*5.0em econometría aplicada para bancos centrales...
TRANSCRIPT

Econometría Aplicada para Bancos CentralesMódulo 2: Análisis de series de tiempo multivariadas
Instructores: Randall Romero y Wilfredo Díaz
San José, Costa Rica, 26-30 de junio de 2017

Contenidos
1. Introducción
2. Modelos SUR
3. Sistemas de ecuaciones simultáneas
4. Vectores Auto-Regresivos (VAR)
5. Cointegración
6. Vector de Corrección de Errores (VECM)
7. Apéndice 1: Resultados importantes
8. Apéndice 2: Demostraciones
9. Apéndice 3: Programas de EViews y Python

Introducción

¿Cómo afecta el dinero al producto? Keynesianos vs Clásicos*
Cuando la oferta de dinero aumenta, el empleo y el productoreal...
Clásicos Keynesianosno se ven afectados. ⇒⇐ también aumentan
En palabras de Lucas (1996):
Esta tensión entre dos ideas incompatibles —quecambios en dinero son cambios neutrales deunidades, y que inducen movimientos en empleo yproducción de la misma direción—ha estado en elcentro de la teoría monetaria al menos desde Hume(1752).
*Basado en Walsh (2010, ch.1) 1

Un econometrista al rescate
• Para resolver este problema, un econometrista estima elmodelo
yt = y0 + α0mt + α1mt−1 + c0zt + c1zt−1 + ut
donde m es dinero, y es producto, z una variable decontrol.
• Si α0 = α1 = 0, los keynesianos estarían en problemas.• Si α0 > 0, los clásicos estarían en problemas.
2

Una regla de política monetaria
• Suponga que el banco central desea estabilizar elproducto alrededor de y0.
• Para ello fija la oferta de dinero así:
m∗t = argmax
mt
E (yt − y0)2
= argmaxmt
E (α0mt + α1mt−1 + c0zt + c1zt−1 + ut)2
= −α1
α0mt−1 −
c1α0
zt−1
donde se supone que el banco central espera E zt = 0.• La regla de política sería
m∗t = π1mt−1 + π2zt−1 + νt
3

Otra versión de los hechos
Ahora suponga que el producto real depende solo de cambiossorpresivos en la oferta de dinero νt:
yt = y0 + d0vt + d1zt + d2zt−1 + ut
Pero la regla de política implicavt = mt − π1mt−1 − π2zt−1.Entonces:
yt = y0 + d0[mt − π1mt−1 − π2zt−1] + d1zt + d2zt−1 + ut
= y0 + d0mt − d0π1mt−1 + d1zt + (d2 − d0π2)zt−1 + ut
4

Un econometrista en problemas
El econometrista compara los dos modelos:
keynes yt = y0 + α0mt + α1mt−1 + c0zt + c1zt−1 + ut
clásico yt = y0 + d0mt − d0π1mt−1 + d1zt + (d2 − d0π2)zt−1 + ut
• La estimación de la regresión no puede distinguir entrelas dos hipótesis propuestas: los modelos resultan enregresiones observacionalmente equivalentes.
• Los parámetros estimados pueden depender de la reglade política.
• Así, el ejercicio estaría sujeto a la crítica de Lucas (1976):no podemos predecir qué pasaría si cambia la política,porque el modelo podría no ser invariante a la políticamisma.
5

Un econometrista con más problemas
• Suponga que el econometrista se conforma con estimar elmodelo
yt = y0 + α0mt + α1mt−1 + c0zt + c1zt−1 + ut
y que zt es el déficit fiscal.• Si τ es la tasa impositiva media y el gasto público g0 esconstante, entonces:
zt = g0 − τyt
• En este caso, estimar el modelo por OLS resulta enestimadores sesgados e inconsistentes!
6

NOTA: Sesgo de simultaneidad
• Considere el modelo
Ct = α+ βYt + ϵ
Yt = Ct + It
• Esto implica que Yt =α+It1−β + ϵt
1−β .• Suponga que se estima la primera ecuación por OLS. Laestimación será inconsistente porque
Cov (Yt, ϵt) = Cov
(ϵt
1− β, ϵt
)=
1
1− βVar (ϵt) = 0
7

Un modelo de ecuaciones simultáneas (VAR estructural)
• Dado que en modelos macro las variables son endógenas,es necesario considerar un sistema de ecuaciones.1 −α0 −c0
0 1 0
τ 0 1
yt
mt
zt
=
y00g0
+0 α1 c1
0 π1 π2
0 0 0
yt−1
mt−1
zt−1
+utνt0
• Su estimación exige imponer (muchas) restricciones. Porejemplo, acá imponemos la restricción de que zt no afectaa mt en el mismo período.
8

Resolviendo el sesgo de simulateidad
Según Sims (1980, pp.14-15)
Debido a que los grandes modelos existentes contienendemasiadas restricciones increíbles, la investigaciónempírica dedicada a probar teorías macroeconómicasalternativas con demasiada frecuencia procede en unmarco de una o pocas ecuaciones.Esta razón es suficientepara que valga la pena investigar la posibilidad de creargrandes modelos en un estilo que no tienda a acumularrestricciones tan caprichosamente…Debe ser factibleestimar modelos macro de gran escala como formasreducidas sin restricciones, tratando todas las variablecomo endógenas.
9

Un vector autor-regresivo (VAR)
Así, lo que Sims (1980) propone† es estimar
yt = y0 + α11yt−1 + α12mt−1 + α13zt−1 + uyt
mt = m0 + α21yt−1 + α22mt−1 + α23zt−1 + umt
zt = z0 + α31yt−1 + α32mt−1 + α33zt−1 + uzt
• Este es un modelo reducido: Las variables yt,mt, zt nointeractuan contemporáneamente.
• También es un modelo SUR: todas las ecuaciones tienenlos mismos regresores; los errores están correlacionados.
• Al ser un modelo SUR, puede estimarse con OLS ecuaciónpor ecuación.
†El modelo original de Sims es de 6 ecuaciones; acá solo ilustramos la propuesta.
10

El curso
En este curso aprenderemos:
• la teoría básica de estimación de sistemas de ecuaciones.• la estimación y uso de los modelos VAR y VECM:
• causalidad de Granger• funciones de impulso respuesta• descomposición de varianza• pronósticos• cointegración• modelos estructural, recursivo, y reducido.
11

Modelos SUR

Introducción‡
• Hay modelos uniecuacionales que aplican a un grupo devariables relacionadas.
• Ejemplos:• Modelo CAPM
rit − rft = αi + βi (rMt − rft) + ϵit
• Modelos de inversión
Iit = β1i + β2iFit + β3iCit + ϵit
• Como los errores ϵit de las distintas ecuaciones puedenestar correlacionados, es preferible considerar losmodelos de manera conjunta.
‡Basado en Greene (2012, capítulo 10)
12

Modelo de regresiones aparentemente no relacionadas (SUR)
• En este modelo se presentan un grupo de variablesdependientes, pero NO simultáneas.
• Cada ecuación puede tener sus propias variablesexplicativas o éstas pueden ser las mismas para todas lasecuaciones.
13

El modelo SUR: ecuaciones no simultáneas
Las ecuaciones del sistema son
y1 = X1β1 + ϵ1
y2 = X2β2 + ϵ2
...yM = XMβM + ϵM
que se pueden expresar comoy1
y2...
yM
Y
=
X1 0 . . . 0
0 X2 . . . 0. . .
0 0 . . . XM
X
β1
β2...
βM
β
+
ϵ1
ϵ2...
ϵM
ϵ
14

El modelo SUR: errores correlacionados
Se asume que perturbaciones de distintas observaciones noestán correlacionadas, aunque las perturbaciones de distintasecuaciones sí pueden estar correlacionados:
E[ϵiϵ
′j |X]= σijI
o bien
E[ϵϵ′|X
]Ω
=
σ11I σ12I . . . σ1MI
σ21I σ22I . . . σ2MI. . .
σM1I σM2I . . . σMMI
Σ⊗I
Producto Kronecker
15

Estimación de un modelo SUR
El modelo SUR
Y = Xβ + ϵ
E [ϵ|X] = 0
Var [ϵ|X] = Ω = Σ⊗ I
supuestos del modelo gene-ralizado de regresión lineal!
puede ser estimado por FGLS:
βGLS =[X′Ω−1X
]−1X′Ω−1Y
=[X′(Σ⊗ I)−1X
]−1X′(Σ⊗ I)−1Y
16

Caso especial del modelo SUR
• Si todas las regresiones tienen los mismos regresores,estimar el sistema SUR por GLS es equivalente a estimarecuación por ecuación con OLS. prueba
• Este resultado justifica que un VAR sin restricciones seestima ecuación por ecuación con OLS.
17

Sistemas de ecuaciones simultáneas

Introducción
• En Economía, muchas de las teorías se construyen comomodelos de ecuaciones simultáneas
• Ejemplos:• Modelo Oferta-Demanda de bienes y/o factores• Modelo IS-LM• Modelos macroeconómicos
18

