universidad polit ecnica de madridoa.upm.es/67419/1/pfc_alvaro_vidal_alegria_2021.pdf · 2021. 6....
TRANSCRIPT

Universidad Politecnica de Madrid
DESARROLLO DE UN SISTEMA DERECONOCIMIENTO DE EJERCICIOS BASICOS DE
MOVILIDAD CORPORAL MEDIANTE SISTEMAS
VISUALES EMPLEANDO TECNICAS DE
APRENDIZAJE PROFUNDO
Grado en Ingenierıa de Tecnologıas y Servicios de Telecomunicacion
Alvaro Vidal Alegrıa
2021


TRABAJO DE FIN DE GRADO
Tıtulo: DESARROLLO DE UN SISTEMA DE RECONOCIMIENTO DE EJERCI-CIOS BASICOS DE MOVILIDAD CORPORAL MEDIANTE SISTEMAS VISUA-LES EMPLEANDO TECNICAS DE APRENDIZAJE PROFUNDO
Autor: Alvaro Vidal Alegrıa
Tutor: Dr. Alberto Belmonte Hernandez
Departamento: Grupo de Aplicacion de Telecomunicaciones Visuales.(GATV)
Fecha de lectura:
Calificacion:


Universidad Politecnica deMadrid
Desarrollo de un sistema de
reconocimiento de ejercicios basicos de
movilidad corporal mediante sistemas
visuales empleando tecnicas de
aprendizaje profundo
Grado en Ingenierıa de Tecnologıas y Servicios de Telecomunicacion
Alvaro Vidal Alegrıa
2021


Resumen
El mundo de la inteligencia artificial esta evolucionando rapidamente y existe una inmensacoleccion de proyectos que estan abriendo las puertas a la modernizacion mediante la digita-lizacion y automatizacion. Esto esta produciendo la aparicion de gran cantidad de artefactostanto software como hardware que permiten trabajar con estas tecnologıas de manera eficienteestando las mismas al alcance de todos. De entre todos los campos de aplicacion, la imagenes uno de los que mas relevancia ha cobrado en los ultimos anos consiguiendo, mediante IA,resolver problemas y tareas muy complejas que se hacıan bastante tediosas por medio detecnicas tradicionales de vision por computador. Empleando la salida de estos algoritmos so-bre imagenes se pueden plantear nuevas soluciones y retos a resolver ampliando el abanicode posibilidades de manera enorme. La monitorizacion de personas es una de las tareas quemas se esta realizando mediante imagen debido a la gran cantidad de ideas que se puedenemplear. Por ejemplo, la deteccion de personas permite realizar el seguimiento e incluso lare-identificacion de individuos. El reconocimiento de la postura humana permite la extraccionde una serie de puntos clave que pueden ayudar a describir que esta realizando una personaen un momento concreto. Siguiendo esto ultimo, por medio de esos puntos caracterısticos esposible realizar la deteccion y reconocimiento de actividades fısicas con aplicacion directa enel deporte o incluso la rehabilitacion. En este trabajo se emplean dichas herramientas paradetectar ejercicios basicos de movilidad y tener un control automatico, sencillo y accesiblecuyo proposito puede estar destinado a la mejora de movilidad o rehabilitacion de personas.Esto podrıa ayudar a fisioterapeutas a tener un control mas exhaustivo de las sesiones de suspacientes. Por tanto, se combinaran dos tipos de soluciones, hardware mediante una camaracapaz de emplear IA mediante un chip integrado destinado a estos propositos donde utili-zar redes neuronales complejas y que pueden conectarse a dispositivos de bajo coste comomini-computadores, y software, mediante el desarrollo de algoritmos propios para el recono-cimiento de las actividades. La salida final del proyecto sera el reconocimiento de diferentesejercicios empleando para ello una camara dedicada que usara algoritmos de deteccion depostura humana, un dispositivo de bajo coste al que se conectara la camara y que realizaralos reconocimientos a traves de IA en tiempo real y el almacenamiento de esta informacionpara ser empleada posteriormente.
Palabras Clave
Machine-Learning, Deep-Learning, RNN, Red neuronal, LSTM, DepthAI, Estimacion de lapose humana, Reconocimiento de acciones, Profundidad, BlazePose, Bidireccional.

Summary
The world of artificial intelligence is rapidly evolving and there are an immense collection ofprojects that are pushing forward to the modernization through digitization and automation.This is producing the appearance of a large number of artifacts, both software and hardware,that allow working with these technologies efficiently, being available to everyone. Among allthe fields of application, the image is one of the most relevant in the recent years, achieving, byAI, the resolution of very complex problems and tasks that have become quite tedious usingtraditional computer vision techniques. By using the output of these algorithms on images,new solutions and challenges can be proposed to be solved, expanding the range of posibilitiesenormously. The monitoring of people is one of the tasks that is being mostly carried outthrough images due to the large number of ideas that can be used. For example, peopledetection enables the tracking and even the re-identification of individuals. The recognitionof human pose allows the extraction of a series of keypoints that can help to describe whata person is doing at a specific moment. Furthermore, through these characteristic points,it is possible to carry out the detection and recognition of physical activities with directapplications in sports or even rehabilitation. In this project, these tools are used to detectbasic mobility exercises and have an automatic, simple and accesible control whose purposemay be aimed to improve the mobility or rehabilitation of people. This could help physicaltherapists to have a more comprehensive control of their patients´ sessions. Therefore, twotypes of solutions will be combined, hardware, through a camera capable of using AI throughan integrated chip destinated for these purposes where complex neural networks can be usedand that can be connected to lowcost devices such as mini-computers, and software, throughthe development of own algorithms for the recognition of activities. The final output of theproject will be the recognition of different exercises using a dedicated camera that will usehuman posture detection algorithms, a lowcost device to which the camera will be connectedand that will perfom the recognition through AI in real time and the storage of this informationto be used later on.
Keywords
Machine-Learning, Deep-Learning, RNN, Neural network, LSTM, DepthAI, Human pose es-timation, Action recognition, Depth, BlazePose, Bidirectional.

Agradecimientos
Gracias a todos los que me han acompanadodurante mis anos de carrera. A mi familia porensenarme a quererla y cuidarla. A mis padrespor darme el apoyo y el carino siempre. A “losSiete”, aunque acabamos siendo cinco, por su-frir conmigo trabajos, asignaturas y horas enla biblioteca sin perder la esperanza. Lo conse-guimos. A mis “Hoplitas” por hacerme sonreıry alegrarme los dıas siempre. Sois los mejores.Y, por supuesto, a mi hermano Juan, que fue,es y siempre sera mi referencia. Os quiero.
Por ultimo, mil gracias a mi tutor AlbertoBelmonte. La situacion del Covid-19 ha impe-dido que pasemos mas horas en la universidadpero aun ası me voy con mucho conocimien-to aprendido. Es un autentico placer saber deprimera mano que hay profesores con tanta de-dicacion y admiracion por lo que hacen comotu. No lo pierdas nunca.


Indice
1 Introduccion y objetivos 1
2 Estado del arte 4
2.1 Algoritmos para deteccion de pose humana . . . . . . . . . . . . . . . . . . . . 4
2.2 Tecnologıas para deteccion de pose humana . . . . . . . . . . . . . . . . . . . . 9
2.3 Algoritmos para reconocimiento de actividades . . . . . . . . . . . . . . . . . . 12
3 Desarrollo 17
3.1 Etapas en un proyecto de aprendizaje profundo . . . . . . . . . . . . . . . . . . 17
3.1.1 Obtencion del dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.2 Pre-procesado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.3 Creacion y entrenamiento del modelo . . . . . . . . . . . . . . . . . . . 18
3.1.4 Test del modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1.5 Despliegue del modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2 Esquema general del proyecto . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3 Obtencion de la informacion para el proyecto . . . . . . . . . . . . . . . . . . . 21
3.4 Creacion del dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.5 Modelo de Deep Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30

3.6 Montaje final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4 Resultados 37
4.1 Resultados red neuronal Vanilla . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 Resultados red neuronal Stacked . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.3 Resultados red neuronal Bidirectional . . . . . . . . . . . . . . . . . . . . . . . 44
4.4 Resultados del montaje final en tiempo tiempo real . . . . . . . . . . . . . . . . 48
5 Conclusiones y Lıneas Futuras 50
Bibliografıa 51
Anexos 54
A Aspectos eticos, economicos, sociales y ambientales . . . . . . . . . . . . . . . . 54
A.1 Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
A.2 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
B Presupuesto economico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56

Listado de figuras
1.1 Rendimientos economicos empresariales derivados de la IA por territorios enuna decada (Millones USD). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Mercado en tecnologıas de vision 3D por sectores en Norte America (MillonesUSD). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Vision global del proyecto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1 Diagrama de la red neuronal de OpenPose. . . . . . . . . . . . . . . . . . . . . 5
2.2 Deteccion de dos partes del cuerpo con los vectores de asociacion y represen-tacion final de un esqueleto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Aproximacion “top-down” usada en AlphaPose. . . . . . . . . . . . . . . . . . . 6
2.4 Esquema de la arquitectura de la red neuronal de AlphaPose. . . . . . . . . . . 7
2.5 Problema de la redundancia en la deteccion de la postura. La imagen de laizquierda muestra dos regiones individuales y en la imagen de la derecha serepresentan dos esqueletos para una misma persona. . . . . . . . . . . . . . . . 7
2.6 Esquema de la arquitectura de la red neuronal de VIBE. . . . . . . . . . . . . . 8
2.7 Representacion de cuerpos SMPL integrados en la tecnologıa VIBE. . . . . . . 8
2.8 Puntos clave de BlazePose y su despliegue en un smartphone. . . . . . . . . . . 9
2.9 Esquema de la red neuronal de BlazePose. . . . . . . . . . . . . . . . . . . . . . 9
2.10 Camara Kinect y representacion de su tecnologıa. . . . . . . . . . . . . . . . . . 10
2.11 Camaras Kinect en sus 2 versiones. . . . . . . . . . . . . . . . . . . . . . . . . . 10

2.12 Camaras RealSense. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.13 Digitalizacion generada con RealSense. . . . . . . . . . . . . . . . . . . . . . . . 12
2.14 A la izquierda, se eliminan las actividades pertenecientes al fondo de imagen. Ala derecha se detectan varias actividades potenciales que se acaban convirtiendoen una. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.15 Modelo BERT para reconocimiento de actividades en imagen. . . . . . . . . . . 14
2.16 Modelo R-C3D. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.17 Imagen que ilustra la variacion de la relacion ancho-alto del rectangulo humano. 15
2.18 Diagrama de la red neuronal del trabajo [1]. . . . . . . . . . . . . . . . . . . . . 16
3.1 Pasos en la creacion de un proyecto de aprendizaje profundo. . . . . . . . . . . 17
3.2 Principales fases del proyecto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3 Camara DepthAI OAK-D. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.4 Representacion de la informacion que recoge BlazePose para su red neuronal. . 22
3.5 Representacion de los puntos clave generados por BlazePose. . . . . . . . . . . 23
3.6 Esquema de la red neuronal de BlazePose. . . . . . . . . . . . . . . . . . . . . . 23
3.7 Puntos clave de BP en una situacion en la que no se muestra todo el cuerpoen pantalla. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.8 Flujo de conversion de un modelo mediante OpenVino. . . . . . . . . . . . . . . 25
3.9 Representacion grafica del calculo de los angulos mediante puntos clavegenerador por BlazePose. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.10 Ejercicios seleccionados para realizar la deteccion. . . . . . . . . . . . . . . . . . 28
3.11 Recoleccion del dataset y representacion mediante puntos clave de una personarealizando un ejercicio. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.12 Variacion de los angulos en un ejercicio de movimiento lateral de brazos. A laizquierda se considera el brazo derecho y a la derecha la pierna derecha. . . . . 29
3.13 Variacion de los angulos en un ejercicio de movimiento lateral de piernas. A laizquierda se considera el brazo derecho y a la derecha la pierna derecha. . . . . 30

3.14 Diagrama de una red neuronal estandar. . . . . . . . . . . . . . . . . . . . . . . 30
3.15 Representacion de neuronas en una RNN. . . . . . . . . . . . . . . . . . . . . . 31
3.16 Estructura de una red LSTM. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.17 Modelo ’many-to-one’. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.18 Nvidia Jetson Nano. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.19 Recursos software/hardware en el proyecto. . . . . . . . . . . . . . . . . . . . . 36
4.1 A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Vanilla con 20 celulas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.2 Matriz de confusion para la red Vanilla con 20 celulas. . . . . . . . . . . . . . . 38
4.3 A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Vanilla con 50 celulas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.4 Matriz de confusion para la red Vanilla con 50 celulas. . . . . . . . . . . . . . . 40
4.5 Comparativa de modelos Vanilla con 20 y 50 celulas para valores de “accuracy”,“recall” y “F1-score”. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.6 A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Vanilla con 5 celulas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.7 A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Stacked con 35 celulas. . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.8 Matriz de confusion para la red Stacked con 35 celulas. . . . . . . . . . . . . . . 42
4.9 A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Stacked con 50 celulas. . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.10 Matriz de confusion para la red Stacked con 50 celulas. . . . . . . . . . . . . . . 43
4.11 Comparativa de modelos Stacked con 35 y 50 celulas para valores de “accuracy”,“recall” y “F1-score”. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.12 A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Bidirectional con 20 celulas. . . . . . . . . . . . . . . . . . . . . . . . . 45
4.13 Matriz de confusion para la red Bidirectional con 20 celulas. . . . . . . . . . . . 46

4.14 A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Bidirectional con 35 celulas. . . . . . . . . . . . . . . . . . . . . . . . . 46
4.15 Matriz de confusion para la red Bidirectional con 35 celulas. . . . . . . . . . . . 47
4.16 Comparativa de modelos Bidirectional con 20 y 35 celulas para valores de“accuracy”, “recall” y “F1-score”. . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.17 Montaje final del proyecto. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.18 Reconocimiento del “Ejercicio 8: elevacion lateral brazos”. . . . . . . . . . . . . 49


Glosario
IA - Inteligencia Artificial
RGB - Red Green Blue
VIBE - Video Inference for human Body pose and shape Estimation
PAF - Part Affinity Field
FPS - Frames Per Second
STN - Spatial Transformer Network
SPPE - Single-Person Pose Estimator
NMS - Red Green Blue
PGPG - Red Green Blue
RMPE - Red Green Blue
HAKE - Red Green Blue
AP - Average Precision
SMPL - Skinned Multi-Person Linear model
AMASS - Archive of Motion capture As Surface Shapes
IR - Infrarrojos
TOF - Time-Of-Flight
HD - High Definition
UAV - Unmanned Aerial Vehicle
BERT - Bidirectional Encoder Representations from Transformers
TGAP - Temporal Global Average Pooling
R-C3D - Region Convolutional 3D Network
CNN y ConvNet - Convolutional Neural Network

CMOS - Complementary Metal-Oxide-Semiconductor
GAN - Generative Adversial Network
RNN - Red Neuronal Recurrente
RoI - Region of Interest
ANN - Artificial Neural Network
USB - Universal Serial Bus
OpenVINO - Open Visual Inference and Neural Network Optimization toolkit
NN - Neural Network
BP - BlazePose
SQL - Structured Query Language
BSON - Binary JavaScript Object Notation
BPTT - BackPropagation Through Time
LSTM - Long-Short Term Memory
GPU - Graphics Processing Unit
CPU - Central Processing Unit
ARM - Advanced RISC Machine
CUDA - Compute Unified Device Architecture
RAM - Random Access Memory
SD - Secure Digital

