prueba de hipÓtesis anidadas y no anidadas y mÉtodos … 382.pdf · prueba de hipÓtesis anidadas...
TRANSCRIPT

PRUEBA DE HIPÓTESIS ANIDADAS Y NO ANIDADAS
Y MÉTODOS DE DISCRIMINACIÓN PARA MODELOS NO LINEALES
T E S I SQue para obtener el grado de Maestría en Ciencias
con Orientación en Probabilidad y Estadística
P r e s e n t a
Roxana Góngora Hernández
Director de Tesis:Dr. Jorge Domínguez y Domínguez
Guanajuato, Gto.. Julio de 2011

Pruebas de Hipotesis No Anidadas y Metodos deDiscriminacion para Modelos No Lineales.
por
Roxana Gongora Hernandez.
Director de Tesina:
Jorge Domınguez Domınguez
para obtener el grado de
Maestrıa en Ciencias con Especialidad en Probabilidad y Estadıstica
Centro de Investigacion en Matematicas, A.C.Guanajuato, Gto., Mexico.
May 15, 2012

ii

iii
Dedicatoria
A mis padres Mario Jesus Gongora Alonzo y Sandra Hernandez Perrusquia, por su apoyo,confianza y animo en cada paso de mi vida.
“Aunque esto pueda parecer una paradoja, toda ciencia exacta esta dominada por la idea de laaproximacion ” – Bertrand Russell.

iv

v
Agradecimientos
Agradezco de manera especial a mis padres, Mario Jesus Gongora Alonzo y Sandra HernandezPerrusquia, por su apoyo incondicional en los momentos difıciles de mi vida, por el amor que mehan demostrado, pero sobretodo por ser el ser humano que hoy soy gracias a ellos. Gracias a mishermanos, Luis Manuel y Mayra Jacqueline por sus comentarios retadores para poder terminar lamaestrıa. Gracias a mi mejor amigo y novio Alejandro Tellez Quinones, por su amor, animo yapoyo en todo momento de mi maestrıa y por ser el motivo de mi esfuerzo de ser mejor cada dıa.Agradezco con profunda sinceridad a mi asesor de tesis, Dr. Jorge Domınguez Domınguez, por suapoyo para poder graduarme y disposicion a ayudarme en momentos difıciles de mi maestrıa, por supaciencia para que este trabajo se realizara y sus consejos tanto del trabajo como de la vida. Graciasa mis sinodales, Enrique Villa y Rogelio Ramos Quiroga, por la paciencia en revisar mi tesis y suscomentarios de provecho en ella, que me ayudaron a comprender mejor mi trabajo. Quiero agradecertambien a cada uno de los investigadores del area de Probabilidad y Estadıstica de CIMAT, quienescon sus ensenanzas, son una parte muy importante en mi formacion academica. Y como olvidara mis companeros de maestrıa, quienes hicieron de mi estancia en Guanajuato agradable, llenade apoyo, paciencia y amor, sobre todo a Carolina Quintanilla, Leticia Escobar, Selomit Uribe,Carlos Campos, Luis castillo, Alfhonse, Joel Iglesias, Pedro Salazar, Gustavo Cano, gracias porsu ayuda y amistad. Tambien expreso mi agradecimiento a todas las personas e instituciones quehicieron posible la persona que hoy soy academicamente. Agradezco al CONACYT, por la becaque me fue concedida (con numero de registro 234019) para llevar a cabo mis estudios de maestrıa.Gracias a CIMAT, A. C. por haberme brindado los recursos humanos, tecnologicos y economicospara la realizacion de mis estudios y tesis de maestrıa. Finalmente, agradezco a Dios, por darmela oportunidad de haber progresado en este mundo y ser feliz estos anos en Guanajuato, pero enespecial por las experiencias que vivı y que me ayudaron a valorar a mi familia, mi pareja y misamigos.

vi
Resumen
En la ultimas decadas la aplicacion de regresion lineal a muchas situaciones de la realidad seha incrementado vertiginosamente donde el objetivo es poder conocer el comportamiento de unfenomeno, con el fin de poder describir su comportamiento y manipularlo. El analisis de regresiones una de las herramientas estadısticas mas ampliamente utilizadas, ya que proporciona metodossencillos para el establecimiento de una relacion funcional entre las variables (variables explicativas)que afectan el fenomeno y la variable respuesta del fenomeno. Generalmente cuando se tratade modelar el comportamiento del fenomeno existen varios modelos alternativos, por lo que elproblema de cual modelo seleccionar del conjunto que se tenga. Actualmente existen metodos dediscriminacion y pruebas de hipotesis que ayudan a seleccionar el modelo mas adecuado para elcomportamiento del fenomeno. A menudo esta relacion funcional entre las variables (variablesexplicativas) que afectan el fenomeno y la variable respuesta del fenomeno es una relacion no linealen los parametros. En tal caso, las tecnicas de regresion lineal no pueden ser aplicadas tal cual ypor tanto deben ser ampliadas, lo que introduce una complejidad considerable.
Este trabajo ofrece una recopilacion de informacion necesaria para poder elegir un modelo nolineal de una coleccion de modelos construidos los cuales son modelos competitivos para describirel comportamiento del fenomeno de interes que se ha publicado en la literatura de investigacion,esto se realizara a traves de dos conjuntos de datos en los cuales existen modelos no lineales quemodelan su comportamiento.

Contenido
1 Introduccion. 1
1.1 Planteamiento del problema. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Antecedentes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.2 Limitaciones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Objetivos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Metodologıa. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Estructura del trabajo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.5 Resultados relevantes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Modelos de Regresion No Lineales. 7
2.1 Estimacion por mınimos cuadrados. . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Estimacion por maxima verosimilitud. . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Inferencia Estadıstica en regresion no lineal. . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Curvas de crecimiento. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.1 Modelo Gompertz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4.2 Modelo Logıstico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3 Problemas de Estudio. 13
3.1 Datos Medicos (Datos Observables). . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Datos Experimentales en Bioquımica. . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Pruebas de Hipotesis y Metodos de Discriminacion para Modelos de RegresionNo Lineal. 17
4.1 Prueba de Hipotesis para Modelos Anidados. . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Pruebas de Hipotesis para los Modelos No Anidados. . . . . . . . . . . . . . . . . . 19
4.2.1 Prueba de Davidson y Mackinnon. . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2.2 Seleccion de Modelos Basado en Metodos de Discriminacion. . . . . . . . . . 23
4.2.3 Seleccion de Modelos basado en Criterios de Informacion. . . . . . . . . . . . 36
5 Analisis Estadıstico de los Datos. 39
5.1 Datos Experimentales en bioquımica. . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.2 Datos Medicos (Mediciones en Fetos). . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.2.1 Analisis descriptivo de las variables. . . . . . . . . . . . . . . . . . . . . . . . 42
5.2.2 Analisis de Correlacion de las variables. . . . . . . . . . . . . . . . . . . . . . 44
5.2.3 Ajuste de modelos para la relacion Gest vs DBP. . . . . . . . . . . . . . . . . 53
vii

viii CONTENIDO
5.2.4 Prediccion del peso de nacimiento de los fetos. . . . . . . . . . . . . . . . . . 605.3 Realizacion de las pruebas de hipotesis y metodos de discriminacion. . . . . . . . . . 67
5.3.1 Aplicacion del Metodo Secuencial 1 (SM1) . . . . . . . . . . . . . . . . . . . . 685.3.2 Aplicacion del Metodo LSE. . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6 Conclusiones y Comentarios. 73
A Metodo de Gauss-Newton. 77
B Graficas de Datos Experimentales. 79B.1 Graficas del Ajuste del modelo Gompertz. . . . . . . . . . . . . . . . . . . . . . . . . 79B.2 Graficas de Ajuste del Modelo Logıstico. . . . . . . . . . . . . . . . . . . . . . . . . . 79
C Teorema de Frisch-Waugh-Lovell. 85
D Programas en R. 87D.1 Ajuste de los modelos propuestos para los datos Medicos. . . . . . . . . . . . . . . . 88D.2 Programa para el Criterio de Informacion de Akaike para Datos Medicos. . . . . . . 89
D.2.1 Calculo del estadıstico de Akaike. . . . . . . . . . . . . . . . . . . . . . . . . . 89D.2.2 Calculo del estadıstico de Akaike Bayesiano. . . . . . . . . . . . . . . . . . . . 89
D.3 Programa para la Prueba tilde de Atkinson. . . . . . . . . . . . . . . . . . . . . . . . 89D.4 Programa de la Prueba de Willians. . . . . . . . . . . . . . . . . . . . . . . . . . . . 90D.5 Calculo de la falta de ajuste. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92D.6 Ranqueo de los modelos con P(CS) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92D.7 Metodo Secuencial 1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
D.7.1 Paso 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93D.7.2 Paso 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
D.8 Programa para el Metodo LSE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94D.9 Ajuste de los modelos propuestos para los datos de bioquımica. . . . . . . . . . . . . 95
D.9.1 Modelo Gompertz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96D.9.2 Modelo Logıstico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
D.10 Programa del Criterio de Informacion de Akaike (Datos bioquımica). . . . . . . . . . 97D.11 Programa de las pruebas de hipotesis de Davidson y MacKinnon. . . . . . . . . . . . 97

Lista de Figuras
2.1 Grafico de un Modelo Senoidal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Grafico del Modelo Gompertz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Grafico de un Modelo Logıstico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1 Medicion del diametro biparietal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Medicion de la Longitud del Femur. . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3 Medicion de la Circunferencia Cefalica. . . . . . . . . . . . . . . . . . . . . . . . . . 15
5.1 Modelos Estimados para el Crecimiento de Nisina. . . . . . . . . . . . . . . . . . . . 41
5.2 Caja y Bigotes para DBP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.3 Caja y Bigotes para CIRCEF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.4 Caja y Bigotes para CIRABD. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.5 Caja y Bigotes para LFemur. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.6 Caja y Bigotes para Peso de Nacimiento. . . . . . . . . . . . . . . . . . . . . . . . . 45
5.7 Grafico de DBP vs CIRCEF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.8 Ajuste del Modelo Lineal para DBP vs CIRCEF . . . . . . . . . . . . . . . . . . . 47
5.9 Grafico de DBP vs CIRABD. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.10 Ajuste del Modelo Lineal DBP vs CIRABD. . . . . . . . . . . . . . . . . . . . . . . 50
5.11 Grafico de DBP vs LFemur. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.12 Ajuste Lineal de DBP vs LFemur. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.13 Grafico de DBP vs gest. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.14 Ajuste del Modelo Lineal de DBP vs gest. . . . . . . . . . . . . . . . . . . . . . . . 53
5.15 Ajuste del Modelo ax2 + bx+ c . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.16 Ajuste Cubico ax3 + bx2 + cx+ d . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.17 Ajuste Cubico ax3 + cx+ d. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.18 Ajuste Cubico ax3 + bx2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.19 Ajuste Cubico ax3 + bx2 + d. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.20 Ajuste del Modelo Gompertz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.21 Ajuste del Modelo Logıstico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.22 Grafico del Peso de Nacimiento vs DBP. . . . . . . . . . . . . . . . . . . . . . . . . 63
5.23 Grafico del Peso de Nacimiento vs CIRCEF. . . . . . . . . . . . . . . . . . . . . . 63
5.24 Grafico del Peso de Nacimiento vs CIRABD. . . . . . . . . . . . . . . . . . . . . . 64
5.25 Grafico del Peso de Nacimiento vs LFemur. . . . . . . . . . . . . . . . . . . . . . . 64
B.1 Graficos del Modelo Gompertz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
ix

x LISTA DE FIGURAS
B.2 Graficos del Modelo Gompertz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81B.3 Graficos del Modelo Logıstico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82B.4 Graficos del Modelo Logıstico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83

Lista de Tablas
3.1 Diseno Experimental para los Datos de Bioquımica. . . . . . . . . . . . . . . . . . . 16
5.1 Estimaciones de los parametros del modelo de crecimiento Gompertz para los tratamien-tos del crecimiento ln(N/No). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.2 El criterio de Akaike para Datos de Bioquımica . . . . . . . . . . . . . . . . . . . . 415.3 P − valores de las pruebas no anidadas para los modelos Gompertz y Logıstico. . . 425.4 Correlaciones entre las variables fetales. . . . . . . . . . . . . . . . . . . . . . . . . . 455.5 Resumen del Ajuste del modelo y = ax+ b para DBP vs CIRCEF. . . . . . . . . . 465.6 Analisis de Varianza del modelo y = ax+ b para DBP vs CIRCEF. . . . . . . . . 475.7 Residuales Atipicos para el ajuste Lineal para BDP vs CIRCEF. . . . . . . . . . . . 475.8 Prueba de Falta de Ajuste del Modelo Lineal para BDP vs CIRCEF. . . . . . . . 485.9 Resumen del ajuste lineal para DBP vs CIRABD. . . . . . . . . . . . . . . . . . . . 485.10 Resumen del Analisis de Varianza del Modelo Lineal para DBP vs CIRABD. . . . . 495.11 Resumen de la prueba de falta de Ajuste del Modelo Lineal para DBP vs CIRABD. 495.12 Residuales Atipicos del Modelo Lineal para DBP vs CIRABD. . . . . . . . . . . . . 495.13 Resumen del ajuste lineal para DBP vs LFemur. . . . . . . . . . . . . . . . . . . . . 515.14 Analisis de Varianza del Modelo Lineal para DBP vs LFemur. . . . . . . . . . . . . . 515.15 Prueba de falta de Ajuste para el Modelon Lineal para DBP vs LFemur. . . . . . . . 525.16 Residuales Atıpicos del Modelo Lineal para LFemur y DBP. . . . . . . . . . . . . . . 525.17 Estimacion de Parametros para el Modelo Lineal de DBP vs gest. . . . . . . . . . . 545.18 Analisis de Varianza del Modelo Lineal para DBP vs Gest. . . . . . . . . . . . . . . 545.19 Prueba de falta de Ajuste del Modelo Lineal para DBP vs Gest. . . . . . . . . . . . 545.20 Estimacion de Parametros para el Modelo Cuadratico de DBP vs gest. . . . . . . . 555.21 Analisis de Varianza para el Modelo Cuadratico DBP vs gest. . . . . . . . . . . . . 555.22 Intervalos de confianza Asıntoticos del 95% de confianza del Modelo Lineal para
DBP vs Gest. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 555.23 Analisis de Varianza del Modelo Cubico y = ax3 + bx2 + cx+ d. . . . . . . . . . . . 565.24 Resumen de la Estimacion de Parametros para el Modelo ax3 + bx2 + cx+ d. . . . . 565.25 Analisis de Varianza para el modelo ax3 + bx2. . . . . . . . . . . . . . . . . . . . . . 565.26 Resultados de la Estimacion de Parametros para el modelo ax3 + bx2. . . . . . . . . 565.27 Analisis de Varianza del Modelo ax3 + bx2 + d. . . . . . . . . . . . . . . . . . . . . . 575.28 Estimacion de Parametros para el Modelo ax3 + bx2 + d. . . . . . . . . . . . . . . . . 575.29 Analisis de Varianza del Modelo ax3 + cx+ d. . . . . . . . . . . . . . . . . . . . . . . 585.30 Estimacion de parametros para el Modelo ax3 + cx+ d. . . . . . . . . . . . . . . . . 585.31 Criterio de Informacion de Akaike y Bayesiano para Modelos Cubicos. . . . . . . . . 58
xi

xii LISTA DE TABLAS
5.32 Resumen de la Estimacion de Parametros para el modelo Gompertz. . . . . . . . . . 595.33 Analisis de Varianza para el modelo Gompertz. . . . . . . . . . . . . . . . . . . . . . 595.34 Intervalos de confianza del 95% para el modelo Gompertz. . . . . . . . . . . . . . . . 595.35 Resumen de la Estimacion de Parametros para el modelo Logistico. . . . . . . . . . . 595.36 Analisis de Varianza para el modelo Logistico. . . . . . . . . . . . . . . . . . . . . . . 605.37 Intervalos de Confianza del 95% para los Parametros del Modelo Logıstico. . . . . . 615.38 Analisis de Varianza para el Modelo de Regresion Multiple ax1 + bx2 + cx3 + dx4 + e. 645.39 Estimacion de Parametros para el Modelo de Regresion Multiple ax1 + bx2 + cx3 +
dx4 + e. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 655.40 Analisis de Varianza el Modelo de Regresion Multiple cx3 + dx4 + e. . . . . . . . . . 655.41 Estimacion de Parametros para el Modelo de Regresion Multiple cx3 + dx4 + e. . . . 655.42 Estimacion de Parametros del Modelo a0 + a1x1 + a2x2 + a3x3 + a4x4 + a5x1x2 +
a6x2x3 + a7x3x4 + a8x4x1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 665.43 Estimacion de Parametros para el Modelo a0 +a1x1 +a2x2 +a3x3 +a4x4 +a5x1x2 +
a6x2x3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 665.44 Estimacion de Parametros para el Modelo a0 + a4x4 + a6x2x3. . . . . . . . . . . . . 665.45 Criterio de Akaike y Bayesiano para los Modelos del Datos Medicos. . . . . . . . . . 675.46 Limites de probabilidades Modelo Seleccionado. . . . . . . . . . . . . . . . . . . . . . 685.47 Falta de ajuste para los Modelos de Datos Medicos. . . . . . . . . . . . . . . . . . . . 685.48 Procedimiento SM1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 695.49 P (CS) de las Secuencias para el Metodo 1. . . . . . . . . . . . . . . . . . . . . . . . 705.50 Metodo LSE para el modelo 1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 705.51 Metodo LSE para el modelo 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 705.52 Metodo LSE para el modelo 3. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.53 Metodo LSE para el modelo 4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71

Capıtulo 1
Introduccion.
El objetivo de la tesis es utilizar pruebas de hipotesis no anidadas y metodos de discriminacionen modelos de regresion no lineal, de los cuales se tienen dos tipos de modelos: los modelos deregresion no lineal anidados y los modelos de regresion no lineal no anidados.
El trabajo para poder lograr el objetivo de la tesis fue el de considerar un artıculo y materialde informacion que nos indicara el procedimiento para construir los estadısticos de prueba paralos dos tipos de modelos posibles en regresion no lineal. El primer artıculo que se considero fue elartıculo de Jerzy Szroeter (1999), Testing Non-Nested Econometric Models. El cual nos proporcionaun analisis del desarrollo de metodos estadısticos para las pruebas de modelos no anidados, queincluye regresiones, ecuaciones simultaneas, condiciones de Euler y de momentos, parametricos ysemi-parametricos. De este artıculo se tomo la prueba de hipotesis de Davidson y MacKinnonllamada la prueba P, la cual es una prueba de hipotesis para modelos de regresion no lineal noanidados, para la exploracion de esta prueba se reviso el siguiente artıculo, Davidson, R., and J. G.MacKinnon (1981). ”Several tests for model specification in the presence of alternative hypotheses”,Econometrica, 49, 781-793, en el cual presenta la prueba para dos modelos no anidados y mencionanuna extension de esta prueba cuando se tiene un conjunto de modelos competitivos. Se tomo comoreferencia el libro Econometric Theory and Methods de Davidson, R., and J. G. MacKinnon. Paracompletar estas ideas tambien se reviso los Capıtulos 1 y 2 del libro Model Discrimination forNonlinear Regression Models de Borowiak Dale S. (1989). En el cual se presentan otras pruebasbasadas en metodos de discriminacion de modelos con el objetivo de seleccionar un modelo de unconjunto de modelos competitivos. Ademas se realizo una revision de la prueba del criterio deinformacion de Akaike dado que es una prueba muy utilizada para la seleccion de un modelo dentrode un conjunto de modelos competitivos. Todo esto fue escrito en el Capıtulo 4 de la tesis.
Para lograr escribir y entender estas pruebas primero se trabajo con la teorıa de modelos deregresion no lineal para la cual se estudio los libros de Ratkowsky David A (1983) y Davidson yMacKinnon (2003), y se consulto con cierto detalle los libros de Bates D.M. and Watts D.G (1988),Gallant A. Ronald (1987), Greene William H, (2003), Seber George Arthur Frederck and Wild C.J(2003).
Para poder ilustrar el ajuste de modelos no lineales y la aplicacion de las pruebas revisadas de laliteratura de pruebas de hipotesis para modelos de regresion no lineal se utilizaron dos conjuntos dedatos reales, estos dos conjuntos de datos son: Datos Medicos (Datos Observables), en especıficodatos de mediciones realizados a fetos en desarrollo y el segundo conjunto de datos son DatosExperimentales en Bioquımica, donde se midio la produccion de Nisina en un cultivo de Leche.
1

2 CAPITULO 1. INTRODUCCION.
Para el primer conjunto de datos se reviso los siguientes trabajos [6] , [11] y [12] y para el segundoconjunto de datos se uso el siguiente trabajo [5]
1.1 Planteamiento del problema.
1.1.1 Antecedentes.
En muchas situaciones de la realidad se esta interesado en saber el comportamiento de un fenomeno,para poder describir y conocer el impacto de este; por tanto la construccion de modelos estadısticossurge con la finalidad de explicar y predecir el comportamiento de estos fenomenos reales quedependen de distintas variables, para ello, en general se busca establecer la relacion funcional entrelas variables (variables explicativas) que afectan el fenomeno y la variable respuesta del fenomeno,de la siguiente forma, dado un conjunto de variables explicativas x1, x2, ..., xn y una variable derespuesta que es la variable de interes y, se intenta determinar la relacion que existe entre ellas atraves de la forma funcional
y = f (x1, ..., xn) ;
Una forma funcional de interes es la forma funcional no lineal debido al avance tecnologico delas computadoras. Los modelos no lineales han sido objeto de atencion creciente en los ultimosanos. Se ha encontrado que los modelos no lineales son mas frecuentes de lo que se pensaba, dadoque cada dıa mas areas de investigacion requieren la utilizacion de los modelos de regresion nolineal. Algunas aplicaciones se han dado en Medicina, Finanzas, Medio ambiente, redes neuronales,meteorologica, etc. Entenderemos por Modelo de Regresion no lineal por un modelo de la forma
yi = f (xi, θ) + εi, i = 1, ..., n. (1.1)
donde θ es el parametro de interes que aparece de forma no lineal. Por otro lado, cuando se tratade modelar el comportamiento de un fenomeno existen varios modelos alternativos, entonces surgeel problema de seleccionar el modelo mas adecuado del conjunto que se tenga. La seleccion deun mejor modelo de la coleccion de modelos construidos o existentes, a menudo es una eleccionentre teorıas en competencia o la eleccion se basa en resultados empıricos obtenidos a partir dedatos de la muestra. Por tanto la discriminacion de modelos se aplicara la teorıa de la seleccionde modelos rivales entre los modelos basados en la informacion de la muestra para encontrar unmodelo adecuado del conjunto dado. Dentro de la teorıa de seleccion de modelos hay dos tiposde modelos, los cuales son: modelos anidados y modelos no anidados. Por Modelos anidadosentenderemos aquellos en los que se puede establecer una jerarquıa, de tal manera que uno deellos es el denominado modelo general y el o los otros, llamados modelos restringidos, los cualesse pueden obtener mediante la imposicion de restricciones, lineales o no lineales, sobre el modelogeneral, y los Modelos no anidados, son aquellos que no pueden ser jerarquizados en un modelogeneral o modelos restringidos no pueden obtenerse de un modelo general a traves de la imposicionde restricciones.
Como se menciono existen varios modelos alternativos que podrıan modelar un cierto problema,supongamos entonces que existen dos modelos f y g que podrıan describir el problema, entoncessurge dos situaciones naturales, las cuales son, los dos modelos de regresion no lineales pueden ser

1.1. PLANTEAMIENTO DEL PROBLEMA. 3
anidados o no anidados, supongamos que tenemos las siguientes hipotesis
H0 : yi = f (xi, θ) + εi, i = 1, ..., n (1.2)
H1 : yi = g (xi, θ) + εi, i = 1, ..., n (1.3)
donde f y g son de la forma (1.1), cuando se tiene la hipotesis donde los modelos de regresionno lineal son anidados por lo general podemos usar la prueba de razon de verosimilitud paracompararlos y cuando los dos modelos de regresion no lineal sean no anidados, existen una granvariedad de pruebas, pero en el trabajo nos enfocaremos a trabajar con la prueba P de Davidsony MacKinnon para modelos de regresion no lineales. Por tanto podemos decir que el problemasustancial del trabajo se puede definir de la siguiente manera:
La prueba de hipotesis implica generalmente modelos anidados, en la cual el modelo que rep-resenta la hipotesis nula es un caso especial de un modelo mas general que representa la hipotesisalternativa. Para este modelo, siempre se puede probar la hipotesis nula mediante pruebas de lasrestricciones que se imponen a la alternativa. Pero a menudo surgen modelos los cuales no estananidados. Esto significa que ninguno de los modelos puede ser escrito como un caso especial del otrosin imposicion de restricciones en ambos modelos. En tal caso, no podemos simplemente probaruno de los modelos contra el otro, al imponer restricciones en uno de ellos.
Existe una extensa literatura sobre las pruebas de hipotesis no anidadas. Esta proporcionaun gran numero de maneras de probar la especificacion de los modelos estadısticos cuando una omas alternativas no anidadas existen. En este trabajo se presentara un de estos caminos el cual esampliamente utilizado para pruebas de hipotesis no anidadas, principalmente en el contexto de losmodelos de regresion.
Si lo que se desea es seleccionar el ”mejor” modelo de un conjunto de modelos competitivos,entonces se debe usar un enfoque diferente a las pruebas de hipotesis, basado en metodos dediscriminacion y criterios de informacion. En los metodos de discriminacion se sugiere tres hipotesisde las cuales se construye la metodologıa de estos metodos, estas cuestiones fueron presentas porAtkinson (1969) , las cuales son:
A1 Bajo el supuesto que un modelo particular es el verdadero, ¿hay evidencia de que de los otrosmodelos, ajusten mejor a los datos?
A2 Bajo el supuesto que el modelo se ajusta adecuadamente a los datos, ¿hay evidencia estadısticade lo contrario?
A3 Si se asume que uno de los modelos es el verdadero, ¿hay suficiente evidencia para hacer unaseleccion?
La eficacia de estas cuestiones esta basada en la evaluacion del ajuste y la estabilidad de losmodelos.
1.1.2 Limitaciones.
Como se senalo, en la literatura estadıstica existe una gran variedad de publicaciones sobre laspruebas de hipotesis no anidadas y metodos de discriminacion, por lo cual podemos encontrar unagran variedad de maneras de probar la especificacion de los modelos estadısticos cuando una omas alternativas no anidadas existen. Si se desea conocer algunas de estas pruebas, se recomienda

4 CAPITULO 1. INTRODUCCION.
recurrir al artıculo de Jerzy Szroeter [9] . En este trabajo solo se presentara algunos de estos caminos,los cuales fueron de interes, ademas que son ampliamente utilizados en la seleccion de un modelo deun conjunto de modelos competitivos, principalmente en el contexto de los modelos de regresion.Por tanto, se realizara una revision de los estadısticos de prueba para modelos de regresion anidadosy no anidados propuestos por Davidson y MacKinnon, es decir, la prueba de razon de verosimilitudy la prueba P de Davidson y MacKinnon, tambien se revisara la teorıa de modelos de discriminacionen el libro de Borowiak Dale S y el criterio de Informacion de Akaike que como se ha mencionadoes uno de los metodos mas utilizados en todos los ambitos.
En el contexto en el que se desarrolla este trabajo, no se discutira acerca de los problemas quesurgen en el ambito computacional cuando se lleva a cabo el metodo de mınimos cuadrados. Asıcomo tampoco se realizara una verificacion de las potencias de las pruebas que podrıa considerarsecomo una extension de la tesis.
1.2 Objetivos.
La realizacion de este trabajo pretende los siguientes objetivos:
• Conocer, aplicar y ajustar un modelo de regresion no lineal adecuado al comportamiento delos datos del fenomeno en estudio.
• Conocer si el modelo seleccionado es el mejor modelo o existe otro modelo competitivo.
• Plantear, discutir y aplicar las estadısticas de prueba para realizar la prueba de hipotesis noanidadas sobre los modelos de regresion no anidados.
• Plantear, discutir y aplicar los metodos de discriminacion en la seleccion del mejor modelode un conjunto de modelos competitivos.
Debido a que la motivacion del presente trabajo nacio del deseo de resolver los dos problemasreales anteriormente mencionados, surgio ası el hecho de utilizar modelos no lineales, dada lanaturaleza propia de los problemas a tratar, dando lugar a los siguientes objetivos especıficos.
Para el problema con el conjunto de datos medicos los objetivos a perseguir durante el trabajoson
• Se ajustara modelos no lineales a la relacion funcional entre las variables medidas a lo fetoslos datos para tratar de encontrar un modelo que pueda ser usado para poder saber todas lasmediciones ecograficas del feto con solo saber la edad gestional.
• Se realizara un analisis estadıstico para tratar de encontrar un modelo que pueda predecir elpeso de nacimiento de un feto dado que se midieron 4 variables durante su gestacion.
Para el segundo problema de la produccion de nisina los objetivos a seguir en el trayecto deltrabajo son:
• Describir el crecimiento y la produccion de nisina por la bacteria Lactococcus lactis subspen leche en polvo light reconstituida, la cual es usada para preservar alimentos perecederoscomo leche y quesos, a traves de un modelo de regresion no lineal.

1.3. METODOLOGIA. 5
• Encontrar el mejor tratamiento para la produccion de nisina A.
• Ajustar modelos no lineales a cada una de las cineticas realizadas.
• Encontrar un modelo general y compararlo con los modelos de regresion no lineal ajustadopara cada cinetica.
1.3 Metodologıa.
Con el objetivo de poder alcanzar los objetivos planteados, fue necesario realizar una investigacionamplia de distintos libros y artıculos donde se considero que se presentaba de manera clara laspruebas de hipotesis no anidadas para modelos no anidados y los metodos de discriminacion.
Debido a que en este trabajo se utilizaron datos reales se realizo una limpieza de los datos,ası como un analisis de cada una de las variables, los cuales se presentan en el Capıtulo 5. En eltrabajo se consideran dos conjuntos de datos, a cada uno de los cuales les fue ajustado modelos nolineales, entre los que se encuentran los modelos de crecimiento.
Ası como tambien debido a que los paquetes estadısticos carecen de las pruebas de hipotesisanidadas y no anidadas, y para los metodos de discriminacion, fue necesario realizar la programacionde estas pruebas en R, version 2.6.1 (2007-11-26) debido a que es un lenguaje de programaciongratuito, de facil manejo y es utilizado en muchos campos entre los cuales se encuentra el campoestadıstico.
Para el ajuste de los modelos no lineales a los datos se uso el paquete de Statgraphics Plusversion 5.1 (1994− 2000) dado que es paquete comercial muy facil de usar, aunque tambien serealizaron el ajuste en el programa R. El siguiente paso fue utilizar estos modelos ajustados paralas pruebas de hipotesis y los metodos de discriminacion, para encontrar el mejor modelo para elcomportamiento de los datos. Para lograr el objetivo de prediccion del peso de nacimiento del bebese realizo un analisis de entrada y salida de variables.
1.4 Estructura del trabajo.
En la realizacion del trabajo planteado, fue necesario obtener conocimientos acerca de modelosde regresion no lineal, pruebas de hipotesis anidadas y no anidadas, metodos de discriminacion ycriterios de informacion, ası como tambien conocimientos basicos de los campos de los problemasutilizados en la tesis, esto definio la estructura que tendra el trabajo, la cual es presentada acontinuacion.
En el Capıtulo 2 se presenta un resumen de Modelos de Regresion No Lineales, en el cual seabordo como se puede realizar la estimacion de los parametros por estimacion de mınimos cuadradoso por estimacion por maxima verosimilitud, luego se abordo la inferencia estadıstica en regresionno lineal, es decir, como realizar pruebas de hipotesis sobre los parametros y la construccion deintervalos de confianza, por ultimo se presenta modelos de regresion no lineal muy conocidos, loscuales son las curvas de crecimiento, los cuales son utilizados en el trabajo dado el comportamientoque presentaron las relaciones funcionales entre la variable de respuesta y las variables de prediccion,principalmente en los datos experimentales.
Los dos conjuntos de datos analizados durante el trabajo son presentados en el Capıtulo 3. Eneste capıtulo se realiza una breve descripcion de cada uno de los conjuntos de datos.

