albertogallardo.wikispaces.coma... · web vieworacle_home podría ser...
TRANSCRIPT

Guía para Maestría Avanzada de Comandos Linux
Por Arup Nanda Publicado en agosto de 2006
En el excelente artículo de Sheryl Calish, denominado “Guía para Maestría en Comandos de Archivos Linux", usted conoció algunos comandos Linux de rutina, que son especialmente valiosos para principiantes Linux. Pero ahora que conoce los puntos básicos, prosigamos con algunos comandos más sofisticados que encontrará extremadamente útiles.
En esta serie de cuatro partes, conocerá algunos trucos no tan conocidos sobre varios comandos de rutina, así como las variaciones en uso que los hacen más útiles. A medida que la serie avanza, conocerá comandos cada vez más difíciles de dominar.
Tenga en cuenta que estos comandos pueden diferir de acuerdo con la versión específica de Linux que utilice o qué kernel específica se compila, pero en ese caso, probablemente solo sea una diferencia mínima.
Cambios Sencillos a Propietarios, Grupos y PermisosEn el artículo de Sheryl, usted aprendió cómo utilizar los comandos chown y chgrp para cambiar la propiedad y el grupo de los archivos. Supongamos que tiene varios archivos como este:
# ls -ltotal 8-rw-r--r-- 1 ananda users 70 Aug 4 04:02 file1-rwxr-xr-x 1 oracle dba 132 Aug 4 04:02 file2-rwxr-xr-x 1 oracle dba 132 Aug 4 04:02 file3-rwxr-xr-x 1 oracle dba 132 Aug 4 04:02 file4-rwxr-xr-x 1 oracle dba 132 Aug 4 04:02 file5-rwxr-xr-x 1 oracle dba 132 Aug 4 04:02 file6
y necesita cambiar los permisos de todos los archivos para asociar aquellos del archivo 1. Seguramente podría utilizar chmod 644 * para realizar ese cambio— ¿pero qué sucede si está escribiendo un script para hacerlo y no sabe cuáles son los permisos de antemano? O, tal vez esté hacienda varios cambios de permiso basados en muchos archivos diferentes y cree que no es factible examinar los permisos de cada uno y modificarlos en consecuencia.
Un mejor enfoque es hacer que los permisos sean similares a aquellos de otro archivo. Este comando hace que los permisos del archivo 2 sean los mismos que el archivo 1:
chmod --reference file1 file2
Ahora, si verifica:
# ls -l file[12]total 8-rw-r--r-- 1 ananda users 70 Aug 4 04:02 file1-rw-r--r-- 1 oracle dba 132 Aug 4 04:02 file2
Los permisos del archivo 2 fueron cambiados exactamente como el archivo 1. No necesitó obtener primero los permisos del archivo 1.

Usted también puede utilizar el mismo truco para la membresía de grupos en los archivos. Para que el grupo del archivo 2 sea el mismo que el archivo 1, usted manifestaría:
# chgrp --reference file1 file2# ls -l file[12]-rw-r--r-- 1 ananda users 70 Aug 4 04:02 file1-rw-r--r-- 1 oracle users 132 Aug 4 04:02 file2
Desde luego, lo que funciona para el cambio de grupos funcionará para el propietario también. A continuación, mostramos cómo puede utilizar el mismo truco para un cambio de propiedad. Si los permisos son así:
# ls -l file[12] -rw-r--r-- 1 ananda users 70 Aug 4 04:02 file1-rw-r--r-- 1 oracle dba 132 Aug 4 04:02 file2
Usted puede cambiar la propiedad así:
# chown --reference file1 file2# ls -l file[12] -rw-r--r-- 1 ananda users 70 Aug 4 04:02 file1-rw-r--r-- 1 ananda users 132 Aug 4 04:02 file2
Fíjese que el grupo, y el propietario, han cambiado.
Consejo para Usuarios Oracle
Este es un truco que puede utilizar para cambiar la propiedad y los permisos de los ejecutables de Oracle en un directorio basado en un ejecutable de referencia. Esto es especialmente útil en migraciones donde puede (y probablemente deba) instalar un usuario diferente y luego trasladarlo a su propietario de software Oracle usual.
Más sobre Archivos
El comando ls, con su gran cantidad de argumentos, brinda información muy útil sobre los archivos. Un comando diferente y menos conocido – stat – ofrece información incluso más útil. .
Aquí le mostramos cómo puede utilizarlo en el ejecutable “oracle”, que puede encontrarse en $ORACLE_HOME/bin.
# cd $ORACLE_HOME/bin# stat oracle File: `oracle' Size: 93300148 Blocks: 182424 IO Block: 4096 Regular FileDevice: 343h/835d Inode: 12009652 Links: 1 Access: (6751/-rwsr-s--x) Uid: ( 500/ oracle) Gid: ( 500/ dba)Access: 2006-08-04 04:30:52.000000000 -0400Modify: 2005-11-02 11:49:47.000000000 -0500Change: 2005-11-02 11:55:24.000000000 -0500

Fíjese la información que obtuvo con este comando: Además del tamaño de archivo usual (que puede obtener de ls -l), usted obtuvo la cantidad de bloques que ocupa este archivo. El tamaño de bloque Linux típico es de 512 bytes, entonces un archivo de 93.300.148 bytes ocuparía (93300148/512=) 182226.85 bloques. Como los bloques se utilizan en su totalidad, este archivo utiliza un número entero de bloques. En lugar de hacer conjeturas, usted puede saber cuáles son los bloques exactos.
Del output de arriba, usted también puede conocer el GID y UID de la propiedad del archivo y la representación octal de los permisos (6751). Si desea readmitir los mismos permisos que tiene ahora, puede utilizar chmod 6751 oracle en lugar de detallar explícitamente los permisos.
La parte más útil del output de arriba es la información de la fecha de registro del acceso al archivo. Muestra que se accedió al archivo el 04-08-2006 a las 04:30:52 (como se muestra al lado de “Acceso:”), o el 4 de agosto de 2006 a las 4:30:52 AM. Este es el momento en el cual se empezó a utilizar la base de datos. El archivo fue modificado el 02-11-2005 a las 11:49:47 (como se muestra al lado de Modificar:). Finalmente, la fecha de registro al lado de “Cambiar:” muestra cuándo fue cambiado el estado del archivo.
-f, un modificador del comando stat, muestra la información del sistema de archivo en lugar del archivo:
# stat -f oracle File: "oracle" ID: 0 Namelen: 255 Type: ext2/ext3Blocks: Total: 24033242 Free: 15419301 Available: 14198462 Size: 4096Inodes: Total: 12222464 Free: 12093976
Otra opción, -t, brinda exactamente la misma información pero en una sola línea:
# stat -t oracle oracle 93300148 182424 8de9 500 500 343 12009652 1 0 0 1154682061 1130950187 1130950524 4096
Esto es muy útil en shell scripts donde un simple comando de corte puede utilizarse para extraer los valores para el posterior procesamiento.
Consejo para Usuarios Oracle
Cuando usted se vuelve a conectar con Oracle (a menudo se realiza durante la instalación de parches), los ejecutables existentes pasan a un nombre diferente antes de crear el nuevo. Por ejemplo, puede reconectar todos los servicios por
relink utilities
Recopila, entre otras cosas, el ejecutable sqlplus. Mueve el ejecutable existente sqlplus a sqlplus. O Si la recopilación falla por algún motivo, el proceso de reconexión vuelve a nombrar sqlplusO con sqlplus, y los cambios quedan anulados. De manera similar, si descubre un problema de funcionalidad después de aplicar un parche, puede rápidamente anular el parche al renombrar el archivo por su propia cuenta.
A continuación, mostramos cómo puede utilizar stat en estos archivos:
# stat sqlplus* File: 'sqlplus' Size: 9865 Blocks: 26 IO Block: 4096 Regular File

Device: 343h/835d Inode: 9126079 Links: 1 Access: (0751/-rwxr-x--x) Uid: ( 500/ oracle) Gid: ( 500/ dba)Access: 2006-08-04 05:15:18.000000000 -0400Modify: 2006-08-04 05:15:18.000000000 -0400Change: 2006-08-04 05:15:18.000000000 -0400 File: 'sqlplusO' Size: 8851 Blocks: 24 IO Block: 4096 Regular FileDevice: 343h/835d Inode: 9125991 Links: 1 Access: (0751/-rwxr-x--x) Uid: ( 500/ oracle) Gid: ( 500/ dba)Access: 2006-08-04 05:13:57.000000000 -0400Modify: 2005-11-02 11:50:46.000000000 -0500Change: 2005-11-02 11:55:24.000000000 -0500
Muestra que sqlplusO fue modificado el 11 de noviembre d e2005, cuando sqlplus fue modificado el 4 de agosto de 2006, que también corresponde al tiempo de cambio de estado de sqlplusO. Indica que la versión original de sqlplus estuvo vigente desde el 11 de noviembre de 2005 hasta el 4 de agosto de 2006. Si quiere diagnosticar algunos problemas de funcionalidad, este es un buen lugar para empezar. Además de los cambios de archivo, como usted conoce el horario de cambio de los permisos, usted puede correlacionarlo con cualquier problema de funcionalidad percibido.
Otro output importante es el tamaño del archivo, que es diferente—9865 bytes para sqlplus y 8851 para sqlplusO—e indica que las versiones no son meras compilaciones; en realidad cambiaron con bibliotecas adicionales (tal vez). Esto también indica la causa potencial de algunos problemas.
Tipos de Archivo
Cuando ve un archivo, ¿cómo sabe qué tipo de archivo es? El comando file le da esa información. Por ejemplo:
# file alert_DBA102.logalert_DBA102.log: ASCII text
El archivo alert_DBA102.log es un archivo de texto ASCII. Veamos algunos ejemplos más:
# file initTESTAUX.ora.ZinitTESTAUX.ora.Z: compress'd data 16 bits
Esto demuestra que el archivo es un archivo comprimido, ¿pero cómo sabe qué tipo de archivo fue comprimido? Una opción es descomprimirlo y ejecutar el archivo; pero eso haría que sea virtualmente imposible. Una mejor opción es utilizar el parámetro -z:
# file -z initTESTAUX.ora.ZinitTESTAUX.ora.Z: ASCII text (compress'd data 16 bits)
Otra peculiaridad es la presencia de enlaces simbólicos:
# file spfile+ASM.ora.ORIGINAL spfile+ASM.ora.ORIGINAL: symbolic link to /u02/app/oracle/admin/DBA102/pfile/spfile+ASM.ora.ORIGINAL

Esto es útil; ¿pero qué tipo de archivo es al que se apunta? En lugar de ejecutar el archivo otra vez, puede utilizar la opción -l:
# file -L spfile+ASM.ora.ORIGINALspfile+ASM.ora.ORIGINAL: data
Esto demuestra claramente que el archivo es un archivo de datos. Tenga en cuenta que spfile es binario, a diferencia de init.ora; por lo tanto el archivo se muestra como archivo de datos.
Consejo para Usuarios Oracle
Supongamos que está buscando un archivo de localización en el directorio de destino de descargas del usuario pero no está seguro de que el archivo esté ubicado allí o en otro directorio, y meramente está allí como enlace simbólico, o si alguien ha comprimido el archivo (o incluso lo ha renombrado). Hay algo que sí sabe: es definitivamente un archivo ascii. ¿Qué puede hacer?
file -Lz * | grep ASCII | cut -d":" -f1 | xargs ls -ltr
Este comando verifica los archivos ASCII, incluso si están comprimidos, y los enumera en orden cronológico.
Comparar Archivos
¿Cómo descubre si dos archivos—archivo1 y archivo2—son idénticos? Hay varias formas, y cada enfoque tiene su propio atractivo.
diff. El comando más simple es diff, que muestra la diferencia entre dos archivos. Vea los contenidos de dos archivos
# cat file1In file1 onlyIn file1 and file2# cat file2In file1 and file2In file2 only
Si utiliza el comando diff, podrá ver la diferencia entre los archivos, como se muestra abajo:
# diff file1 file21d0< In file1 only2a2> In file2 only#
En el output, un "<" en la primera columna indica que la línea existe en el archivo mencionado primero, —es decir, archivo1. Un ">" en ese lugar indica que la línea existe en el segundo archivo (archivo2). Los caracteres 1d0 de la primera línea del output muestra lo que debe hacerse en sed para operar en el archivo 1 para hacerlo idéntico al archivo 2.

Otra opción, -y, muestra el mismo output, pero uno al lado del otro:
# diff -y file1 file2 -W 120In file1 only <In file1 and file2 In file1 and file2 > In file2 only
La opción -W es opcional; simplemente ordena al comando utilizar una pantalla que permita 120 caracteres, útil para archivos con líneas largas.
Si solo desea saber si los archivos son diferentes, no necesariamente en qué difieren, puede utilizar la opción -q.
# diff -q file3 file4# diff -q file3 file2Files file3 and file2 differ
Los archivos 3 y 4 son los mismos, con lo cual no hay output; caso contrario, se informa si los archivos difieran.
Si está escribiendo un shell script, puede resultar útil generar el output de tal manera que pueda analizarse. La opción -u hace eso:
# diff -u file1 file2 --- file1 2006-08-04 08:29:37.000000000 -0400+++ file2 2006-08-04 08:29:42.000000000 -0400@@ -1,2 +1,2 @@-In file1 only In file1 and file2+In file2 only
El output muestra contenidos de ambos archivos pero suprime los duplicados, los signos + y – de la primera columna indican las líneas de los archivos. Ningún carácter en la primera columna indica su presencia en ambos archivos.
El comando tiene en cuenta el espacio en blanco. Si quiere ignorar el espacio en blanco, use la opción -b. Use la opción -B para ignorar las líneas en blanco. Finalmente, use -i para ignorar el caso.
El comando diff también puede aplicarse a los directorios. El comando
diff dir1 dir2
muestra los archivos presentes en cualquiera de los dos directorios; ya sea que los archivos estén presentes en uno de los directorios o en ambos. Si se encuentra un subdirectorio con el mismo nombre, no se detiene a ver si algún archivo individual difiere. Un ejemplo:
# diff DBA102 PROPRD Common subdirectories: DBA102/adump and PROPRD/adumpOnly in DBA102: afiedt.bufOnly in PROPRD: archiveOnly in PROPRD: BACKUP

Only in PROPRD: BACKUP1Only in PROPRD: BACKUP2Only in PROPRD: BACKUP3Only in PROPRD: BACKUP4Only in PROPRD: BACKUP5Only in PROPRD: BACKUP6Only in PROPRD: BACKUP7Only in PROPRD: BACKUP8Only in PROPRD: BACKUP9Common subdirectories: DBA102/bdump and PROPRD/bdumpCommon subdirectories: DBA102/cdump and PROPRD/cdumpOnly in PROPRD: CreateDBCatalog.logOnly in PROPRD: CreateDBCatalog.sqlOnly in PROPRD: CreateDBFiles.logOnly in PROPRD: CreateDBFiles.sqlOnly in PROPRD: CreateDB.logOnly in PROPRD: CreateDB.sqlOnly in DBA102: dpdumpOnly in PROPRD: emRepository.sqlOnly in PROPRD: init.oraOnly in PROPRD: JServer.sqlOnly in PROPRD: logOnly in DBA102: oradataOnly in DBA102: pfileOnly in PROPRD: postDBCreation.sqlOnly in PROPRD: RMANTEST.shOnly in PROPRD: RMANTEST.sqlCommon subdirectories: DBA102/scripts and PROPRD/scriptsOnly in PROPRD: sqlPlusHelp.logCommon subdirectories: DBA102/udump and PROPRD/udump
Vea que los subdirectorios comunes simplemente se muestran como tal pero no se realiza ninguna comparación. Si desea hacer más desgloses y comparar los archivos de esos subdirectorios, debería utilizar el siguiente comando:
diff -r dir1 dir2
Este comando ingresa repetitivamente en cada subdirectorio para comparar los archivos e informa la diferencia entre los archivos con el mismo nombre.
Consejo para Usuarios Oracle
Un uso común de diff es diferenciar entre distintos archivos init.ora. Como ejemplo modelo, siempre copio el archivo con un nuevo nombre—por ej., initDBA102.ora con initDBA102.080306.ora (para indicar 3 de agosto de 2006) —antes de realizar un cambio. Un simple diff entre todas las versiones del archivo muestra rápidamente qué cambió y cuándo.
Este es un comando bastante poderoso para administrar su página de inicio Oracle. Como ejemplo modelo, nunca actualizo una Página de Inicio de Oracle cuando aplico parches. Por ejemplo, supongamos que las versiones Oracle actuales sean 10.2.0.1. ORACLE_HOME podría ser /u01/app/oracle/product/10.2/db1. Cuando llega el momento de realizar un parche hacia 10.2.0.2, no realizo el parche de esta Página de Inicio Oracle. En cambio, inicio una instalación nueva en /u01/app/oracle/product/10.2/db2 y luego realizo un parche de esa página de inicio. Una vez listo, uso lo siguiente:

# sqlplus / as sysdbaSQL> shutdown immediateSQL> exit# export ORACLE_HOME=/u01/app/oracle/product/10.2/db2# export PATH=$ORACLE_HOME/bin:$PATH# sqlplus / as sysdbaSQL> @$ORACLE_HOME/rdbms/admin/catalog...
y así sucesivamente.
El propósito de este enfoque es que la Página de Inicio Oracle original no se interrumpa y que pueda fácilmente volver atrás en caso de haber problemas. Esto también implica que la base de datos deja de funcionar y vuelve a hacerlo, con bastante rapidez. Si hubiese instalado un parche directamente en la Página de Inicio Oracle, hubiese tenido que interrumpir la base de datos durante mucho tiempo—mientras dure la aplicación del parche. Asimismo, si la aplicación del parche hubiese fallado por algún motivo, no hubiese obtenido una Página de Inicio Oracle “limpia”.
Ahora que tengo varias Páginas de Inicio Oracle, ¿cómo puedo ver qué cambió? Es realmente simple; puedo utilizar:
diff -r /u01/app/oracle/product/10.2/db1 /u01/app/oracle/product/10.2/db2 | grep -v Common
Esto me muestra las diferencias entre ambas Páginas de Inicio Oracle y las diferencias entre los archivos con el mismo nombre. Algunos archivos importantes como tnsnames.ora, listener.ora y sqlnet.ora no deberían mostrar grandes diferencias, pero si lo hacen, debo entender por qué.
cmp. El comando cmp es similar a diff:
# cmp file1 file2 file1 file2 differ: byte 10, line 1
El output vuelve a aparecer como la primera señal de diferencia. Usted puede utilizar esto para identificar en qué pueden diferir los archivos. diff, cmp tiene muchas opciones, la más importante es la opción -s, lo cual sencillamente genera un código
0, si los archivos son idénticos 1, si difieren Algún otro número que no sea cero, si la comparación no pudo realizarse
Un ejemplo:
# cmp -s file3 file4# echo $?0
La variable especial $? indica el código del último comando ejecutado. En este caso, 0, lo cual implica que los archivos 1 y 2 son idénticos.
# cmp -s file1 file2

# echo $?1
implica que los archivos 1 y 2 no son iguales.
Esta propiedad de cmp puede resultar muy útil en shell scripting donde simplemente quiera verificar si dos archivos difieren de alguna manera, pero no necesariamente verificar cuál es la diferencia. Otro uso importante de este comando es comparar los archivos binarios, donde diff puede no ser confiable.
Consejo para Usuarios Oracle
Recuerde de un consejo anterior, cuando vuelve a conectar los ejecutables Oracle, la versión más antigua se guarda antes de sobrescribirla. Por lo tanto, cuando se vuelve a conectar, el ejecutable sqlplus es renombrado como “sqlplusO”, y el recientemente compilado sqlplus es colocado en $ORACLE_HOME/bin. ¿Entonces cómo se asegura de que el sqlplus que se creó recientemente es diferente? Simplemente utilice:
# cmp sqlplus sqlplusOsqlplus sqlplusO differ: byte 657, line 7
Si verifica el tamaño:
# ls -l sqlplus*-rwxr-x--x 1 oracle dba 8851 Aug 4 05:15 sqlplus-rwxr-x--x 1 oracle dba 8851 Nov 2 2005 sqlplusO
A pesar de que el tamaño es el mismo en ambos casos, cmp demostró que los dos programas son diferentes.
comm. El comando comm es similar a los otros pero el output se genera en tres columnas, separadas por etiquetas. Ejemplo:
# comm file1 file2 In file1 and file2In file1 onlyIn file1 and file2 In file2 only
Este comando es útil para ver los contenidos de un archivo y no del otro, no solo una diferencia—una clase de herramienta MINUS en el lenguaje SQL. La opción -1 suprime los contenidos del primer archivo:
# comm -1 file1 file2In file1 and file2In file2 only
Resumen de Comandos de este Documento
Commando Uso
chmod Para cambiar permisos de un archivo, usando el parámetro de referencia - -
chown Para cambiar el propietario de un archivo, usando el parámetro de referencia - -
chgrp Para cambiar el grupo de un archivo, usando el parámetro de referencia - -
stat Para conocer los atributos extendidos de un archivo, como fecha de último acceso
file Para conocer el tipo de archivo, como ASCII, datos, etc.
diff Para ver la diferencia entre dos archivos
cmp Para comparar dos archivos
comm Para ver qué tienen en común dos archivos, con el output en tres columnas
md5sum Para calcular el valor arbitrario MD5 de los archivos, usado para determinar si un archivo ha cambiado

md5sum. Este comando genera un valor arbitrario MD5 de 32 bits de los archivos:
# md5sum file1ef929460b3731851259137194fe5ac47 file1
Dos archivos con la misma suma de control (checksum) pueden considerarse idénticos. No obstante, la utilidad de este comando va más allá de simplemente comparar los archivos. También puede ofrecer un mecanismo para garantizar la integridad de los archivos.
Supongamos que tiene dos archivos importantes—archivo1 y 2—que necesita proteger. Puede utilizar el control de opción --check para confirmar que los archivos no han cambiado. Primero, cree un archivo de suma de control para ambos archivos importantes y manténgalos protegidos:
# md5sum file1 file2 > f1f2
Luego, cuando quiere verificar que los archivos siguen intactos:
# md5sum --check f1f2 file1: OKfile2: OK
Esto muestra claramente que los archivos no han sido modificados. Ahora cambia un archivo y verifique el MD5:
# cp file2 file1# md5sum --check f1f2file1: FAILEDfile2: OKmd5sum: WARNING: 1 of 2 computed checksumsdid NOT match
El output claramente muestra que el archivo 1 ha sido modificado.
Consejo para Usuarios Oracle
md5sum es un comando extremadamente poderoso para implementaciones de seguridad. Algunos archivos de configuración que administra, como listener.ora, tnsnames.ora e init.ora, son demasiado críticos para una infraestructura Oracle exitosa, y cualquier modificación puede dar como resultado momentos de inactividad. Esto en general forma parte de su proceso de control de cambios. En lugar de confiar en la palabra de alguien respecto de que estos archivos no han cambiado, asegúrese utilizando la suma de control MD5. Cree un archivo de suma de control y, cuando realice un cambio planificado, vuelva a crear este archivo. Como parte del cumplimiento, verifique este archivo utilizando el comando md5sum . Si alguien actualizara involuntariamente alguno de estos archivos clave, inmediatamente se daría cuenta del cambio.
En la misma línea, también puede crear sumas de control MD5 para todos los ejecutables de $ORACLE_HOME/bin y compararlas de vez en cuando para realizar modificaciones no autorizadas.
Conclusión

Hasta ahora, ha aprendido solo algunos de los comandos Linux que encontrará útiles para realizar una tarea con eficiencia. En el próximo documento, describiré algunos comandos más sofisticados pero útiles, como strace, whereis, renice, skill, y mucho más.

Guía para Maestría Avanzada de Comandos Linux Parte 2
Por Arup Nanda Publicado en febrero de 2008
En la Parte 1 de la serie, usted aprendió algunos comandos útiles no tan conocidos y algunos de los comandos comúnmente utilizados pero con parámetros no tan conocidos para hacer su trabajo de manera más eficiente. Para continuar con la serie, ahora aprenderá algunos comandos Linux más avanzados útiles para los usuarios Oracle, ya sean desarrolladores o DBAs.
Alias y unalias
Supongamos que quiere verificar el grupo de variables del entorno ORACLE_SID de su shell. Deberá tipear:
echo $ORACLE_HOME
Como DBA o desarrollador, utiliza frecuentemente este comando y pronto se cansa de tipear los 16 caracteres. ¿Hay una manera más simple?
Sí: el comando alias. Con este enfoque, puede crear un breve alias, como "os", para representar todo el comando:
alias os='echo $ORACLE_HOME'
Ahora cuando quiera verificar ORACLE_SID, simplemente escriba "os" (sin comillas) y Linux ejecuta el comando con el alias.
No obstante, si se desconecta y se vuelve a conectar, el alias es eliminado y debe ingresar el comando alias nuevamente. Para eliminar este paso, todo lo que debe hacer es colocar el comando en su archivo de perfil shell. Para bash, el archivo es .bash_profile (note el punto antes del nombre de archivo, es parte del nombre de archivo) en su directorio de inicio. Para los shells bourne y korn, es .profile, y para c-shell, .chsrc.
Usted puede crear un alias para cualquier nombre. Por ejemplo, yo siempre creo un alias para el comando rm como rm -i, que hace que el comando rm sea interactivo.
alias rm=’rm -i’
Cuando emito un comando rm, Linux solicita mi confirmación, y a menos que agregue "y", no elimina el archivo—así quedo protegido ante la posibilidad de eliminar accidentalmente un archivo importante. Utilizo lo mismo para mv (para cambiar el archivo a otro nombre), lo cual evita la sobrescritura accidental de archivos existentes, y cp (para copiar el archivo).
A continuación, presentamos una lista de algunos alias muy útiles que quiero definir:
alias bdump='cd $ORACLE_BASE/admin/$ORACLE_SID/bdump'alias l='ls -d .* --color=tty'alias ll='ls -l --color=tty'alias mv='mv -i'alias oh='cd $ORACLE_HOME'alias os='echo $ORACLE_SID'alias rm='rm -i'

alias tns='cd $ORACLE_HOME/network/admin'
Para ver qué alias han sido definidos en su shell, use alias sin ningún parámetro.
Sin embargo, hay un pequeño problema. He definido un alias, rm, que ejecuta rm -i. Este comando solicitará mi confirmación cada vez que intente eliminar un archivo. ¿Pero qué sucede si quiero eliminar muchos archivos y estoy seguro de que pueden eliminarse sin mi confirmación?
La solución es simple: Para suprimir el alias y utilizar solo el comando, necesitaré ingresar dos comillas simples:
$ ''rm *
Fíjese que se trata de dos comillas simples (') antes del comando rm, no dos comillas dobles. Esto suprimirá el alias rm. Otro enfoque es utilizar una barra inversa (\):
$ \rm *
Para eliminar un alias previamente definido, simplemente utilice el comando unalias:
$ unalias rm
ls
El comando ls es frecuentemente utilizado pero pocas veces es utilizado en su totalidad. Sin ninguna opción, ls despliega meramente todos los archivos y directorios en formato tabular.
$ lsadmin has mesg precompapex hs mgw racgassistants install network rdbms ... output snipped ...
Para mostrarlos en una lista, use la opción -1 (el número 1, no la letra "l").
$ ls -1adminapexassistants ... output snipped ...
Esta opción es útil en shell scripts donde los nombres de archivo necesitan incorporarse en otro programa o comando para la manipulación.

