algebraixwp2011v06.en.es
DESCRIPTION
base de datosTRANSCRIPT

WSOMBRERO YOSA CLOUD
DATABASE?La idoneidad de la tecnología de Algebraix datos de Cloud Computing
Robin Bloor, Ph D
LIBRO BLANCO

© Copyright 2011, El Grupo de Bloor
Reservados todos los derechos. Ni esta publicación ni ninguna parte de ella puede ser reproducida o transmitida o almacenada en cualquier forma o por cualquier medio, ya sea sin el consentimiento previo por escrito del titular de los derechos de autor o la emisión de una licencia por el titular de los derechos de autor. El Grupo de Bloor es el único titular de los derechos de autor de esta publicación.
❏22214 Oban unidad ❏Spicewood TX 78669 ❏Te l: 512 - 524-3689 ❏
Correo electrónico de contacto:
[email protected] w w w. L a V i r t u
a l C i r c l e. c o m
w w w. B l o o r G r o u p. c o m
WHITE PAPER

WSOMBRERO YOSA CFUERTE DATABASE?
1
Resumen EjecutivoEste documento técnico fue encargado por Algebraix Datos. El objetivo del documento es proporcionar una definición de lo que es una base de datos de la nube es, ya la luz de esa definición, examinar la idoneidad de la tecnología de Algebraix datos para cumplir la función de una base de datos de la nube.
Aquí es un breve resumen de los contenidos de este documento:
• Nosotros definir una nube dbms (CDBMS) para ser una base de datos distribuida que puede ofrecer un servicio de consulta a través de múltiples nodos de bases de datos distribuidas ubicados en múltiples centros de datos, incluidos los centros de datos cloud. Consulta de fuentes de datos distribuidas es precisamente el problema que las empresas se encontrarán como la computación en nube crece en popularidad. Dicha base de datos también tiene que ofrecer alta disponibilidad y atender a la recuperación de desastres.
• En nuestra opinión, una CDBMS sólo tiene que proporcionar un servicio de consulta. SOA ya ofrece conectividad e integración de sistemas transaccionales, por lo que no vemos ninguna necesidad de un CDBMS para atender el tráfico transaccional - sólo consultar el tráfico. Un CDBMS necesita escalar a través de grandes redes informáticas, sino que también tiene que ser capaz de abarcar múltiples centros de datos y, en la medida de lo posible, atender a las conexiones de red lentas.
• Revisamos bases de datos tradicionales, centrándose principalmente en las bases de datos relacionales y almacenar bases de la columna, concluyendo que dichas bases de datos, como ingeniería en la actualidad, no podían cumplir con el papel de un CDBMS. Tienen arquitecturas centralizadas y este tipo de arquitecturas encontrarían un límite de escalabilidad en algún momento, tanto dentro como entre los centros de datos. Llegamos a la conclusión de que se necesita una arquitectura de punto a punto distribuido para satisfacer las características CDBMS que hemos definido.
• Nosotros pasar a examinar el entorno Hadoop / MapReduce y su idoneidad como CDBMS. Tiene mucho mejor escalabilidad para muchas cargas de trabajo que almacenar bases de datos relacionales o columna, debido a su arquitectura distribuida. Sin embargo, no fue construido para cargas de trabajo mixtas o para estructuras de datos complejas o incluso para la multitarea. En su forma actual hace hincapié en "la tolerancia a fallos." Tiene éxito como base de datos para grandes volúmenes de datos, pero no tiene las características de un CDBMS.
• Finalmente, se analiza la tecnología de Algebraix datos tal como se aplica en su A2DB producto de base de datos. Nuestra conclusión es que tiene una arquitectura que es adecuado para el despliegue como un CDBMS. Nuestro punto de vista es el siguiente:
- La capacidad única de A2DB reutilizar resultados intermedios de las consultas que se ha ejecutado anteriormente, contribuyen a que ofrece un alto rendimiento en un solo nodo.

WSOMBRERO YOSA CFUERTE DATABASE?
1
- Las mismas características de rendimiento pueden ser empleados para acelerar las consultas que se unen información entre un nodo local y los nodos remotos, ya sea en el mismo centro de datos o en un centro de datos remoto.
- La tecnología de Algebraix de datos es capaz de optimización global, el equilibrio de los requisitos de rendimiento de ambas consultas globales y locales.
- Además la tecnología puede ofrecer alta disponibilidad / operación con tolerancia a fallos.
• Somos conscientes de que Algebraix de datos no se ha implementado y probado su A2DB base de datos en el papel de CDBMS ahí nuestra conclusión no es que califica como un CDBMS, pero que tiene una arquitectura que le permita a ensayar en este papel.

2
WSOMBRERO YOSA CFUERTE DATABASE?
La base de datos de la nube - En ConceptLa computación en nube es una importante tendencia de conducción para TI. Más del 36 por ciento de las empresas estadounidenses ya ejecutar aplicaciones en la nube (encuesta Mimecast, febrero de 2010) y los principales proveedores de la nube están creciendo sus ingresos y base de clientes rápidamente. Dadas las tendencias, muy pronto la mayoría de los departamentos de TI va a correr aplicaciones "en la nube", posiblemente usando más de un proveedor de la nube. Así computación corporativa inevitablemente convertido en mucho más distribuida de lo que actualmente es, que extiendan por múltiples centros de datos. Esta gestión planteará, desafíos arquitectónicos y de rendimiento - y fomentar la innovación para hacer frente a esos desafíos.
La implementación de la nube de transaccionales y de consulta Sistemas
Si pensamos únicamente en términos de tecnología de base de datos, la distribución más amplia de los sistemas transaccionales, tales como los sistemas OLTP, aplicaciones de comunicaciones y sistemas de flujo de trabajo, no va a ser un problema grave a nivel de datos. El éxito arrollador de Salesforce.com demuestra. Los problemas con los datos de poner su sistema de CRM en la nube se resuelven con bastante facilidad por la transferencia regular de los clientes y otros datos de la nube al centro de datos.
De hecho, el amplio éxito de SOA demuestra la misma cosa. Sistemas de transacción silo acoplamiento sin apretar juntos funciona bien en cuanto al flujo de trabajo entre los sistemas transaccionales. Debido a que el volumen de datos que se pasa entre las aplicaciones dentro de una SOA es baja, es muy poco probable que los relativamente lentas velocidades de Internet será prohibitivo para la colocación de algunas de estas aplicaciones en la nube. Habrá excepciones, pero en principio funcionará bien la mayor parte del tiempo.
Para las cargas de trabajo de consulta tipificados por las aplicaciones de BI, la distribución de los datos a través de múltiples centros de datos es más problemático. Hay tres razones principales para esto:
1. Las velocidades de Internet son generalmente lentos en comparación con las velocidades de red de centros de datos y esto limita considerablemente el rendimiento. Este problema puede abordarse a través de conexiones directas de alta velocidad, pero esto se hace caro muy rápidamente.
2. Las cargas de trabajo de consulta no son tan predecibles como las cargas de trabajo transaccionales. Nosotros puede predecir las cargas de trabajo transaccionales precisión razonable, pero no podemos predecir fácilmente específicamente lo cuestiona un usuario podría desear preguntar - por lo tanto, somos menos capaces de predecir la carga de trabajo. Esto tiene profundas implicaciones arquitectónicas para la distribución de los sistemas de consulta. En pocas palabras: no sabemos dónde es mejor para localizar los datos antes de tiempo, porque no sabemos qué conjuntos de usuarios de datos pueden desear unirse.
3. Incluso si logramos una distribución eficiente de los datos, las cargas de trabajo de consulta implican el movimiento de volúmenes mucho mayores de datos que las cargas de trabajo transaccionales.