6 CAPITULO 1. INTRODUCCION.
En el Capıtulo 4 se presenta la teorıa central del trabajo, las pruebas de hipotesis no anidadaspropuestas por Davidson y MacKinnon en su artıculo de 1891 y la teorıa discriminacion de modelospresentada en el libro de Borowiak Dale S. y el criterio de informacion de Akaike y Bayesiano.
En el Capıtulo 5 se presenta el analisis estadıstico de los datos. A continuacion se hace unadiscusion de los metodos utilizados para elegir un modelo de un conjunto de modelos competitivospara describir el comportamiento de los problemas abordados en el trabajo.
En el ultimo Capıtulo se presentan las conclusiones y comentarios del trabajo realizado.
1.5 Resultados relevantes.
En este trabajo se presenta metodos para poder elegir el modelo mas adecuado al comportamientode los datos de los modelos propuestos. Uno de los resultados de interes fue el descubrir que lasvariables utilizadas para tratar de pronosticar el peso de nacimiento de los fetos estan altamentecorrelacionadas y por tanto fue suficiente utilizar una sola variable para poder describir la relacionque hay entre las variables ultrasonograficas y la edad gestional, es decir, que basta con conoceruna sola de estas variables y se sabe la edad gestional del feto, ası como cuales son las medidas delas demas variables. Al tratar de predecir el peso de nacimiento, se encontro que las variables queaparecieron en todas las ecuaciones que fueron relevantes son el diametro abdominal y la longituddel femur, ademas se obtuvo que si el objetivo es predecir el peso de nacimiento con estas variableses necesario tener informacion del feto. Esto debe suceder por la misma cuestion que sucede cuandose trata predecir el peso de una persona con las medidas de su cuerpo, no siempre coincide su pesocon sus medidas corporales, sino hay que tener mas informacion de la persona.
Cuando se aplicaron los criterios de discriminacion para seleccionar el modelo mas competentedel conjunto de modelos propuestos se encontro que el modelo mas adecuado para modelar larelacion funcional entre el diametro biparietal y la edad gestional es el modelo logıstico, el cualtambien resulto seleccionado por el criterio de Informacion Bayesiano, debido a que el tamano demuestra es grande, aunque se observo que la probabilidad de seleccionar este modelo es de 0.301456,lo cual es muy bajo, esto se debio a que existe una variabilidad en los datos y se concluye que todoslos modelos parecen ser bastante adecuados para describir el comportamiento.
Tambien se encontro con respecto a los datos en bioquımica que el tratamiento mas eficientepara producir nisina es el tratamiento 16 aunque no hay que descartar los tratamientos 8, 9,11, 14 y 18, aunque en esta tesis no se tiene conocimiento completo del experimento, se puederecomendar usar el tratamiento que sea mas economico debido a que no habra mucha diferencia enla produccion de nisina entre estos tratamientos, como se observa en el grafico XXX . Se encontroque el modelo mas adecuado para modelar el crecimiento de la nisina fue el modelo gompertz debidoa que el criterio de Akaike nos dice que el 77% de los tratamientos son adecuadamente modelospor el modelo Gompertz, aunque las pruebas de hipotesis de Davidson y MacKinnon nos dice queambos modelos considerados para modelar la produccion de nisina son adecuados para describir elcomportamiento.

Capıtulo 2
Modelos de Regresion No Lineales.
Un modelo de regresion no lineal puede escribirse de la siguiente forma
yi = f (xi, θ) + εi, i = 1, ..., n (2.1)
donde f es la funcion esperada, xi es una variable regresora o variables independientes para lasn observaciones, θ es vector de parametros a estimar, donde θ es el estimador correspondiente yεi representa el error aleatorio. En este trabajo los errores se asumen normales independientese identicamente distribuidos con media cero y varianza desconocida σ2. Entenderemos por unmodelo de regresion no lineal un modelo donde la funcion esperada es una funcion no lineal en losparametros, por ejemplo
yi = xθi + εi
El conjunto de variables {xi} es considerado como un conjunto de variables fijas y no variablesaleatorias. Los supuestos para la regresion no lineal son: homogeneidad de varianzas, los valoresde xi son fijos, los valores de la muestra son tomados sin error.
2.1 Estimacion por mınimos cuadrados.
Los modelos no lineales pueden ser divididos en dos grupos, en los modelos intrınsecamente nolineales y los no intrınsecamente lineales. Estos ultimos surgen cuando a los modelos no linealesse les puede aplicar alguna transformacion de tal manera que el modelo se convierte en lineal.Cuando dicha transformacion no existe estamos ante la presencia de un modelo intrınsecamenteno lineal. Cuando los modelos son modelos de regresion no lineales son intrınsecamente no linealessuelen presentar problemas de resolucion dado que en ocasiones no existe una manera algebraicade resolverlos, por tanto se usan metodos numericos que faciliten la resolucion de estos. Hay unagran riqueza de literatura sobre la forma de determinar los estimadores de mınimos cuadrados delos parametros una vez que un modelo no lineal ha sido especificado y un conjunto de datos a sidoobtenido. Esta combinacion de tener un conjunto de datos y un modelo especificado determinande manera unica los estimadores de mınimos cuadrados, excepto para casos patologicos, algunosesfuerzos computacionales considerables podrıan ser requeridos para llegar a las estimaciones. Entrelos metodos o algoritmos que existen podemos enunciar el metodo de Gauss-Newton y el de Newton-Raphson entre otros.
7

8 CAPITULO 2. MODELOS DE REGRESION NO LINEALES.
En forma similar a los modelos lineales, uno puede usar mınimos cuadrados para estimar losparametros de un modelo no lineal. El metodo o algoritmo que usaremos en la tesis es el de Gauss-Newton, dado que es uno de los mas usado en regresion no lineal. Este se basa en una aproximacionlineal de la funcion f (xi, θ) cuando esta es derivable, es decir, en la minimizacion de la funcion desuma de cuadrados de los residuales.
Se considera el modelo no lineal de la forma (2.1). En forma matricial se expresa por:
Y = f (X, θ) + ε (2.2)
Donde Y = [y1, ..., yn]T , X = [x1, ..., xn]T , ε = [ε1, ..., εn] y θ es el vector de parametros dedimension 1 ∗ p. El objetivo es minimizar la suma de cuadrados de los residuales para encontrarlos estimadores:
S (θ) = [Y − f (X, θ)]T [Y − f (X, θ)] (2.3)
El algoritmo de Gauss-Newton es un procedimiento iterativo. Esto significa que debemos propor-cionar una estimacion inicial del vector de parametros θ1. Entonces para la estimacion m+ 1 de θse puede expresar como:
θm+1 = θm +[F (θm)T F (θn)
]−1F (θm)
′[Y − f (X, θm)] (2.4)
Donde F (θn) = ∂f(X,θ)∂θ |n . La descripcion del metodo se presenta en el apendice A. En el modelo
(2.2) se asume que ε es independiente e identicamente distribuido con media cero y varianza Iσ2.
Tenemos que bajo ciertos supuestos de regularidad, θ y s2 =SSE(θ)(n−p) son estimadores consistentes
de θ y σ2 respectivamente. Con mas condiciones de regularidad, θ tiene una distribucion normal
multivariada p− dimensional con media θ y matriz de varianza-covarianzas σ2[F (θn)T F (θn)
]−1,
es decir:
θ ∼ Np
(θ, σ2
[F (θn)T F (θn)
]−1)
y (n−p)s2σ2 tiene distribucion chi− cuadrada con n− p grados de libertad
(n− p) s2
σ2∼ χ2
(n−p)
tambien se tiene que s2 y θ son independientes. Ademas bajo el supuesto de que los errores sonnormalmente distribuidos, entonces θ es tambien el estimador de maxima verosimilitud.
2.2 Estimacion por maxima verosimilitud.
Si conocemos la distribucion del error entonces podemos usar el metodo de maxima verosimilitudpara estimar los parametros del modelo. Si los errores son normales e identicamente distribuidoscon varianza constante, el metodo de maxima verosimilitud y el metodo de mınimos cuadradoscoinciden en la estimacion de θ.
Consideremos el modelo (2.1), donde los errores son normales e identicamente distribuidos conmedia cero y varianza desconocida σ2, entonces la funcion de verosimilitud es
L(θ, σ2
)=
1
(2πσ2)n2
exp
[− 1
2σ2
n∑i=1
[yi − f (xi, θ)]2
](2.5)

2.3. INFERENCIA ESTADISTICA EN REGRESION NO LINEAL. 9
Debido a que la maximizacion de la funcion de verosimilitud es equivalente a la maximizacion dela log-verosimilitud, procederemos a aplicar ln a (2.5) obtenemos:
lnL(θ, σ2
)= −n
2ln(2πσ2
)− 1
2σ2
n∑i=1
[yi − f (xi, θ)]2
al derivar con respecto a β e igualando a cero la derivada tenemos
1
σ2
n∑i=1
[yi − f (xi, θ)]
[∂f (xi, θ)
∂βj
]θ=b
= 0
de aquı vemos que la eleccion del vector de parametros b que maximiza la log-verosimilitud esequivalente a maximizar la suma de cuadrados de los residuales. Por tanto en el caso de los erroresse distribuyan normal, los estimadores de mınimos cuadrados en regresion no lineal son los mismosque los estimadores de maxima verosimilitud.
2.3 Inferencia Estadıstica en regresion no lineal.
En modelos de regresion lineal, cuando los errores son normales e independientes, las pruebasestadısticas exactas y los intervalos de confianza basados en las distribuciones F y t son viables, yla estimacion de mınimos cuadrados para los parametros (equivalente a la estimacion de maximaverosimilitud) tiene suficientes y atractivas propiedades. Sin embargo, este no es el caso en regresionno lineal, incluso cuando los errores son normalmente e independientemente distribuidos. Esto es,en regresion no lineal la estimacion por mınimos cuadrados (o por maxima verosimilitud) de losparametros no disfrutan de ninguna de las atractivas propiedades como se tiene en modelos lineales,tales como insesgadez, mınima varianza o normalidad. La inferencia estadıstica en regresion nolineal depende de muestras grandes o resultados asintoticos, en otras palabras, las propiedades sonpropiedades asintoticas. Esto es la insesgadez y la mınima varianza son propiedades que se alcanzancuando el tamano de muestra tiende a ser grande. Como resultado, para un modelo y un tamanode muestra especıficos, nada verdaderamente se puede afirmar en relacion con las propiedades delos estimadores. Hay resultados asintoticos de varianza-covarianza que se pueden usar para obtenerintervalos de confianza aproximados y para construir estadısticos t para los parametros.
La clave de los resultados asintoticos puede ser brevemente resumida como sigue. En generalcuando el tamano de muestra n es grande, el valor esperado de θ es aproximadamente igual aθ, el vector verdadero de los valores de los parametros. Ademas la distribucion muestral de θ esaproximadamente normal. La covarianza asintotica de θ es la inversa de la matriz de informacion.La matriz de informacion es la negativa de la matriz Hessiana, a cual es justamente la matriz de lassegundas derivadas de la funcion de log-verosimilitud. Para la respuesta con distribucion normal,la Hessina es −ZTZ
σ2 , donde Z es la matriz de las derivadas parciales del modelo evaluadas en la
ultima iteracion de la estimacion de mınimos cuadrados de θ. Por tanto la matriz de covarianzasasintotica de θ es
var(θ)
= σ2(ZTZ
)−1
Consecuentemente la inferencia estadıstica para regresion no lineal cuando el tamano de muestraes grande es muy semejante a la que se sigue en regresion lineal. Por ejemplo, para la prueba de

10 CAPITULO 2. MODELOS DE REGRESION NO LINEALES.
hipotesis que un coeficiente de regresion individual, o
H0 : θ = 0 vs H1 : θ 6= 0
usamos una razon similar a la prueba t dada por
t0 =θ
se(θ)
donde se(θ)
es el error estandar de θ el cual puede ser obtenido como un elemento de var(θ)
=
σ2(ZTZ
)−1. La distribucion asintotica de t0 es N (0, 1) cuando la hipotesis nula es verdadera.
Rechazamos H0 si |t0| > t1−α2
;n−p. Un intervalo de confianza de Wald de 100 (1− α) % para elparametro θ es
θ − zα2se(θ)≤ θ ≤ θ + zα
2se(θ)
2.4 Curvas de crecimiento.
Las curvas de crecimiento son usadas para describir como una respuesta crece con cambios en lavariable independiente, tales curvas inician en algun punto fijo y aumentar su tasa de crecimientomonotonamente para llegar a un punto de inflexion; despues esta tasa de crecimiento disminuyepara aproximarse asintoticamente a algun punto final. Las curvas de crecimiento tienen formassenoidales como se observa en la figura (2.1), la cual es un ejemplo del crecimiento de raıces defrijoles vs contenido de agua. En este grafico se observa el patron tıpico de una curva de crecimientodescrita anteriormente, inicia en un punto y crece rapidamente de manera monotona hasta llegaral punto de inflexion y luego el crecimiento disminuye hasta llegar a un punto en el cual no crecemas, en la practica se sabe que esto sucede ya sea por el agotamiento de los nutrientes del medioambiente en el que se encuentra o debido a que ha llegado al final de su desarrollo o tiempo devida. Los procesos de produccion senoidal o curvas de crecimiento S-modelar son muy difundidosen biologıa, agricultura, ingenierıa, economıa y medicina.
Figura 2.1: Grafico de un Modelo Senoidal.
Numerosas funciones matematicas se han propuesto para modelar las curvas de crecimiento,algunas de las cuales se tienen cierta base teorica subyacente. Entre ellas estan la Gompertz, la

2.4. CURVAS DE CRECIMIENTO. 11
Logıstica, la Richards (1959), la Morgan −Mercer − Flodin (1975), y un modelo derivado dela distribucion Weibull (1951), esta es designada como un modelo tipo−Weibull. Para el trabajosolo se utilizaran los modelos Gompertz y Logıstico, debido a que estos modelos son usados parael estudio del crecimiento de poblaciones o animales. A continuacion presentaremos una breveexplicacion de estas curvas de crecimiento.
2.4.1 Modelo Gompertz.
El modelo de Gompertz se debe a Benjamin Gompertz que lo propuso en 1825 en su trabajo, ”Onthe nature of the function expressive of the Law of human mortality”. Ha sido un modelo muyutilizado dado que describe relativamente bien la mortalidad humana en edades adultas, poblacionesde tumores, ası como tambien es frecuentemente usado para el estudio de poblaciones y animales encrecimiento en situaciones donde este no es simetrico alrededor del punto de inflexion. El modelofuncional considerado es
Y = α exp (− exp (β − γX)) (2.6)
Observar que la forma del modelo Gompertz (2.6) es una doble exponencial, ademas que es unafuncion no lineal en los parametros, los cuales tienen los siguientes significados:
Figura 2.2: Grafico del Modelo Gompertz
1. El parametro de α es el lımite superior de la curva como se observa en el grafico , es decir lafase estacionaria.
2. El parametro β es el tiempo de adaptacion antes de iniciar la fase exponencial o de crecimientoexponencial.
3. El parametro γ es la tasa de crecimiento.
2.4.2 Modelo Logıstico.
La curva logıstica o curva en forma de S es una funcion matematica que aparece en diversos modelosde crecimiento de poblaciones, propagacion de enfermedades epidemicas y difusion en redes sociales.En este modelo como modelos de crecimiento, las poblaciones inicialmente crecen rapido en unafuente de presion constante, esto debido a que generalmente el medio para la poblacion es optimo,

12 CAPITULO 2. MODELOS DE REGRESION NO LINEALES.
por tanto se vuelven tan numerosos los individuos de dicha poblacion que pierden su capacidadde crecer debido a interacciones entre los miembros de la poblacion, por lo que resulta un estadode equilibrio. Este tipo de crecimiento se llama crecimiento logıstico. El crecimiento logısticoes el balance entre produccion en proporcion a la poblacion, y a las perdidas en proporcion a laoportunidad de interacciones individuales. Un ejemplo es el crecimiento de levadura en el fermentodel pan. Primeramente, el crecimiento de la poblacion es casi exponencial. La disponibilidad dealimento es constante y como la poblacion crece esto implica comer mas y mas. Sin embargo,las celulas de levaduras se vuelven tan numerosas que sus productos comienzan a interferir con elpropio crecimiento. Por lo que resulta un estado de equilibrio entre produccion y perdida de celulas.El modelo logıstico esta dado por:
Y =α
1 + exp (β − γX)
Donde los parametros tienen los siguientes significados:
1. El parametro de α es el lımite superior de la curva como se observa en el siguiente gafico.
2. El parametro β falta su interpretacion pero lo observado en los graficos es el tiempo deadaptacion antes de iniciar la fase exponencial.
3. El parametro γ es la tasa de crecimiento.
Figura 2.3: Grafico de un Modelo Logıstico

Capıtulo 3
Problemas de Estudio.
3.1 Datos Medicos (Datos Observables).
La evaluacion del crecimiento fetal es importante para predecir la posibilidad de padecimientos delneonato, estimar su pronostico a largo plazo y juzgar el resultado de la atencion de mujeres conembarazo de alto riesgo. La evaluacion tradicional consiste en ubicar al recien nacido en una curvapatron de crecimiento intrauterino, de acuerdo con el peso y la edad gestacional.
El ultrasonido ofrece la oportunidad de poder evaluar el crecimiento fetal debido a que se puedenmedir variables que permiten estimar la edad gestacional y evaluar el crecimiento fetal. En generaldespues de la semana 12 se utilizan las siguientes medidas o variables: diametro biparietal (DBP),circunferencia de la cabeza o cefalica, circunferencia abdominal, longitud de la diafisis del femur,entre otras para determinar la edad del feto y analizar su desarrollo. Una descripcion rapida deestas variables es proporcionada a continuacion:
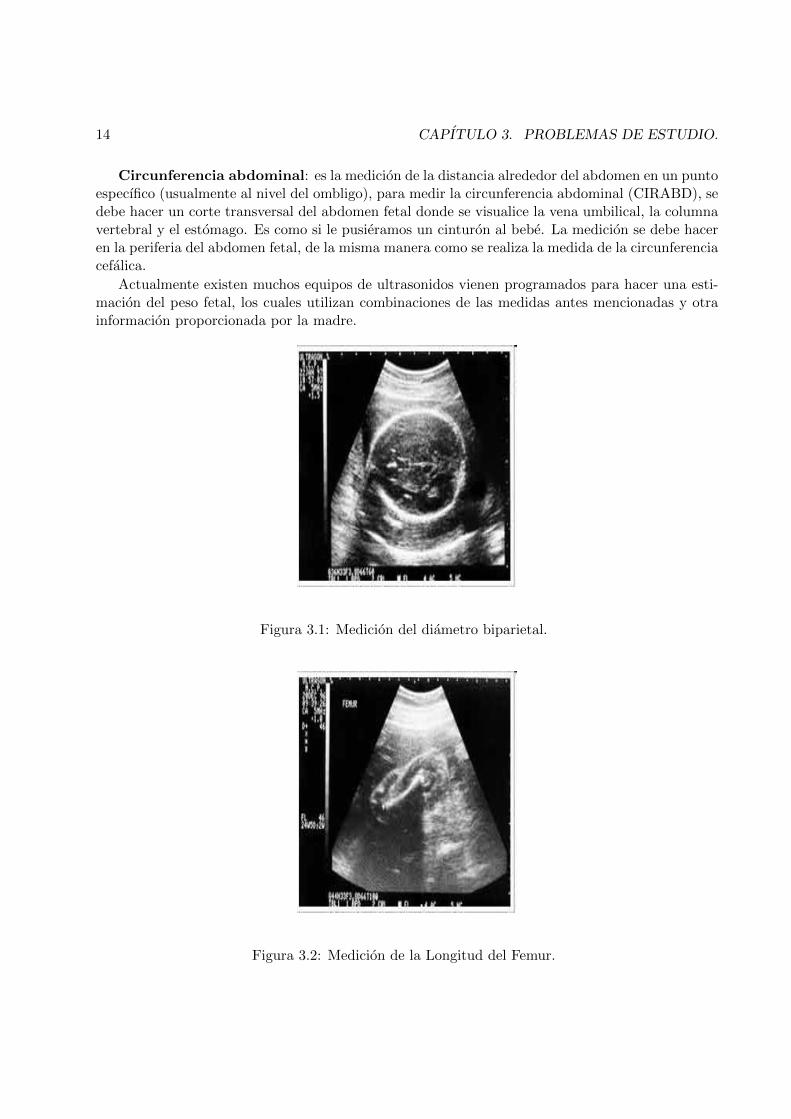
Diametro biparietal. Es uno de los parametros mas usados para la estimacion de la edadgestacional y, ademas, permite predecir el patron de crecimiento del craneo. Se mide entre dosmarcas: una situada en el margen externo del hueso parietal mas proximo y la otra en el margenecogenuco esterno del hueso parietal distal o dependiente como se observa en la figura . La medidaes transversal y unidimensional, es decir la medida se hace a ambos extremos de la cabeza y seutiliza para calcular la edad gestacional, con un rango de error de mas o menos 1 semana entre lassemanas 12 y 20, y de mas o menos 3 semanas, despues de la semana 30. Las medidas obtenidasson llevadas a Tablas especiales, para obtener un estimado de la edad gestacional. La mayorıa delos equipos de ultrasonido vienen con programas para hacer el calculo de la edad gestacional, enbase a la medida del DBP.
Circunferencia cefalica. La medida de la circunferencia cefalica (CIRCEF) ha sido com-parada con el DBP, ya que ambos son similares en el rango de seguridad. Sin embargo, la CCtiene mayor valor cuando se encuentran formas inusuales en la forma del craneo, ocasionadas porla posicion del feto en el utero. La medida de la CC se realiza en el mismo plano que la del DBPy es como si le pusieramos una bandana al bebe. Ambas medidas son utiles para el estudio delcrecimiento y nutricion del feto, un grafico de la medicion de la circunferencia cefalica es la figura .
Longitud del femur. Al igual que el DBP, la medicion de la longitud del femur (LFemur) esuno de los parametros mas utilizados para estimar el crecimiento y la edad gestacional. El femurse identifica por su forma en “palo de golf”, como se observa en la figura y es una de las medidasmas precisas de edad gestacional al final del embarazo.
13
14 CAPITULO 3. PROBLEMAS DE ESTUDIO.
Circunferencia abdominal: es la medicion de la distancia alrededor del abdomen en un puntoespecıfico (usualmente al nivel del ombligo), para medir la circunferencia abdominal (CIRABD), sedebe hacer un corte transversal del abdomen fetal donde se visualice la vena umbilical, la columnavertebral y el estomago. Es como si le pusieramos un cinturon al bebe. La medicion se debe haceren la periferia del abdomen fetal, de la misma manera como se realiza la medida de la circunferenciacefalica.
Actualmente existen muchos equipos de ultrasonidos vienen programados para hacer una esti-macion del peso fetal, los cuales utilizan combinaciones de las medidas antes mencionadas y otrainformacion proporcionada por la madre.
Figura 3.1: Medicion del diametro biparietal.
Figura 3.2: Medicion de la Longitud del Femur.

3.2. DATOS EXPERIMENTALES EN BIOQUIMICA. 15
Figura 3.3: Medicion de la Circunferencia Cefalica.
Los datos a usar en la tesis fueron proporcionados por seguro social de Leon, Guanajuato,consisten de 48 fetos a los cuales se les midio las siguientes variables: diametro biparietal (DBP ),circunferencia de la cabeza o cefalica (CIRCEF ), circunferencia abdominal (CIRABD), longitudde la diafisis del femur (Lfemur), peso del recien nacido (Peso). Las mediciones seriales fueron dela semana 15 a la semana 39, dandose un caso de 41 semanas de gestacion.
3.2 Datos Experimentales en Bioquımica.
La conservacion de alimentos ha evolucionado con el transcurso de los anos, debido a que losconsumidores demandan alimentos menos procesados y sin la presencia de aditivos quımicos, dadaesta necesidad se han seleccionado un gran numero de metodos de conservacion que permitenmantener las caracterısticas de frescura e inocuidad de los alimentos. Algunos de los metodos deconservacion que han sido utilizados son los siguientes: manejo de temperatura, pH, actividadacuosa, atmosferas controladas, agentes quımicos, irradiacion, empaques, etc. la utilizacion de masde uno de estos sistemas de conservacion evita la proliferacion de microorganismos en los alimentos.
A diferencia de las sustancias quımicas adicionadas intencionalmente a los alimentos, las sustan-cias naturales suelen implicar menores riesgos a la salud, ya que la mayorıa de ellas, son generadaspor algun material biologico como metodo de conservacion; algunos de estos compuestos han sidousados durante mucho tiempo, sin que hayan presentado ningun efecto adverso a la salud. Espor ello que el interes por el uso de nuevos metodos de conservacion biologico ha aumentado lautilizacion de las bacterias acido lacticas, debido a que pueden ser aplicadas como conservadoresnaturales para controlar el crecimiento de bacterias patogenas o deterioradoras de los alimentos de-bido al efecto antagonico de estos microorganismos de los metabolitos antimicrobianos. El terminobioconservador ha sido usado para incluir los compuestos antimicrobianos de plantas, animales ycompuestos de origen bacteriano, el uso de estos compuestos alarga la vida de anaquel de alimento(Schillinger y col., 1996).
Debido a que el Lactococcus lactis UQ − 2 es una bacteria nativa de un queso mexicano que

16 CAPITULO 3. PROBLEMAS DE ESTUDIO.
Tabla 3.1: Diseno Experimental para los Datos de Bioquımica.Factores Niveles de Factores Variable/Respuesta
Conc. 0 (n/nisina) MicrobiologicasConc. 1 (nisina 0.05 ug/l) Cuenta de
Concentracion Conc. 2 (nisina 0.65 ug/l) Lactococcus lactis UQ-3de Nisina Conc. 3 (nisina 1.25 ug/l) Actividad de
Conc. 4 (nisina 1.87 ug/l) nisina (Difision en Agar)Conc. 5 (nisina 2.5 ug/l) Fısicas y quımicas
Concentracion Mezcla 0 (Sin sales) pHde mezcla Mezcla 1 (Mg(0.5) y Mn(0.1)) Consumo de lactosa
de sales (Mg y Mn) Mezcla 2 (Mg(0.2) y Mn(0.04))
produce antimicrobianos naturales entre ellos la nisina A. Y debido a que la nisina es un peptidoantimicrobiano capaz de inhibir bacterias Gram positivas, usada como un conservador clasificadocomo GRAS (generalmente reconocida como segura) y dado que ingerida es destruida rapidamentedurante la digestion, por lo que carece de toxicidad para el ser humano, ademas que el uso dela nisina esta comercialmente disponible en mas de 50 paıses alrededor del mundo. Se realizo unexperimento con el objetivo crecer Lactococcus lactis UQ− 2 en leche e incrementar la produccionde nisina A, se modifico las condiciones del medio donde se desarrolla, de manera que pueda serutil para la bioconservacion de productos lacteos.
Los objetivo a perseguir en la tesis para este problema son:
1. Describir el crecimiento ln(NN0
)y la produccion de nisina por la bacteria Lactococcus lactis
subsp en leche en polvo light reconstituida, la cual es usada para preservar alimentos pere-cederos como leche y quesos, a traves de un modelo de regresion no lineal, es decir, ajustarmodelos no lineales a cada una de las cineticas realizadas.
2. Encontrar el mejor tratamiento para la produccion de nisina A.
3. Encontrar un modelo general y compararlo con los modelos de regresion no lineal ajustadopara cada cinetica.
En el experimento se evaluo el efecto que tienen la agregacion de nisina externa y sales (Mg yMn en dos concentraciones diferentes), en el medio de cultivo (leche), sobre la produccion de nisinadel Lactococcus lactis UQ − 2. Se uso un diseno multifactorial con un nivel de significancia deα = 0.05. Todas las muestras experimentales se realizaron por duplicado. La Tabla (3.1) muestrael diseno utilizado para obtener los datos del experimento.

Capıtulo 4
Pruebas de Hipotesis y Metodos deDiscriminacion para Modelos deRegresion No Lineal.
Dentro de la teorıa de seleccion de modelos hay dos tipos de modelos, los cuales son: modelosanidados y modelos no anidados. Por Modelos anidados entenderemos aquellos en los que se puedeestablecer una jerarquıa, de tal manera que uno de ellos es el denominado modelo general y el olos otros, llamados modelos restringidos, los cuales pueden ser obtenidos mediante la imposicion derestricciones, lineales o no lineales, sobre el modelo general, y los Modelos no anidados, son aquellosque no pueden ser jerarquizados en un modelo general y un o unos modelos restringidos no puedenobtenerse de un modelo general a traves de la imposicion de restricciones.
4.1 Prueba de Hipotesis para Modelos Anidados.
La modelacion de un fenomeno natural o fısico a menudo inicia con un modelo basico, la complejidadjunto con un creciente numero de parametros desconocidos, se anade continuamente, formandoseuna sucesion de modelos propuestos. Con esta creciente complejidad los modelos llegan a ser masprecisos en su ajuste para las respuestas, pero su inestabilidad crece. En este sentido un sistemanatural jerarquico de los modelos es construido, este encajamiento de las funciones modelo esllamado sistema anidado. De aquı podemos observar que un modelo de este conjunto de modelosanidados es adecuado para el comportamiento de los datos.
Supongamos que tenemos las siguientes hipotesis:
H0 : yi = f (xi, β) + εi0, i = 1, ..., n y β ∈ Rm1
H1 : yi = g (xi, γ) + εi1, i = 1, ..., n y γ ∈ Rm2
Para comparar dos modelos usaremos la prueba de razon de verosimilitud. Supondremos deinicio que f ⊂ g, entonces se prueba
H0 : Y = f (X,β) + ε0 (4.1)
en contra deH1 : Y = g (X, γ) + ε1 (4.2)
17

18CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
Donde X = [x1, ..., xn], Y = [y1, ..., yn] y εj para j = 0, 1, es el vector de errores. Observemosque en esta hipotesis se prueba cual de los dos modelos anidados ajusta mejor a los datos. Bajo
el modelo correcto, los errores se distribuyen normal εj ∼ N(
0, σ2j I)j = 0, 1 para H0 y H1. Para
poder realizar la prueba de razon de verosimilitud primero encontraremos λ.
λ =supσ2
0 ,β∈Θ0L(σ2
0, β)
supσ21 ,γ∈Θ1
L(σ2
1, γ)
=
sup
[(2πσ2
0
)−n2 e
{− 1
2σ21
∑[Y−f(X,β)]2
}]
sup
[(2πσ2
1
)−n2 e
{− 1
2σ21
∑[Y−g(X,γ)]2
}]
=
(2πσ2
0
)−n2 e
{− 1
2σ21
∑[Y−f(X,β)]
2}
(2πσ2
1
)−n2 e
{− 1
2σ21
∑[Y−g(X,γ)]2
}
=
(2πn
∑[Y − f
(X, β
)]2)−n
2
e
{− n
2∑
[Y−f(X,β)]2∑
[Y−f(X,β)]2}
(2πn
∑[Y − g (X, γ)]2
)−n2e
{− n
2∑
[Y−g(X,γ)]2∑
[Y−g(X,γ)]2}
=
(∑[Y − f
(X, β
)]2)−n
2
e{−n2 }(∑
[Y − g (X, γ)]2)−n
2e{−
n2 }
=
∑[
Y − f(X, β
)]2
∑[Y − g (X, γ)]2
−n
2
=
∑[Y − g (X, γ)]2∑[Y − f
(X, β
)]2
n2
Entonces el estadıstico de la prueba de hipotesis es:
λ =
∑[Y − g (X, γ)]2∑[Y − f
(X, β
)]2
n2
(4.3)
donde observamos que λ es el cociente de la suma de cuadrados de los errores. Entonces bajocondiciones de regularidad generales, sabemos que −2 ln (λ) ∼ χ2 con grados de libertad m2 −m1,

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 19
y por tanto una region rechazo para un nivel de significancia de α es −n ln
[ ∑[Y−g(X,γ)]2∑[Y−f(X,β)]
2
]< χ2
(1−α).
Ası si el p−valor es menor que el nivel de significancia, concluimos que el modelo alternativo ajustaa los datos significativamente mejor que el modelo de hipotesis nula. De lo contrario, la conclusiones que no hay evidencia convincentes de apoyar el modelo alternativo, por lo que aceptar el modelode la hipotesis nula.
Observaciones:
• Esta prueba es referida como la prueba de razon de verosimilitud generalizada (GLRT ) paramodelos anidados.
• La prueba es apropiada para modelos lineales y no lineales.
• Tenga en cuenta que la prueba realmente no nos ayuda a decidir que modelo es el correcto.Lo que hace es ayudar a decidir si se tiene evidencias suficientes para rechazar el modelo massimple de la hipotesis nula.
• Esta prueba solo es valida para comparar modelos anidados. Esta no puede ser usada paramodelos no anidados. En este ultimo caso, se tendra que utilizar un metodo alternativobasado en la teorıa de la informacion o en metodos de discriminacion.
4.2 Pruebas de Hipotesis para los Modelos No Anidados.
Las pruebas de Hipotesis generalmente implican modelos anidados, en los cuales el modelo querepresenta la hipotesis nula es un caso especial de un modelo mas general que representa la hipotesisalternativa. Para este modelo, siempre se puede probar la hipotesis nula mediante las pruebasde las restricciones que este impone en la alternativa. Pero a menudo se da en algunos casosdonde los modelos son no anidados y por tanto no se puede aplicar los procedimientos de laspruebas de modelos anidados. Esto significa que ninguno de los dos modelos se puede escribir comocaso especial del otro sin restricciones imponentes en ambos modelos. En tal caso, no podemossimplemente probar uno de los modelos contra del otro, menos condicionar sobre uno de ellos. Existeuna amplia literatura sobre las pruebas de hipotesis no anidadas, la cual ofrece varias maneras deprobar la especificacion de los modelos estadısticos cuando una o mas alternativas no anidadasexisten. Ahora cuando se tiene k modelos y se realizar k (k − 1) pruebas pareadas, no podemosrazonablemente esperar que uno y solo uno de los modelos sea no rechazado. Por lo tanto, si nuestroobjetivo es elegir el mejor modelo de los k modelos competitivos, y no importa si incluso el mejormodelo es falso, no debemos utilizar las pruebas de hipotesis no anidadas. Estos procedimientosgeneralmente implican el calculo de algun tipo de funcion de criterio para cada uno de los modelosy escoger el modelo para el cual esa funcion sea maximizada o minimizada. Otro metodo es elmetodo de discriminacion en el cual se busca minimizar la probabilidad de elegir un modelo fjcuando el modelo correcto es el modelo fq, es decir, se busca minimizar P [IS (fj | fq)] y maximizarla probabilidad de elegir el modelo fj cuando el modelo correcto es fj .
4.2.1 Prueba de Davidson y Mackinnon.
En los anos de 1980, varios procedimientos se propusieron para mostrar la especificacion de unmodelo de regresion no lineal en contra de la evidencia presentada por una hipotesis alternativa

20CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
no anidada. Una de las primeras de tales pruebas fue presentada por Pesaran(1974) y Pesarany Deaton(1978) y se basaron explıcitamente en el trabajo clasico de Cox(1961, 1962). En el anode 1981 Davidson y MacKinnon propusieron un procedimiento mucho mas simple basado en unmodelo de regresion artificial y mostraron que las pruebas resultantes son asintoticamente equiva-lentes a las pruebas de Cox. Ademas que White(1982) mostro que si se implementa la prueba deCox uno de los procedimientos de Davidson y MacKinnon es obtenido directamente.
La prueba J propuesta en su paper de (1981) para modelos de regresion lineal puede ser ampliadapara modelos de regresion no lineal. Supongamos que hay dos modelos no lineales
Modelo 1 : Y = f (X,β) + ε1 (4.4)
Modelo 2 : Y = g (X, γ) + ε2 (4.5)
donde X representa las observaciones en una matriz de variables exogenas, β y γ son respecti-vamente vectores de parametros a ser estimados y εi se asume como i.i.d N
(0, σ2
i
), entonces las
hipotesis estaran dadas por:
H1 : Y = f (X,β) + ε1
H2 : Y = g (X, γ) + ε2
Cuando decimos que los dos modelos son no anidados, queremos decir que hay valores de β(usualmente una infinidad de valores de β) para los cuales no hay valores de γ admisibles talque f (X,β) = g (X, γ) y viceversa. En otras palabras, ningun modelo es un caso especial del otroa menos que se impongan restricciones sobre ambos modelos. El modelo artificial analogo al modeloartificial para modelos de regresion lineal es
y = (1− α) f (X,β) + αg (X, γ) + ε (4.6)
Por si solo, este modelo no es muy util dado que α, β y γ generalmente no son identificables. Portanto en el paper de Davidson y MacKinnon sugirieron que γ sea reemplazado por γ el cual es elestimador de mınimos cuadrados, entonces (4.6) se convierte en:
y = (1− α) f (X,β) + αg (X, γ) + ε (4.7)
Debido a que algunos de los parametros de la regresion no lineal (4.7) no pueden ser identificadosadecuadamente, el estadıstico J puede ser difıcil de calcular. Esta dificultad puede ser evitada alrealizar una linealizacion del en una forma usual, esto es, realizar un GNR (regresion de Gauss-Newton) es decir, solo se necesita linealizar la ecuacion (4.7) alrededor de β = β. Esta GNRes
y − f(X, β
)= F b+ α
[g (X, γ)− f
(X, β
)](4.8)
donde F es la matriz de derivadas de f (X,β) con respecto a β evaluada en el estimador demınimos cuadrados β. El estadıstico t (ordinario) para α = 0 en la regresion (4.8) es llamado elestadıstico P. Davidson y MacKinnon (1981) sugieren que para el caso de modelos de regresion nolineal la prueba de hipotesis mas adecuada es la prueba P sobre la prueba J, ademas que mostraronque el estadıstico t en α es asintoticamente N (0, 1) cuando H0 es verdadero bajo condiciones deregularidad.