1
Introduccion y objetivos
Con el paso de los anos, la tecnologıa comienza a ser mas sofisticada y al alcance de aquellosque tengan ciertas habilidades tecnicas para su uso eficiente. La Inteligencia Artificial permiteel acercamiento a estas tecnologıas al simplificar todas esas habilidades en acciones muy facilesy comprensibles, al alcance de cualquiera. A dıa de hoy es posible acceder a programas detelevision, internet, musica, informacion, agenda, etc... mediante simples gestos o palabrasdesde el sofa de casa.
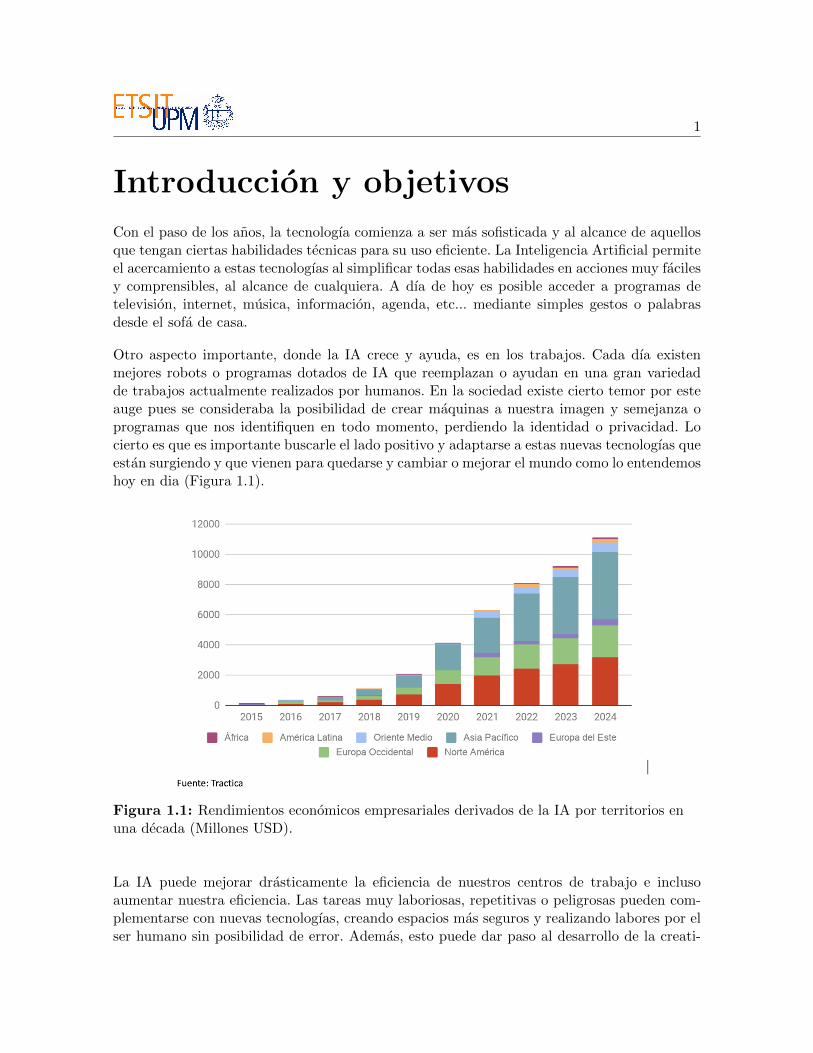
Otro aspecto importante, donde la IA crece y ayuda, es en los trabajos. Cada dıa existenmejores robots o programas dotados de IA que reemplazan o ayudan en una gran variedadde trabajos actualmente realizados por humanos. En la sociedad existe cierto temor por esteauge pues se consideraba la posibilidad de crear maquinas a nuestra imagen y semejanza oprogramas que nos identifiquen en todo momento, perdiendo la identidad o privacidad. Locierto es que es importante buscarle el lado positivo y adaptarse a estas nuevas tecnologıas queestan surgiendo y que vienen para quedarse y cambiar o mejorar el mundo como lo entendemoshoy en dia (Figura 1.1).
Figura 1.1: Rendimientos economicos empresariales derivados de la IA por territorios enuna decada (Millones USD).
La IA puede mejorar drasticamente la eficiencia de nuestros centros de trabajo e inclusoaumentar nuestra eficiencia. Las tareas muy laboriosas, repetitivas o peligrosas pueden com-plementarse con nuevas tecnologıas, creando espacios mas seguros y realizando labores por elser humano sin posibilidad de error. Ademas, esto puede dar paso al desarrollo de la creati-
2
vidad o el ingenio de las personas para conseguir crear nuevas y distintas herramientas muybeneficiosas. Por ejemplo, situaciones como la actual con el Covid-19 paralizando el mundo,se podrıan paliar o controlar eficientemente con mejoras en tratamientos, protocolos o equiposdotados de IA. Otra de las ventajas a tener en cuenta es la gran cantidad de datos con los queestas tecnologıas pueden lidiar y que serıa imposible en la mente de cualquier ser humano. Elmundo en el que vivimos esta cada vez mas repleto de informacion que resulta muy provechosay que es necesario almacenar y procesar.
La seguridad, con la deteccion e identificacion de actos ilıcitos, el bienestar, pudiendo apro-vechar mas el tiempo sin tener que realizar tareas largas, como desplazamientos, en nuestrashoras libres o la salud, generando nuevas formas de combatir enfermedades o mejorando yfacilitando la vida de aquellas personas en situaciones complejas de salud, son pilares basicospara el crecimiento de la sociedad de hoy en dıa.
Por ultimo, es importante comentar el impacto energetico. Esta claro que la energıa va a serun tema recurrente y necesario en la sociedad de los proximos anos. Todos entendemos quedebemos cuidar el planeta y una buena forma para ello es apostando por las energıas renova-bles. La IA tambien ha aportado su granito de arena desarrollando modelos sobre pronosticosde viento o mareas, o creando redes neuronales que controlen y generen diagnosticos de aero-generadores, entre otras cosas.
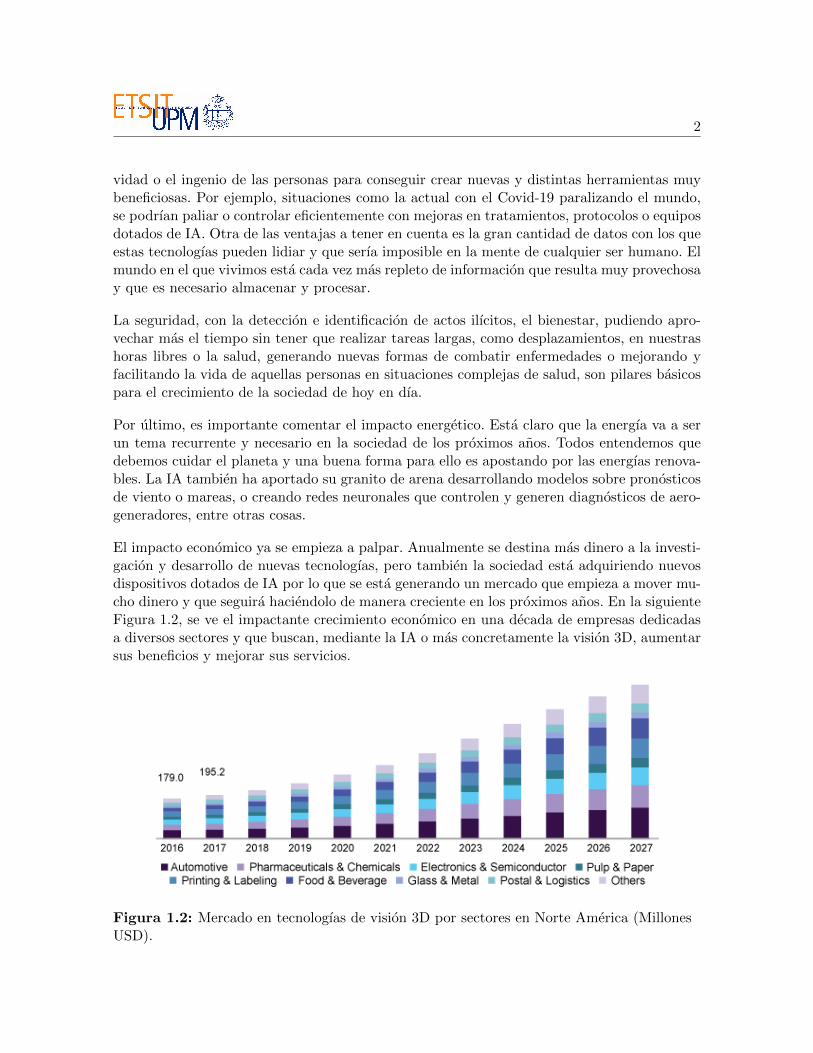
El impacto economico ya se empieza a palpar. Anualmente se destina mas dinero a la investi-gacion y desarrollo de nuevas tecnologıas, pero tambien la sociedad esta adquiriendo nuevosdispositivos dotados de IA por lo que se esta generando un mercado que empieza a mover mu-cho dinero y que seguira haciendolo de manera creciente en los proximos anos. En la siguienteFigura 1.2, se ve el impactante crecimiento economico en una decada de empresas dedicadasa diversos sectores y que buscan, mediante la IA o mas concretamente la vision 3D, aumentarsus beneficios y mejorar sus servicios.
Figura 1.2: Mercado en tecnologıas de vision 3D por sectores en Norte America (MillonesUSD).

3
En este proyecto, la intencion es generar un modelo que permita identificar 12 ejerciciosbasicos de movilidad. Las aplicaciones que puede tener este trabajo son amplias y posiblesmejoras futuras pueden abrir mas puertas. En medicina, cabe la posibilidad de que personasmayores con problemas de movilidad o con la enfermedad de Parkinson puedan beneficiarsedel modelo para una correcta monitorizacion de su actividad fısica. Ademas, en gimnasios ocentros de entrenamiento se pueden aplicar modelos similares con mayor volumen de ejerciciosdetectados para los clientes. Otra perspectiva puede ser la capacidad de tener esta tecnologıaen casa o cualquier otro lugar. En tiempos de Covid-19 han evolucionado los metodos detrabajo y vida. Este modelo ofrece una nueva manera de poder entrenar desde casa sabiendoque ejercicios realizar y sus beneficios.
Esto ultimo se debe a que en este trabajo se ha tenido en cuenta la oportunidad de poderdesplegar el modelo en dispositivos de baja exigencia computacional o portables, como Rasp-berry Pi u otros. Se trata de una manera muy eficaz de hacer llegar las nuevas tecnologıas alalcance de cualquier persona en cualquier momento y lugar. Ademas se hara uso de camarasmuy novedosas y de bajo coste que permiten realizar tareas complejas de vision 3D. Como seobserva en la Figura 1.2, el crecimiento del mercado en este tipo de aplicaciones es exponencialy por ello este trabajo hara uso de estas tecnologıas.
Figura 1.3: Vision global del proyecto.
El trabajo consistira en obtener informacion de una camara de profundidad, con la que segeneraran datos que seran procesados para introducirlos en una red neuronal empleandotecnicas de aprendizaje profundo hasta el objetivo final de identificar los ejercicios que serealicen en vivo en diversos dispositivos (Figura 1.3).
Por tanto, la estructura de este documento se divide como sigue: En primer lugar, esta In-troduccion que presenta la importancia y beneficios del uso de la IA en los proyectos y elimpacto que existe debido a ello. A continuacion se recogera el estado del arte de los algo-ritmos o soluciones que se parecen a las empleadas en este trabajo. El Desarrollo recogeratodos los detalles acerca de las implementaciones y decisiones tomadas en cuanto a algoritmos,arquitecturas y montaje final de la solucion. En el apartado de Resultados se recogeran todasaquellas graficas, metricas y valores que permitan justificar el funcionamiento adecuado delproyecto. Finalmente el apartado Conclusiones y Lıneas Futuras resumira las ideas finales ylos resultados obtenidos de cara a una posterior mejora o continuacion de la solucion actual.

4
Estado del arte
La estimacion de la pose humana consiste en la representacion del cuerpo en formato grafico,conectando puntos clave del esqueleto para describir la orientacion, los movimientos y elcomportamiento de las articulaciones de una persona. En esta seccion se van a presentar losalgoritmos del estado del arte para resolver este tipo de problemas ası como las tecnologıasprincipales que se utilizan para estas tareas.
2.1 Algoritmos para deteccion de pose humana
Con el auge de las nuevas tecnologıas de Machine Learning y Deep Learning, han surgidomuchos proyectos y aplicaciones que utilizan estas herramientas pues son capaces de realizardetecciones con una gran precision sobre imagenes en diversas situaciones y ambitos. Algunasde las aplicaciones mas reconocibles son en animacion cinematografica, en el campo de losdeportes (para analizar tecnicas de disparo o colocacion), videojuegos (generacion de avatarescon mismas caracterısticas moviles que personas reales) e incluso medicina (estudio anatomicodel cuerpo humano).
La complejidad a la hora de visibilizar correctamente dicha pose se debe a la incapacidad dedistinguir partes del cuerpo debido a la ropa, la visibilidad o iluminacion, la obstaculizacion,la variedad de tamanos del cuerpo o la deteccion entre la multitud. Es por ello por lo quese han desarrollado muchos sistemas tanto a nivel de software, con aprendizaje profundo,como de hardware, con camaras de reconocimiento corporal 3D a partir de imagenes RGBy/o sensores.
A continuacion, se van a presentar algunos de los algoritmos que han impulsado la deteccionde la pose humana con aprendizaje profundo, ası como otros mas recientes que han sabidoir dando forma a esta tecnologıa hasta convertirla en una herramienta muy beneficiosa. Secomenzara con la tecnologıa de OpenPose [2] y AlphaPose [3], siendo ambas pioneras y cen-tradas en la deteccion en dos dimensiones del cuerpo humano. Posteriormente se presentaraVIBE [4], una tecnologıa que ha conseguido introducir la tercera dimension (profundidad) demanera eficaz sin necesidad de camaras especiales estimandola automaticamente. Junto a estase presentara BlazePose [5], otro algoritmo para deteccion automatica de pose 3D optimizadopara funcionar en dispositivos de bajo coste.
OpenPose [2] es el primer sistema que detecta tanto el cuerpo, como las manos, pies ycara en tiempo real y considerando una imagen con varias personas. Se trata de un trabajorealizado por Gines Hidalgo, Yaadhav Raaj y otros en el que representan los distintos puntoscon un tiempo de carga constante que permite desplegar un total de 135 puntos clave (entrevarias personas) con una gran precision. La forma de lograr distinguir entre distintos cuerposes usando la aproximacion “bottom-up”, que primero detecta todas las partes del cuerpoen imagen y posteriormente las agrupa para diferenciar unas personas de otras. Los Part

5
Affinity Fields (PAF) [6] son vectores de 2 dimensiones que aprenden a asociar las distintasextremidades para no confundirlas con otras de otros individuos que se puedan interponer.
Su funcionamiento comienza con una prediccion de una red neuronal convolucional (Figura2.1) con kernels 3x3 sobre mapas de confianza de zonas del cuerpo. Cada vuelta a la redconsigue un refinamiento de los PAF´s hasta distinguir perfectamente las extremidades decada individuo en pantalla.
Figura 2.1: Diagrama de la red neuronal de OpenPose.
Ademas, se crean una serie de vectores que determinan el grado de asociacion entre unasextremidades y otras en una misma persona. Estos datos generados son analizados y permitenobtener las imagenes de los puntos clave de cada persona en el plano. Dicho de otra forma,primero se obtienen varios candidatos de detecciones de partes del cuerpo para todas laspersonas visibles. Estas detecciones necesitan asociarse con otras partes del cuerpo de la mismapersona por lo que se examinan dos zonas de deteccion y se calcula el grado de asociacion.Esta operacion se realiza con todas las posibles areas de deteccion hasta obtener las parejasmas optimas de todas las conexiones viables. En la Figura 2.2 se muestra un ejemplo de ello.
Figura 2.2: Deteccion de dos partes del cuerpo con los vectores de asociacion y representa-cion final de un esqueleto.

