centro nacional de investigación y desarrollo tecnológico osslan osiris... · osslan osiris...
TRANSCRIPT

cenidet
Centro Nacional de Investigación y Desarrollo Tecnológico
Departamento de Ciencias Computacionales
TESIS DOCTORAL
Compresión de Imágenes con Preservación de Características para Aplicaciones de Visión Artificial
presentada por
Osslan Osiris Vergara Villegas M. en C. en Ciencias Computacionales por el Centro Nacional de Investigación y Desarrollo Tecnológico
(cenidet)
como requisito para la obtención del grado de: Doctor en Ciencias en Ciencias de la Computación
Director de tesis: Dr. Raúl Pinto Elías
Jurado:
____________________________ ____________________________ Dr. Gerardo Reyes Salgado – Presidente Dr. Raúl Pinto Elías – Secretario ____________________________ ____________________________ Dr. José F. Martínez Trinidad – 1er. Vocal Dra. Patricia Rayón Villela – 2do. Vocal ____________________________ ____________________________ Dr. Marcos A. Capistrán Ocampo – 3er. Vocal Dra. Azucena Montes Rendón – Vocal Suplente Cuernavaca, Morelos, México. 8 de diciembre de 2006

DEDICATORIAS
Quiero dedicarle este trabajo a Dios por que siempre me ha brindado apoyo, esperanza y cuidados durante todo el trabajo doctoral y durante todos los viajes. A mi mamá, que ha tenido que soportar desvelos, preocupaciones, angustias, etc. durante estos 26 años de escuela. Recuerda que en todo esto tú eres la que me da la fuerza, te amo. A mi papá, a pesar de todas las contrariedades….. gracias. A mi hermano, que en esto de los estudios se ha dado cuenta que es difícil y que aún así se quiere animar. Gracias por todos los favores que me hiciste cuando yo no tenía tiempo. Vianey, tu sabes que durante estos dos años y medio tu apoyo, tu paciencia y tu amor fue lo que logro que esto saliera adelante. Gracias panterita, te amo, eres mi vida. Esto en un porcentaje muy grande es tuyo A mis tías Lila y Came que son como mis segundas madres, yo no se que haría sin su apoyo, gracias las quiero mucho y por favor sigan siempre estando allí. A la familia Reyes Torres, que siempre han significado algo muy especial en mi vida, los quiero mucho y gracias por todo. A la familia Villegas Vallejo, por siempre estar en los momentos más importantes de mi vida. Agradezco su amistad incondicional y apoyo a mis grandes amigos en estricto orden alfabético: Fernando Abundez, Enrique Balbas, Cesar Bustamante, Javier García, Roberto Jiménez, Jesús Lagunas y a mi primo y amigo Christian Villegas, esto también esta dedicado a ustedes que siempre han creído en mí. Y por último, al igual que en mi trabajo de maestría, quiero agradecer a todo lo que me da tanta felicidad en la vida: la música, mi guitarra y el club universidad. Como no los voy a querer……

AGRADECIMIENTOS
A mi asesor el Dr. Raúl Pinto Elías, que durante seis años de trabajo compartió conmigo experiencias y conocimientos, que fueron fundamentales para lo que soy ahora. Gracias por su amistad y por sus consejos, nunca olvide que usted es una gran persona, y que es muy bueno para formar recursos humanos. A mis revisores en estricto orden alfabético: Dr. Marcos Aurelio Capistrán Ocampo: Gracias por sus consejos, por esos días de platicas acerca de cómo se podría resolver mi trabajo de investigación, el SVD fue una gran base para comenzar mi trabajo, gracias por su tiempo y por ser mi amigo. Dr. José Francisco Martínez Trinidad: Como olvidar aquellos días en que viajaba a Puebla para visitarlo y mostrarle mi trabajo, de verdad que todos sus comentarios fueron enriquecedores, le agradezco mucho su tiempo y su disponibilidad. Dra. Azucena Montes Rendón: Gracias por todos los seminarios en que me compartió sus ideas y comentarios los cuales están reflejados en este trabajo. Dra. Patricia Rayón Villela: Tener la posibilidad de visitarla en el Tec y trabajar con usted fue muy importante, le agradezco mucho sus comentarios, y las oportunidades para consultar las bases de datos. De verdad, muchas gracias. Dr. Gerardo Reyes Salgado: Gracias, por sus comentarios y por su amistad durante todos estos años. Al Centro Nacional de Investigación y Desarrollo Tecnológico (cenidet) por lo que me dio en estos seis años tan importantes de mi vida. Al Dr. Máximo López Sánchez, por su amistad y apoyo incondicional. A todos mis maestros durante estos seis años. Al Consejo del Sistema Nacional de Educación Tecnológica (cosnet) por el apoyo económico tan importante para la culminación de los estudios doctorales. A todos lo que de alguna forma colaboraron o criticaron el presente trabajo de investigación.

RESUMEN
El gran incremento en el uso de Internet, de dispositivos de comunicación móviles inalámbricos y el importante crecimiento de los servicios de comunicación con imágenes y video ha generado una revolución en la forma en que se realiza el intercambio de información entre los seres humanos. Uno de los aspectos más importantes en dicha revolución es la forma en que la información digital es representada y entregada en los diversos dispositivos, lo cual debe hacerse de forma eficiente.
La eficiencia en la representación, se refiere a la habilidad de capturar información significativa de un objeto de interés en una descripción pequeña. Desde el punto de vista práctico dicha representación debe ser realizada mediante transformaciones estructuradas y algoritmos rápidos.
Una de las tecnologías más importantes en la revolución multimedia es la compresión
de imágenes. El objetivo de la compresión es reducir el volumen de datos necesarios para representar cierta cantidad de información, y esto se logra al remover información redundante de la imagen. El presente trabajo de investigación se centra en los algoritmos de compresión de imágenes con pérdidas de información, con el objetivo de obtener buenos radios de compresión. Unido a la posibilidad de comprimir información existe la restricción del uso de imágenes en diferentes áreas, por ejemplo, en la medicina existen leyes en el uso de las imágenes, por lo que se debe asegurar que en ciertas partes de la imagen no se produzcan pérdidas.
Por lo anterior, el presente trabajo de investigación muestra la metodología para diseñar
un compresor de imágenes que ofrece como ventaja adicional a la del ahorro en el espacio de almacenamiento, la posibilidad de manejar y preservar información importante sobre las características de una imagen, con el objetivo de que las imágenes reconstruidas pueden ser utilizadas en procesos de visión artificial.
Para demostrar la efectividad del compresor diseñado con la metodología se muestran
una serie de pruebas. Las pruebas son subjetivas y objetivas, y además se muestra la posibilidad de usar las imágenes descomprimidas en tareas visión artificial como por ejemplo para la inspección visual de piezas industriales.
Por último, cabe destacar que la principal aportación de la metodología presentada no
esta en la reducción de la medida de los errores entre la imagen original y descomprimida, si no en la correcta preservación y reconstrucción de las características importantes de una imagen como pueden ser los bordes y las texturas aún a tasas de compresión muy bajas.

ABSTRACT
The great increase in the use of Internet, wireless mobile communication devices and the important growth of communication services with images and video has generated a revolution in the way in which the information exchange between the human beings is made. One of the most important aspects in this revolution is the form in which the digital information is represented and delivered in several devices, which must be made in a efficient form. The efficiency in the representation, talks about the ability to capture significant information of an object of interest in a small description. From the practical point of view this representation must be made by means of structured transformations and fast algorithms. One of the most important technologies in that multimedia revolution is image compression. The goal of image compression is to reduce the volume of necessary data to represent certain information amount, and this is obtained by removing image information redundancies. The present research is centered in lossy image compression algorithms, with the goal to obtain good compression rates. Together with the possibility of compressing information there are restrictions of the use of images in different areas, for example, in the medicine there are laws in the use of the images, reason why it is due to assure that in certain parts of the image losses do not take place. By the previous explanation, the present work shows the methodology to design an image coder that offers as additional advantage to the one of the saving storage space, the possibility of handling and preserving important information about the features of an image, with the goal of which the reconstructed images can be used in artificial vision processes. In order to demonstrate the effectiveness of the image coder designed with the methodology we made a series of tests. The tests are subjective and objective, and in addition we show the possibility of using the decompressed images in artificial vision tasks, for example, for the visual inspection of industrial pieces. Finally, it is time to emphasize that the main contribution of the methodology is not in the reduction of the errors measurement between the original images and decompressed, but in the correct preservation and reconstruction of the important features of an image such as edges and textures even at very low bit rates.

i
CONTENIDO
Lista de figuras...................................................................................................................... iv Lista de tablas....................................................................................................................... vii Lista de acrónimos................................................................................................................ ix CAPÍTULO 1 INTRODUCCIÓN
1.1 Antecedentes y trabajos relacionados........................................................................... 2 1.2 Justificación.................................................................................................................. 3 1.3 Descripción del problema............................................................................................. 5 1.4 Objetivo ........................................................................................................................ 6 1.5 Alcances y limitaciones ................................................................................................ 6 1.6 Propuesta de solución ................................................................................................... 7 1.7 Organización de la tesis................................................................................................ 8
CAPÍTULO 2 COMPRESIÓN DE IMÁGENES
2.1 Teoría de la información............................................................................................. 10 2.1.1 Medida de información (entropía)....................................................................... 11
2.2 Clasificación de los algoritmos de compresión de imágenes ..................................... 11 2.3 Tipos de redundancias ................................................................................................ 13
2.3.1 Redundancia de codificación............................................................................... 13 2.3.2 Redundancia entre píxeles ................................................................................... 13 2.3.3 Redundancia psicovisual ..................................................................................... 13
2.4 Esquema general de un compresor de imágenes ........................................................ 14 2.5 Transformación de dominio ....................................................................................... 15
2.5.1 La Transformada Wavelet Discreta (TWD) ........................................................ 16 2.5.2 La Transformada Contourlet Discreta (TCD) ..................................................... 20 2.5.3 La Transformada Contourlet Discreta Basada en una Wavelet (TCDBW)......... 23

ii
2.5.4 Wavelets vs. Contourlets ..................................................................................... 25 2.6 Cuantificación............................................................................................................. 27 2.7 Codificación progresiva.............................................................................................. 28
2.7.1 El algoritmo Set Partitioning In Hierarchical Trees (SPIHT) ............................. 29 2.8 Codificación por entropía ........................................................................................... 32
2.8.1 El algoritmo de Codificación Aritmética (CA) ................................................... 32 2.9 Medidas de compresión y de error (distorsión) .......................................................... 35
2.9.1 Medidas objetivas ................................................................................................ 36 2.9.2 Medidas subjetivas .............................................................................................. 37
2.10 Comentarios.............................................................................................................. 38 CAPÍTULO 3 COMPRESIÓN DE IMÁGENES CON PRESERVACIÓN DE CARACTERÍSTICAS
3.1 Selección de imágenes y definición de características de interés............................... 40 3.2 Extracción del Mapa de Características de Interés (MCI).......................................... 43 3.3 Transformación de dominio ....................................................................................... 45
3.3.1 La Transformada Wavelet Discreta (TWD) ........................................................ 46 3.3.2 La Transformada Contourlet Discreta (TCD) ..................................................... 47 3.3.3 La Transformada Contourlet Discreta Basada en una Wavelet (TCDBW)......... 48
3.4 Mapeo de píxeles al dominio transformado ............................................................... 49 3.5 Codificación con SPIHT modificado ......................................................................... 54 3.6 Codificación aritmética .............................................................................................. 57 3.7 Decodificación aritmética........................................................................................... 58 3.8 Decodificación SPIHT................................................................................................ 58 3.9 Transformación de dominio inversa ........................................................................... 59
3.9.1 La Transformada Wavelet Discreta Inversa (TWDI) .......................................... 59 3.9.2 La Transformada Contourlet Discreta Inversa (TCDI) ....................................... 59
3.10 Comentarios.............................................................................................................. 60 CAPÍTULO 4 EXPERIMENTACIÓN Y RESULTADOS
4.1 Prueba 1: Compresión/descompresión de imágenes con preservación de bordes con wavelets y contourlets ...................................................................................................... 61
4.1.1 Análisis de los resultados de la prueba 1............................................................. 64 4.2 Prueba 2: Preservación de los momentos de inercia con wavelets y contourlets ....... 64
4.2.1 Análisis de los resultados de la prueba 2............................................................. 65 4.3 Prueba 3: Compresión/descompresión de imágenes con preservación de bordes con wavelets y contourlets completo....................................................................................... 66
4.3.1 Análisis de los resultados de la prueba 3............................................................. 69
Contenido

iii
4.4 Prueba 4: Compresión/descompresión de imágenes con preservación de texturas con wavelets y contourlets completo....................................................................................... 70
4.4.1 Análisis de los resultados de la prueba 4............................................................. 73 4.5 Prueba 5: Compresión/descompresión de imágenes con preservación de bordes y texturas con wavelets y contourlets completo .................................................................. 74
4.5.1 Análisis de los resultados de la prueba 5............................................................. 77 4.6 Prueba 6: Compresión/descompresión de imágenes con preservación de bordes resaltados y texturas con wavelets y contourlets completo .............................................. 78
4.6.1 Análisis de los resultados de la prueba 6............................................................. 81 4.7. Prueba 7: Inspección de calidad de piezas industriales con Vision Builder y con imágenes con bordes preservados con wavelets y contourlets ......................................... 82
4.7.1 Análisis de los resultados de la prueba 7............................................................. 85 4.8 Prueba 8: Comparación de los resultados obtenidos contra otros trabajos mostrados en la literatura ................................................................................................................... 86
4.8.1 Análisis de los resultados de la prueba 8............................................................. 87 4.9 Comentarios................................................................................................................ 88
CAPÍTULO 5 CONCLUSIONES Y TRABAJOS FUTUROS
5.1 Aportaciones............................................................................................................... 90 5.2 Trabajos futuros.......................................................................................................... 91
BIBLIOGRAFÍA ................................................................................................................ 92 ANEXO A LA TRANSFORMADA WAVELET DISCRETA (TWD)
A.1 Filtros de descomposición wavelet............................................................................ 98 A.2 Convolución, extensión y downsampling................................................................ 100 A.3 Filtros de reconstrucción wavelet ............................................................................ 103 A.4 Upsampling, extensión y convolución..................................................................... 104
ANEXO B LA TRANSFORMADA CONTOURLET DISCRETA (TCD)
B.1 Filtros de descomposición y reconstrucción contourlet........................................... 107 B.2 Descomposición piramidal ...................................................................................... 108 B.3 Descomposición direccional .................................................................................... 110
ANEXO C RESULTADOS DE LA INVESTIGACIÓN .............................................. 116
Contenido

iv
LISTA DE FIGURAS
Figura 1. 1. Comparación del espacio de almacenamiento entre imágenes ........................... 4 Figura 1. 2. Esquema general del problema planteado para el trabajo doctoral..................... 6 Figura 2. 1. Taxonomía de los métodos de compresión ....................................................... 12 Figura 2. 2. Esquema general de un compresor de imágenes con pérdidas. ........................ 14 Figura 2. 3. Esquema general de procesamiento de imágenes en el dominio transformado.15 Figura 2. 4. Descomposición wavelet de una imagen .......................................................... 17 Figura 2. 5. Fuente de luz representada como la unión de los colores primarios................. 18 Figura 2. 6. TWD a dos niveles de descomposición ............................................................ 20 Figura 2. 7. Proceso de reconstrucción con la TWDI........................................................... 20 Figura 2. 8. Detección de detalles verticales y horizontales en el domino wavelet ............. 21 Figura 2. 9. Detección de detalles diagonales en el dominio wavelet .................................. 21 Figura 2. 10. Transformación multiescala direccional ......................................................... 21 Figura 2. 11. Descomposición con la TCD .......................................................................... 22 Figura 2. 12. La TCD y su proceso multiescala y direccional ............................................. 22 Figura 2. 13. Resultado de la descomposición con la TCD.................................................. 23 Figura 2. 14. Pirámide laplaciana de la TCD. ...................................................................... 24 Figura 2. 15. Resultado de la descomposición con la TCDBW. .......................................... 25 Figura 2. 16. Comparación de transformaciones en la pintura de un paisaje. ...................... 26 Figura 2. 17. Secuencias de imágenes resultantes de la aproximación lineal de la imagen Camman................................................................................................................................ 27 Figura 2. 18. Ejemplo de cuantificación............................................................................... 28 Figura 2. 19. Ejemplo de codificación progresiva con la imagen Lena. .............................. 29 Figura 2. 20. Esquema de compresión SPIHT. .................................................................... 30 Figura 2. 21. Transmisión por planos de bits. ...................................................................... 30 Figura 2. 22. Ejemplo de la construcción (estructura) del árbol SPIHT. ............................. 31 Figura 2. 23. Procedimiento de codificación aritmética....................................................... 34 Figura 2. 24. Etapas para la construcción de la medida PQS. .............................................. 37 Figura 3. 1. Esquema propuesto para el diseño del compresor de imágenes con preservación de características................................................................................................................... 40 Figura 3. 2. Ejemplo de imágenes seleccionadas ................................................................. 42

v
Figura 3. 3. Información contenida en una imagen: bordes, texturas y detalles asociados a los bordes.............................................................................................................................. 42 Figura 3. 4. Máscara circular SUSAN y su respectivo núcleo. ............................................ 44 Figura 3. 5. MCI obtenido con SUSAN ............................................................................... 45 Figura 3. 6. Mapeo de píxeles .............................................................................................. 49 Figura 3. 7. Enumeración de las subbandas wavelet. ........................................................... 50 Figura 3. 8. Relación padre - hijo de la Transformada Wavelet Discreta. ........................... 50 Figura 3. 9. Imágenes para mapeo de píxeles....................................................................... 51 Figura 3. 10. Proceso de mapeo de píxeles........................................................................... 52 Figura 3. 11. Mapeo de píxeles sobre la imagen 3.10c ....................................................... 52 Figura 3. 12. Primer nivel del mapa transformado construido con la figura 3.11c. ............. 52 Figura 3. 13. Mapa de bordes de carita feliz en el dominio transformado. .......................... 53 Figura 3. 14. Mapa de texturas. ............................................................................................ 53 Figura 3. 15. Imágenes ejemplo para codificación............................................................... 54 Figura 3. 16. Imágenes decodificadas .................................................................................. 59 Figura 4. 1. Imágenes reconstruidas con la TWD para la prueba 1...................................... 62 Figura 4. 2. Imágenes reconstruidas con la TCD para la prueba 1....................................... 62 Figura 4. 3. Imágenes reconstruidas para la prueba 3 con wavelets a 0.5............................ 67 Figura 4. 4. Imágenes reconstruidas para la prueba 3 con wavelets a 0.1............................ 67 Figura 4. 5. Imágenes reconstruidas para la prueba 3 con contourlets a 0.5. ....................... 68 Figura 4. 6. Imágenes reconstruidas para la prueba 3 con contourlets a 0.1. ....................... 69 Figura 4. 7. Imágenes reconstruidas para la prueba 4 con wavelets a 0.5............................ 70 Figura 4. 8. Imágenes reconstruidas para la prueba 4 con wavelets a 0.1............................ 71 Figura 4. 9. Imágenes reconstruidas para la prueba 4 con contourlets a 0.5. ....................... 72 Figura 4. 10. Imágenes reconstruidas para la prueba 4 con contourlets a 0.1. ..................... 72 Figura 4. 11. Imágenes reconstruidas para la prueba 5 con wavelets a 0.5.......................... 75 Figura 4. 12. Imágenes reconstruidas para la prueba 5 con wavelets a 0.1.......................... 75 Figura 4. 13. Imágenes reconstruidas para la prueba 5 con contourlets a 0.5. ..................... 76 Figura 4. 14. Imágenes reconstruidas para la prueba 5 con contourlets a 0.1. ..................... 77 Figura 4. 15. Imágenes reconstruidas para la prueba 6 con wavelets a 0.5.......................... 79 Figura 4. 16. Imágenes reconstruidas para la prueba 6 con wavelets a 0.1.......................... 79 Figura 4. 17. Imágenes reconstruidas para la prueba 6 con contourlets a 0.5. ..................... 80 Figura 4. 18. Imágenes reconstruidas para la prueba 6 con contourlets a 0.1. ..................... 81 Figura 4. 19. Imágenes de abrazadera de batería.................................................................. 83 Figura 4. 20. Imágenes de envase de spray .......................................................................... 85 Figura 4. 21. Comparación entre compresores con preservación de bordes ........................ 87 Figura A. 1. Imagen ejemplo para la TWD ........................................................................ 100 Figura A. 2. Extensión periódica en columnas y renglones de la imagen A.1b. ................ 100 Figura A. 3. Convolución con el FPB en los renglones de la figura A.2. .......................... 101
Lista de figuras

vi
Figura A. 4. Convolución con el FPA en los renglones de la figura A.2. .......................... 101 Figura A. 5. Convolución con el FPB en las columnas de la figura A.3............................ 101 Figura A. 6. Convolución con el FPA en las columnas de la figura A.3. .......................... 102 Figura A. 7. Convolución con el FPB en las columnas de la figura A.4............................ 102 Figura A. 8. Convolución con el FPA en columnas de la figura A.4. ................................ 102 Figura A. 9. Descomposición con la TWD. ....................................................................... 103 Figura A. 10. Upsampling en columnas y renglones.......................................................... 104 Figura A. 11. Extensión en columnas y renglones ............................................................. 104 Figura A. 12. Convolución sobre la figura A.11a. ............................................................. 105 Figura A. 13. Convolución sobre la figura A.11b .............................................................. 105 Figura A. 14. Convolución sobre la figura A.11c. ............................................................. 106 Figura A. 15. Reconstrucción con la TWDI....................................................................... 106 Figura B. 1. Imagen ejemplo para la TCD. ........................................................................ 108 Figura B. 2. Extensión en columnas y renglones de la imagen B.1b. ................................ 108 Figura B. 3. Convolución con el FPB de análisis sobre la figura B.2. ............................... 109 Figura B. 4. Imagen de aproximación ................................................................................ 109 Figura B. 5. Sobre muestreo y extensión de la imagen B.4b.............................................. 110 Figura B. 6. Imagen de detalles .......................................................................................... 110 Figura B. 7. Resultado de la convolución con el FPA sobre la figura B.6b....................... 111 Figura B. 8. Resultado de la convolución con el FPB sobre la figura B.6b. ...................... 111 Figura B. 9. Reordenamiento quincunx sobre la imagen B.7............................................. 112 Figura B. 10. Imagen resultante del downsampling y reordenamiento quincunx con el FPA............................................................................................................................................. 112 Figura B. 11. Imagen resultante del downsampling y reordenamiento quincunx con el FPB............................................................................................................................................. 112 Figura B. 12. Extensión, convolución y reordenamiento sobre la figura B.10 .................. 113 Figura B. 13. Extensión, convolución y reordenamiento sobre la figura B.11 .................. 113 Figura B. 14. Extensión, convolución y reordenamiento sobre la figura B.12a................. 114 Figura B. 15. Extensión, convolución y reordenamiento sobre la figura B.12b ................ 114 Figura B. 16. Extensión, convolución y reordenamiento sobre la figura B.13a................. 114 Figura B. 17. Extensión, convolución y reordenamiento sobre la figura B.13b ................ 115 Figura B. 18. Subbandas de la TCD ................................................................................... 115
Lista de figuras

vii
LISTA DE TABLAS
Tabla 1. 1. Datos multimedia y su espacio de almacenamiento. ............................................ 5 Tabla 2. 1. Coeficientes del filtro de escalamiento Haar, B2.2 y D4. .................................. 19 Tabla 2. 2. Filtros de descomposición Haar, B2.2 y D4....................................................... 19 Tabla 2. 3. Alfabeto y probabilidades asociadas para la codificación aritmética................. 34 Tabla 2. 4. Proceso de decodificación aritmética. ................................................................ 35 Tabla 2. 5. Escala MOS para evaluación subjetiva. ............................................................. 38 Tabla 3. 1. Resultados de la clasificación de 18 imágenes seleccionadas para la metodología de diseño del compresor de imágenes con preservación de características.......................... 41 Tabla 3. 2. Número de puntos y umbrales calculados para el MCI...................................... 45 Tabla 3. 3. Proceso de codificación con SPIHT modificado................................................ 56 Tabla 3. 4. Proceso de codificación con SPIHT original...................................................... 56 Tabla 3. 5. Estructura del archivo codificado en escala de gris............................................ 57 Tabla 3. 6. Estructura del archivo codificado en RGB......................................................... 58 Tabla 4. 1. Puntos seleccionados en cada subbanda wavelet para la prueba 1..................... 63 Tabla 4. 2. Puntos seleccionados en cada subbanda contourlet para la prueba 1................. 63 Tabla 4. 3. Medidas de error obtenidas para la prueba 1 con la TWD. ................................ 63 Tabla 4. 4. Medidas de error obtenidas para la prueba 1 con la TCD. ................................. 63 Tabla 4. 5. Momentos para la imagen original “Clown”...................................................... 64 Tabla 4. 6. Momentos para la imagen “Clown” comprimida con wavelets. ........................ 65 Tabla 4. 7. Momentos para la imagen “Clown” comprimida con contourlets. .................... 65 Tabla 4. 8. Medidas de error obtenidas para la prueba 3 con wavelets a 0.5. ...................... 66 Tabla 4. 9. Medidas de error obtenidas para la prueba 3 con wavelets a 0.1. ...................... 67 Tabla 4. 10. Medidas de error obtenidas para la prueba 3 con contourlets a 0.5. ................ 68 Tabla 4. 11. Medidas de error obtenidas para la prueba 3 con contourlets a 0.1. ................ 68 Tabla 4. 12. Medidas de error obtenidas para la prueba 4 con wavelets a 0.5. .................... 70 Tabla 4. 13. Medidas de error obtenidas para la prueba 4 con wavelets a 0.1. .................... 71 Tabla 4. 14. Medidas de error obtenidas para la prueba 4 con contourlets a 0.5. ................ 71 Tabla 4. 15. Medidas de error obtenidas para la prueba 4 con contourlets a 0.1. ................ 72 Tabla 4. 16. Estadísticos de textura obtenidos para imágenes originales y comprimidas. ... 73 Tabla 4. 17. Medidas de error obtenidas para la prueba 5 con wavelets a 0.5. .................... 74

viii
Tabla 4. 18. Medidas de error obtenidas para la prueba 5 con wavelets a 0.1. .................... 75 Tabla 4. 19. Medidas de error obtenidas para la prueba 5 con contourlets a 0.5. ................ 76 Tabla 4. 20. Medidas de error obtenidas para la prueba 5 con contourlets a 0.1. ................ 76 Tabla 4. 21. Medidas de error obtenidas para la prueba 6 con wavelets a 0.5. ................... 78 Tabla 4. 22. Medidas de error obtenidas para la prueba 6 con wavelets a 0.1. .................... 79 Tabla 4. 23. Medidas de error obtenidas para la prueba 6 con contourlets a 0.5. ................ 80 Tabla 4. 24. Medidas de error obtenidas para la prueba 6 con contourlets a 0.1. ................ 80 Tabla 4. 25. Resultados obtenidos en la verificación de la abrazadera de batería................ 83 Tabla 4. 26. Medidas de error obtenidas para la prueba 7 con la abrazadera de batería. ..... 83 Tabla 4. 27. Resultados obtenidos en la verificación del envase de spray. .......................... 84 Tabla 4. 28. Medidas de error obtenidas para la prueba 7 con el envase de spray............... 84
Lista de tablas

ix
LISTA DE ACRÓNIMOS
BFD: Banco de Filtros Direccional. BFDP: Banco de Filtros Direccional Piramidal. CA: Codificación Aritmética. CIPC: Compresión de Imágenes con Preservación de Características. EZW: Embedded Zerotree Wavelet. F: Norma de Frobenius. LIP: List of Insignificant Pixels (lista de píxeles no significativos). LIS: List of Insignificant Sets (lista de conjuntos no significativos). LSB: Least Significant Bit (bit menos significativo). LSP: List of Significant Pixels (lista de píxeles significativos). LZW: Lempel – Ziv – Welch. MCI: Mapa de Características de Interés. MOS: Mean Opinion Score (encuesta de opinión media). MSB: Most Significant Bit (bit más significativo). MSE: Mean Square Error (error cuadrático medio). N2: Norma dos. PDI: Procesamiento Digital de Imágenes. PL: Pirámide Laplaciana. PQS: Picture Quality Scale (escala de calidad de la imagen). PSNR: Peak Signal-to-Noise Ratio (relación señal a ruido pico). ROI: Regions Of Interest (regiones de interés). SPIHT: Set Partitioning In Hierarchical Trees. SUSAN: Smallest Univalue Segment Assimilating Nucleus (método de similitud del núcleo del segmento con valor único más pequeño). TCD: Transformada Contourlet Discreta. TCDI: Transformada Contourlet Discreta Inversa. TCDBW: Transformada Contourlet Discreta Basada en una Wavelet. TWD: Transformada Wavelet Discreta. TWDBR: Transformada Wavelet Discreta Basada en Regiones. TWDI: Transformada Wavelet Discreta Inversa.

Capítulo 1 Introducción
1
CAPÍTULO 1 Introducción Una imagen vale más que mil palabras. Desafortunadamente, almacenar una imagen puede costar más de un millón de palabras. Efectivamente, aunque en la actualidad con la existencia de equipos de cómputo tan sofisticados eso puede no ser considerado un problema (ya que se pueden manejar grandes cantidades de datos), se pueden dar otras situaciones en otros dispositivos como por ejemplo: las cámaras fotográficas no tienen la suficiente capacidad de memoria o la transmisión de una imagen por Internet pueda ser muy lenta debido al gran tamaño en bytes de la imagen.
Aunado a lo anterior y al gran incremento en el uso de Internet, de dispositivos de comunicación móviles inalámbricos y el importante crecimiento de los servicios de comunicación con imágenes y video se ha generado una revolución en la forma en que se realiza el intercambio de información entre los seres humanos, siendo uno de los aspectos más importantes a tratar, la forma en que la información digital (imágenes) es transmitida y entregada. La eficiencia en la entrega de la información y el entendimiento temprano de la misma toma el carácter de imperativo para muchas aplicaciones, y para obtener éxito en dichos procesos se han propuesto diferentes métodos, siendo uno de los más importantes la compresión de imágenes [1].
La posibilidad de representar la información visual de forma eficiente es uno de los principales fundamentos para muchas tareas de procesamiento de imágenes como por ejemplo: clasificación [2], compresión [3], filtrado [4] y extracción de características [5]. La eficiencia en la representación se refiere a la habilidad de capturar información significativa de un objeto de interés en una descripción pequeña. Desde el punto de vista práctico dicha representación debe ser realizada mediante transformaciones estructuradas y algoritmos rápidos [6].
Las imágenes digitales requieren grandes cantidades de bytes para su almacenamiento y
grandes anchos de banda para su transmisión por lo que se ha vuelto una necesidad el poder encontrar formas de representar la información digital utilizando menos información que la original sin afectar el entendimiento de la misma, a dicho proceso se le conoce como compresión. El objetivo de la compresión de datos es reducir el volumen de datos necesarios para representar cierta cantidad de información, y esto se logra al remover información redundante de la imagen [7]. Para el caso de las imágenes, en particular, el proceso puede ser realizado con o sin pérdida de información.

