line
DESCRIPTION
apuntes relacionado con el algebra linealTRANSCRIPT

Curso de Algebra Lineal (septima version, 2012).
Lucıa Contreras Caballero.Depto. Matematicas. Fac. Ciencias.Universidad Autonoma de Madrid.
1

2

PROLOGO.
He escrito este curso tratando de expresar de la forma mas sencilla posible los conceptos de algebralineal, requiriendo solamente los conceptos previos de Bachillerato. Corresponde a los programas delos dos semestres de primer curso de algebra lineal de C.C. Fısicas en la Universidad Autonoma deMadrid. Despues ha sido ampliado para cubrir tambien los programas de los semestres de AlgebraLineal y Algebra Lineal y Geometrıa de CC. Matematicas.
Aquı se encontraban en la tercera version, algunos trabajos originales de la autora: Una intro-duccion geometrica a los determinantes, una demostracion sencilla de la regla de Cramer, demostra-ciones elementales del teorema de Jordan en dimension 2, 3 y 4, la obtencion de la base de Jordanen dimension 2 y 3 y una aplicacion del espacio dual a la obtencion de condiciones necesarias ysuficientes para la diagonalizacion simultanea de formas cuadraticas.
Tambien se encontraba una aplicacion del concepto de dimension al calculo del rango de unamatriz y aplicaciones de la diagonalizacion de formas cuadraticas, y entre los ejercicios, aplicaciones dela diagonalizacion de matrices y de su forma de Jordan a problemas de poblaciones. Y se explicitabanel metodo de Gauss, el teorema de Rouche-Frobenius y el criterio de Sylvester. Otra aplicacioninteresante es la de la tecnica de las proyecciones al metodo de mınimos cuadrados.
En la cuarta version he anadido otros trabajos tambien originales: condiciones necesarias y sufi-cientes para detectar el caracter de las formas cuadraticas degeneradas, una demostracion elementaldel teorema de Jordan general para endomorfismos, un metodo facil para hallar la forma de Jordan yuna demostracion de que el sentido fısico de la regla del sacacorchos del producto vectorial coincidecon el sentido matematico de dicho producto vectorial.
En la quinta version he anadido la dinamica de poblaciones. En la sexta version he anadido uncapıtulo de conicas y otro de cuadricas. En la septima version he anadido una apendice sobre elespacio cociente.
El curso es autocontenido, con todas las demostraciones de los resultados y teoremas expuestosde forma logica y rigurosa.
Intentando que los alumnos estudien los conceptos, se introducen motivaciones de los mismos yse intercalan muchos grupos de ejercicios con dificultad progresiva. Algunos ejercicios se plantean deforma que se puedan resolver de distintas maneras, lo cual permite al alumno la comprobacion desus resultados.
Tambien he intercalado dibujos que facilitan la comprension de los conceptos y de los razonamien-tos y ejemplos resueltos en los ultimos capıtulos.
Lucıa Contreras Caballero.
3

INDICE.
NUMEROS COMPLEJOS.Introduccion. 9Regla de Ruffini para soluciones fraccionarias. 12Numeros Complejos. 14Inverso de un numero complejo. 15Propiedades de las soluciones de las ecuaciones. 19Forma trigonometrica y forma polar de un numero complejo. 22Radicacion. 26MATRICES. SUS OPERACIONES.Introduccion. 31Operaciones en las matrices. 32Tipos de matrices. 38METODO DE GAUSS Y REDUCCION DE GAUSS-JORDAN.Introduccion. 47Metodo de Gauss. 50Operaciones elementales en una matriz. 57Reduccion de Gauss-Jordan. 63Matrices Invertibles. 68Caracterizacion de las matrices invertibles. 69Metodo de Gauss para obtener la inversa de una matriz invertible. 77DETERMINANTES y SISTEMAS de ECUACIONES.Introduccion. 81Propiedades de los determinantes y operaciones elementales. 85Definicion de los determinantes. 90Comprobacion de las propiedades. 91Regla de Cramer sin utilizar la matriz inversa. 98Caracterizacion de las matrices invertibles por su determinante. 100Determinante del producto. 101Desarrollo del determinante por una fila cualquiera y por una columna cualquiera. 104Formula para la inversa. 106Regla de Cramer. 110Teorema de Rouche-Frobenius. 111Producto Vectorial. 116ESPACIOS VECTORIALES.Introduccion. 125
4

Cuerpo. Propiedades. 127Espacio Vectorial. 129Subespacios Vectoriales. 131Bases. 141Teorema de la Base. 147Cambio de base. 153Aplicaciones del concepto de dimension a procesos concretos. 155Independencia del numero de escalones obtenidos escalonando una matriz. 155Extraccion de la base a partir de un sistema generador. 156Aplicacion del rango a la obtencion de las ecuaciones cartesianas de un subespacio dado por sus
generadores. 158Calculo del rango de la matriz A y busqueda del menor distinto de cero de orden igual al rango.
160Aplicacion al metodo de Gauss. 163Suma e interseccion de subespacios vectoriales. 164APLICACIONES LINEALES.Introduccion. 171Expresion matricial de una aplicacion lineal. 174Cambio de base en la expresion matricial de una aplicacion lineal. 177Nucleo de una aplicacion lineal. 183Imagen de una aplicacion lineal. 186Formula de las dimensiones para una aplicacion lineal. 190Isomorfismos. 192Espacio dual. 195ESPACIO EUCLIDEO.Introduccion. 201Ortogonalidad. 202Bases Ortogonales. 205Ortogonalidad entre subespacios. 207Complemento Ortogonal. 207Teorema de Tellegen. 209Proyecciones en general. 211Proyecciones Ortogonales. 212Proyeccion ortogonal de un vector sobre un subespacio. 213Teorema de la aproximacion optima. 215Metodo de Aproximacion de Mınimos Cuadrados. 216Aplicacion del metodo de mınimos cuadrados a la regresion lineal. 218
5

Aplicacion del metodo de mınimos cuadrados a la obtencion de la matriz de la aplicacion proyeccionortogonal sobre un subespacio. 221
ESPACIO EUCLIDEO GENERAL.Una generalizacion mas del Producto Escalar. 222Expresion polinomial de una forma bilineal en un espacio vectorial de dimension finita. 226Expresion matricial de una forma bilineal en un espacio vectorial de dimension finita. 226Complementario Ortogonal en el espacio euclıdeo general. 229Proyecciones ortogonales en un espacio euclıdeo general. 230Metodo para encontrar una base ortonormal en un espacio vectorial de dimension finita. 232Metodo de ortogonalizacion de Gram-Schmidt. 233Ortogonalidad en un espacio euclıdeo general. 238Desigualdad de Schwarz. 239Cambio de base. 241Condiciones Necesarias y Suficientes para que una matriz corresponda a un Producto Escalar.
(Criterio de Sylvester). 243DIAGONALIZACION DE ENDOMORFISMOS. Aplicaciones autoadjuntas en espacios euclıdeos
y hermıticos, y aplicaciones unitarias en espacios hermıticos.Introduccion. 249Vectores propios y valores propios. 250Primera condicion necesaria y suficiente para que el endomorfismo sea diagonalizable. 251Segunda condicion necesaria y suficiente para que el endomorfismo sea diagonalizable. 257Dinamica de poblaciones. 259Multiplicidad de los valores propios. 260Tercera condicion necesaria y suficiente para que el endomorfismo sea diagonalizable. 262Aplicaciones autoadjuntas en un espacio euclıdeo. 264Diagonalizacion de las Aplicaciones Autoadjuntas, (de las matrices simetricas). 268Espacios Hermıticos. 275FORMAS CUADRATICAS.Introduccion. 281Expresion matricial de una forma cuadratica. 281Cambio de base en formas cuadraticas. 285Diagonalizacion de formas cuadraticas. 287Diagonalizacion de una forma cuadratica en una base ortonormal. 287Estudio de Conicas. 291Maximos y mınimos de funciones. 292Maximos y mınimos en la esfera unidad. 293Energıa de rotacion de un solido. 294Diagonalizacion de formas cuadraticas completando cuadrados. 295
6

Ley de inercia de Sylvester. 302Criterio de Sylvester para formas cuadraticas definidas positivas. 306Criterios para formas cuadraticas degeneradas. 311Diagonalizacion simultanea de formas cuadraticas. 319Condiciones necesarias y suficientes para la diagonalizacion simultanea de formas cuadraticas.325FORMAS DE JORDAN EN DIMENSION 2, 3 y 4.Introduccion. 333Consideraciones previas. 334Forma de Jordan de Matrices 2× 2 de numeros reales. 335Forma de Jordan de Matrices 3× 3 de numeros reales. 339Resumen de la forma de Jordan en R3. 354Forma de Jordan compleja de Matrices 4× 4 de numeros complejos. 355Resumen de la forma de Jordan en R4. 360DEMOSTRACION DEL TEOREMA DE JORDAN PARA ENDOMORFISMOS.Teorema de Jordan. 363Ejemplos para un metodo facil para hallar la base de Jordan. 367Metodo general. 378APLICACIONES ORTOGONALES. ESPACIO AFIN Y MOVIMIENTOS.Introduccion. 383Definicion y propiedades. 383Estudio de las transformaciones ortogonales de R2. 389Estudio de las transformaciones ortogonales de R3. 395Espacio Afın. 405Aplicaciones afines con puntos fijos. 414Movimentos en el plano. 420Movimentos en el espacio tridimensional. 425Sentido del producto vectorial. 438CONICAS.Introduccion. 441Ecuaciones de las conicas en posicion canonica. 443Ecuaciones de algunas conicas en posicion no canonica. 446Algunos ejemplos de reduccion de curvas de segundo grado a su ecuacion canonica. 449Reduccion de la ecuacion general de la expresion de una curva de segundo grado a su expresion
canonica. 453Invariantes de las conicas. 455Clasificacion de las conicas. 457Ejes de simetrıa y centro de las conicas no degeneradas. 458Calculos en la elipse del ejemplo 5. 460
7

Calculos en la hiperbola del ejemplo 6. 461Calculos en la parabola del ejemplo 7. 462Unificacion de las conicas en una definicion de lugar geometrico. 465CUADRICAS.Introduccion. 469Estudio general de la superficie de segundo grado. 472Invariantes de las cuadricas. 476Clasificacion de las cuadricas. 478Resumen de la clasificacion de las cuadricas. 479Ejes de simetrıa y centro de las cuadricas no degeneradas. 479Otros invariantes de las cuadricas degeneradas. 482Ley de los signos de Descartes. 484APENDICE: ESPACIO VECTORIAL COCIENTE. 487
8

NUMEROS COMPLEJOS.
Introduccion.
Los distintos tipos de numeros han ido apareciendo en la historia del hombre progresivamente,segun las necesidades de las actividades que realizaba y son estudiados hoy tambien progresivamentedesde la escuela primaria a la Universidad.
Debido a la necesidad de contar las cabezas de ganado surgieron los numeros naturales, (queson todos positivos) con los que se puede sumar; los numeros enteros, (que pueden ser positivos onegativos e incluyen al cero) sirven para indicar los intercambios de mercancıas y dinero; con ellos sepuede sumar y restar. La multiplicacion es una forma mas rapida de hacer una suma de sumandosiguales y entonces se plantea el problema de hacer la operacion inversa a la multiplicacion que es ladivision, pero esta operacion no siempre tiene solucion con numeros enteros, por lo que se crearonotros numeros llamados fraccionarios o racionales.
Los numeros enteros se caracterizan por el hecho de que cualquier ecuacion de la forma x+ a = btiene solucion cuando los numeros que aparecen en ella son enteros.
Los numeros fraccionarios se caracterizan por el hecho de que cualquier ecuacion de la formaa1x+ a = b tiene solucion cuando los numeros que aparecen en ella son fraccionarios y a1 6= 0.
Hay otro conjunto de numeros en los que tambien la ecuacion a1x+a = b tiene solucion si a1 6= 0,son los numeros reales que se construyen como lımites de sucesiones de numeros fraccionarios. Losnumeros reales incluyen a los fraccionarios. La ecuacion anterior es una ecuacion de primer grado conuna incognita, que tambien se puede escribir a1x+ a0 = 0. Nos podemos plantear el problema sobresi una ecuacion mas general: anx
n + an−1xn−1 + · · ·+ a1x+ a0 = 0 tiene siempre solucion cuando los
numeros que aparecen en ella son reales. La respuesta es que no y para obtener respuesta positivatenemos que construir otro conjunto de numeros que se llama numeros complejos y se designa por C.
Hay ejemplos de ecuaciones de segundo grado que no tienen solucion real. La ecuacion massimple que no tiene solucion real es x2 + 1 = 0. La ecuacion general de segundo grado, de la formaax2 + bx+ c = 0 tiene la solucion x = −b±
√b2−4ac
2apero si b2−4ac < 0 no encontramos ningun numero
real para x.Lo asombroso es que escribiendo por i un numero imaginario que satisfaga i2+1 = 0, encontramos
numeros, llamados complejos, que son soluciones de todas las ecuaciones de segundo grado planteadas.Ya que si b2−4ac < 0, tenemos
√b2 − 4ac = i
√4ac− b2 que tiene un sentido imaginario. Entonces, el
conjunto de los numeros soluciones de todas las ecuaciones de segundo grado que se pueden planteares el conjunto de los binomios de la forma −b
2a±√b2−4ac2a
donde el segundo sumando puede ser real
o imaginario. Este es el conjunto de los numeros complejos en el que i2 = −1 por ser i solucionde la ecuacion x2 + 1 = 0. Los representaremos, en general, como a + bi, donde a y b son ahoranumeros reales cualesquiera. El conocimiento de las propiedades de las operaciones de los numeroscomplejos amplıa la cantidad de ecuaciones que podemos resolver. Es muy importante y sorprendente
9

el teorema fundamental del algebra que afirma que cualquier ecuacion de grado n con coeficientescomplejos tiene siempre al menos un numero complejo como solucion.
Haciendo ingeniosas combinaciones con los coeficientes de la ecuacion de tercer grado, del Ferroy Tartaglia encontraron la forma general de sus soluciones, que ha pasado a la historia como formulade Cardano. La resolucion de la ecuacion de cuarto grado fue reducida a la solucion de la ecuacion detercer grado por Ferrari. Pero el problema es mucho mas difıcil si el grado de la ecuacion es mayor,no estando claro ni siquiera que la ecuacion tenga solucion. En este sentido, la importancia de losnumeros complejos, de los que hemos hablado en la introducion, y del Teorema Fundamental delAlgebra demostrado por Gauss estriba en que afirma que cualquier ecuacion de grado n concoeficientes complejos tiene siempre al menos un numero complejo como solucion. Esteteorema afirma la existencia de la solucion pero sigue quedando el problema de como encontrarlaefectivamente. Durante mucho tiempo, los matematicos estuvieron buscando una formula generalpara todas las ecuaciones de un cierto grado expresada por raices de expresiones racionales de suscoeficientes, hasta que un matematico llamado Abel demostro que esta forma general expresada porradicales comun para todas las ecuaciones de un cierto grado no existıa a partir de grado 5. Mastarde, otro matematico llamado Galois encontro las condiciones necesarias y suficientes que han deverificar los coeficientes de la ecuacion para que sus soluciones se puedan expresar por radicales. Aunhoy no todas las ecuaciones estan resueltas y en eso trabajan los algebristas.
Sin embargo, se puede demostrar y lo demostraremos mas adelante que, debido a las propiedadesde los numeros complejos, si los coeficientes de la ecuacion son reales las soluciones complejas aparecenpor parejas conjugadas de la misma multiplicidad. Y de aquı, que toda ecuacion de grado impar concoeficientes reales tiene al menos una solucion real.
El Algebra es el estudio de la resolubilidad de las ecuaciones; en cuanto que las ecuaciones seresuelven haciendo operaciones con los coeficientes que aparecen en ellas, el algebra es tambien elestudio de las propiedades de las operaciones que podemos hacer con esos numeros.
En este capıtulo repasaremos algunos resultados de bachillerato, los generalizaremos y ademasestudiaremos ciertas propiedades de los numeros complejos que nos serviran para ampliar la cantidadde ecuaciones que sabemos resolver.
10

Recordemos conocimientos de Bachillerato sobre las ecuaciones de grado n.Las soluciones enteras de una ecuacion de grado n con coeficientes enteros deben ser divisores del
termino independiente.Veamos por que: Sea anx
n + an−1xn−1 + · · ·+ a1x+ a0 = 0 una ecuacion de grado n donde todos
los ai son enteros y sea a una solucion entera de la ecuacion. Entonces,
anan + an−1a
n−1 + · · ·+ a1a+ a0 = 0 =⇒ anan + an−1a
n−1 + · · ·+ a1a = −a0,
de donde(ana
n−1 + an−1an−2 + · · ·+ a1)a = −a0;
como todos los numeros del parentesis son enteros, la ultima expresion indica que la solucion a dividea a0.
Esta regla nos permite muchas veces encontrar las soluciones enteras de una ecuacion de gradon por tanteo, ya que el numero de divisores de un numero fijado es finito. Y se puede utilizar paraecuaciones con coeficientes fraccionarios, una vez que hemos quitado los denominadores.
En Bachillerato se estudia tambien la regla de Ruffini, que es un algoritmo para hallar Pn(a) ylos coeficientes del polinomio cociente Qn−1(x).
Este algoritmo es un metodo para obtener el resto Pn(a) = anan + an−1a
n−1 + · · · + a1a + a0
resultante de dividir Pn(x) por x− a, consistente en lo siguiente:Se colocan en una fila los coeficientes an, an−1, an−2, · · · a1, a0 y debajo de esta, a la izquierda
el numero a y se hace una lınea horizontal:
an an−1 an−2 · · · a1 a0
a) 0 ana ana2 + an−1a · · · · · · ana
n + · · ·+ a1a−− −− −−−−− −−−−− −−− −−−−− −−−−−−−
an ana+ an−1 ana2 + an−1a+ an−2 · · · ana
n−1 + · · ·+ a1 anan + · · ·+ a1a+ a0
Se suma 0 a an y se pone debajo de la lınea horizontal a la altura de an; se multiplica por a,se pone ana debajo de an−1 al que se suma, obteniendose debajo de la lınea horizontal ana + an−1;de nuevo, se multiplica este numero por a, se coloca debajo de an−2 y se suman los dos numeros,obteniendose ana
2 +an−1a+an−2 debajo de la lınea horizontal; se va repitiendo el mismo proceso conlas sumas que se van obteniendo debajo de la lınea horizontal, teniendose a la altura de a1 la sumaana
n−1 + an−1an−2 + · · · + a2a + a1, que multiplicada por a y sumada a a0 da: ana
n + an−1an−1 +
· · · + a2a2 + a1a + a0 = Pn(a). Segun lo demostrado anteriormente, este numero es cero si y solo si
el polinomio considerado es divisible por x− a.
11

Ademas, los numeros obtenidos debajo de la lınea horizontal son los coeficientes de los terminosde mayor grado de los restos sucesivos obtenidos al hacer la division del polinomio Pn(x) por x− a;por ello son los coeficientes de las potencias de x en el polinomio cociente Qn−1(x).
Por ejemplo, la ecuacion x4 − 10x3 + 35x2 − 50x + 24 = 0 puede admitir como soluciones losdivisores de 24, entre ellos esta el 3; para ver si el 3 es efectivamente una solucion aplicamos la reglade Ruffini para hallar el resto de la division del polinomio dado por x− 3:
1 −10 35 −50 243) 0 3 −21 42 −24−− −− −− −− −− −−
1 −7 14 −8 0
Habiendo salido cero el ultimo numero de abajo a la derecha, el resto de dividir el polinomio porx− 3 es cero y el cociente es x3 − 7x2 + 14x− 8. Efectivamente, una solucion de la ecuacion es 3.
Recordemos estos conocimientos en los Ejercicios:1.1.1. Resolver utilizando la regla de Ruffini las ecuaciones:
x4 − 2x3 − 13x2 + 14x+ 24 = 0.
∣∣∣∣∣∣1− λ 1 3
1 2− λ −20 1 3− λ
∣∣∣∣∣∣ = 0.
1.1.2. Resolver las ecuaciones siguientes:
x4 − 13x2 + 36 = 0. x6 − 14x4 + 49x2 − 36 = 0.
La regla de Ruffini se puede generalizar a soluciones fraccionarias:Regla de Ruffini para soluciones fraccionarias.
Se puede generalizar a las soluciones fraccionarias el resultado 1) demostrado para las solucionesenteras de una ecuacion de grado n con coeficientes enteros, encontrandose que 3) si un numeroracional M/N irreducible es solucion de la ecuacion de grado n con coeficientes enteros,M debe ser divisor del termino independiente y N debe ser divisor del coeficiente deltermino de mayor grado.
Demostracion: Sustituyendo la solucion M/N en la ecuacion dada tenemos:
an(M
N)n + an−1(
M
N)n−1 + · · ·+ a1
M
N+ a0 = 0 =⇒ an
Mn
Nn+ an−1
Mn−1
Nn−1+ · · ·+ a1
M
N+ a0 = 0
12

de donde quitando denominadores y sacando factor comun tenemos
anMn+an−1M
n−1N+· · ·+a1MNn−1 = −a0Nn ≡M(anM
n−1+an−1Mn−2N+· · ·+a1N
n−1) = −a0Nn
donde, debido a que todos los numeros son enteros y a que M no tiene factor comun con N, se tieneque M divide a a0.
Tambien tenemos:
−anMn = an−1Mn−1N+· · ·+a1MNn−1+a0N
n ≡ −anMn = N(an−1Mn−1+· · ·+a1MNn−2+a0N
n−1)
donde, debido a que todos los numeros son enteros y a que N no tiene ningun factor comun con M,se tiene que N divide a an.
La regla de Ruffini tambien se puede aplicar con las raices fraccionarias.Conviene practicar esta generalizacion en los Ejercicios:1.2.1. Resolver las ecuaciones:
a) 6x2 − 5x+ 1 = 0.
b) 12x3 − 40x2 + 27x− 5 = 0.
c) 24x3 − 26x2 + 9x− 1 = 0.
d) 12x3 − 32x2 + 25x− 6 = 0.
e) 6x4 + 7x3 − 3x2 − 3x+ 1 = 0.
13

Numeros Complejos.Veremos ahora los Numeros Complejos, cuyo conocimiento nos permitira la resolucion de mas
ecuaciones:Se llama expresion binomica de un numero complejo a la forma a+ ib, donde a y b son numeros
reales, en la cual a es la parte real y b es la parte imaginaria. El conjugado de un numero complejoz = a+ ib es z = a− ib.
Los numeros complejos se pueden sumar como binomios:
(a+ ib) + (c+ id) = (a+ c) + i(b+ d)
y pueden comprobarse facilmente, utilizando las propiedades de los numeros reales, (lo cual se re-comienda como ejercicio), las propiedades de la suma:
a) Asociativa.b) Tiene elemento neutro: 0+i0 (un elemento que sumado a cualquier otro lo deja igual).c) Todo numero complejo tiene elemento opuesto respecto a la suma: (el elemento opuesto de
uno dado es el elemento que sumado con el da el elemento neutro).d) Conmutativa.La existencia de la suma con las propiedades antes enumeradas se resume en una frase: Los
numeros complejos son un grupo aditivo conmutativo.
Los numeros complejos tambien se pueden multiplicar como binomios donde i2 = −1.
(a+ ib)(c+ id) = (ac− bd) + i(ad+ bc)
y puede comprobarse, tambien utilizando las propiedades de los numeros reales, que el producto es:a) Asociativo.b) Tiene elemento neutro (1).c) Todo elemento distinto del cero tiene elemento inverso.d) Es conmutativo.
La existencia del producto con las propiedades antes enumeradas se resume en la frase: Losnumeros complejos distintos de cero son un grupo multiplicativo conmutativo.
De las propiedades anteriores, solo voy a comprobar aquı que todo numero complejo distinto decero tiene inverso.
14

Inverso de un numero complejo.Si buscamos el inverso x+ iy de un numero complejo a+ ib, buscamos un numero tal que(a+ ib)(x+ iy) = 1 es decir, un numero tal que (ax− by) + i(ay + bx) = 1.Si el numero fuera real: z = a, de a−1a = 1 tenemos que z−1 = a−1. Si el numero fuera imaginario
puro: z = ib, de −ib−1ib = 1 tenemos que z−1 = −ib−1.Podemos suponer en lo que sigue que el numero no es real ni imaginario puro, es decir, que
a 6= 0 6= b.Como dos numeros complejos son iguales cuando tienen la misma parte real y la misma parte
imaginaria, ha de ser:
ax− by = 1bx+ ay = 0
≡ (si a 6= 0, b 6= 0)
a2x− aby = ab2x+ aby = 0
de donde (a2 + b2)x = a. Aquı podemos despejar x por ser a2 + b2 6= 0, ya que estamos suponiendoa 6= 0, b 6= 0. Entonces x = a/(a2 + b2).
Tambien, ha de ser:abx− b2y = babx+ a2y = 0
de donde (a2 + b2)y = −b, donde tambien podemos despejar y = −b/(a2 + b2).
Hemos obtenido que el inverso de a+ ib, es 1(a2+b2)
(a− ib), siempre que a+ bi sea distinto de cero.Compruebese que esta formula es valida para los casos particulares hallados al principio, en los queel numero era real o era imaginario puro.
Para dividir z1 por z2 (si z2 6= 0) multiplicamos z1 por el inverso de z2.
Por un procedimiento similar de igualar partes real e imaginaria podemos hallar, dado un numero complejo c+ di
otro numero complejo a+ bi que elevado al cuadrado de c+di. Ası podemos resolver todas las ecuaciones bicuadradasen el conjunto de los numeros complejos.
e) Ademas el producto es distributivo respecto a la suma (debe comprobarse).
La existencia de la suma y del producto con las propiedades antes enumeradas se expresa en otrafrase: Los numeros complejos son un cuerpo conmutativo.
Otros cuerpos ya conocidos son los conjuntos de los numeros racionales y de los numeros reales.
Ahora se puede comprobar como Ejercicios:
15

1.3.1. Comprobar que, en el cuerpo de los numeros complejos, tienen tantas soluciones como sugrado, las ecuaciones siguientes:
x2 − x+ 1 = 0.
x2 −√
3x+ 1 = 0.
2x3 + 4x2 − 3x+ 9 = 0.
x4 − x3 − 3x2 + 4x− 4 = 0.∣∣∣∣∣∣2 λ 11 2 −λ
2λ 1 1
∣∣∣∣∣∣ = 0.
x6 + 4x4 + 5x2 + 2 = 0.
x4 − x3 − x2 − x− 2 = 0.
x4 + x3 − x− 1 = 0.
6x4 + x3 + 2x2 − 4x+ 1 = 0.
6x5 + 5x4 + 4x3 + 4x2 − 2x− 1 = 0.
x5 + x4 − x− 1 = 0.
6x4 + x3 + 11x2 + 2x− 2 = 0
12x4 + x3 + 11x2 + x− 1 = 0
6x4 − 11x3 + 10x2 − 11x+ 4 = 0
4x4 + 4x3 − 11x2 + 4x− 15 = 0
4x4 + 16x3 + 31x2 + 64x+ 60 = 0
1.3.2. Factorizar los polinomios igualados a cero en las ecuaciones anteriores y en las siguientes:
x5 − 2x4 + 2x3 − 4x2 + x− 2 = 0.
6x4 + 7x3 − 3x2 − 3x+ 1 = 0.
16

x5 + x4 + 2x3 + 2x2 + x+ 1 = 0.
x7 + x6 + 6x5 + 6x4 + 9x3 + 9x2 + 4x+ 4 = 0.
Observar que algunas no son totalmente factorizables en binomios de grado 1 con coeficientesreales. Cuando se admiten los coeficientes complejos, o bien hay tantos factores como el grado de laecuacion, o bien llamando al numero de veces que se repite un factor, multiplicidad de ese factor, lasuma de las multiplicidades de los factores de primer grado es igual al grado de la ecuacion.
1.3.3. Demostrar que en un cuerpo, se tiene b · 0 = 0, cualquiera que sea b.1.3.4. Demostrar que en un cuerpo, si a 6= 0, ax = 0⇒ x = 0.1.3.5. Probar que en un conjunto de numeros que sea un cuerpo, la ecuacion a1x + a = 0 tiene
solucion unica si a1 6= 0. No tiene solucion si a1 = 0 y a 6= 0. Tiene infinitas soluciones si a1 = 0 = a.
Recordemos que se llama conjugado del numero complejo z = a + ib al numero a − ib que serepresenta por z = a − ib. Utilizando la notacion de conjugado de un numero complejo, hemosobtenido anteriormente respecto a su inverso que: z−1 = 1
(a2+b2)z.
Se puede representar el numero complejo a + ib como el punto del plano que tiene coordenadascartesiamas (a, b). Entonces, el punto correspondiente al conjugado de un numero complejo es elpunto simetrico respecto al eje OX.
a
b
a+ib
a-ib
7
SSSSSSw
17

Por el teorema de Pitagoras, el numero a2 + b2 es el cuadrado de la longitud del vector con origenen el origen de coordenadas y extremo en el punto. Esta longitud se llama modulo del numerocomplejo y se representa por |z|. Entonces, podemos escribir: z−1 = 1
|z|2 z. De donde se deduce
tambien |z|2 = zz.
Para hacer operaciones con los numeros complejos se proponen los Ejercicios:1.4.1. Hallar los siguientes numeros complejos en forma binomica:
(1 + 2i)(1− 2i),1 + 2i
1− 2i, (
1 + 2i
1− 2i)2,
(1 + 2i)3
(2− i)3,
(1 + 2i)3
(2− 2i)3.
1.4.2. Hallar un numero complejo en forma binomica: a+ bi tal que (a+ bi)2 = 1 + i.1.4.3. Resolver la ecuacion x4 − 2x2 + 10 = 0 en el cuerpo de los numeros complejos.1.4.4. Resolver la ecuacion z2 − (1 + i)z + i = 0 en el cuerpo de los numeros complejos.1.4.5. Demostrara) z1 + z2 = z1 + z2
b) z1 · z2 = z1 · z2
1.4.6. Demostrar:a) |z| = |z|b) |z1 · z2| = |z1||z2|c) |z1 + z2| ≤ |z1|+ |z2|
18

Propiedades de las soluciones de las ecuaciones.
A)Utilizando el ejercicio 1.4.5. anterior se obtiene que las soluciones complejas de una ecuacion
con coeficientes reales aparecen por parejas conjugadas:Sea anx
n + an−1xn−1 + · · ·+ a1x+ a0 = 0 una ecuacion de grado n donde todos los ai son reales
y sea z una solucion compleja de la ecuacion. Entonces,
anzn + an−1z
n−1 + · · ·+ a1z + a0 = 0 =⇒ anzn + an−1zn−1 + · · ·+ a1z + a0 = 0 =⇒
anzn + an−1zn−1 + · · ·+ a1z + a0 = 0 =⇒ anzn + an−1z
n−1 + · · ·+ a1z + a0 = 0
donde se ve que tambien z es solucion de la ecuacion.
B)El numero a es solucion de la ecuacion: anx
n + an−1xn−1 + · · · + a1x + a0 = 0, si y solo si el
binomio x − a divide al polinomio anxn + an−1x
n−1 + · · · + a1x + a0. En efecto, llamando Pn(x) aeste polinomio y dividendolo por x− a obtendrıamos:
Pn(x) = Qn−1(x)(x− a) +R(x)
pero R(x) = R es un numero por ser el grado del resto menor que el grado del divisor. Sustituyendoahora el valor a en la expresion de la division, tenemos:
Pn(a) = Qn−1(a)(a− a) +R = R
lo que nos dice que el resto de esta division es cero si y solo si a es solucion de la ecuacion dada,teniendose ası que el polimomio Pn(x) es divisible por x− a si y solo si a es solucion de la ecuacionPn(x) = 0. Con lo que conocida una solucion de una ecuacion, esta queda reducida a otra de gradomenor, presumiblemente mas facil (Qn−1(x) = 0).
No podemos demostrar ahora con los conocimientos que tenemos el teorema fundamental delalgebra, pero sı podemos ver consecuencias suyas:
C)Todo polinomio con coeficientes complejos puede factorizarse en binomios de primer grado con
coeficientes complejos.En efecto, dado un polinomio Pn(x), con coeficientes complejos, al tener la ecuacion Pn(x) = 0
siempre solucion en los numeros complejos por el teorema fundamental del algebra, existe z1, tal
19

que Pn(x) = (x − z1)Qn−1(x), donde el grado del cociente Qn−1(x) es n − 1. Este nuevo polinomiocociente puede factorizarse igualmente por el teorema fundamental del algebra, obteniendose Pn(x) =(x − z1)(x − z2)Qn−2(x). El grado del polinomio cociente puede seguir siendo rebajado hasta 1, encuyo momento, habremos factorizado el polinomio dado en n binomios de primer grado, algunos delos cuales se pueden repetir.
Observando que los binomios de primer grado que factorizan un polinomio se pueden repetir yllamando multiplicidad de cada raiz zi al exponente de x − zi en la factorizacion de Pn(x), ahoravemos que
la suma de las multiplicidades de las soluciones reales y complejas de una ecuacion de grado n concoeficientes complejos es igual al grado de la ecuacion.
Tambien se define la multiplicidad de una raiz zi de un polinomio Pn(x) como el numero ni talque Pn(x) = (x− zi)niQi(x) donde Qi(zi) 6= 0.
D)Si la ecuacion es de grado impar con coeficientes reales, alguna de sus soluciones ha de ser real.Veamos primero que las raices complejas no reales de un polinomio con coeficientes reales, apare-
cen con la misma multiplicidad que sus conjugadas:Si Pn(x) = 0 es una ecuacion con coeficientes reales y z1 y z1 son dos soluciones conjugadas,
siendo z1 = a+ ib; al ser Pn(x) = (x− z1)Qn−1(x) se tiene:
0 = Pn(z1) = (z1 − z1)Qn−1(z1) = −2biQn−1(z1)
donde b 6= 0, por lo que Qn−1(z1) = 0, siendo Qn−1(x) divisible por x− z1; entonces,
Pn(x) = (x− z1)(x− z1)Qn−2(x) = (x− (a+ bi))(x− (a− bi))Qn−2(x) = [(x− a)2 + b2]Qn−2(x)
El polinomio Qn−2(x) debe tener todos sus coeficientes reales, porque Pn(x) y (x − a)2 + b2 lostienen reales, por ello, si Qn−2(x) tiene una raiz compleja no real tambien tiene a su conjugada. Lomismo ocurrre con los sucesivos cocientes de Qn−2k(x)por (x−z1)(x−z1), de ser divisibles por x−z1,por ello la raiz z1 aparece tantas veces como la raiz z1.
Entonces, si todas las raices del polinomio, de grado impar, fueran complejas no reales, la sumade sus multiplicidades serıa par, no coincidiendo con su grado, por tanto, tiene que haber al menosuna solucion real.
E)Si un polinomio de grado n se anula para mas de n valores distintos de la variable x, el polinomio
es el polinomio nulo, (todos los ai son nulos). (De donde si el polinomio no es nulo y es de grado n,no se puede anular para mas de n valores de la variable).
20

En efecto, cogiendo n valores distintos xii∈1...n que anulen al polinomio, por ser Pn(x1) = 0,Pn(x) es divisible por x − x1, es decir, Pn(x) = Qn−1(x)(x − x1). Si x2 6= x1 anula al polinomio,Pn(x2) = 0 implica que Qn−1(x2)(x2− x1) = 0, lo cual a su vez implica que Qn−1(x2) = 0, por lo queQn−1(x) = Qn−2(x)(x−x2), y Pn(x) = Qn−2(x)(x−x2)(x−x1). Repitiendo el mismo procedimientocon n raices distintas, llegamos a que podemos expresar:
Pn(x) = Q0(x− xn)(x− xn−1) · · · (x− x2)(x− x1)
donde Q0 es un numero, que debe ser igual a an. Cogiendo un valor mas: (xn+1), que anule alpolinomio, suponiendo que existe, tenemos:
0 = Pn(xn+1) = an(xn+1 − xn)(xn+1 − xn−1) · · · (xn+1 − x1)
donde por estar en un cuerpo y ser todos los parentesis distintos de cero, ha de ser an = 0. Por lamisma razon, an−1 = 0 y ası sucesivamente hasta el a0. (Un polinomio igual a una constante se anulapara algun valor de x solo si esta constante es cero).
F)Con un razonamiento analogo se puede demostrar que encontradas k raices de un polinomio, cuya
suma de multiplicidades es igual al grado del polinomio, no puede haber otra raiz mas.En efecto, una vez escrito:
Pn(x) = (x− z1)n1(x− z2)
n2 · · · (x− zk)nkan donde Σni = n, y an 6= 0
si hubiera otra solucion mas: zn+1, se tendrıa:
0 = Pn(zn+1) = (zn+1 − z1)n1(zn+1 − z2)
n2 · · · (zn+1 − zk)nkan
Por ser los numeros complejos un cuerpo, el producto de una serie de factores es cero si y solo sialguno de los factores es cero, por lo que zn+1 debe coincidir con alguno de los zi anteriores.
21

Forma trigonometrica y forma polar de un numero complejo.
La forma binomica de los numeros complejos es adecuada para la suma, pero para la multiplicacionhay otra forma mas adecuada que es la forma polar.
Ademas, para expresar de formas analogas entre sı las soluciones de la ecuacion xn − 1 = 0 ≡xn = 1 vamos a utilizar la forma trigonometrica y la forma polar de un numero complejo.
Ya hemos dicho que los numeros complejos se pueden poner en correspondencia con los puntos delplano. Para ello, trazamos en el plano dos rectas perpendiculares, una horizontal y la otra vertical,llamamos O (origen) al punto interseccion de las dos rectas e introducimos una unidad de medida.Entonces al numero complejo a + ib puede asociarse el punto P que esta a distancia ”a” unidadesde medida del eje vertical y ”b” unidades de medida del eje horizontal. Al mismo tiempo podemosdibujar un vector con origen O y extremo P. Por el teorema de Pitagoras la longitud de este vectorcoincide con el modulo del numero complejo. El vector esta perfectamente determinado tambien porsu longitud y por el angulo que hace con la direccion positiva de uno de los ejes; vamos a escoger el ejehorizontal y al angulo que forma el vector con este eje le llamamos argumento del modulo complejo.Hemos llegado a otra determinacion de un numero complejo por su modulo y su argumento que dalugar a la forma trigonometrica y a la forma polar.
a
b
a+ib
r
φ$
7
La forma polar del numero complejo a + ib es el sımbolo reiφ donde r es el modulo y φ es elargumento del numero complejo. (El modulo r es siempre positivo).
Es de observar que cuando r = 0, cualquiera que sea φ, el numero es el cero. Y que reiφ = rei(φ+2π),es decir, todos los numeros complejos con el mismo r y argumentos diferenciandose en un multiplode 2π coinciden.
22

Dado que a = rcosφ y b = rsenφ, el numero complejo es tambien a+ ib = r(cosφ+ isenφ), siendoesta la forma trigonometrica del numero complejo. Se ve que tanφ = b/a. La forma trigonometrica
y la forma polar dan la relacion eiφ = (cosφ+ isenφ).
Otros ejercicios para la familiarizacion con estas formas son:1.5.1. De los numeros complejos enunciados a continuacion calcular su modulo y su argumento y
escribirlos en forma trigonometrica y en forma polar.
1 + i, 1− i, −1− i, 1
2+ i
√3
2,
√3
2+ i
1
2
1.5.2. Comprobar que cualquier numero complejo tiene el mismo modulo que su conjugado y quesu opuesto. ¿Cual es la relacion entre los argumentos de un numero complejo, su conjugado y suopuesto?
1.5.3. Suponiendo conocidos el modulo y el argumento de un numero complejo, hallar el moduloy el argumento de su inverso.
Las formas trigonometrica y polar nos pasan de la naturaleza puramente algebraica de losnumeros complejos a su representacion geometrica, lo cual va a revertir en el descubrimiento demas propiedades de dichos numeros.
Por ejemplo, la expresion de la multiplicacion de numeros complejos se simplifica:Sean z1 = r1e
iφ1 = r1(cosφ1 + isenφ1) y z2 = r2eiφ2 = r2(cosφ2 + isenφ2) y multipliquemoslos
segun la regla que tenemos para multiplicarlos en forma binomica:
r1eiφ1r2e
iφ2 = z1z2 = r1(cosφ1 + isenφ1) · r2(cosφ2 + isenφ2) =
(r1cosφ1r2cosφ2 − r1senφ1r2senφ2) + i(r1cosφ1r2senφ2 + r1senφ1r2cosφ2) =
r1r2(cosφ1cosφ2 − senφ1senφ2) + ir1r2(cosφ1senφ2 + senφ1cosφ2) =
= r1r2(cos(φ1 + φ2) + isen(φ1 + φ2) = r1r2ei(φ1+φ2)
Donde vemos que la multiplicacion de numeros complejos dados en forma polar o trigonometricase hace multiplicando sus modulos y sumando sus argumentos. Debido a ello, la asociatividad delproducto se demuestra mucho mas facilmente utilizando la forma polar.
Otros ejercicios son:1.6.1. Demostrar utilizando la forma binomica y la forma polar de los numeros complejos que:a) El producto de un numero por su conjugado es un numero real.
23

b) El cociente de un numero por su conjugado es de modulo 1.Observar que la demostracion usando la forma polar es mas corta.c) Comprobar los resultados anteriores en los calculos siguientes:
(1 + 2i)(1− 2i),3 + 4i
3− 4i,
d) Utilizar los resultados anteriores para calcular:
(
√2
2+ i
√2
2)(
√2
2− i√
2
2),
√2
2+ i
√2
2√2
2− i
√2
2
1.6.2. Probar la asociatividad de la multiplicacion de numeros complejos usando su expresion enforma polar y comparar la simplicidad del calculo respecto del que hay que hacer para demostrarlaen forma binomica.
24

La potenciacion sale tambien beneficiada de esta forma simple de multiplicar en forma polar.Segun lo visto:
zn = (reiφ)n = rneinφ = rn(cos(nφ) + isen(nφ))
de donde se obtiene la formula de Moivre:
cos(nφ) + isen(nφ) = (cosφ+ isenφ)n
en la que desarrollando el ssegundo miembro por el binomio de Newton y separando partes reales eimaginarias tenemos expresiones para cos(nφ) y sen(nφ) en funcion de cosφ y senφ.
Otra repercusion geometrica de la forma polar de un numero complejo se pone de manifiesto siobservamos lo que ocurre al multiplicar numero de modulo 1 por otro numero complejo dado:
eiφ · reiα = rei(φ+α)
Vemos que el resultado es un numero complejo del mismo modulo resultante de girar el numerocomplejo dado un angulo φ.
Por tanto, la operacion geometrica giro se expresa algebraicamente como una multiplicacion.
2+i
i(2+i)
AA
*
AAAAAAAAAAK
25

Radicacion.
La extraccion de raices tambien se hace mucho mas facilmente cuando los numeros vienendados en forma polar.
Extraer las raices n-esimas de un numero complejo z es hallar los numeros x tales que xn = z,es decir, resolver la ecuacion xn − z = 0. Si z es real, esta ecuacion, por ser de coeficientes reales,tiene las raices complejas por parejas conjugadas, es decir, las raices complejas de un numero realaparecen por parejas conjugadas.
Las soluciones de la ecuacion xn − z = 0 (si z 6= 0) tienen multiplicidad 1: vamos a ver que nopueden tener multilicidad mayor o igual que 2:
Si una solucion z1 la tuviera, se podrıa escribir xn − z = (x − z1)2Qn−2(x), entonces, derivando
en los dos miembros tendrıamos nxn−1 = 2(x− z1)Qn−2(x) + (x− z1)2Q′n−2(x), que al sustituir x por
z1, da nzn−11 = 0, imposible si zn1 6= 0.
Al ser cada raiz de multiplicidad 1, debe haber n raices distintas.
Veamos como se obtienen:Dado z = |z|eiα, un numero complejo x es raiz n-esima de z si xn = z, es decir, escribiendo
x = reiφ en forma polar, si rneinφ = |z|eiα, pero tambien si rneinφ = |z|ei(α+2π) o rneinφ = |z|ei(α+k2π),cualquiera que sea k, para lo cual es suficiente que rn = |z| y nφ = α + k2π, cualquiera que sea k.
La condicion rn = |z| siempre tiene solucion porque |z| es positivo pero puede tener dos solucionesreales para r si n es par, de las cuales solo cogemos la positiva porque el modulo es siempre positivo.Pero lo mas importante es que debido a la no unicidad de la expresion polar de un numero complejo,cuando k varıa, tenemos distintas posibilidades para φ de la condicion nφ = α+ k2π. Lo que nos dapara φ las soluciones:
φ0 = αn
φ1 = αn
+ 2πn
φ2 = αn
+ 22πn
φ3 = αn
+ 32πn
· · · · · ·φn−1 = α
n+ (n− 1)2π
n
φn =α
n+ n
2π
n≡ α
n
Para el valor de r = + n√|z| hay n posibles argumentos, (ya que φn es equivalente a φ0), por lo
que hay n raices complejas de cada numero complejo dado.
26

Las raices n-esimas del numero complejo 1 tienen modulo 1 y argumentos k2π/n, donde k varıade cero a n − 1. El conjunto de estos n numeros con la operacion multiplicacion es un ejemplo degrupo multiplicativo finito. Sus puntos correspondientes determinan un polıgono regular de n ladoscon un vertice en el punto (1,0). Cada raiz determina tambien un giro del plano de angulo k2π/nEstos giros del plano dejan invariante cualquier polıgono regular de n lados con centro en el origen.Dos de estos giros se pueden realizar sucesivamente, lo cual da un giro que se llama composicionde los dos giros. La operacion composicion de giros corresponde a la multiplicacion de los numeroscomplejos que los representan. Por ello, el conjunto de los giros que dejan invariante un polıgonoregular con centro en el origen es un grupo multiplicativo finito.
Se proponen los siguientes Ejercicios: donde se pide hacer los calculos en forma polar.
1.7.1. Calcular en forma polar y en forma binomica los siguientes numeros complejos:
√−4,
√i,√−i, .
Comprobar que los resultados son los mismos.1.7.2. Calcular en forma binomica y en forma trigonometrica los siguientes numeros complejos:
√1 + i,
√−2 + 2i
Comparando las expresiones determinar el valor de cos(π/8) y cos(3π/8). Comprobar que cos2(π/8)+cos2(3π/8) = 1. ¿Por que?
1.7.3. Expresar las siguientes raices en forma binomica utilizando la forma trigonometrica corres-pondiente y el ejercicio anterior.
4√−16, 3
√−8, 3
√−27i,
4√
16i.
1.7.4. Hallar las raices cuartas de −i y representarlas graficamente.1.7.5. Hallar las raices quintas de la unidad. Senalar cuales son las raices que son conjugadas
entre sı.1.7.6. Hallar las siguientes raices:
3
√√3
2+ i
1
2,
6
√1
2+ i
√3
2
¿Como estan relacionadas entre sı?1.7.7. Resolver en el cuerpo de los numeros complejos las ecuaciones:
x6 + 1 = 0,
27

x6 + 2x3 + 1 = 0,
x6 + x3 + 1 = 0,
x6 + 2x4 + 2x2 + 1 = 0,
3x7 + x6 + 6x4 + 2x3 + 6x+ 2 = 0.
2x7 − x6 + 4x4 + 2x3 + 2x− 1 = 0
2x7 + x6 + 4x4 + 2x3 + 2x+ 1 = 0
4x8 − x6 − 8x5 + 2x3 + 4x2 − 1 = 0
2x5 + x4 − 2x3 − x2 + 2x+ 1 = 0
Comprobar que la suma de las multiplicidades de las soluciones complejas (entre ellas las reales)de cada ecuacion es igual a su grado.
1.7.8. Habiendo comprobado que (xn−1 + xn−2 + xn−3 + · · ·+ x+ 1)(x− 1) = xn − 1, demostrarque
a) La ecuacion x4 + x3 + x2 + x+ 1 = 0 no tiene ninguna solucion real.b) La ecuacion xn + xn−1 + xn−2 + · · · + x + 1 = 0 no tiene ninguna solucion real si n es par y
tiene exactamente una solucion real si n es impar. ¿Cual es la solucion real si n es impar?c) Las raices (n+ 1)− esimas de la unidad que no coinciden con 1, son soluciones de la ecuacion
xn + xn−1 + xn−2 + · · ·+ x+ 1 = 0.1.7.9. Resolver en el cuerpo de los numeros complejos las ecuaciones:
x6 + x5 − x− 1 = 0,
x7 + x6 − x− 1 = 0,
2x5 + x4 + x3 + x2 + x− 1 = 0,
6x6 + 5x5 + 4x4 + 4x3 + 4x2 − 2x− 1 = 0.
Comprobar que la suma de las multiplicidades de las soluciones complejas (entre ellas las reales)de cada ecuacion es igual a su grado.
1.7.10. Deducir de la fomula de Moivrea) Las formulas del coseno del angulo triple y del seno del angulo triple.b) Las formulas analogas para el angulo quıntuple.1.7.11. Hallar cos(π/12) calculando la raiz de eiπ/6 utilizando las formas binomica, trigonometrica
y polar de los numeros complejos y comparando los resultados.
28

1.7.12. Comprobar que las raices de orden n de la unidad y por ello los giros que dejan invarianteun polıgono regular de n lados con centro en el origen y un vertice en 1, son un grupo multiplicativoconmutativo.
Otros ejemplos y problemas se pueden encontrar en el capıtulo 1 del libro [A], en el capıtulo 4 de[B], en el apendice A2 de [G] en el capıtulo 20 de [S] y en el capıtulo 4 del libro [H] de la bibliografıa.
Soluciones de 1.2.1: a) 1/2,1/3, b) 1/2,1/3,5/2, c) 1/2,1/3,1/4, d) 1/2, 2/3,3/2. e) 1/2,1/3,−1(doble).Soluciones de las cinco ultimas ecuaciones de 1.3.1: −1/2, 1/3, i
√2,−i
√2; −1/3, 1/4, i,−i; 1/2, 4/3, i,−i;
3/2,−5/2, i,−i; −3/2,−5/2, 2i,−2i.
29

Bibliografıa.
[A1]. Algebra Lineal y aplicaciones. Jorge Arvesu Carballo, Renato Alvarez Nodarse, FranciscoMarcellan Espanol. Ed. Sıntesis 1999.
[A2] La Matematica: su contenido, metodos y significado. A. D. Alexandrov, A. N. Kolmogorov,M. A. Laurentief y otros. Ed. Alianza Universidad. 1981.
[B] Numeros y Convergencia. B. Rubio. Ed. B. Rubio. 2006.[D]. El Universo de las Matematicas. Willian Dunham. Ed. Piramide. 1994.[G1] Matematicas 1 Bachillerato. Carlos Gonzalez Garcıa. Jesus Llorente Medrano. Maria Jose
Ruiz Jimenez. Ed. Editex. 2008.[G]. Algebra Lineal con aplicaciones. Stanley I. Grossman. Ed. McGraw-Hill. 1992.[H]. Algebra y Geometrıa. E. Hernandez. Ed. Addison-Wesley-U.A.M. 1994.[S]. Algebra Superior. M. R. Spiegel. Ed. Mc Graw Hill 2000.
30

MATRICES. SUS OPERACIONES.
Introduccion.
Definicion: Una matriz es una disposicion rectangular y entre parentesis de numeros; Es portanto, una tabla de numeros entre parentesis y tiene un determinado numero de filas, que llamamosm y un determinado numero de columnas que llamamos n. Entonces se dice que la matriz es m× n.
Puede ser de numeros positivos, de numeros enteros, de numeros racionales, de numeros reales ode numeros complejos.
Las tablas aparecen bastante en la vida cotidiana. P. ej. la tabla de valores de compra y venta de distintasmonedas con una fija (sea esta el euro), es una tabla de tantas filas como monedas consignemos y de dos columnas.Otro ejemplo es la tabla de porcentaje de composicion de unos alimentos determinados segun los hidratos de carbono,grasas y proteınas; esta es una tabla de tantas filas como alimentos hayamos listado y tres columnas. Las presionesy temperaturas de un conjunto de n gases forman una tabla de dos filas y n columnas. Las tablas se transforman enmatrices cuando sus datos son utilizados para calculos.
Una matriz de una fila y una columna es un numero entre parentesis.La derivada de una funcion real de variable real es un numero, y se generaliza a la derivada de una funcion real
de varias variables por una matriz de una fila y varias columnas, cada una de las cuales es una derivada parcial. Deespecial interes en fısica son las derivadas de una funcion real de tres variables, que se llaman gradientes y son tresnumeros entre parentesis.
Un punto de R3 se representa por tres coordenadas entre parentesis, lo cual es una matriz 1× 3.Algunas veces, para comodidad de calculo, un vector de R3 se representa por los numeros en columna;entonces es una matriz 3× 1.
En algebra lineal aparecen las matricesm×n al expresar de forma global los sistemas de ecuacioneslineales de m ecuaciones con n incognitas. Para ello se define el producto de matrices.
Tambien se utilizan para expresar las aplicaciones llamadas lineales y los productos escalares. Ypara relacionar distintos sistemas de coordenadas en el mismo espacio vectorial.
Ciertas operaciones del conjunto de numeros que aparecen en la matriz se trasfieren a operacionescon las matrices pero no siempre con las mismas propiedades que las operaciones de los numeros delos que estan formadas. Nuestro objetivo en este capıtulo es definir y estudiar dichas operaciones.
31

Operaciones en las matrices.
Si representamos por K un conjunto de numeros, se representa por Mm×n(K) el conjunto de lasmatrices de m filas y n columnas que tienen numeros de ese conjunto. Cada sitio de la matriz sellama entrada. Introducimos la notacion general de una matriz: se escribe
A = (aij)i∈1,2,...m,j∈1,2,...n
donde aij es el numero que ocupa el lugar de la fila i y la columna j. Cuando estan claras en elcontexto, las variaciones de i y de j, no se especifican por sencillez de escritura.
Si K tiene un producto, cualquier matriz puede multiplicarse por un numero del conjunto del queesta formada. Si A = (aij) ∈Mm×n(K) y s ∈ K, se define s · A = (saij).
Este producto verifica:Si K tiene unidad (1): 1 · A = AEs distributivo si el producto de K es distributivo respecto a una suma: (s+ t) ·A = s ·A+ t ·AHay asociatividad mixta si K es asociativo: (st) · A = s · (t · A)
Si en el conjunto K hay una suma, tambien ciertas matrices se pueden sumar, pero para esotienen que tener el mismo numero de filas y de columnas. La suma no es una operacion en elconjunto de todas las matrices sino en Mm×n(K) cuando se han fijado m y n.
Entonces, se define: siA = (aij)i∈1...mj∈1...n ∈Mm×n(K) yB = (bij)i∈1...mj∈1...n ∈Mm×n(K),A+B = (aij + bij)i∈1...mj∈1...n ∈Mm×n(K), Se propone comprobar como ejercicios que
2.1.1. La suma es asociativa si la suma en K lo es.2.1.2. La matriz cero (que tiene cero en todos los sitios), es elemento neutro para la suma si cero
es el elemento neutro de K respecto a su suma.2.1.3. Si cada elemento de K tiene elemento opuesto respecto a la suma, cada matriz tiene
elemento opuesto.Recordando la definicion de grupo, los ejercicios 2.1.1., 2.1.2., y 2.1.3. se expresan conjuntamente
afirmando que si K es un grupo aditivo, Mm×n(K) lo es.Se puede comprobar tambien como ejercicio que si K es un grupo aditivo conmutativo,Mm×n(K)
tambien lo es.Ademas la suma es distributiva respecto al producto por los elementos de K si lo es en K.
Compruebese como ejercicio que s · (A+B) = s · A+ s ·B.Estas operaciones con todas las propiedades enumeradas se dan p. ej. en M1×3(R) que coincide
con el espacio de los vectores y por analogıa, la estructura de Mm×n(K) con estas dos operacionescon las propiedades enumeradas se llama espacio vectorial.
32

Para pasar a otra operacion entre matrices llamada producto, observemos que una matriz fila1× n y una matriz columna n× 1 se pueden multiplicar numero a numero:
(a1j)j∈1...n · (bi1)i∈1...n =n∑k=1
a1k · bk1
dando otro numero.Esto es lo que se hace para calcular el producto escalar de dos vectores de R3: se coloca uno de
los vectores en fila y el otro en columna y se multiplican numero a numero.Es tambien lo que se hace para calcular lo que tenemos que pagar en una compra multiplicando la matriz fila de
los precios de los artıculos que hemos comprado por la matriz columna de las cantidades que hemos comprado de cadauno de ellos.
Observemos tambien que una matriz A ∈Mm×n(K) puede escribirse como superposicion de filas:
A =
F1
F2...Fm
o como yuxtaposicion de columnas:
B = (C1, C2, · · · , Cn)
Si las filas de A tienen el mismo numero de elementos que las columnas de B, A y B se puedenmultiplicar multiplicando las filas de A por las columnas de B, siendo
(AB)ij = Fi · Cj =n∑k=1
aikbkj que escribiremosn∑k=1
AikBkj
Este producto es una operacion que va de Mm×n(K)× Mn×u(K) en Mm×u(K). Para que seaoperacion en Mm×n(K), ha de ser m = n.
Podemos decir, por tanto, que las matrices cuadradas tienen otra operacion, el producto, con lassiguientes propiedades:
a) El producto es asociativo si el producto en K lo es: A(BC) = (AB)C.En efecto, vamos a ver que el numero de la entrada (i,j) de A(BC) es el mismo que el numero de
la entrada (i,j) de (AB)C:Suponiendo que A ∈Mm×n(K), B ∈Mn×u(K), C ∈Mu×s(K).
33

(A(BC))i,j =n∑k=1
Aik(BC)kj =n∑k=1
Aik(u∑l=1
BklClj) =n∑k=1
u∑l=1
Aik(BklClj)
((AB)C)i,j =u∑l=1
(AB)ilClj =u∑l=1
(n∑k=1
AikBkl)Clj =u∑l=1
n∑k=1
(AikBkl)Clj
Comparando las dos expresiones finales se puede ver que contienen los mismos sumandos debido ala propiedad asociativa del producto en K. La diferencia esta solamente en la forma de agruparlos:
En el primer sumatorio agrupamos primero los del mismo k, sumamos los Aik(BklClj), para todoslos valores posibles de ‘l′ y luego volvemos a sumar estas sumas para todos los valores posibles de ‘k′
En el segundo sumatorio agrupamos primero los del mismo l, sumamos los (AikBkl)Clj, para todoslos valores posibles de ‘k′ y luego volvemos a sumar estas sumas para todos los valores posibles de‘l′;
Pero la forma de agruparlos para la suma no importa debido a su propiedad conmutativa.
Representaremos las matrices cuadradas n× n con elementos de K por Mn(K).Se indica como ejercicios la demostracion de2.2.1. b) El producto es distributivo respecto a la suma de matrices si el producto de K lo es
respecto a la suma.Como todavıa no hemos comprobado que el producto sea conmutativo y de hecho no lo es, la
distributividad tiene dos facetas, a la derecha y a la izquierda:
A(B + C) = AB + AC, (A+B)C = AC +BC
2.2.2. c) El producto es asociativo respecto al producto por los elementos de K si el producto enK lo es.
s(AB) = (sA)B, (AB)s = A(Bs)
Pero existen matrices distintas de cero que no tienen inverso respecto a la multiplicacion. Paraello vease como ejercicio:
2.2.3. Dada la matriz
A =
(1 01 0
)Comprobar que no existe una matriz B tal que AB = I = BA.
34

El conjunto de las matrices cuadradas de orden n con elementos de un cuerpo es un grupo aditivoconmutativo respecto a su suma. Respecto al producto no constituyen un grupo multiplicativo niaun prescindiendo de la matriz cero, porque existen matrices no nulas que no poseen inversa segun elejercicio 2.2.3; por esto no son un cuerpo; la estructura de grupo aditivo con un producto asociativo ydistributivo se denomina anillo. Ademas, el elemento unidad del cuerpo permite construir el elementounidad del conjunto de las matrices cuadradas de orden n respecto a la multiplicacion que es la matrizque tiene 1 en todos los elementos de la diagonal y ceros en el resto. Por eso, se dice que Mn(K) esun anillo unitario.
Nos podemos dar cuenta de que el producto en general no es conmutativo viendo que una matrizfila y una matriz columna del mismo numero de elementos son multiplicables en los dos sentidosdistintos pero en un sentido el producto es un numero y en otro sentido el producto es una matrizcuadrada de orden igual al numero de elementos de las matrices dadas.
Se puede comprobar como ejercicios la no conmutatividad de matrices cuadradas y otras propiedadespeculiares:
2.2.4. Siendo A y B las matrices dadas a continuacion calcular los productos AB y BA cuandosea posible y comparar los resultados.
a) A =
(1 1−1 1
)B =
(3 45 6
)b) A =
(2 30 1
)B =
(1 30 0
)
c) A =
2 4 05 0 30 1 0
B =
5 501 601 86
d) A =
(2 3 44 3 2
)B =
1 21 04 4
¿Sera cierta para las matrices cuadradas la relacion (A+B)2 = A2 + 2AB +B2?
2.2.5. Comprobar que el producto de dos matrices puede ser nulo sin que lo sean ninguno de losfactores, hallando los productos AB siendo A y B las matrices dadas a continuacion:
a) A =
(1 11 1
)B =
(1−1
)b) A =
(3 61 2
)B =
(−2
1
)
c) A =(
5 6)
B =
(−6
5
)d) A =
(1 01 0
)B =
(0 01 1
)¿Es cierto que AB = 0⇒ BA = 0? Comprobarlo.
35

2.2.6. Hallar la forma general de las matrices 3× 3 de numeros reales o complejos que conmutancon 1 1 0
0 1 10 0 1
.
2.2.7. Hallar matrices 2× 2 de numeros reales, tales que su cuadrado es −I.2.2.8. Hallar matrices A ∈M2×2 de numeros reales, tales que A 6= I y A2 = A.
2.2.9. Siendo
A =
1 10 11 1
= (C1, C2), B =
(2 −44 5
)=
(F1
F2
)Comprobar que AB = C1F1 + C2F2
Generalizar este resultado para matrices de dimensiones multiplicables.
2.2.10. ¿Que transformacion tiene lugar en la matriz C dada a continuacion cuando la multipli-camos a la derecha o a la izquierda por la matriz D diagonal dada tambien a continuacion:
C =
6 −2 02 0 11 1 0
D =
2 0 00 4 00 0 6
¿Cuales son las matrices diagonales que conmutan con todas las demas?2.2.11. Demostrar que si una matriz no es diagonal, no conmuta con todas las demas. Deducir
de este ejercicio y del anterior la forma de las matrices que conmutan con todas las demas.
2.2.12. Multiplicando las dos matrices A y B dadas a continuacion,
A =
2 4 05 0 30 1 0
B =
6 −2 02 0 11 1 0
Comprobar que:a) La primera fila del producto AB es la suma de las filas de B multiplicadas por los numeros de
la primera fila de A considerados como coeficientes.b) La primera columna de AB es la suma de las columnas de A multiplicados por los numeros de
la primera columna de B considerados como coeficientes.¿Que ocurre analogamente con las demas filas y las demas columnas del producto?
36

2.2.13. Se llaman matrices elementales las obtenidas de la matriz identidad, haciendo una de lassiguientes transformaciones:
a) Permutacion de filas.b) Suma a una fila de otra fila multiplicada por un numero.c) Multiplicacion de una fila por un numero distinto de cero.Escribir todas las matrices elementales de tamano 3× 3.Escoger una matriz cualquiera de numeros y comprobar que al multiplicar esta matriz por otra
elemental colocando a la izquierda la matriz elemental, se realiza en la matriz escogida, la trans-formacion que habıa tenido lugar en la identidad para obtener la matriz elemental. Generalizar elresultado.
37

La trasposicion es otra aplicacion definida en el conjunto de las matrices con imagen en estemismo conjunto que hace corresponder a una matriz A = (aij)i∈1,2,...m,j∈1,2,...n, la matriz represen-tada por tA: tA = (bij)i∈1,2,...n,j∈1,2,...m donde bij = aji. Lo que hacemos es modificar la disposicionde los numeros cambiando filas por columnas.
La trasposicion no es siempre una operacion enMm×n(R), ya que asocia a elementos deMm×n(R),elementos de Mn×m(R). Para que una aplicacion sea operacion en un conjunto, tiene que quedarseen ese conjunto, para lo cual ha de ser Mm×n(R) =Mn×m(R), es decir, m = n.
La traspuesta de la matriz suma de otras dos matrices es la suma de las traspuestas de las matricesdadas.
En cuanto a la relacion del producto con la trasposicion tenemos la siguiente igualdad:
t(AB) = tBtA
ya que
(t(AB))ji = (AB)ij =∑k
AikBkj =∑k
BkjAik =∑k
(tB)jk(tA)ki = (tB · tA)ji
Tipos de matrices.
Entre las matrices cuadradas de numeros reales se definen Las matrices simetricas son las quecoinciden con su traspuesta, para lo cual han de ser cuadradas (m=n): la matriz A = (aij) essimetrica si y solo si aij = aji ∀i, j; tambien se escribe si y solo si A = tA.
Las matrices antisimetricas son las que coinciden con la opuesta de su traspuesta, para lo cualtambien han de ser cuadradas: la matriz A = (aij) es antisimetrica si y solo si aij = −aji, ∀i, j;tambien se escribe A = −tA.
Compruebese como ejercicios que2.3.1. Una matriz antisimetrica tiene nulos todos los elementos de su diagonal principal.2.3.2. Una matriz a la vez simetrica y antisimetrica es una matriz nula (que tiene 0 en todos los
sitios).2.3.3. Comprobar que:a) Dada una matriz cuadrada A, la matriz 1
2(A+ tA) es una matriz simetrica.
b) Dada una matriz cuadrada A, la matriz 12(A− tA) es una matriz antisimetrica.
c) Toda matriz cuadrada se puede escribir como suma de una matriz simetrica y otra antisimetrica.
38

Entre las matrices cuadradas de numeros complejos se definen las matrices hermıticas como lasmatrices que verifican aij = aji, ∀i, j (A = tA) Y las matrices antihermıticas como las matrices queverifican aij = −aji ∀i, j (A = −tA)
Compruebese como ejercicios que2.4.1. Una matriz hermıtica tiene todos los elementos de su diagonal principal reales.2.4.2. En una matriz antihermıtica son imaginarios puros todos los elementos de la diagonal
principal.2.4.3. Una matriz a la vez hermıtica y antihermıtica es una matriz nula.2.4.4. Toda matriz cuadrada compleja se puede escribir como suma de una matriz hermıtica y
otra antihermıtica.
2.4.5. Comprobar que el producto de matrices simetricas no siempre es una matriz simetricarealizando el producto AB en el caso a):
a) A =
1 0 10 1 01 0 1
, B =
1 0 00 2 00 0 3
Sin embargo, sı es simetrico en el caso:
b) A =
1 4 14 3 41 4 1
, B =
0 0 10 1 01 0 0
Comprobar que en el caso a) BA = t(AB) y en el caso b) BA = AB.2.4.6. Demostrar que dadas A y B, dos matrices simetricas, A y B conmutan si y solo si su
producto es una matriz simetrica. Encontrar matrices simetricas que conmuten y matrices simetricasque no conmuten distintas de las del ejercicio anterior.
2.4.7. Si A es una matriz simetrica y B es una matriz antisimetrica, A y B conmutan si y solo sisu producto es una matriz antisimetrica.
2.4.8. Demostrar que toda matriz simetrica 2×2 de numeros reales o complejos que conmute con(1 10 1
)es un multiplo de la identidad.
2.4.9. Demostrar que toda matriz simetrica 3×3 de numeros reales o complejos que conmute con
39

1 1 00 1 10 0 1
es un multiplo de la identidad.
40

Otros subconjuntos importantes de las matrices cuadradas son:Las matrices diagonales: Son aquellas en las que aij = 0 siempre que i 6= j. Son en ellas nulos
todos los elementos situados fuera de la diagonal del cuadrado que va del angulo superior izquierdoal angulo inferior derecho (que se llama diagonal principal).
De las matrices diagonales la mas importante es la identidad que tiene 1 en todos los elementosde la diagonal.
Tambien son importantes entre las matrices cuadradas las matrices triangulares superiores: Sonen ellas nulos todos los elementos que se encuentran debajo de la diagonal principal. Por tanto,aquellas en las que aij = 0 siempre que i > j.
Analogas a estas son las matrices triangulares inferiores: Son en ellas nulos todos los elementosque se encuentran encima de la diagonal principal. Por tanto, aquellas en las que aij = 0 siempreque i < j.
Observese que una matriz a la vez triangular superior y triangular inferior es una matriz diagonal.
2.5.1. Comprobar que la traspuesta de una matriz triangular superior es triangular inferior yrecıprocamente.
2.5.2. Demostrar que:a) El producto de matrices diagonales es diagonal.b) El producto de matrices triangulares superiores es triangular superior.c) El producto de matrices triangulares inferiores es triangular inferior.
Debido al ejercicio 2.4.5, las matrices simetricas de orden n no son un subanillo de las matrices cuadradas de ordenn, (porque el producto de dos matrices simetricas puede no ser simetrica). Sin embargo, debido al ejercicio 2.5.2 lasmatrices diagonales de orden n forman un subanilo unitario del anillo unitario de las matrices cuadradas de orden n ylo mismo ocurre con las matrices triangulares superiores de orden n y con las matrices triangulares inferiores de ordenn.
41

Las matrices que tienen distinto numero de filas que de columnas se llaman matrices rectangulares.En ellas m 6= n.
Pasando ahora a las matrices rectangulares m× n, otro subconjunto importante de ellas son lasmatrices escalonadas: Se llaman ası porque en ellas se puede trazar una escalera por debajo de la cualtodos los elementos son nulos, siendo no nulos los elementos de sus esquinas y recorriendo esta escalerafilas y columnas de manera que no baja mas de una fila en cada escalon; de manera mas precisa, ala izquierda y debajo del primer numero distinto de cero de cada fila, los numeros son todos ceros.Matematicamente se puede expresar ası: (aij) es escalonada si para cada fila i existe una columna kital que los numeros de esa fila anteriores a la columna ki son nulos: aij = 0 si j < ki y los terminosde las filas posteriores situados en dichas ki columnas son tambien nulos: alj = 0 si l > i, j ≤ ki.
0 1 2 3 4 5 6
0 0 2 3 4 5 6
0 0 0 0 4 5 6
0 0 0 0 0 5 6
0 0 0 0 0 0 0
matriz escalonada
0 1 2 3 4 5 6
0 0 2 3 4 5 6
0 0 0 0 4 5 6
0 0 0 0 2 5 6
0 0 0 0 0 0 0
matriz no escalonada
Las matrices escalonadas m × n, donde m y n son fijos, no forman un grupo aditivo respecto ala suma de matrices.
Se puede comprobar que toda matriz cuadrada y escalonada es triangular superior. Para elloobservese como es una matriz escalonada con numero mınimo de ceros (vease la matriz a conti-nuacion). Si tuviera mas ceros seguirıa siendo triangular superior.
1 2 3 4 5 6
0 2 3 4 5 6
0 0 7 4 5 6
0 0 0 9 5 6
0 0 0 0 1 8
0 0 0 0 0 8
matriz escalonada ytriangular superior
42

Se puede ver tambien que en una matriz cuadrada escalonada la ultima fila tiene un elementodistinto de cero, si y solo si el primer escalon esta en la primera columna y cada escalon tiene longitudde una columna. Ya que en otro caso, al ir recorriendo los escalones, agotamos antes las columnas quelas filas, quedando la ultima fila completa debajo de la escalera. (Vease la matriz a continuacion).
1 2 3 4 5 6
0 2 3 4 5 6
0 0 0 4 5 6
0 0 0 0 5 6
0 0 0 0 0 6
0 0 0 0 0 0
matriz escalonada conescalon de dos columnas
43

(Ejercicios tomados del libro [L]),1. Demostrar: a) Si Y es una matriz columna de numeros reales y Y t es la matriz fila traspuesta
de la matriz anterior,Y t · Y = 0⇔ Y = 0
b) Dada una matriz A de numeros reales y una matriz columna Z tambien de numeros reales,multiplicable a la izquierda por A:
tA · AZ = 0⇔ AZ = 0
c) Si X es una matriz de numeros reales multiplicable a la izquierda por otra matriz cuadrada A:
tA · AX = 0⇔ AX = 0 y A · tAX = 0⇔ tAX = 0
d)
A · tA · AX = 0⇔ tA · AX = 0⇔ AX = 0.
e)
(tA · A)kX = 0⇔ AX = 0
f) Usar los resultados anteriores cuando X=I, para probar que son equivalentes las relacionessiguientes:
A = 0, tA · A = 0, A · tA · A = 0, (tA · A)k = 0 A(tA · A)k = 0
2. Una matriz simetrica y no nula de numeros reales, no puede tener ninguna potencia nula.
Ejemplos resueltos y problemas propuestos el el capıtulo 2 de [A], en la seccion 1.3. de [F], en elcapıtulo 2 de [V], en la seccion 1.4 de [H]
44

Bibliografıa.
[A] Algebra Lineal y aplicaciones. J. Arvesu Carballo, R. Alvarez Nodarse, F. Marcellan Espanol.Ed. Sıntesis Madrid. 1999.
[F] J.B: Fraleigh R. A. Beauregard. Algebra Lineal. Addison-Wesley Iberoamericana 1989.[G] Matematicas 2 Bachillerato. Carlos Gonzalez Garcıa. Jesus Llorente Medrano. Maria Jose
Ruiz Jimenez. Ed. Editex. 2009.[L] E. M. Landesman, M. R. Hestenes. Linear Algebra for Mathematics, Science, and Engineering.
Prentice-Hall International, Inc. 1992.
45

46

METODO DE GAUSS Y REDUCCION DE GAUSS-JORDAN.
Introduccion.
Los sistemas de ecuaciones lineales aparecen frecuentemente en problemas elementales de otrasciencias y de la vida corriente. Como ejemplo se enuncian aquı varios problemas de esos:
1. Averiguar si los planos de ecuaciones:
π1 ≡ −y + z = 2, π2 ≡ 3x+ 6y + z = −5, π3 ≡ 2x+ 4y − 2z = −3
tienen un punto comun.Sol: pto comun: 1/8(21,−17,−1)
2. Determinar si en R3 las rectas siguientes se cortan:
r1 ≡2x +3y +z = 5x −3y = 4
r2 ≡
x +y = 2y −z = −1
Sol: no se cortan.
3. Ajustar la reaccion:
xIO3Na+ ySO3HNa→ zSO4Na2 + uSO4HNa+ vH20 + wI2
Sol: x = 2w, y = 5w, z = 2w, u = 3w, v = w.
5. En la red de trafico del dibujo de la pagina siguiente, se conocen las cantidades de coches quecirculan en dos entradas y en algunos tramos. Se desea conocer las cantidades de coches que circulanen todos los tramos. Se podrıa colocar un contador en cada tramo desconocido, entonces harıan faltanueve contadores, sin embargo, se puede demostrar que dos contadores son suficientes, porque lostraficos en los distintos tramos estan relacionados. Demuestrese.
47

? ? ?
- -
@@@@@@@@@@R
@@@@@@@@@@R
?
?
? ?
-
? ? ?
30 x1 30
x2 x3
10 10
10 520
x5x4 x6
10 5
x7 x8 x9
4. Hallar las intensidades de las corrientes que circulan por los tramos horizontales del circuitoelectrico siguiente, conocidas las resistencias: R1 = 8Ω, R2 = 6Ω, R3 = 12Ω, y las diferencias depotencial: V1 = 5v, V2 = 18v, sabiendo que se cumplen las leyes de Kirchoff y la ley de Ohm.
Las leyes de Kirchoff son:1. En cada nodo la suma de las intensidades de las corrientes que entran es igual a la suma de
las corrientes que salen.2. En cada lazo cerrado la diferencia de potencial total es igual a la suma de las diferencias de
potencial correspondientes a cada tramo del circuito.La ley de Ohm dice que la diferencia de potencial correspondiente a un tramo con una resistencia
R por el que corre una corriente de intensidad I es igual al producto RI.
Sol: I1 = −3/36, I2 = 34/36, I3 = 37/36.
48

-
I3
I2
I1
V2
V1
R3
R2
R1
@@@
@
@@@
@
@@@
@
Resolver un sistema de ecuaciones lineales es hallar, cuando es posible, todos los valores de lasincognitas que satisfacen todas las ecuaciones del sistema. Supondremos que los coeficientes de lasincognitas en las ecuaciones son reales o complejos. La teorıa que vamos a desarrollar vale siempreque los coeficientes esten en un cuerpo.
Si no es posible encontrar esos valores, el sistema se llama incompatible. Si es posible encontrar-los, distinguimos el caso en que estos valores estan determinados unıvocamente, llamando al sistemacompatible determinado, del caso en que hay infinitos valores, llamandolo entonces compatible inde-terminado.
En Bachillerato se han visto los metodos de eliminacion, reduccion y sustitucion para resolversistemas de ecuaciones lineales. Cada sistema concreto puede resolverse o verse si es incompatibleusando uno de estos metodos. El Metodo de Gauss es una combinacion sistematica de los metodosde eliminacion y sustitucion valida para todos los sistemas. Habiendo garantıa de poder decidir si unsistema dado cualquiera es incompatible o compatible y resolverlo en este caso, por dicho metodo.
Algunas veces solo interesa saber si el sistema es incompatible, compatible determinado o com-patible indeterminado, sin llegar a resolver efectivamente el sistema. Veremos que esto tambien sepuede hacer, estudiando la evolucion de los sistemas en la primera parte (eliminacion) del metodode Gauss.
49

Metodo de Gauss.
Si el sistema esta formado por una sola ecuacion con una incognita que es de la forma ax = b,sabemos que tiene solucion unica si a tiene inverso (lo cual es equivalente, cuando a esta en uncuerpo, a que a sea distinto de cero); tiene infinitas soluciones cuando a = b = 0; es incompatiblecuando a = 0 y b 6= 0.
Si el sistema es de una ecuacion con mas de una incognita, es de la forma a11x1 + · · ·+a1nxn = b1;este es indeterminado o incompatible, siendo este ultimo el caso cuando todos los coeficientes de lasincognitas son nulos sin serlo el termino independiente.
La idea es, entonces, ir reduciendo la complejidad de un sistema con varias ecuaciones y variasincognitas a la simplicidad de un sistema con una ecuacion.
Lo cual se puede hacer pasando a primera ecuacion una que tenga coeficiente a11 de x1 distintode cero, dividiendo por a11 dicha ecuacion (que se puede hacer porque a11 6= 0) y restando a lassiguientes ecuaciones la primera multiplicada por el coeficiente de x1 en cada ecuacion. Ası hemoseliminado la incognita x1 en las ecuaciones posteriores a la primera y estas dan un sistema de unaecuacion menos con una incognita menos. Repitiendo el procedimiento, llegamos hasta un sistemade una ecuacion, que sabemos resolver o ver si es incompatible.
Veamos un ejemplo: resolvamos por el metodo de Gauss el siguiente sistema:
x1 +2x2 +x3 +2x4 = 162x1 −x2 −x3 −x4 = −7−2x1 +x2 +2x3 −x4 = 2
2x2 +3x3 +x4 = 17
Empezamos eliminando la incognita x1 de las ecuaciones segunda y tercera sumando a estas
ecuaciones la primera multiplicada adecuadamente por los numeros −2, 2. Podemos hacerlo porqueel coeficiente de x1 en la primera ecuacion es distinto de cero. Entonces pasamos a
x1 +2x2 +x3 +2x4 = 16−5x2 −3x3 −5x4 = −39
5x2 +4x3 +3x4 = 342x2 +3x3 +x4 = 17
Ası encontramos dentro del sistema dado un subsistema de tres ecuaciones con tres incognitas,formado por las tres ultimas ecuaciones, mas simple que el dado y que una vez resuelto nos darıa lasolucion del sistema dado considerando tambien la primera ecuacion.
En este subsistema de tres ecuaciones podemos pasar a otro subsistema de dos ecuaciones condos incognitas, eliminando la incognita x2 de las dos ultimas ecuaciones sumando a estas la primera
50

multiplicada adecuadamente, ya que el coeficiente de x2 en la primera ecuacion del subsistema esdistinto de cero.
Pero como tendrıamos que multiplicar la primera ecuacion por −1/5 para conseguir que el co-eficiente de x2 sea 1 y luego multiplicar adecuadamente para eliminar los coeficientes de dicha x2
en las restantes ecuaciones y de este modo surgirıan fracciones, vamos a utilizar otro camino quetambien consiste en multiplicar una ecuacion por un numero y sumar otra ecuacion multiplicada porun numero: vamos a multiplicar la primera ecuacion del subsistema por −1 y le vamos a sumar laultima multiplicada por −2, pasando a:
x2 −3x3 +3x4 = 55x2 +4x3 +3x4 = 342x2 +3x3 +x4 = 17
Hemos conseguido que el coeficiente de la incognita x2 sea 1 en la primera ecuacion. Ahora
multiplicando esta ecuacion por −5 y sumandosela a la segunda ecuacion y luego multiplicando laprimera ecuacion por −2 y sumandosela a la tercera ecuacion tenemos:
x2 −3x3 +3x4 = 519x3 −12x4 = 99x3 −5x4 = 7
donde podemos percibir un subsistema de las dos ultimas ecuaciones con las dos ultimas incognitas.De este subsistema, restando a la penultima ecuacion la ultima multiplicada por 2, obtenemos:
x3 −2x4 = −59x3 −5x4 = 7
y ası eliminamos facilmente la incognita x3 de la ultima ecuacion pasando a
x3 −2x4 = −513x4 = 52
donde aparece al final una ecuacion con una incognita. Resuelta esta ecuacion podemos ir resolviendolos subsistemas de dos y tres ecuaciones que se han ido hallando resolviendo progresivamente unaecuacion mas y llegar a la solucion del sistema dado. En efecto, la ultima ecuacion da x4 = 4, quesustituida en x3 − 2x4 = −5 da x3 = 3, lo cual sustituido en x2 − 3x3 + 3x4 = 5 da x2 = 2 y todoesto sustituido en x1 + 2x2 + x3 + 2x4 = 16 da x1 = 1, teniendo el sistema resuelto por el metodo deGauss.
51

Si el sistema hubiera sido:
2x2 +3x3 +x4 = 172x1 −x2 −x3 −x4 = −7−2x1 +x2 +2x3 −x4 = 2x1 +2x2 +x3 +2x4 = 16
donde el coeficiente de la primera ecuacion en la primera incognita es cero, pasamos a un sistemadonde este coeficiente es distinto de cero, intercambiando ecuaciones.
Veamos otros ejemplos donde se va viendo los subsistemas formados eliminando sucesivamentelas incognitas hasta llegar a una ecuacion.
2)
6x2 +12x3 = 188x1+ 6x2 = 5x1− x2 +x3 = 0
x1 −x2 +x3 = 0
8x1 +6x2 = 56x2 +12x3 = 18
x1 −x2 +x3 = 0
14x2 −8x3 = 56x2 +12x3 = 18
x1 −x2 +x3 = 0
14x2 −8x3 = 5x2 +2x3 = 3
x1 −x2 +x3 = 0
x2 +2x3 = 314x2 −8x3 = 5
x1 −x2 +x3 = 0
x2 +2x3 = 3−36x3 = −37
Como la ultima ecuacion es compatible, el sistema es compatible y como tambien es determinada,
podemos despejar x3 en la ultima ecuacion y sustituyendo en la segunda ecuacion despejar x2, tambiendeterminada. Obtenemos x1 de la primera ecuacion al sustituir los valores de las otras incognitas; elsistema resulta compatible determinado.
Se obtiene x3 = 37/36, x2 = 17/18, x1 = −1/12.
3)
x1 +3x2 −x3 +x4 = 1−2x1 +x2 +3x3 = 7
x2 −x4 = 0
x1 +3x2 −x3 +x4 = 1
7x2 +x3 +2x4 = 9x2 −x4 = 0
x1 +3x2 −x3 +x4 = 1
x2 −x4 = 07x2 +x3 +2x4 = 9
x1 +3x2 −x3 +x4 = 1
x2 −x4 = 0x3 +9x4 = 9
52

Este sistema tambien es compatible por serlo la ultima ecuacion. Pero como esta es indeterminada,el sistema es indeterminado. Despejamos x3 en funcion de x4 en la ultima ecuacion, x2 en funcionde x4 en la penultima ecuacion y luego sustituimos x2 y x3 en la primera ecuacion y obtenemos:x3 = 9− 9x4, x2 = x4, x1 = 10− 13x4, x4 puede ser cualquiera.
Pero, aunque la ultima ecuacion sea compatible determinada, el sitema puede ser incompatibleindeterminado, como ocurre en los ejemplos 4) y 5) siguientes:
4)x1 +3x2 −x3 +x4 = 1
−2x1 +x2 +9x3 = 7x2 +x3 −x4 = 0
x1 +3x2 −x3 +x4 = 1
7x2 +7x3 +2x4 = 9x2 +x3 −x4 = 0
x1 +3x2 −x3 +x4 = 1
x2 +x3 −x4 = 07x2 +7x3 +2x4 = 9
x1 +3x2 −x3 +x4 = 1
x2 +x3 −x4 = 09x4 = 9
Por ser la ultima ecuacion compatible, el sistema es compatible. En este caso, x4 esta determinado
en la ultima ecuacion, pero al sustituir el valor de x4 en las ecuaciones anteriores, la penultimaecuacion queda indeterminada por lo que el sistema es indeterminado. Despejando x2 en funcion dex3 y sustituyendo en la primera ecuacion tenemos las soluciones: x4 = 1, x2 = 1−x3, x1 = −3+4x3,x3 puede ser cualquiera.
5)
x1 +3x2 −x3 +x4 = 1−2x1 +x2 +2x3 = 7
x2 −x4 = 0
x1 +3x2 −x3 +x4 = 1
7x2 +2x4 = 9x2 −x4 = 0
x1 +3x2 −x3 +x4 = 1
x2 −x4 = 07x2 +2x4 = 9
x1 +3x2 −x3 +x4 = 1
x2 −x4 = 09x4 = 9
De nuevo el sistema es compatible por serlo la ultima ecuacion. Tanto esta, como la penultima
ecuacion salen determinadas, pero al sustitir x4 y x2 en la primera ecuacion, obtenemos una ecuacioncon dos incognitas que es indeterminada (tiene infinitas soluciones) por lo que el sistema es compatibleindeterminado.
Sus soluciones son:x4 = 1, x2 = 1, x1 = x3 − 3, x3 puede ser cualquiera.
Por ultimo, veamos un sistema incompatible.
53

6)
x1 +3x2 −x3 +x4 = 1−2x1 +x2 +2x3 −9x4 = 7
x2 −x4 = 0
x1 +3x2 −x3 +x4 = 1
7x2 −7x4 = 9x2 −x4 = 0
x1 +3x2 −x3 +x4 = 1
x2 −x4 = 07x2 −7x4 = 9
x1 +3x2 −x3 +x4 = 1
x2 −x4 = 00x2 +0x4 = 9
Aquı la ultima ecuacion es incompatible, esto es suficiente para que el sistema sea incompatible.
Debido a que cuando encontramos una primera ecuacion de un subsistema con coeficiente ceroen la primera incognita la intercambiamos con otra que tiene coeficiente distinto de cero en esaincognita, la incompatibilidad es relegada a la ultima ecuacion.
Se puede conseguir que el coeficiente de la primera incognita sea 1 utilizando coeficientes de dichaincognita en otras ecuaciones primos entre sı.
Recapitulando, el metodo de Gauss es una combinacion ordenada de los metodos de eliminacion ysustitucion y garantiza nuestra capacidad de decision sobre el caracter de un sistema porque consisteen la reali-zacion de sucesivas etapas con las ecuaciones del sistema de manera que se van formandosubsistemas de una ecuacion menos y una incognita menos (como mınimo) hasta llegar a un sistemade una sola ecuacion, cuyo caracter hemos visto que sabemos decidir. (El caracter sistematico delmetodo de Gauss lo hace preferible a la hora de ejecutarlo por ordenador).
Entonces, si la ultima ecuacion es incompatible, el sistema es incompatible.Si la ultima ecuacion es compatible, se ve facilmente si esta es determinada o indeterminada. Si es
indeterminada, el sistema es indeterminado. Si es compatible determinada, despejando la incognitaen la ultima ecuacion conseguida y sustituyendo regresivamente en las anteriores, obtenemos otrosistema equivalente con una incognita menos y al menos una ecuacion menos, en el cual el caracter dela ultima ecuacion nos dirıa que el sistema es indeterminado si esta ecuacion fuera indeterminada; perosi dicha ecuacion es determinada, para ver el caracter del sistema tenemos que repetir el procedimientode sustitucion regresiva y seguir ası hasta que quede alguna ecuacion indeterminada en cuyo caso elsistema sera indeterminado o que todas las ecuaciones hayan resultado determinadas en cuyo casoel sistema es determinado y hemos ido obteniendo sus soluciones. Si el sistema es indeterminado,podemos despejar en las ecuaciones indeterminadas la primera incognita que aparezca en ellas concoeficiente distinto de cero, en funcion de las siguientes y sustituyendo regresivamente obtener unsubconjunto de incognitas despejado en funcion de otro subconjunto de incognitas que pueden variarlibremente.
54

La formacion de subsistemas de al menos una incognita menos y al menos una ecuacion menospuede hacerse con las siguientes etapas:
1) Pasar a primer lugar una ecuacion que tenga coeficiente distinto de cero de la primera incognita.
2) Sumar a las restantes ecuaciones la primera multiplicada adecuadamente para que el coeficientede la primera incognita en ellas salga cero.
3) Considerar las ecuaciones excepto la primera como un subsistema que no tiene la primeraincognita y repetir las etapas 1) y 2) anteriores para la siguiente incognita que no tiene coeficientenulo en todas las ecuaciones. Si todas las ecuaciones tuvieran coeficientes nulos de las incognitaspero quedara alguna con termino independiente distinto de cero (el sistema serıa incompatible) sereducen todas las ecuaciones incompatibles a una sola por etapas analogas a la 2) anterior para losterminos independientes.
4) Para resolver el sistema (en el caso en que sea compatible) se despeja la incognita que aparezcacon coeficiente distinto de cero en primer lugar en la ultima ecuacion, (si esta ultima ecuacion tienevarias incognitas, en funcion de las restantes) y se sustituye en las demas ecuaciones con lo que sereduce en uno el numero de ecuaciones del sistema obtenido y se repite el proceso hasta agotar lasecuaciones. Al final, tendremos los valores de las incognitas si el sistema es compatible determinadoo un subconjunto de incognitas despejado en funcion de las otras, que seran independientes y podrantomar cualquier valor si el sistema es compatible indeterminado.
Desmenuzando el tipo de operaciones que hacemos, las etapas 1), 2) y 3) del metodo de Gaussse hacen realizando en las ecuaciones de un sistema lo que llamamos
Operaciones Elementales en un sistema:
1) Intercambio de las ecuaciones.
2) Suma de una ecuacion multiplicada por un numero a otra ecuacion distinta.
3) Multiplicacion de una ecuacion por una constante distinta de cero. (Para despejar las incognitas).
Estas operaciones son suficientes para su resolucion. Cualquier operacion elemental en un sistemalo transforma en otro equivalente.
55

Ejercicios:
3.1.1. Utilizar el metodo de Gauss para determinar el caracter de cada uno de los sistemasenunciados a continuacion y resolver los que sean compatibles:
a)x1 +x2 +x3 = 6x1 +2x2 +3x3 = 14
2x1 −x2 −x3 = −3
b)x1 −x2 +x3 −2 = 0
2x1 +x2 −x3 −1 = 0−x1 +2x2 +3x3 +3 = 0
c)
x1 +x2 +x3 +x4 = 0x1 +2x2 +x3 +2x4 = 0−x1 −2x2 +x3 +2x4 = 03x1 +x2 +2x3 −x4 = 0
d)x1 +x2 +x3 +x4 = −1x1 +2x2 +x3 +2x4 = −1−x1 −2x2 −x3 −2x4 = 1
e)
x1 +x2 −x3 = 1−x1 +x2 +x3 = 12x1 −x2 +x3 = 25x1 +2x2 −x3 = 5
f)
x1 +x2 +x3 +x4 = 0x1 −x2 +2x3 −2x4 = 1−x1 −x2 −x3 +2x4 = −62x1 +x2 +2x3 +x4 = 0−2x1 −3x2 +3x3 −x4 = −9
3.1.2. Hallar los valores de los parametros α, β y γ para que se verifique A · At = I siendo A la
matriz:
A = 1/9
7 −4 α−4 β −8−γ −8 1
3.1.3. Hallar e y f en la matriz (
1 e 4−1 f 8
)para que exista una matriz A de tamano 2× 2 que multiplicada a la izquierda por(
3 2 0−2 1 4
)de
(1 e 4−1 f 8
)Sol 3.1.1: a) x1 = 1, x2 = 2, x3 = 3; b) x1 = 1, x2 = −1, x3 = 0; c) x1 = 2x4 = 2k, x2 = −x4 =
−k, x3 = −2x4 = −2k, x4 = k; d) x1 = −1 − x3 = −1 − α, x2 = −x4 = −β, x3 = α, x4 = β; e)incompatible ; f) x1 = 1, x2 = 2, x3 = −1, x4 = −2;
Sol. 3.1.2: α = −4, β = 1, γ = 4.Sol. 3.1.3: e = 3, f = 4.
56

Operaciones elementales en una matriz.
Lo que importa al resolver un sistema son los coeficientes de las incognitas y los terminos inde-pendientes. Ellos foman la matriz de los coeficientes y la matriz ampliada del sistema. Un sistema sepuede escribir en forma matricial: AX=b donde A es la matriz de los coeficientes de las incognitas,X es la columna de las incognitas y b es la columna formada por los terminos independientes.
Los ejemplos 2), 3), 4), 5) dados anteriormente serıan:
0 6 128 6 01 −1 1
x1
x2
x3
=
1850
1 3 −1 1−2 1 3 0
0 1 0 −1
x1
x2
x3
x4
=
170
1 3 −1 1−2 1 9 0
0 1 1 −1
x1
x2
x3
x4
=
170
1 3 −1 1−2 1 2 0
0 1 0 −1
x1
x2
x3
x4
=
170
Llamamos matriz ampliada del sistema a la matriz A|b. Las matrices A y A|b van evolucionando,al irse realizando las operaciones elementales en el sistema, cuando se usa el metodo de Gauss.
Las transformaciones que tienen lugar en la matriz de un sistema cuando se realizan operacioneselementales en el, se llaman operaciones elementales en la matriz. Se obtienen ası tres tipos deoperaciones elementales en matrices que corresponden a los tres tipos de operaciones elementales enel sistema.
Llamamos Operaciones Elementales en una matriz a:
1) Intercambio de las filas de la matriz.
2) Suma de una fila de la matriz multiplicada por un numero a otra fila de la matriz.
3) Multiplicacion de una fila por una constante distinta de cero.
La evolucion de las matrices en los ejemplos 2), 3), 4), 5) y 6) ha sido:
57

2) 0 6 128 6 01 −1 1
∣∣∣∣∣∣1850
→ 1 −1 1
8 6 00 6 12
∣∣∣∣∣∣05
18
→ 1 −1 1
0 14 −80 6 12
∣∣∣∣∣∣05
18
→ 1 −1 1
0 14 −80 1 2
∣∣∣∣∣∣053
→ 1 −1 1
0 1 20 14 −8
∣∣∣∣∣∣035
→ 1 −1 1
0 1 20 0 −36
∣∣∣∣∣∣03
−37
.
3) 1 3 −1 1−2 1 3 0
0 1 0 −1
∣∣∣∣∣∣170
→ 1 3 −1 1
0 7 1 20 1 0 −1
∣∣∣∣∣∣190
→ 1 3 −1 1
0 1 0 −10 7 1 2
∣∣∣∣∣∣109
→ 1 3 −1 1
0 1 0 −10 0 1 9
∣∣∣∣∣∣109
4) 1 3 −1 1
−2 1 9 00 1 1 −1
∣∣∣∣∣∣170
→ 1 3 −1 1
0 7 7 20 1 1 −1
∣∣∣∣∣∣190
→ 1 3 −1 1
0 1 1 −10 7 7 2
∣∣∣∣∣∣109
→ 1 3 −1 1
0 1 1 −10 0 0 9
∣∣∣∣∣∣109
5) 1 3 −1 1
−2 1 2 00 1 0 −1
∣∣∣∣∣∣170
→ 1 3 −1 1
0 7 0 20 1 0 −1
∣∣∣∣∣∣190
→ 1 3 −1 1
0 1 0 −10 7 0 2
∣∣∣∣∣∣109
→ 1 3 −1 1
0 1 0 −10 0 0 9
∣∣∣∣∣∣109
58

6) 1 3 −1 1−2 1 2 −9
0 1 0 −1
∣∣∣∣∣∣170
→ 1 3 −1 1
0 7 0 −70 1 0 −1
∣∣∣∣∣∣190
→ 1 3 −1 1
0 1 0 −10 7 0 −7
∣∣∣∣∣∣109
→ 1 3 −1 1
0 1 0 −10 0 0 0
∣∣∣∣∣∣109
La observacion de las matrices de un sistema en las distintas etapas de su resolucion nos indica
que vamos escalonando la matriz de coeficientes del sistema dado, fila a fila, por medio de lasoperaciones elementales y cuando tanto la matriz de coeficientes del sistema como la matriz ampliadason escalonadas, podemos decidir si el sistema es incompatible o compatible.
En ese momento, el sistema es incompatible si y solo si la ultima ecuacion es incompatible,lo cual se traduce en que la matriz escalonada del sistema tiene un escalon menos que la matrizescalonada ampliada del sistema (vease el ultimo ejemplo). Si la ultima ecuacion es compatible,en cuyo caso las dos matrices escalonadas mencionadas tienen el mismo numero de escalones, elsistema es compatible indeterminado cuando queda indeterminada alguna de las ecuaciones al irsustituyendo, regresivamente en las ecuaciones anteriores, los valores de las incognitas determinadas.Se observa que queda alguna ecuacion indeterminada si y solo si alguno de los escalones de la matrizdel sistema tiene longitud superior a una columna (veanse los ejemplos 3, 4 y 5); habiendo entoncesalguna ecuacion indeterminada con mas de una incognita donde se pueden pasar al segundo miembrolas incognitas correspondientes a las columnas que no dan escalon y despejar las otras en funcionde ellas, lo que da la indeterminacion. El sistema es determinado si todas las ecuaciones quedandeterminadas, lo cual solo ocurre cuando todos los escalones son de una columna (veanse el ejemplo2).
Vemos que en el proceso de resolucion de sistemas, podemos decidir el caracter del sistema inicialsin resolverlo totalmente y por ello enunciamos la version del Teorema de Rouche-Frobeniuspara matrices escalonadas: un sistema es incompatible cuando la matriz escalonada a la quehemos reducido la matriz ampliada del sistema tiene un escalon mas que la matriz escalonada a laque ha quedado reducida la matriz de los coeficientes del sistema; en otro caso es compatible, siendocompatible determinado si todos los escalones de la matriz escalonada del sistema tienen longituduna columna y compatible indeterminado si hay algun escalon de longitud superior a una columna.
Cuando la columna b es nula el sistema se llama homogeneo. Entonces, esta columna no anadeningun escalon, a pesar de las operaciones elementales, por lo que en estos sistemas las matrices
59

escalonadas provenientes de la matriz de los coeficientes y de la matriz ampliada tienen siempre elmismo numero de escalones. Concluimos que los sistemas homogeneos son siempre compatibles.
Ejercicios:
3.2.1. Haciendo operaciones elementales en la matriz ampliada del sistema y aplicando el Teoremade Rouche-Frobenius, decidir el caracter de los siguientes sistemas de ecuaciones lineales:
x1 +2x2 −x3 = 1x2 +x3 = 2
x1 +3x2 = 3
x1 +2x2 −x3 = 1
x2 +x3 = 2x1 +3x2 = 4
2x1 +x2 = 5x1 −x2 = 1x1 +2x2 = 4
x1 −3x2 +x3 +x4 = 2
3x1 −8x2 +2x3 +x4 = 22x1 −5x2 +x3 = 3
3.2.2. Hallar todas las matrices cuadradas de orden 2 que conmutan con la matriz(
1 23 4
)3.2.3. Considerar los sistemas:
a)x1 +2x2 −x3 = cx1 +x2 +2x3 = 2
−2x1 +3x2 +bx3 = −4
b)x1 +x2 −x3 = 1
2x1 +cx2 +x3 = d5x1 +5x2 −x3 = e
i). Encontrar los valores de b para los que el sistema a) tiene solucion, cualquiera que sea c.ii). Existe un valor de b para el que el sistema a) no tiene siempre solucion, sino solo para un
valor de c. ¿Cuales son estos valores de b y de c?iii). Encontrar las condiciones que han de cumplir c, d y e para que el sistema b) tenga solucion.3.2.4.a) Hallar y para que exista una matriz X2×2 tal que
X
(1 23 4
)−(
1 23 4
)X =
(0 y−3 0
).
b) Hallar la forma general de todas las matrices X que verifican la igualdad anterior con el valorhallado de y.
60

3.2.5. Dado el sistema 1 a 1a 0 1− a1 1− a 1
xyz
=
b00
,
Encontrar los valores de a y b para los que el sistema es:a) compatible determinado.b) incompatible.c) compatible indeterminado.
3.2.6. Considerar el sistema de ecuaciones siguiente:
x+ y + z = 1x+ y + az = 2x+ y + bz = 3
a) ¿Existen valores de a, b para los que el sistema es compatible determinado?b) ¿Para que valores de a, b, el sistema es incompatible?
3.2.7. Consideremos el sistema de ecuaciones lineales:
x −y +2z = 2x +y −z = 12x +az = c3x +y +bz = 4
a) Hallar las condiciones que tienen que cumplir los valores de a, b, c para que el sistema sea
compatible indeterminado.b) Hallar las condiciones que tienen que cumplir los valores de a, b, c para que el sistema sea
compatible determinado.
3.2.8. Dado el sistema de ecuaciones lineales:
x +2y −2z +2t = 4−3y +z +t = 1
x +5y −3z +t = m−x +y +z +mt = 1
a) Mostrar que si el sistema tiene solucion, esta no es unica.b) Encontrar los valores de m para que exista solucion.
61

3.2.9. Consideremos el sistema de ecuaciones lineales:
x +y +(1 +m)z = 4−m(1−m)x −y +2z = −2
2x +my +3z = 2−m
dependiente de m.
Hallar razonadamente:a) Para que valores de m el sistema es compatible determinado.b) Para que valores de m el sistema es compatible.c) Para que valores de m el sistema es incompatible.
Sol. 3.2.3ii).: b = −19, c = 2.Sol. 3.2.4 a).: y = 2.
62

Reduccion de Gauss-Jordan.
Una vez decidido el caracter del sistema, hemos visto que si es compatible, la sustitucion re-gresiva de las incognitas que son determinadas o se pueden despejar en funcion de otras, da lassoluciones del sistema. Mirando de nuevo las matrices de los sistemas que van quedando al sustituir,vemos que van evolucionando de manera que se van haciendo 1 los elementos de las esquinas de losescalones (llamados pivotes), y se hacen cero los elementos sobre estos pivotes. Lo podemos hacertodo matricialmente hasta el final y entonces se dice que se resuelve el sistema por la Reduccionde Gauss-Jordan
Veamoslo en el ejemplo 4) (pags. 53 y 58): Una vez conseguido el sistema en la forma escalonada,despejar x4 es pasar del ultimo sistema
x1 +3x2 −x3 +x4 = 1x2 +x3 −x4 = 0
9x4 = 9
de matriz
1 3 −1 10 1 1 −10 0 0 9
∣∣∣∣∣∣109
al sistema
x1 +3x2 −x3 +x4 = 1x2 +x3 −x4 = 0
x4 = 1
de matriz
1 3 −1 10 1 1 −10 0 0 1
∣∣∣∣∣∣101
obtenidos dividiendo la ultima fila por 9.
Sustituir x4 en las ecuaciones anteriores es pasar al sistema:
x1 +3x2 −x3 = 0x2 +x3 = 1
x4 = 1
de matriz 1 3 −1 0
0 1 1 00 0 0 1
∣∣∣∣∣∣011
obtenida de
1 3 −1 10 1 1 −10 0 0 1
∣∣∣∣∣∣101
restando la tercera fila a la primera y sumando la tercera fila a la segunda.
Como sustituir en las ecuaciones anteriores es pasar a un sistema donde no aparece la incognitax4, es decir, donde los coeficientes de x4 son nulos en todas las ecuaciones excepto en la ultima, en lamatriz escalonada ampliada, del ultimo sistema, los numeros de la columna de x4, excepto el ultimo,son ceros.
63

Despejar x2 y sustituirla en la primera ecuacion es pasar a otro sistema donde solo aparece x2
en la segunda ecuacion. Este sistema tiene una matriz escalonada ampliada que tiene ceros en lacolumna de x2 encima del 1 correspondiente a x2 en la segunda ecuacion:
Ahora hemos pasado al sistema:
x1 −4x3 = −3x2 +x3 = 1
x4 = 1
de matriz 1 0 −4 0
0 1 1 00 0 0 1
∣∣∣∣∣∣−3
11
obtenida de
1 3 −1 00 1 1 00 0 0 1
∣∣∣∣∣∣011
restando la segunda fila multiplicada por 3 de la primera fila.
Como la columna de x3 no da escalon, se puede pasar al segundo miembro, y es indeterminadaporque puede tomar cualquier valor; si x3 = k, se tienen las soluciones:
x1 = 4k −3x2 = −k +1x3 = k
x4 = 1
≡
x1
x2
x3
x4
= k
4−1
10
+
−3
101
.
El procedimiento descrito, realizado en las matrices, desde el principio al final, en las matrices A yA|b es la Reduccion de Gauss-Jordan para resolver el sistema AX=b: consiste en escribir lamatriz ampliada del sistema, y reducirla a forma escalonada mediante operaciones elementales. En elcaso en que sea compatible, hacer 1 todos los pivotes y anular los elementos por encima de los pivotescon mas operaciones elementales. Luego rellenamos las incognitas en las columnas correspondientesy tenemos en el caso compatible determinado, los valores de las incognitas; en el caso compatibleindeterminado pasamos al segundo miembro las incognitas cuyas columnas no dan escalon y lassustituimos por parametros variables.
Veamos ahora un ejemplo resuelto con la reduccion de Gauss-Jordan desde el principio.7)
x1 +2x2 +x3 +2x4 +x5 +3x6 = 02x1 +5x2 +x3 +2x4 +4x5 +7x6 = 2−2x1 −3x2 −3x3 −x4 +20x5 +14x6 = 21x1 +x2 +2x3 +6x4 +7x5 +10x6 = 8
64

equivalente a 1 2 1 2 1 32 5 1 2 4 7−2 −3 −3 −1 20 14
1 1 2 6 7 10
x1
x2
x3
x4
x5
x6
=
02
218
La reduccion de Gauss-Jordan de las matrices del sistema y ampliada da:
1 2 1 2 1 32 5 1 2 4 7−2 −3 −3 −1 20 14
1 1 2 6 7 10
∣∣∣∣∣∣∣∣02
218
→
1 2 1 2 1 30 1 −1 −2 2 10 1 −1 3 22 200 −1 1 4 6 7
∣∣∣∣∣∣∣∣02
218
→
1 2 1 2 1 30 1 −1 −2 2 10 0 0 5 20 190 0 0 2 8 8
∣∣∣∣∣∣∣∣02
1910
→
1 2 1 2 1 30 1 −1 −2 2 10 0 0 1 4 30 0 0 2 8 8
∣∣∣∣∣∣∣∣02−110
→
1 2 1 2 1 30 1 −1 −2 2 10 0 0 1 4 30 0 0 0 0 2
∣∣∣∣∣∣∣∣02−112
→
1 2 1 2 1 30 1 −1 −2 2 10 0 0 1 4 30 0 0 0 0 1
∣∣∣∣∣∣∣∣02−1
6
→
1 2 1 2 1 00 1 −1 −2 2 00 0 0 1 4 00 0 0 0 0 1
∣∣∣∣∣∣∣∣−18−4−19
6
→
1 2 1 0 −7 00 1 −1 0 10 00 0 0 1 4 00 0 0 0 0 1
∣∣∣∣∣∣∣∣20−42−19
6
→
1 0 3 0 −27 00 1 −1 0 10 00 0 0 1 4 00 0 0 0 0 1
∣∣∣∣∣∣∣∣104−42−19
6
Rellenando ahora las incognitas:
x1 +3x3 −27x5 = 104x2 −x3 +10x5 = −42
x4 +4x5 = −19x6 = 6
≡x1 = 104 −3x3 +27x5
x2 = −42 +x3 −10x5
x4 = −19 −4x5
x6 = 6
65

donde hemos pasado al segundo miembro las incognitas que no dan escalon.Las soluciones del sistema estan constituidas por los (x1, x2, x3, x4, x5, x6), tales que:
x1 = 104 −3x3 +27x5
x2 = −42 +x3 −10x5
x3 = x3
x4 = −19 −4x5
x5 = x5
x6 = 6
≡
x1
x2
x3
x4
x5
x6
=
104−42
0−19
06
+ x3
−3
11000
+ x5
27−10
0−4
10
≡
x1
x2
x3
x4
x5
x6
=
104−42
0−19
06
+ λ1
−3
11000
+ λ2
27−10
0−4
10
donde λ1 y λ2 varian arbitraria e independientemente.
Ejercicios:
3.3.1. Resolver utilizando la reduccion de Gauss-Jordan los siguientes sistemas de ecuacioneslineales.
a)x +2y −z = −3
3x +7y +2z = 14x −2y +z = −2
b)
2y −z +t = 6x −4y +z −2t = −9
2x −7y −2z +t = 103y −4t = −16
c)
x −y +z −t = 02x −2y −z +t = 3−x +y +2z −2t = −3−2x +2y +3z −t = 8
Si tenemos varios sistemas con la misma matriz de coeficientes, podemos resolverlos
todos a la vez, ampliando la matriz del sistema con las columnas de los terminos indepen-dientes de los sistemas dados y haciendo en esta matriz mas ampliada, las operacioneselementales que escalonen la matriz de los coeficientes.
66

3.3.2. Resolver de manera simultanea por el metodo de Gauss-Jordan los siguientes sistemas deecuaciones:
z −2t = 03x −6y +2z = −3x −2y +z −t = −1
2x −3y +3t = −1
z −2t = −1
3x −6y +2z = 2x −2y +z −t = 0
2x −3y +3t = 3
z −2t = −2
3x −6y +2z = −6x −2y +z −t = −3
2x −3y +3t = 0
Sol. 3.3.1: a) x = −1, y = 0, z = 2 b) x = 1, y = 0, z = −2, t = 4 c) (x, y, z, t) =
(1, 0, 11/2, 13/2) + λ(1, 1, 0, 0)Sol. 3.3.2: x1 = 1, y1 = 1, z1 = 0, t1 = 0; x2 = 0, y2 = 0, z2 = 1, t2 = 1; x3 = 0, y3 = 1, z3 =
0, t3 = 1.
La reduccion de Gauss-Jordan vale tambien para una ecuacion matricial AX = B donde X es unamatriz de n filas y m columnas y B es una matriz de m columnas y el mismo numero de filas de A.Llamando Xi a la columna i-esima de X y Bi a la columna i-esima en B, la ecuacion matricial dadaes equivalente al conjunto de sistemas AXi = Bi, i ∈ 1, ...,m. Los sistemas matriciales puedenser incompatibles o compatibles y en este caso, determinados o indeterminados. Se puede ver si soncompatibles escalonando la matriz ampliada A|B, y si son compatibles, resolverlos simultaneamentehaciendo la reduccion de Gauss-Jordan en dicha matriz ampliada A|B.
Cuando B=I, la solucion de la ecuacion AX=I se llama inversa a la derecha de A. Puede no existiry si A no es cuadrada puede no ser unica .
Si A es una matriz cuadrada, la igualdad AX = I ”sı” implica XA = I. Cuando se estudie lateorıa que viene a continuacion, usada para demostrar el teorema de caracterizacion de las matricesinvertibles, se puede demostrar esa implicacion utilizando la proposicion 3’, la expresion final de Aen la proposicion 4 y la unicidad de la inversa. Se propone construir todo el razonamiento en elejercicio 3.5.4.
Ejercicio:
3.3.3. Demostrar que1) Si una matriz A tiene inversa a la izquierda, la inversa a la derecha, de existir, es unica.2) Si una matriz A tiene inversa a la derecha, la inversa a la izquierda, de existir, es unica.3) Si una matriz A tiene inversa a la derecha e inversa a la izquierda, ambas coinciden.
67

