luzayar.files.wordpress.com · web view1.1 principios basicos en capa de red 1.2 direccionamiento...
TRANSCRIPT

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Unidad 1 Capa de Red
1.1 Principios Basicos en Capa de Red
1.2 Direccionamiento Capa de Red
1.2.1 Determinacion Ruta Capa de Red
1.2.1.1 Algoritmos Encaminamiento
1.2.2 Subredes
1.3 Protocolos de Enrutamiento
1.3.1 El Enrutamiento en Entorno Mixtos de medios de LAN
1.3.2 Operaciones Basicas Router
1.3.3 Rutas Estaticas y Dinamicas
1.3.4 Ruta por Defecto
1.3.5 Protocolos Enrutados y de Enrutamiento
1.3.6 Informacion Utilizada por Routers para ejecutar sus funciones basicas
1.3.7 Configuracion de Rip
1.4 Arp , Rarp
1.5 Igrp , Egp
Unidad 2 Capas superiores del modelo OSI
2.1 Capa Transporte Osi
2.1.1 Parametros para lograr la Calidad Servicio de Transporte
2.1.1.1 Servicios Orientados a Conexion

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
2.1.1.2 Servicios Orientados a no Conexion
2.2 Capa De Sesion Osi
2.2.1 Intercambio de Datos
2.2.2 Administracion del Dialogo
2.2.3 Sincronizacion Capa Sesion
2.2.4 Notificacion de Excepciones
2.2.5 Llamada Procedimientos Remotos
2.3 Capa de presentación
2.3.1 Codigos de Representacion de Datos
2.3.2 Tecnicas Compresion Datos
2.3.3 Criptografia Capa Presentacion
2.4 Capa de aplicación
2.4.1 Configuracion Servicios
Unidad 3 Técnicas de conmutación
3.1 Conmutacion Circuitos
3.2 Conmutacion Mensajes
3.3 Conmutacion Paquetes
3.3.1 Topologia Redes de Paquetes
3.3.2 Datagramas y Circuitos Virtuales
3.3.2.1 Estructura Conmutadores
3.3.2.2 Conmutacion de Paquetes

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
3.3.3 Encaminamiento Redes de Paquetes
3.3.4 Gestion de Trafico
3.3.5 Control de Congestion
Unidad 4 TCP/IP
4.1 Modelo Cliente Servidor
4.2 Protocolo de Internet Ip movil
4.3 Protocolos de Transporte Udp Tcp
4.4 Protocolos Nivel Aplicacion
4.4.1 Smtp Protocolo
4.4.2 Ftp Protocolo
4.4.3 http Protocolo
4.4.4 Nfs Protocolo
4.4.5 Dns Protocolo

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Unidad 1 Capa de Red
1.1 Principios Básicos en Capa de Red
REDES INALÁMBRICAS.
Una de las tecnologías más prometedoras y discutidas en esta década es la de poder comunicar computadoras mediante tecnología inalámbrica. La conexión de computadoras mediante Ondas de Radio o Luz Infrarroja, actualmente está siendo ampliamente investigado. Las Redes Inalámbricas facilitan la operación en lugares donde la computadora no puede permanecer en un solo lugar, como en almacenes o en oficinas que se encuentren en varios pisos.
También es útil para hacer posibles sistemas basados en plumas. Pero la realidad es que esta tecnología está todavía en pañales y se deben de resolver varios obstáculos técnicos y de regulación antes de que las redes inalámbricas sean utilizadas de una manera general en los sistemas de cómputo de la actualidad.
No se espera que las redes inalámbricas lleguen a remplazar a las redes cableadas. Estas ofrecen velocidades de transmisión mayores que las logradas con la tecnología inalámbrica.
Mientras que las redes inalámbricas actuales ofrecen velocidades de 2 Mbps, las redes cableadas ofrecen velocidades de 10 Mbps y se espera que alcancen velocidades de hasta 100 Mbps. Los sistemas de Cable de Fibra Optica logran velocidades aún mayores, y pensando futuristamente se espera que las redes inalámbricas alcancen velocidades de solo 10 Mbps.
Sin embargo se pueden mezclar las redes cableadas y las inalámbricas, y de esta manera generar una “Red Híbrida” y poder resolver los últimos metros hacia la estación.
Se puede considerar que el sistema cableado sea la parte principal y la inalámbrica le proporcione movilidad adicional al equipo y el operador se pueda desplazar con facilidad dentro de un almacén o una oficina. Existen dos amplias categorías de Redes Inalámbricas:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
De Larga Distancia.- Estas son utilizadas para transmitir la información en espacios que pueden variar desde una misma ciudad o hasta varios países circunvecinos (mejor conocido como Redes de Area Metropolitana MAN); sus velocidades de transmisión son relativamente bajas, de 4.8 a 19.2 Kbps.
De Corta Distancia.- Estas son utilizadas principalmente en redes corporativas cuyas oficinas se encuentran en uno o varios edificios que no se encuentran muy retirados entre si, con velocidades del orden de 280 Kbps hasta los 2 Mbps.
Existen dos tipos de redes de larga distancia: Redes de Conmutación de Paquetes (públicas y privadas) y Redes Telefónicas Celulares. Estas últimas son un medio para transmitir información de alto precio. Debido a que los módems celulares actualmente son más caros y delicados que los convencionales, ya que requieren circuiteria especial, que permite mantener la pérdida de señal cuando el circuito se alterna entre una célula y otra.
Esta pérdida de señal no es problema para la comunicación de voz debido a que el retraso en la conmutación dura unos cuantos cientos de milisegundos, lo cual no se nota, pero en la transmisión de información puede hacer estragos. Otras desventajas de la transmisión celular son:
La carga de los teléfonos se termina fácilmente. La transmisión celular se intercepta fácilmente (factor importante en lo relacionado con la seguridad).
Las velocidades de transmisión son bajas.
Todas estas desventajas hacen que la comunicación celular se utilice poco, o únicamente para archivos muy pequeños como cartas, planos, etc.. Pero se espera que con los avances en la compresión de datos, seguridad y algoritmos de verificación de errores se permita que las redes celulares sean una opción redituable en algunas situaciones.
La otra opción que existe en redes de larga distancia son las denominadas: Red Pública De Conmutación De Paquetes Por Radio. Estas redes no tienen problemas de pérdida de señal debido a que su arquitectura está diseñada para soportar paquetes de datos en lugar de comunicaciones de voz.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Las redes privadas de conmutación de paquetes utilizan la misma tecnología que las públicas, pero bajo bandas de radio frecuencia restringidas por la propia organización de sus sistemas de cómputo.
REDES DE AREA LOCAL (LAN).
Las redes inalámbricas se diferencian de las convencionales principalmente en la “Capa Física” y la “Capa de Enlace de Datos”, según el modelo de referencia OSI. La capa física indica como son enviados los bits de una estación a otra. La capa de Enlace de Datos (denominada MAC), se encarga de describir como se empacan y verifican los bits de modo que no tengan errores.
Las demás capas forman los protocolos o utilizan puentes, ruteadores o compuertas para conectarse. Los dos métodos para remplazar la capa física en una red inalámbrica son la transmisión de Radio Frecuencia y la Luz Infrarroja.
PUNTOS DE ACCESO. La infraestructura de un punto de acceso es simple: “Guardar y Repetir”, son dispositivos que validan y retransmiten los mensajes recibidos. Estos dispositivos pueden colocarse en un punto en el cual puedan abarcar toda el área donde se encuentren las estaciones. Las características a considerar son :
1.- La antena del repetidor debe de estar a la altura del techo, esto producirá una mejor cobertura que si la antena estuviera a la altura de la mesa.
2.- La antena receptora debe de ser más compleja que la repetidora, así aunque la señal de la transmisión sea baja, ésta podrá ser recibida correctamente.
Un punto de acceso compartido es un repetidor, al cual se le agrega la capacidad de seleccionar diferentes puntos de acceso para la retransmisión. (esto no es posible en un sistema de estación-a-estación, en el cual no se aprovecharía el espectro y la eficiencia de poder, de un sistema basado en puntos de acceso).
La diferencia entre el techo y la mesa para algunas de las antenas puede ser considerable cuando existe en esta trayectoria un obstáculo o una obstrucción.
En dos antenas iguales, el rango de una antena alta es 2x-4x, más que las antenas bajas, pero el nivel de interferencia es igual, por esto es posible

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
proyectar un sistema basado en coberturas de punto de acceso, ignorando estaciones que no tengan rutas de propagación bien definidas entre si.
Los ángulos para que una antena de patrón vertical incremente su poder direccional de 1 a 6 están entre los 0° y los 30° bajo el nivel horizontal, y cuando el punto de acceso sea colocado en una esquina, su poder se podrá incrementar de 1 a 4 en su cobertura cuadral. El patrón horizontal se puede incrementar de 1 hasta 24 dependiendo del medio en que se propague la onda.
En una estación, con antena no dirigida, el poder total de dirección no puede ser mucho mayor de 2 a 1 que en la de patrón vertical. Aparte de la distancia y la altura, el punto de acceso tiene una ventaja de hasta 10 Db en la recepción de transmisión de una estación sobre otra estación .
TOPOLOGIA Y COMPONENTES DE UNA LAN HIBRIDA.
En el proceso de definición de una Red Inalámbrica Ethernet debe de olvidar la existencia del cable, debido a que los componentes y diseños son completamente nuevos. Respecto al CSMA/CD los procedimientos de la subcapa MAC usa valores ya definidos para garantizar la compatibilidad con la capa MAC. La máxima compatibilidad con las redes Ethernet cableadas es, que se mantiene la segmentación.
Además la células de infrarrojos requieren de conexiones cableadas para la comunicación entre sí. La radiación infrarroja no puede penetrar obstáculos opacos. Una LAN híbrida (Infrarrojos/Coaxial) no observa la estructura de segmentación de la Ethernet cableada pero toma ventaja de estos segmentos para interconectar diferentes células infrarrojas.
La convivencia de estaciones cableadas e inalámbricas en el mismo segmento es posible y células infrarrojas localizadas en diferentes segmentos pueden comunicarse por medio de un repetidor Ethernet tradicional. La LAN Ethernet híbrida es representada en donde se incluyen células basadas en ambas reflexiones pasiva y de satélite.
1.2 Direccionamiento Capa de Red
Primeramente tienes que entender que es el direccionamiento, entra a esta dirección y en la próxima clase veremos que entendiste.
http://neo.lcc.uma.es/evirtual/cdd/tutorial/transporte/direcc.html

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
La dirección de red ayuda al router a identificar una ruta dentro de la nube de red, el router utiliza esta dirección de red para identificar la red destino de un paquete dentro de la red. Lee despacio estos conceptos, son muy sencillos y obvios pero si tienes la base clara te ayudará mucho a comprender como funcionan las redes.
Además de la dirección de red, los protocolos de red utilizan algún tipo de dirección de host o nodo. Para algunos protocolos de capa de red, el administrador de la red asigna direcciones de red de acuerdo con un plan de direccionamiento de red por defecto. Para otros protocolos de capa de red, asignar direcciones es una operación parcial o totalmente dinámica o automática. El gráfico muestra tres dispositivos en la Red 1 (dos estaciones de trabajo y un router), cada una de los cuales tiene su propia dirección de equipo exclusiva. (también muestra que el router está conectado a otras dos redes: las Redes 2 y 3).
Fíjate bien en el gráfico. Ten en cuenta que todavía no hemos empezado con las direcciones IP, simplemente hemos puesto nombres 1, 2 y 3 a las tres redes conectadas por el router y además hemos numerado a nuestros dispositivos de cada red: 1.1 para el router, 1.2 para un equipo y 1.3 para el otro. Luego en la segunda red 2 hemos puesto el número 2.1 a la conexión del router y la 3.1 para la tercera red. Es obvio que el router debe estar conectado a las tres redes si debe darnos conectividad a las tres, por eso tiene un nombre de cada red: 1.1, 2.1 y 3.1. Las analogías que usamos anteriormente para una dirección de red incluyen la primera parte (código de provincia) de un número telefónico. Los dígitos restantes de un número telefónico indican el teléfono destino similar a la función de la parte del host de una dirección. La parte host le comunica al router hacia qué dispositivo específico deberá entregar el paquete.
Sin el direccionamiento de capa de red, no se puede producir el enrutamiento. Los routers requieren direcciones de red para garantizar el envío correcto de los paquetes. Si no existiera alguna estructura de direccionamiento jerárquico, los paquetes no podrían transportarse a través de una red. De la misma manera, si no existiera alguna estructura jerárquica para los números telefónicos, las direcciones postales o los sistemas de transporte, no se podría realizar la entrega correcta. La Capa 3 y la movilidad de los ordenadores
La dirección MAC (la que viene grabada de fábrica en las tarjetas de red) se puede comparar con el nombre de las personas, y la dirección de red con su

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
dirección postal. Si una persona se muda a otra ciudad, su nombre propio seguiría siendo el mismo, pero la dirección postal deberá indicar el nuevo lugar donde se puede ubicar. Los dispositivos de red (los routers así como también los ordenadores individuales) tienen una dirección MAC y una dirección de protocolo (capa de red). Cuando se traslada físicamente un ordenador a una red distinta, el ordenador conserva la misma dirección MAC, pero se le debe asignar una nueva dirección de red.
Es obvio, por un lado la dirección MAC que viene grabada de fábrica no se puede cambiar nunca así que si lo movemos dentro de la red de la delegación de Logroño a la de Barcelona esa dirección no varía. En cambio la dirección de red debe cambiarla el administrador, si en Logroño comenzaba con el “1.” cuando viaje a Barcelona el equipo habrá que cambiarle al número de red de allí es decir “2.” Así que tenemos una dirección física (MAC) y otra lógica que configuramos desde el panel de control de Windows. Comparación entre direccionamiento plano y jerárquico
La función de capa de red es encontrar la mejor ruta a través de la red. Para lograr esto, utiliza dos métodos de direccionamiento: direccionamiento plano y direccionamiento jerárquico. Un esquema de direccionamiento plano asigna a un dispositivo la siguiente dirección disponible. No se tiene en cuenta la estructura del esquema de direccionamiento. Un ejemplo de un esquema de direccionamiento plano es el sistema de numeración del DNI. Las direcciones MAC funcionan de esta manera. El fabricante recibe un bloque de direcciones; la primera mitad de cada dirección corresponde al código del fabricante, el resto de la dirección MAC es un número que se asigna de forma secuencial.
Los códigos postales del sistema de correo son un buen ejemplo de direccionamiento jerárquico. En el sistema de código postal, la dirección se determina a través de la ubicación y no a través de un número asignado de forma aleatoria. El esquema de direccionamiento que usaremos a lo largo de este curso es el direccionamiento de Protocolo Internet (IP). Las direcciones IP tienen una estructura específica y no se asignan al azar.
1.2.1 Determinación Ruta Capa de Red
La función que determina la ruta se produce a nivel de Capa 3 (capa de red). Permite al router evaluar las rutas disponibles hacia un destino y establecer el mejor camino para los paquetes. Los servicios de enrutamiento utilizan la información de la topología de red al evaluar las rutas de red. La determinación

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
de ruta es el proceso que utiliza el router para elegir el siguiente salto de la ruta del paquete hacia su destino, este proceso también se denomina enrutar el paquete. Como ves empezamos a entrar en un nivel muy interesante ya que transcendemos de nuestra red local para que, a través de un router, podamos enrutar el tráfico hacia otra red (mi empresa, internet, …)
Los routers, como dispositivos inteligentes que son, verán la velocidad y congestión de las líneas y así elegirán la mejor ruta. Por ejemplo para ir de Logroño a Madrid pueden coger una nacional con poco tráfico en lugar de la autopista con atasco de tráfico. Y viceversa puede decidir ir por autopista aunque sea el camino mas largo (varios routers) que la carretera directa mas lenta.
1.2.1.1 Algoritmos Encaminamiento
Podemos definir encaminamiento como un proceso mediante el cual tratamos de encontrar un camino entre dos puntos de la red: el nodo origen y el nodo destino. El objetivo que se persigue es encontrar las mejores rutas entre pares de nodos
Los algoritmos de encaminamiento pueden agruparse en:
Deterministicos o estáticos
No tienen en cuenta el estado de la subred al tomar las decisiones de encaminamiento. Las tablas de encaminamiento de los nodos se configuran de forma manual y permanecen inalterables hasta que no se vuelve a actuar sobre ellas. Por tanto, la adaptación en tiempo real a los cambios de las condiciones de la red es nula.
El cálculo de la ruta óptima es también off-line por lo que no importa ni la complejidad del algoritmo ni el tiempo requerido para su convergencia.
Adaptativos o dinámicos
Pueden hacer frente a cambios en la subred tales como variaciones en el tráfico, incremento del retardo o fallasen la topología. El encaminamiento dinámico o adaptativo se puede clasificar a su vez en tres categorías, dependiendo de donde se tomen las decisiones y del origen de la información intercambiada:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Adapativo centralizado. Todos los nodos de la red son iguales excepto un nodo central que es quien recoge la información de control y los datos de los demás nodos para calcular con ellos la tabla de encaminamiento. Este método tiene el inconveniente de que consume abundantes recursos de la propia red.
Adaptativo distribuido. Este tipo de encaminamiento se caracteriza porque el algoritmo correspondiente se ejecuta por igual en todos los nodos de la subred. Cada nodo recalcula continuamente la tabla de encaminamiento a partir de dicha información y de la que contiene en su propia base de datos. A este tipo pertenecen dos de los más utilizados en Internet que son los algoritmos por vector de distancias y los de estado de enlace.
Adaptativo aislado. Se caracterizan por la sencillez del método que utilizan para adaptarse al estado cambiante de la red. Su respuesta a los cambios de tráfico o de topología se obtiene a partir de la información propia y local de cada nodo. Un caso típico es el encaminamiento “por inundación” cuyo mecanismo consiste en reenviar cada paquete recibido con destino a otros nodos, por todos los enlaces excepto por el que llegó.
1.2.2 Subredes
En redes de computadoras, una subred es un rango de direcciones lógicas. Cuando una red de computadoras se vuelve muy grande, conviene dividirla en subredes, por los siguientes motivos:
Reducir el tamaño de los dominios de broadcast.
Hacer la red más manejable, administrativamente. Entre otros, se puede
controlar el tráfico entre diferentes subredes, mediante ACLs.
Existen diversas técnicas para conectar diferentes subredes entre sí, se pueden conectar:
← a nivel físico (capa 1 OSI) mediante repetidores o concentradores(Hubs) ← a nivel de enlace (capa 2 OSI) mediante puentes o
conmutadores(Switches)
← a nivel de red (capa 3 OSI) mediante routers
← a nivel de transporte (capa 4 OSI)

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
← aplicación (capa 7 OSI) mediante pasarelas.
También se pueden emplear técnicas de encapsulación (tunneling).
En el caso más simple, se puede dividir una red en subredes de tamaño fijo (todas las subredes tienen el mismo tamaño). Sin embargo, por la escasez de direcciones IP, hoy en día frecuentemente se usan subredes de tamaño variable.
Tabla de contenidos
[ocultar]
1 Máscara de subred 2 Ejemplo de
subdivisión
3 Direcciones reservadas
4 Véase también
5 Enlaces externos
Los routers constituyen los límites entre las subredes. La comunicación desde y hasta otras subredes es hecha mediante un puerto específico de un router específico, por lo menos momentáneamente.
Una típica subred es una red física hecha con un router, por ejemplo una Red Ethernet o una VLAN (Virtual Local Area Network), Sin embargo, las subredes permiten a la red ser dividida lógicamente a pesar del diseño físico de la misma, desde esto es posible dividir una red física en varias subredes configurando diferentes computadores host que utilicen diferentes routers. La dirección de todos los nodos en una subred comienzan con la misma secuencia binaria, que es su ID de red y ID de subred. En IPv4, la subred deben ser identificadas por la base de la dirección y una máscara de subred.
Las subredes simplifican el enrutamiento, ya que cada subred típicamente es representada como una fila en las tablas de ruteo en cada router conectado. Las subredes fueron utilizadas antes de la introducción de las direcciones IPv4, para permitir a una red grande, tener un numero importante de redes más pequeñas dentro, controladas por varios routers. Las subredes permiten el

