tema 8: teoría de la respuesta al Ítem 2. · i son funciones de respuesta al item que dependen de...
TRANSCRIPT

1
Tema 8: Teoría de la Respuesta al Ítem (2).
Índice1. La estimación de los parámetros de los modelos2. Estimación de la habilidad: Método de Máxima
Verosimilitud3. Estimación de los parámetros de los items o calibración4. Ajuste de los datos al modelo5. La escala de la habilidad: Curva característica del test6. La información del ítem y del test7. Función de información y error típico de estimación8. La función eficiencia relativa y la construcción del test9. Otros modelos de la TRI

2
1. Estimación de los parámetros
El aspecto más importante de la aplicación de los modelos de la TRI a los datos de un test es el de la estimación de los parámetros que caracterizan al modelo elegido. En todos los modelos, la probabilidad de una respuesta correcta depende de la aptitud del examinado , y de los parámetros que caracterizan al ítem. Todos estos parámetros son, en principio, desconocidos; lo único conocido son las respuestas de los sujetos a los ítems del test y a partir de ellas debe realizarse la estimación.
1. Estimación de los parámetros
El problema de la estimación consiste en determinar el valor de θ para cada sujeto y el de los parámetros de cada ítem, a partir de las respuestas dadas por una muestra de sujetos a los ítems. Hasta cierto punto, el problema es similar al conocido del análisis de regresión, en el que deben estimarse los parámetros del modelo (α,β) a partir de respuestas observadas en las variables predictoras. No obstante, los problemas de estimación en la TRI son más complejos que en el caso de la regresión lineal, ya que en ésta el modelo es lineal y las variables independientes son observadas.

3
1. Estimación de los parámetros
La estimación de los parámetros puede llevarse a cabo de diversas formas, y en la literatura sobre TRI abundan los métodos. Aunque son muchos, consideraremos aquí únicamente los más conocidos e implementados en los programas de ordenador más utilizados.Normalmente se buscan los valores de los parámetros que mejor se ajustan a los datos. En los modelos de regresión lineal el mejor ajuste se realiza por el criterio de mínimos cuadrados y alternativamente pueden estimarse por procedimientos de máxima verosimilitud, MV (ML, del inglés MaximumLikelihood); este último criterio es el utilizado en la estimación de parámetros en los modelos de la TRI.
2.Estimación de los parámetros: Máxima Verosimilitud.
En la práctica, la estimación de los parámetros debe realizarse utilizando un programa de ordenador, ya que resulta imposible realizar los cálculos requeridos a mano. No obstante, para hacernos una idea del procedimiento de estimación de máxima verosimilitud presentamos a continuación la estimación de la aptitud, supuestos conocidos los parámetros de los ítems.

4
2. Estimación de los parámetros de habilidad
Sea un test compuesto por n items y un sujeto s aleatoriamenteseleccionado de entre los que han respondido al test. Los elementos del test son dicotómicos con respuestas posibles:
uis = 1 si el sujeto acierta el ítemuis = 0 en otro caso
Supongamos que el sujeto tiene un patrón de respuestas a los n items que representamos como
(u1 , u2 ,......, un ) Por el supuesto de independencia local, la probabilidad conjuntade observar dicho patrón de respuesta es el producto de las probabilidades de respuesta de cada item, supuesto un nivel de aptitud , es decir:
1 2 1 21
( , ,....., | ) ( | ) ( | )...... ( | ) ( | )n
n s s n s i si
P U U U P u P u P u P Uθ θ θ θ θ=
= =∏
2. Estimación de los parámetros de habilidad
Puesto que uis es una variable binaria, que solamente toma valores 0 o 1, podemos sustituir las probabilidades indicadas por su función de probabilidad:
11 2
1
( , ,....., | ) ( | ) [1 ( | )]i i
nu u
n s i s i si
P U U U P U P Uθ θ θ −
=
= −∏
11 2
1
( , ,....., | ) i i
nu u
n s i ii
P u u u P Qθ −
=
=∏

5
2.Función de verosimilitudLa expresión anterior representa la probabilidad conjunta de un patrón de respuesta. Cuando es observado, Uis=uis, y la probabilidad conjunta se denomina función de verosimilitud y se denota como:
Puesto que Pi y Qi son funciones de θ y de los parámetros del item, la función de verosimilitud también será función de estos parámetros.
11 2
1
( , ,......., | ) i i
nu u
n i ii
L u u u P Qθ −
=
=∏
2.Función de VerosimilitudComo ejemplo de aplicación de la función de verosimilitud, consideremos el caso de un test formado por tres ítems que siguen un modelo de 2P y de un sujeto con vector de respuestas (0,1,1).Los parámetros de los items son los siguientes:
Item a b1 0,50 0,502 1,00 0,003 1,50 -0,50
Aunque θ es continua, vamos a considerarla para el ejemplo como una escala discreta con solamente siete valores posibles, con saltos de una unidad.
-3,-2,......,+3,