Matrices Invertibles.
Nos interesa caracterizar las matrices A tales que los sistemas que se plantean con ellas tienensolucion y esta es unica, es decir que todos los sistemas que se plantean como Ax = b son compatiblesdeterminados. Estas matrices A son aquellas para las que existe otra matriz B tal que AB = I = BA.Veamoslo:
Si existe B tal que BA=I, dado un sistema de la forma AX = b, multiplicandolo a la izquierdapor B, obtenemos que la solucion, de existir, ha de ser X = Bb; para que efectivamente, esta sea lasolucion hay que comprobar que ABb = b, lo cual se cumple si la matriz B verifica AB=I, es decir,si B es tambien inversa a la derecha de A. siendo esto cierto cualquiera que sea b.
En un ejercicio anterior se probo que si A tiene inversa a la izquierda y inversa a la derecha,ambas coinciden y son unicas. Esta unicidad es necesaria para que todos los sistemas AX=b tengansolucion, porque con matrices A que tuvieran dos inversas a la izquierda distintas, B′ y B′′ podrıaexistir algun b para el que las condiciones necesarias x = B′b y x = B′′b, fueran incompatibles entresı. Por otra parte, para que la condicion necesaria x = Bb sea suficiente cualquiera que sea b, ha deser ABb = b para todo b, para lo cual es necesario que AB = I.
Se llaman invertibles las matrices A tales que existe una matriz B tal que BA = I = AB.Entonces, se llama a B, inversa de A.
Una matriz A invertible no puede tener ninguna columna ni ninguna fila de ceros, porque en estoscasos, se tendrıa, cualquiera que fuera la matriz X, en XA una columna de ceros o en AX una filade ceros, no obteniendose nunca la identidad. Queremos ver que ademas ha de ser cuadrada.
Observemos que una inversa a la derecha X de una matriz A, es una solucion de la ecuacionAX = I y que una matriz A con la primera columna no nula y con mas columnas que filas, alescalonarla da el primer escalon en la primera columna y por ello, algun escalon con mas de unacolumna, por lo que el sistema AX = I, de tener solucion, no tiene solucion unica. Si no tienesolucion, la matriz no es invertible y si existen varias soluciones, como estas soluciones serıan distintasinversas a la derecha de A, segun el problema 3.3.3 no existe inversa a la izquierda. Concluimos queuna matriz con mas columnas que filas no es invertible.
Tambien se puede concluir que una matriz con mas filas que columnas no es invertible, porquesi lo fuera, su traspuesta, que tiene mas columnas que filas serıa invertible, en contra de lo anterior.(Si AB = I = BA, tBtA = t(AB) = I y tAtB = (BA)t = I).
Entonces, una matriz invertible, ademas de no tener ninguna fila ni ninguna columna nula, ha deser cuadrada.
En los ejercicios 3.5.6-3.5.10 de la seccion siguiente, se establece otro camino distinto del vistoahora para demostrar que las matrices invertibles han de ser cuadradas.
68

Caracterizacion de las matrices invertibles.
Observando lo que pasa en las matrices cuando aplicamos el metodo de Gauss a un sistema,podemos deducir propiedades de las matrices que nos dan tambien el metodo de Gauss para hallarla inversa de una matriz. Y al mismo tiempo, podemos demostrar un teorema que caracteriza a lasmatrices invertibles como producto de ciertas matrices llamadas elementales.
Las operaciones elementales en una matriz (pag. 57) se pueden expresar en forma matematicacomo el resultado de multiplicar por la izquierda por las matrices llamadas
Matrices Elementales: Son las matrices obtenidas de las matrices identidad por operaciones ele-mentales. (Diremos que son de tres tipos segun el tipo de operacion elemental realizado).
Se puede comprobar facilmente, caso por caso, que al multiplicar a la izquierda una matrizelemental por otra matriz se produce en esta ultima la operacion elemental realizada en la matriz Ipara obtener la matriz elemental considerada.
Tambien, hagamos las siguientes consideraciones:
a) Si hacemos sucesivamente dos intercambios de las mismas filas de la matriz identidad, la matrizqueda invariante. Esto quiere decir que el producto de una matriz elemental del primer tipo por ellamisma es la identidad. Por tanto, las matrices elementales correspondientes (del primer tipo) soninvertibles y coinciden con su inversa.
b) Si sumamos a una fila de la identidad otra fila multiplicada por un numero y luego le sumamosla misma fila multiplicada por el numero opuesto obtenemos la identidad. Esto quiere decir tambienque las dos matrices elementales correspondientes (del segundo tipo) son inversas una de otra, siendosus inversas del mismo tipo.
c) Si primero multiplicamos una fila de la matriz identidad por un numero distinto de cero yluego la multiplicamos por el inverso de dicho numero, queda igual. Esto quiere decir que el productode las dos matrices elementales correspondientes es la identidad. Por tanto, tambien las matriceselementales del tercer tipo son invertibles y sus inversas son del mismo tipo.
Se deduce de estas consideraciones que las matrices elementales son invertibles y que sus inversasson tambien matrices elementales.
Nuestro teorema sobre matrices invertibles es:
69

TEOREMA 1: Una matriz cuadrada es invertible si y solo si es producto de matriceselementales.
Ya que las matrices elementales son invertibles, la demostracion de que toda matriz producto dematrices elementales es invertible es una facil consecuencia de la siguiente proposicion:
Proposicion 1: El producto de matrices invertibles es invertible.
Sean A1, A2, ..., Am, matrices cuyas inversas respectivas son B1, B2, ..., Bm, se puede comprobarque la matriz producto A = A1 · A2 · ... · Am tiene como inversa B = Bm... ·B2 ·B1.
En efecto, por la propiedad asociativa, en el producto
AB = A1 · A2 · ... · AmBm... ·B2 ·B1
empezando por i=m podemos ir simplificando las Ai con las Bi correspondientes y llegar a la iden-tidad.
Lo mismo podemos hacer, empezando por i=1, en el producto
BA = Bm... ·B2 ·B1A1 · A2 · ... · Am.
Para demostrar el teorema tenemos que demostrar tambien que toda matriz invertible es productode matrices elementales.
Para ello vamos a usar las proposiciones 2, 3 y 4 siguientes:
Proposicion 2: Toda matriz puede reducirse a una matriz escalonada multiplicandola adecuada-mente a la izquierda por matrices elementales.
Su demostracion se deduce de la observacion de la evolucion de la matriz del sistema en elprocedimiento seguido en el metodo de Gauss. Se ve en ese procedimiento que toda matriz sepuede reducir a una matriz escalonada haciendo operaciones elementales en sus filas, olo que es lo mismo, que dada una matriz, multiplicando a la izquierda, sucesivamente, por matriceselementales se puede llegar a una matriz escalonada.
Por tanto, dada la matriz A, existen matrices elementales: E1, E2, ..., Ek, tales que
Ek · Ek−1 · ...E1A = E
donde E es una matriz escalonada.
Conviene comprobarlo en el siguiente Ejercicio:
70

3.4.1. Encontrar una sucesion de matrices elementales E1, · · · , Ek tal que Ek · · ·E1A = E dondeA es una de las matrices dadas a continuacion y E es una matriz escalonada:
a)
1 3−1 0
2 1
b)
(2 3 43 1 2
)c)
0 2 41 1 33 3 7
d)
0 −1 11 0 −12 −1 −1
e)
−2 1 13 −2 11 −1 1
f)
0 −1 −11 0 −12 −1 −3
g)
0 −1 −11 1 02 −1 −3
h)
0 −1 −11 1 12 −1 −1
i)
0 −1 −11 0 −12 −1 −1
j)
0 2 41 0 −11 −2 −3
Para la mejor comprension de las demostraciones de las proposiciones siguientes se proponen los
ejercicios:3.4.2. Comprobar que una vez obtenida la matriz escalonada en los casos c), e), i) y j) anteriores
podemos llegar desde la matriz escalonada a la matriz identidad haciendo mas operaciones elemen-tales, por el mismo procedimiento usado para despejar las incognitas en la reduccion de Gauss-Jordan.
3.4.3. Comprobar que una vez obtenida la matriz escalonada en los casos d), f), g) y h) anteri-ores no podemos llegar desde la matriz escalonada a la matriz identidad haciendo mas operacioneselementales, por el mismo procedimiento usado para despejar las incognitas en la reduccion de Gauss-Jordan.
Antes de pasar a la demostracion completa del teorema, vamos a ver un ejemplo en el que se llegadesde una matriz a la identidad por transformaciones elementales, lo cual equivale a multiplicar lamatriz por matrices elementales y esto pone de manifiesto que la matriz dada es producto de matriceselementales y por tanto invertible:
La matriz
0 2 41 1 33 4 7
pasa, multiplicandola a la izquierda por las matrices elementales:
0 1 01 0 00 0 1
,
1 0 00 1 0−3 0 1
,
1 0 00 1
20
0 0 1
,
1 0 00 1 00 −1 1
sucesivamente, a las matrices 1 1 3
0 2 43 4 7
,
1 1 30 2 40 1 −2
,
1 1 30 1 20 1 −2
,
1 1 30 1 20 0 −4
.
71

Como esta ultima tiene todos los escalones de longitud una columna, siendo por tanto, los elementosde la diagonal principal distintos de cero, podemos conseguir que estos elementos sean unos, divi-diendo adecuadamente las filas, lo que aquı se reduce a dividir la ultima fila por −4, es decir, amultiplicar ahora a la izquierda por la matriz 1 0 0
0 1 00 0 −1
4
habiendo llegado a 1 1 3
0 1 20 0 1
.
En esta matriz con 1 en todos los elementos de la diagonal y ceros en todos los sitios debajo de ladiagonal, podemos seguir haciendo operaciones elementales que anulen tambien los numeros en lossitios por encima de la diagonal, llegando ası a la identidad.
Efectivamente, multiplicando sucesivamente a la izquierda, por las matrices elementales: 1 0 00 1 −20 0 1
,
1 0 −30 1 00 0 1
,
1 −1 00 1 00 0 1
obtenemos la identidad (compruebese).
Hemos multiplicado, en total, por ocho matrices elementales, que designamos por E1, E2, E3, E4, E5,E6, E7, E8, por orden de utilizacion.
Entonces: E8 · E7 · E6 · E5 · E4 · E3 · E2 · E1 · A = I.Como las matrices elementales tienen inversas, multiplicando a la izquierda por sus inversas de
manera que se vayan simplificando dichas matrices, tenemos:A = E−1
1 ·E−12 ·E−1
3 ·E−14 ·E−1
5 ·E−16 ·E−1
7 ·E−18 . Lo cual puede comprobarse teniendo en cuenta
que
E−11 =
0 1 01 0 00 0 1
, E−12 =
1 0 00 1 03 0 1
, E−13 =
1 0 00 2 00 0 1
, E−14 =
1 0 00 1 00 1 1
E−15 =
1 0 00 1 00 0 4
E−16 =
1 0 00 1 20 0 1
, E−17 =
1 0 30 1 00 0 1
, E−18 =
1 1 00 1 00 0 1
72

Como tambien las inversas de matrices elementales son elementales, hemos visto que del hechode tener la matriz escalonada obtenida de A todos los escalones de longitud una columna (y porello, todos los elementos de la diagonal distintos de cero), hemos llegado a la expresion de A comoproducto de matrices elementales. Como estas matrices son invertibles, de la proposicion 1 se deduceque A es invertible.
Seguimos ahora con las siguientes etapas para la demostracion del teorema:
Proposicion 3: Si una matriz A es invertible, la matriz escalonada E a la que se reduce, tienetodos los escalones de longitud una columna, estando el primer escalon en la primera fila y primeracolumna.
Demostracion:Si A es invertible, A tiene que ser cuadrada y la existencia de una matriz B tal que BA=I implica
que la primera columna de A no es toda de ceros, porque entonces la primera columna del productoBA serıa toda de ceros y no coincidirıa con la primera columna de I; por lo que se puede conseguir(si es necesario por un cambio de orden de las filas) que el elemento de la primera fila y primeracolumna sea distinto de cero, empezando por tanto los escalones en este lugar. Veamos que al seguirescalonando la matriz, la matriz escalonada E a la que se reduce A tiene todos los escalones delongitud una columna razonando por reduccion al absurdo: Si tuviera algun escalon con mas deuna columna, al ir recorriendo los pivotes y llegar al primero de tales escalones, nos desplazamos ala derecha por lo menos el espacio de dos columnas, saliendonos de la diagonal y por ello al seguirrecorriendo pivotes agotamos antes las columnas que las filas, quedando por tanto la ultima fila enterapor debajo de la lınea de pivotes y estando por ello formada por ceros. Entonces, multiplicando porlas matrices elementales correspondientes tendrıamos:
E = EkEk−1, ...E1A
donde E es una matriz escalonada con la ultima fila toda de ceros.Ahora bien, si A es invertible, existe B tal que AB=I. Entonces,
EB = EkEk−1...E1AB = EkEk−1...E1I = EkEk−1...E1
y por tanto, como las matrices elementales tienen inversa,
EBE−11 ...E−1
k = EkEk−1...E1E−11 ...E−1
k = I
Si la matriz E tuviera la ultima fila de ceros, la matriz EBE−11 .....E−1
m tendrıa tambien la ultima filade ceros por tenerla E y esto es una contradiccion ya que I tiene un 1 en su ultima fila. Quedandoası demostrada la proposicion 3.
73

Esta proposicion es tambien cierta si se debilita la hipotesis:Proposicion 3’: Si una matriz A cuadrada tiene inversa a la derecha, la matriz escalonada E a
la que se reduce, tiene todos los escalones de longitud una columna, estando el primer escalon en laprimera fila y primera columna.
La demostracion se sigue de que de no ser ası la matriz escalonada E tendrıa la ultima fila deceros, pero esto no puede ocurrir si la matriz A tiene inversa a la derecha como se ha visto en lademostracion de la proposicion 3.
Proposicion 4: Si al escalonar una matriz cuadrada A, todos los escalones son de una columna,estando el escalon de la primera fila en la primera columna, A es producto de matrices elementales.
Demostracion: Sea E la matriz escalonada a la que se reduce A. Como estamos suponiendo queA es cuadrada y el tamano de la matriz queda invariante por las operaciones elementales, E tambienha de ser cuadrada. Tenemos un pivote en el sitio de la primera columna de la primera fila. Silos escalones de E son todos de una columna, al ir recorriendo los pivotes, vamos desplazandonos ala derecha el espacio de una columna al mismo tiempo que nos desplazamos hacia abajo el espaciode cada fila, recorriendo ası, la diagonal principal de E, que por tanto esta formada por numerosdistintos de cero. Dividiendo cada fila por el numero que esta en la diagonal de esa fila, (lo cual eshacer operaciones elementales) podemos hacer todos los elementos de la diagonal iguales a 1. Y conestos 1, podemos seguir haciendo operaciones elementales para anular todos los elementos encima deellos, (segun la reduccion de Gauss-Jordan), llegando entonces a la matriz identidad.
Entonces, podemos afirmar que, en la hipotesis de la proposicion 4, ademas de las matriceselementales: E1, E2, ..., Ek, tales que
Ek · Ek−1...E1A = E
donde E es una matriz escalonada, existen matrices elementales Ek+1, Ek+2...Em tales que
EmEm−1...Ek+1Ek...E1A = I
Como las matrices elementales tienen inversa, multiplicando a la izquierda la igualdad anteriorpor las inversas de las matrices elementales, obtenemos
A = E−11 ...E−1
k ...E−1m
Y como las inversas de matrices elementales son matrices elementales, hemos llegado a unaexpresion de A como producto de matrices elementales.
74

Para terminar la demostracion del Teorema 1, es decir, para demostrar que toda matriz inver-tible es producto de matrices elementales, tenemos en cuenta, primero, que por la proposicion 2,una matriz A siempre se puede escalonar, luego, que cuando A es invertible, segun la proposicion 3,la matriz escalonada E, que se obtiene de A, tiene todos los escalones de una columna, estando elprimer escalon de la primera fila en la primera columna. Entonces, la proposicion 4 establece que lamatriz A invertible es producto de matrices elementales.
Por otra parte, enlazando la proposicion 4 y la proposicion 1, tenemos que si al escalonar unamatriz cuadrada A, todos los escalones son de una columna, estando el escalon de la primera fila enla primera columna, A es invertible.
Ademas, la proposicion 3 implica que si al escalonar una matriz cuadrada A, algun escalon es demas de una columna, A no es invertible, por lo que tambien es cierto el
Teorema 2: Una matriz cuadrada A es invertible si y solo si al escalonar A, se obtiene una matrizescalonada con todos los escalones de longitud una columna, estando el primer escalon en la primeracolumna.
Ejercicios:
3.5.1. Decidir cuales de las matrices del ejercicio 3.4.1 son invertibles mirando la matriz escalonadaa la que han sido reducidas.
3.5.2. Expresar las inversas de las matrices del ejercicio 3.4.1. que sean invertibles como productode matrices elementales.
3.5.3. Expresar las matrices del ejercicio 3.4.1 que sean invertibles como producto de matriceselementales.
3.5.4. Demostrar que toda matriz cuadrada con inversa a la derecha tiene inversa a la izquierda.3.5.5. Demostrar que toda matriz cuadrada con inversa a la izquierda tiene inversa a la derecha.
3.5.6. Demostrar que si una matriz A con mas filas que columnas se puede reducir por operacioneselementales a la matriz:
In0...0
donde n es el numero de columnas de A, puede tener muchas inversas a la izquierda.
3.5.7. Demostrar que dada una matriz con mas filas que columnas, si tiene inversa a la izquierda,esta no es unica.
75

3.5.8. Demostrar que si una matriz tiene mas de una inversa a la izquierda, no puede tener inversaa la derecha.
3.5.9. Demostrar que una matriz con mas filas que columnas no puede ser invertible.3.5.10. Demostrar que una matriz con mas columnas que filas no puede ser invertible.Deducir de los ejercicios anteriores que solo las matrices cuadradas pueden ser invertibles.
76

Metodo de Gauss para obtener la inversa de una matriz invertible:
Al repasar la demostracion de la proposicion 4 nos podemos dar cuenta de que la matriz producto:Em...Ek+1EkEk−1...E1 es inversa a la izquierda de A y dada la expresion de A obtenida al final dela demostracion de dicha proposicion,(A = E−1
1 · · ·E−1m ) podemos comprobar que ese producto es
tambien inversa a la derecha de A. Es decir,
A−1 = Em...Ek+1EkEk−1...E1
Como Em...Ek+1EkEk−1...E1 = Em...Ek+1EkEk−1...E1I, la matriz A−1 se puede obtener haciendoen I las operaciones elementales correspondientes a las matrices elementales escritas, y estas opera-ciones son las mismas que hemos hecho en A para llegar a I. Por eso, para obtener la matriz inversade A colocamos la matriz I al lado de la matriz A en la forma (A| I) y hacemos en la matriz I lasmismas operaciones elementales que en la A. Cuando a la izquierda de la barra hayamos llegado ala matriz I, es que hemos multiplicado A por Em · · ·E1 y lo mismo I, por lo que a la derecha de labarra habremos llegado a la matriz inversa de A.
Veamoslo con la matriz
A =
0 1 11 0 11 1 0
Escribimos: 0 1 1
1 0 11 1 0
∣∣∣∣∣∣1 0 00 1 00 0 1
y ahora hacemos en la union de las dos matrices, las transformaciones elementales que llevan lamatriz A a la identidad.
0 1 11 0 11 1 0
∣∣∣∣∣∣1 0 00 1 00 0 1
∼ 1 0 1
0 1 11 1 0
∣∣∣∣∣∣0 1 01 0 00 0 1
∼ 1 0 1
0 1 10 1 −1
∣∣∣∣∣∣0 1 01 0 00 −1 1
∼ 1 0 1
0 1 10 0 −2
∣∣∣∣∣∣0 1 01 0 0−1 −1 1
∼ 1 0 1
0 1 10 0 1
∣∣∣∣∣∣0 1 01 0 0
1/2 1/2 −1/2
∼ 1 0 1
0 1 00 0 1
∣∣∣∣∣∣0 1 0
1/2 −1/2 1/21/2 1/2 −1/2
∼ 1 0 0
0 1 00 0 1
∣∣∣∣∣∣−1/2 1/2 1/2
1/2 −1/2 1/21/2 1/2 −1/2
77

Entonces: 0 1 11 0 11 1 0
−1
=
−1/2 1/2 1/21/2 −1/2 1/21/2 1/2 −1/2
Observese que la matriz obtenida para A−1 es tambien la matriz que habrıamos obtenido como
solucion de la ecuacion matricial AX = I por el metodo de Gauss-Jordan. Esta solucion X es unainversa a la derecha, y ademas, al haber expresado esta X como producto de matrices elementales,estamos seguros de que es inversa a la derecha y a la izquierda; y la unicidad de la inversa nosasegura la unicidad del resultado, cualquiera que sea el camino seguido, o sea, cualesquiera que seanlas operaciones elementales realizadas.
Ejercicios:
3.6.1. Utilizar el metodo de Gauss para hallar las inversas de las matrices del ejercicio 3.4.1 quesean invertibles y comprobar los resultados del ejercicio 3.5.2.
3.6.2. Los sistemas de ecuaciones lineales:
2y +4z = −3x +y +3z = 1
3x +3y +7z = −2
−2x +y +z = −3
3x −2y +z = 1x −y +z = −2
se pueden expresar matricialmente de la forma AX = b donde A es una matriz invertible. Su inversaha sido calculada en los ejercicios anteriores; usarla para hallar las soluciones de los sistemas.
3.6.3. Demostrar que la traspuesta de la inversa de una matriz es la inversa de la traspuesta dedicha matriz.
3.6.4. Explicar por que una matriz triangular superior es invertible si y solo si todos los elementosde su diagonal son distintos de cero.
3.6.5. Explicar por que la inversa de una matriz triangular superior invertible es tambien trian-gular superior.
3.6.6. Demostrar que una matriz triangular inferior es invertible si y solo si todos los elementosde su diagonal son distintos de cero.
3.6.7. Demostrar que la inversa de una matriz triangular inferior invertible es tambien triangularinferior.
78

La expresion de la inversa como producto de matrices elementales nos permite tambien enten-der la Reduccion de Gauss-Jordan para resolver el sistema AX=b cuando A es matrizinvertible:
Multiplicando a la izquierda por A−1 con la expresion obtenida: A−1 = Er...Em+1EmEm−1...E1,tenemos
X = A−1b = Er...Em+1EmEm−1...E1b
Luego X es el resultado de hacer en b las operaciones elementales que llevan A a I. Escribiendola matriz A|b y haciendo en esta dichas operaciones, cuando a la izquierda de la barra verticalobtengamos la matriz I, a la derecha habremos obtenido la matriz solucion de las X. Ver el ejemplo3 de la pagina 42 del libro de Fraleigh-Beauregard.
Ejemplos resueltos y problemas propuestos el el capıtulo 2 de (A),en el capıtulo 2 de (Vi), en lassecciones 1.2 y 1.4 de (H) y en el capıtulo 5 de (Vi).
79

BIBLIOGRAFIA
(A) Algebra Lineal y aplicaciones. J. Arvesu Carballo, R. Alvarez Nodarse, F. Marcellan Espanol.Ed. Sıntesis Madrid. 1999.
(FB) Algebra lineal. J. B. Fraleigh y R. A. Beauregard. Ed. Addison- Wesley /Iberoamericana,1989.
(H) Algebra y Geometrıa. Eugenio Hernandez. Ed. Addison- Wesley / UAM, 1994.[M] Matematicas 2 Bachillerato. Ma Felicidad Monteagudo Martınez. Jesus Paz Fernandez Ed.
Luis Vives. 2003.(Vi) Problemas de Algebra. A. de la Villa. Ed. Clagsa, 1994.
80

DETERMINANTES y SISTEMAS de ECUACIONES.
Introduccion.
Los determinantes son numeros asociados a las matrices.Hemos visto matrices asociadas a los sistemas de ecuaciones. Veremos que cuando calculamos
determinantes de esas matrices o de submatrices suyas obtenemos informacion sobre la compatibilidady determinacion de dichos sistemas.
Los determinantes tambien tienen interpretacion geometrica. Vamos a empezar motivando sudefinicion por su significado geometrico.
Escribiendo en filas las coordenadas de un vector de la recta, de dos vectores del plano o de tresvectores del espacio tenemos, respectivamente, una matriz 1×1, una matriz 2×2 o una matriz 3×3.
(a11
) (a11 a12
a21 a22
) a11 a12 a13
a21 a22 a23
a31 a32 a33
Al mismo tiempo, dado un vector, podemos considerar su longitud, que es un numero; dados
dos vectores, podemos construir un paralelogramo cuyos lados son los vectores dados y considerar suarea; Dados tres vectores, podemos construir un paralelepıpedo cuyas aristas son los tres vectores yconsiderar su volumen.
*
HHH
HHHY
HHHHH
H
*
HHHH
HHY
HHHH
HH
HHHH
HH
HHHH
HH
81

Las longitudes, las areas y los volumenes son ”numeros” asociados a vectores, a parejas de vectoreso a ternas de vectores y por tanto a las matrices formadas con ellos. Entonces, es logico estudiar quepropiedades han de cumplir, para ver como se pueden calcular.
Si quisieramos que la longitud, el area o el volumen fueran numeros asociados a estas matricesy los designaramos por las matrices entre barras, los ”numeros” asociados a esas matrices tendrıanque cumplir:
a) Si multiplicamos uno de los vectores por una constante positiva o nula, el numero asociadoqueda multiplicado por esa constante:
|ra11| = r|a11|,∣∣∣∣ ra11 ra12
a21 a22
∣∣∣∣ = r
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣ ,∣∣∣∣∣∣ra11 ra12 ra13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ = r
∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣Lo analogo ocurre con las otras filas.b) Si en un vector, una pareja o una terna de vectores, sustituimos un vector por la suma de
otros dos, el numero asociado (longitud, area o volumen) a la matriz correspondiente es la suma delos numeros asociados a las dos matrices de vectores correspondientes a los vectores sumandos:
:
1
*
HHH
HHHY
HHH
HHHY
HHHH
HHY
:
1
*
HHH
a1
a′1
a1 + a′1
a2
82
:
1
HHHH
HHY
HHH
HHH
HHHHH
H
HHHH
HH
HHHHH
H
HHHHHH
|a11 + a′11| = |a11|+ |a′11|∣∣∣∣ a11 + a′11 a12 + a′12
a21 a22
∣∣∣∣ =
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣+
∣∣∣∣ a′11 a′12
a21 a22
∣∣∣∣∣∣∣∣∣∣a11 + a′11 a12 + a′12 a13 + a′13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ =
∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣a′11 a′12 a′13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣Tambien ocurrirıa con las otras filas.
Del apartado b) se deduce que el apartado a) es cierto tambien cuando una fila se multiplica poruna constante negativa ya que si r = −1∣∣∣∣∣∣
a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣−a11 −a12 −a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ =
∣∣∣∣∣∣0 0 0a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ = 0
c) Si uno de los vectores es proporcional a alguno de los otros, el area o el volumen es cero. (Estapropiedad solo tiene sentido cuando la matriz es de orden mayor que 1).
Vamos a deducir que si las areas y los volumenes fueran numeros asociados a las matrices cuyasfilas son los vectores dados, con las propiedades b) c) y a) estos ”numeros” cambiarıan de signo alcambiar el orden de las filas de las matrices por una permutacion de dos filas:
83

En volumenes se verificarıa Proposicion 1:∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ = −
∣∣∣∣∣∣a21 a22 a23
a11 a12 a13
a31 a32 a33
∣∣∣∣∣∣ .En efecto, ∣∣∣∣∣∣
a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ =
=
∣∣∣∣∣∣12(a11 + a21) + 1
2(a11 − a21)
12(a12 + a22) + 1
2(a12 − a22)
12(a13 + a23) + 1
2(a13 − a23)
12(a11 + a21)− 1
2(a11 − a21)
12(a12 + a22)− 1
2(a12 − a22)
12(a13 + a23)− 1
2(a13 − a23)
a31 a32 a33
∣∣∣∣∣∣ =
por b)
=
∣∣∣∣∣∣12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
12(a11 + a21)− 1
2(a11 − a21)
12(a12 + a22)− 1
2(a12 − a22)
12(a13 + a23)− 1
2(a13 − a23)
a31 a32 a33
∣∣∣∣∣∣+
+
∣∣∣∣∣∣12(a11 − a21)
12(a12 − a22)
12(a13 − a23)
12(a11 + a21)− 1
2(a11 − a21)
12(a12 + a22)− 1
2(a12 − a22)
12(a13 + a23)− 1
2(a13 − a23)
a31 a32 a33
∣∣∣∣∣∣ =
por b)
=
∣∣∣∣∣∣12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
−12(a11 − a21) −1
2(a12 − a22) −1
2(a13 − a23)
a31 a32 a33
∣∣∣∣∣∣+
+
∣∣∣∣∣∣12(a11 − a21)
12(a12 − a22)
12(a13 − a23)
12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣12(a11 − a21)
12(a12 − a22)
12(a13 − a23)
−12(a11 − a21) −1
2(a21 − a22) −1
2(a13 − a23)
a31 a32 a33
∣∣∣∣∣∣ =
(porque los volumenes asociados a vectores proporcionales son cero, por c))
=
∣∣∣∣∣∣12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
−12(a11 − a21) −1
2(a12 − a22) −1
2(a13 − a23)
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣12(a11 − a21)
12(a12 − a22)
12(a13 − a23)
12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
a31 a32 a33
∣∣∣∣∣∣84

Por otra parte, analogamente, se tiene:∣∣∣∣∣∣a21 a22 a23
a11 a12 a13
a31 a32 a33
∣∣∣∣∣∣ =
=
∣∣∣∣∣∣12(a11 + a21) + 1
2(a21 − a11)
12(a12 + a22) + 1
2(a22 − a12)
12(a13 + a23) + 1
2(a23 − a13)
12(a11 + a21)− 1
2(a21 − a11)
12(a12 + a22)− 1
2(a22 − a12)
12(a13 + a23)− 1
2(a23 − a13)
a31 a32 a33
∣∣∣∣∣∣ =
=
∣∣∣∣∣∣12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
−12(a21 − a11) −1
2(a22 − a12) −1
2(a23 − a13)
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣12(a21 − a11)
12(a22 − a12)
12(a23 − a13)
12(a11 + a21)
12(a12 + a22)
12(a13 + a23)
a31 a32 a33
∣∣∣∣∣∣expresion opuesta a la anterior, teniendo en cuenta la propiedad a) para r = −1.
El cambio de signo se comprobarıa de la misma manera si permutaramos la segunda y la tercerafilas o la primera y la tercera filas.
La comprobacion del cambio de signo en las areas es exactamente igual al cambio hecho entreprimera y segunda filas. (Hagase como ejercicio).
Propiedades de los determinantes y operaciones elementales.
Podemos relacionar ahora las tres propiedades a), b) y c) que tendrıan que cumplir los ”numeros”asociados a las matrices con las operaciones elementales en las matrices:
De la propiedades b), c) y a) hemos deducido primero la propiedad siguiente: que al hacer en lamatriz una operacion elemental de permutacion de filas cambia de signo el ”numero” asociado; lavamos a llamar propiedad 1).
De la propiedad a) tenemos: al hacer en una matriz la operacion elemental de multiplicar una filapor una constante, el ”numero” asociado queda multiplicado por esa constante. La vamos a llamarpropiedad 2).
De la propiedad c) junto con la propiedad b) podemos deducir la propiedad siguiente: al haceren una matriz la operacion elemental de sumar a una fila de la matriz otra fila multiplicada poruna constante, el ”numero” asociado queda invariante. (Compruebese como ejercicio). La vamos allamar propiedad 3).
85

Las tres propiedades 1), 2) y 3) enunciadas de estos ”numeros” asociados a las matrices nos dicencomo estan relacionados entre sı los ”numeros” asociados a matrices relacionadas por operacioneselementales. Si las propiedades de estos ”numeros” estan relacionadas con las operaciones elemen-tales, que son las que realizamos en las matrices para resolver los sistemas de ecuaciones, podemospensar que esos numeros nos dan informacion sobre la resolubilidad de dichos sistemas.
Asociando a las matrices identidad el numero 1, lo cual es coherente con el valor de la longi-tud, el area y el volumen asociados a las matrices formadas por los vectores coordenados, quedandeterminados los ”numeros” asociados a las matrices elementales por las propiedades 1), 2) y 3):
i) Las matrices elementales obtenidas al intercambiar dos filas de la matriz identidad, tendrıancomo ”numero” asociado el opuesto del asociado a la matriz identidad, es decir, −1.
ii) Las matrices elementales obtenidas al multiplicar una fila de la identidad por una constante cdistinta de cero, segun la propiedad a) (o propiedad 2) tienen como ”numero” asociado el productode esta constante por el numero asociado a la matriz identidad, es decir, c.
iii) Las matrices elementales obtenidas al sumar a una fila de la matriz identidad otra fila mul-tiplicada por una constante tienen el mismo ”numero” asociado que la matriz identidad, es decir,1.
Matematicamente, las operaciones elementales se realizan en una matriz multiplicandola a laizquierda por matrices elementales. Las propiedades 1), 2) y 3) respecto a una matriz general Aquedan resumidas en terminos de matrices elementales en la
Proposicion 2: Si Ei es una matriz elemental, |EiA| = |Ei||A|.
La demostracion de esta proposicion consiste en su comprobacion en cada uno de los tres tiposde matrices elementales teniendo en cuenta las propiedades 1), 2) y 3) y se deja para el lector.
Ejercicios:
4.1.1. Utilizando la proposicion 2 y sin necesidad de calcularlos, demostrar que los siguientesdeterminantes son nulos.
a)
∣∣∣∣∣∣7 1 33 2 1
10 3 4
∣∣∣∣∣∣ b)
∣∣∣∣∣∣a b c−a −b −cd e f
∣∣∣∣∣∣ c)
∣∣∣∣∣∣1 2 32 3 43 4 5
∣∣∣∣∣∣ d)
∣∣∣∣∣∣∣∣12 22 32 42
22 32 42 52
32 42 52 62
42 52 62 72
∣∣∣∣∣∣∣∣4.1.2. Usando las matrices elementales que llevan las matrices siguientes a la identidad y la
proposicion 2, calcular los determinantes de las siguientes matrices:
86

a)
1 1 30 1 10 0 4
b)
(a11 a12
0 a22
)c)
a11 a12 a13
0 a22 a23
0 0 a33
cuando los elementos de la diagonal de las dos ultimas matrices son distintos de cero.
4.1.3.a) Demostrar que el determinante de una matriz triangular superior que tiene algun elemento de
la diagonal igual a cero es nulo, usando las propiedades de los determinantes.b) Demostrar que si escalonando la matriz A se obtiene una matriz triangular superior que tiene
algun elemento de la diagonal igual a cero, el determinante de A ha de ser nulo.4.1.4. Usando las matrices elementales que llevan las matrices siguientes a una triangular superior
y los resultados anteriores, calcular los determinantes de las siguientes matrices:
a)
(2 41 3
)b)
1 0 00 2 40 1 3
c)
0 2 41 0 00 1 3
d)
0 2 40 1 31 0 0
e)
0 2 41 1 33 3 7
f)
0 −1 11 0 −12 −1 −1
g)
−2 1 13 −2 11 −1 1
h)
0 −1 −1 11 0 −1 12 −1 −3 −10 1 −1 0
Sol: a) 2, b) 2 c)4 d) 2) e) 4, f) 0, g) −1, h) −8.
4.1.5. Establecer las igualdades siguientes:∣∣∣∣∣∣1 0 00 a22 a23
0 a32 a33
∣∣∣∣∣∣ =
∣∣∣∣ a22 a23
a32 a33
∣∣∣∣ ,∣∣∣∣∣∣
0 a12 a13
1 0 00 a32 a33
∣∣∣∣∣∣ = −∣∣∣∣ a12 a13
a32 a33
∣∣∣∣ ,∣∣∣∣∣∣
0 a12 a13
0 a22 a23
1 0 0
∣∣∣∣∣∣ =
∣∣∣∣ a12 a13
a22 a23
∣∣∣∣ .Tambien podemos establecer utilizando la proposicion 2 el siguienteTeorema 1: |tA| = |A|.
En efecto, podemos comprobar que el teorema es cierto para matrices elementales: recorriendo lostres tipos de matrices elementales que hay, y considerando las traspuestas de cada tipo, vemos quela traspuesta de cada matriz elemental es elemental del mismo tipo y que le corresponde el mismo”numero” que a la matriz elemental considerada. (Compruebese en las matrices elementales 3× 3).
En cuanto al caso general, distinguimos dos casos:
87

a) A es invertible.Si A es invertible, es producto de matrices elementales.Sea A = Em · · ·E1, entonces tA = tE1 · · · tEm y como las matrices traspuestas de matrices
elementales son, a su vez, matrices elementales, por la proposicion 2:
|tA| = |tE1 · tE2 · · · tEm| = |tE1||tE2 · · · tEm| = |tE1||tE2| · · · |tEm| =
por ser el teorema cierto para matrices elementales,
= |E1||E2| · · · |Em| = |Em| · · · |E2||E1| = |Em · · ·E2E1| = |A|
b) A no es invertible.Entonces tA tampoco es invertible, porque si lo fuera, tA serıa producto de matrices elementales,
en cuyo caso A serıa el producto (en orden inverso) de las traspuestas de esas matrices elementales,siendo por tanto invertible.
Si la matriz A no es invertible, por operaciones elementales se puede reducir a una matriz escalo-nada E con la ultima fila de ceros, teniendose Ek · · ·E1A = E, de donde A = E−1
k · · ·E−11 E, que
podemos escribir de manera generica como A = E ′k · · ·E ′1E, donde E ′i son matrices elementales.Si en una matriz E hay una fila de ceros, su numero asociado es cero, ya que multiplicando la
fila de ceros por un numero distinto de cero, queda la misma matriz; por lo que se verificarıa debidoa la propiedad 2), que c|E| = |E|, cualqiera que sea c, lo cual implica |E| = 0, cuando c 6= 1.
Ahora, en virtud de la proposicion 2, si A = E ′k · · ·E ′1E, se tiene |A| = |E ′k||E ′k−1 · · ·E ′1E| =|E ′k||E ′k−1| · · · |E ′1||E| = 0
El mismo razonamiento para tA, puesto que no es invertible, nos da |tA| = 0, siendo, por tanto,tambien, |tA| = |A|.
Hagamos ahora dos observaciones:Primera: hemos obtenido, si A es invertible, |Em| · · · |E1| = |A| cuando A = Em · · ·E1, es decir,
el ”numero asociado” a A esta determinado por las matrices elementales que llevan A a la identidady es distinto de cero.
Segunda: como al trasponer una matriz, las columnas pasan a filas, las propiedades a) b) c)enunciadas respecto a las filas de una matriz y sus consecuencias son, analogamente ciertas respectoa las columnas en los ”numeros” que buscamos. En particular es cierta la
Proposicion 3. Si una matriz tiene una columna de ceros su ”numero asociado” es cero.
Para la demostracion de la proposicion 3, tengamos en cuenta que se puede ver que si una matriztiene una fila de ceros su ”numero asociado” es cero de manera similar a como hemos demostrado
88

que el ”numero asociado” a una matriz escalonada con la ultima fila de ceros es cero. Entonces,teniendo en cuenta el teorema 1 que pasa filas a columnas, queda establecida la proposicion 3.
En virtud de estas propiedades, se puede hacer el desarrollo del numero asociado a una matriz2× 2.
En efecto, por la propiedad b) respecto a columnas en matrices 2× 2, para una matriz 2× 2, eldeterminante ha de ser:∣∣∣∣ a b
c d
∣∣∣∣ =
∣∣∣∣ a b0 d
∣∣∣∣+
∣∣∣∣ 0 bc d
∣∣∣∣ =
∣∣∣∣ a 00 d
∣∣∣∣+
∣∣∣∣ a b0 0
∣∣∣∣+
∣∣∣∣ 0 bc 0
∣∣∣∣+
∣∣∣∣ 0 0c d
∣∣∣∣ =
debido a que el numero es cero cuando hay una fila de ceros,∣∣∣∣ a 00 d
∣∣∣∣+
∣∣∣∣ 0 bc 0
∣∣∣∣ = ad
∣∣∣∣ 1 00 1
∣∣∣∣+ bc
∣∣∣∣ 0 11 0
∣∣∣∣ = ad
∣∣∣∣ 1 00 1
∣∣∣∣− bc ∣∣∣∣ 1 00 1
∣∣∣∣ = ad− cb
En cuanto a una matriz 3 × 3, tendrıamos (descomponiendo la 1a columna en suma de trescolumnas): ∣∣∣∣∣∣
a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ =
∣∣∣∣∣∣a11 a12 a13
0 a22 a23
0 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
a21 a22 a23
0 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
0 a22 a23
a31 a32 a33
∣∣∣∣∣∣ =
(descomponiendo las filas en sumas de tres filas):
=
∣∣∣∣∣∣a11 0 00 a22 a23
0 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 00 a22 a23
0 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 0 a13
0 a22 a23
0 a32 a33
∣∣∣∣∣∣++
∣∣∣∣∣∣0 a12 a13
a21 0 00 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
0 a22 00 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
0 0 a23
0 a32 a33
∣∣∣∣∣∣+∣∣∣∣∣∣0 a12 a13
0 a22 a23
a31 0 0
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
0 a22 a23
0 a32 0
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
0 a22 a23
0 0 a33
∣∣∣∣∣∣ =
(por la proposicion 3),
=
∣∣∣∣∣∣a11 0 00 a22 a23
0 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
a21 0 00 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣0 a12 a13
0 a22 a23
a31 0 0
∣∣∣∣∣∣ =
89

= a11
∣∣∣∣∣∣1 0 00 a22 a23
0 a32 a33
∣∣∣∣∣∣+ a21
∣∣∣∣∣∣0 a12 a13
1 0 00 a32 a33
∣∣∣∣∣∣+ a31
∣∣∣∣∣∣0 a12 a13
0 a22 a23
1 0 0
∣∣∣∣∣∣Observando ahora que
=
∣∣∣∣∣∣1 0 00 a22 a23
0 a32 a33
∣∣∣∣∣∣ =
∣∣∣∣ a22 a23
a32 a33
∣∣∣∣ya que estas dos matrices se escalonan o se transforman en la identidad con matrices elementalesanalogas de igual ”numero asociado”; que∣∣∣∣∣∣
0 a12 a13
1 0 00 a32 a33
∣∣∣∣∣∣ = −
∣∣∣∣∣∣1 0 00 a12 a13
0 a32 a33
∣∣∣∣∣∣ = −∣∣∣∣ a12 a13
a32 a33
∣∣∣∣por la misma razon anterior, y que∣∣∣∣∣∣
0 a12 a13
0 a22 a23
1 0 0
∣∣∣∣∣∣ = −
∣∣∣∣∣∣0 a12 a13
1 0 00 a22 a23
∣∣∣∣∣∣ =
∣∣∣∣∣∣1 0 00 a12 a13
0 a22 a23
∣∣∣∣∣∣ =
∣∣∣∣ a12 a13
a22 a23
∣∣∣∣por la misma razon, podemos concluir que∣∣∣∣∣∣
a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣ = a11
∣∣∣∣ a22 a23
a32 a33
∣∣∣∣− a21
∣∣∣∣ a12 a13
a32 a33
∣∣∣∣+ a31
∣∣∣∣ a12 a13
a22 a23
∣∣∣∣Este proceso se puede hacer en cualquier dimension y justifica nuestra definicion por induccion
de los ”numeros asociados” que vamos a llamar determinantes
Definicion de los determinantes.
Dada una matriz cuadrada A, se representa por |Aij| el determinante asociado a la submatriz deA, obtenida suprimiendo la fila i y la columna j de A.
Con un proceso analogo al anterior, se llega a que , si cumple las propiedades a), b) y c) anteriores,desglosando la primera columna en suma de n columnas y luego cada fila en suma de n filas, en virtudde la observacion segunda posterior al teorema 1, el determinante de una matriz n× n ha de ser:
|A| = a11|A11| − a21|A21|+ · · ·+ (−1)i+1ai1|Ai1|+ · · ·+ (−1)n+1an1|An1|
90

que se llama desarollo del determinante por la primera columna.
Tambien, desglosando la primera fila en suma de n filas y luego cada columna en suma de ncolumnas, en virtud de la observacion segunda posterior al teorema 1, ha de ser:
|A| = |tA| = a11|A11| − a12|A12|+ · · ·+ (−1)j+1a1j|A1j|+ · · ·+ (−1)n+1a1n|A1n|
que se llama desarollo del determinante por la primera fila.Lo cual, puede obtenerse tambien del desarrollo del de determinante por la primera fila y el
teorema 1: |A| = |tA|.
Para dar completa validez a la definicion, comprobaremos que con ella se verifican las propiedades1), a) y b) enunciadas anteriormente. Una vez comprobadas dichas propiedades para nuestradefinicion, como la propiedad 1), junto con la propiedad a), implica la propiedad c), se tienenpara dicha definicion, las propiedades a), b) y c), que implican 1), 2) y 3), obteniendo ası que laproposicion 2) es cierta para nuestra definicion: |EiA| = |Ei||A| donde Ei es una matriz elementaly A es una matriz cualquiera; de donde, tambien es cierto para nuestra definicion el teorema 1:|tA| = |A|, ya que se puede repetir el proceso de su demostracion.
Tambien el teorema 1. implica las propiedades a), b) y c) respecto a columnas.
Comprobacion de las propiedades.
Comprobemos ahora que con la definicion dada se cumplen las propiedades requeridas al principio.
Recordemos las propiedades:1) Si intercambiamos dos filas en una matriz su determinante cambia de signo.a) Si multiplicamos una fila de una matriz por una constante, el determinante de la matriz queda
multiplicado por esa constante.b) Si descomponemos una fila de una matriz en suma de otras dos filas el determinante de la
matriz dada es la suma de los determinantes de las dos matrices obtenidas sustituyendo en la matrizdada la fila considerada por cada una de las filas sumandos.
c) El determinante de una matriz con filas proporcionales es cero.En lugar de la propiedad c) podemos considerar la propiedad 1), ya que ambas son equivalentes
cuando a) y b) son ciertas. (Compruebese como ejercicio).
La demostracion de las propiedades basicas puede hacerse por induccion ya que ası se ha hechola definicion.
91

Para un determinante de una matriz de orden 1, solo tienen sentido las propiedades a) y b), queson trivialmente ciertas.
Por eso comprobamos las tres propiedades 1), a), b) para determinantes de matrices de orden 2y luego demostramos que supuestas ciertas estas propiedades para determinantes de orden n− 1, loson para determinantes de orden n.
Comprobamos en primer lugar la propiedad 1, porque permite transmitir lo que probemos parala primera fila a las demas filas.
Probemos 1) en matrices 2× 2:Se reduce a comprobar que ∣∣∣∣ a b
c d
∣∣∣∣ = −∣∣∣∣ c da b
∣∣∣∣De la definicion se tiene:∣∣∣∣ a b
c d
∣∣∣∣ = ad− cb y
∣∣∣∣ c da b
∣∣∣∣ = cb− ad = −(ad− cb)
estando por tanto comprobado.
Para comprobar la propiedad a), es suficiente comprobarla con la primera fila, ya que por lapropiedad 1), se trasmite a la segunda fila.
En efecto, ∣∣∣∣ ra rbc d
∣∣∣∣ = rad− crb = r(ad− cb) = r
∣∣∣∣ a bc d
∣∣∣∣Vemos la propiedad b) en matrices 2× 2, respecto a la primera fila,∣∣∣∣ a+ a′ b+ b′
c d
∣∣∣∣ = (a+ a′)d− c(b+ b′) = ad− cb+ a′d− cb′ =∣∣∣∣ a bc d
∣∣∣∣+
∣∣∣∣ a′ b′
c d
∣∣∣∣La propiedad comprobada se trasmite a la segunda fila, usando la propiedad 1).
Ahora, suponiendo que la propiedad 1) se verifica en determinantes de matrices (n− 1)× (n− 1),vamos a comprobarla en determinates de matrices de orden n.
Primero, lo demostramos cuando el intercambio de filas se hace entre dos filas sucesivas (la i y lai− 1):
Por definicion,
92

∣∣∣∣∣∣∣∣∣∣∣∣∣∣
a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · · · · · · ·ai−1,1 ai−1,2 · · · ai−1,n
ai1 ai2 · · · ain· · · · · · · · · · · ·an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣= a11
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣− a21
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+
(−1)iai−1,1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣(−1)i+1ai1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+· · ·+(−1)n+1an1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣=
Por la hipotesis de induccion, estos sumandos son:
= a11
−∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai2 · · · ainai−1,2 · · · ai−1,n
· · · · · · · · ·an,2 · · · an,n
∣∣∣∣∣∣∣∣∣∣∣∣
− a21
−∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai2 · · · ainai−1,2 · · · ai−1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣
+ · · ·+
(−1)i+1ai−1,1
−∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣
+ (−1)iai1
−∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣
+ · · ·+
+(−1)n+1an1
−∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai2 · · · ainai−1,2 · · · ai−1,n
· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣
= −
a11
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai2 · · · ainai−1,2 · · · ai−1,n
· · · · · · · · ·an,2 · · · an,n
∣∣∣∣∣∣∣∣∣∣∣∣− a21
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai2 · · · ainai−1,2 · · · ai−1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣
+
93

· · · −
(−1)iai1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ (−1)i+1ai−1,1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣
+ · · ·
−(−1)n+1an1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai2 · · · ainai−1,2 · · · ai−1,n
· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣= −
∣∣∣∣∣∣∣∣∣∣∣∣∣∣
a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · · · · · · ·ai1 ai2 · · · ainai−1,1 ai−1,2 · · · ai−1,n
· · · · · · · · · · · ·an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣.
Si las filas intercambiadas no son sucesivas, tenemos que darnos cuenta de que el intercambiopuede hacerse en dos etapas compuestas de intercambios de filas sucesivas: intercambiar la fila ”i”y la fila ”j”, suponiendo que j > i, es bajar la fila ”i” al sitio ”j”, para lo cual tenemos que saltarsucesivamente sobre j−i filas y luego subir la fila ”j” (que ya ha quedado en el sitio ”j−1” al sitio ”i”,para lo cual tenemos que saltar sucesivamente otras j−1− i filas. En total, hemos hecho 2(i− j)−1cambios de filas sucesivas, lo cual se traduce en un cambio total de signo: (−1)2(i−j)−1 = −1.
Pasamos a demostrar la propiedad a) en determinantes de orden n, suponiendo que es cierta paradeterminantes de orden n− 1:
Por definicion,
∣∣∣∣∣∣∣∣∣∣∣∣∣∣
ra11 ra12 · · · ra1n
a21 a22 · · · a2n
· · · · · · · · · · · ·ai−1,1 ai−1,2 · · · ai−1,n
ai1 ai2 · · · ain· · · · · · · · · · · ·an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣= ra11
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣− a21
∣∣∣∣∣∣∣∣∣∣∣∣
ra12 · · · ra1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+
94

(−1)iai−1,1
∣∣∣∣∣∣∣∣∣∣∣∣
ra12 · · · ra1n
· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣(−1)i+1ai1
∣∣∣∣∣∣∣∣∣∣∣∣
ra12 · · · ra1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+· · · (−1)n+1an1
∣∣∣∣∣∣∣∣∣∣∣∣
ra12 · · · ra1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣Por la hipotesis de induccion, estos sumandos son:
ra11
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣− a21r
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+ (−1)iai−1,1r
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+
+(−1)i+1ai1r
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+ (−1)n+1an1r
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣=
r
a11
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣− a21
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+ (−1)iai−1,1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣
+
+r
(−1)i+1ai1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+ (−1)n+1an1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣
=
95

r
∣∣∣∣∣∣∣∣∣∣∣∣∣∣
a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · · · · · · ·ai−1,1 ai−1,2 · · · ai−1,n
ai1 ai2 · · · ain· · · · · · · · · · · ·an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣.
Esta propiedad se trasmite a las demas filas usando la propiedad 1).
Para acabar, demostramos la propiedad b) en determinantes n×n, suponiendola cierta en deter-minantes (n− 1)× (n− 1):∣∣∣∣∣∣∣∣∣∣∣∣∣∣
a11 + a′11 a12 + a′12 · · · a1n + a′1na21 a22 · · · a2n
· · · · · · · · · · · ·ai−1,1 ai−1,2 · · · ai−1,n
ai1 ai2 · · · ain· · · · · · · · · · · ·an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣= (a11 + a′11)
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣
−a21
∣∣∣∣∣∣∣∣∣∣∣∣
a12 + a′12 · · · a1n + a′1n· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+ (−1)iai−1,1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 + a′12 · · · a1n + a′1n· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+
(−1)i+1ai1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 + a′12 · · · a1n + a′1n· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+ (−1)n+1an1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 + a′12 · · · a1n + a′1n· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣
96

Por la hipotesis de induccion, estos sumandos son:
a11
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+a′11
∣∣∣∣∣∣∣∣∣∣∣∣
a22 · · · a2n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣−a21
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣−a21
∣∣∣∣∣∣∣∣∣∣∣∣
a′12 · · · a′1n· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+
+ · · ·+ (−1)iai−1,1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ (−1)iai−1,1
∣∣∣∣∣∣∣∣∣∣∣∣
a′12 · · · a′1n· · · · · · · · ·ai−2,2 · · · ai−2,n
ai2 · · · ain· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+
+ · · ·+ (−1)i+1ai1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ (−1)i+1ai1
∣∣∣∣∣∣∣∣∣∣∣∣
a′12 · · · a′1n· · · · · · · · ·ai−1,2 · · · ai−1,n
ai+1,2 · · · ai+1,n
· · · · · · · · ·an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣+ · · ·+
· · ·+ (−1)n+1an1
∣∣∣∣∣∣∣∣∣∣∣∣
a12 · · · a1n
· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣+ (−1)n+1an1
∣∣∣∣∣∣∣∣∣∣∣∣
a′12 · · · a′1n· · · · · · · · ·ai−1,2 · · · ai−1,n
ai2 · · · ain· · · · · · · · ·an−1,2 · · · an−1,n
∣∣∣∣∣∣∣∣∣∣∣∣=
cogiendo los sumandos uno sı, otro no:
=
∣∣∣∣∣∣∣∣∣∣∣∣∣∣
a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · · · · · · ·ai−1,1 ai−1,2 · · · ai−1,n
ai1 ai2 · · · ain· · · · · · · · · · · ·an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣+
∣∣∣∣∣∣∣∣∣∣∣∣∣∣
a′11 a′12 · · · a′1na21 a22 · · · a2n
· · · · · · · · · · · ·ai−1,1 ai−1,2 · · · ai−1,n
ai1 ai2 · · · ain· · · · · · · · · · · ·an1 an2 · · · ann
∣∣∣∣∣∣∣∣∣∣∣∣∣∣.
Esta propiedad demostrada en la primera fila se trasmite a las demas filas por la propiedad 1).
97

Como se ha dicho antes, ahora podrıamos demostrar el Teorema 1 para la definicion dada porinduccion.
Debido al Teorema 1 las propiedades comprobadas para las filas se traducen en propiedadesanalogas para las columnas.
Veamos ahora como dichas propiedades dan una relacion de los numeros buscados con la resolu-bilidad de sistemas de ecuaciones en la Regla de Cramer:
a11x +a12y = b1a21x +a22y = b2
Dado que la propiedad 1) implica que los determinantes de matrices con filas iguales son nulos,
se tiene: ∣∣∣∣∣∣a11 a12 b1a11 a12 b1a21 a22 b2
∣∣∣∣∣∣ = 0 =
∣∣∣∣∣∣a21 a22 b2a11 a12 b1a21 a22 b2
∣∣∣∣∣∣Por tanto, desarrollando por la primera fila, se tiene:
a11
∣∣∣∣ a12 b1a22 b2
∣∣∣∣− a12
∣∣∣∣ a11 b1a22 b2
∣∣∣∣+ b1
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣ = 0
y
a21
∣∣∣∣ a12 b1a22 b2
∣∣∣∣− a22
∣∣∣∣ a11 b1a22 b2
∣∣∣∣+ b2
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣ = 0
o equivalentemente, cambiando columnas en los primeros determinantes, y cambiando los signos,
a11
∣∣∣∣ b1 a12
b2 a22
∣∣∣∣+ a12
∣∣∣∣ a11 b1a22 b2
∣∣∣∣ = b1
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣y
a21
∣∣∣∣ b1 a12
b2 a22
∣∣∣∣+ a22
∣∣∣∣ a11 b1a22 b2
∣∣∣∣ = b2
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣habiendose encontrado que
cuando
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣ 6= 0 los valores : x =
∣∣∣∣ b1 a12
b2 a22
∣∣∣∣∣∣∣∣ a11 a12
a21 a22
∣∣∣∣ y =
∣∣∣∣ a11 b1a22 b2
∣∣∣∣∣∣∣∣ a11 a12
a21 a22
∣∣∣∣satisfacen el sistema dado.
98

Lo analogo ocurre con los sistemas de n ecuaciones con n incognitas.
Podemos demostrar que la solucion considerada del sistema de ecuaciones lineales es unica cuandoel determinante de la matriz de los coeficientes es distinto de cero. Llamando ∆ a este determinante,como
1
∆
(a22 −a12
−a21 a11
)(a11 a12
a21 a22
)=
(1 00 1
)Si
a11x +a12y = b1a21x +a22y = b2
≡(a11 a12
a21 a22
)(xy
)=
(00
)y
a11x′ +a12y
′ = b1a21x
′ +a22y′ = b2
≡(a11 a12
a21 a22
)(x′
y′
)=
(00
)se tiene: (
a11 a12
a21 a22
)(x− x′y − y′
)=
(00
),
de donde
(x− x′y − y′
)=
1
∆
(a22 −a12
−a21 a11
)(a11 a12
a21 a22
)(x− x′y − y′
)=
1
∆
(a22 −a12
−a21 a11
)(00
)=
(00
)
Ejercicios:
4.2.1. Calcular usando la definicion los determinantes de las matrices numericas de los ejerciios4.1.∗ y comprobar que son los mismos que hallados anteriormente.
4.2.2. Calcular los determinantes de las matrices dadas a continuacion:
a)
∣∣∣∣∣∣1/7 3 2 −6
6 −3 22 6 3
∣∣∣∣∣∣ b)
∣∣∣∣∣∣1/9 −8 −1 −4−4 4 7
1 8 −4
∣∣∣∣∣∣
99

4.2.3.a) Comprobar que la ecuacion de un plano que pasa por tres puntos no alineados: (a1, a2, a3),
(b1, b2, b3), (c1, c2, c3) del espacio es ∣∣∣∣∣∣∣∣1 x1 x2 x3
1 a1 a2 a3
1 b1 b2 b31 c1 c2 c3
∣∣∣∣∣∣∣∣ = 0
y hallar la ecuacion cartesiana del plano que pasa por los puntos (1, 2, 1), (−1, 3, 0), (2, 1, 3).b) Escribir la ecuacion de una recta del plano que pasa por los puntos (a, b), (c, d) del plano y
hallar la ecuacion cartesiana de la recta del plano que pasa por los puntos (−1,−2), (2, 2).
Caracterizacion de las matrices invertibles por su determinante.
Teorema 2. Una matriz es invertible si y solo si su determinante es distinto de cero.Dedujimos en la segunda parte de la demostracion del teorema 1 que el determinante de las
matrices no invertibles es cero; (utilizando el teorema 2 del capıtulo anterior).Para ver que el determinante de las matrices invertibles es distinto de cero, empecemos por
las matrices elementales, que son invertibles, recorriendo sus distintos tipos. Se puede ver que susdeterminantes son distintos de cero. (Se hizo en la sexta pagina de este capıtulo)
Para verlo en el caso general, debido al teorema que establecio que una matriz es invertiblesi y solo si es producto de matrices elementales, y a la proposicion 2 de este capıtulo, hacemosel siguiente razonamiento: Sea A = Em · Em−1 · · ·E1 = Em · Em−1 · · ·E1I, entonces es necesario,segun la proposicion 2, que |A| = |Em||Em−1 · · ·E1||I| = |Em||Em−1| · · · |E1| 6= 0 porque todos losdeterminantes de matrices elementales son distintos de cero.
Podıamos haber dado la definicion de determinante de una matriz invertible utilizando las ma-trices elementales en las que se descompone como producto, pero se hubiera planteado el problemasobre si el numero asociado era independiente del camino por el que la matriz llega a la identidadpor transformaciones elementales. Este problema esta resuelto en la definicion dada, ya que solointervienen los numeros de las entradas de la matriz. Segun la definicion que hemos dado, el de-terminante de la matriz solo depende de los numeros que forman la matriz y no de la sucesion dematrices elementales que la transforman en la identidad; es independiente de esta sucesion.
100

Determinante del producto.
Teorema 3: |AB| = |A||B| : El determinante del producto de dos matrices es el productode los determinantes de las matrices. De donde se deduce que |A−1| = 1/|A|.
Demostracion del Teorema 3:Tambien ahora distinguimos dos casos:a) |A| 6= 0. Entonces, A es invertible y tenıamos en la proposicion 4 del capıtulo anterior:
A = E−11 E−1
2 · · ·E−1k · · ·E
−1m
donde Ei y E−1i son matrices elementales, (Estas E1, · · · , Em son las inversas de las del teorema
2.) de donde|A| = |E−1
1 ||E−12 || · · · |E−1
k | · · · |E−1m |
Por otra parte,AB = E−1
1 E−12 · · ·E−1
k · · ·E−1m B
y|AB| = |E−1
1 ||E−12 · · ·E−1
k · · ·E−1m B| = |E−1
1 ||E−12 | · · · |E−1
k | · · · |E−1m ||B| = |A||B|.
b) |A| = 0. Entonces, A no es invertible; al reducir A a una matriz escalonada E, esta matrizescalonada tiene su ultima fila formada por ceros, entonces,
A = E−11 E−1
2 · · ·E−1m E
yAB = E−1
1 E−12 · · ·E−1
m EB
donde la matriz EB tiene la ultima fila de ceros, por tanto su determinante es nulo y
|AB| = |E−11 ||E−1
2 · · ·E−1m · · ·EB| = |E−1
1 ||E−12 | · · · |E−1
m | · · · |EB| = 0 = |A||B|.
Hagamos aquı la observacion de que la unica forma de definir el determinante de la matrizidentidad coherente con este teorema era darle el valor 1, ya que si hubiera sido cero, no hubieradistinguido matrices invertibles de matrices no invertibles y de no ser cero, |I| = |II| = |I||I| implica|I| = 1.
101

Ejercicios.
4.3.1.a) Demostrar que una matriz triangular superior es invertible si y solo si todos los elementos de
su diagonal son distintos de cero.b) Demostrar el resultado analogo para matrices triangulares inferiores.4.3.2.a) Demostrar que una matriz antisimetrica de orden impar no puede ser invertible.b) Encontrar matrices antisimetricas de orden par que sean invertibles.4.3.3. Calcular los determinantes: ∣∣∣∣∣∣
1 1 1x1 x2 x3
x21 x2
2 x23
∣∣∣∣∣∣∣∣∣∣∣∣∣∣1 1 1 1x1 x2 x3 x4
x21 x2
2 x23 x2
4
x31 x3
2 x33 x3
4
∣∣∣∣∣∣∣∣
102

Como un inciso, vamos a ver ahora como se hace en general el determinante n× n:
∆n =
∣∣∣∣∣∣∣∣∣∣∣∣
1 1 1 · · · 1x1 x2 x3 · · · xnx2
1 x22 x2
3 · · · x2n
x31 x3
2 x33 · · · x3
n
· · · · · · · · · · · · · · ·xn−1
1 xn−12 xn−1
3 · · · xn−1n
∣∣∣∣∣∣∣∣∣∣∣∣que se llama determinante de Vandermonde.
Si dos de los xi son iguales, la matriz tiene dos columnas iguales y por tanto su determinante escero.
Suponemos ahora que todos los xi son distintos entre sı.Se reduce su tamano en uno restando a cada fila la anterior multiplicada por x1 si x1 6= 0. Si
x1 = 0 se reduce el tamano en uno, desarrollando por la primera columna y sacando xj de cadacolumna j. Entonces:
∆n =
∣∣∣∣∣∣∣∣∣∣∣∣∣∣
1 1 1 · · · 1x1 x2 x3 · · · xnx2
1 x22 x2
3 · · · x2n
x31 x3
2 x33 · · · x3
n
· · · · · · · · · · · · · · ·xn−2
1 xn−22 xn−2
3 · · · xn−2n
xn−11 xn−1
2 xn−13 · · · xn−1
n
∣∣∣∣∣∣∣∣∣∣∣∣∣∣=
∣∣∣∣∣∣∣∣∣∣∣∣∣∣
1 1 1 · · · 10 x2 − x1 x3 − x1 · · · xn − x1
0 x2(x2 − x1) x3(x3 − x1) · · · xn(xn − x1)0 x2
2(x2 − x1) x23(x3 − x1) · · · x2
n(xn − x1)· · · · · · · · · · · · · · ·0 xn−1
2 (x2 − x1) xn−13 (x3 − x1) · · · xn−1
n (xn − x1)0 xn−2
2 (x2 − x1) xn−23 (x3 − x1) · · · xn−2
n (xn − x1)
∣∣∣∣∣∣∣∣∣∣∣∣∣∣Aquı, podemos prescindir de la primera columna y sacar en las columnas restantes los factores:x2 − x1, x3 − x1, · · · , xn − x1, quedando nuestro determinante igual a
∆n = (x2 − x1)(x3 − x1) · · · (xn − x1)
∣∣∣∣∣∣∣∣∣∣∣∣
1 1 · · · 1x2 x3 · · · xnx2
2 x23 · · · x2
n
x32 x3
3 · · · x3n
· · · · · · · · · · · ·xn−2
2 xn−23 · · · xn−2
n
∣∣∣∣∣∣∣∣∣∣∣∣que es del mismo tipo, donde repitiendo las operaciones con las filas, tenemos que es igual a
103

(x2 − x1)(x3 − x1) · · · (xn − x1)(x3 − x2) · · · (xn − x2)
∣∣∣∣∣∣∣∣∣∣∣∣
1 · · · 1x3 · · · xnx2
3 · · · x2n
x33 · · · x3
n
· · · · · · · · ·xn−3
3 · · · xn−3n
∣∣∣∣∣∣∣∣∣∣∣∣=
n−1∏j=1
n∏i>j
(xi − xj).
Ejercicios:4.4.1.a) Siendo a0 + a1x + a2x
2 + a3x3 = P (x) un polinomio de grado 3, hallar sus coeficientes para
que P (0) = 2, P (1) = 1, P (2) = −1, P (3) = 0b) Demostrar que siempre se puede encontrar un polinomio de grado 3 que cumpla las condiciones
P (xi) = yii∈1,2,3,4, cuando todos los xi son distintos, cualesquiera que sean los yi.c) Generalizar el resultado b): dado un polinomio de grado n, y n + 1 parejas de puntos
(xi, yi)i∈1,2,··· ,n+1, siempre se pueden encontrar los coeficientes del polinomio de manera queP (xi) = yi si todos los xi son distintos.
Observese que la parte c) nos indica como hallar una funcion cuya grafica pase por n+ 1 puntosdel plano siempre que no haya dos puntos en la misma vertical.
Desarrollo del determinante por una fila cualquiera y por una columna cualquiera:La definicion de determinante se ha hecho por induccion utilizando la primera columna. Como
el determinante de la matriz es igual al de la traspuesta por el teorema 1, obtenemos otra expresiontrasponiendo la matriz A y aplicando la definicion de determinante:
|A| = a11|A11| − a12|A12|+ · · ·+ (−1)j+1a1j|A1j|+ · · ·+ (−1)n+1a1n|A1n|
donde hemos cambiado el subındice i por j ya que j es el subındice utilizado usualmente para columnas.Este es el desarrollo del determinante por la primera fila.
Por otra parte, considerando que la fila i-esima puede ser colocada en la primera fila pasandolapor encima de las i-1 anteriores, lo cual da en el determinante de la matriz i-1 cambios de signo ypor la formula anterior, tenemos:
|A| = (−1)i−1(ai1|Ai1| − ai2|Ai2|+ · · ·+ (−1)j+1aij|Aij|+ · · ·+ (−1)n+1ain|Ain|)
= (−1)i+1ai1|Ai1|+ (−1)i+2ai2|Ai2|+ · · ·+ (−1)i+jaij|Aij|+ · · ·+ (−1)i+nain|Ain|
Este es el desarrollo del determinante por cualquier fila.
104

Si queremos desarrollar ahora el determinante por cualquier columna, utilizando el teorema 1,solo tenemos que trasponer la matriz y desarrollar el determinante de la traspuesta por la fila corres-pondiente obteniendo:
|A| = (−1)j+1a1j|A1j|+ (−1)j+2a2j|A2j|+ · · ·+ (−1)i+jaij|Aij|+ · · ·+ (−1)j+nanj|Anj|
Ejercicios:4.5.1. a) Obtener, en funcion de los determinantes de los menores diagonales de la matriz A,
|A− λI| =
∣∣∣∣∣∣a11 − λ a12 a13
a21 a22 − λ a23
a31 a32 a33 − λ
∣∣∣∣∣∣(Indicacion: descomponer las filas en sumandos sin λ y con λ).
b) Aplicar la formula a la obtencion de los siguientes determinantes:∣∣∣∣∣∣1− λ 2 1
0 3− λ 13 1 2− λ
∣∣∣∣∣∣∣∣∣∣∣∣1/3
2 1 −2−1 −2 −2−2 2 −1
− λI∣∣∣∣∣∣
4.5.2. Encontrar los valores de a para que las siguientes matrices sean invertibles.
a)
a 1 11 a 10 1 a
b)
−1 −1 11 4 −a−1 a 0
c)
−1 a aa −1 aa a −1
4.5.3. Dadas A, B y C, matrices cuadradas de orden n y
D =
(A C0 B
)a) Demostrar que |D| = |A||B| utilizando la descomposicion:(
A C0 B
)=
(In 00 B
)(A C0 In
)b) Demostrar, utilizando una descomposicion similar, la misma igualdad, |D| = |A||B|, en el
caso:
D =
(A 0C B
)
105

Formula para la inversa:Del desarrollo del determinante por una fila cualquiera tenıamos
|A| = (−1)i+1ai1|Ai1|+ (−1)i+2ai2|Ai2|+ · · ·+ (−1)i+jaij|Aij|+ · · ·+ (−1)i+nain|Ain|
que se puede expresar matricialmente ası:
= (ai1, ai2, · · · , aij, · · · , ain)
(−1)i+1|Ai1|(−1)i+2|Ai2|
...(−1)i+j|Aij|
...(−1)i+n|Ain|
= |A|
Ahora vamos a hacer la siguiente observacion:
Si k 6= i, la sumaΣ = (−1)i+1ak1|Ai1|+(−1)i+2ak2|Ai2|+· · ·+(−1)i+jakj|Aij|+· · ·+(−1)i+nakn|Ain| corresponde al
desarrollo del determinante de la matriz obtenida cambianndo la fila i-esima de A por la fila k-esimay dejando esta ultima igual, es por tanto, el desarrollo del determinante de una matriz que tiene lasfilas i-esima y k-esima iguales, que es cero. Lo cual matricialmente se puede escribir ası:
(ak1, ak2, · · · , akj, · · · , akn)
(−1)i+1|Ai1|(−1)i+2|Ai2|
...(−1)i+j|Aij|
...(−1)i+n|Ain|
= 0
Por tanto tenemos en una sola expresion:
a11 · · · a1i · · · a1k · · · a1n... · · · · · · · · · · · · · · · ...ai1 · · · aii · · · aik · · · ain... · · · · · · · · · · · · · · · ...ak1 · · · aki · · · akk · · · akn... · · · · · · · · · · · · · · · ...an1 · · · ani · · · ank · · · ann
(−1)i+1|Ai1|...
(−1)i+j|Aii|...
(−1)i+j|Aik|...
(−1)i+n|Ain|
=
00|A|0......0
Ahora, haciendo variar en la columna anterior el subındice i, tenemos:
106

a11 .. a1i .. a1k .. a1n... .. .. .. .. ..
...ai1 .. aii .. aik .. ain... .. .. .. .. ..
...ak1 .. aki .. akk .. akn... .. .. .. .. ..
...an1 .. ani .. anj .. ann
|A11|... (−1)i+1|Ai1|
... (−1)k+1|Ak1|... |An1|
......
......
......
...
(−1)i+1|A1i|... |Aii|
... (−1)k+1|Aki|... (−1)n+i|Ani|
......
......
......
...
(−1)k+1|A1k|... (−1)i+k|Aik|
... |Akk|... (−1)n+k|Ank|
......
......
......
(−1)n+1|A1n|... |Ain|
... (−1)k+1|Akn|... |Ann|
=
|A| 0 · · · · · · 0 · · · 0
0. . . · · · · · · · · · · · · 0
0 · · · |A| 0 0 · · · 0... · · · · · · . . . · · · · · · ...0 · · · 0 · · · |A| · · · 0
0... · · · · · · · · · . . . 0
0 · · · 0 · · · 0 · · · |A|
= |A|I.
Ademas, del desarrollo del determinante por una columna, tenıamos:
|A| = (−1)j+1a1j|A1j|+ (−1)j+2a2j|A2j|+ · · ·+ (−1)i+jaij|Aij|+ · · ·+ (−1)j+nanj|Anj|
que matricialmente se escribe ası:
((−1)j+1|A1j|, (−1)j+2|A2j| · · · (−1)i+jaij|Aij| · · · (−1)n+j|Anj|)
a1j
a2j...aij...anj
= |A|
Tambien ocurre que si k 6= j,0 = (−1)j+1a1k|A1j| + (−1)j+2a2k|A2j| + · · · + (−1)i+jaik|Aij| + · · · + (−1)j+nank|Anj| ya que es
el determinante de la matiz obtenida de A sustituyendo la columna j-esima por la coluna k-esima,
107

(tiene dos columnas iguales), que matricialmente se escribe ası:
((−1)j+1|A1j|, (−1)j+2|A2j| · · · (−1)i+j|Aij| · · · (−1)n+j|Anj|)
a1k
a2k...aik...ank
= 0
y globalmente para todas las columnas se expresa:
|A11|... (−1)j+1|Aj1|
... (−1)k+1|Ak1|... |An1|
......
......
......
...
(−1)j+1|A1j|... |Ajj|
... (−1)k+j|Akj|... (−1)n+j|Anj|
......
......
......
...
(−1)k+1|A1k|... (−1)j+k|Ajk|
... |Akk|... (−1)n+k|Ank|
......
......
......
(−1)n+1|A1n|... |Ajn|
... (−1)k+1|Akn|... |Ann|
a11 .. a1j .. a1k .. a1n... .. .. .. .. ..
...aj1 .. ajj .. ajk .. ajn... .. .. .. .. ..
...ak1 .. akj .. akk .. akn... .. .. .. .. ..
...an1 .. anj .. ank .. ann
=
|A| 0 · · · · · · 0 · · · 0
0. . . · · · · · · · · · · · · 0
0 · · · |A| 0 0 · · · 0... · · · · · · . . . · · · · · · ...0 · · · 0 · · · |A| · · · 0
0... · · · · · · · · · . . . 0
0 · · · 0 · · · 0 · · · |A|
= |A|I.
Entonces, de estas igualdades, tenemos que llamando matriz cofactor de A a cof(A) = (cof(aij)) =((−1)i+j|Aij|) se verifica:
A · tcof(A) = |A|I, tcof(A) · A = |A|Ilo que nos indica la formula de la inversa de una matriz con determinante distinto de cero:
A−1 =1
|A|(tcof(A))
108

que sera inversa a la derecha y a la izquierda, y por tanto unica.
Ejercicios:
4.6.1. Utilizando las matrices de cofactores, hallar las inversas de las matrices de los ejercicios3.4.1. que sean invertibles. Comprobar los resultados obtenidos utilizando el metodo de Gauss paracalcular la inversa.
4.6.2. Mostrar, usando la formula de la inversa, que cuando una matriz es invertible, la traspuestade la inversa coincide con la inversa de la traspuesta.
4.6.3. Mostrar, usando la formula de la inversa, que la matriz inversa de una matriz triangularsuperior invertible es tambien triangular superior. Y que lo analogo ocurre para matrices triangularesinferiores.
109

Regla de Cramer.Sea AX = b un sistema de ecuaciones, escrito de manera resumida, donde A es la matriz de
los coeficientes de las incognitas, X es la columna de las incognitas, y b es la columna de terminosindependientes; si A es una matriz invertible, multiplicando por la inversa de A a la izquierda,tenemos X = A−1b, donde utilizando la formula anterior para la inversa, tenemos:
X =1
|A|(tcof(A))b
que desarrollada incognita a incognita da la regla de Cramer. Para cada incognita xi, que es una filade la matriz X, tenemos:
xi =1
|A|((−1)i+1A1ib1 + (−1)i+2A2ib2 + · · ·+ (−1)i+nAnibn)
donde la expresion del parentesis es el desarrollo por la columna i-esima del determinante de la matrizobtenida de A (la matriz de los coeficientes) cambiando su columna i-esima por la columna de losterminos independientes.
Ejercicios:
4.7.1. Utilizar la regla de Cramer para resolver los siguientes sistemas de ecuaciones:
a)x +2y −z = 7
2x +y +z = 6x −y +3z = −1
b)2x +3y −5z − 2 = 03x −y +2z + 1 = 05x +4y −6z − 3 = 0
c)
2x +y +4z +8t = −1x +3y −6z +2t = 3
3x −2y +2z −2t = 82x −y +2z = 4
Se pueden comprobar los resultados obtenidos sustituyendo o aplicando el metodo de Gauss.Sol: a) (5/3,8/3,0) b) (−1/5, 14/5, 6/5), c)(2,−3,−3/2, 1/2).
110

Volviendo a los sistemas de ecuaciones, para los que hemos encontrado la regla de Cramer cuandoA es invertible, podemos demostrar que X = A−1b, es solucion unica, ya que si hubiera dos solucionesX y X’ para las incognitas, de las igualdades AX = b = AX ′ se tiene A(X − X ′) = 0 de dondemultiplicando por la izquierda por A−1 tenemos X −X ′ = A−10 = 0, es decir, X = X ′.
La unicidad de la solucion de los sistemas AX=b se puede reducir a la unicidad de solucion del sistema AX=0, yaque este es un caso particular de los anteriores y si hay dos soluciones distintas de AX=b para algun b, la diferencia(distinta de cero), es solucion no nula de AX=0.
(Un sistema de la forma AX=0 se llama sistema homogeneo y dado un sistema de la forma AX=b, al sistemaAX=0 se le llama sistema homogeneo asociado al sistema dado.)
Se nos plantea la pregunta sobre que podemos decir de los sistemas AX = b cuando A es unamatriz no invertible e incluso cuando A no es una matriz cuadrada.
Teorema de Rouche-Frobenius.
Cuando A no es invertible (p. ej. si no es cuadrada) en el capıtulo primero hemos enunciado elTeorema de Rouche-Frobenius relativo a los escalones de las matrices escalonadas a las que quedanreducidas A y A|b.
Ahora vamos a expresar numericamente el teorema de Rouche-Frobenius con la definicion derango de una matriz, por medio de determinantes de submatrices suyas.
Para expresar numericamente este teorema definiremos el rango de una matriz no necesaria-mente cuadrada como el maximo de los ordenes de las submatrices cuadradas de A con determinantedistinto de cero.
Recordemos que, denotando por E(A|b) la matriz escalonada que se puede obtener de la matrizampliada del sistema y por E(A) la matriz escalonada a la que queda reducida A, el teorema deRouche-Frobenius enunciado relativo a los escalones de las matrices escalonadas a que se puedenreducir la matriz de los coeficientes del sistema y la matriz ampliada era:
El sistema es incompatible si el numero de escalones de E(A|b) (o numero de filas no nulas deE(A|b)) es distinto del numero de escalones de E(A) (o numero de filas no nulas de E(A)).
El sistema es compatible si los dos numeros anteriores son iguales, siendo compatible determinadosi todos los escalones de E(A) son de longitud una columna y siendo compatible indeterminado si hayalgun escalon en E(A) de mas de una columna. En el primer caso el numero de escalones de las dosmatrices escalonadas o numero de filas no nulas coincide con el numero de columnas, es decir, con elnumero de incognitas; En el segundo caso el numero de filas no nulas de las dos matrices escalonadasanteriores es menor que el numero de columnas o incognitas.
111

Veamos cual es el rango de una matriz escalonada. En una matriz escalonada, cada fila distintade cero determina un escalon. Al numero distinto de cero del angulo del escalon se le llama pivote.Cada fila distinta de cero determina un pivote y recıprocamente cada pivote pertenece a una filadistinta de cero. Tambien cada pivote determina una columna con ese pivote; entonces, si en lasubmatriz formada por las columnas que tienen pivote, suprimimos las filas nulas, obtenemos unasubmatriz cuadrada, ya que tiene tantas filas y tantas columnas como pivotes. Ademas es una matriztriangular superior (de orden igual al numero de filas no nulas de la matriz escalonada o numerode escalones), cuyos elementos en la diagonal son los pivotes, todos distintos de cero; por tanto sudeterminante es no nulo. De ello se deduce que el rango de una matriz escalonada es mayor o igualque su numero de filas no nulas, pero una submatriz de mayor orden tendrıa que incluir filas nulas,y su determinante serıa nulo, por lo que el rango de una matriz escalonada coincide con el numerode sus filas no nulas o numero de escalones.
Ası, podemos dar un primer paso y enunciar el teorema de Rouche-Frobenius diciendo que elsistema es incompatible cuando los rangos de las matrices escalonadas a las que se reducenla matriz de los coeficientes del sistema y la matriz ampliada son distintos. Y que escompatible determinado cuando ademas de ser los dos rangos iguales, lo son al numerode incognitas, siendo en otro caso indeterminado.
Si ahora comprobamos que el rango de una matriz es invariante por operaciones elementales,podemos suprimir en el enunciado anterior la frase: ”las matrices escalonadas a las que se reducen”;quedando el teorema de Rouche-Frobenius antes escrito en letra negrita en su enunciado clasico.
Invariancia del rango por transformaciones elementales.
En efecto, vamos a ver que se conserva el orden de las submatrices con determinante distinto decero, y por tanto su maximo, al realizar cada uno de los tipos de operaciones elementales. Para ellovemos que si hay un menor de un determinado orden distinto de cero en la matriz que resulta deuna dada por una transformacion elemental hay otro menor del mismo orden, distinto de cero (quepuede coincidir con el primero) en la matriz dada.
1.) Hagamos en una matriz un intercambio de filas.Si en la matriz resultante hay un menor distinto de cero, es decir, una submatriz de determinante
no nulo, puede ocurrir que no interseque las filas intercambiadas, en cuyo caso aparece tal cual en laprimera matriz y su determinante es el mismo.
O que contenga a las dos filas intercambiadas, en cuyo caso haciendo el cambio de filas inversoen la submatriz obtenemos otra submatriz de la matriz dada con determinante cambiado de signo
112

respecto a la primera submatriz considerada, pero tambien distinto de cero.O que contenga solo una fila de las intercambiadas y en este caso permutando esta fila con las
otras para intercalarla en el lugar en que aparecıa en la matriz dada obtenemos una submatriz dela primera matriz en la que aparece el trozo correspondiente de la fila de la que provenıa siendosu determinante igual o cambiado de signo respecto al menor considerado, pero siempre distinto decero. Luego el orden de los menores distintos de cero se conserva en el primer tipo de operacioneselementales.
2.) Multipliquemos una fila por un numero distinto de cero.Dado un menor distinto de cero en la matriz modificada, es decir, una submatriz con determinante
distinto de cero, si esta submatriz no interseca la fila multiplicada, aparece tal cual en la matriz daday si aparece la fila multiplicada su determinante es un multiplo distinto de cero del determinantede la submatriz de las mismas filas y las mismas columnas en la matriz dada, que por tanto ha deser tambien distinto de cero. Entonces, el orden de los menores distintos de cero se conserva por elsegundo tipo de operaciones elementales.
3.) Sumemos a una fila otra fila multiplicada por un numero.Un menor distinto de cero de la matriz resultante puede ser el determinante de una submatriz
que no contenga la fila modificada y entonces aparece tal cual en la primera matriz, siendo ya antesdistinto de cero.
Si la submatriz contiene la fila modificada y la fila sumada, su determinante es igual al de lasubmatriz de las mismas columnas y analogas filas en la matriz dada, que por tanto era distinto decero.
Si la submatriz contiene la fila modificada pero no la sumada, descomponemos su determinante enla suma de los dos determinantes de las dos submatrices formadas, primero, por las mismas columnasy las filas analogas de la primera matriz y segundo por la submatriz obtenida de esta sustituyendola fila modificada por la sumada multiplicada por el numero.
Si la submatriz primer sumando tiene determinante no nulo, se ha conservado el orden de losmenores no nulos; si este ultimo determinante es nulo, el otro determinante sumando ha de ser nonulo, pero el otro es multiplo de un menor del mismo orden en la matriz dada (aunque con filaspermutadas), que ha de ser de valor no nulo, por lo que tambien queda igual el orden de los menoresdistintos de cero.
De aquı se deduce que el rango de la matriz modificada por operaciones elementales es menor oigual que el rango de la matriz dada. Como la matriz dada tambien se obtiene de la matriz modificadapor las operaciones elementales inversas, tenemos que los dos rangos son iguales.
Con esto queda establecido el teorema de Rouche-Frobenius en la version de rangos.
113

Apliquemos ahora el teorema de Rouche-Frobenius al sistema AX=b cuando A es una matriz cuadrada invertiblede orden n. Como |A| 6= 0 tenemos el rango de A igual a n y como A es una submatriz de A|b, el rango de A|b esmayor o igual que el de A, pero tambien es siempre menor o igual al numero de sus filas, que es n, por tanto coincidenel rango de A y el de A|b. Entonces, el sistema es compatible. Tambien tenemos que estos rangos son iguales a n, quees el numero de incognitas, por tanto la solucion es unica, cualquiera que sea b (los terminos independientes).
Si la solucion del sistema es unica para todo b, tambien lo es cuando b = 0. Entonces A es invertible porque si Ano fuera invertible, serıa |A| = 0 por lo que al ser A cuadrada, tendrıamos que el mayor orden de los menores distintosde cero es menor que n por lo que el rango de A serıa menor que n, pero al ser igual al rango de A|0, porque unacolumna de ceros no aumenta el orden de los menores distintos de cero, segun el Teorema de Rouche-Frobenius, elsistema serıa compatible indeterminado, por tanto, la solucion no serıa unicamente la trivial segun habıamos supuesto.
Con los mismos razonamientos tambien se puede demostrar elTeorema 4: Dada una matriz cuadrada A, A es invertible si y solo si el sistema AX=0
tiene unicamente la solucion trivial.Este teorema se sigue de la equivalencia entre la unicidad de la solucion del sistema AX=0 y la
del sistema AX=b, cualquiera que sea b.
Ejercicios:
4.8.1. Estudiar la compatibilidad y determinacion de los sistemas siguientes aplicando el teoremade Rouche-Frobenius segun el calculo del rango de las matrices correspondientes a los sistemassiguientes:
x1 +2x2 −x3 = 1x2 +x3 = 2
x1 +3x2 = 3
2x1 +x2 = 5x1 −x2 = 1x1 +2x2 = 0
x1 −3x2 +x3 = 2
3x1 −8x2 +2x3 = 22x1 −5x2 +x3 = 3
4.8.2. Hallar los valores de a para que los sistemas
ax +y +z = 1x +ay +z = 1x +y +az = 1
(a+ 1)x +y +2z = −2
2x +y +(a+ 1)z = 3x +(a+ 1)y +2z = −2
−x +ay +az = 0ax −y +az = 0ax +ay −z = 0
sean compatibles indeterminados.4.8.3. Estudiar los valores de a y b que hacen compatibles los sistemas:
114

bx −ay −az = a−bx −az = a−bx −by = a−bx −by −bz = b
bx −ay −az −at = a−bx −az −at = a−bx −by −at = a−bx −by −bz = a−bx −by −bz −bt = b
115

Producto Vectorial.
El producto vectorial de dos vectores a = (a1, a2, a3), b = (b1, b2, b3) se escribe simbolicamenteası:
a× b =
∣∣∣∣∣∣i j ka1 a2 a3
b1 b2 b3
∣∣∣∣∣∣lo cual representa el vector de coordenadas:(∣∣∣∣ a2 a3
b2 b3
∣∣∣∣ ,− ∣∣∣∣ a1 a3
b1 b3
∣∣∣∣ , ∣∣∣∣ a1 a2
b1 b2
∣∣∣∣) = i
∣∣∣∣ a2 a3
b2 b3
∣∣∣∣− j ∣∣∣∣ a1 a3
b1 b3
∣∣∣∣+ k
∣∣∣∣ a1 a2
b1 b2
∣∣∣∣donde i, j y k son los vectores unitarios en la direccion de los ejes coordenados.
Este vector tiene las siguientes caracterısticas:1) Es perpendicular a cada uno de los vectores (a1, a2, a3) y (b1, b2, b3) de los que es producto.2) Su modulo es igual al area del paralelogramo que tiene por lados los vectores factores.3) Su sentido es el de avance de un sacacorchos que gira desde la recta engendrada por el vector
primer factor hacia la recta engendrada por el vector segundo factor.
Demostracion de la propiedad 1): Veamos que ‖a‖‖b‖cosα = a1b1 + a2b2 + a3b3, donde α es elangulo que forman los dos vectores a y b.
En efecto, segun el dibujo,
1
BBBBBBBBBBB
$α a
b-ab
‖b‖senα
116

‖b− a‖2 = (‖b‖senα)2 + (‖b‖cosα− ‖a‖)2 = ‖b‖2sen2α + ‖b‖2cos2α + ‖a‖2 − 2‖a‖‖b‖cosα =
‖b‖2 + ‖a‖2 − 2‖a‖‖b‖cosα.
Desarrollando ahora los terminos iniciales y finales de la desigualdad anterior,
(b1 − a1)2 + (b2 − a2)
2 + (a3 − b3)2 = b21 + b22 + b23 + a21 + a2
2 + a23 − 2‖a‖‖b‖cosα
donde desarrollando de nuevo, los cuadrados del primer miembro y simplificando, llegamos a laigualdad deseada en 1. (Compruebese como ejercicio.)
De aquı se deduce que dos vectores son perpendiculares si y solo si la suma de los productos delas coordenadas del mismo ındice es cero. Esta suma de productos de coordenadas para los vectoresa y a × b es el determinante de una matriz que tiene dos filas formadas por las coordenadas de a yotra fila formada por las coordenadas de b, siendo por tanto cero. Lo analogo ocurre para los vectoresb y a× b. Por lo que los vectores a y b son perpendiculares al vector a× b.
Las aplicaciones del producto vectorial en matematicas son numerosas: (ademas de ser usado enfısica.):
a) Dada una recta como interseccion de dos planos:
Ax+By + Cz = DA′x+B′y + C ′z = D′
ya que sabemos que dos vectores perpendiculares a dichos planos son correspondientemente: (A,B,C)y (A′, B′, C ′), y que por tanto, son perpendiculares a la recta, el producto vectorial de estos vectoreses un vector en la direccion de la recta.
b) Dada una curva como interseccion de superficies, el vector tangente a la curva en un punto esla interseccion de los planos tangentes a las superficies en ese punto y puede hallarse utilizando elresultado anterior.
Ejercicios:
4.9.1. Hallar el vector de direccion de la recta de R3 dada por las ecuaciones:
2x+ y + 2z = 0x+ 2y + z = 0
4.9.2. Hallar la recta perpendicular comun a las dos rectas determinadas por las dos parejas de
puntos: (3, 1, 0), (1, 1, 3) y (0, 1, 0), (−1, 0, 0).
117

Demostracion de la propiedad 2): Para probar que el modulo del producto vectorial a× b es igualal area del paralelogramo de lados a y b tenemos en cuenta que
(Ar(a, b))2 = ‖a‖2‖b‖2sen2α = ‖a‖2‖b‖2(1− cos2α) = ‖a‖2‖b‖2 − ‖a‖2‖b‖2cos2α =
(a21 + a2
2 + a23)(b
21 + b22 + b23)− (‖a‖‖b‖cosα)2 =
(a21 + a2
2 + a23)(b
21 + b22 + b23)− (a1b1 + a2b2 + a3b3)
2 =∣∣∣∣ a2 a3
b2 b3
∣∣∣∣2 +
∣∣∣∣ a1 a3
b1 b3
∣∣∣∣2 +
∣∣∣∣ a1 a2
b1 b2
∣∣∣∣2formula muy util en R3, donde es laborioso el calculo directo de la altura de un paralelogramo o deun triangulo.
Consecuencia de ello es que si el producto vectorial de dos vectores es cero, uno de los dos esmultiplo del otro. (O sea que estan en la misma recta). Al ser nula el area del paralelogramosubtendido por ellos.
Ejercicios:
4.10.1. Comprobar que el area del cuadrado que tiene tres vertices en los puntos (1, 1), (2, 1), (1, 2)del plano, hallada haciendo el producto de base por altura es la misma que el area hallada usando elproducto vectorial.
4.10.2. Hallar el area de un paralelogramo que tiene tres vertices en los puntos:a) (1, 1), (2, 3), (3, 4).b) (0, 1, 0), (1, 2, 1), (1, 1, 1).4.10.3. Hallar el area del cuadrilatero de vertices: (−2, 0), (−1,−2), (2, 1), (0, 3).
118

La propiedad 3) se demuestra al final del capıtulo de movimientos utilizando mas conocimientosdel curso.
Otras propiedades interesantes son:Propiedad 4). Tambien se puede expresar el volumen de un paralelepıpedo cuyos lados son tres
vectores como un determinante cuyas filas son las coordenadas de los vectores y que se llama productomixto de los tres vectores.
Su demostracion se hace utilizando el producto vectorial. Veamoslo: Si a, b y c son tres vectores nocoplanarios, considerando que a y b determinan la base del paralelepıpedo, el volumen es el productodel area de la base por la altura.
PPPPPPPPq
a
b
1
c
6
p(c)
a× b
PPPPPPPP
PPPPPPPP
PPPPPPPP
El area de la base es el modulo del producto vectorial ‖a × b‖. La altura es el modulo de laproyeccion p(c) del vector c sobre la perpendicular al plano engendrado por a y b (a× b):
p(c) = ‖c‖cosang(c, a× b) = ‖c‖ c · (a× b)‖c‖‖a× b‖
=c · (a× b)‖a× b‖
resultando
V ol(paralpedo)(a, b, c) = ‖a×b‖(c·(a×b)/‖a×b‖) = c·(a×b) = c1
∣∣∣∣ a2 a3
b2 b3
∣∣∣∣−c2 ∣∣∣∣ a1 a3
b1 b3
∣∣∣∣+c3 ∣∣∣∣ a1 a2
b1 b2
∣∣∣∣ =
=
∣∣∣∣∣∣c1 c2 c3a1 a2 a3
b1 b2 b3
∣∣∣∣∣∣ =
∣∣∣∣∣∣a1 a2 a3
b1 b2 b3c1 c2 c3
∣∣∣∣∣∣
119

Del volumen del paralelepıpedo se deduce el volumen de un prisma triangular como la mitad delvolumen del paralelepıpedo y el volumen de una piramide como el tercio del volumen del prisma.Veanse los dibujos siguientes:
PPPPPPPP
PP
PP
PPPPPPPP
PPPPPPPP
PPPPPPPP
"""""""""""""
PP
PP
PPPPPPPP
"""""""""""""
PP
PP
"""""""""""""
PP
PPP
120

Ejercicios:
4.11.1. Hallar el volumen de un paralelepıpedo quea) Tiene como aristas los vectores: (1, 2,−1), (0, 1, 2), (1, 2,−3).b) Tiene un vertice en uno de los puntos: (1, 0, 1), (1, 1, 2), (1, 1, 1), (2, 0, 2) y los otros tres
puntos adyacentes al vertice escogido.4.11.2. Hallar el volumen de un prisma triangular con una base determinada por los puntos:
(1, 0, 1), (0, 1, 1)(1, 1, 0) y con un vertice de la base opuesta en (1, 1, 1)).4.11.3. Los cuatro puntos (0, 0, 0), (1, 0, 0), (0, 1, 0)(0, 0, 1) determinan un tetraedro. Hallar:a) Su volumen.b) El area A de la cara que no esta contenida en ningun plano coordenado.c) Su altura h referida a esta cara.d) Comprobar que el volumen obtenido utilizando determinantes es igual al volumen obtenido
por la formula: V = 1/3(A× h).4.9.4. Los cuatro puntos (3, 1, 0), (2, 0, 0), (0, 1, 0)(1, 1, 3) determinan un tetraedro.Hallar la altura del vertice (3,1,0) respecto al area de la cara de vertices (2, 0, 0), (0, 1, 0)(1, 1, 3)
utilizando el producto vectorial y los determinantes.
121

Propiedad 5). El producto vectorial se usa para calcular el vector normal (perpendicular) a unasuperficie en un punto y por ello, para calcular las integrales en superficies, entre ellas, las areas delas superficies curvadas.
Para ello es necesario saber cual es la relacion entre las areas de distintos paralelogramos de ladosconocidos, contenidos en el mismo plano, cuando sabemos la relacion entre los lados. Esta relacionse usa al hacer cambios de coordenadas en las integrales.
Es suficiente ver dicha relacion para vectores del plano coordenado z = 0, lo cual no restringe lageneralidad: dadas dos parejas de vectores a, b y u, v del plano donde u = c1a+c2b, v = d1a+d2bse cumple:
Ar(u, v) =
∣∣∣∣∣∣∣∣ c1 d1
c2 d2
∣∣∣∣∣∣∣∣Ar(a, b)Demostracion: observemos que si a = (a1, a2, 0) y b = (b1, b2, 0), la formula del area como el
modulo del producto vectorial da
Ar(a, b) =
∣∣∣∣∣∣∣∣ a1 a2
b1 b2
∣∣∣∣∣∣∣∣ y Ar(u, v) =
∣∣∣∣∣∣∣∣ u1 u2
v1 v2
∣∣∣∣∣∣∣∣Ya que es u = (u1, u2) = (c1a1 + c2b1, c1a2 + c2b2) y v = (v1, v2) = (d1a1 + d2b1, d1a2 + d2b2),
Ar(u, v) =
∣∣∣∣∣∣∣∣ c1a1 + c2b1 c1a2 + c2b2d1a1 + d2b1 d1a2 + d2b2
∣∣∣∣∣∣∣∣ =∣∣∣∣∣∣∣∣( c1 c2d1 d2
)(a1 a2
b1 b2
)∣∣∣∣∣∣∣∣ =
∣∣∣∣∣∣∣∣ c1 c2d1 d2
∣∣∣∣∣∣∣∣ ∣∣∣∣∣∣∣∣ a1 a2
b1 b2
∣∣∣∣∣∣∣∣ =
∣∣∣∣∣∣∣∣ c1 d1
c2 d2
∣∣∣∣∣∣∣∣Ar(a, b)Esta relacion se usa al hacer cambios de coordenadas en las integrales. Cuando se vea el cambio
de base entre espacios vectoriales se podra observar que el determinante que relaciona las dos areases el determinante de cambio de base entre la base a, b y la base c, d.
122

BIBLIOGRAFIA
(A) Algebra Lineal y aplicaciones. J. Arvesu Carballo, R. Alvarez Nodarse, F. Marcellan Espanol.Ed. Sıntesis Madrid. 1999.
(FB) Algebra lineal. J. B. Fraleigh y R. A. Beauregard. Ed. Addison- Wesley /Iberoamericana,1989.
[G] Matematicas 2 Bachillerato. Carlos Gonzalez Garcıa. Jesus Llorente Medrano. Maria JoseRuiz Jimnez. Ed. Editex. 2009.
(H) Algebra y Geometrıa. Eugenio Hernandez. Ed. Addison- Wesley / UAM, 1994.[L] Linear Algebra for Mathematics, Science, and Engineering. E. M. Landesman, M. R. Hestenes.
Prentice-Hall International, Inc. 1992.[S] Introduction to Linear Algebra. G. Strang. Wellesley-Cambridge Press 1993.
123

124

ESPACIOS VECTORIALES.
Introduccion.
Consideremos el plano. Fijado un origen O y dado un punto P, uniendo el origen con ese puntopor el camino mas corto obtenemos un segmento orientado que se llama vector.
Los vectores que empiezan en el mismo origen se pueden sumar dando otro vector con el mismoorigen y se pueden multiplicar por un numero real dando otro vector con el mismo origen: dosvectores dados se suman por la regla del paralelogramo: trazando por el extremo del primer vectorotro vector paralelo al vector que queremos sumar y considerando el extremo de este ultimo comoel extremo de la suma. Respecto a la suma son un grupo conmutativo y la otra operacion, que sellama operacion externa, es distributiva respecto a la suma de vectores y a la suma de numeros, esasociativa respecto al producto de numeros y el producto de 1 por cualquier vector v deja invariantea este v. Toda esta estructura recibe el nombre de espacio vectorial real.
Por otra parte, en el plano podemos trazar dos rectas perpendiculares pasando por el origen,(normalmente, una horizontal y otra vertical), llamarlas ejes y llamar origen al punto en que seencuentran. Tambien podemos fijar un segmento como unidad de medida. A este conjunto deelementos lo llamamos sistema de referencia.
Trazando dos rectas paralelas a los ejes por el extremo de un vector que empiece en el origenobtenemos sobre los ejes, segmentos que medidos con la unidad fijada dan dos numeros llamadoscoordenadas del vector o del punto extremo del vector. Ası hemos establecido otra correspondenciabiyectiva entre los puntos del plano y las parejas de numeros reales, es decir, entre los puntos delplano y R×R = R2.
(3,2)
3
Es de observar que las coordenadas del vector suma de dos vectores dados, son la suma de lascoordenadas de los vectores sumandos.
125

(x1, x2)
(y1, y2)
(x1 + y1, x2 + y2)
*
Tambien al multiplicar un vector del plano por un numero real obtenemos un vector de su mismadireccion y de longitud la que tenıa el vector multiplicada por el numero, (si el numero es negativocambia de sentido), quedando las coordenadas del vector multiplicadas por el numero.
Como las operaciones de los vectores se trasmiten a las operaciones de R×R al coger coordenadasde los vectores, la estructura de R × R debida a la suma y a la operacion de multiplicacion por unnumero real, se llama espacio vectorial real.
Podemos hacer lo analogo en el espacio trazando tres rectas perpendiculares dos a dos que secortan en un punto del espacio llamado origen: asociar a cada punto un vector que empiece en elorigen y fijada una unidad de medida, asociar a cada punto tres coordenadas.
En el espacio podemos sumar por la regla del paralelogramo y multiplicar un vector por unnumero, lo cual esta en correspondencia con las dos operaciones en las ternas de numeros reales(R3 = R × R × R): suma y multiplicacion por un numero real. La suma es una operacion interna.La multiplicacion por un numero real es una operacion externa. Estas dos operaciones tienen lasmismas propiedades que las operaciones analogas de R2, por eso R3 tambien tiene estructura deespacio vectorial real.
La estructura de estos conjuntos con estas operaciones puede encontrarse tambien en otros con-juntos utilizados en Geometrıa y en Analisis y por ello se estudia de manera abstracta para poderaplicar sus resultados a todos los conjuntos con la misma estructura.
Ademas, la introduccion del concepto de dimension en los espacios vectoriales permite compararlos conjuntos de soluciones de distintos sistemas de ecuaciones y determinar cuando son coincidentes.
126

Tambien se puede simplificar el calculo del rango de una matriz sin tener que calcular todos susmenores utilizando el concepto de dimension.
Pasamos ahora a una descripcion precisa.
Cuerpo. Propiedades.
En un espacio vectorial generico, la operacion externa esta definida por los elementos de uncuerpo. Por eso, antes de definir un espacio vectorial necesitamos la definicion de cuerpo:
Definicion 1: Cuerpo es un conjunto con dos operaciones internas que llamamos suma y productocon las siguientes propiedades:
1) La suma es:a) Asociativa.b) Tiene elemento neutro (cero).c) Todo elemento tiene elemento opuesto.d) Conmutativa.2) El producto es:α) Asociativo.β) Tiene elemento neutro (unidad).γ) Todo elemento distinto del elemento neutro de la suma tiene elemento inverso (opuesto respecto
a la multiplicacion).δ) El producto es distributivo respecto a la suma (a los dos lados).
Si el producto es conmutativo, el cuerpo se llama cuerpo conmutativo. Los cuerpos utilizadospara los espacios vectoriales son cuerpos conmutativos. Por eso en nuestros cuerpos tambien se dala propiedad:
γ) Conmutativo.
La existencia de la suma con las propiedades a), b), c) configura al conjunto K en grupo aditivo.La propiedad d) lo hace ademas grupo aditivo conmutativo.
La otra operacion llamada multiplicacion o producto estructura a K − 0, en un grupo multi-plicativo.
El conjunto de los numeros reales es un cuerpo, que denotamos por R. Tambien el conjunto delos numeros complejos, que denotamos por C es un cuerpo y el conjunto de los numeros racionales,que denotamos por Q.
127

Estamos tan acostumbrados a que el producto del cero por cualquier otro elemento sea cero quepodemos pensar que este resultado es evidente, pero no lo es a partir de los axiomas establecidos enla definicion de cuerpo.
Denotando por e al elemento neutro de la suma para que deje de parecer tan trivial, vamos aestablecer:
e · x = e ∀x ∈ K
En efecto:
e · x = (e+ e) · x = e · x+ e · x
Sumando ahora a los dos miembros de esta igualdad el elemento x′ opuesto de ex, tenemos:e = x′ + e · x = x′ + e · x+ e · x = e+ e · x = e · x es decir, e = e · x.
Otras propiedades interesantes son:
El elemento neutro de un grupo es unico: Suponiendo la existencia de dos elementos neutrose y e′, llegamos a su igualdad: tendrıamos e = e+ e′ = e′.
De aquı tenemos la unicidad no solo del elemento neutro de la suma sino tambien la unicidaddel elemento neutro de la multiplicacion sin mas que cambiar el signo + por el signo ·. Usualmente,representaremos por 1 el elemento neutro de la multiplicacion.
El elemento opuesto de uno dado x de un grupo es unico: suponiendo la existencia de doselementos opuestos x′ y x′′ de x, tenemos: x′ = x′ + e = x′ + (x+ x′′) = (x′ + x) + x′′ = e+ x′′ = x′′.
Propiedad importante es que λ1λ2 = e implica λ1 = e o λ2 = e.En efecto: si λ2 6= e, λ2 tiene un inverso respecto a la multiplicacion. Sea λ−1
2 este inverso,entonces, segun la primera propiedad anterior,
e = eλ−12 = (λ1λ2)λ
−12 = λ1(λ2λ
−12 ) = λ1.
128

Espacio Vectorial.
Definicion 2: Un conjunto V es un Espacio Vectorial sobre un cuerpo K si
1) Esta dotado de una operacion interna llamada suma respecto de la cual es grupo conmutativo.2) Tiene una multiplicacion externa por los elementos de un cuerpo K, es decir, existe una
aplicacion del conjunto K × V → V que asocia a cada par (λ, v) el elemento denotado por λv conlas siguientes propiedades:
a) λ(v1 + v2) = λv1 + λv2. (Distributividad respecto a la suma de V).b) (λ1 + λ2)v = λ1v + λ2v. (Distributividad respecto a la suma en K).c) (λ1λ2)v = λ1(λ2v). (Asociatividad mixta).d) 1v = v donde 1 es el elemento neutro del cuerpo para la multiplicacion y v es cualquier vector
de v.
El espacio vectorial se representa por VK .En los espacios vectoriales se verifica, si e es el elemento neutro del cuerpo, que e · v = 0 para
cada vector v del espacio. Propiedad analoga a la de los cuerpos, cuya demostracion es tambienexactamente analoga.
Tambien, si λ ∈ K y 0 es el elemento neutro de la suma de V, se verifica λ · 0 = 0. En efecto,llamando v′ al elemento opuesto de λ · 0, tenemos
0 = v′ + λ · 0 = v′ + λ · (0 + 0) = v′ + (λ · 0 + λ · 0) = (v′ + λ · 0) + λ · 0 = 0 + λ · 0 = λ · 0
Otra propiedad interesante: si 1 es la unidad del cuerpo y −1 es el opuesto de 1 en K, el producto(−1)v es el opuesto de v en V. Se deduce de la igualdad:
v + (−1)v = 1 · v + (−1) · v = (1 + (−1))v = e · v = 0
y de la unicidad del elemento opuesto.
Ademas, si un vector v es distinto de cero, la igualdad λv = 0 implica λ = 0, ya que si λ 6= 0,existirıa el inverso de λ : (λ1) y tendrıamos 0 = λ−1(λv) = (λ−1λ)v = 1 · v = v, en contra de losupuesto.
Se puede comprobar facilmente que el conjunto de matrices 2 × 2 de numeros racionales es unespacio vectorial sobre Q.
129

Es interesante observar que R tiene estructura de espacio vectorial sobre R y que cada cuerpo Ktiene estructura de espacio vectorial sobre K.
Tambien se verifica que C tiene estructura de espacio vectorial sobre R y R tiene estructura deespacio vectorial sobre Q.
Es facil comprobar que el conjunto de polinomios de grado ≤ n con coeficientes reales es unespacio vectorial sobre R y que el conjunto de polinomios de grado ≤ n con coeficientes complejoses un espacio vectorial sobre C. A los espacios vectoriales sobre R, se les llama espacios vectorialesreales. A los espacios vectoriales sobre C se les llama espacios vectoriales complejos.
Son espacios vectoriales reales el conjunto de matrices con entradas reales de m filas y n columnas,Mm×n(R), el conjunto de funciones reales de variable real, el conjunto de las sucesiones de numerosreales...
Son espacios vectoriales complejos el conjunto de matrices con entradas complejas de m filas y ncolumnas, Mm×n(C), el conjunto de sucesiones de numeros complejos...
El conjunto de las aplicaciones definidas en un conjunto con imagen en un cuerpo es un espaciovectorial sobre ese cuerpo, sea este R, C o Q.
Ejercicios
5.1.1. Indicar por que el conjunto de todas las matrices de numeros reales de todas las dimensionescon numeros reales no es un espacio vectorial real.
5.1.2. Comprobar que el conjunto de funciones reales continuas de variable real son un subespaciovectorial real.
130

