presentada al consejo de la . facultad de ciencias...
TRANSCRIPT

UNIVERSIDAD RAFAEL LANDIVAR FACULTAD DE CIENCIAS ECONOMICAS y EMPRESARIALES
DEPARTAMENTO DE INFORMATICA
EL USO DE LA ABSTRACCION, AGREGACION y LA HERENCIA COMO TECNICA PARA EL ANALlSIS y DISEÑO DE SISTEMAS
TESIS
Presentada al Consejo de la . Facultad de Ciencias Económicas y Empresariales
Por:
BYRON ALEJANDRO SOLORZANO GARCIA
Previo a conferírsele el Título de
LICENCIADO EN INFORMATICA
Guatemala, noviembre de 2001

Tradición]esuita en Guatemala
AUTORIDADES DE LA UNIVERSIDAD RAFAEL LANDíVAR
RECTOR LIC. GONZALO DE VILLA, S.J.
VICE-RECTOR ACADÉMICO L1CDA. JULIA GUILLERMINA HERRERA PEÑA
VICE-RECTOR ADMINISTRATIVO DR. HUGO EDUARDO BETET A
SECRETARIO GENERAL LIC. RENZO LAUT ARO ROSAL
CONSEJO DE LA FACULTAD DE CIENCIAS ECONÓMICAS
DECANO LIC. JOSE ALEJANDRO ARÉVALO
VICEDECANO L1CDA. L1GIA GARCíA
SECRETARIO L1CDA. ANNABELLA DE MOTT A
DIRECTOR DEL DEPARTAMENTO DE ADMINISTRACiÓN LlCDA. PATRICIA BARANELLO
DIRECTORA DEL DEPARTAMENTO DE ECONOMíA Y COMERCIO INTERNACIONAL L1CDA. L1GIA GARCíA
DIRECTOR DEL DEPARTAMENTO DE CONTADURíA PÚBLICA Y AUDITORíA LIC. MARCO MAURICIO MORALES
DIRECTOR DEL DEPARTAMENTO DE MERCADOTECNIA Y PUBLICIDAD LIC. EUGENIO VALLADARES
DIRECTOR DEL DEPARTAMENTO DE TURISMO LlCDA. LlLIA DE LA SIERRA
REPRESENTANTE DE CATEDRÁTICOS LlCDA. ANA MARíA MICHEO LIC. LUIS ARDÓN
REPRESENTANTE DE ALUMNOS EDUARDO MARROQuíN NICTE MELGAR

Guatemala, 31 de agosto de 2001
Licenciada Anabella Motta Secretaria del Consejo de la Facultad de Ciencias Económicas Universidad Rafael Landívar
Estimada Licenciada:
Cordialmente me dirijo a usted para presentar el informe final de la tesis de graduación elaborada por el alumno Byron Alejandro Solórzano García, carné: 23470-83, de la carrera de Licenciatura en Sistemas titulada "El Uso de la Abstracción, Agregación, y la Herencia como Técnica para el Análisis y Diseño de Sistemas".
Dicho trabajo de tesis provee una metodología consistente y real para el análisis y diseño de sistemas, además muestra claramente los beneficios que el desarrollo de sistemas orientado a objetos puede ofrecer, por 10 que su valor es altamente práctico y provechoso para la comunidad informática guatemalteca.
En el cumplimiento a la designación que me hiciera el Consejo de la Facultad de Ciencias Económicas de la Universidad Rafael Landívar, para asesorar la presente tesis, tengo el agrado de comunicarle que he revisado y estimo que reúne los requisitos académicos exigidos por la Universidad, por 10 que emito una opinión positiva de dicho informe a efecto de que sea aceptado y sea nombrada la tema para que el alumno pueda realizar la defensa de la tesis, previo a su graduación profesional.
Agradezco su distinción al nombrarme Asesora del presente trabajo de Tesis, y aprovecho para suscribirme como su servidora.
Atentamente,

U niversidad Rafael Landívar Facultad de Ciencias Económicas y Empresariales
Reg. E-216-2001-S
LA SECRETARIA DE LA FACULTAD DE CIENCIAS ECONOMICAS y EMPRESARIALES VEINTITRES DE OCTUBRE DEL AÑO DOS MIL UNO
De acuerdo al dictamen rendido por la Ingeniera Brenda Torres Trujillo asesora de la tesis "EL USO DE LA ABSTRACCiÓN, AGREGACiÓN Y LA HERENCIA COMO TECNICA PARA EL ANÁLISIS Y DISEÑO DE SISTEMAS" presentada por el señor Byron Alejandro Solórzano Garcla, y la aprobación de la Defensa Privada de tesis, según consta en el acta No. 355-2001 del 04 de octubre del año 2001, autoriza la impresión previo a su graduación profesional de Licenciado en Informatica.
ce. Archivo er/AO
Licda. Annabella Orellana de Motta Secretaria de Facultad de Ciencias Económicas
Campus Central Vista Hermosa IlI, zona 16. Apartado postal 39 C. Ciudad de Guatemala rels. : (502) 279-7979 - (502) 369-2151 • Fax: (502) 279-7979 Extensión 2333 • E-mail: [email protected]

ACTO QUE DEDICO
A DIOS Y A SU SANTISIMA MADRE Gracias por la vida que me han dado y las bendiciones que he recibido.
A MI MAMA María Luz García, has sido un verdadero regalo de Dios en mi vida. Gracias por todos tus esfurezos y sacrificios para darme un mejor futuro.
A MI PAPA Rigoberto Solórzano por tus consejos.
A MI ESPOSA Lucky, una vida juntos compartiendo alegrías hoy compartimos otra. Te amo.
A MIS HIJOS Andrés y Paola, mi vida esta dedicada a ustedes.
A MI FAMILIA Muy especialmente a mi prima Roxanna.
A LA MEMORIA DE Mi abuela Margarita, siempre has estado conmigo. Este logro es una prueba de ello. A José Garcia, Antonio García, Osear García, Esperanza Solórzano y Max Melgar.
A LAS FAMILIAS Blanco y Klussmann.
A MIS AMIGOS Rita, Patty, Nancy, Ingrid, Ricardo, Victor Hugo, Juan Carlos, Amado, Marvin.
A MI AMIGA Y ASESORA Brenda Torres, gracias por tu amistad y consejos en el presente trabajo.
A MI AMIGO DE TODA LA VIDA Osear Armando Beltetón Aguilar, gracias por tu amistad.
A LAS EMPRESAS EMPAGUA, SOFI. S.A, Cobertura S.A, Centro Distribuidor S.A. y Cementos Progreso S.A. Empresas que me habrieron sus puertas y permitieron mi desarrollo profesional. Lugares de los que estaré siempre agradecido.

INDICE
1. INTRODUCCION ............................................................................................................................................. 1
1.1 ORíGENES .............................................................................. ............................ .. .. ... ...................................... . 2 1.2 ALcANCES y LÍMITES ....................... : ........................................................................................................... .. .. 3 1.3 PLANTEAMIENTO DEL PROBLEMA .................... ... ...................... .. .................... . .............................. .. ............ ... . 3
2. LA ABSTRACCIÓN Y LA AGREGACIÓN ......................•........................................................................... S
2.1 ABSTRACCIÓN .......................................................................... .... ................................................... .... ............ 5 2.1.1 Técnicas de abstracción .... ......... .. ................................................. ....... ........... ............ ..... .......... .. .. ... .... 6
2.1.1.1 Encapsulación ............................................................................................ ...... .. ....... ................ ..... .................... 6 2.1.1.2 Clasificación .. .. ............................................................................... ............ " ............ ...... ........ ........... ... ............. 6 2.1.1.3 Generalización I Especialización ....................................................................................................................... 7 2.1.1.4 Asociación entre objetos .. ......... ...... .... ........................ .. ........................................... ....... .............................. .. ... 7
2.2 AGREGACIÓN ................ .......................................................... .... ..................................................................... 8 2.2.1 Cuando utilizar agregación . ................................................................................................................. 9 2.2.2 Agregacionesfijas, variables y recursivas ........................................... .. ......................................... .... la
3. LA HERENCIA ............................................................................................................................................... 11
3.1 LA IMPORTANCIA DE DEFINIR NIVELES ADECUADOS DE HERENCIA ................................................................. 11 3.2 EL USO DE LA HERENCIA ................................................................. : ............... .... .... ..... ..... ........................... .. 13
3.2.1 Reusabilidad ................................... ............... ........................... ............ .. .......... .... ...... ... ... ... ..... ..... ...... 14 3.2.2 Sub clasificación (subtyping) ................................ ................ ..... ........ ................ ........ ....... .... .... .... .. ..... 14 3.2.3 Especialización ................................................................................................................ .. .. ... ...... ...... 14
3.3 LA HERENCIA Y LA GENERALIZACIÓN/ESPECIALIZACIÓN ............................................. ... ............ .... .... ............ 15 3.3.1 La herencia y la subclasificación( subtyping) ................................................................. ..................... /5
3.4 .LAIMPLEMENTACIÓNDELAHERENCIA .......................................................................................................... 16 3.4.1 El uso de diferentes tipos de herencia en diferentes fases .................................... .. .... .... ... ................. 17
3.5 HERENCIA MÚLTIPLE ..... ............ .......... .......... ...... ................. ............ ............................................................. 17
4. EL DESARROLLO DE SISTEMAS ORIENTADOS A OBJETOS ........................................................... 19
4.1 Los TRES MODELOS ........................................................................................... .. ................ .. ............. .. .... ..... 19 4.1.1 El modelo de objetos ......................................... ..... ................. .... ........................ .... .. .. ........ ..... .. .. ..... .. 20 4.1.2 El modelo dinamico ..... ............ ...... ................ ... .. .................................... : ............. ..... .... .. .. ..... .. ...... .. :.21 4.1.3 El modelo funcional .................................................................................. .. .................. ..... ................. 21
4.2 LA RELACIÓN ENTRE LOS TRES MODELOS ....................................................................... .. ............................. 23 4.2.1 Verificar, iterar y refinar los tres modelos .......................................................................................... 24
4.3 FASES DEL DESARROLLO DE UN SISTEMA ORIENTADO A OBJETOS ............. ....... ........... ................... .. .............. 24 4.3.1 Identificación de requerimientos ......... ... ................ ... .. ....... ............. .. .. ... .. .... .. .. ... .. ....... .... .......... ..... ... . 24 4.3.2 Análisis .......... .... ....... ... ...... ........................ ....... .... ... .......... .......... ........... .. .. ................................ ......... 25 4.3.3 Diseíio .......... .. .................................................................................................................................. ... 25 4.3.4 Implementación ........................ .......................................... ......... ... ............ ............. .. ...... .... .. .. ............ 26 4.3.5 Las pruebas y el mantenimiento del sistema ............ .... ...... .............. .. ............ .. .......... ~ ........................ 26
4.4 CONSISTENCIA DE CONCEPTOS Y FLEXIBILIDAD ENTRE FASES ............ .... .................... ..... ............. .... .............. 26 4.5 UNIDAD DE CONCEPTOS VRS. TÉCNICAS DE FASE ........ ......................... .......... ...... ... ....................................... 26
S. EL PROCESO DEL ANALISIS ..................................................................................................................... 27
5.1 EL MODELO DE REQUERIMIENTOS ....... .......... ...... .. ..... .......... ........ ......... ....... .... ............................................... 28 5.1.1 Desarrollo del modelo de casos de usuario (use-cases) .............. ...................... ............ ....... ........... .. 28
5.1.1.1 Actores.. ......... .... ....................... ............................................................ .. ...... ............................ .. ...................... 28 5.1.1.2 Casos de usuario ............................................................................................................ .................................. 29
5.1.1.2.1 Examinar las especificaciones de los requerimientos ............................................................................ 29

5.1.1.2.2 Nombrar el caso de usuario .................................................................................................. .. ... .. .......... 29 5.1.1 .2.3 Sumarizar cada caso de usuario ..................................................................................... .... ................... 30 5.1.1.2.4 Extender el sumario .: ............................................................................................................................ 30
5.2 EL MODELO DE ANÁLISiS .............. ...... . ...................... ......... .................................. . ........................... .. ............ 30 5.2.1 Capas de la aplicación ...................................... ............... ... ............... ........ .. .... ................................... 31
5.2.1.1 La capa de presentación (View Layer) ............................................................................................................. 31 5.2.1.2 La capa de negocios (Business Layer) . ~ ....................................... ...... ................................ ................. ............. 31 5.2.1.3 La capa de acceso (Access Layer) ........................................................................ ......... .. ............................ .... . 31
5.2.2 Ensambles (Ensembles) ............................................................................. .... .. ...... .. ........... ...... ... ........ 32 5.2.2.1 Objetos de control ............................................................................... ......... ....... ..... ... .. ... ........................ .. ..... 32 5.2.2.2 Agentes .. .......................................................................................... .. ...... : ...... ...... ... ..... ... ............................. ... 32 5.2.2.3 Contenedores ................................................................................................ ....... .. ....... ............................. ..... . 32
5.3 EL PLANTEAMIENTO DEL PROBLEMA ........ ............ ................ .. ............................ ....... ........... . . .. ........ 33 5.3.1 Una vista de/proceso de análisis .................................. .. .......................................................... .......... 33
6. EL DISEÑO DEL SISTEMA .......................................................................................................................... 35
6.1 DIVIDIENDO EL SISTEMA DENTRO DE SUBSISTEMAS ...................... .... ............................................................. 36 6.1.1 Capas ... ....... ....................... ..... .... .. ..... ... .......... ...... ......... .... ... .... .... ...... .... .... ... ...... ................ .. ........ ... .. 36 6.1.2 Particiones ............................................................. .... .. ....... , ... .... ....... ........... .... ......... ......... ....... ......... 37
6.2 IDENTIFICANDO LA CONCURRENCIA ............................................ .. ....... ........ ...... .... .. .. ....... .. ..... ............ .. ... .. ... 37 6.3 LA ADMINISTRACiÓN DEL ALMACENAMIENTO DE LOS DATOS .................................................................. ...... . 38 6.4 MANEJAR LOS ACCESOS A LOS RECURSOS GLOBALES ....................................... .. ...................................... ..... 38 6.5 ESCOGER LA IMPLEMENTACiÓN DE CONTROL EN ELSOFIWARE ................................................................ .. ... 38
6.5.1 Sistemas manejados por procedimientos .................................. ........ .. .... .. ...... .. .......................... .. .. .... 38 6.5.2 Sistemas manejados por eventos .................................................... .................. ........... ............. ....... ... . 39 6.5.3 Sistemas concurrentes ................................................................................... .............. ..... ..... ............ .. 39
6.6 MANEJAR LOS LIMITES O FRONTERAS DEL SISTEMA ........ .. ................ .. .. ...... .................................. .......... .... .. . 39 6.6.1 Inicialización ...................................................................... ................. .. ... .. ............ .. .. ... ...... ................ 39 6.6.2 Finalización ...................... ................ .... .... .............. ......... ............................ ................ ... .... ................ 40 6.6.3 Fallas ........ ............ .......... ...................... .... .. ............ ............... ..... : ................ .... .............. ........ ............ . 40
6.7 PRIORIZAR ACTIVIDADES .. ........ ............. ........ ............................ . .... .......... ............ ........ .............. .... .... .......... . 40 6.8 ESTRUCTURAS COMUNES DE ARQUITECTURAS ............................................ .. .. .. ...... ........ ........ ....... ....... ..... : ... 40
6.8.1 Transformaciones en lotes .............................................................. ..... .......................... .... ................. 41 6.8.2 Transformaciones enforma continua ................................................................................................. 41 6.8.3 Interfases interactivas .................... ........................................... .................. ..... ...... ............................. 42 6.8.4 Simulaciones dinámicas .. ... .. ... ............... ............. .............................................. .. ............. .. .. .... ........... 43 6.8.5 Sistemas en tiempo real.. .... ...... ................................. .. .... .......... .... .. ........................ ............................ 43 6.8.6 Administración de transacciones ........................ ............................................... ..... ............................ 44
7. LA ORIENTACIÓN A OBJETOS Y EL ENFOQUE RELACIONAL ...................................................... 45
7.1 MODELO CONCEPTUAL UNIFICADO ............................................... ...... ........ .......... ....... ............ ...................... 45 7.2 TRES ENFOQUES DE CONSTRUCCIÓN DE BASES DE DATOS ORIENTADAS A OBJETOS ............................ ........ .... 47 7.3 INDEPENDENCIA DE DATOS VERSUS ENCAPSULADO .............................. .... .................................. ................... 48 7.4 RENDIMIENTO .................................................................................. .............................................................. 48 7.5 EVASIÓN DE LA REDUNDANCIA ............... ...... ............................ ... . ....................................................... .... . ..... 49 7.6 DIFERENCIAS ENTRE LAS BASES DE DATOS RELACIONALES Y LAS ORIENTADAS A OBJETOS .................. ...... .... 50
8. NOTACIÓN - UN CASO PRÁCTICO ......................................................................................................... 53
8.1 NOTACIÓN PROPUESTA POR RUMBAUGH .................................................................... ........ .. ....... .................. 53 8.2 CASO PRÁCTICO - IMPLEMENTACiÓN DE UN MÓDULO DE CLIENTES ...... .. .......................... .. .. .......................... 54
8.2.1 Descripción de use-cases . ... ................ .... .......... ..... .......................................................................... ... 55 8.2.1.1 Registro de clientes individuales .................................................................. .................. .. .............................. . 55 8.2.1.2 Registro de clientes jurídicos ...................................................................................... .... ...................... .... ...... . 56 8.2.1.3 Registro de grupos corporativos .. .......................... .... ............................... ...... .............. ...... .......................... ... 56 8.2.1.4 Consulta de vinculaciones .......................................................... ...... .................... .......... ....................... .......... 57 8.2.1.5 Administración de la lista negra ............................................................. .... ... .................................. ............... . 58

8.2.1.6 Modificaciones a la lista negra ................................. ...... .... ...... ..... .................... ...... ....... .. ............................... 58 8.2.1.7 Consulta a la lista negra ....... .................................................................... .. ............................. .. .. .. .... ............... 58 8.2.1.8 Bloqueo de un cliente .. ................... .... ............................. .. ............ .. ... .............................. ..... ... .... ......... ...... .. .. 59
8.3 EL DISEÑO ....... . .... .. . ... ............ . ............ .. .. .. ..... ....... .......... .. ... ..... . . .. ... . ...... . . ... . ..... . .. . . . ..... . . .. .. .. .. ... . . .. ... ... ... ... ... 59
9. CONCLUSIONES ........................................................................................................................................... 64
10. . RECOMENDACIONES ................................................................................................................................. 66
11. BIBLIOGRAFIA ............................................................................................................................................. 67

CAPITULO I
1. INTRODUCCION
Actualmente, el uso de la agregación, la abstracción y la herencia como técnicas para el modelado de sistemas ha tomado auge como método para el análisis y diseño de sistemas. Esta metodología en lugar de examinar e,1 problema mediante el método clásico de entrada-proceso-salida o mediante un modelo derivado exclusivamente de estructuras jerárquicas de información, introduce entre otros, conceptos tales como objetos y atributos, clases e instancias, herencia y polimorfismo, etc.
Al hacer uso de estas tres características fundamentales de la metodología orientada a objetos, se persigue modelar un sistema basado fundamentalmente en los modelos que propone dicha metodología (el modelo de objetos, el modelo funcional y el modelo dinámico).
Para comprender el punto de vista de "orientación a objetos", se somete a consideración el siguiente ejemplo: el objeto "silla", que no es más que un objeto del mundo real, es una instancia de una clase de objetos superior a ella que se denomina "mueble". Por ejemplo, todo mueble tiene un precio, dimensiones, peso y color, entre muchos atributos posibles. Estos atributos se aplican a una mesa, una silla, un sofá, una cómoda, etc. Dado que una silla es' una instancia de la clase mueble, hereda todos los atributos definidos para dicha clase.
Una vez que se ha definido la clase, se pueden reutilizar los atributos creando nuevas instancias de la clase. Cada objeto de la clase mueble puede ser manipulado de muchas formas. Puede ser vendido o comprado, modificado físicamente o movido de un lugar a otro. Cada una de esas operaciones (servicios o métodos) modifican uno o más atributos del objeto. Todas las operaciones válidas para la clase mueble, como por ejemplo: comprar, vender, pesar, etc. están conectadas a la definición del objeto y son heredadas por todas las instancias de la clase mueble. Por ello, el objeto silla encapsula:
• Datos que son valores de los atributos definidos para la silla. • Operaciones que son las acciones que se aplican para cambiar los atributos de
la silla con otros objetos. • Constantes. • Cualquier otro tipo de información relacionada al objeto.
La encapsulación significa que toda esa información está empaquetada bajo un solo nombre y puede ser reutilizada como una especificación o como un componente de un programa.

