biblioteca en java para la aplicación de los conjuntos
TRANSCRIPT

UNIVERSIDAD CENTRAL “MARTA ABREU” DE LAS VILLAS FACULTAD DE MATEMÁTICA, FÍSICA Y COMPUTACIÓN
Biblioteca en Java para la aplicación de los conjuntos aproximados en el
aprendizaje automatizado
Trabajo de Diploma para optar por el Título de
Licenciado en Ciencia de la Computación
Autor
Alejandro Geraldo Gómez Boix
Tutoras
Dra. Leticia Arco García
Lic. Adis Perla Mariño Rivero
Santa Clara, 2013

Hacemos constar que el presente Trabajo de Diploma ha sido realizado en la facultad de Matemática,
Física y Computación de la Universidad Central “Marta Abreu” de Las Villas (UCLV) como parte de la
culminación de los estudios de Licenciatura en Ciencia de la Computación, autorizando a que el
mismo sea utilizado por la institución para los fines que estime conveniente, tanto de forma total
como parcial y que además no podrá ser presentado en eventos ni publicado sin la previa
autorización de la UCLV.
______________________________
Firma del Autor
Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdo de la
dirección de nuestro centro y que el mismo cumple con los requisitos que debe tener un trabajo de
esta envergadura referido a la temática señalada.
______________________________ ______________________________
Firma del Tutor Firma del Tutor
________________________
Jefe del Seminario de Inteligencia Artificial

PENSAMIENTO
La diferencia entre construcción y creación es exactamente esto: una
cosa construida puede ser querida solo después de ser construida; pero
una cosa creada es querida antes de que exista.
Gilbert Keith Chesterton

DEDICATORIA
A la memoria de mis abuelos: Merido y Bertalina.
A quienes le debo mucho.
A mi padre y mi madre, que poco tienen y lo dan todo.
A mi hermana, por estar.

AGRADECIMIENTOS
Quisiera agradecer a todos los que de una forma u otra han hecho
posible la realización de este trabajo.
A mi padre y mi madre por la guía y el tesón.
A mi hermana...
A mis abuelos, que aunque ausentes les debo mucho por la persona en
la que me he convertido.
A mi tía Milagros, por apoyarme siempre.
A mis tutoras Leticia y Adis, por su orientación y su paciencia hacia
mi persona.
A la profesora María Matilde por toda la ayuda brindada.
A mis amigos, con los cuales he pasado estos largos 5 años, por pasar
momentos difíciles y gratos, por aguantarme.
A los viejos amigos, que siempre han estado junto a mí.

RESUMEN
Se dice Aprendizaje Automatizado a aquellos métodos de solución de problemas de aprendizaje por
las computadoras. Existen métodos de aprendizaje automatizado incorporados al Weka que utilizan la
Teoría de los Conjuntos Aproximados (Rough Set Theory; RST) para su funcionamiento; sin embargo,
su incorporación al Weka incluye la implementación por separado de las facilidades de RST necesarias
para el funcionamiento de cada uno de ellos, ya que no existe una biblioteca que encapsule todos los
elementos de RST que se aplican en métodos de aprendizaje automatizado. El objetivo general del
trabajo de diploma consiste en desarrollar una biblioteca en Java que incorpore los principales
elementos de la RST clásica y extendida, aplicables en el desarrollo de métodos de aprendizaje
automatizado y su validación. Los principales resultados obtenidos son: (1) la biblioteca que encapsula
las definiciones, conceptos y medidas de RST aplicables en el desarrollo de métodos de Aprendizaje
Automatizado, con la finalidad de incorporar esta biblioteca a la herramienta Weka, (2) la
implementación de un algoritmo para el cálculo de reductos que utiliza el modelo de optimización
basado en colonias de hormigas y (3) la incorporación al Weka de un paquete para la validación del
agrupamiento, el cual incorpora medidas de la Teoría de conjuntos aproximados, y por tanto, hace
uso de la biblioteca creada.

ABSTRACT
It is called Machine Learning to those problem solving methods of learning by computers. There are
machine learning methods incorporated to Weka that use the Rough Set Theory (RST) for its
operation, however to join it to Weka includes the separated implementation of RST facilities that are
necessary for the operation of each one of them, since there is no library that encapsulates all
elements of RST applied in machine learning methods. The general objective of this research paper is
to develop a Java library that incorporates the main elements of the classical and extended RST,
applicable in the development of machine learning methods and its validation. The main results are:
(1) the library that encapsulates the definitions, concepts and measures of RST, applicable in the
development of Machine Learning methods, in order to incorporate this library to a Weka tool, (2) the
implementation of a algorithm for calculating reducts that uses an optimization model based on ant
colonies and (3) the incorporation to Weka of a package for clustering validation, which incorporates
measures of rough sets theory, and thus makes use of the created library.

TABLA DE CONTENIDOS
INTRODUCCIÓN ................................................................................................................................................. 1
1 TEORÍA DE CONJUNTOS, RELACIONES BINARIAS Y TEORÍA DE CONJUNTOS APROXIMADOS ..................... 7
1.1 TEORÍA BÁSICA DE CONJUNTOS .................................................................................................................. 7
1.1.1 Notaciones de conjuntos ............................................................................................................... 7
1.1.2 Operaciones sobre conjuntos ......................................................................................................... 8
1.2 RELACIONES BINARIAS ............................................................................................................................. 8
1.3 TEORÍA DE CONJUNTOS APROXIMADOS ...................................................................................................... 11
1.3.1 Teoría de los conjuntos aproximados clásica ................................................................................ 13
1.3.2 Conjuntos aproximados en sistemas de información incompletos ................................................. 16
1.3.2.1 Conjuntos aproximados basados en una relación transitiva ................................................................ 17
1.3.2.2 Conjuntos aproximados monótonos ................................................................................................... 18
1.3.2.3 Conjuntos aproximados para sistemas de información incompletos basados en una relación no simétrica
......................................................................................................................................................... 19
1.3.3 Conjuntos aproximados basados en relaciones de similaridad ...................................................... 20
1.3.4 Medidas para realizar inferencias ................................................................................................ 25
1.3.5 Reductos ..................................................................................................................................... 29
1.3.5.1 Tipos de reductos............................................................................................................................... 30
1.3.5.2 Cálculo de reductos ........................................................................................................................... 32
1.4 CONSIDERACIONES PARCIALES DEL CAPÍTULO ............................................................................................... 33
2 BIBLIOTECA EN JAVA QUE PERMITE TRABAJAR CON LOS CONJUNTOS APROXIMADOS ........................... 34
2.1 GENERALIDADES DEL LENGUAJE JAVA ........................................................................................................ 34
2.2 DESARROLLO DE BIBLIOTECAS EN JAVA ....................................................................................................... 35
2.3 CONCEPCIÓN GENERAL DE LA BIBLIOTECA RST ............................................................................................. 36
2.3.1 Diseño de la biblioteca RST .......................................................................................................... 38
2.3.2 Diagrama de clases ..................................................................................................................... 39
2.3.3 Cálculo de reductos ..................................................................................................................... 46
2.3.3.1 Optimización basada en colonias de hormigas.................................................................................... 46
2.3.3.2 Cálculo de reductos usando ACO ........................................................................................................ 48
2.3.3.3 Diseño e implementación ................................................................................................................... 53
2.4 CONCLUSIONES PARCIALES DEL CAPÍTULO ................................................................................................... 54

3 UTILIZACIÓN DE LA BIBLIOTECA RST DESDE WEKA .................................................................................. 56
3.1 MEDIDAS PARA LA VALIDACIÓN DEL AGRUPAMIENTO UTILIZANDO RST ............................................................... 56
3.2 GENERALIDADES DE WEKA ..................................................................................................................... 59
3.2.1 Entrada de datos ......................................................................................................................... 60
3.2.2 Interioridades de Weka ............................................................................................................... 61
3.2.3 Validación del agrupamiento en Weka......................................................................................... 65
3.3 PAQUETE PARA VALIDAR AGRUPAMIENTOS EN WEKA UTILIZANDO RST .............................................................. 67
3.4 CONCLUSIONES PARCIALES DEL CAPÍTULO ................................................................................................... 70
CONCLUSIONES Y RECOMENDACIONES ........................................................................................................... 71
REFERENCIAS BIBLIOGRÁFICAS ........................................................................................................................ 72
ANEXOS ........................................................................................................................................................... 75
ANEXO 1. TRANSFORMACIONES DE DISTANCIAS A SIMILITUDES .................................................................................... 75
ANEXO 2. DISTANCIAS, SIMILITUDES Y DISIMILITUDES MÁS USADAS PARA COMPARAR OBJETOS ............................................ 76
ANEXO 3. ALGUNAS VARIANTES PARA EL CÁLCULO DEL UMBRAL DE SIMILITUD ENTRE OBJETOS ............................................ 78

1
INTRODUCCIÓN
Desde el surgimiento de la computación se han tratado de ingeniar métodos con el objetivo de lograr
que la computadora aprenda por sí misma. El interés es lograr programarla para que mejore
automáticamente con su propia experiencia. En particular, el campo de la Inteligencia Artificial (IA)
que estudia los métodos de solución de problemas de aprendizaje por las computadoras se le
denomina Aprendizaje Automatizado (Machine Learning). Aún no se ha podido lograr que las
computadoras aprendan casi tan bien como el hombre aprende, sin embargo se han creado
algoritmos que son eficaces para ciertos tipos de tareas de este ámbito, emergiendo así una
comprensión teórica de aprendizaje.
El Aprendizaje Automatizado se ha convertido en un campo multidisciplinario, mostrando resultados
de inteligencia artificial, probabilidades y estadística, filosofía, teoría de cómputo, teoría de control,
teoría de información, psicología, neurobiología, ciencia cognoscitiva, complejidad computacional y
otros campos. La creación de diversos algoritmos de aprendizaje automatizado ha traído consigo la
difícil tarea de seleccionar alguno de ellos cuando se requiera su utilización. La herramienta WEKA
(Waikato Environment for Knowledge Analysis) es un ambiente de trabajo para la prueba y validación
de algoritmos de la IA, que ha tenido gran difusión entre los investigadores y docentes de esta área.
En el Laboratorio de Inteligencia Artificial del Centro de Estudios de Informática de la Universidad
Central “Marta Abreu” de Las Villas (CEI-UCLV) se desarrollan varias investigaciones que aplican
elementos de la Teoría de los Conjuntos Aproximados (Rough Set Theory; RST) en el desarrollo de
métodos de aprendizaje automatizado (Mitchel, 1997). Tal es el caso de la aplicación de RST en el
preprocesamiento de los conjuntos de entrenamiento para los algoritmos de aprendizaje
automatizado (Caballero, 2008), el desarrollo de medidas internas de validación del agrupamiento
utilizando RST (Arco, 2009), el desarrollo de algoritmos que combinan RST y optimización basada en
colonias de hormigas para la selección de rasgos (Gómez, 2010), la creación de métodos de
aprendizaje para dominios con datos mezclados basados en la teoría de los conjuntos aproximados
extendida (Filiberto, 2011) y la aplicación de un método de aproximación de funciones basado en el
enfoque de los prototipos más cercanos utilizando relaciones de similaridad (Bello, 2012), por solo

Introducción
2
citar algunos ejemplos.
Es política del laboratorio de Inteligencia Artificial del CEI-UCLV incorporar al Weka1 los nuevos
métodos de aprendizaje automatizado creados. De esta forma es posible comparar los nuevos
métodos con los clásicos ya existentes en una misma plataforma, además, se enriquecen los módulos
del Weka como es el caso de la extensión al módulo de validación del agrupamiento utilizando RST
(Castellanos, 2008).
Una de las teorías que ha servido de base para el desarrollo de nuevos métodos de aprendizaje
automatizado es RST; sin embargo, los investigadores han implementado los elementos de RST
embebidos en el propio código del algoritmo que proponen. Por consiguiente, la implementación de
la nueva forma de selección de rasgos trae incluida la parte de RST que necesita para su
procesamiento, las medidas de validación del agrupamiento incorporan los elementos de RST en su
implementación, el método de aproximación de funciones igualmente incluye los elementos de RST
necesarios para esa propuesta y los métodos de edición también incorporan las facilidades de RST
que permiten preprocesar los conjuntos de entrenamiento. De esta forma se complejiza la
implementación de los nuevos métodos, se requiere mayor esfuerzo de los programadores y se
dificulta la reutilización de código. Todo ello constituye una problemática a la cual aún no se le ha
dado respuestas definitivas, lo cual justifica el planteamiento del problema siguiente.
Planteamiento del problema:
Existen métodos de aprendizaje automatizado incorporados al Weka que utilizan RST para su
funcionamiento; sin embargo, su incorporación al Weka incluye la implementación por separado de
las facilidades de RST necesarias para el funcionamiento de cada uno de ellos, ya que no existe una
biblioteca que encapsule todos los elementos de RST que se aplican en métodos de aprendizaje
automatizado.
El objetivo general del trabajo de diploma consiste en desarrollar una biblioteca en Java que
incorpore los principales elementos de la teoría de los conjuntos aproximados clásica y extendida, en
1 WEKA es una herramienta de código abierto escrita en Java. Está disponible en http://www.cs.waikato.ac.nz/˜ml/weka
bajo licencia pública GNU

Introducción
3
particular aquellas definiciones, conceptos y medidas aplicables en el desarrollo de métodos de
aprendizaje automatizado y su validación.
Este se desglosa en los siguientes objetivos específicos:
1. Seleccionar las definiciones, conceptos y medidas de RST aplicables en los métodos de
aprendizaje automatizado que permiten la edición de conjuntos de entrenamiento, la
selección de rasgos, los métodos de clasificación, el agrupamiento y la aproximación de
funciones, así como medidas de validación.
2. Implementar la biblioteca en Java que incorpore los elementos de RST identificados que
permiten el desarrollo de algoritmos de aprendizaje automatizado.
3. Incorporar al Weka algún algoritmo de aprendizaje automatizado que haga uso de la
biblioteca de RST implementada en Java.
Las preguntas planteadas son:
¿Cuáles conceptos, definiciones, medidas y extensiones de RST se utilizan en la creación de
algoritmos de aprendizaje automatizado?
¿Cómo diseñar la biblioteca de RST de forma tal que sea fácilmente utilizable en la
implementación de métodos de aprendizaje automatizado incorporados al Weka?
¿Qué consideraciones se requieren al incorporar a Weka un método de aprendizaje
automatizado o medidas de validación que requieren la utilización de la biblioteca de RST
implementada en Java?
Justificación del trabajo de diploma:
En el año 1992, Ian Witten, profesor del Departamento de Ciencia de la Computación de la
Universidad de Waikato, Nueva Zelanda, creó una aplicación que más tarde, en 1993, recibiría el
nombre de Weka, creándose con ello una interfaz e infraestructura para la misma. Su nombre Weka
(Gallirallus australis) se debe a un ave endémica de este país, de aspecto pardo y tamaño similar a
una gallina, se encuentra en peligro de extinción y es famosa por su curiosidad y agresividad. En 1994

Introducción
4
fue terminada la primera versión de Weka, aunque no publicada, montada en una interfaz de usuario
con varios algoritmos de aprendizaje escritos en lenguaje C. Muchas versiones de Weka fueron
desarrollándose hasta que en octubre de 1996 se publica una primera versión. En julio de 1997 se
publica la versión 2.2 con la inclusión de nuevos algoritmos de aprendizaje y con la facilidad de
configurar la corrida de una gran escala de experimentos. Cerca de esta fecha se toma la decisión de
rescribir Weka en lenguaje Java. A mediados de 1999 es liberada la versión 3 de Weka con todo su
código implementado en Java. Después de la versión 3 se han publicado varias versiones, cada una de
ellas ofreciendo esencialmente como mejora la adición de nuevos algoritmos.
La aplicación comenzada por Ian Witten en 1992 aún continúa ampliándose. El desarrollo de mejores
extensiones al sistema ha dejado de concentrarse en el lugar donde fue creado, para dispersarse por
todo el mundo, donde cantidad de científicos incluyen y validan sus propios modelos. Este ambiente
de aprendizaje automatizado está contenido por una extensa colección de algoritmos de la
Inteligencia Artificial, útiles para ser aplicados sobre datos mediante las interfaces gráficas de usuario
(GUI: Graphical User Interface) que ofrece o para usarlos dentro de cualquier aplicación. Contiene las
herramientas necesarias para realizar transformaciones sobre los datos, tareas de clasificación,
regresión, agrupamiento, asociación y visualización.
En el CEI-UCLV se han desarrollado y se desarrollan nuevos métodos de aprendizaje automático. Se
han creado varios algoritmos para la selección de rasgo (Gómez, 2010) y edición de conjuntos de
entrenamiento (Caballero, 2008). Se han creado varios clasificadores, entre ellos modelos híbridos
que combinan el razonamiento basado en casos con los sistemas basados en reglas y con los sistemas
neuroborrosos (Rodríguez, 2009), clasificadores basados en reglas, aquellos que resuelven problemas
cuando las clases están desbalanceadas y otros aplicables a problemas de multietiquetas (Filiberto,
2011). También, se han trabajado las redes neuronales recurrentes (Guevara, 2007, Bonet, 2009) y
nuevos modelos de redes bayesianas para la clasificación (Arboláez, 2008, Chávez, 2009). Se han
desarrollado nuevos algoritmos de aproximación de funciones (Bello, 2012). Se ha trabajado con tipos
de datos conjunto y con datos borrosos y las consecuentes particularidades que tienen que tener los
algoritmos que utilicen estos tipos de datos (González, 2010). Se realizan estudios sobre las
peculiaridades de los datos de alta dimensión y las características de los algoritmos que permiten
manejarlos (Carbonell, 2010). Además, nuevos métodos de agrupamiento y medidas de validación del