Capítulo 1 Introducción
2
Algunas de las partes más interesantes que componen una imagen digital son las formas, los contornos, los bordes y las texturas que ofrecen información importante acerca de la imagen que además son vitales para el reconocimiento y entendimiento.
Al realizar un proceso de compresión/descompresión con pérdida de información se
eliminan detalles de la imagen que pudieran haber ayudado al mejor entendimiento de la misma, es por esa razón que se necesita preservar información. Además, de que en muchas industrias como por ejemplo, la médica la forma de manejar la información de las imágenes esta reglamentada por lo que toma mayor importancia la posibilidad de conservar características importantes de las imágenes [8], [9].
La preservación de características significa que la colocación, fuerza y forma de las
características de una imagen no cambien aún después de la aplicación de un filtro general, por supuesto, pueden ocurrir diferencias naturales debido a cambios en el manejo de la resolución [10].
Dado lo anterior, resulta muy interesante el poder definir una metodología para diseñar
un compresor de imágenes con pérdidas que ofrezca como ventaja adicional al ahorro de espacio de almacenamiento, la posibilidad de seleccionar y preservar información importante de una imagen con el objetivo de utilizarla posteriormente en un proceso de visión artificial como por ejemplo el entendimiento y reconocimiento de imágenes. A dicho codificador se le llamará “Compresor de Imágenes con Preservación de Características (CIPC)” 1.1 Antecedentes y trabajos relacionados
Los primeros intentos por diseñar Compresores de Imágenes con Preservación de Características (CIPC) se dieron en los años 80´s cuando se utilizaban esquemas llamados codificadores de Regiones de Interés (ROI´s) en los que la cantidad de bits era en gran parte gastad en las zonas definidas por las ROI y en menor cantidad en otras regiones de la imagen lo que implicaba codificadores híbridos, es decir, codificadores diferentes para cada región de la imagen [11].
Con el pasar de los años aparecieron los codificadores progresivos que permitían cubrir
la necesidad de asignar prioridad a los coeficientes a ser codificados (los que representan las características importantes) con el objetivo de producir un flujo de bits progresivo.
Dichos codificadores permiten la construcción de imágenes a diferentes calidades
asegurando que la imagen entregada tiene la mejor calidad posible perteneciente a la tasa de compresión seleccionada. Los codificadores más importantes de este tipo son el algoritmo Embedded Zerotree Wavelet (EZW) [12] y el algoritmo Set Partitioning In Hierarchical Trees (SPIHT) [13].
Después, se propusieron transformaciones de dominio diseñadas para no actuar sobre las características deseadas (con el fin de conservarlas) como por ejemplo la Transformada Wavelet Discreta Basada en Regiones (TWDBR), en la que las diversas características son

Capítulo 1 Introducción
3
procesadas de forma distinta para conservarlas[14]. En este tipo de codificadores la transmisión de la información se realiza en dos etapas: primero se envía la información de los contornos que es conocida como información de segmentación y luego se envía la información de las texturas que es conocida como contenido de los segmentos.
Los investigadores continuaron con la búsqueda de soluciones al problema de CIPC y
se dieron cuenta que para diseñar codificadores eficientes, es necesario tener la posibilidad de construir un módulo robusto de Procesamiento Digital de imágenes (PDI) de modo que una imagen pueda ser descrita en términos de bordes, texturas, y detalles asociados a los bordes entre otras características.
Con la llegada del año 2000 las tecnologías en compresión de imágenes se volvieron
más importantes con el gran uso de Internet y dispositivos inalámbricos. Aparecieron entonces, esquemas en los que la información de las características es utilizada como conocimiento a priori para la reconstrucción por el compresor, pero se siguen codificando las características con distintos métodos, es decir, lo que se quiere preservar es codificado sin pérdidas y el resto de la imagen con pérdidas [8].
. La aparición del estándar JPEG 200 representó uno de los avances más importantes en
el área de compresión con preservación de características, por que ofrece a los usuarios capacidades de compresión que hasta ese momento no estaban presentes en el mercado, como por ejemplo la codificación con wavelets usando ROI´s [15].
Uno de los principales problemas en compresión de imágenes, es que las medidas de
distorsión por lo regular fallan en medir la calidad de características importantes necesarias para el reconocimiento y percepción de las imágenes reconstruidas. Por lo anterior, se vuelve importante la búsqueda de otra forma de medir la calidad de las imágenes y una solución es la utilización de aplicaciones de visión artificial, para verificar si dichas características fueron conservadas aún después del proceso de compresión/descompresión de una imagen.
En la actualidad la investigación continúa para tener la posibilidad de diseñar un
codificador de imágenes que permita la preservación de características de interés, sin que sea necesario codificarlas de forma distinta a las otras partes de la imagen y que dentro del flujo de compresión puedan ser incluso mejoradas.
1.2 Justificación La compresión de imágenes es un área muy útil e importante dentro del procesamiento digital de imágenes y sus avances tienen repercusiones y aplicaciones en varios campos del quehacer cotidiano. Se pueden encontrar algoritmos de compresión incorporados en dispositivos de uso común como: almacenamiento de imágenes en cámaras digitales; reproductores DVD; transmisiones de televisión y video digital (MPEG); transmisiones de audio y video en telefonía celular; transmisiones de datos, imágenes, audio y video en Internet; y otros

Capítulo 1 Introducción
4
específicos para cierto tipo de datos como los incorporados en los reproductores MP3; por citar algunas aplicaciones. El desarrollo de una metodología para diseñar compresores/descompresores de imágenes que incida de manera importante en las áreas antes mencionadas es un reto matemático muy fuerte, y más aún, si además de comprimir datos se desea conservar algún tipo de información importante presente en los mismos que permita el almacenamiento y la recuperación eficiente para posteriores procesos de reconocimiento de patrones y visión artificial. Por otro lado, un algoritmo de compresión de este tipo toma mayor importancia en áreas como la medicina en donde el uso de las imágenes esta restringido y reglamentado. Es importante el proceso de compresión de imágenes debido al volumen de información necesario para almacenar una imagen estática o un banco de imágenes estáticas. Por ejemplo, si se quiere almacenar una imagen de tamaño 200 x 200 de 24 bits será necesario utilizar 200 x 200 x 3 = 120, 000 bytes, y se debe tomar en cuenta que una imagen de ese tamaño es relativamente pequeña. Por otro lado, si se toma como ejemplo el video que utiliza de 24 a 30 cuadros por segundo, el espacio de almacenamiento necesario es muy grande. La figura 1.1 muestra un ejemplo de una imagen en formato BMP y una comprimida con JPEG que utilizan diferentes tamaños de almacenamiento, en la imagen se observa que aún cuando hubo pérdida de información las diferencias no son distinguibles para el ojo, pero el ahorro de espacio es muy bueno.
Figura 1. 1. Comparación del espacio de almacenamiento entre imágenes. a) Imagen BMP de 231 x 149 píxeles con un espacio de 136 kb, b) Imagen JPEG que utiliza un espacio de 12 kb, c) Imagen
de las diferencias entre a y b.
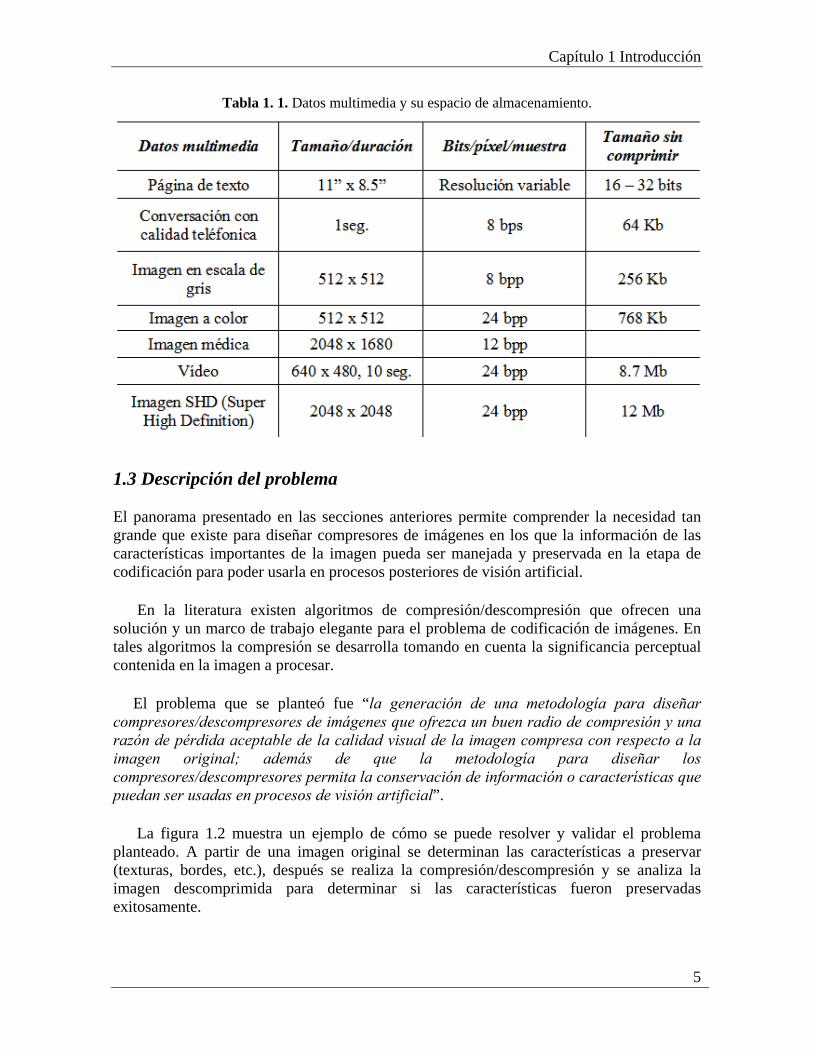
La tabla 1.1 ilustra los tamaños de archivos para almacenar imágenes digitales, audio y vídeo, con lo cual se observa claramente que los espacios de almacenamiento necesarios son muy grandes. Por lo tanto una solución eficiente podría ser comprimir esos datos multimedia antes de almacenarlos o transmitirlos.
Capítulo 1 Introducción
5
Tabla 1. 1. Datos multimedia y su espacio de almacenamiento.
1.3 Descripción del problema El panorama presentado en las secciones anteriores permite comprender la necesidad tan grande que existe para diseñar compresores de imágenes en los que la información de las características importantes de la imagen pueda ser manejada y preservada en la etapa de codificación para poder usarla en procesos posteriores de visión artificial.
En la literatura existen algoritmos de compresión/descompresión que ofrecen una solución y un marco de trabajo elegante para el problema de codificación de imágenes. En tales algoritmos la compresión se desarrolla tomando en cuenta la significancia perceptual contenida en la imagen a procesar. El problema que se planteó fue “la generación de una metodología para diseñar compresores/descompresores de imágenes que ofrezca un buen radio de compresión y una razón de pérdida aceptable de la calidad visual de la imagen compresa con respecto a la imagen original; además de que la metodología para diseñar los compresores/descompresores permita la conservación de información o características que puedan ser usadas en procesos de visión artificial”.
La figura 1.2 muestra un ejemplo de cómo se puede resolver y validar el problema planteado. A partir de una imagen original se determinan las características a preservar (texturas, bordes, etc.), después se realiza la compresión/descompresión y se analiza la imagen descomprimida para determinar si las características fueron preservadas exitosamente.

Capítulo 1 Introducción
6
Figura 1. 2. Esquema general del problema planteado para el trabajo doctoral.
El objetivo perseguido por la metodología de diseño para comprimir/descomprimir
imágenes es reducir los artefactos o errores presentes en las áreas determinadas por las características de la imagen a preservar, para poder obtener imágenes reconstruidas con muy buena calidad en las secciones donde se encuentran dichas características aún con tasas de compresión muy bajas. 1.4 Objetivo El objetivo del trabajo de investigación doctoral es el siguiente:
“Proponer una metodología para diseñar compresores/descompresores que tenga una tasa de compresión mayor que los límites establecidos por la entropía de la imagen en que la imagen resultante pudiera tener un decremento en la calidad visual; además, de que el modelo permita la conservación de información o características que puedan ser utilizadas en procesos de visión artificial”.
1.5 Alcances y limitaciones La metodología de diseño tiene las siguientes características:
• Puede trabajar con imágenes estáticas de 8 y 24 bits. • Las características son obtenidas en un módulo de procesamiento digital de
imágenes que permite crear un mapa de bordes de la imagen original. • Se permite seleccionar diferentes características a preservar: a) Bordes, b) Texturas,
c) Bordes y texturas de manera conjunta y d) Bordes y texturas resaltando los bordes.

Capítulo 1 Introducción
7
• Las imágenes que se utilizan deben ser imágenes cuadradas potencias de dos. • Se puede trabajar con cualquier imagen de 8 o 24 bits sin importar la cantidad de
componentes de frecuencia (bordes), y se asegura que la información seleccionada es preservada.
• El diseño implica un compresor progresivo que funciona al modificar el esquema de
selección de un coeficiente. En el que la importancia de un coeficiente no sólo se determina por su valor numérico sino por su posición en el mapa de características de interés.
• Una imagen a comprimir puede ser transformada tanto en el dominio wavelet como
en el dominio contourlet.
• Las características son reconocidas tanto en el dominio wavelet como en el dominio contourlet, gracias a un mapeo de puntos realizado del dominio original hacia el dominio transformado.
• Además de la imagen descomprimida se obtienen como resultado, las medidas de
error provenientes de la evaluación objetiva (MSE, PSNR, F, N2, PQS) y en el caso de compresión con preservación de bordes y texturas también se muestra una medida subjetiva (MOS) de la imagen.
• Para el desarrollo del codificador se utilizó el lenguaje MATLAB que es la
abreviación del laboratorio de matrices, por que es un lenguaje que brinda herramientas y componentes para la manipulación de imágenes a nivel de píxeles y brinda la posibilidad de realizar pruebas a los algoritmos de manera sencilla a diferencia del lenguaje C++.
1.6 Propuesta de solución Para resolver el problema que se planteó en este trabajo de investigación se realizaron las siguientes actividades: 1. Revisión de artículos, libros y revistas (afines al área), búsqueda del estado del arte, con el fin de conocer a fondo el problema de compresión de imágenes. 2. Proceso para determinar la(s) característica(s) que se desean preservar en la imagen a comprimir, después del estudio se determinó preservar los bordes y las texturas de una imagen. 3. Selección de las técnicas de procesamiento de imágenes que permitan extraer o detectar las características del paso 2, después del estudio se seleccionó el algoritmo de detección de

Capítulo 1 Introducción
8
bordes SUSAN cuyos resultados son utilizados tanto para la extracción de bordes como de texturas. 4. Estudio de los métodos de compresión existentes para determinar las necesidades para poder adaptarlo a la preservación de características. Se observó que ningún algoritmo existente permitía dicho proceso, y que el algoritmo SPIHT es un codificador progresivo que permite la selección de coeficientes por su valor, por lo que dicho algoritmo fue modificado, después de un arduo estudio. 5. Definición de la metodología para diseñar compresores/descompresores de imágenes. 6. Codificación e implementación de un sistema computacional utilizando la metodología de diseño para la compresión/descompresión de imágenes con las adecuaciones necesarias. 7. Validación y pruebas.
7.1. Ejecución de un proceso de visión artificial por medio de Vision Builder para determinar si las características son preservadas correctamente.
7.2. Fase de experimentación para poder medir de manera objetiva y subjetiva el desempeño del compresor/descompresor diseñado con la metodología
8. Ajustes del sistema codificado (en caso de ser necesario después de las pruebas). 9. Análisis de los resultados de investigación. 10. Reporte de investigación. 1.7 Organización de la tesis En los siguientes capítulos se muestra una explicación de todos los procesos necesarios para la solución del problema planteado en el presente trabajo de investigación.
La tesis está organizada de la siguiente manera: en el capítulo 2 se ofrece una introducción al tema de la compresión de imágenes, en el que se dan explicaciones y conceptos importantes, como el de la clasificación de los métodos de compresión, las transformaciones de dominio, codificación aritmética, codificación progresiva, etc.
En el capítulo 3 se presentan los detalles para el diseño de la metodología por medio de la cual se resolvió el problema de CIPC. Se ofrece una explicación de cada uno de los módulos que son: a) Selección de imágenes y definición de características interés, b) Extracción del Mapa de Características de Interés (MCI), c) Transformación de dominio, d) Mapeo de píxeles al dominio transformado, e) Codificación con SPIHT modificado, f) Codificación aritmética, g) Decodificación aritmética, h) Decodificación SPIHT e i) Transformación de dominio inversa.

Capítulo 1 Introducción
9
En el capítulo 4 se muestra una serie de pruebas realizadas para demostrar la efectividad del CIPC, además, se ofrece el análisis y la discusión de los resultados obtenidos para cada una de las pruebas planteadas.
En el capítulo 5 se muestran las conclusiones obtenidas del trabajo de investigación y
las oportunidades de trabajos futuros detectados durante la realización de la misma. Por último, en el anexo A se muestra un ejemplo numérico para el cálculo de la
transformada wavelet discreta, en el anexo B se muestra un ejemplo numérico para el cálculo de la transformada contourlet discreta, y finalmente en el anexo c se muestran los resultados obtenidos del proceso de investigación doctoral.

Capítulo 2 Compresión de imágenes
10
CAPÍTULO 2 Compresión de imágenes
La compresión de imágenes es muy importante para el procesamiento, almacenamiento y transmisión de imágenes digitales, y durante los últimos años se ha observado un gran avance y desarrollo en este campo. Cuando se habla de compresión de imágenes en general, se pueden encontrar dos problemas principales: el modelo de compresión y la implementación del algoritmo de compresión; y adicionalmente, para la visión artificial, la preservación de características importantes en la imagen para lograr un Reconocimiento de Patrones (RP) exitoso.
Uno de los principales factores que impulsaron el desarrollo de la compresión de
imágenes fue la necesidad de reducir el volumen de datos para la transmisión y almacenamiento de las mismas, a la compresión también se le conoce como codificación.
El término compresión de imágenes se refiere al proceso de reducción del volumen de
datos necesarios para representar una imagen cuya percepción final puede ser adaptada a la demanda de un usuario final desde el punto de vista de la distorsión [16].
La compresión de datos como disciplina tiene su origen en la teoría de la información
con el trabajo realizado en 1948 en los laboratorios Bell que abordó el problema de la redundancia de datos y su aplicación para la comunicación de mensajes [17]. 2.1 Teoría de la información ¿Cuál es el número mínimo de datos necesarios para representar una imagen? ¿Existe una cantidad mínima de datos suficiente para describir completamente una imagen sin pérdida de información? La teoría de la información proporciona el marco de trabajo matemático para responder a las preguntas anteriores.
La teoría de la información es la base para la compresión de datos, fue creada en el año de 1948 por Claude Elwood Shannon en los laboratorios Bell, en su inicio, el objetivo principal de la teoría era proporcionar a las comunidades científicas un marco matemático para la teoría de la comunicación estableciendo los límites fundamentales en el funcionamiento de los diferentes sistemas de comunicación. En su artículo Shannon asegura que la información no es un concepto abstracto, si no que es una entidad real que puede ser medida y manipulable matemáticamente [18].

Capítulo 2 Compresión de imágenes
11
¿Cuanta información lleva una señal en particular? La medida es sencilla: simplemente se cuenta el mínimo número de bits que hacen falta para codificar la información. Para hacer esto, se debe mostrar como puede arribar cierta cantidad de información dando las respuestas a una secuencia de preguntas si/no. 2.1.1 Medida de información (entropía)
La generación de información puede ser modelada como un proceso probabilístico que puede ser medido de alguna manera que esté de acuerdo a la intuición. Por ejemplo, un evento aleatorio E que ocurre con una probabilidad P(E) contiene cierta cantidad de información que puede ser calculada con la ecuación 2.1.
)(log)(
1log)( EPEP
EI −== (2.1)
A la cantidad I(E) se le conoce como auto información de E, la cantidad de información
atribuida al evento E está inversamente relacionada a la probabilidad de E. Si P(E) = 1 (el evento siempre ocurre), y si I(E) = 0, entonces no se le atribuye ninguna información. Si P(E) = 0.99 implica que E ha ocurrido y conlleva a una mínima cantidad de información. Al poder decir que E no a ocurrido conlleva mas información dado que es menos probable que suceda.
La base del logaritmo de la ecuación 2.1 determina la unidad usada para medir la
información. Si se usa el logaritmo base m la medida es de m-aria unidades, si la base es 2 a la unidad de información resultante se le llamará bit. Por lo que la entropía es una medida de la cantidad de información (o incertidumbre) contenida en una fuente [19]. 2.2 Clasificación de los algoritmos de compresión de imágenes En la literatura existen diferentes formas de clasificar a las técnicas de compresión de imágenes, siendo una de las principales la división en: a) técnicas basadas en la forma de onda y b) técnicas basadas en modelos.
Los codificadores basados en la forma de onda intentan reproducir la forma de la onda
de la señal de entrada, se generan para ser independientes de la señal, de tal forma que pueden ser usados para codificar una gran variedad de señales. Presentan una degradación aceptable en presencia de ruido y errores de transmisión. La codificación se puede llevar a cabo tanto en el dominio del tiempo como de la frecuencia. Pueden usar las estadísticas de los píxeles de la imagen, se clasifican principalmente en algoritmos con pérdida y sin pérdida de información [20].
En los algoritmos sin pérdida de información la imagen reconstruida es una copia exacta de la original, mientras que en los algoritmos con pérdidas la imagen reconstruida no es en todos los píxeles igual que la imagen original, sin embargo, una técnica de

Capítulo 2 Compresión de imágenes
12
compresión con pérdidas de alta calidad es capaz de reconstruir la imagen con diferencias visuales imperceptibles con respecto a la imagen original [21].
Los métodos de compresión sin pérdida de información (lossless) se caracterizan
porque la tasa de compresión que proporcionan está limitada por la entropía (redundancia de datos) de la señal original. Entre estas técnicas destacan las que emplean métodos estadísticos, basados en la teoría de Shannon, que permite la compresión sin pérdida. Por ejemplo: codificación de Huffman, codificación aritmética y Lempel – Ziv – Welch (LZW).
Los métodos de compresión con pérdida de información (lossy) logran alcanzar tasas de
compresión más elevadas a costa de sufrir una pérdida de información sobre la imagen original. Por ejemplo: JPEG, JPEG 2000, etc. Para la compresión de imágenes es más frecuente emplear métodos lossy, ya que se busca alcanzar una tasa de compresión considerable, pero que se adapte a la calidad deseada que la aplicación exige.
Por otro lado los codificadores basados en modelos funcionan en términos de la
descripción del modelo de la fuente de datos a comprimir más un codificador. El codificador y el decodificador usan un modelo del objeto, el cual es utilizado por el codificador para analizar la imagen y por el decodificador para generar la imagen. Una de las principales técnicas de este tipo es la compresión con fractales.
En la figura 2.1 se muestra una taxonomía de algunos de los métodos de compresión de
audio, vídeo e imágenes existentes en la literatura.
Figura 2. 1. Taxonomía de los métodos de compresión [22].

Capítulo 2 Compresión de imágenes
13
2.3 Tipos de redundancias Los datos son los medios a través de los que se transporta la información. Se pueden utilizar distintas cantidades de datos para describir la misma cantidad de información. Por lo tanto, hay datos que proporcionan información sin relevancia, que pueden ser obtenidos o calculados a partir de otros. Esto es lo que se conoce como redundancia de los datos.
La redundancia de los datos es un punto clave en la compresión de datos digitales. En la compresión de imágenes digitales, se pueden identificar y aprovechar tres tipos básicos de redundancias: de codificación, entre píxeles y psicovisual [7]. 2.3.1 Redundancia de codificación El código de una imagen representa el cuerpo de la información mediante un conjunto de símbolos. La eliminación del código redundante consiste en utilizar el menor número de símbolos para representar la información. Las técnicas de compresión por codificación de Huffman [23] y codificación aritmética [24] utilizan cálculos estadísticos para lograr eliminar este tipo de redundancia y reducir la representación original de los datos.
En general, la redundancia de código aparece cuando los códigos asignados a un conjunto de niveles de gris no han sido seleccionados de modo que se obtenga el mayor rendimiento posible de las probabilidades de estos niveles. Aquí a los códigos menos probables se les asignan códigos largos y a los más probables se les asignan códigos cortos. 2.3.2 Redundancia entre píxeles La mayoría de las imágenes presentan semejanzas o correlaciones1 entre sus píxeles, tales correlaciones se deben a la existencia de estructuras similares en las imágenes, puesto que no son completamente aleatorias. De esta manera, el valor de un píxel puede emplearse para predecir el de sus vecinos.
Las técnicas de compresión Lempel – Ziv – Welch (LZW) [25] implementan algoritmos basados en sustituciones para lograr la eliminación de esta redundancia. En relación con estas dependencias entre píxeles se han generado una serie de nombres como redundancia espacial, redundancia geométrica y redundancia interna. 2.3.3 Redundancia psicovisual
El ojo humano responde con diferente sensibilidad a la información visual que recibe, y la información a la que es menos sensible se puede descartar sin afectar a la percepción de la imagen, se suprime así lo que se conoce como redundancia visual.
1 Medida del grado de relación lineal entre dos variables, permite mostrar cuando y que tan fuerte dos variables se relacionan.

Capítulo 2 Compresión de imágenes
14
La eliminación de esta redundancia está relacionada con la cuantificación de la información, lo que conlleva una pérdida de información irreversible.
Técnicas de compresión como JPEG (Joint Photographic Experts Group) [26], EZW (Embedded Zerotree Wavelet) [12] y SPIHT (Set Patitioning In Hierarchical Trees) [13] hacen uso de este tipo de redundancias.
La redundancia psicovisual está asociada a la información visual real o cuantificable. Su eliminación es únicamente posible porque la propia información no es esencial para el procesamiento visual normal de los seres humanos. Como la eliminación de los datos psicovisualmente redundantes se traduce en una pérdida de información cuantitativa, a menudo se le denomina cuantificación2. Puesto que es una operación irreversible, ya que se pierde información visual, la cuantificación conduce a una compresión con pérdida de datos. 2.4 Esquema general de un compresor de imágenes El esquema general de un compresor de imágenes con pérdidas de información conlleva tres etapas principales: transformación de dominio, cuantificación y codificación por entropía [27].
En el caso de compresión sin pérdidas se omite el proceso de cuantificación y la imagen reconstruida es una copia fiel de la original. Para el caso con pérdidas la imagen tiene un decremento en la calidad determinado por la tasa de compresión. La figura 2.2 muestra el esquema general del proceso de compresión de imágenes con pérdidas.
Figura 2. 2. Esquema general de un compresor de imágenes con pérdidas.
En el caso de la descompresión de imágenes se aplica el mismo proceso que para el
caso de la compresión pero ahora de forma inversa. En las siguientes secciones se da una explicación de cada una de las etapas del esquema general de compresión de imágenes.
2 Cuantificación significa que a un amplio rango de valores de entrada le corresponde un número limitado de valores de salida.

Capítulo 2 Compresión de imágenes
15
2.5 Transformación de dominio Una de las etapas más importantes en los esquemas generales de compresión de imágenes es la transformación de dominio. Los métodos de transformación son muy utilizados para el procesamiento de imágenes y señales, fueron originalmente creados para propósitos de codificación pero después encontraron uso en la restauración, mejora, segmentación, compresión, etc.
Transformar significa cambiar la representación de una señal o una función utilizando operaciones matemáticas, gracias a dicha representación un problema complejo puede ser descompuesto en problemas más pequeños a los que se les pueden dar soluciones simples [28]. La transformación ofrece una representación alternativa que revela características que en el dominio original son difíciles de detectar.
Una transformada representa un cambio hacia un entorno diferente donde de alguna forma se facilita la realización de tareas específicas. Se utiliza un operador T que se aplica a la señal dada por una función f dicho proceso está descrito en la ecuación 2.2.
(2.2) Una imagen puede ser procesada tanto en el dominio espacial como en el dominio
transformado. En el modelo general de procesamiento se toma una imagen de entrada y se realiza una transformación, después se aplica el procesamiento sobre la imagen transformada y a dicha imagen se le calcula la transformada inversa para regresarla al dominio original, dicho esquema se presenta en la figura 2.3.
Figura 2. 3. Esquema general de procesamiento de imágenes en el dominio transformado.
Al aplicar una transformación se persiguen tres objetivos principales:
1. Reducción de la complejidad. 2. Hacer evidentes ciertas características que en el dominio original eran difíciles de
detectar u observar.
3. Obtener la posibilidad de comprimir datos.

Capítulo 2 Compresión de imágenes
16
Las propiedades deseables que debe tener una transformación son [29]:
1. Decorrelación de los datos, explotación de las ventajas del sistema visual humano y compactación de energía.
2. Independencia de los datos (aplicación de la misma transformación a todos los datos).
3. Velocidad y separabilidad. Al aplicar una transformada se sigue un modelo matemático por lo que se deben asumir
las consecuencias que esto conlleva, con el objetivo de interpretar los nuevos métodos empleados.
La transformación de dominio, permite: a) reducir la correlación entre los coeficientes transformados y b) tomar ventaja de la propiedad de compactación de energía para codificar solo una fracción de los coeficientes transformados sin producir demasiada distorsión [28].
Para el presente trabajo de investigación se muestra brevemente el uso de la
transformada wavelet y la transformada contourlet en la siguientes subsecciones, y de manera detallada en los anexos A y B del presente trabajo de investigación. 2.5.1 La Transformada Wavelet Discreta (TWD) La primera señal de lo que ahora se conoce como wavelets surge en 1909 con la tesis de Alfred Haar un matemático húngaro que introdujo las funciones que actualmente se denominan "wavelets de Haar". Dichas funciones consisten simplemente de un breve impulso positivo seguido de un breve impulso negativo. La idea básica de esta transformación es realizar promedios (sumas) y diferencias (restas) de los píxeles vecinos [30].
Durante los últimos años la transformada wavelet ha sido muy utilizada en diferentes áreas de la ciencia y la ingeniería para el procesamiento de imágenes y señales siendo una de las más importantes la compresión de imágenes [31].
La Transformada Wavelet Discreta (TWD) permite descomponer jerárquicamente una señal de entrada en una serie de señales de referencia de menor resolución y sus señales de detalle asociadas [32].
Ofrece una buena representación de los componentes de alta frecuencia en una imagen
y permite representar de una manera más compacta una imagen ya que la mayor parte de la energía se concentra en una cantidad pequeña de coeficientes. La TWD se obtiene convolucionando en los renglones y en las columnas de una imagen un filtro pasa bajos (función de escalamiento Φ o wavelet padre) y un filtro pasa altos (función wavelet Ψ o wavelet madre). La figura 2.4 muestra dicho proceso, y como se define la colocación de las subbandas en la transformación.

Capítulo 2 Compresión de imágenes
17
Figura 2. 4. Descomposición wavelet de una imagen. a) Proceso de filtrado, b) Colocación de las
subbandas.
El proceso de transformación se puede aplicar de manera recurrente sobre la subbanda
marcada como LL la cual representa la imagen de aproximación, dicho concepto esta establecido gracias a la teoría multiresolución [33].
Una wavelet permite construir las bases para la expansión de una señal, una señal x
puede ser representada por la combinación lineal de señales elementales llamadas wavelets { } Nnn ∈ψ por medio de la ecuación 2.3.
∑+∞
=
==0
,:,n
nnnn xCdondeCx ψψ (2.3)
Algunas de las propiedades más importantes de una wavelet son: filtros de
reconstrucción suave, cortos y de fase lineal, soporte compacto, simetría, ortogonalidad, momentos vanishing y suavidad.
Uno de los principales retos en una transformación es seleccionar la base para
aproximar (reproducir) la señal original, para ofrecer una explicación de dicho problema se presenta el siguiente ejemplo [6]:
Asuma que se tiene como fuente, un rayo de luz que puede ser descompuesto en sus
diferentes componentes de color. Con la combinación correcta de dichos colores se puede volver a reproducir la fuente de luz original. Si se tienen los siete colores primarios como base para representar la fuente de luz original, entonces se puede hacer una analogía del uso de una transformación como base para representar una señal.
La descomposición permite tratar cada componente de la señal de forma independiente
teniendo como esencia la estrategia “divide y vencerás”. El modelo del experimento se muestra en la figura 2.5.