6
2. Función de Verosimilitud
θ P1 P2 P3 Verosimilitud
LnVer.
-3 .148 .047 .023 0,001 -6,9900
-2 .223 .119 .095 0,009 -4,7348
-1 .321 .269 .321 0,059 -3,8365
0 .438 .500 .679 0,191 -1,6565
1 .562 .731 .905 0,290 -1,2387
2 .679 .881 .977 0,276 -1,2600
3 .777 .953 .995 0,211 -1,5537
La verosimilitud se calculó como:1 2 3(1 )L P P P= −
2. Función de VerosimilitudPara la obtención de las probabilidades P1 , P2 y P3 , por simplificar los cálculos, no se multiplicó por el factor de escala 1.7, por lo que se trataría del modelo logístico de 2P, 2PL.Puesto que Pi y Qi son funciones de respuesta al item que dependen de los parámetros de éstos y son conocidos, han podido calcularse los valores exactos de la función para diferentes valores de θ. No obstante, es más conveniente transformar la función de verosimilitud a otra escala, tomando logaritmos, para transformar el producto en sumatorioy simplificar los cálculos. El logaritmo de la función de verosimilitud será :
En la última columna de la tabla se presentan los cálculos para los 7 niveles de aptitud. Puede observarse como el máximo se encuentra en θ =1, tanto para L como para lnL.
[ ]1
ln ( | ) ln (1 ) ln(1 )n
i i i ii
L u u P u Pθ=
= + − −∑

7
2. Función de Verosimilitud
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00
habilidad
0,00000
0,05000
0,10000
0,15000
0,20000
0,25000
0,30000
Vero
sim
ilitu
d
2. Ln de la Verosimilitud
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00
habilidad
-7,00000
-6,00000
-5,00000
-4,00000
-3,00000
-2,00000
-1,00000
ln_v
eros
imilu
tud

8
2. Máximo de L y lnLUna propiedad interesante del máximo es que en él la pendiente de la curva es igual a cero. Por lo tanto, para encontrar el valor máximo podemos encontrar el valor de θ en que la pendiente se hace cero. Recordemos que la pendiente de la curva se describe por la derivada primera de la función, por lo tanto, conceptualmente, encontrar el maxconsistirá en establecer la derivada primera de la función L (o de lnL), f'(L), hacer f'(L)=0 y resolver la ecuación para encontrar el máximo.
2. Máximo de L y lnLEl problema de encontrar el máximo de la función, en realidad es difícil; el anterior procedimiento gráfico fue usado para propósitos ilustrativos y con una escala discreta, pero no es factible en general. Determinar la derivada primera de la función, igualarla a 0 y resolver para θ, aunque conceptualmente simple también es extremadamente complejo. La escala es continua con un número infinito de valores posibles. Para obtener de forma precisa el estimador de máxima verosimilitud y tratar a θcomo una escala continua, necesitamos utilizar algoritmos de optimización que sigan este principio básico, pero sin resolver realmente para f'(L) = 0. El algoritmo de optimización usado con más frecuencia en la estimación de los parámetros por máxima verosimilitud, es el procedimiento de Newton-Raphson, que es un algoritmo de optimización de propósito general, que iterativamenteestima valores máximos o mínimos sin calcular el valor exacto, hasta que el verdadero valor se aproxima. En la práctica se trabaja con lnL.Los programas actuales utilizan otros algoritmos como EM y de Fisher

9
3. Estimación de los parámetros de los ítems
En el apartado anterior se ha supuesto que se conocían los parámetros del ítem para estimar la aptitud; para ello se administra un conjunto de ítems a los sujetos y se obtiene el estimador ML de a partir del patrón de respuestas a los n ítems. Recíprocamente, si queremos estimar los parámetros del ítem cuando se conoce para los examinados, administramos el ítem de interés a muchos sujetos y se obtiene la función de verosimilitud para las respuestas de los N sujetos al ítem, es decir:
11 2
1
( , ,....., | , , , ) s s
Nu u
Ns
L u u u a b c P Qθ −
=
=∏
3. Procedimientos de estimación
Aunque hay muchos procedimientos para la estimación de los parámetros los más utilizados son Máxima Verosimilitud Conjunta (MLC) y Máxima verosimilitud Marginal (MLM). El primer procedimiento es posible con los modelos de Rasch, en los que la puntuación total es un estimador suficiente de la aptitud. Los procedimientos de máxima verosimilitud marginal son los utilizados en la actualidad en el software moderno.