El análisis y diseño orientado a objetos, al igual que otras metodologías de diseño orientadas a la información, crean una representación del campo del problema del mundo real y lo hace corresponder con el ámbito de la solución, que es el software aplicativo. A diferencia de otros métodos, la orientación a objetos produce un diseño que interconecta objetos de datos (elementos de datos) y operaciones de procesamiento, de tal forma que modulariza la información y su procesamiento, en lugar de dejarlo por aparte.
La naturaleza del diseño orientado a objetos queda reflejada en su capacidad de construir una aplicación sobre la base de tres conceptos fundamentales: la abstracción, el ocultamiento de la información y la modularidad. Todos los métodos de diseño intentan desarrollar software con esas tres características fundamentales, pero sólo la orientación a objetos proporciona la técnica que permite al diseñador conseguir los tres conceptos sin complejidad.
Utilizando esta metodología, ya no es necesario que el diseñador del sistema haga corresponder el ámbito del problema con estructuras de datos y de control predefinidas que se encuentren en el lenguaje de implementación. En cambio, el diseñador puede crear sus propios tipos abstractos de datos, haciendo corresponder el campo del mundo real con esas abstracciones creadas por el propio programador. Esta correspondencia es por lo general mucho más natural, ya que el rango de tipos de datos abstractos que el diseñador puede inventar es virtualmente ilimitado. Más aún, el diseño del software se desliga de los detalles de implementación, sin que ello afecte al sistema en forma global.
1.1 ORíGENES
Los objetos y las operaciones no son conceptos nuevos en programación, pero el uso de la agregación, la abstracción y la herencia si lo son. En los inicios de la informática, los lenguajes ensambladores permitían a los programadores utilizar instrucciones de máquina para operar elementos de datos, pero el nivel de abstracción que se aplicaba al ámbito de la solución era muy bajo.
Con los lenguajes de programación de alto nivel (como ALGOL, COBOL, FORTRAN, etc.), se podía modelar los objetos y las operaciones del ámbito del problema con estructuras de datos y de control predefinidas que estaban disponibles como parte del lenguaje. En general, el diseño del software se centraba en la representación de los detalles procedurales del lenguaje de programación elegido. Paralelo a ello, fueron evolucionando conceptos de diseño tales como el refinamiento sucesivo de funciones, la modularidad procedural y más adelante, la programación estructurada.
Durante los años setenta, aparecieron conceptos como la abstracción y el ocultamiento de la información, emergiendo los métodos de diseño conducidos por los datos, aunque los desarrolladores de software todavía se centraban en los procesos y
2

sus representaciones. Al mismo tiempo, lenguajes como PASCAL introducen una variedad mucho más rica de estructuras y tipos de datos.
Mientras los lenguajes de alto nivel convencionales evolucionaban, los investigadores trabajaban arduamente en una nueva clase de lenguajes de simulación y creación de prototipos, como SIMULA y Smalltalk. En esos lenguajes, el énfasis estaba en la abstracción de los datos, y los problemas del mundo real eran representados por medio de un conjunto de "objetos de datos" para los que se adjuntaba un conjunto correspondiente de "operaciones". El uso de estos lenguajes era radicalmente diferente del uso de los lenguajes convencionales.
Durante los años ochenta, la rápida evolución de los lenguajes de programación tales como Smalltalk y Ada, seguida de un crecimiento explosivo en el uso de los dialectos orientados a objetos como C++ y Objective-C, produjeron un interés inusitado en el diseño orientado a objetos. En un temprano estudio de los métodos para conseguir el diseño orientado a objetos, se mostró como el análisis de la descripción del problema y su solución en lenguaje natural se podía usar como guía tanto para la parte del desarrollo del software como para el algoritmo concreto de un problema dado.
La orientación a objetos se utilizaba en aplicaciones que iban desde las animaciones gráficas en las computadoras hasta las telecomunicaciones. Actualmente, se cree que en este nuevo milenio, los métodos y los lenguajes de programación orientados a objetos serán los predominantes.
1.2 ALCANCES y LÍMITES
El presente trabajo de investigación cubrirá las técnicas utilizadas durante la fase de análisis y diseño de un sistema utilizando la metodología orientada a objetos haciendo especial hincapié en el uso de la abstracción, la agregación y la herencia. No así en los detalles de programación e implementación del mismo. Es desable, por parte del lector un conocimiento previo en esta metodología.
1.3 PLANTEAMIENTO DEL PROBLEMA
El uso de la agregación, la abstracción y la herencia para el análisis y diseño de sistemas es una metodología utilizada para el modelado de aplicaciones, la cual ofrece una serie de conceptos adecuados para dicho propósito. El utilizar esta metodología como base, ayuda a modelar el sistema descomponiéndolo en una serie de objetos que interactúan entre sí, sin importar el tipo de sistema que esta siendo modelado.
Esta técnica descompone al sistema en un número determinado de objetos que, a su vez, están relacionados el uno con otro de determinada manera. Nuestro entorno está constituido de objetos tales como personas, carros, ciudades, casas, etc. Estos objetos están relacionados los unos con los otros, por lo que su análisis y diseño
3

depende de lo que se desea representar de dichos objetos (características y comportamientos) dentro del modelo.
Lo anterior conduce a organizar el desarrollo de la aplicación como una colección de objetos discretos que. incorporan la estructura de los datos y su comportamiento dentro de una misma entidad, lo cual esta en contraste con las metodologías tradicionales de análisis y diseño de sistemas en las que, la estructura de los datos y su comportamiento están escasamente conectadas.
El análisis y diseño de un sistema utilizando esta metodología se construye sobre una base sólida de la percepción natural del mundo. Por lo que el uso adecuado de esta técnica ofrece grandes beneficios como la reusabilidad del código, la implementación de una modularidad granular entre cada modelo del sistema (modelo de objetos, modelo dinámico y modelo funcional), el uso de la herencia, polimorfismo, encapsulamiento, etc.
Objetivos generales.
• Describir el proceso del análisis y diseño de un sistema haciendo uso de la abstracción, la generalización o herencia y la agregación.
• Establecer los beneficios que ofrece el uso de estas tres técnicas, como metodología para el análisis y diseño de sistemas.
• Presentar y describir en que consiste la diagramación de las estructuras de un modelo basado en esa metodología.
• Presentar y describir un ejemplo práctico haciendo uso de la agregación, la abstracción y la herencia.
Objetivos específicos
• Estudiar y definir los conceptos utilizados en la metodología orientada a objetos. • Describir en que consiste la abstracción. . • Describir en que consiste la generalización o herencia. • Describir enque consiste la agregación. • Describir la notación propuesta por Rumbaugh. • Desarrollar un ejemplo práctico que muestre el uso y la notación propuesta por
Rumbaugh. • Presentar un caso práctico de un módulo de clientes de una entidad financiera.
4

CAPITULO 11
2. LA ABSTRACCiÓN Y LA AGREGACiÓN
En la historia del desarrollo de sistemas han existido diferentes paradigmas, los cuales han sido la base de los distintos métodos existentes para la construcción de software y desarrollo de sistemas. El paradigma de la orientación a objetos ha tomado auge en los últimos años. Las metodologías tradicionales para el desarrollo de sistemas de información no han desaparecido y han sido mejoradas por sus autores. Sin embargo, existe un consenso entre los expertos en desarrollo de sistemas e ingeniería de software en cuanto a la orientación a objetos; las nuevas metodologías, de alguna u otra forma, se basan en los aspectos fundamentales de la orientación a objetos.
La orientación a objetos permite construir modelos más cercanos al mundo real , reduciendo la distancia entre los requerimientos del sistema y la construcción del mismo.
2.1 ABSTRACCiÓN
La abstracción es el prinCipiO de ignorar los aspectos no relevantes de un determinado contexto para concentrarse en los que sí lo son. En la metodología de orientación a objetos intervienen la abstracción procedural y la abstracción de datos.
En la abstracción procedural cualquier operación a través de la cual se obtiene un efecto bien definido, puede ser tratada como una entidad única, a pesar de que la operación se ejecute por medio de una secuencia de operaciones de más bajo nivel. En la abstracción de datos se define una tipología de datos en términos de los atributos y las operaciones que se aplican a los objetos de ese tipo, con la restricción de que los valores de esos objetos sólo pueden ser modificados u observados a través de dichas operaciones.
Por medio de la abstracción se denotan las características esenciales que distinguen a un objeto de otro, definiendo precisas fronteras conceptuales relativas al observador y al sistema que se analiza. Este surge del reconocimiento de similitudes entre ciertos objetos, situaciones o procesos en el mundo real. Se concentra en esas similitudes e ignora las diferencias. Enfatiza detalles con significado para el usuario, suprimiendo aquellos detalles que, por el momento son irrelevantes o distraen de lo esencial.
La abstracción es una de las vías fundamentales por la que los humanos combatimos la complejidad. Una buena abstracción e's aquella que enfatiza los detalles significativos y suprime aquellos que son irrelevantes o causa de distracción. Por ello
5

se puede decir que, por medio del uso de la abstracción se denotan las características esenciales de un objeto que lo distinguen de todos los demás, proporciona fronteras conceptuales nítidamente definidas respecto a la perspectiva del observador, define la relación entre un grupo de objetos tales que, un tipo de objeto representa un conjunto de características que son compartidas por otros tipos de objetos. Una abstracción se centra en la visión externa de un objeto, por lo tanto sirve para separar el comportamiento esencial de un objeto de su implantación.
2.1.1 TÉCNICAS DE ABSTRACCiÓN
Las técnicas de abstracción que se utilizan en la orientación a objetos para extraer y definir las características y comportamientos de los objetos del medio a modelar son:
• Encapsulación. • Clasificación. • Generalización / Especialización. • Asociación.
2.1.1.1 ENCAPSULACIÓN
Define la forma en que vemos, pensamos e interactuamos con los objetos. Su función principal es ·Ia de ocultar los atributos de un objeto o cualquier elemento interno, de manera que no permita una manipulación externa, para que la única forma de afectar internamente a dicho objeto sea a través de la comunicación con uno de sus métodos. De ello se desprende el hecho de que solamente nos interesa "qué" hace un objeto y no "cómo" lo hace.
2.1.1.2 CLASIFICACiÓN
Es un nivel de la abstracción en la que se describe un tipo de objeto dado mediante la descripción de clases. En ellas se definen los atributos y comportamientos comunes de un objeto en particular. Una clase es una descripción de un tipo particular de objeto, no es un objeto en sí.
Cuando nos referimos a un carro, no estamos hablando de un objeto "carro" en particular si no a un concepto general que colecciona un grupo de. atributos y comportamientos. La ejemplificación de objetos es lo opuesto a clasificación. Se utiliza este proceso de ejemplificación cuando nos referimos a un objeto en específico (una instancia).
6

2.1.1.3 GENERALIZACiÓN / ESPECIALIZACiÓN
La generalización es el mecanismo de abstracción mediante el cual un conjunto de clases de objetos es agrupado en una clase de nivel superior (Superclase), en donde las semejanzas de las clases constituyentes (Subclases) son enfatizadas y las diferencias entre ellas son ignoradas. En consecuencia, a través de la generalización, en la superclase se definen los datos generales de las subclases y en las subclases se definen sólo los datos particulares. Esta técnica de abstracción define relaciones entre clases en donde la generalización describe todo lo que tiene en común sus especializaciones. La forma gráfica que utiliza para denotar este tipo de abstracción es la de una estructura de árbol y se caracteriza por:
• Tener una especialización, la cual es una clase que puede ser considerada del tipo de otra clase. La clase más general es la generalización.
• Tener una visión de clases en forma de jerarquías.
• Otorgar una herencia de atributos y comportamientos. La generalización describe todo lo que es común a sus especializaciones (tanto atributos como comportamientos) por lo tanto la especialización no tiene que redefinir la información, esta le ha sido heredada.
2.1.1.4 ASOCIACiÓN ENTRE OBJETOS
La asociación entre objetos permite ver como nuestro sistema utiliza sus objetos. Existen dos tipos básicos de asociaciones (relaciones):
• Asociación: Es una relación débil que define una conexión semántica entre dos objetos. Ejemplo:
'--_PE_R_SO_N_A---'I------~ POSEE 1-----i~~1 CARRO
Figura: 1.1 ejemplo de asociación
• Agregación: Esta describe una relación más fuerte en donde un objeto esta compuesto por otros objetos. Es decir, un objeto es componente de otro objeto. Ejemplo:
Casa se ve como un objeto cuando en realidad es una agregación de varios objetos como ventanas, puertas, paredes, etc.
Las asociaciones frecuentemente corresponden a los verbos, estas generalmente se refieren a la ubicación física de una clase con otra (cerca a, parte de,
7

contenido en), acciones directas (manejar o conducir), o bien a la satisfacción de algún tipo de condición (trabaja para, casado con). Como se analizará en el siguiente apartado, la agregación es un tipo de asociación con connotaciones adicionales.
2.2 AGREGACiÓN
La agregación denota una jerarquía todo / parte, con la capacidad de ir desde el todo (agregado) hasta sus partes (atributos). La agregación puede o no denotar contención física.
La Agregación es un mecanismo de abstracción basado en el criterio "Es parte de", que permite construir una clase de objetos a partir de otras clases u objetos. Este mecanismo permite visualizar a los objetos como un todo y sus partes constituyentes. Estas clases pueden definirse como la agrupación de objetos con características comunes, o bien como una descripción de la estructura y comportamiento uniforme que son comunes a un conjunto de objetos. Todos aquellos objetos que pertenecen a la misma clase son descritos por el mismo conjunto de atributos y métodos.
El agrupar objetos en clases ayuda a evitar la necesidad de especificar y almacenar información redundante. El concepto de jerarquía de clase extiende más esta capacidad de reutilizar información y es el fundamento del concepto de herencia, que es el proceso mediante el cual un objeto de una clase adquiere propiedades definidas de otra clase que lo preceda en una jerarquía de clases.
La agregación representa una relación del tipo "tener un" entre clases. Cuando la clase contenida no existe independientemente de la clase que la contiene se denomina agregación "por valor" y además implica contenido físico, mientras que si existe independientemente y se accede a ella indirectamente, es agregación "por referencia" .
La agregación es utilizada para modelar estructuras en forma total llamados objetos compuestos o agregados, las partes de dichas estructuras son llamadas componentes. Si observamos una bicicleta se puede notar como ésta puede ser representada por componentes (objetos compuestos), los cuales consisten de diversas partes (ruedas, marco, timbre, etc.).
Marco
Figura: 1.2 Diagrama del objeto compuesto "Bicicleta"
8

El ejemplo anterior muestra que una bicicleta debe tener un marco y que un marco no puede existir independientemente de una bicicleta. Una bicicleta no necesita tener timbre ni ruedas, y tanto el timbre como las ruedas pueden existir independientemente de la bicicleta, y que la bicicleta no puede tener más de un timbre pero si puede tener más de una rueda.
Lo anterior introduce el concepto de la cardinalidad de la relación que existe entre los objetos y sus componentes, en la que:
• Un objeto debe forzosamente incluir a un componente. • Un objeto puede incluir más de un componente. • Un componente puede existir independientemente del objeto compuesto.
Los atributos no tienen una existencia independiente del objeto que describen, pero dichos objetos pueden existir independientemente. Ambos pueden unirse vía agregación dentro de ensambles u objetos compuestos los cuales externamente simularan ser un objeto sencillo.
La agregación es un concepto utilizado para describir las relaciones entre los objetos, esta permite describir un objeto en términos de los objetos de los cuales él consiste. Puede ser vista como un tipo de relación la cual es menos cercana a la relación entre un atributo y al objeto que esta describiendo y más cercana al tipo de relación entre dos objetos los cuales son descritos por medio de una relación estática.
Es útil asociar la semántica con la agregación, esto con el propósito de que un objeto compuesto y sus componentes sean tratados como un todo. Por ejemplo, la operación "Copiar" es propagada desde el objeto compuesto hasta sus componentes, para que cuando un documento sea copiado, todos sus párrafos sean copiados. La operación no es propagada en la dirección contraria - copiar un párrafo no implica copiar todo el documento. Esto provee una buena regla para considerar el uso o no de la agregación.
La agregación . difiere de la herencia en que la agregaclon representa una relación "es parte de", mientras que la herencia representa una relación "es una clase de". Algunas veces el uso de la herencia es erróneamente utilizado cuando en su lugar, el uso de la, agregación sería lo más apropiado. La agregación y la herencia pueden ser combinadas, si un objeto compuesto tiene subclases, cada subclase hereda sus agregaciones.
2.2.1 CUANDO UTILIZAR AGREGACiÓN.
Básicamente el uso de la agregación es recomendado cuando existe una relación cercana entre los objetos, tales que:
9

