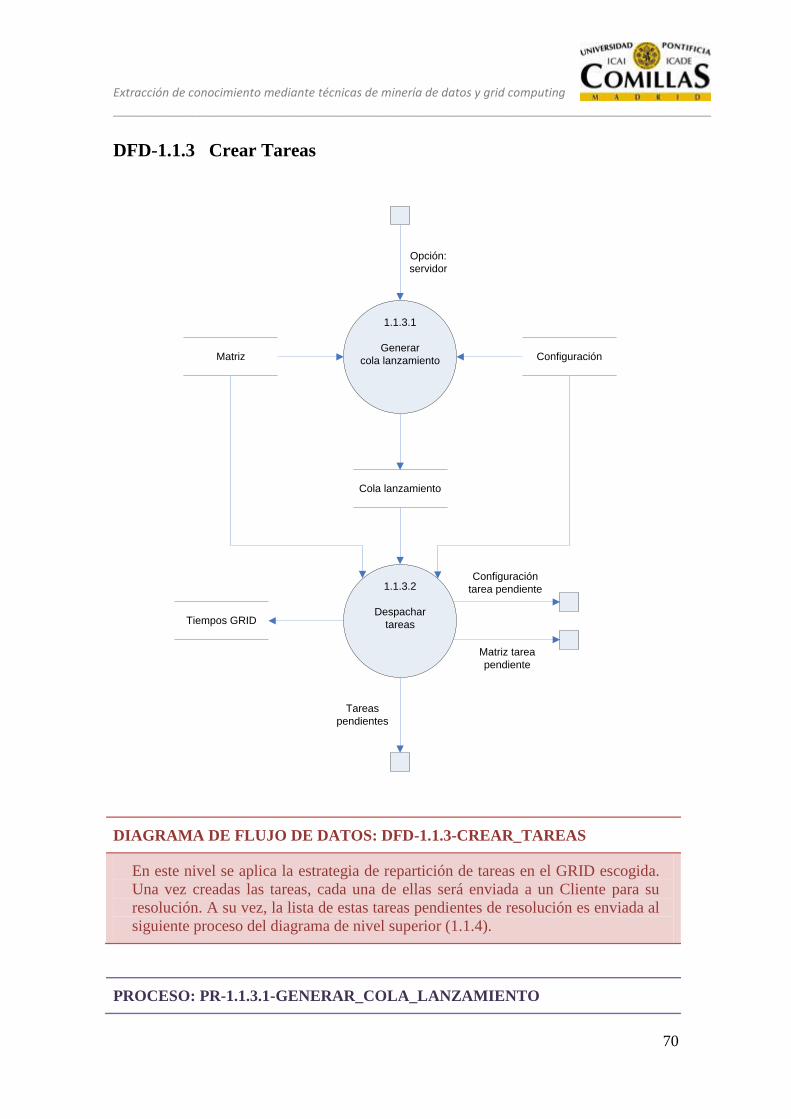
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
70
DFD-1.1.3 Crear Tareas
Opción:
servidor
1.1.3.1
Generar
cola lanzamiento
Cola lanzamiento
1.1.3.2
Despachar
tareas
ConfiguraciónMatriz
Tareas
pendientes
Configuración
tarea pendiente
Matriz tarea
pendiente
Tiempos GRID
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1.3-CREAR_TAREAS
En este nivel se aplica la estrategia de repartición de tareas en el GRID escogida.
Una vez creadas las tareas, cada una de ellas será enviada a un Cliente para su
resolución. A su vez, la lista de estas tareas pendientes de resolución es enviada al
siguiente proceso del diagrama de nivel superior (1.1.4).
PROCESO: PR-1.1.3.1-GENERAR_COLA_LANZAMIENTO

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
71
El proceso aplica la estrategia de repartición de tareas en el GRID según los
parámetros de configuración. Una vez terminado, se crea una cola de lanzamiento
de las tareas obtenidas.
PROCESO: PR-1.1.3.2-DESPACHAR_TAREAS
El proceso se encarga de despachar todas las tareas a resolver entre los clientes del
GRID.
Cuando se despacha a un cliente, se le envía la matriz de datos y la configuración
de acuerdo a las necesidades de la tarea que va a llevar a cabo.
FLUJO DE DATOS: FD-OPCIÓN_SERVIDOR
Parámetro que informa que la manera de operar de la aplicación es en modo
servidor.
FLUJO DE DATOS: FD-CONFIGURACIÓN_TAREA_PENDIENTE
Parámetros iniciales de configuración de la tarea despachada.
FLUJO DE DATOS: FD-MATRIZ_TAREA_PENDIENTE
Matriz de datos necesarios para resolver la tarea despachada.
FLUJO DE DATOS: FD-TAREAS_PENDIENTES
Lista de tareas que han sido despachadas por el servidor.
ALMACÉN: AL-CONFIGURACIÓN
Espacio de memoria donde se vuelcan los parámetros iniciales de configuración.
ALMACÉN: AL-MATRIZ

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
72
Espacio de memoria donde se vuelca la matriz de datos.
ALMACÉN: AL-COLA_LANZAMIENTO
Contiene una cola de las tareas generadas y listas para ser despachadas.
ALMACÉN: AL-TIEMPOS_GRID
Almacén donde se guardan los tiempos empleados durante el proceso de creación
y asignación de cada tarea a los clientes.
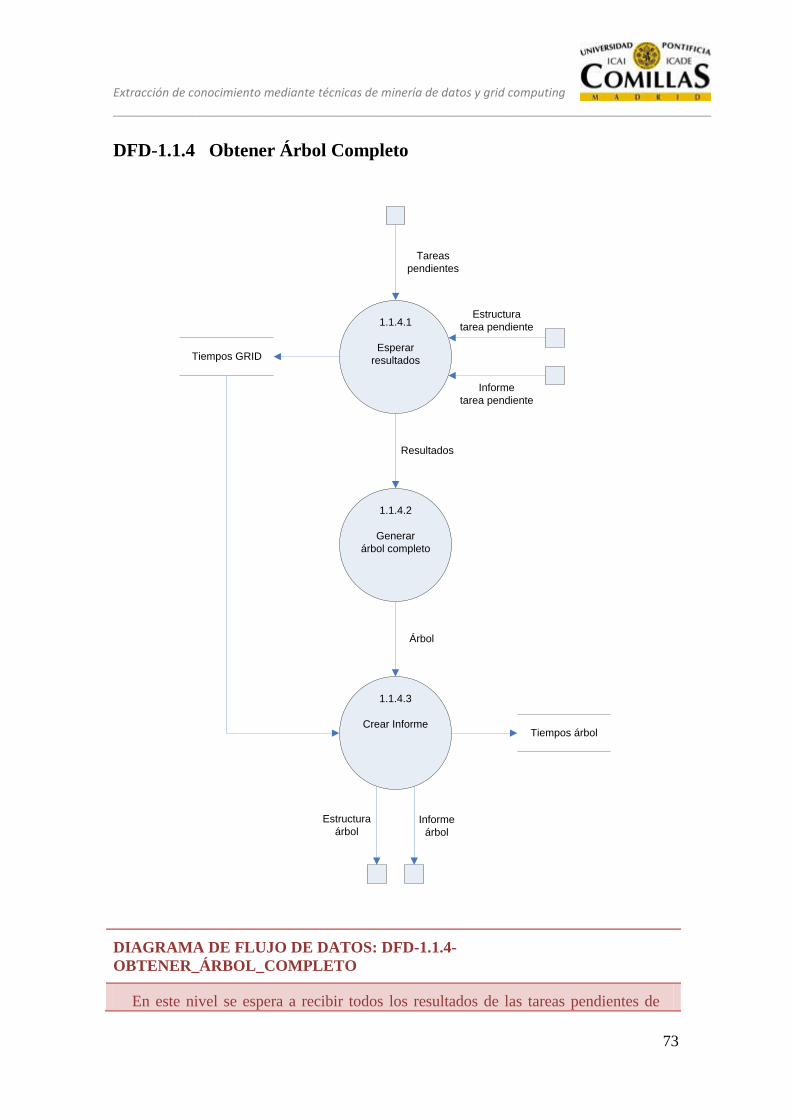
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
73
DFD-1.1.4 Obtener Árbol Completo
1.1.4.1
Esperar
resultados
Tareas
pendientes
Estructura
tarea pendiente
Informe
tarea pendiente
1.1.4.2
Generar
árbol completo
Resultados
Estructura
árbolInforme
árbol
Tiempos GRID
Tiempos árbol
1.1.4.3
Crear Informe
Árbol
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1.4-
OBTENER_ÁRBOL_COMPLETO
En este nivel se espera a recibir todos los resultados de las tareas pendientes de

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
74
resolución para conformar el informe y la estructura del árbol completo. Éstos son
enviados al Investigador y al siguiente proceso del nivel superior (1.2)
respectivamente.
PROCESO: PR-1.1.4.1-ESPERAR_RESULTADOS
El proceso espera a recibir los resultados de todas las tareas pendientes de
resolución. Una vez obtenidos, se los pasa al siguiente proceso.
Los tiempos de llegada de cada una de las tareas son guardados en el almacén
Tiempos GRID para su posterior estudio.
PROCESO: PR-1.1.4.2-GENERAR_ÁRBOL_COMPLETO
El proceso genera el árbol completo a partir de los resultados de las tareas.
PROCESO: PR-1.1.4.3-CREAR_INFORME
Una vez construido el árbol completo se procede a realizar un informe detallado
de todo el proceso de creación: tareas generadas, asignación de tareas a clientes y
una representación del árbol creado.
Además, se guardan todos los tiempos de tratamiento de las tareas y de generación
del árbol definitivo.
FLUJO DE DATOS: FD-TAREAS_PENDIENTES
Lista de tareas que han sido despachadas por el servidor.
FLUJO DE DATOS: FD-ESTRUCTURA_TAREA_PENDIENTE
Estructura de la parte del árbol resuelta por el cliente.
FLUJO DE DATOS: FD-INFORME_TAREA_PENDIENTE
Informe detallado de todo el proceso de creación de la parte del árbol resuelta por
el cliente: pasos seguidos durante el proceso, decisiones tomadas y una
representación del árbol creado.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
75
FLUJO DE DATOS: FD-RESULTADOS
Resultados obtenidos de cada una de las tareas asignadas a los clientes.
FLUJO DE DATOS: FD-ÁRBOL
Árbol obtenido tras recopilar los resultados recibidos de cada una de las tareas
despachadas.
FLUJO DE DATOS: FD-ESTRUCTURA_ÁRBOL
Estructura del árbol completo obtenido.
FLUJO DE DATOS: FD-INFORME_ÁRBOL
Informe detallado de todo el proceso de creación del árbol: tareas generadas,
asignación de tareas a clientes y una representación del árbol creado.
ALMACÉN: AL-TIEMPOS_GRID
Almacén donde se guardan los tiempos empleados durante el proceso de creación
y asignación de cada tarea a los clientes.
ALMACÉN: AL-TIEMPOS_ÁRBOL
Almacén donde se guardan los tiempos de establecimiento de condiciones
iniciales (1.1.2.1), de creación del árbol (1.1.2.2) y de creación del informe
(1.1.2.3), para su análisis en procesos futuros.
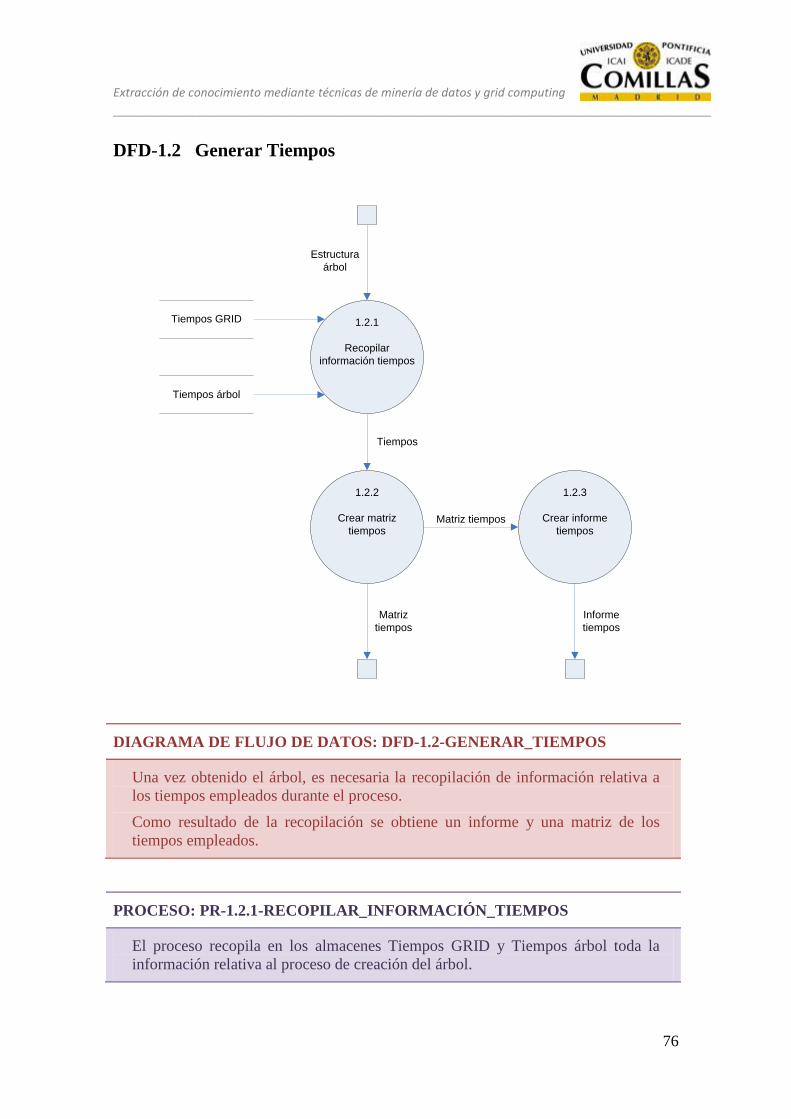
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
76
DFD-1.2 Generar Tiempos
Estructura
árbol
1.2.1
Recopilar
información tiempos
Tiempos GRID
Tiempos árbol
1.2.2
Crear matriz
tiempos
Tiempos
1.2.3
Crear informe
tiemposMatriz tiempos
Matriz
tiempos
Informe
tiempos
DIAGRAMA DE FLUJO DE DATOS: DFD-1.2-GENERAR_TIEMPOS
Una vez obtenido el árbol, es necesaria la recopilación de información relativa a
los tiempos empleados durante el proceso.
Como resultado de la recopilación se obtiene un informe y una matriz de los
tiempos empleados.
PROCESO: PR-1.2.1-RECOPILAR_INFORMACIÓN_TIEMPOS
El proceso recopila en los almacenes Tiempos GRID y Tiempos árbol toda la
información relativa al proceso de creación del árbol.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
77
PROCESO: PR-1.2.2-CREAR_MATRIZ_TIEMPOS
Una vez recibidos todos los datos relativos a los tiempos, el proceso ordena y
selecciona aquellos que son útiles para su análisis y futura representación gráfica.
Como resultado se obtiene una matriz de tiempos.
PROCESO: PR-1.2.3-CREAR_INFORME_TIEMPOS
Con la matriz de tiempos, el proceso crea el informe de tiempos que será
presentado al usuario final o entidad externa Investigador.
FLUJO DE DATOS: FD-ESTRUCTURA_ÁRBOL
Estructura del árbol completo obtenido.
FLUJO DE DATOS: FD-TIEMPOS
Tiempos recopilados de todo el proceso de creación del árbol.
FLUJO DE DATOS: FD-MATRIZ_TIEMPOS
Matriz con los tiempos de la creación del árbol que sean útiles para su análisis y
futura representación gráfica.
FLUJO DE DATOS: FD-INFORME_TIEMPOS
Informe detallado de los tiempos empleados durante todo el proceso de creación
del árbol.
Los tiempos mostrados son los mismos que los representados en la matriz de
tiempos, con la diferencia de que este informe es un documento legible por el
usuario final.
ALMACÉN: AL-TIEMPOS_GRID
Almacén donde se guardan los tiempos empleados durante el proceso de

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
78
creación y asignación de cada tarea a los clientes.
ALMACÉN: AL-TIEMPOS_ÁRBOL
Almacén donde se guardan los tiempos de establecimiento de condiciones
iniciales (1.1.2.1), de creación del árbol (1.1.2.2) y de creación del informe
(1.1.2.3), para su análisis en procesos futuros.
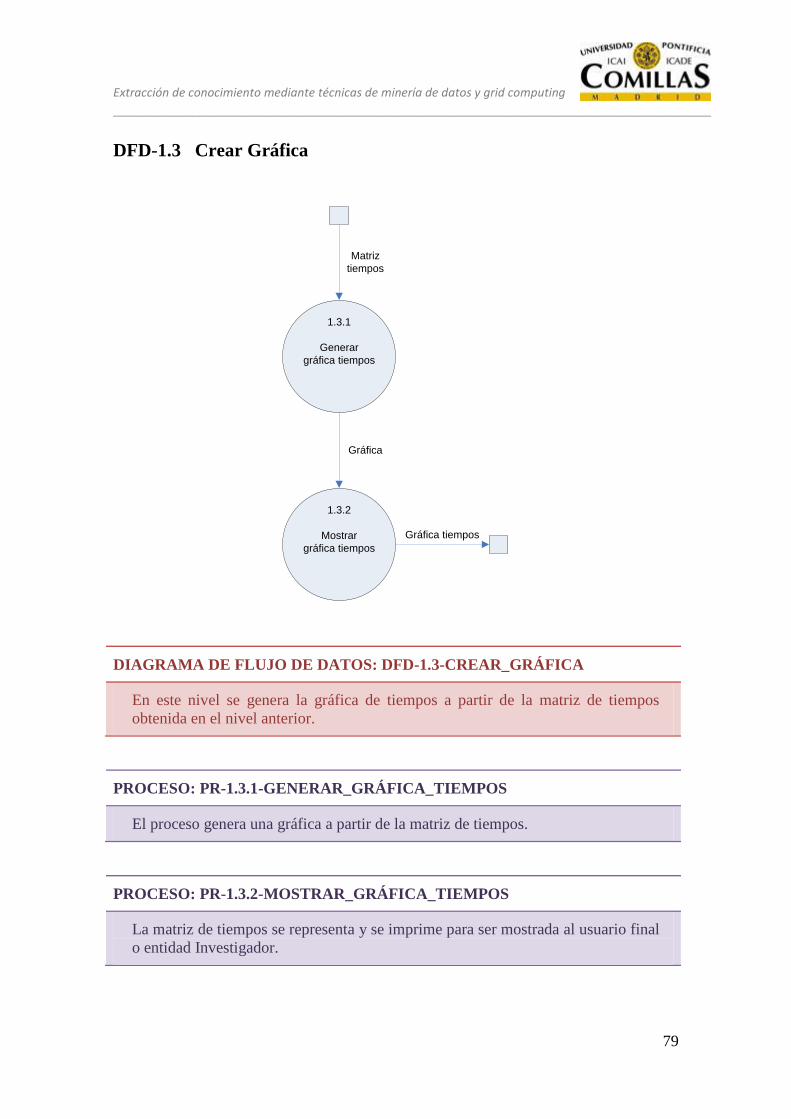
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
79
DFD-1.3 Crear Gráfica
1.3.1
Generar
gráfica tiempos
Matriz
tiempos
1.3.2
Mostrar
gráfica tiempos
Gráfica
Gráfica tiempos
DIAGRAMA DE FLUJO DE DATOS: DFD-1.3-CREAR_GRÁFICA
En este nivel se genera la gráfica de tiempos a partir de la matriz de tiempos
obtenida en el nivel anterior.
PROCESO: PR-1.3.1-GENERAR_GRÁFICA_TIEMPOS
El proceso genera una gráfica a partir de la matriz de tiempos.
PROCESO: PR-1.3.2-MOSTRAR_GRÁFICA_TIEMPOS
La matriz de tiempos se representa y se imprime para ser mostrada al usuario final
o entidad Investigador.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
80
FLUJO DE DATOS: FD-MATRIZ_TIEMPOS
Matriz con los tiempos de la creación del árbol que sean útiles para su análisis y
futura representación gráfica.
FLUJO DE DATOS: FD-GRÁFICA
Gráfica obtenida a partir de la matriz de tiempos.
FLUJO DE DATOS: FD-GRÁFICA_TIEMPOS
Representación final de la gráfica de tiempos.
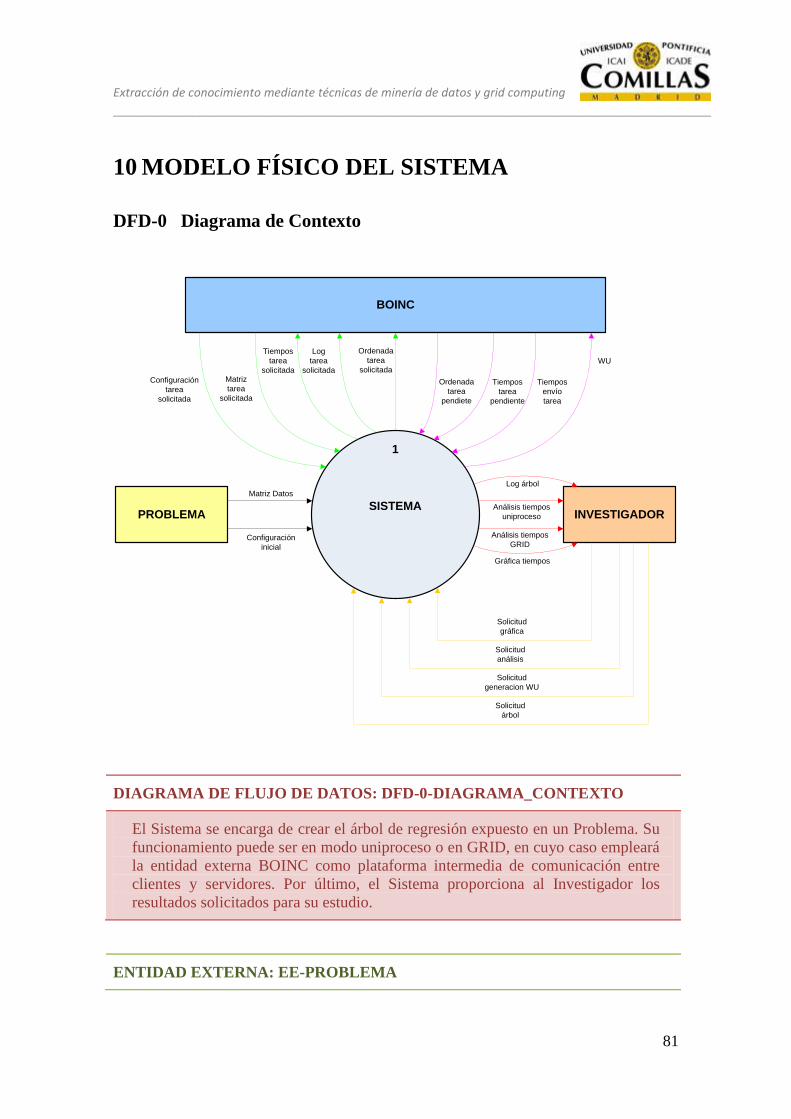
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
81
10 MODELO FÍSICO DEL SISTEMA
DFD-0 Diagrama de Contexto
PROBLEMA
1
SISTEMAINVESTIGADOR
Matriz Datos
Análisis tiempos
uniproceso
Configuración
inicial
Log árbol
Gráfica tiempos
BOINC
Configuración
tarea
solicitada
Matriz
tarea
solicitada
Tiempos
tarea
pendiente
Tiempos
tarea
solicitada
Log
tarea
solicitada
Análisis tiempos
GRID
Solicitud
gráfica
Solicitud
análisis
WU
Tiempos
envío
tarea
Solicitud
árbol
Solicitud
generacion WU
Ordenada
tarea
solicitada
Ordenada
tarea
pendiete
DIAGRAMA DE FLUJO DE DATOS: DFD-0-DIAGRAMA_CONTEXTO
El Sistema se encarga de crear el árbol de regresión expuesto en un Problema. Su
funcionamiento puede ser en modo uniproceso o en GRID, en cuyo caso empleará
la entidad externa BOINC como plataforma intermedia de comunicación entre
clientes y servidores. Por último, el Sistema proporciona al Investigador los
resultados solicitados para su estudio.
ENTIDAD EXTERNA: EE-PROBLEMA

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
82
Enunciado del problema que se desea resolver, incluye:
Matriz de datos: fichero con la matriz de datos que se desean someter a
estudio.
Configuración inicial: fichero con los parámetros de configuración del árbol
que se desea obtener.
ENTIDAD EXTERNA: EE-INVESTIGADOR
Usuario final del Sistema que requiere de los siguientes resultados de éste para su
posterior estudio:
Log árbol: fichero con un informe detallado de todo el proceso de cálculo
del árbol o rama realizada por el sistema.
Análisis tiempos uniproceso:
Análisis tiempos GRID:
Gráfica tiempos:
ENTIDAD EXTERNA: EE-BOINC
Plataforma intermedia de comunicación entre clientes y servidores dentro de un
GRID.
PROCESO: PR-1-SISTEMA
EXPLOSIONA EN: DFD-1-DIAGRAMA_CONCEPTUAL
La resolución uniproceso o GRID de un árbol de regresión y la presentación de
unos informes y gráficas relativas a los tiempos de creación, requieren de un
proceso complejo de cálculo y tratamiento de información.
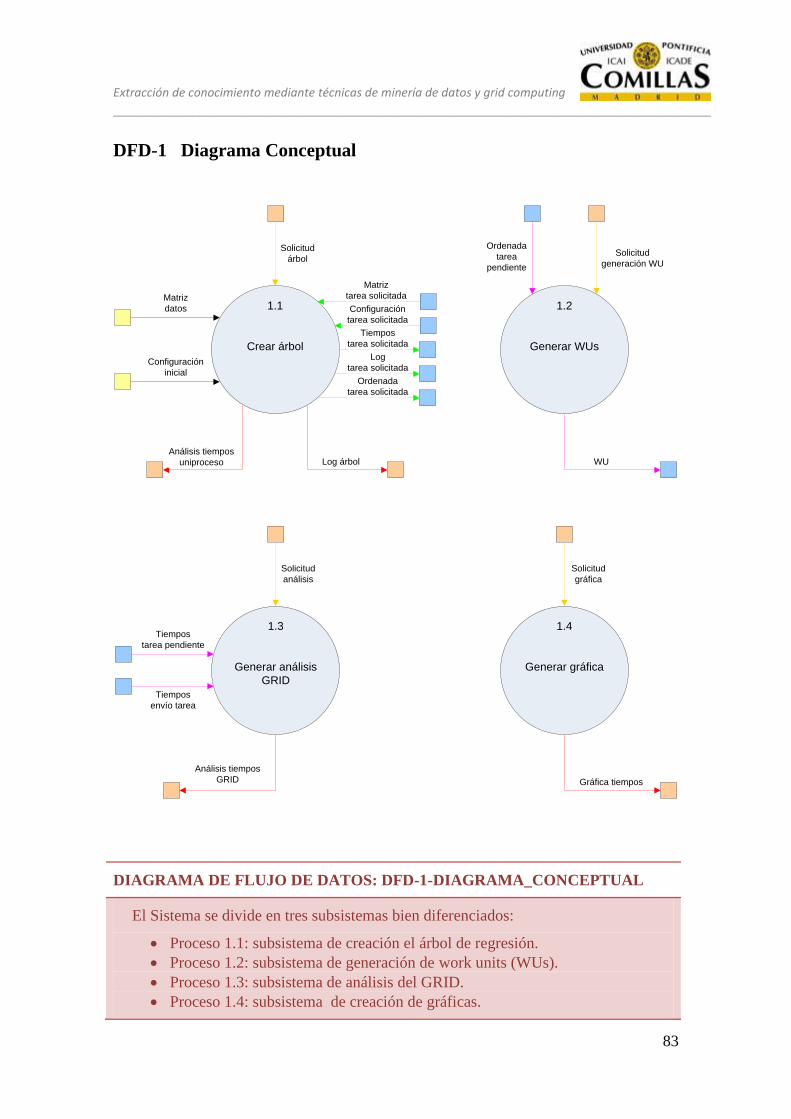
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
83
DFD-1 Diagrama Conceptual
1.1
Crear árbol
1.3
Generar análisis
GRID
1.4
Generar gráfica
Solicitud
gráfica
Gráfica tiempos
Análisis tiempos
GRID
Log
tarea solicitadaConfiguración
inicial
Configuración
tarea solicitada
Matriz
datos
Matriz
tarea solicitada
Tiempos
tarea solicitada
Log árbol WUAnálisis tiempos
uniproceso
Solicitud
análisis
Solicitud
árbol
Tiempos
tarea pendiente
Tiempos
envío tarea
1.2
Generar WUs
Ordenada
tarea solicitada
Solicitud
generación WU
Ordenada
tarea
pendiente
DIAGRAMA DE FLUJO DE DATOS: DFD-1-DIAGRAMA_CONCEPTUAL
El Sistema se divide en tres subsistemas bien diferenciados:
Proceso 1.1: subsistema de creación el árbol de regresión.
Proceso 1.2: subsistema de generación de work units (WUs).
Proceso 1.3: subsistema de análisis del GRID.
Proceso 1.4: subsistema de creación de gráficas.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
84
PROCESO: PR-1.1-CREAR_ÁRBOL
EXPLOSIONA EN: DFD-1.1-CREAR_ÁRBOL
El proceso de creación de un árbol de regresión, ya sea total o parcial, e
independientemente de la estrategia escogida, requiere de dos tipos de entradas:
Matriz de datos.
Configuración.
Las entradas pueden proceder del enunciado del problema completo o de una tarea
solicitada por un servidor del GRID.
Si la configuración solicita que se use el GRID, el proceso generará las unidades
de trabajo o WU para su desarrollo en otros sistemas del GRID.
Como resultado deben obtenerse los siguientes ficheros:
Log del árbol.
Análisis de tiempos uniproceso.
PROCESO: PR-1.2-GENERAR_WUS
EXPLOSIONA EN: DFD-1.2-GENERAR_WUS
Una vez obtenido el árbol de regresión inicial, es precisa la generación de tareas o
WUs para completar de resolverlo a través del GRID.
Las entradas proceden de los resultados de la resolución del árbol inicial, y
además si la estrategia elegida es la B, de los resultados devueltos por un cliente
del GRID.
Como resultado se obtiene un WU.
PROCESO: PR-1.3-GENERAR_ANÁLISIS_GRID
EXPLOSIONA EN: DFD-1.3-GENERAR_ANÁLISIS_GRID
Una vez obtenido el árbol de regresión a través del GRID, es necesaria la
recopilación de información relativa a los tiempos empleados durante el proceso.
Esta información es suministrada por la plataforma BOINC, a partir de sus
ficheros de log y su base de datos.
Como resultado de la recopilación se obtendrá el fichero de Análisis de Tiempos
del GRID.
PROCESO: PR-1.4-CREAR_GRÁFICA