Capítulo 2 Compresión de imágenes
18
Figura 2. 5. Fuente de luz representada como la unión de los colores primarios [6].
Lo que se espera es que la señal pueda ser aproximada dando como entrada la
expansión de su base. Una forma de lograrlo es quedándose con los primeros M componentes, por ejemplo, los primeros dos colores obtenidos de la descomposición: rojo y amarillo. Dicha selección se conoce como aproximación lineal (ecuación 2.4) dado que es equivalente a proyectar el objeto de entrada hacia el subespacio que se extiende sobre los primeros M elementos base.
∑−
=
=1
0
)(M
nnn
ALM Cx ψ (2.4)
El problema con este tipo de aproximación es que si se necesita por ejemplo, reconstruir
un rayo de luz con color verde dominante se obtendrá un resultado muy malo. Por lo que se necesita otro esquema de aproximación en el que se puedan seleccionar los mejores M componentes de la expansión de color. A dicha selección se le conoce como aproximación no lineal (ecuación 2.5) dado que es adaptativa y se basa en la señal de entrada.
∑∈
=IMn
nnANL
M Cx ψ)( (2.5)
El esquema de aproximación no lineal obtendrá mejores resultados con el rayo de luz
verde y de hecho podrá comportarse bien con cualquier fuente de luz compuesta de algunos colores. Aquí, es necesario dejar en claro que no siempre la aproximación no lineal produce los mejores resultados, todo depende de la base seleccionada y los componentes obtenidos de la descomposición. En el anexo A se ofrece una explicación de cómo se seleccionó la base wavelet utilizada para el trabajo de investigación.
Los métodos basados en wavelets distorsionan u obscurecen los objetos con bordes
afilados o los caracteres de texto. Por otro lado, para poder representar de manera eficiente la información de textura mediante wavelets es necesario remover los bordes de la imagen original dado que se reduce la energía causada por los bordes en las bandas de alta frecuencia de la transformación [9].
Los detalles contenidos en una imagen aparecen como coeficientes con magnitudes
grandes en el dominio de transformación wavelet.
Capítulo 2 Compresión de imágenes
19
Los coeficientes wavelet representan máximos locales, orillas, contornos y textura. Durante la transformación wavelet el contenido de alta frecuencia en los bordes de dichas características tienden a resultar en energía significativa concentrada en las bandas más altas de la transformación.
Uno de los principales retos en transformación es seleccionar la transformada wavelet
que mejor se adapte para resolver un problema, y se deben tomar en cuenta aspectos como: familia o base que se utilizará, tipo de extensión que se va a utilizar, número de niveles de descomposición, simetría y momentos vanishing.
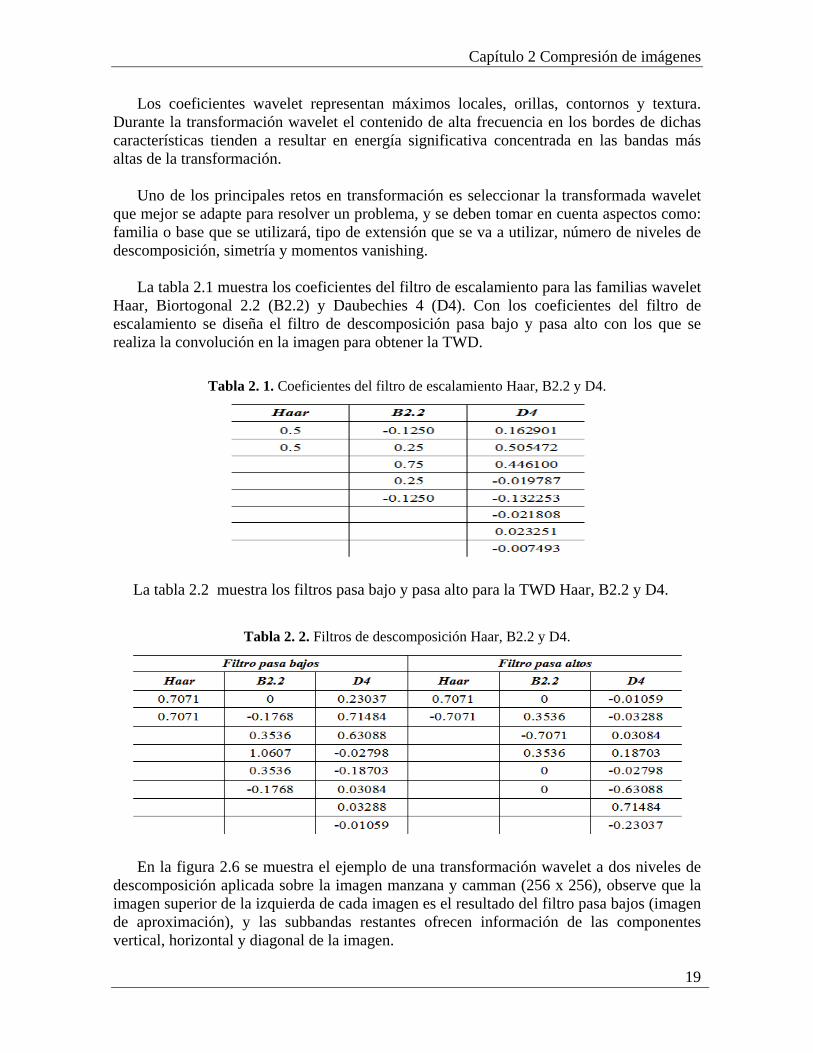
La tabla 2.1 muestra los coeficientes del filtro de escalamiento para las familias wavelet
Haar, Biortogonal 2.2 (B2.2) y Daubechies 4 (D4). Con los coeficientes del filtro de escalamiento se diseña el filtro de descomposición pasa bajo y pasa alto con los que se realiza la convolución en la imagen para obtener la TWD.
Tabla 2. 1. Coeficientes del filtro de escalamiento Haar, B2.2 y D4.
La tabla 2.2 muestra los filtros pasa bajo y pasa alto para la TWD Haar, B2.2 y D4.
Tabla 2. 2. Filtros de descomposición Haar, B2.2 y D4.
En la figura 2.6 se muestra el ejemplo de una transformación wavelet a dos niveles de
descomposición aplicada sobre la imagen manzana y camman (256 x 256), observe que la imagen superior de la izquierda de cada imagen es el resultado del filtro pasa bajos (imagen de aproximación), y las subbandas restantes ofrecen información de las componentes vertical, horizontal y diagonal de la imagen.

Capítulo 2 Compresión de imágenes
20
Figura 2. 6. TWD a dos niveles de descomposición. a) Manzana, b) Camman.
Cada una de las subbandas más altas (imágenes de la parte exterior) tiene un tamaño de
128 x 128, las cuatro subbandas más bajas tienen un tamaño de 64 x 64. La suma de todas las matrices resultantes es: (16384 * 3) + (4096 * 4) = 65536 bytes, que es el tamaño correspondiente a las imágenes originales.
Para regresar los coeficientes transformados del dominio wavelet al dominio espacial se
utiliza la Transformada Wavelet Discreta Inversa (TWDI). El proceso para obtenerla se muestra en la figura 2.7. En caso de no utilizar un proceso de cuantificación los coeficientes obtenidos al aplicar la TWDI son una copia fiel de los originales dado que el proceso de transformación no implica pérdida de información.
Figura 2. 7. Proceso de reconstrucción con la TWDI.
2.5.2 La Transformada Contourlet Discreta (TCD) La TWD es una herramienta muy poderosa en diferentes tareas incluidas el análisis de señales, eliminación de ruido y compresión. Las wavelets son muy buenas para detectar y separar bordes en direcciones horizontales y verticales como se muestra en la figura 2.8. Las wavelets fallan si las direcciones no son horizontales y verticales como se muestra en la figura 2.9, y eso representa un gran problema.

Capítulo 2 Compresión de imágenes
21
Figura 2. 8. Detección de detalles verticales y horizontales en el domino wavelet. a) Imagen
original, b) TWD en la que se detectan las líneas horizontales y verticales.
Figura 2. 9. Detección de detalles diagonales en el dominio wavelet. a) Imagen original, b) TWD
en la que se tienen problemas en la detección cuando las líneas son diagonales.
El principal problema con las wavelets es que se adaptan bien a las singularidades en una dimensión presentes en la imagen como puntos, pero no a las singularidades en dos dimensiones tales como líneas o curvas, dado que no se aprovecha la dependencia a través de las escalas y no se aprovecha la regularidad geométrica. Una posible solución a dicho problema es utilizar una transformación multiescala y direccional (figura 2.10) como por ejemplo la Transformada Contourlet Discreta (TCD) [34].
Figura 2. 10. Transformación multiescala direccional. a) Imagen original, b) Transformada
direccional en la que se localizan exitosamente las líneas que son diagonales.

Capítulo 2 Compresión de imágenes
22
La TCD fue introducida por Do y Vetterli en 2002, permite una descomposición multiescala y direccional de una imagen usando una combinación de una Pirámide Laplaciana (PL) modificada y un Banco de Filtros Direccional (BFD) [35]. La TCD también es conocida como Banco de Filtros Direccional Piramidal (BFDP).
LA TCD permite obtener para diferentes números de direcciones en cada
escala/resolución un muestreo muy cercano al crítico. El BFD es diseñado para capturar los componentes de alta frecuencia los cuales permiten representar direccionalidad. La PL permite la descomposición subbanda para evitar filtrado de las bajas frecuencias en diferentes direcciones de subbanda por lo que la información direccional puede ser capturada de forma eficiente [36]. Contourlets = Segmentos de contornos multiescala, local y direccional. La figura 2.11 muestra el ejemplo de descomposición con la TCD.
Figura 2. 11. Descomposición con la TCD, primero se muestra la descomposición laplaciana y
después la aplicación del banco de filtros en cada canal [6]. En el proceso contourlet multiescala se capturan las discontinuidades de los puntos y en
el proceso direccional se trata de ligar las discontinuidades de los puntos en estructuras lineales, el proceso multiescala y direccional, se muestra en la figura 2.12.
Figura 2. 12. La TCD y su proceso multiescala y direccional [34].
La figura 2.13 muestra un ejemplo de la TCD. Las imágenes inferiores (rectángulos
grandes equivalentes a subbandas más finas) son el resultado de la descomposición

Capítulo 2 Compresión de imágenes
23
piramidal y tres descomposiciones con el filtro direccional, cada subbanda vertical tiene un tamaño de 128 x 64, y cada subbanda horizontal 64 x 128. Las imágenes de la mitad representan una descomposición piramidal y dos descomposiciones direccionales cada una con un tamaño de 128 x 128. Por último las imágenes superiores son el resultado del pasa bajos y tienen un tamaño de 64 x 64.
Figura 2. 13. Resultado de la descomposición con la TCD. a) Imagen Camman con dos
descomposiciones piramidales y tres y dos direcciones respectivamente, b) Imagen manzana con la misma descomposición que a.
La suma de todos los coeficientes obtenidos por la transformada contourlet es: (128 x
64 x 4) + (64 x 128 x 4) + (64 x 64 x 4) + (64 x 64) = 32768 + 32768 + 16384 + 4096 = 86016 coeficientes, que representa una expansión de aproximadamente la tercera parte de la información original (65536), esto es por que la contourlet es una transformación redundante (expansiva). 2.5.3 La Transformada Contourlet Discreta Basada en una Wavelet (TCDBW) Aún con los beneficios adicionales que ofrece la transformada contourlet sobre la transformada wavelet, resulta una desventaja el hecho de que sea una transformación redundante, por lo que se propone una modificación a la transformada contourlet en la que se puedan eliminar las redundancias.

Capítulo 2 Compresión de imágenes
24
La redundancia en la TCD se produce en la etapa donde se obtiene la descomposición piramidal (pirámide laplaciana), dado que como resultado del cálculo se obtienen dos imágenes, una imagen de aproximación resultado del filtro pasa bajos y una imagen de detalle resultado del filtro pasa altos. La imagen de aproximación es de tamaño de la mitad de la resolución de la imagen original, y la imagen de detalles es del mismo tamaño que la imagen original, el proceso se muestra en la figura 2.14.
Figura 2. 14. Pirámide laplaciana de la TCD.
La imagen de detalles obtenida siempre es del mismo tamaño que la inmediata anterior,
es decir no existe una reducción de la resolución. La descomposición direccional se realiza sobre la imagen de detalles, por lo que al realizar más descomposiciones piramidales se va generando al menos la mitad de la información del nivel anterior como redundancias. Por lo que la solución a ese problema es utilizar en la etapa multiescala una transformación no redundante, por ejemplo una wavelet en lugar de la pirámide laplaciana.
Para poder realizar dicha transformación es necesario asegurar que se puede obtener
una reconstrucción perfecta en el mejor de los casos, es decir cuando no existe un proceso de cuantificación. A la nueva transformación se le denominará Transformada Contourlet Discreta Basada en una Wavelet (TCDBW), y esta es una de las principales aportaciones del presente trabajo de investigación.
Al igual que en la transformación wavelet y contourlet en la TCDBW el principal reto es la selección de una base y la familia de filtros para el análisis y síntesis. Después de un arduo estudio se observó que la familia wavelet biortogonal permitía la reconstrucción perfecta desde el punto de vista multiresolución (escala). Y para el caso de la descomposición direccional se seleccionaron los filtros PKVA [37] al igual que en la TCD.
En la figura 2.15 se muestra un ejemplo de la TCDBW con seis escalas de
descomposición wavelet y cinco direcciones en la banda más fina, las cuales se van reduciendo de uno en uno hasta que se alcanza el límite, lo que significa que el último nivel de descomposición es una wavelet pura.

Capítulo 2 Compresión de imágenes
25
Figura 2. 15. Resultado de la descomposición con la TCDBW. a) Imagen Camman con seis
descomposiciones wavelet y cinco direcciones en el nivel más fino, b) Imagen manzana con la misma escala y descomposición que a.
En el capítulo 3 se muestran más detalles acerca de la implementación y éxito en el uso
de la TCDBW. 2.5.4 Wavelets vs. Contourlets A lo largo de las secciones anteriores se hizo hincapié en la aseveración de que la TCD es mejor que la TWD. Resulta de gran importancia el entender por qué la transformada contourlet es mejor que la transformada wavelet al tratar de cubrir las desventajas que la wavelet tiene. Para poder realizar una comparación se utilizará un ejemplo [6]:
Imagine que quiere contratar a una persona para que pinte un paisaje (escenario natural), y usted conoce a dos pintores, uno que pinta con la “técnica wavelet” y otro que pinta con la “técnica contourlet”. Ambos pintores aplican una técnica de refinamiento para incrementar la resolución de lo que van a pintar desde lo más burdo hacia lo más fino.
La eficiencia de los pintores será medida en que tan rápido y exitosamente puede
reproducir el escenario final, teniendo en cuenta cual es el que utiliza el menor número de brochazos para terminar la pintura.
Considere el caso en el que se va a pintar un contorno suave, el pintor que utiliza la
técnica wavelet esta limitado a usar brochas de formas cuadradas a lo largo del contorno y de diferentes tamaños correspondientes a los niveles de resolución wavelet.
Conforme la resolución se vuelva más fina se pone de manifiesto las limitaciones del
esquema wavelet dado que se requieren puntos más finos para capturar el contorno. Por el otro lado, el pintor con la técnica contourlet tiene mayor libertad para realizar los
brochazos dado que lo puede hacer en diferentes direcciones con formas rectangulares para

Capítulo 2 Compresión de imágenes
26
pintar el contorno. Por lo que este pintor será mucho más eficiente que el que pinta con wavelets. El escenario se muestra en la figura 2.16.
Figura 2. 16. Comparación de transformaciones en la pintura de un paisaje. a) Transformada
Wavelet Discreta, b) Transformada Contourlet Discreta [6].
El punto principal es poder observar que la wavelet falla al reconocer contornos suaves,
lo que es resuelto por la contourlet al agregar la componente direccional. Por otro lado, al resolver la desventaja de la contourlet de expansión por medio del uso de la TCDBW se obtiene una herramienta muy poderosa para la aproximación de señales que además resuelve el problema de la transformada contourlet expansiva.
Aunado a la nueva transformación se encuentra el problema de determinar de manera
matemática la relación jerárquica padre – hijo implícita en la transformación. En la figura 2.17 se muestra el ejemplo de reconstrucción de la imagen camman
utilizando wavelets y contourlets, con el objetivo de resaltar las diferencias entre ambas transformaciones.
Como se puede observar las contourlets presentan un conjunto más rico de direcciones
y formas lo que permite capturar las estructuras geométricas de la imagen. Las imágenes de la figura 2.17 son el resultado de la aproximación no lineal tanto con wavelets como con contourlets.
Para un valor dado M se seleccionan los M coeficientes más significativos en cada
transformación de dominio, para después poder comparar las imágenes reconstruidas de ese conjunto obtenido con M coeficientes.
El esquema wavelet captura de forma muy lenta la separación de los puntos, en
contraste con el esquema contourlet que de manera rápida permite hacer refinamientos para lograr una buena adaptación.

Capítulo 2 Compresión de imágenes
27
Figura 2. 17. Secuencias de imágenes resultantes de la aproximación lineal de la imagen Camman,
la selección se realiza con los M coeficientes más significativos en el subespacio de detalle más fino.
2.6 Cuantificación Al calcular la transformación de dominio de una imagen no se obtiene ningún tipo de compresión simplemente se convierten los datos a otro tipo de representación. Para lograr la compresión con pérdidas se realiza un proceso de cuantificación, es decir, se buscan aquellos coeficientes de magnitudes pequeñas para convertirlos en cero y poder codificarlos de manera más sencilla.
La cuantificación es una etapa de pérdida de información y es irreversible, donde el
diseño del cuantificador determina la pérdida obtenida sujeta a ciertas restricciones. Un factor de cuantificación alto da mejores porcentajes de compresión y un factor bajo permite conservar mayor calidad en la imagen reconstruida [38].
Dado que las imágenes a comprimir se encuentran siempre en formato digital es muy
elegante desde el punto de vista matemático tratar a los píxeles de la imagen como si fueran valores continuos. El rol del proceso de cuantificación es representar dichos valores continuos con una cantidad finita y preferiblemente pequeña de información. Obviamente esto no es posible sin que exista al menos una pequeña cantidad de pérdida de datos [27].
Los mejores cuantificadores son aquellos que permiten representar una señal con la
mínima cantidad de distorsión.

Capítulo 2 Compresión de imágenes
28
Algunas de las técnicas de cuantificación más utilizadas son la cuantificación escalar en la que las muestras de la fuente son cuantificadas de manera individual, cuantificación vectorial en la que las muestras son cuantificadas en conjunto [39], cambio a cero de los coeficientes de la diagonal inferior de la imagen (figura 2.18b), y cambio a cero del primer nivel de descomposición o n niveles de descomposición de la imagen (figura 2.18c).
Figura 2. 18. Ejemplo de cuantificación. a) Imagen original en el dominio wavelet,
b) Cuantificación diagonal y c) Cuantificación en el primer nivel de detalle.
Otra forma más efectiva de seleccionar los coeficientes más importantes (cuantificar) es
de acuerdo a su magnitud (significancia), es decir por el valor numérico que tienen en la transformación por lo que valores grandes representan información importante. Uno de los algoritmos más utilizados para realizar este proceso es el codificador progresivo conocido como algoritmo de particionamiento de conjuntos en árboles jerárquicos (Set Partitioning In Hierarchical Trees SPIHT). 2.7 Codificación progresiva Hay dos factores principales que favorecen la compresión de una imagen en el dominio transformado. El primero es la presencia de muchos ceros, por lo que se puede usar un codificador por entropía para eliminar esta redundancia. El segundo tiene que ver con la existencia de cierta dependencia entre los coeficientes de una banda de alta frecuencia de escala gruesa y los coeficientes correspondientes a la misma orientación y posición en una banda de alta frecuencia de escala más fina.
La codificación progresiva surge como un intento de resolver la necesidad de dar prioridad (importancia) a los coeficientes de una transformación que van a ser codificados y producir un flujo de bits progresivo.
Los diseñadores de los codificadores de imágenes enfocan más su atención en el diseño
de algoritmos progresivos que en los no progresivos. Un algoritmo no progresivo se enfoca en obtener la más alta calidad de la imagen a una tasa de compresión dada. Un algoritmo progresivo trata de obtener la más alta calidad de la imagen dentro de un rango completo de tasas de compresión [40].
La figura 2.19 muestra un ejemplo de la imagen Lena reconstruida de forma progresiva
con diferentes tasas de compresión, como se puede observar las imágenes de más a la

Capítulo 2 Compresión de imágenes
29
izquierda tienen una mejor calidad que las imágenes de la parte derecha, aunque las imágenes de la derecha utilizan menos espacio de almacenamiento. En el codificador progresivo el proceso de codificación puede ser terminado en cualquier momento y la calidad de la imagen obtenida es la mejor que se puede lograr en esa tasa de compresión.
Figura 2. 19. Ejemplo de codificación progresiva con la imagen Lena.
En la actualidad el codificador progresivo más utilizado es el algoritmo SPIHT.
2.7.1 El algoritmo Set Partitioning In Hierarchical Trees (SPIHT) En 1996 Said y Pearlman presentaron una versión alternativa de los principios de operación del algoritmo Embedded Zerotree Wavelet (EZW) [12] en la cual proponían una estructura de árbol diferente, a dicho algoritmo le llamaron SPIHT [13]. Los principios explicados en la nueva versión son el ordenamiento parcial por magnitud usando un algoritmo de partición de conjuntos, transmisión por planos de bits ordenados y la explotación de la autosimilitud de las diferentes escalas de una imagen que es transformada por medio de una wavelet.
El principio más importante detrás de SPIHT es definir la significancia de un píxel si su valor es mayor o igual que un umbral dado, si es así, entonces dicho coeficiente puede ser codificado. SPIHT es un algoritmo que utiliza los principios de ordenamiento parcial por magnitud, particionamiento de conjuntos dada la significancia de las magnitudes con respecto a una secuencia de umbrales decrecientes en octavas, transmisión de plano de bits ordenados y autosimilitud entre las escalas en una imagen con transformación wavelet [13].
El funcionamiento de SPIHT se basa en una hipótesis empírica verdadera: “Si un
coeficiente wavelet en una escala de baja resolución no es significativo con respecto a un umbral T entonces todos los coeficientes en la misma orientación y en la misma colocación espacial en escalas más finas seguramente también serán no significativos con respecto a dicho umbral T”. Al igual que el EZW, el SPIHT transforma mediante la TWD la imagen a comprimir, y organiza los coeficientes wavelet resultantes en árboles de orientación espacial. Los coeficientes wavelet obtenidos mediante la transformada wavelet discreta son valores reales, que se convertirán a enteros mediante una cuantificación.

Capítulo 2 Compresión de imágenes
30
Hay que escoger el método más eficaz de cuantificación ya que en este proceso se pierde parte de la información. La figura 2.20 muestra el esquema de compresión SPIHT.
Figura 2. 20. Esquema de compresión SPIHT.
El proceso de codificación es el siguiente:
1) Inicialización: se inicializan tres listas: lista de píxeles no significativos (List of Insignificant Pixels LIP), lista de píxeles significativos (List of Significant Pixels LSP) y lista de conjuntos no significativos (List of Insignificant Sets LIS). LSP esta vacía, LIP toma las coordenadas de los píxeles de nivel más alto y LIS las coordenadas de los píxeles raíz como tipo A. El algoritmo esta dividido en dos etapas: fase de ordenación y fase de refinamiento. Además, el umbral de inicio esta definido por la ecuación 2.6.
{ }( )⎣ ⎦jiCjiT ,2 ),max(log= (2.6)
2) Transmisión de los bits significativos: al final de cada paso de ordenación, LSP
contiene las coordenadas de todos los píxeles significativos para el umbral T correspondiente. También incluye los coeficientes detectados como significativos en pasos anteriores. Las entradas de LIS son coordenadas de píxeles junto con una marca de tipo A o B. La marca es de tipo A cuando representa a todos sus descendientes y de tipo B cuando representa a todos los descendientes a partir de los nietos. En la figura 2.21 se muestra un ejemplo de la transmisión por planos de bits.
Figura 2. 21. Transmisión por planos de bits, la transmisión se realiza de los bits más significativos
(MSB) a los bits menos significativos (LSB).

Capítulo 2 Compresión de imágenes
31
3) Fase de ordenamiento: consiste en verificar si cada entrada de tipo A en LIP es o no significativa para el T actual. Si lo es se trasmite un uno, además del signo del píxel, para luego mover sus coordenadas a LSP. Si no es significativo se trasmite un cero. Se crea un mapa de significancia por cada umbral de estudio. Dicho mapa contendrá información acerca de si un coeficiente está dentro del umbral o no.
4) Mapa de significancia: se obtiene empleando los árboles de orientación espacial
(relación de herencia entre los coeficientes wavelet) y transmitiendo la significancia de hijos a padres. En las etapas sucesivas basta con decrementar el umbral de estudio de la etapa en que se encuentra el algoritmo de uno en uno. La figura 2.22 muestra un ejemplo de la construcción del mapa para SPIHT.
Figura 2. 22. Ejemplo de la construcción (estructura) del árbol SPIHT.
5) Significancia de las entradas en LIS: si no se determina significancia se
transmite un cero, en caso contrario un uno y, de nuevo, se comprueba la significancia de cada miembro de su descendencia. Si lo es se añade a LSP a la vez que se transmite su signo, y si no, se añade a LIP y se transmite un cero. Si ese píxel dispone de más descendientes (nietos en adelante), se colocan sus coordenadas al final de LIS y se marca como tipo B. Por el contrario, si la entrada LIS es de tipo B, se comprueba si tiene descendientes significativos a partir de los nietos (incluidos). Si se confirma se transmite un uno y se añaden sus coordenadas correspondientes al final de LIS marcadas como tipo A. En el caso contrario se transmite un cero y se eliminan sus coordenadas de LIS. Las entradas añadidas a LIS no se tienen en cuenta en la etapa posterior de refinamiento.
6) Refinamiento: se evalúan los componentes de LSP introducidos en las pasadas
anteriores, enviando el enésimo bit más significativo. Por último, se decrementa el umbral en uno y se vuelve al paso de ordenación. El ciclo se repite hasta alcanzar el umbral cero (incluido) si se requiere compresión sin pérdidas o un umbral diferente de cero para compresión con pérdidas.

Capítulo 2 Compresión de imágenes
32
El resultado del algoritmo SPIHT es un vector compuesto por ceros y unos, que serán empaquetados y almacenados. El número de elementos de este vector determina el factor de compresión proporcionado por el algoritmo. En el capítulo 3 se da un ejemplo de codificación con el algoritmo SPIHT y se hace una comparación con la modificación propuesta.
SPIHT representa una gran evolución en el campo de la compresión, dado que rompe con la tendencia compleja de otros métodos. Los métodos tradicionales de compresión se caracterizan por la utilización de métodos sofisticados de cuantificación, mientras que el SPIHT obtiene resultados superiores utilizando métodos sencillos, como es la cuantificación escalar uniforme3.
Una consecuencia de la gran simplicidad de compresión del algoritmo SPIHT es la rapidez del codificador y del decodificador, y la gran simetría existente entre ambos procesos (el tiempo de compresión es muy similar al empleado en la descompresión), lo que es una ventaja sobre los métodos tradicionales de compresión que tienden a emplear más tiempo en comprimir que en descomprimir la imagen. 2.8 Codificación por entropía La codificación por entropía se aplica a los coeficientes obtenidos de una transformación o de la cuantificación, es un proceso sin pérdida de información que remueve la redundancia del flujo de bits a comprimir.
La tarea principal de un codificador por entropía es transformar los coeficientes resultantes de una transformación a su representación con un número menor de bits. Por entropía se entiende la cantidad de información presente en los datos y el conjunto de símbolos que es codificado con el número mínimo de bits requeridos para representarlos.
Uno de los codificadores por entropía más utilizados en la literatura es el compresor
aritmético y a continuación se ofrece una breve descripción de su funcionamiento. 2.8.1 El algoritmo de Codificación Aritmética (CA) La Codificación Aritmética (CA) es una clase especial de la codificación de entropía. A diferencia de la codificación Huffman, no se utiliza un número discreto de bits para cada símbolo a comprimir. Casi alcanza para cada fuente la compresión óptima en el sentido del teorema de Shannon y es conveniente para los modelos adaptativos. Su desventaja más grande es su baja velocidad dado que es necesario realizar varias multiplicaciones y divisiones para cada símbolo [41].
La idea principal detrás de la codificación aritmética es asignar a cada símbolo un intervalo. Comenzando con el intervalo [0..1), cada intervalo es dividido en varios
3 Cuantificación en la que los puntos límite o de decisión están igualmente espaciados.

Capítulo 2 Compresión de imágenes
33
subintervalos, cuyos tamaños son proporcionales a la probabilidad actual de los símbolos correspondientes del alfabeto.
Los códigos más cortos corresponden a subintervalos más grandes y por lo tanto a
conjuntos de datos de entrada más probables. El subintervalo del símbolo codificado se toma como el intervalo para el símbolo siguiente. La salida es el intervalo del último símbolo [42].
El algoritmo para codificar un archivo utilizando codificación aritmética es el siguiente:
1. Se inicializa el “intervalo actual” [L, H) a [0, 1). 2. Para cada símbolo del archivo se realiza lo siguiente:
a) Subdividir el intervalo actual en subintervalos uno para cada símbolo posible del alfabeto. El tamaño del subintervalo de los símbolos es proporcional a la probabilidad estimada de que el símbolo pueda ser el próximo símbolo en el archivo de acuerdo al modelo de entrada.
b) Seleccionar el intervalo correspondiente al símbolo que actualmente ocurre y convertirlo en el intervalo actual.
3. Ofrecer como salida los bits suficientes para distinguir el intervalo actual final de los
otros posibles intervalos finales.
La longitud del subintervalo final es igual al producto de las probabilidades de los símbolos iguales, definida por la probabilidad P de la secuencia particular de símbolos del archivo. Por lo que al final se usan casi de manera exacta –logp bits para distinguir el archivo compreso de otros archivos.
El algoritmo en pseudocódigo para codificar un mensaje de cualquier longitud es [24]:
Inicializa low a 0.0 Inicializa high a 1.0 While existan símbolos en la cadena de entrada do
Tomar un símbolo de entrada Promedio = high - low. high = low + Promedio * Intervalo_mayor (símbolo) low = low + Promedio * Intervalo_menor (símbolo)
End of While Vaciar low
Como ejemplo de codificación suponga que se tiene un alfabeto compuesto por cuatro símbolos a1, a2, a3, y a4 los cuales tienen las probabilidades y los intervalos que se muestran en la tabla 2.3

Capítulo 2 Compresión de imágenes
34
Tabla 2. 3. Alfabeto y probabilidades asociadas para la codificación aritmética.
Suponga además que se quiere codificar la cadena de entrada a1a2a3a3a4, el proceso de codificación se muestra en la figura 2.23.
Figura 2. 23. Procedimiento de codificación aritmética.
El símbolo del mensaje final que debe ser reservado se encuentra en el subintervalo
[0.06752, 0.0688) cualquier número dentro de este intervalo (por ejemplo 0.068) puede ser usado para representar el mensaje.
El algoritmo en pseudocódigo para la decodificación es el siguiente [24]:
Tomar el número codificado Do
Encontrar el símbolo en el rango que se encuentra el número Sacar el símbolo Rango = símbolo high valor – símbolo low valor Substraer símbolo low valor del número codificado Dividir el número codificado por el rango
Until no se encuentren más símbolos
El proceso para decodificar el mensaje se muestra en la tabla 2.4.

Capítulo 2 Compresión de imágenes
35
Tabla 2. 4. Proceso de decodificación aritmética.
En la práctica existen dos factores que causan que el desempeño de este algoritmo no sea bueno: 1) la necesidad de añadir un indicador de fin mensaje para separar un mensaje de otro, y 2) el uso de aritmética de precisión finita. 2.9 Medidas de compresión y de error (distorsión) Los métodos de compresión de imágenes han sido evaluados en base a la minimización de una medida de distorsión objetiva a una cierta tasa de compresión. Sin embargo, una medida menor no siempre significa tener mejor calidad en la imagen reconstruida. Por lo que resulta importante medir la calidad de una imagen tanto de forma objetiva como de forma subjetiva. Una imagen tiene dos implicaciones la fidelidad y la inteligibilidad. La primera describe cómo la imagen reconstruida difiere de la original y la segunda muestra la habilidad que tiene la imagen para poder ofrecer información a sus observadores [43].
Es importante tomar en cuenta que la fidelidad no siempre es objetiva y la inteligibilidad no siempre es subjetiva. Para determinar si una medida objetiva sobre la calidad de una imagen es eficiente o no depende fuertemente de su concordancia con la medida subjetiva. La mayoría de los métodos de compresión de imágenes han sido evaluados en base a minimizar una medida de distorsión objetiva como el MSE a un nivel dado de compresión. También es importante dejar en claro que no siempre una medida baja de MSE significa mejor calidad de la imagen reconstruida.
Generalmente en los esquemas de compresión con pérdidas se presentan artefactos al
codificar a un bit rate (tasa de muestreo) bajo, los principales artefactos son el blurring y el ringing [44].
El blurring (emborronado o desenfoque) resulta de prescindir de la mayoría de los
detalles de alta frecuencia de una imagen que no puede evitarse a tasas de muestreo bajos, y se puede evitar al realizar la colocación de los bits de tal manera que no sea perceptible para los observadores humanos.
El ringing (efecto oscilatorio o anillos falsos) se debe al fenómeno de Gibs4
y ocurre en
los píxeles vecinos de los bordes afilados (sharp), la cantidad de ringing depende de la 4 Comportamiento oscilatorio observado cuando una onda cuadrada es reconstruida con un número finito de armónicos.

Capítulo 2 Compresión de imágenes
36
transformación utilizada y también de la colocación de los bits. A tasas de muestreo bajos los anillos falsos no pueden evitarse.
2.9.1 Medidas objetivas A continuación se muestran algunas medidas de distorsión objetivas numéricas para definir la calidad de una imagen. Todas las medidas son discretas y proporcionan un grado de cercanía entre dos imágenes digitales al explotar las diferencias de las distribuciones estadísticas de los valores de sus píxeles [45].
En las siguientes ecuaciones M y N corresponden al tamaño de la imagen en columnas y renglones, I es la imagen original e I´ es la imagen reconstruida.
Error Cuadrático Medio (Mean Square Error MSE)
[ ]∑∑==
′−=N
y
M
xyxIyxI
MNMSE
1
2
1),(),(1 (2.7)
Relación Señal a Ruido Pico (Peak Signal-to-Noise Ratio PSNR)
⎟⎠
⎞⎜⎝
⎛=MSE
PSNR 255log*10 10 (2.8)
La Norma 2 (N2) que representa el valor singular más grande y la norma de Frobenius
(F) sqrt(sum(diag(A'*A))).
F
F
I
IIFN
,2
,22
´,
−= (2.9)
Escala de Calidad de la Imagen (Picture Quality Scale PQS)
∑=
+=3
10
iii ZbbPQS (2.10)
El PQS es un sistema para calificar la calidad de una imagen basándose en las
características de la imagen que afectan su percepción por el ojo humano, en lugar de las medidas tradicionales que examinan las diferencias para cada píxel. Donde bi son los coeficientes de regresión parcial obtenidos por la regresión lineal múltiple de Zi contra MOS (Mean Opinión Score). En la figura 2.24 se muestran las etapas necesarias para el cálculo del PQS [46].

Capítulo 2 Compresión de imágenes
37
Figura 2. 24. Etapas para la construcción de la medida PQS.
La descripción de los factores uno a cinco es la siguiente: F1 es la relación señal a ruido
normalizada, F2 corrección al modelo de percepción visual, F3 distorsión al final del bloque, F4 correlación de errores y F5 errores en los píxeles vecinos en las transiciones de alto contraste en la imagen.
Por último, se presenta una medida muy importante que ofrece información acerca del
tamaño de compresión obtenido y su diferencia contra la imagen original la cual se conoce como factor de compresión.
Factor de compresión
comprimidaimagenladeTamañooriginalimagenladeTamañoCF =.. (2.11)
2.9.2 Medidas subjetivas La evaluación subjetiva por seres humanos es un método comúnmente usado para medir la calidad de una imagen. Las pruebas subjetivas examinan la fidelidad y al mismo tiempo considera la inteligibilidad de la imagen. Cuando se realizan pruebas subjetivas los visores ponen atención en las diferencias entre la imagen reconstruida y la imagen original, y tratan de encontrar detalles donde la pérdida de información no es aceptable.
El método subjetivo más representativo es el de Calificación Promedio de Opinión
(Mean Opinion Score MOS) [43] el cual tiene dos tipos de calificaciones una absoluta y otra relativa. Se utiliza el método de escala de deterioro de doble estímulo que utiliza referencias y condiciones de prueba ordenadas en pares de tal modo que la primera es la referencia intacta y la segunda es la referencia descomprimida.
Se pide al visor que vote sobre la segunda teniendo en mente la primera. El método usa
cinco grados de escala de deterioro o daño con su propia descripción para cada grado, la tabla 2.5 muestra dichas medidas.

