modelos generalizados lineales con rlmcarrascal.eu/cursos/pres2.pdf · 2017-02-01 · a...
TRANSCRIPT

MODELOS GENERALIZADOS LINEALES CON R
Luis M. Carrascal(www.lmcarrascal.eu)
Depto. Biogeografía y Cambio GlobalMuseo Nacional de Ciencias Naturales, CSIC
Cómo realizarlos,buena praxis e
interpretación de los resultados
curso de la Sociedad de Amigos del Museo Nacional de Ciencias Naturales impartido en Febrero de 2017
1

El predictor lineal incluye la suma lineal de los
efectos de una o más variables explicativas (xj).
j representan los parámetros desconocidos
que es necesario estimar.
Estos valores son llevados a una nueva escala mediante unatransformación adecuada. Esto es, i no representa a yi,sino a una transformación de los valores y mediante lafunción de vínculo.
2

La transformación utilizada viene definida por la función devínculo.
La función de vínculo relaciona la media de los valores y () con elpredictor lineal mediante:
= g()
Para volver a la escala original de medida (y), el valor ajustado esla función inversa de la transformación que define la función devínculo.
Para determinar el ajuste de un modelo,* el procedimiento evalúa el predictor lineal para cada valor de lavariable dependiente (y),
* y luego compara este valor predicho con la transformación de y
3

Mediante el uso de diferentes funciones de vínculo,podemos valorar la adecuación de nuestro modelo a losdatos. Para ello utilizaremos el concepto y parámetrodevianza.
El modelo más apropiado será aquel que minimice ladevianza residual.
En los modelos Generales Lineales operamos con variablesdependientes normales, y los modelos proporcionanresiduos que siguen la distribución normal. Sin embargo,numerosos datos no presentan errores normales.* por sesgo y kurtosis* están acotados (caso de proporciones)* son conteos que no pueden manifestar valores negativos
4

Podemos distinguir las siguientes familias principales de errores:* errores Normales* errores Poisson (conteos de fenómenos raros)* errores Binomiales negativos (Poisson con mayor dispersión)* errores Binomiales (datos que miden respuestas si/no o proporciones)* errores Gamma (datos que muestran un CV constante)* errores Exponenciales (datos de supervivencia)
Para estos errores se han definido las funciones de vínculomás adecuadas (por defecto; canónicas):
ERRORES FUNCIÓN* Normales Identidad* Poisson, Binomiales negativos Log* Binomial Logit* Gamma Recíproca
5

CREACIÓN DEL MODELO GENERALIZADO (POISSON REGRESSION)
En los modelos de regresión lineal clásicos (Gausianos):* definimos una función predictora
g(x) = α+β1X1+ … + βpXp para p predictores* establecemos la relación lineal con la respuesta
Y = g(x) + ε siendo ε la variación residual
En los modelos generalizados de Poisson:* establecemos el valor esperado de la respuesta Y por su parámetro media (μ)* que establece una relación logarítmica con la función predictora g(x)
log(μ) = g(x) + ε o μ = eg(x) + ε'
μ = eα+β1X1+ … + βpXp* esta estructura es muy importante para la interpretación de los coeficientes deregresión.
6

MODELOS GENERALIZADOS LINEALES CON RDefinición de los modelos atendiendo a la distribución de erroresSegún qué tipo de variable respuesta tengamos definiremos la familia y la función de vínculo.Usaremos el comando glm en vez de lm de los modelos generales lineales.
modelo <- glm(eqt, data=datos, family=poisson(link="log"))family = quasipoisson(link="logit")
modelo <- glm.nb(eqt, data=datos, link=log)
modelo <- glm(eqt, data=datos, family=binomial(link="logit"))family = quasibinomial(link="logit") family = binomial(link="cloglog")
cloglog trabaja mejor con distribuciones extremadamente sesgadas
7

Interpretación de los resultadosPrimero valoramos la significación global del modelo, en lo que se conoce como un
omnibus test. SI EL RESULTADO ES SIGNIFICATIVO, PODREMOS SEGUIR CON LOSRESULTADOS. Si no resulta significativo el análisis … ¡se terminó!
Si en los modelos GzLM usados con poisson y binomial aplicamos la corrección porsobredispersión, el resultado de este omnibus test cambia.
8
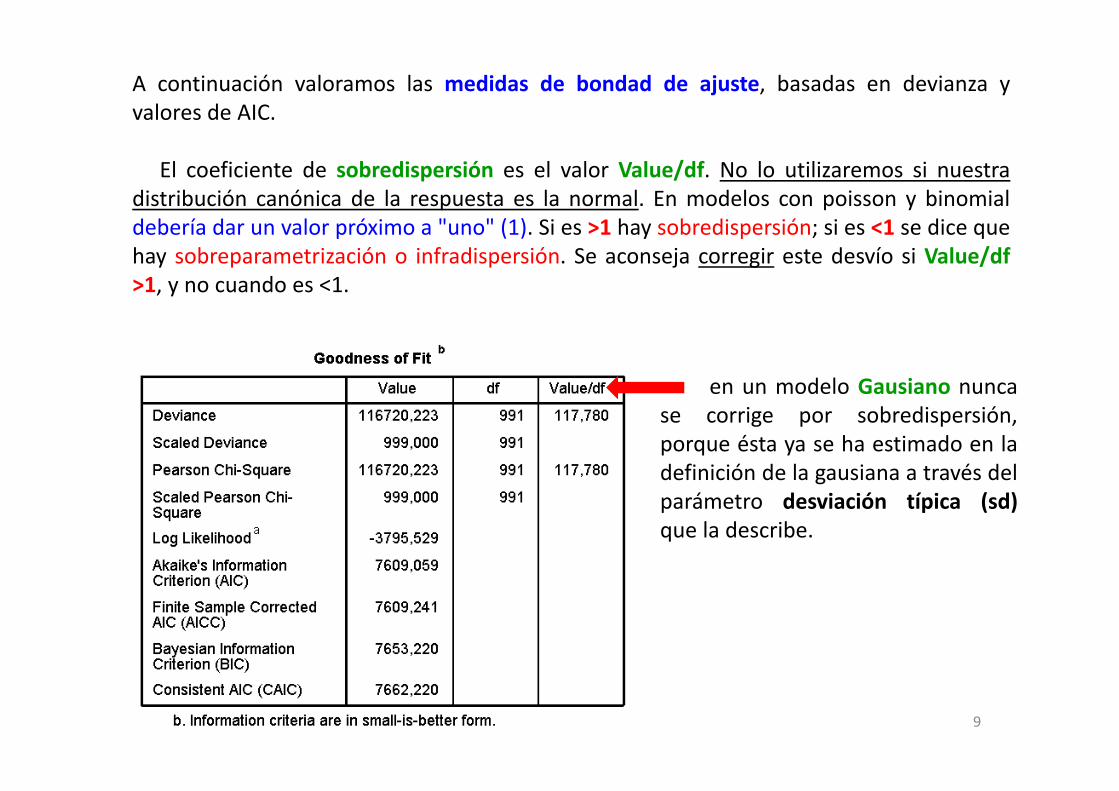
A continuación valoramos las medidas de bondad de ajuste, basadas en devianza yvalores de AIC.
El coeficiente de sobredispersión es el valor Value/df. No lo utilizaremos si nuestradistribución canónica de la respuesta es la normal. En modelos con poisson y binomialdebería dar un valor próximo a "uno" (1). Si es >1 hay sobredispersión; si es <1 se dice quehay sobreparametrización o infradispersión. Se aconseja corregir este desvío si Value/df>1, y no cuando es <1.
en un modelo Gausiano nuncase corrige por sobredispersión,porque ésta ya se ha estimado en ladefinición de la gausiana a través delparámetro desviación típica (sd)que la describe.
9