Un ejemplo en el que se ve la importancia del cuerpo en la estructura de espacio vectorial es el conjunto C delos numeros complejos. C tiene estructura de espacio vectorial sobre R y estructura de espacio vectorial sobre C.Pero son dos estructuras distintas; Como espacio vectorial complejo, fijado un elemento no cero, todo elemento deC se puede obtener multiplicando el elemento fijo por otro del cuerpo. Pero como espacio vectorial real, fijado unelemento distinto de cero solo los elementos de la recta geometrica con direccion el elemento fijado se pueden obtenermultiplicandolo por elementos del cuerpo.
La estructura de espacio vectorial es importante porque permite el concepto de dimension queclasifica a estos espacios y establece diferencias entre los subconjutos de los espacios vectorialesllamados subespacios vectoriales. Se vera como ejercicio que la dimension de C no es la mismacuando se considera espacio vectorial complejo que cuando se considera espacio vectorial real.
Subespacios Vectoriales.
Definicion 3: Un Subespacio vectorial de un espacio vectorial V sobre un cuerpo K es unsubconjunto S no vacıo de V que es un espacio vectorial sobre el mismo cuerpo con las leyes decomposicion inducidas por las leyes de V (con el mismo cuerpo).
El espacio vectorial R contenido en el espacio vectorial C es un subespacio suyo si se considera en C la operacionexterna por los elementos de R, pero no es un subespacio vectorial, si se considera en C la operacion externa por loselementos del mismo C.
El cuerpo sobre el que se considera el espacio vectorial es importante a la hora de considerarsubespacios: fijado un origen, hemos visto que los puntos del plano dan lugar a un espacio vectorialreal formado por los vectores que tienen el mismo origen 0 y que este espacio vectorial se puede hacercoincidir con el espacio vectorial real R × R introduciendo un sistema de referencia. El conjunto delos vectores horizontales, con origen en el punto prefijado, son un subespacio vectorial real del primerespacio vectorial y correspondientemente, el conjunto de las parejas (a, 0)|a ∈ R, es un subespaciovectorial de R×R.
Pero tambien, se pueden poner los puntos del plano en correspondencia con los numeros complejosy trasmitirles la estructura de espacio vectorial complejo de C. En este caso, como el subconjunto delos numeros reales no es subespacio vectorial del espacio de los numeros complejos cuando el cuerpoque se considera es C, la recta horizontal, que es la que corresponde a R no es un subespacio delespacio de los puntos del plano con la estructura vectorial compleja.
Para que un subconjunto S no vacıo de un espacio vectorial sea subespacio vectorial se tendra queverificar que la suma del espacio vectorial sea una operacion del subconjunto, asociativa, con elementoneutro, tal que todo elemento del subconjunto tenga su elemento opuesto en el conjunto, conmutativa
131

y ademas que la multiplicacion externa por los elementos del mismo cuerpo sea otra operacion delsubconjunto con las propiedades distributivas y asociativa mixta y tal que 1× v = v ∀v ∈ S.
Pero hay algunas de estas propiedades, como la asociatividad, la distributividad y la conmutativi-dad, que por verificarse en V, se verifican en cualquier subconjunto S, y por ello, para comprobar queun subconjunto S es subespacio vectorial, solo hay que comprobar que las operaciones se mantienendentro del subconjunto, (se dice que sean cerradas en el subconjunto), y que el subconjunto contieneel elemento neutro de la suma.
Podemos ahorrarnos comprobaciones estableciendo:
Proposicion 1: El subconjunto S es un subespacio vectorial de un espacio vectorial V si:i) S es cerrado respecto a la suma de V. (∀v1, v2 ∈ S, v1 + v2 ∈ S).ii) S contiene el elemento neutro de la suma de V.iii) S es cerrado respecto a la operacion externa. (∀v ∈ S,∀λ ∈ K,λv ∈ S)
En efecto, si S es cerrado respecto a la suma, S esta dotado de esta operacion. Como S tambientiene el elemento neutro por ii), y la operacion es asociativa en S (por serlo en V) lo unico que lefalta a S para ser grupo es que para cada v el elemento opuesto: −v pertenezca a S; Por ser cerradorespecto a la operacion externa, −v = (−1)v pertenece a S. Por lo que tenemos que S es un grupoaditivo.
La conmutatividad de la suma en S viene heredada de la conmutatividad de la suma en V.Luego 1) S es un grupo aditivo conmutativo.Ademas, si S es cerrado respecto a la operacion externa de V, existe la aplicacion K × S → S
que asocia a cada par (λ, v) el elemento λv de S con las propiedades: a), b), c), d), de la definicion2. heredadas de las de V. Es decir,
2) S esta dotado de la operacion externa por ser cerrado respecto a ella. Y las restantespropiedades de las operaciones de un espacio vectorial quedan heredadas.
Hay que anadir la condicion ii) porque el conjunto vacıo verifica i) y iii) pero no es subespaciovectorial.
Sin embargo, podemos simplificar aun mas las condiciones a cumplir por un subespacio vectorialy establecer la
Proposicion 2: El subconjunto S es un subespacio vectorial de un espacio vectorial V si:i) S contiene el elemento neutro del espacio vectorial respecto a la suma.ii) Dados λ1, λ2 cualesquiera de K y dados v1, v2 cualesquiera en S, λ1v1 + λ2v2 esta en S.
132

Demostracion:Veamos primero que si se cumplen las condiciones de la proposicion 2, se cumplen las condiciones
de la proposicion 1.
La condicion i) de la proposicion 2 es la condicion ii) de la proposicion 1.Si se verifica ii) de la proposicion 2, cogiendo λ1 = λ2 = 1, dados dos vectores v1 y v2 de S, el
vector 1 · v1 + 1 · v2 = v1 + v2 pertenece a S, luego S es cerrado respecto a la suma en V.
Ademas, cogiendo λ1 = λ, λ2 = e, v1 = v = v2, tenemos que λ1v+ e · v = λv esta en S, cualquieraque sea λ ∈ K y v ∈ S, luego S es cerrado respecto a la ley de composicion externa.
Recıprocamente, veamos que si se cumplen las condiciones de la proposicion 1, se cumplen lascondiciones de la proposicion 2:
ii) Dados λ1, λ2 de K cualesquiera, y dados v1, v2 en S los vectores λ1v1 y λ2v2 pertenecen a S,por ser S cerrado respecto a la operacion externa y su suma pertenece a S por ser S cerrado respectoa la suma.
La condicion i) de esta proposicion no es superflua, porque en el caso de ser S vacıo se cumplirıala condicion ii) pero no serıa S un grupo aditivo al no contener el elemento neutro.
En realidad, podemos establecer laProposicion 3: El subconjunto S es un subespacio vectorial de un espacio vectorial V si:i) S es no vacıo.ii) Dados λ1 λ2 cualesquiera de K y dados v1, v2 cualesquiera en S, λ1v1 + λ2v2 esta en S.Ya que al ser S no vacıo, existiendo v ∈ S, el vector cero 0 = e · v pertenece a S por ii), cogiendo
λ1 = λ2 = 0 y v1 = v2 = v.
Ejercicios:
5.2.1. Comprobar que el conjunto de vectores con origen en O cuyos extremos estan en una rectaque pasa por el punto O es un subespacio vectorial del espacio vectorial real formado por todos losvectores con origen en O.
5.2.2. Explicar por que el conjunto de vectores con origen en O cuyos extremos estan en unarecta que no pasa por un punto O no es un subespacio vectorial del espacio vectorial real formadopor todos los vectores con origen en O.
133

5.2.3. Comprobar que el subconjunto de R2 formado por las parejas (x, y) con x ≥ 0 no es unsubespacio vectorial de R2.
5.2.4. Estudiar si son subespacios vectoriales de R2 los siguientes subconjuntos:a) S1 = (x, y) ∈ R2| y − x = 0,b) S2 = (x, y) ∈ R2| y − x = 1,c) S3 = (x, y) ∈ R2| xy = 0,d) S4 = (x, y) ∈ R2| y = |x|,e) S5 = (x, y) ∈ R2| |y| = |x|.5.2.5. Estudiar si son subespacios vectoriales de R3 los siguientes subconjuntos:a) S1 = (x, y, z) ∈ R3| y − x = 0,b) S2 = (x, y, z) ∈ R3| y − x = 1,c) S3 = (x, y, z) ∈ R3| xy = 0,d) S4 = (x, y, z) ∈ R3| y = |x|,e) S5 = (x, y, z) ∈ R3| |y| = |x|.5.2.6. Comprobar que aunque Q esta contenido en R y sus operaciones estan inducidas por las de
R, Q no es subespacio vectorial de R. (La multiplicacion de elementos de Q por elementos de R noes cerrada en Q (puede dar elementos de R no contenidos en Q)). Lo mismo ocurre con R respectoa C.
5.2.7. Estudiar si son subespacios vectoriales de C, considerado como espacio vectorial complejo,a) el conjunto de los numeros reales. b) el conjunto de los numeros imaginarios puros.
5.2.8. Comprobar que el conjunto de las matrices diagonales de orden n con elementos de uncuerpo K, es un subespacio vectorial del espacio vectorial sobre el cuerpo dado, de las matricescuadradas de orden n con elementos de ese cuerpo.
5.2.9. Comprobar que el espacio vectorial de las matrices 2 × 2 con numeros racionales no essubespacio vectorial del espacio vectorial real de las matrices 2× 2 con numeros reales.
5.2.10. Estudiar si son subespacios vectoriales del espacio vectorial real de funciones reales devariable real los siguientes subconjuntos: S1 = f |f(0) = 0, S2 = f |f(1) = 0, S3 = f |f(0) = 1.
5.2.11. Averiguar si son subespacios vectoriales de los correspondientes espacios vectoriales lossiguientes subconjuntos:
a) El subconjunto de los polinomios con coeficientes reales dentro del espacio vectorial real de lasfunciones reales de variable real.
b) El subconjunto de los polinomios de grado ≤ n, con coeficientes reales, siendo n fijo, dentrodel espacio vectorial real de las funciones reales de variable real.
c) El conjunto de los polinomios de grado n, siendo n fijo, con coeficientes reales como subconjuntodel espacio vectorial real de los polinomios de cualquier grado con coeficientes reales.
d) El subconjunto de polinomios de grado ≤ 3 con coeficientes reales divisibles por x − 1 comosubconjunto del espacio vectorial real de los polinomios de grado ≤ 3 con coeficientes reales.
134

5.2.12. Averiguar si son subespacios vectoriales del espacio vectorial real de matrices de numerosreales de orden 2× 2 los siguientes subconjuntos:
a) El subconjunto de las matrices de numeros reales de orden 2×2 de traza cero como subconjuntodel espacio vectorial real de las matrices de numeros reales de orden 2 × 2. (Se llama traza de unamatriz a la suma de los elementos de su diagonal).
b) El subconjunto de las matrices de numeros reales de orden 2× 2 de rango 1 como subconjuntodel espacio vectorial real de las matrices de numeros reales de orden 2× 2.
c) El subconjunto de las matrices de numeros reales de orden 2× 2 que conmutan con la matrizB, siendo B una matriz fija 2 × 2, como subconjunto del espacio vectorial real de las matrices denumeros reales de orden 2× 2 .
5.2.13. Averiguar si son subespacios vectoriales de los correspondientes espacios vectoriales lossiguientes subconjuntos:
a) El subconjunto de las matrices triangulares superiores n×n con elementos de un cuerpo comosubconjunto del espacio vectorial sobre ese cuerpo de las matrices cuadradas n×n con elementos delmismo cuerpo.
b) El subconjunto de las matrices simetricas n×n con elementos de un cuerpo como subconjuntodel espacio vectorial sobre ese cuerpo de las matrices cuadradas n × n con elementos del mismocuerpo.
c) El subconjunto de las matrices antisimetricas n×n con elementos de un cuerpo como subcon-junto del espacio vectorial sobre ese cuerpo de las matrices cuadradas n×n con elementos del mismocuerpo.
5.2.14. Averiguar si es subespacio vectorial del espacio vectorial real de matrices de numerosreales de orden m× n el subconjunto de las matrices escalonadas de m filas y n columnas.
Corolario 1:(de la proposicion 2.)La interseccion de una familia de subespacios vectoriales es un subespacio vectorial. La de-
mostracion a partir de la proposicion 2 es facil de ver y se deja como ejercicio.
Corolario 2:El conjunto de soluciones de un sistema homogeneo de ecuaciones lineales con coeficientes en un
cuerpo conmutativo es un subespacio vectorial.Demostracion:Demostrando primero que el conjunto de soluciones de una ecuacion lineal es un subespacio
vectorial, la demostracion se sigue de la observacion de que el conjunto de soluciones del sistema esla interseccion de los subespacios soluciones de cada ecuacion.
Respecto a lo primero, sea a1x1 +a2x2 + · · ·+anxn = 0 una ecuacion con coeficientes en un cuerpoK conmutativo y sea S el conjunto de sus soluciones. Entonces:
i) (0,0,...,0) es solucion de la ecuacion lineal.
135

ii) Sean λ1 y λ2 elementos del cuerpo K y (u1, u2, · · · , un), (v1, v2, · · · , vn), soluciones de laecuacion,
λ1(u1, u2, · · · , un) + λ2(v1, v2, · · · , vn) = (λ1u1 + λ2v1, λ1u2 + λ2v2, · · · , λ1un + λ2vn) es tambiensolucion de la ecuacion porque:
a1(λ1u1 + λ2v1) + a2(λ1u2 + λ2v2) + · · ·+ an(λ1un + λ2vn) =
(por la distributividad del producto)
= a1(λ1u1) + a1(λ2v1) + a2(λ1u2) + a2(λ2v2) + · · ·+ an(λ1un) + an(λ2vn) =
(por la asociatividad del producto)
= (a1λ1)u1 + (a1λ2)v1 + (a2λ1)u2 + (a2λ2)v2 + · · · (anλ1)un + (anλ2)vn =
(por la commutatividad del producto)
= (λ1a1)u1 + (λ2a1)v1 + (λ1a2)u2 + (λ2a2)v2 + · · ·+ (λ1an)un + (λ2an)vn =
(por la commutatividad de la suma)
= (λ1a1)u1 + (λ1a2)u2 + · · ·+ (λ1an)un + (λ2a1)v1 + (λ2a2)v2 + · · ·+ (λ2an)vn =
(por la asociatividad del producto)
= λ1(a1u1) + λ1(a2u2) + · · ·+ λ1(anun) + λ2(a1v1) + λ2(a2v2) + · · ·+ λ2(anvn) =
(por la distributividad del producto respecto a la suma)
= λ1(a1u1 + a2u2 + · · ·+ anun) + λ2(a1v1 + a2v2 + · · ·+ anvn) =
(por ser (u1, v2, · · · , un) y (v1, v2, · · · , vn) soluciones de la ecuacion)
= λ10 + λ20 = 0
porque estos numeros pertenecen a un cuerpo.
Un subespacio vectorial ha sido dado hasta ahora por una condicion que han de cumplir susvectores, pero tambien puede darse por una familia de vectores, a partir de los cuales se obtienentodos los demas. p. ej. los vectores horizontales de R3 son un subespacio de R3 dados por la condicion
136

de ser horizontales, pero tambien se pueden expresar: (x1, x2, 0) = x1(1, 0, 0) +x2(0, 1, 0), es decir,que se pueden obtener a partir de (1, 0, 0), (0, 1, 0) multiplicando por numeros reales y sumando.
Se introduce el concepto de combinacion lineal para expresar un vector a partir de otros.
Definicion 4: se llama combinacion lineal de los vectores v1, v2, ..., vm ⊂ VK a cualquiervector v que se pueda escribir v = λ1v1 + λ2v2 + ...+ λmvm donde los λi pertenecen al cuerpo K.
El vector cero es combinacion lineal de cualquier familia de vectores, ya que tomando λ = 0, seobtiene λv = 0, cualquiera que sea v.
Demonos cuenta de que si S es subespacio vectorial de V , por la propiedad asociativa de la suma,dados m vectores: v1, v2, ..., vm de S, el vector v = λ1v1 +λ2v2 + ...+λmvm (donde los λi pertenecenal cuerpo) permanece en S.
Podemos decir que un subespacio vectorial es un subconjunto no vacıo de un espacio vectorial quecoincide con las combinaciones lineales de todos sus elementos. Pero investigaremos la posibilidad dedeterminar un subespacio por un subconjunto de sus vectores, (cuantos menos mejor), como conjuntode las combinaciones lineales de este subconjunto.
Un ejemplo son los conjuntos de soluciones de un sistema homogeneo de ecuaciones, que se puedenexpresar como combinaciones lineales de un numero finito de vectores. Lo veremos mas adelante enel ejemplo usado para establecer el Teorema 2.
Lema 1: El conjunto de las combinaciones lineales de m vectores fijos de un espacio vecto-rial es un subespacio vectorial del dado con las operaciones inducidas. (Su comprobacion se dejacomo ejercicio). Se llama subespacio vectorial engendrado por los m vectores. Representaremospor Lv1, v2, ...vm al subespacio vectorial engendrado por v1, v2, ..., vm. Llamamos a este con-junto de vectores un sistema generador de dicho subespacio. Y a los vectores del conjunto, vectoresgeneradores.
Como nos interesa la mayor simplicidad, nos interesan los sistemas generadores con el mınimonumero de elementos y por eso introducimos el concepto de vector linealmente dependiente:
Definicion 5: Un vector v depende linealmente de los vectores v1, v2, ..., vm si se puedeexpresar como combinacion lineal de los vectores dados.
Observemos que el vector nulo siempre depende de cualquier conjunto de vectores: se expresacomo una combinacion lineal en la que todos los coeficientes son nulos.
La consideracion de los vectores linealmente dependientes esta justificada por la proposicionsiguiente:
137

Proposicion 4: Si un vector v depende linealmente de los vectores v1, v2 . . . , vm, los subespa-cios vectoriales engendrados por v1, v2 . . . , vm y por v1, v2 . . . , vm, v coinciden.
Demostracion:Esta claro que Lv1, v2, ...vm ⊂ Lv1, v2, ..., vm, v.Recıprocamente, si v = λ1v1 + λ2v2 + ... + λmvm, cualquier elemento de Lv1, v2, ..., vm, v se
escribe:α1v1 + α2v2 + ...+ αmvm + αv =
α1v1 + α2v2 + ...+ αmvm + α(λ1v1 + λ2v2 + ...+ λmvm) =
(α1 + αλ1)v1 + (α2 + αλ2)v2 + ...+ (αm + αλm)vm
Este ultimo es un elemento de Lv1, v2, ..., vm.
Por ejemplo, = L(1, 0, 0)(0, 1, 0) = L(1, 0, 0)(0, 1, 0)(1, 1, 0) dentro de R3.
Definicion 6: Se dice que los vectores v1, v2, ..., vm son linealmente dependientes si y solosi uno de ellos depende del resto.
Si el vector cero es uno de los vectores vi, los vectores son linealmente dependientes. (Release laobservacion posterior a la definicion 5).
Proposicion 5: los vectores v1, v2, ..., vm son linealmente dependientes si y solo si el vectorcero se puede expresar como combinacion lineal de los vectores dados utilizando algun coeficiente nonulo.
Demostracion:⇐).Sea
0 = λ1v1 + λ2v2 + ...+ λmvm
y sea λi 6= 0.Entonces,
λivi = −λ1v1 − λ2v2 − ...− λmvmdonde en el segundo miembro aparecen solo los vectores distintos del vi.
Como λi 6= 0 y K es un cuerpo, existe inverso de λi. Multiplicando por λ−1i tenemos:
vi = −λ−1i λ1v1 − ...− λ−1
i λmvm
donde no aparece el vi en el segundo miembro, por tanto uno de ellos depende linealmente del resto.⇒). Sea vi un vector que depende del resto de vectores. Entonces,
138

vi = λ1v1 + ...+ λmvm
donde no aparece vi en el segundo miembro. Pasandolo al segundo miembro, tenemos
0 = λ1v1 + ...− vi + ...+ λmvm
El coeficiente de vi en el segundo miembro es −1 porque vi antes no aparecıa en el segundo miembro.Hemos conseguido escribir el cero como combinacion lineal de los vectores dados siendo al menosel coeficiente de vi (−1) distinto de cero. Luego, por la definicion 6, los vectores son linealmentedependientes.
Definicion 7: Se dice que los vectores v1, v2, ..., vm son linealmente independientes si noson linealmente dependientes.
En este caso, por la prop. 5, no podemos encontrar una expresion:
0 = λ1v1 + λ2v2 + ...+ λmvm
con algun λi 6= 0, o lo que es lo mismo, en una expresion del tipo
0 = λ1v1 + λ2v2 + ...+ λmvm
todos los λi han de ser nulos.En la practica, en los casos concretos, se comprueba si v1, v2, ..., vm son linealmente indepen-
dientes viendo si la existencia de la expresion:
0 = λ1v1 + λ2v2 + ...+ λmvm
implica que todos los coeficientes sean nulos.Esta regla tambien nos da que un conjunto de vectores formado solo por el vector cero es depen-
diente. Y que un conjunto formado solo por un vector distinto de cero es independiente. (Veanselas propiedades que se demostraron al principio del capıtulo sobre las operaciones en un espaciovectorial).
Ejercicios:
5.3.1. Estudiar si son independientes en su espacio vectorial correspondiente las siguientes familiasde vectores:
a) (1, 2, 0), (0, 1, 1) ⊂ R3,b) (1, 2, 0), (0, 1, 1), (1, 1, 0) ⊂ R3,c) (1, 2, 0), (0, 1, 1), (1, 1,−1) ⊂ R3,
139

d) (1, 2, 0), (0, 1, 1), (1, 1, 0), (3, 2, 1) ⊂ R3,e) (i, 1− i), (2,−2i− 2) ⊂ C2,f) (i, 1,−i), (1, i,−1) ⊂ C3.5.3.2. En los casos de las familias anteriores que sean dependientes, expresar uno de los vectores
como combinacion lineal de los restantes.5.3.3. Estudiar si son independientes en su espacio vectorial correspondiente las siguientes familias
de vectores:a) (
0 10 −2
),
(1 −10 1
),
(−2 5
0 −8
)subconjunto de las matrices 2× 2 de numeros reales.
b) Los polinomios 1, x− 2, (x− 2)2, (x− 2)3 ⊂ P 3R[x].
5.3.4. Demostrar que si f1(x), f2(x), · · · , fk(x) son funciones reales de variable real tales queexisten a1, a2, · · · , ak verificando∣∣∣∣∣∣∣∣∣
f1(a1) f2(a1) · · · fk(a1)f1(a2) f2(a2) · · · fk(a2)
......
. . ....
f1(ak) f2(ak) · · · fk(ak)
∣∣∣∣∣∣∣∣∣ 6= 0
son funciones independientes.5.3.5. Utilizar el resultado anterior paraa) Demostrar que cualquiera que sea n, los polinomios 1, x− 2, (x− 2)2, · · · , (x− 2)n ⊂ P n[x]
son independientes considerados como vectores de dicho espacio vectorial.b) Demostrar que los polinomios: 1, x − a, (x − a)2, · · · , (x − a)n ⊂ P n[x], cualquiera que sea
n, y cualquiera que sea a, son independientes.
140

La proposicion 4 establece que en un conjunto de generadores de un subespacio se puede prescindirde los que dependan linealmente de los otros.
Introducimos el concepto de base para prescindir en el sistema generador de un subespacio de losvectores que dependan de los restantes. Ası obtenemos las bases como sistemas generadores con unnumero mınimo de vectores.
Bases.
Definicion 8: Se llama base de un espacio vectorial a un sistema generador del espacio que a suvez es linealmente independiente.
Ejercicios
5.4.1. Comprobar que los siguientes conjuntos de vectores son bases de los correspondientesespacios vectoriales: (son las llamadas bases canonicas)
a) (1, 0, 0, · · · , 0), (0, 1, 0, · · · , 0), (0, 0, 1, · · · , 0), · · · , (0, 0, 0, · · · , 1) ⊂ Rn.b) (
1 00 0
),
(0 10 0
),
(0 01 0
),
(0 00 1
)⊂M2×2(R)
c) 1, x, x2, · · · , xn ⊂ P nR(x).
5.4.2. Estudiar si las siguientes familias de vectores son bases de los espacios vectoriales dados:
a) (1, 0, 0, 1), (1, 0, 1, 0), (0, 1, 1, 0), (0, 1, 0, 1) ⊂ R4,
b) (1, 0, 0, 1), (1, 0, 1, 0), (0, 2, 1, 0), (0, 1, 0, 1) ⊂ R4,c) (
1 00 1
),
(1 01 0
),
(0 11 0
),
(0 10 1
)⊂M2×2(R),
d) (1 00 1
),
(1 01 0
),
(0 21 0
),
(0 10 1
)⊂M2×2(R),
e) (1 01 1
),
(0 11 1
),
(1 11 2
),
(0 11 0
)⊂M2×2(R),
141

f) (1 01 1
),
(0 11 1
),
(1 11 1
),
(0 11 0
)⊂M2×2(R).
5.4.3. Encontrar bases de los siguientes subespacios vectoriales de M3×3(R) :a) Las matrices diagonales.b) Las matrices triangulares superiores.c) Las matrices triangulares inferiores.d) Las matrices simetricas.e) Las matrices antisimetricas.5.4.4. Siendo e1, e2, · · · , en una base de Rn, demostrar que los vectores:
u1 = e1, u2 = e1 + e2, · · · , un−1 = e1 + e2 + · · ·+ en−1, un = e1 + e2 + · · ·+ en
son otra base de Rn.
Ademas de ser una base un sistema generador mınimo, (por ser un sistema independiente), permitela definicion de coordenadas que asocia a cada vector un conjunto de numeros e identifica el espaciovectorial con un producto cartesiano del cuerpo K por sı mismo un determinado numero de veces.
Definicion 9: Se llaman coordenadas de un vector en una base a los coeficientes que hay queponer a los vectores de dicha base para obtener una combinacion lineal que de el vector dado.
Teorema 1: Las coordenadas estan bien definidas. (Son unicas para un vector fijo en una basefija).
Demostracion:Sean x1, x2, ..., xn y x′1, x′2, ..., x′n dos conjuntos de coordenadas de un vector x respecto a una
base e1, e2, ..., en de V. Entonces,
x1e1 + x2e2 + ...+ xnen = x = x′1e1 + x′2e2 + ...+ x′nen
de donde(x1 − x′1)e1 + (x2 − x′2)e2 + ...+ (xn − x′n)en = 0
Como los vectores ei son independientes, los coeficientes xi − x′i han de ser nulos. Entonces xi = x′ipara todo i.
142

Observemos que si el sistema generador de un subespacio vectorial no es una base, los coeficientesque podemos poner a los vectores del sistema generador para obtener un vector dado no son unicos.En L(1, 0, 0)(0, 1, 0)(1, 1, 0) podemos escribir:
(2, 1, 0) = 2(1, 0, 0) + 1(0, 1, 0) + 0(1, 1, 0) o (2, 1, 0) = 1(1, 0, 0) + 0(0, 1, 0) + 1(1, 1, 0)Y no siempre le corresponderıan al vector cero las coordenadas (0, 0, 0) ya que tambien se tendrıa
(0, 0, 0) = −1(1, 0, 0)− 1(0, 1, 0) + 1(1, 1, 0)Por ello, las coordenadas de un vector en un sistema generador que no sea base no estan bien
definidas. Sin embargo, dada una base de n elementos en un espacio vectorial, cada vector del espacioqueda determinado por los n numeros que son sus coordenadas en esa base.
Ejercicios:
5.5.1. Hallar las coordenadas del vector (3, 2,−1, 0) de R4 en la base de R4 dada en el ejercicio5.4.2 b).
5.5.2. Hallar las coordenadas de los vectores (n, n− 1, · · · , 2, 1) y (1, 2, · · · , n− 1, n) de Rn, en labase u1, u2, ...un dada en el ejercicio 5.4.4 cuando e1, e2, ...en es la base canonica de Rn.
5.5.3. Hallar las coordenadas de
(1 11 1
)en la base
(1 01 1
),
(0 11 1
),
(1 11 2
),
(0 11 0
)⊂M2×2(R)
5.5.4. Hallar las coordenadas de 1 + x+ x2 en la base 1, x− 1, (x− 1)2.
143

Veremos cual es la relacion entre las coordenadas de un vector en bases distintas pero antesdemostraremos una serie de resultados encaminados a demostrar que si un espacio vectorial tieneuna base con n elementos, cualquier otra base tiene tambien n elementos.
Proposicion 6: Todo conjunto formado por n vectores independientes de Rn forma una base deRn.
Demostracion:Sea v1, v2, v3, · · · , vn un conjunto formado por n vectores independientes. Entonces la expresion:
λ1v1 + λ2v2 + ...+ λnvn = 0 solo se cumple cuando todos los coeficientes λi son nulos.Si v1 = (v11, v12, ..., v1n), v2 = (v21, v22, ..., v2n), · · · · · · · · · vn = (vn1, vn2, ..., vnn) (todos elementos
de Rn), el vector λ1v1 + λ2v2 + ...+ λnvn es:(λ1v11 + λ2v21 + ...+ λnvn1, λ1v12 + λ2v22 + ...+ λnvn2, · · · · · · , λ1v1n + λ2v2n + ...+ λnvnn).Si los vectores dados son independientes, estos numeros son todos a la vez nulos solo si los λi son
nulos, es decir si el sistema lineal homogeneo:
λ1v11 + λ2v21 + ...+ λnvn1 = 0λ1v12 + λ2v22 + ...+ λnvn2 = 0
· · · · · · = 0λ1v1n + λ2v2n + ...+ λnvnn = 0
solo tiene la solucion trivial.
Esto es cierto si y solo si
det
v11 v21 · · · vn1
v12 v22 · · · vn2
· · · · · · · · · · · ·v1n v2n · · · vnn
6= 0
Veremos que esta condicion es suficiente para demostrar que los vectores dados son un sistemagenerador, es decir, que L v1, v2, ...vn = Rn
En efecto, dado cualquier vector: (x1, x2, ...xn) de Rn, el sistema lineal
λ1v11 + λ2v21 + ...+ λnvn1 = x1
λ1v12 + λ2v22 + ...+ λnvn2 = x2
· · · · · ·λ1v1n + λ2v2n + ...+ λnvnn = xn
tiene solucion por el Teorema de Rouche Frobenius, ya que al ser el determinante de la matriz de suscoeficientes (el anterior determinante) distinto de cero, el rango de la matriz de los coeficientes delsistema es igual al rango de la matriz ampliada.
144

Cogiendo las soluciones encontradas para los valores de λi en la expresion: λ1v1 + λ2v2 + ... +λnvn, obtenemos el vector dado (x1, x2, ...xn). Esto nos dice que cualquier vector de Rn es unacombinacion lineal de los vectores dados, por tanto, formaban un sistema generador. Como tambieneran independientes, forman un sistema generador independiente, es decir, una base de Rn.
El procedimiento seguido en esta demostracion establece tambien que:n n-uplas de Rn son una base de Rn si y solo si el determinante de la matriz cuyas columnas(o filas)son las n-uplas dadas es distinto de cero.
Ejercicios:
5.6.1. Encontrar los valores de a para los que los vectores (a, 0, 1), (0, 1, 1), (2,−1, a) formenuna base de R3.
5.6.2. Dados dos vectores a = (a1, a2, a3), b = (b1, b2, b3) de R3, se define el producto vectoriala× b como el vector simbolicamente expresado por∣∣∣∣∣∣
i j ka1 a2 a3
b1 b2 b3
∣∣∣∣∣∣ ≡(∣∣∣∣ a2 a3
b2 b3
∣∣∣∣ ,− ∣∣∣∣ a1 a3
b1 b3
∣∣∣∣ , ∣∣∣∣ a1 a2
b1 b2
∣∣∣∣)Demostrar que si los vectores a y b son independientes, los vectores a, b, a× b son una base de
R3.5.6.3. Hallar los numeros complejos z para los cuales los vectores:
(z + i, 1, i), (0, z + 1, z), (0, i, z − 1)
no forman base considerados como vectores del espacio vectorial complejo C3.5.6.4. Los vectores (z, 1, 0), (−1, z, 1), (0,−1, z) ⊂ R3, pueden considerarse contenidos en R3 o
en C3, segun se permita a z variar en R o en C. Aun considerandose contenidos en C3, puede darsea este conjunto estructura de espacio vectorial real y estructura de espacio vectorial complejo. Hallarlos valores de z que los hacen dependientes en cada uno de los tres casos.
145

Se puede generalizar la proposicion 6 a la siguiente proposicion 7: Todo conjunto formado porn vectores independientes de un espacio vectorial que tenga una base de n elementos forma una basede dicho espacio.
Proposicion 8:Si un espacio vectorial VK tiene una base con n vectores, cualquier conjunto con mas de n vectores
es dependiente.Demostracion:Sean e1, e2, ..., en una base de V y v1, v2, ..., vm un conjunto de vectores, donde m > n.
Expresemos los vectores por sus coordenadas en la base dada:
v1 = (v11, v12, ..., v1n)
v2 = (v21, v22, ..., v2n)
· · · · · · · · · · · · · · ·
vm = (vm1, vm2, ..., vmn)
Las coordenadas de una combinacion lineal de estos vectores: λ1v1 + λ2v2 + ...+ λmvm son:
λ1v11 + λ2v21 + ...+ λmvm1
λ1v12 + λ2v22 + ...+ λmvm2
· · · · · ·
λ1v1n + λ2v2n + ...+ λmvmn
La combinacion lineal es nula si y solo si sus coordenadas son nulas. El sistema lineal homogeneo:
λ1v11 + λ2v21 + ...+ λmvm1 = 0λ1v12 + λ2v22 + ...+ λmvm2 = 0
· · · · · ·λ1v1n + λ2v2n + ...+ λmvmn = 0
tiene por el teorema de Rouche-Frobenius, soluciones no nulas para todas las λi ya que como m > n,hay mas incognitas que ecuaciones y por tanto el rango de la matriz de los coeficientes es menor queel numero de incognitas. Estas soluciones pemiten poner el vector nulo como combinacion lineal delos vectores dados con coeficientes no todos nulos, por tanto los vectores dados son dependientes.
Con esta proposicion llegamos al importante
146

Teorema de la Base.Si un espacio vectorial tiene una base con n vectores, cualquier otra base tiene el mismo numero
de vectores.Demostracion: Sea e1, e2, ...en una base de V. Sea e′1, e′2, ...e′m otra base de V.Si m > n, segun la proposicion anterior, los vectores e′1, e′2, ...e′m serıan dependientes y no
podrıan formar base.Si m < n, tomando e′1, e′2, ...e′m como base de partida de V, tendrıamos, tambien, segun la
proposicion anterior, que los vectores e1, e2, ...en serıan dependientes y no podrıan formar base.Luego m = n.
Se llama dimension del espacio vectorial al numero de vectores de una base. (Un espaciovectorial de dimension finita es un espacio vectorial que admite una base de n vectores para algunn ∈ N .) El Teorema de la Base demostrado garantiza que la dimension del espacio vectorial esindependiente de la base considerada, cuando el espacio es de dimension finita.
Una aplicacion del concepto de dimension nos sirve para distinguir el espacio vectorial formadopor los complejos sobre el cuerpo complejo del espacio vectorial formado por los complejos sobre elcuerpo real: vease el siguiente ejercicio:
5.7.1. Comprobar que una base de C considerado como espacio vectorial sobre C esta formadapor 1, pero una base de C considerado como espacio vectorial sobre R es 1, i. Estos dos espaciosvectoriales tienen distinta dimension.
Tambien se deduce de la proposicion 8 que n vectores independientes de un espacio vectorial conuna base de n elementos son otra base, pues cualquier otro vector anadido a los dados es dependientede ellos, siendo por tanto el conjunto dado de vectores independientes un sistema generador delespacio vectorial.
Dado que las bases contienen un menor numero de elementos, hacen los calculos mas cortos ypor eso en el trabajo con espacios vectoriales son utiles las dos proposiciones siguientes:
Proposicion 9: De todo sistema generador finito de un espacio vectorial se puede extraer unabase.
Si el sistema generador no es una base es porque no es linealmente independiente y existe algunvector que depende linealmente del resto. Por la proposicion 4, el espacio de combinaciones linealesdel sistema generador coincide con el espacio de combinaciones lineales del conjunto de vectores quequeda al extraer del sistema generador el vector dependiente. Podemos repetir el proceso mientras elsistema generador sea dependiente hasta que se haga independiente (porque es finito). En el primermomento en que el conjunto de vectores no extraidos sea independiente sera tambien una base delespacio porque sigue siendo un sistema generador.
147

Proposicion 10: Todo sistema independiente de un espacio vectorial de dimension finita sepuede completar a una base.
Sea n la dimension de V y v1, v2, ..., vr un sistema de vectores independientes de V .Por la proposicion 8 no puede ser r > n.Si Lv1, v2, ..., vr = V , v1, v2, ..., vr son tambien un sistema generador de V y por tanto son ya
una base de V . Entonces, por el teorema de la base, r = n.Si Lv1, v2, ..., vr 6= V , debe ser r < n y existir un vector w ∈ V − Lv1, v2, ..., vr, que es
linealmente independiente de los dados. Llamemos vr+1 = w y anadamoslo a los vectores dados. Elconjunto v1, v2, ..., vr, vr+1 es un conjunto de vectores independiente, que sera una base de V siLv1, v2, ..., vr, vr+1 = V , en cuyo caso r + 1 = n y ya hemos completado el conjunto de vectoresdado a una base. Si r + 1 < n, repetimos el proceso anterior para anadir un vr+2 independientede los anteriores y hasta un vn independiente de los anteriormente anadidos y en ese momento, elsistema independiente es un sistema generador por la proposicion 8, habiendo completado el sistemaindependiente dado a una base de V .
El metodo para llevar a cabo los hechos de las dos proposiciones anteriores en casos concre-tos se vera como aplicacion de la relacion entre el rango de una matriz y el numero de sus filasindependientes, mas adelante.
Corolario 3: Dos subespacios vectoriales S1 y S2 son iguales si y solo si S1 ⊂ S2 y dimS1 =dimS2. (S1 y S2 son intercambiables).
Este corolario es cierto porque si S1 ⊂ S2, una base de S1 puede completarse a una base de S2,pero al ser dimS1 = dimS2, no podemos anadir ningun vector porque todas las bases tienen el mismonumero de elementos, lo cual implica que la base de S1 es ya una base de S2, y por tanto, S1 = S2.
Teorema 2: La dimension del subespacio de soluciones de un sistema homogeneo de ecuacioneslineales es igual al numero de incognitas menos el rango de la matriz de los coeficientes de lasincognitas.
Como es mas facil comprobar este teorema en un ejemplo y visto el ejemplo, el teorema resulta ob-vio, aun sabiendo que un ejemplo no es una demostracion, vamos a hallar la dimension del subespaciode soluciones del sistema siguiente:
3x1 +2x2 +x3 +x4 −x5 = 03x1 +2x2 +2x3 +3x4 = 06x1 +4x2 +x3 −3x5 = 0
Una forma sistematica de resolver un sistema homogeneo de ecuaciones lineales, que se puede
escribir en forma matricial por Ax=0, es reducir la matriz A a una matriz escalonada E por opera-
148

ciones elementales y pasar en las ecuaciones de Ex=0, las incognitas de las columnas que no danescalon al segundo miembro.
Como hicimos en el capıtulo del metodo de Gauss:
3x1 +2x2 +x3 +x4 −x5 = 0x3 +2x4 +x5 = 0−x3 −2x4 −x5 = 0
≡ 3x1 +2x2 +x3 +x4 −x5 = 0x3 +2x4 +x5 = 0
Pasamos al segundo miembro las incognitas x2 x4 y x5 :
3x1 +x3 = −2x2 −x4 +x5
x3 = −2x4 −x5
Ahora, al recorrer las ecuaciones de arriba a abajo, las incognitas del primer miembro van dismi-
nuyendo de una en una, apareciendo solo una incognita despejada en el primer miembro en la ultimaecuacion. Sustituyendo esta incognita en la ecuacion anterior, podemos despejar otra incognita masy seguir ası despejando hasta agotar las incognitas de los primeros miembros.
En este ejemplo, sustituyendo el valor de x3 dado por la segunda ecuacion en la primera ecuaciontenemos: 3x1 = −2x2 + x4 + 2x5,.
Podemos considerar todas las incognitas como funciones lineales de las variables pasadas al se-gundo miembro, anadiendo xi = xi para estas ultimas variables.
En este ejemplo, anadiendo x2 = x2, x4 = x4, x5 = x5, obtenemos las condiciones:
x1 = −23x2 +1
3x4+
23x5
x2 = x2
x3 = −2x4 −x5
x4 = x4
x5 = x5
Una solucion cualquiera es una 5-upla de valores, donde las incognitas pasadas al segundo miembropueden variar arbitrariamente y las incognitas del primer miembro estan sujetas a las condicionesdespejadas. Que expresamos por:
x1
x2
x3
x4
x5
= x2
−2
3
1000
+ x4
13
0−2
10
+ x5
23
0−1
01
Haciendo ahora x2 = λ1, x4 = λ2, x5 = λ3 se escribe:
149

x1
x2
x3
x4
x5
= λ1
−2
3
1000
+ λ2
13
0−2
10
+ λ3
23
0−1
01
El subespacio de soluciones del sistema es el subespacio de las combinaciones lineales de los tres
vectores columna del segundo miembro.
En este caso, ninguno de los vectores columna anteriores del segundo miembro de la igualdad essuperfluo a la hora de dar las combinaciones lineales soluciones. En nuestro caso, para comprobarque son independientes, mirarıamos si una combinacion lineal de los vectores igual a cero es posiblecon coeficientes λi distintos de cero. Tendrıa que ser:
00000
= λ1
−2
3
1000
+ λ2
13
0−2
10
+ λ3
23
0−1
01
Considerando la segunda, la cuarta y la quinta filas, tenemos: 0 = λ1, 0 = λ2, 0 = λ3, lo que
implica que los vectores columna escritos son independientes. La dimension del espacio de solucionesde este sistema es 5− 2 = 3, (no de incognitas menos rango de la matriz de los coeficientes).
Para demostrar el teorema 2 en forma general, tenemos en cuenta que la forma sistematica por elMetodo de Gauss, de resolver un sistema homogeneo de ecuaciones lineales, escrito en forma matricialpor Ax=0, es reducir la matriz A a una matriz escalonada E por operaciones elementales y pasaren las ecuaciones de Ex=0, las incognitas de las columnas que no dan escalon al segundo miembro.Se despejan las incognitas que dan escalon en funcion de las que no lo dan y si n es el numero deincognitas, las soluciones son las n-uplas de numeros que se pueden escribir segun las expresionesobtenidas al despejar, donde varıan arbitrariamente las incognitas del segundo miembro. Poniendolas n-uplas soluciones en columna ordenada y desglosando sus expresiones segun las incognitas varia-bles, (que se pueden sustituir por parametros), aparecen las soluciones como combinaciones linealesde tantas columnas como incognitas variables. Estas columnas son un sistema de generadores delconjunto de soluciones del sistema.
Los vectores generadores ası obtenidos tienen el numero 1 en el sitio correspondiente a dichacoordenada y el numero 0 en el sitio correspondiente a las otras coordenadas pasadas al segundomiembro. Por esta condicion son independientes.
150

El numero de incognitas que dan escalon es igual al numero de escalones de E, igual a su vezal rango de la matriz de los coeficientes del sistema, (en terminos de determinantes), por tanto, sepasan al segundo miembro un numero de incognitas igual al numero total de ellas menos el rango dela matriz de los coeficientes. Por ello, la dimension del conjunto de soluciones del sistema es no deincognitas menos rango de la matriz de los coeficientes.
Ejercicios:
5.8.1. Encontrar bases de los siguientes subespacios:
x1 +x3 +2x4 = 0x1 −x3 = 0
⊂ R4
x1 +x2 +x3 +x4 +x5 = 0x1 −x2 +x3 −x4 +x5 = 0
⊂ R5 3x1 −x2 +3x3 −x4 +3x5 = 0
3x1 +x2 +3x3 +x4 +3x5 = 0
⊂ R5
5.8.2. Encontrar una base del subespacio S ⊂M2×2(R) definido por
S =
(a bc d
)∣∣∣∣ 2a+ b− c+ d = 0a+ b+ c− d = 0
5.8.3. Encontrar una base del espacio vectorial de los polinomios de grado menor o igual que tres
divisibles por x− 1.
151

Corolario 4: Dos subespacios vectoriales S1 y S2 dados respectivamente por las ecuacionesmatriciales A1x = 0 y A2x = 0 son iguales si y solo si el rango de A1 es igual al rango de A2 yS1 ⊂ S2. (S1 y S2 son intercambiables).
Se pueden utilizar estos corolarios para averiguar si los conjuntos de soluciones de sistemas ho-mogeneos distintos son coincidentes.
Corolario 5: En el conjunto de ecuaciones Ax = 0 de un subespacio vectorial, podemos suprimirlas ecuaciones tales que al suprimir de A las filas de coeficientes correspondientes a tales ecuaciones,queda una matriz del mismo rango que A.
Ejercicios:
5.9.1. Comprobar que el subespacio de R4 engendrado por (1, 0, 1,−1), (1,−1, 1,−1) coincidecon el espacio de soluciones del sistema:
x1 +x3 +2x4 = 0x1 −x3 = 0
⊂ R4.
5.9.2. Comprobar que los subespacios S1 y S2 de R5 cuyas ecuaciones son los sistemas:
x1 +x2 +x3 +x4 +x5 = 0x1 −x2 +x3 −x4 +x5 = 0
(1)
3x1 −x2 +3x3 −x4 +3x5 = 03x1 +x2 +3x3 +x4 +3x5 = 0
(2)
son iguales.5.9.3. Dos subespacios vectoriales S1 y S2 dados respectivamente por las ecuaciones matriciales
A1x = 0 y A2x = 0 son iguales si y solo si
r
(A1
A2
)= r(A1) = r(A2).
(S1 y S2 son intercambiables).
152

Cambio de base.Veremos aquı cual es la relacion entre las coordenadas de un vector en dos bases distintas.Sean B = e1, e2, ...en, B′ = e′1, e′2, ...e′n dos bases de un espacio vectorial de dimension n.Sean (x1, x2, ...xn), (x′1, x
′2, ...x
′n) las coordenadas respectivas de un vector x en ambas bases.
Entonces, x1e1 +x2e2 + · · ·+xnen = x = x′1e′1 +x′2e
′2 + · · ·+x′ne
′n, lo que tambien se puede escribir:
(e1 e2 ... en
)x1
x2
...xn
= x = (e′1, e′2, ...e
′n)
x′1x′2...x′n
Sean
e′1 = a11e1 + a21e2 + ...+ an1en
e′2 = a12e1 + a22e2 + ...+ an2en
· · ·
e′n = a1ne1 + a2ne2 + ...+ annen
los vectores de la nueva base expresados en la antigua. Tambien los podemos escribir globalmenteası:
(e′1 e′2 ... e′n
)=(e1 e2 ... en
)a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · · · · · · ·an1 an2 · · · ann
,
sustituyendo la expresion anterior de los e′ en la expresion de x, tenemos:
x =(e1 e2 ... en
)a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · · · · · · ·an1 an2 · · · ann
x′1x′2...x′n
que comparada con
x =(e1 e2 ... en
)x1
x2
...xn
,
ya que las coordenadas de un vector en una base fija son unicas, da:
153

x1
x2
...xn
=
a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · · · · · · ·an1 an2 · · · ann
x′1x′2...x′n
Expresion de la relacion entre las coordenadas en las dos bases.
Observemos que las columnas de esta matriz son las coordenadas de cada uno de los vectores dela nueva base expresados en la antigua.
Ejercicios:
5.10.1. Hallar las matrices de cambio de base en R4
a) de la base dada en el ejercicio 5.4.2. b) a la base canonica.b) de la base canonica a la base dada en el ejercicio 5.4.2. b)5.10.2. Siendo v1, v2, v3, v4 = (1, 1, 0, 0), (0, 1, 0,−1), (0, 1, 1, 0), (0, 0, 0, 1)y w1, w2, w3, w4 = (1, 0, 0, 1), (1, 0, 1, 0), (0, 2, 1, 0), (0, 1, 0, 1), hallar:a) Las coordenadas del vector 3w1 + 2w2 + w3 − w4 en la base v1, v2, v3, v4.b) Las coordenadas del vector 3v1 − v3 + 2v2 en la base w1, w2, w3, w4.5.10.3. Escribir las matrices de cambio de base en R4 entre las dos bases del ejercicio 5.10.2 y
comprobar los resultados de ese ejercicio.5.10.4.a) Hallar las matrices de cambio de base en M2×2(R) entre las siguientes bases:(
1 00 1
),
(1 10 0
),
(0 11 0
),
(1 00 0
)y (
−1 01 1
),
(0 −11 1
),
(1 10 −1
),
(1 1−1 0
)b) Hallar las coordenadas de la matriz (
1 11 1
)directamente en las dos bases anteriores y comprobar que estan relacionadas por las matrices decambio de base.
5.10.5. Escribir las matrices de cambio de base en el espacio de los polinomios de grado menor oigual que 3 con coeficientes reales entre las bases 1, x−1, (x−1)2, (x−1)3 y 1, x+1, (x+1)2, (x+1)3.
Hallar las coordenadas del polinomio 1 + x+ x2 + x3 directamente en las dos bases y comprobarque estan relacionadas por las matrices de cambio de base.
154

APLICACIONES DEL CONCEPTO DE DIMENSION A PROCESOS CONCRETOS.
Independencia del numero de escalones obtenidos escalonando una matriz.
Queremos aquı mostrar, sin usar determinantes, que el numero de escalones de la matriz escalona-da E obtenida escalonando una matriz dada A es independiente del itinerario seguido para escalonarla(de las operaciones elementales utilizadas y del orden de estas).
Primero demostramos que las filas no nulas de una matriz escalonada con elementos de un cuerpoK, consideradas como elementos de Kn son independientes:
Sea
E =
e11 e12 · · · e1ne21 e22 · · · e2n· · · · · · · · · · · ·em1 em2 · · · emn
una matriz escalonada.
Sea
λ1(e11, e12, · · · , e1n)+λ2(e21, e22, · · · , e2n)+· · ·+λi(ei1, ei2, · · · , ein)+λr(er1, er2, · · · , ern) = (0, 0, · · · , 0)
una conbinacion lineal nula de sus filasRecordemos que por ser la matriz escalonada, si e1k es el primer numero distinto de cero de la
primera fila eik = 0 para i > 1. Entonces, la k-esima coordenada de la anterior combinacion linealse reduce a λ1e1k, pero si esta combinacion lineal es nula, λ1e1k = 0. Como e1k 6= 0 y pertenece a uncuerpo, existe e−1
1k y entonces tenemos λ1 = (λ1e1k)e−11k = 0.
Sea ahora e2l el primer numero no nulo de la segunda fila. Entonces, eil = 0 para i > 2. Comoλ1 = 0, la l-esima coordenada de la combinacion lineal escrita es λ2e2l, pero como la combinacionlineal es nula, λ2e2l = 0 y concluimos que λ2 = 0, lo mismo que en el caso anterior.
Vamos considerando las filas sucesivamente en orden creciente y llegamos a la conclusion deque todas las λj son nulas ya que lo son las λi anteriores, y en cada fila no nula hay una primeracoordenada no nula tal que las coordenadas en ese lugar de las filas sucesivas son nulas. Por tanto,las filas no nulas de la matriz escalonada son independientes.
Ahora, dada una matriz Am×n, llamamos vii≤m ⊂ Kn a los vectores que tienen por coordenadaslos elementos de las filas de la matriz A y llamamos espacio fila de A: (F(A)) al subespacio de Kn
engendrado por los vectores vii≤m.
155

El numero de escalones de la matriz escalonada E(A) obtenida de A es igual al numero de susfilas no nulas. Veamos que este numero (el de filas no nulas de la matriz escalonada al que quedareducida A) es la dimension del subespacio vectorial F(A). Cuando lo hayamos visto, tendrenos quelos distintos numeros de filas no nulas de distintas matrices escalonadas obtenidas de A son todosiguales, por ser iguales a la dimension de F(A).
Para ello, primero, se puede comprobar que en cada operacion elemental realizada en la matriz Apara hacerla escalonada, sus vectores filas se transforman en otros vectores que dependen linealmentede los anteriores, por lo que el subespacio de las combinaciones lineales de los vectores filas de la matrizobtenida esta contenido en el subespacio fila de la matriz de la que provenıa y al final F (E(A)) ⊂F (A). Como las operaciones elementales tienen como inversas, otras operaciones elementales; alvolver hacia atras desde E(A) a A, en cada operacion elemental ocurre lo mismo: el subespacioengendrado por los vectores filas esta contenido en el anterior, por lo que F (A) ⊂ F (E(A))), luegoF (A) = F (E(A))).
Despues, sean ei = (ei1, ei2....ein) i ≤ m, las filas de E(A) y ei = (ei1, ei2....ein) i ≤ r las filas nonulas de E(A); por lo anterior, F (A) = Lv1, v2, ..., vi, ...vm =L e1, e2, ..., ei, ...em =Le1, e2, ..., ei, ...erya que podemos prescindir de las filas nulas.
Como los vectores filas no nulas de E(A) son independientes y forman un sistema generador delsubespacio Le1, e2, ..., ei, ...er = Lv1, v2, ..., vi, ..., vm, son una base de este subespacio.
Cualquiera que sea la forma en que escalonamos la matriz A, el numero de filas no nulas (y, portanto, el numero de escalones) coincide con la dimension del subespacio F(A).
Dicho de otra manera, si escalonando de otra forma, obtenemos que Le′1, e′2, ..., e′i, ...e′r′ =Lv1, v2, ..., vi, ..., vm, como e1, e2, ..., ei, ...er y e′1, e′2, ..., e′i, ...e′r′ son dos bases del mismo sub-espacio vectorial, han de tener el mismo numero de elementos, luego r = r′.
En el transcurso de esta demostracion hemos hallado una base del subespacio vectorial engen-drado por las filas de una matriz. Por tanto, si nos dan un subespacio vectorial por una familia degeneradores, una manera de obtener una base de ese subespacio es escribir la matriz formada por lascoordenadas de esos vectores en filas y escalonarla y los vectores correspondientes a las filas no nulasde la matriz escalonada obtenida, son una base del subespacio dado.
Si queremos que la base sea un subconjunto del conjunto de generadores dado, seguimos elsiguiente procedimiento:
Extraccion de la base a partir de un sistema generador.
Se deduce de lo visto en la proposicion 9 que para extraer una base de un sistema generador hayque ir eliminando los vectores que dependan de los demas. Esto, a veces, puede hacerse a simple
156

vista, pero, en general, no. Veremos como escoger un sistema generador independiente utilizandoel rango de la matriz que tiene por filas las coordenadas de los vectores generadores en una baseprefijada.
El numero de vectores que tenemos que escoger es igual a la dimension del subespacio considerado.Sea S = Lv1, v2, ..., vi, ...vm donde cada vi = (vi1, vi2....vin) esta expresado en una base prefijada
del espacio total. Llamamos A a la matriz que tiene por filas las coordenadas de cada vi y la reducimosa su forma escalonada a la que llamamos E(A). Sabemos (por el procedimiento de la demostraciondel teorema de Rouche-Frobenius) que el numero de filas no nulas de una matriz escalonada E(A) ala que A se reduzca es igual al maximo de los ordenes de los menores distintos de cero de A, al quevamos a llamar r. Hemos visto que este numero (el de filas no nulas de la matriz escalonada E(A))es la dimension del subespacio vectorial engendrado por los vectores vii≤m. Luego es r, el numerode vectores independientes que tenemos que escoger.
Tenemos que decidir ahora cuales pueden ser esos r vectores. Por la definicion de rango, podemosescoger en A un menor de orden r distinto de cero; consideramos la submatriz formada por las rfilas de las dadas que intersecan con este menor distinto de cero. El rango de esta submatriz es r,por lo que el subespacio engendrado por esas filas es de dimension r. Como este subespacio estacontenido en el dado y es de su misma dimension, coincide con el dado y podemos escoger las r filascorrespondientes a la submatriz considerada para formar una base del subespacio dado.
Ejercicios:
5.11.1. Calcular la dimension y extraer una base del subespacio de R5 engendrado por(1, 0, 1, 0, 1), (0, 1, 1, 0, 1), (1, 1, 3, 1, 1), (0, 0, 1, 1, 1), (0,−1, 1, 2, 1)5.11.2. Encontrar una base de R4 que contenga a los vectores (0, 0, 1, 1), (1, 1, 0, 0)5.11.3. Calculese segun los valores de α, β, γ la dimension del espacio vectorial:S = L(1, 1, 0), (2, 1, α), (3, 0, β), (1, γ, 1)5.11.4. Dado el subespacio vectorial de las matrices cuadradas 2× 2 engendrado por(
1 00 1
),
(0 11 0
),
(1 11 1
),
(1 −1−1 1
)extraer una base del subespacio considerado, de este sistema de generadores.
5.11.5. Dado el subespacio vectorial de los polinomios de grado 3 engendrado por los vectores:x2 − 1, x2 + 1, x3 + 4, x3 extraer una base de este sistema de generadores.
157

Tambien, del procedimiento anterior se deduce que el rango de una matriz A es igual al numerode sus filas independientes, ya que siempre se puede extender un sistema independiente de vectoresa una base de F(A) y un numero de vectores superior al de la dimension del subespacio F(A) esdependiente.
Y como el rango de A, como maximo de los ordenes de los menores distintos de cero de A, esigual al rango de su traspuesta, este rango es igual al numero de filas independientes de tA, es decir,al numero de columnas de A.
Aplicacion del rango a la obtencion de las ecuaciones cartesianas de un subespaciodado por sus generadores.
Para simplificar los calculos, se obtiene primero una base del subespacio dado. Una vez obtenidauna base del subespacio vectorial dado por sus generadores, la condicion necesaria y suficiente paraque un vector (x1, x2, ..., xn) sea del subespacio es que dependa linealmente de los vectores de la base,es decir, que el rango de la matriz que tiene por filas las componentes de los vectores de la base seaigual al rango de esta matriz aumentada con la fila (x1, x2, ..., xn).
Como el rango de la matriz que tiene por filas las coordenadas de los vectores de la base es igualal numero de estos, (llamemoslo r), podemos encontrar en ella un menor de orden r distinto de cero.Agrandamos la matriz formada por las coordenadas de los vectores de la base en filas con la fila(x1, x2, ..., xn) debajo de las anteriores; completando ahora el menor encontrado de todas las formasposibles a un menor de orden r+1 en la matriz agrandada con las columnas que no aparecen endicho menor, obtenemos n-r expresiones lineales en las coordenadas que han de ser cero para que elnuevo vector (x1, x2, ..., xn) pertenezca al subespacio. Estas n-r condiciones necesarias son tambiensuficientes para que el vector dependa linealmente de los de la base. Para darnos cuenta de ello,tengamos en cuenta que al ser el determinante de una matriz igual al de su traspuesta, el rango dela matriz, no solo es el numero de filas independientes, sino el numero de columnas independientesy que la anulacion de cada una de las expresiones obtenidas indica que cada columna de la matrizagrandada depende linealmente de las columnas del menor distinto de cero de orden r encontrado.Por ello aseguran que el numero de columnas independientes de la matriz agrandada es r; y tambien elnumero de sus filas, por lo que aseguran que la fila (x1, x2, ..., xn) pertenece al subespacio considerado.
Ninguna de estas ecuaciones es superflua porque considerando la matriz de los coeficientes delsistema homogeneo formado por ellas, las n-r columnas formadas por los coeficientes de las incognitasque no estan debajo de las del menor distinto de cero tienen solo un elemento distinto de cero devalor absoluto igual al del menor distinto de cero, permutado ademas de tal forma que dan lugar aun menor de orden n-r distinto de cero. Conviene comprobarlo con un ejemplo.
Ası tenemos n-r ecuaciones que son necesarias y suficientes para que un vector (x1, x2, ..., xn)pertenezca al subespacio.
158

Hay una sola ecuacion cuando la dimension del subespacio es n− 1; estos subespacios se llamanhiperplanos. El subespacio solucion de un sistema de ecuaciones homogeneo es una interseccion dehiperplanos. Y segun hemos visto ahora, los subespacios engendrados por una base de r vectores soninterseccion de n− r hiperplanos.
Ejercicios:
5.12.1. Hallar las ecuaciones cartesianas de los siguientes subespacios de R4:S1 = L(1, 0, 1, 0)(2, 1, 0,−1)(1,−1, 3, 1), S2 = L(3, 1, 0,−1)(1, 1,−1,−1), (7, 1, 2,−1), S3 =
L(0, 2, 5, 0).5.12.2. Hallar las ecuaciones cartesianas de los siguientes subespacios de R5:S1 = L(1, 0, 1, 0, 1)(0, 1, 1, 0, 1)(1, 1, 3, 1, 1), (0, 0, 1, 1, 1)(0,−1, 1, 2, 1),S2 = L(1, 0, 1, 0, 0)(2, 1, 0,−1, 1)(2, 0, 1, 0, 0), (3, 1, 0,−1, 1).
159

Calculo del rango de la matriz A y busqueda del menor distinto de cero de ordenigual al rango.
Segun la definicion de rango de A como el maximo de los ordenes de los menores distintos decero, parece que habrıa que calcularlos todos, pero teniendo en cuenta que tambien es el numero defilas independientes de la matriz, no es necesario calcular los determinantes de todas las submatricesde A, segun el procedimiento que vamos a ver.
Veamos antes un ejemplo: calculemos el rango de la matriz:0 1 −1 2 10 0 1 −3 −20 1 −1 −4 −30 2 1 −9 −60 1 0 −3 −2
Podemos prescindir de la primera columna de ceros, porque siempre que aparezca en un menor,
este menor tiene determinante cero.Empezamos aquı por el primer 1 de la primera fila y la segunda columna, que da un menor de
orden uno distinto de cero.Ahora, lo orlamos con elementos de la segunda fila y de la segunda columna para formar un
menor de orden 2.De esta forma, obtenemos:
det
(1 −10 1
)= 1 6= 0
Entonces, el rango de la matriz primitiva es mayor o igual que dos y las filas 1a y 2a son inde-pendientes.
Ampliamos este menor con la fila 3a y columna 3a, obteniendo:
det
1 −1 20 1 −31 −1 −4
= 0
y con la fila 3a
y con la columna 4a
obteniendo:
det
1 −1 10 1 −21 −1 −3
= 0
160

Ya que la anulacion de estos dos determinantes implica la dependencia lineal de las dos ultimascolumnas de la matriz 0 1 −1 2 1
0 0 1 −3 −20 1 −1 −4 −3
respecto a las dos primeras, se sigue de la anulacion de estos dos determinantes, la anulacion de
det
−1 2 11 −3 2−1 −4 −3
ya que sus tres columnas perteneces a un espacio de dimension 2. Por tanto, no es necesario calculareste determinante.
Al mismo tiempo, el numero de filas independientes de la matriz 0 1 −1 2 10 0 1 −3 −20 1 −1 −4 −3
es igual a su numero de columnas independientes igual a 2.
Como calcular el rango de la matriz total es calcular el numero de filas independientes, podemosprescindir de la 3a fila en el calculo de las filas independientes y no tenemos que calcular ningundeterminante de ningun menor de orden mayor que 3 en el que aparezcan las tres primeras filas.
Ampliamos ahora el menor de orden 2 distinto de cero obtenido con elementos de la 4a fila y 3a
columna y obtenemos:
det
1 −1 20 1 −32 1 −9
= −4 6= 0
Entonces, el rango es mayor o igual que 3 y las filas 1a, 2a y 4a son independientes.Para ver si la ultima fila es independiente de las anteriores, ampliamos el menor de orden 3
obtenido a un menor de orden 4, obteniendo:
det
1 −1 2 10 1 −3 −22 1 −9 −61 0 −3 −2
= det
1 −1 2 10 1 −3 −20 3 −13 −80 1 −5 −3
= 0
Ya podemos concluir que el rango de la matriz es tres sin necesidad de calcular mas menores.Podrıamos pensar que quiza otra submatriz de orden cuatro con otras filas pudiera tener determinante
161

distinto de cero. Pero lo que se deduce de que el anterior determinante es cero, es que la ultima filadepende de las otras, luego solo hay tres filas independientes. Entonces, el espacio engendrado porlas filas de la matriz es de dimension 3 y cualesquiera que sean las cuatro filas que escojamos, por laproposicion 8, son dependientes, siendo por tanto el menor formado, nulo y el rango de A no superiora 3.
Nos hemos ahorrado el calculo de los determinantes:∣∣∣∣∣∣∣∣0 1 −3 −21 −1 −4 −32 1 9 −61 0 −3 −2
∣∣∣∣∣∣∣∣ ,∣∣∣∣∣∣∣∣
1 −1 2 11 −1 −4 −32 1 9 −61 0 −3 −2
∣∣∣∣∣∣∣∣ ,∣∣∣∣∣∣∣∣
1 −1 2 10 1 −3 −21 −1 −4 −31 0 −3 −2
∣∣∣∣∣∣∣∣ ,∣∣∣∣∣∣∣∣
1 −1 2 10 1 −3 −21 −1 −4 −32 1 9 −6
∣∣∣∣∣∣∣∣Estableciendo, en general, el procedimiento de calculo del rango de una matriz:
Podemos prescindir de las columnas nulas y de las filas nulas de la matriz porque no aumentanel orden de los menores con determinante distinto de cero.
Hecho esto, despues de una permutacion de filas, (que no altera el rango), si es necesario, podemossuponer que a11 es distinto de cero. Entonces consideramos todos los menores de orden dos en los quefigura a11 con elementos de la segunda fila, si alguno de estos menores es distinto de cero, el rangode la matriz es mayor o igual que dos. En caso contrario, el rango de la matriz formada por las dosprimeras filas es 1. Entonces, la segunda fila es multiplo de la primera, por ello podemos prescindirde ella en el calculo de las filas independientes. Repetimos el proceso con las restantes filas hastaencontrar, o bien que todas son multiplos de la primera y entonces el rango es uno y hemos acabado.O bien un menor de orden dos con determinante no nulo, y entonces, el rango es mayor o igual quedos y hemos encontrado dos filas independientes.
Para averiguar si el rango es mayor que dos, consideramos los menores de orden 3 obtenidos alampliar el primer menor de orden dos con determinante distinto de cero encontrado, con elementoscorrespondientes de las columnas siguientes y de la fila siguiente. Si todos los determinantes delas submatrices de orden 3 con esta fila son cero, esa fila depende de las dos anteriores y podemosprescindir de ella en la formacion de mas menores. Seguimos formando menores de orden 3 con lasfilas siguientes. Si todos los menores formados ası salen con determinante cero, las filas siguientesdependen de las dos primeras. Al haber solo dos filas independientes, otro menor cualquiera de orden3 es cero, el rango es dos y hemos acabado.
Si hay un menor de orden 3 con determinante distinto de cero, el rango de la matriz es mayor oigual que 3 y hemos encontrado tres filas independientes.
El procedimiento es analogo para ver si el rango de la matriz es mayor que 3, ampliando el menorde orden 3 distinto de cero encontrado con elementos de las columnas y de las filas siguientes.
162

Seguimos aumentando el tamano de los menores tanto como sea posible con el mismo proce-dimiento y cuando no podamos aumentar el tamano, hemos llegado al maximo orden de los menorescon determinante distinto de cero en los que aparece parcial o totalmente la primera fila no nula.
Podrıamos pensar que al formar submatrices que no empiecen en la 1a fila no nula, orlandolas luegocon elementos correspondientes de las otras columnas y otras filas se pudieran encontrar submatricesde orden superior al rango establecido anteriormente, con determinante distinto de cero. Pero enel procedimiento seguido hemos hallado el maximo numero de filas independientes. Este numero esla dimension del espacio vectorial engendrado por las filas, independiente del orden considerado alformar las submatrices. Por tanto no tenemos que comprobar mas determinantes de mas submatrices.
Ademas, como el rango de la matriz es la dimension del espacio engendrado por sus vectores filasy del espacio engendrado por sus vectores columnas, el orden de estas no influye en la dimension.Por ello, podemos hacer un intercambio de filas o de columnas antes de empezar a calcular menoressi vemos que las operaciones van a resultar mas faciles.
Ejercicios:
5.13.1. Estudiar, segun el valor de λ, los rangos de las siguientes matrices:
2 3 1 73 7 −6 −25 8 1 λ
,
3 1 1 4λ 4 10 11 7 17 32 2 4 3
,
1 λ −1 22 −1 λ 51 10 −6 1
.
5.13.2. Estudiar, segun los valores de λ la compatibilidad de los sistemas AX = b donde la matrizA|b es la dada a continuacion: 3 2 5
2 4 65 7 λ
∣∣∣∣∣∣135
,
λ 1 11 λ 11 1 λ
∣∣∣∣∣∣111
.
Aplicacion al metodo de Gauss.Las soluciones de un sistema homogeneo son un subespacio vectorial de dimension igual al numero
de incognitas menos el rango de la matriz del sistema y este rango se puede determinar calculandodeterminantes de menores de la matriz de coeficientes de la manera ordenada indicada.
163

SUMA E INTERSECCION DE SUBESPACIOS VECTORIALES.
La interseccion de dos subespacios vectoriales es su interseccion conjuntista. El corolario 1 afirmaque es otro subespacio vectorial.
Se define la suma de dos subespacios vectoriales como el conjunto de los vectores que son suma devectores de los dos subespacios. Puede comprobarse como ejercicio, que es otro subespacio vectorialporque cumple las condiciones de la proposicion 2.
La suma de dos subespacios vectoriales esta engendrada por la union de dos sistemas generadoresde cada uno de los subespacios. Sus ecuaciones se obtienen a partir de este sistema generador,suprimiendo los generadores dependientes.
Las dimensiones de la suma y de la interseccion de dos subespacios estan relacionadas por laformula de las dimensiones para la suma y la interseccion de dos subespacios vectoriales.
Formula de las dimensiones:Si V1 y V2 son dos subespacios vectoriales,
dim(V1) + dim(V2) = dim(V1 + V2) + dim(V1 ∩ V2).
Cuando la interseccion de los dos subespacios es 0, la suma se llama suma directa,y se representa por V1 ⊕ V2.
Si ademas de ser la suma, directa, V1 ⊕ V2 = V , los dos subespacios se llaman complementarios.
Demostracion de la Formula de las dimensiones.Sean V1, V2, los subespacios vectoriales de dimensiones n1 y n2, respectivamente. Sea k la di-
mension de la interseccion. La base del subespacio interseccion se puede ampliar a una base de V1 y auna base de V2; podemos suponer que e1, e2, ..., ek es una base de V1∩V2, e1, e2, ..., ek, ek+1, ..., en1una base de V1, e1, e2, ..., ek, e′k+1, ..., e
′n2 una base de V2.
Nuestra formula esta demostrada si vemos que
e1, e2, ...ek, ek+1, ...en1 , e′k+1, e
′k+2, ...e
′n2
es una base de V1 + V2.Desde luego, los vectores
e1, e2, ...ek, ek+1, ...en1 , e′k+1, e
′k+2, ...e
′n2
son un sistema generador de la suma. En cuanto a la independencia lineal, sea
164

Σn1i=1λiei + Σn2−k
j=1 λ′je′k+j = 0
Veamos que todos los coeficientes han de ser nulos.Escribamos:
Σn1i=1λiei = −Σn2−k
j=1 λ′je′k+j
El vector del primer miembro de esta igualdad esta en V1 y el vector del segundo miembro de laigualdad esta en V2. Al ser iguales estos vectores, estan en la interseccion de V1 y de V2. Este vectorde V1 ∩ V2 se expresa de manera unica en cada una de las bases de V1, V2 y V1 ∩ V2.
Las coordenadas del vector en la base dada de V1 son las (λi)i≤n1 , de forma que si ha de estar enV1 ∩ V2 ha de ser λi = 0, para i tal que k < i ≤ n1, y las λii≤k son las coordenadas del vectoren la base de V1 ∩ V2. La suma considerada: Σn1
i=1λiei + Σn2−kj=1 λ′je
′k+j = 0, queda, entonces, como una
combinacion lineal nula de los vectores de la base de V2 y por tanto sus coeficientes han de ser cero.
Se pueden sacar importantes consecuencias de la formula de las dimensiones para la suma directade subespacios:
Si V1 + V2 = V1
⊕V2, por ser la interseccion de los dos subespacios cero, la union de las bases de
V1 y de V2 es una base de su suma directa. (Basta observar la demostracion).Si ademas los espacios son complementarios, la union de las dos bases es una base del espacio
total. Por eso, dado un subespacio V1, los vectores que se puedan anadir a la base de V1 para daruna base del espacio total, constituyen una base de un espacio complementario de V1.
Aunque la condicion para que dos espacios sean complementarios es que su interseccion sea elcero y su suma sea el total, solo es necesario comprobar una de estas dos condiciones y que la sumade las dimensiones de los dos subespacios es la dimension del espacio total, porque una de ellas seda contando con la otra y la formula de las dimensiones. Es decir:
a) Si V1
⋂V2 = 0, V1 y V2 son complementarios si y solo si la suma de sus dimensiones es la
dimension del espacio total.b) Si la suma de V1 y V2 es el espacio total, V1 y V2 son complementarios si y solo si la suma de
sus dimensiones es igual a la dimension del espacio total.
Veamos a):Si V1
⋂V2 = 0, la formula de las dimensiones implica que dim(V1 +V2) = dim(V1) + dim(V2); sea
V el espacio total, como V1 + V2 = V si y solo si tienen la misma dimension, V1 + V2 = V si y solo sidim(V1) + dim(V2) = dimV .
Veamos b):
165

Si V1+V2 = V , la formula de las dimensiones da dim(V1
⋂V2) = dim(V1)+dim(V2)−dim(V1+V2);
por tanto V1
⋂V2 = 0(≡ dim(V1
⋂V2) = 0) si y solo si dim(V1) + dim(V2) − dim(V1 + V2) = 0, es
decir, si dim(V1) + dim(V2) = dim(V1 + V2) = dimV.
Ejercicios:
5.14.1. Siendo S1 = L(1,−5, 2, 0)(1,−1, 0, 2) y S2 = L(3,−5, 2, 1)(2, 0, 0, 1), hallar una basey las ecuaciones cartesianas de S1 + S2 y de S1
⋂S2.
5.14.2. Siendo S1 = L(1, 0, 1, 0)(2, 1, 0,−1) y S2 = L(3, 1, 0,−1)(1, 1,−1,−1), hallar unabase y las ecuaciones cartesianas de S1 + S2 y de S1
⋂S2.
5.14.3. Sean S1 = L(1, 0, 1, 0, 1)(2, 1, 0,−1, 0)(2, 0, 1, 0, 1) y S2 = L(3, 1, 0,−1, 0)(1, 1,−1,−1,−1),comprobar que S1 + S2 = S1 y S1
⋂S2 = S2.
5.14.4. Siendo S1 = L(1, 1, 2, 0)(−2, 0, 1, 3) y S2 = L(0, 2, 5, 0)(−1, 1, 3, 2), hallar una base ylas ecuaciones cartesianas de S1 + S2 y S1
⋂S2.
5.14.5. Siendo S1 = L(0, 1, 1, 0)(1, 0, 0, 1) y
S2 ≡x1 +x2 +x3 +x4 = 0x1 +x2 = 0
hallar una base y las ecuaciones cartesianas de S1 + S2 y S1
⋂S2.
5.14.6. Siendo
S1 ≡x1 −x3 = 0
x2 −x4 = 0
y
S2 ≡x1 +x2 +x3 +x4 = 0x1 +x2 = 0
hallar una base y las ecuaciones cartesianas de S1 + S2 y S1
⋂S2.
5.14.7. Siendo F1 el plano de ecuacion x+ 2y − z = 0 y F2 la recta de ecuaciones
x −y +2z = 0−2x +2y +z = 0
Averiguar si son complementarios.
5.14.8. Siendo V1 = L(1, 1, 0), (1, 0, 1) y V2 = L(0, 1, 1). Averiguar si son complementarios.5.14.9. Comprobar que son complementarios los subespacios de ecuaciones:
S1 ≡−2x1 −5x2 +4x3 = 0−2x1 +7x2 +4x4 = 0
S2 ≡x1 +2x2 +x4 = 0x1 −2x2 +x3 = 0
5.14.10. Hallar una base y las ecuaciones cartesianas de un espacio complementario de
166

a) S1 = L(0, 2, 5, 0)(−1, 1, 3, 2).b) S2 = L(1, 1, 0, 0)(1, 0, 1, 0)(0, 0, 1, 1)(0, 1, 0, 1)5.14.11. Hallar una base de S1
⋂S2 donde
S1 = L(
1 10 0
),
(0 11 0
),
(0 01 1
)S2 = L
(1 01 0
),
(1 −10 0
),
(0 1−1 0
)¿Cual es S1 + S2?.5.14.12. Hallar una base de S1
⋂S2 y de S1 + S2, donde
S1 = L(
1 10 0
),
(0 01 1
)S2 = L
(1 00 1
),
(0 11 0
)Hallar tambien las ecuaciones cartesianas de S1
⋂S2 y de S1 + S2.
5.14.13. EnM2×2(R) se consideran los subespacios que conmutan con cada una de las siguientesmatrices:
A =
(1 10 2
)B =
(1 11 1
)a) Hallar una base de cada uno de ellos, de su suma y de su interseccion.b) Hallar una base de un espacio complementario del subespacio de las matrices que conmutan
con A.5.14.14. Sea
M =
1 0 00 2 00 0 1
,
y S1 = A|AM = A, S2 = B|MB = B.Encontrar dimensiones y bases de S1
⋂S2 y de S1 + S2.
5.14.15. Hallar los subespacios suma e interseccion de los siguientes subespacios de las matricescuadradas de orden n:
a) El subespacio de las matrices triangulares superiores de orden n y el subespacio de las matricestriangulares inferiores.
b) El subespacio de las matrices simetricas de orden n y el subespacio de las matrices antisimetricasde orden n.
167

5.14.16. Hallar los subespacios suma e interseccion de los siguientes subespacios del espacio delos polinomios de grado ≤ 3: S1 es el subespacio de los polinomios multiplos de x + 1 y S2 es elsubespacio de los polinomios multiplos de x− 1.
5.14.17. En R4 sean U = Lu1, u2 y V = Lv1, v2 donde
u1 = (1, 1, 2,−λ), u2 = (−1, 1, 0,−λ), v1 = (1, λ, 2,−λ), v2 = (2, 3, λ, 1)
Hallar segun los valores de λ las dimensiones de U , V U + V , U⋂V .
Ejemplos resueltos y mas problemas propuestos en el capıtulo 3 de (A), en el capıtulo 4 de (Gr),en el capıtulo 6 de (H) y en el capıtulo 3 de (S2).
168

BIBLIOGRAFIA.
(A) Algebra Lineal y aplicaciones. J. Arvesu Carballo, R. Alvarez Nodarse, F. MarcellanEspanol. Ed. Sıntesis Madrid. 1999.
(Gr) Algebra lineal con aplicaciones. S. I. Grossman. Ed. Mc Graw Hill 2001.[G] Matematicas 2 Bachillerato. Carlos Gonzalez Garcıa. Jesus Llorente Medrano. Maria Jose
Ruiz Jimnez. Ed. Editex. 2009.(H) Algebra y Geometrıa. Eugenio Hernandez. Addison- Wesley / UAM, 1994.[M] Matematicas 2 Bachillerato. Ma Felicidad Monteagudo Martınez. Jesus Paz Fernandez Ed.
Luis Vives. 2003.(S) Algebra lineal y sus aplicaciones. G. Strang Ed. Addison-Wesley Iberoamericana. 1990.(S2) Introduction to Linear Algebra. G.Strang Ed. Wellesley-Cambridge Press 1993.
169

170

APLICACIONES LINEALES.
Introduccion.
Una aplicacion lineal entre espacios vectoriales sobre el mismo cuerpo es una aplicacion querespeta las operaciones de espacio vectorial, es decir, aplica la suma de vectores en la suma de susimagenes y el producto de un escalar por un vector en el producto del escalar por la imagen delvector, respectivamente.
Definicion:Sean V1 y V2 dos espacios vectoriales sobre el mismo cuerpo y f una aplicacion de V1 en V2. Se
dice que f es una aplicacion lineal sia) Dados dos vectores cualesquiera v y v′ de V1, f(v + v′) = f(v) + f(v′).b) Dados un vector v de V1 y un elemento del cuerpo λ, f(λv) = λf(v).
Las aplicaciones lineales se llaman tambien homomorfismos.
Las aplicaciones lineales nos permiten trasvasar los resultados encontrados en unos espacios vec-toriales a otros en los que la intuicion es mas difıcil.
Ademas, la importancia de la estructura de espacio vectorial esta en que no solo la encontramosen los conjuntos de vectores del plano o del espacio, sino en que se puede trasmitir a otros conjuntosque estan en correspondencia biyectiva con algun Rn o algun Cn, haciendo la biyeccion una aplicacionlineal.
Consecuencia inmediata de la definicion es:1) f(0) = f(0 · v) = 0 · f(v) = 0.2) f(−v) = f((−1)v) = (−1)f(v) = −f(v), ∀v ∈ V1.
Cuando el espacio original y el espacio final coinciden, el homomorfismo se llama endomorfismo.Un ejemplo de endomorfismos son las aplicaciones que resultan al multiplicar los vectores del
espacio por un numero fijo: fα(v) = αv ∀v ∈ V . Estas aplicaciones se llaman homotecias.Las proyecciones sobre una recta de R2 o de R3 y sobre un plano de R3 son aplicaciones lineales.
(Vease el dibujo siguiente).
171

*
v
v’
|p(v′)|
CC
CC
CC
CC
CC
CC
CC
CC
CC
CC
CC
CC
CCC
:
:
:
p(v)p(v+v’)
v+v’
Las simetrıas respecto a rectas o planos en R3 son endomorfismos. (Vease el dibujo siguiente).
-3
1
s(v)
s(v’)s(v+v’)
6
vv’
v+v’
172

La aplicacion que hace corresponder a cada matriz cuadrada su traza es una aplicacion linealdefinida en cada espacio vectorial de matrices cuadradas de orden n con valores en el cuerpo del queson las entradas de la matriz.
La aplicacion derivada hace corresponder a un polinomio de grado ≤ n otro polinomio de grado≤ n − 1, por tanto es tambien una aplicacion del espacio vectorial de polinomios de grado ≤ n concoeficientes reales en el espacio vectorial de polinomios de grado ≤ n− 1 con coeficientes reales. Sepuede comprobar que es una aplicacion lineal.
La aplicacion de R en R definida por f(x) = x + 1 no cumple la condicion 1). Por tanto no eslineal. A pesar de que la aplicacion de R en R definida por f(x) = x2 cumple la condicion 1), nocumple la condicion 2), por lo que tampoco es lineal.
Ejercicios:
6.1.1. Averiguar si son aplicaciones lineales las siguientes aplicaciones:a) La aplicacion del espacio vectorial de las matrices cuadradas de orden n en el espacio vectorial
de las matrices antisimetricas de orden n dada por A(B) = 12(B − tB).
b) La aplicacion traza definida en el espacio vectorial de las matrices cuadradas 3×3 con entradasreales sobre R.
c) La aplicacion del espacio vectorial de los polinomios de grado ≤ n en este mismo conjuntodada por T (p(x)) = p(x− 1).
d) La aplicacion del espacio vectorial de los polinomios de grado ≤ n en este mismo espaciovectorial dada por T (p(x)) = p(x)− 1.
e) La aplicacion del espacio vectorial de las matrices cuadradas de orden n en el mismo espaciovectorial dada por P (A) = AB donde B es una matriz fija.
f) La aplicacion del espacio vectorial de las matrices cuadradas de orden n en el mismo espaciodada por Q(A) = A+B donde B es una matriz fija.
g) La aplicacion del espacio vectorial de las matrices cuadradas de orden n en el mismo espaciodada por C(A) = AB −BA donde B es una matriz fija.
173

La suma de aplicaciones lineales es otra aplicacion lineal. El producto de una aplicacion linealpor un numero es una aplicacion lineal. Pueden comprobarse como ejercicio facilmente estas dosafirmaciones y por tanto que el conjunto de las aplicaciones lineales definidas entre dos espaciosvectoriales es otro espacio vectorial, que denotamos por L (V1, V2). Como consecuencia del parrafosiguiente vamos a ver que L (V1, V2) se puede equiparar a un espacio vectorial de matrices.
Expresion matricial de una aplicacion lineal.
Primero, queremos pasar del concepto de aplicacion lineal a ciertos numeros que la determinen yluego obtener numeros que la caractericen.
Fijada e1, e2, ...en, base de V1, f esta determinada por las imagenes de los elementos de esabase y fijada u1, u2, ..., um, base de V2, estas imagenes estan determinadas por sus coordenadas enesa base, como consecuencia, cada aplicacion lineal esta determinada por una matriz m× n:
Para determinarla, escribimos un vector x de V1 como x = x1e1 + x2e2 + ... + xnen y escribimosel vector y = f(x) de V2 como f(x) = y1u1 + y2u2 + ...+ ymum.
Entonces, si x es un vector de V1,
f(x) = f(x1e1 + x2e2 + ...+ xnen) = f(x1e1) + f(x2e2) + ...+ f(xnen) = por a)= x1f(e1) + x2f(e2) + ...+ xnf(en). por b)
Si las coordenadas de f(e1) son (a11, a21, ..., am1), las de f(e2) son (a12, a22, ..., am2)...,las de f(en)son (a1n, a2n, ..., amn), en la base de V2, las de y = f(x) son:
y1
y2...ym
= x1
a11
a21...am1
+ x2
a12
a22...am2
+ · · ·+ xn
a1n
a2n...
amn
=
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...am1 am2 · · · amn
x1
x2...xn
La matriz
A =
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...am1 am2 · · · amn
se llama matriz de la aplicacion f en las bases dadas. Se escribe, de forma abreviada, una aplicacionlineal por f(x) = Ax. Las columnas de esta matriz estan formadas por las coordenadas de losvectores imagenes de los de la base del primer espacio expresados en la base del segundo espacio.
174

Dados dos espacios vectoriales y escogidas una base en cada uno de ellos, hemos visto que corres-ponde a cada aplicacion lineal entre los dos, una matriz A ∈ M m×n. Recıprocamente, dados dosespacios vectoriales V1 y V2 de dimensiones respectivas n y m, y escogidas una base en cada uno deellos, a cada matriz A ∈ M m×n le corresponde una aplicacion lineal definida por f(x) = Ax, dondex es la columna de las coordenadas de un vector de V1 en una base de este y Ax es la columna delas coordenadas de su imagen en una base correspondiente de V2. Se comprueba facilmente que f eslineal utilizando las propiedades del producto de matrices.
Es facil ver que esta correspondencia es biyectiva entre el espacio vectorial de las aplicacioneslineales entre V1 y V2 yM m×n(K) una vez fijadas las bases de estos, y que a su vez es una aplicacionlineal, que por ello identifica L (V1, V2) con M m×n(K).
La expresion abreviada Ax = f(x) nos recuerda la expresion abreviada Ax = b de un sistemade ecuaciones lineales. Nos indica que resolver el sistema Ax = b es encontrar un vector x delprimer espacio que se aplica en b por la aplicacion f de la misma matriz A. Si no existe este vector,el sistema es incompatible, si existe solo un vector, es compatible determinado, si existen muchosvectores cumpliendo esa condicion, el sistema es compatible indeterminado.
Ejercicios:
6.2.1. Escribir la matriz de la simetrıa de R2 respecto a:a) El eje coordenado OX.b) El eje coordenado OY.c) La diagonal del primer cuadrante.d) La diagonal del segundo cuadrante.6.2.2. Escribir las matrices de las proyecciones ortogonales de R2 sobre las distintas rectas enuncia-
das en el ejercicio anterior.6.2.3. Escribir la matriz de un giro:a) de noventa grados en sentido positivo (contrario al de las agujas del reloj), alrededor del origen
en R2
b) de angulo α en sentido positivo alrededor del origen en R2.6.2.4. Escribir la matriz de la simetrıa de R3 respecto a:a) El plano de ecuacion y = x.b) El plano de ecuacion y = z.c) El plano de ecuacion x = z.d) La recta de ecuaciones y = x, z = 0.e) La recta de ecuaciones y = z, x = 0.
175

f) La recta de ecuaciones x = z, y = 0.6.2.5. Escribir las matrices de las proyecciones ortogonales de R3 sobre los distintos planos y
rectas enunciados en el ejercicio anterior.6.2.6. Determinar la matriz que corresponde en la base canonica al endomorfismo de R3 que
transforma los vectores (3, 2, 1)(0, 2, 1)(0, 0, 1) en los vectores (1, 0, 0)(1, 1, 0)(1, 1, 1) respetandoel orden. (Se pueden calcular facilmente las imagenes de los vectores de la base canonica).
6.2.7. Hallar la matriz en las bases canonicas de la aplicacion del espacio de los polinomios degrado ≤ 3 en R4 dada por f(p(x))=(p(-1),p(1),p(-2),p(2)).
6.2.8. Hallar las matrices en las bases canonicas de las siguientes aplicaciones:a) La aplicacion A de R3 en R3 dada por A(x, y, z) = (x− y + 2z, x+ y, 2x+ 2y + z).b) La aplicacion B de C2 en C2 dada por B(z1, z2) = (iz1 + 2z2, z1 − iz2).c) La aplicacion C de R3 en R3 dada por C(x, y, z) = (x+ z, y, x+ y + z).d) La aplicacion D de C2 en C3 dada por D(z1, z2) = (iz1 + z2, z1 + iz2, z1 − iz2).e) La aplicacion E de R2 en R4 dada por E(x, y) = (x, x+ y, 2x, x+ 2y)6.2.9. Hallar la matriz en las bases canonicas de la aplicacion traza considerada en el espacio de
las matrices cuadradas de orden 2 de numeros reales con valores en R.
176

Como la matriz de una aplicacion lineal depende de las bases escogidas, no es un invarianteintrınseco de la aplicacion lineal y por ello tenemos que ver que le ocurre al cambiar las bases.Veamos como estan relacionadas las matrices que coresponden a una aplicacion lineal en las distintasbases.
Cambio de base en la expresion matricial de una aplicacion lineal.Sean e1, e2, ..., en base de V1, u1, u2, ..., um base de V2 y f un homomorfismo dado en estas
bases por
f(x) =
y1
y2...ym
=
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...am1 am2 · · · amn
x1
x2...xn
≡ Ax
Sean e′1, e′2, ..., e′n otra base de V1, u′1, u′2, ..., u′m otra base de V2 y A′ la matriz de f en lasnuevas bases. Si (x′1, x
′2, ..., x
′n) son las coordenadas de x e (y′1, y
′2, ..., y
′n) son las coordenadas de
y = f(x) en las nuevas bases, se tiene la relacion:
f(x) =
y′1y′2...y′m
= A′
x′1x′2...x′n
Para ver la relacion entre A y A’ recordemos que las coordenadas de un vector x de V1 en las dos
bases estan relacionadas porx1
x2...xn
=
c11 c12 · · · c1nc21 c22 · · · c2n...
.... . .
...cn1 cn2 · · · cnn
x′1x′2...x′n
= C
x′1x′2...x′n
Las coordenadas de un vector y de V2 en las dos bases estan relacionadas por
y1
y2...ym
=
d11 d12 · · · d1m
d21 d22 · · · d2m...
.... . .
...dm1 dm2 · · · dmm
y′1y′2...y′m
= D
y′1y′2...y′m
Recordemos que las columnas de las matrices C y D son las coordenadas de los vectores de las
nuevas bases en las antiguas y que estas matrices son invertibles.
177

Sustituyendo respectivamente estas relaciones en la expresion de la aplicacion lineal, tenemos:d11 d12 · · · d1n
d21 d22 · · · d2m...
.... . .
...dm1 dm2 · · · dmm
y′1y′2...y′m
=
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...am1 am2 · · · amn
c11 c12 · · · c1nc21 c22 · · · c2n...
.... . .
...cn1 cn2 · · · cnn
x′1x′2...x′n
De dondey′1y′2...y′m
=
d11 d12 · · · d1n
d21 d22 · · · d2m...
.... . .
...dm1 dm2 · · · dmm
−1
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...am1 am2 · · · amn
c11 c12 · · · c1nc21 c22 · · · c2n...
.... . .
...cn1 cn2 · · · cnn
x′1x′2...x′n
Esta es la expresion matricial de la aplicacion lineal en las nuevas bases. Por lo que A′ = D−1AC.
las columnas de D−1 son las coordenadas de los vectores de la base primera en la base segunda dentrodel segundo espacio.
Otra forma de ver la modificacion que sufre la matriz de la aplicacion lineal al realizar un cambiode base es darse cuenta de que la matriz A de una aplicacion lineal sirve para expresar los vectores¨(f(e1), f(e2), ..., f(en)) en funcion de los vectores (u1, u2, ...um) segun la relacion: ¨
(f(e1), f(e2), ..., f(en)) = (u1, u2, ...um)
a11 a12 · · · a1n
a21 a22 · · · a2n...
.... . .
...am1 am2 · · · amn
= (u1, u2, ...um)A
La matrizA′ expresarıa los vectores ¨(f(e′1), f(e′2), ..., f(e′n)) en funcion de los vectores (u′1, u′2, ...u
′m)
segun la relacion: ¨
(f(e′1), f(e′2), ..., f(e′n)) = (u′1, u′2, ...u
′m)
a′11 a′12 · · · a′1na′21 a′22 · · · a′2n...
.... . .
...a′m1 a′m2 · · · a′mn
= (u′1, u′2, ...u
′m)A′
Como
178

(e′1, e′2, ..., e
′n) = (e1, e2, ..., en)
c11 c12 · · · c1nc21 c22 · · · c2n...
.... . .
...cn1 cn2 · · · cnn
implica
(f(e′1), f(e′2), ..., f(e′n)) = (f(e1), f(e2), ..., f(en))
c11 c12 · · · c1nc21 c22 · · · c2n...
.... . .
...cn1 cn2 · · · cnn
y
(u′1, u′2, ...u
′m) = (u1, u2, ...um)
d11 d12 · · · d1n
d21 d22 · · · d2m...
.... . .
...dm1 dm2 · · · dmm
sustituyendo en la expresion en las nuevas bases tenemos
(f(e1), f(e2), ..., f(en))
c11 c12 · · · c1nc21 c22 · · · c2n...
.... . .
...cn1 cn2 · · · cnn
= (u1, u2, ...um)
d11 d12 · · · d1n
d21 d22 · · · d2m...
.... . .
...dm1 dm2 · · · dmm
A′
de donde(f(e1), f(e2), ..., f(en)) = (u1, u2, ...um)DA′C−1
obteniendose tambien A = DA′C−1.
Si el homomorfismo es un endomorfismo, como coinciden el espacio original y el espacio final dela aplicacion, se utiliza normalmente la misma base en estos dos espacios y un cambio de base enla matriz de la aplicacion lineal se refiere al mismo cambio de base en V considerado como espacioinicial y como espacio final. Entonces C = D y A′ = C−1AC. Todas las matrices correspondientesa un endomorfismo en distintas bases se llaman equivalentes.
179

Como aplicacion del mecanismo de cambio de base en endomorfismos se puede hallar facilmentela matriz de las simetrıas ortogonales y de las proyecciones ortogonales que permiten escoger basesen las que su expresion es muy facil. La expresion de estas aplicaciones en la base canonica seencuentra haciendo el cambio de base necesario en cada caso desde la base que da la expresion facilde la aplicacion a la base canonica.
Aplicacion 1.1) Matriz de la simetrıa ortogonal de R3 respecto al plano de ecuacion x− y + z = 0:Esta simetrıa deja invariantes los vectores del plano y transforma en su opuesto el vector perpen-
dicular al plano.Sean dos vectores independientes del plano e′1 = (1, 1, 0), e′2 = (1, 0,−1). Estos dos vectores
junto al vector perpendicular al plano e′3 = (1,−1, 1) forman una base de R3 en la que la matriz dela simetrıa es:
A′ =
1 0 00 1 00 0 −1
.
Como la matriz de cambio de base de las coordenadas de la nueva base a las coordenadas de labase canonica es x1
x2
x3
=
1 1 11 0 −10 −1 1
x′1x′2x′3
la matriz en la base canonica de la simetrıa considerada es:
A =
1 1 11 0 −10 −1 1
1 0 00 1 00 0 −1
1 1 11 0 −10 −1 1
−1
=1
3
1 2 −22 1 2−2 2 1
Aplicacion 2.Matriz de la proyeccion ortogonal de R3 sobre la recta engendrada por el vector (1,1,1):En esta proyeccion el vector de la recta queda fijo y se aplican en cero los vectores ortogonales a
la recta.El vector de la recta e′1 = (1, 1, 1) junto con dos vectores independientes ortogonales a el: e′2 =
(1,−1, 0) e′3 = (1, 0,−1) forman una base en la que la matriz de la aplicacion es:
A′ =
1 0 00 0 00 0 0
.
180

Como la matriz de cambio de base de las coordenadas de la nueva base a las coordenadas de labase canonica es x1
x2
x3
=
1 1 11 −1 01 0 −1
x′1x′2x′3
la matriz en la base canonica de la proyeccion considerada es:
A =
1 1 11 −1 01 0 −1
1 0 00 0 00 0 0
1 1 11 −1 01 0 −1
−1
=1
3
1 1 11 1 11 1 1
Ejercicios:
6.3.1. Dada la aplicacion de R2 en R4 por la matriz:1 00 11 00 1
en las bases canonicas, hallar la matriz de dicha aplicacion en las bases (0, 1), (1, 1) de R2 y(1, 1, 0, 0), (0, 1, 1, 0), (0, 0, 1, 1)(0, 0, 0, 1) de R4.
6.3.2. Dada la aplicacion de R2 en R4 por la matriz:1 00 11 00 1
en las bases (0, 1), (1, 1) de R2 y (1, 1, 0, 0), (0, 1, 1, 0), (0, 0, 1, 1)(0, 0, 0, 1) de R4, hallar la matrizde dicha aplicacion en las bases canonicas.
6.3.3. Hallar, haciendo un cambio de base, la expresion matricial en la base canonica de laaplicacion lineal f de R3 en R3 tal que: f(1, 1, 0) = (1, 1, 1), f(1, 0,−1) = (0, 1, 1), f(1,−1, 1) =(1, 2, 2).
6.3.4. Comprobar mediante un cambio de base, la matriz en la base canonica obtenida para laaplicacion lineal del ejercicio 6.2.6.
6.3.5. Hallar la matriz de la aplicacion lineal del ejercicio 6.2.6.a) en la base (3, 2, 1)(0, 2, 1)(0, 0, 1).
181

b) en la base (1, 0, 0)(1, 1, 0)(1, 1, 1).c) Comprobar que las matrices obtenidas anteriormente estan relacionadas con la matriz del
endomorfismo en la base canonica por las matrices de cambio de base correspondientes entre lasbases.
6.3.6. Utilizando cambios de base calculense las matrices en las bases canonicas dea) La simetrıa ortogonal de R3 respecto a la recta engendrada por el vector (−1, 1,−1).b) La proyeccion ortogonal de R3 sobre el plano de ecuacion x+ y + z = 0.c) Las rotaciones vectoriales de noventa grados de R3 respecto a la recta de ecuaciones:x+ y = 0, z = 0.
182

A pesar de que la expresion matricial no es una propiedad intrınseca de la aplicacion (porquedepende de las bases escogidas en los espacios), podemos llegar, utilizandola, a la determinacion desubespacios asociados de manera intrınseca a la aplicacion lineal. Estos subespacios son el nucleo yla imagen de la aplicacion lineal. Sus dimensiones son numeros independientes de la base escogidasiendo por tanto, propiedades intrınsecas de dicha aplicacion.
Nucleo de una aplicacion lineal:Es el conjunto de vectores del primer espacio que se aplican en el elemento neutro del segundo
espacio.El nucleo de una aplicacion lineal es un subespacio vectorial ya que
Siempre contiene el cero por 1) ySi v1, v2 ∈ Nf y α1, α2 ∈ K, f(α1v1 + α2v2) = α1f(v1) + α2f(v2) = 0. i. e. α1v1 + α2v2 ∈ Nf .
El subespacio nucleo de la aplicacion lineal es independiente de su expresion matricial.
Fijandonos en la expresion matricial de la aplicacion lineal, vemos que fijada la base (e1, e2, ...en)de V1, el nucleo de la aplicacion lineal f es el conjunto de vectores de coordenadas (x1, x2, ...xn) enesa base tales que
a11 a12 · · · a1n
a21 a22 · · · a2n
· · · · · · . . . · · ·am1 am2 · · · amn
x1
x2...xn
=
00...0
Por tanto, el nucleo es el conjunto de soluciones del sistema homogeneo cuya matriz de coeficientes
es la matriz de la aplicacion lineal.Su dimension es por tanto la dimension del primer espacio menos el rango de la matriz de la
aplicacion lineal. Llegamos, por ello, a que el rango de dicha matriz es siempre el mismo, cualquieraque sean las bases escogidas en los espacios V1 y V2. Es un numero invariante de la aplicacion y sele llama rango de la aplicacion.
Las ecuaciones cartesianas del nucleo se obtienen eliminando en las ecuaciones AX = 0 delsistema, las ecuaciones cuyas filas dependan de las demas.
Una base del nucleo se obtiene resolviendo el sistema homogeneo obtenido.
Como ejemplo, hallemos el nucleo de una aplicacion lineal f de R5 en R3 dada por la matriz:
183

A =
3 2 1 1 −13 2 2 3 06 4 1 0 −3
.
El nucleo de f es el conjunto de vectores (x1, x2, x3, x4, x5) que verifican f(x) = 0, equivalente aA(x) = 0, es decir,
3x1 +2x2 +x3 +x4 −x5 = 03x1 +2x2 +2x3 +3x4 = 06x1 +4x2 +x3 −3x5 = 0
Este es el sistema del ejemplo 2 del capıtulo sobre espacios vectoriales y repito aquı su resolucion.Una forma sistematica de resolver un sistema homogeneo de ecuaciones lineales, que se puede
escribir en forma matricial por Ax=0, es reducir la matriz A a una matriz escalonada E por opera-ciones elementales y pasar en las ecuaciones de Ex=0, las incognitas de las columnas que no danescalon al segundo miembro.
Como hicimos en el capıtulo del metodo de Gauss:
3x1 +2x2 +x3 +x4 −x5 = 0x3 +2x4 +x5 = 0−x3 −2x4 −x5 = 0
≡ 3x1 +2x2 +x3 +x4 −x5 = 0x3 +2x4 +x5 = 0
Pasamos al segundo miembro las incognitas x2 x4 y x5 :
3x1 +x3 = −2x2 −x4 +x5
x3 = −2x4 −x5
Ahora, al recorrer las ecuaciones de arriba a abajo, las incognitas del primer miembro van dismi-
nuyendo de una en una, apareciendo solo una incognita despejada en el primer miembro en la ultimaecuacion. Sustituyendo esta incognita en la ecuacion anterior, podemos despejar otra incognita masy seguir ası despejando hasta agotar las incognitas de los primeros miembros.
En este ejemplo, sustituyendo el valor de x3 dado por la segunda ecuacion en la primera ecuaciontenemos: 3x1 = −2x2 + x4 + 2x5.
Podemos considerar todas las incognitas como funciones lineales de las variables pasadas al se-gundo miembro, anadiendo xi = xi para estas ultimas variables.
En este ejemplo, anadiendo x2 = x2, x4 = x4, x5 = x5, obtenemos las condiciones:
184

x1 = −23x2 +1
3x4+
23x5
x2 = x2
x3 = −2x4 −x5
x4 = x4
x5 = x5
Una solucion cualquiera es una 5-upla de valores, donde las incognitas pasadas al segundo miembropueden variar arbitrariamente y las incognitas del primer miembro estan sujetas a las condicionesdespejadas. Que expresamos por:
x1
x2
x3
x4
x5
= x2
−2
3
1000
+ x4
13
0−2
10
+ x5
23
0−1
01
Haciendo ahora x2 = λ1, x4 = λ2, x5 = λ3 se escribe:
x1
x2
x3
x4
x5
= λ1
−2
3
1000
+ λ2
13
0−2
10
+ λ3
23
0−1
01
El subespacio de soluciones del sistema es el subespacio de las combinaciones lineales de los tres
vectores columna del segundo miembro.Nf = L(−2
3, 1, 0, 0, 0), (1
3, 0,−2, 1, 0), (2
3, 0,−1, 0, 1) y estos tres vectores son una base de Nf .
En efecto, ninguno de los vectores columna es superfluo a la hora de dar las combinaciones linealessoluciones. En nuestro caso, para comprobar que son independientes, mirarıamos si una combinacionlineal de los vectores igual a cero es posible con coeficientes λi distintos de cero. Tendrıa que ser:
00000
= λ1
−2
3
1000
+ λ2
13
0−2
10
+ λ3
23
0−1
01
Considerando la segunda, la cuarta y la quinta filas, tenemos: 0 = λ1, 0 = λ2, 0 = λ3, lo que
implica que los vectores columna escritos son independientes. La dimension del espacio de solucionesde este sistema es 3 = 5− 2 = dim V1 − r(A).
185

Imagen de una aplicacion lineal:Es el conjunto de vectores que se pueden obtener como imagen de algun vector del primer espacio,
por la aplicacion lineal. Se representa por Im(f).Al obtener la expresion matricial de la aplicacion lineal hemos visto que cualquier vector f(x) de
la imagen es combinacion lineal de los vectores f(e1), f(e2), ..., f(en), (vuelvase a leer), es decir, delos vectores columnas de la matriz de la aplicacion lineal. Recıprocamente, cualquier combinacionlineal de estos vectores con los coeficientes α1, α2, ...αn es la imagen del vector (α1e1+α2e2+...+αnen)de V1.
Por ello, la imagen de f es el subespacio de V2 engendrado por f(e1), f(e2), ..., f(en). Comolas coordenadas de estos vectores son las columnas de A, podremos extraer de ellos tantos vectoresindependientes como sea el rango de A, por lo que la dimension de la imagen es el rango de A.
Extrayendo una base de este sistema generador podemos hallar las ecuaciones cartesianas y lasparametricas del subespacio imagen de la aplicacion lineal.
En el ejemplo anterior, (en el que hemos calculado el nucleo de f), la imagen de f es el sube-spacio de R3 engendrado por (3, 3, 6), (2, 2, 4), (1, 2, 1), (1, 3, 0), (−1, 0,−3), de los cuales, solo dosson independientes (compruebese); la imagen de esa aplicacion lineal esta engendrada p.ej. por(1, 3, 0), (−1, 0,−3), siendo su ecuacion:∣∣∣∣∣∣
1 3 0−1 0 −3x1 x2 x3
∣∣∣∣∣∣ = 0 ≡ −9x1 + 3x2 + 3x3 = 0 ≡ 3x1 − x2 − x3 = 0
Teorema de Rouche-Frobenius
Segun hemos visto en un parrafo anterior, resolver el sistema Ax = b es hallar x tal que f(x) = bdonde f es la aplicacion lineal dada por la matriz A. Si b no esta en Im(f), este x no existe, siendoel sistema incompatible. Si b esta en Im(f) el sistema es compatible, siendo determinado, si solo hay”uno” de tales x, e indeterminado si existen muchos x.
Veamos que si Nf es cero, solo puede existir un x tal que f(x) = b: sean x y x′ tales quef(x) = b = f(x′), entonces, f(x− x′) = f(x)− f(x′) = 0 implica que x− x′ = 0, i.e. x = x′.
Veamos tambien que si Nf 6= 0, existen muchas soluciones cuando el sistema es compatible:entonces, ∀a ∈ Nf , a 6= 0, y si f(x) = b, tambien f(x+ a) = b, siendo x 6= x+ a.
En el ejemplo de la aplicacion f anterior y de su matriz A, el sistema Ax = b tiene solucion si ysolo si siendo b = (b1, b2, b3), se verifica 3b1 − b2 − b3 = 0. La solucion no es unica porque Nf 6= 0.Luego ese sistema es compatible indeterminado si 3b1− b2− b3 = 0 e incompatible en caso contrario.
186

Tambien deducimos de las consideraciones anteriores que el sistema Ax = b tiene solucion (escompatible) si y solo si al anadir el vector b a los vectores que generan la imagen de A, (que son lascolumnas de A) el numero de vectores independientes es el mismo, lo cual equivale a que el rango de lamatriz ampliada A|b es igual al rango de la matriz A. Para que la solucion sea unica, (sea compatibledeterminado), ademas, la dimension del nucleo de f debe ser cero, es decir, dim V1 − r(A) = 0, olo que es lo mismo, el rango de A debe ser igual al numero de incognitas. El sistema es compatibleindeterminado si el rango de la matriz ampliada A|b es igual al rango de la matriz A y este es menorque el numero de incognitas. Ası hemos vuelto a encontrar el teorema de Rouche-Frobenius comoconsecuencia de la teorıa estudiada sobre aplicaciones lineales.
Es conveniente, para adquirir agilidad, hacer los siguientesEjercicios:
6.4.1. Determinar cual es el nucleo y cual es la imagen:a) de una proyeccion ortogonal de R2 sobre una de sus rectas.b) de una proyeccion ortogonal de R3 sobre una de sus rectas.c) de una proyeccion ortogonal de R3 sobre uno de sus planos.d) de una simetrıa ortogonal de R2 respecto a una de sus rectas.e) de una simetrıa ortogonal de R3 respecto a una de sus rectas.f) de una simetrıa ortogonal de R3 respecto a uno de sus planos.6.4.2. Hallar las ecuaciones cartesianas y una base de los nucleos y de las imagenes de las siguientes
aplicaciones lineales:a) La aplicacion A de R3 en R3 dada por A(x, y, z) = (x− y + 2z, x+ y, 2x+ 2y + z).b) La aplicacion B de C2 en C2 dada por B(z1, z2) = (iz1 + 2z2, z1 − iz2).c) La aplicacion C de R3 en R3 dada por C(x, y, z) = (x+ z, y, x+ y + z).d) La aplicacion D de C2 en C3 dada por D(z1, z2) = (iz1 + z2, z1 + iz2, z1 − iz2).e) La aplicacion E de R2 en R4 dada por E(x, y) = (x, x+ y, 2x, x+ 2y)6.4.3. Dada la aplicacion lineal f : R5 → R4 en las bases canonicas por la matriz:
1 −2 −1 0 −11 1 1 2 02 0 3 5 −30 3 2 2 1
1) Hallar una base del nucleo de f .2) Seleccionar las ecuaciones del nucleo de f .3) Hallar una base de la imagen de f .4) Hallar las ecuaciones cartesianas de la imagen de f .
187

6.4.4. Siendo A la matriz:
A =
−1 1 1 0
0 0 1 10 1 0 01 0 0 1
Hallar c para que el sistema Ax = b tenga solucion en los dos casos siguientes:
1) b = (1, 0, 1, c)t, 2) b = (1, 0, c, 1)t
2) En los casos anteriores, ¿es el sistema compatible determinado o indeterminado?6.4.5. Hallar las ecuaciones cartesianas y una base del nucleo y de la imagen de la aplicacion
lineal de R4 en R4 (endomorfismo) dada por la matriz:
a)
2 0 −1 −2−2 4 −1 2
2 2 −2 −2−2 2 0 2
La union de las dos bases encontradas correspondientes al nucleo y a la imagen es un conjunto
de cuatro vectores. ¿Es una base de R4? ¿Podrıamos conseguir una base de R4 como union de otrasbases distintas del nucleo y de la imagen de estas aplicaciones?
Responder a las mismas cuestiones para la aplicacion lineal g dada por
b)
2 1 0 −1−1 1 1 2
1 2 1 10 3 2 0
6.4.6. Dada la aplicacion lineal de R4 en R4 (endomorfismo) por la matriz:
1 2 3 1−1 0 −1 1
1 3 4 2−1 0 −1 1
Hallar la dimension del subespacio vectorial f(L) ⊂ R4 en los dos casos siguientes:a) L ≡ x3 = 0. b) L ≡ x1 + x3 − x4 = 0.¿Hay algun hiperplano de R4, cuya imagen es otro hiperplano? (Un hiperplano de Rn es un
subespacio vectorial de dimension n− 1).6.4.7. Dada la aplicacion lineal de R4 en R4 (endomorfismo) por la matriz:
188