10
3. EstimaciónLa función de verosimilitud conjunta cuando N examinados responden a n items, usando el supuesto de independencia local es:
Los estimadores de los parámetros se obtienen buscando los valores a que maximizan la expresión anterior o su logaritmo neperiano, dado por
11 2
1 1
( , ,...., | , , , ) a ai i
i i
N nu u
N a aa i
L u u u a b c P Qθ −
= =
=∏∏
[ ]1 1
ln ln (1 ) lnN n
ai ai ai aia i
L u P u Q= =
= + −∑∑
3. Estimación: Indeterminación de la escala
La escala de habilidad, θ, en la que se estima la habilidad de los sujetos y la dificultad de los ítems, tiene una métrica indeterminadaSuele establecerse la escala típica (media 0, desviación típica 1) en la fase de estimaciónEstá métrica puede transformarse linealmente, mediante constantes de escalamiento, permaneciendo invariantes las probabilidades y todas las propiedades de los estimadoresPara constantes de transformación α y β, son posibles las transformaciones lineales de la habilidad, realizando también las correspondientes transformaciones de los parámetros de los ítems:
*** /
b ba a
θ αθ βα β
α
= += +=

11
4. Ajuste de datos al modeloTests estadísticos de ajuste de los modelos
Test de razón de verosimilitud (programa BILOG-MG)
Análisis de los residuos
( )
( ) 1 ( ) /ij ij
ij
ij ij j
P E Pz
E P E P N
−=
⎡ ⎤−⎣ ⎦
2
11
( )
( )(1 ( )
mj ij ij
j ij ij
N P E PQ
E P E P=
⎡ ⎤−⎣ ⎦=⎡ ⎤−⎣ ⎦
∑
Gl = m-k, m=nº intervalos, k =nºparámetros de items
5. Escala de habilidad y curva característica del test
Recordemos del tema de la TCT que la puntuación observada X se define normalmente como suma de los aciertos a los ítems, siendo definida la puntuación verdadera como la esperanza de las puntuaciones observadas. Aplicando el mismo concepto, basado en las respuestas a los ítems:
Por lo tanto, la puntuación verdadera para un sujeto con nivel de aptitud θ es la suma de las probabilidades de acertar los items en ese nivel de aptitud.
∑=
=n
iiuEV
1
)(
1
( ) (1) ( ) (0) ( ) ( )
( )
i i s i s i s
n
s i si
E u P Q P
V P
θ θ θ
θ=
= + =
=∑