3
WSOMBRERO YOSA CFUERTE DATABASE?
Ese movimiento de datos será inevitablemente más lento que si los datos se encuentra en un solo centro de datos.
Este conjunto de restricciones sugiere que puede ser mejor para centralizar las cargas de trabajo de consulta en una ubicación física. Esta es la forma en que tradicionalmente se han construido la mayoría de los dominios de BI, alrededor de un almacén de datos grande con subconjuntos de datos extraídos a servir aplicaciones de BI individuales. Pero en última instancia, que el enfoque no pasa la prueba de la escalabilidad. Una arquitectura centralizada escalas mal sobre un gran número de nodos. Los cuellos de botella eventualmente surjan.

Datos
Datos
Datos
DatosDatosDat
os
WSOMBRERO YOSA CFUERTE DATABASE?
4
TACIA una base de datos de la nube
Por el momento, vamos a dejar de lado el hecho de que hay muchos desafíos en la implementación de una arquitectura distribuida para cargas de trabajo de consulta mayoría de los centros de datos, y proporcionar una visión de lo que es una base de datos de nube se vería así.
Nosotros puede definir un DBMS en la nube (CDBMS) como una base de datos distribuida que proporciona un servicio de consulta a través de múltiples nodos distribuidos de bases de datos ubicados en múltiples centros de datos distribuidos geográficamente, ambos centros de datos corporativos y centros de datos cloud. Así que pensar en términos de una organización con algunas aplicaciones que se ejecutan en la nube. Quizás Salesforce.com además de algunos
Usuario
Pregunta
CDBMS
CDBMSNodo - 1
CDBMS Nodo - 7 Datos
Datos
Nube Data Center 1
InternetNube Data Center 2
CDBMSNodo - 2
CDBMSNodo - 3
CDBMSNodo - 4
CDBMSNodo - 5
CDBMSNodo - 6
DatosDatos DataData Datos
Data Center 1 Data Center 2
Figura 1. Un CDBMS
alojado aplicaciones transaccionales web en algún centro de datos remoto más aplicaciones locales, incluyendo las aplicaciones de BI dividen entre dos centros de datos. Esta situación se ilustra en la Figura 1. Es la situación típica que las empresas tendrán que hacer frente a medida que avanzamos.
En la práctica, una consulta puede originarse en cualquier parte; desde un PC dentro de la corporación, que está conectado por una línea de rápido acceso al centro de datos local, desde un PC en el hogar a través de una línea de VPN,

WSOMBRERO YOSA CFUERTE DATABASE?
5
desde un ordenador portátil a través de una conexión Wi-Fi, o desde un teléfono inteligente a través de una conexión 3G o 4G . Por eso representamos una consulta aquí como viniendo "a través de Internet" lo que implica que la respuesta será, posiblemente, viajar a través de la red de Internet.
El CDBMS no se concentrará todo el tráfico de búsqueda a través de un solo nodo. Una arquitectura peer-to-peer será mucho más escalable - con cualquier nodo único capaz de recibir cualquier consulta. En tales

Exped
WSOMBRERO YOSA CFUERTE DATABASE?
6
una disposición, cada nodo tiene que tener un mapa de los datos almacenados en cada nodo y conocer las características de rendimiento de cada nodo. Cuando un nodo recibe una consulta su primera tarea es determinar qué nodo es más capaz de responder a la consulta. A continuación, pasa la responsabilidad para la consulta a ese nodo. Ese nodo ejecuta la consulta y devuelve el resultado directamente al usuario.
Figura 1muestra más de un nodo CDBMS en algunos de los centros de datos. En la práctica, probablemente será necesario configurar más de un nodo por cada centro de datos para distribuir la carga de trabajo dentro de la base de datos del centro de datos, así como entre los centros de datos.
Considere la figura 2. Se ilustra la estrategia probable que sería utilizado por un nodo CDBMS en el acceso a los datos almacenados en bases de datos o archivos transaccionales locales. Si los datos se llevó a cabo en una base de datos, la CDBMS puede obtener ya sea en los datos directamente (a través de ODBC, por ejemplo) o acceder a un almacén de datos duplicado. Sólo será necesaria la replicación si el acceso de lectura a los datos impone demasiado grande un impacto en el rendimiento. Los sistemas críticos a menudo tienen un stand- caliente por en su lugar listo para ir si elsistema principal falla, en el que casethestand-bysystems
Figura 2. Un CDBMS Nodo
base de datos podría ser utilizado como una fuente de datos. Los datos también podría ser tomada de funcionamiento almacenes de datos o almacenes de datos, con el mismo tipo de estrategia de replicación que se emplea.
Donde los datos de aplicación se mantiene en un archivo, el CDBMS probablemente será capaz de acceder directamente a los datos. Para los datos no de base de datos, la CDBMS mantendría un mapa metadatos del archivo para que pudiera identificar a los elementos de datos en los registros leídos en el archivo.
Por último, el CDBMS mantendrá su propia tienda de los datos que constan de
ApCDBMS Ap
DB
Nodo
DBMS
Repl. E

WSOMBRERO YOSA CFUERTE DATABASE?
7
datos que se utilizan con frecuencia extraídos de las fuentes de datos a los que accede. Ésta sería probablemente la mayor parte de los datos del nodo CDBMS era responsable, con acceso directo a los almacenes de datos que se utiliza principalmente para la actualización de datos.
Datos locales y de datos distribuidos
En el tratamiento de datos locales, el CDBMS actúa como un almacén de datos operativos. Cuenta con datos de seguimiento hasta la fecha y responde a consultas utilizando esos datos. Mientras que las bases de datos de BI, como un almacén de datos o grande mercado de datos, se podrían incluir, la base de datos de nube podría sustituir en lugar de complementar esos almacenes de datos.
Ya Está es un problema de escalabilidad aquí. Si consideramos un gran centro de datos con muchos terabytes de datos, no importa cuán eficiente es el nodo CDBMS es, probablemente no será capaz de hacer frente a todo el tráfico de consultas. En cada centro de datos es probable que haya varios nodos de base de datos. Y si el tráfico de consultas creció, como suele ocurrir, la CDBMS necesitaría para crear instancias de nodos adicionales para manejar la mayor carga de trabajo.

