taller metodológico - siep.org.pe · ... al final se cuenta con una base que por si sola no dice...
TRANSCRIPT

Taller Metodológico:CONCEPTOS Y FUNDAMENTOS
BÁSICOS EN ANÁLISIS ESTADÍSTICO DESCRIPTIVO
Juan León Jara Almonte
GRADE

¿Por qué hacer análisis descriptivo?
¿ Qué hacer con estos datos?

ESTADISTICA DESCRIPTIVA

DefiniciónCuando se hace una recolección de datos, al final se cuenta con una base que por sisola no dice nada y necesita ser trabajada para poder tener información acerca de loque se recogió en campo.
De esta manera, el análisis descriptivo de una base de datos sirve para tal fin, nospermite describir la información recogida en campo. Asimismo, el tipo de análisisdescriptivo que se realiza dependerá del tipo de variable que se está analizando.
Los tipos de análisis descriptivo que se pueden realizar son:
Análisis de tendencia central (p.ej.: media)
Análisis de dispersión (p.ej.: varianza)
Comparación de medias:
Test Paramétricos (p.ej.: ANOVA)
Test No Paramétricos (p.ej.: Chi cuadrado)

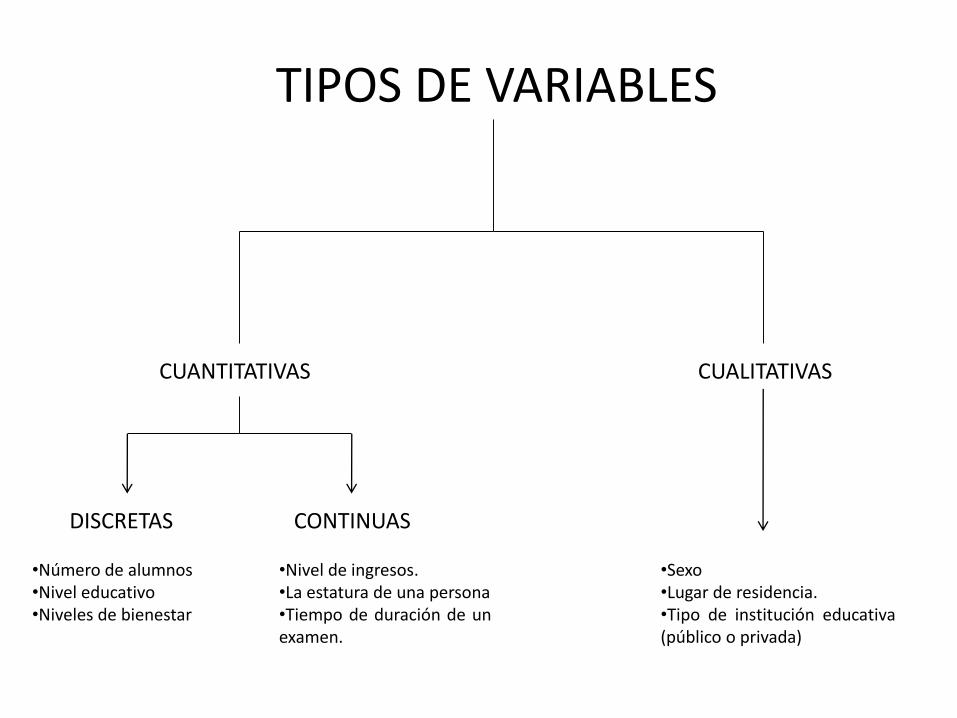
Tipos de Variables
Antes de comenzar a ver los tipos de análisis que se pueden desarrollar, es necesario conocer los tipos de variables que hay, estos son:
Variables Cuantitativas
Variables Cualitativas

Variables Cuantitativas
Los valores de este tipo de variables son números que se pueden ordenar y/o comparar de menor a mayor. Este tipo de variables se pueden dividir en dos:
• Discretas: aquellas que pueden tomar solo valores enteros, como por ejemplo: Número de hijos, Años de escolaridad.
• Continuas: aquellas que pueden tomar cualquier valor dentro de los números reales, como por ejemplo: la estatura de un grupo de personas, el nivel de ingresos de las personas en Lima metropolitana, entre otras.

Variables Cualitativas
• Estas variables representan características y/oatributos de una persona, lugar o cosa. No sepueden ordenar, lo que implica que ningúnvalor que tome es mayor o menor que el otro.
• Algunos ejemplos de este tipo de variables son: el género, estado civil, etnicidad, entre otras.
TIPOS DE VARIABLES
CUANTITATIVAS CUALITATIVAS
DISCRETAS CONTINUAS
•Número de alumnos•Nivel educativo•Niveles de bienestar
•Nivel de ingresos.•La estatura de una persona•Tiempo de duración de unexamen.
•Sexo•Lugar de residencia.•Tipo de institución educativa(público o privada)

MEDIDAS DE TENDENCIA CENTRAL

Medidas de tendencia central (i)
Las medidas de tendencia central nos muestran alrededor de qué punto se agrupan la mayoría de las observaciones de una variable.
Las medidas de tendencia central más usadas son: Media
Mediana
Moda

Medidas de tendencia central (ii)
Media aritmética: es el valor promedio de una serie de datos, el cual se obtiene dividendo la suma de los valores de la variable entre el número de observaciones.
Por ejemplo: 1, 2, 3, 4, 6, 8
∑ = 24 , N=6, Media = 4
N
x
N
xxxxxX
N
i
i
NN
11321 ........