Seguramente, usted utilizó -l (la letra "l", no el número "1") que despliega todos los atributos de los archivos y directorios. Veámoslo una vez más:
$ ls -l total 272drwxr-xr-x 3 oracle oinstall 4096 Sep 3 03:27 admindrwxr-x--- 7 oracle oinstall 4096 Sep 3 02:32 apexdrwxr-x--- 7 oracle oinstall 4096 Sep 3 02:29 assistants
La primera columna muestra el tipo de archivo y los permisos sobre él: "d" significa directorio, "-" significa archivo regular, "c" significa un dispositivo de caracteres, "b" significa un dispositivo de bloques, "p" significa named pipe, y "l" (letra minúscula L, no I) significa enlace simbólico.
Una opción muy útil es --color, que muestra los archivos en muchos colores diferentes de acuerdo con el tipo de archivo. Aquí hay un ejemplo:
Fíjese que los archivos 1 y 2 son archivos comunes. link1 es un enlace simbólico, que se muestra en rojo; dir1 es un directorio y se muestra en amarillo; y pipe1 es un named pipe, y se muestra en diferentes colores para una identificación más fácil.
En algunos distros, el comando ls viene preinstalado con un alias (descripto en la sección anterior) como ls --color; de manera que usted pueda ver los archivos en color cuando tipea "ls". Este enfoque puede no ser aconsejable, especialmente si tiene un output como ese arriba. Puede cambiar los colores, pero una forma más rápida puede ser simplemente suspender el alias:
$ alias ls="''ls"
Otra opción útil es la opción -F, que añade un símbolo después de cada archivo para mostrar el tipo de archivo - una "/" después de los directorios, "@" después de enlaces simbólicos, y "|" después de named pipes.
$ ls -Fdir1/ file1 file2 link1@ pipe1|
Si tiene un subdirectorio en un directorio y quiere hacer solo una lista de ese directorio, ls -l le mostrará los contenidos del subdirectorio también. Por ejemplo, supongamos que la estructura de directorio es la siguiente:
/dir1+-->/subdir1+--> subfile1+--> subfile2
El directorio dir1 tiene un subdirectorio subdir1 y dos archivos: subfile1 y subfile2. Si solo desea ver los atributos del directorio dir1, emite:
$ ls -l dir1total 4drwxr-xr-x 2 oracle oinstall 4096 Oct 14 16:52 subdir1-rw-r--r-- 1 oracle oinstall 0 Oct 14 16:48 subfile1-rw-r--r-- 1 oracle oinstall 0 Oct 14 16:48 subfile2

Fíjese que el directorio dir1 no está en la lista del output. En cambio, se muestran los contenidos del directorio. Este es un comportamiento esperado cuando se procesan directorios. Para mostrar únicamente el directorio dir1, deberá utilizar el comando -d.
$ ls -dl dir1drwxr-xr-x 3 oracle oinstall 4096 Oct 14 16:52 dir1
Vea el output del siguiente output ls -l:
-rwxr-x--x 1 oracle oinstall 10457761 Apr 6 2006 rmanO-rwxr-x--x 1 oracle oinstall 10457761 Sep 23 23:48 rman-rwsr-s--x 1 oracle oinstall 93300507 Apr 6 2006 oracleO-rwx------ 1 oracle oinstall 93300507 Sep 23 23:49 oracle
Notará que los tamaños de los archivos se muestran en bytes. Esto puede ser fácil en archivos pequeños, pero cuando el tamaño de los archivos es grande, puede no ser tan fácil leer un número largo. La opción "-h" es práctica aquí, para mostrar el tamaño de manera legible para personas.
$ ls -lh
-rwxr-x--x 1 oracle oinstall 10M Apr 6 2006 rmanO-rwxr-x--x 1 oracle oinstall 10M Sep 23 23:48 rman-rwsr-s--x 1 oracle oinstall 89M Apr 6 2006 oracleO-rwx------ 1 oracle oinstall 89M Sep 23 23:49 oracle
Fíjese cómo se muestra el tamaño en M (para megabytes), K (para kilobytes), etc.
$ ls -lr
El parámetro -r muestra el output en orden inverso. En este comando, los archivos se mostrarán en orden alfabético inverso.
$ ls -lR
El operador -R hace que el comando ls se ejecute repetitivamente—es decir, explorar los subdirectorios y mostrar esos archivos también.
¿Qué sucede si quiere mostrar los archivos del más grande al más chico? Esto puede realizarse con el parámetro -S.
$ ls -lS
total 308-rw-r----- 1 oracle oinstall 52903 Oct 11 18:31 sqlnet.log-rwxr-xr-x 1 oracle oinstall 9530 Apr 6 2006 root.shdrwxr-xr-x 2 oracle oinstall 8192 Oct 11 18:14 bindrwxr-x--- 3 oracle oinstall 8192 Sep 23 23:49 lib

xargs
La mayoría de los comandos Linux tienen el fin de obtener un output: una lista de archivos, una lista de sucesiones, etc. ¿Pero qué sucede si quiere utilizar algún otro comando con el output del anterior como parámetro? Por ejemplo, el comando file muestra el tipo de archivo (ejecutable, texto ascii, etc.); puede manipular el output para que muestre solo los nombres de archivo y ahora quiere pasar estos nombres al comando ls -l para ver la fecha de registro. El comando xargs hace exactamente eso. Permite ejecutar algunos otros comandos en el output. Recuerde esta sintaxis de la Parte 1:
file -Lz * | grep ASCII | cut -d":" -f1 | xargs ls -ltr
Ahora, queremos utilizar el comando ls -l y pasar la lista de arriba como parámetros, uno a la vez. El comando xargs le permitió hacer eso. La última parte, xargs ls -ltr, toma el output y ejecuta el comando ls -ltr sobre ellos, como si ejecutase:
alert_DBA102.log: ASCII English textalert_DBA102.log.Z: ASCII text (compress'd data 16 bits)dba102_asmb_12307.trc.Z: ASCII English text (compress'd data 16 bits)dba102_asmb_20653.trc.Z: ASCII English text (compress'd data 16 bits)
xargs no es útil por sí mismo, pero es bastante bueno cuando se combina con otros comandos. Aquí se muestra otro ejemplo, donde queremos contaar la cantidad de líneas en esos archivos:
alert_DBA102.logalert_DBA102.log.Zdba102_asmb_12307.trc.Zdba102_asmb_20653.trc.Z
Ahora, queremos utilizar el comando ls -l y pasar la lista de arriba como parámetros, uno a la vez. El comando xargs le permitió hacer eso. La última parte, xargs ls -ltr, toma el output y ejecuta el comando ls -ltr sobre ellos, como si ejecutase:
ls -ltr alert_DBA102.logls -ltr alert_DBA102.log.Zls -ltr dba102_asmb_12307.trc.Zls -ltr dba102_asmb_20653.trc.Z
xargs no es útil por sí mismo, pero es bastante bueno cuando se combina con otros comandos.
Aquí se muestra otro ejemplo, donde queremos contaar la cantidad de líneas en esos archivos:
$ file * | grep ASCII | cut -d":" -f1 | xargs wc -l 47853 alert_DBA102.log 19 dba102_cjq0_14493.trc 29053 dba102_mmnl_14497.trc 154 dba102_reco_14491.trc 43 dba102_rvwr_14518.trc 77122 total

(Nota: la tarea de arriba también puede lograrse con el siguiente comando:)
$ wc -l ‘file * | grep ASCII | cut -d":" -f1 | grep ASCII | cut -d":" -f1‘
La versión xargs está dada para ilustrar el concepto. Linux tiene varias maneras de lograr la misma tarea; use la que mejor se adapte a su situación.
Al utilizar este enfoque, usted puede rápidamente renombrar los archivos de un directorio.
$ ls | xargs -t -i mv {} {}.bak
La opción -i le comunica a xargs que reemplace {} con el nombre de cada elemento. La opción -t ordena a xargs que imprima el comando antes de ejecutarlo.
Otra operación es muy útil cuando quiere abrir los archivos para edición utilizando vi:
$ file * | grep ASCII | cut -d":" -f1 | xargs vi
Este comando abre los archivos uno por uno utilizando vi. Cuando quiere buscar muchos archivos y abrirlos para edición, esto resulta muy útil.
También tiene varias opciones. Tal vez la más útil es la opción -p, que hace que la operación sea interactiva:
$ file * | grep ASCII | cut -d":" -f1 | xargs -p vivi alert_DBA102.log dba102_cjq0_14493.trc dba102_mmnl_14497.trcdba102_reco_14491.trc dba102_rvwr_14518.trc ?...
Aquí xarg le pide confirmación antes de ejecutar cada comando. Si presiona "y", ejecuta el comando. Le resultará extremadamente útil cuando realice algunas operaciones potencialmente perjudiciales e irreversibles en el archivo—como eliminar o sobrescribirlo.
La opción -t utiliza un modo verboso; despliega el comando que está por ejecutar, la cual es una opción muy útil durante la depuración.
¿Qué sucede si el output pasara a xargs en blanco? Considere:
$ file * | grep SSSSSS | cut -d":" -f1 | xargs -t wc -lwc -l 0$
Aquí buscar "SSSSSS" no produce ninguna concordancia; entonces el input de xargs son todos espacios en blanco, como se muestra en la segunda línea (producida al utilizar la opción -t o verbosa). A pesar de que esto puede ser útil, en algunos casos usted puede querer detener xargs si no hay nada que procesar; si lo hay, puede utilizar la opción -r:
$ file * | grep SSSSSS | cut -d":" -f1 | xargs -t -r wc -l$

El comando existe si no hay nada que ejecutar.
Supongamos que quiere eliminar los archivos utilizando el comando rm, que debería ser el argumento para el comando xargs. No obstante, rm puede aceptar una cantidad limitada de argumentos. ¿Qué sucede si su lista de argumentos excede ese límite? La opción -n para xargs limita la cantidad de argumentos en una sola línea de comando.
Aquí mostramos cómo puede limitar solo dos argumentos por línea de comando: Incluso si cinco líneas pasan a xargs ls -ltr, solo dos archivos pasan a ls -ltr por vez.
$ file * | grep ASCII | cut -d":" -f1 | xargs -t -n2 ls -ltr ls -ltr alert_DBA102.log dba102_cjq0_14493.trc -rw-r----- 1 oracle dba 738 Aug 10 19:18 dba102_cjq0_14493.trc-rw-r--r-- 1 oracle dba 2410225 Aug 13 05:31 alert_DBA102.logls -ltr dba102_mmnl_14497.trc dba102_reco_14491.trc -rw-r----- 1 oracle dba 5386163 Aug 10 17:55 dba102_mmnl_14497.trc-rw-r----- 1 oracle dba 6808 Aug 13 05:21 dba102_reco_14491.trcls -ltr dba102_rvwr_14518.trc -rw-r----- 1 oracle dba 2087 Aug 10 04:30 dba102_rvwr_14518.trc
Utilizando este enfoque, usted puede rápidamente renombrar los archivos de un directorio.
$ ls | xargs -t -i mv {} {}.bak
La opción -i le comunica a xargs que reemplace {} con el nombre de cada elemento.
rename
Como sabe, el comando mv renombra los archivos. Por ejemplo,
$ mv oldname newnameoldnamenewnamerename rename .log .log.‘date +%F-%H:%M:%S‘ *
reemplaza todos los archivos con la extensión .log por .log.<dateformat>. Entonces sqlnet.log se convierte en sqlnet.log.2006-09-12-23:26:28.
find
Ente los usuarios Oracle, el más conocido es el comando find. Hasta ahora, sabe cómo utilizar find para buscar archivos en un directorio determinado. Aquí mostramos un ejemplo que comienza con la palabra "file" en el directorio actual:

$ find . -name "file*"./file2./file1./file3./file4
No obstante, ¿qué sucede si quiere buscar nombres como FILE1, FILE2, etc.? -name "file*" no tendrá concordancia. Para una búsqueda con distinción de mayúsculas y minúsculas, use la opción -iname:
$ find . -iname "file*"./file2./file1./file3./file4./FILE1./FILE2
Puede restringir su búsqueda a un tipo específico de archivos. Por ejemplo, el comando de arriba obtendrá archivos de todo tipo: archivos comunes, directorios, enlaces simbólicos, etc. Para buscar solo archivos comunes, puede utilizar el parámetro -type f.
$ find . -name "orapw*" -type f ./orapw+ASM./orapwDBA102./orapwRMANTEST./orapwRMANDUP./orapwTESTAUX
-type puede tomar los modificadores f (para archivos comunes), l (para enlaces simbólicos), d (directorios), b (dispositivos de bloque), p (named pipes), c (dispositivos de caracteres), s (sockets).
Un pequeño cambio en el comando de arriba es combinarlo con el comando file que conoció en la Parte 1. El comando file le dice qué tipo de archivo es. Puede transmitirlo como post procesador para el output desde el comando find. El parámetro -exec ejecuta el comando que sigue el parámetro. En este caso, el comando a ejecutar después de find es file:
$ find . -name "*oraenv*" -type f -exec file {} \;./coraenv: Bourne shell script text executable./oraenv: Bourne shell script text executable
Esto es útil cuando quiere descubrir si el archivo de texto ASCII podría ser algún tipo de shell script.
Si sustituye -exec con -ok, el comando es ejecutado pero solicita confirmación primero. Aquí hay un ejemplo:
$ find . -name "sqlplus*" -ok {} \; < {} ... ./sqlplus > ? y SQL*Plus: Release 9.2.0.5.0 - Production on Sun Aug 6 11:28:15 2006 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.

Enter user-name: / as sysdba Connected to:Oracle9i Enterprise Edition Release 9.2.0.5.0 - 64bit ProductionWith the Partitioning,Real Application Clusters,OLAP and Oracle Data Mining optionsJServer Release 9.2.0.5.0 - Production SQL> exitDisconnected from Oracle9i Enterprise Edition Release 9.2.0.5.0-64bit ProductionWith the Partitioning,Real Application Clusters,OLAP and Oracle Data Mining optionsJServer Release 9.2.0.5.0 - Production< È* ... ./sqlplusO > ? n$
Aquí, hemos pedido al shell que busque todos los programas que comienzan con "sqlplus", y que los ejecute. Fíjese que no hay nada entre -ok y {}, por lo tanto solo ejecutará los archivos que encuentre. Encuentra dos archivos—sqlplus y sqlplusO—y en ambos casos pregunta si usted desea ejecutarlos. Respondemos "y" para el prompt de "sqlplus" y lo ejecuta. Después de salir, solicita el segundo archivo que encontró (sqlplusO) y solicita confirmación una y otra vez, a lo cual respondimos "n"—entonces, no se ejecutó.
Consejo para Usuarios Oracle
Oracle produce varios archivos extraños: archivos de localización, archivos testigo, archivos dump, etc. A menos que se limpien periódicamente, pueden llenar el sistema de archivos e interrumpir la base de datos.
Para garantizar que eso no suceda, simplemente busque los archivos con extensión "trc" y elimínelos si tienen más de tres días de antigüedad. Un comando simple es la solución:
find . -name "*.trc" -ctime +3 -exec rm {} \;
Para eliminarlos antes del límite de tres días, use la opción -f.
find . -name "*.trc" -ctime +3 -exec rm -f {} \;
Si simplemente desea enumerar los archivos:
find . -name "*.trc" -ctime +3 -exec ls -l {} \;
m4
Este comando toma un archivo input y sustituye las cadenas dentro de él con los parámetros transmitidos, lo cual es similar a sustituirlas por variables. Por ejemplo, vea un archivo input:

$ cat tempThe COLOR fox jumped over the TYPE fence.
Si quiere sustituir las cadenas "COLOR" por "brown" y "TYPE" por "broken", puede utilizar:
$ m4 -DCOLOR=brown -DTYPE=broken tempThe brown fox jumped over the broken fence.Else, if you want to substitute "white" and "high" for the same:
$ m4 -DCOLOR=white -DTYPE=high temp The white fox jumped over the high fence.
whence y which
Estos comandos son utilizados para saber dónde se almacenan los ejecutables mencionados en el PROCESO del usuario. Cuando el ejecutable es encontrado en el proceso, se comportan de manera bastante similar y muestran el proceso:
$ which sqlplus /u02/app/oracle/products/10.2.0.1/db1/bin/sqlplus$ whence sqlplus /u02/app/oracle/products/10.2.0.1/db1/bin/sqlplus
El output es idéntico. Sin embargo, si el ejecutable no es encontrado en el proceso, el comportamiento es diferente. El comando which produce un mensaje explícito:
$ which sqlplus1/usr/bin/which: no sqlplus1 in (/u02/app/oracle/products/10.2.0.1/db1/bin:/usr/kerberos/bin:/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin)
whereas El comando whence no produce mensaje:
$ whence sqlplus1]
y vuelve a shell prompt. Esto es útil en casos donde el ejecutable no es encontrado en el proceso (en lugar de mostrar el mensaje):
$ whence invalid_command$ which invalid_commandwhich: no invalid_command in (/usr/kerberos/sbin:/usr/kerberos/bin:/bin:/sbin: /usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:/usr/bin/X11:/usr/X11R6/bin:/root/bin)

Cuando whence no encuentra un ejecutable en el proceso, vuelve sin ningún mensaje pero el código de retorno no es cero. Esto puede utilizarse en shell scripts; por ejemplo:
RC=‘whence myexec‘If [ $RC -ne "0" ]; then echo "myexec is not in the $PATH"fi
Una opción muy útil es la opción -i, que muestra el alias y el ejecutable, si está presente. Por ejemplo, usted pudo ver el uso del alias al comienzo de este artículo. El comando rm es en realidad un alias en mi shell, y también en cualquier lugar donde haya un comando rm en el sistema.
$ which ls /bin/ls $ which -i ls alias ls='ls --color=tty' /bin/ls
El comportamiento por defecto es mostrar la primera ocurrencia del ejecutable en el proceso. Si el ejecutable existe en diferentes directorios del proceso, las ocurrencias subsiguientes son ignoradas. Puede ver todas las ocurrencias del ejecutable mediante la opción -a.
$ which java /usr/bin/java
$ which -a java/usr/bin/java/home/oracle/oracle/product/11.1/db_1/jdk/jre/bin/java
top
El comando top es probablemente el más útil para un Oracle DBA que administra una base de datos sobre Linux. Digamos que el sistema es lento y quiere saber quién está saturando la CPU y/o memoria. Para mostrar los procesos clave, utiliza el comando top.
Fíjese que a diferencia de otros comandos, top no produce un output y permanece inactivo. Actualiza la pantalla para mostrar nueva información. Por lo tanto, si simplemente activa top y deja la pantalla activa, siempre contará con la información más actual. Para cancelar e ir hacia shell, puede presionar Control-C.
$ top
18:46:13 up 11 days, 21:50, 5 users, load average: 0.11, 0.19, 0.18 151 processes: 147 sleeping, 4 running, 0 zombie, 0 stopped CPU states: cpu user nice system irq softirq iowait idle total 12.5% 0.0% 6.7% 0.0% 0.0% 5.3% 75.2% Mem: 1026912k av, 999548k used, 27364k free, 0k shrd, 116104k buff 758312k actv, 145904k in_d, 16192k in_c Swap: 2041192k av, 122224k used, 1918968k free 590140k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND

451 oracle 15 0 6044 4928 4216 S 0.1 0.4 0:20 0 tnslsnr 8991 oracle 15 0 1248 1248 896 R 0.1 0.1 0:00 0 top 1 root 19 0 440 400 372 S 0.0 0.0 0:04 0 init 2 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 keventd 3 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kapmd 4 root 34 19 0 0 0 SWN 0.0 0.0 0:00 0 ksoftirqd/0 7 root 15 0 0 0 0 SW 0.0 0.0 0:01 0 bdflush 5 root 15 0 0 0 0 SW 0.0 0.0 0:33 0 kswapd 6 root 15 0 0 0 0 SW 0.0 0.0 0:14 0 kscand 8 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kupdated 9 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 mdrecoveryd ... output snipped ...
Examinemos los diferentes tipos de información producidos. La primera línea:
18:46:13 up 11 days, 21:50, 5 users, load average: 0.11, 0.19, 0.18
muestra la hora actual (18:46:13), que el sistema ha estado activo durante 11 días; que el sistema ha trabajado durante 21 horas 50 segundos. Se muestra el promedio de carga del sistema (0.11, 0.19, 0.18) para los últimos 1, 5 y 15 minutos respectivamente. (A propósito, usted también puede obtener esta información ejecutando el uptime command.)
Si el promedio de carga no es necesario, presione la letra "l" (L minúscula); lo desactivará. Para volver a activarlo presione l nuevamente. La segunda línea:
151 processes: 147 sleeping, 4 running, 0 zombie, 0 stopped
muestra la cantidad de procesos, en ejecución, inactivos, etc. La tercera y cuarta línea:
CPU states: cpu user nice system irq softirq iowait idle total 12.5% 0.0% 6.7% 0.0% 0.0% 5.3% 75.2%
muestran los detalles del uso de CPU. La línea de arriba muestra que los procesos de los usuarios consumen un 12,5% y el sistema consume un 6,7%. Los procesos del usuario incluyen los procesos Oracle. Presione "t" para activar y desactivar estas tres líneas. Si hay más de una CPU, usted verá una línea por CPU.
Las próximas dos líneas:
Mem: 1026912k av, 1000688k used, 26224k free, 0k shrd, 113624k buff 758668k actv, 146872k in_d, 14460k in_cSwap: 2041192k av, 122476k used, 1918716k free 591776k cached
muestran la memoria disponible y utilizada. La memoria total es "1026912k av", aproximadamente 1GB, de la cual solo 26224k o 26MB está libre. El espacio de intercambio es de 2GB; pero casi no es utilizado. Para activarlo y desactivarlo, presione "m".

El resto muestra los procesos en un formato tabular. A continuación, se explican las columnas:
Columna DescripciónPID El ID del proceso
USER El usuario que ejecuta el proceso
PRI La prioridad del proceso
NI El valor nice: Cuanto más alto es el valor, más baja es la prioridad de la tarea
SIZE Memoria utilizada por este proceso (código+datos+stack)
RSS Memoria física utilizada por este proceso
SHARE Memoria compartida utilizada por este proceso
STAT El estado de este proceso, mostrado en códigos. Algunos códigos importantes de estado son: R – Running (enejecución) S –Sleeping (inactivo) Z – Zombie (vacilante) T – Stopped (detenido)
Usted también puede ver el segundo y tercer carácter, que indican: W – Swapped out process (proceso intercambiado) N – positive nice value (valor nice positivo)
%CPU Porcentaje de CPU utilizado por este proceso
%MEM Porcentaje de memoria utilizado por este proceso
TIME Tiempo total de CPU utilizado por este proceso
CPU Si este es un proceso de procesadores múltiples, esta columna indica el ID de la CPU sobre la cual se está ejecutando este proceso.
COMMAND Comando utilizado por este proceso
Mientras se muestra top, puede presionar algunas teclas para formatear la representación visual como usted quiera. Presionar la tecla mayúscula M clasifica el output por uso de memoria. (Fíjese que utilizar la letra minúscula m activará o desactivará las líneas de resumen de memoria en la parte superior de la representación visual). Esto es muy útil cuando quiere descubrir quién consume la memoria. Vea un ejemplo de output:
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND 31903 oracle 15 0 75760 72M 72508 S 0.0 7.2 0:01 0 ora_smon_PRODB2 31909 oracle 15 0 68944 66M 64572 S 0.0 6.6 0:03 0 ora_mmon_PRODB2 31897 oracle 15 0 53788 49M 48652 S 0.0 4.9 0:00 0 ora_dbw0_PRODB2
Ahora que ya sabe cómo interpretar el output, veamos cómo utilizar los parámetros de línea de comando.
El más útil es -d, que indica la demora entre las actualizaciones de pantalla. Para actualizar cada segundo, use top -d 1.
La otra opción útil es -p. Si solo desea monitorear algunos procesos, no todos, puede especificar solo aquellos después de la opción -p. Para monitorear los procesos 13609, 13608 y 13554:
top -p 13609 -p 13608 -p 13554

Esto mostrará los resultados en el mismo formato que el comando top, pero solo esos procesos específicos.
Consejo para Usuarios Oracle
Es casi innecesario decir que top resulta muy útil para analizar el desempeño de los servidores de base de datos. Aquí mostramos un output top parcial.
20:51:14 up 11 days, 23:55, 4 users, load average: 0.88, 0.39, 0.27 113 processes: 110 sleeping, 2 running, 1 zombie, 0 stopped CPU states: cpu user nice system irq softirq iowait idle total 1.0% 0.0% 5.6% 2.2% 0.0% 91.2% 0.0% Mem: 1026912k av, 1008832k used, 18080k free, 0k shrd, 30064k buff 771512k actv, 141348k in_d, 13308k in_c Swap: 2041192k av, 66776k used, 1974416k free 812652k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND 16143 oracle 15 0 39280 32M 26608 D 4.0 3.2 0:02 0 oraclePRODB2... 5 root 15 0 0 0 0 SW 1.6 0.0 0:33 0 kswapd ... output snipped ...
Analicemos el output cuidadosamente. Lo primero que debería notar es que la columna "inactiva" de la CPU indica; 0,0%—es decir, la CPU está completamente ocupada haciendo algo. La pregunta es, ¿haciendo qué? Preste atención a la columna "sistema", ligeramente a la izquierda; muestra 5,6%. Entonces el sistema no está haciendo mucho. Vaya más a la izquierda hasta la columna "usuario", que muestra 1,0%. Como los procesos de usuarios incluyen Oracle también, Oracle no consume los ciclos de CPU. Por lo tanto, ¿qué consume toda la CPU?
La respuesta está en la misma línea, justo a la derecha en la columna "iowait", que indica un 91,2%. Esto lo explica todo: la CPU está esperando IO el 91,2% del tiempo.
¿Entonces, por qué tanta espera por IO? La respuesta está en la pantalla. Fíjese en el PID del proceso con mayor consumo: 16143. Puede utilizar la siguiente consulta para determinar qué está haciendo el proceso:
select s.sid, s.username, s.programfrom v$session s, v$process pwhere spid = 16143and p.addr = s.paddr/
SID USERNAME PROGRAM------------------- ----------------------------- 159 SYS rman@prolin2 (TNS V1-V3)
El proceso rman está reduciendo los ciclos de CPU relacionados con la espera de IO. Esta información ayuda a determinar el próximo plan de acción.
skill y snice