WSOMBRERO YOSA CFUERTE DATABASE?
Figura 3. Base de datos de la nube Nodo Partición
Considere la situación se ilustra en la Figura 3, donde el nodo A del CDBMS es gestionar las consultas de archivos A1, A5 y bases de datos A2, A3 y A4. Si la carga de trabajo se vuelve demasiado grande para los recursos a su alcance, a continuación, suponiendo que hay otro servidor disponible para su uso, se podría dividir como una ameba que se indican. El nodo original podría asumir la responsabilidad de archivo y bases de datos A1 A2 y A3, mientras que el nodo recién creado A 'asume la responsabilidad de A4 y A5.
Con el fin de hacer esto, el nodo A tendría que tener mantener un historial completo del tráfico de consulta de modo que sería capaz de calcular la división óptima ya que divide en dos. Del mismo modo sería necesario para ser un procedimiento inverso que fusionó dos nodos locales en el caso de que la carga de trabajo de consulta disminuida.
En concepto, que se encarga de las consultas que sólo acceden a los datos locales que el nodo A tiene la responsabilidad de. Sin embargo, no necesariamente habrá consultas que abarcan múltiples nodos.
Consultas distribuidas
Considere las principales entidades que una empresa posee como datos: cliente, producto, transacción de venta, miembro del personal, proveedores, transacción de compra y así sucesivamente. Ellos surgen en muchas aplicaciones. En consecuencia, muchas consultas que buscan información sobre estas importantes entidades inevitablemente abarcar varios nodos de una CDBMS. Incluso si pudiéramos encontrar una manera conveniente de distribuir y agrupar las aplicaciones en torno a estas entidades, no habría muchas consultas que se extendió por varios nodos.
La mayoría de las bases de datos de consulta orientada, almacenar bases de columna o bases de datos relacionales tradicionales, puede ser configurado para atender las consultas de nodo único. Técnicamente, el reto fundamental para la CDBMS es manejar consultas distribuidas de manera efectiva.
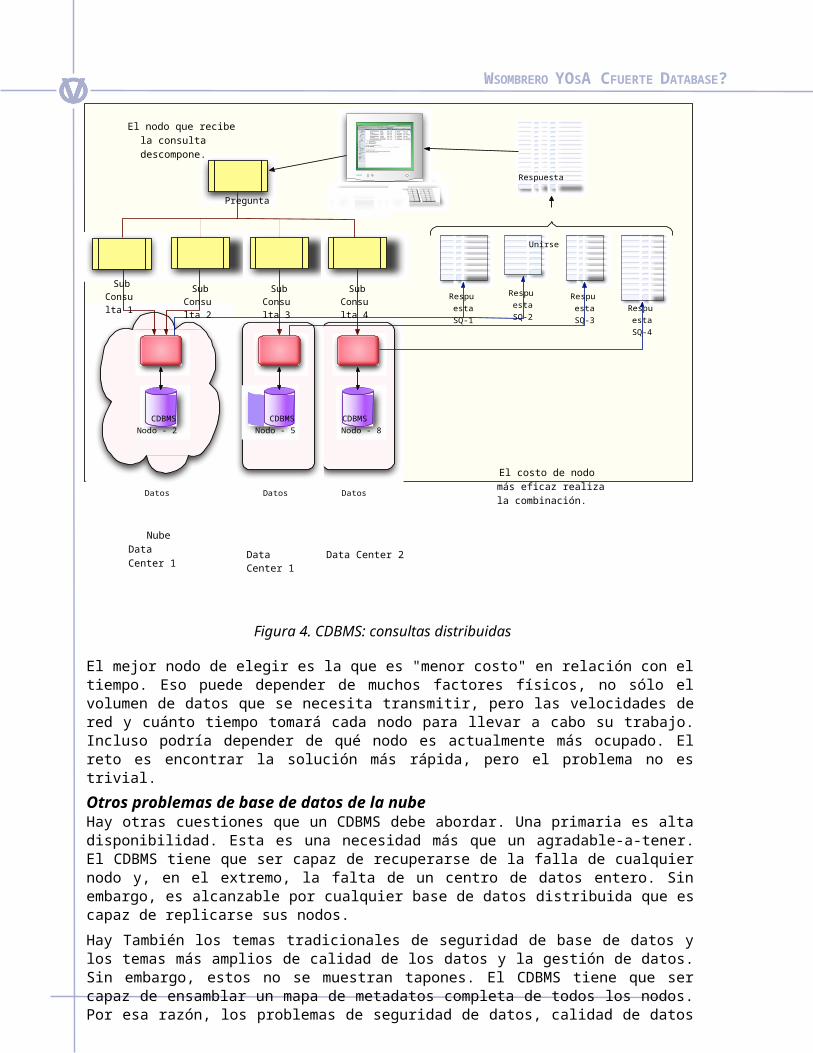
Una consulta distribuida que tiene acceso a múltiples nodos de la CDBMS puede ser pensado como una fusión (unión) de varias consultas que acceden a diferentes estaciones de una CDBMS. Esto se ilustra en la figura 4. Obsérvese
Cuando la carga de trabajo se expande, el nodo Ainstancia un nuevo nodo, A '
DBMS
DBMS
CDBMS
CDBMS
DBMS
Ex
Da
Da No
doLa
NodoA '
Da
Ex

que la resolución de una consulta de esta manera podría dar lugar a más de un conjunto de resultados de cada nodo como se ilustra. Una vez calculadas las respuestas, la CDBMS tiene que determinar qué nodo se unirán a ellos juntos.
5

WSOMBRERO YOSA CFUERTE DATABASE?
El nodo que recibe la consulta descompone.
Respuesta
Pregunta
Unirse
Sub Consulta 1
Sub Consulta 2
Sub Consulta 3
Sub Consulta 4
Respuesta SQ-1
Respuesta SQ-2
Respuesta SQ-3
Respuesta SQ-4
CDBMSNodo - 2
CDBMSNodo - 5
CDBMSNodo - 8
Datos Datos Datos
El costo de nodo más eficaz realiza la combinación.
Nube Data Center 1
Data Center 1 Data Center 2
Figura 4. CDBMS: consultas distribuidas
El mejor nodo de elegir es la que es "menor costo" en relación con el tiempo. Eso puede depender de muchos factores físicos, no sólo el volumen de datos que se necesita transmitir, pero las velocidades de red y cuánto tiempo tomará cada nodo para llevar a cabo su trabajo. Incluso podría depender de qué nodo es actualmente más ocupado. El reto es encontrar la solución más rápida, pero el problema no es trivial.
Otros problemas de base de datos de la nubeHay otras cuestiones que un CDBMS debe abordar. Una primaria es alta disponibilidad. Esta es una necesidad más que un agradable-a-tener. El CDBMS tiene que ser capaz de recuperarse de la falla de cualquier nodo y, en el extremo, la falta de un centro de datos entero. Sin embargo, es alcanzable por cualquier base de datos distribuida que es capaz de replicarse sus nodos.
Hay También los temas tradicionales de seguridad de base de datos y los temas más amplios de calidad de los datos y la gestión de datos. Sin embargo, estos no se muestran tapones. El CDBMS tiene que ser capaz de ensamblar un mapa de metadatos completa de todos los nodos. Por esa razón, los problemas de seguridad de datos, calidad de datos y de control de datos pueden ser manejados como si los CDBMS eran una sola base de datos.
Ya Está es también la necesidad de proporcionar apoyo para una variedad de interfaces de acceso de datos. En última instancia, estos incluirán las interfaces habituales de SQL (ODBC, JDBC, ADO.NET), interfaces web de servicios (HTTP, REST, SOAP, XQuery, etc.) y cualquier otra interfaz especializadas como MDX (para cubos de datos.)