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Rutado Interdominio sin Clases (CIDR). Para que las computadoras puedan comunicarse con una red, es necesario contar con numeros IP propios, pero si tenemos dos o mas redes,es fácil dividir una dirección IP entre todos los hosts de la red. De esta formas se pueden partir redes grandes en redes más pequeñas.
Es necesario para el funcionamiento de una subred, calcular los bits de una IP y quitarle los bits de host, y agregarselos a los bits de network mediante el uso de una operación lógica.
Ejemplo de subdivisión [editar]
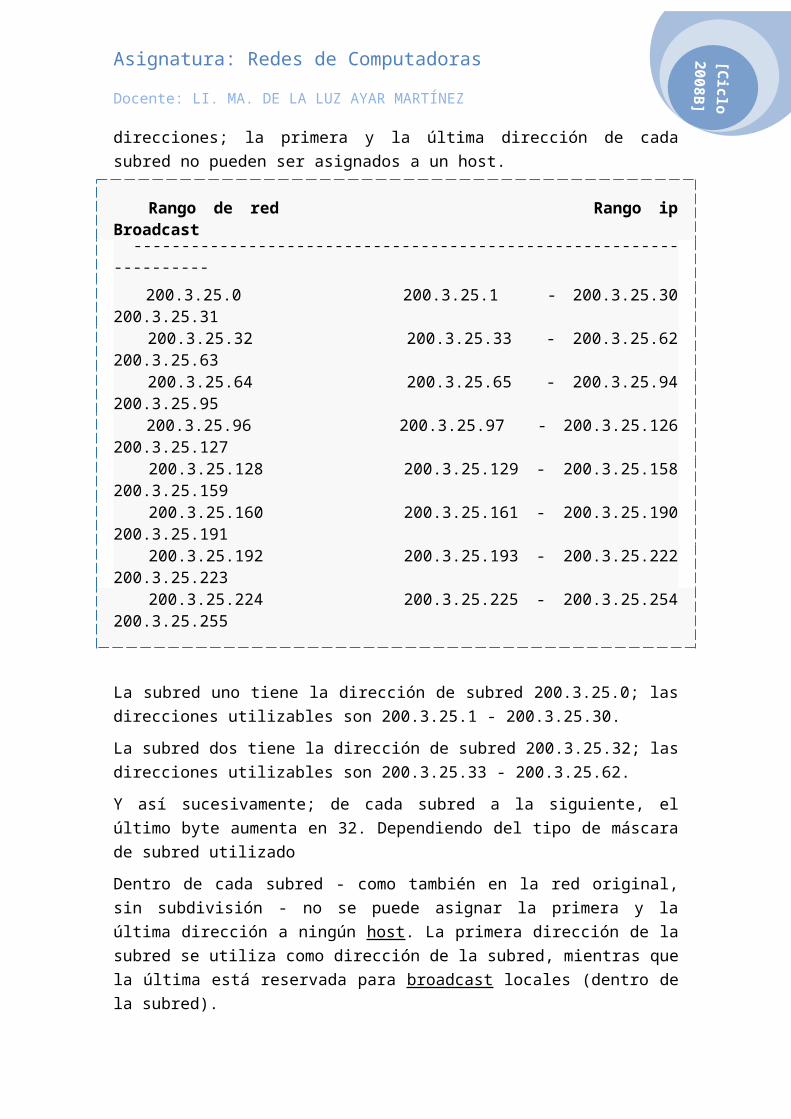
A una compañía se le ha asignado la red 200.3.25.0. Es una red de clase C, lo cual significa que puede disponer de 254 diferentes direcciones. (La primera y la última dirección están reservados, no son utilizables.) Si no se divide la red en subredes, la máscara de subred será 255.255.255.0 (o /24).
La compañía decide dividir esta red en 8 subredes, con lo cual, la máscara de subred tiene que recorrer tres bits más ((25) − 2 = 30. (Se "toman prestados" tres bits de la porción que corresponde al host.) Eso resulta en una máscara de subred /27, en binario 11111111.11111111.11111111.11100000, o en decimal punteado, 255.255.255.224. Cada subred tendrá (25) − 2 = 30 direcciones; la primera y la última dirección de cada subred no pueden ser asignados a un host.
Rango de red Rango ip Broadcast ¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯ 200.3.25.0 200.3.25.1 - 200.3.25.30 200.3.25.31 200.3.25.32 200.3.25.33 - 200.3.25.62 200.3.25.63 200.3.25.64 200.3.25.65 - 200.3.25.94 200.3.25.95 200.3.25.96 200.3.25.97 - 200.3.25.126 200.3.25.127 200.3.25.128 200.3.25.129 - 200.3.25.158 200.3.25.159 200.3.25.160 200.3.25.161 - 200.3.25.190 200.3.25.191 200.3.25.192 200.3.25.193 - 200.3.25.222 200.3.25.223 200.3.25.224 200.3.25.225 - 200.3.25.254 200.3.25.255
La subred uno tiene la dirección de subred 200.3.25.0; las direcciones utilizables son 200.3.25.1 - 200.3.25.30.
La subred dos tiene la dirección de subred 200.3.25.32; las direcciones utilizables son 200.3.25.33 - 200.3.25.62.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Y así sucesivamente; de cada subred a la siguiente, el último byte aumenta en 32. Dependiendo del tipo de máscara de subred utilizado
Dentro de cada subred - como también en la red original, sin subdivisión - no se puede asignar la primera y la última dirección a ningún host. La primera dirección de la subred se utiliza como dirección de la subred, mientras que la última está reservada para broadcast locales (dentro de la subred).
Además, en algunas partes se puede leer que no se puede utilizar la primera y la última subred. Es posible que éstos causen problemas de compatibilidad en algunos equipos, pero en general, por la escasez de direcciones IP, hay una tendencia creciente de usar todas las subredes posibles.
1.3 Protocolos de Enrutamiento
El Protocolo de información de enrutamiento permite que los routers determinen cuál es la ruta que se debe usar para enviar los datos. Esto lo hace mediante un concepto denominado vector-distancia. Se contabiliza un salto cada vez que los datos atraviesan un router es decir, pasan por un nuevo número de red, esto se considera equivalente a un salto. Una ruta que tiene un número de saltos igual a 4 indica que los datos que se transportan por la ruta deben atravesar cuatro routers antes de llegar a su destino final en la red. Si hay múltiples rutas hacia un destino, la ruta con el menor número de saltos es la ruta seleccionada por el router.
Como el número de saltos es la única métrica de enrutamiento utilizada por el RIP, no necesariamente selecciona la ruta más rápida hacia su destino. La métrica es un sistema de medidas que se utiliza para la toma de decisiones. luego veremos otros protocolos de enrutamiento que utilizan otras métricas además del número de saltos, para encontrar la mejor ruta a través de la cual se pueden transportar datos. Sin embargo, RIP continúa siendo muy popular y se sigue implementando ampliamente. La principal razón de esto es que fue uno de los primeros protocolos de enrutamiento que se desarrollaron.
Otro de los problemas que presenta el uso del RIP es que a veces un destino puede estar ubicado demasiado lejos como para ser alcanzable. RIP permite un límite máximo de quince para el número de saltos a través de los cuales se pueden enviar datos. La red destino se considera inalcanzable si se encuentra a más de quince saltos de router. Así que resumiendo, el RIP: * Es un protocolo de enrutamiento por vector de distancia

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
* La única medida que utiliza (métrica) es el número de saltos * El número máximo de saltos es de 15 * Se actualiza cada 30 segundos * No garantiza que la ruta elegida sea la mas rápida * Genera mucho tráfico con las actualizaciones
1.3.1 El Enrutamiento en Entorno Mixtos de medios de LAN
Descripción de los componentes de enrutamiento
El enrutamiento determina cómo fluyen los mensajes entre los servidores de la organización de Microsoft® Exchange y para los usuarios externos a la organización. Para la entrega de mensajes internos y externos, Exchange utiliza el enrutamiento con el fin de determinar primero la ruta más eficiente y, después, la ruta disponible menos costosa. Los componentes del enrutamiento interno toman esta decisión basándose en los grupos de enrutamiento y en los conectores que usted configura, y en los espacios de direcciones y los costos asociados a cada ruta.
El enrutamiento es responsable de las siguientes funciones:
• Determinar el siguiente salto (el siguiente destino para un mensaje en ruta hasta su destino final) según la ruta más eficiente.
• Intercambiar información de estado de los vínculos (el estado y la disponibilidad de los servidores y las conexiones entre los servidores) dentro y entre los grupos de enrutamiento.
En este tema se explica cómo los grupos de enrutamiento, los conectores y la información de estado de los vínculos permiten una entrega de mensajes eficiente.
Tipos de componentes de enrutamiento Los componentes del enrutamiento componen la topología, y las rutas empleadas para entregar correo interno y externo. El enrutamiento utiliza los siguientes componentes que usted define dentro de la topología de enrutamiento:
• Grupos de enrutamiento Conjuntos lógicos de servidores que se utilizan para controlar el flujo de correo y las referencias a carpetas públicas. Los grupos de enrutamiento comparten una o varias conexiones físicas. Dentro de un grupo
[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
de enrutamiento, todos los servidores se comunican y transfieren mensajes directamente entre sí.
• Conectores Rutas designadas entre los grupos de enrutamiento, hacia Internet o hacia otro sistema de correo. Cada conector especifica una ruta unidireccional a otro destino.
• Información de estado de los vínculos Información acerca de grupos de enrutamiento, conectores y sus configuraciones que el enrutamiento utiliza para determinar la ruta de entrega más eficiente para un mensaje.
• Componentes del enrutamiento interno Los componentes del enrutamiento interno, en particular el motor de enrutamiento, que proporcionan y actualizan la topología de enrutamiento para los servidores de Exchange de su organización. Para obtener más información acerca de los componentes del enrutamiento interno, consulte Descripción de los componentes internos del transporte.
Principio de la página Descripción de los grupos de enrutamiento En su estado predeterminado, Exchange Server 2003, como Exchange 2000 Server, funciona como si todos los servidores de una organización formasen parte de un único grupo de enrutamiento grande. Por lo tanto, cualquier servidor de Exchange puede enviar correo directamente a cualquier otro servidor de Exchange de la organización. Sin embargo, en aquellos entornos con necesidades administrativas especiales, una distribución geográfica y conectividad de red variable, puede aumentar la eficacia del flujo de mensajes si se crean grupos de enrutamiento y conectores de grupos de enrutamiento según la infraestructura de red y los requisitos administrativos. Al crear grupos de enrutamiento y conectores de grupo de enrutamiento, los servidores de un grupo de enrutamiento siguen enviándose mensajes directamente entre sí, pero utilizan el conector de grupo de enrutamiento de esos servidores con la mejor conectividad de red para comunicarse con servidores de otro grupo.
Para obtener más información acerca de la creación de grupos de enrutamiento y las consideraciones necesarias, consulte Situaciones de implementación para la conectividad con Internet.
Uso de grupos de enrutamiento en los modos nativo o mixto En Exchange Server 2003 y Exchange 2000 Server, las funciones administrativas y de enrutamiento se dividen en unidades distintas:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
• Los grupos administrativos definen los límites administrativos lógicos para los servidores de Exchange.
• Los grupos de enrutamiento definen las rutas físicas por las que se transmiten los mensajes a través de la red.
Si su organización de Exchange funciona en modo nativo, donde todos los servidores ejecutan Exchange 2000 Server o posterior, esta división entre grupos administrativos y grupos de enrutamiento permite crear grupos de enrutamiento que abarquen varios grupos administrativos y mover servidores entre grupos de enrutamiento que se encuentren en grupos administrativos distintos. Esta funcionalidad también le permite separar las funciones de enrutamiento y de administración. Por ejemplo, puede administrar servidores de dos grupos administrativos centrales si sitúa los servidores de cada grupo administrativo en grupos de enrutamiento distintos, en función de la topología de la red y de los requisitos de uso.
Sin embargo, la funcionalidad de los grupos de enrutamiento en un entorno de modo mixto, donde algunos servidores ejecutan Exchange Server 2003 o Exchange 2000 Server mientras otros ejecutan Exchange Server 5.5, es distinta de la del modo nativo. En modo mixto:
• No puede tener un grupo de enrutamiento que abarque varios grupos administrativos.
• No se pueden mover servidores entre grupos de enrutamiento que se encuentren en grupos administrativos diferentes.
Esta situación se da porque la topología de enrutamiento de Exchange Server 5.5 está definida por sitios; es decir, por combinaciones lógicas de servidores conectados mediante una red confiable con un ancho de banda elevado. Los sitios proporcionan la funcionalidad tanto del grupo administrativo como del grupo de enrutamiento en Exchange Server 2003 y Exchange 2000 Server. Esta diferencia en la topología de enrutamiento limita la funcionalidad de los grupos de enrutamiento en un entorno en modo mixto.
Principio de la página Descripción de los conectores Los conectores proporcionan una ruta unidireccional para el flujo de mensajes hasta un destino específico. Los conectores principales de Exchange Server 2003 son los siguientes:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
• Conectores de grupo de enrutamiento Ofrecen una ruta unidireccional a través de la cual se enrutan los mensajes desde los servidores de un grupo de enrutamiento hasta los servidores de otro grupo de enrutamiento diferente. Los conectores de grupo de enrutamiento utilizan una conexión del Protocolo simple de transferencia de correo (SMTP) para permitir la comunicación con los servidores del grupo de enrutamiento conectado. Los conectores de grupo de enrutamiento son el método preferido para conectar grupos de enrutamiento.
• Conectores para SMTP Se utilizan para definir rutas aisladas para el correo destinado a Internet o a una dirección externa, o a un sistema de correo distinto de Exchange. No se recomienda ni se prefiere el uso del conector para SMTP con el fin de conectar grupos de enrutamiento. Los conectores para SMTP están diseñados para la entrega de correo externo.
• Conectores para X.400 Están diseñados principalmente para conectar servidores de Exchange con otros sistemas X.400 o servidores de Exchange Server 5.5 que no pertenecen a la organización de Exchange. Así, un servidor de Exchange Server 2003 puede enviar mensajes con el protocolo X.400 a través de este conector. Importante:Los conectores para X.400 sólo están disponibles en Exchange Server 2003 Enterprise Edition.
Cada conector tiene asociado un costo y un espacio de direcciones o un grupo de enrutamiento conectado que está designado como punto de destino del conector. A la hora de determinar la ruta más eficiente para un mensaje, la lógica de enrutamiento de Exchange examina primero el espacio de direcciones o el grupo de enrutamiento conectado definido en cada conector para buscar el destino que mejor coincida con el destino del mensaje y, después, el enrutamiento evalúa el costo asociado a cada conector. El enrutamiento sólo utiliza los costos cuando el espacio de direcciones definido o los grupos de enrutamiento conectados son iguales en dos conectores diferentes. En la próxima sección se explica cómo utiliza Exchange esta información.
Principio de la página Descripción de la información del estado de los vínculos Exchange Server 5.5 utilizaba una Tabla de enrutamiento de direcciones de la puerta de enlace (GWART) para determinar la selección de rutas dentro de una organización de Exchange. Este método utiliza un algoritmo de enrutamiento por vector de distancia que puede dar lugar a bucles de enrutamiento en

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
determinadas situaciones. Exchange Server 2003, al igual que Exchange 2000 Server, utiliza un algoritmo de enrutamiento de estado de los vínculos y un protocolo de enrutamiento para propagar la información del estado de los vínculos en forma de una tabla de estado de los vínculos que se almacena en memoria en todos los servidores de Exchange 2000 Server y Exchange Server 2003 de la organización.
Un algoritmo de estado de los vínculos ofrece las siguientes ventajas:
• Cada servidor de Exchange puede seleccionar la ruta óptima de los mensajes en el origen, en lugar de enviar mensajes por una ruta en la que un vínculo (o una ruta) no está disponible.
• Los mensajes ya no van y vuelven entre los servidores porque cada servidor de Exchange tiene información actualizada sobre si hay disponibles rutas alternativas o redundantes.
• Ya no se producen bucles de mensajes.
La tabla del estado de los vínculos contiene información acerca de la topología de enrutamiento de toda la organización de Exchange y de si cada conector dentro de la topología está disponible (activo) o no disponible (inactivo). Además, la tabla del estado de los vínculos contiene los costos y los espacios de direcciones asociados a cada conector disponible. Exchange utiliza esta información para determinar qué ruta tiene el costo menor para la dirección de destino. Si un conector de la ruta con el costo menor no se encuentra disponible, Exchange determina la mejor ruta alternativa basándose en el costo y la disponibilidad de conectores. Entre los grupos de enrutamiento, la información del estado de los vínculos se comunica de forma dinámica mediante el verbo extendido de SMTP X-LINK2STATE.
Uso de la información de estado de los vínculos para la entrega de correo interno Para entender cómo funciona la información del estado de los vínculos y los costos de conectores, considere una topología de enrutamiento, en la que existen cuatro grupos de enrutamiento: Seattle, Bruselas, Londres y Tokio. Existen conectores entre cada grupo de enrutamiento y se les asignan costos según la velocidad de red y el ancho de banda disponible.
Costos y topología de enrutamiento

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Si todas las conexiones entre los grupos de enrutamiento están disponibles, un servidor del grupo de enrutamiento Seattle siempre enviará un mensaje al grupo de enrutamiento Bruselas enviando el mensaje primero a través del grupo de enrutamiento Londres. Esta ruta tiene un costo de 20 y es la ruta con el menor costo disponible. Pero si el servidor cabeza de puente de Londres no está disponible, los mensajes cuyo origen sea Seattle y el destino sea Bruselas viajarán a través del grupo de enrutamiento Tokio, que tiene un costo mayor de 35.
Hay que comprender un concepto importante y es que para que un conector se marque como no disponible, todos los servidores cabeza de puente para ese conector deben estar inactivos. Si ha configurado el conector del grupo de enrutamiento para utilizar la opción predeterminada Cualquier servidor local puede enviar correo por este conector, se considerará que el conector del grupo de enrutamiento siempre está en servicio. Para obtener más información acerca de cómo configurar conectores de grupo de enrutamiento, consulte “Conexión de grupos de enrutamiento” en Definición de grupos de enrutamiento.
Uso de la información de estado de los vínculos para la entrega de correo externo Para la entrega de correo externo, el enrutamiento utiliza la información de la tabla de estado de los vínculos para evaluar primero el conector que tiene el espacio de direcciones que se corresponda mejor con el destino y, después, evalúa el costo. El siguiente diagrama ilustra una empresa con la topología siguiente:
• Un conector para SMTP con un espacio de direcciones *.net y un costo de 20.
• Un conector para SMTP con un espacio de direcciones *, que engloba todas las direcciones externas y tiene un costo de 10.
Cómo utiliza Exchange el espacio de direcciones para enrutar correo
En esta topología, cuando se envía correo a un usuario externo cuya dirección de correo electrónico es [email protected], el enrutamiento busca primero un conector cuyo espacio de direcciones coincida mejor con el destino de treyresearch.net. El conector para SMTP que tiene el espacio de direcciones *.net es el que mejor coincide con el destino, por lo que el enrutamiento utiliza este conector, independientemente de su costo.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Sin embargo, si se envía correo a un usuario cuya dirección es [email protected], el enrutamiento utilizará el conector para SMTP cuyo espacio de direcciones sea * porque es el que mejor coincide. El enrutamiento no evalúa el costo. Si existen dos conectores para SMTP y ambos tienen un espacio de direcciones * pero cada uno tiene un costo diferente, el enrutamiento utilizará la información de la tabla de estado de los vínculos y seleccionará el conector para SMTP que tenga el menor costo. El enrutamiento sólo utiliza el conector de mayor costo si el conector de menor costo no está disponible.
El enrutamiento no conmuta por error desde un conector que tiene un espacio de direcciones específico a un conector que tiene un espacio de direcciones menos específico. En el caso anterior, si todos los usuarios pueden emplear ambos conectores y un usuario intenta enviar correo a un usuario de treyresearch.net, el enrutamiento ve como su destino el conector que tiene el espacio de direcciones .net. Si este conector no está en servicio o no está disponible, el enrutamiento no intentará buscar un conector con un espacio de direcciones diferente y menos restrictivo como *, ya que lo considerará otro destino distinto.
Sin embargo, en esta misma topología, suponga que existen restricciones en el conector que tiene el espacio de direcciones *.net y la restricción sólo permite que los usuarios del departamento de ventas envíen correo a través de este conector. En este caso, si este conector no está en servicio, el enrutamiento no volverá a enrutar el correo enviado por un usuario del departamento de ventas que vaya destinado a una dirección .net a través del conector que tiene la dirección *. Las colas de correo hasta el conector que tiene la dirección *.net estarán disponibles. Sin embargo, los usuarios que no sean del departamento de ventas nunca se verán afectados cuando este conector no esté disponible, ya que su correo siempre se enruta a través del conector para SMTP que tiene el espacio de direcciones *.
1.3.2 Operaciones Básicas Router
Un router (en español: enrutador o encaminador) es un dispositivo hardware o software de interconexión de redes de computadoras que opera en la capa tres (nivel de red) del modelo OSI. Este dispositivo interconecta segmentos de red o redes enteras. Hace pasar paquetes de datos entre redes tomando como base la información de la capa de red.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
El router toma decisiones lógicas con respecto a la mejor ruta para el envío de datos a través de una red interconectada y luego dirige los paquetes hacia el segmento y el puerto de salida adecuados. Sus decisiones se basan en diversos parámetros. Una de las más importantes es decidir la dirección de la red hacia la que va destinado el paquete (En el caso del protocolo IP esta sería la dirección IP). Otras decisiones son la carga de tráfico de red en las distintas interfaces de red del router y establecer la velocidad de cada uno de ellos, dependiendo del protocolo que se utilice.
1.3.3 Rutas Estáticas y Dinámicas
Rutas estáticas:Las rutas estáticas con aquellas que son puestas a mano o que vienen puestas por defecto y que no tienen ninguna reacción ante nuevas rutas o caídas de tramos de la red.Son las habituales en sistemas cliente; o en redes donde solo se sale a Internet.
La configuración de las rutas estáticas se realiza a través del comando de configuración global de IOS ip route. El comando utiliza varios parámetros, entre los que se incluyen la dirección de red y la máscara de red asociada, así como información acerca del lugar al que deberían enviarse los paquetes destinados para dicha red.
La información de destino puede adoptar una de las siguientes formas:
Una dirección IP específica del siguiente router de la ruta.La dirección de red de otra ruta de la tabla de enrutamiento a la que deben reenviarse los paquetes.Una interfaz conectada directamente en la que se encuentra la red de destino.Router(config)#ip route[dirección IP de la red destino+máscara][IP del primer salto/interfaz de salida][distancia administrativa]
Donde:dirección IP de la red destino+máscara hace referencia a la red a la que se pretende tener acceso y su correspondiente mascara de red o subred. Si el destino es un host específico se debe identificar la red a la que pertenece dicho host.
IP del primer salto/interfaz de salida Se bebe elegir entre configurar la IP del próximo salto (hace referencia a la dirección IP de la interfaz del siguiente

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
router) o el nombre de la interfaz del propio router por donde saldrán los paquetes hacia el destino. Por ejemplo si el administrador no conoce o tiene dudas acerca del próximo salto utilizara su propia interfaz de salida, de lo contrario es conveniente hacerlo con la IP del próximo salto.
distancia administrativa parámetro opcional (de 1 a 255) que si no se configura será igual a 1. Este valor hará que si existen más rutas estáticas o protocolos de enrutamiento configurados en el router cada uno de estos tendrá mayor o menor importancia según sea el valor de su distancia administrativa. Cuanto mas baja, mayor importancia
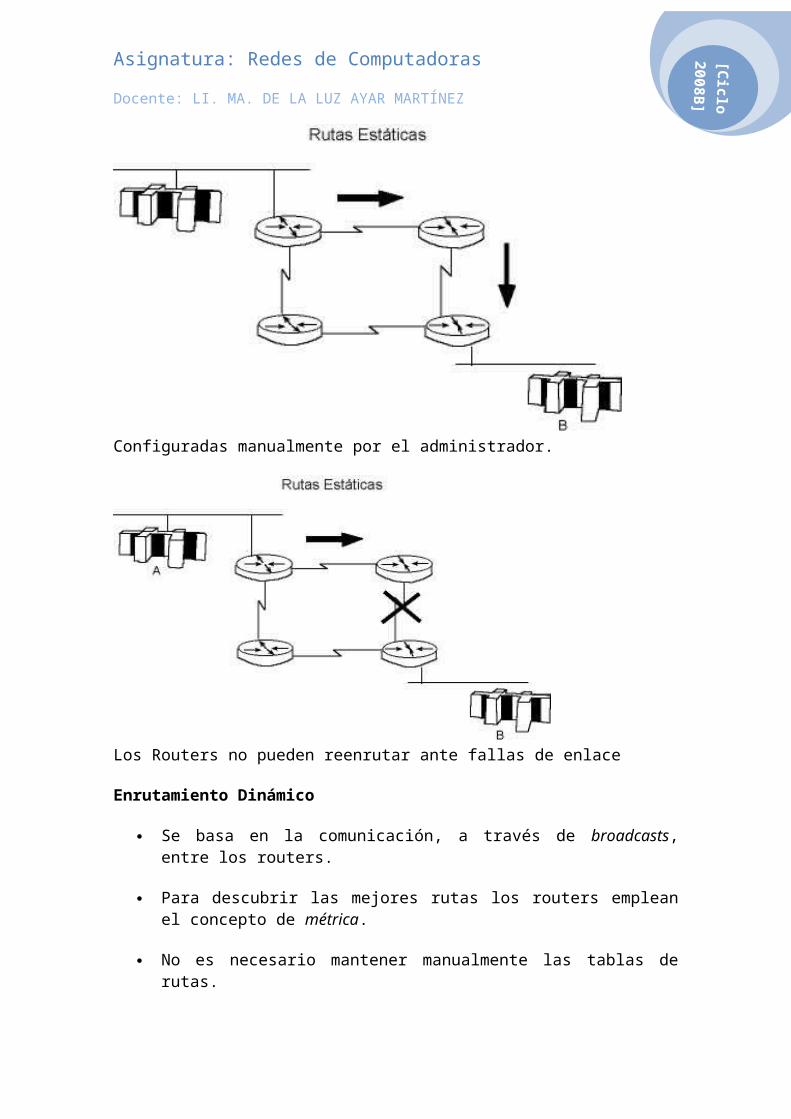
Rutas Estáticas
Permiten la configuración manual de las tablas de enrutamiento.
Las tablas no podrán ser modificadas en forma dinámica
Falta de flexibilidad frente a fallas de los enlaces
No son necesarios las cargas y procesos asociados a un protocolo de descubrimiento de rutas.
Es fácil establecer barreras de seguridad bajo este modelo.
Configuradas manualmente por el administrador.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Los Routers no pueden reenrutar ante fallas de enlace
Enrutamiento Dinámico
Se basa en la comunicación, a través de broadcasts, entre los routers.
Para descubrir las mejores rutas los routers emplean el concepto de métrica.
No es necesario mantener manualmente las tablas de rutas.
El sistema se vuelve más flexible y autónomo frente a caídas de los enlaces
- Los roturers utilizan un protocolo común
Se basan en métricas para la selección de rutas