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
85
EXPLOSIONA EN: DFD-1.4-CREAR_GRÁFICA
La representación de una gráfica de tiempos requiere de unos datos de entrada que
son suministrados mediante la matriz de tiempos almacenada en el proceso
anterior.
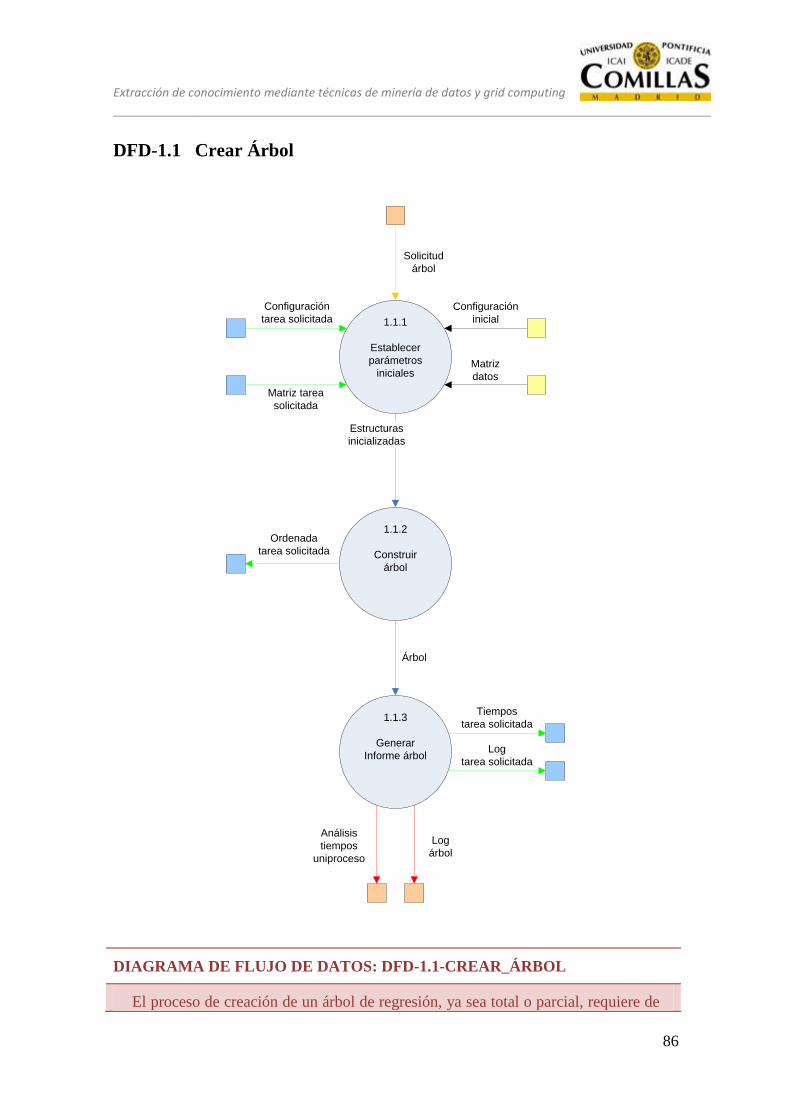
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
86
DFD-1.1 Crear Árbol
1.1.1
Establecer
parámetros
iniciales
1.1.2
Construir
árbol
Estructuras
inicializadas
Configuración
inicial
Configuración
tarea solicitada
Análisis
tiempos
uniproceso
Log
árbol
Matriz
datos
Tiempos
tarea solicitada
Matriz tarea
solicitada
Log
tarea solicitada
1.1.3
Generar
Informe árbol
Árbol
Solicitud
árbol
Ordenada
tarea solicitada
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1-CREAR_ÁRBOL
El proceso de creación de un árbol de regresión, ya sea total o parcial, requiere de

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
87
dos tipos de entradas:
Matriz de datos.
Configuración.
Las entradas pueden proceder del enunciado del problema completo o de una tarea
solicitada por un servidor del GRID.
Si la configuración solicita que se use el GRID, el proceso generará las unidades
de trabajo o WU para su desarrollo en otros sistemas del GRID.
Como resultado deben obtenerse los siguientes ficheros:
Log del árbol.
Análisis de tiempos uniproceso.
PROCESO: PR-1.1.1-ESTABLECER_PARÁMETROS_INICIALES
EXPLOSIONA EN: DFD-1.1.1-ESTABLECER_PARÁMETROS_INICIALES
El primer paso consiste en obtener los datos con los que trabajar y las
especificaciones del problema descritas en la configuración, para así poder
inicializar las variables y estructuras que se emplearán en la construcción del
árbol.
PROCESO: PR-1.1.2-CONSTRUIR ÁRBOL
EXPLOSIONA EN: DFD-1.1.2-CONSTRUIR_ÁRBOL
Se aplica el algoritmo de resolución de árboles de regresión. En caso de que la
resolución implique el uso del GRID, además de resolverse el árbol hasta la
profundidad indicada, se realizará una división del trabajo en forma de ramas del
árbol a resolver.
PROCESO: PR-1.1.3-GENERAR_INFORME_ÁRBOL
EXPLOSIONA EN: DFD-1.1.3-GENERAR_INFORME_ÁRBOL
Se generan los informes de log y de análisis de tiempos de todo el proceso de
resolución realizado por el subsistema. Los dos ficheros generados varían
dependiendo de si se ha trabajado de forma uniproceso o en GRID.
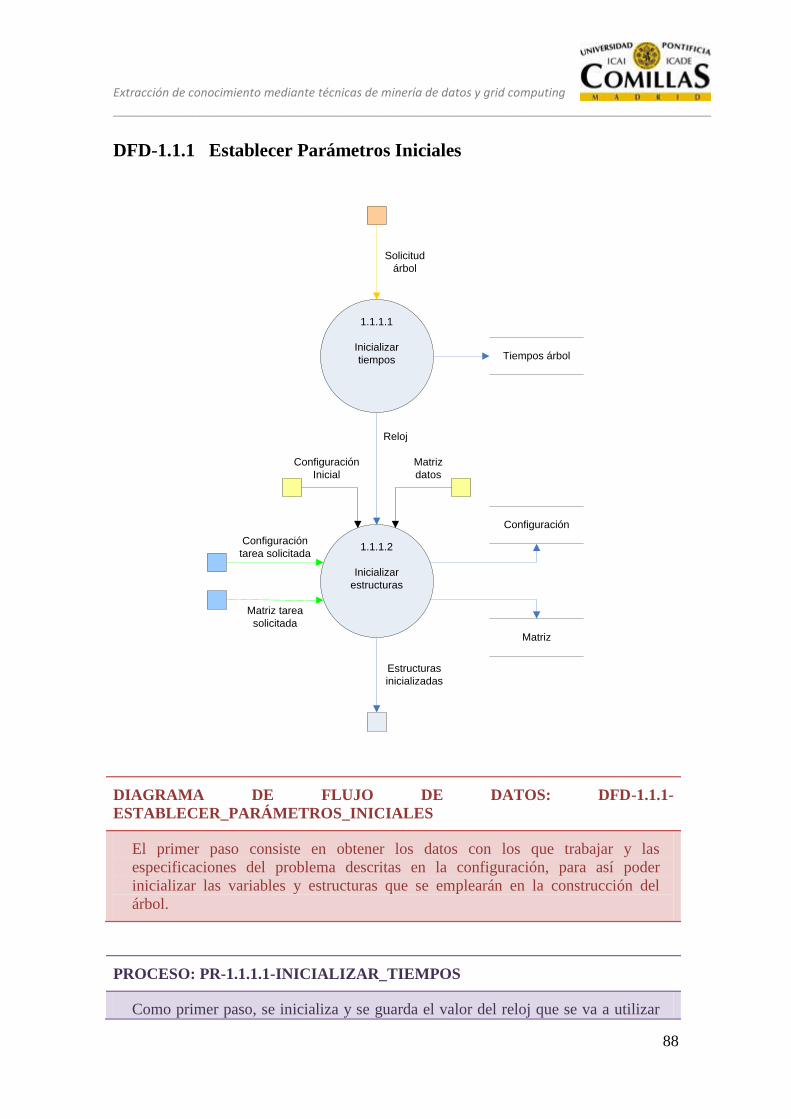
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
88
DFD-1.1.1 Establecer Parámetros Iniciales
1.1.1.2
Inicializar
estructuras
Configuración
Inicial
Configuración
tarea solicitada
Matriz
datos
Matriz tarea
solicitada
Configuración
Estructuras
inicializadas
Matriz
Tiempos árbol
Solicitud
árbol
1.1.1.1
Inicializar
tiempos
Reloj
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1.1-
ESTABLECER_PARÁMETROS_INICIALES
El primer paso consiste en obtener los datos con los que trabajar y las
especificaciones del problema descritas en la configuración, para así poder
inicializar las variables y estructuras que se emplearán en la construcción del
árbol.
PROCESO: PR-1.1.1.1-INICIALIZAR_TIEMPOS
Como primer paso, se inicializa y se guarda el valor del reloj que se va a utilizar

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
89
para la medición de los tiempos de creación del árbol.
PROCESO: PR-1.1.1.2-INICIALIZAR_ESTRUCTURAS
A partir de los ficheros de configuración y matriz de datos, se inicializan las
variables y estructuras que va a manejar el algoritmo de resolución del árbol de
regresión.
FLUJO DE DATOS: FD-SOLICITUD_ÁRBOL
Solicitud de resolución de un árbol por parte de la entidad externa Investigador.
FLUJO DE DATOS: FD-RELOJ
Reloj inicializado con el que se medirán los tiempos de creación del árbol.
FLUJO DE DATOS: FD-CONFIGURACIÓN_INICIAL
Fichero con los parámetros iniciales de configuración del árbol solicitado por la
entidad externa Investigador. Los parámetros de los que consta son los siguientes:
Variables de entrada a tener en cuenta
Variable de salida
Profundidad a la que construir el árbol
Constantes del criterio de parada: mínimo número de elementos por nodo y
MSE mínimo.
Nombre del fichero con la matriz de datos a utilizar.
FLUJO DE DATOS: FD-MATRIZ_DATOS
Fichero con la matriz de datos con los que se desea construir el árbol de regresión
solicitado por la entidad externa Investigador.
FLUJO DE DATOS: FD-CONFIGURACIÓN_TAREA_SOLICITADA
Fichero con los parámetros iniciales de configuración de la rama del árbol
solicitado por la entidad externa BOINC. Los parámetros de los que consta son los

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
90
siguientes:
Variables de entrada a tener en cuenta
Variable de salida
Profundidad a la que construir el árbol
Constantes del criterio de parada: mínimo número de elementos por nodo y
MSE mínimo.
Nombre del fichero con la matriz de datos a utilizar.
FLUJO DE DATOS: FD-MATRIZ_TAREA_SOLICITADA
Fichero con la matriz de datos con los que se desea construir el árbol de
regresión solicitado por la entidad externa BOINC.
FLUJO DE DATOS: FD-ESTRUCTURAS_INICIALIZADAS
Variables y estructuras inicializadas que va a manejar el algoritmo de
resolución del árbol de regresión.
ALMACÉN: AL-CONFIGURACIÓN
Espacio de memoria donde se vuelcan los parámetros iniciales de
configuración.
ALMACÉN: AL-MATRIZ
Espacio de memoria donde se vuelca la matriz de datos.
ALMACÉN: AL-TIEMPOS_ÁRBOL
Almacén donde se guardan los tiempos de inicio (1.1.1.1), de resolución del árbol
(1.1.2.1) y de representación de la estructura del árbol (1.1.3.1), para su análisis en
procesos futuros.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
91
DFD-1.1.2 Construir Árbol
Estructuras
inicializadas
Configuración
Matriz 1.1.2.1
Aplicar
algoritmo
resolución
ÁrbolTiempos árbol
Stop
criteria
Rama
a resolverRamas
Ordenada
tarea solicitada
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1.2-CONSTRUIR_ÁRBOL
Se aplica el algoritmo de ajuste de árboles de regresión. En caso de que la
resolución implique el uso del GRID, además de resolverse el árbol hasta la
profundidad indicada, se realizará una división del trabajo en forma de ramas del
árbol a resolver.
PROCESO: PR-1.1.2.1-APLICAR_ALGORITMO_RESOLUCIÓN
Se ejecuta el algoritmo de ajuste de árboles de regresión sobre la matriz de datos y
siguiendo los parámetros de configuración establecidos.
Como resultado se obtendrá el árbol de regresión total (uniproceso) o parcial
(GRID).
FLUJO DE DATOS: FD-ESTRUCTURAS_INICIALIZADAS
Variables y estructuras inicializadas que va a manejar el algoritmo de ajuste del
árbol de regresión.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
92
FLUJO DE DATOS: FD-RAMA_A_RESOLVER
Nodo del árbol cuyo subárbol o rama resultante se desea calcular en el GRID.
FLUJO DE DATOS: FD-ORDENADA_TAREA_SOLICITADA
Fichero con los nodos aún deben ser calculados en el GRID.
FLUJO DE DATOS: FD-STOP_CRITERIA
Parámetros del criterio de parada establecidos en el fichero de configuración:
mínimo número de elementos por nodo y MSE mínimo.
FLUJO DE DATOS: FD-ÁRBOL
Árbol obtenido tras aplicar el algoritmo de ajuste, junto con los parámetros de
configuración, a la matriz de datos.
ALMACÉN: AL-CONFIGURACIÓN
Espacio de memoria donde se vuelcan los parámetros iniciales de configuración.
ALMACÉN: AL-MATRIZ
Espacio de memoria donde se vuelca la matriz de datos.
ALMACÉN: AL-RAMAS
Almacén donde se guardan los nodos del árbol que deben ser resueltos por el
GRID.
ALMACÉN: AL-TIEMPOS_ÁRBOL

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
93
Almacén donde se guardan los tiempos de inicio (1.1.1.1), de resolución del árbol
(1.1.2.1) y de representación de la estructura del árbol (1.1.3.1), para su análisis en
procesos futuros.
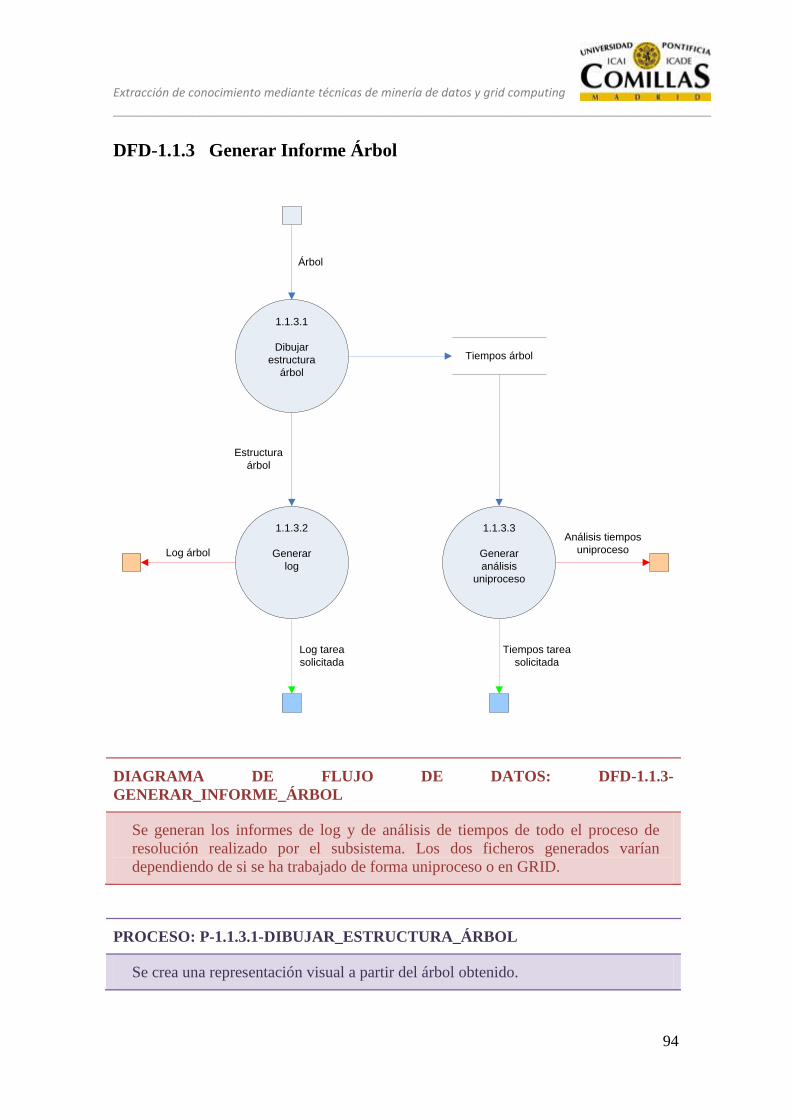
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
94
DFD-1.1.3 Generar Informe Árbol
1.1.3.1
Dibujar
estructura
árbol
Árbol
1.1.3.2
Generar
log
Estructura
árbol
Tiempos árbol
Log árbol
Análisis tiempos
uniproceso
1.1.3.3
Generar
análisis
uniproceso
Log tarea
solicitada
Tiempos tarea
solicitada
DIAGRAMA DE FLUJO DE DATOS: DFD-1.1.3-
GENERAR_INFORME_ÁRBOL
Se generan los informes de log y de análisis de tiempos de todo el proceso de
resolución realizado por el subsistema. Los dos ficheros generados varían
dependiendo de si se ha trabajado de forma uniproceso o en GRID.
PROCESO: P-1.1.3.1-DIBUJAR_ESTRUCTURA_ÁRBOL
Se crea una representación visual a partir del árbol obtenido.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
95
PROCESO: P-1.1.3.2-GENERAR_LOG
Se genera el fichero de log con la representación visual del árbol.
PROCESO:P-1.1.3.3-GENERAR_ANÁLISIS_UNIPROCESO
A partir del almacén de Tiempos Árbol, se genera el fichero de análisis de tiempos
de todo el proceso de resolución realizado por el subsistema.
FLUJO DE DATOS: FD-ÁRBOL
Árbol obtenido tras aplicar el algoritmo de ajuste, junto con los parámetros de
configuración, a la matriz de datos.
FLUJO DE DATOS: FD-ESTRUCTURA_ÁRBOL
Representación visual del árbol de regresión obtenido.
FLUJO DE DATOS: FD-LOG_ÁRBOL
Fichero de log del proceso de resolución del árbol realizado por el subsistema.
FLUJO DE DATOS: FD-LOG_TAREA_SOLICITADA
Fichero de log del proceso de resolución del subárbol o rama realizada por el
subsistema.
FLUJO DE DATOS: FD-ANÁLISIS_TIEMPOS_UNIPROCESO
Fichero de análisis de tiempos de todo el proceso de resolución del árbol realizado
por el subsistema.
FLUJO DE DATOS: FD-TIEMPOS_TAREA_SOLICITADA
Fichero de análisis de tiempos de todo el proceso de resolución del subárbol o

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
96
rama realizada por el subsistema.
ALMACÉN: AL-TIEMPOS_ÁRBOL
Almacén donde se guardan los tiempos de inicio (1.1.1.1), de resolución del árbol
(1.1.2.1) y de representación de la estructura del árbol (1.1.3.1), para su análisis en
procesos futuros.
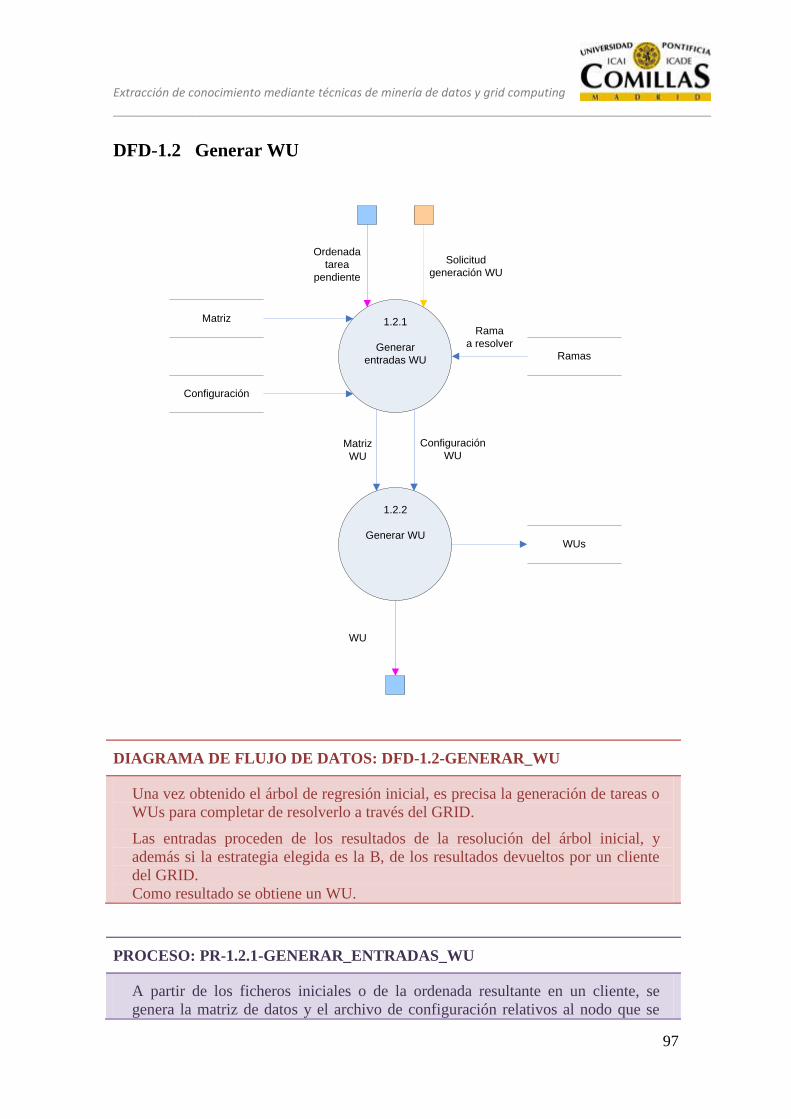
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
97
DFD-1.2 Generar WU
Ramas
Solicitud
generación WU
Ordenada
tarea
pendiente
Rama
a resolver
1.2.1
Generar
entradas WU
Configuración
WU
1.2.2
Generar WU
Configuración
Matriz
WU
Matriz
WU
WUs
DIAGRAMA DE FLUJO DE DATOS: DFD-1.2-GENERAR_WU
Una vez obtenido el árbol de regresión inicial, es precisa la generación de tareas o
WUs para completar de resolverlo a través del GRID.
Las entradas proceden de los resultados de la resolución del árbol inicial, y
además si la estrategia elegida es la B, de los resultados devueltos por un cliente
del GRID.
Como resultado se obtiene un WU.
PROCESO: PR-1.2.1-GENERAR_ENTRADAS_WU
A partir de los ficheros iniciales o de la ordenada resultante en un cliente, se
genera la matriz de datos y el archivo de configuración relativos al nodo que se
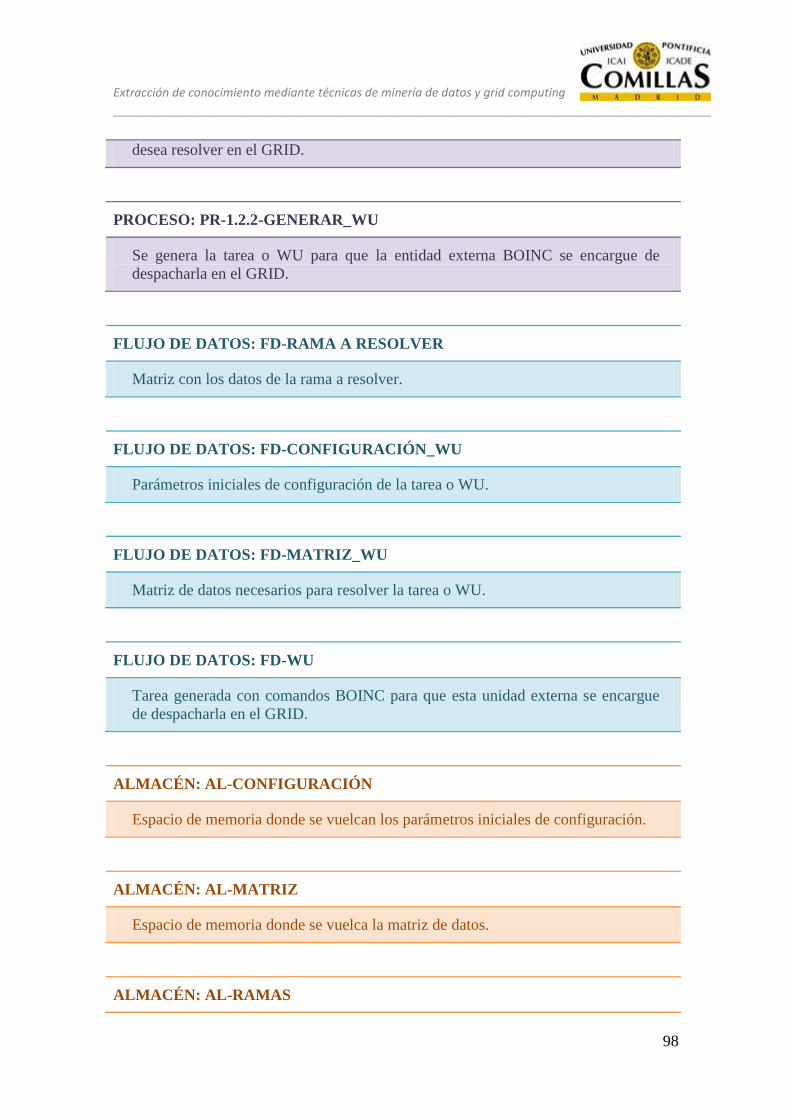
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
98
desea resolver en el GRID.
PROCESO: PR-1.2.2-GENERAR_WU
Se genera la tarea o WU para que la entidad externa BOINC se encargue de
despacharla en el GRID.
FLUJO DE DATOS: FD-RAMA A RESOLVER
Matriz con los datos de la rama a resolver.
FLUJO DE DATOS: FD-CONFIGURACIÓN_WU
Parámetros iniciales de configuración de la tarea o WU.
FLUJO DE DATOS: FD-MATRIZ_WU
Matriz de datos necesarios para resolver la tarea o WU.
FLUJO DE DATOS: FD-WU
Tarea generada con comandos BOINC para que esta unidad externa se encargue
de despacharla en el GRID.
ALMACÉN: AL-CONFIGURACIÓN
Espacio de memoria donde se vuelcan los parámetros iniciales de configuración.
ALMACÉN: AL-MATRIZ
Espacio de memoria donde se vuelca la matriz de datos.
ALMACÉN: AL-RAMAS