Introducción
5
agrupamiento han sido creados (Castellanos, 2008, Arco, 2009).
Desde el año 2006 el Laboratorio de Inteligencia Artificial se ha propuesto incorporar en el Weka los
métodos de aprendizaje automatizado creados. Inicialmente se formuló una metodología para
extender el ambiente de aprendizaje automatizado Weka (Matías and L.I.Araujo, 2006, Morell et al.,
2006) y así guiar la incorporación de los métodos a esta herramienta. A pesar de la existencia de la
metodología, cada uno de los autores fue incorporando los métodos de manera espontánea, sin
permitir la reutilización de código, y mezclando en la implementación elementos de la nueva
propuesta con elementos de las técnicas computacionales y matemáticas necesarias para su
desarrollo.
En la actualidad, a partir de la creación de proyectos entre el CEI-UCLV y la unidad de desarrollo de
software de la FAR (UCI-FAR) se formaliza la propuesta de crear el Weka Cubano que tendrá
encapsulado en forma de paquetes todos los algoritmos de aprendizaje automático desarrollados
como resultados de la labor investigativa en el CEI-UCLV y otros grupos de investigación cubanos.
Esto permitirá no solo la validación de nuevas propuestas, sino que ofrecerá una herramienta
reutilizable para dar solución con tecnología propia a los disímiles problemas de aprendizaje
automático que se presentan en las organizaciones. El diseño, implementación y documentación de la
herramienta facilitarán la inclusión permanente de nuevos paquetes que recojan nuevos algoritmos.
De esta forma se contribuirá a la visibilidad de nuestros resultados científicos, ya que los paquetes
creados se colocan en un repositorio de paquetes en Internet y los desarrolladores de Weka los
revisan antes de ponerlos a disposición del público. Además, se incluirán las publicaciones científicas
que sustentan los resultados incorporados en los paquetes.
Lo anteriormente expuesto justifica este trabajo de diploma que pretende contribuir a la propuesta
de Weka Cubano, ya que se creará una biblioteca de RST para dar soporte a todos los métodos de
aprendizaje automatizado que se incorporarán al Weka Cubano, brindando la posibilidad de
implementación más sencilla y reutilizando código.
El presente trabajo se encuentra estructurado en introducción, tres capítulos, conclusiones,
recomendaciones, referencias bibliográficas y tres anexos. El primer capítulo se dedica al estudio de
los principales elementos de la Teoría de conjuntos aproximados clásica y sus extensiones. Este

Introducción
6
capítulo concluye con el concepto de reducto y la teoría de su cálculo. En el segundo capítulo
abordamos el diseño y concepción de la biblioteca, la cual implementa los conceptos, elementos y
medidas mencionados en el capítulo 1. El tercer capítulo hace alusión a las medidas de validación del
agrupamiento utilizando los conjuntos aproximados, y cómo se logra la creación de un paquete en
Weka que permita el cálculo de las medidas y la aplicación de la biblioteca creada.

7
1 TEORÍA DE CONJUNTOS, RELACIONES BINARIAS Y TEORÍA DE CONJUNTOS APROXIMADOS
En el presente capítulo se presenta una descripción de los conceptos esenciales involucrados en la
teoría básica de conjunto, así como las definiciones, conceptos y medidas de la Teoría de
Conjuntos Aproximados aplicables en los métodos de aprendizaje automatizado, analizando la
teoría clásica para después analizar sus extensiones. Finalmente abordamos el concepto de
reducto, el cual constituye la base de algunos métodos que se desarrollan usando conjuntos
aproximados.
1.1 TEORÍA BÁSICA DE CONJUNTOS
G. Cantor creó una nueva disciplina matemática entre 1874 y 1897: la teoría de conjuntos. Desde
entonces disímiles debates han acontecido en el seno de la teoría de conjuntos, sin dudas por
hallarse estrechamente conectados con importantes cuestiones lógicas. Algunos años más tarde la
teoría axiomática de Zermelo (1908) y refinamientos de ésta debidos a Fraenkel (1922), Skolem
(1923), von Newman (1925) y otros, sentaron las bases para la teoría de conjuntos actual.
Concepto de conjunto:
La definición inicial de Cantor (Devlin, 1993) es totalmente intuitiva: un conjunto es cualquier
colección C de objetos determinados y bien distintos x de nuestra percepción o nuestro
pensamiento (que se denominan elementos de C), reunidos en un todo.
Dado un elemento a y un conjunto X utilizamos la expresión: a X, para declarar que a es un
elemento o miembro de X. Para expresar lo contrario escribimos: a X.
A partir de dos conjuntos X y Y decimos que X es un subconjunto de Y si y solo si cada elemento de
X es un elemento de Y, esto se denota como: X Y.
1.1.1 Notaciones de conjuntos
Si un conjunto es finito podemos describirlo mediante la enumeración de sus miembros: si X
consiste en los objetos a1, a2,…, an, podemos denotar a X mediante {a1, a2,…, an}. Esta definición es
conocida como definición por extensión (Devlin, 1993). Cuando el número de objetos es infinito o

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
8
demasiado numeroso se utiliza el método de definición por intensión (Devlin, 1993), que consiste
en la descripción de un conjunto mediante una o varias propiedades que caracterizan a los
elementos de ese conjunto. En este trabajo solo abarcaremos conjuntos finitos, descritos a partir
del listado de cada uno de sus elementos.
1.1.2 Operaciones sobre conjuntos
Existe un número de operaciones simples (Devlin, 1993) que pueden ser aplicadas a conjuntos,
formando nuevos conjuntos a partir de conjuntos dados. A continuación se consideran las más
comunes:
La unión de dos conjuntos X y Y da como resultado un conjunto consistente en los miembros de X
junto con los miembros de Y, esta operación se denota por X Y.
La intersección de dos conjuntos X y Y da como resultado un conjunto formado por aquellos
objetos que son miembros de ambos conjuntos y se denota por X Y.
La diferencia de dos conjuntos X y Y es el conjunto formado por aquellos elementos de X que no
son miembros de Y, esta operación se denota por X −Y.
En teoría de conjuntos es conveniente definir una colección sin objetos como un conjunto, el
conjunto vacío o nulo. Este conjunto es usualmente denotado mediante el símbolo derivado de
una letra escandinava.
Se dice que dos conjuntos son disjuntos si no tienen ningún miembro en común o lo que es lo
mismo: X Y = .
1.2 RELACIONES BINARIAS
Un par ordenado es un conjunto con dos elementos en un orden específico. Usamos la notación
(a, b) para denotar el par ordenado en la cual el primer elemento o componente es a y el segundo
elemento objeto es b.
De esta forma, dos pares ordenados (a, b) y (c, d) son iguales si sus correspondientes
componentes son iguales. Es decir, (a, b) = (c, d) si y solamente si a = c y b = d.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
9
El producto cartesiano de dos conjuntos A y B es el conjunto de todos los pares ordenados (x, y)
donde x A y y B. Denotándolo, A x B = {(x, y) : x A y B }, por lo tanto (x, y) A x B si y
sólo si x A y B.
El producto cartesiano A x B no es igual al producto cartesiano B x A (no es conmutativo). Si los
conjuntos A y B tienen elementos comunes, entonces los elementos del producto cartesiano de la
forma (a, a), se les llama elementos diagonales. Si el producto cartesiano fuese de un mismo
conjunto A x A puede escribirse de forma simbólica como A2.
Relaciones entre conjuntos
Llamamos relaciones entre los conjuntos A y B y que representaremos por la letra R, a cualquier
subconjunto del producto cartesiano A x B. (No es necesario que todos los elementos de A estén
considerados)
R : A B
Formalmente: una relación binaria de A en B es R* = (A, B, R) con R A x B
Notación: Indistintamente escribimos (x, y)R o xRy
Se dice que b es homólogo o imagen de a a todo elemento del conjunto B tal que el par (a, b)
pertenece al subconjunto relación R es decir: (a, b) R, siendo R el subconjunto relación.
La primera componente del par (a, b) que pertenece a G se llama preimagen, mientras que la
segunda componente recibe el nombre de elemento imagen. Cuando b es el elemento imagen de
a por la relación R escribiremos b = R(a).
Conjunto origen, de partida o inicial: llamaremos así al conjunto A.
Conjunto de llegada o final: Es el conjunto B.
Se llama conjunto dominio, denotándolo Dom(R), al conjunto formados por todos los elementos
de A que son preimagen por la relación R (o que tienen una imagen).
Se llama conjunto recorrido, y se representa por Rec(R), al conjunto formado por todos los
elementos de B que son elementos imágenes por la relaciones R.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
10
Se llama relación inversa a la relación que resulta de cambiar el orden de los conjuntos A x B por
B x A. La relación inversa la designaremos por R−1.
Se llama relación binaria definida en un conjunto A, a la relación de A en A:
Formalmente: una relación binaria de A en B es R* = (A, B, R) con R A x B
Notación: Indistintamente escribimos (x, y)R o xRy
Dominio e imagen de una relación:
Dom (R) = {x A | y B, (x, y)R}
Im (R) = {y B | x A, (x, y)R}
Se llama relación binaria definida en un conjunto X, a la relación de X en X; R X2.
Diremos que una relación binaria sobre un conjunto X es una relación de equivalencia si satisface
las siguientes propiedades:
1. Reflexiva: para todo x X se cumple xRx.
2. Simétrica: si xRy, entonces yRx.
3. Transitiva: si xRy y yRz, entonces xRz.
Llamaremos clase de equivalencia de x X a R(x) = {y X : xRy}.
Si R es una relación de equivalencia sobre el conjunto X. Entonces, se cumple que:
i. R(x) = R(y) si, y sólo si xRy.
ii. Si R(x) ≠ R(y), entonces R(x) R(y)=.
Dada una relación de equivalencia sobre un conjunto X, llamaremos conjunto cociente al formado
por todas las clases de equivalencia, lo notaremos por X/R, indicando así que es el conjunto X
partido por la relación de equivalencia R.
X/R = {R(x) : xX}

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
11
1.3 TEORÍA DE CONJUNTOS APROXIMADOS
La filosofía de los conjuntos aproximados está basada en la suposición de que con todo objeto de
un universo U está asociada una cierta cantidad de información (datos y conocimiento), expresado
por medio de algunos atributos usados para describir el objeto. Todo el conocimiento sobre el
dominio de aplicación está contenido en el conjunto de objetos, llamado Sistema de Decisión; este
sistema puede ser innecesariamente grande, en parte porque es redundante en al menos dos
formas; primero, el mismo objeto u objetos idénticos (según alguna relación) pueden aparecer
varias veces; segundo, algunos de los atributos que describen los objetos del universo son
superfluos.
Informalmente se pueden definir los conjuntos aproximados de la forma siguiente:
Los objetos que tienen la misma descripción son inseparables (similares) con respecto al conjunto
de atributos considerados. Esta relación de inseparabilidad constituye la base matemática de la
teoría, y la misma induce una partición del universo U en bloques de objetos inseparables.
Cualquier subconjunto X del universo U se puede expresar en términos de estos bloques de forma
exacta o aproximada. En el último caso el conjunto X se puede caracterizar por dos conjuntos
ordinarios denominados aproximación inferior y aproximación superior. La aproximación inferior
de X está formada por todos los bloques que son subconjuntos de X, y la aproximación superior
consiste de todos los bloques que tienen una intersección no vacía con X. A la aproximación
inferior de X pertenecen los objetos que con certeza pertenecen a X, a la aproximación superior
pertenecen los objetos que pudieran pertenecer a X, y en el conjunto diferencia de ambos
conjuntos están los objetos que no se puede determinar con certeza su pertenencia a X. La
cardinalidad (cantidad de objetos) de este conjunto diferencia se puede usar como una medida de
la vaguedad de la información sobre X.
En la Teoría de los conjuntos aproximados la estructura de información básica es el Sistema de
información.
Definición 1.1: (Sistema de Información)

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
12
Sea un conjunto de atributos A=A1, A2,...,An y un conjunto U no vacío llamado universo de
ejemplos (objetos, entidades, situaciones o estados, etc.) descritos usando los atributos Ai. Al par
(U,A) se le denomina Sistema de información.
A cada atributo Ai se le asocia un dominio Vi. Se tiene una función f: U x A V tal que f(x,Ai)Vq
para cada Ai A, x U, llamada función de información.
Se dice que un atributo Ai A separa o distingue un objeto “x” de otro “y” si y solo si:
(R1) Separa(Ai,x,y) f(x,Ai) f(y,Ai) (1.1)
En caso contrario se dice que x e y son inseparables respecto al atributo Ai. Para todo sistema de
información se puede definir una matriz de separación MA, la cual es una matriz |U|x|U|, cada
entrada MA(x,y) A contiene el conjunto de atributos que distinguen y separan los elementos x e
y de U:
MA(x,y)={ Ai A : Separa(Ai,x,y) } (1.2)
Si entre los valores de un atributo Ai se puede establecer una organización jerárquica, por
ejemplo, mediante una relación is-a, lo cual se puede modelar mediante una relación de orden
parcial sobre Vi (ab, se lee como a es una instancia de b), entonces la separabilidad se define
como:
(R2) Separa(Ai,x,y) f(x,Ai) not f(y,Ai) y f(y,Ai) not f(x,Ai) (1.3)
Definición 1.2: (Sistema de decisión)
Si a cada elemento de U se le agrega un nuevo atributo d llamado decisión indicando la decisión
tomada en ese estado o situación entonces se obtiene un Sistema de decisión (U, A{d}, donde
dA).
El valor de la decisión puede representar un número de la clase en la cual clasificar el objeto,
mientras que en un sistema de control la decisión significa una acción que se debe ejecutar en el
estado descrito por el objeto, entre otras alternativas de interpretación.
El atributo de decisión d induce una partición del universo de objetos U. Sea Vd el conjunto de
enteros {1,...,m}, entonces {X1,...,Xm} es una colección de clases de equivalencias, llamadas clases

