universidad politécnica de madrid escuela técnica...
TRANSCRIPT

Alumno: Belén Yébenes Calvo
Tutor: Belén Ríos Sánchez
Ponente: Carmen Sánchez Ávila
Miembros del tribunal:
María Luisa Cuadrado Ebrero
María Isabel de Corcuera Labrado
María José Melcón de Giles
Francisco Ballesteros Olmo
Universidad Politécnica de Madrid
Escuela Técnica Superior de Ingenieros de Telecomunicación. Grado en Ingeniería Biomédica
Departamento de matemática aplicada a las tecnologías de la información y las comunicaciones
Realce de imágenes mamográficas mediante técnicas basadas en
histograma para su clasificación por medio de redes neuronales
convolucionales

Alumno: Belén Yébenes Calvo
Tutor: Belén Ríos Sánchez
Ponente: Carmen Sánchez Ávila
Miembros del tribunal:
María Luisa Cuadrado Ebrero
María Isabel de Corcuera Labrado
María José Melcón de Giles
Francisco Ballesteros Olmo
Universidad Politécnica de Madrid
Escuela Técnica Superior de Ingenieros de Telecomunicación. Grado en Ingeniería Biomédica
Departamento de matemática aplicada a las tecnologías de la información y las comunicaciones
Realce de imágenes mamográficas mediante técnicas basadas en
histograma para su clasificación por medio de redes neuronales
convolucionales

palabra
Resumen
El cáncer de mama es una enfermedad que actualmente afecta a una de cada ocho mujeres enel mundo, presente también en hombres aunque con una incidencia menor. Esta patologíacomienza con una división descontrolada de células producida por una alteración en losgenes encargados de controlar los procesos de división y crecimiento celular, dando lugar a laformación de un nódulo o tumor. Estos tumores pueden ser benignos, los cuales no suponenun riesgo para la salud o malignos, denominados también cancerosos, que ponen en riesgo lavida de los pacientes y se caracterizan por ser capaces de metastatizar. La principal formade diagnóstico de esta enfermedad consiste en la realización periódica de mamografías.Este tipo de pruebas permiten la localización de anomalías en el tejido mamario talescomo microcalcificaciones y masas, que son consideradas indicadores de presencia de laenfermedad.
Este trabajo pretende estudiar la influencia de las técnicas de realce de imágenes basadasen el histograma sobre la clasificación de mamografías en cinco conjuntos diferentes: Cal-cificaciones Benignas, Masas Benignas, Calcificaciones Malignas, Masas Malignas y tejidoSano, obtenida por un sistema CAD de clasificación automática de mamografía medianteredes neuronales convolucionales. En concreto, se van a aplicar dos algoritmos diferentes:Histogram Intensity Windowing (HIW) y Contrast-limited adaptive histogram equalization(CLAHE). Mediante estos algoritmos se modifica el histograma de la mamografía aumen-tando el contraste entre los diferentes tejidos de la imagen: fondo, tejido fibroso, tejido densoy tejido patológico, que incluye las microcalcificaciones y las masas. Con este aumento delcontraste se pretende incrementar las diferencias entre los distintos tipos de tejido parafacilitar el aprendizaje de la red neuronal. De este modo, se podría mejorar el número deimágenes clasificadas correctamente.
El objetivo final del trabajo es obtener un algoritmo de realce que forme parte del sistemaCAD y permita mejorar la detección y clasificación automática de microcalcificaiones ymasas. Así, sería posible aumentar las posibilidades de un diagnóstico precoz de la enfer-medad, algo fundamental teniendo en cuenta que su detección en estadios iniciales aumentalas posibilidades de curación hasta prácticamente el 100%.
Palabras clave
Cáncer, Microcalcificaciones, Masas, Mamografía, Computed Aided Diagnosis (CAD),Realce de Contraste, Histogram Intensity Windowing (HIW), Contrast Limited AdaptativeEqualization (CLAHE), Redes Neuronales Convolucionales (CNN).

Abstract
Nowadays, breast cancer affects one in eight women in the world, concerning also men butwith lower the incidence. It begins with an over-excited division of cells produced by agenetic alteration of the genes entrusted to support the division and cell growth processgiving place to the formation of a nodule or tumor. These tumors can be benign, whichdo not pose health risk, or malignant, named also cancerous, that imply a life risk and arecaracterized by their ability to metastasize. Nowadays, mammography is the main form todiagnosis this desease. The use of this kind of image allows the anatomical location of thosebreast defects such as microcalcifications or mases wich are considered risk indicators of thepresence of breast cancer.
This study is aimed to analize the influence of the image histogram-based enhancementtechniques in the automatic clasification of mammography in five different sets according tothe tissue they contain: Benign Calcificactions, Benign Mass, Cancer Calcificacions, CancerMass and Healthy. This clasification generated by a CAD system based on convolutionalneural network (CNN). In detail, two different algorithms are studied: Histogram intensistywindowing (HIW) and Contrast limited adaptative histogram equalization (CLAHE). Bothalgorithms modify the image by increasing the contrast between different breast tissues:background, dense tissue, fibrous tissue and patological tissue wich includes mases andmicrocalcifications. The objective of this enhacement is to increase the diferences betweentissues in order to facilitate the training of the CNN in such a way, that the number ofcorrectly classified images will raise.
The final aim of the study is to select an enhacement algorithm of enhancement to beincluded in the CAD system wich permits improving the automatic detection and classificationof microcalcifications and masses. In this way, it will increase the posibilities of an earlierdiagnosis, which is a crucial step since detection in initial stadiums of the disease increasesthe possibilities of healing to almost 100%.
Key words
Cancer, Microcalcifications, Mass, Mamography, Computed Aided Diagnosis (CAD),Contrast Enhancement, Histogram Intensity Widowing (HIW), Contrast Limited AdaptativeEqualization (CLAHE), Convolutional Neural Network (CNN)

Índice general
1. Introducción 6
2. Estado del arte 10
2.1. Sistemas CAD para el análisis de mamografía . . . . . . . . . . . . . . . . . 10
2.2. Bases de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3. Técnicas de realce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3. Materiales y métodos 17
3.1. Conjunto de imágenes de prueba . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2. Herramienta para la clasificación de tejidos . . . . . . . . . . . . . . . . . . 17
3.3. Metodología . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4. HIW: Histogram based Intensity Windowing . . . . . . . . . . . . . . . . . 22
3.4.1. Fundamentos teóricos . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4.2. Implementación del algoritmo . . . . . . . . . . . . . . . . . . . . . . 24
3.4.3. Elección de parámetros . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.5. CLAHE: Contrast Limited Adaptive Histogram Equalization . . . . . . . . 26
3.5.1. Fundamentos teóricos . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.5.2. Implementación del algoritmo . . . . . . . . . . . . . . . . . . . . . . 30
3.5.3. Elección de parámetros . . . . . . . . . . . . . . . . . . . . . . . . . 30
4. Resultados 33
4.1. Descripción y organización de las pruebas . . . . . . . . . . . . . . . . . . . 33
4.2. Pruebas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.3. Comparación de los resultados . . . . . . . . . . . . . . . . . . . . . . . . . 40
5. Conclusiones 44
6. Líneas futuras 47
5