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
99
Almacén donde se guardan los nodos del árbol que deben ser resueltos por el
GRID.
ALMACÉN: AL-WUS
Espacio de memoria donde se guarda el nombre de los WUs generados.
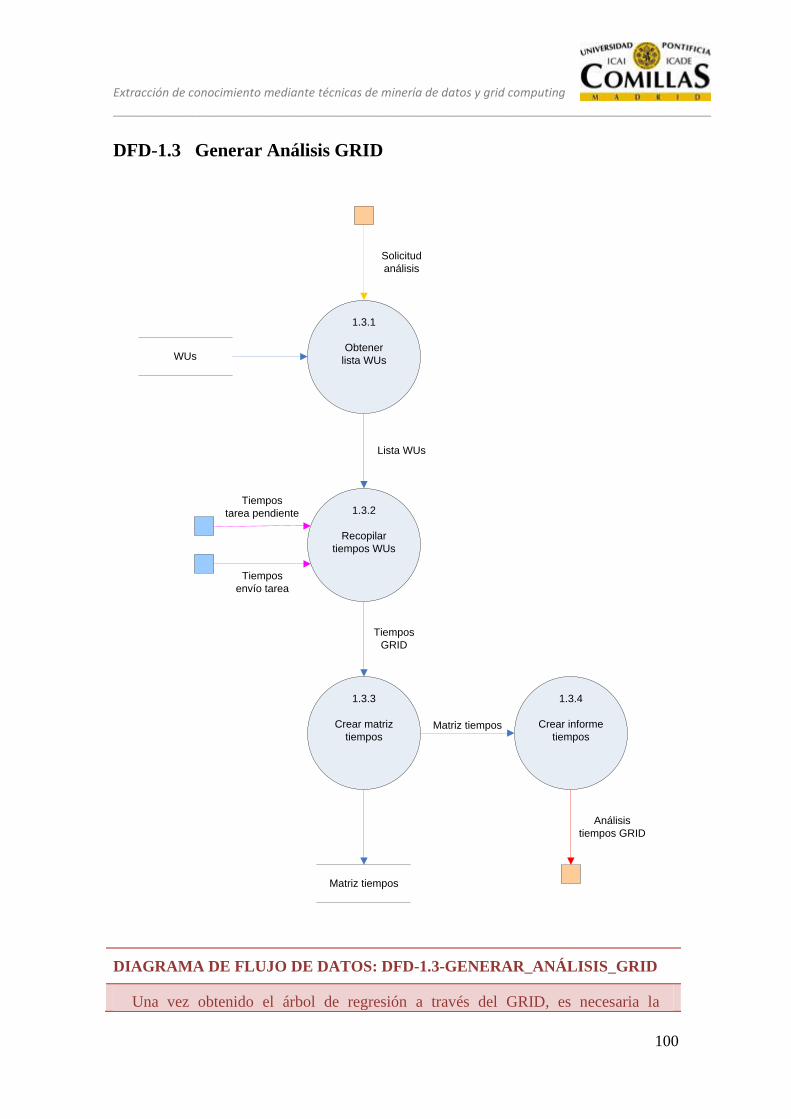
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
100
DFD-1.3 Generar Análisis GRID
1.3.2
Recopilar
tiempos WUs
1.3.3
Crear matriz
tiempos
Tiempos
GRID
1.3.4
Crear informe
tiemposMatriz tiempos
Análisis
tiempos GRID
Solicitud
análisis
1.3.1
Obtener
lista WUsWUs
Lista WUs
Tiempos
tarea pendiente
Tiempos
envío tarea
Matriz tiempos
DIAGRAMA DE FLUJO DE DATOS: DFD-1.3-GENERAR_ANÁLISIS_GRID
Una vez obtenido el árbol de regresión a través del GRID, es necesaria la

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
101
recopilación de información relativa a los tiempos empleados durante el proceso.
Esta información es suministrada por la plataforma BOINC, a partir de sus
ficheros de log y su base de datos.
Este subsistema obtiene como resultado de la recopilación un fichero de Análisis
de Tiempos del GRID.
PROCESO: PR-1.3.1-OBTENER_LISTA_WUS
El proceso obtiene la lista de WUs que han sido creados en la etapa de creación
del árbol de regresión.
PROCESO: PR-1.3.2-RECOPILAR_TIEMPOS_WUS
El proceso recopila toda la información relativa a los tiempos de resolución de las
tareas en el GRID a través de la unidad externa BOINC.
PROCESO: PR-1.3.3-CREAR_MATRIZ_TIEMPOS
Una vez recibida toda la información relativa a los tiempos del GRID, este
proceso ordena y selecciona aquellos que son útiles para su análisis y futura
representación gráfica.
Como resultado se obtiene una matriz de tiempos.
PROCESO: PR-1.3.4-CREAR_INFORME_TIEMPOS
Con la matriz de tiempos, el proceso crea el informe de análisis de tiempos GRID
que será presentado al usuario final o entidad externa Investigador.
FLUJO DE DATOS: FD-SOLICITUD_ANÁLISIS
Solicitud de generación del fichero de análisis de tiempos del GRID y la matriz de
tiempos por parte de la entidad externa Investigador.
FLUJO DE DATOS: FD-LISTA_WUS
Lista de WUs que han sido creados en la etapa de creación del árbol de regresión.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
102
FLUJO DE DATOS: FD-TIEMPOS_TAREA_PENDIENTE
Fichero de análisis de tiempos del proceso de resolución de cada subárbol o rama
realizada por una estación cliente del GRID.
FLUJO DE DATOS: FD-TIEMPOS_ENVÍO_TAREA
Tiempos de envío de cada tarea o WU a una estación cliente del GRID y de
recepción de los resultados generados por esta.
FLUJO DE DATOS: FD-TIEMPOS_GRID
Tiempos relativos al proceso de resolución de ramas y de envío de envío y
recepción de WUs y resultados a través del GRID.
FLUJO DE DATOS: FD-MATRIZ_TIEMPOS
Matriz con los tiempos del proceso de creación del árbol en el GRID que sean
útiles para su análisis y futura representación gráfica.
FLUJO DE DATOS: FD-ANÁLISIS_TIEMPOS_GRID
Informe detallado de los tiempos empleados durante todo el proceso de creación
del árbol en el GRID.
Los tiempos mostrados son los mismos que los representados en la matriz de
tiempos, con la diferencia de que este informe es un documento legible por el
usuario final.
ALMACÉN: AL-WUS
Espacio de memoria donde se guarda el nombre de los WUs generados.
ALMACÉN: AL-MATRIZ_TIEMPOS

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
103
Fichero donde se guarda la matriz de tiempos.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
104
DFD-1.4 Crear Gráfica
1.4.1
Obtener
matriz tiempos
Solicitud
gráfica
1.4.2
Generar
gráfica tiempos
Matriz
tiempos
Gráfica tiempos
Matriz tiempos
DIAGRAMA DE FLUJO DE DATOS: DFD-1.4-CREAR_GRÁFICA
Este subsistema se encarga de generar la gráfica de tiempos a partir de la matriz
de tiempos obtenida en el subsistema anterior.
PROCESO: PR-1.4.1-OBTENER_MATRIZ_TIEMPOS
El proceso obtiene la matriz de tiempos generada en la etapa anterior de
generación del análisis GRID.
PROCESO: PR-1.4.2-GENERAR_GRÁFICA_TIEMPOS
El proceso genera una gráfica a partir de la matriz de tiempos.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
105
FLUJO DE DATOS: FD-SOLICITUD_GRÁFICA
Solicitud de generación de una gráfica de tiempos del GRID por parte de la
entidad externa Investigador.
FLUJO DE DATOS: FD-MATRIZ_TIEMPOS
Matriz con los tiempos del proceso de creación del árbol en el GRID que sean
útiles para su análisis y futura representación gráfica.
FLUJO DE DATOS: FD-GRÁFICA_TIEMPOS
Representación final de la gráfica de tiempos.
ALMACÉN: AL-MATRIZ_TIEMPOS
Fichero donde se encuentra almacenada la matriz de tiempos.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
106
11 DESARROLLO DE ALGORITMOS
Tal como se ha mostrado en el modelo físico, el proyecto se ha divido en cuatro
subsistemas, obteniéndose una aplicación por cada uno de ellos.
Los algoritmos generados para los subsistemas 1 (Creación del Árbol), 2 (Generación
de WUs) y 3 (Análisis del GRID) se han programado en código C y C++.
Como herramienta de programación para estos subsistemas se ha empleado el
compilador MingGW Developer Studio 2.05.
Asimismo, los algoritmos generados para el subsistema 4 (Generación de Gráficas) han
sido programados bajo código Matlab.
Como herramienta de programación para este subsistema, y para la generación de
conjuntos de datos sintéticos necesarios para la realización de las pruebas, se ha
empleado la herramienta matemática Matlab 6.5.
A continuación se procede a describir la aplicación de ajuste de árboles de regresión
(Subsistema 1):
11.1 SUBSISTEMA 1: CREACIÓN DEL ÁRBOL
Este subsistema es el encargado de la resolución del árbol de regresión, sin tener en
cuenta ningún tipo de control sobre qué estrategia se está siguiendo o sobre el proceso
de creación de unidades de proceso (workunits) necesarias para que BOINC gestione el
trasiego de información por el GRID.
Este algoritmo se ha desarrollado bajo el nombre “Arbol.C” de tal manera que
implemente tanto la estrategia de resolución A como la B anteriormente explicadas.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
107
Dado que se desea realizar el cálculo del árbol de regresión en varios ordenadores del
GRID simultáneamente, ha sido necesario diseñar un algoritmo totalmente
paralelizable. En los siguientes apartados se procede a explicar con detalle las medidas
tomadas para conseguirlo.
11.1.1 Código Multiuso
El código es el mismo tanto para el servidor, que se encarga de generar las tareas a
repartir por el GRID, como para las estaciones cliente.
Esto es debido a que ambos tipos de estaciones realizan una misma función principal:
Crear el árbol de regresión resultante a partir de una matriz de datos y con unos
requisitos especificados en un archivo de configuración.
Sin embargo se ha tenido en cuenta una serie de diferencias fundamentales en el modo
de operar del cliente y el servidor. Estas diferencias se han hecho efectivas mediante la
incorporación en el código C de las directivas #ifdef y #ifndef que permiten una
compilación condicional basándose en si está definida una macro (#define) o no
(#undefine). A continuación se muestra un ejemplo de su funcionamiento:
1 #define SERVIDOR
2 ...
3 ...
4 ...
5 #ifndef SERVIDOR
6 #include "BOINC/boinc_api.h"
7 #include "BOINC/filesys.h"
8 #endif
9 ...

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
108
Inicialmente se define la macro SERVIDOR, dado que se pretende que sea el código
que se va a ejecutar en el servidor. En un momento dado se pregunta si la macro
SERVIDOR no está definida, como no es así el compilador obviará dicha parte del
código. Por tanto, el código comprendido entre las líneas 5 y 8 no se tendrá en cuenta en
la compilación.
La diferencia principal existente entre el cliente y el servidor es que el servidor, a parte
de realizar los mismos cálculos que el cliente, es también el encargado de generar las
unidades de trabajo que se van a enviar al GRID y el fichero que contiene sus nombres.
Esta funcionalidad se aplica en la función CreaArbol(), donde se averigua si el árbol ha
llegado a su profundidad máxima especificada en el archivo de entrada de
configuración. Si es así, una vez que se asegura de que la macro SERVIDOR está
definida, se procede a crear el “workunit” pertinente junto a sus ficheros de entrada. Si
la macro SERVIDOR no está definida no realizará ninguno de estos dos pasos:
void CreaArbol(...){
...
if((p->profundidad == n->altura)&&(n-
>conjunto.num_ejemplos > p->min_elementos)&&( n->mse
> p->mse_minimo)){
#ifdef SERVIDOR
// Se crean los ficheros de salida
CreaMatrizSalida(n);
CreaConfigSalida(p, n);
// Se crea el "workunit"
strcpy(aux, "bin/create_work --appname Arbol --
wu_name wu");
itoax(n->id, num_nodo);
#ifdef MOSTRAR_WUS
// Se guarda el nombre del WU
fprintf(p_wus, "wu%s\n", num_nodo);

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
109
#endif
strcat(aux, num_nodo);
strcat(aux, " --wu_template templates/wu.xml --
result_template templates/result.xml --
rsc_fpops_est 100000000000 --rsc_fpops_bound
100000000000 --min_quorum 1 --target_nresults 1
Config");
strcat(aux, num_nodo);
strcat(aux, ".txt Matriz");
strcat(aux, num_nodo);
strcat(aux, ".txt");
system(aux);
#endif
}
}
El fichero donde se guardan los nombres de los workunits generados se ha abierto
previamente siguiendo un mismo control:
#ifdef SERVIDOR
#ifdef MOSTRAR_WUS
p_wus = fopen("download/WUs.txt", "w");
if(p_wus == NULL){
printf("\nError al abrir el fichero de
WUs\n");
exit(1);
}
#endif
#endif
Los clientes requieren de la introducción de una serie de instrucciones básicas
BOINC para la inicialización y terminación de la aplicación, la resolución de
ficheros, e instrucciones de I/O.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
110
Se deben incluir las librerías propias de BOINC:
#ifndef SERVIDOR
#include "BOINC/boinc_api.h"
#include "BOINC/filesys.h"
#endif
En la función principal “Main” de la aplicación se introducen las instrucciones de inicio
y fin de la aplicación:
#ifndef SERVIDOR
int boinc_val; // Para el control de BOINC
int rc; // Para el control de BOINC
char input_path[N]; //Resolución ficheros entrada
char output_path[N];// Resolución ficheros salida
boinc_val = boinc_init();
if(boinc_val){
fprintf(stderr, "boinc_init devolvio %d\n",
boinc_val);
exit(boinc_val);
}
#endif
...
#ifdef SERVIDOR
exit(0); // Fin Aplicacion
#else
boinc_finish(0); // Fin Boinc
#endif

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
111
Para poder hacer operaciones I/O con ficheros, en BOINC es necesario resolver los
ficheros de forma que no se sobreescriba la información en las diferentes ejecuciones de
la misma en la máquina cliente:
#ifdef SERVIDOR
p_config = fopen("download/Config.txt", "r");
if(p_config == NULL){
printf("\nError al abrir el fichero de
configuracion\n");
exit(1);
}
#else
rc = boinc_resolve_filename("Config.txt",
input_path, sizeof(input_path));
if(!rc){
p_config = boinc_fopen(input_path, "r");
if(p_config == NULL){
printf("\nError al abrir el fichero
de configuracion\n");
exit(1);
}
}else{
fprintf(stderr, "APP: error al resolver el
fichero de configuracion. RC = %d\n", rc);
boinc_finish(rc);
}
#endif
11.1.2 Código Modular
Para conseguir la paralelización es fundamental modularizar el código en
subproblemas, siguiendo las técnicas de la programación Top-Down.
Cada subproblema se identifica con una función o un procedimiento, siendo indiferente
en dónde se resuelven, ya sea en la misma máquina o en otra cualquiera del GRID.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
112
A continuación se expone la lista y una pequeña descripción de las principales
funciones en las que se ha dividido el algoritmo:
void Configura: Lee la configuración introducida por el usuario mediante el
fichero "Config.txt".
int CuentaVariables: Calcula el número de variables de la matriz de datos.
int CuentaEjemplos: Calcula el número de ejemplos (filas) de la matriz de datos.
void RellenaVariables: Rellena el array de variables con los elementos de la
matriz de datos.
double CalculaMse: Calcula el MSE de un conjunto de ejemplos.
void CreaNodo: Inicializa un nodo.
void LiberaNodo: Elimina un nodo.
void LiberaVariablesNodo: Libera las variables y ejemplos de un nodo.
void CreaArbol: Contiene la lógica para la expansión de un nodo, trabajando de
forma recursiva.
SEPARADOR BuscaSeparador: Busca el mejor separador para un nodo.
CORTE_NUMERICO BuscaCorteNumerico: Busca los puntos de corte de una
variable numérica.
void AplicaCorteNumerico: Aplica el corte en el nodo.
void InsertaMatrizOrdenada: añade los ejemplos de un nodo en la matriz de
nodos.
void GuardaNodoTerminal: guarda los ejemplos de un nodo terminal en la
matriz de nodos terminales.
void PintaArbol: Pinta el árbol obtenido.
A continuación se muestra la representación de la jerarquía de las funciones
anteriormente expuestas:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
113
11.1.3 Recursividad
Se recuerda que ambas estrategias de distribución del trabajo por el GRID se basan
conceptualmente en la paralelización del cálculo de las distintas ramas del árbol de
regresión. Por ello, el hecho de haber diseñado un código modular no habría bastado
sino se hubiera tenido en cuenta, al mismo tiempo, el haber generado un código de
resolución recursivo.
El hecho de conseguir un algoritmo recursivo permite que indiferentemente del nodo
con el que se desea trabajar, ya sea el nodo raíz (G1) u otro nodo cualquiera (G2, G3,
G4 o G4), la aplicación sea capaz de obtener el árbol resultante.
MAIN
ConfiguraCuenta
variablesCuenta
ejemplosRellena
variablesCrea árbol
Busca separador
Busca corte numérico
Aplica corte numérico
Calcula MSE
Crea nodo
Crea árbol(recursivo)
Inserta matriz ord.
Guarda nodo term.
Libera var. nodo
Pinta árbol

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
114
Como consecuencia, la estación servidora es capaz de generar a partir del nodo raíz
(G1) el árbol resultante hasta cierto nivel (altura 2), obteniendo como resultado un
número de nodos hijos (G2, G3, G4 y G5). Y la misma aplicación, pero en ordenadores
distintos, es capaz de continuar el cálculo las ramas derivadas de los nodos hijos.
La recursividad se centra en el proceso de división de los nodos, o dicho de otra manera,
en el proceso de generación de nodos hijos a partir de un nodo padre. Para ello se hace
fundamental el trabajar con una estructura que guarde la jerarquía padre-hijo del árbol
que se va creando. Al tener que afrontar este aspecto desde el lenguaje de programación
C, la solución más eficiente es crear un vector de estructuras con punteros a otras
estructuras:
typedef struct nodo{
int id;
int altura;
int num_hijos;
struct nodo *padre;
struct nodo **hijos;
int nodo_final;
VARIABLE *var_separador;
char simb_ecuacion[M];
double valor_ecuacion_num;
char *valor_ecuacion_cat;
double mse;
CONJ conjunto;
}NODO;
int id: Identificador del nodo.
int altura: Altura del nodo dentro del árbol.
Num_hijos: Número de nodos hijos.
struct nodo *padre: Puntero a la estructura del nodo padre.
struct nodo **hijos: Vector de punteros a las estructuras de los nodos hijos.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
115
int nodo_final: Indica si es un nodo final o no.
VARIABLE *var_separador: Estructura a la variable separadora.
char simb_ecuacion: Símbolo de la ecuación que lleva a este nodo desde el nodo
padre.
double valor_ecuacion_num: Valor de la ecuación que lleva a este nodo desde el
padre (si la variable separadora ha sido numérica).
char valor_ecuacion_cat: Valor de la ecuación que lleva a este nodo desde el
padre (si la variable separadora ha sido categórica).
doublé mse: MSE del nodo.
CONJ conjunto: Conjunto de ejemplos que forman parte del nodo.
La recursividad se consigue en la función CreaArbol(), donde cada iteración en el
proceso recursivo consta de los siguientes pasos:
1. Comprobación del Stop Criteria para saber si se debe continuar expandiendo el
árbol o no. Este paso incluye comprobar los siguientes criterios:
- Que el nodo supere el umbral mínimo de elementos en un nodo.
- Que el MSE del nodo supere el umbral del MSE mínimo.
- Que el árbol no exceda de la altura máxima permitida.
a. Si el nodo pasa la comprobación se salta al siguiente paso.
b. Si el nodo no pasa la comprobación se detiene en este paso.
2. Búsqueda del mejor separador del nodo.
a. Si el nodo tiene al menos un separador posible se salta al siguiente paso.
b. Si el nodo no tiene ningún separador se detiene en este paso.
3. Se aplica el corte, dividiendo el nodo en varios nodos hijos.
Se vuelve al paso 1 para cada uno de los nodos hijos.
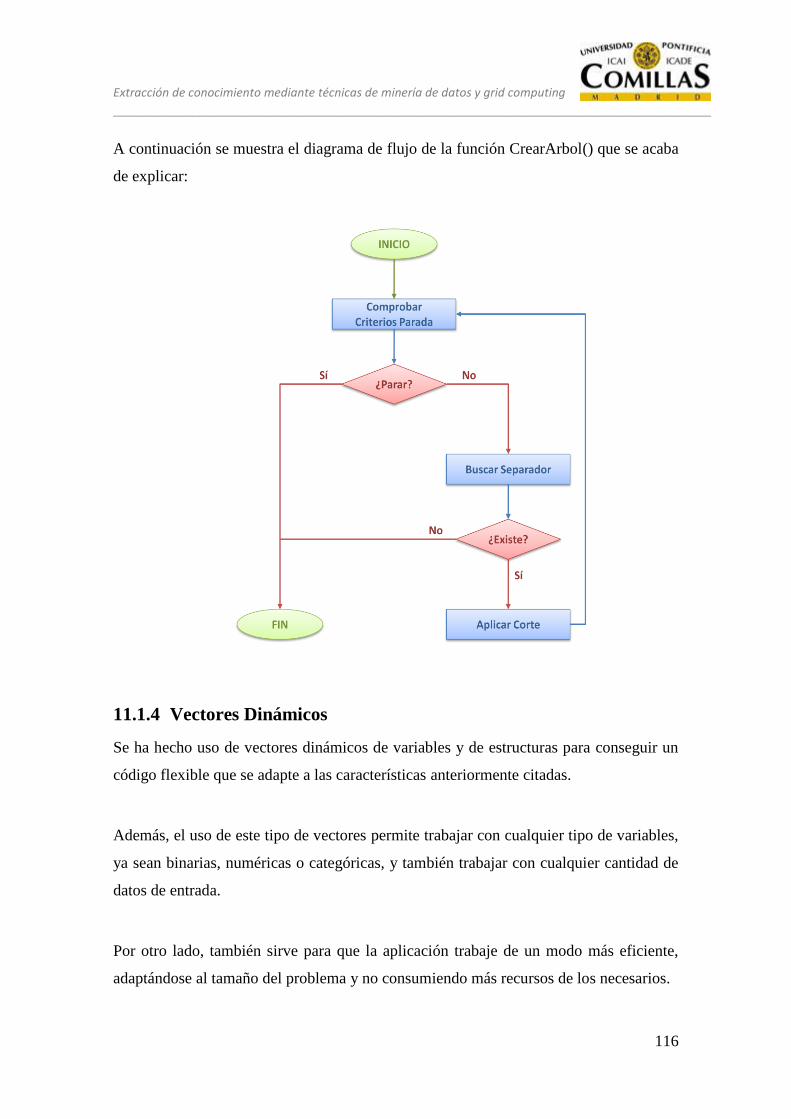
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
116
A continuación se muestra el diagrama de flujo de la función CrearArbol() que se acaba
de explicar:
11.1.4 Vectores Dinámicos
Se ha hecho uso de vectores dinámicos de variables y de estructuras para conseguir un
código flexible que se adapte a las características anteriormente citadas.
Además, el uso de este tipo de vectores permite trabajar con cualquier tipo de variables,
ya sean binarias, numéricas o categóricas, y también trabajar con cualquier cantidad de
datos de entrada.
Por otro lado, también sirve para que la aplicación trabaje de un modo más eficiente,
adaptándose al tamaño del problema y no consumiendo más recursos de los necesarios.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
117
12 PRUEBAS
En este apartado se muestra la planificación de pruebas realizada, así como los
resultados obtenidos en cada una de ellas.
En la realización de las pruebas se han empleado dos conjuntos de datos sintéticos
opuestos, para así poder lograr un análisis de los resultados más fiable y generalizado.
12.1 CONJUNTO DE PRUEBAS DESEQUILIBRADO
El conjunto de pruebas cuenta con 4004001 ejemplos, cada uno de los cuales está
formado por tres variables (x, y, z), de forma que al representarlos se obtiene la
siguiente figura:
El problema de regresión a resolver mediante la construcción de un árbol de regresión
consiste en estimar la variable z a partir de los valores de las variables x e y.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
118
Como puede observarse, se trata de estimar dos planos con ruido bien diferenciados: un
primero formado por aquellos ejemplos con variable z próxima al 0 y otro formado por
el resto de ejemplos con variable z próxima al 1.
El hecho de que el segundo plano contenga una cantidad muy superior de ejemplos que
el primero, condiciona al árbol de regresión que represente este conjunto de pruebas a
estar claramente desequilibrado.
12.2 CONJUNTO DE PRUEBAS EQUILIBRADO
El conjunto de pruebas cuenta con 4004001 ejemplos, cada uno de los cuales está
formado por tres variables (x, y, z), de forma que al representarlos se obtiene la
siguiente figura:
Como puede observarse, en este caso se trata de estimar un plano inclinado sin ruido.
El hecho de que este conjunto de pruebas esté formado por un solo plano condiciona al
árbol de regresión que lo represente a estar muy equilibrado.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
119
12.3 PLANIFICACIÓN
Antes de comenzar las pruebas ha sido necesaria una planificación detallada de las
mismas. Para ello, antes de nada, es necesario analizar qué criterios son más
determinantes para ser sometidos a cambios.
Los criterios seleccionados tras el estudio son los siguientes:
1. Estrategia de la resolución.
Es la estrategia de resolución llevada a cabo. Para la realización de las pruebas se
han seguido tres estrategias: Monotarea, A y B.
Con este criterio se pretende comparar los resultados obtenidos con cada una de
estas tres estrategias y conocer cuál es la mejor alternativa para cada caso.
2. Nivel de profundidad del servidor.
Es el nivel hasta el que va a profundizar el servidor en la resolución del árbol. A
mayor nivel de profundidad, mayor número de tareas se van a generar en el
servidor y mayor tiempo de cálculo.
Con este criterio se pretende comparar los resultados de una repartición rápida de
pocas tareas, frente a los de una repartición más costosa de muchas tareas en el
GRID.
3. Nivel de profundidad de los clientes.
Es el nivel hasta el que puede profundizar un cliente en cada tarea que le es
asignada.
Este factor solo es tenido en cuenta para las pruebas realizadas con una Estrategia
B de resolución, ya que no tendría sentido aplicarlo en la Estrategia A que, por
definición, los clientes resuelven hasta el máximo nivel de profundidad posible.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
120
Con este criterio se pretende comparar los resultados de muchas actuaciones de
poca carga, frente a pocas actuaciones de mucha carga por los clientes del GRID.
4. Número mínimo de ejemplos.
Es uno de los criterios de parada para la generación de árboles de regresión.
Cuanto mayor sea el valor de este factor, más se reduce el tamaño del problema,
ya que los nodos que no superen este valor se darán por concluidos como nodos
terminales.
Con este criterio se pretende tener una casuística que cubra la resolución de
árboles de regresión con distintos criterios de parada, ya que no siempre se desean
los mismos.
Una vez seleccionados los factores que van a intervenir en la generación de las pruebas,
se procede a planificarlas. Ésta es una etapa muy importante ya que de ella dependen los
resultados que posteriormente van a ser analizados.
En la planificación han de decidirse, para cada uno de los factores seleccionados, qué
intervalo de valores son interesantes para el estudio y cuales no lo son.
A continuación se muestra la planificación realizada para cada conjunto de pruebas.
12.3.1 Conjunto de Pruebas Desequilibrado
En las siguientes tablas se muestra la planificación seguida para la realización de las
pruebas relativas al conjunto de pruebas desequilibrado.
Los campos señalados con un punto negro ● son los casos que se ha creído oportunos
probar, mientras que los que no están señalados no son importantes para el estudio.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
121
Los campos señalados con un punto blanco ○ son casos que se han llevado a cabo con
resultados erróneos, por lo que no podrán ser tenidos en cuenta.
Estrategia A Mo
no
Prof. Serv. 2 4 6 ∞ M
in. E
jem
p.
1 ● ●
10.000 ● ● ● ●
50.000 ● ●
Estrategia B B B
Prof. Serv. 2 4 6
Prof. Client. 5 7 10 5 7 10 5 7 10
Min
. E
jem
p. 1
10.000 ● ● ● ● ● ●
50.000 ● ● ● ● ●
12.3.2 Conjunto de Pruebas Equilibrado
En las siguientes tablas se muestra la planificación seguida para la realización de las
pruebas relativas al conjunto de pruebas equilibrado.
Los campos señalados con un punto negro ● son los casos que se ha creído oportunos
probar, mientras que los que no están señalados no son importantes para el estudio.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
122
Los campos señalados con un punto blanco ○ son casos que se han llevado a cabo con
resultados erróneos, por lo que no podrán ser tenidos en cuenta.
Estrategia A Mo
no
Prof. Serv. 2 4 6 ∞ M
in. E
jem
p.
1 ● ○
10.000 ● ● ● ●
50.000 ● ●
Estrategia B B B
Prof. Serv. 2 3 4
Prof. Client. 5 7 10 5 7 10 5 7 10
Min
. E
jem
p.
1
10.000 ● ● ● ● ● ● ● ● ●
50.000 ● ● ● ● ● ●
12.4 RESULTADOS
En este apartado se exponen los resultados de tiempos obtenidos para cada una de las
pruebas planificadas en ambos conjuntos de pruebas.
Los tiempos vienen dados en dos cantidades: la primera es el tiempo de cálculo que ha
invertido el servidor para la generación de tareas, la segunda es el tiempo total de
cálculo para la resolución del árbol completo. Ambas cantidades vienen dadas en
segundos.
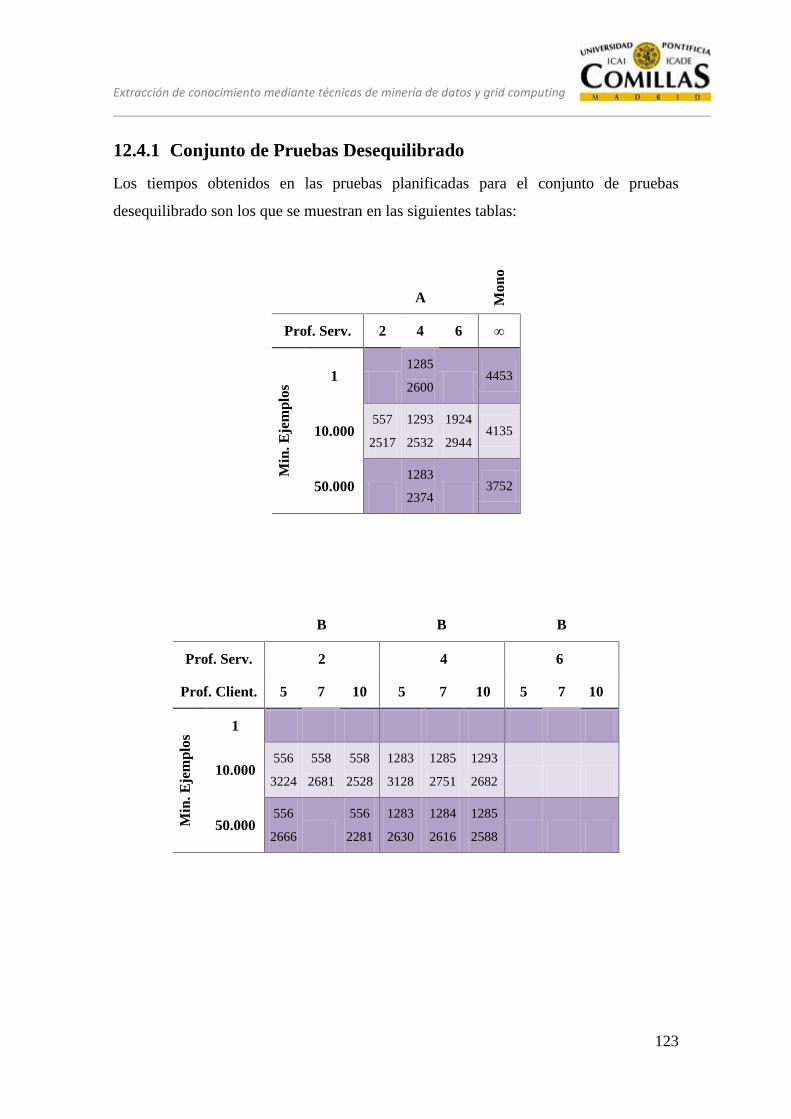
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
123
12.4.1 Conjunto de Pruebas Desequilibrado
Los tiempos obtenidos en las pruebas planificadas para el conjunto de pruebas
desequilibrado son los que se muestran en las siguientes tablas:
A M
on
o
Prof. Serv. 2 4 6 ∞
Min
. E
jem
plo
s
1
1285
2600 4453
10.000 557
2517
1293
2532
1924
2944 4135
50.000
1283
2374 3752
B B B
Prof. Serv. 2 4 6
Prof. Client. 5 7 10 5 7 10 5 7 10
Min
. E
jem
plo
s
1
10.000 556
3224
558
2681
558
2528
1283
3128
1285
2751
1293
2682
50.000 556
2666
556
2281
1283
2630
1284
2616
1285
2588
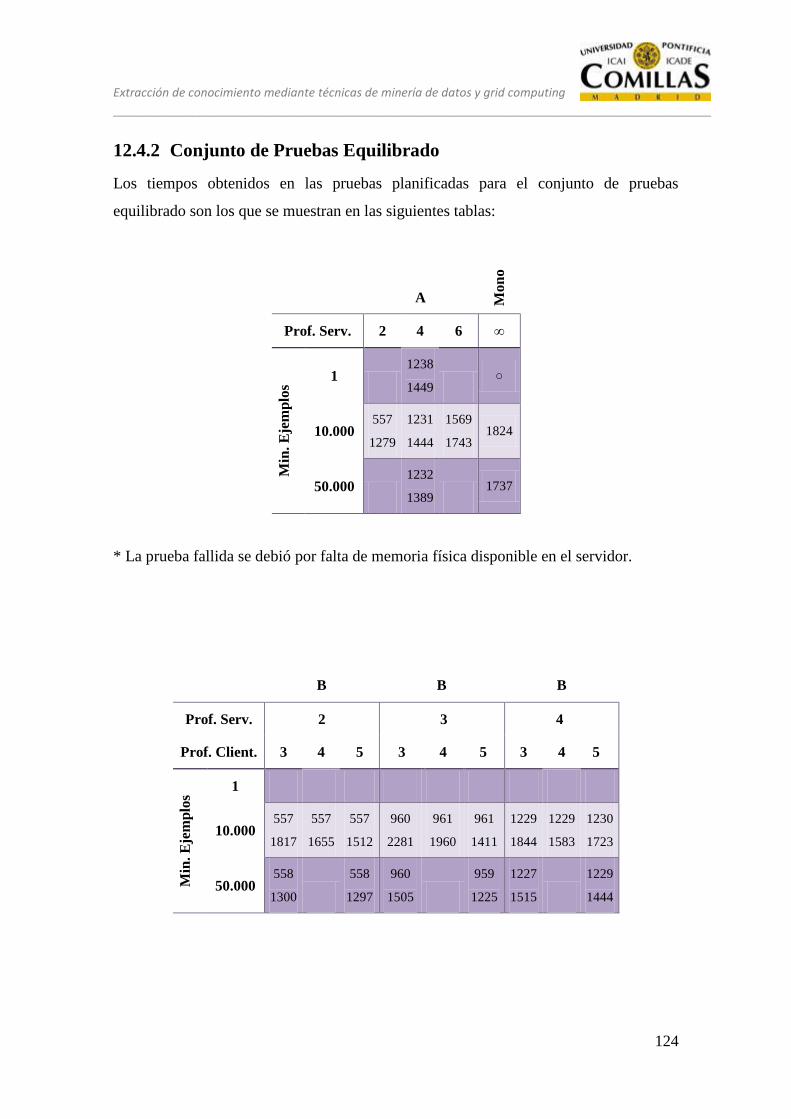
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
124
12.4.2 Conjunto de Pruebas Equilibrado
Los tiempos obtenidos en las pruebas planificadas para el conjunto de pruebas
equilibrado son los que se muestran en las siguientes tablas:
A M
on
o
Prof. Serv. 2 4 6 ∞
Min
. E
jem
plo
s
1
1238
1449 ○
10.000 557
1279
1231
1444
1569
1743 1824
50.000
1232
1389 1737
* La prueba fallida se debió por falta de memoria física disponible en el servidor.
B B B
Prof. Serv. 2 3 4
Prof. Client. 3 4 5 3 4 5 3 4 5
Min
. E
jem
plo
s
1
10.000 557
1817
557
1655
557
1512
960
2281
961
1960
961
1411
1229
1844
1229
1583
1230
1723
50.000 558
1300
558
1297
960
1505
959
1225
1227
1515
1229
1444