VARIABILIDAD EXPLICADA POR EL MODELO (usando devianzas)La devianza es igual a la suma de los cuadrados de los residuos de devianza
proporción de devianza explicada = (devianza residual nula – devianza residual del modelo) (devianza residual nula)
10
Para conocer la proporción de la variación en la variable respuesta que es explicada porel modelo (equivalente a una R2 de un modelo General Lineal) tendremos que:1) construir un nuevomodelo "nulo" sin predictoras (con sólo el intercepto).2) obtener la Devianza de ese modelo nulo en su tabla de Goodness of Fit (Do)3) calcular la siguiente expresión que denominaremos D2:
D2 = (Do ‐ Dmodelo) / DoModelo nulo
D2 = (148801.74 – 116720.22) / 148801.74 =0.2156 = 21.6%
Nuestro modelo de interés
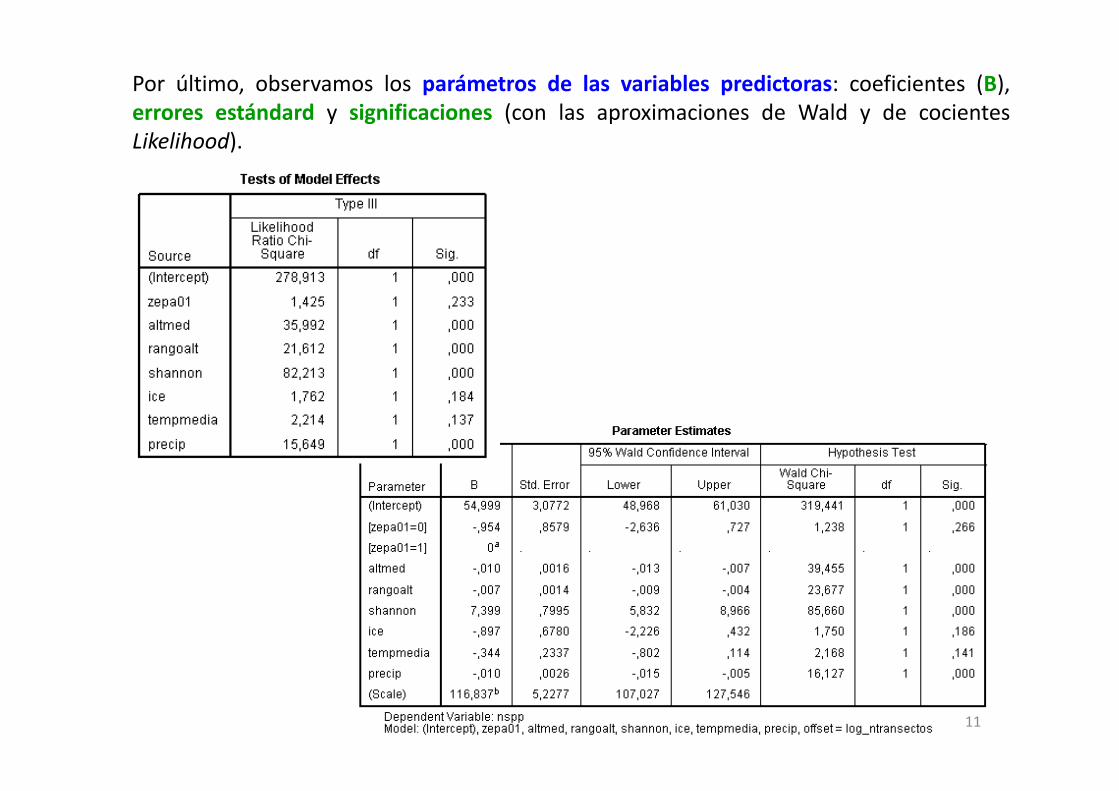
Por último, observamos los parámetros de las variables predictoras: coeficientes (B),errores estándard y significaciones (con las aproximaciones de Wald y de cocientesLikelihood).
11