Capítulo 1
Introducción
A pesar de que la incidencia del cáncer de mama varía dependiendo del país, en la mayorparte del mundo este tipo de tumor se ha convertido en la segunda causa de mortalidadpara la población femenina, después de las enfermedades coronarias. En Estados Unidosse sitúa como la primera causa de mortalidad en las mujeres menores de 85 años [1]. Elúltimo informe de la Organización Mundial de la Salud (OMS) expone que cada año sedetectan 1.38 millones de nuevos casos y fallecen 458 mil personas por esta causa [2]. EnEspaña, se diagnostican unos 26.000 casos al año, lo que representa casi el 30% de todoslos tumores del sexo femenino [3]. La mayoría de estos casos se diagnostican entre los 35y los 80 años, siendo el rango de edad con más número de casos diagnosticados entre los45 y los 65 años. Según la Asociación Española Contra el Cáncer (AECC), actualmente elcáncer de mama afecta a una de cada ocho mujeres a lo largo de su vida [4]. La SociedadEspañola de Oncología (SEOM) corrobora estas cifras a través de un informe elaborado en2014 [5] cuyos resultados se plasman en la figura 1.1.
Esta patología es el resultado de la transformación maligna de las células que forman laglándula mamaria. En organismos sanos los procesos de crecimiento y división celular tie-nen lugar de forma lenta y controlada, permitiendo que nuevas células reemplacen las viejaso dañadas. Con el paso del tiempo, pueden aparecer mutaciones producidas por una alte-ración en los genes encargados de controlar estos procesos y es entonces cuando las célulascomienzan a dividirse de forma descontrolada, dando lugar a un nódulo o tumor. Estostumores pueden ser benignos o malignos. En el primer caso, el crecimiento es lento y lascélulas que lo forman guardan similitud con las originales. Además, se caracterizan por noestar vascularizados y no invadir el tejido adyacente. Por el contrario, los tumores malignospresentan un crecimiento descontrolado y tienen la capacidad de invadir otros tejidos (in-filtrarse) y de proliferar en otras partes del organismo (metastatizar). Este tipo de tumoresson los denominados tumores cancerosos.
Estadio Tasa de supervivencia0 100%I 100%II 93%III 72%IV 22%
Tabla 1.1: Tasa de supervivencia en función del estadio.
6
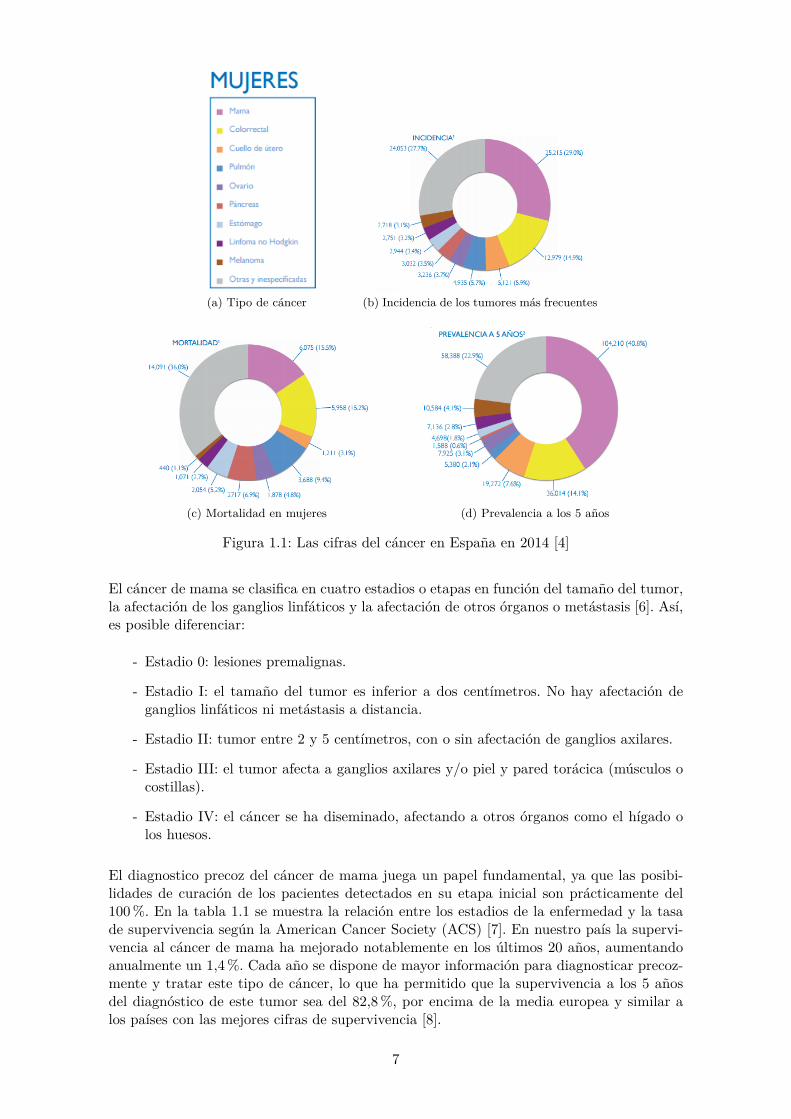
(a) Tipo de cáncer (b) Incidencia de los tumores más frecuentes
(c) Mortalidad en mujeres (d) Prevalencia a los 5 años
Figura 1.1: Las cifras del cáncer en España en 2014 [4]
El cáncer de mama se clasifica en cuatro estadios o etapas en función del tamaño del tumor,la afectación de los ganglios linfáticos y la afectación de otros órganos o metástasis [6]. Así,es posible diferenciar:
- Estadio 0: lesiones premalignas.
- Estadio I: el tamaño del tumor es inferior a dos centímetros. No hay afectación deganglios linfáticos ni metástasis a distancia.
- Estadio II: tumor entre 2 y 5 centímetros, con o sin afectación de ganglios axilares.
- Estadio III: el tumor afecta a ganglios axilares y/o piel y pared torácica (músculos ocostillas).
- Estadio IV: el cáncer se ha diseminado, afectando a otros órganos como el hígado olos huesos.
El diagnostico precoz del cáncer de mama juega un papel fundamental, ya que las posibi-lidades de curación de los pacientes detectados en su etapa inicial son prácticamente del100%. En la tabla 1.1 se muestra la relación entre los estadios de la enfermedad y la tasade supervivencia según la American Cancer Society (ACS) [7]. En nuestro país la supervi-vencia al cáncer de mama ha mejorado notablemente en los últimos 20 años, aumentandoanualmente un 1,4%. Cada año se dispone de mayor información para diagnosticar precoz-mente y tratar este tipo de cáncer, lo que ha permitido que la supervivencia a los 5 añosdel diagnóstico de este tumor sea del 82,8%, por encima de la media europea y similar alos países con las mejores cifras de supervivencia [8].
7
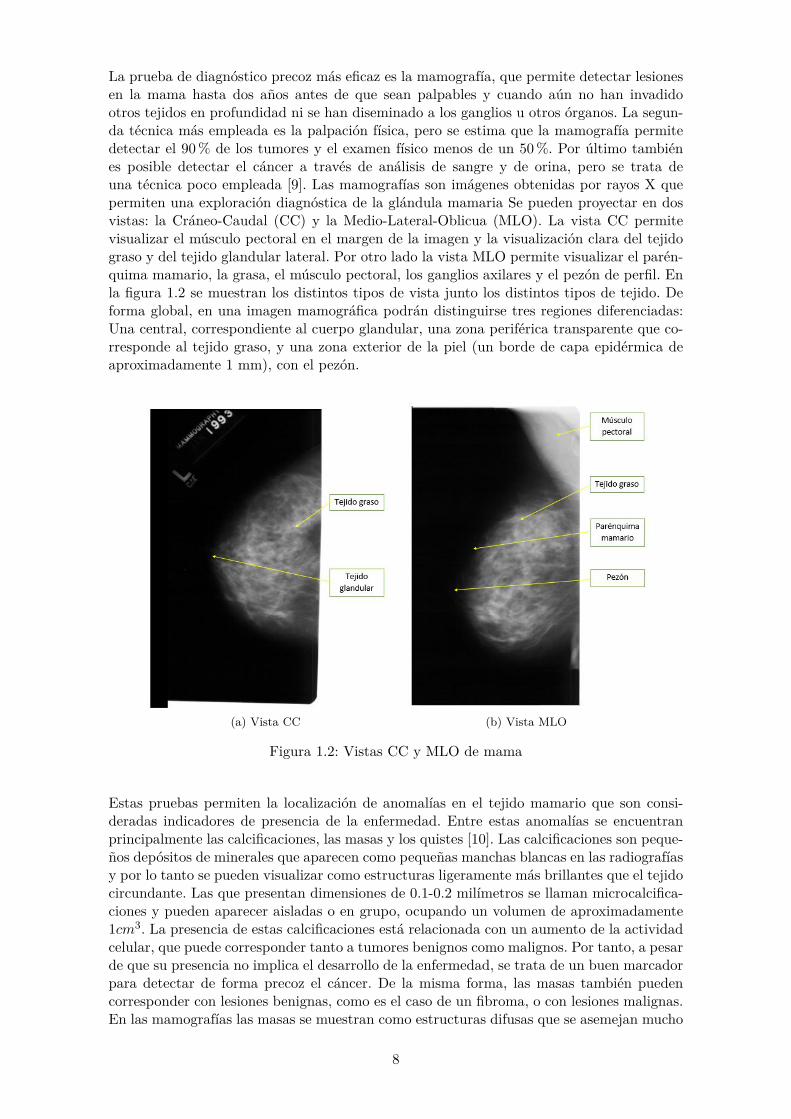
La prueba de diagnóstico precoz más eficaz es la mamografía, que permite detectar lesionesen la mama hasta dos años antes de que sean palpables y cuando aún no han invadidootros tejidos en profundidad ni se han diseminado a los ganglios u otros órganos. La segun-da técnica más empleada es la palpación física, pero se estima que la mamografía permitedetectar el 90% de los tumores y el examen físico menos de un 50%. Por último tambiénes posible detectar el cáncer a través de análisis de sangre y de orina, pero se trata deuna técnica poco empleada [9]. Las mamografías son imágenes obtenidas por rayos X quepermiten una exploración diagnóstica de la glándula mamaria Se pueden proyectar en dosvistas: la Cráneo-Caudal (CC) y la Medio-Lateral-Oblicua (MLO). La vista CC permitevisualizar el músculo pectoral en el margen de la imagen y la visualización clara del tejidograso y del tejido glandular lateral. Por otro lado la vista MLO permite visualizar el parén-quima mamario, la grasa, el músculo pectoral, los ganglios axilares y el pezón de perfil. Enla figura 1.2 se muestran los distintos tipos de vista junto los distintos tipos de tejido. Deforma global, en una imagen mamográfica podrán distinguirse tres regiones diferenciadas:Una central, correspondiente al cuerpo glandular, una zona periférica transparente que co-rresponde al tejido graso, y una zona exterior de la piel (un borde de capa epidérmica deaproximadamente 1 mm), con el pezón.
(a) Vista CC (b) Vista MLO
Figura 1.2: Vistas CC y MLO de mama
Estas pruebas permiten la localización de anomalías en el tejido mamario que son consi-deradas indicadores de presencia de la enfermedad. Entre estas anomalías se encuentranprincipalmente las calcificaciones, las masas y los quistes [10]. Las calcificaciones son peque-ños depósitos de minerales que aparecen como pequeñas manchas blancas en las radiografíasy por lo tanto se pueden visualizar como estructuras ligeramente más brillantes que el tejidocircundante. Las que presentan dimensiones de 0.1-0.2 milímetros se llaman microcalcifica-ciones y pueden aparecer aisladas o en grupo, ocupando un volumen de aproximadamente1cm3. La presencia de estas calcificaciones está relacionada con un aumento de la actividadcelular, que puede corresponder tanto a tumores benignos como malignos. Por tanto, a pesarde que su presencia no implica el desarrollo de la enfermedad, se trata de un buen marcadorpara detectar de forma precoz el cáncer. De la misma forma, las masas también puedencorresponder con lesiones benignas, como es el caso de un fibroma, o con lesiones malignas.En las mamografías las masas se muestran como estructuras difusas que se asemejan mucho
8

al tejido circundante, sobre todo si la mama es muy grasa, donde las masas son difícilmenteidentificables. Por último, los quistes son una colección de líquido en el seno de un pequeñosaco dentro de la mama. Es muy poco habitual que los quistes sean malignos, y en cuantoa visualización se asemejan a las calcificaciones, caracterizándose por presentar niveles deintensidad altos en las mamografías.
Debido a la gran variedad de posibles patologías, la dificultad visual que supone hallarlas,la similitud entre los tejidos y la presencia de ruido en las imágenes, es difícil obtenerun diagnóstico claro incluso para radiólogos experimentados. Por esta razón se realizanun gran número de pruebas innecesarias incluyendo pruebas invasivas como la biopsia.Actualmente se están desarrollando herramientas de ayuda a los expertos que consiganreducir la incertidumbre presente a la hora de diagnosticar. Estas herramientas son lossistemas de detección y ayuda al diagnóstico asistidos por ordenador (CAD), que son capacesde analizar las imágenes y ayudar a detectar lesiones sospechosas, considerándose solucionestecnológicas de apoyo al radiólogo en la toma de decisiones [11]. De este modo, su finalidades servir de ayuda al facultativo para mejorar los porcentajes de acierto en el diagnóstico yla clasificación del cáncer de mama.
Uno de los mayores inconvenientes que tienen que afrontar los sistemas CAD relacionadoscon mamografías es la dificultad de distinguir el contenido de las imágenes. Por una parte,las masas presentan características muy similares al tejido denso mamario dificultado sudiferenciación y por otra, las microcalcificaciones al trataste de estructuras de pequeñotamaño pueden estar enmascaradas por el tejido mamario circundante a ellas, como porejemplo tejido fibroso. Con el fin de aumentar la capacidad diagnóstica de los sistemas CAD,numerosos estudios proponen aplicar técnicas de realce a las mamografías que permitanaumentar las diferencias entre las anomalías y el tejido sano de la mama. El propósitogeneral de las técnicas de realce es mejorar la precisión de las mamografías como imágenesde diagnóstico ya que hasta un 10% de los tumores palpables no son visibles en mamografíasobtenidas con técnicas habituales. Actualmente existen un gran número de algoritmos derealce empleados en el ámbito médico cuya finalidad es ayudar a los especialistas a mejorarla percepción y la interpretación de la información contenida en las imágenes [12]. Duranteuna etapa previa a la clasificación, se aplicarán algoritmos de realce con el fin de aumentarel porcentaje de imágenes clasificadas correctamente en uno de esos subconjuntos.
Un tipo de estos algoritmos de realce son aquellos que se basan en aumentar el contrasteentre las diferentes estructuras. De este modo, el objetivo que se pretende conseguir un au-mento del contraste entre el tejido patológico y el tejido mamario sano. En este trabajo sehan implementado dos algoritmos de contraste basados en histograma: Histogram-based In-tensity Windowing (HIW ) y Contrast Limited Adaptive Histogram Equalization (CLAHE).Además, lo largo del trabajo se han realizado diferentes pruebas variando la configuraciónde ambos algoritmos para estudiar con que parámetros se obtienen mejores resultados.
Para la evaluación del rendimiento de estos algoritmos se ha utilizado un sistema CADmediante redes neuronales convoluciones (CNN) [13]. Esta red permite la clasificación delas mamografías en cinco tipos: masas benignas, masas malignas, calcificaciones malignas,calcificaciones benignas y tejido sano. Los algoritmos de realce son aplicados durante unaetapa previa a la clasificación con el objetivo de aumentar el porcentaje de imágenes clasifi-cadas correctamente. Por lo tanto, este trabajo pretende mejorar la calidad de las imágenespara potenciar la capacidad de localizar y analizar las lesiones mamarias con un sistemade detección y ayuda al diagnóstico asistido por ordenador (CAD) basado redes neuronalesconvolucionales. De esta forma, se pretende contribuir a la lucha contra el cáncer de ma-ma en el ámbito del diagnóstico con una herramienta que sirva de ayuda y soporte a losfacultativos.
9