• El objeto compuesto sea frecuentemente visto o tratado como un todo.
• El objeto compuesto puede ser movido o creado como un todo.
• Exista una relación asimétrica entre el objeto compuesto y sus componentes.
• Exista una propagación de operaciones desde el objeto compuesto hacia sus componentes.
• Exista una propagación de atributos, por ejemplo en la pantalla de un computador, la posición de los componentes de una ventana depende la posición de la ventana como tal.
2.2.2 AGREGACIONES FIJAS, VARIABLES Y RECURSIVAS
En una agregación con estructura fija, el número de componentes de cada tipo es estático. En el ejemplo de la bicicleta, ésta tiene una estructura fija de un marco.
En una agregación variable, el número de componentes de un tipo puede variar, por ejemplo, el número de capítulos de un libro depende del libro en cuestión.
Una agregación recursiva es una agregación que contiene directa o indirectamente un componente que pertenece a la misma clase. Este tipo de agregación es frecuentemente asociado con el uso de subclases.
10

CAPITULO 111
3. LA HERENCIA
3.1 LA IMPORTANCIA DE DEFINIR NIVELES ADECUADOS DE HERENCIA
Muchos objetos pueden ser similares y esas similitudes pueden ser modeladas por medio de una clase, por lo que cada objeto es una instancia de dicha clase la cual le provee su estructura y su comportamiento. Para hacer dicha descripción más flexible se utiliza el polimorfismo. Polimorfismo significa que cuando se definen las relaciones entre los objetos, éstos no necesitan conocer acerca de la otra clase a la que se está relacionando. De esa forma, las nuevas clases pueden ser introducidas sin ser necesario modificar las existentes.
El desarrollo de buenos niveles jerárquicos de herencia es una parte crítica en el proceso del análisis y el diseño del sistema, debido a que ésta tiene una gran influencia en la reusabilidad subsiguiente del diseño así como su robustez para encarar los cambios normales de todo sistema.
Una razón de ello está relacionada al cuestionamiento de qué impacto tendrá el cambio de una clase dentro de la jerarquía de la herencia. Si una operación es modificada o agregada, ¿cuál será el impacto sobre las clases que heredan esta operación? Si la estructura fue planificada y organizada adecuadamente, los cambios tendrán poco o ningún efecto sobre dicha estructura, por el contrario, si no se realiza una adecuada planificación sobre dicha clase, el impacto de dichos cambios harán que sean difíciles de manejar. .
Otra razón es la dificultad de ajustar la herencia una vez está en uso. Si la jerarquía de clases requiere extensiones para acomodar nuevas categorías de objetos, la habilidad de agregar las nuevas subclases en el lugar lógico dentro de la jerarquía depende de que tan bien ha sido definida la herencia. Idealmente, la estructura de la clasificación no necesita ser cambiada. Sin embargo, si es necesario realizar modificaciones, se deberá analizar cuales serán los efectos de dichos cambios en las subclases afectadas así como también los niveles más bajos en la estructura jerárquica de la herencia. Esto puede involucrar un trabajo substancial y su complejidad puede ser mayor en sistemas que se encuentren implementados.
Las clases heredan todos los detalles de su superclase, por lo que también son afectadas cuand() se realizan cambios a dichas superclases. Esto puede ser visto como una violación al principio del ocultamiento de la información, lo que significa que se necesita dar una particular atención a como se debe utilizar la herencia con el objeto de dar reusabilidad y mantenimiento al diseño. Esto también significa que el sobre uso de la herencia debe ser evitado.
11

En el proceso de descripción de clases, es fácil notar las características comunes entre ellas. Por ejemplo si se comparan las clases "Masculino" y "Femenino", se pueden apreciar varias similitudes entre ellas, las que pueden ser compartidas entre las clases extrayéndolas y colocándolas dentro de una clase separada llamada "Persona". Dentro de "Persona" se describe cada atributo que es común a las clases "Masculino" y "Femenino". De esta manera las características comunes pueden ser compartidas entre diferentes clases. Con lo anterior se logra recolectar todas aquellas características comunes a varias clases, agrupándolas dentro de una clase específic:a y permitir a las clases originales heredar esta clase; para luego solamente describir las características que le son específicas a la clase original. Por lo que se le permite a las clases "Masculino" y "Femenino" heredar de la clase "Persona", otorgándoles acceso a todas las características definidas allí.
Lo anterior se podría resumir de la siguiente forma: Si la Clase B hereda de la Clase A, todas las operaciones y la estructura de la información descrita en la Clase A formará parte de la Clase B.
Por medio de la herencia se pueden mostrar las similitudes entre las clases y describir éstas dentro de una clase de la cual otras pueden heredar. De esa cuenta se pueden reusar las descripciones comunes de las clases y es por ello que el uso de la herencia frecuentemente es la idea esencial para la reusabilidad en la industria del software.
Por medio del uso de la herencia, se obtienen ventajas adicionales. En el ejemplo de la clase "Persona" si se quisiera modificar alguna de sus características (por ejemplo, como camina una persona), basta con realizar dicha modificación en un solo lugar para que las clases "Masculino" y "Femenino" hereden esta nueva definición de caminar. La facilidad de estos cambios dentro de las clases no sólo ocurre dentro de ellas. Agregar nuevas clases resulta sumamente fácil, ya que sólo se deben describir dichos cambios en las clases existentes. Sin embargo el agregar nuevas clases, algunas veces involucra la necesidad de reestructurar la jerarquía de la herencia.
Según lo anterior, al extraer y compartir todas aquelfas características comunes de las clases, se está realizando un proceso de "generalización de clases" y definiendo una estructura jerárquica. De la misma forma, si se desea agregar nuevas clases se deberá de encontrar una clase que ofrezca algunas de las operaciones requeridas así como también de una estructura de datos similar para luego permitir a la nueva clase heredar de ésta, e ir agregando aquello que le es único. A este proceso se le conoce como "especialización de clases".
A las clases que se encuentran por debajo de una clase dentro de la jerarquía de la herencia se le conoce como descendiente o subclase y a aquellas clases que se encuentran por encima de una clase dentro de la jerarquía de la herencia se le conocen como ancestros o superclases.
12

Las superclases son desarrolladas con el propósito de heredar todas sus características a otras clases y son frecuentemente llamadas clases abstractas. Generalmente no se crean instancias de las superclases, pero ésto es posible. Una clase que es desarrollada con el propósito principal de crear instancias de ella se le conoce como clases concretas.
Otra de sus ventajas es que por medio de ella, se evita la redundancia, lo que conlleva a modelar estructuras pequeñas que son fáciles de entender.
3.2 EL USO DE LA HERENCIA
La estructuración de las clases ocurre con la ayuda de la jerarquía de la herencia, esta estructuración permite trabajar con clases y definir nuevas por medio de la especificación de las diferencias que existen entre las nuevas y las existentes dentro del modelo.
Cuando una nueva clase es agregada, se debe seleccionar una clase candidata que juegue el rol de su superclase. Si fuese necesario modificar algunas operaciones que le fueron heredadas, básicamente se tiene cuatro posibilidades:
• Evaluar los niveles superiores en la jerarquía de la herencia con el propósito de encontrar la superclase más adecuada para la herencia, con el fin de evaluar si en esa nueva superclase candidata no exista la operación que se desea evitar.
• Describir la clase desde su inicio, esto es sin hacer uso de la herencia.
• Reestructurar la jerarquía de la herencia, para obtener una superclase que proporcione la herencia requerida, lo que algunas veces no es posible realizar.
• Redefinir o reescribir las características u operaciones que se desean cambiar.
Las primeras dos soluciones son triviales. La tercera solución es la más aceptable, debido a que mantiene claridad dentro de la estructura jerárquica de la herencia. Realizar este tipo de reestructuración requiere de trabajo, particularmente el que involucra encontrar la mejor estructura posible y poder medir las consecuencias que dichas modificaciones tendrán dentro del diseño del sistema ..
La cuarta solución implica reescribir o redefinir el comportamiento de la estructura de la superclase. Esto es fácil y flexible de usar, pero puede dañar el entendimiento y claridad de la herencia, ya que una operación con el mismo nombre puede tener un diferente sentido semántico dentro de diferentes clases, y para poder comprender estas diferencias semánticas es necesario seguir la cadena de la herencia hasta el lugar en donde fue reescrita para entender su definición. Después de que la herencia ha sido pasada de una clase a otra, las características heredadas pueden ser
13

modificadas. Con el uso de la sobre escritura de dichas estructuras y operaciones, el uso de la herencia no es transitivo.
Para comprender como se debe de utilizar la herencia, se deben entender los principales propósitos de ella.
3.2.1 REUSABILIDAD
La razón más común para utilizar la herencia es que ésta simplifica el poder reusar el código. El reuso, en principio ocurre de dos diferentes formas en combinación con la herencia. El primero es que dos clases poseen partes similares; estas partes son extraídas y colocadas dentro de una clase abstracta, de la cual heredarán las clases originales. Esta clase abstracta representa las partes comunes a cada una de ellas. La otra forma de reusar es comenzar desde una librería .de clases, encontrar que clase contiene las operaciones que son necesarias para luego heredar esta clase y realizar las modificaciones requeridas.
3.2.2 SUBCLASIFICACIÓN (SUBTYPING)
Una clase puede servir como un tipo especial de implementación. Una clase A define cierto comportamiento, si es posible utilizar una subclase de A dentro de cualquier lugar del modelo en donde la clase A esté siendo utilizada, se dice que estas clases son de un comportamiento compatible. Las subclases representan un subtipo de la clase A. En la práctica esto significa que las subclases deben por lo menos tener la misma interfase que su superclase. Por lo que dicha superclase representa un conjunto de comportamientos comunes a todas sus subclases. La subclasificación normalmente ocurre si la herencia ejecuta solamente una extensión, y raramente una sobre escritura de "algo" que está definido en la superclase.
3.2.3 ESPECIALIZACiÓN
Si la subclase es modificada de tal forma que ya no es más de comportamiento compatible con su superclase, se dice que esta clase ha sido especializada. Normalmente las operaciones y la estructura de la información han sido modificadas o eliminadas. Una superclase que ha sido especializada no puede ser reemplazada por sus subclases. Un ejemplo de especialización se da si se crea una clase "Adulto" que hereda de la clase "Persona". La clase "Adulto" tiene una restricción en cuanto al intervalo de la edad de la "Persona".
14

3.3 LA HERENCIA Y LA GENERALIZACiÓN/ESPECIALIZACiÓN
El uso de la generalización/especialización es una forma básica para la construcción de la herencia. Sin embargo, la herencia dentro de la orientación a objetos ha tomado una ruta diferente, y es importante entender sus diferencias, así como también sus similitudes.
La diferencia más importante entre estas, es que la herencia y la generalización / especialización surgen de diferentes necesidades, necesidades que surgen de diferentes ciclos del desarrollo del sistema.
La generalización / especialización es una técnica conceptual utilizada para el modelado de sistemas para describir las relaciones entre las clases. Cuando el diseño es implementado, es mapeado hacia un tipo de implementación que toma otra forma. Esto es comprendido desde el punto de vista que existirá una transición entre el diseño y el proceso de la implementación.
Por otra parte, la herencia es fundamentalmente un concepto de implementación, no sólo una técnica conceptual del modelado del sistema.
3.3.1 LA HERENCIAY LA SUBCLASIFICACIÓN(SUBTYPING)
¿Qué implicaciones especiales tiene el uso de la herencia si es usada con propósitos de implementación? La respuesta se encuentra en el contexto del lenguaje de programación. Lasclases tienen que ser capaces de funcionar de una manera similar a los tipos de datos, como ejemplo los enteros o caracteres que vienen predefinidos dentro del lenguaje de programación. Las clases también pueden ser consideradas como tipos de datos (éstas son efectivamente tipos de datos definidas por el usuario), que una vez creadas están disponibles dentro del lenguaje de programación.
Para poder apreciar el porqué las clases son consideradas como tipos de datos, se debe de evaluar como son utilizadas dentro de un lenguaje de programación orientado a objetos. En la mayoría de los lenguajes, se puede utilizar un entero como parámetro dentro de una función; dentro de un lenguaje orientado a objetos, esto también se aplica para una clase, debido a que esta puede ser enviada como parámetro a una función u operación de invocación como si se tratase de un entero.
En el caso de una operación como la siguiente: EnteroA = EnteroB+ DecimalC es deseable poder ser capaz de predecir como los distintos tipos de datos involucrados se comportarán cuando la suma sea llevada a cabo. ¿El resultado será truncado si el campo que almacenará el resultado no tiene posiciones decimales definidas, o será redondeado? Cualquiera que fuere la respuesta, lo importante es que lo que se desea ser es consistente.
15

¿Cuáles son las implicaciones si los "Decimales" y los "Enteros" son clases de objetos? Supóngase que se diseñó un sistema en el que la clase "Enteros" trunque los resultados que son demasiado grandes. Luego dos subclases, "EnterosTruncados" y "EnterosRedondeados" son introducidas. El resultado de la operación anterior (EnteroA = EnteroB + DecimalC) dependerá del comportamiento de la clase que se halla utilizado como receptora del resultado (EnteroA).
Una buena regla de diseño es que si un objeto es perteneciente a una clase superior, esta clase propietaria siempre debe poder ser substituible por otro objeto perteneciente a la superclase, el cual deberá tener el comportamiento de su superclase como un subconjunto de su propio comportamiento.
Según el Object Management Group, lo anterior es lo que conduce al concepto de substituibilidad, que lo define de la siguiente forma:
La substituibilidad significa ser capaz de substituir un objeto de tipo S cuando un objeto de tipo T es esperado, en donde T es el supertipo de S, garantizando que la substitución soportará la misma operación especificada por el supertipo T.
Se deberá considerar a la substituibilidad como un concepto importante y no como un mandato, pero se deberán diseñar subclases que puedan ser substituibles por sus superclases.
En la corriente de la orientación a objetos, el uso de la herencia en las que las clases pueden ser substituibles es llamado subtyping.
3.4 LA IMPLEMENTACiÓN DE LA HERENCIA
Se podría definir a la herencia como una relación entre clases que permite a una clase poder incluir los atributos y las operaciones definidas por otra clase más general a ella. Lo cual no es más que una simple técnica que permite reusar la definición de otra clase.
Esto significa que la herencia puede ser usada como una herencia de implementación. Un ejemplo de este tipo de implementación sería la definición de un Archivo Binario como una subclase de un Archivo ASCII debido a la conveniencia de reusar parte de la definición de la implementación del Archivo ASCII.
El uso de la herencia es frecuentemente evocada como una forma de extender una aplicación sin desorganizar el código que actualmente está en uso. Si es requerida una funcionalidad diferente, la herencia permite ir agregando la funcionalidad deseada sin alterar la implementación actual mediante la definición de nuevas subclases. Esto es un uso válido de la herencia en donde los cambios son realmente una extensión. Sin embargo el uso de la herencia es de utilidad en donde la subclase fuese introducida en forma de un "arreglo rápido".
16

3.4.1 EL USO DE DIFERENTES TIPOS DE HERENCIA EN DIFERENTES FASES
Existen básicamente tres tipos de herencia:
• La generalización / especialización conocida también como "es-un(a)". • Subtyping conocida también como herencia de especificación. • Implementación de la herencia, conocida como el proceso de diseñar
subclases.
Estos tres tipos de herencia pueden estar asociados con el análisis, el diseño y la construcción de las fases del sistema.
• La generalización / especialización está identificada en la fase del análisis. • La herencia de especificación (subtyping) tiene sus raíces dentro de las
consideraciones del diseño. Con el propósito de determinar si la jerarquía de la herencia usará subtyping, es necesario considerar las operaciones asociadas a las clases, lo cual puede ser fácilmente verificado durante el diseño.
• La implementación de la herencia colaboré;l con los problemas del mantenimiento del sistema.
El comienzo del análisis se inicia estableciendo la jerarquía de la herencia por medio de la generalización / especialización, a medida que el diseño avanza esta es verificada y modificada si fuere necesario con el propósito de garantizar que la herencia de clasificación esta siendo utilizada.
La generalización / especialización es implementada desde el modelado del sistema, describe una clase de objetos como un caso especial de otro objeto. Por ejemplo, un carro es un tipo especial de un vehículo.
La herencia de especificación o subtyping, frecuentemente se sobrepone a la especialización. Muchas especializaciones son tipos válidos de herencia de subtyping. En el ejemplo de especialización (un carro es un tipo especial de vehículo) es ciertamente una herencia de especificación válida. Se dice "ciertamente", debido a que es fácil probar que una subclase en este contexto no es substituible.
3.5 HERENCIA MÚLTIPLE
Cuando se describe una nueva clase y se desea que herede características de dos o más clases se le conoce como herencia múltiple. Esto significa que una clase puede tener más de una superclase.
17

La mayor desventaja del uso de la herencia múltiple, es que reduce la comprensión de la herencia y no todos los lenguajes orientados a objetos soportan esta característica.
El hecho de que un sistema presente herencia múltiple se traduce en que una subclase puede tener más de una superclase. Así, si un sistema ofrece herencia múltiple pueden surgir una serie de conflictos, como el hecho de que dos o más superclases tengan un atributo con el mismo nombre, pero con dominios diferentes. En estos casos se deben establecer reglas apropiadas para resolver dichos conflictos: si los dominios están ligados por una relación de inclusión, entonces debe tomarse el dominio más especifico como dominio de la subclase. Si no existiera este tipo de relación, entonces, una posible solución sería escoger el dominio de acuerdo con un orden de precedencia entre las superclases definido a priori. Ejemplo: Si modelamos la relación que existente entre un vehículo anfibio y sus superclase el modelo quedaría de la siguiente forma:
Figura: 3.1 Herencia múltiple
18