INTERPRETACIÓN DE LOS COEFICIENTES DE REGRESIÓNLos modelos de regresión de Poisson son multiplicativos… porque la función de vínculo es el logaritmo: familia = poisson vínculo = log
En la regresión de Poisson log (Y) = a + b∙X o Y = exp(a + b∙X)log(Y) cambia linealmente en función de las variables predictorasY cambia linealmente en función del antilogaritmo de la función de las predictoras
El coeficiente b en antilogaritmo, exp(b), mide el cambio en esa variable predictoraque implica el cambio en una unidad en la variable respuesta Y.
O dicho de otro modo, el coeficiente b es el cambio esperado en el log(Y) cuando la variable predictora aumenta una unidad.
En el caso de las predictoras categóricas (definidas por nº categorías del factor – 1) el antilogaritmo del coeficiente, exp(b), es el término multiplicativo relativo a la "base" del factor. El antilogaritmo del intercepto, exp(a), es el valor basal en relación con el cual se estiman los cambios definidos por los coeficientes.
12

ejemplo con factoresfactor edu de 4 niveles factor res de 4 niveles
13

SOBREDISPERSIÓN DEL MODELO
Medida para estimar la bondad de ajuste del modelo (ϕ).
Mide la existencia de una mayor (o menor) variabilidad que la esperable en la variable respuesta considerando los supuestos acerca de su distribución canónica y la función de vínculo (que liga los valores transformados de la variable a las predicciones del modelo)http://en.wikipedia.org/wiki/Overdispersion
ϕ debería valer 1.Si >1 sobredispersión se "inflan" las significacionesSi <1 infradispersión asociado a la sobreparametrización
¡¡¡SOBREDISPERSIÓN!!!las estimas de significación están "infladas"
Con estos valores (ϕ) recalculamos nuevas estimas de significación a través de la F.F = diferencias en Devianza / (dif. en g.l. x ϕ)
aparecerán en los resultados en:Test of Model Effects 14

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## para importar datos de internet y ponerlos en uso## abro una conexión con internetmeconecto <- url("http://www.lmcarrascal.eu/cursos/nwayGENERALIZADO.RData")## cargo el archivo de la conexiónload(meconecto)## cierro la conexión y borro el objeto "meconecto"close(meconecto); rm(meconecto)
## con la siguiente línea de código veo las variablesnames(datos)
## creamos una función de asociaciones que llamo "eqt"eqt <- as.formula(abundancia ~ covariante + insolacion*tratamiento)
15

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## CARGAMOS PAQUETES##library(lmtest)library(MASS)library(car)library(MuMIn)library(phia)library(sandwich)library(robustbase)library(psych)library(fit.models)
16

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## establecemos los tipos de contrastes para las variables## predictoras nominales (factores)## antes cargamos la siguiente línea de código para obtener los## mismos resultados que en STATISTICA o SPSS utilizando type III SS## "factor" para los factores no ordenados## "ordered" para factores con niveles ordenados##options(contrasts=c(factor="contr.sum", ordered="contr.poly"))
## ahora creamos nuestro modelo tipo ANCOVA Generalizado Linealmodelo <- glm(eqt, data=datos, family=poisson(link="log"))
## los valores de la Devianza nula (modelo nulo: "respuesta ~ 1")## y Devianza residual del modelo se encuentran en el modelo## como modelo$null.deviance y modelo$deviance## con ellos calculamos lo que explica el modelo:d2 <- round(100*(modelo$null.deviance-modelo$deviance)/modelo$null.deviance, 2)print(c("D2 de McFadden (%) =",d2), quote=FALSE)[1] D2 de McFadden (%) = 63.15
17

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estima de significación global del modelo de interés ## comparándolo con el modelo nulo## sólo procederemos valorando los resultados de este modelo, ## SÍ Y SÓLO SÍ, este "omnibus test" ha sido significativo## podemos utilizar estos dos test con resultados similares
## likelihood ratio testlrtest(modelo)
Likelihood ratio test
Model 1: abundancia ~ covariante + insolacion * tratamientoModel 2: abundancia ~ 1#Df LogLik Df Chisq Pr(>Chisq)
1 5 -163.01 2 1 -279.54 -4 233.05 < 2.2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
18

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## test de Waldwaldtest(modelo)
Wald test
Model 1: abundancia ~ covariante + insolacion * tratamientoModel 2: abundancia ~ 1Res.Df Df F Pr(>F)
1 1072 111 -4 41.609 < 2.2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
19

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## valores AICc del modelo de interés y el modelo nulomodelo.nulo <- glm(modelo$model[,1]~1, family=poisson(link="log"))
AICc(modelo, modelo.nulo)veces.mejor <- exp(-0.5*(AICc(modelo)-AICc(modelo.nulo)))print(c("Veces que MI MODELO es mejor que el modelo NULO =", veces.mejor), quote=FALSE)
df AICcmodelo 5 336.5938modelo.nulo 1 561.1163
[1] Veces que MI MODELO es mejor que el modelo NULO = 5.6812671423727e+48
Este resultado es consistente con el anterior, pero en coordenadas de teoría de la información.El modelo de interés de 6*1048 veces mejor que el modelo nulo.
Estos dos tests nos proporcionan que nuestro modelo es altamente significativo, con lo cual podemos continuar valorando sus resultados.
Pero antes tenemos que comprobar si hemos cumplido los supuestos canónicos de los modelos a través de la exploración de sus residuos.
20