6
El sistema incluye: 15, 18 o 25 puntos del cuerpo incluidos 6 puntos del pie, 21 puntos pormano y 70 puntos para la cara (Figura 2.2). Dependiendo del uso que se necesite, se podranutilizar con mas o menos puntos pagando por mayor o menor velocidad de carga. El tiempode carga en el caso de los puntos clave generados por la mano y la cara dependera del numerode gente que haya en imagen. Sin embargo, para obtener los puntos del cuerpo y pies, esinvariante el numero de gente capturada pues se mantiene lineal, siendo un avance muy utilque se logro gracias al uso de los PAF. Ademas de esto, existe la deteccion de personas, elseguimiento de un individuo o la posibilidad de calibrar la camara como otras alternativasque otorga OpenPose. Todo ello a tiempo real y entre 15-20 fps.
A diferencia del metodo “bottom-up” de OpenPose, AlphaPose o Regional Multi-PersonPose Estimation(RMPE) [3] utiliza la aproximacion “top-down” (Figura 2.3) para la es-timacion de la pose humana. En este caso, por lo tanto, primero se detecta a la persona paradespues ir calculando sus distintos puntos y areas donde se situan las extremidades de cadaindividuo y ası formar la representacion del esqueleto. Se trata de un sistema desarrolladopor Jiefeng Li, Hao-Shu Fang y Cewu Lu que consiguieron la tecnologıa con mayor precisionmedia de entre las existentes.
Figura 2.3: Aproximacion “top-down” usada en AlphaPose.
El procedimiento que siguieron fue estimar la pose dividiendo el frame captado por la camaraen regiones y aplicar la deteccion de la postura humana a cada una de estas regiones. Paraello, hacen uso de una red neuronal convolucional (Figura 2.4) compuesta por una SpatialTransformer Network(STN) [7] sumado a la Single-Person Pose Estimation(SPPE) para de-tectar con buena calidad las posturas de cada individuo a partir de una region delimitada notan precisa.
Ademas, para eliminar una posible redundancia en la deteccion pues las regiones puedenestar superpuestas (Figura 2.5), emplean el algoritmo Non-Maximun-Suppression(NMS) [8]que compara similitudes entre poses mediante una distancia metrica entre ellas. Finalmente,anadieron un Pose-Guided Proposals Generator(PGPG) [9] que aumenta el numero de datosadecuados que necesitaran las redes previamente citadas para su correcto entrenamiento. Todo

7
ello compone el RMPE o estimacion de la pose regional para varias personas que da nombrea su tecnologıa.
Figura 2.4: Esquema de la arquitectura de la red neuronal de AlphaPose.
AlphaPose ha conseguido ofrecer 3 funcionalidades con distinta cantidad de puntos clave paraformar la representacion del esqueleto: 17, 26 y 136. Los dos ultimos se desarrollaron con lacolaboracion de HAKE [10] y Halpe [11]. Los 26 puntos pertenecen a la representacion delesqueleto como tal pero consiguieron anadir 68 puntos para la cara y 21 puntos para cadamano. El gran avance con la tecnologıa que desplegaron fue el alto nivel de precision. Losvalores en los que trabajan estan alrededor de 70 mAP, por encima de los 60 mAP que ofrecela tecnologıa de OpenPose.
Figura 2.5: Problema de la redundancia en la deteccion de la postura. La imagen de laizquierda muestra dos regiones individuales y en la imagen de la derecha se representan dosesqueletos para una misma persona.
Video Inference for human Body pose and shape Estimation o VIBE [4] es unatecnologıa muy reciente desarrollada por Muhammed Kocabas, Nikos Athanasiou y MichaelJ. Black que introduce una novedad respecto a las anteriores. Se trata de poder visualizarel cuerpo humano entero en 3 dimensiones solo con algoritmos de aprendizaje profundo. El

8
metodo utilizado es predecir cuerpos SMPL[12] (Skinned Multi-Person Linear model), modelorealista de un cuerpo humano en 3D como los mostrados en la figura 2.7, utilizando un redneuronal convolucional que produce puntos clave del esqueleto en 2D (Figura 2.6).
Figura 2.6: Esquema de la arquitectura de la red neuronal de VIBE.
El resultado de ello se introduce en un discriminador movil junto con otra prediccion delmovimiento de un cuerpo proporcionado por un enorme dataset 3D llamado Archive of MotionCapture as Surface Shapes (AMASS) [13]. Esto conseguira darle un aspecto mas realista delo que el movimiento de un cuerpo humano es, puliendo las imperfecciones que puedan surgiren la estimacion resultante de la red neuronal.
Figura 2.7: Representacion de cuerpos SMPL integrados en la tecnologıa VIBE.
Otro modelo cuyos puntos del esqueleto se presentan en 3D es BlazePose [5]. El trabajorealizado por Valentin Bazarevsky y su equipo permite la obtencion de 33 puntos clave delcuerpo a una velocidad de 30 fps para una persona individual en un dispositivo pequenocomo un smartphone Pixel 2 (Figura 2.8). Para ellos la deteccion del cuerpo recae primeroen detectar la cara. Los rasgos faciales contienen muchas caracterısticas, ocasionando buenassenales en las redes neuronales a la hora de detectarlas. Ademas, hay muy pocas variaciones,en general, entre unas caras y otras por lo que se puede adaptar a cualquier persona. Otraventaja es que se puede predecir facilmente la alineacion del cuerpo, por ejemplo, sabiendo quelas caderas se encuentran en el punto medio entre la cara y los pies. Esto permitira acelerarel proceso de carga a cambio de perder cierta eficiencia. La contra que tiene es que la camaranecesita tener obligatoriamente vision de la cara para que el modelo funcione.

9
Figura 2.8: Puntos clave de BlazePose y su despliegue en un smartphone.
La deteccion se realiza utilizando mapas de calor, compensacion y regresion en su red neuronal(Figura 2.9). Tambien omiten ciertas conexiones entre distintas etapas de la red para conseguirun balance entre las caracterısticas mas o menos relevantes. Ello sumado a limitaciones enlos rangos de angulos y escalas hace que esta tecnologıa sea apta para ser desplegada endispositivos con pocos recursos computacionales.
Figura 2.9: Esquema de la red neuronal de BlazePose.
2.2 Tecnologıas para deteccion de pose humana
En el mundo de los videojuegos Microsoft introdujo en 2010 un controlador llamado Kinect[14] que permitıa a los jugadores interactuar con la consola mediante gestos y movimientos.Mas tarde, los desarrolladores liberaron el codigo a la comunidad, surgiendo un gran abanicode usos en distintos campos, ademas de continuar mejorando y generando nuevas versionespara sus propios dispositivos.

10
La clave del controlador pionero se halla en la aparicion de sensores de profundidad y un buenprocesador para recoger y analizar toda la informacion. El sistema contiene una camara RGBque detecta la luz visible y sigue los movimientos del jugador ademas de un proyector IR quemanda rayos infrarrojos en todas las direcciones y estos rebotan en los objetos de la sala. Unsensor CMOS crea el espacio de juego, es decir, simula el entorno para posteriormente poderinteractuar con el. El uso de los rayos IR hace que se pueda diferenciar la profundidad por loque se obtienen imagenes 3D. La tecnica de generacion del espacio mediante la proyeccion deun patron de luz empleada se denomina Structured Light (escaner de luz estructurada). Sepuede apreciar el funcionamiento interno del aparato en la figura 2.10.
Figura 2.10: Camara Kinect y representacion de su tecnologıa.
Figura 2.11: Camaras Kinect en sus 2 versiones.
La segunda version, la Kinect v2, no utiliza los rayos infrarrojos y los desarrolladores optaronpor los sensores TOF (Time of Flight) que emiten senales lumınicas hacia los obstaculos de lahabitacion y son acumuladas a su vuelta para medir el tiempo que tarda en recorrer el trayectoy ası calcular la distancia a la que se encuentran en el procesador. El mayor problema quesurgıa era minimizar el desenfoque que realiza la camara con los movimientos pues afectabamucho para su correcto funcionamiento. Todo ello se logro solucionar y se consiguio procesar6,5 millones de pıxeles por segundo de manera muy precisa e incluso en condiciones de extrema

11
baja visibilidad. Otras mejoras con la nueva version fueron la capacidad de funcionar a 30fps a alta definicion, capacidad de rastrear a 6 personas, a diferencia de las 2 personas de laversion 1, identificar mas articulaciones, mayor distancia de profundidad y mayor angulo devision. Las diferencias fısicas de las dos versiones de la camara se muestran en la Figura 2.11.
Gracias a la liberacion del codigo han aparecido aplicaciones mas alla de los videojuegosque pueden ser muy interesantes. Skanect permite obtener un modelado en 3D de cualquierobjeto con la tecnologıa Kinect para poder imprimirlo en un objeto real o incluso incorporardichos elementos en juegos o pelıculas. Tambien se usa en el campo de la salud para adquirirobservaciones delicadas durante cirugıas, o como traductor de lenguajes de signos a textoidentificando los gestos del comunicador. Otros empleos de las camaras Kinect son en robotica,domotica, agricultura o realidad aumentada.
Intel tambien ha apostado por camaras de profundidad y sacaron al mercado las RealSense[15]. Se trata de otro sistema que salio a la luz en 2014 y que tiene caracterısticas muy similaresa las de la camara Kinect.
Esta compuesto por 3 escaneres opticos: una camara de alta definicion 1080p, una camarainfrarroja y un proyector laser. Se trata de un dispositivo muy preciso y en el que Intel haquerido ofrecer dos alternativas para satisfacer las necesidades que pueda tener cada cliente.Cada camara tiene dos aplicaciones diferentes: corto o largo alcance. La primera se centraespecialmente en los gestos de las manos, la cara (Figura 2.12) y reconocimiento de objetos.Por ello, su uso es mas adecuado en espacios interiores para que un usuario individual tengadiversas formas de interactuar con el dispositivo. La opcion de largo alcance tiene aplicacionessimilares pero con la ventaja de poder usarlo en espacios exteriores o interiores a larga distanciacon maxima precision. La resolucion del aparato es HD de hasta 1280x720 con 90 fps.
Figura 2.12: Camaras RealSense.
La idea de esta tecnologıa es poder adaptarla al dıa a dıa de las personas integrandola enlos dispositivos cotidianos como portatiles, smartphones, tablets, etc. Asimismo estan traba-jando paralelamente en la creacion de distintos software para acoplar funcionalidades en susdispositivos. Algunas que ofrecen actualmente son el escaner e impresion 3D, digitalizacion yreconocimiento de voz.

12
Muchas son las empresas que ya introducen la tecnologıa RealSense en sus proyectos. Yuneecanuncio el primer UAV (Unmanned Aerial Vehicle) inteligente, DAQRI impulso la seguri-dad y eficacia en el trabajo esencialmente industrial, Zappos o Memomi pretenden mejorarla experiencia de compra de ropa online reconociendo las medidas del consumidor o incluso”probandose”la ropa online mediante la camara y, por supuesto, hay muchas empresas dedi-cadas al mundo de los drones que usan estos dispositivos. En la Figura 2.13 puede verse unaposible utilidad.
Figura 2.13: Digitalizacion generada con RealSense.
Finalmente y para mostrar la gran importancia que tienen estos dispositivos hoy en dıa, sepresentan otros fabricantes que estan trabajando con este tipo de tecnologıas. PrimeSense,desarrollado por Apple, busca el control de AppleTV mediante gestos. Canesta, actualmenteincorporada en los equipos de Microsoft, tambien desarrolla sensores 3D de un solo chipbasados en CMOS. Las camaras de los fabricantes de Orbbec ofrecen muy buenas prestacionesen cuanto a rango, precision y resolucion. Fastree3D, TriDiCam, LMI Technologies o EsprosPhotonics son otros productores de este sector.
2.3 Algoritmos para reconocimiento de actividades
Como se puede observar, son muchas las aplicaciones y las tecnologıas que se estan nutriendodel reconocimiento del cuerpo, la cara, los gestos e incluso las emociones. Una de ellas es elestudio de las actividades fısicas realizadas por personas. En este trabajo se van a detectarciertos movimientos/ejercicios por lo que se van a presentar diferentes algoritmos y solucionesexistentes en la literatura.
Al principio se clasificaban exclusivamente imagenes con redes neuronales y, posteriormente,vıdeos grabados. El problema con estos ultimos surgıa en recortar, de la forma mas precisa,el inicio y fin de una accion, especialmente si se trataba de movimientos largos.

