uam - 148.206.53.84148.206.53.84/tesiuami/uam8457.pdf · por ejemplo en el reconocimiento de...
TRANSCRIPT

UAM Casa Abierta al Tiempo
Universidad Autónoma Metropolitana
Unidad Iztapalapa Ciencias Básicas e Ingeniería
Ingeniería Electrónica
Proyecto de Ingeniería Electrónica Redes Neuronales: Estudio y Aplicación al Reconocimiento de Caracteres y Control
Joelkorrea Martinez (mat. 90220452) Jorge Porras Espinosa (mat. 89329279)
+ e 9 9 3 Asesor: Mariko Nakano Coordinador: Victor Manuel Ramos Ramos
Abril de 1999

Índice General
Introducción 3
1 Redes Neuronales: herramienta natural 5 1.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 1.2 Historia de l a s Redes Neuronales . . . . . . . . . . . . . . . . 6 1.3 Bases de Redes Neuronales . . . . . . . . . . . . . . . . . . . . 8 1.4 Características de las Redes Neuronales . . . . . . . . . . . . . 31 1.5 Mecanismo de Aprendizaje . . . . . . . . . . . . . . . . . . . . 37 1.6 Tipo de Asociación Entrada/Salida . . . . . . . . . . . . . . . 49 1.7 Representación de la Información . . . . . . . . . . . . . . . . 52
2 Algunos modelos 53 2.1 El Perceptrón . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 2.2 Adaline y el combinador lineal Adaline . . . . . . . . . . . . . 63 2.3 El Madaline . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70 2.4 Red de Propagación hacia atrás (BPN) . . . . . . . . . . . . . 74 2.5 El Modelo de Hopfield . . . . . . . . . . . . . . . . . . . . . . 84 2.6 El Modelo de Kohonen . . . . . . . . . . . . . . . . . . . . . . 95 2.7 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
3 Neocognitrón 105 3.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105 3.2 La Red Neuronal Neocognitrón . . . . . . . . . . . . . . . . . 107
3.2.1 El Sistema Visual Humano . . . . . . . . . . . . . . . . 107 3.2.2 Estructura de la Red Neocognitrón . . . . . . . . . . . 110 3.2.3 Valor de las Células S . . . . . . . . . . . . . . . . . . 114 3.2.4 Valor de las Células C . . . . . . . . . . . . . . . . . . 118 3.2.5 Entrenamiento de la Red . . . . . . . . . . . . . . . . . 120
1

2 INDICE GENERAL
3.2.6 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . 126
4 Identificacidn y Control 127 4.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127 4.2 Preliminares, Conceptos Básicos y Notación . . . . . . . . . . 129
4.2.1 Caracterización e Identificación de Sistemas . . . . . . 129 4.2.2 Identificación y Control . . . . . . . . . . . . . . . . . . 132 4.2.3 Concepto y Andisis de Estabilidad . . . . . . . . . . . 134
4.3 Identificación . . . . . . . . . . . . . . . . . . . . . . . . . . . 138 4.4 Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144 4.5 Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
Bibliografia 149

INDICE GENERAL 3
Introducción A lo largo de la historia pocos son los campos cinetíficos que han experi-
mentado avances tan formidables como la computación. Comparadas con los seres vivos, las computadoras presentan ventajas y desventajas. Por un lado, es innegable la sorprendente ventaja que tienen en relación con las tareas de tipo secuencial, por ejemplo en cálculos numéricos. Pero por otro, es evidente también su incapacidad para llevar a cabo tareas en las cuales los seres vivos, en particular los humanos, aventajan fácilmente a la más poderosas compu- tadoras; además, para aquéllos, estas tareas no representan esfuerzo alguno, por ejemplo en el reconocimiento de rostros y patrones. Las habilidades que despliegan, por un lado, las computadoras y, por otro, los seres humanos, tienen su base en los mecanismos bajo los cuales operan cada uno de ellos. La potencia secuencial de las primeras viene de que es éste precisamente su principio de funcionamiento, siendo, por otro lado, éste también su princi- pal desventaja en tareas que requieren procesamiento paralelo, característica esencial de operación del cerebro de los seres vivos.
El cerebro de los humanos esta conformado por elementos de procesa- miento con una potencia de cálculo bastante reducida, se trata de simples sumadores capaces de ponderar sus entradas. Sin embargo, se presentan en cantidades astronómicas y juntos pueden formar ese órgano de habilidades prodigiosas de que nos ha dotado la naturaleza.
Las computación convencional parece haber llegado a un escollo en rela- ción a la ejecución de tareas sencillas para los seres humanos. Se presenta como alternativa, para solventar esta problemática, desarrollar nuevos méto- dos basados en las características del cerebro. Durante más de medio siglo distintos científicos se han dado a esta tarea, resultando lo que se ha dado en llamar redes neuronales, por su principio de operación.
Dentro de las redes neuronales desarrolladas, una de las más interesantes es la denominada Neocognitrón (en su primera versión llamada Cognitrón). Esta es una red que pretende m.imetizar los mecanismos que sigue el sistema visual de los humanos para llevar a cabo el fenómeno de la visión.
En la Universidad Autónoma Metropolitana Iztapalapa, dentro del plan de estudios de la licenciatura en Ingeniería Electrónica, se contempla el llevar a cabo un trabajo de investigac,ión relacionado con los estudios. El presente trabajo es el resultado de la investigación llevada a cabo por los alumnos Joel Correa Martinez y Jorge Porras Espinosa y efectuada bajo la dirección de la profra. Mariko Nakano.

4 fNDICE GENERAL
Si bien originalmente el proyecto se plante6 en terminos de llevar a cabo el estudio de la red Neocognitrh, inmediatamente se present6 como actividad necesaria el estudio de los principios de l a s redes neuronales en general a fin de poder entender con mayor profundidad la red que primordialmente interesaba. Además, el estudio de aplicaciones específicas de estas nuevas herramientas era necesario para obtener un conocimiento completo y d i d o del tema. Los autores de estas notas juzgan conveniente para los lectores dar al presente trabajo una estructura similar a la seguida en su investigacibn, por ello el escrito contiene mucho más que lo relativo a la red Neocognitrh.
La estructura que presenta el texto es como sigue: En el primer capítulo se tratan los fundamentos y principios de las redes neuronales; en el segundo, abordamos el estudio más detallado de los seis tipos de redes más conocidas; en el tercero, aprovechando el conocimiento adquirido en los dos previos, se aborda la red Neocognitr6n; y, finalmente en el cuarto, se lleva a cabo todo el andisis necesario para emplear una red neuronal en la soluci6n de un problema real: la identificacidn y posterior control de un sistema dinhico.
Joel Correa Martinez Jorge Porras Espinosa Iztapalapa, abril de 1999.

Capítulo 1
Redes Neuronales: herramienta natural
1.1 Introducción
Probablemente el título de este capítulo le pueda generar algún tipo de asom- bro al lector, motivando dicho asombro a dar una breve explicación del porqué de este nombre. En el deseo d.e encontrar solución a los problemas que la ciencia nos presenta, hemos caminado en una sola dirección, la de las ideas de la transformación del entorno para obtener un beneficio aparente, pero po- cas veces nos detuvimos a intentar entenderlo, sólo lo modificamos sin darnos cuenta que lo destruíamos (podemos pensar que el hombre destruye lo que no comprende), hasta que poco a poco las circunstancias nos han obligado a volver la vista a un laboratorio milenario con experimentos que nos llevan millones de años de ventaja en el desarrollo de herramientas y por ende con un alto grado de eficiencia y sabiduría: ese laboratorio se llama "naturaleza". E n estos últimos años, muchas de las investigaciones se han dado a la tarea de entender los complejos procesos que se llevan a cabo en la naturaleza y las soluciones que brinda para hacerle frente a circunstancias adversas, te- niendo como resultado un gran maestro que está dispuesto a entregar todo su conocimiento sin ningún tipo de egoísmo. De esa clase de investigaciones surgieron las Redes Neuronales Artificiales, las cuales son el resultado de la observación del funcionamiento básico de las Redes Neuronales Biológicas (sistemas nerviosos de los animales) y los intentos de emular su comporta- miento en forma artificial. Con ello se creó una nueva herramienta que sirve
5

6 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
para abordar problemas similares a los que la Redes Neuronales Biol6gicas dan soluci6n en la naturaleza. Después de lo anterior serti fticil suponer la raz6n del nombre de "Redes Neuronales: una herramienta natural".
1.2 Historia de l a s Redes Neuronales
Diseñar y construir mtiquinas capaces de realizar procesos con cierta inteli- gencia ha sido una de las metas del mundo cientifico a lo largo de la historia. Los primeros resultados de estos intentos fueron mhuinas que realizaban de una u otra forma funciones tipicas de los seres humanos, estando basadas en el desarrollo técnico y la habilidad mectinica de los constructores de esos artefactos. Con el paso del tiempo estas herramientas fueron adoptando for- mas m& sofisticadas y con resultados sorprendentes. De las herramientas m& recientes podemos mencionar a la microinformAtica.
Sin embargo, a pesar de contar con elementos que permiten el desarrollo de estas mtiquinas inteligentes, se tienen límites que, por m& espectaculares y complejas que lleguen a ser en el fondo, siguen siendo herramientas mectinicas incapaces de presentar un buen desempeño en procesos que resultan sencillos para los seres humanos, como el reconocimiento de formas, el habla, etc.
La linea de investigaci6n que ha tomado m& fuerza en las ultimas décadas es la de observar, entender y emular las herramientas que la naturaleza ha desarrollado a lo largo de su evoluci6n. En esa linea de investigaci6n se encuentran l a s Redes Neuronales Artificiales, las cuales surgen a raíz de la necesidad de construir herramientas para realizar procesos que las Redes Neuronales Biol6gicas ejecutan con gran eficiencia.
A continuaci6n daremos un resumen de la forma en que fue evolucionando el conocimiento de l a s Redes Neuronales.
Las primeras explicaciones te6ricas sobre el cerebro y el pensamiento fue- ron dadas por algunos antiguos fil6sofos griegos, como Plat6n (427-347 a. C.) y Arist6teles (384-422 a. C.). Las mismas ideas sobre el proceso mental también las mantuvo Descartes (1596-1650) y los fil6sofos empiristas del siglo XVIII.
Heron el Alejandrino construy6 un aut6mata hidrtiulico cerca del año 100 a. C. Tambikn se han construido numerosos modelos de animales para demos- trar el comportamiento necesidad - adaptacidn sobre diferentes condiciones de vida, como las distintas versiones del rat6n en el laberinto.
Alan Turing, en 1936, estudi6 por primera vez el cerebro bajo una 16gi-

1.2. HISTORIA DE LAS REDES NEURONALES 7
ca computacional. Sin embargo, quienes concibieron los fundamentos de la computación neuronal fueron Warren McCulloh, un neurofisiólogo, y Walter Pitts, un matemático, los cuales, en 1943, propusieron una teoría del modo de trabajar de las neuronas modelando mediante un circuito eléctrico una red neuronal. E n 1949, Donald Hebb llevó a cabo investigaciones sobre la orga- nización del comportamiento, estableciendo una conexión entre la psicología y la fisiología.
E l Perceptrón hace su aparición en 1957. Desarrollado por Frank Rosen- blatt era capaz de reconocer patrones similares a los que se le había presenta- do anteriormente para su aprendizaje. El Perceptrón es la red neuronal más antigua. Lamentablemente esta, red tiene una serie de limitaciones, quizá la más conocida sea la incapacidad de dar una solución al problema de XOR y, en general, el no poder clasificar clases de patrones no separables linealmente, desanimando a varios investigadores por un largo tiempo.
E n 1959, Bernard Widrow y Marcial Hoff, de Stanford, desarrollaron el modelo ADALINE (ADAptativle LINear Element), el cual fue la primera red aplicada a un problema real, como el de la construcción de filtros adaptativos para eliminar ecos en las líneas telefónicas.
Stephen Grossberg desarrol1.ó en 1967 una red, llamada Avalancha, des- arrollada en base a elementos discretos con una actividad que varía con el tiempo según leyes dadas por ecuaciones diferenciales continuas, para lle- var a cabo actividades tales como reconocimiento continuo del habla y el aprendizaje de movimientos de los brazos de un robot.
En 1969 varias críticas detuvieron el aumento que se venía observando en las investigaciones de redes neuronales. Marvin Minsky y Seymour Papert, del Instituto Tecnológico de Massachusetts publicaron un libro, Perceptrons; en él presentaban un análisis completo sobre el Perceptrón y el Perceptrón Multinivel y mostraban las limitaciones para resolver problemas interesantes.
Algunos investigadores fueron fieles a las redes neuronales y continuaron con sus estudios, como James Anderson, desarrollador del Asociador Lineal, consistente en elementos integradores lineales (neuronas) que sumaban sus entradas. Este modelo se basó en el principio de que las conexiones entre neuronas son reforzadas cada vez que son activadas. También implementó una extensión muy potente del Asociador Lineal, llamada Brain-State-in-a- Box (BSB).
En Europa y Japón continuaron las investigaciones, teniendo como re- sultado de ellas redes neuronales como el Neocognitrón, desarrollado por Kunihiko Fukushima, para reconocimiento de patrones visuales y la red de

8 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
mapas autoorganizativos, de Teuvo Kohonen, similar al funcionamiento del Asociador Lineal.
En 1982 coincidieron muchos eventos que hicieron resurgir el interés por las redes neuronales. John Hopfield present6 un trabajo en el que describe con claridad y correctitud matemaitica una red que es una variacidn del Asociador Lineal, mostrando de manera completa c6mo trabaja y qu6 puede hacer esta red, llamada por su creador Red de Hopfield.
A partir de ese año surgieron varios tipos de redes como Temple Simulado (1983), desarrollada por Kirkpatrick, Galatt y Vecchi; la Memoria Asociati- va Bidireccional (1985), creada por Bart Kosko; la Mhuina de Boltzmann y Cauchy (1985), elaborada por Jeffrey Hinton, Terry Sejnowski y Harold Szu; la Red de Retropropagaci6n (1985), desarrollada por Paul Werbos, Da- vid Parker y David Rumelhart; La Teoria de Resonancia Adaptativa (ART) (1986), creada por Gail Carpenter y Stephen Grossberg; La Red de Contra- propagaci6n (1986), elaborada por Robert Hecht-Nielsen. Los anteriores son s610 algunos ejemplos y han seguido los desarrollos hasta nuestros dias.
1.3 Bases de Redes Neuronales
Como se dijo anteriormente, la teoría y modelado de las redes neuronales artificiales estain inspirados en la estructura y funcionamiento de los sistemas nerviosos. El poder entender el funcionamiento del sistema nervioso se debe en gran medida a los trabajos de Ram6n y Cajal (1911), quien introdujo la idea de que el cerebro estaba compuesto de estructuras de neuronas, siendo la neurona el elemento fundamental. Existen neuronas de diferentes formas, tamaños y longitudes. Estos atributos son importantes para determinar la funci6n y utilidad de la neurona. La clasificaci6n de estas células en tipos esthdar ha sido realizada por muchos neuroanatomistas.
La corteza cerebral en humanos es una larga y delgada hoja de 2 a 3 milimetros de grueso que cubre una superficie de 2,200 cm2. La corteza cerebral contiene cerca de 10l1 neuronas, que es aproximadamente el número de estrellas en la vía laictea. Cada neurona tiene de lo3 a lo4 conexiones a otras neuronas. En total, los humanos contienen en su cerebro alrededor de io14 a interconexiones.
Otras características que las redes neuronales del cerebro ofrecen son: una respuesta del orden segundos y un consumo de energía por segundo de operaci6n del orden de Joules.

1.3. BASES DE REDES NEURONALES 9
La Neurona
Una neurona es una célula viva y, por ende, los elementos que la forman son los mismos que a todas las células biológicas. También tienen características que las hacen diferentes a las demás. Una neurona por lo general cuenta con un cuerpo celular más o menos; esférico, de 5 a 10 micras de diámetro, del que salen una rama principal, el axón, y varias ramas más cortas, llamadas dendritas. A su vez, el axón puede producir ramas en torno a su punto de arranque, y con frecuencia se ramifica extensamente cerca de su extremo. La Figura l. 1 representa los componentes principales de una célula nerviosa típica perteneciente al sistema nervioso central.
.
71 \ \ Fjúcleo 1 Cuerpo de la célula
Figura 1.1. Entre las estructuras fundamentales de una célula nerviosa típica se cuentan las dendritas, el cuerpo de la célula y el Único axón. El
axón de muchas neuronas está rodeado por una membrana que se denomina vaina de mielina. Los nodos de Ranvier interrumpen periódicamente la vaina de mielina a lo largo del axón. Las sinapis conectan el axón de la
neurona con distintas partes de otras neuronas.
Una de las características que hacen diferentes a las neuronas de las otras células vivas es la capacidad que tienen las neuronas para comunicarse. El funcionamiento general de las neuronas es el siguiente: las dendritas y el cuerpo celular reciben señales de entrada; el cuerpo celular las combina, integra y emite señales de salida. El axón transporta esas señales a los terminales axónicos, que se encargan de distribuir información a un nuevo conjunto de neuronas.

10 CAPITULO 1. REDES NEURONALES: HEZRRAMIENTA NATURAL
En la neurona se utilizan señales de naturaleza distinta: eléctrica y quimi- ca. La señal generada por la neurona y transportada a lo largo del axón es un impulso eléctrico, mientras que la señal que se trasmite entre los termina- les ax6nicos de una neurona y las dendritas de las neuronas siguientes es de origen quimico; concretamente se realiza mediante moléculas de sustancias transmisoras (neurotransmisores) que fluyen a través de unos contactos espe- ciales, llamados sinapsis, que tienen la funci6n de receptor y estan localizados entre los terminales ax6nicos y las dendritas de la neurona siguiente.
La membrana de la neurona separa el plasma intracelular del fluido inters- ticial que se encuentra fuera de la célula. La membrana es permeable para ciertas especies iónicas, y actúa de tal forma que mantiene una diferencia de potencial entre el fluido intracelular y el fluido extracelular. Este efecto se consigue primordialmente por la acción de una bomba de sodio-potasio. También estan presentes otras especies i6nicas, como son los iones cloruro e iones orghicos negativos.
Todas las especies iónicas se pueden difundir a través de la membrana, con la excepción de los iones organices, que son demasiado grandes. Dado que los iones orghicos no pueden salir de la célula por difusidn, su carga negativa neta dificulta la entrada en la célula de iones cloro por difusión; por tanto, habra una concentraci6n m& alta de iones cloro fuera de la célula. La bomba de sodio-potasio determina una concentracidn más alta de potasio dentro de la célula y una concentración más alta de sodio fuera de ella.

1.3. BASES DE REDES NEURONALES 11
" ++++*+++++++++++,+++++++*+" " - . . . . . . . . . . . . . . . . . . . . . . . . . . . .
N a
I I INTERIOR _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ - - - - - * * + + + """""""""""""- DE La K
"EM8RANP ""_"""""""""" + + + + + """""""""""-"-- t+*+*++*****+ttt~++*t++it - - - - - + + t + t + + t t t t + + t + + + + + * + * + + + * + *
I I
Na
CENT1 METROS 0 S I0 15 20 25 30
CONCENTRACION DE I M S SODIO Y POTASIO M LH MEMBRANP DEL AXON
(b) Membrana de la célula rl , interno Electrodo ~7
Orgbnico
Na+ - externo Electrodo CI -
Figura 1.2. Esta figura ilustra el potencial de reposo que se establece a ambos lados de la membrana de una neurona. Los tamaños relativos de los rótulos de las especies iónicas denotan aproximadamente la concentración
relativa de cada especie en las regiones internas y externas de la célula.
La membrana celular es selectivamente más permeable para los iones de potasio que para los iones de sodio. El gradiente químico del potasio tiende a hacer que los iones de pota.:io salgan de la célula por difusión, pero la fuerte atracción de los iones orgánicos negativos tiende a mantener dentro el potasio. E l resultado de estas fuerzas opuestas es que se alcanza un equilibrio en el cual hay más iones de sodio y cloro fuera de la célula (10 veces más rico en sodio fuera que dentro de la célula), y más iones orgánicos y de potasio dentro de ella (10 veces más rico en potasio dentro que fuera de la célula). Además, el equilibrio resultante produce una diferencia de potencial a través de la membrana de la célula de unos 70 a 100 milivoltios (mv) , siendo el más negativo el fluido intracelular. Este potencial, que se denomina potencial de
12 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
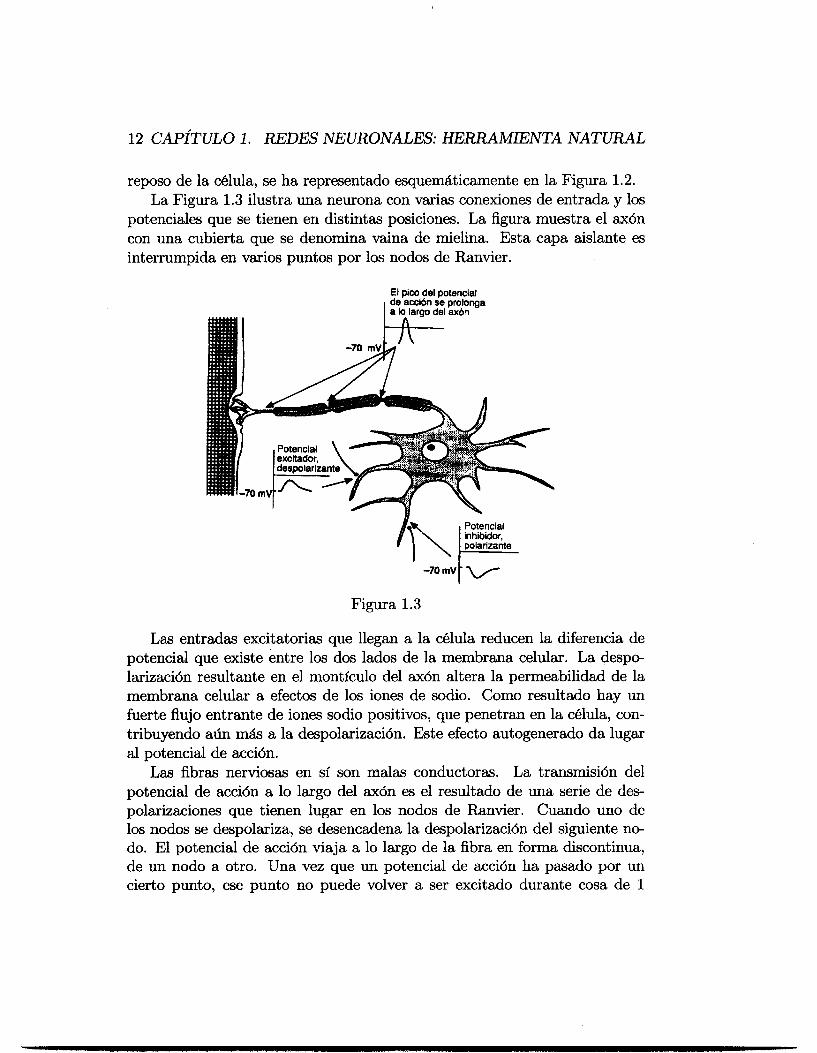
reposo de la cklula, se ha representado esquemáticamente en la Figura 1.2. La Figura 1.3 ilustra una neurona con varias conexiones de entrada y los
potenciales que se tienen en distintas posiciones. La figura muestra el ax6n con una cubierta que se denomina vaina de mielina. Esta capa aislante es interrumpida en varios puntos por los nodos de Ranvier.
El pico del potencial de acción se prolonga I a lo larao del axbn
pohrizante
-7QmV
Figura 1.3
Las entradas excitatorias que llegan a la c6lula reducen la diferencia de potencial que existe entre los dos lados de la membrana celular. La despe larizaci6n resultante en el montículo del ax6n altera la permeabilidad de la membrana celular a efectos de los iones de sodio. Como resultado hay un fuerte flujo entrante de iones sodio positivos, que penetran en la cblula, con- tribuyendo aún m& a la despolarisaci6n. Este efecto autogenerado da lugar al potencial de wci6n.
Las fibras nerviosas en sí son malas conductoras. La transmisih del potencial de wci6n a lo largo del ax6n es el resultado de una serie de des- polarizwiones que tienen lugar en los nodos de Ranvier. Cuando uno de los nodos se despolariza, se desencadena la despolarizaci6n del siguiente n e do. El potencial de wci6n viaja a lo largo de la fibra en forma discontinua, de un nodo a otro. Una vez que un potencial de accidn ha pasado por un cierto punto, ese punto no puede volver a ser excitado durante cosa de 1

1.3. BASES DE REDES NEURONALES 13
milisegundo, que es el tiempo q.ue tarda en volver a su potencial de reposo. Este periodo refractario limita la frecuencia de transmisión de los impulsos nerviosos a unos 1,000 por segundo.
La unión sináptica
Examinemos brevemente la actividad que se desarrolla en una unión existen- te entre dos neuronas, que se denomina unión sináptica o sinapsis (espacio sináptico, entre 50 y 200 Angstroms). La comunicación entre las neuronas es resultado de la liberación de unas sustancias llamadas neurotransmisores por parte de la célula presináptica, y la absorción de estas sustancias por la célula postsináptica. La Figura 1.4 muestra esta actividad. Cuando el potencial de acción llega a la membrana presináptica, los cambios de permeabilidad de la membrana dan lugar a un flujo entrante de iones de calcio. Estos iones dan lugar a que las vesículas que contienen los neurotransmisores se fundan con la membrana sináptica, liberando así sus neurotransmisores en la separación sináptica.
La llegada de señales procedentes de otras neuronas a través de las den- dritas actúa acumulativamente.
Los neurotransmisores se difunden a través de la unión y se unen a la membrana postsináptica en ciertos lugares llamados receptores. La acción

14 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
química que se produce en los receptores da lugar a cambios de permeabilidad de la membrana postsinAptica para ciertas especies idnicas. Un flujo entrante de especies positivas hacia la célula tenderti a despolarizar el potencial de reposo; este efecto es excitatorio. Si entran iones negativos, se producir& un efecto hiperpolarizante; este efecto es inhibitorio. Estos dos efectos son locales, y actúan tan s610 a lo largo de una pequeña distancia hacia el interior de la c6lula; sumhdose en el montículo del axdn. Si la suma es mayor que un cierto valor umbral se genera un potencial de accidn.
Para establecer una similitud directa entre la actividad sintiptica y la analogia con las redes neuronales artificiales, vamos a fijar los siguientes aspectos: Las señales que llegan a la sinapsis son las entradas a la neurona; éstas son ponderadas (atenuadas o amplificadas) a travh de un partimetro, denominado peso, asociado a la sinapsis correspondiente. Estas señales de entrada pueden excitar a la neurona (sinapsis con peso positivo) o inhibirla (peso negativo). El efecto es la suma de las entradas ponderadas. Si la suma es igual o mayor que el umbral de la neurona, entonces la neurona se activa (da salida). Esta es una situacidn todo o nada; cada neurona se activa o no se activa. La facilidad de transmisión de señales se altera mediante al actividad del sistema nervioso. Las sinapsis son susceptibles a la fatiga, deficiencia de oxígeno y a agentes tales como los anestésicos. Otros eventos pueden incrementar el grado de activacidn. Esta habilidad de ajustar señales es un mecanismo de aprendizaje. Las funciones umbral integran la energía de las señales de entrada en el espacio y en el tiempo.
Elementos de una red neuronal artificial
Las redes neuronales son modelos que intentan reproducir el comportamien- to del cerebro. Como todo modelo, realiza una simplificacidn, averiguando cudes son los elementos relevantes del sistema, bien porque la cantidad de informacidn de que se dispone es excesiva o bien porque es redundante. Una eleccidn adecuada de sus características, m& una estructura conveniente, es el procedimiento convencional utilizado para construir redes capaces de realizar una determinada tarea.
Cualquier modelo de red neuronal consta de dispositivos elementales de proceso: las neuronas. A partir de ellas, se pueden generar representaciones especificas, de tal forma que un estado conjunto de ellas puede significar una letra, un número o cualquier otro objeto. En el siguiente apartado se realiza la idealizacidn del funcionamiento neurobioldgico descrito anteriormente, que

1.3. BASES DE REDES NEURONALES 15
sirve de base de las redes neuronales artificiales (RNA). Generalmente, se pueden encontrar tres tipos de neuronas.
1) Aquellas que reciben estímulos externos, relacionadas con el aparato
2) Dicha información se transmite a ciertos elementos internos que se ocupan de su procesado. Es en las sinapsis y neurona correspondientes a este segundo nivel donde se genera cualquier tipo de representación interna de la información. Puesto que no tienen relación directa con la información de entrada ni con la de salida, estos elementos se denominan unidades ocultas.
3) Una vez ha finalizado el periodo de procesado, la información llega a
sensorial, que tomarán la información de entrada.
las unidades de salida, cuya misión es dar la respuesta del sistema. La neurona artificial pretende mimetizar las características más impor-
tantes de las neuronas biológicas. Cada neurona i-ésima está caracterizada en cualquier instante por un valor numérico denominado valor o estado de activación ai ( t ) ; asociado a cada unidad, existe una función de salida, f i , que transforma el estado actual de activación en una señal de salida, yi. Dicha señal es enviada a través de los canales de comunicación unidireccionales a otras unidades de la red; en estos canales la señal se modifica de acuerdo con la sinapsis (el peso, wji) asociada a cada uno de ellos según una deter- minada regla. Las señales moduladas que han llegado a la unidad j-ésima se combinan entre ellas, generando así la entrada total, N e t j .
Una función de activación, F , determina el nuevo estado de activación a j ( t + 1) de la neurona, teniendo en cuenta la entrada total calculada y el anterior estado de activación aj ( t ) .
La dinámica que rige la actualización de los estados de las unidades (evo- lución de la red neuronal) puede ser de dos tipos: modo asíncrono y modo síncrono. En el primer caso, las neuronas evalúan su estado continuamente, según les va llegando información, y lo hacen de forma independiente. E n el caso síncrono, la información también llega de forma continua, pero los cambios se realizan simultáneamente, como si existiera un reloj interno que decidiera cuándo deben cambiar su estado. Los sistemas biológicos quedan probablemente entre ambas posibilidades.

16 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
Unidad U,
Y1
Figura 1.5. Entradas y salidas de una neurona Uj.
Unidades de proceso: La neurona artificial
Si se tienen N unidades (neuronas), podemos ordenarlas arbitrariamente y designar la j-ésima unidad como Uj. Su trabajo es simple y Único, y consiste en recibir las entradas de las células vecinas y calcular un valor de salida, el cual es enviado a todas las células restantes.
En cualquier sistema que se esté modelando, es útil caracterizar tres tipos de unidades: entradas, salidas y ocultas. Las unidades de entrada reciben señales desde el entorno; estas entradas (que son a la vez entradas a la red) pueden ser señales provenientes de sensores o de otros sectores del sistema. Las unidades de salida envían la señal fuera del sistema (salidas de la red); estas señales pueden controlar directamente potencias u otros sistemas. Las unidades ocultas son aquellas cuyas entradas y salidas se encuentran dentro del sistema, es decir, no tienen contacto con el exterior.
Se conoce como capa o nivel a un conjunto de neuronas cuyas entradas provienen de la misma fuente (que puede ser otra capa de neuronas) y cuyas salidas se dirigen al mismo destino (que puede ser otra capa de neuronas). El estudio m& detallado de la estructura de las redes neuronales los trataremos al final del capítulo, ahora nos centraremos en el modelado de la neurona artificial.