12
5. Ejemplo para θ=1Item a b c P (θ=1)
1 1,00 -1,00 0,00 0,97
2 1,20 0,00 0,10 0,90
3 1,50 1,00 0,15 0,58
4 2,00 2,00 0,20 0,22
V = 0,97 + 0,90 + 0,58 + 0,22 = 2,67
5. Ejemplo de Función Característica del Test
θ P1(θ) P2(θ) P3(θ) P4(θ) ∑= )( aiPV θ
-3 0.03 0.10 0.15 0.20 0.48-2 0.15 0.11 0.15 0.20 0.61-1 0.50 0.20 0.16 0.20 1.060 0.85 0.55 0.21 0.20 1.811 0.97 0.90 0.58 0.22 2.672 0.99 0.99 0.94 0.60 3.523 1.00 1.00 1.00 0.96 3.96
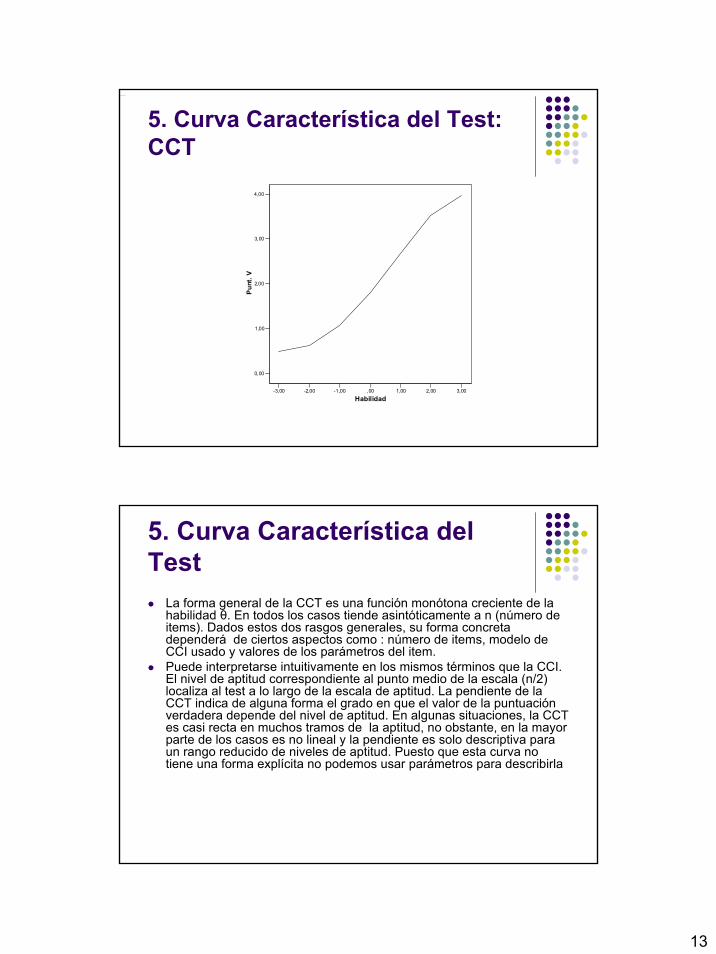
13
5. Curva Característica del Test: CCT
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00Habilidad
0,00
1,00
2,00
3,00
4,00
Punt
. V
5. Curva Característica del Test
La forma general de la CCT es una función monótona creciente de la habilidad θ. En todos los casos tiende asintóticamente a n (número de items). Dados estos dos rasgos generales, su forma concreta dependerá de ciertos aspectos como : número de items, modelo de CCI usado y valores de los parámetros del item. Puede interpretarse intuitivamente en los mismos términos que la CCI. El nivel de aptitud correspondiente al punto medio de la escala (n/2) localiza al test a lo largo de la escala de aptitud. La pendiente de la CCT indica de alguna forma el grado en que el valor de la puntuación verdadera depende del nivel de aptitud. En algunas situaciones, la CCT es casi recta en muchos tramos de la aptitud, no obstante, en la mayor parte de los casos es no lineal y la pendiente es solo descriptiva para un rango reducido de niveles de aptitud. Puesto que esta curva no tiene una forma explícita no podemos usar parámetros para describirla

14
5. Curva característica del testCuando usamos modelos de 1 y 2 parámetros para los n ítems de un test, el lado izquierdo de la curva se aproxima a 0 a medida que la aptitud tiende a y el límite superior se aproxima al número de ítems, a medida que la aptitud tiene a + infinito. Si usamos el modelo de tres parámetros para los n ítems, la cota inferior de la CCT tiende a la suma de los parámetros c de los ítems del test en vez de a 0. Esto significa que bajo este modelo, sujetos con una aptitud extremadamente baja pueden tener puntuaciones verdaderas distintas de 0 simplemente por adivinación.
5. Curva característica del testEl papel de la CCT es proporcionar un procedimiento para transformar las puntuaciones de aptitud en puntuaciones verdaderas. Esto suele ser de interés en situaciones prácticas donde el usuario del test puede ser incapaz de interpretar una puntuación de aptitud. De esta forma tiene un número que guarda relación con el número de ítems del test, que será un marco de referencia familiar. También jugará un importante papel, como veremos, en los procedimientos de equiparación de puntuaciones de los tests y en ciertas transformaciones útiles equivalentes al porcentaje de aciertos, muy interesantes para la presentación de resultados en las evaluaciones a gran escala.