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
125
13 ANÁLISIS
Una vez realizadas las pruebas, se procede a analizar los resultados obtenidos según los
criterios establecidos en la etapa anterior.
Los resultados de cada prueba se presentan mediante cuatro tipos de gráficas ideadas
para obtener la máxima información posible. Estas gráficas se describen a continuación:
1. Gráfica de generación de tareas.
Representa el proceso de generación de tareas por el algoritmo, así como el tiempo
invertido. Incluye información sobre el nombre y tamaño (en número de ejemplos) de
cada tarea, y sobre el ordenador y CPU encargados de procesarlas. Cada tarea está
compuesta por 5 etapas representadas en distintos colores:
Download: envío de ficheros de entrada del servidor al cliente.
Ejecución: ejecución de la tarea en el cliente. A su vez, la ejecución de la tarea en
el cliente se divide en cuatro subetapas:
o Inicialización: apertura y lectura de ficheros e inicialización de estructuras.
o Cálculo: construcción del árbol de regresión.
o Liberación: cierre de ficheros y liberación de estructuras.
Upload: envío de ficheros de salida del cliente al servidor.
Tar
eas
gen
erad
as
Tiempo transcurrido en segundos
Nombre tarea y nº de ejemplos
Ordenador y CPU asignado

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
126
2. Gráfica de utilización total.
Representa el porcentaje de aprovechamiento de las CPUs del GRID durante todo el
proceso de construcción del árbol, incluyendo la primera etapa de generación de tareas
por el servidor.
La utilización en cada instante del proceso se representa mediante una línea azul,
mientras que la utilización media se representa por otra de color rojo, tal y como se
observa en el siguiente ejemplo:
3. Gráfica de utilización del GRID.
Representa el porcentaje de aprovechamiento de las CPUs del GRID durante el proceso
de construcción del árbol en el GRID.
La utilización en cada instante del proceso se representa mediante una línea azul,
mientras que la utilización media se representa por otra de color rojo, tal y como se
observa en el siguiente ejemplo:
Po
rcen
taje
de
CP
Us
usa
do
Tiempo transcurrido en segundos
Utilización media
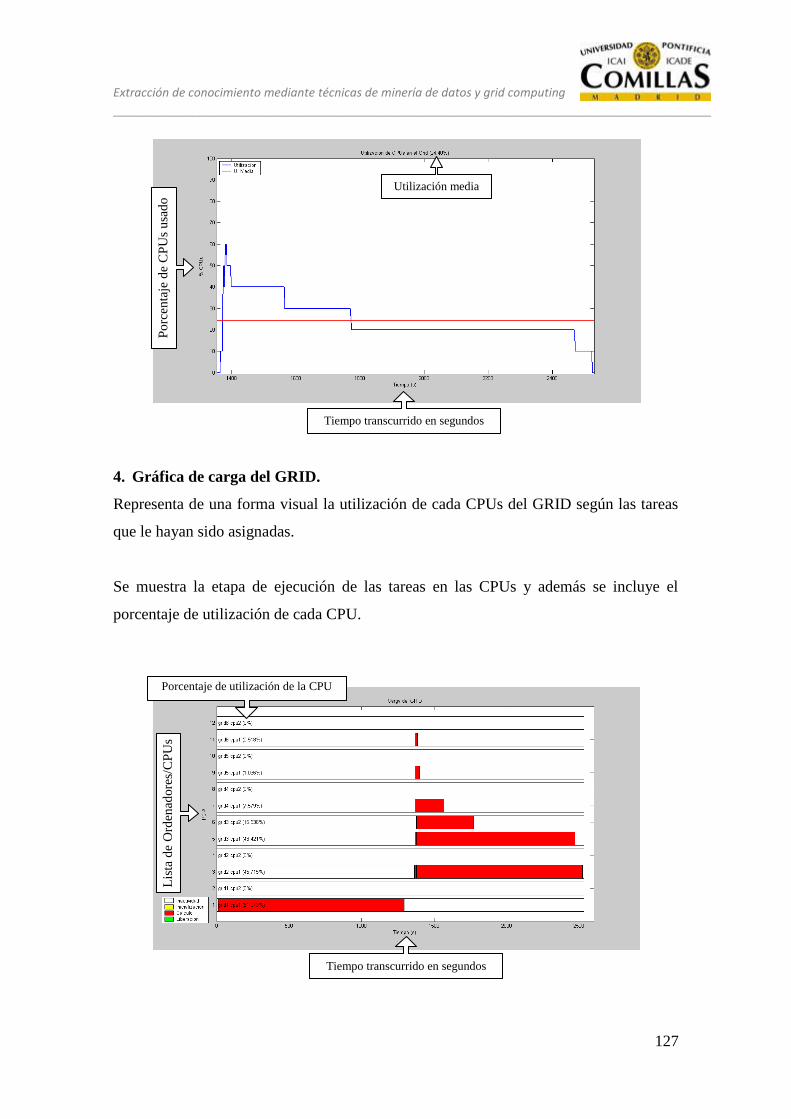
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
127
4. Gráfica de carga del GRID.
Representa de una forma visual la utilización de cada CPUs del GRID según las tareas
que le hayan sido asignadas.
Se muestra la etapa de ejecución de las tareas en las CPUs y además se incluye el
porcentaje de utilización de cada CPU.
Po
rcen
taje
de
CP
Us
usa
do
Tiempo transcurrido en segundos
Utilización media
Lis
ta d
e O
rden
adore
s/C
PU
s
Tiempo transcurrido en segundos
Porcentaje de utilización de la CPU
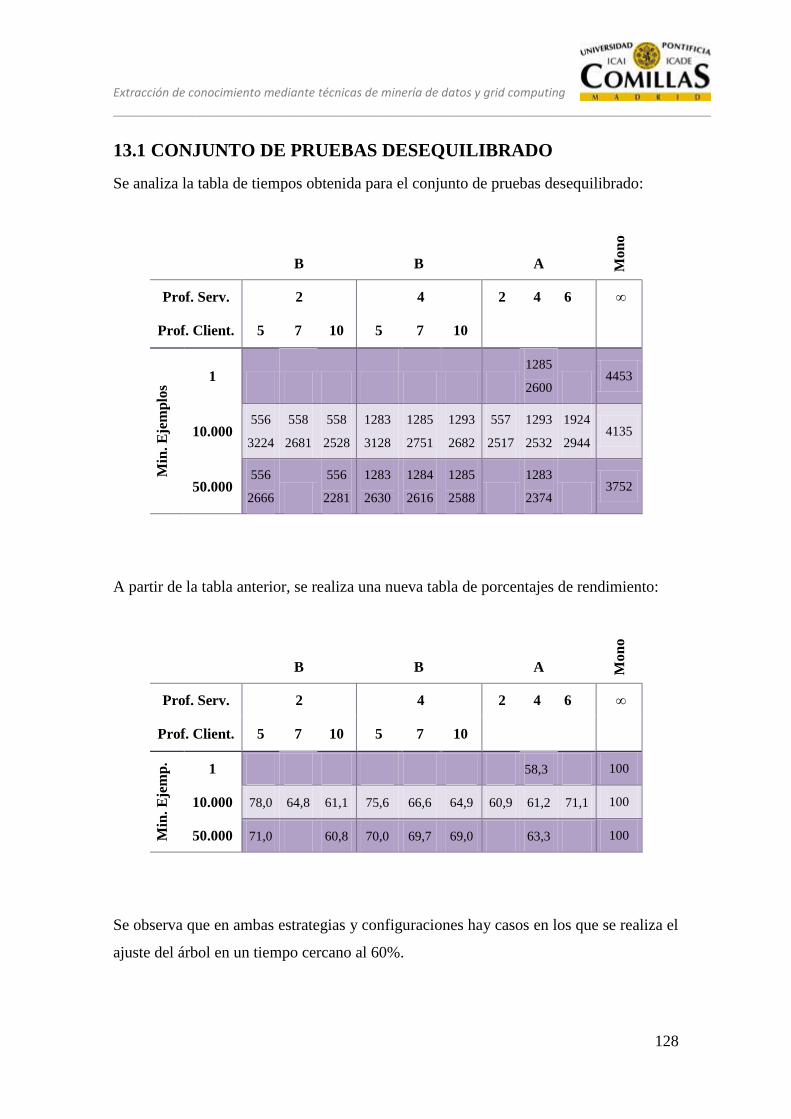
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
128
13.1 CONJUNTO DE PRUEBAS DESEQUILIBRADO
Se analiza la tabla de tiempos obtenida para el conjunto de pruebas desequilibrado:
B B A Mo
no
Prof. Serv. 2 4 2 4 6 ∞
Prof. Client. 5 7 10 5 7 10
Min
. E
jem
plo
s
1
1285
2600 4453
10.000 556
3224
558
2681
558
2528
1283
3128
1285
2751
1293
2682
557
2517
1293
2532
1924
2944 4135
50.000 556
2666
556
2281
1283
2630
1284
2616
1285
2588
1283
2374 3752
A partir de la tabla anterior, se realiza una nueva tabla de porcentajes de rendimiento:
B B A Mon
o
Prof. Serv. 2 4 2 4 6 ∞
Prof. Client. 5 7 10 5 7 10
Min
. E
jem
p.
1 58,3 100
10.000 78,0 64,8 61,1 75,6 66,6 64,9 60,9 61,2 71,1 100
50.000 71,0 60,8 70,0 69,7 69,0 63,3 100
Se observa que en ambas estrategias y configuraciones hay casos en los que se realiza el
ajuste del árbol en un tiempo cercano al 60%.
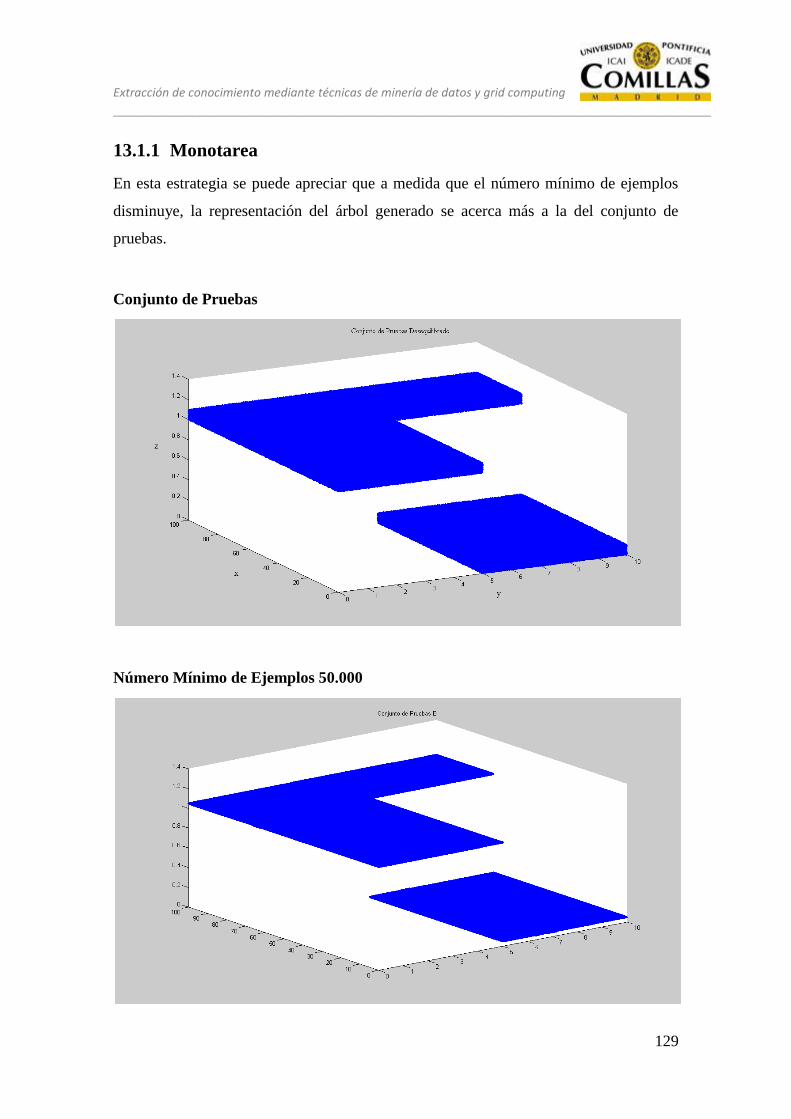
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
129
13.1.1 Monotarea
En esta estrategia se puede apreciar que a medida que el número mínimo de ejemplos
disminuye, la representación del árbol generado se acerca más a la del conjunto de
pruebas.
Conjunto de Pruebas
Número Mínimo de Ejemplos 50.000
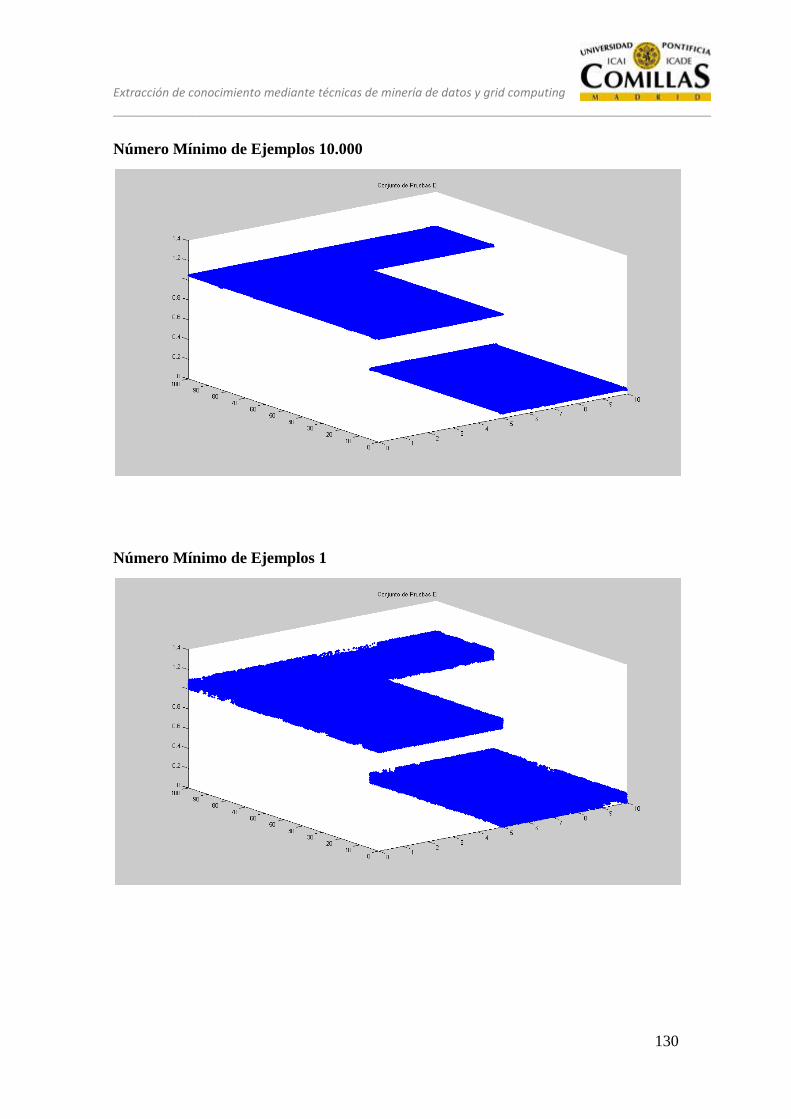
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
130
Número Mínimo de Ejemplos 10.000
Número Mínimo de Ejemplos 1

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
131
13.1.2 Estrategia A
Nivel de Profundidad del Servidor
Se han analizado tres casos distintos con niveles de profundidad del servidor de 2, 4 y 6,
todos ellos con número mínimo de 10000 ejemplos. El servidor generará así un máximo
de 2, 8 y 32 tareas respectivamente.
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos, así como el tiempo invertido:
Prof. Servidor 2 (557s – 2517s) Prof. Servidor 4 (1293s – 2532s)
Prof. Servidor 6 (1924s – 2944s)
La estrategia más rápida ha sido la primera, seguida muy de cerca por la segunda (2517
y 2532 segundos respectivamente). Estas estrategias destacan por tener las siguientes
características:
Un tiempo no muy elevado de cálculo del servidor, lo que implica una rápida
asignación de tareas al GRID.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
132
Una escasa utilización de los recursos del GRID existentes, ya que al profundizar
poco el servidor se obtienen pocas tareas y por tanto se asignan tareas a un
número pequeño de CPUs.
Como puede observarse en las siguientes gráficas, la utilización media de las CPUs
durante todo el proceso de resolución es muy similar en los tres casos. Esto se debe a
que para obtener cantidades mayores de tareas a repartir en el GRID se requiere un
tiempo de proceso del servidor demasiado alto:
Prof. Servidor 2 (13,68%) Prof. Servidor 4 (13,73%)
Prof. Servidor 6 (11,77%)
Además observamos que en este tipo de árbol claramente desequilibrado, la utilización
media del tiempo de resolución del GRID no se ve muy afectada por el número de
tareas generadas por el servidor. Esto se debe a que la mayor parte de la carga
computacional está contenida en una pequeña parte de las tareas, siendo el resto muy
pequeñas o despreciables:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
133
Prof. Servidor 2 (18,59%) Prof. Servidor 4 (24,40%)
Prof. Servidor 6 (23,06%)
A continuación se muestra la utilización de una forma más visual por estación y CPU
del GRID:
Profundidad Servidor 2 Profundidad Servidor 4
Profundidad Servidor 6

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
134
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Una pronta asignación de una cantidad reducida de tareas es más rápida que un
proceso costoso para la obtención de muchas tareas.
La creación de muchas tareas no implica una mejora notable en la utilización total
ni tampoco parcial del GRID.
Número Mínimo de Ejemplos
Se han analizado dos casos distintos con números mínimos de ejemplos por nodo de 1 y
50000, ambos con un nivel de profundidad del servidor de 4.
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos, así como el tiempo invertido:
Min. Ejemplos 1 (1285s – 2600s) Min. Ejemplos 50000 (1283s – 2374s)
La estrategia más rápida ha sido la segunda (2374 segundos). Esta estrategia destaca por
tener un número más reducido de tareas, ya que desaparecen aquellas cuyo número de
ejemplos son inferiores a la cota (50000).
Como puede observarse en las siguientes gráficas, la utilización media de las CPUs
durante todo el proceso de resolución es muy similar en los dos casos. Esto se debe a
que las tareas generadas son las mismas en ambos casos, a excepción de las más
pequeñas y despreciables que desaparecen en el segundo. Esto provoca que la
utilización sea ligeramente superior en la primera estrategia:
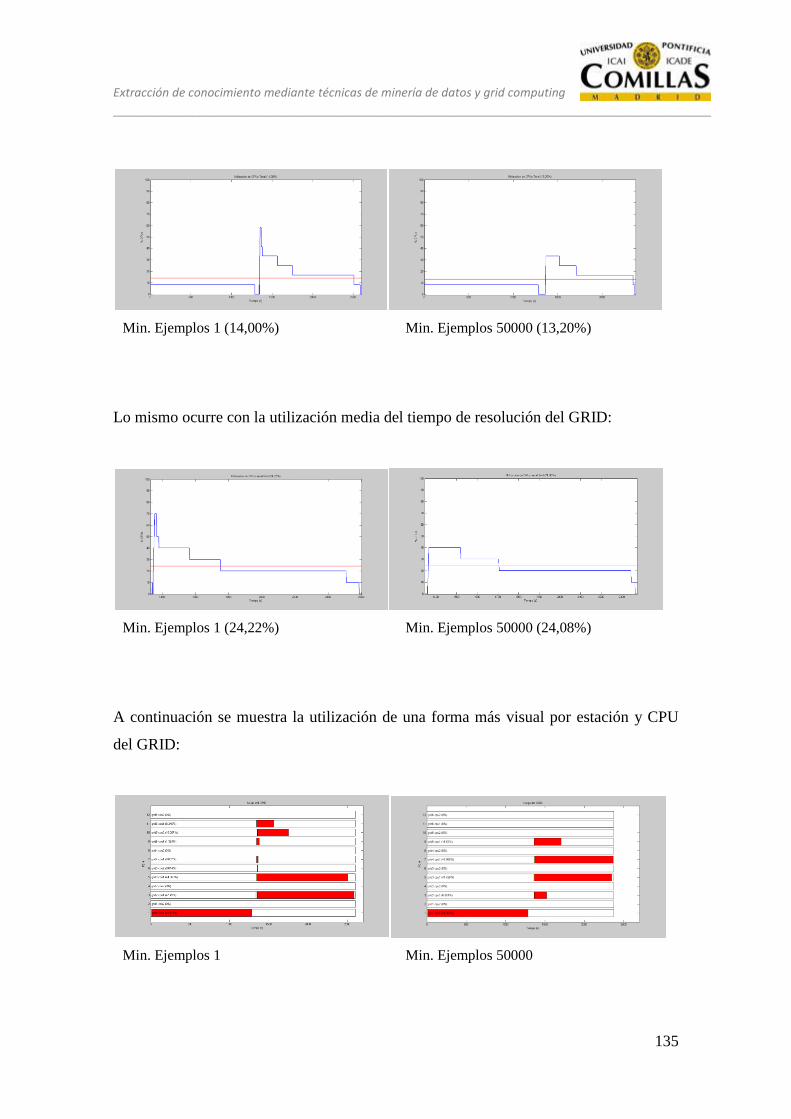
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
135
Min. Ejemplos 1 (14,00%) Min. Ejemplos 50000 (13,20%)
Lo mismo ocurre con la utilización media del tiempo de resolución del GRID:
Min. Ejemplos 1 (24,22%) Min. Ejemplos 50000 (24,08%)
A continuación se muestra la utilización de una forma más visual por estación y CPU
del GRID:
Min. Ejemplos 1 Min. Ejemplos 50000