CAPITULO IV
4. EL DESARROLLO DE SISTEMAS ORIENTADOS A OBJETOS
El análisis y diseño de sistemas utilizando la metodología de orientación a objetos ofrece una nueva forma de pensar en la solución de problemas utilizando modelos que giran en conceptos del mundo real. Su base fundamental son los objetos, combina la estructura de los datos y su comportamiento en una sencilla entidad.
Esta metodología se basa en una clara y comprensible vista del dominio del problema. No depende de la implementación del lenguaje en el que se pretenda desarrollar el sistema. Las técnicas de orientación a objetos habilitan al desarrollador a enfocarse en identificar y organizar la aplicación de los objetos. Los detalles de las estructuras de los datos y las funciones están contenidos dentro de las aplicaciones de los objetos.
El desarrollo de un sistema orientado a objetos emplea una nueva forma de pensar acerca del dominio de la aplicación. Los modelos son usados para capturar y organizar los resultados de esta nueva forma de pensar, los cuales son utilizados durante todas las fases del desarrollo a través de una serie de refinamientos.
Un modelo es una abstracción de algo con el propósito de entenderlo como un todo previo a la construcción del mismo. Debido a que un modelo omite detalles innecesarios, es más fácil su manipulación como si se estuviera tratando con la entidad completa. En muchas áreas se construyen modelos con el propósito de realizar pruebas y simulaciones previas a su construcción. La abstracción, como se mencionó en el Capítulo 11, es la capacidad humana que nos permite tratar con problemas complejos. El desarrollador debe hacer uso de ella para abstraer aspectos de diferentes vistas del sistema usando notaciones precisas, verificando que el modelo satisfaga los requerimientos del sistema e ir gradualmente, agregando detalles para transformar el modelo en la implementación del mismo.
4.1 Los TRES MODELOS
Esta metodología usa tres clases de modelos para describir un sistema: el modelo de objetos describe los objetos en el sistema y' sus relaciones; el modelo dinámico describe las interacciones a lo largo de los objetos en el sistema; y el modelo funcional describe las transformaciones de los datos del sistema. Cada modelo es aplicable durante todos los escenarios del desarrollo y obtiene los detalles de la implementación. Una descripción completa de un sistema requiere de los tres modelos.
19

4.1.1 EL MODELO DE OBJETOS
El primer paso en el análisis de requerimientos es la' construcción del modelo de objetos. Este modelo muestra la estructura estática de los datos y la organiza dentro de piezas trabajables. En el modelo de objetos se describen las clases y sus relaciones. La parte crucial del análisis del sistema es definir como se organizan las conexiones entre las clases de más alto nivel por medio de asociaciones para luego ir particionándolas en niveles de abstracción más bajos llamados subclases.
El modelo de objetos precede al modelo dinámico y al modelo funcional debido a que su estructura estática es usualmente mejor definida, existen menos dependencias sobre los detalles de la aplicación y es más estable en la medida que la solución se desarrolla.
El modelo de objetos captura la estructura estática de un sistema mostrando los objetos en él, las relaciones entre ellos, sus atributos y las operaciones que caracterizan cada clase. La construcción de un sistema se basa alrededor de los objetos, rara vez alrededor de su funcionalidad. Provee una representación gráfica del sistema que es ' de sumo valor para la comunicación con el cliente y para la documentación del sistema.
Si el diseñador no es un experto en el sistema que se planea desarrollar, la información debe ser obtenida del usuario de la aplicación, realizando verificaciones en contra del modelo repetidas veces. Los diagramas del modelo de objetos promueven la comunicación entre los profesionales de la computación y los usuarios del sistema.
Se debe identificar las clases y las asociaciones como primer paso, luego se debe agregar atributos para luego describir la red básica de las clases y sus asociaciones. Luego se combinarán y organizarán las clases usando herencia. Se deberá intentar especificar la herencia directamente sin describir las clases de más bajo nivel y sus atributos, luego se agregarán operaciones a las clases con el propósito de construir el modelo dinámico y el modelo funcional.
Algunos aspectos del problema pueden ser analizados con detenimiento a lo largo de varias interacciones, mientras que otros aspectos quedan tan solo como un bosquejo.
Los siguientes pasos son ejecutados en la construcción del modelo de objetos:
• Identificar objetos y clases. • Preparar el diccionario de datos. • Identificar asociaciones (incluyendo agregaciones) entre objetos. • Identificar los atributos de los objetos y sus uniones o enlaces. • Organizar y simplificar las clases por medio de herencia.
20

• Verificar que las rutas de acceso existan para el desarrollo de búsquedas estructuradas (queries).
• Iterar y refinar el modelo. • Agrupar clases dentro de módulos.
Modelo de objetos = diagrama del modelo de objetos + diccionario de datos.
4.1.2 EL MODELO DINAMICO
LoS aspectos del sistema que están relacionados con los cambios en el tiempo son los que constituyen el modelo dinámico, los cuales están en contraste con los aspectos estáticos del sistema, que constituyen el modelo de objetos. El concepto fundamental sobre el que gira el modelo dinámico son los "eventos" que representan estímulos externos, y los "estados" que representan los valores de los objetos en un momento dado; el uso de estos dos términos (eventos y estados) son empleados para denotar "control" y muy rara vez para realizar construcciones algebraicas. El control es aquel aspecto del sistema que describe las secuencias de operaciones que ocurren en respuesta a estímulos externos, sin considerar lo que las operaciones realizan, sobre que están operando o como fueron implementadas. Los estados y los eventos pueden ser organizados dentro de una jerarquía en la que comparten su estructura y su comportamiento.
Los siguientes pasos son ejecutados en la construcción del modelo dinámico:
• Preparar los escenarios sólo de las secuencias típicas del sistema. • Identificar los eventos existentes entre los objetos y preparar un escenario para
cada uno de ellos. • Preparar un diagrama de flujo de eventos para el sistema. • Desarrollar un diagrama de estado para cada clase que tiene un comportamiento
dinámico importante. • Verificar la consistencia de aquellos eventos que se comparten dentro del
diagrama de estado.
Modelo dinámico = diagramas de estado + diagramas de flujo de eventos globales.
4.1.3 EL MODELO FUNCIONAL
El modelo funcional describe las interacciones dentro de un sistema. Se puede decir que el modelo funcional es la tercera pierna del trípode, en adición al modelo de objetos y al modelo dinámico. El modelo funcional especifica qué sucede, el modelo dinámico especifica cuándo sucede y el modelo de objetos especifica a quién o a quiénes les sucede.
21

El modelo funcional muestra como determinados valores de salida son derivados de un ingreso de valores, sin considerar el orden en que los valores fueron computados. Consiste de múltiples diagramas de flujo de datos que muestran el flujo de los valores desde el ingreso de los mismos, así como sus operaciones, su almacenamiento interno y su salida. El modelo funcional también incluye restricciones entre valores dentro del modelo de objetos. Los diagramas de flujo de datos no muestran el control o la estructura de la información de los objetos ya que esto pertenece al modelo dinámico y al modelo de objetos.
El modelo funcional especifica el significado de las operaciones en el modelo de objetos y las acciones en el modelo dinámico, así como también cualquier restricción en el modelo de objetos. Programas no interactivos, tales como compiladores, tienen un modelo dinámico trivial, cuyo propósito es el computar una función, en cambio su modelo funcional es de suma importancia debido a sus programas, no obstante el modelo de objetos es importante para cualquier problema con estructuras de datos no triviales; existen muchos programas interactivos que tienen un importante modelo funcional, en contraste con las bases de datos que frecuentemente tienen un modelo funcional . simple, debido a que su propósito fundamental es almacenar y organizar datos, no transformarlos.
Una hoja electrónica es un ejemplo de un modelo funcional común. En la mayoría de los casos, los valores de la hoja electrónica son comunes y no pueden ser estructurados más adelante. El único objeto de interés en la estructura es la celda en la hoja electrónica como tal. El propósito de la hoja electrónica es el de especificar valores en términos de otros valores.
Un compilador es puramente computacional. El ingreso (input) es el texto de un programa en un lenguaje en particular; y su salida (output) es un archivo objeto que implementa el programa en otro lenguaje. Los mecanismos de compilación son irrelevantes para la aplicación.
El código de una aplicación de impuestos es una descripción funcional, se especifican fórmulas para computar los impuestos basados . en los ingresos, gastos, donaciones, estado civil, etc. El código de la aplicación también define objetos (ingresos, deducciones) y contiene información dinámica (cuando los impuestos están vencidos, cuando las formas de ingresos deben ser enviadas a los trabajadores). Un conjunto de formas de impuestos e instrucciones es un algoritmo que implementa el modelo funcional. Las formas de impuestos especifican como calcular los mismos basados en un conjunto de valores de entrada, tales como ingresos, gastos, deducciones etc. Se debe notar que las formas de impuestos sólo proveen el algoritmo para el cálculo de los impuestos, ellos por si solos no definen la función del cálculo del impuesto. En contraste, el código de la aplicación usualmente define dicha función sin especificar el algoritmo para calcularla.
Los siguientes pasos son ejecutados en la construcción del modelo funcional:
• Identificar los valores de entrada y salida.
22

• Utilizar los diagramas de flujo para mostrar las dependencias funcionales. • Describir que hace cada función. • Identificar las restricciones. • Especificar criterios de optimización.
Modelo funcional = diagrama de flujo de datos + restricciones.
4.2 LA RELACIÓN ENTRE LOS TRES MODELOS
El modelo funcional muestra que es lo que el sistema debe o tiene que hacer. El modelo de objetos muestra los actores -los objetos-o Cada proceso es implementado por un método en algún objeto. El modelo dinámico muestra la secuencia en la cual las operaciones son ejecutadas. Los tres modelos colaboran en la implementación de los métodos; siendo el modelo funcional la guía para el desarrollo de los métodos.
Los procesos en el modelo funcional corresponden a las operaciones dentro del modelo de objetos. Algunas veces, a un proceso le corresponden diversas operaciones o bien a una operación le corresponden diversos procesos.
Los procesos en el modelo funcional muestran objetos que están relacionados por una función. Frecuentemente el valor de ingreso de un proceso puede ser identificado como el objeto destino, y el resto como parámetros de la operación. El objeto destino es el cliente de los demás objetos (llamados proveedores), debido a que los usa para la ejecución de las operaciones. El objeto destino conoce a cerca de los clientes, pero los clientes no necesariamente conocen de los objetos destino. Una clase de objetos es dependiente de los argumentos de la clase para realizar sus operaciones. La relación entre clientes-proveedores establece la implementación de dependencias entre clases; los clientes son implementados en términos de, y por lo tanto dependientes de la clase proveedora.
Los actores son objetos explícitos dentro del modelo de objetos. Los flujos de datos que se dirigen o vienen de los actores representan operaciones para los objetos. Los valores de los flujos de datos son los argumentos o resultados de las operaciones. Debido a que los actores son objetos automotivados, el modelo funcional no es capaz de indicar cuando ellos actúan, es el modelo dinámico el que especifica cuando actúa.
Los medios de almacenamiento de datos son también objetos dentro del modelo de objetos, cada flujo dentro de ellos son procesos de actualización, y cada salida de ellos son operaciones de queries. Los medios de almacenamiento son objetos pasivos que responden a eventos de actualización o bien a operaciones queries.
Los flujos de datos son valores puros dentro del modelo de objetos, muchos de ellos son simplemente valores, como números, strings, o una lista de ellos; estos pueden ser modelados como clases e implementados como objetos en la mayoría de los lenguajes, pero ellos no tiene una identidad. Estos valores puros no tienen estado y no poseen estructura dentro de un modelo dinámico.
23

Refiriéndose al modelo de objetos, éste muestra las operaciones sobre las clases y los argumentos de cada operación, por lo tanto muestra la relación del cliente y el proveedor entre las clases. El modelo dinámico muestra los estados de cada objeto y las operaciones que son ejecutadas al momento. de recibir eventos que cambian o modifican su estado.
Refiriéndose al modelo dinámico y al modelo funcional, éstos muestran las definiciones de las acciones y actividades que no están definidas dentro del modelo de objetos. El modelo de objeto muestra qué es lo que hace cambiar un estado y las operaciones a las que es sometido.
El modelo funcional muestra una computación y las derivaciones funcionales de los valores de los datos dentro de él sin indicar cómo, cuándo o porqué esos valores fueron computados. El modelo dinámico controla que operaciones son ejecutadas así como el orden en el cual son aplicadas. El modelo de objetos define la estructura de los valores sobre los cuales las operaciones serán ejecutadas.
4.2.1 VERIFICAR, ITERAR Y REFINAR LOS TRES MODELOS.
• Agregar operaciones que se consideren claves que hayan sido determinadas durante la preparación del modelo funcional.
• Verificar que las clases, asociaciones, atributos y operaciones sean consistentes a determinado nivel de abstracción comparando los tres modelos con la declaración del problema y probándolos utilizando escenarios.
• Desarrollar escenarios más detallados (incluyendo condiciones de error) como una variación a los escenarios básicos.
Documento de análisis = declaración del problema + modelo de objetos + modelo dinámico + modelo funcional.
4.3 FASES DEL DESARROLLO DE UN SISTEMA ORIENTADO A OBJETOS
Las fases del desarrollo de un sistema orientado a objetos son similares a las técnicas tradicionales en el sentido de que se habla de una fase de análisis, una fase de diseño, una fase de implementación, etc. La diferencia esta en la transición de una fase a otra y en la consistencia de las técnicas usadas en cada una de ellas.
4.3.1 IDENTIFICACiÓN DE REQUERIMIENTOS
En esta fase se establecen claramente las necesidades del sistema. Los roles que los usuarios desarrollaran son identificados junto con la identificación preliminar del dominio de los objetos, se especifican los escenarios detallando como los usuarios interactúan con el sistema.
24

4.3.2 ANÁLISIS
Esta fase comienza desde las proposiciones del problema. La identificación de los requerimientos es transformada a un sólido sistema que incluye el desarrollo de un modelo detallado de objetos y un modelo dinámico. En este punto no se especifican detalles de implementación.
El análisis construye un modelo de una situación real en la que se muestran sus propiedades más relevantes. El modelo del análisis es conciso, precisa realizar una abstracción del "qué" el sistema debe realizar, y no del "cómo" deber ser hecho. Los objetos en el modelo deben ser los conceptos del dominio de la aplicación y no los conceptos de la implementación en la computadora, tales como estructuras de datos. Un buen modelo debe ser entendido y criticado por un experto, el cual no debe ser programador. El modelo de análisis no debe contener ninguna decisión de implementación.
4.3.3 DISEÑO
El diseñador realiza decisiones de alto nivel acerca de toda la arquitectura del sistema. Durante la fase del diseño, el sistema es organizado en subsistemas basados en la estructura desarrollada en la fase del análisis la cual proporciona el propósito de la arquitectura del sistema. El diseñador del sistema debe decidir que características de desempeño debe optimizar, escoger la estrategia para el diseño, y realizar cálculos tentativos para fuentes de almacenamiento.
El diseñador de objetos desarrolla el diseño del modelo basado en el modelo de análisis conteniendo detalles de implementación. El diseñador agrega detalles al modelo en concordancia con la estrategia establecida durante el diseño del sistema. El foco del diseño de los objetos es la estructura de datos y los algoritmos necesarios para implementar cada clase.
El modelo de objetos y el modelo dinámico desarrollados durante la fase de análisis son refinados y en esta fase se introducen los aspectos de implementación, esto incluye:
• La arquitectura de la aplicación. • Consideraciones de desempeño. • Ambientes de hardware. • Ambientes de software.
• etc.
25

4.3.4 IMPLEMENTACiÓN
La codificación es creada durante esta fase. Los modelos de objetos y dinámicos que han sido refinados, deben ser convertidos fácilmente a definiciones de clases y métodos utilizando algún lenguaje de programación orientado a objetos tal como C++ o Smalltalk.
4.3.5 LAS PRUEBAS Y EL MANTENIMIENTO DEL SISTEMA
Esta es la fase encargada de probar el sistema así como también de la puesta en producción del mismo y su mantenimiento.
4.4 CONSISTENCIA DE CONCEPTOS Y FLEXIBILIDAD ENTRE FASES
La consistencia de conceptos ayudan a aplicar el mismo conjunto de técnicas de modelado a todos los escenarios del desarrollo, especialmente en el modelo de objetos y en el modelo dinámico.
Debido a que .Ios mismos conceptos y técnicas de modelado son aplicados a lo largo del proceso de desarrollo, las fronteras entre las fases (especialmente en el análisis y el diseño) se vuelven menos aparentes. Esta consistencia de conceptos y la flexibilidad entre las fases conllevan una gran iteratividad y recursión durante el proceso del desarrollo.
4.5 UNIDAD DE CONCEPTOS VRS. TÉCNICAS DE FASE
En un sistema estructurado se utilizan diferentes técnicas de modelado para la fase de análisis y diseño, por ejemplo:
En la fase de análisis los diagramas de flujo son utilizados para representar el modelo de datos de los procesos del sistema y las tareas complejas son incrementalmente subdivididas dentro de tareas más simples. En la fase de diseño los diagramas de flujo se grafican para mostrar estructuras en forma de árbol.
Un sistema orientado a objetos muestra una vista consistente del sistema sin importar en que parte del proceso de desarrollo se esté.
26

CAPITULO V
5. EL PROCESO DEL ANALlSIS
El proceso del análisis tiene diversos propósitos: clarifica los requerimientos, provee las bases para el acuerdo entre los requisito res del sistema y los desarrolladores del mismo, se convierte en la estructura base para el diseño y la implementación.
El análisis comienza con el relato de un problema por los clientes, el cual puede ser completo o informal; el análisis lo transforma en más preciso y expone sus ambigüedades e inconsistencias, refinándolo y haciéndolo llegar a los requerimientos reales. Luego de que el sistema ha sido descrito, debe ser entendido y sus características esenciales abstraídas dentro de un modelo. El modelo del análisis es una representación precisa y concisa del problema que permite responder preguntas y modelar una solución.
El modelo del análisis se refiere a tres aspectos de los objetos: su estructura estática (el modelo de objetos), la secuencia de sus interacciones (el modelo dinámico), y las transformaciones que sufren los datos (el modelo funcional); los tres modelos no son igualmente importantes en cada problema, debido a que la mayoría de los problemas tienen modelos de objetos que se derivan de entidades del mundo real. Problemas concernientes a interacciones tales como interfases de usuarios y controles de procesos, tienen un modelo dinámico importante. Problemas conteniendo una cantidad significante de cálculos, tales como compiladores poseen un modelo funcional importante.
El análisis no puede ser siempre llevado como una secuencia rígida, debido a que en modelos muy largos, un subconjunto (subset) es construido, luego extendido hasta que el problema completo sea entendido. El análisis no es un proceso mecánico, la mayoría de los relatos del problema carecen de información esencial, la cual debe ser obtenida del conocimiento que el analista tenga del dominio del problema, y que a su vez debe mantener comunicación con el usuario para clarificar las ambigüedades del problema. El modelo del análisis facilita una comunicación precisa.
El principal propósito del proceso del análisis es entender los alcances que el sistema deberá cumplir, para dicho efecto se basa en dos modelos:
• El modelo de requerimientos. • El modelo de análisis.
27

