lectura 3. equipos no reparables · curva de la bañera la curva de la bañera es un gráfico que...
TRANSCRIPT

LECTURA 3 Confiabilidad de Equipos No Reparables
“INGENIERÍA DE CONFIABILIDAD….. ……PORQUE UNA DE LAS FORMAS MÁS IMPORTANTES DE
AGREGAR VALOR, ES EVITAR QUE SE DESTRUYA”
Medardo Yañez

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
2
4.3.1. CONFIABILIDAD EN ACTIVOS NO REPARABLES 4.2.1.1 ACTIVOS NO REPARABLES Como se mencionó previamente, definimos como activos no reparables, aquellos que tienen las siguientes características fundamentales: • Su condición operativa no puede ser restaurada después de una falla. • Su vida termina con una “única” falla y debe ser reemplazado. La mayoría de los componentes electrónicos suelen ser considerados “no reparables”. Los bombillos o bulbos de luz son los clásicos ejemplos de equipos no reparables. Sin embargo, es importante destacar que en esencia, cualquier equipo es reparable; inclusive un bombillo, y es la política o estrategia de mantenimiento y/o reparación la que realmente dice como debemos clasificar un equipo o componente. Si la política de mantenimiento es “reemplazar” después de la falla, entonces se clasificará al activo como “no reparable”; si por el contrario, la política es “reparar y reinstalar” después de la falla, clasificaremos al activo como “reparable”. Adicionalmente, para clasificar activos, debe tenerse en cuenta el “volumen de control y contexto operacional especifico” al cual se hace referencia. Para entender estos conceptos analicemos la figura 4.2. Si se define volumen de control, a nivel de componentes, en este caso los tubos de un intercambiador, y se analiza la falla de un tubo, estos son “reemplazados al fallar” y en la mayoría de las plantas de proceso poseen tubos de repuesto para este fin. En este caso, el tubo es considerado un activo no reparable; no obstante, si el volumen de control se define como el intercambiador de calor completo, al fallar un tubo, no se reemplaza todo el intercambiador; solo el tubo. En este caso, el tubo sigue siendo un activo no reparable, pero el intercambiador es un activo reparable.
Otro ejemplo sería analizar una lámpara de luz; cuando le falla el bombillo. En este caso, el bombillo es un activo “no reparable” y la lámpara; es un “activo reparable”. Adicionalmente existen otros aspectos de carácter estratégicos como el contexto operacional considerado, que contribuyen a catalogar para efectos prácticos, un componente o sistema como reparable o no reparable.
COMPONENTE
TUBO
EQUIPO
INTERCAMBIADORDE CALOR
Fig. 4.2: Diferentes Volúmenes de Control (Componente, Equipo)

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
3
Por ejemplo, un sensor instalado en el fondo de un pozo de crudo profundo, de fallar conllevaría a una logística de recursos técnicos y económicos significativos para proceder a extraerlo del subsuelo y bien repararlo o reemplazarlo. Ese mismo sensor, instalado en una planta en la superficie, debidamente atendida, muy posiblemente pueda ser reparado sin muchos inconvenientes. Bajo esta panorámica, el sensor en el subsuelo muy posiblemente convenga clasificarlo como componente no reparable, en cuyo caso será importante estudiar su confiabilidad; mientras que el sensor en la superficie se clasifique como componente reparable, en cuyo caso además de la confiabilidad, la disponibilidad es otro parámetro de interés. Como conclusión, para clasificar un activo como reparable o no reparable, debemos tomar en cuenta la política de mantenimiento y/o reparación, el volumen de control al que nos referimos y el contexto operacional especifico.
4.3.1.2 CONCEPTOS BÁSICOS 4.3.1.2.1 LA FUNCIÓN CONFIABILIDAD (C(T)) Confiabilidad de un activo no reparable, evaluada en un tiempo misión (tm), es la probabilidad de que la variable aleatoria “tiempo para la falla” sea igual o mayor al periodo de análisis o tiempo misión (tm). En otras palabras, es la probabilidad de que el activo opere sin fallas un tiempo igual o superior al periodo de análisis o tiempo misión (tm).
)ttPr()t(dadConfiabili m≥= Ecuación 4.2 Supóngase que se tiene una muestra representativa de datos; es decir, períodos de operación hasta la falla (ti, i=1,2……n) de n equipos similares. Supóngase adicionalmente que con estos datos, y siguiendo los procedimientos descritos en el Capítulo II (ver secciones 2.3.3 y 2.3.3.1), se logra caracterizar esta muestra con una distribución de probabilidades. La figura 4.3, muestra distribuciones de probabilidad de frecuencia y acumuladas directa e inversa, de la variable aleatoria objeto de estudio “tiempo para la falla”. Como el lector habrá deducido ya en este punto, la función “Confiabilidad” definida en la ecuación 4.2, corresponde a la distribución acumulada inversa del tiempo para la falla, ya que esta distribución expresa la probabilidad de que t (tiempo de falla) sea mayor o igual que tm (tiempo misión). Apoyándonos en la ecuación 4.2 y en la ecuación 2.29 del Capítulo II, lo anterior se expresa matemáticamente con la siguiente ecuación:
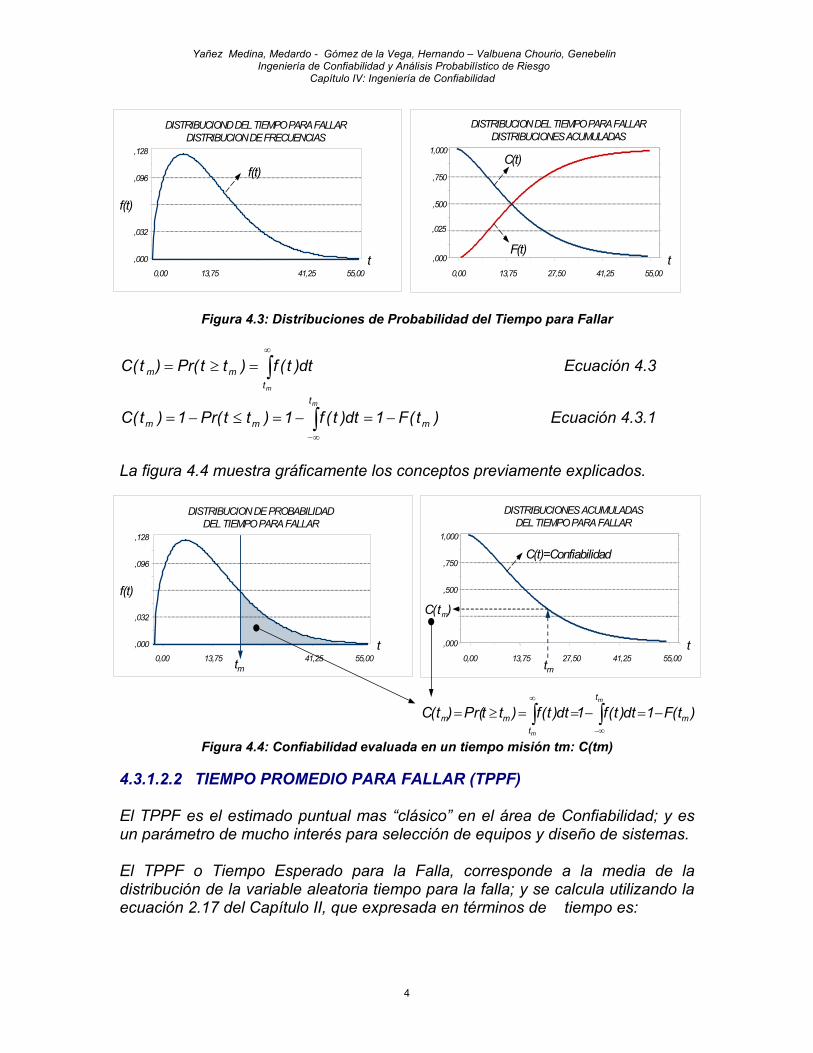
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
4
Figura 4.3: Distribuciones de Probabilidad del Tiempo para Fallar
∫∞
=≥=mt
mm dt)t(f)ttPr()t(C Ecuación 4.3
∫∞−
−=−=≤−=mt
mmm )t(F1dt)t(f1)ttPr(1)t(C Ecuación 4.3.1
La figura 4.4 muestra gráficamente los conceptos previamente explicados.
Figura 4.4: Confiabilidad evaluada en un tiempo misión tm: C(tm)
4.3.1.2.2 TIEMPO PROMEDIO PARA FALLAR (TPPF) El TPPF es el estimado puntual mas “clásico” en el área de Confiabilidad; y es un parámetro de mucho interés para selección de equipos y diseño de sistemas. El TPPF o Tiempo Esperado para la Falla, corresponde a la media de la distribución de la variable aleatoria tiempo para la falla; y se calcula utilizando la ecuación 2.17 del Capítulo II, que expresada en términos de tiempo es:
,000
,032
,096
,128
,000
,500
,750
1,000
0,00 13,75 27,50 41,25 55,00
f(t)
tm
t0,00 13,75 41,25 55,00
C(t)=Confiabilidad
DISTRIBUCION DE PROBABILIDADDEL TIEMPO PARA FALLAR
DISTRIBUCIONES ACUMULADASDEL TIEMPO PARA FALLAR
∫∫∞−
∞
−=−==≥=m
m
t
mt
mm )t(F1dt)t(f1dt)t(f)ttPr()t(C
t
)t(C m
tm
,000
,032
,096
,128
f(t)
t0,00 13,75 41,25 55,00
DISTRIBUCIOND DEL TIEMPO PARA FALLARDISTRIBUCION DE FRECUENCIAS
,000
,500
,750
1,000
0,00 13,75 27,50 41,25 55,00
C(t)
F(t)
DISTRIBUCION DEL TIEMPO PARA FALLARDISTRIBUCIONES ACUMULADAS
t
f(t)
,025

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
5
∫∫∞∞
===00
t dt)t(Cdt)t(f.tTPPFµ Ecuación 4.4
Figura 4.5: TPPF 4.3.1.2.3 LA FUNCIÓN DE VELOCIDAD DE INCREMENTO DEL PELIGRO
(H(T)) O TASA DE FALLAS La función de velocidad de incremento del peligro o tasa de fallas h(t), es un camino alternativo a la función confiabilidad C(t), para describir el comportamiento de la variable aleatoria tiempo para la falla. La función h(t) describe el comportamiento del numero de fallas de una población por unidad de tiempo, y viene dada por la siguiente expresión:
)t(F1)t(f
)t(C)t(f)t(h
−== Ecuación 4.5
En términos probabilísticos, la ecuación 4.5 dice que h(t) es la probabilidad condicional de falla en un intervalo de tiempo t+∆t; dado que el componente, equipo o sistema ha sobrevivido hasta el tiempo t. (Ver concepto de probabilidad condicional Capítulo II). Al igual que las funciones f(t), F(t) y C(t) que se observan en la figura 4.3, la función h(t) es una característica única de la variable tiempo para fallar de una población de componentes, equipos o sistemas. Existe una importante relación entre la función Confiabilidad C(t) y la función h(t), que se resume en la siguiente expresión:
dt)).t(h(
e)t(C ∫=−
Ecuación 4.6 La ecuación 4.6 implica que al definir la función h(t) podemos definir la función C(t), y viceversa.
,000
,032
,096
,128
f(t)
µt=TPPFt
0,00 41,25 55,00
DISTRIBUCION DE PROBABILIDADDEL TIEMPO PARA FALLAR
27,50
∫∫∞∞
===00
t dt)t(Cdt)t(f.tTPPFµ