Todas estas características son a la vez necesaria e importante, pero catering para ellos no es ahí donde radica el principal reto CDBMS. El mayor reto de ingeniería es en la optimización de las cargas de trabajo variadas de consulta a través de un espacio de recursos ampliamente distribuidos de una manera que realiza consistentemente bien.
6
WSOMBRERO YOSA
¿Puede un tradicional Bases de datos Evolve ser un CDBMS?Bases de datos surgieron hace más de 40 años a causa de las limitaciones de los sistemas de archivos. Eran un mecanismo más eficaz para el almacenamiento de datos, por muchas razones. El principal fue que hicieron los metadatos (datos de definición de datos) disponible, por lo que muchos programas diferentes pueden utilizar el mismo almacén de datos. La situación mejoró aún más con la aparición de un lenguaje de acceso de datos estándar; SQL. Esto significaba que, en su mayor parte, el programador ya no es necesario pensar en cómo se almacenan los datos.
Naturalmente, cuando aparecieron por primera vez las bases de datos, una esperanza surgió que con el tiempo será posible almacenar todos los datos de una empresa en una sola base de datos. Era una esperanza vana.
Relacional Evolución de base de datos
Bases de datos relacionales (RDBMS) se convirtió en el tipo dominante de la base de datos tan pronto como hardware era lo suficientemente rápido como para permitir su uso para OLTP. La base de datos relacional se consideraba originalmente como una base de datos más apropiado para cargas de trabajo de consulta, y así fue. Pero en el tiempo que fue diseñado para ser adecuado para OLTP.
Una vez que las bases de datos se habían normalizado en torno a un modelo de datos (relacional) y un lenguaje de acceso (SQL), la esperanza de que sería posible implementar una única base de datos corporativa para su uso por todos los programas de fortalecimiento. Había muchas razones por qué esto no ocurrió. Las más importantes fueron:
• Productos RDBMS podrían atender a muchas estructuras de datos diferentes, pero nunca se ocuparon de cada estructura de datos posible. El modelo relacional no era un modelo universal de datos y para agravar este problema, SQL no era un lenguaje de acceso de datos universal que podría acceder a cualquier tipo de estructura de datos.
• En la práctica esto significaba que RDBMS era simplemente no aptos para el almacenamiento de algunos tipos de datos. En concreto, RDBMS no atienden adecuadamente para muchos tipos de datos importantes (por ejemplo, texto, tipos de datos compuestos, etc.) Por lo tanto otro tipo de base de datos surgieron (por ejemplo, las bases de datos de objetos, bases de datos de texto, bases de datos de contenido, etc.)
• A pesar de que RDBMS se basaron en el uso de una estructura de dos dimensiones (la mesa) nunca se ocuparon de estructuras de una dimensión superior. Esto significaba que no atienden a los cubos de datos en 3D o cubos de datos de dimensiones superiores. En consecuencia bases de datos específicas surgieron para hacer frente a este tipo de estructuras (bases de datos OLAP.) Lo más importante, RDBMS no atienden directamente a la dimensión del tiempo y de datos de series de tiempo.
• Mientras RDBMS podría servir tanto a las cargas de trabajo OLTP y de consulta, que nunca tuvo la capacidad de rendimiento para atender a ambos tipos de carga de trabajo al mismo tiempo. Desde una perspectiva de la ingeniería que hizo mucho más sentido tener dos instancias de base

WSOMBRERO YOSA
de datos, uno que fue configurado para OLTP y otro, alimentado desde la primera, que fue configurado y ajustado para el tráfico de consultas.
• La mayoría de los productos RDBMS pagan derechos de licencia, proveedores de software de manera independiente (ISV) rara vez los utilizan. Pero incluso cuando los productos RDBMS de código abierto se convirtió disponible sin cargo, la mayoría de los proveedores de software independientes continuaron haciendo caso omiso de ellos, prefiriendo sus estructuras de archivos propios.
La industria de TI ni siquiera trató de ponerse de acuerdo sobre un formato de archivo estándar que expone los metadatos de un archivo. Así, los sistemas operativos comúnmente utilizadas nunca proporcionan un tipo tal archivo. Este
7

WSOMBRERO YOSA
significaba que no había alternativa para ISVs pero inventar constantemente nuevos tipos de archivos, e incluso nuevos tipos de datos, por los datos que almacenan.
Esto nos ha llevado a la situación en la que la industria comenzó a aceptar una realidad de facto:
• Ya Está fueron los datos estructurados; los datos almacenados en bases de datos con sus metadatos disponibles.
• Ya Está Fue datos no estructurados; los datos contenidos en los archivos de varios tipos donde estaba disponible o incompletos los metadatos.
Escala y Escalabilidad
A la luz de estas limitaciones, las bases de datos han evolucionado en dos direcciones. Por un lado, las bases de datos alojados algunos datos no estructurados - por extensiones al modelo relacional, la implementación de alguna versión de un modelo objeto-relacional. Por otro lado, el sueño de una única base de datos de las empresas continuó - pero sólo para el tráfico de consultas - dando lugar a la idea del almacén de datos.
En la práctica, los almacenes de datos fueron un intento de ampliar mediante el almacenamiento de todos los datos en una sola instancia de una base de datos. Pero en la práctica nunca lo hicieron escalar. De los usuarios primer momento se vieron obligados a subconjuntos de datos de tiendas en mercados de datos. Centrándose todas las cargas de trabajo de consulta en el almacén de datos habría paralizado. Debido a las limitaciones del modelo relacional, algunos de los mercados de datos eran las bases de datos OLAP que sostienen los cubos de datos multidimensionales.
La impresionante marcha de la Ley de Moore, que vaporiza problemas de rendimiento en muchas áreas de TI, nunca estuvo cerca de solucionar este problema de escalabilidad - y todavía no lo ha hecho. Datos fluía de los sistemas operativos, a través de programas de ETL y de calidad de datos en un almacén de datos para posterior extracción en un mercado de datos para su uso eventual. Este fue un proceso lento. En consecuencia, el software diseñado para atajo esa ruta peatonal surgió, llamada Enterprise Information Integration software (EII). Herramientas EII crearon "Tiendas datos operativos", que no eran más que "data marts acelerados".
RDBMS no escalar y poco esfuerzo se puso en eso. Así que cuando la talla de Yahoo y Google se reunieron grandes centros de datos con miles de servidores, no había la tecnología de base de datos en todo lo que podía escalar a través de estas grandes redes informáticas. Esto dio lugar a un enfoque completamente diferente a la ampliación hacia fuera para grandes volúmenes de datos, que fue por el nombre de MapReduce y que dio lugar a Hadoop, un marco de programación para la implementación de MapReduce a través de grandes redes de servidores.
La llegada de la Columna tienda
Como idea de base de datos, la tienda columna es muy viejo. Se remonta a la década de 1970. Edward Glaser, desarrollador principal del proyecto MIT MULTICS, propuso por primera vez la idea y fue utilizado por IBM en una base de datos llamada APLDI. Se volvió a poner de moda a través de Sybase and Sand Tecnología cuando las limitaciones de escalabilidad de las estructuras de datos indexados que RDBMS utilizados se hicieron más evidentes. Bases de datos de