1 1 0 00 1 1 00 0 1 11 0 0 1
a) Hallar las ecuaciones cartesianas del subespacio vectorial f(L) ⊂ R4 si L ≡ x3 − x4 = 0.b) Hallar las ecuaciones cartesianas de un subespacio vectorial L 6= R4, tal que su imagen sea un
hiperplano de R4. (Un hiperplano de Rn es un subespacio vectorial de dimension n− 1).c) ¿Hay algun hiperplano de R4, cuya imagen sea una recta?6.4.8. Cualquier matriz puede expresarse como suma de una matriz simetrica y de una matriz
antisimetrica. Considerar en M3×3(R) las aplicaciones lineales:a) La que hace corresponder a cada matriz su matriz simetrica sumando.b) La que hace corresponder a cada matriz su matriz antisimetrica sumando.Hallar el nucleo y la imagen de cada aplicacion.
189

Formula de las dimensiones para una aplicacion lineal.
Repitiendo, la dimension de la imagen de una aplicacion lineal es, por tanto, el numero de vectoresindependientes de los f(e1), f(e2), ..., f(en), es decir, de columnas independientes de la matriz dela aplicacion, o sea, el rango de la matriz de la aplicacion lineal. Como hemos visto que la dimensiondel nucleo es la dimension del espacio original menos el rango de esta misma matriz, tenemos larelacion:
dim(Nf) + dim(Im f) = dim(espacio origen)− r(A) + r(A) = dim(espacio origen).
Si las dimensiones del espacio original y el espacio final coinciden, la dimension del nucleo es cerosi y solo si la dimension del espacio imagen coincide con la dimension del espacio total.
Es un ejercicio conveniente comprobar la fomula de las dimensiones en cada uno de los ejerciciosanteriores en los que se han hallado ambos espacios.
Hasta ahora, dada una aplicacion lineal, hemos hallado su nucleo y su imagen. Podemos plantearnosel problema inverso: dados dos espacios vectoriales V1 y V2, si W1 ⊂ V1 y W2 ⊂ V2 son dos subespa-cios vectoriales, ¿se pueden construir aplicaciones lineales de V1 en V2 tales que su nucleo sea W1 ysu imagen sea W2?
Para que se puedan construir, en virtud de la formula de las dimensiones, es necesario quedimW1 + dimW2 = dimV1. Vamos a ver que esta condicion es suficiente. En efecto, podemos cogeruna base de W1 y extenderla a una base de V1, para lo cual necesitamos tantos vectores como hay enuna base de W2. Como una aplicacion lineal queda determinada por las imagenes de los elementos deuna base, definimos la aplicacion lineal aplicando los elementos de la base de W1 en cero y aplicandolos anadidos para obtener una base de V1, en una base de W2 con cualquier biyeccion posible.
Ejercicios
6.5.1. Comprobar la formula de las dimensiones en todas las aplicaciones lineales de los ejerciciosanteriores en las que se han calculado nucleo e imagen.
6.5.2. Comprobar que es posible hallar una aplicacion definida en R3 con imagen en R3, tal que:a) Su nucleo es el plano de ecuacion x+ y + z = 0 y su imagen es la recta x = y = 2z.b) Su imagen es el plano de ecuacion x+ y + z = 0 y su nucleo es la recta x = y = 2z.c) Hallar las matrices correspondientes en la base canonica.6.5.3. Comprobar que es posible hallar una aplicacion definida en R4 con imagen en R4, tal que
tanto su nucleo como su imagen sean el subespacio de ecuaciones:
190

x1+ x2 + x3 +x4 = 0x2 + x3 = 0
Hallar la matriz de dicha aplicacion en la base canonica de R4.
191

Isomorfismos.Los homomorfismos cuyo nucleo es cero y cuya imagen es el espacio total se llaman isomorfismos.
Los isomorfismos son aplicaciones lineales que hacen coresponder a cada elemento de un espacio otroelemento del otro espacio y solo uno, por ello, identifican distintos espacios vectoriales y permiten eltrasvase de propiedades de un espacio a otro.
Un isomorfismo es un homomorfismo cuyo nucleo es cero y cuya imagen es el total.
El caracter de isomorfismo de una aplicacion lineal queda reflejado en la matriz de la aplicacionlineal: Veremos que para que la aplicacion lineal sea isomorfismo es necesario y suficiente que lamatriz sea cuadrada y que su determinante sea distinto de cero.
Si f es isomorfismo, por por ser N(f) = 0 y por la formula de las dimensiones dimIm(f) =dimN(f) + dimIm(f) = dim(V1); como tambien Im(f) = V2, dimIm(f) = dim(V2), por lo quedimV1 = dimV2. Ya que la matriz de una aplicacion lineal f : V1 −→ V2 es m × n donde m es ladimension de V2 y n es la dimension de V1, la matriz de un isomorfismo es cuadrada. Por otra parte,el nucleo de f sera cero si y solo si 0 = dimNf = dimV1 − r(A), es decir, si y solo si r(A) = dimV1,(que es su numero de columnas) o sea si y solo si el determinante de A es distinto de cero.
Recıprocamente, si A es cuadrada, dimV1 = dimV2 y si |A| 6= 0, dimN(f) = dimV1−r(A) = 0, porlo que N(f) = 0 y utilizando otra vez la formula de las dimensiones, dimIm(f) = dimV1 = dimV2,por lo que Im(f) = V2.
Teorema 1: Si f : V1 −→ V2 es isomorfismo, existe la aplicacion inversa de f , que es lineal, ysi A es la matriz de f en dos bases prefijadas de V1 y de V2, A
−1 es la matriz de la aplicacion linealinversa de f en las mismas bases.
Demostracion:La aplicacion inversa g de f existe si sabemos hacer corresponder a cada y ∈ V2 un x tal que
f(x) = y, entonces serıa x = g(y).Si f es isomorfismo, por ser Im(f) = V2, cualquiera que sea el y ∈ V2, existe x tal que f(x) = y;
este x es un candidato a ser g(y), pero podrıamos tener problemas si existieran varios de estos x yno supieramos cual escoger. Veremos que solo existe uno cuando f es un isomorfismo. En efecto, sif(x) = f(x′), para algun otro x′, 0 = f(x) − f(x′) = f(x − x′) implica que x − x′ ∈ Nf = 0, esdecir que x = x′. Luego podemos construir la aplicacion inversa de f , haciendo corresponder a caday ∈ V2 el unico x ∈ V1, tal que f(x) = y.
Esta aplicacion es lineal, porque si f(g(y1)) = y1 y f(g(y2)) = y2, se tiene f(g(y1) + g(y2)) =f(g(y1)) + f(g(y2)) = y1 + y2, de donde g(y1 + y2) = g(y1) + g(y2) por una parte y si f(g(y)) = y,f(αg(y)) = αf(g(y)) = αy, de donde αg(y) = g(αy).
El hecho de que la matriz de g es la inversa de la matriz de f se sigue de que al ser g f = Id yf g = I, si la matriz de f es A y la matriz de g es B, AB=I y BA=I.
192

Tambien tenemos el siguienteTeorema 2: Dos espacios vectoriales son isomorfos si y solo si tienen la misma dimension.Demostracion:Si f : V1 −→ V2 es un isomorfismo, dimV1 = dim(Im(f)) por la formula de las dimensiones y
por ser N(f) = 0, y por la definicion de isomorfismo, dim(Im(f)) = dimV2, por lo que dimV1 =dim(Im(f)) = dimV2
El recıproco tambien es cierto: si dos espacios tienen la misma dimension, son isomorfos.
En efecto, sea dim(V1) = dim(V2) = n y sean e1, e2, ..., en una base de V1 y u1, u2, ..., un unabase de V2, definimos:
f(x) = f(x1e1 + x2e2 + ...+ xnen) = x1u1 + x2u2 + ...+ xnun
Se puede comprobar facilmente que la aplicacion f es lineal:a)
f(x+ y) = f((x1e1 + x2e2 + ...+ xnen) + (y1e1 + y2e2 + ...+ ynen)) =
= f((x1 + y1)e1 + (x2 + y2)e2 + ...+ (xn + yn)en) = (x1 + y1)u1 + (x2 + y2)u2 + ...+ (xn + yn)un =
(x1u1 + x2u2 + ...+ xnun) + (y1u1 + y2u2 + ...+ ynun) = f(x) + f(y)
b)
f(αx) = f(α(x1e1 + x2e2 + ...+ xnen)) = f(αx1e1 + αx2e2 + ...+ αxnen)) =
= (αx1)u1 + (αx2)u2 + ...+ (αxn)un = α(x1u1 + x2u2 + ...+ xnun) = αf(x).
Como Imf = L u1, u2, ..., un = V2 y segun la formula de las dimensiones, Nf = 0, f esisomorfismo.
Quedando ası demostrado el teorema.
El teorema nos da una forma facil para calcular la dimension del espacio vectorial de las aplica-ciones lineales entre dos espacios vectoriales.
Corolario:Si V1 y V2 son dos espacios vectoriales sobre el mismo cuerpo K, de dimensiones respectivas n y
m, dim L (V1, V2) = m× n.Ya que hemos visto anteriormente que fijadas las bases de V1 y de V2, hay una aplicacion lineal
biyectiva entre L (V1, V2) y M m×n(K). y se puede comprobar facilmente que esta aplicacion esisomorfismo.
193

Ejercicios:6.6.1. Compruebese que:a) La composicion de dos aplicaciones lineales es una aplicacion lineal yb) La matriz de la composicion de ellas es el producto de sus matrices.6.6.2. Sea f un isomorfismo en R3 y g otro homomorfismo tal que la dimension de la imagen de
g f es 2.a) ¿Cual es el rango de la matriz de g.b) ¿Cual es la dimension de la imagen de f g?6.6.3. Demostrar que una aplicacion lineal con nucleo cero tiene inversa a la izquierda tambien
lineal. ¿Es unica?6.6.4. Demostrar que una aplicacion lineal cuya imagen coincide con el espacio final, tiene inversa
a la derecha tambien lineal. ¿Es unica?6.6.5. Estudiar si son isomorfismos las aplicaciones del ejercicio 6.4.1. ¿Cuales son los isomorfismos
inversos en los casos que existen?6.6.6. Considerar las aplicaciones lineales de los ejercicios 6.2.6. y 6.3.3. y estudiar si son
isomorfismos.En los casos que lo sean hallar la matriz del isomorfismo inverso.
194

Espacio Dual.
Un tipo especial de aplicaciones lineales, que merecen un nombre especial, son las aplicacioneslineales de un espacio vectorial real V n en R. Se llaman formas lineales, forman el espacio L(V n, R)que segun lo visto anteriormente, son un espacio vectorial de dimension n. Este espacio vectorial sellama espacio dual de V n.
Un ejemplo de forma lineal en R3 es la aplicacion que resulta de multiplicar escalarmente unvector fijo a = (a1, a2, a3) por los distintos vectores de R3:
f
x1
x2
x3
= (a1, a2, a3)
x1
x2
x3
= a1x1 + a2x2 + a3x3.
Una vez escogida una base de V n, una forma lineal, como aplicacion lineal de un espacio dedimension n en un espacio de dimension 1, viene determinada por una matriz 1 × n, (la base de Rse da por supuesta como 1). Por eso, tanto un elemento de Rn como un elemento de su dual vienendeterminados por n numeros reales.
Si f es una forma lineal de Rn,
f(x) ≡ f
x1
x2...xn
= (a1, a2, · · · , an)
x1
x2...xn
= a1x1 + a2x2 + · · ·+ anxn
expresion que nos recuerda la del producto escalar.
Proposicion: Si una forma lineal no es nula, es suprayectiva.Demostracion: Si la forma lineal no es nula, existe un vector x que no se aplica en el cero.
Entonces, para cada valor r ∈ R, podemos encontrar el vector rf(x)
x que se aplica en r.
Son de especial significado geometrico los conjuntos de nivel de estas aplicaciones. Se llamaconjunto de nivel de una aplicacion con valores reales al conjunto de puntos que se aplican en unodado de R. Por ser las formas lineales no nulas, suprayectivas, los conjuntos de nivel de cada r ∈ Rson no vacıos.
Consideremos una forma lineal sobre R2 no nula,Ya que la forma lineal viene dada en general por:
f
(xy
)= (a1, a2)
(xy
)= a1x+ a2y,
195

el conjunto de nivel r ∈ R de f es: (x, y)|a1x+ a2y = r. Este conjunto es una recta del plano dadapor su ecuacion implıcita.
Para cada forma lineal no nula de R3 los conjuntos de nivel son planos geometricos dados por suecuacion impıcita. En efecto, ya que la forma lineal viene dada en general por
f
xyz
= (a1, a2, a3)
xyz
= a1x+ a2y + a3z,
el conjunto de nivel r ∈ R de f es: (x, y, z)|a1x+ a2y + a3z = r.
Dada una forma lineal en Rn, el conjunto de nivel cero es el nucleo de la forma lineal, que es unsubespacio de Rn, cuya dimension es n − 1, por la formula de las dimensiones y por ser la formalineal suprayectiva.
Si x0 es un vector tal que f(x0) = r, el conjunto de nivel r ∈ R se obtiene sumando al vector x0
todos los vectores de N(f). Ya que si x ∈ N(f), f(x0+x) = f(x0)+f(x) = f(x0). Y recıprocamente,si y0 esta en el conjunto de nivel r, se puede escribir y0 = x0 + (y0 − x0), donde y0 − x0 ∈ N(f).
Es decir, el conjunto de nivel r: f−1(r) = x0 +x|x0 ∈ f−1(r) y x ∈ N(f) se obtiene trasladandopor un vector x0 ∈ f−1(r) el nucleo de la forma lineal.
Dada una base B = e1, e2, ...en ⊂ V n, se definen los elementos e∗i (duales de los ei) por
e∗i (ej) =
1 si i = j0 si i 6= j
Se puede comprobar facilmente que si f ∈ V ∗, esta definida en B por
f(x) = f
x1...xn
= (a1 · · · an)
x1...xn
se tiene f = a1e∗1 · · ·+ ane
∗n
(Ya que coinciden en todos los elementos de la base).Por ello, los elememtos e∗i i∈1...n son un sistema de generadores de V ∗. Tambien se puede ver
facilmente que son independientes. Por ello, forman una base de V ∗, llamada base dual de B.Las coordenadas de f en la base dual de B son (a1, ..., an), donde ai = f(ei).
Un problema que se plantea es como varıan las coordenadas de f al cambiar de base en V . ¿Cuales la relacion entre la matriz de cambio de base en V y la matriz de cambio de base en V ∗?
196

Sean B y B′, dos bases de V , tales que la relacion entre las coordenadas de un vector x en esasbases viene dada por: x1
...xn
= C
x′1...x′n
Sean (a1, ..., an) y (a′1, ..., a
′n), las coordenadas de una aplicacion f en las bases duales de las dos
anteriores.Entonces, dado que
(a1, ..., an)
x1...xn
= f(x) = (a′1, ..., a′n)
x′1...x′n
(a1, ..., an)C
x′1...x′n
= (a′1, ..., a′n)
x′1...x′n
,
de donde
(a1...an)C = (a′1...a′n) ≡
a′1...a′n
= Ct
a1...an
≡
a1...an
= (Ct)−1
a′1...a′n
que es la relacion buscada.
Representando los duales de dos espacios vectoriales por V ∗1 = L(V1, K), V ∗2 = L(V2, K), a cadaaplicacion f : V1 → V2, le corresponde la aplicacion f ∗ : V ∗2 → V ∗1 que hace corresponder a ω ∈ V ∗2la aplicacion ω f . Esta aplicacion es lineal, se llama aplicacion dual de f y se representa por f ∗.
El problema que se plantea ahora es encontrar la matriz de f ∗ en las bases duales de dos basesde V1 y V2, conocida la matriz de f en dichas bases.
Recordemos que si B1 = e1, ...en ⊂ V1 y B′1 = e′1, ...e′m ⊂ V2, las columnas de la matriz queexpresa f son las coordenadas de los vectores f(ei) en la base B′1. Analogamente, las columnas dela matriz de f ∗ son las coordenadas de las aplicaciones f ∗(e
′∗k ) en e∗1, ..., e∗n. Hallemoslas: Sea A la
matriz de f ,
f ∗(e′∗k )(ei) = (e
′∗k f)(ei) = e
′∗k (f(ei)) = e
′∗k (∑
alie′l) = aki
197

Al variar i vamos obteniendo los elementos de la fila k de la matriz de f . Luego las columnas dela matriz de f ∗ son las filas de la matriz de f . Sus matrices, en las bases duales, son traspuestas launa de la otra.
Ejercicios:
6.6.1. Sea f un elemento del dual de R3 tal que f(1, 1, 0) = 1, f(0, 1, 1) = 1, f(1, 0, 1) = 3.Hallar las coordenadas de f en la base dual de la canonica.
6.6.2. Sea f : R3 → R3 una aplicacion determinada porf(1, 1, 0) = (−1, 0, 1), f(0, 1, 1) = (0,−1, 1), f(1, 0, 1) = (1,−1, 0).Hallar la matriz de la aplicacion dual de f en la base dual de la base canonica de R3.6.6.3. Expresar en la base dual de la canonica de R3 los elementos de la base dual de la base B,
siendo B:a) B = (1, 1, 0), (0, 1, 1), (1, 0, 1)b) B = (1, 1, 0), (0, 1, 1), (1, 0, 2)Observar que aunque el primer vector coincide en estas dos bases, su dual no coincide en los dos
casos.Ejemplos resueltos y problemas propuestos en el capıtulo 4 de [A], en el capıtulo 6 de [H] y en el
capıtulo 3 de [V]
198

BIBLIOGRAFIA.
[A] Algebra Lineal y aplicaciones. J. Arvesu Carballo, R. Alvarez Nodarse, F. MarcellanEspanol. Ed. Sıntesis Madrid. 1999.
[G] Matematicas 2 Bachillerato. Carlos Gonzalez Garcıa. Jesus Llorente Medrano. Maria JoseRuiz Jimnez. Ed. Editex. 2009.
[H] Algebra y Geometrıa. Eugenio Hernandez. Addison- Wesley / UAM, 1994.[S] Algebra lineal y sus aplicaciones. G. Strang Ed. Addison-Wesley Iberoamericana. 1990.[S2] Introduction to Linear Algebra. G.Strang Ed. Wellesley-Cambridge Press 1993.[V] Problemas de Algebra. A. de la Villa. Ed. Clagsa, 1994.
199

200

ESPACIO EUCLIDEO.
Proyecciones y Metodo de Mınimos Cuadrados.
Introduccion.Un espacio euclıdeo es un espacio vectorial real en el que se define un producto entre vectores
que a cada par de vectores asocia un numero real. El producto se llama producto escalar.El producto escalar usual en R2 y en R3 esta dado por las formulas:
u · v = (u1, u2) · (v1, v2) = u1 · v1 + u2 · v2
u · v = (u1, u2, u3) · (v1, v2, v3) = u1 · v1 + u2 · v2 + u3 · v3
Observemos que debido al teorema de Pitagoras, en R2 y en R3, el cuadrado de la longitud deun vector es igual al producto escalar del vector por sı mismo. Representando la longitud del vectoru por ‖u‖: ‖u‖2 = u · u. La longitud de un vector tambien se llama modulo del vector.
Un vector se llama unitario si es de longitud 1. Normalizar un vector cualquiera es obtener otro dependiente deel y unitario. Se normaliza un vector dividiendolo por su longitud o modulo.
De lo anterior se deduce que la distancia entre dos puntos viene dada por la raiz cuadrada delproducto escalar por sı mismo del vector cuyas componentes son las diferencias de coordenadas delos puntos.
En espacios con n variables, es util tener un concepto similar al de distancia. Se generaliza elconcepto de longitud de un vector y de distancia entre dos puntos a Rn utilizando el producto escalargeneralizado.
Definicion 1: Producto escalar generalizado: dados dos vectores u y v de Rn, u · v =
= (u1, · · · , ui, · · · , un)·(v1, · · · , vi, · · · , vn) = u1·v1+· · ·+ui·vi+· · ·+un·vn = (u1, · · · , ui · · · , un)
v1...vi...vn
Cuando u y v representan vectores fila, se ha escrito u · v = u · vt. Cuando u y v representan vectores columna,
se escribe u · v = ut · v.
Tenemos tambien la idea de que la distancia mas corta desde un punto a una recta viene dadapor la perpendicular trazada a la recta por el punto. De aquı que tambien sea importante el concepto
201

de perpendicularidad u ortogonalidad. Que se generaliza a Rn para hallar distancias de puntos asubespacios de mayor dimension.
Ortogonalidad.En R3 la recta perpendicular a otra engendrada por un vector v es la mediatriz del segmento
formado al yuxtaponer los vectores v y −v. Si u es perpendicular a v, u esta en esa mediatriz yya que entonces los angulos formados por la mediatriz y v y por la mediatriz y −v son iguales, laslongitudes de los vectores u+ v y u− v son iguales.
PPPP
PPPP
PPPP
PPPP
PPi
AAAAAAAAAAAAAA
v
-v
u
u-v
u+v
*
AAAAAAAAAAAAK
Por tanto, (u + v) · (u + v) = (u − v) · (u − v). Sustituyendo las coordenadas de los vectores enlos dos productos escalares, desarrollando y simplificando, tenemos:
2u1v1 + 2u2v2 + 2u3v3 = −2u1v1 − 2u2v2 − 2u3v3
de donde si los vectores u y v son perpendiculares u ortogonales, u1v1 + u2v2 + u3v3 = 0, es decir, suproducto escalar es cero. Recıprocamente, puede comprobarse que si su producto escalar es cero, losvectores son perpendiculares.
El concepto de ortogonalidad se generaliza a Rn:Definicion 2:Dos vectores de Rn son ortogonales si su producto escalar es nulo.Si u es ortogonal a v, escribimos u ⊥ v. Entonces la definicion anterior se expresa por:
u ⊥ v ≡ u · v = 0.
202

Para hacer calculos sin sustituir todas las coordenadas y para una posible generalizacion posteriorobservemos que el producto escalar tiene las propiedades 1), 2), 3) y 2’) siguientes: es simetrico, linealen cada una de las variables vectores que multiplicamos, y tiene la propiedad de ser definido positivoexpresada en 3):
1)∀u, v ∈ Rn, u · v = v · u2)
∀u, u′, v ∈ Rn, (u+ u′) · v = u · v + u′ · v.∀u ∈ Rn,∀c ∈ R, cu · v = c(u · v).
3)∀u ∈ Rn, u · u ≥ 0 y u · u = 0 ≡ u = 0.
2’) Aunque en 2) solo hemos explicitado la linealidad del producto escalar en la primera variable,de la simetrıa del producto escalar y de 2) se sigue la linealidad en la segunda variable, analoga a 2),para v.
La linealidad del producto escalar en las dos variables se expresa diciendo que el producto escalares una forma bilineal.
Por la propiedad definida positiva del producto escalar, ningun vector distinto de cero es ortogonala el mismo.
Veamos ahora como, sin sustituir coordenadas, utilizando las propiedades 1) y 2) del productoescalar podemos comprobar de nuevo, que la recta de direccion u es perpendicular a la recta dedireccion v si y solo si el producto escalar u · v es nulo: el extremo del vector u es equidistante delos extremos de v y de −v, por lo que ‖u − v‖2 = ‖u − (−v)‖2 = ‖u + v‖2. Al desarrollar los dosextremos de esta igualdad utilizando la bilinealidad y la simetrıa, tenemos:
u · u− 2u · v + v · v = ‖u− v‖2 = ‖u+ v‖2 = u · u+ 2u · v + v · v,
o equivalentemente, 4u · v = 0 ≡ u · v = 0.Tambien, utilizando la linealidad y la simetrıa del producto escalar, tenemos en Rn el teorema
de Pitagoras generalizado:Los vectores u y v son ortogonales si y solo si ‖u+ v‖2 = ‖u‖2 + ‖v‖2.En efecto:
‖u+v‖2 = (u+v)·(u+v) = u·u+u·v+v·u+v·v = ‖u‖2+‖v‖2+2u·v = ‖u‖2+‖v‖2 si y solo si u·v = 0
.
203

Ejercicios:
7.1.1. Demostrar:
‖u1 + u2 + · · ·+ un‖2 = ‖u1‖2 + ‖u2‖2 + · · ·+ ‖un‖2
si los vectores ui ⊂ Rn son ortogonales dos a dos.7.1.2. Sean u y v vectores de Rn. Demostrar:a) ‖u+ v‖2 + ‖u− v‖2 = 2(‖u‖2 + ‖v‖2). (ley del paralelogramo).b) ‖u+ v‖2 − ‖u− v‖2 = 4u · v. (identidad de polarizacion).c) ‖u+ v‖2 − ‖u‖2 − ‖v‖2 = 2u · v.7.1.3. Demostrar que dados dos vectores u y v cualesquiera, los vectores u + v y u − v son
ortogonales si y solo si ‖u‖ = ‖v‖.7.1.4. Demostrar:a) Las diagonales de un rombo son perpendiculares.b) Un paralelogramo es un rombo si sus diagonales son perpendiculares.7.1.5. Demostrar que las bisectrices de dos rectas secantes de R3 son perpendiculares utilizando
el problema 7.1.3.
204

La ortogonalidad es tambien util cuando se combina con el concepto de base. Vamos a verlo.
Bases Ortogonales.Un conjunto ortogonal de vectores es un conjunto de vectores no nulos en el que cada dos vectores
distintos son ortogonales.Ejemplos de vectores ortogonales dos a dos son los de las bases canonicas de R2 o de R3. Se
comprueba facilmente que sus productos escalares cruzados son nulos.
Proposicion 1: Todo conjunto ortogonal de vectores distintos de cero es un conjunto indepen-diente de vectores:
Demostracion:Consideremos un conjunto x1, x2, ..., xk de k vectores ortogonales dos a dos: sea
λ1x1 + λ2x2 + ...+ λkxk = 0
Multiplicando escalarmente esta combinacion lineal por el vector xi tenemos:
(λ1x1 + λ2x2 + ...+ λkxk) · xi = 0
es decir,
(λ1x1) · xi + (λ2x2) · xi + ...(λkxk) · xi = 0
por tanto,
0 = (λixi) · xi = λi(xi · xi)
como xi ·xi > 0, ha de ser λi = 0 ∀ i, que era lo requerido para que los vectores fueran independientes.
Corolario: Un conjunto ortogonal de n vectores distintos de cero de Rn forman una base.
Las bases formadas por conjuntos ortogonales se llaman bases ortogonales y son interesantesporque las coordenadas de un vector en una base ortogonal pueden calcularse de una manera directautilizando el producto escalar:
Teorema 1: Si v1, v2, ..., vn son una base ortogonal de Rn, y x es un vector de Rn, las coorde-nadas de x en esta base son:
(x · v1
v1 · v1
, ...,x · vivi · vi
, ...,x · vnvn · vn
).
205

Demostracion: Sea x = x1v1 + · · · + xivi + · · · + xnvn, haciendo el producto escalar de x por v1,tenemos:
x · v1 = (x1v1 + · · ·+ xivi + · · ·+ xnvn) · v1 = (x1v1) · v1 + · · ·+ (xivi) · v1 + · · ·+ (xnvn) · v1 == x1(v1 · v1) + 0 + · · ·+ 0 = x1(v1 · v1)
de donde despejando x1, tenemos la expresion de x1 en el teorema. Haciendo lo analogo para lascoordenadas restantes tenemos sus expresiones en el teorema.
Si los vectores de una base ortogonal estan normalizados la base se llama ortonormal. En estecaso, si la base es u1, u2, ..., un, xi = x · ui. Y el vector x se expresa:
x = (x · u1)u1 + (x · u2)u2 + · · ·+ (x · ui)ui + · · ·+ (x · un)un
Ejercicios:
7.2.1. Comprobar que son bases ortonormales de R3 con el producto escalar usual, las siguientes:B1 = (1/3(2,−2, 1), 1/3(2, 1,−2), 1/3(1, 2, 2) B2 = (1/7(2, 3, 6), 1/7(6, 2,−3), 1/7(3,−6, 2)
7.2.2. Hallar las coordenadas del vector (1, 1, 1) en las bases anteriores.
206

Ortogonalidad entre subespacios.Tambien se define la ortogonalidad entre subespacios: Si U y V son dos subespacios de Rn,
U es ortogonal a V si y solo si ∀u ∈ U y ∀v ∈ V, u · v = 0.
U es ortogonal a V se escribe U ⊥ V .
Proposicion 2: U ⊥ V ⇒ U ∩ V = 0.En efecto, si w ∈ U ∩ V , por ser w ∈ U y w ∈ V , es w · w = 0, lo que implica w = 0, por ser el
producto escalar definido positivo.Por ello, si U y V son ortogonales, U + V = U ⊕ V .
Ejercicio:7.3.1. Comprobar que el subespacio U es ortogonal a V si y solo si todos los vectores de U son
ortogonales a los vectores de una base de V.
Complemento Ortogonal.Dado un subespacio U , hay un subespacio ortogonal a U que contiene a todos los subespacios
ortogonales a U , es el llamado complemento ortogonal del subespacio dado. Lo denotaremos porU⊥. Es el conjunto de todos los vectores que son ortogonales a todos los de U . Es facil de comprobar(y es un ejercicio conveniente) que este conjunto es un subespacio vectorial en virtud de la linealidaddel producto escalar en cada uno de sus factores. Tambien hemos visto antes que dos subespaciosortogonales solo se intersecan en el cero. Por ello, U ∩ U⊥ = 0. Para justificarle el nombre decomplemento tenemos que demostrar que su dimension es igual a la dimension del espacio totalmenos la dimension de U , con lo cual U y U⊥ seran complementarios, es decir, Rn = U ⊕ U⊥.
Observemos que un vector v esta en U⊥ si y solo si es ortogonal a todos los vectores de una baseescogida de U (compruebese tambien).
Sea la base de U u1 = (a11, a12, ...a1n), u2 = (a21, a22, ...a2n), · · · , up = (ap1, ap2, ...apn), laortogonalidad de un vector x = (x1, x2, · · · , xn) con los uii∈1...p es equivalente a las igualdades:(x · ui = 0)
a11x1 + a12x2 + · · ·+ a1nxn = 0a21x1 + a22x2 + · · ·+ a2nxn = 0
· · ·ap1x1 + ap2x2 + · · ·+ apnxn = 0
Estas igualdades son un sistema de p ecuaciones con n incognitas, cuya matriz de coeficientes esla matriz que tiene por filas las coordenadas de cada uno de los vectores de la base de U . Por ser
207

estos vectores independientes, el rango de esta matriz es p y por tanto la dimension del subespaciode soluciones del sistema (que es el complemento ortogonal), es n− p = n− dim(U).
Resumiendo, tenemos:U⊥ es un subespacio vectorial de dimension n−dim(U) y U∩U⊥ = 0, de donde U+U⊥ = U⊕U⊥y como dim(U ⊕ U⊥) = dim(U) + dim(U⊥) = dim(U) + n− dim(U) = n, U ⊕ U⊥ = Rn.
Al mismo tiempo observemos que U⊥ puede tener distintos sistemas de ecuaciones correspon-dientes a distintas bases del subespacio U dado. Pero el complementario de un subespacio vectoriales unico por la forma de definirlo; lo que ocurre es que los distintos sistemas de ecuaciones correspon-dientes a distintas bases son equivalentes porque los vectores de una base de U son combinacioneslineales de los vectores de otra base de U . (Las transformaciones que llevan los vectores de una base alos vectores de la otra base se pueden traducir en transformaciones elementales que llevan un sistemaal otro).
Ejercicios:
7.4.1. Hallar una base de W⊥ siendo W los siguientes subespacios:a) W=Lu, v ⊂ R3 donde u = (1, 0, 1) y v = (2,−1, 1).b) W=Lu, v ⊂ R4 donde u = (1, 0, 1, 0) y v = (2,−1, 1, 0).c)
W =
x ∈ R4
∣∣∣∣ x1 + x2 + x3 + x4 = 02x1 − x2 = 0
Ejemplos de subespacios complementarios ortogonales:
Dada una matriz A, podemos considerar el subespacio de Rn engendrado por los vectores filasde A, lo llamamos el espacio fila de A y podemos considerar el espacio de las soluciones del sistemaAX = 0, que llamamos espacio nulo de A. Estos dos subespacios son ortogonales y complementarios.
Por ello, dado un plano de R3 por la ecuacion Ax + By + Cz = 0, su complemento ortogonal esla recta engendrada por el vector (A,B,C).
Cuando una recta de R3 viene dada como interseccion de dos planos de ecuacionesAx+By+Cz=0, A’x+B’y+C’z=0, el subespacio ortogonal a la recta esta engendrado por los
vectores (A,B,C) y (A’,B’,C’).
La observacion de que el producto vectorial de dos vectores es ortogonal a los dos vectores factoresda un metodo para hallar un generador del complementario ortogonal en R3 de un plano dado pordos vectores independientes.
208

Teorema de Tellegen.Otra aplicacion de la ortogonalidad puede demostrar un teorema de electricidad llamdo teorema
de Tellegen. (Tomado del libro Algebra Lineal y sus Aplicaciones. G. Strang).Consideramos una red formada por las aristas de un tetraedro; son seis aristas convergentes en
cuatro nodos. (Ver pagina siguiente).Llamamos p1, p2, p3, p4 a los potenciales en cada uno de los nodos e I1, I2, I3, I4, I5, I6 a las inten-
sidades que corren por cada arista. Si E1, E2, E3, E4, E5, E6 son las diferencias de potencial en cadaarista, se cumple:
I1E1 + I2E2 + I3E3 + I4E4 + I5E5 + I6E6 = 0
Demostracion:Podemos escribir:
(E1, E2, E3, E4, E5, E6) = (p1, p2, p3, p4)
1 0 −1 1 0 0−1 1 0 0 1 0
0 −1 1 0 0 −10 0 0 −1 −1 1
(1)
-
A
AAAAAAAAAAAAAAAAAAAK6
@@
@@@
@@@
@@I
p1 p2
p3
p4
I1
I2I3
I6
I5I4
Tambien, por la primera ley de Kirchoff, en cada nodo la suma de las intensidades que entran esigual a la suma de las intensidades que salen, por tanto:
209

I3 = I1 + I4I1 = I2 + I5
I2 + I6 = I3I4 + I5 = I6
Pasando todos los terminos al segundo miembro en estas ecuaciones, obtenemos un sistema ho-mogeneo en las intensidades, que se puede escribir:
1 0 −1 1 0 0−1 1 0 0 1 0
0 −1 1 0 0 −10 0 0 −1 −1 1
I1I2I3I4I5I6
=
0000
(2)
Volvemos ahora a la expresion (1) y vemos que expresa la fila de las diferencias de potencial comocombinacion lineal de las filas de la matriz de los coeficientes de este sistema de ecuaciones lineales.
Por otra parte, (2) expresa la columna de las intensidades como ortogonal para el producto escalarusual de R6 a cada una de las filas de esa matriz.
Como el producto escalar es lineal, la propiedad (2) de la definicion implica que la columna delas intensidades es tambien ortogonal a cualquier combinacion lineal de las filas de esa matriz, enparticular, a la fila de las diferencias de potencial.
Al multiplicar escalarmente la fila de las diferencias de potencial por la columna de las intensi-dades, obtenemos la expresion del Teorema.
210

Proyecciones en general.Veamos ahora que, en general, si Rn = U ⊕W , la descomposicion de un vector y ∈ Rn como
suma de un vector de U y otro de W es unica. Esto quiere decir que si u+ w = y = u′ + w′, dondeu, u′ ∈ U y w, w′ ∈ V , se tiene u = u′ y w = w′.
En efecto,
u+ w = u′ + w′ ⇒ u− u′ = w′ − w ∈ U ∩ V ⇒ u− u′ = w′ − w = 0⇒ u = u′ y w′ = w.
La unicidad de la descomposicion de los vectores por una suma directa permite asociar a cadavector generico y el unico vector sumando u de U . Esta aplicacion se llama, en general, proyeccionsobre U paralela al subespacio W y si W = U⊥ se llama proyeccion ortogonal. Debe comprobarsecomo ejercicios:
7.5.1. Demostrar que la aplicacion proyeccion es una aplicacion lineal.7.5.2. Demostrar que si p es una aplicacion proyeccion, p2 = p.7.5.3. Demostrar que si p es una aplicacion proyeccion, I − p es otra aplicacion proyeccion.7.5.4. Comprobar que si p es una aplicacion proyeccion, (I − p)2 = I − p.
Por ser lineal, la aplicacion proyeccion se expresa por una matriz, una vez elegida una base deRn.
Dado el procedimiento que hemos seguido para definir la proyeccion, la manera natural de hallarsu matriz es considerar que en una proyeccion sobre un espacio U , los vectores de U quedan fijos ylos vectores de W se proyectan en el el cero. En una base de Rn formada por la yuxtaposicion deuna base de U y una base de W (que puede ser U⊥), la matriz de la proyeccion es:(
Ip 00 0
)donde p es la dimension de U . En la base canonica de Rn, la matriz de la proyeccion es:
C
(Ip 00 0
)C−1
donde C es la matriz que tiene en columnas las coordenadas de los vectores de la base (de Rn)yuxtaposicion de una base de U y otra base de W .
Debido a que si n es grande, la inversa de la matriz C puede ser pesada de calcular, vamos aestudiar tambien otros metodos para hallar las matrices de las proyecciones ortogonales.
211

Proyecciones Ortogonales.Dada la matriz de una proyeccion, se puede hallar la proyeccion de un vector multiplicando la matriz de la
proyeccion por la columna correspondiente al vector. Tambien se puede hallar la proyeccion de un vector directamenterealizando su descomposicion en suma. Ademas, en el caso de las proyecciones ortogonales se puede hallar la proyeccionde un vector utilizando el producto escalar.
En el sentido geometrico comun proyectar ortogonalmente un punto sobre una recta o sobre unplano es obtener un punto de la recta o del plano trazando la perpendicular a la recta o al plano porel punto dado.
En sentido analıtico, en Rn, para proyectar ortogonalmente un vector sobre una recta, sobre unplano o sobre un subespacio de dimension mayor, descomponemos el vector dado en suma de unvector del subespacio sobre el que estamos proyectando y de otro vector perpendicular a el, o lo quees lo mismo, perteneciente al subespacio ortogonal al subespacio considerado. Siendo la proyecciondel vector sobre el subespacio, el vector obtenido en el subespacio considerado.
La descomposicion puede hacerse comodamente utilizando el producto escalar. Lo vemos a con-tinuacion.
Proyeccion ortogonal de un vector sobre una recta.Si la recta esta engendrada por el vector v, la proyeccion sobre esa recta de un vector y es un
vector de la forma cv, tal que y = cv + w, donde w ⊥ v; entonces,
y · v = (cv + w) · v = cv · v + w · v = c(v · v),
de donde c = y·vv·v y cv = y·v
v·vv. Expresamos esta proyeccion por PUy y tenemos:
PUy =y · vv · v
v.
Ejercicio:7.6.1. Comprobar que el vector PUy no depende del generador v que cojamos de la recta.
Volviendo a mirar las coordenadas de un vector en una base ortogonal, (pag 206), vemos queestas coinciden con los coeficientes de las proyecciones del vector sobre las rectas engendradas por losvectores de la base. Y tambien vemos que el vector es la suma de sus proyecciones sobre esas rectas.
212

Proyeccion ortogonal de un vector sobre un subespacio.Dado un subespacio U = Lv1, ..., vp, la proyeccion de y sobre U es un vector u de U tal que
y = u+ w, donde w ⊥ u (w ∈ U⊥).La validez de la definicion estriba en el hecho de que el vector de U que buscamos es unico. Esta
unicidad se sigue del razonamiento conceptual, hecho para proyecciones en general.
Escribamos PUy = u para calcularlo.Por ser PUy ∈ U , tendrıamos: PUy = c1v1 + · · ·+ civi + · · ·+ cpvp, y
y = c1v1 + · · ·+ civi + · · ·+ cpvp + w donde w · vi = 0 ∀i
Calcular PUy es calcular los coeficientes c1, c2, ..., cp. Para ello tenemos:
y · v1 = (c1v1 + · · ·+ civi + · · ·+ cpvp + w) · v1 = (c1v1 + · · ·+ civi + · · ·+ cpvp) · v1 =c1v1 · v1 + · · ·+ civi · v1 + · · ·+ cpvp · v1
· · ·y · vj = (c1v1 + · · ·+ civi + · · ·+ cpvp + w) · vj = (c1v1 + · · ·+ civi + · · ·+ cpvp) · vj =
c1v1 · vj + · · ·+ civi · vj + · · ·+ cpvp · vj· · ·y · vp = (c1v1 + · · ·+ civi + · · ·+ cpvp + w) · vp = (c1v1 + · · ·+ civi + · · ·+ cpvp) · vp =
c1v1 · vj + · · ·+ civi · vj + · · ·+ cpvp · vp
considerando las ci como incognitas, cuyo valor determina PUy, hemos encontrado el sistema:y · v1 = c1v1 · v1+ · · ·+ civi · v1+ · · ·+ cpvp · v1
· · · · · · · · · · · · · · · · · ·y · vj = c1v1 · vj+ · · ·+ civi · vj+ · · ·+ cpvp · vj· · · · · · · · · · · · · · · · · ·
y · vp = c1v1 · vp+ · · ·+ civi · vp+ · · ·+ cpvp · vp
Este sistema siempre tiene solucion unica debido a que la definicion de la aplicacion proyecciones buena. Segun el teorema de Rouche-Frobenius la matriz de los coeficientes de este sistema esinvertible, pudiendose resolver el sistema por Cramer o por Gauss.
Vamos a observar que si la base v1, ..., vi, ...vp de U es ortogonal, la matriz de los coeficienteses diagonal y se puede obtener para cada i:
ci =y · vivi · vi
por lo que en este caso:
PUy =y · v1
v1 · v1
v1 +y · v2
v2 · v2
v2 + · · ·+ y · vpvp · vp
vp
213

Esta es una de las razones de la importancia de las bases ortogonales.Si la base es ortonormal, ci = y · vi.
Ya que hemos utilizado una base de U para obtener la proyeccion del vector sobre el subespacioU , es posible plantearse la cuestion sobre si el vector proyeccion obtenido es dependiente de la baseutilizada. Pero no es ası, porque ya hemos visto que la descomposicion de un vector por una sumadirecta es unica y la aplicacion proyeccion esta bien definida.
Otra forma de obtener la matriz de la proyeccion en la base e1, e2, ..., en es tener en cuenta quesus columnas son las coordenadas de las imagenes de los vectores de la base y hallar por tanto, unaa una, las proyecciones pU(ei) de los vectores de la base, una vez encontrada una base ortogonalv1, v2, · · · , vp de U , por la formula:
PU(ei) =ei · v1
v1 · v1
v1 +ei · v2
v2 · v2
v2 + · · ·+ ei · vpvp · vp
vp
donde ei recorre los vectores de la base canonica de Rn.Si consideramos una base ortonormal de U , esta formula se simplifica pero puede ser que los
vectores se compliquen al tener que dividirlos por raices cuadradas.Ejercicios:7.7.1. Siendo U = L(1, 0, 1), (2,−1, 1) ⊂ R3, hallara) Una base ortogonal de U .b) La proyeccion ortogonal del vector (1, 1, 1) sobre U .c) La matriz (en la base canonica) de la aplicacion proyeccion ortogonal de R3 sobre U por los
dos metodos para comprobar que sale lo mismo.7.7.2. Siendo U el subespacio de R3 de ecuacion x+y+z = 0, resolver los tres apartados analogos
a los del problema anterior.7.7.3. Dados los vectores u1 = (2, 1, 1,−1), u2 = (1, 1, 3, 0) de R4 y el vector a = (5, 2,−2, 2),
descomponer el vector a = b+ c donde b es un vector perteneciente al subespacio Lu1, u2 y c es unvector perteneciente al ortogonal a dicho subespacio.
7.7.4. Dados los vectores u1 = (1, 2, 0,−1, 1), u2 = (0, 1,−1, 1, 0) de R5 y el vector a =(0, 0, 1, 2, 1), descomponer el vector a = b + c donde b es un vector perteneciente al subespacioLu1, u2 y c es un vector perteneciente al ortogonal a dicho subespacio.
7.7.5. Hallar la matriz de la proyeccion ortogonal de R4 sobre L(1, 1,−1, 0), (0, 0, 2, 1).7.7.6. Hallar la matriz de la proyeccion ortogonal de R4 sobre el subespacioU = L(1, 1,−1, 0), (0, 0, 2, 1), (0, 1, 1, 1). (Usar el ortogonal a U).
214

Teorema de la aproximacion optima:La importancia de la proyeccion ortogonal de un vector sobre un subespacio esta en que da el
vector del subespacio que mas se acerca o aproxima al vector dado. Por ello, la distancia del puntoa un subespacio es la distancia del punto a la proyeccion ortogonal de su vector de posicion sobre elsubespacio. Esto se demuestra en el teorema de la aproximacion optima:
Dado un vector y de Rn y un subespacio U ⊂ Rn, si y = PUy, ‖y − y‖ ≤ ‖y − u‖ ∀u ∈ U .Demostracion:Por el teorema de Pitagoras generalizado,
∀u ∈ U, ‖y − u‖2 = ‖y − y + y − u‖2 = ‖y − y‖2 + ‖y − u‖2 ≥ ‖y − y‖2
al ser y − y ∈ U⊥, y − u ∈ U ,
Ejercicios:
7.8.1 Hallar la distancia del vector a al subespacio Lu1, u2 en los problemas 7.7.3 y 7.7.4anteriores.
7.8.2. Dado el plano π de ecuacion Ax + By + Cz = 0 y el punto p de coordenadas (a, b, c),demostrar que la distancia de p a π es
d(p, π) =|Aa+Bb+ Cc|√A2 +B2 + C2
.
215

Metodo de Aproximacion de Mınimos Cuadrados.El teorema de Rouche-Frobenius da condiciones necesarias y suficientes para que un sistema de
ecuaciones de la forma AX = b sea compatible, es decir, para que exista un X tal que AX − b = 0.Nos podemos preguntar, en el caso en que el sistema sea incompatible, si existe una aproximacionoptima de la solucion, es decir, unos valores de las incognitas X, tales que la diferencia AX − b seamınima. La respuesta es que el problema de la aproximacion optima siempre tiene solucion, y a vecesno unica.
Como siempre, para llegar a la solucion de un problema, lo estudiamos y hacemos observaciones:Si existe una solucion del sistema, el vector b es combinacion lineal de los vectores columnas
de A con coeficientes precisamente iguales a las soluciones del sistema. Si no existe solucion, alprobar distintos valores de las incognitas como posibles aproximaciones, y realizar la operacion AX,obtenemos vectores que pertenecen al espacio engendrado por los vectores columnas de A. Si de todosestos vectores AX queremos el que mas se aproxime a b, podemos pensar en el anterior Teoremade la aproximacion optima y considerar que el vector que estamos buscando es de los vectores delsubespacio engendrado por las columnas de A, el mas proximo a b, es decir, la proyeccion ortogonalde b sobre dicho subespacio.
Por tanto, para aproximar el problema, podemos proyectar ortogonalmente el vector b sobre elsubespacio engendrado por las columnas de A (que vamos a llamar espacio columna de A), y si es b
esta proyeccion, resolver despues el sistema AX = b que siempre tiene solucion.Pero podemos elaborar un poco mas el procedimiento.Nuestra solucion X que verificara AX = b es la que verifica que AX − b = b − b es ortogonal
al espacio engendrado por las columnas de A; La condicion necesaria y suficiente para ello es queel vector AX − b sea ortogonal a todos los vectores columna de A. O lo que es lo mismo, que elproducto escalar de estos vectores columna y el vector AX − b sea cero. Podemos expresar en unasola ecuacion matricial la ortogonalidad requerida por
tA(AX − b) = 0 ≡ tAAX = tAb
La solucion del ultimo sistema es unica si la matriz tAA es invertible y multiple, si la matriz noes invertible.
Cuando la solucion es unica, esta es
X = (tAA)−1tAb.
En este caso, es la unica aproximacion optima a una solucion del sistema incompatible AX = b.
Podemos demostrar ahora que la matriz tAA es invertible si y solo si las columnas de A sonindependientes.
216

Por una parte, la matriz tAA es invertible si y solo si el sistema tAAX = 0 tiene unicamente lasolucion trivial.
Por otra parte, al resolver el sistema AX = 0, estamos tratando de encontrar los coeficientes quehay que poner a las columnas de A para obtener una combinacion lineal nula; estos coeficientes sonunicamente ceros si las columnas de A son independientes. Entonces vemos que AX = 0 tiene solola solucion trivial si y solo si las columnas de A son independientes.
Viendo que las soluciones de tAAX = 0 y de AX = 0 son las mismas quedara establecida laequivalencia enunciada. En efecto:
tAAX = 0⇒ X ttAAX = 0⇒ AX = 0⇒ tAAX = 0
217

Aplicacion del metodo de mınimos cuadrados a la regresion lineal.Cuando se cree que existe una dependencia lineal entre dos magnitudes x e y, es decir, se cree que
y = cx+ d para ciertos c y d, se trata de determinar c y d haciendo experimentos. Si la dependencialineal fuera perfecta y las medidas de los experimentos tambien, haciendo dos experimentos en losque a la magnitud variable x dieramos los valores x1 y x2 distintos, para los cuales midieramos y1 ey2, las dos relaciones
y1 = cx1 + dy2 = cx2 + d
darıan un sistema de dos ecuaciones con las dos incognitas c y d con solucion unica. Entonces, alhacer mas experimentos, si estos y las medidas fueran perfectos, al darle a la magnitud variable x elvalor xi obtendrıamos un valor yi tal que yi = cxi + d. Y los pares de valores (xi, yi), que se puedenrepresentar por puntos en el plano, quedarıan alineados y todos sobre la recta de ecuacion y = cx+d.
experimentos ideales
Pero en la practica, la dependencia lineal no es perfecta y las medidas en los experimentos no sonexactas, por lo que al hacer los experimentos y representar los puntos (xi, yi) obtenidos, se obtieneuna nube de puntos que admitimos que se aproxima a la grafica de una recta. Entonces, el problemaconsiste en determinar cual es la recta que mas se aproxima a la nube de puntos representada y comose trata de una aproximacion, utilizamos el metodo de los mınimos cuadrados.
218

experimentos reales
Supongamos que tenemos un conjunto de parejas de valores (x1, y1), (x2, y2), · · · , (xn, yn) obtenidosexperimentalmente. Si existiera una recta de ecuacion y = cx+ d conteniendo a todos los puntos, elsistema:
y1 = cx1 + dy2 = cx2 + d
......
yn = cxn + d
serıa satisfecho para ciertos valores de c y de d, es decir, tendrıa solucion en las incognitas c y d. Sino estan contenidos en una recta, no existe esa solucion.
El sistema anterior lo podemos escribir matricialmente:x1 1x2 1...xn 1
(cd
)=
y1
y2...yn
donde las incognitas son c y d y la matriz de los coeficientes correspondiente a la discusion teoricageneral es:
A =
x1 1x2 1... 1xn 1
219

Si todas las xi son iguales, todos los puntos estan sobre una recta vertical, por tanto no es el casoque nos ocupa.
Es suficiente que haya dos xi distintas para que las dos columnas de A sean independientes y portanto que la matriz tAA sea invertible.
Utilizando la formula obtenida anteriormente en el metodo de mınimos cuadrados, las aproxima-ciones optimas para c y d son:
(cd
)=
( x1 x2 · · · xn1 1 · · · 1
)x1 1x2 1· · ·xn 1
−1(
x1 x2 · · · xn1 1 · · · 1
)y1
y2
· · ·yn
Haciendo operaciones: (
cd
)=
( ∑ni=1 x
2i
∑ni=1 xi∑n
i=1 xi n
)−1( ∑ni=1 xiyi∑ni=1 yi
)=
=1
n∑n
i=1 x2i − (
∑ni=1 xi)
2
(n −
∑ni=1 xi
−∑n
i=1 xi∑n
i=1 x2i
)( ∑ni=1 xiyi∑ni=1 yi
)O sea,
c =n∑n
i=1 xiyi − (∑n
i=1 xi)(∑n
i=1 yi)
n∑n
i=1 x2i − (
∑ni=1 xi)
2
d =−(∑n
i=1 xi)(∑n
i=1 xiyi) + (∑n
i=1 x2i )(∑n
i=1 yi)
n∑n
i=1 x2i − (
∑ni=1 xi)
2
Tambien, aparentemente mas simple para d, es la formula:
d =
∑ni=1 yi − c
∑ni=1 xi
n
Comprobemos que son iguales.∑ni=1 yi − c
∑ni=1 xi
n=
1
n(n∑i=1
yi −n∑n
i=1 xiyi − (∑n
i=1 xi)(∑n
i=1 yi)
n∑n
i=1 x2i − (
∑ni=1 xi)
2
n∑i=1
xi) =
=1
n
(∑n
i=1 yi)(n∑n
i=1 x2i − (
∑ni=1 xi)
2)− (n∑n
i=1 xiyi − (∑n
i=1 xi)(∑n
i=1 yi))∑n
i=1 xin∑n
i=1 x2i − (
∑ni=1 xi)
2=
220

=1
n
n(∑n
i=1 yi)(∑n
i=1 x2i )− (
∑ni=1 yi)(
∑ni=1 xi)
2 − n(∑n
i=1 xiyi)(∑n
i=1 xi) + (∑n
i=1 xi)2(∑n
i=1 yi)
n∑n
i=1 x2i − (
∑ni=1 xi)
2=
=(∑n
i=1 yi)(∑n
i=1 x2i )− (
∑ni=1 xiyi)
∑ni=1 xi
n∑n
i=1 x2i − (
∑ni=1 xi)
2
Aplicacion del metodo de mınimos cuadrados a la obtencion de la matriz de la apli-cacion proyeccion ortogonal sobre un subespacio.
La proyeccion sobre un subespacio puede ser aplicada a un vector cualquiera. En ese sentido esuna aplicacion de Rn en Rn y puede demostrarse como un ejercicio que es lineal. Es un endomorfismode Rn.
Llegados a este punto vamos a aprovechar la expresion del vector b, proyeccion de b sobre elespacio columna de A para obtener la expresion matricial de la aplicacion lineal proyeccion sobre unsubespacio U .
En el desarrollo anterior, cuando la solucion es unica: (cuando tAA es una matriz invertible o
equivalentemente las columnas de A son una base de U), b es la proyeccion de b sobre U , siendo
b = AX = A(tAA)−1tAb
Si queremos proyectar un vector generico x sobre un subespacio U , construimos la matriz A cuyascolumnas son un conjunto de vectores base de U y vemos que entonces tAA es una matriz invertible,despues aplicamos la formula anterior a x. De forma que
PU(x) = AX = A(tAA)−1tAx
Por tanto, la aplicacion proyeccion que hace corresponder a cada vector x su proyeccion sobre elsubespacio es una aplicacion lineal que tiene de matriz A(tAA)−1tA.
Si comparamos este metodo con el primero desarrollado para obtener la matriz de una proyeccionobservamos que tambien tenemos que hallar la inversa de una matriz pero p×p, siendo p la dimensionde U en lugar de n× n y nos ahorramos el trabajo de hallar la base de U⊥.
Ejercicios:7.9.1. Comprobar con la formula obtenida en ultimo lugar, las matrices obtenidas para las
proyeciones ortogonales en los problemas 7.6.*.
221

ESPACIO EUCLIDEO GENERAL.
Condiciones necesarias y suficientes para que una matriz corresponda a unproducto escalar.
Una generalizacion mas del Producto Escalar.Hemos dado la definicion de producto escalar usual utilizando las coordenadas de los vectores en
la base canonica. La base canonica es un instrumento auxiliar para definir ese producto; podemosprescindir de ella utilizando solamente las propiedades del producto escalar que lo caracterizan,obteniendo ası una definicion de mayor calidad y de mayor generalidad.
Quedandonos con las propiedades 1), 2) y 3) vistas anteriormente del producto escalar en Rn,definimos un producto escalar general en un espacio vectorial VR real como una aplicacion f delproducto cartesiano VR × VR en R, que cumple esas tres condiciones:
Definicion 1:Un producto escalar en un espacio vectorial real VR es una aplicacion f : VR × VR → R tal que:1) f es simetrica ≡ f(x, y) = f(y, x).2) f es lineal en cada variable: (Por la simetrıa, es lineal en la segunda variable si lo es en la
primera) ∀x, x′, y ∈ Rn, f(x+ x′, y) = f(x, y) + f(x′, y)∀x ∈ Rn,∀c ∈ R, f(cx, y) = cf(x, y).
3) f es definida positiva: ∀x ∈ Rn, f(x, x) ≥ 0 y f(x, x) = 0 ≡ x = 0.
Como llamamos forma lineal a una aplicacion del espacio vectorial real en R y forma bilineal auna aplicacion del producto cartesiano VR × VR en R, lineal en cada una de las variables vectorestenemos, resumidamente, la
Definicion 1’:Un producto escalar en un espacio vectorial real es una forma bilineal, simetrica y definida positiva.
Veremos en este capıtulo que dado un producto escalar segun la definicion anterior en un espaciovectorial de dimension finita, existe siempre una base en la que el producto escalar se expresa comoel usual de Rn. Siendo, por tanto, mediante un cambio de base, esta definicion equivalente a la delproducto escalar usual; entonces nos quedamos con la definicion que no depende de la base.
Tambien se suele escribir f(x, y) =< x, y >= x · y cuando no haya lugar a confusion.
222

Un ejemplo de producto escalar en R4 es el dado por la expresion:
f(x, y) = x1y1 + x1y2 + x2y1 + 2x2y2 + 3x3y3 + x3y4 + x4y3 + x4y4
En efecto, esta expresion es1)Simetrica: (escribiendo en lo que sigue x · y para f(x, y)
y · x = y1x1 + y1x2 + y2x1 + 2y2x2 + 3y3x3 + y3x4 + y4x3 + y4x4 =
(por la conmutatividad del producto de numeros reales)
= x1y1 + x2y1 + x1y2 + 2x2y2 + 3x3y3 + x4y3 + x3y4 + x4y4 =
(por la conmutatividad de la suma de numeros reales)
= x1y1 + x1y2 + x2y1 + 2x2y2 + 3x3y3 + x3y4 + x4y3 + x4y4 = x · y
2) Lineal en cada variable:a)
(x+ x′) · y =
= (x1+x′1)y1+(x1+x
′1)y2+(x2+x
′2)y1+2(x2+x
′2)y2+3(x3+x
′3)y3+(x3+x
′3)y4+(x4+x
′4)y3+(x4+x
′4)y4 =
(por la distributividad del producto)
= x1y1+x′1y1+x1y2+x
′1y2+x2y1+x
′2y1+2x2y2+2x′2y2+3x3y3+3x′3y3+x3y4+x
′3y4+x4y3+x
′4y3+x4y4+x
′4y4 =
(por la conmutatividad de la suma)
= x1y1+x1y2+x2y1+2x2y2+3x3y3+x3y4+x4y3+x4y4+x′1y1+x
′1y2+x
′2y1+2x′2y2+3x′3y3+x
′3y4+x
′4y3+x
′4y4 =
= x · y + x′ · y
b)(αx) · y =
= (αx)1y1 + (αx)1y2 + (αx)2y1 + 2(αx)2y2 + 3(αx)3y3 + (αx)3y4 + (αx)4y3 + (αx)4y4 =
= (αx1)y1 + (αx1)y2 + (αx2)y1 + 2(αx2)y2 + 3(αx3)y3 + (αx)3y4 + (αx4)y3 + (αx4)y4 =
(por la asociatividad del producto de numeros reales)
223

= α(x1y1) + α(x1y2) + α(x2y1) + 2α(x2y2) + 3α(x3y3) + α(x3y4) + α(x4y3) + α(x4y4) =
(por la distributividad del producto de numeros reales)
= α(x1y1 + x1y2 + x2y1 + 2x2y2 + 3x3y3 + x3y4 + x4y3 + x4y4 = α(x · y)
3) Es definida positiva:
x · x = x1x1 + x1x2 + x2x1 + 2x2x2 + 3x3x3 + x3x4 + x4x3 + x4x4 =
= x21 + 2x1x2 + 2x2
2 + 3x23 + 2x3x4 + x2
4 = (x1 + x2)2 + x2
2 + 2x23 + (x3 + x4)
2 ≥ 0.
De ser x · x = 0, habrıa de ser
x1 +x2 = 0x2 = 0
x3 = 0x3 +x4 = 0
≡x1 = 0x2 = 0x3 = 0x4 = 0
≡ x = 0
Definicion 2:Un Espacio Vectorial Euclıdeo es un espacio vectorial real con un producto escalar f .
En un espacio vectorial euclıdeo podemos definir la longitud o el modulo de un vector como‖x‖ =
√f(x, x) por ser la forma bilineal f definida positiva. Escribimos este modulo por |x| cuando
no hay lugar a confusion.El concepto de ortogonalidad se generaliza a un producto escalar general, siendo dos vectores
ortogonales si y solo si su producto escalar es nulo. (x ⊥ y ⇔ f(x, y) = 0).Una base ortogonal es una base tal que cada dos vectores distintos son ortogonales.Una base ortonormal es una base ortogonal tal que todos sus vectores son de modulo 1.A partir de una base ortogonal se construye una base ortonormal dividiendo cada vector por su
modulo (calculado con f).
Ejercicios:
7.9.1. Comprobar que es un producto escalar en R3, el dado por la expresion:f(x, y) = x · y = (x1 + x2)(y1 + y2) + (x1 + x3)(y1 + y3) + (x2 + x3)(y2 + y3).7.9.2. Comprobar que es un producto escalar en R4, el dado por la expresion:
224

x · y = x1y1 + x1y2 + x2y1 + 2x2y2 + 3x3y3 + x2y4 + x4y2 + 2x4y4.7.9.3. Demostrar que vectores ortogonales respecto a un producto escalar general son indepen-
dientes.7.9.4. Comprobar que las aristas opuestas de un tetraedro regular son ortogonales. Sugerencia:
colocar los vertices en los puntos: (0,0,0), (1,1,0),(1,0,1),(0,1,1).
225

Tanto el producto escalar usual como el ejemplo de producto escalar en R4 que hemos visto vienendados por expresiones polinomiales, donde cada monomio tiene un xi y un yj.
Aunque parezca que un producto escalar general puede ser un ente extrano, como es una formabilineal, admite en un espacio de dimension finita una expresion polinomial y una expresion matricial,encontrandonoslo casi siempre en una de estas dos formas.
Expresion polinomial de una forma bilineal en un Espacio Vectorial de dimensionfinita.
Se comprueba que todo producto escalar definido en un espacio vectorial de dimension finita tieneuna expresion polinomial haciendo el siguiente desarrollo:
Sea e1, e2, ...en una base del espacio vectorial V n sobre el que esta definida la forma bilineal.Sean x = (x1, x2, ..., xn), y = (y1, y2, ...yn) dos vectores del espacio vectorial expresados por suscoordenadas en esa base y sea f la forma bilineal.
Entonces, por ser f bilineal,
f(x, y) = f(x1e1 + x2e2 + ...+ xnen, y1e1 + y2e2 + ...+ ynen) =
x1f(e1, y1e1 +y2e2 + ...+ynen)+x2f(e2, y1e1 +y2e2 + ...+ynen)+ ...+xnf(en, y1e1 +y2e2 + ...+ynen) =
= x1(y1f(e1, e1)+...+ynf(e1, en))+x2(y1f(e2, e1)+...+ynf(e2, en))+...+xn(y1f(en, e1)+...+ynf(en, en)) =
= x1y1f(e1, e1) + ...+ x1ynf(e1, en) + x2y1f(e2, e1) + ...+ x2ynf(e2, en) + · · ·
· · ·+ xny1f(en, e1) + ...+ xnynf(en, en) = x1Σjyjf(ei, ej) + ...+ xnΣjyjf(en, ej) =∑i,j
xiyjf(ei, ej)
expresion polinomial de la forma bilineal, donde se ve que en todos los monomios aparece un xi y unyj y el coeficiente de xiyj es f(ei, ej). Por ser el producto escalar simetrico el coeficiente de xiyj esel mismo que el de xjyi y por ser definido positivo son positivos los coeficientes de los xiyi.
Veamos la expresion matricial:
Expresion matricial de una forma bilineal en un Espacio Vectorial de dimension finita.
Con la misma notacion del apartado anterior tambien tenemos:
f(x, y) = f(x1e1 + x2e2 + ...+ xnen, y1e1 + y2e2 + ...+ ynen) =
x1f(e1, y1e1 +y2e2 + ...+ynen)+x2f(e2, y1e1 +y2e2 + ...+ynen)+ ...+xnf(en, y1e1 +y2e2 + ...+ynen) =
226

= x1(y1f(e1, e1)+...+ynf(e1, en))+x2(y1f(e2, e1)+...+ynf(e2, en))+...+xn(y1f(en, e1)+...+ynf(en, en)) =
= (x1, x2, ..., xn)
y1f(e1, e1) + y2f(e1, e2) + ...+ ynf(e1, en)y1f(e2, e1) + y2f(e2, e2) + ...+ ynf(e2, en)
...y1f(en, e1) + y2f(en, e2) + ...+ ynf(en, en)
=
= (x1, x2, ..., xn)
f(e1, e1) f(e1, e2) ... f(e1, en)f(e2, e1) f(e2, e2) ... f(e2, en)· · · · · · · · · · · ·
f(en, e1) f(en, e2) ... f(en, en)
y1
y2
...yn
expresion matricial de la forma bilineal.
La matriz correspondiente a una forma bilineal que sea ademas un producto escalar, es simetricadebido a que f(ei, ej) = f(ej, ei) y los elementos de su diagonal son positivos debido a que f esdefinida positiva.
Ademas esta matriz, que generalmente se escribe G tiene determinante distinto de cero. Enefecto, si fuera |G| = 0, el sistema lineal homogeneo GX = 0 tendrıa soluciones no triviales. Si(a1, a2, ..., an) 6= (0, 0, ..., 0) es una solucion no trivial de ese sistema se tendrıa:
G
a1
a2...an
=
00...0
de donde (a1, a2, ..., an)G
a1
a2...an
= 0
pero esto implicarıa (a1, a2, ..., an) = (0, 0, ..., 0) por ser el producto escalar definido positivo, teniendoseuna contradiccion.
Veremos que en virtud de que |G| 6= 0 se puede definir el complemento ortogonal de un subespaciorespecto al producto escalar general de manera analoga a como se definıa para el producto escalarusual. Y se tiene tambien la descomposicion V n = U ⊕ U⊥, que permite definir las proyeccionesortogonales respecto al producto escalar general.
A pesar de que todas las expresiones matriciales del tipo txAy, donde x e y son vectores columna, dan expresionespolinomiales de segundo grado, hay expresiones polinomiales de segundo grado que no se pueden expresar matricial-mente, no dando lugar a una forma bilineal. Esto ocurre cuando en algun monomio no aparecen las xi y las yj almismo tiempo. Ejemplos de estos casos se dan en el ejercicio 7.10.3.
227

Ejercicios.
7.10.1. Comprobar:a) Que al producto escalar usual le corresponde la matriz identidad en la base canonica.b) Que a un producto escalar general en Rn le corresponde una matriz diagonal en una base
ortogonal respecto a ese producto escalar.c) Que a un producto escalar general en Rn le corresponde la matriz identidad en una base
ortonormal respecto a ese producto escalar.7.10.2. Encontrar las expresiones matriciales de las siguientes expresiones polinomiales en R2 o
R3:a) < x, y >= x1y1 − 3x1y2 + 2x2y1 + 2x2y2
b) < x, y >= x1y1 − x2y2
c) < x, y >= x1y1 + 2x1y2 + 3x2y1 + 7x2y2
d) < x, y >= x1y1 + 3x1y2 + 3x2y1 + 2x2y2
e) < x, y >= 2x1y1 + 2x1y2 + 2x2y1 + 3x2y2.f) < x, y >= x1y1 + x2y2 + x3y3 − x1y3 − x3y1 − x2y1 − x1y2
g) < x, y >= x1y1 + x2y2 + x3y3 − 2x1y3 − 2x3y1
h) < x, y >= x1y2 + x2y1 + x2y3 + x3y2
i) < x, y >= 2x1y1 − 2x1y2 + x2y1 + 2x1y3 + 2x3y1 − 3x2y3 − 3x3y2 + 11x3y3
j) < x, y >= x1y1 + x1y2 + x2y1 + 2x2y2 + 3x3y3 + x3y4 + x4y3 + x4y4
k) < x, y >= x1y1 + x1y2 + x2y1 + 2x2y2 + 3x3y3 + x2y4 + x4y2 + 2x4y4
7.10.3. Comprobar que las siguientes expresiones polinomiales no dan formas bilineales de R2.a) < x, y >= x2
1 + y21
b) < x, y >= x1x2 − y1y2.7.10.4. Escribir expresiones polinomiales que no den formas bilineales en R3.7.10.5. Estudiar si las expresiones polinomiales de los ejercicios anteriores dan productos escalares.
228

Complementario Ortogonal en el espacio euclıdeo general.Sea V n un espacio vectorial euclıdeo con producto escalar f . Dado un subespacio U de V n, se
define el subespacio complementario ortogonal de U como el conjunto de los vectores ortogonales atodos los de U : U⊥ = x|f(x, y) = 0,∀y ∈ U. Es otro subespacio de V n (debido a la bilinealidaddel producto escalar).
Demostremos que U y U⊥ son complementarios (U + U⊥ = U ⊕ U⊥ = V n):Primero, se comprueba que U ∩ U⊥ = 0 debido a que el producto escalar es definido positivo.
En efecto, si x ∈ U ∩ U⊥, habrıa de ser f(x, x) = 0, lo que implica x = 0.
Veamos que tambien, dim(U⊥) = n− dim(U): como |G| 6= 0, la aplicacion h:a1
a2...an
→ G
a1
a2...an
es un isomorfismo, que por tanto manda vectores independientes a vectores independientes (ejercicio).
Ademas, si una base de U es: u1 = (a11, a12, ..., a1n), u2 = (a21, a22, ..., a2n), ..., up = (ap1, ap2, ..., apn),tenemos (x1, x2, ..., xn) ∈ U⊥ si y solo si f(x, ui) = 0 ∀i (ejercicio), es decir, si y solo si
(x1, x2, ..., xn)G
a11
a12...a1n
= 0
· · · ...
(x1, x2, ..., xn)G
ap1ap2...apn
= 0
≡
b11x1 + b12x2 + · · ·+ b1nxn = 0b21x1 + b22x2 + · · ·+ b2nxn = 0
· · · ...bp1x1 + bp2x2 + · · ·+ bpnxn = 0
donde bi1bi2...bin
= G
ai1ai2...ain
229

y los vectores (bi1, bi2, ..., bin)i∈1,...p son independientes, por ser imagenes por la aplicacion h devectores independientes. Entonces U⊥ es un subespacio de dimension n− p = n− dim(U).
Por tanto, dim(U ⊕ U⊥) = p+ n− p = n, de donde, U + U⊥ = U ⊕ U⊥ = V n.
Ejercicios.
7.11.1. Hallar el complemento ortogonal del subespacio L(1, 1, 0, 0), (0, 1, 1, 0) ⊂ R4 respectoal producto escalar dado en el ejercicio 7.9.2.
7.11.2. Hallar el complemento ortogonal del subespacio de ecuaciones
x1 +x2 = 0x3 +x4 = 0
en R4, respecto al producto escalar dado en el ejercicio 7.9.2.
Proyecciones ortogonales en un espacio euclıdeo general.
La descomposicion U ⊕U⊥ = V n permite realizar las proyecciones ortogonales analogas a las quehacıamos en el espacio euclıdeo usual.
Repetimos aquı el procedimiento para obtener la proyeccion ortogonal de un vector sobre unsubespacio, ahora, con un producto escalar general.
Dado un subespacio U = Lv1, ..., vp, la proyeccion ortogonal de y sobre U es un vector u de Utal que y = u+ w, donde w ∈ U⊥ (f(u,w) = 0).
La validez de la definicion estriba en el hecho de que el vector de U determinado ası es unico.Esta unicidad se sigue de la descomposicion en suma directa del espacio total.
Escribamos PUy = u para calcularlo.Por ser PUy ∈ U , tendrıamos: PUy = c1v1 + · · ·+ civi + · · ·+ cpvp, y ademas,
y = c1v1 + · · ·+ civi + · · ·+ cpvp + w donde f(w, vi) = 0 ∀iCalcular PUy es calcular los coeficientes c1, c2, ..., cp. Para ello tenemos:
f(y, v1) = f(c1v1 + · · ·+ civi + · · ·+ cpvp + w, v1) = f(c1v1 + · · ·+ civi + · · ·+ cpvp, v1) =c1f(v1, v1) + · · ·+ cif(vi, v1) + · · ·+ cpf(vp, v1)
· · · · · · · · ·f(y vj) = f(c1v1 + · · ·+ civi + · · ·+ cpvp + w, vj) = f(c1v1 + · · ·+ civi + · · ·+ cpvp, vj) =
c1f(v1, vj) + · · ·+ cif(vi, vj) + · · ·+ cpf(vp, vj)· · · · · · · · ·
f((y, vp) = f(c1v1 + · · ·+ civi + · · ·+ cpvp + w, vp) = f(c1v1 + · · ·+ civi + · · ·+ cpvp, vp) =c1f(v1 · vj) + · · ·+ cif(vi, vj) + · · ·+ cpf(vp, vp)
230

Considerando las ci como incognitas, cuyo valor determina PUy, hemos encontrado el sistema:f(y, v1) = c1f(v1, v1)+ · · ·+ cif(vi, v1)+ · · ·+ cpf(vp, v1)· · · · · · · · · · · · · · · · · ·
f(y, vj) = c1f(v1, vj)+ · · ·+ cif(vi, vj)+ · · ·+ cpf(vp, vj)· · · · · · · · · · · · · · · · · ·
f(y, vp) = c1f(v1, vp)+ · · ·+ cif(vi, vp)+ · · ·+ cpf(vp, vp)
Este sistema siempre tiene solucion unica debido a que la definicion de aplicacion proyecciones buena. Y ademas porque la matriz de los coeficientes del sistema es la matriz de la restricciondel producto escalar al subespacio vectorial sobre el que se proyecta, en la base considerada dedicho subespacio, a fin de cuentas, la matriz de un producto escalar en un espacio vectorial, cuyodeterminante es distinto de cero.
Vamos a observar que si la base v1, ..., vi, ...vp de U es ortogonal, la matriz de los coeficienteses diagonal y se puede obtener para cada i:
ci =f(y, vi)
f(vi, vi)
por lo que en este caso,
PUy =f(y, v1)
f(v1, v1)v1 +
f(y, v2)
f(v2, v2)v2 + · · ·+ f(y, vp)
f(vp, vp)vp
Esta es una de las razones de la importancia de las bases ortogonales.Si la base es ortonormal, ci = f(y, vi).
Ya que hemos utilizado una base de U para obtener la proyeccion del vector sobre el subespacio U , es posibleplantearse la cuestion sobre si el vector proyeccion obtenido es dependiente de la base utilizada. Pero no es ası, puesya hemos visto que la descomposicion de un vector por una suma directa es unica y la aplicacion proyeccion esta biendefinida.
Para obtener la matriz de la proyeccion en la base e1, e2, ..., en podemos tener en cuenta quesus columnas son las coordenadas de las imagenes de los vectores de la base y hallar, por tanto, unaa una, las proyecciones pU(ei) de los vectores de la base, una vez encontrada una base ortogonalv1, ..., vp de U , por la formula:
PU(ei) =f(ei, v1)
f(v1, v1)v1 +
f(ei, v2)
f(v2, v2)v2 + · · ·+ f(ei, vp)
f(vp, vp)vp
231

Si consideramos una base ortonormal de U , esta formula se simplifica pero puede ser que losvectores de la base se compliquen al tener que dividirlos por raices cuadradas.
Tambien se puede hallar la matriz de la proyeccion mediante un cambio de base utilizando una base formada poruna base de U y otra base de U⊥.
Como para realizar las proyecciones sobre un subespacio son utiles las bases ortogonales, veremosahora como se pueden obtener bases ortogonales de un espacio vectorial para un producto escalargeneral.
Metodo para encontrar una base ortonormal en un espacio vectorial de dimensionfinita.
Si la dimension del espacio vectorial es 1, n=1 y dividiendo este vector por su modulo, tenemosuna base ortonormal.
Supondremos en lo que sigue que la dimension del espacio es mayor que 1.Sea x1 = (x11, x12, ..., x1n) un vector cualquiera no nulo del espacio vectorial V n.Otro vector y = (y1, y2, ...yn) es ortogonal a x1 si y solo si
(y1, y2, ..., yn)G
x11
x12
...x1n
= 0
donde G es la matriz del producto escalar.Al hacer el producto de G por la columna de x1, obtenemos una columna (a11, a12, ...a1n)t no nula
debido a que la aplicacion h(x) = Gx es un isomorfismo. Al hacer el producto total, obtenemos unaecuacion:
(y1, y2, ..., yn)
a11
a12...a1n
= a11y1 + a12y2 + ...+ a1nyn = 0 donde
a11
a12...a1n
= G
x11
x12...x1n
Siempre podemos encontrar un vector no nulo x2 que satisfaga esta ecuacion si la dimension del
espacio, y por tanto, el numero de incognitas es superior o igual a dos. Este vector es ortogonal a x1.
232

Se puede demostrar que vectores ortogonales son independientes usando la bilinealidad del productoescalar, por tanto x2 es independiente de x1.
Si la dimension del espacio es dos, ya tenemos una base ortogonal de la que podemos obtener unabase ortonormal dividiendo cada vector por su modulo.
Si la dimension del espacio es superior a dos, buscamos otro vector x3, ortogonal a los dos vectoresanteriores, x1 y x2 teniendo en cuenta que ha de verificar la ecuacion a11y1+a12y2+ ...+a1nyn = 0 porser ortogonal a x1 y ademas la analoga correspondiente al vector x2: a21y1 + a22y2 + ...+ a2nyn = 0.Estas dos ecuaciones son independientes debido a que los vectores coeficientes de las incognitas sonlas imagenes por el isomorfismo h de vectores independientes.
Podemos encontrar el vector x3 6= 0 porque solo tiene que satisfacer dos ecuaciones con tres omas incognitas. Los vectores x1, x2, x3 son independientes por ser ortogonales.
Podemos seguir con el mismo procedimiento hasta obtener tantos vectores ortogonales dos a doscomo sea el numero de incognitas, igual a la dimension del espacio. Entonces tenemos una baseortogonal de la que sabemos pasar a una base ortonormal, dividiendo cada vector por su modulo,calculado usando la matriz G.
Cuando estamos interesados en obtener una base ortogonal de un subespacio, distinto del espaciototal, podemos seguir el mismo metodo, escogiendo un primer vector del subespacio y encontrandolos vectores siguientes de forma que ademas de satisfacer las ecuaciones de ortogonalidad, satisfaganlas ecuaciones del subespacio.
Metodo de ortogonalizacion de Gram-Schmidt:Este metodo es interesante debido a la condicion subrayada a continuacion.Dada una base e1, e2, ...en de un espacio vectorial euclıdeo V n
R , existe una base ortonormalu1, u2, ..., un tal que u1, u2, ...ui es una base ortonormal de L e1, e2, ..., ei.
Construccion:En lo que sigue denotamos por x · y a f(x, y), producto escalar de dos vectores que puede ser no
usual.
Primero construimos una base ortogonal con la propiedad subrayada y despues dividimos cadavector por su modulo:
La idea es:1) Dejar e1 = v1.
2) Considerar el espacio Le1, e2, que es un plano, y dentro de el modificar e2 para que llegue apertenecer al subespacio ortogonal a v1 en Le1, e2 = Lv1, e2.
233

Serıa:
v2 = e2 + α21v1 cumpliendo v2 · v1 = 0.
Ha de ser0 = (e2 + α21v1) · v1 = e2 · v1 + α21v1 · v1
Para ello es suficiente con que
α21 = −e2 · v1
v1 · v1
Esta operacion es posible porque v1 · v1 > 0.El vector v2 obtenido es distinto de cero porque e2, v1 son independientes y su coeficiente en e2
es 1. Al mismo tiempo Lv1, v2 = Lv1, e2 = Le1, e2
3) Considerar el espacio Le1, e2, e3 y modificar e3 dentro de el para que quede ortogonal a los dosvectores v1 y v2 obtenidos, llevandolo al subespacio ortogonal a Lv1, v2 dentro de Le1, e2, e3 =Lv1, v2, e3.
Serıa ahorav3 = e3 + α32v2 + α31v1
Como queremos que v3 · v1 = 0, y v3 · v2 = 0, ha de ser
0 = (e3 + α32v2 + α31v1) · v1 = e3 · v1 + α32v2 · v1 + α31v1 · v1
Tambien,0 = (e3 + α32v2 + α31v1) · v2 = e3 · v2 + α32v2 · v2 + α31v1 · v2
Como v2 · v1 = 0, es:
α31 = −e3 · v1
v1 · v1
, α32 = −e3 · v2
v2 · v2
Esta operacion es posible porque tambien v2 · v2 > 0 por ser v2 6= 0.El vector v3 obtenido es distinto de cero porque e3, v1, v2 son independientes. Al mismo tiempo
Lv1, v2, v3 = Lv1, v2, e3 = Le1, e2, e3
4) Con la misma idea seguimos calculando los vi: Una vez obtenidos v1, v2, ...vi−1, todos distintosde cero, para obtener vi tenemos en cuenta que ha de ser
vi = ei + αi,i−1vi−1 + ....+ αi,1v1
Y como vi · vj = 0 ∀j < i, tenemos para cada j:
234

0 = (ei +αi,i−1vi−1 + ...+αi,jvj + ...+αi1v1) · vj = ei · vj +αi,i−1vi−1 · vj...+αijvj · vj + ...+αi1v1 · vj
que queda reducido a
0 = ei · vj + αijvj · vj ∀j
de donde
αij = − ei · vjvj · vj
∀j
Ası se determinan todos los αijj∈1...i−1 y por tanto, todos los vii∈1...n.
Observese que todos los vi son distintos de cero porque los ei son independientes de los v1, ..., vi−1.Una base ortonormal esta formada por los vectores ui = vi/‖vi‖i∈i,...,n.
Las formulas de los αij tienen denominadores que a su vez dan denominadores en los vi, que luegopueden ir complicando los calculos. Para que no se de esta complicacion, como lo que nos interesade los vi es que sean ortogonales a todos los anteriores, y eso se cumple para cualquier multiplode los vectores vi obtenidos, podemos quitar los denominadores en el momento de ser obtenidos,multiplicando adecuadamente, lo cual simplifica los calculos posteriores.
Observemos que a veces, las propiedades de los espacios vectoriales y de las aplicaciones lineales seobtienen utilizando bases. Utilizando una base ortonormal, (que hemos visto que podemos encontrar)en un espacio vectorial real de dimension finita con producto escalar general, este producto escalarse expresa en dicha base ortonormal por la misma expresion que el producto escalar usual en la basecanonica, por tanto, todas las propiedades y calculos que hemos hecho anteriormente con el productoescalar usual son transferibles al producto escalar general.
Ejercicios.
7.12.1. Hallar bases ortonormales de R3 y R4 para los productos escalares de los ejercicios 7.9.1y 7.9.2 anteriores, respectivamente.
7.12.2.a) Encontrar una base ortogonal respecto al producto escalar del ejercicio 7.9.2 del subespacio de
ecuacion x1 + x2 + x3 + x4 = 0.
235

b) Hallar la proyeccion ortogonal para el mismo producto escalar, sobre el subespacio anteriordel vector (1, 1, 1, 1)
c) Hallar la distancia del punto del apartado b) al subespacio del apartado a) con el mismoproducto escalar.
d) Hallar la matriz de la proyeccion ortogonal respecto al mismo producto escalar de R4 sobre elsubespacio del apartado a).
7.12.3. Repetir los apartados del ejercicio anterior para R4 con el producto escalar del primerejemplo de producto escalar no usual de este capıtulo.
7.12.4. Se da en R3 un producto escalar no usual por
x · y = x1y1 + x1y2 + x2y1 + 2x2y2 + x2y3 + x3y2 + 3x3y3.
Se define la simetrıa ortogonal correspondiente a un producto escalar respecto a un subespacio Ude R3 como SU(y) = PU(y)−PU⊥(y). (PU y PU⊥ son las proyecciones ortogonales correspondientes).
a) Hallar el vector simetrico ortogonal con el producto escalar dado del vector (1,0,1) respecto alplano de ecuacion x2 + x3 = 0.
b) Hallar la distancia del extremo del vector (1,0,1) al extremo del vector simetrico con esteproducto escalar.
7.12.5.a) Modificar la base canonica por el metodo de ortogonalizacion de Gram-Schmidt para obtener
una base ortonormal para el producto escalar:
f(x, y) = x · y = (x1 + x2)(y1 + y2) + (x1 + x3)(y1 + y3) + (x2 + x3)(y2 + y3)
b) Dada la base (1, 1, 0), (4,−2, 0), (1, 5, 5) construir a partir de ella una base ortonormal deR3 utilizando el metodo de ortogonalizacion de Gram-Schmidt para el producto escalar dado.
c) Hallar una base ortonormal para el producto escalar anterior del subespacio M de R3 deecuacion x1 + 2x2 + 3x3 = 0, tambien por el metodo de Gram-Schmidt.
7.12.6. Dada la cadena de subespacios vectoriales U1 ⊂ U2 ⊂ U3 ⊂ R4, de ecuaciones:
x1 +x2 +x3 +x4 = 02x1 +x3 = 0
2x2 +x4 = 0
x1 +x2 +x3 +x4 = 02x1 +x3 = 0
x1 +x2 +x3 +x4 = 0
Utilizar el metodo de Gram-Schmidt para obtener una base ortonormal respecto al producto escalarusual de R4: u1, u2, u3, u4 tal que Lu1, · · · , ui = Ui.
7.12.7. Sea U = L(−1, 0,−1, 0, 1), (0, 1, 1, 0,−1), (1, 1, 0, 1,−1) ⊂ R5.a) Hallar la matriz en la base dada de U de la restriccion del producto escalar usual a dicho
subespacio.
236

b) Obtener una base ortogonal de U para el producto escalar usual de R5, utilizando el metodode ortogonalizacion de Gram-Schmidt y la matriz hallada en a).
c) Hallar una base ortogonal de R5 para el producto escalar usual, que contenga a la base de Uobtenida en b).
7.12.8. Sea U = L(−1, 0,−1, 0, 1), (0, 1, 1, 0,−1), (1, 1, 0, 1,−1) ⊂ R5. Consideremos en R5 elproducto escalar dado por la matriz:
1 2 1 0 02 5 0 1 11 0 6 0 00 1 0 6 10 1 0 1 22
a) Hallar la matriz en la base dada de U de la restriccion del producto escalar usual a dicho
subespacio.b) Obtener una base ortogonal de U para el producto dado en R5, utilizando el metodo de
ortogonalizacion de Gram-Schmidt y la matriz hallada en a).c) Hallar una base ortogonal de R5 para el producto escalar dado que contenga a la base de U
obtenida en b).
237

Ortogonalidad en un espacio euclıdeo general.
En R3, ademas de la ortogonalidad o perpendicularidad, tenemos angulos. Tambien veremos quelos angulos se pueden definir en un espacio euclıdeo general:
La relacion entre el producto escalar usual de R3 y los angulos es x · y = ‖x‖‖y‖cosα, donde αes el angulo que forman los vectores x e y. Se demuestra utilizando el teorema de Pitagoras. Unavez demostrado esto en R3 con el producto escalar usual, veremos como se generaliza a un espaciovectorial con un producto general.
Dados dos vectores x e y, el vector y−x determina con x e y un triangulo, siendo el lado opuestodel angulo de lados x e y, Sea α el angulo que forman x e y.
1
BBBBBBBBBBB
$α x
y − xy
‖y‖senα
‖y‖cosα− ‖x‖
Entonces, utilizando el teorema de Pitagoras, tenemos:
‖y − x‖2 = (‖y‖cosα− ‖x‖)2 + (‖y‖senα)2 = ‖y‖2cos2α + ‖x‖2 − 2‖x‖‖y‖cosα + ‖y‖2sen2α =
= ‖y‖2 + ‖x‖2 − 2‖x‖‖y‖cosα
desarrollando el primer miembro, tenemos:
y · y − 2y · x+ x · x = y · y + x · x− 2‖x‖‖y‖cosα
donde simplificando, sale:
238

x · y = ‖x‖‖y‖cosα.de donde
cosα =x · y‖x‖‖y‖
y como el coseno de un angulo es siempre de valor absoluto menor o igual que 1, tomando valoresabsolutos tenemos:
|x · y| ≤ ‖x‖‖y‖Para generalizar el concepto de angulo entre dos vectores en un espacio vectorial con un producto
escalar f general veremos que tambien se cumple la desigualdad:
|f(x, y)| ≤ ‖x‖‖y‖
donde ‖x‖ =√f(x, x) y ‖y‖ =
√f(y, y), llamada desigualdad de Schwarz, definiendose entonces
en general:
cosα =f(x, y)
‖x‖‖y‖
Demostracion de la desigualdad de Schwarz:Veremos primero el teorema de Pitagoras generalizado:Si x = y + z, siendo f(y, z) = 0, se tiene f(x, x) = f(y, y) + f(z, z), ya que
f(x, x) = f(y + z, y + z) = f(y, y) + f(y, z) + f(z, y) + f(z, z) = f(y, y) + f(z, z)
Ahora, siguiendo Axler [Ax], sean x e y dos vectores distintos no nulos, el vector w = x− f(x,y)f(y,y)
y
es ortogonal a y y se verifica x = f(x,y)f(y,y)
y + w; entonces, por el teorema de Pitagoras generalizado,
f(x, x) = (f(x, y)
f(y, y))2f(y, y) + f(w,w) ≥ f(x, y)2
f(y, y)2f(y, y) =
f(x, y)2
f(y, y)
de donde
|f(x, y)| ≤√f(x, x)
√f(y, y) = ‖x‖‖y‖
Por este motivo se pueden medir angulos en un espacio euclıdeo no usual definiendo
cos(ang(x, y)) =f(x, y)
‖x‖‖y‖.
239

Proposicion:El modulo definido por un producto escalar f verifica la Desigualdad Triangular:
‖x+ y‖ ≤ ‖x‖+ ‖y‖
Demostracion:
‖x+ y‖2 = f(x+ y, x+ y) = f(x, x) + 2f(x, y) + f(y, y) ≤ f(x, x) + 2|f(x, y)|+ f(y, y) ≤
≤ ‖x‖2 + 2‖x‖‖y‖+ ‖y‖2 = (‖x‖+ ‖y‖)2
La desigualdad triangular permite comprobar que el lado de un triangulo es menor o igual que lasuma de los otros dos, ya que
d(x, z) = ‖x− z‖ ≤ ‖x− y‖+ ‖y − z‖ = d(x, y) + d(y, z)
Ejercicios:
7.13.3. Demostrar que la desigualdad de Schwarz es una igualdad si y solo si los vectores sonproporcionales.
7.13.4. Demostrar que si x e y son dos vectores de un espacio euclıdeo V ,
‖x− y‖ ≥ |‖x‖ − ‖y‖|
240

Cambio de base.Hay algunos problemas en los que por las caracterısticas de la situacion es mas conveniente utilizar
otra base distinta de la canonica (p. ej. porque se simplifica en otra base la expresion de algunafuncion que estemos estudiando); conviene por ello obtener la expresion del producto escalar en lanueva base. Nos planteamos por eso, como se refleja el cambio de base en la matriz del productoescalar.
Otras veces, debido a la simplificacion que suponen en los calculos las matrices diagonales, nosinteresa cambiar a bases ortogonales u ortonormales y ver la relacion que hay entre la matriz delproducto escalar y la matriz del cambio de base a una base ortonormal.
Cambio de base en la Expresion Matricial de una forma bilineal. (de un productoescalar).
Un cambio de base cambia la expresion del producto escalar de la siguiente forma:Sean e1, e2, ...en y e′1, e′2, ..., e′n dos bases del espacio vectorial V n sobre el que esta definido el
producto escalar.Sean x = (x1, x2, ..., xn), y = (y1, y2, ...yn) y x = (x′1, x
′2, ..., x
′n), y = (y′1, y
′2, ...y
′n) expresados
respectivamente en las dos bases.El producto escalar en forma matricial en las distintas bases serıa:
(x1, · · · , xn)G
y1...yn
= x · y = (x′1, · · · , x′n)G′
y′1...y′n
Las coordenadas de los vectores en las dos bases estan relacionadas por una matriz de cambio de
base: x1
x2...xn
= C
x′1x′2...x′n
;
y1
y2...yn
= C
y′1y′2...y′n
donde la matriz C tiene como columnas las coordenadas de los vectores de la base e′1, e′2, ..., e′n enla base e1, e2, ...en.
Trasponiendo la columna de las coordenadas de x y sustituyendo en la primera expresion matricialdel producto escalar las coordenadas de x y de y tenemos:
241

x · y = (x′1, x′2, ..., x
′n)CtGC
y′1y′2...y′n
;
comparando las dos expresiones del producto escalar en la segunda base, tenemos:
CtGC = G′
Hemos visto antes que aunque la base canonica no sea ortonormal respecto a un producto escalargeneral, siempre podemos encontrar otra base ortonormal respecto al producto escalar dado, en laque su expresion es analoga a la del producto escalar usual.
El hecho de que podamos obtener siempre una base ortonormal se traduce en que siempre hayuna matriz C de cambio de base tal que
CtGC = I.
Y entonces, despejando, tenemos G = (Ct)−1C−1, de donde se deduce que |G| = |(Ct)−1||C−1| =|(C−1)t||C−1| = |C−1|2 > 0; otra condicion que necesariamente ha de cumplir G.
Ejercicios:
7.14.1. Hallar la matriz del producto escalar usual deR3 en la baseB = (1, 1, 0), (2, 0, 1), (1, 1, 1)a) Utilizando el cambio de base de la base canonica a la base dada.b) Calculando directamente la matriz de la forma bilineal producto escalar en esta base.Comprobar que los dos metodos dan la misma solucion.7.14.2. Hallar la matriz del producto escalar en la baseB = (1, 1, 0, 1), (2, 0, 1, 0), (1, 1, 1, 0), (1, 0, 0, 1)
de R4 dado en la base canonica por
x · y = x1y1 + x1y2 + x2y1 + 2x2y2 + 3x3y3 + x3y4 + x4y3 + x4y4
a) Utilizando el cambio de base de la base canonica a la base dada.b) Calculando la matriz de la forma bilineal producto escalar en esta base.Comprobar que los dos metodos dan la misma solucion.7.14.3. Sean u1 = (−2,−1, 1), u2 = (0,−1, 0), u3 = (1,−1, 0), tres vectores linealmente indepen-
dientes de R3. Se puede definir un producto escalar en R3 de manera que sea bilineal con la condicionde que los tres vectores anteriores son una base ortonormal para ese producto escalar. Hallar la matrizde dicho producto escalar en la base canonica de R3.
242

Condiciones Necesarias y Suficientes para que una matriz corresponda a un ProductoEscalar.
Se puede comprobar que fijada una base de V nR , en la que las coordenadas de los vectores x e y
son (x1, x2, ..., xn) e (y1, y2, ..., yn), la aplicacion f : V nR × V n
R → R dada por:
f(x, y) = (x1, x2, ..., xn)A
y1
y2...yn
es una aplicacion bilineal, cualquiera que sea la matriz A, debido a la distributibidad y asociatividaddel producto de matrices.
f(x+ x′, y) = (x1 + x′1, x2 + x′2, ..., xn + x′n)A
y1y2...yn
= [(x1, x2, ..., xn) + (x′1, x′2, ..., x
′n)]A
y1y2...yn
=
= (x1, x2, ..., xn)A
y1y2...yn
+ (x′1, x′2, ..., x
′n)A
y1y2...yn
= f(x, y) + f(x′, y).
f(αx, y) = (αx1, αx2, ..., αxn)A
y1y2...yn
= α[(x1, x2, ..., xn)A
y1y2...yn
] = αf(x, y).
y analogamente para la variable y.
Hemos visto que para que la forma bilineal determinada por G sea un producto escalar, G ha deser simetrica; recıprocamente, si la matriz A es simetrica, la forma bilineal determinada es simetrica:en efecto, se puede ver la simetrıa de la expresion anterior trasponiendo el numero
(x1, x2, ..., xn)A
y1
y2...yn
243

considerado como una matriz 1× 1; entonces,
f(x, y) = (x1, x2, ..., xn)A
y1
y2...yn
= (y1, y2, ..., yn)tA
x1
x2...xn
= (y1, y2, ..., yn)A
x1
x2...xn
= f(y, x).
Hemos visto antes tambien que si la matriz corresponde a un producto escalar, todos los terminosde la diagonal son positivos y su determinante ha de ser distinto de cero.
Se ve en el siguiente ejemplo que no es suficiente que la matriz sea simetrica, que los terminos dela diagonal sean positivos y que su determinante sea distinto de cero para que la forma bilineal seadefinida positiva: sea
f(x, y) = (x1, x2)
(1 22 1
)(y1
y2
)Calculemos f(x, x) = x2
1 + 4x1x2 + x22 = (x1 + 2x2)
2 − 3x22; podemos coger el vector x = (−2, 1)
y se tiene f(x, x) = −3 < 0, no siendo, por tanto, definida positiva.
Esta forma bilineal no es un producto escalar porque el determinante de su matriz es negativo yhabıamos visto al final de la seccion sobre cambio de base que ese determinante tiene que ser positivo.
Sin embargo, se ve en el siguiente ejemplo que no es suficiente que el determinante de la matrizsea mayor que cero para que la forma bilineal determinada por ella sea definida positiva.
Sea
f(x, y) = (x1, x2, x3)
2 −4 −2−4 4 4−2 4 1
y1
y2
y3
Aunque el determinante de la matriz es 8, calculando f((2, 1, 0), (2, 1, 0)) obtenemos −4, lo que
indica que la forma bilinal correspondiente no es definida positiva.
Nos planteamos por ello, la pregunta: ¿Cuales son las condiciones necesarias y suficientes queha de cumplir una matriz para que la forma bilineal correspondiente sea un producto escalar? Lacondicion necesaria y suficiente para que una matriz simetrica determine un producto escalar la dael Criterio de Sylvester:
La matriz G determina un producto escalar en cualquier base si y solo si es simetrica y todos susmenores angulares superiores izquierdos tienen determinante positivo.
244

Demostracion:Primero, observemos que si G proviene de un producto escalar, al tener siempre este una base
ortonormal, existe una matriz C de cambio de base tal que CtGC = I, por lo que G = (Ct)−1C−1,donde C es una matriz con determinante distinto de cero, entonces, |G| = |(Ct)−1||C−1| = |C−1|2 > 0.
Despues, observemos que la restricion de un producto escalar a un subespacio es tambien unproducto escalar en dicho subespacio, y que de ser G la matriz de un producto escalar en un espaciovectorial de base e1, e2, · · · , en, esta restricion al subespacio Le1, e2, · · · , ei vendrıa dada por lasubmatriz angular superior izquierda de G formada por la interseccion de las i primeras filas y delas i primeras columnas (que escribimos Gii). Entonces ha de ser tambien |Gii| > 0 ∀i. Pues vamosa demostrar que esta condicion necesaria es tambien suficiente para que el producto f dado por lamatriz G, simetrica, en cualquier base e1, e2, · · · , en sea definido positivo.
La forma bilineal f dada por G es simetrica por serlo G.
Luego, para demostrar la segunda parte del teorema, veremos que podemos construir a partir dela base e1, e2, · · · , en otra base e′1, e′2, ..., e′n tal que
1)f(e′i, e′j) = 0 si i 6= j
2)f(e′i, e′i) = αii > 0 ∀i
en la cual, si (x′1, x′2, ..., x
′n) son las coordenadas de x en la nueva base, se tiene
f(x, x) = α11(x′1)
2 + α22(x′2)
2...+ αnn(x′n)2 ≥ 0
lo que muestra que la forma cuadratica es definida positiva porque todos los αii son mayores quecero.
Para construir la base e′1, e′2, ..., e′n veremos que es suficiente encontrar
e′i = αi1e1 + ...+ αijej + ...+ αiiei tales que
a) f(e′i, ej) = 0 ∀j < ib) f(e′i, ei) = 1 ∀i
donde los e1, e2, · · · , en son la base de partida.En efecto, entonces, si
j < i, f(e′i, e′j) = f(e′i,
j∑1
αjkek) =
j∑1
f(e′i, ej) = 0,
tambien f(e′i, e′j) = f(e′j, e
′i) = 0, si j > i por simetrıa y
f(e′i, e′i) = f(e′i,
i∑1
αjkek) = αiif(e′i, ei) = αii
245

El hecho de que los αii sean todos positivos se sigue despues del procedimiento utilizado para encon-trarlos.
Para encontrar los vectores e′i que segun lo dicho anteriormente son:
e′1 = α11e1e′2 = α21e1 + α22e2... =
...e′i = αi1e1 + ...+ αijej + ...+ αiiei
vemos que para e′1 debe ser:
α11 =1
f(e1, e1)
Para que se cumpla a) y b) para e′i debe ser:
f(αi1e1 + ...+ αijej + ...+ αiiei, e1) = 0
f(αi1e1 + ...+ αijej + ...+ αiiei, e2) = 0
..........
f(αi1e1 + ...+ αijej + ...+ αiiei, ei) = 1
Es decir,
αi1f(e1, e1) + ...+ αijf(ej, e1) + ...+ αiif(ei, e1) = 0αi1f(e1, e2) + ...+ αijf(ej, e2) + ...+ αiif(ei, e2) = 0
........... = 0αi1f(e1, ei) + ...+ αijf(ej, ei) + ...+ αiif(ei, ei) = 1
Este es un sistema no homogeneo en las αij cuya matriz de coeficientes es el menor angular
superior izquierdo de dimension i, de la matriz considerada G; su determinante es distinto de ceroporque |Gii| > 0, y por tanto, existe solucion para las αij pudiendo por tanto encontrar los vectorese′i que cumplen a) y b).
Observando el sistema no homogeneo y aplicando la regla de Cramer, vemos que
αii =|Gi−1,i−1||Gii|
> 0
en las condiciones del teorema, con lo que hemos concluido la demostracion.
246

Ejercicios.
7.15.1. Las siguientes expresiones dan formas bilineales de R2. Determinar cuales de ellas danproductos escalares utilizando el criterio de Sylvester.
a) < x, y >= x1y1 + 3x1y2 + 3x2y1 + 2x2y2.b) < x, y >= 2x1y1 + 2x1y2 + 2x2y1 + 3x2y2.7.15.2. Las siguientes expresiones dan formas bilineales de R3. Determinar cuales de ellas dan
productos escalares.a) < x, y >= x1y1 + x2y2 + x3y3 − x1y3 − x3y1 − x2y1 − x1y2.b) < x, y >= x1y1 + x2y2 + x3y3 − 2x1y3 − 2x3y1.c) < x, y >= 2x1y1 − 2x1y2 − 2x2y1 + 3x2y2 + 2x1y3 + 2x3y1 − 3x2y3 − 3x3y2 + 11x3y3.d) < x, y >= x1y2 + x2y1 + x2y3 + x3y2.e) < x, y >= 2x1y1 + x1y2 + x2y1 + 2x1y3 + 2x3y1 − 3x2y3 − 3x3y2 + 11x3y3
f) < x, y >= x1y1 + 2x2y2 + 2x3y3 − x1y3 − x3y1 + x2y3 + x3y2.
247

Bibliografıa:[A] J. Arvesu Carballo, R. Alvarez Nodarse, F. Marcellan Espanol. Algebra Lineal y aplicaciones.
Ed. Sıntesis. 1999.[Ax] S. Axler. Linear Algebra done right. Springer. 1997.[H] E. Hernandez. Algebra y Geometrıa. Ed. Addison-Wesley/U.A.M. 1994.[L] D. C. Lay. Algebra Lineal y sus Aplicaciones. Ed. Prentice-Hall 2001.[S] G. Strang. Algebra Lineal y sus Aplicaciones Ed. Addison-Wesley Iberoamericana. 1990.
248

DIAGONALIZACION DE ENDOMORFISMOS.
Aplicaciones autoadjuntas en espacios euclıdeos y hermıticos,y aplicaciones unitarias en espacios hermıticos.
Introduccion.
Una aplicacion lineal definida en un espacio vectorial con imagen en el mismo espacio vectorialse llama endomorfismo. Utilizaremos a partir de ahora la palabra endomorfismo por razones debrevedad.
La expresion matricial de un endomorfismo de un espacio vectorial depende de la base escogida.La matriz correspondiente es una matriz cuadrada. Al hacer un cambio de base la matriz cambiay puede llegar a ser mas sencilla. La interpretacion geometrica de los endomorfismos con matricesdiagonales es mas facil. Puede ser una proyeccion, una simetrıa, una composicion de dilatacionesy contracciones segun determinadas direcciones. Nos planteamos por ello el problema de encontraruna base en la que la matriz de dicha expresion matricial sea diagonal.
Diagonalizar un endomorfismo es encontrar una base del espacio vectorial en el que la matrizcorrespondiente es diagonal. No todos los endomorfismos son diagonalizables.
Las distintas matrices que corresponden a un endomorfismo al cambiar de base estan relacionadasde la forma siguiente: Si A y A′ corresponden al mismo endomorfismo en distintas bases, A′ = C−1ACdonde C (la matriz del cambio de base) es una matriz con determinante distinto de cero. Estasmatrices se llaman equivalentes. Si un endomorfismo es diagonalizable, existe una matriz diagonalequivalente a la matriz del endomorfismo.
Diagonalizar una matriz es encontrar una matriz diagonal equivalente a la dada. No todas lasmatrices son diagonalizables.
Si una matriz es diagonalizable, el endomorfismo expresado por dicha matriz (en cualquier base) es diagonalizable.En efecto, si dada la matriz A, existe una matriz C de cambio de base tal que C−1AC = D, el endomorfismo expresadopor la matriz A en la base B = e1, e2, ..., en es diagonalizable, porque este endomorfismo se expresa por la matrizdiagonal D en la base B = u1, u2, ..., un = e1, e2, ..., enC. Entonces, el endomorfismo expresado por la mismamatriz A en otra base B′ = e′1, e′2, ..., e′n se expresa tambien por D en la base B
′= u′1, u′2, ..., u′n = e′1, e′2, ..., e′nC
puesto que el cambio de base viene dado por la misma matriz C.
Las operaciones con el endomorfismo que se hacen utilizando su matriz, p. ej., sus potencias,se hacen mas facilmente con una matriz diagonal ya que las potencias de matrices diagonales sepueden hallar mas facilmente. Respecto al calculo de las potencias de matrices, se observa que si
249

C−1AC = D, A = CDC−1, por lo que
An = CDC−1CDC−1 · · ·CDC−1 = CDnC−1
calculable de manera relativamente facil ya que Dn es una matriz diagonal cuyos elementos diagonalesson las potencias de los elementos diagonales de D.
Veremos como ejemplos de endomorfismos diagonalizables, las aplicaciones autoadjuntas de unespacio euclıdeo o hermıtico y las aplicaciones unitarias de un espacio hermıtico. Ejemplos de matricesdiagonalizables son las matrices simetricas.
En un tema posterior veremos que en los casos en que el endomorfismo de un espacio vectorial sobre el cuerpode los numeros complejos, si la matriz correspondiente no es diagonalizable, existe una matriz relativamente facilequivalente a la dada llamada matriz de Jordan, que tambien simplifica los calculos.
Nuestro objetivo ahora es encontrar condiciones necesarias y suficientes para que un endomorfismoo analogamente una matriz sea diagonalizable. Empezamos dando las siguientes definiciones:
Vectores propios y valores propios.Observemos que si
D =
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
es la matriz que corresponde a un endomorfismo en la base B = v1, v2, ..., vn, los vectores vi sondistintos de cero y f(vi) = λivi ∀i.
Esta es la motivacion de las siguientes definiciones:Definicion 1: Se llama vector propio de un endomorfismo f de un espacio vectorial V sobre un
cuerpo K a un vector v 6= 0 que verifica f(v) = λv para algun λ ∈ K.Definicion 2: Se llama valor propio de un endomorfismo f de un espacio vectorial sobre un
cuerpo K a un elemento λ ∈ K tal que existe v ∈ V , v 6= 0, verificando f(v) = λv.Las definiciones analogas se pueden dar para una matriz.Definicion 3: Se llama vector propio de una matriz A ∈Mn×n(K) con elementos de un cuerpo
K, a un vector v 6= 0 de Kn que verifica Av = λv para algun λ ∈ K.Definicion 4: Se llama valor propio de una matriz A ∈ Mn×n(K) con elementos de un cuerpo
K, a un elemento λ ∈ K tal que existe v ∈ Kn, v 6= 0 verificando Av = λv.
250