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
6
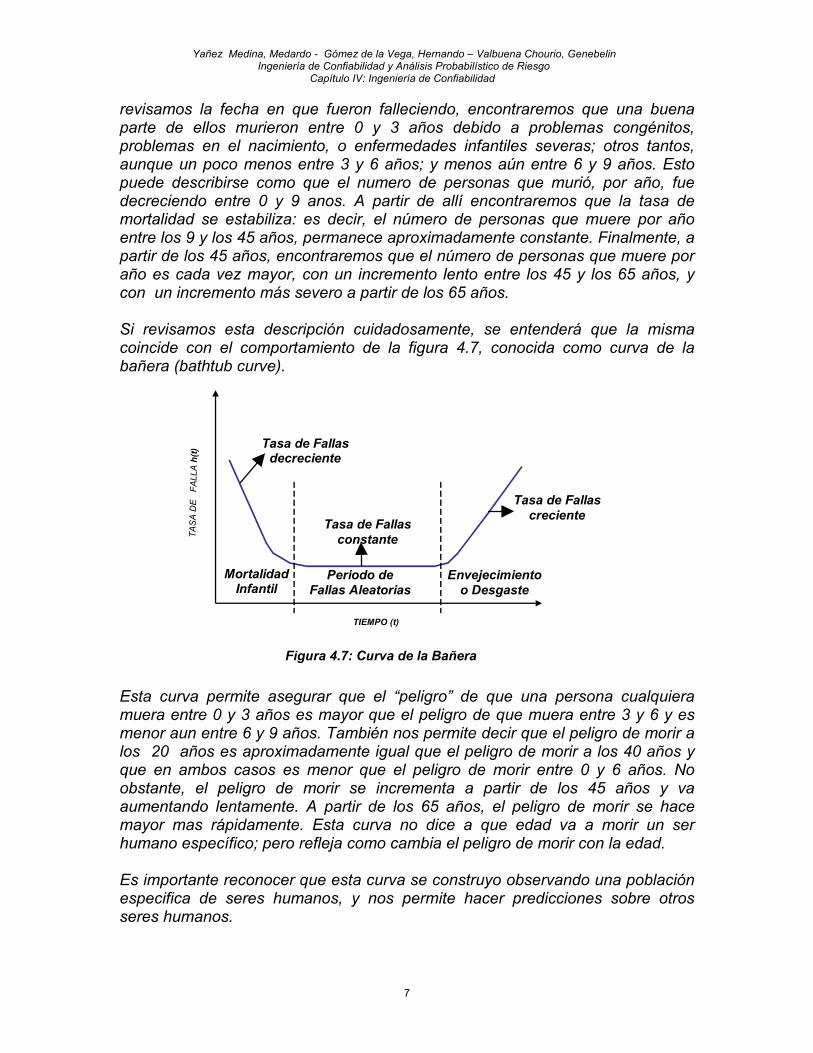
Como se explicó previamente, la función h(t) describe el comportamiento del número de fallas de una población por unidad de tiempo, y la misma puede ser creciente (el número de componentes de la población que fallan por unidad de tiempo aumenta progresivamente), decreciente (el número de componentes de la población que fallan por unidad de tiempo disminuye progresivamente), o constante. El análisis del comportamiento de fallas de una gran cantidad de poblaciones de componentes o equipos observados durante largos períodos de estudio, han mostrado una función tasa de fallas decreciente en el primer período, la primera etapa del período de observación (fenómeno conocido como mortalidad infantil), seguido por una función tasa de fallas aproximadamente constante, y finalmente una función tasa de fallas creciente durante la última etapa del período de observación. La figura 4.6 muestra la forma que toma la función tasa de fallas para el comportamiento previamente descrito.
Figura 4.6: Comportamiento típico de h(t) para poblaciones de componentes
La forma de la función h(t) mostrada en la figura 4.6, es ampliamente conocida como curva de la bañera. En la siguiente sección explicaremos como interpretar en detalle la curva mencionada. Curva de la Bañera La Curva de la Bañera es un gráfico que muestra el probable comportamiento de la tasa de fallas de un tipo de componente o equipo para diferentes instantes de tiempo; y se construye observando y registrando el comportamiento histórico de fallas de una población de ese tipo de componente o equipo. Una forma práctica de entender la curva de la bañera es analizar el caso de los seres humanos. Supongamos que se analizan las vidas de 100 personas, nacidas en el año 1900, seleccionadas aleatoriamnte. Con toda seguridad, si
TASA
DE
FAL
LAh (
t )
TIEMPO (t)
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
7
revisamos la fecha en que fueron falleciendo, encontraremos que una buena parte de ellos murieron entre 0 y 3 años debido a problemas congénitos, problemas en el nacimiento, o enfermedades infantiles severas; otros tantos, aunque un poco menos entre 3 y 6 años; y menos aún entre 6 y 9 años. Esto puede describirse como que el numero de personas que murió, por año, fue decreciendo entre 0 y 9 anos. A partir de allí encontraremos que la tasa de mortalidad se estabiliza: es decir, el número de personas que muere por año entre los 9 y los 45 años, permanece aproximadamente constante. Finalmente, a partir de los 45 años, encontraremos que el número de personas que muere por año es cada vez mayor, con un incremento lento entre los 45 y los 65 años, y con un incremento más severo a partir de los 65 años.
Si revisamos esta descripción cuidadosamente, se entenderá que la misma coincide con el comportamiento de la figura 4.7, conocida como curva de la bañera (bathtub curve). Esta curva permite asegurar que el “peligro” de que una persona cualquiera muera entre 0 y 3 años es mayor que el peligro de que muera entre 3 y 6 y es menor aun entre 6 y 9 años. También nos permite decir que el peligro de morir a los 20 años es aproximadamente igual que el peligro de morir a los 40 años y que en ambos casos es menor que el peligro de morir entre 0 y 6 años. No obstante, el peligro de morir se incrementa a partir de los 45 años y va aumentando lentamente. A partir de los 65 años, el peligro de morir se hace mayor mas rápidamente. Esta curva no dice a que edad va a morir un ser humano específico; pero refleja como cambia el peligro de morir con la edad. Es importante reconocer que esta curva se construyo observando una población especifica de seres humanos, y nos permite hacer predicciones sobre otros seres humanos.
TAS
A D
E F
ALLA
h(t )
TIEMPO (t)
Mortalidad Infantil
Periodo de Fallas Aleatorias
Envejecimiento o Desgaste
Tasa de Fallas creciente
Tasa de Fallas decreciente
Tasa de Fallas constante
Figura 4.7: Curva de la Bañera
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
8
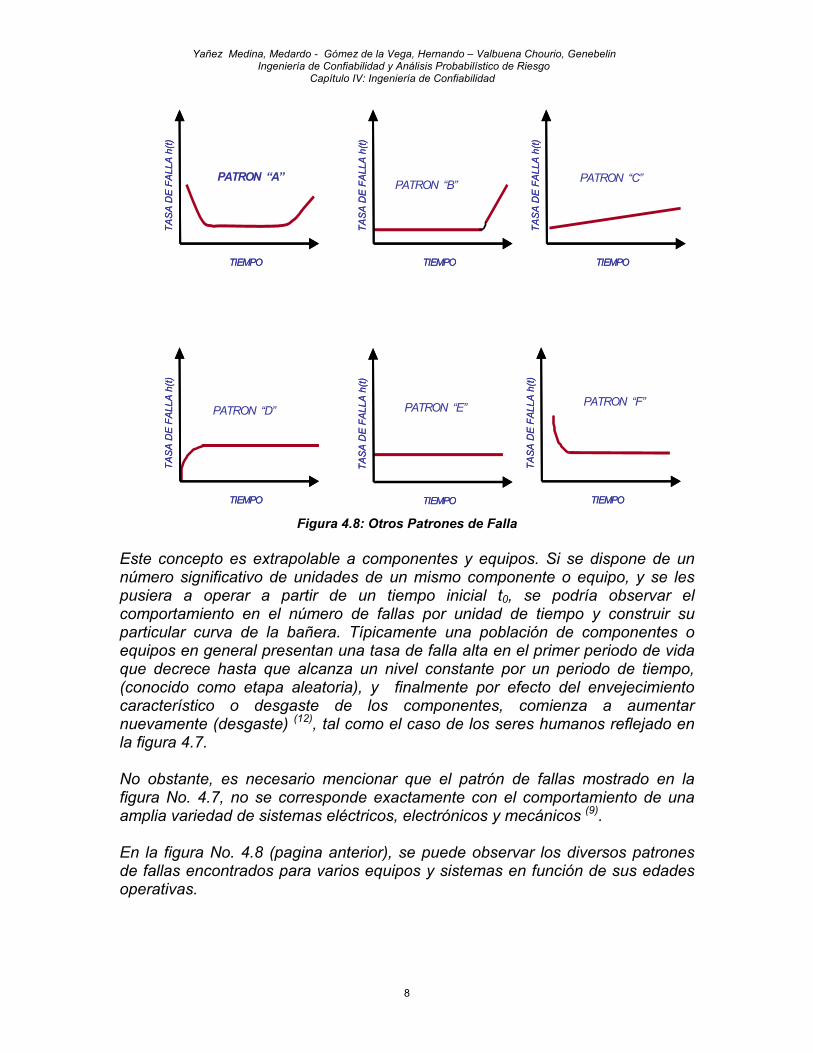
Figura 4.8: Otros Patrones de Falla Este concepto es extrapolable a componentes y equipos. Si se dispone de un número significativo de unidades de un mismo componente o equipo, y se les pusiera a operar a partir de un tiempo inicial t0, se podría observar el comportamiento en el número de fallas por unidad de tiempo y construir su particular curva de la bañera. Típicamente una población de componentes o equipos en general presentan una tasa de falla alta en el primer periodo de vida que decrece hasta que alcanza un nivel constante por un periodo de tiempo, (conocido como etapa aleatoria), y finalmente por efecto del envejecimiento característico o desgaste de los componentes, comienza a aumentar nuevamente (desgaste) (12), tal como el caso de los seres humanos reflejado en la figura 4.7. No obstante, es necesario mencionar que el patrón de fallas mostrado en la figura No. 4.7, no se corresponde exactamente con el comportamiento de una amplia variedad de sistemas eléctricos, electrónicos y mecánicos (9). En la figura No. 4.8 (pagina anterior), se puede observar los diversos patrones de fallas encontrados para varios equipos y sistemas en función de sus edades operativas.
PATRON “C”
PATRON “D” PATRON “E” PATRON “F”
PATRON “A”PATRON “B”
TIEMPO
TAS
A D
E F
ALL
A h
(t)
TIEMPO
TAS
A D
E F
ALL
A h
(t)
TIEMPO
TAS
A D
E F
ALL
A h
(t)
TIEMPO
TAS
A D
E F
ALL
A h
(t)
TIEMPO
TAS
A D
E F
ALL
A h
(t)
TIEMPO
TAS
A D
E F
ALL
A h
(t)
TIEMPO
TASA
DE
FA
LLA
h(t)
TIEMPO
TASA
DE
FA
LLA
h(t)
TIEMPO
TAS
A D
E FA
LLA
h(t)
TIEMPO
TAS
A D
E FA
LLA
h(t)
TIEMPO
TASA
DE
FA
LLA
h(t)
TIEMPO
TASA
DE
FA
LLA
h(t)