Medidas de tendencia central (iii)
Mediana: La mediana de una variable es el valor quedivide los datos en dos partes iguales. El número deobservaciones menores a la mediana es igual alnumero de observaciones mayores a esta.
Por ejemplo: 1, 6, 12, 72, 144
Mediana: 12
Cuando se cuenta con una serie de datos par, lamediana es el promedio de los números del medio.

Medidas de tendencia central (iv)
Moda: es el valor de una variable que se presenta con mayor frecuencia en la variable.
Por ejemplo: 1, 2, 3, 3, 3, 3, 3, 4, 5, 6
Moda: 3

MEDIDAS DE DISPERSIÓN

Medidas de dispersión (i)
Medidas que permiten medir la variabilidad que presenta los valores de una variable, es decir, nos dan un alcance de la dispersión de los datos.
Las medidas de dispersión más usadas son: La varianza
La desviación estándar
El coeficiente de variación

Medidas de dispersión (ii)
Varianza: es la medida de dispersión de unavariable, es decir son las diferencias entre el valorobservado y su valor medio o esperado alcuadrado. Suele denotarse con la letra griegasigma ( σ ) elevada al cuadrado.
Donde X es la variable que estamos analizando yn es el número de observaciones
1
)()(
2
2
n
XXVar
x

Medidas de dispersión (iii)
Desviación estándar: es la raíz cuadrada de lavarianza. Al igual que la varianza, sueledenotarse con la letra griega sigma.
Donde X es la variable que estamosanalizando y n el numero de observaciones.
1
)()(
2
n
XXDE
x

Medidas de dispersión (iv)
Coeficiente de variación (CV): se utiliza paracomparar la dispersión de dos distribucionesdistintas dado que elimina la escala (p.ej.:kilogramos, metros) de las variables que secomparan.
El CV se obtiene del ratio de la desviación estándarde una variable y su media.
X
XVar
XMedia
EDXVC
)(..).(.
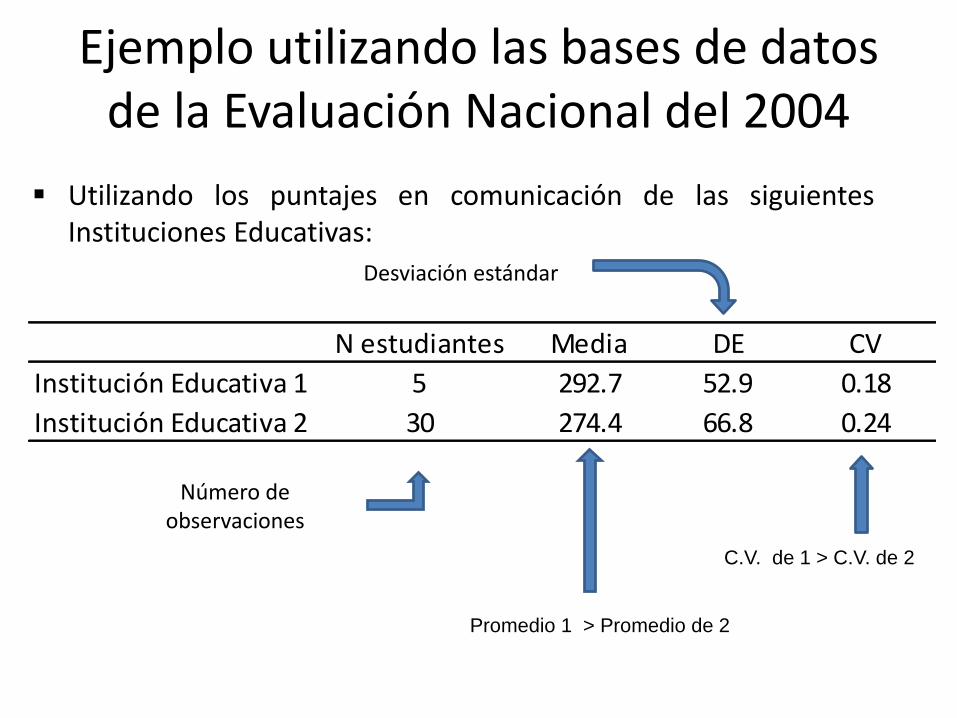
Ejemplo utilizando las bases de datos de la Evaluación Nacional del 2004
Utilizando los puntajes en comunicación de las siguientesInstituciones Educativas:
Promedio 1 > Promedio de 2
C.V. de 1 > C.V. de 2
Número de observaciones
Desviación estándar
N estudiantes Media DE CV
Institución Educativa 1 5 292.7 52.9 0.18
Institución Educativa 2 30 274.4 66.8 0.24

Ejemplo usando diferentes variables
N Edad (años) Estatura (cm) Peso (kg)
1 18 167 60
2 35 172 85
3 20 160 70
4 46 184 67
5 51 167 55
6 24 171 74
Media
DE
Varianza
CV

Ejemplo usando diferentes variables
N Edad (años) Estatura (cm) Peso (kg)
1 18 167 60
2 35 172 85
3 20 160 70
4 46 184 67
5 51 167 55
6 24 171 74
Media 32 170 69
DE 13.9 8.0 10.6
Varianza 193.9 63.8 112.3
CV 0.43 0.05 0.15
Mayor Variación

CARACTERÍSTICAS DE UNA DISTRIBUCIÓN

Normalidad de una variable
• Para ver si una variable sigue una distribuciónnormal, se puede realizar una pruebaestadística como el Kolmogorov-Smirnov test,Jarque-Bera test, entre otros.
• Lo que todas estas pruebas o tests tienen en común es que evalúan la existencia de normalidad a partir de dos estadísticos: Skewness y la Kurtosis.