Modelo de ecuaciones simultáneas
• En este modelo se presentan un grupo de variablesdependientes que se determinan simultáneamente en unsistema de ecuaciones.
• Se asume que existen tantas ecuaciones como variablesdependientes en el sistema.
19

Modelo en forma estructural
• Hay K variables exógenas, M endógenas, y M ecuaciones.• Se cuenta con T observaciones de cada variable.
γ11yt1 + · · ·+ γM1ytM + β11xt1 + · · ·+ βK1xtK = ϵt1
γ12yt1 + · · ·+ γM2ytM + β12xt1 + · · ·+ βK2xtK = ϵt2
...γ1Myt1 + · · ·+ γMMytM + β1Mxt1 + · · ·+ βKMxtK = ϵtM
20

Modelo en forma estructural: Matrices
Escribimos las ecuaciones como y′tΓ + x′tB = ϵt:
[y1 . . . yM
]t
y′t
γ11 . . . γ1M. . .
γM1 . . . γMM
Γ
+ . . .
[x1 . . . xK
]t
x′t
β11 . . . β1M. . .
βK1 . . . βKM
B
=[ϵ1 . . . ϵM
]t
ϵ′t
Juntando todas las observaciones obtenemos
FormaEstructural
Y Γ +XB = E
21

Ejemplo 1:
Modelos en forma estructural

Un modelo de oferta y demandaqdt = α1pt + α2xt + ϵdt
qst = β1pt + ϵst
qdt = qst = q
[qt pt
]y′t
[1 1
−α1 −β1
]Γ
+[1 xt
]x′t
[−α1 −β1
−α2 0
]B
=[ϵdt ϵst
]ϵ′t
Note que cada columna de Γ y de B corresponden a unaecuación del modelo.
22

Un modelo de demanda agregadaCt = α0 + α1Yt + ϵ1t
It = β0 + β1 (Yt − Yt−1) + ϵ2t
Yt = Ct + It +Gt
1 0 −α1
0 1 −β1
−1 −1 1
Γ′
Ct
It
Yt
yt
+
−α0 0 0
−β0 β1 0
0 0 −1
B′
1
Yt−1
Gt
xt
=
ϵ1tϵ2t
0
ϵt
Como tomamos la transpuesta, note que cada fila de Γ′ y deB′ corresponden a una ecuación del modelo.
23

Modelo en forma reducida
Postmultiplicando la forma estructural por Γ−1 tenemos
• y′tΓΓ−1 = −x′tBΓ−1 + ϵtΓ
−1 ⇒ y = x′tΠ+ ν ′t
• Y ΓΓ−1 = −XBΓ−1 + EΓ−1 ⇒ Y = XΠ+ V
donde hemos definido Π ≡ BΓ−1 como los parámetrosreducidos del sistema.
FormaReducida
Y = XΠ+ V
24

Ejemplo 2:
Oferta y demanda

Partiendo del modelo estructural
qt = α0 + α1pt + α2xt + ϵdt (demanda)qt = β0 + β1pt + ϵst (oferta)
escribimos[pt qt
]y′t
[−α1 −β1
1 1
]Γ
+[1 xt
]x′t
[−α0 −β0
−α2 0
]B
=[ϵdt ϵst
]ϵ′t
y llegamos a la forma reducida:
p∗t =α0 − β0β1 − α1
π11
+α2
β1 − α1π21
xt +ϵdt − ϵstβ1 − α1
ν1
q∗t =α0β1 − α1β0
β1 − α1π12
+β1α2
β1 − α1π22
xt +β1ϵ
dt − α1ϵ
st
β1 − α1ν2 25

Supuestos acerca del término de error: esperanza
Forma estructural Forma reducida
E [ϵt|xt] = 0 E [νt|xt] =(Γ−1
)′0 = 0
E[ϵtϵ
′t|xt]= Σ E
[νtν
′t|xt]=(Γ−1
)′ΣΓ−1 = Ω
E[ϵtϵ
′s|xt, xs
]= 0 E
[νtν
′s|xt, xs
]=(Γ−1
)′0Γ−1 = 0
26

Supuestos acerca del término de error: limíte de probabilidad
Si suponemos que
plim(1T E
′E)= Σ
plim(1T X
′X)= Q
plim(1T X
′E)= 0
Tenemos que
plim
1
T
Y ′
X ′
V ′
[Y X V] =
Π′QΠ+Ω Π′Q Ω
QΠ Q 0′
Ω 0 Ω
plim
27

Supuestos acerca del término de error: limíte de probabilidad
Forma estructural Forma reducida
plim(1T E
′E)= Σ plim
(1T V
′V)=(Γ−1
)′ΣΓ−1 = Ω
plim(1T X
′X)= Q plim
(1T X
′X)= Q
plim(1T X
′E)= 0 plim
(1T X
′V)= 0Γ−1 = 0
28

Consistencia de MCO de la forma reducida
El estimador MCO de las pendientes Π es consistente
plim Π = plim[(X ′X
)−1X ′Y
]= plim
[(1T X
′X)−1 1
T X′Y]
=(plim 1
T X′X)−1
plim(1T X
′Y)
= Q−1 (QΠ)
= Π
29

Consistencia de MCO de la forma reducida (cont’n)
El estimador MCO de la varianza Ω también es consistente
plim Ω = plim[1T V
′V]
= plim
[1T
(Y −XΠ
)′ (Y −XΠ
)]= plim
(1T Y
′Y)− plim
(1T Y
′XΠ)− plim
(Π′ 1
T X′Y)+ . . .
. . . plim(Π′ 1
T X′XΠ
)= Π′QΠ+Ω−
(Π′Q
)Π−Π′ (QΠ) + Π′ (Q)Π
= Ω
30

Identificación
• El problema de identificación en ecuaciones simultáneasse refiere a cómo obtener los parámetros estructuralesB,Γ,Σ a partir de los parámetros reducidos Π,Ω.
Π = −BΓ−1
Ω =(Γ−1
)′ΣΓ−1
⇒
B =?
Γ =?
Σ =?
• No es un problema de estimación, sino de resolución deun sistema de ecuaciones no lineales.
31

Identificación (cont’n)
• Considere la matriz F = I , y defina Γ = ΓF y B = BF .Entonces
Y Γ +XB = E (estructura verdadera)Y Γ +XB = E (estructura falsa)
• Pero ambas tienen la misma forma reducida!:
Π = −BΓ−1
= −BFF−1Γ−1
= −BΓ−1
= Π
• Decimos que las estructuras son observacionalmenteequivalentes.
32
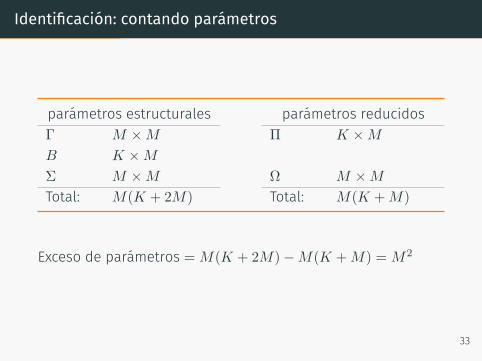
Identificación: contando parámetros
parámetros estructurales parámetros reducidosΓ M ×M Π K ×M
B K ×M
Σ M ×M Ω M ×M
Total: M(K + 2M) Total: M(K +M)
Exceso de parámetros = M(K + 2M)−M(K +M) = M2
33

Identificación de la ecuación j
Dado que tenemos más parámetros estructurales quereducidos, es necesario tener información no muestral:
• normalizaciones• identidades• exclusiones
• restricciones lineales• restricciones en varianza
La más sencilla son las normalizaciones: en cada ecuación, elparámetro de una variable (usualmente endógena) es uno.
34

Identificación via restricciones lineales por ecuación
La forma estructural puede escribirse como Azt = ϵt:
γ11 . . . γM1 β11 . . . βK1
γ12 . . . γM2 β12 . . . βK2...
γ1M . . . γMM β1M . . . βKM
yt1...
ytM
xt1...
xtK
=
ϵt1
ϵt2...
ϵtM
Algunos de los parámetros de la fila j:[γ1j . . . γMj β1j . . . βKj
]están restringidos porque:
• una variable endógena está normalizada, ej: γjj = 1
• alguna variable está excluida, ej: γ3j = 0 o bien β2j = 0
• dos variables tienen el mismo coeficiente, ej: β2j = β3j 35

La condición de rango
Sea Aj la matriz formada por aquellas columnas de A en lasque la ecuación j tiene restricciones.
Condición de rangoLa ecuación j está idenficada si y solo si la matriz Aj tienerango fila completo; es decir
rango[Aj
]= M
Esta condición es necesaria y suficiente.rango de una matriz
36

La condición de orden
Note que para que se cumpla la condición de rango, esnecesario que Aj tenga al menos M columnas.
Condición de ordenPara que la ecuación j esté identificada, es necesario que elnúmero de restricciones en tal ecuación sea mayor o igual alnúmero de variables endógenas del sistema (= al número deecuaciones)
Esta condición es necesaria pero no suficiente.
37