1.3. BASES DE REDES NEURONALES 17
Est ado de activación
Adicionalmente al conjunto de unidades, la representación necesita los es- tados del sistema en un tiempo t . Esto se especifica por un vector de N números reales A(t) , que representa el estado de activación del conjunto de unidades de procesamiento. Cada elemento del vector representa la activa- ción de una unidad en el tiempo t . La activación de una unidad Vi en el tiempo t se designa por ai ( t) ; es decir,
E l procesamiento que realiza la red se ve como la evolución de un patrón de activación en el conjunto de unidades que lo componen a través del tiempo.
Todas las neuronas que componen la red se hallan en cierto estado. En una visión simplificada, podemos decir que hay dos posibles estados, reposo y excitado, a los que denominaremos globalmente estados de activación, y a cada uno de los cuales se le asigna un valor. Los valores de activación pueden ser continuos o discretos. Además, pueden ser limitados o ilimitados. Si son discretos, suelen tomar un conjunto pequeño de valores o bien valores binarios. En notación binaria, un estado activo se indicaría por un 1 , y se caracteriza por la emisión de un impulso por parte de la neurona (potencial de acción), mientras que un estado pasivo se indicaría por un O , y significaría que la neurona está en reposo. En otros modelos se considera un conjunto continuo de estados de activación, en lugar de sólo dos estados, en cuyo caso se les asigna un valor entre [O, 11 o en el intervalo [- 1,1] , generalmente siguiendo una función sigmoidal.
Finalmente, es necesario saber qué criterios o reglas siguen las neuronas para alcanzar tales estados de activación. En principio, esto va a depender de dos factores: a) Por, un lado, puesto que las propiedades microscópicas de las redes neuronales no son producto de actuación de elementos individua- les, sino del conjunto como un todo, es necesario tener idea del mecanismo de interacción entre las neuronas; el estado de activación estará fuertemente influenciado por tales interacciones, ya que el efecto que producirá una neu- rona sobre otra será proporcional a la fuerza, peso o magnitud de la conexión entre ambas. b) Por otro lado, la señal que envía cada una de las neuronas a sus vecinas dependerá de su propio estado de activación.

18 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
F’uncidn de salida o de transferencia
Entre las unidades o neuronas que forman una red neuronal artificial existe un conjunto de conexiones que unen unas a otras. Cada unidad transmite señales a aquellas que e s t h conectadas con su salida. Asociada con cada unidad Vi hay una funci6n de salida f i (a i ( t ) ) , que transforma el estado actual de activacidn ai (t) en una señal de salida yi ( t ) , es decir:
El vector que contiene las salidas de todas las neuronas en un instante t es:
Y(t) = [f&l(t)), f2(az( t>) , * * * , fiv(aiv(t))l * En algunos modelos, esta salida es igual al nivel de activacidn de la unidad,
en cuyo caso la funci6n f i es la funci6n identidad, fi (ai (t)) = ai (t) . A menudo, f i es de tipo sigmoidal, y suele ser la misma para todas las unidades.
Existen cuatro funciones de transferencia típicas que determinan distintos tipos de neuronas:
o Funci6n escal6n
o Funcidn lineal y mixta
o Sigmoidal
o Funci6n gaussiana.
La funcidn escal6n o umbral únicamente se utiliza cuando las salidas de la red son binarias (dos posibles valores). La salida de una neurona se presenta s610 cuando el estado de activaci6n es mayor o igual que cierto valor umbral (la funci6n puede estar desplazada sobre los ejes). La funcidn lineal o identidad equivale a no aplicar funcidn de salida. Se usa muy poco. Las funciones mixta y sigmoidal son las m& apropiadas cuando queremos como salida informaci6n anal6gica. Veamos con m& detalle las distintas funciones:
Neurona de funcidn escaldn
La forma m& fzicil de definir la activaci6n de una neurona es considerar que 6sta es binaria. La funci6n de transferencia escal6n se asocia a neuronas binarias en las cuales cuando la suma de las entradas es mayor o igual que

1.3. BASES DE REDES NEURONALES 19
el umbral de la neurona, la activación es 1; si es menor, la activación es O (6 -1). Por otro lado, las redes formadas por este tipo de neuronas son fáciles de implementar en hardware, pero a menudo sus capacidades están limitadas.
Y I I Y -Fx - 1
En ambos casos .w ha tomoda que el umbral es cero: en caso de que no lo fuera. el exal6n quedona desplazado.
Figura 1.6. Función de transferencia escalón.
Neuronas de función lineal y mixta
La función lineal o identidad responde a la expresión f(x) = x. En las neuronas con función mixta, si la suma de las señales de entrada es menor que un límite inferior, la activación se define como O (6 -1). Si dicha suma es mayor o igual que el límite superior, entonces la activación es 1. Si la suma de entrada está comprendida entre ambos límites, superior e inferior, entonces la activación se define como una función lineal de la suma de las señales de entrada. Podemos representar las funciones de activación como indican la Figura 1.7, se toma el límite superior de la suma de todas las entradas de activación que afectan a la neurona durante el ciclo de operación (x) como c y el limite inferior como -e, y es la salida de activación de la neurona.

20 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
Y I , Y
Figura 1.7. Funciones de activaci6n mixta.
Neuronas de funci6n continua (sigmoidal)
Cualquier funci6n definida simplemente en un intervalo de posibles valores de entrada, con un incremento monot6nico y que tenga ambos límites superb res e inferiores (por ejemplo, las funciones sigmoidal o arcotangente), podr4 realizar la funci6n de activaci6n o de transferencia de forma satisfactoria.
Con la funci6n sigmoidal, para la mayoría de los valores del estimulo de entrada (variable independiente), el valor dado por la funci6n es cercano a uno de los valores asintbticos. Esto hace que en la mayoría de los casos, el valor de salida esté comprendido en la zona alta o baja del sigmoide. De hecho, cuando la pendiente es elevada, esta funci6n tiende a la funci6n escalh. Sin embargo, la importancia de la funci6n sigmoidal (o cualquier otra funci6n similar) es que su derivada es siempre positiva y cercana a cero para los valores grandes positivos o negativos; además, toma su valor m&mo cuando z es O. Esto hace que se puedan utilizar las reglas de aprendizaje definidas para las funciones escaldn, con la ventaja, respecto a esta funci6n, de que la derivada est4 definida en todo el intervalo. La funci6n escal6n no podía definir la derivada en el punto de transicidn, y esto no ayuda a los mktodos de aprendizaje en los cuales se usan derivadas.

1.3. BASES DE REDES NEURONALES 21
Figura 1.8. Funciones de activación continuas.
Función de transferencia ga.ussiana
Los centros y anchura de estas funciones pueden ser adaptados, lo cual las hace más adaptativas que las funciones sigmoidales. Mapeos que suelen re- querir dos niveles ocultos (neuronas en la red que se encuentran entre las de entrada y las de salida) utilizando neuronas con funciones de transferencia sigmoidales; algunas veces se pueden realizar con un solo nivel en redes con neuronas de función gaussiana.
Funcl6n de Gauss
Figura 1.9. Función de transferencia gaussiana.
Conexiones entre neuronas
Las conexiones que unen a las neuronas que forman una RNA tienen asociado un peso, que es el que hace que la red adquiera conocimiento. Consideremos yi como el valor de salida de una neurona i en un instante dado. Una neurona recibe un conjunto de señales que le dan información del estado de activación de todas las neuronas con las que se encuentra conectada. Cada conexión

22 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
(sinapsis) entre la neurona i y la neurona j est6 ponderada por un peso wji
Normalmente, como simplificacidn, se considera que el efecto de cada señal es aditivo, de tal forma que la entrada neta que recibe una neurona (potencial postsináptico) Netj es la suma del producto de cada señal individual por el valor de la sinapsis que conecta ambas neuronas:
N
Netj =x wji yi. i=l
Esta regla muestra el procedimiento a seguir para combinar los valores de entrada a una unidad con los pesos de las conexiones que llegan a esa unidad y es conocida como regla de propagación.
Suele utilizarse una matriz W con todos los pesos utji que reflejan la influencia que sobre la neurona j tiene la neurona i. W es un conjunto de elementos positivos, negativos o nulos. Si wji es positivo, indica que la interaccidn entre las neuronas i y j es excitadora; es decir, siempre que la neurona i esté activada, la neurona j recibir6 una señal de i que tendera a activarla. Si es negativo, la sinapsis será inhibidora. En este caso, si z esta activada, enviará una señal a j que tendera a desactivar a ésta. Finalmente, si wji = O, se supone que no hay conexión entre ambas.
F’unci6n o regla de activaci6n
Así como es necesario una regla que combine las entradas a una neurona con los pesos de las conexiones, también se requiere una regla que combine las entradas con el estado actual de la neurona para producir un nuevo estado de activacidn. Esta funcidn F produce un nuevo estado de activación en una neurona a partir del estado (ai) que existía y la combinacidn de las entradas con los pesos de las conexiones (Neti).
Dado el estado de activacidn ai(t) de la unidad Vi y la entrada total que llega a ella, Neti, el estado de activacidn siguiente, ai(t + l), se obtiene aplicando una funcidn F , llamada función de activación.
ai(t + 1) = F (ai(t), Neti)
En la mayoría de los casos, F es la función identidad, por lo que el estado de activacidn de una neurona en t + 1 coincidir6 con el Net de la misma en t En este caso, el parámetro que se le pasa a la funcidn de salida, f , de la neurona sera directamente el Net. El estado de activacidn anterior no se

1.3. BASES DE REDES NEURONALES 23
tiene en cuenta. Según esto, la salida de una neurona i, (pi) quedará según la expresión:
Y N
Figura 1.10
Por tanto, y en lo sucesivo, consideraremos únicamente la función f que denominaremos indistintamente de transferencia o de activación. Además, normalmente la función de activación no está centrada en el origen del eje que representa el valor de la entrada neta, sino que existe cierto desplazamiento debido a las características internas de la propia neurona y que no es igual en todas ellas. Este valor se denota como qi y representa el umbral de activación de la neurona i.

24 CAPITULO 1. REDES NEURONALES: HEMIENTA NATURAL
Yu
Figura 1.11
La salida que se obtiene en una neurona para las diferentes formas de la
a) F'unci6n de activaci6n escalh. Si el conjunto de los estados de activaci6n es E = { O , l}, tenemos que:
funcidn f serhn:
{ 1 si [Neti > Oil
O si [Neti < Oil yi(t + 1) = yi(t) si [Neti = 6i]
Si el conjunto es E = { - 1 , l}, tendremos que:
Figura l. 12

1.3. BASES DE REDES NEURONALES 25
b) Función de activación lineal o identidad. El conjunto de estados E puede contener cualquier número real; el estado
de activación coincide con la entrada total que ha llegado a la unidad.
p i ( t + 1) = Neti - Bi .
Figura l. 13
c) Función de activación lineal-mixta. Con esta función, el estado de activación de la unidad está obligado a
permanecer dentro de un intervalo de valores reales prefijados.
b si [Neti 5 b + Oil
B si [Neti 2 Oil
Neti - Bi si [b + Oi < Neti < B + Oi l
Figura 1.14
d) Función de activación sigmoidal. Es una función continua, por tanto el espacio de los estados de activación
es un intervalo del eje real.

26 CAPk!VLO 1. REDES NEURONALES: HERRAMIENTA NATURAL
y*@+ 11 1
O Net, - e,
Figura 1.15
Para simplificar la expresidn de la salida de una neurona i , es habitual considerar la existencia de una neurona ficticia, con valor de salida unidad, asociada a la entrada de cada neurona i mediante una conexidn con peso de valor -8i. De esta forma la expresidn de salida quedar&:
Figura 1.16
Regla de aprendizaje
Existen muchas definiciones del concepto general de aprendizaje, una de ellas podria ser: La modificacidn del comportamiento inducido por la interaccidn con el entorno y como resultado de experiencias conducente al estableci- miento de nuevos modelos de respuesta a estimulos externos. Esta definicidn

1.3. BASES DE REDES NEURONALES 27
fue enunciada muchos años antes de que surgieran las redes neuronales, sin embargo puede ser aplicada tarnbién a los procesos de aprendizaje de estos sistemas.
Biológicamente, se suele aceptar que la información memorizada en el cerebro está mas relacionada con los valores sinápticos de las conexiones entre las neuronas que con ellas mis:mas; es decir, el conocimiento se encuentra en las sinapsis. En el caso de las redes neuronales artificiales, se puede considerar que el conocimiento se encuentra representado en los pesos de las conexiones entre neuronas. Todo proceso de aprendizaje implica cierto número de cambios en estas conexiones. En realidad, puede decirse que se aprende modificando los valores de los pesos de la red.
Al igual que el funcionamie:nto de una red depende del número de neu- ronas de las que disponga y de cómo estén conectadas entre sí, cada modelo dispone de su o sus propias técnicas de aprendizaje.
Representación vectorial
En ciertos modelos de redes neuronales, se utiliza la forma vectorial como herramienta de representación de algunas magnitudes. Si consideramos una red formada por varias capas de neuronas idénticas, podemos considerar las salidas de cierta capa de n unidades como un vector n-dimensional Y = [ y l , y2, . . . , yn]). Si este vector n-dimensional de salida representa los valores de entrada de todas las unidades de una capa m-dimensional, cada una de las unidades de esta capa poseerá n pesos asociados a las conexiones procedentes de la capa anterior. Por tanto, hay m vectores de pesos n-dimensionales asociados a la capa m.
El vector de pesos de la j-&sima unidad tendrá la forma:
y = ( Y j l , Yj2, . . * , Yjn)
La entrada neta de la j-ésima unidad se puede escribir en forma de producto escalar del vector de (entradas por el vector de pesos. Cuando los vectores tienen igual dimensión., este producto se define como la suma de los productos de los componentes correspondientes a ambos vectores:
n
2=1
en donde n representa el número de conexiones de la j-ésima unidad. La ventaja de la notación vectorial es que la anterior ecuación se puede escribir

28 CAPÍTULO I. REDES NEURONALES: HERRAMIENTA NATURAL
de la forma:
Netj = W Y.
Estructura de una Red Neuronal Artificial
Se han presentado los componentes m& importantes de una red neuronal:
o Unidades de procesamiento (la neurona artificial).
o Estado de activaci6n de cada neurona.
o Patr6n de conectividad entre neuronas.
o Regla de propagaci6n.
o finci6n de transferencia..
o Regla de activacibn.
o Regla de aprendizaje.
Ahora, centrados, sobre todo, en las características de cada nodo de la red (microestructura), veamos c6mo est& organizada dicha red (mesoestructura) en funci6n de:
o Número de niveles o capas.
o Número de neuronas por nivel.
o Patrones de conexi6n.
o Flujo de informacidn.

1.3. BASES DE REDES NEURONALES 29
Número de weles
Caracterizaci6n de un grupo de neuronas
Figura 1.17. Factores modificables de una red a nivel de mesoestructura.
Niveles o capas de neuronas
La distribución de neuronas dentro de la red se realiza formando niveles o capas de un número determinado de neuronas cada una. A partir de su situación dentro de la red, se pueden distinguir tres tipos de capas:
o De entrada: es la capa que recibe directamente la información prove- niente de las fuentes externas a la red.
o Ocultas: son internas a la red y no tienen contacto directo con el en- torno exterior. El número de niveles ocultos puede estar entre cero y un número elevado. Las neuronas de las capas ocultas pueden estar interconectadas de distintas maneras, lo que determina, junto con su número, las distintas topologías de redes neuronales.
o De salida: transfieren información de la red hacia el exterior.
E n la Figura 1.18 se muestra el esquema de la estructura de una posible red multicapa en la que cada nodo o neurona únicamente está conectada con neuronas de un nivel superior. Nótese que hay muchas más conexiones que nodos. E n este sentido, se dice 'que una red es totalmente conectada si todas las salidas desde un nivel llegan a todos y cada uno de los nodos del nivel siguiente.

30 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
Figura 1.18. Estructura de una red multinivel con todas las conexiones hacia adelante.
Formas de conexi6n entre neuronas
La conectividad entre los nodos de una red neuronal está relacionada con la forma en que las salidas de las neuronas est& canalizadas para convertirse en entradas de otras neuronas. La señal de salida de un nodo puede ser una entrada de otro elemento de proceso, o incluso ser una entrada de si mismo (conexi6n autorrecurrente).
Cuando ninguna salida de las neuronas es entrada de neuronas del mismo nivel o de niveles precedentes, la red se describe como de propagaci6n hacia adelante (Figura l . 18). Cuando las salidas pueden ser conectadas como en- tradas de neuronas de niveles previos o del mismo nivel, incluyhdose ellas mismas, la red es de propagaci6n hacia atrh (Figura 1.19). Las redes de propagaci6n hacia atrás que tienen lazos cerrados son sistemas recurrentes.

1.4. CARACTEN’STICAS DE: LAS REDES NEURONALES
Nodo con prOpagaCI6n hacia &¿S sobre si m h o ,
O,
31
Red con propagaci6n hacia && a nodos de niveles anteriores
Figura 1.19. Conexiones con propagación hacia atrás.
1.4 Características de las Redes Neuronales
Existen cuatro aspectos que caracterizan una red neuronal: su topología, el mecanismo de aprendizaje, tipo de asociación realizada entre la información de entrada y de salida, y por último, la forma de representación de esta información. Pero previamente hablaremos de los primeros intentos de ver las redes neuronales como un organismo computacional.
Circuitos neuronales y computación
La Figura 1.20 muestra varios circuitos neuronales básicos que se encuentran en el sistema nervioso central. Las Figuras 1.20 (a) y (b) ilustran los princi- pios de convergencia y divergencia en la circuitería neuronal. Cada neurona envía impulsos a muchas otras neuronas (divergencia) y recibe impulsos pro- cedentes de muchas neuronas (convergencia). Esta sencilla idea parece ser el fundamento de toda la activj.dad del sistema nervioso central, y forma la base de la mayoría de los modelos de redes neuronales.
Obsérvense las vías de realimentación que aparecen en los circuitos de las Figuras 1.20 (b), (c) y (d) . Dado que las conexiones sinápticas pueden ser tanto excitatorias como inhibitorias, estos circuitos hacen posible que los sistemas de control puedan tener tanto realimentación positiva como reali- mentación negativa. Por supuesto, estos circuitos tan sencillos no describen

32 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
adecuadamente la gran complejidad de la neuroanatomía.
Figura 1.20 Estos esquemas muestran ejemplos de circuitos neuronales del sistema nervioso central. Los cuerpos de las células (incluyendo las
dendritas) se han representado mediante círculos grandes. Los círculos pequeños se encuentran al final de los axones. En a) y b) se ilustran los conceptos de divergencia y de convergencia. En b), c) y d) se pueden ver
ejemplos de circuitos con vías de realimentach.
Ahora que ya tenemos una idea de la forma en que operan las neuronas individuales, y de la forma en que e s t h conectadas entre sí, podemos for- mularnos una pregunta fundamental: iC6mo se combinan estos conceptos relativamente sencillos para dar al cerebro sus enormes capacidades? El pri- mer intento significativo para responder a esta pregunta se hizo en 1943, a trav6s del trabajo seminal de McCulloch y Pitts. Este trabajo es importante por muchas razones, y no es la de menor peso el hecho consistente en que fueron los primeros en tratar al cerebro como a un organismo computacional.
La teoría de McCulloch-Pitts se basa en cinco suposiciones: 1. La actividad de una neurona es un proceso todo-nada. 2. Es preciso que un número fijo de sinapsis (> 1) sean excitadas dentro
de un periodo de adici6n latente para que se excite una neurona. 3. El Único retraso significativo dentro del sistema nervioso es el retardo
sinAptico.

1.4. CARACTEH’STICAS DE: LAS REDES NEURONALES 33
4. La actividad de cualquier sinapsis inhibitoria impide por completo la excitación de la neurona en ese momento.
5. La estructura de la red de interconexiones no cambia con el transcurso del tiempo.
La primera suposición indica que las neuronas son binarias: o bien están activadas o bien están desactivadas. Por tanto, se puede definir un predicado Ni( t ) , que denota la afirmación consistente en que la i-ésima neurona dispara en el instante t . La notación l N i ( t ) denota la afirmación consistente en que la i-ésima neurona no ha disparado en el instante t . Empleando esta notación, se puede describir la acción de ciertas redes empleando la lógica de proposiciones. Se pueden escribir expresiones proposicionales sencillas para describir el comportamiento de los cinco casos de la Figura 1.21. En (a) la expresión es N2 ( t ) = N1 (t - 1). De manera similar, las expresiones de las partes desde (b) hasta (d) de la, figura son las que siguen:
N3(t ) = N I ( t - 1) V N2(t - 1) (disyunción),
N3(t) = N1 (t - 1)&N2(t - 1) (conjunción) y
N3(t) = Nl( t - 1)&1N2(t - 1) (conjunción con negación)
Una de las pruebas m& potlentes de esta teoría consiste en que cualquier red que no tenga conexiones de realimentación se puede describir en términos de combinaciones de estas cuatro expresiones sencillas, y viceversa. La Figura 1.21 (e) es un ejemplo de red construida a partir de una combinación de las redes que aparecen en las partes de la (a) a la (d) .

34 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
Figura 1.21 Estos dibujos son ejemplos de redes sencillas de McCulloch-Pitts, que se pueden definir en términos de la notaci6n de la
16gica proposicional. Los círculos grandes con rdtulos representan cuerpos celulares. Los círculos negros pequeños representan conexiones excitatorias; los círculos pequeños y vacios representan conexiones inhibitorias. Las redes
ilustran (a) la precesidn, (b) la disyunci6n, (c) la conjuncidn y (d) la conjuncidn con negacidn. En (e) se muestra una combinacidn de las redes
de la (a) a la (d).
Aunque la teoría de McCulloch-Pitts ha resultado no ser un modelo pre- ciso de la actividad cerebral, la importancia de este trabajo no debe infra- valorarse. La teoría ha ayudado a dar forma a los pensamientos de muchas personas y que han tenido importancia en el desarrollo de las ciencias de la computaci6n en la actualidad. Tal como indican Anderson y Rosenfeld, hay una idea fundamental que no se pone de manifiesto en el artículo de McCulloch-Pitts: aunque las neuronas son dispositivos sencillos, se puede obtener una gran potencia de cBculo cuando se interconectan adecuadamen- te estas neuronas y se imbrican dentro del sistema nervioso.

1.4. CARACTERISTICAS DE: LAS REDES NEURONALES 35
Topología de las Redes Neuronales
La topología o arquitectura de las redes neuronales consiste en la organización y disposición de las neuronas en la red formando capas o agrupaciones de neuronas más o menos alejadas de la entrada y salida de la red. En este sentido, los parámetros fundam'entales de la red son: el número de capas, el número de neuronas por capa, el grado de conectividad y el tipo de conexiones entre neuronas.
Cuando se realiza una clasificación de las redes en términos topológicos, se suele distinguir entre las redes con una sola capa o nivel de neuronas y las redes con múltiples capas (2, 3, etc.).
Redes monocapa ( 1 capa)
En las redes monocapa, como la red de HOPFIELD y la red BRAIN-STATE IN-A-BOX, se establecen conexiones laterales entre las neuronas que perte- necen a la única capa que constituye la red. También pueden existir conexio- nes autorrecurrentes (salida de luna neurona conectada a su propia entrada), aunque en algunos modelos, colno el de HOPFIELD, esta recurrencia no se utiliza.
Una topología equivalente a la de las redes de 1 capa es la denominada topología crossbar (barras cruzadas). Una red de este tipo (por ejemplo, la red LEARNING MATRIX) consiste en una matriz de terminales (de entrada y salida) o barras que se cruzan en unos puntos a los que se les asocia un peso. Esta representación crossbar suele utilizarse como etapa de transición cuando se pretende implementar físicamente una red monocapa, puesto que es relativamente sencillo desarrollar como hardware una estructura como la indicada (por ejemplo, las barras cruzadas serían cables, y los puntos de conexión, resistencias cuyos valores representarían los pesos de la red).
Finalmente, hay que indicar que las redes monocapa se utilizan típica- mente en tareas relacionadas con lo que se conoce como autoasociación; por ejemplo, para regenerar la información de entrada que se presenta a la red de forma incompleta o distorsionada.
Redes mult icapa
Las redes multicapa son aquellas que disponen de conjuntos de neuronas agrupadas en varios (2, 3, etc.) niveles o capas. En estos casos, una forma para distinguir la capa a la que pertenece una neurona, consistiría en fijarse

36 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
en el origen de las señales que recibe a la entrada y el destino de la señal de salida. Normalmente, todas las neuronas de una capa reciben señales de entrada de otra capa anterior, m& cercana a las entrada de la red, y envian las señales de salida a una capa posterior, m& cercana a la salida de la red. A estas conexiones se les denomina conexiones hacia adelante o feedforward.
Sin embargo, en un gran número de estas redes también existe la posibili- dad de conectar las salidas de l a s neuronas de capas posteriores a las entradas de las capas anteriores, a estas conexiones se les denomina conexiones hacia a t r h o feedback.
Estas dos posibilidades permiten distinguir entre dos tipos de redes con múltiples capas: las redes con conexiones hacia adelante o redes feedforward, y las redes que disponen de conexiones tanto hacia adelante como hacia atrás o redes feedforward/feedback.
Redes con conexiones hacia adelante (feedforward)
En las redes feedforward todas las señales neuronales se propagan hacia ade- lante a través de las capas de la red. No existen conexiones hacia a t r h (ninguna salida de neuronas de una capa i se aplica a la entrada de neuronas de capas i - 1, i - 2,.. .), y normalmente tampoco autorrecurrentes (salida de una neurona aplicada a su propia entrada), ni laterales (salida de una neurona aplicada a la entrada de neuronas de la misma capa), excepto en el caso de los modelos de red propuestos por Kohonen denominados LEAR- NING VECTOR QUANTIZER (LVQ) y TOPOLOGY PRESERVING MAP (TPM), en las que existen unas conexiones implícitas muy particulares entre las neuronas de la capa de salida.
Las redes con conexiones hacia adelante m& conocidas son: PERCEP- TRON, ADALINE, MADALINE, LINEAR ADAPTIVE MEMORY (LAM), DRIVEREINFORCEMENT, BACKPROPAGATION. Todas ellas son espe- cialmente útiles en aplicaciones de reconocimiento o clasificaci6n de patrones.
Redes con conexiones hacia adelante y hacia atr& (denominadas feedforward/feedback)
En este tipo de redes circula informaci6n tanto hacia adelante (forward) como hacia a t r h (backward) durante el funcionamiento de la red. Para que esto sea posible, existen conexiones feedforward y feedback entre las neuronas.
En general, excepto en las redes COGNITRON y NEOCOGNITRON,

1.5. MECANISMO DE APRENDIZAJE 37
suelen ser bicapa (dos capas), existiendo por tanto dos conjuntos de pesos: los correspondientes a las conexiones feedforward de la primera capa (capa de entrada) hacia la segunda (ca.pa de salida) y los de las conexiones feedback de la segunda a la primera. Los valores de los pesos. de estos dos tipos de conexiones no tienen porqué coincidir, siendo diferentes en la mayor parte de los casos.
Este tipo de estructura (bicapa) es particularmente adecuada para reali- zar una asociación de una información o patrón de entrada (en la primera capa) con otra información o pa,trón de salida en la segunda capa (lo cual se conoce como heteroasociación), aunque también pueden ser utilizadas para la clasificación de patrones.
Algunas redes de este tipo tienen un funcionamiento basado en lo que se conoce como resonancia, de tal manera que la información en la primera y segunda capa interactúa entre sí hasta que alcanzan un estado estable. Este funcionamiento permite un mejor acceso a la información almacenada en la red.
Los dos modelos de red feedforward/feedback de dos capas más conocidos son la red ART (Adaptive Resonance Theory) y la red BAM (Bidirectional Associative Memory).
También en este grupo de redes existen algunas que tienen conexiones laterales entre neuronas de la misma capa. Estas conexiones se diseñan co- mo conexiones excitadoras (con peso positivo) , permitiendo la cooperación entre neuronas, ó como inhibidoras (con peso negativo), estableciéndose una competición entre las neuronas correspondientes. Una red de este tipo que, además, dispone de conexiones autorrecurrentes es la denominada CABAM (Competitive Adaptive Bidirectional Associative Memory).
Finalmente, hay que comentar la existencia de un tipo de red feedfor- ward/feedback multicapa muy particular, denominada NEOCOGNITRON, en la que las neuronas se disponen en planos superpuestos (capas bidimen- sionales), lo cual permite que puedan eliminarse las variaciones geométricas (tamaños, giros, desplazamientos) o distorsiones que presente la información o patrones de entrada a la red.
1.5 Mecanismo de Aprendizaje
El aprendizaje es el proceso por el cual una red neuronal modifica sus pesos en respuesta a una información de entrada. Los cambios que se producen

38 CAPITULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
durante el proceso de aprendizaje se reducen a la destruccih, modificaci6n y creacidn de conexiones entre las neuronas. En los sistemas biol6gicos existe una continua creacidn y destruccidn de conexiones. En los modelos de redes neuronales artificiales, la creaci6n de una nueva conexidn implica que el peso de la misma pasa a tener un valor distinto de cero. De la misma forma, una conexi6n se destruye cuando su peso pasa a ser cero.
Durante el proceso de aprendizaje, los pesos de las conexiones de la red sufren modificaciones, por tanto se puede a firmar que este proceso ha ter- minado (la red ha aprendido) cuando los valores de los pesos permanecen estables (dwijldt = O).
Un aspecto importante respecto al aprendizaje en las redes neuronales es el conocer c6mo se modifican los valores de los pesos; es decir, cudes son los criterios que se siguen para cambiar el valor asignado a las conexiones cuando se pretende que la red aprenda una nueva informacibn.
Estos criterios determinan lo que se conoce como la regla de aprendizaje de la red. De forma general, se suelen considerar dos tipos de reglas: las que responden a lo que habitualmente se conoce como aprendizaje supervisado, y las correspondientes a un aprendizaje no supervisado.
Es por ello por lo que una de las clasificaciones que se realizan de las redes neuronales obedece al tipo de aprendizaje utilizado por dichas redes. Así, se pueden distinguir:
- Redes neuronales con aprendizaje supervisado. - Redes neuronales con aprendizaje no supervisado. La diferencia fundamental entre ambos tipos estriba en la existencia o no
de un agente externo (supervisor) que controle el proceso de aprendizaje de la red.
Otro criterio que se puede utilizar para diferenciar las reglas de aprendi- zaje se basa en considerar si la red puede aprender durante su funcionamiento habitual o si el aprendizaje supone la desconexi6n de la red; es decir su in- habilitacibn hasta que el proceso termine. En el primer caso, se trataría de un aprendizaje ON LINE, mientras que el segundo es lo que se conoce como aprendizaje OFF LINE.
Cuando el aprendizaje es OFF LINE, se distingue entre una fase de apren- dizaje o entrenamiento y una fase de operaci6n o funcionamiento, existiendo un conjunto de datos de entrenamiento y un conjunto de datos de test o prueba que S e r b utilizados en la correspondiente fase. En las redes con aprendizaje OFF LINE, los pesos de las conexiones permanecen fijos después que termina la etapa de entrenamiento de la red. Debido precisamente a su

1.5. MECANISMO DE APRE.IVDIZAJE 39
carácter estático, estos sistemas no presentan problemas de estabilidad en su funcionamiento.
En las redes con aprendizaje ON LINE no se distingue entre fase de en- trenamiento y de operación, de tal forma que los pesos varían dinámicamente siempre que se presente una nueva información al sistema. En este tipo de redes, debido al carácter dinámico de las mismas, el estudio de la estabilidad suele ser un aspecto fundamental.
Redes con aprendizaje supervisado
El aprendizaje supervisado se caracteriza porque el proceso de aprendizaje se realiza mediante un entrenamiento controlado por un agente externo (su- pervisor, maestro) que determina la respuesta que debería generar la red a partir de una entrada determinada. El supervisor comprueba la salida de la red y en el caso de que ésta no coincida con la deseada, se procederá a modificar los pesos de las conexiones, con el fin de conseguir que la salida obtenida se aproxime a la deseada.
En este tipo de aprendizaje se suelen considerar, a su vez, tres formas de llevarlo a cabo que dan lugar a los siguientes aprendizajes supervisados:
- Aprendizaje por corrección. de error. - Aprendizaje por refuerzo.
- Aprendizaje estocástico.
Aprendizaje por corrección de error
Consiste en ajustar los pesos de las conexiones de la red en función de la diferencia entre los valores deseados y los obtenidos en la salida de la red; es decir, en función del error cometido en la salida.
Una regla o algoritmo simple de aprendizaje por corrección de error podría ser el siguiente:

40 CAPkCULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
\
L unldad u,
Figura 1.22
Siendo Awji: Variaci6n en el peso de la conexi6n entre las neuronas i y j
yi: Valor de salida de la neurona i. d j : Valor de salida deseado para la neurona j. yj: Valor de salida obtenido en la neurona j . a: Factor de aprendizaje (O < a 5 1) que regula la velocidad del apren-
dizaje. Un ejemplo de este tipo de algoritmo lo constituye la regla de aprendizaje
del Perceptrh, utilizada en el entrenamiento de la red del mismo nombre y que desarro116 Rosenblatt en 1958. Sin embargo, existen otros algoritmos m& evolucionados que éste, que presenta algunas limitaciones, como el no considerar la magnitud del error global cometido durante el proceso completo de aprendizaje de la red, ya que toma en cuenta únicamente los errores individuales (locales) correspondientes al aprendizaje de cada informaci6n por separado.
Un algoritmo muy conocido que mejora el del Perceptr6n y permite un aprendizaje m& r6pido y un campo de aplicaci6n m& amplio es el propuesto por Widrow y Hoff en 1960, denominado regla delta o regla del minimo error cuadrado (LMS Error: Least-Mean-Squared Error), también conocida como regla de Widrow-Hoff, que se aplic6 en las redes desarrolladas por los mismos autores, conocidas como ADALINE (Adaptive Linear Element), con

1.5. MECANISMO DE APRE-NDIZAJE 41
una única neurona de salida, y MADALINE (Multiple ADALINE), con varias neuronas de salida.
Widrow y Hoff definieron una función que permitía cuantificar el error global cometido en cualquier momento durante el proceso de entrenamiento de la red, lo cual es importante, ya que entre más información se tenga sobre el error cometido, más rápido se puede aprender.
Este error medio se expresa de la siguiente forma:
"
k=l j = 1
Siendo: N: Número de neuronas de ,salida (en el caso de ADALINE N = 1). P: Número de datos que debe aprender la red.
N 2 (gjk) - d y ) ) 2 : Error cometido en el aprendizaje del dato k-ésimo.
1=1
Por tanto, de lo que se trata es de encontrar unos pesos para las conexiones de la red que minimicen esta función de error. Para ello, el ajuste de los pesos de las conexiones de la red se puede hacer de forma proporcional a la variación relativa del error que se obtiene al variar el peso correspondiente:
Mediante este procedimiento, se llegan a obtener un conjunto de pesos con los que se consigue rninimkar el error medio.
Otro algoritmo de aprendizaje por corrección de error lo constituye el de- nominado regla delta generalizada o algoritmo de retropropagación del error (error backpropagation), tambilén conocido como regla LMS (Least-Mean- Square Error) multicapa. Se trata de una generalización de la regla delta para poder aplicarla a redes con conexiones hacia adelante (feedforward) con capas o niveles internos u ocultos de neuronas que no tienen relación con el exterior. Son redes con capa de entrada, capas ocultas y capa de salida.
Estas redes multicapa pueden utilizarse en muchas más aplicaciones que las ya conocidas para el Perceptrón, el ADALINE y el MADALINE, pero su proceso de aprendizaje es much'o más lento, debido a que durante el mismo se debe explorar el espacio de p'osibles formas de utilización de las neuronas de las capas ocultas; es decir, se debe establecer cuál va a ser su papel en el funcionamiento de la red.