15
5. Proporción de aciertos
En el contexto de los Tests Referidos al Criterio y de las interpretaciones basadas en estándares, suele obtenerse la proporción de aciertos o puntuación del dominio que se calcula dividiendo V por el número de items del test:
Esta proporción de aciertos está acotada al intervalo [0,1] para los modelos 1P y 2P. Para el modelo 3P es la asíntota inferior, es decir: .
∑=
=n
iaia P
n 1
)(1 θπ
∑= nciπ
5. Relaciones entre θ, V y πθ V π
_________________________-3 0.48 0.12-2 0.61 0.15-1 1.06 0.260 1.81 0.451 2.67 0.672 3.52 0.883 3.96 0.99

16
6. Información de un ítemEl concepto de información sustituye al de la fiabilidad de la TCTLa función de información del ítem en un nivel concreto θ, es función de:
La discriminación del ítem (directamente proporcional) , representada por la pendiente ai en el punto θ (derivada primera en dicho punto), de modo que a mayor pendiente, mayor información. La desviación típica del ítem en θ (inversamente proporcional) , de modo que a menor desviación típica o varianza mayor información
6. Información del ítem
[ ])()(
)()(2'
θθθθ
ii
ii QP
PI =
donde:
[ ])(' θiP es la derivada primera de la CCI en θ
[ ]( ) ( )i iP Qθ θ es la varianza del ítem en θ

17
7. Función de información del ítem
La definición concreta de la función de información del item depende del modelo de CCI y debemos examinar estas definiciones para cada modelo. Sustituyendo P' (θ) por las correspondientes derivadas en cada caso, obtendremos las diferentes funciones de información.
7. Información del ítem
Para el modelo de tres parámetros :
ii
iiiii Pc
cPQaDI 2
222
)1()()(
−−
=θ
Para el modelo de dos parámetros:
iiii QPaDI 22)( =θ
Para el modelo de un parámetro:
iii QPDI 2)( =θ