Clasificación de ecuaciones
Condición de orden Condición de rango
Sobre-identificada Se cumple condesigualdad
Se cumple
Exactamenteidentificada
Se cumple conigualdad
Se cumple
Sub-identificada alguna condición no se cumple
• Se dice que está identificada sólo si está“sobre-identificada” o “exactamente-identificada”
• Solo las ecuaciones identificadas pueden ser estimadas
38

Ejemplo 3:
Identificación de la oferta y lademanda

• El modelo estructural es
qt = α0 + α1pt + α2xt + ϵdt (demanda)qt = β0 + β1pt + ϵst (oferta)
• Las variables endógenas son qt, pt• Las variables exógenas son: 1, xt
39

Azt =
[1 −α1 −α0 −α2
1 −β1 −β0 0
]pt
qt
1
xt
=
[ϵdtϵst
]
Entonces
A1 =
[1
1
]A2 =
[1 −α2
1 0
]Demanda No cumple condición de orden ⇒ no-identificada
Oferta Cumple condición de rango si y solo si α2 = 0.
En conclusión, podemos estimar la oferta siempre y cuando lademanda efectivamente dependa de xt. La demanda no puedeser estimada.
40

Ejemplo 4:
Identificación de un modelo dedemanda agregada

• Considere el sistema
Ct = α0 + α1Yt + ϵ1t
It = β0 + β1 (Yt − Yt−1) + ϵ2t
Yt = Ct + It +Gt
• Las variables endógenas son Ct, It, Yt• Las variables exógenas/predeterminadas son: 1, Yt − 1, Gt
41
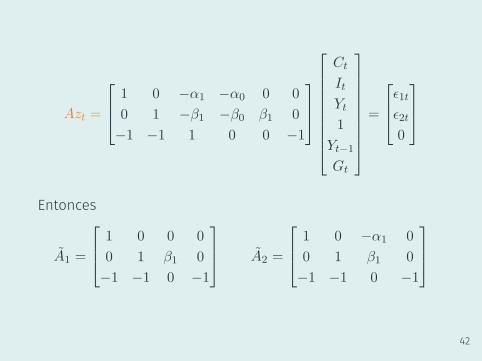
Azt =
1 0 −α1 −α0 0 0
0 1 −β1 −β0 β1 0
−1 −1 1 0 0 −1
Ct
It
Yt
1
Yt−1
Gt
=
ϵ1tϵ2t
0
Entonces
A1 =
1 0 0 0
0 1 β1 0
−1 −1 0 −1
A2 =
1 0 −α1 0
0 1 β1 0
−1 −1 0 −1
42

Ecuación 1 • Tenemos rango[A1
]= 3 ⇒ identificada.
• A1 tiene 4 columnas pero 3 filas ⇒sobre-identificada.
Ecuación 2 • Ahora rango[A2
]= 3 ⇒ identificada.
• A2 tiene 4 columnas pero 3 filas ⇒sobre-identificada.
Ecuación 3 • Es una identidad ⇒ no hay nada que estimar.
43

Ejemplo 5:
Identificación de un SVAR(1)

• Considere el modelo[1 ϕ
γ 1
][xt
yt
]=
[β11 β12
β21 β22
][xt−1
yt−1
]+
[ϵxt
ϵyt
]• Hay 2 ecuaciones pero cada una tiene únicamente unarestricción (la normalización), por lo que la condición deorden no se cumple ⇒ ninguna ecuación estáidentificada.
• Para poder estimar este modelo, sería necesario añadirnuevas restricciones.
• Suponga que estamos dispuestos a asumir que loserrores no están correlacionados y que xt no responde ayt contemporaneamente:
Var[ϵt] =
[σ2x 0
0 σ2y
]ϕ = 0
44

Si Ω es la varianza de los errores de forma reducida, entonces
Ω ≡
[ω21 ρω1ω2
ρω1ω2 ω22
]=
[1 01γ 1
][σ2x 0
0 σ2y
][1 1
γ
0 1
]
=
[σ2x
σ2xγ
σ2xγ
σ2x
γ2 + σ2y
]
Así, conociendo Ω (estimado a partir de la forma reducida), losparámetros estructurales estarían identificados!
σ2x = ω2
1 γ =ω1
ρω2σ2y =
(1− ρ2
)ω22
45

• Antes de continuar, observe que
Ω ≡
[ω21 ω12
ω12 ω22
]=
[1 01γ 1
][σ2x 0
0 σ2y
][1 1
γ
0 1
]
=
[σx 0σxγ σy
][σx
σxγ
0 σy
]
• Es decir, hemos descompuesto Ω como el producto deuna matriz triangular inferior y su transpuesta: Ω = LL′
• Toda matriz simétrica semi-definida positiva puede serdescompuesta así.
• Esta es la descomposición de Choleski.
46

Métodos de estimación
• Se clasifican en métodos indirectos y métodos directos.• Los directos se clasifican en dos grupos:
Métodos deinformación limitada
Métodos deinformación completa
• OLS• IV• 2SLS• GMM• LIML
• 3SLS• FIML• GMM
47

Mínimos cuadrados indirectos (ILS)
• Es posible estimar Π y Ω consistentemente con OLS, peroestos parámetros no son de interés (excepto paraproyectar Y |X).
• No obstante, si el sistema está identificado, se puede usarMínimos Cuadrados Indirectos (ILS), que consiste enestimar ΓILS, BILS y ΣILS en función de ΠOLS y ΩOLS.
• Propiedades:• factible pero ineficiente• puede haber más de una solución (si está sobre-identificado).
48

Mínimos cuadrados ordinarios (OLS)
Escribimos la ecuación j como
yj = Y ′j γj +X ′
jβj + ϵj =[Yj Xj
]Zj
[γj
βj
]δj
+ ϵj = Zjδj + ϵj
Estimador OLS
δjOLS
=(Z ′jZj
)−1Z ′jyj
= δj +(Z ′jZj
)−1Z ′jϵj
= δj +
[Y ′jYj Y ′
jXj
X ′jYj X ′
jXj
]−1 [Y ′j ϵj
X ′jϵj
]
OLS es inconsistente porque plim[1T Y
′j ϵj
]= 0
49

Caso particular: Modelo recursivo
En el modelo recursivo
y1 = x′β1 + ϵ1
y2 = x′β2 + γ12y1 + ϵ2
...yM = x′βM + γ1My1 + · · ·+ γM−1,MyM−1 + ϵM
Γ es triangular y Σ es diagonal, entonces OLS es consistente yeficiente, porque
Cov [y1, ϵ2] = Cov[x′β1 + ϵ1, ϵ2
]= 0
y así sucesivamente.
50

Variables instrumentales (IV)
• Para la ecuación yj = Y ′j γj +X ′
jβj + ϵj = Zjδj + ϵj
suponemos que existe matriz WjT×(Mj+Kj)
tal que:
plim(1T W
′jZj
)= ΣWZ (instrumento correlacionado con regresores)
plim(1T W
′jWj
)= ΣWW (instrumento tiene varianza finita)
plim(1T W
′jϵj)= 0 (instrumento NO correlacionado con errores)
Estimador IVδj
IV=(W ′
jZj
)−1W ′
jyj
= δj +(1T W
′jZj
)−1 ( 1T W
′jϵj)
IV es consistente porque plim[1T W
′jϵj
]= 0
51

Mínimos cuadrados en dos etapas (2SLS)
Consiste en usar como intrumentos para Yj los valoresajustados por la regresión de Yj en todas las X ’s del sistema.
Etapa 1 Ajustar Yj por OLS usando todas las X
YjOLS
= XΠjOLS
= X(X ′X
)−1X ′Yj
Etapa 2 Usar IV con W =[Yj
OLSX]:
Estimador 2SLS δj2SLS
=
[Y ′j
OLSYj Y ′
j
OLSXj
X ′jYj X ′
jXj
]−1 [Y ′j
OLSyj
X ′jyj
]
Si no hay autocorrelación ni heteroscedasticidad entonces2SLS es el estimador IV más eficiente usando sólo lainformación de X
52

Ejemplo 6:
El Modelo Klein I

En 01-modelo klein.prg estimamos el Modelo I de Klein(1950)§:
Ctconsumo
= α0 + α1Pt + α2Pt−1 + α3(Wpt +Wgt) + ϵ1t
Itinversión
= β0 + β1Pt + β2Pt−1 + β3Kt−1 + ϵ2t
Wptsalariosprivados
= γ0 + γ1Xt + γ2Xt−1 + γ3At + ϵ3t
Xtproducto
= Ct + It +Gt
Ptutilidades
= Xt − Tt −Wpt
Ktcapital
= Kt−1 + It−1
§Basado en Greene (2012, pp332-333)
53

• Las variables exógenas son:• Gt = gasto (no salarial) del gobierno• Tt = impuestos indirectos a las empresas + exportacionesnetas
• Wgt = gastos salarial del gobierno• At = tendecia, años desde 1931
• Hay tres variables predeterminadas: los rezagos del stockde capital, utilidades privadas, y demanda total.
• El modelo contiene 3 ecuaciones de comportamiento, unacondición de equilibrio, y dos identidades contables.
• En este laboratorio replicaremos el trabajo de Klein, quienestimó este modelo con datos anuales de 1921 a 1941.
54