Primera condicion necesaria y suficiente para que el endomorfismo sea diagonalizable.
Observando que la matriz del endomorfismo de un espacio vectorial es diagonal si y solo si los vec-tores de la base son vectores propios tenemos que la existencia de una base de vectores propios, es de-cir, la existencia de un numero de vectores propios independientes igual a la dimension del espacio vec-torial, es la inmediata condicion necesaria y suficiente para que el endomorfismo sea diagonalizable.
No es necesario llegar hasta hallar una base de vectores propios si lo que queremos es solamentesaber si el endomorfismo es diagonalizable ya que tenemos:
Lema 1:Vectores propios correspondientes a valores propios distintos son independientes.
Demostracion: La haremos por induccion.En el caso en que hay solo un valor propio, un solo vector propio correspondiente a dicho valor
es independiente por ser distinto de cero.Consideremos ahora dos vectores propios v1, v2 correspondientes a dos valores propios distintos
λ1 6= λ2 de un endomorfismo f .Sea α1v1 + α2v2 = 0 una combinacion lineal nula de estos dos vectores. Entonces, por ser f una
aplicacion lineal,
f(α1v1 + α2v2) = α1f(v1) + α2f(v2) = α1λ1v1 + α2λ2v2 = 0.
Ademas, multiplicando por λ2 la expresion de la combinacion lineal, tenemos:
α1λ2v1 + α2λ2v2 = 0.
Restando las expresiones finales, tenemos: α1(λ1−λ2)v1 = 0, de donde, como v1 6= 0 y λ1−λ2 6= 0,ha de ser α1 = 0, sustituyendo este valor en la combinacion lineal dada se obtiene α2v2 = 0, quecomo v2 es vector propio, implica α2 = 0, por tanto, los dos vectores son independientes.
Suponiendo cierto que n−1 vectores propios correspondientes a n−1 valores propios distintos sonindependientes, demostraremos que n vectores propios correspondientes a n valores propios distintosson independientes.
Sean v1, v2, · · · , vn−1, vn, n vectores propios correspondientes a λ1, λ2, · · · , λn−1, λn, n valorespropios distintos.
De forma analoga a la realizada cuando son dos los vectores propios correspondientes a valorespropios distintos, consideremos una combinacion lineal
α1v1 + α2v2 + · · ·+ αn−1vn−1 + αnvn = 0;
251

por ser f una aplicacion lineal,
f(α1v1 + α2v2 + · · ·+ αn−1vn−1 + αnvn) = α1f(v1) + α2f(v2) + · · ·+ αn−1f(vn−1) + αnf(vn) =
α1λ1v1 + α2λ2v2 + · · ·+ αn−1λn−1vn−1 + αnλnvn = 0
Multiplicando ahora la combinacion lineal considerada por λn, tenemos
α1λnv1 + α2λnv2 + · · ·+ αn−1λnvn−1 + αnλnvn = 0
Restando las dos ultimas expresiones, se obtiene
α1(λ1 − λn)v1 + α2(λ2 − λn)v2 + · · ·+ αn−1(λn−1 − λn)vn−1 = 0
En la hipotesis de que la proposicion es cierta para n − 1 vectores, ya que λi − λn 6= 0,∀i, laultima igualdad implica que α1 = α2 = αn−1 = 0; sustituyendo estos valores en la combinacion linealdada, obtenemos αnvn = 0, que como vn 6= 0 implica tambien αn = 0. Por tanto, los n vectorespropios considerados son independientes.
Corolario 1: Si un endomorfismo de un espacio vectorial de dimension n tiene n valores propiosdistintos es diagonalizable.
Demostracion: Por el lema, el endomorfismo tiene n vectores propios independientes, es decir,una base de vectores propios.
Nos interesa, pues, ver como se calculan los valores propios para ver si son todos distintos.
Segun la definicion de valor propio, λ es valor propio de f si y solo si existe x 6= 0 tal quef(x) = λx, es decir, si existe x 6= 0 tal que (f − λI)x = 0 o lo que es lo mismo, si existe x 6= 0,x ∈ ker(f − λI).
Mas detalladamente, para poder hacer calculos tomamos una base B = u1, · · · , un del espaciovectorial en el que estamos trabajando, en la que las coordenadas de un vector x sean (x1, · · · , xn)y la matriz de f en dicha base sea A. Entonces, las coordenadas de f(x) son:
f(x) ≡ A
x1...xn
,
teniendose, por tanto que
252

f(x) = λx⇐⇒ A
x1...xn
= λ
x1...xn
= λI
x1...xn
⇐⇒ (A− λI)
x1...xn
= 0.
Desarrollando la ultima expresion matricial obtenemos las ecuaciones cartesianas del ker(f −λI)para las coordenadas de x en la base B. Para que λ sea valor propio, este sistema homogeneo deecuaciones ha de tener como solucion al menos un vector v 6= 0 (vector propio). Como la matriz delos coeficientes de las incognitas de este sistema es A− λI,
λ es valor propio de f ⇐⇒ |A− λI| = 0⇐⇒ λ es raiz de |A− λI|.
El polinomio |A − λI| se llama polinomio caracterıstico y la ecuacion |A − λI| = 0 se llamaecuacion caracterıstica del endomorfismo f y de la matriz A.
Ejemplo 1.Consideremos el endomorfismo de R2 dado en la base canonica por la matriz(
12
12
12
12
)Sus valores propios son los que verifican
0 =
∣∣∣∣( 12
12
12
12
)− λI
∣∣∣∣ =
∣∣∣∣ 12− λ 1
212
12− λ
∣∣∣∣ = −λ+ λ2.
Tiene dos valores propios distintos que son λ1 = 0 y λ2 = 1 y por ello es diagonalizable.
Con el objetivo de hallar la base que lo diagonaliza, hallamos los vectores propios correspondientesa los dos vectores propios distintos, que por ello seran una base de vectores propios de R2.
Correspondiente a λ = 1, v = (v1, v2) sera vector propio si
f(v) = 1 · v ≡(
12
12
12
12
)(v1
v2
)=
(v1
v2
)≡(
12− 1 1
212
12− 1
)(v1
v2
)=
(00
)o lo que es lo mismo, −v1 + v2 = 0, luego, (1, 1) es vector propio para el valor propio λ = 1.
Puede comprobarse que para el valor propio λ = 0, el vector (1,−1) es vector propio.Los vectores: (1, 1), (1,−1) son dos vectores propios independientes que por ello forman una
base de R2 en la que la matriz del endomorfismo es diagonal:(1 00 0
)253

Ya que la matriz diagonal a la que hemos llegado y la matriz dada corresponden al mismoendomorfismo en distintas bases, estan relacionadas por el cambio de base entre dichas bases en R2:compruebese que: (
1 00 0
)=
(1 11 −1
)−1( 12
12
12
12
)(1 11 −1
)Una disgresion no necesaria para entender el resto del tema es la interpretacion geometrica que
se puede hacer del endomorfismo del ejemplo: los vectores de la recta engendrada por (1, 1) quedanfijos, los vectores de la recta (1,−1) se aplican en el cero. Cada vector puede descomponerse ensuma de dos vectores contenidos en cada una de las rectas anteriores. Como la aplicacion es lineal, laimagen de cada vector es la suma de las imagenes de los vectores sumandos, que se reduce al sumandocontenido en la recta engendrada por (1, 1). Al ser las dos rectas consideradas perpendiculares, estesumando es la proyeccion ortogonal del vector sobre esa recta. La aplicacion que nos dieron es laproyeccion ortogonal sobre la recta de vectores fijos, que es en este caso, la diagonal del primer ytercer cuadrante.
Otra aplicacion de la diagonalizacion al calculo de potencias de una matriz en este caso es lacomprobacion de que la matriz dada en este ejemplo elevada a cualquier potencia coincide con lamatriz dada. Ello se sigue de que cualquier potencia de la matriz diagonal correspondiente coincidecon ella misma.
Los valores propios se llaman tambien autovalores y los vectores propios, autovectores.Los valores propios de un endomorfismo de un espacio vectorial real han de ser numeros reales,
mientras que los valores propios de un endomorfismo de un espacio vectorial complejo pueden sercomplejos, aun cuando la matriz correspondiente sea de numeros reales.
Ejercicios:
8.1.1. Comprobar que son diagonalizables los endomorfismos de R2 dados en la base canonicapor las matrices:
a)
(5 6−3 −4
)b)
(1 −21 4
)c)
(5 −26 −2
)d)
(−5 2−6 2
)Hallar tambien bases que diagonalicen a los endomorfismos.Escribir la matriz de cambio de base desde la base canonica a la base diagonalizante y la relacion
matricial entre la matriz dada y la diagonal.8.1.2. Calcular la potencia de orden 10 de las matrices del ejercicio 8.1.1.
254

8.1.3. Se celebran unas elecciones en un paıs en el que solo hay dos partidos, el conservadory el progresista. En un determinado ano cuarenta por ciento del electorado votaron al partidoprogresista y sesenta por ciento del electorado votaron al conservador. Cada mes que va pasandolos progresistas conservan exactamente un 80 por ciento del electorado perdiendo el resto y losconservadores conservan exactamente un 70 por ciento perdiendo el resto. ¿Cual es la distribuciondel electorado tres anos despues?
8.1.4. Averiguar si son diagonalizables los endomorfismos de R3 dados en la base canonica porlas matrices:
a)
0 −1 0−1 1 −1
0 −1 0
b)
−1 2 12 −1 1−1 1 −2
c)
2 −1 −22 −1 −21 −1 −1
d)
1 −1 11 −1 −11 −1 −1
Hallar tambien bases que diagonalicen a los endomorfismos.Escribir la matriz de cambio de base desde la base canonica a la base diagonalizante y la relacion
matricial entre la matriz dada y la diagonal.8.1.5. Probar que toda matriz triangular (superior o inferior) con todos los elementos de su
diagonal distintos es diagonalizable.8.1.6.a) Demostrar que si λ es valor propio de f , λn es valor propio de fn.b) Si la base B = e1, e2, ..., en diagonaliza a f , diagonaliza tambien a cualquier potencia de f .8.1.7. Mostrar que A15 es diagonalizable, cuando A es una de las matrices del ejercicio 8.1.4.
¿Cuales son las bases que diagonalizan A15 en cada uno de los casos?8.1.8.a) Demostrar que una matriz A es invertible si y solo si todos sus valores propios son distintos
de cero.b) Decidir cuales de las matrices del ejercicio 8.1.4. son invertibles a la vista de sus valores
propios.c) Hallar, en el caso en que sean invertibles, las inversas de las matrices anteriores, usando la
inversa de la diagonal D que diagonaliza a A.8.1.9. Demostrar que si f es isomorfismo y λ es un valor propio suyo, λ−1 es valor propio de f−1.8.1.10. Demostrar que si f es un endomorfismo con valor propio λ1,a) el endomorfismo f − λ1I tiene el cero como valor propio.b) el endomorfismo f − aI tiene λ1 − a como valor propio.8.1.11. Comprobar que los endomorfismos diagonalizables con un solo valor propio son multiplos
de la identidad.
255

8.1.12. a)Comprobar que no es diagonalizable el endomorfismo de R2 dado por la matriz(1 −11 1
)b) Observar, sin embargo, que sı es diagonalizable el endomorfismo de C2 dado por la misma
matriz.8.1.13. Se definio una proyeccion en el capıtulo sobre espacio euclıdeo.a) Comprobar que los numeros 1 y 0 son valores propios de una proyeccion.b) Demostrar que una proyeccion no tiene mas valores propios que el 1 y el 0 y es diagonalizable.c) Comprobar que cualquier potencia de una proyeccion coincide con la proyeccion.8.1.14. Probar que si f es un endomorfismo de V n con n valores propios distintos, y g es otro
endomorfismo de V n que conmuta con f , todo autovector de f lo es de g y por eso g es diagonalizable.8.1.15. Demostrar que todo valor propio de la potencia de orden m de una matriz, de numeros
reales o complejos, es potencia de orden m de algun valor propio de la matriz (real o complejo).
256

No es necesario que haya n valores propios distintos para que un endomorfismo de un espaciovectorial de dimension n sea diagonalizable. (La condicion dada anteriormente en el corolario essuficiente pero no necesaria). Podemos debilitar esa condicion:
Segunda condicion necesaria y suficiente para que el endomorfismo sea diagonalizable.
Proposicion 1:Un endomorfismo de un espacio vectorial V n es diagonalizable si y solo si la suma de las di-
mensiones de los subespacios de vectores propios correspondientes a cada valor propio es igual a ladimension del espacio.
Demostracion: Sean λ1, ..., λi, ..., λm los valores propios de un endomorfismo f .Llamando E(λi) = Ker(f−λiI), (subespacio de vectores propios para λi), se tiene que si λi 6= λj,
E(λi) ∩ E(λj) = 0. Por tanto, si λi 6= λj, E(λi) + E(λj) = E(λi) ⊕ E(λj) y como tambien ∀i,E(λi) ∩ (E(λi−1)⊕ E(λi−2)⊕ ...⊕ E(λ1)) = 0,
E(λ1) + E(λ2) + · · ·+ E(λi) + · · ·+ E(λm) = E(λ1)⊕ E(λ2)⊕ · · · ⊕ E(λi)⊕ · · · ⊕ E(λm)Si dimE(λ1) = n1 y v1
1, · · · , v1n1 son base de Eλ1 , dimE(λi) = ni y vi1, · · · , vini son base de Eλi
y dimE(λm) = nm y vm1 , · · · , vmnm son base de Eλm , por ser la suma de estos subespacios directa,la dimension de esta suma es la suma de las dimensiones y la union de las bases de los subespaciossumandos es base del subespacio suma. Si la suma de las dimensiones de todos estos subespacioses la dimension del espacio total, este coincide con el subespacio suma y una base de este ultimo estambien una base del espacio total. Entonces, v1
1, · · · , v1n1, · · · , vi1 · · · , vini · · · , v
m1 , · · · , vmnm es base
de vectores propios del espacio total que diagonaliza al endomorfismo, quedando demostrada la parte”si” de la proposicion. Para la parte ”solo si” basta observar que en el caso en que el endomorfismoes diagonalizable, la cantidad de vectores propios correspondiente a cada valor propio es la dimensiondel nucleo del correspondiente f−λiI y que la suma de todas estas cantidades es igual a la dimensiondel espacio.
Se llama multiplicidad geometrica de un valor propio λi a la dimension del espacio ker(f − λiI).Con ello, la proposicion anterior se enuncia:
Un endomorfismo de un espacio vectorial V n es diagonalizable si y solo si la suma de las multi-plicidades geometricas de sus valores propios es igual a la dimension del espacio.
Se da aquı una formula para obtener el polinomio caracterıstico de matrices 3× 3:
|A− λI| =
∣∣∣∣∣∣a11 − λ a12 a13
a21 a22 − λ a23
a31 a32 a33 − λ
∣∣∣∣∣∣ =
∣∣∣∣∣∣a11 a12 a13
a21 a22 − λ a23
a31 a32 a33 − λ
∣∣∣∣∣∣+
∣∣∣∣∣∣−λ 0 0a21 a22 − λ a23
a31 a32 a33 − λ
∣∣∣∣∣∣ =
257

∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33 − λ
∣∣∣∣∣∣+
∣∣∣∣∣∣a11 a12 a13
0 −λ 0a31 a32 a33 − λ
∣∣∣∣∣∣+
∣∣∣∣∣∣−λ 0 0a21 a22 a23
a31 a32 a33 − λ
∣∣∣∣∣∣+
∣∣∣∣∣∣−λ 0 00 −λ 0a31 a32 a33 − λ
∣∣∣∣∣∣ =
=
∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣a11 a12 a13
a21 a22 a23
0 0 −λ
∣∣∣∣∣∣+
∣∣∣∣∣∣a11 a12 a13
0 −λ 0a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣a11 a12 a13
0 −λ 00 0 −λ
∣∣∣∣∣∣+∣∣∣∣∣∣−λ 0 0a21 a22 a23
a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣−λ 0 0a21 a22 a23
0 0 −λ
∣∣∣∣∣∣+
∣∣∣∣∣∣−λ 0 00 −λ 0a31 a32 a33
∣∣∣∣∣∣+
∣∣∣∣∣∣−λ 0 00 −λ 00 0 −λ
∣∣∣∣∣∣ =
|A| − (
∣∣∣∣ a11 a12
a21 a22
∣∣∣∣+
∣∣∣∣ a11 a13
a31 a33
∣∣∣∣+
∣∣∣∣ a22 a23
a23 a33
∣∣∣∣)λ+ (a11 + a22 + a33)λ2 − λ3
Ejercicios:
8.2.1.a) Averiguar si son diagonalizables los endomorfismos de R3 dados en la base canonica por las
matrices:
a)
−1 0 10 0 01 0 −1
b)
−1 0 −1−1 0 −1
1 0 1
c)
5 −1 −11 3 −11 −1 3
d)
3 −2 22 −1 2−1 1 0
e)
−1 3 12 −2 −1−2 −1 −2
f)
−1 −1 −21 2 11 0 2
b) Escribir la relacion entre las matrices dadas y las matrices diagonales correspondientes cuando
son diagonalizables.c) Hallar la potencia de orden 5 de las matrices anteriores que sean diagonalizables.8.2.2. La poblacion de un paıs esta repartida en tres regiones, A, B y C. En en momento actual,
hay cuarenta por ciento de la poblacion en la region A, cuarenta y cinco por ciento en la region By quince por ciento en la region C. Cada mes que va pasando hay un flujo de poblacion entre lasregiones en el que cada region pierde el cuarenta por ciento de su poblacion, el cual se reparte porigual entre las otras dos regiones. ¿Cual es la distribucion de la poblacion dos anos despues?
8.2.3. En un pueblo hay tres panaderıas, A, B, y C. Sus clientelas constituyen, respectivamente, eltreinta, cincuenta y veinte por ciento de la poblacion total del pueblo. Al pasar cada mes hay cambiode clientela: la panaderıa A pierde veinte por ciento de su clientela, pasando el quince por ciento ala panaderıa B y el cinco por ciento a la panaderıa C; la panaderıa B pierde el treinta por ciento,
258

pasando el veinte por ciento a la panaderıa A y el diez por ciento a la panaderıa C; la panaderıa Cpierde el cuarenta por ciento, pasando veinte por ciento a la panaderıa A y veinte por ciento a lapanaderıa B. ¿Cual es el reparto de la clientela al cabo de un ano?
8.2.4. En un bosque hay una poblacion de depredadores y otra poblacion de presas devoradas porellos. Cada medio ano la poblacion de presas se reproduce en una proporcion de 20 por ciento respectoa su poblacion existente, es devorada en una proporcion de 10 por ciento respecto a la poblacionde depredadores y muere en una proporcion de 10 por ciento respecto a su propia poblacion. Losdepredadores se reproducen en una proporcion de 40 por ciento respecto a la poblacion de presasy en una proporcion de 10 por ciento respecto a la proporcion de su poblacion existente muriendotambien en una proporcion de un 40 por ciento respecto a su poblacion. Probar que si la poblacionde presas es la mitad que la poblacion de depredadores, esta relacion se mantiene constante.
Nota: Estos tres ultimos problemas se llaman problemas de dinamica de poblaciones. Sepuede demostrar que a largo plazo la poblacion queda distribuida proporcionalmente al vector propiocorrespondiente al valor propio de mayor valor absoluto de la matriz de transicion de una etapa a lasiguiente:
Supongamos por sencillez que la matriz A es 2×2 y tiene dos valores propios λ1 y λ2 con vectorespropios v1 y v2 respectivamente, siendo |λ1| > |λ2|; entonces, como v1, v2 son base, cualquiera quesea el vector v (de distribucion de la poblacion), se puede expresar:
An(v) = An(α1v1 + α2v2) = α1λn1v1 + α2λ
n2v2
de donde1
λn1An(v) = α1v1 + α2(
λ2
λ1
)nv2 por lo que limn→∞1
λn1An(v) = α1v1
porque |λ1| > |λ2|, teniendose que limn→∞An(v) = λn1α1v1, proporcional a v1. quedando demostrado
lo enunciado.
Como todos los multiplos de un vector propio son vectores propios para el mismo valor propio,la igualdad anterior muestra que limn→∞A
n(v) es un vector propio para el mismo valor propiocualquiera que sea v. Siendo ademas An+1(v) ≈ λ1A
n(v), es decir, a largo plazo la poblacion tiendea quedar multiplicada por el valor propio λ1.
Si λ1 > 1 crece indefinidamente y si λ1 < 1 decrece y tiende a extinguirse. En los problemas enlos que solo hay trasvase de poblacion de unas regiones a otras, la poblacion no crece ni decrece, porlo que el valor propio de mayor valor absoluto es 1. Y la poblacion tiende a distribuirse segun elvector propio del valor propio 1.
259

Multiplicidad de los valores propios.
La teorıa que sigue es para abreviar el calculo de las multiplicidades geometricas de algunosvalores propios y esta motivada por el estudio de la ecuacion caracterıstica.
Definicion 5: Se llama polinomio caracterıstico de un endomorfismo f o de su matriz A, aldeterminante |A− λI|. Este es un polinomio de grado n en λ. Su definicion depende de la matriz Aque a su vez depende de la base escogida para expresar f pero puede demostrarse que en realidad,solo depende de f , es decir, que permanece constante al cambiar la base.
En efecto, si A′ es la matriz de f en otra base, existe una matriz C de cambio de base tal queA′ = C−1AC. La matriz C tiene inversa por corresponder a un cambio de base y tiene determinantedistinto de cero. El polinomio caracterıstico de f , usando esta matriz serıa
|A′ − λI| = |C−1AC − λI| = |C−1AC − λC−1C| = |C−1(A− λI)C| =
= |C−1||(A− λI)||C| = 1/|C||(A− λI)||C| = |(A− λI)|
(por ser las matrices C y C−1 de numeros e invertibles y por ello producto de matrices elementalesy tener los determinantes de las matrices polinomiales, las mismas propiedades que las matricesde numeros, respecto a la suma de filas (o de columnas), intercambio de filas (o de columnas) ymultiplicacion por un numero de una fila (o de una columna).
Se puede comprobar que si n es el orden de A,
|λI − A| = λn −n∑i=1
aiiλn−1 +
∑ij
∣∣∣∣ aii aijaji ajj
∣∣∣∣λn−2 + · · ·+ (−1)n|A|
siendo el coeficiente de λi, la suma de los menores diagonales de orden n− i, que tienen su diagonalen la diagonal de la matriz, multiplicada por (−1)n−i.
Observese que |A− λI| = (−1)n|λI − A|.Al ser el polinomio caracterıstico un invariante de f (independiente de la base escogida), tambien
son invariantes de f los coeficientes de las potencias de λ en cada uno de sus terminos y el terminoindependiente. Este ultimo es el determinante de A que por eso se llama tambien determinante def . Otro invariante facil de calcular es el coeficiente de λn−1 que es la suma de los terminos de ladiagonal de A multiplicada por (−1)n−1. Como el signo solo depende de n, la suma de los terminosde la diagonal de A, que se llama traza de A, es tambien invariante de f .
260

Volviendo a los valores propios, cada uno de ellos es raiz λi de |A− λI| y tiene una multiplicidadalgebraica αi, tal que |A− λI| = (λ− λi)αiq(λ), donde λi no es raiz de q(λ).
Vamos a dar un lema que implica que la multiplicidad geometrica de los valores propios simplesdel endomorfismo (de multiplicidad algebraica 1) es tambien 1. Por lo que al comprobar si el endo-morfismo verifica la condicion enunciada en la proposicion 1 para ser diagonalizable solo tendremosque hallar las dimensiones de los subespacios de vectores propios correspondientes a valores propiosmultiples.
Demostramos el siguiente Lema 2: La multiplicidad geometrica de un valor propio λi es menoro igual que su multiplicidad algebraica.
Una vez demostrado el lema, tendremos que la multiplicidad geometrica de los valores propiossimples es 1, ya que por el lema es ≤ 1 pero como siempre hay por lo menos un vector propio paraun valor propio, es tambien ≥ 1, deduciendose que es 1.
Demostracion del lema 2: Como el polinomio caracterıstico es independiente de la base utilizadapara calcularlo, vamos a utilizar una base adaptada al resultado que queremos demostrar. Seami = dim ker(f − λiI); podemos entonces escoger v1, · · · , vmi vectores propios independientespara el mismo valor propio λi y extender este conjunto independiente a una base de todo el espaciovectorial. Expresando f en esta base extendida, se obtiene una matriz ası:
A =
λi 0 · · · 0 a1,mi+1· · · a1,n
0 λi · · · 0 a2,mi+1· · · a2,n
......
. . . 0 · · · · · · · · ·0 0 · · · λi ami,mi+1
· · · ami,n0 0 · · · 0 ami+1,mi+1
· · · ami+1,n
0 0... 0
......
...0 0 · · · 0 an,mi+1
· · · an,n
y
|A− λI| =
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣
λi − λ 0 · · · 0 a1,mi+1 · · · a1,n
0 λi − λ · · · 0 a2,mi+1 · · · a2,n...
.... . . 0 · · · · · · · · ·
0 0 · · · λi − λ ami,mi+1 · · · ami,n0 0 · · · 0 ami+1,mi+1
− λ · · · ami+1,n
0 0... 0
......
...0 0 · · · 0 an,mi+1 · · · an,n − λ
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣=
261

= (λi − λ)mi
∣∣∣∣∣∣∣ami+1,mi+1
− λ · · · ami+1,n...
. . ....
an,mi+1 · · · an,n − λ
∣∣∣∣∣∣∣ = (λi − λ)miq(λ)
donde q(λ) es un polinomio que podrıa tener λi como raiz. Entonces λi es raiz de |A − λI| demultiplicidad mayor o igual que mi = dim ker(f − λiI), por tanto, dim ker(f − λiI) ≤ αi c.q.d.
Como por el teorema fundamental del algebra, la suma de las multiplicidades algebraicas de lasraices del polinomio caracterıstico (reales y complejas), es igual al grado del polinomio, (que en elcaso del polinomio caracterıstico coincide con la dimension del espacio vectorial), tambien se deducedel lema que si la matriz de un endomorfismo de un espacio vectorial real tiene valores propioscomplejos, el endomorfismo no es diagonalizable, porque la suma de las multiplicidades geometricasde los valores propios reales es menor o igual que la suma de las multiplicidades algebraicas de dichosvalores propios, y esta suma solo llega a n sumandole ademas la multiplicidad de las raices complejas.
Planteandonos las causas por las que un endomorfismo puede no ser diagonalizable, encontramosque son: a) que la multiplicidad geometrica de algun valor propio no coincida con su multiplicidadalgebraica, b) en el caso de endomorfismos de espacios vectoriales reales, que el polinomio carac-terıstico tenga valores propios complejos. Si el espacio vectorial es complejo no aparece esta ultimadificultad, teniendose los resultados siguientes:
Tercera condicion necesaria y suficiente para que el endomorfismo sea diagonalizable.Teorema 1: Un endomorfismo de un espacio vectorial complejo es diagonalizable si y solo si
la dimension del subespacio de vectores propios correspondiente a cada valor propio es igual a lamultiplicidad (algebraica) de ese valor propio en el polinomio caracterıstico.
Demostracion: En efecto, si para todo λi la dimension del ker(f −λiI) coincide con la multiplici-dad algebraica de la raiz λi, se verifica que la suma de las dimensiones de los subespacios de vectorespropios es igual a la suma de las multiplicidades algebraicas de los valores propios, (igual a n), loque por la proposicion 1 demuestra que el endomorfismo f es diagonalizable.
Recıprocamente, por reduccion al absurdo, ha de ser en el caso diagonalizable, dim ker(f−λiI) =multiplicidad algebraica de λi ya que si fuera menor para algun λi, no se darıa que el numero devectores propios independientes de f fuera igual a la dimension del espacio.
Una matriz A ∈ M n×n(R) de numeros reales determina un endomorfismo f de Rn en la basecanonica y tambien un endomorfismo f de Cn. Diagonalizar f es encontrar una base de vectorespropios de Rn para A y diagonalizar f es encontrar una base de vectores propios de Cn para A.
262

Como los vectores de Rn, son vectores de Cn, toda diagonalizacion de f da una diagonalizacion def , pero el recıproco no es cierto si los vectores propios de Cn tienen coordenadas no reales.
Veamos un ejemplo de una matriz A ∈ M3×3(R) tal que el endomorfismo f : R3 7→ R3 corres-pondiente no es diagonalizable y el endomorfismo f : C3 7→ C3 correspondiente sı lo es:
A =
2 0 00 0 −10 1 0
Su polinomio caracterıstico es (2−λ)(λ2 +1) cuyas raices son λ1 = 2, λ2 = i, λ3 = −i. Las tres raicesson valores propios de f . Por ser distintas, f es diagonalizable. Pero solo la raiz real λ = 2 es valorpropio real. Entonces f tiene un solo valor propio cuya multiplicidad algebraica es 1, siendo 1 < 3, lasuma de las multiplicidades geometricas de los valores propios de f . Por ello f no es diagonalizable.
Dado un endomorfismo f de Rn de matriz A, aunque el teorema 1 de diagonalizacion anteriorsolo se aplica al endomorfismo f de la misma matriz, cuando f es diagonalizable y los valores propiosde f , (que son los de A), son todos reales, la matriz diagonal D equivalente a A es de numeros realesy tambien lo es la matriz de cambio de base C, tal que D = C−1AC. Esta diagonalizacion es validaentonces, en M n×n(R) y nos dice que f es tambien diagonalizable. Por tanto, el teorema puedeaplicarse entonces a endomorfismos de Rn, segun el
Corolario 2: Un endomorfismo de un espacio vectorial sobre R es diagonalizable si y solo si sumatriz tiene todos los valores propios reales y la dimension del subespacio de vectores propios paracada valor propio (multiplicidad geometrica) es igual a la multiplicidad algebraica de ese valor propioen el polinomio caracterıstico.
Ejercicios:
8.3.1. Estudiar, segun los valores de los parametros a y b, la diagonalizacion de las siguientesmatrices:
a)
−1 0 b0 1 00 0 a
b)
1 −1 00 a 0a 1 a
c)
1 2 b0 a 01 0 b
8.3.2. Comprobar la formula dada para |λI − A| posteriormente a la definicion 5 cuando A es
una matriz cuadrada 4× 4.
263

Aplicaciones Autoadjuntas en un espacio euclıdeo.
Vamos a utilizar la letra f para aplicaciones y a representar, a partir de este momento, el productoescalar (que no tiene por que ser el usual), por < x, y >.
Dada una aplicacion f : V → V definida en un espacio vectorial euclıdeo, se llama aplicacion adjuntade f a otra aplicacion g : V → V tal que
< f(x), y >=< x, g(y) > ∀x, y ∈ V
Una aplicacion se llama autoadjunta cuando es adjunta de ella misma:
< f(x), y >=< x, f(y) > .
Ejemplos de aplicaciones autoadjuntas son las proyecciones ortogonales sobre un subespacio vec-torial. En efecto, sea PU la aplicacion proyecion ortogonal sobre el subespacio U , entonces, para todovector x, tenemos x = PU(x) + PU⊥(x), por lo que
< PU(x), y >=< PU(x), PU(y) + PU⊥(y) >=
=< PU(x), PU(y) > + < PU(x), PU⊥(y) >=< PU(x), PU(y) >
ya que por ser PU(x) ∈ U, PU⊥(x) ∈ U⊥, < PU(x), PU⊥(y) >= 0. Por otra parte, cambiando el papelde x por y, se obtiene de la anterior igualdad:
< x, PU(y) >=< PU(y), x >=< PU(y), PU(x) >
De donde < PU(x), y >= < x, PU(y) >.
Teorema 2:a) Si la aplicacion dada f es lineal, existe una aplicacion adjunta de f tambien lineal.b) Si existe la aplicacion adjunta de una aplicacion dada, es unica.
a) Es logico pensar que la adjunta de una aplicacion lineal sea lineal, y suponiendo que en unabase determinada f se expresa por la matriz A y su adjunta g se exprese por una matriz B se puedehallar la relacion necesaria que tendrıa que haber entre A y B. Comprobamos despues que estarelacion es suficiente.
264

Sea f(x) = A(x) en una base cualquiera y G la matriz del producto escalar en esa base. Sig(x) = B(x) y g es adjunta de f :
(x1, x2, ..., xn)tAG
y1
y2...yn
=< A(x), y >=< x,B(y) >= (x1, x2, ..., xn)GB
y1
y2...yn
Como esta igualdad debe ser cierta para todo x e y, debe tenerse:
tAG = GB, es decir, B = G−1tAG
En una base ortonormal, G = I y entonces obtenemos B = tA.
Comprobamos que esta condicion necesaria para B es suficiente para que g sea adjunta de f :1) Si f es una aplicacion lineal que se expresa en una base ortonormal por A, la aplicacion lineal
que se expresa en esa misma base por tA es adjunta de la anterior.2) Si f es una aplicacion lineal que se expresa en una base cualquiera por A, la aplicacion lineal
g que se expresa en esa misma base por G−1tAG donde G es la matriz del producto escalar en esabase, es adjunta de la anterior.
En efecto:1) En una base ortonormal,
< f(x), y >=
A
x1
x2...xn
t
·
y1
y2...yn
= (x1, x2, ..., xn)tA
y1
y2...yn
y
< x, g(y) >= (x1, x2, ..., xn)tA
y1
y2...yn
siendo, por tanto iguales.
2) En una base cualquiera,
< f(x), y >=
A
x1
x2...xn
t
G
y1
y2...yn
= (x1, x2, ..., xn)tAG
y1
y2...yn
265

y
< x, g(y) >= (x1, x2, ..., xn)GG−1tAG
y1
y2...yn
= (x1, x2, ..., xn)tAG
y1
y2...yn
son iguales.
b) Veamos ahora que en el caso de existir la aplicacion adjunta de otra aplicacion, serıa unica.
Sean g y h dos adjuntas de la aplicacion f , entonces:
< x, g(y) >=< f(x), y >=< x, h(y) > ∀x, y ∈ V
de donde< x, g(y)− h(y) >= 0 ∀x, y ∈ V
Cogiendo x = g(y)− h(y), tenemos:
< g(y)− h(y), g(y)− h(y) >= 0 ∀y ∈ V
Por las propiedades del producto escalar, esto implica g(y)− h(y) = 0 ∀y ∈ V . Es decir,
g(y) = h(y) ∀y ∈ V
En virtud de b), podemos hablar de la aplicacion adjunta de una aplicacion lineal y afirmar quees lineal, siendo su matriz la que hemos calculado en el apartado a).
Para que la aplicacion lineal sea autoadjunta, debe coincidir con su adjunta, por tanto, segun lovisto anteriormente, si la expresamos en una base ortonormal, ha de ser A = tA y si la expresamosen una base cualquiera, ha de ser A = G−1tAG, lo cual es equivalente a GA = tAG = tAGt = (GA)t,es decir, que GA ha de ser una matriz simetrica, siendo G la matriz del producto escalar en dichabase.
Corolario: Como hemos visto que las proyecciones ortogonales son aplicaciones autoadjuntas, silas expresamos en una base ortonormal, su matriz ha de ser simetrica.
266

Ejercicios.
8.4.1. Encontrar las matrices en la base canonica de las aplicaciones adjuntas respecto al productoescalar usual de los endomorfismos de R3 dados en la base canonica por
a) f(x, y, z) = (x+ y + z, 2x+ y + 2z, x+ y + 3z)b) f(x, y, z) = (y + z, 2x+ 2z, 2x+ y + 3z)c) f(x, y, z) = (−y + z,−x+ 2z, x+ 2y).d) f(x, y, z) = (x+ y + z, x+ 2y + 2z, x+ 2y + 3z).8.4.2. Senalar cuales de los endomorfismos del ejercicio anterior son autoadjuntos.8.4.3.a) Averiguar si son autoadjuntos respecto al producto escalar usual los endomorfismos de R3
dados en la base (1, 1, 1), (1, 2, 0), (1, 0, 3) por
a)
−1 0 −21 2 11 0 2
b)
6 4 10−3 −2 −5−1 −1 −1
b) Comprobar el resultado mirando las matrices de dichos endomorfismos en la base canonica.c) Hay una aplicacion que no es autoadjunta. Hallar la matriz en la base dada y en la base
canonica de su aplicacion adjunta y comprobar que estan relacionadas por el correspondiente cambiode base.
8.4.4. Se considera una base ortonormal e1, e2, e3 en un espacio vectorial euclıdeo de dimension3 y en el la aplicacion lineal dada por
3f(e1) = 2e1 − 2e2 + e3 3f(e2) = αe1 + e2 − 2e3 3f(e3) = βe1 + γe2 + 2e3
Encontrar α, β, γ para que la aplicacion f sea autoadjunta.
267

Diagonalizacion de las Aplicaciones Autoadjuntas, (de las matrices simetricas).
Hemos visto que una aplicacion autoadjunta se expresa en una base ortonormal por una ma-triz simetrica y la aplicacion expresada por una aplicacion simetrica en una base ortonormal esautoadjunta, por ello es equivalente la diagonalizacion de aplicaciones autoadjuntas y de matricessimetricas.
Recordemos que un endomorfismo es diagonalizable si y solo si la suma de las multiplicidadesgeometricas de sus valores propios es igual a la dimension del espacio y la dimension del espacio esel grado del polinomio caracterıstico, que coincide con la suma de las multiplicidades algebraicas delos valores propios. Como la multiplicidad geometrica de un valor propio es menor o igual que sumultiplicidad algebraica, una razon para que un endomorfismo de un espacio vectorial real no seadiagonalizable es que una de las raices de su polinomio caracterıstico sea compleja. Veamos que nose da este caso para los endomorfismos expresados por matrices simetricas.
Proposicion 2: Una matriz simetrica de numeros reales no tiene valores propios complejos.
Demostracion:Sea A la matriz simetrica de numeros reales A. Una matriz cuadrada de numeros reales determina
un endomorfismo f de Rn y tambien un endomorfismo f de Cn. Los valores propios de f son sololas raices reales del polinomio caracterıstico de la matriz. Los valores propios de f son las raices,reales o complejas, del polinomio caracterıstico de la matriz.
Consideremos el endomorfismo f dado por la matriz A en el espacio vectorial Cn donde n es elorden de A. Si α + iβ fuera un valor propio de este endomorfismo, existirıa un vector propio (nonulo) de coordenadas complejas:
w = (w1, w2, ...wn) = (u1 + iv1, u2 + iv2, ..., un + ivn) = (u1, u2, ..., un) + i(v1, v2, ..., vn) = u+ iv
tal quef(u+ iv) = (α + iβ)(u+ iv) equiv. a A(u+ iv) = (α + iβ)(u+ iv)
es decir,Au+ iAv = αu− βv + i(αv + βu),
igualando partes reales y partes imaginarias, existirıan dos vectores u y v del espacio vectorial realRn, tales que
Au = αu− βvAv = αv + βu
268

Como Au = f(u) y Av = f(v), se tiene
f(u) = αu− βvf(v) = αv + βu
y como f es autoadjunta en el espacio vectorial real, tenemos, sustituyendo ahora f(u) y f(v) porsus valores en < f(u), v >=< u, f(v) >,
< αu− βv, v >=< u, αv + βu >⇒ α < u, v > −β < v, v >= α < u, v > +β < u, u >
o sea,β(< u, u > + < v, v >) = 0
Tenemos, de aquı, β = 0 porque el producto escalar es definido positivo y el vector w = u + ivno era nulo. Por ello, el valor propio ha de ser real.
Como una matriz simetrica n× n de numeros reales no tiene valores propios complejos, sabemosque si todos los valores propios son de multiplicidad 1, tiene que tener n valores propios reales distintosy por tanto la matriz es diagonalizable en R. Y mas aun, en virtud de la proposicion siguiente, la baseque diagonaliza a la matriz simetrica (o a la aplicacion autoadjunta correspondiente) es ortogonal.
Proposicion 3:Dos vectores propios de una aplicacion autoadjunta (de una matriz simetrica) correspondientes a
distintos valores propios son ortogonales:Demostracion:Sean v1, v2 vectores propios de f tales que f(v1) = λ1v1, f(v2) = λ2v2, siendo λ1 6= λ2.
< f(v1), v2 >=< v1, f(v2) >⇒< λ1v1, v2 >=< v1, λ2v2 >⇒ λ1 < v1, v2 >= λ2 < v1, v2 >
de donde(λ1 − λ2) < v1, v2 >= 0
y como λ1 − λ2 6= 0 ha de ser < v1, v2 >= 0.
Por la misma razon, subespacios de vectores propios correspondientes a distintos valores propiosson ortogonales.
269

EJEMPLO 2:Al diagonalizar la matriz 7 2 0
2 6 −20 −2 5
obtenemos su polinomio caracterıstico −λ3 + 18λ2 − 99λ + 162 = (3 − λ)(λ − 6)(λ − 9). Por tantolos valores propios son λ1 = 3, λ2 = 6 λ3 = 9.
Los vectores propios para λ1 son los que verifiquen la ecuacion 7 2 02 6 −20 −2 5
xyz
= 3
xyz
≡ 4 2 0
2 3 −20 −2 2
xyz
=
000
,
uno de ellos es (1,−2,−2).Los vectores propios para λ2 son los que verifiquen la ecuacion 7 2 0
2 6 −20 −2 5
xyz
= 6
xyz
≡ 1 2 0
2 0 −20 −2 −1
xyz
=
000
,
uno de ellos es (−2, 1,−2).Los vectores propios para λ3 son los que verifiquen la ecuacion 7 2 0
2 6 −20 −2 5
xyz
= 9
xyz
≡ −2 2 0
2 −3 −20 −2 −4
xyz
=
000
,
uno de ellos es (2, 2,−1).Se ve que el producto escalar de dos distintos de estos vectores propios es nulo y por tanto son
ortogonales o perpendiculares. Por tanto, la base que diagonaliza al endomorfismo correspondiente ala matriz dada es una base ortogonal, que puede transformarse en ortonormal dividiendo cada vectorpor su modulo.
De hecho, tenemos el interesante Teorema 3: Todo endomorfismo autoadjunto de un espaciovectorial euclıdeo es diagonalizable en una base ortonormal.
Utilizamos un argumento que se basa en la siguiente propiedad:Proposicion 4: Si f : V n
R → V nR es una aplicacion autoadjunta y U es un subespacio invariante
por f , el subespacio ortogonal a U es tambien invariante por f .
270

En efecto, si v′ ∈ U⊥ y v ∈ U , < v, f(v′) >=< f(v), v′ >= 0 ∀v ∈ U .
Demostracion del teorema:Damos ahora una demostracion constructiva. Otra demostracion por induccion del teorema se
puede encontrar al final del capıtulo.Sea λ1 un valor propio real del endomorfismo autoadjunto f con el vector propio v1. (Existe por
la proposicion 2).Entonces el subespacio Lv1 es invariante por f y por tanto Lv1⊥ es invariante por f .Completando v1 a una base de V con una base u2, u3, ..., un del ortogonal a v1, la matriz de f
en esa base serıa: λ1 0 0 · · · 00 ∗ ∗ · · · ∗0 ∗ ∗ · · · ∗0 ∗ ∗ · · · ∗
porque como para j > 1, f(uj) ∈ Lu2, u3, ..., un, su coordenada en v1 es nula.
Aquı las * llenarıan la matriz de la restriccion de f al ortogonal a v1. Como esta restriccion f |v⊥1es autoadjunta, podemos encontrar otro λ2 valor propio real de esta restriccion (y a su vez de f) yotro v2, vector propio del subespacio ortogonal a v1 para f y λ2.
El subespacio Lv1, v2⊥ es tambien invariante por f por serlo Lv1, v2.Expresando f en una base formada por v1, v2 ampliada con una base del subespacio ortogonal
a estos dos vectores, tendrıamos una matriz del tipo:λ1 0 0 · · · 00 λ2 0 · · · 00 0 ∗ · · · ∗0 0 ∗ · · · ∗
donde las * llenarıan la matriz de la restriccion de f al ortogonal a Lv1, v2.
Podemos seguir repitiendo el razonamiento hasta reducir la matriz de las estrellas a dimensionuno porque la restriccion del endomorfismo dado a cualquier subespacio invariante sigue siendo au-toadjunto y por tanto teniendo valores propios reales. Al final hemos hecho nulos todos los elementosque no estan en la diagonal y hemos encontrado una base en la que f se expresa por una matrizdiagonal, por tanto f es diagonalizable.
Observemos tambien que la base de vectores propios que se han ido obteniendo de esta forma sonortogonales a todos los anteriores. Son por tanto una base ortogonal que diagonaliza a f y se puedehacer ortonormal dividiendo cada vector por su modulo sin perder la propiedad de diagonalizar a f .
Para el procedimiento practico para encontrar una base ortonormal que diagonalice a una apli-cacion autoadjunta utilizamos la
271

Observacion 1:Cuando f es autoadjunta, al ser f diagonalizable, la suma de las multiplicidades geometricas
de todos sus valores propios (que son reales) es igual a la dimension del espacio. Por lo que V n =⊕m1 ker(f − λiI).Ademas, todos estos subespacios sumandos son ortogonales entre sı segun se ha visto. En cada uno
de los subespacios podemos coger una base ortonormal y la union de todas las bases ortonormalesde los ker(f − λiI) da una base ortonormal de V n que diagonaliza a f .
En la practica tambien obtenemos primero una base ortogonal que diagonaliza a f y luego di-vidimos cada vector de la base por su modulo.
EJEMPLO 3: Diagonalizar en una base ortonormal el endomorfismo de R3, dado por la matriz
A =
2 −1 −1−1 2 −1−1 −1 2
Su polinomio caracterıstico es −λ3 + 6λ2 − 9λ de raices λ1 = 0, simple y λ2 = 3, doble.Como sabemos que el endomorfismo es diagonalizable, la dimension del subespacio de vectores
propios para λ2 = 3 ha de ser 2. Las ecuaciones de este subespacio son 2 −1 −1−1 2 −1−1 −1 2
− 3I
xyz
=
−1 −1 −1−1 −1 −1−1 −1 −1
xyz
=
000
es decir, la ecuacion −x− y − z = 0. En el plano de esta ecuacion podemos encontrar dos vectorespropios ortogonales: Escogido uno: (0, 1,−1), el otro, para ser ortogonal a el ha de verificar laecuacion y − z = 0 ademas de verificar −x− y − z = 0, y puede ser, por tanto (−2, 1, 1). Un vectorpropio correspondiente al valor propio λ1 = 0 es perpendicular a los otros dos, por lo que ha de serproporcional al vector que tiene de coordenadas los coeficientes de las incognitas en la ecuacion delplano de vectores propios para λ2 = 3: (−1,−1,−1).
Una base ortogonal que diagonaliza al endomorfismo es (0, 1,−1), (−2, 1, 1)(−1,−1,−1).Una base ortonormal que diagonaliza al endomorfismo es 1√
2(0, 1,−1), 1√
6(−2, 1, 1), 1√
3(−1,−1,−1).
Las relaciones entre la matriz de f y la diagonal son: C−1AC = D donde
D =
3 0 00 3 00 0 0
272

y C puede ser 0 −2 −11 1 −1−1 1 −1
o
0 1√6(−2) 1√
3(−1)
1√2
1√6
1√3(−1)
1√2(−1) 1√
61√3(−1)
.
Para diagonalizar formas cuadraticas (que veremos mas adelante) y tambien para tener otrometodo de hallar bases ortogonales de un producto escalar, hacemos la
Observacion 2:Si C es la matriz de cambio de base de la canonica a otra ortonormal, Ct · C = I, es decir,
Ct = C−1. (Compruebese en el caso anterior, en particular y como ejercicio, en general). Entonces,la diagonalizacion de una matriz simetrica A, que implica la existencia de una matriz C de cambio debase tal que C−1AC = D, por poderse hacer en una base ortonormal, tambien implica la existenciade una matriz de cambio de base C tal que CtAC = D.
Observacion 3:Si C es la matriz de cambio de base de la canonica a otra ortogonal, Ct · C no es la identidad
pero es una matriz diagonal cuyos elementos diagonales son los modulos de los vectores columna deC: (‖vi‖2). Entonces,
CtAC =
λ1‖v1‖2 0 · · · 0
0 λ2‖v2‖2 · · · 0...
.... . .
...0 0 · · · λn‖vn‖2
Compruebese como ejercicio.
Ejercicios:
8.5.1. Diagonalizar en una base ortonormal los endomorfismos de R3 dados en la base canonicapor las siguientes matrices:
a)
−3 6 06 0 −60 −6 3
b)1
3
2 −2 1−2 1 −2
1 −2 2
c)
1 0 10 1 11 1 −1
Sol. Valores propios: a) 0, 9,−9 b)1/3,−1/3, 5/3 c) 1,
√3, −√
38.5.2. Diagonalizar en una base ortonormal las aplicaciones lineales de R3 dadas en la base
canonica por las siguientes matrices:
273

a)
3 2 42 0 24 2 3
b)
−2 −2 1−2 1 −2
1 −2 −2
c)
3 −1 0−1 3 0
0 0 2
d)
−7 −4 −4−4 −1 8−4 8 −1
Sol. Valores propios: a) 8, −1 (doble). b) 3, −3(doble) c) 4, 2(doble), d) 9, −9 (doble).
274

Espacios Hermıticos.
En Cn se puede definir un producto llamado hermıtico de la siguiente forma:
(z1, z2, · · · , zn) · (z′1, z′2, · · · , z′n) = z1z′1 + z2z′2 + · · ·+ znz′n = (z1, z2, · · · , zn)
z′1z′2...z′n
Puede comprobarse que es una aplicacion de Cn×Cn en C que cumple las siguientes propiedades:1) z · z′ = z′ · z2) Es sesquilineal: Si z, z′, z′′ ∈ Cn
(z + z′) · z′′ = z · z′′ + z′ · z′′λz · z′ = λz · z′z · λz′ = λz · z′
z · (z′ + z′′) = z · z′ + z · z′′
3) Es definido positivo: z · z ≥ 0 y z · z = 0 ≡ z = 0 (z · z es real)
Un producto hermıtico generalizado en un espacio vectorial V nC complejo es una aplicacion
h : V nC × V n
C 7→ C que cumple las propiedades 1), 2) y 3) anteriores.Un espacio hermıtico general es un espacio vectorial complejo con un producto hermıtico
general.
Se puede definir el modulo de un vector de un espacio hermıtico, por ser este definido positivo.(‖z‖ =
√h(z, z)).
Tambien se cumple la desigualdad de Schwarz: ||z · z′|| ≤ ‖z‖‖z′‖ y la desigualdad triangular,pero no podemos definir angulos, ya que los cosenos son numeros reales y los productos de vectorescomplejos son numeros complejos.
Lo mismo que se hizo con el producto escalar, se puede encontrar una expresion matricial delproducto hermıtico generalizado, que viene dado por una matriz H que tiene determinante distintode cero, por ser el producto definido positivo. Por ello, se puede definir el subespacio ortogonal aotro dado de manera analoga a como se define en el espacio euclıdeo, teniendose que el espacio totales suma directa de un subespacio suyo y de su subespacio ortogonal. Por lo que tambien se puedendefinir las proyecciones ortogonales en el espacio hermıtico.
275

Tambien podemos encontrar bases ortonormales para el producto hermıtico en el que la matrizde dicho producto es I. El procedimiento de Gram-Schmidt es valido para un producto hermıtico,por ser este definido positivo.
La matriz H necesariamente ha de cumplir que su traspuesta es igual a su conjugada. Talesmatrices se llaman hermıticas. Ademas, para que una matriz hermıtica corresponda a un productohermıtico, todos sus menores angulares superiores izquierdos han de ser numeros reales positivos,siendo esta condicion suficiente. Puede comprobarse de manera analoga a como se demostro el criteriode Sylvester para la matriz de un producto escalar.
En un espacio hermıtico se define la adjunta de una aplicacion lineal de la misma forma que enun espacio euclıdeo y una aplicacion es autoadjunta si ∀z, z′ ∈ V n
C :
f(z) · z′ = z · f(z′)
Expresada en una base ortonormal la aplicacion f por la matriz A, tendrıamos:
Az · z′ = (z1, z2, · · · , zn)tA
z′1z′2...z′n
= (z1, z2, · · · , zn)A
z′1z′2...z′n
∀z, z′ ∈ Cn
de donde para que la aplicacion sea autoadjunta, tA = A (hermıtica).
Proposicion 4: Los autovalores de una aplicacion autoadjunta de un espacio hermıtico sonreales:
En efecto, si f(v) = λv, se tiene
λ(v · v) = (λv) · v = f(v) · v = v · f(v) = v · λv = λv · v
Como < v, v > es distinto de cero, esta igualdad implica λ = λ.
Otras aplicaciones importantes entre los espacios hermıticos son las aplicaciones unitarias: sonlas que conservan el producto hermıtico: f(z) · f(z′) = z · z′ ∀z, z′ ∈ V n
C .Si U es la matriz de una aplicacion unitaria en una base ortonormal, ∀z, z′ ∈ V n
C , tenemos:
276

(z1, z2, · · · , zn)U t · U
z′1z′2...z′n
= (z1, z2, · · · , zn)
z′1z′2...z′n
∀z, z′ ∈ V nC
lo que implica que U t · U = I. Estas matrices se llaman unitarias.Proposicion 5:Los valores propios de una aplicacion unitaria son numeros complejos de modulo 1.En efecto, si f(z) = λz, f(z) · f(z) = z · z implica z · z = λz · λz = λλz · z = |λ|2z · z lo cual
implica |λ| = 1.Como consecuencia, los valores propios de las aplicaciones unitarias son distintos de cero, siendo
por tanto estas aplicaciones inyectivas y por tanto suprayectivas, es decir, isomorfismos, cuyo iso-morfismo inverso es tambien unitario.
Teorema 4. Tanto las aplicaciones autoadjuntas como las aplicaciones unitarias de un espaciohermıtico son diagonalizables en bases ortonormales.
La demostracion se sigue por induccion del siguiente lema:Lema 2: Si v1 es un vector propio de una aplicacion autoadjunta o unitaria, el subespacio Lv1⊥
es invariante por f .En efecto:1) Si f es autoadjunta y v ∈ Lv1⊥, f(v) · v1 = v · f(v1) = v · λ1v1 = λ1v · v1 = 0, de donde
f(v) ∈ Lv1⊥.2) Si f es unitaria, sea v1 un vector propio de f para el valor propio λ; entonces, v1 es tambien
un valor propio de f−1 para 1/λ. Si v ∈ Lv1⊥, v1 · f(v) = f−1(v1) · f−1f(v) = (1/λ)v1 · v = 0, dedonde f(v) ∈ Lv1⊥.
Demostracion de la diagonalizacion de aplicaciones autoadjuntas y unitarias en una base ortonormal:La diagonalizacion de un endomorfismo en una base ortonormal es equivalente a la diagonalizacion
del endomorfismo en una base ortogonal dividiendo cada vector por su modulo.Hacemos la demostracion por induccion sobre la dimension del espacio. Sea esta n.Tengamos en cuenta que el endomorfismo es diagonalizable en una base ortogonal si podemos
encontrar n vectores propios independientes ortogonales dos a dos.Cuando n = 1, la matriz se reduce a un numero y es ya diagonal.Suponemos que toda aplicacion autoadjunta o unitaria de un espacio hermıtico de dimension n−1
es diagonalizable en una base ortogonal.Sea v1 un vector propio. El subespacio Lv1⊥ es invariante por f segun hemos visto en el lema 1
y es de dimesion n−1. Segun la hipotesis de induccion, la restriccion de f a Lv1⊥ es diagonalizable
277

en una base ortogonal, por lo que existen n− 1 vectores propios para f , ortogonales dos a dos. Estabase unida al vector propio v1 es una base de vectores propios ortogonales dos a dos del espacio totalque diagonaliza a f .
Dividiendo cada vector por su modulo podemos obtener una base ortonormal diagonalizante.Ejercicios:
8.6.1. Determinar si son autoadjuntas o unitarias las aplicaciones de C3 en C3 cuyas matrices enla base canonica son las siguientes:
A)
1 0 i0 2 0−i 0 3
B)
6 0 −2√
2− 2i0 −4 0
−2√
2 + 2i 0 2
C) 1/2
1 + i√
2 0 i0 2 0
i 0 1− i√
2
D)
7 −√
2 + i −2√
2 + 2i
−√
2− i 7 −2
−2√
2− 2i −2 −8
E)
2 −2√
2 + 2i 2√
2− 2i
−2√
2− 2i 8 −2
2√
2 + 2i −2 4
F )
0 0 −i0 −1 0−i 0 0
G)1
2
1− i√
2 0 10 2 0
−1 0 1 + i√
2
H)1
3
−2 i 2i2 2i i−1 2i −2i
I)1
9
−4i −1 8i4i −8 i7i 4 4i
J)1
4
−1 + i(2√
2− 1) 0 −1−√
2 + i(√
2 + 1)0 4 0
1−√
2 + i(√
2 + 1) 0 −1 + i(1− 2√
2)
K)
3i+ 4 2− 6i −42− 6i 1 −2− 6i−4 −2− 6i 4− 3i
8.6.2.a) Comprobar que las matrices anteriores que son autoadjuntas tienen los valores propios reales.b) Comprobar que las matrices anteriores que son unitarias tienen los valores propios de modulo
1.c) Diagonalizar las matrices A), F), H), K) anteriores. (Encontrar una base de vectores propios
de cada aplicacion y la matriz de la aplicacion en esta base).8.6.3.a) Demostrar que si un subespacio W es invariante por una aplicacion autoadjuta, el subespacio
W⊥ tambien lo es.b) Demostrar que si un subespacio W es invariante por una aplicacion unitaria, el subespacio W⊥
tambien lo es.8.6.4. Demostrar que vectores propios correspondientes a distintos valores propios de una apli-
cacion unitaria son ortogonales.
278

Bibliografıa:[A] J. Arvesu Carballo, R. Alvarez Nodarse, F. Marcellan Espanol. Algebra Lineal y aplicaciones.
Ed. Sıntesis. 1999.[B] J. de Burgos. Curso de Algebra y Geometrıa. Ed. Alhambra 1982.[C] M. Castellet, I. Llerena. Algebra Lineal y Geometrıa. Ed. Reverte. 1991.[G] L. Golovina. Algebra Lineal y algunas de sus Aplicaciones. Ed. Mir. 1980.[H] E. Hernandez. Algebra y Geometrıa. Ed. Addison-Wesley/U.A.M. 1994.[L] D. C. Lay. Algebra Lineal y sus Aplicaciones. Ed. Prentice-Hall 2001.[S] G. Strang. Algebra Lineal y sus Aplicaciones Ed. Addison-WesleyIberoamericana. 1990.[V] A. de la Villa. Problemas de Algebra. Ed. Clagsa, 1994.
279

280

FORMAS CUADRATICAS.
Introduccion.
Ya hemos estudiado ciertas formas bilineales, los productos escalares. Las formas bilineales engeneral, no tienen porque ser simutricas ni definidas positivas.
A cada forma bilineal se le asocia una forma cuadratica; aunque a distintas formas bilinealesresulta asociada la misma forma cuadratica, encontramos slo una forma bilineal simetrica (de matrizsimetrica) asociada a esta forma cuadratica. Veremos que su matriz puede llegar a ser diagonal,haciendo un cambio de base. Hallar la matriz diagonal, la base y el nuevo sistema de coordenadasen la que le corresponde es diagonalizar la forma cuadratica. Todas las formas cuadraticas sondiagonalizables.
Definicion 1. Dado un espacio vectorial sobre un cuerpo K, se llama forma bilineal en V a todaaplicacion f : V × V −→ K que es lineal en cada una de las variables, es decir,
∀x, x′, y, y′ ∈ V, ∀α ∈ K
f(x+ x′, y) = f(x, y) + f(x′, y)f(αx, y) = αf(x, y)
f(x, y + y′) = f(x, y) + f(x, y′)f(x, αy) = αf(x, y)
Definicion 2. Dado un espacio vectorial V sobre un cuerpo K, se llama forma cuadratica en Va una aplicacion Q : V −→ K si existe una forma bilineal f tal que Q(x) = f(x, x)
La forma cuadratica Q verifica Q(αx) = f(αx, αx) = α2f(x, x) = α2Q(x).
Expresion matricial de una forma cuadratica.Toda forma cuadratica en un espacio vectorial de dimension finita admite una expresion matricial
deducida de la expresion matricial de la forma bilineal en el espacio vectorial de dimension finita:Sea e1, e2, ...en una base del espacio vectorial V n sobre el que esta definida la forma bilineal.
Sean x = (x1, x2, ..., xn), y = (y1, y2, ...yn) dos vectores del espacio vectorial expresados por suscoordenadas en esa base y sea f la forma bilineal.
Entonces,
f(x, y) = f(x1e1 + x2e2 + ...+ xnen, y1e1 + y2e2 + ...+ ynen) =
x1f(e1, y1e1 +y2e2 + ...+ynen)+x2f(e2, y1e1 +y2e2 + ...+ynen)+ ...+xnf(en, y1e1 +y2e2 + ...+ynen) =
281

= x1(y1f(e1, e1)+...+ynf(e1, en))+x2(y1f(e2, e1)+...+ynf(e2, en))+...+xn(y1f(en, e1)+...+ynf(en, en)) =
= (x1, x2, ..., xn)
y1f(e1, e1) + y2f(e1, e2) + ...+ ynf(e1, en)y1f(e2, e1) + y2f(e2, e2) + ...+ ynf(e2, en)
...y1f(en, e1) + y2f(en, e2) + ...+ ynf(en, en)
=
= (x1, x2, ..., xn)
f(e1, e1) f(e1, e2) ... f(e1, en)f(e2, e1) f(e2, e2) ... f(e2, en)· · · · · · · · · · · ·
f(en, e1) f(en, e2) ... f(en, en)
y1
y2...yn
=
= (x1, x2, ..., xn)B
y1
y2...yn
.
donde la matriz denotada por B es la matriz de la forma bilineal.
Como Q(x) = f(x, x), la forma cuadratica tambien puede escribirse en forma matricial:
Q(x) = f(x, x) = (x1, x2, ..., xn)B
x1
x2...xn
Recıprocamente, cualquiera que sea la matriz B, las expresiones matriciales:
(x1, x2, ..., xn)B
y1
y2...yn
y (x1, x2, ..., xn)B
x1
x2...xn
donde las coordenadas se refieren a una base fijada, corresponden respectivamente a formas bilinealesy formas cuadraticas.
Ejemplo 1:
282

Veamos lo que resulta al desarrollar la forma bilineal y la forma cuadratica correspondiente a lamatriz:
B =
1 −1 13 1 10 1 1
f(x, y) = (x1, x2, x3)
1 −1 13 1 10 1 1
y1
y2
y3
= (x1, x2, x3)
y1 − y2 + y3
3y1 + y2 + y3
y2 + y3
=
= x1y1 − x1y2 + x1y3 + 3x2y1 + x2y2 + x2y3 + x3y2 + x3y3
Es un polinomio en xiyj donde el coeficiente de cada xixj es el numero de la entrada (i,j) de la matrizB.
Al realizar Q(x) obtenemos:
Q(x) = (x1, x2, x3)
1 −1 13 1 10 1 1
x1
x2
x3
= (x1, x2, x3)
x1 − x2 + x3
3x1 + x2 + x3
x2 + x3
=
= x1x1 − x1x2 + x1x3 + 3x2x1 + x2x2 + x2x3 + x3x2 + x3x3
donde podemos agrupar los terminos −x1x2 + 3x2x1 y los terminos x2x3 + x3x2 obteniendo:
Q(x) = x21 + 2x1x2 + x1x3 + x2
2 + 2x2x3 + x23
.Tambien al desarrollar la forma cuadratica correspondiente a la forma bilineal
f ′(x, y) = (x1, x2, x3)
1 −2 14 1 10 1 1
y1
y2
y3
obtenemos
x1x1 − 2x1x2 + x1x3 + 4x2x1 + x2x2 + x2x3 + x3x2 + x3x3
donde agrupando los terminos −2x1x2 +4x2x1 y los terminos x2x3 +x3x2 obtenemos la misma formacuadratica anterior.
Lo mismo ocurre al desarrollar la forma cuadratica correspondiente a la forma bilineal
f ′′(x, y) = (x1, x2, x3)
1 −1 13 1 30 −1 1
y1
y2
y3
283

de la cual obtenemos la misma forma cuadr tica:
x1x1 − x1x2 + x1x3 + 3x2x1 + x2x2 + 3x2x3 − x3x2 + x3x3
agrupando los terminos −x1x2 + 3x2x1 y los terminos 3x2x3 − x3x2.Pero si se exige a la forma bilineal de la que proviene la forma cuadratica que tenga matriz
simetrica, como la suma b12 + b21 ha de ser el coeficiente de x1x2, tanto b12 como b21 han de ser lamitad de ese coeficiente, en este caso b12 = b21 = 1, estando entonces perfectamente determinado.Lo analogo ocurre con b13 y b31, siendo la matriz simetrica asociada, la siguiente: 1 1 1/2
1 1 11/2 1 1
.
En general, al desarrollar las expresiones matriciales tenemos:
f(x, y) =n∑ij
xiyjf(ei, ej);
Q(x) =nn∑ij
xixjf(ei, ej) =n∑i<j
xixj(f(ei, ej) + f(ej, ei)) +n∑i=1
x2i f(ei, ei)
lo que nos dice que mientras que una forma bilineal es una expresion polinomial de segundo gradoen xi, yj en la que en todos los monomios aparecen xi y yj, una forma cuadratica es unaexpresion polinomial homogenea de segundo grado en las xi i ∈ 1, ..., n.
Observando las expresiones anteriores, deducimos que dada la expresion polinomial de una formabilineal, pasamos a escribir la matriz correspondiente B poniendo en el lugar (i, j) de B el coeficientede xiyj. Sin embargo, debido a que al pasar de la forma bilineal a la cuadratica, se suman loscoeficientes de xixj y xjxi para dar el monomio xixj(f(ei, ej) + f(ej, ei)), f(ei, ej) y f(ej, ei) sepueden compensar de distintas formas para dar el mismo numero y distintas matrices de distintasformas bilineales pueden dar iguales formas cuadraticas.
Pero si se exige a la forma bilineal de la que proviene la forma cuadratica que cumpla la condicionf(ei, ej) = f(ej, ei), como la suma de estos dos numeros es el coeficiente de xixj en la formacuadratica, el numero f(ei, ej) ha de ser la mitad de ese coeficiente y entonces sı esta perfectamentedeterminado. Con esta condicion, la matriz correspondiente a la forma cuadratica es simetrica yunica y la escribiremos poniendo en los sitios (i, j) y (j, i) la mitad del coeficiente de xixj.
284

Ası podremos utilizar los resultados de diagonalizacion de las matrices simetricas para diagonalizartambien las formas cuadraticas.
Cambio de base en formas cuadraticas.Un cambio de coordenadas en el espacio vectorial, que es un cambio de base, induce un cambio en
la expresion matricial de una forma bilineal y de una forma cuadratica y puede llevar a una expresionmas sencilla.
Veamoslo en la siguiente forma cuadratica:Ejemplo 2:
Q(x1, x2) = x21 + 4x1x2 + x2
2 = (x1, x2)
(1 22 1
)(x1
x2
)Haciendo el cambio de base que lleva de la base canonica e1, e2 = (1, 0), (0, 1) a e′1, e′2 =
(1,−1), (1, 1) que induce el cambio de coordenadas(x1
x2
)=
(1 1−1 1
)(x′1x′2
)≡ x1 = x′1 + x′2
x2 = −x′1 + x′2
obtenemos primero sustituyendo en la expresion matricial:
Q(x′1, x′2) = (x′1, x
′2)
(1 −11 1
)(1 22 1
)(1 1−1 1
)(x′1x′2
)= (x′1, x
′2)
(−2 00 6
)(x′1x′2
)Por otra parte, sustituyendo despues en la expresion polinomial de Q, obtenemos:
Q(x′1, x′2) = (x′1 + x′2)
2 + 4(x′1 + x′2)(−x′1 + x′2) + (−x′1 + x′2)2 =
= x′21 + 2x′1x2 + x′
22 + 4(x′1 + x′2)(−x′1 + x′2) + x′
21 − 2x′1x2 + x′
22 = −2x′
21 + 6x′
22
donde se ve la correspondencia entre la expresion final como suma de cuadrados con coeficientes yla expresion final diagonal de la forma cuadratica.
Nos interesa expresar la forma cuadratica de la manera mas simple posible y de la manera masmanejable. Si la forma cuadratica fuera suma de cuadrados de las coordenadas con coeficientes, serıa:
Q(x) = λ1x21 + λ2x
22 + · · ·+ λnx
2n = (x1, x2, ..., xn)
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
x1
x2...xn
285

en cuyo caso la matriz correspondiente es diagonal. Diagonalizar una forma cuadratica es encontrarun sistema de cordenadas en el que se exprese como suma de cuadrados de coordenadas con coefi-cientes, lo cual es equivalente a hacer un cambio de base, de forma que la matriz en la nueva base seadiagonal. Para ello miraremos lo que pasa al hacer un cambio de coordenadas del espacio vectorialen las expresiones matriciales y polinomiales de una forma bilineal y de una forma cuadratica.
En general, si C es una matriz con determinante distinto de cero, haciendo el cambio de coorde-nadas:
x1
x2...xn
= C
x′1x′2...x′n
que induce el mismo cambio en (y1, y2, ..., yn), al sustituir en la expresion matricial primera de laforma bilineal tenemos:
f(x, y) = (x′1, x′2, ..., x
′n)CtBC
y′1y′2...y′n
y sustituyendo en la expresion matricial de la forma cuadratica tenemos:
Q(x) = (x′1, x′2, ..., x
′n)CtBC
x′1x′2...x′n
El cambio realizado en la matriz de la forma bilineal coincide con el mismo cambio en la matriz
de la forma cuadratica asociada. La matriz de Q en la nueva base es B′ = CtBC.
Dado que una forma cuadratica puede provenir de distintas formas bilineales, al realizar un cambio de coordenadas,las distintas matrices de partida de las formas bilineales de las que procede (B) dan lugar a distintas matrices de llegada(Ct ·B · C).
Observemos que en el ejemplo 2 anterior, tambien
Q(x1, x2) = (x1, x2)(
1 31 1
)(x1
x2
)
286

y
Q(x′1, x′2) = (x′1, x
′2)(−2 1−1 6
)(x′1x′2
)pero sin embargo, (
1 −11 1
)(1 31 1
)(1 1−1 1
)=(−2 2−2 6
)6=(−2 1−1 6
)Es decir, que las distintas matrices no simetricas correspondientes a la forma cuadratica, antes y despues de un
cambio de base pueden no estar relacionadas por la formula de cambio de base, aunque sı las simetricas. Ello se debea que las matrices simetricas asociadas a la forma cuadratica son unicas.
Dada una forma cuadratica por su expresion polinomial, existe una unica matriz simetrica de la que proviene.Cuando hacemos un cambio de coordenadas en la expresion polinomial de la forma cuadratica y luego volvemos aescribir la matriz simetrica correspondiente, esta nueva matriz tambien corresponde solamente a una forma bilinealsimetrica que la induce. Por ello, la nueva matriz simetrica esta relacionada con la primitiva simetrica por la ex-presion B′ = CtBC aunque no ocurra lo mismo con todas las distintas matrices no simetricas que le podemos hacercorresponder al principio y al final.
La forma cuadratica Q(x1, x2) = x21 + 2x1x2 + x2
2 se puede expresar
Q(x1, x2) = (x1, x2)(
1 11 1
)(x1
x2
)Haciendo el cambio de coordenadas x′1 = x1 + x2 x
′2 = x2, equivalente a x1 = x′1 − x′2 x2 = x′2, obtenemos
Q(x) = x′21 = (x′1, x
′2)(
1 00 0
)(x′1x′2
)y en efecto, (
1 00 0
)=(
1 0−1 1
)(1 11 1
)(1 −10 1
)
Diagonalizacion de formas cuadraticas.El problema de diagonalizacion de las formas cuadraticas consiste en hallar una nueva base en la
que su expresion matricial sea diagonal o un sistema de coordenadas en que su expresion polinomialsea suma de cuadrados con coeficientes. Lo haremos por dos metodos esencialmente distintos, uno,utilizando la diagonalizacion ortogonal de las matrices simetricas y otro, completando cuadrados.
Diagonalizacion ortogonal de una forma cuadratica en una base ortonormal.Si la forma cuadratica fuera suma de cuadrados de las coordenadas con coeficientes, serıa
287

Q(x) = λ1x21 + λ2x
22 + · · ·+ λnx
2n = (x1, x2, ..., xn)
λ1 0 · · · 00 λ2 · · · 0...
.... . .
...0 0 · · · λn
x1
x2...xn
Para diagonalizarla, por tanto, tenemos que conseguir una matriz C de cambio de coordenadas
tal que CtBC sea diagonal.Sabemos que se pueden diagonalizar matrices simetricas, es decir, que se puede obtener una
matriz C de cambio de base tal que C−1BC sea diagonal y ademas que se pueden diagonalizar enuna base ortonormal. La matriz de cambio de base a una base ortonormal es ortogonal, es decir,verifica CtC = I y equivalentemente Ct = C−1. Entonces, este cambio de coordenadas que, enprincipio, es para diagonalizar la aplicacion de matriz simetrica B, tambien sirve para diagonalizarla forma cuadratica de matriz B, al ser CtBC = C−1BC = D.
Hecho este cambio de base, la forma cuadratica serıa
Q(x) = (x1, x2, ..., xn)
λ1 0 · · · 00 λ2 · · · 0
· · · · · · . . . · · ·0 0 · · · λn
x1
x2
...xn
= λ1x21 + λ2x
22 + · · ·+ λnx
2n
donde los λi son los valores propios de B.
Si los valores propios son todos positivos, la forma cuadratica toma siempre valores positivos yse anula solo en el vector cero. Se llama definida positiva.
Si los valores propios son todos negativos, la forma cuadratica toma siempre valores negativos yse anula solo en el vector cero. Se llama definida negativa.
Ejemplo 3:
Una forma cuadratica en R3 es una forma cuadratica de las tres coordenadas de cada vector:Q(x) = Q(x1, x2, x3). Para no escribir subındices escribimos Q(x, y, z).
Sea Q(x, y, z) = 3y2 +3z2 +4xy+4xz−2yz; podemos encontrar un nuevo sistema de coordenadasen el que Q pueda escribirse como suma de cuadrados de las nuevas coordenadas de la siguiente forma:
Primero, escribimos la forma cuadratica de forma matricial simetrica:
Q(x, y, z) = (x, y, z)
0 2 22 3 −12 −1 3
xyz
288

Esta matriz es diagonalizable en una base ortonormal. Para diagonalizarla calculamos los valorespropios, soluciones de |B − λI| = −λ3 + 6λ2 − 32 = −(λ − 4)2(λ + 2) y obtenemos: λ = 4, doble yλ = −2, simple.
Los vectores propios correspondientes a λ = 4 son los que verifican: 0 2 22 3 −12 −1 3
− 4I
xyz
=
−4 2 22 −1 −12 −1 −1
xyz
=
000
es decir, el plano de ecuacion 2x− y− z = 0. En este plano podemos encontrar dos vectores propiosortogonales: (0, 1,−1) y (1, 1, 1).
Ademas existe otro vector propio correspondiente al valor propio λ = −2. Como vectores propiosde matrices simetricas correspondientes a valores propios distintos son ortogonales, (demostrado en laseccion de diagonalizacion de aplicaciones autoadjuntas) este vector propio que nos falta es ortogonala los dos anteriores, estando por ello, formado por los coeficientes de las incognitas en la ecuaciondel plano: el nuevo vector es (2,−1,−1).
Entonces, una base ortonormal que diagonaliza la matriz B es: 1√
2(0, 1,−1), 1√
3(1, 1, 1), 1√
6(2,−1,−1). Lo cual quiere decir que 0 1√
32√6
1√2
1√3− 1√
6
− 1√2
1√3− 1√
6
−1 0 2 2
2 3 −12 −1 3
0 1√
32√6
1√2
1√3− 1√
6
− 1√2
1√3− 1√
6
=
4 0 00 4 00 0 −2
Por ser la base buscada ortonormal, la matriz formada por esos vectores en columna, es ortogonal,por tanto, coinciden su inversa y su traspuesta, teniendose, 0 1√
2− 1√
21√3
1√3
1√3
2√6− 1√
6− 1√
6
0 2 2
2 3 −12 −1 3
0 1√
32√6
1√2
1√3− 1√
6
− 1√2
1√3− 1√
6
=
4 0 00 4 00 0 −2
Y esta justamente serıa la matriz de Q en las coordenadas (x′, y′, z′), tales que x
yz
=
0 1√3
2√6
1√2
1√3− 1√
6
− 1√2
1√3− 1√
6
x′
y′
z′
o equivalentemente, x′
y′
z′
=
0 1√2− 1√
21√3
1√3
1√3
2√6− 1√
6− 1√
6
x
yz
289

siendoQ(x′, y′, z′) = 4x′2 + 4y
′2 − 2z′2
Otros ejercicios a realizar por el lector son:9.1.1. Diagonalizar en una base ortonormal las siguientes formas cuadraticas:a) Q(x, y) = −2x2 + y2 + 4xy.b)Q(x, y, z) = x2 + y2 − 2xz + 2yz.c)Q(x, y, z) = x2 + y2 + 2z2 − 2xz + 2yz.d) Q(x, y, z) = x2 + y2 + z2 − 4xz.e) Q(x, y, z) = xy + yz + zx.f) Q(x, y, z, t) = x2 + 4xt+ 4y2 + 4yz + z2 + 4t2
g) Q(x, y, z, t) = 32x2 + 32xy − 44xz − 12xt+ 2y2 + 12yz + 4yt− 7z2 + 32zt+ 23t2 (val propios:0, 25, -25, 50).
h) Q(x, y, z, t) = 60x2 +16xy−12xz−40xt+15y2−40yz+12yt+45z2 +16zt+30t2 (val propios:0, 25, 50, 75).
i) Q(x, y, z, t) = −9x2 + 40xz + 24xt − 9y2 − 24yz + 40yt + 9z2 + 9t2 (val propios: 25(doble) y−25(doble)).
i) Q(x, y, z, t) = 41x2 − 24xz + 34y2 + 24yt+ 34z2 + 41t2 (val propios: 25(doble) y 50(doble)).
290

Aplicacion 1:
Estudio de Conicas.
El estudio de las curvas dadas por un polinomio homogeneo de segundo grado igualado a unnumero se hace utilizando la diagonalizacion de formas cuadraticas:
Estudiemos en este momento, las curvas de ecuacion: Ax2 + 2Bxy + Cy2 = D. Son el conjuntode nivel D de la funcion cuadratica Ax2 + 2Bxy + Cy2 = Q(x, y) que diagonalizada es Q(x′, y′) =λ1x
′2 + λ2y′2, donde las coordenadas x′, y′ estan relacionadas con las x, y por una matriz de cambio
de base C ortogonal.La curva es entonces el conjunto de puntos con coordenadas (x′, y′) tales que λ1x
′2 + λ2y′2 = D.
Dividiendo por D (si D 6= 0), la ecuacion de la curva en las nuevas coordenadas es
λ1
Dx′2 +
λ2
Dy′2 = 1
que segun los signos de λ1, λ2 y de D es una elipse, una hiperbola o el conjunto vacıo; si λ1 = 0 oλ2 = 0, dos rectas paralelas a uno de los nuevos ejes o el conjunto vacıo.
Si D=0, la curva tiene la ecuacion λ1x′2 + λ2y
′2 = 0, que representa dos rectas concurrentes silos valores propios son distintos de cero y de distinto signo, un solo punto si los valores propios sondel mismo signo y distintos de cero y uno de los ejes y′ = 0 o x′ = 0, si uno de los valores propios escero.
Las direcciones de los nuevos ejes se obtienen de los antiguos por la matriz ortogonal C por laque hemos hecho la diagonalizacion. Como el eje OX’tiene de ecuacion y′ = 0, podemos obtener suecuacion despejando y′ en funcion de x, y a traves de la matriz C−1. Lo analogo ocurre con el ejeOY’. El eje OX’ esta engendrado por el vector e′1 y el eje OY’ esta engendrado por el eje e′2.
Ejercicios:
9.2.1. Estudiar las curvas de nivel de las formas cuadraticas que se dan en cada caso, para losvalores D que se indican en cada caso:
a) Q(x, y) = x2 + xy + y2 para D=2, D = −2,, D = 0b) Q(x, y) = x2 + 4xy + y2 para D=1, D = −1, D = 0c) Q(x, y) = −2x2 + 4xy + y2 para D=8, D = −8, D = 0d) Q(x, y) = 3x2 + 2xy + 3y2 para D=1, D = −1, D = 0e) Q(x, y) = x2 + 4xy + 4y2 para D=4, D = −4, D = 0f) Q(x, y) = 3x2 + 8xy − 3y2 para D=5, D = −5, D = 0g) Q(x, y) = 3x2 + 10xy − 3y2 para D=4, D = −4, D = 0
291

9.2.2. Escribir los cambios de coordenadas que diagonalizan en una base ortonormal las anterioresformas cuadraticas y comprobar que siempre se puede conseguir que el cambio de coordenadascorresponda a un giro.
9.2.3. Observar que si la curva de nivel de una forma cuadratica es una elipse, el determinantede la forma cuadratica es positivo y si es una hiperbola, es negativo. Demostrar por que.
Aplicacion 2:
Maximos y mınimos de funciones.
Se ve facilmente utilizando el desarrollo en serie de Taylor de una funcion de dos variables quesi el Hessiano de una funcion en un punto crıtico no degenerado (que es una forma cuadratica) esdefinido positivo, ese punto crıtico es un mınimo de la funcion y si es definido negativo, ese puntoes un maximo. El primer caso se da cuando los dos valores propios del hessiano son positivos, elsegundo caso cuando los dos valores propios son negativos.
Una funcion de dos variables f(x, y) tiene un punto crıtico en (x0, y0) si δfδx
(x0, y0) = δfδy
(x0, y0) = 0.El punto crıtico es no degenerado si∣∣∣∣∣ δ2f
δx2 (x0, y0)δ2fδxδy
(x0, y0)δ2fδxδy
(x0, y0)δ2fδy2
(x0, y0)
∣∣∣∣∣ 6= 0
Segun el desarrollo en serie de Taylor de la funcion f en el punto crıtico,
f(x, y) = f(x0, y0) +1
2(x− x0, y − y0)
(δ2fδx2 (x0, y0)
δ2fδxδy
(x0, y0)δ2fδxδy
(x0, y0)δ2fδy2
(x0, y0)
)(x− x0
y − y0
)+ ...
donde los puntos suspensivos engloban terminos comparativamente pequenos con los anteriores.
El termino que anadimos a f(x0, y0) para obtener f(x, y), es aproximadamente una forma cuadraticaen (x− x0, y − y0).
Diagonalizandola, serıa f(x, y) = f(x0, y0)+λ1x′12+λ2x
′22. Si los dos valores propios son positivos,
al movernos del punto (x0, y0), sumamos terminos positivos, por lo que f(x, y) aumenta, siendo portanto (x0, y0) un mınimo.
Si los dos valores propios son negativos, f(x, y) disminuye siempre al movernos del punto (x0, y0),siendo por tanto este punto un maximo.
Si un valor propio es positivo y el otro es negativo, f(x, y) unas veces aumenta y otras vecesdisminuye al movernos del punto (x0, y0) y el punto se llama punto silla.
292

Como el hessiano esta relacionado con la matriz diagonal, cuyos elementos en la diagonal sonlos valores propios por CtHC = D, tenemos |C|2|H| = λ1λ2. Por ello el determinante del hessianoes negativo en los puntos silla y positivo en los maximos y en los mınimos. Para distinguir porel hessiano los maximos y los mınimos, tenemos en cuenta que cuando los dos valores propios sonpositivos, la forma cuadratica determinada por el hessiano es definida positiva, por lo que si nosacordamos del criterio de Sylvester, demostrado en un capıtulo anterior, ha de ser δ2f
δx2 (x0, y0) > 0, en
cuyo caso el punto es un mınimo; si δ2fδx2 (x0, y0) < 0 se trata de un maximo.
Ejercicios:
9.3.1. Encontrar y clasificar los puntos crıticos (maximo, mınimo o punto silla) de las siguientesfunciones de dos variables:
a) f(x, y) = x2 + xy + y2 − 3x− 3y.b) f(x, y) = −x2 − y2 + xy + 2xc) f(x, y) = x2 + xy + y2 + 3x+ 1.d) f(x, y) = −2x2 − y2 + xy + 7.e) f(x, y) = 3xy − x2 − y2 + 3.f) f(x, y) = xy + y2 + 2x+ 2y + 1
Aplicacion 3:
Maximos y mınimos de las formas cuadraticas en la esfera unidad.
Otra consecuencia importante de la diagonalizacion de una forma cuadratica por medio de uncambio de base ortonormal es el hecho de que toda forma cuadratica alcanza un maximo y un mınimosobre la esfera unidad, es decir, sobre el conjunto de vectores de modulo 1.
Siendo (x′1, ..., x′n) las coordenadas que diagonalizan, veamos que los vectores que verifican x2
1 +x2
2 + · · ·+ x2n = 1 son los mismos que los que verifican x
′21 + x
′22 + · · ·+ x
′2n = 1, es decir, que la esfera
unidad respecto a las nuevas coordenadas es la misma que la esfera unidad respecto a las antiguasporque el cambio de coordenadas lo hemos hecho por medio de una matriz ortogonal. (La matriz decambio de base C verifica Ct · C = I): en efecto,
x21 + x2
2 + · · ·+ x2n = (x1, x2, · · · , xn)
x1
x2...xn
= (x′1, x′2, · · · , x′n)CtC
x′1x′2...x′n
=
293

= (x′1, x′2, · · · , x′n)I
x′1x′2...x′n
= x′21 + x
′22 + · · ·+ x
′2n
En la esfera unidad respecto a las nuevas coordenadas:
Q(x) = λ1x′21 + λ2x
′22 + · · ·+ λnx
′2n =
= λ1(x′21 +x
′22 + · · ·+x
′2n )+(λ2−λ1)x
′22 + · · ·+(λn−λ1)x
′2n = λ1 +(λ2−λ1)x
′22 + · · ·+(λn−λ1)x
′2n ≥ λ1
si λ1 el mınimo de los valores propios, por lo que λ1 es el mınimo en la esfera unidad que se obtienecuando (x′1, x
′2, ..., x
′n) = (1, 0, ..., 0)
Por otra parte, suponiendo que λn es el maximo de los valores propios podemos ver que λn es elmaximo de Q(x) en la esfera unidad. En las nuevas coordenadas:
Q(x) = λ1x′21 + λ2x
′22 + · · ·+ λnx
′2n =
= (λ1−λn)x′21 +· · ·+(λn−1−λn)x
′2n−1+λn(x
′21 +x
′22 +· · ·+x′2n ) = (λ1−λn)x
′21 +· · ·+(λn−1−λn)x
′2n−1+λn ≤ λn
por lo que λn es el maximo en la esfera unidad que se obtiene cuando (x′1, x′2, ..., x
′n) = (0, 0, ..., 1)
Este resultado es utilizado en Calculo Vectorial (lema 1 pag 183 Marsden/Tromba).
Aplicacion 4:
Energıa de rotacion de un solido.
La energıa de un solido rıgido que gira alrededor de un eje se expresa por una forma cuadraticacuya matriz se llama tensor de inercia.
2E = mv2 = mv · v = m(Ω× r) · v = m(r × v) · Ω =
m(r × (Ω× r)) · Ω = m[(r · r)Ω− (r · Ω)r] · Ω = m[(rt · rI − r · rt)Ω] · Ω = ΣΩiIijΩj
donde Iij es el tensor de inercia.
294

Diagonalizacion de formas cuadraticas completando cuadrados.La diagonalizacion de la forma cuadratica usando los valores propios, metodo teoricamente claro,
en la practica puede ser difıcil de aplicar si los valores propios, que son las raices del polinomiocaracterıstico no son faciles de hallar, p.ej. si no son ni siquiera fraccionarios, como ocurre en loscasos siguientes:
Sea Q(x, y, z) = x2 + 2y2 + 2xy + 2yz + 2z2, entonces,
Q(x, y, z) = (x, y, z)
1 1 01 2 10 1 2
xyz
El polinomio caracterıstico de la matriz B en este caso es p(λ) = −λ3 + 5λ2−6λ+ 1, cuyas raices
no son enteras ni fraccionarias.Sea Q(x, y, z) = x2 + 5y2 − 2xy + 2xz, entonces,
Q(x, y, z) = (x, y, z)
1 −1 1−1 5 0
1 0 0
xyz
El polinomio caracterıstico de la matriz B en este caso es p(λ) = −λ3 + 6λ2−3λ−5, cuyas raices
no son enteras ni fraccionarias.Ademas, puede ser que solo sea necesario saber si la forma cuadratica es siempre positiva. Y esto
puede hacerse agrupando los terminos de la forma cuadratica, p.ej.
Q(x, y) = x2 + 4xy + 5y2 = (x+ 2y)2 + y2 = x′2 + y′2 ≥ 0
de forma que Q(x, y) = 0 implica x + 2y = 0, y = 0, lo cual solo se da si x = 0, y = 0, porque larelacion de cambio de coordenadas:(
x′1x′2
)=
(1 20 1
)(x1
x2
)corresponde a un cambio de base.
Existe otro metodo para reducir una forma cuadratica a suma de cuadrados de coordenadas concoeficientes, que se llama el metodo de completar cuadrados o metodo de Gauss. que sehace agrupando terminos y que puede ser mas factible que la resolucion del polinomio caracterısticocuando la dimension del espacio vectorial en el que esta definida la forma cuadratica es mayor que 2.
Vamos a ver que siempre se pueden formar parentesis que elevados al cuadrado y sumados concoeficientes dan la forma cuadratica y igualando los parentesis a nuevas coordenadas tenemos un
295

cambio de coordenadas que diagonaliza la forma cuadratica. (Este cambio de coordenadas, sinembargo, no vendra dado en general, por una matriz ortogonal).
Si la forma cuadratica esta definida sobre un espacio vectorial de dimension 1, es de una solavariable y ya es un cuadrado con un coeficiente.
Si la forma cuadratica esta definida sobre un espacio de dimension 2, de dos variables, tenemos:Q(x, y) = a11x
2 + 2a12xy + a22y2, y entonces podemos escribirla como
Q(x, y) = a11(x2 + 2
a12
a11
xy + (a12
a11
)2y2)− a212
a11
y2 + a22y2 =
= a11(x+a12
a11
y)2 + (a22 −a2
12
a11
)y2 = a11x′2 + (a22 −
a212
a11
)y′2
donde se ha hecho el cambio de coordenadas:
x′ = x+ (a12/a11)yy′ = y
≡(x′
y′
)=
(1 a12/a11
0 1
)(xy
).
Es un verdadero cambio de coordenadas porque corresponde a una matriz con determinante dis-tinto de cero y tenemos la forma cuadratica escrita como suma de cuadrados de coordenadas concoeficientes.
Antes de pasar al caso de dimension n veremos ejemplos de diagonalizacion completando cuadra-dos de formas cuadraticas de tres variables.
Veamos este metodo sobre la practica con los ejemplos anteriores:Ejemplo 3:Q(x, y, z) = x2 + 2y2 + 2xy + 2yz + 2z2 = (x+ y)2 + y2 + 2yz + 2z2 = (x+ y)2 + (y + z)2 + z2 =
x′2 + y′2 − z′2 donde hemos hecho el cambio de coordenadas:
x′ = x+ yy′ = y + zz′ = z
≡
x′
y′
z′
=
1 1 00 1 10 0 1
xyz
que efectivamente corresponde a una matriz con determinante distinto de cero, teniendo entonces laforma cuadratica escrita como suma de cuadrados de coordenadas con coeficientes.
Ejemplo 4:Q(x, y, z) = x2 + 5y2 − 2xy + 2xz = (x2 − 2xy + 2xz + y2 + z2 − 2yz) − y2 − z2 + 2yz + 5y2 =
= (x−y+ z)2−y2− z2 + 2yz+ 5y2 = (x−y+ z)2 + 4y2 + 2yz− z2 = (x−y+ z)2− (z2−2yz) + 4y2 =
296

= (x− y + z)2 − (z2 − 2yz + y2) + y2 + 4y2 = (x− y + z)2 − (z − y)2 + 5y2 = x′2 + 5y′2 − z′2 dondehemos hecho el cambio de coordenadas:
x′ = x− y + zy′ = yz′ = −y + z
≡
x′
y′
z′
=
1 −1 10 1 00 −1 1
xyz
que efectivamente corresponde a una matriz con determinante distinto de cero, teniendo entonces laforma cuadratica escrita como suma de cuadrados de coordenadas con coeficientes.
Ejemplo 5: (nigun coficiente de los cuadrados de las coordenadas es 1),Sea
Q(x, y, z) = 3x2 + 6xy + 3y2 + 6yz + 5z2 + 12xz
Escogemos una coordenada que este elevada al cuadrado y agrupamos todos los terminos que tienenesa coordenada:
Q(x, y, z) = (3x2 + 6xy + 12xz) + 3y2 + 6yz + 5z2
despues, sacamos el coeficiente del cuadrado factor comun de los terminos agrupados:
Q(x, y, z) = 3(x2 + 2xy + 4xz) + 3y2 + 6yz + 5z2
y ahora completamos el parentesis hasta que sea un cuadrado de una suma de las tres coordenadas,en este caso ha de ser (x + y + 2z)2, para lo cual, restando a continuacion los terminos anadidos,escribimos:
Q(x, y, z) = 3(x2 + 2xy + 4xz + y2 + 4z2 + 4yz)− 3(y2 + 4z2 + 4yz) + 3y2 + 6yz + 5z2
que serıa:Q(x, y, z) = 3(x+ y + 2z)2 − 7z2 − 6yz
En esta expresion, en los terminos posteriores al cuadrado aparecen ya solo dos coordenadas, con lasque podemos seguir completando cuadrados:
Q(x, y, z) = 3(x+ y + 2z)2 − 7z2 − 6yz = 3(x+ y + 2z)2 − 7(z2 +6
7yz) =
= 3(x+ y + 2z)2 − 7(z2 +6
7yz + (
3
7)2y2) +
9
7y2 = 3(x+ y + 2z)2 − 7(z +
3
7y)2 +
9
7y2
297

Haciendo el cambio de coordenadas:
x′ = x+ y + 2zy′ = yz′ = 3
7y + z
≡
x′
y′
z′
=
1 1 20 1 00 3/7 1
xyz
que corresponde a una matriz de cambio con determinante distinto de cero, tenemos la formacuadratica escrita como suma de cuadrados:
Q(x′, y′, z′) = 3x′2 − 7z′2 +9
7y′2
Ejemplo 6: (en el que al sacar factor comun surgen fracciones),
Q(x, y, z) = 2x2 + 3xy + 2y2 + xz − 3z2 + yz = 2(x2 +3
2xy +
1
2xz) + 2y2 − 3z2 + yz =
2(x+3
4y +
1
4z)2 − 9
8y2 − 1
8z2 − 3
8yz + 2y2 − 3z2 + yz = 2(x+
3
4y +
1
4z)2 +
7
8y2 − 25
8z2 +
5
8yz =
2(x+3
4y +
1
4z)2 +
7
8(y2 +
5
7yz)− 25
8z2 = 2(x+
3
4y +
1
4z)2 +
7
8(y +
5
14z)2 − 25
224z2 − 25
8z2 =
2(x+3
4y +
1
4z)2 − 7
8(y +
5
14z)2 − 25
8· 29
28z2 =
Se deja para el lector escribir el cambio a las nuevas coordenadas y la comprobacion de que es uncambio bueno.
Ejemplo 7:
Q(x, y, z) = 2x2 − 3xy − 2y2 + xz − 3z2 + yz = 2(x2 − 3
2xy +
1
2xz)− 2y2 − 3z2 + yz =
2(x− 3
4y +
1
4z)2 − 9
8y2 − 1
8z2 +
3
8yz − 2y2 − 3z2 + yz = 2(x− 3
4y +
1
4z)2 − 25
8y2 − 25
8z2 +
11
8yz =
2(x− 3
4y +
1
4z)2 − 25
8(y2 − 11
25yz)− 25
8z2 = 2(x− 3
4y +
1
4z)2 − 25
8(y − 11
50z)2 +
25
8
121
2500z2 − 25
8z2 =
298

2(x− 3
4y +
1
4z)2 − 25
8(y − 11
50z)2 − 2379
800z2 =
Se deja para el lector escribir el cambio a las nuevas coordenadas y la comprobacion de que es uncambio bueno.
Si en el ejemplo no hubiera aparecido ningun cuadrado en la expresion dada, como en
Q(x, y, z) = xy + xz + yz
se hace primero el siguiente cambio de coordenadas:
x = x′ + y′
y = x′ − y′z = z′
cuya matriz tiene determinante distinto de cero y que la transforma en
Q(x, y, z) = x′2 − y′2 + 2x′z′
en la que ya tenemos cuadrados con coeficientes no nulos que podemos coger para realizar el metodode Gauss segun los primeros ejemplos.
El funcionamiento del metodo de Gauss en el caso general, se ve por induccion (en Golovina)primero a), cuando hay aii 6= 0; despues b) haciendo el cambio de coordenadas apropiado si todoslos aii son nulos.
En el caso general a), haciendo una renumeracion si es necesario, podemos suponer que ann 6= 0.Despues reordenamos la expresion de la forma cuadratica ası:
Q(x) = a11x21 + 2a12x1x2 + 2a13x1x3...+ 2a1n−1x1xn−1 + 2a1nx1xn+
a22x22 + 2a23x2x3 + ...+ 2a2n−1x2xn−1 + 2a2nx2xn+
+...++an−1,n−1x
2n−1 + 2an−1,nxn−1xn
+annx2n =
= ann[(2 a1n
annx1xn + ...+ 2an−1n
annxn−1xn + x2
n]+
+a11x21 + 2a12x1x2 + ...+ 2a1,n−1x1xn−1
+a22x22 + 2a23x2x3 + · · ·+ 2a2,n−1x2xn−1
+...++an−1,n−1x
2n−1 =
299

= ann[2( a1n
annx1 + ...+ 2an−1n
annxn−1)xn + x2
n]+
+a11x21 + 2a12x1x2 + ...+ 2a1,n−1x1xn−1
+a22x22 + 2a23x2x3 + · · ·+ 2a2,n−1x2xn−1
+...++an−1,n−1x
2n−1 =
= ann[( a1n
annx1 + ...+ an−1n
annxn−1) + xn]2 − ann( a1n
annx1 + ...+ an−1n
annxn−1)
2+
+a11x21 + 2a12x1x2 + ...+ 2a1,n−1x1xn−1 + a22x
22 + 2a23x2x3 + · · ·+ 2a2,n−1x2xn−1
+...++an−1n−1x
2n−1
= annx′2n +Q′(x1, x2, ...xn−1)
dondex′n =
a1n
annx1 + ...+
an−1n
annxn−1 + xn
y Q′(x) es el polinomio homogeneo de segundo grado restante que es una forma cuadratica en n-1coordenadas en la que no aparece xn.
Por la hipotesis de induccion Q′ puede reducirse a una suma de cuadrados de coordenadas concoeficientes con una matriz de cambio de coordenadas con determinante distinto de cero.
El cambio de coordenadas de x1, x2, ..., xn a x1, x2, ..., x′n viene dado por la matriz de deter-
minante distinto de cero: 1 0 · · · 0 00 1 · · · 0 0... · · · · · · · · · ...... · · · · · · 1 0
a1n
ann· · · · · · an−1,n
ann1
En el caso b) cuando todos los coeficientes de los cuadrados de las variables son nulos, tiene que
haber algun aij 6= 0. Entonces, hacemos el cambio de variable x′i = xi +xj x′j = xi−xj, obteniendo
ası en la forma cuadratica el termino 2aij(x′2i −x
′2j ) que aporta dos cuadrados con coeficiente distinto
de cero y seguimos como en el caso a).
Ejemplos a realizar por el lector son:Ejercicio 9.4.1.Diagonalizar completando cuadrados y escribiendo los cambios de coordenadas, las siguientes
formas cuadraticas:
300

a) Q(x, y, z) = 3x2 + 2y2 + z2 − 6xy + 4xz.b) Q(x, y, z) = 2x2 + y2 + 5z2 − 2xy + 6xz − 2yz.c) Q(x, y, z) = xy + 2xz.d) Q(x, y, z) = x2 − z2 − 2xy + xz.
301

El metodo de completar cuadrados no es unıvoco, puede hacerse de muchas maneras, segun elcuadrado que escojamos para empezar de la expresion inicial. Y los coeficientes de los cuadradossaldran distintos segun el camino que escojamos. Pero, sea por uno de los caminos del metodo deGauss o sea por el metodo de diagonalizacion de la matriz simetrica, tenemos la sorprendente Leyde inercia de Sylvester que establece que el numero de coeficientes positivos es siempre el mismoy lo mismo ocurre con el numero de coeficientes negativos.
El numero de coeficientes positivos que aparece en la expresion de una forma cuadratica reducidaa suma de cuadrados se escribe p y se llama ındice de inercia positivo de Q y el numero de coeficientesnegativos que aparece en dicha expresion se escribe q y se llama ındice de inercia negativo de Q.
Ley de inercia de Sylvester: SeaQ : V nR → R una forma cuadratica y x1, x2, ..., xn, x′1, x′2, ..., x′n,
dos sistemas de coordenadas de V nR , en los que
Q(x) = a1x21 + a2x
22 + ...+ apx
2p − ap+1x
2p+1 − ap+2x
2p+2 − ...− ap+qx2
p+q =
a′1x′21 + a′2x
′22 + ...+ a′p′x
′2p′ − a′p′+1x
′2p′+1 − a′p′+2x
′2p′+2 − ...− a′p′+q′x
′2p′+q′
donde ai > 0 ∀i y a′j > 0 ∀j. Entonces, p = p′ y q = q′.
Demostracion:Sea e1, e2, ..., en la base correspondiente a las coordenadas xi y e′1, e′2, ..., e′n la base corres-
pondiente a las coordenadas x′i.Entonces, si cogemos x ∈ Le1, e2, ...ep y x 6= 0, Q(x) > 0 y si cogemos x ∈ Le′p′+1, e
′p′+2, ...e
′n
y x 6= 0, Q(x) ≤ 0. Esto implica que Le1, e2, ...ep∩Le′p′+1, e′p′+2, ...e
′n debe ser solo el vector nulo.
Entonces,
dimLe1, e2, ...ep+ dimLe′p′+1, e′p′+2, ...e
′n− dim(Le1, e2, ...ep∩Le′p′+1, e
′p′+2, ...e
′n) = p+n− p′
Segun la formula de las dimensiones,
dimLe1, e2, ...ep+ dimLe′p′+1, e′p′+2, ...e
′n − dim(Le1, e2, ...ep ∩ Le′p′+1, e
′p′+2, ...e
′n) =
dim(Le1, e2, ...ep+ Le′p′+1, e′p′+2, ...e
′n)
Pero la dimension de esta suma es menor o igual que la dimension del espacio total que es n, porlo que p+ n− p′ ≤ n, de donde p ≤ p′.
Considerando Le′1, e′2, ...e′p′∩Lep+1, ep+2, ...en y haciendo el razonamiento analogo al anteriorcambiando p por p′, obtenemos p′ ≤ p de donde p = p′.
Para ver que q = q′, basta considerar −Q y aplicar el razonamiento anterior.
302

Como aplicacion de la ley de inercia de Sylvester se puede terminar la diagonalizacion de la forma cuadraticaQ(x, y, z) = xy + xz + yz por el metodo de Gauss y se puede hacer tambien su diagonalizacion por el metodo delos valores propios y comprobar que el numero de valores propios positivos es el numero de cuadrados que salen concoeficiente positivo y analogamente para los negativos.
Tambien podemos hacer el metodo de Gauss en el ejemplo 4, empezando por la coordenada y, obteniendo:
Q(x, y, z) = x2 + 5y2 − 2xy + 2xz = 5(y2 − 25xy) + x2 + 2xz =
= 5(y − 15x)2 − 5
x2
25+ x2 + 2xz = 5(y − 1
5x)2 +
45x2 + 2xz = 5(y − 2
5x)2 +
45
(x2 +52xz) =
= 5(y − 25x)2 +
45
(x+54z)2 − 5
4z2
donde el numero de cuadrados con coeficiente positivo es 2 y el de cuadrados con coeficientes negativos es 1, igual queen la anterior agrupacion.
”Dos formas cuadraticas son equivalentes” si y solo si existe un isomorfismo de V n que lleve unaa la otra, lo cual se cumple si y solo si existe un cambio de base que lleva una a la otra; podemos verque son equivalentes si tienen los mismos indices de inercia.
Comprobemoslo: sean
Q(x) = a1x21 + a2x
22 + ...+ apx
2p − ap+1x
2p+1 − ap+2x
2p+2 − ...− ap+qx2
p+q
= Q′(x) = a′1x′21 + a′2x
′22 + ...+ a′px
′2p − a′p+1x
′2p+1 − a′p+2x
′2p+2 − ...− a′p+qx
′2p+q
donde las coordenadas estan referidas a dos bases e1, e2, ..., en y e′1, e′2, ..., e′n y las p primerastienen coeficientes positivos mientras que las q siguientes tienen coeficientes negativos. Entonces,Q(ei/
√ai) = 1 = Q′(e′i/
√a′i) ∀i ≤ p, Q(ei/
√ai) = −1 = Q′(e′i/
√a′i) si p < i ≤ p + q, Q(ei) = 0 =
Q′(e′i)∀i > p+ q.El isomorfismo ϕ de Rn dado por ϕ(ei/
√ai) = (e′i/
√a′i) si i ≤ p + q, ϕ(ei) = (e′i) si i > p + q
verifica: Q′ ϕ(x) = Q ya que Q(ei) = ai = Q′(ϕ(ei)) si 1 ≤ i ≤ p, Q(ei) = −ai = Q′(ϕ(ei)) sip < i ≤ p+ q, Q(ei) = 0 = Q′(e′i)∀i > p+ q.
Recıprocamente, si Q y Q′ son equivalentes, se pasa de una a otra por un cambio de coordenadasy entonces la ley de inercia de Sylvester garantiza que tienen los mismos ındices de inercia.
Por ello, se pueden clasificar la formas cuadraticas mirando los signos de los coeficientes de loscuadrados de las coordenadas de las expresiones obtenidas por el metodo de Gauss y tambien mirandolos signos de los valores propios.
Tambien podemos demostrar que la suma de los ındices de inercia positivo y negativo de la formacuadratica es igual al rango de su matriz simetrica.
303

Desde luego, p + q es el rango de la matriz diagonal correspondiente a Q y es siempre el mismocuando la matriz este expresada como suma de cuadrados, en virtud de la ley de inercia de Sylvester.Pero tambien es el rango de cualquier matriz simetrica que corresponda a Q en cualquier sistema decoordenadas. Aunque matrices no simetricas correspondientes a la misma forma cuadratica puedentener distinto rango.
La forma cuadratica Q(x1, x2) = x21 + 2x1x2 + x2
2 se puede expresar:
Q(x1, x2) = (x1, x2)(
1 11 1
)(x1
x2
)= (x1, x2)
(1 20 1
)(x1
x2
)siendo las dos matrices de distinto rango.
En un cambio de coordenadas, las distintas matrices de partida B de la forma cuadratica danlugar a distintas matrices de llegada: Ct · B · C. Pero como la matriz simetrica asociada a la formacuadratica es unica, si le hacemos corresponder matrices simetricas a la partida y a la llegada de uncambio de coordenadas, la una se tiene que transformar en la otra. La matriz simetrica B de Q enuna base pasa a otra simetrica de Q, por un cambio CtBC, donde C es una matriz de cambio decoordenadas.
Veamos ahora que las distintas matrices simetricas de Q en distintas bases, tienen el mismorango: si C es una matriz invertible, Ct tambien lo es, y las columnas de CtB son las imagenes delas columnas de B por el isomorfismo de matriz Ct, por tanto hay el mismo numero de columnasindependientes en B que en CtB. Es decir, el rango de B es el mismo que el rango de CtB. Por lamisma razon, el rango de tC(BC) es el mismo que el rango de BC, igual al rango de tCtB, igual alrango de tB, y este igual al de B.
Un ejemplo tomado de [B] que aparentemente contradice p+q=r es el siguiente:
Q(x, y, z) = 2x2 + 2xy + 2yz = (x, y, z)
2 1 11 0 01 0 0
xyz
El rango de esta forma cuadratica es 2, pero se puede escribir
Q(x, y, z) = 2x2 + 2xy + 2yz = (x+ y + z)2 − (y + z)2 + x2 = x′2 − y′2 + z′
2
que aparentemente tiene p=2, q=1, siendo entonces p+q distinto de r. Lo que ocurre es que x′
y′
z′
=
1 1 10 1 11 0 0
xyz
304

no es un verdadero cambio de coordenadas porque viene dado por una matriz de determinante nulo.
Las formas cuadraticas se llaman no degeneradas si su rango es igual al numero de coordenadas,y degeneradas en caso contrario.
Las no degeneradas se llaman definidas positivas si el ındice de inercia positivo es igual al numerode coordenadas (su ındice de inercia negativo es nulo) y definidas negativas si el ındice de inercianegativo es igual al numero de coordenadas (su ındice de inercia positivo es nulo). En otro caso, sellaman indefinidas.
Las degeneradas se llaman semidefinidas positivas si su ındice de inercia negativo es nulo, semidefi-nidas negativas si su ındice de inercia positivo es nulo e indefinidas en otro caso.
Si reducimos la forma cuadratica a suma de cuadrados con coeficientes, utilizando los valorespropios, la forma cuadratica es no degenerada si todos sus valores propios son distintos de cero,entonces, la forma cuadratica es definida positiva si y solo si todos sus valores propios son positivos.Es definida negativa si y solo si todos sus valores propios son negativos. Es indefinida si hay valorespropios de los dos signos.
Ejercicios:
9.5.1. Encontrar el caracter de las formas cuadraticas de los ejercicios 9.1.1. y estudiar si sonequivalentes.
9.5.2. Encontrar el caracter de las formas cuadraticas del ejercicio 9.4.1 y estudiar si son equiva-lentes.
305

Las formas cuadraticas mas interesantes son las definidas positivas. Lo son cuando todos losvalores propios son positivos, pero aunque el calculo de los valores propios de una forma cuadraticade orden dos consiste en la resolucion de una ecuacion de segundo grado, siempre resoluble, y auncuando el metodo de completar cuadrados puede usarse para ver si es definida positiva cuando laecuacion a resolver es de mayor orden y no se puede resolver bien, puede ser latoso. Por ello es utilutilizar el criterio de Sylvester.
Criterio de Sylvester para formas cuadraticas definidas positivas:La matriz G simetrica determina una forma cuadratica definida positiva en cualquier base si y
solo si todos sus menores angulares superiores izquierdos son positivos.Nos ahorra hacer todo el proceso del metodo de Gauss en cada caso particular.
El criterio de Sylvester sirve tambien para decidir si una forma cuadratica es definida negativa, yaque en este caso su opuesta es definida positiva. Por tanto la matriz simetrica de una forma cuadraticadefinida positiva ha de tener todos los menores angulares superiores izquierdos de orden impar ne-gativos y todos los menores angulares superiores izquierdos de orden par positivos.
Si la forma cuadratica es no degenerada y no es definida positiva ni definida negativa, es indefinida,p.ej. si algun menor angular superior izquierdo de orden par es negativo o si hay dos menoresangulares superiores izquierdos de orden impar de distinto signo.
Demostracion del criterio de Sylvester:Ya se hizo una demostracion del criterio en el capıtulo del producto escalar no usual. Se da aquı
otra demostracion completando cuadrados.
Lo vamos a hacer por inducion sobre la dimension del espacio.
Estamos interesados en comprobar que si |Gii| > 0 ∀i,
x · x = (x1, x2, · · · , xn)G
x1
x2...xn
≥ 0, siendo x · x = 0 ≡ x = 0
Vamos a probar el teorema haciendo cambios de coordenadas que lleven la expresion x · x a seruna suma de cuadrados de coordenadas con coeficientes y vamos a ver que estos coeficientes sonpositivos en las condiciones del Teorema, por lo que entonces, sera x · x > 0 siempre que el vector xsea distinto de cero. Es decir, la forma bilineal, ademas de simetrica, sera definida positiva.
306

Hacemos la demostracion por induccion sobre la dimension del espacio.
Cuando la dimension del espacio es 1, solo hay un menor angular, que coincide con el determinantede la matriz: Es el numero g11; el producto escalar es x · y = g11x1y1, siendo x · x = g11x
21, mayor o
igual que cero si g11 > 0, ademas x · x = 0 ≡ x = 0, si g11 > 0, quedando por tanto establecido elteorema en esta dimension.
Cuando la dimension del espacio es 2, hay dos menores angulares superiores: g11 = G11 y G = G22.Entonces,
x · x = (x1, x2)
(g11 g12
g12 g22
)(x1
x2
)= g11x
21 + 2g12x1x2 + g22x
22 =
= g11(x21 +
2g12
g11
x1x2 + (g12
g11
x2)2)− g11(
g12
g11
x2)2 + g22x
22 = g11(x1 +
g12
g11
x2)2 + (g22 −
g212
g11
)x22 =
= g11(x1 +g12
g11
x2)2 +
g22g11 − g212
g11
x22
Hacemos el cambio de coordenadas:x′1 = x1 + g12
g11x2
x′2 = x2≡
(x′1x′2
)=
(1 g12
g11
0 1
)(x1
x2
)(Hacer un cambio de coordenadas por una matriz de determinante distinto de cero es equivalente ahacer un cambio de base) y queda el producto
x · x = g11x′21 +|G|g11
x′22
que es siempre mayor o igual que cero si |G11| > 0 y |G| = |G22| > 0 siendo igual a cero solo cuandox′1 = 0 = x′2, es decir, cuando el vector x es cero por ser los x′ un sistema de coordenadas.
Cuando la dimension es 3, tendrıamos:
x ·x = (x1, x2, x3)
g11 g12 g13
g12 g22 g23
g13 g23 g33
x1
x2
x3
= g11x21 +2g12x1x2 +g22x
22 +2g13x1x3 +2g23x2x3 +g33x
23
307