En el debate anterior, aprendió cómo identificar un recurso de consumo de CPU. ¿Qué sucede si descubre que un proceso consume mucha CPU y memoria, pero no quiere cancelarlo? Considere este output top:
$ top -c -p 16514
23:00:44 up 12 days, 2:04, 4 users, load average: 0.47, 0.35, 0.31 1 processes: 1 sleeping, 0 running, 0 zombie, 0 stopped CPU states: cpu user nice system irq softirq iowait idle total 0.0% 0.6% 8.7% 2.2% 0.0% 88.3% 0.0% Mem: 1026912k av, 1010476k used, 16436k free, 0k shrd, 52128k buff 766724k actv, 143128k in_d, 14264k in_c Swap: 2041192k av, 83160k used, 1958032k free 799432k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND 16514 oracle 19 4 28796 26M 20252 D N 7.0 2.5 0:03 0 oraclePRODB2...
Ahora que confirmó que el proceso 16514 consume mucha memoria, puede "congelarlo"—pero no cancelarlo—usando el comando skill.
$ skill -STOP 1
Luego, vea el output top:
23:01:11 up 12 days, 2:05, 4 users, load average: 1.20, 0.54, 0.38 1 processes: 0 sleeping, 0 running, 0 zombie, 1 stopped CPU states: cpu user nice system irq softirq iowait idle total 2.3% 0.0% 0.3% 0.0% 0.0% 2.3% 94.8% Mem: 1026912k av, 1008756k used, 18156k free, 0k shrd, 3976k buff 770024k actv, 143496k in_d, 12876k in_c Swap: 2041192k av, 83152k used, 1958040k free 851200k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND 16514 oracle 19 4 28796 26M 20252 T N 0.0 2.5 0:04 0 oraclePRODB2...
La CPU ahora está un 94% inactiva, de 0%. El proceso queda efectivamente congelado. Después de algún tiempo, puede querer reanudar el proceso del coma:
$ skill -CONT 16514
Este enfoque es muy útil para congelar temporalmente los procesos a fin de hacer lugar para finalizar los procesos más importantes.
El comando es muy versátil. Si desea detener todos los procesos de usuario "oracle", hay únicamente un solo comando que lo hace todo:

$ skill -STOP oracle
Puede utilizar un usuario, PID, un comando o terminal id como argumento. Lo que se muestra a continuación detiene todos los comandos rman.
$ skill -STOP rman
Como puede ver, skill decide ese argumento que ingresó—un ID para el proceso, un id de usuario o un comando—y actúa en consecuencia. Esto puede causar problemas en algunos casos, donde puede tener un usuario y un comando con el mismo nombre. El mejor ejemplo es el proceso "oracle", que en general es ejecutado por el usuario "oracle". Por lo tanto, cuando quiere detener el proceso denominado "oracle" y realiza:
$ skill -STOP oracle
todos los procesos del usuario "oracle" se detienen, incluso la sesión que puede estar ejecutando en ese momento. Para ser completamente ambiguo, puede opcionalmente ofrecer un nuevo parámetro para especificar el tipo de parámetro. Para detener un comando llamado oracle, puede:
$ skill -STOP -c oracle
El comando snice es similar. En lugar de detener un proceso, hace que su prioridad sea más baja. Primero, vea el output:
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND 3 root 15 0 0 0 0 RW 0.0 0.0 0:00 0 kapmd 13680 oracle 15 0 11336 10M 8820 T 0.0 1.0 0:00 0 oracle 13683 oracle 15 0 9972 9608 7788 T 0.0 0.9 0:00 0 oracle 13686 oracle 15 0 9860 9496 7676 T 0.0 0.9 0:00 0 oracle 13689 oracle 15 0 10004 9640 7820 T 0.0 0.9 0:00 0 oracle 13695 oracle 15 0 9984 9620 7800 T 0.0 0.9 0:00 0 oracle 13698 oracle 15 0 10064 9700 7884 T 0.0 0.9 0:00 0 oracle 13701 oracle 15 0 22204 21M 16940 T 0.0 2.1 0:00 0 oracle
Ahora, reduzca cuatro puntos la prioridad de los procesos de "oracle". Fíjese que cuanto mayor es el número, más baja es la prioridad.
$ snice +4 -u oracle
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND 16894 oracle 20 4 38904 32M 26248 D N 5.5 3.2 0:01 0 oracle

Guía para Maestría Avanzada en Comandos Linux, Parte 3: Administración de Recursos
por Arup Nanda
Publicado en mayo de 2009
En esta entrega, aprenda los comandos avanzados de Linux para monitorear componentes físicos
Un sistema Linux está conformado por varios componentes físicos clave como CPU, memorias, tarjetas de red y dispositivos de almacenamiento. Para administrar de manera efectiva el entorno Linux, usted debería poder evaluar varias métricas de estos recursos—cuánto procesa cada componente, si existen cuellos de botella, entre otras cosas —con una precisión razonable.
En otras partes de esta serie usted aprendió algunos comandos para medir las métricas en un nivel macro. En esta entrega, no obstante, aprenderá los comandos avanzados de Linux para monitorear componentes físicos. En especial, aprenderá acerca de los comandos en las siguientes categorías:
Component Commands
Memory free, vmstat, mpstat, iostat, sar
CPU vmstat, mpstat, iostat, sar
I/O vmstat, mpstat, iostat, sar
Processes ipcs, ipcrm
Como puede observar, algunos comandos aparecen en más de una categoría. Esto se debe a que los comandos pueden desempeñar muchas tareas. Algunos comandos se ajustan mejor a otros componentes –por ej., iostat para I/O—pero debería comprender las diferencias en sus trabajos y utilizar aquellos con los que se sienta más cómodo.
En la mayoría de los casos, un solo comando no es útil para comprender lo que realmente está sucediendo. Usted debería conocer múltiples comandos para obtener la información que desea.
"free"Una pregunta común es, “¿Cuánta memoria está siendo utilizada por mis aplicaciones y los distintos servidores, usuarios y procesos de sistemas?” O, “¿Cuánto espacio de memoria tengo libre en este momento?” Si la memoria utilizada por los procesos en ejecución es mayor la memoria RAM disponible, los procesos se trasladan a la memoria swap (memoria virtual). Por lo tanto, una pregunta complementaria sería, “¿Qué cantidad de memoria swap se está utilizando?”.
El comando “free” responde a todas estas preguntas. Es más, una opción muy útil, –m , muestra la memoria libre en megabytes:
# free -m total used free shared buffers cachedMem: 1772 1654 117 0 18 618-/+ buffers/cache: 1017 754Swap: 1983 1065 918

El output muestra que el sistema tiene 1.772 MB de RAM, de los cuales se utilizan 1.654 MB, dejando 117 MB de memoria libre. La segunda línea muestra los cambios de tamaño de caché y buffers en la memoria física. La tercera línea muestra la utilización de memoria swap.
Para expresar lo mismo en kilobytes y gigabytes, reemplace la opción -m con -k o -g respectivamente. Usted puede colocarse en el nivel de bytes también, utilizando la opción –b.
# free -b total used free shared buffers cachedMem: 1858129920 1724039168 134090752 0 18640896 643194880-/+ buffers/cache: 1062203392 795926528Swap: 2080366592 1116721152 963645440
La opción –t muestra el total al final del output (suma de memoria física más swap):
# free -m -t total used free shared buffers cachedMem: 1772 1644 127 0 16 613-/+ buffers/cache: 1014 757Swap: 1983 1065 918Total: 3756 2709 1046
A pesar de que “free” no muestra los porcentajes, podemos extraer y formatear partes específicas del output para mostrar la memoria utilizada como porcentaje del total solamente:
# free -m | grep Mem | awk '{print ($3 / $2)*100}' 98.7077
Esto viene bien para los shell scripts en donde las cantidades específicas son importantes. Por ejemplo, usted quizás quiera generar un alerta cuando el porcentaje de memoria libre descienda por debajo de cierto límite.
De modo similar, para encontrar el porcentaje de swap utilizado, usted puede emitir:
free -m | grep -i Swap | awk '{print ($3 / $2)*100}'
Puede utilizar free para observar la carga de memoria empleada por una aplicación. Por ejemplo, controle la memoria libre antes de iniciar una aplicación de backup y luego contrólela inmediatamente luego de iniciarla. La diferencia podría atribuirse al consumo por parte de la aplicación de backup.
Para Usuarios de Oracle
Entonces, ¿cómo puede utilizar este comando para administrar el servidor Linux que ejecuta su entorno de Oracle? Una de las causas más comunes de los problemas de desempeño es la falta de memoria, lo que provoca que el sistema “intercambie” áreas de memoria en el disco de manera temporal. Cierto grado de intercambio es probablemente inevitable pero experimentar una gran cantidad de intercambio puede indicar falta de memoria libre.
En cambio, usted puede utilizar free para obtener información de la memoria libre y ahora hacer el seguimiento con el comando sar (que se muestra luego) para controlar la tendencia histórica del consumo de memoria y swap. Si el uso de swap es temporario, es probable que se trate de un pico (spike) por única vez; pero si se declara durante un período de tiempo, debería hacerlo notar. Existen algunas sospechas posibles y obvias de sobrecarga crónica de memoria:

SGA más amplia que la memoria disponible Amplia asignación en PGA Algunos procesos con bugs que producen la fuga de de memoria
Para el primer caso, usted debería asegurarse de que SGA sea menor a la memoria disponible. La regla general es utilizar alrededor del 40 por ciento de la memoria física para SGA, no obstante, debería definir ese parámetro sobre la base de su situación específica. En el segundo caso, usted debería intentar reducir la amplia asignación de buffers en consultas. En el tercer caso debería utilizar el comando “ps” (descripto en entregas anteriores de esta serie) para identificar el proceso específico que podría producir la fuga de memoria.
"ipcs"Cuando se ejecuta un proceso, se adopta desde la “memoria compartida”. Puede haber uno o muchos segmentos de memoria compartida por proceso. Los procesos intercambian mensajes entre ellos (“comunicaciones entre procesos”, o IPC) y utilizan semáforos. Para desplegar información sobre segmentos de memoria compartida, colas de mensajes IPC y semáforos, usted puede utilizar un solo comando: ipcs.
La opción –m es muy conocida; despliega los segmentos de memoria compartida.
# ipcs -m ------ Shared Memory Segments --------key shmid owner perms bytes nattch status 0xc4145514 2031618 oracle 660 4096 0 0x00000000 3670019 oracle 660 8388608 108 0x00000000 327684 oracle 600 196608 2 dest 0x00000000 360453 oracle 600 196608 2 dest 0x00000000 393222 oracle 600 196608 2 dest 0x00000000 425991 oracle 600 196608 2 dest 0x00000000 3702792 oracle 660 926941184 108 0x00000000 491529 oracle 600 196608 2 dest 0x49d1a288 3735562 oracle 660 140509184 108 0x00000000 557067 oracle 600 196608 2 dest 0x00000000 1081356 oracle 600 196608 2 dest 0x00000000 983053 oracle 600 196608 2 dest 0x00000000 1835023 oracle 600 196608 2 dest
Este output, tomado de un servidor que ejecuta software de Oracle, muestra los distintos segmentos de memoria compartida. Cada uno se identifica exclusivamente por un ID de memoria compartida, y se muestra en la columna “shmid”. (Más adelante verá cómo utilizar el valor de esta columna.) El “owner”, por supuesto, muestra el propietario del segmento, la columna “perms” muestra los permisos (igual que los permisos unix), y “bytes” muestra el tamaño de los bytes.
La opción -u muestra un breve resumen:
# ipcs -mu
------ Shared Memory Status --------segments allocated 25pages allocated 264305pages resident 101682pages swapped 100667Swap performance: 0 attempts 0 successes

La opción –l muestra los límites (en contraposición a los valores actuales):
# ipcs -ml ------ Shared Memory Limits --------max number of segments = 4096max seg size (kbytes) = 907290max total shared memory (kbytes) = 13115392min seg size (bytes) = 1
Si usted ve que los valores reales se acercan o se encuentran en el límite, debería extender ese límite.
Puede obtener un panorama detallado de un segmento de memoria compartida utilizando el valor shmid. La opción –i logra esto. Usted verá los detalles de shmid 3702792:
# ipcs -m -i 3702792 Shared memory Segment shmid=3702792uid=500 gid=502 cuid=500 cgid=502mode=0660 access_perms=0660bytes=926941184 lpid=12225 cpid=27169 nattch=113att_time=Fri Dec 19 23:34:10 2008 det_time=Fri Dec 19 23:34:10 2008 change_time=Sun Dec 7 05:03:10 2008
Más adelante verá un ejemplo de cómo interpretar el output de arriba.
La opción -s muestra los semáforos en el sistema:
# ipcs -s ------ Semaphore Arrays --------key semid owner perms nsems 0x313f2eb8 1146880 oracle 660 104 0x0b776504 2326529 oracle 660 154 … and so on …
Esto muestra algunos de datos valiosos. Se observa que el grupo de semáforos de ID 1146880 posee 104 semáforos, y el otro tiene 154. Si usted los suma, el valor total debe ser menor al límite máximo definido por el parámetro kernel (semmax). Mientras se instala el software de la Base de Datos de Oracle, el controlador de preinstalación debe controlar los parámetros para semmax. Luego, cuando el sistema alcanza el estado seguro, usted puede controlar la utilización real y luego ajustar el valor kernel de manera adecuada.
Para Usuarios de Oracle
¿Cómo puede descubrir los segmentos de memoria compartida utilizados por la instancia de Base de Datos de Oracle? Para lograrlo, utilice el comando oradebug. Primero conéctese a la base de datos como sysdba:
# sqlplus / as sysdba

En el SQL, utilice el comando oradebug como se muestra abajo:
SQL> oradebug setmypidStatement processed.SQL> oradebug ipcInformation written to trace file.
Para descubrir el nombre del archivo de rastreo:
SQL> oradebug TRACEFILE_NAME/opt/oracle/diag/rdbms/odba112/ODBA112/trace/ODBA112_ora_22544.trc
Ahora, si abre un archivo de rastreo, usted verá los IDs de la memoria compartida. Aquí se muestra un extracto del archivo:
Area #0 `Fixed Size' containing Subareas 0-0 Total size 000000000014613c Minimum Subarea size 00000000 Area Subarea Shmid Stable Addr Actual Addr 0 0 17235970 0x00000020000000 0x00000020000000 Subarea size Segment size 0000000000147000 000000002c600000 Area #1 `Variable Size' containing Subareas 4-4 Total size 000000002bc00000 Minimum Subarea size 00400000 Area Subarea Shmid Stable Addr Actual Addr 1 4 17235970 0x00000020800000 0x00000020800000 Subarea size Segment size 000000002bc00000 000000002c600000 Area #2 `Redo Buffers' containing Subareas 1-1 Total size 0000000000522000 Minimum Subarea size 00000000 Area Subarea Shmid Stable Addr Actual Addr 2 1 17235970 0x00000020147000 0x00000020147000 Subarea size Segment size 0000000000522000 000000002c600000... and so on ...
El ID de memoria compartida se muestra en letra mayúsculas rojas. Usted puede utilizar este ID de memoria compartida para obtener los detalles de la memoria compartida:
# ipcs -m -i 17235970
Otra observación útil es el valor de lpid – el ID del proceso que por última vez alcanzó el segmento de memoria compartida. Para demostrar el valor en ese atributo, utilice SQL*Plus para conectarse a la instancia desde una sesión distinta.
# sqlplus / as sysdba
En esa sesión, descubra el PID del proceso del servidor:
SQL> select spid from v$process 2 where addr = (select paddr from v$session

3 where sid = 4 (select sid from v$mystat where rownum < 2) 5 ); SPID------------------------13224
Ahora vuelva a ejecutar el comando “ipcs” frente al mismo segmento de memoria compartida:
# ipcs -m -i 17235970 Shared memory Segment shmid=17235970uid=500 gid=502 cuid=500 cgid=502mode=0660 access_perms=0660bytes=140509184 lpid=13224 cpid=27169 nattch=113att_time=Fri Dec 19 23:38:09 2008 det_time=Fri Dec 19 23:38:09 2008 change_time=Sun Dec 7 05:03:10 2008
Preste atención al valor de “lpid”, que fue cambiado a 13224 desde el valor original 12225. El “lpid” muestra el PID del último proceso que alcanzó el segmento de memoria compartida, y observe cómo cambiaron los valores.
El comando por sí mismo, ofrece poco valor. El próximo comando – ipcrm – le permite actuar en base al output, como verá en la próxima sección.
ipcrmAhora que ha identificado la memoria compartida y demás métricas de IPC ¿qué hacer con ellas? Usted ya ha conocido su uso, por ejemplo, identificar le memoria compartida utilizada por Oracle, asegurar que el parámetro kernel para la memoria compartida haya sido establecido, etc. Otra aplicación común es eliminar la memoria compartida, la cola de mensajes IPC, o los grupos de semáforos.
Para eliminar el segmento de memoria compartida, observe su “shmid” del output del comando “ipcs”. Luego utilice la opción –m para eliminar el segmento. Para remover el segmento con ID 3735562, utilice
# ipcrm –m 3735562
Esto eliminará la memoria compartida. Usted también puede utilizarlo para eliminar colas de mensajes IPC y semáforos (utilizando los parámetros –s y –q).
Para Usuarios de Oracle
Algunas veces cuando se cierra la instancia de base de datos, los segmentos de memoria compartida pueden no eliminarse por completo por el kernel de Linux. La memoria compartida que queda no es utilizada; no obstante, invade los recursos del sistema reduciendo la cantidad de memoria disponible para otros procesos. En ese caso, usted puede controlar cualquier segmento de memoria compartida persistente que posee el usuario “oracle” y luego eliminarlo, si corresponde, utilizando el comando ”ipcrm”.
vmstat

Cuando se invoca vmstat, denominado el “abuelo” de todas las visualizaciones relacionadas con procesos y memorias, continuamente ejecuta y entrega su información. Toma dos segmentos:
# vmstat <interval> <count>
<interval> es el intervalo en segundos entre dos ejecuciones. <count> es la cantidad de repeticiones que vmstat realiza. Vea un ejemplo de cuando usted desea que vmstat se ejecute cada cinco segundos y se detenga luego de la décima vez. Cada línea en el output se despliega después de cinco segundos y muestra las estadísticas en ese momento.
# vmstat 5 10 procs -----------memory---------- --swap-- ----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 0 0 1087032 132500 15260 622488 89 19 9 3 0 0 4 10 82 5 0 0 1087032 132500 15284 622464 0 0 230 151 1095 858 1 0 98 1 0 0 1087032 132484 15300 622448 0 0 317 79 1088 905 1 0 98 0… shows up to 10 times.
El output muestra mucha información sobre los recursos del sistema. Veámoslos en detalle:
procs Muestra la cantidad de procesos
r Proceso en espera para ser ejecutado. Cuanto mayor es la carga del sistema, mayor la cantidad de procesos que esperan que los ciclos de CPU se ejecuten.
b Procesos en espera ininterrumpible, también conocidos como procesos “bloqueados”. Estos procesos generalmente esperan una I/O, pero también podrían referirse a otras cosas.
Algunas veces hay otra columna que se denomina “w”, la cual muestra la cantidad de procesos que pueden ser ejecutados pero que se han intercambiado al área de swap.
La cantidad que muestra “b” debería ser cercana a 0. Si la cantidad que se muestra en “w” es elevada, usted puede necesitar más memoria.
El siguiente cuadro muestra las métricas de memoria::
swpd Cantidad de memoria virtual o memoria swap (en KB)
free Cantidad de memoria física libre (en KB)
buff Cantidad de memoria utilizada como buffer (en KB)
cache Kilobytes de memoria física utilizados como caché
La memoria de buffer se utiliza para almacenar metadatos de archivos como i-nodes y datos de dispositivos de bloques en bruto. La memoria de caché se utiliza para datos de archivos.
El siguiente cuadro muestra la actividad de swap:
si Índice en el cual la memoria realiza el intercambio del disco a la RAM física (en KB/seg.)

so Índice en el cual la memoria realiza el intercambio al disco desde la memoria RAM física (en KB/seg.)
El siguiente cuadro muestra la actividad de I/O:
bi Índice en el cual el sistema envía datos a los dispositivos de bloque (en bloques/seg.)
bo Índice en el cual el sistema lee los datos desde los dispositivos de bloque (en bloques/seg.)
El siguiente cuadro muestra las actividades relacionadas con el sistema:
in Cantidad de interrupciones del sistema por segundo
cs Índice de cambios de contexto en el espacio del proceso (en cantidad /seg.)
El último cuadro es probablemente el más utilizado –información sobre la carga de CPU:
us Muestra el porcentaje de CPU utilizado en los procesos del usuario. Los procesos de Oracle se presentan en esta categoría.
sy Porcentaje de CPU utilizado por los procesos del sistema, tales como los procesos de raíz
id Porcentaje de CPU libre
wa Porcentaje utilizado en “espera por I/O”
Veamos cómo interpretar estos valores. La primera línea del output es un promedio de todas las métricas desde el reinicio del sistema. Por lo tanto, ignore esa línea ya que no muestra el estado real. Las demás líneas muestran las métricas en tiempo real.
De modo ideal, la cantidad de procesos en espera o bloqueados (bajo el encabezado “procs”) debería ser 0 o cercana a 0. Si ésta es elevada, entonces el sistema no tiene demasiados recursos como CPU, memoria o I/O. Esta información resulta útil al momento de diagnosticar los problemas de desempeño.
Los datos bajo “swap” indican si se está produciendo un exceso de intercambio. Si ese es el caso, entonces quizás tenga memoria física inadecuada. Usted debería reducir la demanda de memoria o aumentar la memoria RAM física.
Los datos bajo “io” indican el flujo de datos desde y hasta el disco. Esto muestra la actividad del disco, sin indicar necesariamente la existencia de algún problema. Si usted observa un número elevado en “proc” y luego en la columna “b” (procesos que están siendo bloqueados) y I/O elevado, el problema podría deberse a una contención I/O severa.
La información más útil se presenta en el encabezado “cpu”. La columna “id” muestra la CPU inactiva. Si usted resta 100 a esa cantidad, obtiene el porcentaje de CPU ocupada. ¿Recuerda el comando “top” descripto en otra entrega de esta serie? Ese también muestra el porcentaje de CPU libre. La diferencia es: el comando “top” muestra el porcentaje libre para cada CPU mientras que el vmstat muestra la visión consolidada de todas las CPU.
El comando “vmstat” también muestra el desglose del uso de CPU: qué cantidad es utilizada por el sistema Linux, qué cantidad por un proceso de usuarios y por la espera para I/O. A partir de este desglose usted puede determinar qué contribuye al consumo de la CPU. Si la carga del sistema de CPU es alta, ¿podría haber algún proceso raíz como un backup en ejecución?

La carga del sistema debería ser consistente durante un período de tiempo. Si el sistema muestra una cantidad elevada, utilice el comando “top” para identificar el porcentaje de consumo de CPU.
Para Usuarios de Oracle
Los procesos de Oracle (los procesos de antecedentes y del servidor) y los procesos de usuarios (sqlplus, apache, etc.) figuran bajo “us”. Si esta cantidad es elevada, utilice “top” para identificar los procesos. Si la columna “wa” muestra una cantidad elevada, esto indica que el sistema I/O no puede alcanzar la cantidad de lectura o escritura. Esto podría ocasionalmente disparar un resultado de picos en actualizaciones a la base de datos, lo que podría causar un cambio de registro y un pico posterior en los procesos de archivo. Pero, si muestra consistentemente una cifra elevada, entonces podría estar en presencia de un cuello de botella de I/O.
Las obstrucciones de I/O en una base de datos de Oracle pueden causar serios problemas. Aparte de los problemas de desempeño, el lento flujo de I/O podría provoca enlentecer las escrituras de “controlfile”, lo que provocaría la espera de un proceso hasta adquirir “controlfile” en cola. Si la espera es de más de 900 segundos, y un proceso crítico está en espera, como LGWR, se elimina la instancia de base de datos.
Si el nivel de intercambio (swapping) es elevado, tal vez el tamaño de SGA sea muy alto para ajustarse a la memoria física. Usted debería reducir el tamaño de SGA o aumentar la memoria física.
mpstatOtro comando útil para obtener las estadísticas relacionadas con la CPU es “mpstat”. Aquí se muestra un ejemplo del output:
# mpstat -P ALL 5 2Linux 2.6.9-67.ELsmp (oraclerac1) 12/20/2008 10:42:38PM CPU %user %nice %system %iowait %irq %soft %idle intr/s10:42:43PM all 6.89 0.00 44.76 0.10 0.10 0.10 48.05 1121.6010:42:43PM 0 9.20 0.00 49.00 0.00 0.00 0.20 41.60 413.0010:42:43PM 1 4.60 0.00 40.60 0.00 0.20 0.20 54.60 708.40 10:42:43PM CPU %user %nice %system %iowait %irq %soft %idle intr/s10:42:48PM all 7.60 0.00 45.30 0.30 0.00 0.10 46.70 1195.0110:42:48PM 0 4.19 0.00 2.20 0.40 0.00 0.00 93.21 1034.5310:42:48PM 1 10.78 0.00 88.22 0.40 0.00 0.00 0.20 160.48 Average: CPU %user %nice %system %iowait %irq %soft %idle intr/sAverage: all 7.25 0.00 45.03 0.20 0.05 0.10 47.38 1158.34Average: 0 6.69 0.00 25.57 0.20 0.00 0.10 67.43 724.08Average: 1 7.69 0.00 64.44 0.20 0.10 0.10 27.37 434.17
Muestra las distintas estadísticas para las CPU del sistema. Las opciones –P ALL ordena al comando desplegar las estadísticas de todas las CPU, no solamente de una específica. Los parámetros 5 2 ordenan al comando ejecutarse cada 5 segundos y durante 2 veces. El output de arriba muestra las métricas para todas las primeras CPU (agrupadas) y para cada CPU individualmente. Finalmente, el porcentaje para todas las CPU se muestra al final.
Veamos el significado de los valores de las columnas:
%user Indica el porcentaje de procesamiento para la CPU consume por proceso de usuario. Los procesos de usuarios son procesos que no son kernel utilizados para aplicaciones como las

de la base de datos de Oracle. En este output de ejemplo, el porcentaje de CPU de usuario es muy pequeño.
%nice Indica el porcentaje de CPU cuando un proceso ha bajado su categoría por el comando nice. El comando nice ha sido descripto en una entrega anterior. En resumen, el comando nice cambia la prioridad de un proceso.
%system Indica el porcentaje de CPU utilizado por los procesos kernel
%iowait Muestra el porcentaje de tiempo de CPU utilizado por la espera de I/O
%irq Indica el porcentaje de CPU utilizado para manejar las interrupciones del sistema
%soft Indica el porcentaje utilizado para las interrupciones de software
%idle Muestra el tiempo de inactividad de la CPU
%intr/s Muestra la cantidad total de interrupciones que la CPU recibe por segundo
Usted podría preguntarse cuál es el propósito del comando mpstat cuando usted ya posee vmstat, descripto anteriormente. Existe una gran diferencia: mpstat puede mostrar las estadísticas por procesador, mientras que vmstat ofrece una visión consolidada de todos los procesadores. Por lo tanto, es posible que una aplicación escasamente escrita que no utilice una arquitectura de múltiples threads se ejecute sobre un motor de múltiples procesadores pero que no utilice todos los procesadores. Como resultado, se produce la sobrecarga de una CPU mientras que las demás permanecen libres. Usted puede diagnosticar fácilmente estas clases de problemas por medio de mpstat.
Para Usuarios de Oracle
De modo similar a vmstat, el comando mpstat también produce estadísticas relacionadas con la CPU de manera que todos los debates relacionados con los problemas de CPU también se aplican a mpstat. Cuando usted observa un bajo nivel de %idle, sabe que está en presencia de una insuficiencia de CPU. Cuando observa una cantidad de %iowait mayor, usted sabe que existe algún problema con el subsistema I/O en torno a la carga actual. Esta información resulta útil para resolver rápidamente los problemas de desempeño de la base de datos de Oracle.
iostatUna parte clave de la evaluación de desempeño es el desempeño del disco. El comando iostat brinda las métricas de desempeño de las interfaces de almacenamiento.
# iostatLinux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 avg-cpu: %user %nice %sys %iowait %idle 15.71 0.00 1.07 3.30 79.91 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtncciss/c0d0 4.85 34.82 130.69 307949274 1155708619cciss/c0d0p1 0.08 0.21 0.00 1897036 3659cciss/c0d0p2 18.11 34.61 130.69 306051650 1155700792cciss/c0d1 0.96 13.32 19.75 117780303 174676304cciss/c0d1p1 2.67 13.32 19.75 117780007 174676288sda 0.00 0.00 0.00 184 0sdb 1.03 5.94 18.84 52490104 166623534sdc 0.00 0.00 0.00 184 0sdd 1.74 38.19 11.49 337697496 101649200sde 0.00 0.00 0.00 184 0sdf 1.51 34.90 6.80 308638992 60159368

sdg 0.00 0.00 0.00 184 0... and so on ...
La primera parte del output muestra las métricas como el espacio de CPU libre y las esperas I/O como ha podido ver en el comando mpstat.
La próxima parte del output muestra métricas muy importantes para cada uno de los dispositivos de disco en el sistema. Veamos lo que significan estas columnas:
Device Nombre del dispositivo
tps Cantidad de transferencias por segundo, es decir, cantidad de operaciones I/O por segundo. Nota: esta es solamente la cantidad de operaciones I/O; cada operación podría ser extensa o pequeña.
Blk_read/s Cantidad de bloques leídos desde este dispositivo por segundo. Generalmente los bloques tienen un tamaño de 512 bytes. Este es el mejor valor de utilización de disco.
Blk_wrtn/s Cantidad de bloques escritos en este dispositivo por segundo
Blk_read Cantidad de bloques leídos desde este dispositivo al momento. Preste atención; no se refiere a lo que está sucediendo en ese momento. Estos bloques ya fueron leídos desde el dispositivo. Es posible que no se esté leyendo nada en ese momento. Observe esto por un rato para ver si se producen cambios.
Blk_wrtn Cantidad de bloques escritos en el dispositivo
En un sistema con muchos dispositivos, el output podría aparecer a través de varias pantallas—haciendo que las cosas sean un poco difícil de examinar, especialmente si busca un dispositivo específico. Usted puede obtener las métricas para un dispositivo específico solamente utilizando ese dispositivo como parámetro.
# iostat sdaj Linux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 avg-cpu: %user %nice %sys %iowait %idle 15.71 0.00 1.07 3.30 79.91 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtnsdaj 1.58 31.93 10.65 282355456 94172401
Las métricas de CPU mostradas al comienzo pueden no ser demasiado útiles. Para eliminar las estadísticas relacionadas con la CPU en el comienzo del output, utilice la opción -d. Usted puede establecer parámetros adicionales al final para que iostat despliegue las estadísticas de dispositivo en intervalos regulares. Para obtener las estadísticas para este dispositivo cada 5 segundos durante 10 veces, emita lo siguiente:
# iostat -d sdaj 5 10
You can display the stats in kilobytes instead of just bytes using the -k option:
# iostat -k -d sdaj Linux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsdaj 1.58 15.96 5.32 141176880 47085232