El estimador 2SLS del sistema es¶:
Ct = 16.55(11.28)
+ 0.02(0.13)
Pt + 0.22(1.81)
Pt−1 + 0.81(18.11)
(Wpt +Wgt) + ϵ1t
It = 20.28(2.42)
+ 0.15(0.78)
Pt + 0.62(3.40)
Pt−1 − 0.16(3.93)
Kt−1 + ϵ2t
Wpt = 0.07(0.06)
+ 0.44(11.08)
Xt + 0.15(0.04)
Xt−1 + 0.13(4.02)
At + ϵ3t
¶Estadístico t en paréntesis
55

Ejemplo 7:
El modelo de la telaraña

En el modelo de la telaraña para los mercados de maíz y detrigo
qsmt = 0.5pm,t−1 − 0.2pw,t−1 + 200 + ϵsmt (oferta de maíz)qswt = −0.2pm,t−1 + 0.4pw,t−1 + 80 + ϵswt (oferta de trigo)qdmt = −0.2pmt + 1.2pwt + 100 + ϵdmt (demanda de maíz)qdwt = 1.1pmt − 0.4pwt + 50 + ϵdwt (demanda de trigo)
Este modelo lo analizamos con Python en 01telaraña.ipynb y con EViews en 02-sistemasdinamicos.prg
56

Vectores Auto-Regresivos (VAR)

Las tareas del macroeconometrista ‖
Los macroeconometristas hacen cuatro cosas:
1. describen y resumen datos macroeconómicos2. realizan pronósticos macroeconómicos3. cuantifican lo que sabemos (y lo que no sabemos) acerca
de la verdadera estructura de la macroeconomía4. aconsejan (y a veces llegan a ser) a los hacedores de
política.
‖Esta introducción está basada en Stock y Watson (2001)
57

Un poco de historia
• En los 1970s, estas cuatro tareas se realizaban usando unavariedad de técnicas.
• Pero después del caos macroeconómico de los 1970s,ninguna de esas técnicas parecía apropiada.
• En 1980, Sims (1980, pp.15) afirma queDebe ser factible estimar modelos macro de granescala como formas reducidas sin restricciones,tratando todas las variable como endógenas.
58

La propuesta de Sims
• En 1980, Sims propone una nueva técnicamacroeconométrica: el vector autorregresivo (VAR)
• Un VAR es un modelo lineal de n ecuaciones y n variables,en el cual cada variable es explicada por sus propiosrezagos, más los valores actuales y rezagados de las otrasn− 1 variables.
• Este sencillo esquema provee una manera sistemática decapturar la gran dinámica en series de tiempo múltiples, ylas herramientas estadísticas que vienen con los VAR sonfáciles de usar y de interpretar.
59
Las series de tiempo
• En lo que sigue, asumimosque hay n series detiempo.
• La observación t sedenota yt, corresponde aun vector columna con n
datos (uno por cada serie)
60

Distintos “sabores” de VAR
• En general, hay tres variedades de VAR:1. VAR en forma reducida2. VAR recursivo3. VAR estructural
• Se distinguen por cómo se presentan las relacionescontemporáneas entre las variables.
61

El proceso VAR(p) en forma reducida
• El VAR reducido expresa cada variable como función linealde los rezagos de todas las variables en el sistema y deun término de error sin correlación serial.
• Si hay p rezagos, el VAR reducido se representa
VAR(p) yt = c+Φ1yt−1 +Φ2yt−2 + · · ·+Φpyt−p + ϵt
donde Φj es la matriz n× n de coeficientes del rezago j.• El término de error cumple:
E ϵt = 0 Var ϵt = Ω Cov[ϵt, ϵs] = 0 if t = s
• No hay relación contemporánea entre las variables.62

El proceso VAR(p) estructural
• El VAR estructural es similar al reducido, pero lasvariables tienen relación contemporánea.
• Para determinarla, se use teoría económica.• Se requiere de “supuestos de identificación” quepermitan interpretar correlaciones como causalidad.
• Se representa como
Γ0yt = d+ Γ1yt−1 + Γ2yt−2 + · · ·+ Γpyt−p + εt
donde Γj es la matriz n× n de coeficientes del rezago j.• El término de error cumple:
E εt = 0 Cov[εit, εjs] =
σ2i , if t = s and i = j
0, de lo contrario.
63

El proceso VAR(p) en forma recursiva
• El VAR recursivo es un caso particular del VAR estructural,donde las variables tienen relación contemporánea demanera recursiva:
• y1t es “exógena”• y2t depende sólo de y1t• y3t depende de y1t y de y2t• ynt depende de todas las demás.
• Note que el ordenamiento de las variables es importante,habiendo n! formas de ordenarlas.(Por ejemplo, en unVAR de cinco variables, hay 5! = 120 ordenamientos).
• Al igual que el VAR estructural, se representa como
Γ0yt = d+ Γ1yt−1 + Γ2yt−2 + · · ·+ Γpyt−p + εt
pero con la restricción de que Γ0 es uni-triangular inferior.
64

Ejemplo 8:
Distintas versiones de un VAR

Forma reducidayt = y0 + α11yt−1 + α12mt−1 + α13zt−1 + uy
t
mt = m0 + α21yt−1 + α22mt−1 + α23zt−1 + umt
zt = z0 + α31yt−1 + α32mt−1 + α33zt−1 + uzt
Forma estructuralyt + β1mt = y0 + α11yt−1 + α12mt−1 + α13zt−1 + uy
t
mt + β2zt = m0 + α21yt−1 + α22mt−1 + α23zt−1 + umt
zt + β3yt + β4mt = z0 + α31yt−1 + α32mt−1 + α33zt−1 + uzt
Forma recursivayt =y0 + α11yt−1 + α12mt−1 + α13zt−1 + uy
t
γ1yt +mt =m0 + α21yt−1 + α22mt−1 + α23zt−1 + umt
γ2yt + γ3mt + zt =z0 + α31yt−1 + α32mt−1 + α33zt−1 + uzt
65

Pasando de un VAR estructural (o recursivo) a uno reducido
• Si la matriz Γ0 es invertible (lo que está garantizado en elVAR recursivo), entonces se puede convertir el VARreducido así:
Γ0yt = d+ Γ1yt−1 + · · ·+ Γpyt−p + εt
yt = Γ−10 d+ Γ−1
0 Γ1yt−1 + · · ·+ Γ−10 Γpyt−p + Γ−1
0 εt
= c+Φ1yt−1 +Φ2yt−2 + · · ·+Φpyt−p + ϵt
• Las matrices de covarianza cumplen
Ω = Γ−10 ΣΓ′−1
0
66

La descomposición de Cholesky
• Recuerde que
Σ =
σ21 0 . . . 0
0 σ22 . . . 0
. . .0 0 . . . σ2
n
⇒ Σ1/2 =
σ1 0 . . . 0
0 σ2 . . . 0
. . .0 0 . . . σn
• Así
Ω =[Γ−10 Σ1/2
] [Γ−10 Σ1/2
]′• En el caso de un VAR recursivo, Γ0 es tringular inferior, ypor tanto Γ−1
0 Σ1/2 también lo es.• Así, hemos obtenido la descomposición de Cholesky de Ω.
67

Ejemplo 9:
Descomposición de Cholesky

Ω = PP ′ =[Γ−10 Σ1/2
] [Γ−10 Σ1/2
]′= Γ−1
0 ΣΓ′−10
Si y′t =[mt rt kt
]y la matriz de covarianza reducida es
Ω =
1 0.5 −1
0.5 4.25 2.5
−1 2.5 12.25
=
1 0 0
0.5 2 0
−1 1.5 3
P
1 0.5 −1
0 2 1.5
0 0 3
P ′
=
1 0 0
0.5 1 0
−1 0.75 1
Γ−10
1 0 0
0 4 0
0 0 9
Σ
1 0.5 −1
0 1 0.75
0 0 1
Γ′−1
0
Por lo que
Γ0 =
[1 0 0
−0.5 1 0
1.375 −0.75 1
]Entonces σ2
r = 4 y un aumento de una unidad en mt provocauna disminución contemporanea de 1.375 en kt.
68