42 CAPITULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
Las bases de este nuevo método de aprendizaje (al que Rumelhart, Hinton y Williams llamaron backpropagation) fueron sentadas por diferentes inves- tigadores que propusieron soluciones al problema del entrenamiento de redes multicapa, de forma independiente y sin conocimiento de la existencia de otros trabajos paralelos.
Existe también una versión recurrente del algoritmo backpropagation que se suele utilizar en redes multicapa que presentan conexiones recurrentes con el fin de que estas redes aprendan la naturaleza temporal de algunos datos.
Para concluir con los algoritmos por corrección de error, hay que men- cionar que también se utilizan en algunas redes monocapa con conexiones laterales y autorrecurrentes, como es el caso de la red BRAIN-STATEIN- A-BOX (BSB), introducida por Anderson, Silverstein, Ritz y Jones en 1977. Aunque en una primera fase el aprendizaje de esta red es sin supervisión, se suelen refinar los valores de los pesos de las conexiones mediante un apren- dizaje por corrección de error basado en una adaptación de la regla delta de Widrow-Hoff.
Aprendizaje por refuerzo
Se trata de un aprendizaje supervisado, m& lento que el anterior, que se basa en la idea de no disponer de un ejemplo completo del comportamiento deseado; es decir, de no indicar durante el entrenamiento exactamente la salida que se desea que proporcione la red ante una determinada entrada.
En el aprendizaje por refuerzo la función del supervisor se reduce a indicar mediante una señal de refuerzo si la salida obtenida en la red se ajusta a la deseada (ézito = +1 o fracaso = - 1), y en función de ello se ajustan los pesos bashdose en un mecanismo de probabilidades. Se podría decir que en este tipo de aprendizaje la función del supervisor se asemeja m& a la de un critico (que opina sobre la respuesta de la red) que a la de un maestro (que indica a la red la respuesta concreta que debe generar), como ocurría en el caso de supervisión por corrección de error.
Un ejemplo de algoritmo por refuerzo lo constituye el denominado Linear Reward-Penalty o LR-P (algoritmo lineal con recompensa y penalización) presentado por Narendra y Thathacher en 1974. Este algoritmo ha sido am- pliado por Barto y Anandan, quienes en 1985 desarrollaron el denominado Associative &ward-Penalty o AR-P (algoritmo asociativo con recompensa y penalización), que se aplica en redes con conexiones hacia adelante de dos capas cuyas neuronas de salida presentan una función de activación e s t o c b

1 .5 . MECANISMO DE APRENDIZAJE 43
tica. Otro algoritmo por refuerzo es el conocido como Adaptive Heuristic Cri-
tic, introducido por Barto, Sutton y Anderson en 1983, que se utiliza en redes feedforward de tres capas especialmente diseñadas para que una parte de la red sea capaz de generar un valor interno de refuerzo que es aplicado a las neuronas de salida de la red.
Aprendizaje estocástico
Este tipo de aprendizaje consiste básicamente en realizar cambios aleatorios en los valores de los pesos de las conexiones de la red y evaluar su efecto a partir del objetivo deseado y de distribuciones de probabilidad.
E n el aprendizaje estocástico se suele hacer una analogía en términos ter- modinámicos, asociando la red :neuronal con un sólido físico que tiene cierto estado energético. En el caso de la red, la energía de la misma representa- ría el grado de estabilidad de la red, de tal forma que el estado de mínima energía correspondería a una situación en la que los pesos de las conexiones consiguen que su funcionamiento sea el que más se ajusta al objetivo deseado.
Según lo anterior, el aprendizaje consistiría en realizar un cambio aleatorio de los valores de los pesos y determinar la energía de la red (habitualmente la función energía es una función denominada de Lyapunov). Si la energía es menor después del cambio; es decir, si el comportamiento de la red se acerca al deseado, se acepta el cambio. Si, por el contrario, la energía no es menor, se aceptaría el cambio en función de una determinada y preestablecida distribución de probabilidades.
Una red que utiliza este tipo de aprendizaje es la conocida como Boltz- mann Machine, ideada por Hinton, Ackley y Sejnowski en 1984, que lo combi- na con el aprendizaje Hebbiano (se describirá más adelante) o con aprendizaje por corrección de error (como la regla delta). La red Boltzmann Machine es una red con diferentes topologías alternativas, pero siempre con unas neu- ronas ocultas que permiten, mediante un ajuste probabilístico, introducir un ruido que va decreciendo durante el proceso de aprendizaje para escapar de los mínimos relativos (locales) de la función de energía favoreciendo la bdsqueda del mínimo global.
El procedimiento de utilizar ruido para escapar de mínimos locales suele denominarse simulated annealing (temple simulado) y su combinación con la asignación probabilística mediante la capa oculta es lo que se conoce como aprendizaje estocástico. El término simulated annealing proviene del símil

44 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
termodinámico antes mencionado. La idea es asemejar la red con un sólido fisico que inicialmente presenta una alta temperatura (ruido) y que se va en- friando gradualmente hasta alcanzar el equilibrio térmico (mínima energía).
Existe otra red basada en este tipo de aprendizaje, denominada Cauchy Machine, desarrollada por Szu en 1986, que es un refinamiento de la anterior y que utiliza un procedimiento m& rápido de búsqueda del mínimo global y una función de probabilidad diferente (la distribución de probabilidad de Cauchy frente a la de Boltzmann, utilizada en la red anterior).
Redes con aprendizaje no supervisado
Las redes con aprendizaje no supervisado (también conocido como aut@ supervisado) no requieren influencia externa para ajustar los pesos de las conexiones entre sus neuronas. La red no recibe ninguna informacidn por parte del entorno que le indique si la salida generada en respuesta a una determinada entrada es o no correcta; por ello, suele decirse que estas redes son capaces de autoorganizarse.
Estas redes deben encontrar las características, regularidades, correlacie nes o categorias que se puedan establecer entre los datos que se presenten en su entrada. Puesto que no hay un supervisor que indique a la red la respuesta que debe generar ante una entrada concreta, cabría preguntarse precisamen- te por lo que la red genera en estos casos. Existen varias posibilidades en cuanto a la interpretación de la salida de estas redes, que dependen de su estructura y del algoritmo de aprendizaje empleado.
En algunos casos, la salida representa el grado de familiaridad o similitud entre la información que se le está presentando en la entrada y la información que se le ha mostrado hasta entonces (en el pasado). En otro caso, podría realizar un establecimiento de categorías, indicando la red a la salida a qué categoria pertenece la información presentada a la entrada, siendo la propia red quien debe encontrar las categorías apropiadas a partir de correlaciones entre la información presentada. Una variación de esta categorización es el prototipado. En este caso, la red obtiene ejemplares o prototipos represen- tantes de las clases a las que pertenece las información de entrada.
También el aprendizaje sin supervisión permite realizar una codificación de los datos de entrada, generando a la salida una versión codificada de la entrada, con menos bits, pero manteniendo la información relevante de los datos.
Finalmente, algunas redes con aprendizaje no supervisado lo que reali-

1.5. MECANISMO DE APRENDIZAJE 45
zan es un mapeo de características (feature mapping), obteniéndose en las neuronas de salida una disposición geométrica que representa un mapa topo- gráfico de las características de los datos de entrada, de tal forma que si se presenta a la red información similar, siempre serán afectadas neuronas de salida próximas entre sí, en la misma zona del mapa.
E n cuanto a los algoritmos de aprendizaje no supervisado, en general se suelen considerar dos tipos que dan lugar a los siguientes aprendizajes:
- Aprendizaje hebbiano. - Aprendizaje competitivo y cooperativo. En el primer caso, normalmente se pretende medir la familiaridad o ex-
traer características de los datos de entrada, mientras que el segundo suele orientarse hacia la clasificación de dichos datos.
Aprendizaje hebbiano
Este tipo de aprendizaje se basa, en el siguiente postulado formulado por Do- nald O. Hebb en 1949: Cuando un axón de una celda A está suficientemente cerca como para conseguir excitar una celda B y repetida o persistentemente toma parte en su activación, algún proceso de crecimiento o cambio me- tabólico tiene lugar en una o ambas celdas, de tal forma que la eficiencia de A, cuando la celda a activar es B, aumenta. Por celda, Hebb entiende un conjunto de neuronas fuertemente conectadas a través de una estructura compleja. La eficiencia podría identificarse con la intensidad o magnitud de la conexión; es decir, con el peso.
Se puede decir, por tanto, que el aprendizaje hebbiano consiste básica- mente en el ajuste de los pesos de las conexiones de acuerdo con la correlación (multiplicación en el caso de valores binarios +1 y -1) de los valores de ac- tivación (salidas) de las dos newonas conectadas:
Esta expresión responde a la idea de Hebb, puesto que si las dos unidades son activas (positivas), se produce un reforzamiento de la conexión. Por el contrario, cuando una es activa y la otra pasiva (negativa), se produce un debilitamiento de la conexic'm. Se trata de una regla de aprendizaje no supervisado, pues la modificación de los pesos se realiza en función de los estados (salidas) de las neuron.as obtenidos tras la presentación de cierto estímulo (información de entrada a la red), sin tener en cuenta si se deseaba obtener o no esos estados de activación.
Este tipo de aprendizaje fue empleado por Hopfield en la conocida red que lleva su nombre (RED HOPFIELD), introducida en 1982 y muy exten-

46 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
dida en la actualidad, debido principalmente a la relativa facilidad en su implementacidn en circuitos integrados VLSI.
Grossberg lo utilizd en 1968 en la red denominada ADDITIVE GROSS- BERG y en 1973 en la red SHUNTING GROSSBERG. En ambos casos se trataba de redes de una capa con conexiones laterales y autorrecurrentes.
La red feedforward llamada LEARNING MATRIX (LM), desarrollada por Steinbuch en 1961, también aprendfa mediante la correlacidn hebbiana. En esta red, las neuronas se conectaban en forma matricid, asign&ndose un peso a cada punto de conexidn, peso que se obtenía mediante una regla tipo hebbiana.
Otras redes que utilizan el aprendizaje hebbiano son: la red feedfor- ward/feedback de 2 capas denominada BIDIRECTIONAL ASSOCIATIVE MEMORY (BAM), desarrollada por Kosko en 1988; la red desarrollada por Amari en 1972 llamada TEMPORAL ASSOCIATIVE MEMORY (TAM), con la misma topología que la anterior, pero ideada para aprender la na- turaleza temporal de la informacidn que se le muestra (para recordar valo- res anteriores en tiempo); la red feedforward de dos capas conocida como LINEAR ASSOCIATIVE MEMORY (LAM), introducida por Anderson en 1968 y refinada por Kohonen, y la red OPTIMAL LINEAR ASSOCIATIVE MEMORY (OLAM), desarrollada de forma independiente por Wee en 1968 y por Kohonen y Ruohonen en 1973, que presenta dos variantes, una con to- pología feedback/feedforward con una única capa y otra feedforward de dos capas, utilizando una versidn optimizada del método de correlacidn hebbiano usado en la red LAM, denominado optimal least mean square correlation.
Existen muchas variaciones del aprendizaje hebbiano; por ejemplo, Sejno- wski en 1977 utilizd la correlacidn de la covariancia de los valores de activacidn de las neuronas. Sutton y Barto en 1981 utilizaron la correlacidn del valor medio de una neurona con la variancia de la otra. Klopf en 1986 propuso una correlacidn entre las variaciones de los valores de activacidn en dos instantes de tiempo sucesivos, aprendizaje al que denomind drive-reinforcement y que utilizd en redes del mismo nombre con topologia feedforward de dos capas.
Otra versidn de este aprendizaje es el denominado hebbiano diferencial, que utiliza la correlaci6n de las derivadas en el tiempo de las funciones de activacidn de las neuronas. El aprendizaje hebbiano diferencial es utilizado en la red feedforward/feedback de dos capas denominada ABAM (Adaptive Bidirectional Associative Memory) introducida por Kosko en 1987. También este autor en 1987 present6 una red con la misma topología que la anterior, pero utilizando otra versidn de este aprendizaje, el denominado aprendizaje

1.5. MECANISMO DE APREJVDIZA JE 47
hebbiano difuso (Fuzzy Hebbiart learning); esta red tenía por nombre Fuzzy Associative Memory (FAM), y se basa en la representación de la información que debía aprender la red en forma de conjuntos difusos.
Finalmente, hay que comentar la existencia de redes basadas en mecanis- mos de aprendizaje que resultan de la combinación de la correlación hebbiana con algún otro método, como e;s el caso de las redes Boltzmann Machine y Cauchy Machine, que lo combinan con el ya comentado simulated annea- ling. También la red feedforward de tres capas llamada Counterpropagation (CPN), desarrollada por Hecht-Nielsen en 1987, utiliza un aprendizaje que es combinación del hebbiano y de un tipo de aprendizaje competitivo intro- ducido por Kohonen denominado learning vector quantization (LVQ).
Aprendizaje competitivo y cooperativo
En las redes con aprendizaje competitivo (y cooperativo), suele decirse que las neuronas compiten (y cooperan) unas con otras con el fin de llevar a cabo una tarea dada. Con este tipo de aprendizaje, se pretende que cuando se presente a la red cierta información de entrada, sólo una de las neuronas de salida de la red, o una por cierto grupo de neuronas, se active (alcance su valor de respuesta máximo). Por tanto, las neuronas compiten por activarse, quedando finalmente una, o una por grupo, como neurona vencedora (winner- take-all unit), quedando anuladas el resto, que son forzadas a sus valores de respuesta mínimos.
La competición entre neuronas se realiza en todas las capas de la red, existiendo en estas neuronas conexiones recurrentes de autoexcitación y co- nexiones de inhibición (signo negativo) por parte de neuronas vecinas. Si el aprendizaje es cooperativo, estas conexiones con las vecinas serán de excita- ción (signo positivo).
El objetivo de este aprendizaje es categorizar los datos que se introducen en la red. De esta forma, la información similar es clasificada formando parte de la misma categoría, y por tanto deben activar la misma neurona de salida. La clases o categorías deben ser creadas por la propia red, puesto que se trata de un aprendizaje no supervisado, a través de las correlaciones entre los datos de entrada.
Una forma de aplicar este tipo de aprendizaje fue propuesta por Rumel- hart y Zisper en 1985, quienes utilizaban redes multicapa dividiendo cada capa en grupos de neuronas, de tal forma que éstas disponían de conexiones inhibitorias con otras neuronas de su mismo grupo, y conexiones excitado-

48 CAPITULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
ras con las neuronas de la siguiente capa. En una red de este tipo, después de recibir diferente informaci6n de entrada, cada neurona en cada grupo se especializa en la respuesta a determinadas características de los datos de entrada.
En este tipo de redes, cada neurona tiene asignado un peso total, suma de todos los pesos de l a s conexiones que tiene a su entrada. El aprendizaje afecta s610 a las neuronas ganadoras (activas), redistribuyendo este peso total entre sus conexiones, sustrayendo una porci6n a los pesos de todas las conexiones que llegan a la neurona vencedora y repartiendo esta cantidad por igual entre todas las conexiones procedentes de unidades activas. Por tanto, la variaci6n del peso de una conexi6n entre una unidad i y otra j sera nula si la neurona j no recibe excitacidn por parte de la neurona i (no vence en presencia de un estímulo por parte de ij, y se modificara (se reforzara) si es excitada por dicha neurona i.
Un ejemplo de este tipo de aprendizaje es el desarrollado por Kohonen, conocido como Learning Vector Quantization (LVQ), aplicado a redes feed- forward de dos capas. El LVQ puede aplicarse de forma diferente, según se precise obtener una o varias unidades vencedoras en la capa de salida. Existe tambi6n una extensi6n supervisada del LVQ basada en un mecanismo por correcci6n de error.
Una variacidn del aprendizaje supervisado aplicado a redes multicapa consiste en imponer una inhibici6n mutua entre neuronas únicamente cuando estan a cierta distancia unas de otras (suponiendo que l a s neuronas se han dispuesto geométricamente, por ejemplo formando capas bidimensionales) . Existe entonces un Brea o regi6n de vecindad alrededor de l a s neuronas que constituye su grupo local.
Fukushima empled esta idea en 1975 en una red multicapa llamada Cog- nitrdn, fuertemente inspirada en la anatomía y fisiología del sistema visual humano, y en 1980, en una versidn mejorada de la anterior, denominada Neo- cognitrdn (también en 1983, se present6 una variaci6n de esta red, utilizando aprendizaje supervisado). E l Neocognitr6n disponía de un gran número de capas con una arquitectura muy específica de interconexiones entre ellas, y era capaz de aprender a diferenciar caracteres, aunque 6stos se presentasen a diferente escala, en diferente posicidn o distorsionados.
El aspecto geométrico de la disposici6n de las neuronas de una red tam- bién es la base de un caso particular de aprendizaje competitivo introducido por Kohonen en 1982, conocido como feature mapping (mapeo de caracteris- ticas), aplicado en redes con una disposici6n bidimensional de l a s neuronas

1.6. TIPO DE ASOCIACION ENTRADA/SALIDA 49
de salida, que permiten obtener mapas topológicos o topográficos (topology preserving maps, topographic maps, selforganizating maps) en los que, de algún modo, estarían representa,das las características principales de la infor- mación presentada a la red. De esta manera, si la red recibe información con características similares, se gen.erarían mapas parecidos, puesto que serían afectadas neuronas de salida pr6ximas entre sí.
Para concluir, hay que comentar la existencia de otro caso particular del aprendizaje competitivo, denominado teoría de la resonancia adaptativa (Adaptive Resonance Theory’), desarrollado por Carpenter y Grossberg en 1986 y utilizado en la red feedfcrward/feedback de dos capas conocida como ART (en sus dos variantes: AFtT1, que trabaja con información binaria, y ART2, que maneja información analógica). Esta red realiza un prototipado de la información que recibe a la entrada, generando como salida un ejem- plar o prototipo que representa toda la información que podría considerarse pertenecientes a la misma clase o categoría.
La t,eoría de la resonancia adaptativa se basa en la idea de hacer resonar la información de entrada con los prototipos de las categorías que reconoce la red; si entra en resonancia con alguno (es suficientemente similar), la red considera que pertenece a dicha categoría y únicamente realiza una pequeña adaptación del prototipo (para que se parezca algo más al dato presentado). Cuando no resuena con ningún prototipo, no se parece a ninguno de los existentes (recordados por la red) hasta ese momento, la red se encarga de crear una nueva categoría con el dato de entrada como prototipo de la misma.
1.6 Tipo de Asociación Entrada/Salida
Las redes neuronales son sistemas que almacenan cierta información apren- dida; esta información se registra de forma distribuida en los pesos asociados a las conexiones entre neuronas. Por tanto, puede imaginarse una red como cierto tipo de memoria que almacena unos datos de forma estable, datos que se grabarán en dicha memoria como consecuencia del aprendizaje de la red y que podrán ser leídos a la salida como respuesta a cierta información de entrada, comportándose entonces la red como lo que habitualmente se co- noce por memoria asociativa; es decir, cuando se aplica un estímulo (dato de entrada) la red responde con una salida asociada a dicha información de entrada.
Existen dos formas primarias de realizar esta asociación entrada/salida

50 CAPfTULO 1. RXDES NEURONALES: HERRAMIENTA NATURAL
que corresponden a la naturaleza de la informaci6n almacenada en la red. Una primera sería la denominada heteroasociaci6n, que se refiere al caso en el que la red aprende parejas de datos [(Al,&), (A2, Bz), - . a , (AN,BN)] , de tal forma que cuando se presente cierta informacidn de entrada Ai, de- ber& responder generando la correspondiente salida asociada &. La segun- da se conoce como autoasociaci6n, donde la red aprende cierta informaci6n Al, A2, , AN, de tal forma que cuando se le presenta una informaci6n de entrada realizar& una autocorrelaci6n, respondiendo con uno de los datos almacenados, el m& parecido al de entrada.
Estos dos mecanismos de asociaci6n dan lugar a dos tipos de redes neu- ronales: las redes heteroasociativas y las autoasociativas. Una red heteroa- sociativa podría considerase aquella que computa cierta funcidn, que en la mayoría de los casos no podrS expresarse analíticamente, entre un conjunto de entradas y un conjunto de salidas, correspondiendo a cada posible entrada una determinada salida. Por otra parte, una red autoasociativa es una red cuya principal misi6n es reconstruir una determinada informacidn de entrada que se presenta incompleta o distorsionada (le asocia el dato almacenado m& parecido).
En realidad, estos dos tipos de modelos de redes no son diferentes en principio, porque una red heteroasociativa puede siempre ser reducida a una autoasociativa mediante la concatenaci6n de una informaci6n de entrada y su salida (respuesta) asociada, para obtener la informacibn de entrada de la red autoasociativa equivalente. También puede conseguirse que una red autoasociativa se comporte como una heteroasociativa, simplemente presen- tando, como entrada parcial de la autoasociativa, la informaci6n de entrada para la heteroasociativa y haciendo que la red complete la informaci6n para producir lo que sería la salida de la red heteroasociativa equivalente.
Redes heteroasociativas
Las redes heteroasociativas, al asociar informaci6n de entrada con diferente informaci6n de salida, precisan al menos de 2 capas, una para captar y retener la informaci6n de entrada y otra para mantener la salida con la informaci6n asociada. Si esto no fuese así, se perdería la informaci6n inicial al obtenerse el dato asociado, lo cual no debe ocurrir, ya que en el proceso de obtenci6n de la salida se puede necesitar acceder varias veces a esta informacibn, que, por tanto, deber& permanecer en la capa de entrada.
En cuanto a su conectividad, existen redes heteroasociativas con conexio-

1.6. TIPO DE ASOCIACIóN ENTRADA/SALIDA 51
nes hacia adelante o feedforward (Perceptron, Backpropagation, etc.) , redes con conexiones hacia atrás o feedforward/feedback (ART, BAM, etc.) y re- des con conexiones laterales (CABAM). También hay redes heteroasociativas con las neuronas dispuestas en capas multidimensionales (Neocognitrón, To- pology preserving map). El aprendizaje de este tipo de redes puede ser con supervisión (Perceptrón, Backpropagation, etc.) o sin supervisión (ART, BAM, etc.).
Las redes heteroasociativas pueden también clasificarse según el objetivo pretendido con su utilización. Así, en algunos casos el objetivo es computar una función general de su entrada. En otros casos el objetivo es realizar una clasificación, relacionando (mapeando) un gran número de información de entrada con un pequeño número de información de salida, que representan los conjuntos en los que se pueden clasificar los datos de entrada.
Redes autoasociativas
Una red autoasociativa asocia luna información de entrada con el ejemplar más parecido de los almacenad'os conocidos por la red. Este tipo de redes pueden implementarse con una ;sola capa de neuronas. Esta capa comenzará reteniendo la información inicial presentada a la entrada, y terminará repre- sentando la información autoasociada. Si se quiere mantener la información de entrada y salida, se deberían añadir capas adicionales; sin embargo, la funcionalidad de la red puede conseguirse en una sola capa.
En cuanto a la conectividad en este tipo de redes! existen conexiones laterales entre las neuronas (HOPFIELD, etc.) y en algunos casos conexiones autorrecurrentes (salida de una neurona como entrada de la misma), como ocurre con las redes BRAIN-STATE-IN-A-BOX, ADDITIVE GROSSBERG, etc.
En relación con el tipo de aprendizaje, habitualmente el utilizado por estas redes es no supervisado (HOPFIELD, ADDITIVE GROSSBERG, etc.), aunque existe alguna con aprendizaje supervisado (BRAIN-STATEIN-A- BOX).
Las redes autoasociativas suelen utilizarse en tareas de filtrado de in- formación para la reconstrucción de datos, eliminando distorsiones o ruido. También se utilizan para explorar relaciones entre información similar, para facilitar la búsqueda por contenido en bases de datos y para resolver proble- mas de optimización.

52 CAPfTULO 1. REDES NEURONALES: HERRAMIENTA NATURAL
1.7 Representaci6n de la Información
Las redes neuronales pueden también clasificarse en funci6n de la forma en que se representa la informaci6n de entrada y las respuestas o datos de sa- lida. Así, en un gran número de redes, tanto los datos de entrada como de salida son de naturaleza analbgica; es decir, son valores reales continuos, normalmente estar& normalizados y su valor absoluto sera menor que la mi- dad. Cuando esto ocurre, las funciones de activacidn de las neuronas seran tambih continuas, del tipo lineal o sigmoidal.
Otras redes, por el contrario, S610 admiten valores discretos o binarios {O, 1) a su entrada, generando también unas respuestas en la salida de tipo binario. En este caso, las funciones de activacidn de las neuronas ser& del tipo escalbn. Debido a su mayor sencillez, es habitual encontrar algunos mo- delos de redes reales que aunque inicialmente habían sido desarrollados como discretos por sus autores, posteriormente se ha realizado una versi6n conti- nua de los mismos, como es el caso del modelo de HOPFIELD (DISCRETE HOPFIELD, CONTINOUS HOPFIELD) y el denominado ADAPTIVE R E SONANCE THEORY (ART1, ART2). Existe también un tipo de redes (que podrian denominarse híbridas) en las que la informaci6n de entrada puede tomar valores continuos, aunque en la salida de la red sean discretos.

Capítulo 2
Algunos modelos
En este capítulo llevamos a cabo el estudio de algunos de los modelos mencio- nados en la parte previa. La razón de este estudio es concretar y profundizar los conceptos que fueron mencionados sólo de manera general.
2.1 El Perceptrón
Este fue el primer modelo de red neuronal artificial, fue desarrollado por Rosenblatt en 1958. Despertó un enorme interés en los años 60, debido a su capacidad para aprender a reconocer patrones sencillos: un Perceptrón, formado por varias neuronas lineales para recibir las entradas a la red y una neurona de salida, es capaz de decidir cuándo una entrada presentada a la red pertenece a una de las dos clases que puede reconocer.
53

54 CAPITULO 2. ALGUNOS MODELOS
J
. .
Figura 2.1. El Perceptrbn.
La única neurona de salida del Perceptr6n realiza la suma ponderada de las entradas, resta el umbral y pasa el resultado a una funci6n de transferencia de tipo escal6n. La regla de decisidn es responder +1 si el patr6n presentado pertenece a la clase A, 6 -1 si el patr6n pertenece a la clase B (Figura 2.1). La salida depender& de la entrada neta (suma de las entradas xi ponderadas) y del valor umbral 8.
Una tkcnica utilizada para analizar el comportamiento de redes como el Perceptr6n es representar en un mapa las regiones de decisi6n creadas en el espacio multidimensional de entradas a la red. En estas regiones se visualiza qu6 patrones pertenecen a una clase y cusles a otra. El Perceptr6n separa las regiones por un hiperplano cuya ecuaci6n queda determinada por los pesos de las conexiones y el valor umbral de la funci6n de activaci6n de la neurona. En este caso, los valores de los pesos pueden fijarse o adaptarse utilizando diferentes algoritmos de entrenamiento de la red.
Sin embargo, el Perceptrdn, al constar S610 de una capa de entrada y otra de salida con una única neurona, tiene una capacidad de representaci6n bastante limitada. Este modelo s610 es capaz de discriminar patrones muy sencillos, linealmente. separables. El caso m& conocido es la imposibilidad del Perceptr6n de representar la funci6n OR-EXCLUSIVA.

2.1. EL PERCEPTRÓN 55
La separabilidad lineal limitma a las redes con sólo dos capas a la resolu- ción de problemas en los cuales el conjunto de puntos (correspondientes a los valores de entrada) sean separables geométricamente. En el caso de dos entradas, la separación se lleva a cabo mediante una línea recta. Para tres entradas, la separación se realiza mediante un plano en el espacio tridimen- sional, y así sucesivamente hasta el caso de N entradas, en el cual el espacio N-dimensional es dividido en un hiperplano.
Regla de aprendizaje del Perceptrón
El algoritmo de aprendizaje del Perceptrón es de tipo supervisado, lo cual requiere que sus resultados seaa evaluados y se realicen las oportunas mo- dificaciones del sistema si fuera. necesario. Los valores de los pesos pueden determinar, como se ha dicho, 121 funcionamiento de la red; estos valores se pueden fijar o adaptar utilizando diferentes algoritmos de entrenamiento de la red. El algoritmo original de convergencia del Perceptrón fue desarrollado por Rosenblatt y lo veremos más adelante. Se pueden usar Perceptrones como máquinas universales de aprendizaje. Desgraciadamente, no puede aprender a realizar todo tipo de clasificaciones: en realidad, sólo se pueden aprender clasificaciones fáciles (problemas de orden 1 en la terminología de Minsky y Papert). Esa limitación se d.ebe a que un Perceptrón usa un separador lineal como célula de decisión, con lo cual no es posible realizar sino una sola separación lineal (por medio de un hiperplano).
Como ejemplo de funcionamiento de una red neuronal de tipo Perceptrón, veamos cómo resolver el problema de la función OR. Para esta función, la red debe ser capaz de devolver, a partir de los cuatro patrones de entrada, a qué clase pertenece cada uno. Es decir, para el patrón de entrada O0 debe devolver la clase O y para los restantes la clase 1. Para este caso, las entradas serán dos valores binarios. La salida que produce, sin tener en cuenta el valor umbral, es la siguiente:
donde
la salida es igual a su entrada).
capa de salida.
2 1 , x2 son las entradas a la neurona (en las neuronas de la capa de entrada,
w1,7U2 son los pesos entre las neuronas de la capa de entrada y la de la

56 CAPITULO 2. ALGUNOS MODELOS
f es la funcidn de salida o transferencia (la funci6n de activaci6n es la funci6n identidad).
Si wlxl + w2x2 es mayor que O , la salida será 1, y en caso contrario, será - 1 (funci6n de salida en escal6n). Como puede observarse, la suma que se le pasa como partímetro (entrada total) a la funci6n f (funci6n de salida o transferencia) es la expresi6n matemática de una recta, donde w1,y w2 son constantes y x1 y x2 son las variables. En la etapa de aprendizaje se irán variando los valores de los pesos obteniendo distintas rectas.
Lo que se pretende al modificar los pesos de las conexiones es encontrar una recta que divida el plano en las dos regiones de las dos clases de valores de entrada. Concretamente, para la funci6n OR se deben separar los valores 01, 10 y 11 del valor OO. En este caso, al no existir término independiente en la ecuaci6n porque el umbral 8 es cero, las posibles rectas pasarán por el origen de coordenadas, por lo que la entrada O0 quedará sobre la propia recta.
Si se pretende resolver el problema de la funci6n AND de la misma mane- ra, se llega a la conclusi6n de que es imposible si el umbral es cero, ya que no existe ninguna recta que pase por el origen de coordenadas y que separe los valores 00, O1 y 10 de entrada del valor 11, por lo que es necesario introducir un término independiente para poder realizar esta tarea.
Para ello, se considera una entrada de valor fijo 1 a través de una conexidn con peso wo, que representa el umbral (wo = -8) y cuyo valor deberá ser ajustado durante la etapa de aprendizaje. Asi, el partímetro que se le pasa a la funci6n de transferencia de la neurona queda: wlx l+ ~2x2 + wo 1, donde wo es el término independiente que permitirá desplazar la recta del origen de coordenadas. Si aplicamos esta solucidn para el caso de la red que calcula la funci6n OR, aumentamos el número de soluciones, ya que, adem& de las rectas sin término independiente (wo = O) que dan solucidn al problema, existirán otras con término independiente que también lo harán.