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
9
Estudios realizados han mostrado que el 4% de los sistemas se corresponden con el patrón “A”, 2% con el patrón “B”, 5% con el patrón “C”, 7% con el patrón “D”, 14% con el patrón “E” y aproximadamente el 68% con el patrón “F” (9). 4.3.1.3 ESTIMACIÓN DE LA CONFIABILIDAD Hasta este punto se han descrito las funciones y parámetros más importantes de un análisis de confiabilidad para equipos no reparables (C(t), h(t), TPPF). Como el lector puede constatar en las ecuaciones 4.3, 4.4 y 4.5, para definir estas funciones, es necesario definir la distribución paramétrica de probabilidades del tiempo para la falla f(t). En caso de no encontrar ninguna distribución paramétrica que ajuste al conjunto de datos disponibles, se debe hacer uso de una distribución “no paramétrica o empírica” (ver sección 2.3.2 Capítulo II) y estimar la confiabilidad apoyados en “estadística no paramétrica o estadística de la muestra”. En las secciones sucesivas se estudiará como estimar confiabilidad usando estadística paramétrica y usando estadística no paramétrica. 4.3.1.3.1 ESTIMACIÓN DE CONFIABILIDAD DE ACTIVOS NO REPARABLES CON ESTADÍSTICA PARAMÉTRICA Para estimar confiabilidad con estadística paramétrica, es necesario caracterizar probabilísticamente la variable tiempo para fallar, es decir; encontrar la distribución paramétrica f(t) que mejor se ajusta a los datos; usando para ello el procedimiento descrito en la sección 2.3.3 del Capítulo II. En nuestro caso los datos a analizar deben ser tiempos de operación de n equipos similares con los cuales se definirá la distribución de densidad de probabilidades f(t). Una vez definida f(t), utilizando las ecuaciones 2.29 y 2.31 del Capítulo II, se obtienen la distribución acumulada directa F(t) que corresponde a la probabilidad de fallas y la distribución acumulada inversa C(t) que corresponde a la confiabilidad. Sin embargo, el proceso de caracterización probabilística de la variable “tiempo de operación para la falla” requiere un tratamiento especial para su caracterización; que esta relacionado con el concepto de datos censados, que se explica a continuación. Para entender el concepto de datos censados, es necesario analizar la figura 4.9-A. En la misma se representan con líneas los tiempos de operación de una población de “n” equipos. Estos tiempos fueron medidos de manera continua en cada equipo desde que iniciaron su operación. Las líneas punteadas, con una “X” al final representan aquellos equipos que han fallado antes del tiempo tmisión o periodo de análisis, y las líneas continuas aquellos equipos que no han fallado y continúan operando después de finalizado el periodo de análisis.

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
10
Las líneas punteadas constituyen la información de fallas; mientras que las líneas continuas; es decir, los tiempos t3 y t6 son datos de equipos que permanecen confiables (no han fallado) para el momento del análisis; y son parte importante de la información. A t3 y t6 se les conoce como datos censados.
Figura 4.9-A: Datos censados y no censados
La existencia de datos censados es generalmente obviada por los analistas quienes en la mayoría de las ocasiones se concentran en los equipos que han fallado, y no toman en cuenta los datos censados. Esto se traduce en cálculos pesimistas de la confiabilidad. En este punto el lector podría estarse preguntando como incluir los datos censados en el cálculo de confiabilidad, y la respuesta está en el proceso de caracterización probabilística; como se explica a continuación: El paso 1 de una caracterización probabilística es plantear las hipótesis acerca de las distribuciones paramétricas que podrían hacer un buen ajuste con los datos. El paso 2, es calcular los parámetros de cada una de las distribuciones hipótesis con los datos de la muestra. Las ecuaciones para calcular estos parámetros normalmente se obtienen con el método de máxima verosimilitud explicado en la sección 2.4.1 del capítulo II. El paso 3 consiste en realizar alguna de las pruebas de bondad de ajuste estudiadas en la sección 2.3.3.2 en las que normalmente se comparan cada una
0 Tiempo t
Equipo 1
Equipo 2
Equipo 3
Equipo 4
Equipo 5
Equipo 6
Equipo n
X
X
X
X
X
t1
t2
t3
t4
t5
t6
tn
tmision

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
11
de las curvas de las distribuciones hipótesis teóricas obtenidas con los parámetros estimados en el paso anterior, con el histograma de los datos de la muestra. De esta comparación se calcula para cada distribución hipótesis un valor llamado “valor del test” y se compara contra un valor llamado “valor critico”. Si el valor del test es menor que el valor crítico para un determinado nivel de significancia, entonces la distribución hipotética se considera un buen ajuste y la hipótesis no es rechazada. Si por el contrario, el valor del test es mayor que el valor crítico, la hipótesis se rechaza. El paso 4 es seleccionar entre las distribuciones hipotéticas no rechazadas, aquella que tenga el valor del test más bajo, y esta se considera el mejor ajuste y por lo tanto la distribución paramétrica que mejor representa el set de datos de la muestra. La forma de tomar en cuenta los datos censados en el proceso de caracterización probabilística se centra en el paso 2 del procedimiento previamente descrito; es decir, en el cálculo de los parámetros con los datos de la muestra; ya que las ecuaciones para el cálculo de los parámetros de las distribuciones probabilísticas son diferentes cuando existen datos censados. Como el lector recordara de la sección de la sección 2.4.1, el método de máxima verosimilitud permite definir las ecuaciones de los parámetros. Para refrescar la memoria, recordemos el método de máxima verosimilitud: Paso 1: Para un set de datos ti (i=1, 2, 3.......n) crear la ecuación de máxima verosimilitud:
∏=
=n
1ii ),t(fL θ ; donde ti son los tiempos de ocurrencia de fallas y t el parámetro o
los parámetros de la distribución probabilística
Paso 2: Derivar la ecuación de verosimilitud respecto a cada parámetro;θ∂
∂L
Paso 3: Hallar el valor de θ que maximiza L; es decir resolver 0L=
∂∂θ
En caso de existir datos censados, la ecuación de verosimilitud definida en el paso 1, cambia a la siguiente forma:
∏∏==
=w
1jj
m
1ii ),t(C*),t(fL θθ ;
Donde: m = Número de equipos que han fallado. ti = Tiempo de falla del equipo i. w = Número de datos censados o equipos no fallados tj = Tiempos de operación de equipos que no han fallado (datos censados)
=θ Parámetros de la distribución de probabilidad

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
12
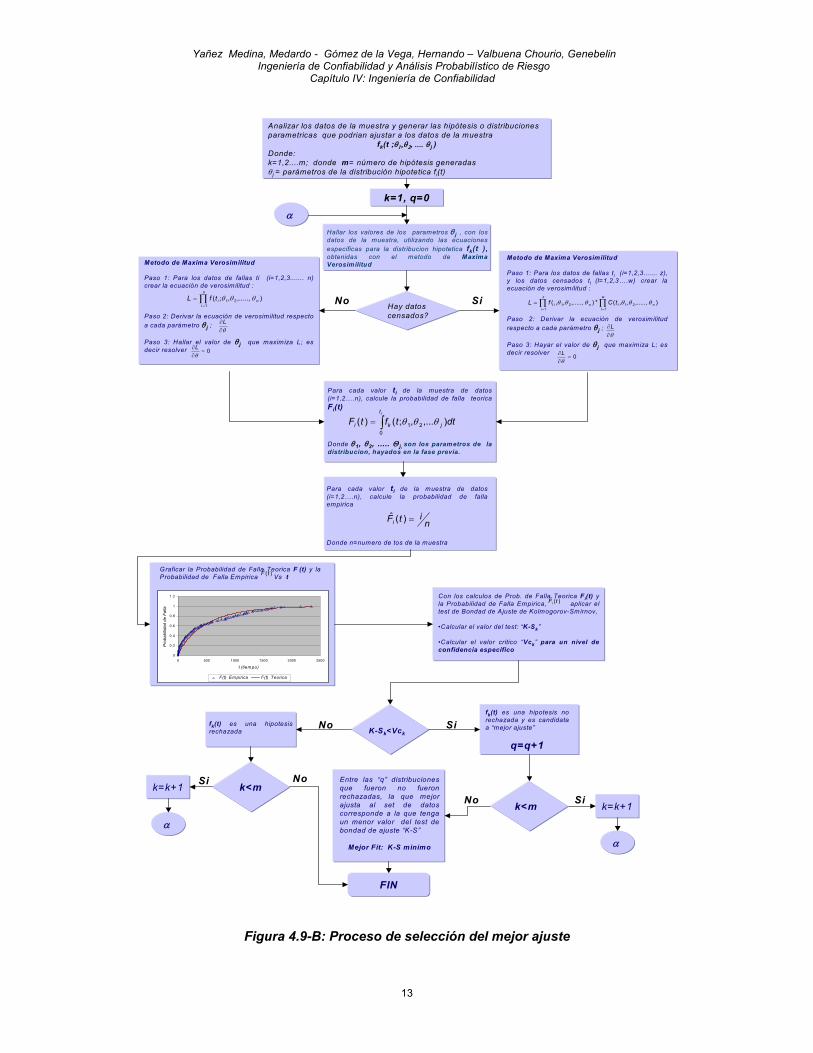
Por esta variación en el procedimiento, las ecuaciones para el cálculo de parámetros que se obtienen cuando existen datos censados son diferentes a las ecuaciones que se obtienen cuando no los hay. La figura 4.9-B muestra un flujograma del proceso de selección de la distribución que mejor ajusta a una muestra de datos que incluye datos censados.
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
13
Figura 4.9-B: Proceso de selección del mejor ajuste
Analizar los datos de la muestra y generar las hipótesis o distribuciones parametricas que podrian ajustar a los datos de la muestra
fk(t ;θ1,θ2, .... θ j )Donde:k=1,2....m; donde m= número de hipótesis generadasθ j = parámetros de la distribución hipotetica fi(t)
Hay datoscensados?
k=1, q=0
SiNo
Metodo de Maxima Verosimilitud
Paso 1: Para los datos de fallas ti (i=1,2,3....... n)crear la ecuación de verosimilitud :
Paso 2: Derivar la ecuación de verosimilitud respectoa cada parámetro θ j ;
Paso 3: Hallar el valor de θ j que maximiza L; es decir resolver
∏=
=n
initfL
121 ),.....,,;( θθθ
θ∂∂L
0=∂∂
θL
Metodo de Maxima Verosimilitud
Paso 1: Para los datos de fallas ti (i=1,2,3....... z), y los datos censados tl (l=1,2,3….w) crear laecuación de verosimilitud :
Paso 2: Derivar la ecuación de verosimilitud respecto a cada parámetro θ j ;
Paso 3: Hayar el valor de θ j que maximiza L; es decir resolver
θ∂∂L
0=∂∂θL
∏∏==
=w
lnl
z
ini tCfL
121
121 ),.....,,,(*),.....,,,( θθθθθθ
Hallar los valores de los parametros θ j , con los datos de la muestra, utilizando las ecuaciones especificas para la distribucion hipotetica fk(t ), obtenidas con el metodo de Maxima Verosimilitud
Para cada valor ti de la muestra de datos (i=1,2….n), calcule la probabilidad de falla teorica Fi(t)
Donde θ1, θ2, ..... Θ j, son los parametros de la distribucion, hayados en la fase previa.
∫=it
jki dttftF0
21 ),...,;()( θθθ
Para cada valor ti de la muestra de datos(i=1,2….n), calcule la probabilidad de falla empirica
Donde n=numero de tos de la muestra
nitFi =)(ˆ
0
0.2
0.4
0.6
0.8
1
1.2
0 500 1000 1500 2000 2500
t (tiem po)
Pro
babi
lidad
de
Falla
F(t) Em pirica F(t) Teorica
Graficar la Probabilidad de Falla Teorica F (t) y la Probabilidad de Falla Empirica Vs t )(ˆ tF
Con los calculos de Prob. de Falla Teorica Fi(t) y la Probabilidad de Falla Empirica, aplicar el test de Bondad de Ajuste de Kolmogorov-Smirnov,
•Calcular el valor del test: “K-Sk”
•Calcular el valor critico “Vck” para un nivel de confidencia especifico
)(ˆ tFi
K-Sk<VckSiNo
fk(t) es una hipotesis no rechazada y es candidata a “mejor ajuste”
q=q+1
fk(t) es una hipotesis rechazada
k<m
k<m
k=k+1
α
α
Si
No
No
k=k+1
α
Si
FIN
Entre las “q” distribuciones que fueron no fueron rechazadas, la que mejor ajusta al set de datos corresponde a la que tenga un menor valor del test de bondad de ajuste “K-S”
Mejor Fit: K-S minimo