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Ruteo por estado de enlace
Cada nodo es responsable de aprender todo lo posible acerca de sus vecinos y colocarlo en un LSP (Link State Packet)
Este LSP es enviado a todos los otros nodos.
Usando los LSP de los otros nodos se establece un mapa de la topología
Una vez completo el mapa se utiliza un algoritmo Dijsktra para encontrar la mejor ruta
Ruteo por vector - distancia
Conocido como algoritmo Bellman - Ford
Cada nodo mantiene una tabla con las distancias entre el mismo y los rout era más cercanos
Las distancias son calculadas en base a lo que los otros le cuenten
Redes bajo administración común.
Determinan la mejor ruta en forma dinámica
Protocolo de Enrutamiento Interior
RIP
IGRP
OSPF
RIP (Routing Information Protocol)
Especificado en el RFC 1058
Se basa en la filosofía de vector - distancia

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Utiliza como métrica el concepto de salto (hop)
El número máximo de saltos permitidos es 15
Se actualiza cada 30 segundos
IGRP (Interior Gatway Routing Protocol)
Desarrollado por CISCO
Se basa en la filosofía de vector - distancia
Utiliza una mezcla de criterios para determinar la métrica
Ancho de banda del canal
Retardos
Carga
Confiabilidad
Se actualiza cada 90 segundos
OSPF (Open Shortest Path First)
Especificado en el RFC 1131 y en el RFC 1247
Se basa en la filosofía de estado del enlace
Utiliza el concepto de costo para determinar la métrica
Diseñado para ser usado en un único sistema autónomo
Protocolo de Búsqueda Exteriores
EGP (Exterior Gateway Protocol)
BGP (Border Gateway Protocol)
EGP (Exterior Gateway Protocol)
Especificado en los RFC 827 y RFC 904
Rutea en base a los routers vecinos
No utiliza métrica

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Los routers se comunican el estado de los enlaces
BGP (Border Gateway Protocol)
Especificado en los RFC 1105, RFC 1163 Y RFC 1267
Utiliza conexiones del tipo TCP
Realiza medidas periódicas para determinar las mejores rutas
Ejemplo de Rutas Estáticas
Configuración de Rutas Estáticas
Cisco # conf t
Enter configuration commands, one per line. End with CNTOL/Z
Cisco (config) #ip route130.110.2.0 255.255.255.0 130.110.1.1
Cisco#
% SYS-5-CONFIG_1: Configured from console by console
Cisco#
El comando para configuración de rutas estáticas es:
IP ROUTE dirección - red - destino máscara - red - destino dirección - router distancia
DRD: Es la dirección IP de la red o subred a la cual se quiere alcanzar
MRD: Es la máscara de la DRD

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
DR: Es la dirección IP del router que puede alcanzar dicha red
D: Especifica una métrica adiministrativa
Usando PING (Packet Internet Groper)
Cisco # ping
Protocol (ip):
Target IP address: 150.1.1.2
Repeat count (5):
Datagram size (100):
Timeout in seconds (2):
Extended commands (n):
Sweep range of sizes (n):
Type escape sequence to abort.
Sending 5, 100 - byte ICMP Echos to 150.1.1.2, timeout is 2 seconds:
!!!!!
Success rate is 0 percent (5/5)
Cisco#
Los caracteres de respuesta posible del PING son:
CARÁCTER SIGNIFICADO! Recepción exitosa del paquete. En espera o, paquete murió por timeoutU Destino inalcanzableN Red inalcanzableP Protocolo inalcanzable? Paquete de tipo desconocido
Configurando el Protocolo RIP
Cisco#conf t
[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Enter configuration commands, one per line. End with CNTL/Z.
Cisco (config)# router rip
Cisco (config - router)# network 200.6.40.1
Cisco (config - router)# network 190.4.50.1
Cisco (config - router) # "Z
Cisco#
% SYS-5-CONFIG_1: Configured from console by console
Cisco#
Para intercambiar información usa paquetes UDP (User Datagram Protocol)
Las actualizaciones se realizan cada 30 segundos.
Una ruta es declarada inalcanzable si al cabo de tres periodos (90 seg.) no responde
La ruta es eliminada de la tabla si al cabo de ocho periodos (240 seg.) no responde.
Averiguando Rutas Descubiertas
Cisco# show ip route
Codes: 1 - IGRP derived, R - RIP derived, O - OSPF derived
C - Connected, S - static, E - EGP derived, B - BGP derived
¡ - IS - IS derive, D - EIGRP derived
- candidate default route, IA - OSPF inter area route
E1 - OSPF EXGERNAL UPE 1 route, E2 - OSPF external type 2 route
L1 - IS -IS level -1 route, L2 - IS IS level -2 route
EX - EIGRP external route
Gateway of last resort is not set
C 200.6.40.1 is directly connected, serial 0

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
C 190.4.50.1 is directly connected, serial 1
C 121.120.1.0 is directly connected, tokenring 0
R 140.12.7.0 (120/1) vía 200.6.40.2, 18 sec, serial 0
R 190.1.1.0 (120/1) vía 190.4.50.2, 22 sec, serial 1
Cisco#
Configuración el Protocolo IGRP
Cisco# conf t
Enter configuration commands, one per line. End with CNTL/Z
Cisco (config)# router igrp 1
Cisco (config - router)# network 200.6.40.1
Cisco (config - router)# network 190.4.50.1
Cisco (config - router)# "Z
Cisco#
% SYS - 5 - CONFIG_1: Configured from console by console
Cisco#
Acepta hasta 4 rutas distintas para alcanzar una red cualquiera.
Se actualiza cada 90 segundos.
Una ruta es declarada inalcanzable si al cabo de tres periodos (270 seg.) no responde.
La ruta es eliminada de la tabla si al cabo de siete periodos (630 seg.) no responde
El protocolo realiza balanceo de rutas.
Rutas Descubiertas
Cisco# show ip route
Codes:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
I - IGRP derived, R - RIP DERIVED, O - OSPF derived
C - connected, S - static, E - EGP derived, B - BGP derived
¡ - IS - IS derived, D - EIGRP derived
* - candidate default route, IA - OSPF inter area route
E1 - OSPF external tuype 1 route, L2 - IS - IS level - 2 route
EX - EIGRP external route
Gatway of last resort is not set
C 200.6.40.1 is directly connected, serial 0
C 190.4.50.1 is directly connected, serial 1
C 121.120.1.0 is directly connected, tokenring 0
I 140.12.7.0 (120/1) vía 200.6.40.2, 18 sec, serial 0
I 190.1.1.0 (120/1) vía 190.4.50.2, 22 sec, serial 1
Cisco#
Chequeando Rutas con TRACE
TRACE: destino
El parámetro destino indica la dirección de la red o el nombre del host hacia donde viajan los paquetes que se desean rastrear.
El protocolo pro defecto a rastrear es IP, sin embargo el comando soporta además al ISO, CLNS y VINES.
En caso de que se desee no utilizar los parámetros adicionales por omisión bastará con digitar el comando sin destino, lo cual activará el comando en su versión extendida. En este caso se podrá especificar protocolo, destino, timeouts y otros.
Para interrumpir el proceso TRACE, deberá usarse la secuencia de escape estándar (CTRL",X); la cual se obtiene presionando las teclas (CTRL)+(SHIFT) +(6), soltándolas y presionando a continuación la tecla (X)
Subcomandos de Ruteo Dinámico
(NO) NETWORK identificación de red

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Se debe especificar para cada una de las redes directamente conectadas al router.
El parámetro identificación de red está basado en la notación NIC de IP, no se permite el uso de números de subredes o direcciones individuales.
Este comando es indispensable y mandatorio para cada proceso de enrutamiento IP
La opción NO remueve alguna asignación hecha con anterioridad.
Rutas dinámicas:
Un router con encaminamiento dinámico; es capaz de entender la red y pasar las rutas entre routers vecinos. Con esto quiero decir que es la propia red gracias a los routers con routing dinámico los que al agregar nuevos nodos o perderse algún enlace es capaz de poner/quitar la ruta del nodo en cuestión en la tabla de rutas del resto de la red o de buscar un camino alternativo o más óptimo en caso que fuese posible.
1.3.4 Ruta por Defecto
La “ruta por defecto” se utiliza sólamente cuando no se puede aplicar ninguna de las otras rutas existentes
Cuando el sistema local necesita realizar una conexión con una máquina remota se examina la tabla de rutas para determinar si se conoce algún camino para llegar al destino. Si la máquina remota pertenece a una subred que sabemos cómo alcanzar (rutas clonadas) entonces el sistema comprueba si se puede conectar utilizando dicho camino.
Si todos los caminos conocidos fallan al sistema le queda una única opción: la “ruta por defecto”. Esta ruta está constituída por un tipo especial de pasarela (normalmente el único “router” presente en la red área local) y siempre posée el “flag” c en el campo de “flags”. En una LAN, la pasarela es la máquina que posée conectividad con el resto de las redes (sea a través de un enlace PPP, DSL, cable modem, T1 u otra interfaz de red.)

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Si se configura la ruta por defecto en una máquina que está actuando como pasarela hacia el mundo exterior la ruta por defecto será el “router” que se encuentre en posesión del proveedor de servicios de internet (ISP).
1.3.5 Protocolos Enrutados y de Enrutamiento
PROTOCOLOS ENRUTADOS.-
Funciones: - Incluir cualquier conjunto de protocolos de red que ofrece información suficiente en su dirección de capa para permitir que un Router lo envíe al dispositivo siguiente y finalmente a su destino. - Definir el formato y uso de los campos dentro de un paquete.
El Protocolo Internet (IP) y el intercambio de paquetes de internetworking (IPX) de Novell son ejemplos de protocolos enrutados. Otros ejemplos son DE Cnet, Apple Talk?, Banyan VINES y Xerox Network Systems (XNS).
PROTOCOLOS DE ENRUTAMIENTO.- Los Routers utilizan los protocolos de enrutamiento para intercambiar las tablas de enrutamiento y compartir la información de enrutamiento. En otras palabras, los protocolos de enrutamiento permiten enrutar protocolos enrutados.
Funciones: - Ofrecer procesos para compartir la información de ruta. - Permitir que los Routers se comuniquen con otros Routers para actualizar y mantener las tablas de enrutamiento.
Los ejemplos de protocolos de enrutamiento que admiten el protocolo enrutado IP incluyen: el Protocolo de información de enrutamiento (RIP) y el Protocolo de enrutamiento de Gateway interior (IGRP), el Protocolo primero de la ruta libre más corta (OSPF), el Protocolo de Gateway fronterizo (BGP), y el IGRP mejorado (EIGRP). Los protocolos no enrutables no admiten la Capa 3. El protocolo no enrutable más común es el Net BEUI?. Net Beui? es un protocolo pequeño, veloz y eficiente que está limitado a la entrega de tramas de un segmento.
Los routers guardan la información en una tabla de enrutamiento y la comparten. Intercambian información acerca de la topología de la red mediante los protocolos de enrutamiento. La determinación de la ruta permite que un Router compare la dirección destino con las rutas disponibles en la tabla de enrutamiento, y seleccione la mejor ruta. Si no hay información acerca de una

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
red destino en la tabla de enrutamiento, el router envía el paquete al Gateway predeterminado (ruta por defecto). Los Routers conocen las rutas disponibles por medio del enrutamiento estático o dinámico.
1.3.6 Información Utilizada por Routers para ejecutar sus funciones básicas
Los protocolos de enrutamiento son aquellos protocolos que utilizan los routers o encaminadores para comunicarse entre sí y compartir información que les permita tomar la decisión de cual es la ruta más adecuada en cada momento para enviar un paquete. Los protocolos más usados son RIP (v1 y v2), OSPF (v1, v2 y v3), y BGP (v4), que se encargan de gestionar las rutas de una forma dinámica. aunque no es estrictamente necesario que un router haga uso de estos protocolos, pudiéndosele indicar de forma estática las rutas (caminos a seguir) para las distintas subredes que estén conectadas al dispositivo.
1.3.7 Configuracion de Rip
RIP son las siglas de Routing Information Protocol (Protocolo de información de encaminamiento). Es un protocolo de pasarela interior o IGP (Internal Gateway Protocol) utilizado por los routers (enrutadores), aunque también pueden actuar en equipos, para intercambiar información acerca de redes IP.
Mensajes RIP
Tipos de mensajes RIP
Los mensajes RIP pueden ser de dos tipos.
Petición: Enviados por algún enrutador recientemente iniciado que solicita información de los enrutadores vecinos.
Respuesta: mensajes con la actualización de las tablas de enrutamiento. Existen tres tipos: Mensajes ordinarios: Se envían cada 30 segundos. Para indicar que el enlace y la ruta siguen activos.
Mensajes enviados como respuesta a mensajes de petición.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Mensajes enviados cuando cambia algún coste. Sólo se envían las rutas que han cambiado .
Funcionamiento RIP
RIP utiliza UDP para enviar sus mensajes y el puerto bien conocido 520.
RIP calcula el camino más corto hacia la red de destino usando el algoritmo del vector de distancias. La distancia o métrica está determinada por el número de saltos de router hasta alcanzar la red de destino.
RIP tiene una distancia administrativa de 120 (la distancia administrativa indica el grado de confiabilidad de un protocolo de enrutamiento, por ejemplo EIGRP tiene una distancia administrativa de 90, lo cual indica que a menor valor mejor es el protocolo utilizado)
RIP no es capaz de detectar rutas circulares, por lo que necesita limitar el tamaño de la red a 15 saltos. Cuando la métrica de un destino alcanza el valor de 16, se considera como infinito y el destino es eliminado de la tabla (inalcanzable).
La métrica de un destino se calcula como la métrica comunicada por un vecino más la distancia en alcanzar a ese vecino. Teniendo en cuenta el límite de 15 saltos mencionado anteriormente. Las métricas se actualizan sólo en el caso de que la métrica anunciada más el coste en alcanzar sea estrictamente menor a la almacenada. Sólo se actualizará a una métrica mayor si proviene del enrutador que anunció esa ruta.
1.4 Arp , Rarp
ARP son las siglas en inglés de Address Resolution Protocol (Protocolo de resolución de direcciones).
Es un protocolo de nivel de red responsable de encontrar la dirección hardware (Ethernet MAC) que corresponde a una determinada dirección IP. Para ello se envía un paquete (ARP request) a la dirección de multidifusión de la red (broadcast (MAC = ff ff ff ff ff ff)) conteniendo la dirección IP por la que se pregunta, y se espera a que esa máquina (u otra) responda (ARP reply) con la dirección Ethernet que le corresponde. Cada máquina mantiene una caché con las direcciones traducidas para reducir el retardo y la carga. ARP permite a la

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
dirección de Internet ser independiente de la dirección Ethernet, pero esto solo funciona si todas las máquinas lo soportan.
ARP está documentado en el RFC (Request For Comments) 826.
El protocolo RARP realiza la operación inversa.
En Ethernet, la capa de enlace trabaja con direcciones físicas. El protocolo ARP se encarga de traducir las direcciones IP a direcciones MAC (direcciones físicas).Para realizar ésta conversión, el nivel de enlace utiliza las tablas ARP, cada interfaz tiene tanto una dirección IP como una dirección física MAC.
RARP son las siglas en inglés de Reverse Address Resolution Protocol (Protocolo de resolución de direcciones inverso).
Es un protocolo utilizado para resolver la dirección IP de una dirección hardware dada (como una dirección Ethernet). La principal limitación era que cada MAC tenía que ser configurada manualmente en un servidor central y se limitaba solo a la dirección IP, dejando otros datos como la máscara de subred, puerta de enlace y demás información que tenían que ser configurados a mano. Otra desventaja de este protocolo es que utiliza como dirección destino, evidentemente, una dirección MAC de difusión para llegar al servidor RARP. Sin embargo, una petición de ese tipo no es reenviada por el router del segmento de subred local fuera de la misma, por lo que este protocolo, para su correcto funcionamiento, requiere de un servidor RARP en cada subred.
Posteriormente el uso de BOOTP lo dejó obsoleto, ya que éste ya funciona con paquetes UDP, los cuales se reenvían a través de los routers (eliminando la necesidad de disponer de un servidor BOOTP en cada subred) y, además, BOOTP ya tiene un conjunto de funciones mayor que permite obtener más información y no sólo la dirección IP.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
1.5 Igrp , Egp
IGRP (Interior Gateway Routing Protocol, o Protocolo de enrutamiento de gateway interior) es un protocolo patentado y desarrollado por CISCO que se emplea con el protocolo TCP/IP según el modelo (OSI) Internet. La versión original del IP fue diseñada y desplegada con éxito en 1986. Se utiliza comúnmente como IGP pero también se ha utilizado extensivamente como Exterior Gateway Protocol (EGP) para el enrutamiento inter-dominio.
IGRP es un protocolo de enrutamiento basado en la tecnología vector-distancia. Utiliza una métrica compuesta para determinar la mejor ruta basándose en el ancho de banda, el retardo, la confiabilidad y la carga del enlace. El concepto es que cada router no necesita saber todas las relaciones de ruta/enlace para la red entera. Cada router publica destinos con una distancia correspondiente. Cada router que recibe la información, ajusta la distancia y la propaga a los routers vecinos. La información de la distancia en IGRP se manifiesta de acuerdo a la métrica. Esto permite configurar adecuadamente el equipo para alcanzar las trayectorias más óptimas.
Funcionamiento:
IGRP manda actualizaciones cada 90 segundos, y utiliza un cierto número de factores distintos para determinar la métrica. El ancho de banda es uno de estos factores, y puede ser ajustado según se desee.
IGRP utiliza los siguientes parámetros:
Retraso de Envío: Representa el retraso medio en la red en unidades de 10 microsegundos.
Ancho de Banda (Band Width ? – Bw): Representa la velocidad del enlace, dentro del rango de los 12000 mbps y 10 Gbps. En realidad el valor usado es la inversa del ancho de banda multiplicado por 107.
Fiabilidad: va de 0 a 255, donde 255 es 100% confiable.
Distancia administrativa (Load): toma valores de 0 a 255, para un enlace en particular, en este caso el valor máximo (255) es el pero de los casos.
La fórmula usada para calcular el parámetro de métrica es:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
(K1*Ancho de Banda) + (K2*Ancho de Banda)/(256-Distancia) + (K3*Retraso)*(K5/(Fiabilidad + K4)). EGP (Exterior Gateway Protocol) es un protocolo estándar. Su status es recomendado.
EGP es el protocolo utilizado para el intercambio de información de encaminamiento entre pasarelas exteriores (que no pertenezcan al mismo Sistema Autónomo AS). Las pasarelas EGP sólo pueden retransmitir información de accesibilidad para las redes de su AS. La pasarela debe recoger esta información, habitualmente por medio de un IGP, usado para intercambiar información entre pasarelas del mismo AS (ver Figura - La troncal ARPANET).
EGP se basa en el sondeo periódico empleando intercambios de mensajes Hello/I Hear You, para monitorizar la accesibilidad de los vecinos y para sondear si hay solicitudes de actualización. EGP restringe las pasarelas exteriores al permitirles anunciar sólo las redes de destino accesibles en el AS de la pasarela. De esta forma, una pasarela exterior que usa EGP pasa información a sus vecinos EGP pero no anuncia la información de accesibilidad de estos(las pasarelas son vecinos si intercambian información de encaminamiento) fuera del AS. Tiene tres características principales:
A dos routers que intercambian información de ruteo se les llama vecinos exteriores, si pertenecen a dos sistemas autónomos diferentes, y vecinos interiores si pertenecen al mismo sistema autónomo. El protocolo que emplea vecinos exteriores para difundir la información de accesibilidad a otros sistemas autónomos se le conoce como Protocolo de pasarela Exterior (EGP). Un protocolo de rutado exterior está diseñado para el uso entre dos redes bajo el control de dos organizaciones diferentes.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Unidad 2 Capas superiores del modelo OSI
Introducción al modelo OSI
En 1977, la Organización Internacional de Estándares (ISO), integrada por industrias representativas del medio, creó un subcomité para desarrollar estándares de comunicación de datos que promovieran la accesibilidad universal y una interoperabilidad entre productos de diferentes fabricantes.
El resultado de estos esfuerzos es el Modelo de Referencia Interconexión de Sistemas Abiertos (OSI).
El Modelo OSI es un lineamiento funcional para tareas de comunicaciones y, por consiguiente, no especifica un estándar de comunicación para dichas tareas. Sin embargo, muchos estándares y protocolos cumplen con los lineamientos del Modelo OSI.
Como se mencionó anteriormente, OSI nace de la necesidad de uniformizar los elementos que participan en la solución del problema de comunicación entre equipos de cómputo de diferentes fabricantes.
Estos equipos presentan diferencias en:
Procesador Central. Velocidad. Memoria. Dispositivos de Almacenamiento. Interfaces para Comunicaciones. Códigos de caracteres. Sistemas Operativos.
Estas diferencias propician que el problema de comunicación entre computadoras no tenga una solución simple.
Dividiendo el problema general de la comunicación, en problemas específicos, facilitamos la obtención de una solución a dicho problema.
Esta estrategia establece dos importantes beneficios: Mayor comprensión del problema.
La solución de cada problema especifico puede ser optimizada individualmente. Este modelo persigue un objetivo claro y bien definido:
Formalizar los diferentes niveles de interacción para la conexión de computadoras habilitando así la comunicación del sistema de cómputo independientemente del:
Fabricante. Arquitectura. Localización. Sistema Operativo.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Este objetivo tiene las siguientes aplicaciones: Obtener un modelo de referencia estructurado en varios niveles en los que se contemple desde el concepto BIT hasta el concepto APLIACION.
Desarrollar un modelo en el cual cada nivel define un protocolo que realiza funciones especificas diseñadas para atender el protocolo de la capa superior.
No especificar detalles de cada protocolo.
Especificar la forma de diseñar familias de protocolos, esto es, definir las funciones que debe realizar cada capa.
Estructura del Modelo OSI de ISOEl objetivo perseguido por OSI establece una estructura que presenta las siguientes particularidades:
Estructura multinivel: Se diseñó una estructura multinivel con la idea de que cada nivel se dedique a resolver una parte del problema de comunicación. Esto es, cada nivel ejecuta funciones especificas.
El nivel superior utiliza los servicios de los niveles inferiores: Cada nivel se comunica con su similar en otras computadoras, pero debe hacerlo enviando un mensaje a través de los niveles inferiores en la misma computadora. La comunicación internivel está bien definida. El nivel N utiliza los servicios del nivel N-1 y proporciona servicios al nivel N+1.
Puntos de acceso: Entre los diferentes niveles existen interfaces llamadas "puntos de acceso" a los servicios.
Dependencias de Niveles: Cada nivel es dependiente del nivel inferior y también del superior.
Encabezados: En cada nivel, se incorpora al mensaje un formato de control. Este elemento de control permite que un nivel en la computadora receptora se entere de que su similar en la computadora emisora esta enviándole información. Cualquier nivel dado, puede incorporar un encabezado al mensaje. Por esta razón, se considera que un mensaje esta constituido de dos partes: Encabezado e Información. Entonces, la incorporación de encabezados es necesaria aunque representa un lote extra de información, lo que implica que un mensaje corto pueda ser voluminoso. Sin embargo, como la computadora destino retira los encabezados en orden inverso a como fueron incorporados en la computadora origen, finalmente el usuario sólo recibe el mensaje original.
Unidades de información: En cada nivel, la unidad de información tiene diferente nombre y estructura :