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## exploración de los residuos del modelo## vemos unos gráficos generales que ya nos dan muchas pistas: ## normalidad, usando los residuos de devianza## (¡¡no en la escala original de la respuesta!!)## homocedasticidad de los residuos a través de las predicciones## del modelo (aplicando la transformación de la link function)## existencia de datos influyentes y perdidos## con la distancia de Cook y Leverage## en una sola figura con cuatro paneles
par(mfcol=c(1,1)) ## fija un sólo panel gráficopar(mfcol=c(2,2)) ## fija cuatro paneles con 2 columnas y 2 filasplot(modelo, c(1:2,4,6)) par(mfcol=c(1,2))par(mfcol=c(1,1)) ## volvemos al modo gráfico de un solo panel
21
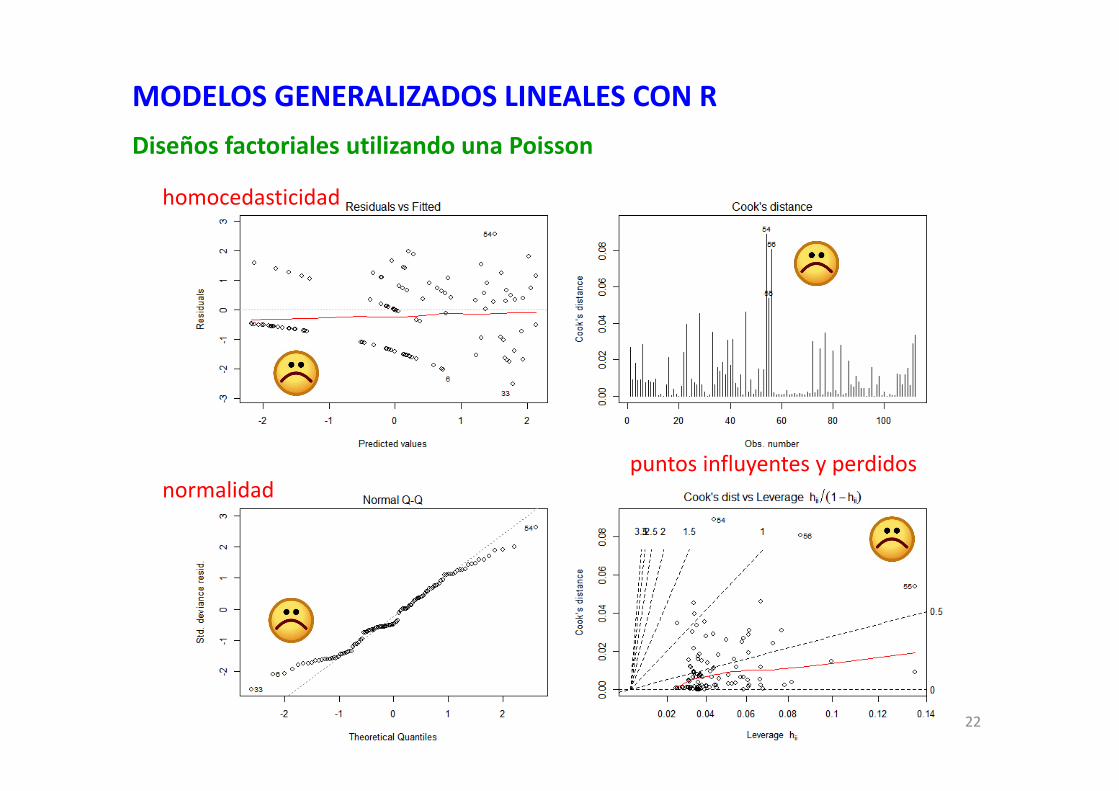
MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
22
homocedasticidad
normalidadpuntos influyentes y perdidos

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## test de Shapiro-Wilk de la normalidad de los residuos de devianzashapiro.test(residuals(modelo, type="deviance"))
Shapiro-Wilk normality testdata: residuals(modelo, type = "deviance")W = 0.976, p-value = 0.04078
## el desvío de la normalidad no es muy grave## hemos identificado que hay una leve violación de homocedasticidad## y existen algunas observaciones con elevada distancia de Cook
## puntos influyentes y perdidos con dffits## dffits con sus límites "críticos"## niveles críticos 2*raiz((g.l. del modelo)/(Número de datos))plot(dffits(modelo)) abline(h=2*((length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals))^0.5, col="red")abline(h=-2*((length(modelo$residuals)-modelo$df.residual-1)/length(modelo$residuals))^0.5, col="red")
identify(dffits(modelo))## terminad dando clik en Finish del panel Plots
23
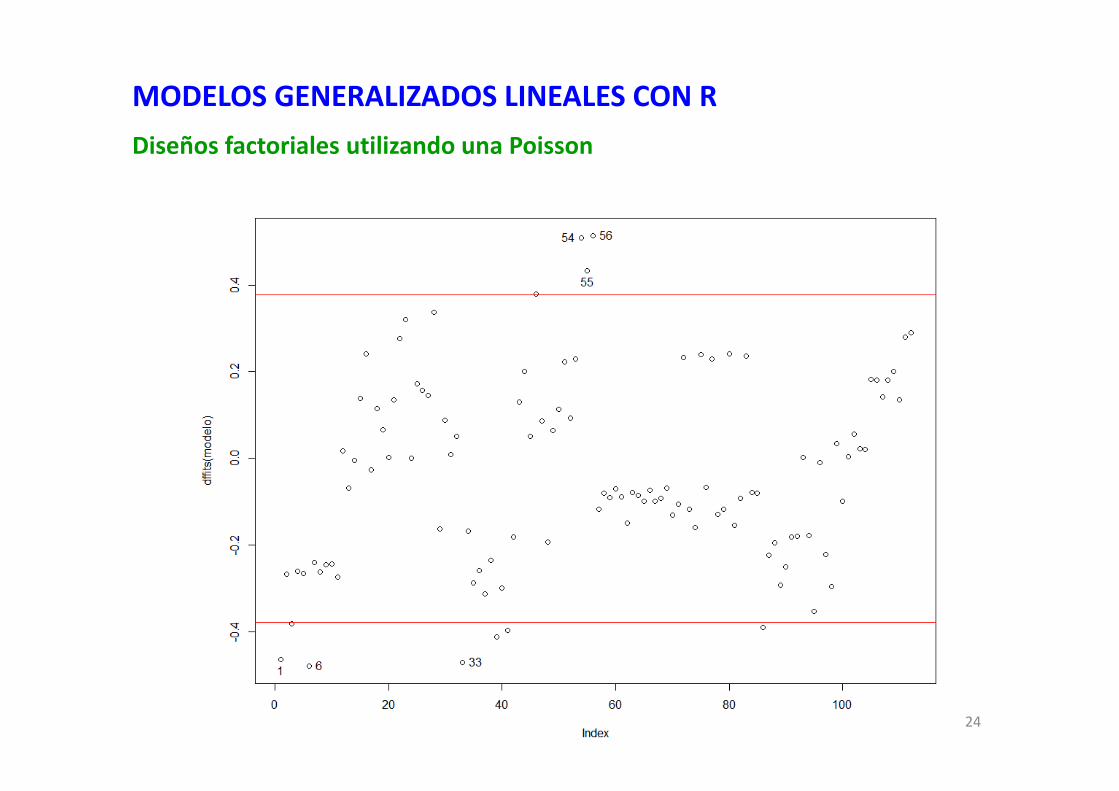
MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
24