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
14
La tabla 4.1 resume las ecuaciones para el cálculo de parámetros para las distribuciones probabilísticas más usadas en análisis de confiabilidad de equipos no reparables, tanto para muestras con solo datos de falla, como para muestras con datos censados.
Tabla 4.1: Ecuaciones de parámetros
Distribución Parámetros Todos los “n” equipos de la muestra han fallado (ti :1,2...n)
Solo “m” equipos han fallado (ti :1,2...m) y “w” equipos no han
fallado( tj:1,2.... w ) (datos censados)
Exponencial λ ∑=
= n
1iit
nλ
∑∑==
+= w
1jj
m
1ii tt
mλ
α
ββ
α
/1n
1ii
n
t
=∑
= ( ) ( ) β
ββ
α
1w
1jj
m
1ii
m
tt
+
=∑∑
==
Weibull
β
( )[ ]( )∑
∑
∑=
=
= =−n
1iin
1ii
n
1iii
tlnn11
t
tlnx
ββ
β
( )[ ] ( )[ ]
( )∑∑∑
∑∑=
==
== =−
+
+m
1iiw
1jj
m
1ii
w
1jjj
m
1iii
tlnm11
tt
tlnttlnt
βββ
ββ
α
( )
( )∑
∑
=
=
−
−
= n
1i
2Xi
2
2n
1ii
tn
t1n
µα Solución numérica
Gamma
β
( )
∑
∑
=
=
−
−= n
1ii
n
1i
2Xi
t)1n(
t.n µβ Solución numérica
µ
n
tn
1ii∑
==µ Solución numérica
Normal
σ ( ) ( )∑=
−−
=n
1i
2i
2 t1n
1 µσ Solución numérica
µτ
n
)tln(n
1ii
t
∑==µ
Solución numérica
Log- Normal
στ ( ) ( )∑=
−=n
1i
2i
2t )tln(
n1
τµσ Solución numérica
ti

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
15
Adicionalmente, en la tabla 4.2 que se muestra a continuación, se resumen las ecuaciones para el cálculo de la probabilidad de fallas F(t), la confiabilidad C(t), la velocidad de incremento del peligro o tasa de fallas h(t) y el TPPF, para las distribuciones probabilísticas mas usadas en análisis de confiabilidad de equipos no reparables.
Tabla 4.2: Ecuaciones para diversas distribuciones de probabilidad
Distribución f(t) F(t) C(t) h(t) TPPF
Exponencial te)t(f λλ −= te1)t(F λ−−= te)t(C λ−= λ=)t(h λ1TPPF =
Weibull
−−
=
β
α
β
β
αβ
t
ettf1
)(
−
−=
β
αt
etF 1)(
−
=
β
αt
e)t(C
1t)t(h−
=
β
ααβ
+=
βΓα 11TPPF
Gamma ( )
βα
α
αΓβ
t1
et)t(f−−
= ( ) dtettF
ttβα
α αβ
−−∫Γ
= 1
0
1)( )t(F1)t(C −= )t(F1
)t(f)t(h−
= βα=TPPF
Normal 2t
21
e2
1)t(f
−−
= σµ
πσ dtetF
t
∫∞+
∞−
−−
=
2
21
21)( σ
µ
πσ )t(F1)t(C −=
)t(F1)t(f)t(h
−= µ=TPPF
Log- Normal
2
t
t)tln(21
t
e2t
1)t(f
−−
= σ
µ
πσ ∫
∞
=0
dt)t(f)t(F )t(F1)t(C −= )t(F1
)t(f)t(h−
=
+
=2
21
eTPPFττ σµ
Para fijar los conceptos y procedimientos asociados a la estimación de confiabilidad, a continuación se presentan dos ejemplos prácticos de aplicación que serán de gran utilidad para el lector. Ejemplo 4.1 Análisis de Confiabilidad Equipos No Reparables En el presente ejemplo se analizará una base de datos correspondiente una población de 53 bombas electro-sumergibles instaladas en sendos pozos de producción de petróleo. Se ha hecho un seguimiento a cada bomba desde su instalación hasta la falla. De las 53 bombas en observación 49 han fallado en los periodos observados en la tabla 4.3; mientras que las 4 bombas restantes, aun permanecen operando, acumulando las horas de operación mostradas en la tabla 4.4. Por política de mantenimiento, estas bombas son reemplazadas por una bomba nueva al fallar, para minimizar el tiempo de paro del pozo productor.
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
16
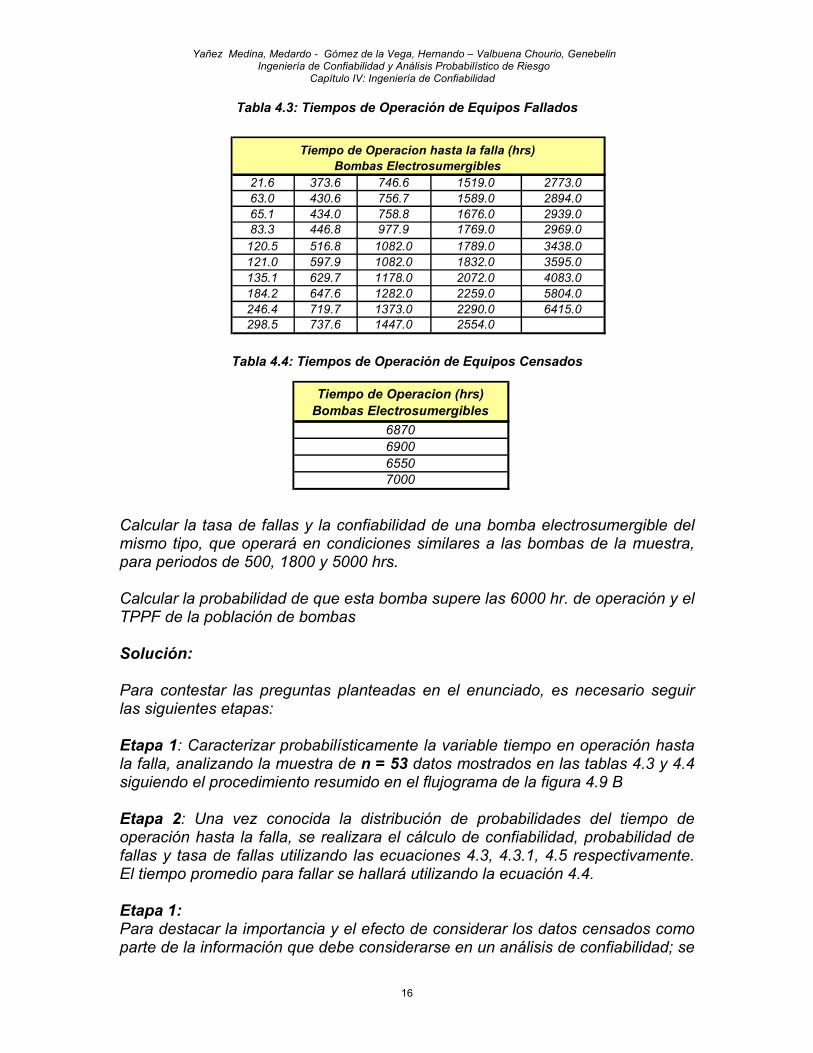
Tabla 4.3: Tiempos de Operación de Equipos Fallados
Tabla 4.4: Tiempos de Operación de Equipos Censados
Calcular la tasa de fallas y la confiabilidad de una bomba electrosumergible del mismo tipo, que operará en condiciones similares a las bombas de la muestra, para periodos de 500, 1800 y 5000 hrs. Calcular la probabilidad de que esta bomba supere las 6000 hr. de operación y el TPPF de la población de bombas Solución: Para contestar las preguntas planteadas en el enunciado, es necesario seguir las siguientes etapas: Etapa 1: Caracterizar probabilísticamente la variable tiempo en operación hasta la falla, analizando la muestra de n = 53 datos mostrados en las tablas 4.3 y 4.4 siguiendo el procedimiento resumido en el flujograma de la figura 4.9 B Etapa 2: Una vez conocida la distribución de probabilidades del tiempo de operación hasta la falla, se realizara el cálculo de confiabilidad, probabilidad de fallas y tasa de fallas utilizando las ecuaciones 4.3, 4.3.1, 4.5 respectivamente. El tiempo promedio para fallar se hallará utilizando la ecuación 4.4. Etapa 1: Para destacar la importancia y el efecto de considerar los datos censados como parte de la información que debe considerarse en un análisis de confiabilidad; se
21.6 373.6 746.6 1519.0 2773.063.0 430.6 756.7 1589.0 2894.065.1 434.0 758.8 1676.0 2939.083.3 446.8 977.9 1769.0 2969.0
120.5 516.8 1082.0 1789.0 3438.0121.0 597.9 1082.0 1832.0 3595.0135.1 629.7 1178.0 2072.0 4083.0184.2 647.6 1282.0 2259.0 5804.0246.4 719.7 1373.0 2290.0 6415.0298.5 737.6 1447.0 2554.0
Tiempo de Operacion hasta la falla (hrs) Bombas Electrosumergibles
Tiempo de Operacion (hrs) Bombas Electrosumergibles
6870690065507000