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
2.1 Capa Transporte Osi
La capa transporte es el cuarto nivel del modelo OSI encargado de la transferencia libre de errores de los datos entre el emisor y el receptor, aunque no estén directamente conectados, así como de mantener el flujo de la red. Es la base de toda la jerarquía de protocolo. La tarea de esta capa es proporcionar un transporte de datos confiable y económico de la máquina de origen a la máquina destino, independientemente de la red de redes física en uno. Sin la capa transporte, el concepto total de los protocolos en capas tendría poco sentido.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
2.1.1 Parámetros para lograr la calidad en el servicio de transporte.
Retardo de Establecimiento de Conexión
Tiempo que transcurre entre la solicitud de una conexión y la confirmación del usuario
Probabilidad de falla de establecimiento de Conexión
Posibilidad de que una conexión no se establezca en un lapso máximo de tiempo.
Rendimiento Mide la cantidad de bytes de datos transferidos pos segundo
Retardo de tránsito Mide el tiempo entre el envío de un mensaje y su recepción por el destino.
Tasa de errores residual
Mide la cantidad de mensajes perdidos o alterados como una fracción del total enviado.
Protección Mecanismo por el cual el usuario indique su interés en que la capa de transporte, proporcione protección contra terceros no autorizados
Prioridad Mecanismo para que un usuario indique que conexiones son más importantes.
Tenacidad Probabilidad de que la capa de transporte termine por si misma una transmisión debido a problemas interno o congestionamiento.
2.1.1.1 Servicios orientados a la conexión.
Un servicio de conexión orientado se caracteriza por la iniciación de la conexión previa al envío y/o a la recepción de información entre capas iguales. Una vez iniciada la conexión ambas capas pueden comenzar a enviar y/o recibir los datos de la aplicación. Un servicio de conexión orientado es diseñado para corregir errores que pueden ocurrir durante el envío y/o recepción de datos, como también es diseñado para controlar el flujo de envío y recepción de datos.
2.1.1.2 Servicios orientados a no conexión
Un servicio de conexión no orientado se caracteriza por el envío y recepción de datos sin la previa iniciación de la conexión entre capas iguales. Es un servicio que no está diseñado para corregir errores que puedan ocurrir durante el envío y/o recepción de datos ya que este tipo de servicio es utilizado cuando la probabilidad de error durante en el envío y/o recepción de datos es prácticamente nula. Tampoco está diseñado para controlar el flujo de envío y recepción de datos.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
2.2 Capa de sesión.
Definición 1: Permite a los usuarios de diferentes maquinas de una red establecersesiones entre ellos. A través de una sesion se puede llevar a cabo un transportede datos ordinario, aunque esta capa se diferencia de la de transporte en losservicos que proporciona.
Definición 2: La capa de sesión permite que los usuarios de diferentes maquinas puedan establecer sesiones entre ellos. A través de una sesión se puede llevar a cabo un transporte de datos ordinario, tal y como lo hace la capa de transporte, pero mejorando los servicios que esta proporciona y que se utilizan en algunas aplicaciones.
Una sesión podría permitir al usuario acceder a un sistema de tiempo compartido a distancia, o transferir un archivo a distancia.
Estas son las operaciones de la capa de sesión.
Una comunicación en la red tiene dos tipos. Con conexión lógica (conection oriented, como el TCP) o sin conexión lógica entre los nodos (conection less como el UDP).
En la comunicación con conexión primero se establece un conexión lógica (una serie de mensages se envian para saber primero si es que podemos establecer la comunicación entre los nodos).

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Una vez que la comunicación ha sido establecida, entonces los datos fluyen entre los dos destinos de la red.
Cuando la comunicación ya no es necesaria entonces la conexión se libera.
Este tipo de comunicación nos da la certidumbre de que el nodo remoto nos esta oyendo, aunque se pierde un tiempo y procesamiento en establecr y liberar la conexión entre dos nodos.
Noten que en las gráficas solo se ven dos nodos aydacentes, los nodos pueden ser parte de una red y tener muchos nodos entre ellos, sin embargo en este nivel esos nodos son irrelevantes. esta es una de las características de el modelo de referencia OSI, A cierto nivel solo se ve lo relevante, lo que esta abajo se toma por hecho que existe y no es necesario ni siquiera el mencionarlo.
En la comunicación sin conexión solamente enviamos los datos al nodo remoto y no sabemos a ciencia cierta si el nodo nos escucha o no, sin embargo se ahorra tiempo y procesamiento por que no necesitamos establecer ni leberar conexiones. este tipo de comuniacaciónes es muy usado en las redes que son muy confiables (Como la red de señalización telefónica C7)
* Funciones esencialeso Esta encargada de proporcionar sincronización y gestion de testigos.o Establece, administra y finaliza las sesiones entre dos host que se estancomunicando.o Restaura la sesión a partir de un punto seguro y sin perdida de datos.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
o Sincroniza el dialogo entre las capas de presentación de los host yadministra su intercambio de datos.o Sincroniza el dialogo entre las capas de presentación de los host yadministra su intercambio de datos.o Ofrece disposiciones para una eficiente transferencia de datos.o Manejar tokenso Hacer checkpoints.o Cronometra y controla el flujo.o Coordina el intercambio de información entre sistemas mediante técnicasde conversación o diálogos.o Puede ser usada para efectuar un login a un sistema de tiempo compartidoremoto.o Permite que los usuarios de diferentes maquinas puedan establecersesiones entre ellos.
2.2.1 Intercambio de datos.
2.2.2 Administración del dialogo.
El nivel de sesión se dedica a establecer, finalizar y gestionar las sesiones de diferentes máquinas. Una sesión es el diálogo entre dos o más entidades.
Estandariza el proceso de establecimiento y terminación de una sesión, si por algún motivo esta sesión falla este restaura la sesión sin perdida de datos o si esto no es posible termina la sesión de una manera ordenada chequeando y recuperando todas sus funciones. Establece las reglas o protocolos para el dialogo entre maquinas y así poder regular quien habla y por cuanto tiempo o si hablan en forma alterna es decir las reglas del dialogo que son acordadas. Provee mecanismos para organizar y estructurar diálogos entre procesos de aplicación. Actúa como un elemento moderador capaz de coordinar y controlar el intercambio de los datos. Controla la integridad y el flujo de los datos en ambos sentidos. Algunas de las funciones que realiza son las siguientes:
- Establecimiento de la conexión de sesión. - Intercambio de datos. - Liberación de la conexión de sesión. - Sincronización de la sesión. - Administración de la sesión. - Permite a usuarios en diferentes máquinas establecer una sesión. - Una sesión puede ser usada para efectuar un login a un sistema de tiempo compartido remoto, para transferir un archivo entre 2 máquinas, etc. - Controla el diálogo (quién habla, cuándo, cuánto tiempo, half duplex o full duplex). - Función de sincronización.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
2.2.3 Sincronización.
En una platica de chat o en una red. Explicarla
2.2.4 Notificación de excepciones.
Una excepción se puede dar por ejemplo en un correo.
2.2.5 Llamada a procedimientos remotos.
RPCLlamada a procedimiento remoto (Remote Procedure Call)Birrell y Nelson (1984)Intentar que los programas puedan llamar a procedimientoslocalizados en otras máquinas• De manera similar a como se hace una llamada a procedimientolocal• Proporciona transparencia de distribuciónCuando un proceso en una máquina A llama a unprocedimiento en la máquina B:• El proceso que realiza la llamada desde A se suspende• La ejecución del procedimiento se realiza en B• La información se puede pasar de un proceso a otro comoparámetros, y regresar como resultado del procedimiento• El programador no se preocupa de la transferencia deMensajes
Problemas que resuelve:Ambos procesos están en espacios de direcciones distintosTransferencia de parámetros y resultadosHeterogeneidad• Qué pasa si las dos máquinas tienen arquitecturas distintasFiabilidad• Qué pasa si hay fallos en alguna de las máquinas• Qué pasa si hay fallos en el canal de comunicacionesLocalización y selección de serviciosSeguridad

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
2.3 Capa de presentación
Es generalmente un protocolo de paso de la información desde las capasadyacentes y permite la comunicación entre las aplicaciones en distintos sistemasinformáticos de manera tal que resulte transparente para las aplicaciones, seocupa del formato y la representación de los datos y, si es necesario, esta capapuede traducir entre distintos formatos de datos. Además, también se ocupa de lasestructuras de los datos que se utilizan en cada aplicación, aprenderá cómo estacapa ordena y organiza los datos antes de su transferencia.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
2.3.1 Códigos de representación de los datos.
Representación de datos
Para entender la manera en que las computadoras procesan datos,
es importante conocer cómo la computadora representa los datos.
Las personas se comunican a través del habla combinando palabras
en oraciones. El habla humana es análoga porque utiliza señales
continuas que varían en fortaleza y calidad. Las computadoras son
digitales, pues reconocen solo dos estados: encendido (on) y
apagado (off). Esto es así porque las computadoras son equipos
electrónicos que utilizan electricidad, que también tiene solo dos
estados: on y off. Los dos dígitos 0 y 1 pueden fácilmente representar
estos dos estados. El dígito cero representa el estado electrónico
apagado (la ausencia de carga electrónica). El dígito uno representa
el estado electrónico encendido (presencia de carga electrónica).
El
sistema binario es un sistema numérico que tiene tan solo dos
dígitos, 0 y 1, llamados bits. Un bit (binary digit) es la unidad de datos
más pequeña que la computadora puede representar. Por sí solo, un
bit no es muy informativo. Cuando ocho bits se agrupan como una
unidad, forman un byte. El byte es informativo porque provee
suficientes combinaciones diferentes de 0 y 1 para representar 256

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
caracteres individuales. Esos caracteres incluyen números, letras
mayúsculas y minúsculas, signos de puntuación y otros.
Las combinaciones de 0 y 1 que representan caracteres son definidas
por patrones llamados esquemas de códigos (coding scheme).
Esquemas de códigos populares son:
1. ASCII – American Standard Code for
information Interchange – es el sistema de
código para representar datos que más se
utiliza. La mayoría de las computadoras
personales y servidores mid-range utilizan el
esquema de código ASCII.
2. EBCDIC – Extended Binary Coded Decimal
Interchange Code – es utilizado
principalmente en computadoras mainframe.
3. Unicode – es el único esquema de código
capaz de representar todos los lenguajes del
mundo actual. Se desarrolló precisamente
porque el ASCII y el EBCDIC no eran
suficientes para representar lenguajes para
alfabetos diferentes al inglés o Europeo, como
los asiáticos y otros.
2.3.2 Técnicas de compresión de datos.
La compresión de datos se define como el proceso de reducir la cantidad de datos necesarios para representar eficazmente una información, es decir, la eliminación de datos redundantes. En el caso de las imágenes, existen tres maneras de reducir el número de datos redundantes: eliminar código redundante, eliminar píxeles redundantes y eliminar redundancia visual.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
CÓDIGO REDUNDANTE
El código de una imagen representa el cuerpo de la información mediante un conjunto de símbolos. La eliminación del código redundante consiste en utilizar el menor número de símbolos para representar la información.
Las técnicas de compresión por codificación de Huffman y codificación aritmética utilizan cálculos estadísticos para lograr eliminar este tipo de redundancia y reducir la ocupación original de los datos.
PIXELES REDUNDANTES
La mayoria de las imágenes presentan semejanzas o correlaciones entre sus píxeles. Estas correlaciones se deben a la existencia de estructuras similares en las imágenes, puesto que no son completamente aleatorias. De esta manera, el valor de un píxel puede emplearse para predecir el de sus vecinos.
Las técnicas de compresión Lempel-Ziv implementan algoritmos basados en sustituciones para lograr la eliminación de esta redundancia.
REDUNDANCIA VISUAL
El ojo humano responde con diferente sensibilidad a la información visual que recibe. La información a la que es menos sensible se puede descartar sin afectar a la percepción de la imagen. Se suprime así lo que se conoce como redundancia visual.
La eliminación de la redundancia esta relacionada con la cuantificación de la información, lo que conlleva una pérdida de información irreversible. Técnicas de compresión como JPEG, EZW o SPIHT hacen uso de la cuantificación.
CLASIFICACIÓN Los métodos de compresión se pueden agrupar en dos grandes clases:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
métodos de compresión sin pérdida de información y métodos con pérdida de información.
LOSSLESS
Los métodos de compresión sin pérdida de información (lossless) se caracterizan porque la tasa de compresión que proporcionan está limitada por la entropía (redundancia de datos) de la señal original. Entre estas técnicas destacan las que emplean métodos estadísticos, basados en la teoría de Shannon, que permite la compresión sin pérdida. Por ejemplo: codificación de Huffman, codificación aritmética y Lempel-Ziv. Son métodos idóneos para la compresión dura de archivos.
LOSSY
Los métodos de compresión con pérdida de información (lossy) logran alcanzar unas tasas de compresión más elevadas a costa de sufrir una pérdida de información sobre la imagen original. Por ejemplo: JPEG, compresión fractal, EZW, SPIHT, etc. Para la compresión de imágenes se emplean métodos lossy, ya que se busca alcanzar una tasa de compresión considerable, pero que se adapte a la calidad deseada que la aplicación exige sobre la imagen objeto de compresión.
2.3.3 Criptografía.
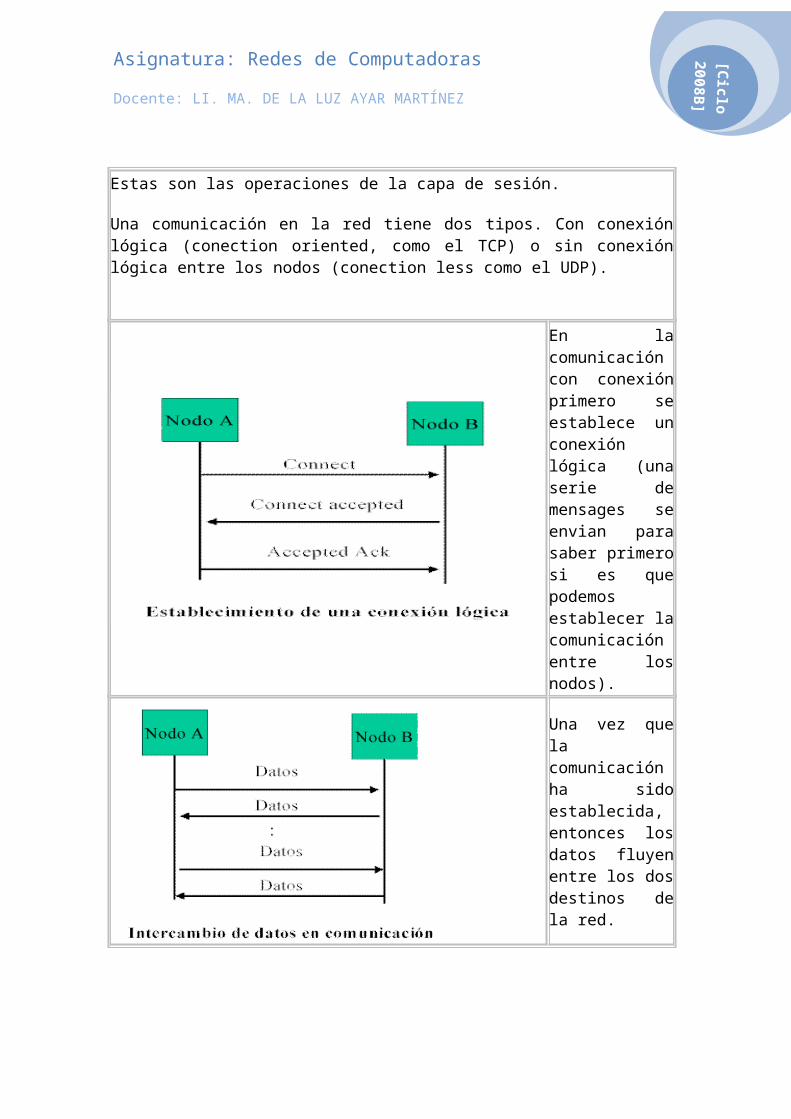
[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Ver presentación…………….
2.4 Capa de aplicación.
Contiene toda la lógica necesaria para llevar a cabo las aplicaciones deusuario. Para cada tipo específico de aplicación, como es por ejemplo latransferencia de un fichero, se necesitará un módulo particular dentro de estacapa; brinda servicios de red a las aplicaciones del usuario
* Procesos de aplicaciónla capa de aplicación soporta el componente de comunicación de unaaplicación. La capa de aplicación es responsable por lo siguiente:* Identificar y establecer la disponibilidad de los socios de la comunicacióndeseada* Sincronizar las aplicaciones* Establecer acuerdos con respecto a los procedimientos para larecuperación de errores* Controlar la integridad de los datos
* Aplicaciones de red directasLa mayoría de las aplicaciones que operan en un entorno de red se clasifican como aplicaciones cliente/servidor. Estas tienen todas dos componentes que les permiten operar: el lado del cliente y el lado del servidor. El lado del cliente se encuentra ubicado en el computador local y es el que solicita los servicios. El lado del servidor se encuentra ubicado en un computador remoto y brindaservicios en respuesta al pedido del cliente. Una aplicación cliente/servidor funciona mediante la repetición constante de la siguiente rutina cíclica: petición del cliente, respuesta del servidor; petición delcliente, respuesta del servidor; etc. Por ejemplo, un navegador de Web accede a una página Web solicitando un Localizador de recursos uniforme (URL), el servidor de Web responde a la petición. Posteriormente, tomando como base la Capas de Sesión, Presentación y Aplicación
* Soporte indirecto de redCorresponde a una función cliente/servidor. Si un cliente desea guardar unarchivo en un servidor de red, el redirector permite que la aplicación se transforme en un cliente de red.El redirector es un protocolo que funciona con los sistemas operativos delos computadoresEl proceso del redirector es el siguiente:1. El cliente solicita que el servidor de archivos de la red permita que losarchivos de datos se puedan guardar.2. El servidor responde guardando el archivo en el disco o rechaza la peticióndel cliente3. Si el cliente solicita que el servidor de impresión de la red permita que losarchivos de datos se impriman en una impresora, procesa la peticiónimprimiendo el archivo o rechaza la petición.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
La ventaja de usar un redirector de red para un cliente local es que lasaplicaciones del cliente nunca tienen que reconocer a la red
* Obtención e interrupción de una conexiónEn los ejemplos anteriores una vez que se ha completado el procesamiento,la conexión se interrumpe y se debe reestablecer para que la siguiente petición de procesamiento se pueda llevar a cabo. Esta es una de las dos maneras en que se produce el proceso de comunicación, pero Telnet y FTP establecen una conexión con el servidor y la mantienen hasta que se haya ejecutado todo el proceso. El computador cliente finaliza la conexión cuando determina que ha finalizado.
2.4.1 Configuración de servicios.
3 Técnicas de conmutación.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
La conmutación es una técnica que nos sirve para hacer un uso eficiente de los enlaces. Si no existiese una técnica de conmutación en la comunicación entre dos nodos, se tendría que enlazar en forma de malla, o sea, de la siguiente forma:
El número de enlaces máximos que pueden darse en este esquema es de n(n-1)/2 enlaces; mientras que con una técnica de conmutación (la primera que surgió fue la conmutación de circuitos) o un conmutador, este esquema se simplificaría de la siguiente forma:
En las redes de telecomunicaciones surgió un problema: existían programas que deseaban conectarse y ejecutar acciones de una computadora al mismo tiempo. Con la técnica de conmutación de circuitos, esto no era posible o no era óptimo. Además, el flujo de la información no es de tipo continuo, es discreto; por ejemplo, una persona puede llegar a escribir hasta 2 caracteres por segundo, y esto para una red de telecomunicaciones es muy lento, considerando que normalmente se transmiten hasta 1,600 caracteres por segundo. Esto comenzó a causar problemas, por lo que pensaron en hacer más eficiente este esquema, así que se pensó en otra técnica de conmutación: la conmutación de mensajes.
Existen tres técnicas de conmutación y son las siguientes:
3.1 Conmutación de circuitos.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Circuitos físicos
Los circuitos físicos son canales de comunicaciones a través de los cuales los usuarios finales que operan terminales y computadoras se comunican entre sí. A estos también se los llama canales, enlaces, líneas y troncales.
Circuitos virtuales
El termino circuito virtual se utiliza para describir el caso en el que un circuito es compartido por más de un usuario pero estos no tienen conocimiento del uso compartido del mismo. El hecho de compartir el circuito implica el uso de alguna técnica de multiplexación, generalmente multiplexación por frecuencia o por tiempo.
Redes de conmutación de circuitos
La comunicación entre dos estaciones utilizando conmutación de circuitos implica la existencia de un camino dedicado entre ambas estaciones. Dicho camino esta constituido por una serie de enlaces entre algunos de los nodos que conforman la red. En cada enlace físico entre nodos, se utiliza un canal lógico para cada conexión. Esto se denomina circuitos virtuales y en un escenario ideal los usuarios del circuito no perciben ninguna diferencia con respecto a un circuito físico y no tienen conocimiento del uso compartido de circuitos físicos.
Una comunicación mediante circuitos conmutados posee tres etapas bien definidas
Establecimiento del circuito
Cuando un usuario quiere obtener servicios de red para establecer una comunicación se deberá establecer un circuito entre la estación de origen y la de destino. En esta etapa dependiendo de la tecnología utilizada se pueden establecer la capacidad del canal y el tipo de servicio.
Transferencia de datos
Una vez que se ha establecido un circuito puede comenzar la transmisión de información. Dependiendo del tipo de redes y del tipo de servicio la transmisión será digital o analógica y el sentido de la misma será unidireccional o full duplex.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Cierre del circuito
Una vez que se ha transmitido todos los datos, una de las estaciones comienza la terminación de la sesión y la desconexión del circuito. Una vez liberado los recursos utilizados por el circuito pueden ser usados por otra comunicación.
En una conmutación por circuitos, la capacidad del canal se reserva al establecer el circuito y se mantiene durante el tiempo que dure la conexión, incluso si no se transmiten datos.
Un caso típico de utilización de conmutación de circuitos es el sistema telefónico original. En donde al realizar una llamada se establecía un circuito, el cual se mantenía hasta la finalización de la comunicación.
3.2 Conmutación de mensajes.
Consiste en lo siguiente: en lugar de tener las líneas dedicadas a un origen y un destino, lo que se va a hacer es que cada mensaje sea conmutado a un circuito. El mensaje va a llegar al conmutador, y el conmutador va a asignar el mensaje a su nodo correspondiente; así podemos tener varios mensajes, pero ¿Cómo reconoce el conmutador qué mensaje corresponde a cada nodo? Pues con una clave o con un identificador de encabezado del nodo destino (un encabezado del mensaje).
3.3 Conmutación de paquetes.
Una ventaja adicional de la conmutación de paquetes (además de la seguridad de transmisión de datos) es de que, como se parte en paquetes el mensaje, éste se está ensamblando de una manera más rápida en el nodo destino, ya que se están usando varios caminos para transmitir el mensaje, produciéndose un fenómeno conocido como "transmisión en paralelo". Además, si un mensaje tuviese un error en un bit de información, y estuviésemos usando la conmutación de mensajes, tendríamos que retransmitir todo el mensaje; mientras que con la conmutación de paquetes solo hay que retransmitir el paquete con el bit afectado, lo cual es mucho menos problemático. Lo único negativo, quizás, en el esquema de la conmutación de paquetes es de que su encabezado es más grande. Así, para la conmutación de paquetes tenemos el tercer caso del datagrama mostrado en la figura anterior.
En síntesis, una red de conmutación de paquetes consiste en una "malla" de interconexiones facilitadas por los servicios de telecomunicaciones, a través de la que los paquetes viajan desde la fuente hasta el destino.
[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Existen servicios de datagramas, en los cuales cada paquete se encamina a través de la red como si fuera una entidad independiente, el camino físico entre los extremos de la conexión puede variar a menudo debido a que los paquetes aprovechan aquellas rutas de menor costo, y evitan las zonas congestionadas. Algunos protocolos de conmutación de paquetes existentes son:
X.25 .- Protocolo normalizado, revisado y probado, ideal para cargas ligeras de tráfico. Las redes de conmutación de paquetes X.25 no son adecuadas para la mayoría del tráfico entre LAN´s por ser lentas y requerir una gran porción de ancho de banda para el tratamiento de errores.
Frame Relay .- Servicio más rápido y eficiente que asume el hecho de que la red este libre de errores, lo que ahorra costosos reconocimientos de errores durante su funcionamiento, como en el caso de X.25.
SMDS .- Servicio Conmutado de Datos Multimegabit ( Switched Multimegabit Data Service ), consiste en un servicio basado en celdas, proporcionado por las compañías regionales de operaciones Bell en algunas zonas escogidas. ( RBOC's - Regional Bell Operational Corp.) SMDS utiliza la conmutación ATM y ofrece servicios tales como facturación basada en la utilización y gestión de red.
Conmutación de Celdas .-
Conocidas como Modo de Transferencia Asíncrona ( ATM - Asyncronous Transfer Mode ), ofrece servicios de conmutación de paquetes rápidos que pueden transmitir a mega o a gigabits por segundo.
Ahora, lo que actualmente se utiliza es la conmutación de celdas, que son paquetes aun más pequeños, pero la conmutación se realiza a nivel hardware, y no de software.
Nombramiento y Direccionamiento