VAR con series como desviación de la media
• Si el VAR es estacionario, su media E yt ≡ µt es constante• Así,
yt = Φ1yt−1 + · · ·+Φpyt−p +c+ ϵt
µ = Φ1µ + · · ·+Φpµ +c+ E ϵt
yt − µ = Φ1 (yt−1 − µ) + · · ·+Φp (yt−p − µ) +ϵt
• La media del proceso es
µ = (I − Φ1 − Φ2 · · · − Φp)−1 c
• Definimos y ≡ yt − µ. El VAR(p) con series comodesviación de la media es
yt = Φ1yt−1 + · · ·+Φpyt−p + ϵt
69
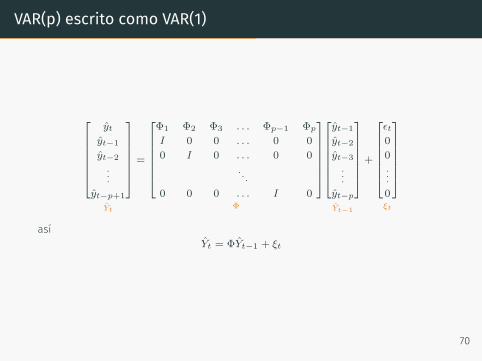
VAR(p) escrito como VAR(1)
ytyt−1
yt−2
...yt−p+1
Yt
=
Φ1 Φ2 Φ3 . . . Φp−1 Φp
I 0 0 . . . 0 0
0 I 0 . . . 0 0
. . .0 0 0 . . . I 0
Φ
yt−1
yt−2
yt−3
...yt−p
Yt−1
+
ϵt0
0...0
ξt
asíYt = ΦYt−1 + ξt
70

Ejemplo 10:
VAR(2) a VAR(1)

El VAR(2)[xt
yt
]=
[.5 .1
.4 .5
][xt−1
yt−1
]+
[0 0
.25 0
][xt−2
yt−2
]+
[ϵxt
ϵyt
]
se escribe como VAR(1)xt
yt
xt−1
yt−1
=
.5 .1 0 0
.4 .5 .25 0
1 0 0 0
0 1 0 0
xt−1
yt−1
xt−2
yt−2
+
ϵxt
ϵyt
0
0
71

Dinámica de un proceso VAR(1)
• A menudo necesitamos iterar en la fórmula del AR(1) paraanalizar su dinámica.
• En esos casos, es útil observar que:(1 + ΦL+Φ2L2 + · · ·+ΦsLs
)(I − ΦL) =
(I − Φs+1Ls+1
)• Así, si queremos expresar Yt en términos de Yt−s−1
(I − ΦL) Yt = ξt(I − Φs+1Ls+1
)Yt =
(1 + ΦL+Φ2L2 + · · ·+ΦsLs
)ξt
Yt − Φs+1Yt−s−1 = ξt +Φξt−1 + · · ·+Φsξt−s
72

Pasado versus futuro
Pasado Cuando queremos analizar Yt en función deshocks pasados, utilizamos
Yt = ξt +Φξt−1 + · · ·+Φsξt−s +Φs+1Yt−s−1
Futuro Para analizar el efecto de nuevos shocks sobrefuturos valores de Y , aplicamos L−s a la últimaecuación:
Yt+s = ξt+s +Φξt+s−1 + · · ·+Φsξt +Φs+1Yt−1
73

VAR(1) escrito como VMA(∞)
Yt = ξt + Φξt−1 + · · ·+ Φsξt−s + Φs+1Yt−s−1
• Si los eigenvalores de Φ están en el círculo unitario ellímite s → ∞ converge a
Yt = ξt +Φξt−1 +Φ2ξt−2 + . . .
74

Impulso respuesta
Yt+s = ξt+s + Φξt+s−1 + · · ·+ Φsξt + Φs+1Yt−1
• La función de impulso-respueta mide la respuestaobservada en la variable m-ésima s períodos después(Yt+s,m) de que se presenta un impulso en la k-ésimavariable (ξt,k)
• Viene dada por∂Yt+s,m
∂ξt,k= (Φs)km
es decir, por el elemento en la fila k, columna m, de lamatriz Φ elevada al número de períodos s.
75

Interpretando la función de impulso-respuesta
Yt+s = ξt+s + Φξt+s−1 + · · ·+ Φsξt + Φs+1Yt−1
• Suponga que• el sistema estaba en equilibrio en t− 1, es decir Yt−1 = 0
• hay un shock v′ =[v1 . . . vn
]a las variables en t, ξt = v
• el shock es transitorio: 0 = ξt+1 = ξt+2 = . . .
• En este caso, la desviación del sistema respecto a suequilibrio s períodos después del shock es
Yt+s = Φsv
76

Impulso respuesta (cont’n)
Ω = PP ′ =[Γ−10 Σ1/2
] [Γ−10 Σ1/2
]′= Γ−1
0 ΣΓ′−10
• En la práctica, estamos interesados en shocks εt a lasecuaciones estructurales, en vez de a las ecuacionesreducidas ϵt. Esto para tomar en cuenta los efectoscontemporáneos del shock.
• Para calcular las respuestas, nos valemos de ϵt = Γ−10 εt y
de la descomposición de Cholesky de la covarianza de loserrores reducidos Ω:
Tamaño delimpulso
Impulsoestructural
Impulsoreducido
Respuesta
unitarios εt = I v = Γ−10 ΦsΓ−1
0
1 st. dev. εt = Σ1/2 v = Γ−10 Σ1/2 ΦsΓ−1
0 Σ1/2
77

Ejemplo 11:
Impulso respuesta ydescomposición de Cholesky

Siguiendo con el ejemplo 9, si y′t =[mt rt kt
]y la matriz de
covarianza reducida es
Ω =
1 0.5 −1
0.5 4.25 2.5
−1 2.5 12.25
=
1 0 0
0.5 2 0
−1 1.5 3
P
1 0.5 −1
0 2 1.5
0 0 3
P ′
=
1 0 0
0.5 1 0
−1 0.75 1
Γ−10
1 0 0
0 4 0
0 0 9
Σ
1 0.5 −1
0 1 0.75
0 0 1
Γ′−1
0
La respuesta del sistema a un shock en kt se calcula a partirde …
• v′ =[0 2 1.5
]si el shock es de una desviación estándar.
• v′ =[0 1 0.75
]si el shock es unitario.
78

Condiciones para la estacionariedad
• Y es estacionario si y solo si todos los eigenvalores de Φ
están dentro del círculo unitario. EXPLICACIÓN
• Los eigenvalores λ de Φ satisfacen:∣∣Iλp − Φ1λp−1 − · · · − Φp
∣∣ = 0
79

Ejemplo 12:
Estacionariedad de un VAR(2)

Para el VAR(2) del ejemplo 10:
0 =
∣∣∣∣∣[1 0
0 1
]λ2 −
[.5 .1
.4 .5
]λ−
[0 0
.25 0
]∣∣∣∣∣=
∣∣∣∣∣[
λ2 − .5λ −.1λ
−.4λ− .25 λ2 − .5λ
]∣∣∣∣∣=
(λ2 − .5λ
) (λ2 − .5λ
)− (−.4λ− .25) (−.1λ)
= λ4 − λ3 + 0.21λ2 − 0.025λ
Las raíces de este polinomio son λ1 = 0, λ2 = 0.7693,λ3 = 0.1154 + 0.1385i, y λ4 = 0.1154− 0.1385i, todas ellasdentro del círculo unitario. Por lo tanto, el VAR es estacionario.
80

Ejemplo 13:
Dinámica de un VAR

• Hasta el momento hemos estudiado• cómo determinar si un VAR es estacionario• la función de impulso respuesta
• En el cuaderno de Jupyter 02 Simulacion de unVAR.ipynb se introduce un ejemplo para analizar un VAR.
• En el cuaderno de Jupyter 03 VAR(1) clase.ipynb sepresentan 5 modelos VAR reducidos. Acá definimos unaclase para representar un VAR.
81

Especificación de un VAR
• Para especificar un VAR, hay dos cosas que escoger:• Las n series que conforman el VAR• El número p de rezagos a ser incluidos en el modelo
• En contraste con la metodología de Box-Jenkins, elmodelo VAR no es parsimonioso ⇒ un VAR estásobreparametrizado:
• hay n+ pn2 parámetros.• muchos de sus coeficientes no son significativos• regresores posiblemente son altamente colineales,estadísticos t no confiables.
• No obstante, en un VAR los coeficientes individuales noson de interés. Interesa determinar la dinámica delmodelo (impulso respuesta) y la causalidad (Granger).
82

Estimación de un VAR
• El VAR reducido es un sistema de ecuaciones SUR, dondetodas las ecuaciones tienen los mismos regresores.
• Por lo tanto, la estimación OLS ecuación por ecuación esinsesgada, eficiente y consistente.
• La matriz de covarianza de los errores se estima a partirde los residuos
Ω =1
T − np− 1
T∑t=1
ϵtϵt′
83

Estimación de un VAR no estacionario
Si las series son I(1), ¿hay que diferenciarlas para estimar elVAR? Hay un debate respecto:
NO: Algunos aconsejan no diferenciar las series,porque se pierde información, alegando que lameta del VAR es determinar relaciones entrevariables, no los parámetros mismos.
SÍ: Otros advierten que si las series son integradas,el VAR en niveles no es consistente con el procesogenerador de datos. En este caso se aconsejaestudiar la cointegración de las series ⇒ VECM
84