Capítulo 2 Compresión de imágenes
38
Tabla 2. 5. Escala MOS para evaluación subjetiva.
Para calcular el MOS se utiliza la ecuación 2.12.
∑=
•=5
1)(
iipiMOS (2.12)
Donde: i es el grado de escala y p (i) es la probabilidad de selección de un valor en la
escala. 2.10 Comentarios En el capítulo se mostró un panorama de las principales formas de clasificar a los algoritmos de compresión, así como de las principales técnicas para la compresión de imágenes con pérdidas y sin pérdidas.
Resulta importante destacar que las imágenes pueden ser calificadas de manera objetiva
como de manera subjetiva, y que además dichas medidas no pueden dar buena información acerca de las características preservadas por lo que se necesita una etapa de reconocimiento de patrones.
Además, se realizó un estudio y una explicación de las etapas necesarias para construir un compresor de imágenes con pérdidas de información, el cual es la base para la construcción del compresor/descompresor diseñado por medio de la metodología propuesta en el capítulo 3.
Se mostraron ejemplos de cada una de las etapas, incluyendo la propuesta de una nueva
transformación conocida como Transformada Contourlet Discreta Basada en una Wavelet (TCDBW).
La realización de cada una de las etapas del compresor general implica una gran
cantidad de decisiones para el correcto desempeño del mismo, aunado a esto se añade la complejidad de las siguientes etapas propuestas para cumplir el objetivo final.

Capítulo 3 Compresión de imágenes con preservación de características
39
CAPÍTULO 3 Compresión de imágenes con preservación de características La posibilidad de comprimir imágenes con preservación de características toma mucha importancia en áreas donde la conservación en la calidad de ciertas partes de las imágenes se vuelve un proceso crítico, como en el área médica, la textil, el sensado remoto, vigilancia en tiempo real y sistemas de identificación de huellas y rostros por citar algunos ejemplos [47].
Para diseñar un compresor de imágenes con preservación de características es importante identificar las características de la imagen que se quieren preservar, diseñar la tarea de procesamiento digital de imágenes para extraer exitosamente las características de la imagen, y una vez obtenidas, se puede sacrificar fidelidad o calidad en otras regiones de la imagen para gastar una mayor cantidad de bits en las características de interés [8].
Teniendo el conocimiento de las etapas que debe tener un compresor de imágenes con pérdidas de información se realizó un estudio para determinar la factibilidad de poder tener el control del gasto de los bits con el objetivo de asignar una mayor cantidad a las características deseadas. Además, otro de los retos importantes en el diseño de la metodología es la definición de una estrategia con la que se pueda demostrar que la preservación de características se logra de manera exitosa
La metodología esta compuesta por elementos, esquemas y algoritmos. En la figura 3.1
se muestra un esquema que permite observar los diferentes elementos necesarios para resolver el problema de CIPC y como interactúan dichos módulos. La figura es el resultado de un estudio muy laborioso en el que se analizaron los componentes necesarios para la solución del problema.
Los elementos necesarios para la metodología de diseño del compresor/descompresor
de imágenes con preservación de características son: a) Selección de imágenes y definición de características interés, b) Extracción del Mapa de Características de Interés (MCI), c) Transformación de dominio, d) Mapeo de píxeles al dominio transformado, e) Codificación con SPIHT modificado, f) Codificación aritmética, g) Decodificación aritmética, h) Decodificación SPIHT e i) Transformación de dominio inversa.
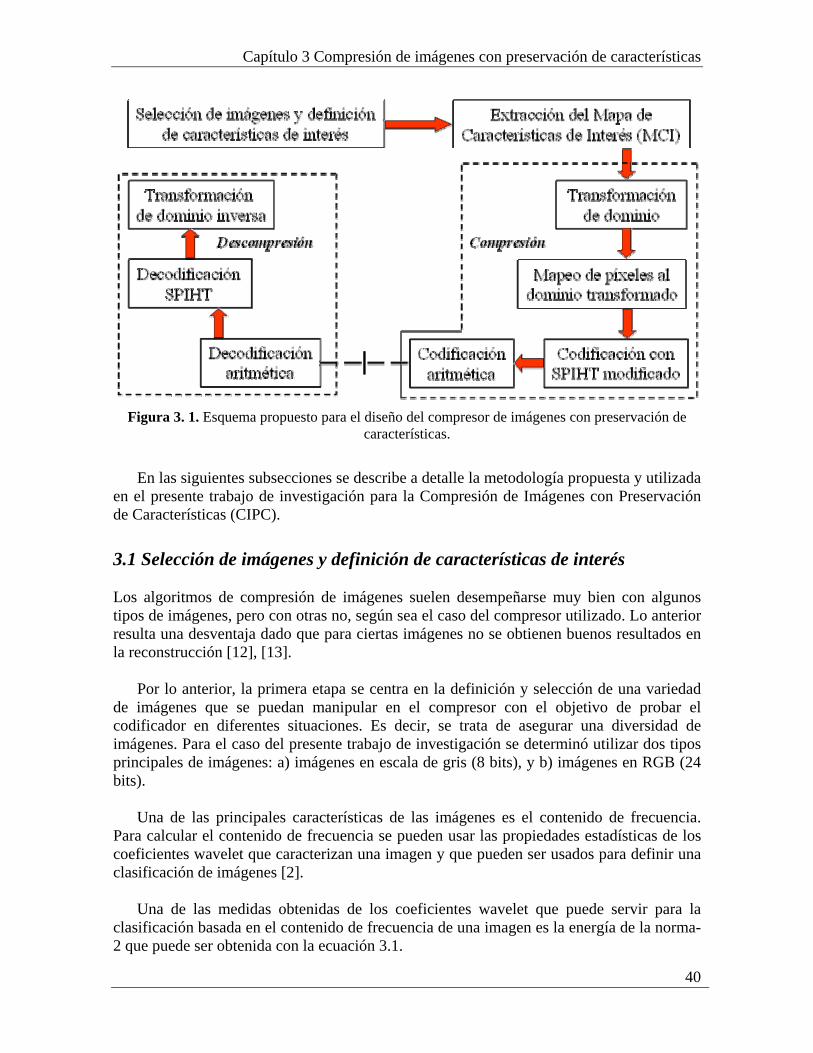
Capítulo 3 Compresión de imágenes con preservación de características
40
Figura 3. 1. Esquema propuesto para el diseño del compresor de imágenes con preservación de
características.
En las siguientes subsecciones se describe a detalle la metodología propuesta y utilizada
en el presente trabajo de investigación para la Compresión de Imágenes con Preservación de Características (CIPC). 3.1 Selección de imágenes y definición de características de interés Los algoritmos de compresión de imágenes suelen desempeñarse muy bien con algunos tipos de imágenes, pero con otras no, según sea el caso del compresor utilizado. Lo anterior resulta una desventaja dado que para ciertas imágenes no se obtienen buenos resultados en la reconstrucción [12], [13].
Por lo anterior, la primera etapa se centra en la definición y selección de una variedad de imágenes que se puedan manipular en el compresor con el objetivo de probar el codificador en diferentes situaciones. Es decir, se trata de asegurar una diversidad de imágenes. Para el caso del presente trabajo de investigación se determinó utilizar dos tipos principales de imágenes: a) imágenes en escala de gris (8 bits), y b) imágenes en RGB (24 bits).
Una de las principales características de las imágenes es el contenido de frecuencia. Para calcular el contenido de frecuencia se pueden usar las propiedades estadísticas de los coeficientes wavelet que caracterizan una imagen y que pueden ser usados para definir una clasificación de imágenes [2].
Una de las medidas obtenidas de los coeficientes wavelet que puede servir para la
clasificación basada en el contenido de frecuencia de una imagen es la energía de la norma-2 que puede ser obtenida con la ecuación 3.1.
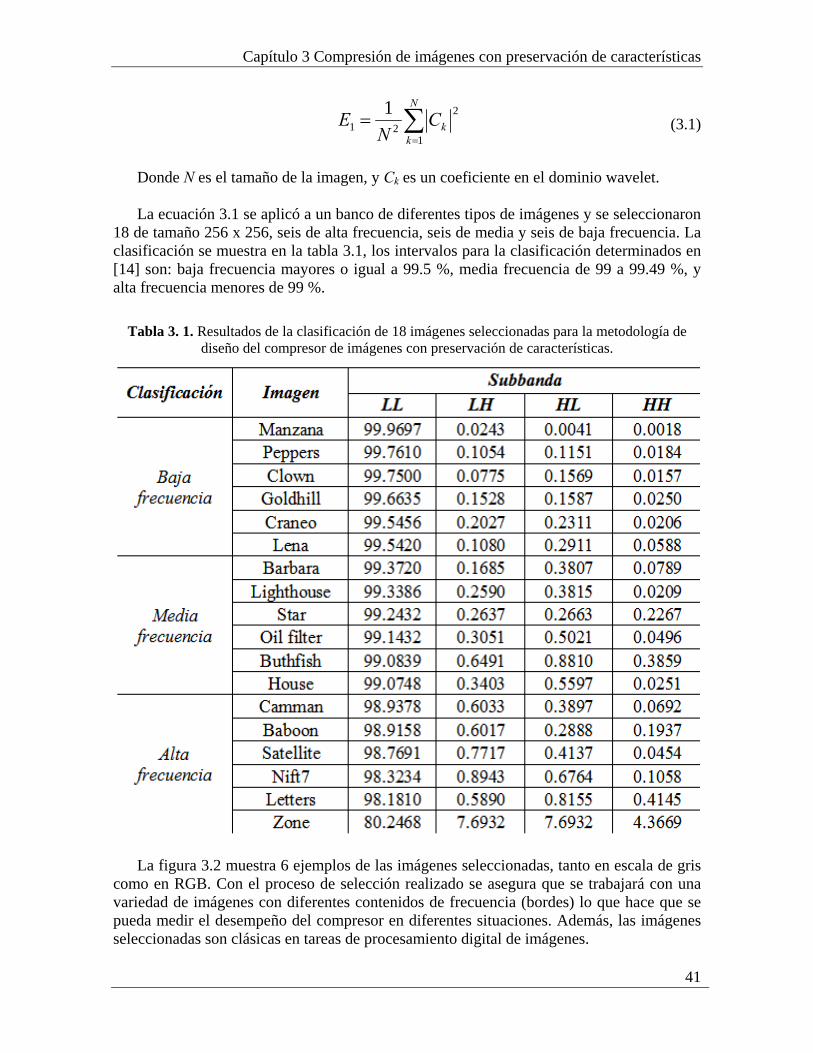
Capítulo 3 Compresión de imágenes con preservación de características
41
∑=
=N
kkC
NE
1
221
1 (3.1)
Donde N es el tamaño de la imagen, y Ck es un coeficiente en el dominio wavelet.
La ecuación 3.1 se aplicó a un banco de diferentes tipos de imágenes y se seleccionaron
18 de tamaño 256 x 256, seis de alta frecuencia, seis de media y seis de baja frecuencia. La clasificación se muestra en la tabla 3.1, los intervalos para la clasificación determinados en [14] son: baja frecuencia mayores o igual a 99.5 %, media frecuencia de 99 a 99.49 %, y alta frecuencia menores de 99 %.
Tabla 3. 1. Resultados de la clasificación de 18 imágenes seleccionadas para la metodología de
diseño del compresor de imágenes con preservación de características.
La figura 3.2 muestra 6 ejemplos de las imágenes seleccionadas, tanto en escala de gris
como en RGB. Con el proceso de selección realizado se asegura que se trabajará con una variedad de imágenes con diferentes contenidos de frecuencia (bordes) lo que hace que se pueda medir el desempeño del compresor en diferentes situaciones. Además, las imágenes seleccionadas son clásicas en tareas de procesamiento digital de imágenes.

Capítulo 3 Compresión de imágenes con preservación de características
42
Figura 3. 2. Ejemplo de imágenes seleccionadas. RGB: a) Lena, b) Barbara, c) Baboon. Imágenes
en escala de gris: d) Clown, e) Buthfish y f) Camman. Las imágenes digitales contienen información importante (características) que son
esenciales para el reconocimiento, las cuales se pueden distorsionar u oscurecer cuando son codificadas a tasas de compresión muy bajas. En un compresor de imágenes con preservación de características el objetivo primordial es detectar las características de la imagen que son importantes para el reconocimiento y entendimiento por seres humanos, y que dichas características preserven su claridad aún a tasas de compresión muy pequeñas a expensas de tener fidelidad reducida en otras zonas de la imagen.
Una imagen puede ser analizada como la composición de tres señales de información
principales: a) bordes, b) texturas y c) detalles asociados a los bordes. Los bordes representan información de gran valor para el entendimiento de una imagen, por ejemplo los caracteres de texto. Las texturas de fondo representan la información restante después de remover los bordes. Por último, los detalles asociados a los bordes representan información de color cercana a los lados de los bordes (partes de la izquierda y derecha de los bordes) [8]. En la figura 3.3 se muestra un ejemplo de cada uno de los componentes.
Figura 3. 3. Información contenida en una imagen: bordes, texturas y detalles asociados a los
bordes.

Capítulo 3 Compresión de imágenes con preservación de características
43
Para el caso del presente trabajo de investigación, después de un estudio arduo se determinó que se pueden seleccionar cuatro combinaciones de características de interés para preservar: a) los bordes, b) las texturas, c) combinación de bordes y texturas y d) combinación de bordes y texturas con los bordes resaltados. 3.2 Extracción del Mapa de Características de Interés (MCI) Una vez que se selecciona una imagen a codificar y se definen las características a preservar se debe realizar la construcción del Mapa de Características de Interés (MCI), el cual esta representado por el mapa de bordes de la imagen que se desea codificar. Dicho mapa contiene las coordenadas (columna, renglón) de la posición donde se encuentran ubicadas cada una de las características de la imagen. Es importante tener en cuenta que en el caso de las imágenes a color (RGB) se debe obtener un mapa para cada una de las subbandas (rojo, verde y azul).
La base para la creación del mapa de características es un proceso de detección de bordes. Los bordes son los puntos de alto contraste en una imagen, es decir donde la intensidad de la imagen aumenta o disminuye bruscamente. Para la selección de un detector de bordes se deben tomar en cuenta los siguientes criterios:
1. Buena detección: minimizar el número de falsos positivos y falsos negativos.
2. Buena localización: los bordes deben marcarse en el lugar real.
3. Respuesta única: como resultado deben generarse bordes de un píxel de anchura.
Uno de los detectores de bordes más utilizados en la literatura es el conocido como Canny [48]. Aún con el gran uso de Canny en tareas de detección de bordes, se observó que presenta algunos problemas tales como que la conectividad en las uniones de los bordes es mala y que las esquinas son redondeadas. Después del estudio de diferentes detectores de bordes como Roberts, Canny, Sobel, Prewitt y SUSAN, se seleccionó este último como el mejor método para la obtención del mapa de bordes.
El método de similitud del núcleo del segmento con valor único más pequeño (SUSAN por las siglas en ingles de Smallest Univalue Segment Assimilating Nucleus) es un método más robusto y efectivo que los otros cuatro detectores en el sentido de que proporciona una mejor conectividad y localización de bordes.
SUSAN utiliza una máscara predeterminada centrada en cada píxel de la imagen, con la
que se aplica un conjunto de reglas locales para proporcionar las respuestas de los bordes. Dicha respuesta es procesada para ofrecer como salida el conjunto de bordes [49].
El concepto de que cada punto de la imagen tiene asociado un área local de similitud de
brillo es la base del principio SUSAN. El área local USAN contiene bastante información sobre la estructura de la imagen. SUSAN no utiliza una derivada ni tampoco una etapa de

Capítulo 3 Compresión de imágenes con preservación de características
44
reducción de ruido a diferencia de otros detectores de bordes. En resumen SUSAN realiza los siguientes tres procedimientos en cada píxel de la imagen:
1. Coloca una máscara circular alrededor del píxel en cuestión (el núcleo: círculo
mostrado en la figura 3.4). El tamaño de la máscara es de 37 píxeles en total y se muestra en la figura 3.4.
Figura 3. 4. Máscara circular SUSAN y su respectivo núcleo.
2. Calcula el número de píxeles dentro de la máscara circular que tienen un valor
similar al brillo del núcleo por medio de la ecuación 3.2.
60 )()(
0 ),(⎟⎠⎞
⎜⎝⎛ −
−= t
rIrI
errcrr
rr (3.2)
Donde 0r
r es la posición del núcleo en la imagen 2D, rr es la posición de cualquier
otro punto dentro de la máscara, )(rI r es el brillo de un píxel, t determina el máximo contraste de las características que serán detectadas y también la mínima cantidad de ruido que será ignorado y c es la salida de la comparación. La comparación se realiza para cada píxel dentro de la máscara y es calculada un número total de n veces de las salidas de (c).
3. Substrae el tamaño de USAN del umbral geométrico para producir una imagen de
bordes, lo cual es realizado con la ecuación 3.3.
( ) ( ) ( )casootro
grnsirngrR
000
0
<−=
rrr (3.3)
Donde g es el umbral geométrico inicializado en 4/3 maxn , donde maxn es el máximo valor que puede tomar n, para este trabajo de investigación es igual a 37 y )( 0rR r es la respuesta inicial del borde.
La figura 3.5 muestra el mapa de características de interés (mapa de bordes) obtenido
para las imágenes de la figura 3.2, todos los píxeles que no son parte del mapa son considerados como texturas. Los detalles del número de puntos pertenecientes a los bordes obtenidos para cada imagen y el valor del umbral usado se muestran en la tabla 3.2.

Capítulo 3 Compresión de imágenes con preservación de características
45
Figura 3. 5. MCI obtenido con SUSAN. a) Lena, b) Barbara, c) Baboon, d) Clown, e) Buthfish y
f) Camman.
Tabla 3. 2. Número de puntos y umbrales calculados para el MCI.
Una de las principales razones para seleccionar SUSAN como el mejor detector de bordes es la conectividad y el grosor de los bordes detectados que permite que en la etapa de mapeo de píxeles no se pierda información.
En el caso de la creación del mapa para texturas los puntos que se toman en cuenta son
los que complementan al mapa de bordes, en el caso de preservación de bordes y texturas se toma el mapa completo, por último, en el caso de los bordes resaltados se realiza una copia del mapa de bordes a la posición correspondiente en la imagen original. 3.3 Transformación de dominio Como se mencionó en el capítulo dos una de las etapas más importantes de la compresión de imágenes con pérdidas es la transformación de dominio. Para la metodología del presente trabajo de investigación las transformaciones utilizadas son: la Transformada Wavelet Discreta (TWD), la Transformada Contourlet Discreta (TCD) y la Transformada Contourlet Discreta Basada en una Wavelet (TCDBW).

Capítulo 3 Compresión de imágenes con preservación de características
46
3.3.1 La Transformada Wavelet Discreta (TWD) La transformada wavelet se aplica de la forma en que se explicó en el capítulo 2, y en el anexo A se da una explicación numérica. Después de un arduo estudio realizado en [50] se seleccionó como base la transformada wavelet biortogonal 2.2 [15] con extensión periódica, dado que es la transformación que permite obtener mejores resultados contra las otras transformadas estudiadas. Otra de las decisiones importantes es el número de niveles en el que se decompone la wavelet y para este trabajo de investigación está definido por log2 (tamaño de la imagen) - 1 como se utilizó en [51].
El proceso para obtener la transformación wavelet de una imagen es: 1. Seleccione y diseñe los filtros de descomposición wavelet (pasa bajos y pasa altos)
correspondientes a la familia wavelet a utilizar (biortogonal 2.2). 2. Seleccione una técnica de extensión de coeficientes de la imagen con el objetivo de
realizar de manera adecuada el proceso de convolución para obtener una imagen extendida (Imext), para motivos del trabajo de investigación se seleccionó la extensión periódica.
3. Convolucione Imext con el filtro pasa bajos en los renglones y en las columnas para
obtener una imagen de aproximación (LL).
4. Convolucione Imext con el filtro pasa bajos en los renglones y con el filtro pasa altos en las columnas para obtener una imagen de coeficientes horizontales (LH).
5. Convolucione Imext con el filtro pasa altos en los renglones y con el filtro pasa
bajos en las columnas para obtener una imagen de coeficientes verticales (HL).
6. Convolucione Imext con el filtro pasa altos en los renglones y con el filtro pasa altos en las columnas para obtener una imagen de coeficientes diagonales (HH).
7. Realice el proceso de submuestreo en renglones y columnas sobre las imágenes
obtenidas en los pasos 3, 4, 5 y 6 para obtener una imagen de la mitad del tamaño de la resolución a la que se está trabajando.
8. Repita los pasos 2 - 7 sobre la imagen LL resultante hasta alcanzar el nivel de
descomposición definido por log2 (tamaño de la imagen) - 1. En el caso de que se haya seleccionado la preservación de características con bordes
resaltados se realiza una tarea adicional a los ocho pasos descritos anteriormente, que consiste en descomponer tanto la imagen original como la del mapa de bordes y después se copia la información de la matriz de coeficientes de aproximación (LL) de la imagen original a su respectiva posición en la imagen del mapa de bordes para obtener el proceso final de resaltado.

Capítulo 3 Compresión de imágenes con preservación de características
47
3.3.2 La Transformada Contourlet Discreta (TCD) Al igual que en la transformada wavelet, los retos más importantes en la transformada contourlet es la selección de la base piramidal y direccional, y el número de niveles y direcciones en que se va a realizar la descomposición.
La selección de la familia de filtros y descomposiciones contourlet implica un estudio como el que se realizó para la transformada wavelet, y en el anexo B se muestra un ejemplo numérico, en resumen el proceso para calcular la TCD es:
1. Seleccione y diseñe los filtros para realizar las descomposiciones piramidales y
direccionales, para este trabajo se seleccionaron los filtros PKVA con 23 y 45 coeficientes para la descomposición direccional y para la descomposición piramidal con el objetivo de lograr una reconstrucción perfecta en el mejor de los casos.
2. Realice un proceso de extensión de la imagen para obtener la descomposición
piramidal, para este trabajo se seleccionó la extensión periódica.
3. Convolucione la imagen con los filtros piramidales, como resultado se obtienen dos imágenes, una resultante del filtrado pasa bajos que representa una imagen de aproximación (mitad de resolución de la imagen original) y una imagen resultante del filtrado pasa altos que representa los detalles de la imagen (del mismo tamaño que la imagen original).
4. Realice la descomposición direccional, para lo que se usa la imagen de detalles
obtenida en el paso 3. El proceso se realiza por medio de un banco de filtros bidimensional que descompone una imagen en n direcciones arbitrarias potencias de dos con un máximo de 5 direcciones (25) o 32 subbandas.
5. Realice una descomposición quincunx multifase [52] (muestreo) para obtener dos
imágenes subbanda las cuales son usadas para la siguiente descomposición direccional, hasta que se alcanza el número máximo definido por la descomposición direccional, para este trabajo de investigación se seleccionaron 5, 4, 3, y 2 direcciones.
6. Repita los pasos 2, 3, 4 y 5 hasta que se alcanza el número máximo definido por la
pirámide (escala) en este trabajo de investigación definida por log2 (tamaño de la imagen) - 2.
En el caso de que se haya seleccionado el realce de bordes se agregan los siguientes
procesos:
1. Se obtienen las descomposiciones piramidales y direccionales de la imagen original y la imagen correspondiente al mapa de bordes.

Capítulo 3 Compresión de imágenes con preservación de características
48
2. La información resultante del pasa bajos en la imagen original se copia a la respectiva posición en la imagen resultante del filtro pasa bajos con la imagen de bordes.
3.3.3 La Transformada Contourlet Discreta Basada en una Wavelet (TCDBW) La TCD presenta la desventaja de ser una transformación expansiva, la expansión sucede en la etapa de descomposición piramidal así que la solución es utilizar otro tipo de transformación, en este caso una wavelet como se explicó en el capítulo 2. A la modificación propuesta se le conoce como Transformada Contourlet Discreta Basada en una Wavelet (TCDBW) y para obtenerla es necesario realizar los siguientes pasos:
1. Diseñe los filtros wavelet y direccional, para el caso de los filtros wavelet se
seleccionó el biortogonal 2.2 y para el caso direccional los filtros PKVA.
2. Seleccione un proceso de extensión de coeficientes de la imagen con el objetivo de realizar de manera adecuada el proceso de convolución para obtener una imagen extendida (Imext), para el caso del presente trabajo de investigación se seleccionó una extensión periódica.
3. Convolucione Imext con el filtro pasa bajos wavelet en los renglones y en las
columnas para obtener una imagen de aproximación (LL).
4. Convolucione Imext con el filtro wavelet pasa bajos en los renglones y con el filtro pasa altos en las columnas para obtener una imagen de coeficientes horizontales (LH).
5. Convolucione Imext con el filtro wavelet pasa altos en los renglones y con el filtro
pasa bajos en las columnas para obtener una imagen de coeficientes verticales (HL).
6. Convolucione Imext con el filtro wavelet pasa altos en los renglones y con el filtro pasa altos en las columnas para obtener una imagen de coeficientes diagonales (HH).
7. Realice el proceso de submuestreo en renglones y columnas sobre las imágenes
obtenidas en los pasos 3, 4, 5 y 6 para obtener una imagen de la mitad del tamaño de la resolución a la que se está trabajando.
8. Obtenga la descomposición direccional (como se explicó en el proceso contourlet)
sobre las imágenes LH, HL y HH con el número de dirección correspondiente a la escala en cuestión, comenzando con el valor máximo (5).
9. Repita los pasos hasta alcanzar la escala máxima definida por log2 (tamaño de la
imagen) - 2.

Capítulo 3 Compresión de imágenes con preservación de características
49
3.4 Mapeo de píxeles al dominio transformado Es esta etapa se realiza un proceso de mapeo (correspondencia) de las posiciones de los píxeles del MCI en el dominio original (espacial) a las posiciones de los píxeles en el dominio transformado. A continuación se da una explicación del proceso de mapeo.
En una descomposición wavelet un coeficiente de escala i afecta un área de 2i x 2i posiciones de la imagen original, por lo que existe una relación jerárquica entre los coeficientes que permite definir una estructura conocida como árbol de orientación espacial (spatial orientation tree).
Un quadtree en la coordenada (i, j) es un árbol formado por la coordenada (i, j) como su
raíz y {(2i, 2j), (2i, 2j + 1), (2i + 1, 2j), (2i + 1, 2j + 1)} representando sus cuatro hijos. Un coeficiente en LL es padre de los tres coeficientes que se encuentran en la misma posición en las bandas de alta frecuencia de la misma escala, lo que se puede observar en la figura 3.6a. Cualquier otro coeficiente que no pertenezca a LL tiene cuatro hijos (salvo los coeficientes de HL1, LH1, HH1 que no tienen descendencia), lo que se puede observar en la figura 3.6b.
Figura 3. 6. Mapeo de píxeles. a) Correspondencia de píxeles para LL, b) Correspondencia de
píxeles para HL, LH y HH.
Los hijos en una subbanda ocupan la misma posición que el padre ocuparía si la
posición en que se encuentra fuera ampliada al doble de su tamaño. Para calcular de forma automática los descendientes de una subbanda considere una estructura como la que se muestra en la figura 3.7.
Las subbandas son enumeradas, y a cada una le corresponden coordenadas x e y lo que
implica una representación con tres variables (x, y, s) en la que la correspondencia es la posición de un píxel en las coordenadas (x, y) correspondiente a una subbanda s.

Capítulo 3 Compresión de imágenes con preservación de características
50
Figura 3. 7. Enumeración de las subbandas wavelet.
Un píxel en la subbanda wavelet más burda es padre de tres coeficientes en la misma
posición en las subbandas de alta frecuencia en la misma escala. Cualquier otro coeficiente que no pertenece a la banda más baja tiene cuatro hijos, obtenidos con la ecuación 3.4.
)2,2()12,2()2,12(
)12,12(
1),,(
yxyx
yxyx
syxhijos−
−−−
=≠ (3. 4)
Los descendientes de un coeficiente se calculan recursivamente aplicando la función
hijos a los coeficientes ya calculados, la figura 3.8 muestra un ejemplo de dicha relación.
Figura 3. 8. Relación padre - hijo de la Transformada Wavelet Discreta.
El proceso de mapeo es realizado de igual forma tanto para la TWD como para la
TWDBC. Aún cuando la relación jerárquica padre - hijo de la contourlet es diferente dado

Capítulo 3 Compresión de imágenes con preservación de características
51
que los hijos pueden estar divididos en diferentes subbandas, aunque esto implica una ligera desventaja en el proceso de reconstrucción [53].
El proceso para mapear los coeficientes del dominio espacial al dominio transformado
es el siguiente:
1. Tome el mapa de bordes extraído con SUSAN. 2. Duplique la posición de cada píxel perteneciente al mapa (tamaño 2 x 2).
3. Realice un proceso de submuestreo en las columnas y renglones de la imagen para
obtener una imagen a la mitad de la resolución.
4. Repita los pasos dos y tres hasta llegar al máximo valor permitido, para este trabajo se seleccionó log2 (tamaño de la imagen) - 2.
5. Sin importar si las características a preservar son bordes o texturas, cambie el valor
de los cuatro coeficientes más significativos del mapa, es decir las coordenadas {(0, 0), (0, 1), (1, 0), (1,1)} a uno con el objetivo de tomar ventaja de la compactación de energía de la wavelet y que el proceso de codificación SPIHT resulte exitoso.
Como ejemplo para la creación del mapa con preservación de bordes suponga que se
tiene como entrada la imagen que se muestra en la figura 3.9a (carita feliz) y su respectivo mapa en el dominio espacial en la figura 3.9b.
Figura 3. 9. Imágenes para mapeo de píxeles. a) Carita feliz, b) Mapa de bordes.
El primer paso es realizar un proceso de definición de la resolución del espacio que
ocupará cada uno de los coeficientes pertenecientes al MCI en el siguiente nivel subbanda de la wavelet (recuerde que es de 2i x 2i), el resultado de este proceso se muestra en la figura 3.10a. Después de realizar el proceso de submuestreo en las columnas se obtiene la imagen que se muestra en la figura 3.10b. Por último, se realiza el submuestreo en los renglones y se obtiene una imagen como la que se muestra en la figura 3.10c.

Capítulo 3 Compresión de imágenes con preservación de características
52
Figura 3. 10. Proceso de mapeo de píxeles. a) Imagen con coeficientes duplicados, b) Submuestreo
en las columnas y c) submuestreo en los renglones.
El proceso se repite sobre la imagen obtenida en la figura 3.10c hasta alcanzar la escala
determinada. La figura 3.11a muestra el resultado del proceso de duplicar coeficientes, la figura 3.11b muestra el resultado del submuestreo en columnas, y la figura 3.11c el resultado del submuestreo en los renglones.
Figura 3. 11. Mapeo de píxeles sobre la imagen 3.10c. a) Imagen con coeficientes duplicados,
b) Submuestreo en las columnas y c) Submuestreo en los renglones.
Después de encontrar la imagen en el último nivel de resolución se comienza con la
construcción del mapa wavelet, el primer nivel de descomposición tiene una relación de un píxel a tres, por lo que el primer nivel completo del mapa se muestra en la figura 3.12.
Figura 3. 12. Primer nivel del mapa transformado construido con la figura 3.11c.
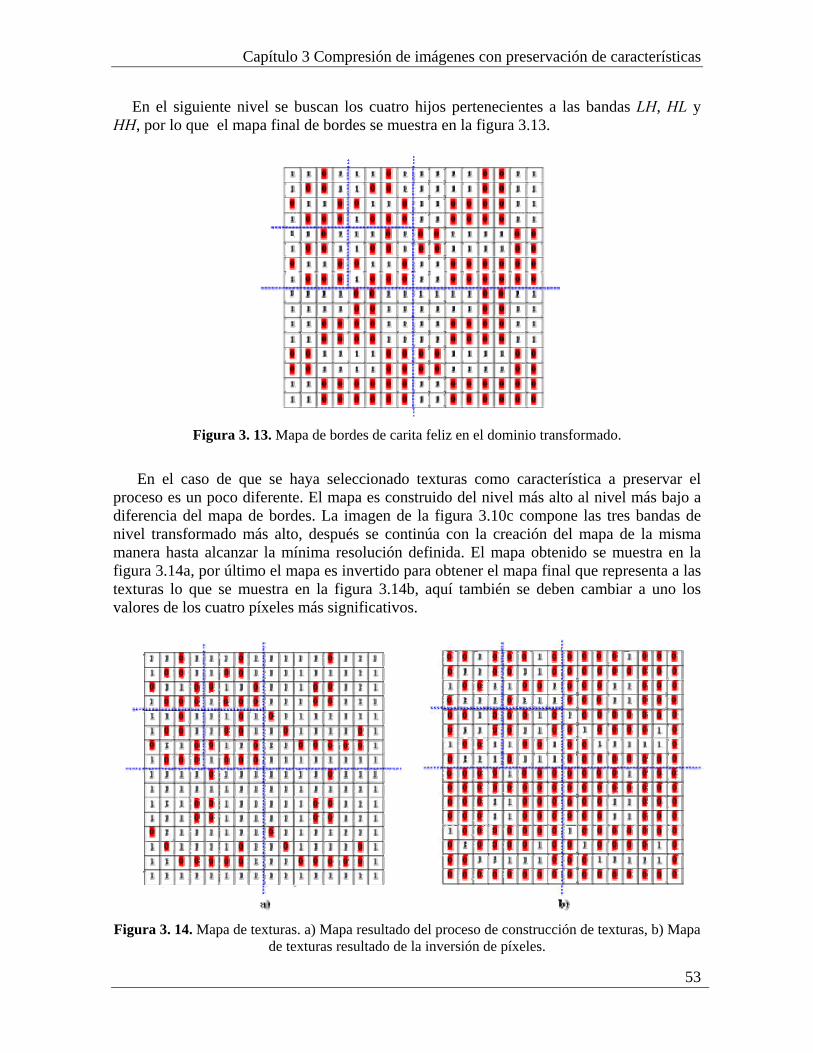
Capítulo 3 Compresión de imágenes con preservación de características
53
En el siguiente nivel se buscan los cuatro hijos pertenecientes a las bandas LH, HL y HH, por lo que el mapa final de bordes se muestra en la figura 3.13.
Figura 3. 13. Mapa de bordes de carita feliz en el dominio transformado.
En el caso de que se haya seleccionado texturas como característica a preservar el
proceso es un poco diferente. El mapa es construido del nivel más alto al nivel más bajo a diferencia del mapa de bordes. La imagen de la figura 3.10c compone las tres bandas de nivel transformado más alto, después se continúa con la creación del mapa de la misma manera hasta alcanzar la mínima resolución definida. El mapa obtenido se muestra en la figura 3.14a, por último el mapa es invertido para obtener el mapa final que representa a las texturas lo que se muestra en la figura 3.14b, aquí también se deben cambiar a uno los valores de los cuatro píxeles más significativos.
Figura 3. 14. Mapa de texturas. a) Mapa resultado del proceso de construcción de texturas, b) Mapa
de texturas resultado de la inversión de píxeles.