2.1. EL PERCEPTR~N 57
y= n & W , + xaw2 + w o I A: Soluclón a la OR con dos entradas y umbral m a . I;\:;; dos entradas y umbral# O.
semepnte al umbral. dos entradas y umbral p O.
f: función escalón. B: Solución a la OR con
x,,w, cumplen UM función C Solución a la AND con
00 IO \
I Figura 2.2. Ejemplo del Perceptrón aplicado a la solución de la función OR.
En el proceso de entrenamiento, el Perceptrón se expone a un conjunto de patrones de entrada, y los pesos de la red son ajustados de forma que al final del entrenamiento se obtengan las salidas esperadas para cada uno de esos patrones de entrada.
A continuación veremos el algoritmo de convergencia de ajuste de pesos para realizar el aprendizaje de un Perceptrón (aprendizaje por corrección de error) con N elementos procesales de entrada y un Único elemento procesal de salida:
1. Inicialización de los pesos y del umbral. Inicialmente se asignan valores aleatorios a cada uno de los pesos (wi) de
2. Presentación de un nuevo par (Entrada, Salida esperada). Presentar un nuevo patrón de entrada X p = ( X I , z2, - . , zN) junto con la
3. Cálculo de la salida actuad.
las conexiones y al umbral (-wg = e) .
salida esperada d( t ) .
Siendo f ( z ) la función de transferencia escalón. 4. Adaptación de los pesos.

58 CAPI'TULO 2. ALGUNOS MODELOS
donde d(t) representa la salida deseada, y ser& 1 si el patr6n pertenece a la clase A, y - 1 si es de la clase B. En estas ecuaciones, a, E [O, 11 es un factor de ganancia. Este factor debe ser ajustado de forma que satisfaga tanto los requerimientos de aprendizaje rapid0 como la estabilidad de las estimaciones de los pesos (en el ejemplo de la operaci6n OR, se considera (Y = 1). Este proceso se repite hasta que el error que se produce para cada uno de los patrones (diferencia entre el valor de salida deseado y obtenido) es cero o bien menor que un valor preestablecido. Obsérvese que los pesos no se cambian si la red ha tomado la decisi6n correcta.
5. Volver al paso 2. Este algoritmo es extendible al caso de múltiples neuronas en la capa de
salida. El Perceptr6n sera capaz de aprender a clasificar todas sus entradas, en un número finito de pasos, siempre y cuando el conjunto de los patrones de entrada sea linealmente separable. En tal caso, puede demostrarse que el aprendizaje de la red se realiza en un número finito de pasos.
Solucidn al problema de la separabilidad lineal
El ejemplo expuesto de ajuste de pesos de una red para solucionar el problema de la funci6n OR no es aplicable, como se dijo anteriormente, a otro problema no trivial, como es la funci6n OR-EXCLUSIVA (XOR). En el caso de esta funcidn se pretende que para los valores de entrada O0 y 11 se devuelva la clase O , y para los patrones O 1 y 10, la clase 1. Como puede comprobarse en la Figura 2.3, el problema radica en que no existe ninguna recta que separe los patrones de una clase de los de la otra.
Figura 2.3. Funci6n XOR: no existe una recta que separe las dos clases.

2.1. EL PERCEPTRÓN 59
La soluci6n podría darse si descompusiéramos el espacio en tres regiones: una región pertenecería a una de las clases de salida y las otras dos perte- necerían a la segunda clase. Si en lugar de utilizar únicamente una neurona de salida se utilizaran dos, se obtendrían dos rectas, por lo que podrían de- limitarse tres zonas. Para poder elegir entre una zona u otra de las tres, es necesario utilizar otra capa con una neurona cuyas entradas serán las salidas de las neuronas anteriores. Las (dos zonas o regiones que contienen los puntos ( O , O) y (1,l) se asocian a una salida nula de la red, y la zona central se asocia a la salida con valor 1. De esta manera, es posible encontrar una solución al problema de la función XOR.
Por tanto, se ha de utilizar una red de tres neuronas, distribuidas en dos capas, para solucionar el problema de la función XOR.
4
Figura 2.4. Solución del problema de la función XOR.
Hay que indicar que para el. caso de la XOR se tienen que ajustar seis pesos (sin incluir las conexiones que representan los umbrales). En el caso de los pesos de las conexiones de la capa de salida (tus1 y w32), el ajuste de los pesos se realiza de forma idéntica a la estudiada anteriormente, pues conocemos la salida deseada. Sin embargo, no se tiene por qué conocer cuál debe ser la salida deseada de las células de la capa oculta, por lo que el método utilizado en la función O R no es aplicable en la función XOR. La solución

60 CAPfTULO 2. ALGUNOS MODELOS
para el aprendizaje en este tipo de redes, donde existen niveles ocultos es diferente.
El Perceptr6n Multinivel
Un Perceptr6n multinivel o multicapa es una red de tipo feedforward com- puesta de varias capas de neuronas entre la entrada y la salida de la misma. Esta red permite establecer regiones de decisidn mucho m& complejas que las de dos semiplanos, como hacía el Perceptrón de un solo nivel.
XI
x, . . . . . . . . . . . . . . . . .
x,
Figura 2.5. Perceptr6n Multinivel (red feedforward multicapa).
Las capacidades del Perceptrón con dos, tres y cuatro niveles o capas y con una única neurona en el nivel de salida, se muestra en la Figura 2.6. En la segunda columna se muestra el tipo de regi6n de decisi6n que se puede formar con cada una de las configuraciones. En la siguiente columna se indica el tipo de región de decisi6n que se formaria para el problema de la XOR. En las dos últimas columnas se muestran las regiones formadas para resolver el problema de clases con regiones mezcladas y las formas de regiones m& generales para cada uno de los casos.
El Perceptrón bhico de dos capas (la de entrada con neuronas lineales y la de salida con funcidn de activaci6n de tipo escalón) s610 puede establecer dos regiones separadas por una frontera lineal en el espacio de patrones de entrada. Un Perceptrón con tres niveles de neuronas puede formar cualquier regidn convexa en este espacio. Las regiones convexas se forman mediante

2.1. EL PERCEPTRÓN 61
la intersección entre las regiones formadas por cada neurona de la segunda capa. Cada uno de estos elementos se comporta como un Perceptrón simple, activándose su salida para los patrones de un lado del hiperplano. Si el valor de los pesos de las conexiones entre las N2 neuronas de la segunda capa y una neurona del nivel de salida son todos 1 y el umbral de la de salida es (N2 - a), donde O < a < 1, entonces la salida de la red se activará sólo si las salidas de todos los nodos de la segunda capa están activos. Esto equivale a ejecutar la operación lógica AND en el nodo de salida, resultando una región de decisión la intersección de todos los semiplanos formados en el nivel anterior. La región de decisión resultante de la intersección serán regiones convexas con un número de lados a lo sumo igual al número de neuronas de la segunda capa.
Este análisis nos introduce en el problema de la selección del número de neuronas ocultas de un Perceptrón de tres capas. En general, este número deberá ser lo suficientemente grande como para que se forme una región lo suficientemente compleja para la resolución del problema. Sin embargo, tam- poco es conveniente que el número de nodos sea tan grande que la estimación de los pesos no sea fiable para el conjunto de patrones de entrada disponibles.
Un Perceptrón con cuatro capas puede formar regiones de decisión arbi- trariamente complejas. El proceso de separación en clases que se lleva a cabo consiste en la partición de la región deseada en pequeños hipercubos (cua- drados para dos entradas de la red). Cada hipercubo requiere 2N neuronas en la segunda capa (siendo N el número de entradas a la red), una por cada lado del hipercubo, y otra en la tercera capa, que lleva a cabo el AND lógico de las salidas de los nodos del nivel anterior. Las salidas de los nodos de este tercer nivel se activarán sólo para las entradas de cada hipercubo. Los hipercubos se asignan a la región de decisión adecuada mediante la conexión de la salida de cada nodo del tercer nivel sólo con la neurona de salida (cuar- ta capa) correspondiente a la región de decisión en la que está comprendido el hipercubo, llevándose a cabo una operación lógica OR en cada nodo de salida. La operación lógica OR se llevará a cabo sólo si el valor de los pesos de las conexiones de los nodos del tercer nivel vale 1 , y además el valor de los umbrales de los nodos de salida es 0.5. Este procedimiento se puede ge- neralizar de manera que la forma de las regiones convexas sea arbitraria, en lugar de hipercubos.

62 CAPÍTULO 2. ALGUNOS MODELOS
Figura 2.6. Distintas formas de las regiones generadas por un Perceptr6n Multinivel.
El andisis anterior demuestra que no se requieren m& de cuatro capas en una red de tipo Perceptrón, pues, como se ha visto una red con cuatro niveles, puede generar regiones de decisión arbitrariamente complejas. Sólo en ciertos problemas se puede simplificar el aprendizaje mediante el aumento del número de neuronas ocultas. Sin embargo, la tendencia es el aumento de la extensidn de la funci6n de activaci611, en lugar del aumento de la comple- jidad de la red. Esto de nuevo nos lleva al problema del número de neuronas que debemos seleccionar para un Perceptrón con cuatro capas.
El número de nodos de la tercera capa (N3) debe ser mayor que uno cuando las regiones de decisión e s t h desconectadas o endentadas y no se pueden formar con una regi6n convexa. Este número, en el peor de los casos, es igual al número de regiones desconectadas en las distribuciones de entrada. El número de neuronas en la segunda capa (N2) normalmente debe ser suficiente para proveer tres o m& hgulos por cada &rea convexa generada por cada neurona de la tercera capa. Así, deber& de haber m& de tres veces el número de neuronas de la tercera capa (N2 > 3N3). En la pr&tica, un número de neuronas excesivo en cualquier capa puede generar ruido. Por otro lado, si existe un número de neuronas redundantes se obtiene mayor tolerancia a fallos.

2.2. ADALINE Y EL COMBINADOR LINEAL ADALINE 63
2.2 Adaline y el cornbinador lineal Adaline
El Adaline es un dispositivo que consta de un Único elemento de procesamien- to; como tal, técnicamente no es una red neuronal. Sin embargo, se trata de una estructura muy importante, merecedora de un estudio detallado.
I I
Figura 2.7. El Adaline completo consta del combinador adaptativo lineal, que está dentro del cuadro de trazos, y de una función bipolar de salida.
El término Adaline es una sigla; sin embargo, su significado ha cambiado ligeramente con el paso de los años. Inicialmente se llamaba .ADAptive LI- near NEuron (Neurona Lineal Adaptativa); pasó a ser el ADAptive LINear Element (Elemento Lineal Adaptativo) cuando las redes neuronales cayeron en desgracia al final de los años sesenta. La Figura 2.7 muestra la estructura del Adaline. E l cuadro de trazos que se ve en la Figura 2.7 encierra una parte del Adaline que es lo que se denomina combinador adaptativo lineal (ALC). Si la salida del ALC es positiva, la salida del Adaline es +l. Si la salida del ALC es negativa, entonces la salida del Adaline es - 1. Dado que una gran parte del tratamiento interesante se produce en la parte ALC del Adaline, nos concentraremos en el ALC. .Después volveremos a añadir la condición de salida binaria.
El ALC lleva a cabo el cálculo de una suma de productos empleando los vectores de entrada y de peso, ;y aplica una función de salida para obtener un Único valor de salida. Empleando la notación de la Figura 2.7,
n
y =I Wof E wjxj j=1

64 CAPkl'ULO 2. ALGUNOS MODELOS
en donde wo es el peso de tendencia. Si se hace la identificaci6n zo = 1 , se puede reescribir la ecuaci6n anterior en la forma
j = O
o bien, en notaci6n vectorial y = w x. T
La funcidn de salida en este caso es la funci6n identidad, así como la funci6n de activaci6n. El uso de la funcidn identidad como funcidn de salida y como funci6n de activaci6n significa que la salida es igual a la activaci6n, que es lo mismo que la entrada neta de la unidad.
El Adaline (o el ALC) es ADAptativo en el sentido de que existe un pro- cedimiento bien definido para modificar los pesos con objeto de hacer posible que el dispositivo proporcione el valor de salida correcto para la entrada dada. El significado de correcto a efectos del valor de salida depende de la funcidn de tratamiento de señales que esté siendo llevada a cabo por el dispositivo. El Adaline (o el ALC) es LIneal porque la salida es una funci6n lineal sencilla de los valores de la entrada.
La regla de aprendizaje LMS
Dado un vector de entrada x, resulta sencillo determinar un conjunto de pesos w que dé lugar a un valor de salida concreto y. Supongamos que se dispone de un conjunto de vectores de entrada {XI, x2, , XL}, cada uno de los cuales posee su propio valor correcto d k , k = 1, - , L, que quiz& sea Único. El problema de hallar un Único vector de pesos que pueda asociar con éxito cada vector de entrada con el valor de salida deseado ya no es sencillo. El aprendizaje de mínimos cuadrados (LMS) es un método para hallar el vector de pesos deseado. Aludiremos a este proceso para hallar el vector de pesos diciendo que estamos entrenando al ALC. La regla de aprendizaje se puede incorporar al propio dispositivo, que entonces se puede autoadaptar a medida que se le vayan presentando las entradas y salidas deseadas. Se hacen pequeños ajustes en los valores de los pesos cada vez que se procesa una combinacidn entrada-salida, hasta que el ALC da unas salidas correctas. En cierto sentido, este proceso es un verdadero proceso de entrenamiento, porque no necesitamos calcular explícitamente el valor del vector de pesos.

2.2. ADALINE Y EL COMBINADOR LINEAL ADALINE 65
Antes de describir con detalle el proceso de entrenamiento, vamos a llevar a cabo el cálculo manualmente.
Cálculo de w*. Para empezar, vamos a formular el problema de un modo ligeramente distinto: dados los ejemplos (x1, dl), (x2, dz) , . . ., (XL, d ~ ) , de alguna función de procesamiento que asocia a los vectores de entrada x k a (o los proyecta sobre) los valores de salida deseados, dk, ¿cuál es el mejor vector de pesos, w*, para un ALC que lleve a cabo esta proyección?
Para responder a esta pregunta, primero hay que definir lo que constituye el mejor vector de pesos. Está claro que, una vez que se haya encontrado el mejor, desearíamos que al aplicar todos los vectores de entrada se obtuviese como resultado un valor de salida que fuese, con precisión, el valor correcto. Por tanto, es necesario eliminar, o por lo menos minimizar, la diferencia entre la salida deseada y la salida real para todos los vectores de entrada. La aproximación que se emplea aquí consiste en minimizar el error cuadrático medio para el conjunto de valores de entrada.
Si el valor de la salida es y k para el k-ésimo vector de entrada, entonces el término de error correspondiente es ek = d k - yk. El error cuadrático medio, o valor esperado del error, se define en la forma:
( f :k) 2 = - ' x e : L
IC= 1
en donde L es el número de vectores de entrada que haya en el conjunto de entrenamiento.
Empleando la Ecuación (2. l), se puede desarrollar el error cuadrático medio como sigue:
En el desarrollo previo, se ha hecho la suposición consistente en que el conjunto de entrenamiento permanece estacionario estadísticamente, lo cual quiere decir que los valores esperados sólo van a cambiar lentamente con el transcurso del tiempo. Esta suposición nos permite eliminar los vectores de pesos que aparecen en los términos de valores esperados dentro de la Ecuación (2.3).
Definase una matriz R = (xkxc), llamada matriz de correlación de en- tradas, y un vector p = (&x:). Adicionalmente, hágase la identificación

66 CAPfTULO 2. ALGUNOS MODELOS
5 = (e:). Utilizando estas definiciones, se puede reescribir la Ecuaci6n (2.3) en la forma
= (dz) + W ~ R W - 2pTw. (2.4)
Esta ecuaci6n muestra a 5 como funcidn explícita del vector de pesos, w. En otras palabras, = (w).
Para hallar el vector de pesos correspondiente al error cuadrdtico medio minimo se deriva en la Ecuacidn (2.4), se evalúa el resultado en w* y se hace el resultado igual a cero:
de donde W* = R-lp.
Obsérvese que aunque E es un escalar, es un vector. La Ecuaci6n (2.5) es una expresi6n del gradiente de t , VE que es el vector
[ at (w) , 1 at ( 4 % (w) 05 = - - . . . - awl ’ h 2 8% 7 ’ (2.8)
Lo Único que hemos hecho con este proceso es demostrar que es posible hallar un punto en el cual la pendiente de la funci6n t (w) es cero. En general, ese punto puede ser un m&mo o un mínimo. La grAfica de (w) es un hiperparaboloide. Ademh tiene que poseer una concavidad dirigida hacia arriba, puesto que todas las combinaciones de pesos deben dar lugar a un valor no negativo para el error cuadrdtico medio, c. Este resultado es general, y se obtiene independientemente de las dimensiones del vector de pesos. En caso de que las dimensiones sean m& de dos, el paraboloide se conoce con el nombre de hiperparaboloide.
CAlculo de w* mediante el mbtodo del descenso m& pronunciado Como se puede imaginar, el cdlculo analítico para determinar los pesos 6 p timos de un cierto problema es bastante dificil en general. No s610 se vuelve engorrosa la manipulaci6n de matrices para dimensiones grandes, sino que adem& cada uno de los componentes de R y p es, a su vez, un valor espe- rado. Por tanto, los c6lculos explícitos de R y p requieren un conocimiento estadístico de las seiiales de entrada. Una aproximaci6n mejor consistiría

2.2. ADALINE Y EL COMBINADOR LINEAL ADALINE 67
en dejar que el ALC buscase por sí mismo los pesos óptimos, haciendo que explorase la superficie de pesos para hallar el mínimo. Una búsqueda pura- mente aleatoria podría no ser productiva o no ser eficiente, así que vamos a aÍiadirle un poco de inteligencia al proceso.
Empezaremos por asignar unos valores arbitrarios a los pesos. A partir de ese punto de la superficie de pe:;os, se determina la dirección de la pendiente más pronunciada en dirección hacia abajo. Luego se modifican ligeramente los pesos para que el nuevo vector de pesos se encuentre un poco más abajo en la superficie. Este proceso se repite hasta haber alcanzado el mínimo. El procedimiento se muestra en la Figura 2.8. E n este método se encuentra implícitamente la suposición consistente en que sabemos por anticipado el aspecto que va a tener la superficie de pesos. No lo sabemos, pero veremos en seguida la forma en que se puede evitar ese problema.
Figura 2.8. Se puede utilizar este diagrama para visualizar el método del descenso más pronunciado. La selección inicial del vector de pesos da lugar
a un error inicial. El método del descenso más pronunciado consiste en deslizar este punto hacia abajo siguiendo la superficie hacia el fondo, y
desplazándose siempre según la dirección de la pendiente más pronunciada hacia abajo.
Típicamente, el vector de pesos no se desplaza al principio directamente hacia el punto mínimo. La secci6n transversal de la superficie paraboloidal de

68 CAPITULO 2. ALGUNOS MODELOS
pesos suele ser eliptica, de modo que el gradiente negativo puede no apuntar directamente hacia el punto minimo, al menos al principio. La situaci6n se muestra con m& claridad en el diagrama de contornos de la superficie de pesos que hay en la Figura 2.9.
\ -2. -1. o. 1. 2 3. 4. w2
Figura 2.9. En el diagrama de contornos de la superficie de pesos de la Figura 2.8, la direcci6n del descenso m& pronunciado es perpendicular a las
lfneas de contorno de cada punto, y esta direccidn no siempre apunta al punto mínimo.
Dado que el vector de pesos de este procedimiento es variable, lo escribi- mos como funcidn explícita del paso temporal, t. El vector inicial de pesos se denota en la forma w(O), y el vector de pesos del instante t es w(t). En cada paso, el pr6ximo vector de pesos se calcula según
w(t + 1) = w(t) + Aw(t) (2.9)
en donde Aw(t) es el cambio que sufre w en el t-ésimo instante. Estamos buscando la direccidn del descenso m& pronunciado en cada
punto de la superficie, así que necesitamos calcular el gradiente de la super- ficie (que proporciona la direccih de la pendiente más pronunciada hacia arriba). La direcci6n opuesta del gradiente es la direcci6n de descenso m&

2.2. ADALINE Y EL COMBI.IVADOR LINEAL ADALINE 69
pronunciado. Para obtener la magnitud del cambio, se multiplica el gradien- te por una constante apropiada, p. El valor apropiado de p se tratará más adelante. Este procedimiento da lugar a la expresión siguiente:
w(t + 1) = w(t) - pVl(w(t)) . (2.10)
Lo Único que se necesita pasa finalizar lo tratado, es determinar el valor de Vl(w(t)) en cada paso sucesivo de iteración.
El valor de V[(w ( t ) ) se determinó analíticamente en la sección anterior. La Ecuación (2.5) o la Ecuación (2.6) se pueden utilizar aquí para determi- nar analíticamente w*: necesitaríamos conocer R y p por anticipado. Este conocimiento equivale a saber por anticipado el aspecto que va a tener la superficie de pesos. Para sosla,yar esta dificultad, se utiliza una aproxima- ción del gradiente que es posible calcular a partir de una información que se conoce de forma explícita en cada iteración.
Se hace lo siguiente para cada paso del proceso de iteración: 1. Se aplica un vector de entrada, xi,, en las entradas del Adaline. 2. Se determina el valor del error cuadrático, e i ( t ) , empleando el valor
actual del vector de pesos
ef(t) == (di, - wyt )xk)2 (2.11)
3. Se calcula una aproximación de V(( t ) empleando e:(t) como aproxi-
Vei(t) ==: v (e:) (2.12)
Vei ( t ) = -2ek(t)xk (2.13)
en las cuales se ha utilizado la :Ecuación (2.11) para calcular explícitamente el gradiente.
4. Se actualiza el vector de pesos según la Ecuación (2.10), empleando la (2.13) como aproximación del gradiente:
mación de (e:)
w(t + 1) = w(t) + 2pekxi, (2.14)
5. Se repiten los pasos del 1 al 4 con el siguiente vector de entrada, hasta que el error quede reducido a u:n valor aceptable.
La Ecuación (2.14) es una expresión del algoritmo LMS. E l parámetro p determina la estabilidad y la velocidad de convergencia del vector de pesos hacia el valor de error mínimo.

70 CAPÍTULO 2. ALGUNOS MODELOS
o. 1. 2. 3. 4.
%
Figura 2.10. La ruta hipotética que sigue el vector de pesos en la búsqueda del error minimo utilizando el algoritmo LMS no es una curva suave,
porque se está aproximando el gradiente en cada punto. Obsérvese también que el tamaño del paso se vuelve cada vez m& pequeño a medida que nos
aproximamos a la soluci6n de error mínimo.
Dado que se ha utilizado una aproximaci6n del gradiente en la Ecuacidn (2.14), el camino que sigue el vector de pesos al bajar por la superficie de pesos hacia el mínimo no será tan suave como se indica en la Figura 2.9. La Figura 2.10 muestra un ejemplo del aspecto que podría tener la ruta de búsqueda con el algoritmo LMS de la Ecuacidn (2.14). Los cambios del vector peso deben hacerse relativamente pequeños en cada iteraci6n. Si los cambios son demasiado grandes, el vector de pesos podría vagar por la superficie, sin encontrar nunca el mínimo, o podría alcanzarlo s610 por accidente en lugar de ser el resultado de una convergencia sostenida hacia él. La misi6n del parAmetro p es evitar esta búsqueda sin tino.
2.3 El Madaline
Como se puede ver, el Adaline se parece mucho al Perceptr6n; también posee algunas de las limitaciones de éste. Por ejemplo, un Adaline de dos entra-

2.3. EL MADALINE 71
das no puede calcular la función XOR. La combinación de Adalines en una estructura de capas sí puede superar esta dificultad, tal como sucede con el Perceptrón. Se muestra una de estas estructuras en la Figura 2.11.
Figura 2.11. Muchos Adalines (el Madaline) pueden calcular la función XOR de dos entradas. Obsérvese la adición de términos de tendencia a
cada Madaline. Una salida analógica positiva de un ALC da lugar a una salida +1 del Adaline asociado; una salida analógica negativa da lugar a un
-1. De manera similar, todas las entradas al dispositivo que sean de naturaleza binaria deben utilizar d~1 en lugar de 1 y O.
Arquitectura del Madaline
Madaline son las siglas de Múltiples Adalines. Cuando se organiza con una arquitectura multicapa como la que se muestra en la Figura 2.12, el Madaline se asemeja a la estructura general de una red neuronal. E n esta configura- ción, se le podría presentar al Madaline un vector de entrada de grandes dimensiones. Con un entrenamiento apropiado, sería posible enseñar a la red a responder con un +1 binario en uno de entre varios nodos de salida, cada uno de los cuales correspondiese a una categoría distinta de imágenes de entrada. Ejemplos de estas categorías son {gato, perro, armadillo, jabalina}

72 CAPfTULO 2. ALGUNOS MODELOS
y {Canelo, Zapirdn, Aguila, F’ulcro}. En una red como ésta, cada uno de los cuatro nodos de la capa de salida corresponde a una sola clase. Para una trama de entrada dada, un cierto nodo tendria la salida +1 si la trama de entrada correspondiese a la clase representada por ese nodo concreto. Los otros tres nodos tendrían una salida de -1. Si la trama de entrada no fuera miembro de ninguna clase conocida, los resultados de la red podrían resultar ambiguos.
Para entrenar una de estas redes, podriamos sentirnos tentados de em- pezar con el algoritmo LMS en la capa de salida. Dado que la red va a ser entrenada, como cabe suponer, empleando tramas de entrada definidas pre- viamente, el vector de salida deseado es conocido. Lo que no sabemos es la salida deseada para un nodo dado de una de las capas ocultas. M& aún, el algoritmo L M S funcionaría en las salidas anal6gicas del ALC, y no en los valores bipolares de salida del Adaline. Por estas razones, se ha desarrollado una estrategia de entrenamiento distinta para el Madaline.
de Madelines
o . . Capa de entrada
capa oculta de Madelines
t t t Figura 2.12. Se pueden unir muchos Adalines en una red neuronal formada
por capas tal como ksta.

2.3. EL MADALINE 73
El algoritmo de entrenamiento MRII
Es posible diseñar un método para entrenar una estructura del tipo del Ma- daline basándose en el algoritmo LMS; sin embargo, el método se fundamenta en sustituir la función de salida, con umbral lineal por una función derivable con continuidad (la función umbral es discontinua en O ; por tanto, no se pue- de derivar allí). Por el momento, consideramos un método conocido con el nombre de regla I1 del Madaline (MRII). La regla original del Madaline era un método anterior que no trataremos aquí.
El MRII se parece a un procedimiento de acierto y error, con una inteli- gencia adicional en la forma de un principio de mínima perturbación. Dado que la salida de la red es una serie de unidades bipolares, el entrenamiento equivale a reducir el número de nodos de salida incorrectos para cada trama de entrenamiento que se dé como entrada. El principio de mínima perturba- ción establece que aquellos nodos que puedan afectar al error de salida y que sufran los cambios más pequeños en sus pesos deberían tener prioridad en el proceso de aprendizaje. Este principio se plasma en el algoritmo siguiente:
1. Se aplica un vector a las entradas del Madaline y se hace que se pro- pague hasta las unidades de salida.
2. Se cuenta el número de valores incorrectos que haya en la capa de salida; se denomina error a este número.
3. Para todas las unidades de la capa de salida:
(a) Se selecciona el primer nodo que no haya sido seleccionado antes y cuya salida analógica esté más próxima a cero. (Este es el nodo que puede invertir su salida bipolar con el menor cambio de sus pesos; de aquí viene el nombre de mínima perturbación.)
(b) Se cambian los pesos de la unidad seleccionada de tal modo que cambie la salida bipolar de la unidad.
(c) Se hace que se propague el vector de entrada hacia adelante, par- tiendo de las entradas y en dirección a las salidas, una vez más.
(d) Si el cambio de pesos da lugar a una reducción del número de erro- res, se admite el cambio de pesos; en caso contrario, se restauran los pesos originales.
4. Se repite el paso 3 para toldas las capas, salvo la de salida.

74 CAPfTULO 2. ALGUNOS MODELOS
5. Para todas las unidades de la capa de salida:
(a) Se selecciona el par de unidades que no hayan sido seleccionadas anteriormente y cuyas salidas analdgicas estén m& prdximas a cero.
(b) Se aplica una correccidn de pesos a ambas unidades, con objeto
(c) Se hace que se propague hacia adelante el vector de entradas,
de modificar la salida bipolar de ambas.
partiendo de las entradas y hasta llegar a las salidas.
(d) Si el cambio de pesos da lugar a una reduccidn del número de erro- res, se admite el cambio de pesos; en caso contrario, se restauran los pesos originales.
6. Se repite el paso 5 para todas las capas salvo la de entrada.
Si es necesario, se puede repetir la secuencia de los pasos 5 y 6 con ternas de unidades, o grupos de cuatro unidades, o incluso formando combinaciones aun mayores, hasta que se obtengan resultados satisfactorios. Hay indicacio- nes preliminares que afirman que las parejas son apropiadas para redes de dimensiones modestas, con un mhimo de 25 unidades por capa.
2.4 Red de Propagación hacia atrás (BPN) Para empezar, la red BPN aprende un conjunto predefinido de pares de entradas y salidas dados como ejemplo, empleando un ciclo propagacidn- adaptacidn de dos fases. Una vez que se ha aplicado una trama de entrada como estimulo para la primera capa de unidades de la red, ésta se va pro- pagando a través de todas l a s capas superiores hasta generar una salida. La señal de salida se compara entonces con la salida deseada, y se calcula una señal de error para cada unidad de salida.
Las señales de error se transmiten entonces hacia atr&, partiendo de la capa de salida, hacia todos los nodos de la capa intermedia que contribuyan directamente a la salida. Sin embargo, las unidades de la capa intermedia s610 reciben una fraccidn de la señal total de error, bashdose aproximadamente en la contribucidn relativa que haya aportado la unidad a la salida original. Este proceso se repite, capa por capa, hasta que todos los nodos de la red hayan recibido una señal de error que describa su contribucidn relativa al

2.4. RED DE PR0PAGACIÓ.N HACIA ATRÁS (BPN) 75
error total. Basándose en la sefial de error percibida, se actualizan los pesos de conexión de cada unidad, para hacer que la red converja hacia un estado que permita codificar todas las tramas de entrenamiento.
La importancia de este proceso consiste en que, a medida que se entre- na la red, los nodos de las capas intermedias se organizan a sí mismos de tal modo que los distintos nodos aprenden a reconocer distintas caracterís- ticas del espacio total de entradas. Después del entrenamiento, cuando se les presente una trama arbitraria de entrada que contenga ruido o que esté incompleta, las unidades de las capas ocultas de la red responderán con una salida activa si la nueva entrada contiene una trama que se asemeje a aque- lla característica que las unidades individuales hayan aprendido a reconocer durante su entrenamiento. Y a la inversa, las unidades de las capas ocultas tienen una tendencia a inhibir sus salidas si la trama de entrada no contiene la característica para la cual han sido entrenadas.
A medida que las señales se propagan a través de las diferentes capas de la red, la trama de actividad que está presente en todas las capas superiores se puede ver como una trama con características que son reconocidas por las unidades de la capa subsiguiente. La trama de salida que se genera se puede ver como un mapa de características que ofrece una indicación de la presen- cia o ausencia de muchas combinaciones distintas de características dentro de la entrada. El resultado global de este comportamiento es que la BPN constituye un medio eficiente para permitir a un sistema de computadores examinar tramas de datos que pueden ser ruidosas, o estar incompletas, y reconocer tramas sutiles a partir de entradas parciales.
Hay varios investigadores que han demostrado que, durante el entrena- miento, las BPN tienden a desarrollar relaciones internas entre nodos con el fin de organizar los datos de entrenamiento en clases de tramas. Esta tendencia se puede extrapolar, para llegar a la hipótesis consistente en que todas las unidades de capas ocultas de una BPN son asociadas de alguna manera a características específicas de la trama de entrada como consecuen- cia del entrenamiento. Lo que sea o no sea exactamente la asociación puede no resultar evidente para el observador humano. Lo importante es que la red ha encontrado una representación interna que le permite generar las salidas deseadas cuando se le dan las entradas de entrenamiento. Esta misma repre- sentación interna se puede aplicar a entradas que no fueran utilizadas durante el entrenamiento. La BPN clasificará estas entradas que no había visto has- ta el momento según las características que compartan con los ejemplos de entrenamiento.