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
17
realizará la caracterización probabilística en dos fases; primero considerando solo los datos de equipos fallados y posteriormente se incluirían los datos de los equipos que no han fallado aun para constatar y discutir las diferencias. Caracterización probabilística con datos de equipos fallados solamente: Según el flujograma de la figura 4.9-B, el primer paso para caracterizar probabilísticamente una variable es plantear hipótesis de posibles modelos paramétricos que pudieran ajustar bien en los datos de la muestra. En este ejemplo, por tratarse de tiempos, las hipótesis que se plantean son los modelos paramétricos mas usados tradicionalmente para este fin, es decir: Hipótesis 1: Distribución Exponencial Hipótesis 2: Distribución Weibull Hipótesis 3: Distribución Gamma Seguidamente es necesario calcular los parámetros de cada distribución, con los de la tabla 4.3, y las ecuaciones para parámetros resumidas en la tabla 4.1: Hipótesis 1: Parámetros de Distribución Exponencial:
000682,0t
49
t
n49
1ii
n
1ii
=⇒==
∑∑==
λλ
Hipótesis 2: Parámetros de la Distribución Weibull:
( )[ ]
( )∑∑
∑=
=
= =⇒=−n
1iin
1ii
n
1iii
9987.0tlnn11
t
tlntβ
ββ
β
; 869.1464n
t/1n
1ii
=⇒
=∑
= αα
ββ
Hipótesis 3: Parámetros de la Distribución Gamma:
( )
( )0469.1
tn
t1n
n
1i
2Xi
2
2n
1ii
=⇒−
−
=
∑
∑
=
= αµ
α ; ( )
87.1399t)1n(
t.n
n
1ii
n
1i
2Xi
=⇒−
−=
∑
∑
=
= βµ
β
Una vez calculados los parámetros para las diferentes hipótesis, deben calcularse las probabilidades acumuladas hipotéticas F(ti) para cada valor ti de la muestra. Para hacer esto, debemos ordenar en forma ascendente, los datos de la muestra, y aplicar las ecuaciones para cálculo de F(t) de la tabla 4.2:

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
18
• Hipótesis 1: Distribución Exponencial:
ii t000682.0i
ti e1)t(Fe1)t(F −− −=⇒−= λ
; Ecuación 4.7 (En Excel la función “Expdist(ti,λ,verdadero)=” realiza este cálculo)
• Hipótesis 2: Distribución Weibull :
−
−
−=⇒−=
998.0ii
86.1464t
i
t
i e1)t(Fe1)t(F
β
α; Ecuación 4.8
(En Excel la función “Weibull(ti,α,β,verdadero)=” realiza este cálculo)
• Hipótesis 3: Distribución Gamma:
( ) dtet1)t(Ft
1i
t
0i
βαα αΓβ
−−∫= Ecuación 4.9
(En Excel la función “Gammadist(ti,α,β,verdadero)=” realiza este cálculo) Seguidamente, deben calcularse los valores de la probabilidad acumulada empírica, para cada valor ti de la muestra. Como se indico en el diagrama de la figura 4.9 B una vez que los datos de la muestra se han ordenado en forma ascendente, la probabilidad empírica se calcula con la siguiente expresión:
ni)t(F i = ; Ecuación 4.10
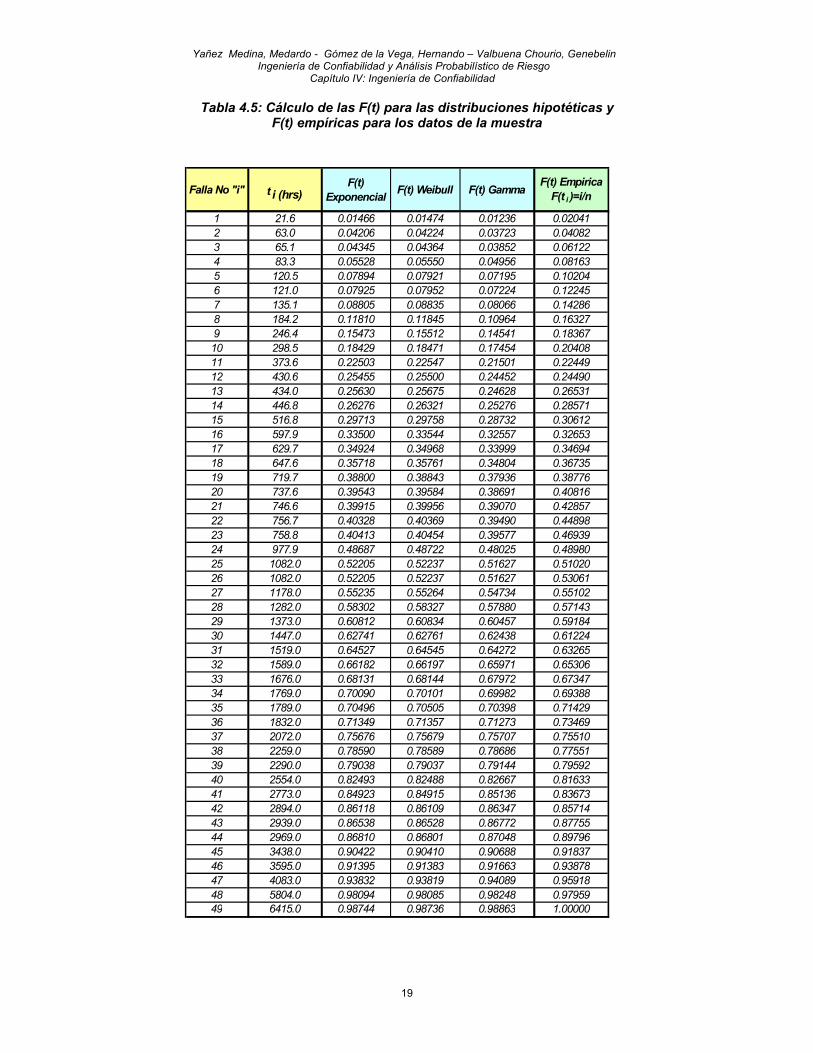
Donde: i = número acumulado de fallas en el periodo ti n = número de elementos de la muestra = 49 La tabla 4.5 muestra los resultados de aplicar las ecuaciones 4.7, 4.8, 4.9 y 4.10 a los datos de la tabla 4.3
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
19
Tabla 4.5: Cálculo de las F(t) para las distribuciones hipotéticas y F(t) empíricas para los datos de la muestra
Falla No "i" t i (hrs)F(t)
Exponencial F(t) Weibull F(t) GammaF(t) Empirica
F(t i )=i/n
1 21.6 0.01466 0.01474 0.01236 0.020412 63.0 0.04206 0.04224 0.03723 0.040823 65.1 0.04345 0.04364 0.03852 0.061224 83.3 0.05528 0.05550 0.04956 0.081635 120.5 0.07894 0.07921 0.07195 0.102046 121.0 0.07925 0.07952 0.07224 0.122457 135.1 0.08805 0.08835 0.08066 0.142868 184.2 0.11810 0.11845 0.10964 0.163279 246.4 0.15473 0.15512 0.14541 0.1836710 298.5 0.18429 0.18471 0.17454 0.2040811 373.6 0.22503 0.22547 0.21501 0.2244912 430.6 0.25455 0.25500 0.24452 0.2449013 434.0 0.25630 0.25675 0.24628 0.2653114 446.8 0.26276 0.26321 0.25276 0.2857115 516.8 0.29713 0.29758 0.28732 0.3061216 597.9 0.33500 0.33544 0.32557 0.3265317 629.7 0.34924 0.34968 0.33999 0.3469418 647.6 0.35718 0.35761 0.34804 0.3673519 719.7 0.38800 0.38843 0.37936 0.3877620 737.6 0.39543 0.39584 0.38691 0.4081621 746.6 0.39915 0.39956 0.39070 0.4285722 756.7 0.40328 0.40369 0.39490 0.4489823 758.8 0.40413 0.40454 0.39577 0.4693924 977.9 0.48687 0.48722 0.48025 0.4898025 1082.0 0.52205 0.52237 0.51627 0.5102026 1082.0 0.52205 0.52237 0.51627 0.5306127 1178.0 0.55235 0.55264 0.54734 0.5510228 1282.0 0.58302 0.58327 0.57880 0.5714329 1373.0 0.60812 0.60834 0.60457 0.5918430 1447.0 0.62741 0.62761 0.62438 0.6122431 1519.0 0.64527 0.64545 0.64272 0.6326532 1589.0 0.66182 0.66197 0.65971 0.6530633 1676.0 0.68131 0.68144 0.67972 0.6734734 1769.0 0.70090 0.70101 0.69982 0.6938835 1789.0 0.70496 0.70505 0.70398 0.7142936 1832.0 0.71349 0.71357 0.71273 0.7346937 2072.0 0.75676 0.75679 0.75707 0.7551038 2259.0 0.78590 0.78589 0.78686 0.7755139 2290.0 0.79038 0.79037 0.79144 0.7959240 2554.0 0.82493 0.82488 0.82667 0.8163341 2773.0 0.84923 0.84915 0.85136 0.8367342 2894.0 0.86118 0.86109 0.86347 0.8571443 2939.0 0.86538 0.86528 0.86772 0.8775544 2969.0 0.86810 0.86801 0.87048 0.8979645 3438.0 0.90422 0.90410 0.90688 0.9183746 3595.0 0.91395 0.91383 0.91663 0.9387847 4083.0 0.93832 0.93819 0.94089 0.9591848 5804.0 0.98094 0.98085 0.98248 0.9795949 6415.0 0.98744 0.98736 0.98863 1.00000