Skewness y Kurtosis• La skewness es una medida de simetría de la
distribución de una variable. Así, una variable se lellama simétrica si la distribución luce similar tantopor encima como por debajo del promedio.
• Los tipos de skewness que hay son: i) positive skew, yii) negative skew.
Skewness igual a 0 : normalSkewness mayor a 0: negative skewSkewness menor a 0: positive skew

Skewness y Kurtosis
• La kurtosis es un estadístico que nos indica quetanto es el apuntalamiento de los datos en lavariable que se está trabajando. Es decir, nosdice qué tan plana es la distribución de los datos.
• Al igual que en la skewness, existen diferentestipos de kurtosis, que nos indican que tanaplanada es la distribución de los datos.
Kurtosis igual a 0 : normalKurtosis mayor a 0: leptokurticKurtosis menor a 0: mesocurtic
Nota: Algunos programas (como el SPSS) usan el 3 en lugar de 0

Códigos para calcular los estadísticos descriptivos en STATA y SPSS
STATA• Para calcular los estadísticos
descriptivos de una o más variables, hay varios comandos en STATA que permiten obtener estos indicadores.
Los principales son:
summarize [variables], detail
tabstat [variables], s(mean sd sdskew kurtosis)
SPSS• Para calcular los estadísticos
descriptivos de una o más variables, en SPSS se tiene el comando descriptives.
Códigos para obtener los estadísticos descriptivos:
descriptives [variables]/statistics = mean stddev
variance min max semeankurtosis skewness.
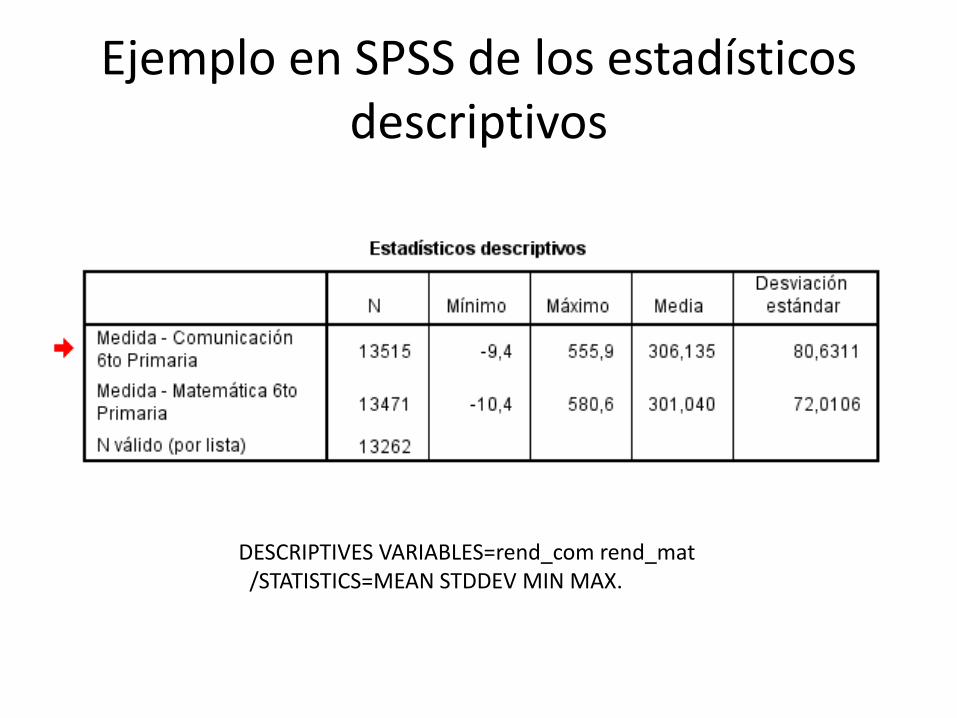
Ejemplo en SPSS de los estadísticos descriptivos
DESCRIPTIVES VARIABLES=rend_com rend_mat/STATISTICS=MEAN STDDEV MIN MAX.
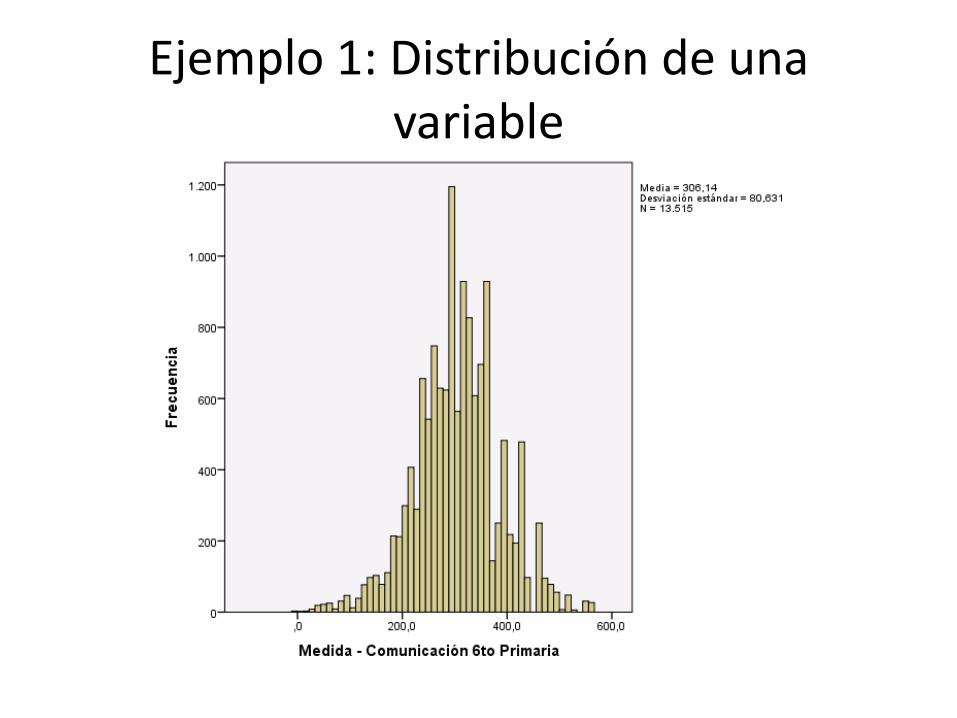
Ejemplo 1: Distribución de una variable