Capítulo 3 Compresión de imágenes con preservación de características
54
En el caso de la selección de bordes y texturas se utiliza un mapa construido con unos en todas las posiciones de los píxeles, en el caso del resaltado el proceso es el mismo que en el caso anterior con la respectiva copia de coeficientes explicada anteriormente.
El éxito en la obtención del mapa se debe en gran parte por la ventaja de compactación
de energía ofrecida en el dominio transformado, es importante resaltar que la última verificación que se realiza al obtener los mapas es el cambio de valor a uno (prendido) de los cuatro coeficientes de la posición superior izquierda de la transformación obtenida. 3.5 Codificación con SPIHT modificado Después del proceso de mapeo de píxeles, comienza el proceso de codificación de la imagen. La etapa principal es la de cuantificación en donde se seleccionan los coeficientes más importantes para resolver una tarea determinada y otros coeficientes son descartados.
Para poder comprimir una imagen preservando características se realizó una modificación al algoritmo SPIHT en su versión original. Es decir, la significancia de un píxel no será solamente definida por su magnitud sino también por la posición del píxel con respecto al mapa obtenido en el dominio transformado.
Una idea similar fue presentada en [9] y las principales diferencias con respecto a dicho
trabajo son: la utilización del algoritmo SPIHT en lugar de EZW, en la modificación propuesta se pueden preservar hasta dos características al mismo tiempo, la última gran diferencia es el uso de una familia wavelet biortogonal.
Con el objetivo de mostrar como funciona la modificación propuesta se utilizará una
estructura similar a la que se presenta en [13]. Se utilizan tablas para mostrar las diferencias entre los codificadores, como entrada se utilizan las imágenes de la figura 3.15 que representan una imagen de 4 x 4 en el dominio wavelet y su respectivo MCI.
Figura 3. 15. Imágenes ejemplo para codificación. a) Porción de una imagen en el dominio wavelet,
b) MCI correspondiente a la figura 3.15a.
De la figura 3.15a suponga que se quiere conservar la característica definida por la
posición (0, 1) es decir el coeficiente -34, por lo que en la figura 3.15b se muestra el mapa en el dominio transformado necesario para lograr dicho fin. En la figura 3.15b se marca el coeficiente que se quiere preservar junto con sus hijos correspondientes, que análogamente sería el mapa obtenido en la extracción de características usando SUSAN y mapeado al dominio transformado.

Capítulo 3 Compresión de imágenes con preservación de características
55
Para la modificación de SPIHT, primero, se deben inicializar los conjuntos básicos definidos por:
O (i, j) es el conjunto de descendientes directos de un nodo del árbol definido por la
colocación de un píxel (i, j). D (i, j) es el conjunto de descendientes de un nodo definido por la colocación de un
píxel. L (i, j) es el conjunto definido por L (i, j) = D (i, j) − O (i, j). La siguiente explicación corresponde a los números en las entradas de la tabla 3.3 para
el SPIHT modificado y para la tabla 3.4 con el SPIHT original.
1. Sintonización inicial SPIHT. El umbral inicial toma el valor de 32 obtenido del logaritmo base dos de 64, utilizando la ecuación 2.6. Las listas LIS (List of Insignificant Sets), LIP (List of Insignificant Pixels) y LSP (List of Significant Pixels) son inicializadas.
2. SPIHT comienza codificando la significancia de los píxeles en LIP. La posición (0, 1)
es significativa por que es mayor que el umbral y pertenece a una coordenada del mapa de referencia (marcada con un uno). A diferencia del SPIHT original en el que los coeficientes significativos son (0, 0) y (0, 1).
3. Después de realizar la verificación a nivel de píxel con la lista LIP, SPIHT comienza
a buscar en los diferentes conjuntos de píxeles siguiendo las entradas de LIS. La primera búsqueda la define D (0, 1) que representa un conjunto de cuatro coeficientes {(0, 2), (0, 3), (1, 2), (1, 3)}. Dado que D (0, 1) es significativo, entonces se debe verificar la significancia de los cuatro hijos y se encuentra que en su conjunto existen píxeles significativos y además pertenecientes al mapa. Finalmente (0, 1) es removido de la lista.
4. El mismo procedimiento descrito en el punto tres se realiza sobre D (1, 0), y dado que
no es significativo no se realiza ninguna acción y se verifica el siguiente elemento de LIS.
5. D (1,1) es también no significativo, tampoco se realiza ninguna acción, por lo que la
primera pasada para la etapa de ordenamiento termina. La etapa de refinamiento continúa de la misma manera que lo hace SPIHT en su versión original. El proceso continúa hasta que se alcanza la tasa de compresión deseada.

Capítulo 3 Compresión de imágenes con preservación de características
56
Tabla 3. 3. Proceso de codificación con SPIHT modificado.
Tabla 3. 4. Proceso de codificación con SPIHT original.
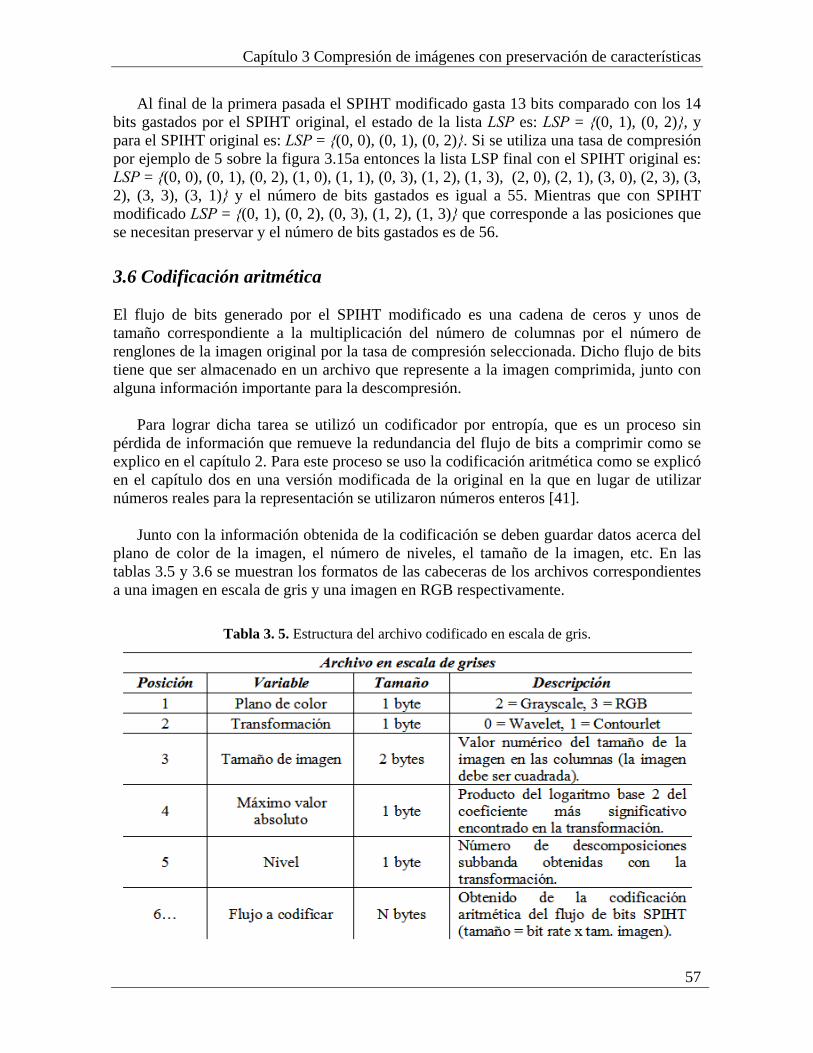
Capítulo 3 Compresión de imágenes con preservación de características
57
Al final de la primera pasada el SPIHT modificado gasta 13 bits comparado con los 14 bits gastados por el SPIHT original, el estado de la lista LSP es: LSP = {(0, 1), (0, 2)}, y para el SPIHT original es: LSP = {(0, 0), (0, 1), (0, 2)}. Si se utiliza una tasa de compresión por ejemplo de 5 sobre la figura 3.15a entonces la lista LSP final con el SPIHT original es: LSP = {(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (0, 3), (1, 2), (1, 3), (2, 0), (2, 1), (3, 0), (2, 3), (3, 2), (3, 3), (3, 1)} y el número de bits gastados es igual a 55. Mientras que con SPIHT modificado LSP = {(0, 1), (0, 2), (0, 3), (1, 2), (1, 3)} que corresponde a las posiciones que se necesitan preservar y el número de bits gastados es de 56. 3.6 Codificación aritmética El flujo de bits generado por el SPIHT modificado es una cadena de ceros y unos de tamaño correspondiente a la multiplicación del número de columnas por el número de renglones de la imagen original por la tasa de compresión seleccionada. Dicho flujo de bits tiene que ser almacenado en un archivo que represente a la imagen comprimida, junto con alguna información importante para la descompresión.
Para lograr dicha tarea se utilizó un codificador por entropía, que es un proceso sin pérdida de información que remueve la redundancia del flujo de bits a comprimir como se explico en el capítulo 2. Para este proceso se uso la codificación aritmética como se explicó en el capítulo dos en una versión modificada de la original en la que en lugar de utilizar números reales para la representación se utilizaron números enteros [41].
Junto con la información obtenida de la codificación se deben guardar datos acerca del
plano de color de la imagen, el número de niveles, el tamaño de la imagen, etc. En las tablas 3.5 y 3.6 se muestran los formatos de las cabeceras de los archivos correspondientes a una imagen en escala de gris y una imagen en RGB respectivamente.
Tabla 3. 5. Estructura del archivo codificado en escala de gris.
Capítulo 3 Compresión de imágenes con preservación de características
58
Tabla 3. 6. Estructura del archivo codificado en RGB.
Después del proceso de codificación aritmética la imagen se encuentra comprimida en
un archivo guardado en algún medio como puede ser un disco duro y lista para el proceso posterior de decodificación, es aquí donde se puede comprobar el tamaño real del archivo codificado. 3.7 Decodificación aritmética Para realizar el proceso de descompresión de imágenes se debe obtener la información resultante del proceso de compresión como por ejemplo el plano de color, el nivel que se utilizó para la transformación, etc., para después aplicar el proceso inverso para reconstruir la imagen.
En esta etapa se debe aplicar el algoritmo de decodificación inverso que se seleccionó en la codificación es decir el decodificador aritmético. Como resultado, se obtiene el flujo de bits (unos y ceros) listo para ser usado como entrada en la decodificación con el algoritmo SPIHT. 3.8 Decodificación SPIHT El proceso de decodificación SPIHT se realiza siguiendo el algoritmo original [13], es decir, existe una pasada de ordenamiento y una pasada de refinamiento comenzando por el umbral mínimo hasta llegar al umbral máximo (número de nivel) leído en el archivo comprimido.

Capítulo 3 Compresión de imágenes con preservación de características
59
El resultado obtenido de la decodificación con SPIHT sobre la imagen 3.15a se muestra en la figura 3.16a para el SPIHT original y en 3.16b para el SPIHT modificado.
El error cuadrático medio (MSE) obtenido en la imagen con SPIHT original es de
8.3125 y la relación señal a ruido pico (PSNR) 38.9335. Para el caso del SPIHT modificado el MSE es de 403.0625 y el PSNR de 22.0771, lo que no da ninguna información acerca de las características preservadas. En la imagen 3.16b se puede observar que a diferencia de la imagen 3.16a la cantidad de bits solamente fue gastada en las partes definidas por el MCI de la figura 3.15b, lo que demuestra que la modificación propuesta funciona de manera exitosa.
Figura 3. 16. Imágenes decodificadas. a) SPIHT Original, b) SPIHT modificado.
3.9 Transformación de dominio inversa Después de la decodificación SPIHT se obtiene como resultado una imagen en el dominio transformado (wavelet o contourlet), para obtener la imagen reconstruida en el dominio espacial se debe realizar el proceso de transformación inverso. Como resultado se obtienen los coeficientes obtenidos en el proceso de transformación. 3.9.1 La Transformada Wavelet Discreta Inversa (TWDI) Para el proceso de descompresión wavelet se utiliza la Transformada Wavelet Discreta Inversa (TWDI) que permite transformar los coeficientes obtenidos en el dominio wavelet al dominio espacial con el fin de obtener la imagen reconstruida. En el anexo A se muestra un ejemplo de este tipo de transformación. 3.9.2 La Transformada Contourlet Discreta Inversa (TCDI) Para descomprimir las imágenes en el dominio contourlet se utiliza la Transformada Contourlet Discreta Inversa (TCDI) que permite transformar los coeficientes del dominio contourlet al dominio espacial para poder observar la calidad de la imagen reconstruida.
En el caso de la transformación wavelet basada en contourlet se debe primero transformar la correspondiente subbanda en el dominio contourlet (para regresar al dominio wavelet) para posteriormente aplicar la transformada wavelet con el objetivo de regresar al dominio original. En el anexo B se muestra un ejemplo de este tipo de transformación.

Capítulo 3 Compresión de imágenes con preservación de características
60
Después de la aplicación de la metodología para diseñar el compresor/descompresor, se obtiene como resultado una imagen descomprimida en donde las características de interés definidas son preservadas. Dicha imagen está lista para utilizarse en un proceso de visión artificial. Para demostrar dicha aseveración en el capítulo 4 se muestran las pruebas y los resultados obtenidos para el CIPC en diferentes situaciones.
3.10 Comentarios En el presente capítulo se mostró la metodología para diseñar un compresor /descompresor que permite resolver el problema de compresión de imágenes con preservación de características. Cada una de las etapas planteadas juega un papel importante y esencial en el éxito completo del codificador.
El resultado de la metodología propuesta se obtuvo gracias a tres años de investigación exhaustiva en el área de compresión de imágenes. El reto siguiente es el de poder demostrar que efectivamente la metodología para diseñar un compresor/descompresor funciona y que las imágenes provenientes del proceso de compresión/descompresión pueden ser utilizadas en una tarea o en un proceso de visión artificial o reconocimiento de patrones.
Las medidas objetivas no dan información acerca de las características preservadas por
lo que la verificación se debe hacer con una combinación de medidas objetivas, subjetivas y una tarea de visión artificial como se muestra en el siguiente capítulo.

Capítulo 4 Experimentación y resultados
61
CAPÍTULO 4 Experimentación y resultados En las siguientes secciones se muestran las diferentes pruebas realizadas para medir el desempeño del compresor/descompresor construido con la metodología para compresión de imágenes con preservación de características. Las pruebas tienen el objetivo de observar como se comporta el compresor en diferentes situaciones, como es la preservación de bordes, la preservación de texturas, la preservación de bordes y texturas y el realzado de bordes. Se presenta una descripción de cada una de las pruebas, las cuales se realizaron con wavelets como con contourlets y se ofrece un análisis de los resultados obtenidos.
Para la realización de las pruebas se seleccionaron las seis imágenes de la figura 3.2 por lo que se tienen imágenes tanto en RGB como en escala de gris y para cada categoría se seleccionó una representante de alta, baja, y media frecuencia. Los umbrales y los puntos obtenidos en los respectivos mapas de bordes para cada imagen de prueba son los que se mostraron en la tabla 3.2 y serán utilizados durante todas las pruebas.
Para medir el desempeño de manera objetiva se calcula el factor de compresión, el MSE, el PSNR, la norma de Frobenius, la norma 2, y el PQS y para el caso de preservación de bordes y texturas se añade la medida objetiva MOS. 4.1 Prueba 1: Compresión/descompresión de imágenes con preservación de bordes con wavelets y contourlets El objetivo de esta prueba es medir el desempeño del compresor diseñado con la metodología en su forma más pura, es decir, el factor de compresión obtenido esta determinado solamente por el número de puntos encontrados en el mapa de bordes.
Aquí, se utiliza el esquema explicado en el capítulo dos, donde para la preservación se realiza una copia de los coeficientes de aproximación de la imagen original a su correspondiente transformación obtenida con el mapa de bordes.
En este tipo de compresión no se utiliza ningún tipo de codificación por entropía y la
cuantificación es realizada por la misma creación del mapa de bordes. Las figuras 4.1 y 4.2 muestran las imágenes reconstruidas para la prueba 1 con wavelets y con tres niveles de descomposición y contourlets con dos niveles de descomposición y 2 y 3 direcciones respectivamente.

Capítulo 4 Experimentación y resultados
62
Figura 4. 1. Imágenes reconstruidas con la TWD para la prueba 1.
Figura 4. 2. Imágenes reconstruidas con la TCD para la prueba 1.
El factor de compresión se obtiene con la suma de los puntos correspondientes a los
bordes en cada una de la subbandas de la transformación correspondiente. La tabla 4.1 muestra los puntos seleccionados para las imágenes con wavelets y la tabla 4.2 para las imágenes con contourlets.
La tabla 4.3 muestra los resultados de las medidas de error obtenidas con wavelets y la
tabla 4.4 los resultados obtenidos con contourlets.

Capítulo 4 Experimentación y resultados
63
Tabla 4. 1. Puntos seleccionados en cada subbanda wavelet para la prueba 1.
Tabla 4. 2. Puntos seleccionados en cada subbanda contourlet para la prueba 1.
Tabla 4. 3. Medidas de error obtenidas para la prueba 1 con la TWD.
Tabla 4. 4. Medidas de error obtenidas para la prueba 1 con la TCD.

Capítulo 4 Experimentación y resultados
64
4.1.1 Análisis de los resultados de la prueba 1 De los resultados mostrados en las tablas 4.3 y 4.4 se pueden ofrecer los siguientes comentarios: primero, tomando en cuenta cualquier medida, es notable el desempeño superior que tiene la TCD sobre la TWD tanto en calidad como en el factor de compresión. Segundo, las imágenes de media frecuencia son las que presentan más errores en la reconstrucción y las mejor reconstruidas son las de baja frecuencia. Por último, los factores de compresión y errores pueden ser mejorados obteniendo mapas con una menor cantidad de puntos pero obviamente con una calidad menor en lo que a preservación de bordes se refiere.
Con los resultados obtenidos en esta prueba se demuestra que la CIPC es posible con un
esquema sencillo, pero queda de manifiesto la necesidad de construir un compresor de imágenes que utilice otros esquemas de cuantificación, así como, la necesidad de la etapa de codificación por entropía. Un esquema completo del compresor se presenta en las pruebas de las siguientes subsecciones. 4.2 Prueba 2: Preservación de los momentos de inercia con wavelets y contourlets La aplicación de un proceso de compresión/descompresión sobre una imagen puede verse de manera muy general como un proceso en el cual una función f(x) es aplicada sobre la imagen original para modificarla, es decir, se puede ver como si fuese una operación de filtrado, de adición de ruido, como una función de cambio de contraste, etc.
En la prueba 2 se presentan ejemplos con el objetivo de demostrar que por la naturaleza del proceso de compresión se puede lograr la preservación de los momentos estadísticos [54] presentes en cada imagen. La tabla 4.5 muestra los resultados obtenidos al calcular los momentos sobre la imagen original “Clown” (figura 3.2d), la tabla 4.6 los momentos obtenidos con la misma imagen comprimida con wavelets (figura 4.1d) y la tabla 4.7 de la imagen comprimida con contourlets (figura 4.2d) de la prueba 1.
Tabla 4. 5. Momentos para la imagen original “Clown”.

Capítulo 4 Experimentación y resultados
65
Tabla 4. 6. Momentos para la imagen “Clown” comprimida con wavelets.
Tabla 4. 7. Momentos para la imagen “Clown” comprimida con contourlets.
4.2.1 Análisis de los resultados de la prueba 2
Como se puede observar al comparar las tablas 4.6 (wavelets) y 4.7 (contourlets) contra la tabla 4.5 (imagen original), las medidas de los momentos de inercia son conservadas aún después del proceso de compresión/descompresión, esto se debe a la naturaleza del método aplicado el cual como se mencionó anteriormente puede ser visto como la aplicación de un filtro para el cambio de contraste.
Los momentos se conservan de la mejor manera en la columna de los momentos de
Maitra [55] dado que son invariantes al contraste, aunque en las otras columnas dichas medidas también son muy cercanas. Con esto queda demostrado que la compresión puede verse como un proceso de cambio de contraste.
Con esta prueba se demuestra que se pueden usar las imágenes reconstruidas y obtener
los momentos estadísticos para describir cuantitativamente las formas de los segmentos de borde de una imagen con el objetivo de utilizarlas posteriormente en tareas de visión artificial.

Capítulo 4 Experimentación y resultados
66
4.3 Prueba 3: Compresión/descompresión de imágenes con preservación de bordes con wavelets y contourlets completo Un codificador de imágenes con pérdidas tiene tres partes principales: a) transformación de dominio, b) cuantificación y c) codificación por entropía, el objetivo de esta prueba es presentar un codificador de imágenes en el que se preserva la información de los bordes.
Como se mencionó en la metodología los bordes son extraídos con SUSAN y después son mapeados al dominio transformado, para que dichas posiciones sean preservadas en la codificación. Un compresor se denomina completo por que conlleva todas las etapas necesarias de un compresor con pérdidas además de las etapas extras definidas por la metodología, como el codificador diseñado es progresivo entonces se tiene el control del rango de compresión.
En la mayoría de los codificadores existentes en la literatura se mide el desempeño a
tasas de compresión muy bajas, por lo que para las siguientes pruebas se seleccionaron tasas de compresión de 0.5 para obtener un factor de compresión aproximado de 16:1 y de 0.1 para obtener un factor aproximado de 80:1 los cuales son adecuados para medir el desempeño del compresor presentado.
La tasa de compresión a 0.1 se considera el peor caso al que se puede someter un
compresor de imágenes, aunque se puede ir mas allá de esa medida, no es recomendable dado que diversos estudios de la literatura han demostrado que dicha medida es adecuada pues el sistema visual humano sólo puede percibir diferencias hasta 0.1 [56].
Los resultados obtenidos para preservación de bordes usando wavelets y una tasa de
compresión de 0.5 se muestran en la tabla 4.8 y las imágenes reconstruidas se muestran en la figura 4.3.
Los resultados obtenidos usando wavelets y una tasa de compresión de 0.1 se muestran
en la tabla 4.9, y en la figura 4.4 se muestran las imágenes reconstruidas.
Tabla 4. 8. Medidas de error obtenidas para la prueba 3 con wavelets a 0.5.
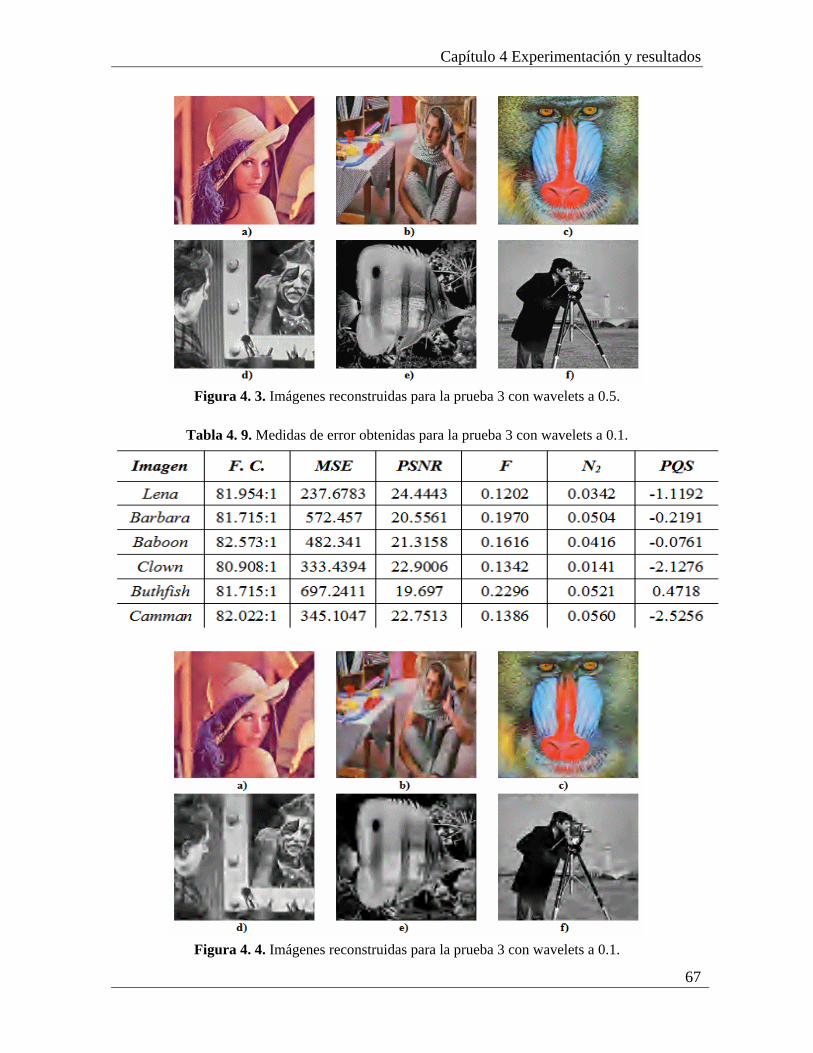
Capítulo 4 Experimentación y resultados
67
Figura 4. 3. Imágenes reconstruidas para la prueba 3 con wavelets a 0.5.
Tabla 4. 9. Medidas de error obtenidas para la prueba 3 con wavelets a 0.1.
Figura 4. 4. Imágenes reconstruidas para la prueba 3 con wavelets a 0.1.
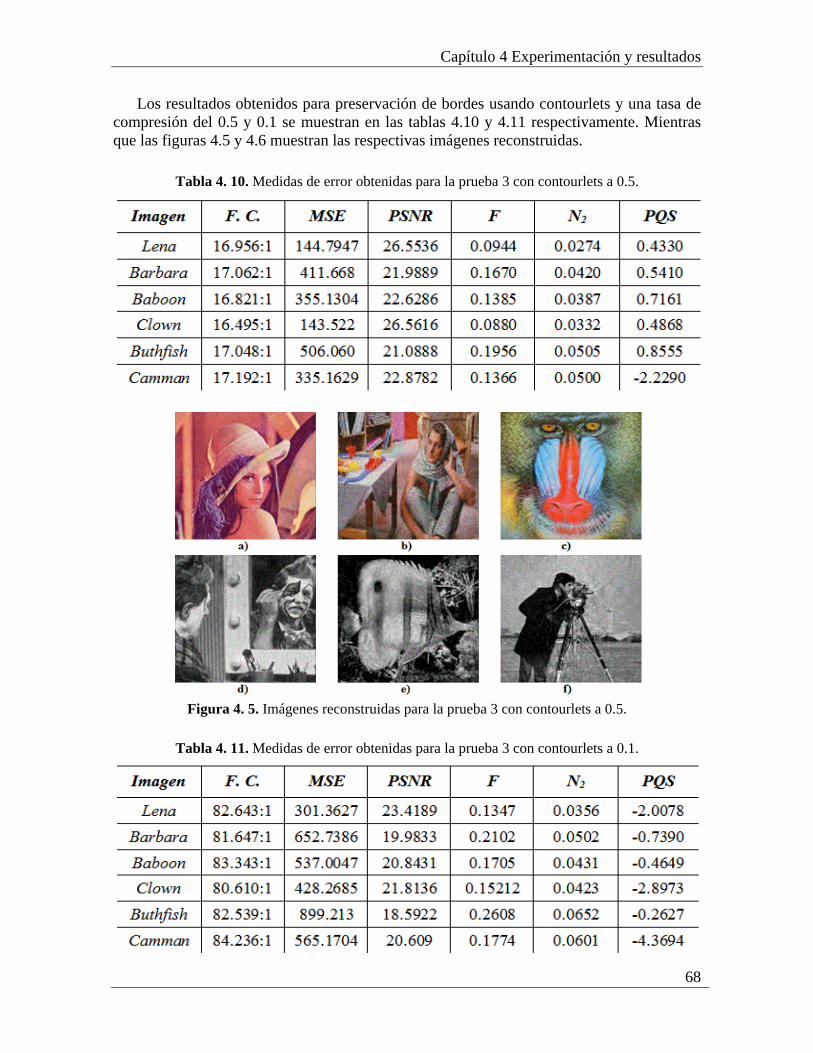
Capítulo 4 Experimentación y resultados
68
Los resultados obtenidos para preservación de bordes usando contourlets y una tasa de compresión del 0.5 y 0.1 se muestran en las tablas 4.10 y 4.11 respectivamente. Mientras que las figuras 4.5 y 4.6 muestran las respectivas imágenes reconstruidas.
Tabla 4. 10. Medidas de error obtenidas para la prueba 3 con contourlets a 0.5.
Figura 4. 5. Imágenes reconstruidas para la prueba 3 con contourlets a 0.5.
Tabla 4. 11. Medidas de error obtenidas para la prueba 3 con contourlets a 0.1.

Capítulo 4 Experimentación y resultados
69
Figura 4. 6. Imágenes reconstruidas para la prueba 3 con contourlets a 0.1.
4.3.1 Análisis de los resultados de la prueba 3
Con los resultados mostrados en las tablas 4.8, 4.9, 4.10 y 4.11 se demuestra que se tiene el completo control del archivo comprimido con respecto a la tasa de compresión, lo que se puede observar en la columna dos de factor de compresión.
Los ligeros cambios en los resultados obtenidos se deben a la etapa de codificación por
entropía que depende de la frecuencia de los datos. Con respecto a la comparación de los errores en la misma tasa de compresión con wavelets y contourlets se puede observar que las wavelets tienen un mejor desempeño en cuanto a las medidas de error, pero se debe tener en claro que dichas medidas no son determinantes en la selección de la mejor imagen, dado que lo que interesa es la preservación de los bordes y no las medidas obtenidas.
De forma individual en las pruebas mostradas se observa que la mejor imagen
reconstruida es Lena en todos los casos y que Buthfish es la que presenta más problemas a los compresores. Se puede observar también, que las imágenes de media frecuencia son con las que se obtiene menor calidad en la reconstrucción y que con las imágenes de alta frecuencia se tiene la mejor reconstrucción lo que permite demostrar que efectivamente el compresor tiene un muy buen desempeño en la preservación de bordes. Dicha aseveración queda visualmente de manifiesto.
Resulta también interesante el observar en cada una de las imágenes que una gran
cantidad de la información de textura es perdida, dado que se gastan bits solo en los bordes y la poca información de textura conservada se debe al aprovechamiento de la propiedad de compactación de energía en el dominio transformado (la retención de los cuatro píxeles de la esquina superior izquierda de la imagen).