18
7. Información máxima del ítem
Birbaum (1968) demostró que un ítem proporciona información máxima en aquel valor de θ coincidente con el parámetro de dificultad, en los modelos de uno y dos parámetros. En el modelo de tres parámetros, la información máxima se alcanza en:
[ ]ii
i cDa
bI 81150.ln1)(max +++=θ
7. Función de información de un itemcon b=1, para diferentes niveles de aptitud.
-3 -4,0 897,85 0,001 0,999 0,000 2,89 .0000 -2 -3,0 164,02 0,006 0,994 0,006 2,89 .0173 -1 -2,0 29,96 0,032 0,968 0,031 2,89 .0896 0 -1,0 5,47 0,154 0,846 0,130 2,89 .3757 1 0,0 1,00 0,500 0,500 0,250 2,89 .7225 2 1,0 0,18 0,846 0,154 0,130 2,89 .3757 3 2,0 0,03 0,968 0,032 0,031 2,89 .0896
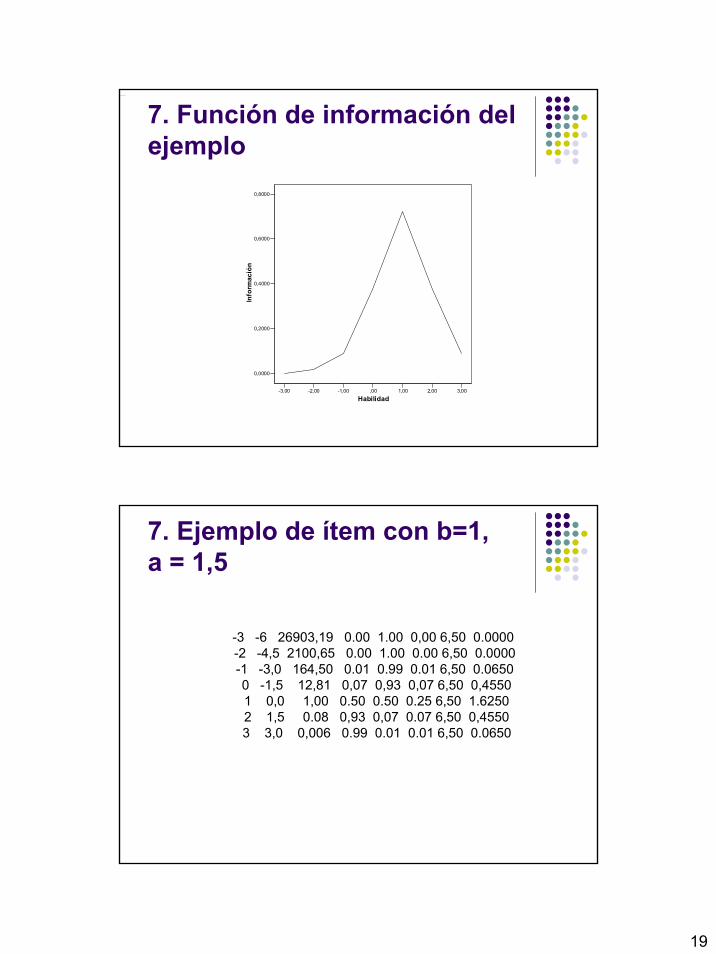
19
7. Función de información del ejemplo
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00Habilidad
0,0000
0,2000
0,4000
0,6000
0,8000
Info
rmac
ión
7. Ejemplo de ítem con b=1, a = 1,5
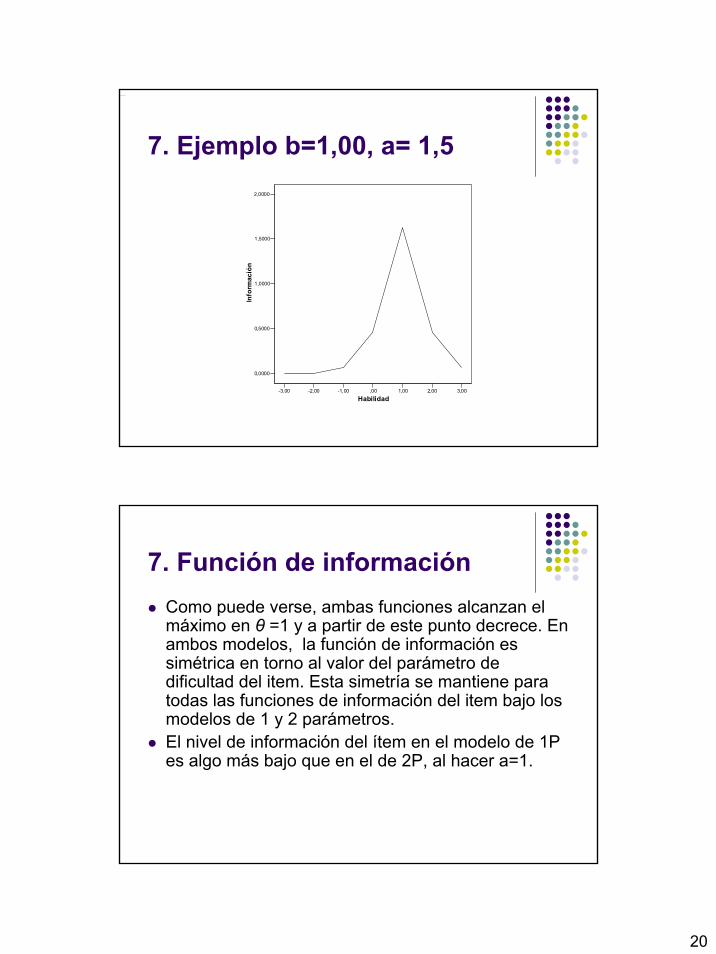
-3 -6 26903,19 0.00 1.00 0,00 6,50 0.0000 -2 -4,5 2100,65 0.00 1.00 0.00 6,50 0.0000 -1 -3,0 164,50 0.01 0.99 0.01 6,50 0.0650 0 -1,5 12,81 0,07 0,93 0,07 6,50 0,4550 1 0,0 1,00 0.50 0.50 0.25 6,50 1.6250 2 1,5 0.08 0,93 0,07 0.07 6,50 0,4550 3 3,0 0,006 0.99 0.01 0.01 6,50 0.0650
20
7. Ejemplo b=1,00, a= 1,5
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00Habilidad
0,0000
0,5000
1,0000
1,5000
2,0000
Info
rmac
ión
7. Función de informaciónComo puede verse, ambas funciones alcanzan el máximo en θ =1 y a partir de este punto decrece. En ambos modelos, la función de información es simétrica en torno al valor del parámetro de dificultad del item. Esta simetría se mantiene para todas las funciones de información del item bajo los modelos de 1 y 2 parámetros. El nivel de información del ítem en el modelo de 1P es algo más bajo que en el de 2P, al hacer a=1.