5.1 EL MODELO DE REQUERIMIENTOS
Este modelo clarifica exactamente que es lo que se espera que el sistema deba realizar, este debe ser desarrollado desde el punto de vista del usuario, deberá ser fácil de entender (no deberá contener vocabulario técnico) y deberá ser discutido con los usuarios para asegurar su exactitud.
La información que da origen al modelo de requerimientos esta constituida por:
• Un documento formal de requerimientos especificando las necesidades del sistema.
• El conjunto de discusiones con los usuarios del sistema. • Una combinación de los dos puntos anteriores.
El producto que proporciona el modelo de requerimientos es considerado el principal resultado de este proceso, constituye el fundamento para el análisis, el diseño y la implementación. Esta constituido por:
• El desarrollo del modelo de casos de usuario (use-cases). • El dominio del modelo de objetos. • El modelo de las interfases de usuario.
5.1.1 DESARROLLO DEL MODELO DE CASOS DE USUARIO (USE-CASES)
Proveen una completa especificación de como el sistema debe funcionar desde el punto de vista del usuario. En este modelo se definen los actores del sistema así como los casos de usuario.
5.1.1.1 ACTORES
Describen el papel que desempeñan los usuarios dentro del sistema. Un sencillo usuario puede desempeñar el papel de más de un actor. Los actores generalmente modelan usuarios humanos aunque pueden modelar cualquier cosa que interactúe con el sistema, inclusive otros sistemas. Esencialmente los actores modelan cualquier cosa externa al sistema que se comunica con él o bien que ejecuta tareas sobre él.
Los actores primarios son los principales usuél.rios del sistema. El sistema se diseña básicamente para dichos actores. Los actores secundarios son aquellos que mantienen el sistema o que lo utilizan en forma ocasional.
28

5.1.1.2 CASOS DE USUARIO
Estos describen en detalle como un actor utiliza el sistema y como ejecuta determinada tarea, describen el curso completo de los eventos requeridos para llevar a cabo una tarea desde su inicio hasta su final. Se hace mucho énfasis en la interacción entre el sistema y el actor.
Cada actor desempeña un determinado número de tareas dentro del sistema, por lo que a cada tarea le corresponde un caso de usuario. En este punto es necesario examinar cada actor e identificar el respectivo caso de usuario para definir la funcionalidad completa de él dentro del sistema. Al realizar dicho proceso se deberá comenzar con los actores primarios. Los pasos a seguir para la formulación de casos de usuario son:
5.1.1.2.1 Examinar las especificaciones de los requerimientos
Se deben examinar las especificaciones de los requerimientos desde el punto de vista del usuario para determinar que tareas realiza. Las preguntas que se deben incluir en este punto son:
• ¿Cuáles son las tareas principales del actor? • ¿Qué información debe suministrar el actor al sistema para llevar a cabo dicha
tarea? • ¿Qué información debe el sistema proporcionar al actor para que éste lleve a
cabo dicha tarea? • ¿Qué información debe el actor cambiar para llevar a cabo la tarea?
5.1.1 .2.2 Nombrar el caso de usuario
El siguiente paso es nombrar el caso de usuario que se ha identificado por cada uno de ellos. Por ejemplo un "Cliente" desea hacer un retiro de cuenta de ahorros, por lo que se podría nombrar este caso de usuario como "Retiro de Cuenta".
• ¿Qué otros casos de usuario puede el "Cliente" realizar? • ¿Qué otros casos de usuario puede el "Funcionario" realizar?
• Transferencias de fondos. • Modificar los datos del "Cliente". • Etc.
29

5.1.1.2.3 Sumarizar cada caso de usuario
Se deberá escribir un breve sumario describiendo cada caso de usuario. En el caso del ejemplo anterior se podría sumarizar de la siguiente forma: "El retiro de una cuenta lo inicia el Cliente cuando desea llevar a cabo un retiro de alguna de sus cuentas, el sistema le solicita información sobre cual cuenta se desea realizar el retiro, el Cliente indica la cuenta y el total del retiro. El sistema realiza la verificación del saldo y si procede realiza el retiro de fondos y ajusta el saldo de la cuenta"
5.1.1.2.4 Extender el sumario
Extender las descripciones del sumario por medio de un algoritmo- Este proceso frecuentemente identifica áreas que no están claras dentro de la especificación de los requerimientos. Ejemplo:
• El cliente inicia el proceso del retiro de efectivo, para ello selecciona la cuenta de la que desea realizar el retiro.
• El sistema le solicita al Cliente que indique la cuenta y la cantidad del retiro . • El sistema realiza la verificación del saldo. • Si procede, el sistema realiza el retiro de la cuenta por la cantidad indicada. • Si procede, el sistema ajusta el saldo de la cuenta y despliega el saldo.
Los casos de usuario generalmente siguen un curso básico, el cual proporciona claridad y entendimiento al mismo. Las variaciones que surjan de ese curso básico son llamadas cursos alternos, los cuales incluyen:
• Decisiones presentadas por un actor durante la ejecución de un caso de usuario.
• Errores encontrados durante la ejecución de un caso de usuario.
Los cursos alternos pueden ser separados de los casos de usuario como una extensión de los mismos, lo que permite ir adicionando extensiones sin alterar el caso de usuario original. Así por ejemplo, si el "Cliente" desea sobregirarse en el retiro de una de sus cuentas, el sistema automáticamente verificará una protección en contra de ello. Lo cual deberá estar definido como una extensión al caso de usuario llamada "Sobregiro" que maneje este tipo de eventualidades.
5.2 EL MODELO DE ANÁLISIS
El modelo de análisis adiciona estructura al modelo de requerimientos, describe los detalles necesarios para entender el sistema lo cual incluye: quién lo usa, qué
30

pueden los usuarios realizar con él y con qué objetos interactúan. El modelo de análisis es llevado a cabo mediante el desarrollo del modelo de objetos y el modelo dinámico.
Con este modelo, la identificación del dominio de los objetos es concluida y los casos de usuarios son examinados en búsqueda de objetos que no hayan sido identificados. Con este modelo:
• Las capas de la aplicación son definidas. En donde: las interfases con los usuarios, el modelo de negocios, los requerimientos para el acceso y recuperación de la información son separados.
• Los objetos son agrupados dentro de subsistemas llamados ensambles (ensembles).
• Los objetos son divididos dentro de objetos de control. • Los detalles de implementación no se consideran en este modelo.
5.2.1 CAPAS DE LA APLICACIÓN
Los sistemas orientados a objetos están construidos por tres distintas capas que constituyen la aplicación:
5.2.1.1 LA CAPA DE PRESENTACIÓN (VIEW LAYER)
Esta describe las interfases con los usuarios por medio de las cuales se accede y manipula el sistema (GUI Graphic User Interface).
5.2.1.2 LA CAPA DE NEGOCIOS (BUSINESS LAYER)
Esta es la capa en la que las necesidades del negocio son modeladas, incluyen todos aqUellos objetos relacionados dentro del sistema como por ejemplo: los clientes, las facturas, los empleados, etc.
5.2.1.3 LA CAPA DE ACCESO (ACCESS LAYER)
Esta capa provee los accesos externos del sistema. Incluye el almacenamiento y recuperación de la información, accesos a disco y accesos a bases de datos, etc.
El modelo del análisis se enfoca en el desarrollo de la capa de negocios. La capa de presentación y de acceso, que involucran los detalles de implementación son analizadas durante el proceso del diseño.
31

5.2.2 ENSAMBLES (ENSEMBLES)
El primer paso para adicionar estructura al modelo de requerimientos es visualizar al sistema como una colección de objetos agrupados lógicamente. Un ensamble representa una colección de objetos agrupados sobre cierto criterio en común. Al igual que todos los objetos, los ensambles:
• Encapsulan sus detalles de implementación del mundo exterior. • Tienen una muy bien definida interfase por la que otros objetos o ensambles
se comunican entre ellos. • Pueden consistir de otros ensambles.
Si se analiza el caso en el que un cliente acude a una empresa en búsqueda de un bien o seNicio, al Cliente le interesa colocar la orden y recibir el producto. Al cliente no le interesa como la compañía maneja la orden en forma interna. Dentro de la compañía existen pequeños departamentos (ensambles), cada uno de los cuales es responsable de determinados aspectos dentro de la compañía.
Los ensambles describen una estructura jerárquica del sistema en términos de diferentes niveles de abstracción. Todos los objetos dentro de un ensamble pueden ser categorizados como objetos de control, agentes o contenedores.
5.2.2.1 OBJETOS DE CONTROL
Estos controlan el comportamiento de su ensamble por medio de delegar operaciones a otros objetos. Los objetos de control nunca pueden ser operados por otros objetos dentro de su propio ensamble. Estos objetos ejercen un gran control debido a que ellos afectan a otros objetos.
5.2.2.2 AGENTES
Estos son objetos que pueden delegar operaciones y recibir requerimientos de otros objetos, pueden responder a los requerimientos de los objetos de control así como también a otros agentes. Estos objetos tienen un moderado control dentro del sistema.
5.2.2.3 CONTENEDORES
Estos objetos representan la porción más estática del sistema, estos típicamente no pueden delegar operaciones y sólo responden a los requerimientos acerca de la información que ellos contienen.
32

5.3 EL PLANTEAMIENTO DEL PROBLEMA
El primer paso en el desarrollo es la declaración de los requerimientos, esto aplica tanto a programas simples como a aquellos que requieren un gran esfuerzo de equipo. Definiendo vagamente estos requerimientos ocasiona que más adelante se tenga que realizar modificaciones que resultan muy costosas.
En la definición del problema, se expondrá que debe realizar el sistema y. no como se llevará a cabo. Se deberá desarrollar una lista de necesidades, y no una propuesta de solución. Un manual de usuario para el sistema deseado sería un buen planteamiento del problema. El usuario deberá indicar que características son obligatorias y cuales son opcionales, para evitar el no cubrir restricciones de diseño.
5.3.1 UNA VISTA DEL PROCESO DE ANÁLISIS
Presentación de requerimientos
• Amplitud del problema. • Que se necesita. • El contexto de la aplicación. • Lo que se asume del problema. • Necesidades de desempeño.
Diseño e implementación
• Acercamiento general. • Algoritmos. • Estructuras de datos. • Arquitectura. • Optimizaciones.
Un problema común que afrontan los analistas es el mezclar requerimientos del sistema con decisiones de diseño. Así mismo, el analista debe separar los verdaderos requerimientos del diseño de las decisiones de implementación ocultas como requerimientos, los cuales pueden llegar a restringir la flexibilidad del sistema.
El planeamiento del problema se puede desarrollar con mucho o poco detalle dependiendo de los requerimientos del producto que se pretende desarrollar. Por ejemplo en un sistema de nómina o de control de chequeras, se debe tener un detalle considerable; por otra parte los requerimientos para un sistema de investigación en una nueva área pueden carecer de mucho detalle.
La mayoría de los planteamientos del problema son ambiguos, incompletos y aún inconsistentes; algunos de ellos simplemente planeados equivocadamente. Algunos planteamientos, a pesar de que han sido establecidos en forma precisa,
33

tienen desagradables consecuencias sobre el comportamiento del sistema o simplemente imponen irrazonables costos de implementación. Algunos planteamientos parecen razonables al principio pero no resuelven el problema de la forma en la que el usuario pensó. El planteamiento del problema es el punto de arranque para comprender el problema y no es un documento inmutable. El propósito de un análisis subsiguiente es el entender completamente el problema y sus implicaciones.
El analista debe trabajar muy estrechamente con el usuario para refinar los requerimientos y verificar que lo que se ha obteniendo, es lo que el usuario realmente espera del sistema.
34

CAPITULO VI
6. EL DISEÑO DEL SISTEMA
Luego de haber analizado el problema, se debe decidir como afrontar el diseño. El diseño del sistema es una estrategia de alto nivel para solucionar el problema y desarrollar una solución, en él se incluyen decisiones de como se organizará el sistema dentro de subsistemas, el alojamiento de los mismos dentro de componentes de software y hardware, y las mayores decisiones conceptuales que formarán la estructura de un diseño detallado.
El sistema puede ser dividido en capas horizontales y particiones verticales. Cada capa define una parte abstracta del sistema que lo diferencia completamente de las otras. Cada capa es proveedora de servicios para las capas por debajo de ella y suministra servicios para las capas que están arriba. Los sistemas pueden ser divididos dentro de particiones, de las cuales cada una ejecuta una clase general de servicio.
Durante el análisis, el foco de interés es saber y entender qué se necesita hacer, independientemente de como será realizado. Durante el diseño, las decisiones son realizadas en torno a como el problema será solucionado, primeramente a un alto nivel y luego adicionando varios niveles de detalle.
En el diseño, el primer escenario es seleccionar un acercamiento básico para la solución del problema. Durante esta fase toda la estructura y los estilos del diseño son decididos. El diseñador realizará las siguientes decisiones acerca de como:
• Organizar el sistema dentro de subsistemas.
• Identificar la concurrencia inherente dentro del problema.
• Escoger un acercamiento para la administración del almacenamiento de los datos.
• . Manejar los accesos a los recursos globales.
• Escoger la implementación de control en el software.
• Manejar los límites o fronteras del sistema.
• Priorizar actividades.
• Realizar estructuras comunes para el diseño del sistema.
35

6.1 DIVIDIENDO EL SISTEMA DENTRO DE SUBSISTEMAS
Para cualquier aplicación por pequeña que sea, el primer paso es dividir el sistema dentro de pequeños componentes llamados subsistemas.
Un susbsistema define una forma coherente de un aspecto del problema. Un subsistema no es un objeto ni una función, es un grupo de clases, asociaciones, operaciones, eventos y restricciones que están interrelacionadas y que tienen una bien definida interfase con otros subsistemas. Un subsistema es usualmente identificado por los servicios que provee. Un servicio es un grupo de funciones relacionadas que comparten algún propósito común, tales como entradas y salidas de procesamiento, despliegue de imágenes o cálculo de operaciones aritméticas.
Debido a que los sistemas son divididos dentro de subsistemas, la mayoría de interacciones son dentro de ellos y rara vez a lo largo de las fronteras del mismo, esto con el propósito de reducir las dependencias entre los subsistemas. Cada subsistema puede ser aún descompuesto dentro de pequeños subsistemas, los cuales son llamados módulos.
La descomposición de los subsistemas dentro de módulos puede ser organizada como una secuencia horizontal de capas o particiones verticales.
6.1.1 CAPAS
Un sistema descompuesto en capas es un conjunto ordenado de sistemas virtuales, cada uno construido en términos de las capas inferiores que proveen las bases de implementación de las capas superiores.
Las arquitecturas en forma de capas se dan de dos formas: cerradas y abiertas. En una arquitectura cerrada, cada capa es construida en términos de la capa por debajo de ella. Esto reduce las dependencias entre capas y permite cambios de forma más fácil debido a que la interfase de la capa sólo afecta a la capa siguiente. En una arquitectura abierta, una capa puede usar características de cualquier capa por debajo de ella. Esto redl!ce la necesidad de redefinir las operaciones a cada nivel, lo que implementado en forma adecuada puede brindar un código eficiente y compacto. Sin embargo, una arquitectura abierta no observa el principio del ocultamiento de la información. Los cambios en un subsistema pueden afectar cualquier subsistema de capas superiores, por lo que una arquitectura abierta es menos robusta que una arquitectura cerrada.
Ambas arquitecturas son útiles, por lo que el diseñador debe pesar el valor relativo de la eficiencia y la modularidad.
36

Usualmente, sólo la capa superior e inferior son especificadas en el planteamiento del problema. La capa superior es el sistema deseado que se planea construir, la capa inferior la constituyen los recursos disponibles (sistemas operativos, equipo, software, etc.). Si la disparidad entre las dos capas es muy grande, el diseñador debe introducir capas intermedias para reducir ese espacio conceptual entre las mismas.
Un sistema construido en capas puede ser portado a otras plataformas de software y hardware por medio de la reescritura de una capa. Es una buena práctica introducir como mínimo una capa de abstracción entre la aplicación y cualquier servicio provisto por el sistema operativo o el hardware.
6.1.2 PARTICIONES
Las particiones verticales dividen a un sistema dentro de diversas particiones independientes, las cuales proveen una clase de servicio. Un sistema puede ser descompuesto sucesivamente dentro de subsistemas usando capas y particiones por medio de la combinación entre ellas: las capas pueden ser particionadas y las particiones pueden ser estratificadas en capas.
6.2 IDENTIFICANDO LA CONCURRENCIA
En el análisis del modelo, todos los objetos son concurrentes. Sin embargo dentro de una implementación no todo el software es concurrente, debido a que un procesador puede dar soporte a muchos objetos.
El modelo dinámico es la guía para identificar la concurrencia. Dos objetos son inherentemente concurrentes si ellos pueden recibir eventos al mismo tiempo sin interactuar entre ellos. Si los eventos no son sincronizados, los objetos no pueden ser llevados dentro de un mismo proceso de control. Por ejemplo, el motor y los controles de las alas de un avión deben operar concurrentemente. Los sistemas independientes son deseables debido a que ellos pueden ser asignados a diferentes unidades de equipos sin ningún costo de comunicación.
Debido a que los objetos son conceptualmente concurrentes, en la práctica, muchos objetos dentro de un sistema son interdependientes. Examinando en el intercambio de eventos de un objeto individual en un diagrama de estado, se observa que muchos de ellos, pueden enlazarse dentro de un mismo flujo. El flujo de control es el conjunto de estados por los que un objeto a estado activo. El flujo continua activo dentro de un diagrama de estado hasta que un objeto envía un evento hacia otro objeto, el que espera por otro evento. El flujo es pasado al objeto receptor hasta que eventualmente retorna a su objeto original.
37