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## INDEPENDENCIA ENTRE LAS PREDICTORAS: VIF = 1 / (1 - R2), ## de cada predictora por las restantes## GVIF or VIF specifically indicate the magnitude of the inflation in the standard errors
## associated with a particular beta weight that is due to multicollinearity
## la raiz cuadrada de un valor VIF o GVIF es el número de veces que ## se inflan los errores standard de esa predictora##vif(modelo)sqrt(vif(modelo))
> vif(modelo)covariante insolacion tratamiento insolacion:tratamiento
1.165977 1.872718 2.481296 3.228086 > sqrt(vif(modelo))
covariante insolacion tratamiento insolacion:tratamiento1.079804 1.368473 1.575213 1.796687
25

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estima de la sobredispersión del modelo## este valor canónico debería de ser igual a la unidad##phi <- sum((residuals(modelo, type="pearson"))^2)/modelo$df.residualprint(c("Pearson overdispersion =", round(phi, 3)), quote=FALSE)
[1] Pearson overdispersion = 1.176
Si este valor hubiese sido muy diferente de uno (e.g., > 2) recalcularíamos el modelo teniendo en cuenta ese valor de sobredispersión, aplicando la pseudofamilia quasipoisson.No corregiremos por sobredispersión si phi <1
modelo2 <- glm(eqt, data=datos, family=quasipoisson(link="log"))
Y procederíamos con este nuevo modelo.
26

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## representación de los valores observados y predichos en la respuesta## usando la escala original de medida (habiendo destransformado los datos## desde la transformación incluida en la link function)plot(modelo$y~fitted(modelo), ylab="respuesta original")abline(lm(modelo$y~fitted(modelo)), col="red", lwd=2)
27
MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
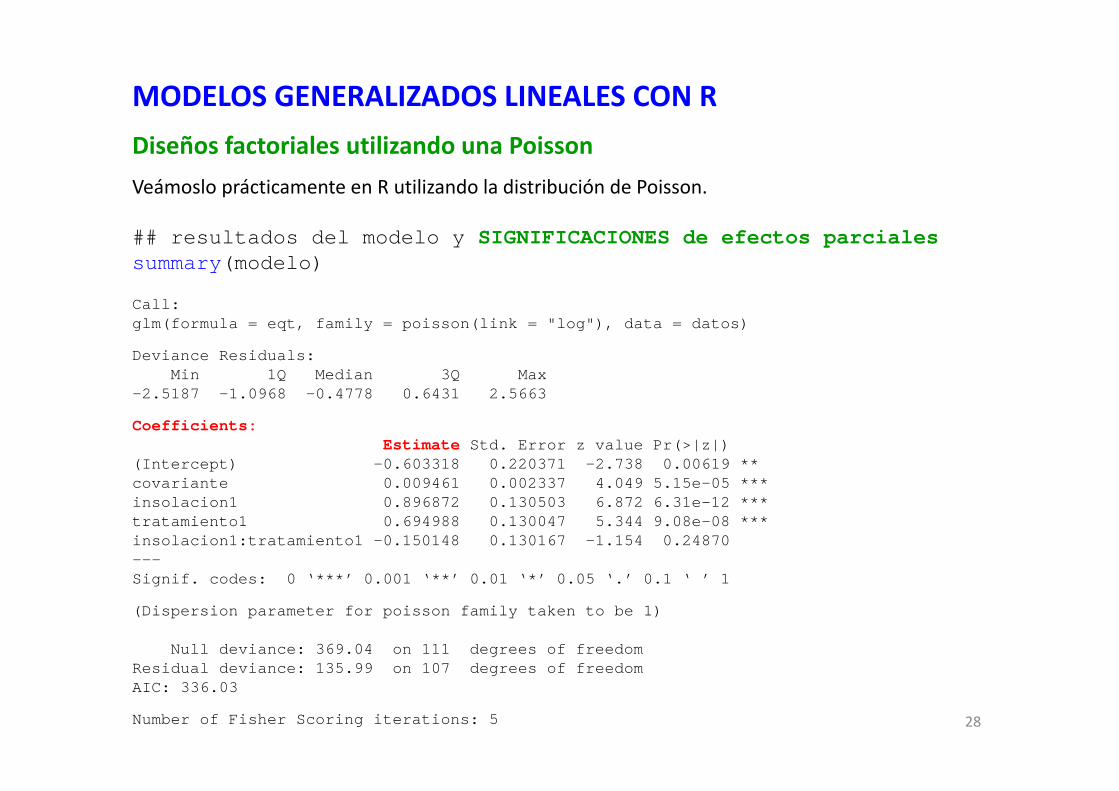
## resultados del modelo y SIGNIFICACIONES de efectos parcialessummary(modelo)
Call:glm(formula = eqt, family = poisson(link = "log"), data = datos)
Deviance Residuals: Min 1Q Median 3Q Max
-2.5187 -1.0968 -0.4778 0.6431 2.5663
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.603318 0.220371 -2.738 0.00619 ** covariante 0.009461 0.002337 4.049 5.15e-05 ***insolacion1 0.896872 0.130503 6.872 6.31e-12 ***tratamiento1 0.694988 0.130047 5.344 9.08e-08 ***insolacion1:tratamiento1 -0.150148 0.130167 -1.154 0.24870 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 369.04 on 111 degrees of freedomResidual deviance: 135.99 on 107 degrees of freedomAIC: 336.03
Number of Fisher Scoring iterations: 5 28

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estimas parciales, al estilo SS type-III## esto nos proporciona la significación de los efectos## la Deviance nos vincula a las magnitudes de los efectos## <none> indica la devianza residual sin quitar efectos## los otros valores indican la devianza quitando ese efecto## a más valor más magnitud del efecto##dropterm(modelo, ~., test="Chisq", sorted=FALSE)
Single term deletions
Model:abundancia ~ covariante + insolacion * tratamiento
Df Deviance AIC LRT Pr(Chi) <none> 135.99 336.03 covariante 1 152.63 350.67 16.638 4.524e-05 ***insolacion 1 212.52 410.56 76.533 < 2.2e-16 ***tratamiento 1 176.48 374.52 40.490 1.976e-10 ***insolacion:tratamiento 1 137.45 335.49 1.466 0.2259 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
29