Capítulo 4 Experimentación y resultados
70
Por último, en la prueba 7 que será presentada más adelante se muestran los resultados obtenidos con las imágenes preservando bordes en el proceso de verificación de la calidad de piezas industriales, con el objetivo de volver a poner de manifiesto la efectividad del compresor propuesto para la preservación de los bordes. 4.4 Prueba 4: Compresión/descompresión de imágenes con preservación de texturas con wavelets y contourlets completo Como se mencionó en secciones anteriores una de las señales más importantes presentes en una imagen son las texturas, que se obtienen al separar los bordes presentes en una imagen. Las texturas han sido estudiadas durante muchos años con diferentes enfoques [57], [58] y los más importantes son la clasificación, reconocimiento y la recuperación para lo cual se suelen utilizar estadísticos que describen las propiedades de textura.
El objetivo de esta prueba es demostrar que el compresor/descompresor puede preservar también la información de textura presente en una imagen. La tabla 4.12 muestra los resultados obtenidos con wavelets a una tasa de compresión de 0.5, y la figura 4.7 muestra los resultados obtenidos de la reconstrucción de imágenes.
Tabla 4. 12. Medidas de error obtenidas para la prueba 4 con wavelets a 0.5.
Figura 4. 7. Imágenes reconstruidas para la prueba 4 con wavelets a 0.5.
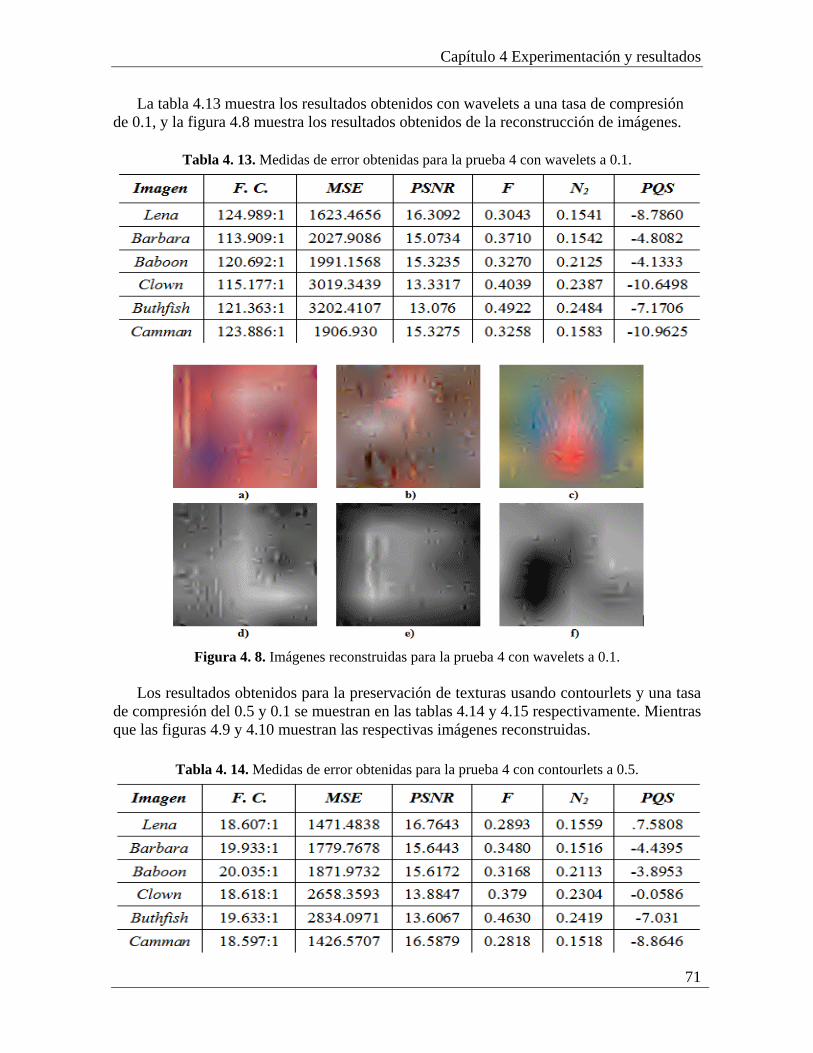
Capítulo 4 Experimentación y resultados
71
La tabla 4.13 muestra los resultados obtenidos con wavelets a una tasa de compresión de 0.1, y la figura 4.8 muestra los resultados obtenidos de la reconstrucción de imágenes.
Tabla 4. 13. Medidas de error obtenidas para la prueba 4 con wavelets a 0.1.
Figura 4. 8. Imágenes reconstruidas para la prueba 4 con wavelets a 0.1.
Los resultados obtenidos para la preservación de texturas usando contourlets y una tasa
de compresión del 0.5 y 0.1 se muestran en las tablas 4.14 y 4.15 respectivamente. Mientras que las figuras 4.9 y 4.10 muestran las respectivas imágenes reconstruidas.
Tabla 4. 14. Medidas de error obtenidas para la prueba 4 con contourlets a 0.5.

Capítulo 4 Experimentación y resultados
72
Figura 4. 9. Imágenes reconstruidas para la prueba 4 con contourlets a 0.5.
Tabla 4. 15. Medidas de error obtenidas para la prueba 4 con contourlets a 0.1.
Figura 4. 10. Imágenes reconstruidas para la prueba 4 con contourlets a 0.1.
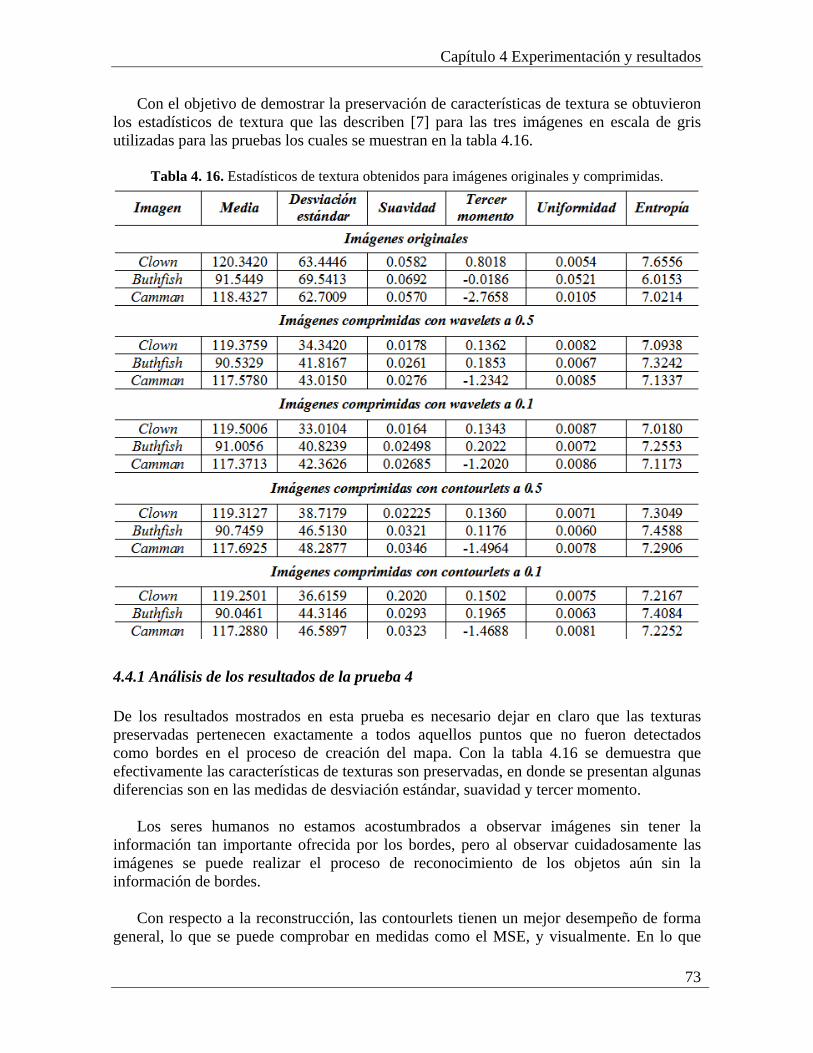
Capítulo 4 Experimentación y resultados
73
Con el objetivo de demostrar la preservación de características de textura se obtuvieron los estadísticos de textura que las describen [7] para las tres imágenes en escala de gris utilizadas para las pruebas los cuales se muestran en la tabla 4.16.
Tabla 4. 16. Estadísticos de textura obtenidos para imágenes originales y comprimidas.
4.4.1 Análisis de los resultados de la prueba 4
De los resultados mostrados en esta prueba es necesario dejar en claro que las texturas preservadas pertenecen exactamente a todos aquellos puntos que no fueron detectados como bordes en el proceso de creación del mapa. Con la tabla 4.16 se demuestra que efectivamente las características de texturas son preservadas, en donde se presentan algunas diferencias son en las medidas de desviación estándar, suavidad y tercer momento.
Los seres humanos no estamos acostumbrados a observar imágenes sin tener la
información tan importante ofrecida por los bordes, pero al observar cuidadosamente las imágenes se puede realizar el proceso de reconocimiento de los objetos aún sin la información de bordes.
Con respecto a la reconstrucción, las contourlets tienen un mejor desempeño de forma
general, lo que se puede comprobar en medidas como el MSE, y visualmente. En lo que

Capítulo 4 Experimentación y resultados
74
respecta a los factores de compresión se observa que son mucho mayores a los presentados en la prueba 3 y la explicación es muy sencilla. Dado que la información de textura suele presentar uniformidad, esta se ve reflejada en el flujo de bits obtenidos con SPIHT, por lo tanto cuando se codifica por entropía la información puede ser representada de una manera más compacta.
Se puede concluir que para el caso de las texturas con el proceso de codificación por
entropía se puede obtener hasta un 20 por ciento de compresión adicional sin pérdidas. En lo que respecta a las imágenes de forma individual, se puede observar que Barbara es la imagen que es reconstruida con menor calidad, y que las imágenes Clown y Lena son las mejores reconstruidas dado que son imágenes de baja frecuencia lo que significa menor cantidad de detalles. Un caso especial de buena reconstrucción se obtiene con la imagen de Camman que aunque es una imagen de alta frecuencia tiene bien delimitada la información de textura. 4.5 Prueba 5: Compresión/descompresión de imágenes con preservación de bordes y texturas con wavelets y contourlets completo El objetivo de esta prueba es medir el desempeño del compresor/descompresor utilizando tanto la información de bordes como la información de texturas. Aquí el mapa construido pertenece a todas las posiciones del mapa extraído en la fase de extracción de bordes.
Se espera que las imágenes descomprimidas en esta etapa sean mejor reconstruidas
teniendo en cuenta las medidas de error lo que en este caso si daría información de la calidad de la reconstrucción. En esta prueba es la única en que se agrega la medida subjetiva MOS como una medida adicional al cálculo de errores. El MOS es el resultado de la evaluación de cinco observadores los cuales calificaron las imágenes en las escalas ya explicadas anteriormente, dichos observadores no fueron sometidos a ningún tipo de entrenamiento en lo que respecta al conocimiento de la información preservada en las imágenes, y no son expertos en ningún tipo de tarea de procesamiento digital de imágenes.
La tabla 4.17 muestra los resultados obtenidos de la compresión de imágenes con
preservación de bordes y texturas usando wavelets a una tasa de compresión de 0.5 y la figura 4.11 muestra el ejemplo de las imágenes reconstruidas.
Tabla 4. 17. Medidas de error obtenidas para la prueba 5 con wavelets a 0.5.
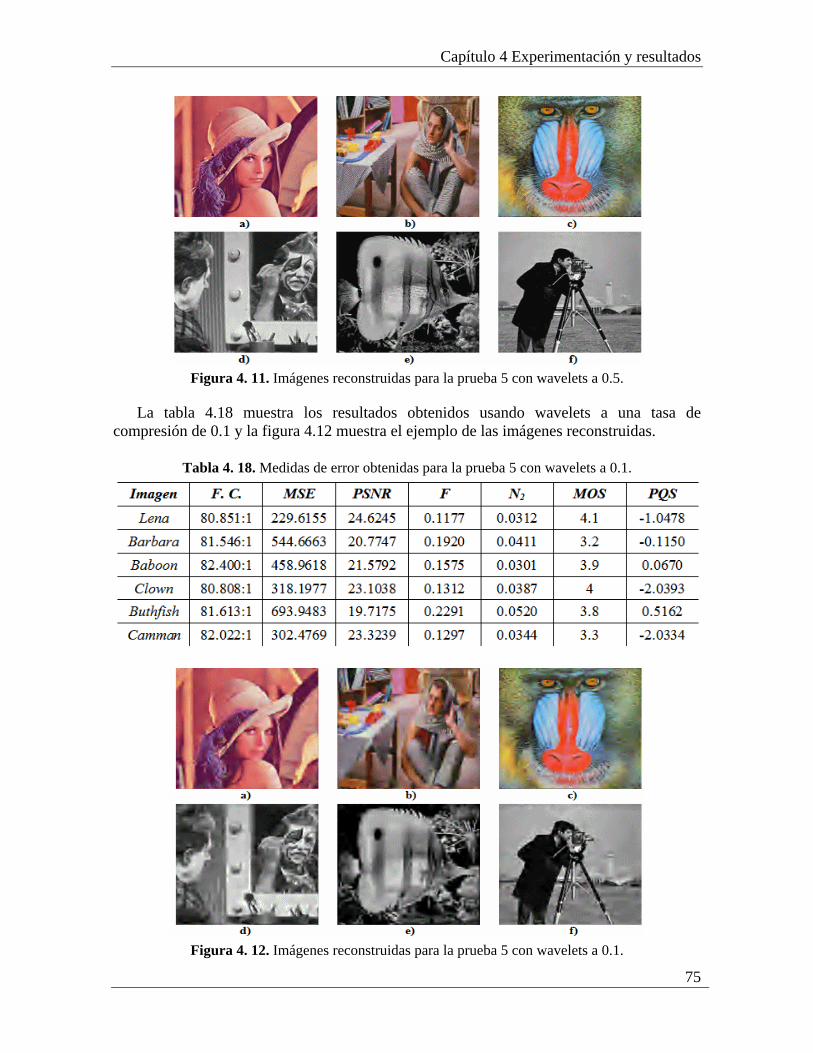
Capítulo 4 Experimentación y resultados
75
Figura 4. 11. Imágenes reconstruidas para la prueba 5 con wavelets a 0.5.
La tabla 4.18 muestra los resultados obtenidos usando wavelets a una tasa de
compresión de 0.1 y la figura 4.12 muestra el ejemplo de las imágenes reconstruidas.
Tabla 4. 18. Medidas de error obtenidas para la prueba 5 con wavelets a 0.1.
Figura 4. 12. Imágenes reconstruidas para la prueba 5 con wavelets a 0.1.
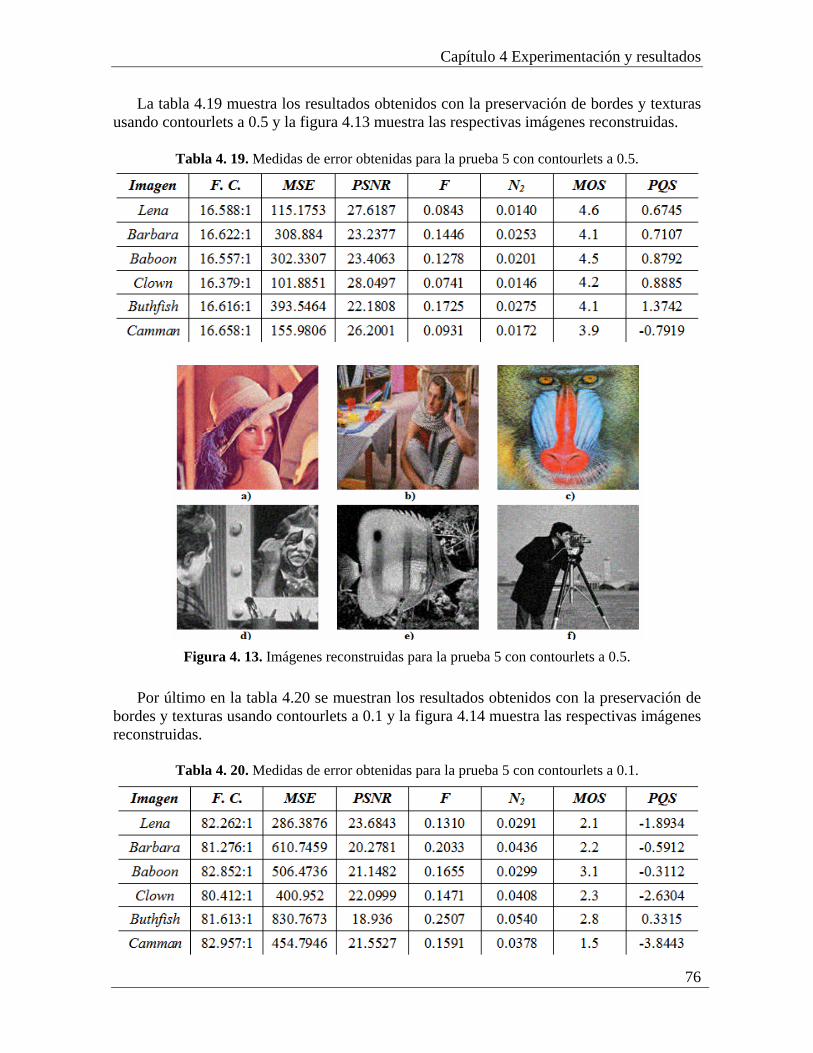
Capítulo 4 Experimentación y resultados
76
La tabla 4.19 muestra los resultados obtenidos con la preservación de bordes y texturas usando contourlets a 0.5 y la figura 4.13 muestra las respectivas imágenes reconstruidas.
Tabla 4. 19. Medidas de error obtenidas para la prueba 5 con contourlets a 0.5.
Figura 4. 13. Imágenes reconstruidas para la prueba 5 con contourlets a 0.5.
Por último en la tabla 4.20 se muestran los resultados obtenidos con la preservación de
bordes y texturas usando contourlets a 0.1 y la figura 4.14 muestra las respectivas imágenes reconstruidas.
Tabla 4. 20. Medidas de error obtenidas para la prueba 5 con contourlets a 0.1.

Capítulo 4 Experimentación y resultados
77
Figura 4. 14. Imágenes reconstruidas para la prueba 5 con contourlets a 0.1.
4.5.1 Análisis de los resultados de la prueba 5 Como se puede observar las imágenes obtenidas en esta prueba son en general las mejores reconstruidas de todas las pruebas presentadas, lo cual se puede demostrar tanto en las medidas de error, como visualmente. Lo anterior se debe a que en la imagen descomprimida existe un balance de la información de bordes como de texturas lo que permite reconstruirla de mejor forma.
Aunque se ha mencionado a lo largo del trabajo de investigación que las cotourlets son
mejores que las wavelets en esta prueba se podría pensar que no es así. El principal problema es que la relación jerárquica padre-hijo que se usa para codificar las imágenes es la de las wavelets, y no la de las contourlets, lo que añade la granularidad a las imágenes contourlet. Por lo que, si en un futuro se resuelve el problema de la relación padre-hijo de las contourlets entonces se observaría la gran mejora que ofrecen sobre las wavelets, aunque los resultados presentados aquí son un muy buen comienzo.
En lo que respecta a la medida del PQS, es en esta prueba donde tiene los valores más
grandes dado que las imágenes originales contra las reconstruidas son menos diferentes, aunque aún no se acercan mucho a las medidas subjetivas obtenidas con el MOS. Aquí los observadores no necesitan mucho esfuerzo visual para evaluar las imágenes y solamente se les presentan 24 imágenes lo que no les produce fatiga visual.
En esta prueba de forma general la imagen que es mejor reconstruida es la imagen Lena
seguida de la imagen Clown mientras que las imágenes que menor calidad de reconstrucción tienen son Buthfish y Barbara respectivamente. Este resultado es determinado solamente en base a las medidas de error y no al observar la calidad de las imágenes reconstruidas.
Capítulo 4 Experimentación y resultados
78
Las imágenes obtenidas en esta prueba pueden ser usadas para cualquier proceso de visión artificial en lugar de las imágenes originales, con la ventaja del ahorro en el tamaño del espacio de almacenamiento utilizado.
El nivel óptimo en la reconstrucción de las imágenes de esta prueba se obtendría al
añadir una fase de tratamiento en otra de las señales importantes presentes en una imagen que son los detalles asociados a los bordes, lo que permitiría reducir de manera considerable el ringing presente y así se podría ofrecer la mejor reconstrucción posible. 4.6 Prueba 6: Compresión/descompresión de imágenes con preservación de bordes resaltados y texturas con wavelets y contourlets completo Además de la preservación de bordes y texturas, se puede añadir un proceso de postprocesamiento que implica el realzado de los bordes, al igual que en la prueba 1, con el objetivo no solo de preservarlos si no de remarcar los bordes definidos en el mapa de características.
Una implicación que tiene el proceso de realzado es que los valores de los bordes numéricamente son más grandes tanto en el dominio original como en el dominio transformado, y dichos valores son dispersados a los detalles asociados a los bordes y las texturas lo que causa emborronamiento y artefactos en las imágenes.
El objetivo de esta prueba es realizar el proceso de preservación de texturas y bordes aplicando un proceso de resaltado. Para lograr el objetivo se aplica el proceso de preservación de bordes y texturas, tanto en la imagen original como en el mapa de características. Después se copia la información de la matriz de aproximación a su posición correspondiente en el mapa de bordes para obtener la imagen reconstruida final.
La tabla 4.21 muestra los resultados obtenidos con la preservación de bordes resaltados
y texturas usando wavelets a 0.5 y la figura 4.15 muestra las respectivas imágenes reconstruidas.
Tabla 4. 21. Medidas de error obtenidas para la prueba 6 con wavelets a 0.5.

Capítulo 4 Experimentación y resultados
79
Figura 4. 15. Imágenes reconstruidas para la prueba 6 con wavelets a 0.5.
La tabla 4.22 muestra los resultados de la preservación de bordes resaltados y texturas
con wavelets a 0.1 y la figura 4.16 muestra las respectivas imágenes reconstruidas.
Tabla 4. 22. Medidas de error obtenidas para la prueba 6 con wavelets a 0.1.
Figura 4. 16. Imágenes reconstruidas para la prueba 6 con wavelets a 0.1.
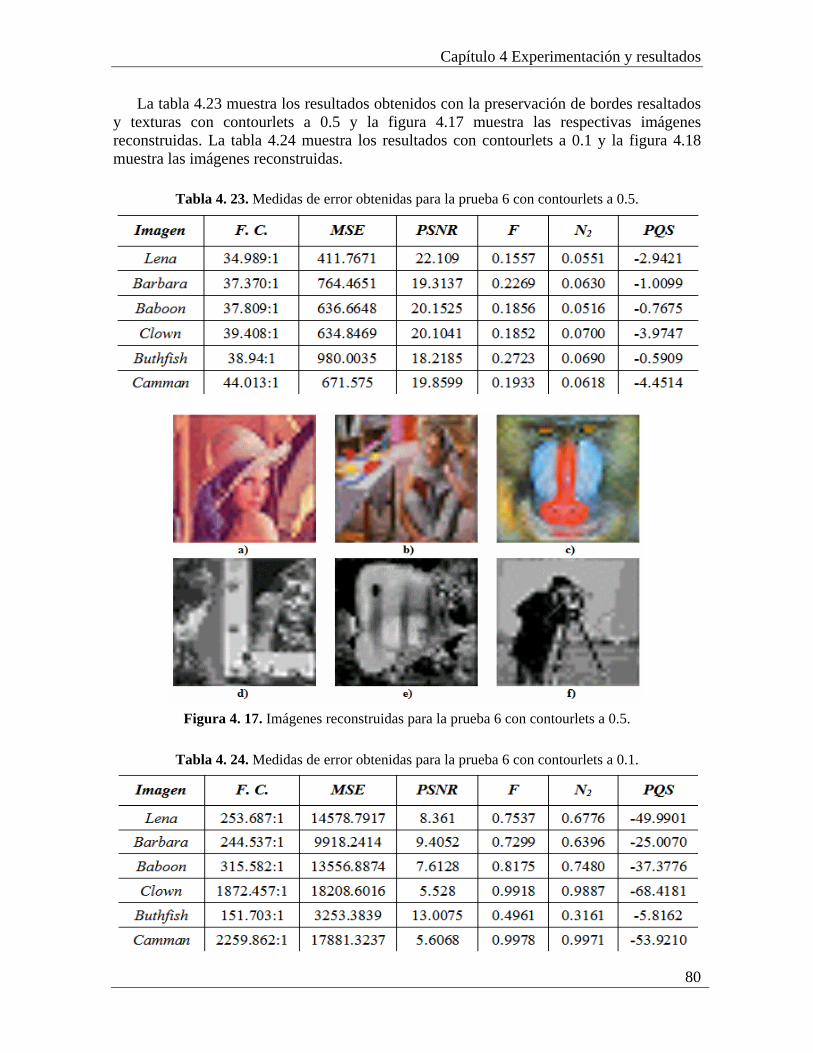
Capítulo 4 Experimentación y resultados
80
La tabla 4.23 muestra los resultados obtenidos con la preservación de bordes resaltados y texturas con contourlets a 0.5 y la figura 4.17 muestra las respectivas imágenes reconstruidas. La tabla 4.24 muestra los resultados con contourlets a 0.1 y la figura 4.18 muestra las imágenes reconstruidas.
Tabla 4. 23. Medidas de error obtenidas para la prueba 6 con contourlets a 0.5.
Figura 4. 17. Imágenes reconstruidas para la prueba 6 con contourlets a 0.5.
Tabla 4. 24. Medidas de error obtenidas para la prueba 6 con contourlets a 0.1.

Capítulo 4 Experimentación y resultados
81
Figura 4. 18. Imágenes reconstruidas para la prueba 6 con contourlets a 0.1.
4.6.1 Análisis de los resultados de la prueba 6
Como se puede observar en la tabla 4.21 y en la figura 4.15 la compresión con preservación de bordes realzados utilizando wavelets tiene muy buen desempeño en el caso de la tasa de compresión de 0.5. Para las pruebas restantes no se tienen buenos resultados dado que se obtiene una gran cantidad de cuadriculado (blocking) y pérdida de otros detalles de las imágenes (texturas).
El proceso de realzado de bordes implica una degradación en otras partes importantes
de la imagen, por la dispersión de los valores altos hacia otras zonas de la imagen y por que se calculan menos niveles de descomposición en la transformación. Lo que implica que el algoritmo SPIHT no logre capturar de manera adecuada la información a preservar y que la propiedad de compactación de energía no sea aprovechada.
El precio que se debe pagar por la preservación de bordes y realzado es un decremento
en la calidad de la imagen reconstruida. Además, la pérdida de calidad se debe a que para tener éxito en el realzado el número de descomposiciones debe ser pequeño por ejemplo para wavelets se descompone en tres niveles y para contourlets en cuatro.
En el caso de la última prueba (contourlets a 0.1) las imágenes reconstruidas son
extremadamente malas debido a la falta de niveles de reconstrucción aunada al proceso de cuantificación, la pequeña cantidad de coeficientes seleccionados y la falta de la solución del problema de la relación padre-hijo. Las imágenes obtenidas para este caso no pueden utilizarse para un proceso de visión artificial por que son completamente diferentes a las imágenes originales.

Capítulo 4 Experimentación y resultados
82
De manera individual en esta prueba la imagen de Lena también es la que es reconstruida con mejor calidad seguida de Baboon. Una vez más las imágenes que son reconstruidas con menor calidad son las imágenes de media frecuencia Barbara y Buthfish.
4.7. Prueba 7: Inspección de calidad de piezas industriales con Vision Builder y con imágenes con bordes preservados con wavelets y contourlets El objetivo de esta prueba es aplicar un proceso de reconocimiento de patrones (inspección de piezas industriales) utilizando las imágenes provenientes del compresor/descompresor diseñado con la metodología propuesta, en este caso con preservación de bordes como con bordes y texturas de manera conjunta.
El proceso es realizado con el software comercial de National Instruments llamado “Vision Builder”. Vision Builder es un ambiente de desarrollo configurable para visión por computadora que no requiere programación [59].
El software puede ser utilizado para comprobar visualmente cuando un producto es
ensamblado y manufacturado correctamente. De dicho software se utilizaron dos módulos de inspección y clasificación de piezas industriales que verifica criterios de calidad para clasificar piezas correspondientes a la clase de buena o mala calidad.
Para realizar las pruebas se tomaron las imágenes originales y se sometieron al proceso de compresión/descompresión con preservación de bordes y se introdujeron al sistema para el proceso de verificación. Se espera que el proceso de inspección con las imágenes descomprimidas pueda obtener los mismos resultados que con las imágenes originales.
La primera prueba consiste en la verificación de la calidad de la abrazadera de una batería, donde lo primero que se hace es la detección de la abrazadera en la imagen. Después, se determina un sistema de referencia basado en la localización de la parte, se buscan los orificios circulares y se verifica el radio de la abrazadera y por último se mide la distancia (apertura) que existe entre los dos brazos.
La tabla 4.25 muestra los resultados obtenidos de la verificación con la imagen original,
y las imágenes comprimidas a una tasa de compresión de 0.5. El primer renglón presenta el resultado obtenido con la imagen original, el segundo
renglón muestra el resultado con la imagen obtenida con preservación de bordes utilizando wavelets (Batterybordwav), el tercer renglón muestra el resultado obtenido con preservación de bordes y contourlets (Batterybordcont), el cuarto renglón el resultado obtenido con preservación de texturas y bordes con wavelets (Batterycomwav) y el último renglón con preservación de texturas y bordes con contourlets (Batterycomcont).
Los resultados son presentados en el idioma inglés por que es así como se calculan en
Vision Builder, y no se realizan los cambios de idioma para respetar la esencia y los datos obtenidos del proceso de inspección.

Capítulo 4 Experimentación y resultados
83
Tabla 4. 25. Resultados obtenidos en la verificación de la abrazadera de batería.
La tabla 4.26 muestra las medidas de error obtenidas para cada una de las imágenes de prueba de abrazadera de batería. La figura 4.19 muestra las imágenes reconstruidas utilizadas para la inspección de calidad de la abrazadera de la batería.
Tabla 4. 26. Medidas de error obtenidas para la prueba 7 con la abrazadera de batería.
Figura 4. 19. Imágenes de abrazadera de batería. a) Imagen original, b) Batterybordwav, c) Batterybordcont,
d) Batterycomwav y e) Batterycomcont.

Capítulo 4 Experimentación y resultados
84
La segunda prueba consiste en la inspección de un envase de spray que verifica lo siguiente: primero localiza el borde izquierdo del bote, enseguida se crea un sistema de referencia para después localizar los otros dos bordes izquierdos del envase. Después mide la distancia hacia la izquierda y localiza los bordes de la derecha con su respectiva distancia, por último se verifica la presencia del atomizador y de la tapa del envase.
La tabla 4.27 muestra los resultados obtenidos de la verificación del envase de spray con la imagen original, y las imágenes comprimidas a una tasa de compresión de 0.5. El primer renglón presenta el resultado obtenido con la imagen original, el segundo renglón muestra el resultado con la imagen obtenida con preservación de bordes utilizando wavelets (Spraybordwav), el tercer renglón muestra el resultado obtenido con preservación de bordes y contourlets (Spraybordcont), el cuarto renglón el resultado obtenido con preservación de texturas y bordes con wavelets (Spraycomwav) y el último renglón con preservación de texturas y bordes con contourlets (Spraycomcont).
Tabla 4. 27. Resultados obtenidos en la verificación del envase de spray.
Las medidas de error obtenidas para cada imagen se muestran en la tabla 4.28 y las
imágenes reconstruidas en la figura 4.20.
Tabla 4. 28. Medidas de error obtenidas para la prueba 7 con el envase de spray.

Capítulo 4 Experimentación y resultados
85
Figura 4. 20. Imágenes de envase de spray. a) Imagen original, b) Spraybordwav, c)
Spraybordcont, d) Spraycomwav y e) Spraycomcont.
4.7.1 Análisis de los resultados de la prueba 7
De los resultados mostrados en la tabla 4.25 se puede observar que tanto con la imagen original como con las reconstruidas el proceso de inspección es exitoso excepto con la imagen comprimida con preservación de bordes y contourlets.
El fracaso se debe a la gran cantidad de ruido introducido a la imagen en la etapa de
compresión, el proceso falla en la última etapa de la inspección donde la distancia entre los brazos es muy pequeña puesto que lo que mide como borde es una parte del ruido de la imagen, lo anterior sucede aún cuando los bordes fueron preservados exitosamente.
Las medidas de error obtenidas son muy diversas y obviamente no pueden ofrecer
información alguna acerca del fracaso o del éxito del proceso de inspección. Pero en general la imagen con menos error es la imagen obtenida con wavelets y preservando bordes y texturas, y la imagen con mayor error es la imagen obtenida con preservación de bordes y contourlets. Lo anterior se ve reflejado también en la falla del proceso de inspección.
En lo que respecta a los resultados mostrados en la tabla 4.27, otra vez se obtiene una
falla en la inspección con la imagen en la que se preservaron los bordes con contourlets y la falla se debe al exceso de ruido. El proceso de inspección fracasa desde la primera etapa por lo que las siguientes etapas también fallan. Con las restantes imágenes el proceso es exitoso al igual que en la prueba de la abrazadera de la batería.