Capítulo 2
Estado del arte
2.1. Sistemas CAD para el análisis de mamografía
Los sistemas CAD pueden ser de gran ayuda al médico a la hora de detectar y diagnosticarlas posibles anomalías existentes en la imagen mamográfica. Algunos de estos sistemassimplemente mejoran la visibilidad de las anomalías dentro de la imagen que va a serrevisada por el especialista. Otros, sin embargo, realizan de forma automática el diagnósticoque se utilizará como segunda opinión por el radiólogo. El principal objetivo de los sistemasCAD es que puedan asistir al radiólogo procesando la mayor cantidad de imágenes deforma automatizada y con la mayor precisión posible [14]. Los sistemas CAD empleadosen la detección del cáncer de mama están estructurados en cuatro módulos: preprocesado,segmentación del tejido, extracción de características y clasificación, tal y como se puedever en la figura 2.1.
Figura 2.1: Esquema de un sistema CAD genérico. Modificado de [15] .
En la fase de preprocesado tiene lugar la eliminación de ruido y el realce de las diferentesestructuras mamarias. Los diferentes sistemas CAD implementan distintas soluciones eneste módulo que pueden ser agrupadas en dos grandes grupos: técnicas globales y técnicaslocales. En el primer grupo cabe destacar la ecualización del histograma, la normalizacióndel histograma y el uso de máscaras de convolución, mientras que en el segundo conjuntodestacan el realce adaptativo de regiones vecindario y los métodos de realce basados enregiones.
Por otro lado, el módulo de segmentación tiene como objetivo separar las diferentes estruc-turas o tejidos de la mamografía. De la misma forma que ocurría en el módulo anterior,
10
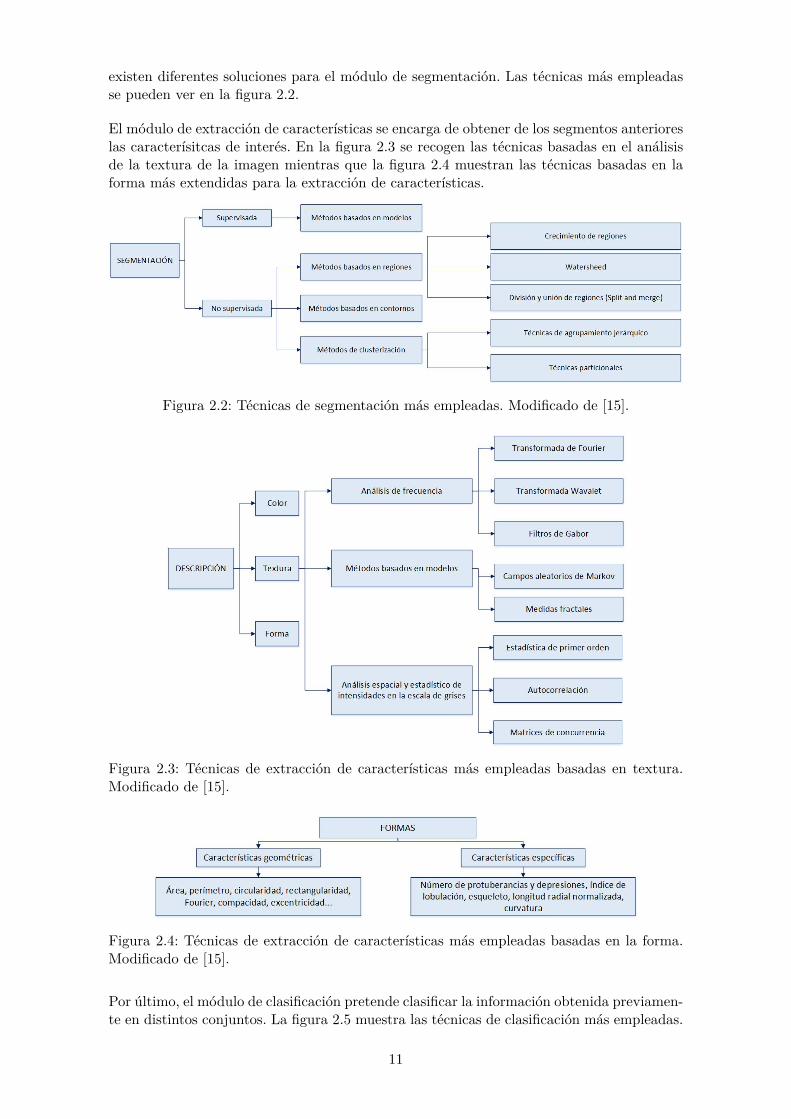
existen diferentes soluciones para el módulo de segmentación. Las técnicas más empleadasse pueden ver en la figura 2.2.
El módulo de extracción de características se encarga de obtener de los segmentos anterioreslas caracterísitcas de interés. En la figura 2.3 se recogen las técnicas basadas en el análisisde la textura de la imagen mientras que la figura 2.4 muestran las técnicas basadas en laforma más extendidas para la extracción de características.
Figura 2.2: Técnicas de segmentación más empleadas. Modificado de [15].
Figura 2.3: Técnicas de extracción de características más empleadas basadas en textura.Modificado de [15].
Figura 2.4: Técnicas de extracción de características más empleadas basadas en la forma.Modificado de [15].
Por último, el módulo de clasificación pretende clasificar la información obtenida previamen-te en distintos conjuntos. La figura 2.5 muestra las técnicas de clasificación más empleadas.
11

Si bien, la mayor parte de los sistemas utiliza clasificadores independiente, actualmente seha comenzado a utilizar la combinación de varios clasificadores con el fin de mejorar laprecisión [15].
Figura 2.5: Técnicas de clasificación más empleadas. Modificado de [15].
El análisis actual de los sistemas CAD muestra que los mejores resultados obtenidos en laclasificación cuentan con un 90% de acierto empleando una configuración concreta. Estacifra no se considera suficientemente elevada para implantar el sistema en la rutina clínicapara el diagnóstico, pero si presenta grandes ventajas como sistema de apoyo al facultativo[16]. Un estudio llevado a cabo por Women’s Diagnostic and Breast Health Center de laSociedad de Radiología de Norte América (RSNA) en el año 2001 demostró que los sistemasCAD detectan al menos un 20.5% de las patologías que no habían sido detectadas por losexpertos. Las estadísticas confirman que entre un 5 y un 20% de las patologías no sonvisualizadas con una única lectura de la mamografía por parte del especialista. En cambio,si se realizan dos lecturas, el número de falsos negativos se reduce a 5-15% [14].
La mayoría de los sistemas actuales se basan en técnicas de aprendizaje automático y sufinalidad es clasificar de forma binaria las imágenes. Estos sistemas se dividen en aquellosque evalúan el tipo de lesión presente en la mamografía, y aquellos que permiten clasificar lalesión como maligna o benigna. En 2015 se presentó un nuevo esquema de clasificación quepermite diferenciar en función del tipo de anomalía si la hubiera y su malignidad, separandolas imágenes en: calcificaciones benignas, calcificaciones malignas, masas benignas, masasmalignas o tejido sano [13].
Independientemente de la implementación y el tipo de sistema, estos presentan principal-mente dos ventajas relacionadas con la reproducibilidad y la sensibilidad. En primer lugar,con el uso de los sistemas CAD aumenta la capacidad de reproducir los análisis. En segundolugar, la sensibilidad global empleando el sistema como herramienta de soporte al diagnós-tico aumenta al 94-99%, aunque las sensibilidades individuales varían en función del tipode mamografía y el tipo de lesión. En cuanto al tipo de mamografía las cifras más altasde sensibilidad aparecen con los sistemas aplicados a mamografía digital. Por otro lado, enrelación al tipo de lesión, la sensibilidad es superior para las microcalcificaciones que paralas masas. En relación a las microcalcificaciones, las mamografías digitales detectan el 89%
12

frente al 86% que detectan las analógicas, y respecto a las masas el 81% son detectadas conmamografía digital y únicamente el 67% con analógica [17]. Por otro lado, estos sistemastambién preentan limitaciones entre las que cabe destacar la baja especificidad causadapor el elevado número de falsos positivos. Estos son casos en los que el sistema consideraque tienen anomalías pero que el radiólogo clasifica como tejido sano. En este sentido, esnecesario diferenciar entre los radiólogos con mayor número de años de experiencia y ma-yores cargas de trabajo, que tienen un mayor grado de sensibilidad, y los radiólogos conmenor experiencia. La especificidad en la detección de los CAD utilizados por radiólogoscon menor experiencia y formación es mayor que la de aquellos usados por radiólogos ex-pertos. Otro punto muy estudiado es el impacto de la mama densa en los sistemas CAD. Amedida que aumenta la densidad mamaria, la capacidad de detección disminuye, por lo quela sensibilidad es mayor en microcalcificaciones que en masas. Esto se debe a que mientrasque las masas poseen niveles de intensidad similares al tejido graso, las microcalcificacionespresentan niveles mayores de intensidad, pudiendo ser detectadas más fácilmente.
Un estudio llevado a cabo por diferentes departamentos franceses de radiología en colabo-ración con departamentos de Ginebra estudió el impacto de un sistema CAD de detecciónde masas en la toma de decisiones de los radiólogos expertos y los radiólogos jóvenes. Porun lado se realizó un análisis del sistema CAD y por otro lado una comparación entre losresultados aportados por los radiólogos y por el sistema. El sistema estudiado toma comoentrada mamografías digitalizadas y genera como resultado las mismas mamografías seña-lando con un círculo el área donde ha detectado una masa. Estas marcas fueron revisadasposteriormente por los radiólogos. Los resultados obtenidos están recogidos en la tabla 2.1,donde se puede observar cómo el sistema clasificó correctamente 89 de las 100 lesiones. Porotro lado, de los 100 casos sanos, en 16 de ellos el sistema CAD no señaló ninguna región.Por lo tanto, el sistema presenta una sensibilidad del 89% mientras que su especificidades solamente del 16%. Estos datos implican que el sistema CAD tiene una capacidad muyelevada de detectar lesiones en las mamografías, pero que en muchos casos aquellas que nopresentan lesiones el sistema las define como patológicas. Durante el proceso los radiólogospasaron por alto tres lesiones. De estos tres casos, el sistema CAD detectó dos de ellos, loque supondría que únicamente una de las masas no sería detectada si los radiólogos tuvie-ran en cuenta esta información. Por otro lado, el sistema muestra tres falsos positivos, peroteniendo en cuenta que los radiólogos emplean este sistema como un sistema de soporte yayuda a la decisión, si siguen su propio criterio estos positivos sería rechazados evitandopruebas invasivas a los pacientes [17].
CAD Cáncer Sano Total
Test+ 89 84 183Test- 11 16 27Total 100 100 200
Tabla 2.1: Resultados obtenidos en el estudio del sistema CAD. Modificado de [17].
2.2. Bases de datos
Existen un gran número de bases de datos de imágenes mamográficas, como la B-SCREEN(Bayesian Decision Support in Medical Screening), IRMA (Image Retrieval in MedicalApplications) o AMDI (Indexed Atlas of Digital Mammograms) [18]. Estas bases de da-tos no son de libre acceso y en general son propiedad de Universidades, Hospitales o centrostecnológicos de diferentes países.
13