Los tres primeros sumandos corresponden a la expresion del producto escalar en un espacio dedimension 2, en el que hemos visto que con el cambio de coordenadas anterior, se reducen a unasuma de cuadrados con coeficientes positivos, debido a que los dos primeros menores angulares sonpositivos. Entonces, la expresion queda:
x · x = b1x′21 + b2x
′22 + 2g13(x
′1 −
g12
g11
x′2)x3 + 2g23x′2x3 + g33x
23 =
b1x′21 + b2x
′22 + 2g13x
′1x3 + (2g23 −
2g13g12
g11
)x′2x3 + g33x23 donde b1 > 0 y b2 > 0.
Llamamos 2b23 al coeficiente de x′2x3 y seguimos arreglando los terminos para conseguir una sumade cuadrados de coordenadas con coeficientes positivos:
x · x = b1x′21 + b2x
′22 + 2g13x
′1x3 + 2b23x
′2x3 + g33x
23 =
= b1(x′21 + 2
g13
b1x′1x3 + (
g13
b1x3)
2) + b2(x′22 + 2
b23
b2x′2x3 + (
b23
b2x3)
2) + (g33 −g213
b1− b223
b2)x2
3 =
= b1(x′1 +
g13
b1x3)
2 + b2(x′2 +
b23
b2x3)
2 + b3x23 = b1x
”21 + b2x
”22 + b3x
”23
donde hemos llamado b3 = g33 − g213b1− b223
b2y hemos hecho otro cambio de coordenadas: x′′1
x′′2x′′3
=
1 0 g13/b10 1 b23/b20 0 1
x′1x′2x3
cuya matriz es de determinante distinto de cero,Ya tenıamos de antes que b1 > 0 y b2 > 0. Necesitamos que sea tambien b3 > 0 para que
x · x ≥ 0 siendo x · x = 0, solo cuando x = 0.Escribamos:
x · x = b1x”21 + b2x
”22 + b3x
”23 = (x”1, x”2, x”3)
b1b2
b3
x”1
x”2
x”3
= (x”1, x”2, x”3)B
x”1
x”2
x”3
Relacionando la matriz B con la matriz G dada, vamos a obtener que b3 es tambien positivo.Sabemos como repercuten los cambios de coordenadas que hemos hecho en la matriz de una
forma cuadratica. Si C es la matriz de cambio de coordenadas total, la forma bilineal en las ultimas
308

coordenadas es x · y = x”ttCGCy” lo cual induce el mismo cambio en la expresion de x · x en lasnuevas coordenadas: x · x = x”ttCGCx”.
Aunque nosotros hemos hecho los cambios en la expresion polinomial x · x = xtCx y despues dehacerlos hemos llegado a una expresion que se puede poner en forma matricial x · x = x”tBx” conmatriz diagonal, podemos concluir que B = tCGC, haciendo la consideracion de que cuando hacemosun cambio de coordenadas en la expresion polinomial de la forma cuadratica y luego volvemos aescribir la matriz simetrica correspondiente, esta nueva matriz tambien corresponde solamente auna forma bilineal simetrica que la induce. Por ello, la nueva matriz simetrica esta relacionada conla primitiva simetrica por una expresion B′ = tCBC donde |C| 6= 0, aunque no ocurre lo mismocon todas las distintas matrices no simetricas que podemos que le podemos hacer corresponder alprincipio y al final.
Entonces, existe C matriz de cambio de base, tal que
tCGC =
b1b2
b3
de donde se tiene b1b2b3 = |C|2|G|, lo que implica b3 > 0 por las condiciones del criterio y ser b1 > 0,b2 > 0.
Con esto queda hecha la demostracion del criterio en un espacio vectorial de dimension 3.
Supuesta hecha la demostracion cuando la dimension del espacio es n−1, se hace la demostracioncuando el espacio es de dimension n reduciendo los terminos de la expresion x ·x a suma de cuadradoscon coeficientes positivos en dos etapas.
Por la hipotesis de induccion se pueden reducir a una tal suma de cuadrados todos los terminosen los que figuran solo las n− 1 primeras coordenadas, quedando una expresion:
x · x = b1x′21 + b2x
′22 + · · ·+ bn−1x
′2n−1 + 2b1nx
′1xn + 2b2nx
′2xn + · · ·+ gnnx
2n
donde todos los bi son positivos, y que se puede arreglar a
x · x = b1x”21 + b2x
”22 + · · ·+ bn−1x
”2n−1 + (gnn −
b21nb1− b22n
b2−b21n−1
bn−1
)x2n
Llamando bn al coeficiente de x2n, como todos los arreglos de coordenadas corresponden a cambios
de base, tenemos, de forma analoga a la utilizada en dimension 3:
b1b2 · · · bn = |C|2|G|
309

para la matriz C de cambio de base total, de donde resulta bn tambien positivo por serlo todos losdemas numeros de la expresion.
Ası queda demostrado el teorema para cualquier espacio vectorial real de dimension finita.
Serıa conveniente hacer los ejercicios siguientes:Ejercicios.
9.6.1. Estudiar para que valores de a, la formas cuadraticas siguientes son definidas positivas:a) Qa(x, y, z) = x2 + 4y2 + z2 + 2axy + 10xz + 6yz.b) Qa(x, y, z) = x2 + 4y2 + z2 + 2axy + 2ayz.c) Qa(x, y, z) = 5x2 + y2 + az2 + 4xy − 2xz − 2yz.d) Qa(x, y, z) = x2 + 2xy + ay2 + 2xz + 2ayz + 3z2.e) Qa(x, y, z) = ax2 + y2 + z2 + 2axy + 2a2xz + 2ayz.f) Qa(x, y, z) = x2 + a(a− 1)y2 + 2axy + 2xz + 4ayz.g)Qa(x, y, z) = x2 + a(a− 1)y2 + 2axy + 2xz + 4ayz.h) Qa(x, y, z) = (a+ 1)x2 + (a+ 1)y2 + az2 + 2xy − 2ayz.i) Qa(x, y, z) = (a− 1)x2 + 3ay2 + az2 + 2(a− 1)xy + 2ayz.9.6.2. Estudiar si para algunos valores de a, las formas cuadraticas anteriores son definidas
negativas o indefinidas.9.6.3. Hallar los ındices de inercia de las formas cuadraticas anteriores para los valores de a que
las hacen degeneradas.9.6.4. Hallar los ındices de inercia de las formas cuadraticas anteriores para los valores de a que
las hacen indefinidas no degeneradas.Tambien se pueden estudiar los ındices de inercia de las formas cuadraticas de los ejercicios
anteriores segun los valores de a, utilizando el metodo de Gauss, comprobando en particular losresultados correspondientes a formas cuadraticas definidas positivas.
310

Criterios para formas cuadraticas degeneradas.
En cuanto a las formas cuadraticas degeneradas, Smirnov afirma sin demostrar en [S] que esnecesario y suficiente para que una forma cuadratica sea positiva que todos los menores principales(es decir, todos aquellos cuya diagonal esta contenida en la diagonal principal) tengan determinanteno negativo. Esta condicion se traduce en la sucesion de signos de los coeficientes del PolinomioCaracterıstico.
Aquı damos otros tres criterios para decidir si una forma cuadratica degenerada es definidapositiva en los que el numero de los determinantes a calcular y el orden de los mismos es menor.Los dos primeros se deben a la autora del curso y el tercero a Fernando Chamizo (1990) [CCh]. Lademostracion del tercer criterio depende del segundo y este del primero. Tambien se ve que dichoscriterios son equivalentes al de Smirnov. Esta demostracion es tambien debida a la autora.
Sea e1, e2, .., en una base de V n tal que si x es un vector de V n con coordenadas (x1, ..., xn) enesta base,
Q(x) = (x1, ..., xn)A
x1...
xn
siendo A simetrica y sea f la forma bilineal asociada a Q tal que si y = y1e1 + ...+ ynen,
f(x, y) = (x1, ..., xn)A
y1...
yn
.
Hagamos antes algunas consideraciones sobre las formas cuadraticas indefinidas:
Consideremos aii. Si existe algun aii nulo siendo aij 6= 0, la forma cuadratica
Q |Lei,ejes indefinida por el criterio de Sylvester y por tanto Q es indefinida.
Prescindiendo de filas y columnas nulas, podemos suponer que aii 6= 0, ∀i.Si existen i 6= j tales que aii > 0, ajj < 0, Q es indefinida.Para hacer el estudio de Q, como Q es positiva si y solo si −Q es negativa, cambiando el signo
de Q si es necesario podemos suponer que aii > 0, ∀i.
311

Si existiera algun Aii tal que |Aii| < 0, como Aii es una matriz simetrica, Aii es diagonalizablepor una matriz ortogonal y |Aii| = λ1λ2....λi es el producto de los valores propios del endomorfismodefinido por Aii en Le1, ..., ei, tenemos algun λi = Q(ui, ui) negativo. Teniendo en cuenta quea11 > 0 concluirıamos que Q es indefinida.
Notacion.
Llamaremos Akrr al menor de A formado al orlar Arr con la fila (ak1...akr...akk) y la columna(a1k...ark...akk)
t donde k > r.En una forma cuadratica degenerada, |A| = 0, por tanto cogiendo r = n − 1, k = n, tenemos
|Ann−1,n−1| = 0.Si |Arr| 6= 0 y |Akrr| = 0 denotamos por Uk
r ∈ Le1, ..., er, ek el vector propio correspondiente alvalor propio nulo de Akrr. Observemos que entonces la k-esima coordenada Uk
rk de Ukr es no nula.
Sea Akjrr el menor obtenido de Akrr al orlarlo con la fila (aj1 · · · ajr · · · ajk · · · ajj) y la columna(a1j · · · arj · · · akj · · · ajj)t donde j > k.
Criterios:Sea Q una forma cuadratica degenerada de matriz simetrica A.Supongamos ahora que |Ass| > 0, ∀s ≤ m y |Akmm| = 0, ∀k > m, lo cual siempre se puede
conseguir con una reordenacion de las filas y columnas de A. Decimos entonces que Q esta en formam-positiva y ası lo suponemos en los criterios a continuacion. Entonces:
I. Q es semidefinida positiva si y solo si su matriz simetrica puede ponerse en forma m-positivay cada vector Uk
m es vector propio de A.
II. Q es semidefinida positiva si y solo si su matriz simetrica puede ponerse en forma m-positivay ∀k, k′ > m, |Akk′mm| = 0.
III. Q es semidefinida positiva si y solo si su matriz simetrica puede ponerse en forma m-positivay r(A) = m.
EJEMPLOS.
1) Estudiar la forma cuadratica Q definida en R4 por la matriz
312

A =
2 1 0 31 1 1 20 1 2 13 2 1 6
Como |A| = 0, Q es degenerada.Cogiendo los menores angulares: |A11| > 0 , |A22| > 0 pero |A33| = 0, entonces pasamos a
|A422| > 0 e intercambiamos tercera y cuarta filas y tercera y cuarta columnas para hacer la forma
cuadratica 3− positiva:
A =
2 1 3 01 1 2 13 2 6 10 1 1 2
En esta matriz |A11| > 0 , |A22| > 0 y |A33| > 0 y |A4
33| = |A| = 0, por lo que Q es semidefinidapositiva.
2) Estudiar la forma cuadratica Q definida en R4 por la matriz
A =
1 0 1 00 2 0 21 0 1 00 2 0 2
Como |A| = 0, Q es degenerada.
Empezamos cogiendo los menores angulares: |A11| > 0 y |A22| > 0, entonces pasamos a |A322| = 0
y |A422| = 0. Por tanto Q esta en forma 2-positiva.
Aplicando el segundo criterio en este caso, podemos concluir que la forma cuadratica es semidefinidapositiva directamente ya que |A34
22| = |A| = 0.
Para aplicar el tercer criterio tendrıamos que calcular el menor formado por la interseccion de lastres primeras filas y las columnas primera, tercera y cuarta, que tambien sale cero.
Para aplicar el primer criterio, hallamos U32 vector propio de A3
22 = A33 para el valor propio nulode A3
22 y lo sumergimos canonicamente en R4, por ejemplo, U32 = (1, 0,−1, 0) solucion de
313

x1 + x3 = 0
2x2 = 0
x1 + x3 = 0
Se ve facilmente que U32 es vector propio de A.
Hallamos U42 vector propio de A4
22 para el valor propio nulo de A422 y lo sumergimos canonicamente
en R4, por ejemplo, U42 = (0, 1, 0,−1) solucion de
x1 = 0
2x2 + 2x4 = 0
2x2 + 2x4 = 0
Se ve facilmente que U42 es vector propio de A.
Se puede concluir por tanto que Q es semidefinida positiva por el primer criterio.
Se puede comprobar que efectivamente Q es semidefinida positiva viendo que
1
2
2 1 0 −1−1 0 1 0
0 −1 0 11 2 −1 0
t
1 0 1 00 2 0 21 0 1 00 2 0 2
1
2
2 1 0 −1−1 0 1 0
0 −1 0 11 2 −1 0
=
1 0 0 00 2 0 00 0 0 00 0 0 0
3) Estudiar la forma cuadratica definida en R5 por la matriz
A =
6 8 6 2 88 13 8 3 116 8 6 2 82 3 2 1 38 11 8 3 11
.
Como |A| = 0, Q es degenerada.
Empezamos cogiendo los menores principales superiores del angulo izquierdo:
|A11| > 0 y |A22| > 0, pero |A33| = 0 aunque |A422| > 0 entonces hacemos una reordenacion de la
matriz correspondiente a una permutacion de los vectores e3 y e4 de la base y obtenemos
314

A =
6 8 2 6 88 13 3 8 112 3 1 2 36 8 2 6 88 11 3 8 11
.
Ahora |A11| = |A11| > 0, |A22| = |A22| > 0, |A33| > 0. |A4
33| = 0, |A5
33| = 0, luego Q esta en forma2-positiva.
Aplicando el criterio II, como |A4533| = |A| = 0, podemos concluir que Q y por tanto Q es
semidefinida positiva.
Para aplicar el criterio III tendrıamos que calcular el menor correspondiente a las cuatro primerasfilas y a las columnas primera, segunda, tercera y quinta, que tambien sale cero.
Para aplicar el criterio I, observemos que los vectores propios U4
33 = (1, 0, 0,−1, 0) y U5
33 =(1, 0, 1, 0,−1) lo son de A, siendo por tanto semidefinida positiva.
Se puede comprobar que es semidefinida positiva porque
1
2
2 1 0 −1 −3−1 0 1 0 0
0 −1 0 1 11 2 −1 0 −20 0 0 0 2
t
6 8 6 2 88 13 8 3 116 8 6 2 82 3 2 1 38 11 8 3 11
1
2
2 1 0 −1 −3−1 0 1 0 0
0 −1 0 1 11 2 −1 0 −20 0 0 0 2
=
2 1 1 0 01 1 1 0 01 1 2 0 00 0 0 0 00 0 0 0 0
.
Demostraciones.
Damos primero dos lemas utilizados en las demostraciones de los criterios.Lema 1: Sean U1, ..., Um los vectores propios que diagonalizan Am,m transformandola en I. Si Q
esta en forma m-positiva, f(Ui, Ukm) = 0, ∀i, ∀m.
315

Demostracion: La matriz de Q |Le1,e2,..,em,ek en la base U1, ..., Um, Ukm, que es de la forma
b1I .
.
.bm
b1 ... bm 0
ha de tener determinante nulo, por tanto, desarrollando por la ultima columna tenemos −(b21 + b22 +...+ b2m) = 0, de donde 0 = bk = f(Ui, U
km) ∀i, ∀k.
Lema 2: Si Q esta en forma m-positiva, Q es semidefinida positiva si y solo si f(Ukm, U
k′m ) = 0,
∀k, k′ > m.
Demostracion. Los vectores Um+1m , ..., Un
m son independientes entre sı ya queUkm ∈ Le1, e2, ..., em, ek − Le1, .., em. Los vectores U1, ..., Um, U
m+1m , ..., Un
m son base de V n.Segun el Lema 1, Q se expresa en esta base por(
Imm 00 C
)donde todos los terminos de la diagonal principal de C son nulos. Observando que ckk′ = f(Uk
m, Uk′m )
tenemos demostrado el lema 2.
Demostracion del Criterio I.
Ahora probamos que f(Ukm, U
k′m ) = 0 ∀k, k′ > m si y solo si los vectores Uk
m son vectorespropios de A.
Es claro que si los vectores Ukm son vectores propios de A solo pueden serlo para el valor propio
nulo y en este caso Um+1m,1 ... Um+1
m,n
...Unm,1 ... Un
m,n
A = 0
por lo que C = 0.Recıprocamente, si algun Uk
m no es vector propio de A, alguna coordenada de UkmA es distinta
de cero. Sea a el valor de esta coordenada en el lugar s. Encontramos f(Ukm, U
sm) = aU s
ms 6= 0.Contradiccion.
316

Demostracion del Criterio II.
La matriz de Q |L(e1,...,em,ek,ek′ )en la base e1, ..., em, ek, ek′ es Akk
′m,m. Los vectores
U1, ..., Um, Ukm, U
k′m son tambien una base de L(e1, ..., em, ek, ek′ luego si |Akk′m,m| = 0 tambien∣∣∣∣∣∣
I 0 00 0 f(Uk
m, Uk′m )
0 f(Ukm, U
k′m ) 0
∣∣∣∣∣∣ = 0
por tanto f(Ukm, U
k′m ) = 0. Es decir, Q es semidefinida positiva segun el lema 2.
Demostracion del Criterio III.
Considerando la base U1, ..., Um, U1m, ..., U
nm vemos que r(A) = r(Q) = m si y solo si ckk′ = 0,
es decir si y solo si f(Ukm, U
k′m ) = 0 o equivalentemente Q es semidefinida positiva.
Equivalencia entre estos Criterios y el Criterio de Smirnov.
Cada menor diagonal es la matriz de la restriccion de Q a un cierto subespacio engendrado porvectores de la base, por tanto, si Q es semidefinida positiva el determinante de estos menores ha deser no negativo.
Recıprocamente, observemos que Akk′
mm es un menor diagonal y
|Akk′mm| = −(f(Ukm, U
k′
m ))2|D|2
donde D es la matriz de cambio de base de e1, ..., em, ek, ek′ a U1, ..., Um, Ukm, U
k′m.
Por tanto, en las hipotesis del Criterio de Smirnov ha de ser f(Ukm, U
k′m ) = 0 y segun nuestro lema
2, Q es semidefinida positiva.
317

Esquema. Formas cuadraticas.
a) |Ass| > 0 ∀s⇔ Q es definida positiva.b) Si en alguna reordenacion de A
∃k < n \ |Ass| > 0 ∀s ≤ m y |Akmm| = 0 ∀k > m entonces
AUkm = 0 o
|Akk′mm| = 0 o
r(A) = m
⇐⇒ Q es semidefinida positiva.
c) −A cumple a) ⇔ Q es definida negativa.d) −A cumple b) ⇔ Q es semidefinida negativa.e) casos restantes ⇔ Q es indefinida.
318

Diagonalizacion simultanea de formas cuadraticas.
Este problema consiste, dadas dos formas cuadraticas distintas definidas en un espacio vectorial,en encontrar una base del espacio vectorial en la que las dos se expresen como suma de cuadrados (concoeficientes) de las coordenadas correspondientes a esta misma base. Entonces, ambas expresionesmatriciales son diagonales. Se trata tambien de encontrar una base en la que las dos formas bilinealessimetricas de las que provienen las formas cuadraticas tengan una expresion matricial diagonal.
En Fısica se utiliza la diagonalizacion simultanea para expresar la energıa cinetica, (que es unaforma cuadratica de las derivadas de las coordenadas) y la energıa potencial, (que salvo una constante,es una forma cuadratica de las coordenadas). Las ecuaciones de Lagrange y una diagonalizacionsimultanea de las dos formas cuadraticas determinan entonces el movimiento. (Puede verse [B])
Pasando al problema, si una de ellas, p.ej. Q de matriz simetrica A, es definida positiva, podemoshacer un razonamiento relativamente corto: Por ser Q definida positiva, Q determina un productoescalar que admite bases ortonormales. Existe, por tanto un cambio de base de matriz C, tal quetCAC = I. Sea Q′ otra forma cuadratica de matriz simetrica A′; El mismo cambio de base en Q′
da lugar a la matriz tCA′C, que es otra matriz simetrica. tCA′C se puede diagonalizar en una baseortonormal, es decir, existe otra matriz ortogonal P tal que tP tCA′CP = D; por ser P ortogonal,tambien tP tCACP = P tIP = I. Por tanto, la matriz CP diagonaliza simultaneamente a las dosmatrices simetricas y a las dos formas cuadraticas.
Para hallar la matriz CP , tenemos en cuenta que las columnas de la matriz P son los vectorespropios de tCA′C, soluciones de (tCA′C − λI)v = 0 para algun λ; Pero esta ecuacion se puedeescribir:
(tCA′C − λtCAC)v = 0 ≡ tC(A′ − λA)Cv = 0 ≡ (A′ − λA)Cv = 0
Entonces, los vectores columna de CP son los vectores Cv = V , que satisfacen el sistema
(A′ − λA)V = 0
para los λ tales que |A′ − λA| = 0.A pesar de que al resolver el sistema anteriormente escrito, no solo se obtienen los vectores Cv sino tambien sus
multiplos, y las soluciones que cojamos del sistema no siempre diagonalizaran la matriz A hasta la matriz I, en cualquiercaso, la base formada por los vectores escogidos, cuya matriz de cambio de base fuera CP ′ sigue diagonalizandosimultaneamente, porque los productos de filas por columnas cruzadas en t(CP ′)ACP ′ y t(CP ′)A′CP ′ son multiplosde los que corresponderıan a la matriz t(CP )ACP y t(CP )A′CP .
319

Cuando todos los λi son de multiplicidad 1, estando interesados solamente en la diagonalizacion,no tenemos que preocuparnos de la eleccion que hacemos de los vectores V :
Observemos que los vectores que verifican (A′ − λA)V = 0 son los mismos que los que verifican(A−1A′ − λI)V = 0.
Sean Vi = (vi1, vi2...vin) y Vj = (vj1, vj2...vjn), correspondientes a valores propios distintos λi 6= λj,entonces,
(vi1, vi2...vin)A′
vj1vj2
...vjn
= (vi1, vi2...vin)AA−1A′
vj1vj2
...vjn
=
= (vi1, vi2...vin)Aλj
vj1vj2
...vjn
= λj(vi1, vi2...vin)A
vj1vj2
...vjn
Tambien, por ser las matrices simetricas,
(vi1, vi2...vin)A′
vj1vj2
...vjn
= (vj1, vj2...vjn)A′
vi1vi2
...vin
= (vj1, vj2...vjn)AA−1A′
vi1vi2
...vin
=
(vj1, vj2...vjn)Aλi
vi1vi2
...vin
= λi(vj1, vj2...vjn)A
vi1vi2
...vin
= λi(vi1, vi2...vin)A
vj1vj2
...vjn
La igualdad de las dos ultimas expresiones cuando λi 6= λj, implica que V t
i AVj = 0 = V ti A′Vj.
Pero si algun λ es de multiplicidad mayor que 1, tenemos que preocuparnos de coger entre losvectores correspondientes al mismo valor propio, Vi, Vj, tales que tViAVj = tViA
′Vj = 0. Observemosque los vectores que cogiendolos de manera que tViAVj = 0, tambien se verifica que tViA
′Vj =tViA(A−1A′)Vj = tViAλVj = λtViAVj = 0.
Veamos dos ejemplos:
320

Ejemplo 1: Sean
Q(x, y) = x2 + 2y2 + 2xy = (x, y)
(1 11 2
)(xy
)
Q′(x, y) = x2 + 2xy = (x, y)
(1 11 0
)(xy
)dos formas cuadraticas que queremos diagonalizar simultaneamente. Hallamos primero los valoresde λ tales que |A′ − λA| = 0: son λ1 = 1, λ2 = −1, ya que∣∣∣∣( 1 1
1 0
)− λ
(1 11 2
)∣∣∣∣ =
∣∣∣∣ 1− λ 1− λ1− λ −2λ
∣∣∣∣ = λ2 − 1
Para λ1 = 1, los vectores V que verifican (A′ − λ1A)V = 0 son las soluciones del sistema:(0 00 −2
)(xy
)=
(00
)≡ y = 0
Para λ2 = −1, los vectores V que verifican (A′ − λ2A)V = 0 son las soluciones del sistema:(2 22 2
)(xy
)=
(00
)≡ x+ y = 0
Cogiendo como V1 = (1, 0) y como V2 = (1,−1) tenemos la diagonalizacion simultanea:(1 01 −1
)(1 11 2
)(1 10 −1
)=
(1 00 1
)(
1 01 −1
)(1 11 0
)(1 10 −1
)=
(1 00 −1
)Cualquier otro V ′1 que podamos coger es un multiplo de V1 y cualquier otro V ′2 que podamos coger
es un multiplo de V2. Por ello la diagonalizacion se sigue dando. Por ejemplo, cogiendo V ′1 = (2, 0),V ′2 = (−3, 3), entonces, (
2 0−3 3
)(1 11 2
)(2 −30 3
)=
(4 00 9
)(
2 0−3 3
)(1 11 0
)(2 −30 3
)=
(4 00 −9
)Ejemplo 2:Diagonalizar simultaneamente:
321

Q(x, y, z, t) = 2x2 + 2y2 + 2z2 + 2t2 + 2xz − 2yt Q′(x, y, z, t) = x2 − y2 + z2 − t2 + 4xz + 4yt.Escritas matricialmente:
Q(x, y, z, t) = (x, y, z, t)
2 0 1 00 2 0 −11 0 2 00 −1 0 2
xyzt
Q′(x, y, z, t) = (x, y, z, t)
1 0 2 00 −1 0 22 0 1 00 2 0 −1
xyzt
Entonces,
|A′ − λA| =
∣∣∣∣∣∣∣∣1− 2λ 0 2− λ 0
0 −1− 2λ 0 2 + λ2− λ 0 1− 2λ 0
0 2 + λ 0 −1− 2λ
∣∣∣∣∣∣∣∣ = 9(λ2 − 1)2,
de donde para los valores de λ iguales a 1 o a −1, se pueden obtener los vectores de una base quediagonaliza simultaneamente a las dos formas cuadraticas.
Para λ = 1, las ecuaciones−1 0 1 0
0 −3 0 31 0 −1 00 3 0 −3
xyzt
= 0 ≡ −x +z = 0−3y +3t = 0
nos permiten coger V1 = (1, 1, 1, 1). El vector V2 = (a, b, c, d) tiene que satisfacer esas mismasecuaciones y ademas verificar:
(a, b, c, d)
2 0 1 00 2 0 −11 0 2 00 −1 0 2
1111
= 0 ≡ 3a+ b+ 3c+ d = 0
Podemos coger V2 = (1,−3, 1− 3)Para λ = −1, las ecuaciones
3 0 3 00 1 0 13 0 3 00 1 0 1
xyzt
= 0 ≡ 3x +3z = 0y +t = 0
322

nos permiten coger V3 = (1, 1,−1,−1). El vector V4 = (a, b, c, d) tiene que satisfacer esas mismasecuaciones y ademas verificar:
(a, b, c, d)
2 0 1 00 2 0 −11 0 2 00 −1 0 2
11−1−1
= 0 ≡ a+ 3b− c− 3d = 0
Podemos coger V4 = (3,−1,−3, 1).La base (1, 1, 1, 1), (1,−3, 1−3), (1, 1,−1,−1), (3,−1,−3, 1) diagonaliza a las dos formas cuadraticas
simultaneamente.
Ejercicios:
9.7.1. Diagonalizar simultaneamente las formas cuadraticas:a) Q(x, y) = x2 + 26y2 + 10xy, Q′(x, y) = x2 + 56y2 + 16xyb) Q(x, y) = −4xy, Q′(x, y) = x2 + 2xy + 2y2.c) Q1(x, y, z) = x2−8xy−4y2 + 10xz+ 4yz+ 2z2, Q2(x, y, z) = 6x2 + 8xy+ 4y2−2xz−4yz+ 2z2
(valores de λ : −1, 2, 3).d)Q1(x, y, z) = −2x2−4xy−2y2 + 2xz+ 2yz− z2, Q2(x, y, z) = 4x2 + 4xy+ 2y2−2xz−2yz+ z2,(valores de λ : −1, 0).
323

Bibliografıa:
B] F. Brickell. Matrices and vector spaces. George Allen and Unwin Ltd, 1972.[C] P.M. Cohn. Algebra. vol. 1. Ed. Wiley & Sons, 1982.[CCh] L. Contreras y F. Chamizo. Actas XV Jornadas Luso-Espanholas de Matematica, U. Evora
1990.[G] L.I. Golovina. Algebra Lineal y algunas de sus aplicaciones. Ed. Mir. Moscu, 1980.[S] V. Smirnov. Linear Algebra and group theory. Ed. Mc. Graw-hill, 1961.
324

Condiciones necesarias y suficientes para la diagonalizacion simultanea deformas cuadraticas.
Dadas dos formas cuadraticas, si una de ellas es definida positiva, se puede encontrar una base enla que las dos diagonalizan simultaneamente. Se encuentra aquı una condicion necesaria y suficientepara que dos formas cuadraticas sean diagonalizables simultaneamente, viendose que no es necesarioque una de las dos sea definida positiva, sino que es necesario y suficiente que una de las formascuadraticas sea no degenerada y que si A es la matriz de la forma cuadratica no degenerada y A′ esla matriz de la otra forma cuadratica A−1A′ ha de ser diagonalizable. Este es un trabajo original dela autora.
Si queremos estudiar un caso mas general en el que solo exigimos que una de las formas cuadraticassea no degenerada podemos utilizar aquı los conocimientos sobre el espacio dual para encontrarcondiciones necesarias y suficientes para que dos formas bilineales simetricas (y por tanto, las formascuadraticas asociadas) sean diagonalizables simultaneamente.
Recordemos que el espacio dual V n∗ de un espacio vectorial real V n es el espacio vectorial de lasaplicaciones lineales definidas en ese espacio con valores reales.
Cada elemento del dual es una aplicacion lineal ψ : V n 7→ K a la que corresponde una matriz1× n : (a1, a2, · · · , an), tal que
ψ(y) = (a1, a2, · · · , an)
y1
y2...yn
K es el cuerpo del espacio vectorial (puede ser R o C).
El nucleo de ψ es el conjunto de vectores y que verifican: a1y1 + a2y2 + · · · + anyn = 0. Es dedimension n− 1 salvo que todos los ai sean nulos en cuyo caso la aplicacion ψ es nula y su nucleo estodo el espacio.
Si e1, e2, · · · , en es una base de V n, su base dual es e∗1, e∗2, · · · , e∗n en V n∗. Los elementos dela base dual estan caracterizados por e∗i (ej) = 0, si i 6= j y e∗i (ei) = 1.
En esta base las coordenadas de la ψ anterior son (a1, a2, · · · , an).
Pasando ahora al problema que nos ocupa, si f : V n × V n 7→ R es una forma bilineal, al fijar unvector x ∈ V n, la aplicacion: y 7→ f(x, y) es lineal. Vamos a escribir ϕ(x) esta aplicacion que es portanto un elemento del dual: (ϕ(x))(y) = f(x, y). (ϕ(x) ∈ V n∗).
325

Al mismo tiempo ϕ puede considerarse como una aplicacion de V n en V n∗. Es otra aplicacionlineal. Para hallar su matriz en una base dada de V n y en la dual de ella en V n∗ tendremos quehallar las coordenadas de las imagenes de los vectores de la base:
Tenemos
ϕ(e1)(y) = (1, 0, · · · , 0)A
y1
y2...yn
= (a11, a12, · · · , a1n)
y1
y2...yn
lo que nos dice que las coordenadas de ϕ(e1) en el dual son (a11, a12, · · · , a1n). (pimera fila de A).
Haciendo la misma operacion para cada ei, tenemos:
ϕ(ei)(y) = (0, 0, · · · , 1, · · · , 0)A
y1
y2...yn
= (ai1, ai2, · · · , ain)
y1
y2...yn
lo que nos dice que las coordenadas de ϕ(ei) en la base dual de la considerada son (ai1, ai2, · · · , ain).(i-esima fila de A).
Al colocar estas coordenadas en columnas obtenemos la matriz tA como matriz de la aplicacionϕ.
Dadas dos formas cuadraticas de matrices simetricas A y A′ donde |A| 6= 0, Condicion necesariapara que los vectores de una base diagonalicen simultaneamente a dos formas cuadraticas es quedichos vectores sean vectores propios de A−1A′.
Demostracion:Suponiendo resuelto el problema de diagonalizacion simultanea de las formas cuadraticas Q de
matriz simetrica A y Q′ de matriz simetrica A′, existe una base de vectores v1, v2, · · · , vn talesque f(vi, vj) = 0 = f ′(vi, vj) si i 6= j, o lo que es lo mismo ϕ(vi)(vj) = 0 = ϕ′(vi)(vj) si i 6= j;dicho de otra manera: existe una base de vectores v1, v2, · · · , vn tal que kerϕ(vi) 3 vj si i 6= j ykerϕ′(vi) 3 vj si i 6= j. Para cada i estos dos nucleos tienen en comun al menos n− 1 vectores. Porlo tanto, o son coincidentes o uno de ellos es todo el espacio V n.
Las ecuaciones de los nucleos kerϕ(x) y kerϕ′(x) son:
326

kerϕ(vi) ≡ (a1, a2, · · · , an)
y1
y2...yn
= 0 donde (a1, a2, · · · , an) = (vi1, vi2, · · · , vin)A
kerϕ′(vi) ≡ (a′1, a′2, · · · , a′n)
y1
y2...yn
= 0 donde (a′1, a′2, · · · , a′n) = (vi1, vi2, · · · , vin)A′
Si los dos nucleos son iguales, existe λ tal que
λ(a1, a2, · · · , an) = (a′1, a′2, · · · , a′n)
Si el segundo nucleo es todo el espacio,
0(a′1, a′2, · · · , a′n) = (0, 0, · · · , 0) = 0(a1, a2, · · · , an)
Si el primer nucleo es todo el espacio,
(a1, a2, · · · , an) = (0, 0, · · · , 0) = 0(a′1, a′2, · · · , a′n)
Los tres casos los podemos englobar en que existe λ, tal que
λ(a1, a2, · · · , an) = (a′1, a′2, · · · , a′n) o (a1, a2, · · · , an) = λ(a′1, a
′2, · · · , a′n)
Como a1
a2...an
= tA
v1
v2...vn
= A
v1
v2...vn
, y
a′1a′2...a′n
= A′t
v1
v2...vn
= A′
v1
v2...vn
La igualdad anterior se expresa:
λA
v1
v2...vn
= A′
v1
v2...vn
o A
v1
v2...vn
= λ′A′
v1
v2...vn
327

Si |A| 6= 0, la matriz A es invertible por lo que el vector Av es distinto de cero siempre que v seadistinto de cero (lo que ha de ocurrir para que este en una base), por lo que λ′ no puede ser cero.Entonces, dividiendo por λ′ en la ultima igualdad, podemos reducirla a
1
λ′A
v1
v2...vn
= A′
v1
v2...vn
similar a λA
v1
v2...vn
= A′
v1
v2...vn
que resume a las dos cuando Q es no degenerada.
Multiplicando la ultima por A−1 tenemos que
λ
v1
v2...vn
= A−1A′
v1
v2...vn
el vector v esta en una base que las diagonaliza simultanemente, si v es vector propiode A−1A′.
Es Condicion suficiente para que los vectores v1, v2, · · · , vn diagonalicen simultaneamente a Qy a Q′ cuando Q es no degenerada, es que los vectores propios de A−1A′ correspondan a valorespropios distintos.
Demostracion:Vamos a comprobar que
f(vi, vj) = ϕ(vi)(vj) = 0 = ϕ′(vi)(vj) = f ′(vi, vj)
Si vi, vj corresponden a valores propios distintos de A−1A′ (λi 6= λj)Entonces, por ser las formas bilineales simetricas,
(ϕ′(vi))(vj) = (ϕ′(vj))(vi) y (ϕ(vi))(vj) = (ϕ(vj))(vi)
Tambien,
(ϕ′(vi))(vj) = (ϕ ϕ−1(ϕ′(vi))(vj) = (ϕ(ϕ−1 ϕ′)(vi))(vj) = ϕ(λivi)(vj) = λiϕ(vi)(vj)
(ϕ′(vj)(vi) = (ϕ ϕ−1(ϕ′(vj))(vi) = (ϕ(ϕ−1 ϕ′)(vj))(vi) = ϕ(λjvj)(vi) = λjϕ(vj)(vi)
328

de dondeλiϕ(vi)(vj) = λjϕ(vj)(vi)
lo que implica 0 = ϕ(vi)(vj) = f(vi, vj) y (ϕ′(vi))(vj) = λiϕ(vi)(vj) = 0.
Segun esta condicion podremos encontrar la base que las diagonaliza simultaneamente si A−1A′
es diagonalizable para valores propios distintos.
Con el fin de resolver el problema cuando hay valores propios multiples veamos que en los subes-pacios de vectores propios correspondientes a cada valor propio, podemos encontrar vectores propiosortogonales respecto a la forma cuadratica no degenerada Q:
Si Lλi es el subespacio de vectores propios de A−1A′ para el valor propio λi, la restriccion de Q aese subespacio admite una matriz simetrica, que es diagonalizable en ese espacio, los vectores de Lλique diagonalicen esta restriccion son vectores propios de A−1A′ que tambien verifican f(vi, vj) = 0 ypor tanto f ′(vi, vj) = (ϕ′(vi))(vj) = λiϕ(vi)(vj) = 0.
Podemos concluir que si Q es una forma cuadratica no degenerada y Q′ es otra formacuadratica cualquiera, si la matriz A−1A′ es diagonalizable, podemos encontrar una basede vectores propios de A−1A′ que diagonaliza simultaneamente a Q y a Q′.
En particular, siA−1A′ es simetrica las dos formas cuadraticas son diagonalizables simultaneamente.Y si despues de un cambio de base conseguimos que (tCAC)−1tCA′C sea simetrica, las dos formascuadraticas son diagonalizables simultaneamente.
Si una de las formas cuadraticas p.ej. Q es definida positiva, como corresponde a un productoescalar, siempre se puede encontrar una base en la que la matriz correspondiente sea I. Si la matrizde Q′ en la base primitiva era A′, al cambiar de base se transforma en una del tipo tCA′C. En estanueva base el endomorfismo ϕ−1 ϕ′ se expresa por I tCA′C = tCA′C, matriz simetrica, que portanto es diagonalizable. Concluimos que Dos formas cuadraticas, una de las cuales es definidapositiva, siempre pueden diagonalizarse simultaneamente.
Calculo de la base que diagonaliza simultaneamente a dos formas cuadraticasUn λ es valor propio de A−1A′ si y solo si
0 = |A−1A′ − λI| = |A−1A′ − λA−1A| = |A−1||A′ − λA| ≡ 0 = |A′ − λA|
esta es la ecuacion que resolveremos para no calcular inversas.En cuanto a los subespacios de vectores propios que las diagonalizan, tienen que satisfacer
0 = (A−1A′ − λI)v = (A−1A′ − λA−1A)v = A−1(A′ − λA)v = 0 ≡ (A′ − λA)v = 0
329

Si los valores propios son distintos y cada uno de estos espacios es de dimension 1, los vectoresque los engendran son una base que diagonaliza simultaneamente a Q y a Q′.
Si para algun valor propio λi el subespacio de vectores propios correspondiente Lλi es de dimensionmayor tendremos que encontrar en cada uno de ellos una base que diagonalice a Q y la union deestas bases diagonaliza simultaneamente a Q y a Q′.
Ejercicios:9.9.1. Diagonalizar simultaneamente las formas cuadraticas:a) Q(x, y) = −4xy, Q′(x, y) = x2 + 4xy + 2y2.b) Q(x, y) = −4xy, Q′(x, y) = x2 + 2xy + 2y2.c) Q1(x, y, z) = x2−8xy−4y2 + 10xz+ 4yz+ 4z2, Q2(x, y, z) = 6x2 + 8xy+ 4y2−2xz−4yz+ 2z2
(valores de λ : −1, 2, 3).d)Q1(x, y, z) = −2x2− 4xy− 2y2 + 2xz+ 2yz− z2 Q1(x, y, z) = 4x2 + 4xy+ 2y2− 2xz− 2yz+ z2,(valores de λ : −1, 0).9.9.2. Comprobar que pueden diagonalizarse simultaneamente:Q(x, y, z, t) = 2xy + 2xz − 4yz + 4yt+ 4t2 Q′(x, y, z, t) = x2 + 4xt+ 4y2 + 4yz + z2 + 4t2.9.9.3. Comprobar que no son diagonalizables simultaneamente las formas cuadraticas:Q(x, y, z) = 2xy + 2xz + 2yz Q′(x, y, z) = 2xy − 2xz − 2yz.9.9.4. Diagonalizar simultaneamente:Q(x, y, z, t) = 2x2 + 2y2 + 2z2 + 2t2 + 2xz − 2ytQ′(x, y, z, t) = x2 − y2 + z2 − t2 + 4xz + 4yt.
330

Bibliografıa:
B] F. Brickell. Matrices and vector spaces. George Allen and Unwin Ltd, 1972.[G] L. I. Golovina. Algebra Lineal y algunas de sus aplicaciones. Ed. Mir 1974.
331

332

FORMAS DE JORDAN EN DIMENSION 2, 3 y 4.
Introduccion.Las ”formas de Jordan” son matrices relativamente sencillas correspondientes a endomorfismos
no diagonalizables. Aunque no siempre son diagonales, son casi siempre matrices mas sencillas quelas correspondientes a los endomorfismos en la base canonica.
Las cajas de Jordan son matrices cuadradas que tienen iguales todos los elementos de la diagonal,tienen 1 en todos los sitios inmediatamente encima de la diagonal y ceros en los demas sitios:
La matriz: λ 1 00 λ 10 0 λ
es una caja de Jordan de orden 3.
Una caja de Jordan de orden 1 es un numero. Por lo que las matrices diagonales son yuxtaposicionde cajas de Jordan de orden 1.
Se llaman formas de Jordan o matrices de Jordan a las matrices formadas por cajas de Jordanyuxtapuestas en la diagonal.
Se llaman ”bases de Jordan” las bases en las que el endomorfismo se expresa por una forma deJordan.
Cuando un endomorfismo es diagonalizable, si su matriz en una base dada es A, existe una matrizde cambio de base C tal que C−1AC es diagonal. Si el endomorfismo no es diagonalizable, esto noes posible, pero llamando J a la forma de Jordan, que es bastante sencilla, existe una matriz decambio de base C tal que C−1AC = J . Hay un teorema general, que no demostraremos aquı, queafirma la equivalencia de toda matriz de numeros complejos a una matriz de Jordan.
Ademas, a un endomorfismo dado le corresponde solo una forma de Jordan salvo el orden delas cajas. Entonces, a todas las matrices que corresponden al mismo endomorfismo en distintasbases corresponde una sola forma de Jordan. Teniendose por tanto, que las formas de Jordanclasifican a las matrices y que matrices con formas de Jordan diferentes no pueden corresponder almismo endomorfismo ni siquiera en distintas bases. Lo cual puede servir para descartar si matricesprovenientes de distintos observadores, corresponden al mismo fenomeno observado.
En este capıtulo se demuestran los casos particulares del teorema anterior para matrices 2 × 2y 3 × 3 de numeros reales, y para matrices 4 × 4 de numeros complejos por metodos directos yelementales.
333

La forma de Jordan de una matriz con numeros reales y valores propios reales es un caso particularde la forma de Jordan de una matriz con numeros complejos. Las construcciones dadas para matricesde numeros reales sirven para las demostraciones analogas para matrices de estas dimensiones denumeros complejos no diagonalizables.
Demostraciones distintas del teorema en el caso 2 × 2 se encuentran en Grosman [G] y enHernandez [H]. Una demostracion corta, por induccion, de que toda matriz de orden n × n tieneuna base de Jordan compleja, que es real si todos los valores propios son reales se encuentra en [S].Demostraciones mas clasicas de la existencia de la forma de Jordan de una matriz que incluyen laforma de encontrar la base de Jordan se encuentran en [C] y en [H].
Consideraciones previas.Las matrices de numeros reales de Mn×n(R) pueden considerarse tambien matrices de numeros
complejos. Determinan endomorfismos de Rn y de Cn. Dada una matriz A ∈Mn×n(R) con numerosreales, vamos a llamar f al endomorfismo de Rn de matriz A en la base canonica y f al endomorfismode la misma matriz en Cn, tambien en la base canonica. Diremos que A es diagonalizable sobre Rsi f es diagonalizable y que A es diagonalizable sobre C si f es diagonalizable. Es obvio que si f esdiagonalizable, f lo es y que si f no es diagonalizable, f tampoco lo es.
Se deduce de lo anterior que la matriz A es diagonalizable sobre R si y solo si existe una matriz denumeros reales: C, tal que C−1AC = D sea diagonal. En este caso se dice que A es equivalente a Den R. Se deduce tambien que la matriz A es diagonalizable sobre C si y solo si existe una matriz de
numeros complejos: C, tal que C−1AC = D sea diagonal. En este caso se dice que A es equivalente
a D en C. La equivalencia de A a D en C no implica la equivalencia de A a D en R .
Cuando consideramos espacios vectoriales sobre C, la suma de las multiplicidades algebraicas delos valores propios de un endomorfismo es igual a la dimension del espacio; esto sigue siendo ciertopara endomorfismos de espacios vectoriales sobre R si todos sus valores propios son reales.
Cuando hablamos de los valores propios de A, hablamos indistintamente de los valores propiosde f o de f . El problema para que una matriz de numeros reales sea no diagonalizable en R, esque tenga algun valor propio complejo o que siendo todos los valores propios reales, haya algun valorpropio, cuya multiplicidad geometrica sea menor que la multiplicidad algebraica. Si tiene algun valorpropio complejo, y es diagonalizable en C, a partir de su forma de Jordan compleja se obtiene unamatriz con numeros reales, equivalente a la dada, que se llama forma de Jordan real de la matriz convalores propios complejos. Tiene otras cajas de Jordan, llamadas reales, correspondientes a matrices
334

con valores propios complejos que en R2 y en R3 son de la forma:(α β−β α
).
Forma de Jordan de Matrices 2× 2 de numeros reales.Sea A ∈M2×2(R). Entonces, los casos que se pueden presentar son:1) Los valores propios de A son distintos y reales. (Entonces A es diagonalizable en R.)2) Los valores propios de A son distintos y complejos. (Entonces A es diagonalizable en C pero
no en R.)3) Los valores propios de A son iguales, en cuyo caso tienen que ser reales. Llamemos λ a este
valor propio. Entonces tenemos dos subcasos:a) dimker(f − λI) = 2, entonces A es diagonalizable.b) dimker(f − λI) = 1, entonces A no es diagonalizable en R ni en C .En el caso 2) y en el caso 3b), que no son diagonalizables, las matrices son equivalentes a las
llamadas formas de Jordan.
Caso 2). Sea A ∈M2×2(R), y α + iβ un valor propio complejo de A. Entonces A no es diagona-lizable en R pero sı es diagonalizable en C, siendo A equivalente en R a una matriz de la forma deJ:
J =
(α β−β α
).
Demostracion:Los valores propios complejos de una matriz de numeros reales aparecen por parejas de valores
conjugados: α+ iβ y α− iβ, por ser raices del polinomio caracterıstico de la matriz, que tiene todossus coeficientes reales.
Para el valor propio complejo α + iβ , existe un vector propio de coordenadas complejas w, quese puede descomponer w = u + iv en su parte real y su parte imaginaria. Podemos calcular f(u) yf(v), teniendo en cuenta que:
f(w) = (α + iβ)w =⇒f(u) + if(v) = f(u) + if(v) = f(u+ iv) = (α + iβ)(u+ iv) = αu− βv + i(βu+ αv)
de donde, igualando partes reales y partes imaginarias:
f(u) = αu− βv , f(v) = βu+ αv.
Podemos comprobar tambien que el vector complejo correspondiente a α− βi es w = u− iv. Ya que
335

f(u− iv) = f(u)− if(v) = f(u)− if(v) = αu− βv − i(βu+ αv) = (α− βi)(u− iv).
Los vectores w = u + iv, w = u − iv son vectores linealmente independientes de C2 por servectores propios correspondientes a valores propios distintos. Por tanto engendran un plano de C2.A su vez los vectores w,w son combinacion lineal de los u, v y recıprocamente. Entonces, el subespacioengendrado por u, v es el mismo que el engendrado por w,w, (un plano) y por tanto, los vectoresu, v son independientes en C2 y en R2. Por tanto, los vectores u, v son una base de R2, llamadabase de Jordan real y f se expresa en esa base por:(
α β−β α
)= J.
Que es la forma de Jordan real del endomorfismo f no diagonalizable en R, pero sı diagonalizableen C.
Ejercicios:
10.1.1. Hallar la forma de Jordan real y la base de Jordan real de las siguientes matrices:
a)
(−1 −4
2 3
)b)
(4 10−1 2
)c)
(2 −101 4
)d)
(8 18−1 2
)e)
(−1 4−2 3
)f)
(3 −42 −1
)10.1.2. Escribir las matrices de los giros de R2 de angulos π/4, π/3 y π/6 y comprobar que son
matrices de Jordan reales.
336

Caso 3b). Sea A ∈M2×2(R), con un valor propio doble λ y dimker(f−λI) = 1(≡ r(A−λI) = 1),entonces A es no diagonalizable en C, pero A es equivalente en R a una matriz J, donde
J =
(λ 10 λ
).
La base de R3 en la que f se expresa por J se llama base de Jordan de f y base de Jordan paraA. Se vera como se encuentra en el transcurso de la demostracion.
Demostracion:Por ser dim(ker(f−λI)) = 1, tambien dim(Im(f−λI)) = 1; consideremos el espacio Im(f−λI)
(una recta). Este espacio es invariante por f : En efecto, si cogemos un vector de Im(f −λI), que esde la forma (f − λI)v, la imagen por f de este vector es de la misma forma:
f((f − λI)v) = f(f(v)− λv) = f(f(v))− λf(v) = (f − λI)(f(v))
Entonces, si w es un generador de Im(f − λI), el vector f(w), o es cero, o es otro generador deIm(f − λI). En los dos casos, f(w) es un multiplo de w, por tanto w 6= 0 es un vector propio de f(que ha de serlo para el valor propio λ).
Sea v un vector de R2, entonces, (f − λI)v ∈ Im(f − λI). Si (f − λI)v 6= 0, (f − λI)v = w esun generador de Im(f − λI) y por ello un vector propio de f segun lo expuesto previamente. Tal vexiste porque dimIm(f − λI) = 1.
Los vectores w, v (donde w 6= 0) son independientes porque uno es vector propio y el otro no.Mas explıcitamente, se da la implicacion:
α1w + α2v = 0⇒ α1 = 0 = α2
En efecto,
α1w+α2v = 0⇒ 0 = (f−λI)(α1w+α2v) = α1(f−λI)w+α2(f−λI)v = α2(f−λI)v = α2w ⇒ α2 = 0
de donde, sustituyendo en la combinacion lineal inicial dada, obtenemos α1w = 0, lo cual implicatambien α1 = 0.
Los vectores v, w forman por tanto una base de R2. Como f(w) = λw y f(v) = w + λvconcluimos que f se expresa en esta base por la matriz J y que por tanto A es equivalente a J.
La base w, v es una base de Jordan que se ha obtenido a partir de un v /∈ ker(f−λI) y hallandow = (f−λI)v. (Se puede escoger el vector v a simple vista, cuidando de que (A−λI)v 6= 0). Tambien,como los vectores columna de A−λI) son los vectores que engendran Im(f−λI), cualquier columnano nula de A− λI es un vector w = (f − λI)v donde v pertenece a la base canonica.
337

Ejercicios:
10.2.1. Comprobar que las matrices dadas a continuacion no son diagonalizables y hallar su formade Jordan y una base de Jordan para cada una de ellas.
a)
(0 1−1 2
)b)
(3 1−1 1
)c)
(5 −14 1
)d)
(4 1−1 2
)e)
(3 −41 −1
)f)
(2 1−1 0
)10.2.2. Demostrar que (
a 10 a
)n=
(an nan−1
0 an
)10.2.3. Hallar la potencia quinta de cada una de las matrices del ejercicio 10.2.1.10.2.4. En un bosque hay una poblacion de depredadores y otra poblacion de presas devoradas
por ellos. Cada medio ano la poblacion de presas es devorada en una proporcion de 20 por cientorespecto a la poblacion de depredadores, se reproduce en una proporcion respecto a su poblacionexistente igual a la proporcion en la que muere por enfermedades. Los depredadores se reproducenen una proporcion de 80 por ciento respecto a la poblacion de presas y en una proporcion de 10por ciento respecto a la proporcion de su poblacion existente, muriendo tambien por enfermedadesen una proporcion de un 90 por ciento respecto a su poblacion. Si al principio hay una relacion depresas a depredadores de 3 a 1. ¿Cual es esta relacion al cabo de 5 anos?
338

Forma de Jordan de Matrices 3× 3 de numeros reales.
Sea A ∈M3×3(R). Entonces, los casos que se pueden presentar son:1) A tiene algun valor propio complejo no real. En este caso, como la matriz es de numeros reales,
el polinomio caracterıstico tiene todos los coeficientes reales y sus raices complejas aparecen porparejas conjugadas, tambien es valor propio de A el conjugado del valor propio complejo consideradoy como el polinomio caracterıstico es de grado impar, A tiene al menos un valor propio real. Entonces,todos los valores propios de A son distintos, aunque no reales, siendo A diagonalizable en C pero noen R)
2) Todos los valores propios de A son distintos y reales. (En este caso, A es diagonalizable en R).3) Todos los valores propios son iguales. Con los siguientes subcasos:3a) dimker(f − λI) = 3, (es diagonalizable).3b) dimker(f − λI) = 2, (no es diagonalizable).3c) dimker(f − λI) = 1, (no es diagonalizable).4) Hay solo dos valores propios distintos; sean estos λ1 simple y λ2, doble. Con los siguientes
subcasos:4a) dimker(f − λ2I) = 2, (es diagonalizable).4b) dimker(f − λ2I) = 1, (no es diagonalizable).
Las formas de Jordan no diagonales corresponden a los casos 1), 3b), 3c) y 4b)Caso 1.)Sea A ∈ M3×3(R), y α + iβ un valor propio complejo de A. Entonces A no es diagonalizable en
R pero sı es diagonalizable en C, siendo A equivalente en R a una matriz J:
J =
λ 0 00 α β0 −β α
donde λ es el valor propio real de A.
En efecto, sean α+ iβ, α− iβ, los valores propios complejos, y w = u+ iv, w = u− iv, los vectorespropios correspondientes. Si v1 es el vector propio correspondiente al valor propio real λ, la basev1, w, w diagonaliza al endomorfismo correspondiente de C3 pero tiene dos vectores complejos y lamatriz de cambio de base tiene numeros complejos. Sin embargo, puede verse igual que en el caso 2de matrices 2× 2 de numeros reales, que en la base v1, u, v de C3 y de R3, f se expresa por λ 0 0
0 α β0 −β α
= J,
339

de numeros reales.Es la forma de Jordan real del endomorfismo, o de la matriz, cuando hay dos valores propios
complejos conjugados.
EJEMPLO 1:Consideremos el endomorfismo f de R3 dado por la matriz:
A :
−1 −1 2−1 −2 1−1 −3 2
Vamos a ver que no es diagonalizable en R pero si es diagonalizable en C y hallaremos su forma
de Jordan real y la correspondiente base de Jordan real.Su polinomio caracterıstico es
|A− λI| =
∣∣∣∣∣∣−1− λ −1 2−1 −2− λ 1−1 −3 2− λ
∣∣∣∣∣∣ = (1− λ)(λ2 + 2λ+ 2).
Las raices de este polinomio son λ1 = 1, λ2 = −1 + i y λ3 = −1 − i. Como solo hay un valorpropio real, solo hay un vector propio de R3. Al no poder encontrar una base de vectores propiosde R3, este endomorfismo no es diagonalizable en R3. Sin embargo, considerando el endomorfismof de C3 con la misma matriz, podemos tener en cuenta los valores propios complejos, que son tresdistintos a los que corresponden tres vectores propios distintos con coordenadas reales o complejas.
Para λ1 = 1 tenemos:
ker(f − I) ≡
−2 −1 2−1 −3 1−1 −3 1
xyz
=
000
= 0 ≡−2x −y +2z = 0−x −3y +z = 0−x −3y +z = 0
cuyas soluciones son los vectores multiplos de (1, 0, 1).
Para λ2 = −1 + i tenemos:
ker(f−(−1+i)I) ≡
−i −1 2−1 −1− i 1−1 −3 3− i
z1
z2
z3
=
000
= 0 ≡−iz1 − z2 + 2z3 = 0−z1 − (1 + i)z2 + z3 = 0−z1 − 3z2 + (3− i)z3 = 0
cuyas soluciones son los vectores multiplos complejos de (1, i, i).
Al valor propio λ3 = −1−i le corresponden los vectores propios conjugados de los vectores propioscorrespondientes a λ2, es decir, los vectores propios multiplos de (1,−i,−i).
340

El endomorfismo f de C3 se expresa por
D :
1 0 00 −1 + i 00 0 −1− i
en la base de vectores complejos: (1, 0, 1), (1, i, i), (1,−i,−i).
Si queremos una base de vectores reales en la que f se exprese de la manera mas facil posiblepodemos descomponer el vector (1, i, i) = (1, 0, 0) + i(0, 1, 1), teniendose
f(1, 0, 0) = (−1)(1, 0, 0)− (0, 1, 1) y f(0, 1, 1) = (1, 0, 0) + (−1)(0, 1, 1); el endomorfismo f de R3
se expresa en la base de vectores reales: (1, 0, 1), (1, 0, 0), (0, 1, 1) por
J :
1 0 00 −1 10 −1 −1
Ejercicios.
10.3.1. Hallar la forma de Jordan real y la base de Jordan real de las siguientes matrices:
a)
1 0 1−1 0 1−1 −2 3
b)
3 4 −2−4 −5 4−4 −6 5
c)
1 4 −2−2 −1 2−2 0 1
10.3.2. Escribir las matrices de las rotaciones en R3 alrededor de cada eje coordenado de angulos
π/4, π/3 y π/6 y comprobar que son formas de Jordan reales.10.3.3. Hallar la forma de Jordan real de la siguiente matriz:
0 0 −1 10 0 0 −11 1 0 00 1 0 0
341

Para los otros casos no diagonalizables, tenemos elTeorema 2.
Sea A ∈M3×3(R), no diagonalizable en C, entonces A es equivalente en R a una matriz J, siendo
J =
λ 1 00 λ 10 0 λ
o J =
λ1 0 00 λ2 10 0 λ2
donde λ, λ1 y λ2 son valores propios reales de A, pudiendo ser λ1 = λ2.
Las bases en las que f se expresa por J se llaman bases de Jordan de f o de A.
Supuesto demostrado el teorema y conocidos los valores propios de A, podemos decidir cual es laforma de Jordan que le corresponde de la siguiente manera:
A la matriz A corresponde la matriz J =
λ1 0 00 λ2 10 0 λ2
, solo si estamos en el caso 4b), es
decir, si A tiene dos valores propios distintos y la multiplicidad geometrica del valor propio doble es1.
Si la matriz tiene un solo valor propio, le puede corresponder
J =
λ 1 00 λ 10 0 λ
o J =
λ 0 00 λ 10 0 λ
;
se distinguen una de la otra calculando dimker(f − λI), que no depende de la matriz de f usada,siendo dimker(f − λI) = 1 para la primera de ellas y dimker(f − λI) = 2 para la segunda.
Demostracion del teorema:a). Caso en el que A tiene un solo valor propio λ.
Sea f el endomorfismo de R3 expresado por A en la base canonica. Entonces, por ser A nodiagonalizable, dimker(f − λI) < 3, teniendose dos subcasos:
3 b) dimker(f − λI) = 2 y3 c) dimker(f − λI) = 1.
3 b) Si dimker(f−λI) = 2, tenemos dimIm(f−λI) = 1. Entonces, el subespacio Im(f−λI) esuna recta invariante por f , (puede comprobarse como en el teorema 1), por ello, un generador suyo
342

w es un vector propio de f . Este generador es de la forma (f − λI)v = w 6= 0, siendo v y w vectoresindependientes. Como dim ker(f − λI) = 2, existe otro vector propio v1 independiente de w.
Los tres vectores v1, w, v son independientes y por tanto forman una base de R3:Se da la implicacion:
α1v1 + α2w + α3v = 0⇒ α1 = α2 = α3 = 0
En efecto, analogamente a como hemos hecho en el caso 2× 2,
α1v1 + α2w + α3v = 0⇒ 0 = (f − λI)(α1v1 + α2w + α3v) = α3w ⇒ α3 = 0
Sustituyendo ahora en la combinacion lineal dada, tenemos α1v1 + α2w = 0 donde los vectoresson independientes, (por la eleccion de v1), por lo que tambien se tiene α1 = α2 = 0.
Esta base es una base de Jordan porque la matriz de f en esta base es
λ 0 00 λ 10 0 λ
Para
encontrar una base de Jordan, podemos darnos cuenta de que si A es la matriz de f en la basecanonica, los vectores columna de la matriz A− λI son vectores del subespacio Im(f − λI), siendopor tanto, las columnas no nulas, vectores propios w, que a su vez son imagen por f −λI de vectoresv de la base canonica. Completando con v1 vector propio de f independiente de w tenemos una basede Jordan.
Podemos hallar mas bases de Jordan encontrando el vector v tal que (f − λI)v 6= 0, (que nosatisfaga las ecuaciones de ker(f − λI)), hallar w = (f − λI)v y completando con v1 vector propiode f independiente de w.
EJEMPLO 2:Consideremos el endomorfismo f de R3 dado por la matriz:
A =
−5 2 2−1 −2 1−1 1 −2
Veamos que no es diagonalizable y hallemos su forma de Jordan y una base de Jordan:
El polinomio caracterıstico es
|A− λI| =
∣∣∣∣∣∣−5− λ 2 2−1 −2− λ 1−1 1 −2− λ
∣∣∣∣∣∣ = −(λ+ 3)3
De aquı que el unico valor propio de f (o de A) sea λ1 = −3.
343

Como
ker(f + 3I) ≡
−2 2 2−1 1 1−1 1 1
xyz
=
000
≡ −x+ y + z = 0
la dimension de ker(f + 3I) = 2 6= 3 siendo por tanto f no diagonalizable y estando en el caso 3b).Como dim(Im(f + 3I)) = 1 y el subespacio Im(f + 3I) es invariante por f , cualquier vector w
distinto de cero de este espacio es un vector propio de f . Uno de tales vectores es la primera columnade A+ 3I, que es (f + 3I)(1, 0, 0) ya que −2 2 2
−1 1 1−1 1 1
100
=
−2−1−1
6= 0
siendo (−2,−1,−1) un vector propio w.Como la dimension del subespacio de vectores propios es 2, podemos encontrar otro vector propio
v1 independiente de w, que tambien lo sera de v. Puede ser v1 = (1, 1, 0).Ası tenemos una base de Jordan: (1, 1, 0), (−2,−1,−1), (1, 0, 0) en la que f se expresa por
J =
−3 0 00 −3 10 0 −3
.
El vector w se puede tambien obtener haciendo la imagen por f + 3I de cualquier vector v talque (f + 3I)v 6= 0. Este vector v se ha de obtener de manera que no satisfaga las ecuaciones deker(f + 3I) o por tanteo, de forma que (A + 3I)v 6= 0 pudiendo ser en este caso v = (1, 0, 0) yteniendo la misma base anterior. Pero otra base se puede obtener para v = (1, 2, 0), siendo entoncesw = (2, 1, 1).
El cambio de base da lugar a la equivalencia entre A y la forma de Jordan J : 1 −2 11 −1 00 −1 0
−1 −5 2 2−1 −2 1−1 1 −2
1 −2 11 −1 00 −1 0
=
−3 0 00 −3 10 0 −3
.
Ejercicios:
10.4.1. Comprobar que las matrices dadas a continuacion no son diagonalizables y hallar su formade Jordan y una base de Jordan para cada una de ellas.
344

a)
2 −1 10 1 0−1 1 0
b)
1 2 −20 2 −10 1 0
c)
−1 0 −1−1 0 −1
1 0 1
d)
1 2 −34 8 −123 6 −9
e)
−2 0 10 −1 0−1 0 0
f)
2 −2 12 −3 23 −6 4
10.4.2. Hallar la potencia quinceava de cada una de las matrices del ejercicio 10.4.1.
345

3c) Si dim ker(f − λI) = 1, suponiendo demostrado que dim ker(f − λI)2 = 2 y por tantodimIm(f−λI)2 = 1, vamos a encontrar la forma de Jordan y la base de Jordan y luego demostraremosese hecho; se puede ver que Im(f − λI)2 es un subespacio invariante por f de la misma forma quehemos visto que Im(f −λI) lo es en los casos anteriores; es una recta y entonces, un generador w deeste subespacio es un vector propio, que a su vez es w = (f − λI)2v, w 6= 0. Comprobaremos que losvectores (f −λI)2v, (f −λI)v, v son una base de Jordan porque son independientes y la matriz def en esta base es:
J =
λ 1 00 λ 10 0 λ
por lo que esos vectores forman una base de Jordan de f .
Para encontrar la base de Jordan indicada en este caso, vemos que si A es la matriz de f en la basecanonica, cualquier vector distinto de cero de (A−λI)2 es un vector propio w, imagen por (f −λI)2
del vector correspondiente de la base canonica. Teniendo ası directamente la base w, (f − λI)v, v.Podemos hallar mas bases de Jordan buscando un v /∈ ker(f − λI)2 y hallando los vectores
(f − λI)v, (f − λI)2v.
Comprobemos que (f − λI)2v, (f − λI)v, v son vectores independientes:Veremos que se da la implicacion:
α1w + α2(f − λI)v + α3v = 0⇒ α1 = α2 = α3 = 0.
Para ello, observemos que 0 = (f − λI)w = (f − λI)3v y tambien 0 = (f − λI)4v.Ahora vemos:
0 = α1w + α2(f − λI)v + α3v = α1(f − λI)2v + α2(f − λI)v + α3v ⇒
0 = (f − λI)2(α1(f − λI)2v + α2(f − λI)v + α3v) = α3w ⇒ α3 = 0
Entonces, la combinacion lineal inicial es: α1w + α2(f − λI)v = 0, que implica(f − λI)(α1w + α2(f − λI)v) = 0 ⇒ α2w = 0, lo que da α2 = 0. Volviendo a la primera
combinacion lineal considerada, sacamos tambien α1 = 0.Demostremos ahora que dimIm(f − λI)2 = 1:El espacio Im(f −λI), que es de dimension 2, es invariante por f . Los valores propios y vectores
propios de la restriccion de f a Im(f − λI) lo son tambien de f y por tanto de f , que no esdiagonalizable. Entonces, f |Im(f−λI) tiene un unico valor propio real que tiene que coincidir conλ y un vector propio u. Solo puede haber un vector propio independiente en Im(f − λI) por serdimker(f − λI) = 1, entonces, por la formula de las dimensiones para la restriccion de f − λI a
346

Im(f−λI), tenemos dimIm(f−λI) = dimker(f−λI)+dimIm(f−λI)2, de donde dimIm(f−λI)2 =1.
Otra forma de demostrar lo mismo serıa viendo que dimker(f − λI)2 = 2:El espacio Im(f −λI), que es de dimension 2, es invariante por f . Los valores propios y vectores
propios de la restriccion de f a Im(f − λI) lo son tambien de f y por tanto de f , que no esdiagonalizable. Entonces, f |Im(f−λI) tiene un unico valor propio real que tiene que coincidir con λy un vector propio de la forma u = (f − λI)u′. Por tanto, u′ ∈ ker(f − λI)2. Como u′ no esta enker(f − λI) y ker(f − λI) ⊂ ker(f − λI)2, deducimos que dim ker(f − λI)2 ≥ 2.
Para ver que dimker(f − λI)2 < 3, consideremos que si fuera dimker(f − λI)2 = 3, serıaker(f − λI)2 = R3, es decir, (f − λI)2(R3) = 0, siendo entonces (f − λI)[(f − λI)(R3)] = 0, conlo que ker(f − λI) contendrıa a Im(f − λI), lo cual es imposible, porque hemos supuesto que elprimero es de dimension 1, con lo cual el segundo es de dimension 2. Con esto queda terminada lademostracion.
EJEMPLO 3:Consideremos el endomorfismo f de R3 dado por la matriz:
A =
−1 1 −1−1 0 0
0 1 −2
Veamos que no es diagonalizable y hallemos su forma de Jordan y una base de Jordan.
El polinomio caracterıstico es
|A− λI| =
∣∣∣∣∣∣−1− λ 1 −1−1 −λ 0
0 1 −2− λ
∣∣∣∣∣∣ = −(λ+ 1)3
De aquı que el unico valor propio de f (o de A) sea λ1 = −1.Como
ker(f + I) ≡
0 1 −1−1 1 0
0 1 −1
xyz
=
000
≡ y −z = 0−x +y = 0
y −z = 0
la dimension de ker(f + I) = 1 6= 3 siendo por tanto f no diagonalizable y estando en el caso 3c) ysiendo por tanto su forma de Jordan:
J =
−1 1 00 −1 10 0 −1
.
347

Como dim(Im(f + I)) = 2, segun se ha demostrado anteriormente, dim(Im(f + I)2) = 1 y alser este espacio invariante por f , cualquier vector distinto de cero w ∈ Im(f + I)2 es un vectorpropio. Los vectores columna distintos de cero de (A+ I)2 son este tipo de vectores, pudiendo cogerw = (−1,−1,−1) = (f + I)2(1, 0, 0) 0 1 −1
−1 1 00 1 −1
2 100
=
−1 0 1−1 0 1−1 0 1
100
=
−1−1−1
6= 0
que es vector propio.El vector intermedio es 0 1 −1
−1 1 00 1 −1
100
=
0−1
0
Ası tenemos una base: (−1,−1,−1), (0,−1, 0), (1, 0, 0) que es una base de Jordan porque f se
expresa en ella por J . El cambio de base que da lugar a la equivalencia entre A y la forma de JordanJ es: −1 0 1
−1 −1 0−1 0 0
−1 −1 1 −1−1 0 0
0 1 −2
−1 0 1−1 −1 0−1 0 0
=
−1 1 00 −1 10 0 −1
.
El vector w se puede obtener tambien haciendo la imagen por (f + I)2 de un vector v tal que(f+I)2v 6= 0. Este vector v se ha de obtener de manera que no satisfaga las ecuaciones de ker(f+I)2
o por tanteo, de forma que (A + I)2v 6= 0 pudiendo ser en este caso tambien v = (1, 0, 2) en cuyocaso, w = (1, 1, 1) y el vector intermedio es (−2,−1,−2).
Ejercicios:
10.5.1. Comprobar que las matrices dadas a continuacion no son diagonalizables y hallar su formade Jordan y una base de Jordan para cada una de ellas.
a)
−1 −1 −21 2 11 0 2
b)
−2 1 −1−1 −1 0
0 1 −3
c)
2 −1 30 2 10 0 2
d)
4 −1 −21 −1 11 0 −1
e)
1 −1 −11 −2 02 −1 −2
f)
6 −2 47 −2 61 −1 2
10.5.2. Demostrar que
348

a 1 00 a 10 0 a
n
=
an nan−1 n(n−1)2
an−2
0 an nan−1
0 0 an
10.5.3. Hallar la potencia quinceava de cada una de las matrices del ejercicio 10.5.1.
b) 4b). La matriz A tiene dos valores propios distintos λ1 y λ2, siendo 2 la multiplicidad algebraicade λ2 y dimker(f − λ2I) = 1
Entonces, f es no diagonalizable y dim ker(f −λ2I) = 1⇒ dim Im(f −λ2I) = 2. El subespacioIm(f −λ2I) es invariante por f , lo cual se comprueba de la misma forma que en el teorema 1. Tienesentido por ello hablar de la restriccion f |Im(f−λ2I), de f a Im(f − λ2I), cuyos valores propios yvectores propios lo son tambien de f .
Si λ2 no fuera valor propio de f |Im(f−λ2I), serıa ker(f − λ2I)∩ Im(f − λ2I) = 0. Debido a susdimensiones, serıa tambien, ker(f − λ2I)⊕ Im(f − λ2I) = R3.
En una base u1, u2, u3 donde fuera u1 ∈ ker(f − λ2I) y u2, u3 ⊂ Im(f − λ2I), por ser esteultimo espacio invariante, f se expresarıa por una matriz del tipo:
B =
λ2 0 00 c d0 m n
donde la matriz (
c dm n
)serıa la matriz de la restriccion f |Im(f−λ2I), en la base u2, u3 que no tendrıa λ2 como valor propio.
Tendrıamos:
|B − λI| = (λ2 − λ)
∣∣∣∣( c dm n
)− λI
∣∣∣∣Como el polinomio caracterıstico de f es independiente de la base escogida, el valor propio λ2
serıa solo valor propio simple de f , en contra de lo supuesto.Por tanto, ha de ser ker(f − λ2I) ∩ Im(f − λ2I) 6= 0.Si 0 6= w ∈ ker(f − λ2I) ∩ Im(f − λ2I), se tiene: (f − λ2I)w = 0, siendo w = (f − λ2I)v para
algun v. Los vectores w, v son independientes porque uno de ellos es vector propio para λ2 y elotro no. Junto a un vector v1 propio para λ1, forman una base de R3 en la que f se expresa por
J =
λ1 0 00 λ2 10 0 λ2
.
349

Por ello, v1, w, v forman una base de Jordan de f o de A.
Comprobemos explıcitamente que los vectores v1, w, v son independientes (v1 y w son indepen-dientes por ser vectores propios correspondientes a valores propios distintos):
α1v1 + α2w + α3v = 0⇒ (f − λ2I)(α1v1 + α2w + α3v) = 0⇒
α1(f − λ2I)v1 + α2(f − λ2I)w + α3(f − λ2I)v) = 0⇒ α1(λ1 − λ2)v1 + α3w = 0⇒ α1 = α3 = 0
Entonces la combinacion lineal considerada se transforma en α2w = 0, que implica α2 = 0.
Cualquier vector v ∈ ker(f−λ2I)2−ker(f−λ2I) es valido para encontrar w. Estos v existen porlos razonamientos anteriores. Son los vectores v de ker(f −λ2I)2 que no satisfacen las ecuaciones deker(f − λ2I) o alternativamente que verifican (f − λ2I)v 6= 0.
Tambien se puede recurrir a las matrices (A−λ2I)2 y A−λ2I: llamando c1, c2, c3 a las columnasde A − λ2I un vector propio w de Im(f − λI) es de la forma w = α1c1 + α2c2 + α3c3 6= 0, siendo(A − λ2I)(α1c1 + α2c2 + α3c3) = 0, por lo que llamando d1, d2, d3 a las columnas de (A − λ2I)2, yencontrados α1, α2, α3, tales que α1d1 + α2d2 + α3d3 = 0, y w = α1c1 + α2c2 + α3c3 6= 0, tenemos wy v = α1e1 + α2e2 + α3e3 = (α1, α2, α3), donde e1, e2, e3 son los vectores de la base canonica.
A la hora de encontrar una base de Jordan de f , en este caso, tenemos que anadir a los vectoresw = (f − λ2I)v, v anteriores el vector propio v1 para λ1.
EJEMPLO 4:Consideremos el endomorfismo f de R3 dado por la matriz
A =
1 0 −11 −1 −1−2 3 2
Veamos que no es diagonalizable y hallemos su forma de Jordan y una base de Jordan.
Tiene como polinomio caracterıstico |A−λI| = λ2(−λ+2); por tanto tiene un valor propio simpleλ1 = 2, y otro valor propio doble λ2 = 0.
Por otra parte, dim(ker(A− 0I) = dim(ker(A)) = 3− rango(A) = 3− 2 = 1, lo cual implica queno es diagonalizable. Por la teorıa demostrada en este caso, su forma de Jordan es:
J =
2 0 00 0 10 0 0
350

Para encontrar la base de Jordan buscamos v ∈ ker(f − 0I)2 − ker(f − 0I) = kerf 2 − kerf .Como
A2 =
1 0 −11 −1 −1−2 3 2
2
=
3 −3 −32 −2 −2−3 3 3
la ecuacion de ker(f 2) es x− y − z = 0 y las ecuaciones de ker(f) son x− z = 0, x− y − z = 0. Unv posible que satisface la primera pero no las dos segundas es v = (2, 1, 1). El vector w = Av que seobtiene es w = (1, 0, 1), que esta en ker(f) siendo por tanto vector propio para el valor propio 0.
Alternativamente, se puede comprobar si un vector v que satisfaga las ecuaciones de ker(f 2) noesta en ker(f) viendo si Av 6= 0.
Para completar la base de Jordan nos falta un vector propio v1 para el valor propio λ1 = 2, queha de verificar (A− 2I)v1 = 0, es decir, las ecuaciones: −1 0 −1
1 −3 −1−2 3 0
xyz
=
000
≡ −x −z = 0−2x +3y = 0
Puede ser el vector v1 = (3, 2,−3).
Entonces una base de Jordan para la forma de Jordan obtenida es (3, 2,−3), (1, 0, 1), (2, 1, 1),siendo 3 1 2
2 0 1−3 1 1
−1 1 0 −11 −1 −1−2 3 2
3 1 22 0 1−3 1 1
=
2 0 00 0 10 0 0
.
Por el otro metodo, poniendo los coeficientes 0, 1,−1 a las columnas de A2, obtenemos el vectornulo y poniendo los mismos coeficientes a las columnas de A, obtenemos el vector w = (1, 0, 1) =f(0, 1,−1). Por lo que otra base de Jordan es: (3, 2,−3), (1, 0, 1), (0, 1,−1)
Acabada la obtencion de la forma de Jordan y de la base de Jordan de la matriz vamos a hacerla aplicacion a obtener la potencia quinta de A:
A5 =
1 0 −11 −1 −1−2 3 2
5
=
3 1 22 0 1−3 1 1
2 0 00 0 10 0 0
5 3 1 22 0 1−3 1 1
−1
=
351

3 1 22 0 1−3 1 1
2 0 00 0 00 0 0
1
4
1 −1 −15 −9 −1−2 6 2
=
3 1 22 0 1−3 1 1
1
4
25 −25 −25
0 0 00 0 0
=
1
4
3 · 25 −3 · 25 −3 · 25
2 · 25 −2 · 25 −2 · 25
−3 · 25 3 · 25 3 · 25
= 23
3 −3 −32 −2 −2−3 3 3
Ejercicios:
10.6.1. Comprobar que las matrices dadas a continuacion no son diagonalizables y hallar su formade Jordan y una base de Jordan para cada una de ellas.
a)
1 −1 30 2 10 0 2
b)
0 3 12 −1 −1−2 −1 −1
c)
1 0 −11 −1 −1−2 3 2
d)
0 0 −11 −2 −1−2 3 1
e)
2 0 0−1 1 15
3 0 1
2 −5 11 −1 −23 −3 −2
10.6.2. Hallar la potencia quinta de cada una de las matrices del ejercicio 5.1.
10.6.3. Estudiar, segun los valores de los parametros a y b, la forma de Jordan de las matricesdadas a continuacion cuando no son diagonalizables.
a)
−1 0 b0 1 00 0 a
b)
1 −1 00 a 0a 1 a
c)
1 2 b0 a 01 0 b
10.6.4. Suponiendo que A es una matriz 3× 3 de numeros reales y conocida su forma de Jordan,
hallar la forma de Jordan de −A en todos los casos.10.6.5. Suponiendo que A es una matriz 3× 3 de numeros reales y conocida su forma de Jordan,
hallar la forma de Jordan de kA en todos los casos.10.6.6. Suponiendo que A es una matriz 3× 3 de numeros reales invertible y conocida su forma
de Jordan, hallar la forma de Jordan de A− kI en todos los casos.
10.6.7. Suponiendo que A es una matriz 3× 3 de numeros reales invertible y conocida su formade Jordan, hallar la forma de Jordan de A−1 en todos los casos.
10.6.8. Suponiendo que A es una matriz 3× 3 de numeros reales y conocida su forma de Jordan,hallar la forma de Jordan de At en todos los casos.
352

10.6.9.a) Hallar la matriz de jordan de Jm para m > 0, de la matriz de jordan de un endomorfismo f
de R3 en todos los casos posibles.b) Hallar la matriz de jordan de fm, cualquiera que sea m, conocida la matriz de jordan de f ,
donde f es un isomorfismo de R3, en todos los casos posibles.10.6.10. Demostrar que si f es un endomorfismo de Rn con dos valores propios distintos λ1 y λ2
y (f − λ1I)(f − λ2I) = 0, f es diagonalizable.10.6.11.a) Comprobar que si f es un endomorfismo de R3 con un unico valor propio real λ, se deduce del
teorema general de Jordan, que (f − λI)3 = 0b) Observar que si f es un endomorfismo de R3 con un unico valor propio real λ y (f −λI)2 = 0,
f admite una forma de Jordan con cajas de Jordan de orden 2 y 1.
353

Resumen de la Diagonalizacion y forma de Jordan de endomorfismos deR3 sin valores propios complejos.
Los casos que se presentan en endomorfismos de C3 (donde los valores propios pueden ser realeso complejos) son los mismos.
Denotamos por f un endomorfismo de matriz A , por λ1, λ2, λ3 sus valores propios, por B su basede Jordan e identificamos ker(f − λI) con ker(A− λI).
1.λ1 6= λ2 6= λ3 6= λ1 f es diagonalizable, J =
λ1 0 00 λ2 00 0 λ3
,
B = v1, v2, v3 donde para cada i, vi ∈ ker(A− λiI)
2.λ1 6= λ2 = λ3
a)dimker(A− λ2I) = 2 f es diagonalizable J =
λ1 0 00 λ2 00 0 λ2
B = v1, v2, v3 donde para cada i, vi ∈ ker(A− λiI)
b)dimker(A− λ2I) = 1 f no es diagonalizable J =
λ1 0 00 λ2 10 0 λ2
B = v1, w, v, donde
v1 ∈ ker(A− λ1I) v ∈ ker(A− λ2I)2 − ker(A− λ2I) w = ker(A− λ2I)v
3.λ1 = λ2 = λ3
a)dimker(A− λ1I) = 3 f es diagonalizable
A = C−1
λ1 0 00 λ1 00 0 λ1
C =
λ1 0 00 λ1 00 0 λ1
B cualquiera
b)dimker(A− λ1I) = 2 f no es diagonalizable J =
λ1 0 00 λ1 10 0 λ1
B = v1, w, v, donde v /∈ ker(A− λ1I), w = ker(A− λ1I)v, v1 ∈ ker(A− λ1I)
independiente de ww puede ser una columna no nula de A− λ1I, v la columna de I tal que w = (A− λ1I)v
c)dimker(A− λ1I) = 1 f no es diagonalizable J =
λ1 1 00 λ1 10 0 λ1
B = (A− λ1I)2v, (A− λ1I)v, v, donde v /∈ ker(A− λ1I)2
w puede ser una columna no nula de (A− λ1I)2, v la columna de I tal que w = (A− λ1I)2v.
354

Forma de Jordan compleja de Matrices 4× 4 de numeros complejos.
Aquı se estudian las formas de Jordan de matrices 4× 4 en los casos no diagonalizables en C.Sea A ∈ M4×4(R) con valores propios reales o complejos. La forma de Jordan compleja es una
suma diagonal de cajas de Jordan corespodientes a los valores propios. Si estos valores propios sonreales, la forma de Jordan es real.
Los casos que se pueden presentar son:1) Todos los valores propios de A son distintos. (En este caso, A es diagonalizable).2) Todos los valores propios son iguales. Con los siguientes subcasos:2a) dimker(f − λI) = 4, (es diagonalizable).2b) dimker(f − λI) = 3, (no es diagonalizable).2c) dimker(f − λI) = 2, (no es diagonalizable).2d) dimker(f − λI) = 1, (no es diagonalizable).3) Hay solo dos valores propios distintos;3’) Sean estos λ1 simple y λ2 triple. Con los siguientes subcasos:3’a) dimker(f − λ2I) = 3, (es diagonalizable).3’b) dimker(f − λ2I) = 2, (no es diagonalizable).3’c) dimker(f − λ2I) = 1, (no es diagonalizable).3”) Sean estos λ1 doble y λ2, doble. Con los siguientes subcasos:3”a) dimker(f − λ1I) = 2 = dimker(f − λ2I), (es diagonalizable).3”b) dimker(f − λ1I) = 2, dimker(f − λ2I) = 1 (no es diagonalizable).3”c) dimker(f − λ1I) = 1, dimker(f − λ2I) = 1 (no es diagonalizable).4) Hay exactamente tres valores propios distintos; Sean estos λ1 simple, λ2 simple y λ3 doble, con
los subcasos:4a) dimker(f − λ3I) = 2, (es diagonalizable).4b) dimker(f − λ3I) = 1, (no es diagonalizable).
Estudiemos las formas de Jordan en los casos no diagonalizables.2b) dimker(f − λI) = 3, (no es diagonalizable).Entonces dimIm(f − λI) = 1, por lo que el subespacio Im(f − λI) es una recta invariante y
cualquier generador suyo w es un vector propio para el valor propio λ. Este generador es de la formaw = (f−λI)v; como dimker(f−λI) = 3, existen dos vectores propios v1, v2 distintos de forma quev1, v2, w son independientes. Entonces, v1, v2, w, v son una base de Jordan de f para la forma
355

de Jordan:
J =
λ 0 0 00 λ 0 00 0 λ 10 0 0 λ
.
Puede comprobarse por los metodos usados para las matrices 3 × 3 que los vectores anterioresson independientes y que la matriz de f en esa base es J.
2c) dimker(f − λI) = 2, (no es diagonalizable).Entonces dimIm(f − λI) = 2; de nuevo pueden aparecer dos subcasos.2c1) Im(f − λI) = ker(f − λI),2c2) Im(f − λI) 6= ker(f − λI),En el caso 2c1, los dos generadores w1, w2 de Im(f−λI) son vectores independientes de la forma
w1 = (f − λI)v1, w2 = (f − λI)v2. Se comprueba por los metodos anteriores que w1, v1, w2, v2son una base de Jordan de f para la forma de Jordan:
J =
λ 1 0 00 λ 0 00 0 λ 10 0 0 λ
.
En el caso 2c2), al ser el subespacio Im(f − λI) invariante de f y los valores propios (reales ocomplejos) de la restriccion de f a este subespacio, valores propios de f , λ es valor propio de dicharestriccion, por lo que dim(Im(f − λI)
⋂ker(f − λI)) = 1, luego dim((f − λI)(Im(f − λI))) =
dim(Im(f − λI)2)) = 1.Al ser (Im(f − λI)2)) una recta invariante, un generador suyo sera w = ((f − λI)2)v, existiendo
otro vector propio w′ ∈ ker(f − λI) independiente de w. Los vectores w′, w, (f − λI)v, v son unabase de Jordan de f para
J =
λ 0 0 00 λ 1 00 0 λ 10 0 0 λ
.
lo cual puede comprobarse ya facilmente.
2d) dimker(f − λI) = 1, (no es diagonalizable).
356

Entonces, dimIm(f − λI) = 3; como Im(f − λI) es un subespacio invariante de f y los valorespropios (reales o complejos) de la restriccion de f a este subespacio son tambien valores propiosde f , se tiene ker(f − λI) ⊂ Im(f − λI) y dimIm(f − λI)2 = 2. Por el mismo procedimiento sedemuestra que dimIm(f − λI)3 = 1. Al ser Im(f − λI)3 una recta invariante, un generdor suyow = (f − λI)3v es un vector propio y se comprueba facilmente que w, (f − λI)2v, (f − λI)v, v esuna base de Jordan de f para
J =
λ 1 0 00 λ 1 00 0 λ 10 0 0 λ
.
Para los casos siguientes necsitamos el siguientelema:El polinomio caracterıstico de la restriccion de un endomorfismo f a un subespacio invariante
divide al polinomio caracterıstico de f .En efecto, si f es un endomorfismo de V y V1 es un subespacio de V invariante de f y A1 es la
matriz de la restriccion de f a V1, en una base B1 de V1, completando la base B1 de V1 a una baseB de V , la matriz de f en B es de la forma:(
A1 CO D
).
Al ser el polinomio caracterıstico independiente de la base utilizada para calcularlo, el polinomiocaracterıstico de f calculado de esta matriz es |A1 − λI||C − λI|, como querıamos demostrar.
Seguimos ahora con los distintos casos.
3’b) Hay solo dos valores propios distintos; sean estos λ1 simple y λ2 triple y dimker(f−λ2I) = 2.Entonces, dimIm(f − λ2I) = 2. El subespacio Im(f − λ2I) es invariante por f y contiene a
(λ1 − λ2)v1, donde v1 es el vector propio de f para λ1. El vector (λ1 − λ2)v1 es un vector propiopara λ1, y como λ1 es valor propio simple de f , y el polinomio caracterıstico de la restriccion de f aIm(f−λ2I) divide al polinomio caracterıstico de f , Im(f−λ2I) ha de contener otro vector propio wpara el valor propio λ2; este vector propio es de la forma w = (f −λ2I)v. Ademas, existe otro vectorpropio w′ de f para λ2 independiente de w, por ser dimker(f − λ2I) = 2. Se comprueba facilmente
357

que los vectores v1, w′, w, v son una base de Jordan de f para
J =
λ1 0 0 00 λ2 0 00 0 λ2 10 0 0 λ2
.
3’c) Hay solo dos valores propios distintos; sean estos λ1 simple y λ2 triple y dimker(f−λ2I) = 1.Entonces, dimIm(f − λ2I) = 3. El subespacio Im(f − λ2I) es invariante por f y contiene a
(λ1 − λ2)v1, donde v1 es el vector propio de f para λ1. El vector (λ1 − λ2)v1 es un vector propiopara λ1, y como λ1 es valor propio simple de f , y el polinomio caracterıstico de la restriccion de f aIm(f−λ2I) divide al polinomio caracterıstico de f , ha de contener otro vector propio w para el valorpropio λ2; solo puede contener un vector propio independiente para λ2, por ser dimker(f −λ2I) = 1.Luego dimIm(f − λ2I)2 = 2, conteniendo este subespacio el vector (λ1 − λ2)
2v1, que es un vectorpropio para λ1. Aplicando al subespacio Im(f −λI)2 los mismos razonamientos anteriores, llegamosa que contiene un vector propio para λ2, que sera w = (f − λI)2v. Se puede comprobar que losvectores v1, w, (f − λI)v, v son una base de Jordan de f para
J =
λ1 0 0 00 λ2 1 00 0 λ2 10 0 0 λ2
.
3”b) Hay solo dos valores propios distintos; sean estos λ1 doble y λ2 doble y dimker(f−λ1I) = 2,dimker(f − λ2I) = 1.
Entonces, dimIm(f − λ2I) = 3. El subespacio Im(f − λ2I) es invariante por f y contiene a(λ1 − λ2)v1, (λ1 − λ2)v2, donde v1, v2 son vectores propios independientes de f para λ1. Comoel polinomio caracterıstico de la restricion de f a Im(f − λ2I) divide al polinomio caracterısticode f , debe existir un w = (f − λ2I)v, vector propio para v2. Puede comprobarse que los vectoresv1, v2, w, v son una base de Jordan de f para
J =
λ1 0 0 00 λ1 0 00 0 λ2 10 0 0 λ2
.
358

3”c) Hay solo dos valores propios distintos; sean estos λ1 doble y λ2 doble y dimker(f−λ1I) = 1,dimker(f − λ2I) = 1.
Entonces, dimIm(f − λ2I) = 3. El subespacio Im(f − λ2I) es invariante por f y contiene a(λ1−λ2)v1, donde v1 es vector propio independiente de f para λ1. Como el polinomio caracterısticode la restricion de f a Im(f − λ2I) divide al polinomio caracterıstico de f , debe existir un w2 =(f − λ2I)v2, vector propio para λ2.
De la misma forma existe un vector propio w1 = (f − λ1I)v1, vector propio para λ1.Puede comprobarse que los vectores w1, v1, w2, v2 son una base de Jordan de f para
J =
λ1 1 0 00 λ1 0 00 0 λ2 10 0 0 λ2
.
4b) Hay exactamente tres valores propios distintos; Sean estos λ1 simple, λ2 simple y λ3 doble, ydimker(f − λ3I) = 1.
Entonces, el subespacio Im(f − λ3I), invariante por f contiene al vector (λ1 − λ3)v1 que esun vector propio para λ1 y al vector (λ2 − λ3)v2 que es un vector propio para λ2, y como estosvalores propios son simples de f , y el subespacio es de dimension 3 y el polinomio caracterısticode la restriccion de f a Im(f − λ3I) divide al polinomio caracterıstico de f , ha de contener otrovector propio w para el valor propio λ3; este vector propio es de la forma w = (f − λ3I)v. Se puedecomprobar que los vectores v1, v2, w, v son una base de Jordan de f para
J =
λ1 0 0 00 λ2 0 00 0 λ3 10 0 0 λ3
.
359

Resumen de la Diagonalizacion y forma de Jordan de endomorfismos deR4 con valores propios reales o complejos.
Denotamos por f un endomorfismo de matriz A , por λ1, λ2, λ3, λ4 sus valores propios, por B subase de Jordan e identificamos ker(f − λI) con ker(A− λI).
1. Todos los autovalores son distintos. Entonces A es diagonalizable.
2.λ1 6= λ2 6= λ3 6= λ1, λ3 = λ4a)dimker(A− λ3I) = 2 f es diagonalizable
b)dimker(A− λ3I) = 1 f no es diagonalizable J =
λ1 0 0 00 λ2 0 00 0 λ3 10 0 0 λ3
3.λ1 = λ2 6= λ3 = λ4
a)dimker(A− λ1I) = 2 = dimker(A− λ3I) f es diagonalizable
b)dimker(A− λ2I) = 1, dimker(A− λ3I) = 2 f no es diagonalizable J =
λ1 1 00 λ1 0 00 0 λ3 00 0 0 λ3
c)dimker(A− λ2I) = 2, dimker(A− λ3I) = 1 f no es diagonalizable J =
λ1 0 00 λ1 0 00 0 λ3 10 0 0 λ3
d)dimker(A− λ2I) = 1, dimker(A− λ3I) = 1 f no es diagonalizable J =
λ1 1 00 λ1 0 00 0 λ3 10 0 0 λ3
Sigue en la pagina siguiente.
360

4.λ1 6= λ2 = λ3 = λ4
a)dimker(A− λ2I) = 3 f es diagonalizable.
b)dimker(A− λ2I) = 2 f no es diagonalizable, J =
λ1 0 0 00 λ2 0 00 0 λ2 10 0 0 λ2
c)dimker(A− λ2I) = 1 f no es diagonalizable, J =
λ1 0 0 00 λ2 1 00 0 λ2 10 0 0 λ2
5.λ1 = λ2 = λ3 = λ4
a)dimker(A− λ1I) = 4 f es diagonalizable.
b)dimker(A− λ1I) = 3 f no es diagonalizable, J =
λ1 0 0 00 λ1 0 00 0 λ1 10 0 0 λ1
c)dimker(A− λ1I) = 2 f no es diagonalizable, J =
λ1 0 0 00 λ1 1 00 0 λ1 10 0 0 λ1
d)dimker(A− λ1I) = 1 f no es diagonalizable, J =
λ1 1 0 00 λ1 1 00 0 λ1 10 0 0 λ1
361

Bibliografıa:
[C] M. Castellet, I Llerena. Algebra Lineal y Geometrıa. Ed. Reverte.[Co] L. Contreras. Una Observacion al hallar la base de Jordan de un Endomorfismo. XV
Jornadas Luso-Espanholas de Matematica. Universidade de Evora. 1990.[G] L. I. Golovina. Algebra Lineal y algunas de sus aplicaciones. Ed. Mir 1974.[Gr] Stanley I. Grossman. Algebra Lineal con aplicaciones. Ed. McGraw-Hill 1991.[H] E. Hernandez. Algebra y Geometrıa. Ediciones de la Universidad Autonoma de Madrid.
1987.[S] G. Strang. Algebra Lineal y sus Aplicaciones. Addison-Wesley Iberoamericana. 1990.
362

DEMOSTRACION DEL TEOREMA DE JORDAN PARAENDOMORFISMOS.
Teorema de Jordan:Todo endomorfismo f : V n → V n donde V n es un espacio vectorial complejo, admite una base
de V n llamada base de Jordan de f tal que f se expresa en esa base por una matriz que es sumadirecta diagonal de matrices del tipo
λ 1 0 . . . 0 00 λ 1 . . . 0 0
0 0 0. . . 0 0
......
.... . . 1 0
0 0 0 . . . λ 10 0 0 . . . 0 λ
que tienen iguales todos los elementos de la diagonal, 1 sobre todos los elementos de la diagonal y 0en el resto.
Cada una de estas ultimas matrices se llaman caja de Jordan y esta en correspondencia con unsubconjunto de vectores elj−1+1
i , ..., elji de la base de Jordan que verifica (f − λkI)(ejki ) = ejk−1
i si
lj−1 + 1 < jk ≤ lj y (f − λkI)(elj−1+1i ) = 0. Este subconjunto de vectores se llama cadena de Jordan.
Vamos a llamar vectores directores de la cadena a los vectores elj−1+1i , que son vectores propios. La
dimension de la caja es lk − lk−1.
Las demostraciones clasicas de este teorema [C], [F], [G], [H], [Hr], [M] son largas y laboriosas.Demostraciones cortas pueden encontrarse en [Fp], [F-S], [G-W], [W], [S].
Se da aquı una demostracion sencilla por induccion del teorema en el que solo se utilizanconocimientos de aplicaciones lineales y los conceptos de dependencia e independencia lineal enun espacio vectorial. Por ello puede ser entendida por alumnos de primer curso de grado en laUniversidad.
Demostracion:
Es claro que el teorema es cierto cuando la dimension del espacio es 1.Suponiendo que el teorema es cierto cuando la dimension del espacio es menor o igual que n− 1,
sea f : V n → V n un endomorfismo de un espacio vectorial complejo; entonces, siempre existe un valor
363

propio real o complejo de f : sea este λ1. El espacio imagen de V n por el endomorfismo f −λ1I es unespacio de dimension menor que n, invariante por f , en el que se verifica la hipotesis de induccion.
Sea
e11, ..., er11 , e
r1+11 , ..., er21 , ..., e
rc11 , e12, ..., e
s12 , e
s1+12 , ..., es22 , ..., e
sc22 , ..., e1k, ..., e
t1k , e
t1+1k , ..., etkk , ...e
tck−1+1
k , ...etckk
una base de Jordan de la restriccion de f a Im(f − λ1I), donde e11, ..., er11 es la cadena de Jordan
correspondiente a la primera caja de Jordan de λ1, er1+11 , ..., er21 es la cadena de Jordan correspon-
diente a la segunda caja de Jordan de λ1, erci−1+1
1 , ..., erc11 es la cadena de Jordan correspondiente
a la ultima caja de Jordan de λ1. (Hay c1 cajas de Jordan para λ1.)
Tambien, e1i , ..., el1i , e
l1+1i , ..., el2i , ..., e
lcii es la union de las cadenas de Jordan correspondiente a
las cajas de valor propio λi y ci es el numero de cajas de Jordan correspondientes a λi.
Por estar contenidos en Im(f − λ1I), los vectores er11 , er21 , ..., erc11 son vectores imagenes respec-
tivas por f − λ1I de otros tantos vectores e′r11 e′r21 , ..., e′rc11 de V n, que son independientes de los
anteriores porque erj1 = (f − λ1I)(e
′rj1 ) es independiente de las imagenes de todos los restantes: (e
rj1
es un vector de una base y las imagenes de los demas vectores por f − λ1I son otros vectores de labase, (si son de la cadena de Jordan correspondiente a λ1), o combinacion lineal de vectores de labase, independientes de e
rj1 , (si son de las cadenas de Jordan de las cajas de los λi 6= λ1)).
Ademas puede ocurrir que los vectores e1, er1+11 ..., eri+1
1 , ..., erc1−1+11 , que son vectores propios
para λ1 no sean una base de ker(f − λ1I), porque algunos de los vectores propios para λ1 se puedenhaber anulado al hacer su imagen por f − λ1I; en ese caso agregamos los vectores propios indepen-
dientes e1, e2, ..., eh que haga falta para que junto a los e1, er1+11 ..., eri+1
1 , ..., erc1−1+11 anteriores
formen una base de ker(f − λ1I), (agregamos un numero de ellos igual a dim(ker(f − λ1I)) menosel numero de cajas con λ1).
Ahora, los vectores e′rii , i ∈ 1...c1 unidos a los nuevos vectores propios agregados y a los dela base de Jordan primitiva de Im(f − λ1I) forman una base de Jordan para f :
Para demostrarlo, sigamos los siguientes pasos:
Observemos que el espacio engendrado por e12, ..., es12 , e
s1+12 , ..., e
sc2−1+12 , ..., e
sc22 (los vectores de
la base de Jordan para λ2) es tambien invariante por f − λ1I y lo mismo ocurre con los subespaciosengendrados por las uniones de las cadenas de Jordan correspondientes a cada valor propio.
Observemos tambien que si esj2 es el ultimo vector de una cadena de Jordan correspondiente a
λ2, se tiene (f − λ1I)e2sj = (λ2 − λ1)esj2 + e
sj−12 Ademas, ningun vector del conjunto que queremos
demostrar que es base se transforma por la aplicacion f − λ1I en esj2 ni en una combinacion lineal
en la que aparezca. Y se tiene la propiedad analoga para todos los vectores finales de las distintascajas.
364

Consideremos ahora que hay una combinacion lineal igual a cero de todos los vectores del conjuntoque queremos demostrar que es base. Tambien serıa igual a cero la imagen por f − λ1I de dichacombinacion lineal, que serıa ahora una combinacion lineal de los vectores de la base de Jordanprimitiva de Im(f−λ1I). Si es α2sj el coeficiente del vector e
sj2 en la combinacion lineal considerada,
el coeficiente de este vector en la imagen por f −λ1I de dicha combinacion lineal serıa (λ2−λ1)α2sj .Este coeficiente debe ser cero porque los vectores que han quedado en la imagen de la combinacionlineal son de la base de Jordan de Im(f − λ1I) y por tanto independientes. Lo que implica queα2sj = 0. Lo mismo ocurre con todos los vectores ultimos correspondientes a cada caja de Jordan decada valor propio distinto de λ1.
Despues, el mismo razonamiento demuestra que los coeficientes de los vectores penultimos de cadacadena de Jordan correspondiente a λi 6= λ1 son tambien cero; y ası podemos seguir con todos, porlo que los coeficientes en la combinacion lineal dada de todos los vectores de la base correspondientesa cajas de valor propio distinto de λ1 son nulos.
Llegados a este punto, podemos concluir que tambien son nulos los coeficientes de los restantesvectores no propios de la combinacion lineal considerada (de cajas de Jordan del valor propio λ1),porque deben ser nulos los coeficientes de los vectores imagenes correspondientes en la imagen dedicha combinacion lineal por f − λ1I.
Y concluimos tambien que los coeficientes de los vectores propios que aparecen son todos nulosporque una parte de ellos eran vectores propios de cadenas de Jordan de Im(f−λ1I) y los que hemosagregado eran independientes de ellos.
Luego no hay combinacion lineal nula de la totalidad de los vectores con coeficientes no nulos.Por tanto, todos los vectores considerados son independientes.
Por otra parte, el numero de vectores agregado a la base de Im(f − λ1I) es el numero de cajasde Jordan para λ1 mas la dimension de ker(f − λ1I) menos ese mismo numero de cajas, es decir, ladimension de ker(f −λ1I), siendo por tanto dimIm(f −λ1I) + dimker(f −λ1I) = dimV el numerototal de vectores; Al ser independientes y su cantidad igual a dimV , son una base de V.
Es facil de ver que el conjunto de vectores e11, ..., er11 e′r11 es una cadena de Jordan correspondiente
a una caja de Jordan de orden r1 +1. Lo analogo ocurre con las restantes partes de la base de Jordanpara las cajas de λ1. Como los otros vectores que hemos agregado son vectores propios, entre todosforman una base de Jordan, quedando ası demostrado el teorema.
365

Unicidad.
Veamos que el numero de cajas de Jordan de orden k correspondiente a cada valor propio λidepende solo de las caracterısricas de la matriz y no de la forma de obtener una base de Jordan.
Sea qki el numero de celdas de orden k para el valor propio λi y ni la multiplicidad algebraica deλi. Debido a la invariancia del polinomio caracterıstico: r(J) = q1i + q2i + ...+ qnii + Σnj 6=ninj.
Observemos ahora que si Jk(0) es la caja de Jordan de orden k con el valor propio 0, cada vez queelevamos a una potencia la matriz Jk(0), su rango disminuye en 1, por lo que el rango de (Jk(0))j esk− j. Sin embargo, el rango de (Jk(λi− λj))m = k si i 6= j ∀m y ∀k. Por lo que si qki es el numerode cajas de Jordan Jk(λi), se tiene (denotando por r(A) el rango de A):
r(J − λiI) = Σnj − q1i − q2i − ...− qji − ...− qnii
r(J − λiI)2 = Σnj − q1i − 2(q2i + ...+ qji + ...+ qnii)
r(J − λiI)j−1 = Σnj − q1i − 2q2i − ...− (j − 1)(qj−1i + ...+ qnii)
r(J − λiI)j = Σnj − q1i − 2q2i − ...− j(qji + ...+ qnii)
r(J − λiI)j+1 = Σnj − q1i − 2q2i − ...− jqji − (j + 1)(qj+1i + ...+ qnii)
r(J − λiI)ni = Σnj 6=ninj
por lo que
qji = −(r(J−λiI)j−r(J−λiI)j−1)+r(J−λiI)j+1−r(J−λiI)j = r(J−λiI)j+1−2r(J−λiI)j+r(J−λiI)j−1.
Si C es la matriz que tiene en columnas las coordenadas de los vectores de la base de Jordan, yJ es la forma de Jordan correspondiente a A, se tiene C−1AC = J y C−1(A− λiI)jC = (J − λiI)j,por lo que los rangos de (A − λiI)jy (J − λiI)j son iguales. Entonces, r(J − λiI)j = r(A − λiI)j yel numero qij solo depende de A.
366

Ejemplos para un metodo facil para hallar la base de Jordan.
Ejemplo 1.Sea f un endomorfismo de matriz A:
A =
−18 11 2 3 15 −9−10 7 1 2 8 −5−24 13 3 6 20 −12−5 3 0 3 4 −2−21 12 2 3 18 −10−15 9 1 3 13 −7
Su unico valor propio es el 1 con multiplicidad 6. Por tanto (A− I)6 = 0. En efecto:
A− I =
−19 11 2 3 15 −9−10 6 1 2 8 −5−24 13 2 6 20 −12−5 3 0 2 4 −2−21 12 2 3 17 −10−15 9 1 3 13 −8
, (A− I)2 =
8 −9 −2 1 −7 83 −4 −1 1 −3 48 −10 −3 2 −8 111 −1 −1 1 −1 29 −10 −2 0 −8 93 −5 −1 0 −4 6
,
(A− I)3 =
8 −1 −3 −1 −3 15 −1 −2 0 −2 1
13 −2 −5 −1 −5 21 1 −1 0 0 0
10 −2 −3 −2 −4 111 −4 −3 −1 −5 2
, (A− I)4 =
−17 13 4 −4 10 −7−10 8 2 −2 6 −4−27 21 6 −6 16 −11−5 4 1 −1 3 −2−19 14 5 −5 11 −8−17 13 4 −4 10 −7
,
(A− I)5 =
12 −12 0 0 −8 46 −6 0 0 −4 2
18 −18 0 0 −12 63 −3 0 0 −2 1
15 −15 0 0 −10 512 −12 0 0 −8 4
, (A− I)6 = 0
Debido a que (A − I)6 = 0, las columnas distintas de cero de (A − I)5 son vectores propios.Mirandolos vemos que hay solo uno independiente.
367

Podemos coger la ultima columna de (A−I)5 como vector propio; entonces, la ultima columna de(A− I)4 se transforma por A− I en la ultima columna de (A− I)5; la ultima columna de (A− I)3 setransforma por A− I en la ultima columna de (A− I)4; la ultima columna de (A− I)2 se transformapor A− I en la ultima columna de (A− I)3; la ultima columna de A− I se transforma por A− I enla ultima columna de (A− I)2; la ultima columna de I se transforma por A− I en la ultima columnade A− I
Llamando e5, e4, e3, e2, e1, e0 a los vectores obtenidos, en ese mismo orden, se tiene (f − I)iej =ej+i si j+i ≤ 5, (f−I)iej = 0 si j+i > 5. Entonces, dada una combinacion lineal α5e
5+α4e4+α3e
3+α2e
2 +α1e1 +α0e
0 = 0, se tiene tambien (f−I)5(α5e5 +α4e
4 +α3e3 +α2e
2 +α1e1 +α0e
0) = 0, es decir,α0e
5 = 0, lo que implica α0 = 0. Volviendo a la combinacion lineal dada en la que no aparece e0 yhaciendo la imagen por (f − I)4 de dicha combinacion lineal obtenemos de manera similar α1 = 0 ysiguiendo repitiendo el mismo proceso con las combinaciones lineales que van quedando van saliendotodos los αi nulos, por tanto, los vectores considerados son independientes.
Teniendose que todas las ultimas columnas enunciadas encadenadas en ese mismo orden formanuna base de Jordan del endomorfismo de R6 correspondiente a A.
La base de Jordan es entonces:(4,2,6,1,5,4),(-7,-4,-11,-2,-8,-7),(1,1,2,0,1,2),(8,4,11,2,9,6),(-9,-5,-12,-2,-10,-8),(0,0,0,0,0,1)para
J =
1 1 0 0 0 00 1 1 0 0 00 0 1 1 0 00 0 0 1 1 00 0 0 0 1 10 0 0 0 0 1
Ejemplo 2.Sea f un endomorfismo de matriz A:
A =
10 −6 −3 1 −8 6−10 9 5 −3 8 −7−8 6 4 −2 7 −5−6 4 2 0 5 −4
7 −5 −3 1 −5 5−20 15 8 −5 17 −12
Su unico valor propio es el 1 con multiplicidad 6. Por tanto (A− I)6 = 0. En efecto:
368