76 CAPÍTULO 2. ALGUNOS MODELOS
La regla Delta generalizada
Presentaremos una derivaci6n detallada de la regla Delta generalizada (GDR) , que es el algoritmo de aprendizaje de la red.
La Figura 2.13 sirve como referencia para la mayoria de las descripciones. La BPN es una red formada por capas, con propagaci6n hacia adelante, que est& completamente interconectada entre capas. Por tanto, no hay conexiones de realimentaci6n ni conexiones que salten una capa para ir directamente a una capa anterior. Aunque s610 se utilizan tres capas en nuestro tratamiento, se puede admitir m& de una capa oculta.
y y C a L d : 6 n : a d a y x, k x,
Figura 2.13. La arquitectura de una BPN de tres capas. " . ~ . - ." ~- . ~ - ." -
Se dice que una red neuronal es una red de correspondencia si se demues- tra capaz de calcular alguna relacidn funcional entre su entrada y su salida. Por ejemplo, si la entrada de la red es el valor de un 6ngulo 0 y la salida es el coseno del Angulo, la red establece la correspondencia 8 H cos(@). Para una funci6n tan sencilla, no se necesita una red neuronal; sin embargo, po- dria ser necesario llevar a cabo una correspondencia complicada en la que no se conociera la forma de describir la relaci6n funcional por anticipado, pero fueran conocidos ejemplos de correspondencias correctas. En esta situaci6n, la potencia de una red neuronal para descubrir su propio algoritmo es de enorme utilidad.

2.4. RED DE PROPAGACIÓ2W HACIA ATRAS (BPN) 77
Supongamos que se tiene u.n conjunto de P pares de vectores ( X I , yl), (x2, y2), . . . , (xp, yp) , que son ejemplos de una correspondencia funcional y = #(x): x E RN, y E R’. Deseamos entrenar a la red para que aprenda una aproximación o = y’ = $’(x). Vamos a derivar un método para hacer este entrenamiento, que suele Funcionar bajo la hipótesis de que los pares de vectores de entrenamiento se hayan seleccionado adecuadamente y que haya un número suficiente de ellos. Recuérdese que el aprendizaje, en una red neuronal, significa hallar un conjunto adecuado de pesos. La técnica de aprendizaje que se describe aquí se asemeja al problema de hallar la ecuación de una línea que sea la que mejor se ajuste a un cierto número de puntos conocidos. Además, es una generalización de la regla LMS. Para un proble- ma de ajuste de líneas, es probable que utilizásemos una aproximación de mínimos cuadrados. Dado que la relación que pretendemos estudiar será, probablemente, no lineal, además de multidimensional, empleamos una ver- sión iterativa del sencillo método de mínimos cuadrados, denominada técnica del descenso más pronunciado.
Para empezar, revisemos las ecuaciones para el procesamiento de infor- mación que hay en la red de tres capas de la Figura 2.13. Se aplica un vector de entrada, xp = (xpl, xp2, . . ., I I : ~ N ) ~ , en la capa de entrada de la red. Las unidades de entrada distribuyen los valores a las unidades de la capa oculta. La entrada neta de la j-ésima unidad oculta es
N
(2.15) i=l
en donde es el peso de la conexión procedente de la i-ésima unidad de entrada, y 0: es el término de tendencia. El índice ’h’ se refiere a magnitudes de la capa oculta. Se supone que la activación de este nodo es igual a la entrada neta; entonces, la salida de este nodo es
2, = j ) (netapj) h . (2.16)
Las ecuaciones para los nodos de salida son las que siguen:
L
neta;,, =x wijipj + e; j=1
(2.17)
(2.18)

78 CAPfTULO 2. ALGUNOS MODELOS
en donde el indice '0' se refiere a magnitudes de la capa de salida. El conjunto inicial de valores de pesos representa una primera aproxima-
ci6n de los pesos correctos para el problema. A diferencia de otros mktodos, la tknica que empleamos aquí no depende de hacer una buena primera apro- ximaci6n:
1. Se aplica un vector de entrada a la red, y se calculan los correspondien- tes valores de salida.
2. Se comparan las salidas obtenidas con las salidas correctas, y se deter- mina una medida del error.
3. Se determina en qu6 direcci6n (+ 6 -) debe cambiar cada peso con objeto de reducir el error.
4. Se determina la cantidad en que es preciso cambiar cada peso.
5. Se aplican las correcciones a los pesos.
6. Se repiten los pasos del 1 al 5 con todos los vectores de entrenamiento hasta que el error para todos los vectores del conjunto de entrenamiento quede reducido a un valor aceptable.
Una ley iterativa de cambio de pesos para redes sin unidades ocultas y con unidades de salida lineales, denominada regla LMS o regla Delta es:
w(t + = w(t)i + 2pekxki (2.19)
en donde p es una constante positiva, xki es la i-ésima componente del k-ksimo vector de entrenamiento y ek es la diferencia entre la salida obtenida y el valor correcto, ek = (dk - gk). La Ecuaci6n (2.19) es solamente la forma en componentes de la (2.4).
Se obtiene una ecuacidn similar cuando la red tiene m& de dos capas, o cuando las funciones de salida son no lineales.
Actualizacibn de pesos de la capa de salida
Al derivar la regla Delta, el error del k-ésimo vector de entrada es ek = (dk - g k ) , en donde la salida deseada es d k y la salida real es gk. Dado que en una capa hay muchas unidades, para la BPN no basta con un Único

2.4. RED DE PROPAGACIóN HACIA ATRÁS (BPN) 79
valor de error ek. Definiremos el error de una sola unidad de salida en la forma S,k = (ypk - o p k ) , en donde el subíndice 'p' se refiere al p-ésimo vector de entrenamiento, y 'k' se refiere a la k-ésima unidad de salida. En este caso, ypk es el valor de salida deseado, y opk es la salida obtenida a partir de la k-ésima unidad. El error que se minimiza por GDR es la suma de los cuadrados de los errores de todas las unidades de salida:
(2.20)
E l factor 1/2 de la Ecuación (2.20) aparece por conveniencia para calcular derivadas. Dado que aparecerá una constante arbitraria en el resultado final, la presencia de este factor no in.valida la derivación.
Para determinar el sentido en que se deben cambiar los pesos, se calcula el valor negativo del gradiente de Ep, VE,, respecto a los pesos wkj. Después se pueden ajustar los valores de los pesos de tal forma que se reduzca el error total. Suele resultar útil pensar que E, es una superficie en el espacio de pesos. La Figura 2.14 muestra un ejemplo sencillo en el que la red sólo tiene dos pesos.
Figura 2.14. Esta superficie hipotética del espacio de pesos da una idea de la complejidad de estas superficies.

80 CAPÍTULO 2. ALGUNOS MODELOS
Para no complicar las cosas, consideramos por separado cada componente de V Ep. Partiendo de la Ecuaci6n (2.20) y de la definici6n de bpk,
k=l
V
(2.21)
(2.22)
en donde se ha utilizado la Ecuaci6n (2.18) como valor de salida, opk y la regla de la cadena para las derivadas parciales. Por el momento, no intentaremos evaluar l a s derivadas de f;, sino que nos limitaremos a escribirlas en la forma f l ‘ (netu;,). El último factor de la Ecuaci6n (2.22) es
(2.23)
Combinando las Ecuaciones (2.22) y (2.23), tenemos lo siguiente para el gradiente negativo
En lo tocante a la magnitud del cambio de peso, consideramos que ser& proporcional al gradiente negativo. De esta manera, los pesos de la capa de salida se actualizan según lo siguiente:
w& (t + 1) = wij ( t ) + APw& ( t ) (2.25)
en donde A p w g j ( t ) = ‘V(!/pk - 0 P k ) f i ’ ( n e t a g k ) i p j . (2.26)
El factor 7 se denomina pardmetro de velocidad de aprendizaje; dicho es positivo y menor que l.
Volvamos a examinar la funci6n fg’. En primer lugar, obsérvese el requi- sito consistente en que fg’ sea derivable. Este requisito elimina la posibilidad de utilizar una unidad de umbral lineal, puesto que la funcidn de salida para una unidad como ésta no es derivable en el valor umbral.

2.4. RED DE PROPAGACIÓN HACIA ATRÁS (BPN)
Y
Aquí hay dos formas de la función de salida que tienen interés:
81
La primera función define la. unidad lineal de salida. La segunda función es lo que se denomina una sigmoide, o función logística; se ha representado en la Figura 2.15. La selección de la función de salida depende de la forma en que se decida representar los datos de salida. Por ejemplo, si se desea que las unidades de salida sean binaria.s, se utiliza una función de salida sigmoide, puesto que la sigmoide limita la salida y es casi biestable, pero también es derivable. En otros casos, es tan aplicable una función de salida lineal como una sigmoide.
Figura 2.15. Esta gráfica muestra la forma en S característica de la función sigmoide.
En el primer caso, f;’ = 1; en el segundo, f;’ = f; (1 - f;) = opk (1 - o p k ) .
Para ambos casos, tenemos
w& ( t + 1) =: w& ( t ) + V(7Jpk - 0pk)ipj (2.27)
para la salida lineal, y

82 CAPfTULO 2. ALGUNOS MODELOS
para la salida en forma de sigmoide.
magnitud Deseamos resumir las ecuaciones de actualizaci6n de pesos definiendo una
bik = ( y p k - 0 p k ) f ; ' (neta;,) = bpkf,"' (net($&) 9 (2.28)
Entonces se puede escribir la ecuaci6n de actualizaci6n de pesos en la forma
(2.29)
independientemente de la forma funcional de la funci6n de salida, f i . Deseamos hacer un comentario acerca de la relaci6n existente entre el
método de descenso del gradiente que se ha descrito aquí y la técnica de los minimos cuadrados. Si estuviésemos intentando hacer que la regla Delta generalizada fuera completamente anQoga al método de los mínimos cua- drados, no cambiaríamos, en realidad, ninguno de los valores de los pesos hasta que se hubiesen presentado a la red todas las tramas de entrenamien- to al menos una vez. Simplemente, acumulariamos los cambios a medida que fuera procesada cada trama, los sumaríamos y haríamos una actualiza- ci6n en los pesos. Entonces repetiriamos el proceso hasta que el error fuera aceptablemente bajo. El error que minimiza este proceso es
P
E =x p= 1
(2.30)
en donde P es el número de tramas del conjunto de entrenamiento. En la prhtica, resulta poco ventajoso este seguimiento estricto de la analogia con el método de los mínimos cuadrados. Adem&, para utilizar este método es preciso almacenar una gran cantidad de informacih. Recomendamos llevar a cabo las actualizaciones de los pesos a medida que se va procesando cada trama de entrenamiento.
Actualizaciones de los pesos de capas ocultas
Deseariamos repetir para la capa oculta el mismo tipo de ctilculo que se ha realizado para la capa de salida. Surge un problema cuando se intenta de- terminar una medida del error de las salidas para las unidades de la capa oculta. Sabemos cual es la salida obtenida, pero no tenemos forma de saber por anticipado cual debería ser la salida correcta para estas unidades. In- tuitivamente, el error Ep debe estar relacionado de alguna manera con los

2.4. RED DE PROPAGACIÓN HACIA ATRÁS (BPN) 83
valores de salida de la capa oculta. Podemos comprobar la veracidad de nuestra intuición volviendo a la Ecuación (2.21).
Sabemos que i,j depende de los pesos de las capas ocultas a través de las Ecuaciones (2.15) y (2.16). Podemos aprovechar este hecho para calcular el gradiente de Ep respecto a los pesos de las capas ocultas.
(2.31)
Cada uno de los factores de la Ecuación (2.31) puede calcularse explícita- mente a partir de ecuaciones anteriores. El resultado es el que sigue:
(2.32)
Actualizamos los pesos de la capa oculta proporcionalmente al valor negativo de la Ecuación (2.32):
apw:i = 7 f:’ (netallj) xpi (y$ - 0pk)f;’ (neta;,) W i j (2.33) k
en donde q es, una vez mas, la velocidad de aprendizaje.
escribir Se puede utilizar la definición de 6ik dada en la Ecuación (2.32) para
k
Obsérvese que todas las actualizaciones de pesos de la capa oculta depen- den de todos los términos de error, 6;kj de la capa de salida. Este resultado

84 CAPITULO 2. ALGUNOS MODELOS
es el lugar en que surge la nocidn de propagacidn hacia atrh. Los errores conocidos de la capa de salida se propagan hacia a t rh , hacia la capa oculta, para determinar término de error
se da lugar a que
los cambios de peso adecuados en esa capa. Si se define un para la capa oculta
k
(2.35)
las ecuaciones de actualizacidn de pesos pasen a ser analogas a las correspondientes a la capa de salida:
Por último, para cerrar el cerco puesto al GDR, obsérvese que tanto la Ecuacidn (2.29) como la (2.36) tienen la misma forma que la Ecuación (2.19), la regla Delta.
2.5 El Modelo de Hopfield
Sin duda, uno de los principales responsables del desarrollo que ha experi- mentado el campo de la computacidn neuronal ha sido J. Hopfield, quien construyd un modelo de red con el número suficiente de simplificaciones co- mo para poder extraer analiticamente informacidn sobre las características relevantes del sistema, conservando las ideas fundamentales de las redes cons- truidas en el pasado y presentando una serie de funciones bhicas de sistemas neuronales reales. Ademh, Hopfield supo establecer un paralelismo entre su modelo y ciertos sistemas extensamente estudiados en fisica estadfstica, lo cual ha permitido aplicar todo un conjunto de técnicas bien conocidas en este campo y, con ello, producir un avance en la comprensidn del funcionamiento de las redes neuronales.
Con su aportacidn, Hopfield redescubrid el mundo casi olvidado de las redes autoasociativas, caracterizadas por una nueva arquitectura y un nuevo funcionamiento, a las que se tuvo que añadir otro tipo de reglas de aprendi- zaje. Las consecuencias fueron redes con un comportamiento diferente a las diseñadas con estructura feedforward (ADALINEI/MADALINE, PERCEP- TRON, ...).

2.5. EL MODELO DE HOPFIELD 85
Arquitectura de la Red
El modelo de Hopfield (Figura 2.16) consiste en una red monocapa con N neuronas cuyos valores de salida son binarios: O/ 1 ó - 1/ + l. En la versión original del modelo (DH: Discrete Hopfield) las funciones de activación de las neuronas eran del tipo escalón. Se trataba, por tanto, de una red discreta, con entradas y salidas binarias; sin embargo, posteriormente Hopfield desarrolló una versión continua con entradas y salidas analógicas, utilizando neuronas con funciones de activación tipo sigmoidal (CH: Continous Hopfield).
Cada neurona de la red se encuentra conectada a todas las demás (co- nexiones laterales), pero no consigo misma (no existen conexiones autorre- currentes). Además, los pesos' asociados a las conexiones entre pares de neuronas son simétricos. Esto significa que el peso de la conexión de una neurona i con otra neurona j es de igual valor que el de la conexión de la neurona j con la i (wij = wji).
/ . . . . . .
Figura 2.16. Red Hopfield. La versión discreta de esta red fue ideada para trabajar con valores bi-
narios -1 y +1 (aunque mediante un ajuste en los pesos pueden utilizarse en su lugar los valores 1 y O). Por tanto, la función de activación de cada neurona i de la red (f(x)) es de tipo escalón:
f (x> = { +1 x > 02 -1 x < 8i

86 CAPITULO 2. ALGUNOS MODELOS
P t X )
*I . . . . . . . . . .
e ai X
-1
Figura 2.17.
Cuando el valor de z coincide exactamente con 8i la salida de la neurona i permanece con su valor anterior. 8i es el umbral de disparo de la neurona i , que representa el desplazamiento de la función de transferencia a lo largo del eje de ordenadas (x). En el modelo de Hopfield discreto suele adoptarse un valor proporcional a la suma de los pesos de las conexiones de cada neurona con el resto:
Si se trabaja con los valores binarios - 1 y +1, suele considerarse el valor nulo para 8i.. Si los valores binarios son O y 1, se toma un valor de 1/2 para k.
En el caso de las redes de Hopfield continuas, se trabaja con valores reales en los rangos [ - 1, +1] o [O, 11. En ambos casos, la función de activacidn de las neuronas es de tipo sigmoidal. Si se trabaja con valores entre - 1 y +1, la funcidn que se utiliza es la tangente hiperbólica:

2.5. EL MODELO DE HOPFIELD 87
......................... -
Figura 2.18.
Si el rango es [O, 11, se utiliza la misma función que para la red backpro- pagation:
Figura 2.19.
En ambos casos, a es un parámetro que determina la pendiente de la función sigmoidal.
Funcionamiento
Una de las características del modelo de Hopfield, es que se trata de una red autoasociativa. Así, varios patrones diferentes pueden ser almacenados en la red, como si de una memoria. se tratase, durante la etapa de aprendizaje. Posteriormente, si se presenta a la entrada alguno de los patrones almacena- dos, la red evoluciona hasta estabilizarse, ofreciendo entonces en la salida la

88 CAPÍTULO 2. ALGUNOS MODELOS
informaci6n almacenada, que coincide con la presentada en la entrada. Si, por el contrario, la informaci6n de entrada no coincide con ninguno de los pa- trones almacenados, por estar distorsionada o incompleta, la red evoluciona generando como salida la m& parecida.
La informaci6n que recibe esta red debe haber sido previamente codificada y representada en forma de vector (como una configuracidn binaria si la red es discreta, y como conjunto de valores reales si es continua) con tantas componentes como neuronas ( N ) tenga la red.
Esa informaci6n es aplicada directamente a la única capa de que consta la red, siendo recibida por las neuronas de dicha capa (cada neurona recibe una parte de la informacidn, un elemento del vector que representa dicha informaci6n). Si consideramos en principio el caso de una neurona concreta de la red, esta neurona recibiría como entrada las salidas de cada una de las otras neuronas, valores que inicialmente coincidirh con los de entrada, multiplicadas por los pesos de las conexiones correspondientes. La suma de todos estos valores constituir& el valor de entrada neta de la neurona, al que le ser& aplicada la funci6n de transferencia, obteniéndose el valor de salida correspondiente, 0/1 6 - 1/ + 1 si la red es discreta, y un número real en el rango [O, 11 6 [-I) +I] si es continua.
La descripción anterior correspondería a un primer paso en el procesa- miento realizado por la red. Este proceso continúa hasta que las salidas de las neuronas se estabilizan, lo cual ocurrir& cuando dejen de cambiar de valor. Entonces, el conjunto de estos ( N ) valores de salida de todas las neuronas constituye la informacidn de salida que ha generado la red, que se correspon- derá con alguna de las informaciones que durante la etapa de aprendizaje fueron almacenadas en la misma.
Este funcionamiento puede expresarse matemAticamente de la siguiente
1. En el instante inicial (t = O) se aplica la informaci6n de entrada forma:
(valores el, e2,. , eN).
si(t = O) = ei 1 5 i 5 N
Inicialmente, la salida de las neuronas coincide con la informacidn apli-
2. La red realiza iteraciones hasta alcanzar la convergencia (hasta que cada a la entrada.

2.5. EL MODELO DE HOPFlELD 89
si(t + 1) sea igual a s i ( t ) )
Donde f es la función de transferencia (activación) de las neuronas de la red. En el caso del modelo discreto, si se trabaja con valores binarios - 1 y +1 , la salida se obtendría según la función escalón:
N u l i j S j ( t ) > oi
j = 1 N
wijsj ( t ) = ei N j = 1
W i j S j ( t ) < Bi j=1
El proceso se repite hasta qu.e las salidas de las neuronas permanecen sin cambios durante algunas iteraciones. En ese instante, la salida (sl , s2, . . . , sN) representa la información almacenada por la red que más se parece a la información presentada en la entrada (e l , e2, , eN).
El funcionamiento descrito corresponde a una red Hopfield discreta clási- ca, ya que trabaja con datos birtarios. Sin embargo, existe una variación del modelo desarrollada también por Hopfield que pretende parecerse un poco m&s al funcionamiento de las neuronas reales, se trata de la red Hopfleld continua, con funciones de activación de las neuronas de tipo sigmoidal, que ofrece más posibilidades que la anterior, ya que permite almacenar patrones formados por valores reales (por ejemplo, imágenes en color o en blanco y negro con diferentes tonalidades de grises), y además facilita la resolución de determinados problemas generales de optimización.
Tanto en este caso como en el de la red discreta, se pueden distinguir diferentes versiones del modelo en función de la forma temporal en que se lleva a cabo la generación o actualización de las salidas de las neuronas de la red. Si esta actualización se realiza (de forma simultánea en todas las neuronas, se trata de una red Hopfield con funcionamiento paralelo o síncrono, ya que supone que todas las neuronas son capaces de operar sincronizadas y que, por tanto, la salida es generada al mismo tiempo por todas ellas en cada iteración, de tal forma que en la próxima iteración (t + 1) todas van a utilizar como entradas las salidas generadas por las otras en el instante anterior (t). Si, por

90 CAPITULO 2. ALGUNOS MODELOS
el contrario, las neuronas trabajan de forma secuencial, actualiz&ndose s610 la salida de una neurona en cada iteracibn, se tratar& de una red Hopfield con funcionamiento secuencial o asfncrono. En este caso, ocurre que la salida a la que converge la red puede ser diferente en funci6n del orden de la secuencia de activaci6n de las neuronas.
También existe la posibilidad, s610 utilizada en las redes Hopfield conti- nuas, que trabajan con valores no binarios, de que la generaci6n de la salida de todas las neuronas se realice de forma simultanea (síncrona) y continua- da en el tiempo. En este caso, el funcionamiento de la red tendria que ser representado en forma de una ecuaci6n diferencial:
Ti% dt = f (2 wzjsj -02) -sa j=l
Donde f es la funci6n de activación de las neuronas, que ser& de tipo sig- moidal, y ri es un parkmetro, denominado tasa de retardo, que pretende representar una característica biológica de las neuronas, como es el retraso que se produce en la recepci6n por parte de una neurona i de los valores de las salidas generados por las otras neuronas a las que est& conectada.
Si se pretende simular una red Hopfield continua como la anterior, pue- de. hacerse resolviendo la ecuaci6n diferencial utilizando métodos numéricos, aunque también, y sobre todo, puede implementarse fisicamente de forma directa mediante un circuito anal6gico que tenga un comportamiento gober- nado por una ecuaci6n similar.
Aprendizaje
La red Hopfield tiene un mecanismo de aprendizaje OFF LINE. Por tanto, existe una etapa de aprendizaje y otra de funcionamiento de la red. En la etapa de aprendizaje se fijan los valores de los pesos en funcidn de los datos que se pretende que memorice o almacene la red. Una vez establecidos, la red entra en funcionamiento tal y como se describid en el apartado anterior.
Esta red utiliza un aprendizaje no supervisado de tipo hebbiano, de tal forma que el peso de una conexi6n entre una neurona i y otra j se obtiene mediante el producto de los componentes i-ésimo y j - ésimo del vector que representa la informaci6n o patr6n que debe almacenar. Si el número de patrones a aprender es M, el valor definitivo de cada uno de los pesos se obtiene mediante la suma de los M productos obtenidos por el procedimiento anterior, un producto por informaci6n a almacenar.

2.5. EL MODELO DE HOPFIELD 91
E n el caso de la red Hopfield discreta, que trabaja con valores -1/ + 1, este algoritmo de aprendizaje puede expresarse de la siguiente forma:
Siendo: wij: Peso asociado a la conexión entre la neurona j y la neurona i , que
e!"): Valor de la componente i-ésima del vector correspondiente a la
N: Número de neuronas de la red, y por tanto, tamaño de los vectores
coincide con wji.
información Ic-ésima que debe aprender la red.
de aprendizaje. M: Número de patrones que debe aprender la red. Si la red trabajase con valores discretos 0/1, en lugar de - 1/ + 1, entonces
los pesos se calculan según la expresión:
El algoritmo de aprendizaje también se suele expresar utilizando una notación matricial. En tal caso se podría considerar una matriz W de di- mensiones N x N que representase todos los pesos de la red:
W =
Esta matriz es simétrica, al cumplirse que wij = wji y tiene una diagonal principal con valores nulos debido a la no existencia de conexiones auto- recurrentes (wii = O).
También se tendría el conjunto de los M vectores que representan los

92 CAPfTULO 2. ALGUNOS MODELOS
patrones que ha de aprender la red:
Utilizando esta notacidn, el aprendizaje consistiría en la creaci6n de la ma- triz de pesos W a partir de los M vectores o datos de entrada (El , - . . , E M ) que se enseiían a la red. MatemBticamente se expresaría:
M
W =x [Ek'Ek - I] k=l
Donde la matriz E: es la traspuesta de la matriz Ek e I es la matriz identidad de dimensiones N x N que anula los pesos de las conexiones auto- rrecurrentes (wii).
La funcidn energia
Como ya se ha comentado, el aprendizaje de la red Hopfield es de tipo heb- biano. La elecci6n de esta regla de aprendizaje por Hopfield fue, entre otras razones, debido a que asegura la estabilidad de la red; es decir, la conver- gencia hacia una respuesta estable cuando se presenta una informaci6n de entrada.
Muchas de las investigaciones acerca de la estabilidad de l a s redes se basan en el establecimiento de una funcidn, denominada funci6n energia de la red, para representar los posibles estados (puntos de equilibrio) de la red. De hecho, una de las causas por la que se considera a Hopfield responsable de impulsar el desarrollo en el campo de las redes neuronales, es precisamente el haber aplicado modelos matemhticos como éste, lo cual constituy6 la base de posteriores
La funci6n trabajos sobre este campo. energia de una red Hopfield discreta tiene la siguiente forma:
. N N N

2.5. EL MODELO DE HOPFIELD 93
Siendo: wij : Peso de la conexión entre las neurona i y j . si: Valor de salida de la neurona i . s j : Valor de salida de la neurona j . Bi: Umbral de la función de activación de la neurona i . Esta expresión guarda una profunda similitud formal con la energía me-
cánica clásica. Trata de representar la evolución del sistema, considerando cada configuración (vector) de las salidas de las neuronas de la red como pun- tos en un espacio de dimensión N y relacionando el estado de la red en cada momento con un punto de ese espacio. La función energía puede imaginarse entonces como una superficie que presenta determinados valores mínimos, algo semejante a un paisaje montañoso donde los mínimos serían los valles (Figura 2.20). Cuando en la red se han almacenado A4 patrones, los posi- bles estados estables de la red serán también M (durante su funcionamiento podrá responder ante una entrada con una salida que represente alguno de esos A4 patrones registrados). Estos M estados corresponden precisamente a los mínimos de la función energía. Cuando se presenta a la entrada de la red una nueva información, ésta evoluciona hasta alcanzar un mínimo de la función energía, generando una salida estable.
Figura 2.20. Funcihn energía de una red Hopfleld.
Cuando la red Hopfield se ut'iliza como memoria asociativa, el objetivo es conseguir que los patrones que debe memorizar se sitúen en los mínimos de

94 CAPfTULO 2. ALGUNOS MODELOS
la funcidn y, consecuentemente, sean los estados estacionarios (estables) de la red. Puede demostrarse que esto se consigue si se verifica que los pesos de las conexiones autorrecurrentes son nulos (wii = O) y si el resto cumple la regla de Hebb (wij = sisj) , de ahí que Hopfleld eligiera dicho aprendizaje.
En cuanto a las redes de Hopfield continuas, su autor considera que una posible expresidn de su funcidn de energía es la siguiente:
donde f - l es la inversa de la funci6n de activaci6n sigmoidal ( f ) de una neurona. Si la funcidn f fuese, por ejemplo,
entonces la inversa sería
con lo que la funcidn energía quedaría de la siguiente forma:
1 ” N N 1 P .
N 1\
Puede observarse que coincidirta con la fwlcidn energía de la red Hopfield discreta si no existiera eE t5ltimo término, cuyo valor depende del parámetro a de la funcidn de activacidn de las neuronas, que representa la ganancia o la pendiente de esta fuzaci6n sigmoidal. Por ello, habrá que tener especial cuidado en la elecci6n de su d o r , ya que idiuye directamente en los m’nimos de la funcidn energía. Si a tiene un valor 00 (funci6n de activacidn de tipo escaldn), este término se hace cero y la red se convierte en una red Hopfield discreta. Si el valor de Q es finito, pero muy grande ( a >> l), el término puede despreciarse y los m’nimos de la funcidn de energía siguen siendo los mismos. Pero si Q tiene valores pequeños, disminuye el número de mínimos de esta funci6n y, como consecuencia, el número de posibles estados estables de la red, reduciéndose a un solo mínimo cuando a = O.

2.6. EL MODELO DE KOHONEN
2.6 El Modelo de Kohonen
95
Existen evidencias que demuestran que en el cerebro hay neuronas que se organizan en muchas zonas, de forma que la información captada del entorno a través de los órganos sensoriales se representa internamente en forma de mapas bidimensionales. Por ejemplo, en el sistema visual se han detectado mapas del espacio visual en zona3 del córtex (capa externa del cerebro). Tam- bién en el sistema auditivo se detecta una organización según la frecuencia a la que cada neurona alcanza la mayor respuesta (organización tonotópica).
Aunque en gran medida esta. organización neuronal está predeterminada genéticamente, es probable que parte de ella se origine mediante el apren- dizaje. Esto sugiere, por tanto., que el cerebro podría poseer la capacidad inherente de formar mapas topológicos de la información recibida del exte- rior. De hecho, esta teoría podría explicar su poder de operar con elementos semánticos: algunas áreas del cerebro simplemente podrían crear y ordenar neuronas especializadas o grupos con características de alto nivel y sus com- binaciones. Se trataría, en definitiva, de construir mapas espaciales para atributos y características..
A partir de estas ideas, T. Kohonen presentó en 1982 un sistema con un comportamiento semejante. Se trataba de un modelo de red neuronal con capacidad para formar mapas de características de manera similar a como ocurre en el cerebro. El objetivo de Kohonen era demostrar que un estímulo externo (información de entrada,) por sí solo, suponiendo una estructura pro- pia y una descripción funcional del comportamiento de la red, era suficiente para forzar la formación de los mapas.
Este modelo tiene dos variantes, denominadas LVQ (Learning Vector Quantization) y TPM (Topology-Preserving Map) o SOM (Selftorganizing Map). Ambas se basan en el principio de formación de mapas topológicos para establecer características comunes entre la información (vectores) de entrada a la red, aunque difieren en las dimensiones de éstos, siendo de una sola dimensión en el caso de LVQ, y bidimensional, e incluso tridimensional, en la red TPM.