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
13
de decisión, donde dos objetos pertenecen a la misma clase si ellos tienen el mismo valor para el
atributo decisión.
Xi= { x U : d(x)=i } (1.4)
Definición 1.3: (Relación de inseparabilidad):
Si (x,y) IB se dice que los objetos x e y son B- inseparables.
1.3.1 TEORÍA DE LOS CONJUNTOS APROXIMADOS CLÁSICA
Una relación de inseparabilidad (indiscernibility relation) que sea definida a partir de formar
subconjuntos de elementos de U que tienen igual valor para un subconjunto de atributos B de A
(BA) es una relación de equivalencia. Es decir, es una relación binaria R UxU que es reflexiva,
simétrica y transitiva.
La clase de equivalencia de un elemento x de U es el conjunto de todos los elementos y de U tal
que xRy; es decir, los elementos de U que son similares a x considerando los atributos contenidos
en B. Una relación de equivalencia induce una partición del universo U. Por B(x) se denota al
conjunto de todos los yU tal que yRx; es decir, el elemento de la partición al que pertenece el
objeto x.
Sea el sistema de información (U,A), y los conjuntos BA y XU, se puede aproximar X usando
solamente la información contenida en B construyendo dos conjuntos llamados aproximación
inferior (B*) y aproximación superior (B*) respectivamente del conjunto X para la relación B. Un
conjunto aproximado es cualquier subconjunto XU definido a través de sus aproximaciones
inferior y superior.
Definición 1.4: (Aproximaciones de un conjunto)
La aproximación inferior de un conjunto (con respecto a un conjunto dado de atributos) se define
como la colección de casos cuyas clases de equivalencia están contenidas completamente en el
conjunto; mientras que la aproximación superior se define como la colección de casos cuyas clases
de equivalencia están al menos parcialmente contenidas en el conjunto.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
14
A partir de diferentes representaciones de una relación de equivalencia, se pueden obtener tres
definiciones constructivas de las aproximaciones (Bello et al., 2012):
Definición basada en Elemento:
B*(X) = {x U: B(x) X}
B*(X) = {x U: B(x) X }
Definición basada en Gránulo:
B*(X) = {B(x) U/B: B(x) X}
B*(X) = {B(x) U/B: B(x) X }
Definición basada en Subsistema:
B* (X) = {Z: Z U/B, Z X}
B* (X) = {Z: Z U/B, X Z}
Los elementos de B*(X) son todos y solamente aquellos objetos del universo U los cuales
pertenecen a las clases de equivalencia generadas por la relación IB contenidas en X; mientras que
los elementos de B*(X) son todos y solamente aquellos objetos de U los cuales pertenecen a las
clases de equivalencia generadas por la relación de inseparabilidad conteniendo al menos un
objeto x perteneciente a X.
Estas tres definiciones son equivalentes y ofrecen diferentes interpretaciones de las
aproximaciones. De acuerdo a la primera definición, un elemento x pertenece a la aproximación
inferior de un conjunto X si todos sus objetos inseparables están también en X, mientras que un
elemento pertenece a la aproximación superior si al menos uno de los objetos inseparables a él
pertenece a X.
En el caso de la definición basada en gránulo, la aproximación inferior de X es la unión de las
clases de equivalencias que son subconjuntos de X, mientras que la aproximación superior es la
unión de las clases de equivalencias que tienen una intersección no vacía con X.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
15
Un tercer enfoque para definir las aproximaciones inferior y superior se basa en el concepto de
subsistema. En este sentido, la aproximación inferior de X es el mayor conjunto definible en el
subsistema (U/B) que está contenido en X, y la aproximación superior es el menor conjunto
definible en (U/B) que contiene a X.
Basada en estas definiciones, es posible establecer enlaces entre los conjuntos aproximados y
otras teorías.
A partir de las aproximaciones inferiores y superiores de un conjunto se define la región límite de
X para la relación de equivalencia B:
Definición 1.5: (Región límite)
BNB(X)= B*(X) – B*(X) (1.5)
Si el conjunto BNB es vacío entonces el conjunto X es exacto respecto a la relación de equivalencia
B. En caso contrario, BNB(X) , el conjunto X es inexacto o aproximado con respecto a B. El
principal objetivo de esta teoría es la síntesis de aproximaciones para los conceptos. En la Figura
1.1 se representan estos conceptos.
Usando las aproximaciones inferior y superior de un concepto X se definen tres regiones para
caracterizar el espacio de aproximación:
i) la región positiva: POS(X)= B*(X).
ii) la región límite: BND(X)= BNB(X).
iii) la región negativa: NEG(X)= U- B*(X).
De acuerdo a los estudios presentados en (Bell and Guan, 1998) y (Deogun, 1998), la complejidad
computacional de encontrar el conjuntos B*(X) o el conjunto B*(X) es O(lm2), donde l es el número
de atributos que describen los objetos y m es la cantidad de objetos en el universo.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
16
Figura 1.1 Regiones de los conjuntos aproximados.
Aquí U está representado por un conjunto de celdas. La Aproximación inferior B*(X) la constituyen
las celdas marcadas con “+”. La aproximación superior B*(X) la representa la unión de las celdas
blancas y las marcadas con “+”. La región límite de X, BNB(X) la conforma la colección de las celdas
blancas. Los elementos del conjunto de las celdas marcadas con “–“ con certeza no pertenecen a X
(conforman la también llamada “región negativa”) .
1.3.2 Conjuntos aproximados en sistemas de información incompletos
Usualmente existen dos enfoques para atender el problema de la información incompleta en el
contexto de los conjuntos aproximados. El primero es un método indirecto que consiste en
transformar el sistema de información incompleto en uno completo empleando algún
procedimiento de los que existen para este problema. El segundo es extender la teoría de los
conjuntos aproximados clásica para procesar sistemas de información incompletos (Bello et al.,
2012).
Definición 1.6: (Sistema información incompleto)
Se denomina Sistema de información incompleto a todo sistema de información en el cual exista
al menos un objeto el cual posee al menos un atributo cuyo valor no se conoce.
Un valor nulo para un atributo puede significar que el valor es desconocido, pero también que no
es aplicable ese atributo al objeto específico. Puede ocurrir en modelos como las bases de datos
relacionales y los sistemas de información tal y como se definen para la teoría de conjuntos
aproximados, pues en ambos todos los objetos del universo tienen los mismos atributos.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
17
El problema de valores omitidos tiene una complejidad diferente para rasgos continuos y rasgos
discretos. Para atributos continuos poco se puede en tal caso, mientras que para los rasgos
discretos es posible tratar el valor omitido como un valor más del dominio de ese rasgo. Grzymala-
Buze (Grzymala-Busse, 1991), enfrenta el problema transformando una tabla de decisión con
valores desconocidos a otra, posiblemente inconsistente, en la cual los valores para todos los
atributos son conocidos, reemplazando los valores desconocidos por todos los valores del dominio
de ese atributo. En otras palabras, convierte el problema de valores desconocidos al problema de
datos inconsistentes, y luego los procesa usando los conjuntos aproximados. En (Barbara, 1992),
los valores omitidos se interpretan como valores no interesantes de un atributo con los cuales se
asocia una medida de probabilidad.
1.3.2.1 Conjuntos aproximados basados en una relación transitiva
El enfoque clásico de los conjuntos aproximados basados en las relaciones de inseparabilidad
requiere que los datos sean completos, es decir, se conocen los valores para los atributos
condición en todos los objetos. Usualmente hay dos formas para enfrentar el problema de los
datos incompletos en la teoría de los conjuntos aproximados. El primero es una vía indirecta, en la
cual el sistema de información incompleto se transforma en uno completo usando algún método
de completamiento; la segunda es una alternativa directa en la cual se extiende la teoría de los
conjuntos aproximados para procesar los sistemas de información incompletos (Bello et al., 2012).
Definición 1.7: (Relación I)
Sean x, y U, donde y es el sujeto y x es el objeto referente. Se dice que y es inseparable de x, con
respecto al conjunto de atributos P C, denotándolo por yIPx, si para todo q P, se cumple:
i) f(x,q) *,
ii) f(x,q) = f(y,q) or f(y,q )= *.
Nótese que el objeto referente x no puede tener valores desconocidos en el conjunto de atributos
P.
La clase de objetos inseparables de x se representa como:

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
18
IP(x)= {y U : yIPx) (1.6)
La relación IP no es necesariamente reflexiva ni simétrica, pero si transitiva.
Para cada P C se define el conjunto UP de objetos sin valores desconocidos para los atributos en
P.
UP={x U : f(x,q)* para cada qP (1.7)
A partir de estas definiciones y la relación I se puede construir la aproximación inferior y superior
de un conjunto X U con respecto a un conjunto de atributos de condición P C según la
definición 1.8:
Definición 1.8: (Aproximaciones de un conjunto según la relación I)
IP*(X) = {x UP : IP(x) X} (1.8)
IP*(X)= { x UP : IP(x) X≠} (1.9)
Se satisfacen las relaciones de inclusión y complementariedad siguientes:
Para cada X U y para cada P C: IP*(X) IP*(X).
Para cada X U y para cada P C: IP*(X) = UP - IP*(U-X).
1.3.2.2 Conjuntos aproximados monótonos
Una propiedad muy útil de la aproximación inferior en los conjuntos aproximados clásicos es la
monotonía. Lo cual significa que si un objeto x U pertenece a la aproximación inferior de un
conjunto X con respecto a P C, entonces x pertenece también a la aproximación inferior de X
con respecto a cualquier conjunto de atributos RC cuando PR.
Sin embargo, la forma de construir las aproximaciones para sistemas de información incompletos
no satisface esta propiedad. Lo cual queda claro dado el hecho siguiente:
Es posible que f(x,q) * para todo q P pero f(x,q)=* para algún q R-P.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
19
Para obtener la propiedad de monotonía se redefine la relación de inseparabilidad I, denotándola
por II.
Definición 1.9: (Relación II)
Sean x, y U y P C, yIIPx, significa que para todo q P, se cumple:
i) f(x,q) = f(y,q),
ii) f(x,q) = * and/or f(y,q) = *.
La relación IIP es reflexiva y simétrica, pero no transitiva.
Para cada P C se define el conjunto U*P de objetos sin valores desconocidos para algún atributo
en P.
U*P={xU : f(x,q) * para algún qP } (1.10)
La clase de objetos inseparables de x de acuerdo a la nueva relación se representa como:
IIP(x)= {y U : yIIPx } (1.11)
A partir de estas definiciones se puede construir la aproximación inferior y superior de un
conjunto X U con respecto a un conjunto de atributos de condición P C como sigue:
Definición 1.10: (Aproximaciones de un conjunto según la relación II)
IIP*(X)= { x U*P : IIP(x) X } (1.12)
IIP*(X)= { x U*
P : IIP(x) X } (1.13)
1.3.2.3 Conjuntos aproximados para sistemas de información incompletos basados en
una relación no simétrica
Otra alternativa de relación para el caso de los sistemas de información incompletos se define de
la forma siguiente (Bello et al., 2012):
Definición 1.11: (Relación III)

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
20
Sean x, y U, el objeto x es similar al objeto y (xIIIy), para todo q BA, si y solo si:
i) f(x,q) = f(y,q), o
ii) f(x,q) = *.
La relación III es reflexiva y transitiva, pero no simétrica. Se basa en la idea de una relación de
inclusión, es decir, un objeto x se considera similar a otro y, si y solo si, la descripción de x está
incluida en la descripción de y. Aquí el principio en que se basa el autor es que un valor
desconocido significa que ese atributo no se necesita para describir el objeto; a diferencia de las
dos relaciones anteriores donde los valores desconocidos se interpretan como falta de
información o conocimiento imperfecto sobre el objeto.
Usando la relación III se construyen dos conjuntos, RB(x) y RB-1(x), el primero es el conjunto de los
objetos similares a x, y el segundo el conjunto de objetos a los cuales x es similar:
RB(x)={ y U : yIIIx },
RB-1(x)={ y U : xIIIy }.
Dados estos conjuntos las aproximaciones inferior y superior de un conjunto X dado BA y un
sistema de información incompleto se definen como:
Definición 1.12: (Aproximaciones de un conjunto según la relación III)
B*(X)= { x U : RB-1(x) X} (1.14)
B*(X)= RB(x), x X (1.15)
Este modelo para la teoría de los conjuntos aproximados para sistemas de información
incompletos es un caso particular de la definición de conjuntos aproximados basados en
relaciones de similaridad, tomando como relación de similaridad la Relación III.
1.3.3 Conjuntos aproximados basados en relaciones de similaridad
Diariamente se encuentran situaciones donde se tiene que distinguir entre grupos similares o se
tiene que clasificar algunos elementos como similares. Por eso, la medida de similaridad se

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
21
convierte en una importante herramienta para decidir la semejanza (el grado de similaridad) entre
dos grupos o entre dos elementos. Ella puede definirse sobre un conjunto arbitrario de objetos de
interés como objetos físicos, situaciones, problemas, etc.. El uso del término similaridad en la
Inteligencia Artificial da la idea de una relación borrosa entre las representaciones de dos objetos.
Una medida de similaridad consiste de tres partes principales (Bello et al., 2012):
Medidas locales de similaridad usadas para comparar los valores de los rasgos
(denominadas funciones de comparación de rasgos, en (Bello et al., 2012) se proponen
algunas).
Pesos asociados a los rasgos los cuales representan la importancia relativa de cada
atributo.
Una medida de similaridad global que indica el grado de similaridad entre dos objetos a
partir de las medidas locales y los pesos (llamada función de semejanza, algunas aparecen
en (Arco, 2009)).
Una generalización del enfoque clásico de los conjuntos aproximados es reemplazar la relación de
inseparabilidad binaria, la cual es una relación de equivalencia, por una relación de similaridad
binaria más débil. En la definición original del concepto de conjuntos aproximados, existe una
relación R que define la inseparabilidad entre los objetos que tienen el mismo valor para los
atributos considerados por R. Por eso, cada relación es una relación de equivalencia.
Tal definición de R puede ser muy restrictiva en muchos casos. Considerar el uso de una relación
de similaridad en lugar de una relación de inseparabilidad resulta relevante. En realidad debido a
la imprecisión en la descripción de los objetos, pequeñas diferencias entre objetos no se
consideran significativas en el proceso de discriminación (formación de las clases de
equivalencias); como sucede frecuentemente con los atributos cuantitativos debido a
imprecisiones en la medición de los mismos, fluctuación aleatoria de algunos parámetros, etc..
Una opción para enfrentar este problema es discretizar tales atributos, lo cual puede traer
consecuencias indeseadas, como el hecho de asociar valores muy cercanos a valores discretos
diferentes. Otra alternativa es considerar la similaridad entre los valores. Entre los conceptos de

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
22
similaridad e incertidumbre existe una relación mayor que el simple hecho de la definición de
ambas medidas sobre un intervalo real [0,1].
El propósito es extender la relación de inseparabilidad R aceptando que los objetos que no son
inseparables, pero sí suficientemente cercanos o similares se pueden agrupar en la misma clase.
En otras palabras, construir una relación de similaridad R' a partir de R flexibilizando las
condiciones originales de inseparabilidad (Arco, 2009).
Definición 1.13: (Relación de similaridad extendida)
Sea R una relación de inseparabilidad que es una relación de equivalencia definida sobre U. Se
dice que R' es una relación de similaridad extendida desde R, si y solo si,
(i) Para todo x U, R(x)R'(x)
(ii) Para todo x U, Para todo y R'(x), R(y)R'(x)
Donde R'(x) es la clase de similaridad de x, es decir,
R'(x)={ y U : yR'x } (1.16)
Realmente, las relaciones de similaridad son frecuentemente definidas directamente, no como
extensiones de relaciones de equivalencia.
Desde la perspectiva de las propiedades de las relaciones, el carácter transitivo de la relación de
separabilidad es la base. Si la relación es transitiva entonces ella define una partición de U en
bloques de elementos indistinguibles; mientras que relaciones no transitivas dan pie al uso de
relaciones de similaridad. Las similaridades entre los objetos se pueden representar por una
relación binaria R que forma clases de objetos los cuales son idénticos o al menos no
notablemente diferentes en términos de la información disponible sobre ellos.
En general las relaciones de similaridad no generan particiones sobre el universo U, sino clases de
similaridad para cada objeto x U (cubrimientos). La clase de similaridad de x, de acuerdo a la
relación de similaridad R se denota por R(x) y se define como:

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
23
R(x)= { y U : yRx } (1.17)
Se lee como conjunto de elementos y que son similares a x de acuerdo a la relación R.
La relación R es sólo reflexiva (cada objeto es similar a si mismo). Pero no es transitiva: y es similar
a x y a z, pero z no es similar a x.
y R(x) y y R(z) NOT z R(x), para x, y y z U.
La no transitividad de la relación de similaridad está dada por el hecho de que una serie de
pequeñas diferencias no pueden ser propagadas manteniendo el carácter de pequeñas. Tampoco
tiene que ser simétrica: y es similar a x según R, pero x no es similar a y de acuerdo a R.
y R(x) NOT x R(y), para x, y U.
Pues la relación R es direccional, donde el sujeto es y, y el referente es x. Aunque la mayoría de las
funciones de semejanza son simétricas, varios autores han argumentado el hecho de que la
similaridad no debe ser tratada como una relación simétrica.
Definición 1.14: (Relación de tolerancia y Espacio de tolerancia)
Cuando la relación R XxU es reflexiva (xRx) para cualquier xU, y es simétrica (xRy yRx) para
cualquier par de elementos x, y U, se denomina Relación de tolerancia. El par (U,R) se denomina
Espacio de tolerancia.
Entonces se define la relación inversa R-1, donde xR-1y significa también los objetos y de U
similares a x; luego R-1(x) es la clase de los objetos referentes a los cuales x es similar:
R-1(x)= { y U : xRy } (1.18)
De acuerdo a las propiedades de la relación de similaridad R, un objeto puede pertenecer a
diferentes clases de similaridad simultáneamente. Esto significa que la relación de similaridad
induce un cubrimiento sobre U que no tiene que ser una partición. Un concepto relacionado a la
similaridad entre objetos es el de objeto no ambiguo.
Definición 1.15: (Objeto no ambiguo)

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
24
Dado un subconjunto X U y una relación de similaridad R sobre U, un objeto x U se llama no
ambiguo si se cumple una de las condiciones siguientes:
i) x X sin ambigüedad, es decir, xX y R-1(x) X, los cuales se denominan positivos.
ii) x X sin ambigüedad, es decir, xU-X y R-1(x) U-X, es decir, R-1(x) X=, los cuales se
denominan negativos.
Los objetos yU que no son positivos ni negativos se denominan ambiguos respecto a X.
Las relaciones de equivalencia inducen particiones del universo U, mientras las relaciones de
similaridad generan un cubrimiento del universo. Un cubrimiento del universo U es una familia de
subconjuntos no vacíos cuya unión es igual a U, y es posible que exista una intersección no vacía
entre pares de esos subconjuntos. Una partición de U es un cubrimiento de U, de modo que el
concepto de cubrimiento es una extensión (generalización) del concepto de partición.
Una vez definido el concepto de relación de similaridad se pueden construir los conjuntos
aproximados basados en éstas. Esta extensión de la teoría de los conjuntos aproximados también
evita la necesidad de discretizar los atributos de dominio continuo. En (Greco, 2001) se presenta
un estudio de esta problemática. Entre las extensiones realizadas a la RST basadas en relaciones
de similaridad está la siguiente.
Definición 1.16: (Aproximaciones basadas en similaridad)
R. Slowinski y D. Vanderpooten (Slowinski and Vanderpooten, 2000) definen la aproximación
inferior y superior de un conjunto X de la forma siguiente. Sea XU y R una relación binaria
reflexiva definida sobre U, entonces:
R*(X)={ xU : R-1(x) X } (1.19)
R*(X)= R(x), xX; (1.20)
lo cual es equivalente a:
R*(X)= { xU : R-1(x) X } (1.21)

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
25
También se cumple, como en los conjuntos aproximados basados en relaciones de equivalencia,
que:
R*(X) X R*(X) (1.22)
R*(X)= U – R*(U-X) (1.23)
El uso de relaciones de similaridad ofrece mayores posibilidades para la construcción de las
aproximaciones; sin embargo, se tiene que pagar por ésta mayor flexibilidad, pues es más difícil
desde el punto de vista computacional buscar las aproximaciones relevantes en este espacio
mayor.
Finalmente en la Figura 1.2 se muestra la RST extendida.
Figura 1.2 Representación de RST extendida.
1.3.4 Medidas para realizar inferencias
Sobre la base del conocimiento en B los objetos que pertenecen a B*(X) pueden ser clasificados
con certeza como miembros de X, los objetos miembros de B*(X) pueden ser solamente
clasificados como posibles miembros de X. Los elementos en BNB no pueden ser clasificados con