13
Un metodo que desarrollaron alumnos de la Universidad de Hong Kong, China, fue generarvarias propuestas de region temporal mediante un procedimiento ascendente [16]. Primeroextraıan pequenos fragmentos aleatoriamente, posteriormente evaluaban y clasificaban las ac-ciones presentes en dichas particiones para finalmente agruparlos en propuestas de regionesdonde se realiza un determinado movimiento. Este conjunto de candidatos se catalogaba me-diante una canalizacion en cascada. El primer paso era eliminar acciones que no se encontrabanen primer plano y clasificaba los restantes. Como estas todavıa podıan contener instancias in-completas, procedieron a filtrar tales propuestas utilizando filtros completos especıficos paracada clase que hara que se entrelacen dos fragmentos esencialmente iguales. Vease un ejemplode ello en la Figura 2.14
Figura 2.14: A la izquierda, se eliminan las actividades pertenecientes al fondo de imagen.A la derecha se detectan varias actividades potenciales que se acaban convirtiendo en una.
Otros alumnos de la Universidad Tecnica del Medio Oriente, en Turquıa, optaron por reem-plazar en sus redes neuronales la capa de TGAP (Temporal Global Average Pooling) paraintroducir Bidirectional Encoder Representations from Transformers (BERT). TGAP [17] esuna operacion que pretende sustituir las capas conectadas de las redes neuronales convolucio-nales clasicas en un mapa de caracterısticas para cada categorıa correspondiente de la tareade clasificacion. El problema que detectaron era que esta capa obstaculizaba la riqueza dela informacion temporal que consideraban, junto a la informacion espacial, las dos grandesherramientas a utilizar para el reconocimiento de acciones.
BERT [18] consiguio hacer uso de los datos temporales al poseer la bidireccionalidad. Estapropiedad permite fusionar la informacion contextual de ambas direcciones, en lugar de depen-der solo de una direccion. Gracias a esta nueva arquitectura se propagan todos los fotogramasseleccionados de la secuencia a traves de la red neuronal convolucional 3D sin aplicar lospromedios temporales propios de TGAP. Finalmente y con el fin de preservar la informacionposicional, agregaron una codificacion posicional a las caracterısticas extraıdas. La deteccionde una accion se predice mediante el vector de clasificacion ycls (Figura 2.15) que se entrega

14
a la capa completamente conectada para obtener la etiqueta predicha de salida.
Figura 2.15: Modelo BERT para reconocimiento de actividades en imagen.
Otro algoritmo de deteccion de actividades pero esta vez con vıdeos transmitidos continua-mente sin recortes ni grabaciones fue realizado en la Universidad de Boston, Estados Unidosde America. Huijuan Xu y su equipo propusieron la Region Convolutional 3D Network (R-C3D) [19]. La idea principal es que este modelo codifica el video que se transmite usandouna red neuronal tridimensional completamente convolucional, despues genera regiones tem-porales candidatas a contener acciones y finalmente clasifica dichas regiones en actividadesespecıficas.
Figura 2.16: Modelo R-C3D.
Como se observa en la Figura 2.16, la red consiste en 3 componentes. Primero se encuentraun extractor compartido de caracterısticas 3D ConvNet [20]. Su funcion es extraer eficiente-mente jerarquıas de caracterısticas espacio-temporales pues, como se ha visto en la tecnologıaBERT, son propiedades muy importantes en representacion de vıdeos. La subred de propues-tas, de color rosado en la Figura, predice segmentos temporales de longitud variable que sonpotenciales de contener una actividad tomando como referencia segmentos fijos que se defi-nen previamente. La ultima parte es la subred de clasificacion. Sus 3 funciones principalesson: selecciona segmentos propuestos por la capa anterior, agrupa regiones de interes (RoI)3D para extraer singularidades de tamano fijo de las propuestas previamente seleccionadasy, por ultimo, clasifica las actividades y analiza la regresion de lımites para las propuestasseleccionadas basado en las caracterısticas agrupadas.

15
Esta tecnologıa tambien emplea el algoritmo NMS para eliminar posibles superposicionesentre propuestas de actividades. Otra innovacion importante que ejecutaron fue extenderel agrupamiento de RoI´s 2D en Faster R-CNN (rapidas redes neuronales convolucionalesbasadas en regiones que permiten reducir el coste compotucional compartiendo convolucionesentre propuestas) a agrupamientos de RoI´s 3D. Esto permite extraer caracterısticas cuandoaparecen varias resoluciones para las propuestas que varıan en tamano.
Todos los metodos anteriores se basan directamente en el analisis de imagen mediante redesneuronales para extraccion de caracterısticas que puedan representar eficientemente diferentesactividades. Otro tipo de soluciones se basan en el empleo directo del esqueleto extraıdomediante cualquier algoritmo previo o detectado por las tecnologıa presentadas anteriormente.
Figura 2.17: Imagen que ilustra la variacion de la relacion ancho-alto del rectangulo hu-mano.
Por ejemplo, un trabajo realizado por estudiantes de la Universidad de Geociencias, China,desarrollo un modelo para detectar caıdas haciendo uso de la pose humana de OpenPose [21].La razon que detectaron en las caıdas, especialmente en personas mayores, es que el centro degravedad del cuerpo humano no esta estable o rompe su simetrıa, por lo que el cuerpo pierdeel equilibrio. El proyecto gira en torno al principio de simetrıa. Primero, obtienen los puntosclave del esqueleto e identifican las caıdas segun tres parametros: la velocidad de descenso delpunto situado en la cadera, el angulo existente entre la lınea vertical centrada del cuerpo y elsuelo, y la relacion ancho-alto del rectangulo externo del cuerpo humano que se puede generarcon su silueta (ver Figura 2.17).

16
Ademas, consideran en el trabajo si la persona que ha sufrido una caıda se puede levantaro no. Si durante un perıodo de tiempo no se detecta que la persona se ha puesto de pie,sonarıa una alarma para una posible atencion medica. La manera en la que implementan estoes exactamente igual que la deteccion de caıdas pero en orden inverso y considerando que esmas lento el proceso de ponerse de pie que el de caerse. Su modelo funciona a un 97 % deprecision.
Un modelo muy interesante que desarrollaron en la Universidad de Paris-Seine combina la esti-macion de la postura humana con el reconocimiento de acciones [1]. La Figura 2.18 representade manera sencilla la metrica que siguen. Primero adquieren los puntos de la pose humanasobre imagenes en estatico ademas de caracterısticas visuales y temporales que puedan serviren la deteccion. Con las coordenadas de los puntos, producen mapas de calor de accionessencillas usando redes neuronales convolucionales. En combinacion con esto, realizan otro re-conocimiento en una red muy similar pero esta vez usan como entrada las caracterısticas deapariencia y los mapas probabilısticos que se obtienen al final de la parte de la estimacion de lapose. La idea es que esta combinacion distinga acciones similares en cuanto a movimiento delcuerpo, como beber cafe y llamar por telefono, pero que con la informacion visual se puedandiferenciar.
Figura 2.18: Diagrama de la red neuronal del trabajo [1].

17
Desarrollo
La deteccion de ejercicios es una herramienta muy util en una inmensidad de problematicas. Elobjetivo del proyecto es poder detectar de forma automatica ejercicios de movilidad basica quepuedan valer tanto para ensenanza como para facilitar a posibles pacientes en rehabilitacionsu correcto posicionamiento y realizacion de cada ejercicio. La parte mas interesante es tenerla posibilidad de desplegar este sistema en cualquier lugar deseado.
En este apartado se van a presentar detalladamente los pasos seguidos a lo largo del trabajo.Para empezar, se presentara la manera de proceder que todo proyecto de “aprendizaje profun-do” aplica, se mostrara posteriormente como se ha obtenido el dataset utilizado para mas tardeexplicar en profundidad el modelo creado para el reconocimiento de ejercicios. Finalmente semostrara el montaje final del proyecto mostrando su funcionamiento y disposicion.
3.1 Etapas en un proyecto de aprendizaje profundo
Todo proyecto de aprendizaje profundo sigue siempre la misma dinamica. En esta seccionse va a explicar cada uno de sus puntos para facilitar la comprension del trabajo. Como seobserva en la Figura 3.1, los 5 pasos son: obtencion del dataset, pre-procesado de los datosrecolectados, creacion del modelo, entrenamiento y analisis, test de dicho modelo y desplieguedel mismo.
Figura 3.1: Pasos en la creacion de un proyecto de aprendizaje profundo.
3.1.1 Obtencion del dataset
Los metodos de Deep Learning aprenden mediante ejemplos. Estos no son mas que una ampliacantidad de datos que sean de calidad y que contemplen todas las variantes posibles de lo quese quiere predecir para poder entrenar optimamente la red al reconocer ciertos patrones enellos.

18
La manera mas sencilla es buscar datasets existentes y libres que ofrecen gratuitamente atraves de internet diversas empresas o grupos de investigacion. Tambien existe la posibilidadde pagar por datos a companıas especializadas que buscaran lo que mas se adecue a tu pro-yecto. Por ultimo, la creacion propia del dataset es una buena forma de dotarse con los datosnecesarios para tu propio diseno siempre y cuando sea posible y viable recolectar informacionsuficiente y anotarla adecuadamente. Las redes se entrenan con numeros por lo que los datasetson filas y columnas repletas de cifras que pueden representar otro tipo de datos no-numericos,como imagenes.
Finalmente, se debe tener en cuenta que parte del dataset va a ser utilizado para entrenarla red (Training Dataset), otra parte para validar el modelo entrenado (Evaluation Dataset)y finalmente se reserva una parte para testeo final cuando el modelo cumple los requisitosdeseados.
3.1.2 Pre-procesado
A continuacion, se va a seleccionar y dar forma a los datos del dataset para crear senalespredictivas que viajaran a traves de la red neuronal. Hay modelos que requieren tambienparte de los datos para comprobar si funciona la red final, pero en este trabajo se pretendeque las detecciones se hagan en vivo.
Esta seccion es muy importante. Si bien la obtencion de datos necesita que se realice cuida-dosamente para que sean claros, aquı es fundamental que nuestros datos queden dispuestosde la manera correcta porque sino la red no los entendera y no se podra entrenar.
Dentro de este apartado se aplican diferentes algoritmos, o tecnicas para limpiar los datos yadaptarlos adecuadamente para que sean mejor entendidos por los modelos de aprendizaje.Por ejemplo cuando se tienen datasets de datos en crudo, muchas veces hay valores que noestan completos o son erroneos. En el caso de imagenes, a veces es necesario realizar algunascorrecciones de iluminacion, eliminar rotaciones o filtrar imagenes mal captadas y que no seanutiles.
3.1.3 Creacion y entrenamiento del modelo
En tercer lugar, se van a utilizar los datos anteriormente tratados para entrenar la maquina.Existen una multitud de modelos que puedan encajar en diversos proyectos. Se van a presentaralgunos importantes y que tipo de datos o tareas son mas utiles para cada uno de ellos.
Las redes neuronales artificiales profundas (ANN) son usadas cuando la entrada se componede un vector de informacion con caracterısticas extraıdas de los datos con algoritmos previoso empleando los datos en crudo preprocesados y adaptados.

19
Las redes neuronales convolucionales (CNN) han sido disenadas para el procesamiento dematrices estructuradas, como imagenes. Las imagenes contienen informacion numerica dondepueden encontrarse patrones o variaciones de gran utilidad donde hay una relacion espacialde la informacion. Es por ello por lo que se usan principalmente en proyectos relacionadoscon la vision artificial como clasificacion de imagenes, deteccion de objetos y segmentacion.
Existen tambien las redes neuronales recurrentes (RNN). Normalmente las redes actuan enuna direccion, es decir, los datos viajan desde la capa de entrada hacia la capa de salidasin tener en consideracion valores previos. En este caso, las RNN recorren ambas direccionescomo si de una retroalimentacion se tratase. Estas redes son muy utiles para analizar datosde series temporales, considerando el tiempo un dato o dimension mas a tener en cuenta,extraıdo gracias a su estructura.
Las redes generativas antagonicas (GAN) [22] consisten en usar 2 redes neuronales artificialesque se van a oponer la una a la otra. Una de las redes, denominada generativa, va a producirmuestras de lo que se quiera crear (imagenes, textos, sonidos...) y la otra, llamada discrimi-nadora, las analiza y decide si se ajusta o no al conjunto de datos utilizados para entrenar, esdecir, el dataset ya pre-procesado. Si la muestra se descarta, la red generadora sera notificadasobre cuanto se ha equivocado respecto a la referencia. Las aplicaciones mas comunes son engeneradores de imagenes, vıdeos o voces ası como generacion de texto.
Seleccionado el modelo para el proyecto a desarrollar se tienen que adecuar otra serie dehyper-parametros para realizar el entrenamiento. La seleccion adecuada de estos parametroses un problema bastante complejo y que necesita de experimentacion suficiente para escogerloscorrectamente.
3.1.4 Test del modelo
En este paso se procede a comprobar la eficacia de la red enfrentandola a datos nunca vistospor esta. Se dispone de un nuevo dataset de evaluacion y se hace pasar por la red para evaluar,con distintas metricas, si el modelo es optimo y sabe responder a ellas.
Si se cumplen los requisitos perseguidos en terminos de los valores aportados por las metricasse procede al despliegue del modelo. Si no se cumplen los requisitos de precision o de valo-res esperados en las metricas entonces se vuelve atras, se seleccionan nuevos parametros deentrenamiento o se elige un modelo diferente y se procede de nuevo al entrenamiento hastaconseguir los resultados esperados.
En el caso de las predicciones que se veran en este proyecto, los datos que van a testear la redse recolectan en vivo mediante una camara por lo que no se necesitarıa de un banco de datosdistinto al del entrenamiento.

20
3.1.5 Despliegue del modelo
El ultimo paso consiste en la integracion del modelo en la aplicacion o proyecto que se esta de-sarrollando. Esta etapa es de vital importancia pues cada proyecto funcionara de una maneradistinta y la integracion correcta del modelo necesita recoger los datos de entrada correcta-mente para poder hacer las predicciones y que sean usadas posteriormente para cualquierfin.
3.2 Esquema general del proyecto
Figura 3.2: Principales fases del proyecto.
En la Figura 3.2 se presenta de forma esquematica los pasos que sigue este proyecto hastael resultado final, la deteccion de ejercicios basicos de movilidad. En primer lugar, se realizauna grabacion de todos los ejercicios con distintas personas con el dispositivo OAK-D, estosera el dataset usado para entrenar el algoritmo de deteccion. A traves del modelo BlazePoseque se incorpora (para deteccion automatica de puntos en 3D), se obtienen las coordenadasde los puntos del esqueleto en cada frame para mas tarde tratarlos, obteniendo los angulos

21
entre diferentes articulaciones y dividiendo los datos en ventanas. Los datos generados en eldataset se introducen en una red neuronal para el entrenamiento. Finalmente, el modelo seracapaz de identificar los 12 ejercicios que se realicen en vivo.
3.3 Obtencion de la informacion para el proyecto
Para la realizacion del proyecto, se ha utilizado material hardware y software muy necesario ala hora de obtener los datos que seran introducidos en la red neuronal. Primero se comentarala camara con la que se van a grabar los ejercicios de distintas personas. Mas adelante,se explicara en detalle el algoritmo de BlazePose que devolvera los puntos clave en 3D delesqueleto con los que se va a trabajar. Finalmente, la camara no tiene incluido dicho modeloen su software interno por lo que se procedera a describir la manera de convertir dicho modelopara que sea compatible con la camara.
DepthAI es una plataforma de inteligencia artificial espacial construida alrededor de la My-riad X, unidad de procesamiento de vision de Intel que incorpora un acelerador de hardwareespecıfico para el uso de redes neuronales profundas. La camara OAK-D, que se utiliza en elproyecto, reune un sistema completo de hardware, firmware, software y capaz de incorporarinteligencia artificial personalizada de manera eficaz y rapida. Esto ayuda a liberar el procesa-miento de datos en los dispositivos personales. Asimismo, ofrece informacion de profundidad,ademas de diferentes aplicaciones incluidas y ya desarrolladas por el fabricante para su usoinmediato como la deteccion de objetos, vehıculos y caras o el seguimiento de personas.
La OAK-D (Figura 3.3) es un dispositivo que contiene 3 lentes: 2 laterales que funcionan a720p, 120 fps y 1MP y una central RGB a 12MP y 4k de resolucion y un maximo de 60 fps. Elcampo de vision es de 81º en vertical y entorno a 70º horizontal, dotado con autoenfoque. Suinstalacion es sencilla y puede funcionar en varios dispositivos mediante un cable USB3C-USBy su fuente de alimentacion.
Figura 3.3: Camara DepthAI OAK-D.