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 21
Numerosas pruebas no anidadas estan disponibles para los modelos de regresion no lineal.Entre ellas esta la prueba PA la cual esta relacionada con la prueba P precisamente como la pruebaJA esta relacionada a la prueba J en el caso de modelos lineales. Al igual que la prueba JAtiene mejores propiedades para muestras finitas bajo la hipotesis nula que la prueba P ordinaria.Lamentablemente, el excelente desempeno de la prueba PA bajo la hipotesis nula no va acompanadade un buen desempeno bajo la hipotesis alternativa. En consecuencia γ puede diferir grandementede γ cuando H1 es falsa, y la evidencia que el modelo H1 es incorrecta puede ser suprimida.Cabe mencionar que γ se puede obtener al realizar una regresion de PXy en X. Simulacion deexperimentos han mostrado que la prueba PA puede ser menos potente que la prueba P, para ellovease Davidson y MacKinnon (1982) . Por tanto un rechazo de la prueba PA debe ser tomada muyseriamente pero si no hay un rechazo esta puede proporcionar muy poca informacion. Entoncesla prueba PA, puede sufrir de una seria falta de poder. En contraste una version Bootstrap de laprueba P es razonablemente confiable y altamente potente. Por tanto es recomendable usar estaprueba en vez de la prueba PA, si el tiempo de la computadora no es una restriccion.
El estadıstico t de α de (4.8) esta dado por:
t =
(y − f
)TM0
(g − f
)σ
√(g − f
)TM0
(g − f
) (4.9)
donde y = [y1, ..., yn], f =[f1, ..., fn
]y g = [g1, ..., gn] , σ es el estimador del error estandar de (4.8)
y
M0 = I − F(F T F
)−1F T
donde F es la matriz cuya n− esima fila es Fn.
Demostracion.
Para demostrar que (4.9) es el estadıstico t de α de (4.8) usaremos el Teorema de Frisch-Waugh-Lovell el cual se presenta en el Apendice C, por tanto tendremos el siguiente modelo:
MF
(y − f
)= αM
F
(g − f
)+ residuales (4.10)
recordemos que el estimador de mınimos cuadrados de (4.10) es identico al estimador de mınimos

22CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
cuadrados de (4.8) por tanto tenemos que
α =
[(MF
(g − f
))T (MF
(g − f
))]−1 (MF
(g − f
))T (y − f
)
=
(MF
(g − f
))T (y − f
)(MF
(g − f
))T (MF
(g − f
))=
(g − f
)TMTF
(y − f
)(g − f
)TMTFMF
(g − f
)=
(g − f
)TMF
(y − f
)(g − f
)TMF
(g − f
)y la varianza de α esta dada por
V ar (α) = σ2
[(MF
(g − f
))T (MF
(g − f
))]−1
=σ2(
g − f)T
MF
(g − f
)por tanto el estadıstico t de α es
t =α√
V ar (α)
=
(g−f)TMF (y−f)
(g−f)TMF (g−f)√σ2
(g−f)TMF (g−f)
=
(g−f)TMF (y−f)
(g−f)TMF (g−f)
σ√(g−f)
TMF (g−f)
=
√(g − f
)TMF
(g − f
)[(g − f
)TMF
(y − f
)]σ(g − f
)TMF
(g − f
)
=
(g − f
)TMF
(y − f
)σ
√(g − f
)TMF
(g − f
)

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 23
Bajo los supuestos de Davidson y MacKinnon se puede mostrar que bajo H0 (4.9) tiende enprobabilidad a
εT0 M0 (g − f)
σ0
√(g − f)T M0 (g − f)
(4.11)
donde las cantidades sin sombrero son evaluadas en β0 el verdadero valor de β o en γ0 el plim de γbajo H1. Debido al papel desempenado por la matriz de proyeccion M0 en (4.9) se puede observarque (4.11) es N (0, 1). Davidson y MacKinnon llamaron a esta prueba basada en (4.8) la pruebaP.
Una extension de esta prueba es mencionada en el paper de Davidson y MacKinnon, la cualpuede ser utilizada para probar la veracidad de una hipotesis contra varias alternativas a la vez, esdecir, para probar H0 contra m modelos alternativos gj (Zji, γj) para la prueba se debe estimar
yi − fi =m∑j=1
αj
(gji − fi
)+ Fib+ εi
y realizar una prueba de razon de verosimilitud de la restriccion de que todos los αjs son cero.Aunque cabe mencionar que en su libro Econometric Theory and Methods, no mencionan estaextension de la prueba P , sino que sugieren que no se debe usar pruebas de hipotesis para seleccionarun modelo de un conjunto de modelos competitivos, y mencionan que hay que usar criterios deinformacion para estos casos, es decir, dado que las pruebas de hipotesis no anidadas estan disenadascomo pruebas especificas, en lugar de procedimientos para elegir entre los distintos modelos no essorprendente que a veces no nos lleven a elegir un modelo sobre el otro. Si nosotros simplementequeremos elegir el ”mejor” modelo de algun conjunto de modelos competentes o si alguno de ellos essatisfactorio, debemos utilizar un enfoque muy diferente, basandose en un criterio de informacion.
Interpretacion de las Pruebas No Anidadas.
Si rechazamos H0 la hipotesis nula, no hay implicacion de que la hipotesis H1 es verdadera. Paradecir cualquier cosa acerca de la validez del modelo (4.4), hay que probarlo. Esto puede ser hechoal intercambiar los roles de los dos modelos.
Al Probar H0 y H1 uno en contra del otro, pueden ocurrir cuatro posibles resultados: H0 esrechazado pero no rechazamos H1, H1 es rechazado pero no rechazamos H0, ambos son rechazadoso ninguno de los dos modelos son rechazados. Dado que los dos primeros resultados nos llevan apreferir uno de los dos modelos, se tiene el deseo de ver estos resultados como naturales y deseables.Sin embargo los dos ultimos resultados que no son pocos frecuentes en la practica, pueden tambienser muy informativos. Si ambos modelos son rechazados, entonces hay que buscar otro modelo quemejore el ajuste y si ambos modelos no son rechazados, entonces hemos aprendido que los datosparecen ser compatibles con ambas hipotesis.
4.2.2 Seleccion de Modelos Basado en Metodos de Discriminacion.
Metodo de Discriminacion propuesto por Atkinson.
La construccion de modelos estadısticos surge de la necesidad de explicar y predecir un fenomenoreal que dependen de variables. Generalmente cuando se trata de modelar este comportamiento

24CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
existen variosmodelos alternativos, surge el problema de cual modelo seleccionar del conjunto quese tenga, dado ası modelos competitivos que pueden surgir de una teorıa o un conjunto de teorıas.La seleccion de un mejor modelo de la coleccion de modelos construidos a menudo es una eleccionentre teorıas en competencia, y se basa en resultados empıricos obtenidos a partir de datos dela muestra. Por tanto modelos de discriminacion es la teorıa de la seleccion de modelos rivalesbasados en informacion de la muestra.
Podemos decir que dos propiedades caracterizan una propuesta de un modelo de utilidad en elanalisis de los datos. Primero es el modelo ajustado adecuado a los datos empıricos. En segundolugar, en el caso de los modelos que contengan parametros desconocidos a ser estimados, es ladependencia del modelo ajustado, o estimacion de parametros, en particular del conjunto de datosobservados. Esta segunda propiedad se llama estabilidad del modelo. En la construccion de losprocedimientos de seleccion de modelos y pruebas, estos dos rasgos de modelado deben tenerse encuenta.
Basados en el ajuste de los modelos rivales, Atkinson (1969) sugiere tres puntos de vistahipoteticos para pruebas estadısticas en discriminacion de modelos. Estas son resumidas en lassiguientes preguntas:
A1 Bajo el supuesto que un modelo particular es el verdadero, ¿hay evidencia de que de los otrosmodelos, ajusten mejor a los datos?
A2 Bajo el supuesto que el modelo se ajusta adecuadamente a los datos, ¿hay evidencia estadısticade lo contrario?
A3 Al asumir que uno de los modelos es el verdadero, ¿hay suficiente evidencia para hacer unaseleccion?
El merito de estas preguntas basicas se sostiene con la evaluacion de la estabilidad del modeloy su ajuste. Estos puntos basicos son puntos de partida para el modelo de discriminacion. Sicualquiera de las cuestiones A1 o A3 es considerada, entonces asumimos que F contiene un modeloverdadero unico. En este caso, las ideas de seleccionar correcta e incorrecta un modelo junto con susprobabilidades correspondientes pueden ser exploradas. Si la pregunta A2 es presentada, entoncesno tenemos que definir un verdadero modelo, si no las caracterısticas del modelo son contrastadas.En el libro de Borowiak Dale S, se realiza exploraciones de estos metodos de discriminacion.
En esta seccion se usara una nueva notacion para la cual se presentara a continuacion. Engeneral en los problemas de discriminacion del modelo el investigador se enfrenta con k modelos,los cuales pueden ser adecuados para el comportamiento observado en el fenomeno, denotados porfj para j = 1, ..., k. El conjunto de modelos rivales se define como F.
F = {fj | fj es un modelo competitivo con j = 1, ..., k} .
Para un modelo fj ∈ F, el modelo de regresion es dado por
yi = fj (xi) + εi (fj) (4.12)
Donde εi (fj) es el termino asociado al error de la xi asociado a la forma funcional fj tal queE (εi (fj)) = 0 para todo i = 1, ..., n.
Como se menciono los metodos de discriminacion consiste en seleccionar el mejor modelo de unconjunto de k modelos competitivos, por tanto se construyen funciones o estadısticos usados para

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 25
seleccionar el mejor o el verdadero modelo, los cuales son usados para eliminar los modelos menosprobables, o designar cuando los modelos son similares a los modelos verdaderos o falsos. Estasfunciones son referidas como funciones de discriminacion, denotadas como DFs. Bajo A1 o A3, unmetodo de discriminacion, denotado como DM , selecciona el mejor modelo de F y puede ser usaruna DF o una serie de DFs. La eleccion de un DM a utilizar dependera de las circunstanciasparticulares del problema.
Comunmente, las DFs se basan en los errores observados o los residuales de los modelos rivales.Una DF que esta basada en una funcion cuadratica de residuales es llamado una funcion dediscriminacion cuadratica or QDF. Para un modelo fj ∈ F, una QDF toma la forma
Qj = RTj SjRj + Cj (4.13)
donde, Sj es una matriz positiva semidefinida de nxn, Cj es una constante y Rj = Y − fj .Observemos los siguientes dos puntos.
1. Si tomamos Sj = I y definimos Cj = 0, entonces (4.13) se convierte en la suma de cuadradosde residuales de fj , denotado por RSS.
2. La principal tarea en la construccion de un DM consiste en definir una o mas DFs quenos permita realizar pruebas o procedimientos en el enfoque de las cuestiones de Atkinson(A1, A2 o A3) . No solo las DFs evaluan los ajustes como los residuales, sino tambien en elcaso de estimacion de modelos, las medidas de estabilidad son empleadas.
Al considerar la discriminacion de modelos desde el punto de vista de las cuestiones A1 o A3,donde se asume que F contiene un modelo verdadero. El metodo de discriminacion simple seleccionade F, el modelo con el menor QDF. Este procedimiento es referido como el metodo de mınimoscuadrados o LQM. La discriminacion del mınimo error cuadratico es un LQM donde Sj = I yCj = 0 para todo j = 1, .., k. Este DM selecciona el modelo con menor RSS y es referido comoLSE.
Al igual que en libro de Borowiak Dale S, se asumira que F contiene el modelo verdadero yun DM es empleado. Este DM selecciona con probabilidad 1, un unico mejor modelo. En estepanorama, las selecciones correctas y incorrectas, junto con sus respectivas probabilidades, son laherramienta basica en la construccion y evaluacion de un DM eficiente. Hay dos decisiones inher-entes en un metodo de discriminacion. Si fj ∈ F es el verdadero modelo y este es seleccionado, unaseleccion correcta a ocurrido la cual denotaremos por CS (fj). Por otro lado, si fj es seleccionadomientras fq es el modelo correcto, una seleccion incorrecta a ocurrido, la cual denotaremos porIS (fj | fq) . Al tomar en cuenta todos los modelos que estan contenidos en F, tenemos
IS (fj | fq) = ∩{seleccionar fi sobre fm | fq es verdadero}
yCS (fj) = ∩{seleccionar fj sobre fm | fj es verdadero}
donde las intersecciones son sobre fm ∈ F y m 6= i. Cuando sea posible en conjuncion con unmetodo de discriminacion, la eleccion del mejor modelo es evaluada por las probabilidades de losdos eventos anteriores. Bajo el modelo menos favorable, la probabilidad de una eleccion incorrecta,cuando se selecciono fj es denotado por IS (fj) . Por tanto
P (IS (fj)) = maxfq∈F
P (IS (fj | fq))

26CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
De forma analoga, la probabilidad una eleccion correcta, cuando fj es seleccionado es denotadopor P (CS (fj)) . Si todas las elecciones de un modelo verdadero hipotetico son consideradas, lasprobabilidades que son independientes del modelo seleccionado se pueden construir
P (IS) = max1≤m≤k
P (∪i 6=mIS (fj | fm))
Equivalentemente, la probabilidad total de una eleccion correcta es
P (CS) = min1≤i≤k
P (CS (fj))
El tipo mas simple de metodo de discriminacion utiliza funciones de discriminacion que comparanlos modelos a pares. En el caso de dos modelos fj y fq ∈ F y un metodo de discriminacion fijo,la probabilidad de seleccionar fj sobre fq bajo el supuesto que fq es verdadero es denotado porP (fj | fq) .
Teorema 1 Asumir que F contiene un modelo verdadero. Utilice un metodo de discriminacion elcual selecciona el mejor modelo con probabilidad 1, al condicionar en el modelo seleccionado
P (IS (fj)) ≤ maxq 6=j
P (fj | fq)
y
P (CS (fj)) ≥ 1−∑q 6=j
P (fq | fj) (4.14)
Ademas sin condicionamiento
P (IS) ≤ max1≤q≤k
∑j 6=q
P (fj | fq) (4.15)
Observar que podemos usar estas probabilidades de seleccion o lımites apropiados pueden uti-lizarse para probar las cuestiones A1 o A3 de Atkinson. A continuacion se presentan las dos pruebasque pueden considerarse cuando se toman en cuenta las cuestiones de Atkinson.
Prueba 1.. Consideremos la cuestion A1 de Atkinson donde fj es fijado y compite contratodos los otros modelos de F. Aquı probaremos
H0 : fj es correcto vs H1 : fj es incorrecto (4.16)
rechazamos H0 si fj , con q 6= j es seleccionado y para algun determinado α, 0 ≤ α ≤ 1, tenemosque P (IS (fq | fj)) ≤ α. Con (4.14) bajo la hipotesis del modelo fj , se obtiene que la probabilidadde un error tipo uno esta limitado superiormente por α
k−1 .Prueba 2 Con la cuestion A3 un modelo es elegido para comparaciones. Supongamos que al
usar un metodo de discriminacion, fj es seleccionado. Se tiene que no hay suficiente evidencia parauna seleccion si P (IS (fj)) > α para algun α, con 0 ≤ α ≤ 1. Si una seleccion puede hacerse,entonces la magnitud de P (IS (fj)) medira la confianza de la seleccion.
El tamano de k afecta a la eficiencia de los metodos de discriminacion (considere los limites (4.15)y (4.14). Por esta razon, la investigacion se vera favorecida si los modelos altamente improbablesson eliminados de F antes de emplear un metodo de discriminacion. Una funcion de discriminacion,o estadıstico, basado en los RSS para medir la falta de ajuste del modelo puede aplicarse a los

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 27
modelos individuales de F. Para el modelo verdadero fj ∈ F tenemos queRSS(fj)
σ2 ∼ χ2(n). Entonces
un modelo es eliminado si la medida de falta de ajuste
LOF (fj) = P
[χ2n >
rss (fj)
σ2
](4.17)
es pequena (menor que α), donde rss (fj) es el RSS observado del modelo fj . Esta prueba dela exactitud del modelo esta basado en la cuestion A2 de Atkinson dado que los modelos no sondirectamente contrastados sino simplemente avaluados por LOF. Un estadıstico, el cual es unaextension de (4.17) cuando se estima σ2, para la prueba de falta de ajuste para el modelo fj es:
LOF (fj) = P
[F(n,m) >
rss(fj)
nσ2
](4.18)
Donde m =∑s
j=1(rj − 1) y rj son las repeteciones.Caso para dos modelos.Cuando se tienen dos modelos y se desea elegir el mas adecuado para el comportamiento delfenomeno existe en la literatura de pruebas de hipotesis varias pruebas que podemos usar entreellas se encuentra la prueba de Davidson y MacKinnon(1981) la cual se menciono anteriormente ylas siguientes dos pruebas mencionadas en libro de Borowiak (1989), las cuales son: la prueba deHoel(1947) y una prueba basada en las probabilidades de una seleccion correcta o incorrecta.
Prueba de Hoel (1947) . Consideremos que F contiene dos modelos completamente determinadosy la cuestion A1 es considerada, por tanto la hipotesis que se tendra sera
H0 : fj es correcto vs H1 : f∗ es correcto
y uno de los modelos es considerado verdadero bajo H0. En esta prueba al igual que en la pruebade Davidson y MacKinnon se define un modelo de regresion artificial de la forma
f∗ (xi) = af1 (xi) + (1− a) f2 (xi)
y sera probado contra fj . El valor de a que minimiza RSS (f∗) es
a =
∑ni=1R2 (i) [f1 (xi)− f2 (xi)]∑n
i=1 [f1 (xi)− f2 (xi)]2
El estadıstico a usarse es un estadıstico F con 1 y n− 1 grados de libertad, dado por
F =(n− 1) [RSS (f1)−RSS (f∗)]
RSS (f∗)
Rechazamos H0 si F > F1−α,1,n−1 a un nivel de significancia α.Ahora de la cuestion A3, en la cual se asume que uno de los modelos es el verdadero, ¿hay
suficiente evidencia para hacer una seleccion Borowiak propone una prueba donde?. El cual espresentado en el siguiente teorema.
Teorema 2 Consideremos que F contiene 2 modelos, es decir, k = 2 y la normalidad de los erroreses asumida, el metodo de mınimos cuadrados el cual minimiza la IP (IS) = IP (f1 | f2) es el LSE

28CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
con Sj = I y Cj = 0, para j = 1, 2, el cual es el metodo de discriminacion que selecciona el modelocon menor RRS. Con este metodo de discriminacion
IP (IS) = IP
Z >
√[f1 (xi)− f2 (xi)]
T [f1 (xi)− f2 (xi)]
2σ
Si IP (IS) es lo suficiente pequeno, una seleccion puede ser hecha y la confianza de la decision esmedida por IP (IS) .
Caso de mas de dos modelos.A continuacion se mencionaran dos pruebas en las cuales se tienen el caso de k > 2 , y la cuestionA2 es examinada antes de continuar con los metodos de discriminacion secuencial, es decir, bajo elsupuesto de que los modelos ajustan a los datos igualmente bien, hay evidencia estadıstica de loscontrario, por tanto se realizan pruebas para ver si los modelos son estadısticamente iguales, cabemencionar que estas dos pruebas fueron presentadas por Williams (1959) en su libro RegressionAnalysis y por Atkinson (1969) en su paper ”A test discriminating between models” respectiva-mente.
1. La prueba de Williams(1959), la cual esta basada en una prueba de homogeneidad devarianza dada por Wilks (1946). Definamos el modelo de medias de cada observacion sobretodos los modelos.
f (xi) =1
k
k∑j=1
fj (xi)
Este modelo es comparado con f∗ definido por el vector de valores de f∗ = xβ∗, donde1Tβ∗ = 1, 1T = (1, ..., 1) y x es una matriz formada por las filas de (f1 (xi) , ..., fk (xi)) coni = 1, ..., n. El valor de β∗ el cual minimiza RSS, esta dado por
β =(xTx
)−1 (xTY − c1
)donde c = 1T
(xTx
)−1xTY − 1. Las hipotesis son
H0 : f es correcto vs H1 : f∗ es correcto
y se usa un estadıstico F con k − 1 y n− k + 1 grados de libertad
F =(n− k + 1)
[RSS
(f)−RSS
(f∗)]
(k − 1)RSS(f∗)
Si H0 se acepta a un nivel de α, es decir, F < F1−α,k−1,n−k+1, entonces los modelos sonconsiderados demasiado cercas para poder discriminar. Cuando H0 es rechazado, el modelocon menor RSS es seleccionado como correcto, pero esta eleccion no es cuantificada comopor ejemplo por IP (IS (fj)) .

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 29
2. La segunda prueba basado en A2, es la prueba llamada prueba tilde y fue propuesta porAtkinson (1969) . La prueba de la hipotesis nula es que la desviacion cuadrada media de cadamodelo es la misma, es decir,
H0 :n∑i=1
[E (yi)− fj (xi)]2 es constante para j = 1, ..., k.
Para la construccion de este estadıstico hay que notar que la hipotesis nula es equivalente a
H0 :
n∑i=1
E (yi) fj (xi)−1
k
n∑i=1
f2j (xi) es constante para j = 1, ..., k.
Sea Z (xi) =n∑i=1
yifj (xi) −n∑i=1
f2j (xi) para 1 ≤ j ≤ k y notar bajo H0 se tiene que Z (xi) ∼
N
(c, σ2
n∑i=1
f2j (xi)
). Ahora se define
Q =
ZT(xTx
)−1Z−
(ZT(xTx
)−11)2
1T (xTx)−1 1
donde ZT = (Z1, ..., Zn) y 1T = (1, ..., 1) . El estadıstico de la prueba es un estadıstico F conk − 1 y n− k grados de libertad
F =(n− k)Q
(k − 1)RSS(f)
Si F > F(1−α,k−1,n−k) rechazamos H0.
Metodos Secuenciales.Una prueba con la misma intension que las dos anteriores es presentada a continuacion basandose enlas probabilidades de seleccion correcta o incorrecta, dado que estos dos previos metodos de discrim-inacion no contrastan de manera directa a los modelos. A continuacion consideremos la cuestionA3, donde se asume que uno de los modelos es el verdadero, entonces se busca si hay suficienteevidencia para poder realizar una seleccion. Para ello consideremos un metodo de discriminaciondonde se usara un metodo de mınimos cuadrados donde Sj = S y Cj = 0 para 1 ≤ j ≤ k. Condicho metodo de mınimos cuadrados,
2 (fq − fj)T SRj ≤ (fj − fq)T S (fj − fq)
implica que fj ⊂ F es seleccionado si el evento
∩q 6=j{
2 (fq − fj)T SRj < (fq − fj)T S (fq − fj)}
(4.19)
Basandonos en los pares optimos de LSE, entonces tenemos que S = I y por tanto (4.19) seconvierte en
∩q 6=j{
2 (fq − fj)T Rj < (fq − fj)T (fq − fj)}
(4.20)

30CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
Para facilidad de manejo tendremos que
δ(q,j) =[(fq − fj)T (fq − fj)
]1/2
Del teorema 1, donde se construye las probabilidades lımites en los procedimientos por pareja demodelos, las probabilidades de seleccion son construidas en conjunto con el metodo de discrimi-nacion que selecciona el modelo con menor RRS, tenemos que de (4.20), los lımites condicionales
IP [IS (fj)] = maxq 6=j
P
[Z >
δ(q,j)
2σ
](4.21)
y
IP [CS (fj)] = minq 6=j
P
[Z ≤
δ(q,j)
2σ
]El lımite superior de IP (IS) dado por
IP (IS) ≤ max1≤q≤k
∑j 6=q
P (fj | fq)
puede ser construido con
IP (f1 | f2) = IP
[Z >
∣∣AT (f1 − f2)∣∣
2σ (ATA)12
]donde Z ∼ N (0, 1) y A = S (f1 − f2) .
Para un fj ∈ F fijo, definiremos un conjunto que consiste de otros dos modelos de F por
SN (j) = {fr, fq : δj (r, q) < 0} donde δj (r, q) = (fr − fi)T (fq − fi) . Observemos que SN (j) no esnecesariamente unico y es elegido de acuerdo a las consideraciones que se veran mas tarde.
Teorema 3 Sea k ≥ 3 y los errores se distribuyen normal. Sea fj elegido con LSE donde δ (i, r) <δ (i, q) para q 6= r. Ademas, suponemos que existe al menos un modelo fq ∈ F tal que SN (j) ={fr, fq : δj (r, q) < 0} . Entonces
IP [IS (fj)] ≤ min IP
[Z >
δ (r, i)
2σ
]IP
[Z ≤ [4 (q, r) + ρδ (q, j)]
2σ (1− ρ2)12
](4.22)
y
IP [CS (fj)] ≤ min IP
[Z ≤ δ (r, i)
2σ
]IP
[Z ≤ [δ (q, j)− ρδ (r, j)]
2σ (1− ρ2)12
](4.23)
donde
4 (q, r) =δ2 (q, j)− 2δj (r, q)
δ (q, j)
y
ρ =δj (r, q)
δ (r, i) δ (q, j)
y los minimos son tomados sobre todos los fq contenidos en SN (j).

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 31
Cuando existen modelos para formar SN (j), la probabilidad condicional lımite IS (4.22) esuna mejora sobre (4.21). Con este lımite se puede probar A3, es decir, se encontrara que no haysuficiente evidencia para realizar una seleccion si P (IS(fj)) ≥ α.
Cuando se presente esta situacion sera necesario utilizar metodos secuenciales que ayuden aelegir el mejor modelo. Ahora presentaremos dos metodos secuenciales para elegir el mejor modelo,pero primero se presentara la estructura general de un metodo secuencial.
Bajo el punto de vista de la cuestion A3, los metodos de discriminacion los cuales consistende una serie de comparaciones de modelos son a continuacion construidos. Las comparaciones sonreferidos como pasos de el procedimiento. En cada paso un modelo es considerado fijo y una funcionde discriminacion cuadratica definida por
Qj = RTj SjRj + Cj
es utilizado para seleccionar si el modelo es el modelo verdadero o si se elimina de la competencia.El metodo de discriminacion es utilizado hasta que un modelo es seleccionado. Estos metodossecuenciales son denotamos por SM, y fueron propuestos por primera vez por Borowiak(1983). Enel paso j, supongamos que se tienen s = k − j + l posibles modelos contenidos en un conjunto Fj .Entonces
Fj = {s modelos propuestos de F}
y se tiene que Fj ⊆ F. Ahora seleccionemos un f(j) ∈ Fj y consideramos un metodo de los mınimos
cuadraticos en el cual tomamos Sj = AjATj . De (4.19) observamos que f(j) es seleccionado sobre
todos los modelos rivales en Fj si los eventos
∩r∈Bj,1
2ATj Rj <
(fr − f(j)
)TAj(
ATj Aj
)1/2
∩ ∩r∈B,2
2ATj Rj ≥(fr − f(j)
)TAj(
ATj Aj
)1/2
ocurren, donde Bj,1 =
{r :(fr − f(j)
)TAj ≥ 0
}y Bj,2 =
{r :(fr − f(j)
)TAj < 0
}. Para un f(j) y
fr donde Fj , r 6= (j), sea
d(j) (r) =
(fr − f(j)
)TAj(
ATj Aj
) 12
(4.24)
y definimos
bj =
{miny∈Bj,1
{d(j) (r)
}si Bj,1 6= ∅
∞ si Bj,1 = ∅ (4.25)
y
aj =
{maxy∈Bj,2
{d(j) (r)
}si Bj,2 6= ∅
−∞ si Bj,2 = ∅ (4.26)
El metodo secuencial general esta en el siguiente teorema.

32CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
Teorema 4 Sean los modelos de F completamente determinados donde la normalidad de los erroreses asumido. Definimos un metodo secuencial de la siguiente manera; en el paso j elegimos f(j) ⊆ Fjy se detiene y decimos que f(j) es correcto si este es seleccionado basandose en un metodo de
mınimos cuadrados al usar Sr = AjATj para r 6= (j), esto es, se selecciona f(j) si
aj ≤2ATj Rj(ATj Aj
) 12
≤ bj (4.27)
donde aj y bj son definidos por (4.26) y (4.25) , respectivamente. De lo contrario, quitamos f(j) yformamos un nuevo conjunto Sj+1, y continuamos con el paso j + 2. Si el paso k− 1 es rechazado,la seleccion es hecha entre los modelos dos modelos restantes, los cuales son denotados por f(k−1)
y f(k). Sea γj = max
{|d(j)(r)|
2σ , fr ∈ Fj y r 6= j
}, αj = min
{|aj |2σ ,
bj2σ
}, y βj = max
{|aj |2σ ,
bj2σ
}para
1 ≤ j ≤ k1. Tambien supongamos
ATj Aj = 0 para j 6= r (4.28)
Si f(1) es seleccionado
IP[CS
(f(1)
)]= IP (−α1 ≤ Z ≤ β1)
para j ≥ 2
IP(IS(f(1) | fj
))≤ IP (α1 ≤ Z ≤ β1 + 2α1)
Por otro lado, si f(1) es correcto
IP[IS(f(j) | f(1)
)]≤ IP (Z > α1) + IP (Z > β1)
para j ≥ 2. Ademas, para 2 ≤ j ≤ m
IP[IS(f(j) | f(m)
)]≤ IP (αj < Z < βj + 2αj) ∗
j−1∏r=1
[IP (Z ≤ 2γr − αr) + IP [Z > βr + 2γr]]
y para j ≥ m ≥ 2
IP[IS(f(j) | f(m)
)]≤ [IP (Z > αj) + IP (Z > βj)] ∗
m−1∏r=1
[IP (Z ≤ 2γr − αr) + IP [Z > βr + 2γr]]
Ademas para 2 ≤ j ≤ k − 1
IP[CS
(f(j)
)]≥ IP (−αj ≤ Z ≤ βj) ∗
j−1∏m=1
[IP (Z ≤ αm) + IP [Z > βm + 2γm]]
y IP[CS
(f(k)
)]= IP
[CS
(f(k−1)
)].
Corolario 1 Bajo los supuestos y el metodo secuencial del teorema 4, sea
p1 = IP (Z > α1) + IP (Z > β1)

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 33
yt1 = IP [α1 ≤ Z ≤ β1 + 2α1]
y para 2 ≤ j ≤ k − 1 definimos
p1 = [IP (Z > αj) + IP (Z > βj)] ∗j−1∏m=1
[IP (Z ≤ 2γm − αm) + IP [Z > βm + 2γm]]
y
t1 = IP [αj ≤ Z ≤ βj + 2αj ] ∗m−1∏m=1
[IP (Z ≤ 2γm − αm) + IP [Z > βm + 2γm]]
AsıIP[IS(f(1)
)]≤ t1
y para 2 ≤ j ≤ k − 1IP[IS(f(j)
)]≤ max {p1, ..., pj−1, tj}
Como podemos observar el metodo secuencial general permite muchas variedades a traves dela eleccion de Aj de acuerdo con la condicion de que ATj Ar 6= 0 para j 6= r. Por tanto a con-tinuacion se mencionaran dos metodos secuenciales, el primero proporciona calculos exactos de lasprobabilidades de seleccion, mientras que el segundo busca construir pasos para acercarse al optimo.
Primer Metodo Secuencial. El primer metodo secuencial es derivado de una serie de lemas.En el paso j fijamos f(j) donde Fj = {f1, ..., fs} y definimos una matriz n∗(s− 1) donde s = k−j+1de la siguiente manera
GTj =[(f1 − f(j)
), ...,
(f(j)−1 − f(j)
),(f(j)+1 − f(j)
), ...,
(fs − f(j)
)]en esta matriz asumimos que s ≤ n+ 1 y Gj tiene rango s− 1.
Lema 1 Para 1 ≤ j ≤ k − 1 definimos
Aj = GTj(GjG
Tj
)−11 (4.29)
donde 1T = (1, ..., 1). Para algun fq ∈ Fj, q 6= (j),[fq − f(j)
]TAj = 1
y
d(j) (q) =[1TGjG
Tj 1]− 1
2 (4.30)
Ademas (4.30) es un maximo sobre el conjunto de valores de (4.24).
Lema 2 En un metodo secuencial para los pasos j y m con j > m, notemos que Fj ⊆ Fm ydefinamos Aj y Am de la forma (4.29) . Entonces ATj Am = 0.
Lema 3 Para el metodo secuencial descrito en el teorema 4, si se considera el metodo secuencial1, se cumple que ATj Aj = 0 para j 6= r, βj =∞, y γj = αj para j = 1, ..., k − 1.

34CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
Teorema 5 Con el metodo secuencial 1 bajo las condiciones del teorema 4 y si definimos
p1 = IP
[Z >
d1
2σ
]para 2 ≤ s ≤ k − 1
ps = IP
[Z >
ds2σ
] s−1∏m=1
IP
[Z ≤ dm
2σ
]y pk = pk−1. Se tiene que
IP[IS(f(j)
)]= max {p1, ..., pj} (4.31)
y
IP[CS
(f(j)
)]=
j∏m=1
IP
[Z ≤ dm
2σ
](4.32)
tambien,
IP (CS) = min1≤j≤k
IP(CS
(f(j)
))es el mınimo sobre f(j), 1 ≤ j ≤ k − 1, de IP
[CS
(f(j)
)].
Segundo metodo secuencial. En el segundo metodo, que denotamos como SM2, se tratade optimizar las probabilidades de seleccion en cada paso bajo la condicion ATj Aj = 0 para j 6= r.De este modo, un metodo secuencial mas poderoso, sobre el metodo secuencial 1, es construidocuando el verdadero modelo se produce en los primeros pasos, es decir, grandes P [CS (fj)] para jpequenas. Este aumento tambien se puede realizar sobre LSE. Por ejemplo, si f(1) es le modeloverdadero el evento de un una correcta seleccion con LSE en la interseccion de k − 1 eventos estadado por (4.20) . Por otra parte, la correcta eleccion al usar un metodo secuencial corresponde a laocurrencia de un simple evento, (4.27) con j = 1. Esta comparacion es particularmente convincenteen la construccion de pruebas basadas en la cuestion A1.
La optimizacion en terminos de probabilidades de seleccion para metodos secuenciales no esfacil de obtener, por lo que la busqueda de una construccion cerca del optimo.
En el paso la eleccion de Aj del teorema 4 esta basado en la maximizacion de la funcion de αjpara 1 ≤ j ≤ k − 1. Para un f(j) ∈ F maximizamos
Mj=∏m 6=j
d(j) (m) (4.33)
donde (4.28) se mantiene y d(j) (m) esta dado por (4.24). En el paso j denotamos un vector de
pesos por W Tj = (wj,1, ..., wj,s) para j = 1, ..., k.
Teorema 6 Bajo las condiciones del teorema 4, el metodo secuencial el cual maximiza (4.33) encada paso sujeto a las restriccion (4.28), es denotado por SM2, con valores de Aj definidos deacuerdo a las siguientes condiciones: en el paso j = 1 sea
A1 = GT1 W1

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 35
donde W1 es una solucion para W ∗1 = G1GT1 W1, y para el paso j, j ≥ 2, definimos
Aj = GjWj −j−1∑m=1
qmAm
donde
qm =ATmGmWj
ATmAm
y Wj es una solucion para W ∗j = GjGTj Wj −
∑qmGjAm.
Para el empleo del metodo secuencial 2, Wj para 1 ≤ j ≤ k − 1, el cual resuelve las ecuacionesadecuadas debe ser encontrada. La solucion es generalmente unica, un posible procedimiento paraencontrar las Wjs del teorema 10 es resolver un sistema iterativo. Para W inicial encontramos,para j = 1,
V = G1GT1 W (4.34)
y para j ≥ 2
V = GjGTj −
j−1∑j=1
qmGjAm (4.35)
donde qm = ATmGj ,W
ATmAmpara 1 ≤ m ≤ j − 1. Tanto en (4.34) y (4.35) sea
V T = (v1, ..., vs−1)
y tomamos el siguiente vector en lugar de W(c
v1, ...,
c
vs−1
)
donde c =
[1∑ 1
v2j
] 12
. Continuamos iterativamente hasta converger, segun lo medido por el cambio
en las sucesivas W , se ha alcanzado.
La fuerza del metodo radica en su capacidad para discriminar en los primeros pasos. Por estarazon, este metodo de discriminacion es especialmente adecuado para la construccion de pruebasde la forma (4.16), basada en el punto de vista de A1.
Dada estos tres metodos de discriminacion lo siguiente es saber cual de ellso tres se debe aplicarun metodo adecuado para seleccionar cual metodo utilizar es seleccionar el metodo de discriminacionel cual maximice P (CS) definido por
P (CS) = min1≤j≤k
P (CS (fj))

36CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.
4.2.3 Seleccion de Modelos basado en Criterios de Informacion.
Criterio de Informacion de Akaike.
Supongamos que, para alguna variable dependiente o variables dependientes, tenemos k modelosen competicion, que son estimados por maxima verosimilitud, mınimos cuadrados ordinarios o pormınimos cuadrados no lineales. Sea θi el pi − vector de parametros para el i − esimo modelo, y
sea `i
(θi
)el valor maximo de la funcion de logverosimilitud para este modelo, el cual podemos
tomar para ser −12nSSR en el caso de modelos estimados por mınimos cuadrados. Esto parecer
natural elegir el modelo con valor mayor de `i
(θi
). Sin embargo, si los modelos estan anidados,
esto simplemente nos conduce a elegir el modelo con mayor numero de parametros, incluso cuandootros modelos ajusten muy bien. Esto viola el principio de que, cuando cada uno de un conjuntode modelos anidados se ha especificado correctamente, debemos preferir el que tiene menor numerode parametros ha estimar. Este modelo es llamado el modelo mas parsimonioso del conjunto. Conmodelos no anidados, no es necesariamente el caso de que el menos parsimonioso de ellos obtiene elmayor valor de la funcion de logverosimilitud, pero, cuando pi > pj , el modelo fi claramente tieneuna ventaja sobre el modelo fj y por tanto tiende a ser elegido con demasiada frecuencia, por loque la parsimonia es una preocupacion en la eleccion de un modelo.
Para evitar este problema, se necesita penalizar a los modelos con un gran numero de parametros.Esta idea conduce a varias funciones de criterios que pueden ser usados para ordenar o ranquearlos modelos competitivos. El mas ampliamente usado de estos es probablemente el criterio de in-formacion de Akaike, o AIC (Akaike, 1973). Hay mas de una version del criterio de informacionde Akaike. Para el modelo i, el mas sencillo es
AICi = `i
(θi
)− pi (4.36)
La funcion de verosimilitud es una medida de la capacidad de ajuste del modelo, mientras quepi representa una penalizacion debida al numero de parametros, asi se reduce la funcion de log-verosimilitud de cada modelo por 1 por cada parametro estimado, y entonces elegir el modelo quemaximice AICi. La forma original del criterio de informacion de Akaike es equivalente a (4.36) peroun poco mas complicado, y que se supone que debe ser minimizado en lugar de maximizado.
El AIC mide la informacion que se pierde cuando se utiliza un modelo alterno para aproximarseal modelo real o desconocido. El objetivo es buscar el modelo aproximado, partiendo del modelocompleto, que proporcione la menor perdida de informacion posible.
La AIC no siempre respeta la necesidad de parsimonia mas que la de maximizar la funcionde log-verosimilitud. Considere dos modelos anidados, f1 y f2, con p y p + 1 parametros respec-tivamente. Asintoticamente, el doble de la diferencia entre las dos funciones log-verosmilitud sedistribuye como χ2
1, si f1 esta correctamente especificado. Por tanto, la probabilidad que AIC2 seamayor que AIC1 tiende en muestras grandes a la masa de probabilidad en el lado derecho de lacola de la distribucion χ2
1 mas alla de 2, la cual es 0.1573. Ası, incluso con una muestra de tamanoinfinito, nosotros elegimos el modelo con menor parsimonia casi el 16% de las veces. Este ejemplomuestra un problema general. Cuando dos o mas modelos estan anidados, el AIC puede fallar alelegir el mas parsimonioso de estos que son correctamente especificados. Si todos los modelos sonno anidado, y solo uno de ellos esta bien especificado, el AIC elige este uno asintoticamente, perotambien puede simplemente elegir el modelo con el mayor valor de la funcion de log-verosimilitud.

4.2. PRUEBAS DE HIPOTESIS PARA LOS MODELOS NO ANIDADOS. 37
Una popular alternativa para el AIC, el cual evita el problema discutido en el parrafo anterior,es el Criterio de informacion de Schwarz o de informacion Bayesiano o BIC, el cual fue propuestopor Schwarz (1978). Para un modelo i, el BIC es
BICi = `i
(θi
)− 1
2ki log n.
El factor de log n en el termino penalizado asegura que, cuando n → ∞, la pena por tener unparametro adicional sera muy grande. En consecuencia, asintoticamente, no hay peligro de ele-gir un modelo parsimonioso insuficiente. Si comparamos un falso pero parsimonioso modelo f2
con un modelo especificado correctamente f1 que puede tener mas parametros, el BIC elegira f1
asintoticamente.El contexto de este criterio es bayesiano pero sus principales aplicaciones son frecuentistas
debido a que se basa solo en el calculo de la verosimilitud del modelo y no requiere especificarninguna distribucion a priori. Se deriva en el proceso de seleccionar un modelo de entre modelosalternativos con diferentes dimensiones pero con igualdad de informacion a priori, de manera quemaximice la probabilidad a posteriori de los parametros.

38CAPITULO 4. PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION PARA MODELOS DE REGRESION NO LINEAL.

Capıtulo 5
Analisis Estadıstico de los Datos.
Para realizar los analisis de este capıtulo en el marco del estudio de pruebas de hipotesis no anidadasy metodos de discriminacion de modelos no lineales, se cuenta con dos conjuntos de datos, loscuales fueron descritos en el Capıtulo 3. El primer conjunto de datos son un conjunto de datosexperimentales en bioquımica y el segundo conjunto de datos es un conjunto de datos medicos.
En el primer conjunto de datos se aplicara las pruebas de hipotesis debido a que es este caso,es mas evidente los modelos posibles para el comportamiento observado, los modelos seleccionadosson dos modelos senoidales, los cuales son el modelo gompertz y el modelo logistico los cuales sonmodelos no anidados, ademas se aplicara el criterio de informacion de Akaike.
Para el segundo conjunto de datos se aplicaran los metodos de discriminacion: criterio deinformacion de Akaike y Bayesiano y los metodos de discriminacion propuestos por BorowiakDale S en su libro Model Discrimination for Nonlinear Regression Models (1983).
5.1 Datos Experimentales en bioquımica.
Como se menciono en el Capıtulo 3, el conjunto de datos en bioquımica consiste de 18 tratamientoscon dos repeticiones cada tratamiento, donde el primer tratamiento es un tratamiento de referenciay la respuesta observada fue el crecimiento de nisina. A continuacion realizaremos el ajuste delos modelos gompertz y logıstico a cada uno de los tratamientos realizados. Las Tablas 5.1 y ??muestran la estimacion de los parametros para cada uno de los tratamientos con su respectivo R2.
Al comparar las R2 obtenidas de los modelos ajustados para cada tratamiento, observamosque son muy similares para ambos, es decir, que uno y otro de los modelos describen el mismoporcentaje de variabilidad de los datos, ademas se observa que las estimaciones de los parametrosson muy semejantes, esto debido a que los dos modelos son modelos de crecimiento y tienden atener el mismo comportamiento.
De la Tabla 5.2 del criterio de Akaike observamos que el modelo predominante fue el modelogompertz por tanto se puede concluir que el modelo general para los tramientos realizados para laproduccion de nisina es el modelo gompertz. Debido a que el 77% de los modelos seleccionadospara los tratamientos fueron el modelo gompertz, al usar el criterio de Akaike.
39
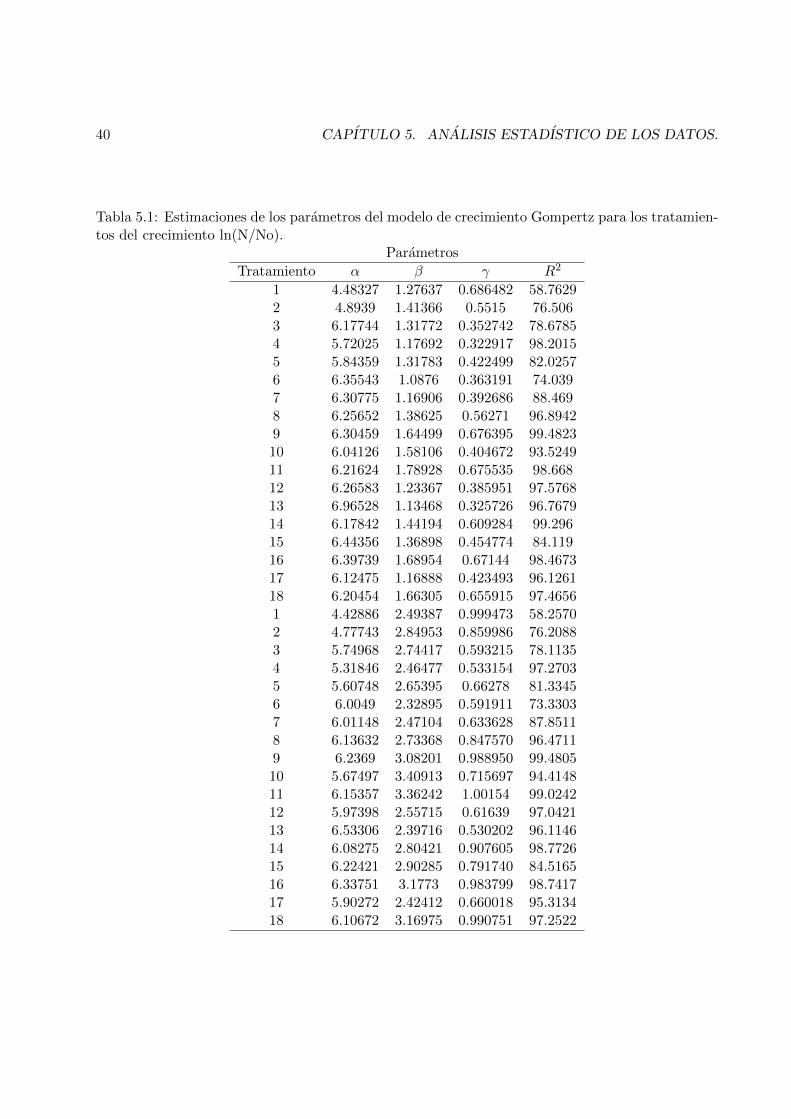
40 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.1: Estimaciones de los parametros del modelo de crecimiento Gompertz para los tratamien-tos del crecimiento ln(N/No).
Parametros
Tratamiento α β γ R2
1 4.48327 1.27637 0.686482 58.76292 4.8939 1.41366 0.5515 76.5063 6.17744 1.31772 0.352742 78.67854 5.72025 1.17692 0.322917 98.20155 5.84359 1.31783 0.422499 82.02576 6.35543 1.0876 0.363191 74.0397 6.30775 1.16906 0.392686 88.4698 6.25652 1.38625 0.56271 96.89429 6.30459 1.64499 0.676395 99.482310 6.04126 1.58106 0.404672 93.524911 6.21624 1.78928 0.675535 98.66812 6.26583 1.23367 0.385951 97.576813 6.96528 1.13468 0.325726 96.767914 6.17842 1.44194 0.609284 99.29615 6.44356 1.36898 0.454774 84.11916 6.39739 1.68954 0.67144 98.467317 6.12475 1.16888 0.423493 96.126118 6.20454 1.66305 0.655915 97.46561 4.42886 2.49387 0.999473 58.25702 4.77743 2.84953 0.859986 76.20883 5.74968 2.74417 0.593215 78.11354 5.31846 2.46477 0.533154 97.27035 5.60748 2.65395 0.66278 81.33456 6.0049 2.32895 0.591911 73.33037 6.01148 2.47104 0.633628 87.85118 6.13632 2.73368 0.847570 96.47119 6.2369 3.08201 0.988950 99.480510 5.67497 3.40913 0.715697 94.414811 6.15357 3.36242 1.00154 99.024212 5.97398 2.55715 0.61639 97.042113 6.53306 2.39716 0.530202 96.114614 6.08275 2.80421 0.907605 98.772615 6.22421 2.90285 0.791740 84.516516 6.33751 3.1773 0.983799 98.741717 5.90272 2.42412 0.660018 95.313418 6.10672 3.16975 0.990751 97.2522
5.1. DATOS EXPERIMENTALES EN BIOQUIMICA. 41
Tabla 5.2: El criterio de Akaike para Datos de BioquımicaTratamiento Gompertz Logıstico Modelo Seleccionado
1 -25.54439 -25.62973 Gompertz2 -21.33622 -21.4242 Gompertz3 -22.67736 -22.67736 Gompertz4 -2.177403 -5.097096 Gompertz5 -21.02924 -21.29322 Gompertz6 -24.62503 -24.81349 Gompertz7 -17.97563 -18.34090 Gompertz8 -8.90443 -9.798324 Gompertz9 3.35974 3.336439 Gompertz10 -13.35467 -12.31929 Logıstico11 -3.332184 -1.153368 Logıstico12 -6.337184 -7.732785 Gompertz13 -9.090884 -10.37949 Gompertz14 1.752258 -0.8940919 Gompertz15 -21.43066 -21.25320 Logıstico16 -4.572419 -3.191580 Logıstico17 -9.535804 -10.86824 Gompertz18 -7.762252 -7.762252 Gompertz
Seguidamente se aplica la prueba de hipotesis de Davidson y MacKinnon, para seleccionar cuales el mejor modelo describir el comportamiento del crecimiento de nisina para lo cual se usa elestadıstico (4.9) y se rechazara la hipotesis nula cuando p− valor < α. Al efectuar dichas pruebasobtenemos la Tabla 5.3 en la cual se encuentran los p− valores para las pruebas de hipotesis H0 :Modelo Gompertz vs H1 : Modelo Logıstico y H0 : Modelo Logıstico vs H1 : Modelo Gompertz,en el cual se observa que se ambos modelos no son rechazados por lo que se concluye que losdatos parecen ser compatibles con ambas hipotesis. Esto a diferencia del criterio de Akaike nosproporciona la informacion de que ambos modelos son adecuados para describir el comportamientodel crecimiento de la nisina en los tratamientos propuestos.
Figura 5.1: Modelos Estimados para el Crecimiento de Nisina.

42 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.3: P − valores de las pruebas no anidadas para los modelos Gompertz y Logıstico.H0 : Gompertz H0 :Logısticop− valor p− valor
Tratamiento 1 0.4811 0.5432Tratamiento 2 0.4868 0.5341Tratamiento 3 0.4771 0.5517Tratamiento 4 0.4682 0.5535Tratamiento 5 0.4757 0.5563Tratamiento 6 0.4658 0.5533Tratamiento 7 0.4717 0.5497Tratamiento 8 0.4831 0.5474Tratamiento 9 0.4969 0.5339Tratamiento 10Tratamiento 11 0.5068 0.5215Tratamiento 12 0.4752 0.5492Tratamiento 13 0.4556 0.5604Tratamiento 14 0.4864 0.5436Tratamiento 15Tratamiento 16 0.5025 0.5280Tratamiento 17 0.4693 0.5548Tratamiento 18 0.4940 0.5359
En la figura 5.1 aparecen todos los modelos Gompertz para los 18 tratamientos, con el obje-tivo de encontrar cual es el tratamiento mas eficiente para producir nisina, y observamos que lostratamientos 8, 9, 11, 14, 16 y 18 fueron los tratamientos que en menor tiempo produjeron mayorcantidad de nisina, el tiempo optimo las 6 horas donde la cinetica alcanza su fase estacionaria,por lo que se recomienda utilizar estos tratamientos para la produccion de nisina en leche deslac-tosada, aunque fue el tratamiento 16 el cual produjo durante todo el perıodo de tiempo observadomayor cantidad de nisina. Observe que los p− valores de los tratamientos 10 y 15 no pudieron sercalculados dado que generaban valores NAN en las probabilidades y no se encontro error en loscalculos.
5.2 Datos Medicos (Mediciones en Fetos).
5.2.1 Analisis descriptivo de las variables.
Para realizar los analisis de este capıtulo en el marco del estudio de las hipotesis no anidadas paramodelos no lineales se cuenta con un conjunto de datos proporcionados por seguro social de Leon,Guanajuato, el consiste de 47 fetos a los cuales se les midio las siguientes variables: diametrobiparietal, circunferencia de la cabeza o cefalica, circunferencia abdominal, longitud de la diafisisdel femur durante su desarrollo gestional, estas mediciones se realizaron entre la semana 15 a lasemana 39 de la gestacion, con un caso de 41 semanas de gestacion, ademas se midio el peso delrecien nacido. Cabe mencionar que los registros viene dados en mm para las variable diametro

5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 43
biparietal, circunferencia de la cabeza o cefalica, circunferencia abdominal, longitud de la diafisis yen gramos para el peso. Los objetivos a perseguir en este analisis como se menciono anteriormenteson poder predecir el peso del feto en el momento del nacimiento.
Para el diametro biparietal el numero de observaciones realizadas durante toda la gestacion delos fetos fue de 252 en diferentes tiempos. La media y la varianza de este conjunto de datos son69.9206 y 340.4. El maximo y el mınimo observados son 30.0 y 98.0. En la figura 5.2, se muestrael grafico de caja de bigotes para DBP en cual podemos observar que los datos mas concentradospor debajo de la mediana y que hay un ligero sesgo a la izquierda.
Figura 5.2: Caja y Bigotes para DBP
Para el circunferencia de la cabeza o cefalica el numero de observaciones realizadas durantetoda las gestacion de los fetos fue de 252 en diferentes tiempos. La media y la varianza de esteconjunto de datos son 250.448 y 4138.49. El maximo y el mınimo observados son 103.0 y 340.0.En la figura se muestra el grafico de caja y bigotes para CIRCEF en el cual se observa en mismocomportamiento que en la figura 5.2.
Figura 5.3: Caja y Bigotes para CIRCEF
Para el circunferencia abdominal el numero de observaciones realizadas durante toda las gestacionde los fetos fue de 252 en diferentes tiempos. La media y la varianza de este conjunto de datosson 233.524 y 5013.59. El maximo y el mınimo observados son 83.0 y 354.0. En la figura 5.4 semuestra el grafico de caja y bigotes para CIRABD en el cual se observa que hay un ligero sesgo ala izquierda.
Para la longitud de la diafisis del femur el numero de observaciones realizadas durante toda lasgestacion de los fetos fue de 252 en diferentes tiempos. La media y la varianza de este conjunto de