WSOMBRERO YOSA
columna tiendas volvieron cada vez más popular entre la aparición de nuevas empresas de base de datos de nueva creación como Vertica y ParAccel que tuvieron este enfoque.
Las tiendas de las columnas eran RDBMS en el sentido de que emplean SQL como lenguaje de acceso a datos primarios y que tenían datos en tablas, pero a un nivel físico que almacenan columnas en lugar de tablas, hicieron gran uso de la compresión de datos y no se usan índices. El simple hecho es que, mientras que la velocidad a la cual los datos pueden ser leídos desde el disco había sido
8

WSOMBRERO YOSA
ataataataataata
ataataataataata
ataataataataata
creciente rápidamente durante los años, la velocidad del movimiento de la cabeza de lectura / escritura a través del disco no había aumentado mucho. En consecuencia, a través de índices de acceso a los datos en el disco se había convertido en un pasivo. Causó movimiento de la cabeza del disco y frenó todo. Se había convertido en mucho más rápido para leer los datos en serie desde el disco.
La consulta se descompone en una
sub-querypara cada nodo
Pregunta
Base de datos Mesa
Sub Consult
a 1
Server 1
Sub Consult
a 2
Server 2
La base de datos columnar escalas
arriba y hacia fuera mediante la adición de
más servidores
Server 3
Los datos se comprimen después se repartió en el disco por columna y por rango
D D DD D
Datos
D D DD D
Datos
D D DD D
Datos
Figura 5. Columna DBMS Tienda Escalabilidad
Esto dio lugar a la escalabilidad enfoque se ilustra en la Figura 5. Esto representa el enfoque general de los DBMS tienda columna a la escalabilidad. En primer lugar, los datos se comprimen cuando se carga, lo que resulta en un volumen mucho más pequeño de los datos - una vigésima parte de los datos en bruto original es alcanzable. A continuación, los datos se almacenan en columnas. Las columnas también pueden ser divididos entre los discos y entre servidores. Esto asegura un buen paralelismo. Una consulta puede tener que leer la totalidad de una columna de una tabla, por ejemplo, por lo que si la columna se divide entre 12 discos que se dividen entre dos servidores, entonces la recuperación de datos puede ser 12 veces más rápido.
Por otra parte, los servidores lo más probable es ser configurados para un alto
UP UP UP UPUP UP
Como Mucho
Memoria posible
Como Mucho
Memoria posible
Como toda la
memoria posible

WSOMBRERO YOSA
nivel de memoria de modo que una buena parte de los datos ya están en la memoria. Los algoritmos de caché probablemente se repartirán una buena cantidad de la memoria en partes iguales entre los discos para "equilibrar la carga de trabajo promedio." Además de esto, varios procesos se ejecutan y que serán distribuidos entre múltiples núcleos en la CPU en cada servidor.
9

WSOMBRERO YOSA
El rendimiento global de la tienda columna DBMS dependerá de lo bien que el software equilibra la carga de trabajo cuando se procesan varias consultas. Esta solución tiene la ventaja de que usted puede simplemente añadir más servidores ya que el volumen de datos se expande y el equilibrio de la carga de trabajo entre 3 y luego 4 y luego 5 servidores normalmente funciona bien. Esta solución escalas a cabo en varios servidores con más eficacia que el RDBMS tradicional - que es precisamente por eso que se ha vuelto popular.
Por desgracia, llegará a un límite en algún momento. Es evidente que ese límite dependerá de la estructura de los datos y la variedad de consultas que se está procesando. A pesar de que se escala a cabo de manera más eficaz, todavía es una arquitectura centralizada. A medida que la carga de trabajo aumenta un cuello de botella de mensajería desarrollará de forma natural en el nodo principal de la base de datos de almacén de la columna y en última instancia, lo que limita el número de servidores que puede ampliar en.
Hadoop y Mapa / Reducir: una arquitectura distribuida
El marco de desarrollo Hadoop MapReduce para ha atraído una gran atención por dos razones. En primer lugar, no escalar a cabo a través de grandes redes de ordenadores y en segundo lugar es el producto de un proyecto Open Source, por lo que las empresas pueden probarlo a bajo costo. MapReduce es una arquitectura paralela diseñada por Google específicamente para la búsqueda y análisis de datos de escala grande. Es muy escalable y obrasde una manera distribuida. El entorno Hadoop es un marco MapReduce que permite la adición de componentes de software de Java. También proporciona HDFS (el sistema de archivos distribuidos Hadoop) y se ha ampliado para incluir HBase, que es una especie de base de datos de almacén de columnas.Figura 6muestra cómo Hadoop
BackUp/ Recov
MapPartitionCombineReduce
Programador
Nodo i + 1
BackUp/ Recov
Nodo 1
BackUp/ Recov
trabaja. Básicamente, una asignación de función particiones de datos y luego se lo pasa a una función de reducción, que calcula un resultado. En el diagrama que mostramos muchos nodos (servidores) con nodos 1 a i que ejecutan el proceso de asignación y los nodos i
1 a k ejecutar el proceso de reducción. El med
io ambiente es (diseñada para recuperarse del fracaso de cualqui
er nodo. El HDFS
mantiene una copia redundante de todos los datos, por lo que si un nodo falla, los mismos datos estará disponible a través de otro
Proceso de

WSOMBRERO YOSA
Proceso de
HDFS
HDFS
BackUp
/ Recov
Nodo yo
Nodo j
Nodo k
BackUp/ Recov
BackUp/ Recov
Figura 6. Hadoop MapReduce y
10
Proceso de
Proceso de
Proceso de