La base de datos AMDI [19] además de las mamografías contiene información radiológica,los resultados de la biopsia si se ha realizado, la historia clínica del paciente y la informaciónrelativa a su estilo de vida. Está organizada por exámenes que contienen cuatro vistas cadauno, una vista CC y una vista MLO de cada mama. Con el fin de facilitar los estudiosrelacionados con el cáncer, la base de datos además contiene imágenes con el contorno de lamama, el límite que se considera pectoral en las vistas MLO y en caso de estar presentes,el contorno de las masas, las regiones de las microcalcificaciones y el número de las mismas.Además, permite el acceso a otros exámenes que se le hayan realizado al paciente a lo largodel tiempo.
Por otro lado, las bases de datos B-SCREEN y IRMA todavía se encuentran en desarrollo[20]. La base de datos B-SCREEN se creó en Alemania en el año 2006 con el objetivo derecopilar una gran base de datos nacional, a la que se tuviera acceso desde diferentes institu-ciones como hospitales o centros de investigación. Con la misma idea, se creó en Aquisgránla base de datos IRMA como resultado de la cooperación de diferentes departamentos de laUniversidad Tecnológica.
Además de estas bases de datos existen otras que son de libre acceso y por lo tanto de graninterés para llevar a cabo diferentes estudios. Entre estas cabe destacar la DDSM (DigitalDatabase for Screening Mammography), Magic-5 y la mini-MIAS (MiniMammographyDatabase), las cuales además contienen información proporcionada por radiólogos expertossobre las anomalías y una descripción detallada de las mamografías. Esta descripción sebasa en el estándar Breast Imaging Reporting and Data System (BI-RADS) creado por laAmerican College of Radiology (ACR), el cual asigna un valor a cada mamografía. De estamanera, cuanto mayor sea el valor asignado a la mamografía por el radiólogo mayor es laseguridad del radiólogo sobre la presencia de patologías. Además, esta clasificación tiene encuenta el tipo de tejido mamario clasificándolo en cuatro categorías: mamas grasas, mamasde densidad media, mamas heterogéneamente densas y mamas de patrón denso. Esta infor-mación aporta fiabilidad al diagnóstico, ya que cuanto más denso sea el seno mayor es laprobabilidad de no detectar la presencia de anomalías [21].
La base de datos mini-MIAS [22] es una base de datos que contiene mamografías digitali-zadas reducidas. Estas mamografías se han obtenido mediante la digitalización de mamo-grafías analógicas procedentes de la base de datos MIAS, creada por la MammographicImage Analysis Society. Tiene disponibles 322 mamografías de tamaño 1024x1024 con unaresolución espacial de 200 µm/píxel. Además contiene información añadida por radiólogosexpertos indicando la localización de las anomalías.
Por otro lado, la base de datos MAGIC-5 [23] contiene mamografías procedentes de hospita-les italianos capturadas con la idea de emplearlas para el desarrollo de sistemas CAD. Estabase de datos contiene un número mayor de imágenes, 3.369 mamografías procedentes de967 pacientes y clasificadas acorde con el tipo de lesión, la morfología de la mama, el tipo detejido y el tipo de patología. Estas imágenes tienen un tamaño de 2067x2067 píxeles y unaresolución de 85 µm/píxel. Al igual que el resto de bases de datos mencionadas, contienemamografías en ambas vistas, medio-lateral y cráneo-caudal.
Por último, la base de datos DDSM [24] contiene mamografías procedentes del HospitalGeneral de Massachusetts, la Escuela de Medicina de la universidad de West Forest, elHospital Sacred Heart y la Escuela de Medicina de la Universidad de ST.Louis. El númerode imágenes disponibles está en torno a 5000 imágenes digitales obtenidas de 2500 pacien-tes caracterizadas por un aumento de la calidad con respecto a otras bases de datos quecontienen mamografías analógicas digitalizadas. Las imágenes son de diferentes tamaños,
14

alrededor de 3000x5000 píxeles y una resolución aproximada de 75 mm/píxel. Para cadapaciente, se incluye una vista CC y MLO de cada mama, información personal como laedad, el sexo o la procedencia y el análisis radiológico acompañado por el número y el tipode anomalías si es que las presenta. La DDSM está organizada en casos y volúmenes, siendoun caso la colección de imágenes e información correspondiente a un examen mamográficode un paciente y un volumen una colección de casos ordenados con el fin de facilitar la dis-tribución de las imágenes. En la figura 2.6 se puede observar un caso concreto pertenecientea un volumen de la base de datos [25].
Figura 2.6: Ejemplo de un caso de la DDSM. Fuente [26]
2.3. Técnicas de realce
Las mamografías, especialmente en pacientes con tejidos muy densos, se consideran imágenesde bajo contraste. El realce de imágenes introduce la capacidad de mejorar el contraste entre
15

el tejido sano y el tejido insano, facilitando la detección de tejido patológico [12]. La figura2.7 muestra de forma esquemática los tres grupos principales en los que se engloban losdiferentes algoritmos de realce empleados en sistemas de ayuda a la detección.
Figura 2.7: Técnicas de realce mamográfico en sistemas CAD. Modificado de [27].
Los algoritmos de supresión de ruido, también denominados algoritmos de suavizado, tienencomo objetivo reducir el ruido aditivo, como el Gaussiano o el de Poisson a través de técnicasque son capaces de separar la información de interés de dicho ruido. Este hecho se resumede forma matemática en la expresión 2.1
x(n) = y(n) + η(n) (2.1)
donde:
y es la señal ruidosax es la señal sin ruidoη es la señal original
Los algoritmos de realce de bordes están basados en entender el borde como una disconti-nuidad de luminosidad entre dos regiones que están en contacto en la imagen. El principalinconveniente de estos algoritmos es que pueden sobrerrealzar algunas estructuras completao parcialmente. Además, es difícil conseguir realzar los bordes las estructuras y eliminar elruido simultáneamente.
Por último, las técnicas de realce de contraste permiten aumentar la diferencia de contrasteentre las estructuras de la mama sin realzar el ruido y sin distorsionar los bordes de di-chas estructuras. Las dos formas principales de definir el contraste son las expuestas porMichalson y Weber.
ContrastedeMichaelson = (Lmax − Lmin)(Lmax + Lmin) (2.2)
ContrastedeWeber = Lmax
Lmin(2.3)
donde:
Lmax es el máximo de intensidadLmin es el mínimo de intensidad
Los métodos de realce de contraste son capaces de acentuar o enfatizar objetos o estructuras,en este caso tejido mamográfico, mediante la manipulación de los niveles de gris de la imagen.Estos métodos emplean funciones de transformación que aumentan la diferencia entre losvalores de intensidad de las diferentes estructuras. Estos métodos no pretenden modificaro incrementar la información presente en la mamografía, sino simplemente potenciar elcontraste realzando las características intrínsecas de la mamografía [27].
16

Capítulo 3
Materiales y métodos
3.1. Conjunto de imágenes de prueba
Las imágenes utilizadas en este trabajo proceden de la base de datos DDSM descrita enel apartado 2.2. En función de la información que contiene, destacando la valoración de lamamografía y el tipo de las anomalías, se pueden diferenciar cinco tipos de mamografías:
- Imágenes con microcalcificaciones benignas
- Imágenes con microcalcificaciones malignas.
- Imágenes con masas benignas.
- Imágenes con masas malignas.
- Imágenes con tejido sano.
Debido al elevado número de mamografías que contiene la DDSM, no es viable trabajar conla base de datos completa, ya que el tiempo de entrenamiento y validación del sistema seríamuy elevado. Por este motivo se han seleccionado un conjunto de mamografías (trainingset) que permita evaluar los resultados del trabajo en un tiempo aceptable. Por otro lado,el resultado de la clasificación se ve fuertemente afectado por el número de imágenes que seusa para entrenarla. A la hora de seleccionar las mamografías se debe tener en cuenta quelos resultados se ven afectados por el número de imágenes utilizadas para entrenar la red.Además, se debe procurar que el número de imágenes de cada conjunto sea el mismo paraevitar la obtención de resultados sesgados [28].
El training set empleado en el trabajo cuenta con diez mamografías de cada conjunto deimágenes. De las diez mamografías, cinco de ellas son en vista CC y las otras cinco en vistaMLO.
3.2. Herramienta para la clasificación de tejidos
Para la clasificación de tejidos se ha utilizado un sistema CAD de clasificación automáticamediante redes neuronales convolucionales (CNN). Las CNN son un tipo de redes neurona-les artificiales (ANN) donde las neuronas corresponden a campos receptivos muy similaresa las neuronas en la corteza visual primaria de un cerebro biológico. Las ANN son unaherramienta de procesamiento automático inspirada en el funcionamiento de las redes neu-ronales cerebrales, que pretenden imitar el proceso de aprendizaje neuronal biológico. La
17

utilidad de esta herramienta se basa en su capacidad de aprendizaje. Así partiendo de unconjunto de datos de entrada suficientemente significativo, se puede conseguir que la redaprenda un conjunto de características que permita obtener una clasificación de nuevosdatos de entrada. Debido a la gran cantidad de información que son capaces de procesarresultan adecuadas para la decisión clínica, ya que tienen la capacidad de aprender patronescomplejos de datos que no son identificables por el cuadro médico [29].
Las ANN están formadas por diferentes elementos:
- Unidad de proceso o neurona. Pueden ser de tres tipos: entradas, salidas u ocultas.Cada neurona recibe una entrada y emite una salida. Las de entrada suponen la víade acceso de los datos a la red, las ocultas son aquellas cuyas entradas y salidas seencuentran dentro del sistema y las de salida muestran el resultado final de la red.Las neuronas se agrupan en capas o niveles.
- Función de salida o de transferencia. Asociada a cada neurona hay una función desalida que transforma el estado de activación en una señal de salida.
- Función de activación. Los valores de activación de la red pueden ser continuos odiscretos, tomando valores entre [0,1]. Esta función define la salida de dicha neuronaen relación al conjunto de sus entradas.
- Conexiones entre neuronas. Estas conexiones tienen asociado un peso que simula lasconexiones sinápticas de las neuronas biológicas y se ajustan durante la fase de entre-namiento de la red. Este peso refleja el conocimiento adquirido por la red. Se consideraque el efecto de cada señal es aditivo, de tal forma que la entrada neta que recibe unaneurona es la suma del producto de cada señal individual por el valor de la sinapsisque conecta ambas neuronas. Se utiliza una matriz W con todos los pesos, si wji espositivo indica que la relación entre las neuronas es excitadora, es decir, siempre quela neurona i esté activada, la neurona j recibirá una señal que tenderá a activarla. Siwji negativo, la sinapsis será inhibidora. En este caso si i está activada, enviará unaseñal que desactivará a j. Finalmente, si wji es 0 significa que no hay conexión entreambas.
Las ANN presentan un inconveniente a la hora de emplear un conjunto de imágenes comoparámetro de entrada: el elevado número de conexiones que se establece entre las neuronas,que implica una elevada carga computacional y un alto tiempo de procesamiento. La figura3.1a muestra un ejemplo de ANN. Las redes neuronales convoluciones (CNN) evitan esteproblema al introducir el concepto de capas con distintos propósitos y una nueva estructura.Se trata de un tipo de red que pertenece a la familia de las Deep Neural Networks cuyacaracterística principal es la presencia de múltiples capas de convolución de los datos deentrada. Estas capas están sucedidas por representaciones intermedias y transformacionesno lineales a las que se le pueden añadir capas especializadas. En cuanto a su estructura, lasneuronas de las CNN solo se conectan a un subconjunto de neuronas de la siguiente capa,reduciendo el número de pesos, por la que todas las neuronas de una misma capa compartenlos mismos pesos, reduciendo el número de parámetros del modelo. Por todo ello, las CNNpresentan una mayor velocidad de computación.
18