22
La camara se va a dotar de la arquitectura de BlazePose [5]. Se trata de un modelo de redneuronal convolucional ligero para la estimacion de la pose humana en 3D con la ventaja defuncionar en vivo en dispositivos de baja exigencia computacional como smartphones.
El algoritmo se centra en la cara de la persona en pantalla. Tras varias observaciones, se llegoa la conclusion de que donde habıa un mayor contraste de caracterısticas y menos variacionesentre distintos sujetos era en el rostro. Esto resulta muy util para la deteccion de la posicion deltorso y, por consiguiente, para la futura estimacion de la postura humana. Entonces, primerose detecta la cara y, posteriormente, se predicen datos importantes como el punto situado enel medio del cuerpo, alrededor de la cadera, el tamano del cırculo que circunscribe el cuerpoentero y la inclinacion, que se trata del angulo entre la lınea de los hombros y la cadera. Enla Figura 3.4 se aprecian con claridad estos elementos.
Figura 3.4: Representacion de la informacion que recoge BlazePose para su red neuronal.
El equipo encargado de esta tecnologıa necesito de un dataset donde la persona en pantallaestuviese visible entera y en todo momento con la cara visible, aunque utilizaron un aumentosustancial que simula la oclusion para asegurarse de que el modelo soporta posibles obstruc-ciones entre personas u objetos. Este dataset consta de 60K imagenes de una o pocas personasen escena en posturas comunes y 25K imagenes de una persona realizando ejercicios fısicos.
La topologıa nueva que ofrecen consta de 33 puntos clave del cuerpo humano basados enlos que usan BlazeFace [23], BlazePalm [24] y Coco. Al contrario que OpenPose y Kinect, elmodelo no genera muchos puntos clave en las manos, cara y pies para un mejor procesadosino que produce los necesarios para estimar la rotacion, tamano y posicion de la region deinteres para el modelo subsiguiente. En la Figura 3.5 se muestran los puntos que conformanel cuerpo de una persona.
La forma en la que consiguen generar estos puntos es combinando mapas de calor, compen-sacion y aproximacion regresiva (Figura 3.6). Las dos primeras se utilizan en la etapa deentrenamiento y eliminan las capas de salida correspondientes al modelo antes de ejecutar la

23
Figura 3.5: Representacion de los puntos clave generados por BlazePose.
deduccion. Por lo tanto, usan de manera efectiva los mapas de calor para supervisar la incrus-tacion ligera, que luego es utilizada por la red de codificacion de regresion. Tambien empleanactivamente conexiones de salto entre todas las etapas de la red para lograr un equilibrioentre las caracterısticas de bajo y alto nivel. Sin embargo, los gradientes del codificador deregresion no se propagan de vuelta a las caracterısticas de los mapas de calor entrenados. Estono solo mejora las predicciones de mapas de calor, sino que tambien aumenta sustancialmentela precision de la regresion de las coordenadas.
Figura 3.6: Esquema de la red neuronal de BlazePose.
Finalmente, para respaldar la prediccion de puntos invisibles, simulan oclusiones durante elentrenamiento e introducen un clasificador de visibilidad por puntos que indica si un punto enparticular es ocluido y si la posicion predicha se considera inexacta. Esto permite el rastreode personas constantemente incluso en situaciones de nula vision directa del cuerpo, comocuando la mayorıa del cuerpo esta fuera de la escena o solo la parte superior del cuerpo esvisible (Figura 3.7). Destacar de nuevo que los puntos detectados son en 3 dimensiones.

24
Figura 3.7: Puntos clave de BP en una situacion en la que no se muestra todo el cuerpoen pantalla.
Para el uso de este modelo dentro de la camara propuesta es necesario convertirlo a un formatoentendible por el dispositivo. La camara incorpora la tecnologıa OpenVINO (Open VisualInference and Neural Network Optimization toolkit) gracias a la cual se pueden desarrollaraplicaciones y soluciones que emulan la vision humana sobre arquitecturas de Intel. OpenVINOse basa en una red neuronal (NN) que se implementa sobre una gran variedad de recursoshardware de Intel para maximizar el rendimiento.
OpenVINO [25] es un conjunto de herramientas pensado para disenar soluciones de Vision porComputador con las mejores prestaciones y menores tiempos de desarrollo posibles. Permiteun acceso muy sencillo a todo el conjunto de opciones hardware de Intel para mejorar elrendimiento, reducir el consumo de energıa y maximizar la utilizacion del hardware, con laintencion de poder hacer mas con menos recursos y abrir nuevas posibilidades de diseno.
El conjunto de herramientas de Intel Deep Learning Deployment (Intel DL DeploymentTool-kit) esta integrado en el conjunto de herramientas de OpenVINO y esta disenado para acelerarlos resultados de la inferencia del aprendizaje profundo. Estas herramientas incorporan un mo-tor de inferencia con plugins para distintas plataformas hardware de manera individual (CPU,GPU, VPU, y FPGA), pero tambien formando sistemas heterogeneos con cualquier combi-nacion de ellas. Un optimizador de modelos capaz de tomar como entrada descripciones deentornos de aprendizaje profundo como Caffe y TensorFlow y generar representaciones inter-medias (IR) sobre las que poder trabajar. La Figura 3.8 representa el flujo de conversion deun modelo previamente entrenado con otros frameworks de programacion.
En el caso de este trabajo el modelo original BlazePose esta desarrollado en el framework deprogramacion de redes neuronales “Tensorflow”. Debido a esto y gracias a OpenVino, medianteel uso de diferentes herramientas se puede convertir el modelo original a una representacionintermedia entendible por el software y hardware de la camara y que permite trabajar demanera optimizada con el modelo.

25
Figura 3.8: Flujo de conversion de un modelo mediante OpenVino.
Tras la conversion del modelo y el uso en la camara se comprueba que se consigue unavelocidad de procesado de entre 10-15 fps para deteccion de una sola persona visible. Cabedestacar que el modelo BlazePose esta disenado para dispositivos menos potentes y conseguiresta velocidad de procesado en esta camara es un resultado muy interesante debido a la grancantidad de informacion que se puede recolectar en tiempo real (objetivo del trabajo).
3.4 Creacion del dataset
Un buen dataset es basico para cualquier proyecto de Deep Learning. Para poder entrenar a lamaquina y que sepa predecir aquello que se busca, es necesario entregarle mucha informacionque represente con claridad el patron que siguen las caracterısticas que se desea que la redaprenda.
En este trabajo se pretende detectar 12 ejercicios basicos de movilidad. Estos ejercicios, selec-cionados cuidadosamente para que participen la mayor cantidad de musculos y articulacionesdel cuerpo, no se encuentran en datasets ya creados por comunidades o empresas dedicadasespecıficamente a esta tarea. Es por ello que se opta por la creacion propia del dataset.
En el dataset de este proyecto se quiere obtener informacion suficiente sobre el movimientogenerado por los ejercicios de manera que la red neuronal aprenda los patrones que sigue ymas tarde consiga detectar dichos patrones cuando se realicen ejercicios en vivo e identificarde que ejercicio se trata.
El procedimiento para calcular y obtener esta informacion es operando sobre los puntos clavedel esqueleto que genera el modelo de BlazePose para conseguir angulos. Los angulos van aser los datos de entrada que la red dispondra para el entrenamiento. La decision de porqueusar los angulos tiene varias razones principales. La primera de ellas, es que no existe unadependencia entre el tamano de la persona y los puntos clave que se extraen. Se elimina ası

26
por tanto, tener que normalizar los esqueletos detectados en el espacio. La segunda razones que habra diferencias notables dependiendo del ejercicio realizado pues en un ejercicio debrazos donde no intervengan las piernas, los angulos calculados para las piernas presentaranun valor practicamente constante mientras que los angulos extraıdos de los brazos variaranen un rango concreto. Finalmente, se esta trabajando con datos recolectados en el tiempopor lo que hay una dependencia temporal completa en los datos lo cual sera util de cara aseleccionar un modelo de redes neuronales para la deteccion.
Para el calculo de los angulos, se han considerado dos planos de 2 dimensiones. El primero enel plano x-y y el segundo en el z-y. De esta manera, se podra realizar cualquier movimiento entodo el espacio disponible y se recolectara la informacion necesaria. Es importante estableceren primer lugar un eje de coordenadas en uno de los dos puntos en los que se quiere calcularel angulo. Se ha considerado uno de ellos como centro del eje y el otro punto el que genera eseangulo respecto al centro. Seguido a esto, se obtiene la hipotenusa, que es el segmento de uneambos puntos del esqueleto, del triangulo rectangulo formado tambien por los catetos, que sonlas proyecciones de x e y sobre los ejes. Los catetos, o las proyecciones sobre el eje, se calculanrestando las coordenadas x e y del punto del centro del eje menos las mismas coordenadas delotro punto. Finalmente, se calcula el arcoseno de la division de la proyeccion sobre el plano xentre la hipotenusa. Finalmente, se transforma el angulo generado en radianes a grados paramejor comprension. En la siguiente Figura 3.9 se muestra visualmente este proceso.
Figura 3.9: Representacion grafica del calculo de los angulos mediante puntos clave gene-rador por BlazePose.
Con estas operaciones, se han estimado que seran necesarios para la deteccion de los ejerciciosdel proyecto 56 angulos, 28 angulos entre puntos clave pero en los dos planos considerados. Seha evaluado que estos reflejan adecuadamente el comportamiento de los movimientos y existeuna variacion notable de algunos de estos angulos en cada uno de los ejercicios seleccionados.Por ejemplo, un ejercicio en el que se levanta la pierna lateralmente, generara angulos utiles

27
entre los puntos de la cadera y el pie, pero los angulos entre la mano y el hombro no sufriranapenas variaciones.
El modelo que se va a desarrollar va a detectar 12 ejercicios basicos de movimientos del cuerpo,en especial extremidades. Tambien se pretende entrenar a la red para que identifique si no seesta realizando ningun ejercicio, siendo este el ’ejercicio’ o etiqueta numero 13. Los ejerciciosson los siguientes y se muestran en la Figura 3.10:
• 1. Movimiento rotacional de la cabeza: implicacion de los musculos cervicales.
• 2. Rotacion del tronco: implicacion de los musculos abdominales y extensores de laespalda.
• 3. Flexion lateral del tronco: implicacion de los musculos abdominales con mayor enfasisen los oblicuos.
• 4. Flexion de tronco inclinado: implicacion de gluteos, flexores de la cadera y lumbar.
• 5. Elevacion unipodal con flexion de rodilla: estabilizacion de los musculos del treninferior.
• 6. Abduccion de cadera: implicacion de los musculos flexores de cadera, gluteos y mejoradel equilibrio.
• 7. Flexion de rodilla: implicacion del bıceps femoral.
• 8. Elevacion lateral de hombros: implicacion del deltoides anterior y lateral.
• 9. Elevacion frontal de hombro: implicacion del deltoides anterior y pectoral mayorsuperior.
• 10. Rotacion interna y externa de hombro: mejora de la estabilidad del hombro.
• 11. Flexion de codo: implicacion de la musculatura bicipital.
• 12. Ejercicio de coordinacion locomotriz: mejora de la coordinacion motora.
• 13. Etiqueta ”No se esta realizando ningun ejercicio”.
La grabacion del dataset se realizo en un lugar cerrado, con buena iluminacion para conseguirla maxima eficiencia del modelo. A la izquierda de la Figura 3.11, se presenta el lugar dondese realizo la recoleccion de datos. La camara se situo a una altura de unos 2 metros, de talforma que la persona de la imagen entraba siempre en el plano, incluso con los brazos estiradosvertical y horizontalmente. Todos los ejercicios grabados se realizaban a una persona en indi-vidual y con la cara mirando al objetivo constantemente. Esto era necesario porque el modelode BlazePose comete errores si no detecta los rasgos faciales y se pierden muchos puntos. En

28
la Figura (3.11) se ve con claridad la representacion de los puntos claves generados por BPpara el mismo ejercicio que la imagen anterior. Una cualidad importante de estos modelos derepresentacion es la capacidad de mantener la anonimidad de las personas, pudiendo operary analizar exclusivamente con los puntos clave.
1 2 3 4 5 6
7 8 9 10 11 12
Figura 3.10: Ejercicios seleccionados para realizar la deteccion.
Todos los puntos, que genera cada frame, de la Figura 3.11 se almacenaron en una base dedatos de codigo abierto llamada MongoDB. Se trata de una base de datos NoSQL, orientadaa documentos y que guarda estructuras de datos BSON, que logra que la integracion de datossea rapida y facil.
Figura 3.11: Recoleccion del dataset y representacion mediante puntos clave de una perso-na realizando un ejercicio.
Para obtener muchos datos y variados, se grabaron 20 repeticiones de cada ejercicio a 5personas con caracterısticas fısicas diferentes con la intencion de enriquecer el dataset y con-siderar muchas posibilidades que se daran posteriormente en la deteccion cuando el modeloeste creado. Ademas, la camara con el modelo funciona a unos 10 fps, lo que significa quecada segundo se obtendran aproximadamente 10 listas de 56 angulos, y se ha consideradoque cada repeticion se realiza en aproximadamente 5 segundos. Por lo tanto, se dispone de1200 repeticiones, lo que implica en torno a 60000 frames de informacion con la que se podra

29
trabajar. Mas adelante, en el pre-procesado, se dividira toda esta informacion en ventanas dedatos comprendidas en esos 5 segundos, es decir, una repeticion.
El dataset recolectado contiene un total de 56 angulos por frame, y 77995 frames. Esto setraduce en 4.367.720 datos que la red dispondra para entrenar o testar y ası conseguir ladeteccion de los 13 ejercicios. No todos ellos acabaran siendo utilizados pues el siguiente pasoes realizar el pre-procesado para preparar esos datos y que la red los entienda y los sepainterpretar. Esto supondra que se van a perder una pequena parte de los datos mencionados.
Finalmente, se van a presentar dos ejemplos visuales reales para demostrar el patron de losangulos en dos ejercicios distintos y dos angulos entre puntos que no afectan el uno al otro. Elprimero es un ejercicio en el que se mueve el brazo lateralmente de abajo a arriba. La Figura3.12 muestra a la izquierda los angulos que generan 1000 frames entre los puntos clave delhombro derecho (referencia) y la mano derecha, con valores entre 90º y 270º, pasando por180º pues se disenaron los angulos manteniendo el sistema de coordenadas pero incluido enlas imagenes del esqueleto de la Figura 3.11, no como primera persona. Mientras que a laderecha de la imagen se presentan los angulos del mismo ejercicio pero esta vez entre puntosclave de la cadera derecha (referencia) y el pie derecho, la pierna derecha, que se mantienenen 270º pues no sufre variaciones ni se mueve dicha articulacion.
Figura 3.12: Variacion de los angulos en un ejercicio de movimiento lateral de brazos. A laizquierda se considera el brazo derecho y a la derecha la pierna derecha.
En la Figura 3.13 se presenta el caso de un ejercicio en el que se elevan lateralmente laspiernas. A la derecha de la imagen, se aprecia la variacion de los angulos considerando lospuntos clave de la cadera derecha (referencia) y el pie derecho, generando angulos entre 270º y180º a lo largo de 1000 frames. A la izquierda se presenta el mismo ejercicio pero esta vez conel angulo que generan los puntos clave del hombro derecho (referencia) y la mano derecha. Alestar los brazos pegados al cuerpo durante la grabacion, el movimiento de las piernas generaesa pequena modificacion en los angulos. Esto no supone ningun problema pues cuando serealice el ejercicio en vivo para su reconocimiento por la red, se realizara de la misma manera

30
y la red ya habra aprendido dichas variaciones.
Figura 3.13: Variacion de los angulos en un ejercicio de movimiento lateral de piernas. Ala izquierda se considera el brazo derecho y a la derecha la pierna derecha.
3.5 Modelo de Deep Learning
En esta seccion se va a explicar en detalle el modelo utilizado para la deteccion de los ejercicios.Las redes neuronales (Figura 3.14) son una serie de operaciones matematicas organizadas encapas de neuronas que calculan valores de salida para unos valores de entrada que atraviesanciertas funciones.
Figura 3.14: Diagrama de una red neuronal estandar.
En el caso de este trabajo y teniendo en cuenta la naturaleza temporal de los datos de entradala red empleada es una Red Neuronal Recurrente (RNN). Estas redes no tienen una estructurade capas definida, sino que permiten conexiones arbitrarias entre neuronas, pudiendo crearciclos, con los que se consigue la temporalidad, permitiendo a la red tener memoria. Se tratade redes muy eficaces para el analisis de secuencias, ya sea de textos, sonidos o vıdeos.