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
En una red se tienen los siguientes elementos necesarios para establecer la conexión y comunicación entre dos computadoras: Nombre, Dirección y Ruta. Para lo cual, se requieren los siguientes elementos básicos:
Procesos Nodos
Dispositivos
Servicios
3.3.1 Topología de las redes de paquetes.
Conmutadas por Paquetes: En este tipo de red los datos de los usuarios se descomponen en trozos más pequeños. Estos fragmentos o paquetes, estás insertados dentro de informaciones del protocolo y recorren la red como entidades independientes.
Estrella
En este esquema, todas las estaciones están conectadas por un cable a un módulo central ( Central hub ), y como es una conexión de punto a punto, necesita un cable desde cada PC al módulo central. Una ventaja de usar una red de estrella es que ningún punto de falla inhabilita a ninguna parte de la red, sólo a la porción en donde ocurre la falla, y la red se puede manejar de manera eficiente. Un problema que sí puede surgir, es cuando a un módulo le ocurre un error, y entonces todas las estaciones se ven afectadas.
Anillo
En esta configuración, todas las estaciones repiten la misma señal que fue mandada por la terminal transmisora, y lo hacen en un solo sentido en la red. El mensaje se transmite de terminal a terminal y se repite, bit por bit, por el repetidor que se encuentra conectado al controlador de red en cada terminal. Una desventaja con esta topología es que si algún repetidor falla, podría hacer que toda la red se caiga, aunque el controlador puede sacar el repetidor defectuoso de la red, evitando así algún desastre.
Bus
También conocida como topología lineal de bus, es un diseño simple que utiliza un solo cable al cual todas las estaciones se conectan. La topología usa un medio de transmisión de amplia cobertura ( broadcast medium ), ya que todas las estaciones pueden recibir las transmisiones emitidas por cualquier estación. Como es bastante simple la configuración, se puede implementar de manera barata. El problema inherente de este esquema es que si el cable se daña en

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
cualquier punto, ninguna estación podrá transmitir. Aunque Ethernet puede tener varias configuraciones de cables, si se utiliza un cable de bus, esta topología representa una red de Ethernet.
Árbol
Esta topología es un ejemplo generalizado del esquema de bus. El árbol tiene su primer nodo en la raíz, y se expande para afuera utilizando ramas, en donde se encuentran conectadas las demás terminales. Ésta topología permite que la red se expanda, y al mismo tiempo asegura que nada más existe una "ruta de datos" ( data path ) entre 2 terminales cualesquiera.
3.3.2 Datagramas y circuitos virtuales
CIRCUITOS VIRTUALES
El concepto de circuito virtual se refiere a una asociación bidireccional, a través de la red, entre dos ETD, circuito sobre el cual se realiza la transmisión de los paquetes.
Al inicio, se requiere una fase de establecimiento de la conexión, denominado:
"llamada virtual"
Durante la llamada virtual los ETDs se preparan para el intercambio de paquetes y la red reserva los recursos necesarios para el circuito virtual.
Los paquetes de datos contienen sólo el número del circuito virtual para identificar al destino.
Si la red usa encaminamiento adaptativo, el concepto de circuito virtual garantiza la secuenciación de los paquetes, a través de un protocolo fin-a-fin (nodo origen/nodo destino).
El concepto de CV permite a un ETD establecer caminos de comunicación concurrentes con varios otros ETDs, sobre un único canal físico de acceso a la red.
El CV utiliza al enlace físico sólo durante la transmisión del paquete.
Existen 2 tipos de CV
o CVP: Circuito virtual permanente
o CVT: Circuito virtual temporario

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
CVP: no requiere fase de establecimiento o llamada virtual por ser un circuito permanente (punto a punto) entre ETDs.
CVT: Requiere de la llamada virtual.
El protocolo para uso de circuitos virtuales está establecido en la recomendación X.25 del CCITT.
o (existe confirmación de mensajes recibidos, paquetes perdidos, etc.)
DATAGRAMAS
Es un paquete autosuficiente (análogo a un telegrama) el cual contiene información suficiente para ser transportado a destino sin necesidad de, previamente, establecer un circuito.
No se provee confirmación de recepción por el destinatario, pero puede existir un aviso de no entrega por parte de la red.
Algunas redes privadas trabajan en base a DATAGRAMAS, pero en redes públicas, donde existen cargos por paquetes transmitidos, no existe buena acogida para este tipo de servicios.
Una alternativa al servicio de DATAGRAMA propuesto al CCITT, es la facilidad de selección rápida o Fast Select, la cual es aplicable en la llamada virtual CVT
Fast Select permite transmitir datos en el campo de datos del paquete de control que establece el circuito virtual. La respuesta confirma la recepción y termina el CV.
cuadro comparativo a nivel de subred:
asunto datagramas circuito virtual establecimiento n/a se requiere
direccionamientode origen y destino en cada paquete
sólo número de CV
información de estado
la sub red no tiene información de estado.
cada CV requiere una entrada en la tabla de sub red
encaminamientocada paquete con ruta independiente.
todos los paquetes siguen la ruta establecida.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
efectos de falla en nodo
ninguno, perdida de paquetes
todos los CV a través del nodo con falla, terminan.
control de congestión difícil
fácil si un número suficiente de buffers son pre-asignados.
complejidad en la capa de transporte
en la capa de red
adecuado para
servicios orientados a con y sin conexión.
servicios orientados a conexión.
3.3.2.1 Estructura de conmutadores.
El conmutador de estructura Cisco MDS 9134 ofrece una conmutación de almacenamiento Fibre Channel para una capacidad avanzada de trabajo en red de almacenamiento con funciones que permiten "pagar en la medida en que crece" por la activación de puertos y que se inicia con 24 puertos. Este conmutador se ha diseñado para clientes de medianas y grandes empresas, con puertos con una velocidad de línea de 4 Gbps y 10 Gbps diseñados para admitir funciones de alto rendimiento, alta densidad y categoría empresarial. El conmutador es rentable, ya que ofrece flexibilidad, alta disponibilidad, seguridad y facilidad de uso a un precio asequible en una unidad de bastidor de formato compacto (1RU) o 2 unidades de bastidor (2RU) para soluciones apiladas de 48 y 64 puertos. Con la flexibilidad de poder ampliar de forma opcional de 24 a 32 puertos en incrementos de 8 puertos o activar 2 puertos de 10 Gbps para obtener un rendimiento mayor, el conmutador de estructura Cisco MDS 9134 se ha diseñado para proporcionar las densidades de bastidor y puerto necesarias para un conmutador sobre el bastidor en el centro de datos y proporciona conectividad de borde en las SAN de empresa.
3.3.2.2 Conmutación de paquetes. Tema visto
3.3.3 Encaminamiento en redes de paquetes
El problema del encaminamiento Consiste en cómo establecer una ruta óptima para una instancia de comunicación desde una fuente a un destino. La ruta elegida debe optimizar en lo posible algún parámetro o conjunto de parámetros, como el retardo de tránsito, el número de saltos, el tamaño de las colas, el caudal de salida. . . En general, las decisiones de encaminamiento son

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
incrementales. Cada nodo de conmutación sólo debe decidir a qué nodo adyacente debe transmitir los datos, quedando así establecida la parte correspondiente de la ruta.Para calcular las rutas se usa un algoritmo de encaminamiento, que dado un destino decide la línea de salida adecuada. Es necesario además una estructura de información donde almacenar localmente los pares (destino línea de salida) resultantes, que recibe el nombre de tabla de encamina- miento. Asímismo, los nodos deben coordinar el cálculo de las rutas e informarse entre sí de los cambios que se produzcan por ejemplo en la topología de la red, tarea que es llevada a cabo por un protocolo de encaminamiento
Propiedades exigibles a los algoritmos de encaminamiento:Deben ser robustos, capaces de adaptarse a los posibles cambios de topología (fallos, bajas o altas en enlaces y nodos) sin necesidad de abortary reinicializar toda la red. Deben ser estables, en el sentido de converger a un resultado de la forma más rápida posible.No deben generar bucles en el encaminamiento.
Clasificación de los algoritmos de encaminamiento
Estáticos o no adaptativos: Las rutas son calculadas de antemano y cargadas en los nodos durante su inicialización y permanecen invariantes durante largos períodos de tiempo.
Dinámicos o adaptativos: Cambian sus decisiones de encaminamiento para re_ejar cambios en la topología y/o en el tráfico. Pueden diferir en los instantes de adaptación (de manera periódica o cuando cambie de manera signi_cativa la topología o el trá_co) y en la forma de obtener la información y tomar las decisiones:_ Aislados: Los nodos basan sus decisiones en información obtenida localmente._ Centralizados: Un nodo de control utiliza la información obtenida de todos los nodos de la red y toma las decisiones de encaminamiento, que transmite posteriormente al resto de los nodos de la red._ Distribuidos: Las decisiones de encaminamiento se toman localmente en los nodos y se basan en información que obtienen de parte (sólo adyacentes) o de la totalidad del resto de nodos.En las redes actuales el encaminamiento es dinámico y distribuido. SC:
3.3.4 Gestión de tráfico.
En telefonía la gestión de tráfico o gestión de red es una actividad de administración de la red telefónica cuyo objetivo es asegurar que el mayor número posible de llamadas telefónicas son conectadas a su destino.
Principios de gestión de tráfico

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Mantener todos los circuitos ocupados con llamadas exitosas. Utilizar todos los circuitos disponibles.
Dar prioridad a aquellas llamadas que para su conexión requieren el mínimo número de circuitos o enlaces cuando todos los circuitos disponibles están ocupados.
Inhibir congestión central y evitar que se difunda.
Basado en estos principios, el departamento de gestión de red del operador telefónico desarrolla planes y estrategias para controlar y manejar el tráfico telefónico.
Principios operacionales
Debe existir un foco de congestión antes de que se considere una acción de control
Resolver problemas locales antes de involucrar áreas distantes
Usar controles expansivos antes de usar controles protectivos
Terminología
Intento: un intento de obtener el servicio de un recurso, por ejemplo, un intento de llamada sobre un circuito.
Toma: un intento exitoso, esto es, un llamada llevada sobre un circuito.
Desborde: un intento no exitoso de obtener un recurso (circuito) sobre la ruta escogida).
Utilización
o Ocupación: medida de la carga llevada por un servidor (circuito), expresada como porcentaje.
o Intensidad de tráfico: medida de la carga llevada por un recurso, expresada en erlangs.
o Tiempo: medición de la duración de una toma exitosa.
Tiempo de expiración: medida del retraso en la obtención de un recurso.
Llamadas rechazadas: una toma sobre un circuito entrante que es rechazada por el procesador central.
Respuesta: señal de retorno indicando que la llamada ha sido contestada.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Ocupado: condición de un recurso que está siendo utilizado en una toma. Se aplica normalmente en servicio al cliente.
Congestión: estado en el cual el establecimiento de una nueva llamada no es posible debido a falta de acceso a un recurso.
3.3.5 Control de congestión.
El control de flujo permite al receptor controlar el ritmo de envío del transmisor en función de sus recursos (buffer de recepción). Cumple su cometido si ambos están en la misma red.
Si NO, los datagramas deben atravesar múltiples redes y uno o más routers con sus recursos (buffers) más o menos limitados. ¡¡Los routers también pueden ver agotado el espacio en sus buffers!!. ¡Los routers SOLO tienen un módulo IP y un módulo de protocolo de encaminamiento, NO tienen un módulo TCP (TCP es un protocolo extremo a extremo, y los dos extremos son las aplicaciones que residen en los hosts)!.
Podría haber zonas congestionadas, con un router con los buffers muy llenos. A la larga, el control de flujo acomodaría el ritmo de envío a lo que permitiese la zona más congestionada, pero en el transitorio podrían perderse datagramas (time-outs, retransmisiones, etc) – Hay que controlar el flujo de envío del transmisor a Internet para reducir el ritmo cuando ésta está próxima a la congestión: Control de congestión.
Para llevarlo a cabo, primero hay que averiguar a qué ritmo podemos enviar datos a Internet: algorítmo slowstart. Cuando el ritmo comienza a ser alto para la situación de la red, hay que hacer actuar a un algoritmo de control de congestión: congestion avoidance.
4 TCP/IP
HISTORIA El Protocolo de Internet (IP) y el Protocolo de Transmisión (TCP), fueron desarrollados inicialmente en 1973 por el informático estadounidense Vinton Cerf como parte de un proyecto dirigido por el ingeniero norteamericano Robert Kahn y patrocinado por la Agencia de Programas Avanzados de Investigación (ARPA, siglas en inglés) del Departamento Estadounidense de Defensa. Internet comenzó siendo una red informática de ARPA (llamada ARPAnet) que conectaba redes de ordenadores de varias universidades y laboratorios en investigación en Estados Unidos. World Wibe Web se desarrolló en 1989 por el

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
informático británico Timothy Berners-Lee para el Consejo Europeo de Investigación Nuclear (CERN, siglas en francés). QUÉ ES Y ARQUITECTURA DE TCP/IP TCP/IP es el protocolo común utilizado por todos los ordenadores conectados a Internet, de manera que éstos puedan comunicarse entre sí. Hay que tener en cuenta que en Internet se encuentran conectados ordenadores de clases muy diferentes y con hardware y software incompatibles en muchos casos, además de todos los medios y formas posibles de conexión. Aquí se encuentra una de las grandes ventajas del TCP/IP, pues este protocolo se encargará de que la comunicación entre todos sea posible. TCP/IP es compatible con cualquier sistema operativo y con cualquier tipo de hardware.TCP/IP no es un único protocolo, sino que es en realidad lo que se conoce con este nombre es un conjunto de protocolos que cubren los distintos niveles del modelo OSI. Los dos protocolos más importantes son el TCP (Transmission Control Protocol) y el IP (Internet Protocol), que son los que dan nombre al conjunto. La arquitectura del TCP/IP consta de cinco niveles o capas en las que se agrupan los protocolos, y que se relacionan con los niveles OSI de la siguiente manera:
Aplicación: Se corresponde con los niveles OSI de aplicación, presentación y sesión. Aquí se incluyen protocolos destinados a proporcionar servicios, tales como correo electrónico (SMTP), transferencia de ficheros (FTP), conexión remota (TELNET) y otros más recientes como el protocolo HTTP (Hypertext Transfer Protocol).
Transporte: Coincide con el nivel de transporte del modelo OSI. Los protocolos de este nivel, tales como TCP y UDP, se encargan de manejar los datos y proporcionar la fiabilidad necesaria en el transporte de los mismos.
Internet: Es el nivel de red del modelo OSI. Incluye al protocolo IP, que se encarga de enviar los paquetes de información a sus destinos correspondientes. Es utilizado con esta finalidad por los protocolos del nivel de transporte.
Físico : Análogo al nivel físico del OSI.
Red : Es la interfaz de la red real. TCP/IP no especifíca ningún protocolo concreto, así es que corre por las interfaces conocidas, como por ejemplo: 802.2, CSMA/CD, X.25, etc.
NIVEL DE APLICACIÓN