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
26
absoluta certeza como miembros del conjunto X. Los elementos del conjunto U-B*(X) con certeza
no pertenecen a X.
Por eso, los conjuntos aproximados pueden ser vistos como un modelo matemático de los
conceptos vagos, es decir, aquellos en los que los elementos del universo no pueden ser
clasificados con certeza como elementos o no del concepto. Las principales medidas construidas a
partir de los conjuntos aproximados son las siguientes(Bello et al., 2012).
Definición 1.17: Precisión de la aproximación (accuracy of the approximation)
La vaguedad del concepto o conjunto X, también llamada precisión de la aproximación (accuracy),
con respecto a la relación B se puede caracterizar matemáticamente por el coeficiente:
XB
XBXB *
* (1.24)
Donde X denota la cardinalidad del conjunto X, y 0B(X)1. Si B(X)=1, el conjunto X será duro
o exacto con respecto a la relación de equivalencia B, mientras que si B(X)1, el conjunto X es
aproximado o vago con respecto a B. Esta magnitud mide el grado de perfección o integridad del
conocimiento sobre el conjunto X considerando los atributos incluidos en la relación de
equivalencia.
Definición 1.18: Calidad de la aproximación (quality of approximation)
La calidad de la aproximación de X por medio de los atributos en B se define por:
X
XBXB
*
(1.25)
Esta medida de calidad representa la frecuencia relativa de los objetos correctamente clasificados
por medio de los atributos en B. Además, 0 B(X) B(X) 1.
La medida de Deogun es una unificación de estas dos medidas, la cual se define en la expresión:

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
27
XPOS*sX*s
XPOSXXB
21
)(
(1.26)
donde s1 y s2 son factores de escala tal que s1+s2=1.
Las definiciones para las aproximaciones de un conjunto X se pueden extender a una clasificación,
es decir, una partición Y= {Y1, ..., Yn} de U. Los subconjuntos Yi son clases disjuntas de Y. Las
aproximaciones inferior y superior se definen como B*Y= {B*Y1,..., B*Yn}, y B*Y= {B*Y1,..., B*Yn},
respectivamente.
Definición 1.19: Calidad de la clasificación (quality of classification)
El coeficiente:
U
YiB
Y
n
iB
1
*
)(
(1.27)
se denomina calidad de la clasificación. Esta es una de las medidas más usadas de la RST, pues ella
permite medir el grado de consistencia del sistema.
Empleando el concepto de inseparabilidad se puede definir la función de pertenencia a conjuntos
aproximados. Si el concepto o conjunto X es vago sus contornos no están rigurosamente definidos
por lo que surge la incertidumbre relacionada con la cuestión de la pertenencia de los elementos
al conjunto.
Definición 1.20: Función de pertenencia aproximada (Rough membership function)
La función de pertenencia de un elemento x a un conjunto X según la relación de equivalencia B se
define como:
xB
xBXxB
X
(1.28)
Obviamente el grado de pertenencia está en el intervalo [0,1]. La función de pertenencia puede
ser comprendida como un coeficiente de la certidumbre que un elemento x sea miembro del

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
28
conjunto X. Esta medida cuantifica el grado de correspondencia relativa entre el conjunto X y la
clase de equivalencia a la cual pertenece x.
Con esta medida de pertenencia se pueden redefinir los conceptos de aproximaciones inferior y
superior de un conjunto de la forma siguiente:
B*(X)= xU XB(x) (1.29)
B*(X)= xU X
B(x) > 1- (1.30)
Otra medida asociada a los conjuntos aproximados es la denominada aspereza (roughness) del
conjunto, la cual representa el grado de incompletitud del conocimiento sobre el conjunto
aproximado a partir de los atributos considerados en la relación de equivalencia y se calcula como:
B(X)=1 - B(X) (1.31)
Las medidas precisión y calidad de la aproximación están asociadas a cada concepto, por tanto,
ofrecen una valoración local de cada grupo obtenido. Sin embargo, en muchos casos es necesario
medir la calidad y la precisión como un todo considerando el sistema de información y los
conceptos X1, …, Xk definidos sobre él, con k total de conceptos. El coeficiente calidad de la
clasificación, expresión (1.32), describe la inexactitud de los conceptos, expresando la proporción
de los objetos que pueden estar correctamente asignados a los grupos en el sistema. Si ese
coeficiente es uno, el sistema de información según los conceptos definidos es consistente, en
otro caso es inconsistente (Pawlak, 1991).
U
XRk
i
i 1
* )(
(1.32)
La precisión de la clasificación, definida en (Arco, 2009), expresa las posibles clasificaciones
correctas. En la expresión (1.33) se observa que su esencia es mostrar la proporción entre la
cantidad de objetos que pudieran estar bien clasificados y la cantidad de objetos que pudieran o
no pertenecer a las clases del sistema de información.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
29
k
i
i
k
i
i
XR
XR
1
*
1
*
)(
)(
(1.33)
En (Magdaleno, 2008) se propone la Medida-F aproximada (Rough F-measure; RFM) y la forma de
cálculo se muestra en (1.34), donde α es un parámetro entre 0 y 1 que permite regular la
influencia de la precisión y la calidad de la clasificación en el índice general. Si α =1 entonces RFM
coincide con la precisión, si α =0 entonces RFM coincide con la calidad de la clasificación. α =0.5
significa igual peso para la precisión y la calidad de la clasificación.
)/1)(1()/1(
1
GG
RFM
(1.34)
En (Arco, 2009) se proponen las expresiones (1.35) y (1.36) como otras formas para medir la
pertenencia aproximada de un objeto x a un concepto X.
X
xRXxX
)()(
(1.35)
)(
)()(
xRX
xRXxX
(1.36)
1.3.5 Reductos
Definición 1.21: (Reducto)
Dado un sistema de información S=(U,A), donde U es el universo y A es el conjunto de atributos,
un reducto de éste es un conjunto mínimo de atributos BA tal que IA = IB.
En otras palabras, un subconjunto E de atributos es un reducto del conjunto de atributos A si E es
ortogonal y preserva la clasificación generada por A:
E=RED(A) ( EA, IND(E)=IND(A), E es ortogonal).

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
30
El cálculo de reductos es una tarea compleja; de allí que se hayan desarrollado diversos métodos
para ejecutarla. El problema de encontrar el conjunto de reductos mínimos es NP-duro y
representa uno de los principales punto de atención en la teoría de los conjuntos aproximados. En
este proceso no es posible escapar del costo computacional exponencial del mismo, a menos que
se aplique alguna técnica de Inteligencia artificial. Existen buenos métodos heurísticos que
computan reductos de una manera satisfactoria, decreciendo el costo de cómputo.
Definición de Núcleo
Asociado al concepto de reducto, está el concepto de núcleo (core) del sistema de información S.
El núcleo está constituido por el conjunto de atributos que pertenecen a la intersección de todos
los reductos del sistema de información.
Definición 1.22: (Núcleo)
SductR
RSNucleoRe
(1.37)
Una alternativa es considerar como relevantes a aquellos atributos que pertenecen al núcleo del
sistema. También se consideran relevantes aquellos atributos que pertenecen a reductos
dinámicos con una estabilidad suficientemente alta (Bello et al., 2012).
Comenzar la búsqueda de los reductos o sus variantes a partir de los rasgos en el núcleo puede
conducir a una rápida identificación de subconjuntos de rasgos útiles, estrechándose la búsqueda
considerablemente. Pero está claro que identificar los atributos que pertenecen al núcleo a partir
del sistema de información es un problema de inducción en sí.
1.3.5.1 Tipos de reductos
El cálculo de los reductos de un sistema de decisión es un proceso computacionalmente costoso.
Por otra parte, usualmente los ruidos presentes en el universo obligan a trabajar con cierta
incertidumbre. Esto ha llevado al desarrollo de algunas variantes para el concepto de reducto que
constituyen métodos para calcularlos. En (Bello et al., 2012) se muestran dos variantes del
concepto de reducto, denominadas: reductos dinámicos (dynamic reducts) y reductos
aproximados (approximated reducts).

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
31
Una alternativa es computar los llamados reductos dinámicos. El procedimiento consiste en
calcular reductos para algún subconjunto del universo, y seleccionar los reductos más estables, es
decir, los que aparecen más frecuentemente, estos se denominan reductos dinámicos, pueden ser
inconsistentes con el sistema de decisión original, pero son adecuados para inferir reglas a partir
de ellos.
Los reductos dinámicos son calculados a partir del coeficiente de estabilidad de un reducto en una
familia de subsistemas de un sistema de decisión.
Sea un sistema de decisión S=(U, A{d}). Un subsistema de S es cualquier sistema de información
Si=(Ui, A{d}), tal que UiU. Sea F una familia de subsistemas de S.
Definición 1.23: (Coeficiente de estabilidad de un reducto)
El coeficiente de estabilidad (CoefSta) de un reducto CRED(Si,d) se define por la expresión (1.38)
F
dSREDCFSCCoefSta
ii ,:
(1.38)
Definición 1.24: (Reductos dinámicos)
Sea un número real en el intervalo [0,1]. El conjunto DR(S,F) de (F, )-reductos dinámicos se
define por la expresión:
1:,, CCoefStadSREDCFSDR (1.39)
Definición 1.25: (Reducto aproximado)
Si en lugar de considerar el conjunto de atributos de condición C, se usa un subconjunto BC de
él, entonces se obtiene un reducto aproximado de C. El error de utilizar ese reducto aproximado
se calcula según la expresión (1.40).
DC
DBBe DC
,
,1,
(1.40)

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
32
Este valor expresa cuán exactamente el conjunto de atributos B aproxima el conjunto de atributos
de condición C con relación al conjunto de atributos de decisión D.
El concepto de reducto aproximado es una generalización del concepto de reducto. Un
subconjunto mínimo B de los atributos de condición C, tal que e(C,D)(B)=0, es un reducto.
1.3.5.2 Cálculo de reductos
El cálculo de reductos se puede ver como un caso de particular de un problema más general de
selección de rasgos en el cual el objetivo es encontrar un subconjunto que maximiza algún criterio
y donde cada rasgo se selecciona o no. Los algoritmos para la selección de rasgos buscan a través
del espacio de rasgos el mejor subconjunto entre los 2N-1 subconjuntos candidatos, donde N
denota la cantidad de rasgos. Cada estado representa un subconjunto de rasgos en el espacio de
búsqueda. Todas las técnicas de selección tienen en común dos componentes importantes: una
función de evaluación usada para evaluar subconjuntos de rasgos y un procedimiento de
búsqueda que genera los subconjuntos.
La función de evaluación estima la capacidad discriminatoria del subconjunto de rasgos para
distinguir entre diferentes clases. Esta mide la calidad (goodness) de un subconjunto que ha sido
generado por el procedimiento de búsqueda. Existen diferentes tipos de funciones de evaluación
tales como medidas de distancia, medidas de información (por ejemplo, la entropía), medidas de
dependencia, medidas de consistencia y medidas de error en la clasificación. Una de las medidas
de la RST más populares es la calidad de la clasificación. Algunas de las medidas satisfacen la
llamada propiedad de monotonía; es decir, (X+) (X), donde denota una función de
evaluación, X describe un subconjunto de rasgos y X+ denota un subconjunto extendido que
contiene a X (Bello et al., 2012).
La segunda componente del proceso de selección de rasgos es el procedimiento de búsqueda. Las
estrategias de búsqueda son importantes porque el proceso de búsqueda es muy costoso, y una
búsqueda exhaustiva del subconjunto óptimo no es factible para problemas de dimensión media.
Por eso, los métodos aproximados son más apropiados. Ejemplo de estas estrategias son la
búsqueda heurística, métodos probabilísticos, y los algoritmos híbridos.

Capítulo 1: Teoría de conjuntos, relaciones binarias y teoría de conjuntos aproximados
33
Los métodos de búsqueda heurísticas (del griego heuriskein, que significa encontrar) están
orientados a reducir la cantidad de búsqueda requerida para encontrar una solución. Cuando la
solución de un problema se presenta como un árbol de búsqueda el enfoque heurístico intenta
reducir el tamaño del árbol cortando nodos pocos prometedores. La calidad del nodo se estima
numéricamente por una función de evaluación heurística f(n). Una función de evaluación
heurística es una función que hace corresponder situaciones del problema con números, (f(n)
). Es decir, da una medida conceptual de la distancia entre un estado dado y el estado objetivo.
Estos valores son usados para determinar cuál operación ejecutar a continuación, típicamente
seleccionando la operación que conduce a la situación con máxima o mínima evaluación. En (Bello
et al., 2012) se proponen algunas heurísticas para el cálculo de reductos, tal como el ascenso de
colina (Hill-Climbing), con algunas de sus adaptaciones y la metaheurística Optimización basada en
colonias de hormigas (Ant Colony Optimization, ACO).
1.4 CONSIDERACIONES PARCIALES DEL CAPÍTULO
En el presente capítulo hemos abordado los principales conceptos y definiciones de la teoría
básica de conjuntos, la cual sirve de base para la Teoría de Conjuntos Aproximados. En un primer
momento se analizó la teoría clásica la cual está sostenida sobre las relaciones de equivalencia.
Posteriormente analizamos una de sus extensiones la cual hace referencia a Sistemas de Decisión
con información incompleta, en este aspecto se analizaron tres relaciones de inseparabilidad
entre objetos. La primera analizada no permite que el objeto referente tenga valores perdidos,
mientras que las otras si dan esta posibilidad.
A continuación se analiza la extensión basada en relaciones de similaridad, esta es de gran
importancia dado que en situaciones donde se tiene que distinguir entre grupos similares o se
requiere clasificar algunos elementos como similares esta extensión se convierte en una
importante herramienta para decidir el grado de semejanza entre grupos o elementos.
Finalmente, se da a conocer el concepto de reducto, el cual constituye prácticamente la base de
los métodos que se desarrollan usando conjuntos aproximados, pues están directamente
relacionado con la relación de separabilidad.

34
2 BIBLIOTECA EN JAVA QUE PERMITE TRABAJAR CON LOS CONJUNTOS APROXIMADOS
Este capítulo alude a las generalidades de la biblioteca RST: su diseño, características y lenguaje de
desarrollo. Expone los diagramas creados para las fases de análisis y diseño de la biblioteca y el
funcionamiento de la misma. Además, presenta una reseña del lenguaje Java en el cual esta fue
creada.
2.1 GENERALIDADES DEL LENGUAJE JAVA
Dado que Weka está desarrollo en Java se escogió este lenguaje, desarrollado por Sun
Microsystems de ORACLE, para desarrollar la biblioteca de RST. Java es un lenguaje de
programación que es distribuido actualmente como software libre bajo una licencia GNU GPL
(General Public License), lo cual lo hace un gran candidato para el uso en el desarrollo de
aplicaciones en países del tercer mundo. El lenguaje Java fue creado para trabajar con objetos y
de manera independiente a la plataforma. Esto es posible debido a la JVM (Java Virtual Machine)
la cual es una máquina genérica, que ejecuta un código creado al compilar un programa, que corre
indistintamente en cualquier ordenador que tenga instalada dicha máquina virtual. Java es un
lenguaje robusto justamente por la forma en que está diseñado, no permite el manejo directo del
hardware ni de la memoria. Implementa además mecanismos de seguridad que limitan el acceso a
recursos de las máquinas donde se ejecuta.
La Plataforma Java (Wikipedia, 2013)se compone de un amplio abanico de tecnologías, cada una
de las cuales ofrece una parte del complejo de desarrollo o del entorno de ejecución en tiempo
real. Por ejemplo, los usuarios finales suelen interactuar con la máquina virtual de Java y el
conjunto estándar de bibliotecas. Para el desarrollo de aplicaciones, se utiliza un conjunto de
herramientas conocidas como JDK (Java Development Kit) o herramientas de desarrollo para Java.
Principales características de Java (Schildt, 2001):
Universalidad: Aunque es un programa interpretado no es en principio tan rápido como
un programa equivalente compilado, las prestaciones de Java son sin embargo mejores

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
35
que las de cualquier lenguaje interpretado. Este hecho, junto con la sencillez de
programación en Java ha propiciado que se hayan escrito intérpretes de pequeño tamaño
adaptados a prácticamente cualquier plataforma, desde mainframes y ordenadores
personales (con cualquier sistema operativo: Windows, Macintosh OS, Unix,...) hasta
dispositivos electrónicos de bajo coste. También se suele hacer referencia a la
universalidad de Java con términos equivalentes como transportabilidad, o independencia
de plataforma, pues para ejecutar un programa basta compilarlo una sola vez, a partir de
entonces, se puede hacer correr en cualquier máquina que tenga implementado un
intérprete de Java.
Sencillez: Java es un lenguaje de gran facilidad de aprendizaje, pues en su concepción se
eliminaron todos aquellos elementos que no se consideraron absolutamente necesarios.
Por otro lado, Java dispone de un mecanismo conocido como "recogida de basura", el cual
usando la capacidad multitarea de Java hace que, durante la ejecución de un programa,
los objetos que ya no se utilizan se eliminen automáticamente de la memoria. Dicho
mecanismo facilita enormemente el diseño de un programa y optimiza los recursos de la
máquina que se esté usando para la ejecución del mismo (con los lenguajes tradicionales,
la eliminación de objetos y la consiguiente optimización de recursos debe planificarse
cuidadosamente al idear el programa).
Orientación a objetos: Un objeto es un elemento de programación, autocontenido y
reutilizable, y que podríamos definir como la representación en un programa de un
concepto, representación que está formada por un conjunto de variables (los datos) y un
conjunto de métodos (o instrucciones para manejar los datos).
Seguridad: En general, se considera que un lenguaje es tanto más seguro cuanto menor es
la posibilidad de que errores en la programación, o diseños malintencionados de
programas (virus), causen daños en el sistema.
2.2 DESARROLLO DE BIBLIOTECAS EN JAVA
En Ciencia de la Computación, una biblioteca (library) es un conjunto de subprogramas utilizados
para desarrollar software. Las bibliotecas contienen código y datos, que proporcionan servicios a