(a) Red neuronal artificial (b) Red neurona convolucional
Figura 3.1: Redes neuronales: ANN y CNN. Fuentes:[30], [31]
Las CNN se dividen en dos fases: la fase de extracción de características, y la fase de clasi-ficación a partir de las características extraídas. La fase de extracción de características secompone de capas alternas de neuronas convolucionales y neuronas de reducción de mues-treo. Las características extraídas en esta fase son características locales de la imagen, talescomo bordes o texturas. Según progresan los datos a lo largo de esta fase, se disminuye sudimensionalidad, siendo las neuronas en capas lejanas mucho menos sensibles a perturbacio-nes en los datos de entrada, pero al mismo tiempo siendo estas activadas por característicascada vez más complejas. La figura 3.1b muestra un ejemplo de red neuronal convolucio-nal. En ella se puede ver una primera capa que toma como entrada una imagen de 32x32donde está escrito el número 3. En las capas intermedias se encuentran los filtros de convo-lución que hacen posible la extracción de características. En las capas finales se clasifica laimagen en uno de los subconjuntos que corresponden con números enteros a partir de lascaracterísticas extraídas [32].
La herramienta empleada en este trabajo se desarrolló en el Departamento de MatemáticaAplicada a las Tecnologías de la Información y las Comunicaciones de la Universidad Politéc-nica de Madrid [13]. El conjunto de datos de entrada son recortes de imágenes mamográficasorganizadas en cinco carpetas diferentes: masas benignas, masas malignas, calcificacionesbenignas, calcificaciones malignas y tejido sano.
En concreto, la estructura de la CNN empleada está formada por un total de diez capas tal ycomo se puede ver en la figura 3.2. En la fase de extracción de características se encuentranlas capas: conv, pool, rnorm y local. En las neuronas de las capas convolucionales conv1 yconv2 se procesan en 2D partes de la imagen aplicando operaciones de convolución. Lascapas pool1 y pool2 reducen la cantidad de datos en dos de las tres dimensiones mediante laaplicación de filtros. Por otro lado, las neuronas de las capas rnorm1 y rnorm2 se encargande la normalización de los datos, que permiten detectar características similares en distintasimágenes aún teniendo distintos valores. Las últimas capas de esta fase son local3 y local4que tienen un funcionamiento similar a las capas convolucionales en cuanto a que aplicanfiltros convolucionales, pero difieren en que no presentan compartición de pesos. En la fasede clasificación de la red se encuentran las capas fc10, probs y logprob. Las neuronas de lacapa fc10 están totalmente conectadas, y su función es generar cinco salidas multiplicandolos resultados de la capa local4 por una matriz de pesos. Se trata de la primera etapade clasificación. Las neuronas de la capa probs generan cinco salidas que representan laprobabilidad de que la imagen de entrada pertenezca a una de las cinco clases. Por último,logprob genera como salida la clase más probable a la que pertenece cada mamografía.Además, esta capa define el tipo de función de aprendizaje de la red: retropropagación, queconsiste en que los errores de las salidas se propagan hacia atrás. Los errores parten de lacapa de salida hacia todas las neuronas de la capa oculta que contribuyen directamente aella que reciben una fracción de la señal total del error, basándose en la contribución relativa
19

que haya aportado cada neurona a la salida original. Este proceso se repite, capa por capa,hasta que todas las neuronas de la red hayan recibido una señal de error que describa sucontribución relativa al error total. Tras esto tiene lugar una fase de adaptación que consisteen la modificación de los pesos de las neuronas teniendo en cuenta el error propagado conel fin de disminuirlo.
Figura 3.2: Estructura de la red neuronal convolucional utilizada en este trabajo. Cada unade las capas se muestra acompañada de la dimensionalidad de los datos de entrada y salida.
3.3. Metodología
En la figura 3.3 se describe la metodología seguida para realzar el contraste de las imágenesy acoplarlas a los requisitos del clasificador previamente descrito en la sección 3.2.
Figura 3.3: Esquema del procedimiento de obtención de los recortes
En primer lugar se obtiene la silueta de la mama para cada una de las mamografías. Estasilueta se obtiene con una ecualización del histograma de la mamografía y una serie de ope-raciones morfológicas que permiten obtener el contorno de la mama. El resultado obtenidoes una imagen binaria que representa la silueta de la mama como se puede ver en la figura3.4b.
En segundo lugar, se obtiene la mama recortada aplicando la silueta obtenida en al puntoanterior sobre la imagen original. En la imagen resultante la mama recortada tendrá los
20

bordes de la silueta pero el tejido mamario permanecerá inalterado. De esta forma se obtieneuna imagen que contiene únicamente información de la mama, eliminando la etiqueta yotros elementos que pudieran estar en el fondo. La figura 3.4c corresponde con una imagenobtenida en esta fase.
A continuación tiene lugar la fase de realce de la imagen donde se aplica uno de los dosalgoritmos de aumento de contraste con unos parámetros detallados en la sección 4.2. Deesta forma se obtiene como resultado una imagen realzada que se caracteriza por presentarun aumento de contraste entre los diferentes tejidos.
Tras esto, a las imágenes realzadas que contienen alguna patología se les aplica una máscaraque fue creada por radiólogos y señala la localización de la anomalía (figura 3.4d). Estamáscara permite obtener por un lado el tejido anómalo 3.4f, que corresponde con el interiorde la máscara, y por otro el tejido sano, que corresponde con el resto del tejido 3.4e.
Por último, se dividen las imágenes correspondientes al tejido sano y al tejido insano enfragmentos de 32x32 para introducirlas en la red neuronal. La red, requiere que las imágenesesten organizadas según las clases en que se quiere clasificar. De este modo constará decinco subconjuntos de imágenes de 32x32: calcificaciones benignas, calcificaciones malignas,masas malignas, masas benignas y tejido sano. El número de imágenes de cada subconjuntoes diferente y esto podría sesgar los resultados. Por lo tanto, para que la red neuronalesté compensada, es necesario ponderar el número de imágenes que introducimos en elsistema con el fin de que se introduzca el mismo número de imágenes de cada tipo. Estaponderación se realiza en función de la carpeta con el menor número de imágenes que eneste caso corresponde a los 890 recortes de tejido asociado a masas benignas.
(a) Original (b) Silueta (c) Mama recortada
(d) Máscara original (e) Tejido sano (f) Tejido insano
Figura 3.4: Imágenes obtenidas durante la formación del TrainingSet
21

3.4. HIW: Histogram based Intensity Windowing
3.4.1. Fundamentos teóricos
El método HIW es una extensión del método IW (Intensity windowing). IW es una técnicade procesamiento de imagen donde las intensidades de los píxeles se determinan a partirde una transformación lineal que mapea el rango de intensidades del conjunto de pixelesseleccionado con los valores de gris disponibles en el dispositivo. De este modo, permite queun conjunto de intensidades de la imagen abarque todo el rango de contraste disponible enel dispositivo. A los píxeles que quedan fuera del rango se les asigna el valor de intensidad0 (color negro) si están por debajo, o el valor 1 (blanco) si se salen del rango por arriba.Un estudio realizado por el departamento de Ingeniería Biomédica de la Universidad deCarolina de Norte analizó el efecto del algoritmo IW en la detección de masas simuladasintroducidas en el tejido denso mamario de mamografías digitalizadas [27]. Tras analizar losresultados comprobaron cómo el algoritmo de enventanado mejora la detección de masas enlas mamografías, pero también que la elección de los parámetros adecuados es importante,ya que pueden dan lugar a una degradación significativa de la imagen.
HIW [33] es una extensión de esta técnica en la cual se determina dinámicamente un su-brango de intensidades basado en el histograma de la imagen y que fue desarrollado en laUniversidad de Carolina del Norte. Este algoritmo dispone de métodos de búsqueda de pi-cos y valles para identificar las zonas del histograma correspondientes a cada tipo de tejido:denso, graso y muscular. Se debe tener en cuenta que no todos los picos que aparecen enel histograma corresponden con tejidos, como por ejemplo aquellos debidos a etiquetas omarcadores. Partiendo de los picos o valles conocidos se selecciona automáticamente unaventana de intensidad en base a unos percentiles que marcarán el tipo de tejido. Los percen-tiles se entienden como las intensidades por debajo de la cual se encuentra un porcentaje delos píxeles de la imagen. Por ejemplo, el percentil 30, se corresponde con aquella intensidadpara la cual el 30% de los píxeles tienen una intensidad menor. A partir de estos valores sepuede obtener la ventana de intensidad del histograma que se corresponde con el tejido quese quiere realzar. La figura 3.5 muestra un ejemplo de histograma en el que se indica el tipode tejido al que corresponde cada pico. En este caso, el algoritmo HIW selecciona el rango20-100% para que el tejido denso comprendido en ese rango obtenga el máximo contrasteposible.
Este algoritmo permite hacer una selección del tejido que se quiere realzar en función delas características de la mama del paciente. Si la mama se caracteriza por ser muy grasa,la ventana de intensidad permite obtener el máximo contraste a la parte del histogramaque corresponde con el tejido graso. Si la mama es mixta, es decir, presenta tanto tejidograso como tejido denso, la ventana se seleccionará en base a ambas porciones y el rango queelegido será mayor que en el caso anterior. En función de qué percentil se tome como mínimoel contraste de la imagen resultante será diferente. Por ejemplo, si se elige el rango 30-100aparecerán en la imagen de salida el 30% de los pixeles con un nivel de intensidad cero [34].La principal ventaja de HIW frente a IW reside en la elección dinámica del tamaño de laventana, ya que en IW es fijo y por tanto no se adapta al tejido mamario característico decada paciente. [34]
22

Figura 3.5: Percentiles del histograma de una mamografía y resultado del mapeo HIW enfunción de la intensidad que permite el dispositivo. El valor más bajo de HIW correspondecon el percentil 20. Fuente: [34].
Un estudio similar al mencionado anteriormente sobre los efectos de IW realizado tambiénpor la Universidad de Carolina del Norte [33] concluye que esta técnica presenta un altopotencial diagnóstico. El estudio se basa en la simulación de masas, permitiendo así conocerperfectamente su localización. Estas masas son de aproximadamente 5 mm de diámetrocreadas mediante la convolución de un kernel de tipo gaussiano. Estas masas se añadieroncon cuatro niveles de contraste prefijados: 2.00, 2.88, 4.17 y 6.03. En este caso, el contrastefue definido como la luminosidad insertada localmente entre la luminosidad del fondo dela imagen (sin tener en cuenta la etiquetas). Las imágenes mamográficas sobre las que seintrodujeron las masas eran mamografías de tamaño (512 x 512) correspondientes a vistastanto cráneo-caudales como medio-laterales.
La finalidad del estudio era demostrar si este algoritmo aumentaba la capacidad de detecciónde las masas, para lo que se estudiaron 3 hipótesis diferentes:
- Hipótesis 1: Las diferencias entre imágenes procesadas y sin procesar no dependende las condiciones de la ventana HIW. El resultado de esta hipótesis fue que sí exis-ten diferencias significativas en la detección de masas en función de los valores HIWempleados.
- Hipótesis 2: Una mejor observación de las masas se asocia con valores mínimos deintensidad de HIW en percentiles bajos. Para ello se testaron las diferencias obtenidasentre imágenes sin procesar e imágenes procesadas con estos valores mínimos. Losresultados se puede observar en la figura 3.6
- Hipótesis 3: Los parámetros clínicos más útiles corresponden con percentiles bajos. Elresultado fue que aquellas imágenes procesadas con una ventana HIW con valor demínima intensidad fijado en el percentil 20 obtuvieron mejores resultados. En el restode los percentiles no se obtuvieron diferencias significativas. La tabla 3.1 muestra losresultados obtenidos en la comparación de HIW tanto con IW como con diferentesconfiguraciones de parámetros.
Por lo tanto, la elección de los parámetros de la ventana HIW marca la diferencia en lamejora de la visualización de las masas, y hay que tener en cuenta que si la elección eserrónea podría empeorarla. Hasta el momento los experimentos han demostrado que lasventanas fijadas con valores de intensidad mínimos más bajos obtienen mejores resultadosvisualmente.
23