Ejemplo 2: Distribución de una variable

COMPARACIÓN DE MEDIAS

Comparaciones de Medias(i)
Las pruebas de comparaciones de medias sirven para probar si las medias de dos grupos son estadísticamente diferentes.
Estas pruebas se pueden realizar asumiendo normalidad o sin asumir normalidad en la variable que se va comparar.
En el caso de normalidad en la variable a analizar, la pruebas que se pueden utilizar son paramétricas tales como: i) el análisis de varianza, o ii) el test de la t de student (ttest)
En el caso de no normalidad en la variable a analizar, las pruebas que se pueden utilizar son no-paramétricas tales como: i) la prueba de U Mann-Whitney , o ii) Wilcoxon test.

Comparaciones de Medias(ii)
Asimismo las comparaciones de media se pueden realizar para muestras independientes o muestras no independientes (dos observaciones en el tiempo)
Finalmente, se puede asumir igualdad o no de las varianzas en cada grupo que se va comparar.

PRUEBAS PARAMÉTRICAS

Pruebas paramétricas: ANOVA
El análisis de varianza es una prueba que permite comparar las medias de diferentes grupos de tal forma de ver si son estadísticamente diferentes.
La hipótesis nula es que las muestras para cada grupo han sido realizadas de forma aleatoria y por lo tanto las medias deben ser iguales.
Finalmente, esta prueba asume que las variables a comparar siguen una distribución normal.
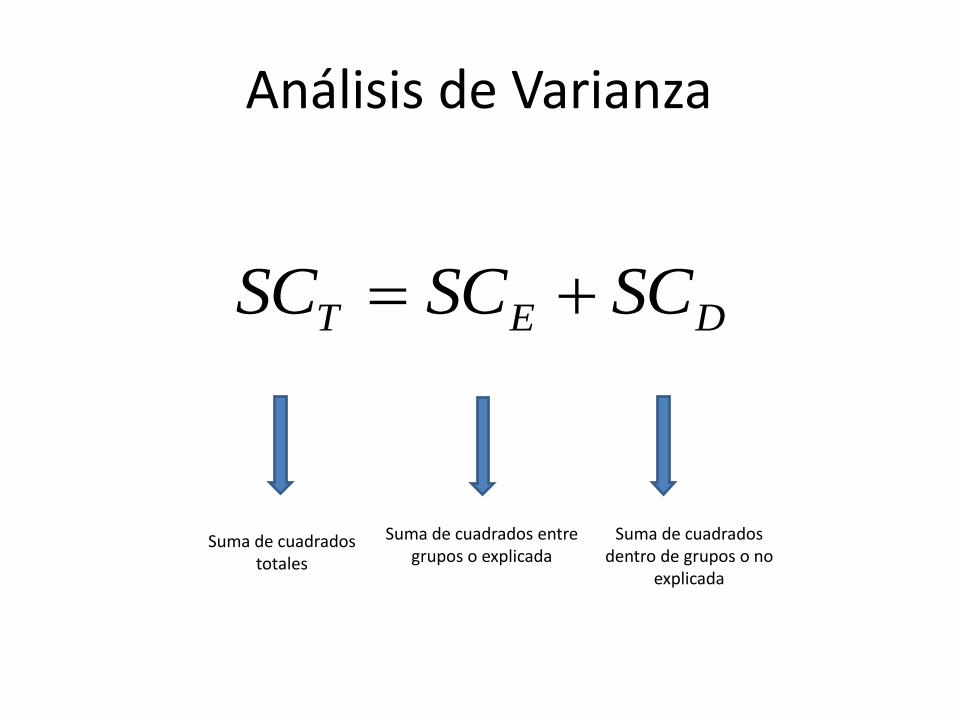
DET SCSCSC
Suma de cuadrados totales
Suma de cuadrados entre grupos o explicada
Suma de cuadrados dentro de grupos o no
explicada
Análisis de Varianza

Ejemplo
Promedio por colegio en
comprensión de lectura
Promedio total

Suma total de cuadrados o variación total
2)( totalcasoT YYSC Promedio total = 12