A pesar de que el output de arriba puede ser útil, aún queda demasiada información que no está lista para ser desplegada. Por ejemplo, una de las causas de los problemas de disco es el tiempo de servicio de disco, es decir, la rapidez con la que el disco obtiene los datos para el proceso que los pide. Para alcanzar ese nivel de métricas, debemos obtener las estadísticas “extendidas” en el disco, utilizando la opción -x.
# iostat -x sdajLinux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 avg-cpu: %user %nice %sys %iowait %idle 15.71 0.00 1.07 3.30 79.91 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s ... sdaj 0.00 0.00 1.07 0.51 31.93 10.65 15.96 ...
Device: wkB/s avgrq-sz avgqu-sz await svctm %util sdaj 5.32 27.01 0.01 6.26 6.00 0.95
Veamos el significado de las columnas:
Device Nombre del dispositivo
rrqm/s Cantidad de solicitudes de lectura fusionas por segundo. Las solicitudes de disco que se colocan en cola. Cuando es posible, kernel intenta fusionar varias solicitudes en una. Esta métrica mide las transferencias de fusión de las solicitudes de lectura.
wrqm/s Similar a la de lectura, esta es la cantidad de solicitudes de escritura fusionadas.
r/s Cantidad de solicitudes de lectura por segundo emitidas en este dispositivo
w/s Del mismo modo, se refiere a la cantidad de solicitudes de escritura por segundo
rsec/s Cantidad de sectores leídos desde este dispositivo por segundo
wsec/s Cantidad de sectores escritos en el dispositivo por segundo
rkB/s Datos leídos por segundo desde este dispositivo, en kilobytes por segundo
wkB/s Datos escritos en este dispositivo, en kb/s
avgrq-sz Tamaño promedio de solicitudes de lectura, en sectores
avgqu-sz Longitud promedio de la cola de solicitudes para este dispositivo
await Promedio de tiempo transcurrido (en milisegundos) para el dispositivo de solicitudes I/O. Esto es la suma del tiempo de servicio + el tiempo de espera en cola.
svctm Promedio del tiempo de servicio (en milisegundos) del dispositivo
%util Utilización de ancho de banda del dispositivo. Si es cercano al 100%, el dispositivo está saturado.
Ahora bien, tanta información puede presentar un desafío sobre cómo utilizarla de manera efectiva. La próxima sección muestra cómo utilizar el output.
Cómo Utilizarlo

Puede utilizar una combinación de comandos para obtener información del output. Recuerde, los discos podrían demorar en obtener la solicitud de los procesos. La cantidad de tiempo que le lleva al disco obtener los datos desde el disco y hasta la cola se denomina tiempo de servicio. Si desea ver los discos con los tiempos de servicio más elevados, usted debe emitir:
# iostat -x | sort -nrk13sdat 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ... sdv 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ... sdak 0.00 0.00 0.00 0.14 0.00 1.11 0.00 ... sdm 0.00 0.00 0.00 0.19 0.01 1.52 0.01 ... sdat 0.00 18.80 0.00 64.06 64.05 0.00sdv 0.00 17.16 0.00 18.03 17.64 0.00sdak 0.55 8.02 0.00 17.00 17.00 0.24sdm 0.76 8.06 0.00 16.78 16.78 0.32... and so on ...
Esto muestra que el sdat de disco tiene el tiempo de servicio más elevado (64.05 ms). ¿Por qué es tan alto? Puede haber varias posibilidades pero posiblemente éstas sean las tres más importantes:
1. El disco contiene muchas solicitudes, por lo tanto el tiempo de servicio promedio es alto2. El disco está utilizando el máximo de ancho de banda.3. El disco es inherentemente lento.
Al observar el output vemos que reads/sec y writes/sec es de 0.00 (no sucede prácticamente nada), por lo tanto podemos excluir la #1. La utilización también es de 0.00% (la última columna), por lo tanto podemos excluir la #2. Así queda la #3. No obstante, antes de llegar a la conclusión de que el disco es inherentemente lento, necesitamos observar aquel disco un poco más de cerca. Podemos examinar ese disco solo cada 5 segundos, unas 10 veces.
# iostat -x sdat 5 10
Si el output muestra el mismo porcentaje de tiempo de servicio, los mismos índices de lectura, podemos concluir que el #3 es el factor más probable. Si ellos cambian, entonces podemos obtener más claves para comprender por qué el tiempo de servicio es alto para este dispositivo.
De manera similar, podemos buscar en la columna de índice de lectura para desplegar el disco bajo índices constantes de lectura.
# iostat -x | sort -nrk6 sdj 0.00 0.00 1.86 0.61 56.78 12.80 28.39 ... sdah 0.00 0.00 1.66 0.52 50.54 10.94 25.27 ... sdd 0.00 0.00 1.26 0.48 38.18 11.49 19.09 ... sdj 6.40 28.22 0.03 10.69 9.99 2.46sdah 5.47 28.17 0.02 10.69 10.00 2.18sdd 5.75 28.48 0.01 3.57 3.52 0.61 ... and so on ...
La información lo ayuda a localizar un disco que está “activo”—es decir, sujeto a muchas lecturas o escrituras. Si el disco se encuentra verdaderamente activo, usted debería identificar la razón de ello; tal vez un filesystem definido en el disco está sujeto a demasiadas lecturas. Si ese es el caso, usted debería considerar el hecho de descartar filesystem de los discos para distribuir la carga, minimizando así la posibilidad de que un disco específico esté activo.

sar
De los debates anteriores, surge un thread común: Obtener métricas en tiempo real no es lo más importante; la tendencia histórica también es importante.
Además, tenga en cuenta esta situación: ¿cuántas veces alguien plantea un problema de desempeño y cuando usted comienza a investigar, todo vuelve a la normalidad? Los problemas de desempeño que han ocurrido en el pasado son difíciles de diagnosticar si carece de datos específicos. Finalmente, usted decidirá examinar el desempeño de los datos en los últimos días para obtener algunos parámetros o para realizar algunos ajustes.
El comando sar cumple con ese objetivo. sar significa System Activity Recorder, y registra las métricas de los componentes clave del sistema Linux—CPU, Memoria, Discos, Redes, etc.—en un lugar especial: directory /var/log/sa. Los datos se graban cada día en un archivo denominado sa<nn> en donde <nn> es el día de dos dígitos del mes. Por ejemplo, el archivo sa27 contiene los datos para el día 27 de ese mes. Estos datos pueden ser consultados por el comando sar.
La manera más sencilla de utilizar sar es sin ningún argumento ni opción. Por ejemplo:
# sarLinux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 12:00:01 AM CPU %user %nice %system %iowait %idle12:10:01 AM all 14.99 0.00 1.27 2.85 80.8912:20:01 AM all 14.97 0.00 1.20 2.70 81.1312:30:01 AM all 15.80 0.00 1.39 3.00 79.8112:40:01 AM all 10.26 0.00 1.25 3.55 84.93... and so on ...
El output muestra las métricas relacionadas con la CPU recogidas en intervalos de 10 minutos. Las columnas significan:
CPU Identificador de CPU; “all” significa todas las CPU
%user Porcentaje de CPU utilizado para los procesos de usuarios. Los procesos de Oracle se presentan en esta categoría.
%nice El % de utilización de CPU mientras se ejecuta una prioridad nice
%system El % de CPU que ejecuta los procesos del sistema
%iowait El % de CPU en espera para I/O
%idle El % de CPU inactiva en espera de trabajos
En el output anterior, podemos ver que el sistema se encuentra bien balanceado; en realidad, por debajo del nivel infrautilizado (como se muestra en el alto grado de inactividad). Profundizando más el output podemos ver lo siguiente:
... continued from above ...03:00:01 AM CPU %user %nice %system %iowait %idle03:10:01 AM all 44.99 0.00 1.27 2.85 40.8903:20:01 AM all 44.97 0.00 1.20 2.70 41.1303:30:01 AM all 45.80 0.00 1.39 3.00 39.8103:40:01 AM all 40.26 0.00 1.25 3.55 44.93... and so on ...

Esto nos muestra otra historia: el sistema fue cargado por algunos procesos de usuarios entre las 3:00 y las 3:40. Tal vez se estaba ejecutando una consulta extensa; o tal vez se estaba ejecutando un trabajo RMAN, consumiendo así toda esa CPU. Aquí es en donde el comando sar es útil –despliega los datos registrados que muestran información de un momento específico, no del momento actual. Esto es exactamente lo que usted necesita para cumplir con los tres objetivos detallados al comienzo de esta sección: obtener datos históricos, encontrar patrones de uso y comprender las tendencias.
Si usted desea ver datos sar de un día específico, simplemente abra sar con ese nombre de archivo, utilizando la opción -f como se muestra abajo (para abrir los datos del día 26)
# sar -f /var/log/sa/sa26
También se pueden desplegar datos en tiempo real, similar a vmstat o mpstat. Para obtener los datos cada 5 segundos, durante 10 veces, utilice:
# sar 5 10Linux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 01:39:16 PM CPU %user %nice %system %iowait %idle01:39:21 PM all 20.32 0.00 0.18 1.00 78.5001:39:26 PM all 23.28 0.00 0.20 0.45 76.0801:39:31 PM all 29.45 0.00 0.27 1.45 68.8301:39:36 PM all 16.32 0.00 0.20 1.55 81.93… and so on 10 times …
¿Notó el valor “all” debajo el título CPU? Esto significa que las estadísticas fueron cargadas para todas las CPU. Para un sistema de procesador único, esto está bien; pero en sistemas con múltiples procesadores usted desea obtener las estadísticas tanto para cada CPU individual, como para el conjunto. La opción -P ALL cumple con esto.
#sar -P ALL 2 2Linux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 01:45:12 PM CPU %user %nice %system %iowait %idle01:45:14 PM all 22.31 0.00 10.19 0.69 66.8101:45:14 PM 0 8.00 0.00 24.00 0.00 68.0001:45:14 PM 1 99.00 0.00 1.00 0.00 0.0001:45:14 PM 2 6.03 0.00 18.59 0.50 74.8701:45:14 PM 3 3.50 0.00 8.50 0.00 88.0001:45:14 PM 4 4.50 0.00 14.00 0.00 81.5001:45:14 PM 5 54.50 0.00 6.00 0.00 39.5001:45:14 PM 6 2.96 0.00 7.39 2.96 86.7001:45:14 PM 7 0.50 0.00 2.00 2.00 95.50 01:45:14 PM CPU %user %nice %system %iowait %idle01:45:16 PM all 18.98 0.00 7.05 0.19 73.7801:45:16 PM 0 1.00 0.00 31.00 0.00 68.0001:45:16 PM 1 37.00 0.00 5.50 0.00 57.5001:45:16 PM 2 13.50 0.00 19.00 0.00 67.5001:45:16 PM 3 0.00 0.00 0.00 0.00 100.00
01:45:16 PM 4 0.00 0.00 0.50 0.00 99.5001:45:16 PM 5 99.00 0.00 1.00 0.00 0.00

01:45:16 PM 6 0.50 0.00 0.00 0.00 99.5001:45:16 PM 7 0.00 0.00 0.00 1.49 98.51 Average: CPU %user %nice %system %iowait %idleAverage: all 20.64 0.00 8.62 0.44 70.30Average: 0 4.50 0.00 27.50 0.00 68.00Average: 1 68.00 0.00 3.25 0.00 28.75Average: 2 9.77 0.00 18.80 0.25 71.18Average: 3 1.75 0.00 4.25 0.00 94.00Average: 4 2.25 0.00 7.25 0.00 90.50Average: 5 76.81 0.00 3.49 0.00 19.70Average: 6 1.74 0.00 3.73 1.49 93.03Average: 7 0.25 0.00 1.00 1.75 97.01
Esto muestra el identificador de CPU (comenzando con 0) y las estadísticas para cada uno. Al final del output usted verá el promedio de ejecuciones de cada CPU.
El comando sar no solo es para estadísticas relacionadas con la CPU. También es útil obtener las estadísticas relacionadas con la memoria. La opción -r muestra la utilización de memoria extensiva.
# sar -rLinux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 12:00:01 AM kbmemfree kbmemused %memused kbbuffers kbcached ...12:10:01 AM 712264 32178920 97.83 2923884 25430452 ...12:20:01 AM 659088 32232096 98.00 2923884 25430968 ...12:30:01 AM 651416 32239768 98.02 2923920 25431448 ...12:40:01 AM 651840 32239344 98.02 2923920 25430416 ...12:50:01 AM 700696 32190488 97.87 2923920 25430416 ...
12:00:01 AM kbswpfree kbswpused %swpused kbswpcad12:10:01 AM 16681300 95908 0.57 38012:20:01 AM 16681300 95908 0.57 38012:30:01 AM 16681300 95908 0.57 38012:40:01 AM 16681300 95908 0.57 38012:50:01 AM 16681300 95908 0.57 380
Veamos el significado de cada columna:
kbmemfree Memoria libre disponible en KB en ese momento
kbmemused Memoria utilizada en KB en ese momento
%memused % de memoria utilizada
kbbuffers % de memoria utilizado como buffers
kbcached % de memoria utilizado como caché
kbswpfree Espacio de swap libre en KB en ese momento
kbswpused Espacio de swap utilizado en KB en ese momento
%swpused % de swap utilizado en ese momento
kbswpcad Swap en caché en KB en ese momento

Al final del output, usted verá la cifra promedio para el período.
También puede obtener las estadísticas específicas relacionadas con la memoria. La opción -B muestra la actividad relacionada con la paginación.
# sar -BLinux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 12:00:01 AM pgpgin/s pgpgout/s fault/s majflt/s12:10:01 AM 134.43 256.63 8716.33 0.0012:20:01 AM 122.05 181.48 8652.17 0.0012:30:01 AM 129.05 253.53 8347.93 0.00... and so on ...
La columna muestra las métricas en ese momento, no las actuales.
pgpgin/s Cantidad de páginas en la memoria desde el disco, por segundo
pgpgout/s Cantidad de páginas fuera del disco, desde la memoria, por segundo
fault/s Fallos de página por segundos
majflt/s Principales fallos de página por segundo
Para obtener un output similar para la actividad relacionada con el swapping, usted puede utilizar la opción -W.
# sar -WLinux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008 12:00:01 AM pswpin/s pswpout/s12:10:01 AM 0.00 0.0012:20:01 AM 0.00 0.0012:30:01 AM 0.00 0.0012:40:01 AM 0.00 0.00... and so on ...
Las columnas probablemente se explican por si mismas; pero aquí se detalla la descripción de cada una:
pswpin/s Páginas de memoria que vuelven a intercambiarse en la memoria desde el disco, por segundo
pswpout/s Páginas de la memoria intercambiadas al disco desde la memoria, por segundo
Si usted observa que el nivel de swapping es demasiado elevado, quizás podría estar quedándose sin memoria. No se trata de una conclusión anticipada, sino de una posibilidad.
Para obtener las estadísticas de los dispositivos de disco, utilice la opción -d:
# sar -dLinux 2.6.9-55.0.9.ELlargesmp (prolin3) 12/27/2008
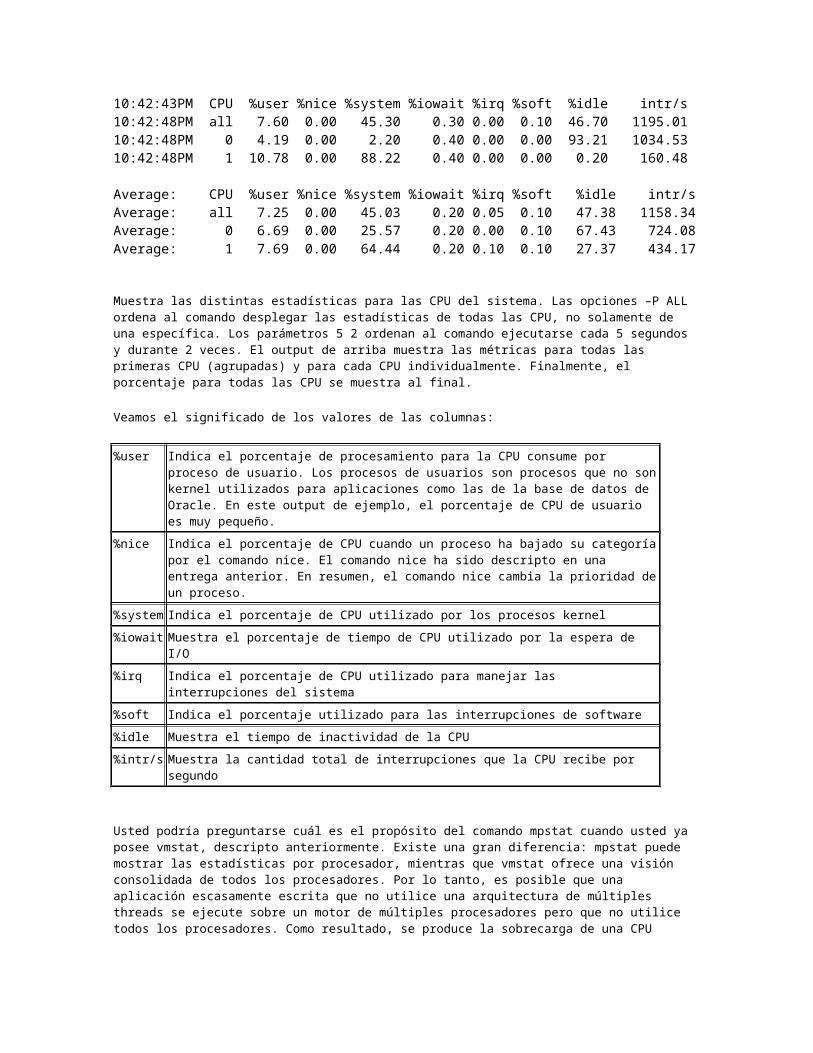
12:00:01 AM DEV tps rd_sec/s wr_sec/s12:10:01 AM dev1-0 0.00 0.00 0.0012:10:01 AM dev1-1 5.12 0.00 219.6112:10:01 AM dev1-2 3.04 42.47 22.2012:10:01 AM dev1-3 0.18 1.68 1.4112:10:01 AM dev1-4 1.67 18.94 15.19... and so on ...Average: dev8-48 4.48 100.64 22.15Average: dev8-64 0.00 0.00 0.00Average: dev8-80 2.00 47.82 5.37Average: dev8-96 0.00 0.00 0.00Average: dev8-112 2.22 49.22 12.08
Aquí está la descripción de las columnas. Nuevamente, ellas muestran las métricas en ese momento.
tps Transferencias por segundo. El término transferencias se refiere a las operaciones I/O. Nota: es solamente la cantidad de operaciones; cada operación puede ser extensa o pequeña. Por lo tanto, esto, por sí mismo, no es la historia completa.
rd_sec/s Cantidad de sectores leídos desde el disco por Segundo
wr_sec/s Cantidad de sectores escritos en el disco por Segundo
Para obtener el historial de estadísticas de red, usted puede utilizar la opción -n:
# sar -n DEV | moreLinux 2.6.9-42.0.3.ELlargesmp (prolin3) 12/27/2008 12:00:01 AM IFACE rxpck/s txpck/s rxbyt/s txbyt/s rxcmp/s txcmp/s rxmcst/s12:10:01 AM lo 4.54 4.54 782.08 782.08 0.00 0.00 0.0012:10:01 AM eth0 2.70 0.00 243.24 0.00 0.00 0.00 0.9912:10:01 AM eth1 0.00 0.00 0.00 0.00 0.00 0.00 0.0012:10:01 AM eth2 0.00 0.00 0.00 0.00 0.00 0.00 0.0012:10:01 AM eth3 0.00 0.00 0.00 0.00 0.00 0.00 0.0012:10:01 AM eth4 143.79 141.14 73032.72 38273.59 0.00 0.00 0.9912:10:01 AM eth5 0.00 0.00 0.00 0.00 0.00 0.00 0.0012:10:01 AM eth6 0.00 0.00 0.00 0.00 0.00 0.00 0.0012:10:01 AM eth7 0.00 0.00 0.00 0.00 0.00 0.00 0.0012:10:01 AM bond0 146.49 141.14 73275.96 38273.59 0.00 0.00 1.98… and so on …Average: bond0 128.73 121.81 85529.98 27838.44 0.00 0.00 1.98Average: eth8 0.00 0.00 0.00 0.00 0.00 0.00 0.00

Average: eth9 3.52 6.74 251.63 10179.83 0.00 0.00 0.00Average: sit0 0.00 0.00 0.00 0.00 0.00 0.00 0.00
En resumen, usted tiene estas opciones para el comando sar a fin de obtener las métricas para los componentes:
Utilice esta opción … … para obtener estadísticas sobre:-P CPU(s) Específica(s)
-d Discos
-r Memoria
-B Paginación
-W Intercambio
-n Red
¿Qué sucede si usted desea tener todas las estadísticas disponibles en un solo output? En lugar de invocar sar con todas estas opciones, usted puede utilizar la opción -A que muestra todas las estadísticas almacenadas en los archivos sar.
ConclusiónPara resumir, al utilizar estos grupos de comandos limitados usted puede manejar la mayoría de las tareas que intervienen en la administración de recursos en un entorno Linux. Sugiero que los practique en su entorno a fin de familiarizarse con estos comandos y con las opciones aquí descriptas.
En las próximas entregas, aprenderá cómo monitorear y administrar la red. También aprenderá varios comandos que lo ayudarán a administrar un entorno Linux: para descubrir quién se ha registrado para establecer procesos shell profile, realizar backups utilizando cpio y tar, entre otras cosas.