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
136
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Cuanto mayor sea la cota, menor será el tiempo de resolución del árbol. Esto es
lógico, ya que se reduce el tamaño del problema, desestimándose aquellos nodos
demasiado pequeños.
13.1.3 Estrategia B
Nivel de profundidad del servidor
Se han llevado a cabo cuatro comparativas de configuraciones iguales pero a diferente
nivel de profundidad del servidor (2 y 4).
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos de las cuatro comparativas, así como el tiempo
invertido:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
137
Prof 2-5, Min. Ej. 10000 (556s – 3224s) Prof 4-5, MinEj. 10000 (1283s – 3128s) 2,98%
Prof 2-10, Min. Ej. 10000 (558s – 2528s) 5,74% Prof 4-10, Min. Ej. 10000 (1293s – 2682s)
Prof 2-5, Min. Ej. 50000 (556s – 2666s) Prof 4-5, Min. Ej. 50000 (1283s – 2630s) 1,35%
Prof 2-10, Min. Ej. 50000 (556s – 2281s) 11,86% Prof 4-10, Min. Ej. 50000 (1285s – 2588s)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
138
En las cuatro comparaciones los resultados son muy parecidos sin una estrategia
claramente vencedora: la máxima diferencia se consigue en la última comparativa con
un 12%, en el resto varía entorno al 5%.
Si se atiende a la utilización media de las CPUs durante todo el proceso de resolución
puede observarse que ésta es prácticamente igual en todos los casos (en torno al 12%).
Esta baja utilización se debe a cuatro motivos:
1. Un proceso de cálculo del servidor muy largo en los casos en los que éste alcanza
diez niveles de profundidad.
2. En los casos en los que el servidor tan solo profundiza cinco niveles, la suma de
este proceso mas el primer ciclo de proceso en clientes es muy larga y de poco
aprovechamiento del GRID.
3. La resolución de tareas demasiado pequeñas resulta ineficiente debido a los
retrasos de transmisión.
4. Al tratarse de un árbol claramente desequilibrado, se dan casos en los que una de
las tareas contiene la mayor parte de la carga de proceso, reduciéndose así la
paralelización del cálculo al centrarse éste en una sola CPU. En las primeras
etapas, mientras esta tarea de gran carga no es resuelta el resto del GRID está
infrautilizado a la espera de nuevas tareas.
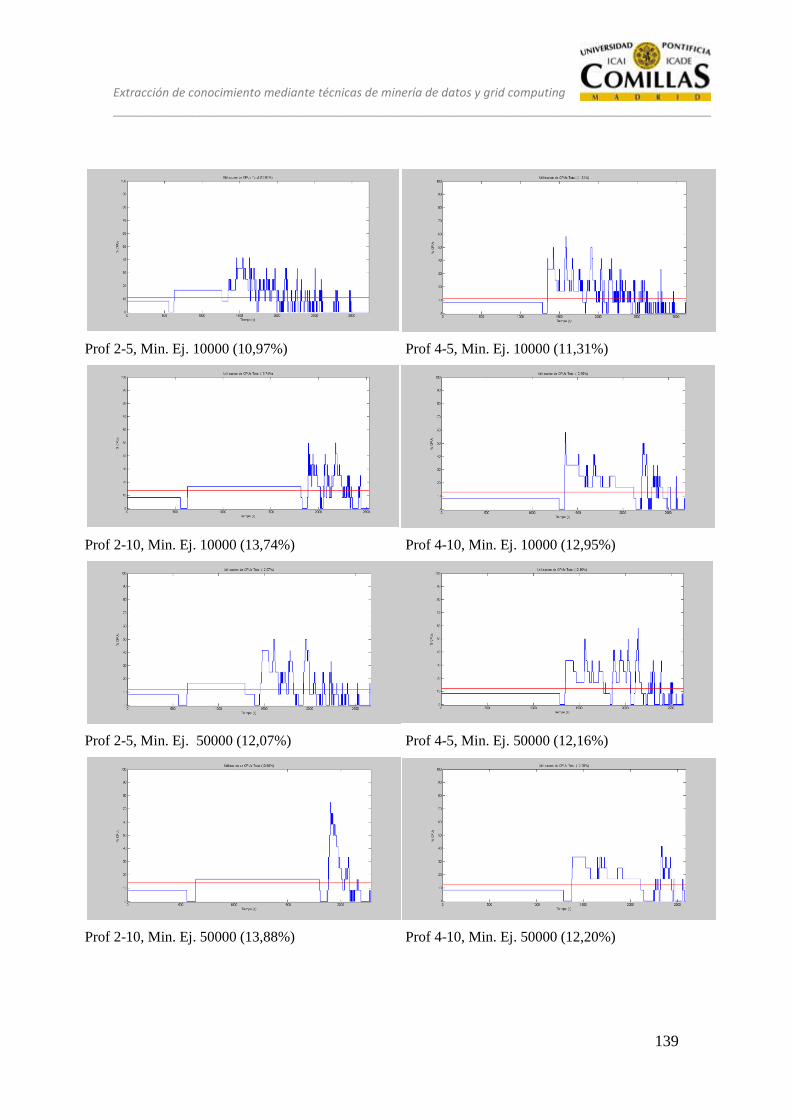
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
139
Prof 2-5, Min. Ej. 10000 (10,97%) Prof 4-5, Min. Ej. 10000 (11,31%)
Prof 2-10, Min. Ej. 10000 (13,74%) Prof 4-10, Min. Ej. 10000 (12,95%)
Prof 2-5, Min. Ej. 50000 (12,07%) Prof 4-5, Min. Ej. 50000 (12,16%)
Prof 2-10, Min. Ej. 50000 (13,88%) Prof 4-10, Min. Ej. 50000 (12,20%)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
140
A la hora de analizar la utilización media del tiempo de resolución del GRID, se
observan que ésta aumenta más del 50% respecto a la total. Pero tampoco se aprecian
grandes diferencias entre los casos en los que el servidor profundiza cinco niveles o diez
(siendo la utilidad de los primeros casos un 2% más alta).
Tampoco se producen grandes diferencias entre los casos con número mínimo de
10000 ejemplos y 50000. Esto es debido a que en las últimas etapas, donde el número
de tareas de pequeño tamaño es mayor, siempre hay unas pocas de tamaño medio que
ayudan a que no decaiga en exceso:
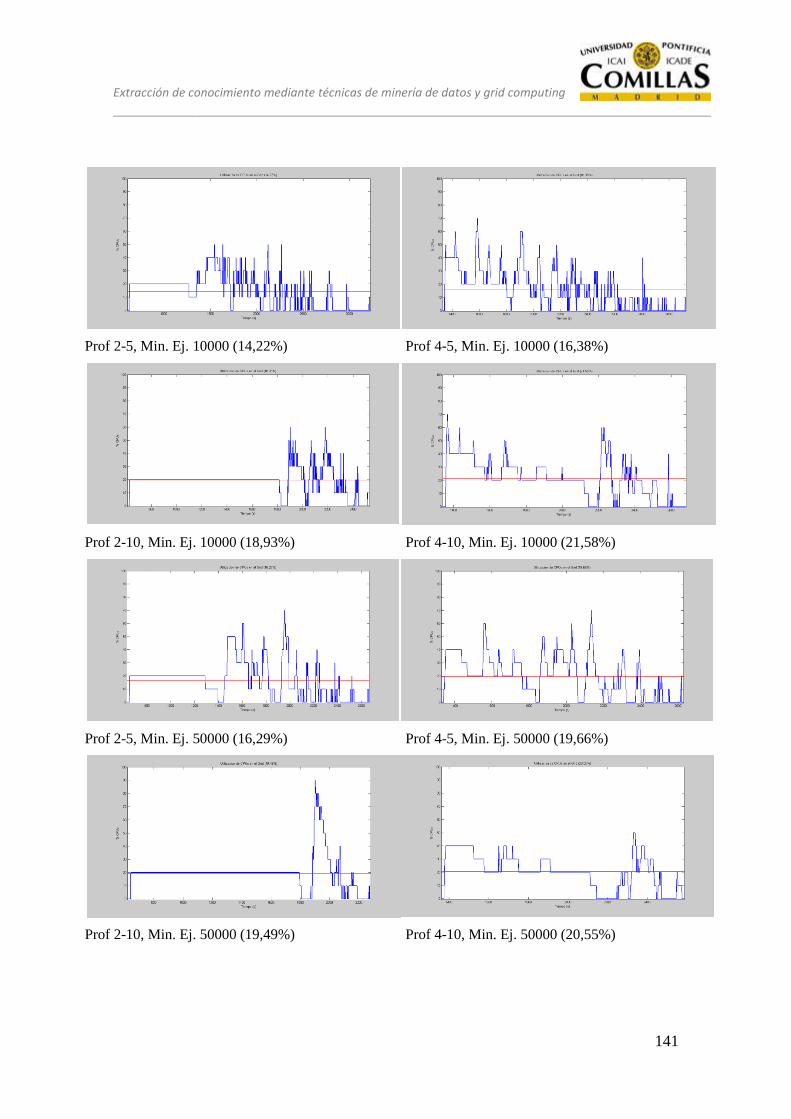
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
141
Prof 2-5, Min. Ej. 10000 (14,22%) Prof 4-5, Min. Ej. 10000 (16,38%)
Prof 2-10, Min. Ej. 10000 (18,93%) Prof 4-10, Min. Ej. 10000 (21,58%)
Prof 2-5, Min. Ej. 50000 (16,29%) Prof 4-5, Min. Ej. 50000 (19,66%)
Prof 2-10, Min. Ej. 50000 (19,49%) Prof 4-10, Min. Ej. 50000 (20,55%)
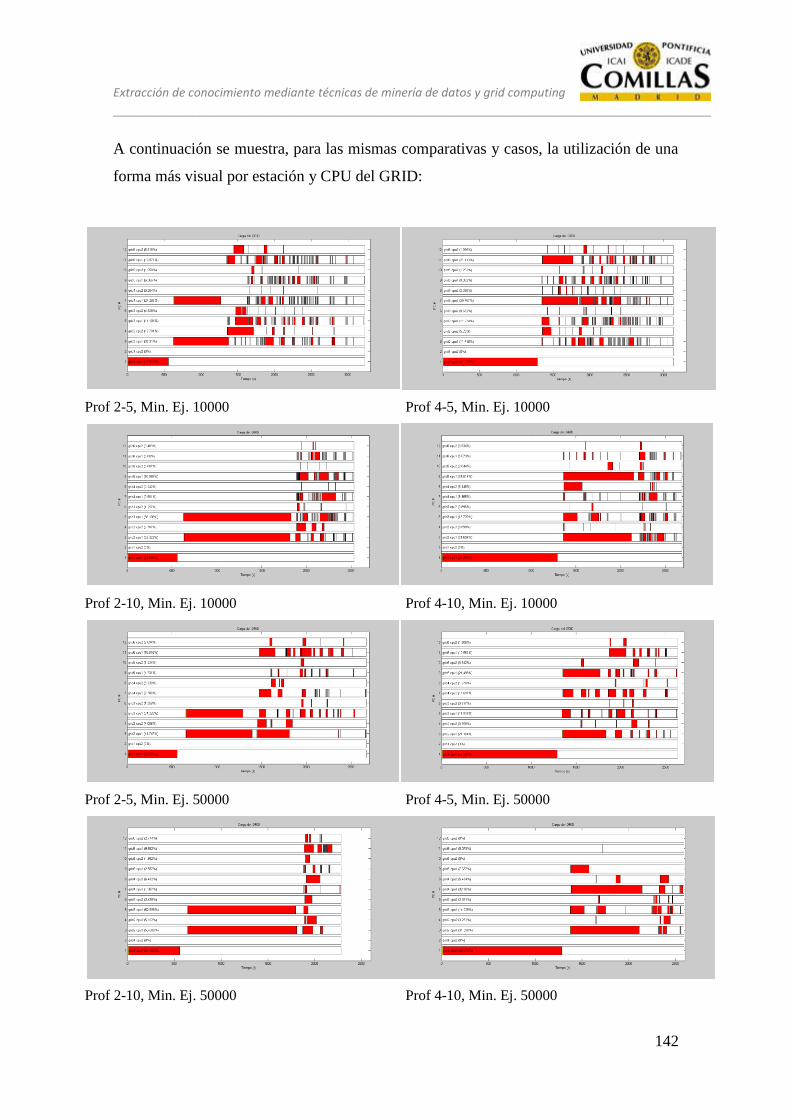
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
142
A continuación se muestra, para las mismas comparativas y casos, la utilización de una
forma más visual por estación y CPU del GRID:
Prof 2-5, Min. Ej. 10000 Prof 4-5, Min. Ej. 10000
Prof 2-10, Min. Ej. 10000 Prof 4-10, Min. Ej. 10000
Prof 2-5, Min. Ej. 50000 Prof 4-5, Min. Ej. 50000
Prof 2-10, Min. Ej. 50000 Prof 4-10, Min. Ej. 50000

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
143
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Una pronta asignación de una cantidad reducida de tareas es igual de rápida que
un proceso costoso para la obtención de muchas tareas.
La utilización total del GRID se mantiene baja (12%), independientemente del
nivel de profundidad que alcanza el servidor. Esto se debe a que en todos los
casos hay uno o varios procesos iniciales muy costosos y de baja utilización (1 ó 2
CPUs).
Al tratarse de un árbol claramente desequilibrado, se dan casos en los que una de
las tareas contiene la mayor parte de la carga de proceso, reduciéndose así la
paralelización del cálculo al centrarse éste en una sola CPU. Mientras esta tarea de
gran carga no es resuelta, el GRID está infrautilizado a la espera de nuevas tareas.
En etapas iniciales la existencia de tareas desequilibradas provoca una
disminución de la utilización del GRID. Esto es debido a que mientras estas tareas
no son resueltas el resto del GRID se mantiene a la espera.
En etapas finales la existencia de tareas desequilibradas provoca una mejora en la
utilización del GRID. Esto es debido a que en estas etapas, caracterizadas por la
presencia de numerosas tareas pequeñas ineficientes, la presencia de otras pocas
de tamaño medio ayuda a mantener más estable el porcentaje de utilización.
Los casos donde se crean numerosas tareas obtienen una utilización parcial del
GRID semejante a los que generan menos tareas.
Nivel de profundidad de los clientes
Se han llevado a cabo cuatro comparativas de configuraciones iguales pero a diferente
nivel de profundidad de los clientes (5 y 10).
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos de las cuatro comparativas, así como el tiempo
invertido:
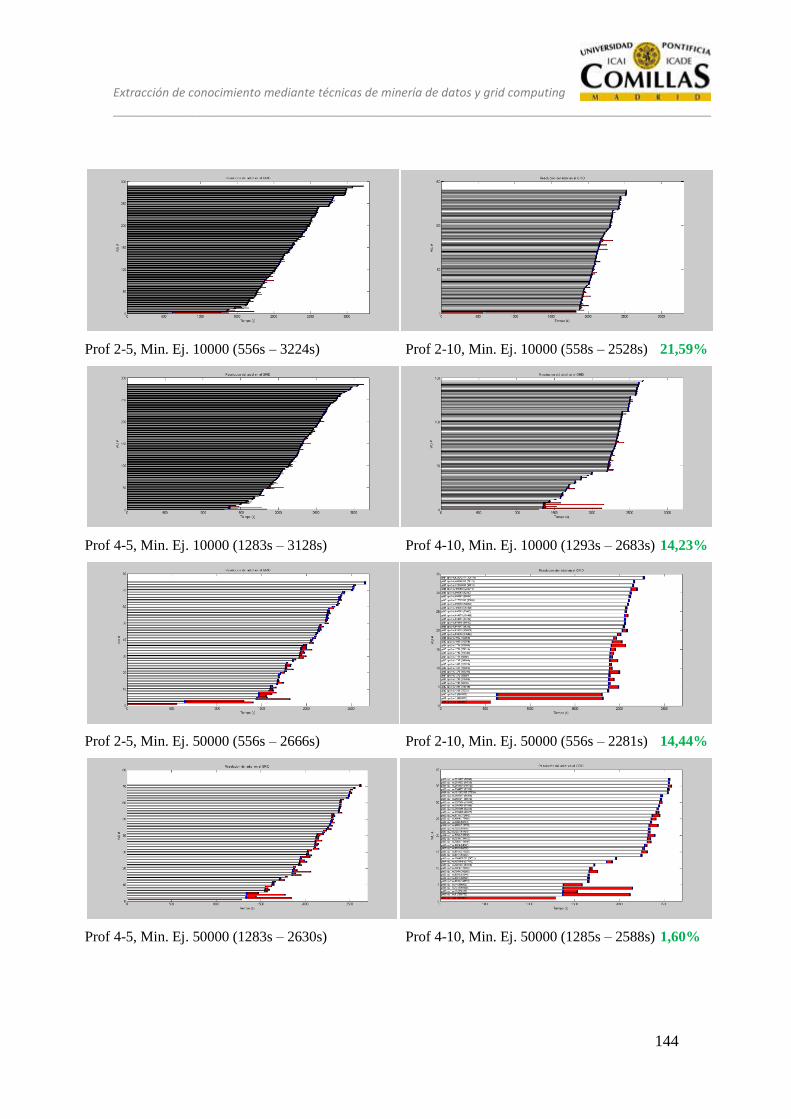
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
144
Prof 2-5, Min. Ej. 10000 (556s – 3224s) Prof 2-10, Min. Ej. 10000 (558s – 2528s) 21,59%
Prof 4-5, Min. Ej. 10000 (1283s – 3128s) Prof 4-10, Min. Ej. 10000 (1293s – 2683s) 14,23%
Prof 2-5, Min. Ej. 50000 (556s – 2666s) Prof 2-10, Min. Ej. 50000 (556s – 2281s) 14,44%
Prof 4-5, Min. Ej. 50000 (1283s – 2630s) Prof 4-10, Min. Ej. 50000 (1285s – 2588s) 1,60%

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
145
En tres de las cuatro comparativas los resultados son entre un 15% y un 20% más
rápidos cuando se emplea la estrategia que aplica un mayor nivel de profundidad de los
clientes. Esta diferencia se debe a que el hecho de asignar más trabajo a los clientes
implica una reducción significativa del número de tareas de pequeño tamaño en los
ciclos finales que, como ya se ha visto, son ineficientes debido a los retrasos de
transmisión.
Como caso extraordinario se encuentra la última comparativa, donde la diferencia tan
solo es del 1,6%. Esto se debe a que en ambos casos se produce un estado de espera en
las primeras etapas de proceso debido a la existencia de tareas muy desequilibradas y
largas. Siendo este tiempo improductivo de espera superior en la estrategia donde se
aplica un mayor de nivel de profundidad de los clientes.
Si se atiende a la utilización media de las CPUs durante todo el proceso de resolución,
puede observarse que ésta es prácticamente igual en todos los casos (en torno al 12%).
Esta baja utilización se debe a tres motivos:
1. Un proceso de cálculo del servidor muy largo en los casos en los que éste alcanza
cuatro niveles de profundidad.
2. En los casos en los que el servidor tan solo profundiza dos niveles, la suma de este
proceso mas el primer ciclo de proceso en clientes es muy larga y de poco
aprovechamiento del GRID.
3. La resolución de tareas demasiado pequeñas resulta ineficiente debido a los
retrasos de transmisión.
4. Al tratarse de un árbol claramente desequilibrado, se dan casos en los que una de
las tareas contiene la mayor parte de la carga de proceso, reduciéndose así la
paralelización del cálculo al centrarse éste en una sola CPU. En las primeras
etapas, mientras esta tarea de gran carga no es resuelta el resto del GRID está
infrautilizado a la espera de nuevas tareas.
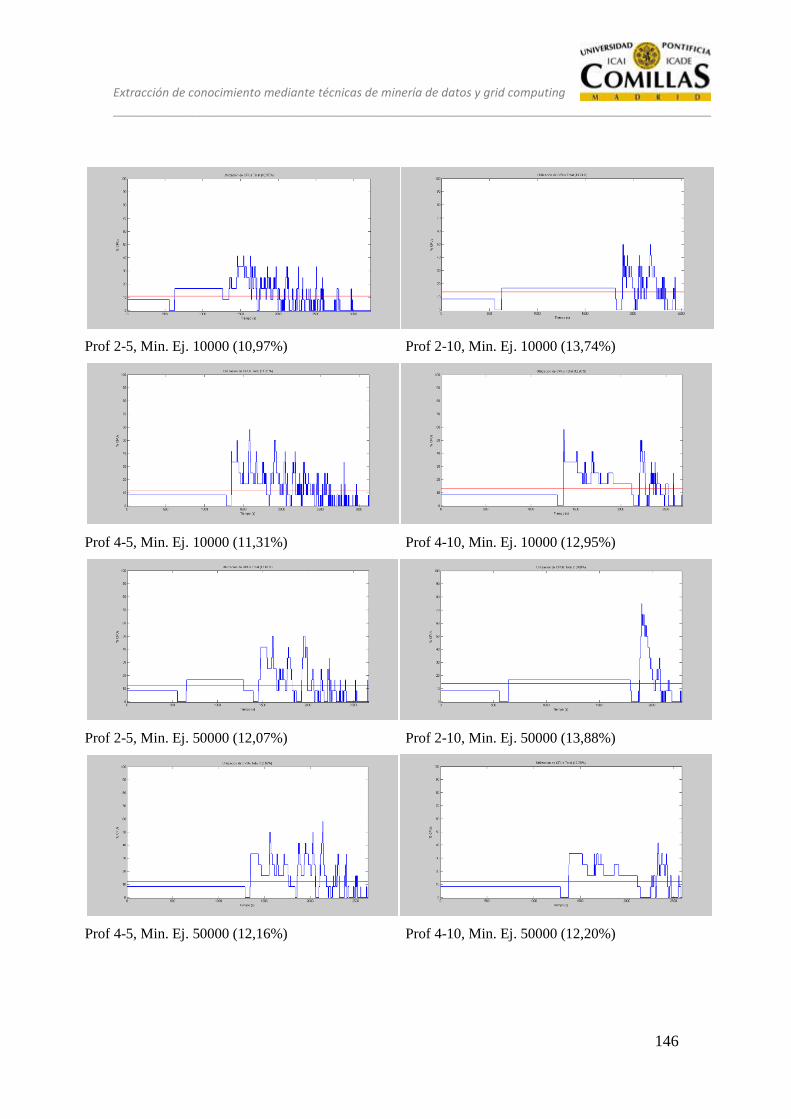
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
146
Prof 2-5, Min. Ej. 10000 (10,97%) Prof 2-10, Min. Ej. 10000 (13,74%)
Prof 4-5, Min. Ej. 10000 (11,31%) Prof 4-10, Min. Ej. 10000 (12,95%)
Prof 2-5, Min. Ej. 50000 (12,07%) Prof 2-10, Min. Ej. 50000 (13,88%)
Prof 4-5, Min. Ej. 50000 (12,16%) Prof 4-10, Min. Ej. 50000 (12,20%)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
147
A la hora de analizar la utilización media del tiempo de resolución del GRID, se
observan que ésta llega a aumentar más del 50% respecto a la total. Pero tampoco se
aprecian grandes diferencias entre los casos en los que el servidor profundiza cinco
niveles o diez (siendo la utilidad de los primeros casos un 5% más alta), a excepción del
último caso donde la utilización es casi idéntica debido al reducido número de tareas
que se generan en ambas estrategias.
Tampoco se producen grandes diferencias entre los casos con número mínimo de 10000
ejemplos y 50000. Esto es debido a que en las últimas etapas, donde el número de tareas
de pequeño tamaño es mayor, siempre hay unas pocas de tamaño medio que ayudan a
que no decaiga en exceso:
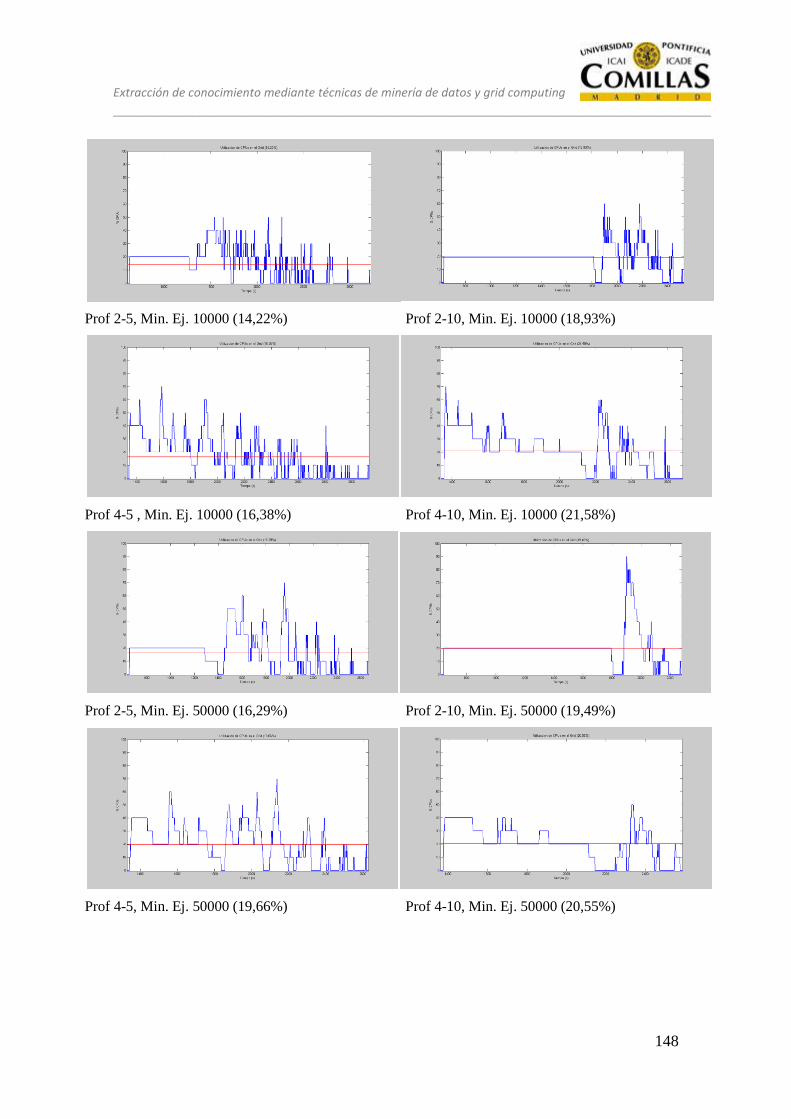
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
148
Prof 2-5, Min. Ej. 10000 (14,22%) Prof 2-10, Min. Ej. 10000 (18,93%)
Prof 4-5 , Min. Ej. 10000 (16,38%) Prof 4-10, Min. Ej. 10000 (21,58%)
Prof 2-5, Min. Ej. 50000 (16,29%) Prof 2-10, Min. Ej. 50000 (19,49%)
Prof 4-5, Min. Ej. 50000 (19,66%) Prof 4-10, Min. Ej. 50000 (20,55%)
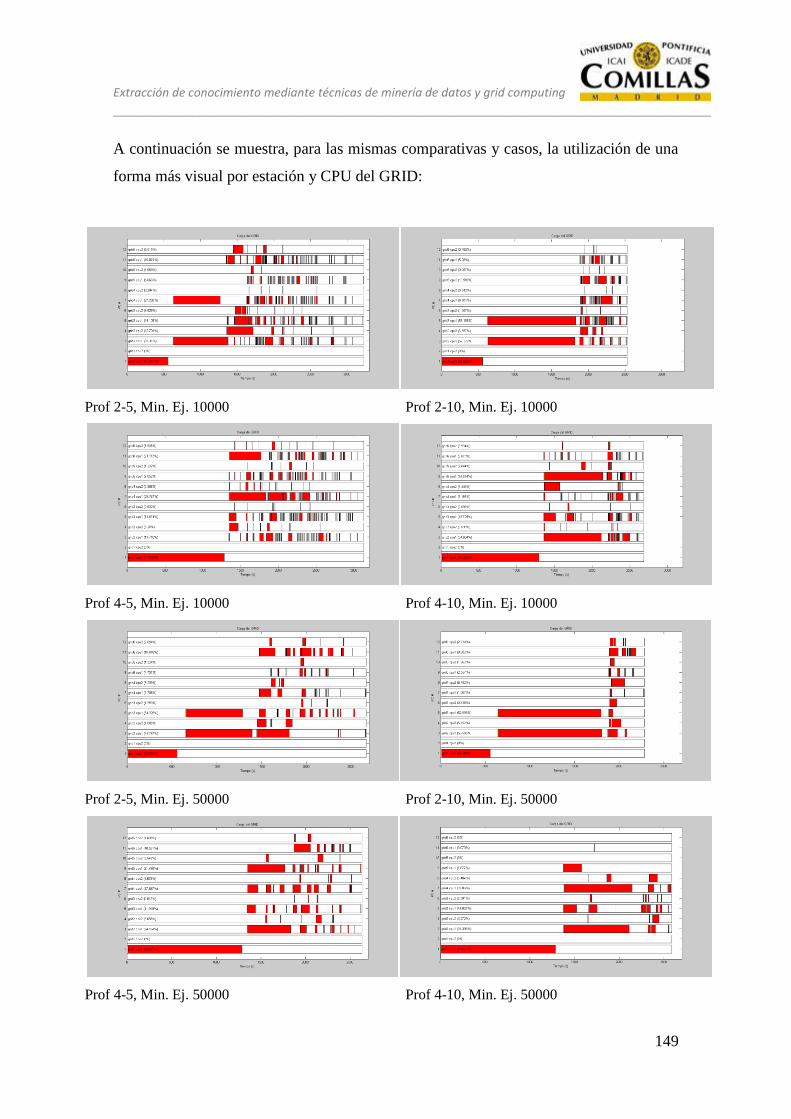
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
149
A continuación se muestra, para las mismas comparativas y casos, la utilización de una
forma más visual por estación y CPU del GRID:
Prof 2-5, Min. Ej. 10000 Prof 2-10, Min. Ej. 10000
Prof 4-5, Min. Ej. 10000 Prof 4-10, Min. Ej. 10000
Prof 2-5, Min. Ej. 50000 Prof 2-10, Min. Ej. 50000
Prof 4-5, Min. Ej. 50000 Prof 4-10, Min. Ej. 50000