21
7. Función de Información del test
Puesto que lo que usamos para estimar la habilidad son tests formados por conjuntos de ítems, nos interesa conocer la cantidad de información proporcionada por el test en los diversos niveles de habilidad. La información de los ítems es aditiva, por lo que la información del test en un nivel de habilidad no es más que la suma de las informaciones de sus ítems en este nivel. Por lo tanto, la función de información de un test de n ítems se define como
∑=
=n
iiII
1)()( θθ
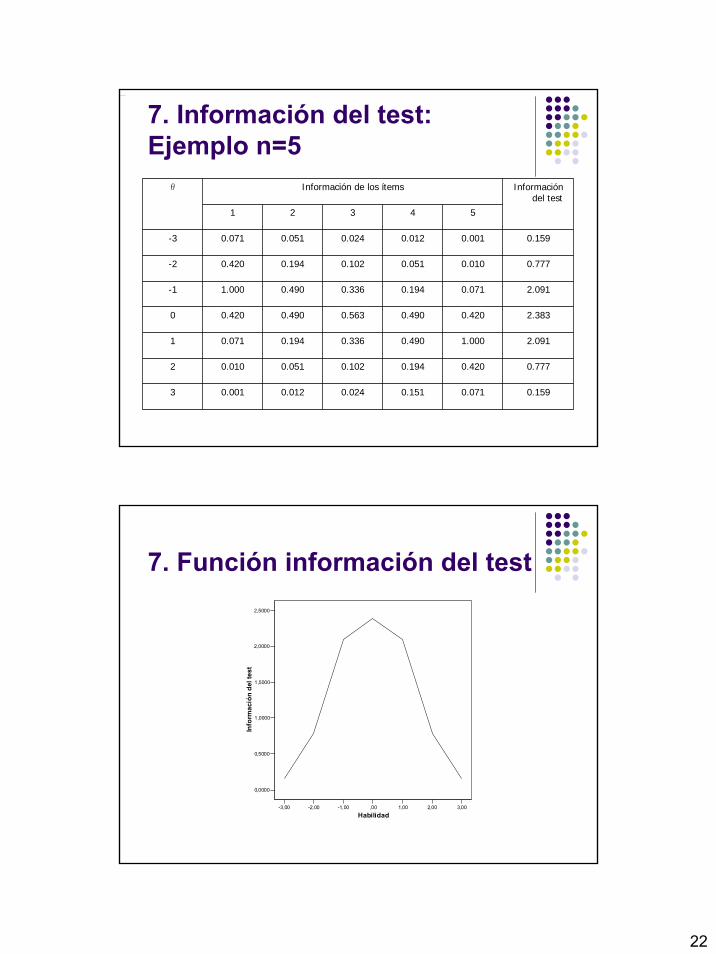
7. Información del test: Ejemplo de test con 5 items
Item b a
1 -1.0 2.0
2 -0.5 1.5
3 0.0 1.5
4 0.5 1.5
6 1.0 2.0
22
7. Información del test: Ejemplo n=5
Información de los ítemsθ
1 2 3 4 5
-3 0.071 0.051 0.024 0.012 0.001 0.159
-2 0.420 0.194 0.102 0.051 0.010 0.777
-1 1.000 0.490 0.336 0.194 0.071 2.091
0 0.420 0.490 0.563 0.490 0.420 2.383
1 0.071 0.194 0.336 0.490 1.000 2.091
2 0.010 0.051 0.102 0.194 0.420 0.777
3 0.001 0.012 0.024 0.151 0.071 0.159
Información del test
7. Función información del test
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00Habilidad
0,0000
0,5000
1,0000
1,5000
2,0000
2,5000
Info
rmac
ión
del t
est

23
7. Error típico de estimación de θ
La función de información permite obtener un error típico de estimación o de medida en cada nivel de habilidad. Este es otro de los aspectos importantes de la TRI, ya que nos libera del supuesto de la homocedasticidad de la TCT. La función error típico tiene una relación inversa con la función de información (como sucedía en la TCT con el error típico de medida y el coeficiente de fiabilidad) y se define como:
Conceptualmente es un análogo en cuanto a su interpretación del error típico de medida de la TCT, pero no es un índice único para el test, sino una función que cambia con los valores de θ. Para un test cualquiera habrá tantos errores típicos como valores diferentes tome la habilidad. Un test podrá ser preciso para ciertos valores de θ e impreciso para otros. Permite la construcción de intervalos de confianza para θ
)(1)(θ
θI
ET =
Ejemplo: Error típicoΘ ET(θ)
-3 5,95
-2 2.22
-1 0.47
0 0.41
1 0.47
2 2.22
3 5.95

24
7. Función error típico
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00Habilidad
0,50
1,00
1,50
2,00
2,50
Err
or tí
pico
7. Funciones de información y error típico de estimación
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00Habilidad
0,0
0,5
1,0
1,5
2,0
2,5
3,0
Valo
res
inftestetipico