Ejemplo 14:
Propiedades de la estimaciónOLS de un VAR

• En el cuaderno de Jupyter 04 VAR insesgado.ipynbse presenta un ejercicio de simulación para ilustrar que elestimador OLS de un VAR es insesgado y consistente.
• Se simula el VAR(1)(xt
yt
)Yt
=
(0.8 0.7
−0.2 0.5
)Φ
(xt−1
yt−1
)Yt−1
+
(ϵx,t
ϵy,t
)ϵt
Ω =
(0.9 0
0 0.9
)
85
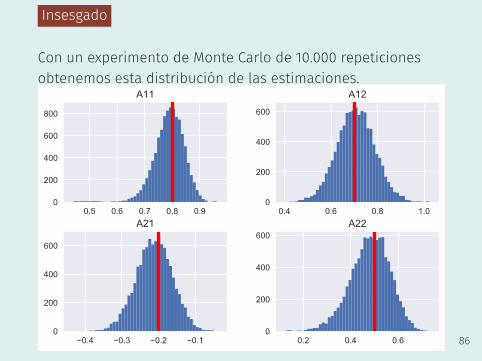
Insesgado
Con un experimento de Monte Carlo de 10.000 repeticionesobtenemos esta distribución de las estimaciones.
0.5 0.6 0.7 0.8 0.90
200
400
600
800
A11
0.4 0.6 0.8 1.00
200
400
600
A12
0.4 0.3 0.2 0.10
200
400
600
A21
0.2 0.4 0.60
200
400
600A22
86

Consistente
Simulando una sola muestra, se estima el VAR agregando unaobservación a la vez. Las estimaciones convergen hacia losverdaderos parámetros poblacionales.
0.8
1.0
1.2A11
0.4
0.3
0.2
A12
0 50 100 150 200 250
1.0
1.5
2.0 A21
0 50 100 150 200 250
0.4
0.6
0.8A22
87

Escogiendo el óptimo número de rezagos del VAR
• La selección del número de rezagos p es crítica.• Si p es demasiado pequeño, el modelo está malespecificado
• Si p es demasiado grande, se desperdician grados delibertad.
• Una opción: dejar que p difiera para cada ecuación yvariable ⇒ el VAR no podría estimarse con OLS.
• Por tanto, se determina un sólo p para todas las variablesy ecuaciones, usando dos enfoques distintos
• Descartando los últimos rezagos si no son significativos• Utilizando un criterio de selección que contraponga elajuste a los grados de libertad.
88

Escogiendo el p óptimo con pruebas de significancia
• Suponga que queremos decidir entre p y q número derezagos, con q < p.
• Obtenemos Ω para ambos modelos, usando la mismamuestra.
• Comprobamos la significancia conjunta de los rezagosq + 1, . . . , p con la prueba de razón de verosimilitud
(T − 1− pn)(ln∣∣∣Ωq
∣∣∣− ln∣∣∣Ωp
∣∣∣) asym∼ χ2(n2(p− q))
• Si no se rechaza la hipótesis nula, puede escogerse q
rezagos.• Limitaciones:
• Resultado asintótico, pero muestras usualmente pequeñas• Resultado sensible a escogencia de p y q.
89

Escogiendo el p óptimo con criterios de selección
• En la práctica, el número óptimo de rezagos se escogeminimizando el valor de AIC o de SBC:
AIC = T ln∣∣∣Ω∣∣∣+ 2N
SBC = T ln∣∣∣Ω∣∣∣+N lnT
donde N = n2p+ n es el número total de parámetrosestimados
• Rezagos adicionales reducen Ω, pero incrementando N
90

Usando un VAR para describir los datos
• La práctica usual en el análisis VAR es reportar• pruebas de causalidad de Granger• funciones de impulso respuesta• descomposición de varianza del error de pronóstico
• Usualmente no se reportan los coeficientes estimados niel R2, porque no son tan informativos.
91
Causalidad de Granger
• Las pruebas de causalidad de Granger determinan si losvalores rezagados de una variable ayudan a predecir otravariable.
• Si los rezagos de A no ayudan a predecir B, entoncescoeficientes de los rezagos de A en la ecuación de B sonceros.
• Si alguna variable no es causada en el sentido de Grangerpor ninguna otra, no implica que la variable sea exógena.Bien podría haber causalidad contemporánea.
92

Ejemplo 15:
Causalidad de Granger

En el modelo VAR(2) con variables yt,mt:
yt = y0 + α11yt−1 + α12mt−1 + β11yt−2 + β12mt−2 + uyt
mt = m0 + α21yt−1 + α22mt−1 + β21yt−2 + β22mt−2 + umt
las pruebas de causalidad de Granger son:
Hipótesis nula Restricciones
m no causa y α12 = β12 = 0
y no causa m α21 = β21 = 0
Si se rechaza, por ejemplo, la primera hipótesis, decimos quem causa y en el sentido de Granger.
93

Pronóstico
Yt+s = ξt+s + Φξt+s−1 + · · ·+ Φs−1ξt+1 + ΦsYt
• Suponga que Φ ha sido estimado con datos hasta t = T .• El mejor pronóstico del sistema s períodos adelante es
E[YT+s | YT
]= ΦsYT
• El error de pronóstico es
YT+s − E[YT+s | YT
]= ξt+s +Φξt+s−1 + · · ·+Φs−1ξt+1
• y su varianza (MSPE) es
Var[YT+s | YT
]= Ω+ ΦΩΦ′ + · · ·+Φs−1ΩΦ′s−1
94

Descomposición de la varianza del shock reducido
• Recuerde que los errores reducidos están relacionadoscon los estructurales por ϵt = Γ−1
0 εt.
• Sea Γ−10 ≡ A =
[a1 . . . an
], con ai la i-ésima columna
de i.• Entonces
ϵt = a1ε1t + a2ε2t + · · ·+ anεnt
Ω = E[ϵtϵ′t] = σ21a1a
′1 + σ2
2a2a′2 + · · ·+ σ2
nana′n
=
n∑j=1
σ2jaja
′j
95

Ejemplo 16:
Descomposición de Ω

Tomando Ω del ejemplo 9
Ω =
1 0.5 −1
0.5 4.25 2.5
−1 2.5 12.25
=
1 0 0
0.5 1 0
−1 0.75 1
Γ−10
1 0 0
0 4 0
0 0 9
Σ
1 0.5 −1
0 1 0.75
0 0 1
Γ′−1
0
Entonces a′1 =[1 0.5 −1
], a′2 =
[0 1 0.75
], a′3 =
[0 0 1
]y
Ω = 1
1
0.5
−1
[1 0.5 −1
]+ 4
0
1
0.75
[0 1 0.75
]+ 9
001
[0 0 1
]
= 1σ21
1 0.5 −1
0.5 0.25 −0.5
−1 −0.5 1
a1a
′1
+ 4σ22
0 0 0
0 1 0.75
0 0.75 0.5625
a2a
′2
+ 9σ23
0 0 0
0 0 0
0 0 1
a3a
′3
Observe que esta descomposición depende del ordenamientode las variables.
96

Descomposición de la varianza del pronóstico
• Sustituyendo Ω =∑n
j=1 σ2jaja
′j en Var
[YT+s | YT
]tenemos
Var[YT+s | YT
]=
n∑j=1
σ2j
aja
′j +Φaja
′jΦ
′ + · · ·+Φs−1aja′jΦ
′s−1
• Con esta expresión, podemos cuantificar la contribucióndel j-ésimo shock estructural al error cuadrático mediodel pronóstico s-períodos adelante.
• Observe que esto asume que conocemos los parámetrosdel modelo! No toma en cuenta los errores de estimación.
97

Cointegración

Motivation
• A continuación estudiamos la manera de estimar un VARcuyas series no son estacionarias.
• En procesos univariados, basta con diferenciar la serie yaplicar técnicas de Box-Jenkins.
• En proceso multivariados, es necesario determinar si lasseries están cointegradas.
98

Cointegración como equilibrio de largo plazo
• Considere el modelo monetario
mtoferta
= β0 + β1pt + β2yt + β3rtdemanda
+ ϵtbrecha
• Para que la noción de equilibrio tenga sentido, la brechaϵt debe ser estacionaria (I(0))
• Esto a pesar de que mt, pt, yt y rt sean I(1).• Es decir, la combinación lineal de variables I(1)
[1 −β1 −β2 −β3
]mt
pt
yt
rt
= β0 + ϵt
resulta en un proceso I(0)• Decimos que mt, pt, yt y rt están cointegradas, con vectorde cointegración
[1 −β1 −β2 −β3
]. 99

Cointegración como equilibrio de largo plazo (cont’n)
• Teorías de equilibrio con variables no estacionariasrequieren la existencia de una combinación lineal de lasvariables que sea estacionaria
• Otros ejemplos:• Teoría de la función de consumo:
ct = βypt + ctt ⇒[1 −β
] [ctypt
]= ctt es estacionario
• Teoría de la paridad del poder de compra:
et + p∗t − pt =[1 1 −1
]etp∗tpt
es estacionario
100