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
150
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Un nivel de profundidad mayor en los clientes logra una mejora considerable en el
tiempo (del 15% al 20%), a excepción del uno de los casos que tan solo logra un
1%, debido a los tiempos de espera que se comentan en el siguiente punto.
Al tratarse de un árbol claramente desequilibrado, se dan casos en los que una de
las tareas contiene la mayor parte de la carga de proceso, reduciéndose así la
paralelización del cálculo al centrarse éste en una sola CPU. Mientras esta tarea de
gran carga no es resuelta, el GRID está infrautilizado a la espera de nuevas tareas.
La utilización total del GRID se mantiene baja (12%), independientemente del
nivel de profundidad que alcanza los clientes. Esto se debe a que en todos los
casos hay uno o varios procesos iniciales muy costosos y de baja utilización (1 ó 2
CPUs).
En etapas iniciales la existencia de tareas desequilibradas provoca una
disminución de la utilización del GRID. Esto es debido a que mientras estas tareas
no son resueltas el resto del GRID se mantiene a la espera.
En etapas finales la existencia de tareas desequilibradas provoca una mejora en la
utilización del GRID. Esto es debido a que en estas etapas, caracterizadas por la
presencia de numerosas tareas pequeñas ineficientes, la presencia de otras pocas
de tamaño medio ayuda a mantener más estable el porcentaje de utilización.
Los casos donde se crean numerosas tareas obtienen una utilización parcial del
GRID semejante a los que generan menos.
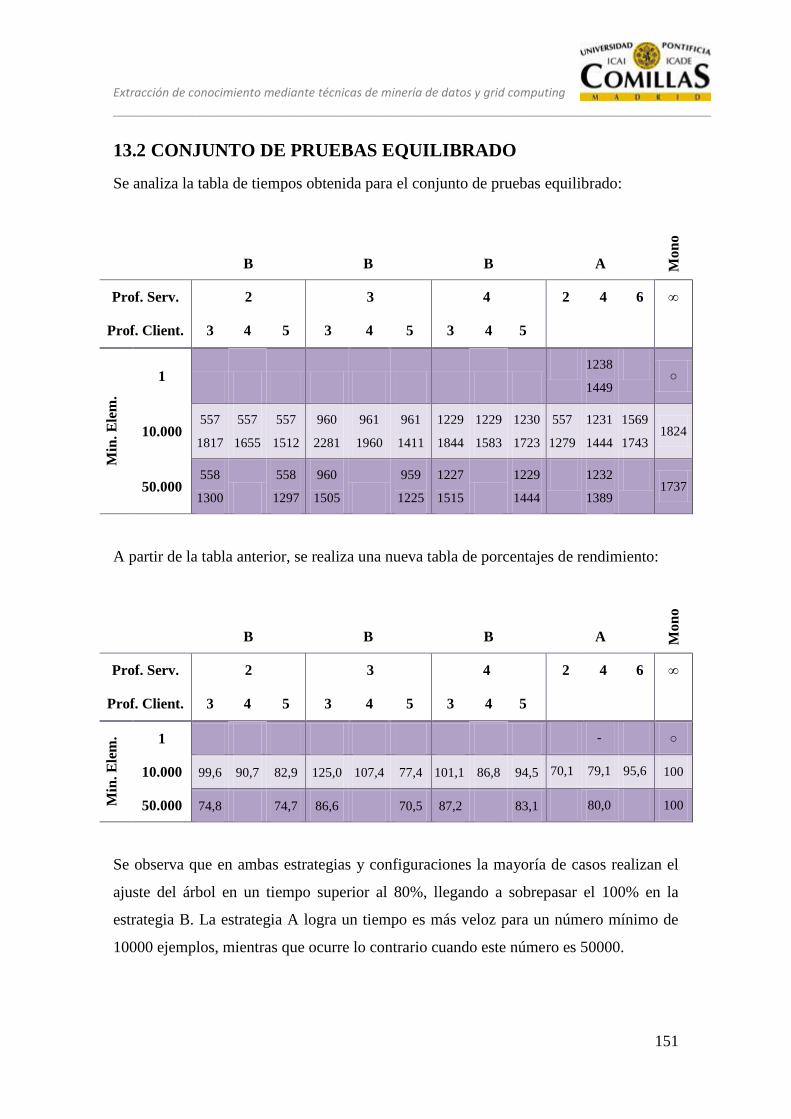
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
151
13.2 CONJUNTO DE PRUEBAS EQUILIBRADO
Se analiza la tabla de tiempos obtenida para el conjunto de pruebas equilibrado:
B B B A Mo
no
Prof. Serv. 2 3 4 2 4 6 ∞
Prof. Client. 3 4 5 3 4 5 3 4 5
Min
. E
lem
.
1
1238
1449
○
10.000 557
1817
557
1655
557
1512
960
2281
961
1960
961
1411
1229
1844
1229
1583
1230
1723
557
1279
1231
1444
1569
1743 1824
50.000 558
1300
558
1297
960
1505
959
1225
1227
1515
1229
1444
1232
1389
1737
A partir de la tabla anterior, se realiza una nueva tabla de porcentajes de rendimiento:
B B B A Mon
o
Prof. Serv. 2 3 4 2 4 6 ∞
Prof. Client. 3 4 5 3 4 5 3 4 5
Min
. E
lem
. 1 - ○
10.000 99,6 90,7 82,9 125,0 107,4 77,4 101,1 86,8 94,5 70,1 79,1 95,6 100
50.000 74,8 74,7 86,6 70,5 87,2 83,1 80,0 100
Se observa que en ambas estrategias y configuraciones la mayoría de casos realizan el
ajuste del árbol en un tiempo superior al 80%, llegando a sobrepasar el 100% en la
estrategia B. La estrategia A logra un tiempo es más veloz para un número mínimo de
10000 ejemplos, mientras que ocurre lo contrario cuando este número es 50000.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
152
13.2.1 Monotarea
En esta estrategia se puede apreciar que a medida que el número mínimo de ejemplos
disminuye, la representación del árbol generado se acerca más a la del conjunto de
pruebas.
Conjunto de Pruebas
Número Mínimo de Ejemplos 50.000

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
153
Número Mínimo de Ejemplos 10.000

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
154
13.2.2 Estrategia A
Nivel de profundidad del servidor
Se han analizado tres casos distintos con niveles de profundidad del servidor de 2, 4 y 6,
todos ellos con un número mínimo de 10000 ejemplos. El servidor generará así un
máximo de 2, 8 y 32 tareas respectivamente.
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos, así como el tiempo invertido:
Prof. Servidor 2 (557s – 1279s) Prof. Servidor 4 (1231s – 1444s)
Prof. Servidor 6 (1569s – 1743s)
La estrategia más rápida ha sido la primera (1279 segundos), mejorando el tiempo total
en un 11,43% y 26,62% respecto a la segunda y tercera estrategia. Esta estrategia
destaca por tener las siguientes características:
Un tiempo reducido de cálculo del servidor (la mitad y la tercera parte respecto a
las otras estrategias), lo que implica una rápida asignación de tareas al GRID.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
155
Una escasa utilización de los recursos del GRID existentes, ya que al profundizar
dos niveles el servidor se obtienen tan solo dos tareas, empleándose el mismo
número de CPUs para su resolución.
Como puede observarse en las siguientes gráficas, la utilización media de las CPUs
durante todo el proceso de resolución es muy similar en los tres casos. Esto se debe a
que para obtener cantidades mayores de tareas a repartir en el GRID se requiere un
tiempo de proceso del servidor demasiado alto:
Prof. Servidor 2 (11,93%) Prof. Servidor 4 (10,66%)
Prof. Servidor 6 (8,80%)
Además observamos que en este tipo de árbol equilibrado, la utilización media del
tiempo de resolución del GRID es muy superior en las estrategias que generan muchas
tareas, destacando especialmente la segunda. Esta estrategia destaca por generar un
número de tareas aproximado a la cantidad de CPUs del GRID y de tamaño
considerable, tal como se podrá observar en las últimas gráficas de carga del GRID.
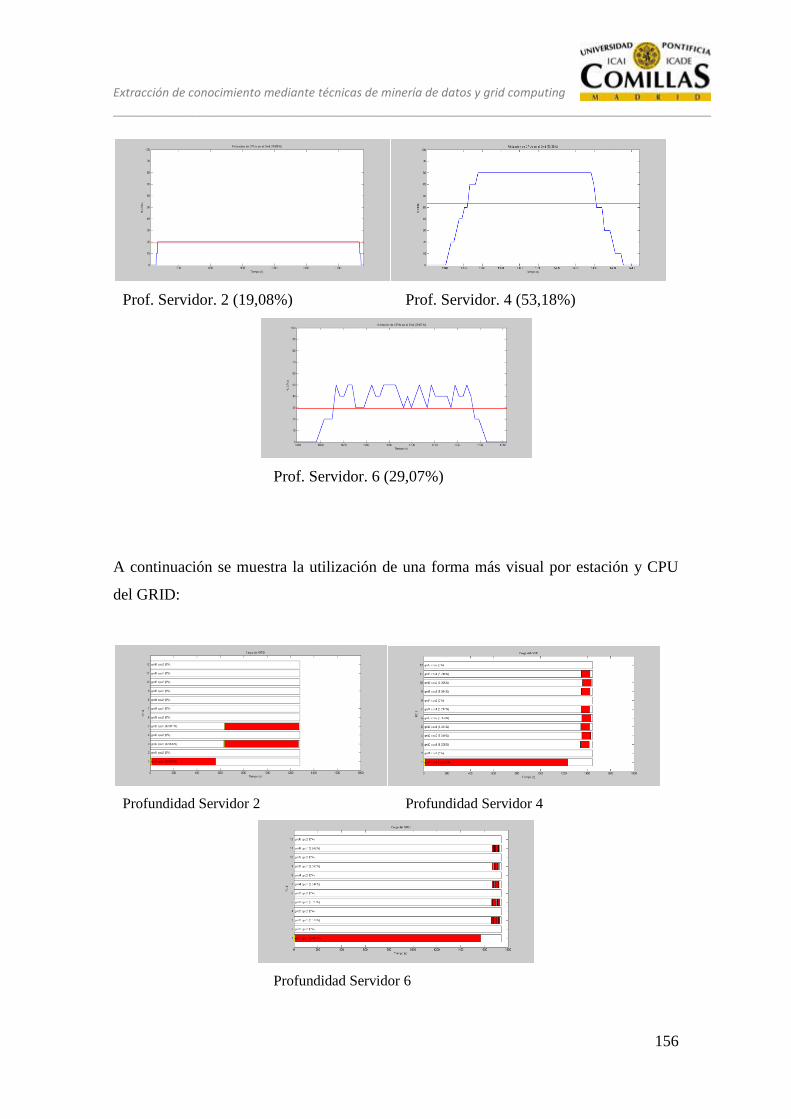
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
156
Prof. Servidor. 2 (19,08%) Prof. Servidor. 4 (53,18%)
Prof. Servidor. 6 (29,07%)
A continuación se muestra la utilización de una forma más visual por estación y CPU
del GRID:
Profundidad Servidor 2 Profundidad Servidor 4
Profundidad Servidor 6

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
157
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Una pronta asignación de una cantidad reducida de tareas es más rápida que un
proceso costoso para la obtención de muchas tareas.
La creación de muchas tareas no implica una mejora notable en la utilización total
del GRID.
Un número de tareas aproximado a la cantidad de CPUs del GRID obtiene una
utilización parcial del GRID superior a un número muy escaso (tan solo se llega a
usar una cantidad muy pequeña de CPUs) o demasiado elevado de las mismas
(debido a los tiempos muertos de transmisión).
Número Mínimo de Ejemplos
Se han analizado dos casos distintos con números máximos de elementos por nodo de 1
y 50000, ambos con un nivel de profundidad del servidor de 4.
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos, así como el tiempo invertido:
Min. Ejemplos 1 (1238s – 1449s) Min. Ejemplos 50000 (1232s – 1389s)
La estrategia más rápida ha sido la segunda (1389 segundos). Esta estrategia destaca por
tener un número más reducido de tareas, ya que desaparecen aquellas cuyo número de
ejemplos son inferiores a la cota (50000).

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
158
Como puede observarse en las siguientes gráficas, la utilización media de las CPUs
durante todo el proceso de resolución es muy similar en los dos casos. Esto se debe a
que las tareas generadas son las mismas en ambos casos, a excepción de las más
pequeñas y despreciables que desaparecen en el segundo. Esto provoca que la
utilización sea ligeramente superior en la primera estrategia:
Min. Ejemplos 1 (11,48%) Min. Ejemplos 50000 (10,56%)
Lo mismo ocurre con la utilización media del tiempo de resolución del GRID:
Min. Ejemplos 1 (58,22%) Min. Ejemplos 50000 (50,93%)
A continuación se muestra la utilización de una forma más visual por estación y CPU
del GRID:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
159
Min. Ejemplos 1 Min. Ejemplos 50000
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Cuanto mayor sea la cota, menor será el tiempo de resolución del árbol. Esto es
lógico, ya que se reduce el tamaño del problema, desestimándose aquellos nodos
demasiado pequeños.
13.2.3 Estrategia B
Nivel de profundidad del servidor
Se han llevado a cabo cuatro comparativas de configuraciones iguales pero a diferente
nivel de profundidad del servidor (2 y 4).
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos de las cuatro comparativas, así como el tiempo
invertido:
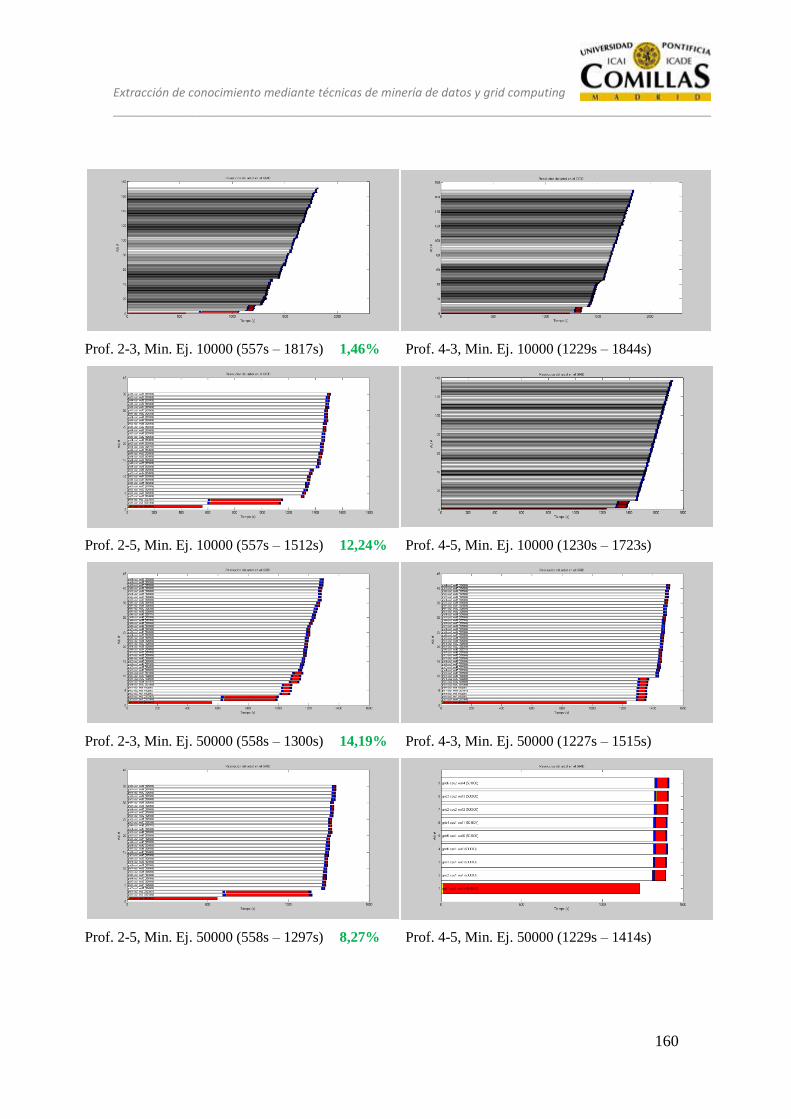
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
160
Prof. 2-3, Min. Ej. 10000 (557s – 1817s) 1,46% Prof. 4-3, Min. Ej. 10000 (1229s – 1844s)
Prof. 2-5, Min. Ej. 10000 (557s – 1512s) 12,24% Prof. 4-5, Min. Ej. 10000 (1230s – 1723s)
Prof. 2-3, Min. Ej. 50000 (558s – 1300s) 14,19% Prof. 4-3, Min. Ej. 50000 (1227s – 1515s)
Prof. 2-5, Min. Ej. 50000 (558s – 1297s) 8,27% Prof. 4-5, Min. Ej. 50000 (1229s – 1414s)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
161
En las cuatro comparaciones los resultados son muy parecidos: las estrategias que se
basan en un menor nivel de profundidad del servidor mejoran entre un 1,5% y un 14%
los tiempos totales (dependiendo de las irregularidades en los tiempos muertos de
tránsito).
Si se atiende a la utilización media de las CPUs durante todo el proceso de resolución
puede observarse que ésta es prácticamente igual en todos los casos (en torno al 10%).
Esta baja utilización se debe a tres motivos:
1. Un proceso de cálculo del servidor muy largo en los casos en los que éste alcanza
cuatro niveles de profundidad.
2. En los casos en los que el servidor tan solo profundiza dos niveles, la suma de este
proceso mas el primer ciclo de proceso en clientes es muy larga y de poco
aprovechamiento del GRID.
3. La resolución de tareas demasiado pequeñas resulta ineficiente debido a los
retrasos de transmisión.
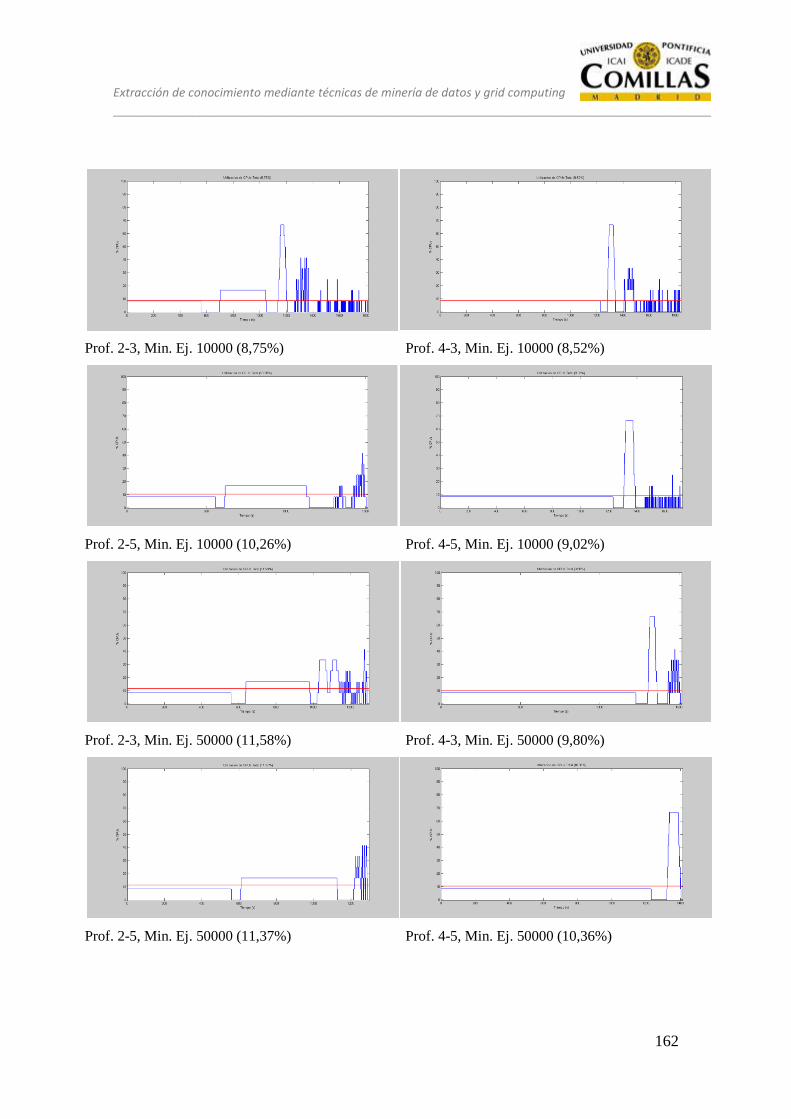
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
162
Prof. 2-3, Min. Ej. 10000 (8,75%) Prof. 4-3, Min. Ej. 10000 (8,52%)
Prof. 2-5, Min. Ej. 10000 (10,26%) Prof. 4-5, Min. Ej. 10000 (9,02%)
Prof. 2-3, Min. Ej. 50000 (11,58%) Prof. 4-3, Min. Ej. 50000 (9,80%)
Prof. 2-5, Min. Ej. 50000 (11,37%) Prof. 4-5, Min. Ej. 50000 (10,36%)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
163
Sin embargo, a la hora de analizar la utilización media del tiempo de resolución del
GRID, se observan importantes diferencias entre los distintos casos:
En las estrategias con número mínimo de ejemplos de 10000, donde en los ciclos
finales se crean abundantes tareas demasiado pequeñas (y por tanto ineficientes),
se obtiene una utilización media que oscila entre el 10% y el 15%.
En las estrategias con número mínimo de ejemplos de 50000, donde se suprimen
tareas demasiado pequeñas e ineficaces, la utilización media aumenta
notablemente, llegando a cotas entre el 17% y 50%.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
164
Prof. 2-3, Min. Ej. 10000 (12,06%) Prof. 4-3, Min. Ej. 10000 (11,37%)
Prof. 2-5, Min. Ej. 10000 (14,32%) Prof. 4-5, Min. Ej. 10000 (14,82%)
Prof. 2-3, Min. Ej. 50000 (18,29%) Prof. 4-3, Min. Ej. 50000 (24,53%)
Prof. 2-5, Min. Ej. 50000 (17,32%) Prof. 4-5, Min. Ej. 50000 (50,81%)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
165
A continuación se muestra, para las mismas comparativas y casos, la utilización de una
forma más visual por estación y CPU del GRID:
Prof. 2-3, Min. Ej. 10000 Prof. 4-3, Min. Ej. 10000
Prof. 2-5, Min. Ej. 10000 Prof. 4-5, Min. Ej. 10000
Prof. 2-3, Min. Ej. 50000 Prof. 4-3, Min. Ej. 50000
Prof. 2-5, Min. Ej. 50000 Prof. 4-5, Min. Ej. 50000

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
166
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Una pronta asignación de una cantidad reducida de tareas es más rápida que un
proceso costoso para la obtención de muchas tareas, con unas mejoras entre el
1,5% y el 15%.
La utilización total del GRID se mantiene baja, independientemente del nivel de
profundidad que alcanza el servidor. Esto se debe a que en todos los casos hay
uno o varios procesos iniciales muy costosos y de baja utilización (1 ó 2 CPUs).
La creación de muchas tareas no implica una mejora notable en la utilización
parcial del GRID. Es más eficaz la creación de un número menor de tareas si éstas
no sobrepasan cierto tamaño mínimo que las hace ineficaces (debido a los tiempos
muertos de transmisión).
Nivel de profundidad de los clientes
Se han llevado a cabo cuatro comparativas de configuraciones iguales pero a diferente
nivel de profundidad de los clientes (3 y 5).
En las siguientes gráficas se representa el proceso de ajuste del árbol seguido por el
algoritmo en cada uno de los casos de las cuatro comparativas, así como el tiempo
invertido:
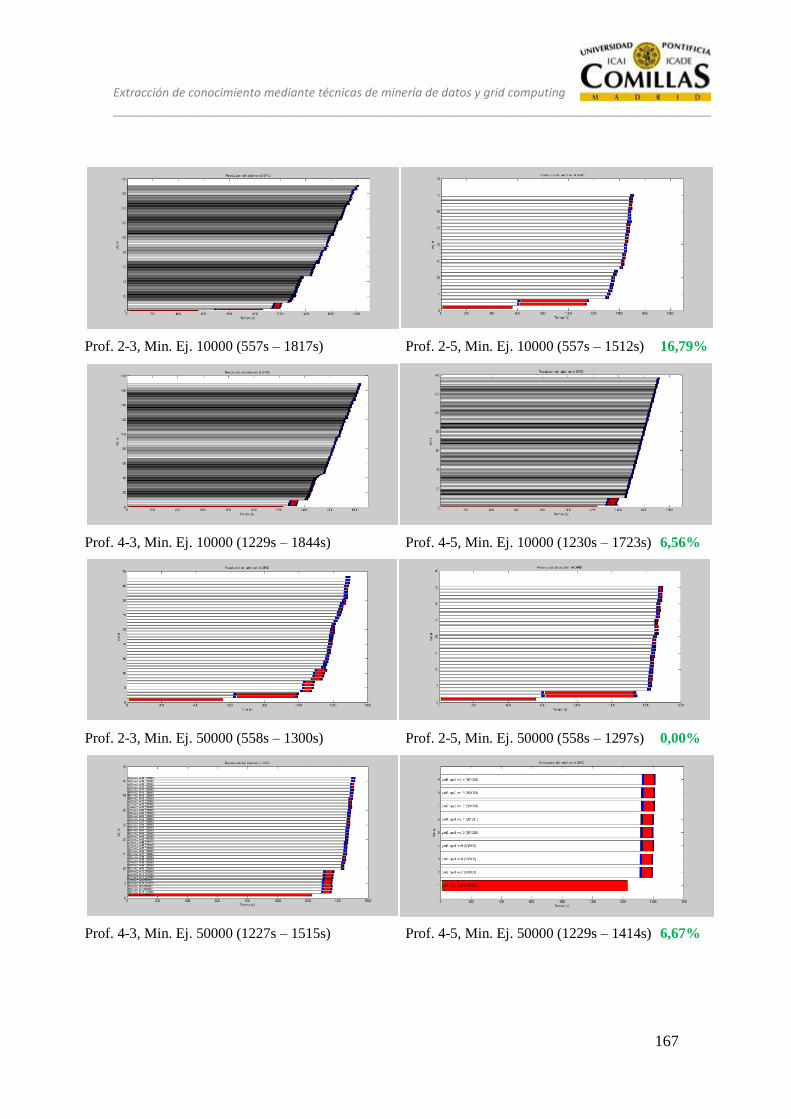
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
167
Prof. 2-3, Min. Ej. 10000 (557s – 1817s) Prof. 2-5, Min. Ej. 10000 (557s – 1512s) 16,79%
Prof. 4-3, Min. Ej. 10000 (1229s – 1844s) Prof. 4-5, Min. Ej. 10000 (1230s – 1723s) 6,56%
Prof. 2-3, Min. Ej. 50000 (558s – 1300s) Prof. 2-5, Min. Ej. 50000 (558s – 1297s) 0,00%
Prof. 4-3, Min. Ej. 50000 (1227s – 1515s) Prof. 4-5, Min. Ej. 50000 (1229s – 1414s) 6,67%