WSOMBRERO YOSA
nodo. Cada servidor registra lo que está haciendo y se puede recuperar utilizando su archivo de respaldo / recuperación, si falla. Debido a eso, Hadoop / MapReduce es bastante lento en cada nodo, pero compensa esta escalando a lo largo de miles de nodos. Se ha utilizado de manera productiva en las redes de más de 5.000 servidores. Fallo de nodo es un hecho cotidiano cuando se tiene que muchos servidores básicos trabajando juntos, por lo que a esa escala, su recuperabilidad es una ventaja.
Con MapReduce, todos los registros de datos consiste en un sencillo par "clave y valor". Un ejemplo podría ser un archivo de registro, que consiste en códigos de mensajes (la clave) y los detalles de la condición que está siendo informado (el valor). En aras de ilustrar el proceso de MapReduce, imaginemos que tenemos un archivo de registro de gran tamaño de muchos terabytes contienen mensajes y códigos de mensaje y simplemente queremos contar cada tipo de registro de mensaje. Se podría hacer de la siguiente manera:
El archivo de registro se carga en el sistema de archivos HDFS. Cada nodo mapeo leerá algunos de los registros. Los cartógrafos se verá en cada registro que leen y salida de un par de valores clave que contiene el código del mensaje como la clave y "1" como el valor (el recuento de citas). El reductor (s) se ordenará por la llave y agregar los conteos. Con repetidas reducciones eventualmente llegará al resultado; un mapa de teclas distintas con sus recuentos totales de todas las entradas.
Aunque este ejemplo es muy simple, si tuviéramos una mesa muy grande hecho del tipo que podría residir en un almacén de datos, podríamos ejecutar consultas SQL de la misma manera. El proceso de la hoja sería el SELECT de SQL y el proceso de reducir simplemente podría ser la selección y combinación de resultados. Usted puede agregar cualquier tipo de lógica que sea el mapa o la de reducir el paso y usted también puede tener un mapa múltiple y reducir los ciclos de una única tarea.
También, mediante el despliegue de HBase que es posible tener una gran base de datos de la columna de la tienda masivamente paralelo que preside petabytes de datos y más de lo que pueden ser actualizados con regularidad.
La CDBMS
En última instancia, ni almacenar bases de datos de columna ni Hadoop (con Hbase) actualmente tienen las capacidades necesarias para funcionar como un CDBMS.
Columna-tienda DBMS son (en la mayoría de los casos) las bases de datos centralizadas que se encontrará con límites de escalabilidad como volúmenes y cargas de trabajo de datos de aumento. En última instancia, todas las arquitecturas centralizadas sufren ese destino no importa cuán espléndida la ingeniería subyacente. Por eso algunos de los vendedores columna tiendas están integrando con Hadoop y la mejora de varias maneras.
Debido Hadoop ofrece un entorno totalmente distribuida es poco proclive a encontrar un límite escalabilidad del tipo que haría piso una arquitectura centralizada. Hadoop fue deliberadamente diseñado para presidir mesas masivas y, en ese papel, puede ser útil, especialmente para aquellas organizaciones que se ejecutan en los límites de escalabilidad con bases de datos de almacén de columnas. Sin embargo, en su forma actual se procesa una sola carga de trabajo

WSOMBRERO YOSA
a la vez - que no tiene capacidad de multiprocesamiento en absoluto. Además, no funciona bien con estructuras de datos complejas, incluso cuando sólo contienen datos estructurados. Grandes mesas, "sí"; pero un montón de pequeñas mesas de gran cantidad de bases de datos de todos con diferentes estructuras de datos, decididamente "no".
Tampoco está equipado Hadoop para distribuir fácilmente las cargas de trabajo a través de redes complejas que funcionan a distintas velocidades. Hadoop espera un ambiente limpio de servidores de tamaño similar todos conectados en red a la misma velocidad de una manera ordenada. Su ingrediente secreto es la homogeneidad en todo lo que hace.
A CDBMS tiene que ser capaz de manejar la heterogeneidad en cada nivel.
11

WSOMBRERO YOSA
Algebraix Base de datos de datos y la nubeA2DB de Algebraix de datos es, únicamente, una base de datos algebraico. Como tal, es capaz de representar cualquier tipo de datos en una forma algebraica y gestionar en consecuencia. Muchas bases de datos (RDBMS y productos derivados) están limitadas por el modelo relacional de datos, incapaz de manejar los datos que no encajan en ese entorno limitado. A2DB no está limitado de ese modo. Su naturaleza algebraica le permite representar jerarquías, listas ordenadas, estructuras de datos recursivas y objetos de datos compuesto de ningún tipo. (Para una explicación matemática más detallada de cómo se logra esto, lee el libro blanco Bloor Grupo: Hacer las matemáticas).
Algebraico Optimización y el uso de los resultados intermedios
A entender cómo la tecnología de Alegbraix datos podría implementar un CDBMS, es necesario entender la estrategia de optimización que aplica. Las tiendas de productos A2DB todos los conjuntos se calcula, incluyendo todos los conjuntos de resultados intermedios para su posible reutilización.
Considere una consulta bastante simple que accede a algunas filas y columnas de una tabla y luego se une a ellos a algunas filas y columnas de otra tabla. La mayoría de las bases de datos seleccionarán los datos de la primera tabla, selecciónelo de la segunda tabla y luego unir las dos tablas resultantes juntos para proporcionar la respuesta. A2DB se comporta de la misma manera, pero con el matiz adicional que almacena la primera selección y la segunda selección y el resultado unido, para su posible uso posterior. Si las consultas posteriores hacen la misma selección o hacer una selección de un subconjunto de cualquiera de las dos selecciones almacenados, entonces A2DB reutilizará esos resultados. Una vez A2DB ha procesado muchas consultas que ha reunido a un razonablemente grande población de estos resultados intermedios.
No sólo almacenar cada una de esas conjunto de datos, también almacena su representación algebraica. Así que cuando se procesa una consulta nueva, simplemente examina su tienda de representaciones algebraicas y selecciona aquellos que pueden contribuir a la resolución de la consulta. A continuación, se resuelve que de ellos tiene el menor costo en términosde los recursos de uso, y utiliza esos conjuntos para resolver la consulta.
La gráfica adyacente ilustra cómo el desempeño de A2DB mejora cuando el mismo tipo de consulta se repite.
La primera vez que se ejecuta una consulta, la respuesta es lenta.