Capítulo 4 Experimentación y resultados
86
En lo que respecta a los resultados de la tabla 4.28 el comportamiento es similar a los de la prueba de batería donde la imagen mejor reconstruida es la de wavelet y bordes y texturas preservadas y la peor reconstruida es la wavelet y bordes preservados.
Con las dos pruebas de inspección presentadas queda demostrada la efectividad del
compresor/descompresor diseñado con la metodología propuesta para la compresión de imágenes con preservación de características para aplicaciones de visión artificial, en este caso para dos procesos de inspección de calidad de piezas industriales. 4.8 Prueba 8: Comparación de los resultados obtenidos contra otros trabajos mostrados en la literatura En la literatura existen muy pocos trabajos que abordan el tema de compresión de imágenes con preservación de características. El objetivo de la última prueba es presentar una comparación del desempeño del sistema contra los otros codificadores existentes en la literatura.
La realización de esta prueba estuvo restringida a la utilización de la imagen Camman, dado que sólo se tienen ejemplos de codificación de esa imagen con los compresores a comparar y no se tiene propiamente el compresor para realizar más pruebas.
Para realizar esta prueba se utilizaron las imágenes Camman obtenidas en la
compresión con preservación de bordes a una tasa de compresión de 0.1 con wavelets y contourlets de las figuras 4.4f y 4.6f. Dichas imágenes se utilizan para la comparación por que fueron comprimidas en las condiciones más parecidas posibles a las que presentan Mertins y Schilling.
Los compresores comparados son: el compresor con preservación de bordes propuesto
por Mertins [44], el compresor con preservación de bordes propuesto por Schilling [8] y el compresor propuesto en este trabajo de investigación utilizando tanto wavelets como contourlets.
La imagen obtenida con el compresor de Mertins tiene un PSNR = 22.39 dB, la imagen
obtenida con el compresor de Schilling tiene un PSNR = 22.39 dB, la imagen obtenida con wavelets con el compresor aquí presentado tiene un PSNR = 22.7513 y con la imagen obtenida con contourlets se obtiene un PSNR = 20.609.
Como se mencionó anteriormente las medidas objetivas de error no proporcionan
información acerca del éxito de la preservación de los bordes, pero aún con eso los resultados aquí presentados son muy cercanos a los de Mertins y Schilling tomando en cuenta las medidas de distorsión.
La figura 4.21 muestra las cuatro imágenes comparadas.

Capítulo 4 Experimentación y resultados
87
Figura 4. 21. Comparación entre compresores con preservación de bordes. a) Imagen Camman
obtenida con el compresor de Mertins, b) Imagen Camman obtenida con el compresor de Schilling, c) Imagen Camman obtenida con la metodología propuesta y wavelets y d) Imagen Camman
obtenida con la metodología propuesta y contourlets.
4.8.1 Análisis de los resultados de la prueba 8
De las imágenes de la figura 4.21 se puede observar que la imagen con menor calidad es la obtenida con el compresor presentado en este trabajo de investigación y contourlets, aunque se puede observar que los bordes fueron bien preservados aún con la granularidad introducida por la falta de la solución de la relación padre-hijo.
De acuerdo a las medidas la siguiente imagen con menor calidad es la obtenida con wavelets pero se puede cotejar visualmente que es la que mejor preservó los bordes, en dicha imagen (4.21c) no se pierde ninguna parte del tripie y los detalles de la cara y la

Capítulo 4 Experimentación y resultados
88
cámara son más claros. También se nota la superioridad en los detalles del fondo de la imagen.
Las imágenes obtenidas por Mertins y Schilling tienen el PSNR más alto pero en la
imagen de Mertins (4.21a) se pierde una gran parte del tripie de la cámara además de los detalles de la cara y del fondo. Por último la imagen de Schilling (4.21b), también pierde una parte del tripie, cámara y la cara.
Con lo anterior queda una vez más demostrado que las imágenes no pueden ser
comparadas en su calidad con las medidas objetivas, sino que se necesita otra clase de criterio aparte del visual para demostrar la preservación de características, ese proceso puede obtenerse de la medición de los estadísticos preservados y por medio de un proceso de visión artificial así como se demostró en la prueba 7 de este trabajo de investigación.
Con el análisis mostrado se puede concluir que los compresores/descompresores
diseñados con la metodología obtenida del trabajo de investigación son mejores que los existentes en la literatura. Además, se debe tomar en cuenta que no se envía ningún tipo de información de los bordes en la cabecera del archivo hacia el descompresor, lo que representa una ventaja sobre los compresores de Mertins y Schilling.
En dichos compresores se codifica sin pérdida la información de los bordes y la
información se introduce en la cabecera del archivo para que pueda ser leído por el decodificador, por lo que realmente no se trabaja de manera estricta en el proceso de preservación. 4.9 Comentarios Se mostraron las pruebas que dan sustento a la validez de la investigación doctoral, además se presentó una discusión y comparación de los resultados obtenidos.
La metodología mostrada y probada consiste en el primer compresor de la literatura que no guarda información de las características a preservar en la cabecera de la imagen lo que hace que este sea más efectivo que los existentes. La única forma de compararlo contra los otros dos codificadores es con las imágenes que se tienen como resultado de la codificación.
La única forma de poder demostrar la conservación de las características es visualmente
y por el uso de las imágenes en un proceso de visión artificial o reconocimiento de patrones.

Capítulo 5 Conclusiones y trabajos futuros
89
CAPÍTULO 5 Conclusiones y trabajos futuros La posibilidad de comprimir imágenes con preservación de características ofrece un amplio campo de aplicación en diferentes áreas donde este proceso se vuelve imperativo como por ejemplo en la medicina, en dispositivos móviles y en sistemas de reconocimiento de rostros y huellas digitales por citar algunos ejemplos.
Como producto final de la investigación se obtuvo una metodología para diseñar compresores/descompresores de imágenes que permite preservar características importantes de una imagen como son los bordes y las texturas. Las imágenes provenientes de dichos compresores pueden ser utilizadas para procesos de visión artificial, con la ventaja adicional del ahorro en el espacio de almacenamiento.
Para comprimir una imagen primero, se deben definir las características a preservar y se
debe obtener un mapa de bordes el cual es obtenido con el detector SUSAN, después se debe transformar de dominio a la imagen por medio de wavelets o contourlets. Enseguida, se realiza un mapeo de los puntos del dominio original al dominio transformado dichos puntos pertenecen a las características a preservar y explotan la relación jerárquica padre-hijo existente en el dominio wavelet.
Después la imagen es codificada con el algoritmo SPIHT con la modificación propuesta
y el flujo resultante es codificado por entropía con el compresor aritmético. La reconstrucción de la imagen se obtiene al realizar el proceso inverso.
Con las pruebas y los resultados presentados se demostró la habilidad de los compresores/descompresores para reconstruir imágenes gastando más bits y dando más calidad a aquellas partes importantes de la imagen. Las medidas objetivas no ofrecen una buena información acerca de la bondad del método, y se debe recordar que el objetivo es la preservación de características aún a tasas de compresión muy bajas.
La importancia de los compresores/descompresores diseñados con la metodología
presentada no está en la medida de los errores entre la imagen original y descomprimida, si no en la correcta preservación y reconstrucción de los bordes y texturas. El éxito es gracias a la utilización de la Transformada Wavelet Discreta (TWD) y de la Transformada Contourlet Discreta (TCD) como herramientas para modelar los bordes de una imagen por medio de un análisis multiescala y direccional.

Capítulo 5 Conclusiones y trabajos futuros
90
Es importante reiterar que las medidas clásicas de comparación de la calidad entre imágenes no son efectivas para demostrar la calidad de las imágenes descomprimidas y menos para ofrecer información acerca de las características preservadas. Por lo que el proceso de visión artificial se vuelve muy importante para la determinación del éxito de las características preservadas. 5.1 Aportaciones Después de la realización del trabajo de investigación doctoral se resolvieron una gran cantidad de problemas asociados al diseño de la metodología de compresión de imágenes con preservación de características, haciendo un resumen, las principales aportaciones de este trabajo de investigación son:
• Diseño e implementación de una metodología para el diseño de un compresor/descompresor de imágenes (progresivo) que ofrece como ventaja adicional al ahorro en el espacio de almacenamiento la posibilidad de preservar características (bordes, texturas, bordes y texturas) importantes para aplicaciones de visión artificial.
• Se propuso una modificación del algoritmo SPIHT para que la selección de los
píxeles no sea realizada solo por significancia, sino también, por la posición determinada por su pertenencia a un mapa de características de interés, lo que permite gastar más bits en las áreas de interés para conseguir el objetivo de preservación.
• La metodología permite trabajar con el algoritmo SPIHT modificado tanto en el
dominio wavelet como en el dominio contourlet lo que representa una innovación muy importante.
• Se diseñó una técnica de mapeo de coeficientes del dominio espacial al dominio
transformado que permite seleccionar las características importantes en el nuevo dominio. El diseño y la construcción de dicho mapa representa un gran avance y una aportación muy importante para el éxito del compresor de imágenes.
• Se presentó una solución al problema de redundancia de la transformada contourlet,
al proponer el cálculo de la transformada contourlet dentro de una wavelet, a lo que se le dio el nombre de Transformada Contourlet Discreta Basada en una Wavelet (TCDBW). Esta transformación no se encuentra reportada en ningún tipo de literatura y su validez queda demostrada con las pruebas presentadas.
• La metodología obtenida permite trabajar tanto con imágenes en escala de gris
como con imágenes a color lo que ofrece la posibilidad de aumentar el rango de aplicaciones, y además permite ser el primer compresor de imágenes con preservación de características que permite utilizar imágenes en color.

Capítulo 5 Conclusiones y trabajos futuros
91
• El diseño de la metodología está realizado de tal forma que los compresores/descompresores obtenidos estén equilibrados con respecto al tiempo en las etapas de compresión y descompresión. Lo anterior quiere decir que los tiempos para ambas etapas son muy parecidos lo que representa una ventaja adicional a las ya presentadas con el codificador.
5.2 Trabajos futuros
Actualmente en la literatura se continúa en la búsqueda de nuevas soluciones para resolver el problema aquí planteado y se tiene un amplio panorama de aplicaciones. Durante el proceso de la investigación se detectaron algunas áreas que a futuro sería muy importante explotar, a continuación se mencionan algunas:
• Abordar el problema de formular matemáticamente la relación padre-hijo implícita
en una transformación contourlet.
• Abordar el problema de preservación de características usando otras transformaciones como por ejemplo bandelets [60], ridgelets [61] o wedgelets [62].
• Proponer una transformación que ofrezca la posibilidad de detectar características
multiescala, direccional, local y global.
• Trabajar arduamente en el diseño de filtros de coeficientes para las diferentes familias wavelet.
• Proponer una forma de medir la calidad de las imágenes reconstruidas, dado que se
demostró que las medidas objetivas no son suficientes.
• Poner especial énfasis en el estudio de la geometría de las imágenes dado que gran parte del éxito de la obtención de las características de una imagen se encuentra en la geometría de las mismas.
• Proponer una forma de determinar de manera automática los parámetros necesarios
para codificar una imagen con el objetivo de obtener la mejor reconstrucción posible.
• Realizar el proceso de detección de características de manera no supervisada, es
decir, sin la obtención de un mapa, y hacerlo directamente en el dominio transformado.

Bibliografía
92
Bibliografía 1. O. O. Vergara Villegas, R. Pinto Elías y V. G. Cruz Sánchez, “Feature Preserving
Image Compression: A survey”, Proc. of the Electronics, Robotics and Automotive Mechanics Conference (CERMA), vol. 2, pp. 35 – 40, Cuernavaca, Morelos, México, septiembre de 2006.
2. K. Muneeswaran, L. Ganesan, S. Arumugam y K. Ruba Soundar, “Texture
Classification with Combined Rotation and Scale Invariant Wavelet Features”, Pattern Recognition, vol. 38, no. 10, pp. 1495 – 1506, octubre de 2005.
3. S.- C. Lo, H. Li y M. T. Freedman, “Optimization of Wavelet Decomposition for Image
Compression and Feature Preservation”, IEEE Transactions on Medical Imaging, vol. 22, no. 9, pp. 1141 – 1151, septiembre de 2003.
4. Ö. N. Gerek y A. Enis Cetin, “A 2-D Orientation-Adaptive Prediction Filter in Lifting
Structures for Image Coding”, IEEE Transactions on Image Processing, vol. 15, no. 1, pp. 106 – 111, enero de 2006.
5. M. Penedo, W. A. Pearlman, P. G. Tahoces, M. Souto y J.J. Vidal, “Region-Based
Wavelet Coding Methods for Digital Mammography”, IEEE Transactions on Medical Imaging, vol. 22, no. 10, pp. 1288 – 1296, octubre de 2003.
6. M. N. Do, Directional Multiresolution Image Representations, Tesis doctoral,
laboratorio de procesamiento de señales de la Escuela Politécnica Federal de Lausanne (EPFL), Lausanne Suiza, octubre de 2003.
7. R. C. Gonzalez y R. E. Woods, Digital Image Processing, Addison Wesley / Díaz de
Santos, U. S. A., 2000. 8. D. Schilling y P. Cosman, “Feature-Preserving Image Coding for Very Low Bit Rates”,
Proc. of the IEEE Data Compression Conference (DCC), pp. 103 – 112, Snowbird, Utah, U.S.A., marzo de 2001.
9. K. R. Namuduri y V. N. Ramaswamy, “Feature Preserving Image Compression”,
Pattern Recognition Letters, vol. 24, no. 15, pp. 2767 – 2776, noviembre de 2003. 10. G. Craciun, M. Jiang, D. Thompson y R. Machiraju, “Spatial Domain Wavelet Design
for Feature Preservation in Computational Data Sets”, IEEE Transactions on Visualization and Computer Graphics, vol. 11, no. 2, pp. 149 – 159, abril de 2005.

Bibliografía
93
11. M. Kunt, A. Ikonomopoulos y M. Kocher, “Second-Generation Image Coding Techniques”, Proceedings of the IEEE, vol. 73, no. 4, pp. 549 - 574, abril de 1985.
12. J. M. Shapiro, “Embedded Image Coding Using Zerotrees of Wavelet Coefficients”,
IEEE Transactions on Signal Processing, vol. 41, no. 12, pp. 3445 - 3463, diciembre de 1993.
13. A. Said y W. A. Pearlman, “A New Fast and Efficient Image Codec Based on Set
Partitioning in Hierarchical Trees”, IEEE Transactions on Circuits and Systems for Video Technology, vol. 6, no. 3, pp. 243 - 250, junio de 1996.
14. H. J. Barnard, Image and Video Coding Using a Wavelet Decomposition, Tesis
doctoral, Universidad Tecnológica de Delft, Grupo de teoría de la información del departamento de ingeniería eléctrica, Holanda, 1994.
15. A. Skodras, C. Christopoulos y T. Ebrahimi, “The JPEG 2000 Still Image Compression
Standard”, IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 36 – 58, septiembre de 2001.
16. O. O. Vergara Villegas, R. Pinto Elías, P. Rayón Villela y A. Magadán Salazar, “Edge
Preserving Lossy Image Compression with Wavelets and Contourlets”, Proc. of the Electronics, Robotics and Automotive Mechanics Conference (CERMA), vol. 1, pp. 3 – 8, Cuernavaca, Morelos, México, septiembre de 2006.
17. D. J. Jackson y S. J. Hannah, “Comparative Analysis of Image Compression
Techniques”, Proc. of the Twenty-Fifth Southeastern Symposium on System Theory (SSST), pp. 513 – 517, Alabama, U.S.A, marzo de 1993.
18. P. N. Chen y F. Alajaji, Lecture Notes on Information Theory, vol.1, mayo de 2003. 19. C. E. Shannon, “A Mathematical Theory of Communication”, The Bell System
Technical Journal, vol. 27, pp. 379 – 423, octubre de 1948. 20. J. R. Clarke, “Image and Video Compression: A Survey”, Departamento de
computación e ingeniería eléctronica, Heriot - Watt University, Riccarton, Escocia, 1999.
21. K. Dezhgosha, A. K. Sylla, y E. Ngouyassa, “Lossless and Lossy Image Compression
Algorithms for On-Board Processing in Spacecrafts”, Proc. of the IEEE National Aerospace and Electronics Conference (NAECON), vol. 1, pp. 416 – 423, Dayton, OH, U.S.A., mayo de 1994.
22. V. Bhaskaran y K. Konstantinides, Image and Video Compression Standards:
Algorithms and Architectures, Kluwer International Series in Engineering and Computer Science, noviembre de 1995.

Bibliografía
94
23. D. A. Huffman, “A method for the Construction of Minimum Redundancy Codes”, Proc. of the Institute of Radio Engineers (IRE), vol. 40, pp. 1098 - 1101, septiembre de 1952
24. M. Nelson, “Arithmetic Coding + Statistical Modeling = Data Compression, Part 1
Arithmetic Coding”, Dr. Dobb`s Journal, febrero de 1991. 25. V. G. Ruíz e I. García, “Una Implementación del Algoritmo de Compresión Lempel –
Ziv – Welch (LZW)”, Proc. de las I Jornadas de Informática, Tenerife, España, julio de 1995.
26. G. K. Wallace, “The JPEG Still Picture Compression Standard”, Communications of the
ACM, vol. 34, no. 4, pp. 30 – 44, abril de 1991. 27. G. Davis y A. Nosratinia, “Wavelet-Based Image Coding: An Overview”, Applied and
Computational Control, Signals, and Circuits, vol. 1, no. 1. pp. 205 – 269, 1998. 28. R. Ôktem, Transform Domain Algorithms for Image Compression and Denoising, Tesis
de maestría, Laboratorio de procesamiento de señales, Universidad Tecnológica de Tampere, Finlandia, mayo de 2000.
29. A. Youssef y A. Nakassis., “Lossy Compression Transforms a Lecturer Series of Data
Compression”, Instituto Nacional de Estándares y Tecnología, Gaithersburg Maryland, diciembre de 1999.
30. A. Haar, Zur Theorie der orthogonalen Funktionensysteme, Tesis doctoral, Universidad
de Göttingen, Alemania, 1909. 31. M. Antonini, M. Barlaud, P. Mathieu e I. Daubechies, “Image Coding Using Wavelet
Transform”, IEEE Transactions on Image Processing, vol. 1, no. 2, pp. 205 – 220, abril de 1992.
32. J. Villaseñor, B. Belzer B. y J. Lia, “Wavelet Filter Evaluation for Image
Compression”, IEEE Transactions on Image processing, vol. 4, no. 8, pp. 1053 – 1060, agosto de 1995.
33. S. G. Mallat, “A theory for Multiresolution Signal Decomposition: The Wavelet
Representation”, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 11, no. 2, pp. 674 – 693, julio de 1989.
34. M. N. Do y M. Vetterli, “The Contourlet Transform: An Efficient Directional
Multiresolution Image Representation”, IEEE Transactions on Image Processing, vol. 14, no. 12, pp. 2091 – 2106, diciembre de 2005.

Bibliografía
95
35. M. N. Do y M. Vetterli, “Contourlets: A Directional Multiresolution Image Representation”, Proc. of the IEEE International Conference on Image Processing (ICIP), Rochester, New York, U.S.A., septiembre de 2002.
36. A. N. Belbachi y P. M. Goebel, “The Contourlet Transform for Image Compression”,
Proc. of the Conference Physics in Signal and Image Processing (PSIP), Toulouse, Francia, febrero de 2005.
37. S. M. Phoong, C. W. Kim, P. P. Vaidyanathan y R. Ansari, “A New Class of Two-
Channel Biorthogonal Filter Banks and Wavelet Bases”, IEEE Transactions on Signal Processing, vol. 43, no. 3, pp. 649 – 665, marzo de 1995.
38. A. Vasuki y P. T. Vanathi, “A review of Vector QuantizationTechniques”, IEEE
Potentials, vol. 25, no. 4, pp. 39 – 47, julio/agosto de 2006. 39. P. C. Cosman, K. L. Oehler, E. A. Riskin y R. M. Gray, “Using Vector Quantization for
Image processing”, Proceedings of the IEEE, vol. 81, no. 9, pp 1236 – 1341, septiembre de 1993.
40. D. Schilling y P. C. Cosman, “Preserving Step Edges in Low Bit Rate Progressive
Image Compression”, IEEE Transactions on Image Processing, vol. 12, no. 12, pp. 1473 – 1484, diciembre de 2003.
41. A. Moffat, R. M. Neal e I. H. Witten, “Arithmetic Coding Revisited”, ACM
Transactions on Information Systems, vol. 16, no. 3, pp. 256 – 294, julio de 1998. 42. P. G. Howard y J. S. Vitter, “Analysis of Arithmetic Coding for Data Compression”,
Information Processing and Management, vol. 28, no. 6, pp. 749 – 763, noviembre de 1992.
43. A. Saffor, R. A. Bin Ramli, K. Hoong Ng y D. Dowsett, “Objective and Subjective
Evaluation of Compressed Computed Tomography (CT) Images”, The Internet Journal of Radiology, vol. 2, no. 2, junio de 2002.
44. A. Mertins, “Image Compression Via Edge-Based Wavelet Transform”, Optical
Engineering, vol. 38, no. 6, pp. 991 – 1000, junio de 1999. 45. M. Mrak, S. Grgic y M. Grgic, “Reliability of Objective Picture Quality Measures”,
Journal of Electrical Engineering, vol. 55, no. 1 - 2, pp. 3 – 10, 2004. 46. M. Miyahara, K. Kotani y V. R. Algaza, “Objective Picture Quality Scale (PQS) for
Image Coding”, IEEE Transactions on Communications, vol. 46, no. 9, pp. 1215 – 1226, septiembre de 1998.

Bibliografía
96
47. A. J. Naseer y S. Jassim, “Feature-Preserving Image/Video Compression”, Proc. of the SPIE Unmanned/Unattended Sensors and Sensor Networks II, vol. 5986, pp. 87 – 95, octubre de 2005.
48. J. F. Canny, “A Computational Approach to Edge Detection”, IEEE Transactions on
Pattern Analysis and Machine Intelligence, vol. 8, no. 6, pp. 679 - 698, noviembre de 1986.
49. S. M. Smith y J. M. Brady, “SUSAN - A New Approach to Low Level Image
Processing”, International Journal of Computer Vision, vol. 23, no. 1, pp. 45 - 78, mayo de 1997.
50. O. O. Vergara Villegas, R. Pinto Elías y V. G. Cruz Sánchez, “Arquitectura de un
Sistema de Compresión de Imágenes con Wavelets”, en revisión para su publicación en la revista Ingeniería, Investigación y Tecnología de la UNAM.
51. R. L. Lagendijk, “Image and Video Compression Learning Tool, VcDemo 5.03”, Grupo
de teoría de la información y comunicación de la Universidad tecnológica de Delft, Holanda, septiembre de 2004.
52. J. A. Nalon, J. Baptista y T. Yabu-Uti, “Compression of Quincunx Subbands”, Proc. of
the XV Brazilian Symposium on Computer Graphics and Image Processing (SIBGRAPI), pp. 335 – 341, Fortaleza, Brasil, octubre de 2002
53. D. D.Y Po y M. N. Do, “Directional Multiscale Modelling of Images using The
Contourlet Transform”, IEEE Transactions on Image Processing, vol. 15, no. 6, pp. 1610 - 1620, junio de 2006.
54. J. Flusser, “Moment Invariants in Image Analysis”, Enformatika Transactions on
Engineering, Computing and Technology, vol. 11, pp. 196 – 201, febrero de 2006. 55. S. Maitra, “Moment Invariants”, Proceedings of the IEEE, vol. 67, pp. 697 – 699, abril
de 1979. 56. S. Cen, H. Persson, D. Schillin, P. C. Cosman y C. Berry, “Human Observer Responses
to Progressively Compressed Images”, Proc. of the 31st Asilomar conference on Signals, Systems, Computers, vol. 1, pp. 657 – 661, Pacific Grove, CA, U.S.A., noviembre de 1997.
57. K. L. Lee y L. H. Chen, “Unsupervised Texture Segmentation by Determining the
Interior of Texture Regions Based on Wavelet Transform”, International Journal of Pattern Recognition and Artificial Intelligence, vol. 15, no. 8, pp. 1231 – 1250, diciembre de 2001.

Bibliografía
97
58. J. Portilla y E. P. Simoncelli, “A Parametric Texture Model based on Joint Statistics of Complex Wavelet Coefficients”, International Journal of Computer Vision, vol. 40, no. 1, pp. 49 - 71, octubre de 2000.
59. National Instruments, Vision Builder, available [on line]:
http://www.ni.com/vision/vbai.htm, U.S.A., 2005. 60. E. Le Pennec y S. G. Mallat, “Sparse Geometric Image Representations with
Bandelets”, IEEE Transaction on Image Processing, vol. 14, no. 4, pp. 423 - 438, abril de 2005.
61. E. J. Candès, Ridgelets: Theory and Applications, Tesis doctoral, Departamento de
estadística, Universidad de Stanford, U.S.A, 1998. 62. D. L. Donoho, “Wedgelets: Nearly - Minimax Estimation of Edges”, Annals of
Statistics, vol. 27, no. 3, pp. 859 - 897, junio de 1999.

Anexo A La Transformada Wavelet Discreta (TWD)
98
Anexo A La Transformada Wavelet Discreta (TWD) La TWD es el núcleo de la compresión de imágenes y la selección de la familia wavelet a utilizar afecta directamente, junto con otros factores, a la calidad de la imagen reconstruida.
Para la selección se debe tomar en cuenta la suavidad (orden del filtro) y los momentos
vanishing (poder de aproximación de la función wavelet de escalamiento). Es decir, mientras mayor sea el número de momentos la función de escalamiento puede representar con mayor precisión señales más complejas.
Por otro lado, es importante seleccionar el nivel de descomposición wavelet que
determina la resolución del nivel más bajo obtenido en el dominio wavelet, es decir el número de veces que se aplicará la TWD a la imagen. Un estudio demostró que el número ideal de niveles es obtenido buscando un equilibrio entre la naturaleza de la señal y un criterio como el de la entropía, el nivel máximo de descomposiciones esta definido por: Log2(N) donde N es el tamaño de la imagen. Además, se asegura que el primer nivel de descomposición contiene aproximadamente el 98 % de la compresión. A.1 Filtros de descomposición wavelet Para el diseño del filtro es importante tomar en cuenta el propósito final de la imagen, por ejemplo, si se diseñan filtros de orden alto se obtiene buena localización de frecuencia dado que se incrementa la compactación de energía. Los filtros de orden bajo tienen mejor localización en el tiempo y pueden preservar información importante acerca de los bordes. Lo ideal, al diseñar el filtro es encontrar un balance entre la longitud del filtro, el grado de suavidad y la complejidad de diseño.
La TWD ortogonal está completamente definida por el filtro de escalamiento, que es un
filtro RIF (Respuesta de Impulso Finito) de longitud 2N y suma 1. Primero se deben obtener los coeficientes del filtro de escalamiento para después crear el filtro de descomposición que está determinado por su longitud y orden N.
Los coeficientes se pueden obtener del toolbox de wavelets de Matlab. Otra forma de
obtener los coeficientes es con el algoritmo de Shensa que consta de dos pasos: Primero se

Anexo A La Transformada Wavelet Discreta (TWD)
99
debe calcular el filtro L "Lagrange à trous" de orden N que es un filtro simétrico de longitud 4N - 1 raíces, definido por la ecuación A.1.
)](0..0)2(0)1(1)1(0...0)1(0)([ NaaaaNaNaL −= (A.1)
Donde:
( )Nkpara
ik
i
ka N
kiNi
N
kiNi
,....,121
)(
1
1
=−
⎟⎠⎞
⎜⎝⎛ −
=
∏
∏
≠+−=
≠+−=
(A.2)
Después, se obtiene el vector R que contiene las raíces cuadradas en módulos complejos
de los polinomios cuyos coeficientes son elementos del vector L ordenadas de forma descendiente. Lo que se traduce al cálculo de los valores propios de L. Al final se obtiene el polinomio con raíces específicas que define los coeficientes del filtro.
Con los coeficientes del filtro de escalamiento se diseña el filtro de descomposición pasa bajo y pasa alto. Primero se deben normalizar los coeficientes (Coef) obtenidos con la ecuación A.3.
)(/ CoefsumCoefCoef = (A.3)
Donde sum es la sumatoria de todos los coeficientes del filtro de escalamiento. El filtro de descomposición pasa bajo (Lo_D) se obtiene con la ecuación A.4.
CoefDLo *2_ = (A.4)
Y el filtro de descomposición pasa alto (Hi_D) con la ecuación A.5.
)_(_ DLoqmfDHi = (A.5)
Donde qmf (por sus siglas en inglés de Quadrature Mirror Filter) es un banco de filtros
que cambia el orden de los coeficientes del vector (el último es el primero) y que cambia los signos de cada entrada par.
Para las wavelets biortogonales (B2.2) se definen de forma separada los filtros de
descomposición y reconstrucción. Primero se obtienen los coeficientes del filtro de escalamiento después se realiza un rellenado dado que no es simétrico. Por ejemplo, para la TWD B2.2 se agrega un 0 al final y se obtiene un nuevo vector de tamaño 6. Por último se realiza el proceso de filtros ortogonales como se explicó anteriormente. Un ejemplo de los filtros pasa bajos y pasa altos se mostró en la tabla 2.2

Anexo A La Transformada Wavelet Discreta (TWD)
100
A.2 Convolución, extensión y downsampling Para transformar una imagen con wavelets se utiliza un Filtro Pasa Altos (FPA) para representar las frecuencias altas (partes detalladas de la imagen) y un Filtro Pasa Bajos (FPB) para las frecuencias bajas (partes suaves de la imagen). Los filtros son trasladados y escalados mediante convolución en el eje del tiempo para producir un conjunto de funciones wavelets en diferentes colocaciones y en diferentes escalas.
En una imagen la convolución puede producir problemas en las orillas, dado que puede
introducir información que no estaba presente en la imagen original. Algunas soluciones a dicho problema son: extensión periódica y extensión simétrica de la entrada. Considere la submatriz de 4 x 4 correspondiente a la imagen Lena de la figura A.1.
Figura A. 1. Imagen ejemplo para la TWD. a) Lena, b) Submatriz de píxeles de Lena.
Para el presente trabajo de investigación se utilizó la extensión periódica. Sobre la
imagen se debe realizar la extensión en las columnas y en los renglones que se obtiene añadiendo N/2 muestras al principio y al final de los cuatro extremos de la imagen (N = tamaño del filtro). Para la TWD Haar se añade una muestra en cada extremo (2/1) (6 x 6) y para D4 se añaden 4 muestras (8/2) (12 x 12). La figura A.2 muestra el resultado de la extensión con la TWD Haar, para la figura A.1b.
Figura A. 2. Extensión periódica en columnas y renglones de la imagen A.1b.
Después de la extensión se realiza la convolución con el FPB en los renglones de la
figura A.2 el resultado se muestra en la figura A.3.

Anexo A La Transformada Wavelet Discreta (TWD)
101
Figura A. 3. Convolución con el FPB en los renglones de la figura A.2.
La matriz resultante es de tamaño: [ma + mb - 1, na + nb - 1] donde m son los renglones
y n son las columnas de las respectivas matrices (a: matriz original y b: filtro). Enseguida se realiza la convolución en los renglones de la figura A.2 con el FPA, el resultado se muestra en la figura A.4.
Figura A. 4. Convolución con el FPA en los renglones de la figura A.2.
La figura A.3 es convolucionada en las columnas con el FPB, el resultado se muestra en
la figura A.5.
Figura A. 5. Convolución con el FPB en las columnas de la figura A.3.

Anexo A La Transformada Wavelet Discreta (TWD)
102
A continuación se realiza la convolución en las columnas con el FPA sobre la matriz de la figura A.3, el resultado se muestra en la figura A.6. Después, la figura A.4 se convoluciona en las columnas con el FPB el resultado se muestra en la figura A.7.
Figura A. 6. Convolución con el FPA en las columnas de la figura A.3.
Figura A. 7. Convolución con el FPB en las columnas de la figura A.4.
Por último, se convolucionan las columnas con el FPA sobre la figura A.4 el resultado
obtenido se muestra en la figura A.8.
Figura A. 8. Convolución con el FPA en columnas de la figura A.4.
Las líneas punteadas en las matrices delimitan el tamaño de la matriz original (4 x 4).
En las figuras A5, A6, A7 y A8 es necesario seleccionar una de cada dos muestras en columnas y renglones (matrices de 2 x 2), a ese proceso se le conoce como downsampling (submuestreo).

Anexo A La Transformada Wavelet Discreta (TWD)
103
Del downsampling en la figura A.5 se obtiene la matriz de coeficientes de aproximación (LL de la figura A.9). Al aplicarla sobre la figura A.6 se obtiene la matriz de coeficientes verticales (LH de la figura A.9). Al aplicarla sobre la figura A.7 se obtiene la matriz de coeficientes horizontales (HL de la figura A.9). Y al aplicarla en la figura A.8 se obtiene la matriz de coeficientes diagonales (HH de la figura A.9).
La matriz de descomposición wavelet compuesta por las cuatro submatrices resultantes
del downsampling se muestra en la figura A.9.
Figura A. 9. Descomposición con la TWD. a) Descomposición a un nivel, b) Descomposición a
dos niveles.
El proceso se repite de acuerdo al número de nivel de resolución seleccionado y se aplica a la matriz de coeficientes LL, la figura A.9b muestra el proceso de descomposición a dos niveles.
A.3 Filtros de reconstrucción wavelet Para el caso de las wavelets ortogonales los filtros de reconstrucción se obtienen de los filtros de descomposición. El filtro de reconstrucción pasa bajos (Lo_R) se obtiene con la ecuación A.6.
)_(_ DLoCoefrevRLo = (A.6)
El filtro de reconstrucción pasa altos (Hi_R) con la ecuación A.7.
)_(_ DHiCoefrevRHi = (A.7)
Donde Coefrev reordena las posiciones del vector, el último elemento es ahora el
primero, el penúltimo el segundo y así sucesivamente. Para las wavelets biortogonales los coeficientes de reconstrucción no son iguales a los
coeficientes de descomposición. Primero, se deben crear los coeficientes de descomposición, para la wavelet biortogonal 2.2 son: 0.5, 0.25, 0.5. Después se realiza el rellenado para igualar el tamaño del filtro de descomposición (tamaño 6). Por último, se obtiene el filtro ortogonal de reconstrucción con el proceso que se explicó anteriormente.