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
168
En las cuatro comparaciones los resultados son muy parecidos: las estrategias que se
basan en un mayor nivel de profundidad de los clientes mejoran entre un 0% y un 7%
los tiempos totales. Esta pequeña diferencia se debe a que el hecho de asignar más
trabajo a los clientes implica una reducción en el número de tareas de pequeño tamaño
en los ciclos finales que, como ya se ha visto, son ineficientes debido a los retrasos de
transmisión.
Como caso extraordinario se encuentra la primera comparativa, en la que debido al azar,
se ha encontrado que, para este conjunto de entrenamiento, con una configuración de
cinco niveles de profundidad en los clientes se reduce drásticamente el número de tareas
pequeñas y se consigue una mejora del 16,79%.
Si se atiende a la utilización media de las CPUs durante todo el proceso de resolución,
puede observarse que ésta es prácticamente igual en todos los casos (en torno al 10%).
Esta baja utilización se debe a tres motivos:
1. Un proceso de cálculo del servidor muy largo en los casos en los que éste alcanza
cuatro niveles de profundidad.
2. En los casos en los que el servidor tan solo profundiza dos niveles, la suma de este
proceso mas el primer ciclo de proceso en clientes es muy larga y de poco
aprovechamiento del GRID.
3. La resolución de tareas demasiado pequeñas resulta ineficiente debido a los
retrasos de transmisión.
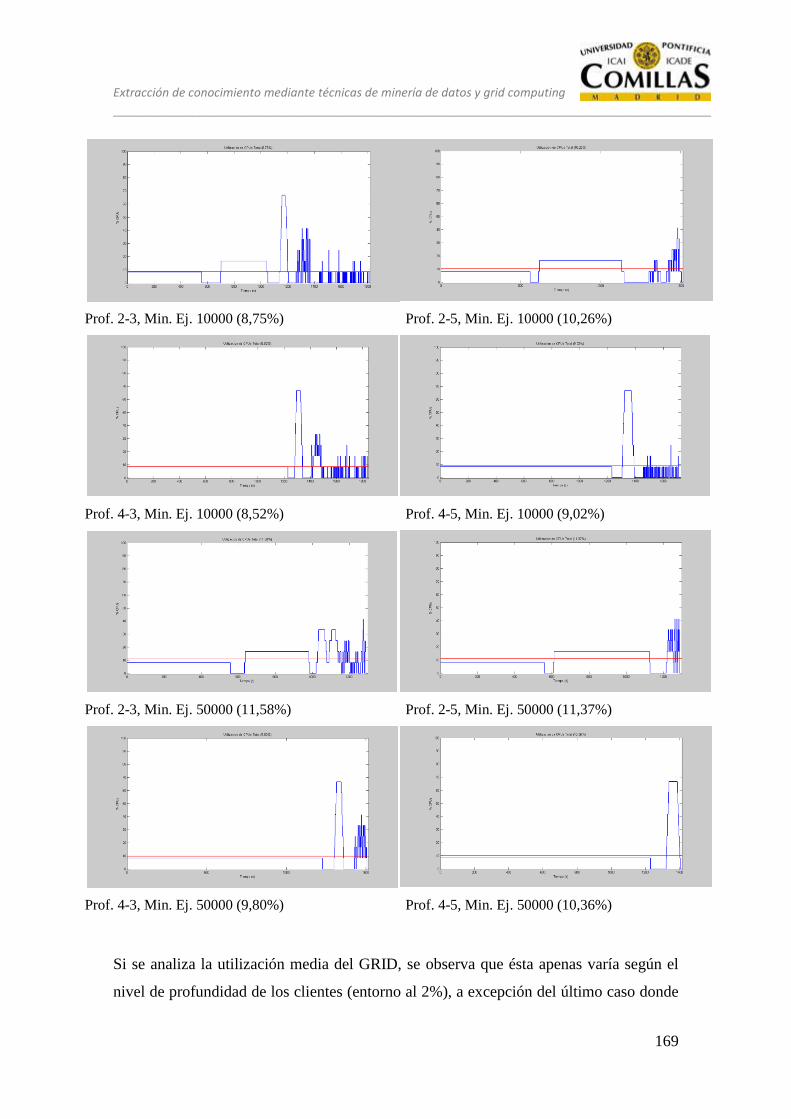
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
169
Prof. 2-3, Min. Ej. 10000 (8,75%) Prof. 2-5, Min. Ej. 10000 (10,26%)
Prof. 4-3, Min. Ej. 10000 (8,52%) Prof. 4-5, Min. Ej. 10000 (9,02%)
Prof. 2-3, Min. Ej. 50000 (11,58%) Prof. 2-5, Min. Ej. 50000 (11,37%)
Prof. 4-3, Min. Ej. 50000 (9,80%) Prof. 4-5, Min. Ej. 50000 (10,36%)
Si se analiza la utilización media del GRID, se observa que ésta apenas varía según el
nivel de profundidad de los clientes (entorno al 2%), a excepción del último caso donde
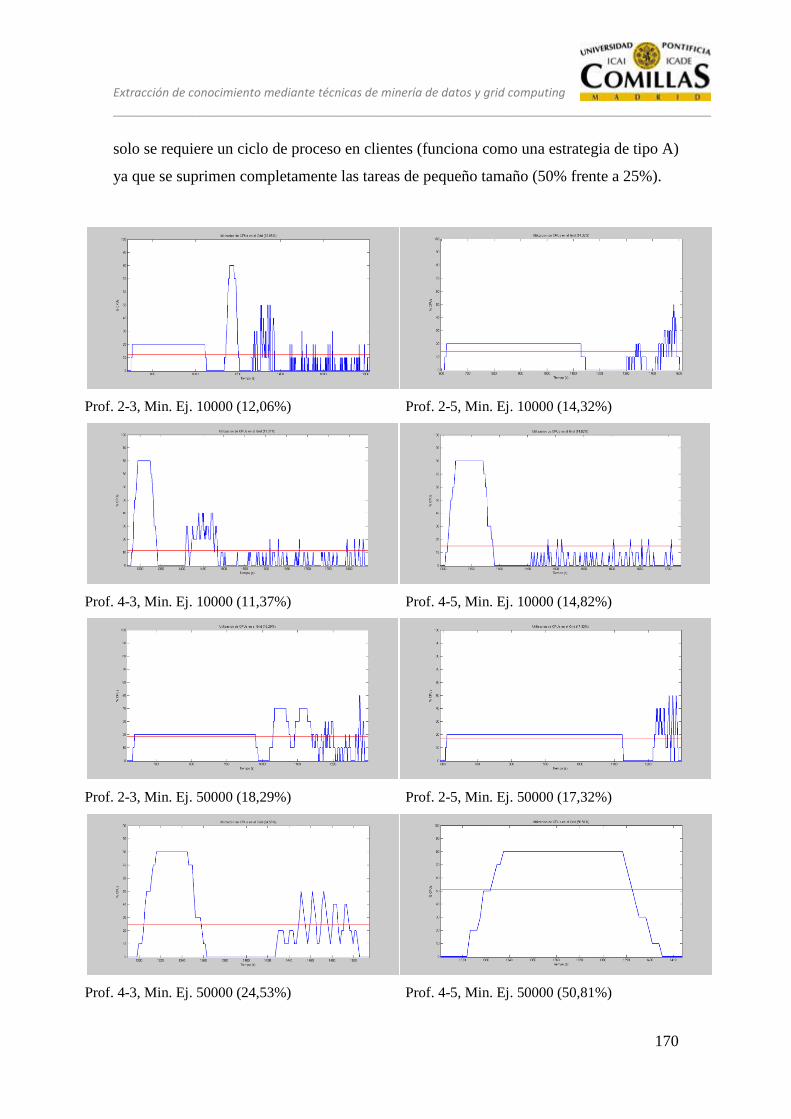
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
170
solo se requiere un ciclo de proceso en clientes (funciona como una estrategia de tipo A)
ya que se suprimen completamente las tareas de pequeño tamaño (50% frente a 25%).
Prof. 2-3, Min. Ej. 10000 (12,06%) Prof. 2-5, Min. Ej. 10000 (14,32%)
Prof. 4-3, Min. Ej. 10000 (11,37%) Prof. 4-5, Min. Ej. 10000 (14,82%)
Prof. 2-3, Min. Ej. 50000 (18,29%) Prof. 2-5, Min. Ej. 50000 (17,32%)
Prof. 4-3, Min. Ej. 50000 (24,53%) Prof. 4-5, Min. Ej. 50000 (50,81%)

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
171
A continuación se muestra, para las mismas comparativas y casos, la utilización de una
forma más visual por estación y CPU del GRID:
Prof. 2-3, Min. Ej. 10000 Prof. 2-5, Min. Ej. 10000
Prof. 4-3, Min. Ej. 10000 Prof. 4-5, Min. Ej. 10000
Prof. 2-3, Min. Ej. 50000 Prof. 2-5, Min. Ej. 50000
Prof. 4-3, Min. Ej. 50000 Prof. 4-5, Min. Ej. 50000

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
172
Tras analizar este caso, se pueden deducir las siguientes conclusiones:
Un nivel de profundidad mayor en los clientes logra una mejora en el tiempo de
resolución ligera (de 0% a 7%), y en algunos casos extraordinarios una mejora
considerable (17%).
La utilización total del GRID se mantiene baja, independientemente del nivel de
profundidad que alcanza los clientes. Esto se debe a que en todos los casos hay
uno o varios procesos iniciales muy costosos y de baja utilización (1 ó 2 CPUs).
La utilización parcial del GRID se ve aumentada cuando hay un número no
elevado de tareas de tamaño mediano o grande.
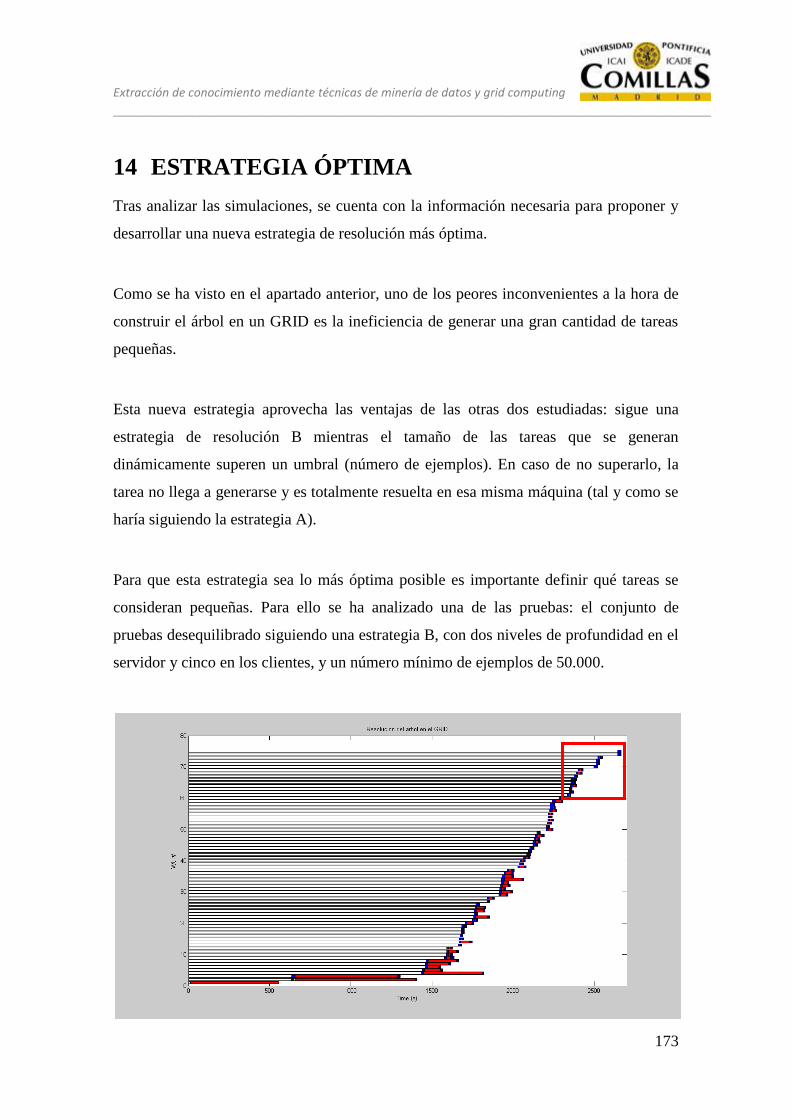
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
173
14 ESTRATEGIA ÓPTIMA
Tras analizar las simulaciones, se cuenta con la información necesaria para proponer y
desarrollar una nueva estrategia de resolución más óptima.
Como se ha visto en el apartado anterior, uno de los peores inconvenientes a la hora de
construir el árbol en un GRID es la ineficiencia de generar una gran cantidad de tareas
pequeñas.
Esta nueva estrategia aprovecha las ventajas de las otras dos estudiadas: sigue una
estrategia de resolución B mientras el tamaño de las tareas que se generan
dinámicamente superen un umbral (número de ejemplos). En caso de no superarlo, la
tarea no llega a generarse y es totalmente resuelta en esa misma máquina (tal y como se
haría siguiendo la estrategia A).
Para que esta estrategia sea lo más óptima posible es importante definir qué tareas se
consideran pequeñas. Para ello se ha analizado una de las pruebas: el conjunto de
pruebas desequilibrado siguiendo una estrategia B, con dos niveles de profundidad en el
servidor y cinco en los clientes, y un número mínimo de ejemplos de 50.000.
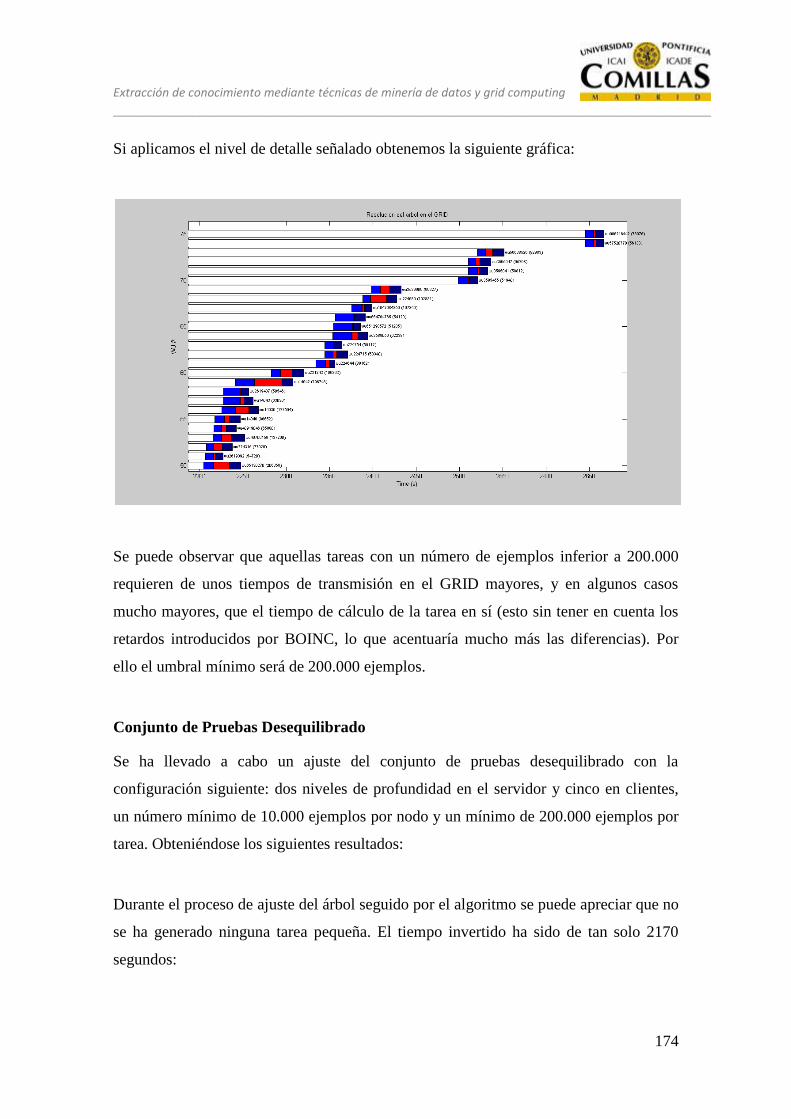
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
174
Si aplicamos el nivel de detalle señalado obtenemos la siguiente gráfica:
Se puede observar que aquellas tareas con un número de ejemplos inferior a 200.000
requieren de unos tiempos de transmisión en el GRID mayores, y en algunos casos
mucho mayores, que el tiempo de cálculo de la tarea en sí (esto sin tener en cuenta los
retardos introducidos por BOINC, lo que acentuaría mucho más las diferencias). Por
ello el umbral mínimo será de 200.000 ejemplos.
Conjunto de Pruebas Desequilibrado
Se ha llevado a cabo un ajuste del conjunto de pruebas desequilibrado con la
configuración siguiente: dos niveles de profundidad en el servidor y cinco en clientes,
un número mínimo de 10.000 ejemplos por nodo y un mínimo de 200.000 ejemplos por
tarea. Obteniéndose los siguientes resultados:
Durante el proceso de ajuste del árbol seguido por el algoritmo se puede apreciar que no
se ha generado ninguna tarea pequeña. El tiempo invertido ha sido de tan solo 2170
segundos:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
175
La media de la utilización total de las CPUs del GRID es del 16,18%, apreciándose que
no hay etapas de grandes fluctuaciones en espacios de tiempo muy cortos:
La utilización media del tiempo de ajuste del GRID asciende hasta el 23,22% del total
de CPUs:
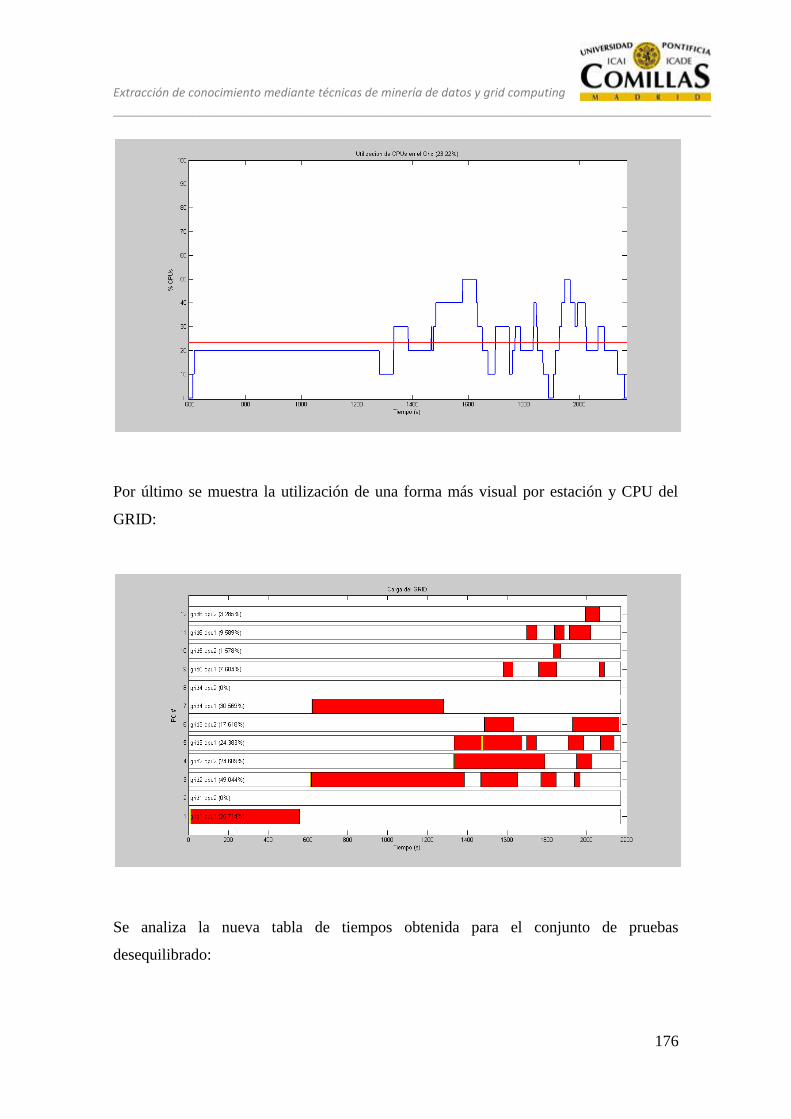
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
176
Por último se muestra la utilización de una forma más visual por estación y CPU del
GRID:
Se analiza la nueva tabla de tiempos obtenida para el conjunto de pruebas
desequilibrado:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
177
B B A Mo
no
Óp
tim
o
Prof. Serv. 2 4 2 4 6 ∞ 2
Prof. Client. 5 7 10 5 7 10 5
Min
. E
jem
plo
s
1 1285
2600 4453
10.000 556
3224
558
2681
558
2528
1283
3128
1285
2751
1293
2682
557
2517
1293
2532
1924
2944 4135
558
2170
50.000 556
2666
556
2281
1283
2630
1284
2616
1285
2588
1283
2374 3752
A partir de la tabla anterior, se realiza una nueva tabla de porcentajes de rendimiento.
La nueva estrategia logra ajustar el árbol en un 52,5% de tiempo, mejorando el caso más
rápido en un 8,3%:
B B A Mon
o
Óp
tim
o
Prof. Serv. 2 4 2 4 6 ∞ 2
Prof. Client. 5 7 10 5 7 10 5
Min
. E
jem
p.
1 58,3 100
10.000 78,0 64,8 61,1 75,6 66,6 64,9 60,9 61,2 71,1 100 52,5
50.000 71,0 60,8 70,0 69,7 69,0 63,3 100
Si se compara la utilización total respecto a su estrategia B predecesora, se observa que
es una vez y media más grande que ésta:
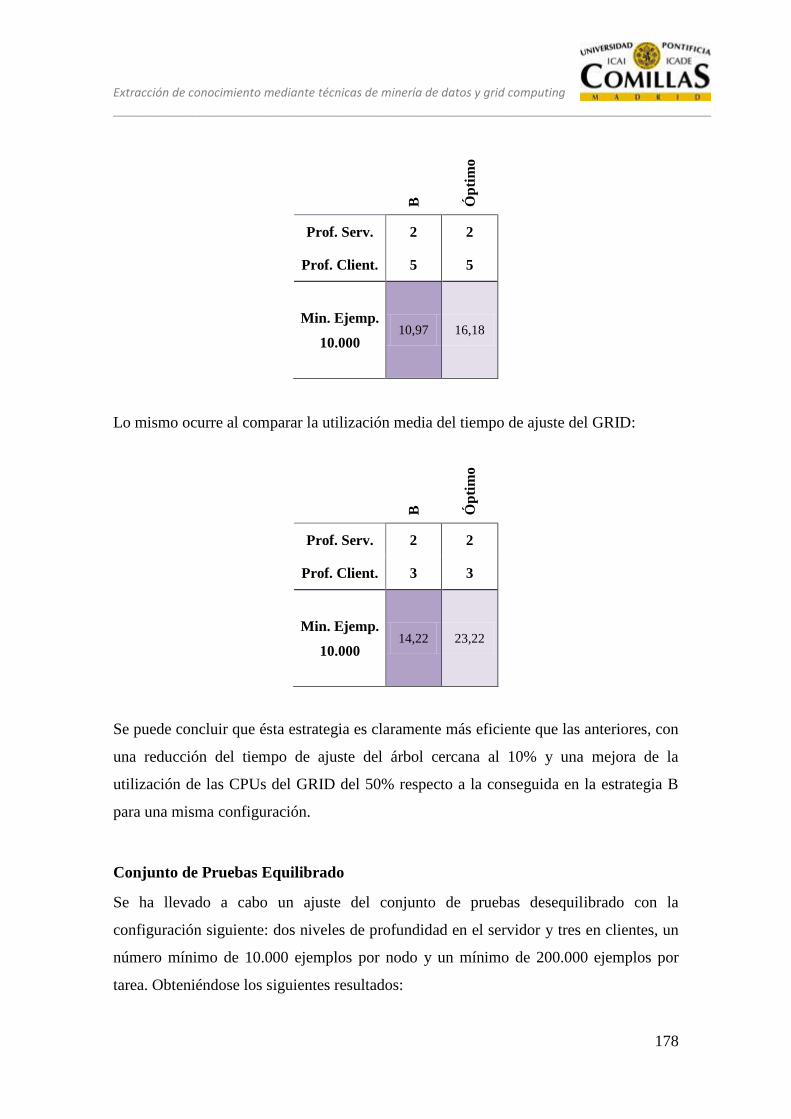
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
178
B
Óp
tim
o
Prof. Serv. 2 2
Prof. Client. 5 5
Min. Ejemp.
10.000 10,97 16,18
Lo mismo ocurre al comparar la utilización media del tiempo de ajuste del GRID:
B
Óp
tim
o
Prof. Serv. 2 2
Prof. Client. 3 3
Min. Ejemp.
10.000 14,22 23,22
Se puede concluir que ésta estrategia es claramente más eficiente que las anteriores, con
una reducción del tiempo de ajuste del árbol cercana al 10% y una mejora de la
utilización de las CPUs del GRID del 50% respecto a la conseguida en la estrategia B
para una misma configuración.
Conjunto de Pruebas Equilibrado
Se ha llevado a cabo un ajuste del conjunto de pruebas desequilibrado con la
configuración siguiente: dos niveles de profundidad en el servidor y tres en clientes, un
número mínimo de 10.000 ejemplos por nodo y un mínimo de 200.000 ejemplos por
tarea. Obteniéndose los siguientes resultados:
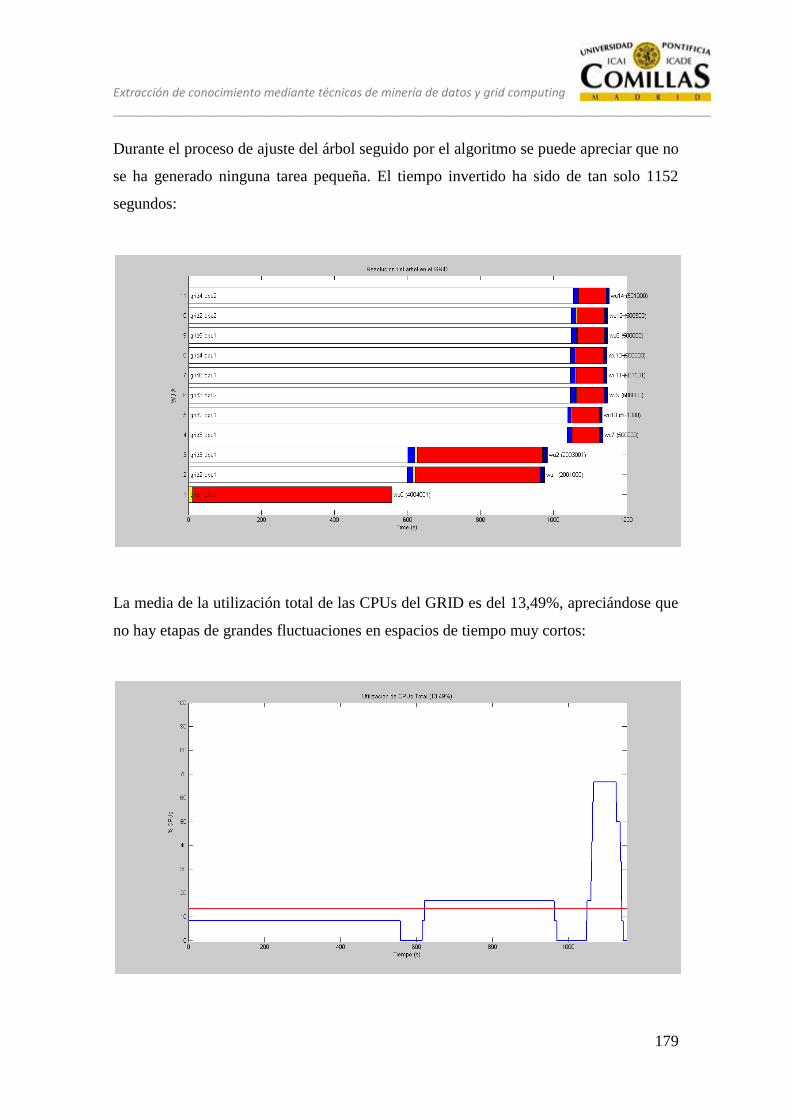
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
179
Durante el proceso de ajuste del árbol seguido por el algoritmo se puede apreciar que no
se ha generado ninguna tarea pequeña. El tiempo invertido ha sido de tan solo 1152
segundos:
La media de la utilización total de las CPUs del GRID es del 13,49%, apreciándose que
no hay etapas de grandes fluctuaciones en espacios de tiempo muy cortos:
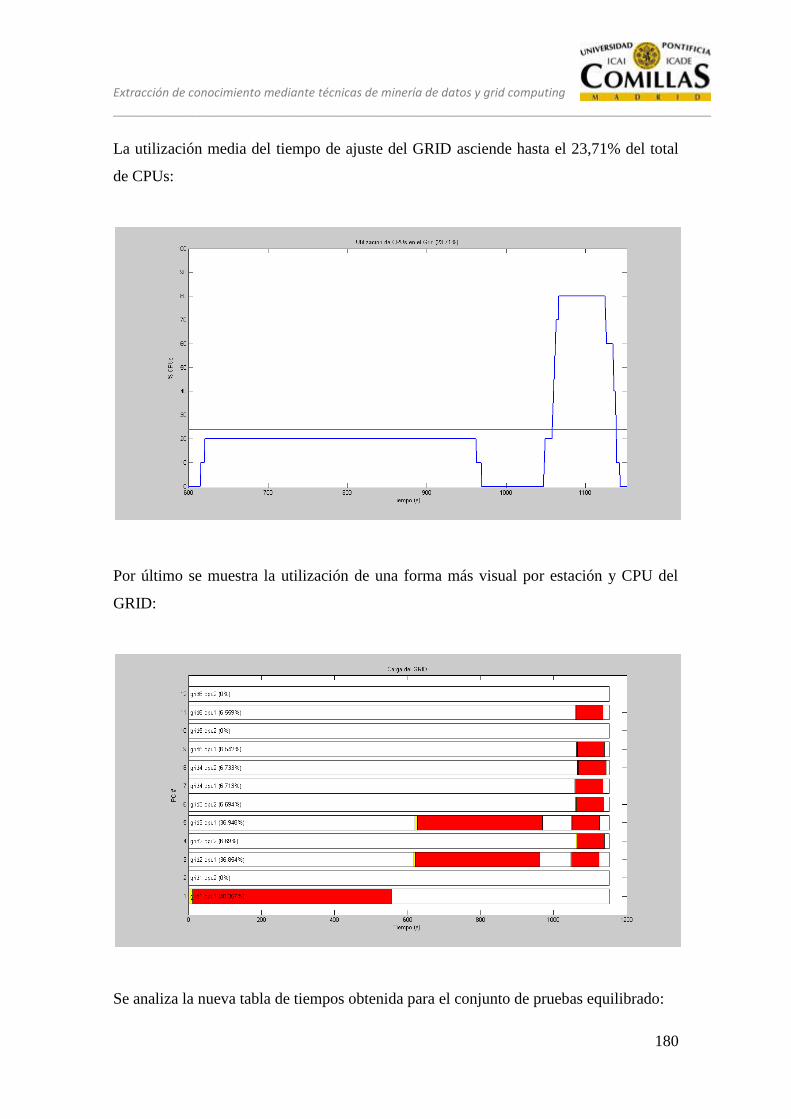
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
180
La utilización media del tiempo de ajuste del GRID asciende hasta el 23,71% del total
de CPUs:
Por último se muestra la utilización de una forma más visual por estación y CPU del
GRID:
Se analiza la nueva tabla de tiempos obtenida para el conjunto de pruebas equilibrado:
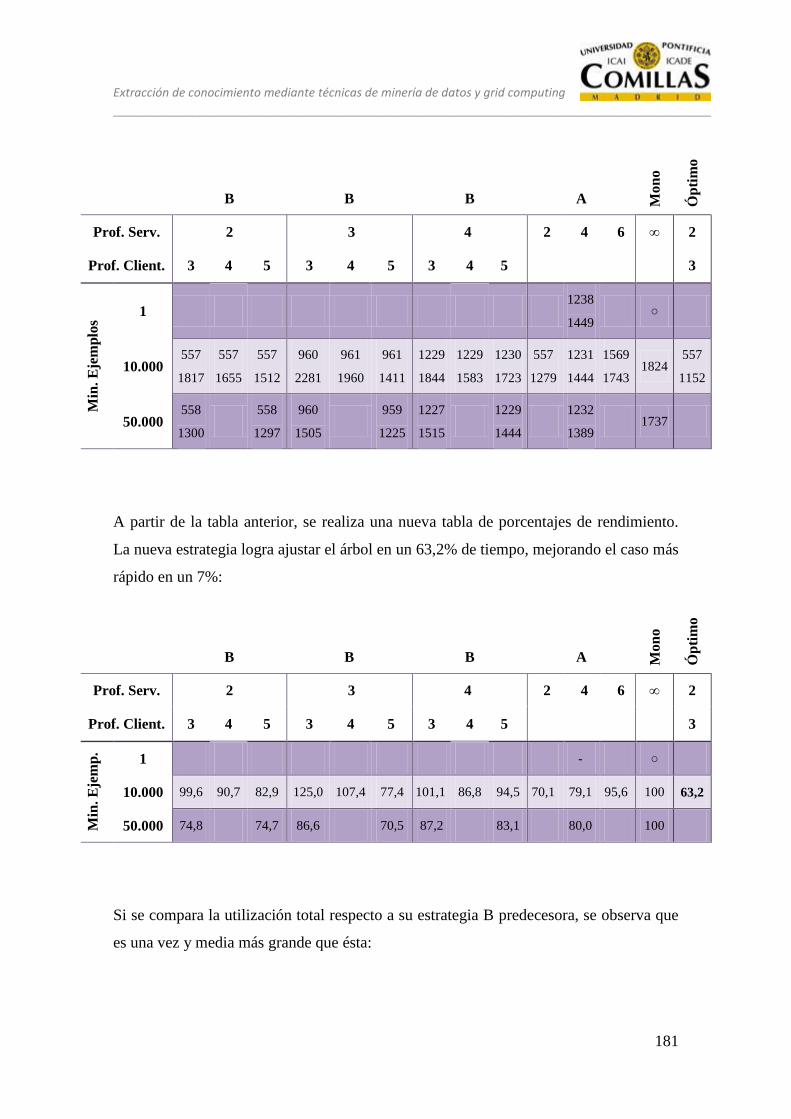
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
181
B B B A Mo
no
Óp
tim
o
Prof. Serv. 2 3 4 2 4 6 ∞ 2
Prof. Client. 3 4 5 3 4 5 3 4 5 3
Min
. E
jem
plo
s
1 1238
1449 ○
10.000 557
1817
557
1655
557
1512
960
2281
961
1960
961
1411
1229
1844
1229
1583
1230
1723
557
1279
1231
1444
1569
1743 1824
557
1152
50.000 558
1300
558
1297
960
1505
959
1225
1227
1515
1229
1444
1232
1389 1737
A partir de la tabla anterior, se realiza una nueva tabla de porcentajes de rendimiento.
La nueva estrategia logra ajustar el árbol en un 63,2% de tiempo, mejorando el caso más
rápido en un 7%:
B B B A Mon
o
Óp
tim
o
Prof. Serv. 2 3 4 2 4 6 ∞ 2
Prof. Client. 3 4 5 3 4 5 3 4 5 3
Min
. E
jem
p.
1 - ○
10.000 99,6 90,7 82,9 125,0 107,4 77,4 101,1 86,8 94,5 70,1 79,1 95,6 100 63,2
50.000 74,8 74,7 86,6 70,5 87,2 83,1 80,0 100
Si se compara la utilización total respecto a su estrategia B predecesora, se observa que
es una vez y media más grande que ésta:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
182
B
Óp
tim
o
Prof. Serv. 2 2
Prof. Client. 3 3
Min. Ejemp.
10.000 8,75 13,49
La utilización media del tiempo de ajuste del GRID es el doble:
B
Óp
tim
o
Prof. Serv. 2 2
Prof. Client. 3 3
Min. Ejemp.
10.000 12,06 23,71
Se puede concluir que para este conjunto de pruebas esta estrategia también es
claramente más eficiente que las anteriores, con una reducción del tiempo de ajuste del
árbol del 7% y una mejora de la utilización total y parcial de las CPUs del GRID del
50% y 100% respecto a la conseguida en la estrategia B para una misma configuración.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
183
15 CONCLUSIONES
Tras el desarrollo del proyecto “Extracción de conocimiento mediante técnicas de
minería de datos y GRID computing” se obtienen una serie de conclusiones que se
describen a continuación:
Arquitectura BOINC: es una arquitectura válida para la ejecución de procesos en
GRID. Aún así, no es del todo aconsejable si se desea un alto rendimiento del GRID,
ya que introduce unos retardos demasiado elevados a la hora de gestionar las tareas
entre clientes y servidores. Aunque en principio esta arquitectura no está diseñada
para una generación de tareas dinámica, se ha conseguido adaptarla para tal fin.
Estrategia de construcción de árboles de regresión en anchura y profundidad:
se han desarrollado con éxito dos estrategias distintas de construcción de árboles de
regresión en GRID: una en anchura y otra en profundidad. Para ello se ha llevado a
cabo una paralelización de las tareas del algoritmo de ajuste de árboles de regresión,
obteniendo unos resultados superiores a la construcción uniproceso.
Estrategia óptima: se ha verificado que una estrategia que combina la construcción
de árboles de regresión en profundidad y en anchura obtiene unos resultados más
eficientes en cuanto a tiempo de creación y utilización de los recursos del GRID.
Como conclusión final se recomienda el uso de un GRID para el ajuste de árboles de
regresión.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
184
16 TRABAJOS FUTUROS
En este apartado se propone una serie de mejoras al trabajo realizado en este proyecto:
Arquitectura de la estrategia B: desarrollar la estrategia B para la construcción de
árboles de regresión en GRID bajo una arquitectura Netsolve. Al contrario de
BOINC, es una arquitectura pensada para una generación dinámica de tareas.
Estrategia óptima: se puede hacer un estudio en mayor profundidad de las ventajas
e inconvenientes de la estrategia óptima propuesta.
Algoritmo de ajuste de árboles de regresión: una ampliación de las
funcionalidades del algoritmo de ajuste implementado para incluir el tratamiento de
variables categóricas y la existencia de datos ausentes.
Estas posibles mejoras enriquecerían en gran medida el análisis realizado y las
prestaciones del algoritmo de ajuste de árboles de regresión.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
185
17 BIBLIOGRAFÍA
En este apartado se hace referencia a la bibliografía en la que se ha apoyado el autor
para la realización del proyecto.
http://boinc.berkeley.edu
Página oficial del proyecto BOINC, incluyendo manual y API de programación.
http://www.boinc-wiki.info
Página no oficial del proyecto BOINC.
Aprendizaje automático, árboles de decisión.
Apuntes de la asignatura de Inteligencia Artificial de quinto curso de ingeniería
informática de la Universidad Pontificia Comillas ICAI.
Apuntes de aprendizaje automático (IA)
Apuntes de la asignatura de Inteligencia Artificial de ingeniería informática de la
Facultad de Informática de Barcelona.
ANSI C for Programmers on UNIX Systems
Manual de introducción a C del departamento de ingeniería de la Universidad de
Cambridge.
Plataformas GRID
Estudio sobre distintas plataformas GRID del departamento de informática de la
Universidad de Oviedo.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
186
Apéndice I MANUAL DE USUARIO
SERVIDOR BOINC
1. ABRIR UN TERMINAL PARA ACCEDER A LA BASE DE DATOS.
Una vez entramos en el motitor MySQL, accedemos a la base de datos del proyecto:
1.1. Borrar contenido de las tablas “workunit” y “results”.
Antes de ejecutar un nuevo caso en el servidor boinc es necesario borrar las entradas
relativas a los WUs y resultados obtenidos en casos anteriores:
mysql >> delete from workunit;
mysql >> delete from result;
mysql >> use gridiit
>> mysql -u root -p
>> Enter password:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
187
2. ACCEDER A LA CARPETA DEL PROYECTO.
2.1. Eliminar ficheros antiguos.
Antes de ejecutar un nuevo caso es necesario borrar los siguientes ficheros:
Ficheros de log: se elimina la carpeta “log_grid1”.
Ficheros de aplicación: dentro de la carpeta “download” se eliminan todas las
entradas excepto:
- El ejecutable de la aplicación.
- El fichero con la matriz de datos.
- El fichero de configuración de la aplicación.
Ficheros de resultados: se eliminan todas las entradas de la carpeta “upload”.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
188
2.2. Copiar el fichero con la matriz de datos en la carpeta “download”.
2.3. Introducir los parámetros deseados de configuración en el fichero
“Config.txt”, dentro de la carpeta “download”.
VARIABLES_ENTRADA: lista de nombres de las variables de entrada.
- Separar variables mediante espacios " ".
- Dejar vacío si se desean usar todas.
VARIABLES_SALIDA: nombre de la variable de salida.
- Solo puede haber una única variable de salida.
DATOS: nombre del fichero donde se encuentra la matriz de datos.
PROFUNDIDAD: profundidad máxima hasta la que se desarrollará el árbol.
- El primer nodo tiene profundidad "0".
- Si no se desea limitar se indica con "-1".
MINIMO_ELEMENTOS: mínima cantidad de ejemplos por nodo. Si el nodo
contiene una cantidad igual o inferior no se expandirá.
MINIMO_MSE: mínimo mse por nodo. Si el nodo tiene un mse igual o
inferior no se expandirá.
NODO_RAIZ: identificador del nodo raíz.
PROFUNDIDAD_TOTAL: nivel de profundidad del nodo raíz.
3. ABRIR OTRO TERMINAL EN EL DIRECTORIO DEL PROYECTO.
3.1. Inicializar el servidor boinc
>> cd Escritorio/Proyecto/gridiit
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
189
3.2. Ejecutar la aplicación
3.3. Generar los WU
Los WU son generados mediante el ejecutable “GeneraWU”. Este ejecutable tiene dos
modos de funcionamiento para el usuario:
Estrategia A: Si se desea emplear la estrategia de resolución A, se añadirá el
siguiente argumento a la llamada del ejecutable:
A: indica que se desea usar esta estrategia de resolución.
Estrategia B: Si se desea emplear la estrategia de resolución B, se añadirán los
siguientes argumentos a la llamada del ejecutable:
>> ./GeneraWU A
>> ./Arbol
>> bin/start