Suma de cuadrados entre grupos o explicada
2)( totalYgrupoYSCE
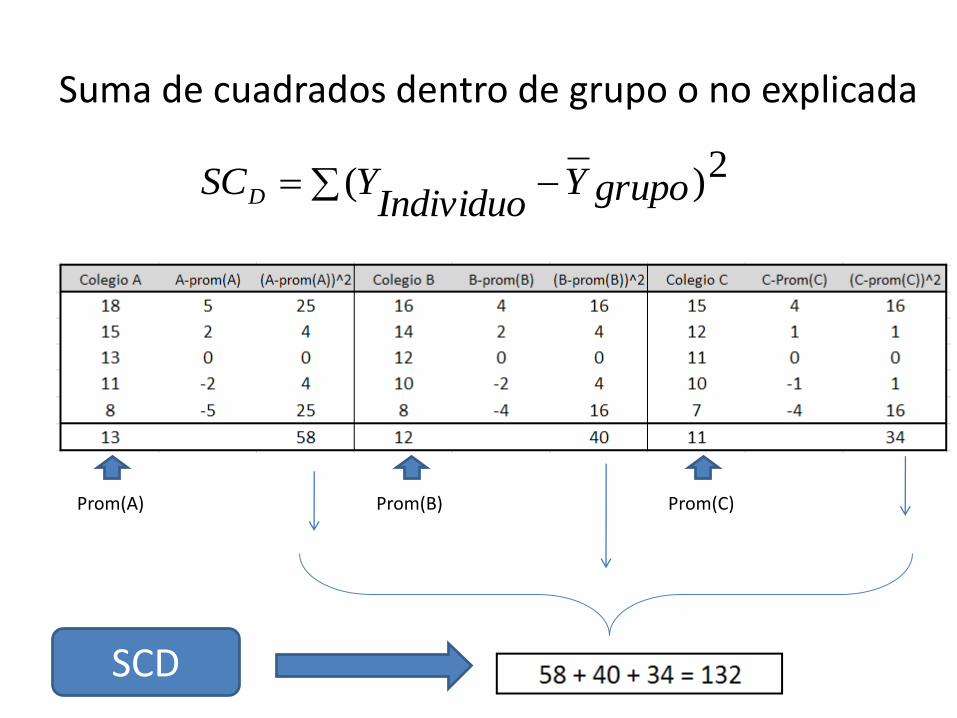
Suma de cuadrados dentro de grupo o no explicada
Prom(A) Prom(B) Prom(C)
2)( grupoYIndividuo
YSCD
SCD

DET SCSCSC
142 10 132
Suma de cuadrados totales
Suma de cuadrados entre grupos o explicada
Suma de cuadrados dentro de grupos o no
explicada

Varianza entre grupos (between)
1)-(K grupos entre libertad de grados
grupos entre cuadrados de Sumagrupos entre medio cuadrado del Varianza
Para este caso “K “ es igual a 3, pues son 3 colegios.
52
10
13
10
1-Kgrupos entre medio cuadrado del Varianza
ESC

Varianza al interior de los grupos (within)
K)-(n grupos de dentro libertad de grados
grupos los de dentro cuadrados de Sumagrupos de dentro medio cuadrado del Varianza
En este caso “n” es igual a 15 (observaciones) “K” es igual a 3 (colegios)
11.8312
142
3)-(15
142
K)-(n
142grupos de dentro medio cuadrado del Varianza

Varianza del cuadrado medio total
1)-(n totallibertad de grados
totalescuadrados de Suma totalmedio cuadrado del Varianza
En este caso “n” es igual a 15 (observaciones)
10.14(14)
142
1)-(15
142
1)-(n
142 totalmedio cuadrado del Varianza

Estadístico de prueba de la razón de F
explicada no Varianza
explicada Varianza Frazón la de oEstadístic
.42011.83
5 Frazón la de oEstadístic
3.89.4220
F de la distribución de Fisher, con 2 (K-1)grados de libertad en el numerador y 12(n-K) grados de libertad del denominador.No se rechaza la hipótesis nula deigualdad de las medias para este ejemplo.La hipótesis nula se evalúa al 95%

Comandos para hacer un ANOVA en STATA y SPSS
STATA
El comando para hacer un ANOVA en STATA se llama: oneway.
El código para correr este análisis es:
oneway [outcome] [group]
SPSS El comando para hacer un t-test en
SPSS se llama oneway.
El código para correr este análisis es:
Oneway [outcome] by [group] ([values])
/statistics = all.

Pruebas Paramétricas: T-Test
varianzala es
estándarerror el es
:dondeEn
2
)()1()()1()(
2
21
21
21
2
2
21
2
121
S
nn
nn
nn
XnXnXXS
Supuesto: Normalidad de la distribución de la variable

)(
0 :
)(
)(
21
21
21210
21
2121
XXS
XXtprueba
H
XXS
XXtprueba
xxxx
xx
Prueba t para diferencia de medias
Prueba original
Prueba con remplazo de la hipótesis
nula
Hipótesis nula