31
La estructura tiene, por lo tanto, realimentacion. En la Figura 3.15 se aprecia que para cadainstante de tiempo, la neurona en cuestion recibe informacion tanto de la salida del instanteanterior como de la entrada en ese mismo instante para generar su propia salida. Esta es laclave para entender que estas redes se nutren de la informacion temporal. Matematicamentese puede representar lo que cada neurona contiene de la siguiente manera:
yt = f(Wxt + Uyt−1 + b) (3.1)
Donde W y U son los pesos de la matriz, con la peculiaridad de que U opera sobre el estadode la red en el instante de tiempo anterior, y b es un parametro que orienta a la funcion deactivacion. Estos pesos son parametros que ponderan la informacion que atraviesa la celulade memoria. Existen pesos de entrada (W) y de salida (U) que son utilizados para ponderarla entrada del instante actual y la salida del instante anterior respectivamente.
Figura 3.15: Representacion de neuronas en una RNN.
Los pesos se van ajustando mediante la fordward propagation (propagacion hacia delante) yla backward propagation (propagacion hacia atras). La primera evalua la desviacion entre lasalida generada por el modelo y la salida real o esperada proveniente de los datos, obteniendo lafuncion de Loss o perdidas. El backward propagation calcula el gradiente sobre cada neurona,partiendo de la ultima capa hasta la primera, para que todas reciban una senal de error quedescriba cuanto estan aportando al error total del modelo. En las RNN existe el algoritmobackpropagation through time (BPTT) [26], que es practicamente igual que el backwardpropagation pero se deben propagar los datos en base al tiempo.
Todo ello se ejecuta un numero determinado de vueltas o epochs que se realiza a la red. Cadavuelta ira disminuyendo los errores y acercando a la red a un porcentaje de acierto que seconsidere optimo. Se trata de un parametro que se debe ajustar a la hora de hacer el procesode entrenamiento. A mayor numero de vueltas, mayor exigencia computacional, lo que signi-fica que debe encontrarse cierto equilibrio. Otros arreglos para acercarnos a valores deseadosson el tamano de los lotes de datos de nuestro dataset (batch size), el metodo de optimizaciono el numero de celulas. Este ultimo significa la cantidad de celulas que hay en cada capa yes necesaria una buena configuracion para evitar posibles problemas de ’overfitting’ o ’un-

32
derfitting’. Un numero excesivamente alto de celulas causa ’overfitting’ mientras un numerorecudido de ellas puede generar ’underfitting’, produciendo errores en la red al no conseguircapturar la tendencia que siguen los datos a lo largo del tiempo.
La memory cell o celula de memoria es una peculiaridad de estas redes pues su funcion espreservar un estado a traves del tiempo para dotarla de la capacidad de tener cierta memoria.Las RNN pueden recordar informacion importante sobre la entrada que recibieron, lo que lespermite ser mas precisas en la prediccion de lo que vendra despues. Otras redes no tienenforma de conseguir esos datos excepto lo reflejado en los pesos a traves de su entrenamiento.
En relacion con esto, existen varias arquitecturas distintas. La ’vanilla LSTM’ es un tipode red neuronal simple pues solo tiene una capa de celulas de memoria. La arquitectura’stacked LSTM’ tiene, sin embargo, varias capas de celulas de memoria. Finalmente existe la’bidirectional LSTM’, cuya peculiaridad reside en que tiene una capa de memoria que recibelos datos en el orden temporal normal y la otra en el orden temporal inverso. Para esteproyecto se emplearan distintas configuraciones para entrenar cada una de estas 3 redes paraevaluar cual es el modelo mas eficiente y, ası, aplicarlo en nuestro montaje final.
Un problema que surge en las RNN es el crecimiento o desvanecimiento de los gradientes re-tropropagados con el tiempo. El gradiente depende de los errores presentes y tambien pasadospor lo que la acumulacion de errores provoca dificultades a la red para memorizar variablesa largo plazo. Una extension de las redes neuronales recurrentes que solventa este dilemaes la Long-Short Term Memory (LSTM) [27]. Su principal fuerte es que pueden ampliar sumemoria para aprender experiencias importantes que han pasado hace mucho tiempo. Dichode otra forma, estas redes recuerdan durante un largo perıodo de tiempo las entradas en lasneuronas. Y no solo eso, sino que tambien pueden leer, escribir y borrar la informacion de sumemoria.
Figura 3.16: Estructura de una red LSTM.
Esto se consigue con un sistema de puertas en la unidad de memoria LSTM. En la Figura3.16 se aprecia una lınea horizontal en la parte superior que se trata del estado de la celula.La informacion fluye por ella a lo largo de la cadena, sufriendo algunas interacciones quemodificaran su estado. Las puertas son las encargadas de agregar o eliminar informacion adicho estado de celula. Se componen de una capa de red neuronal sigmoidea y una operacion

33
de multiplicacion puntual. La primera produce numeros entre cero y uno, que describe lacantidad de cada componente que debe dejar pasar, siendo 1 el valor que permite el plenoacceso de los elementos. Las 3 puertas que pertenecen a este tipo de redes se describen acontinuacion:
• Puerta de entrada: permite el acceso de nueva informacion a la memoria.
• Puerta del olvido: controla cuando se olvida parte de la informacion. A veces existendatos innecesarios por lo que esta puerta los discriminara, dejando mas sitio a datosimportantes.
• Puerta de salida: ordena si se debe utilizar en el resultado o salida algun recuerdoalmacenado en la celda.
Para la prediccion, generacion o clasificacion de secuencias, existen 4 modelos distintos:
• One-to-one model (modelo uno a uno): genera una salida y(t) por cada entrada x(t). Seutiliza, por ejemplo, para la prediccion del siguiente valor real en una serie temporal.
• One-to-many model (modelo uno a varios): genera varias salidas y(t) para una unicaentrada x(t). Se trata de un modelo muy util para descripcion generar descripciones oinformacion anadida sobre un dato concreto de entrada.
• Many-to-one model (modelo de varios a uno): genera una unica salida y(t) para variosvalores de entrada x(t). Si se tiene una secuencia de observaciones de entrada, se puedepredecir el siguiente valor real. Este es el modelo que se emplea en este proyecto pues senecesita la clasificacion de un ejercicio en concreto cuando introducimos una secuenciade datos de entrada. Se muestra, en la Figura 3.17, la estructura de este modelo.
• Many-to-many model (modelo de varios a varios): genera varias salidas y(t) para multi-ples entradas x(t). Este modelo se puede aplicar en clasificacion de una secuencia deaudio en otra secuencia de palabras (frases) o en traduccion.
Figura 3.17: Modelo ’many-to-one’.

34
Otro aspecto que se debe mencionar es la forma en la que estas redes exigen que se repre-senten los datos de entrada. Los datos deben ser tridimensionales, en forma de matriz cuyasdimensiones corresponden a las siguientes:
• Muestras: componen las filas en la matriz. Una muestra puede ser, por ejemplo, unasecuencia en un instante de tiempo T.
• Caracterısticas: componen las columnas en la matriz. Recogen todos los “Features” quese quieren usar en un instante de tiempo T.
• Perıodo de tiempo: es la tercera dimension de la matriz, corresponde al tamano del lotede secuencias temporales.
Por lo tanto el pre-procesado en este proyecto debe seguir la estructura anterior para que lasredes LSTM puedan entenderlos. Partiendo de nuestros datos originales las filas de la matrizse corresponderan con cada datos en sı utilizado para entrenar. Estos datos se componenno de los angulos extraıdos en solo un instante de tiempo sino en una ventana temporalpredefinida que como se comento en el apartado anterior sera de unos 5 segundos lo quepermite contemplar en un dato al menos una interaccion completa de cualquier ejercicio enel dataset.
Las columnas seran todas las caracterısticas extraıdas, en este caso, los 56 angulos extraıdos.Finalmente la tercera dimension sera el tamano de la ventana, es decir, cuantos puntos con-forman esas ventanas temporales. como las ventanas son de unos 4-5 segundos y se tienenaproximadamente unas 10 medidas por segundo, las ventanas se ha decidido que sean de 40instantes de tiempo. Estas ventanas se han escogido solapando informacion. La idea es crearventanas temporales de 40 muestras pero que vaya avanzando de 20 en 20. Esto se debe aque cuando se realiza un ejercicio, como mover el brazo, puedes empezar con el brazo estiradohacia abajo o con el brazo estirado hacia arriba. Para que la red no aprenda que el patrondebe empezar siempre en un lugar en concreto, se trataron los datos con solapamientos.
Por tanto, despues de amoldar los datos para ajustarlo a las necesidades de la red, se hanobtenido 1503 muestras que contienen 40 frames con 56 datos cada frame. Al crear el modelose va a necesitar especificar cuantos datos deben de ser utilizados para el entrenamiento ycuantos para la validacion. Se ha decidido que el 20 % de los datos sirvan como validacion yası tener aproximadamente 1200 muestras de datos para el entrenamiento.
3.6 Montaje final
En esta seccion se va a explicar el despliegue necesario para poner en marcha este proyecto.La finalidad es que el sistema pueda ser utilizado en cualquier espacio con buena visibilidad

35
y sin necesidad de equipos sofisticados teniendo la posibilidad de tener un sistema portable yde facil instalacion.
Para ello, se va a hacer empleo de una Nvidia Jetson Nano (Figura 3.18) y la camara pre-sentada al comienzo de la seccion, la OAK-D. Este dispositivo es un micro-ordenador cuyaaplicacion principal se centra en el desarrollo de proyectos de IA y robotica dado que contieneuna pequena GPU interna que permite el empleo de modelos de Machine/Deep Learning contiempos de procesado aceptables para diferentes aplicaciones. Nvidia ofrece una distribucionLinux optimizada para el dispositivo y el uso de la GPU integrada de manera comoda yrapida.
Figura 3.18: Nvidia Jetson Nano.
Su tamano es reducido (69,6 x 45 mm), lo que no le impide albergar una CPU ARM Cortex-A57 MPCore de 4 nucleos (capaz de proporcionarnos 472 gigaflops de potencia), una GPUNvidia Maxwell con 128 nucleos CUDA (capaz de ejecutar la librerıa de procesado de datosCUDA-X AI), 4 Gb de RAM, 16/32 GB de almacenamiento (depende de la tarjeta micro SDempleada) y 4 puertos USB 3.0.
Se pretende colocar este equipo en una posicion donde la camara capture a una persona alcompleto y ası proceder a la deteccion de los 12 ejercicios de movilidad basica seleccionadospara el proyecto. Dicha deteccion se hara a tiempo real, donde al ir realizando los ejercicios,se podra visualizar mediante un mensaje que ejercicio se esta realizando en ese instante.Los elementos necesarios entonces son un trıpode donde montar la camara para su correctoposicionamiento y un cable USB 3.0 para la conexion entre la camara y el micro-ordenador.
Para que el sistema funcione correctamente en su despliegue, se ha decidido que la red neuronaldebe estar entrenada para detectar correctamente, al menos, un 90 % de los mismos. Por tanto,el proyecto queda como se presenta en la Figura 3.19 donde se destaca cada elemento softwarey hardware empleado.

36
Figura 3.19: Recursos software/hardware en el proyecto.
En la camara se incluira el algoritmo BlazePose para la deteccion de los puntos caracterısticos3D, esta deteccion se realiza a unos 10-15 fps. La informacion de las detecciones se envıade la camara conectada por USB a la Nvidia Jetson Nano que contiene la red neuronaldesarrollada para la deteccion de ejercicios optimizada por el software de Nvidia para utilizarla GPU interna y realizar el reconocimiento en tiempo real. Finalmente tanto los puntosdetectados como el ejercicio reconocido se almacenaran en una base de datos para su posteriortratamiento.
Con todo el equipo montado, se procede a la realizacion de los ejercicios enfrente de la camara.Un aspecto importante es colocar la cara siempre mirando hacia el objetivo para el correctofuncionamiento de algoritmo de BlazePose. Durante los ejercicios, se iran recolectando losdatos de los puntos clave y se calcularan los angulos. Estos se deben ir acumulando y orga-nizando segun el pre-procesado que se realizo anteriormente en el entrenamiento. Por ello,se almacenaran en lotes de 40 muestras de tamano, con los 56 angulos por cada frame. Loslotes se introduciran en la red para que proceda al reconocimiento del ejercicio continuamentedurante la sesion.
El uso tanto de la camara como del micro-ordenador de Nvidia aporta dos ventajas muyimportantes. La primera, conseguir dividir los esfuerzos de procesamiento en distintos dis-positivos logrando tiempo real en el sistema. La segunda, conseguir un despliegue preciso,rapido, con pocos recursos, muy manejables y, sobretodo, portables.