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## estimas parciales, al estilo SS type-III## esto nos proporciona la significación de los efectos#### otra manera con Likelihood Ratio test##Anova(modelo, type=3, test="LR")
Analysis of Deviance Table (Type III tests)
Response: abundanciaLR Chisq Df Pr(>Chisq)
covariante 16.638 1 4.524e-05 ***insolacion 76.533 1 < 2.2e-16 ***tratamiento 40.490 1 1.976e-10 ***insolacion:tratamiento 1.466 1 0.2259 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
30
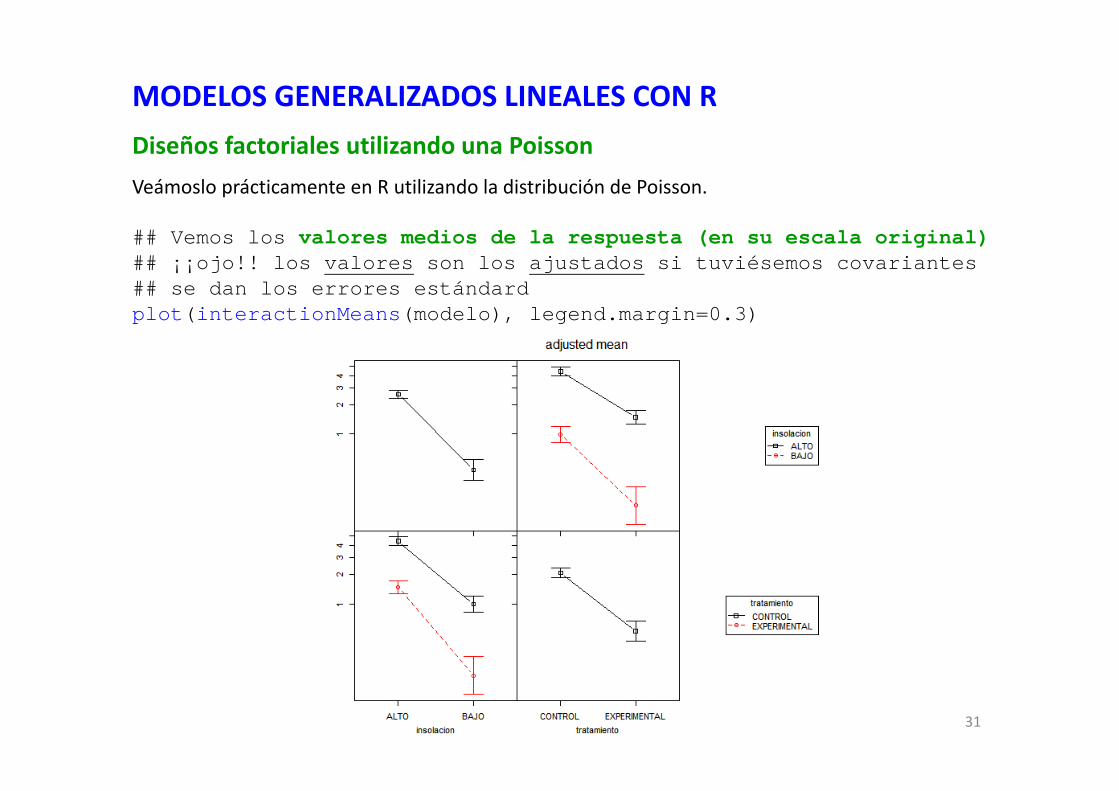
MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## Vemos los valores medios de la respuesta (en su escala original)## ¡¡ojo!! los valores son los ajustados si tuviésemos covariantes## se dan los errores estándardplot(interactionMeans(modelo), legend.margin=0.3)
31

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## EXAMEN DEL EFECTO DE LA VIOLACIÓN DEL SUPUESTO DE HOMOCEDASTICIDAD## Recálculo de significaciones; realmente sin mucho interés porque## se refiere a los coeficientes y no al efecto global de cada factor## método Sandwich (que es type="HC0"): sólo para el cálculo de ## nuevos errores standard y las significaciones asociadas## no cambian las estimas de los coeficientes##coeftest(modelo, vcov=sandwich)
z test of coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.6033185 0.2282439 -2.6433 0.0082101 ** covariante 0.0094608 0.0024835 3.8094 0.0001393 ***insolacion1 0.8968718 0.1224953 7.3217 2.449e-13 ***tratamiento1 0.6949877 0.1212844 5.7302 1.003e-08 ***insolacion1:tratamiento1 -0.1501483 0.1212557 -1.2383 0.2156130 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
32