Figura 3.6: Resultados de la comparación entre imágenes sin procesar e imágenes procesadascon valores de intensidad mínimos fijados por 4 percentiles diferentes. La línea de referenciacorresponde con una ventana IW prefijada de contraste fijo considerada como control. Elvalor 0.0 corresponde con la ausencia de diferencia significativas entre la imagen sin procesary la imagen procesada. Modificado de: [33].
Comparación Diferencia ± (Derivación estándar)IW vs HIW al 20% -0.038 ± 0.010IW vs HIW al 35% -0.012 ± 0.009IW vs HIW al 50% 0.045 ± 0.007IW vs HIW al 65% -0.009 ± 0.009HIW al 20% vs 35% 0.025 ± 0.008HIW al 20% vs 50% 0.083 ± 0.010HIW al 20% vs 65% 0.029 ± 0.010HIW al 35% vs 50% 0.058 ± 0.010HIW al 35% vs 65% 0.003 ± 0.009HIW al 50% vs 65% -0.054 ± 0.010
Tabla 3.1: Resultados de la comparación entre los parámetros de los algoritmos IW y HIW.Modificado de: [33].
3.4.2. Implementación del algoritmo
El algoritmo HIW segmenta la imagen mamográfica en diferentes regiones según el tipode tejido que contenga: fondo de la imagen, tejido graso mamario, tejido denso y masastumorales y microcalcificaciones. En ocasiones, las dos últimas regiones son difícilmentediferenciables, sobre todo cuando las mamas son muy densas, ya que presentan niveles deluminosidad muy similares.
Una vez segmentada la imagen en las diferentes regiones se seleccionarán los umbralesde la ventana, en función de los umbrales elegidos el algoritmo realzará la o las regionescomprendidas entre ellos, mapeándolas a un rango de intensidades que contenga todo elcontraste disponible. Es decir, las mapeará entre 0 y 1. Como resultado se obtiene unaimagen de las mismas dimensiones y características que la imagen de entrada, pero con laregión de interés realzada.
El código esta implementado en Matlab y consta de cuatro fases: normalización de la imagen,etiquetado de regiones, selección de la región estableciendo el percentil inferior y superior yla obtención de la imagen de salida.
Tras la normalización, para etiquetar las regiones que dividen la imagen en diferentes tejidosse calculan una serie de umbrales mediante la función multithresh de Matlab. La función
24

toma como parámetros de entrada la imagen mamográfica que se quiere realzar y el númerode regiones en las que se desee segmentar. Devuelve un array que contiene el valor numéricode los umbrales que dividen la imagen normalizada. Por ejemplo, en caso de dividir la imagenen cuatro regiones, el array de salida contiene los valores de los tres umbrales necesariospara segmentar la imagen. Esta información permite etiquetar las regiones de la imagen enfunción de los umbrales.
A continuación selecciona la región que se desea realzar. Como la información que deseamosrealzar es el tejido patológico, y se corresponde con valores altos de intensidad, el valor su-perior corresponderá siempre con el percentil 100% (el valor 1 del histograma normalizado),y el valor inferior variará según la(s) región(es) que se quieran realzar. Si se desea aumentarel contraste del tejido denso y el patológico se fija como mínimo el segundo umbral y comomáximo el valor la intensidad máxima.
Para obtener la imagen realzada se ha utilizado la función imadjust. Esta función tomacomo parámetros de entrada la imagen normalizada, el percentil inferior y el superior quese mapearan y los valores de contraste, que en este caso serán siempre 0 y 1.
3.4.3. Elección de parámetros
Los parámetros que se deben fijar para el realce mediante HIW son el número de umbralesen los que se quiere segmentar la imagen, y los valores inferior y superior que se estableceráncomo los percentiles límites de la función.
La elección del número de regiones se realiza a partir del histograma característico de las imá-genes mamográficas. La figura 3.7 muestran el histograma normalizado de una mamografíacon vista CC y el histograma de una segunda mamografía con vista MLO respectivamente.El histograma de la vista CC corresponde con una mama muy densa y por lo tanto, se puedeobservar como no se diferencian de una forma clara las distintas regiones de la mama. Encambio, el histograma de la vista MLO corresponde con una mama con tejido denso y tejidofibroso a partes iguales. En este caso si se observan cuatro partes diferenciadas correspon-dientes a las cuatro regiones descritas anteriormente. El primer pico se corresponde con elfondo de la imagen; a continuación, el histograma se aplana en una zona que correspondecon el tejido fibroso de la mama; le sigue un segundo pico correspondiente a las regionesmás densas de la mama, y finalmente, entre las intensidad 0.6 y 1 aproximadamente seencuentra un número pequeño de píxeles correspondiente con las de mayor intensidad de laimagen que corresponderán con patologías. Dadas estas características, la imagen originalse divide empleando tres umbrales diferentes dando lugar a cuatro regiones etiquetadas co-mo: fondo, tejido graso mamario, tejido denso y microcalcificaciones. La figura 3.8 muestralos umbrales y los tejidos a los que pertenece cada región del histograma. Las patologíasincluidas en la última etiqueta corresponden solo a microcalcificaciones ya que las masas,tanto malignas como benignas, por sus características estructurales en la mayoría de loscasos se solapan o pertenecen a la región de tejido denso. Aquí reside una de las principalesdificultades de analizar mamografías de tejido muy denso.
25

Figura 3.7: Histogramas de mamografías en vista CC (izquierda) y MLO (derecha).
Figura 3.8: Umbrales sobre el histograma de una imagen mamográfica en vista CC y tejidosque forman la imagen.
3.5. CLAHE: Contrast Limited Adaptive Histogram Equali-zation
3.5.1. Fundamentos teóricos
La ecualización adaptativa del histograma de contraste limitado (CLAHE) [35] es una técni-ca basada en la ecualización adaptativa del histograma (AHE) [36], donde el histograma dela imagen resultante se calcula a partir del histograma de una ventana local centrada cadapixel, que se denomina región vecindario. Se ha demostrado que el algoritmo AHE es capazde realzar zonas de interés en imágenes médicas aunque se produce una sobrerealzamientodel ruido.
26

El algoritmo AHE surge a partir del algoritmo LAHE: Local-Area Histogram Equalizationque consiste en obtener el valor para la ecualización de cada pixel en función del histogramade un área a su alrededor. La transformación se traduce pixel a pixel, lo que provocaque el método LAHE sea muy lento. Para paliar el elevado tiempo de computación surgeel algoritmo AHE. En AHE, la ecualización, se realiza únicamente sobre algunos puntosen lugar de aplicarla sobre todos los píxeles. Cada uno de estos puntos o píxeles posee unaregión contextual en la que se modifica únicamente el pixel central mediante la ecualización,y obtienen los demás por interpolación, permitiendo reducir el tiempo de computación. Laecualización del histograma de cada región contextual afecta a una zona que tiene el doblede tamaño tal y como se puede ver en la figura 3.9a. De esta forma cada zona centralde la imagen se ve afectada por cuatro regiones, produciéndose un mapeo de los puntospertenecientes a ella por interpolación de las cuatro zonas como se observa en las figura3.9b y 3.9c. En las esquinas no es necesario interpolar ya que cada esquina solamente estáafectada por una región como plasma la figura 3.9d. Por último, los bordes se ven afectadospor dos zonas, como se observa en la figura 3.9e.
A continuación se muestra la formalización de la obtención del nuevo valor de intensidadpara un pixel [36]. Considerando:
M−− = Mapeo de la zona superior izquierda. (x−, y−)
M+− = Mapeo de la zona superior derecha. (x+, y−)
M−+ = Mapeo de la zona inferior izquierda. (x−, y+)
M++ = Mapeo de la zona inferior derecha. (x+, y+)
El valor final de cada pixel se obtiene por la aplicación del mapeo del pixel con su pesocorrespondiente en cada zona interpolada siguiendo la siguiente fórmula:
m(i) = a[b.M−−(i) + (1 − b).M+−(i)] + [1 − a].[b.M−+(i) + (1 − b).M++(i)] (3.1)
donde:a = [y+ − y−]/[y+ − y−] (3.2)
yb = [x+ − x−]/[x+ − x−] (3.3)
La Ecualización Adaptativa del Histograma de Contraste Limitado (CLAHE) modifica elvalor de la intensidad de la imagen de forma no lineal para maximizar el contraste en todoslos píxeles. En esta técnica se limita el contraste máximo estableciendo un valor límite conel fin de evitar el realce del ruido que ocurre cuando el rango de la intensidad en una regióndel contexto no tiene un buen reparto en comparación con el nivel de ruido. En AHE lospicos de mayor intensidad que aparecen en el histograma y que además son estrechos, comopuede ser un pico debido a una masa maligna, se ecualizan y se mapean a un ancho rangode valores de intensidad de salida, lo que puede dar lugar al sobrerrealzamiento del ruido. Alestablecer un factor máximo de contraste en el histograma se limita la cantidad de realce decontraste y, por lo tanto, también del ruido. El factor máximo de contraste es un parámetroque se suele establecer en función de las características de la imagen que se desea realzar.Por lo tanto, la diferencia principal entre ambas técnicas es que CLAHE previene el realcedel ruido y reduce el contorno de sombras que puede producirse debido a un factor de realcemuy elevado.
27

(a) Región Rij y región a la queafecta Sij
(b) Cuatro regiones vecinas y suzona de afectación (línea doble)
(c) Pixel (marcado enazul) afectado por cua-tro regiones
(d) Esquinas de la imagen (e) Bordes de la imagen
Figura 3.9: Regiones que afectan a cada parte de la imagen: parte central, esquinas y bordes.Fuente: [36].
De la misma forma que el algoritmo AHE, CLAHE divide la imagen en regiones del mismotamaño sin solapamiento. Tras esto se calcula el histograma de cada una de estas regiones.La amplificación del contraste en cada región de píxeles viene dada por la pendiente dela función de transformación que modifica las intensidades de los píxeles para obtener laimagen de salida. Debido a que CLAHE limita el histograma con un valor predefinido antesde calcular la función de distribución, la pendiente de la función de transformación se verámodificada al fijar el valor límite. Este valor límite está relacionado con la normalizacióndel histograma, y por tanto depende del tamaño de la región.
Este valor límite se obtiene a partir de la ecuación [35]:
β = M
N(1 + α
100(S − 1)) (3.4)
Donde M, representa el rango de intensidad en valor absoluto a la cual es posible mapear,N el rango de intensidad valor absoluto de los píxeles de la imagen, S el número de píxelesde cada región y α es el valor normalizado introducido. Este valor establece el valor límitereal que se aplica sobre el histograma. Si este factor es igual a 0, el valor límite real coincidecon
β = M
N(3.5)
que equivale a mapear la región con todo el rango de contraste disponible. El valormáximo que puede adquirir el límite es 100. Los píxeles que sobrepasan el límite no sedeben descartar, si no que se deben redistribuir en otras áreas para que el rango completo deentradas de intensidad sea mapeado al rango completo de salidas de intensidad, consiguiendoque el área vuelva a su valor original como se puede observar en la figura 3.10. Por último,las regiones vecinas se combinan usando una interpolación bilineal [35].
El tamaño de las regiones y el factor que se va a emplear sobre el histograma son parámetrosde entrada del algoritmo CLAHE. En Noviembre de 1998 la revista Journal of Digital
28

Imaging publicó un artículo [37] en el que se exponía un estudio para comprobar si latécnica era capaz de mejorar la detección de anomalías en mamografías. El estudio concluyeque aplicando esta técnica aumenta el contraste entre las anomalías y el fondo de la imagen.En este caso también se seleccionaron mamografías de 512x512 en las que se introdujeron lasanomalías con cuatro orientaciones y cuatro intensidades distintas. Por otro lado, el estudioafirma que si los parámetros de tamaño de región y valor límite no se eligen cuidadosamenteel resultado puede ser la degradación de la imagen.
Figura 3.10: Proceso de la técnica CLAHE donde se muestra la función de transformacióndel histograma sin aplicar el valor límite en comparación con la función de transformaciónque se aplica tras la ecualización adaptativa. Fuente: [37].
Por otro lado, en el mismo estudio en el que se analizó la capacidad de detección demasas del algoritmo HIW mencionado en la sección 3.4, se evaluó la capacidad del algoritmoCLAHE para tal fin [33]. Las hipótesis propuestas en este caso son:
- Hipótesis 1: Los parámetros del tamaño de las regiones y el valor límite introducenmodificaciones en los resultados. En primer lugar se quiso comprobar si estos paráme-tros están o no relacionados, llegando a la conclusión de que sí que lo están. Es decir,la elección del tamaño de la región debe depender del valor límite impuesto y vicever-sa. Debido a que se comprobó esta relación directa, no se estudiaron las variacionesindividuales que pueden introducir cada uno de los parámetros por separado. La tabla3.2 muestra las relaciones obtenidas entre el tamaño de las regiones y el valor límite.
- Hipótesis 2: comprobar las diferencias entre las imágenes no preprocesadas y las imá-genes preprocesadas con CLAHE empleando diferentes configuraciones de los pará-metros con el fin de encontrar los valores óptimos. Los resultados obtenidos se recogenen la tabla 3.3.
Tamaño de la región Valor límite=1 Valor límite=2 Valor límite=45 -0.014 -0.079 -0.1556 -0.048 -0.052 -0.1525 -0.0005 -0.028 -0.053
Tabla 3.2: Relación entre el tamaño de las regiones y el valor límite. Modificado de: [37].
29