Comandos para hacer un t-test en STATA y SPSS
STATA El comando para poder hacer
un t-test en STATA se llama: ttest.
Los códigos para correr este análisis es:
Varianzas igualesttest [outcome], by([group])
Varianzas diferentesttest [outcome], by([group]) unequal
SPSS El comando para poder hacer un t-
test en SPSS se llama t-test.
Los códigos para correr este análisis es:
t-test groups = [group] ([values])
/variables = [outcome]
/criteria = CIN (.99).
El SPSS en su ventana de resultados da los resultados de la prueba asumiendo igualdad o no de varianzas.
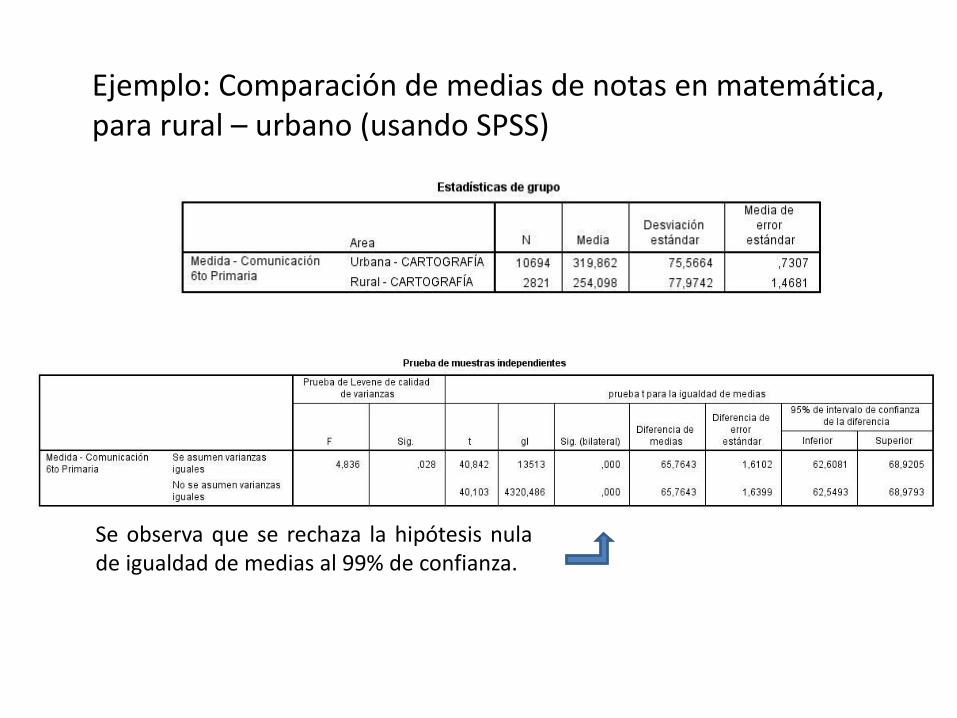
Ejemplo: Comparación de medias de notas en matemática, para rural – urbano (usando SPSS)
Se observa que se rechaza la hipótesis nulade igualdad de medias al 99% de confianza.

PRUEBAS NO PARAMÉTRICAS

Pruebas No-Paramétricas: Test U de Mann-Whitney
• Esta prueba tiene las siguientes características:
No asume distribución normal para las variables.
Compara las medianas en cada grupo
Se utiliza para variables discretas
La hipótesis nula es que las medianas entre gruposson iguales

Pruebas No-Paramétricas: Test U Mann-Whitney
• El estadístico de U Mann-Whitney es:
U : el estadístico de U Mann Whitney
N1 o N2 : el número de observaciones en cada grupo.
R1 : La suma del ranking para el primer grupo
111
212
)1(R
NNNNU

Códigos para hacer el análisis en STATA y SPSS
STATA
• El comando para hacer la prueba no-paramétrica del U Mann-Whitney es ranksum.
• El código es:
ranksum [outcome], by([group])
SPSS
• El comando para hacer la prueba no-paramétrica del U Mann-Whitney es NPAR TESTS.
• El código es:
NPAR TESTS
/ M-W=[outcome] BY [group]([values])
/ MISSING ANALYSIS.
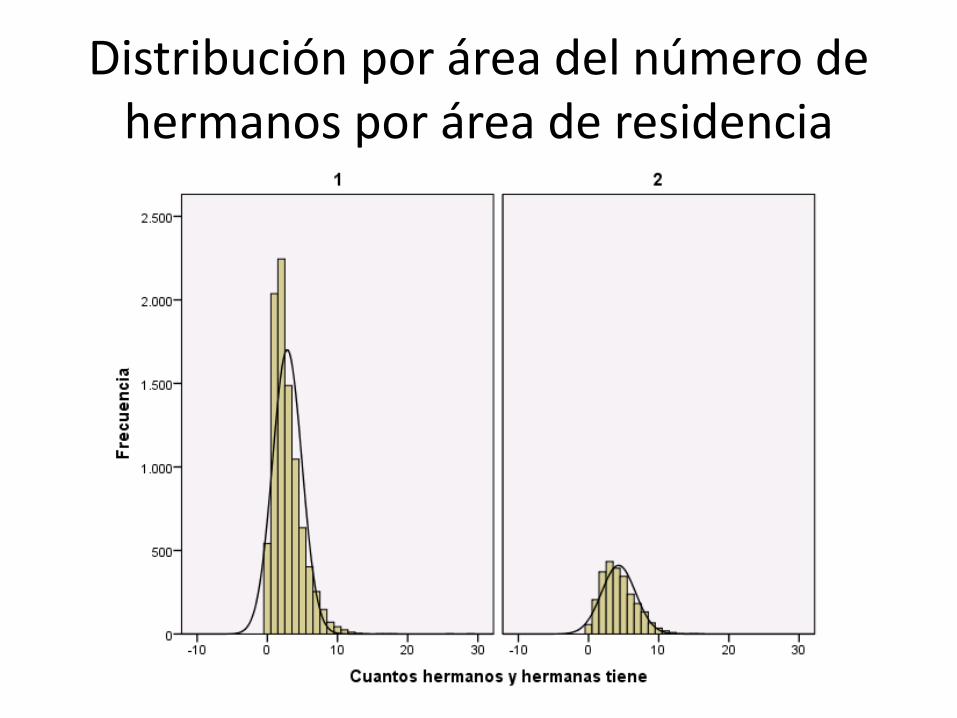
Distribución por área del número de hermanos por área de residencia