Anexo A La Transformada Wavelet Discreta (TWD)
104
A.4 Upsampling, extensión y convolución Para descomprimir una imagen se toma cada una de las matrices de coeficientes (2 x 2), y se aplica la operación de upsampling (proceso que agrega muestras en los renglones y las columnas) para obtener el tamaño de la matriz original (4 x 4).
La figura A.10a muestra el resultado del upsampling sobre la matriz wavelet de aproximación (LL). La figura A.10b muestra el resultado con la matriz horizontal (LH) y la figura A.10c con la matriz vertical (HL). Los cálculos para la matriz diagonal (HH) no se muestran dado que son ceros.
Figura A. 10. Upsampling en columnas y renglones. a) Matriz LL, b) Matriz LH y c) Matriz HL.
Es necesario realizar una extensión de las matrices de la figura A.10a, A.10b, A.10c en
los renglones y en las columnas, el resultado se muestra en las figuras A.11a, A.11b y A.11c respectivamente.
Figura A. 11. Extensión en columnas y renglones. a) Matriz LL, b) Matriz HL y c) Matriz LH.

Anexo A La Transformada Wavelet Discreta (TWD)
105
Después se aplica el proceso de convolución sobre la figura A.11a en las columnas con
el FPB, el resultado se muestra en la figura A.12a, posteriormente se aplica el mismo filtro en los renglones y el resultado se muestra en la figura A.12b.
Figura A. 12. Convolución sobre la figura A.11a. a) En columnas con el FPB, b) En renglones con
el FPB.
Para la figura A.11b se aplica el proceso de convolución con el FPA en las columnas,
el resultado se muestra en la figura A.13a, después se aplica el FPB en los renglones y el resultado se muestra en la figura A.13b.
Figura A. 13. Convolución sobre la figura A.11b. a) En columnas con el FPA, b) En renglones con
el FPB.
En el caso de la figura A.11c se aplica el proceso de convolución con el FPB en las
columnas el resultado se muestra en la figura A.14a, después se aplica el FPA en los renglones y el resultado se muestra en la figura A.14b.
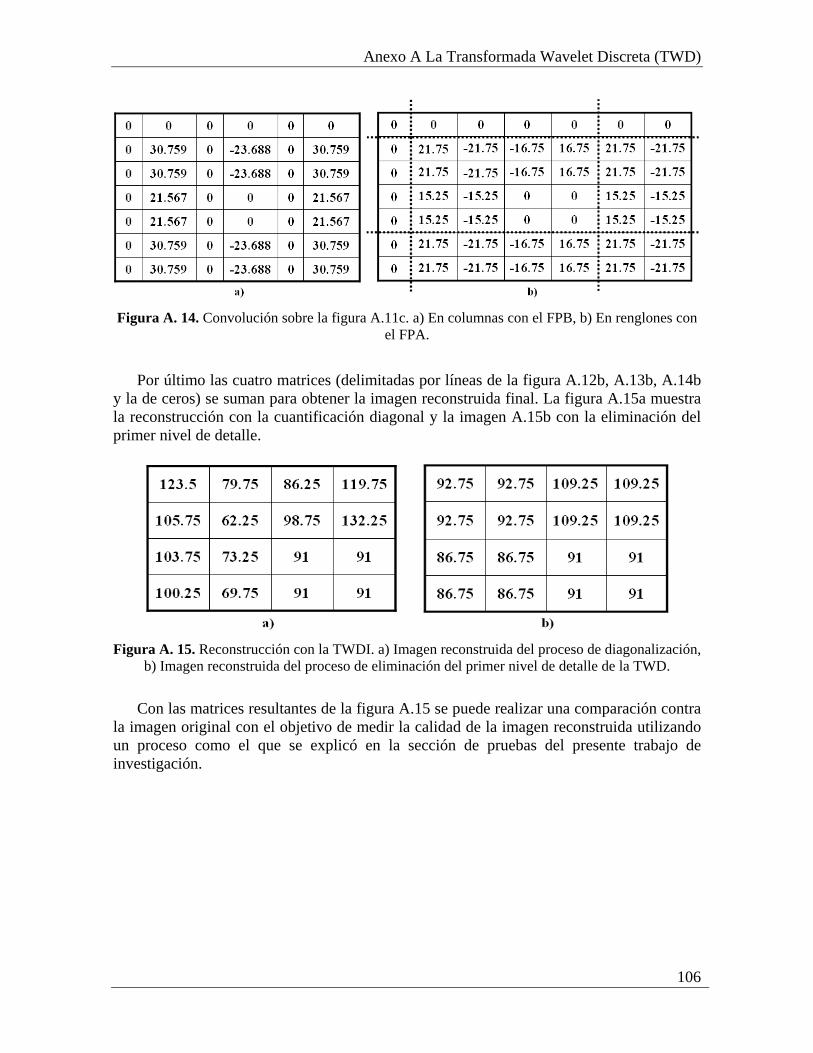
Anexo A La Transformada Wavelet Discreta (TWD)
106
Figura A. 14. Convolución sobre la figura A.11c. a) En columnas con el FPB, b) En renglones con
el FPA.
Por último las cuatro matrices (delimitadas por líneas de la figura A.12b, A.13b, A.14b
y la de ceros) se suman para obtener la imagen reconstruida final. La figura A.15a muestra la reconstrucción con la cuantificación diagonal y la imagen A.15b con la eliminación del primer nivel de detalle.
Figura A. 15. Reconstrucción con la TWDI. a) Imagen reconstruida del proceso de diagonalización,
b) Imagen reconstruida del proceso de eliminación del primer nivel de detalle de la TWD.
Con las matrices resultantes de la figura A.15 se puede realizar una comparación contra
la imagen original con el objetivo de medir la calidad de la imagen reconstruida utilizando un proceso como el que se explicó en la sección de pruebas del presente trabajo de investigación.

Anexo B La Transformada Contourlet Discreta (TCD)
107
Anexo B
La Transformada Contourlet Discreta (TCD) La TCD permite resolver los problemas o desventajas que la TWD tiene para detectar singularidades en 2D, por medio de un análisis direccional. Al igual que en la TWD los principales retos para la TCD son la selección de una base, la construcción de los filtros de reconstrucción y descomposición y la selección del número de niveles (tanto piramidales como direccionales). En las siguientes secciones se muestra una explicación de los pasos a realizar para el cálculo de la TCD de una imagen. B.1 Filtros de descomposición y reconstrucción contourlet Para obtener la TCD lo primero que se debe realizar es el proceso de selección de los filtros de reconstrucción y descomposición laplaciana y direccional. En el caso de la descomposición piramidal se utilizará como ejemplo el filtro Haar cuya construcción es similar a la que ya se explicó en el anexo A para el caso de las wavelets.
En el caso del filtro direccional se diseña un banco de filtros que proporciona un método estructurado y eficiente para descomponer y analizar una señal discreta. Se utilizará también como ejemplo el filtro Haar.
La base para la construcción del filtro direccional es la de poder ofrecer la posibilidad
de realizar un submuestreo en múltiples direcciones para lo que se necesita utilizar una latice (matriz). Dicho muestreo esta definido como submuestreo en las subbandas quincunx.
Para efectos de este ejemplo se seleccionó un nivel de descomposición piramidal con
ocho direcciones respectivamente y como ya se mencionó tanto para la descomposición como para la reconstrucción se utilizará el filtro Haar.
Como ejemplo para la explicación del cálculo de la transformada contourlet discreta
suponga que se tiene como entrada la imagen que se muestra en la figura B.1a (Camman) que es de tamaño 16 x 16 y sus respectivos valores de píxeles mostrados en la figura B.1b.

Anexo B La Transformada Contourlet Discreta (TCD)
108
Figura B. 1. Imagen ejemplo para la TCD. a) Camman, b) Matriz de valores de los píxeles de
Camman.
B.2 Descomposición piramidal Después de la selección y construcción de los filtros se procede a la etapa donde se obtiene la descomposición piramidal de la imagen. Los filtros piramidales son los filtros pasa bajos de análisis (descomposición) y síntesis (reconstrucción) Haar cuyos coeficientes son [0.7071, 0.7071]. Al igual que en la TWD primero, se debe realizar una extensión de la imagen en las columnas y en los renglones. La extensión seleccionada es la periódica que a diferencia de la TWD sólo se aplica a la parte derecha e inferior de la imagen, el resultado de aplicarla sobre la imagen B.1b se muestra en la figura B.2.
Figura B. 2. Extensión en columnas y renglones de la imagen B.1b.

Anexo B La Transformada Contourlet Discreta (TCD)
109
Después de la extensión se debe convolucionar la imagen de la figura B.2 en las columnas y en los renglones con el filtro pasa bajos de análisis, el resultado de dicho proceso se muestra en la figura B.3.
Figura B. 3. Convolución con el FPB de análisis sobre la figura B.2.
Enseguida se debe realizar el proceso de downsampling en columnas y renglones para
obtener la imagen de aproximación (suavizada) la cual es del tamaño de la mitad de resolución de la imagen original (8 x 8) como se muestra en la figura B.4.
Figura B. 4. Imagen de aproximación. a) Camman obtenido del submuestreo, b) Píxeles
correspondientes a la figura B.4a.
La imagen obtenida en B.4b es sobre muestreada en las columnas y renglones para
regresarla a su tamaño original (16 x 16) y después es extendida periódicamente en la parte izquierda y superior de la imagen. El resultado se muestra en figura B.5.
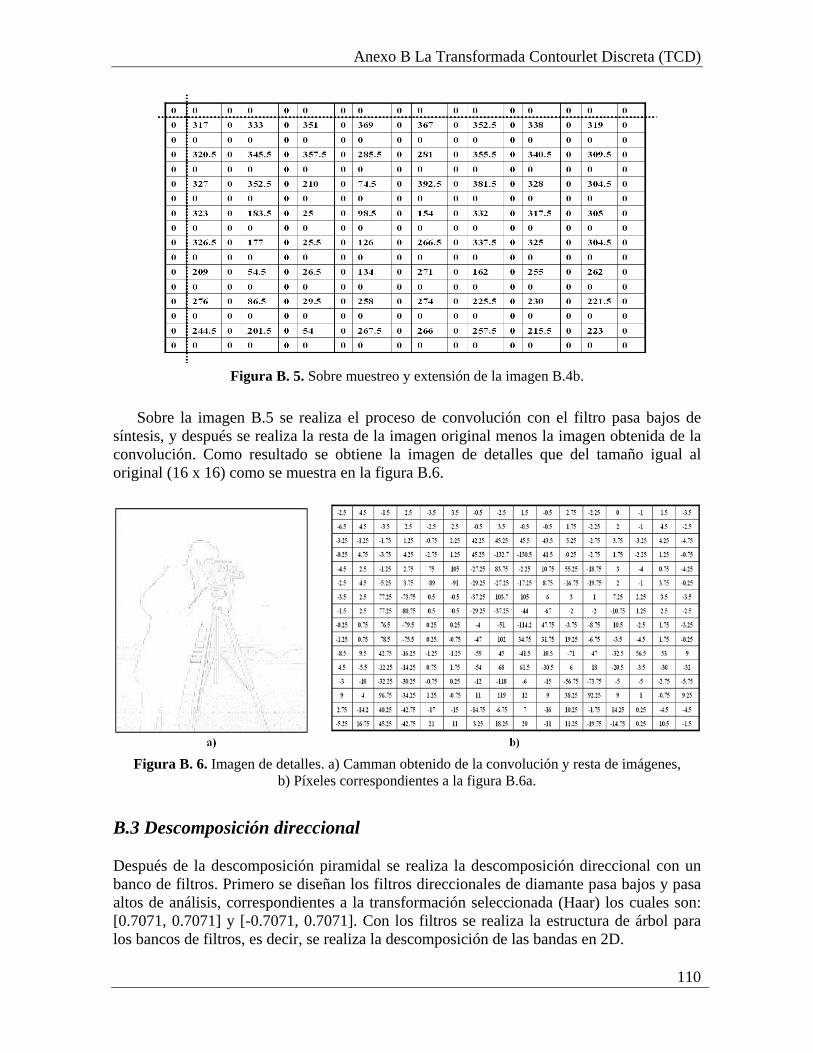
Anexo B La Transformada Contourlet Discreta (TCD)
110
Figura B. 5. Sobre muestreo y extensión de la imagen B.4b.
Sobre la imagen B.5 se realiza el proceso de convolución con el filtro pasa bajos de
síntesis, y después se realiza la resta de la imagen original menos la imagen obtenida de la convolución. Como resultado se obtiene la imagen de detalles que del tamaño igual al original (16 x 16) como se muestra en la figura B.6.
Figura B. 6. Imagen de detalles. a) Camman obtenido de la convolución y resta de imágenes,
b) Píxeles correspondientes a la figura B.6a.
B.3 Descomposición direccional
Después de la descomposición piramidal se realiza la descomposición direccional con un banco de filtros. Primero se diseñan los filtros direccionales de diamante pasa bajos y pasa altos de análisis, correspondientes a la transformación seleccionada (Haar) los cuales son: [0.7071, 0.7071] y [-0.7071, 0.7071]. Con los filtros se realiza la estructura de árbol para los bancos de filtros, es decir, se realiza la descomposición de las bandas en 2D.

Anexo B La Transformada Contourlet Discreta (TCD)
111
La matriz de la figura B.6b (16 x 16) es extendida en las columnas periódicamente, posteriormente se aplica el proceso de convolución con el filtro pasa altos y el resultado se muestra en la B.7. Después se realiza el mismo proceso con el filtro pasa bajos, el resultado de la convolución se muestra en la figura B.8.
Figura B. 7. Resultado de la convolución con el FPA sobre la figura B.6b.
Figura B. 8. Resultado de la convolución con el FPB sobre la figura B.6b.
A las dos matrices resultantes de la convolución (figura B.7 y B.8) se les aplica un
proceso de downsampling en los renglones de tipo quincunx. Para lograr dicho proceso, primero, se debe realizar un reordenamiento (resampling) quincunx de las imágenes B7 y B8 con la matriz R2 = [1, -1; 0, 1] que es de tipo 2. El resultado del reordenamiento se muestra en la figura B.9 para la figura B.7, el resultado para B.8 no se muestra pero el proceso de reordenamiento es idéntico.

Anexo B La Transformada Contourlet Discreta (TCD)
112
Figura B. 9. Reordenamiento quincunx sobre la imagen B.7.
Después del proceso de reordenamiento a las matrices se les aplica un proceso de
dowsampling en los renglones (8 x 16) y de nuevo un reordenamiento quincunx pero ahora con la matriz R3 = [1, 0; 1, 1] que es de tipo 3, sobre la matriz transpuesta obtenida del downsampling. El resultado obtenido de dicho proceso con la matriz pasa altos se muestra en la figura B. 10 y el resultado obtenido con la matriz del pasa bajos en la figura B.11.
Figura B. 10. Imagen resultante del downsampling y reordenamiento quincunx con el FPA.
Figura B. 11. Imagen resultante del downsampling y reordenamiento quincunx con el FPB.
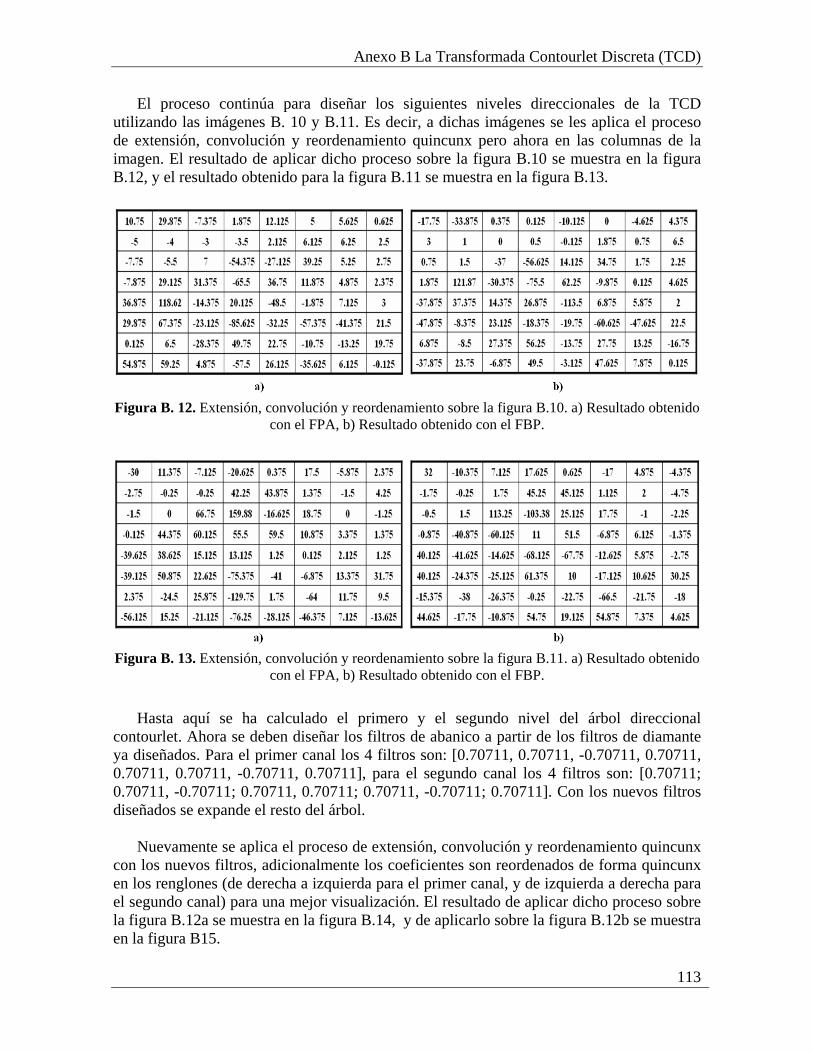
Anexo B La Transformada Contourlet Discreta (TCD)
113
El proceso continúa para diseñar los siguientes niveles direccionales de la TCD utilizando las imágenes B. 10 y B.11. Es decir, a dichas imágenes se les aplica el proceso de extensión, convolución y reordenamiento quincunx pero ahora en las columnas de la imagen. El resultado de aplicar dicho proceso sobre la figura B.10 se muestra en la figura B.12, y el resultado obtenido para la figura B.11 se muestra en la figura B.13.
Figura B. 12. Extensión, convolución y reordenamiento sobre la figura B.10. a) Resultado obtenido
con el FPA, b) Resultado obtenido con el FBP.
Figura B. 13. Extensión, convolución y reordenamiento sobre la figura B.11. a) Resultado obtenido
con el FPA, b) Resultado obtenido con el FBP.
Hasta aquí se ha calculado el primero y el segundo nivel del árbol direccional
contourlet. Ahora se deben diseñar los filtros de abanico a partir de los filtros de diamante ya diseñados. Para el primer canal los 4 filtros son: [0.70711, 0.70711, -0.70711, 0.70711, 0.70711, 0.70711, -0.70711, 0.70711], para el segundo canal los 4 filtros son: [0.70711; 0.70711, -0.70711; 0.70711, 0.70711; 0.70711, -0.70711; 0.70711]. Con los nuevos filtros diseñados se expande el resto del árbol.
Nuevamente se aplica el proceso de extensión, convolución y reordenamiento quincunx
con los nuevos filtros, adicionalmente los coeficientes son reordenados de forma quincunx en los renglones (de derecha a izquierda para el primer canal, y de izquierda a derecha para el segundo canal) para una mejor visualización. El resultado de aplicar dicho proceso sobre la figura B.12a se muestra en la figura B.14, y de aplicarlo sobre la figura B.12b se muestra en la figura B15.

Anexo B La Transformada Contourlet Discreta (TCD)
114
Figura B. 14. Extensión, convolución y reordenamiento sobre la figura B.12a. a) Resultado
obtenido con el filtro 1 del primer canal, b) resultado obtenido con el filtro 1 del segundo canal.
Figura B. 15. Extensión, convolución y reordenamiento sobre la figura B.12b. a) Resultado
obtenido con el filtro 2 del primer canal, b) resultado obtenido con el filtro 2 del segundo canal.
El mismo proceso se aplica sobre la figura B.13a y el resultado se muestra en la figura B16, por último se muestra el resultado obtenido con la figura B13b en la figura 17.
Figura B. 16. Extensión, convolución y reordenamiento sobre la figura B.13a. a) Resultado
obtenido con el filtro 3 del primer canal, b) resultado obtenido con el filtro 3 del segundo canal.

Anexo B La Transformada Contourlet Discreta (TCD)
115
Figura B. 17. Extensión, convolución y reordenamiento sobre la figura B.13b. a) Resultado
obtenido con el filtro 4 del primer canal, b) resultado obtenido con el filtro 4 del segundo canal. Por último el orden de las matrices resultantes de las figuras B16, y B17 es cambiado
con lo que se obtiene la descomposición piramidal y 8 direcciones. Al flujo de coeficientes se le añade el resultado obtenido de la aproximación (figura B.4b). La figura B.18 muestra gráficamente el ordenamiento de las subbandas y sus respectivos tamaños.
Figura B. 18. Subbandas de la TCD. a) Tamaño de las subbandas, b) Visualización de las
subbandas.
El proceso para la reconstrucción se realiza de manera inversa, es decir, primero se aplica la descomposición direccional inversa y después la descomposición piramidal inversa para obtener la imagen reconstruida final.

Anexo C Resultados de la investigación
116
Anexo C Resultados de la investigación Durante el tiempo en que se realizó la investigación doctoral se desarrollaron una gran cantidad de trabajos muy importantes para la solución del problema a continuación se ofrece un breve resumen de las publicaciones y actividades realizadas. DISTINCIONES 1. Incluido en el catálogo internacional Who’s Who in Science and Engineering, 2006 –
2007 (9th edition), por Marquis Who’s Who, U.S.A. pp. 2255, ISBN: 0-8379-5766-4, ISSN: 0083-9817.
REVISTAS 1. Osslan Osiris Vergara Villegas, “Comprimir los Datos Hasta que se Asfixien”,
Hypatia, Revista de divulgación científica tecnológica, Año 5, no. 4, enero – marzo 2005, pp. 15.
2. Osslan Osiris Vergara Villegas y Raúl Pinto Elías, “Digital Image Processing in
Wavelet Domain”, IEEE Looking Forward, vol. 13, Summer 2006, pp. 13 – 16, IEEE Computer Society.
3. Osslan Osiris Vergara Villegas y Raúl Pinto Elías, “Procesamiento Digital de
Imágenes en el Dominio Wavelet”, IEEE Looking Forward, vol. 13, Verano de 2006, pp. 13 – 16, IEEE Computer Society.
4. Osslan Osiris Vergara Villegas y Raúl Pinto Elías, “Feature Preserving Image
Coding with Contourlet Transform”, WSEAS Transactions on Signal Processing, vol. 2, no. 9, septiembre de 2006, pp. 1230 – 1237, ISSN: 1790-5022.
5. Raúl Pinto Elías, Osslan Osiris Vergara Villegas, Máximo López Sánchez y Vianey
Guadalupe Cruz Sánchez, “SPIHT Modification for Edge Preserving Wavelet Lossy Image Coding: An application for Automatic Inspection”, WSEAS Transactions on Signal Processing, vol. 2, no. 11, noviembre de 2006, pp. 1515 – 1522, ISSN: 1790-5022.

Anexo C Resultados de la investigación
117
6. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y José Ruíz Ascencio, “Performance of Lossy Image Compression Algorithms on Textures”, Research in Computing Science, Special Issue: Neural Networks and Associative Memories, vol. 21, noviembre de 2006, pp. 249 – 258, ISSN: 1870-4069.
7. Osslan Osiris Vergara Villegas, Raúl Pinto Elías, Patricia Rayón Villela y Andrea
Magadán Salazar, “Edge Preserving Lossy Image Compression with Wavelets and Contourlets”, Aceptado para su publicación en la revista “IEEE Latin America Transactions”. ISSN: 1548-0992.
8. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
“Arquitectura de un Sistema de Compresión de Imágenes con Wavelets”, En revisión para la revista “Ingeniería, Investigación y Tecnología” de la UNAM. ISSN: 1405-7743.
CONGRESOS INTERNACIONALES 9. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Marcos Aurelio Capistrán
Ocampo, “Lossy Image Compression with Refactoring Matrices”, Proceedings of the 6th International Conference on Computer Vision, Pattern Recognition and Image Processing (CVPRIP), Salt Lake City, Utah, USA, julio de 2005.
10. Osslan Osiris Vergara Villegas, René Arnulfo García Hernández, José Fco. Martínez
Trinidad, Raúl Pinto Elías, Jesús Ariel Carrasco Ochoa, “Data Preprocessing by Sequential Pattern Mining for LZW Compression”, Proceedings of the Mexican Internacional Conference on Computer Science (ENC), Puebla Puebla, México, septiembre de 2005, pp. 82 – 87, ISBN: 0-7695-2454-0, ISSN: 1550- 4069, IEEE Computer Society.
11. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
“Estudio e Implementación de Cuatro Transformaciones de Dominio y su Aplicación a la Compresión de Imágenes”, Memorias de las VII Jornadas Internacionales de las Ciencias Computacionales, Colima, Colima, México, noviembre de 2005, pp. 334 – 341.
12. Osslan Osiris Vergara Villegas, Raúl Pinto Elías, Andrea Magadán Salazar y Marco
Antonio Martínez Pérez, “Wavelet Lossy Image Compression: An Application to Pattern Recognition”, Proceedings of the International conference on Computational Intelligence and Security (CIS), Xi´an China, diciembre de 2005, pp.252 - 257, ISBN: 7-5606-1607-0. Xidian University press.
13. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
“Lossy Image Compression for Object Recognition Using Singular Value Decomposition”, Proceedings of the International conference on Computational

Anexo C Resultados de la investigación
118
Intelligence and Security (CIS), Xi´an China, diciembre de 2005, pp. 298 – 303, ISBN: 7-5606-1607-0. Xidian University press.
14. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
”Singular Value Decomposition Image Compression System for Automatic Object Recognition”, Proceedings of the IASTED International Conference on Advances in Computer Science and Technology (ACST), Puerto Vallarta, Jalisco, México, enero de 2006, pp. 95 – 100, ISBN: 0-88986-545-0, ISSN: 1482-7905. Acta Press.
15. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
“Apple Classification System with EZW and Daubechies D4 Lossy Image Compression”, Proceedings of the 16th International Conference on Electronics, Communications and Computers (CONIELECOMP), Puebla, Puebla, México, febrero de 2006, ISBN: 0-7695–2505-9. IEEE Computer Society.
16. Osslan Osiris Vergara Villegas y Raúl Pinto Elías, “Contourlet Based Lossy Image
Compression with Edge Preserving”, Proceedings of the 6th WSEAS International Conference on Signal Speech and Image Processing (SSIP), Lisboa, Portugal, septiembre 2006, pp. 116 – 121, ISBN: 969-8457-53-X, ISSN: 1790-5117.
17. Osslan Osiris Vergara Villegas, Raúl Pinto Elías, Patricia Rayón Villela y Andrea
Magadán Salazar, “Edge Preserving Lossy Image Compression with Wavelets and Contourlets”, Proceedings of the Electronics, Robotics and Automotive Mechanics Conference (CERMA), Vol. 1, Cuernavaca Morelos México, septiembre de 2006, pp. 3 – 8, ISBN: 0-7695-2569-7, ISSN: 2006-9213-49, IEEE computer Society.
18. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
“Feature Preserving Image Compression: A survey”, Proceedings of the Electronics, Robotics and Automotive Mechanics Conference (CERMA), Vol. 2, Cuernavaca Morelos México, septiembre de 2006, pp. 35 – 40, ISBN: 0-7695-2569-7, ISSN: 2006-9213-49, IEEE computer Society.
19. Raúl Pinto Elías, Osslan Osiris Vergara Villegas y Máximo López Sánchez, “Wavelet
Lossy Image Coding for Edge and Texture Preserving Using a Modified SPIHT”, Proceedings of the International Conference on Computational Intelligence and Security (CIS), Guangzhou, China en noviembre de 2006, ISBN: 1-4244-0604-8, IEEE computer Society.
20. Raúl Pinto Elías, Osslan Osiris Vergara Villegas, Máximo López Sánchez y Vianey
Guadalupe Cruz Sánchez, “SPIHT Modification for Edge Preserving Wavelet Lossy Image Coding: An application for Automatic Inspection”, Proceedings of the 5th WSEAS International Conference on Circuits, Systems, Electronics, Control and Signal processing (CSECS), Dallas Texas, noviembre de 2006, pp. 78 - 83, ISBN: 960-8457-55-6, ISSN: 1790-5117.

Anexo C Resultados de la investigación
119
CONGRESOS NACIONALES 21. Osslan Osiris Vergara Villegas y Raúl Pinto Elías, “Estudio Sobre Técnicas para
Compresión de Imágenes: Enfoques con y sin Pérdidas”, Memorias del Tercer Encuentro de Inteligencia Artificial (EnIA), Oaxtepec Morelos, México, octubre de 2003, pp. 462 – 469, ISBN: 968-5823-02-2.
22. Osslan Osiris Vergara Villegas y Raúl Pinto Elías, “Compresión de Imágenes por
Descomposición de Valores Singulares”, Memorias del Congreso Interuniversitario de Electrónica, Computación y Eléctrica (CIECE), Puebla Puebla, México, marzo de 2005.
23. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
“Lossy image compression with Daubechies D4 and Embedded zerotree wavelet coder”, Memorias del 6to Simposium Iberoamericano de Computación e Informática (SICI) Monterrey, Nuevo León, México, noviembre de 2005, pp. 210 – 218, ISBN: 968-5823-21-9.
24. Osslan Osiris Vergara Villegas, Raúl Pinto Elías y Vianey Guadalupe Cruz Sánchez,
“Compresión de Imágenes con Preservación de Características”, Memorias del 5to Congreso Internacional de Cómputo (AGECOMP), Cuernavaca Morelos, noviembre de 2006, ISBN: 968-878-273-4.
PONENCIAS INVITADO 1. Ponente en el sexto Simposium Internacional en ciencias en el Instituto Tecnológico de
Chetumal con la conferencia: “Compresión de Imágenes”, Chetumal México, Marzo 2005.
PARTICIPACIÓN EN TESIS 1. Asesor de la tesis de maestría “Análisis e Implementación de Algoritmos para la
Compresión/Descompresión de Imágenes”, por Marco Antonio Martínez Pérez en cenidet en marzo de 2006.
CONTACTO CON GRUPOS DE INVESTIGACIÓN 1. Profesora Pamela C. Cosman, Departamento de ingeniería en computación y eléctrica
de la “Universidad de California en San Diego (UCSD)”, Estados Unidos. Se encuentra a cargo del laboratorio de codificación de información y es autora de una gran cantidad de artículos en compresión de imágenes, incluyendo compresión con preservación de características.

Anexo C Resultados de la investigación
120
2. Profesor Reginald L. Lagendijk, Grupo de información y teoría de comunicación de “Univesidad Delft de tecnología” en Holanda. Creador del único programa de compresión de imágenes disponible en el mercado llamado VCdemo.
3. Profesores Amir Said y William A. Pearlman, Centro de investigación en
procesamiento de imágenes del “Instituto Politécnico Rensselaer”, Estados Unidos. Creadores del algoritmo de compresión Set Partitioning In Hierarchical Trees (SPIHT) y pioneros en los métodos de compresión progresivos.
4. Profesor Stéphane Mallat, Centro de matemáticas aplicadas de la “Escuela Politécnica
de Paris”, Francia. Pilar fundamental en la teoría de la compresión de imágenes con wavelets, propuso la teoría multiresolución. Además, es el creador de un nuevo paradigma de representación multiresolución conocido como bandelets.
5. Profesor Gabriel Peyre, Centro de matemáticas aplicadas de la “Escuela Politécnica de
Paris”, Francia. Creador de un muevo paradigma de representación multiresolución conocido como bandelets.
6. Profesor Minh N. Do, Departamento de ingeniería en computación y eléctrica de la
“Universidad de Illinois en Urbana-Champaign”, Estados Unidos. Creador de uno de los nuevos paradigmas multiresolución direccional más utilizados en la actualidad conocido como contourlets.
ACTIVIDADES 1. Miembro del comité técnico del 9th world Multiconferenece on Systemics, Cybernetics
and Informatics (WMSCI) en Orlando, Florida, USA, en Julio de 2005. 2. Miembro del comité técnico del Journal of Systemics, Cybernetics and Informatics. 3. Miembro del comité técnico del 2nd International Conference on Natural Computation
(ICNC) and the 3rd International Conference on Fuzzy Systems and Knowledge Discovery (FSKD) en Xi´an, China en septiembre de 2006.
4. Miembro del comité técnico del International Conference on Computational
Intelligence and Security (CIS) en Guangzhou, China en noviembre de 2006. 5. Miembro del comité técnico del Treceavo Congreso Internacional de Investigación en
Ciencias Computacionales (CIICC) en Tampico Madero Tamaulipas en noviembre de 2006.