44 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Figura 5.4: Caja y Bigotes para CIRABD.
datos son 51.8929 y 270.12. El maximo y el mınimo observados son 17.0 y 79.0. En la figura 5.5se muestra el grafico de caja y bigotes para LFemur donde se observa que hay un sesgo hacia laizquierda.
Figura 5.5: Caja y Bigotes para LFemur.
Para el peso de nacimiento el numero de observaciones realizadas durante toda las gestacionde los fetos fue de 57. La media y la varianza de este conjunto de datos son 51.8929 y 270.12. Elmaximo y el mınimo observado son 2.050 y 3.850. En la figura 5.6 se muestra el grafico de caja ybigotes del peso de nacimiento donde podemos observar que hay un punto atıpico que correspondeal feto con menor peso de nacimiento de 2050 gramos, este es un caso en el cual el feto nacio conun peso menor por debajo del peso mınimo adecuado de 2500 gramos.
5.2.2 Analisis de Correlacion de las variables.
Debido a que uno de nuestros interes es encontrar una funcion con la cual se pueda saber lasmedidas fetales con solo saber la edad gestional, es decir buscar una ecuacion de la forma
medida de interes del feto = f (gest)
esta medida puede ser cualquiera las variables medidas al feto durante su desarrollo y ası podersaber si el feto se tiene un desarrollo adecuado para edad gestional que posee, es decir, si estadentro del intervalo de confianza para esta medida. Por tanto, es de interes conocer la correlacionque existe entre la edad gestional del feto y las demas variables ecograficas, ası como la relacion que
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 45
Figura 5.6: Caja y Bigotes para Peso de Nacimiento.
Tabla 5.4: Correlaciones entre las variables fetales.CORRELACIONES
Gest DBP CIRCEF CIRABD LFemur PesoN
Gest: Correlacion de Pearson 1 0.983∗∗ 0.974∗∗ 0.977∗∗ 0.981∗∗ 0.026Sig (Bilateral) 0.000 0.000 0.000 0.000 0.677
DBP: Correlacion de Pearson 0.983∗∗ 1 0.990∗∗ 0.980∗∗ 0.980∗∗ 0.066Sig (Bilateral) 0.000 0.000 0.000 0.000 0.296
CIRCEF: Correlacion de Pearson 0.974∗∗ 0.990∗∗ 1 0.980∗∗ 0.978∗∗ 0.68Sig (Bilateral) 0.000 0.000 0.000 0.000 0.281
CIRABD: Correlacion de Pearson 0.977∗∗ 0.980∗∗ 0.980∗∗ 1 0.976∗∗ 0.082Sig (Bilateral) 0.000 0.000 0.000 0.000 0.193
LFemur: Correlacion de Pearson 0.981∗∗ 0.980∗∗ 0.978∗∗ 0.976∗∗ 1 0.038Sig (Bilateral) 0.000 0.000 0.000 0.000 0.545
PesoN: Correlacion de Pearson 0.026 0.066 0.68 0.082 0.038 1Sig (Bilateral) 0.677 0.296 0.281 0.193 0.545
∗∗ . La correlacion es significativa al nivel 0.01(bilateral) .
existe entre ellas. Como podemos observar en la Tabla 5.4 de la matriz de correlacion las variablesGest, DBP, CIRCEF, CIRABD y LFemur estan altamente correlacionadas entre sı, por lo quepodemos concluir que con una sola de las variables podemos describir el comportamiento de lasdemas variables y de esta manera podemos proceder a tratar de estimar cualesquiera de las variablesmedidas al feto con sola la edad gestional (semanas) del feto. Pero tambien vemos que la variablepeso de nacimiento no esta correlacionada con ninguna de las variables medidas al feto, por lo quepodemos intuir que el objetivo de poder predecir el peso de nacimiento del feto con las variablesGest, DBP , CIRCEF , CIRABD y LFemur no se podra lograr. Ahora para el primer objetivomencionado de poder ver si el desarrollo del feto es adecuada tomaremos la variable que este masaltamente correlacionada con la variable gest, debido a que todas estan altamente correlacionadas,la cual es la variable de Diametro biparietal (DBP ) .
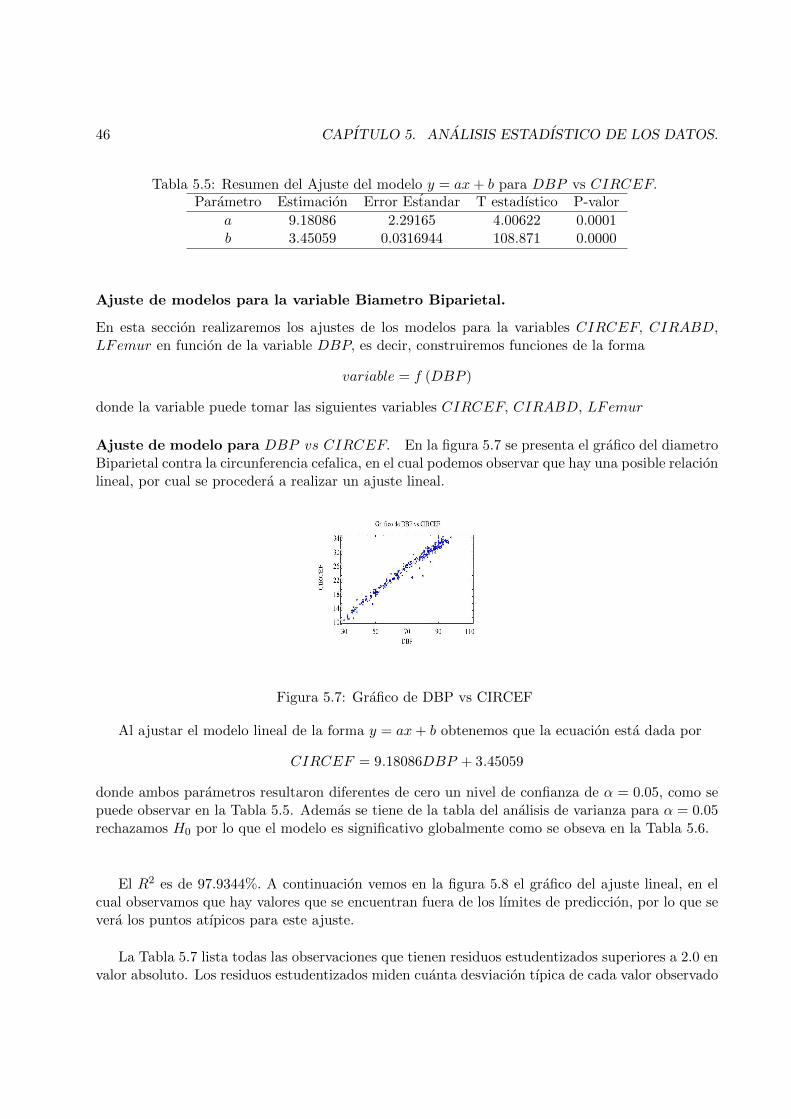
46 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.5: Resumen del Ajuste del modelo y = ax+ b para DBP vs CIRCEF.Parametro Estimacion Error Estandar T estadıstico P-valor
a 9.18086 2.29165 4.00622 0.0001b 3.45059 0.0316944 108.871 0.0000
Ajuste de modelos para la variable Biametro Biparietal.
En esta seccion realizaremos los ajustes de los modelos para la variables CIRCEF, CIRABD,LFemur en funcion de la variable DBP, es decir, construiremos funciones de la forma
variable = f (DBP )
donde la variable puede tomar las siguientes variables CIRCEF, CIRABD, LFemur
Ajuste de modelo para DBP vs CIRCEF. En la figura 5.7 se presenta el grafico del diametroBiparietal contra la circunferencia cefalica, en el cual podemos observar que hay una posible relacionlineal, por cual se procedera a realizar un ajuste lineal.
Figura 5.7: Grafico de DBP vs CIRCEF
Al ajustar el modelo lineal de la forma y = ax+ b obtenemos que la ecuacion esta dada por
CIRCEF = 9.18086DBP + 3.45059
donde ambos parametros resultaron diferentes de cero un nivel de confianza de α = 0.05, como sepuede observar en la Tabla 5.5. Ademas se tiene de la tabla del analisis de varianza para α = 0.05rechazamos H0 por lo que el modelo es significativo globalmente como se obseva en la Tabla 5.6.
El R2 es de 97.9344%. A continuacion vemos en la figura 5.8 el grafico del ajuste lineal, en elcual observamos que hay valores que se encuentran fuera de los lımites de prediccion, por lo que severa los puntos atıpicos para este ajuste.
La Tabla 5.7 lista todas las observaciones que tienen residuos estudentizados superiores a 2.0 envalor absoluto. Los residuos estudentizados miden cuanta desviacion tıpica de cada valor observado
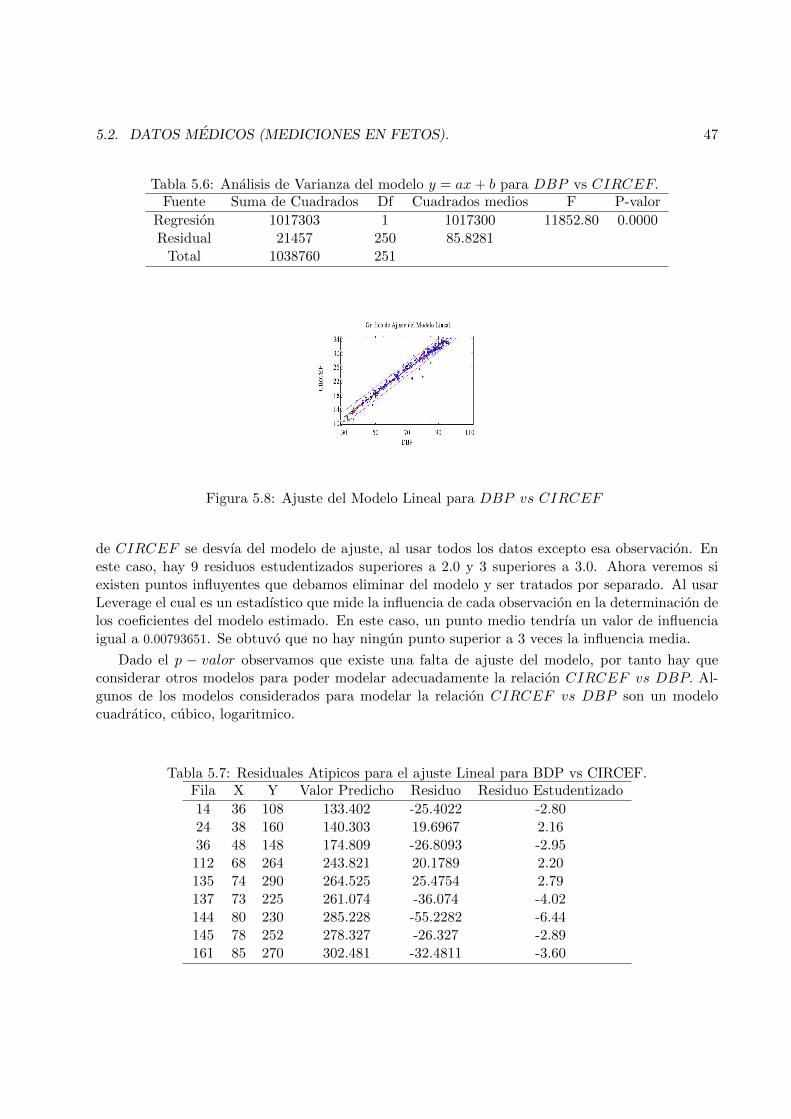
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 47
Tabla 5.6: Analisis de Varianza del modelo y = ax+ b para DBP vs CIRCEF.Fuente Suma de Cuadrados Df Cuadrados medios F P-valor
Regresion 1017303 1 1017300 11852.80 0.0000Residual 21457 250 85.8281
Total 1038760 251
Figura 5.8: Ajuste del Modelo Lineal para DBP vs CIRCEF
de CIRCEF se desvıa del modelo de ajuste, al usar todos los datos excepto esa observacion. Eneste caso, hay 9 residuos estudentizados superiores a 2.0 y 3 superiores a 3.0. Ahora veremos siexisten puntos influyentes que debamos eliminar del modelo y ser tratados por separado. Al usarLeverage el cual es un estadıstico que mide la influencia de cada observacion en la determinacion delos coeficientes del modelo estimado. En este caso, un punto medio tendrıa un valor de influenciaigual a 0.00793651. Se obtuvo que no hay ningun punto superior a 3 veces la influencia media.
Dado el p − valor observamos que existe una falta de ajuste del modelo, por tanto hay queconsiderar otros modelos para poder modelar adecuadamente la relacion CIRCEF vs DBP. Al-gunos de los modelos considerados para modelar la relacion CIRCEF vs DBP son un modelocuadratico, cubico, logaritmico.
Tabla 5.7: Residuales Atipicos para el ajuste Lineal para BDP vs CIRCEF.Fila X Y Valor Predicho Residuo Residuo Estudentizado
14 36 108 133.402 -25.4022 -2.8024 38 160 140.303 19.6967 2.1636 48 148 174.809 -26.8093 -2.95112 68 264 243.821 20.1789 2.20135 74 290 264.525 25.4754 2.79137 73 225 261.074 -36.074 -4.02144 80 230 285.228 -55.2282 -6.44145 78 252 278.327 -26.327 -2.89161 85 270 302.481 -32.4811 -3.60
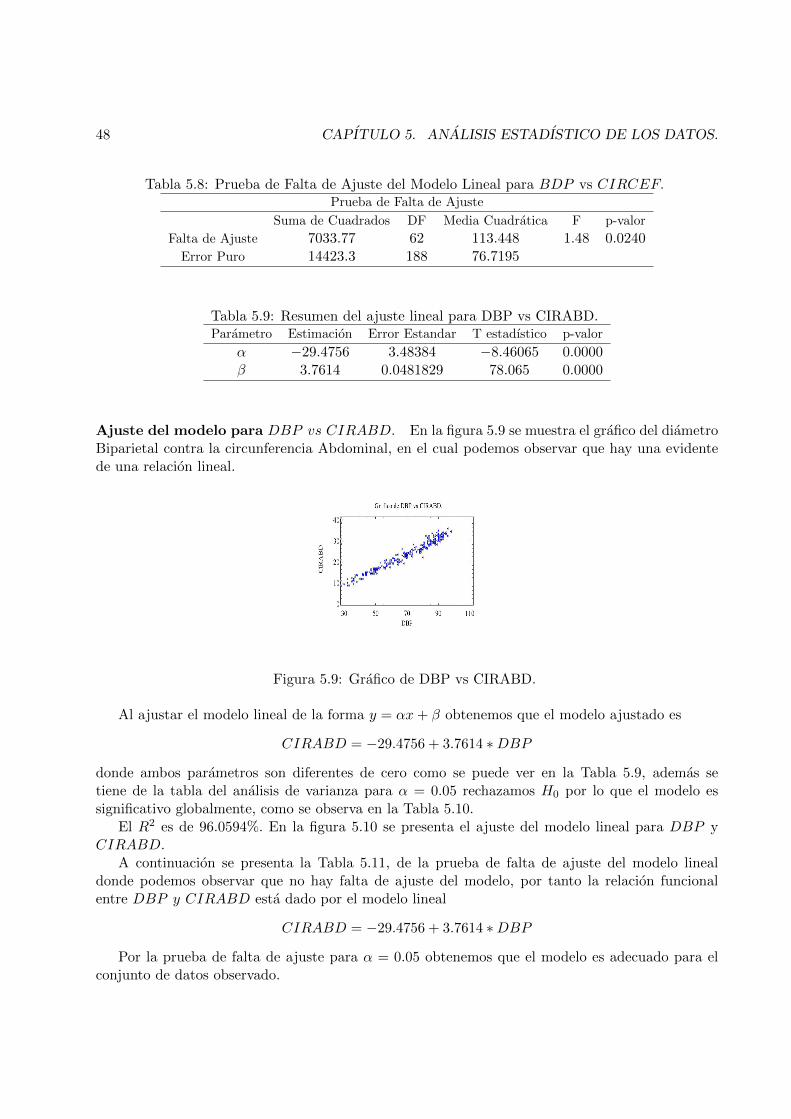
48 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.8: Prueba de Falta de Ajuste del Modelo Lineal para BDP vs CIRCEF.Prueba de Falta de Ajuste
Suma de Cuadrados DF Media Cuadratica F p-valor
Falta de Ajuste 7033.77 62 113.448 1.48 0.0240Error Puro 14423.3 188 76.7195
Tabla 5.9: Resumen del ajuste lineal para DBP vs CIRABD.Parametro Estimacion Error Estandar T estadıstico p-valor
α −29.4756 3.48384 −8.46065 0.0000β 3.7614 0.0481829 78.065 0.0000
Ajuste del modelo para DBP vs CIRABD. En la figura 5.9 se muestra el grafico del diametroBiparietal contra la circunferencia Abdominal, en el cual podemos observar que hay una evidentede una relacion lineal.
Figura 5.9: Grafico de DBP vs CIRABD.
Al ajustar el modelo lineal de la forma y = αx+ β obtenemos que el modelo ajustado es
CIRABD = −29.4756 + 3.7614 ∗DBP
donde ambos parametros son diferentes de cero como se puede ver en la Tabla 5.9, ademas setiene de la tabla del analisis de varianza para α = 0.05 rechazamos H0 por lo que el modelo essignificativo globalmente, como se observa en la Tabla 5.10.
El R2 es de 96.0594%. En la figura 5.10 se presenta el ajuste del modelo lineal para DBP yCIRABD.
A continuacion se presenta la Tabla 5.11, de la prueba de falta de ajuste del modelo linealdonde podemos observar que no hay falta de ajuste del modelo, por tanto la relacion funcionalentre DBP y CIRABD esta dado por el modelo lineal
CIRABD = −29.4756 + 3.7614 ∗DBP
Por la prueba de falta de ajuste para α = 0.05 obtenemos que el modelo es adecuado para elconjunto de datos observado.
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 49
Tabla 5.10: Resumen del Analisis de Varianza del Modelo Lineal para DBP vs CIRABD.Fuente Suma de Cuadrados Df Cuadrados medios F p-valor
Regresion 1208820 1 1208826 6094.14 0.0000Residual 49589.5 250 198.358
Total 1, 258410 251
Tabla 5.11: Resumen de la prueba de falta de Ajuste del Modelo Lineal para DBP vs CIRABD.Suma de Cuadrados DF Media Cuadratica F p-valor
Falta de Ajuste 11348.0 62 183.032 0.90 0.6805Error Puro 38241.5 188 203.412
Tabla 5.12: Residuales Atipicos del Modelo Lineal para DBP vs CIRABD.Fila X Y Valor Predicho Residuo Residuo Estudentizado
95 67 257 222.538 34.4619 2.48105 68 188 226.3 −38.2995 −2.76129 80 218 271.436 −53.4363 −3.91135 74 280 248.868 31.1321 2.23180 84 320 286.482 33.5181 2.41186 84 320 286.482 33.5181 2.41187 83 314 282.721 31.2795 2.25197 82 320 278.959 41.0409 2.97221 89 335 305.289 29.7111 2.13228 86 332 294.005 37.9953 2.74241 90 346 309.05 36.9497 2.67
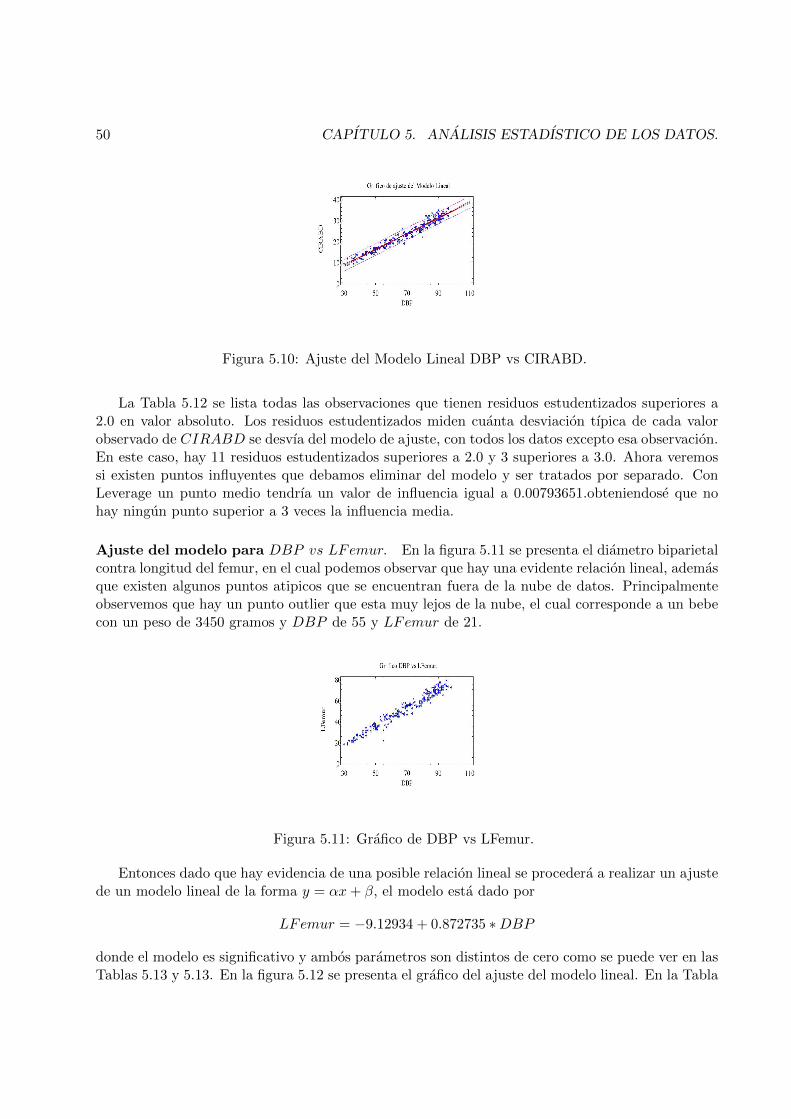
50 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Figura 5.10: Ajuste del Modelo Lineal DBP vs CIRABD.
La Tabla 5.12 se lista todas las observaciones que tienen residuos estudentizados superiores a2.0 en valor absoluto. Los residuos estudentizados miden cuanta desviacion tıpica de cada valorobservado de CIRABD se desvıa del modelo de ajuste, con todos los datos excepto esa observacion.En este caso, hay 11 residuos estudentizados superiores a 2.0 y 3 superiores a 3.0. Ahora veremossi existen puntos influyentes que debamos eliminar del modelo y ser tratados por separado. ConLeverage un punto medio tendrıa un valor de influencia igual a 0.00793651.obteniendose que nohay ningun punto superior a 3 veces la influencia media.
Ajuste del modelo para DBP vs LFemur. En la figura 5.11 se presenta el diametro biparietalcontra longitud del femur, en el cual podemos observar que hay una evidente relacion lineal, ademasque existen algunos puntos atipicos que se encuentran fuera de la nube de datos. Principalmenteobservemos que hay un punto outlier que esta muy lejos de la nube, el cual corresponde a un bebecon un peso de 3450 gramos y DBP de 55 y LFemur de 21.
Figura 5.11: Grafico de DBP vs LFemur.
Entonces dado que hay evidencia de una posible relacion lineal se procedera a realizar un ajustede un modelo lineal de la forma y = αx+ β, el modelo esta dado por
LFemur = −9.12934 + 0.872735 ∗DBP
donde el modelo es significativo y ambos parametros son distintos de cero como se puede ver en lasTablas 5.13 y 5.13. En la figura 5.12 se presenta el grafico del ajuste del modelo lineal. En la Tabla
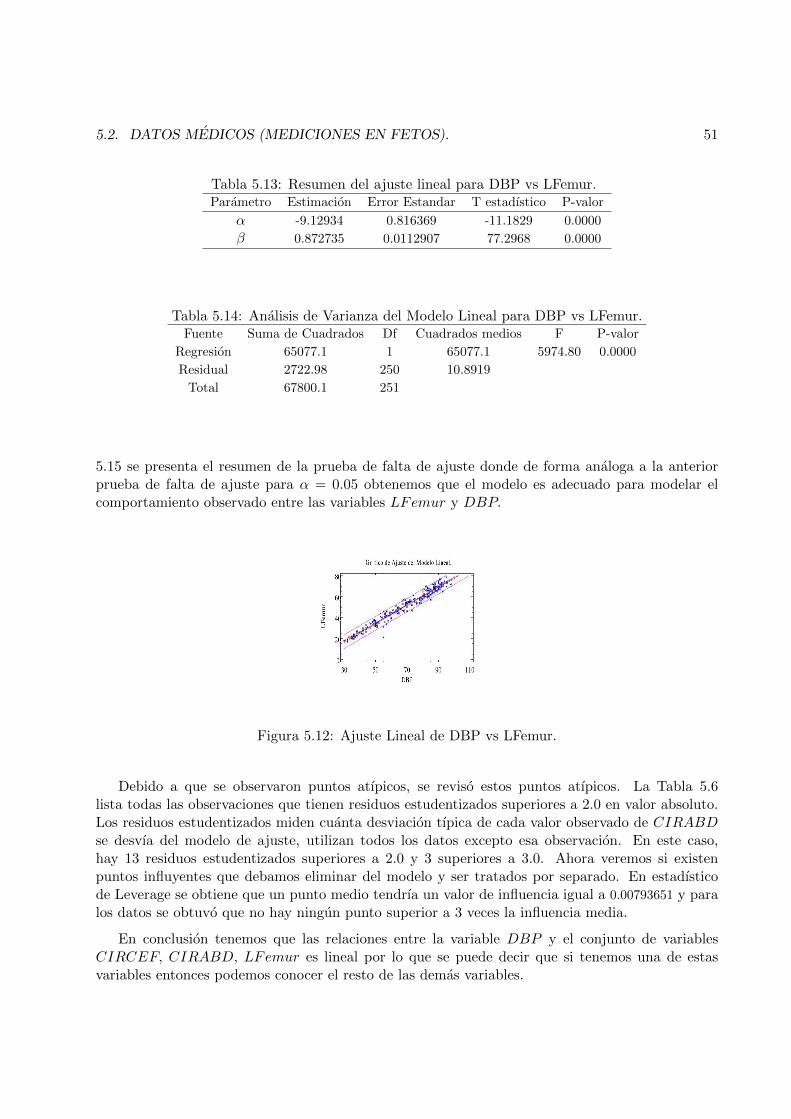
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 51
Tabla 5.13: Resumen del ajuste lineal para DBP vs LFemur.Parametro Estimacion Error Estandar T estadıstico P-valor
α -9.12934 0.816369 -11.1829 0.0000
β 0.872735 0.0112907 77.2968 0.0000
Tabla 5.14: Analisis de Varianza del Modelo Lineal para DBP vs LFemur.Fuente Suma de Cuadrados Df Cuadrados medios F P-valor
Regresion 65077.1 1 65077.1 5974.80 0.0000
Residual 2722.98 250 10.8919
Total 67800.1 251
5.15 se presenta el resumen de la prueba de falta de ajuste donde de forma analoga a la anteriorprueba de falta de ajuste para α = 0.05 obtenemos que el modelo es adecuado para modelar elcomportamiento observado entre las variables LFemur y DBP.
Figura 5.12: Ajuste Lineal de DBP vs LFemur.
Debido a que se observaron puntos atıpicos, se reviso estos puntos atıpicos. La Tabla 5.6lista todas las observaciones que tienen residuos estudentizados superiores a 2.0 en valor absoluto.Los residuos estudentizados miden cuanta desviacion tıpica de cada valor observado de CIRABDse desvıa del modelo de ajuste, utilizan todos los datos excepto esa observacion. En este caso,hay 13 residuos estudentizados superiores a 2.0 y 3 superiores a 3.0. Ahora veremos si existenpuntos influyentes que debamos eliminar del modelo y ser tratados por separado. En estadısticode Leverage se obtiene que un punto medio tendrıa un valor de influencia igual a 0.00793651 y paralos datos se obtuvo que no hay ningun punto superior a 3 veces la influencia media.
En conclusion tenemos que las relaciones entre la variable DBP y el conjunto de variablesCIRCEF, CIRABD, LFemur es lineal por lo que se puede decir que si tenemos una de estasvariables entonces podemos conocer el resto de las demas variables.
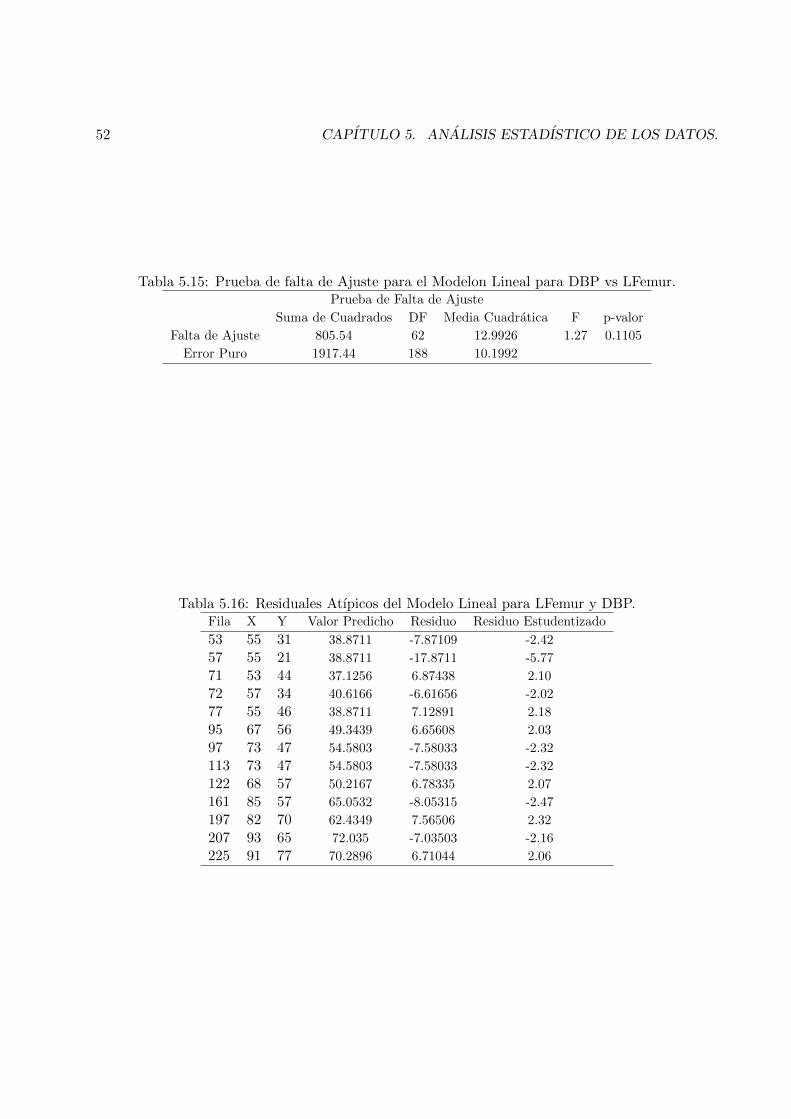
52 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.15: Prueba de falta de Ajuste para el Modelon Lineal para DBP vs LFemur.Prueba de Falta de Ajuste
Suma de Cuadrados DF Media Cuadratica F p-valor
Falta de Ajuste 805.54 62 12.9926 1.27 0.1105
Error Puro 1917.44 188 10.1992
Tabla 5.16: Residuales Atıpicos del Modelo Lineal para LFemur y DBP.Fila X Y Valor Predicho Residuo Residuo Estudentizado
53 55 31 38.8711 -7.87109 -2.42
57 55 21 38.8711 -17.8711 -5.77
71 53 44 37.1256 6.87438 2.10
72 57 34 40.6166 -6.61656 -2.02
77 55 46 38.8711 7.12891 2.18
95 67 56 49.3439 6.65608 2.03
97 73 47 54.5803 -7.58033 -2.32
113 73 47 54.5803 -7.58033 -2.32
122 68 57 50.2167 6.78335 2.07
161 85 57 65.0532 -8.05315 -2.47
197 82 70 62.4349 7.56506 2.32
207 93 65 72.035 -7.03503 -2.16
225 91 77 70.2896 6.71044 2.06
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 53
5.2.3 Ajuste de modelos para la relacion Gest vs DBP.
Ahora dado que ya se tiene una relacion funcional entre DBP y las variables CIRCEF, CIRABDy LFemur, el siguiente paso a seguir es encontrar una relacion funcional entre DBP y la edadgestional con el objetivo de poder conocer todas las medidas ecograficas de un feto con solo conocerla edad gestional. En la figura 5.13 se presenta la grafica de la edad gestional contra el diametroBiparietal. En la cual observamos que la relacion existen entre las dos variables no tiene unatendencia lineal sino posiblemente cuadratica, cubica o de crecimiento. Entonces dado que no hayuna relacion funcional se procedio a ajustar varios modelos que a nuestra consideracion puedenllegar a describir el comportamiento observado en la figura 5.13. Entre los modelos propuestosestan, el modelo Cuadratico, Cubico, Gompertz y el modelo Logıstico.
Figura 5.13: Grafico de DBP vs gest.
Resultados del ajuste lineal Para el ajuste del modelo lineal y = ax+ b obtenemos el modelo
DBP = −2.71255 + 2.55601 ∗ gest
donde ambos parametros son diferentes de cero y el modelo es significativo de forma general comose observa en las Tablas 5.17 y 5.18 respectivamente. En la figura 5.14 se tiene el ajuste del Modelolineal donde podemos observar que el ajuste no es muy bueno como se observo por primera vez ycomo veremos en la prueba de falta de ajuste el ajuste no es adecuado.
Figura 5.14: Ajuste del Modelo Lineal de DBP vs gest.

54 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.17: Estimacion de Parametros para el Modelo Lineal de DBP vs gest.Parametro Estimacion Error Estandar T estadıstico P-valor
α −2.71255 0.894384 −3.03287 0.0027β 2.55601 0.0305406 83.6921 0.0000
Tabla 5.18: Analisis de Varianza del Modelo Lineal para DBP vs Gest.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 82496 1 82496 7004.36 0.0000Residual 2944.45 250 11.7778
Total 85440.4 251
De la tabla del analisis de varianza para α = 0.05 rechazamos H0 por lo que el modelo essignificativo globalmente. El R2 de 96.5538%, esto pareciera indicar que hay un 96.5538% dedescripcion de la variabilidad de los datos, pero como vemos en la prueba de falta de ajuste estemodelo no es adecuado para el comportamiento de los datos, por lo que podemos concluir que hayuna alta variabilidad en los datos.
De la prueba de falta de ajuste para α =0.05 se tiene falta de ajuste en el modelo por lo quepodemos descartar el modelo lineal como un modelo competitivo para modelar DBP vs gest.
Resultados del ajuste del modelo cuadratico. Para el ajuste del modelo lineal y = αx2 +βx+ γ obtenemos que el modelo esta dado por
DBP = −0.0496039gest2 + 5.31726gest− 38.6386
En la Tabla 5.21 obsevamos que el modelo es significativo globalmente, ademas todos sus parametrosson distintos de cero.
Para α = 0.05 y 249 grados de libertad tenemos que 1 − funcTInv(0.05; 249) = 2.651 0, portanto rechazamos la hipotesis nula y concluimos que α, β y γ son diferentes de cero.
En la figura 5.15 vemos el ajuste del modelo cuadratico, donde podemos observar que hay unadecuado ajuste.
Resultados del ajuste del modelo cubico. Al realizar el ajuste del modelo lineal y = ax3 +bx2 + cx+ d obtenemos que el modelo es
DBP = −0.00233817x3 + 0.14341x2 + 0.221802x+ 4.13203
Tabla 5.19: Prueba de falta de Ajuste del Modelo Lineal para DBP vs Gest.Suma de Cuadrados DF Media Cuadratica F p-valor
Falta de Ajuste 1533.14 24 63.8809 10.23 0.0000
Error Puro 1411.31 226 6.24473