Guía para Maestría Avanzada en Comandos Linux, Parte 4: Administración del Entorno Linux
Por Arup Nanda Publicado en mayo de 2009
En esta serie, sepa cómo administrar el entorno Linux de manera efectiva a través de estos comandos ampliamente utilizados.
ifconfig
El comando ifconfig muestra los detalles de la/s interfaz/interfaces de red definidas en el sistema. La opción más común es -a , lo cual permite mostrar todas las interfaces.
# ifconfig -a
El nombre usual de la interfaz de red Ethernet primaria es eth0. Para encontrar los detalles de una interfaz específica, por ej., eth0, puede utilizar:
# ifconfig eth0
A continuación se muestra el output con su respectiva explicación:

Éstas son algunas partes claves del output:
Link encap: corresponde al tipo de medio de hardware físico soportado por esta interfaz (Ethernet, en este caso)
HWaddr: es el identificador exclusivo de la tarjeta NIC. Cada tarjeta NIC tiene un identificador exclusivo asignado por el fabricante, denominado MAC o dirección MAC. La dirección de IP se adjunta al MAC del servidor. Si esta dirección de IP cambia, o esta tarjeta se mueve desde este servidor a otro, el MAC continúa siendo el mismo.
Mask: corresponde a la máscara de red inet addr: es la dirección de IP que se adjunta a la interfaz RX packets: se refiere a la cantidad de paquetes recibidos por esta interfaz TX packets: se refiere a la cantidad de paquetes enviados errors: es la cantidad de errores de envío y recepción
El comando no se utiliza solamente para controlar los parámetros; también se utiliza para configurar y administrar la interfaz. A continuación presentamos un breve listado de los parámetros y opciones de este comando:
up/down – activa o desactiva una interfaz específica. Usted puede utilizar el parámetro down para desconectar una interfaz (o desactivarla):
# ifconfig eth0 down
De manera similar, para conectarla (o activarla), usted debería utilizar:
# ifconfig eth0 up
media – establece el tipo de medio Ethernet como 10baseT, 10 Base 2, etc. Los valores comunes para el parámetro de medios son 10base2, 10baseT, y AUI. Si usted desea que Linux detecte el medio automáticamente, puede especificar “auto”, como se muestra a continuación:
# ifconfig eth0 media auto
add – establece una dirección de IP específica para la interfaz. Para determinar una dirección de IP 192.168.1.101 para la interfaz eth0, usted debería emitir lo siguiente:
# ifconfig eth0 add 192.168.1.101
netmask – determina el parámetro de máscara de red de la interfaz. A continuación se presenta un ejemplo en dónde puede establecer la máscara de red de la interfaz eth0 en 255.255.255.0
# ifconfig eth0 netmask 255.255.255.0
En un entorno Oracle Real Application Clusters usted debe establecer la máscara de red en cierto modo, utilizando este comando.
En algunas configuraciones avanzadas, usted puede cambiar la dirección de MAC asignada a la interfaz de red. El parámetro hw lo hace posible. El formato general es:
ifconfig <Interface> hw <TypeOfInterface> <MAC>

<TypeOfInterface> muestra el tipo de interfaz, por ej., ether, para Ethernet. Aquí se muestra cómo la dirección MAC ha cambiado para eth0 a 12.34.56.78.90.12 (Nota: la dirección MAC que aquí se muestra es ficticia. En caso de ser igual a otra MAC real, es pura coincidencia):
# ifconfig eth0 hw ether 12.34.56.78.90.12
Esto es útil cuando usted agrega una nueva tarjeta (con una nueva dirección MAC) pero no desea cambiar la configuración relacionada con Linux como por ejemplo las interfaces de red.
Para Usuarios de Oracle
El comando, junto con nestat descripto anteriormente, es uno de los comandos más frecuentemente utilizados para administrar Oracle RAC. El desempeño de Oracle RAC depende en gran medida de la interconexión utilizada entre los nodos del cluster. Si la interconexión se satura (es decir, que no puede soportar más tráfico adicional) o falla, usted podrá observar una disminución de desempeño. Lo mejor en este caso es observar el output ifconfig para detectar las fallas. Este es un ejemplo típico:
# ifconfig eth9eth9 Link encap:Ethernet HWaddr 00:1C:23:CE:6F:82 inet addr:10.14.104.31 Bcast:10.14.104.255 Mask:255.255.255.0 inet6 addr: fe80::21c:23ff:fece:6f82/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:1204285416 errors:0 dropped:560923 overruns:0 frame:0TX packets:587443664 errors:0 dropped:623409 overruns:0 carrier:0collisions:0 txqueuelen:1000RX bytes:1670104239570 (1.5 TiB) TX bytes:42726010594 (39.7 GiB)Interrupt:169 Memory:f8000000-f8012100
Observe el texto resaltado en rojo. El conteo arrojado es extremadamente elevado; la cantidad ideal debería ser 0 o cercana a 0. Una cantidad mayor a medio millón implicaría una interconexión defectuosa que rechaza los paquetes, provocando que la interconexión los reenvíe—lo cual sería clave para el diagnóstico de problemas.
netstat
El estado input y output a través de una interfaz de red se evalúa por medio del comando netstat. Este comando puede brindar información completa sobre el desempeño de la interfaz de red, incluso por debajo del nivel de socket. Aquí vemos un ejemplo:
# netstatActive Internet connections (w/o servers)Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 prolin1:31027 prolin1:5500 TIME_WAIT

tcp 4 0 prolin1l:1521 applin1:40205 ESTABLISHED tcp 0 0 prolin1l:1522 prolin1:39957 ESTABLISHED tcp 0 0 prolin1l:3938 prolin1:31017 TIME_WAITtcp 0 0 prolin1l:1521 prolin1:21545 ESTABLISHED … and so on …
El output de arriba muestra todos los sockets abiertos. En términos más simples, un socket es similar a una conexión entre dos procesos. [Por favor tenga en cuanta que, estrictamente hablando, los conceptos “sockets” y “conexiones” son técnicamente diferentes. Un socket podría existir sin una conexión. De todas maneras, el debate entre sockets y conexiones escapa del alcance de este artículo. Por eso simplemente me limité a presentar el concepto de una manera fácil de comprender]. Naturalmente, una conexión debe tener un origen y un destino, denominados dirección local y remota. Los puntos de destino podrían estar en el mismo servidor o en servidores distintos.
En muchos casos, los programas se conectan al mismo servidor. Por ejemplo, si dos procesos se comunican entre ellos, la dirección local y remota será la misma, como puede observar en la primera línea –tanto la dirección local como la remota corresponden al servidor “prolin1”. No obstante, los procesos se comunican a través de un puerto, que es diferente. El puerto se muestra luego del nombre de host, después de los dos puntos “:”. El programa del usuario envía los datos que deben remitirse a través del socket a una cola y el receptor los lee desde la cola de destino remoto. Éstas son las columnas del output:
1. la columna del extremo izquierdo denominada “ Proto” muestra el tipo de conexión – tcp en este caso.
2. La columna Recv-Q muestra los bytes de datos en cola a ser enviados al programa del usuario que estableció la conexión. Este valor debería ser un valor cercano a 0, preferentemente. En los servidores ocupados este valor será mayor a 0 pero no debería ser demasiado alto. Una cantidad mayor no podría significar mucho, a menos que observe una cantidad elevada en la columna Send-Q, descripta a continuación.
3. La columna Send-Q denota los bytes en cola a ser enviados al programa remoto, es decir, el programa remoto aún no ha confirmado su recepción. Esta cantidad debería ser cercana a 0. Una cantidad mayor podría indicar un cuello de botella en la red.
4. Local Address se refiere al origen de la conexión y el número de puerto del programa.5. Foreign Address hace referencia al host de destino y el número de puerto. En la primera línea, tanto
el origen como el destino corresponden al mismo host: prolin1. La conexión se encuentra simplemente en espera. La segunda línea muestra una conexión establecida entre el puerto 1521 de proiln1 hasta el puerto 40205 del host applin1. Lo más probable es que una conexión de Oracle venga del applin1 cliente hasta el servidor prolin1. El listener de Oracle en prolin1 se ejecuta en el puerto 1521; de manera que el puerto de origen es 1521. En esta conexión, el servidor envía los datos solicitados al cliente.
6. La columna State muestra el estado de la conexión. Aquí vemos algunos valores comunes.7.o ESTABLISHED – implica que la conexión ha sido establecida. No significa que los datos
fluyen entre los puntos de destino; simplemente que se ha establecido una comunicación entre ellos.
o CLOSED – la conexión se ha cerrado, es decir, no está siendo utilizada.o TIME_WAIT – la conexión se está cerrando pero aún hay paquetes pendientes en la red.o CLOSE_WAIT – el destino remoto ha sido cerrado y se ha solicitado el cierre de conexión.
Pues bien, a partir de las direcciones locales (local) y externas (foreign), y especialmente a partir de los números de puertos, probablemente podamos deducir que las conexiones son conexiones relacionadas a Oracle, pero ¿no sería mejor estar seguros? Por supuesto. La opción -p también muestra la información del proceso:
# netstat -pProto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
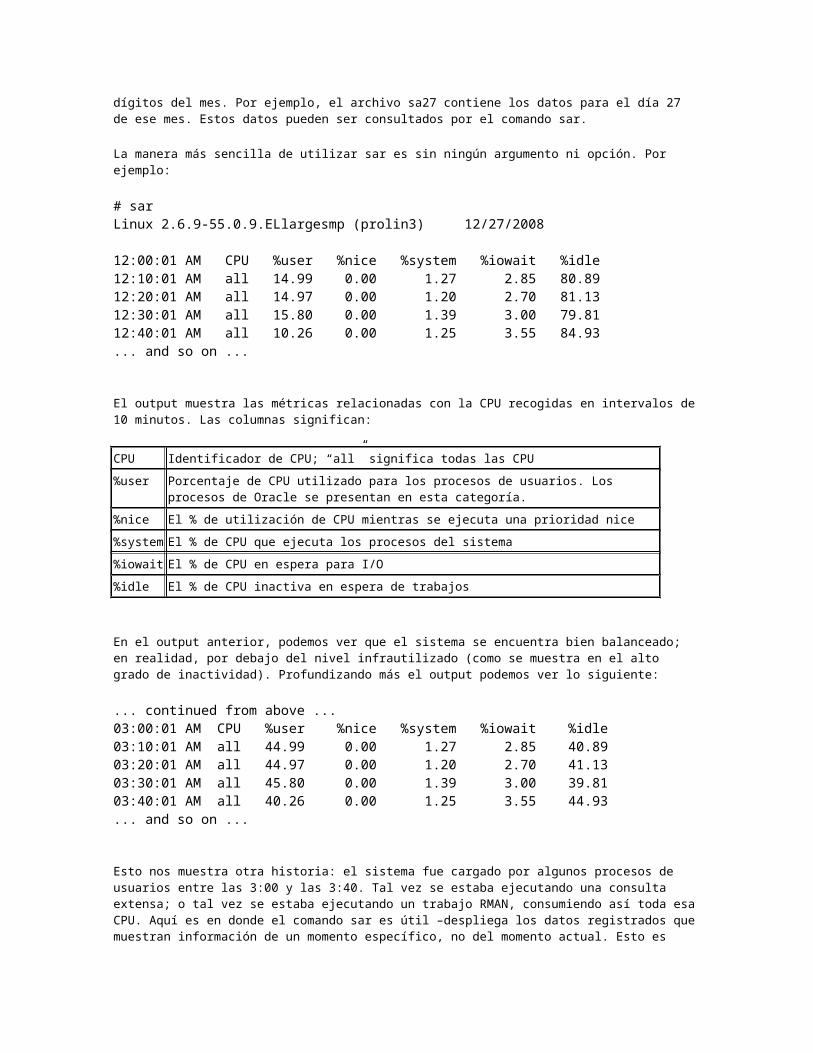
tcp 0 0 prolin1:1521 prolin1:33303 ESTABLISHED 1327/oraclePROPRD1 tcp 0 0 prolin1:1521 applin1:51324 ESTABLISHED 13827/oraclePROPRD1 tcp 0 0 prolin1:1521 prolin1:33298 ESTABLISHED 32695/tnslsnr tcp 0 0 prolin1:1521 prolin1:32544 ESTABLISHED 15251/oracle+ASM tcp 0 0 prolin1:1521 prolin1:33331 ESTABLISHED 32695/tnslsnr
Esto muestra claramente el IP del proceso y el nombre del proceso en la última columna, la cual confirma que corresponden a procesos del servidor de Oracle, al proceso listener, y a los procesos del servidor ASM.
El comando netstat puede presentar varias opciones y parámetros. A continuación se detallan los más importantes:
Para ver las estadísticas de red de las distintas interfaces, utilice la opción -i.
# netstat -iKernel Interface tableIface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flgeth0 1500 0 6860659 0 0 0 2055833 0 0 0 BMRUeth8 1500 0 2345 0 0 0 833 0 0 0 BMRUlo 6436 0 14449079 0 0 0 14449079 0 0 0 LRU
Esto muestra las distintas interfaces presentes en el servidor (eth0, eth8, etc.) y las métricas relacionadas con la interfaz.
RX-OK muestra la cantidad de paquetes que son exitosamente enviados (para esta interfaz) RX-ERR muestra la cantidad de errores RX-DRP muestra los paquetes rechazados que debieron ser reenviados (ya sea con éxito o no) RX-OVR muestra un exceso de paquetes
El próximo grupo de columnas (TX-OK, TX-ERR, etc.) muestra las stats (estadísticas) correspondientes a los datos enviados.
La columna Flg expresa un valor compuesto de la propiedad de la interfaz. Cada letra indica una propiedad específica presente. A continuación se detalla el significado de las letras.
B – Broadcasting (Difusión) M –Multicast (Multidifusión) R – Running (En ejecución) U – Up (Activado) O – ARP Off (ARP desactivado) P – Point to Point Connection (Conexión Punto a Punto) L – Loopback (Circuito cerrado) m – Master s - Slave
Usted pude utilizar la opción --interface (nota: hay dos guiones, no uno) para desplegar una interfaz específica.
# netstat --interface=eth0 Kernel Interface table
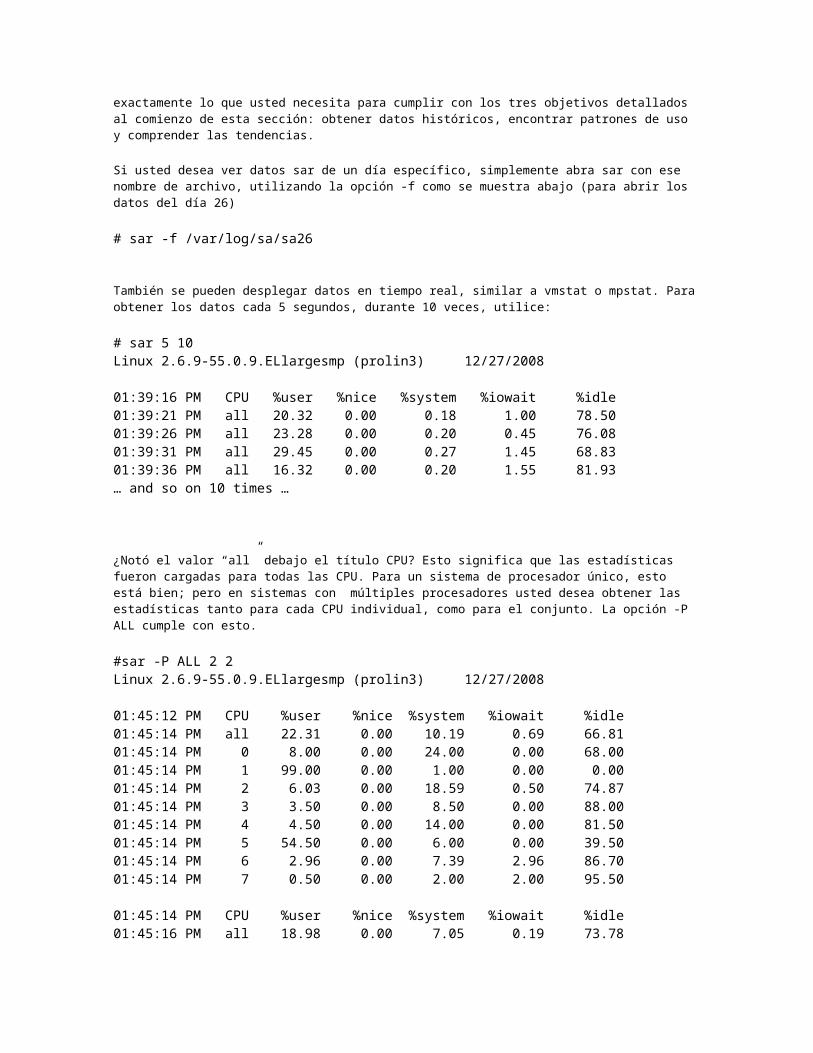
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flgeth0 1500 0 277903459 0 0 0 170897632 0 0 0 BMsRU
De más está decir que, el output es amplio y un poco difícil de captar de un solo intento. Si usted está realizando una comparación entre interfaces, sería lógico tener un output tabular. Si desea examinar los valores en un formato más legible, utilice la opción -e para producir un output extendido:
# netstat -i -eKernel Interface tableeth0 Link encap:Ethernet HWaddr 00:13:72:CC:EB:00 inet addr:10.14.106.0 Bcast:10.14.107.255 Mask:255.255.252.0 inet6 addr: fe80::213:72ff:fecc:eb00/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:6861068 errors:0 dropped:0 overruns:0 frame:0 TX packets:2055956 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:3574788558 (3.3 GiB) TX bytes:401608995 (383.0 MiB) Interrupt:169
¿El output le resulta conocido? Debería ser así ya que es el mismo que el output de ifconfig.
Si prefiere que el output despliegue las direcciones de IP en lugar de los nombres del host, utilice la opción -n.
La opción -s muestra el resumen de estadísticas de cada protocolo, en vez de mostrar los detalles de cada conexión. Esto puede combinarse con el flag específico del protocolo, Por ejemplo, -u muestra las estadísticas relacionadas con el protocolo UDP. # netstat -s -uUdp: 12764104 packets received 600849 packets to unknown port received. 0 packet receive errors 13455783 packets sent
Del mismo modo, para ver las stats de tcp, utilice -t y para raw, -r.
Una de las opciones realmente útiles es desplegar la tabla de ruta, utilizando la opción -r. # netstat -rKernel IP routing tableDestination Gateway Genmask Flags MSS Window irtt Iface10.20.191.0 * 255.255.255.128 U 0 0 0 bond0172.22.13.0 * 255.255.255.0 U 0 0 0 eth9169.254.0.0 * 255.255.0.0 U 0 0 0 eth9default 10.20.191.1 0.0.0.0 UG 0 0 0 bond0
La segunda columna del output netstat – Gateway–muestra el gateway de asignación de ruta. Si no se utiliza ningún gateway, aparece un asterisco. La tercera columna– Genmask–muestra la “generalidad” del enrutamiento, es decir, la máscara de red para esta ruta. Al dar una dirección de IP para encontrar una ruta adecuada, el kernel sigue el proceso de cada una de las entradas de enrutamiento, tomando el nivel de bits AND de la dirección y la máscara de red antes de compararlo con el destino de ruta.
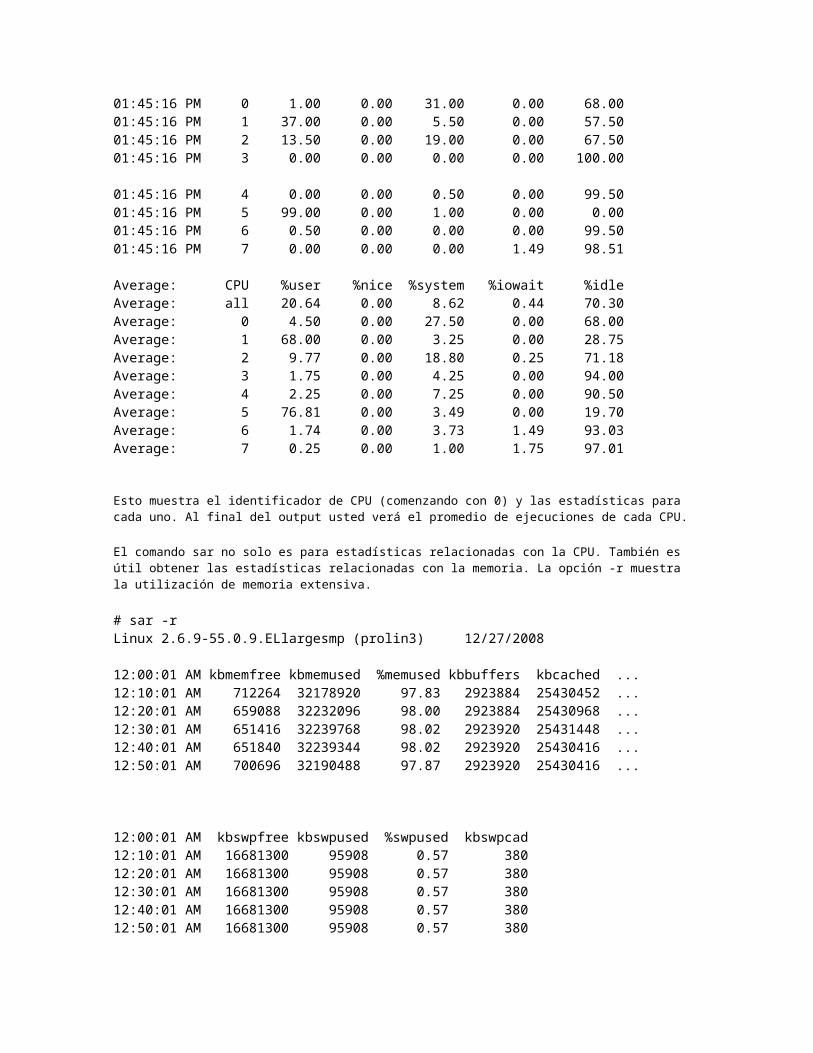
La cuarta columna, denominada Flags, despliega las siguientes etiquetas que describen la ruta:
G significa que la ruta utiliza un gateway. U implica que la interfaz a ser utilizada se encuentra activa (disponible). H implica que solo puede alcanzarse un único host a través de la ruta. Por ejemplo, el caso de la
entrada de loopback (circuito cerrado) 127.0.0.1. D significa que esta ruta ha sido dinámicamente creada. ! significa que la ruta ha sido rechazada y se descartarán los datos.
La siguientes tres columnas muestran los valores MSS, Window e irtt que se aplicarán a las conexiones TCP establecidas por medio de esta ruta.
MSS representa la sigla Maximum Segment Size (Tamaño de Segmento Máximo) –es el tamaño del datagrama más amplio para realizar la transmisión a través de esta ruta.
Window se refiere a la cantidad máxima de datos que el sistema aceptará en modo single burst desde un host remoto y para esta ruta.
irtt representa la sigla de Initial Round Trip Time (el Valor Inicial del Temporizador TCP). Es un poco difícil de explicar, pero lo haré por separado.
El protocolo TCP posee un control de fiabilidad incorporado. Si un paquete de datos falla durante la transmisión, éste es retransmitido. El protocolo lleva un registro de cuánto tiempo tardan los datos en llegar a destino y en confirmarse su recepción. Si la confirmación no llega dentro de ese plazo de tiempo, el paquete es retransmitido. La cantidad de tiempo que el protocolo debe esperar antes de retransmitir los datos se establece solo una vez para la interfaz (la cual puede cambiarse) y ese valor es conocido como initial round trip time. Un valor de 0 implica que el valor por defecto es utilizado.
Finalmente, el último campo despliega la interfaz de red que utilizará esta ruta.
nslookup
Cada host accesible en una red debería tener una dirección de IP que le permita identificarse exclusivamente en la red. En Internet, que es una red extensa, las direcciones de IP permiten que las conexiones lleguen a los servidores que ejecutan sitios Web, por ej., www.oracle.com. Por lo tanto, cuando un host (como un cliente) desea conectarse a otro (como un servidor de base de datos) utilizando su nombre y no su dirección de IP ¿cómo el browser cliente sabe a qué dirección conectarse?
El mecanismo de traspaso del nombre de host a las direcciones de IP es conocido como resolución de nombre. En el nivel más rudimentario, el host tiene un archivo especial denominado hosts, que almacena la Dirección de IP – Hostname. Este es un archivo de muestra: # cat /etc/hosts# Do not remove the following line, or various programs# that require network functionality will fail.127.0.0.1 localhost.localdomain localhost192.168.1.101 prolin1.proligence.com prolin1192.168.1.102 prolin2.proligence.com prolin2
Esto muestra que el nombre del host prolin1.proligence.com se traduce a 192.168.1.101. La entrada especial con la dirección de IP 127.0.0.1 se denomina entrada loopback, la cual vuelve al servidor mismo por medio de una interfaz de red especial denominada lo (que se menciona anteriormente en los comandos ifconfig y netstat).
Ahora bien, de todas formas, usted posiblemente no puede colocar todas las direcciones de IP del mundo en este archivo. Por lo que debería haber otro mecanismo que establezca la resolución del nombre. Un servidor con un propósito especial denominado nameserver realiza esa función. Es como un directorio que provee su compañía telefónica; no su directorio personal. Pueden existir varios nameservers disponibles dentro y fuera