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
36
programas independientes, es decir, pasan a formar parte de éstos. Esto permite que el código y
los datos se compartan y puedan modificarse de forma modular. Algunos programas ejecutables
pueden ser a la vez programas independientes y bibliotecas, pero la mayoría de éstas no son
ejecutables. Ejecutables y bibliotecas hacen referencias (llamadas enlaces) entre sí a través de un
proceso conocido como enlace, que por lo general es realizado por un software denominado
enlazador (Barrientos, 2009).
Ventajas de Java para el desarrollo de Bibliotecas (Alwang et al., 1998):
Se intensifica y acelera la entrega de mejoras de la aplicación, garantizando por
consiguiente una mayor versatilidad y adaptabilidad a las tecnologías emergentes y a las
necesidades crecientes, en materia de servicios, de la comunidad de usuarios de las
Bibliotecas.
No sólo las mejoras llegan antes a las Bibliotecas, incrementando su rendimiento, sino que
también llegan con un menor coste financiero del mantenimiento del software.
La sencillez de las construcciones de que consta Java permiten obtener un código de
tamaño reducido, por lo que la penalización en que se incurre (con respecto a la
utilización de un lenguaje compilado) por la necesidad de interpretarlo se reduce
considerablemente, y las diferencias en la rapidez de ejecución serán inapreciables por el
usuario.
2.3 CONCEPCIÓN GENERAL DE LA BIBLIOTECA RST
Entre los IDE disponibles para Java se seleccionó el NetBeans 6.8, el cual es un ambiente de
programación cómodo, que compila en tiempo real y fácil de usar para depurar un programa.
La biblioteca se encuentra encapsulada como un paquete bajo el nombre de RST, para la creación
de la misma accedemos en la barra de menú File/New Project, como se muestra en la Figura 2.1.
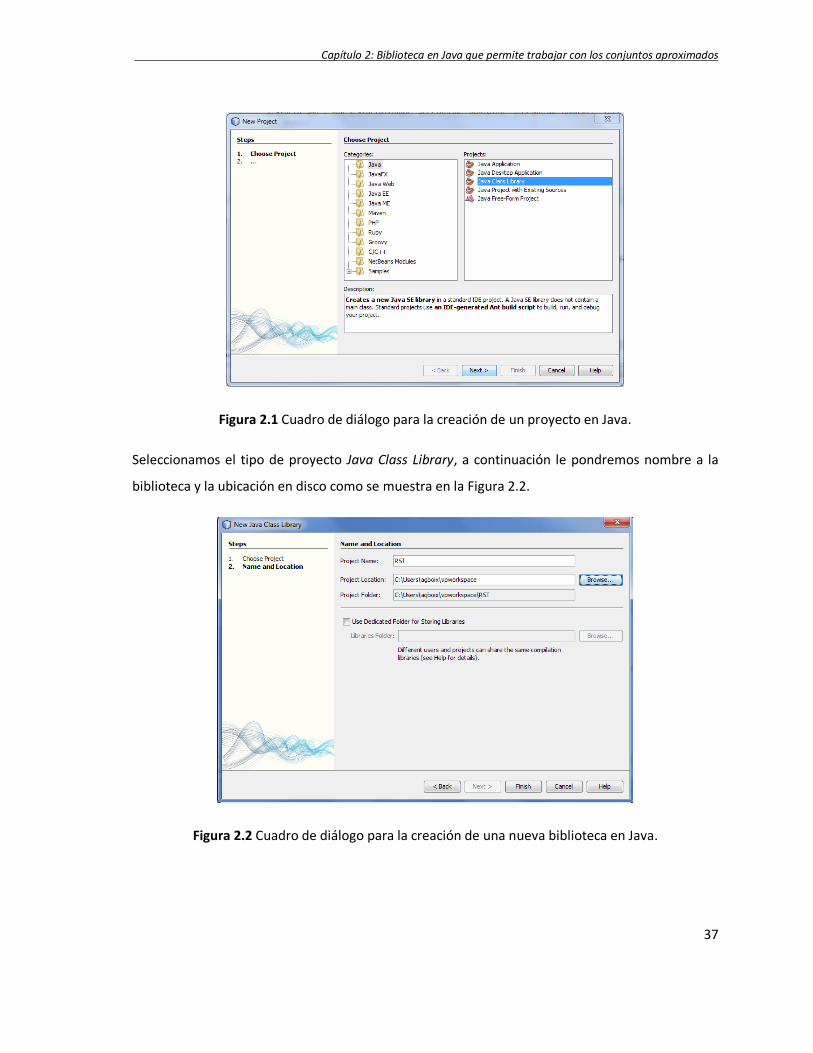
Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
37
Figura 2.1 Cuadro de diálogo para la creación de un proyecto en Java.
Seleccionamos el tipo de proyecto Java Class Library, a continuación le pondremos nombre a la
biblioteca y la ubicación en disco como se muestra en la Figura 2.2.
Figura 2.2 Cuadro de diálogo para la creación de una nueva biblioteca en Java.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
38
Para utilizar la misma la importamos mediante import RST, o en caso que deseemos acceder a
sus componentes internas lo hacemos mediante
import RST.<nombre_de_la_componente>
La compilación y construcción del paquete RST el cual contiene las extensiones agregadas a Weka
fue realizada usando Apache Ant versión 1.9.1 (Foundation, 2013), dicho paquete puede cargarse
en cualquier versión de Weka posterior a la 3.7.7.
2.3.1 Diseño de la biblioteca RST
Como planteamos con anterioridad, la biblioteca se encuentra encapsulada en un paquete con el
nombre RTS, para su concepción se ha diseñado una estructura de paquetes, uno dentro de otro,
para de esta manera separar las diferentes extensiones de la teoría de conjuntos aproximados.
Como se muestra en la Figura 2.3 se ha desglosado en los paquetes missing, reducts y measures,
dentro de este último se encuentran distance, similarity y conversor.
En el paquete missing hemos agrupado las clases correspondientes a los conjuntos aproximados
en sistemas de información incompletos. En measures se encuentran encapsuladas las clases que
hacen tratamiento a los conjuntos aproximados basados en relaciones de similaridad. Dentro de
distance se encuentran medidas de distancia, análogamente en similarity se encuentran medidas
de similaridad. Finalmente en conversor se han implementado varias formas de convertir una
medida de distancia en una medida de similaridad.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
39
Figura 2.3 Diagrama de paquetes.
2.3.2 Diagrama de clases
La técnica del diagrama de clases se ha vuelto muy importante en los métodos orientados a
objetos. El diagrama de clases describe los tipos de objetos que hay en un sistema y las diversas
clases de relaciones estáticas (asociaciones, subtipos) que existen entre ellos. También muestran
los atributos y operaciones de una clase y las restricciones a que se ven sujetos, según la forma en
que se conecten los objetos (Fowler and & Scott, 1997).
En la Figura 2.4 se ilustran las clases principales de la biblioteca mediante un diagrama de clases
en UML. En el mismo, solo se hace mención a las clases más importantes de la biblioteca, ya que
se omitieron algunas medidas de similitud y distancia, para así hacer el diagrama menos extenso y
facilitar su concepción general.
El paquete RST contiene a las clases RoughSet y ClassicRoughSet, como se observa en la Figura 2.5.
La clase RoughSet, es una clase abstracta de la cual heredan todas clases que correspondan a una
extensión de RST. Esta contiene las principales medidas internas de RST para realizar inferencia:
accuracyAprox(): Precisión de la aproximación, según la expresión (1.24).

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
40
qualityAprox(): Calidad de la aproximación, según la expresión (1.25).
Deogun(): Deogun, según la expresión (1.26).
qualityClassification (): Calidad de la clasificación, según la expresión (1.27).
membership(): Función de pertenencia aproximada, según la expresión (1.28).
roughness(): Aspereza del conjunto, según la expresión (1.31).
qualityGeneral(): Calidad de la clasificación, según la expresión (1.32).
accuracyGeneral(): Precisión de la clasificación, según la expresión (1.33).
roughFMeasure(): Medida-F aproximada, según la expresión (1.34).
membershipConcept(): Pertenencia aproximada, según la expresión (1.35).
membershipUnion(): Pertenencia aproximada, según la expresión (1.36).
Además, posee el método concept(), el cual es el encargado de buscar los elementos que
pertenecen a la clase pasada por parámetro y los métodos abstractos relationshipClasses(),
lowerAprox(), upperAprox() y relationship(), los cuales son necesarios sobrescribir según las
particularidades y definiciones de la extensión de la teoría. El método relationship() constituye la
base de la teoría ya que él establece la relación entre dos objetos (instancias) para los atributos
especificados. El método relationshipClasses() devuelve todas las clases de relación según la
relación establecida en relationship(). Los métodos lowerAprox() y upperAprox() calculan la
aproximación inferior y superior de un conjunto dado, respectivamente. Esta clase, además, posee
los métodos positiveRegion(), negativeRegion() y boundaryRegion(), estos calculan la región
positiva, región negativa y región frontera de los conceptos, respectivamente. La clase
ClassicRoughSet corresponde a la teoría de los conjuntos aproximados clásica, y además de los
métodos heredados por RoughSet, posee los métodos lowerAproxMembership() y
upperAproxMembership(), los cuales calculan la aproximación inferior y superior de un conjunto
según las expresiones (1.29) y (1.30), respectivamente.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
41
En la Figura 2.6 se muestra el diagrama de clases del paquete missing. Este contiene tres clases:
MissingValuesRI, MissingValuesRII y MissingValuesRIII, estas clases corresponden a las
extensiones mencionadas en el epígrafe 1.3.2. Las clases MissingValuesRI y MissingValuesRII
poseen, además, un método llamado noMissValues(), el cual calcula el conjunto de objetos que no
poseen valores perdidos, según las expresiones (1.7) y (1.10), respectivamente. La clase
MissingValuesRIII posee el método relationshipXTo() que calcula los elementos a los cuales x es
similar.
El paquete measure se muestra en la Figura 2.7, este contiene a las clases SimilarityRelationship,
Measure y Threshold. La clase SimilarityRelationship, tiene como atributos un objeto de tipo
Measure y un objeto de tipo Conversor, contiene el método relationshipXTo() que calcula los
elementos a los cuales x es similar, según la expresión (1.18). Además, contiene los métodos
lowerAproxMembership() y upperAproxMembership(), los cuales calculan la aproximación inferior
y superior de un conjunto según las expresiones (1.29) y (1.30), respectivamente.
De la clase Measure extienden dos clases: Similarity y Distance. Para implementar una medida de
similitud basta con extender de Similarity e implementar el método relation(), de forma análoga
procedemos si queremos implementar una medida de distancia, pero extendiendo de la clase
Distance. En el Anexo 2 se muestran las funciones de distancias y similitudes implementadas en la
biblioteca.
El otro atributo de la clase SimilarityRelationship es el objeto Conversor, esta interfaz tiene como
objetivo permitir que se utilicen distintas variantes para convertir de una medida de distancia a
una de similitud, en el Anexo 1 se muestran las variantes implementadas en la biblioteca.
La clase Threshold posee distintos métodos para el cálculo del umbral de similitud entre objetos,
en la biblioteca se incluyen todos aquellos relacionados en el Anexo 3.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
42
Figura 2.4 Diagrama de clases.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
43
Figura 2.5 Clases del paquete RST.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
44
Figura 2.6 Clases del paquete missing.
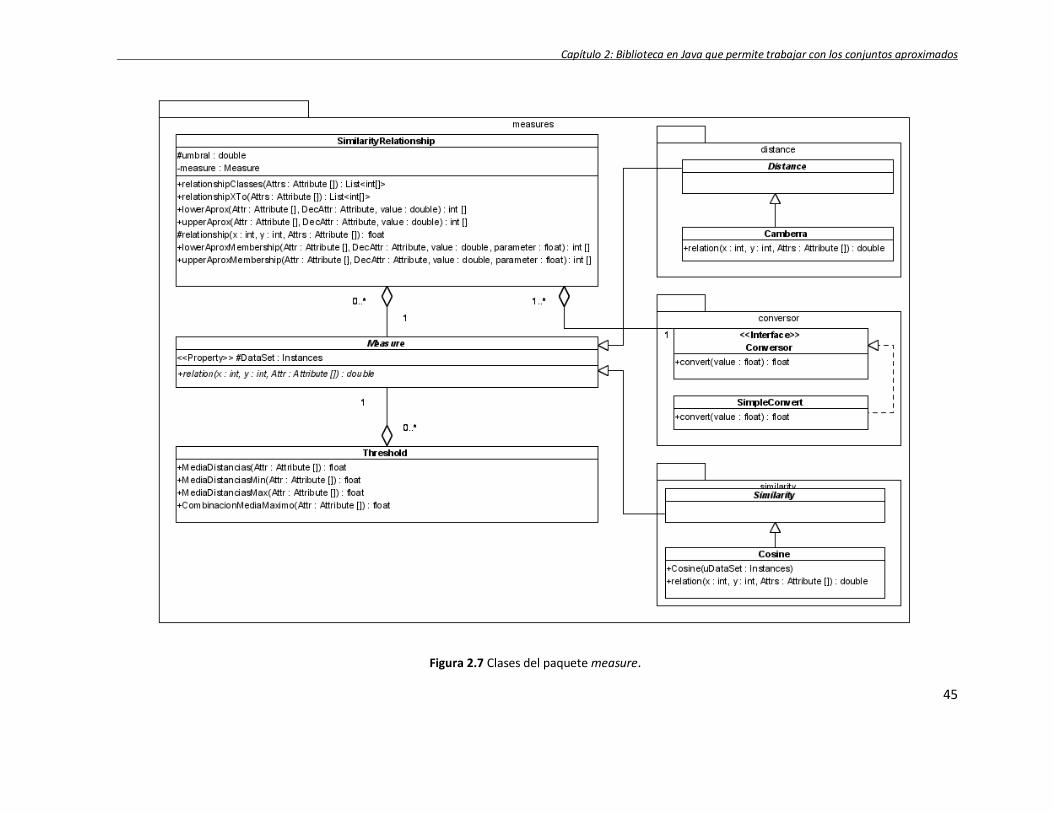
Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
45
Figura 2.7 Clases del paquete measure.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
46
2.3.3 Cálculo de reductos
En la literatura varias metaheurísticas han sido utilizadas para calcular reductos, incluyendo
Recocido Simulado (González, 2011), Algoritmos Genéticos (Bello et al., 2012), Colonias de
Hormigas (Bello, 2005b, Bello, 2005a, Bello, 2005c). En este Trabajo de Diploma se utilizan
Colonias de Hormigas pues los algoritmos de optimización de colonias de hormigas se aplican
exitosamente en muchos problemas de optimización combinatoria. Ellos tienen una ventaja sobre
los enfoques recocido simulado y los algoritmos genéticos en problemas similares cuando el grafo
puede cambiar su estructura de manera dinámica, el algoritmo de colonia de hormigas puede
seguir corriendo continuamente y adaptar los cambios en tiempo real (Dorigo, 2007).
2.3.3.1 Optimización basada en colonias de hormigas
La Optimización basada en Colonias de hormigas (Ant Colony Optimization; ACO) son modelos
poblacionales inspirados en el comportamiento de las hormigas naturales. Para el cual realizan un
proceso constructivo y estocástico guiado por unos rastros de feromona que va depositando cada
hormiga, dando una medida de cuan deseado ha sido un determinado camino, y a través de una
función de visibilidad que evalúa la calidad del desplazamiento. Es un ejemplo clásico de
comunicación indirecta (stigmergy) (Dorigo, 2007).
Los algoritmos ACO se inspiran directamente en el comportamiento de las colonias reales de
hormigas para solucionar problemas de optimización combinatoria. Se basan en una colonia de
hormigas artificiales, esto es, unos agentes computacionales simples que trabajan de manera
cooperativa y se comunican mediante rastros de feromona artificiales. Los algoritmos de ACO son
esencialmente algoritmos constructivos: en cada iteración del algoritmo, cada hormiga construye
una solución al problema recorriendo un grafo de construcción G. Cada arista del grafo, que
representa los posibles pasos que la hormiga puede dar, tiene asociada dos tipos de información
que guían el movimiento de la hormiga:
• Información heurística, que mide la preferencia heurística de moverse desde el nodo r
hasta el nodo s, o sea, de recorrer la arista ars. Se denota por ηrs. Las hormigas no
modifican esta información durante la ejecución del algoritmo.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
47
• Información de los rastros de feromona artificiales, que mide la “deseabilidad aprendida”
del movimiento de r a s. Imita a la feromona real que depositan las hormigas naturales en
forma numérica. Esta información se modifica durante la ejecución del algoritmo
dependiendo de las soluciones encontradas por las hormigas. Se denota por τrs.
El modo de operación básico de un algoritmo ACO es como sigue: las m hormigas (artificiales) de
la colonia se mueven, concurrentemente y de manera asíncrona, a través de los estados
adyacentes del problema (que puede representarse en forma de grafo con pesos). Este
movimiento se realiza siguiendo una regla de transición que está basada en la información local
disponible en las componentes (nodos). Esta información local incluye la información heurística y
memorística (rastros de feromona) para guiar la búsqueda. Al moverse por el grafo de
construcción, las hormigas construyen incrementalmente soluciones. Opcionalmente, las
hormigas pueden depositar feromona cada vez que crucen un arco (conexión) mientras que
construyen la solución (actualización en línea paso a paso de los rastros de feromona). Una vez
que cada hormiga ha generado una solución se evalúa ésta y puede depositar una cantidad de
feromona que es función de la calidad de su solución (actualización en línea de los rastros de
feromona). Esta información guiará la búsqueda de las otras hormigas de la colonia en el futuro.
Además, el modo de operación genérico de un algoritmo de ACO incluye dos procedimientos
adicionales, la evaporación de los rastros de feromona y las acciones del demonio. La evaporación
de feromona la lleva a cabo el entorno y se usa como un mecanismo que evita el estancamiento
en la búsqueda y permite que las hormigas busquen y exploren nuevas regiones del espacio. Las
acciones del demonio son acciones opcionales -que no tienen un contrapunto natural- para
implementar tareas desde una perspectiva global que no pueden llevar a cabo las hormigas por la
perspectiva local que ofrecen. Ejemplos son: observar la calidad de todas las soluciones generadas
y depositar una nueva cantidad de feromona adicional sólo en las transiciones/componentes
asociadas a algunas soluciones, o aplicar un procedimiento de búsqueda local a las soluciones
generadas por las hormigas antes de actualizar los rastros de feromona. En ambos casos, el
demonio reemplaza la actualización en línea a posteriori de feromona y el proceso pasa a llamarse
actualización fuera de línea de rastros de feromona.
Para los modelos existen distintos criterios de parada, entre los que se encuentran:

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
48
• Se alcanza un número máximo de iteraciones o ciclos.
• Se obtiene una solución con una calidad deseada.
• Se alcanza un tiempo límite o predeterminado de procesamiento.
• Se obtiene un número máximo de evaluaciones de la función objetivo.
En ACO el significado de los rastros de feromona y la función heurística o de visibilidad, dependen
totalmente del problema a resolver. En el caso de los rastros de feromona, cuando tenemos un
problema de secuenciación (Viajante de Comercio, Secuenciación de Tareas,..), donde el orden en
que aparezcan las componentes en una solución, influye en la calidad de esta. En este caso los
rastros de feromona son asociados a los arcos del grafo, con el objetivo de premiar las buenas
secuencias de las componentes. En otros problemas (Selección de Rasgos, Cubrimiento de
Conjuntos,..), donde los cambios de posición entre componentes de una solución no varía la
calidad de esta, los rastros de feromona se asocian a los nodos del grafo. En estos problemas, lo
que interesa es qué componente se seleccionó y no el orden en que aparecen.
Dentro de los algoritmos ACO las diferencias fundamentales radican; en la regla de transición de
estados que utilizan para la construcción de las soluciones, y en el momento y la forma en que
actualizan los rastros de feromona. De aquí la justificación de la cantidad de modelos existentes.
2.3.3.2 Cálculo de reductos usando ACO
El cálculo de reductos es un ejemplo de problema discreto complejo. Este problema puede ser
modelado de la forma siguiente usando un enfoque híbrido en el cual la generación de
subconjuntos se realiza mediante un algoritmo ACO y la evaluación de estos subconjuntos se
ejecuta usando una medida de calidad de la RST. Sea A={a1, a2,…; aNr} un conjunto de rasgos. Este
conjunto se puede visualizar como una red de nodos cada uno de los cuales representa un rasgo y
que están completamente conectados por enlaces bidireccionales. Valores de feromona i están
asociados a cada nodo ai. Esta es una diferencia del modelo respecto a la representación
tradicional de los modelos basados en colonias de hormigas (Bello et al., 2012) donde la feromona
se asocia a los enlaces, y también con respecto al algoritmo propuesto por Jensen and Shen

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
49
(Jensen and Shen, 2003). De modo que en el modelo usado no es significativo el orden en que
fueron seleccionados los rasgos a los efectos de la actualización de los valores de la feromona.
En el primer paso cada hormiga se asigna a un nodo. El conjunto bk denota el subconjunto de
rasgos que forma la k-ésima hormiga. De modo que inicialmente bk {ai}, donde ai es el rasgo
asociado al nodo donde es asignada inicialmente la k-ésima hormiga. Las hormigas ejecutan un
proceso de selección hacia delante en que cada hormiga k expande su subconjunto bk paso a paso
añadiendo nuevos rasgos; para realizar esto, la k-ésima hormiga analiza todos los rasgos del
conjunto A-bk, y selecciona el próximo rasgo a incluir en bk de acuerdo a la regla de selección del
algoritmo ACO. Se usa la medida calidad de la aproximación de la clasificación, según la expresión
(1.25), como información heurística en la regla. Este valor también se usa para determinar si el
subconjunto bk es un reducto.
Se realizó el estudio del algoritmo ACS-RST-FS (Bello, 2005c) basado en Ant Colony System.
Aspectos fundamentales de ACS-RST-FS:
a) Espacio de búsqueda: Se utiliza un grafo completo en el cual hay un nodo por cada
atributo. Cada nodo ai, correspondiendo al i-ésimo rasgo tiene asociado un valor de
feromona i.
b) Distribución inicial de las hormigas: Al inicio de cada ciclo las hormigas se distribuyen
sobre los nodos del grafo de acuerdo a la relación entre la cantidad de hormigas (m) que
se utiliza y la cantidad de rasgos (Nr), siguiendo las reglas siguientes, donde na es la
cantidad de atributos:
i) If m < na, then Distribución inicial aleatoria de las hormigas.
ii) If m = na, then Una hormiga es asociada con cada nodo.
ii) If m > na, Las primeras Nr hormigas se sitúan según la regla (ii) y el resto según (i).
c) Función heurística y regla de selección: La función heurística () de los algoritmos ACO
usada como función de evaluación de un subconjunto de rasgos B es (B)= B(Y).

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
50
caseotherinI
qqifYi i
k aBi 0)(*max
(2.1)
donde I se selecciona usando la expresión:
k
j
BAa
b
aB
a
j
b
aB
a
j
k
j
j
k
k BAaifY
Y
Baif
aBp
kj
jk
jk
*
*
0
,
(2.2)
d) Cálculo del valor de feromona inicial: Se estudiaron tres alternativas para calcular los
valores iniciales de feromona:
i) valores aleatorios para i (0), i=1,…,Nr
ii) i (0)=1/Nr,
iii) i (0)= wA,D(ai), donde wA,D(ai) es el peso del rasgo ai de acuerdo a la RST, es
decir,
}{,
}{,1,
dA
daAaw i
idA
(2.3)
Donde (A,{d}) expresa el grado de dependencia entre el conjunto de atributos A y el
rasgo de decisión {d}.
e) Criterio de parada de una hormiga (Ant Stopping Criteria; ASC): El criterio de parada de
una hormiga establece la condición que indica cuando una hormiga termina su trabajo en
un ciclo. Esto se produce cuando el conjunto bk ya contiene los Nr rasgos o cuando se
alcanza un subconjunto de rasgos B con igual calidad de la aproximación de la clasificación
que el conjunto de todos los rasgos.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
51
f) Criterio de parada del proceso (Process Stopping Criteria; PSC): Los algoritmos desarrollan
una secuencia de ciclos (NC=1, 2, ..., NCmax). En cada ciclo todas las hormigas construyen
un subconjunto de rasgos. El proceso termina cuando se alcanza el valor NCmax.
g) Tamaño de la población: en (Bello et al., 2012) derivaron las siguientes reglas que
permiten calcular el tamaño de la población en función de la cantidad de rasgos (m=f(n)),
las reglas establecidas son:
R1: If n19 then m = n;
R2: If 20n49 then
[If 2/3*n24 then m=24 else m = Round[2/3*n]]
R3: If n 50 then
[If [1/2 * n 33 then m = 33 else m = Round[1/2*n]]
donde Round[x] denota el valor entero más cercano a x.
Complejidad
Considerando que el costo de encontrar las aproximaciones inferior y superior es O(Nr*n2), donde
n es la cantidad de objetos, según (Bell and Guan, 1998) y (Deogun, 1998), la complejidad de los
algoritmos anteriores se puede estimar en O(NC*m*Nr2*n2), donde NC es la cantidad de ciclos. En
el caso en que la cantidad de hormigas sea similar a la cantidad de rasgos la complejidad es
O(NC*Nr3*n2).
En el algoritmo ACS-RST-FS se consideran las variables:
• m: cantidad de hormigas.
• n: número de atributos.
• i: el valor de feromona asociado al rasgo ai.
• NCmax: número máximo de ciclos.
• Bk: denota el subconjunto de rasgos B asociado con la hormiga k.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
52
• ASC: Criterio de parada de las hormigas, es verdadero cuando el conjunto B ha sido
completado, es decir, el conjunto B tiene la misma calidad de la clasificación que A.
• PSC: Criterio de parada del proceso de búsqueda es verdadero si se alcanza la condición
de parada (número máximo de ciclos).
Algoritmo ACS-RST-FS:
PSC Falso
NC 1
Calcular i (0) i=1,.., na, (valores iniciales de la
feromona)
Repeat
P1: Estado inicial para cada ciclo.
La colonia de hormigas se distribuye en el espacio de
rasgos de acuerdo a las reglas en b).
Cada hormiga k se asocia al rasgo ai, k=1,…,m,
Set Bk {ai} de acuerdo a las reglas.
ASCk False, k=1,…,m.
P2: Repeat
for k=1 to m do
if ASCk = False then
Seleccionar el nuevo rasgo ai* a ser agregado a
Bk (Bk Bk {ai*}) de acuerdo expresión (2.1)
i (1-) * i + * i(0), donde ai* es el
rasgo más recientemente agregado (regla de
actualización local de la feromona)
Update ASCk. ¿Encontró la hormiga k un
reducto?
endIf
endFor
Until ASCk is True for all ants.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
53
En (Bello et al., 2012) se realizó un estudio experimental para evaluar el algoritmo propuesto
previamente y analizar el comportamiento de los parámetros del modelo ACO. Para el mismo se
estudió el desempeño para diversas combinaciones de parámetros. Seguidamente se muestran los
resultados alcanzados, los cuales muestran la relevancia que tiene en el proceso de selección de
rasgos la asignación de los valores adecuados para algunos de los parámetros.
La relación clave es entre los parámetros y q0 se muestra en la Tabla 2.1 Relación de parámetros
para el algoritmo ACS-RST-FS.. La combinación (=1, q0=0.3) produce aproximadamente tres
veces más reductos que la combinación (=5, q0=0.9), independientemente de la cantidad de
hormigas (m) y el número de ciclos. Pero en el caso de la combinación (=5, q0=0.9) se obtienen
reductos más cortos.
Tabla 2.1 Relación de parámetros para el algoritmo ACS-RST-FS.
Parámetros m=9 m=15 m=24 m=33
=1, q0=0.3
58 104 143 175
=5, q0=0.9
30 33 45 56
2.3.3.3 Diseño e implementación
Dado que el propio diseño de la biblioteca incluye el paquete reducts, el cual tiene como finalidad
encapsular todos los reductos que se calculen en la Teoría de conjuntos aproximados,
P3: Cuando todas las hormigas han terminado en el ciclo:
Seleccionar el mejor subconjunto de rasgos Bk y
For each ai Bk do
i (1-) * i + * Bk(Y)
endFor
NC NC+ 1
Update PSC ¿Se alcanzó el número máximo de ciclos?
Until PSC is True.

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
54
procederemos a incorporar en el mismo las clases que permitan implementar el algoritmo ACS-
RST-FS. En la Figura 2.8 se muestran las clases para la implementación de dicho algoritmo.
La interfaz ACOinterfaz define el comportamiento de los algoritmos inspirados en ACO. La
principal función de la clase ACOabtract es SetAllAnts(), la cual se encarga de ubicar a las
hormigas.
La clase ACSabstract brinda la base para la clase ACSrstfs, cuyo método principal es Run(), como
tal este método ejecuta el algoritmo para el cálculo de reductos. Una vez que ejecutemos el
algoritmo ACS-RST-FS la clase ACSrstfs posee dos métodos para dar resultados: getAllReducts() y
getBestReduct(), el primero nos devuelve una lista con todos los reductos, cada reducto se
devuelve como un arreglo de atributos y el segundo nos da el mejor reducto (basado en el
tamaño, mientras menos atributos tenga el reducto, mejor es).
Figura 2.8 Clases del paquete reducts.
2.4 CONCLUSIONES PARCIALES DEL CAPÍTULO
En este capítulo se presentó el diseño de la biblioteca RST, la cual está desarrollada en Java, como
IDE se utilizó el NetBeans 6.8 ya que es un ambiente de programación cómodo, que compila en

Capítulo 2: Biblioteca en Java que permite trabajar con los conjuntos aproximados
55
tiempo real y fácil de usar para depurar un programa. Abordamos las principales características y
ventajas del lenguaje Java, argumentando de esta manera por qué su usó para el desarrollo de la
biblioteca.
La biblioteca RST logró incorporar los elementos de la teoría de conjuntos aproximados
identificados en el Capítulo 1 que permiten el desarrollo de algoritmos de aprendizaje
automatizado. Como resultado se obtuvo un paquete global y dentro de este los paquetes missing
y measures, los cuales cubren las extensiones para valores perdidos y la extensión basada en
relaciones de similaridad, respectivamente.
Finalmente se incorporó el algoritmo ACS-RST-FS para el cálculo de reductos, dicho algoritmo está
inspirado en la Optimización basada en colonias de hormigas.
Se verificó el funcionamiento de cada método de la biblioteca a partir de la aplicación de los
mismos a pequeños Sistemas de Información, para los cuales se conoce los valores a obtener en
cada caso.

56
3 UTILIZACIÓN DE LA BIBLIOTECA RST DESDE WEKA
En el presente capítulo se ilustra la factibilidad del uso de la biblioteca RST desde la incorporación
de métodos en el Weka. Particularmente presentaremos cómo implementar en Weka las medidas
para validar el agrupamiento basadas en la Teoría de Conjuntos Aproximados, utilizando la
biblioteca RST. Abordaremos sobre las generalidades de la herramienta para el Aprendizaje
Automatizado: Weka. Ofreceremos detaller de la implementación del paquete de validación del
agrupamiento en Weka.
3.1 MEDIDAS PARA LA VALIDACIÓN DEL AGRUPAMIENTO UTILIZANDO RST
En este epígrafe describiremos aquellas medidas definidas en (Arco, 2009) para evaluar resultados
de agrupamientos, así como el algoritmo que permite su utilización para tales efectos.
La validación del agrupamiento utilizando RST es no supervisada y permite que el cálculo común
inicial de las relaciones y aproximaciones inferiores y superiores pueda ser reutilizado por varias
medidas de calidad, inclusión y proximidad de conceptos.
Los objetos a agrupar están descritos por rasgos y constituyen el sistema de información que es el
punto de partida para aplicar RST. Cada grupo resultante de un proceso de agrupamiento al cual
dichos objetos son sometidos constituye un concepto Xi. En esta propuesta solo consideran
resultados de agrupamientos duros y deterministas, precisamente la mayoría de los métodos de
agrupamiento implementados en el Weka tienen esta clasificación. De ahí la importancia de
incorporar estas medidas para enriquecer el módulo de evaluación del agrupamiento del Weka.
Estas medidas de validación se basan en la Teoría de los Conjuntos Aproximados extendida,
utilizando relaciones de similaridad.
La propuesta de validación del agrupamiento utilizando RST (Arco, 2009) considera las medidas
clásicas de calidad y precisión de aproximaciones y de sistemas de decisión (1.24).
Adicionalmente, en (Arco, 2009) se presentan nuevas medidas que permiten caracterizar mejor
los resultados de los agrupamientos.