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
NIVEL DE TRANSPORTE
NIVEL DE INTERNET
NIVEL DE RED
NIVEL FÍSICO
FIG: Arquitectura TCP/IP
El TCP/IP necesita funcionar sobre algún tipo de red o de medio físico que proporcione sus propios protocolos para el nivel de enlace de Internet. Por este motivo hay que tener en cuenta que los protocolos utilizados en este nivel pueden ser muy diversos y no forman parte del conjunto TCP/IP. Sin embargo, esto no debe ser problemático puesto que una de las funciones y ventajas principales del TCP/IP es proporcionar una abstracción del medio de forma que sea posible el intercambio de información entre medios diferentes y tecnologías que inicialmente son incompatibles.
Para transmitir información a través de TCP/IP, ésta debe ser dividida en unidades de menor tamaño. Esto proporciona grandes ventajas en el manejo de los datos que se transfieren y, por otro lado, esto es algo común en cualquier protocolo de comunicaciones. En TCP/IP cada una de estas unidades de información recibe el nombre de "datagrama" (datagram), y son conjuntos de datos que se envían como mensajes independientes.
PROTOCOLOS TCP/IP
FTP, SMTP,
TELNET
SNMP, X-WINDOWS,
RPC, NFS
TCP UDP
IP, ICMP, 802.2, X.25
ETHERNET, IEEE 802.2, X.25
FTP (File Transfer Protocol). Se utiliza para transferencia de archivos.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
SMTP (Simple Mail Transfer Protocol). Es una aplicación para el correo electrónico.
TELNET: Permite la conexión a una aplicación remota desde un proceso o terminal.
o RPC (Remote Procedure Call). Permite llamadas a procedimientos situados remotamente. Se utilizan las llamadas a RPC como si fuesen procedimientos locales.
o SNMP (Simple Network Management Protocol). Se trata de una aplicación para el control de la red.
o NFS (Network File System). Permite la utilización de archivos distribuidos por los programas de la red.
o X-Windows. Es un protocolo para el manejo de ventanas e interfaces de usuario.
CARACTERÍSTICAS DE TCP/IP Ya que dentro de un sistema TCP/IP los datos transmitidos se dividen en pequeños paquetes, éstos resaltan una serie de características.
o La tarea de IP es llevar los datos a granel (los paquetes) de un sitio a otro. Las computadoras que encuentran las vías para llevar los datos de una red a otra (denominadas enrutadores) utilizan IP para trasladar los datos. En resumen IP mueve los paquetes de datos a granel, mientras TCP se encarga del flujo y asegura que los datos estén correctos.
o Las líneas de comunicación se pueden compartir entre varios usuarios. Cualquier tipo de paquete puede transmitirse al mismo tiempo, y se ordenará y combinará cuando llegue a su destino. Compare esto con la manera en que se transmite una conversación telefónica. Una vez que establece una conexión, se reservan algunos circuitos para usted, que no puede emplear en otra llamada, aun si deja esperando a su interlocutor por veinte minutos.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
o Los datos no tienen que enviarse directamente entre dos computadoras. Cada paquete pasa de computadora en computadora hasta llegar a su destino. Éste, claro está, es el secreto de cómo se pueden enviar datos y mensajes entre dos computadoras aunque no estén conectadas directamente entre sí. Lo que realmente sorprende es que sólo se necesitan algunos segundos para enviar un archivo de buen tamaño de una máquina a otra, aunque estén separadas por miles de kilómetros y pese a que los datos tienen que pasar por múltiples computadoras. Una de las razones de la rapidez es que, cuando algo anda mal, sólo es necesario volver a transmitir un paquete, no todo el mensaje.
o Los paquetes no necesitan seguir la misma trayectoria. La red puede llevar cada paquete de un lugar a otro y usar la conexión más idónea que esté disponible en ese instante. No todos los paquetes de los mensajes tienen que viajar, necesariamente, por la misma ruta, ni necesariamente tienen que llegar todos al mismo tiempo.
o La flexibilidad del sistema lo hace muy confiable. Si un enlace se pierde, el sistema usa otro. Cuando usted envía un mensaje, el TCP divide los datos en paquetes, ordena éstos en secuencia, agrega cierta información para control de errores y después los lanza hacia fuera, y los distribuye. En el otro extremo, el TCP recibe los paquetes, verifica si hay errores y los vuelve a combinar para convertirlos en los datos originales. De haber error en algún punto, el programa TCP destino envía un mensaje solicitando que se vuelvan a enviar determinados paquetes.
CÓMO FUNCIONA TCP/IP - IP:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
IP a diferencia del protocolo X.25, que está orientado a conexión, es sin conexión. Está basado en la idea de los datagramas interred, los cuales son transportados transparentemente, pero no siempre con seguridad, desde el hostal fuente hasta el hostal destinatario, quizás recorriendo varias redes mientras viaja.El protocolo IP trabaja de la siguiente manera; la capa de transporte toma los mensajes y los divide en datagramas, de hasta 64K octetos cada uno. Cada datagrama se transmite a través de la red interred, posiblemente fragmentándose en unidades más pequeñas, durante su recorrido normal. Al final, cuando todas las piezas llegan a la máquina destinataria, la capa de transporte los reensambla para así reconstruir el mensaje original.Un datagrama IP consta de una parte de cabecera y una parte de texto. La cabecera tiene una parte fija de 20 octetos y una parte opcional de longitud variable. En la figura 1 se muestra el formato de la cabecera. El campo Versión indica a qué versión del protocolo pertenece cada uno de los datagramas. Mediante la inclusión de la versión en cada datagrama, no se excluye la posibilidad de modificar los protocolos mientras la red se encuentre en operación.El campo Opciones se utiliza para fines de seguridad, encaminamiento fuente, informe de errores, depuración, sellado de tiempo, así como otro tipo de información. Esto, básicamente, proporciona un escape para permitir que las versiones subsiguientes de los protocolos incluyan información que actualmente no está presente en el diseño original. También, para permitir que los experimentadores trabajen con nuevas ideas y para evitar, la asignación de bits de cabecera a información que muy rara vez se necesita.Debido a que la longitud de la cabecera no es constante, un campo de la cabecera, IHL, permite que se indique la longitud que tiene la cabecera en palabras de 32 bits. El valor mínimo es de 5. Tamaño 4 bit.El campo Tipo de servicio le permite al hostal indicarle a la subred el tipo de servicio que desea. Es posible tener varias combinaciones con respecto a la seguridad y la velocidad. Para voz digitalizada, por ejemplo, es más importante la entrega rápida que corregir errores de transmisión. En tanto que, para la transferencia de archivos, resulta más importante tener la transmisión fiable que entrega rápida. También, es posible tener algunas otras combinaciones, desde un tráfico rutinario, hasta una anulación instantánea. Tamaño 8 bit.La Longitud total incluye todo lo que se encuentra en el datagrama -tanto la cabecera como los datos. La máxima longitud es de 65 536 octetos(bytes). Tamaño 16 bit.El campo Identificación se necesita para permitir que el hostal destinatario determine a qué datagrama pertenece el fragmento recién llegado. Todos los fragmentos de un datagrama contienen el mismo valor de identificación. Tamaño 16 bits.Enseguida viene un bit que no se utiliza, y después dos campos de 1 bit. Las letras DF quieren decir no fragmentar. Esta es una orden para que las pasarelas no fragmenten el datagrama, porque el extremo destinatario es incapaz de poner las partes juntas nuevamente. Por ejemplo, supóngase que

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
se tiene un datagrama que se carga en un micro pequeño para su ejecución; podría marcarse con DF porque la ROM de micro espera el programa completo en un datagrama. Si el datagrama no puede pasarse a través de una red, se deberá encaminar sobre otra red, o bien, desecharse.Las letras MF significan más fragmentos. Todos los fragmentos, con excepción del último, deberán tener ese bit puesto. Se utiliza como una verificación doble contra el campo de Longitud total, con objeto de tener seguridad de que no faltan fragmentos y que el datagrama entero se reensamble por completo.El desplazamiento de fragmento indica el lugar del datagrama actual al cual pertenece este fragmento. En un datagrama, todos los fragmentos, con excepción del último, deberán ser un múltiplo de 8 octetos, que es la unidad elemental de fragmentación. Dado que se proporcionan 13 bits, hay un máximo de 8192 fragmentos por datagrama, dando así una longitud máxima de datagrama de 65 536 octetos, que coinciden con el campo Longitud total. Tamaño 16 bits.El campo Tiempo de vida es un contador que se utiliza para limitar el tiempo de vida de los paquetes. Cuando se llega a cero, el paquete se destruye. La unidad de tiempo es el segundo, permitiéndose un tiempo de vida máximo de 255 segundos. Tamaño 8 bits.Cuando la capa de red ha terminado de ensamblar un datagrama completo, necesitará saber qué hacer con él. El campo Protocolo indica, a qué proceso de transporte pertenece el datagrama. El TCP es efectivamente una posibilidad, pero en realidad hay muchas más.Protocolo: El número utilizado en este campo sirve para indicar a qué protocolo pertenece el datagrama que se encuentra a continuación de la cabecera IP, de manera que pueda ser tratado correctamente cuando llegue a su destino. Tamaño: 8 bit.El código de redundancia de la cabecera es necesario para verificar que los datos contenidos en la cabecera IP son correctos. Por razones de eficiencia este campo no puede utilizarse para comprobar los datos incluidos a continuación, sino que estos datos de usuario se comprobarán posteriormente a partir del código de redundancia de la cabecera siguiente, y que corresponde al nivel de transporte. Este campo debe calcularse de nuevo cuando cambia alguna opción de la cabecera, como puede ser el tiempo de vida. Tamaño: 16 bitLa Dirección de origen contiene la dirección del host que envía el paquete. Tamaño: 32 bit. La Dirección de destino: Esta dirección es la del host que recibirá la información. Los routers o gateways intermedios deben conocerla para dirigir correctamente el paquete. Tamaño: 32 bit. LA DIRECCIÓN DE INTERNET

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
El protocolo IP identifica a cada ordenador que se encuentre conectado a la red mediante su correspondiente dirección. Esta dirección es un número de 32 bit que debe ser único para cada host, y normalmente suele representarse como cuatro cifras de 8 bit separadas por puntos.La dirección de Internet (IP Address) se utiliza para identificar tanto al ordenador en concreto como la red a la que pertenece, de manera que sea posible distinguir a los ordenadores que se encuentran conectados a una misma red. Con este propósito, y teniendo en cuenta que en Internet se encuentran conectadas redes de tamaños muy diversos, se establecieron tres clases diferentes de direcciones. EN QUE SE UTILIZA TCP/IP Muchas grandes redes han sido implementadas con estos protocolos, incluyendo DARPA Internet "Defense Advanced Research Projects Agency Internet", en español, Red de la Agencia de Investigación de Proyectos Avanzados de Defensa. De igual forma, una gran variedad de universidades, agencias gubernamentales y empresas de ordenadores, están conectadas mediante los protocolos TCP/IP. Cualquier máquina de la red puede comunicarse con otra distinta y esta conectividad permite enlazar redes físicamente independientes en una red virtual llamada Internet. Las máquinas en Internet son denominadas "hosts" o nodos.TCP/IP proporciona la base para muchos servicios útiles, incluyendo correo electrónico, transferencia de ficheros y login remoto.El correo electrónico está diseñado para transmitir ficheros de texto pequeños. Las utilidades de transferencia sirven para transferir ficheros muy grandes que contengan programas o datos. También pueden proporcionar chequeos de seguridad controlando las transferencias.El login remoto permite a los usuarios de un ordenador acceder a una máquina remota y llevar a cabo una sesión interactiva.SIMILITUDES Y DIFERENCIAS ENTRE LA CLASE 4 DEL MODELO OSI Y TCP El protocolo de transporte de clase 4 del modelo OSI (al que con frecuencia se le llama TP4), y TCP tienen numerosas similitudes, pero también algunas diferencias. A continuación se dan a conocer los puntos en que los dos protocolos son iguales. Los dos protocolos están diseñados para proporcionar un servicio de transporte seguro, orientado a conexión y de extremo a extremo, sobre una red insegura, que puede perder, dañar, almacenar y duplicar paquetes. Los dos deben enfrentarse a los peores problemas como sería el caso de una subred que pudiera almacenar una secuencia válida de paquetes y más tarde volviera a entregarlos.Los dos protocolos también son semejantes por el hecho de que los dos tienen una fase de establecimiento de conexión, una fase de transferencia de datos y

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
después una fase de liberación de la conexión. Los conceptos generales del establecimiento, uso y liberación de conexiones también son similares, aunque difieren en algunos detalles. En particular, tanto TP4 como TCP utilizan la comunicación ida-vuelta-ida para eliminar las dificultades potenciales ocasionadas por paquetes antiguos que aparecieran súbitamente y pudiesen causar problemas.Sin embargo, los dos protocolos también presentan diferencias muy notables, las cuales se pueden observar en la lista que se muestra en la figura 3. Primero, TP4 utiliza nueve tipos diferentes de TPDU, en tanto que TCP sólo tiene uno. Esta diferencia trae como resultado que TCP sea más sencillo, pero al mismo tiempo también necesita una cabecera más grande, porque todos los campos deben estar presentes en todas las TPDU. El mínimo tamaño de la cabecera TCP es de 20 octetos; el mínimo tamaño de la cabecera TP4 es de 5 octetos. Los dos protocolos permiten campos opcionales, que pueden incrementar el tamaño de las cabeceras por encima del mínimo permitido.
CARACTERÍSTICA OSI TP4 TCP
Numero de tipos de TPDU 9 1
Fallo de Conexión 2 conexiones 1 conexión
Formato de direcciones No está definido 32 bits
Calidad de servicio Extremo abierto Opciones específicas
Datos del usuario en CR Permitido No permitido
Flujo Mensajes Octetos
Datos importantes Acelerados Acelerados
Superposición No Sí
Control de flujo explícito Algunas veces Siempre
Número de subsecuencia Permitidos No Permitido
Liberación Abrupta OrdenadaFigura 3: Diferencias entre el protocolo tp4 del modelo OSI y TCP Una segunda diferencia es con respecto a lo que sucede cuando los dos procesos, en forma simultánea, intentan establecer conexiones entre los mismos dos TSAP (es decir, una colisión de conexiones). Con TP4 se establecen dos conexiones duplex independientes; en tanto que con TCP, una conexión se identifica mediante un par de TSAP, por lo que solamente se establece una conexión.Una tercera diferencia es con respecto al formato de direcciones que se utiliza. TP4 no especifica el formato exacto de una dirección TSAP; mientras que TCP utiliza números de 32 bits.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
El concepto de calidad de servicio también se trata en forma diferente en los dos protocolos, constituyendo la cuarta diferencia. TP4 tiene un mecanismo de extremo abierto, bastante elaborado, para una negociación a tres bandas sobre la calidad de servicio. Esta negociación incluye al proceso que hace la llamada, al proceso que es llamado y al mismo servicio de transporte. Se pueden especificar muchos parámetros, y pueden proporcionarse los valores: deseado y mínimo aceptable. A diferencia de esto, TCP no tiene ningún campo de calidad de servicio, sino que el servicio subyacente IP tiene un campo de 8 bits, el cual permite que se haga una relación a partir de un número limitado de combinaciones de velocidad y seguridad.Una quinte diferencia es que TP4 permite que los datos del usuario sean transportados en la TPDU CR, pero TCP no permite que los datos del usuario aparezcan en la TPDU inicial. El dato inicial (como por ejemplo, una contraseña), podría ser necesario para decidir si se debe, o no, establecer una conexión. Con TCP no es posible hacer que el establecimiento dependa de los datos del usuario.Las cuatro diferencias anteriores se relacionan con la fase de establecimiento de la conexión. Las cinco siguientes se relacionan con la fase de transferencia de datos. Una diferencia básica es el modelo del transporte de datos. El modelo TP4 es el de una serie de mensajes ordenados (correspondientes a las TSDU en la terminología OSI). El modelo TCP es el de un flujo continuo de octetos, sin que haya ningún límite explícito entre mensajes. En la práctica, sin embargo, el modelo TCP no es realmente un flujo puro de octetos, porque el procedimiento de biblioteca denominado push puede llamarse para sacar todos los datos que estén almacenados, pero que todavía no se hayan transmitido. Cuando el usuario remoto lleva a cabo una operación de lectura, los datos anteriores y posteriores al push no se combinarán, por lo que, en cierta forma un push podría penarse como si definiesen una frontera entre mensajes.La séptima diferencia se ocupa de cómo son tratados los datos importantes que necesitan de un procesamiento especial (como los caracteres BREAK). TP4 tiene dos flujos de mensajes independientes, los datos normales y los acelerados multiplexados de manera conjunta. En cualquier instante únicamente un mensaje acelerado puede estar activo. TCP utiliza el campo Acelerado para indicar que cierta cantidad de octetos, dentro de la TPDU actualmente en uso, es especial y debería procesarse fuera de orden.La octava diferencia es la ausencia del concepto de superposición en TP4 y su presencia en TCP. Esta diferencia no es tan significativa como al principio podría parecer, dado que es posible que una entidad de transporte ponga dos TPDU, por ejemplo, DT y AK en un único paquete de red.La novena diferencia se relaciona con la forma como se trata el control de flujo. TP4 puede utilizar un esquema de crédito, pero también se puede basar en el esquema de ventana de la capa de red para regular el flujo. TCP siempre utiliza un mecanismo de control de flujo explícito con el tamaño de la ventana especificado en cada TPDU.La décima diferencia se relaciona con este esquema de ventana. En ambos protocolos el receptor tiene la capacidad de reducir la ventana en forma voluntaria. Esta posibilidad genera potencialmente problemas, si el

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
otorgamiento de una ventana grande y su contracción subsiguiente llegan en un orden incorrecto. En TCP no hay ninguna solución para este problema; en tanto en TP4 éste se resuelve por medio del número de subsecuencia que está incluido en la contracción, permitiendo de esta manera que el emisor determine si la ventana pequeña siguió, o precedió, a la más grande.Finalmente, la onceava y última diferencia existente entre los dos protocolos, consiste en la manera como se liberan las conexiones. TP4 utiliza una desconexión abrupta en la que una serie de TPDU de datos pueden ser seguidos directamente por una TPDU DR. Si las TPDU de datos se llegaran a perder, el protocolo no los podría recuperar y la información, al final se perdería. TCP utiliza una comunicación de ida-vuelta-ida para evitar la pérdida de datos en el momento de la desconexión. El modelo OSI trata este problema en la capa de sesión. Es importante hacer notar que la Oficina Nacional de Normalización de Estados Unidos estaba tan disgustada con esta propiedad de TP4, que introdujo TPDU adicionales en el protocolo de transporte para permitir la desconexión sin que hubiera una pérdida de datos. Como consecuencia de esto, las versiones de Estados Unidos y la internacional de TP4 son diferentes.
4.1 Modelo Cliente Servidor.
Arquitectura Cliente/Servidor
Con la proliferación de ordenadores personales de bajo coste en el mercado, los recursos de sistemas de información existentes en cualquier organización se pueden distribuir entre ordenadores de diferentes tipos: ordenadores personales de gama baja, media y alta, estaciones de trabajo, miniordenadores o incluso grandes ordenadores.
El concepto de cliente/servidor proporciona una forma eficiente de utilizar todos estos recursos de máquina de tal forma que la seguridad y fiabilidad que proporcionan los entornos mainframe se traspasa a la red de área local. A esto hay que añadir la ventaja de la potencia y simplicidad de los ordenadores personales.
La arquitectura cliente/servidor es un modelo para el desarrollo de sistemas de información en el que las transacciones se dividen en procesos independientes que cooperan entre sí para intercambiar información, servicios o recursos. Se denomina cliente al proceso que inicia el diálogo o solicita los recursos y servidor al proceso que responde a las solicitudes.
En este modelo las aplicaciones se dividen de forma que el servidor contiene la parte que debe ser compartida por varios usuarios, y en el cliente permanece sólo lo particular de cada usuario.
Los clientes realizan generalmente funciones como:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Manejo de la interfaz de usuario. Captura y validación de los datos de entrada.
Generación de consultas e informes sobre las bases de datos.
Por su parte los servidores realizan, entre otras, las siguientes funciones:
Gestión de periféricos compartidos.
Control de accesos concurrentes a bases de datos compartidas.
Enlaces de comunicaciones con otras redes de área local o extensa.
Siempre que un cliente requiere un servicio lo solicita al servidor correspondiente y éste le responde proporcionándolo. Normalmente, pero no necesariamente, el cliente y el servidor están ubicados en distintos procesadores. Los clientes se suelen situar en ordenadores personales y/o estaciones de trabajo y los servidores en procesadores departamentales o de grupo.
Entre las principales características de la arquitectura cliente/servidor se pueden destacar las siguientes:
El servidor presenta a todos sus clientes una interfaz única y bien definida.
El cliente no necesita conocer la lógica del servidor, sólo su interfaz externa.
El cliente no depende de la ubicación física del servidor, ni del tipo de equipo físico en el que se encuentra, ni de su sistema operativo.
Los cambios en el servidor implican pocos o ningún cambio en el cliente.
Características funcionales
Esta arquitectura se puede clasificar en cinco niveles, según las funciones que asumen el cliente y el servidor, tal y como se puede ver en el siguiente diagrama:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
En el primer nivel el cliente asume parte de las funciones de presentación de la aplicación, ya que siguen existiendo programas en el servidor dedicados a esta tarea. Dicha distribución se realiza mediante el uso de productos para el "maquillaje" de las pantallas del mainframe. Esta técnica no exige el cambio en las aplicaciones orientadas a terminales, pero dificulta su mantenimiento. Además, el servidor ejecuta todos los procesos y almacena la totalidad de los datos. En este caso se dice que hay una presentación distribuida o embellecimiento.
En el segundo nivel la aplicación está soportada directamente por el servidor, excepto la presentación que es totalmente remota y reside en el cliente. Los terminales del cliente soportan la captura de datos, incluyendo una validación parcial de los mismos y una presentación de las consultas. En este caso se dice que hay una presentación remota.
En el tercer nivel la lógica de los procesos se divide entre los distintos componentes del cliente y del servidor. El diseñador de la aplicación debe definir los servicios y las interfaces del sistema de información de forma que los papeles de cliente y servidor sean intercambiables, excepto en el control de los datos que es responsabilidad exclusiva del servidor. En este tipo de situaciones se dice que hay un proceso distribuido o cooperativo.
En el cuarto nivel el cliente realiza tanto las funciones de presentación como los procesos. Por su parte, el servidor almacena y gestiona los datos que permanecen en una base de datos centralizada. En esta situación se dice que hay una gestión de datos remota.
En el quinto y último nivel, el reparto de tareas es como en el anterior y además el gestor de base de datos divide sus componentes entre el cliente y el servidor. Las interfaces entre ambos están dentro de las funciones del gestor de datos y, por lo tanto, no tienen impacto en el desarrollo de las aplicaciones. En este nivel se da lo que se conoce como bases de datos distribuidas.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Características físicas
El diagrama del punto anterior da una idea de la estructura física de conexión entre las distintas partes que componen una arquitectura cliente / servidor. La idea principal consiste en aprovechar la potencia de los ordenadores personales para realizar sobre todo los servicios de presentación y, según el nivel, algunos procesos o incluso algún acceso a datos locales. De esta forma se descarga al servidor de ciertas tareas para que pueda realizar otras más rápidamente.
También existe una plataforma de servidores que sustituye al ordenador central tradicional y que da servicio a los clientes autorizados. Incluso a veces el antiguo ordenador central se integra en dicha plataforma como un servidor más. Estos servidores suelen estar especializados por funciones (seguridad, cálculo, bases de datos, comunicaciones, etc.), aunque, dependiendo de las dimensiones de la instalación se pueden reunir en un servidor una o varias de estas funciones.
Las unidades de almacenamiento masivo en esta arquitectura se caracterizan por incorporar elementos de protección que evitan la pérdida de datos y permiten multitud de accesos simultáneos (alta velocidad, niveles RAID, etc.).
Para la comunicación de todos estos elementos se emplea un sistema de red que se encarga de transmitir la información entre clientes y servidores. Físicamente consiste en un cableado (coaxial, par trenzado, fibra óptica, etc.) o en conexiones mediante señales de radio o infrarrojas, dependiendo de que la red sea local (RAL), metropolitana (MAN) o de área extensa (WAN).