Ejemplo: Comparación de medias del número de hermanos por estudiante por área (usando SPSS)

CORRELACIÓN

Correlación (i)
La correlación nos indica la fuerza y dirección de la asociación de dos variables.
Se considera a dos variables están correlacionadas cuando los valores de una varía sistemáticamente con respecto a los valores de la otra.
Por ejemplo, se dice que la variable A esta correlacionada con la variable B, si al aumentar los valores de A también los valores de B aumentan o viceversa.

Correlación (ii)
Hay dos aspectos que se tienen que tomar en cuenta al momento de ver una correlación:
La magnitud: mide la intensidad o fuerza en que dos variables están asociadas. De acuerdo a Cohen (1988): i) pequeña r ≤ 0.20, ii) mediana 0.20 < r ≤ 0.50, iii) grande r > 0.50.
La dirección de la relación: dada dos variables A y B, si la correlación es positiva entonces conforme los valores de A aumentan, los valores de B también aumentan. En cambio, si la correlación es negativa entonces conforme los valores de A aumentan, los valores de B disminuyen.

Correlación (iii)

TIPOS DE CORRELACIÓN

Tipos de Correlación (i)
Existen dos tipos de correlación:
Correlación simple: indica la asociación únicamente entre dos variables.
Correlación parcial: indica la asociación entre dos variables controlando por el efecto de una variable exógena.

Índices de Correlación
Existen diferentes índices de correlación. Entre los índices más comunes tenemos:
Pearson : variables continuas.
Spearman y Policorica : variables ordinales.
Phi, tetracorica y Chi cuadrado: variables cualitativas dicotómicas.

Correlación Lineal
Se define al coeficiente de correlación lineal como:
𝜌 =𝑐𝑜𝑣 (𝐴, 𝐵 )
𝜎𝐴 ∗ 𝜎𝐵=
1𝑛 𝑖=1
𝑛 (𝐴𝑖 − 𝐴)(𝐵𝑖 − 𝐵)
1𝑛
𝑖=1𝑛 (𝐴𝑖 − 𝐴)2 𝑖=1
𝑛 (𝐵𝑖 − 𝐵)2

Ejemplo (i)
Fuente: Las Evaluaciones Nacionales e Internacionales de rendimiento escolar en el Perú: Balance y perspectivas, Cueto (2007)
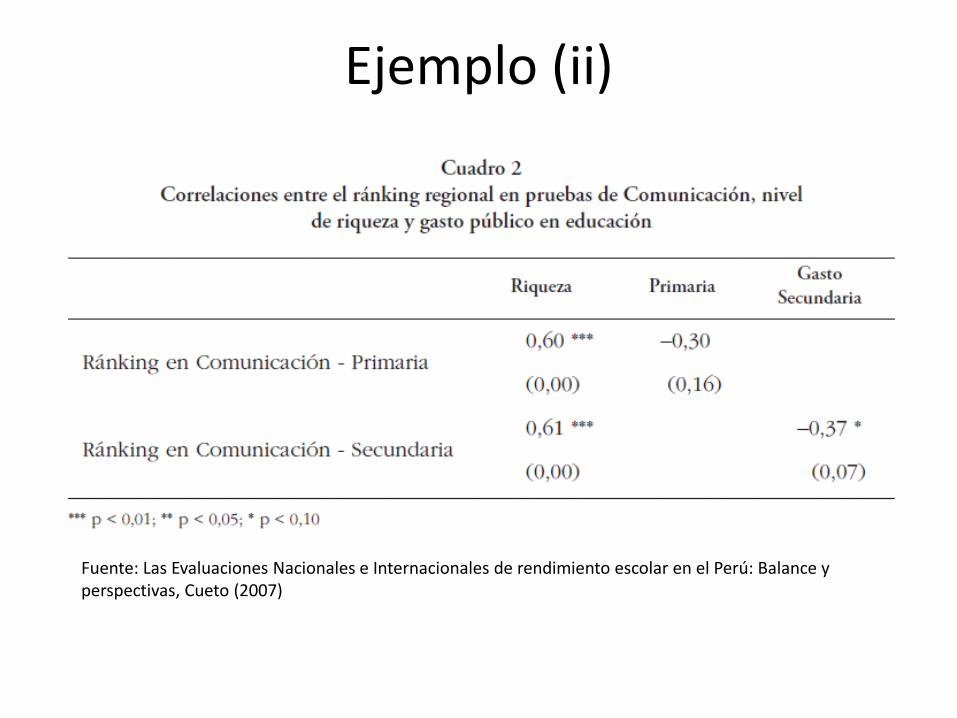
Ejemplo (ii)
Fuente: Las Evaluaciones Nacionales e Internacionales de rendimiento escolar en el Perú: Balance y perspectivas, Cueto (2007)

REGRESIÓN LINEAL

Regresión Lineal
El análisis de regresión sirve para poder predecir una variable en función de una o más variables.
– Y = Variable dependiente
Otras formas de llamarla: predicha o explicada
– X = Variable independiente
Otras formas de llamarla: predictora o explicativa