96 CAPfTULO 2. ALGUNOS MODELOS
NEUROW DE
f f
Figura 2.21. Arquitectura de la red LVQ (Learning Vector Quantization) de Kohonen.
Arquitectura
La arquitectura de la versión original (LVQ) del modelo de Kohonen es pare- cida a la de la red ART, aunque en este caso no existen conexiones feedback (Figura 2.21). Se trata de una red de dos capas con N neurona de entrada y M de salida. Cada una de las N neuronas de entrada se conecta a las M de salida a través de conexiones hacia adelante (feedforward).
Entre las neuronas de la capa de salida, puede decirse que existen conexio- nes laterales de inhibición (peso negativo) implícitas, pues aunque no est& conectadas, cada una de estas neurona va a tener cierta influencia sobre sus vecinas. El valor que se asigne a los pesos de las conexiones feedforward entre las capas de entrada y salida ( u r i j ) durante el proceso de aprendizaje de la red va a depender precisamente de esta interacción lateral.
La influencia que una neurona ejerce sobre las dem& es función de la distancia entre ellas, siendo muy pequeiía cuando estiin muy alejadas. Es frecuente que dicha influencia tenga la forma de un sombrero mexicano, como se ilustra en la Figura 2.22. Esta afirmación tiene una base biológica, ya que existen evidencias fisiológicas de interconexiones laterales de este tipo entre las neuronas del sistema nervioso central de los animales. Así, se ha podido comprobar que en determinados primates se producen interacciones laterales

2.6. EL MODELO DE KOHOICrEN 97
de tipo excitatorio entre neurona,s próximas en un radio de 50 a 100 micras, de tipo inhibitorio en una c0ron.a circular de 150 a 400 micras de anchura alrededor del círculo anterior, y cle tipo excitatorio muy débil, prácticamente nulo, desde ese punto hasta una distancia de varios centímetros.
i lateral
Interaccl6n
Distancia entre neuronas
Figura 2.22. Interacción entre neuronas de la capa de salida.
Por otra parte, la versión del modelo llamado TPM (Topology-Preserving Map) trata de establecer una correspondencia entre los datos de entrada y un espacio bidimensional de salida, creando mapas topológicos de dos dimen- siones, de tal forma que ante datos de entrada con características comunes se deben activar neuronas situaddas en zonas próximas de la capa de salida. Por esta razón, la representacih habitual de esta red suele ser la mostrada en la Figura 2.23, donde las M neuronas de salida se disponen de forma bidimensional para representar precisamente los mapas de características.

98 CAPfTULO 2. ALGUNOS MODELOS
t t t t t
TT" Y CAPA DE ENTRADA
Figura 2.23. Arquitectura de la red TPM (Topology-Preserving Map) de Kohonen.
La interacci6n lateral entre las neuronas de la capa de salida sigue existien- do, aunque ahora hay que entender la distancia como una zona bidimensional que existe alrededor de cada neurona. Esta zona puede ser circular (Figu- ra 2.24), cuadrada, hexagonal o cualquier otro polígono regular centrado en dicha neurona.

2.6. EL MODELO DE KOHONEN 99
Figura 2.24. Interacción circular entre neuronas de la capa de salida.
Funcionamiento
El funcionamiento de esta red es relativamente simple. Cuando se presenta a la entrada alguna información Ek = (e?), . . , e:)), cada una de las M neuronas de la capa de salida la recibe a través de las conexiones feedforward con pesos wji. También estas neuronas reciben las correspondientes entradas debidas a las conexiones laterales con el resto de las neuronas de salida y cuya influencia dependerá de la distancia a la que se encuentren.
Así, la salida generada por una neurona de salida j ante un vector de entrada E k sería:
donde Intpj es una función del tipo sombrero mexicano (Figuras 2.22 y 2.24) que representa la influencia lateral de la neurona p sobre la neurona j. La función de activación de las neuronas de salida ( f ) será del tipo continuo, lineal o sigmoidal, ya que esta red trabaja con valores reales.
Es evidente que se trata de una red de tipo competitivo, ya que al pre- sentar una entrada EI, la red evoluciona hasta una situación estable en la

100 CAPfTULO 2. ALGUNOS MODELOS
que se activa una neurona de salida, la vencedora. Por ello, la formulaci6n matemhtica de su funcionamiento puede simplificarse mediante la siguiente expresidn, que representa cual de l a s M neuronas se activara al introducir dicha informacidn Ek:
1 min - WjII = min sj =
t O resto
donde l l E k - Wjll es una medida (por ejemplo, distancia euclídea) de la di- ferencia entre el vector de entrada Ek = (e?), - , e E)) y el vector de los pesos Wj = (wjl, - , w j ~ ) de las conexiones entre cada una de las neuronas de entrada y la neurona de salida j . En estos pesos se registran los datos almacenados en la red durante el proceso de aprendizaje. En la fase de fun- cionamiento, lo que se pretende es encontrar el dato aprendido más parecido al de entrada para, en consecuencia, averiguar qué neurona se activara y, sobre todo, en qué zona del espacio bidimensional de salida se encuentra.
Lo que hace la red de Kohonen, en definitiva, es realizar una tarea de clasificaci6n, ya que la neurona de salida activada ante una entrada repre- senta la clase a la que pertenece dicha informaci6n de entrada. Además, como ante otra entrada parecida se activa la misma neurona de salida, u otra cercana a la anterior, debido a la semejanza entre las clases, se garantiza que las neuronas topol6gicamente pr6ximas sean sensibles a entradas física- mente similares. Por esta causa, la red es especialmente útil para establecer relaciones, desconocidas previamente, entre conjuntos de datos.
Aprendizaje
El aprendizaje en el modelo de Kohonen es de tipo OFF LINE, por lo que se distingue una etapa de aprendizaje y otra de funcionamiento. En la etapa de aprendizaje se fijan los valores de los pesos de las conexiones (feedforward) entre la capa de entrada y la de salida.
Esta red utiliza un aprendizaje no supervisado de tipo competitivo. Las neuronas de la capa de salida compiten por activarse y s610 una de ellas permanece activa ante una determinada informaci6n de entrada a la red. Los pesos de las conexiones se ajustan en funci6n de la neurona que haya resultado vencedora.

2.6. EL MODELO DE KOHONEN 101
Durante la etapa de entrenamiento, se presenta a la red un conjunto de datos de entrada (vectores de entrenamiento) para que ésta establezca, en función de la semejanza entre los datos, las diferentes categorías (una por neurona de salida) que servirán durante la fase de funcionamiento para realizar clasificaciones de nuevos datos que se presenten a la red. Los valores finales de los pesos de las conexiones entre cada neurona de la capa de salida con las de entrada se corresponderán con los valores de los componentes del vector de aprendizaje que consigue activar la neurona correspondiente. En el caso de existir más patrones de entrenamiento que neuronas de salida, más de uno deberá asociarse con la :misma neurona; es decir, pertenecerán a la misma clase. En tal caso, los pesos se obtienen como un promedio de dichos patrones.
En este modelo, el aprendizaje no concluye después de presentarle una vez todos los patrones de entrada, sino que habrá que repetir el proceso varias veces para refinar el mapa topol6gico de salida, de tal forma que cuantas más veces se presenten los datos, tanto más se reducirán las zonas de neuronas que se deben activar ante entradas parecidas, consiguiendo que la red pueda realizar una clasificación más selectiva.
El algoritmo de aprendizaje utilizado para establecer los valores de los pesos de las conexiones entre las N neuronas de entrada y las M de salida es el siguiente:
1. En primer lugar, se inicializan los pesos (wij) con valores aleatorios pequeños y se fija la zona inicial de vecindad entre las neuronas de salida.
2. A continuación se presenta a la red la información de entrada (la que debe aprender) en forma cle vector EI, = (e?), . , e$)) ? cuyas compo-
nentes eJk) serán valores continuos.
3. Puesto que se trata de un aprendizaje competitivo, se determina la neurona vencedora de la capa de salida. Esta será aquella j cuyo vector de pesos Wj (vector cuyas componentes son los valores de los pesos de las conexiones entre esa neurona y cada una de las neuronas de la capa de entrada) sea el más parecido a la información de entrada EI, (patrón o vector de entrada). Para ello, se calculan las distancias o diferencias entre ambos vectores, considerando una por una todas las neuronas de salida. Suele utilizarse la distancia euclídea o la siguiente expresión,

102 CAPÍTULO 2. ALGUNOS MODELOS
que es similar a aqublla, pero eliminando la raíz cuadrada:
Siendo:
eik) : Componente i - ésimo del vector k - ésimo de entrada. wji : Peso de la conexidn entre la neurona i de la capa de entrada y la neurona j de la capa de salida.
4. Una vez localizada la neurona vencedora ( j * ) , se actualizan los pesos de las conexiones entre las neuronas de entrada y dicha neurona, así como los de las conexiones entre las de entrada y las neuronas vecinas de la vencedora. En realidad, lo que se consigue con esto es asociar la informaci6n de entrada con una cierta zona de la capa de salida:
Zonajt (t) es la zona de vecindad alrededor de la neurona vencedora en la que se encuentran las neuronas cuyos pesos son actualizados. El tamaño de esta zona se puede reducir en cada iteración del proceso de ajuste de los pesos, con lo que el conjunto de neuronas que pueden considerarse vecinas cada vez es menor (Figura 2.25). Sin embargo, en la practica es habitual considerar una zona fija en todo el proceso de entrenamiento de la red. El término a ( t ) es un parametro de ganancia o coeficiente de aprendizaje, con un valor entre O y 1, decrece con el número de iteraciones ( t ) del proceso de entrenamiento. De tal forma que cuando se ha presentado un gran número de veces todo el juego de patrones de aprendizaje (500 5 t 5 10000) su valor es prácticamente nulo, con lo que la modificaci6n de los pesos es insignificante. Suele utilizarse alguna de las siguientes expresiones:
1 a ( t ) = -
t ’ cK(q=al(l-;).
Siendo a1 un valor de O. 1 6 0.2 y a2 un valor pr6ximo al número total de iteraciones del aprendizaje. Suele tomarse un valor a2 = 10000.

2.7. CONCLUSIONES 103
~0000000 O 0 lolo o o o
O 0 O 0 O 0 O 0
E O 0 0
I
P Zona, (t$
Figura 2.25. Posible evolución de la zona de vecindad.
5 . E l proceso se debe repetir, volviendo a presentar todo el juego de pa- trones de aprendizaje El , &, . . . , un mínimo de 500 veces (t2500).
2.7 Conclusiones
En el capítulo anterior se han rnencionado de manera muy general los fun- damentos de las redes neuronales. Se han descrito los tipos principales que han recibido más atención por parte de los investigadores y que resultan interesantes tanto porque abren posibilidades a estudios futuros como a apli- caciones. Asimismo se han mencionado todos los elementos que se requiere para tener una idea general, pero clara, del funcionamiento, arquitectura y leyes de aprendizaje de modo que sirve como una introducción, sobre todo a aquellos lectores que se internan. por primera vez en este campo relativamen- te nuevo de los sistemas y la computación. No obstante lo anterior, la mejor comprensión de estos tópicos se logra sólo en base a ejemplos específicos que permitan aterrizar todos los conceptos abstractos vertidos anteriormente, es por ello que se incluyen en este capítulo 2, el estudio y discusión detallada de 6 de las arquitecturas más conocidas, poniendo especial atención a la descrip- ción del algoritmo de aprendizaje. Se comienza por el principio, es decir, el Perceptrón, que es la célula básica sobre la que se han construido todas las re- des. Se continúa con el Adaline y el Madaline, primeras aplicaciones exitosas de la computación neuronal. A continuación se aborda la red más conocida y que más aplicaciones tiene a la fecha, es decir la red de retropropagación,

104 CAPÍTULO 2. ALGUNOS MODELOS
especialmente interesante, porque resuelve los problemas planteados a su red generatriz, el Perceptr6n. La red que se trata a continuaci6n pertenece a una modalidad de funcionamiento esencialmente distinta a l a s anteriores, esto se debe a la particularidad de que su operacih es dinzimica, en contraposici6n a la operaci6n estzitica de las otras. Finalmente, la red última es también de tipo estzitico, pero el interés que nos motiva a incluirla es la maravillosa capacidad que presenta de generar mapas que mimetizan la realidad según las características que se presenten.
Es deseo de quienes escriben estas notas que ambos capítulos ayuden a los lectores a obtener una informaci6n general, pero suficientemente detallada, de las redes neuronales.

Capítulo 3
Neocognitrón
Este capítulo presenta las características fundamentales de la red neuronal Neocognitrón, la cual es un mod,elo de red basado en el funcionamiento del sistema visual de los humanos y que resulta un mecanismo aplicable, entre otros, al reconocimiento visual de patrones con la propiedad de que no es afectado por corrimientos, variaciones en el tamaño y deformaciones conside- rables del patrón de entrada. Primeramente se hace una revisión del modelo del sistema visual de los seres humanos haciendo énfasis en los elementos en los cuales se sustenta esta red. Posteriormente se describe detalladamente la red neuronal y su relación con el modelo del sistema visual descrito.
3.1 Introducción
Las redes neuronales han sido un tema de intensa investigación durante la última década, extendiéndose considerablemente, año con año, el número de investigaciones realizadas, tanto sobre nuevas estructuras y métodos de aprendizaje como sobre las posibles aplicaciones de estos sistemas en la so- lución de diversos problemas prácticos.
La investigación realizada hasta la fecha sobre redes neuronales ha produ- cido diversos tipos de estructuras, l a s cuales se pueden dividir en dos grupos. El primer grupo corresponde a lo que se conoce como redes neuronales de tipo ” application driven”, o dependientes de una aplicación específica, y el segun- do tipo corresponde a las llamaddas redes neuronales biológicas. El principal objetivo de las redes neuronales de tipo ”application driven” es resolver cier- ta clase de problemas, tal como el reconocimiento de caracteres manuscritos,
105

106 CAPITULO 3. NEOCOGNITR~N
que no han podido ser resueltos eficientemente usando métodos tradiciona- les. Para resolver estos problemas, las redes neuronales de tipo "application driven" pasan por un proceso de entrenamiento o aprendizaje en donde, en forma generalmente supervisada, son entrenadas para responder de una ma- nera específica a diferentes clases de estímulos. Las estructuras de las redes neuronales de tipo "application driven" consisten de varias neuronas o célu- las conectadas entre sí. Sin embargo, las estructuras de las redes neuronales de este tipo, así como los algoritmos de aprendizaje usados para entrenarlas, tienen poca, o ninguna, relacidn con la estructura o el modo de aprendiza- j e del cerebro humano. La mayoria de las estructuras de redes neuronales propuestas hasta hoy pertenecen al tipo de "application driven". Un ejem- plo típico de este tipo de redes es la red neuronal de retropropugacidn, en la cual los pesos de cada conexi6n se adaptan usando un algoritmo basado en la búsqueda del gradiente descendente, en forma tal que cierto criterio de la señal de error, usualmente el valor cuadrhtico medio de ésta, sea minimizado. Obviamente esta manera de aprendizaje es diferente al proceso seguido por los seres humanos.
Por su parte las redes neuronales bioldgicas tienen dos objetivos principa- les. El primero es obtener la solucidn de cierto tipo de problemas prhcticos, tal como sucede con las redes de tipo "application driven". Por otra parte, el segundo, tan importante como el primero, es explicar el comportamien- to y el funcionamiento de ciertas partes del cerebro humano. Sobre estos aspectos una parte importante se ha comprendido mediante experimentos biol6gicos. Sin embargo, el conocimiento sobre el cerebro humano a partir de esos experimentos es aún limitado ya que existen un sinnúmero de interro- gantes todavía no resueltas. Las redes neuronales bioldgicas esthn basadas en modelos del cerebro humano, fundamentados en hipdtesis sobre el funciona- miento del mismo, por ejemplo la fragmentacidn de los estímulos de entrada. Por lo tanto, otro objetivo de este tipo de redes es el poder comprobar ciertas hipdtesis relativas al funcionamiento del cerebro humano y que no pueden ser comprobadas fdcilmente por medio de experimentos bioldgicos.
Un problema con el que se enfrentan las redes neuronales bioldgicas es la gran cantidad de memoria necesaria para modelar ciertas funciones del cerebro humano. Así también, en general, las ecuaciones que describen el funcionamiento de la red no se pueden derivar de una manera rigurosa, siendo necesario, en la mayoria de los casos, hacerlo en forma empírica. Este hecho ha dado como resultado que hasta ahora sean muy pocas las redes neuronales biol6gicas propuestas. En las siguientes secciones se presenta una revisidn de

3.2. LA RED NEURONAL NEOCOGNITRÓN 107
la red neuronal llamada neocognitrón, la cual es una red representativa del tipo biológico, siendo, hasta ahora, la más exitosa de este género.
3.2 La Red Neuronal Neocognitrón
La red neuronal neocognitrón, propuesta por el Dr. Fukushima ([2], [3], [4], [5], [6], [7], [8], [9]), es una red :multicapas que ha sido aplicada de manera exitosa en el reconocimiento de caracteres manuscritos. Primeramente el Dr. Fukushima prestó atención al funcionamiento del sistema visual de los seres humanos. A raíz de este estudio varias interrogantes surgieron, como por ejemplo la forma en que la retina capta la información, la forma en que esta información es transmitida al campo visual del cerebro y cómo éste la procesa: etc. Para resolver tales interrogantes, este investigador propuso un modelo del sistema visual basado en hipótesis acerca del funcionamiento del sistema visual humano propuestas por otros investigadores y en teorías que afirman que el procesamiento biológico de la información se realiza en forma fragmentada. El modelo propuesto inicialmente se ha ido mejorando a partir de los resultados obtenidos. Recientemente la red neuronal neocognitrón ha sido aplicada de manera exitosa al reconocimiento tanto de caracteres en cursiva como de fonemas.
3.2.1 El Sistema Visual Humano
El sistema visual humano se explica usando hechos biológicos y algunas hi- pótesis que tienen apoyo, generalmente, en experimentos realizados. En los ojos, el estímulo visual entra por el cristalino y se proyecta a la retina que se encuentra en el fondo. E l estímulo proyectado en la retina se transforma en una señal eléctrica y se transmite al campo visual del cerebro a través de varias células que llevan a cabo diferentes papeles, según el modelo de Hubel y Wiesel ([13], [14]). En la vía de información visual existen varios tipos de células, las cuales fueron nombradas por Hubel y Weisel como ”célula sencilla”, ”célula compleja”, ” cdula hipercompleja de bajo orden” y ”célula hipercompleja de alto orden”, etc., En el modelo propuesto por estos investi- gadores, tales células están arregladas en una red neuronal según la siguien- te estructura jerárquica: núcleo geniculado lateral-célula sencilla”+célula compleja-+célula hipercompleja, de bajo orden-xélula hipercompleja de alto orden.

108 CAPITULO 3. NEOCOGMTR~N
Las células sencillas colocadas cerca de la retina reaccionan específica- mente con un segmento de cierta inclinacidn. Por ejemplo una cierta célula S reacciona con un segmento horizontal, mientras que otra célula S' reaccio- na a un segmento de 45 grados de inclinacidn, etc. Las salidas de las células sencillas que se encuentran dentro de un &ea pequeña de la retina y que re- accionan, cada una, al mismo segmento con cierto grado de inclinacidn, van a ser entrada de una célula compleja. Por lo tanto, esa célula compleja resulta tener la capacidad de absorber pequeños movimientos en posicidn así como cierta cantidad de deformacidn. Aqui el Area pequeña de la retina se llama "campo receptivo". La Figura 3.1 muestra el proceso que ejecutan tanto las células sencillas como las células complejas. En esta figura el rect&ngulo ex- terior representa a un retina, y el rect&ngulo interior representa a un campo receptivo de ésta. En las Figuras 3.l(a), 3.l(b) y 3.l(c) la retina recibid la misma informacidn visual, pero la posici6n de la informacidn est& movida en paralelo.
Figura 3.1. Proceso ejecutado por las células sencillas y complejas.
Supdngase que las células sencillas SI, Sz, S3 tienen la capacidad de ex- traer una característica de segmento horizontal, o sea todas las células re- accionan con un segmento horizontal. Supdngase ademh que todas estas células e s t h conectadas con una célula compleja C. En 3.l(a) solamente la célula S2 reacciona y se cambia su condicidn a célula activa. En 3.l(b), solamente la célula S1 reacciona, mientras que en 3.l(c), solamente S, reac- ciona. Sin embargo, en las tres situaciones se excita la célula compleja C. Esta reaccidn entra las células sencillas y l a s células complejas permite tener la capacidad de reconocer objetos cambiados de posicidn o deformados.

3.2. LA RED NEURONAL NEOCOGNITRÓN 109
A continuación se verá la relación entre las células complejas y la células hipercomplejas de bajo orden.
Figura 3.2. Relación entre las células complejas e hipercomplejas de bajo orden.
Varias células complejas que tienen la capacidad de extraer diferentes características de los patrones de entrada están conectadas con una célula hipercompleja de bajo orden. L'a Figura 3.2 muestra este proceso. E n esta figura una información visual 'A' se ha recibido en la retina. Se considera que cuatro células complejas C1 - C4 están conectadas a un campo receptivo, el cual se representa por el rectjngulo interno. Se supone además que cada una de estas células tiene la capacidad de extraer segmentos horizontales, segmentos verticales, segmentos con una inclinación de 45 grados y segmen- tos con una inclinación de 135 grados, respectivamente. En esta figura, se considera que la célula hipercompleja de bajo orden tiene la capacidad de extraer una característica 'A', es decir el estímulo al que responde esta célula es más complejo. Con este mismo esquema, en la vía de información visual que va desde la retina al campo visual del cerebro, existen varias capas de células que tienen la capacidad de extraer diferentes características, cada vez más complejas conforme aumenta la profundidad de la capa dentro de la red, así, las células colocadas cerca de la retina reaccionan con una característica primitiva, tales como segmentos con cierto grado de inclinación, mientras que las células que están en la capa más profunda (cerca del campo visual del cerebro) tienen la capacidad de extraer características combinadas, y final- mente las células del campo visual pueden extraer y reconocer la información completa recibida en la retina.
Ahora se consideran los requisitos para un modelo del sistema visual basado en los hechos biológicos y las hipótesis mencionadas anteriormente.

110 CAPITULO 3. NEOCOGNITR~N
1. El modelo debe consistir de multicapas de células, en las cuales la primera capa corresponde a la retina y la última al campo visual del cerebro.
2. En l a s capas cerca de la retina (capa de entrada), las células tienen la capacidad de extraer una característica primitiva, tal como un seg- mento con cierto grado de inclinacidn, y las capas profundas (cerca del campo visual del cerebro) tienen la capacidad de extraer características combinadas y m& complejas. En la tiltima capa, la cual corresponde al campo visual del cerebro, las células pueden extraer y reconocer las características completas de la imagen proyectada en la retina.
3. Cada capa consiste de un grupo de células sencillas (o células hiper- complejas de bajo orden) y un grupo de células complejas (o células hipercomplejas de alto orden). El grupo de células sencillas desempeña el papel de extraer determinadas características, y el grupo de células complejas desempeña el papel de absorber ciertos cambios de posici6n, e inclusive deformaci6n.
4. La capacidad de extraer las características de la imagen de entrada se obtiene y desarrolla por medio de entrenamiento (experiencia visual).
3.2.2 Estructura de la Red Neocognitrdn
La red neuronal neocognitr6n, la cual se ha desarrollado a partir del modelo visual mencionado anteriormente, es una red multicapas con una estructura jerkquica similar al modelo jerarquizado propuesto por Hubel y Weisel.
Como se muestra en la Figura 3.3, la red neocognitr6n est& compuesta de una conexi6n en cascada de varias estructuras modulares precedidas por una capa de entrada U, consistente de un arreglo de fotorreceptores. Cada una de

3.2. LA RED NEURONAL NEOCOGNITR~N 111
las estructuras modulares se compone de una secuencia de dos capas de célu- las, a saber, una capa Us consistente de células S, y una capa Uc compuesta de células C. Las capas Us y Uc en el l-ésimo módulo se denotan mediante Usl y Ucl, respectivamente. Una, célula S tiene una respuesta característica similar a una célula simple o a una célula hipercompleja de bajo orden de acuerdo con la clasificación presentada arriba, mientras que una célula C se comporta como una célula compleja o hipercompleja de alto orden. En esta red, una célula en una etapa más profunda generalmente tiene una tendencia a responder selectivamente a características miis complicadas de los estímu- los de entrada y, al mismo tiemp'o, tiene un campo receptivo mayor y resulta menos sensible a corrimientos en. la posición, si la entrada es un patrón.
Cada célula S tiene conexiones sinápticas de entrada que son modifica- bles y reforzadas mediante aprendizaje, y de esa forma adquiere la habilidad de extraer una característica específica del estímulo. Es decir, después del entrenamiento, una célula S reisponde al estímulo sólo si éste presenta la característica dada.
Cada célula C tiene conexionles sinápticas aferentes de un grupo de células S con idéntica respuesta y cuyos campos receptivos guardan características espaciales similares sobre las capa de entrada. Esto significa que todas las células presinápticas S extraen del estímulo la misma característica, pero de posiciones ligeramente diferentes en la capa de entrada. Las eficiencias de las sinapsis se determinan en tal forma que la célula C se activará siempre que al menos una de sus células presinápticas S esté activa. Por lo tanto, aun cuando el patrón de estímulo que ha provocado una respuesta por parte de la célula C sufra un corrimj.ento en la posición, la célula C permanece respondiendo como antes, dado que alguna otra de sus células presinápticas S será activada en lugar de la anterior. En otras palabras, una célula C responde a la misma característica del estímulo como lo hacen sus células presinápticas S, pero es insensible a los corrimientos en la posición.
Las células S y C en cualquier capa son arregladas en subgrupos de acuer- do a las características que las células extraen de los estímulos presentes en sus campos receptivos. Puesto que las células de cada subgrupo son acomo- dadas en un arreglo bidimensional, se le llama al subgrupo "plano celular". Se usa también la terminología plano S y plano C para representar los planos formados de células S y células C, respectivamente. Todas las células en un plano celular tienen sinapsis de entrada con la misma distribución espacial, y sólo las posiciones de las células presinápticas están corridas en paralelo dependiendo de la posición de la célula postsináptica. Esta restricción se

112 CAPITULO 3. NEOCOGNITR~N
respeta siempre, aun en el proceso de aprendizaje, en el cual las eficiencias de las sinapsis resultan modificadas. La Figura 3.4 ilustra esquemAticamente los detalles previos. Cada tetragono con lineas gruesas representa un plano S o un plano C, y cada tetrtigono vertical con lineas delgadas, en el cual est& contenidos los planos S o C, representa una capa S o una capa C. En dicha figura tambih se representan las conexiones sindpticas entre capas.
Figura 3.4. Diagrama esquemAtico ilustrando la interconexión entre capas en la red neocognitrón.
En la Figura 3.4, para fines de simplificación, sólo se muestra una célula en cada plano celular. Cada una de estas células recibe entradas sinApticas desde las células situadas en la capa previa que se encuentran dentro del Area encerrada por la elipse. Si se trata de una célula S, esto se verifica para cada uno de los planos en su capa precedente, mientras que si la célula es de tipo C, la conexión se verifica solamente sobre algunos planos de la capa anterior, según el diseño particular elegido para la red. Como se ha dicho, todas l a s células en el mismo plano celular guardan entradas sinApticas de la misma distribución espacial, y sólo las posiciones de las células presinApticas estan corridas en paralelo de célula a célula. Por tanto, todas las células en un plano celular tienen campos receptivos con la misma función, pero en diferentes posiciones.
Ya que las células en la red estan interconectadas en una cascada como muestra la Figura 3.4, cuanto más profunda es la capa tanto mayor resulta el campo receptivo de cada célula en esa capa. La cantidad de las células en cada plano celular se determina en forma tal que decrezca de acuerdo con el incremento del tamaño de los campos receptivos. A manera de ilustración, un ejemplo del número de células en cada capa se muestra al pie de la Figura

3.2. LA RED NEURONAL NEOCOGNITR~N 113
3.4. En el módulo más profundo, el campo receptivo de cada célula C resulta suficientemente grande como para cubrir completamente la capa de entra,da, y cada plano C contiene una sola célula C. La Figura 3.5 ilustra de forma concreta como las células de cada plano celular se interconectan a las células de los planos celulares siguientes.
Figura 3.5. Vista unidimensional de las interconexiones entre l a s células de diferentes planos celulares. Sólo se representa un plano celular de cada capa.
Las células S y C son células excitatorias. Aun cuando no se muestra en las Figs. 3.4 y 3.5, las capas S y C contienen sendos planos Vs y V . de células inhibitorias denominados planos inhibitorios para las células C y S, respectivamente. Cada etapa contiene un par de estos planos cuya función, como su nombre lo indica, es inhibir la actividad de las células C y S de la correspondiente capa siguiente. Cada plano Vc tiene el mismo número de células que cada uno de los planos S cuyas células inhibe. Las células Vc tienen los mismos campos receptivos que las células S situadas en las posiciones correspondientes del plano. La salida de una célula VC va a una sola célula S en cada uno de los planos de la capa que inhibe. Las células S que reciben entradas de una cierta célula Vc son aquellas que ocupan una posición en el plano que corresponde con la posición de la célula VC. La Figura 3.6 muestra los detalles de conexión de una sola célula S junto con su correspondiente célula inhibitoria. En esta figura se aprecia como las entradas inhibitorias a las células S se presentan con un mecanismo en paralelo. Todo lo dicho, con los correspondientes cambios, es cierto para los planos Vs.