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
20
La figura 4.10 muestra los gráficos de Probabilidad Acumulada Empírica y Probabilidad Acumulada Teórica calculada con cada una de las distribuciones hipotéticas vs. Tiempo.
Figura 4.10: F(t) teórica y F(t) empírica vs. tiempo A simple vista, las tres distribuciones hipotéticas (Exponencial, Weibull y Gamma) parecen ajustar bastante bien a los datos de la muestra; no obstante, para saber si estas hipótesis son estadísticamente validas y para seleccionar la que mejor ajusta a los datos, se debe realizar un Test de Bondad de Ajuste, de los estudiados en el Capítulo II, sección 2.3.3.2 En este ejercicio realizaremos el Test de Kolmogorov – Smirnov. Como se indicó en el Capítulo II, sección 2.3.3.2.2, el Test de Kolmogorov-Smirnov consiste básicamente en calcular los valores absolutos de las diferencias entre valores de las probabilidades acumuladas teóricas )( itF y empíricas )(ˆ itF para todos los datos de la muestra, como se indica en las
0.0
0.2
0.4
0.6
0.8
1.0
1.2
0.0 1000.0 2000.0 3000.0 4000.0 5000.0 6000.0 7000.0
tiem po (hrs)
Pro
babi
lidad
de
Fal
las
F(t) Exponencial F(t) Empirica F(ti)= i/n
0.0
0.2
0.4
0.6
0.8
1.0
1.2
0.0 1000.0 2000.0 3000.0 4000.0 5000.0 6000.0 7000.0
tiempo (hrs)
Pro
bab
ilida
d de
Fal
las
F(t) W eibull F(t) Empirica F(ti)= i/n
F(t) Empírica y F(t) Exponencial Vs. tiempo
F(t) Empírica y F(t) Weibull Vs. tiempo
F(t) Empírica y F(t) Gamma Vs. tiempo
0.0
0.2
0.4
0.6
0.8
1.0
1.2
0.0 1000.0 2000.0 3000.0 4000.0 5000.0 6000.0 7000.0
tiem po (hrs)
Pro
babi
lidad
de
Fal
las
F(t) Gam m a F(t) Em pirica F(ti)=i/n

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
21
siguientes ecuaciones: )t(F)t(F ii − y )t(F)t(F 1ii −− . El resultado o valor del
test, denotado como K-Svalue, es el valor absoluto de la máxima diferencia encontrada: ( ))t(F)t(F;)t(F)t(FimomaxSK 1iiiivalue −−−=−
La tabla 4.6 muestra los resultados del test de Kolmogorov para la hipótesis 1; es decir la distribución exponencial:
Tabla 4.6: Test de Kolmogorov-Smirnov para la hipótesis 1
Falla "i" t i F(t i ) Teorica F(t i ) Empirica1 21.646 0.014660515 0.020408163 0.00575 0.020412 62.976 0.042058395 0.040816327 0.00124 0.0216502313 65.108 0.043450862 0.06122449 0.01777 0.0026345364 83.339 0.055275672 0.081632653 0.02636 0.0059488175 120.518 0.078939267 0.102040816 0.02310 0.0026933866 121.009 0.079247779 0.12244898 0.04320 0.0227930377 135.095 0.088054614 0.142857143 0.05480 0.0343943668 184.197 0.118100713 0.163265306 0.04516 0.024756439 246.375 0.15473188 0.183673469 0.02894 0.008533426
10 298.546 0.18429101 0.204081633 0.01979 0.00061754111 373.64 0.22503249 0.224489796 0.00054 0.02095085812 430.552 0.254548475 0.244897959 0.00965 0.03005867913 434.005 0.256302675 0.265306122 0.00900 0.01140471614 446.787 0.262760367 0.285714286 0.02295 0.00254575515 516.76 0.297131034 0.306122449 0.00899 0.01141674816 597.924 0.334996455 0.326530612 0.00847 0.02887400617 629.654 0.349238623 0.346938776 0.00230 0.02270801118 647.641 0.357176292 0.367346939 0.01017 0.01023751719 719.667 0.388003078 0.387755102 0.00025 0.0206561420 737.55 0.395425019 0.408163265 0.01274 0.00766991721 746.601 0.39914706 0.428571429 0.02942 0.00901620622 756.717 0.403279949 0.448979592 0.04570 0.02529147923 758.804 0.404129049 0.469387755 0.06526 0.04485054324 977.918 0.48687326 0.489795918 0.00292 0.01748550525 1082 0.522049183 0.510204082 0.01185 0.03225326526 1082 0.522049183 0.530612245 0.00856 0.01184510227 1178 0.552352033 0.551020408 0.00133 0.02173978828 1282 0.583015919 0.571428571 0.01159 0.03199551129 1373 0.608118757 0.591836735 0.01628 0.03669018530 1447 0.627413688 0.612244898 0.01517 0.03557695331 1519 0.645274873 0.632653061 0.01262 0.03302997532 1589 0.661818656 0.653061224 0.00876 0.02916559433 1676 0.681308909 0.673469388 0.00784 0.02824768534 1769 0.700902841 0.693877551 0.00703 0.02743345435 1789 0.704956593 0.714285714 0.00933 0.01107904236 1832 0.71348708 0.734693878 0.02121 0.00079863537 2072 0.756764067 0.755102041 0.00166 0.0220701938 2259 0.785900259 0.775510204 0.01039 0.03079821839 2290 0.790381184 0.795918367 0.00554 0.0148709840 2554 0.824933867 0.816326531 0.00861 0.029015541 2773 0.849232286 0.836734694 0.01250 0.03290575542 2894 0.86117944 0.857142857 0.00404 0.02444474643 2939 0.865376942 0.87755102 0.01217 0.00823408444 2969 0.868104526 0.897959184 0.02985 0.00944649445 3438 0.904224056 0.918367347 0.01414 0.00626487246 3595 0.913953262 0.93877551 0.02482 0.00441408547 4083 0.938321912 0.959183673 0.02086 0.00045359848 5804 0.980938087 0.979591837 0.00135 0.02175441349 6415 0.987436351 1 0.01256 0.007844515
Probabilidad AcumuladaDatos de la muestra
K-S value = 0.06526
Hipotesis 1: Distribucion ExponencialTest de Kolmogorov-Smirnov
)(ˆ)( ii tFtF − )(ˆ)( 1−− ii tFtF
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
22
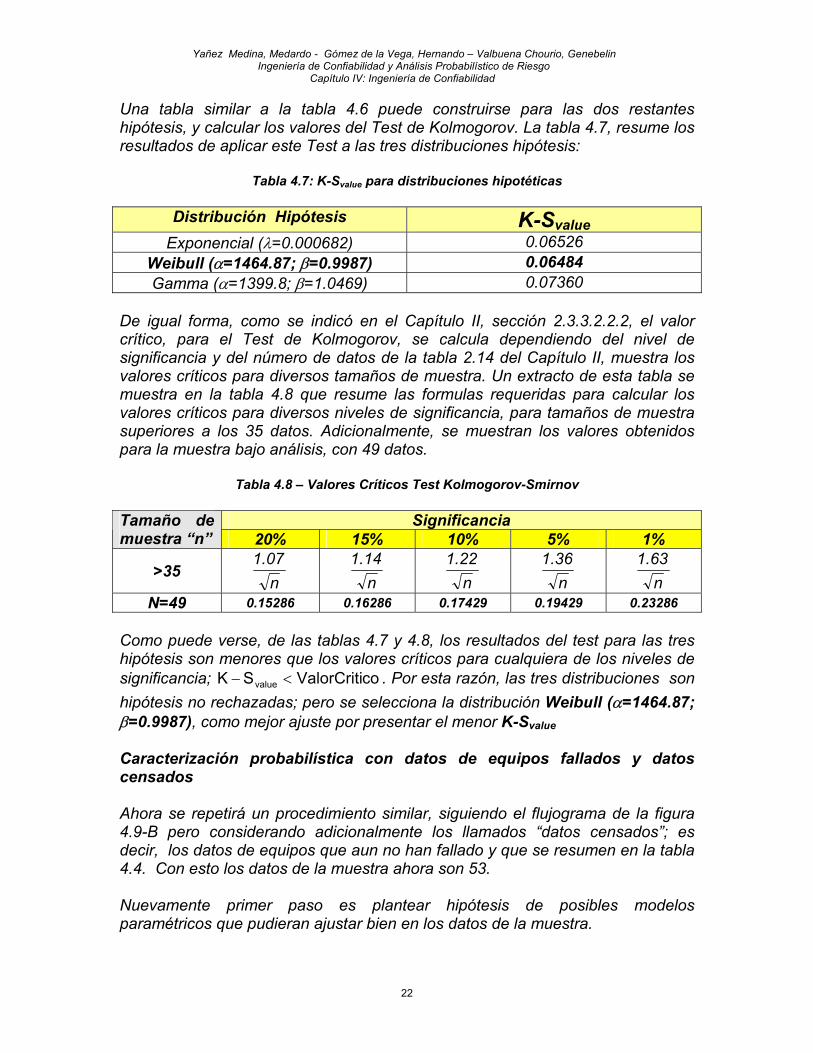
Una tabla similar a la tabla 4.6 puede construirse para las dos restantes hipótesis, y calcular los valores del Test de Kolmogorov. La tabla 4.7, resume los resultados de aplicar este Test a las tres distribuciones hipótesis:
Tabla 4.7: K-Svalue para distribuciones hipotéticas
Distribución Hipótesis K-Svalue Exponencial (λ=0.000682) 0.06526
Weibull (α=1464.87; β=0.9987) 0.06484 Gamma (α=1399.8; β=1.0469) 0.07360
De igual forma, como se indicó en el Capítulo II, sección 2.3.3.2.2.2, el valor crítico, para el Test de Kolmogorov, se calcula dependiendo del nivel de significancia y del número de datos de la tabla 2.14 del Capítulo II, muestra los valores críticos para diversos tamaños de muestra. Un extracto de esta tabla se muestra en la tabla 4.8 que resume las formulas requeridas para calcular los valores críticos para diversos niveles de significancia, para tamaños de muestra superiores a los 35 datos. Adicionalmente, se muestran los valores obtenidos para la muestra bajo análisis, con 49 datos.
Tabla 4.8 – Valores Críticos Test Kolmogorov-Smirnov Significancia Tamaño de
muestra “n” 20% 15% 10% 5% 1%
>35 n07.1
n14.1
n22.1
n36.1
n63.1
N=49 0.15286 0.16286 0.17429 0.19429 0.23286 Como puede verse, de las tablas 4.7 y 4.8, los resultados del test para las tres hipótesis son menores que los valores críticos para cualquiera de los niveles de significancia; coValorCritiSK value <− . Por esta razón, las tres distribuciones son hipótesis no rechazadas; pero se selecciona la distribución Weibull (α=1464.87; β=0.9987), como mejor ajuste por presentar el menor K-Svalue Caracterización probabilística con datos de equipos fallados y datos censados Ahora se repetirá un procedimiento similar, siguiendo el flujograma de la figura 4.9-B pero considerando adicionalmente los llamados “datos censados”; es decir, los datos de equipos que aun no han fallado y que se resumen en la tabla 4.4. Con esto los datos de la muestra ahora son 53. Nuevamente primer paso es plantear hipótesis de posibles modelos paramétricos que pudieran ajustar bien en los datos de la muestra.