En cada flujo de control, solo un objeto esta activo a la vez. Los flujos de control son implementados como tareas dentro de un sistema de computadoras.
6.3 LA ADMINISTRACiÓN DEL ALMACENAMIENTO DE LOS DATOS
El almacenamiento interno y externo de los datos dentro de un sistema provee puntos claros de separación entre los subsistemas por medio de bien definidas interfases. En general cada almacenamiento de datos puede combinar estructuras de datos, archivos y bases de datos que son implementados por medio de dispositivos secundarios de almacenamiento.
6.4 MANEJAR LOS ACCESOS A LOS RECURSOS GLOBALES
El diseñador debe identificar las fuentes globales del sistema y determinar las técnicas para controlar los accesos hacia ellos. Si el recurso del que se trate es un objeto físico, este puede controlarse él mismo por medio de un protocolo adecuado.
6.5 ESCOGER LA IMPLEMENTACiÓN DE CONTROL EN EL SOFTWARE
Durante el análisis, todas las interacciones son mostradas como eventos entre objetos, por lo que no es necesario que todos los subsistemas usen la misma implementación. Usualmente el diseñador escoge un estilo sencillo de control para todo el sistema. Existen dos clases de flujos de control en el desarrollo del software de una aplicación: los controles externos y los controles internos.
El control externo es el flujo que hace visible los eventos entre los objetos y el sistema. Existen tres clases de control para eventos externos: procedimientos secuenciales, eventos secuenciales y concurrencia. El estilo de control implementado, depende de los recursos disponibles (lenguajes de programación, sistemas operativos) y sobre el patrón de las interacciones dentro de la aplicación.
El control interno es el flujo del control dentro de un proceso. Este existe sólo en la implementación, por lo tanto no es inherentemente concurrente ni secuencial.
6.5.1 SISTEMAS MANEJADOS POR PROCEDIMIENTOS
En un sistema manejado por procedimientos secuenciales, el control reside dentro del código de un programa. La mayor ventaja de este tipo de control de procedimientos es que son fáciles de implementar en lenguajes convencionales de programación, su desventaja es que requieren de concurrencia en los objetos que son mapeados dentro de flujos secuenciales de control. Una operación típica de ello le
38

corresponde a un par de eventos: la salida de un evento que ejecuta outputs y a su vez requiere de inputs y un evento de input que genera nuevos valores.
6.5.2 SISTEMAS MANEJADOS POR EVENTOS
En un sistema manejado por eventos, el control reside dentro del despachador o monitor provisto por el lenguaje, subsistema o sistema operativo. Los procedimientos de la aplicación son unidos a los eventos y son invocados por el despachador cuando el evento correspondiente suceda (callback). El procedimiento le indica al despachador que envíe un output o habilite un input pero no espera por ninguno de ellos en línea. Todos los procedimientos retornan el control al despachador, rara vez retienen el mismo en espera de un evento.
Estos tipos de sistemas permiten patrones más flexibles de control que los sistemas manejados por procedimientos, los sistemas manejados por eventos simulan procesos cooperativos dentro de una tarea. Un procedimiento errado puede bloquear la aplicación completa, por lo que se debe ser cuidadoso con ellos.
Estos sistemas se deben utilizar de preferencia para controles externos en vez de los sistemas manejados por procedimientos cuando sea posible, debido a la construcción de la programación es mucho más simple y poderosa, son más modulares y pueden manejar mejor las condiciones de error.
6.5.3 SISTEMAS CONCURRENTES
Dentro de un sistema concurrente el control reside concurrentemente dentro de diversos objetos independientes, cada · uno con tareas separadas. Los eventos son implementados directamente como mensajes que viajan en un solo sentido entre los objetos. Una tarea puede esperar por un input, mientras que otra tarea continua su ejecución. El sistema operativo usualmente provee de mecanismos para la administración de colas para eventos, por lo que dichos eventos se pierden si una tarea esta siendo ejecutada al momento de su arribo.
6.6 MANEJAR LOS LIMITES O FRONTERAS DEL SISTEMA
A pesar de que muchos de los esfuerzos en el diseño de sistemas están orientados hacia el comportamiento de los estados, el diseñador deberá considerar las siguientes posibles condiciones del sistema: inicialización, finalización y fallas.
6.6.1 INICIALIZACiÓN
El sistema debe arrancar desde un sistema inicial estático hasta una condición estable. Entre los objetos que deben inicializarse están: datos constantes, parámetros,
39

variables globales, tareas, así como también clases de jerarquía. Durante la inicialización sólo un subconjunto de la funcionalidad del sistema esta usualmente disponible.
6.6.2 FINALIZACiÓN
La finalización es usualmente más simple que la inicialización debido a que diversos objetos internos del sistema pueden ser simplemente abandonados, por lo que la tarea encargada de la finalización simplemente deberá liberar cualquier recurso externo que la aplicación haya reservado para ella. En un ambiente concurrente, una tarea debe notificar a las demás de su terminación.
6.6.3 FALLAS
Una falla es la finalización no planeada del sistema, la cual se puede deber a errores del usuario, por el debilitamiento de los recursos del sistema, por algún factor externo o bien por fallas dentro del sistema.
6.7 PRIORIZAR ACTIVIDADES
El diseñador deberá desarrollar una lista de prioridades que le servirán de guía durante · el resto del diseño, así mismo deberá determinar la importancia relativa que tienen los intercambios de decisiones durante el diseño. No todos estos intercambios de decisiones son elaborados durante el diseño del sistema, lo único que se establece durante esta etapa son las prioridades para el desarrollo del mismo.
Todo el sistema se ve afectado por dichas decisiones, por lo que el éxito o el fracaso del producto final puede depender de sí la priorización fue llevada acabo en forma correcta.
6.8 ESTRUCTURAS COMUNES DE ARQUITECTURAS
Existen diversos prototipos de arquitecturas que son comunes en sistemas existentes, cada una de ellas se acopla perfectamente a cada clase del sistema. Si existe alguna aplicación con similares características, se pueden ahorrar esfuerzos utilizando dicha arquitectura, o por lo menos usándola como punto de inicio para el diseño. Estas clases de diseño incluyen:
• Transformaciones en lotes (la transformación de los datos se realiza una sola vez sobre un conjunto de datos).
40

• Transformaciones en forma continua (la transformación de los datos se realiza en forma continua al momento en que los datos arriban).
• Interfases interactivas (cuando un sistema es dominado por medio de interacciones externas).
• . Simulaciones dinámicas (por medio de un sistema que simula la evolución de un objeto).
• Sistemas en tiempo real (un sistema que es dominado por restricciones estrictas de tiempo).
• Administración de transacciones (un sistema centrado en el almacenamiento y actualización de los datos, que muy frecuentemente incluye accesos concurrentes de diferentes localizaciones físicas).
6.8.1 TRANSFORMACIONES EN LOTES
Una transformación en lotes es una transformación secuencial de inputs y outputs, en la que los primeros son suministrados al inicio y su propósito es computar una respuesta; no existe ninguna interacción con el exterior. Ejemplos de ello incluyen problemas estándares computacionales, tales como compiladores, aplicaciones de nómina, etc.
Los pasos para el diseño de las transformaciones por lotes son las siguientes:
• Dividir el sistema dentro de escenarios, de forma que cada escenario realice una parte de la transformación.
• Definir clases intermedias para los flujos de datos entre cada par de eventos sucesivos. Cada escenario conoce solo los objetos al lado de él, así como sus propios inputs y outpus.
• Expandir cada escenario hasta que las operaciones sean implementadas.
6.8.2 TRANSFORMACIONES EN FORMA CONTINUA
Una transformación en forma continua, es un sistema en el cual los outputs dependen de los cambios realizados sobre los inputs, y los cuales deben ser actualizados en forma periódica; en contraposición de las transformaciones en lotes, en la que los outputs son computados una sola vez. Debido a las severas restricciones de tiempo, el output completo no puede ser recomputado cada vez que un input cambia (de otra forma la aplicación seria en lotes). En lugar de ello, los valores de un nuevo output deben ser computados incrementalmente. Aplicaciones típicas de este
41

tipo de transformaciones incluyen: procesos de señal, sistemas de ventanas, compiladores incrementales y sistemas de procesos de monitoreo.
Los pasos para el diseño de esta interfase son los siguientes:
• Modelar un diagrama de flujo de datos para el sistema. Los actores para los inputs y outputs corresponden a las estructuras de datos cuyos valores están en constante cambio. El almacenamiento de los datos dentro del sistema muestra los parámetros que afectan el mapeo de los inputs-outputs.
• Definir objetos intermedios entre cada par de escenarios sucesivos, tal como se realiza en las transformaciones en lotes.
• Diferenciar cada operación para obtener cambios incrementales para cada escenario.
• Agregar objetos intermedios con el propósito de optimizar el diseño del sistema.
6.8.3 INTERFASES INTERACTIVAS
Una interfase interactiva es un sistema dominado por las interacciones entre el sistema y los agentes externos, tales como humanos, dispositivos, programas, etc. Los agentes externos son independientes del sistema, por lo que sus inputs no pueden ser controlados, aunque el sistema pueda solicitar alguna respuesta por parte de ellos.
Una interfase interactiva usualmente incluye solo una parte de la aplicación, la cual frecuentemente puede ser manejada independientemente desde la parte computacional de la aplicación. Estas interfases son dominadas por medio del modelo dinámico. Los objetos dentro del modelo de objetos representan la interacción con los elementos, tales como inputs, outputs y formatos de presentación. El modelo funcional describe que funciones de la aplicación son ejecutadas en respuesta a una secuencia de eventos, pero la estructura interna de las funciones no tienen importancia para el comportamiento de la interfase. Un sistema interactivo se concentra en la apariencia externa y no en la estructura semántica de la aplicación.
Los pasos para el diseño de esta interfase son los siguientes:
• Aislar los objetos que forman la interfase de los objetos que definen la semántica de la aplicación.
• Usar objetos predefinidos para interactuar con los agentes externos, si es posible.
42

• Usar el modelo dinámico como estructura para los programas.
• Aislar los eventos físicos de los eventos lógicos.
• Especificar completamente las funciones de la aplicación que son invocadas por las interfases.
6.8.4 SIMULACIONES DINÁMICAS
Una simulación dinámica modela los objetos de la aplicación. Ejemplos de éstas: el modelo del movimiento molecular, el cálculo de la trayectoria de una nave espacial, modelos económicos y juegos de video.
Las simulaciones son probablemente los sistemas más simples de diseñar usando la metodología orientada a objetos. Los objetos y las operaciones vienen directamente de la aplicación. El control puede ser implementado de dos formas: un controlador externo explícito a la aplicación puede simular un estado, o bien los objetos pueden intercambiar mensajes entre ellos, en forma similar a la realidad.
El modelo dinámico es el modelo más importante para el diseño de los sistemas de simulación.
Los pasos para el diseño de las simulaciones dinámicas son los siguientes:
• Identificar los actores del modelo de objetos. Los actores tienen atributos, que son actualizados en forma periódica.
• Identificar eventos discretos. Estos eventos corresponden a interacciones discretas con los objetos, tales como el encender un motor o aplicar los frenos. Los eventos discretos pueden ser implementados como operaciones sobre los objetos.
• Identificar dependencias continuas. Los atributos del sistema pueden depender de circunstancias que pueden variar, por ejemplo: el tiempo, la altitud, la velocidad, la posición del volante de un automóvil, etc. Estos atributos deben ser actualizados en intervalos periódicos de tiempo.
El problema más serio con las simulaciones es usualmente el de proveer un adecuado desempeño.
6.8.5 SISTEMAS EN TIEMPO REAL
Un sistema en tiempo real es un sistema interactivo para los cuales las restricciones sobre acciones son . particularmente cerrados o bien en la que cualquier
43

demora de tiempo no puede ser tolerada, por lo que el sistema debe garantizar una respuesta dentro de un intervalo de tiempo sumamente corto.
El diseño de estos tipos de sistemas involucran aspectos tales como manejo de interrupciones, priorización de tareas y coordinar múltiples unidades centrales de información.
6.8.6 ADMINISTRACiÓN DE TRANSACCIONES
Un administrador de transacciones es un sistema de base de datos cuya función principal es la de almacenar y acceder información. La información llega desde alguna aplicación en particular. La mayoría de los administradores de transacciones deben tratar con múltiples usuarios y concurrencia. Ejemplos de ellos son: sistemas · de reservaciones de líneas, sistemas de control de inventarios, sistemas de administración de bases de datos, etc.
En estos tipos de sistemas, el modelo de objetos es el más importante, el modelo funcional es el de menor importancia debido a que las operaciones tienden a ser predefinidas y se centran en la actualización, almacenamiento y búsqueda de la información. El modelo dinámico muestra los accesos concurrentes para la información que se encuentra en forma distribuida.
Frecuentemente se puede utilizar un sistema administrador de bases de datos, en tal caso, el problema principal es construir el modelo de objetos y seleccionar la granularidad de las transacciones que deben ser consideradas como atómicas dentro del sistema.
Los pasos para el diseño de un administrador de transacciones son los siguientes:
• Mapear directamente el modelo de objetos dentro de la base de datos.
• Determinar las unidades de concurrencia.
• Determinar las unidades de transacciones.
• Diseñar los controles de concurrencia para las transacciones. La mayoría de los administradores de bases de datos tienen incorporada esta característica.
44

CAPITULO VII
7. LA ORIENTACiÓN A OBJETOS Y EL ENFOQUE RELACIONAL
Las bases de datos orientadas a objetos surgieron en un principio para soportar la programación orientada a objetos. Los programadores de Smalltalk y C++ necesitaban almacenar lo que llamaban datos persistentes, datos que permanecen después de terminado un proceso. Estas bases de datos se volvieron importantes para ciertos tipos de aplicaciones con datos complejos, como CAD (diseño apoyado por computadora) y CAE (ingeniería apoyada por computadora). También se volvieron importantes para el manejo de los BLOB (objetos binarios de gran tamaño), como las imágenes, el sonido, el video, etc.
Varias de las necesidades no cubiertas por las bases de datos relacionales convergieron para formar una nueva generación de sistemas para la administración de datos. Las bases de datos activas se implementan mejor con técnicas de orientación a objetos. Las bases con conocimiento se orientaron a los marcos, donde el marco es un objeto con un conjunto de reglas asociadas a él. Los tipos de datos abstractos (tipos de datos definidos por el usuario), necesitaban un soporte que incluyera habla, imágenes y video. Los datos complejos necesitaban técnicas de acceso que mejorasen el desempeño sobre las bases de datos relacionales. Entre las mayores necesidades que convergieron para la existencia de la tecnología de las bases de datos orientadas a objetos están:
• Mejor rendimiento que las bases de datos relacionales. • Bases de datos activas. • Objetos binarios de gran tamaño (sonido, video, ,etc.). • Bases con conocimiento (sistemas expertos). • Datos persistentes para lenguajes como C++, Smalltalk, etc. • Tipos de datos abstractos definidos por el usuario.
7.1 MODELO CONCEPTUAL UNIFICADO
En la computación tradicional, los modelos conceptuales para el análisis, diseño, definición y acceso a las bases de datos eran diferentes. Por el contrario, las técnicas de orientación a objetos utilizan los mismos modelos conceptuales para el análisis, diseño y construcción de software.
El análisis tradicional utiliza los modelos relacionales entre entidades y la descomposición funcional. Los analistas generan matrices que asocian las funciones con los tipos de entidades. El diseño tradicional utiliza diagramas de flujo de datos,
45

tablas de estructuras y diagramas de acción. los lenguajes de programación tienen un modelo conceptual del código distintO. los programadores no piensan en términos de diagramas de flujo de datos. la tecnología de las bases de datos relacionales utiliza otro modelo conceptual más, con tablas que necesitan funciones JOIN y PROJECT. El modelo conceptual de Sal es distinto a los modelos conceptuales de los diagramas de relación entre entidades, la descomposición funcional, los diagramas de flujo de datos, tablas estructuradas, diagramas de acción, etc. El desarrollo tradicional tiene cuatro modelos conceptuales:
• Análisis. • Diagramas de entidad - relación. • Descomposición funcional. • Diagramas de dependencia entre procesos.
• Diseño. • Diagramas de flujo de datos. • Estructuración de tablas. • Diagramas de acción.
• Programación. • COBOL. .PU1. • FORTRAN.
• C. • Bases de datos.
• Tablas. • SOL. • SOl++.
Por el contrario, las bases de datos orientadas a objetos se diseñaron para integrarse con lenguajes de programación orientados a objetos, como C++ o Smalltalk. Utilizan el mismo modelo de objetos. No es necesario un lenguaje de base de datos distinto del lenguaje de programación. Por ejemplo, con ciertos productos de bases de datos orientadas a objetos, se utiliza C++ para todas las definiciones y manejo de la base de datos. También se utiliza el mismo modelo de objetos para el análisis y el diseño. El analista debe determinar los objetos y comportamientos de alto nivel. El diseñador lleva esto a los objetos de bajo nivel que heredan el comportamiento y las propiedades de los objetos de mayor nivel. Con una herramienta CASE, tan pronto se especifican los objetos en la pantalla, se puede generar el código para ellos en forma interpretativa.
El diseño de una base de datos relacional es de algún modo independiente del diseño del programa. El programador debe idear la forma de extraer o introducir datos de las tablas. Con las bases de datos orientadas a objetos, el programador trabaja con objetos temporales y persistentes de manera uniforme. los objetos persistentes están en la base de datos, con lo que se derriban los muros conceptuales entre la programación y la base de datos. Una herramienta CASE puede crear el código mientras el analista y el diseñador discuten las posibles soluciones. Una persona que
46

utilice el mismo modelo conceptual puede hacer de manera iterativa el análisis, diseño, generación de código y la generación de la base de datos. Esto puede aumentar en gran medida la razón con la que una persona creativa idea y refina los sistemas.
En resumen, el uso de un modelo cqnceptual unificado para el análisis, diseño, programación y la base de datos trae como consecuencia:
• Mayor productividad. Se evita el trabajo de traducción entre paradigmas. • Menos errores. los errores · aparecen durante la traducción entre los
paradigmas. • Mejor comunicación entre los usuarios, analistas e implantadores. • Mejor calidad. • Mayor flexibilidad. • Mayor inventiva.
El mundo no es una colección de tablas. Un modelo común del mundo es la jerarquía de un ensamble que se encuentra en los elementos manufacturados. En este caso, una parte se descompone en sus subpartes constituyentes, las cuales, a su vez, se descomponen en subpartes adicionales. Estas son difíciles de representar y manejar mediante tablas. De hecho, mediante el Sal estándar, todas las subpartes de una parte no se pueden determinar de forma típica mediante un enunciado interrogativo. Por el contrario, una base de datos orientada a objetos soporta tanto la capacidad de los objetos de referirse en forma directa a los demás como la habilidad computacional de los lenguajes para el procesamiento de objetos.
7.2 TRES ENFOQUES DE CONSTRUCCiÓN DE BASES DE DATOS ORIENTADAS A OBJETOS
las bases de datos orientadas a objetos se pueden construir mediante alguno de los tres enfoques siguientes. El primero utiliza un sistema de administración convencional y añade un nivel para procesamiento de las solicitudes y métodos de almacenamiento orientado a objetos. Este enfoque tiene un mérito: se puede utilizar el código actual altamente complejo de los sistemas de administración de bases de datos, de modo que una base de datos orientada a objetos se implante más rápido sin partir de cero.
El segundo enfoque considera a la base de datos orientada a objetos como una extensión de las bases de datos relacionales. De este modo, las herramientas, las técnicas y la vasta experiencia de la tecnología relacional se utilice para construir un nuevo sistema de administración de base de datos. Se pueden añadir apuntadores a las tablas de relación para ligarlas a objetos binarios de gran tamaño (BlOB).
El tercer enfoque reflexiona sobre la arquitectura de los sistemas de bases de datos y produce una nueva arquitectura optimizada, que cumple las necesidades de la tecnología orientada a objetos. las estructuras de datos relacionales se podrían utilizar en los casos adecuados, pero lo usual es que para los objetos complejos sean mejores
47