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Para la comunicación de los procesos con la red se emplea un tipo de equipo lógico denominado middleware que controla las conversaciones. Su función es independizar ambos procesos (cliente y servidor). La interfaz que presenta es la estándar de los servicios de red que hace que los procesos "piensen" en todo momento que se están comunicando con un red.
Características lógicas
Una de las principales aportaciones de esta arquitectura a los sistemas de información es la interfaz gráfica de usuario. Gracias a ella se dispone de un manejo más fácil e intuitivo de las aplicaciones mediante el uso de un dispositivo tipo ratón. En esta arquitectura los datos se presentan, editan y validan en la parte de la aplicación cliente.
En cuanto a los datos, cabe señalar que en la arquitectura cliente/servidor se evitan las duplicidades (copias y comparaciones de datos), teniendo siempre una imagen única y correcta de los mismos disponible en línea para su uso inmediato.
Todo esto tiene como fin que el usuario de un sistema de información soportado por una arquitectura cliente/servidor trabaje desde su estación de trabajo con distintos datos y aplicaciones, sin importarle dónde están o dónde se ejecuta cada uno de ellos.
Ventajas e inconvenientes
Ventajas
Aumento de la productividad:
Los usuarios pueden utilizar herramientas que le son familiares, como hojas de cálculo y herramientas de acceso a bases de datos.
Mediante la integración de las aplicaciones cliente/servidor con las aplicaciones personales de uso habitual, los usuarios pueden construir soluciones particularizadas que se ajusten a sus necesidades cambiantes.
Una interfaz gráfica de usuario consistente reduce el tiempo de aprendizaje de las aplicaciones.
Menores costes de operación:
Permiten un mejor aprovechamiento de los sistemas existentes, protegiendo la inversión. Por ejemplo, la compartición de servidores (habitualmente caros) y dispositivos periféricos (como impresoras) entre máquinas clientes permite un mejor rendimiento del conjunto.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Proporcionan un mejor acceso a los datos. La interfaz de usuario ofrece una forma homogénea de ver el sistema, independientemente de los cambios o actualizaciones que se produzcan en él y de la ubicación de la información.
El movimiento de funciones desde un ordenador central hacia servidores o clientes locales origina el desplazamiento de los costes de ese proceso hacia máquinas más pequeñas y por tanto, más baratas.
Mejora en el rendimiento de la red:
Las arquitecturas cliente/servidor eliminan la necesidad de mover grandes bloques de información por la red hacia los ordenadores personales o estaciones de trabajo para su proceso. Los servidores controlan los datos, procesan peticiones y después transfieren sólo los datos requeridos a la máquina cliente. Entonces, la máquina cliente presenta los datos al usuario mediante interfaces amigables. Todo esto reduce el tráfico de la red, lo que facilita que pueda soportar un mayor número de usuarios.
Tanto el cliente como el servidor pueden escalarse para ajustarse a las necesidades de las aplicaciones. Las UCPs utilizadas en los respectivos equipos pueden dimensionarse a partir de las aplicaciones y el tiempo de respuesta que se requiera.
La existencia de varias UCPs proporciona una red más fiable: un fallo en uno de los equipos no significa necesariamente que el sistema deje de funcionar.
En una arquitectura como ésta, los clientes y los servidores son independientes los unos de los otros con lo que pueden renovarse para aumentar sus funciones y capacidad de forma independiente, sin afectar al resto del sistema.
La arquitectura modular de los sistemas cliente/servidor permite el uso de ordenadores especializados (servidores de base de datos, servidores de ficheros, estaciones de trabajo para CAD, etc.).
Permite centralizar el control de sistemas que estaban descentralizados, como por ejemplo la gestión de los ordenadores personales que antes estuvieran aislados.
Inconvenientes
Hay una alta complejidad tecnológica al tener que integrar una gran variedad de productos.
Requiere un fuerte rediseño de todos los elementos involucrados en los sistemas de información (modelos de datos, procesos, interfaces,

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
comunicaciones, almacenamiento de datos, etc.). Además, en la actualidad existen pocas herramientas que ayuden a determinar la mejor forma de dividir las aplicaciones entre la parte cliente y la parte servidor.
Es más difícil asegurar un elevado grado de seguridad en una red de clientes y servidores que en un sistema con un único ordenador centralizado.
A veces, los problemas de congestión de la red pueden degradar el rendimiento del sistema por debajo de lo que se obtendría con una única máquina (arquitectura centralizada). También la interfaz gráfica de usuario puede a veces ralentizar el funcionamiento de la aplicación.
El quinto nivel de esta arquitectura (bases de datos distribuidas) es técnicamente muy complejo y en la actualidad hay muy pocas implantaciones que garanticen un funcionamiento totalmente eficiente.
Fases de implantación
Una arquitectura cliente/servidor debe mostrar los sistemas de información no como un cliente que accede a un servidor corporativo, sino como un entorno que ofrece acceso a una colección de servicios. Para llegar a este estado pueden distinguirse las siguientes fases de evolución del sistema:
Fase de Iniciación
Esta etapa se centra sobre todo en la distribución física de los componentes entre plataformas. Los dos tipos de plataforma son:
Una plataforma cliente para la presentación (generalmente un ordenador personal de sobremesa).
Una plataforma servidora (como por ejemplo el servidor de una base de datos relacional) para la ejecución de procesos y la gestión de los datos.
Un ejemplo sería el de una herramienta de consulta que reside en un ordenador personal a modo de cliente y que genera peticiones de datos que van a través de la red hasta el servidor de base de datos. Estas peticiones se procesan, dando como resultado un conjunto de datos que se devuelven al cliente.
En esta fase pueden surgir los siguientes problemas:
Cómo repartir la lógica de la aplicación entre las plataformas cliente y servidor de la forma más conveniente.
Cómo gestionar la arquitectura para que permita que cualquier cliente se conecte con cualquier servidor.
Fase de Proliferación

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
La segunda etapa de una arquitectura cliente/servidor se caracteriza por la proliferación de plataformas clientes y servidoras. Ahora, el entorno para la interacción entre clientes y servidores se hace mucho más complejo. Puede hacerse una distinción entre:
Datos de servidores a los que se accede a través de una red de área extensa (WAN) y
Datos a los que se accede a través de una red de área local (RAL).
Los mecanismos de conexión son muy variados y suelen ser incompatibles.
En esta fase los problemas que se pueden plantear son:
La gestión de accesos se convierte en crítica y compleja debido a la estructura del organismo donde se está implantando la arquitectura. El mercado ofrece algunas soluciones que mejoran la interoperabilidad y que se basan en conexiones modulares que utilizan entre otros:
Drivers en la parte cliente
Pasarelas (gateways) a bases de datos
Especificaciones de protocolos cliente/servidor, etc.
Los requisitos de actualización de datos pasan a formar parte de los requisitos solicitados al sistema cliente/servidor. Ahora no sólo se consultan datos, sino que se envían peticiones para actualizar, insertar y borrar datos.
Fase de Control
En esta fase se consolidan los caminos de acceso desde una plataforma cliente particular a una plataforma servidora particular.
Los conceptos en los que se debe poner especial énfasis son los siguientes:
Transparencia en la localización. Significa que la aplicación cliente no necesita saber nada acerca de la localización (física o lógica) de los datos o los procesos. La localización de los recursos debe estar gestionada por servidores y estar representada en las plataformas adecuadas de forma que se facilite su uso por parte de las plataformas cliente.
Gestión de copias. El sistema se debe configurar de forma que se permita copiar la información (datos o procesos) de los servidores.
Especialización de los equipos servidores en servidores de bases de datos o en servidores de aplicaciones. Los servidores de

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
bases de datos continúan ofreciendo servicios orientados a datos a través de llamadas SQL o a través de procedimientos almacenados. En cualquier caso, los servicios se orientan a mantener la integridad de los datos. Por otro lado, los servidores de aplicaciones se centran en los procesos implementando partes de la lógica de la aplicación en la parte servidora.
Fase de Integración
Esta etapa se caracteriza por el papel conjunto que juegan la gestión de accesos, la gestión de copias y la gestión de recursos. La gestión de la información se debe realizar de forma que se pueda entregar la información controlada por los servidores que contienen los datos a las plataformas clientes que los requieran. El concepto en que se basa este tipo de gestión es la distinción entre dos tipos de datos: datos de operación y datos de información. Para ajustarse a los posibles cambios en los procesos, los datos de operación varían continuamente mientras que los datos de información son invariables porque son de naturaleza histórica y se obtienen tomando muestras en el tiempo de los datos de operación.
Fase de Madurez
Esta es la etapa final de una arquitectura cliente/servidor. Se caracteriza por una visión más flexible de las plataformas físicas del sistema que se contemplan como una única unidad lógica. Este estado también se caracteriza porque la tecnología cliente/servidor se ha generalizado en la empresa. Ya no es un problema saber qué componentes se distribuyen en qué plataformas, porque los recursos se pueden redistribuir para equilibrar la carga de trabajo y para compartir los recursos de información. Lo fundamental aquí es saber quién ofrece qué servicios. Para ello es necesario distinguir qué tipo de servicios y recursos se demandan y conocer las características de esta arquitectura basada en servicios.
En la fase de integración veíamos que se establecía una distinción entre datos de operación y datos de información histórica. Por contra, en un entorno de operación cliente/servidor que se encuentre en la fase de madurez, lo interesante es distinguir entre dos nuevos términos: organismo y grupo de trabajo. Esta distinción se establece basándose en sus diferencias organizativas. El grupo de trabajo es el entorno en el que grupos organizados de personas se centran en tareas específicas de la actividad del organismo al que pertenecen. Estos equipos de personas requieren una información propia y unas reglas de trabajo particulares, que pueden ser diferentes de las del organismo en su globalidad.
Una arquitectura basada en servicios es la que se contempla como una colección de consumidores de servicios poco relacionados entre sí y los productores de dichos servicios. La utilización de este tipo de arquitectura permite pensar en nuevos retos de diseño:

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Desarrollo de componentes reutilizables entre distintas aplicaciones y distintos grupos de trabajo
Desarrollo de aplicaciones distribuidas
Gestión del desarrollo de aplicaciones entre distintos equipos, etc.
Criterios de utilización
El mercado de los sistemas cliente/servidor está marcando nuevos caminos porque:
La información puede ahora residir en redes de ordenadores personales. Los usuarios pueden tener un mayor acceso a los datos y a la capacidad
de proceso.
El marketing también juega un papel importante. Muchos sistemas que se denominan cliente/servidor en realidad distan bastante de serlo y muchas aplicaciones aseguran ser tan fiables como sus homólogas en el host.
En realidad, el cambio hacia tecnologías cliente/servidor está aún en sus comienzos, pero de ninguna manera debe ignorarse.
La forma de asegurar la futura utilización productiva de sistemas cliente/servidor, asumiendo un bajo riesgo, debe considerar:
Comenzar por el downsizing: utilizar redes de área local y familiarizar a los usuarios con el uso de ordenadores personales.
Estudiar las herramientas cliente/servidor que se encuentren disponibles y aquellas que se encuentren en fase de desarrollo; la mayoría están basadas en algún sistema de gestión de base de datos en red local.
Permitir el acceso de los usuarios a los datos de la organización conectando las redes locales entre sí.
Añadir interfaces de usuario amigables al equipo lógico del ordenador central y desarrollar prototipos.
Una organización tiene que decidir cuándo y cómo debe migrar en su caso, hacia un entorno cliente/servidor, teniendo en cuenta la evolución de las herramientas cliente/servidor y desarrollando una estrategia que se base en los estándares predominantes en el mercado.
Relación con otros conceptos
Arquitectura cliente/servidor y downsizing
Muchas organizaciones están transportando sus aplicaciones a plataformas más pequeñas (downsizing) para conseguir la ventaja que proporcionan las nuevas plataformas físicas más rentables y la arquitectura cliente/servidor. Este

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
transporte siempre supone un coste, debido a la necesidad de rediseñar las aplicaciones y de re-entrenar a los usuarios en los nuevos entornos.
Independencia de Bases de Datos
Las arquitecturas cliente/servidor permiten aprovechar los conceptos de cliente y servidor para desarrollar aplicaciones que accedan a diversas bases de datos de forma transparente. Esto hace viable cambiar la aplicación en la parte servidora, sin que la aplicación cliente se modifique. Para que sea posible desarrollar estas aplicaciones es necesaria la existencia de un estándar de conectividad abierta que permita a los ordenadores personales y estaciones de trabajo acceder de forma transparente a bases de datos corporativas heterogéneas.
Relación con los Sistemas Abiertos
Las arquitecturas cliente/servidor se asocian a menudo con los sistemas abiertos, aunque muchas veces no hay una relación directa entre ellos. De hecho, muchos sistemas cliente/servidor se pueden aplicar en entornos propietarios.
En estos entornos, el equipo físico y el lógico están diseñados para trabajar conjuntamente, por lo que, en ocasiones se pueden realizar aplicaciones cliente/servidor de forma más sencilla y fiable que en los entornos que contienen plataformas heterogéneas.
El problema surge de que los entornos propietarios ligan al usuario con un suministrador en concreto, que puede ofrecer servicios caros y limitados. La independencia del suministrador que ofrecen los entornos de sistemas abiertos, crea una competencia que origina mayor calidad a un menor precio.
Pero, por otra parte, debido a la filosofía modular de los sistemas cliente/servidor, éstos se utilizan muchas veces en entornos de diferentes suministradores, adecuando cada máquina del sistema a las necesidades de las tareas que realizan. Esta tendencia está fomentando el crecimiento de las interfaces gráficas de usuario, de las bases de datos y del software de interconexión.
Debido a esto, se puede afirmar que los entornos cliente/servidor facilitan el movimiento hacia los sistemas abiertos. Utilizando este tipo de entornos, las organizaciones cambian sus viejos equipos por nuevas máquinas que pueden conectar a la red de clientes y servidores.
Los suministradores, por su parte, basan uno de los puntos clave de sus herramientas cliente/servidor en la interoperabilidad.
Relación con Orientación a Objetos

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
No hay una única forma de programar aplicaciones cliente/servidor; sin embargo, para un desarrollo rápido de aplicaciones cliente/servidor y para obtener una reducción importante de costes, la utilización de la tecnología cliente/servidor puede considerarse en conjunción con la de orientación a objetos.
4.2 Protocolo de Internet, IP móvil.
El Protocolo IP Móvil define procedimientos por los cuales los paquetes pueden ser enrutados a un nodo móvil, independientemente de su ubicación actual y sin cambiar su dirección IP. Los paquetes destinados a un nodo móvil primeramente son dirigidos a su red local. Allí, un agente local los intercepta y mediante un túnel los reenvía a la dirección temporal recientemente informada por el nodo móvil. En el punto final del túnel un agente foráneo recibe los paquetes y los entrega al nodo móvil.
En los últimos años se han producido importantes avances en el campo de las tecnologías de las comunicaciones. Dos de ellos han sido, indudablemente, el rápido desarrollo de la informática portátil y la importante implantación de los sistemas de comunicaciones móviles. La conjunción de ambos factores permite a los usuarios acceder a una red en cualquier momento y en cualquier lugar, aún cuando se encuentren en movimiento.
Sin embargo, ciertas arquitecturas de protocolos, entre ellos TCP/IP presentan serias complicaciones al momento de tratar con terminales que requieren de cierto grado de movilidad entre redes. La mayoría de las versiones del protocolo IP (Internet Protocol) asumen de manera implícita que el punto al cual el nodo se conecta a la red es fijo. Por otra parte, la dirección IP del nodo o terminal, lo identifica de manera unívoca en la red a la que se encuentra conectado. Cualquier paquete destinado a ese nodo es encaminado en función de la información contenida en el prefijo de red de su dirección IP. Esto implica que un nodo móvil que se desplaza de una red a otra y que mantiene su dirección IP no será localizable en su nueva ubicación ya que los paquetes dirigidos hacia este nodo serán encaminados a su antiguo punto de conexión a la red.
“El protocolo IP Móvil (Mobile Internet Protocol) fue diseñado para soportar movilidad, en cualquier tipo de medio y en una extensa área geográfica. Su objetivo es dotar a los terminales con la capacidad de mantenerse conectados a Internet independientemente de su localización, permitiendo rastrear a un nodo móvil sin necesidad de cambiar su dirección IP”.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
La distribución del presente documento es como se detalla: en primer lugar se exponen las características del protocolo IP Móvil y la definición de los términos que se utilizan a lo largo del documento, clasificados en entidades y servicios. A continuación se explica el funcionamiento del protocolo, contemplando los procesos de descubrimiento y registración de direcciones y de encaminamiento de paquetes hacia las direcciones. Posteriormente se mencionan problemas y posibles soluciones a cuestiones del protocolo, como así las diferencias entre las versiones 4 y 6.
Características de IP Móvil
No posee limitaciones geográficas: un usuario podría usar su computadora portátil (laptop, notebook, palmtop, etc.) en cualquier lugar sin perder conexión a su red.
No requiere conexión física: IP Móvil encuentra enrutadores (routers) y se conecta automáticamente, sin necesidad de fichas telefónicas ni cables.
No requiere modificar enrutadores ni terminales: a excepción del nodo o enrutador móvil, los demás enrutadores y terminales permanecen usando su dirección IP actual. IP Móvil no afecta a los protocolos de transporte ni a los protocolos de más alto nivel.
No requiere modificar las direcciones IP actuales ni su formato: las direcciones IP actuales y sus formatos no varían.
Soporta seguridad: utiliza mecanismos de autenticación para garantizar la protección de los usuarios.
Entidades
Nodo Móvil (Mobile Nodo)
Terminal o enrutador que puede cambiar su punto de unión desde una red o subred a otra. Esta entidad tiene pre-asignada una dirección IP fija sobre una red local o de base (Home Network) que es utilizada por otros nodos para dirigir paquetes destinados al nodo móvil independientemente de su ubicación actual.
Agente Local (Home Agent)
Enrutador que mantiene una lista de visitas con información de nodos móviles registrados, los que temporalmente no se encuentran en su red local. Esta lista

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
es usada para reenviar a la red apropiada los paquetes destinados al nodo móvil.
Agente Foráneo (Foreign Agent)
Enrutador que asiste a un nodo móvil localmente alcanzable mientras el nodo móvil está lejos de su red local. Este agente entrega información entre el nodo móvil y el agente local.
Figura 1: relación entre las principales entidades de IP Móvil
Dirección de auxilio (Care-of-Address)
Dirección IP que identifica la ubicación del nodo móvil en un momento determinado.
Nodo Correspondiente (Correspondent Node)
Nodo que envía paquetes destinados al nodo móvil.
Dirección Local (Home Address)
Dirección IP fija asignada al nodo móvil. Permanece invariable independientemente de la ubicación actual de dicho nodo. Por ejemplo, la dirección IP asignado por un ISP -Internet Service Provider-.
Agente de Movilidad (Mobility Agent)
Agente que soporta movilidad. Este podría ser tanto un agente local como uno foráneo.
Túnel (Tunnel)

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Camino que toman los paquetes desde el agente local hasta el agente foráneo.
Servicios
Descubrimiento de Agente (Agent Discover)
Los agentes locales y foráneos emiten mensajes de difusión (broadcast), llamados avisos de agente (agent advertisements), advirtiendo periódicamente su presencia en cada enlace en donde pueden proveer servicios. Los nodos móviles escuchan estos avisos y determinan si están conectados o no a su red local. Además, un nodo móvil recientemente arribado a una red podría enviar una solicitud para saber si un agente de movilidad está presente y forzarlo a que inmediatamente envíe un aviso de agente. Si un nodo móvil determina que se encuentra conectado a un enlace foráneo, adquiere una dirección de auxilio.
Registración (Registration)
Una vez que el nodo móvil adquiere una dirección de auxilio, debe registrarla con su agente local, para que el agente local sepa a dónde reenviar sus paquetes o proveerle servicio. Dependiendo de la configuración de la red, el nodo móvil podría registrarse directamente con su agente local o indirectamente mediante la ayuda de un agente foráneo.
Encapsulamiento (Encapsulation)
Proceso de encerrar a un paquete IP dentro de otro encabezado IP, el cual contiene la dirección de auxilio del nodo móvil. Durante el proceso de encapsulación el paquete IP no es modificado.
Desencapsulamiento
Proceso de despojar el encabezado IP de más afuera del paquete entrante para que el paquete encerrado dentro de él pueda ser accedido y entregado al destino apropiado. Es el proceso inverso al de encapsulación.
El funcionamiento del protocolo IP Móvil consiste de varias operaciones:
Cuando un nodo móvil se encuentra lejos de su red local debe encontrar algún agente para no perder conectividad a Internet. Existen dos caminos para encontrar agentes: uno de ellos es seleccionando a un agente de movilidad captado a través de mensajes de difusión que éstos emiten periódicamente advirtiendo su disponibilidad en cada enlace en donde pueden proveer servicios; el otro camino es mediante la emisión de solicitudes sobre el enlace, por parte del nodo móvil recientemente arribado, hasta obtener respuesta de

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
algún agente de movilidad que esté presente. Una vez encontrado el agente, el nodo móvil deduce si se encuentra en su red local o en una red externa. Si se encuentra en su red local opera sin servicios de movilidad, mientras que si se encuentra en una red externa obtiene su dirección de auxilio que puede ser asignada dinámicamente o asociada con su agente foráneo.
Una vez obtenida la dirección de auxilio, el nodo móvil debe registrarla con su agente local para obtener servicios. El proceso de registración puede ser realizado a través de una solicitud de registro enviada directamente desde el nodo móvil al agente local y recibiendo de éste un mensaje de contestación, o indirectamente reenviada por el agente foráneo al local, dependiendo de si la dirección de auxilio fue asignada dinámicamente o asociada con su agente foráneo. Después del proceso de registración el nodo móvil permanece en el área de servicio hasta que expire el tiempo de servicio otorgado o hasta que cambie su punto de enlace a la red. Durante este tiempo el nodo móvil obtiene paquetes reenviados por el agente foráneo, los cuales fueron originalmente enviados desde el agente local. El método túnel (tunneling) es usado para reenviar los mensajes desde el agente local al agente foráneo y finalmente al nodo móvil.
Después de que el nodo móvil regresa a su red, se desregistra con su agente local para dejar sin efecto su dirección de auxilio, enviando un requerimiento de registración con tiempo de vida igual a cero. El nodo móvil no necesita desregistrarse del agente foráneo dado que el servicio expira automáticamente cuando finalizar el tiempo de servicio.
“El protocolo Mobile IP es entendido mejor como la cooperación de tres mecanismos separables: Discovering the care-of address, Registering the care-of address, Tunneling to the care-of address.”.
Proceso de descubrimiento - Discovering the care-of address
El proceso de descubrimiento utilizado por el protocolo IP Móvil permite a un nodo móvil determinar si se encuentra conectado o no a su red local, detectar si se ha desplazado de un enlace a otro y, dado el caso en que el nodo móvil se encuentre conectado a una red externa, obtener su dirección de auxilio.
El protocolo IP móvil provee dos modos alternativos para la adquisición de una dirección de auxilio: Foreign Agent care-of address y co-located care-of address.
Foreign Agent care-of address

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Es una dirección de auxilio temporaria provista por un agente foráneo a través de mensajes avisos de agente. La dirección de auxilio, en este caso, es la dirección IP de un agente foráneo. El agente foráneo está en el punto final del túnel donde recibe los paquetes, los desencapsula y entrega el paquete original al nodo móvil. Este modo de adquisición permite que algunos nodos compartan la misma dirección de auxilio y en consecuencia, evita que se produzca una demanda innecesaria del limitado espacio de direcciones, en IPv4.
Co-located care-of address
Es una dirección de auxilio adquirida por el nodo móvil como una dirección IP fija mediante algún medio externo, al cual el nodo móvil luego se asocia con una de sus propias interfaces de red. La dirección puede ser adquirida dinámicamente como una dirección transitoria, como por ejemplo a través de un DHCP (Dynamic Host Configuration Protocol), o puede ser apropiada por el nodo móvil como una dirección perdurable para su uso, solamente, mientras se encuentre visitando una red distinta a su red local. Usando una co-located care-of address el nodo móvil actúa como punto final del túnel y él mismo realiza la desencapsulación de los paquetes. La ventaja de usar una co-located care-of address radica en que permite al nodo móvil funcionar sin un agente foráneo.
El proceso de descubrimiento no modifica los campos originales de los avisos de ruteo existentes, simplemente los extiende para asociarle funciones de movilidad. Así, un aviso de ruteo puede llevar información de ruteo por defecto, como antes, e información adicional sobre una o más dirección de auxilio. Cuando los avisos de ruteo son extendidos para que contengan la dirección de auxilio necesaria se denominan avisos de agente. Si un nodo móvil necesita obtener una dirección de auxilio, pero no desea esperar por un aviso de agente, podría emitir una solicitud de agente.
Avisos de Agente -Agent Advertisements-
Los agentes de movilidad anuncian su disponibilidad para brindar servicios al nodo móvil mediante mensajes de difusión de avisos de agente a intervalos regulares (por ejemplo cada un segundo). El nodo móvil utiliza estos mensajes para determinar su punto de conexión actual a Internet.
El agente local deberá estar siempre listo para servir a sus nodos móviles. Para evitar una posible saturación, debida al exceso de nodos móviles en una determinada red, es posible configurar múltiples agente locales en una única red, asignando a cada agente local una porción de la población de nodos móviles. Los agentes locales usan avisos de agente para darse a conocer a sí

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
mismos aunque no ofrezcan alguna dirección de auxilio. Por otro lado, es posible que un agente foráneo no tenga capacidad para servir a un nodo móvil no perteneciente a su red. Aún en ese caso, el agente foráneo debe continuar emitiendo avisos de agente para que el nodo móvil sepa que se encuentra dentro de su área de cobertura o que no ha fallado.
Los avisos de agente cumplen las siguientes funciones:
permiten la detección de agentes de movilidad. listan una o más dirección de auxilio disponibles.
informan al nodo móvil sobre características especiales para agentes foráneos, por ejemplo, técnicas alternativas de encapsulación.
permiten al nodo móvil determinar el número de red y el estado de su enlace a Internet.
permiten al nodo móvil conocer si el agente es local y/o externo y en consecuencia determinar si se encuentra en su red o en una red externa.
El mensaje avisos de agente consiste en un mensaje ICMP (Internet Control Message Protocol) al cual se le ha añadido una extensión para permitir la gestión de los nodos móviles. Dicha extensión (Figura 2) consta de los campos:
Tipo: 16 Longitud: (6+4*n), donde n es el número de dirección de auxilio
anunciadas.
Número de secuencia: número total de mensajes avisos de agente enviados desde que el agente fue inicializado.
Tiempo de vida de registración: tiempo de vida máximo que el agente acepta en una solicitud de registro.
R: registro solicitado.
B: el agente foráneo no puede aceptar nuevos registros, al estar ocupado
H: este agente ofrece servicios de agente local en la red.
F: este agente ofrece servicios de agente foráneo en la red.
M: el agente soporta encapsulado mínimo.
G: el agente soporta encapsulado GRE.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
V: el agente soporta la compresión de cabecera Van Jacobson.
Reservado.
Dirección de auxilio: la/s dirección de auxilio anunciadas por el agente foráneo.
Para que un nodo móvil pueda averiguar si se encuentra en su red local o si se ha desplazado a otra red debe verificar los bits F y H de alguno de los mensajes avisos de agente que capture.
0 1 2 3 4 5 6 7 8 9 10111213141516 17 18 19202122232425262728293031
Vers. HL Tipo de Servicio Total Leng
Identificación BanderasFragmentación
Tiempo de vida Protocolo = ICMP Suma de Comprobación de encabezado
Dirección fuente = dirección del agente local o foráneo sobre este enlace
Dirección destino = difusión o multidifusión
Tipo Código Suma de Comprobación
Nro. de direcciones
Asoc. Tamaño entrada
Tiempo de vida
Dirección enrutador
Nivel de preferencia
……
Tipo Longitud Número de secuencia
Registration Lifetime R B H F M G V Reservado
Direcciones de auxilio ……
Tipo Longitud Longitud Prefijo …….