37
Resultados
En esta seccion se van a presentar los resultados obtenidos de entrenar 3 redes neuronalesrecurrentes LSTM diferentes. Para cada una de ellas se mostraran graficas y metricas de eva-luacion con distintas configuraciones y se valoraran hasta encontrar la opcion mas precisa. Elobjetivo al principio es obtener una precision mayor del 90 % pero se buscaran los parametrosque consigan los mejores resultados.
A continuacion, se veran las redes “Vanilla”, la mas simple (solo una capa de celulas dememoria) y util en secuencias pequenas, las redes “Stacked”, mas sofisticadas que las redes“Vanilla” al contener varias capas de celulas de memoria, y la red “Bidirectional”, que tieneel beneficio de recorrer la secuencia de entrada de datos en ambas direcciones.
Antes de entrar en los resultados, se van a mencionar algunas configuraciones que se van amantener fijas durante el entrenamiento. Los valores que se van a moldear para cada red vana ser el numero de celulas. Es importante refinar esta variable porque un exceso o escasez decantidad de celulas puede provocar “overfitting” o “underfitting”, respectivamente, imposibi-litando a la red a aprender correctamente. Ademas, una gran cantidad de celulas de memoriahara que la red requiera mas tiempo para detectar los ejercicios al ser mas compleja, y estosupone que los reconocimientos a tiempo real sean mas lentos, algo que no interesa para elproyecto.
El tamano del lote es una variable que permanecera fija, 40 muestras. El numero de vueltaso epochs tambien es un valor importante. A mayor numero de vueltas, la red tendra masposibilidades de aprender, pero un exceso de vueltas puede producir que la red se sobre entrene.Es por ello que se ha fijado en 350 epochs para este trabajo. Finalmente, el optimizador que seva a utilizar se denomina ”Stochastic Gradient Descent”(SGD), que actualiza los parametroscon cada muestra de entrenamiento y es uno de los optimizadores mas utilizados por lacomunidad. Los parametros de este son: 0,001 de ’learning rate’, 0,9 en ’momentun’, un’decay’ de 1e-6 y no se aplica el ’Nesterov momentum’. Se ha decidido este optimizador dadoque Adam en redes recurrentes tiende, dependiendo del proyecto, a ser demasiado rapido yno encontrar eficientemente los mınimos optimos de la funcion.
4.1 Resultados red neuronal Vanilla
Se comienza con la red mas sencilla. Tras varias pruebas, se presentan dos modelos. El primerotendra un numero de 20 celulas y el segundo 50.
En la Figura 4.1 se recogen las graficas de “accuracy” (izquierda) y “loss” (derecha) para 20celulas de memoria. El primero, debe tener una tendencia hacia 1, siendo este el maximo puesimplicarıa una precision del 100 %. Se aprecia que la grafica se va acercando a esos valores a

38
medida que avanzan los epochs. En el caso de la grafica de “loss”, la tendencia es hacia 0 puesse pretende que haya el menor numero de perdidas o errores en la red a la hora de identificarlos ejercicios.
El comportamiento es el esperado y no se observa ningun indicio de “overfitting” teniendo unabuena precision final con un error reducido. Analizando los resultados con otras metricas deevaluacion se podra indagar mas en detalle en el comportamiento de la red con los diferentesejercicios.
Figura 4.1: A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Vanilla con 20 celulas.
Figura 4.2: Matriz de confusion para la red Vanilla con 20 celulas.
Otra grafica importante es la que se presenta en la Figura 4.2. Se trata de la matriz de

39
confusion, que nos permite visualizar el numero de predicciones acertadas o erroneas que hacometido la red en el proceso de aprendizaje. Lo ideal es que la matriz tenga solo valores enla diagonal, lo que implicarıa que siempre acierta cuando detecta un ejercicio y que el restosean cero.
Figura 4.3: A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Vanilla con 50 celulas.
El resultado es bastante positivo, se puede calificar el modelo como bueno, pero es cierto quecomete algunos errores puntuales. En el caso de la etiqueta 12, que corresponde a “No seestan realizando ejercicios”, se aprecia que la red no consigue distinguir del todo esa accion,confundiendolo especialmente con el primer ejercicio de movimientos rotacionales de la cabeza.La razon principal de esta confusion es que los datos recolectados para esta clase concreta sonpequenos movimientos simples o andar donde no existen grandes movimientos de brazos nipiernas. Esto se podrıa mejorar con otras configuraciones o redes.
Por ello, se va a testar con 50 celulas de memoria. Se ha comprobado que a partir de 50, lared empieza a tener problemas, sobretodo de velocidad de procesamiento, por lo que sera ellımite en estas evaluaciones.
De nuevo, se adjuntan las graficas de “accuracy” y “loss”. En la Figura 4.3 se ve que latendencia de la cuerva es positiva, ambas graficas se acaban concentrando en los valoresoptimos.
En cuanto a la matriz de confusion (Figura 4.4), esta vez la red comete errores algo masimportantes en otros ejercicios, como el 8º que se confunde en 3 ocasiones con el ejercicioanterior o el 1º, y se considera que estos errores, aun pequenos, pueden ser mas determinantesposteriormente. Nuevamente, la ultima etiqueta presenta ciertos errores, esta vez mas disper-sos entre varios ejercicios, no centrados en uno solo como en el caso del modelo anterior. Todoesto se debe a que ahora el aumento del numero de celulas esta introduciendo un problema

40
en la memoria de la red por ser un numero muy elevado que en este caso no consigue captaradecuadamente las variaciones. Con valores mas elevados comenzarıa a existir el fenomenosde “overfitting” o “unferfitting”.
Figura 4.4: Matriz de confusion para la red Vanilla con 50 celulas.
Figura 4.5: Comparativa de modelos Vanilla con 20 y 50 celulas para valores de “accu-racy”, “recall” y “F1-score”.
Ademas del analisis de estas graficas, se pueden revisar valores muy utiles para comprobar elcomportamiento de la red como son el ’recall’ (exhaustividad) y el ’F1-score’ (Valor F), ademasde la exactitud final o ’accuracy’. El primer valor indica la cantidad, siendo 0 el mınimo y1 el maximo, de etiquetas que el modelo es capaz de identificar. El valor de F1 combina las

41
medidas de precision y ’recall’ en un solo valor para facilitar el analisis. El ’accuracy’ es elporcentaje que refleja la cantidad de casos en los que el modelo ha acertado. En la Figura 4.5se presentan las dos tablas para cada caso:
Con estos datos se puede confirmar que la red con 20 celulas es ligeramente mejor que la de50. Ambos valores son muy positivos y una exactitud de casi el 97 % es muy buena senal. Elunico problema grave esta relacionado con la ultima etiqueta pues no es capaz de aprenderbien cuando no se esta realizando ningun ejercicio.
Finalmente, en este sub-apartado se quiere presentar un modelo con problemas de “underfit-ting”, es decir, que es muy simple e incapaz de capturar los matices o particularidades de losdatos. Se ha testado un modelo “Vanilla” con 5 celulas de memoria y el resultado se muestraen la Figura 4.6:
Figura 4.6: A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Vanilla con 5 celulas.
Como se aprecia, no parece alcanzar en ningun momento el valor maximo de ’accuracy’. Lamatriz de confusion tambien nos dice que el modelo comete ciertos errores, especialmente en lacuarta y la ultima etiqueta. Es importante destacar que la red no ha detectado correctamenteni una sola vez la ultima etiqueta. El valor final de exactitud es de 73 %, valido dependiendodel objetivo final pero insuficiente para este proyecto.
4.2 Resultados red neuronal Stacked
La red Stacked tiene mas capas con celulas de memoria por lo que deberıa tener mas facilidadespara aprender los patrones de movimiento. En este caso, se presentan dos redes, una con 35

42
celulas y otra con 50.
La primera presenta el siguiente aspecto (Figura 4.7) en cuanto a precision y valor de perdidas.La red alcanza unos valores elevados en ambas metricas y presenta un comportamiento co-rrecto durante el entrenamiento. Como curiosidad no se alcanzan unos valores tan altos comocon la red “Vanilla”. Esto puede estar ocurriendo debido a que se ha elevado la complejidaddel modelo y el numero de datos con el que se cuenta no es suficiente para que este modelo,que deberıa ser mas potente, aprenda adecuadamente.
Figura 4.7: A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Stacked con 35 celulas.
Figura 4.8: Matriz de confusion para la red Stacked con 35 celulas.

43
La matriz de confusion (Figura 4.10) es bastante positiva. La red es capaz de acertar practi-camente todos los ejercicios adecuadamente exceptuando, de nuevo, la ultima etiqueta. Lospequenos movimientos y gestos que realiza una persona estando de pie la red los asocia aotros ejercicios y no es capaz de identificarlo como es debido. Se seguira probando con otrasconfiguraciones para intentar mejorar este caso. Lo que esta pasando con esta clase y porquese confunde con diferentes ejercicios es que los pequenos movimientos recogidos como datos enesta clase se parecen en una version reducida a alguno de los ejercicios simples. Un pequenomovimiento de pierna puede confundirse con un ejercicio de pierna, lo mismo puede sucedercon los brazos.
Figura 4.9: A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Stacked con 50 celulas.
Figura 4.10: Matriz de confusion para la red Stacked con 50 celulas.

44
La otra red, con 50 celulas de memoria por capa, se muestra a continuacion (Figura 4.9).Parece que consigue llegar a valores optimos. El problema que existe es el margen entre laprecision con los datos de entrenamiento y los datos de validacion. Esto implica que la red estaentrenando adecuadamente pero que a la hora de comprobar con algunos datos de validaciondel dataset su precision, se aleja un poco de los valores deseados. Esto puede ser un primerindicio de “overfitting” o de nuevo falta de datos para aprender adecuadamente.
En cuanto a la matriz de confusion (Figura 4.10), sigue la lınea de otros resultados. Aparecenerrores puntuales en algunos ejercicios, siendo el de la etiqueta 10 el mas preocupante, perocon resultados positivos en terminos generales. El problema de la ultima etiqueta no se hapodido solucionar con estos parametros.
En la Figura 4.11 se presentan valores muy similares en general en cuanto los resultados deesta configuracion. Practicamente todos superan el 90 % en todos los ejercicios. El ejercicio oetiqueta que determina cual es mejor es el ultimo, pues es el que mayores problemas presenta.En la red con 35 celulas los valores son muy bajos, inferiores al 50 %, por lo que se debedescartar esta configuracion. En el caso de la red con 50 celulas, consigue ser preciso en un50 % de las ocasiones por lo que es mas positivo aunque todavıa lejos de lo que se busca.Ambas cifras de exactitud son buenas, rondando el 94 % pero se sigue buscando refinar laultima etiqueta.
Figura 4.11: Comparativa de modelos Stacked con 35 y 50 celulas para valores de “accu-racy”, “recall” y “F1-score”.
4.3 Resultados red neuronal Bidirectional
La ultima red que se va a testar es la Bidireccional. Como la peculiaridad de estas redes essu capacidad de recorrer los datos hacia delante y hacia atras, se cree que puede ser la redque mas encaje en este proyecto porque puede reconocer los patrones en ambas direcciones altener el mismo aspecto, duplicando la capacidad de entrenamiento.

45
Se vuelven a mostrar otras dos redes con configuraciones diferentes que han obtenido mejoresresultados que otras. La primera contiene 20 celulas de memoria por capa, la segunda 35.
A continuacion, se presentan los resultados graficos de “accuracy” y “loss” (Figura 4.12). Elresultado es bastante positivo. Ambas curvas se acercan adecuadamente a los valores optimosambos conjuntos, entrenamiento y validacion presentan resultados similares.
Figura 4.12: A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Bidirectional con 20 celulas.
La matriz de confusion (Figura 4.13) alberga buenos resultados tambien. Exceptuando fallosmuy concretos, la mayorıa de los casos los ha podido detectar a la perfeccion. Respecto a laultima etiqueta, se encuentran con el mejor de los casos vistos hasta el momento. Si bien escierto que se equivoca 2 veces en el segundo ejercicio y tan solo en 4 ocasiones acierta, es lared que mejores resultados ha obtenido en este aspecto por lo que se tendra en cuenta a lahora de modificar los parametros, buscando otro que se acerque mas a la maxima eficienciade todos los ejercicios pero especialmente del ultimo.
Por ello, se va a testar ahora la misma red con 35 celulas de memoria. Las dos graficas de laFigura 4.14 revelan que la red funciona adecuadamente. La tendencia es positiva y, ademas,las ultimas vueltas que realiza mantienen el valor maximo posible constante. Se trata de algomuy positivo porque implica que la red ha aprendido con los datos y ya no es capaz de cambiarel resultado. Esto puede ser debido a que la red ha llegado a un mınimo local de la funciondel cual no puede escapar y el optimizador por su configuracion no es capaz de salir de estasituacion. El margen entre training y validacion no es muy amplio y se puede considerar queno es un problema muy grave, no obstante se valorara con los datos numericos si supone o nouna desventaja respecto a la red anterior.

46
Figura 4.13: Matriz de confusion para la red Bidirectional con 20 celulas.
Figura 4.14: A la izquierda, grafica de “accuracy” y a la derecha, grafica de “loss” para elmodelo Bidirectional con 35 celulas.
La matriz es muy positiva. Todos los resultados excepto el ultimo contienen valores quedemuestran que la red es valida. Apenas comete errores puntuales sino que la diagonal es casiperfecta. La etiqueta ’No hay ejercicio’ tiene unos resultados algo peores que la anterior alcometer el fallo en varios ejercicios en vez de en uno solamente. Tras todos los experimentos,se deduce que los datos recogidos para esta clase no son adecuados y habrıa que buscar otrasmaneras mas efectivas de decidir cuando no se esta haciendo un ejercicio. Se podrıan analizarlas probabilidades de salida de la red y definir unos umbrales para decidir si la deteccion escorrecta o no.

47
Figura 4.15: Matriz de confusion para la red Bidirectional con 35 celulas.
En la Figura 4.16 se aprecia que ambas configuraciones son muy buenas, rondando el 97 % ycon valores de ’recall’ y ’F1-score’ de 1 o muy cercanos. Esto demuestra la efectividad de estasredes para este tipo de proyectos y datos de entrada. De los dos, se prefiere la configuracioncon 35 celulas porque la ultima etiqueta presenta mejores resultados.
Figura 4.16: Comparativa de modelos Bidirectional con 20 y 35 celulas para valores de“accuracy”, “recall” y “F1-score”.
Se concluye por tanto que los mejores resultados se han obtenido con la configuracion “Bi-directional” como se esperaba. Se observa como las configuraciones “Vanilla” y “Stacked”

48
ofrecen resultados buenos pero algo inferiores al escogido. Un problema que pueden tener esla cantidad de caracterısticas de entrada, en este caso 56 angulos. Es un numero pequeno dedatos y por ello es posible que arquitecturas mas complejas y profundas no sean capaces decaptar adecuadamente los patrones buscados sin un dataset mucho mas completo. La configu-racion bidireccional permite ese entrenamiento en ambos sentidos lo que la hace superior a laconfiguracion Vanilla cuando los datos pueden tratarse adecuadamente en las dos direcciones.
4.4 Resultados del montaje final en tiempo tiempo real
Para cerrar el apartado de Resultados, se va a mostrar una imagen con el montaje final y elfuncionamiento del modelo en tiempo real. En la Figura 4.17 se puede apreciar, a la izquierda,la camara OAK-D, conectada a una Nvidia Jetson Nano. A la derecha se ilustra lo que serıala disposicion final del proyecto, con ambos aparatos previamente mencionados funcionandopara detectar los ejercicios que realice el sujeto enfocado.
Figura 4.17: Montaje final del proyecto.
El modelo es capaz de detectar los ejercicios correctamente en un porcentaje muy alto (alrede-dor del 92 % de precision) funcionando en tiempo real, como indicaban las graficas y resultadosrecogidos previamente sobre el entrenamiento de la red. Es importante que la cara este visibleen todo momento para el correcto funcionamiento de BlazePose y, por consiguiente, de la redcreada para el proyecto. Se realizaron pruebas con mascarilla y con menor visibilidad de lacara y se comprobo que el numero de detecciones de puntos caracterısticos descendıa en tornoa un 20 %.
En cuanto a la etiqueta “No hay ejercicio”, consigue detectarse adecuadamente en torno al50 % de las veces. Cuando la persona esta totalmente estatica suele confundirse con otrosejercicios, pero si la persona no realiza ejercicios pero si ciertos movimientos muy sutiles,

49
la red detecta que no esta haciendo ejercicios. Esto se debe a dos razones principales, laprimera se trata de la grabacion. Cuando se recolecto el dataset, se le pidio a las personasque estuviesen estaticos pero moviendose ligeramente, como si se tratase de una personanormal esperando. La segunda esta relacionada con el dataset. Se escogio que el dato que va aaportar la informacion necesaria para el entrenamiento de la red era el angulo. Al realizar unejercicio, muchos angulos se mantienen constantes y solo existe variacion en unos pocos. Enel caso de estar completamente parado, la red detecta muchos angulos constantes y reconoceerroneamente un ejercicio, especialmente el primero que solo varıan unos pocos angulos de lacabeza y de manera muy leve.
En la Figura 4.18, se puede observar como se identifican los ejercicios. Los datos deben entraren la red igual que los datos utilizados para el entrenamiento, es decir, 40 muestras de 56angulos cada una. Por tanto, se realiza una deteccion cada aproximadamente 4 segundos. Elterminal ira mostrando que ejercicio se esta realizando en todo momento. En el caso de lafigura, la persona estaba realizando un ejercicio en el que se levantaban los brazos lateralmentey la red lo estaba identificando correctamente.
Figura 4.18: Reconocimiento del “Ejercicio 8: elevacion lateral brazos”.
En relacion al dispositivo Nvidia Jetson Nano, ha mostrado buenos resultados y ha soportadola exigencia computacional para poder realizar la deteccion en vivo (en torno a 200 ms). Setrata de un avance muy importante porque posibilita la instalacion del proyecto en cualquierlugar y con una alta eficiencia. En lıneas futuras, se podrıa enviar la informacion sobre ladeteccion a una web y no se necesite ningun dispositivo de visualizacion mas alla de cualquierSmartphone del que dispongan las personas. Tambien, se podrıan anadir explicaciones, analisiscuantitativo de los movimientos e incluso correcciones si se esta realizando mal para conseguirun sistema muy completo y accesible para todos los publicos.