114 CAPfTULO 3. NEOCOGNITRbN
Figura 3.6. Se muestra una única célula S y la célula inhibitoria correspon- diente dentro de la capa Vsl. Cada una de las unidades recibe las mismas nueve entradas procedentes de la capa de la retina. Los pesos ai de la célu- la S determinan la caracterfstica a la cual es sensible la célula. Tanto los pesos ai que estAn en las conexiones procedentes de la retina como el peso procedente de las células Vc son modificables, y se determinan empleando un proceso de entrenamiento.
Las c6lulas inhibitorias desempeñan dos papeles importantes, los cuales son, primeramente, la discriminaci6n de dos características con cierta seme- janza y que se deben clasificar de diferente forma, y, seguidamente, evitar que los valores de las células S y C crezcan indefinidamente durante el en- trenamiento.
3.2.3 Valor de las Células S En la rnayorfa de las redes neuronales multicapa propuestas hasta la fecha, las ecuaciones usadas para calcular los valores de las células de cada capa son iguales, sin embargo en la red neuronal neocognitr6n, los valores de las células S, C e inhibitorias se calculan de diferente manera. Aquí se describen las sa- lidas de estas células con expresiones numkricas. Todas las células empleadas en la red neocognitr6n son de tipo anal6gico; esto es, las señales de entrada y salida de las células toman valores anal6gicos no negativos. La salida de un fotorreceptor se denota por u0 (n) donde n representa las coordenadas bidimensionales que indican la posici6n de la cklula dentro de su plano. Se usan las notaciones us1 (IC, n) para representar la salida de una célula S en el k-ésimo plano S del I-ésimo m6dulo, y uc1 (IC, n) para representar la salida de una célula C en el IC-ésimo plano C de ese m6dulo. Asimismo, las notaciones

3.2. LA RED NEURONAL NEOCOGNITR~N 115
wsl (n) y ZIC~ (n) denotan, respectivamente, las salidas de las células inhibi- torias S y C del I-ésmo módulo. En todos los casos, el vector n representa las coordenadas bidimensionales que indican las posiciones de estas células sobre sus respectivos planos. Se empleará el vector v para referirse a la po- sición relativa dentro del campo receptivo en la capa anterior de una célula dada que se encuentre en la posición n de su plano celular. Finamente, las constantes Ksl y denotan el número de planos contenidos en las capas S y C del I-ésmo módulo, respectivamente.
Las definiciones anteriores permiten escribir la expresión para la salida de una célula S del k-ésimo plano S del I-ésimo módulo, la cual está dada por
con
Q (x) = max (x, O ) .
donde e denota el término excitatorio neto y h es el término inhibitorio neto. La Figura 3.7 ilustra gráficamente los conceptos relacionados.
Figura 3.7. Característica entrada-salida de la célula S.
Aquí al (6, v, k ) y bl ( k ) denotan las eficiencias de las sinapsis modificables excitatoria e inhibitoria, respectivamente. Como se ha dicho antes, todas las células S en el mismo plano S tienen un conjunto idéntico de sinapsis

116 CAP~TULO 3. NEOCOGNITR~N
aferentes. Por tanto, al (K, v, IC) y bl (IC) no contienen ningún argumento que represente la posici6n n del campo receptivo de la célula us1 (IC, n) .
En (3.1) , la suma interna e es el conocido cálculo de suma de productos de las entradas uCl-1 (K, n + Y ) por los pesos al (K, Y , IC) . La suma se extiende a todas las c6lulas del K-6simo plano de la capa C anterior que pertenezcan al campo receptivo de la unidad n. Estas células se han indicado mediante el vector n + v. Ya que se parte de que todos los pesos y todos los valores de salida son no negativos, el ctilculo de la suma de productos produce una medida del grado de coincidencia de la trama de entrada y el valor de pesos de la unidad n. Se denota el campo receptivo mediante Al, indicando que la geometría del campo receptivo es la misma para todas las células de la capa. La suma externa de (3.1) se extiende a los Kcl-1 planos de la capa C pre- cedente. En el caso de us1 no habría necesidad de hacer esta suma exterior, pues, entonces, ucl-1 ( IC, n) representa a u0 (n) y se tiene que Kcl-1 = 1.
El producto bl (IC) " U C ~ - ~ (n) que se encuentra en la expresi6n para el calcu- lo de h, representa la contribuci6n inhibitoria de la célula V correspondiente. El parhetro r1, donde O 5 r1 5 0 0 , controla la intensidad de la inhibici6n y de esa forma determina la selectividad de la célula us1 (IC, n) con respecto a una trama específica, Cuanto m& grande es el valor de r1, m& selectiva se vuelve la respuesta de la célula a una característica específica. El factor & va desde cero hasta 1 a medida que r1 va desde cero hasta infinito. Por tanto, para valores pequeños de rl el valor del denominador de (3.1) podría ser rela- tivamente pequeño en comparacih con el numerador, aun en el caso de que la trama de entrada no coincidiese exactamente con el vector de pesos. Esta situaci6n podrfa dar lugar a un argumento positivo para la funcidn @. Si r1 fuera grande, entonces la coincidencia entre la trama de entrada y los pesos, dada por el numerador en (3.1), tendría que ser m& exacta para superar los efectos inhibitorios de la salida de la célula VS en cuesti6n. Obsérvese tam- bién que el parametro r1 aparece como factor multiplicativo de la funci6n @. Si rl es pequeño, la selectividad de la célula es pequeña, este factor asegura que la salida de la célula en sí no pueda hacerse demasiado grande.
Se puede visualizar el efecto de rl de otra manera. Se reescribe el argu- mento de @ en la forma
De acuerdo con (3.1), la salida de la célula S sera no nula s610 en el caso de

3.2. LA RED NEURONAL NEOCOGNITRÓN 117
e r1 - > - h 1+rl
Por tanto, la magnitud de r1 determina la intensidad de excitación relativa mínima frente a la inhibición que dará lugar a una salida no nula de la unidad. A medida que aumenta T L , T L / (1 + 7-1) + 1. Entonces, un valor mayor de ~1
requiere una excitación más grande en relación con la inhibición para obtener una salida no nula.
Ahora es preciso especificar la salida de los nodos inhibitorios. La célula VCL-~ (n) , que se encuentra en la posición n, recibe sinapsis aferentes del mismo grupo de células que us1 (IC, n) . Su salida es proporcional a la raíz cuadrada de la suma pesada de los valores cuadrados de sus entradas, es decir
( ) 1’2
Kcl-1
?Jc¿-l(n) = Cl-1 (u) U L (6, n + Y ) ( 3 4 n=l V E A L
en donde (u) es el peso de la conexión que procede de una célula situada en la posición u del campo receptivo de la célula ~ ~ 1 - 1 (n) . Las eficiencias de las sinapsis clPl (u) son fijas, es decir, no se modifican durante el entre- namiento, se determinan de forma tal que decrezcan monotónicamente con respecto a la magnitud JvJ . Una de estas funciones es
en donde r ( Y ) es la distancia normalizada entre la célula situada en la posi- ción u y el centro del campo receptivo, y ~ 1 1 - 1 es una constante menor que 1 que determina la rapidez de atenuación al aumentar la distancia. E l elemento C L - ~ es una constante de normalización
Kc1 - 1
La condición para que los peso:; se normalicen puede expresarse en la forma
Kc¿ - 1

118 CAPfTULO 3. NEOCOGNITR6N
lo cual cumplen (3.3) y (3.4). La forma de la funcidn q-l ( Y ) afecta también a la selectividad de tramas de las células S, favoreciendo aquellas tramas que e s t h situadas en posicidn central dentro del campo receptivo. Se ve- r& después que esta misma funcidn modula los pesos al (K, Y , IC) durante el aprendizaje. De esta manera, tanto las entradas excitatorias como las inhi- bitorias ser& m& intensas si la trama de entrada est$ situada centralmente en el campo receptivo de la célula.
La forma particular de (3.2) es una raíz cuadr&tica media ponderada de las entradas de la célula vc1-1 (n) . Volviendo a (3.1) , se puede apreciar que en las c6lulas S la entrada excitatoria neta que llega a la cblula se est6 comparando con una medida de la señal de entrada media. Si la razdn de la entrada excitatoria a la entrada inhibitoria neta es mayor que 1, la célula ten&& una salida positiva.
3.2.4 Valor de l a s Células C Las funciones que describen el procesamiento de las capas C son de forma similar a las correspondientes a las células S. También como en la capas S, cada capa C tiene asociada a ella un único plano de unidades inhibitorias que se comportan de manera similar a las células VC de las capas S. La salida de estas unidades se denota en la forma us1 (n) .
En general, las unidades de un plano C dado reciben conexiones de entra- da procedentes de un plano S, o todo lo m& de un pequeño número de ellos, situados en la capa anterior. Las células Vs reciben conexiones de entrada procedentes de todos los planos S de la capa anterior.
La salida de una célula C colocada en la posicidn n del IC-ésimo plano C del I-ésimo mddulo se calcula usando la ecuacidn que sigue
en donde Ksl es el número de planos S que contiene el nivel I ; j , (6, IC) es uno o cero dependiendo de si existe o no la conexidn desde el K-esimo plano S al Ic-6simo plano C; dl (v) es el peso de la conexidn existente entre la célula S situada en la posicidn Y del campo receptivo de la célula uc1 (IC, n) y Dl define la geometría del campo receptivo correspondiente.

3.2. LA RED NEURONAL NEOCOGNITRÓN 119
La función 9 está definida por
en donde el parámetro ,Bl es una constante positiva que determina el grado de saturación de la salida, y puede depender posiblemente del módulo en cuestión.. La salida de las células del plano inhibitorio Vsl está dada por
Los pesos dl (v) representa las eficiencias de las sinapsis excitatorias des- de las células S, y son valores fijos cuya forma general es la misma que los cl (v, k ) descritos anteriormente, aunque se han dado a conocer resultados satisfactorios si dl (v) es un valor uniforme a lo largo de todo el campo recep- tivo. El tamaño del área de conexión Dl es tal que sea pequeño en el primer módulo y que se incremente con el valor de 2 como se muestra en la Figura 3.5.
Obsérvese la ausencia de pesos en la conexión procedente de la célula 'us1 (n) , según indica el denominador de (3.5). Además, sustitúyase (3.6) en (3.5) y se observará el parecido entre el numerador y el denominador del primer término que aparece entre corchetes. La ecuación (3.6) indica que la célula 'us1 (n) está calculando el valor medio de la entrada para todos los planos S. En ese caso, (3.5) puede tener un valor no nulo sólo si la respuesta excitatoria de la célula q ( Y , k ) es mayor que la media.
En síntesis, sólo un cierto porcentaje de células S y C de cada nivel responde con un valor de salida positivo. Se trata de aquellas células cuyo nivel de excitación supera al de las células medias.
El proceso de reconocimiento de patrones es esta red multicapas pue- de sumarizarse como sigue. Primeramente el patrón de estímulo se observa dentro de una ventana estrecha por cada una de las células S en el primer módulo, y se extraen varias características del patrón. En el siguiente módu- lo, se combinan estas características por la observación sobre una ventana ligeramente mayor, y se extraen características de orden superior. Se repite esta operación sobre la conexión en cascada de todos los módulos de la red. En cada etapa de esta operacih, se tolera una pequeña cantidad de error posicional. La condición de que los errores posicionales se toleren poco a poco y no por una sola etapa juega un papel importante en la habilidad de la red para reconocer inclusive patrones distorsionados.

120 CAPITULO 3. NEOCOGNITR~N
3.2.5 Entrenamiento de la Red
En el campo de las redes neuronales al proceso de entrenamiento o apren- dizaje de una red también se le llama autoorganizaci6n. Ndtese que aquí amplfamos este concepto según fue definido en el capítulo 1. Este proceso frecuentemente se clasifica en ”aprendizaje supervisado” (o aprendizaje con ”maestro”), y ”aprendizaje no supervisado” (o aprendizaje sin ”maestro”).
La red neocognitr6n puede ser entrenada empleando tanto el paradigma de autoorganizaci6n supervisada como no supervisada. En el primer caso, el algoritmo para el refuerzo de las sinapsis se determina con vistas al empleo de la red en alguna aplicacidn ingenieril específica, en tanto que en el segundo caso la finalidad de la red es m& bien su utilizaci6n como modelo biol6gico.
Aprendizaje no Supervisado
En este paradigma de aprendizaje, durante le proceso de autoorganizacidn, a la red se le presenta repetidamente en su capa de entrada el conjunto de patrones de entrenamiento, y no recibe ninguna otra informaci6n sobre las categorías en las cuales los patrones de entrenamiento deben ser clasificados. Durante la presentacidn repetida de dichos patrones, en forma gradual cada célula en la etapa de salida de la red va respondiendo selectivamente a s610 uno de los patrones empleados. Es decir, la presentaci6n repetida del con- junto de patrones de entrenamiento a la etapa de entrada es suficiente para que se lleva a cabo la autoorganizacidn de la red.
Como se ha mencionado anteriormente, una de las hip6tesis bbicas em- pleadas en la red neocognitrdn es que todas las células S en el mismo plano S tienen sinapsis de entrada de la misma distribucidn espacial, y que s610 las posiciones de estas células presinzipticas esth corridas en paralelo de acuerdo con el corrimiento en la posici6n del campo receptivo correspondiente a cada cklula. Adem&, los pesos excitatorios y los pesos inhibitorios conectados con la capa S se modifican durante el entrenamiento, mientras que los pesos conectados con la capa C o con el plano de células inhibitorias son fijos. En la Figura 3.8 se muestra la interconexidn general que guardan las células de la red.

3.2. LA RED NEURONAL NEOCOGNITRÓN 121
I : I
L """""~ L """""-.
Figura i3.8. Estructura de la red neocognitrón. Se muestra la interconexión entre dos capas adyacentes Ul-l y Ul, donde U, representa la I-ésima capa
dentro del modelo jerárquico de la red.
La autoorganización de la red, en este esquema de entrenamiento, se efectúa bajo un cierto tipo de aprendizaje competitivo: entre las células situadas en una cierta área pequeña, aquella que responde más fuertemente se le llalma célula "representante" y sólo ésta es reforzada en sus sinapsis de entrada. El monto del refuerzo de cada conexión de entrada de esta célula representante es proporcional a la intensidad de la respuesta de la célula dlesde la cual viene la conexión. Este principio se aplica tanto a las conexiones excitatorias como inhibitorias. g , g? r' 9 .
(a) Estado Inicial (b) Estimulación (c) Después del refuerzo
Figura 3.9. Proceso de refuerzo de las conexiones de entrada.
La Figura 3.9 ilustra el proceso de refuerzo, mostrando sólo las conexiones que convergen a una célula excitatoria us1 de la Z-ésima capa, la cual ha sido elegida como representante. La célula us1 recibe conexiones variables de un grupo de células excitatorias U C I - ~ de la capa precedente. La célula también recibe una conexión variable desde una célula inhibitoria V C I - ~ . La célula vcl-1 recibe conexiones excitatorias fijas del mismo grupo de células ucl-1
que la célula us1, y siempre responde con la intensidad promedio de las salidas de las células ucl-1, como ya ha sido establecido.

122 CAP~TULO 3. NEOCOGNITR~N
Supdngase que la célula US¿ mostrada en la Figura 3.9(b) responde m& fuertemente entre las células us¿ contenidas en su vecindad ante un cierto patr6n de estimulo, por lo cual ha pasado a ser la representante. De acuerdo al principio arriba mencionado, la conexiones variables que vienen desde las c6lulas activadas uC1-1 y vC1-1 se refuerzan como se muestra en la Figura 3.9(c). Las conexiones excitatorias variables de la célula us1 crecen siguiendo la distribucidn espacial de los pesos no modificables de las células C en la capa precedente. La conexidn variable inhibitoria de la célula vS1-1 se refuerza al mismo tiempo. Dado que en el neocognitrdn, los pesos compartidos en un plano dado significan que sdlo una célula de cada plano necesita participar en el proceso de aprendizaje, una vez que los pesos de la célula representante han sido actualizados, se puede distribuir una copia del nuevo vector de pesos a las otras células del mismo plano.
Las células en los planos S de los cuales no se seleccion6 representante no sufren ningún refuerzo en sus sinapsis de entrada.
A fin de llevar a cabo la autoorganizacidn bajo las condiciones mencio- nadas, el refuerzo de las sinapsis modificables se efectúa bajo los siguientes procedimientos.
Primeramente, cada vez que se presenta a la red un patr6n de entra- da especifico, en cada capa S se seleccionan varias células que son posibles "representantes". Las representantes de cada capa se seleccionan entre las cblulas S que han presentado las salidas m& grandes, pero se restringe el número de representantes de tal manera que en ningún plano S se elige m& de una. Todas estas relaciones se pueden expresar cualitativamente como sigue.
Sea la célula us¿ ( k , 6) la seleccionada como representante del k-ésimo plano S del m6dulo 1. Las sinapsis modificables al ( K, Y , IC) y bl (IC) , l a s cuales son aferentes a las células S de este plano celular S, se refuerzan en las cantidades dadas, respectivamente, por
donde q es una constante positiva que determina la cantidad y la velocidad del refuerzo, cl-1 (v) es la funci6n mon6tona decreciente (3.3) ya descrita y 6 es la posici6n de la célula elegida como representante.
En el estado inicial, l a s sinapsis excitatorias modificables al ( K , Y, IC) reci- ben valores positivos pequeños tal que l a s células S muestren una muy débil

3.2. LA RED NEURONAL NEOCOGNITRÓN 123
selectividad por cierta orientación, y que esa orientación varíe de plano S a plano S. Es decir, los valores iniciales de estas sinapsis modificables están dados por una función de u, de la capa y del plano, pero no son aleatorios. Los valo.res iniciales de las sinapsis modificables bl ( k l ) se eligen todas cero.
Obsérvese que los incrementos más grandes de los pesos se producen en aquellas conexiones que tienen la mayor señal de entrada, ucl-l (IC, íi + v) . Obsérvese que los pesos sólo pueden aumentar, y que no hay una cota para los valores de éstos. La forma de la Ec. (3.1) para la salida de la célula S garantiz.a que el valor de salida seguirá siendo finito, incluso para grandes valores de los pesos.
El procedimiento para seleccionar la representante se da a continuación. En primer lugar, se observa un grupo de células S cuyos campos receptivos estén situados dentro de un área pequeña de la capa de entrada. Si se arreglan los planos S de una capa S en la manera mostrada en la Figura 3.10, el grupo de células S constituyen una columna en esa capa S. De acuerdo con esto, este grupo recibe el nombre de columna S. Una columna S contiene células S de todos los planos S. Esto es, una columna S contiene células con la capacidad de extraer varias clases de características, pero los campos receptivos de estas células están situados en casi la misma posición. Existe gran cantidad de tales columnas S en una sola capa S. Dado que las columnas S tienen traslapes entre ellas, existe la posibilidad de que una célula S dada esté contenida en dos o m.& columnas S.
S-plane
S-column
-Figura 3.10. Relación entre planos S y columnas S dentro de .una capa S.
De cada columna S, cada vez que se presenta un patrón de estímulo a la retina, la célula S con la mayor salida se escoge como un candidato para ser representativa. Entonces, existe la posibilidad de que varios candidatos aparezcan en mismo plano S. Si dos o más candidatos aparecen en un solo

124 CAPfTULO 3. NEOCOGNITRdN
plano S, aquel que presente la mayor salida entre ellos se selecciona como la celda representante de ese plano S. En el caso de que S610 un candidato aparezca en un plano S, este candidato resulta ser incondicionalmente la celda representante de ese plano. Si ningún candidato aparece en un plano S dado, no se escoge celula representante de ese plano.
La determinaci6n de las células representantes de la forma descrita lleva a que cada plano S resulte selectivamente sensible a una de las características de los patrones de estímulo.
Una vez que se ha completado el entrenamiento, las células S de cada plano S adquieren la habilidad de extraer una característica de los patrones de estimulo usados durante el periodo de entrenamiento. Vía las conexio- nes excitatorias, las células S reciben señales indicando la existencia de la caracteristica a ser extraida. Si una caracteristica irrelevante se presenta, la señal inhibitoria de la celula V viene a ser mayor que las señales excitatorias directas de las c6lulas C correspondientes, suprimiendo, entonces, la salida.
A causa del principio "el ganador toma todo", empleado en el proceso de autoorganizacidn, la formacidn de dos o m& células en un Area pequeña con la habilidad de extraer la misma característica no puede ocurrir, y se presenta una "divisi6n del trabajo" entre las células de forma automhtica. En otras palabras, se previene la formaci6n de conexiones redundantes que puedan hacer que dos o m& planos S se empleen para la deteccibn de la misma característica.
Con este principio, la red también exhibe la propiedad de auto repararse. Si una célula que ha respondido fuertemente a un cierto estímulo sufre un daño y cesa de responder, otra célula, la cual responde de manera más fuerte entre las que restan, empieza a desarrollarse y termina por sustituir a la cklula dañada. Hasta entonces, la mayor respuesta de la célula primera había prevenido el desarrollo de la segunda.
Los patrones de entrenamiento dependen de las aplicacidn específica en que se quiere utilizar la red. Por lo tanto los patrones con que se entrena la red para una aplicacidn de reconocimiento de patrones son obviamente distintos de aquellos con que se entrenaría en el caso de una aplicacidn de reconocimiento de fonemas.
Aprendizaje Supervisado
Esta forma de entrenamiento es diferente al de otras redes de tipo multica- pas, tal como la red de retropropagacih, o el esquema de autoorganizaci6n

3.2. LA RED NEURONAL NEOCOGNITRÓN 125
previamente descrito, en la cual la modificación de los pesos de cada etapa se realiza después de calcular todas las salidas de la red. En este esquema de autoorganización, en la red neocognitrón, la modificación de los pesos de cada capa se realiza independientemente de las otras capas. Por lo tanto los pesos de una capa que se han modificado, y ya alcanzaron valores acepta- bles no sufren ya cambios cuando se realiza el entrenamiento de las capas subsecuentes. En este paradigma de aprendizaje, durante el proceso de en- trenamiento, a la red se le presenta el conjunto de patrones escogidos para entrenada junto con una serie de instrucciones sobre las células que deben responder a cada uno de los patrones. Este esquema es adecuado cuando se tiene un conocimiento previo de las características a las cuales se desea que resp0nd.a cada nivel y cada plano dentro de cada nivel.
El aprendizaje supervisado es especialmente útil cuando se desea entre- nar el sistema para reconocer, por ejemplo, caracteres manuscritos que deben ser clasificados no sólo sobre la base de similitud en la forma, sino también considerando ciertas convenciones. Esto es, el algoritmo se determina con el criterio de obtener el mejor desempeño en el reconocimiento de un conjunto dado de caracteres. En estas circunstancias, se pueden desarrollar un con- junto de vectores de entrenamiento para cada capa, y las capas se pueden entrenar independientemente. Sin embargo, en este esquema de autoorga- nización, el refuerzo de las conexiones sinápticas debe llevarse a cabo en secuencia comenzando con la primera capa y avanzando hacia las capas de salida. Es decir, el refuerzo de las sinapsis de entrada de la I-ésima capa se lleva a cabo sólo después de haber completado el refuerzo de las capas previas hasta la ( I - 1)-ésima.
Varios planos celulares componen cada capa S. Estos planos celulares se refuerzan uno cada vez. A fin de reforzar un plano celular, el "maes- tro" presenta un patrón de entrenamiento a la capa de entrada, y al mismo tiempo elige una célula S para que se desempeñe como la célula "represen- tante" de ese plano celular. Las sinapsis de entrada a la célula representante se refuerzan en función del estímulo recibido, es decir, sólo son reforzadas aquella5 sinapsis que reciben un estímulo no nulo. Como resultado, la célula representante adquiere la capacidad de responder selectivamente al patrón de entrenamiento que está presente en la entrada de la red. A continuación, una ve:z que los pesos de la célula representante han sido actualizados, se distribuye una copia del nuevo vector de pesos a las otras células del mismo plano.
Las expresiones matemáticas que describen el algoritmo anterior son las

126 CAP~TULO 3.
mismas que en el caso del aprendizaje no supervisado (3.7) y (3.8), por lo cual la descripci6n de éstas, hecha en el apartado anterior, es completamente d i d a q u i . Sin embargo, para este caso, los valores iniciales de las sinapsis aferentes tanto excitatorias como inhibitorias se eligen todas cero.
Se puede tomar como representante cualquier célula del plano celular, y la elecci6n no tiene ningún efecto sobre el resultado del entrenamiento. Es preciso tener cuidado, sin embargo, para asegurarse de que la trama de en- trada sea presentada en la posici6n correcta con respecto al campo receptivo de la célula representante, lo cual no es restrictivo si el supervisor posee por anticipado un conocimiento de las caracteristicas deseadas, ya que entonces sabe cud es la c6lula representante correspondiente a cada patrón de entre- namiento..
3.2.6 Conclusiones Fukushima, en su articulo [9], ha introducido varios ejemplos de modelos de sistemas visuales. Estos casos son útiles para la obtenci6n de principios de diseño para nuevos procesadores de información que resulten superiores a los sistemas convencionales. La red neocognitrón es un ejemplo de la superiori- dad de estos procesadores avanzados.
En la red neuronal neocognitrón el entrenamiento puede basarse tanto en el aprendizaje supervisado como no supervisado. Sin embargo, al igual que en el caso de otras redes basadas en el principio de aprendizaje no su- pervisado, tal como la red de Kohonen, no existe condición terminal para el entrenamiento, por lo tanto el número suficiente de iteraciones del proceso se decide a partir de ensayo y error. En el neocognitrón la selección de los pa- trones para el entrenamiento es sumamente importante para obtener el mejor funcionamiento, especialmente en el caso de entrenamiento supervisado.

Capítulo 4
Identificación y Control
En este (capítulo se demuestra que la redes neuronales pueden usarse de mane- ra efectiva para la identificación y control de sistemas dinámicos no lineales.
4.1 Introducción
La teorla mat,emática de sistemas, que ha evolucionado en las cinco décadas pasadas hasta convertirse en una disciplina científica de gran aplicabilidad, trata del análisis y síntesis de sistemas dinámicos. E l aspecto mejor desarro- llado de la teoría es el que concierne a los sistemas definidos por operadores lineales y usa técnicas bien establecidas basadas en álgebra lineal, teoría de variable compleja y la teoría de ecuaciones diferenciales ordinarias lineales.
Los sistemas dinámicos (en lo sucesivo también llamados plantas) están relacionados de manera indisoluble con el concepto de estabilidad, y las téc- nicas dle diseño para estos sistemas tienen que considerar de manera muy cercana, sus propiedades en relación con este concepto. Ya que dentro del campo de los sistemas lineales, durante el siglo pasado, han sido establecidas condiciones necesarias y suficientes de muy fácil aplicación para la determi- nación de la estabilidad de sistemas lineales invariantes en el tiempo, se han desarrollado técnicas sencillas bien conocidas para el diseño de tales sistenlas. Por el contrario, la estabilidad de sistemas no lineales puede ser establecida en general sólo sistema por sistema y por lo tanto no es sorprendente que los procedimientos de diseño que simultáneamente cumplan con los requisi- tos de estabilidad, robustez y buena respuesta dinámica no estén, por regla, disponjbles para clases grandes de tales sistemas.
127

128 CAPITULO 4. IDENTIFICACI6N Y CONTROL
En las tres décadas pasadas se han hecho grandes avances en identifica- ci6n y control adaptables para su empleo en plantas lineales invariantes en el tiempo con parhetros desconocidos. La elecci6n de las estructuras para el identificador y el controlador se basa en resultados bien establecidos en la teo- ría de sistemas lineales. En estos casos existen leyes adaptables estables para el ajuste paramétrico que aseguran estabilidad global; estzin basadas en las propiedades de sistemas lineales y en resultados de estabilidad que son bien conocidos para tales sistemas. Aquí nuestro interés está en la identificaci6n y control de plantas dintimicas no lineales usando redes neuronales. Puesto que existen muy pocos resultados en la teoría de sistemas no lineales de di- recta aplicacibn, debe tenerse un cuidado considerable en el enunciado de los problemas, la elecci6n de las estructuras del identificador y el controlador y la generaci6n de leyes para el ajuste de los parámetros.
En el &ea de las redes neuronales artificiales la clase de las redes neu- ronales recurrentes ha recibido una considerable atenci6n en años recientes; estas redes se han usado exitosamente como memorias asociativas y en la so- luci6n de problemas de optimizaci6n. Desde el punto de vista de la teoría de sistemas, las redes recurrentes estzin representadas por sistemas no lineales dinhicos retroalimentados con posibilidad de adaptacidn.
Este capítulo esta escrito con dos objetivos. El primero es la utilizaci6n de las redes neuronales recurrentes como estructuras para identificadores y controladores adaptables de sistemas dinthicos no lineales desconocidos. El segundo objetivo es la presentaci6n de un método prescriptivo para el ajuste d inhico de los parzimetros de la red, el cual se obtiene vía la prueba de estabilidad realizada sobre el conjunto sistema-red. Para la ilustraci6n de los conceptos introducidos se incluyen representaciones de sistemas en diagrama de bloques, las cuales son comúnmente empleadas en la teoría de sistemas, así como un ejemplo de aplicaci6n con simulaciones por computadora. El capitu- lo esta organizado como sigue: la Seccidn 2 trata de los conceptos bhicos y los detalles de la notacidn utilizada; en la Secci6n 3 se hace un tratamiento de las redes recurrentes como identificadores adaptables mientras en la Seccidn 4 se hace lo correspondiente pero como controladores adaptables. Finalmente, en la Secci6n 5 se hacen algunas conclusiones sobre el tdpico tratado.

4.2. PRELIMINARES, CONCEPTOS BÁSICOS Y NOTACI6N 129
4.2 Preliminares, Conceptos Básicos y Nota- ción
En esta sección se presentan algunos conceptos relacionados con el proble- ma de idlentificación y control. Aunque solamente algunos de ellos se usan en forma directa en las secciones que siguen, todos son relevantes para una com- prensión completa del papel que juegan las redes neuronales en los sistemas dinámicos.
4.2.1 Caracterización e Identificación de Sistemas
La caracterización e identificación de sistemas son problemas fundamentales en la teoría de sistemas. El problema de caracterización se refiere a la repre- sentacidn matemática de un sistema. Un modelo de un sistema se expresa como un operador P que transforma elementos de un espacio de entrada U en elementos de un espacio de salida Y y el objetivo es caracterizar la cla- se p a 1.a cual pertenece P. Dada una clase p y el hecho de que P E p, el problema de identificación es determinar una subclase 6 C y un elemento P^ E 6 tal que P̂ aproxime P en algún sentido deseado. En sistemas estáticos los espacios U y Y son subconjuntos de Rn y Rm, respectivamente, mientras que en sistemas dinámicos, aquéllos generalmente son conjuntos de funcio- nes acotadas integrables en el intervalo [O, T ] o [O, m). En ambos casos, el operador P está definido de manera implícita por el conjunto especificado de parejas entrada-salida. La elección de la clase de modelos de identificación 6, así como el método específico usado para la determinación de p, depende de una variedad de factores relacionados con la precisión deseada y la dificultad en el tratamiento analítico. Éstos incluyen lo adecuado que resulta P para representar P, su simplicidad, la facilidad para extenderlo si las especifica- ciones 110 se satisfacen y finalmente si el P elegido va a ser usado en línea o fuera de línea. En las aplicaciones prácticas muchas de estas decisiones de- penden naturalmente de la información disponible en relación con la planta a ídent ificarse.
Identificación de Sistemas Estúticos y Dinúmicos: El problema del re- conocimiento de patrones es un ejemplo típico de la identificación de siste- mas estáticos. Conjuntos compactos Ui c Xn se t'ransforman en elementos gi C 8'"; ( i = 1 ,2 , . S ) en el espacio de salida vía una función de decisión P. Los elementos de Ui denotan los vectores de los patrones correspondientes
h
h

130 CAPfTULO 4. IDENTIFICACI6N Y CONTROL
a la clase gi. En sistemas dinhicos, el operador P que define a una planta dada esta implícitamente definida por las parejas entrada-salida de funciones temporales u(t) , y(t) , t E [O, TI . En ambos casos el objetivo es determinar F tal que
u € U
para algún E deseado y alguna cierta norma definida (denotada 11.11) en el espacio de salida. En (4.1) , F(u) = 9 denota la salida del modelo de identi- ficacidn y por lo tanto y^ - y =: e es el error entre la salida generada por P y la salida observada y.
En lo dicho antes se da por hecho que existen la subclase 6 c p y el modelo E 6 que aproxima el operador especificado P E p; un aspecto pri- mordial del problema de la caracterizacih y la consiguiente identificacih de plantas, es el que concierne a la determinacidn de la existencia de la subclase y el modelo que cumplan con las características pedidas. Este problema ha sido resuelto matemáticamente pero su tratamiento esta fuera del objetivo de estas notas; así que sdlo estableceremos como suposici6n que tratamos con el conjunto de plantas para las que se asegura la existencia de 6 y P como ha sido establecido.
Asimismo, el problema de caracterizacidn esta íntimamente ligado al pro- blema de la eleccih de una representacidn matemática para el sistema. Aquí estamos principalmente interesados en las representaciones que permitan, en linea, la identificacidn y control de sistemas dinhicos en t6rminos de ecua- ciones diferenciales no lineales finito-dimensionales. Tales modelos son de uso actual muy extendido y son el motivo de la siguiente subseccidn.
h
h
Representaciones de Sistemas en la Forma Entrada-Estadesalida
El metodo de representacidn de sistemas dinámicos por ecuaciones diferen- ciales vectoriales está actualmente bien establecido en la teoría y se aplica a una gran cantidad de sistemas. Por ejemplo, las ecuaciones diferenciales

4.2. PRELIMINARES, CONCEPTOS BASEOS Y NOTACION 131
donde
representan un sistema de orden n con p entradas y m salidas, x:i(t) denota las variables de estado, ui(t) las entradas y yi(t) las salidas del sistema. @ y @ son transformaciones no lineales estáticas definidas como
El vectos z ( t ) denota el estado del sistema al tiempo t y es determinado por el estadco al tiempo t o < t y la entrada u definida sobre el intervalo [ t o , t ) . La salida y(t) está determinada completamente por el estado del sistema al tiempo t . La ecuación (4.2) se conoce como la representación entrada-estado- salida del sistema. En este capítulo nos restringiremos a sistemas descritos en esta representación.
Si suponemos que el sistema descrito por (4.2) es lineal e invariante en el tiempo, las ecuaciones que gobiernan su comportamiento pueden expresarse como
Z ( t ) = Az(t) + Bu@), t E = Cx:(t )
(4.3)
donde A , B y C son matrices constantes de dimensiones (n x n) , (n x p) y (m x n) , respectivamente. El sistema está entonces parametrizado por la tripleta {A, B, C} . La teoría de sistemas lineales invariantes en el tiempo, cuando A, B y C son conocidas, está muy bien desarrollada y conceptos tales como controlabilidad, estabilidad y observabilidad de tales sistemas han sido estudiados extensamente en las tres décadas pasadas. Métodos para la deter- minaciiin de entradas de control u(.) para la optimización de algún criterio de desempeño son también bien conocidas. E l tratamiento de estos diferentes problemas se reduce a la solución de n ecuaciones con n incógnitas. En con- traste EL lo anterior, los problemas que envuelven ecuaciones no lineales de la forma (4.2), donde las funciones <p y 9 son conocidas resultan en ecuaciones algebramicas no lineales cuya solución requiere métodos igualmente poderosos que no existen. En consecuencia, como se muestra en las secciones siguien- tes, numerosas hipótesis deben hacerse para tener problemas analíticamente tratables.