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
23
En este ejemplo, tomando como premisa los resultados de la sección anterior, haremos una sola hipótesis: Hipótesis 1: Distribución Weibull Seguidamente se calcularán los parámetros, con las ecuaciones para parámetros considerando datos censados, resumidas en la columna derecha de la tabla 4.1. Hipótesis 1: Parámetros de Distribución Weibull, con datos de fallas y datos censados:
( )[ ] ( )[ ]( ) 873.0tln
4911
tt
tlnttlnt49
1ii4
1jj
49
1ii
4
1jjj
49
1iii
=⇒=−
+
+
∑∑∑
∑∑=
==
== ββββ
ββ
( ) ( )45.1734
49
tt873.01
4
1jj
49
1ii
=⇒
+
=∑∑
== αα
ββ
Una vez calculados los parámetros la hipótesis, deben calcularse las probabilidades acumuladas hipotéticas F(ti) para cada valor ti de la muestra. Para hacer esto, debemos ordenar en forma ascendente, los datos de la muestra, y aplicar las ecuaciones para cálculo de F(t) de la tabla 4.2: Hipótesis 1: Distribución Weibull :
−
−
−=⇒−=
873.0ii
45.1734t
i
t
i e1)t(Fe1)t(F
β
α; Ecuación 4.11
(En Excel la función “Weibull(ti,α,β,verdadero)=” realiza este cálculo) Seguidamente, deben calcularse los valores de la probabilidad acumulada empírica, para cada valor ti de la muestra. Como se indico en el diagrama de la figura 4.9 B una vez que los datos de la muestra se han ordenado en forma ascendente, la probabilidad empírica se calcula con la siguiente expresión:
Ni)t(F i = ; Ecuación 4.12
Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
24
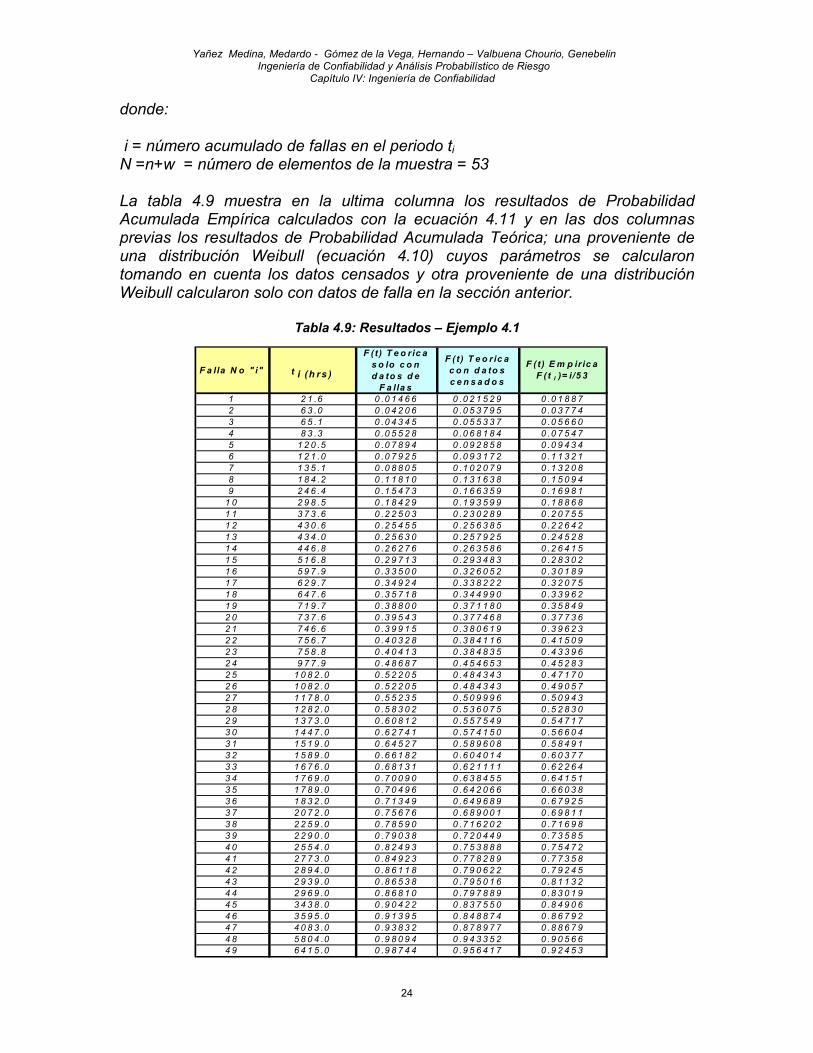
donde: i = número acumulado de fallas en el periodo ti N =n+w = número de elementos de la muestra = 53
La tabla 4.9 muestra en la ultima columna los resultados de Probabilidad Acumulada Empírica calculados con la ecuación 4.11 y en las dos columnas previas los resultados de Probabilidad Acumulada Teórica; una proveniente de una distribución Weibull (ecuación 4.10) cuyos parámetros se calcularon tomando en cuenta los datos censados y otra proveniente de una distribución Weibull calcularon solo con datos de falla en la sección anterior.
Tabla 4.9: Resultados – Ejemplo 4.1
F a lla N o " i" t i (h rs )
F (t ) T e o ric a s o lo c o n d a to s d e
F a lla s
F ( t ) T e o r ic a c o n d a to s c e n s a d o s
F ( t ) E m p ir ic a F ( t i )= i/5 3
1 2 1 .6 0 .0 1 4 6 6 0 .0 2 1 5 2 9 0 .0 1 8 8 72 6 3 .0 0 .0 4 2 0 6 0 .0 5 3 7 9 5 0 .0 3 7 7 43 6 5 .1 0 .0 4 3 4 5 0 .0 5 5 3 3 7 0 .0 5 6 6 04 8 3 .3 0 .0 5 5 2 8 0 .0 6 8 1 8 4 0 .0 7 5 4 75 1 2 0 .5 0 .0 7 8 9 4 0 .0 9 2 8 5 8 0 .0 9 4 3 46 1 2 1 .0 0 .0 7 9 2 5 0 .0 9 3 1 7 2 0 .1 1 3 2 17 1 3 5 .1 0 .0 8 8 0 5 0 .1 0 2 0 7 9 0 .1 3 2 0 88 1 8 4 .2 0 .1 1 8 1 0 0 .1 3 1 6 3 8 0 .1 5 0 9 49 2 4 6 .4 0 .1 5 4 7 3 0 .1 6 6 3 5 9 0 .1 6 9 8 1
1 0 2 9 8 .5 0 .1 8 4 2 9 0 .1 9 3 5 9 9 0 .1 8 8 6 81 1 3 7 3 .6 0 .2 2 5 0 3 0 .2 3 0 2 8 9 0 .2 0 7 5 51 2 4 3 0 .6 0 .2 5 4 5 5 0 .2 5 6 3 8 5 0 .2 2 6 4 21 3 4 3 4 .0 0 .2 5 6 3 0 0 .2 5 7 9 2 5 0 .2 4 5 2 81 4 4 4 6 .8 0 .2 6 2 7 6 0 .2 6 3 5 8 6 0 .2 6 4 1 51 5 5 1 6 .8 0 .2 9 7 1 3 0 .2 9 3 4 8 3 0 .2 8 3 0 21 6 5 9 7 .9 0 .3 3 5 0 0 0 .3 2 6 0 5 2 0 .3 0 1 8 91 7 6 2 9 .7 0 .3 4 9 2 4 0 .3 3 8 2 2 2 0 .3 2 0 7 51 8 6 4 7 .6 0 .3 5 7 1 8 0 .3 4 4 9 9 0 0 .3 3 9 6 21 9 7 1 9 .7 0 .3 8 8 0 0 0 .3 7 1 1 8 0 0 .3 5 8 4 92 0 7 3 7 .6 0 .3 9 5 4 3 0 .3 7 7 4 6 8 0 .3 7 7 3 62 1 7 4 6 .6 0 .3 9 9 1 5 0 .3 8 0 6 1 9 0 .3 9 6 2 32 2 7 5 6 .7 0 .4 0 3 2 8 0 .3 8 4 1 1 6 0 .4 1 5 0 92 3 7 5 8 .8 0 .4 0 4 1 3 0 .3 8 4 8 3 5 0 .4 3 3 9 62 4 9 7 7 .9 0 .4 8 6 8 7 0 .4 5 4 6 5 3 0 .4 5 2 8 32 5 1 0 8 2 .0 0 .5 2 2 0 5 0 .4 8 4 3 4 3 0 .4 7 1 7 02 6 1 0 8 2 .0 0 .5 2 2 0 5 0 .4 8 4 3 4 3 0 .4 9 0 5 72 7 1 1 7 8 .0 0 .5 5 2 3 5 0 .5 0 9 9 9 6 0 .5 0 9 4 32 8 1 2 8 2 .0 0 .5 8 3 0 2 0 .5 3 6 0 7 5 0 .5 2 8 3 02 9 1 3 7 3 .0 0 .6 0 8 1 2 0 .5 5 7 5 4 9 0 .5 4 7 1 73 0 1 4 4 7 .0 0 .6 2 7 4 1 0 .5 7 4 1 5 0 0 .5 6 6 0 43 1 1 5 1 9 .0 0 .6 4 5 2 7 0 .5 8 9 6 0 8 0 .5 8 4 9 13 2 1 5 8 9 .0 0 .6 6 1 8 2 0 .6 0 4 0 1 4 0 .6 0 3 7 73 3 1 6 7 6 .0 0 .6 8 1 3 1 0 .6 2 1 1 1 1 0 .6 2 2 6 43 4 1 7 6 9 .0 0 .7 0 0 9 0 0 .6 3 8 4 5 5 0 .6 4 1 5 13 5 1 7 8 9 .0 0 .7 0 4 9 6 0 .6 4 2 0 6 6 0 .6 6 0 3 83 6 1 8 3 2 .0 0 .7 1 3 4 9 0 .6 4 9 6 8 9 0 .6 7 9 2 53 7 2 0 7 2 .0 0 .7 5 6 7 6 0 .6 8 9 0 0 1 0 .6 9 8 1 13 8 2 2 5 9 .0 0 .7 8 5 9 0 0 .7 1 6 2 0 2 0 .7 1 6 9 83 9 2 2 9 0 .0 0 .7 9 0 3 8 0 .7 2 0 4 4 9 0 .7 3 5 8 54 0 2 5 5 4 .0 0 .8 2 4 9 3 0 .7 5 3 8 8 8 0 .7 5 4 7 24 1 2 7 7 3 .0 0 .8 4 9 2 3 0 .7 7 8 2 8 9 0 .7 7 3 5 84 2 2 8 9 4 .0 0 .8 6 1 1 8 0 .7 9 0 6 2 2 0 .7 9 2 4 54 3 2 9 3 9 .0 0 .8 6 5 3 8 0 .7 9 5 0 1 6 0 .8 1 1 3 24 4 2 9 6 9 .0 0 .8 6 8 1 0 0 .7 9 7 8 8 9 0 .8 3 0 1 94 5 3 4 3 8 .0 0 .9 0 4 2 2 0 .8 3 7 5 5 0 0 .8 4 9 0 64 6 3 5 9 5 .0 0 .9 1 3 9 5 0 .8 4 8 8 7 4 0 .8 6 7 9 24 7 4 0 8 3 .0 0 .9 3 8 3 2 0 .8 7 8 9 7 7 0 .8 8 6 7 94 8 5 8 0 4 .0 0 .9 8 0 9 4 0 .9 4 3 3 5 2 0 .9 0 5 6 64 9 6 4 1 5 .0 0 .9 8 7 4 4 0 .9 5 6 4 1 7 0 .9 2 4 5 3