otras estructuras de datos; éstas permiten el acceso a los datos de un objeto complejo sin desplazar el mecanismo de ·acceso.
7.3 INDEPENDENCIA DE DATOS VERSUS ENCAPSULADO
Uno de los objetivos principales de la tecnología tradicional de las bases de datos es la independencia de los datos. Las estructuras de datos deben ser independientes de los procesos que utilizan los datos. Así, los datos se pueden utilizar en la forma que des.een los usuarios.
Por el contrario, uno de los principales objetivos de la tecnología orientada a objetos es el encapsulado. Esto significa que los datos sólo pueden ser utilizados con los métodos que forman parte de una clase. Se pretende que las clases sean reutilizables. Por lo tanto, otro objetivo de esta tecnología es lograr la máxima reutilización. Debido a esto, la clase debe estar libre de errores y sólo debe modificarse en un caso absolutamente necesario. La tecnología tradicional esta diseñada para soportar procesos sujetos a modificación infinita. Por ello, es necesaria la independencia de los datos. Las bases de datos orientadas a objetos soportan clases, algunas de las cuales rara vez son modificadas. Los cambios provienen de clases ligadas entre sí de varias formas. Las estructuras de datos en las bases de datos orientadas a objetos deben estar optimizadas para soportar la clase en la que están encapsuladas. Así, los objetivos en las bases de datos relacionadas y las orientadas a objetos son fundamentalmente diferentes.
7.4 RENDIMIENTO
Las bases de datos orientadas a objetos superan en mucho el rendimiento de las bases de datos relacionales para las aplicaciones de gran conexión entre datos. Esta es una de las principales razones por las que las aplicaciones que comparten esta característica utilizan este tipo de bases de datos en la actualidad.
Las bases de datos orientadas a objetos permiten que los objetos hagan referencia directamente a otro mediante apuntadores suaves. Esto hace que estas bases de datos pasen más rápido del objeto A al objeto B que las bases de datos relacionales, las cuales deben utilizar comandos JOIN para lograr esto. Así, incluso sin alguna afinación especial, una base de datos orientada a objetos es en general más rápida en este tipo de mecánica.
Las bases de datos orientadas a objetos hacen que el agrupamiento sea más eficiente. La mayoría de los sistemas de bases de datos permiten que el operador coloque cerca las estructuras relacionadas entre sí, en el espacio de almacenamiento en disco. Esto reduce en forma radical el tiempo de recuperación de los datos relacionados, puesto que todos los datos se leen con una lectura a disco en vez de varias. Sin embargo, en una base de datos relacional, los objetos de la implantación se
48

traducen en representaciones tabulares que generalmente se dispersan en varias tablas. Así, en una base de datos relacional, estos renglones relacionados deben quedar agrupados, de modo que todo el objeto se pueda recuperar mediante una única lectura a disco. Est() es automático en una base de datos orientada a objetos. Además, el agrupamiento de los datos relacionados, como todas las subpartes de un ensamble, puede afectar radicalmente el rendimiento general de una aplicación. Esto es relativamente directo en una base de datos orientada a objetos, puesto que representa el primer nivel de agrupamiento. Por el contrario, el agrupamiento físico es imposible en una base de datos relacional, puesto que esto requiere un segundo nivel de agrupamiento: un nivel para agrupar hileras que representan a los niveles individuales y un segundo para los grupos de hileras que representan a los objetos relacionados.
Las bases de datos orientadas a objetos utilizan diversas estructuras de almacenamiento. En una base de datos relacional, es difícil almacenar y acceder aquellos datos que no se pueden expresar con facilidad en forma tabular. Por ejemplo, las aplicaciones multimedia requieren el almacenamiento de grandes flujos de datos, que representan video y audio digitalizado. Las aplicaciones CAD suelen necesitar almacenar una gran cantidad de objetos muy pequeños, como los puntos que definen la geometría de una parte mecánica. Ninguno de estos casos es adecuado para la representación mediante una tabla. Por lo tanto, las bases de datos relacionales no pueden ofrecer una administración eficiente del almacenamiento para estas áreas de la aplicación. El modelo de almacenamiento de las bases de datos orientadas a objetos es ilimitado, puesto que el sistema es extendible por naturaleza, estas pueden ofrecer diferentes mecanismos de almacenamiento para distintos tipos de datos. Como resultado, han demostrado ser muy eficientes en el soporte de aplicaciones multimedia y CAD.
7.5 EVASiÓN DE LA REDUNDANCIA
Con las bases de datos relacionales, los datos se normalizan para reducir la redundancia y los inconvenientes que esta ocasiona. La tecnología orientada a objetos utiliza la herencia para reducir el desarrollo redundante de los métodos. También crea clases diseñadas para utilizarse en más de una aplicación. El encapsulado y la herencia reducen la cantidad de código redundante, así como los datos redundantes, de dos maneras: mediante la herencia y la reutilización de las clases. Esto también reduce el costo del desarrollo y el mantenimiento.
Con la tecnología de las bases de datos tradicionales, el procesamiento común se produce a través de distintas aplicaciones, lo que provoca una menor productividad y mayores costos de mantenimiento. De manera más reciente, las bases de datos relacionales han introducido el concepto de reglas de activación o procedimientos que puede ejecutar la base de datos. El uso de estas capacidades para colocar el procesamiento común dentro de la base de datos es un avance. Sin embargo, sigue separado el procesamiento de aquellas entidades naturalmente asociadas con el procesamiento. Por ejemplo, uno podría escribir una regla de activación que impusiera el comportamiento donde el salario de un empleado despedido fuese cero. Sin
49

embargo, el proceso de despido no se puede asociar con la tabla empleado. En una base de datos orientada a objetos, este proceso es directo, ya que la clase empleado definirá el método "despedir" e impondrá la restricción del salario cero.
7.6 DIFERENCIAS ENTRE LAS BASES DE DATOS RELACIONALES Y LAS ORIENTADAS A OBJETOS
Las bases de datos relacionales y las orientadas a objetos tienen objetivos y características fundamentalmente diferentes. En ciertos ambientes de computación, predominan las bases de datos relacionales, y en otros estas no cubren de manera adecuada las necesidades por lo que las bases de datos orientadas a objetos tienen grandes ventajas.
El análisis de las ventajas de una tecnología de base de datos sobre la otra requiere comprender el proceso de desarrollo de la aplicación. Este proceso de desarrollo no es totalmente general. Una tecnología de base de datos no puede satisfacer todos los dominios de la aplicación y se debe tomar en cuenta los requerimientos de la misma para analizar las ventajas que pueda ofrecer una tecnología sobre la otra.
Uno de los principales objetivos de las bases de datos relacionales es la independencia de datos, en la que los datos se separan .del procesamiento y se normalizan para luego utilizarse en varias aplicaciones, muchas de las cuales pueden pasar inadvertidas al diseñar las estructuras de datos.
Uno de los objetivos principales de las bases de datos orientadas a objetos es el encapsulamiento. Los datos están asociados con una clase específica que a su vez utiliza métodos particulares. La base de datos almacena tanto datos como métodos, estos son inseparables. Los datos no están diseñados para cualquier tipo de uso, sino para ser utilizados por medio de una clase, la cual será útil en varias aplicaciones. Con ello se logra obtener independencia de clases y no sólo independencia de datos.
Las bases de datos orientadas a objetos soportan estructuras de datos complejas y no las separa en tablas. Estas estructuras se encapsulan en las clases al igual que el ADN se encapsula dentro de las células biológicas. El hecho de tomar las estructuras complejas de datos y descomponerlas en tablas cada vez, equivaldría a descomponer un automóvil en sus componentes cada vez que se guarda en la cochera. Cuanto más compleja sea la estructura de datos, . mayores serán las ventajas de las bases de datos orientadas a objetos.
Bases de datos relacionales Bases de datos orientadas a objetos
Objetivo principal: Independencia de los Objetivo principal: Encapsulado. datos
so

Unicamente datos: En general, la base de Datos más métodos: La base de datos datos sólo almacena precisamente datos. almacena datos y métodos.
Datos compartidos: Los datos pueden compartirse entre varios procesos. Los datos están diseñados para cualquier tipo de uso.
Datos pasivos: Los datos son pasivos, aunque se pueden activar en forma automática ciertas operaciones limitadas al utilizarlos.
Encapsulado: Los datos sólo pueden utilizarse por métodos de clase. Los datos están diseñados para su uso exclusivo por métodos particulares
Objetos activos: Los objetos son activos. Las solicitudes hacen que los objetos ejecuten métodos. Algunos de estos métodos pueden ser muy complejos; por ejemplo, aquellos que utilicen reglas.
Cambio constante: Los procesos que Clases diseñadas para su reutilización: utilizan los datos cambian de manera Las clases diseñadas para una alta constante. reutilización rara vez se modifican.
Independencia de datos: Los datos Independencia de clases: Las clases se pueden reorganizarse físicamente sin pueden reorganizar sin afectar su forma afectar su forma de uso. de uso.
Sencillez: Los usuarios perciben los datos como columnas, hileras y tablas.
Tablas independientes: Cada relación (tabla) es independiente. Los comandos JOIN relacionan los datos en las diversas tablas.
Complejidad: Las estructuras de datos pueden ser complejas. Los usuarios no están conscientes de la complejidad debido al encapsulado.
Datos ligados entre sí: Los datos pueden estar ligados entre sí, de modo que los métodos de la clase logren un mejor rendimiento. Las tablas son sólo una de las estructuras de datos que pueden utilizar. Los objetos binarios de gran tamaño (BLOB) se utilizan para sonido, imágenes, video y grandes flujos de bits sin estructura.
Datos no redundantes: La normalización Métodos no redundantes: Con el de los datos se efectúa para ayudar a encapsulado y la herencia se obtienen reducir la redundancia en los datos. datos y métodos no redundantes. La
herencia ayuda a reducir la redundancia en los métodos, mientras que la reutilización de las clases ayuda a reducir la redundancia general en el rendimiento.
SOL: El lenguaje SOL se utiliza para el Solicitudes orientadas a objetos: Las manejo de las tablas. solicitudes provocan la ejecución de
51

Rendimiento: El rendimiento es una preocupaclon en el caso de las estructuras de datos altamente complejas.
Distinto modelo conceptual: El modelo de estructura de datos y acceso representado por tablas y comandos JOIN es distinto del modelo para análisis, diseño y programación. El diseño debe traducirse en tablas de relación y acceso al estilo SQL.
métodos. Se pueden utilizar diversos métodos.
Optimización de clases: Los datos de un objeto se pueden ligar entre sí y almacenar juntos, de modo que se pueda tener acceso a ellos desde una posición del mecanismo de acceso. Estas bases de datos ofrecen un rendimiento mucho mejor que las· relacionales para ciertas aplicaciones con datos complejos.
Modelo conceptual consistente: Los modelos utilizados para análisis, diseño, programación, acceso y estructura de base de datos son similares. Los conceptos de la aplicación se representan de manera directa mediante clases. Cuanto más compleja sea la aplicación y su base de datos, más tiempo y dinero se ahorrarán en el desarrollo de aplicaciones.
52

CAPITULO VIII
8. NOTACiÓN - UN CASO PRÁCTICO
8.1 NOTACiÓN PROPUESTA POR RUMBAUGH
Exactamente uno I Uno O más
2'
---.~'------' ----1qL-_-' I Cero o más , Cero o uno
1-2 Numéricamente especificado
Figura: 6.1 Cardinalidades
Superclase Superclase B
Figura: 6.2 Herencia y herencia múltiple
Parte 1 Parte 2
Figura: 6.3 Agregación
53

8.2 CASO PRÁCTICO - IMPLEMENTACiÓN DE UN MÓDULO DE CLIENTES
Para una institución financiera es importante poder contar con los datos de sus clientes en forma centralizada. En algunos casos el registro de estos no es del todo eficiente es decir, sus datos pueden estar registrados más de una vez dentro del sistema ocasionando problemas de inconsistencia. Esto es debido a que esos sistemas fueron planificados de tal modo que el registro de sus clientes fuera dependiente del producto financiero que el cliente aperturara, así por ejemplo, el cliente poseerá un código para el área de monetarios, otro para el área de cartera, otro para el área de ahorros, etc.
Por las razones anteriores, es deseable implementar un sistema eficiente para el manejo de clientes, en donde el cliente tenga un identificador único al cual se haga referencia en forma unívoca cuando éste aperture un producto financiero dentro de la institución.
Se desea registrar básicamente dos tipos de clientes: Individuales y Jurídicos. Dentro de los clientes Individuales se registran a las personas naturales, y dentro de los clientes Jurídicos se registran a las instituciones gubernamentales, autónomas, semi-autónomas y privadas.
Entre los datos comunes a los dos tipos de clientes se determinaron los siguientes: el identificador único del cliente, nombres, apellidos, tipo de documento de identificación y número asociado, estado, domicilio, numero telefónico y observaciones. Los clientes individuales deben tener fecha de nacimiento, sexo, estado civil, profesión y lugar de trabajo. Los clientes jurídicos deben tener el tipo de institución, escritura de constitución y representante legal.
Dentro del domicilio se desea registrar la dirección, código postal, munrclplo, departamento y país, al igual que los números telefónicos asociados. Y dentro de los números telefónicos, la extensión si existiera. Dentro de las observaciones se desea registrar los antecedentes negativos y referencias de terceros.
Además se necesitan generar grupos de clientes, es decir agrupar a los clientes según la · institución o grupo corporativo al que estos pertenezcan. En un grupo se desea registrar el código del grupo, nombre y tipo de grupo
Según los requerimientos anteriores, el sistema esperado es un sistema maestro de clientes en los que se eliminen los datos redundantes y en donde se lleve un eficiente control de los clientes registrados. '
Desde el punto de vista del usuario, el sistema consiste en el registro de datos básicos de clientes en un sistema. En general, los datos aquí registrados pueden provenir en su mayoría de un formulario de registro de clientes de la institución.
54

El escenario general del sistema consiste de dos personas interactuando, una registrando información y la otra proporcionándola, por lo que dentro del sistema analizado existen básicamente dos actores, el funcionario de la institución y el cliente.
8.2.1 DESCRIPCiÓN DE USE-CASES.
8.2.1.1 REGISTRO DE CLIENTES INDIVIDUALES
En este use-case se definen los pasos generales requeridos para el ingreso de un nuevo cliente individual.
a) El funcionario le solicita alguna identificación al interesado. b) El funcionario verifica que el interesado no figure dentro de la lista negra. c) El funcionario verifica, ya sea por nombre y/o identificación, que el interesado no se
encuentre ya registrado como cliente de la institución. d) El funcionario solicita al interesado los datos requeridos que lo convierte como
cliente para la institución. e) El funcionario ingresa al sistema la información proporcionada e imprime el
formulario correspondiente. f) El cliente revisa la información contenida en el formulario. g) El cliente firma el formulario y lo entrega al funcionario. h) El funcionario confirma la información y el sistema genera el código de
identificación único para el cliente.
Curso alterno: El interesado es miembro de la lista negra.
Este use-case extiende "Registro de clientes individuales" y "Registro de clientes jurídicos" como una ampliación al punto b) de los mismos.
a) El sistema despliega al operador un mensaje indicándole que el interesado es una persona impedida para trabajar con la institución y que para su registro correspondiente deberá solicitar de una autorización especial.
b) El funcionario solicita autorización para continuar con el proceso de apertura del nuevo cliente.
c) La autoridad superior autoriza, y el funcionario finaliza con el proceso.
Curso alterno: El interesado ya existe como cliente dentro de la institución.
Este use-case extiende "Registro de clientes individuales" y "Registro de clientes jurídicos" como ampliación al punto c) de los mismos.
a) El sistema despliega al operador un mensaje indicando que el interesado ya es cliente registrado de la institución.
55

b) El funcionario le indica al interesado que ya es un cliente, le indica cual es su número de código y finaliza el proceso.
Curso alterno: El interesado encuentra errores en el registro de sus datos.
Este use-case extiende "Registro de clientes individuales" y "Registro de clientes jurídicos" como una ampliación al punto f) de los mismos.
a) El interesado realiza las correcciones en el formulario y devuelve el mismo al funcionario.
b) El funcionario ingresa los datos correctos y vuelve a imprimir el formulario para que el interesado lo firme.
8.2.1.2 REGISTRO DE CLIENTES JURíDICOS
En este use-case se definen los pasos generales requeridos para el ingreso de un nuevo cliente jurídico.
a) El funcionario solicita al representante la escritura de constitución de la sociedad. b) El funcionario verifica que dicha sociedad no figure dentro de la lista negra. c) El funcionario verifica que la sociedad no se encuentre registrada como cliente
dentro de la institución. d) El funcionario solicita al representante los datos requeridos que convertirán a la
sociedad como cliente de la institución. e) El funcionario ingresa al sistema la información proporcionada e imprime el
formulario correspondiente. f) El representante revisa la información contenida en el formulario. g) El representante firma el formulario y lo entrega al funcionario. h) El funcionario confirma la información y el sistema genera el código de
identificación único para el cliente.
8.2.1.3 REGISTRO DE GRUPOS CORPORATIVOS
En este use-case se definen aquellos grupos en los que se tiene asociado a un determinado grupo de clientes de la institución, con el propósito de ofrecerles determinados servicios o bien con el propósito de ejercer un especial control y/o atención para los clientes.
a) El funcionario solicita el nombre del grupo al representante del mismo. b) El funcionario verifica que el grupo no exista. c) El funcionario solicita los datos del grupo y sus miembros. d) El representante da el nombre y/o códigos de los miembros.
56

e) El funcionario realiza una selección de cada uno de los miembros del grupo por medio de una búsqueda directa (por código de cliente) o bien por medio de una búsqueda alfabética. .
f) El funcionario imprime el formulario correspondiente con la información del grupo y la entrega al representante para que este la revise.
g) El representante firma el formulario y lo devuelve al funcionario . h) El funcionario confirma la información del grupo y el sistema le asigna un código
único de grupo.
Curso alterno: Grupo ya esta registrado en la institución.
Este use-case extiende "Registro de grupos corporativos" como una ampliación al punto b) del mismo.
a) El sistema despliega un mensaje al funcionario indicándole que el grupo ya está registrado en la institución.
b) El funcionario suspende el proceso.
Curso alterno: Asignación de clientes a un grupo.
Este use-case extiende "Registro de grupos corporativos" como una ampliación al punto e) del mismo. .
a) El sistema despliega un mensaje al funcionario indicándole que el cliente que se desea registrar como miembro del grupo no figura como cliente dentro de la institución.
b) El funcionario registra al nuevo cliente según el use-case "Registro de clientes individuales" .
c) El funcionario registra al nuevo cliente como miembro del grupo.
8.2.1.4 CONSULTA DE VINCULACIONES
Este use-case ofrece información referente a todas las vinculaciones que un cliente tiene dentro de la institución.
a) El funcionario realiza la búsqueda del cliente que desea consultar, por medio de su nombre, documento de identificación o código de cliente.
b) El funcionario selecciona al cliente y le indica al sistema que realice la búsqueda. c) El sistema devuelve las vinculaciones del cliente con los diferentes módulos de la
institución. d) El funcionario selecciona una de las vinculaciones y accede al módulo
correspondiente para consultar en detalle las operaciones del cliente dentro de dicho módulo.
57