Regresión espuria
• Considere dos caminatas aleatorias independientes
yt = yt−1 + ut ut ruido blancoxt = xt−1 + vt vt ruido blanco
• Como yt es independiente de xt, uno esperaría que en laregresión
yt = β0 + β1xt + ϵt
el R2 y el β1 tendieran a cero.• Pero este no es el caso. Con series no estacionarias, lacorrelación espuria puede persistir aún en muestrasgrandes.
101

Ejemplo 17:
Regresión espuria

Jupyter 05 Relacion espuria.ipynbRegresión con series I(1):
log(GDP.COSTA.RICAt) = β0 + β1 log(GDP.MALTAt) + ϵt
OLS Regression Results==============================================================================Dep. Variable: CRI R-squared: 0.796Model: OLS Adj. R-squared: 0.791Method: Least Squares F-statistic: 171.6Date: Thu, 22 Jun 2017 Prob (F-statistic): 8.75e-17Time: 21:12:47 Log-Likelihood: 34.112No. Observations: 46 AIC: -64.22Df Residuals: 44 BIC: -60.57Df Model: 1Covariance Type: nonrobust==============================================================================coef std err t P>|t| [0.025 0.975]------------------------------------------------------------------------------Intercept 4.6104 0.308 14.976 0.000 3.990 5.231MLT 0.4284 0.033 13.098 0.000 0.362 0.494==============================================================================Omnibus: 19.096 Durbin-Watson: 0.071Prob(Omnibus): 0.000 Jarque-Bera (JB): 3.965Skew: 0.253 Prob(JB): 0.138Kurtosis: 1.653 Cond. No. 169.==============================================================================
102

Regresión con series I(0):
∆log(GDP.COSTA.RICAt) = β0 + β1∆log(GDP.MALTAt) + ϵt
OLS Regression Results==============================================================================Dep. Variable: CRI R-squared: 0.036Model: OLS Adj. R-squared: 0.014Method: Least Squares F-statistic: 1.625Date: Thu, 22 Jun 2017 Prob (F-statistic): 0.209Time: 21:21:34 Log-Likelihood: 95.392No. Observations: 45 AIC: -186.8Df Residuals: 43 BIC: -183.2Df Model: 1Covariance Type: nonrobust==============================================================================coef std err t P>|t| [0.025 0.975]------------------------------------------------------------------------------Intercept 0.0142 0.007 2.179 0.035 0.001 0.027MLT 0.1465 0.115 1.275 0.209 -0.085 0.378==============================================================================Omnibus: 26.266 Durbin-Watson: 1.184Prob(Omnibus): 0.000 Jarque-Bera (JB): 52.988Skew: -1.613 Prob(JB): 3.12e-12Kurtosis: 7.226 Cond. No. 26.0==============================================================================
103

Definición de cointegración (Engle y Granger 1987)
Se dice que los componentes del vector xt = (x1t, x2t, . . . , xnt)′
están cointegrados de orden (d, b), denotado por xt ∼ CI(d, b),si
1. Todos los componentes de xt son integrados de orden d.2. Existe al menos un vector β = (β1, β2, . . . , βn) tal que la
combinación lineal βxt = β1x1t + β2x2t + · · ·+ βnxnt esintegrada de orden (d− b), donde b > 0.
A β se le llama vector de cointegración
104

Algunas observaciones acerca de la definición de cointegración
1. Cointegración se refiere a combinaciones lineales devariables no estacionarias
2. Si existe, el vector de cointegración no es único3. Cointegración se refiere a variables del mismo
orden;aunque es posible encontrar relaciones deequilibrio entre variables de distinto orden
4. Pueden existir varios vectores de cointegraciónindependientes para un conjunto de variables xt
5. En la mayor parte de la literatura se entiendecointegración como el caso CI(1, 1).
105

Pruebas de cointegración: Engle-Granger
Una receta para determinar si las series están cointegradas:Ingredientes: series de tiempo,
software econométricoPaso 1: Determinar orden de
integración de las seriesPaso 2: Estimar la relación de
equilibrio de largo plazoPaso 3: Estimar el modelo de
corrección de erroresPaso 4: Evaluar si el modelo es
adecuado
106

Los valores críticos de MacKinnon
En la prueba (aumentada) de Engle y Granger,
∆ϵt = γϵt−1 +
n∑i=1
ai∆ϵt−i + εt (nc)
∆ϵt = α0 + γϵt−1 +n∑
i=1
ai∆ϵt−i + εt (c)
∆ϵt = α0 + α1t+ γϵt−1 +
n∑i=1
ai∆ϵt−i + εt (ct)
∆ϵt = α0 + α1t+ α2t2 + γϵt−1 +
n∑i=1
ai∆ϵt−i + εt (ctt)
si γ = 0 los residuos ϵt presentan raíz unitaria, y por ello lasseries no estaría cointegradas.
107

Los valores críticos de MacKinnon (cont’n)
• Para probar la hipótesis nula H0 : γ = 0 contra laalternativa H1 : γ < 0, se utiliza el estadístico tγ .
• No obstante, tγ no tiene la distribución t−student, nisiquiera asintóticamente.
• Dado que no es posible derivar la distribución de tγ
analíticamente, es necesario aproximarla consimulaciones de Monte Carlo.
• A partir de tales simulaciones, MacKinnon (2010) presentavalores críticos, que dependen de
• la especificación determinística (nc, c, ct, ctt),• del número de series en el vector de cointegración• y del tamaño de muestra T .
108

Los valores críticos de MacKinnon (cont’n)
• Los valores se obtienen evaluando un polinomio en 1T
C(p) = β∞ + β1T−1 + β2T
−2 + β3T−3
• Por ejemplo, para probar la cointegración de N = 3
variables, con constante y tendencia (ct), la tabla es
Nivel β∞ β1 β2 β3
1 % -4.663 -18.769 -49.793 104.2445 % -4.119 -11.892 -19.031 77.33210% -3.835 -9.072 -8.504 35.403
• Así, si tenemos 50 observaciones:
C(5%) = −4.119− 11.89250 − 19.031
502+ 77.332
503= −4.3637
109

Ejemplo 18:
Valores críticos de Mackinnon

• En el cuaderno de Jupyter 06 Mackinnon valorescríticos para test de cointegración sepresentan más ejemplos.
• Se muestra cómo los valores críticos cambian con eltamaño de muestra, el número de series que conformanel vector, y la especificación de los componentesdeterminísticas de las series.
110

Vector de Corrección de Errores(VECM)

De VAR a VECM
yt = Φ1yt−1 +Φ2yt−2 +Φ3yt−3 + ϵt
∆yt = (Φ1 − I) yt−1 +Φ2yt−2 +Φ3yt−3 + ϵt
= (Φ1 − I) yt−1 + (Φ2 +Φ3) yt−2 +Φ3 (yt−3 − yt−2) + ϵt
=(Φ1 +Φ2 +Φ3 − I) yt−1 + (Φ2 +Φ3) (yt−2 − yt−1)+
· · ·+Φ3 (yt−3 − yt−2) + ϵt
= (Φ1 +Φ2 +Φ3 − I) yt−1 − (Φ2 +Φ3)∆yt−1 − Φ3∆yt−2 + ϵt
= Πyt−1 + Γ1∆yt−1 + Γ2∆yt−2 + ϵt
Si hay 0 < r < n vectores de cointegración, entonces Π puede serdescompuesta como el producto de los vectores de cointegración β
y los coeficientes de corrección de errores α: rango
VEC ∆yt = αβ′yt−1 +Γ1∆yt−1 + · · ·+Γp−1∆yt−p+1 + ϵt111

Ejemplo 19:
Inflación y depreciación en unmodelo VEC

• Suponga que en el largo plazo se cumple la PPP:pt = et + p∗t + errort y que las tres variables son I(1) yrelacionadas como un VAR(2)
• La representación VECM es∆p∗t = α1 (pt − et − p∗t ) + γ11∆p∗t−1 + γ12∆et−1 + γ13∆pt−1 + ϵ1t
∆et = α2 (pt − et − p∗t ) + γ21∆p∗t−1 + γ22∆et−1 + γ23∆pt−1 + ϵ2t
∆pt = α3 (pt − et − p∗t ) + γ31∆p∗t−1 + γ32∆et−1 + γ33∆pt−1 + ϵ3t
• o bien∆p∗t∆et
∆pt
=
α1
α2
α3
[−1 −1 1]p∗t−1
et−1
pt−1
+ Γ1
∆p∗t−1
∆et−1
∆pt−1
+ ϵt
• Este modelo explica la inflación internacional, ladepreciación, y la inflación doméstica en función de suspropios rezagos y la desviación de los precios y tipo decambio respecto a su equilibrio de largo plazo.
112

Pruebas de cointegración: Johansen
• La prueba de Johansen puede verse como unageneralización multivariada de la prueba aumentada deDickey-Fuller
• La prueba y estrategia de estimación permiten estimartodos los vectores de cointegración
• Similar a la prueba ADF, la existencia de raíces unitariasimplican que la teoría asintótica estándar no esapropiada.
113