5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 55
Tabla 5.20: Estimacion de Parametros para el Modelo Cuadratico de DBP vs gest.Parametro Estimacion Error Estandar Asintotico T estadıstico P-valor
α -0.0496039 0.00356875 -13.900 0.0000
β 5.31726 0.199988 26.588 0.0000
γ -38.6386 2.67085 -14.467 0.0000
Tabla 5.21: Analisis de Varianza para el Modelo Cuadratico DBP vs gest.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1315780 3 438595 65868 0.0000Residual 1658.01 249 6.65867Total 1317440 252
Observemos que en la Tabla 5.23 del analisis de varianza se tiene que el modelo es globalmentesignificativo pero, al realizar la prueba sobre cada uno de los parametros observamos que hayparametros que son diferentes de cero. Al examinr los valores de los p− valores, podemos concluirque los parametros c y d son no significativos para el modelo y por tanto podemos excluirlos delmodelo.
En la Tabla 5.23 notamos que el modelo es significativo globalmente para α = 0.05. El R2 =98.1997% por lo que podemos decir que el 98% de la variabilidad de los datos es explicado por elmodelo, pero recordemos que esta medida no es del todo confiable como se observo en el ajuste delmodelo lineal.
Dado que los parametros c y d pueden ser excluidos del modelo, a continuacion se realizara unajuste cubico de la forma ax3 + bx2 y de la forma ax3 + cx + d y ax3 + bx2 + d y compararemoscual modelo es el mas adecuado al conjunto de datos. Primero realizaremos el ajuste del modelode la forma ax3 + bx2 donde el modelo ajustado esta dado por
DBP = −0.002929gest3 + 0.174112gest2
y de la Tabla 5.25 se tiene que el modelo es globalmente significativo para α = 0.05 y que ambosparametros son significativamente diferentes de cero como se observa en la Tabla 5.26.
R2 = 97.9312%.Para el ajuste del modelo de la forma ax3 + bx2 + d obtenemos que el modelo es
DBP = −0.0024372gest3 + 0.151691gest2 + 6.02267
Tabla 5.22: Intervalos de confianza Asıntoticos del 95% de confianza del Modelo Lineal para DBPvs Gest.
Parametro Intervalo de Confianza Asintotico de 95%
α ( -0.0566308 , -0.0425732 )β ( 4.92337 , 5 71114 )γ ( -4 .899 , -33.3783 )
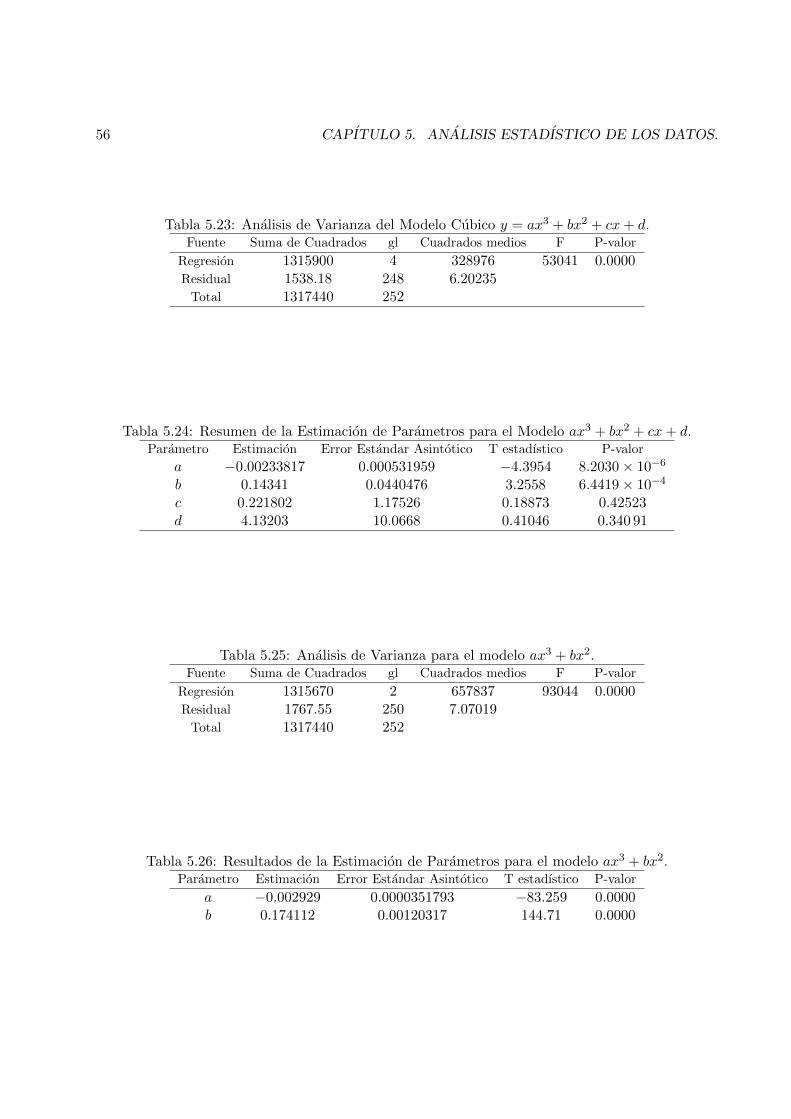
56 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.23: Analisis de Varianza del Modelo Cubico y = ax3 + bx2 + cx+ d.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1315900 4 328976 53041 0.0000Residual 1538.18 248 6.20235
Total 1317440 252
Tabla 5.24: Resumen de la Estimacion de Parametros para el Modelo ax3 + bx2 + cx+ d.Parametro Estimacion Error Estandar Asintotico T estadıstico P-valor
a −0.00233817 0.000531959 −4.3954 8.2030× 10−6
b 0.14341 0.0440476 3.2558 6.4419× 10−4
c 0.221802 1.17526 0.18873 0.42523d 4.13203 10.0668 0.41046 0.340 91
Tabla 5.25: Analisis de Varianza para el modelo ax3 + bx2.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1315670 2 657837 93044 0.0000Residual 1767.55 250 7.07019
Total 1317440 252
Tabla 5.26: Resultados de la Estimacion de Parametros para el modelo ax3 + bx2.Parametro Estimacion Error Estandar Asintotico T estadıstico P-valor
a −0.002929 0.0000351793 −83.259 0.0000b 0.174112 0.00120317 144.71 0.0000
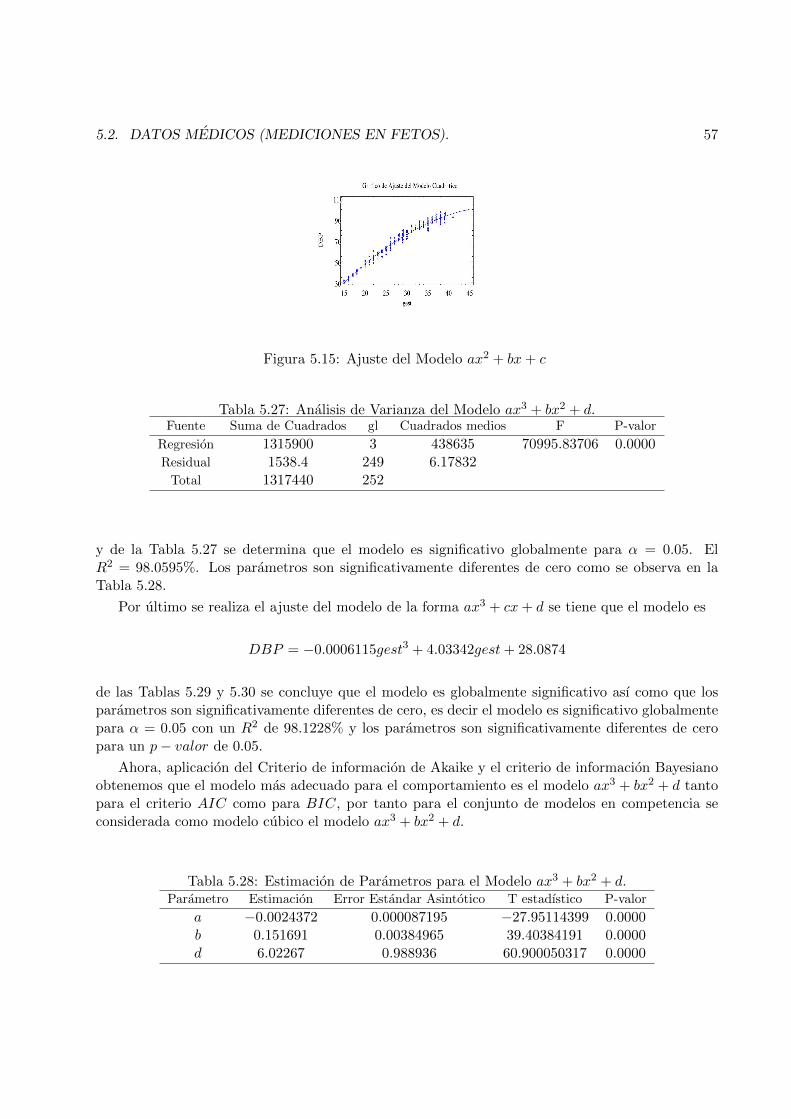
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 57
Figura 5.15: Ajuste del Modelo ax2 + bx+ c
Tabla 5.27: Analisis de Varianza del Modelo ax3 + bx2 + d.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1315900 3 438635 70995.83706 0.0000Residual 1538.4 249 6.17832
Total 1317440 252
y de la Tabla 5.27 se determina que el modelo es significativo globalmente para α = 0.05. ElR2 = 98.0595%. Los parametros son significativamente diferentes de cero como se observa en laTabla 5.28.
Por ultimo se realiza el ajuste del modelo de la forma ax3 + cx+ d se tiene que el modelo es
DBP = −0.0006115gest3 + 4.03342gest+ 28.0874
de las Tablas 5.29 y 5.30 se concluye que el modelo es globalmente significativo ası como que losparametros son significativamente diferentes de cero, es decir el modelo es significativo globalmentepara α = 0.05 con un R2 de 98.1228% y los parametros son significativamente diferentes de ceropara un p− valor de 0.05.
Ahora, aplicacion del Criterio de informacion de Akaike y el criterio de informacion Bayesianoobtenemos que el modelo mas adecuado para el comportamiento es el modelo ax3 + bx2 + d tantopara el criterio AIC como para BIC, por tanto para el conjunto de modelos en competencia seconsiderada como modelo cubico el modelo ax3 + bx2 + d.
Tabla 5.28: Estimacion de Parametros para el Modelo ax3 + bx2 + d.Parametro Estimacion Error Estandar Asintotico T estadıstico P-valor
a −0.0024372 0.000087195 −27.95114399 0.0000b 0.151691 0.00384965 39.40384191 0.0000d 6.02267 0.988936 60.900050317 0.0000

58 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.29: Analisis de Varianza del Modelo ax3 + cx+ d.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1315840 3 438613 68092 0.0000Residual 1603.93 249 6.44148
Total 1317440 252
Tabla 5.30: Estimacion de parametros para el Modelo ax3 + cx+ d.Parametro Estimacion Error Estandar Asintotico T estadıstico P-valor
a −0.0006115 0.0000423907 −14.425 0.0000c 4.03342 0.104879 38.458 0.0000d 28.0874 1.8793 14.946 0.0000
Resultado del ajuste del modelo gompertz.
Para el modelo gompertz y = α exp (− exp (β − γx)) el ajuste para el conjunto de datos es
DBP = 112.09 exp (− exp 1.46478− 0.0808253gest)
Al examinar los p−valores de la Tabla 5.32 rechazamos la hipotesis nula, por lo que los parametrosson diferentes de cero, ademas de la Tabla 5.33se concluye que el modelo es globalmente signi-ficativo. Observe en la figura 5.20 que el modelo gompertz parece describir adecuadamente elcomportamiento de la relacion entre gest y DBP.
A continuacion tenemos los intervalos de confianza para los parametros del modelo gompertzcon un nivel de confianza del 95%.
El ajuste del modelo es
DBP = 112.09 exp (− exp (1.46478− 0.0808253gest))
Resultados del ajuste del Modelo Logıstico. Por ultimo se ajusto el modelo logıstico y =α
1+exp(β−γx) y se obtuvo que para el conjunto de datos el modelo esta dado por
DBP =102.777
1 + exp (2.67237− 0.1252gest)
Tabla 5.31: Criterio de Informacion de Akaike y Bayesiano para Modelos Cubicos.Modelo AIC BIC
ax3+cx+ d −110.0131 −112.064ax3+bx −110.4216 −111.7889ax3+bx2+d −109.4883 −111.4592
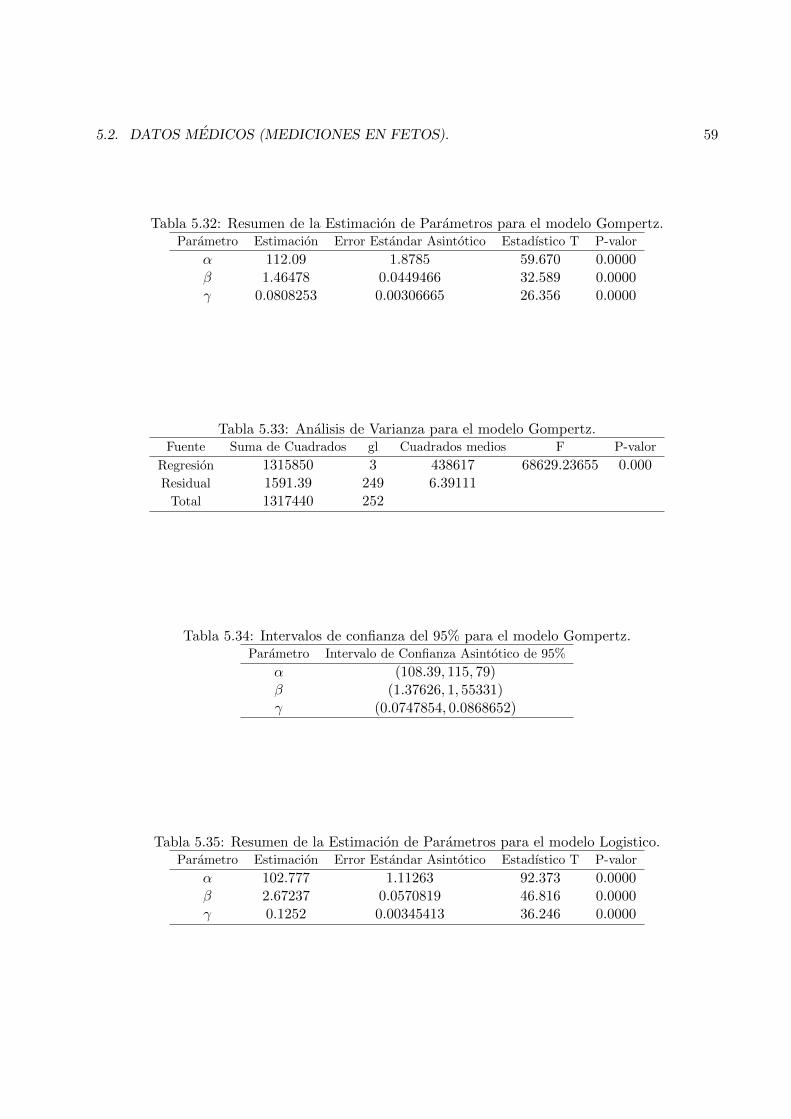
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 59
Tabla 5.32: Resumen de la Estimacion de Parametros para el modelo Gompertz.Parametro Estimacion Error Estandar Asintotico Estadıstico T P-valor
α 112.09 1.8785 59.670 0.0000β 1.46478 0.0449466 32.589 0.0000γ 0.0808253 0.00306665 26.356 0.0000
Tabla 5.33: Analisis de Varianza para el modelo Gompertz.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1315850 3 438617 68629.23655 0.000Residual 1591.39 249 6.39111
Total 1317440 252
Tabla 5.34: Intervalos de confianza del 95% para el modelo Gompertz.Parametro Intervalo de Confianza Asintotico de 95%
α (108.39, 115, 79)β (1.37626, 1, 55331)γ (0.0747854, 0.0868652)
Tabla 5.35: Resumen de la Estimacion de Parametros para el modelo Logistico.Parametro Estimacion Error Estandar Asintotico Estadıstico T P-valor
α 102.777 1.11263 92.373 0.0000β 2.67237 0.0570819 46.816 0.0000γ 0.1252 0.00345413 36.246 0.0000

60 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Figura 5.16: Ajuste Cubico ax3 + bx2 + cx+ d
Figura 5.17: Ajuste Cubico ax3 + cx+ d.
de las Tablas 5.35 y 5.36 se tiene que todos los parametros resultaron significativamente diferentesde cero para un α = 0.05 y del analisis de varianza para α = 0.05 rechazamos H0 por lo que elmodelo es significativo globalmente.
En la Tabla 5.37 se muestra los intervalos de confianza ajustados para los parametros del modeloLogıstico con un nivel de confianza del 95%.
Y al igual que en los anteriores modelos podemos observar en la figura 5.21, que el ajustoLogıstico es adecuado para el comportamiento de la relacion de DBP con gest.
5.2.4 Prediccion del peso de nacimiento de los fetos.
Para realizar el objetivo de tratar de predecir el peso de nacimiento de los fetos con las variables(ultrasonograficas) diametro biparietal, circunferencia cefalica, circunferencia abdominal y longitud
Tabla 5.36: Analisis de Varianza para el modelo Logistico.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1315900 3 438635 71047 0.0000Residual 1537.3 249 6.17391
Total 1317440 252
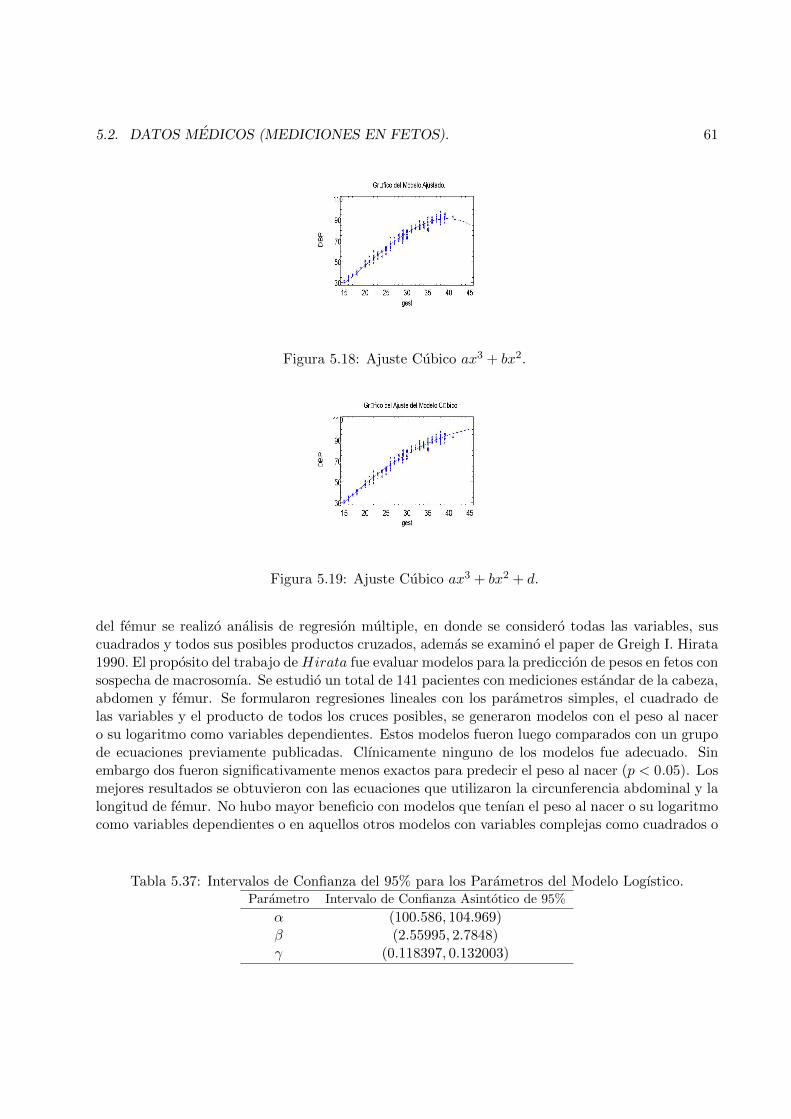
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 61
Figura 5.18: Ajuste Cubico ax3 + bx2.
Figura 5.19: Ajuste Cubico ax3 + bx2 + d.
del femur se realizo analisis de regresion multiple, en donde se considero todas las variables, suscuadrados y todos sus posibles productos cruzados, ademas se examino el paper de Greigh I. Hirata1990. El proposito del trabajo de Hirata fue evaluar modelos para la prediccion de pesos en fetos consospecha de macrosomıa. Se estudio un total de 141 pacientes con mediciones estandar de la cabeza,abdomen y femur. Se formularon regresiones lineales con los parametros simples, el cuadrado delas variables y el producto de todos los cruces posibles, se generaron modelos con el peso al nacero su logaritmo como variables dependientes. Estos modelos fueron luego comparados con un grupode ecuaciones previamente publicadas. Clınicamente ninguno de los modelos fue adecuado. Sinembargo dos fueron significativamente menos exactos para predecir el peso al nacer (p < 0.05). Losmejores resultados se obtuvieron con las ecuaciones que utilizaron la circunferencia abdominal y lalongitud de femur. No hubo mayor beneficio con modelos que tenıan el peso al nacer o su logaritmocomo variables dependientes o en aquellos otros modelos con variables complejas como cuadrados o
Tabla 5.37: Intervalos de Confianza del 95% para los Parametros del Modelo Logıstico.Parametro Intervalo de Confianza Asintotico de 95%
α (100.586, 104.969)β (2.55995, 2.7848)γ (0.118397, 0.132003)

62 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Figura 5.20: Ajuste del Modelo Gompertz.
Figura 5.21: Ajuste del Modelo Logıstico.
productos cruzados de las medidas. En conclusion, al evaluar pacientes con macrosomıa, las mejoresestimaciones del peso fetal se obtienen con modelos que utilicen la circunferencia abdominal y lalongitud de femur.
Primero se realizo un analisis exploratorio con graficos del peso de nacimiento con las variablesde interes, este analisis fue realizado en statgraphic. Recordemos que las variables estan altamentecorrelacionadas entre sı y con la edad gestional, como se puede observar en la Tabla 5.4, peroque tambien se observa que el peso de nacimiento de los fetos no esta correlacionado fuertementecon estas variables, lo que indica que no sera facil poder encontrar una funcion que nos ayude apoder predecir el peso de nacimiento. Esto tambien puede ser visto en los siguientes graficos delpeso de nacimiento con cada una de las variables, en los cual solo se grafico la ultima medicion decada una de las variables ultrasonografica, debido a que en el desarrollo fetal las ultimas semanasde gestacion el feto presenta una estabilizacion en el crecimiento como se observa en los graficosde las variables ultrasonograficas contra la edad gestional, por tanto si hay una relacion entre lasvariables ultrasonograficas y el peso de nacimiento esta debe ser mas notable en las ultimas semanasde gestacion. Observamos por ejemplo el grafico del peso de nacimiento contra el DBP, el cual quela variable mas altamente correlacionada con la edad gestional y observamos que no hay una relacionfuncional obvia entre estas dos variables, sino que observamos que para una medida determinadadel diametro biparietal se dieron diferentes pesos, por ejemplo para un diametro biparietal de 93el rango de pesos de nacimiento fue de 2750 gramos a los 3450 gramos. Aun dado esto si podemosdecir que los fetos con mayor peso en el nacimiento presentan medidas en las variables de interes

5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 63
altas con respecto a los fetos que tuvieron un peso de nacimiento muy bajo, esto nos lleva a intuirque existe una relacion entre estas variables y el peso de nacimiento la cual no es obvio o facil deencontrar, tambien podemos intuir que quizas los modelos no presenten una muy buena predicciondebido a que se presenta una dispersion grande en los pesos de nacimiento para las mediciones delas variables observadas.
Figura 5.22: Grafico del Peso de Nacimiento vs DBP.
Figura 5.23: Grafico del Peso de Nacimiento vs CIRCEF.
Ahora procedamos a realizar las regresiones multiples simple con todas las variables ultrasono-graficas. Primero realicemos la regresion multiple donde se encuentren todas las variables de interes,donde se obtuvo que el modelo ajustado esta dado por
PesoN = 2975.5 + 2.27837DBP + 0.64589CIRCEF + 3.8115CIRABD − 20.2418LFemur
Dado que el p − valor en la Tabla 5.38 es inferior a α = 0.05, existe relacion estadısticamentesignificativa entre las variables para un nivel de confianza del 95%.
El R2 obtenido es de 4.46006%, el cual es muy pequeno, es decir, el modelo describe solo un4% de la variabilidad de los datos. Al examinar la Tabla 5.39 de estimacion de los parametros porel metodo de mınimos cuadrados tenemos que las variables DBP y CIRCEF tienen un p− valormas alto que α = 0.05 dados por 0.7949 y 0.7909 respectivamente, por tanto estos terminos noson estadısticamente significativos para un nivel de confianza del 95% o superior. Por tanto, seconsiderara eliminarlos del modelo.
Seguidamente realizaremos la regresion multiple para las variables longitud del femur y circun-ferencia abdominal como variables independientes y peso de nacimiento como variable dependiente,

64 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Figura 5.24: Grafico del Peso de Nacimiento vs CIRABD.
Figura 5.25: Grafico del Peso de Nacimiento vs LFemur.
es decir, se ajustara el nuevo modelo con las variables que resultaron estadısticamente significativas.El modelo para la regresion multiple es
PesoN = 3028.79 + 4.433CIRABD − 17.8784LFemur
Dado que el p−valor en la Tabla 5.40 del analisis de varianza es inferior a α = 0.05, existe relacionestadısticamente significativa entre las variables para un nivel de confianza del 95%.
El R2 obtenido es de 4.30908%, el cual es muy pequeno, es decir, el modelo solo describe un 4%de la variabilidad de los datos, por lo que podemos concluir que estas dos variables independientesson importantes para poder predecir el peso de nacimiento del feto, pero el modelo de prediccion esmuy malo para predecir el peso. Ahora al examinar la Tabla 5.41 de estimacion de los parametrospor el metodo de mınimos cuadrados tenemos que las variables CIRABD y LFemur tienen unp− valor menor que α = 0.05 dados por 0.0011 y 0.0023 respectivamente, por tanto estos terminos
Tabla 5.38: Analisis de Varianza para el Modelo de Regresion Multiple ax1 + bx2 + cx3 + dx4 + e.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1242600 4 310650.0 2.88 0.0232Residual 26618000 247 107765.0
Total 27860600 251
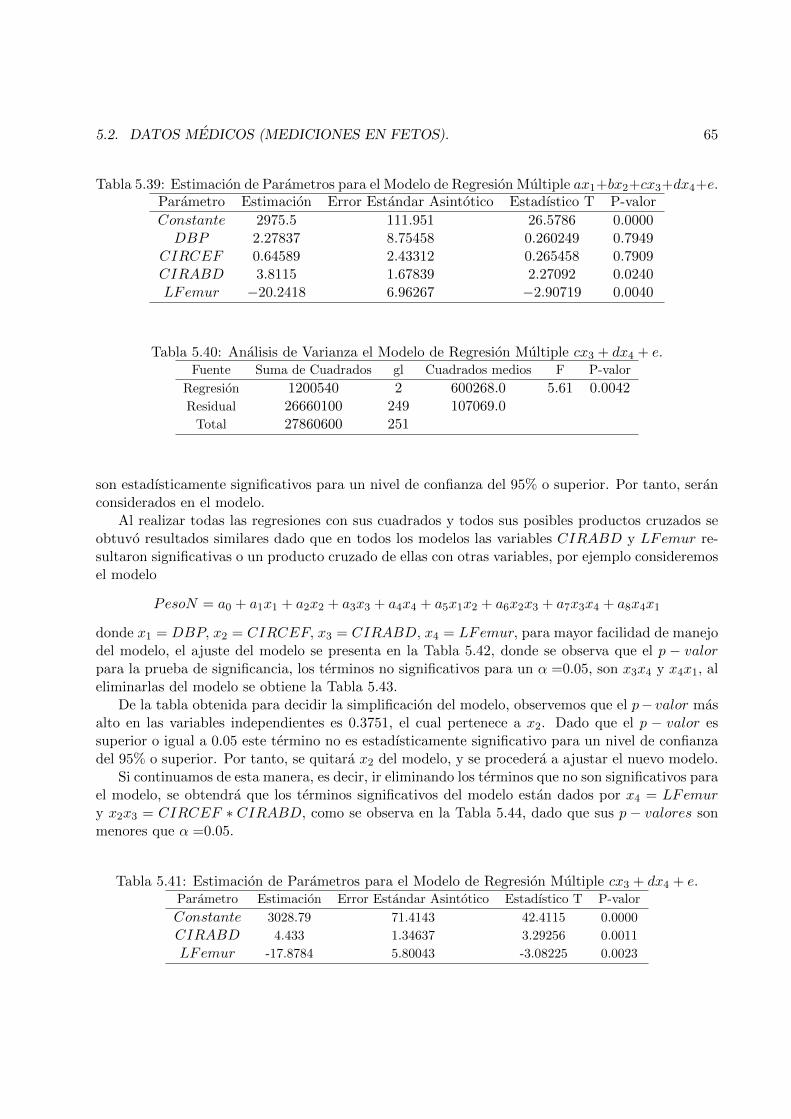
5.2. DATOS MEDICOS (MEDICIONES EN FETOS). 65
Tabla 5.39: Estimacion de Parametros para el Modelo de Regresion Multiple ax1+bx2+cx3+dx4+e.Parametro Estimacion Error Estandar Asintotico Estadıstico T P-valor
Constante 2975.5 111.951 26.5786 0.0000DBP 2.27837 8.75458 0.260249 0.7949
CIRCEF 0.64589 2.43312 0.265458 0.7909CIRABD 3.8115 1.67839 2.27092 0.0240LFemur −20.2418 6.96267 −2.90719 0.0040
Tabla 5.40: Analisis de Varianza el Modelo de Regresion Multiple cx3 + dx4 + e.Fuente Suma de Cuadrados gl Cuadrados medios F P-valor
Regresion 1200540 2 600268.0 5.61 0.0042Residual 26660100 249 107069.0
Total 27860600 251
son estadısticamente significativos para un nivel de confianza del 95% o superior. Por tanto, seranconsiderados en el modelo.
Al realizar todas las regresiones con sus cuadrados y todos sus posibles productos cruzados seobtuvo resultados similares dado que en todos los modelos las variables CIRABD y LFemur re-sultaron significativas o un producto cruzado de ellas con otras variables, por ejemplo consideremosel modelo
PesoN = a0 + a1x1 + a2x2 + a3x3 + a4x4 + a5x1x2 + a6x2x3 + a7x3x4 + a8x4x1
donde x1 = DBP, x2 = CIRCEF, x3 = CIRABD, x4 = LFemur, para mayor facilidad de manejodel modelo, el ajuste del modelo se presenta en la Tabla 5.42, donde se observa que el p − valorpara la prueba de significancia, los terminos no significativos para un α =0.05, son x3x4 y x4x1, aleliminarlas del modelo se obtiene la Tabla 5.43.
De la tabla obtenida para decidir la simplificacion del modelo, observemos que el p− valor masalto en las variables independientes es 0.3751, el cual pertenece a x2. Dado que el p − valor essuperior o igual a 0.05 este termino no es estadısticamente significativo para un nivel de confianzadel 95% o superior. Por tanto, se quitara x2 del modelo, y se procedera a ajustar el nuevo modelo.
Si continuamos de esta manera, es decir, ir eliminando los terminos que no son significativos parael modelo, se obtendra que los terminos significativos del modelo estan dados por x4 = LFemury x2x3 = CIRCEF ∗ CIRABD, como se observa en la Tabla 5.44, dado que sus p − valores sonmenores que α =0.05.
Tabla 5.41: Estimacion de Parametros para el Modelo de Regresion Multiple cx3 + dx4 + e.Parametro Estimacion Error Estandar Asintotico Estadıstico T P-valor
Constante 3028.79 71.4143 42.4115 0.0000
CIRABD 4.433 1.34637 3.29256 0.0011
LFemur -17.8784 5.80043 -3.08225 0.0023
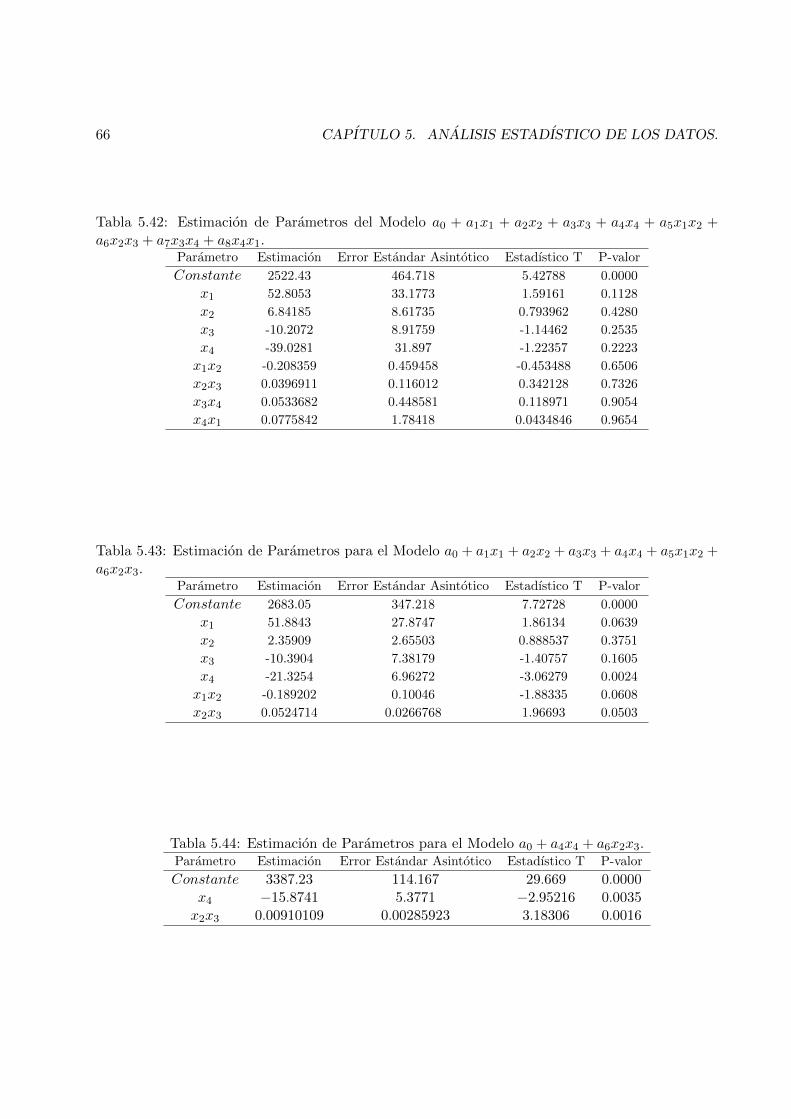
66 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.42: Estimacion de Parametros del Modelo a0 + a1x1 + a2x2 + a3x3 + a4x4 + a5x1x2 +a6x2x3 + a7x3x4 + a8x4x1.
Parametro Estimacion Error Estandar Asintotico Estadıstico T P-valor
Constante 2522.43 464.718 5.42788 0.0000
x1 52.8053 33.1773 1.59161 0.1128
x2 6.84185 8.61735 0.793962 0.4280
x3 -10.2072 8.91759 -1.14462 0.2535
x4 -39.0281 31.897 -1.22357 0.2223
x1x2 -0.208359 0.459458 -0.453488 0.6506
x2x3 0.0396911 0.116012 0.342128 0.7326
x3x4 0.0533682 0.448581 0.118971 0.9054
x4x1 0.0775842 1.78418 0.0434846 0.9654
Tabla 5.43: Estimacion de Parametros para el Modelo a0 + a1x1 + a2x2 + a3x3 + a4x4 + a5x1x2 +a6x2x3.
Parametro Estimacion Error Estandar Asintotico Estadıstico T P-valor
Constante 2683.05 347.218 7.72728 0.0000
x1 51.8843 27.8747 1.86134 0.0639
x2 2.35909 2.65503 0.888537 0.3751
x3 -10.3904 7.38179 -1.40757 0.1605
x4 -21.3254 6.96272 -3.06279 0.0024
x1x2 -0.189202 0.10046 -1.88335 0.0608
x2x3 0.0524714 0.0266768 1.96693 0.0503
Tabla 5.44: Estimacion de Parametros para el Modelo a0 + a4x4 + a6x2x3.Parametro Estimacion Error Estandar Asintotico Estadıstico T P-valor
Constante 3387.23 114.167 29.669 0.0000x4 −15.8741 5.3771 −2.95216 0.0035x2x3 0.00910109 0.00285923 3.18306 0.0016