Supuestos del Modelo de Regresión Lineal (i)
Los principales supuestos del modelo de regresión lineal:
Linealidad: la relación entre la variable dependiente y explicativa es lineal ( Yi = α0 + α1Xi ). Forma de verificar: Gráficos de dispersión entre la variable
dependiente y cada explicativa. Solución: Linealizar la relación.
Independencia: no existe correlación entre los errores de las diferentes observaciones ( cov(uiuj) = 0 ). Forma de verificar: calcular la correlación intra-grupo o intra-cluster
(ICC). Valores menores a 0.10 indican que la correlación entre los errores es 0.
Solución: Corregir la matriz de varianzas y covarianzas o usar un modelo de regresión lineal que tome en consideración la correlación entre observaciones (modelos multinivel)

Supuestos del Modelo de Regresión Lineal
Los principales supuestos del modelo de regresión lineal:
Homocedasticidad: la variación de los residuos sea uniforme a lo largo de todas las observaciones ( var(ui) = σ2 ). Forma de verificar: Realizar test de homocedasticidad (Goldfeld y Quand,
Breusch y Pagan, Glesjer entre otros) Solución: Ponderar las variables de acuerdo a la variable que causa la
heterocedasticidad.
Normalidad: los residuos del análisis de regresión siguen una distribución normal con media 0 y desviación estandar 1. Forma de verificar: hacer test de normalidad de los residuos de la regresión
realizada. Se pueden hacer test como Jarque Bera, Kolmogorov-Smirnov o simplemente revisar la simetria y curtosis de los errores.
Solución: Incrementar el número de observaciones o verificar el modelo conceptual planteado.

Efecto Marginal
El efecto marginal esta definido como «en cuanto varia la variable dependiente ante la variación en una unidad de la variable explicativa»
30
40
50
60
70
80
90
100
140 150 160 170 180 190 200
m = pendiente = 1
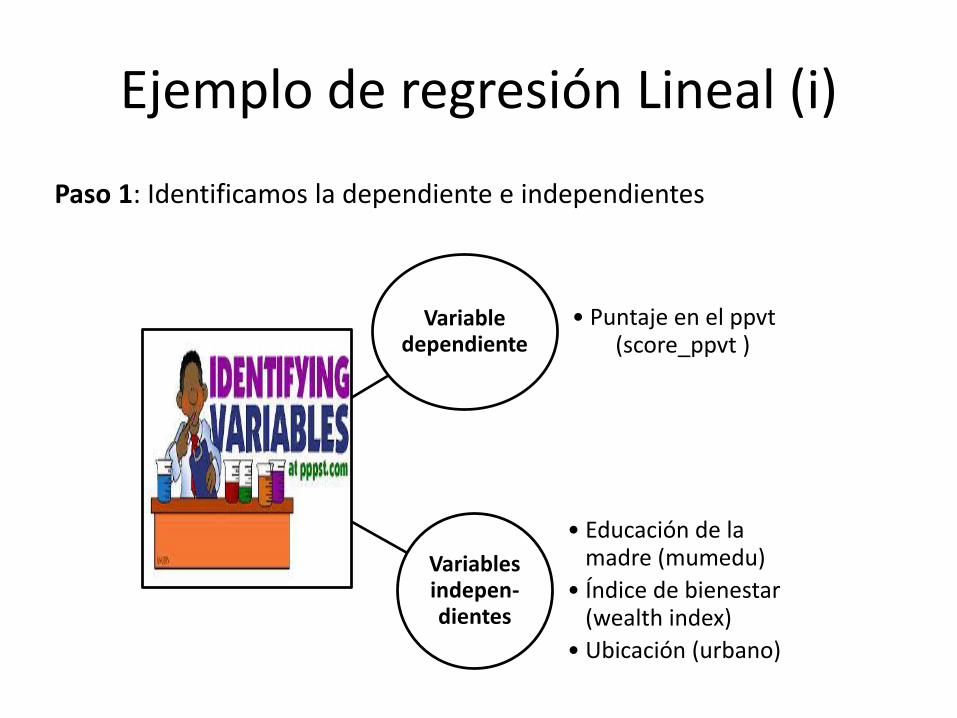
Ejemplo de regresión Lineal (i)
Paso 1: Identificamos la dependiente e independientes
Variable dependiente
• Puntaje en el ppvt(score_ppvt )
Variables indepen-dientes
• Educación de la madre (mumedu)
• Índice de bienestar (wealth index)
• Ubicación (urbano)

Paso 2. Planteamos la ecuación a estimar
Paso 3. Hacemos la matriz de correlaciones de nuestras variables para ver que no haya correlaciones por encima de 0.60 entre las variables predictoras o independientes.
Score ppvt = β1 WealthI+β2 urban+ β3 momedu+ ξ
Ejemplo de regresión Lineal (ii)
score_ppvt wi urban momedu
score_ppvt 1.00
wi 0.64 1.00
urban 0.51 0.64 1.00
momedu 0.52 0.53 0.41 1.00

Paso 4. Estimar el modelo de regresión usando cualquier paquete estadístico (STATA, SPSS, EXCEL). En nuestro caso usamos el STATA.
Ejemplo de regresión Lineal (iii)
Paso 5. Interpretar los resultados obtenidos en el análisis de regresión.Recordar los indicadores de significancia individual de cada variable(estadístico t) y los de significancia conjunta (R2 y el estadístico F ).