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
190
B: indica que se desea usar esta estrategia de resolución.
Prof_cliente: número de niveles del árbol que se desarrollarán en el cliente.
3.4. Esperar a la finalización de la resolución.
Se debe esperar a que todas las WUs sean resueltas en el GRID.
3.5. Generar análisis de tiempos.
Los ficheros de análisis de tiempos se generan mediante el ejecutable “Tiempos”:
Obteniéndose los siguientes ficheros de análisis:
Analisis.txt: fichero con los tiempos detallados del servidor y WUs resueltas
en el GRID.
MTiempos.txt: matriz de los tiempos señalados en el fichero “Analisis.txt”.
MEjemplos.txt: matriz relacionada con el fichero “MTiempos” y que añade
información acerca del ordenador, cpu, y número de ejemplos empleados por el
servidor o un determinado WU.
MCarga.txt: matriz de carga de trabajo por ordenador y cpu del GRID.
MGrid.txt: matriz relacionada con el fichero “MCarga” y que añade
información acerca del trabajo total y la utilización de un determinado
ordenador y cpu.
3.6. Terminar el servidor boinc.
>> bin/stop
>> ./Tiempos
>> ./GeneraWU B Prof_cliente

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
191
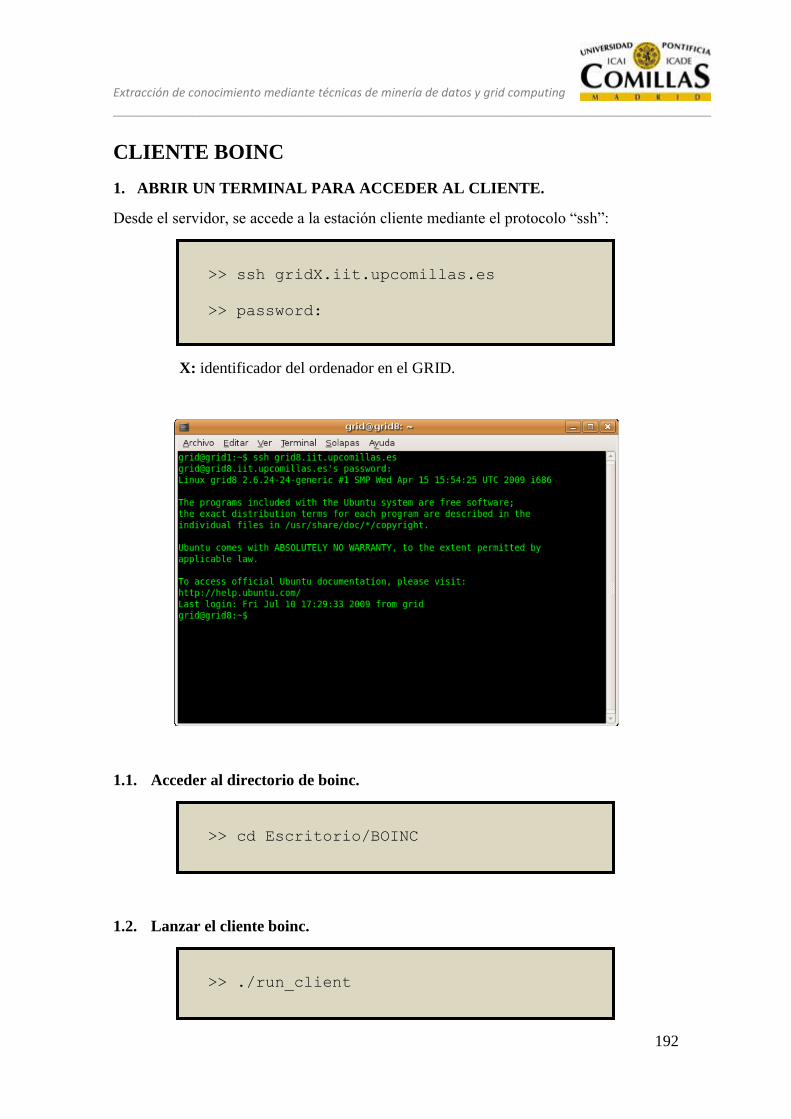
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
192
CLIENTE BOINC
1. ABRIR UN TERMINAL PARA ACCEDER AL CLIENTE.
Desde el servidor, se accede a la estación cliente mediante el protocolo “ssh”:
X: identificador del ordenador en el GRID.
1.1. Acceder al directorio de boinc.
1.2. Lanzar el cliente boinc.
>> ./run_client
>> cd Escritorio/BOINC
>> ssh gridX.iit.upcomillas.es
>> password:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
193
2. ABRIR OTRO TERMINAL PARA ACCEDER AL CLIENTE.
X: identificador del ordenador en el GRID.
2.1. Acceder al directorio de boinc.
2.2. Comandos boinc
A traves de este terminal se lanzan las instrucciones al cliente boinc:
>> boinc_cmd –project grid.iit.upcomilla
s.es/gridiit Instruccion
>> cd Escritorio/BOINC
>> ssh gridX.iit.upcomillas.es
>> password:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
194
Se recomienda que antes de comenzar la resolución del arbol se lancen las siguientes
instrucciones:
Reset: restablece el proyecto a su configuración inicial, eliminando cualquier
archivo existente, incluido el ejecutable de la aplicación.
Resume: reinicia la actividad del cliente, si éste estaba suspendido.
Otras instrucciones que pueden resultar útiles son:
Suspend: suspende la actividad del cliente.
Update: fuerza la comunicación con el servidor, en busca de nuevo trabajo.
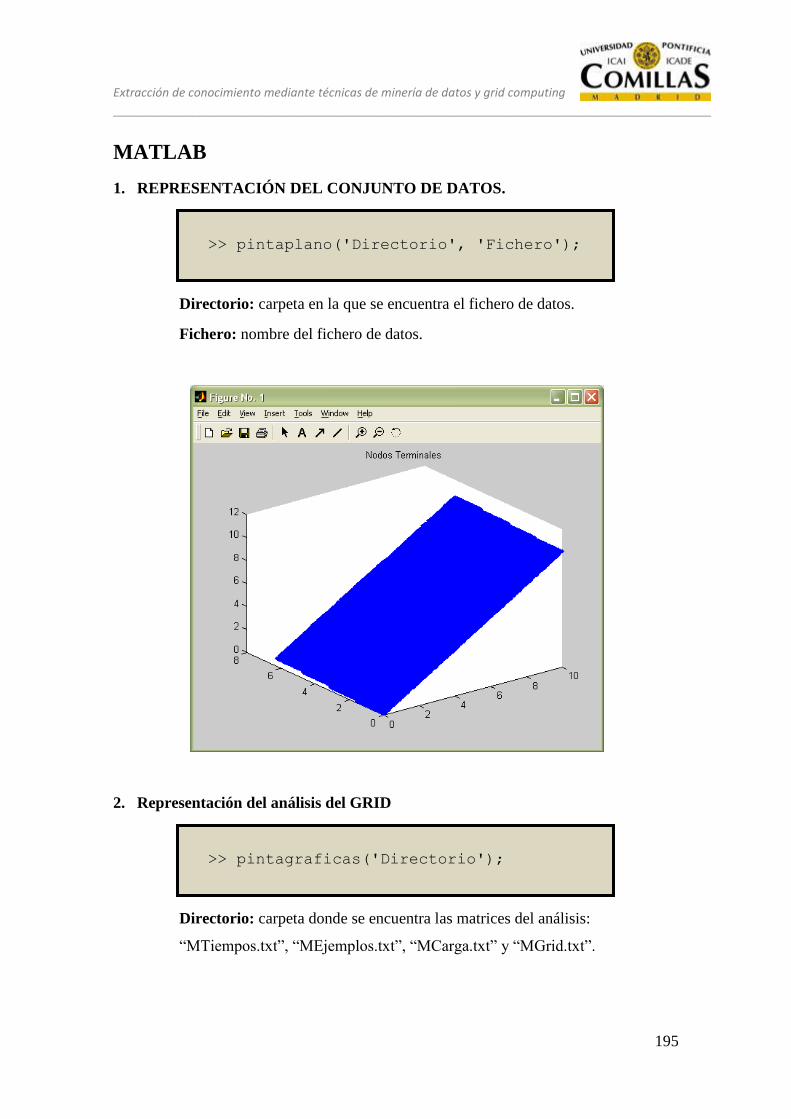
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
195
MATLAB
1. REPRESENTACIÓN DEL CONJUNTO DE DATOS.
Directorio: carpeta en la que se encuentra el fichero de datos.
Fichero: nombre del fichero de datos.
2. Representación del análisis del GRID
Directorio: carpeta donde se encuentra las matrices del análisis:
“MTiempos.txt”, “MEjemplos.txt”, “MCarga.txt” y “MGrid.txt”.
>> pintagraficas('Directorio');
>> pintaplano('Directorio', 'Fichero');

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
196

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
197
Apéndice II MANUAL INSTALACIÓN
SERVIDOR BOINC
1. INSTALAR HERRAMIENTAS NECESARIAS.
En este paso, se instalarán todas las herramientas que puedan ser usadas por BOINC.
1.1. Paquetes necesarios para poder compilar BOINC.
Instalar los paquetes: gcc, g++, automake y autoconf.
1.2. Servidor apache con MySQL, php, phpmyadmin y openssl.
Abrir el fichero de configuración “/etc/apache2/apache2.conf” y añadir la
siguiente línea para evitar tener errores de verificación de firma:
DefaultType application/octet-stream
>> sudo apt-get install phpmyadmin apach
e2 mysql-server libmysqlclient12-dev py
thon-mysqldb php4-gd libapache2-mod-auth
-mysql libssl-dev
>> sudo apt-get install gcc g++ automake
1.9 autoconf make

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
198
Modificar “/etc/group” para que apache2 funcione como “boincadmin”:
Cambiar:
Por:
Añadir las siguientes dos líneas al comienzo del script de arranque de apache
(apache2ctl) en el directorio “/usr/sbin”:
Rearrancar apache2:
Es posible tener que realizar el siguiente paso en caso de error:
Añadir:
>> sudo nano /etc/apache2/httpd.conf
>> sudo /etc/init.d/apache2 restart
umask 2
export umask
www-data:x:33:admin
www-data:x:33:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
199
1.3. Instalar CVS.
2. INSTALAR BOINC.
Se instala el servidor boinc en “~/boinc”.
Ejecutar en el directorio “~/boinc”:
Comprobar que todo ha ido bien y deshabilitar el cliente.
Se compila.
>> ./configure --disable-client
>> ./_autosetup
>> cd ~
>> svn co http://boinc.berkeley.edu/svn/
branches/server__stable boinc
>> sudo apt-get install cvs
ServerName localhost

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
200
3. CREAR UN PROYECTO.
3.1. Crear dos claves de 1024 bits.
3.2. Crear el proyecto.
>> crypt_prog –genkey 1024 code_sign_
private code sign_public
>> crypt_prog –genkey 1024 code_sign_
private code sign_public
>> make

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
201
3.3. Configurar el contrab.
Cuando se genera un proyecto se debe configurar el contrab para que se active dicho
proyecto al arrancarse el servidor. Para ello hay que añadir en el contrab de root:
3.4. Configurar apache2 para que muestre la página web.
Copiar el archivo “$project/$project_name.httpd.conf” en “/etc/apaches/sites-available”.
3.5. Reiniciar apache2.
0,5,10,15,20,25,30,35,40,45,50,55 * * *
* $project/bin/start cron
>> tools/make_project
--projet_root <path>
--db_user root
--db_passwd <password>
--db_host localhost
--key_dir <key path>
--url_base <url>
--delete_prev_inst
--drop_db_first
<short_project_name>
<long_project_name>

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
202
>> sudo /etc/init.d/apache2 restart

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
203
CLIENTE BOINC
1. ABRIR UN TERMINAL PARA INSTALAR EL CLIENTE BOINC.
2. ABRIR UN TERMINAL PARA UNIRSE A UN PROYECTO.
2.1. Acceder al directorio de boinc.
2.2. Acceder al interfaz gráfico del gestor del cliente boinc.
>> ./run_manager
>> cd ~/BOINC
>> sudo apt-get install boinc-client
boinc-manager
>> password:
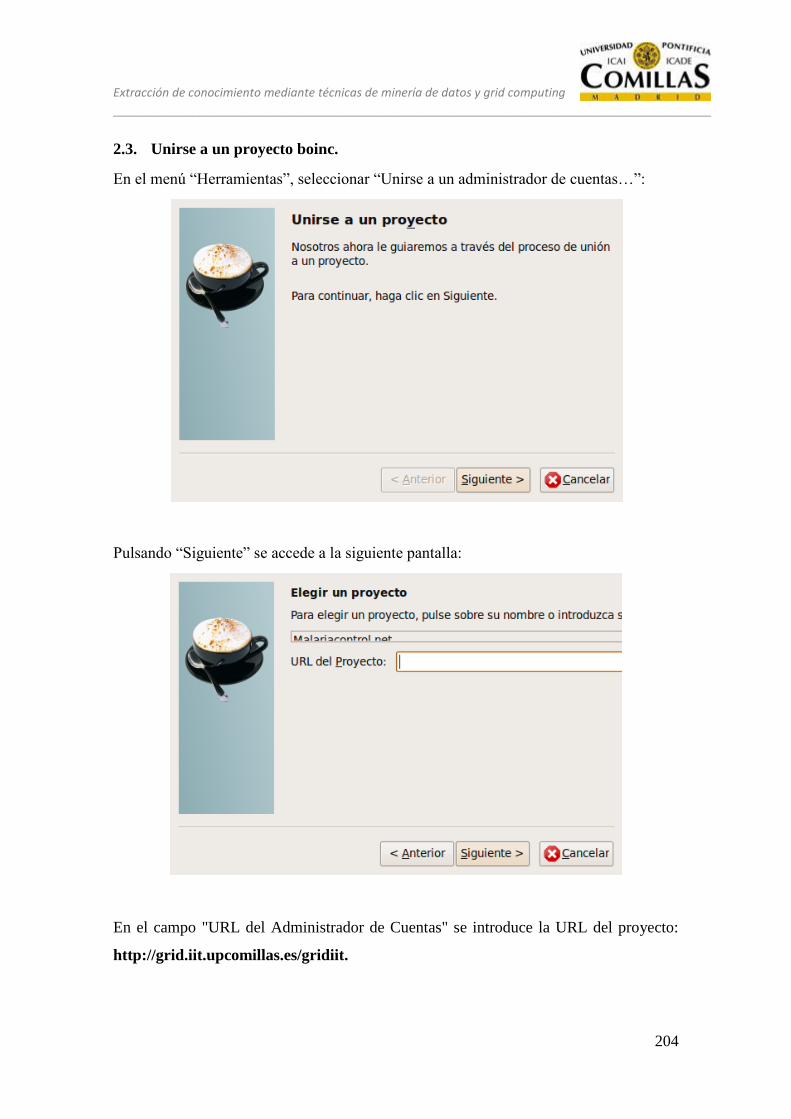
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
204
2.3. Unirse a un proyecto boinc.
En el menú “Herramientas”, seleccionar “Unirse a un administrador de cuentas…”:
Pulsando “Siguiente” se accede a la siguiente pantalla:
En el campo "URL del Administrador de Cuentas" se introduce la URL del proyecto:
http://grid.iit.upcomillas.es/gridiit.
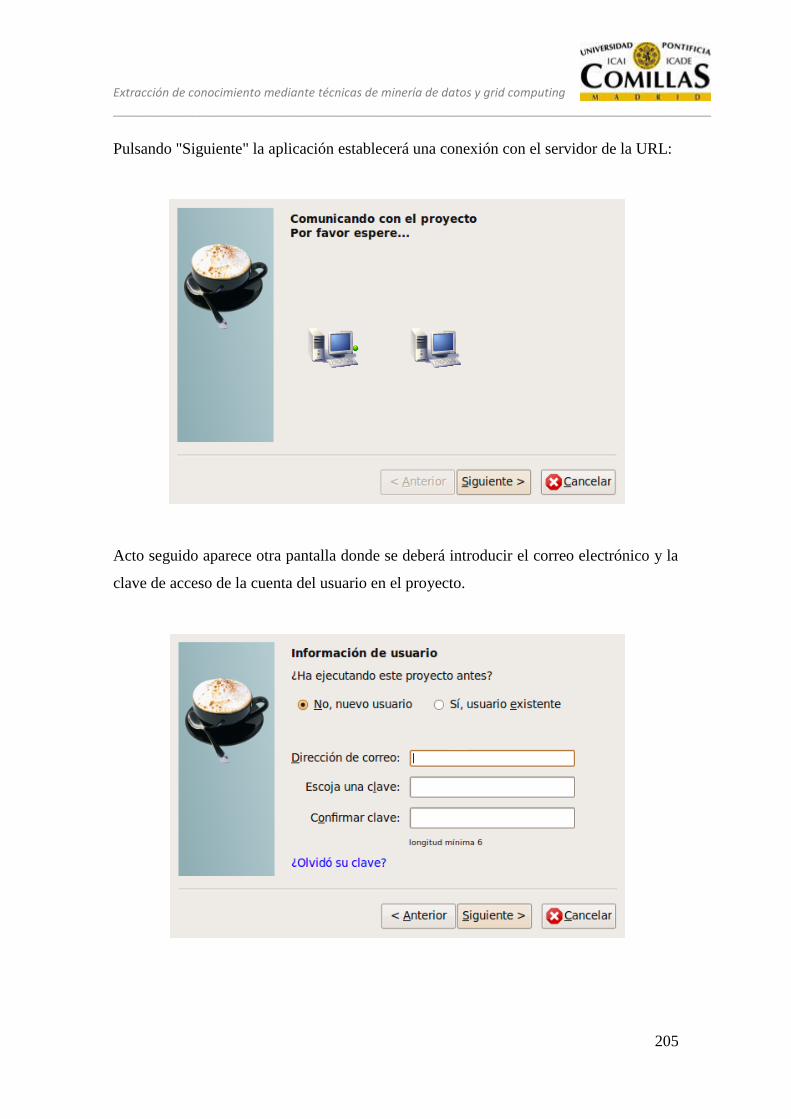
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
205
Pulsando "Siguiente" la aplicación establecerá una conexión con el servidor de la URL:
Acto seguido aparece otra pantalla donde se deberá introducir el correo electrónico y la
clave de acceso de la cuenta del usuario en el proyecto.
Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
206
Finalmente aparecerá la siguiente pantalla:
Pulsando “Finalizar” se finicializa el proceso de unión a un proyecto boinc. El
ordenador ya está colaborando con el proyecto, a la espera de recibir tareas:

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
207
Las acciones posibles con los comandos son:
Actualizar: pedir al servidor del proyecto nuevas tareas.
Suspender: esperar a terminar el trabajo pendiente y no pedir nuevas tareas.
No pedir nuevas tareas: suspender las peticiones de nuevas tareas.
Reiniciar proyecto: suspender todo el trabajo pendiente.
Separase: dejar de estar unido a un determinado proyecto.
Por otro lado, no hay que preocuparse de iniciar la aplicación manualmente cada vez
que se encienda el ordenador, puesto que durante la instalación (comando apt-get
install), ya se ha configurado para que se inicie automáticamente con el arranque del
ordenador.
3. CONFIGURAR PARÁMETROS BOINC.
En el menú “Avanzado” del interfaz gráfico, seleccionar la opción “Parámetros”.
3.1. Parámetros de CPU.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
208
Parámetros a tener en cuenta:
Computación permitida cuando el ordenador esté en uso: marcar.
% de los procesadores: Usar todos los CPUs (100%).
% del tiempo de la CPU: Usar todo el tiempo de CPU (100%).
3.2. Parámetros de red.
Parámetros a tener en cuenta:
Velocidad máx. de descarga: Usar todo el ancho de banda (0%).
Velocidad máx. de envío: Usar todo el ancho de banda (0%).
Conectar cada: 0,1 días.
Buffer de trabajo adicional: 0,25 días.
Saltar verificación de archivos de imagen: desmarcar.

Extracción de conocimiento mediante técnicas de minería de datos y grid computing
__________________________________________________________________________________________
209
3.3. Parámetros de disco y memoria.
Parámetros a tener en cuenta:
% de archivo de paginación: Usar todos los CPUs (100%).
% de memoria cuando se usa: Usar toda la memoria (100%).
% de memoria cuando está inactivo: Usar toda la memoria (100%).