Raíces unitarias: modelo univariado versus multivariado
• Comparemos la prueba ADF con el VECM
∆yt = πyt−1 + γ1∆yt−1 + · · ·+ γp∆yt−p + ϵt (univariado)∆yt = Πyt−1 + Γ1∆yt−1 + · · ·+ Γp∆yt−p + ϵt (multivariado)
• En la prueba ADF, probamos si yt tiene raíz unitaria conH0 : π = 0
• En el caso multivariado, Johansen determina si las seriesestán cointegradas a partir del rango de Π
114

Rango de una matriz vectores de cointegración
• Posibles casos del rango:0: implica Π = 0, todas las series son I(1) pero
no están cointegradas. VAR en diferencias0 < r < N : hay r vectores de cointegración, y escribimos
Π = αβ′. VECMN: cualquier combinación lineal es estacionaria,
lo que implica que las series originales eranestacionarias.
115

Usando los eigenvalores para determinar el rango
• El rango de una matriz es igual al número de suseigenvalores distintos de cero.
• Por ello, las pruebas de Johansen están basadas en loseigenvalores de una matriz Π∗ semidefinida positiva,derivada a partir de Π.
• Suponga que obtenemos Π∗ y ordenamos suseigenvalores de manera tal que
λ1 ≥ λ2 ≥ · · · ≥ λN ≥ 0
116

Prueba de la traza y del máximo eigenvalor
Prueba de latraza λtraza(r) = −T
N∑i=r+1
ln(1− λi
)
Prueba delmáximo
eigenvalorλmax(r, r + 1) = −T ln
(1− λr+1
)
• Note que λi ≥ 0 ⇒ ln (1− λi) ≤ 0. Ambos estadísticos sonno-negativos
• Valores grandes de los estadísticos apuntan a que loseigenvalores son positivos, implicando la existencia decointegración.
117

Ejemplo 20:
Pruebas de Johansen
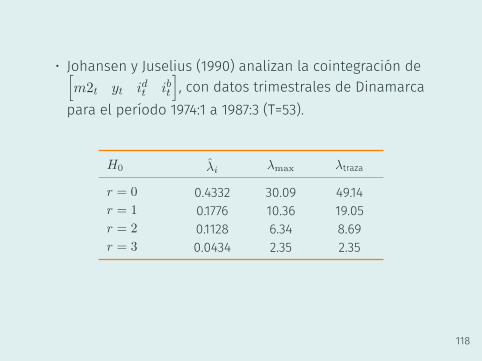
• Johansen y Juselius (1990) analizan la cointegración de[m2t yt idt ibt
], con datos trimestrales de Dinamarca
para el período 1974:1 a 1987:3 (T=53).
H0 λi λmax λtraza
r = 0 0.4332 30.09 49.14r = 1 0.1776 10.36 19.05r = 2 0.1128 6.34 8.69r = 3 0.0434 2.35 2.35
118

Referencias

Referencias
Engle, Robert F. y C.W.J. Granger (1987). “Co-integration andError Correction: Representation, Estimation, and Testing”.En: Econometrica 55.2, págs. 251-276.
Greene, William H. (2012). Econometric Analysis. 7a ed. PrenticeHall. isbn: 0-13-139538-6.
Lucas, Robert E. (1996). “Nobel Lecture: Monetary Neutrality”.En: Journal of Political Economy 104.4, págs. 661-682.
Lucas, Robert Jr (1976). “Econometric policy evaluation: Acritique”. En: Carnegie-Rochester Conference Series onPublic Policy 1.1, págs. 19-46.
119

MacKinnon, James G. (2010). Critical values for cointegrationtests. Queen’s Economics Department Working Paper 1227.Kingston, Ont.
Sims, Christopher A. (1980). “Macroeconomics and Reality”. En:Econometrica 48.1.
Stock, James H. y Mark W. Watson (2001). “VectorAutoregressions”. En: Journal of Economic Perspectives 15.4(Fall), págs. 101-115.
Walsh, Carl E. (2010). Monetary Theory and Policy. 3a ed. MITPress. isbn: 978-0262-013772.
120

Apéndice 1: Resultados importantes

El producto Kronecker
• Si A =
[a b
c d
]y B son matrices, el producto Kronecker se
define por
A⊗B =
[aB bB
cB dB
]• Algunas propiedades importantes:
(A⊗B)′ = A′ ⊗B′
(A⊗B)−1 = A−1 ⊗B−1
(A⊗B)(C ⊗D) = (AC)⊗ (BD)
x
121

Convergencia en probabilidad
• Una secuencia Xn de variables aleatorias converge enprobabilidad hacia la variable aleatoria X si para todoϵ > 0
limn→∞
Pr (|Xn −X| > ϵ) = 0
• Para denotar que Xn converge en probabilidad hacia X
escribimos
Xnp−→ X o bien plimXn = X
x
122

Propiedades de la convergencia en probabilidad
Sean c una constante, g() una función continua, y Xn, Yn dossecuencias de variables aleatorias. Entonces:
• plim c = c
• plim cXn = cplimXn
• plim (Xn + Yn) = plimXn + plimYn
• plim (XnYn) = (plimXn) (plimYn)
• plim g(Xn) = g (plimXn)
x
123

El rango de una matriz
• El rango de una matriz A de tamaño M ×N se denota porrango[A] y se define como el número de filas (o columnas)que son linealmente independientes.
• Necesariamente, se cumple que
rango[A] ≤ min M,N
• Si rango[A] = M , decimos que A tiene rango fila completo.• Si rango[A] = N , decimos que A tiene rango columnacompleto.
x
124

Factorización de rango
Suponga que A es una matriz n× n con rango r < n. Existenlas matrices X y Y de dimensión r × n tal que:
A = X ′Y
x
125

Descomposición espectral de una matrix
Si los eigenvectores de la matriz cuadrada A son linealmenteindependientes, entonces
Descomposiciónespectral
A = CΛC−1
donde Λ es la matriz diagonal formada por los eigenvalores deA:
Λ =
λ1 0 . . . 0
0 λ2 . . . 0. . .
0 0 . . . λn
y las columnas de C son los correspondientes eigenvectoresde A. x
126

Potencia de una matriz
Si A tiene la descomposición espectral A = CΛC−1 es fácilcalcular su t-ésima potencia:
At = CΛtC−1
ya que
Λt =
λt1 0 . . . 0
0 λt2 . . . 0
. . .0 0 . . . λt
n
x
127
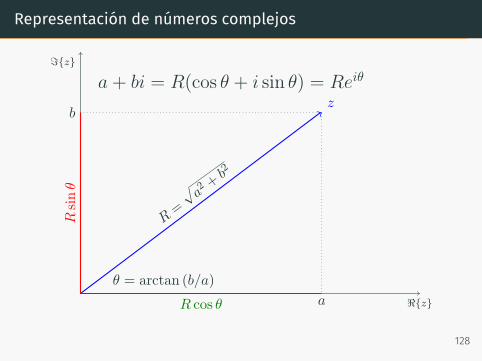
Representación de números complejos
ℑz
ℜz
b
a
z
θ = arctan (b/a)
R=
√ a2 +
b2
R cos θ
Rsinθ
a+ bi = R(cos θ + i sin θ) = Reiθ
128

Multiplicación de números complejos
• Si z = Reiθ y w = Seiφ, entonces su producto es
zw = RSei(θ+φ)
• Así, si elevamos z a la n-ésima potencia:
zn =(Reiθ
)n= Rneinθ
• Es decirlimn→∞
zn = 0 ⇔ |R| < 1
x
129

Ejemplo de potencia de números complejo
x 130

Apéndice 2: Demostraciones

SUR: las regresiones tienen los mismos regresores
En el caso especial X1 = · · · = XM = X tenemos
X =
X1 0 . . . 0
0 X2 . . . 0. . .
0 0 . . . XM
=
X 0 . . . 0
0 X . . . 0. . .
0 0 . . . X
= I ⊗ X
y el estimador GLS es
βGLS =[X′(Σ⊗ I)−1X
]−1X′(Σ⊗ I)−1Y
=[(I ⊗ X)′(Σ⊗ I)−1(I ⊗ X)
]−1(I ⊗ X)′(Σ⊗ I)−1Y
=[(I ⊗ X′)(Σ−1 ⊗ I)(I ⊗ X)
]−1(I ⊗ X′)(Σ−1 ⊗ I)Y
=[Σ−1 ⊗ (X′X)
]−1 [Σ−1 ⊗ X′]Y
=[Σ⊗ (X′X)−1
] [Σ−1 ⊗ X′]Y
=[I ⊗ (X′X)−1X′]Y 131

βGLS =[I ⊗ (X′X)−1X′]Y
=
(X′X)−1X′ 0 . . . 0
0 (X′X)−1X′ . . . 0. . .
0 0 . . . (X′X)−1X′
y1
y2...
yM
=
(X′X)−1X′y1
(X′X)−1X′y2...
(X′X)−1X′yM
=
βOLS1
βOLS2...
βOLSM
Si todas las regresiones tienen los mismos regresores, elsistema SUR puede estimarse con OLS ecuación por ecuación.x
132

Apéndice 3: Programas de EViews yPython