Capítulo 3: Utilización de la biblioteca RST desde Weka
57
Si bien las medidas calidad y precisión del agrupamiento (expresiones (1.32) y (1.33),
respectivamente) logran medir globalmente el nivel de inconsistencia, calidad y precisión de los
conceptos en un sistema de información dado, consideran que cada grupo tiene igual repercusión
en la evaluación. Sin embargo, no todos los grupos deben tener igual influencia al evaluar el
agrupamiento, en (Arco, 2009) se ponderan los mismos. Por tal motivo, se obtienen expresiones
generalizadas de precisión y calidad de la clasificación considerando la ponderación de los grupos
por su cardinalidad, calculando el peso wi asociado al grupo Xi como wi = │Xi│/│U│. En (Arco, 2009)
se propone la calidad y precisión generalizadas del agrupamiento, como se muestran en las
expresiones (3.1) y (3.2), respectivamente. El peso asociado a un grupo Xi se representa por wi,
cumpliéndose las restricciones wi0 y 11
k
i
iw .
U
wXRk
i
ii
G
1
* )('
(3.1)
k
i
ii
k
i
ii
G
wXR
wXR
1
*
1
*
)('
)('
(3.2)
Varios criterios pueden ser empleados para ponderar los grupos y así captar mejor las
propiedades deseadas; por ejemplo, similitud dentro del grupo, pertenencia de los objetos al
grupo y cardinalidad del grupo.
La media de la pertenencia aproximada de los objetos a cada grupo también puede ser empleada
para ponderar los grupos (Arco, 2009). Su expresión se muestra en (3.3).
i
XxiX
iX
x
w i
(3.3)

Capítulo 3: Utilización de la biblioteca RST desde Weka
58
En (Arco, 2009) se propusieron dos nuevas medidas de pertenencia aproximada, descritas en las
expresiones (1.35) y (1.36). Las expresiones (3.4) y (3.5) muestran las variantes de ponderación
que se derivan de ellas, respectivamente.
A partir de los conceptos de RST a aplicar y las definidas, en (Arco, 2009) se propone un algoritmo
para guiar la aplicación de RST en la validación del agrupamiento. Las entradas a este algoritmo
son: la colección de objetos (sistema de información), el resultado del agrupamiento (conceptos),
la medida y umbral de similitud, y formas de ponderación de los grupos. Las salidas del algoritmo
son los valores de las medidas de precisión y calidad aplicadas a los grupos y al agrupamiento en
general.
Algoritmo. Aplicación de RST en la validación del agrupamiento.
1. Obtener las clases de similitud (1.17) para cada objeto en
el sistema de información.
2. Calcular las aproximaciones inferiores (1.19) y superiores
(1.20) por grupo.
3. Calcular calidad (1.24) y precisión (1.25) por grupo.
4. Calcular calidad (1.32) y precisión (1.33) del
agrupamiento.
5. Para cada variante de cálculo de peso especificada:
a. Calcular los pesos por grupos.
b. Calcular calidad (3.1) y precisión (3.2) generalizadas
del agrupamiento.
De esta forma es posible medir la vaguedad o imprecisión de cada grupo obtenido y del
agrupamiento en su totalidad. Si la región límite es pequeña, entonces se obtendrán mejores
i
XxiX
iX
x
w i
(3.4)
i
XxiX
iX
x
w i
(3.5)

Capítulo 3: Utilización de la biblioteca RST desde Weka
59
resultados de las medidas utilizadas en la evaluación (valores cercanos a uno). Valores altos de las
medidas indican un mejor agrupamiento.
Los resultados de los pasos 1 y 2 del algoritmo son comunes para la aplicación posterior de
cualquier medida de validación basada en RST. En el cálculo de la complejidad temporal de estos
dos pasos interviene la complejidad de la medida de similitud que se emplee. En el cálculo de la
complejidad se considera: n número de objetos, m número de rasgos que describen dichos
objetos, y k número de grupos. La complejidad temporal del primer paso es O(mn2), la que está
dada por la obtención del conjunto de objetos relacionado con cada objeto. La complejidad
temporal del cálculo de las aproximaciones es O(kn2), ya que para el peor caso se considera que a
cada grupo pertenecen todos los objetos y cada objeto está relacionado con todos. Por tanto, la
complejidad de este procesamiento, previo al cálculo de las medidas basadas en RST, es O(wn2),
donde w = max{k, m} (Arco, 2009).
3.2 GENERALIDADES DE WEKA
Weka es un sistema multiplataforma y de amplio uso probado bajo sistemas operativos Linux,
Windows y Macintosh. Puede ser usado desde la perspectiva de usuario mediante las seis
interfaces que brinda, a través de la línea de comando desde donde se pueden invocar cada uno
de los algoritmos incluidos en la herramienta como programas individuales y mediante la creación
de un programa Java que llame a las funciones que se desee.
Weka (versión 3.5.2) dispone de seis interfaces de usuario diferentes que pueden ser accedidas
mediante la ventana de selección de interfaces (GUI Chooser), que constituye la interfaz de
usuario gráfica (GUI: Grafic User Interface):
Interfaz para línea de comando (Simple CLI: Command Line Interface): permite invocar
desde la línea de comandos cada uno de los algoritmos incluidos en Weka como
programas individuales. Los resultados se muestran únicamente en modo texto. A pesar
de ser en apariencia muy simple es extremadamente potente porque permite realizar
cualquier operación soportada por Weka de forma directa; no obstante, es muy
complicada de manejar ya que es necesario un conocimiento completo de la aplicación. Su
utilidad es pequeña desde que se fue recubriendo Weka con interfaces. Actualmente ya

Capítulo 3: Utilización de la biblioteca RST desde Weka
60
prácticamente sólo es útil como una herramienta de ayuda a la fase de pruebas. Es muy
beneficiosa principalmente para los sistemas operativos que no proporcionan su propia
interfaz para línea de comandos.
Explorador (Explorer): interfaz de usuario gráfica para acceder a los algoritmos
implementados en la herramienta para realizar el aprendizaje automatizado. Es el modo
más usado y descriptivo. Permite realizar operaciones sobre un sólo archivo de datos.
Experimentador (Experimenter): facilita la realización de experimentos en lotes, incluso
con diferentes algoritmos y varios conjuntos de datos a la vez.
Flujo de conocimiento (KnowledgeFlow): proporciona una interfaz netamente gráfica para
el trabajo con los algoritmos centrales de Weka. Esencialmente tiene las mismas
funciones del Explorador aunque algunas de ellas aún no están disponibles. El usuario
puede seleccionar los componentes de Weka de una barra de herramientas, y conectarlos
juntos para formar un “flujo del conocimiento” que permitirá procesar y analizar datos.
Visualizador de Arff (ArffViewer): interfaz para la edición de ficheros con extensión arff.
Log: muestra la traza de la máquina virtual de acuerdo a la ejecución del programa.
3.2.1 Entrada de datos
Weka denomina instancia a cada uno de los casos proporcionados en el conjunto de datos de
entrada, cada una de las cuales posee propiedades o rasgos que la definen. Los rasgos presentes
en cada conjunto de datos son llamados atributos.
El formato de archivos con el que trabaja Weka es denominado arff, acrónimo de Attribute-
Relation File Format. Este formato está compuesto por una estructura claramente diferenciada en
tres partes:
Sección de encabezamiento: se define el nombre del conjunto de datos.
Sección de declaración de atributos: se declaran los atributos a utilizar especificando su tipo. Los
tipos aceptados por la herramienta son:

Capítulo 3: Utilización de la biblioteca RST desde Weka
61
a) Numérico (Numeric): expresa números reales2
b) Entero (Integer): expresa números enteros
c) Fecha (Date): expresa fechas
d) Cadena (String): expresa cadenas de textos, con las restricciones del tipo String3
e) Enumerado: expresa entre llaves y separados por comas los posibles valores (caracteres o
cadenas de caracteres) que puede tomar el atributo.
Sección de datos: se declaran los datos que componen el conjunto de datos.
El formato por defecto de los ficheros que usa Weka es el arff, pero eso no significa que sea el
único que admita. Esta herramienta tiene intérpretes de otros formatos como CSV, que son
archivos separados por comas o tabuladores (la primera línea contiene los atributos) y C4.5 que
son archivos codificados según el formato C4.5, donde los datos se agrupan de tal manera que en
un fichero .names estarán los nombres de los atributos y en un fichero .data los datos en sí. Al leer
Weka ficheros codificados según el formato C4.5 asume que ambos ficheros (el de definición de
atributos y el de datos) están en el mismo directorio, por lo que sólo es necesario especificar uno
de los dos. Además, las instancias pueden leerse también de un URL (Uniform Resource Locator) o
de una base de datos en SQL usando JDBC.
3.2.2 Interioridades de Weka
Weka se implementa en Java, lenguaje de alto nivel ampliamente difundido y multiplataforma, lo
que posibilita que sistemas escritos en este lenguaje como Weka puedan ejecutarse en cualquier
plataforma sobre la que haya una máquina virtual Java disponible. Esta herramienta sigue los
preceptos del código abierto (open source), por lo su código fuente está totalmente disponible,
permitiendo la modificación del mismo. Solo es necesario recompilarlo para posteriormente
2 debido a que weka es un programa anglosajón la separación de la parte decimal y entera de los números reales se
realiza mediante un punto en vez de una coma.
3 entendiendo como tipo string el ofrecido por java.

Capítulo 3: Utilización de la biblioteca RST desde Weka
62
agregar extensiones al sistema. Además es un software de distribución gratuita lo que posibilita su
uso, copia, estudio, modificación y redistribución sin restricciones de licencias.
Las clases de Weka están organizadas en paquetes. Un paquete es la agrupación de clases e
interfaces donde lo habitual es que las clases que lo formen estén relacionadas y se ubiquen en un
mismo directorio. Esta organización de la estructura de Weka hace que añadir, eliminar o
modificar elementos no sea una tarea compleja. Está formado por 10 paquetes globales, y dentro
de ellos se agrupan otros paquetes que aunque su contenido se ajusta al paquete padre ayudan a
organizar aún mejor la estructura de clases e interfaces.
Los paquetes globales son:
“associations”: contiene las clases que implementan los algoritmos de asociación.
“attributeSelection”: contiene las clases que implementan técnicas de selección de
atributos.
“classifiers”: agrupa todas las clases que implementan algoritmos de clasificación y estas a
su vez se organizan en subpaquetes de acuerdo al tipo de clasificador.
“clusterers”: contiene las clases que implementan algoritmos de agrupamiento.
“core”: paquete central que contiene las clases controladoras del sistema.
“datagenerators”: paquete que contiene clases útiles en la generación de conjuntos de
datos atendiendo al tipo de algoritmo que será usado.
“estimators”: clases que realizan estimaciones (generalmente probabilísticas) sobre los
datos.
“experiment”: contiene las clases controladoras relacionadas con el modo
Experimentador.
“filters”: está constituido por las clases que implementan algoritmos de
preprocesamiento.

Capítulo 3: Utilización de la biblioteca RST desde Weka
63
“gui”: contiene todas las clases que implementan los paneles de interacción con el
usuario, agrupadas en subpaquetes correspondientes a cada una de las interfaces.
El paquete “core” constituye el centro del sistema Weka. Es usado en la mayoría de las clases
existentes. Las clases principales del paquete “core” son: Attribute, Instante, e Instances.
Mediante un objeto de la clase Attribute podremos representar un atributo. Su contenido es el
nombre, el tipo y en el caso de que sea un atributo nominal, los posibles valores.
Los métodos más usados de la clase Attribute son:
enumerateValues: retorna una enumeración de todos los valores de un atributo si es de
tipo nominal, cadena, o una relación de atributos, o valor nulo en otro caso.
index: retorna el índice de un atributo.
Los métodos isNominal, isNumeric, isRelationValued, isString, isDate retornan verdadero si el
atributo es del tipo especificado en el nombre del método.
name: retorna el nombre del atributo
numValues: retorna el número de valores del atributo. Si este no es nominal, cadena o
relación de valores retorna cero.
toString: retorna la descripción de un atributo de la misma manera en que puede ser
declarado en un archivo “.arff”.
value: retorna el valor de los atributos nominales o de cadena
La clase Instance se utiliza para manejar una instancia. Un objeto de esta clase contiene el valor
del atributo de la instancia en particular. Todos los valores (numérico, nominal o cadena) son
internamente almacenados como números en punto flotante. Si un atributo es nominal (o
cadena), se almacena el valor del índice del correspondiente valor nominal (o cadena), en la
definición del atributo. Se escoge esta representación a favor de la programación orientada a
objetos, incrementando la velocidad de procesamiento y reduciendo el consumo de memoria.

Capítulo 3: Utilización de la biblioteca RST desde Weka
64
Esta clase es serializable por lo que los objetos pueden ser volcados directamente sobre un fichero
y también cargados de uno. En Java un objeto es serializable cuando su contenido (datos) y su
estructura se transforman en una secuencia de bytes al ser almacenado. Esto hace que los objetos
puedan ser enviados por algún flujo de datos con comodidad.
Un objeto de la clase Instances contiene un conjunto ordenado de instancias, lo que conforma un
conjunto de datos. Las instancias son almacenadas, al igual que la clase Instance, como números
reales, incluso las nominales, que como se explicó anteriormente, utilizando como índice la
declaración del atributo e indexándolas según este orden.
Los métodos más útiles de la clase Instance son:
• classAttribute: devuelve la clase de la que procede el atributo
• classValue: devuelve el valor de la clase del atributo
• value: devuelve el valor del atributo que ocupa una posición determinada
• enumerateAttributes: devuelve una enumeración de los atributos que contiene esa
instancia
• weight: devuelve el peso de una instancia en concreto
Los métodos más útiles de la clase Instances:
• numInstances: devuelve el número de instancias que contiene el conjunto de datos.
• instance: devuelve la instancia que ocupa la posición i.
• enumerateInstances: devuelve una enumeración de las instancias que posee el conjunto
de datos.
• attribute: existen dos métodos con este nombre, la diferencia es que uno recibe como
parámetro el índice del atributo, y el otro el nombre, ambos retornan el atributo.
• enumerateAttributes: retorna una enumeración de todos los atributos.

Capítulo 3: Utilización de la biblioteca RST desde Weka
65
• numAttributes: retorna el número de atributos como un entero.
• attributeStats: calcula estadísticos de los valores un atributo especificado.
Una de las características más interesantes de Weka es la posibilidad de modificar su código y
obtener versiones adaptadas con funcionalidades que no contengan las versiones oficiales,
ampliando así sus posibilidades de uso. Desde el inicio se diseñó como una herramienta orientada
a la extensibilidad, por lo que se creó una estructura factible para ello. Sin embargo, cuando se
desean incorporar nuevos métodos al Weka y lograr que sean utilizados por toda la comunidad de
aprendizaje automatizado, no debemos modificar el código y así tener que recompilarlo, porque
de esta forma se limitará el uso de los métodos incorporados. Por tal motivo, Weka posee
módulos para la incorporación de nuevos paquetes sin la necesidad de modificar el código fuente.
De esta forma, se hace uso de la verdadera posibilidad de extensibilidad de Weka.
3.2.3 Validación del agrupamiento en Weka
Muchos de los algoritmos de clasificación supervisada disponibles en Weka antes de ser usados
necesitan especificar qué datos serán usados como conjunto de entrenamiento y como conjunto
de prueba. Estos son conjuntos disjuntos, el primero de ellos utilizado por los algoritmos de
Aprendizaje Automatizado supervisado para realizar el proceso de aprendizaje fijando sus
parámetros (ejemplo, los pesos de una RNA), mientras que los ejemplos del conjunto de prueba se
utilizan para medir el desempeño del algoritmo. Estos conjuntos se utilizan para la validación,
tanto de los métodos supervisados, como de los métodos no supervisados (aunque por supuesto
en estos últimos no se realiza un proceso de aprendizaje).
Weka implementa cuatro variantes para la validación:
• Usar los mismos datos como conjunto de entrenamiento y de prueba, conformado con
todas las instancias del archivo de datos (Use training set).
• Usar todas las instancias del conjunto de datos solamente como conjunto de
entrenamiento, y proporcionar como conjunto de prueba un nuevo archivo de datos
(Supplied test set).

Capítulo 3: Utilización de la biblioteca RST desde Weka
66
• Realizar una validación cruzada estratificada con un número de particiones dado (Folds
Crossvalidation). La validación cruzada (Witten et al., 2011) parte de dividir los datos en n
partes. Luego, se forman n muestras diferentes tomando como conjunto de prueba una
de ellas, y como conjunto de entrenamiento las n−1 partes restantes. Se dice estratificada
porque cada una de las partes conserva las propiedades de la muestra original (porcentaje
de elementos de cada clase).
• Tomar un porcentaje del conjunto de datos como muestra de entrenamiento y lo restante
como muestra de prueba (Percentage split).
Los algoritmos de agrupamiento que se encuentran en el paquete weka.clusterers funcionan de
una manera similar a los métodos de clasificación en weka.classifiers, salvo que una validación
cruzada no se realiza de forma predeterminada si el archivo de prueba no se encuentra.
Si el agrupamiento se lleva a cabo mediante el modelado de la distribución probabilística de los
casos, es posible determinar lo bien que el modelo se ajusta a los datos mediante el cálculo de la
probabilidad de un conjunto de datos de prueba dado por el modelo. Weka mide la bondad de
ajuste por el logaritmo de la probabilidad, o log-likelihood: y mientras mayor sea el valor, mejor
será el modelo que se ajusta a los datos. En lugar de utilizar un único conjunto de prueba, también
es posible calcular una estimación de la validación cruzada de probabilidad logarítmica
Weka también da como salida cuántos casos son asignados a cada grupo. Para los algoritmos de
agrupamiento que no modelan la distribución probabilística de instancias, éstas son las únicas
estadísticas que da Weka. Es fácil saber qué grupos generan una distribución probabilística: ellos
son subclases de la clase weka.clusterers.DistributionClusterer.
Validación cruzada (cross-validation)
Cuando la cantidad de datos para el entrenamiento y las pruebas es limitada el método de
retención se reserva una cierta cantidad para la prueba y utiliza el resto para el entrenamiento (y
establece parte de eso a un lado para la validación, si es necesario). Es común mantener una
tercera parte de los datos para prueba y utilizar las restantes dos terceras partes para el
entrenamiento.