A− I =
9 −6 −3 1 −8 6
−10 8 5 −3 8 −7−8 6 3 −2 7 −5−6 4 2 −1 5 −4
7 −5 −3 1 −6 5−20 15 8 −5 17 −13
, (A− I)2 =
−17 14 8 −6 14 −11
4 −3 −1 2 −3 25 −4 −2 2 −4 3
11 −9 −5 4 −9 7−11 9 5 −4 9 −7
15 −12 −6 6 −12 9
(A− I)3 =
−3 3 3 0 3 −3
1 −1 −1 0 −1 11 −1 −1 0 −1 12 −2 −2 0 −2 2−2 2 2 0 2 −2
3 −3 −3 0 −3 3
, 0 = (A− I)4 = (A− I)5 = (A− I)6.
Los vectores columna distintos de cero de (A− I)3 son vectores propios. Ademas el ultimo vectorcolumna de (A− I)3 es imagen por A− I de la ultima columna de (A− I)2, que a su vez es imagenpor A− I de la ultima columna de A− I y este es imagen por A− I de la ultima columna de I. Asıtenemos cuatro vectores independientes (se ve como en el ejercicio anterior) que en el orden:(−3, 1, 1, 2,−2, 3), (−11, 2, 3, 7,−7, 9), (6,−7,−5,−4, 5,−13), (0, 0, 0, 0, 0, 1) forman una cadena
de Jordan para una caja de Jordan de dimension 4.Llegados a esta situacion solo hay dos formas de completar los vectores enunciados a una base
de Jordan: con dos vectores propios independientes entre sı y del anterior vector propio o con unacadena w, v de dos vectores tales que w es vector propio y (A− I)v = w.
Si fuera la primera forma, al haber tres vectores independientes, el rango de A− I (igual al rangode J-I) serıa 3, pero el rango de A− I es 4 porque∣∣∣∣∣∣∣∣
−6 −3 1 68 5 −3 −76 3 −2 −54 2 −1 −4
∣∣∣∣∣∣∣∣ = −2 6= 0
y todos los menores de orden 5 son nulos. Entonces, le corresponde la segunda forma.Por otra parte r(A− I)2 = 2. Como al pasar de A− I a (A− I)2 por A− I, el rango disminuye
en 2, hay en el espacio engendrado por las columnas de A − I dos vectores propios independientes,pudiendose, por tanto, encontrar un vector propio independiente de −3, 1, 1, 2,−2, 3). (Tambien esindependiente de los otros vectores (porque no son propios) de la cadena anterior). Ademas, al seriguales las segunda y la quinta columnas de (A−I)2, el vector diferencia de esas columnas en (A−I)es un vector propio (que es independiente de todos los anteriores; es el vector (2, 0,−1,−1, 1,−2)t =
369

(A− I)(0, 1, 0, 0,−1, 0)t. Los dos vectores (2, 0,−1,−1, 1,−2), (0, 1, 0, 0,−1, 0) son una cadena deJordan correspondiente a una caja de Jordan de dimension 2, siendo todos independientes. (El unicoque queda por probar que es independiente es el (0, 1, 0, 0,−1, 0) y lo es porque su imagen por f − Ies independiente de las imagenes por f − I de los vectores anteriores.) Entonces,
(2,0,-1,-1,1,-2),(0,1,0,0,-1,0);(-3,1,1,2,-2,3),(-11,2,3,7,-7,9),(6,-7,-5,-4,5,-13),(0,0,0,0,0,1) una base deJordan para
J =
1 1 0 0 0 00 1 0 0 0 00 0 1 1 0 00 0 0 1 1 00 0 0 0 1 10 0 0 0 0 1
Ejemplo 3.Sea f un endomorfismo de matriz A,
A =
−4 5 2 −3 5 −2
2 −1 −1 1 −2 12 −2 0 1 −2 14 −4 −2 3 −4 2−3 3 1 −2 4 −1
6 −6 −3 3 −6 4
Su unico valor propio es 1. Por eso (A− I)6 = 0. en efecto:
A−I =
−5 5 2 −3 5 −2
2 −2 −1 1 −2 12 −2 −1 1 −2 14 −4 −2 2 −4 2−3 3 1 −2 3 −1
6 −6 −3 3 −6 3
, 0 = (A−I)2 = (A−I)3 = (A−I)4 = (A−I)5 = (A−I)6
Los vectores de A − I son vectores propios. Solo hay dos vectores independientes, que son a suvez, vectores imagenes de vectores columna de I por A− I: el vector propio (2,−1,−1,−2, 1,−3)t =(A − I)(0, 0, 1, 0, 0, 0)t y el vector propio (−3, 1, 1, 2,−2, 3)t = (A − I)(0, 0, 0, 1, 0, 0)t. Dan lugar ados cadenas de Jordan.
Al ser el rango de I igual a 6 y haber pasado a ser 2 en A− I, hay cuatro vectores propios inde-pendientes en R6, pudiendose encontrar otros dos vectores propios independientes de los anteriores.
370

Viendo que la suma de la primera y la segunda columnas de A − I es cero, tenemos un vectorpropio: (1,1,0,0,0,0). Viendo que la suma de la tercera y la sexta columnas de A− I es cero, tenemosotro vector propio: (0,0,1,0,0,1).
Los cuatro vectores propios son independientes porque∣∣∣∣∣∣∣∣1 1 0 00 0 1 02 −1 −1 −2−3 1 1 2
∣∣∣∣∣∣∣∣ = −2 6= 0
y lo son de los vectores no propios porque lo son sus imagenes por f − I.Los vectores: (1,1,0,0,0,0);(0,0,1,0,0,1);(2,-1,-1,-2,1,-3),(0,0,1,0,0,0);(-3,1,1,2,-2,3),(0,0,0,1,0,0) cons-
tituyen una base de Jordan del endomorfidmo dado por A para
J =
1 0 0 0 0 00 1 0 0 0 00 0 1 1 0 00 0 0 1 0 00 0 0 0 1 10 0 0 0 0 1
.
Ejemplo 4.Sea f un endomorfismo de matriz A,
A =
−12 27 4 0 −8 4−3 7 1 0 −2 1−18 40 6 −1 −12 6−10 23 2 2 −6 5
5 −11 −1 −1 3 −23 −8 0 −1 2 −2
.
con valores propios 1 con multiplicidad 5 y −1 con multiplicidad 1. Entonces, como el maximo delos ordenes de las celdas para λ1 = 1 es 5, (A− I)5(A+ I) = 0 = (A+ I)(A− I)5.
Las columnas de A+ I engendran el subespacio ker(f − I)5. Hallemos la cadena de matrices:
A+I =
−11 27 4 0 −8 4−3 8 1 0 −2 1−18 40 7 −1 −12 6−10 23 2 3 −6 5
5 −11 −1 −1 4 −23 −8 0 −1 2 −1
, (A−I)(A+I) =
−38 81 11 0 −22 11−10 21 3 0 −6 3−44 95 13 −2 −26 11−20 43 5 2 −10 7
10 −22 −2 −2 4 −42 −4 0 −2 0 −2
371

(A− I)2(A+ I)
−24 54 6 0 −12 6−8 18 2 0 −4 2−24 54 6 0 −12 6−8 18 2 0 −4 2
0 0 0 0 0 00 0 0 0 0 0
, (A− I)3(A+ I) = 0
Se ve que el vector (6, 2, 6, 2, 0, 0) (ultima columna de (A − I)2(A + I)) es vector propio paraλ = 1. Entonces, las ultimas columnas de las matrices precedentes dan una cadena de Jordan deorden 3: (6, 2, 6, 2, 0, 0), (11, 3, 11, 7,−4,−2), (4, 1, 6, 5,−2,−1).
Ademas la cuarta columna de (A−I)(A+I) se transforma en cero por A−I (en (A−I)2(A+I)),por tanto es un vector propio para 1, independiente del anterior. Entonces, junto a la cuarta columnade A+ I, dan una cadena de Jordan de orden 2: (0, 0,−2, 2,−2,−2), (0, 0,−1, 3,−1,−1)
Como las matrices A − I y A + I conmutan, tambien se tiene (A + I)(A − I)3 = 0, siendo lascolumnas distintas de cero de (A− I)3 vectores propios de A para el valor propio −1.
Como
(A− I)3 =
0 0 0 0 0 00 0 0 0 0 0−8 −24 0 0 −8 8−8 −24 0 0 −8 8
0 0 0 0 0 08 24 0 0 8 −8
,
el vector (0, 0, 8, 8, 0,−8) es vector propio para −1. Solo hay una columna independiente.Juntando las tres cadenas de Jordan obtenidas tenemos una base de Jordan de f :(6,2,6,2,0,0),(11,3,11,7,-4,-2),(4,1,6,5,-2,-1);(0,0,-2,2,-2,-2),(0,0,-1,3,-1,-1);(0,0,8,8,0,-8)para
J =
1 1 0 0 0 00 1 1 0 0 00 0 1 0 0 00 0 0 1 1 00 0 0 0 1 00 0 0 0 0 −1
.
Ejemplo 5.Sea f un endomorfismo de matriz A
372

A =
−6 2 4 −7 8 1−10 9 5 −3 8 −7−9 7 2 −2 8 −5
1 −1 −2 2 −2 01 −3 0 −3 1 4−8 9 2 1 5 −8
.
de valores propios 1 y −1, ambos de multiplicidad algebraica 3. Entonces, como el maximo de losordenes de las cajas para λ1 = 1 y λ2 = −1 es 3, (A− I)3(A+ I)3 = 0 = (A+ I)3(A− I)3
(A+ I)3 =
−140 118 70 −72 142 −68−84 74 42 −24 66 −60
4 −2 −2 8 −10 −496 −80 −48 48 −96 48−48 40 24 −32 56 −16
12 −6 −6 24 −30 −12
(A− I)(A+ I)3 =
−216 188 108 −80 188 −136−8 4 4 0 4 −840 −36 −20 16 −36 24
128 −112 −64 48 −112 80−128 112 64 −48 112 −80
120 −108 −60 48 −108 72
,
(A− I)2(A+ I)3 =
−144 120 72 −48 120 −96
48 −40 −24 16 −40 3248 −40 −24 16 −40 3296 −80 −48 32 −80 64−96 80 48 −32 80 −64144 −120 −72 48 −120 96
(A− I)3(A+ I)3 = 0
Todas las columnas de (A−I)2(A+I)3 son dependientes, y se transforman en cero al multiplicarlaspor A−I, una columna cualquiera es un vector propio; escojamos la cuarta: (−48, 16, 16, 32,−32, 48)t,esta es al mismo tiempo el producto de A − I por la cuarta columna de (A − I)(A + I)3 y estaultima es el producto de A − I por la cuarta columna de (A + I)3. Entonces, los tres vectores:(−48, 16, 16, 32,−32, 48), (−80, 0, 16, 48,−48, 48), (−72,−24, 8, 48,−32, 24) son una cadena de Jor-dan para λ = 1.
Analogamente, considerando las matrices:
373

(A− I)3 =
20 −38 10 −18 −20 280 0 0 0 0 0
−68 46 14 −22 68 −28−36 22 6 −14 36 −12
12 −26 6 −14 −12 20−48 48 0 0 48 −32
(A+ I)(A− I)3 =
−72 60 12 −12 72 −40
0 0 0 0 0 024 −12 −12 12 −24 824 −12 −12 12 −24 8−40 36 4 −4 40 −24
64 −48 −16 16 −64 32
,
(A+ I)2(A− I)3 =
32 −24 −8 8 −32 160 0 0 0 0 0
32 −24 −8 8 −32 1632 −24 −8 8 −32 1632 −24 −8 8 −32 160 0 0 0 0 0
(A+ I)3(A− I)3 = 0
vemos que las terceras columnas de las tres ultimas matrices:(−8, 0,−8,−8,−8, 0), (12, 0,−12,−12, 4,−16), (10, 0, 14, 6, 6, 0) son una cadena de Jordan para
λ = −1.Y una base de Jordan de f es la union de las dos cadenas:(−48, 16, 16, 32,−32,−72), (−80, 0, 16, 48,−48, 48), (−72,−24, 8, 48,−32, 24); ∪(−8, 0,−8,−8,−8, 0), (12, 0,−12,−12, 4,−16), (10, 0, 14, 6, 6, 0)para
J =
1 1 0 0 0 00 1 1 0 0 00 0 1 0 0 00 0 0 −1 1 00 0 0 0 −1 10 0 0 0 0 −1
.
374

Ejemplo 6.Sea f un endomorfismo de matriz A
A =
0 0 0 1 −1 0 −11 1 −3 −2 −1 −4 01 1 −5 −5 0 −7 10 3 3 10 −10 0 00 3 0 6 −8 −3 0−1 −3 3 −2 7 7 −1
1 0 3 2 0 3 2
con un unico valor propio igual a 1. Entonces (A− I)7 = 0. En efecto,
A− I =
−1 0 0 1 −1 0 −11 0 −3 −2 −1 −4 01 1 −6 −5 0 −7 10 3 3 9 −10 0 00 3 0 6 −9 −3 0−1 −3 3 −2 7 6 −1
1 0 3 2 0 3 1
(A− I)2 =
0 0 0 0 0 0 00 0 0 0 0 0 02 0 0 0 −1 −1 16 0 0 0 −3 −3 36 0 0 0 −3 −3 3−6 0 0 0 3 3 −3
0 0 0 0 0 0 0
(A− I)3 = 0
Solo hay una columna independiente en (A − I)2, que se transforma en cero al multiplicarla porA− I. Por tanto esta columna es un vector propio de f . Escojamos la ultima columna de (A− I)2:
(0, 0, 1, 3, 3,−3, 0)t = (A − I)(−1, 0, 1, 0, 0,−1, 1)t = (A − I)2(0, 0, 0, 0, 0, 0, 1). Entonces, losvectores (0, 0, 1, 3, 3,−3, 0), (−1, 0, 1, 0, 0,−1, 1), (0, 0, 0, 0, 0, 0, 1) forman una cadena de Jordan paraλ = 1.
Como el rango de A− I es 4, hay tres combinaciones lineales de las columnas de A− I que sonvectores propios para λ = 1. Pero como Im(f − λI) ⊃ Im(f − λI)2, solo podemos encontrar dos
375

combinaciones lineales que sean vectores propios, a la vez independientes del anterior. Lo son latercera y la cuarta columna de A− I:
(0,−3,−6, 3, 0, 3, 3) = (f − I)(0, 0, 1, 0, 0, 0, 0)(1,−2,−5, 9, 6,−2, 2) = (f − I)(0, 0, 0, 1, 0, 0, 0)dando lugar a dos cadenas de Jordan de orden 2.
La union de(0,-3,-6,3,0,3,3),(0,0,1,0,0,0,0);(1,-2,-5,9,6,-2,2),(0,0,0,1,0,0,0)con (0,0,1,3,3,-3,0),(-1,0,1,0,0,-1,1),(0,0,0,0,0,0,1) es una base de Jordan de f para
J =
1 1 0 0 0 0 00 1 0 0 0 0 00 0 1 1 0 0 00 0 0 1 0 0 00 0 0 0 1 1 00 0 0 0 0 1 10 0 0 0 0 0 1
.
Se ve que todos los vectores de la base son independientes por procedimientos analogos a losanteriores.
Ejemplo 7.Sea f un endomorfismo de matriz A
A =
5 −3 −1 −3 4 2 26 2 1 0 −2 0 23 −3 2 −3 3 1 2−6 3 0 5 −2 −1 −3
3 0 0 0 2 1 10 −3 0 −3 3 2 1−9 9 3 9 −12 −6 −4
de unico valor propio λ = 2. Entonces, (A− 2I)7 = 0. En efecto,
376
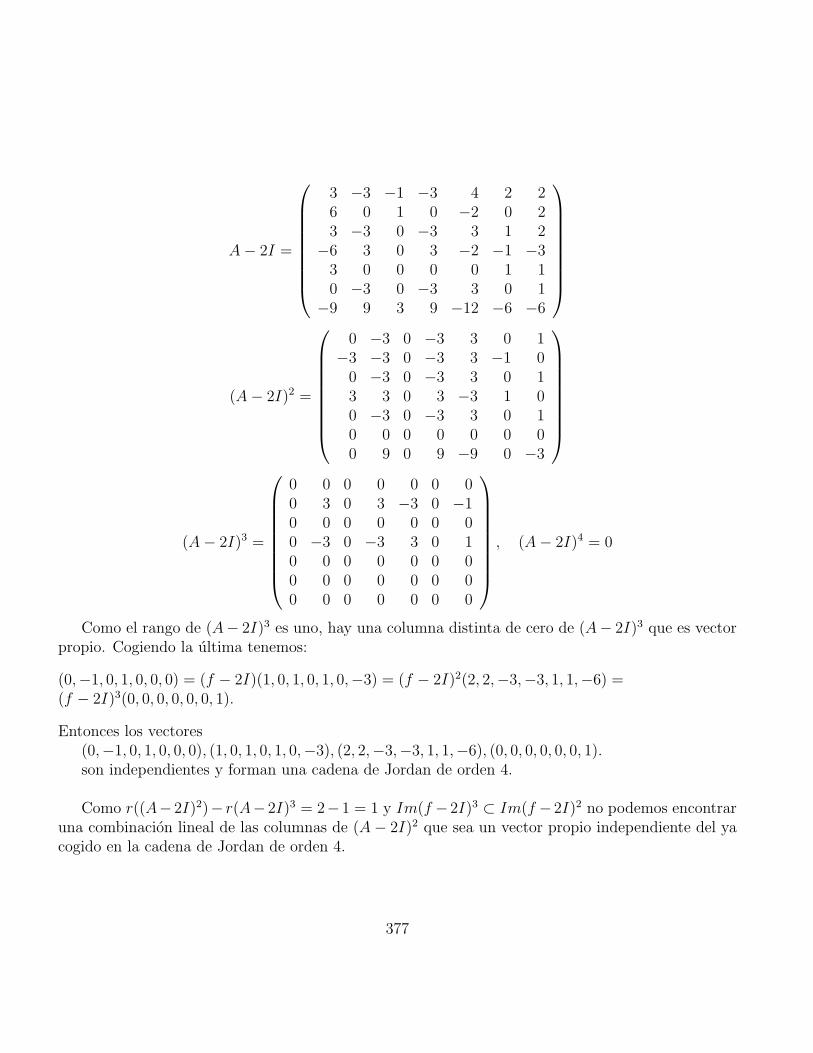
A− 2I =
3 −3 −1 −3 4 2 26 0 1 0 −2 0 23 −3 0 −3 3 1 2−6 3 0 3 −2 −1 −3
3 0 0 0 0 1 10 −3 0 −3 3 0 1−9 9 3 9 −12 −6 −6
(A− 2I)2 =
0 −3 0 −3 3 0 1−3 −3 0 −3 3 −1 0
0 −3 0 −3 3 0 13 3 0 3 −3 1 00 −3 0 −3 3 0 10 0 0 0 0 0 00 9 0 9 −9 0 −3
(A− 2I)3 =
0 0 0 0 0 0 00 3 0 3 −3 0 −10 0 0 0 0 0 00 −3 0 −3 3 0 10 0 0 0 0 0 00 0 0 0 0 0 00 0 0 0 0 0 0
, (A− 2I)4 = 0
Como el rango de (A− 2I)3 es uno, hay una columna distinta de cero de (A− 2I)3 que es vectorpropio. Cogiendo la ultima tenemos:
(0,−1, 0, 1, 0, 0, 0) = (f − 2I)(1, 0, 1, 0, 1, 0,−3) = (f − 2I)2(2, 2,−3,−3, 1, 1,−6) =(f − 2I)3(0, 0, 0, 0, 0, 0, 1).
Entonces los vectores(0,−1, 0, 1, 0, 0, 0), (1, 0, 1, 0, 1, 0,−3), (2, 2,−3,−3, 1, 1,−6), (0, 0, 0, 0, 0, 0, 1).son independientes y forman una cadena de Jordan de orden 4.
Como r((A− 2I)2)− r(A− 2I)3 = 2− 1 = 1 y Im(f − 2I)3 ⊂ Im(f − 2I)2 no podemos encontraruna combinacion lineal de las columnas de (A− 2I)2 que sea un vector propio independiente del yacogido en la cadena de Jordan de orden 4.
377

Sin embargo, como r(A − 2I) − r(A − 2I)2 = 4 − 2 = 2 y Im(f − 2I)3 ⊂ Im(f − 2I) podemosencontrar una combinacion lineal de las columnas de A− I que sea un vector propio independientedel ya cogido en la cadena de Jordan de orden 4. Mirando se ve que la tercera columna de A − 2Ise transforma en cero al pasar a (A− 2I)2, luego (−1, 1, 0, 0, 0, 0, 3)t = (A− 2I)(0, 0, 1, 0, 0, 0, 0)t esun vector propio. Se ve facilmente que es independiente del anterior.
Ademas el rango de I es 7. Si ha pasado a 4 al multiplicar I por A− 2I, hay tres combinacioneslineales de las columnas de I que son vectores propios, aunque solo podemos encontrar otra combi-nacion lineal de las columnas de I, que sea vector propio independiente de los dos anteriores. Comola primera columna de A − 2I sumada al triple de la cuarta mas el triple de la quinta menos eltriple de la sexta es cero, el vector (1, 0, 0, 3, 3,−3, 0) es un vector propio para λ = 2, que se puedecomprobar que es independiente de los dos anteriores.
Ası tenemos que(1, 0, 0, 3, 3,−3, 0); (−1, 1, 0, 0, 0, 0, 3), (0, 0, 1, 0, 0, 0, 0); ∪(0,−1, 0, 1, 0, 0, 0), (1, 0, 1, 0, 1, 0,−3), (2, 2,−3,−3, 1, 1,−6), (0, 0, 0, 0, 0, 0, 1)son todos independientes y forman una base de Jordan de f para
J =
2 0 0 0 0 0 00 2 1 0 0 0 00 0 2 0 0 0 00 0 0 2 1 0 00 0 0 0 2 1 00 0 0 0 0 2 10 0 0 0 0 0 2
.
La obtencion del ultimo vector (1, 0, 0, 3, 3,−3, 0) no ha sido tan facil. Ha habido que resolver el sistema deecuaciones homogeneo de matriz A − 2I, pero con este metodo no hemos tenido que calcular los nucleos de lasdistintas potencias de A− 2I, lo cual supone resolver muchos mas sistemas de ecuaciones.
Metodo general.
El procedimiento que vamos a describir para hallar la base de Jordan de un endomorfismo fde matriz A se basa en el hecho de que multiplicando adecuadamente las matrices A − λkI de losendomorfismos f − λkI podemos obtener facilmente los vectores directores de las cadenas de Jordany todos los siguientes que les corresponden.
Observemos que debido a la invariancia del Polinomio Caracterıstico de un endomorfismo lasuma de las dimensiones de las cajas de Jordan correspondientes a un valor propio λk coincide con
378

la multiplicidad nk de este valor propio.
Tambien, una vez desplegada la base de Jordan, se ve que la union de las cadenas de Jordancorrespondientes a un valor propio λk es ker(f − λkI)nk que denotaremos por Ek y V n = ⊕Ek.Siendo la base de Jordan de V n para f la union de las bases de Jordan de f en cada Ek.
Cada subespacio Ej es invariante por f y por f−λiI cualquiera que sea i, siendo (f−λiI)niEi = 0y por el contario la restriccion de (f − λiI)ni a Ej es un isomorfismo si j 6= i. Esto hace que(Πi 6=k((f − λiI)ni)V n ⊂ Ek = ker(f − λkI)nk , siendo de la misma dimension que Ek, por lo que(Πi 6=k((f − λiI)ni)V n = Ek = ker(f − λkI)nk , estando, por tanto, Ek engendrado por las columnasde Πi 6=k((A− λiI)ni) que denotamos por Ak
Para obtener la base de Jordan de f en Ek calculamos la sucesion de matrices
(A− λkI)mkAk, mk ∈ 0, 1, ..., nk.
Sabemos que (A−λkI)nkAk = 0. Puede ocurrir que para 1 ≤ dk < nk, (A−λkI)dkAk = 0. En estecaso todas las columnas de (A−λkI)dk−1Ak son vectores propios para λk; Sea edk−1
k un vector columnadistinto de cero de esta matriz en el lugar `-esimo, entonces las columnas en el lugar ` de las matrices(A − λkI)dk−2Ak, ..., Ak dan lugar a vectores edk−2
k , ..., e0i que verifican (f − λkI)ejkk = ejk+1
k siendoedk−1
k , edk−2k , ..., e0k la cadena correspondiente a una caja de Jordan de dimension dk. Cogiendo el
maximo numero rk = r(A−λkI)dkAk de columnas edk−1k independientes y repitiendo el mismo proceso
tenemos las cadenas de Jordan correspondientes a las cajas de dimension k. (Todos esos vectoresson independientes).
Si dk · rk = nk hemos acabado en Ek.
En caso contrario existen cajas de Jordan de dimension inferior. Observemos que en el casoanterior r(A − λkI)dk−j−1Ak − r(A − λkI)dk−jAk es independiente de j e igual a rk, pero en casocontrario existe d′k < dk tal que
r(A− λkI)d′k−1Ak − r(A− λkI)d
′kAk > rk.
Consideramos el maximo de tales d′k, entonces, como las columnas de (A−λkI)d′k−1Ak engendran
el subespacio imagen de (f − λkI)d′k−1, existen r(A − λkI)d
′k−1Ak − r(A − λkI)d
′kAk combinaciones
lineales de las columnas de (A− λkI)d′k−1Ak que son vectores propios para λk.
Sin embargo, como el subespacio imagen de (f − λkI)d′k−1 contiene al subespacio imagen de
(f − λkI)dk−1, solo podemos encontrar r(A− λkI)d′k−1Ak − 2r(A− λkI)d
′kAk combinaciones lineales
379

de las columnas de (A−λkI)d′k−1Ak que son vectores propios de λk y son ademas, independientes de
los rk primeros vectores propios escogidos.
Si uno de ellos ed′k−1
k es combinacion lineal de las n columnas de (A−λkI)d′k−1Ak con los coeficientes
α1, α2, ..., αn consideremos las combinaciones lineales de las columnas de (A−λkI)d′k−2Ak, ..., Ak con
los mismos coeficientes y en el mismo orden y ası encontramos una sucesion de vectores ed′k−1
k , ..., e0kque es una cadena de Jordan correspondiente a una caja de Jordan de dimension d′k < dk.
Repetimos el procedimiento para todos los ed′k−1
k escogidos. Si el numero de estos es `′k y sidk · rk + d′k · `′k = nk hemos acabado en Vk.
En caso contrario existen cajas de Jordan de dimension inferior d′′k < d′k < dk y por tanto algund′′k < d′k tal que
r(A− λkI)d′′k−1Ak − r(A− λkI)d
′′kAk > rk + `′k
Escogemos combinaciones lineales de las columnas de (A− λkI)d′′k−1 que sean vectores propios y
al mismo tiempo independientes de los edk−1k y de los ed
′k−1
k . Obtenemos las cadenas de Jordan
correspondientes a estos ultimos vectores directores ed′′k−1
k con el mismo procedimiento que los hemos
obtenido para los ed′k−1
k . El numero de vectores que podemos y debemos escoger es el numero decajas de Jordan de dimension d”k que segun calculamos en el apartado de la unicidad es
r(A− λiI)d”k+1 − 2r(A− λiI)d”k + r(A− λiI)d”k−1.Seguimos ası hasta tener nk vectores independientes que son una base de Jordan de Ek.
Como dijimos al principio, la base de Jordan de f en V es la union de las bases de Jordan de fen cada Ek.
380

Bibliografıa.
[A] A. Almeida Costa. Cours d’Algebre Generale, Ed. Fundacao Calouste Gulbekian. Lisboa,1974.
[B] J. de Burgos. Curso de Algebra y Geometrıa. Ed. Alhambra Universidad. Madrid 1982.[C] M. Castellet, I. LLerena. Algebra Lineal y Geometrıa. Ed. Reverte. 8991.[C] L. Contreras Caballero. Un metodo facil para hallar una base de Jordan. XV Jornadas
Luso-Espanolas de Matematicas. (1990).[Fp] A. F. Filippov. A short proof of the theorem on the reduction of a matrix to Jordan form.
Moscow Univ. Math. Bull.,26 (1971) 70-71.[F-S]R. Fletcher and D.C. Sorensen. An algorithmmic derivation of the Jordan cannonical form.
Amer. Math. Monthly, 90 (1983) 12-16.[F] J. Frenkel, Geometrie pour l’eluve professeur, Ed. Hermann, Parıs, 1973.[G-W]A. Galperin and Z. Waksman. An elementary approach to Jordan theory. Amer. Math.
Monthly 87 (1981),728-732.[G] R. Godement, Algebra, Ed. Tecnos, Madrid, 1976.[H] E. Hernandez. Algebra y Geometrıa. Ediciones de la Universidad Autonoma de Madrid.
1987.[Hr] I.N. Herstein, Topics in Algebra, Ed. Wiley Sons, New York, 1975.[M] A.I. Maltsev, Fundamentos de Algebra Lineal, Ed. Mir. Moscow.[S] G. Strang. Algebra Lineal y sus Aplicaciones. Addison-Wesley Iberoamericana. 1990.[W] H. Waliao. An elementary approach to the Jordan form of a matrix. Amer. Math. Monthly.
93 (1986)711-714.
381

382

APLICACIONES ORTOGONALES.ESPACIO AFIN y MOVIMIENTOS.
Introduccion.
Dados dos espacios vectoriales euclıdeos, las aplicaciones lineales entre ellos que respetan la es-tructura euclıdea se llaman aplicaciones ortogonales. Estas aplicaciones conservan las distancias yel origen. Ejemplos de transformaciones ortogonales son los giros y las simetrıas ortogonales en elplano y las rotaciones vectoriales en el espacio.
Existe un teorema que reduce cualquier transformacion ortogonal de Rn a un producto (o com-posicion) de estos dos tipos de aplicaciones ortogonales (rotaciones vectoriales y simetrıas). Ademasuna rotacion vectorial o un giro se pueden descomponer en composicion de dos simetrıas ortogo-nales, de donde se deduce que toda transformacion ortogonal se puede descomponer en producto (ocomposicion) de simetrıas ortogonales.
Definicion y Propiedades.
Definicion 1: Una aplicacion lineal entre dos espacios vectoriales euclıdeos es ortogonal si con-serva el producto escalar:
La aplicacion lineal f : V → V ′ es ortogonal si < f(x), f(y) >=< x, y > ∀x, y ∈ V .
Las transformaciones ortogonales conservan, por tanto, tambien los modulos. Como en R3 seidentifican los puntos con los vectores y se establece que d(x, y) = ||x − y||, las transformacionesortogonales de R3 conservan las distancias y se llaman isometrıas.
Por conservar el modulo de los vectores, toda aplicacion ortogonal es inyectiva y si los espaciosoriginal y final tienen la misma dimension, es biyectiva.
Aunque la estructura de espacio euclıdeo comprende la linealidad y el producto escalar, se de-muestra que es suficiente que una aplicacion entre espacios vectoriales euclıdeos conserve el productoescalar para que sea lineal:
Proposicion 1: Toda aplicacion entre espacios vectoriales euclıdeos que conserva el productoescalar es lineal.
Demostracion:Sea f : V 7→ V ′ tal que < f(x), f(y) >=< x, y >,1) Vamos a comprobar primero que f(x+y) = f(x)+f(y) viendo que ||f(x+y)−f(x)−f(y)|| = 0.
(Recordemos que si un vector tiene modulo cero es el vector cero).En efecto,
383

||f(x+ y)− f(x)− f(y)||2 =< f(x+ y)− f(x)− f(y), f(x+ y)− f(x)− f(y) >=
(por la linealidad del producto escalar)
=< f(x+ y), f(x+ y) > + < f(x+ y),−f(x) > + < f(x+ y),−f(y) > +< −f(x), f(x+ y) > + < −f(x),−f(x) > + < −f(x),−f(y) > +< −f(y), f(x+ y) > + < −f(y),−f(x) > + < −f(y),−f(y) >=
< f(x+ y), f(x+ y) > − < f(x+ y), f(x) > − < f(x+ y), f(y) > −< f(x), f(x+ y) > + < f(x), f(x) > + < f(x), f(y) > −< f(y), f(x+ y) > + < f(y), f(x) > + < f(y), f(y) >=
(por conservar f el producto escalar)
=< x+y, x+y > − < x+y, x > − < x+y, y > − < x, x+y > + < x, x > + < x, y > − < y, x+y >+ < y, x > + < y, y >=< x+ y, x+ y − x− y > − < x, x+ y − x− y > − < y, x+ y − x− y >= 0
de donde f(x+ y) = f(x) + f(y)2) Despues vemos que f(αx) = αf(x) comprobando que ||f(αx)− αf(x)|| = 0.En efecto, por la linealidad del producto escalar y por ser este conservado por f :
||f(αx)− αf(x)||2 =< f(αx)− αf(x), f(αx)− αf(x) >=
< f(αx), f(αx) > + < f(αx),−αf(x) > + < −αf(x), f(αx) > + < −αf(x),−αf(x) >
=< f(αx), f(αx) > −α < f(αx), f(x) > −α < f(x), f(αx) > +(−α)2 < f(x), f(x) >=
=< αx, αx > −α < αx, x > −α < x, αx > +(−α)2 < x, x >=
= α2 < x, x > −α2 < x, x > −α2 < x, x > +α2 < x, x >= 0
de donde f(αx) = αf(x).
En el sentido inverso, solo es necesario exigir a una aplicacion lineal que conserve el modulo delos vectores para que conserve el producto escalar:
Proposicion 2: Si una aplicacion es lineal y conserva el modulo, conserva el producto escalar.(Por tanto es ortogonal).
Veamoslo: Si f conserva el modulo de los vectores,< f(x+ y), f(x+ y) >= ‖f(x+ y)‖2 = ‖x+ y‖2 =< x+ y, x+ y >,ademas, por ser f lineal y por la linealidad del producto escalar,
< f(x+ y), f(x+ y) >=< f(x) + f(y), f(x) + f(y) >=
< f(x), f(x) > + < f(x), f(y) > + < f(y), f(x) > + < f(y), f(y) >,
384

considerando la expresion
< x+ y, x+ y >=< x, x > + < x, y > + < y, x > + < y, y >
vemos que si < f(x), f(x) >=< x, x > y < f(y), f(y) >=< y, y >, por la simetrıa del productoescalar tenemos < f(x), f(y) >=< x, y >.
Con la proposicion anterior hemos demostrado elTeorema 1: Una aplicacion entre dos espacios vectoriales euclıdeos es una aplicacion ortogonal
si y solo si es lineal y conserva el modulo de los vectores.Como aplicacion de este teorema podemos deducir que los giros y las simetrıas del plano son
aplicaciones ortogonales. Puesto que son lineales y conservan los modulos.El dibujo siguiente muestra como las simetrıas son lineales:
-3
1
s(v)
s(v’)s(v+v’)
6
vv’
v+v’
Observando tambien que la imagen de un giro por un paralelogramo es un paralelogramo, con-cluimos que un giro es una aplicacion lineal.
Otra propiedad importante de las aplicaciones ortogonales es que conservan la ortogonalidad devectores, es decir, dos vectores son ortogonales si y solo si sus imagenes por la aplicacion ortogonalson ortogonales.
385

Debido a ello, tenemos elTeorema 2: Una aplicacion lineal entre espacios vectoriales euclıdeos de la misma dimension es
ortogonal si y solo si es lineal y transforma una base ortonormal en otra base ortonormal.Cuya demostracion se deja como ejercicio.
Corolario 1: Si A es la matriz de una transformacion ortogonal en una base ortonormal, tA ·A =I. Esta condicion de la matriz es tambien suficiente para que la aplicacion sea ortogonal.
En efecto, las columnas de la matriz A son las coordenadas de los vectores de otra base ortonormal.Son de modulo 1 y al multiplicarlas escalarmente de manera cruzada obtenemos 0. La primeracondicion implica que la suma de los cuadrados de los elementos de cada columna es 1 y la segundaimplica que los productos de columnas diferentes elemento a elemento siguiendo un orden ascendenteo descendente son cero. Como las columnas de A son las filas de tA, al realizar el producto tA · Aestamos multiplicando columnas de A por columnas de A, por lo que sale I.
Este corolario se puede obtener tambien de la definicion de aplicacion ortogonal entre dos espaciosvectoriales:
Sea f una aplicacion ortogonal que se escribe en una determinada base por f(x) = Ax y sean G,G′ las matrices de los correspondientes productos escalares. Por conservar f el producto escalar hade ser:
(x1, x2, ...xn)G
y1
y2...yn
=< x, y >=< f(x), f(y) >= (x1, x2, ...xn)tAG′A
y1
y2...yn
cualesquiera que sean los vectores x e y. Entonces tenemos la igualdad de las matrices centrales:
G = tAG′A
Expresando f en bases ortonormales G = I = G′ , de donde tenemos:
tA · A = I
Corolario 2: Si A es la matriz de una aplicacion ortogonal entre espacios vectoriales de la mismadimension, A es una matriz invertible.
Demostracion:
386

Si los dos espacios vectoriales son de la misma dimension, la matriz correspondiente A es cuadraday como acabamos de obtener que si G y G′ son las matrices de los productos escalares en V y en V’,G = tAG′A, tenemos |G| = |tA||G′||A|, lo que implica |tA||A| = |G|/|G′| 6= 0.
Por tanto, una aplicacion ortogonal entre espacios de la misma dimension tiene inversa, la cuales tambien ortogonal, porque la conservacion del producto escalar se hace en los dos sentidos.
Por ello, si la transformacion ortogonal se ha expresado en una base ortonormal por A, la matrizA−1 existe y tambien verifica: A−1t ·A−1 = I expresion de la que al tomar inversas tenemos A·tA = I.Es decir que si A es cuadrada, y tA · A = I, tambien A · tA = I. Siguiendo el razonamiento a lainversa, se ve que esta condicion es suficiente para que la matriz corresponda en una base ortonormala una aplicacion ortogonal.
A las matrices cuadradas tales que tA · A = I o A · tA = I se les llama matrices ortogonales.
Ademas, Corolario 3: El determinante de la matriz de una transformacion ortogonal es 1 o −1.Demostracion:Si A es la matriz de una transformacion ortogonal expresada en una base ortonormal,
|tA||A| = |A|2 = 1
La matriz A′ de la transformacion en otra base esta relacionada con A por A′ = C−1AC de donde
|A′| = |C−1||A||C| = 1
|C||A||C| = |A| = ±1
Ejercicios:
11.1.1. Averiguar si son ortogonales los endomorfismos expresados en las bases canonicas de R2
o R3 (segun corresponda), por las matrices:
a)
(1√2− 1√
21√2
1√2
)b)
(1√2
1√2
1√2− 1√
2
)c)
0 1 1√2
1 0 00 0 1√
2
d)
−1√2
1√6
1√3
0 − 2√6
1√3
1√2
1√6
1√3
.
cuando se usa el producto escalar usual.
387

11.1.2. Sea E un espacio vectorial euclıdeo de dimension 3 y f un endomorfismo de ese espaciodado en una base ortonormal B = e1, e2, e3 por
7f(e1) = 2e1 + αe2 + βe3, 7f(e2) = 6e1 + 2e2 + γe3, 7f(e3) = 3e1 − 6e2 + 2e3
Hallar α, β, γ para que f sea ortogonal.11.1.3. Sea B = u1, u2, u3 una base de R3, donde u1 = (1, 1, 0), u2 = (1, 0, 1), u3 = (0, 1, 1).
Estudiar si son ortogonales los endomorfismos de R3 dados en esa base por las matrices:
a)
1 0 10 1 01 0 0
b)
1 1 10 −1 00 0 −1
11.1.4. Sea A la matriz de un endomorfismo f de R3 en la base canonica. Comprobar que si
A2 = I, f es ortogonal si y solo si la matriz A es simetrica.11.1.5. Sea U un subespacio de un espacio vectorial euclıdeo V , PU la proyeccion ortogonal de V
sobre U y PU⊥ la proyeccion ortogonal de V sobre U⊥.a) Comprobar que la aplicacion SU = PU − PU⊥ es una aplicacion ortogonal de V y S2 = I. (SU
es la simetrıa ortogonal respecto a U).b) Comprobar que SU = I − 2PU⊥ = 2PU − I.c) Justificar por que la matriz de la simetrıa ortogonal respecto a un subespacio vectorial de un
espacio vectorial euclıdeo expresada en una base ortonormal es simetrica.11.1.6. Demostrar que una aplicacion ortogonal de R3 solo admite como valores propios reales
los valores 1 y −1.11.1.7. Considerando una matriz ortogonal como unitaria, deducir que condicion han de cumplir
sus valores reales complejos.11.1.8. Demostrar que vectores propios de una aplicacion ortogonal correspondientes a valores
propios reales distintos son ortogonales.11.1.9. Sea f una transformacion ortogonal de un espacio vectorial V , y W un subespacio de V ,
invariante por f . Demostrar que W = f(W ).11.1.10. Sea f una transformacion ortogonal de un espacio vectorial V , y W un subespacio de V ,
invariante por f . Demostrar que W es tambien invariante por f−1.11.1.11. Sea f una transformacion ortogonal de un espacio vectorial euclıdeo V y W un subespacio
de V invariante por f . Demostrar que W⊥ es invariante por f .
388

Estudio de las transformaciones ortogonales de R2.
Recordemos que las matrices de los giros de angulo φ son(cosφ −senφsenφ cosφ
)como se deduce del dibujo:
-7
6
φcosφ
senφ
e1
g(e1)
ZZ
ZZ
ZZZ
ZZZ
cosφ
senφ
e2
g(e2)
φ
y que dada una simetrıa respecto a una recta los vectores de esta recta quedan fijos y los vectoresperpendiculares a la recta se transforman en sus opuestos, por lo que en una base formada por unvector de la recta y otro perpendicular, la matriz de la simetrıa es(
1 00 −1
)Veremos a continuacion que solo hay estos dos tipos de transformaciones ortogonales en el plano.Para ello estudiamos las restricciones que da la condicion tA · A = I, necesaria y suficiente para
que la matriz A corresponda a una aplicacion ortogonal en una base ortonormal y las posibilidades detransformaciones ortogonales de un espacio vectorial euclıdeo en R2 expresadas en la base canonica.
Teorema 3. Las transformaciones ortogonales de R2 son giros alrededor del origen o simetrıasortogonales respecto a rectas.
Demostracion: Sea
389

A =
(a cb d
)la matriz de una transformacion ortogonal en la base canonica.
A es ortogonal si y solo si
(a bc d
)(a cb d
)= I ≡
a2 + b2 = 1c2 + d2 = 1ac+ bd = 0
La primera ecuacion hace que podamos expresar
a = cosφ, b = senφ
La ultima ecuacion da
ac = −bd, de donde, si a 6= 0 y b 6= 0,d
a= −c
b= k
Entonces, la segunda ecuacion da entonces:
1 = k2b2 + k2a2 = k2(a2 + b2) = k2,
por lo que k = ±1.Si k = 1, d = a, c = −b, y si k = −1, d = −a, c = b. Con lo que las posibles matrices a obtener
cuando a 6= 0 6= b, son:Si k = 1, (
cosφ −senφsenφ cosφ
)correspondiente a un giro de angulo φ
Si k = −1, (cosφ senφsenφ −cosφ
)que estudiaremos despues.
Cuando a = 0, por la primera ecuacion ha de ser b2 = 1, (b = ±1), y como b 6= 0, por la terceracondicion ha de ser d = 0, siendo por la segunda condicion, c2 = 1, obteniendose c = ±1, de dondelas posibles matrices en este caso son:(
0 11 0
) (0 −11 0
) (0 1−1 0
) (0 −1−1 0
)De estas, la segunda y la tercera son tambien giros de angulos π
2,−π
2.
390

Los razonamientos analogos cuando b = 0, dan a = ±1, c = 0 y d = ±1. Las posibles matricesen este caso son: (
1 00 1
) (1 00 −1
) (−1 00 1
) (−1 00 −1
)De estas, la primera y la cuarta son tambien giros de angulos 0, π.
Podemos ver, (dibujando las imagenes de los vectores de la base de los ejes coordenados), quede las matrices obtenidas ultimamente para a = 0 o b = 0 las matrices que no corresponden a giros,corresponden a simetrıas ortogonales respecto a las diagonales o respecto a los ejes coordenados.
Dada esta situacion nos preguntamos si las transformaciones ortogonales de R2 que no son girosson simetrıas ortogonales respecto a una recta. De hecho ası ocurre y para ello estudiaremos la formageneral que nos quedaba: (
cosφ senφsenφ −cosφ
)segun sus vectores propios y valores propios.
El lector puede comprobar facilmente que todas las matrices numericas que surgieron anterior-mente y corresponden a simetrıas, se pueden englobar en la forma general cuando φ = π/2, φ = −π/2,φ = 0 y φ = π.
El teorema 3 quedara completo cuando hayamos demostrado la
Proposicion 3: Si f es una transformacion ortogonal de R2 de matriz(cosφ senφsenφ −cosφ
)f es una simetrıa respecto a una recta.
Demostracion:Esta matriz es una matriz simetrica, por lo que es diagonalizable y si tiene dos valores propios
distintos es diagonalizable en una base ortogonal.Hallemos sus valores propios:∣∣∣∣ cosφ− λ senφ
senφ −cosφ− λ
∣∣∣∣ = (cosφ− λ)(−cosφ− λ)− sen2φ =
= λ2 − cos2φ− sen2φ = λ2 − 1 = 0
391

tiene las dos soluciones λ = 1 y λ = −1 como valores propios.Entonces, si f(v1) = v1 y f(v2) = −v2, < v1, v2 >= 0.Si f(v1) = v1 y f(v2) = −v2, la recta engendrada por v1 queda fija por f y la recta engendrada
por v2 (que es perpendicular a la anterior), se transforma simetricamente respecto al origen. Por serf lineal, f queda determinada por su efecto en estas dos rectas y resulta ser la simetrıa ortogonalrespecto a la recta fija, ya que serıa:
f(v) = f(x1v1 + x2v2) = x1f(v1) + x2f(v2) = x1v1 + x2(−v2) = x1v1 − x2v2.
Haciendo el dibujo se ve que el vector f(v) es el vector simetrico del vector v respecto a la rectadeterminada por el vector v1.
v1
@@@@R−x2v2
@@
@@I
@@Iv2
x2v2
1
f(v)
x1v1
v
@
@
@
@
@
Para el lector que no haya estudiado la diagonalizacion de matrices simetricas, una vez que tenemos los dosvalores propios de esta transformacion ortogonal, vemos que los dos vectores propios correspondientes son ortogonaleshaciendo el siguiete razonamiento:
< v1, v2 >=< f(v1), f(v2) >=< v1,−v2 >= − < v1, v2 >⇒< v1, v2 >= 0
Conviene saber distinguir mediante calculos los giros de las simetrıas. Para ello vemos la proposicionsiguiente:
392

Proposicion 4: El determinante de la matriz de un endomorfismo es un invariante del endo-morfismo (no depende de la base en que se haya expresado el endomorfismo).
Demostracion:Sea f(x) = Ax en una determinada base. Al hacer un cambio de base, la matriz de f se transforma
en A′ = C−1AC cuyo determinante es
|A′| = |C−1AC| = |C−1||A||C| = 1
|C||A||C| = |A|
Volviendo a mirar las matrices obtenidas para los giros y para las simetrıas de R2 en la basecanonica, en el primer estudio que hemos hecho, vemos que los giros tienen determinante 1 y lassimetrıas determinante −1. Debido a la invariancia del determinante de la matriz en un cambio debase, este es 1 para los giros y −1 para las simetrıas axiales, cualquiera que sea la base en la que seexpresen. Distinguiendose los giros de las simetrıas por el valor del determinante.
Desde el punto de vista de los valores propios, recordemos que las simetrıas axiales son las quetienen dos valores propios distintos y son diagonalizables, por ello, el determinante de su matriz esel producto de sus valores propios que es −1.
El giro de angulo cero es la identidad y el giro de angulo π es la simetrıa central respecto alorigen. Los demas giros no dejan ninguna direccion fija, por lo que no tienen valores propios reales.
El eje de una simetrıa es el conjunto de vectores fijos por la simetrıa, que es tambien el conjuntode vectores propios para el valor propio 1.
El angulo de un giro de R2 viene dado por su coseno y su seno, que son los numeros de la primeracolumna de su matriz en la base canonica. Si el giro no viene dado en la base canonica, se puedehallar el seno y el coseno del angulo haciendo el cambio de base de la matriz dada a la base canonica.
Ejercicios:
11.2.1. Comprobar que la matriz:
1/5
(4 −3−3 −4
)corresponde a una simetrıa ortogonal dada en la base canonica de R2.
Hallar su eje de simetrıa.11.2.2. Considerar las aplicaciones lineales de R2 dadas en la base (1, 0), (1, 1) por las matrices:
393

a) 1/2
(0 2√
2√2 0
)b) 1/2
( √3− 1 −2
1 1 +√
3
)Determinar
a) Si son ortogonales.b) Cual corresponde a un giro y cual corresponde a una simetrıa.c) El angulo del giro en su caso.d) El eje de la simetrıa en su caso.11.2.3. Hallar la matriz en la base canonicaa) del giro que lleva el eje OX a la recta de ecuacion 2x+ y = 0.b) del giro que lleva la recta de ecuacion 2x+ y = 0 al eje OX.c) de la simetrıa ortogonal respecto a la recta de ecuacion 2x+ y = 0.
394

Estudio de las transformaciones ortogonales de R3.
Teorema 5.Las transformaciones ortogonales de R3 son simetrıas respecto a planos, rotaciones vectoriales o
productos de ambas.
Demostracion:Cualquier aplicacion lineal f de R3 en R3 tiene al menos un valor propio real por ser impar
el grado de su polinomio caracterıstico. Los valores propios reales de las aplicaciones ortogonalesson 1 o −1. Sea v1 el vector propio correspondiente tal que f(v1) = v1 o f(v1) = −v1, entonces,W = Lv1 es un subespacio invariante, por lo que tambien, W⊥ es un plano invariante por laaplicacion ortogonal (Ejercicio 11.1.11). Por ser un plano, es isomorfo a R2 y la restriccion al planode la transformacion ortogonal es una de las estudiadas anteriormente. Segun hemos visto al estudiarlas transformaciones ortogonales de R2, la restriccion de la transformacion ortogonal al plano es ungiro o una simetrıa y existe una base ortonormal del plano W⊥: v2, v3 en la que esta restricciontiene la matriz del giro: (
cosϕ −senϕsenϕ cosϕ
)o la de la simetrıa: (
cosϕ senϕsenϕ −cosϕ
).
Las posibles combinaciones de las actuaciones de la transformacion ortogonal sobre W y sobre W⊥
dan las posibles transformaciones ortogonales de R3. En principio son cuatro, las posibles matricesque se obtienen para la transformacion ortogonal en la base Lv1, v2, v3:
1 0 00 cosφ −senφ0 senφ cosφ
−1 0 00 cosφ −senφ0 senφ cosφ
1 0 00 cosφ senφ0 senφ −cosφ
−1 0 00 cosφ senφ0 senφ −cosφ
Las transformaciones ortogonales del tipo primero dejan fijo el eje engendrado por v1 y realizan un
giro de angulo φ en el plano perpendicular a este eje. Como la aplicacion es lineal, descomponiendocada vector en sus componentes segun el eje y el plano, se ve que la transformacion ortogonal esuna rotacion vectorial alrededor del eje. (Se ve tambien que todos los planos perpendiculares al ejeengendrado por v1 son invariantes, aunque estos planos no son subespacios vectoriales de R3).
395

@@@@@@R
AAAAAAK
ZZZZZZ
v
v’
A(v)
A(v’)
ϕ
O
ϕ
BBBBBBBBBBN
AAAAAAKJJJJJ
v”
v’
A(v”)
A(v’)
O
ϕ
En la segunda se realiza un giro en el plano v2, v3 y se cambia de signo el vector v1. Se puedenhacer los dos pasos en dos etapas seguidas correspondientes a hacer primero una rotacion vectorialy despues una simetrıa precisamente respecto al plano perpendicular al eje de giro de la rotacionvectorial. Los vectores del eje de la rotacion se transforman en sus opuestos, por tanto, aunque eleje ya no es una recta de vectores fijos, sı es una recta invariante, globalmente considerada.
JJJJ]
AAAAAAAAU
@@@@R
@@
@@
−→v
p(−→v )
A(p(−→v ))ϕ
A(−→v )
396

Para entender la tercera y la cuarta, tengamos en cuenta que la restriccion de la transformacionortogonal a W⊥ es una simetrıa axial, por lo que existen vectores v′2 y v′3 en este plano, ortogonalesentre sı, tales que f(v′2) = v′2 y f(v′3) = −v′3. Entonces v1, v
′2, v′3 son una base de R3 en la que f se
expresa por
a)
1 0 00 1 00 0 −1
o b)
−1 0 00 1 00 0 −1
En las transformaciones ortogonales del tipo a), queda fijo el plano v1, v
′2 y cambia de signo el
vector v′3. Por ello, estas aplicaciones son simetrıas respecto al plano v1, v′2.
En las transformaciones ortogonales del tipo b), queda fija la recta v′2 y cambian de signo losvectores del plano v1, v
′3. Por ello, son simetrıas respecto a la recta v′2 que tambien se pueden
considerar rotaciones vectoriales de angulo π respecto a la recta fija.Hemos demostrado ası el teorema.
Solo diremos que una tranformacion ortogonal de R3 es una composicion de rotacion vectorialcon simetrıa si la rotacion vectorial que aparece en ella es de angulo distinto de cero.
Para distinguir entre sı los distintos tipos de transformaciones ortogonales de R3 consideramosel invariante determinante (ya visto) y ademas otro invariante que es la traza de la matriz delendomorfismo: (La traza es la suma de los elementos de la diagonal de la matriz del endomorfismo).
Proposicion 5: La traza de la matriz de un endomorfismo es un invariante del endomorfismo.Demostracion: La matriz del endomorfismo, despues de hacer el cambio de base es A′ = C−1AC;
entonces,
|A′ − λI| = |C−1AC − λI| = |C−1(A− λI)C| = |C−1||A− λI||C| = 1
|C||A− λI||C| = |A− λI|
Por tanto, los coeficientes de este polinomio son invariantes de f . El coeficiente de λn−1 en estepolinomio es (−1)n−1traza(A), por tanto, la traza de A es invariante.
Clasificacion y caracterizacion de las transformaciones ortogonales de R3.
Las rotaciones vectoriales son las unicas que tienen determinante positivo (=1). El eje de unarotacion vectorial es la recta engendrada por el vector propio de la transformacion ortogonal parael valor propio 1. El plano perpendicular a este eje es invariante. El angulo de la rotacion vectorialverifica
1 + 2cosφ = traza(rot)
397

Si cosφ = 1, φ = 0, si cosφ = −1, φ = π. Cada valor del coseno distinto de 1 y de −1, determinael angulo salvo el signo, es decir, salvo el sentido de giro. Dados dos vectores u2, u3 hay dos sentidosde giro de u2 hacia u3: el sentido del arco mas corto que va de u2 hacia u3 y que es el que usualmentese considera como giro de u2 hacia u3 y el opuesto, que es el sentido del arco mas largo va de u2 haciau3 y es el mismo que el sentido del arco que lleva u3 hacia u2 por el arco mas corto. La distinciondel signo del angulo de giro, o lo que es lo mismo, del sentido del giro en la rotacion vectorial se hacecon referencia a una base ortonormal escogida en el plano de rotacion. Si esta base es u2, u3 y sisenang(u2, f(u2)) > 0, como senang(u2, f(u2)) es la proyeccion de f(u2) sobre la recta de direccionu3, la rotacion va de u2 hacia u3 por el arco mas corto, y si senang(u2, f(u2)) < 0, va de u2 haciau3 por el arco mas largo, lo que tambien es de u3 hacia u2 por el arco mas corto, segun se ve en eldibujo siguiente:
6
-@@
@@@I
@@@@@
@@@
@@
@@@I
@@@@@
@@@
u2u3
f(u2)senφ > 0
senφ
u2u3
f(u2)
senφ < 0
senφ
Este seno se calcula por
senang(u2, f(u2)) = cosang(f(u2), u3) =< f(u2), u3 >
|f(u2)||u3|
Puede verse que es suficiente que u2, u3 sean ortogonales para calcular el seno del angulo, locual nos proporciona numeros mas sencillos a la hora de hacer el calculo. En efecto, utilizando αu2
y βu3 donde α > 0 y β > 0, en lugar de u2 y u3, se ve que la fraccion final del calculo anterior es lamisma. Y como solo nos interesa el signo, tampoco hay que calcular |f(u2)||u3|.
Los otros dos tipos tienen determinante negativo (= −1), pero se pueden distinguir entre sı porla traza, que es 1 en el caso de las simetrıas respecto a un plano y −1 + 2cosφ 6= 1 si φ 6= 0 en lacomposicion de rotacion vectorial con la simetrıa respecto a un plano.
El plano de simetrıa de una simetrıa es el subespacio de vectores fijos, es decir, de vectores propiospara el valor propio 1.
398

En cuanto al caso del producto de la rotacion vectorial por la simetrıa, los vectores del eje de larotacion vectorial que interviene se transforman en sus opuestos. Constituyen la recta engendrada porel vector propio correspondiente al valor propio −1. Globalmente considerado, es un eje invariantede la transformacion ortogonal, aunque sus vectores no nulos no son fijos.
En el plano de simetrıa de la simetrıa que interviene se realiza solamente la rotacion. Este planoes, globalmente considerado, invariante por la transformacion ortogonal. Es perpendicular al eje devectores propios para el valor propio −1.
El coseno del angulo de dicha rotacion vectorial viene dado por la traza, segun la formula:
−1 + 2cosφ = traza(f)
Para cada valor del coseno distinto de 1 y de −1, hay dos angulos opuestos posibles. La distinciondel signo del angulo de giro, o lo que es lo mismo del sentido del giro en la rotacion vectorial se hacecon referencia a una base ortonormal escogida en el plano de rotacion. Si esta base es u2, u3, larotacion va de u2 hacia u3 en el sentido del arco mas corto si senang(u2, f(u2)) > 0 y va de u3 haciau2 en el sentido del arco mas corto si senang(u2, f(u2)) < 0. Este seno se calcula por
senang(u2, f(u2)) = cos(ang(f(u2), u3)) =< f(u2), u3 >
|f(u2)||u3|Como solo nos interesa el signo del seno del angulo, podemos coger u2, u3 simplemente ortogonalesy no necesitamos calcular |f(u2)||u3|.
Ejemplo a:Consideremos la aplicacion ortogonal dada por
f
xyz
=1
9
7 4 −44 1 8−4 8 1
xyz
Se determina que transformacion ortogonal es, por el determinante y la traza de la matriz. El
determinante es −1 y la traza es 1; se trata, por tanto, de una simetrıa ortogonal respecto a unplano. Este plano es el plano de vectores fijos. Los vectores de la recta perpendicular a este plano setransforman en sus opuestos, por lo que esta recta, considerada globalmente es tambien invariante.
Los vectores fijos de la aplicacion f son los que verifican: xyz
=1
9
7 4 −44 1 8−4 8 1
xyz
399

de donde se obtienen las ecuaciones:
9x = 7x +4y −4z9y = 4x +y +8z
9z = −4x +8y +z
≡−2x +4y −4z = 04x −8y +8z = 0−4x +8y −8z = 0
≡ x− 2y + 2z = 0
y forman por tanto un plano de vectores fijos que es el plano de simetrıa. La recta vectorial invariante(no de vectores fijos) esta engendrada por el vector (1,−2, 2).
Todas las rectas paralelas a la recta vectorial invariante son invariantes en la simetrıa pero lasque no pasan por el origen no son subespacios vectoriales.
Ejemplo b:Estudiemos ahora la aplicacion ortogonal dada por
f
xyz
=1
3
2 2 1−2 1 2
1 −2 2
xyz
.
Determinamos el tipo de transformacion ortogonal que es, viendo el valor del determinante y dela traza de la matriz. En este caso solo necesitamos el determinante porque siendo este 1, se tratade una rotacion vectorial. Su eje de vectores fijos es la recta solucion del sistema:
xyz
=1
3
2 2 1−2 1 2
1 −2 2
xyz
≡ 2x +2y +z = 3x−2x +y +2z = 3yx −2y +2z = 3z
≡ −2x −2y +2z = 0x −2y −z = 0
≡ x +y −z = 0x −2y −z = 0
≡ x −2y −z = 0
3y = 0
x −z = 0
y = 0
Su vector director es (1, 0, 1).En el plano perpendicular a este eje, de ecuacion x + z = 0, los vectores giran un angulo φ
permaneciendo en el plano, por lo que este plano vectorial es invariante globalmente considerado.Podemos hallar tambien el angulo de la rotacion vectorial: Llamando A a la matriz de la aplicacion
ortogonal:
1 + 2cosφ = Traza(A) =1
3· 5 =⇒ cosφ =
1
3=⇒ |φ| = arccos
1
3.
400

El signo del angulo indica el sentido del giro; lo podemos determinar escogiendo una base ortogonaldel plano de direccion de los planos invariantes. Sea esta base: u2, u3 = (0, 1, 0), (1, 0,−1)(perpendiculares al eje de giro). Si el giro va en el sentido que lleva la direccion de u2 hacia ladireccion de u3 en el sentido del arco mas corto, el angulo en esta base es positivo, lo cual se producesi y solo si el seno del angulo que forma u2 con A(u2) es positivo (En caso contrario la rotacion llevala direcion y sentido de u3 hacia la direccion y sentido de u2 en el sentido del arco mas corto). Esteseno se puede hallar ası:
senφ = senang(u2, A(u2)) = cosang(A(u2), u3) =< A(u2), u3 >
|A(u2)||u3|En nuestro caso, ya que A(u2) = 1
3(2, 1,−2),
senφ =< 1
3(2, 1,−2) · (1, 0,−1) >
|A(u2)||u3|=
4
3|A(u2)||u3|> 0
Entonces, la rotacion es de angulo arccos13
siendo el sentido el que lleva la recta de direccion delvector (0, 1, 0) hacia la recta de direccion del vector (1, 0,−1) de forma que el vector (0, 1, 0) girahacia el vector (1, 0,−1) en el sentido del arco mas corto.
-
ϕ
El vector (0,1,0) va hacia adelante de derecha a izquierda.
Para los que les gusta utilizar el producto vectorial, observemos que si u2 gira hacia u3 en el sentido del arco mascorto, los productos vectoriales u2 ×A(u2) y u2 × u3 tienen el mismo sentido, por lo que al calcularlos cada uno tieneque ser multiplo positivo del otro.
401

Se puede observar que la eleccion de u3 esta determinada salvo el signo y por eso vamos a verahora que aunque cambiemos el signo de u3 el resultado del sentido de la rotacion es el mismo: Sihubiera sido u′3 = (−1, 0, 1),
senφ =< 1
3(2, 1,−2) · (−1, 0, 1) >
|A(u2)||u′3|=
−4
3|A(u2)||u3|< 0,
lo que indicarıa que el vector (0, 1, 0) gira en el sentido del arco mas largo que lo lleva hacia u′3 =(−1, 0, 1), pero este sentido es el del arco mas corto que lo lleva hacia u3 = (1, 0,−1).
Ejemplo c:Sea f una aplicacion ortogonal de R3 dada por:
f
xyz
=
x′
y′
z′
=1
3
2 2 −1−2 1 −2
1 −2 −2
xyz
≡ A
xyz
Es facil de comprobar que |A| = −1. Teniendo en cuenta solo el determinante de la matriz, te-
nemos dos posibilidades para la aplicacion ortogonal: una simetrıa o una composicion de simetrıa conrotacion vectorial. Pero la aplicacion ortogonal no es una simetrıa porque la traza de A es 1/3, enlugar de ser 1.
Segun hemos visto teoricamente, esta aplicacion ortogonal tiene un unico vector fijo que es el ceroy es una rotacion vectorial compuesta con simetrıa.
En efecto, los vectores fijos de f son las soluciones del sistema:
xyz
=1
3
2 2 −1−2 1 −2
1 −2 −2
xyz
≡ 3x = 2x +2y −z3y = −2x +y −2z3z = x −2y −2z
≡0 = −x +2y −z0 = −2x −2y −2z0 = x −2y −5z
sistema de soluciones: x = 0, y = 0, z = 0, por ser el determinante de la matriz de coeficientes deeste sistema distinto de cero.
Hay una recta invariante por f (aunque sus vectores no son fijos), es el eje de la rotacion vectorialque interviene en f . El plano perpendicular al eje de la rotacion que interviene en f es tambieninvariante (aunque sus vectores no son fijos).
Para hallar la direccion de la recta invariante de f hallamos los vectores propios de A para elvalor propio −1:
−
xyz
=1
3
2 2 −1−2 1 −2
1 −2 −2
xyz
≡ −3x = 2x +2y −z−3y = −2x +y −2z−3z = x −2y −2z
≡402

≡0 = 5x +2y −z0 = −2x +4y −2z0 = x −2y +z
≡ 0 = x −2y +z0 = 12y −6z
≡ x −2y = −z
2y = z
Haciendo z = 1, obtenemos y = 1
2, x = 0, siendo por tanto, el vector de direccion del eje, (0, 1
2, 1) ∼
(0, 1, 2). El plano perpendicular a este eje, de ecuacion y + 2z = 0, queda invariante en la transfor-macion ortogonal. Solo hay un plano invariante. Los planos paralelos a este no son invariantes.
El coseno del angulo de la rotacion que interviene en f se puede hallar por la traza de la matrizA: −1 + 2cosφ = Traza(A) = 1
3, de donde cosφ = 2
3, siendo |φ| = arccos2
3.
El sentido de la rotacion respecto a una base ortogonal u2, u3 del plano vectorial invariante sedetermina de manera analoga a como se hacıa en las rotaciones vectoriales: dos vectores ortogonalesen el plano invariante (ortogonales tambien a la direccion de la recta invariante), son u2, u3 =(1, 0, 0), (0, 2,−1), Como A(u2) = 1
3(2,−2, 1), tenemos:
senang(u2, A(u2)) = cosang(A(u2), u3) =< 1
3(2,−2, 1)(0, 2,−1) >
|A(u2)||u3|=
1
3
−5
|A(u2)||u3|< 0
siendo, por tanto, el sentido del angulo el que lleva la recta de direccion del (0, 2,−1) hacia la rectade direccion del vector (1, 0, 0) de forma que el vector (0, 2,−1) gira hacia el vector (1, 0, 0) en elsentido del arco mas corto. O bien, el que lleva la recta engendrada por (1, 0, 0) hacia la engendradapor (0, 2,−1) de forma que el vector (1, 0, 0) gira hacia el vector (0, 2,−1) en el sentido del arco maslargo.
Observacion: Una vez visto el invariante traza para aplicaciones lineales, observemos que podemos usarlo en lastransformaciones ortogonales de R2 para reconocer los giros cuando la traza sea distinta de cero, lo cual nos ahorrael calculo del determinante. A pesar de ello puede haber giros de traza cero (de ±π/2). Las simetrıas siempre tienentraza cero. Si la traza es cero hay que recurrir al determinante para distinguir giros de simetrıas en R2. La traza siguesirviendo para calcular el coseno del angulo de giro.
Ejercicios:
11.3.1. Escribir la matriz de las siguientes aplicaciones ortogonales de R3:a) La simetrıa ortogonal respecto al origen.b) La simetrıa ortogonal respecto al eje coordenado OX.c) La simetrıa ortogonal respecto al plano coordenado z=0.11.3.2. i) Clasificar las transformaciones ortogonales de R2 o R3 dadas en la base canonica por
las matrices del ejercicio 1.1. y por las siguientes:
a)
0 0 11 0 00 1 0
b)
0 0 10 1 01 0 0
c)
0 1 01 0 00 0 1
d)
0 1 01 0 00 0 −1
e)
0 1 00 0 1−1 0 0
403

f)
0 −1 00 0 11 0 0
g)1
9
1 8 −48 1 4−4 4 7
h)1
7
2 6 33 2 −66 −3 2
i)1
3
2 −2 12 1 −21 2 2
j)
1
3
2 2 12 −1 −21 −2 2
k)1
3
2 2 −1−2 1 −2−1 2 2
l)1
9
7 4 −4−4 −1 −8
4 −8 −1
m)
−1√2− 1√
20
1√6− 1√
62√6
− 1√3
1√3
1√3
n)
− 1√2
0 − 1√2
13√
2− 4
3√
21
3√
223
13
23
o)
−1√2
0 − 1√2
1√6
2√6
1√6
1√3− 1√
31√3
ii) Si son giros, hallar el angulo de giro.iii) Si son rotaciones vectoriales, hallar el eje de rotacion y el angulo de giro.iv) Si son simetrıas, hallar el eje o el plano de simetrıa.v) Si son composicion de rotacion vectorial con simetrıa, hallar la recta invariante pero no fija, el
plano invariante y el angulo de la rotacion vectorial que interviene.11.3.3. Escribir la matriz de la simetrıa ortogonal de R3 respecto a la recta engendrada por el
vector (1,1,1).11.3.4. Escribir la matriz de la simetrıa ortogonal de R3 respecto al plano de ecuacion x+ z = 0.11.3.5. Escribir las matrices de las rotaciones vectoriales cuyo eje director es la recta de vector
(1, 1, 1) y cuyo angulo es π/6.11.3.6. Escribir la matriz de una rotacion vectorial que lleve el vector (3, 4, 5) al eje vertical en
sentido hacia arriba. (Indicacion: considerar una rotacion que lleve primero el vector a un planocoordenado conteniendo el eje vertical y despues otra rotacion en este ultimo plano).
11.3.7. Escribir la matriz de la rotacion vectorial de eje engendrado por (1, 1, 1) y que lleve(1, 0,−1) a (0, 1,−1).
11.3.8. Escribir la matriz de la rotacion vectorial compuesta con simetrıa de eje invariante en-gendrado por (1, 1, 1) y que lleve (2, 1, 0) a (−1, 0,−2).
11.3.9. Encontrar las transformaciones ortogonales de R3 que conmutan con la simetrıa respectoal plano horizontal.
404

Espacio Afın.
Hasta ahora hemos estudiado el espacio vectorial, que sirve de modelo matematico del espacioambiente cuando fijamos en este un punto que llamamos origen de coordenadas. Una vez fijado elorigen, cada punto determina un vector, que fijados tambien tres vectores representando las tresdimensiones del espacio, determina a su vez tres numeros reales que son las coordenadas del vectory por tanto del punto. Ası es como identificamos el espacio ambiente en que nos movemos con R3.
JJJJ]
BBBBBBBBBBN
@@@R
Haciendo operaciones con las coordenadas de los vectores, obtenemos propiedades de las figurasgeometricas, p. ej. hemos calculado distancias de puntos a planos que pasan por el origen. Ylas expresiones matriciales de ciertas proyecciones y simetrıas. Tambien podemos obtener areas yvolumenes cuyos lados son vectores conocidos usando el producto vectorial.
Pero aunque es muy util el modelo matematico espacio vectorial, tiene sus limitaciones, porquetodos los vectores tienen su origen comun, no habiendo vectores paralelos; todas las rectas co-rrespondientes a subespacios vectoriales pasan por el mismo punto (el origen); y todas las aplicacioneslineales dejan fijo el origen. Sin embargo, si miramos al espacio, percibimos que hay rectas que notienen puntos comunes y si pensamos en las aplicaciones del espacio en el mismo tambien aparecenaplicaciones que no dejan ningun punto fijo (como las traslaciones).
Para recoger mas propiedades del espacio, se construye en algebra lineal la estructura de espacioafın, haciendo las siguientes consideraciones:
405

Para tener en cuenta todos los vectores con distintos puntos origen, tenemos que considerar todoslos puntos del espacio como posibles orıgenes y hacernos la idea de que en cada punto hay colocadoun espacio vectorial que da una correspondencia biyectiva entre los puntos y los vectores.
JJJJ]
BBBBBBBBBBN
@@@R
JJJJ]
BBBBBBBBBBN
@@@R
JJJJ]
BBBBBBBBBBN
@@@R
Se pasa de un origen a otro por una traslacion, que tambien traslada un espacio vectorial a otro yrelaciona las distintas biyecciones entre el conjunto de puntos y el espacio vectorial. Las traslacionestransforman un vector en otro paralelo.
JJJJ]
BBBBBBBBBBN
@@@R
JJJJ]
BBBBBBBBBBN
@@@R
O
O’
:
406

Todo este entramado se recoge en la estructura de espacio afın.
Es decir, el espacio afın esta formado por todos los espacios vectoriales que se pueden construir conorigen en todos los puntos del espacio, relacionados entre sı por las traslaciones. Axiomaticamente,se expresa ası:
Definicion 2: Un espacio afın es un conjunto de puntos A con un espacio vectorial asociado:E, tal que a cada pareja ordenada de puntos (p, q) ∈ A × A corresponde un vector −→pq ∈ E y estacorrespondencia tiene las propiedades:
a) Fijado p ∈ A, la aplicacion que a cada q ∈ A hace corresponder el vector −→pq ∈ E es biyectiva.b) Dados tres puntos p q y r,
−→pq +−→qr = −→pr
1
>
p
q
r
En este conjunto llamado espacio afın existen asociadas a cada vector del espacio vectorial abs-tracto unas aplicaciones llamadas traslaciones definidas de la siguiente forma:
A cada vector u ∈ E le asociamos la traslacion Tu : A −→ A que hace corresponder a cada puntop el unico punto q tal que −→pq = u.
Las traslaciones tienen las siguientes propiedades: (en correspondencia con a) y b))α) ∀(p, q) ∈ A×A existe un vector unico u ∈ E tal que Tu(p) = q.β) Tu Tv = Tu+v donde u y v son dos vectores cualesquiera de E.
407

El vector −→pq es paralelo al vector−→p′q′ si existe u ∈ E, tal que Tu(p) = p′ y Tu(q) = q′. (−→pq coincide
con−→p′q′ en el espacio vectorial E).
*
*
p
p’
q
q’
u
u
En el espacio afın, para operar, asociamos a cada punto un conjunto de numeros, escogiendo,en lugar de una base, un sistema de referencia formado por un punto del conjunto y una base delespacio vectorial asociado, lo que permite que cada punto este determinado por las coordenadas delvector con origen en el punto del sistema de referencia y extremo el punto considerado. Ası vamos apoder sacar propiedades geometricas haciendo operaciones aritmeticas.
Concretando, sea A3 el espacio en que vivimos y O, e1, e2, e3 un sistema de referencia de A3
donde O ∈ A3 y e1, e2, e3 son tres vectores no coplanarios, las coordenadas de un punto p en dicho
sistema de referencia son las del vector−→Op en la base e1, e2, e3.
El punto p tiene de coordenadas (p1, p2, p3) si−→Op = p1e1 + p2e2 + p3e3. El punto q tiene de
coordenadas (q1, q2, q3) si−→Oq = q1e1 + q2e2 + q3e3. Dos puntos distintos p y q determinan un vector
−→pq de origen p y extremo q. Por la propiedad b) del espacio afın
−→Op+−→pq =
−→Oq,
6
-
1
>
O
p
q
408

de donde−→pq =
−→Oq −
−→Op = (q1 − p1)e1 + (q2 − p2)e2 + (q3 − p3)e3
teniendose que las coordenadas de −→pq son la diferencia de las coordenadas de los puntos p y q; poreso se representa
−→pq = q − p y q = p+−→pq.
Distintos orıgenes dan distintas coordenadas de los puntos p y q, pero mientras mantengamos labase e1, e2, e3, las coordenadas del vector ~pq son las mismas.
6
-
1
@@
@@
@I
O
p
q
6
-
O’
−→pq =−→Oq −
−→Op =
−→O′q −
−→O′p
409

Las aplicaciones afines del espacio afın en el mismo son las que respetan la estructura de espacioafın, esto quiere decir que
Definicion 3: Una aplicacion f de un espacio afın en el mismo es una aplicacion afın si existe
una aplicacion lineal asociada f : E −→ E en el espacio vectorial asociado tal que−−−−−→f(p)f(q) = f(−→pq).
Se deduce de esta definicion que vectores paralelos se transforman en vectores paralelos.
Las aplicaciones afines mas simples son las Traslaciones.Una traslacion Tu de vector u = (u1, u2, u3) aplica cada punto p en el punto Tu(p) tal que
−−−−→pTu(p) = u, es decir, en el punto Tu(p) = p+ u. Verifica la condicion de aplicacion afın, ya que
−−−−−−−→Tu(p)Tu(q) = q + u− (p+ u) = q − p = −→pq = I(−→pq)
donde I es la aplicacion lineal identidad asociada.Se expresa por:
Tu
x1
x2
x3
=
u1
u2
u3
+
x1
x2
x3
=
u1
u2
u3
+ I
x1
x2
x3
Respecto a las aplicaciones afines en general, con la notacion anterior podemos escribir:
f(q) = f(p) +−−−−−→f(p)f(q) = f(p) + f(−→pq).
Esta expresion indica que la aplicacion afın es homogenea respecto al espacio afın, siendo laaplicacion lineal f la que da la homogeneidad.
Ahora queremos hallar la expresion analıtica general de una aplicacion afın, es decir, la expresion
matricial que da la relacion entre las coordenadas (x1, x2, x3) de p (−→Op = x1e1 + x2e2 + x3e3) y las
(x′1, x′2, x′3) de f(p) (
−−−→Of(p) = (x′1e1 + x′2e2 + x′3e3)).
Por las propiedades del espacio afın,−−−→Of(p) =
−−−−→Of(O) +
−−−−−−→f(O)f(p) y por ser f una aplicacion afın,
existe una aplicacion lineal f tal que−−−−−−→f(O)f(p) = f(
−→Op), Entonces, denotando por (a1, a2, a3) las
coordenadas de−−−−→Of(O), y A la matriz de f tenemos: x′1
x′2x′3
= f
x1
x2
x3
=
a1
a2
a3
+ A
x1
x2
x3
para una aplicacion afın.
En una traslacion (a1, a2, a3) = (u1, u2, u3) ya que−−−−→Of(O) = (u1, u2, u3) y A = I
410

Si el punto O queda fijo por f , f(O) = O, teniendose (a1, a2, a3) = (0, 0, 0) y la expresion de laaplicacion afın coincide con la expresion de una aplicacion lineal vectorial. Las aplicaciones linealesson casos particulares de las aplicaciones afines.
Segun la expresion anterior de las aplicaciones afines, toda aplicacion afın es composicion de unatraslacion con una aplicacion lineal.
Para determinar una aplicacion afın tenemos que conocer como actua la aplicacion lineal asociadasobre los vectores del espacio vectorial asociado y como se transforma el origen escogido del sistemade referencia. Sin embargo, la imagen del origen del sistema de referencia puede deducirse tambien,conocida la aplicacion lineal asociada, al conocer la imagen de cualquier otro punto.
Ejemplo 1:1. Obtener la expresion analıtica de la rotacion en sentido positivo en R3 de angulo π/2 cuyo eje
es la recta de ecuaciones x = 1, y = 1. (el sentido positivo es el sentido de giro de un sacacorchosque avanza hacia la direccion positiva del eje OZ).
En esta aplicacion todos los vectores paralelos al plano horizontal giran un angulo de π/2, y losvectores verticales quedan fijos si estan en el eje o se transforman en otros paralelos a ellos, por esoes una aplicacion afın. Su aplicacion lineal asociada es una rotacion vectorial y sabemos escribir lamatriz que le corresponde en la base canonica. La imagen del origen puede verse haciendo un dibujocomprobando que es el punto (2, 0, 0):
@@
@@@
(1,1)
(2,0)
π2
HHHH
π2
(2,0,0)
411

Entonces la expresion analıtica de la aplicacion en el sistema de referencia O;u1, u2, u3 es
f
xyz
=
x′
y′
z′
=
200
+
cosπ2−senπ
20
senπ2
cosπ2
00 0 1
xyz
≡ x′
y′
z′
=
200
+
0 −1 01 0 00 0 1
xyz
Hay veces que no es facil ver mediante un dibujo la imagen del origen pero la existencia de otro
punto fijo o el conocimiento de la imagen de algun punto puede servir para calcular el vector a.En el ejemplo anterior, como el punto (1, 1, 0) es fijo, ha de ser: 1
10
= f
110
=
a1
a2
a3
+
0 −1 01 0 00 0 1
110
de donde resulta
1 = a1 − 11 = a2 + 10 = a3
≡ a1
a2
a3
=
200
igual que haciendo el dibujo.
Por otra parte observemos que la expresion de esta aplicacion afın en el sistema de referencia(1, 1, 0); (1, 0, 0), (0, 1, 0), (0, 0, 1) es:
f
xyz
=
0 −1 01 0 00 0 1
xyz
(Como si fuera lineal). Ya que en este sistema de referencia el origen coincide con su imagen.
Ejercicios:
11.4.1. Escribir la expresion analıtica de la traslacion de R3 de vector (2, 1, 0).11.4.2. Encontrar la expresion analıtica de las siguientes aplicaciones afines de R2:a) Giro de centro (1, 1) y angulo 2π/3.b) Giro de angulo π/2 que lleve (1, 1) a (2, 2).
412

c) Simetrıa ortogonal de R2 respecto a la recta de ecuacion x+ y + 1 = 0.11.4.3. Encontrar la expresion analıtica de las siguientes aplicaciones afines de R3:a) Proyeccion ortogonal de R3 sobre el plano de ecuacion x+ z = 1.b) Simetrıa ortogonal de R3 respecto al plano de ecuacion x+ z = 1.c) Rotaciones vectoriales de angulos π/6, cuyo eje es la recta que pasa por los puntos (1, 1, 0) y
(0, 0,−1).11.4.4. Hallar la expresion analıtica de las dos aplicaciones afines que se pueden obtener com-
poniendo entre sı dos de las aplicaciones de los dos ejercicios 11.4.2. y 11.4.3. respectivamente.Comprobar que la composicion de aplicaciones afines no es conmutativa.
413

Aplicaciones afines con puntos fijos.Aunque el punto origen O del primer sistema de referencia no quede fijo puede existir otro punto
que quede fijo. Como en el espacio afın podemos escoger cualquier punto como origen, podemos cogercomo nuevo origen ese punto fijo, si existe; entonces, cambiando el origen del sistema de referenciaa ese punto fijo, sin cambiar los vectores de la base de E, la expresion de la aplicacion afın cambiadando lugar a la anulacion del vector (a1, a2, a3) pero dejando igual la matriz A, de forma que laexpresion de la aplicacion afın coincide con la expresion de una aplicacion vectorial con la mismamatriz A y como tal se puede interpretar.
Ejemplo 2:Consideremos la aplicacion afın de A3 dada en el sistema de referencia canonico por
M
xyz
=1
3
422
+1
3
−1 −2 −2−2 2 −1−2 −1 2
xyz
Los puntos fijos de la aplicacion afın M son los que verifican: x
yz
= M
xyz
=1
3
422
+1
3
−1 −2 −2−2 2 −1−2 −1 2
xyz
de donde se obtienen las ecuaciones:
3x = 4 −x −2y −2z3y = 2 −2x +2y −z3z = 2 −2x −y +2z
≡4x +2y +2z = 42x +y +z = 22x +y +z = 2
≡ 2x+ y + z = 2
y forman por tanto un plano de puntos fijos. Cogiendo como nuevo origen un punto O en este plano,la aplicacion afın se escribe en O; (1, 0, 0), (0, 1, 0), (0, 0, 1) por
M
xyz
=1
3
−1 −2 −2−2 2 −1−2 −1 2
xyz
lo cual la hace equivalente a una transformacion ortogonal ya que, llamando A a su matriz, tA·A = I.Se determina que transformacion ortogonal es por el determinante y la traza de la matriz. Eldeterminante es −1 y la traza es 1; se trata de una simetrıa ortogonal respecto a un plano. Esteplano es el antes hallado como plano de puntos fijos.
414

Las rectas perpendiculares al plano de puntos fijos son tambien invariantes globalmente consi-deradas, aunque sus puntos no son fijos. Ya que (α, β, 2− 2α − β) es la forma general de un puntodel plano, estas rectas son de ecuaciones parametricas: (x, y, z) = (α, β, 2− 2α− β) + λ(2, 1, 1).
Ejemplo 3:Estudiemos ahora la aplicacion afın de A3 dada en el sistema de referencia canonico, por
M
xyz
=1
3
112
+
0 1 00 0 −1−1 0 0
xyz
Para ver si tiene puntos fijos estudiamos si tiene solucion el sistema x
yz
=1
3
112
+
0 1 00 0 −1−1 0 0
xyz
≡ 13
+y = x13
−z = y23−x = z
Operando se tiene:
1 −3x +3y = 01 −3y −3z = 02 −3x − 3z = 0
≡3x −3y = 1
3y +3z = 13x +3z = 2
≡ 3x +3z = 23y +3z = 1
ecuaciones compatibles cuya solucion es una recta de puntos fijos. Cogiendo como nuevo origen unpunto O en esta recta, la aplicacion afın se escribe enO; (1, 0, 0), (0, 1, 0), (0, 0, 1) por
M
xyz
=
0 1 00 0 −1−1 0 0
xyz
que es equivalente a una transformacion ortogonal ya que, llamando A a su matriz, tA · A = I.Determinamos el tipo de transformacion ortogonal que es, viendo el valor del determinante y de latraza de la matriz. En este caso solo necesitamos el determinante porque siendo este 1, se trata deuna rotacion vectorial. Su eje de puntos fijos es la recta de puntos fijos hallada anteriormente, cuyasecuaciones parametricas son: x
yz
=1
3
210
+ λ
−1−1
1
Los planos perpendiculares a este eje son invariantes en la rotacion vectorial. Sus ecuaciones sonx+ y − z +D = 0.
415

Podemos hallar tambien el angulo de la rotacion vectorial: Llamando A a la matriz de la aplicacionafın:
1 + 2cosφ = Traza(A) =1
3· 0 = 0 =⇒ cosφ = −1
2=⇒ |φ| = 2π
3
El signo del angulo indica el sentido del giro; lo podemos determinar escogiendo una base ortogonaldel plano de direccion de los planos invariantes. Sea esta base: u2, u3 = (1, 0, 1), (1. − 2,−1)(perpendiculares al eje de giro). Si el giro va en el sentido que lleva la direccion de u2 hacia ladireccion de u3 por el arco mas corto, el angulo en esta base es positivo, lo cual se produce si y solosi el seno del angulo que forma u2 con A(u2) es positivo. Este seno se puede hallar ası:
senφ = senang(u2, A(u2)) = cosang(A(u2), u3) =< A(u2), u3 >
|A(u2)||u3|En nuestro caso, ya que A(u2) = (0,−1,−1),
senφ =3√2√
6=
√3
2> 0
Entonces el sentido del angulo 2π/3 es el que lleva la direccion del vector u2(1, 0, 1) hacia la direcciondel vector u3(1,−2,−1) en el sentido del arco mas corto.
JJJJJ]
El vector (1,0,1) va hacia abajo por delante.
416

Ejemplo 4:Sea M una aplicacion afın de R3 dada por:
M
xyz
=
x′
y′
z′
=
210
+
0 −1 00 0 −1−1 0 0
xyz
≡ a+ A
xyz
en el sistema de referencia (0, 0, 0); (1, 0, 0), (0, 1, 0), (0, 0, 1).
Los puntos fijos de M son las soluciones del sistema:
xyz
= M
xyz
=
210
+
0 −1 00 0 −1−1 0 0
xyz
≡ x = 2 −yy = 1 −zz = −x
sistema de soluciones: x = 1
2, y = 3
2, z = −1
2, siendo por tanto el punto O = (1
2, 3
2,−1
2), el unico
punto fijo de la aplicacion.En el sistema de referencia O; (1, 0, 0), (0, 1, 0), (0, 0, 1) la aplicacion afın se expresa por
M
xyz
= A
xyz
=
0 −1 00 0 −1−1 0 0
xyz
Entonces, la aplicacion afın es respecto a O, lo mismo que la aplicacion de la misma matriz esrespecto a (0, 0, 0); esta es una aplicacion ortogonal ya que tA · A = I. Es facil de comprobar que|A| = −1. Teniendo en cuenta solo el determinante de la matriz, tenemos dos posibilidades para laaplicacion ortogonal asociada: una simetrıa o una composicion de simetrıa con rotacion vectorial.Pero la aplicacion lineal asociada no es una simetrıa porque la traza de A es cero, en lugar de ser 1.Por tanto, es una rotacion vectorial compuesta con simetrıa.
Hay una recta invariante por M , es el eje de la rotacion vectorial que interviene en M y es eltrasladado del eje de la rotacion vectorial de matriz A al punto O. El plano trasladado a O del planoinvariante de la rotacion vectorial de matriz A, (que es perpendicular al eje de dicha rotacion) estambien invariante por M.
Para hallar la direccion de la recta invariante, hallamos los vectores propios de A para el valorpropio −1:
−
xyz
= A
xyz
=
0 −1 00 0 −1−1 0 0
xyz
≡ −x = −y−y = −z−z = −x
417

que es el eje de ecuaciones x = y = z, engendrado por el vector (1, 1, 1). Entonces, la recta invariantede M viene dada parametricamente por x
yz
=1
2
13−1
+ λ
111
En cuanto al plano invariante, que es el perpendicular a este eje pasando por O, tendra la ecuacion:
x+ y + z − 3
2= 0
para que se cumplan los dos requisitos.El angulo de la rotacion que interviene enM es el mismo que el angulo de la rotacion que interviene
en M y su coseno se puede hallar por la traza de la matriz A: −1+2cosφ = Traza(A) = 0, de dondecosφ = 1
2, siendo |φ| = π/3.
El sentido de la rotacion respecto a una base ortogonal u2, u3 del plano vectorial invariantese hace de manera analoga a como se hacıa en las transformaciones ortogonales: La direccion delplano invariante es x + y + z = 0; dos vectores ortogonales en dicho plano (ortogonales tambien ala direccion de la recta invariante), son u2, u3 = (1,−1, 0), (1, 1,−2), Como A(u2) = (1, 0,−1),tenemos:
senang(u2, A(u2)) = cosang(A(u2), u3) =< (1, 0,−1)(1, 1,−2) >√
2√
6=
3
2√
3=
√3
2> 0
siendo entonces el sentido del angulo el que lleva el vector (1,−1, 0) hacia el vector (1, 1,−2) en elsentido del arco mas corto.
Movimientos.
Definicion 3: Se llaman movimientos a las aplicaciones afines que conservan las distancias.
Las traslaciones son un ejemplo de movimientos. Las aplicaciones ortogonales consideradas comoaplicaciones afines son movimientos.
Tenemos la interesante Proposicion 7: Todo movimiento es composicion de una traslacion conuna transformacion ortogonal y recıprocamente.
En efecto, toda aplicacion afın f es composicion de una traslacion con una aplicacion vectorial fy en un movimiento,
‖−→pq‖ = ‖−−−−−→f(p)f(q)‖ = ‖f(−→pq)‖
418

conservando, por tanto, la aplicacion lineal f el modulo y siendo, por tanto, una aplicacion ortogonal.
Las aplicaciones afines de los tres ultimos ejemplos son movimientos.
Proposicion 8: La composicion de movimientos es un movimiento.Esta proposicion se sigue de que la composicion de aplicaciones afines es una aplicacion afın y de
que las distancias se siguen conservando en las dos aplicaciones.
El estudio de los movimientos consiste en el estudio de las aplicaciones afines cuya matriz A esortogonal y en el analisis de como el vector de traslacion a influye sobre la aplicacion ortogonal.Las distintas clases de movimientos en el espacio afın surgen al considerar las distintas clases de lasaplicaciones ortogonales asociadas y estudiar como el vector a de la traslacion asociada afecta a lossubespacios de puntos fijos de estas aplicaciones ortogonales.
Se llaman movimentos directos a los movimientos tales que el determinante de la matriz de laaplicacion ortogonal asociada es 1. Se llaman movimentos inversos a los movimientos tales que eldeterminante de la matriz de la aplicacion ortogonal asociada es −1.
Los movimientos con puntos fijos se identifican con las transformaciones ortogonales. Veremosque los movimientos que no tienen puntos fijos admiten descomposiciones llamadas canonicas quepermiten su interpretacion geometrica, en traslaciones llamadas canonicas compuestas con trans-formaciones ortogonales vectoriales tambien llamadas canonicas. Ası se obtienen en el plano y enel espacio, ademas de los giros y las simetrıas, las simetrıas deslizantes y los movimientos helicoidales.
Cada uno de ellos queda caracterizado por la naturaleza de ciertos subespacios que dejan inva-riantes y por los angulos de giro.
Dos movimientos son equivalentes si existe un isomorfismo del espacio que los pone en correspon-dencia. Este debe ser isomorfismo en el sentido afın y en el sentido euclıdeo.
En notacion matematica, dos movimentos f y g son equivalentes si existe otra aplicacion afınϕ, cuya aplicacion lineal asociada es un isomorfismo afın y euclıdeo, tal que ϕ f = g ϕ. Estaaplicacion afın ϕ transforma los subespacios afines invariantes de f en subespacios afines invariantesde g.
Por eso es importante calcular los subespacios invariantes.
Proposicion 9: Dos movimientos son equivalentes si y solo si existen dos sistemas de referenciaen los que ambos tienen la misma expresion analıtica.
En efecto, si f y g son equivalentes, el isomorfismo ϕ transforma un sistema de referencia en otrosistema de referencia en el que g tiene la misma expresion analıtica que f .
419

Recıprocamente, si existen dos sistemas de referencia en los que f y g tienen la misma expresionanalıtica, el isomorfismo ϕ que transforma uno de los dos sistemas de referencia en el otro da laequivalencia de los movimientos.
Movimientos en el plano:Segun ocurre en general, los movimentos del plano con puntos fijos se reducen a las transforma-
ciones ortogonales del plano, es decir, a los giros y a las simetrıas. Los movimientos del plano sinpuntos fijos pueden ser traslaciones o como veremos, simetrıas deslizantes.
1.1. Movimientos directos de A2.En estos movimientos del plano, la matriz A corresponde a un giro, por ser ortogonal y de
determinante 1.La matriz de un giro en R2 en cualquier base ortonormal es
A =
(cosφ −senφsenφ cosφ
)Entonces, la expresion analıtica general de un movimiento directo del plano en un sistema de
referencia con base ortonormal es:
f
(x1
x2
)=
(a1
a2
)+
(cosφ −senφsenφ cosφ
)(x1
x2
)Para ver si puede identificarse el movimiento a una transformacion ortogonal estudiamos la exis-
tencia de puntos fijos.Si la matriz A es la identidad, el movimiento es una traslacion y no tiene puntos fijos.Veamos lo que ocurre si A 6= I. Sus puntos fijos se obtendrıan resolviendo el sistema:(
x1
x2
)=
(a1
a2
)+
(cosφ −senφsenφ cosφ
)(x1
x2
)equivalente al (
−a1
−a2
)=
(cosφ− 1 −senφ
senφ cosφ− 1
)(x1
x2
)Aplicando el teorema de Rouche-Frobenius, vemos que al ser el determinante de la matriz de los
coeficientes del sistema |A| = (cosφ − 1)2 + (senφ)2 = 2(1 − cosφ) distinto de cero cuando A no esla matriz identidad, este sistema tiene solucion unica cuando el movimiento no es una traslacion.Como hemos dicho ya anteriormente, podemos coger este punto fijo C como origen del sistema dereferencia y al coincidir la expresion del movimiento en el nuevo sistema de referencia con la de la
420

aplicacion ortogonal asociada, identificando ambos, concluir que el movimiento es un giro alrededordel punto fijo C. Entonces, todo movimiento directo del plano es un giro alrededor de un punto ouna traslacion.
@@@@@@
-
%%
$$
AAAAAAAA
ϕϕ
P
A(P) M(P)−→a
CO
Si el movimiento viene dado en una base ortonormal, tanto el seno como el coseno del angulo degiro vienen dados directamente escritos en la matriz como a11, a21, respectivamente. Si viene dado enuna base no ortonormal, el coseno del angulo de giro puede determinarse por la traza de la matriz.
Dos traslaciones son equivalentes si y solo si coinciden sus vectores de traslacion. Dos giros sonequivalentes si y solo si tienen el mismo angulo.
1.2. Movimientos inversos de A2.En los movimientos inversos del plano el determinante de la matriz A es −1, por lo que la
aplicacion lineal asociada es una simetrıa.Para estudiar los puntos fijos de un movimiento inverso del plano hacemos la observacion geometrica
de que si el vector de traslacion a es perpendicular a la direcion fija (s) de la simetrıa vectorial dematriz A, trasladando en el plano afın el eje de la simetrıa vectorial segun un vector igual a la mitaddel vector de traslacion obtenemos una recta (e) de puntos invariantes por el movimiento.
421

e
s
P
A(P) P’
A(P’)
@
@
@
@
@
@
@@@@
@I
@@
@@I
M(P ) = A(P ) +−→a = Se(P )
−→a
−→a
Cogiendo como origen del sistema de referencia cualquiera de los puntos de la recta trasladada,el movimiento queda identificado a una simetrıa respecto a esta recta de puntos fijos. Todas lassimetrıas de este tipo son equivalentes.
Si el movimiento inverso del plano no tiene puntos fijos, de lo anterior se deduce que el vectorde traslacion no es perpendicular a la direccion fija de la simetrıa vectorial. Ahora bien, podemos
descomponer el vector a =−−−−−→OM(O) de la traslacion de la expresion dada en un vector perpendicular
c al eje fijo de la simetrıa vectorial asociada y un vector paralelo a dicho eje b.
422

Q
M(Q)
e
s
P
A(P)
−→b
−→a
A(P ) +−→a = M(P ) = Se(P ) +−→b
−→b
M2(P )
@
@
@@
@@I
@@@
@I
@
@
@@
@
@
@
@
Se(P ) = A(P ) +−→c
−→c
−→c
El movimiento dado es la composicion de la traslacion de vector b con el movimiento resultanteal hacer la composicion de la traslacion de vector c y de la transformacion ortogonal de la mismamatriz A dada. Esta segunda composicion es una simetrıa respecto a una recta de puntos fijos, porlo que el movimiento dado resulta ser la composicion de una traslacion de vector b paralelo al ejede simetrıa con una simetrıa de puntos fijos. Se llama simetrıa deslizante. La descomposicion quehemos hecho se llama descomposicion canonica de la simetrıa deslizante.
La simetrıa deslizante no tiene puntos fijos, pero el eje de simetrıa de su simetrıa canonica quedainvariante por su traslacion canonica y por tanto por la simetrıa deslizante total.
Haciendo un dibujo se puede ver que el vector de la traslacion canonica de la simetrıa deslizante es
la mitad del vector determinado por un punto P y la imagen M2(P ) del movimiento: b = 12
−−−−−→PM2(P ),
cualquiera que sea P. Para los calculos conviene tomar P = O, el origen de coordenadas.Dos simetrıas deslizantes son equivalentes si y solo si son iguales los vectores de sus traslaciones
canonicas.
Ejercicios:
11.5.1. Clasificar los movimientos de R2 dados por las siguientes expresiones matriciales:
423

a)
(y1
y2
)=
(−21
)+
(12−√
32√
32
12
)(x1
x2
), b)
(y1
y2
)=
(10
)+
( √3
2−1
212
√3
2
)(x1
x2
)
c)
(y1
y2
)=
(20
)+
(−1 0
0 1
)(x1
x2
), d)
(y1
y2
)=
2
17
(14
)+
1
17
(15 −8−8 −15
)(x1
x2
)
e)
(y1
y2
)=
3
5
(12
)+
1
5
(3 −4−4 −3
)(x1
x2
), f)
(y1
y2
)=
(11
)+
1
17
(15 −8−8 −15
)(x1
x2
)
g)
(y1
y2
)=
(11
)+
(−√
32
12
−12−√
32
)(x1
x2
), h)
(y1
y2
)=
(11
)+
1
5
(3 −4−4 −3
)(x1
x2
)
i)
(y1
y2
)=
(11
)+
( √2
2
√2
2√2
2−√
22
)(x1
x2
), j)
(y1
y2
)=
(−21
)+
(12
√3
2√3
2−1
2
)(x1
x2
)11.5.2. Volver a considerar los movimientos anteriores ya) Hallar los centros y angulos de giro de los que sean giros.b) Hallar los ejes de simetrıa de los que sean simetrıas axiales.c) Hallar la descomposicion canonica y recta invariante de los que sean simetrıas deslizantes.11.5.3. Encontrar la expresion analıtica de la simetrıa deslizante de A2 cuya recta invariante tiene
la direccion 2x+ y = 0 y que transforma el punto (2, 1) en el punto (1, 0).11.5.4. Encontrar la expresion analıtica de la simetrıa deslizante de A2 cuya recta invariante tiene
la ecuacion 2x + y = 1 y cuyo vector de traslacion paralelo a la recta invariante es de modulo√
5yde sentido hacia arriba.
424

Movimientos en el espacio tridimensional A3:Segun ocurre en general, los movimientos con puntos fijos se identifican geometricamente a las
transformaciones ortogonales de R3. Las transformaciones ortogonales de R3 son las rotacionesvectoriales, las simetrıas respecto a un plano y las composiciones de ambas de forma que el eje de larotacion vectorial (de angulo distinto de cero), es perpendicular al plano de la simetrıa.
Ademas tenemos los movimientos sin puntos fijos, para cuya discusion tenemos que estudiar larelacion entre la traslacion del vector origen en la aplicacion dada y los subespacios invariantes de laaplicacion vectorial asociada.
En el caso del espacio tridimensional son mas faciles de estudiar los movimientos inversos que losdirectos.
Movimientos inversos de A3
2.1.a)Empecemos por el caso en que la matriz A corresponde a la aplicacion ortogonal composicion de
una rotacion vectorial de angulo distinto de cero, con una simetrıa respecto a un plano perpendicularal eje de la rotacion vectorial.
JJJJ]
AAAAAAAAU
@@@@R
@@
@@
O
−→v
p(−→v )
A(p(−→v ))ϕ
A(−→v )
JJJJ]
AAAAAAAAU
@@@@R
@@
@@
C
P
p(P)
ϕ
A(P)
425

En un sistema de referencia O; e1, e2, e3 en el que la base de R3 e1, e2, e3 es ortonormal, siendoe1 de la direccion del eje de la rotacion y e2, e3 una base ortonormal del plano de puntos fijos dela simetrıa, (que coincide con un plano invariante para el giro) la matriz es
A =
−1 0 00 cosφ − sinφ0 sinφ cosφ
y la expresion analıtica del movimiento en un sistema de referencia con esa base es:
f
x1
x2
x3
=
a1
a2
a3
+
−1 0 00 cosφ − sinφ0 sinφ cosφ
x1
x2
x3
Sus puntos fijos se obtendrıan resolviendo el sistema: x1
x2
x3
=
a1
a2
a3
+
−1 0 00 cosφ − sinφ0 sinφ cosφ
x1
x2
x3
equivalente al sistema: −a1
−a2
−a3
=
−2 0 00 cosφ− 1 − sinφ0 sinφ cosφ− 1
x1
x2
x3
El determinante de la matriz de los coeficientes del sistema es |A| = −2(2(1− cosφ)) distinto de
cero en el caso que estamos considerando (φ 6= 0), lo que implica por el teorema de Rouche-Frobeniusque si φ 6= 0 este tipo de movimientos tienen un unico punto fijo C y geometricamente son analogos alas transformaciones vectoriales asociadas. Son composiciones de rotaciones afines con simetrıas, deforma que el eje de la rotacion afın es perpendicular al plano de simetrıa. El movimiento tiene unarecta invariante, el eje de la rotacion afın, que es la recta paralela al eje de rotacion de la rotacionvectorial asociada pasando por el unico punto fijo.
El angulo de la rotacion que interviene en M es el mismo que el angulo de la rotacion queinterviene en M y se puede hallar por la traza de la matriz A: −1 + 2cosφ = Traza(A), de dondecosφ = 1
2(Traza(A) + 1).
El sentido de la rotacion respecto a una base ortogonal u2, u3 del plano vectorial invariante sehace de manera analoga a como se hacıa en las transformaciones ortogonales.
Dos movimientos de este tipo son equivalentes si y solo si tienen el mismo angulo de rotacion.
El ejemplo 4 visto anteriormente es un movimiento de este tipo.
426

Si φ = 0, la transformacion vectorial asociada es una simetrıa respecto a un plano, caso queestudiamos despues.
2.1.b)Veamos ahora el caso en que la transformacion vectorial asociada es una simetrıa respecto a un
plano.Este caso es completamente analogo al de los movimientos inversos del plano y aparecen dos posi-
bilidades: simetrıa respecto a un plano de puntos fijos y simetrıa deslizante. Para verlo, observamosigualmente que podemos distinguir dos subcasos segun que la direccion del vector de traslacion delmovimiento dado sea perpendicular a la direccion del plano de vectores fijos de la simetrıa vectorialo no.
2.1.b1). En el primer subcaso, en el que la direccion del vector de traslacion del movimiento dadosea perpendicular a la direccion del plano de vectores fijos de la simetrıa vectorial, considerando enel espacio afın el plano obtenido desplazando el plano fijo de la simetrıa vectorial asociada segun unvector igual a la mitad del vector de traslacion y observando que sus puntos quedan invariantes porel movimiento, podemos concluir que el movimiento queda identificado a una simetrıa respecto a esteplano de puntos fijos. Todas las simetrıas de este tipo son equivalentes.
Considerando en el dibujo siguiente las rectas s y e como perfiles de planos perpendiculares alplano del papel, tenemos una interpretacion de estos movimientos.
e
s
P
A(P) P’
A(P’)
@
@
@
@
@
@
@@@@
@I
@@
@@I
M(P ) = A(P ) +−→a = Se(P )
−→a
−→a
427

El ejemplo 2 visto anteriormente es un movimiento de este tipo.
2.1.b2). En el segundo subcaso podemos descomponer el vector a =−−−−−→OM(O) de la traslacion de
la expresion dada en un vector perpendicular (c) al plano fijo de la simetrıa vectorial asociada y unvector paralelo a dicho plano (b).
El movimiento dado es la composicion de la traslacion de vector b y el movimiento resultante alhacer la composicion de la traslacion de vector c y de la aplicacion ortogonal de la misma matrizA que el dado. Esta segunda composicion es una simetrıa respecto a un plano de puntos fijos, porlo que el movimiento dado queda descompuesto como una traslacion de vector b paralelo al planode simetrıa con una simetrıa respecto a un plano. Se llama simetrıa deslizante. La descomposicionrealizada se llama descomposicion canonica del movimiento dado.
La simetrıa deslizante no tiene puntos fijos, pero la simetrıa canonica de su descomposicioncanonica sı tiene un plano de puntos fijos que queda invariante por la traslacion canonica y por tantopor la simetrıa deslizante.
Lo mismo que en el caso de las simetrıas deslizantes de A2, haciendo un dibujo se puede ver queel vector de la traslacion canonica de la simetrıa deslizante es la mitad del vector determinado por un
punto P y la imagen M2(P ) del movimiento: b = 12
−−−−−→PM2(P ), cualquiera que sea P. Para los calculos
conviene tomar P = O, el origen de coordenadas, con lo cual b = 12M2(O).
Considerando en el dibujo siguiente las rectas s y e como perfiles de planos perpendiculares alplano del papel, tenemos una interpretacion de estos movimientos.
e
s
P
A(P)
−→b
−→a
A(P ) +−→a = M(P ) = Se(P ) +−→b
−→b
M2(P )
@
@
@@
@@I
@@@
@I
@
@
@@
@
@
@
@
Se(P ) = A(P ) +−→c
−→c
−→c
428

Dos simetrıas deslizantes son equivalentes si y solo si son iguales los vectores de sus traslacionescanonicas.
Vamos a ver ahora un ejemplo de simetrıa deslizante:Ejemplo 5:
M
xyz
=
x′
y′
z′
=
110
+1
3
1 −2 −2−2 1 −2−2 −2 1
xyz
≡ a+ A
xyz
Al ser |A| = −1 y traza(A) = 1 la aplicacion lineal asociada es una simetrıa. Si el movimiento
total tuviera puntos fijos serıa una simetrıa respecto al plano de puntos fijos. Si no tiene puntos fijos,es una simetrıa deslizante.
Los puntos fijos de M son las soluciones de la ecuacion matricial: xyz
= M
xyz
=
110
+1
3
1 −2 −2−2 1 −2−2 −2 1
xyz
que desarrollada da
2x+ 2y + 2z = 32x+ 2y + 2z = 32x+ 2y + 2z = 0
incompatible
por tanto, no hay puntos fijos y se trata de una simetrıa deslizante que tiene un plano invarianteconstituido por los puntos fijos de la simetrıa canonica de la descomposicion canonica de M .
Para hallar esta simetrıa canonica, hallamos primero el vector de la traslacion canonica:
b =1
2M2(O) =
1
2M
110
=1
2
110
+1
3
1 −2 −2−2 1 −2−2 −2 1
110
=1
3
11−2
La expresion analıtica del movimiento dado se puede descomponer en
M
xyz
=1
3
11−2
+2
3
111
+1
3
1 −2 −2−2 1 −2−2 −2 1
xyz
429

donde el primer sumando corresponde a la traslacion canonica y los otros dos a la simetrıa canonica,cuyo plano de puntos fijos es el plano invariante de la simetrıa deslizante M . Este plano se obtendrapor tanto resolviendo la ecuacion matricial: x
yz
=2
3
111
+1
3
1 −2 −2−2 1 −2−2 −2 1
xyz
equivalente a x
yz
=2
3
111
+1
3
1 −2 −2−2 1 −2−2 −2 1
xyz
donde cada renglon puede reducirse a
2x+ 2y + 2z = 2 ≡ x+ y + z = 1
La simetrıa deslizante tiene ademas invariantes las rectas de este plano que son paralelas al vectorde la traslacion canonica. Como un punto generico del plano se puede escribir (x0, y0, 1 − x0 − y0),las rectas invariantes son las de ecuaciones parametricas: x
yz
=
x0
y0
1− x0 − y0
+ λ
11−2
Nota: Otro elemento que distingue si un movimento cuya aplicacion ortogonal asociada es simetrıa
es simetrıa deslizante o simetrıa respecto a un plano de puntos fijos es el vector 12M2(O). Si este
vector es distinto de cero, se trata de una simetrıa deslizante y si el vector es cero se trata de unasimetrıa respecto a un plano de puntos fijos.
2.2.Movimientos directos de A3.La aplicacion ortogonal asociada a un movimiento directo es una rotacion vectorial, que puede
visualizarse como una superposicion de giros en planos paralelos (perpendiculares al eje de la rotacionvectorial), alrededor de puntos fijos alineados que forman dicho eje.
Si el vector de traslacion dado en la expresion del movimiento esta contenido en el plano invariantede la rotacion vectorial asociada, al realizar esta traslacion despues de la rotacion, los puntos de losplanos perpendiculares al eje quedan en dichos planos. En cada uno de estos planos considerados porseparado ocurre un giro seguido de una traslacion, que ya hemos visto en el apartado de movimientosde R2, que siempre es un giro alrededor de otro punto fijo (Vuelvase a mirar los movimientos directos
430

del plano). Considerando uno de estos puntos fijos como origen de un nuevo sistema de referencia,el movimiento se puede identificar con la aplicacion vectorial asociada, que es una rotacion vectorial.Su eje es paralelo al de la rotacion vectorial asociada y esta constituido por los puntos fijos de losgiros en todos los planos perpendiculares a dicho eje. Entonces, el movimiento directo tiene una rectade puntos fijos y una familia de planos invariantes, que son los planos perpendiculares a la recta depuntos fijos.
@@@@R
,
1
O
C
O’
C’
/
@@@@@R
PA(P)
M(P)−→c
ϕ
ϕ
@@@@R
,
1
/
@@@@@R
P’A(P’)
M(P’)−→c
ϕ
ϕ
El ejemplo 3 visto anteriormente es un movimiento de este tipo.
Si el movimiento directo no tiene puntos fijos es porque el vector de traslacion a del movimientoen la expresion dada no pertenece al plano invariante (π) de la rotacion vectorial asociada, o lo quees lo mismo no es perpendicular al eje de la rotacion. En ese caso se puede descomponer el vector acomo suma de dos vectores a = b+ c, donde b es paralelo al eje de la rotacion y c es paralelo al planoinvariante de la rotacion vectorial asociada (b y c son perpendiculares). El movimiento consistente enhacer la rotacion vectorial dada y despues la traslacion de vector c es otra rotacion afın de eje paraleloal eje e de la rotacion vectorial asociada segun hemos visto anteriormente. Al hacer posteriormentela traslacion de vector b, los puntos del eje e son trasladados segun b, quedando en el mismo eje, quepor tanto, es una recta invariante. Los puntos de los planos perpendiculares al eje, ademas de sergirados, son desplazados segun el vector b que es perpendicular a ellos y paralelo al eje de la rotacionvectorial.
431