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
## afrontemos ahora el efecto de puntos influyentes y/o perdidos## RECÁLCULO DEL MODELO QUITANDO ALGUNOS PUNTOS## mejor no hacemos estomodelo.sin_outliers <- glm(eqt, data=datos[c(-6, -33, -54, -55, -56),]), family=poisson(link="log"))
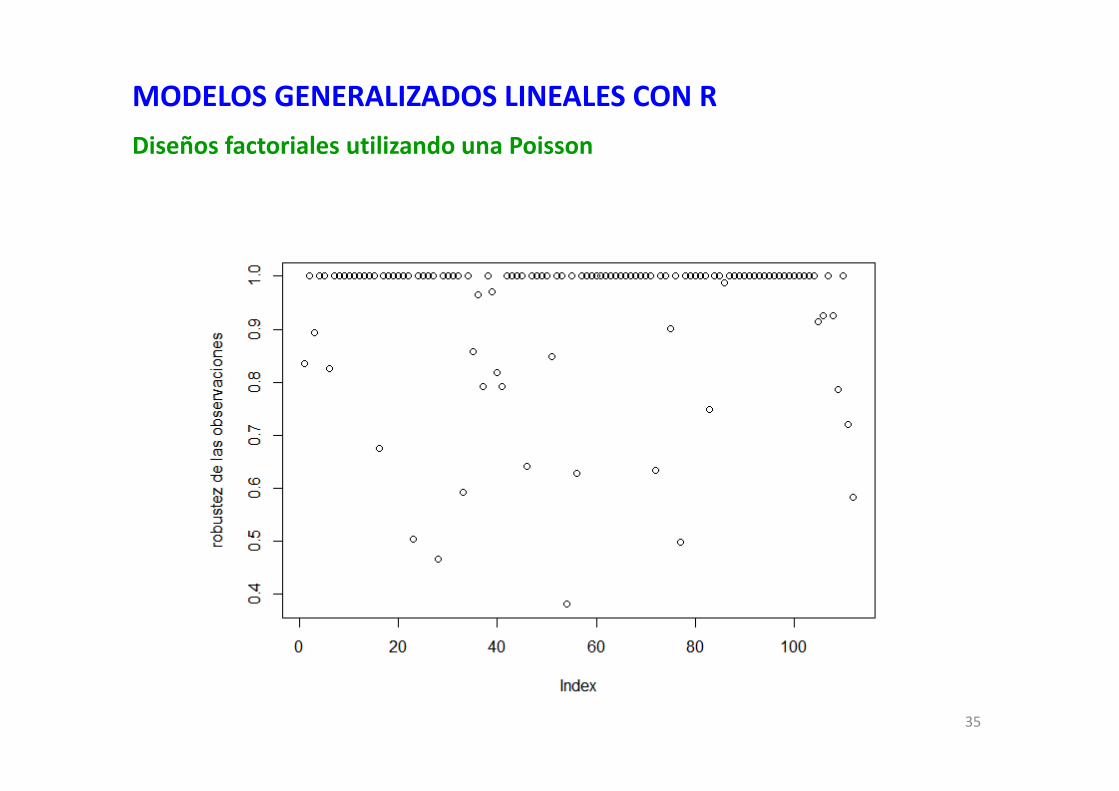
## ESTIMACIONES ROBUSTAS## sin quitar datos del modelo; aproximación robusta más seria,## que estima nuevos coeficientes y errores standard## Mqle es el método Mallows-Hubber quasi-liquelihood.modelo.robusto <- glmrob(eqt, data=datos, family=poisson(link="log"), weights.on.x="hat", method="Mqle", control=glmrobMqle.control(tcc=1.2, maxit=100))##summary(modelo.robusto)par(mfcol=c(1,1))## robustez de los datos individualesplot(modelo.robusto$w.r, ylab="robustez de las observaciones")identify(modelo.robusto$w.r)plot(modelo.robusto$w.x, leverage(modelo) , xlab="peso de las observaciones")
33

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una PoissonVeámoslo prácticamente en R utilizando la distribución de Poisson.
> summary(modelo.robusto)
Call: glmrob(formula = eqt, family = poisson(link = "log"), data = datos, method = "Mqle", weights.on.x = "hat", control = glmrobMqle.control(tcc = 1.2, maxit = 100))
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.637792 0.230571 -2.766 0.00567 ** covariante 0.010387 0.002448 4.243 2.20e-05 ***insolacion1 0.847448 0.133664 6.340 2.30e-10 ***tratamiento1 0.663203 0.133265 4.977 6.47e-07 ***insolacion1:tratamiento1 -0.129810 0.133560 -0.972 0.33109 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Robustness weights w.r * w.x:
Min. 1st Qu. Median Mean 3rd Qu. Max. 0.3520 0.8800 0.9042 0.8563 0.9246 0.9298
Number of observations: 112 Fitted by method ‘Mqle’ (in 5 iterations)
(Dispersion parameter for poisson family taken to be 1)
34
MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
35

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Poisson
36

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Binomial NegativaRepetiremos todos los pasos previos, sólo que en esta ocasión nuestro modelos será:
modelo <- glm.nb(eqt, data=datos, link=log)
> summary(modelo)
Call:glm.nb(formula = eqt, data = datos, link = log, init.theta = 10.08705502)
Deviance Residuals: Min 1Q Median 3Q Max
-2.1470 -1.0874 -0.4259 0.5242 2.0050
Coefficients:Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.591067 0.244692 -2.416 0.015711 * covariante 0.009298 0.002735 3.399 0.000676 ***insolacion1 0.896394 0.134216 6.679 2.41e-11 ***tratamiento1 0.698006 0.133797 5.217 1.82e-07 ***insolacion1:tratamiento1 -0.149458 0.134011 -1.115 0.264736 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for Negative Binomial(10.0032) family taken to be 1)
Null deviance: 305.36 on 111 degrees of freedomResidual deviance: 114.48 on 107 degrees of freedomAIC: 335.01
Number of Fisher Scoring iterations: 1
Theta: 10.00 En esta ocasión el modelo estima un parámetro más ThetaStd. Err.: 7.52 que mide la sobredispersión de un modelo Binomial Negativo
este parámetro se relaciona con el "size" de la distribución NegBin2 x log-likelihood: -3223.012 no deberíamos corregir por sobredispersión 37

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una BinomialRepetiremos todos los pasos previos, sólo que en esta ocasión nuestro modelos será:
modelo <- glm(eqt, data=datos, family=binomial(link="logit"))
Si hay sobredispersión utilizaremos la pseudofamilia:family=quasibinomial(link="logit")
Si no hay buenos ajustes o alta sobredispersión utilizaremos la función de vínculo:family = binomial(link ="cloglog")
cloglog trabaja mejor con distribuciones extremadamente sesgadaspor ejemplo: porporciones de un estado <0.1 o >0.9
38

MODELOS GENERALIZADOS LINEALES CON RDiseños factoriales utilizando una Binomial
Si nuestra variable respuesta no es una binomial con estados [0‐1] ó [SI‐NO]entonces podremos construir un modelo definiendo esa variable respuesta "frecuencia".
Hay dos modos:• la respuesta es un valor "proporción" (acotado entre cero y uno)• la respuesta es un valor combinado de dos vectores: valores SI, valores NO
Para proporciones, tenemos que definir el denominador que genera la frecuencia en weights
modelo <- glm(eqt, data=datos, family=binomial(link="logit"), weights=denominador)
Para respuestas combinadas, tenemos que definir los dos vectores conteo‐SI, conteo‐NO en una nueva variable respuesta con el comando cbind
cbind(valoresSI, valoresNO)
## ejemplo con los datos de trabajoeqt <- as.formula(cbind(presen8, ausen8) ~ covariante + insolacion * tratamiento)
modelo <- glm(eqt, data=datos, family=binomial(link="logit")
39