25
7. Usos de la función de información en el diseño de tests
La forma deseada de la función de información depende del propósito para el que el test estédiseñado, pero pueden darse algunas reglas generales. Una función de información con un pico en algún punto de la escala revela que el test mide con diferente precisión a lo largo del continuo de habilidad. Este test será mejor para estimar las habilidades de sujetos que estén próximos a este máximo. En algunos tests la función es casi plana en alguna región del continuo, lo que indica que en ese rango estima con una precisión muy similar.
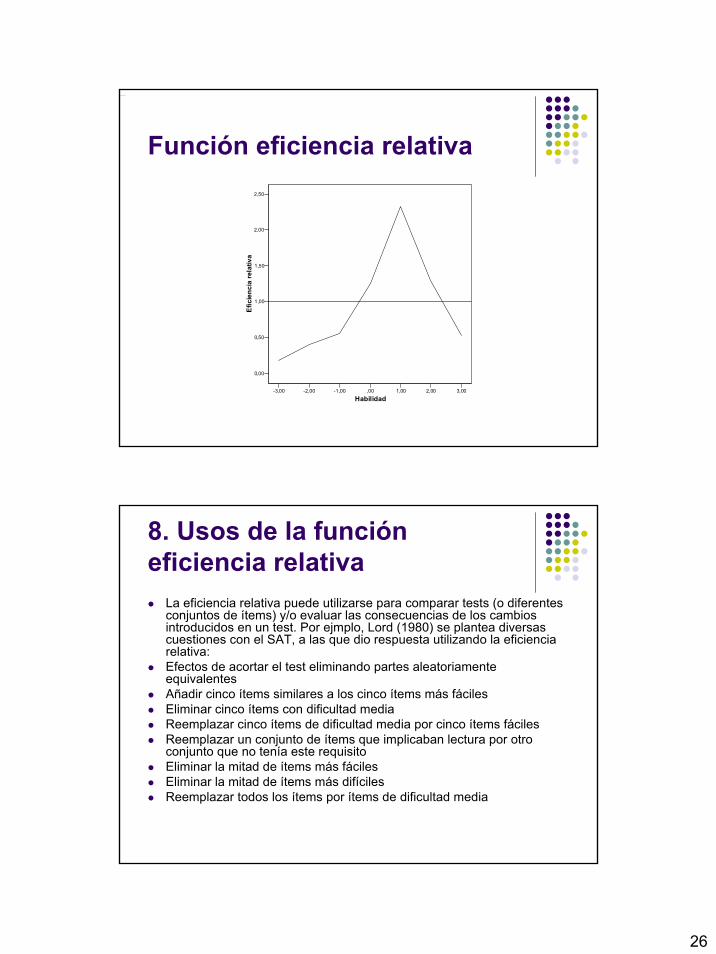
8. Eficiencia relativa del test
La función de información del test tiene otra importante aplicación en la construcción de tests por medio de la función de eficiencia relativa de dos tests o de dos conjuntos diferentes de ítems, que denotamos como X e Y. Definimos la función como:
)()(),;(
θθθ
Y
X
IIYXER =
26
Función eficiencia relativa
-3,00 -2,00 -1,00 ,00 1,00 2,00 3,00Habilidad
0,00
0,50
1,00
1,50
2,00
2,50
Efic
ienc
ia re
lativ
a
8. Usos de la función eficiencia relativa
La eficiencia relativa puede utilizarse para comparar tests (o diferentes conjuntos de ítems) y/o evaluar las consecuencias de los cambios introducidos en un test. Por ejmplo, Lord (1980) se plantea diversas cuestiones con el SAT, a las que dio respuesta utilizando la eficiencia relativa:Efectos de acortar el test eliminando partes aleatoriamenteequivalentesAñadir cinco ítems similares a los cinco ítems más fácilesEliminar cinco ítems con dificultad mediaReemplazar cinco ítems de dificultad media por cinco ítems fácilesReemplazar un conjunto de ítems que implicaban lectura por otro conjunto que no tenía este requisitoEliminar la mitad de ítems más fácilesEliminar la mitad de ítems más difícilesReemplazar todos los ítems por ítems de dificultad media

27
9. Modelos para itemspolitómicosSuperan el nivel del curso. Puede encontrarse información en:
Embretson & Reise (2000). Item response theory forpsychologists. Erlbaum. Martínez Arias, R., Hernández Lloreda, V. y Hernández Lloreda, MJ. (2006). Psicometría. Alianza Universidad. Ostini, R., & Nering, ML (2005). Polytomous item response theory. Sage. Revuelta, J., Abad, F.J. y Ponsoda, V. (2006). Modelos politómicos de la respuesta al ítem. La Muralla. Madrid.Van der Linden & Hambleton (eds.) (1997). Handbbok of Itemresponse Theory. Springer.