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Encabezado IP ICMP Extensiones Extension Longitud-Prefijo
Figura 2 Extensión del mensaje avisos de agente
Solicitud de Agente -Agent Solicitation
Los nodos móviles podrían emitir solicitudes mediante mensajes de difusión, con el objetivo de forzar a cualquier agente de movilidad ubicado en el mismo enlace a transmitir un aviso de agente de manera inmediata. Esto resulta muy útil en aquellos casos en los cuales la frecuencia de los avisos de agente es demasiado baja para un nodo móvil que cambia rápidamente de enlace. El formato de los mensajes solicitud de agente es similar al de los mensajes ICMP usados para avisos de agente (Figura 2), con la diferencia de que deben tener su campo de tiempo de vida igualado a 1.
Si el nodo móvil conoce de ante mano la dirección de red de un agente de movilidad, podría insertarla en el encabezado de un mensaje de requerimiento de registración y enviarlo a dicho agente para obtener servicios.
4.3 Protocolos de transporte (UDP,TCP).
El grupo de protocolos de Internet también maneja un protocolo de transporte sin conexiones, el UDP (User Data Protocol, protocolo de datos de usuario). El UDP ofrece a las aplicaciones un mecanismo para enviar datagramas IP en bruto encapsulados sin tener que establecer una conexión. Muchas aplicaciones cliente-servidor que tienen una solicitud y una respuesta usan el UDP en lugar de tomarse la molestia de establecer y luego liberar una conexión. El UDP se describe en el RFC 768. Un segmento UDP consiste en una cabecera de 8 bytes seguida de los datos. La cabecera se muestra a continuación. Los dos puertos sirven para lo mismo que en el TCP: para identificar los puntos terminales de las máquinas origen y destino. El campo de longitud UDP incluye la cabecera de 8 bytes y los datos. La suma de comprobación UDP incluye la misma pseudocabecera de formato, la cabecera UDP, y los datos, rellenados con una cantidad par de bytes de ser necesario. UDP no admite numeración de los datagramas, factor que, sumado a que tampoco utiliza señales de confirmación de entrega, hace que la garantía de que un paquete llegue a su destino sea mucho menor que si se usa TCP. Esto también origina que los datagramas pueden llegar duplicados y/o desordenados a su destino. Por estos motivos el control de envío de datagramas, si existe, debe ser implementado por las aplicaciones que usan

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
UDP como medio de transporte de datos, al igual que el reeensamble de los mensajes entrantes. Es por ello un protocolo del tipo best-effort (máximo esfuerzo), porque hace lo que puede para transmitir los datagramas hacia la aplicación, pero no puede garantizar que la aplicación los reciba.
Udp
El grupo de protocolos de Internet también maneja un protocolo de transporte sin conexiones, el UDP (User Data Protocol, protocolo de datos de usuario). El UDP ofrece a las aplicaciones un mecanismo para enviar datagramas IP en bruto encapsulados sin tener que establecer una conexión. Muchas aplicaciones cliente-servidor que tienen una solicitud y una respuesta usan el UDP en lugar de tomarse la molestia de establecer y luego liberar una conexión. El UDP se describe en el RFC 768. Un segmento UDP consiste en una cabecera de 8 bytes seguida de los datos. La cabecera se muestra a continuación. Los dos puertos sirven para lo mismo que en el TCP: para identificar los puntos terminales de las máquinas origen y destino. El campo de longitud UDP incluye la cabecera de 8 bytes y los datos. La suma de comprobación UDP incluye la misma pseudocabecera de formato, la cabecera UDP, y los datos, rellenados con una cantidad par de bytes de ser necesario. UDP no admite numeración de los datagramas, factor que, sumado a que tampoco utiliza señales de confirmación de entrega, hace que la garantía de que un paquete llegue a su destino sea mucho menor que si se usa TCP. Esto también origina que los datagramas pueden llegar duplicados y/o desordenados a su destino. Por estos motivos el control de envío de datagramas, si existe, debe ser implementado por las aplicaciones que usan UDP como medio de transporte de datos, al igual que el reeensamble de los mensajes entrantes. Es por ello un protocolo del tipo best-effort (máximo esfuerzo), porque hace lo que puede para transmitir los datagramas hacia la aplicación, pero no puede garantizar que la aplicación los reciba.
Tcp
Protocolo TCP/IP Una red es una configuración de computadora que intercambia información. Pueden proceder de una variedad de fabricantes y es probable que tenga diferencias tanto en hardware como en software, para posibilitar la comunicación entre estas es necesario un conjunto de reglas formales para su interacción. A estas reglas se les denominan protocolos.
Un protocolo es un conjunto de reglas establecidas entre dos dispositivos para permitir la comunicación entre ambos.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
DEFINICION TCP / IP
Se han desarrollado diferentes familias de protocolos para comunicación por red de datos para los sistemas UNIX. El más ampliamente utilizado es el Internet Protocol Suite, comúnmente conocido como TCP / IP.
Es un protocolo DARPA que proporciona transmisión fiable de paquetes de datos sobre redes. El nombre TCP / IP Proviene de dos protocolos importantes de la familia, el Transmission Contorl Protocol (TCP) y el Internet Protocol (IP). Todos juntos llegan a ser más de 100 protocolos diferentes definidos en este conjunto.
El TCP / IP es la base del Internet que sirve para enlazar computadoras que utilizan diferentes sistemas operativos, incluyendo PC, minicomputadoras y computadoras centrales sobre redes de área local y área extensa. TCP / IP fue desarrollado y demostrado por primera vez en 1972 por el departamento de defensa de los Estados Unidos, ejecutándolo en el ARPANET una red de área extensa del departamento de
4.4 Protocolos a nivel aplicación.
4.4.1 SMTP
Abreviatura de Simple Mail Transfer Protocol, un protocolo utilizado para enviar mensajes de correo electrónico entre servidores. La mayoría de los servidores de correo que envían mensajes a través de Internet utilizan SMTP para tal efecto; los mensajes pueden luego ser descargados desde un cliente de correo usando protocolos como IMAP o POP3. SMTP es generalmente utilizado además, para enviar mensajes desde un cliente al servidor de correo. Debido a esto es la necesidad de especificar un servidor IMAP o POP3 y un servidor SMTP para configurar una aplicación cliente de correo.
4.4.2 FTP
FTP (File Transfer Protocol) es un protocolo de transferencia de archivos entre sistemas conectados a una red TCP basado en la arquitectura cliente-servidor, de manera que desde un equipo cliente nos podemos conectar a un servidor para descargar archivos desde él o para enviarle nuestros propios archivos independientemente del sistema operativo utilizado en cada equipo.
El Servicio FTP es ofrecido por la capa de Aplicación del modelo de capas de red TCP/IP al usuario, utilizando normalmente el puerto de red 20 y el 21. Un problema básico de FTP es que está pensado para ofrecer la máxima velocidad en la conexión, pero no la máxima seguridad, ya que todo el

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
intercambio de información, desde el login y password del usuario en el servidor hasta la transferencia de cualquier archivo, se realiza en texto plano sin ningún tipo de cifrado, con lo que un posible atacante puede capturar este tráfico, acceder al servidor, o apropiarse de los archivos transferidos.
Para solucionar este problema son de gran utilidad aplicaciones como scp y sftp, incluidas en el paquete SSH, que permiten transferir archivos pero cifrando todo el tráfico.
4.4.3 http
El Protocolo de Transferencia de HiperTexto (Hypertext Transfer Protocol) es un sencillo protocolo cliente-servidor que articula los intercambios de información entre los clientes Web y los servidores HTTP. La especificación completa del protocolo HTTP 1/0 está recogida en el RFC 1945. Fue propuesto por Tim Berners-Lee, atendiendo a las necesidades de un sistema global de distribución de información como el World Wide Web.
Desde el punto de vista de las comunicaciones, está soportado sobre los servicios de conexión TCP/IP, y funciona de la misma forma que el resto de los servicios comunes de los entornos UNIX: un proceso servidor escucha en un puerto de comunicaciones TCP (por defecto, el 80), y espera las solicitudes de conexión de los clientes Web. Una vez que se establece la conexión, el protocolo TCP se encarga de mantener la comunicación y garantizar un intercambio de datos libre de errores.
HTTP se basa en sencillas operaciones de solicitud/respuesta. Un cliente establece una conexión con un servidor y envía un mensaje con los datos de la solicitud. El servidor responde con un mensaje similar, que contiene el estado de la operación y su posible resultado. Todas las operaciones pueden adjuntar un objeto o recurso sobre el que actúan; cada objeto Web (documento HTML, fichero multimedia o aplicación CGI) es conocido por su URL.
Etapas de una transacción HTTP.Para profundizar más en el funcionamiento de HTTP, veremos primero un caso particular de una transacción HTTP; en los siguientes apartados se analizarán las diferentes partes de este proceso.
Cada vez que un cliente realiza una petición a un servidor, se ejecutan los siguientes pasos:
Un usuario accede a una URL, seleccionando un enlace de un documento HTML o introduciéndola directamente en el campo Location del cliente Web.
El cliente Web descodifica la URL, separando sus diferentes partes. Así identifica el protocolo de acceso, la dirección DNS o IP del servidor, el posible puerto opcional (el valor por defecto es 80) y el objeto requerido del servidor.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Se abre una conexión TCP/IP con el servidor, llamando al puerto TCP correspondiente. Se realiza la petición. Para ello, se envía el comando necesario (GET, POST, HEAD,…), la dirección del objeto requerido (el contenido de la URL que sigue a la dirección del servidor), la versión del protocolo HTTP empleada (casi siempre HTTP/1.0) y un conjunto variable de información, que incluye datos sobre las capacidades del browser, datos opcionales para el servidor,…
El servidor devuelve la respuesta al cliente. Consiste en un código de estado y el tipo de dato MIME de la información de retorno, seguido de la propia información.
Se cierra la conexión TCP.
Este proceso se repite en cada acceso al servidor HTTP. Por ejemplo, si se recoge un documento HTML en cuyo interior están insertadas cuatro imágenes, el proceso anterior se repite cinco veces, una para el documento HTML y cuatro para las imágenes.
4.4.4 NFS
Puesto que uno de los objetivos de NFS es soportar un sistema heterogéneo, con clientes y servidores que tal vez ejecuten diferentes sistemas operativos con un hardware distinto, es esencial que la interfaz entre los clientes y los servidores esté bien definida. Sólo entonces es posible que cualquiera pueda escribir una nueva implantación cliente y espere que funcione de manera correcta con los servidores existentes y viceversa.
NFS logra este objetivo al definir dos protocolos cliente-servidor. Un protocolo es un conjunto de solicitudes enviadas por los clientes a los servidores, junto con las respuestas enviadas de regreso de los servidores a los clientes. Mientras un servidor reconozca y pueda controlar todas las solicitudes en los protocolos, no necesita saber nada de sus clientes. De manera análoga, los clientes pueden tratar a los servidores como "cajas negras" que aceptan y procesan un conjunto especifico de solicitudes. La forma en que lo hacen es asunto de ellos.
El primer protocolo NFS controla el anclaje. Un cliente puede enviar un nombre de ruta de acceso a un servidor y solicitar que monte ese directorio en alguna parte de su jerarquía de directorios. El lugar donde se montará no está contenido en el mensaje, ya que el servidor no se preocupa por dicho lugar. Si la ruta es válida y el directorio especificado ha sido exportado, el servidor regresa un identificador de archivo al cliente. El asa de archivo contiene campos que identifican de manera única al tipo de sistema de archivo, el disco, el número de inodo del directorio, e información de seguridad. Las llamadas

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
posteriores para la lectura y escritura de archivos en el directorio montado utilizan el identificador del archivo.
Muchos clientes están configurados de modo que monten ciertos directorios remotos sin intervención manual. Por lo general, estos clientes contienen un archivo llamado /etc/rc, que es un shellscript que contiene las instrucciones para el montaje remoto. Este shellscript se ejecuta de manera automática cuando el cliente se arranca.
Otra alternativa a la versión de UNIX de Sun soporta también el automontaje. Esta característica permite asociar un conjunto de directorios con un directorio local. Ninguno de los directorios remotos se monta (ni se realiza el contacto con sus servidores) cuando arranca el cliente. En vez de esto, la primera vez que se abre un archivo remoto, el sistema operativo envía un mensaje a cada uno de los servidores. El primero en responder gana, y se monta su directorio.
El automontaje tiene dos ventajas principales sobre el montaje estático por medio del archivo /etc/rc. La primera es que si uno de los servidores NFS llamados en /etc/rc no está sirviendo peticiones, es imposible despertar al cliente, al menos no sin cierta dificultad, retraso y unos cuantos mensajes de error. Si el usuario ni siquiera necesita ese servidor por el momento, todo ese trabajo se desperdicia. En segundo lugar, al permitir que el cliente intente comunicarse con un conjunto de servidores en paralelo, se puede lograr cierto grado de tolerancia a fallos (puesto que sólo se necesita que uno de ellos esté activo) y se puede mejorar el desempeño (al elegir el primero que responda, que supuestamente tiene la menor carga).
Por otro lado, se supone de manera implícita que todos los sistemas de archivos especificados como alternativas para el automontaje son idénticos. Puesto que NFS no da soporte para la réplica de archivos o directorios, el usuario debe lograr que todos los sistemas de archivos sean iguales. En consecuencia, el automontaje se utiliza con más frecuencia para los sistemas de archivos exclusivos para lectura que contienen binarios del sistema y para otros archivos que rara vez cambian.
El segundo protocolo NFS es para el acceso a directorios y archivos. Los clientes pueden enviar mensajes a los servidores para que manejen los directorios y lean o escriban en archivos. Además, también pueden tener acceso a los atributos de un archivo, como el modo, tamaño y tiempo de su última modificación. La mayor parte de las llamadas al sistema UNIX son soportadas por NFS, con la probable sorpresa de OPEN y CLOSE.
La omisión de OPEN y CLOSE no es un accidente. Es por completo intencional. No es necesario abrir un archivo antes de leerlo, o cerrarlo al terminar. En vez de esto, para leer un archivo, un cliente envía al servidor un mensaje con el nombre del archivo, una solicitud para buscarlo y regresar un identificador de archivo, que es una estructura de identificación del archivo. A diferencia de una llamada OPEN,esta operación LOOKLJP no copia información a las tablas internas del sistema. La llamada READ contiene al

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
identificador de archivo que se desea leer, el ajuste para determinar el punto de inicio de la lectura y el número de bytes deseados. Cada uno de estos mensajes está autocontenido. La ventaja de este esquema es que el servidor no tiene que recordar lo relativo a las conexiones abiertas entre las llamadas a él. Así, si un servidor falla y después se recupera, no se pierde información acerca de los archivos abiertos, puesto que no hay ninguno. Un servidor como éste, que no conserva información del estado de los archivos abiertos se denomina sin estado.
Por el contrario, en el sistema V de UNIX, el sistema de archivos remotos (RFS) requiere abrir un archivo antes de leerlo o escribir en él. El servidor crea entonces una entrada de tabla con un registro del hecho de que el archivo está abierto y la posición actual del lector, de modo que cada solicitud no necesita un ajuste. La desventaja de este esquema es que si un servidor falla y vuelve a arrancar rápidamente, se pierden todas las conexiones abiertas, y fallan los programas cliente. NFS no tiene esta característica.
Por desgracia, el método NFS dificulta el hecho de lograr la semántica de archivo propia de UNIX. Por ejemplo, en UNIX un archivo se puede abrir y bloquear para que otros procesos no tengan acceso a él. Al cerrar el archivo, se liberan los bloqueos. En un servidor sin estado como NFS, las cerraduras no se pueden asociar con los archivos abiertos, puesto que el servidor no sabe cuáles son los archivos están abiertos. Por lo tanto, NFS necesita un mecanismo independiente adicional para controlar los bloqueos.
NFS utiliza el mecanismo de protección de UNIX, con los bits rwx para el propietario, grupo y demás personas. En un principio, cada mensaje de solicitud sólo contenía los identificadores del usuario y del grupo de quien realizó la llamada, lo que utilizaba el servidor NFS para validar el acceso. De hecho, confiaba en que los clientes no mintieran. Varios años de experiencia han demostrado ampliamente que tal hipótesis era un tanto ingenua. Actualmente, se puede utilizar la criptografía de claves públicas para establecer una clave segura y validar al cliente y al servidor en cada solicitud y respuesta. Cuando esta opción se activa, un cliente malicioso no puede personificar a otro cliente, pues no conoce la clave secreta del mismo. Por cierto, la criptografía sólo se utiliza para autenticar a las partes. Los datos nunca se encriptan.
Todas las claves utilizadas para la autenticación, así como la demás información, son mantenidas por el NIS (servicio de información de la red). NIS se conocía antes como el directorio de páginas amarillas (yellow pages). Su función es la de guardar parejas (clave, valor). Cuando se proporciona una clave, regresa el valor correspondiente. No sólo controla las claves de cifrado, sino también la asociación de los nombres de usuario con las contraseñas (cifradas), así como la asociación de los nombres de las máquinas con las direcciones de la red, y otros elementos.
Los servidores de información de la red se duplican mediante un orden maestro/esclavo. Para leer sus datos, un proceso puede utilizar al maestro o cualquiera de sus copias (esclavos). Sin embargo, todas las modificaciones

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
deben ser realizadas únicamente en el maestro, que entonces las propaga a los esclavos. Existe un breve intervalo después de una actualización en el que la base de datos es inconsistente.
4.4.5 DNS
El DNS ( Domain Name System ) o Sistema de Nombres de Dominio es una base de datos jerárquica y distribuida que almacena informacion sobre los nombres de dominio de de redes cómo Internet. También llamamos DNS al protocolo de comunicación entre un cliente ( resolver ) y el servidor DNS.
La función más común de DNS es la traducción de nombres por direcciones IP, esto nos facilita recordar la dirección de una máquina haciendo una consulta DNS ( mejor recordar www.programacionweb.net que 62.149.130.140 ) y nos proporciona un modo de acceso más fiable ya que por multiples motivos la dirección IP puede variar manteniendo el mismo nombre de dominio.
La estructura jerárquica
Un nombre de dominio consiste en diferentes partes llamadas etiquetas y separadas por puntos. La parte situada más a la derecha es el llamado dominio de primer nivel ( Top Level Domain ) y cada una de las partes es un subdominio de la parte que tiene a su derecha.
De esta manera, si tenemos www.programacionweb.net:
net - Es el dominio de primer nivel programacionweb - Es un subdominio de net www - Es un subdominio de programacionweb
Cada dominio o subdominio tiene una o más zonas de autoridad que publican la información acerca del dominio y los nombres de servicios de cualquier dominio incluido.Al inicio de esa jerarquía se encuentra los servidores raíz, que responden cuando se busca resolver un dominio de primer nivel y delegan la autoridad a los servidores DNS autorizados para dominios de segundo nivel.

[Ci cl o 2008B]
Asignatura: Redes de Computadoras
Docente: LI. MA. DE LA LUZ AYAR MARTÍNEZ
Tipos de consulta Una consultas de un cliente (resolver) a un servidor DNS puede ser recursiva si el servidor al que consultamos consulta a su vez otro servidor o iterativa si responde a partir de los datos que tiene almacenados localmente.
Tipos de regístro Hay diferentes tipos de regístro DNS que se pueden consultar:
A (Dirección) - Este registro se usa para traducir nombres de hosts a direcciones IP. CNAME (Nombre Canónico) - Se usa para crear nombres de hosts adicionales, o alias, para los hosts de un dominio. NS (Servidor de Nombres) - Define la asociación que existe entre un nombre de dominio y los servidores de nombres que almacenan la información de dicho dominio. Cada dominio se puede asociar a una cantidad cualquiera de servidores de nombres. MX (Intercambiador de Correo) - Define el lugar donde se aloja el correo que recibe el dominio. PTR (Indicador) - También conocido como 'registro inverso', funciona a la inversa del registro A, traduciendo IPs en nombres de dominio.