de la red privada. El host contacta a uno de estos nameservers primero, obtiene la dirección de IP del host de destino que desea contactar y luego intenta conectarse a la dirección de IP.
¿Y cómo el host sabe cuáles son estos nameservers? Busca en un archivo especial llamado /etc/resolv.conf para obtener esa información. Aquí vemos un archivo resolv de ejemplo. ; generated by /sbin/dhclient-scriptsearch proligence.comnameserver 10.14.1.58nameserver 10.14.1.59nameserver 10.20.223.108
¿Pero cómo podemos estar seguros de que la resolución del nombre está funcionando perfectamente para un nombre de host específico? En otras palabras, usted quiere asegurarse de que cuando el sistema de Linux intente contactarse a un host denominado oracle.com, pueda encontrar la dirección de IP en el nameserver. El comando nslookup es útil para eso. Vea a continuación cómo utilizarlo:
# nslookup oracle.comServer: 10.14.1.58Address: 10.14.1.58#53
** server can't find oracle-site.com: NXDOMAIN
Analicemos el output. El output del Server (Servidor) es la dirección del nameserver. El nombre oracle.com establece la dirección de IP 141.146.8.66. El nombre fue definido por el nameserver próximo a la palabra Server en el output.
Si usted escribe esta dirección de IP en un browser–http://141.146.8.66 en lugar de http://oracle.com--el browser se dirigirá al sitio oracle.com.
Si usted cometió un error o buscó un host equivocado:
# nslookup oracle-site.comServer: 10.14.1.58Address: 10.14.1.58#53
** server can't find oracle-site.com: NXDOMAIN
El mensaje es bastante claro: este host no existe.
dig
El comando nslookup ha caído en desuso. En su lugar debería utilizarse un comando nuevo y más poderoso – dig ( domain information groper). En algunos servidores Linux más nuevos, el comando nslookup podría no estar aún disponible.
Aquí vemos un ejemplo; para verificar la resolución del nombre del host oracle.com, debería utilizar el siguiente comando:
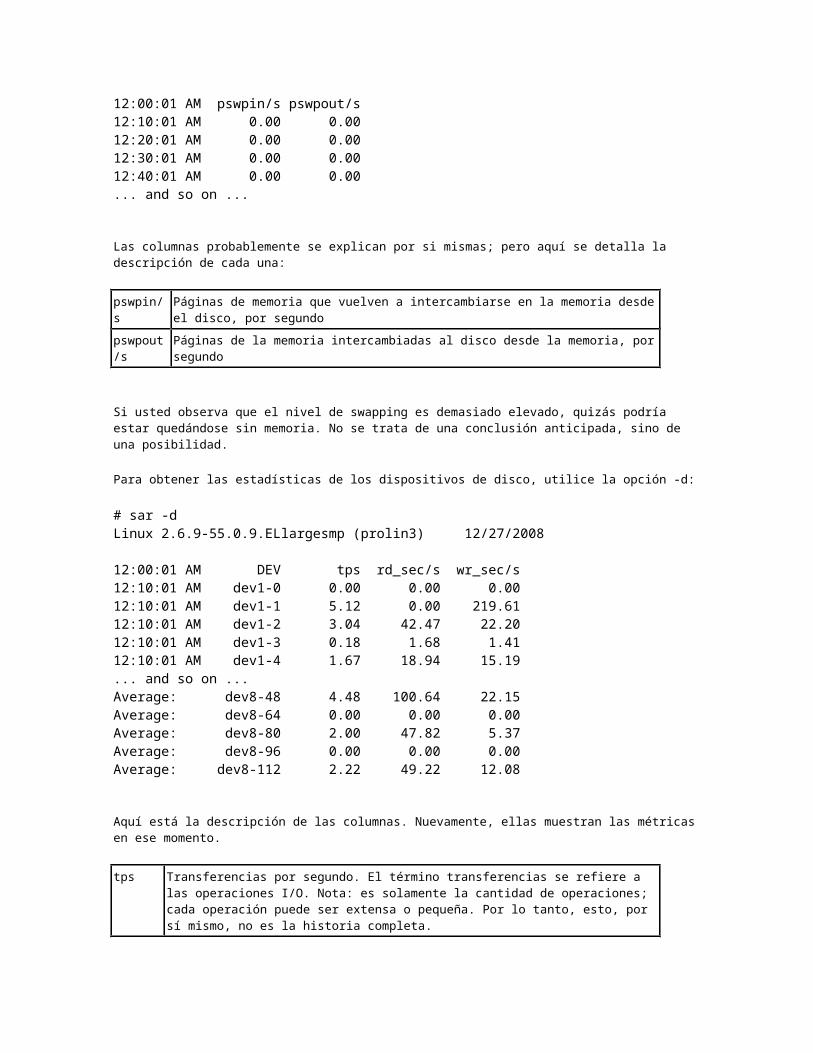
# dig oracle.com
; <<>> DiG 9.2.4 <<>> oracle.com;; global options: printcmd;; Got answer:;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62512;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 8, ADDITIONAL: 8 ;; QUESTION SECTION:;oracle.com. IN A ;; ANSWER SECTION:oracle.com. 300 IN A 141.146.8.66 ;; AUTHORITY SECTION:oracle.com. 3230 IN NS ns1.oracle.com.oracle.com. 3230 IN NS ns4.oracle.com.oracle.com. 3230 IN NS u-ns1.oracle.com.oracle.com. 3230 IN NS u-ns2.oracle.com.oracle.com. 3230 IN NS u-ns3.oracle.com.oracle.com. 3230 IN NS u-ns4.oracle.com.oracle.com. 3230 IN NS u-ns5.oracle.com.oracle.com. 3230 IN NS u-ns6.oracle.com. ;; ADDITIONAL SECTION:ns1.oracle.com. 124934 IN A 148.87.1.20ns4.oracle.com. 124934 IN A 148.87.112.100u-ns1.oracle.com. 46043 IN A 204.74.108.1u-ns2.oracle.com. 46043 IN A 204.74.109.1u-ns3.oracle.com. 46043 IN A 199.7.68.1u-ns4.oracle.com. 46043 IN A 199.7.69.1u-ns5.oracle.com. 46043 IN A 204.74.114.1u-ns6.oracle.com. 46043 IN A 204.74.115.1 ;; Query time: 97 msec;; SERVER: 10.14.1.58#53(10.14.1.58);; WHEN: Mon Dec 29 22:05:56 2008;; MSG SIZE rcvd: 328
Desde el output mammoth, se destacan varias cosas. Muestra que el comando ha enviado una consulta al nameserver y el host obtuvo una respuesta del nameserver. La resolución del nombre también ha sido efectuada en otros nameservers como ns1.oracle.com. Esto demuestra que la consulta tardó 97 milisegundos en ejecutarse.
Si el tamaño del output no es el adecuado, usted puede utilizar la opción +short para eliminar las palabras redundantes del output:
# dig +short oracle.com141.146.8.66
También puede utilizar la dirección de IP para realizar una búsqueda inversa del nombre de host a partir de la dirección de IP. Para esto se utiliza la opción -x.
# dig -x 141.146.8.66
El parámetro +domain es útil cuando usted busca un host dentro de un dominio. Por ejemplo, supongamos que usted está buscando el host otn en el dominio oracle.com, usted puede utilizar:
# dig +short otn.oracle.com
O puede utilizar el parámetro +domain:
# dig +short +tcp +domain=oracle.com otnwww.oracle.com.www.oraclegha.com.141.146.8.66
Para Usuarios de Oracle
Se establece la conectividad entre el servidor de aplicaciones y el servidor de base de datos. El archivo TNSNAMES.ORA, utilizado por SQL*Net puede parecerse a este:
prodb3 = (description = (address_list = (address = (protocol = tcp)(host = prolin3)(port = 1521)) ) (connect_data = (sid = prodb3) ) )
El nombre de host prolin3 debería ser determinado por el servidor de aplicaciones. En cualquiera de los casos, éste debería figurar en el archivo /etc/hosts; o el host prolin3 debería definirse en el DNS. Para asegurarse de que la resolución del nombre funciona, y que funciona de manera correcta para dirigirse al host adecuado, usted puede utilizar el comando dig.
Con estos dos comandos usted puede manejar la mayoría de las tareas de red en un entorno Linux. En la que queda de esta presentación, usted aprenderá a administrar un entorno Linux de manera efectiva.
uptime
Usted ha ingresado al servidor y ha observado que algunas cosas que deberían estar funcionando, en verdad no lo están. Tal vez algunos procesos fueron cancelados o quizás todos los procesos han sido finalizados debido a un cierre del sistema. En lugar de hacer suposiciones, descubra si el servidor ha sido realmente reiniciado utilizando el comando uptime. El comando muestra el plazo de tiempo durante el cual el servidor ha estado funcionando desde su último reinicio.
# uptime 16:43:43 up 672 days, 17:46, 45 users, load average: 4.45, 5.18, 5.38

El output muestra mucha información de utilidad. La primera columna muestra el momento real en que el comando fue ejecutado. La segunda parte – activo 672 días, 17:46 – muestra el tiempo en que el servidor ha estado activo. Las cifras 17:46 representan las horas y minutos. Por lo tanto, este servidor ha estado funcionando por 672 días, 17 horas y 46 minutos hasta el momento.
El siguiente elemento – 45 usuarios – muestra la cantidad de usuarios que han iniciado sesión en el servidor justo en ese momento.
Los últimos bits del output muestran el promedio de carga del servidor en el último minuto, y en los último 5 y 15 minutos respectivamente. El término “carga promedio” es una cifra compuesta que representa la carga del sistema sobre la base de las métricas de I/O y CPU. Cuanto mayor es el promedio de carga, mayor la carga en el sistema. No se basa en una escala; a diferencia de los porcentajes, no finaliza con una cantidad determinada, como 100. Además, la carga promedio de dos sistemas no puede compararse entre sí. Dicha cifra se utiliza para cuantificar la carga en un sistema y solo es relevante para ese único sistema. Este output muestra que la carga promedio fue de 4,45 en el último minuto, 5,18 en los últimos 5 minutos y así sucesivamente.
El comando no tiene ninguna opción ni acepta ningún parámetro que no sea -V, el cual muestra la versión del comando.
# uptime -Vprocps version 3.2.3
Para Usuarios de Oracle
No existe un uso específico de Oracle en torno a este comando, salvo que usted puede conocer la carga del sistema para explicar algunos problemas de desempeño. Si observa algunos problemas de desempeño en la base de datos, y éstos surgen debido a la elevada carga de I/O o CPU, usted inmediatamente debería controlar las cargas promedio utilizando el comando uptime. Si observa un promedio de carga elevado, su próximo paso será realizar un examen detallado para detectar la causa del problema. Para realizar este análisis, usted cuenta con una gran cantidad de herramientas como mpstat, iostat y sar (descriptas en esta presentación de la serie).
Preste atención al output que se muestra a continuación:
# uptime 21:31:04 up 330 days, 7:16, 4 users, load average: 12.90, 1.03, 1.00
Es interesante ver cómo el promedio de carga era bastante elevado (12,90) en el último minuto y luego ha disminuido bastante, incluso hasta niveles irrelevantes, llegando a 1,03 y 1,00 en los últimos 5 y 15 minutos respectivamente. ¿Qué significa esto? Esto demuestra que en menos de 5 minutos, se inició algún proceso que provocó que el promedio de carga subiera repentinamente en el último minuto. Este proceso no estaba presente anteriormente ya que el promedio de carga era bastante bajo. Este análisis nos lleva a concentrarnos en los procesos iniciados en los últimos minutos – acelerando así el proceso de resolución.
Lógicamente, como esto demuestra la cantidad de tiempo en que el servidor ha estado funcionando, también explica por qué la instancia ha estado activa desde aquel momento.
who

¿Quién ha ingresado en el sistema en este momento? Esa es una simple pregunta que usted podría hacerse especialmente si desea rastrear a algún usuario errante que está ejecutando algunos comandos que consumen recursos.
El comando who responde esa pregunta. Observe aquí el uso más simple de este comando, sin argumentos ni parámetros.
# whooracle pts/2 Jan 8 15:57 (10.14.105.139)oracle pts/3 Jan 8 15:57 (10.14.105.139)root pts/1 Dec 26 13:42 (:0.0)root :0 Oct 23 15:32
El comando puede presentar varias opciones. La opción -s es la opción por defecto; que produce el mismo output que arriba.
Observando el output, usted quizás esté haciendo memoria para recordar lo que significan las columnas. Bueno, relájese. Puede utilizar la opción -H para desplegar el encabezado:
# who -HNAME LINE TIME COMMENToracle pts/2 Jan 8 15:57 (10.14.105.139)oracle pts/3 Jan 8 15:57 (10.14.105.139)root pts/1 Dec 26 13:42 (:0.0)root :0 Oct 23 15:32
Ahora el significado de las columnas es claro. La columna NAME muestra el nombre de usuario registrado. LINE muestra el nombre de terminal. En Linux cada conexión se denomina como una terminal con el convenio de denominación pts/<n> en donde <n> es un número que comienza con 1. La terminal :0 es una denominación para la terminal X. TIME muestra la primera vez en que se registraron. Y COMMENTS muestra la dirección de IP desde donde se registraron.
¿Pero qué sucede si usted solo quiere obtener un listado con los nombres de usuarios en lugar de ver todos esos detalles superfluos? La opción -q logra eso. Despliega los nombres de usuarios en una sola línea, ordenados alfabéticamente. También despliega la cantidad total de usuarios al final (45, en este caso):
# who -qananda ananda jsmith klome oracle oracle root root … and so on for 45 names# users=45
Algunos usuarios podrían haber iniciado sesión pero no estar realizando ninguna actividad en realidad. Usted puede controlar por cuánto tiempo han estado inactivos utilizando la opción -u, lo cual es realmente útil, especialmente si usted es el jefe.
# who -uHNAME LINE TIME IDLE PID COMMENToracle pts/2 Jan 8 15:57 . 18127 (10.14.105.139)oracle pts/3 Jan 8 15:57 00:26 18127 (10.14.105.139)root pts/1 Dec 26 13:42 old 6451 (:0.0)root :0 Oct 23 15:32 ? 24215

La nueva columna IDLE muestra el tiempo de inactividad con el formato hh:mm. ¿Observa el valor “old” en esa columna? Implica que el usuario ha estado inactivo durante más de 1 día. La columna PID muestra el ID del proceso de su conexión shell.
Otra opción útil es -b que muestra cuando el sistema ha sido reiniciado.
# who -b system boot Feb 15 13:31
Muestra que el sistema ha sido reiniciado el 15 de febrero a la 1:31 p.m. ¿Recuerda el comando uptime? También muestra la cantidad de tiempo durante el cual el sistema ha estado activo. Usted puede restar los días que se observan en uptime para saber la fecha de reinicio. El comando -b facilita esto ya que directamente muestra la fecha de reinicio.
Advertencia Importante: El comando who -b muestra el mes y la fecha únicamente, no el año. De modo que si el sistema ha estado activo por más de un año, el output no reflejará el valor correcto. Por consiguiente el comando uptime siempre es el enfoque preferido, incluso si usted tiene que hacer algunos cálculos. Aquí vemos un ejemplo:
# uptime 21:37:49 up 675 days, 22:40, 1 user, load average: 3.35, 3.08, 2.86# who -b system boot Mar 7 22:58
Observe que la fecha de reinicio es el 7 de marzo. Eso fue en 2007 ¡no en 2008! El uptime muestra la fecha correcta – ha estado activo durante 675 días. Si las restas no son su fuerte, puede utilizar un simple SQL para obtener esa fecha, 675 días atrás:
SQL> select sysdate - 675 from dual;
SYSDATE-6---------07-MAR-07
La opción -l muestra los inicios de sesión al sistema:
# who -lH NAME LINE TIME IDLE PID COMMENTLOGIN tty1 Feb 15 13:32 4081 id=1LOGIN tty6 Feb 15 13:32 4254 id=6
Para descubrir las terminales del usuario que ya no están en uso, utilice la opción -d:
# who -dHNAME LINE TIME IDLE PID COMMENT EXIT Feb 15 13:31 489 id=si term=0 exit=0 Feb 15 13:32 2870 id=l5 term=0 exit=0 pts/1 Oct 10 14:53 31869 id=ts/1 term=0 exit=0 pts/4 Jan 11 00:20 22155 id=ts/4 term=0 exit=0 pts/3 Jun 29 16:01 0 id=/3 term=0 exit=0 pts/2 Oct 4 22:35 8371 id=/2 term=0 exit=0 pts/5 Dec 30 03:15 5026 id=ts/5 term=0 exit=0

pts/4 Dec 30 22:35 0 id=/4 term=0 exit=0
Algunas veces el proceso init (el proceso que primero se ejecuta cuando se reinicia el sistema) inicia otros procesos. La opción -p muestra todos esos inicios de sesión que están activos.
# who -pHNAME LINE TIME PID COMMENT Feb 15 13:32 4083 id=2 Feb 15 13:32 4090 id=3 Feb 15 13:32 4166 id=4 Feb 15 13:32 4174 id=5 Feb 15 13:32 4255 id=x Oct 4 23:14 13754 id=h1
Más adelante en este documento, usted conocerá un comando – write – que permite enviar y recibir mensajes en tiempo real. También aprenderá a desactivar la capacidad de otros para escribir en su terminal (el comando mesg). Si desea saber qué usuarios permiten y no permiten a los demás escribir en sus terminales, utilice la opción -T:
# who -THNAME LINE TIME COMMENToracle + pts/2 Jan 11 12:08 (10.23.32.10)oracle + pts/3 Jan 11 12:08 (10.23.32.10)oracle - pts/4 Jan 11 12:08 (10.23.32.10)root + pts/1 Dec 26 13:42 (:0.0)root ? :0 Oct 23 15:32
El signo + sign antes del nombre de la terminal implica que la terminal acepta los comandos de escritura de otros; el signo “-” significa que la terminal no lo permite. El signo “?” en este campo significa que la terminal no soporta escrituras, por ejemplo, una sesión X-window.
El nivel actual de ejecución del sistema puede obtenerse a través de la opción -r: # who -rHNAME LINE TIME IDLE PID COMMENT run-level 5 Feb 15 13:31 last=S
Con la opción -a (all) puede obtenerse un listado más descriptivo. Esta opción combina las opciones -b -d -l -p -r -t -T -u. De modo que estos dos comandos producen el mismo resultado:
# who -bdlprtTu# who -a
Aquí vemos un output de muestra (con el encabezado, para que usted puede comprender mejor las columnas):
# who -aHNAME LINE TIME IDLE PID COMMENT EXIT Feb 15 13:31 489 id=si term=0 exit=0 system boot Feb 15 13:31 run-level 5 Feb 15 13:31 last=S

Feb 15 13:32 2870 id=l5 term=0 exit=0LOGIN tty1 Feb 15 13:32 4081 id=1 Feb 15 13:32 4083 id=2 Feb 15 13:32 4090 id=3 Feb 15 13:32 4166 id=4 Feb 15 13:32 4174 id=5LOGIN tty6 Feb 15 13:32 4254 id=6 Feb 15 13:32 4255 id=x Oct 4 23:14 13754 id=h1 pts/1 Oct 10 14:53 31869 id=ts/1 term=0 exit=0oracle + pts/2 Jan 8 15:57 . 18127 (10.14.105.139)oracle + pts/3 Jan 8 15:57 00:18 18127 (10.14.105.139) pts/4 Dec 30 03:15 5026 id=ts/4 term=0 exit=0 pts/3 Jun 29 16:01 0 id=/3 term=0 exit=0root + pts/1 Dec 26 13:42 old 6451 (:0.0) pts/2 Oct 4 22:35 8371 id=/2 term=0 exit=0root ? :0 Oct 23 15:32 ? 24215 pts/5 Dec 30 03:15 5026 id=ts/5 term=0 exit=0 pts/4 Dec 30 22:35 0 id=/4 term=0 exit=0
Para ver su propio inicio de sesión, utilice la opción -m:
# who -moracle pts/2 Jan 8 15:57 (10.14.105.139)
¿Observa el valor pts/2? Es el número de terminal. Usted puede encontrar su propia terminal a través del comando tty:
# tty/dev/pts/2
En Linux existe una estructura de comando especial para mostrar su propio registro de inicio de sesión –who am i. Produce el mismo output como en la opción -m.
# who am ioracle pts/2 Jan 8 15:57 (10.14.105.139)
Los únicos argumentos permitidos son “am i" y “mom likes” (¡si, aunque no lo crea!). Ambos producen el mismo output,
Original Instant Messenger System
Con la llegada de la mensajería instantánea o los programas de chat quedó comprobado que hemos

conquistado el desafío global de mantener un intercambio de información en tiempo real, sin olvidarnos de las comunicaciones de voz. ¿Pero estos programas solo se encuentran en el ámbito de los llamados programas atractivos?
El concepto de chat o mensajería instantánea ha estado disponible durante bastante tiempo en *nix. De hecho, usted tiene un sistema IM seguro y completo incorporado en Linux. Éste le permite conversar de manera segura con cualquier persona conectada al sistema; sin requerir conexión de internet. El chat es activado a través de los comandos – write, mesg, wall y talk. Examinemos cada uno de ellos.
El comando write permite escribir en la terminal de un usuario. Si el usuario ha iniciado sesión en más de una terminal, usted puede dirigirse a una dirección específica. Aquí se muestra cómo escribir el mensaje “Cuidado con el virus” para el usuario “oracle” que inició sesión en la terminal “pts/3”: # write oracle pts/3Beware of the virusttyl <Control-D>#
La combinación de teclas Control-D finaliza el mensaje, devuelve el shell prompt (#) al usuario final y lo envía a la terminal del usuario. Cuando éste se envía, el usuario “oracle” verá en la terminal pts/3 los mensajes:
Beware of the virusttyl
Cada línea aparecerá a medida que el remitente presione ENTER después de las líneas. Cuando el remitente presiona Control-D, finalizando la transmisión, el receptor verá EOF en la pantalla. El mensaje se desplegará independientemente de la actual acción del usuario. Si el usuario está editando un archivo en vi, el mensaje aparece y el usuario puede eliminarlo al presionar Control-L. Si el usuario se encuentra en SQL*Plus prompt, el mensaje aún aparece pero no afecta los registros del teclado del usuario.
¿Pero qué sucede si usted no quiere sufrir estas pequeñas molestias? Usted no quiere que nadie le envíe mensajes del tipo –“descuelga el teléfono”. Usted puede hacerlo a través del comando mesg. Este comando desactiva la capacidad de los demás para enviarle mensajes. El comando sin ningún argumento muestra la siguiente capacidad: # mesgis y
Muestra que otros pueden escribirle. Para desactivarlo:
# mesg n
Ahora para confirmar:
# mesg is n
Cuando usted intenta escribir en las terminales de los usuarios, quizás desee saber qué terminales han sido desactivadas para que otros no puedan escribir en ellas. El comando -T (descripto anteriormente en este documento) muestra que:
# who -THNAME LINE TIME COMMENToracle + pts/2 Jan 11 12:08 (10.23.32.10)

oracle + pts/3 Jan 11 12:08 (10.23.32.10)oracle - pts/4 Jan 11 12:08 (10.23.32.10)root + pts/1 Dec 26 13:42 (:0.0)root ? :0 Oct 23 15:32
El signo + antes del nombre de terminal indica que ésta acepta escribir comandos de otros; el signo “-“ indica que esto no está permitido. El signo “?” indica que la terminal no soporta escrituras en ella, por ej., una sesión X-window.
¿Y qué ocurre cuando usted desea escribir a todos los usuarios que han iniciado sesión? En lugar de tipear cada uno, utilice el comando wall: # wallhello everyone
Una vez que se envía, aparece el siguiente texto en las terminales de todos los usuarios que han iniciado sesión:
Broadcast message from oracle (pts/2) (Thu Jan 8 16:37:25 2009):
hello everyone
Esto es muy útil para los usuarios root. Cuando usted quiere cerrar el sistema, desmontar un sistema de archivos, o realizar funciones administrativas similares, quizás desee que todos los usuarios cierren su sesión. Utilice el comando para enviar un mensaje a todos.
Finalmente, el programa talk le permite conversar en tiempo real. Simplemente tipee lo siguiente # talk oracle pts/2
Si desea conversar con algún usuario en un servidor diferente – prolin2 –puede utilizar
# talk oracle@prolin2 pts/2
Esto abre una ventana de conversación en la otra terminal y ahora usted puede conversar con esa persona en tiempo real. ¿Es esto distinto a cualquier otro programa de conversación “profesional” que actualmente utiliza? Probablemente no. A propósito, para que la conversación funcione correctamente, asegúrese de que el talkd daemon esté ejecutándose, ya que éste podría estar desinstalado.
w
Si, es un comando ¡a pesar de que tenga solo una letra! El comando w es una combinación de los comandos uptime y who ejecutados uno inmediatamente luego del otro, en ese orden. Veamos un output muy común sin argumentos ni opciones.
# w17:29:22 up 672 days, 18:31, 2 users, load average: 4.52, 4.54, 4.59USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAToracle pts/1 10.14.105.139 16:43 0.00s 0.06s 0.01s w

oracle pts/2 10.14.105.139 17:26 57.00s 3.17s 3.17s sqlplus as sysdba … and so on …
El output tiene dos partes distintas. La primera parte muestra el output del comando uptime (descripto arriba en este documento) el cual muestra el tiempo en que el servidor ha esta activo, cuantos usuarios han iniciado sesión y el promedio de carga en el último minuto y en los últimos 5 y 15 minutos. Las partes del output han sido explicadas en el comando uptime. La segunda parte del output muestra el output del comando who con la opción -H (también explicado en este documento). Nuevamente, las numerosas columnas también han sido explicadas en el comando who.
Si usted prefiere no desplegar el encabezado, utilice la opción -h. # w -horacle pts/1 10.14.105.139 16:43 0.00s 0.02s 0.01s w -h
Esto elimina el encabezado del output. Es útil en los shell scripts en donde quiere leer y actuar en base al output sin la carga adicional de saltear el encabezado.
La opción -s produce una versión compacta (corta) del output, eliminando el tiempo de inicio de sesión, y los tiempos de JPCU y PCPU.
# w -s 17:30:07 up 672 days, 18:32, 2 users, load average: 5.03, 4.65, 4.63USER TTY FROM IDLE WHAToracle pts/1 10.14.105.139 0.00s w -soracle pts/2 10.14.105.139 1:42 sqlplus as sysdba
Usted podría encontrar que el campo “FROM” realmente no es muy útil. Muestra la dirección de IP del mismo servidor, ya que los registros de inicio de sesión son todos locales. Para ahorrar espacio en el output, usted podría suprimir este campo. La opción -f desactiva la impresión del campo FROM:
# w -f 17:30:53 up 672 days, 18:33, 2 users, load average: 4.77, 4.65, 4.63USER TTY LOGIN@ IDLE JCPU PCPU WHAToracle pts/1 16:43 0.00s 0.06s 0.00s w -foracle pts/2 17:26 2:28 3.17s 3.17s sqlplus as sysdba
El comando acepta solo un parámetro: el nombre de un usuario. Por defecto muestra el proceso e inicio de sesión de todos los usuarios. Si usted coloca el nombre de usuario, se muestra el registro de inicio de sesión de ese usuario solamente. Por ejemplo, para mostrar solo el inicio de sesión de los usuarios root, debe emitir:
# w -h rootroot pts/1 :0.0 26Dec08 13days 0.01s 0.01s bashroot :0 - 23Oct08 ?xdm? 21:13m 1.81s /usr/bin/gnome-session
La opción -h fue utilizada para ocultar el encabezado.
kill

Un proceso se está ejecutando y usted desea que el proceso finalice. ¿Qué debería hacer? El proceso se ejecuta en un segundo plano, de modo que no necesita ir a la terminal y presionar Control-C; o, tal vez el proceso pertenece a otro usuario (utilizando el mismo userid, como “oracle”) y usted desea que termine. El comando kill justamente va al rescate; hace lo que su nombre sugiere – finaliza el proceso. Su uso más común es:
# kill <Process ID of the Linux process>
Supongamos que usted quiere finalizar un proceso denominado sqlplus emitido por el usuario oracle, usted debe conocer su processid, o PID:
# ps -aef|grep sqlplus|grep anandaoracle 8728 23916 0 10:36 pts/3 00:00:00 sqlplusoracle 8768 23896 0 10:36 pts/2 00:00:00 grep sqlplus
Ahora para finalizar el PID 8728:
# kill 8728
Y así se finaliza el proceso. Por supuesto usted debe ser el mismo usuario (oracle) para finalizar un proceso iniciado por oracle. Para finalizar procesos iniciados por otros usuarios usted debe ser un super usuario – root.
Algunas veces usted puede querer simplemente detener el proceso en vez de finalizarlo. Puedo utilizar la opción -SIGSTOP con el comando kill.
# kill -SIGSTOP 9790# ps -aef|grep sqlplus|grep oracleoracle 9790 23916 0 10:41 pts/3 00:00:00 sqlplus as sysdbaoracle 9885 23896 0 10:41 pts/2 00:00:00 grep sqlplus
Esto es útil para los trabajos que se realizan en segundo plano pero con procesos de primer plano. Simplemente detiene el proceso y le quita el control al usuario. De modo que, si usted verifica el proceso nuevamente luego de emitir el comando:
# ps -aef|grep sqlplus|grep oracleoracle 9790 23916 0 10:41 pts/3 00:00:00 sqlplus as sysdbaoracle 10144 23896 0 10:42 pts/2 00:00:00 grep sqlplus
Usted observa que el proceso aún se está ejecutando. No ha finalizado. Para finalizar este proceso, y cualquier proceso que se resista a ser finalizado, debe enviar una nueva señal denominada SIGKILL. La señal por defecto es SIGTERM.
# kill -SIGKILL 9790# ps -aef|grep sqlplus|grep oracleoracle 10092 23916 0 10:42 pts/3 00:00:00 sqlplus as sysdbaoracle 10198 23896 0 10:43 pts/2 00:00:00 grep sqlplus
Tenga en cuenta las opciones -SIGSTOP y -SIGKILL, que envían una señal específica (detener y finalizar,

respectivamente) al proceso. Del mismo modo hay otras señales que puede utilizar. Para obtener un listado de todas las señales disponibles, utilice la opción -l (la letra “L”, no el número “1”):
# kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR213) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+136) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+540) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+944) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+1348) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-1352) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-956) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-560) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-164) SIGRTMAX
También puede utilizar el numeral equivalente de la señal en lugar del verdadero nombre de la señal. Por ejemplo, en lugar de kill -SIGKILL 9790, usted puede utilizar kill -9 9790.
A propósito, este es un comando interesante. Recuerde que casi todos los comandos Linux generalmente son archivos ejecutables localizados en /bin, /sbin/, /user/bin y directorios similares. El PATH ejecutable determina en dónde pueden encontrarse estos archivos de comando. Algunos otros comandos son en realidad comandos “incorporados”, es decir, son parte del shell mismo. Un ejemplo de esto es el comando kill. Para demostrarlo, observe lo siguiente:
# kill -h -bash: kill: h: invalid signal specification
Observe el output que arroja el bash shell. El uso es incorrecto ya que el argumento -h no era el adecuado. Ahora utilice el siguiente:
# /bin/kill -husage: kill [ -s signal | -p ] [ -a ] pid ... kill -l [ signal ]
Esta versión del comando kill como ejecutable en el directorio /bin aceptó la opción -h adecuadamente. Ahora usted ya conoce esta sutil diferencia entre los comandos shell incorporados y sus utilidades homónimas (namesake) en la forma de archivos ejecutables.
¿Por qué es importante conocer la diferencia? Es importante porque la funcionalidad varía de manera significativa entre estas dos formas. El comando kill incorporado tiene menos funcionalidad que su utilidad equivalente. Cuando usted emite el comando kill, en verdad está invocando el comando incorporado, no la utilidad. Para incorporar la otra funcionalidad, usted tiene que utilizar la utilidad /bin/kill.
La utilidad kill tiene muchas opciones y argumentos. El más conocido es el comando kill utilizado para finalizar los proceso con los nombres del proceso, en lugar de PIDs. Aquí vemos un ejemplo en el que usted puede finalizar todos los procesos con el nombre sqlplus:
# /bin/kill sqlplus[1] Terminated sqlplus