WSOMBRERO YOSA
Pero mejora con cada repetición hasta que el tiempo de respuesta cae a un nivel muy bajo. Esto sucede con todatipos de consulta. El uso
Figura 7. Las curvas de rendimiento A2DB Optimizer
12

Ca
Ar
DBMS
Aplicaci
Ca
Ar
DBMS
Aplicaci
Ca
Ar
DBMS
Aplicaci
Ex
Aplicaci
Ex
Aplicaci
ConsCons
WSOMBRERO YOSA CFUERTE DATABASE?
Fuentes de datos Consultas
Aplicaciones
Expediente
Archivos de registro
Universo Gerente
(Modelo algebraic
o)
LÓGICO
Acceso Local
XSNTraductor
Optimizer
Conjunto Procesad
or
Storage Manager
Administrador de
recursos
(CPU / núcleos, memoria,
disco)
FÍSICA
De acceso remoto
Respuestas Respuestas
Cargar
archivos Resultado Local Conjuntos Conjuntos de
resultados remotos
Mgt datos
CDBMSNodo yo
CDBMSNodo k
Aplicaciones
DDBBMMSS DDBBMMSS
CDBMSNodo j
CDBMSNodo l
DBMSDatos
Local Data Center
A distancia del Centro de Datos
Figura 8. Tecnología de Algebraix de datos en una operación distribuida
de conjuntos de resultados intermedios resulta valioso en un entorno distribuido y un entorno de nube. La Figura 8 ilustra esto. La arquitectura distribuida es peer-to-peer, por lo que podría ser muchos de estos nodos, incluso miles - de todo el funcionamiento de la misma manera. A la izquierda del diagrama son las fuentes de datos que este nodo en particular toma la entrada desde y es responsable. Con el fin de cargar el nodo de base de datos sólo es necesario para crear archivos de carga de las bases de datos fuente. La base de datos no se carga inmediatamente los datos, sólo carga los metadatos de esos archivos. La forma en que la tecnología funciona es que no hay carga de datos per se. Como consultas llegan se hace referencia a los archivos de carga (o archivos u otros archivos de datos de registro) y se acumula gradualmente conjuntos de resultados intermedios, que constituyen su almacén de datos administrados - como se ilustra.
Utiliza mecanismos físicamente eficientes para almacenar estos datos, las mismas técnicas que la base de datos típica tienda de la columna; sin índices, compresión de datos y partición de datos. Hay una separación completa entre la representación lógica de los conjuntos de datos almacenados y el almacenamiento físico de los conjuntos de datos. Funciona de la siguiente manera:

El XSN traductor traduce una consulta en una representación algebraica que se corresponde con los conjuntos algebraicos definidos a nivel lógico en el Administrador Universo. (XSN significa Extended notación Set.) El Gerente Universo tiene un modelo lógico de todos los conjuntos de la base de datos y sus relaciones.
El Optimizador trabaja primero qué conjuntos almacenados podrían participar en una solución. Se puede deducir que tiene que ir a la fuente de datos (archivos de carga) para la totalidad o parte de los datos solicitados por la consulta.
13

WSOMBRERO YOSA
En cualquier caso, la búsqueda de alternativas producirá una o más soluciones posibles. El Optimizador ahora asesora al Administrador de recursos y pone a prueba cada una de sus soluciones algebraicas contra información física realizada por el Administrador de recursos. Armado con información precisa de costos, el optimizador resuelve el costo físico de cada solución algebraica y elige el más rápido. El Administrador de recursos sabe si los datos está en el disco o en la memoria caché y sabe cómo se organiza físicamente. Una vez que el optimizador ha decidido por una solución, que pasa al conjunto de procesadores, que lo ejecuta.
La consulta distribuida
Ahora considere lo que ocurre si la consulta pide algunos datos que no está en este nodo de base de datos. ¿Cómo sabe qué hacer? Por su diseño, el Administrador Universo no sólo contiene un mapa de datos locales, sino que también tiene un mapa mundial que identifica a todos los demás nodos de bases de datos y los datos que son responsables.
Cuando describimos cómo la base de datos maneja una consulta, omitimos para discutir la forma en que maneja una consulta que se extiende por más de un nodo. Dicha consulta será naturalmente implicar una combinación de algún tipo con una o más partes de la operación de unión referencia a datos remotos.
El modo de funcionamiento de la tecnología de Algebraix de datos es esencialmente el mismo, pero ligeramente más complejo. El Optimizador siempre comprueba para ver si alguno de los datos solicitados es parte del "universo remoto" en lugar de "universo local." Si se descubre que algún elemento en los datos remotos referencias de consulta, que deconstruye la consulta en varias partes, como de la siguiente manera:
• Una subconsulta de este nodo
• Una subconsulta para cada nodo remoto que está involucrado
• Una consulta principal que une todos los resultados de todas las subconsultas
Se calcula qué nodo es el mejor nodo para ejecutar la consulta maestra mediante la estimación del costo de los recursos de transporte de datos de resultados desde un lugar a otro. Si decide pasar esa responsabilidad a otro nodo entonces se comporta de la siguiente manera:
• Pasa el resto de subconsultas a los nodos donde tienen que ejecutar.
• También informa a cada nodo en el que para entregar el resultado de su subconsulta.
• A continuación, ejecuta su propia subconsulta y pasa el resultado al nodo principal cuando el procesamiento local completa. En ese momento se ha terminado con esa consulta.
Si se ha determinado que es, en sí, el mejor nodo para ejecutar la consulta maestra, se comporta de la siguiente manera:
• Pasa el resto de subconsultas a los nodos donde tienen que ejecutar.
• Se da a sí misma como la dirección de retorno de los resultados de esas subconsultas.
• Se ejecuta su propia subconsulta.
• Cuando se recibe todos los conjuntos de resultados remotos, ejecuta la consulta maestra.
• Finalmente se distribuye el resultado final al programa que envió la consulta.
Tenga en cuenta que en la realización de una consulta como la base de datos

WSOMBRERO YOSA
distribuida reúne algunos conjuntos de resultados remotos en el nodo que domina la consulta distribuida. Se ahorrará estos resultados como "número remoto
14