Por lo tanto, la elección de los parámetros de entrada del algoritmo influye en la formadirecta en los resultados. Una elección acertada permite mejorar la detección de anomalíasmientras que el caso contrario puede empeorar la capacidad diagnóstica de la imagen. Paraello se debe tener en cuenta la relación existente entre el valor límite y el tamaño de laimagen.
Tamaño de la región Valor límite=1 Diferencia ± (Derivación estándar)32x32 2 -0.014 ± 0.05664x64 2 -0.048 ± 0.059
128x128 2 -0.005 ± 0.05232x32 4 -0.079 ± 0.04764x64 4 -0.052 ± 0.056
128x128 4 -0.028 ± 0.06032x32 16 -0.155 ± 0.06964x64 16 -0.112 ± 0.054
128x128 16 -0.053 ± 0.072
Tabla 3.3: Comparaciones llevadas a cabo entre imágenes preprocesadas con CLAHE y sinpreprocesar. Modificado de: [37]
3.5.2. Implementación del algoritmo
El algoritmo CLAHE consta de cuatro etapas: establecimiento de los parámetros de entrada,preprocesado, procesado de las regiones e interpolación.
En primer lugar, hay que establecer los parámetros de entrada del algoritmo: la imagen, elnúmero de regiones especificado en filas y columnas, número de barras del histograma queestablecerán la función de transferencia y el valor límite normalizado entre 0 y 1.
En segundo lugar se preprocesan los datos de entrada, mediante el que se determina elvalor límite real a partir del valor normalizado introducido con el fin de adaptarlo a lascaracterísticas de la imagen.
En tercer lugar, se procesa cada región, obteniendo como resultado un mapa de niveles degris. Para ello se extrae cada región de la imagen y se crea un histograma local usando elnúmero específico de barras del histograma introducido como parámetro. A continuaciónse ajusta el histograma con el valor límite seleccionado y se mapea la región empleando lafunción de transformación.
Por último, se interpolan los resultados del punto anterior para conseguir la imagen finalecualizada. Esta imagen final a partir de 4 regiones vecindario. Se extrae cada pixel, se leaplican cuatro funciones de transferencia, una correspondiente a cada región y se interpolanlos resultados para obtener el pixel de salida. Realizando este procedimiento sobre cadapixel se obtiene la imagen final.
Para la implementación de CLAHE se ha utilizado la función adapthisteq de Matlab.
3.5.3. Elección de parámetros
En el algoritmo CLAHE se pueden modificar los siguientes parámetros, recogidos en la tabla3.4
.
30

Parámetro ValorTamaño de lasregiones
Parámetro que establece las dimensiones de las regiones. Se trata de un arrayde dimensiones [M,N] donde M especifica el número de filas y N el de columnasde las regiones donde se aplicará la transformación de contraste.
Valor límite Escalar real en el rango [0 1] que define el valor límite.Número de ba-rras del histo-grama
Escalar entero positivo que especifica el número de intervalos del histograma.A mayor número, mayor será el rango dinámico.
Rango Establece el rango de salida de la imagen. Puede tomar valor original, dondeel rango de salida está limitado al de la imagen original, o completo donde elrango depende del tipo de imagen utilizada.
Distribución Especifica la distribución del histograma que se usa para realizar la transfor-mación. Puede ser de tres tipos: uniforme, donde el histograma es uniformeo plano, Rayleigh donde presenta forma de campana o exponencial con histo-gramas exponenciales o curvados.
Alfa Es un escalar real positivo que especifica el parámetro de distribución.
Tabla 3.4: Parámetros modificables en el algoritmo.
Resultados empíricos han demostrado que dadas las características de las imágenes mamo-gráficas los mejores valores para los parámetros: Tamaño de las regiones, Rango, Distribu-ción y Alfa son 256, completo y uniforme. Al manipular las imágenes como matrices de tipouint16, el valor completo del parámetro rango se traduce como [0 255]. El parámetro Alfano se define ya que con la distribución ’full’ no es necesario.
En cuanto al número de barras del histograma empleadas para representar el histogramaecualizado, los resultados establecen que el mejor valor es ’256’. En la figura 3.11 se puedeobservar como aumentando el número de barras del histograma no se aprecian diferenciassignificativas en la imagen ni en el histograma, mientras que si lo disminuimos la imagenpresenta número mayor de pixeles en la zona media del histograma, por lo que el contrasteel menor y se obtiene el efecto contrario al aumento de contraste entre tejidos.
Figura 3.11: Variación del número de barras del histograma en la función CLAHE y sushistogramas.
31

En cuanto al parámetro distribución, en la figura 3.12 se puede observar como los histogra-mas de las tres posibles distribuciones son prácticamente iguales. A lo largo del trabajo sefija el tipo de distribución a uniforme.
Figura 3.12: Distribuciones disponibles en la función CLAHE y sus histogramas. De izquier-da a derecha uniforme, Rayleigh y exponencial.
Finalmente se estudian las modificaciones que puede introducir el parámetro rango. La figura3.13 muestra las imágenes correspondientes a sus dos posibles valores y los histogramasobtenidos con cada uno de ellos. Ambos histogramas presentan las mismas característicascon valores muy similares. A lo largo del trabajo se fijará el valor del rango a completo.
Figura 3.13: Rangos disponibles en la función CLAHE y sus histogramas. De izquierda aderecha: completo y original.
32

Capítulo 4
Resultados
4.1. Descripción y organización de las pruebas
Con el objetivo de comprobar si los algoritmos de realce aplicados mejoran el número deaciertos en la clasificación de las mamografías y con qué parámetros se obtienen los mejoresresultados, se han realizado una serie de pruebas para cada algoritmo. Las diferentes pruebasde ambos algoritmos consisten en aumentar el contraste entre los diferentes tejidos de lamama, pero unos de forma más moderada que en otros. La tabla 4.1 recoge las pruebasrealizadas indicando el algoritmo empleado junto a sus parámetros.
Nombre de prueba Algoritmo ParámetrosPrueba 0 Sin preprocesar
Prueba 1 HIW Número de umbrales: 4Umbral inferior: 2
Prueba 2 HIW Número de umbrales: 3Umbral inferior: 2
Prueba 3 HIW Número de umbrales: 3Umbral inferior: 1
Prueba 4 CLAHE Tamaño de las regiones: [8 8]Valor límite: 0.01
Prueba 5 CLAHE Tamaño de las regiones: [3 3]Valor límite: 0.01
Prueba 6 CLAHE Tamaño de las regiones: [8 8]Valor límite: 0.05
Tabla 4.1: Descripción de las pruebas realizadas.
Para cada prueba los resultados se muestran en forma de tabla, donde se detalla la precisiónindividual de la clasificación obtenida en cada conjunto de imágenes. La precisión se definecomo:
Precisión = V P + V N
TP + TN + FP + FN(4.1)
donde VP y VN representan el número de verdaderos positivos y verdades negativos, FP yFN el número de falsos positivos y falsos negativos respectivamente y TP y TN que repre-sentan el número total de positivos y negativos. Es decir, el cociente entre los verdaderospositivos y el conjunto total de todos los elementos. Además, los resultados de cada pruebase muestran mediante una matriz de confusión que permite visualizar los resultados obte-nidos mediante un código de colores. Cada columna representa el número de predicciones
33