[2] Terminated sqlplus[3] Terminated sqlplus[4] Terminated sqlplus[5] Terminated sqlplus[6] Terminated sqlplus[7]- Terminated sqlplus[8]+ Terminated sqlplus
Algunas veces usted quiere ver todos los IDs de los procesos que serán finalizados. La opción -p logra esto. Imprime los PIDs que deberían finalizarse, sin realmente finalizarlos. Sirve como confirmación previa a la acción:
# /bin/kill -p sqlplus67986802680368076808681268136817
Algunas veces usted quiere ver todos los IDs de los procesos que serán finalizados. La opción -p logra esto. Imprime los PIDs que deberían finalizarse, sin realmente finalizarlos. Sirve como confirmación previa a la acción:
# man -k builtin. [builtins] (1) - bash built-in commands, see bash(1): [builtins] (1) - bash built-in commands, see bash(1)[ [builtins] (1) - bash built-in commands, see bash(1)alias [builtins] (1) - bash built-in commands, see bash(1)bash [builtins] (1) - bash built-in commands, see bash(1)bg [builtins] (1) - bash built-in commands, see bash(1) … y así …
El output muestra los PIDs de los procesos que serían finalizados. Si usted reemite el comando sin la opción -p, se finalizarán todos esos procesos.
A esta altura usted quizás desee saber cuáles son los otros comandos “incorporados” en el shell, en lugar de las utilidades.
# /bin/kill perl rman perl dbca dbua java
Algunas entradas parecen conocidas – alias, bg, entre otras. Algunas se encuentran meramente incorporadas, por ej., alias. No existe ningún archivo ejecutable llamado alias.
Para Usuarios de Oracle
Finalizar un proceso ofrece muchos usos – mayormente se utiliza para finalizar procesos fantasmas, procesos que se encuentran en segundo plano y otros que han sido detenidos en respuesta a un cierre normal de los comandos. Por ejemplo, cuando la instancia de base de datos de Oracle no se está cerrado debido a un

problema de memoria. Usted debe cerrarla finalizando uno de los procesos clave como pmon o smon. Esto no debería realizarse todo el tiempo, solo cuando no haya opción.
Si quizás desee finalizar todas las sesiones sqlplus o todos los trabajos rman utilizando el comando de utilidad kill. Los procesos Oracle Enterprise Manager se ejecutan como procesos perl; o procesos DBCA o DBUA, los cuales quizás quiera finalizar rápidamente:
# /bin/kill perl rman perl dbca dbua java
Existe también un uso más común de este comando. Cuando usted quiere finalizar una sesión de usuario en la Base de Datos de Oracle, generalmente realiza alguna de las siguientes acciones:
Busca el SID y Serial# de la sesión Finaliza la sesión utilizando el comando ALTER SYSTEM
Veamos qué sucede cuando desea finalizar la sesión del usuario SH.
SQL> select sid, serial#, status 2 from v$session 3* where username = 'SH'; SID SERIAL# STATUS---------- ---------- -------- 116 5784 INACTIVE SQL> alter system kill session '116,5784' 2 / System altered. La sesión ha finalizado; no obstante cuando usted controla en estado de la sesión: SID SERIAL# STATUS---------- ---------- -------- 116 5784 KILLED
Se muestra como KILLED (finalizada), pero no se ha eliminado por completo. Eso sucede porque Oracle espera hasta que el usuario SH inicie su sesión e intente hacer algo, en ese momento recibe el mensaje “ORA-00028: su sesión ha sido finalizada”. Luego de ese momento la sesión desaparece de V$SESSION.
Una manera más rápida de finalizar una sesión es eliminar el correspondiente proceso del servidor en el nivel de Linux. Para hacerlo, primero busque el PID del proceso del servidor:
SQL> select spid 2 from v$process 3 where addr = 4 ( 5 select paddr 6 from v$session 7 where username = 'SH' 8 );SPID------------------------30986

El SPID es el ID de Proceso del proceso del servidor. Ahora puede finalizar este proceso:
# kill -9 30986
Ahora si verifica la visión V$SESSION, ésta desaparecerá inmediatamente. El usuario no recibirá el mensaje instantáneamente; pero si intenta realizar una consulta a la base de datos, el obtendrá el siguiente mensaje:
ERROR at line 1:ORA-03135: connection lost contactProcess ID: 30986Session ID: 125 Serial number: 34528
Este en método rápido para finalizar una sesión, no obstante hay ciertos inconvenientes. La base de datos de Oracle debe realizar una limpieza de sesión –deshacer cambios (rollback), etc. Y esto debería realizarse solo cuando las sesiones se encuentran inactivas. Caso contrario, usted puede utilizar una de las dos otras maneras de finalizar una sesión inmediatamente:
alter system disconnect session '125,35447' immediate;alter system disconnect session '125,35447' post_transaction;
killall
A diferencia de la naturaleza dual del comando kill, killall es meramente una utilidad, es decir, es un programa ejecutable en el directorio /usr/bin. El comando es similar a kill en funcionalidad pero en vez de finalizar un proceso sobre la base de su PID, éste acepta el nombre del proceso como argumento. Por ejemplo, para finalizar todos los procesos sqlplus, emita:
# killall sqlplus
Esto finaliza todos los procesos denominados sqlplus (los cuales usted tiene permiso de finalizar, por supuesto). A diferencia del comando kill incorporado, usted no necesita conocer el ID de Proceso de los procesos a finalizar.
Si el comando no finaliza el proceso o el proceso no responde a una señal TERM, usted puede enviar una señal SIGKILL explícita como pudo ver en el comando kill utilizando la opción -s.
# killall -s SIGKILL sqlplus
Como en el comando kill, usted puede utilizar la opción -9 en lugar de -s SIGKILL. Para obtener un listado de todas las señales disponibles, usted puede utilizar la opción -l.
# killall -lHUP INT QUIT ILL TRAP ABRT IOT BUS FPE KILL USR1 SEGV USR2 PIPE ALRM TERMSTKFLT CHLD CONT STOP TSTP TTIN TTOU URG XCPU XFSZ VTALRM PROF WINCH IO PWR SYSUNUSED

Para obtener el output completo del comando killall, utilice la opción -v:
# killall -v sqlplusKilled sqlplus(26448) with signal 15Killed sqlplus(26452) with signal 15Killed sqlplus(26456) with signal 15Killed sqlplus(26457) with signal 15 … and so on …
Algunas veces usted quizás quiera examinar el proceso antes de finalizarlo. La opción -i le permite ejecutarlo interactivamente. Esta opción solicita su input antes de finalizarlo:
# killall -i sqlplusKill sqlplus(2537) ? (y/n) nKill sqlplus(2555) ? (y/n) nKill sqlplus(2555) ? (y/n) yKilled sqlplus(2555) with signal 15
¿Qué sucede cuando usted aprueba un nombre de proceso equivocado?
# killall wrong_processwrong_process: no process killed
No existe ningún proceso de ejecución denominado wrong_process entonces no se ha finalizado nada y el output lo ha mostrado claramente. Para eliminar este reclamo “no process killed”, utilice la opción -q. Esa opción es muy útil en shell scripts en donde usted no puede analizar el output. En cambio, si usted desea capturar el código de retorno del comando:
# killall -q wrong_process# echo $?1
El código de retorno (que se muestra en la variable shell $?) es “1”, en vez de “0”, lo cual indica una falla. Usted puede controlar el código de retorno para examinar si el proceso killall resultó exitoso, es decir, si el código de retorno es “0”.
Algo interesante en torno a este comando es que no se finaliza por si mismo. Por supuesto hace finalizar otros comandos killall en otro sitio pero no en si mismo.
Para Usuarios de Oracle
Al igual que el comando kill, el comando killall también es utilizado para finalizar procesos. La mayor ventaja de killall es la capacidad de desplegar el processid y la naturaleza interactiva que posee. Supongamos que usted desea finalizar todos los procesos perl, java, sqlplus, rman y dbca pero no de manera interactiva; usted puede emitir:

# killall -i -p perl sqlplus java rman dbcaKill sqlplus(pgid 7053) ? (y/n) nKill perl(pgid 31233) ? (y/n) n ... and so on ...
Esto le permite ver el PID antes de finalizarlos, lo cual puede ser muy útil.
Conclusion
En este documento usted conoció los siguientes comandos (mostrados alfabéticamente)
dig Una nueva versión de nslookup
ifconfig Para desplegar información en las interfaces de red
kill Para finalizar un proceso específico
killall Para finalizar un proceso específico, un grupo de procesos y los nombres que coinciden con un patrón
mesg Para activar o desactivar la capacidad de los demás para desplegar algo en la terminal de uno.
netstat Para desplegar estadísticas y otras métricas sobre el uso de la interfaz de red
nslookup Para buscar el nombre de host de su dirección de IP o buscar la dirección de IP para su nombre de host en DNS
talk Para establecer un sistema de Mensajería Instantánea entre dos usuarios para lograr una conversación en tiempo real
uptime Para saber por cuánto tiempo ha estado funcionando el sistema y conocer su carga promedio en 1, 5 y 15 minutos
w Es una combinación de uptime y who
wall Para desplegar texto en las terminales de todos los usuarios que han iniciado sesión
who Para desplegar a todos los usuarios que han iniciado sesión en el sistema y para saber lo que están haciendo
write Para desplegar instantáneamente algo en la sesión de la terminal de un usuario específico
Como he mencionado anteriormente, no es mi intención presentarles cada comando disponible en los sistemas Linux. Usted debe conocer solo algunos de ellos para administrar un sistema de manera efectiva y esta serie le muestra los más importantes. Practíquelos en su entorno para comprenderlos mejor – con sus parámetros y opciones. En el próximo documento, el último de ellos, usted aprenderá a administrar un entorno Linux – en una máquina común, en una máquina virtual, y en la nube.

Guía para Maestría Avanzada en Comandos Linux, Parte 5: Administración del Entorno Linux - Continuación
Por Arup Nanda Publicado en octubre de 2009
En esta quinta y última presentación de la serie, describiremos más comandos y técnicas para administrar un entorno Linux – incluyendo un entorno virtualizado.
Variables de las Palabras Claves de ShellCuando se encuentra en la línea de comando, usted utiliza un ''shell'' – generalmente el bash shell. En un shell usted puede definir una variable y fijar un valor para luego ser recuperado. Aquí vemos un ejemplo de una variable denominada ORACLE_HOME:
# export ORACLE_HOME=/opt/oracle/product/11gR2/db1/
Posteriormente puede referirse a la variable colocando el prefijo ''$'' delante del nombre de la variable, por ej.:
## cd $ORACLE_HOME
Esto se denomina variable definida por el usuario. Asimismo, existen numerosas variables definidas en el shell mismo. Estas variables – cuyos nombres han sido predefinidos en el shell – controlan la manera en que usted interactúa con el shell. Usted debería conocer estas variables (al menos algunas de las más importantes) para mejorar la calidad y eficiencia de su trabajo.
PS1Esta variable establece el command prompt de Linux. A continuación se muestra un ejemplo en donde el comando cambia el prompt ''# '' establecido por defecto, a ''$ '':
''# '' to ''$ '':# export PS1="$ "$
¿Observa cómo el prompt cambió a $? Usted puede colocar aquí cualquier caracter para cambiar el prompt que establezca por defecto. Las comillas dobles no son necesarias pero como queremos colocar un espacio después del signo ''$'', debemos escribir las comillas al comienzo y al final. ¿Entonces eso es todo – para mostrar el prompt en un caracter predefinido o una cadena de caracteres? En realidad no. Usted también puede incluir símbolos especiales en la variable para mostrar valores especiales. Por ejemplo, el símbolo \u muestra el nombre de usuario que ha iniciado sesión y \h muestra el nombre de host. Si utilizamos estos dos símbolos, el prompt puede personalizarse para mostrar quién ha iniciado sesión y dónde:

$export PS1="\u@\h# "oracle@oradba1#
Esto muestra el prompt tal como Oracle inició sesión en el servidor: oradba1 – y es suficiente para recordarle quién es y en dónde se encuentra. También puede personalizar el prompt utilizando otro símbolo, \W, que muestra el basename del directorio actual. Aquí vemos como aparece el prompt ahora:
# export PS1="\u@\h \W# "
oracle@oradba1 ~#
El directorio actual es HOME; por lo tanto éste se muestra como ''~''. Cuando usted cambia a un directorio distinto, éste también cambia.
Agregar el directorio actual es una buena manera de recordarle en dónde se encuentra y cuáles son las consecuencias de sus acciones. Ejecutar rm * produce un impacto diferente en /tmp que si usted se encontrara en /home/oracle ¿no es así?
Existe también otro símbolo - \w. Pero tenga en cuenta que hay una gran diferencia entre \w y \W. La última produce el basename del directorio actual mientras que la anterior muestra todo el directorio:
oracle@oradba1 11:59 AM db1# export PS1="\u@\h \@ \w# "oracle@oradba1 12:01 PM /opt/oracle/product/11gR2/db1#
¿Nota la diferencia? En el prompt anterior, en donde se utilizó \W, se mostró solo el directorio db1, que es el basename. En el siguiente prompt, en donde se utilizó \w, se desplegó el directorio completo /opt/oracle/product/11gR2/db1.
En muchos casos mostrar el nombre del directorio completo en el prompt puede resultar de gran ayuda. Supongamos que usted tiene tres Oracle Homes. Cada una tendrá un subdirectorio denominado db1. ¿Cómo sabrá entonces en dónde se encuentra exactamente si solo se despliega ''db1''? Mostrar el directorio completo no dejará lugar a dudas. No obstante, mostrar el directorio completo hará que el prompt sea más largo, lo cual podría generar ciertos inconvenientes.
El símbolo ''\@'' muestra el tiempo real con el formato horas:minutos AM/PM:
# export PS1="\u@\h \@ \W# "oracle@oradba1 11:59 AM db1#
Aquí vemos algunos otros símbolos que usted puede utilizar en la variable shell PS1:
\!El número de comando en el historial (se explicará más adelante)
\d La fecha en formato Día y Mes\H El nombre del host con el nombre de dominio. \h es el nombre de host sin el dominio\T Lo mismo que \@ pero incluyendo segundos.\A El tiempo en horas:minutos, como en el formato \@, pero en un formato de 24 horas\t Lo mismo que \A pero incluyendo los segundos incluidos
IFS

Esta variable ordena al shell tratar a las variables del shell como un conjunto o por separado. Si desea hacerlo por separado, el valor establecido para la variable IFS se utiliza como separador. De ahí el nombre Input Field Separator (IFS). Para demostrarlo, definamos una variable como se muestra a continuación.
# pfiles=initODBA112.ora:init.ora
En realidad, éstos son dos archivos: initODBA112.ora e init.ora. Ahora, si quiere desplegar la primera línea de cada uno de estos archivos, deberá utilizar el comando head -1.
# head -1 $pfiles head:cannot open `initODBA112.ora:init.ora' for reading: No such file or directory
El output lo dice todo; el shell interpretó la variable en su totalidad: `initODBA112.ora:init.ora', que no corresponden al nombre de ningún archivo. Por eso el comando head falla. Si el shell interpretó el '':'' como algún tipo de separador, tendría que haber realizado el trabajo adecuadamente. Por lo tanto, eso es lo que debemos hacer al establecer la variable IFS:
# export IFS=":"# head -1 $pfiles==> initODBA112.ora <==# first line of file initODBA112.ora ==> init.ora <==# first line of file init.ora
Ahora sí. El shell expandió el comando head -1 $pfiles a head -1 initODBA112.ora y head -1 init.ora, y por lo tanto, el comando se ejecutó correctamente.
PATHCuando usted utiliza un comando en Linux, este se encuentra en un shell -como puedo observarse en el comando kill, de la Parte 4- o puede tratarse de un archivo ejecutable. Si es un archivo ejecutable, ¿cómo saber en dónde se encuentra? Tome por ejemplo el comando rm, el cual elimina algunos archivos. El comando puede obtenerse desde cualquier directorio. Por supuesto que el archivo ejecutable rm no existe en todos los directorios, entonces ¿cómo sabe Linux en dónde buscar? La variable PATH mantiene las localizaciones en donde el shell debe buscar ese ejecutable. Aquí vemos un ejemplo de una configuración PATH:
# echo $PATH /usr/kerberos/bin:/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:.
Cuando usted ejecuta un comando como rm, el shell buscan un archivo rm en estas localizaciones, en el siguiente orden:
/usr/kerberos/bin/usr/local/bin

/bin/usr/bin/usr/X11R6/bin. (the current directory)
Si el archivo no se encuentra en ninguna de estas localizaciones, el shell devuelve un mensaje de error -bash: rm: command not found. Si usted desea agregar más localizaciones a la variable PATH, hágalo utilizando '':'' como separador.
¿Nota algo interesante arriba? La localización ''directorio actual'' se establece al final, no al comienzo. El sentido común puede sugerirle que lo coloque al principio para que el shell busque primero un archivo ejecutable en el directorio actual, antes de buscarlo en otro lado. Colocarlo al final hará al shell busque en el directorio actual, al finalizar el proceso. ¿Pero hay alguna alternativa mejor?
Los expertos recomiendan que usted coloque el directorio actual (.) al final del comando PATH, no al comienzo. ¿Por qué? Esta práctica es para una mayor seguridad. Supongamos que usted quiera experimentar algunas ideas para mejorar los comandos shell comunes y sin advertirlo deja ese archivo en su directorio de origen. Cuando usted inicie sesión, se encontrará en el directorio de origen y cuando ejecute ese comando, usted no ejecutará el comando común sino el archivo ejecutable en su directorio de origen.
Esto podría ser desastroso en algunos casos. Supongamos que usted está utilizando una nueva versión del comando ''cp'' y hay un archivo llamado cp en su directorio de origen. Este archivo posiblemente haga algún daño. Si usted tipea ''cp somefile anotherfile'', su versión del archivo cp será ejecutada, causando daños. Colocando el directorio actual al final, se ejecuta el comando ''cp'' normal, evitando dicho riesgo.
También evita el riesgo de que algún hacker coloque algún archivo de comando maligno como comando común. Algunos expertos incluso sugieren eliminar el ''.'' del PATH para evitar cualquier ejecución involuntaria. Si usted ha ejecutado algo en el directorio actual, simplemente utilice la anotación ./ como en este caso:
# ./mycommand
Esto ejecuta un archivo denominado mycommand en el actual directorio.
CDPATHEs muy similar a PATH, esta variable extiende el alcance del comando cd más allá del directorio actual. Por ejemplo, cuando usted tipea el comando cd como se muestra abajo:
# cd dbs -bash: cd: dbs: No such file or directory
Tiene sentido ya que el directorio dbs no existe en el directorio actual. Se encuentra bajo /opt/oracle/product/11gR2/db1. Es por ese motivo que el comando cd falla. Usted puede por supuesto ir al directorio /opt/oracle/product/11gR2 y luego ejecutar con éxito el comando cd. Si desea incrementar el alcance para incluir /opt/oracle/product/11gR2/db1, puede emitir:
# export CDPATH=/opt/oracle/product/11gR2/db1
Ahora, si usted emite el comando cd desde cualquier directorio:
# cd dbs

/opt/oracle/product/11gR2/db1/dbs# pwd/opt/oracle/product/11gR2/db1/dbs
El comando cd ahora busca otros directorios para ese subdirectorio. Existen otras variables; pero éstas son las más utilizadas y usted debería saber dominarlas.
setEste comando controla el comportamiento del shell. Tiene muchas opciones y argumentos pero explicaré los más importantes. Un error muy común que las personas cometen cuando sobrescriben comandos como cp y mv es sobrescribir los archivos correctos sin darse cuenta. Usted puede evitar ese riesgo al utilizar un ''alias'' (como se muestra en la Parte 1 de esta serie), por ej., utilizando mv –i en vez de mv. No obstante, ¿cómo puede evitar que alguien o algún script sobrescriba los archivos utilizando el operador de re-direccionamiento (''>'')? Veamos un ejemplo. Supongamos que usted tiene un archivo denominado very_important.txt. Alguien (o algún script) involuntariamente utilizó algo como:
# ls -l > very_important.txt
El archivo inmediatamente se sobrescribió y usted pierde los contenidos originales del archivo. Para evitar este riesgo, usted puede utilizar el comando set con la opción -o noclobber como se muestra abajo:
# set -o noclobber
Luego de este comando, si alguien intenta sobrescribir el archivo:
# ls -l > very_important.txt-bash: very_important.txt: cannot overwrite existing file
El shell ahora evita que se sobrescriba un archivo existente. ¿Qué sucedería si desea sobrescribirlo? Usted puede utilizar el operador >|.
# ls -l >| very_important.txt
Para desactivarlo:
# set +o noclobber
El comando set es también muy útil para utilizar el editor vi para editar comandos. Más adelante, en este documento aprenderá a controlar los comandos que usted ha generado y cómo pueden ser reejecutados. Una manera rápida de reejecutar el comando es repitiendo los comandos utilizando el editor vi. Para que éste ejecute este comando primero:
# set -o vi

Ahora supongamos que usted está buscando un comando que contenga la letra ''v'' (como en vi, o vim, etc.). Para buscar el comando, ejecute estas teclas. Las teclas que deben presionarse se encuentran dentro del corchete:
# [Escape Key][/ key][v key][ENTER Key]
Esto muestra el último comando ejecutado que contenga la letra ''v''. El último comando en este caso fue set –o vi; por lo tanto eso aparece en el command prompt.
# set -o vi
Si ese no es el comando que usted está buscando, presione la tecla ''n'' para obtener el siguiente comando más reciente. De esta manera usted puede recorrer todos los comandos ejecutados con la letra ''v''. Cuando usted ve el comando, puede presionar [tecla ENTER] para ejecutarlo. La búsqueda puede ser explícita si lo desea. Supongamos que usted está buscando un comando mpstat ejecutado anteriormente. Todo lo que tiene que hacer es ingresar esta cadena de búsqueda ''mpstat'':
# [Escape Key][/ key]mpstat[ENTER Key]
Supongamos que el comando de arriba muestra mpstat 5 5 y usted realmente desea ejecutar mpstat 10 10. En vez de retipearlo, puede editar el comando en el editor vi. Para hacerlo, presione [Tecla Escape] y la tecla [v], la cual colocará el comando en el editor vi. Ahora puede editar el comando que desee. Cuando lo guarda en vi presionando :wq, el comando modificado será ejecutado.
typeEn la Parte 4 usted conoció al comando kill, que es un comando especial – ya que es tanto una utilidad (un ejecutable en algunos directorios) y un shell incorporado. Además, usted ya aprendió acerca de los alias en el documento anterior. Algunas veces hay ciertos comandos utilizados en shell scripts – ''do'', ''done'', ''while'', por mencionar algunos, que no son realmente comandos. Ellos son denominados shell keywords. ¿Pero cómo puede saber qué tipo de comando es? El comando type muestra eso precisamente. Aquí vemos cómo debemos utilizarlo para mostrar los tipos de comandos mv, do, fc y oh.
# type mv do fc ohmv is /bin/mvdo is a shell keywordfc is a shell builtinoh is aliased to `cd $ORACLE_HOME'
Muestra claramente que mv es una utilidad (junto con su ubicación), do es una clave utilizada dentro de los scripts, fc es un shell built-in y oh es un alias (y muestra el elemento al que se lo asocia).
historyCuando usted inicia sesión en el sistema Linux generalmente ejecuta una variedad de comandos en el command prompt. ¿Pero cómo sabe usted qué comandos ha ejecutado? Quizás quiera saberlo por varias

razones – desea reejecutarlo sin volver a tipearlo, quiere asegurarse de haber ejecutado el comando adecuado (por ej., eliminó el archivo adecuado), quiere verificar qué comandos fueron emitidos, entre otros motivos. El comando history le brinda un historial de los comandos ejecutados.
# history 1064 cd dbs1065 export CDPATH=/opt/oracle/product/11gR2/db11066 cd dbs1067 pwd1068 env1069 env | grep HIST… y así …
Observe los números antes de cada comando. Este es el número de comando o evento. Usted aprenderá a utilizar esta característica más adelante. Si desea desplegar solo unas pocas líneas del historial en vez de todas las que se encuentran disponibles, por ej., los cinco comandos más recientes:
# history 5
La mayor utilidad del comando history realmente proviene de su capacidad de reejecutar un comando sin volver a tipearlo. Para ello, ingrese la marca ! seguida del evento o número de comando que precede al nombre del comando en el output del historial. Para reejecutar el comando cd dbs que se muestra en el número 1066, usted puede emitir:
# !1066cd dbs/opt/oracle/product/11gR2/db1/dbs
El comando !! (doble signo de exclamación) ejecuta el último comando ejecutado. También puede agregar una cadena luego del comando !, lo cual reejecuta el último comando con el patrón como la cadena en la posición inicial. El siguiente comando reejecuta el comando más reciente que comienza con cd:
# !cdcd dbs/opt/oracle/product/11gR2/db1/dbs
¿Qué sucede si desea reejecutar un comando que contiene una cadena (y no que comienza con una)? El modificador ? realiza una asociación de patrones en los comandos. Para buscar un comando que se relacione con él, emita:
# !?network?cd network/opt/oracle/product/11gR2/db1/network
También puede modificar el comando a ser reejecutado. Por ejemplo, supongamos que anteriormente había establecido un comando cd /opt/oracle/product/11gR2/db1/network y desea reejecutarlo luego de agregar /admin al final, usted emitirá:
# !1091/admincd network/admin/opt/oracle/product/11gR2/db1/network/admin

fcEste comando es un shell built-in utilizado para mostrar el historial del comando, como en history. La opción más común es -l (la letra ''L'', no el número ''1'') que muestra los 16 comandos más recientes:
# fc -l1055 echo $pfiles1056 export IFS=... and so on ...1064 cd dbs1065 export CDPATH=/opt/oracle/product/11gR2/db11066 cd dbs
También puede pedir a fc mostrar unos pocos comandos dando un rango de los números de eventos, por ej., 1060 y 1064:
# fc -l 1060 10641060 pwd1061 echo CDPATH1062 echo $CDPATH1063 cd1064 cd dbs
La opción -l también requiere de otros dos parámetros – la cadena para realizar una asociación de patrones. Aquí vemos un ejemplo en donde usted puede desplegar el historial de comandos que comienza con la palabra echo hasta el comando más reciente que comienza con pwd.
# fc -l echo pwd1062 echo $CDPATH1063 cd1064 cd dbs1065 export CDPATH=/opt/oracle/product/11gR2/db11066 cd dbs1067 pwd
Si desea reejecutar el comando cd dbs (número de comando 1066), puede simplemente ingresar ese número después de fc con la opción -s:
# fc -s 1066cd dbs/opt/oracle/product/11gR2/db1/dbs
Otro importante uso del comando fc -l es la sustitución de comandos. Supongamos que usted desea ejecutar un comando similar a 1066 (cd dbs) pero desea emitir cd network, no cd dbs, puede utilizar el argumento de sustitución como se muestra a continuación:
# fc -s dbs=network 1066cd network/opt/oracle/product/11gR2/db1/network