MODELOS GENERALIZADOS USANDO UNA BINOMIAL
Nuestro modelo ahora tendrá la forma:p: proporción de un "estado" respecto a toda la muestra(80 "ceros" y 20 "unos", N=100: p = 20/100 = 0.20)
X: k variables predictoras
logit ( p ) = log [ p / (1 – p) ] = β0 + β1X1 + β2X 2 + β3X3 +... + βkXk
p / (1 – p) = exp ( β0 + β1X1 + β2X 2 + β3X3 +... + βkXk ) exp: antilogaritmo
[ exp ( β0 + β1X1 + β2X 2 + β3X3 +... + βkXk ) ]p =
1 + [ exp ( β0 + β1X1 + β2X 2 + β3X3 +... + βkXk ) ]
El modelo Generalizado Lineal Logit predice valores de probabilidad continua (p):entre 0 y 1.
40

RESIDUOS DE MODELOS GENERALIZADOS BINOMIALESLa exploración de los residuos en esta ocasión es un tanto diferente, debido al estado binomial de la respuesta con dos valores discretos (e.g., 0‐1, sí‐no).
Con la "normalidad de los residuos" de devianza, en el mejor de los casos, tendríamos algo parecido a lo siguiente (con antisimetría en los dos lados del "bigote"):
cuanto más explique el modelomás cerca estarán los dos extremos
mayor densidadde puntos
menor densidadde puntos
41
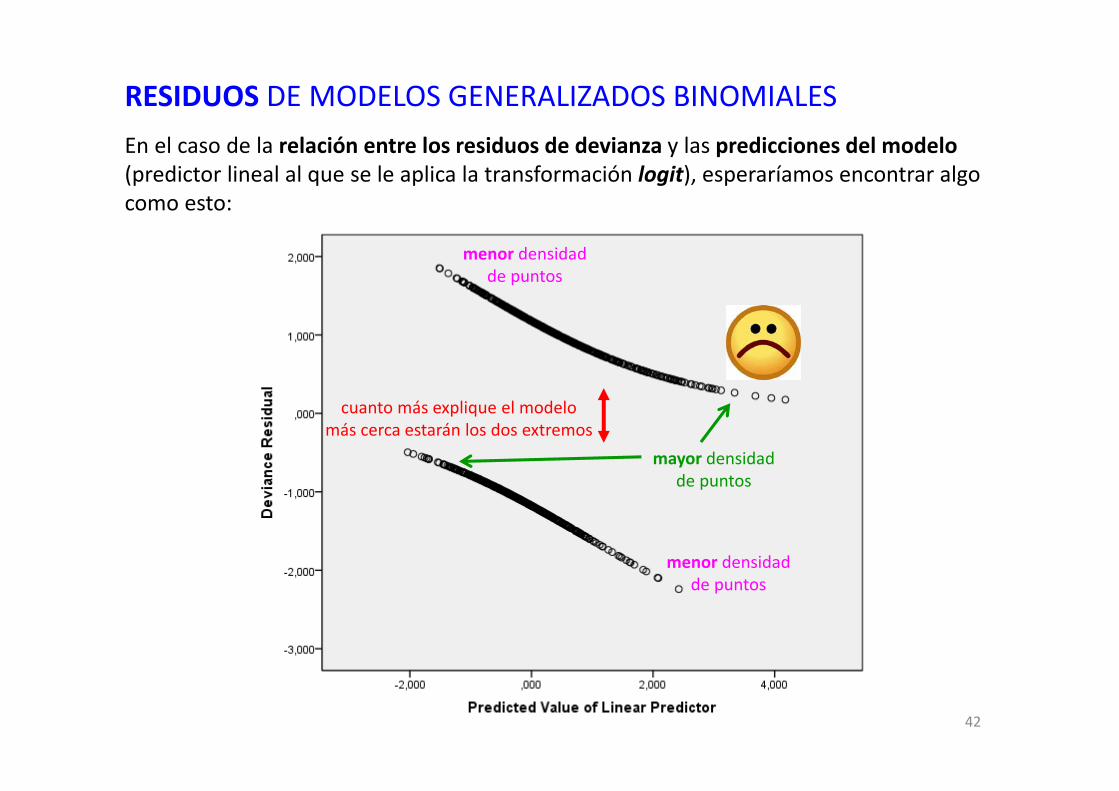
RESIDUOS DE MODELOS GENERALIZADOS BINOMIALESEn el caso de la relación entre los residuos de devianza y las predicciones del modelo(predictor lineal al que se le aplica la transformación logit), esperaríamos encontrar algo como esto:
cuanto más explique el modelomás cerca estarán los dos extremos
mayor densidadde puntos
menor densidadde puntos
menor densidadde puntos
42

DIAGRAMAS ROC EN MODELOS GENERALIZADOS BINOMIALESEl Modelo Generalizado Binomial produce probabilidades de ocurrencia p de uno de los estados de la variable respuesta (e.g., el valor 1 en 0‐1, o sí en sí‐no).
Estos valores de p, continuos entre 0 y 1, hay que convertirlos a "estados" 0 o 1, utilizando umbrales de corte.
Estos valores umbrales nos permitirán convertir "probabilidades" en "estados".
si p<0.5 entonces es "cero"por ejemplo, si el umbral es p=0.5
si p>0.5 entonces es "uno"
Podemos utilizar como umbral de corte (cut‐off point) la proporción real observada.No obstante, en muchas ocasiones este es un valor incierto, y es conveniente preguntarse:¿cómo de bueno es nuestro modelo "clasificando las observaciones" independiente‐mente de los valores umbral de corte?
Para ello podemos contar con los diagramas ROC (Receiver operating characteristic):https://en.wikipedia.org/wiki/Receiver_operating_characteristichttp://www.anaesthetist.com/mnm/stats/roc/Findex.htm (excelente página)
43

DIAGRAMAS ROC EN MODELOS GENERALIZADOS BINOMIALES
El área en el cuadrado morado suma "uno". De esa área,¿cuánto ocupa la superficie bajo la curva azul? (la proporción es el valor AUC)
AUC
44