5.3. REALIZACION DE LAS PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION.67
por tanto el modelo obtenido al usar el metodo de eliminar terminos no significativos esta dadopor
PesoN = 3387.23− 15.8741 ∗ LFemur + 0.00910109 ∗ CIRCEF ∗ CIRABD
Ademas se observo que todas las R2 de los modelos no excedıan de el 6%, por lo cual podemos decirque todos los modelos encontrados tienen un podre desempeno para estimar el peso de nacimiento.Esto nos lleva concluir que el modelo para predecir el peso de nacimiento debe considerarse otrotipo de analisis estadıstico en el cual se considere mas informacion del feto y quizas de la madre,aunque podemos concluir que para poder predecir el peso de nacimiento de manera mas eficiente sedebe considerar las variables ultrasonograficas, circunferencia abdominal y la longitud del femur.
5.3 Realizacion de las pruebas de hipotesis y metodos de discrim-inacion.
En el caso del conjunto de datos medicos, para facilidad de la utilizacion de los modelos en las prue-bas y metodos de discriminacion, seran renombrados de la siguiente manera: f1 :modelo cuadratico,f2 :modelo cubico, f3 :modelo gompertz, f4 :modelo logıstico. Por tanto el conjunto de modeloscompetitivos esta dado por F = {f1, f2, f3, f4} . Como se meciono anteriormente se utilizo el paqueteR para realizar las pruebas y los metodos de discriminacion.
Al aplicar el criterio de informacion de Akaike el modelo Logıstico resulto ser el mas adecuadoaunque la diferencia entre este y el modelo cubico es mınima como se observa en la Tabla 5.45.Ahora dado que el tamano de la muestra es considerablemente grande, es conveniente aplicar elcriterio de informacion Bayesiana, al utilizar el BIC nos arroja que el modelo el cual maximizaes el modelo Logıstico con un valor de −111.4488,al igual que con el criterio de informacion deAkaike, ademas de manera similar el modelo cubico no difiere mucho del valor obtenido para elmodelo logıstico. Ahora dado las dos pruebas podemos decir que el modelo mas adecuado para elcomportamiento del fenomeno de los fetos es el modelo Logıstico.
Tabla 5.45: Criterio de Akaike y Bayesiano para los Modelos del Datos Medicos.Modelo
f1 f2 f3 f4
AIC −110.4939 −109.4083 −109.8992 −109.3979BIC −112.448 −111.4592 −111.9502 −111.4488
Ahora realizemos las pruebas de Williams y Atkinson junto con la prueba basada en las proba-bilidades de seleccionar correcta e incorrectamente el modelo para poder saber si podemos realizaruna discriminacion de los modelos con un metodo de discriminacion.
Al aplicar la prueba de Williams propuesta en su libro Regression Analysis, obtenemos queel estadıstico observado es de 1.506051 y el estadıstico para α = 0.05 es de 2.640854, esto esF < F1−α,k−1,n−k+1, por tanto los modelos considerados para modelar el fenomeno de los fetos sondemasiado cercanos para poder realizar una discriminacion.
Con la prueba tilde propuesta por Atkinson (1969) , obtenemos que F = 0.000002382555 yF(1−α,k−1,n−k) = 2.640854, asi F < F1−α,k−1,n−k por tanto aceptamo H0 y al igual que en la prueba

68 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
de Williams concluimos que no hay suficiente evidencia para realizar una discriminacion entre losmodelos, es decir, los modelos son muy parecidos.
Recordemos que estas dos pruebas no realizan un contraste directo de los modelos por lo quese realizara a continuacion es el de aplicar un metodo de discriminacion basado en el Teorema 3.Bajo la posibilidad de seleccionar el modelo los limites condicionales (4.22) y (4.23) son calculadoscon σ = 7.092797. Estos estan listados en la Tabla (5.46). Hay que notar que en la aplicacion delprocedimiento establecido en el teorema 2.3.1, tenemos que para los modelos f1 y f2 tenemos queSN = ∅. Ası sobre los modelos que estan en F, se tiene que maxP [IS (fj)] ≤ 0.4000657. Entoncesbasado en la cuestion A3, se acepta H0, es decir, no hay suficiente evidencia para realizar unaseleccion debido a la grandes probabilidades de seleccionar incorrectamente el modelo.
Tabla 5.46: Limites de probabilidades Modelo Seleccionado.f1 f2 f3 f4
P [IS (fj)] 0.3882566 0.4000657 0.006997732 0.005868674P [CS (fj)] 0.6117434 0.5999343 0.86662 0.5955264
De estas tres pruebas realizadas, en las cuales se concluyo lo mismo, podemos deducir que loscuatro modelos seleccionados son adecuados para modelar el comportamiento de la variable DBPcon gest.A continuacion se realizara la aplicacion del metodo secuencial para seleccionar el modelomas adecuado del conjunto de cuatro modelos propuestos para modelar el comportamiento de DBPvs gest.
5.3.1 Aplicacion del Metodo Secuencial 1 (SM1) .
Este metodo fue utilizado dado que Borowiak Dale S, menciona en su libro que este metodo se-cuencial tiene mas ventaja sobre el metodo secuencial 2 y el LSE, dado que es le mas potente paraseleccionar el modelo cuando se selecciona entre modelos internos, es decir aquellos que cumplencon tener SN (j), ademas que se menciona que el metodo secuencial 2 es mas edecuado cuando sonde interes dos o tres modelos.
Antes de realizar el metodo secuencial primero se realizara la prueba de falta de ajuste paraeliminar los modelos menos probables para modelar el comportamiento observado, notar que nopodemos aplicar las pruebas de falta de ajuste propuestas en la literatura por lo que se aplicarala prueba de falta de ajuste no con los errores puros, si no con creacion de subconjuntos de datos,los valores junto con RSS estan listados en la Tabla 5.47. Ninguno de los modelos tuvo una faltade ajuste serio, por tanto ninguno de los modelos sera eliminado. Por consiguiente, el conjunto demodelos competitivos es F = {f1, f2, f3, f4} .
Tabla 5.47: Falta de ajuste para los Modelos de Datos Medicos.f1 f2 f3 f4
RSS 1658.008 1538.403 1591.386 1537.304LOF .1 .1 0.202 0.629
Para la seleccion de las f(j), 1 ≤ j ≤ 4, se ranqueo con respecto al que maximize P (CS) , la

5.3. REALIZACION DE LAS PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION.69
Tabla 5.49 muestra todos los P (CS) y observamos que la secuencia que maximiza P (CS) esta dada
por f(1) = f3, f(2) = f4, f(3) = f1 y f(4) = f2. Entonces en el primer paso 2ATj Rj
(ATj Aj
)− 12
=
3.213827 > 0.6644409, de aqui eliminamos f3 y en el segundo paso 2ATj Rj
(ATj Aj
)− 12
= 1.673862 <
2.907512, por lo cual seleccionamos f4 de F, es decir, el modelo Logıstico resulto elegido del conjuntode modelos competitivos, lo cual es similar a los resultados obtenidos con el criterio de Akaike. Lasprobabilidades de seleccion son obtenidas al sustituir σ = 7.092797 en (4.31) y en (4.32). EntoncesP [IS (f4)] = 0.4813207 y P [CS (f4)] = 0.301456, donde podemos observar que la probabilidad deseleccionar correctamente el modelo es muy pequena esto debe ser debido a que los modelos son muyparecidos y como las pruebas nos indicaron es dificil discriminar entre ellos. Estos resultados noson tan buenos como se esperaban, dado que P [IS (f1)] > P [CS (f1)] , esto se debe posiblementea los resultados obtenidos en la prueba de Williams y la prueba tilde de Atkinson. Dado que estaspruebas concluyeron que no hay suficiente evidencia para poder discriminar entre los modelos.
Tabla 5.48: Procedimiento SM1.
fj 2ATj Rj
(ATj Aj
)− 12
dj Decision
Paso 1 f3 3.213827 0.6644409 Eliminamos f3
Paso 2 f4 1.673862 2.907512 Seleccionamos f4
5.3.2 Aplicacion del Metodo LSE.
La aplicacion del metodo LSE se sencillo ya que fj ∈ F si el evento (4.20) ocurre. Los calculos seque obtuvo son presetados en las siguientes Tablas
De la Tabla 5.50 podemos concluir que el modelo cuadratico no es elegido dado que ninguno delos tres eventos cumplio con el evento (4.20).
De la Tabla 5.51 podemos concluir de forma analoga que el modelo cubico no es elegido dadoque para el modelo logıstico no se cumple el evento (4.20).
De la Tabla 5.52 podemos concluir que el modelo gompertz no es elegido dado que solo el modelocuadratico cumplio con el evento (4.20).
De la Tabla 5.53 podemos observar que el modelo Logıstico cumple con el evento (4.20),portanto del conjunto de modelos competitivos este es el modelo seleccionado por el metodo LSE paradescribir mas adecuadamente el comportamiento de DBP vs Gest, y la probabilidad de seleccionarcorrectamente el modelo Logıstico es de 0.818398.
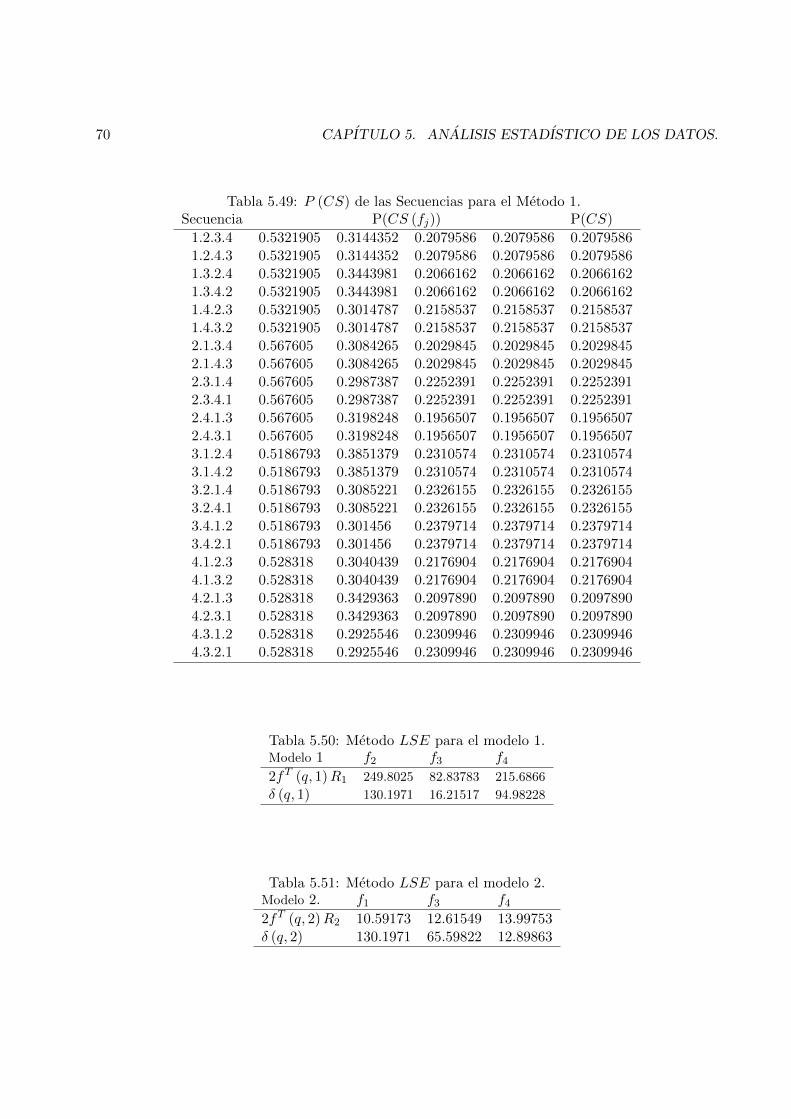
70 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.
Tabla 5.49: P (CS) de las Secuencias para el Metodo 1.Secuencia P(CS (fj)) P(CS)
1.2.3.4 0.5321905 0.3144352 0.2079586 0.2079586 0.20795861.2.4.3 0.5321905 0.3144352 0.2079586 0.2079586 0.20795861.3.2.4 0.5321905 0.3443981 0.2066162 0.2066162 0.20661621.3.4.2 0.5321905 0.3443981 0.2066162 0.2066162 0.20661621.4.2.3 0.5321905 0.3014787 0.2158537 0.2158537 0.21585371.4.3.2 0.5321905 0.3014787 0.2158537 0.2158537 0.21585372.1.3.4 0.567605 0.3084265 0.2029845 0.2029845 0.20298452.1.4.3 0.567605 0.3084265 0.2029845 0.2029845 0.20298452.3.1.4 0.567605 0.2987387 0.2252391 0.2252391 0.22523912.3.4.1 0.567605 0.2987387 0.2252391 0.2252391 0.22523912.4.1.3 0.567605 0.3198248 0.1956507 0.1956507 0.19565072.4.3.1 0.567605 0.3198248 0.1956507 0.1956507 0.19565073.1.2.4 0.5186793 0.3851379 0.2310574 0.2310574 0.23105743.1.4.2 0.5186793 0.3851379 0.2310574 0.2310574 0.23105743.2.1.4 0.5186793 0.3085221 0.2326155 0.2326155 0.23261553.2.4.1 0.5186793 0.3085221 0.2326155 0.2326155 0.23261553.4.1.2 0.5186793 0.301456 0.2379714 0.2379714 0.23797143.4.2.1 0.5186793 0.301456 0.2379714 0.2379714 0.23797144.1.2.3 0.528318 0.3040439 0.2176904 0.2176904 0.21769044.1.3.2 0.528318 0.3040439 0.2176904 0.2176904 0.21769044.2.1.3 0.528318 0.3429363 0.2097890 0.2097890 0.20978904.2.3.1 0.528318 0.3429363 0.2097890 0.2097890 0.20978904.3.1.2 0.528318 0.2925546 0.2309946 0.2309946 0.23099464.3.2.1 0.528318 0.2925546 0.2309946 0.2309946 0.2309946
Tabla 5.50: Metodo LSE para el modelo 1.Modelo 1 f2 f3 f4
2fT (q, 1)R1 249.8025 82.83783 215.6866
δ (q, 1) 130.1971 16.21517 94.98228
Tabla 5.51: Metodo LSE para el modelo 2.Modelo 2. f1 f3 f4
2fT (q, 2)R2 10.59173 12.61549 13.99753δ (q, 2) 130.1971 65.59822 12.89863

5.3. REALIZACION DE LAS PRUEBAS DE HIPOTESIS Y METODOS DE DISCRIMINACION.71
Tabla 5.52: Metodo LSE para el modelo 3.Modelo 3 f1 f2 f4
2fT (q, 3)R3 −50.40748 118.5810 88.94101δ (q, 3) 16.21517 65.59822 34.85935
Tabla 5.53: Metodo LSE para el modelo 4.Modelo 4 f1 f2 f3
2fT (q, 4)R4 −25.72201 11.79973 −19.22225δ (q, 4) 94.98228 12.89863 34.85938

72 CAPITULO 5. ANALISIS ESTADISTICO DE LOS DATOS.

Capıtulo 6
Conclusiones y Comentarios.
Este capıtulo esta dedicado presentar algunas conclusiones generales sobre el analisis desarrolladoa lo largo de este trabajo. Ası mismo, se discuten algunos de los aspectos observados en la seleccionde modelos de un conjunto de modelos propuestos con base a los resultados obtenidos.
Las conclusiones con respecto al analisis realizado a los datos observados de bioquımica podemosconcluir que ambos modelos propuestos son adecuados para los datos, pero al considerar el criteriode informacion de Akaike podemos concluir que el modelo mas apropiado para describir a todos lostratamientos es el modelo Gompertz. Esto nos da mucha informacion dado que si solo se hubieseusado el criterio de informacion de Akaike, no se hubiese podido concluir que ambos modelos sonadecuados para el comportamiento observado, y el AIC nos proporciono cual de los dos modelos esel mas apropiado para describir a la gran mayorıa de tratamientos realizados. Con respecto a laspruebas de hipotesis de Davidson y MacKinnon podemos decir que son bastante adecuados parausarse cuando solo se tiene dos modelos para el fenomeno observado y que su utilizacion es bastantesencilla en comparacion con los metodos de discriminacion.
Con respecto a predecir el peso de los fetos al nacer como se observo en el analisis de correlacion yen los graficos no es evidente como poder predecir el peso de nacimiento de los fetos con las variablespropuestas en la tesis, y como se observo las ecuaciones propuestas fueron pobres en prediccion delpeso de nacimiento debido a que la gran mayorıa de las ecuaciones tienen un R2 por debajo del 7%de variabilidad descrita por el modelo, tambien cabe recordar que se considero el paper de Hirata enel cual se obtuvo el mismo resultado obtenido para fetos con macrosomıa, las relaciones funcionalessignificativas contienen a las variables diametro abdominal y longitud del femur. En conclusion, aligual que en el paper de Hirata, al tratar de predecir el peso de nacimiento de un feto, las mejoresestimaciones se obtienen con modelos que utilicen la circunferencia abdominal y la longitud defemur, en este caso podemos decir que sin importar si el feto presenta macrosomıa o no. Esto noslleva a pensar que el poder predecir el peso de nacimiento necesita de mas informacion del feto yquizas de la madre, ası como tambien un tipo de analisis estadıstico distinto al utilizado en la tesis,si el objetivo es el mismo, tratar de predecir el peso de nacimiento con medidas ultrasonograficas.Dado todo lo anterior nuestro objetivo de comparar la ecuacion de Rossavick con nuestro modelopropuesto, no podra llevarse a cabo debido a que no se encontro un modelo lo suficientementebueno para competir con el modelo de Rossavick.
De acuerdo a lo observado con el criterio de informacion de Akaike y el criterio de informacionBayesiano, concluimos que el modelo mas adecuado para la relacion funcional entre el diametrobiparietal y la edad gestional fue el modelo Logıstico, aunque la diferencias entre los valores fue
73

74 CAPITULO 6. CONCLUSIONES Y COMENTARIOS.
muy pequena, esto nos lleva a intuir que los modelos son todos bastante adecuados para dicharelacion funcional.
Con respecto a la aplicacion del metodo secuencial 1, podemos concluir que es un metodosuficientemente util para elegir el modelo mas adecuado al comportamiento del fenomeno, ademasque se puede obtener una probabilidad que nos evalua la eleccion que se realice, en este trabajose encontro que el modelo mas adecuado para la relacion entre DBP y la edad gestional es elmodelo logıstico y ademas se obtuvo que la probabilidad de seleccionar este modelo como correctofue de 0.301456, esta probabilidad tan baja se obtuvo debido a que los cuatro modelos resultaronser adecuados al comportamiento observado, esto nos dice que muestras mas adecuados sean todoslos modelos propuestos mas difıcil es seleccionar el modelo mas competitivo o adecuado para elfenomeno observado, esto se pudo concluir gracias a las pruebas de hipotesis para aplicadas paradeterminar si los modelos estan muy cercanos para poder discriminar.
De forma analoga a los dos metodos anteriores, en el metodo LSE se obtuvo el mismo resultadode que el modelo Logıstico es el mas adecuado para modelar la relacion funcional entre DBP yGest.
En conclusion para los datos medicos podemos asegurar que el modelo mas adecuado es elmodelo Logıstico, debido a que todos los criterios usados dieron el mismo resultado.
Como conclusion para poder discriminar de un conjunto de modelos competitivos considero quesi es posible, tratar tener solo dos modelos competitivos ya que el tener muchos modelos complica, elpoder discriminar cual de todos es el mas adecuado, pero si no hay remedio de tener k = 2 modelos,considero que serıa conveniente usar mas de un metodo para poder discernir cual es el modelo masadecuado, mas si los modelos propuestos todos son adecuados para describir el comportamientoobservado, pero el primer metodo que se recomienda por su facil aplicacion el criterio de informacionde Akaike o Bayesiano de acuerdo a la situacion, para tener una idea rapida del ranqueo posiblede los modelos y luego aplicar un metodo que nos pueda evaluar la probabilidad de realizar unaseleccion correcta del modelo.

Bibliografıa
[1] Bates D.M. and Watts D.G (1988). Nonlinear Regression Analysis and its Applications, JonhWiley and Sons.
[2] Borowiak Dale S. (1989), Model Discrimination for Nonlinear Regression Models, New York:Marcel Dekker, INC.
[3] Davidson, R., and J. G. MacKinnon (1981). “Several tests for model specificationin the pres-ence of alternative hypotheses,” Econometrica, 49, 781− 793.
[4] Rusell Davidson and James G. MacKinnon. Econometric Theory and Methods.
[5] Garcıa Parra Marıa Dolores (2009). Estudio del crecimiento y produccion de nisina A, porLactococcus Lactis UQ− 2 en leche descremada.
[6] Hirata G; Medearis A; Horenstein J;: Bear M; Platt L. Estimacion ultrasonografica del pesoen el feto clinicamente macrosomico. Am J Obstet Gynecol, 1990; 162 : 238− 242.
[7] Gallant A. Ronald (1987), Nonlinear Statistical Models, New York: Jonh Willey.
[8] Greene William H, (2003) Econometric Analysis, New Jersey: Printice Hall.
[9] Jerzy Szroeter (1999), Testing Non-Nested Econometric Models. The current State of economicScience.
[10] Ratkowsky David A. (1983) . Nonlinear Regression Modeling A Unified Practical Approach,New York: Dekker.
[11] Russell L. Deter, Ivar K. Rossavik and Ronald B. Harrist, (May 1988) , Development of Indi-vidual Growth Curve Standards for Estimated Fetal Weight: I. Weight Estimation Procedure.J Clin Ultrasound 16 : 215− 225.
[12] Russell L. Deter and Ivar K. Rossavik, (1987), A simplified Method for Determining IndividualGrowth Curve Standards, Obstetrics & Gynecology.
[13] Seber George Arthur Frederck and Wild C.J (2003) , Nonlinear Regression, New York: JonhWiley.
75

76 BIBLIOGRAFIA

Apendice A
Metodo de Gauss-Newton.
El algoritmo de Gauss-Newton se utiliza para resolver problemas no lineales de mınimos cuadrados.Es una modificacion del metodo de optimizacion de Newton que no usa segundas derivadas y sedebe a Carl Friedrich Gauss.
Consideremos un modelo no lineal de la forma
Yn = f (xn, θ) + εn
en donde θ es el parametro a estimar, εn es el error con media 0 y varianza σ2. En forma matricialesta dada por
Y = f (X, θ) + ε (A.1)
Donde:
1. Y = [Y1, ..., Yn]T
2. X = [x1, ..., xn]T
3. E (ε) = 0, E(ε′ε)
= Iσ2.
El objetivo es minimizar la suma de cuadrados de los residuales para encontrar los estimadores:
S (θ) = [Y − f (X, θ)]′[Y − f (X, θ)]
Al derivar con respecto a θ, tendremos
∂S (θ)
∂θ= −2
∂f (X, θ)′
∂θ[Y − f (X, θ)] = 0
donde ∂f(X,θ)′
∂β es el jacobiano de f (X, θ) . Al usar la aproximacion a traves de el desarrollo de laserie de taylor de primer orden alrededor del punto inicial β1, tendremos
f (xi, θ) ≈ f (xi, θ1) +
[∂f (xi, θ)
∂θ|θ1 · · ·
∂f (xi, θ)
∂θ|θp]
(θ − θ1)
En forma matricial:f (X, θ) ≈ f (X, θ1) + Z (θ1) (θ − θ1)
77

78 APENDICE A. METODO DE GAUSS-NEWTON.
donde Z (θ1) = ∂f(X,θ)∂θ |θ1 , si sustituimos esta aproximacion en (A.1) obtenemos
Y ≈ f (X, θ1) + Z (θ1) (θ − θ1) + ε
si definimos Y (θ1) = Y − f (X, θ1) + Z (θ1) θ1, obtenemos un pseudomodelo lineal, de la forma
Y (θ1) = Z (θ1) θ + ε
Por mınimos cuadrados ordinarios, ya que el modelo es lineal, obtenemos un segundo valor para θ :
θ2 =[Z (θ1)T Z (θ1)
]−1Z (θ1)
′Y (θ1)
Al continuar el proceso de manera iterativa, se llegara a la estimacion n+ 1 dado por
θn+1 =[Z (θn)T Z (θn)
]−1Z (θn)
′Y (θn)
=[Z (θn)T Z (θn)
]−1Z (θn)T [Y − f (X, θn) + Z (θn) θn]
= θn +[Z (θn)T Z (θn)
]−1Z (θn)
′[Y − f (X, θn)]
Una vez alcanzado el valor por medio del proceso iterativo anteriormente descrito, falta deter-minar si el valor alcanzado corresponde realmente a un mınimo (0 si el valor es un maximo), si esası, si este mınimo es de caracter global o local.
Para tratar de maximizar las posibilidades de que se trata de un mınimo absoluto y no tan solode un mınimo local, una de las practicas habituales consiste en utilizar el algoritmo para diferentesvalores inıciales de θ. Para los distintos valores inıciales, podemos obtener distintos mınimos dela funcion, el mınimo que corresponde a la menor suma de cuadrados de los residuales sera elestimador del parametro por mınimos cuadrados no lineales.
El algoritmo por si solo no puede conducir en direccion a un maximo, ya que si partimos de
∂S (θ)
∂θ= −2
∂f (X, θ)′
∂θ[Y − f (X, θ)]
= −2Z (θ)′[Y − f (X, θ)]
= 0
entonces para la estimacion n+ 1 de θ se puede expresar como:
θn+1 = θn +[Z (θn)T Z (θn)
]−1Z (θn)
′[Y − f (X, θn)]
= θn +1
2
[Z (θn)T Z (θn)
]−1 ∂S (θ)
∂θ|θn
Dado que[Z (θn)T Z (θn)
]−1sera siempre positiva debido a que es una funcion cuadratica, se
comienza el procedimiento con un valor inicial de θ situado a la derecha de un mınimo, la pendientede la funcion a minimizar S (θ) sera positiva, por lo cual el algoritmo conducira en la direccioncorrecta, es decir al mınimo de la funcion. Ahora si se comienza con un valor inicial de θ situadoa la izquierda de un mınimo, la pendiente de S (θ) sera negativa, por lo cual el cambio en θ serapositivo y nuevamente nos moveremos hacia un mınimo.

Apendice B
Graficas de Datos Experimentales.
B.1 Graficas del Ajuste del modelo Gompertz.
B.2 Graficas de Ajuste del Modelo Logıstico.
79
80 APENDICE B. GRAFICAS DE DATOS EXPERIMENTALES.
Trat 1. Trat 2
Trat 3. Trat 4
Trat 5. Trat 6
Trat 7. Trat 8
Figura B.1: Graficos del Modelo Gompertz
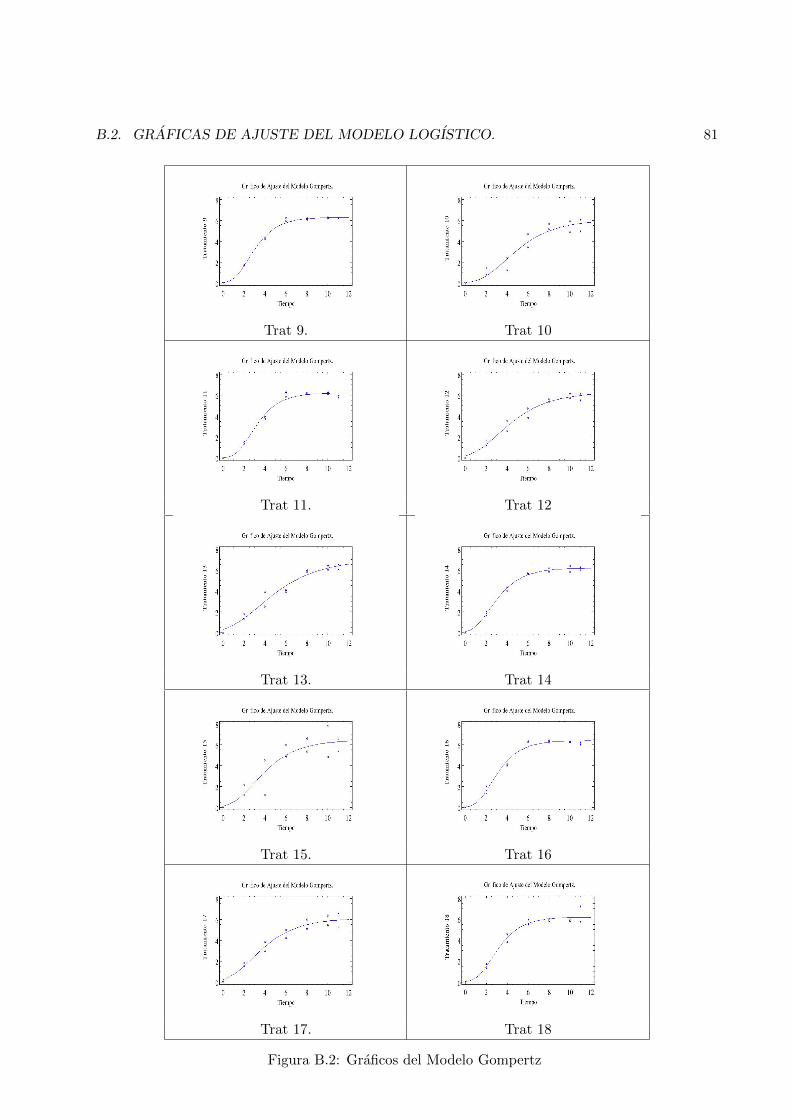
B.2. GRAFICAS DE AJUSTE DEL MODELO LOGISTICO. 81
Trat 9. Trat 10
Trat 11. Trat 12
Trat 13. Trat 14
Trat 15. Trat 16
Trat 17. Trat 18
Figura B.2: Graficos del Modelo Gompertz
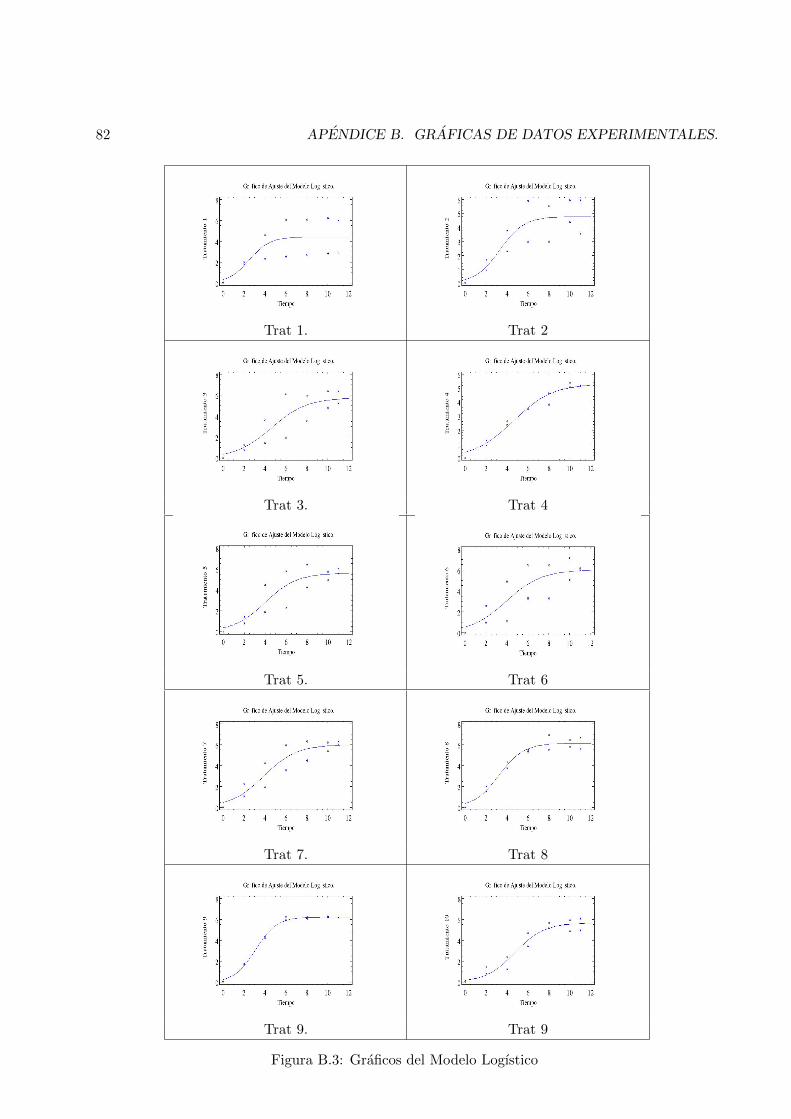
82 APENDICE B. GRAFICAS DE DATOS EXPERIMENTALES.
Trat 1. Trat 2
Trat 3. Trat 4
Trat 5. Trat 6
Trat 7. Trat 8
Trat 9. Trat 9
Figura B.3: Graficos del Modelo Logıstico
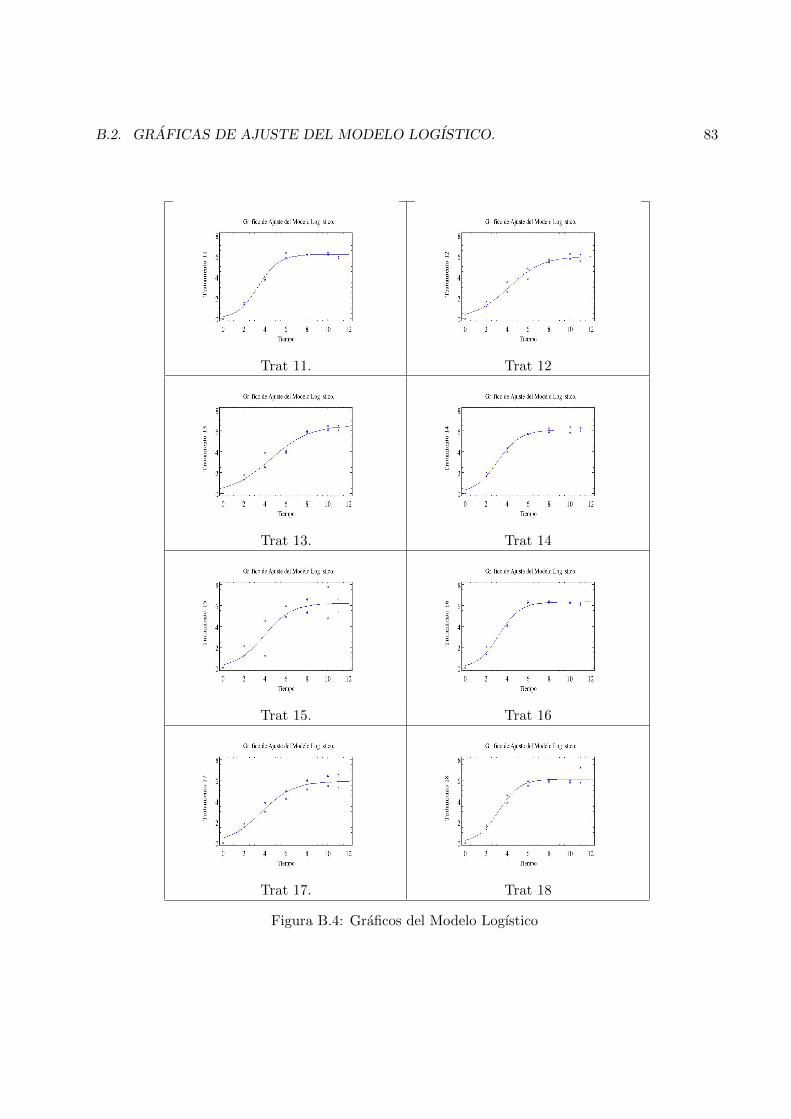
B.2. GRAFICAS DE AJUSTE DEL MODELO LOGISTICO. 83
Trat 11. Trat 12
Trat 13. Trat 14
Trat 15. Trat 16
Trat 17. Trat 18
Figura B.4: Graficos del Modelo Logıstico