WSOMBRERO YOSA
conjuntos "de la misma manera que se ahorra conjuntos de resultados locales, de modo que cuando más búsquedas de ese tipo venir en ella pueden ser capaces de resolver esas consultas localmente en lugar de en una manera distribuida.
Conmutación por error
Con Hadoop, el fracaso de cualquier nodo pueden ser atendidas. Lo mismo es cierto de la tecnología de Algebraix de datos. Es bastante fácil de configurar espejos de nodos completos para que un nodo en espera puede hacerse cargo de inmediato si un nodo activo falla. Sería sin embargo económico más utilizar una SAN en cada centro de datos, y sólo los datos de espejo que se escriben en el disco (los resultados intermedios). Entonces, si un nodo falla, será posible recuperar el nodo de la SAN. Esto inyecta un mayor retraso en el proceso de recuperación, ya que la base de datos recuperada tendría que recrear el último estado conocido del nodo que ha fallado.
En la práctica, la tecnología de Algebraix datos puede ejecutarse en servidores de los productos básicos. Aunque puede parecer que tiene un requisito sustancial para el almacenamiento de datos, a causa de su estrategia de almacenar resultados intermedios, en la práctica esto no es el caso. Esto se debe a que, una vez transcurrido un tiempo adecuado, la base de datos elimina los resultados intermedios que no vuelva a utilizar. La base de datos rara vez requiere el despliegue de almacenamiento adicional (como NAS o un SAN). Para cargas de trabajo atípicas configuraciones especiales se pueden implementar para cualquier nodo dado.
La división de nodos
La división de nodos resulta necesario cuando la carga de la consulta para un nodo se vuelve demasiado grande. La necesidad se hace evidente cuando el rendimiento del nodo comienza a declinar. Sin embargo, la división de nodos es fácil de lograr:
Un nodo de réplica se crea del nodo y las fuentes de datos que el nuevo nodo será responsable de se definen - eliminando aquellos que no será responsable de desde el Administrador Universo. La tecnología puede estimar lo que es probable que sea de un análisis de las cargas de trabajo de consulta últimos la mejor división. También puede reconocer que los resultados intermedios se derivan de que los archivos de origen o bases de datos. Así que reclasifique esos resultados intermedios como a distancia en lugar de local. La configuración del nodo original está configurado de la misma manera, la eliminación de las fuentes de datos que ya no es responsable. La naturaleza de los cambios están a continuación, transmite a todos los nodos de la CDBMS.
Crecimiento de Datos
La mayoría de los datos de origen consistirán en bases de datos que son a su vez que se añade a sobre una base regular. Ese crecimiento de los datos es mejor tratado por la alimentación de las imágenes de archivo de registro de base de datos a la base de datos. Para otras aplicaciones que simplemente utilizan sistemas de archivos, es mejor para alimentar el equivalente de una pista de auditoría para la actualización de la base de datos. Hay una razón específica para ello. La tecnología de Algebraix datos no está pensado para los datos actualizados de la manera más bases de datos hacen.

WSOMBRERO YOSA
Typically, actualizaciones de la base de destruir datos sobre-escritura de un valor a otro. Esta tecnología de base de datos es diferente. Se trata actualizaciones como (es decir nuevo) datos adicionales. En efecto, se convierten en cambios no destructivos, con un registro de los valores previos restantes. Para borrado, simplemente marca el conjunto de datos o un elemento de datos como "ya no es actual." Para lograr esto, la base de datos añade una marca de tiempo a todos los datos, ya que llega y se utiliza (si un sello tal vez no existe en los datos de origen.) Todas las consultas a la base de datos especificar el momento en que se aplica, por lo que el resultado tiene una "correspondiente a la fecha / hora" u omitir el tiempo, en cuyo caso la corriente
15

WSOMBRERO YOSA
se aplica fecha y hora. Así que todos los cambios se tienen en cuenta cuando los datos asociados se procesa de acuerdo con sello de tiempo. Debido a esto, todas las tablas de resultados intermedios también tienen un "correspondiente a la fecha / hora" asociados con ellos.
La base de datos está configurado en cada nodo para aceptar los nuevos datos sobre la base de un interruptor temporizado. No es aconsejable colocar el interruptor de tiempo para un período demasiado corto ya que esto aumenta rápidamente el número de juegos en poder del Administrador Universo - y esta actuación, a su vez, podría afectar.
La Economía de A2DB
En cualquier base de datos y, sobre todo, en cualquier base de datos distribuida, siempre es posible plantear preguntas que tendrán mucho tiempo para responder. Esta tecnología no tiene ese problema de repente desaparece. Por ejemplo si se inscribe en dos mesas con terabytes juntos que están en diferentes nodos, un terabyte de datos debe pasar a través de la red. Si se trata de una línea de red lenta, la consulta podría tomar un tiempo muy largo. Si una consulta de este tipo se pasan con frecuencia, la base de datos va a resolver este problema de rendimiento determinado de forma natural por la celebración de una de las mesas terabyte como un resultado intermedio.
Si usted tiene un petabyte o incluso varios petabytes de datos que desea consultar regularmente, entonces la base de datos podría ser utilizado para la tarea por su despliegue de un número suficiente de nodos. En tales circunstancias, podría parecer muy similar a Hadoop (con HBase). Sin embargo ese no es el requisito primordial de un CDBMS. Un CDBMS tiene que ser capaz de manejar cargas de trabajo heterogéneas algunos de los cuales tienen acceso a las estructuras de datos complejas, y hay que hacerlo con la economía y con la velocidad. Eso es lo que hace la tecnología de Algebraix Datos.
En el entorno distribuido es ayudado por el hecho de que los usuarios y los programas que solicitan datos normalmente no plantean preguntas que tienen respuestas terabytes de largo. Plantean preguntas que tienen respuestas muy cortas - unos pocos megabytes o menos. Una excepción es cuando los usuarios están descargando un extracto de datos de gran tamaño para un análisis más detallado, pero este tipo de descargas son relativamente raros.
Este enfoque distribuido tiene la virtud de que se localiza de forma natural datos para adaptarse al tráfico de consultas. En cada nodo se localiza los datos que se consulta con frecuencia en la memoria. En un entorno distribuido con múltiples nodos que será, a través de sus mecanismos de funcionamiento natural, localizar gradualmente los datos para adaptarse al tráfico de consultas locales y globales. Si los volúmenes de consulta se elevan demasiado a un determinado nodo, el nodo puede dividir como una ameba para atender la carga de trabajo en aumento.
Si el tráfico de consultas cambia con, por ejemplo, un tipo de consulta no se plantea con tanta frecuencia y un nuevo conjunto de consultas previamente desconocidos cada vez más común la base de datos sólo tiene que ajustar, mediante el ajuste de los resultados intermedios que contiene. Después de tres o cuatro preguntas de cada nuevo tipo de consulta será restablecido su funcionamiento natural.

WSOMBRERO YOSA
La naturaleza de esta tecnología, junto con el hecho de que puede ser configurado para alta disponibilidad, lo califica como adecuado para el despliegue como un CDBMS.
16

WSOMBRERO YOSA
Sobre el Grupo de Bloor
El Grupo de Bloor es una empresa de consultoría, investigación y analista de la empresa que se centra en la investigación y el análisis de las nuevas tecnologías de la información en todo el espectro de la industria de TI de calidad. La investigación de la firma se centra en la comprensión tanto de las características técnicas y el valor de negocio de las tecnologías de la información y la forma en que se implementan con éxito dentro de los entornos informáticos modernos. Información adicional sobre El Grupo Bloor se puede encontrar en www.TheBloorGroup.com y www.TheVirtualCircle.com. El Grupo de Bloor es el único titular de los derechos de autor de esta publicación.
❏22214 Oban unidad ❏Spicewood TX 78669 ❏Te l: 512 - 524-3689 ❏
w w w. L a V i r t u a l C i r c l e. c o m w
w w. B l o o r G r o u p. c o m
17