El movimiento directo de A3 sin puntos fijos se llama movimiento helicoidal.
6
-6
−→a−→b
−→c
O
@@@@@@R
6
PA(P)+−→c
ϕ
C
M(P)=A(P)+−→a
−→b
Se llama descomposicion canonica del movimiento helicoidal a su descomposicion como rotacionvectorial canonica seguida de traslacion canonica de vector paralelo al eje de la rotacion.
El vector de traslacion de la traslacion canonica se obtiene proyectando el vector de traslacion delorigen en el movimiento dado sobre el eje invariante de la rotacion vectorial asociada al movimientodado.
La expresion de la rotacion vectorial canonica se obtiene restando este vector a la expresiondel movimiento dado. El eje de puntos fijos de la rotacion vectorial canonica es eje invariante delmovimento helicoidal.
El angulo de giro de la rotacion vectorial canonica es el mismo que el de la rotacion vectorialasociada.
Dos movimientos helicoidales son equivalentes si y solo si son iguales los vectores de las traslacionescanonicas asociadas y los angulos de giro de las rotaciones canonicas asociadas.
432

Vamos a estudiar un caso sencillo:Ejemplo 6:Sea
M
xyz
=
210
+
0 0 −10 1 01 0 0
xyz
Los puntos fijos deberıan satisfacer las tres ecuaciones: x = 2 − z, y = 1 + y, z = x. Como estesistema de ecuaciones no tiene solucion, el movimiento no tiene puntos fijos.
La aplicacion vectorial asociada
M
xyz
=
0 0 −10 1 01 0 0
xyz
es una rotacion vectorial de eje Oy y por lo tanto tiene como plano vectorial invariante el planoy = 0. Podemos descomponer el vector (2, 1, 0) = (0, 1, 0) + (2, 0, 0) como suma del vector (0, 1, 0),perpendicular al plano y = 0 y otro vector (2, 0, 0), contenido en dicho plano.
Consideramos ahora el movimiento
Mc
xyz
=
200
+
0 0 −10 1 01 0 0
xyz
La traslacion de vector (2,0,0) que hacemos a continuacion de la rotacion vectorial asociada deja
invariante el plano invariante de dicha rotacion. Este plano sigue siendo invariante por Mc.El movimiento Mc puede considerarse como una yuxtaposicion de movimientos identicos en planos
paralelos al plano y = 0 (que es el plano de las coordenadas XOZ )y por tanto su estudio puedereducirse al estudio de Mc en este plano. Para ello podemos prescindir de la segunda coordenada,obteniendo
Gc
(xz
)=
(20
)+
(0 −11 0
)(xz
)expresion que corresponde a un giro de centro (1,1) y angulo π
2respecto a la base (1, 0), (0, 1) del
plano XOZ. Lo mismo ocurre en todos los planos paralelos al XOZ.Los centros de giro en estos planos son los puntos de la forma (1, k, 1); quedan invariantes por
Mc y forman un eje de giro de Mc paralelo al eje de la rotacion vectorial M . Mc es por tanto otrarotacion vectorial, aunque su eje no pasa por el origen (por tanto es una recta afın).
En el movimiento total, los puntos del eje de la rotacion Mc solo quedan trasladados por el vector(0, 1, 0). Forman una recta invariante de M. (Aunque sus puntos no son fijos).
433

Cualquier punto (x, k, z) puede considerarse contenido en un plano afın de ecuacion y = kparalelo al plano y = 0 y como tal queda en este plano paralelo al realizar la rotacion vectorialasociada y luego la traslacion del vector (2,0,0) contenido en el plano vectorial invariante. Lo cuales como hacer una rotacion en el plano y = k alrededor del punto (1, k, 1).
Para completar el movimiento dado M, tenemos que realizar ademas de Mc, la traslacion devector (0, 1, 0), esto es, trasladar todos los puntos en la direccion del eje OY, que es la misma que ladireccion del eje invariante de Mc.
Veamos otro ejemplo de movimiento helicoidal mas complicado.Ejemplo 7: Estudiar el movimiento dado en el sistema de referencia canonico por x′
y′
z′
=
110
+
0 1 00 0 −1−1 0 0
xyz
≡ a+ A
xyz
Como el determinante de A es 1, se trata de un movimiento directo, siendo la aplicacion vectorial
asociada al movimiento una rotacion vectorial. El movimiento sera por tanto una rotacion vectorialsi tiene puntos fijos y un movimiento helicoidal si no los tiene. Los puntos fijos son las soluciones delsistema: x
yz
=
110
+
0 1 00 0 −1−1 0 0
xyz
equivalente a
x = 1 +yy = 1 −zz = −x
donde haciendo operaciones se obtiene: x = 1 + y, z = 1 − y, z = −1 − y siendo las dos ultimasecuaciones incompatibles. Por tanto no hay puntos fijos y M es un movimiento helicoidal.
El movimiento helicoidal se descompone en una rotacion vectorial llamada canonica y una traslacioncanonica de vector paralelo al eje de la rotacion vectorial canonica.
El eje de la rotacion vectorial canonica es paralelo al eje de la rotacion vectorial asociada dematriz A. Por eso hallamos esa direccion resolviendo x
yz
=
0 1 00 0 −1−1 0 0
xyz
434

de donde se obtiene x = y, z = −y, ecuaciones de la recta engendrada por (1, 1,−1).Ahora el vector a lo descomponemos a = b+c donde b es paralelo a (1, 1,−1) y c es perpendicular
a (1, 1,−1): 110
= λ
11−1
+
c1c2c3
que cumplen
(1, 1,−1)
110
= (1, 1,−1)λ
11−1
+ (1, 1,−1)
c1c2c3
≡ 2 = 3λ
por tanto sale el vector b = 23(1, 1,−1) que es el vector de la traslacion canonica paralelo al eje de
la rotacion canonica. La expresion matricial de esta se obtiene restando el vector b a la expresionmatricial de M :
Mc
xyz
=1
3
112
+
0 1 00 0 −1−1 0 0
xyz
cuyo eje de puntos fijos ha de salir paralelo a (1, 1,−1) y es una recta invariante del movimientohelicoidal. Para hallarla resolvemos x
yz
=1
3
112
+
0 1 00 0 −1−1 0 0
xyz
obteniendo
x = 1/3 +yy = 1/3 −zz = 2/3 −x
≡x = 1/3 + yy = 1/3− zz = 2/3− x
≡x = 1/3 + yy = yz = 1/3− y
sistema compatible, cuyas soluciones son x
yz
=
13
013
+ λ
11−1
eje efectivamente paralelo al de la rotacion vectorial asociada.
435

Nos queda calcular el angulo de la rotacion vectorial canonica asociada. Para ello tenemos0 = traza(A) = 1 + 2cosφ, lo que implica cosφ = −1/2 y por tanto φ = ±2π/3. El sentido delgiro esta determinado respecto a una base ortogonal del plano vectorial de direccion invariante,(ortogonal al eje de direccion de la rotacion), en este caso de ecuacion x + y − z = 0; cogiendou2, u3 = (1, 0, 1), (−1, 2, 1), al ser A(u2) = (0,−1,−1),
senφ = sen(ang(u2, A(u2))) = cos(ang(A(u2), u3)) =< A(u2), u3 >
|A(u2)||u3|=−3√2√
3= −√
3
2< 0
siendo por tanto el sentido de la rotacion el que lleva la direccion y sentido del vector (1, 0, 1) haciala direccion y sentido del vector (−1, 2, 1) en el sentido del arco mas largo.
Ejercicios:
11.6.1. Clasificar los movimientos de R3 dados por las siguientes expresiones analıticas:
a)
x′
y′
z′
=
210
+
0 0 −10 −1 01 0 0
xyz
, b)
x′
y′
z′
=
111
+1
9
7 4 −44 1 8−4 8 1
xyz
c)
x′
y′
z′
=
210
+1
9
1 8 −48 1 44 −4 −7
xyz
, d)
x′
y′
z′
=
101
+1
7
−2 −3 −6−3 6 −2−6 −2 3
xyz
e)
x′
y′
z′
=
200
+
0 0 −10 1 01 0 0
xyz
, f)
x′
y′
z′
=
1−1
0
+
12
√2
212√
22
0 −√
22
12−√
22
12
x
yz
g)
x′
y′
z′
=
121
+
1 0 00 0 10 1 0
xyz
, h)
x′
y′
z′
=
111
+1
9
1 8 −4−8 −1 −4−4 4 7
xyz
436

k)
x′
y′
z′
=
210
+
0 1 00 0 −1−1 0 0
xyz
, l)
x′
y′
z′
=
11−2
+
0 1 00 0 −1−1 0 0
xyz
m)
x′
y′
z′
=
210
+1
9
1 8 −48 1 4−4 4 7
xyz
, n)
x′
y′
z′
=
210
+1
7
2 6 33 2 −66 −3 2
xyz
o)
x′
y′
z′
=
21−2
+
0 1 0−1 0 0
0 0 1
xyz
, p)
x′
y′
z′
=
221
+
1 0 00 0 −10 1 0
xyz
q)
x′
y′
z′
=1 +√
2
4
1
−√
2−1
+1
2
1√
2 1√2 0 −
√2
1 −√
2 1
xyz
11.6.2. a) Seleccionar de los movimientos anteriores los que son movimientos helicoidales y hallar
sus ejes de rotacion y sus angulos de rotacion.b) Seleccionar de los movimientos anteriores los que son simetrıas y hallar sus planos de simetrıa.c) Seleccionar de los movimientos anteriores los que sean simetrıas deslizantes y hallar sus des-
composiciones canonicas, planos invariantes y rectas invariantes.d) Seleccionar de los movimientos anteriores los que sean producto de simetrıa por rotacion
vectorial y hallar su punto fijo, recta invariante y plano invariante.11.6.3. Siendo x′
y′
z′
=
443
+1
7
−2 3 αβ 6 2−6 γ 3
xyz
la expresion de una aplicacion afın de A3.
a) Hallar los valores de los parametros para que dicha expresion corresponda a un movimiento.b) Determinar el tipo de movimiento.c) Hallar, si tiene sentido, su descomposicion canonica.d) Hallar, si tiene sentido, sus rectas y planos invariantes.11.6.4. Estudiar cuales son los movimentos resultantes de componer dos simetrıas respecto a
planos distintos de A3.11.6.5. Comprobar que el movimiento resultante de componer una simetrıa axial con un traslacion
de vector perpendicular al eje de la simetrıa es ota simetrıa axial. ¿Cual es el eje de la nueva simetrıa?
437

Sentido del producto vectorial.
Veremos aquı, utilizando los conocimientos sobre rotaciones vectoriales, que el sentido del pro-ducto vectorial de dos vectores (perpendicular al plano de dichos vectores) es el de avance de unsacacorchos dextrogiro que gira en el sentido del primer vector al segundo segun el arco mas cortoque lleva el primero al segundo.
Se ve facilmente aplicando la formula del producto vectorial que i× j = k y se ve a simple vistaque el sentido de k es el de avance de un sacacorchos dextrogiro que gira de i a j en el cuadrantedeterminado por los dos, es decir, que se cumple la regla del sacacorhos.
Tambien se ve, haciendo los calculos que i× (ai+ bj) = bk. Si b es positivo, bk va hacia arriba ysi b es negativo, bk va hacia abajo. Viendo que si b es positivo el sentido de giro segun el arco mascorto de i a ai+ bj es el mismo que el del giro de arco mas corto de i a j y que es el contrario si b esnegativo, vemos tambien que se cumple la regla del sacacorchos en este caso. Lo mismo ocurre paracualquier producto pi× (ai+ bj), donde p es un numero positivo.
Consideremos ahora dos vectores u = ci+dj, v = ei+fj y veamos que su producto u×v cumplela regla del sacacorchos: Como estos dos vectores son horizontales, su producto vectorial es vertical,es decir de la direccion del eje engendrado por k. Una rotacion vectorial R de este eje, deja invarianteel sentido de giro de u a v y tambien deja invariante el sentido de los vectores verticales. Por tanto, sipara alguna rotacion vectorial de este eje se cumple que R(u)×R(v) cumple la regla del sacacorchos,tambien se cumple para u× v. Como siempre existe una rotacion vectorial que lleva u a pi (p > 0),la cual transformara v en un R(v) = ai+ bj y hemos visto anteriormente que pi× (ai+ bj) cumplela regla del sacacorchos, tambien la cumple u× v.
Para probar la regla del sacacorchos en general, demostramos ahora que para cualquier rotacionvectorial R se verifica que R(u × v) = R(u) × R(v), lo cual nos permite asegurar que la regla delsacacorchos es cierta para u × v si lo es para R(u) × R(v), ya que una rotacion vectorial conservaen el sacacorchos su sentido de avance. Para ello, tengamos en cuenta que si ∀y ∈ V , x · y = x′ · y,se tiene (x − x′) · y = 0, ∀y ∈ V , y cogiendo y = x − x′, la igualdad (x − x′) · (x − x′) = 0 implicax−x′ = 0, es decir, x = x′. Entonces, lo que vamos a probar es que R(u× v) ·w = (R(u)×R(v)) ·w,∀w ∈ R3.
En efecto, como R es una aplicacion ortogonal
R(u× v) · w = R(u× v) ·RR−1w = u× v ·R−1w = [u, v, R−1w]
siendo este ultimo el determinante de la matriz que tiene por filas las coordenadas de los vectoresu, v, R−1w
438

Por otra parte,
R(u)×R(v) · w = (R(u)×R(v)) ·RR−1w = [R(u), R(v), RR−1w]
siendo este ultimo el determinante de la matriz que tiene por filas las coordenadas de los vectoresR(u), R(v), RR−1w; Pero esta matriz es la que tiene por filas las coordenadas de los vectoresu, v, R−1w multiplicada a la derecha por la traspuesta de la matriz de R, cuyo determinante es 1;por eso,
[R(u), R(v), RR−1w] = [u, v, R−1w]
teniendose la igualdad requerida anteriormente.
Ahora consideramos el producto i × v cuando v = ai + bj + ck es general. Hay una rotacionvectorial R del eje engendrado por i que lleva el plano engendrado por i y v al plano horizontal,llevando por tanto v a un vector horizontal R(v). Como el producto i × R(v) cumple la regla delsacacorchos, tambien lo cumple i× v. Lo mismo ocurre para cualquier producto pi× v, donde p esun numero positivo.
Para el caso general u × v, donde u es cualquiera, observamos que u puede llevarse a un vectorde la forma pi, donde p > 0 con una rotacion vectorial R de eje perpendicular a los dos vectores u ei, quedando entonces reducidos al caso anterior que verifica la regla del sacacorchos.
439

Bibliografıa.[C] M. Castellet, I. Llerena. Algebra Lineal y Geometrıa. Ed. Reverte,1991.[G] L. Golovina. Algebra Lineal y algunas de sus Aplicaciones. Ed. Mir. 1980.[H] E. Hernandez. Algebra y Geometrıa. Ed. Addison-Wesley-U.A.M. 1994.
440

Conicas.Elipse, Hiperbola, Parabola.
Introduccion.Encontramos aquı las ecuaciones de la elipse, hiperbola y parabola en sus posiciones canonicas
y luego vemos como cambian a las ecuaciones de las mismas curvas en una posicion cualquiera.Concluimos que no solo las ecuaciones de estas curvas son ecuaciones de segundo grado sino quelas soluciones de cualquier ecuacion de segundo grado con dos incoginitas constituyen una de estascurvas (una conica) admitiendo los casos degenerados que son dos rectas que se cortan, dos rectasparalelas, una recta doble o el conjunto vacıo.
Tambien se ve como se detecta el tipo de curva y como se obtienen sus elementos caracterısticos.
441

442

Ecuaciones de las conicas en posicion canonica.
La elipse es el lugar geometrico de los puntos cuya suma de distancias a dos puntos fijos llamadosfocos es constante. (1a figura).
Colocando los focos en el eje OX a distancia c del origen, la ecuacion de la elipse se obtiene ası:sean (c, 0) y (−c, 0) los focos y llamemos 2a a la suma de las distancias de un punto de la elipse aestos dos focos.
El mınimo de la suma de las distancias de un punto a otros dos puntos dados se encuentra cuandoel punto esta en la recta determinada por esos dos puntos y en el interior del segmento determinadopor ellos. (Por la propiedad triangular). Veamos que c ≤ a: consideramos la desigualdad triangularen el triangulo formado por los dos focos y un punto de la elipse. (ver el dibujo de la elipse).
2c ≤ d1 + d2 = 2a
Tenemos:
∀P, d((c, 0)P ) =√
(x− c)2 + y2 , d((−c, 0)P ) =√
(x+ c)2 + y2
P esta en la elipse si y solo si√(x− c)2 + y2 +
√(x+ c)2 + y2 = 2a ≡
√(x− c)2 + y2 = 2a−
√(x+ c)2 + y2
Elevando al cuadrado:
(x− c)2 + y2 = 4a2 + (x+ c)2 + y2 − 4a√
(x+ c)2 + y2
−4xc− 4a2 = −4a√
(x+ c)2 + y2 o xc+ a2 = a√
(x+ c)2 + y2
Elevando al cuadrado otra vez:
x2c2 + a4 + 2xca2 = a2(x2 + c2 + 2xc+ y2)
Agrupando terminos:a2(a2 − c2) = x2(a2 − c2) + a2y2
Llamando b2 = a2 − c2 y dividiendo los dos terminos por a2b2, se obtiene
1 =x2
a2+y2
b2
ecuacion canonica de la elipse, llamada ası porque corresponde a la elipse en posicion canonica.
443

Esta elipse es simetrica respecto a los ejes coordenados y respecto al origen porque si (x0, y0)satisface la ecuacion de la elipse, tambien la satisfacen (−x0, y0) (x0,−y0) (−x0,−y0).
Los puntos de interseccion con el eje OX se obtienen haciendo y=0, por tanto son (a, 0) y (−a, 0).Analogamente, los puntos de interseccion con el eje OY se obtienen haciendo x=0, por tanto son(0, b) y (0− b). Estos puntos se llaman vertices de la elipse.
El semieje mayor mide a y el semieje menor mide b. El eje que contiene los focos se llama ejefocal. La distancia focal es 2c. Se llama excentricidad de la elipse al numero c/a.
El centro de simetrıa de la elipse se llama centro de la elipse. La elipse es una circunferenciacuando la excentricidad es cero y los dos focos coinciden con el centro.
Si la excentricidad es 1 se obtiene en la ecuacion (1) y2 = 0 que es la ecuacion de dos rectascoincidentes con el eje OX.
La hiperbola es el lugar geometrico de los puntos cuya diferencia de distancias a dos puntos fijosllamados focos es constante. 2a figura.
La ecuacion de la hiperbola se obtiene ası: sean (c, 0) y (−c, 0) los focos en un sistema decordenadas cartesianas y llamemos 2a a la diferencia de las distancias de un punto de la hiperbola aestos dos focos.
∀P, d((c, 0)P ) =√
(x− c)2 + y2 , d((−c, 0)P ) =√
(x+ c)2 + y2
P esta en la hiperbola si y solo si√(x+ c)2 + y2 −
√(x− c)2 + y2 = 2a ≡
√(x+ c)2 + y2 = 2a+
√(x− c)2 + y2
Elevando al cuadrado:
(x+ c)2 + y2 = 4a2 + (x− c)2 + y2 + 4a√
(x− c)2 + y2
4xc− 4a2 = 4a√
(x− c)2 + y2 ≡ xc− a2 = a√
(x− c)2 + y2
Elevando al cuadrado otra vez:
x2c2 + a4 − 2xca2 = a2(x2 + c2 − 2xc+ y2)
Agrupando terminos:a2(a2 − c2) = x2(a2 − c2) + a2y2
444

Veamos que ahora c ≥ a aplicando la desigualdad triangular al triangulo formado por los focos yun punto de la hiperbola. (Ver el dibujo de la hiperbola).
2c+ d2 ≥ d1 i.e. 2c ≥ d1 − d2 = 2a
Llamando b2 = c2 − a2 y dividiendo los dos terminos por a2b2, se obtiene
−1 = −x2
a2+y2
b2
1 =x2
a2− y2
b2
ecuacion canonica de la hiperbola, llamada ası porque corresponde a la hiperbola en posicioncanonica.
Esta hiperbola es simetrica respecto a los ejes coordenados por la misma razon que lo era la elipse.Los puntos de interseccion con el eje OY se obtendrıan haciendo x = 0, pero en este caso no
existen. Los puntos de interseccion con el eje OX se obtienen haciendo y = 0, por tanto son (a, 0) y(−a, 0). Estos puntos se llaman vertices de la hiperbola.
El eje que contiene los focos se llama eje focal. La distancia focal es 2c. Se llama excentricidadde la hiperbola al numero c/a.
El semieje real vale a. El otro semieje se llama semieje imaginario.
El punto O se llama centro de la hiperbola. La excentricidad de la hiperbola nunca es cero.Cuandola excentricidad es 1 la hiperbola se reduce a dos rectas coincidentes con ell eje OX.
La parabola es el lugar geometrico de los puntos que equidistan de un punto llamado foco y deuna recta llamada directriz. 3a figura.
La ecuacion de la parabola se obtiene ası: Supongamos que la directriz es paralela al eje OY a unadistancia igual a c a la izquierda de este eje y que el foco esta situado en el eje OX a una distancia cdel origen. (se deduce de la definicion que la parabola pasa por el origen, que luego veremos que esel vertice de la parabola).
Entonces, el punto P(x,y) pertenece a la parabola si y solo si d(P, F ) = d(P, directriz), es decir,si y solo si
(x− c)2 + y2 = (x+ c)2 ≡ x2 − 2xc+ c2 + y2 = x2 + 2xc+ c2
445

de dondey2 = 4cx
es la ecuacion canonica de la parabola, llamada ası porque esta en posicion canonica.
Es simetrica respecto al eje OX y el origen es el punto de la parabola mas proximo a la directriz,es el vertice.
Ecuaciones de algunas conicas en posicion no canonica.
Naturalmente existen elipses, hiperbolas y parabolas que no estan colocadas en posiciones canonicasy se van a ver ahora ejemplos de obtencion de sus ecuaciones:
1.Obtener la ecuacion de una elipse de semieje mayor 2, vertical y semieje menor 1 y centro en el
origen: tendrıamos que cambiar el eje OX por el eje OY y serıa
1 =y2
4+ x2.
2.Obtener la ecuacion de la elipse E de semieje mayor 2 en la direccion de la diagonal del primer
cuadrante y semieje menor 1 y centro en el punto (1,2).
La ecuacion de esta elipse en la posicion canonica (llamemosla E” )serıa
1 =x2
4+ y2 ≡ x2 + 4y2 − 4 = 0
Llamemos E’ a la elipse obtenida de girar la canonica un angulo de π/4 en sentido positivo; unpunto (x, y) pertenece a E’ si y solo si al girarlo un angulo un angulo de π/4 en sentido negativo sesitua en E”, por tanto si
1
2
( √2√
2
−√
2√
2
)(xy
)satisface la ecuacion de la elipse E”. Sustituyendo, tenemos que ha de ser:
1
4(√
2x+√
2y)2 + 41
4(−√
2x+√
2y)2 − 4 = 0
donde haciendo operaciones se llega a
5x2 − 6xy + 5y2 − 8 = 0,
446

que es la ecuacion de E’.Buscamos la ecuacion de la elipse pedida en el enunciado que vamos a llamar E. E coincide con
E’ al trasladarla de forma que su centro vaya al origen. Entonces, un punto (x, y) esta en E si y solosi al trasladarlo segun el vector (−1,−2) obtenemos un punto de E’, o sea, si (x− 1, y − 2) satisfacela ecuacion de E’; sustituyendo y haciendo operaciones se obtiene:
5(x− 1)2 − 6(x− 1)(y − 2) + 5(y − 2)2 − 8 = 0 ≡ 5x2 − 6xy + 5y2 + 2x− 14y + 5 = 0
que es la ecuacion pedida.
3.Obtener la ecuacion de la hiperbola H de semieje real 3 en el primer cuadrante formando un
angulo de π/3 con el eje de abscisas, de excentricidad 5/3 y centro en el punto (1,−1).
Primero obtenemos la ecuacion de una hiperbola H” de las mismas caracterısticas de la pedidapero en posicion canonica.
Como e = c/a, c = 5 y b =√c2 − a2 = 4, por lo que la ecuacion de la hiperbola H” es
x2
9− y2
16= 1 ≡ 16x2 − 9y2 − 144 = 0
Ahora obtenemos la ecuacion de la hiperbola H’ obtenida de H” al girarla para que el eje deabcisas forme un angulo de π/3 positivo con su eje real:(
xy
)∈ H ′ ≡ 1
2
(1√
3
−√
3 1
)(xy
)∈ H ′′ ≡ 1
2
(x+√
3y
−√
3x+ y
)∈ H ′′
Sustituyendo en la ecuacion de H” y haciendo operaciones, tenemos
39y2 + 50√
3xy − 11x2 − 576 = 0
que es la ecuacion de H’. Para obtener la ecuacion de H observamos que una traslacion de vector(−1, 1), lleva el centro de H al origen, que es el centro de H’ y lleva H a H’ porque coinciden enla direccion y el tamano del eje real, por lo que (x, y) ∈ H ≡ (x − 1, y + 1) ∈ H ′. Sustituyendo(x− 1, y + 1) en la ecuacion de H’ y haciendo operaciones obtenemos:
39y2 + 50√
3xy − 11x2 + (78− 50√
3)y + (22 + 50√
3)x− 548− 50√
3 = 0
ecuacion de la hiperbola pedida.
447

4.Obtener la ecuacion de la parabola P cuya directriz es la diagonal del primer cuadrante, cuya
distancia del foco a la directriz es√
2, con vertice en la diagonal del segundo cuadrante y dirigidahacia arriba.
Como en los ejemplos anteriores hallamos la ecuacion de la parabola P” de las mismas carac-terısticas de P colocada en posicion canonica (c =
√2/2) siendo esta:
y2 = 2√
2x ≡ y2 − 2√
2x = 0
La directriz de la parabola canonica es vertical; para que coincida su direccion con la de la diagonaldel primer cuadrante tenemos que hacer un giro de angulo 3π/4 positivo. Hallamos la ecuacion dela parabola P’ obtenida al girar la canonica un angulo de 3π/4 positivo sustituyendo en la ecuacionde la canonica las coordenadas de un punto girado un angulo de −3π/4:
La matriz de dicho giro es1
2
(−√
2√
2
−√
2 −√
2
)por lo que (
xy
)∈ P ′ ≡ 1
2
(−√
2√
2
−√
2 −√
2
)(xy
)∈ P ′′ ≡ 1
2
(−√
2x+√
2y
−√
2x−√
2y
)∈ P ′′
Sustituyendo estas expresiones en la ecuacion de P” obtenemos
(−√
2
2x−√
2
2y)2 − 2
√2(−√
2
2x+
√2
2y) = 0
Haciendo operaciones se obtiene
x2 + y2 + 2xy + 4x− 4y = 0
que es la ecuacion de P’El vertice de P es el punto a distancia c =
√2
2del origen sobre la diagonal del segundo cuadrante
y en el semiplano de las ordenadas positivas porque va hacia arriba. Es el punto (−12, 1
2)
Haciendo ahora la traslacion que lleva el vertice de la parabola pedida al origen y sustituyendoen la ecuacion de P’ obtenemos la ecuacion de P:
(x+1/2)2+(y−1/2)2+2(x+1/2)(y−1/2)+4(x+1/2)−4(y−1/2) = 0 ≡ x2+y2+2xy+4x−4y+4 = 0
siendo esta ultima la ecuacion de la parabola pedida.
448

Ejercicios:
12.1.1 Hallar la ecuacion de la elipse de eje mayor 10 y distancia focal 6, cuyo eje mayor formaun angulo de π/6 con el eje de abscisas, siendo su centro el origen.
12.1.2. Hallar la ecuacion de la elipse de eje menor 8 y excentricidad 3/5, cuyo eje mayor formaun angulo de π/3 con el eje de ordenadas, siendo su centro el punto (1,1).
12.1.3. Hallar la ecuacion de una hiperbola de distancia focal 10 y excentricidad 5/3, cuyo ejereal forma un angulo de π/3 con el eje de abscisas, siendo su centro el punto (−1, 2)
12.1.4. Hallar la ecuacion de una hiperbola cuyos vertices distan 6, con excentricidad 4/5, concentro en el punto (1,−2) y cuyo eje real forma un angulo de +π/3 con el eje de ordenadas.
12.1.5. Hallar la ecuacion de la parabola con directriz la diagonal del primer cuadrante y verticeen al punto (
√2, 2√
2).12.1.6. Hallar la ecuacion de la parabola de directriz paralela a la diagonal del segundo cuadrante
y foco en el punto (√
2− 1,√
2 + 1).
Algunos ejemplos de reduccion de curvas de segundo grado a su ecuacion canonica.
En los tres casos anteriores hemos obtenido como ecuaciones de las conicas, polinomios de segundogrado con dos incognitas igualados a cero. Vamos a ver ahora en tres casos particulares como podemosdar marcha atras, es decir, como los polinomios de segundo grado con dos incognitas pueden sertransformados mediante cambios de coordenadas en las expresiones canonicas de la elipse, la hiperbolay la parabola.
5. Consideremos la curva de ecuacion:
52x2 − 72xy + 73y2 + 200x− 350y + 325 = 0
La parte cuadratica del polinomio se puede escribir:
52x2 − 72xy + 73y2 = (x, y)
(52 −36−36 73
)(xy
)Toda forma cuadratica se puede diagonalizar mediante un cambio de base ortogonal, por eso
podemos encontrar un nuevo sistema de coordenadas relacionado con el anterior por una matrizortogonal en el que la forma cuadratica tiene matriz diagonal. Lo encontramos calculando los valorespropios y los vectores propios.
Los valores propios son λ1 = 25, λ2 = 100, a los que corresponden los vectores propios normali-zados: v1 = (4, 3)/5, v2 = (−3, 4)/5. Entonces, con el cambio de coordenadas:
449

(xy
)=
1
5
(4 −33 4
)(x′
y′
)(como la matriz de cambio de base es ortogonal su inversa coincide con su traspuesta) la partecuadratica considerada se transforma en
(x′, y′)1
5
(4 3−3 4
)(52 −36−36 73
)1
5
(4 −33 4
)(x′
y′
)= (x′, y′)
1
5
(25 00 100
)(x′
y′
)En este cambio de coordenadas la parte no cuadratica tambien se transforma:
200x− 350y + 325 = 200(1
5(4x′ − 3y′))− 350(
1
5(3x′ + 4y′)) + 325 = −50x′ − 400y′ + 325
haciendo operaciones, con lo que el polinomio total se transforma en
25x′2
+ 100y′2 − 50x′ − 400y′ + 325 = 25(x′
2 − 2x′) + 100(y′2 − 4y′) + 325 =
= 25(x′ − 1)2 − 25 + 100(y′ − 2)2 − 400 + 325 = 25(x′ − 1)2 + 100(y′ − 2)2 − 100
Haciendo ahora el cambio de coordenadas x′′ = x′−1, y′′ = y′−2, igualando a cero y dividiendopor 100 se obtiene:
x′′2
4+ y′′
2 − 1 = 0 ≡ x′′2
4+ y′′
2= 1
que es la ecuacion de una elipse de semieje mayor 2 y semieje menor 1 en posicion canonica.6. Consideremos la ecuacion
7x2 − 48xy − 7y2 − 70x− 10y − 1 = 0
La parte cuadratica
7x2 − 48xy − 7y2 = (x, y)
(7 −24
−24 −7
)(xy
)se transforma mediante el cambio de coordenadas ortogonal dado por los vectores propios normali-zados en una forma cuadratica diagonal, es decir, sin termino en xy. Sus valores propios son λ1 =25, λ2 = −25, y los vectores propios normalizados correspondientes: v1 = (4,−3)/5, v2 = (3, 4)/5por lo que el cambio de coordenadas es(
xy
)=
1
5
(4 3−3 4
)(x′
y′
)siendo
450

7x2 − 48xy − 7y2 = (x, y)
(7 −24
−24 −7
)(xy
)= (x′, y′)
(25 00 −25
)(x′
y′
)= 25x′
2 − 25y′2
La parte no cuadratica tambien se transforma en este cambio de coordenadas:
−70x− 10y − 1 = −70(1
5(4x′ + 3y′))− 10(
1
5(−3x′ + 4y′))− 1 = −50x′ − 50y′ − 1
Entonces el polinomio dado completo se transforma en
25x′2 − 25y′
2 − 50x′ − 50y′ − 1,
que a su vez se transforma en
25(x′2 − 2x′)− 25(y′
2+ 2y′)− 1 = 25(x′ − 1)2 − 25− 25(y′ + 1)2 + 25− 1
Llamando ahora x′′ = x′−1, y′′ = y′+1, y dividiendo adecuadamente la expresion de la ecuacionse transforma en
x′′2
125
− y′′2
125
= 1
expresion de una hiperbola.7. Consideremos la ecuacion
9x2 − 24xy + 16y2 + 70x− 10y + 75 = 0
Como en los casos anteriores, la parte cuadratica de la ecuacion se transforma en una suma decuadrados mediante un cambio de coordenadas ortogonal.
9x2 − 24xy + 16y2 = (x, y)
(9 −12
−12 16
)(xy
)se transforma mediante el cambio de coordenadas(
xy
)=
1
5
(4 −33 4
)(x′
y′
)dado por los vectores propios normalizados v1 = (4, 3)/5, v2 = (−3, 4)/5 correspondientes a losvalores propios λ1 = 0, λ2 = 25 en
(x′, y′)
(0 00 25
)(x′
y′
)= 25y′
2
451

La parte no cuadratica del polinomio se transforma en este cambio de coordenadas segun
70x− 10y + 75 = 70(1
5(4x′ − 3y′))− 10(
1
5(3x′ + 4y′)) + 75 = 50x′ − 50y′ + 75
con lo que la ecuacion completa se transforma en
25y′2
+ 50x′ − 50y′ + 75 = 25(y′ − 1)2 + 50(x′ + 1) = 0
Llamando ahora x′′ = x′ + 1, y′′ = y′ − 1 y dividiendo por 25 obtenemos
y′′2
+ 2x′′ = 0 ≡ y′′2
= −2x′′
expresion de una parabola.
452

Reduccion de la ecuacion general de la expresion de una curva de segundo grado asu expresion canonica.
La elipse, hiperbola y parbola se llaman conicas no degeneradas. Antes de pasar al caso generalvamos a darnos cuenta de que existen otras configuraciones de soluciones de ecuaciones de segundogrado ademas de las conicas no degeneradas. Son las llamadas conicas degeneradas:
Las soluciones de a2x2 − b2y2 = 0 son las dos rectas diagonales de ecuaciones ax − by = 0 eax+by = 0, que se cortan en el origen. Se pueden considerar como una degeneracion de la hiperbola.
Las soluciones de a2x2 − k = 0 son dos rectas paralelas si k > 0 y el conjunto vacıo si k < 0.Se pueden considerar como una degeneracion de la hiperbola cuando b = ∞. Son una recta doblecuando k = 0. que se puede considerar una degeneracion de la parabola si c = 0.
Las soluciones de a2x2 + b2y2 = 0 estan constituidas por el origen unicamente. Y las solucionesde a2x2 + b2y2 = −k son el conjunto vacıo si k > 0.
Admitiendo estas configuraciones como conicas degeneradas, podemos demostrar que el conjuntode soluciones de una ecuacion dada por un polinomio de segundo grado con dos incognitas igualadoa cero es una conica (sea o no degenerada). Lo vamos a hacer a continuacion haciendo cambios decoordenadas que conservan las distancias y por tanto las formas de las curvas:
La expresion general de una de tales curvas es
a11x2 + 2a12xy + a22y
2 + 2a1x+ 2a2y + a0 = 0
La forma cuadratica a11x2 + 2a12xy + a22y
2 se puede expresar matricialmente
(x, y)
(a11 a12
a12 a22
)(xy
)con una matriz simetrica que se puede diagonalizar por una matriz ortogonal utilizando los valorespropios y los vectores propios.
Mediante un cambio de coordenadas(xy
)=
(v11 v21
v12 v22
)(x′
y′
)dado por los vectores propios normalizados, la parte cuadratica pasa a
(x′, y′)
(λ1 00 λ2
)(x′
y′
)453

En ese cambio, los coeficientes de x y de y tambien varıan en el polinomio dado pasando elpolinomio completo a ser de la forma:
λ1x′2 + λ2y
′2 + 2b1x′ + 2b2y
′ + b0 = 0
Ahora distinguimos dos casos:a) Si los dos valores propios son distintos de cero,b) Si algun valor propio es cero.En el primer caso podemos agrupar los terminos en x′ y los terminos en y′ dando
λ1x′2 + 2b1x
′ + λ2y′2 + 2b2y
′ + b0 = λ1(x′2 + 2
b1λ1
x′) + λ2(y′2 + 2
b2λ2
y′) + b0 =
= λ1(x′ +
b1λ1
)2 + λ2(y′ +
b2λ2
)2 + b0 −b21λ1
− b22λ2
= 0
Mediante otro cambio de coordenadas x′′ = x′ + 2 b1λ1
, y′′ = y′ + 2 b2λ2
y llamando co al terminoindependiente pasamos a
x′′2
−c0λ1
+y′′2
−c0λ2
= 1
que es la ecuacion de una elipse si λ1, λ2 y −c0 son del mismo signo, es el conjunto vacıo si λ1, λ2 yco son del mismo signo, y es un solo punto si λ1, λ2 son del mismo signo y c0 = 0.
Si λ1, λ2 son de distinto signo, tenemos la ecuacion de una hiperbola si c0 6= 0 y la ecuacion dedos rectas que se cortan si c0 = 0.
Pasamos ahora al caso b): supongamos que λ1 = 0, la ecuacion entonces, por la diagonalizacionde la parte cuadratica pasa a ser
λ2y′2 + 2b1x
′ + 2b2y′ + b0 = 0
que podemos transformar en
λ2(y′ +
b2λ2
)2 − b22λ2
+ 2b1x′ + b0 = λ2(y
′ +b2λ2
)2 + 2b1(x′ +
b0 − b22λ2
b1) = 0
si b1 6= 0. Aquı llamando x′′ = x′+b0−
b22λ2
b1, y′′ = y′+ b2
λ2que es otro cambio de coordenadas obtenemos
λ2y′′2 + 2b1x
′′ = 0
454

donde dividiendo por λ2 obtenemos la ecuacion de una parabola.
Si b1 = 0, obtenemos
λ2(y′ +
b2λ1
)2 − b22λ2
+ b0 = 0
donde llamando y′′ = y′ + b1λ2
y c0 =b22λ2− b0 se llega a
λ2y′′2 = c0
que es la ecuacion de dos rectas paralelas si c0 > 0, una recta doble si c0 = 0 y el conjunto vacıo sic0 < 0.
Si λ1 = λ2 = 0, la matriz que hemos diagonalizado es nula, no siendo entonces la ecuacion quenos han dado de segundo grado.
Hemos llegado a que si el conjunto de puntos soluciones de una ecuacion de segundo grado con dosincognitas es no vacıo, constituye una conica (no degenerada o degenerada). Las conicas se llamantambien curvas de segundo grado.
Invariantes y Clasificacion de las Conicas.
Invariantes de las Conicas.Dada la ecuacion de una curva de segundo grado, podemos realizar los cambios de coordenadas
considerados en el parrafo anterior para ver de que tipo de conica se trata; sin embargo existen ciertosnumeros asociados a los coeficientes del polinomio de la curva que quedan invariantes en cualquiercambio de coordenadas que conserva las distancias y que determinan el tipo de curva que es. Sellaman invariantes de las conicas y vamos a verlos ahora.
Como se vio en el capıtulo de los movimientos, dichos cambios de coordenadas son transforma-ciones ortogonales, traslaciones o composicion de ambas. Las vamos a estudiar separadamente.
Puede suponerse que la ecuacion general de la conica es
a11x2 + 2a12xy + a22y
2 + 2a1x+ 2a2y + a0 = 0
que se puede escribir de forma matricial:
(1, x, y)
a0 a1 a2
a1 a11 a12
a2 a12 a22
1xy
= 0
455

llamandose la matriz que aparece, matriz de la conica, que representaremos por A.Los cambios de coordenadas correspondientes a transformaciones ortogonales vienen dados por
matrices: 1xy
=
1 0 00 c11 c12
0 c21 c22
1x′
y′
donde
C =
(c11 c12
c21 c22
)es una matriz ortogonal. Pasando la conica a la ecuacion:
(1, x′, y′)
1 0 00 c11 c12
0 c21 c22
t a0 a1 a2
a1 a11 a12
a2 a12 a22
1 0 00 c11 c12
0 c21 c22
1x′
y′
= 0
donde Ct = C−1 y |C| = ±1.Se puede observar que el determinante de la matriz producto, que es la matriz de la conica en
el nuevo sistema de coordenadas coincide con el determinante de la primera matriz asociada a laconica.
Miremos ahora lo que pasa en un cambio de coordenadas correspondiente a una traslacion.En una traslacion las coordenadas cambian segun x = c1 + x′, y = c2 + y′, lo cual se puede
expresar por 1xy
=
1 0 0c1 1 0c2 0 1
1x′
y′
= 0
Pasando la ecuacion de la conica a ser
(1, x′, y′)
1 c1 c20 1 00 0 1
a0 a1 a2
a1 a11 a12
a2 a12 a22
1 0 0c1 1 0c2 0 1
1x′
y′
= 0
donde se ve tambien que el determinante de la matriz producto correspondiente a la conica despuesdel cambio de coordenadas coincide con el determinante de la matriz primera, ya que el determinantede la matriz de cambio es 1.
Podemos concluir que el determinante de la matriz de la conica es invariante en cualquier cambiode coordenadas que conserve las distancias.
456

Tambien, llamando
A0 =
(a11 a12
a21 a22
)se ve que en los cambios anteriores A0 cambia a(
c11 c12
c21 c22
)t(a11 a12
a21 a22
)(c11 c12
c21 c22
)en un cambio de coordenadas ortogonal en el que Ct = C−1 y en un cambio correspondiente a unatraslacion queda igual.
Por esta razon, lo mismo que antes,
|A0| = det
(a11 a12
a21 a22
)es invariante. Y al ser
(c11 c12
c21 c22
)una matriz ortogonal, su inversa y su traspuesta coinciden, por lo que A0 cambia como la matriz deun endomorfismo y es invariante tambien su polinomio caracterıstico y por tanto su traza: a11 + a22.
Tenemos, pues, tres invariantes: |A|, |A0|, y traza(A0)Al final del proceso de reduccion de la ecuacion de una conica a la ecuacion canonica se divide para obtener la
ecuacion canonica hallada al principio de las conicas. La division o multiplicacion de los coeficientes por un numerono es un cambio de coordenadas que conserve las distancias y por tanto los invariantes no se conservan en esta ultimaetapa, aunque si se conserva su signo si dividimos por numeros positivos.
Clasificacion de las Conicas.Con estos resultados y mirando en las ecuaciones canonicas de la elipse, hiperbola y parabola:
elipse:(
1, x, y) −1 0 0
0 1a2 0
0 0 1b2
1xy
= 0
hiperbola:(
1, x, y) −1 0 0
0 1a2 0
0 0 − 1b2
1xy
= 0
parabola:(
1, x, y) 0 −2c 0−2c 0 0
0 0 1
1xy
= 0.
457

y mirando otra vez la ecuacion de las conicas, degeneradas y no degeneradas, podemos dada unacurva de segundo grado distinguir el tipo de conica que es.
En las conicas no degeneradas y solo en ellas, (|A| 6= 0) Entonces, puede ocurrir:|A0| > 0 en cuyo caso es una elipse si sig|A| 6= sig|A0| y el conjunto vacıo si sig|A| = sig|A0|.|A0| = 0 en cuyo caso es una parabola.|A0| < 0 en cuyo caso es una hiperbola.En las degeneradas, (|A| = 0), la parabola se reduce a dos rectas paralelas o coincidentes, la elipse
se reduce a un punto y la hiperbola se reduce a dos rectas secantes que tambien pueden coincidir.Si |A0| > 0 es un punto.Si |A0| = 0 es dos rectas paralelas que podrıan coincidir o el conjunto vacıo.Si |A0| < 0 son dos rectas secantes.
Ejes de simetrıa y centro o vertice de las conicas no degeneradas.
Volviendo a mirar las ecuaciones reducidas de las conicas, vemos que si P = (p1, p2) es un puntoque satisface la ecuacion reducida de una elipse o de una hiperbola, tambien los puntos de coordenadas(−p1, p2), (p1,−p2), (−p1,−p2) satisfacen dicha ecuacion, por lo que los ejes de las coordenadas x′′
e y′′ son ejes de simetrıa de dichas curvas y el origen de dichas coordenadas es centro de simetrıa.En cuanto a la parabola, si P = (p1, p2) satisface la ecuacion reducida de la parabola, tambien lasatisface (p1,−p2), por lo que el eje de las x′′ es eje de simetrıa de la parabola, que ademas tiene suvertice en el punto origen del ultimo sistema de coordenadas.
Para determinar los ejes de la elipse y de la hiperbola tenemos en cuenta que para pasar dela ecuacion general a la ecuacion reducida hemos hecho un cambio de coordenadas dado por unatransformacion ortogonal y otro cambio dado por una traslacion. Como en la traslacion no cambianlas direcciones de los ejes, la direccion de los ejes de las coordenadas x′′ e y′′ son las mismas que lasde los ejes de coordenadas de x′ e y′. Estas coordenadas se habıan obtenido diagonalizando la matrizA0; el endomorfismo dado por A0 es el mismo que el dado por la matriz diagonal cuya diagonalesta formada por los valores propios, coincidiendo sus vectores propios y siendo los vectores propiosde A0, los vectores propios de la matriz diagonal que son los vectores de direccion de las nuevascoordenadas, por tanto el eje x′ tiene la direccion del vector propio de A0 correspondiente a λ1 y eleje y′ tiene la direccion del vector propio de A0 correspondiente al valor propio λ2 en la elipse y enla hiperbola.
La longitud de los ejes se puede calcular usando los invariantes y se vera en los ejercicios.
458

Al hacer esta reduccion no siempre el eje x′ es el eje mayor de la elipse o el eje real de la hiperbola, esto dependede cual de los valores propios sea mayor en la elipse y del signo del termino independiente en la hiperbola.
Para determinar el centro de simetrıa, que es el origen del sistema de coordenadas x′′, y′′, tenemosen cuenta que tambien podemos llegar a este sistema de coordenadas haciendo primero un cambiode coordenadas correspondiente a una traslacion de vector determinado por el origen y el centro desimetrıa y luego un cambio de coordenadas correspondiente a la transformacion ortogonal que cambiala direccion de los ejes. Como al final no hay terminos lineales en las coordenadas, haciendo el cambiode coordenadas inverso al de la transformacion ortogonal, sigue sin haber terminos lineales. Perolo que se obtiene al hacer en la ecuacion reducida el cambio inverso a la transformacion ortogonalque cambiaba la direccion de los ejes es la ecuacion resultante de hacer el cambio de coordenadascorrespondiente a la traslacion del origen al centro de simetrıa que por tanto no debe tener terminoslineales.
Sustituyendo x = x + c1, y = y + c2 en la ecuacion general de las conicas, los terminos linealesque obtenemos son
(2a11c1 + 2a12c2 + 2a1)x, (2a12c1 + 2a22c2 + 2a2)y
que tienen que ser nulos, lo cual nos da las ecuaciones que debe satisfacer el centro:
a11c1 + a12c2 + a1 = 0a12c1 + a22c2 + a2 = 0
Este sistema de ecuaciones tiene solucion unica en la elipse y la hiperbola porque en ellas |A0| 6= 0
La ecuacion de los ejes de simetrıa se obtiene sabiendo que pasan por el centro y que tienen ladireccion de los vectores propios de A0.
En cuanto a la parabola, el eje x′ tiene la direccion del vector propio que corresponde al valor pro-pio nulo y la tangente en el vertice y la directriz tienen la direccion del vector propio correspondienteal valor propio no nulo. El vertice es el nuevo origen de coordenadas y se obtiene teniendo en cuentaque la tangente en el vertice es perpendicular al eje de simetrıa que lleva la direccion del vectorpropio de A0 para el valor propio nulo, por tanto paralela a (a11, a12). La pendiente de la tangente ala parabola en cada punto se puede calcular derivando implıcitamente en la ecuacion de la parabola:si f(x, y) es la ecuacion de la parabola fx(x, y) + fy(x, y)y′ = 0 nos dice que (fy(x, y),−fx(x, y)) esun vector en la direccion de la tangente a la parabola, que en el vertice ha de ser paralelo a (a11, a12),por tanto:
fy(x, y)
a11
=−fx(x, y)
a12
459

Aquı obtenemos una relacion entre las coordenadas del vertice, que juntamente con la ecuacion dela parabola da dichas coordenadas.
La ecuacion del eje de simetrıa se obtiene sabiendo que pasa por el vertice y que tiene la direcciondel vector propio nulo de A0.
Una vez reducida la ecuacion de la parabola a su forma canonica podemos calcular c, estando elfoco sobre el eje x′′ a distancia c del vertice. (Tambien se puede calcular c usando los invariantescomo se ve en los ejercicios). Como hay dos puntos sobre el eje x′′ a distancia c del vertice decidimoscual es considerando la perpendicular al eje de simetrıa que pasa por esos puntos; si pasa por el focointerseca a la parabola en dos puntos y si no pasa por el foco no interseca a la parabola.
Otra manera de distinguir el foco, cuyo fundamento esta fuera del alcance de este libro es teneren cuenta que la parabola divide el plano en dos regiones de puntos cuyas coordenadas sustituidasen el polinomio de su ecuacion dan el mismo signo en cada region y distinto en distintas regiones.Los puntos distintos del vertice de la tangente a la parabola en dicho punto estan en distinta regionque el foco.
Calculo del centro de simetrıa y de los ejes de simetrıa de la elipse del ejemplo 5.
El centro debe satisfacer las ecuaciones:
52c1 − 36c2 + 100 = 0−36c1 + 73c2 − 175 = 0
Resolviendo el sistema se obtiene C = (−2, 11)/5.
El eje focal pasa por el centro de simetrıa y lleva la direccion de las x′ que es la del vector propiocorrespondiente al valor propio 25: v1 = (4, 3)/5, por tanto sus ecuaciones parametricas son:(
xy
)=
1
5
(−211
)+ λ
(43
)El otro eje de simetrıa tambien pasa por el centro y es perpendicular a este, teniendo, por tanto,
de ecuaciones parametricas (xy
)=
1
5
(−211
)+ λ
(−3
4
)Una forma de comprobar si la direccion de los ejes de simetrıa estan bien hallados es tener en
cuenta que el eje de la direccion de las x′ tiene de ecuacion y′ = 0 y el eje de la direccion de y′ tienede ecuacion x′ = 0 y despejar x′, y′ en funcion de x, y, obteniendo:
460

(x′
y′
)=
1
5
(4 3−3 4
)(xy
)por lo que
y′ = 0 ≡ −3x+ 4y = 0 satisfecha por v1 = (4, 3)/5
analogamentex′ = 0 ≡ 4x+ 3y = 0 satisfecha por v2 = (−3, 4)/5.
Los vertices del eje focal estan en dicho eje a una distancia igual a 2 del centro, obteniendose(−2, 11)/5± 2/5(4, 3).
Los otros vertices del eje menor estan en el otro eje a una distancia del centro igual a 1,obteniendose (−2, 5)/5± 1/5(−3, 4)
En este caso sabemos que la medida del semieje mayor es 2 y la del semieje menor es 1 porquehemos reducido previamente la ecuacion a su forma canonica. Sin reducir la ecuacion a su formacanonica, los podemos calcular utilizando los invariantes: cuando la ecuacion esta en la forma λ1x
′′2+λ2y
′′2 + c0 = 0 solo hemos hecho cambios de coordenadas sin dividir; entonces |A| = λ1λ2c0, siendoc0 = |A|/λ1λ2, despues pasamos c0 al segundo miembro y dividimos por −c0, viendose que loscuadrados de los dos semiejes son a2 = −c0/λ1 y b2 = −c0/λ2. Los focos estan a distancia
√a2 + b2
del vertice sobre el eje de mayor longitud.
Calculo del centro de simetrıa y de los ejes de simetrıa de la hiperbola del ejemplo6.
El centro debe satisfacer las ecuaciones:
7c1 − 24c2 − 35 = 0−24c1 − 7c2 − 5 = 0
Resolviendo el sistema se obtiene C = (1,−7)/5.
El eje focal pasa por el centro de simetrıa y lleva la direccion de las x′ que es la del vector propiocorrespondiente al valor propio 25: v1 = (4,−3)/5, por tanto sus ecuaciones parametricas son:
461

(xy
)=
1
5
(1−7
)+ λ
(4−3
)El otro eje de simetrıa tambien pasa por el centro y es perpendicular a este, siendo sus ecuaciones:(
xy
)=
1
5
(1−7
)+ λ
(34
)Los vertices de la hiperbola estan a distancia igual a 1/5 del centro de simetrıa sobre el eje focal
y son (1,−7)/5± (4,−3)/25.Los focos de la hiperbola estan a distancia igual a
√2/5 del centro de simetrıa sobre el eje focal
y son (1,−7)/5± (4,−3)√
2/25.
En este caso sabemos que la medida del semieje real es 1/5 porque hemos reducido previamentela ecuacion a su forma canonica. Lo podemos calcular sin reducir la ecuacion a su forma canonicautilizando los invariantes: cuando la ecuacion esta en la forma λ1x
′′2 + λ2y′′2 + c0 = 0 solo hemos
hecho cambios de coordenadas sin dividir; entonces |A| = λ1λ2c0, siendo c0 = |A|/λ1λ2, despuespasamos c0 al segundo miembro y dividimos por −c0, viendose que el cuadrado del semieje real es elque sea positivo de los dos numeros −c0/λ1 y −c0/λ2. Los focos estan a distancia c del vertice sobreel eje real
Calculo del vertice y del eje de simetrıa y del foco de la parabola del ejemplo 7.
El vertice es el punto en el que la tangente a la parabola es perpendicular al eje de simetrıa. Ladireccion del eje de simetrıa es la del vector propio de la matriz A0 correspondiente al valor propionulo, por tanto es perpendicular al vector (a11, a12), que entonces ha de ser paralelo a la tangente enel vertice.
Podemos calcular la pendiente de la tangente a la parabola en cada punto derivando la ecuacionde la parabola de manera implıcita. En nuestro caso, derivamos en la ecuacion:
9x2 − 24xy + 16y2 + 70x− 10y + 75 = 0
obteniendo(18x− 24y + 70) + (−24x+ 32y − 10)y′ = 0
lo que da
y′ =−(18x− 24y + 70)
−24x+ 32y − 10
Un vector que tiene esta pendiente es (−24x + 32y − 10,−(18x − 24y + 70)), que por lo dichoanteriormente ha de ser paralelo a (9,−12), debiendo ser
462

−24x+ 32y − 10
9=−(18x− 24y + 70)
−12
de donde y = (3x+ 5)/4, lo cual sustituido en la ecuacion de la parabola, que debe ser satisfecha porlas coordenadas del vertice da x = −7/5, de donde y = 1/5
Se puede comprobar que estas son las coordenadas del vertice porque en la ecuacion reducida ala que habıamos llegado el ejemplo 7 con las coordenadas x′, y′ el vertice era (−1, 1). Haciendo elcambio indicado allı de las coordenadas x′, y′ a las coordenadas x, y obtenemos la misma solucion, locual da otro metodo par calcular el vertice.
El eje de simetrıa pasa por el vertice y tiene direccion el vector propio correspondiente al valorpropio nulo, es decir, (4, 3), por lo que sus ecuaciones parametricas son(
xy
)=
1
5
(−7
1
)+ λ
(43
)
El foco esta sobre el eje de simetrıa a una distancia del vertice igual a c.Para calcular c tenemos en cuenta que para llegar a la ecuacion λ2y
′′2+2px′′ = 0 solo hemos hechocambios de coordenadas por lo que al ser el determinante de la matriz de las conicas invariante porcambios de coordenadas se tiene |A| = −λ2p
2; luego, para pasar a la ecuacion canonica dividimos porλ2 y pasamos 2px′′ al segundo miembro. Comparando con la ecuacion canonica tenemos 4c = −2p/λ2,o sea c = −p/2λ2.
En este caso, λ2 = 25 por lo que |A| = −253 = −25p2 ⇒ p = 25, de donde c = −25/50 = −1/2.
Como el foco esta a distancia c del vertice y sobre el eje de simetrıa, es uno de los dos puntos:(xy
)=
1
5
(−7
1
)± λ
(43
)donde ‖λ(4, 3)‖ = 1/2, para lo cual ha de ser λ = ±1/10, obteniendose los dos puntos posibles(−2, 1)/2, (−18,−1)/10. Decidimos cual es considerando la perpendicular al eje de simetrıa quepasa por esos puntos; si pasa por el foco interseca a la parabola en dos puntos y si no pasa por elfoco no interseca a la parabola.
La perpendicular al eje de simetrıa por el punto (−2, 1)/2 tiene la ecuacion(xy
)=
1
2
(−2
1
)+ β
(−3
4
)=
1
2
(−2− 6β
1 + 8β
)
463

Sustituyendo un punto generico de esta recta en la ecuacion de la parabola da 625β2 + 25 = 0,ecuacion que no tiene solucion en β, lo que quiere decir que esta recta no corta a la parabola. Entoncesel foco es (−18,−1)/10.
Al sustituir el punto 12 (−2,−6β, 1 + 8β) = (−1, 1/2) + (−3, 4)β en la ecuacion de la parabola se obtiene
(1,−1,12
)A
1−1
12
+ 2β(1,−1,12
)A
0−3
4
+ β2(0,−3, 4)A
0−3
4
donde A es la matriz de la parabola.
Tambien podemos distinguir el foco porque sustituidas sus coordenadas en la ecuacion de laparabola tiene que dar un numero de distinto signo del numero obtenido sustituyendo un puntodistinto del vertice de la tangente a la parabola en este punto; la tangente es la recta de direcciondel vector propio para λ2 que pasa por el vertice.
Un punto distinto del vertice de la tangente en el dicho punto a la parabola es
1
5
(−7
1
)+
1
5
(−3
4
)=
(−2
1
)Al sustituir este punto en el polinomio de la ecuacion de la parabola da 25 > 0. Si sustituimos(−2, 1)/2 obtenemos tambien 25 > 0, luego el foco es (−18,−1)/10.
Ejercicios:
12.2.1. Clasificar las conicas dadas por las siguientes ecuaciones:a). 3x2 + 3y2 − 2xy − 2x− 2y − 7 = 0b) 41x2 + 24xy + 34y2 − 58x+ 44y + 26 = 0c) 23x2 + 2y2 − 72xy − 110x+ 20y − 25 = 0d) 23x2 + 2y2 + 72xy − 50x− 100y − 25 = 0e) 2x2 + 23y2 − 72xy + 68x+ 26y + 47 = 0f) x2 − 6xy + 9y2 + 4x+ 2y − 1 = 0h) 4x2 + 4xy + y2 − 6x+ 8y − 5 = 0i) y2 − 2x2 + xy − 3x− 1 = 0j) 9x2 − 6xy + y2 + 3x− y − 2 = 0k) 4x2 + 4xy + y2 − 2y − 4x− 6 = 0l) x2 − 2xy + y2 − 2x+ 4y + 4 = 0
464

m) x2 + 9y2 − 6xy + 10x− 30y + 25 = 0n) x2 + y2 − 2xy + 6x− 6y + 6 = 0o) 5x2 + 6xy + 5y2 − 16x− 16y − 5 = 012.2.2. Hallar los centros de simetrıa y los ejes de simetrıa de las conicas anteriores que sean
elipses o hiperbolas.12.2.3. Hallar el vertice, el eje de simetrıa y el foco de las conicas anteriores que sean parabolas.
Unificamos la elipse, la hiperbola y la parabola en una definicion de lugar geometrico:
Son los lugares geometricos de los puntos cuya razon de distancias a un punto llamado foco yuna recta llamada directriz es constante. Si esta razon es menor que 1, la conica es una elipse. Si larazon es mayor que uno la conica es una hiperbola. Si la razon es uno, la conica es una parabola.
La ecuacion de la rectas directrices de la elipse y de la hiperbola en posicion canonica es x = a/e,donde e es la excentricidad, obteniendose la parabola en posicion canonica cuando e = 1 siendo enesta a = −c cuando c es la abscisa del foco en el eje OX.
Como en la elipse e < 1, se tiene a/e > a, por lo que la recta directriz de la elipse esta a la derechadel vertice. Por el contrario en la hiperbola, al ser e > 1, a/e < a, por lo que la recta directriz de lahiperbola esta entre el vertice y el centro de simetrıa. (Hay otras dos directrices simetricas a estasrespecto al eje de ordenadas debido a la simetrıa de las curvas).
Comprobacion:
Hacemos primero la comprobacion para la elipse en posicion canonica. Si P es un punto de laelipse y (c, 0) el foco,
d(P, F ) =√
(x− c)2 + y2 =
√(x− c)2 + b2(1− x2
a2) =
=
√x2 + c2 − 2xc+ b2 − b2
a2x2 =
√x2(1− b2
a2) + a2 − 2xc =
=√x2e2 + a2 − 2xea =
√(xe− a)2 = |xe− a|
Sea d1 la recta de ecuacion x = a/e,
d(P, d1) = |x− a
e| = 1
e|xe− a| = 1
ed(P, F )
465

o equivalentemente,d(P, F )
d(P, d1)= e
Ahora lo hacemos para la hiperbola
d(P, F ) =√
(x− c)2 + y2 =
√(x− c)2 + b2(
x2
a2− 1) =
=
√x2 + c2 − 2xc− b2 +
b2
a2x2 =
√x2(1 +
b2
a2) + a2 − 2xc =
=
√x2c2
a2+ a2 − 2xea =
√(xe− a)2 = |xe− a|
Sea d1 la de ecuacion x = a/e.
d(P, d1) = |x− a
e| = 1
e|xe− a| = 1
ed(P, F )
o equivalentemente,d(P, F )
d(P, d1)= e
En las dos expresiones finales anteriores se ve que cuando e = 1 se obtiene la parabola.
Hemos englobado en la definicion de lugar geometrico las curvas: elipse, hiperbola y parabola.
Recıprocamente, dada la recta r de ecuacion x = k, si queremos una conica tal que los puntos Pde la conica verifiquen d(P, F ) = ed(P, r), podemos considerar los puntos de abscisas k, ke, ke2 deleje OX que verifican d(ke2, ke) = ed(ke, k) = ed(ke, r)y son distintos si e 6= 1, es decir, el punto deleje OX de abscisa ke2 vale de foco de una conica que tiene vertice en ke, excentricidad e y r comodirectriz.
Obtengamos su ecuacion canonica:√(x− ke2)2 + y2 = e|x− k| ⇔ x2 + k2e4 − 2xke2 + y2 = e2(x2 + k2 − 2xk)⇔
x2(1− e2) + y2 = e2k2 − e4k2 = e2k2(1− e2)
Dividiendo:
466

x2
k2e2+ y2 1
e2k2(1− e2)= 1
es la ecuacion de una elipse si e < 1 y de una hiperbola si e > 1.
Tambien quedan unificadas las tres conicas como intersecciones de un cono por un plano, segunque este plano corte a todas las generatrices por el mismo lado respecto al vertice del cono, (elipse),sea paralelo a una generatriz, (parabola), o corte a unas generatrices a un lado del vertice y otrasgeneratrices por el otro lado. Pueden verse los dibujos en los libros de E. Hernandez y S. Xambo.
Ejercicios:
12.3.1. Calcular las ecuaciones de las directrices de las elipses que aparecen en el ejercicio 12.2.*.12.3.2. Calcular las ecuaciones de las directrices de las hiperbolas que aparecen en el ejercicio
12.2.*.12.3.3. Calcular las ecuaciones de las directrices de las parabolas que aparecen en el ejercicio
12.2.*.12.3.4. Calcular la ecuacion de una elipse con directriz la recta de ecuacion x = 2 y excentricidad
1/2.12.3.5. Calcular la ecuacion de una hiperbola con directriz la recta de ecuacion x = 2 y excentri-
cidad 2.12.3.6. Calcular la ecuacion de la elipse con directriz la recta de ecuacion x = 2, foco en (1,0) y
excentricidad 1/2.12.3.7. Calcular la ecuacion de la hiperbola con directriz la recta de ecuacion x = 2, foco en (4,0)
y excentricidad 2.
BIBLIOGRAFIA
L. I. Golovina. Algebra Lineal y algunas de sus aplicaciones. Ed. Mir 1980.E. Hernandez. Algebra y Geometrıa. Ed. Addison-Wesley iberoamericana, S. A. 1994.S. Xambo Deschamps. Geometrıa. Ediciones UPC,1997.
467

468

Cuadricas
Introduccion.En este capıtulo se estudian las superficies de segundo grado, es decir, las superficies que son
conjuntos de soluciones de una ecuacion de segundo grado en las variables x, y, z. El estudio essimilar al de las conicas, encontrandose muchos mas casos. En su clasificacion influyen no solo losinvariantes de las matrices simetricas asociadas a las ecuaciones sino el rango de estas. Los ejesy planos de simetrıa de las cuadricas no degeneradas se determinan de manera analoga a como sedeterminan en las conicas no degeneradas.
A continucion se enuncian las ecuaciones reducidas de las cuadricas, y luego los correspondientesdibujos. Se puede comprobar la correspondencia estudiando las secciones de cada cuadrica con planosparalelos a los ejes.
Elipsoide:x2
a2 + y2
b2+ z2
c2= 1.
Hiperboloide elıptico o de una hoja:x2
a2 + y2
b2− z2
c2= 1.
Hiperboloide hiperbolico o de dos hojas:x2
a2 − y2
b2− z2
c2= 1.
Cono:x2
a2 + y2
b2− z2
c2= 0.
Paraboloide elıptico:x2
a2 + y2
b2− 2pz = 0.
Paraboloide hiperbolico:x2
a2 − y2
b2− 2pz = 0.
Cilindro elıptico:x2
a2 + y2
b2= 1.
Cilindro parabolico:x2
a2 − 2py = 0.
Cilindro hiperbolico:x2
a2 − y2
b2= 1.
Par de planos que se cortan:x2
a2 − y2
b2= 0.
Par de panos paralelos:x2
a2 = 1.
Par de planos coincidentes:x2
a2 = 0.
469
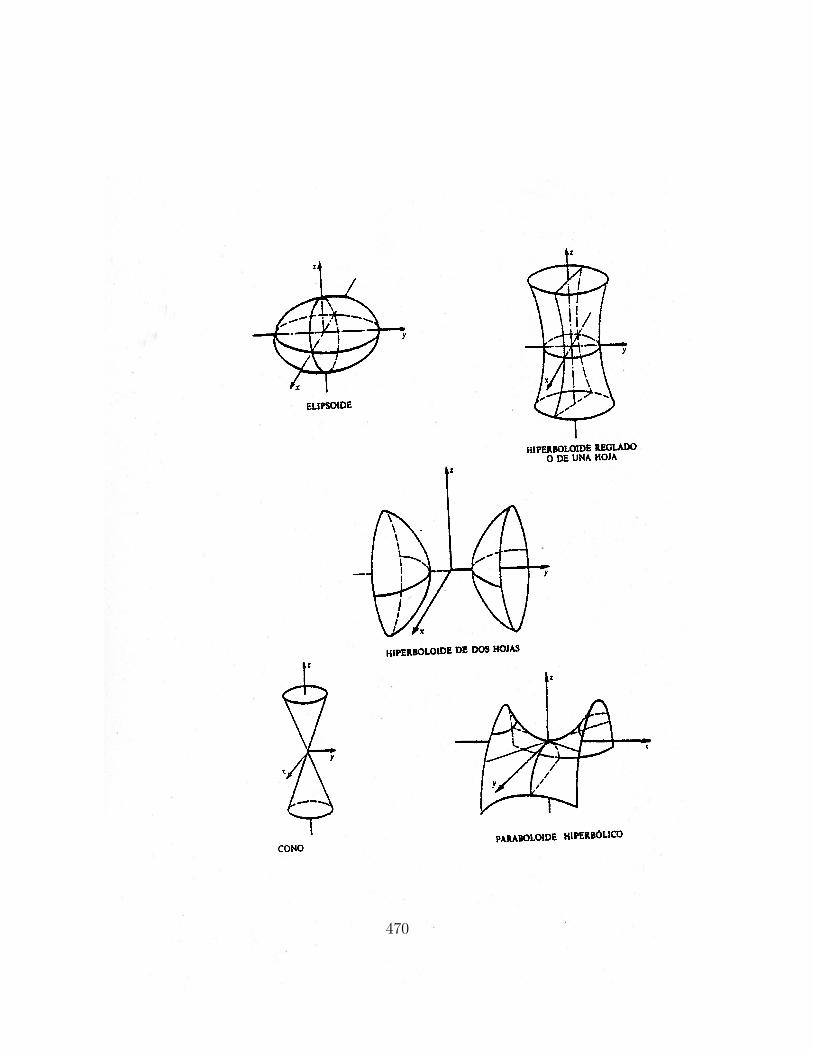
470

471

Estudio general de la superficie de segundo grado.La expresion general de una de tales superficies es
a11x2 + 2a12xy + a22y
2 + 2a13xz + 2a23yz + a33z2 + 2a1x+ 2a2y + 2a3z + a0 = 0
Vamos a simplificar progresivamente todo lo posible esta ecuacion mediante cambios de coorde-nadas que conservan las distancias, (por tanto las formas), lo cual nos va a permitir visualizar quetipo de superficie es cada una de las obtenidas.
La forma cuadratica a11x2 + 2a12xy + a22y
2 + 2a13xz + 2a23yz + a33z2 se puede expresar matri-
cialmente
(x, y, z)
a11 a12 a13
a12 a22 a23
a13 a23 a33
xyz
con una matriz simetrica que se puede diagonalizar por una matriz ortogonal utilizando los valorespropios y los vectores propios.
Mediante un cambio de coordenadas ortogonal xyz
=
v11 v21 v31
v12 v22 v32
v13 v23 v33
x′
y′
z′
dado por los vectores propios normalizados, la parte cuadratica pasa a
(x′, y′, z′)
λ1 0 00 λ2 00 0 λ3
x′
y′
z′
En ese cambio, los coeficientes de x, de y y de z tambien varıan en el polinomio dado por la
transformacion ortogonal considerada, pasando el polinomio completo a ser de la forma:
λ1x′2 + λ2y
′2 + λ3z′2 + 2b1x
′ + 2b2y′ + 2b3z
′ + b0 = 0
Ahora distinguimos tres casos con distintos subcasos:
a) Si los tres valores propios son distintos de cero,b) Si solo un valor propio es cero.c) Si dos valores propios son cero.
472

Los tres valores propios no pueden ser cero porque entonces serıa cero la forma cuadratica y elpolinomio dado no serıa de segundo grado.
Estudiemos el caso a)En este caso podemos agrupar los terminos en x′, los terminos en y′ y los terminos en z′ dando
λ1x′2+2b1x
′+λ2y′2+2b2y
′+λ3z′2+2b3z
′+b0 = λ1(x′2+2
b1λ1
x′)+λ2(y′2+2
b2λ2
y′)+λ3(z′2+2
b3λ3
z′)+b0 =
= λ1(x′ +
b1λ1
)2 + λ2(y′ +
b1λ1
)2 + λ3(z′ +
b3λ3
)2 + b0 −b21λ1
− b22λ2
− b23λ3
= 0
Mediante otro cambio de coordenadas x′′ = x′ + b2λ2
, y′′ = y′ + b2λ2
, z′′ = z′ + b3λ3
correspondiente auna traslacion y llamando co al termino independiente, si c0 6= 0, pasamos a
x′′2
−c0λ1
+y′′2
−c0λ2
+z′′2
−c0λ3
= 1
que es la ecuacion de un elipsoide si λ1, λ2, λ3 son del mismo signo, distinto del de c0, es el conjuntovacıo si λ1, λ2, λ3 y c0 son del mismo signo. Si c0 = 0 y λ1, λ2, λ3 son del mismo signo es un solopunto.
Si λ3 es de signo distinto de λ1, λ2 siendo estos del mismo signo, tenemos la ecuacion de un conosi c0 = 0 y de un hiperboloide si c0 6= 0; hay dos tipos de hiperboloides: suponiendo c0 > 0, lo cualsiempre se puede conseguir cambiando el signo de la ecuacion si es necesario, pueden quedar dosde los cuadrados de coordenadas con coeficiente positivo, en cuyo caso se trata de un hiperboloidehiperbolico o dos de los cuadrados de las coordenadas con coeficiente negativo, en cuyo caso se tratade un hiperboloide elıptico.
Pasamos ahora al caso b):Suponiendo que λ3 = 0, λ1 6= 0, λ2 6= 0, la parte cuadratica de la ecuacion pasa a ser por la
diagonalizacion correspondiente a una transformacion ortogonal a:
λ1x′2 + λ2y
′2
y la ecuacion completa pasa a:
λ1x′2 + λ2y
′2 + 2b1x′ + 2b2y
′ + 2b3z′ + b0 = 0
473

que podemos transformar en
λ1(x′+b1λ1
)2+λ2(y′+b2λ2
)2− b21
λ1
− b22
λ2
+2b3z′+b0 = λ1(x
′+b1λ1
)2+λ2(y′+b2λ2
)2+2b3(z′+b0 − b21
λ1− b22
λ2
b3) = 0
si b3 6= 0. Aquı llamando x′′ = x′ + b1λ1, y′′ = y′ + b2
λ2, z′′ = z′ +
b0−b21λ1− b22λ2
b3, que es un cambio de
coordenadas correspondiente a una traslacion obtenemos:
λ1x′′2 + λ2y
′′2 + 2b3z′′ = 0
ecuacion de un paraboloide elıptico si λ1 y λ2 son del mismo signo y de un paraboloide hiperbolicosi son de distinto signo.
Si en los pasos anteriores sale b3 = 0 no eliminamos el termino independiente b0 en un cambio decoordenadas de traslacion, quedando la ecuacion de la forma
λ1x′′2 + λ2y
′′2 + b0 −b21λ1
− b22λ2
= 0
donde llamando c0 = b0 − b21λ1− b22
λ2tenemos
λ1x′′2 + λ2y
′′2 + c0 = 0
Aquı tenemos distintos subcasos:Cuando c0 6= 0, es el conjunto vacıo si λ1, λ2 y c0 son del mismo signo; es un cilindro elıptico si
λ1 y λ2 son del mismo signo, siendo este distinto del signo de c0 y un cilindro hiperbolico si λ1 y λ2
son de distinto signo.Cuando c0 = 0, es un punto si λ1, λ2 son del mismo signo y y un par de planos secantes si λ1 y
λ2 son de distinto signo.
Pasamos al caso c)Supongamos que λ2 = 0 = λ3, λ1 6= 0; la parte cuadratica de la ecuacion pasa a λ1x
′2. Agrupandolos terminos en x′ en la ecuacion completa tenemos
λ1(x′ +
b1λ1
)2 + 2b2y′ + 2b3z
′ + b0 −b1
2
λ1
= 0
Si b2 = 0 = b3, llamando x′′ = x′ + b1λ1
y c0 = b0 − b12
λ1se obtiene
λ1x′′2 + c0 = 0
474

que es la ecuacion de dos planos paralelos si λ1 y c0 son de distinto signo, dos planos coincidentes sic0 = 0 y el conjunto vacıo si λ1 y c0 son del mismo signo.
Si b2 6= 0 o b3 6= 0, podemos anular el termino independiente, englobandolo en la incognita concoeficiente distinto de cero. Suponiendo que b2 6= 0, y llamando c0 = b0 − b1
2
λ1escribimos
λ1(x′ +
b1λ1
)2 + 2b2(y′ +
c0b2
) + 2b3z′ = 0
Ahora llamando x′′ = x′ + b1λ1
, y′′ = y′ + c0b2z′′ = z′ tenemos
λ1x′′2 + 2b2y
′′ + 2b3z′′ = 0
donde si b3 = 0 tenemos la ecuacion de un cilindro parabolico. Si b3 6= 0 haciendo el cambio decoordenadas ortogonal (
y′′
z′′
)=
1√b22 + b23
(b2 −b3b3 b2
)(y′′′
z′′′
), x′′′ = x′′
obtenemosλ1x
′′′2 + 2√a2 + b2y′′′ = 0 ≡ λ1x
′′′2 + 2py′′′ = 0
que es un cilindro parabolico.Hemos concluido el estudio progresivo de todas las superficies de segundo grado que pueden
aparecer.
475

Invariantes de las Cuadricas.Dada la ecuacion de una superficie de segundo grado, podemos realizar los cambios de coordenadas
considerados en el parrafo anterior para ver de que tipo de cuadrica se trata; sin embargo existenciertos numeros asociados a la matriz de coeficientes de la ecuacion de la curva que quedan invariantesen cualquier cambio de coordenadas que conserva las distancias y que determinan el tipo de superficieque es. Se llaman invariantes de las cuadricas y vamos a verlos ahora.
Como se vio en el capıtulo de los movimientos, dichos cambios de coordenadas son transforma-ciones ortogonales, traslaciones o composicion de ambas. Las vamos a estudiar separadamente.
Puede suponerse que la ecuacion general de la cuadrica es
a11x2 + 2a12xy + a22y
2 + 2a13xz + 2a23yz + a33z2 + 2a1x+ 2a2y + 2a3z + a0 = 0
que se puede escribir de forma matricial:
(1, x, y, z)
a0 a1 a2 a3
a1 a11 a12 a13
a2 a12 a22 a23
a3 a13 a23 a33
1xyz
llamandose la matriz simetrica que aparece, matriz de la cuadrica, que representaremos por A.
Los cambios de coordenadas correspondientes a transformaciones ortogonales vienen dados pormatrices:
1xyz
=
1 0 0 00 c11 c12 c13
0 c21 c22 c23
0 c31 c32 c33
1x′
y′
z′
=
(1 00 C
)1x′
y′
z′
donde C es una matriz ortogonal que verifica Ct = C−1 y por tanto |C| = ±1. Pasando la ecuacionde la cuadrica por uno de estos cambios a:
(1, x′, y′, z′)
1 0 0 00 c11 c12 c13
0 c21 c22 c23
0 c31 c32 c33
t
a0 a1 a2 a3
a1 a11 a12 a13
a2 a12 a22 a23
a3 a13 a23 a33
1 0 0 00 c11 c12 c13
0 c21 c22 c23
0 c31 c32 c33
1x′
y′
z′
= 0
Se puede observar que el determinante de la matriz producto, que es la matriz de la cuadricaen el nuevo sistema de coordenadas coincide con el determinante de la primera matriz asociada a lacuadrica.
476

Miremos ahora lo que pasa en un cambio de coordenadas correspondiente a una traslacion.En una traslacion las coordenadas cambian segun x = c1 + x′, y = c2 + y′, z = c3 + z′, lo cual se
puede expresar por 1xyz
=
1 0 0 0c1 1 0 0c2 0 1 0c3 0 0 1
1x′
y′
z′
= 0
Pasando la ecuacion de la cuadrica a ser
(1, x′, y′, z′)
1 c1 c2 c30 1 0 00 0 1 00 0 0 1
a0 a1 a2 a3
a1 a11 a12 a13
a2 a12 a22 a23
a3 a13 a23 a33
1 0 0 0c1 1 0 0c2 0 1 0c3 0 0 1
1x′
y′
z′
= 0
donde se ve tambien que el determinante de la matriz producto correspondiente a la cuadrica despuesdel cambio de coordenadas coincide con el determinante de la matriz primera, ya que el determinantede la matriz de cambio es 1.
Podemos concluir que el determinante de la matriz de la cuadrica es invariante en cualquier cam-bio de coordenadas que conserve las distancias.
Tambien, llamando
A0 =
a11 a12 a13
a12 a22 a23
a13 a23 a33
se ve que en los cambios correspondientes a un cambio de coordenadas ortogonal cambia a c11 c12 c13
c21 c22 c23
c31 c32 c33
t a11 a12 a13
a12 a22 a23
a13 a23 a33
c11 c12 c13
c21 c22 c23
c31 c32 c33
= CtA0C
siendo Ct = C−1 y en un cambio correspondiente a una traslacion queda igual.Por esta razon, lo mismo que antes, |A0| es invariante. Y al ser C una matriz ortogonal, su inversa
y su traspuesta coinciden, por lo que A0 cambia como la matriz de un endomorfismo y es invariantetambien su polinomio caracterıstico y por tanto los coeficientes del polinomio caracterıstico: su traza:
477

a11 + a22 + a33 y el numero α = α11 + α22 + α33, donde αii es el menor diagonal adjunto de aii en lamatriz A0.
Tenemos, pues, cuatro invariantes: |A|, |A0|, α y traza(A0)
Ademas como se vio en el capıtulo de formas cuadraticas, el rango de la matriz simetrica de unaforma cuadratica es invariante por un cambio de coordenadas, por lo que tambien son invariantes elrango de A y el rango de A0.
Clasificacion de las cuadricas.Repasando los distintos casos que hemos encontrado en el estudio general de las superficies de
segundo grado y las ecuaciones reducidas a las que hemos llegado, teniendo en mente los invariantesque hemos hallado podemos hacer una clasificacion de las cuadricas.
En el caso a) cuando los tres valores propios son distintos de cero, se tiene |A0| 6= 0; en este caso,si ademas c0 = 0, lo cual es equivalente a que |A| = 0, tenemos un punto si los tres valores propiosson del mismo signo y un cono si no lo son; si c0 6= 0, lo cual es equivalente a que |A| 6= 0 tenemosun elipsoide si todos los valores propios son del mismo signo, distinto del de c0, es decir, si todoslos valores propios son del mismo signo, siendo sig|A0| 6= sig|A| pero si los valores propios son delmismo signo, siendo sig|A0| = sig|A|, tenemos el conjunto vacıo. Si c0 6= 0 y no son todos los valorespropios del mismo signo tenemos un hiperboloide, teniendo en el elıptico |A| > 0 y en el hiperbolico|A| < 0.
En el caso b), cuando hay un solo valor propio igual a cero, |A0| = 0 y α 6= 0 y se tiene unparaboloide si |A| 6= 0, este paraboloide es elıptico si α > 0 y es hiperbolico si α < 0.
Si |A0| = 0, α 6= 0 y |A| = 0, se tienen cilindros si r(A) = 3, elıpticos si los dos valores propiosson del mismo signo: α > 0 y el signo de los valores propios distintos de cero es distinto del signode c0, pero se obtiene el conjunto vacıo si α > 0 y el signo de los valores propios distintos de cero esigual al signo de c0; se tienen cilindros hiperbolicos si los dos valores propios son de distinto signo:α < 0
Si |A0| = 0, α 6= 0 y |A| = 0, se tienen planos secantes cuando r(A) = 2 si α < 0 y una recta siα > 0
En el caso c), cuando hay dos valores propios iguales a cero, |A0| = 0 y α = 0, encontrandosecilindros parabolicos si r(A) = 3, pares de planos paralelos si r(A) = 2 y el signo del valor propiodistinto de cero es distinto del signo de c0, el conjunto vacıo si r(A) = 2 y el signo del valor propiodistinto de cero es igual al signo de c0, y planos coincidentes si r(A) = 1.
478

Clasificacion de las Cuadricas.
1. |A0| 6= 0
|A| 6= 0
sigλ1 = sigλ2 = sigλ3
elipsoide si sig|A| 6= sig|A0|.conjunto vacio si sig|A| = sig|A0|.
sigλ1 = sigλ2 6= sigλ3 hiperboloide
elıptico si sig|A| = sig|A0|hiperbolico si sig|A| 6= sig|A0|
|A| = 0
sigλ1 = sigλ2 6= sigλ3 cono.sigλ1 = sigλ2 = sigλ3 un punto
2.|A0| = 0
|A| 6= 0 es un paraboloide
elıptico si α > 0hiperbolico si α < 0
|A| = 0
α > 0
cilindro elıptico o ∅ si r(A) = 3una recta si r(A) = 2
α < 0
cilindro hiperbolico si r(A) = 3par de planos secantes si r(A) = 2
α = 0
cilindro parabolico si r(A) = 3par de planos paralelos o ∅ si r(A) = 2par de planos coincidentes si r(A) = 1
Se llaman cuadricas no degeneradas aquullas en que |A| 6= 0.
Ejes de simetrıa y centro de las cuadricas no degeneradas.
Volviendo a mirar las ecuaciones reducidas de las cuadricas, vemos que si P = (p1, p2, p3) es unpunto que satisface la ecuacion reducida de un elipsoide o de un hiperboloide, tambien los puntosobtenidos cambiando el signo de algunas de las coordenadas satisfacen dicha ecuacion, por lo que losplanos coordenados x′′ = 0, y′′ = 0, z′′ = 0 son planos de simetrıa de dichas superficies, los ejes de lascoordenadas x′′, y′′, z′′ son ejes de simetrıa y el origen de dichas coordenadas es centro de simetrıa.
Para determinar los ejes del elipsoide y del hiperboloide tenemos en cuenta que para pasar dela ecuacion general a la ecuacion reducida hemos hecho un cambio de coordenadas dado por una
479

transformacion ortogonal, cuyos nuevos ejes hemos llamado x′, y′ z′ y otro cambio dado por unatraslacion, llegando a los ejes x′′, y′′, z′′. Como en la traslacion no cambian las direcciones de los ejes,la direccion de los ejes de las coordenadas x′′, y′′, z′′ son las mismas que las de los ejes de coordenadasde x′, y′ z′. Estas coordenadas se habıan obtenido diagonalizando la matriz A0; el endomorfismo dadopor A0 es el mismo que el dado por la matriz diagonal cuya diagonal esta formada por los valorespropios, coincidiendo sus vectores propios y siendo los vectores propios de A0, los vectores propiosde la matriz diagonal, que son los vectores de direccion de las nuevas coordenadas, por tanto el eje x′
tiene la direccion del vector propio correspondiente a λ1, el eje y′ tiene la direccion del vector propiocorrespondiente al valor propio λ2 y el eje z′ tiene la direccion del vector propio correspondiente alvalor propio λ3 en el elipsoide y en el hiperboloide.
Por otra parte, se determinan las direcciones de los planos de simetrıa de estas superficies teniendoen cuenta que son perpendiculares a los vectores propios.
Para determinar el centro de simetrıa, que es el origen del sistema de coordenadas x′′, y′′, z′′,tenemos en cuenta que tambien podemos llegar a este sistema de coordenadas haciendo primero uncambio de coordenadas correspondiente a una traslacion de vector determinado por el origen y elcentro de simetrıa y luego un cambio de coordenadas correspondiente a la transformacion ortogonalque cambia la direccion de los ejes. Como al final no hay terminos lineales en las coordenadas,haciendo el cambio de coordenadas inverso al de la transformacion ortogonal en la ecuacion reducida,deben desaparecer los terminos lineales. Pero lo que se obtiene al hacer en la ecuacion reducida elcambio inverso a la transformacion ortogonal que cambiaba la direccion de los ejes es la ecuacionresultante de hacer el cambio de coordenadas correspondiente a la traslacion del origen al centro desimetrıa que por tanto no debe tener terminos lineales.
Sustituyendo x = x + c1, y = y + c2, z = z + c3 en la ecuacion general de las cuadricas, losterminos lineales que obtenemos son
(2a11c1 + 2a12c2 + 2a13c3 + 2a1)x, (2a12c1 + 2a22c2 + 2a23 + 2a2)y, (2a13c1 + 2a23c2 + 2a33 + 2a3)z
que tienen que ser nulos, lo cual nos da las ecuaciones que debe satisfacer el centro:
a11c1 + a12c2 + a13c3 + a1 = 0a12c1 + a22c2 + a23c3 + a2 = 0a13c1 + a23c2 + a33c3 + a3 = 0
Este sistema de ecuaciones tiene solucion unica en el elipsoide y en el hiperboloide porque en ellas|A0| 6= 0
Los ejes de simetrıa son las rectas que pasan por el centro y tienen la direccion de los vectorespropios y los planos de simetrıa son los planos que pasan por el centro y son perpendiculares a dichosvectores propios.
480

En cuanto a los paraboloides, que tambien son cuadricas no degeneradas, podemos decir quetienen dos planos de simetrıa perpendiculares a los vectores propios correspondientes a los valorespropios no nulos y un eje de simetrıa que es la interseccion de ambos, que lleva la direccion del vectorpropio correspondiente al valor propio nulo. Tanto planos como eje de simetrıa pasan por el verticedel paraboloide, que se puede encontrar como sigue:
El plano tangente en el vertice es perpendicular al vector propio correspondiente al valor propionulo. Por otra parte, el plano tangente en cada punto esta engendrado por los vectores tangentes alas curvas de interseccion del paraboloide con cada uno de los planos coordenados xOz y yOz.
Derivando y llamando f(x, y, z) = 0 a la ecuacion de la cuadrica se obtienen fx + fzdzdx
= 0,fy + fz
dzdy
= 0, que nos dicen que los vectores (−fz, 0, fx), (0,−fz, fy) son vectores tangentes a lascurvas descritas anteriomente y por tanto han de ser perpendiculares al vector propio correspondienteal valor propio nulo, que por otra parte es la solucion no trivial del sistema
a11v31 + a12v32 + a13v33 = 0a12v31 + a22v32 + a23v33 = 0a31v31 + a32v32 + a33v33 = 0
y que puede expresarse por el producto vectorial de dos vectores no proporcionales de los vectoresfilas de coeficientes del sistema, pudiendo suponer que son las dos primeras.
Entonces v3 = (a11, a12, a13) × (a12, a22, a23) y expresando que el producto escalar de v3 por(−fz, 0, fx) y (0,−fz, fy) es nulo obtenemos dos ecuaciones que unidas a la ecuacion del paraboloideson tres ecuaciones que determinan el vertice del paraboloide.
Ejercicios.
13. 1. 1. Hallar la ecuacion reducida y el tipo de las cuadricas dadas por las siguientes ecuaciones:1. 45x2 + 54y2 + 63z2 − 36xy + 36yz − 24x− 24y + 6z + 1 = 0.2. 45x2 + 99y2 + 18z2 + 144xy − 180xz + 36yz − 36x+ 72y + 72z + 1 = 0.3. 45x2 + 99y2 + 18z2 + 144xy − 180xz + 36yz + 72x− 36y + 72z + 1 = 0.4. −3y2 + 3z2 − 12xy + 12xz − 2x+ 4y + 4z + 2 = 0.5. 36x2 + 18y2 + 27z2 + 36xz + 36yz − 22x+ 28y + 8z = 0.6. 36x2 + 18y2 + 27z2 + 36xz − 36yz + 2x+ 34y − 40z = 0.7. x2 − y2 + z2 + 2xz − 2y + 1 = 0.8. x2 + y2 + z2 − 2xy + 2xz − 2yz + 4x+ 2y + 4z + 2 = 0.9. x2 + y2 + z2 − 2xy + 2xz − 2yz + 4x− 4y + 4z + 2 = 0.10.x2 − y2 + z2 + 2xz − 2y − 1 = 0.11. x2 + y2 + z2 − 2xy + 2xz − 2yz − 1 = 0.
481

12. x2 + y2 + z2 + 2xz − 1 = 0.13. x2 + y2 + z2 + 2xz + 4 = 0.14. x2 + y2 + z2 + 2xz − 2y + 1 = 0.
Otros invariantes de las cuadricas degeneradas.
Para distinguir los cilindros elıpticos del conjunto vacıo cuando |A| = |A0| = 0, α > 0, r(A) = 3,sirve otro invariante de los cilindros: A11 + A22 + A33, donde A es la matriz completa del cilindro yAii es el adjunto del elemento aii en A.
Llamando
B =
(1 00 C
)en un cambio de coordenadas ortogonal la matriz A cambia a BtAB donde Bt = B−1. De existirA−1 tambien cambiarıa de la misma manera por ser B ortogonal y tambien lo harıa la matriz adjuntade A: adj(A) = |A|A−1, siendo por lo tanto invariante su polinomio caracterıstico. En los cilindrosno existe A−1, porque |A| = 0 pero podemos considerar la matriz polinomial A(γ) = A + γI cuyodeterminante es un polinomio no nulo, y por tanto tiene inversa. Tanto A(γ) como su adjuntavarıan de la misma forma en un cambio de coordenadas ortogonal, siendo por ello invariante sutraza: A0(γ) + A11(γ) + A22(γ) + A33(γ). Haciendo γ = 0, y debido a que en un cilindro |A0| = 0,obtenemos que A0 + A11 + A22 + A33 = A11 + A22 + A33 es invariante en un cambio de coordenadasortogonal.
Veamos que A11 + A22 + A33 es tambien invariante para los cilindros en una traslacion:En la forma reducida de los cilindros se tiene A01 = A02 = A03 = 0. Cualquier traslacion se
puede descomponer en dos traslaciones a traves del origen de coordenadas de la forma reducida, poreso es suficiente comprobar que A11 + A22 + A33 es invariante en una traslacion desde el origen decoordenadas de la forma reducida al origen de coordenadas de la forma dada. La adjunta de la formareducida cambia en una traslacion segun
1 c1 c2 c30 1 0 00 0 1 00 0 0 1
0 0 0 00 A11 A12 A13
0 A12 A22 A23
0 A13 A23 A33
1 0 0 0c1 1 0 0c2 0 1 0c3 0 0 1
cuya matriz producto tiene la caja inferior derecha 3 × 3 igual a la de la matriz adj(A), siendo portanto invariante A11 + A22 + A33 en cada traslacion de este tipo.
482

Con lo cual queda demostrada la existencia de este invariante en los cilindros. Tambien servirıapara los pares de planos por el mismo razonamiento, pero en los pares de planos es cero.
En el cilindro elıptico, este invariante es de distinto signo que los valores propios mientras que sies del mismo signo obtenemos el conjunto vacıo.
Ahora vamos a ver otro invariante en los pares de planos que nos permite distinguir los pares deplanos paralelos de los coincidentes y del conjunto vacıo cuando |A| = |A0| = α = 0 y r(A) = 2.
Se trata de ∣∣∣∣ a00 a01
a01 a11
∣∣∣∣+
∣∣∣∣ a00 a02
a02 a22
∣∣∣∣+
∣∣∣∣ a00 a03
a03 a33
∣∣∣∣Debido a que en un par de planos el rango de la matriz A0 es 1, el termino anterior es el coeficiente
de λ2 en el polinomio caracterıstico de la matriz A, que queda invariante en una transformacionortogonal.
Por otra parte en una traslacion desde el sistema de ejes en que la cuadrica tiene la matrizreducida, esta cambia segun
1 c1 c2 c30 1 0 00 0 1 00 0 0 1
a00 0 0 00 λ1 0 00 0 0 00 0 0 0
1 0 0 0c1 1 0 0c2 0 1 0c3 0 0 1
=
a00 + λ1c
21 c1λ1 0 0
c1λ1 λ1 0 00 0 0 00 0 0 0
donde ∣∣∣∣ a00 + λ1c
21 c1λ1
c1λ1 λ1
∣∣∣∣ =
∣∣∣∣ a00 0c1λ1 λ1
∣∣∣∣ =
∣∣∣∣ a00 00 λ1
∣∣∣∣ha quedado igual. Como toda traslacion puede descomponerse en dos traslaciones que pasen porel origen de coordenadas de la ecuacion reducida, llegamos a la conclusion de que queda igual encualquier traslacion y lo mismo ocurre para los otros menores. Con lo que tenemos demostrada lainvariancia del numero anterior en los pares de planos.
Entonces podemos afirmar que si este numero es cero, se trata de dos planos coincidentes, si estenumero es de distinto signo que el valor propio distinto de cero de A0, se trata de dos planos paralelosy si este numero es del mismo signo que el valor propio distinto de cero, se trata del conjunto vacıo.
483

Como hemos visto, para la clasificacion de las cuadricas interesa conocer cuantos valores propiospositivos tiene la matriz de una cuadrica sin tener que resolver la ecuacion caracterıstica. Para ellovemos ahora la Ley de los signos de Descartes: Si se sabe que las raices de un polinomio sontodas reales, el numero de raices positivas que tiene el polinomio es igual al numero de cambios designo que hay en la sucesion de numeros formada por los coeficientes de los monomios del polinomioordenados segun su potencia.
Se puede suponer que el coeficiente del monomio de mayor grado es positivo, cambiandolo designo si es necesario, lo cual no afecta al signo de las raices.
La demostracion se hace por induccion sobre el grado del polinomio.
Si el polinomio es de grado 1, la solucion es positiva si el termino independiente es negativo;entonces, hay tantas soluciones positivas como cambios de signo en la sucesion de coeficientes delpolinomio, cumpliendose por tanto la ley de los signos en polinomios de grado 1.
Para hacer la induccion al caso de un polinomio de grado n a partir del caso de un polinomio degrado n− 1: anx
n + . . .+ a1x+ a0 hacemos las siguientes consideraciones:
Dejando de considerar las raices nulas podemos suponer que el termino independiente del poli-nomio es distinto de cero.
Por otra parte, si factorizamos el polinomio con el coeficiente de mayor grado positivo en factoreslineales, vemos que el termino independiente es del signo (−1)p, donde p es el numero de raicespositivas. Si a1 y a0 son del mismo signo, la paridad del numero de raices positivas del polinomio esigual a la paridad del numero de raices positivas de la derivada y si a1 y a0 son de distinto signo, laparidad del numero de raices positivas del polinomio es distinta de la paridad del numero de raicespositivas de su derivada.
Por el teorema de Rolle, si un polinomio tiene n raices reales, su polinomio derivada tiene almenos n − 1 raices reales. Si sabemos que el polinomio tiene tantas raices reales como su grado,el polinomio derivada tiene tambien tantas raices reales como su grado, es decir, n − 1, porque nopuede tener mas por el teorema fundamental del algebra.
Las raices reales de dicho polinomio y de su derivada estan intercaladas, determinando intervalosen la recta real. Si el cero esta a la derecha todos estos intervalos son todas las raices negativas, si elcero esta a la izquierda de todos los intervalos son todas las raices positivas habiendo por tanto dos
484

casos una raiz positiva mas para el polinomio que para su derivada. Si el cero esta en un intervaloque tiene a la izquierda una raiz del polinomio o coincide con ella y a la derecha una raiz de laderivada, hay el mismo numero de raices positivas en el polinomio que en la derivada mientras quesi el cero esta en un intervalo que tiene a la izquierda una raiz de la derivada o coincide con ella y ala derecha una raiz del polinomio hay una raiz positiva mas para el polinomio que para la derivada(hagase el dibujo). En cualquier caso, el numero de raices positivas del polinomio y de la derivada,o coinciden o se diferencian en una unidad.
Coincidiran si tienen la misma paridad, que es cuando a1 y a0 son del mismo signo, en cuyo caso,el numero de raices positivas del polinomio es igual al numero de raices positivas de la derivada,igual al numero de cambios de signo en la sucesion de coeficientes de los monomios de la derivada,(suponiendo la ley de los signos cierta para los polinomios de grado n− 1), que es igual, en este caso,al numero de cambios de signo de la misma sucesion en el polinomio; cuando a1 y a0 son de distintosigno el numero de raices positivas del polinomio y el numero de raices positivas de la derivada sonde distinta paridad, siendo, por tanto uno mas en el polinomio, siendo entonces igual al cambio designos en la sucesion de coeficientes de los monomios de la derivada mas uno, que coincide con elnumero de cambios de signo en la sucesion de coeficientes de los monomios del polinomio.
Podrıa suceder que a0 6= 0 y a1 = 0, entonces el mismo razonamiento se harıa con el primer ak 6= 0,no contandose los ceros de la sucesion de coeficientes en los cambios de signo de dicha sucesion.
Recordemos el teorema de Rolle: Si f es una funcion continua en un intervalo cerrado y dife-renciable en su interior, coincidendo su valor en los dos extremos del intervalo, existe un punto delinterior del intervalo en el que su derivada se anula.
Demostracion:Si la funcion es constante, su derivada en todo el intervalo es nula, no teniendo nada que demostrar.Supongamos que la funcion no es constante. La imagen por una funcion continua en un intervalo
cerrado alcanza su maximo y su mınimo. Si la funcion vale lo mismo en los dos extremos y noes constante, o bien el maximo o el mınimo es distinto de ese valor y se alcanza en el interior delintervalo. En ese punto la derivada se anula, porque si no se anulara la funcion serıa creciente odecreciente en ese punto, en cuyo caso no serıa maximo o mınimo.
BIBLIOGRAFIA
P. Abellanas. Geometrıa Basica. Ed. Romo S. L. 1961.A.D. Aleksandrov, A.N. Kolmogorov, M. A. Laurentiev y otros. La matematica: su contenido.
metodos y significado. 1. Alianza Universidad. Alianza Ed. 1981.
485

J. de Burgos. Algebra Lineal y Geometrıa cartesiana. Ed. McGraw-Hill Interamericana deEspana S. A. U. 2006.
L. I. Golovina. Algebra Lineal y algunas de sus aplicaciones. Ed. Mir 1980.E. Hernandez. Algebra y Geometrıa. Ed. Addison-Wesley iberoamericana, S. A. 1994.S. L. Salas. E. Hille. Calculus. 3a ed. Ed. Reverte, S. A. 1995.S. Xambo Deschamps. Geometrıa. Ediciones UPC,1997.
486

APENDICE: ESPACIO VECTORIAL COCIENTE.
Introduccion.
El espacio vectorial cociente resume la estructura de los conjuntos imagen inversa de un puntopor una aplicacion lineal y por ello de la estructura de los conjuntos de soluciones de los sistemasde ecuaciones lineales no homogeneos. Estos conjuntos se llaman variedades afines y se encuentrantambien entre los elementos caracterısticos de las aplicaciones afines.
Variedades afines del plano (R2).Ademas de las rectas del plano que pasan por el origen y pueden ser representadas matematicamente
como subespacios vectoriales del espacio vectorial R2, hay otras rectas que no pasan por el origen.Las rectas que no pasan por el origen se llaman variedades afines de dimension 1.
Cada recta que no pasa por el origen es paralela a una recta que pasa por el origen y tambienpor cada punto del plano pasa una recta paralela a la recta dada. Todas las rectas paralelas sonvariedades afines paralelas, llamandose la que pasa por el origen, recta de direccion de dichas rectasparalelas.
Dado un vector v distinto de cero de la recta de direccion, esta r es el conjunto r = λv|λ ∈ R.Cada recta paralela a la recta de direccion esta formada por los puntos extremos de los vectoresu+ λv|λ ∈ R.
1
>
487

Considerada r como subespacio vectorial se denota por W y cualquier recta paralela a ella sedenota por u + W . Es importante observar que u + W = u′ + W si u′ ∈ u + W : En efecto, siu′ = u+ αv, todos los vectores que se pueden obtener haciendo sumas u+ λv, cuando λ varıa en Rpueden obtenerse de u′ + λ′v haciendo λ′ = λ− α.
Conjunto cociente.Las rectas paralelas a una dada son una descomposicion del plano en partes, siendo vacıa la
interseccion de dos de estas partes. Se dice que forman una particion del plano y considerando cadaparte como un elemento tenemos un conjunto de elementos que se llama conjunto cociente de R2 porW y se denota por R2/W .
Espacio vectorial cociente.Se pueden definir dos operaciones en R2/W :1) Suma:Dadas dos rectas paralelas r1 = u1 + λv|λ ∈ R, r2 = u2 + λv|λ ∈ R, definimos r1 + r2 =
u1 + u2 + λv|λ ∈ R.Se puede comprobar que esta suma esta bien definida, es decir, que aunque cambiemos el vector
u1 por otro u′1 que tenga extremo en la misma recta r1 y cambiemos el vector u2 por otro vector u′2,que tenga extremo en la recta r2, la recta suma obtenida a partir de u′1 y u′2 es la misma: el vectoru′1 + u′2 esta en la recta u1 + u2 + λv|λ ∈ R
1
QQQQQQs -
>
>
-QQQQQQs
1
488

El elemento cero del espacio vectorial cociente es la variedad W que pasa por el origen.2) Multiplicacion por un numero:Dada una recta r = u+ λv|λ ∈ R y un numero k ∈ R, definimos kr = ku+ λv|λ ∈ R.Se puede comprobar que esta multiplicacion no depende del vector u escogido con extremo en r:
Si u′ = u + αv la recta ku′ + λv|λ ∈ R es ku + kαv + λv|λ ∈ R = ku + (kα + λ)v|λ ∈ R =ku+ λ′v|λ′ ∈ R.
1
>
-
1
>
-
Observese que el vector que va del extremo de u al extremo de u′ es v y entonces el vector queva del extremo de ku al extremo de ku′ es kv, por lo que la recta que pasa por el extremo de ku ytiene direccion v es la misma que la que pasa por ku′ y tiene direccion v.
Es facil comprobar que estas dos operaciones tienen las propiedades asociativas, distributivas,etc... que estructuran al conjunto cociente R2/W como un espacio vectorial, que se llama espaciovectorial cociente.
489

La aplicacon que asocia a cada vector del plano la recta que pasa por su extremo y es paralela a W se llamaaplicacion cociente de R2 en R2/W y es lineal.
Es curioso observar que el doble de una recta se puede obtener sumando vectores con extremosen dicha recta, por lo que cualesquiera que sean las parejas de vectores que cojamos con extremosen la recta, los vectores suma de estas parejas tienen extremos en la misma recta. Vease el dibujo acontinuacion.
1
>
-
1
1
>
>
-
Otro ejemplo: Si W es un plano que pasa por el origen de R3, el espacio cociente R3/W es elconjunto de planos paralelos a W , que se pueden sumar y multiplicar por un numero. El elementocero de este espacio vectorial es W .
Podemos hacer en cualquier espacio vectorial V y con cualquier subespacio suyo W el mismoproceso:
Los conjuntos u+λv|λ ∈ R = u+W se llaman variedades afines, paralelas a W . Consideradascomo elementos forman el conjunto cociente V/W , que se puede estructurar en espacio vectorial con
490

las operaciones suma y multiplicacion por los numeros del cuerpo de V , analogas a las de R2/Wresultando ası el espacio vectorial cociente V/W .
La aplicacion natural p(u) = u + W definida en V sobre V/W se llama aplicacion cociente y eslineal.
Relacion entre las aplicaciones lineales y los conjuntos cociente.
Empecemos por considerar aplicaciones lineales sencillas de R2 en R.Sea f : R2 −→ R definida por f(x, y) = x. Para cada a ∈ R, el conjunto de puntos de R2 que se
aplican en a esf−1(a) = (x, y)|x = a = (a, y)|y ∈ R = (a, 0) + (0, y)|y ∈ R = (a, 0) + y(0, 1)|y ∈ R,
que podemos escribir (a, 0) +W como una variedad afın, llamando W = (0, y)|y ∈ R. Es la rectaque pasa por (a, 0) y es paralela a W . Como W es el conjunto de vectores del eje de ordenadas, estarecta es la vertical que pasa por (a, 0). Observemos que W, la recta de direccion de estas variedadesafines es el nucleo de la aplicacion lineal f .
Las distintas imagenes inversas de puntos de R son las distintas rectas verticales que forman unaparticion de R2 y consideradas como elementos son el conjunto cociente R2/W , que asociando a cadaa ∈ R la variedad afın f−1(a), es biyectivo al espacio R.
No es difıcil comprobar que la biyeccion considerada es tambien lineal y por tanto un isomorfismo,teniendose R2/Nf = R2/W ≈ Im(f) = R.
El lector puede repetir la construccion anterior para la aplicacion lineal f : R2 −→ R definidapor f(x, y) = y, obteniendo que el conjunto de las rectas horizontales con la estructura de espaciocociente por el subespacio del eje de abscisas es tambien isomorfo a R.
Para la aplicacion f : R2 −→ R definida por f(x, y) = x+ y, cada f−1(a) = (x, y)|x+ y = a esuna recta paralela a la diagonal del segundo y cuarto cuadrante. El conjunto de todas estas rectasestructurado en espacio vectorial es isomorfo a R. El isomorfismo asocia a cada recta la abscisa desu punto de interseccion con este eje.
Consideremos la aplicacion f : R3 −→ R definida por f(x, y, z) = x+ y + z.Para cada a ∈ R, el conjunto f−1(a) = (x, y, z)|x+ y+ z = a es un plano. Los distintos planos
que se obtienen para los distintos a son paralelos y forman el conjunto cociente de R3 por el planoW ≡ x + y + z = 0. Este conjunto es isomorfo a R. El isomorfismo asocia a cada plano la abscisade su punto de interseccion con este eje.
491

Consideremos la aplicacion f : R3 −→ R2 definida por f(x, y, z) = (x+ y, y + z).Para cada (a, b) ∈ R2, el conjunto f−1(a, b) es el conjunto (x, y, z)|x + y = a, y + z = b =
(x, y, z)|x = a−λ, y = λ, z = b−λ = (x, y, z)|(x, y, z) = (a, 0, b) +λ(−1, 1,−1) que es una rectaparalela a la recta (x, y, z)|x = −λ, y = λ, z = −λ = Nf .
El conjunto de todas estas rectas paralelas es un conjunto cociente de R3 por la recta Nf y conla estructura de espacio vectorial cociente es isomorfo a R2. El isomorfismo asocia a cada recta lapareja de coordenadas no nulas de su punto de interseccion con el plano y = 0.
Si fuera la aplicacion f : R3 −→ R2 definida por f(x, y, z) = (x + y, 0), tenemos dos tipos depuntos en R2: cuando b 6= 0, el punto (a, b) no pertenece a la imagen de f , por tanto su imageninversa es vacıa, pero para cada (a, 0) ∈ R2, el conjunto f−1(a, 0) es el conjunto (x, y, z)|x+ y = a,que es un plano. Para los distintos a ∈ R, obtenemos distintos planos paralelos, que forman el espaciocociente de R3 por W = (x, y, z)|x + y = 0. El espacio vectorial cociente R3/W es isomorfo aR ≈ Im(f).
El mismo proceso se puede hacer para cualquier aplicacion lineal f : V −→ V ′ entre dos espaciosvectoriales, teniendose V/Nf ≈ Imf .
Si f : V −→ V es una aplicacion lineal con un subespacio invariante U , hay una aplicacion linealV/U −→ V/U inducida por f que aplica cada variedad afın v + U en f(v) + U . Puede comprobarseque esta bien definida y que es lineal.
Relacion del espacio cociente con los sistemas de ecuaciones.Dado un sistema de m ecuaciones con n incognitas, que designamos simplificadamente por Ax = b,
donde A es una matrizm×n, considerando la aplicacion lineal f : Rn −→ Rm de matriz A, el conjuntode soluciones del sistema es la imagen inversa de b por f , que segun hemos visto es una variedadafın y un elemento del conjunto cociente de Rn por el nucleo de f , que es, a su vez, el conjunto desoluciones del sistema homogeneo Ax = 0.
Dada una aplicacion afın f(x) = a + Ax, la imagen inversa de un punto b ∈ Imf es el conjuntode puntos x|a+Ax = b = x|Ax = b− a, conjunto de soluciones de un sistema, que segun hemosvisto es tambien una variedad afın paralela al conjunto de soluciones del sistema Ax = 0 y por tantoun elemento del conjunto cociente de Rn por x|Ax = 0.
Otro ejemplo es el conjunto de puntos fijos de una aplicacion afın:x|f(x) = x = x|a + Ax = x = x|a = (I − A)x; es una variedad afın paralela al conjunto
de soluciones del sistema (I − A)x = 0.
492

Bibliografıa.Juan de Burgos. Algebra Lineal y Geometrıa cartesiana. 3a edicion. Ed. McGraw Hill/Interamericana
de Espana. S. A. U. 2006.M. Castellet, I. LLerena. Algebra Lineal y Geometrıa. Ed. Reverte. S. A. 1991.S. Lipschutz. Algebra Lineal. 2a edicion. Ed. McGraw Hill/Interamericana de Espana. S. A. U.
1992.
493