84 APENDICE B. GRAFICAS DE DATOS EXPERIMENTALES.

Apendice C
Teorema de Frisch-Waugh-Lovell.
1. Los estimadores de mınimos cuadrado de β2 de las regresiones
y = X1β1 +X2β2 + u (C.1)
y
M1y = M1X2β2 + residuales (C.2)
son numericamente identicos
2. Los residuales de las regresiones de (C.1) y (C.2) son numericamente identicos.
Demostracion.
El estimador de β2 de (C.2) , esta dado por
β2 =(XT
2 M1X2
)−1XT
2 M1y
Sean β1 y β2 los dos vectores de estimadores de mınimos cuadrados de (C.1). Entonces si X =[X1 X2]
y = Iy
= (PX +MX)
= PXy +MXy
= Xβ +MXy
= X1β1 +X2β2 +MXy
85

86 APENDICE C. TEOREMA DE FRISCH-WAUGH-LOVELL.
Si multiplicamos por ambos lados de la igualdad por XT2 M1 tenemos
y = X1β1 +X2β2 +MXy
XT2 M1y = XT
2 M1X1β1 +XT2 M1X2β2 +XT
2 M1MXy
= XT2 (1− PX1)X1β1 +XT
2 M1X2β2 +XT2 (1− PX1) (1− PX) y
= XT2
(1−X1
(XT
1 X1
)−1XT
1
)X1β1+XT
2 M1X2β2+XT2 (1−PX1−PX+PX1PX) y
= XT2
(X1−X1
(XT
1 X1
)−1XT
1 X1
)β1+XT
2 M1X2β2+XT2 (1−PX1−PX+PX1PX) y
= XT2 (X1 −X1I) β1 +XT
2 M1X2β2 +XT2 (1− PX1 − PX + PX1) y
= XT2 M1X2β2 +XT
2 (1− PX) y
= XT2 M1X2β2 +MXX2y
= XT2 M1X2β2
Despejando β2 obtenemos que
β2 =(XT
2 M1X2
)−1XT
2 M1y
El cual coincide con β2 de (C.2). Esto demuestra la primera parte del teorema.Para demostrar la segunda parte del teorema multiplicamos por M1 a la siguiente igualdad
y = X1β1 +X2β2 +MXy
Entonces
M1y = M1X1β1 +M1X2β2 +M1MXy
= 0 +M1X2β2 +MXy
= M1X2β2 +MXy (C.3)
Al comparar con (C.2) y (C.3), observamos que sus regresandos son iguales. Dado que β2 es elestimador de β2 de (C.2), por la primera parte del teorema, el primer termino de (C.3) es el vectorde valores ajustados de esta regresion. Entonces el segundo termino debe ser el vector de residualesde (C.2). Pero MXy es tambien el vector de residuales de (C.1) y esto demuestra la segunda partedel teorema.

Apendice D
Programas en R.
Como se cito antenriormente, el programa que se uso para programar las pruebas de hipotesis, losmetodos de informacion y los criterios de informacion fue el paquete R version 2.6.1 (2007-11-26).A continuacion se presenta una descripcion del contenido de este capıtulo. La primera seccionpresenta los modelos ajustados a los datos medicos, los cuales son; el modelo cubico, modelocuadratico, el modelo gompertz y el modelo Logıstico. En la siguiente seccion se programo loscriterios de informacion de Akaike y Bayesiano, posteriormente estan los programas para la pruebade Williams y la prueba tilde de Atkinson, ası como la prueba LSE, despues se encuentra la pruebapara verificar que no halla falta de ajuste en los modelos propuesto, posteriomente esta el programapara realizar el ranqueo de las probabilidades de una seleccion correcta para el metodo secuencial1 y luego esta el programa para realizar el metodo secuencial 1 y por ultimo esta el programa parael ajuste de los modelos propuestos para los datos de bioquımica junto con los programas, pararealizar las pruebas de hipotesis de Davidson y MacKinnon.
87

88 APENDICE D. PROGRAMAS EN R.
D.1 Ajuste de los modelos propuestos para los datos Medicos.
datos=read.csv(”datosmedicos.csv”,header=T,sep=”;”,na.string=”NA”)
gest=datos[,1]
DBP=datos[,2]
CIRCEF=datos[,3]
CIRABD=datos[,4]
LFemur=datos[,5]
PesoN=datos[,6]
###########################
#### Modelo Cubico ####
###########################
model3¡-nls(DBP˜a*gestˆ3+b*gest ˆ2+d, start=list(a=0,b=0,d=6))
summary(model3)
p.cubico=3
Predict.3 ¡- predict(model3)
residual.cubico=matrix(DBP-Predict.3,nrow=252,ncol=1,byrow=FALSE)
SSR.cubico=t(residual.cubico)%*%residual.cubico
##############################
#### Modelo Cuadratico ####
##############################
model.cuadratico¡-nls(DBP˜a*gestˆ2+b*gest+c, start=list(a=0,b=5,c=-30))
summary(model.cuadratico)
p.cuadratico=3
Predict.cuadratico ¡- predict(model.cuadratico)
residual.cuadratico=matrix(DBP-Predict.cuadratico,nrow=252,ncol=1,byrow=FALSE)
SSR.cuadratico=t(residual.cuadratico)%*%residual.cuadratico
##############################
#### Modelo Gompertz ####
##############################
model.gompertz¡-nls(DBP˜a*exp(-exp(b-c*gest)), start=list(a=110,b=0.1,c=0.1))
summary(model.gompertz)
p.gompertz=3
Predict.gompertz ¡- predict(model.gompertz)
residual.gompertz=matrix(DBP-Predict.gompertz,nrow=252,ncol=1,byrow=FALSE)
SSR.gompertz=t(residual.gompertz)%*%residual.gompertz
#############################
#### Modelo Logıstico ####
#############################
model.Logistico¡-nls(DBP˜a/(1+exp(b-c*gest)), start=list(a=100,b=2,c=0.1))
summary(model.Logistico)
p.Logistico=3
Predict.Logistico ¡- predict(model.Logistico)
residual.Logistico=matrix(DBP-Predict.Logistico,nrow=252,ncol=1,byrow=FALSE)
SSR.Logistico=t(residual.Logistico)%*%residual.Logistico

D.2. PROGRAMA PARA EL CRITERIO DE INFORMACION DE AKAIKE PARA DATOS MEDICOS.89
D.2 Programa para el Criterio de Informacion de Akaike paraDatos Medicos.
D.2.1 Calculo del estadıstico de Akaike.
AIC.cuadratico= -(1/2)*n*log(SSR.cuadratico)-p.cuadratico
AIC.cubico= -(1/2)*n*log(SSR.cubico)-p.cubico
AIC.gompertz= -(1/2)*n*log(SSR.gompertz)-p.gompertz
AIC.Logistico= -(1/2)*n*log(SSR.Logistico)-p.Logistico
AIC.cuadratico
AIC.cubico
AIC.gompertz
AIC.Logistico
modelo.AIC=max(AIC.cuadratico,AIC.cubico,AIC.gompertz,AIC.Logistico)
modelo.AIC
D.2.2 Calculo del estadıstico de Akaike Bayesiano.
BIC.cuadratico= -(1/2)*n*log(SSR.cuadratico)-(1/2)*p.cuadratico*log(n)
BIC.cubico= -(1/2)*n*log(SSR.cubico)-(1/2)*p.cubico*log(n)
BIC.gompertz= -(1/2)*n*log(SSR.gompertz)-(1/2)*p.gompertz*log(n)
BIC.Logistico= -(1/2)*n*log(SSR.Logistico)-(1/2)*p.Logistico*log(n)
BIC.cuadratico
BIC.cubico
BIC.gompertz
BIC.Logistico
modelo.BIC=max(BIC.cuadratico,BIC.cubico,BIC.gompertz,BIC.Logistico)
modelo.BIC
D.3 Programa para la Prueba tilde de Atkinson.
##############################
#### Regresion Multiple ####
##############################
model.multiple¡-lm(DBP˜f1+f2+f3+f4)
summary(model.multiple)
Predict.Multiple ¡- predict(model.multiple)
residual.Multiple=DBP-Predict.Multiple
SSR.Multiple=sum(residual.Multipleˆ2)
######################################
#### Construccion del estadıstico. ####
######################################
f1.1=matrix(f1,nrow=252,ncol=1,byrow=FALSE)
f2.1=matrix(f2,nrow=252,ncol=1,byrow=FALSE)
f3.1=matrix(f3,nrow=252,ncol=1,byrow=FALSE)

90 APENDICE D. PROGRAMAS EN R.
f4.1=matrix(f4,nrow=252,ncol=1,byrow=FALSE)DBP.1=matrix(DBP,nrow=252,ncol=1)→⊂Z.1=t(DBP.1)%*%f1.1-t(f1.1)%*%f1.1Z.2=t(DBP.1)%*%f2.1-t(f2.1)%*%f2.1Z.3=t(DBP.1)%*%f3.1-t(f3.1)%*%f3.1Z.4=t(DBP.1)%*%f4.1-t(f4.1)%*%f4.1Z=matrix(c(Z.1,Z.2,Z.3,Z.4),nrow=4,ncol=1,byrow=FALSE)m=c(f1,f2,f3,f4)length(m)x=matrix(m, nrow = 252, ncol = 4, byrow = FALSE)d=matrix(c(rep(1,4)),nrow=4,ncol=1)Q=t(Z)%*%solve(t(x)%*%x)%*%Z-((t(Z)%*%solve(t(x)%*%x)%*%d)
ˆ2)/(t(d)%*%solve(t(x)%*%x)%*%d)n=252k=4F.observado=((n-k)%*%Q)/((k-1)%*%SSR.Multiple)F.stat ¡- qf(p=0.95,df1=3,df2=249);
D.4 Programa de la Prueba de Willians.
########################################## Construccion del estadıstico. ##########################################m=c(f1,f2,f3,f4)length(m)x=matrix(m, nrow = 252, ncol = 4, byrow = FALSE)d=matrix(c(rep(1,4)),nrow=4,ncol=1)DBP.1=matrix(DBP,nrow=252,ncol=1)c=t(d)%*%solve(t(x)%*%x)%*%t(x)%*%DBP-1C=c(c,c,c,c)beta.gorro=(solve(t(x)%*%x))%*%(t(x)%*%DBP.1-C*d)f.x=x%*%beta.gorrof.bar ¡- apply(x,1,mean);residual.f.bar=DBP-f.barRSS.f.bar=sum(residual.f.barˆ2)residual.f.x=DBP-f.xRSS.f.x=sum(residual.f.xˆ2)n=252k=4F=((n-k+1)*(RSS.f.bar-RSS.f.x))/((k-1)*RSS.f.x)F.stat=qf(p=0.95,df1=3,df2=249)############################################# Calculos necesarios. #############################################f.1.2=matrix(f1-f2,nrow=252,ncol=1,byrow=FALSE)

D.4. PROGRAMA DE LA PRUEBA DE WILLIANS. 91
f.1.3=matrix(f1-f3,nrow=252,ncol=1,byrow=FALSE)
f.1.4=matrix(f1-f4,nrow=252,ncol=1,byrow=FALSE)
f.2.1=matrix(f2-f1,nrow=252,ncol=1,byrow=FALSE)
f.2.3=matrix(f2-f3,nrow=252,ncol=1,byrow=FALSE)
f.2.4=matrix(f2-f4,nrow=252,ncol=1,byrow=FALSE)
f.3.1=matrix(f3-f1,nrow=252,ncol=1,byrow=FALSE)
f.3.2=matrix(f3-f2,nrow=252,ncol=1,byrow=FALSE)
f.3.4=matrix(f3-f4,nrow=252,ncol=1,byrow=FALSE)
f.4.1=matrix(f4-f1,nrow=252,ncol=1,byrow=FALSE)
f.4.2=matrix(f4-f2,nrow=252,ncol=1,byrow=FALSE)
f.4.3=matrix(f4-f3,nrow=252,ncol=1,byrow=FALSE)
delta.1.2=t(f.1.2)%*%f.1.2
delta.1.3=t(f.1.3)%*%f.1.3
delta.1.4=t(f.1.4)%*%f.1.4
delta.2.1=t(f.2.1)%*%f.2.1
delta.2.3=t(f.2.3)%*%f.2.3
delta.2.4=t(f.2.4)%*%f.2.4
delta.3.1=t(f.3.1)%*%f.3.1
delta.3.2=t(f.3.2)%*%f.3.2
delta.3.4=t(f.3.4)%*%f.3.4
delta.4.1=t(f.4.1)%*%f.4.1
delta.4.2=t(f.4.2)%*%f.4.2
delta.4.3=t(f.4.3)%*%f.4.3
delta.1.2.3=sum((f2-f1)*(f3-f1))
delta.1.2.4=sum((f2-f1)*(f3-f1))
delta.1.3.2=sum((f3-f1)*(f2-f1))
delta.1.3.4=sum((f3-f1)*(f4-f1))
delta.1.4.2=sum((f4-f1)*(f2-f1))
delta.1.4.3=sum((f4-f1)*(f3-f1))
delta.2.1.3=sum((f1-f2)*(f3-f2))
delta.2.1.4=sum((f1-f2)*(f4-f2))
delta.2.3.1=sum((f3-f2)*(f1-f2))
delta.2.3.4=sum((f3-f2)*(f4-f2))
delta.2.4.1=sum((f4-f2)*(f1-f2))
delta.2.4.3=sum((f4-f2)*(f3-f2))
delta.3.1.2=sum((f1-f3)*(f2-f3))
delta.3.1.4=sum((f1-f3)*(f4-f3))
delta.3.2.1=sum((f2-f3)*(f1-f3))
delta.3.2.4=sum((f2-f3)*(f4-f3))
delta.3.4.1=sum((f4-f3)*(f1-f3))
delta.3.4.2=sum((f4-f3)*(f2-f3))
delta.4.1.2=sum((f1-f4)*(f2-f4))
delta.4.1.3=sum((f1-f4)*(f3-f4))
delta.4.2.1=sum((f2-f4)*(f1-f4))
delta.4.2.3=sum((f2-f4)*(f3-f4))

92 APENDICE D. PROGRAMAS EN R.
delta.4.3.1=sum((f3-f4)*(f1-f4))
delta.4.3.2=sum((f3-f4)*(f2-f4))
D.5 Calculo de la falta de ajuste.
t.cuadratico=SSR.cuadratico/var.gest
t.cubico=SSR.3/var.gest
t.gompertz=SSR.gompertz/var.gest
t.Logistico=SSR.Logistico/var.gest
p.cuadratico=1-pchisq(t.cuadratico, 252, ncp=0, lower.tail = TRUE, log.p = FALSE)
p.cubico=1-pchisq(t.cubico, 252, ncp=0, lower.tail = TRUE, log.p = FALSE)
p.gompertz=1-pchisq(t.gompertz, 252, ncp=0, lower.tail = TRUE, log.p = FALSE)
p.Logistico=1-pchisq(t.Logistico, 252, ncp=0, lower.tail = TRUE, log.p = FALSE)
D.6 Ranqueo de los modelos con P(CS)
Para sacar las probabilidades del ranqueo del modelo , las letras m, j, k y ` toman los valores 1, 2,3 y 4. Recuerde que no se puden tener valores repetidos en las letras, es decir, no se puede sacarlas probabilidades de la secuencia 1.3.3.4.
### m.j.k.`
g.1=c(f.j.m,f.k.m,f.`.m) # Paso 1
length(g.1)
G.1=matrix(g.1,nrow=252,ncol=3)
d=matrix(rep(1,3),nrow=3,ncol=1,byrow=FALSE)
A.1=G.1%*%solve(t(G.1)%*%G.1)%*%d
d.1=(t(d)%*%solve(t(G.1)%*%G.1)%*%d)ˆ(-1/2)
w.1=d.1/(2*sigma)
P.CS.1=pnorm(w.1)
P.CS.1
P.IS.1=1-pnorm(w.1.1)
P.IS.1
g.2=c(f.k.j,f.`.j) # Paso 2
G.2=matrix(g.j,nrow=252,ncol=2)
d=matrix(rep(1,2),nrow=2,ncol=1,byrow=FALSE)
A.2=G.2%*%solve(t(G.2)%*%G.2)%*%d
d.2=(t(d)%*%solve(t(G.2)%*%G.2)%*%d)ˆ(-1/2)
w.2=d.2/(2*sigma)
P.CS.2=pnorm(w.1)*pnorm(w.2)
P.CS.2
g.3=c(f.`.k) # Paso 3
G.3=matrix(g.3,nrow=252,ncol=1)
d=matrix(rep(1,1),nrow=1,ncol=1,byrow=FALSE)
A.3=G.3%*%solve(t(G.3)%*%G.3)%*%d
d.3=(t(d)%*%solve(t(G.3)%*%G.3)%*%d)ˆ(-1/2)

D.7. METODO SECUENCIAL 1. 93
w.3=d.3/(2*sigma)
P.CS.3=pnorm(w.1)*pnorm(w.2)*pnorm(w.3)
P.CS.3
D.7 Metodo Secuencial 1.
D.7.1 Paso 1
g.1=c(f.1.3,f.2.3,f.4.3)
G.1=matrix(g.1,nrow=252,ncol=3)
d=matrix(rep(1,3),nrow=3,ncol=1,byrow=FALSE)
A.1=G.1%*%solve(t(G.1)%*%G.1)%*%d
d.1=(t(d)%*%solve(t(G.1)%*%G.1)%*%d)ˆ(-1/2)
h.1=2*t(A.1)%*%residual.cubico/((t(A.1)%*%A.1)ˆ(1/2))
### Construccion del B.1.1 y B.1.2
t(f.1.3)%*%A.1
t(f.2.3)%*%A.1
t(f.4.3)%*%A.1
alpha.1=d.1/(2*sigma)
xi.1=alpha.1
#beta.1=infinito
### Nota: Para este caso tenemos que B.1.1 es vacio por tanto el limite
### inferior es infinito y el limite superior es el maximo de las
### d.i en este caso es 0.6644409.
### Nota: El resultado obtenido es que h.1=3.213827 por tanto el modelo
### es rechazado.
D.7.2 Paso 2
g.2=c(f.1.4,f.2.4)
G.2=matrix(g.2,nrow=252,ncol=2)
d=matrix(rep(1,2),nrow=2,ncol=1,byrow=FALSE)
A.2=G.2%*%solve(t(G.2)%*%G.2)%*%d
d.2=(t(d)%*%solve(t(G.2)%*%G.2)%*%d)ˆ(-1/2)
h.2=2*t(A.2)%*%residual.Logistico/((t(A.2)%*%A.2)ˆ(1/2))
### Construccion del B.1.1 y B.1.2
t(f.1.4)%*%A.2
t(f.2.4)%*%A.2
alpha.2=d.2/(2*sigma)
xi.2=alpha.2
#beta.2=infinito
### Nota: Para este caso tenemos que B.1.1 es vacio por tanto el limite
### inferior es infinito y el limite superior es el maximo de las
### d.2 en este caso es 2.907512.
### Nota: El resultado obtenido es que h.2=1.673862 por tanto el modelo

94 APENDICE D. PROGRAMAS EN R.
### es aceptado.################################################# Probabilidades de seleccion. ##################################################### P(CS(f.(4)))P.CS=pnorm(d.1/(2*sigma))*pnorm(d.2/(2*sigma))P.CS#### P.ISp.1=pnorm(d.1/(2*sigma),lower.tail = FALSE)p.2=pnorm(d.2/(2*sigma),lower.tail = FALSE)*pnorm(d.1/(2*sigma))P.IS=max(p.1,p.2)P.IS#### Nota: Del teorema 2.4.2 tenemos que P.IS=0.4813207#### y P.CS= 0.301456. Podemos ver que la pobrabilidad P.CS es muy pequena.
D.8 Programa para el Metodo LSE.
########################### Modelo 1 ###########################e.1.2=2*t(f.2.1)%*%residual.cuadraticoe.1.3=2*t(f.3.1)%*%residual.cuadraticoe.1.4=2*t(f.4.1)%*%residual.cuadraticoe.1.2e.1.3e.1.4delta.2.1delta.3.1delta.4.1#### Nota: el modelo cuadratico no es elegido dado que no ninguno cumple con 2f.q.1*R.1¡delta.q.1########################### Modelo 2 ###########################e.2.1=2*t(f.1.2)%*%residual.cubicoe.2.3=2*t(f.3.2)%*%residual.cubicoe.2.4=2*t(f.4.2)%*%residual.cubicoe.2.1e.2.3e.2.4delta.1.2delta.3.2delta.4.2 #### Nota: tampoco el modelo cubico no es elegido########################### Modelo 3 ###########################

D.9. AJUSTE DE LOS MODELOS PROPUESTOS PARA LOS DATOS DE BIOQUIMICA. 95
e.3.1=2*t(f.1.3)%*%residual.gompertze.3.2=2*t(f.2.3)%*%residual.gompertze.3.4=2*t(f.4.3)%*%residual.gompertze.3.1e.3.2e.3.4delta.1.3delta.2.3delta.4.3#### Nota: tampoco el modelo gompertz es seleccionado.########################### Modelo 4 ###########################e.4.1=2*t(f.1.4)%*%residual.Logisticoe.4.2=2*t(f.2.4)%*%residual.Logisticoe.4.3=2*t(f.3.4)%*%residual.Logisticoe.4.1e.4.2e.4.3delta.1.4delta.2.4delta.3.4#### Nota: El modelo Logistico cumple con el evento por lo tanto es el modelo selec-
cionado del conjunto de modelos competitivos.######################################### Probabilidades de seleccion #########################################p.1=1-pnorm((delta.4.1)/(2*sigma))p.2=1-pnorm((delta.4.2)/(2*sigma))p.3=1-pnorm((delta.4.3)/(2*sigma))P.IS.Logistico=max(p.1,p.2,p.3)P.IS.Logisticop.1=pnorm((delta.4.1)/(2*sigma))p.2=pnorm((delta.4.2)/(2*sigma))p.3=pnorm((delta.4.3)/(2*sigma))P.CS.Logistico=min(p.1,p.2,p.3)P.CS.Logistico
D.9 Ajuste de los modelos propuestos para los datos de bioquımica.
datos=read.csv(”datosbioquimicos.csv”,header=T,sep=”;”,na.string=”NA”)Tiempo=datos[,1]Trat.1=datos[,2]Trat.2=datos[,3]Trat.3=datos[,4]

96 APENDICE D. PROGRAMAS EN R.
Trat.4=datos[,5]
Trat.5=datos[,6]
Trat.6=datos[,7]
Trat.7=datos[,8]
Trat.8=datos[,9]
Trat.9=datos[,10]
Trat.10=datos[,11]
Trat.11=datos[,12]
Trat.12=datos[,13]
Trat.13=datos[,14]
Trat.14=datos[,15]
Trat.15=datos[,16]
Trat.16=datos[,17]
Trat.17=datos[,18]
Trat.18=datos[,19]
var=var(Tiempo)
sigma=sqrt(var)
D.9.1 Modelo Gompertz
Para realizar el ajuste del modelo Gompertz hay que correr el programa para los 18 tratamientos,es decir, i = 1, ...18. Tener cuidado con los puntos inciales para los parametros, estos varian detratamiento a tratamiento.
model.gompertz.trat.i¡-nls(Trat.i˜a*exp(-exp(b-c*Tiempo)), start=list(a=4,b=1,c=0.1))
summary(model.gompertz.trat.i)
p.gompertz=3
Predict.gompertz.trat.i ¡- predict(model.gompertz.trat.i)
residual.gompertz.trat.i=matrix(Trat.i-Predict.gompertz.trat.i,nrow=14,ncol=1,byrow=FALSE)
SSR.gompertz.trat.i=t(residual.gompertz.trat.i)%*%residual.gompertz.trat.i
a.g.i=4.4836 # Estos parametros son los obtenidos de ajuste del modelo logıstico acada tramiento.
b.g.i=1.2750
c.g.i=0.6859
D.9.2 Modelo Logıstico
Para realizar el ajuste del modelo Logıstico hay que correr el programa para los 18 tratamientos,es decir, i = 1, ...18. Tener cuidado con los puntos inciales para los parametros, estos varian detratamiento a tratamiento.
model.Logistico.trat.i¡-nls(Trat.i˜a/(1+exp(b-c*Tiempo)), start=list(a=5,b=2,c=1))
summary(model.Logistico.trat.i)
p.Logistico=3
Predict.Logistico.trat.i ¡- predict(model.Logistico.trat.i)
residual.Logistico.trat.i=matrix(Trat.i-Predict.Logistico.trat.i,nrow=14,ncol=1,byrow=FALSE)
SSR.Logistico.trat.i=t(residual.Logistico.trat.i)%*%residual.Logistico.trat.i

D.10. PROGRAMA DEL CRITERIO DE INFORMACION DE AKAIKE (DATOS BIOQUIMICA).97
a.l.i=4.4302 # Estos parametros son los obtenidos de ajuste del modelo logıstico a cadatramiento.
b.l.i=2.4822c.l.i=0.9944
D.10 Programa del Criterio de Informacion de Akaike (Datosbioquımica).
Para realizar Criterio de Informacion de Akaike hay que correr el programa para los 18 tratamientos,es decir, i = 1, ...18.
AIC.gompertz.trat.i= -(1/2)*n*log(SSR.gompertz.trat.i)-p.gompertzAIC.Logistico.trat.i= -(1/2)*n*log(SSR.Logistico.trat.i)-p.LogisticoAIC.trat.i=max(AIC.gompertz.trat.i,AIC.Logistico.trat.i)AIC.gompertz.trat.iAIC.Logistico.trat.iAIC.trat.i
D.11 Programa de las pruebas de hipotesis de Davidson y MacK-innon.
Para realizar las pruebas de hipotesis de Davidson y MacKinnon hay que correr el programa paralos 18 tratamientos, es decir, i = 1, ...18.
#### H0: modelo Gompertz H1: Modelo Logistico. Tratamiento i.d.f.alpha=exp(-exp(b.g.i-c.g.i*Tiempo))d.f.beta=-a.g.i*exp(-exp(b.g.i-c.g.i*Tiempo))*exp(b.g.i-c.g.i*Tiempo)d.f.gamma=a.g.i*Tiempo*exp(-exp(b.g.i-c.g.i*Tiempo))*exp(b.g.i-c.g.i*Tiempo)q=c(d.f.alpha,d.f.beta,d.f.gamma)F=matrix(q,ncol=3,nrow=14,byrow=FALSE)I=matrix(rep(1,196),ncol=14,nrow=14,byrow=TRUE)M=I-F%*%solve(t(F)%*%F)%*%t(F)numerador=t(Trat.i-Predict.gompertz.trat.i)%*%t(M)%*
%(Predict.Logistico.trat.i-Predict.gompertz.trat.i)denominador=sigma*sqrt(t(Predict.Logistico.trat.i-Predict.gompertz.trat.i)%*%t(M)
%*%(Predict.Logistico.trat.i-Predict.gompertz.trat.i))estadistico.t=numerador/denominadorp.valor=pt(estadistico.t, df=11, lower.tail = TRUE, log.p = FALSE)p.valor######################################
H0: modelo Logistico H1: Modelo Gompertz. Tratamiento 1.d.f.alpha=1/(1+exp(b.l.i-c.l.i*Tiempo))d.f.beta=-a.l.i*exp(b.l.i-c.l.i*Tiempo)/((1+exp(b.l.i-c.l.i*Tiempo))ˆ2)d.f.gamma=a.l.i*Tiempo*exp(b.l.i-c.l.i*Tiempo)/((1+exp(b.l.i-c.l.i*Tiempo))ˆ2)q=c(d.f.alpha,d.f.beta,d.f.gamma)F=matrix(q,ncol=3,nrow=14)

98 APENDICE D. PROGRAMAS EN R.
I=matrix(rep(1,196),ncol=14,nrow=14,byrow=TRUE)M=1-F%*%solve(t(F)%*%F)%*%t(F)numerador=t(Trat.i-Predict.Logistico.trat.i)%*%t(M)%*
%(Predict.gompertz.trat.i-Predict.Logistico.trat.i)denominador=sigma*sqrt(t(Predict.gompertz.trat.i-Predict.Logistico.trat.i)%*%t(M)%*%
(Predict.gompertz.trat.i-Predict.Logistico.trat.i))estadistico.t=numerador/denominadorp.valor=pt(estadistico.t, df=11, lower.tail = TRUE, log.p = FALSE)p.valor