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
25
La figura 4.11 A muestra los gráficos de los resultados que se resumen en la tabla 4.9. En este grafico pueden observarse la curva de Probabilidad Acumulada Empírica y dos curvas de Probabilidad Acumulada Teórica; una curva Weibull cuyos parámetros se calcularon tomando en cuenta los datos censados y otra curva Weibull cuyos parámetros se calcularon solo con datos de falla que fue obtenida en la sección anterior.
Figura 4.11-A: Resultados – Ejemplo 4.1
Como puede verse en la figura 4.11-A, a simple vista la curva que mejor ajusta a los valores de F(t) empírica es la curva de la distribución de Weibull cuyos parámetros se calcularon tomando en cuenta los datos censados. También puede observarse claramente que la curva de la distribución de Weibull cuyos parámetros se calcularon solo con los datos de falla no ajusta a los valores de la F(t) empírica o F(t) de la muestra. Para saber si las hipótesis planteadas son estadísticamente válidas y para seleccionar la que mejor ajusta a los datos, se debe realizar un test de bondad de ajuste, de los estudiados en el Capítulo II, sección 2.3.3.2. Se utilizará nuevamente el test de Kolmogorov – Smirnov; es decir, calcularán los valores absolutos de las diferencias entre valores de las probabilidades acumuladas teóricas )( itF y empíricas )(ˆ itF para estimar K-Svalue, es decir el valor absoluto de la máxima diferencia encontrada:
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
0.0 1000.0 2000.0 3000.0 4000.0 5000.0 6000.0 7000.0
tiempo (hrs)
Pro
babi
lidad
de
Falla
s
F(t) Teorica solo con datos de Fallas F(t) Teorica con datos censadosF(t) Empirica

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
26
( ))t(F)t(F;)t(F)t(FimomaxSK 1iiiivalue −−−=−
La tabla 4.10 muestra los resultados del test de Kolmogorov para la hipótesis 1; es decir la distribución weibull con parámetros estimados considerando los datos censados:
Tabla 4.10: Resultados Kolmogorov-Smirnov
Falla "i" t i F(t i ) Teorica F(t i ) Empirica1 21.6 0.02153 0.018868 0.002661 0.0188682 63.0 0.05379 0.037736 0.016059 0.0349273 65.1 0.05534 0.056604 0.001267 0.0176014 83.3 0.06818 0.075472 0.007287 0.0115815 120.5 0.09286 0.094340 0.001482 0.0173866 121.0 0.09317 0.113208 0.020035 0.0011677 135.1 0.10208 0.132075 0.029997 0.0111298 184.2 0.13164 0.150943 0.019306 0.0004389 246.4 0.16636 0.169811 0.003452 0.015416
10 298.5 0.19360 0.188679 0.004920 0.02378811 373.6 0.23029 0.207547 0.022742 0.04161012 430.6 0.25639 0.226415 0.029970 0.04883813 434.0 0.25793 0.245283 0.012642 0.03151014 446.8 0.26359 0.264151 0.000565 0.01830315 516.8 0.29348 0.283019 0.010464 0.02933216 597.9 0.32605 0.301887 0.024165 0.04303317 629.7 0.33822 0.320755 0.017468 0.03633618 647.6 0.34499 0.339623 0.005367 0.02423519 719.7 0.37118 0.358491 0.012690 0.03155820 737.6 0.37747 0.377358 0.000110 0.01897821 746.6 0.38062 0.396226 0.015607 0.00326122 756.7 0.38412 0.415094 0.030978 0.01211023 758.8 0.38483 0.433962 0.049128 0.03026024 977.9 0.45465 0.452830 0.001823 0.02069125 1082.0 0.48434 0.471698 0.012645 0.03151326 1082.0 0.48434 0.490566 0.006223 0.01264527 1178.0 0.51000 0.509434 0.000562 0.01943028 1282.0 0.53607 0.528302 0.007773 0.02664129 1373.0 0.55755 0.547170 0.010379 0.02924730 1447.0 0.57415 0.566038 0.008113 0.02698131 1519.0 0.58961 0.584906 0.004702 0.02357032 1589.0 0.60401 0.603774 0.000240 0.01910833 1676.0 0.62111 0.622642 0.001531 0.01733734 1769.0 0.63846 0.641509 0.003054 0.01581435 1789.0 0.64207 0.660377 0.018312 0.00055636 1832.0 0.64969 0.679245 0.029556 0.01068837 2072.0 0.68900 0.698113 0.009112 0.00975638 2259.0 0.71620 0.716981 0.000779 0.01808939 2290.0 0.72045 0.735849 0.015400 0.00346840 2554.0 0.75389 0.754717 0.000829 0.01803941 2773.0 0.77829 0.773585 0.004704 0.02357242 2894.0 0.79062 0.792453 0.001830 0.01703843 2939.0 0.79502 0.811321 0.016305 0.00256344 2969.0 0.79789 0.830189 0.032299 0.01343145 3438.0 0.83755 0.849057 0.011506 0.00736246 3595.0 0.84887 0.867925 0.019050 0.00018247 4083.0 0.87898 0.886792 0.007815 0.01105248 5804.0 0.94335 0.905660 0.037692 0.05655949 6415.0 0.95642 0.924528 0.031889 0.050757
K-S value = 0.056559
Hipotesis: Distribucion Weibull ( α=1734,45 β=0,873)Datos de la muestra Probabilidad Acumulada Test de Kolmogorov-Smirnov
)(ˆ)( ii tFtF − )(ˆ)( 1−− ii tFtF

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
27
La tabla 4.11, resume los resultados de los valores críticos calculados para diversos niveles de significancia, para una muestra que incluyendo los datos censados es de 53 valores.
Tabla 4.11: Valores Críticos Test Kolmogorov-Smirnov Significancia Tamaño de
muestra “n” 20% 15% 10% 5% 1%
>35 n07.1
n14.1
n22.1
n36.1
n63.1
N=53 0.1470 0.1566 0.1676 0.1868 0.2239 Como puede verse, K-Svalue =0,05656 < Valor Critico, para todos diversos niveles de significancia; por esta razón, la distribución hipótesis Weibull (α=1464.87; β=0.9987) no es rechazada, y puede considerarse un buen ajuste para los datos de muestra. Etapa 2: Una vez conocida la distribución de probabilidades del tiempo de operación hasta la falla, se realizará el cálculo de confiabilidad, probabilidad de fallas, tasa de fallas y tiempo promedio para fallar utilizando las ecuaciones de la tabla 4.2 para la distribución de Weibull; es decir:
Confiabilidad:
−
−
=⇒=
873.0
45.1734tt
e)t(Ce)t(C
β
α Ecuación 4.13
Tasa de Fallas: )1837,0(1
45,1734t
45,17348734,0t)t(h
−−
⇒
=
β
ααβ
Ecuación 4.14
El enunciado del problema pide calcular estos valores para t = 500, 1800, 5000 y 6000 hrs. La tabla 4.12 resume los resultados para los tiempos mencionados:
Tabla 4.12: Cálculos de Confiabilidad y Tasa de Fallas Bombas Electro-sumergibles
t C(t) h(t)500.0 0.710501061 0.000589455
1800.0 0.292742126 0.0005010455000.0 0.033105476 0.0004401376000.0 0.016760356 0.000430074

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
28
Adicionalmente, se debe calcular el TPPF de este tipo de bombas. Para ello nos apoyaremos en la ecuación 4.4, que desarrollada para una distribución weibull resulta:
hrs1857TPPF873,01145,1734TPPF11TPPF BOMBASBOMBAS =⇒
+=⇒
+= Γ
βΓα
Ecuación 4.15
Por último, la grafica de la figura 4.11-B que se muestra a continuación; resume los resultados del cálculo de Confiabilidad C(t), para la muestra de datos, con dos curvas; una que considera solo los datos de fallas (Distribución Weibull (α=1464.86 y β=0.998)) , y otra que considera los datos de fallas mas los datos censados o no fallados ( Distribución Weibull (α=1734,45 y β=0,873)).
Figura 4.11-B: Confiabilidad C(t) – Ejemplo 4.1 Como puede observarse, la curva que considera solo los datos de fallas, es bastante mas “pesimista” que la curva que considera los datos de falla mas los datos censados. Esto realza la importancia de considerar los datos censados, cuando los haya, como parte de la evidencia que debe incluirse en un análisis de confiabilidad, ya que al omitirlos se esta sobrestimando la probabilidad de fallas y subestimando la confiabilidad.
Confiabilidad C(t)
00.10.20.30.40.50.60.70.80.9
1
0.0 1000.0 2000.0 3000.0 4000.0 5000.0 6000.0 7000.0
tiempo t (hrs)
Pro
babi
lidad
C(t) (Fallados solamente) C(t) Fallados + Censados

Yañez Medina, Medardo - Gómez de la Vega, Hernando – Valbuena Chourio, Genebelin Ingeniería de Confiabilidad y Análisis Probabilístico de Riesgo Capítulo IV: Ingeniería de Confiabilidad
29
4.3.1.3.2 ESTIMACIÓN DE CONFIABILIDAD DE ACTIVOS NO REPARABLES CON ESTADÍSTICA NO PARAMÉTRICA En muchas oportunidades no se considera conveniente asociarle a un conjunto de valores de una variable en particular una distribución paramétrica de las que se han estudiado en el Capítulo II; bien sea porque no se conoce la dinámica de la variable a modelar, no existe relación alguna entre esta dinámica y los principios matemáticos o físicos que sustentan la distribución paramétrica que más se adapta a las muestras de esta variable, o simplemente no se encuentra ninguna distribución paramétrica que se ajuste al conjunto de datos disponibles. Bajo estas circunstancias, puede optarse por seleccionar una distribución no paramétrica, que tal como se explicó en secciones previas, es una distribución cuyo comportamiento es definido en su totalidad por la data disponible. En otras palabras, es como si se construyera una distribución muy particular para el conjunto de datos bajo análisis. Existen diferentes esquemas para el cálculo de la confiabilidad tasa de falla y otras figuras de mérito utilizando representación no paramétrica, muchos de ellos varían en función de la muestra, de cómo ha sido recolectada y consolidada la muestra, entre otros. En este texto, se limitará el tratamiento de este tópico a mostrar las ecuaciones más importantes para análisis de confiabilidad con estadística no paramétrica; pero no se profundizará debido a lo extenso del tema. Para estudiar este tema en detalle, se recomiendan las referencias [10], [11]
La tabla 4.13 resume las ecuaciones más importantes para análisis de confiabilidad con estadística no paramétrica, para una muestra de n datos ti donde i=1,2,..., n.
Tabla 4.13: Ecuaciones para análisis de confiabilidad con estadística no paramétrica.
Figura de Mérito Muestras Pequeñas n<25 Muestras Grandes n ≥ 25
Confiabilidad )(ˆ itC 25,0n625,0in)t(C i +
+−=
ni)t(C i =
Prob. de Falla )(ˆ itF
++−
−=25,0n625,0in1)t(F i
−=
ni1)t(F i
Tasa de Fallas )(ˆ ith ( )( )i1ii tt625,0in
1)t(h−+−
=+
( )i1ii tt
1)t(h−
=+