Capítulo 3: Utilización de la biblioteca RST desde Weka
67
Puede ocurrir que la muestra utilizada para el entrenamiento (o de prueba) podría no ser
representativa. En general, no se puede saber si una muestra es representativa o no. Pero hay una
sencilla comprobación que pueda ser útil: Cada clase en el conjunto de datos debe estar
representada aproximadamente por la proporción adecuada entre los conjuntos de
entrenamiento y prueba. Si todos los ejemplos con una determinada clase fueron omitidos en el
conjunto de entrenamiento, difícilmente se podría esperar que lo aprendido de esos datos
pudieran realizar un buen modelado de los ejemplos de esta clase y la situación se agravaría por el
hecho de que la clase podría ser sobre-representada en la prueba debido a que ninguna de sus
instancias lo hizo en el conjunto de entrenamiento. Debe asegurarse de que la toma aleatoria de
muestras, se realice de una manera que garantiza que cada clase se representa correctamente en
los conjuntos de entrenamiento y prueba. Este procedimiento se llama estratificación, y se podría
hablar de retención estratificada. Es de importancia señalar que la estratificación sólo proporciona
una salvaguardia contra la representación primitiva y desigual en la formación de los conjuntos de
prueba y entrenamiento.
Una forma más general para mitigar cualquier margen de error causado por la muestra elegida en
particular es repetir todo el proceso, el entrenamiento y las pruebas, varias veces con diferentes
muestras aleatorias. En cada iteración una cierta proporción, por ejemplo las dos terceras partes,
de los datos se seleccionaron al azar para la formación, posiblemente con estratificación y el resto
se utiliza para la prueba. Las tasas de error en las diferentes iteraciones se promedian para
producir una tasa de error global. Este es el método de estimación de retención repetida de la
tasa de error.
3.3 PAQUETE PARA VALIDAR AGRUPAMIENTOS EN WEKA UTILIZANDO RST
El objetivo de este epígrafe consiste en ilustrar el uso de la biblioteca RTS mediante la creación de
un paquete cuyo propósito incorporar la validación del agrupamiento basado en RST al Weka.
Para lograr lo antes descrito fue necesario la creación de dos clases: RSTEvaluation.java y
ClustererAndEvaluationPanel.java. Estas clases se encapsularon en un paquete, la primera se le
incorporará al Weka en el paquete weka.clusterers y la segunda en el paquete weka.gui.explorer.
La estructura del paquete, para incorporar al Weka dichas clases, se presenta en la Figura 3.1.

Capítulo 3: Utilización de la biblioteca RST desde Weka
68
Figura 3.1 Estructura del paquete a incorporar.
La clase RSTEvaluation.java es la encargada de guiar la aplicación de RST en la validación del
agrupamiento. Sus métodos principales son: evaluateClusterer(), setRoughSet() y
printClusterStats(). El método evaluateClusterer() tiene como función agregar a un conjunto de
instancias un nuevo atributo, dicho atributo es el grupo al cual pertenece la instancia, este recibe
como parámetros un conjunto de instancias, un arreglo el cual contiene el grupo al que pertenece
cada instancia y la cantidad de grupos. El método setRoughSet() recibe una instanciación de la
clase RoughSet, la cual contiene los elementos y medidas necesarias de RST para la validación del
agrupamiento. El método printClusterStats(), retorna una cadena de caracteres con la salida del
algoritmo para la aplicación de RST en la validación del agrupamiento.
Para visualizar y guiar el uso de la clase RSTEvaluation.java fue necesario agregar una nueva
pestaña al Explorer del Weka. Con esta finalidad se creó la clase ClustererAndEvaluationPanel.java.
En el sitio web http://weka.wikispaces.com/ se ilustra la metodología para agregar una nueva
pestaña al Explorer del Weka (esto es posible a partir de la versión 3.5.5) la cual describiremos a
continuación:
1. La clase tiene que heredar de javax.swing.JPanel.

Capítulo 3: Utilización de la biblioteca RST desde Weka
69
2. La clase tiene que implementar la interfaz weka.gui.explorer.Explorer.ExplorerPanel.
3. Agregar el nombre de la clase a las propiedades de las pestañas, las cuales se encuentran
en el archivo Explorer.props.
Esta nueva “componente” mantiene la misma estructura funcional y visual que la pestaña
Clusterer, pero se le agregaron nuevas funcionalidades. Se le da la opción al usuario para que este
decida si quiere validar o no el agrupamiento con las medidas ofrecidas por RST. En caso que
decida validar el agrupamiento con RST, se le ofrecen varias extensiones de la teoría: la teoría
clásica, tres relaciones para valores omitidos y una extensión basada en relaciones de similaridad
la cual ofrece varias medidas de comparación entre objetos. Si la extensión seleccionada es
basada en relaciones de similaridad, el usuario decide si aplicar una función para el cálculo del
umbral de similitud o si lo desea pasar por parámetro.
Internamente esta clase mantiene en una primera etapa las mismas funciones de la pestaña
Clusterer, si el usuario decide validar con RST, se procede a crear un objeto de la clase
RSTEvaluation.java, se conforman las nuevas instancias a partir de los resultados obtenidos por el
método de agrupamiento (llamada al método evaluateClusterer() de la clase RSTEvaluation.java),
se conforma la extensión a usar de RST (dicho objeto, el cual es una instancia de la clase
RoughSet.java, se le pasa por parámetro RSTEvaluation.java mediante el método setRoughSet()) y
se procede a validar el agrupamiento (esto se hace mediante una llamada al método
printClusterStats() de la clase RSTEvaluation.java).
La pestaña incorporada al Weka a partir del nuevo paquete creado se muestra en la Figura 3.2.

Capítulo 3: Utilización de la biblioteca RST desde Weka
70
Figura 3.2 Nueva pestaña agregada al Weka.
3.4 CONCLUSIONES PARCIALES DEL CAPÍTULO
Con la incorporación del nuevo paquete, el cual contiene las clases RSTEvaluation.java y
ClustererAndEvaluationPanel.java, se logró ilustrar el uso de la biblioteca RST, mediante la
aplicación de un algoritmo, el cual guía la aplicación de las medidas internas ofrecidas por la
Teoría de conjuntos aproximados para la validación del agrupamiento.

71
CONCLUSIONES Y RECOMENDACIONES
Como resultado de este trabajo de diploma se implementó una biblioteca en Java que logró
encapsular los elementos de la Teoría de los Conjuntos Aproximados aplicables en varios
métodos de Aprendizaje Automatizado, cumpliéndose de esta forma el objetivo general
planteado, ya que:
La definición de los sistemas de información y decisión, las relaciones entre objetos tanto
las de equivalencia, las basadas en similaridad, como las relaciones para sistemas de
información incompletos, y los consecuentes cálculos de las aproximaciones inferiores y
superiores, así como las medidas de inferencia, son los elementos que esencialmente
utilizan los métodos de aprendizaje automatizado que utilizan RST. Adicionalmente, el
cálculo de reductos es muy utilizado en métodos de aprendizaje automatizado.
La biblioteca RST implementada en Java consta de paquetes que manejan las relaciones
de equivalencia, las relaciones con presencia de valores ausentes, las relaciones de
similitud, permite el cálculo de reductos utilizando la metaheurística ACO, permite la
incorporación de varias distancias y medidas de similitud y tiene un diseño extensible
permitiendo la incorporación de otros elementos de RST.
Se creó el paquete en Weka y se agregó una nueva pestaña que ilustran el uso de la
biblioteca RST, mediante la aplicación de un algoritmo, el cual guía la aplicación de las
medidas internas ofrecidas por la Teoría de conjuntos aproximados para la validación del
agrupamiento.
Teniendo en consideración que el Weka es extensible se recomienda:
Incorporar nuevas medidas de similitud entre objetos y de semejanza entre rasgos.
Crear nuevos paquetes en Weka que incluyan métodos de aprendizaje automatizado
basados en RST.

72
REFERENCIAS BIBLIOGRÁFICAS
ALWANG, G., CLYMAN, J., DRAGAN, R. V. & SELTZER, L. (1998) Java Guide. PC Magazine, 17, 101-
209.
ARBOLÁEZ, A. (2008) Extensiones al ambiente de aprendizaje automatizado Weka-parallel con
distintos algoritmos de aprendizaje en redes bayesianas. Aplicaciones Bioinformáticas. .
Trabajo de diploma en Ciencia de la Computación. .
ARCO, L. (2009) Agrupamiento basado en la intermediación diferencial y su valoración utilizando
la teoría de los conjuntos aproximados. . Tesis de doctorado en Ciencias Técnicas. .
BARBARA, D. (1992) The management of probabilistic data. IEEE Trans. of Knowledge and Data
Engineering.
BARRIENTOS, H. (2009) Java para todos.
BELL, D. & GUAN, J. (1998) Computational methods for rough classification and discovery. Journal
of ASIS, 49.
BELLO, M. (2012) Un método de aproximación de funciones basado en el enfoque de los
prototipos más cercanos utilizando relaciones de similaridad. Trabajo de diploma en
Ciencia de la Computación.
BELLO, R. (2005a) A Model based on Ant System Colony and Rough Set Theory to Feature
Selection. Proceedings of Genetic and Evolutionary Computation Conference(GECCO05).
BELLO, R. (2005b) Using ACO and Rough Set Theory for Feature Selection. WSEAS Transactions on
Information Science and Applications.
BELLO, R. (2005c) Using Ant colony System meta-heuristic and Rough Set Theory to Feature
Selection. Proceeding of The 6th Metaheuristics International Conference (MIC2005).
BELLO, R., GARCÍA, M. M. & PÉREZ, J. N. (2012) Teoría de los conjuntos aproximados: conceptos y
métodos computacionales, Bogotá.
BONET, I. (2009) Modelo para la clasificación de secuencias, en problemas de la Bioinformática,
usando técnicas de Inteligencia Artificial. Tesis de doctorado en Ciencias Técnicas.

Referencias bibliográficas
73
CABALLERO, Y. (2008) Aplicación de la Teoría de los conjuntos aproximados en el
preprocesamiento de los conjuntos de entrenamiento para los algoritmos de aprendizaje
automatizado. . Tesis de doctorado en Ciencias Técnicas.
CARBONELL, E. (2010) Extensiones al ambiente de aprendizaje automatizado Weka para datos de
alta dimensión. Trabajo de diploma en Ciencia de la Computación. .
CASTELLANOS, M. (2008) Extensiones al módulo de validación del agrupamiento en Weka y su
evaluación. Trabajo de diploma en Ciencia de la Computación.
CHÁVEZ, M. C. (2009) Modelos de redes bayesianas en el estudio de secuencias genómicas y otros
problemas biomédicos. . Tesis de doctorado en Ciencias Técnicas.
DEOGUN, J. S. (1998) Feature selection and effective classifiers. Journal of ASIS, 49.
DEVLIN, K. J. (1993) The Joy of Sets. Springer-Verlag, p. 1-7.
DORIGO, M. (2007) Ant Colony Optimization.
FILIBERTO, Y. (2011) Métodos de aprendizaje para dominios con datos mezclados basados en la
teoría de los conjuntos aproximados extendida. Tesis de doctorado en Ciencias Técnicas.
FOUNDATION, A. S. (2013) http://ant.apache.org. .
FOWLER, M. & & SCOTT, K. (Eds.) (1997) UML Distilled, Massachusetts, E.U.A, Addison Wesley
Longman.
GARCÍA, M. M. (1999) Monografía de reconocimiento de patrones. Santa Clara, Villa Clara,
Universidad Central "Marta Abreu" de Las Villas.
GÓMEZ, Y. (2010) Algoritmos que combinan conjuntos aproximados y optimización basada en
colonias de hormigas para la selección de rasgos. Extensión a múltiples fuentes de datos. .
Tesis de doctorado en Ciencias Técnicas.
GONZÁLEZ, F. F. (2011) Feature selection in cancer research.
GONZÁLEZ, M. (2010) Extensión de algoritmos representativos del aprendizaje automático al
trabajo con datos tipo conjunto. . Tesis de Maestría en Ciencia de la Computación.
GRECO, S. (2001) Rough sets theory for multicriteria decision analysis. European Journal of
Operational Research.
GRZYMALA-BUSSE, J. W. (1991) On the unknow attributes values in learning from examples.
GUEVARA, L. E. (2007) Extensión del sistema Weka con la incorporación de Redes Neuronales
Recurrentes. . Trabajo de diploma en Ciencia de la Computación. .

Referencias bibliográficas
74
JENSEN, R. & SHEN, Q. (2003) Finding rough set reducts with ant colony optimization. Proceeding
of UK Workshop on Computational Intelligence.
MAGDALENO, D. (2008) Refinamiento, evaluación y etiquetamiento de grupos textuales basados
en la teoría de conjuntos aproximados. Tesis de Master en Ciencia de la Computación.
MATÍAS, H. & L.I.ARAUJO (2006) Extensiones al ambiente de aprendizaje automatizado Weka.
Trabajo de diploma en Ciencia de la Computación.
MITCHEL, T. M. (1997) Machine learning.
MORELL, C., RODRÍGUEZ, Y., MATÍAS, H. & ARAUJO, L. I. (2006) Una metodología para extender el
ambiente de aprendizaje automatizado Weka. Informe de investigación terminada.
PAWLAK, Z. (1991) Rough Sets: Theoretical Aspects of Reasoning about Data, Dordrecht, Academic
Publishers.
RODRÍGUEZ, Y. (2009) Generalización de la métrica basada en la diferencia de valores (VDM) para
variables lingüísticas y su aplicación en sistemas basados en el conocimiento. . Tesis de
doctorado en Ciencias Técnicas.
SCHILDT, H. (2001) Java 2: The Complete Reference. McGraw-Hill.
SLOWINSKI, R. & VANDERPOOTEN, D. (2000) A generalized definition of rough approximations
based on similarity. IEEE Transactions on Data and Knowledge Engineering.
WIKIPEDIA (2013) Plataforma Java.
WITTEN, I. H., FRANK, E. & HALL, M. A. (2011) Data Mining: Practical Machine Learning Tools and
Techniques. IN THIRD (Ed., Morgan Kaufmann.

75
ANEXOS
ANEXO 1. TRANSFORMACIONES DE DISTANCIAS A SIMILITUDES
Distancia: Sea X un conjunto, una función d: X x X es llamada distancia en X si para todo x,y
X se cumple:
1. d(x, y) (no negatividad);
2. d(x, y) = d(y, x) (simétrica);
3. d(x, x) = 0.
Similaridad (Similitud): Sea X un conjunto, una función s: X x X es llamada similaridad en X si
es:
1. No negativa
2. Simétrica
3. s(x, y) < s(x, x) para todo x,y X, con igualdad si y solo si x = y.
Las principales transformaciones usadas para obtener una distancia de una similitud son:
d = 1 - s
d = (1 – s)/s
sd 1
)1(2 2sd
d = -ln s
d = arcos s

Anexos
76
ANEXO 2. DISTANCIAS, SIMILITUDES Y DISIMILITUDES MÁS USADAS PARA COMPARAR
OBJETOS
(Arco, 2009) propone las siguientes funciones de distancias:
Sean los objetos Oi y Oj descritos por m rasgos, donde Oi=(oi1, …, oim) y Oj=(oj1, …, ojm)
Distancia Euclidiana
m
k
jkikjiEuclideana ooOOD1
2, (A2.1)
Distancia Minkowski
1
1
,
m
k
jkikjiMinkowski ooOOD donde 1 (A2.2)
La distancia Minkowsky es equivalente a la distancia Manhattan o city-block, y a la distancia
Euclidiana cuando es 1 y 2, respectivamente. Para los valores de 2, la distancia Minkowsky
equivale a Supermum.
Distancia Euclidiana heterogénea (Heterogenous Euclidean – Overlap Metric; HEOM)
m
k
jkiklocaljiHEOM oodOOD1
2,, , donde
numéricoksiood
simbólicoksioodood
jkikeanNormEuclid
jkikOverlap
jkiklocal,
,,
casootroen
oosiood
jkik
jkikOverlap,1
,0, y
kk
jkik
jkikeanNormEuclid
ooood
minmax,
(A2.3)
Distancia Camberra
m
k jkik
jkik
jiCamberraoo
ooOOD
1
, (A2.4)
Correlación de Pearson

Anexos
77
m
k
kjk
m
k
kik
m
k
kjkkik
jiPearson
atributooatributoo
atributooatributoo
OOD
1
2
1
2
1, (A2.5)
donde katributo es el valor promedio que toma el atributok en el conjunto de datos.
Las expresiones de Chebychev, Mahalanobis, distancia de Hamming y la máxima distancia son
otras variantes de cálculo de distancias entre objetos.
Similitudes propuestas en (Arco, 2009):
Coeficiente Dice
m
k
jk
m
k
ik
m
k
jkik
jiDice
oo
oo
OOS
1
2
1
2
1
2
, (A2.6)
Coeficiente de Jaccard
m
k
jkik
m
k
jk
m
k
ik
m
k
jkik
jiJaccad
oooo
oo
OOS
11
2
1
2
1, (A2.7)
Coeficiente Coseno
m
k
jk
m
k
ik
m
k
jkik
jiCoseno
oo
oo
OOS
1
2
1
2
1, (A2.8)

Anexos
78
ANEXO 3. ALGUNAS VARIANTES PARA EL CÁLCULO DEL UMBRAL DE SIMILITUD ENTRE
OBJETOS
Algunas expresiones para el cálculo inicial del umbral (García, 1999):
a) La media de las similitudes entre todos los pares de objetos posibles; expresión (A3.1):
1
1 1
),()1(
2 n
i
n
ij
ji OOsnn
X (A3.1)
b) La media de los valores máximos de las similitudes entre cualquier par de objetos; expresión
(A3.2):
n
i
ji
jinj
OOsn
X1
..1max ),(max
1
(A3.2)
c) La media de los valores mínimos de las similitudes entre cualquier par de objetos; expresión
(A3.3):
n
i
ji
jinj
OOsn
X1
..1min ),(min
1
(A3.3)
d) La media ponderada de la media de las similitudes y la media de los máximos; expresión
(A3.4):
max)1( XXX w (A3.4)
La descripción de la notación utilizada es la siguiente: n es la cantidad de objetos de la colección,
ji OOs , es el valor de la similitud entre los vectores Oi y Oj, y es un valor entre 0 y 1 que
permite ponderar la media y la media de los máximos en la expresión (A3.4).