132 CAPITULO 4. IDENTIFICACI~N Y CONTROL
4.2.2 Ident ificaci6n y Control
l. Identificacidn: Cuando las funciones y 9 en (4.2), o las matrices A, B y C en (4.3), son desconocidas aparece el problema de identificacidn de la planta desconocida. Esto puede establecerse formalmente como sigue:
Dendtese la entrada y salida de una planta dinhmica causal e invariante en el tiempo por u(.) y yp(-), respectivamente, donde u(.) es una funcidn uniformemente acotada del tiempo. La planta se considera estable con una parametrizacidn conocida pero con d o r e s desconocidos de los parhetros. El objetivo es construir un modelo de identificacidn (Figura 4.l(a)) el cual cuando se sujete a la misma entrada u(t) de la planta, produzca una salida GP(t) que aproxime yP(t) en el sentido descrito por (4.1).
Modelo de idenbficaci6n
(4 (3)
Figura 4.1. (a) Identificacidn. (b) Control adaptable por modelo de referencia.
2. Control: La teoría de Control trata con el andisis y sintesis de sistemas dinbicos en los cuales una o m& variables se mantienen dentro de límites prescritos. Si l a s funciones <P y 9 en (4.2) son conocidas el problema de control es el diseño de un controlador que genere la entrada de control deseada u(-¿) en base a toda la informacidn disponible en el instante t. Mientras un amplio cuerpo de técnicas en el dominio del tiempo y la frecuencia existen para la sintesis de controladores en el caso de sistemas lineales de la forma (4.3) con A, B y C conocidos, mbtodos similares no existen para sistemas no lineales, aún en el caso de que las funciones <P ( e , S ) y 9 ( e ) estén especificadas. El problema se complica si a la dinAmica que describe el comportamiento de la planta se le afiaden incertidumbres, cosa común en el modelado de sistemas prhcticos. Aparece entonces el control adaptable como una alternativa seria para el control de plantas con dinhicas tanto desconocidas como inciertas. Aqui nuestro interés se enfoca primordialmente en la identificacidn y control de sistemas dinhicos no lineales desconocidos.
Una técnica de uso común utilizada por sistemas adaptables para el esta- blecimiento del objetivo de control es el uso explicit0 de modelos de control;

4.2. PR,ELIMINARES, CONCEPTOS B Á s I c o s Y NOTACION 133
éstos se han estudiado en forma extensa. Tales sistemas se conocen común- mente como sistemas de control adaptable por modelo de referencia (CAMR). La hipótesis implícita en la formulación del problema CAMR es que el di- señador está suficientemente familiarizado con la planta bajo consideración de modo tal que puede especificar el comportamiento de la planta en térmi- nos de 1.a salida de un modelo de referencia. El problema CAMR se puede establecer cualitativamente como sigue (Figura 4.1 (b)).
a. Control adaptable por modelo de referencia: Se da una planta P con la pareja entrada-salida {u( t ) , y p ( t > } . Se especifica un modelo de referencia estable por su pareja entrada-salida { r(t), ym(t)} donde r : %+ "--f P es una función acotada. La salida ym(t) es la salida deseada de la planta. El objetivo es la determinación de la entrada de control u(t) b't 2 O de manera que
para alguna constante especificada E 2 O. Se ha establecido que la elección del modelo de identificación (es decir, su
parameltrización) y el método para ajustar sus parámetros en base al error de identificación constituyen las dos principales partes del problema de identifi- cación. Por otro lado, la determinación de la estructura del controlador y el ajuste cle sus parámetros para minimizar el error entre la salida de la planta y la sali.da deseada, representan las partes correspondientes del problema de control.
En la formulación de los problemas de identificación y control para sis- temas lineales, los conceptos de controlabilidad y observabilidad resultan fundamentales. Además, se utilizan resultados adicionales bien conocidos en la teoría de sistemas lineales para la elección del modelo de referencia y la para-metrización de la planta a fin de asegurar la existencia del controla- dor deseado. En años recientes un cierto número de autores ha desarrollado conceptos tales como controlabilidad, observabilidad, estabilización por re- troalimentación y diseño de observadores para sistemas no lineales. A pesar de tales intentos, en sistemas no lineales no existen procedimientos construc- tivos silmilares a aquéllos disponibles para sistemas lineales. Por esta razón, la elección de modelos de identificación y control para plantas no lineales es un problerna formidable y el logro de tales objetivos dependen de suposiciones muy fuertes sobre el comportamiento entrada-salida de la planta.
Aún cuando la función @ en (4.2) sea conocida y el vector de estado sea accesible, la determinación de la entrada u(.) que hace que la planta siga la

134 CAPfTULO 4. IDENTIFICACIhJ Y CONTROL
trayectoria deseada es un problema igualmente dificil. Por lo tanto, para la generacih de las entradas de control, ha de suponerse la existencia de ciertos operadores inversos. Aún si se considera que existe una estructura para el controlador que genere la entrada de control u( e ) , deben hacerse hip6tesis adicionales para asegurar la existencia de un vector de parhetros constantes que aseguren que el controlador ha de lograr el objetivo propuesto. Todo lo anterior indica que se han de lograr avances considerables en la teoria de control de sistemas no lineales a fin de obtener soluciones rigurosas a los problemas de identificaci6n y control.
La variedad de consideraciones discutidas motivan la incorporaci6n de redes neuronales como estructuras para identificadores y controladores en el caso de sistemas no lineales. La funci6n @ ( a , m), cuando representa una transformaci6n esthtica puede ser aproximada por una red neuronal esthtica multicapa, mientras que para el sistema dinámico completo
se puede emplear una red neuronal recurrente, dada su naturaleza dinhmica. Ambas arquitecturas de red han sido estudiadas extensamente y como ha sido mencionado son de uso común. En estas notas nos inclinaremos por la segunda opci6n.
El concepto de estabilidad y su determinacidn en sistemas dinámicos, en particular los controlados, es fundamental. Para nuestros fines, cuando hablemos del concepto de estabilidad en el contexto de sistemas no lineales, entenderemos que la estabilidad es en el sentido de Liupunov. En la secci6n siguiente se dan los conceptos b&icos suficientes para el entendimiento de este tema y de los desarrollos matemáticos posteriores.
4.2.3 Concepto y A d i s i s de Estabilidad
Comenzamos por dar las definiciones de estado de equilibrio, estabilidad y estabilidad asint6tica. Luego se establecen los conceptos de definicih, semidefinici6n e indefinicih de funciones escalares.
Sea el sistema vectorial dinhmico autdnomo (no depende explicitamente del tiempo) descrito por
a: (t) = f [xWl 7 (4.4) donde x E Xn es el vector de estado n-dimensional y f (x) es un vector n- dimensional cuyos elementos son funciones de x. El par tiempo-estado ( t o , .o)

4.2. PRELIMINARES, CONCEPTOS BASICOS Y NOTACION 135
se llama condición inicial para el sistema (4.4) y a la solución de dicho sistema que en t = t o pasa por x. se le indica por ~ ( t , t o , xo). Dados un sistema y una condición inicial, al problema de encontrar la solución correspondiente se le conoce por Problema de Cauchy. Existen condiciones suficientes que aseguran si un problema de Cauchy dado tiene solución única (véase [16]), sin embargo, aquí daremos por hecho que así es.
En el sistema de la Ec. (4.4), a un estado constante Z E Rn que satisface la condición
f (E) = o, vt 2 o se le llama estado de equilibrio del sistema. Claramente, los estados de equi- librio de (4.4) son los valores del vector x en los cuales el sistema se estanca, es decir deja de presentar cambios.
El análisis de estabilidad en el contexto de la teoría de Liapunov está relacionada con la determinación de la estabilidad de los estados de equili- brio, se establecen distintas clases de estabilidad y convergencia, las cuales formalmente se definen como sigue.
Definición 1 El estado de equilibrio Z se dice que es uniformemente estable si para cualquier E > O existe S > O tal que la condición
implica
vt > o.
Esta definición establece que la trayectoria del sistema puede hacerse que permanezca dentro de una vecindad pequeña del estado de equilibrio E si el estado inicial x(0) está suficientemente cerca de T .
Definición 2 El estado de equilibrio Z se dice convergente si existe S > O tal que la condición
Il@> - Zll < 6 implica
x(t) "-f cuando t "+ m.

El significado de esta segunda definici6n es que si el estado inicial de una trayectoria esta suficientemente cerca del estado de equilibro Z, entonces la trayectoria descrita por el vector de estado x(t) se aproximara a T conforme t se aproxima al infinito.
Definicidn 3 El estado de equilibrio Z se dice asintdticamente estable si es a la vez estable y convergente.
Notemos que la estabilidad y la convergencia son propiedades indepen- dientes. S610 cuando se satisfacen ambas tenemos estabilidad asint6tica.
Definicidn 4 El estado de equilibrio Z se dice globalmente asintdticamente estable si es estable y todas l a s trayectorias del sistema convergen a Z wn- forme t se aproxima al infinito.
Por supuesto, esta definici6n implica que el sistema s610 tiene a 3 como Único equilibrio y que para cualquier elecci6n de las condiciones iniciales, el sistema terminara en 3.
En 1892, A. M. Liapunov, matemtitico ruso, present6 dos métodos (de- nominados primer y segundo métodos) para determinar la estabilidad de los estados de equilibrio en sistemas dinhicos descritos por ecuaciones diferen- ciales ordinarias.
El primer método consiste en todos los procedimientos en los cuales se utiliza para el anAlisis la forma explícita de las soluciones de las ecuaciones diferenciales. Como es sabido, la obtenci6n de tales soluciones s610 es posible para un número pequeño de clases de ecuaciones diferenciales, de donde se desprende que el uso de este método esta muy restringido.
Por otro lado, el segundo método (también llamado método directo) no requiere l a s soluciones de las ecuaciones diferenciales, característica que re- presenta el verdadero aporte de Liapunov, por lo cual resulta muy poderoso y de aplicaci6n general, en particular para el andisis de estabilidad de siste- mas no lineales en los cuales la obtenci6n de las soluciones es muy difícil si no imposible. Aquí trataremos s610 lo relativo al segundo método y para ello debemos definir antes lo que se entiende por una funcidn positiva definida.
Definicidn 5 Una funcidn real V(x) definida en una regidn R (que incluye al origen del espacio de estado), con derivadas parciales continuas respecto de los elementos del vector x E gn y que tiene la particularidad de que
V ( 4 { > O V x # O = o s i x = o

4.2. PRELIMINARES, CONCEPTOS BASICOS Y NOTACION 137
se denomina función positiva definida.
Definición 6 Se dice que una función escalar V(x) es negativa definida si -V(x) es positiva definida.
Definición 7 Se dice que una función escalar V(x) es positiva semidefinida si es po.sitiva en todos los estados de 0 excepto en el origen y en ciertos estados determinados, donde vale cero.
Definición 8 Se dice que una función escalar V(x) es negativa semidefinida si -V(x) es positiva semidefinida.
Teorema 1 El estado de equilibrio Z es estable si en una pequeña vecindad de Z exwte una función positiva definida V(x) tal que su derivada temporal sea negativa semidefinida en tal región.
Teorema 2 El estado de equilibrio Z es asintóticamente estable si en una pequeña vecindad de Z existe una función positiva definida V(x) tal que su derivada temporal sea negativa definida en tal región.
Una función escalar V(x) que satisface estos requisitos se denomina fun- ción de Liapunov para el estado de equilibrio Z.
Nótese que los teoremas sólo dan condiciones suficientes pero no nece- sarias para la estabilidad de un punto de equilibrio, por tanto que no se encuentre una función de Liapunov para un sistema determinado no prueba inestabilidad de tal sistema.
La demostración del teorema en que se basa el segundo método de Lia- punov es larga y al lector interesado lo remitimos a la literatura (véase, por ejemplo [16]). Aquí sólo daremos la idea intuitiva en que se basa.
En sistemas mecánicos existe asociada al sistema una función real que dependle de todas las variables que determinan el estado del sistema (veloci- dad y posición), esta función es la energía del sistema. La energía mecánica tiene la particularidad de que está acotada por debajo, y es función creciente del estado, es decir, al aumentar la velocidad y/o la posición aumenta la energía; adem&, el mínimo de la energía corresponde con un valor nulo de la velocidad y un mínimo para la posición. Por las características que presenta la energía para describir lo que sucede en el sistema, se ve claramente que si la energía no aumenta (es decir, su derivada temporal es 5 O) al evolucionar el sistema, las variables no aumentan más allá de un cierto valor, este es

138 CAPfTULO 4. IDENTIFICACIoN Y CONTROL
justamente la idea de la estabilidad; por otro lado, si la energía disminuye (es decir, su derivada temporal es < O) al evolucionar el sistema, el valor de las variables disminuye a un mfnimo dado por velocidad nula y posicidn minima, este es claramente el caso de estabilidad asintdtica. Como se ve, en el caso de sistemas mechicos la función de energía funge como una función de Liapunov, y por esta razdn a las funciones de Liapunov tambih se les lla- ma funciones de energfa, aun cuando no siempre correspondan a una energia asociada al sistema en cuestidn.
Con los conceptos dados en esta seccidn estamos en la posibilidad de abordar los resultados principales sobre la identificacidn y el control, mismos que abordamos en las siguientes secciones.
4.3 Identificacih En lo que sigue, siempre que no haya lugar a confusión, se suprime de la notacidn la dependencia de t.
En esta seccidn consideramos el problema de identificar el sistema di- neto no lineal en tiempo continuo descrito por
donde x E M, una variedad suave, u E U c Sm, con U representando la clase de entradas vectoriales admisibles (i.e., acotadas), f es un campo vectorial y x( O) =: x0 es la condicidn inicial sobre M.
Definicidn 9 Sea D c S", diremos que D es un dominio si es abierto y conexo.
Definicidn 10 La funcidn f (x, u) se dice que es uniformemente localmente Lipschitz sobre el dominio D s i Qu E U y Qx, x' E D 3 O < L E $2 tal que se verifica la desigualdad
si D = !Rn, entonces se dirh que la funcidn en cuestidn es uniformemente globalmente Lipschitz.
Del andisis de nuestro problema, imponemos l a s siguientes hipdtesis sobre el sistema a aproximar.

139
H2. Dada una clase U de entradas admisibles, para cualquier u E U y cualquier condición inicial finita, las trayectorias del estado son uniformemen- te acotadas para cualquier tiempo finito T > O. Por lo tanto, Ilz(T)II < m.
HZ. f es continua con respecto a sus argumentos y satisface la condición de ser ulniformemente localmente Lipschitz.
Las suposiciones anteriores son necesarias para garantizar la existencia y unicidad de la solución z ( t ) de la ecuación diferencial (4.5) dadas cualesquiera condición inicial y u E U.
Como ha sido establecido, con objeto de identificar el sistema dinámico no lineal (4.5), empleamos una red neuronal dinámica, la cual es recurrente, totalmente interconectada y que contiene elementos dinámicos en sus neuro- n a ; recibe como entradas el estado del sistema (4.5) y el mismo vector u. Entonces, queda descrita por el siguiente conjunto de ecuaciones diferencia- les:
donde 3: E M, las entradas u E U c 8"; Wl E S""", W2 E Rn"" son matrices de pesos sinápticos y A, B1, B2 E 8""" son matrices diagonales cuyos elementos son los escalares ai, bli, b2i, i = 1 , 2 , . . , n. Finalmente, S(z) es un vector n-dimensional y S'(z) E TInx" es una matriz diagonal, con elementos S( xi) y s'(zi) respectivamente, ambos funciones suaves (al menos dos veces diferenciables) y monótonamente crecientes, los cuales son usualmente representados por funciones sigmoidales de la forma
k S ' ( X 2 ) := + x 1 + & X i
para to'da i = 1 , 2 , . . , n , donde k, I son parámetros que representan la cota, k , y la pendiente, 1, o la curvatura de la sigmoide y A > O es una constante que corre la sigmoide sobre el eje de las ordenadas. Un diagrama de bloque de la red neuronal usada se muestra en la Figura 4.2.

140 CAPÍTULO 4. IDENTIFICACIdN Y CONTROL
roc. 1 ""f *'m.) w. .u
Figura 4.2. La red neuronal dintimica.
Para facilidad de la discusi6n en el resto del capitulo, denotaremos por S la clase de las sistemas dintimicos no lineales generados por la red (4.6) y estableceremos sobre (4.5) la siguiente hip6tesis. H3. El sistema (4.5) pertenece a 3. l. Ley de aprendizaje: En este apartado se obtiene una ley de aprendizaje
que garantiza estabilidad de la red neuronal adem& de la convergencia de su salida y de sus pesos a unos valores deseados. Por H3 se asegura la existencia de un conjunto de valores para los pesos W;, W; tales que el sistema (4.5) queda completamente descrito por una red neuronal de la forma
donde todas las matrices son como se definieron antes.
sistema real como Definamos el error entre los estados del identificador y los estados del
e := x - X , (4.8) h
entonces, de (4.6) y (4.7) obtenemos la ecuaci6n dintimica del error
e= Ae + B1RS(z) + BZS'(X)W~U
donde

4.3. IDENTIFICACI~N 141
Y - w2 := w2 - w;.
Usanlos ahora el método de síntesis de Liapunov para derivar leyes adap- tables estables. Por lo tanto consideremos la candidata a función de Liapunov " 1
2 v(e , Wl , ~ 2 ) = -eTPe+ (4.10)
donde F' E ?XR""" es una matriz positiva definida (todos sus valores propios tienen partes reales positivas), la cual se elige de forma tal que satisfaga la denominada ecuación matricial de Liapunov
P A + ATP = -I ,
y tr ( S } representa el operador traza. Obsérvese que ya que A es una matriz diagonal, P puede elegirse también diagonal, lo cual simplifica los cálculos.
Diferenciando (4.10) a lo largo de las trayectorias del sistema de error (4.9) obtenemos
o bien, considerando que W,;C y W; son constantes
Dado que ST(x)@TB1 Pe y [email protected]'(x)Bg Pe son escalares
m
Entonces V pasa a ser
V = - l e T , + ST(x)@TBIPe + u T-T W, S I (x)B,Pe + (4.11) 2

142
Si ahora elegimos
CAPfTULO 4. IDENTIFICACI6N Y CONTROL
I
entonces (4.11) resulta
o bien
De (4.12) y (4.13) obtene
1 , V= --e e, 2
1 V= -5 5 O.
(4.12)
(4.13)
!mos las leyes de control, mismas que resultan
(4.14)
w1= -&PeST(x),
w2= - s ' ( x ) B ~ P ~ u ~ ,
o bien, en forma de elemento
w2ij= -bzipieis'(xi)uj,
Vi , j = 1,2,..- , n .
lector interesado en los detalles de la demostracidn lo remitimos a [16]. Ahora enunciamos sin prueba un resultado necesario en lo que sigue. Al
Lema 1 (De Barbalat) Sea 4 : 92 + 8 una funcidn uniformemente conti- nua en [O, 00) (lo cual se cumple s i tiene de7-ivada acotada en ese mismo intervalo). Supdngase que lim $(s)ds existe y es finito. Entonces,
t+oo
$(t) + O cuando t "+ OO.
Dos detalles sobre la notacibn. Sea 4 : 8 + 92 una funcibn definida en
Se dice que 4 E L, si es uniformemente acotada sobre [O, 00). Se dice que 4 E L2 si es cuadraticamente integrable sobre [O, 00). E n vista de los resultados y las definiciones previas estamos en posibilidad
[O, 4 .
de demostrar el siguiente teorema.

4.3. IDENTIFICACI~N 143
Teorema 3 Considérese el esquema de identificación (4.9). La ley de apren- dizaje
wlij= -blipieis(xj) w2i j= -b2ipieis’(xi)uj
’di,j = 1 , 2 , - . - , n (4.15)
garantiza las propiedades siguientes
o e , 2 , Wl , W2 E L,, además e E L2
o lirn e(t) = O , l i r n ~ 1 ( t ) = O, l i m ~ 2 ( t ) = O . t+x, t-icc t+cc
Prueba. Ya hemos mostrado que usando la ley de aprendizaje (4.15) V resulta
1 2 V= -- / ( e ( ( 5 O. 2
Por lo tanto V E L,, lo cual implica que e , W1 , E L,. Además, 2 = e +x también. es acotado. Puesto que V es una función no creciente del tiempo y
acotada por debajo, el lim V =: V, existe. Por lo tanto, integrando V entre O e 00 tenemos 1, //e(t)ll2 d t = 2 [v(o) - < m
lo cual implica que e E L2. Por definición de las funciones sigmoidales, s(xi), i = 1 , 2!, . , n son acotadas para toda x y por hipótesis las entradas a la red neuronal son acotadas, por tanto, de (4.9) tenemos que e € L,. Puesto que e E L2 n L, y e€ L,, usando el Lema de Barbalat concluimos que
“
t”*,
lirn e(t) = O. Ahora, usando en (4.15) el acotamiento de u, S(x), S’(x) y t-icc
la convergencia de e(t) a cero, tenemos que también W1 y W2 convergen a cero.
Observación 1 Bajo las hipótesis del teorema anterior, no podemos concluir nada acerca de la convergencia de los pesos a sus valores óptimos. A fin de garantizar la convergencia, se requiere que u, S(x), S’(x) satisfagan una condición de excitación persistente. Una señal z ( t ) E Rn es persistentemente excitadora en Rn si existen las constante positivas Po, PI, T tales que

144 CAPfTULO 4. IDENTIFICACI6N Y CONTROL
sin embargo, tal condicidn no puede verificarse a priori puesto que S(x) y S'(x) son funciones no lineales del estado x.
4.4 Control
En esta secci6n investigamos el problema CAMR para el sistema desconocido (4.5), el cual como ha sido establecido antes, consiste en obtener el contro- lador adaptable que genere la entrada u adecuada para que (4.5) haga el seguimiento de la trayectoria generada por algún modelo de referencia cono- cido. Partimos de la consideraci6n de que no se ha identificado el sistema a controlar, por lo cual ha de hacerse la identificacidn y control simultheamen- te y en línea. Por supuesto) el problema ha de resolverse con un identificador basado en una red neuronal.
Emplearemos como identificador la misma red (4.6) y la misma hip6tesis H3 de la secci6n anterior. Entonces, bajo la misma definici6n del error de identificaci6n (4.8), la ecuaci6n dinAmica que gobierna su comportamiento esta dada por (4.9).
Se desea ahora que los estados de (4.5) sigan los estados del modela de referencia descrito por un sistema de la forma
donde x, E !Rn son los estados del modelo, r(t) E U, A, es una matriz constante de dimensiones n X n. Suponemos que (4.16) y la funci6n g cumple con las hip6tesis H1 y H2, respectivamente) de modo que para el sistema (4.16) existen soluciones xm(t) únicas y acotadas.
Establecemos ahora un resultado conocido.
Lema 2 Sean dos vectores a, b n-dimensionales cualesquiera, entonces
Prueba. Partimos de que
pero Ila - bIl2 = (a' - b') (a - b) = a'a + b'b - 2a'b 2 O.

4.4. CONTROL 145
Definimos el error entre los estados del identificador y los estados del
e, := x -x,. (4.17) modelo como
h
Derivando (4.17) obtenemos
e,=x - x, h
o bien, al sustituir las expresiones (4.6) y (4.16)
Sea u* el valor óptimo de u dado por
donde I V . denota la pseudoinversa de W2. Al sustituir (4.19) en (4.18) ob- tenemos finalmente
e,= Ae, + T, donde T representa el error al considerar u* en lugar de un valor que am- lara los 4 últimos términos de (4.18), el cual no existe, y si existiera sería justamente u*.
Usa:mos nuevamente el método de síntesis de Liapunov para derivar las le- yes adaptables y que resulten estables. Empleando como candidata a función de Liapunov
V(e , e,,, Wl, Wz) = -eTP1e+-e~P2e,+~tr { @T@l}+:t~ { E.%2} (4.20) ” 1 1
2 2 2
donde PI se elige como P en (4.10) y P2 es una matriz positiva definida diagonal que se elige de manera que satisfaga la ecuación de Liapunov
P A + A T P = -21,

obtenemos (siguiendo el mismo procedimiento de la secci6n anterior) las leyes de aprendizaje (4.15) y obtenemos para v
1 2 V = -- lle112 + 5 [(e, T T A + 'YT) &e, + e:& (Ae, + T)] =
1 1 - - -- lle1I2 + 5 [e: (AT& + P2A) e, + 2YTP2e,] .
2
En base al lema anterior
2'YTP2ec I l lP2TI l2 + llec112 L llP21I2 llT1I2 + llecl12
donde, para el caso presente
Entonces V resulta
1 1 VI -5 lle1I2 + 'z [e: (ATP2 + P2A + 1') e, + l l ~ 2 1 I 2 llTl12] ,
es decir, según la forma como se ha elegido P2
2 VI - lle1I2 - llecll2 + llP21I2 llTll2 - (4.21)
Establecemos ahora una suposici6n sobre los errores. H4. e, e,, T son acotados para todo t 2 O. Con H4 podemos integrar (4.21); asi que si lo hacemos sobre el intervalo
[O, TI y luego dividimos sobre T, obtenemos los valores promedio
2 T 0 I - [V(T) - V(O)] I
Arreglando la expresidn anterior y considerando que V ( T ) 2 0 VT > 0 -

4.4. CONTROL 147
Tomando ahora límite al infinito obtenemos finalmente
Estamos ahora en la posibilidad de demostrar el siguiente teorema.
Teoremla 4 Sea el esquema CAMR descrito por la tripleta {(4.5), (4.6), (4.16)). Si los sistemas de la tripleta anterior cumplen con las hipótesis H l - H4, entonces el error de seguimiento e, := x - x, e n la trayectoria seguida por el sistema (4.5) respecto de la descrita por el modelo (4.16) está acotada por
Prueba. Es inmediato si consideramos que el error de seguimiento puede expresarse como
A h e , = x - - + x - x , = - e + e c
y que, en base al lema 1 , tenemos que
Observación 2 Si m 2 n (es decir, el número de entradas es al menos el número de variables del sistema, caso correspondiente al de sistemas hiperac- tuados o completamente actuados, lo cual, huelga decir, no es el caso general) y la matriz W, es de rango pleno (es decir de rango n), entonces se tiene que W2 W; = I y consecuentemente = O ; e n este caso (4.21) adopta la forma simplificada
de donde, siguiendo un razonamiento similar al desarrollado en la parte final del teorema 3, se concluye que
e , , e , e c , E , W l , W 2 EL,, e, ,e ,ec E L2
lim e,@) = O , lim e ( t ) = O , lim e,(t) = O
-N
t-+W t-w t+m
limWl ( t ) = O , Z i m ~ 2 ( t ) = O . &+m t+w

148 CAP~TULO 4. IDENTIFICACI~N Y CONTROL
Por otro lado, si m < n, que corresponde al caso de sistemas subactuados y que en la priictica se presenta con mayor frecuencia, W2Wz # I , de donde
# O y con el algoritmo de control propuesto s610 se logra una aproximacidn al problema de seguimiento.
4.5 Conclusiones
En este capitulo se estudian algunos modelos para la identificacih y control de sistemas no lineales desconocidos. Otros modelos se han propuesto en la literatura [18]. Estos modelos, que incluyen redes neuronales multicapas y sistemas lineales, pueden ser vistos como redes neuronales generalizadas. El empleo de técnicas de Liapunov permite obtener algoritmos de aprendizaje estables para los modelos específicos dados. Varias suposiciones se .hicieron en relación con l a s caracteristicas de la planta, por ejemplo, se supone que ésta tiene salidas acotadas para la clase de entradas especificada.
Puesto que la planta es desconocida, se considera un algoritmo de dos pasos. E n el paso uno, se emplea un identificador basado en una red neuronal dintimica para llevar a cabo la identificación. Se prueba la convergencia de los errores de identificacidn y de pesos (bajo la condición de suficiencia en la excitación) a cero y a unos valores constantes, respectivamente. Dado que para fines de control sólo se requiere de una estimación gruesa de la región a la cual deben pertenecer los pesos, se puede proceder a la segunda fase del algoritmo, es decir el control, en el cual se desarrolla una retroalimentación dintimica de estado tal que las salidas de la planta desconocida sigan las salidas de un modelo de referencia. Se prueba la convergencia a cero del error y el acotamiento de las señales en lazo cerrado.

Bibliografía
[l] J. A . Freeman y D. M. Skapura, Redes Neuronales: algoritmos, apli- caciones y técnicas de programación. Addison-Wesley/Díaz de Santos, 1991.
[a] K. Fukushima, ”Cognitron: a self organizing multilayered neural net- work”. Biological Cybernetics, 20, pp. 121-136, 1975.
[3] K. Fukushima, ”Neocognitron: a self organizing neural network model for a mechanism of pattern recognition unaffected by shift in position”. Biological Cybernetics, 36, pp. 193-202, 1980.
[4] K. Fukushima and S. Miyake, ”Neocognitron: a new algorithm for pat- ter:n recognition tolerant of deformation and shifts in position”. Pattern Recognition, 15, pp. 455-469, 1982.
[5] K. Fukushima, S. Miyake and T. Ito, ”Neocognitron: a neural network moldel for a mechanism of visual pattern recognition”. IEEE Trans. on Systems, Man and Cybernetics, SMC-13, pp. 826-834, 1983.
[6] K. Fukushima, ”Neural network model for selective attention in visual pattern recognition and associative recall”. Applied Optics, 26, pp. 4985- 4992, 1987.
[7] K. Fukushima, ”Neocognitron: a hierarchical neural network capable of visual pattern recognition”. Neural Networks, 1, pp. 119-130, 1988.
[8] K. Fukushima, ”A neural network for visual pattern recognition”. Com- puter (IEEE Computer Soc.), 21, pp. 65-75, 1988.
[9] K. Fukushima, ”Neural Networks for visual pattern recognition”. IEICE Transactions, E-74, pp. 179-190, 1991.
149

4
150 BIBLIOGRAF~A
[lo] S. Haykin, Neural networks: a comprehensive foundation. Macmillan College Publishing Company, 1994.
[ll] R. Hecht-Nielsen, Neurowmputing. Addison-Wesley Publishing, 1990.
[12] J. R. Hilera, y V. J. Martinez, Redes Neuronales Artificiales: fundamen- tos, modelos y aplicaciones. Addison-Wesley Iberoamericana, 1995.
[13] D. H. Hubel and T. N. Weisel, "Receptive fields, binocular interaction and functional architecture in cat's visual cortex". J. Phisiol., 160, pp. 106-154, Jan. 1962.
[14) D. H. Hubel and T. N. Weisel, "Receptive fields and functional archi- tecture in two nonstriate visual areas (18 and 19) of the cat". J. Neuro- phisiol., 28, PP. 229-289, 1965.
[15] A. K. Jain, J. Mao and K. M. Mohiuddin, "Artificial Neural Networks: A Tutorial". Computer, IEEE, March 1996, pp. 31-44.
[16] H. K. Khalil, Nonlinear systems, Prentice Hall, 1996.
[17] R. P. Lippmann, "An Introduction to Computing with Neural Networ- ks", IEEE ASSP Mag., april 1987, pp. 4-22.
[18] K. S. Narendra and K. Parthasarathy, "Identification and control of dy- namical systems using neural networks", IEEE Dans. Neural Networks, 1, pp. 4-27, 1990.
[19] K. Ogata, Ingenieda de wntrol moderna, Prentice Hall, 1980.
[20] G. A. Rovithakis and M. A. Christodoulou, "Adaptive control of unkno- wn plants using'dynamical neural networks", IEEE Trans. on Systems, Man and Cybernetics, 24, pp. 400-412, 1994.