8.2.1.5 ADMINISTRACiÓN DE LA LISTA NEGRA
Este use-case administra a todas aquellas personas que están impedidas a trabajar con la institución.
a) El funcionario ingresa los datos del cliente para realizar la búsqueda del mismo. b) El funcionario selecciona el o los motivos por los que el cliente debe figurar dentro
de la lista negra. c) El funcionario confirma que el cliente debe de figurar dentro de la lista negra de la
institución. d) El sistema registra al cliente como miembro de la lista negra.
8.2.1.6 MODIFICACIONES A LA LISTA NEGRA.
Este use-case permite modificar la situación de un cliente de la institución con relación a la lista negra de la misma, si el cliente ha solucionado su situación.
a) El funcionario ingresa los datos del cliente para realizar la búsqueda del mismo. b) El funcionario confirma al sistema que el cliente ya no debe formar parte de la lista
negra de la institución. c) El sistema genera una bitácora de los motivos por los que el cliente figuró dentro de
la lista negra de la institución y desmarca al cliente de la lista negra.
8.2.1 . 7 CONSULTA A LA LISTA NEGRA.
Este use-case permite consultar la lista negra de la institución.
a) El funcionario ingresa los datos del cliente para realizar la búsqueda del mismo. b) El sistema ofrece la información del cliente solicitado.
Curso alterno: Cliente solicitado no existe dentro de la lista negra.
Este use-case extiende "Consulta a la lista negra" como una ampliación al punto b) del mismo.
a) El sistema despliega un mensaje indicándole al funcionario que el cliente no está registrado dentro de la lista negra.
b) El sistema despliega un segundo mensaje indicándole al funcionario que si desea consultar en los registros históricos de la institución.
Curso alterno: Consulta histórica de la lista negra.
Este use-case extiende el curso alterno "Cliente solicitado no existe dentro de la lista negra" del use-case "Consulta a la lista negra".
58

a) El sistema realiza la búsqueda histórica de la lista negra. b) Si el sistema recupera información del cliente solicitado, ofrece el despliegue de la
información. Caso contrario, el sistema despliega un mensaje indicándole al funcionario que el cliente no tiene registros históricos dentro de la lista negra.
8.2.1.8 BLOQUEO DE UN CLIENTE
a) El funcionario ingresa los datos del cliente para realizar la búsqueda del mismo. b) El funcionario procede a bloquear las vinculaciones que el cliente tiene con la
institución. c) El funcionario selecciona el o los motivos por los que se está bloqueando al cliente. d) El funcionario confirma el bloqueo.
8.3 EL DISEÑO
Una vez determinado el escenario de interacción del sistema y los actores, el siguiente paso es identificar los objetos y las relaciones de los mismos dentro del escenario.
El objeto central del análisis son los clientes, los cuales pueden ser divididos en dos tipos: Individuales y Jurídicos. Para nuestro caso se definirán los aspectos comunes dentro de una clase común a ellos que nombraremos como "Cliente".
La clase Cliente proveerá la estructura de datos común a las clases Individual y Jurídico, las cuales contienen datos especializados para cada tipo de cliente. El proceso de refinamiento o especialización de clases es modelado por medio del uso de la herencia.
Cliente
Figura: 6.4 Identificación de la herencia entre clases
59

El objeto Cliente tiene relacionados más de un domicilio y el domicilio más de un teléfono por lo que se identifican dos nuevas clases: Domicilio y Teléfono. Por el tipo de relación que existen entre ellas, la clase Domicilio es una agregación al objeto Cliente, y la clase Teléfono es una agregación al objeto Domicilio. Debido a que independientemente de qué tipo de cliente se trate, es necesario registrar la firma del cliente. Ésta es . modelada por medio de agregación en la superclase. Luego del refinamiento de clases, es necesario almacenar la imagen de los clientes individuales y la escritura de constitución de la sociedad de los clientes jurídicos.
Vinculacion Cliente
1:lm:aQ:en;;-l---~<>I Individual Juridico I<>-----.¡ Escritura
Figura: 6.5 Identificación de las agregaciones entre clases
A nivel general es deseable poder agrupar los clientes por medio de grupos corporativos, así como realizar observaciones acerca de ellos. De igual forma, un Cliente Individual puede tener asociado un celular.
Observacion Cliente 1+ I : GrupoCliente
Celular p----.r;;;;lnd~iv~idu~all l
Figura: 6.6 Identificación de las asociaciones entre clases
60

Con los objetos identificados dentro del sistema, se puede determinar las clases que son la parte integral del modelo de objetos. Las clases identificadas son:
• Cliente. • Individual. • Jurídico. • Domicilio. • Teléfono. • Celular. • Observación. • . Escritura. • GrupoCliente. • Vinculación. • Imagen. • Firma.
A continuación se presenta el esquema del modelo como una propuesta de solución al problema analizado utilizando un diagrama Entidad / relación con notación Rumbaugh de las clases identificadas.
Vinculación GrupoCliente
1+
1 + .-----:::.....::...-...., Observacion >-----~--------~
ImaQen
Escritura
Figura: 6.7 Modelo de Clientes
En el modelo anterior se pueden observar las clases identificadas, se visualizan las relaciones de herencia, agregación y asociación así como la cardinalidad que existe entre ellas.
Según las clases identificadas, se puede definir con más detalle los atributos de las mismas. Como norma de diseño, para nominar las clases y sus atributos no se hará uso de tildes, por lo que se omitirán de los mismos.
61
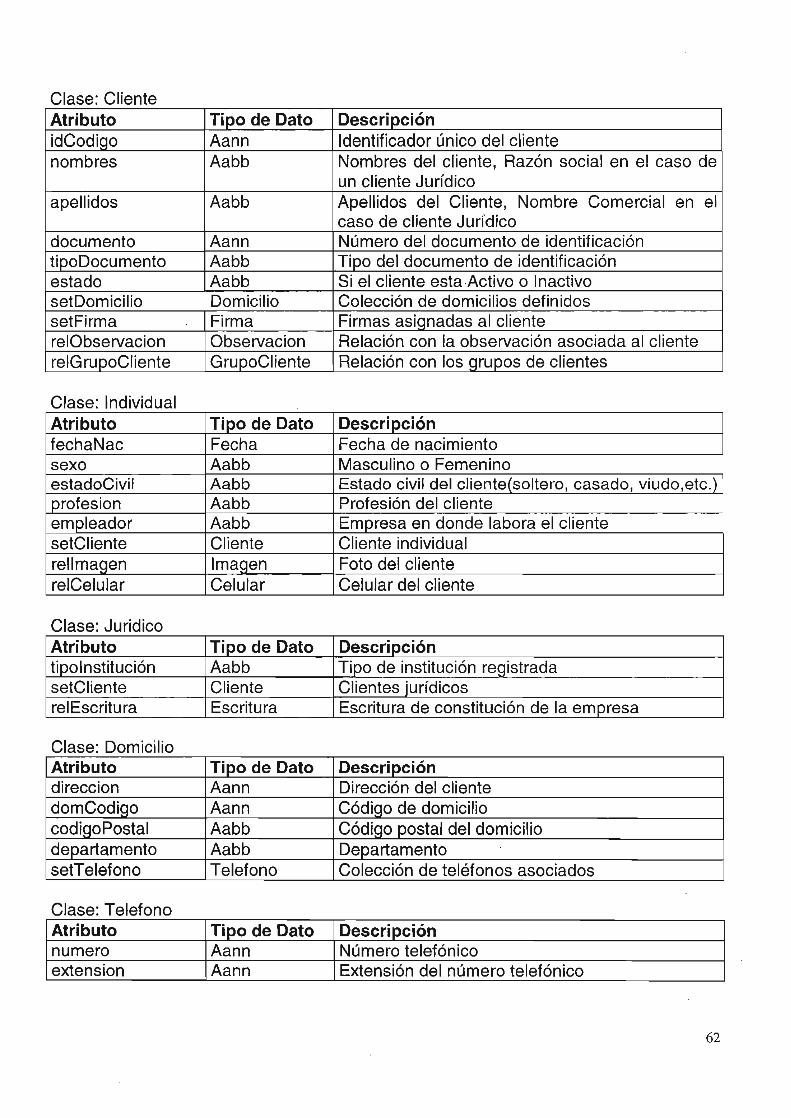
Clase: Cliente Atributo Tipo de Dato Descripción idCodigo Aann Identificador único del cliente nombres Aabb Nombres del cliente, Razón social en el caso de
un cliente Jurídico apellidos Aabb Apellidos del Cliente, Nombre Comercial en el
caso de cliente Jurídico documento Aann Número del documento de identificación tipo Documento Aabb Tipo del documento de identificación estado Aabb Si el cliente esta Activo o Inactivo setDomicilio Domicilio Colección de domicilios definidos setFirma Firma Firmas asignadas al cliente relObservacion Observacion Relación con la observación asociada al cliente relG rupoCliente GruQoCliente Relación con los grupos de clientes
Clase: Individual Atributo Tipo de Dato DescriQción fechaNac Fecha Fecha de nacimiento sexo Aabb Masculino o Femenino estadoCivil Aabb Estado civil del cliente(soltero, casado, viudo,etc.) profesion Aabb Profesión del cliente empleador Aabb Empresa en donde labora el cliente setCliente Cliente Cliente individual rellmagen Imagen Foto del cliente relCelular Celular Celular del cliente
Clase: Juridico Atributo Tipo de Dato Descripción tipolnstitución Aabb Tipo de institución registrada setCliente Cliente Clientes jurídicos relEscritura Escritura Escritura de constitución de la empresa
Clase' Domicilio Atributo Tipo de Dato Descripción direccion Aann Dirección del cliente domCodigo Aann Código de domicilio codigoPostal Aabb Código _Qostal del domicilio departamento Aabb Departamento setTelefono Telefono Colección de teléfonos asociados
Clase: Telefono Atributo Tipo de Dato Descripción numero Aann Número telefónico extension Aann Extensión del número telefónico
62

Clase: Celular Atributo Tipo de Dato Descripción numero Aann Número telefónico
Clase: Observacion Atributo Tipo de Dato Descripción antecedentesNeg . Aann Notas sobre antecedentes negativos referencia3ros Aann Notas sobre referencia de terceros
Clase' Escritura Atributo Tipo de Dato Descripción asiento Aann Asiento de la escritura fechaConst Fecha Fecha de constitución folio Aann Folio del registro tomo Aann Tomo del registro noPatente Aann Número de patente noRegNotario Aann Número del registro del notario
CI ase: G rupo CI' t len e Atributo Tipo de Dato Descripción codigo Aann Código del grupo nombre Aann Nombre asignado al grupo setCliente Cliente Clientes asignados al grupo
CI ase: magen Atributo Tipo de Dato Descripción foto Img Foto del cliente
Clase: Firma Atributo Tipo de Dato Descripción firma Img Firma del cliente
Clase: Vinculacion Atributo Tipo de Dato Descripción setCaQtaciones Captaciones Vinculaciones con el módulo de captaciones setColocaciones Colocaciones Vinculaciones con el módulo de colocaciones setExtranjero Extranjero Vinculaciones con el módulo extranjero
63

CAPITULO IX
9. CONCLUSIONES
1. El desarrollo de un sistema orientado a objetos está construido sobre una sólida base de la percepción natural del mundo.
2. El desarrollo de un sistema orientado a objetos incluye estructuras básicas del sistema tradicional pero sus beneficios adicionales son:
• La iteratividad y recursión entre sus fases. • Unidad de conceptos y esquemas a lo largo del proceso . .
3. La función principal del proceso del análisis es formalizar y estructurar el sistema de requerimientos tomados desde el punto de vista del usuario, construyendo el modelo de requerimientos y el modelo del análisis.
4. El modelo del análisis adiciona la estructura al modelo de requerimientos formalizando las vistas estáticas y dinámicas del sistema.
5. Es necesario aprender a distinguir claramente la diferencia entre las capas de la aplicación (presentación, negocios y acceso), para enfocarse únicamente en la capa de negocios al estar realizando el análisis. Esto ayudará al analista a obviar las necesidades o limitaciones del ambiente de implementación.
6. El proceso de diseño es el encargado de adicionar al ambiente de implementación los detalles de la aplicación. El refinamiento de los modelos de objetos y dinámico es el input para el desarrollo de este proceso.
7. El modelado de casos de usuario define la funcionalidad del sistema, los cuales han sido desarrollados basándose en las necesidades de los usuarios. Estos son construidos basándose en los actores del sistema.
8. El uso de esta metodología facilita el manejo de la complejidad de las aplicaciones debido a que refleja exactamente las "cosas" como son en el mundo real, mostrando el comportamiento y los atributos de los objetos.
9. La orientación a objetos permite en forma fácil la reusabilidad del código debido en gran parte al uso de la herencia dentro del sistema.
10. Se debe mantener los paradigmas de la asociación entre objetos y evitar la tentación de utilizar stacks, pointers u otras estructuras de datos. En la mayoría de los casos el uso de la asociación elimina la necesidad de estas estructuras de datos complejas.
64

11. El uso de un número limitado de paradigmas y una librería rica en contenido de clases, elimina en gran parte el número de bugs e incrementa la productividad en la etapa de desarrollo.
12. Cuando se realicen mejoras no se deberá pensar únicamente en el diseño, se deberá reconsiderar el análisis también.
13. Una de las ventajas del análisis orientado a objetos es la reducción de la distancia semántica entre el dominio del sistema y el modelo del mismo.
65

CAPITULO X
10. RECOMENDACIONES
1. Deberá definir niveles óptimos de herencia, ya que el uso desmedido y no planeado de este principio puede traer problemas inesperados al momento de realizar mantenimiento cuando el sistema se encuentre implementado.
2. Una de las principales ventajas de la orientación a objetos es la reusabilidad de clases, pero la misma de ser bien planeada para que su implementación en otras aplicaciones o submódulos del sistema sea llevada a cabo sin problemas.
3. Deberá tratar de evitar el uso de la herencia múltiple ya que la mayoría de las herramientas case y lenguajes de programación orientados a objetos no soportan dicha funcionalidad. El uso de ésta reduce la comprensión de la jerarquía de la herencia y el modelo pierde claridad.
4. Deberá implementar niveles óptimos de herencia y agregación dentro del diseño del sistema, con ello aprovechará el encapsulamiento que ofrecen las clases del modelo de objetos, proporcionando un alto grado de seguridad al sistema en forma intrínseca. .
5. Cuando el análisis y diseño del sistema que está modelando se base en esta metodología, debe pensar en la reusabilidad de clases ya existentes, ya que las mismas han sido probadas e implementadas. Con ello ahorrará tiempo e implementará sistemas de mejor calidad.
6. Se deberá contar con al menos un usuario experto en el manejo y administración del sistema que se está modelando para que realice una crítica constructiva en cada ciclo de la definición de los modelos, de esa forma se garantizará la coherencia de su diseño.
7. Debido a la muy creciente aceptación y aplicabilidad de esta "nueva" forma de desarrollar sistemas, deberá estar consciente que el esfuerzo inicial de "mover" a su equipo de desarrollo de una forma tradicional de análisis y diseño de sistemas a una metodología orientada a objetos puede consumir tiempos inesperados.
66

CAPITULO XI
11. BIBLlOGRAFIA
1. Coad P., Yourdon E. (1991) Object-Oriented Analysis (2da Edición). Englewood Cliffs, NJ: Yourdon Press/Prentice Hall.
2. Coad P., Yourdon E. (1991) Object-Oriented Design. Englewood Cliffs, NJ: Yourdon Press/Prentice Hall.
3. De La Cruz, R. (1997). Definición de una Metodología de Analisis y Diseño Orientado a Objetos. Tesis inédita. Universidad Rafael Landivar. Guatemala.
4. Easel Corporation (1995). Object-Oriented Analisis and Design. Training Material. Burlington, MA.
5. Internet: http://ccs.mit.edu/papers
6. Internet: http://www.go.comrritles
7. Internet: http://www.isg.de/people/marc/UmIDocCollection
8. Internet: http://www.telemann.cic.ipn.mx/-jmb/poo
9. Jacobson l., Christerson M., Jonson P., Overgaard G. (1992) Object-Oriented Software Engineering: A Use Case Driven Approach. Reading MA: AddisonWeskey, ACM Press.
10. Martin J. Odell J. (1992) Object-Oriented Anlysis and Design. Englewood Cliffs, NJ: Yourdon Press/Prentice Hall.
11. McClanahan D. (1996). Revista Data Base Advisor, 74-81.
12.Rambaug J., Blaha M., Premerlan, W., Eddy F., Lorensen W., (1991) ObjectOriented Modeling and Design. Englewood Cliffs, NJ: Prentice Hall.
13.Riel A. (1996). Object-Oriented Design Heuristics. Reading, MA: Addison-Wesley.
14. Rivera, A. (1996). Implementación de Bases de Datos Orientadas a Objetos Bajo UniSQUX. Tesis inédita. Universidad Francisco Marroquín. Guatemala.
15. Taylor D. (1991) Object-Oriented Technology: A Manager's Guide. Reading, MA: Addison-Wesley.
67

16.Yourdon E., Whitehead K., Thomann J., Oppel K., Nevermann P. (1995) Mainstream Objects an Analysis Design Approach for Business. Upper Saddle River, NJ: Yourdon Press/Prentice Hall.
17.Yourdon E., (1994) Object-Oriented System Design: An Integrated Approach. Englewood Cliffs,NJ: Yourdon Press/Prentice Hall.
68