50
Conclusiones y Lıneas FuturasTras el analisis del proyecto, se ha comprobado que se han conseguido todos los hitos princi-pales del mismo, desde la perspectiva hardware como software. Los dispositivos seleccionadoshan sido muy utiles y han cumplido los requisitos de procesado para realizar la cadena com-pleta de la deteccion en tiempo real. Por otra parte, las redes neuronales seleccionadas hancumplido su funcion ofreciendo resultados muy prometedores con una gran precision.
En primer lugar, la seleccion del algoritmo BlazePose ha sido muy acertada dada la capacidady el rendimiento que ofrece para ser desplegada en dispositivos de bajo coste como la camaraempleada en el proyecto. Se ha podido comprobar que el modelo no es del todo preciso cuandono se detecta adecuadamente la cara de la persona pero ha cumplido la funcion de crear elesqueleto 3D en cada imagen procesada. Ademas, el algoritmo se ha podido convertir alformato proporcionado por OpenVino para ser empleado adecuadamente en dispositivos debajo coste.
En cuanto a la segunda parte del proyecto, se ha desarrollado una cadena completa de DeepLearning desde la recoleccion de datos hasta el despliegue del modelo. En primer lugar eldataset recolectado ha sido suficiente para realizar la tarea de entrenamiento. En cuanto alpreprocesado y limpieza, se ha realizado una anotacion visual de los vıdeos y una extraccionpor bloques de datos. Cabe destacar la conversion de los puntos 3D a los angulos seleccionadospara el proyecto. Esta parte ha sido un gran acierto observando los resultados finales en cuantoa la precision en la deteccion. Centrandose en las redes neuronales seleccionadas, se ha optadopor el uso de arquitecturas recurrentes debido a su potencial para trabajar con datos que sondependientes en el tiempo. Ademas, en este caso, las redes LSTM y, especıficamente, las redesBidireccionales han ofrecido resultados muy positivos por su capacidad de tener memoria ypoder aprender patrones de datos de aspecto muy similar tanto en una direccion como en otra.Se ha conseguido en validacion una precision de mas del 97 % lo cual ha sido un resultadomejor que el esperado y fijado como meta.
La solucion se puede desplegar en cualquier lugar, con un equipo sencillo y al alcance demuchas personas que se pueden beneficiar de esta tecnologıa, con aproximadamente un 92 %de precision medido en tiempo real. El abaratamiento por el uso de chips de IA es otro de losaspectos fundamentales.
Como lıneas futuras, se pueden realizar muchas mejoras para poder completar este proyecto yque se pueda convertir en una herramienta muy util para muchos profesionales del deporte yde la salud. Para empezar, se puede realizar un dataset mas extenso, considerando mas angulosy realizando mas ejercicios de movilidad, de distintas complejidades. Ademas, para facilitarsu uso, se pueden enviar los datos de deteccion vıa web para que las personas puedan accederfacilmente a comprobar los datos. Se podrıan extraer numerosas estadısticas que permitananalizar el ejercicio realizado para dar directrices o presentar resultados sobre objetivos fijadosde cara ayudar a personal de la salud monitorizando pacientes o deportistas.

51
Bibliografıa
[1] D. Luvizon, D. Picard, and H. Tabia, “2d/3d pose estimation and action recognitionusing multitask deep learning,” 2018 IEEE/CVF Conference on Computer Vision andPattern Recognition, pp. 5137–5146, 2018.
[2] Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh, “Openpose: Realtime multi-person 2d pose estimation using part affinity fields,” IEEE Transactions on PatternAnalysis and Machine Intelligence, vol. 43, pp. 172–186, 2021.
[3] H.-S. Fang, S. Xie, Y.-W. Tai, and C. Lu, “Rmpe: Regional multi-person pose estimation,”2017.
[4] M. Kocabas, N. Athanasiou, and M. J. Black, “Vibe: Video inference for human body poseand shape estimation,” 2020 IEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR), pp. 5252–5262, 2020.
[5] V. Bazarevsky, I. Grishchenko, K. Raveendran, T. L. Zhu, F. Zhang, and M. Grundmann,“Blazepose: On-device real-time body pose tracking,” ArXiv, vol. abs/2006.10204, 2020.
[6] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estima-tion using part affinity fields,” 2017 IEEE Conference on Computer Vision and PatternRecognition (CVPR), pp. 1302–1310, 2017.
[7] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformernetworks,” in NIPS, 2015.
[8] N. Bodla, B. Singh, R. Chellappa, and L. Davis, “Soft-nms — improving object detectionwith one line of code,” 2017 IEEE International Conference on Computer Vision (ICCV),pp. 5562–5570, 2017.
[9] W. Zhao, Q. Xie, Y. Ma, Y. Liu, and S. Xiong, “Pose guided person image generation ba-sed on pose skeleton sequence and 3d convolution,” 2020 IEEE International Conferenceon Image Processing (ICIP), pp. 1561–1565, 2020.
[10] Y.-L. Li, L. Xu, X. Huang, X. Liu, Z. Ma, M. Chen, S. Wang, H. Fang, and C. Lu, “Hake:Human activity knowledge engine,” ArXiv, vol. abs/1904.06539, 2019.

52
[11] Y.-L. Li, L. Xu, X. Liu, X. Huang, Y. Xu, S. Wang, H.-S. Fang, Z. Ma, M. Chen, andC. Lu, “Pastanet: Toward human activity knowledge engine,” in CVPR, 2020.
[12] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “Smpl: a skinnedmulti-person linear model,” ACM Trans. Graph., vol. 34, pp. 248:1–248:16, 2015.
[13] N. Mahmood, N. Ghorbani, N. Troje, G. Pons-Moll, and M. J. Black, “Amass: Archiveof motion capture as surface shapes,” 2019 IEEE/CVF International Conference onComputer Vision (ICCV), pp. 5441–5450, 2019.
[14] Z. Zhang, “Microsoft kinect sensor and its effect,” IEEE Multim., vol. 19, pp. 4–10, 2012.
[15] L. Keselman, J. Woodfill, A. Grunnet-Jepsen, and A. Bhowmik, “Intel(r) realsense(tm)stereoscopic depth cameras,” 2017 IEEE Conference on Computer Vision and PatternRecognition Workshops (CVPRW), pp. 1267–1276, 2017.
[16] Y. Xiong, Y. Zhao, L. Wang, D. Lin, and X. Tang, “A pursuit of temporal accuracy ingeneral activity detection,” ArXiv, vol. abs/1703.02716, 2017.
[17] M. Lin, Q. Chen, and S. Yan, “Network in network,” CoRR, vol. abs/1312.4400, 2014.
[18] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirec-tional transformers for language understanding,” in NAACL-HLT, 2019.
[19] H. Xu, A. Das, and K. Saenko, “R-c3d: Region convolutional 3d network for temporalactivity detection,” 2017 IEEE International Conference on Computer Vision (ICCV),pp. 5794–5803, 2017.
[20] D. Tran, L. D. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotem-poral features with 3d convolutional networks,” 2015 IEEE International Conference onComputer Vision (ICCV), pp. 4489–4497, 2015.
[21] W.-M. Chen, Z. Jiang, H. Guo, and X. Ni, “Fall detection based on key points of human-skeleton using openpose,” Symmetry, vol. 12, p. 744, 2020.
[22] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C.Courville, and Y. Bengio, “Generative adversarial nets,” in NIPS, 2014.
[23] V. Bazarevsky, Y. Kartynnik, A. Vakunov, K. Raveendran, and M. Grundmann, “Blaze-face: Sub-millisecond neural face detection on mobile gpus,” ArXiv, vol. abs/1907.05047,2019.
[24] F. Zhang, V. Bazarevsky, A. Vakunov, A. Tkachenka, G. Sung, C.-L. Chang, andM. Grundmann, “Mediapipe hands: On-device real-time hand tracking,” ArXiv, vol. ab-s/2006.10214, 2020.
[25] Intel, “Openvino toolkit.” https://docs.openvinotoolkit.org/latest/index.html,2021.

53
[26] P. Werbos, “Backpropagation through time: What it does and how to do it,” 1990.
[27] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation,vol. 9, pp. 1735–1780, 1997.

54
Anexos
A Aspectos eticos, economicos, sociales y ambientales
A.1 Introduccion
Hoy en dıa existen una gran variedad de proyectos y tecnologıas que innovan constantementelas que estan establecidas, por lo que es importante generar ideas para mejorar y avanzar lasociedad a un mundo mejor. Ademas, es muy difıcil hacerse hueco en un mundo en el quelas empresas grandes consiguen acaparar todos los nichos de mercado. Es por ello que todoproyecto pequeno debe estar destinado a mejorar aspectos muy especıficos y teniendo muy encuenta lo que la gente necesita.
El reconocimiento de ejercicios basicos es algo que permite que cualquier persona que necesiteesta tecnologıa centrada en su forma de trabajo tan solo se tendrıa que crear un dataset es-pecıfico y disenado para cumplir sus necesidades. La medicina y el entrenamiento son aspectosrelacionados con la salud por lo que suponen una oportunidad para pequenos proyectos derealizar trabajos muy necesarios, muy solicitados y bien recibidos por la sociedad.
Este proyecto nacio para cumplir ese objetivo y no contento con ello, se busco realizarlo enaparatos baratos y de baja exigencia computacional para que se pudieran beneficiar el mayornumero de personas. Ademas se trata de un trabajo que puede servir como los cimientos deotros proyectos mas completos y que satisfazcan las necesidades de aquellos que lo soliciten.
A.1.1 Impacto etico, economico y social
El aspecto etico es crucial en cualquier proyecto de estas caracterısticas. Es importante ofrecertoda la informacion y pasos seguidos para el entendimiento de cualquiera, ademas de aseguraruna precision en las tareas que se realizan y siempre mantener la privacidad de las personasen todo momento. Con los datos de los puntos clave se consigue esto ultimo al no tener lainformacion de la imagen, si no se desea. Finalmente, se debe asegurar la seguridad en el

55
proceso, y en este proyecto no se considera que pueda afectar negativamente.
El impacto economico y social que puede generar un proyecto como este es bastante positivo.La situacion del Covid-19 ha acercado cualquier actividad, trabajo o educacion a las viviendasde las personas por lo que cualquier sistema que se pueda instalar en las casas para mejorar elestilo de vida de las personas es muy practico. En este caso se esta hablando de la posibilidadde tener una herramienta barata, pequena y manejable con la que cualquier entrenador oterapeuta pueda utilizar para realizar un seguimiento sobre sus clientes o pacientes.
Un problema que puede surgir es que los profesionales necesiten otro tipo de ejercicios omovimientos con los que trabajan mas habitualmente, pero tiene una solucion tan facil comocrear un dataset especıfico para cada caso. Aunque en este proyecto se hayan considerado 12ejercicios, la gran novedad es que mediante el sistema de angulos se han conseguido resultadosmuy prometedores. Es por ello que se podrıa ampliar el dataset a otros movimientos y teneruna precision alta.
Finalmente, destacar que este proyecto esta especialmente pensado para personas con movi-lidad reducida. El avance de las tecnologıas para conseguir que este tipo de personas puedantener herramientas para mejorar y acelerar el proceso para adquirir la movilidad deseada esalgo que la sociedad ve con buenos ojos y por lo que mucha gente estarıa dispuesta a invertir.
Finalmente, aparte de personas particulares, muchos centros podrıan querer apostar por estosproyectos para incluirlos en sus instalaciones y ofrecer algo novedoso para sus clientes, lo quegenerarıa un impacto economico considerable.
A.1.2 Impacto medioambiental
En cuanto al impacto medioambiental, este proyecto consta de una camara, una mini-computadoray un ordenador donde visualizar la informacion. Si bien es cierto que son aparatos cuya fabri-cacion danan al medioambiente, la intencion es poder instalar este sistema en las casas de laspersonas por lo que se ahorrarıan danos medioambientales causados por los desplazamientosde estos y de sus terapeutas o entrenadores.
A.2 Conclusiones
Visto cada impacto por separado, se podrıa considerar este proyecto como un avance muypositivo en la sociedad en lıneas generales. El estado fısico esta extremadamente relacionadocon la salud y eso es algo que cualquier persona en el mundo considera vital para el progresode la sociedad. Ello, unido a la sencilla accesibilidad en un mundo en el que se busca facilitarla vida de las personas hace de este trabajo algo muy interesante y a tener en cuenta en unfuturo proximo.

56
B Presupuesto economico
CO
ST
ED
EM
AN
OD
EO
BR
A(c
ost
ed
irecto
)H
ora
sP
recio
/h
ora
Tota
l
300
15€
4500.0
0€
CO
ST
ED
ER
EC
UR
SO
SM
AT
ER
IAL
ES
(cost
ed
irecto
)P
recio
de
com
pra
Uso
en
mese
sA
mort
izacio
n(e
nan
os)
Tota
l
Ord
enad
orp
erso
nal
(con
Sof
twar
e)
700,
00€
65
70,0
0€
Nvid
iaJet
son
Nan
o85
€4
55.
70€
Cam
ara
Dep
thA
IO
AK
-D15
0,00
€4
510
,00
€
CO
ST
ET
OT
AL
DE
RE
CU
RS
OS
MA
TE
RIA
LE
S85,7
0€
GA
ST
OS
GE
NE
RA
LE
S(c
ost
es
ind
irecto
s)15
%so
bre
CD
687,8
5€
BE
NE
FIC
IOIN
DU
ST
RIA
L6
%so
bre
CD
+C
I316.4
1€
SU
BT
OT
AL
PR
ES
UP
UE
ST
O5.5
89,9
6€
IVA
AP
LIC
AB
LE
21%
1.1
73,8
9€
TO
TA
LP
RE
SU
PU
ES
TO
6.7
63,8
5€