Si omite la opción -s, como se muestra abajo:
# fc 1066
Se abre el archivo vi con el comando cd dbs dentro, el cual puede editar y ejecutar.
cpioConsidere esta situación: usted desea enviar un grupo de archivos a alguien o a alguna parte y no quiere correr el riesgo de que sus archivos se pierdan. ¿Qué puede hacer para asegurarse de que eso no suceda? Es simple. Si usted pone todos estos archivos en uno solo y envía este único archivo a su destino, puede estar seguro de que todos los archivos van a llegar de manera segura. El comando cpio tiene tres opciones principales:
-o (create) para crear un fichero (archive) -i (extract) para extraer archivos de un fichero -p (pass through) para copiar archivos a un directorio diferente
Cada opción tiene su propio grupo de subopciones. Por ejemplo, la opción -c se aplica para el caso de -i y -o pero no en caso de -p. Veamos los grupos de opciones más importantes y cómo se utilizan. La opción -v se utiliza para desplegar un output completo, lo cual puede ser útil en casos en que desee obtener un feedback definido sobre lo que está sucediendo. Primero, veamos cómo crear un fichero a partir de un grupo de archivos. Aquí colocamos todos los archivos con la extensión ''trc'' en un directorio específico y luego los colocamos en un archivo denominado myfiles.cpio:
$ ls *.trc | cpio -ocv > myfiles.cpio+asm_ora_14651.trcodba112_ora_13591.trcodba112_ora_14111.trcodba112_ora_14729.trcodba112_ora_15422.trc9 blocks
La opción -v fue utilizada para obtener el output completo y cpio nos mostró cada archivo que fue incorporado al fichero. La opción -o se utilizó para crear un fichero. La opción -c se utilizó para que cpio escriba la información del encabezado en ASCII, lo cual facilita el traspaso entre plataformas.
Otra opción es -O que acepta el output archive file como parámetro.
# ls *.trc | cpio -ocv -O mynewfiles.cpio
Para extraer los archivos:
$ cpio -icv < myfiles.cpio+asm_ora_14651.trccpio: odba112_ora_13591.trc not created: newer or same age version existsodba112_ora_13591.trc
Aquí las opciones -v y –i son utilizadas para obtener un output completo y para la extracción de archivos desde los ficheros. La opción –c ha sido utilizada para ordenar a cpio a que lea la información del encabezado como ASCII. Cuando cpio extrae un archivo y éste ya existe (como en el caso de odba112_ora_13591.trc), no

sobrescribe el archivo; sino que simplemente lo pasa por alto con un mensaje. Para que lo sobrescriba, utilice la opción -u.
# cpio -icvu < myfiles.cpio
Para desplegar solamente los contenidos sin tener que extraerlos, utilice la opción –t junto con –i (extracción):
# cpio -it < myfiles.cpio+asm_ora_14651.trcodba112_ora_13591.trcodba112_ora_14111.trc
¿Qué sucede si usted extrae un archivo que ya existe? Y aún así desea extraerlo pero tal vez con un nombre distinto. Un ejemplo sería cuando usted intenta recuperar un archivo denominado alert.log (que es un archivo log para una instancia Oracle) y no quiere sobrescribir el archivo alert.log actual. Una de las opciones muy útiles es –r, que le permite reasignar un nombre a los archivos que se extraen, de manera interactiva.
# cpio -ir < myfiles.cpiorename +asm_ora_14651.trc -> a.trcrename odba112_ora_13591.trc -> b.trcrename odba112_ora_14111.trc -> [ENTER] which leaves the name alone
Si usted creó un fichero cpio de un directorio y desea extraer la misma estructura de directorio, utilice la opción –d mientras lo extrae. Mientras lo crea, puede agregar archivos a un fichero existente (append) utilizando la opción -A como se muestra debajo:
# ls *.trc | cpio -ocvA -O mynewfiles.cpio
Los comandos tienen muchas otras opciones; no obstante, usted solo necesita conocer algunas de éstas para poder utilizarlas de manera efectiva.
tarOtro mecanismo para crear un fichero es tar. Originalmente creado para archivar unidades de cinta (de ahí el nombre Tape Archiver), tar es un comando muy conocido por su simplicidad. Ofrece tres opciones principales
-c para crear un fichero (archive) -x para extraer archivos de un fichero -t para desplegar los archivos de un fichero
De esta forma es como se crea un fichero tar. La opción –f le permite asignar un nombre a un output file que tar creará como fichero. En este ejemplo estamos creando un fichero denominado myfiles.tar a partir de todos los archivos con extensión ''trc''.
# tar -cf myfiles.tar *.trc

Una vez creado, usted puede enumerar los contenidos de un fichero utilizando la opción –t.
# tar tf myfiles.tar+asm_ora_14651.trcodba112_ora_13591.trcodba112_ora_14111.trcodba112_ora_14729.trcodba112_ora_15422.trc
Para mostrar el detalle de los archivos, utilice la opción –v (completa):
# tar tvf myfiles.tar-rw-r----- oracle/dba 1150 2008-12-30 22:06:39 +asm_ora_14651.trc-rw-r----- oracle/dba 654 2008-12-26 15:17:22 odba112_ora_13591.trc-rw-r----- oracle/dba 654 2008-12-26 15:19:29 odba112_ora_14111.trc-rw-r----- oracle/dba 654 2008-12-26 15:21:36 odba112_ora_14729.trc-rw-r----- oracle/dba 654 2008-12-26 15:24:32 odba112_ora_15422.trc
Para extraer archivos del fichero, utilice la opción –x. Aquí vemos un ejemplo (la opción –v ha sido utilizada para mostrar el output completo):
# tar xvf myfiles.tar
zipLa compresión es una parte muy importante de la administración de Linux. Quizás usted tenga que comprimir varios archivos para hacer espacio a otros nuevos, o para enviarlos por email y así sucesivamente. Linux ofrece numerosos comandos de compresión; aquí examinaremos los más comunes: zip y gzip. El comando zip produce un archivo único al consolidar otros archivos y comprimirlos en un archivo zip. Aquí vemos un ejemplo del comando:
# zip myzip *.aud
Se genera un archivo denominado myzip.zip con todos los archivos en el directorio asignado con la extensión a .aud. El zip acepta varias opciones. La más común es -9, que ordena al zip realizar la mayor compresión, mientras se sacrifican los ciclos del CPU (y por lo tanto es el proceso más largo). La otra opción, -1, ordena justamente lo contrario: realizar la compresión lo más rápido posible aunque se sacrifique la capacidad de compresión. También puede proteger el archivo zip al encriptarlo con una contraseña. Sin la contraseña adecuada, el archivo zip no puede ser desencriptado ( unzip). Esto se realiza con la opción –e (encriptar):
# zip -e ze *.audEnter password: Verify password: adding: odba112_ora_10025_1.aud (deflated 32%) adding: odba112_ora_10093_1.aud (deflated 31%)... y así ..

La opción -P permite dar una contraseña a la línea de comando. Debido a que esto permite a otros usuarios ver la contraseña en plaintext al controlar los procesos o en el historial de comandos, la opción -e no es muy recomendada.
# zip -P oracle zp *.aud updating: odba112_ora_10025_1.aud (deflated 32%)updating: odba112_ora_10093_1.aud (deflated 31%)updating: odba112_ora_10187_1.aud (deflated 31%)… y así ..
También puede controlar la integridad de los archivos zip utilizando al opción -T. Si el zipfile se encriptó con una contraseña, debe proporcionarla.
# zip -T ze[ze.zip] odba112_ora_10025_1.aud password: test of ze.zip OK
Por supuesto que cuando usted comprime (zip) archivos, luego es necesario descomprimirlos (unzip). Y el comando es unzip. Aquí vemos un simple ejemplo del uso del comando unzip para descomprimir el archivo zip, ze.zip.
# unzip myfiles.zip
Si el archivo zip ha sido encriptado con una contraseña, se le pedirá esta contraseña. Cuando la ingrese, ésta no se repetirá en la pantalla.
# unzip ze.zipArchive: ze.zip[ze.zip] odba112_ora_10025_1.aud password: password incorrect--reenter: password incorrect--reenter: replace odba112_ora_10025_1.aud? [y]es, [n]o, [A]ll, [N]one, [r]ename: N
En el ejemplo de arriba, usted ingresó la contraseña incorrecta primero; por lo tanto el sistema volvió a pedírsela. Luego de ingresarla correctamente, el comando unzip descubrió que ya existe un archivo denominado odba112_ora_10025_1.aud; por lo tanto unzip requiere de su acción. Vea las alternativas – también tiene la posibilidad de asignar un nuevo nombre para renombrar el archivo descomprimido. ¿Recuerda el zip protegido con contraseña que fue trasmitido en la línea de comando con el comando zip –P? Usted puede descomprimir este archivo al trasmitir el comando en la línea de comando también, utilizando la misma opción –P.
# unzip -P mypass zp.zip
La opción -P difiere de la opción -p. La opción -p ordena la descompresión para descomprimir archivos del output estándar, el cual puede luego ser redirigido a otro archivo o programa. Lo atractivo del comando zip es que es el más portátil. Usted puede comprimirlo en Linux y descomprimirlo en OS X o Windows. La utilidad de descompresión está disponible para varias plataformas. Supongamos que usted ha comprimido varios archivos en varios subdirectorios que se encuentran en un directorio. Cuando usted descomprime este archivo, se crean los subdirectorios que sean necesarios. Si desea ver todos los archivos a ser descomprimidos en el actual directorio, utilice en cambio la opción -j.

# unzip -j myfiles.zip
Una de las combinaciones más útiles es utilizar el comando tar para consolidar los archivos y comprimir el archive file resultante por medio del comando zip. En lugar de realizar un proceso de dos pasos con tar y zip, puede pasar el output de tar a zip como se muestra a continuación:
# tar cf - . | zip myfiles - adding: - (deflated 90%)
El caracter especial ''-'' en zip representa el nombre del archivo. El comando tar de arriba crea un zip llamado myfiles.zip. De manera similar, mientras descomprime el archivo descomprimido y extrae los archivos del fichero zip, usted puede eliminar el proceso de dos pasos y realizar ambos en uno solo:
# unzip -p myfiles | tar xf -
gzipEl comando gzip (denominación corta de GNU zip), es otro comando para comprimir archivos. Intenta reemplazar la antigua utilidad de compresión UNIX. La principal diferencia práctica entre zip y gzip es que la primera crea un archivo zip a partir de un conjunto de archivos mientras que la última crea un archivo comprimido para cada archivo input. Vemos aquí un ejemplo:
# gzip odba112_ora_10025_1.aud
Observe que no pide un nombre para el archivo zip. El comando gzip toma cada archivo (por ej., odba112_ora_10025_1.aud) y simplemente crea un archivo zip denominado odba112_ora_10025_1.aud.gz. Asimismo, observe cuidadosamente este punto, se elimina el archivo original odba112_ora_10025_1.aud. Si usted pasa un grupo de archivos como parámetros al comando:
# gzip *
Se crea un archivo zip con la extensión .gz para cada uno de estos archivos presentes en el directorio. Al principio, el directorio contenía estos archivos:
a.txtb.pdfc.trc
Después de utilizar el comando gzip *, los contenidos del directorio serán:
a.txt.gzb.pdf.gzc.trc.gz
También se utiliza el mismo comando para descomprimir (o uncompress, o decompress). La opción es,

intuitivamente, -d para descomprimir los archivos comprimidos por gzip Para verificar los contenidos del archivo comprimido con gzip y el índice de compresión, puede utilizar la opción -l. En verdad no comprime ni descomprime nada, simplemente muestra los contenidos.
# gzip -l * compressed uncompressed ratio uncompressed_name 698 1150 42.5% +asm_ora_14651.trc 464 654 35.2% odba112_ora_13591.trc 466 654 34.9% odba112_ora_14111.trc 466 654 34.9% odba112_ora_14729.trc
463 654 35.3% odba112_ora_15422.trc 2557 3766 33.2% (totals
También puede comprimir los archivos en un directorio, utilizando la opción (-r). Para comprimir todos los archivos que se encuentran en el directorio log, utilice:
# gzip -r log
Para controlar la integridad de un archivo comprimido con gzip, utilice la opción -t:
# gzip -t myfile.gz
Cuando desea crear un nombre distinto para el archivo comprimido con gzip, no el .gz establecido por defecto, debería utilizar la opción –c. Esto ordena al comando gzip escribir el output estándar al cual puede ser direccionado el archivo. Puede utilizar la misma técnica para colocar más de un archivo en el mismo archivo comprimido con gzip. Aquí vemos dos archivos comprimidos - odba112_ora_14111.trc, odba112_ora_15422.trc – en el mismo archivo comprimido denominado 1.gz.
# gzip -c odba112_ora_14111.trc odba112_ora_15422.trc > 1.gz
Observe cuando se despliega el contenido del archivo comprimido:
# gzip -l 1.gz compressed uncompressed ratio uncompressed_name 654 -35.9% 1
El índice de compresión mostrado simplemente se aplica al último archivo en el listado (es por eso que muestra un tamaño menor para el original que para el comprimido). Cuando usted descomprime este archivo, ambos archivos originales se despliegan uno tras otro y ambos se descomprimen adecuadamente. La opción -f obliga al output a sobrescribir los archivos, si ese es el caso. La opción –v muestra el output de manera más completa. Aquí vemos un ejemplo:
# gzip -v *.trc+asm_ora_14651.trc: 42.5% -- replaced with +asm_ora_14651.trc.gzodba112_ora_13591.trc: 35.2% -- replaced with odba112_ora_13591.trc.gzodba112_ora_14111.trc: 34.9% -- replaced with odba112_ora_14111.trc.gzodba112_ora_14729.trc: 34.9% -- replaced with odba112_ora_14729.trc.gzodba112_ora_15422.trc: 35.3% -- replaced with odba112_ora_15422.trc.gz

Un comando relacionado es el comando zcat. Si desea desplegar el contenido del archivo comprimido con gzip sin descomprimirlo primero, utilice el comando zcat:
# zcat 1.gz
El comando zcat es similar a gzip -d | cat en el archivo; pero no descomprime verdaderamente el archivo. Como el comando zip, gzip también acepta opciones para los grados de compresión:
# gzip -1 myfile.txt … Least compression consuming least CPU and fastest# gzip -9 myfile.txt … Most compression consuming most CPU and slowest
El comando gunzip está disponible, y es equivalente a gzip -d (para descomprimir un archivo comprimido con gzip)
Administración de Linux en un Entorno VirtualLinux se utiliza en los centros de datos de todo el mundo. Tradicionalmente, el concepto de “servidor” se relaciona con una máquina física distinta de otras máquinas físicas. Esto ha sido así hasta la llegada de la virtualización, en donde un único servidor podía ser dividido para así convertirse en varios servidores virtuales, cada uno como si funcionaran de manera independientes con la red. Contrariamente, un ''grupo'' de servidores integrado por varios servidores físicos puede dividirse a medida que sea necesario. Debido a que ya no existe una relación uno-a-uno entre un servidor físico y uno lógico o virtual, algunos conceptos podrían resultar confusos. Por ejemplo, ¿qué es la memoria disponible? ¿Es la memoria disponible de: (1) el servidor virtual, (2) el servidor físico individual desde donde el servidor virtual se ha dividido, o (3) el grupo total de servidores del que el servidor virtual es parte? Es así entonces que los comandos de Linux pueden comportarse de manera un poco distinta cuando se ejecutan en un entorno virtual. Además, el entorno virtual también debe ser administrado, y para ello existen algunos comandos que se especializan en la administración de infraestructuras virtualizadas. En esta sección usted conocerá los comandos especializados y las actividades relacionadas al entorno virtual. Utilizaremos una Oracle VM como ejemplo. Uno de los componentes clave de la virtualización en un entorno Oracle VM es Oracle VM Agent, el cual debe estar activo para que Oracle VM funcione completamente. Para controlar si el agente está activo, debe ir al servidor de Administración (provm1, en este caso) y utilizar el comando service:
[root@provm1 vnc-4.1.2]# service ovs-agent statusok! process OVSMonitorServer exists.ok! process OVSLogServer exists.ok! process OVSAgentServer exists.ok! process OVSPolicyServer exists.ok! OVSAgentServer is alive.
El output muestra claramente que todos los procesos clave se encuentran activos. Si no están activos es porque pueden haberse desconfigurado y quizás usted quiera volver a configurarlos (o configurarlos por primera vez):
# service ovs-agent configure
El mismo comando service también se utiliza para iniciar, reiniciar y frenar los procesos del agente:
service ovs-agent start

service ovs-agent restartservice ovs-agent stop
No obstante, la mejor manera de administrar el entorno es por medio de la consola GUI, la cual se basa en la Web. Manager Webpage está disponible en el servidor Admin, en el puerto 8888, por defecto. Usted puede obtenerlo al ingresar lo siguiente en cualquier navegador de Web (suponiendo que el nombre del servidor admin es oradba2).
http://oradba2:8888/OVS
Inicie sesión como admin y la contraseña que usted creó durante la instalación. Esto le trae la siguiente pantalla:
La parte inferior de la pantalla muestra los servidores físicos del grupo de servidores. Aquí el grupo de servidores se denomina provmpool1 y el IP del servidor es 10.14.106.0. Desde esta pantalla, usted puede reiniciar el servidor, apagarlo, quitarlo del grupo y editar los detalles del servidor. También puede agregar un nuevo servidor físico a este grupo al hacer click en el botón Add Server.Al hacer click en la dirección de IP del servidor, aparecen los detalles de ese servidor físico, como se muestra debajo:

Tal vez lo más útil sea la etiqueta Monitor. Si hace click en ella, se muestra la utilización de los recursos del servidor – CPU, disco y memoria, como se muestra abajo. Desde esta página usted puede controlar visualmente si los recursos están siendo desaprovechados o si se están utilizando en exceso, o si usted necesita agregar más servidores físicos, entre otras cosas:

Volviendo a la página principal, la etiqueta Server Pools muestra los numerosos grupos de servidores definidos. Aquí puede definir otro grupo, finalizarlo, restablecer el grupo y así sucesivamente:
Si desea agregar un usuario u otro administrador, usted debe hacer click en la etiqueta Administration. Existe un administrador por defecto denominado ''admin''. Usted puede controlar todos los admins aquí y establecer sus prioridades, como las direcciones de email, los nombres, etc.:
Tal vez la actividad más frecuente que usted realice sea la administración de máquinas virtuales. Casi todas las funciones se encuentran el la etiqueta Virtual Machines en la página principal. Ésta muestra las VM

creadas hasta el momento. Aquí vemos una captura de pantalla que muestra dos máquinas denominadas provmlin1 y provmlin2:
La VM denominada provmlin2 se muestra como ''powered off'', es decir, aparece como inactivo para los usuarios finales. La otra – provmlin1 – presenta algún tipo de error. Primero comencemos con VM provmlin2. Seleccione el botón radio cerca de éste y haga click en el botón Power On. Después de un momento se mostrará como ''Running'', tal como se ve abajo:
Si hace click en el nombre VM, podrá ver los detalles de VM, como se observa debajo:
Desde la pantalla de arriba podemos saber qué VM ha sido asignada con 512MB de RAM; ejecuta Oracle Enterprise Linux 5; solo presenta un núcleo, etc. La página también brinda información clave, por ejemplo, que el puerto VNC port: 5900. Utilizando esto, usted puede poner en funcionamiento la terminal VNC de esta máquina virtual. Aquí he utilizado un visualizador VNV, con el nombre de host provm1 y el puerto 5900:
Esto inicia la sesión VNC en el servidor. Ahora puede iniciar una sesión terminal:

Debido a que el puerto VNC 5900 apunta a la máquina virtual denominada provmlin4, aparece la terminal en esa VM. Ahora usted puede emitir sus comandos Linux en esta terminal.
xmEn el servidor sobre el que se ejecutan las máquinas virtuales, los comandos de medición de desempeño como uptime (descriptos en la Parte 3) y top (descriptos en la Parte 2) tienen distintos significados en comparación con sus contrapartes del servidor físico. En un servidor físico el uptime se refiere a la cantidad de tiempo en que el servidor ha estado activo, mientras que en un mundo virtual podría ser ambiguo – refiriéndose a los servidores virtuales individuales en ese servidor. Para medir el desempeño del grupo de servidores físicos, utilice un comando distinto, xm. Los comandos son emitidos desde este comando principal. Por ejemplo, para enumerar los servidores virtuales, puede utilizar la lista del comando xm:
[root@provm1 ~]# xm listName ID Mem VCPUs State Time(s)22_provmlin4 1 512 1 -b---- 27.8Domain-0 0 532 2 r----- 4631.9
Para medir el uptime, usted podría utilizar xm uptime:
[root@provm1 ~]# xm uptimeName ID Uptime 22_provmlin4 1 0:02:05Domain-0 0 8:34:07
Los demás comandos disponibles en xm se muestran a continuación. Muchos de estos comandos pueden también ejecutarse a través de GUI.
console Adjunta un elemento a la consola de <Domain>.create Crea un dominio basado en <ConfigFile>. new Agrega un dominio a la gestión de dominio Xend delete Elimina un dominio desde la gestión de dominio Xend.destroy Finaliza un dominio inmediatamente.dump-core Aplica

dump core para un dominio específico.help Despliega este mensaje.list Enumera la información sobre todos/algunos dominios.mem-set Establece el uso de memoria actual para un dominio.migrate Migra un dominio a otra máquina.pause Pausa la ejecución de un dominio.reboot Reinicia un dominio.restore Restablece un dominio desde el estado guardado.resume Reanuda un dominio administrado por Xend.save Guarda el estado de un dominio para restablecerlo luego.shell Lanza un shell interactivo.shutdown Cierra un dominio.start Inicia un dominio administrado por Xend.suspend Suspende un dominio administrado por Xend.top Monitorea un host y los dominios en tiempo real.unpause Reanuda un dominio en pausa.uptime Imprime el tiempo de actividad para un dominio.vcpu-set Establece la cantidad de VCPUs activos permitidos para el dominio.
Veamos los más utilizados. Además de uptime, usted también puede estar interesado en el desempeño del sistema por medio del comando top. Este comando xm top actúa como el comando top en el shell del servidor regular – se actualiza automáticamente, tiene algunas claves para mostrar distintos tipos de mediciones como CPU, I/O, Red, etc. Aquí vemos el output del comando xm top básico:
xentop - 02:16:58 Xen 3.1.42 domains: 1 running, 1 blocked, 0 paused, 0 crashed, 0 dying, 0 shutdownMem: 1562776k total, 1107616k used, 455160k free CPUs: 2 @ 2992MHzNAME STATE CPU(sec) CPU(%) MEM(k) MEM(%) MAXMEM(k)MAXMEM(%) VCPUS NETS 22_provmlin4 --b--- 27 0.1 524288 33.5 1048576 67.1 1 ... Domain-0 -----r 4647 23.4 544768 34.9 no limit n/a 2 ...
22_provmlin4 --b--- 1 9 154 1 06598 1207 0Domain-0 -----r 8 68656 2902548 0 0 0 0
Muestra estadísticas como el porcentaje de CPU utilizado, la memoria utilizada, etc., para cada Máquina Virtual. Si presiona N, verá las actividades de red como se muestra a continuación:
xentop - 02:17:18 Xen 3.1.42 domains: 1 running, 1 blocked, 0 paused, 0 crashed, 0 dying, 0 shutdownMem: 1562776k total, 1107616k used, 455160k free CPUs: 2 @ 2992MHzNet0 RX: 180692bytes 2380pkts 0err 587drop TX: 9414bytes Domain-0 -----r 4650 22.5 544768 34.9 no limit n/a 2 8 68665 2902570 0 0 0 0 0Net0 RX:2972232400bytes 2449735pkts 0err 0drop TX:70313906bytes ...Net1 RX: 0bytes 0pkts 0err 0drop TX: 0bytes ...Net2 RX: 0bytes 0pkts 0err 0drop TX: 0bytes ...Net3 RX: 0bytes 0pkts 0err 0drop TX: 0bytes ...

Net4 RX: 0bytes 0pkts 0err 0drop TX: 0bytes ...Net5 RX: 0bytes 0pkts 0err 0drop TX: 0bytes ...Net6 RX: 0bytes 0pkts 0err 0drop TX: 0bytes ...Net7 RX: 0bytes 0pkts 0err 0drop TX: 0bytes ...
Net0 RX: 1017641pkts 0err 0dropNet1 RX: 0pkts 0err 0dropNet2 RX: 0pkts 0err 0dropNet3 RX: 0pkts 0err 0dropNet4 RX: 0pkts 0err 0dropNet5 RX: 0pkts 0err 0dropNet6 RX: 0pkts 0err 0dropNet7 RX: 0pkts 0err 0drop
Presionando V se ven las estadísticas de VCPU (CPU Virtual).
xentop - 02:19:02 Xen 3.1.42 domains: 1 running, 1 blocked, 0 paused, 0 crashed, 0 dying, 0 shutdownMem: 1562776k total, 1107616k used, 455160k free CPUs: 2 @ 2992MHzNAME STATE CPU(sec) CPU(%) MEM(k) MEM(%) MAXMEM(k) MAXMEM(%) VCPUS ...22_provmlin4 --b--- 28 0.1 524288 33.5 1048576 67.1 ... NETS NETTX(k) NETRX(k) VBDS VBD_OO VBD_RD VBD_WR SSID1 1 9 282 1 06598 1220 0
VCPUs(sec): 0: 28sDomain-0 -----r 4667 1.6 544768 34.9 no limit n/a 2 8 68791 2902688 0 00 0 0
VCPUs(sec): 0: 2753s 1: 1913s
Examinemos algunas actividades bastante comunes – una de las cuales es la distribución de la memoria disponible entre las VM. Supongamos que usted quiera tener cada VM de 256 MB de RAM, debería utilizar el comando xm mem-set como se muestra abajo. Luego debería utilizar el comando xm list para confirmarlo.
[root@provm1 ~]# xm mem-set 1 256 [root@provm1 ~]# xm mem-set 0 256 [root@provm1 ~]# xm listName ID Mem VCPUs State Time(s)22_provmlin4 1 256 1 -b---- 33.0Domain-0 0 256 2 r----- 4984.4
Conclusion
Con esto concluimos la extensa serie de cinco presentaciones sobre comandos avanzados de Linux. Como

mencioné al comienzo de esta serie, Linux tiene numerosos comandos que son útiles en muchos casos, y nuevos comandos que van desarrollándose e incorporándose gradualmente. Conocer todos los comandos disponibles no es tan importante como saber cuáles se adaptan mejor a sus necesidades.
En esta serie he presentado y explicado algunos comandos necesarios para realizar la mayoría de sus tareas diarias. Si usted practica estos pocos comandos, junto con sus opciones y argumentos, podrá manejar cualquier infraestructura de Linux con facilidad.
Gracias por leer esta serie y mucha suerte.