de cada clase, mientras que cada fila representa a las instancias en la clase real. Permiteobtener de forma práctica información acerca de la precisión de la red junto con informaciónsobre los falsos positivos y negativos obtenidos en cada prueba.
4.2. Pruebas
Prueba0
En primer lugar, se ha realizado una prueba inicial con imágenes sin preprocesar. Estaprueba se emplea como referencia para poder comparar los resultados obtenidos en el restode las pruebas.
CONJUNTO DE IMÁGENES PRECISIÓN (%)Calcificaciones benignas 0.75
Masas benignas 0.79Calcificaciones malignas 0.83
Masas malignas 0.82Tejido sano 0.56TOTAL 0.75ERROR 0.25
Tabla 4.2: Resultados obtenidos durante la prueba0. Se muestra la precisión total junto alas precisiones individuales de cada conjunto de imágenes por separado.
(a) Imagen sin pre-procesar
(b) Matriz de confusión de la prueba0
Figura 4.1: Resultados obtenidos durante la prueba0
La tabla 4.2 muestra los resultados de la prueba0, en la que se ha obtenido una precisióndel 75%. En todos los conjuntos de imágenes esta precisión es superior al 75% a excepcióndel conjunto de imágenes sanas donde desciende al 56%.
Prueba1
En la primera prueba realizada se utiliza el algoritmo HIW. Se calculan cuatro umbralesquedando dividida la imagen en cinco tipos de tejidos: fondo, tejido graso, tejido denso,masas y microcalcificaciones. Como valor mínimo se utiliza el segundo umbral que corres-ponde con el tejido denso mamario, y como valor máximo la intensidad 1. De este modo serealzan las estructuras más densas de la imagen, las patológicas y las microcalcificaciones.
34
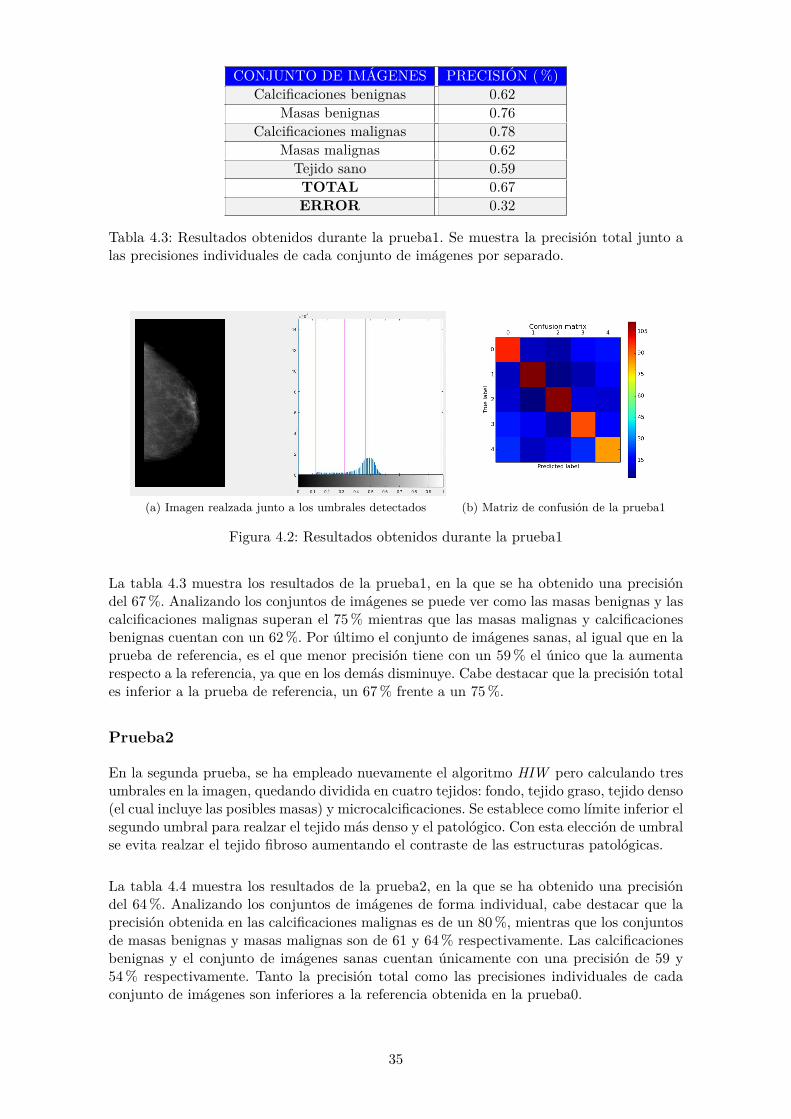
CONJUNTO DE IMÁGENES PRECISIÓN (%)Calcificaciones benignas 0.62
Masas benignas 0.76Calcificaciones malignas 0.78
Masas malignas 0.62Tejido sano 0.59TOTAL 0.67ERROR 0.32
Tabla 4.3: Resultados obtenidos durante la prueba1. Se muestra la precisión total junto alas precisiones individuales de cada conjunto de imágenes por separado.
(a) Imagen realzada junto a los umbrales detectados (b) Matriz de confusión de la prueba1
Figura 4.2: Resultados obtenidos durante la prueba1
La tabla 4.3 muestra los resultados de la prueba1, en la que se ha obtenido una precisióndel 67%. Analizando los conjuntos de imágenes se puede ver como las masas benignas y lascalcificaciones malignas superan el 75% mientras que las masas malignas y calcificacionesbenignas cuentan con un 62%. Por último el conjunto de imágenes sanas, al igual que en laprueba de referencia, es el que menor precisión tiene con un 59% el único que la aumentarespecto a la referencia, ya que en los demás disminuye. Cabe destacar que la precisión totales inferior a la prueba de referencia, un 67% frente a un 75%.
Prueba2
En la segunda prueba, se ha empleado nuevamente el algoritmo HIW pero calculando tresumbrales en la imagen, quedando dividida en cuatro tejidos: fondo, tejido graso, tejido denso(el cual incluye las posibles masas) y microcalcificaciones. Se establece como límite inferior elsegundo umbral para realzar el tejido más denso y el patológico. Con esta elección de umbralse evita realzar el tejido fibroso aumentando el contraste de las estructuras patológicas.
La tabla 4.4 muestra los resultados de la prueba2, en la que se ha obtenido una precisióndel 64%. Analizando los conjuntos de imágenes de forma individual, cabe destacar que laprecisión obtenida en las calcificaciones malignas es de un 80%, mientras que los conjuntosde masas benignas y masas malignas son de 61 y 64% respectivamente. Las calcificacionesbenignas y el conjunto de imágenes sanas cuentan únicamente con una precisión de 59 y54% respectivamente. Tanto la precisión total como las precisiones individuales de cadaconjunto de imágenes son inferiores a la referencia obtenida en la prueba0.
35
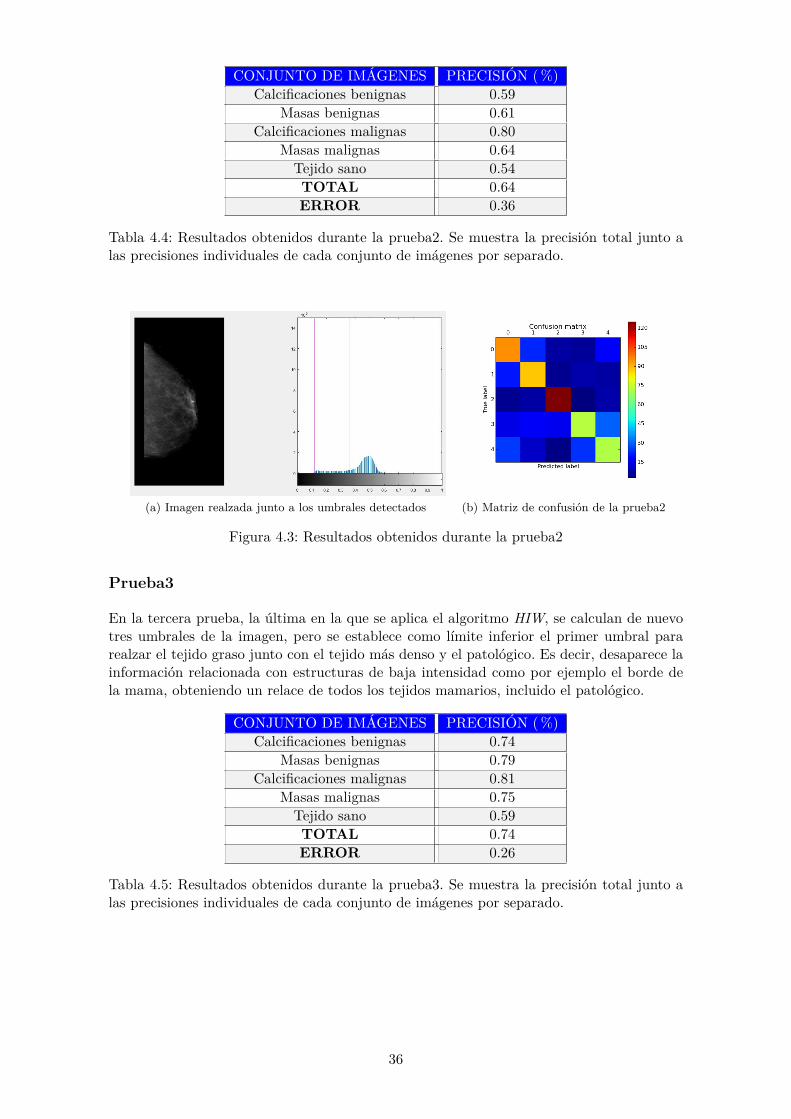
CONJUNTO DE IMÁGENES PRECISIÓN (%)Calcificaciones benignas 0.59
Masas benignas 0.61Calcificaciones malignas 0.80
Masas malignas 0.64Tejido sano 0.54TOTAL 0.64ERROR 0.36
Tabla 4.4: Resultados obtenidos durante la prueba2. Se muestra la precisión total junto alas precisiones individuales de cada conjunto de imágenes por separado.
(a) Imagen realzada junto a los umbrales detectados (b) Matriz de confusión de la prueba2
Figura 4.3: Resultados obtenidos durante la prueba2
Prueba3
En la tercera prueba, la última en la que se aplica el algoritmo HIW, se calculan de nuevotres umbrales de la imagen, pero se establece como límite inferior el primer umbral pararealzar el tejido graso junto con el tejido más denso y el patológico. Es decir, desaparece lainformación relacionada con estructuras de baja intensidad como por ejemplo el borde dela mama, obteniendo un relace de todos los tejidos mamarios, incluido el patológico.
CONJUNTO DE IMÁGENES PRECISIÓN (%)Calcificaciones benignas 0.74
Masas benignas 0.79Calcificaciones malignas 0.81
Masas malignas 0.75Tejido sano 0.59TOTAL 0.74ERROR 0.26
Tabla 4.5: Resultados obtenidos durante la prueba3. Se muestra la precisión total junto alas precisiones individuales de cada conjunto de imágenes por separado.
36

(a) Imagen realzada junto a los umbrales detectados (b) Matriz de confusión de la prueba3
Figura 4.4: Resultados obtenidos durante la prueba3
La tabla 4.5 muestra los resultados de la prueba3, en la que se ha obtenido una precisióndel 74%. En cuanto a las precisiones individuales, únicamente el conjunto de imágenes de lacarpeta de calcificaciones malignas supera el 80%. Las imágenes sanas cuentan con un 59%de precisión y los conjuntos de calcificaciones benignas, masas benignas y masas malignascon 74%, 79% y 75% respectivamente. En este caso, únicamente el conjunto de imágenessanas, a pesar de que su precisión se puede considerar baja, es superior a la de referenciacon un 59% frente a un 56%. Si bien, el resto de precisiones, o mantiene el mismo valor oson solamente un poco inferiores.
Prueba4
En esta prueba se ha empleado el algoritmo CLAHE. En este caso, se fija el tamaño de laspequeñas regiones que emplea el algoritmo en matrices de 8x8 y se fija el valor límite a 0.01.Como se puede observar en la imagen 4.5a el contraste entre las estructuras más densas ylas patológicas y las estructuras fibrosas aumenta.
CONJUNTO DE IMÁGENES PRECISIÓN (%)Calcificaciones benignas 0.81
Masas benignas 0.81Calcificaciones malignas 0.80
Masas malignas 0.84Tejido sano 0.63TOTAL 0.78ERROR 0.22
Tabla 4.6: Resultados obtenidos durante la prueba4. Se muestra la precisión total junto alas precisiones individuales de cada conjunto de imágenes por separado.
La tabla 4.6 muestra los resultados de la prueba4, en la que se ha obtenido una precisióndel 78%. En cuanto a la precisión individual de cada uno de los conjuntos, excepto lasimágenes sanas cuya precisión es de un 63%, todas cuentan con una precisión superior al80%. Únicamente el conjunto de calcificaciones malignas muestra una precisión inferior ala de referencia.
37

(a) Imagen original (derecha) e imagen realzada (izquierda) (b) Matriz de confusión de la prueba4
Figura 4.5: Resultados obtenidos durante la prueba4
Prueba5
En esta prueba se ha utilizado el algoritmo CLAHE. El valor límite no se modifica conrespecto a la prueba anterior manteniéndose en 0.01, pero se modifica el tamaño de lasregiones estableciéndolo en matrices de 3x3. En la imagen 4.6a se puede observar cómoquedan resaltados todos los tipos de tejido, aumentando el contraste entre los más densosy el resto.
CONJUNTO DE IMÁGENES PRECISIÓN (%)Calcificaciones benignas 0.79
Masas benignas 0.80Calcificaciones malignas 0.82
Masas malignas 0.89Tejido sano 0.72TOTAL 0.80ERROR 0.19
Tabla 4.7: Resultados obtenidos durante la prueba5. Se muestra la precisión total junto alas precisiones individuales de cada conjunto de imágenes por separado.
La tabla 4.7 muestra los resultados de la prueba5, en la que se ha obtenido una precisióndel 80%. En cuanto a las precisiones individuales, las masas benignas, calcificaciones ma-lignas y masas malignas han obtenido un 80, 82 y 89% respectivamente y las calcificacionesbenignas y las imágenes sanas con un 79 y 72% respectivamente. En este caso, únicamenteel conjunto de calcificaciones malignas se encuentra ligeramente por debajo del valor dereferencia (83%).
38

(a) Imagen original (derecha) e imagen realzada (izquierda) (b) Matriz de confusión de la prueba5
Figura 4.6: Resultados obtenidos durante la prueba5
Prueba6
En la última prueba se ha empleado el algoritmo CLAHE fijando el valor límite a 0.05 yel tamaño de las regiones a matrices de 8x8. En la imagen 4.7a se puede observar comoaparecen diferentes estructuras de la mama muy realzadas. A simple vista incluso podríanparecer realzadas en exceso, aumentando el contraste entre diferentes regiones del mismotejido. Por otro lado, se puede observar como los tejidos más densos quedan completamentecontrastados con el resto de las estructuras.
CONJUNTO DE IMÁGENES PRECISIÓN (%)Calcificaciones benignas 0.82
Masas benignas 0.85Calcificaciones malignas 0.80
Masas malignas 0.81Tejido sano 0.76TOTAL 0.81ERROR 0.18
Tabla 4.8: Resultados obtenidos durante la prueba6. Se muestra la precisión total junto alas precisiones individuales de cada conjunto de imágenes por separado.
La tabla 4.8 muestra los resultados de la prueba6, en la que se ha obtenido una precisión del81%. Únicamente las imágenes sanas presentan una precisión individual inferior al 80%,con un 76%. El resto, están por encima del 81% de precisión. En este caso, a pesar de quela precisión total es superior a la de referencia, las individuales de los conjuntos malignos,tanto masas como calcificaciones se encuentran por debajo.
39

(a) Imagen original (derecha) e imagen realzada (izquierda) (b) Matriz de confusión de la prueba6
Figura 4.7: Resultados obtenidos durante la prueba6
4.3. Comparación de los resultados
El estudio mencionado en las secciones 3.5 y 3.4 tenía como fin analizar las diferencias en ladetección de masas simuladas realzando las imágenes con HIW y CLAHE para encontrarel algoritmo que obtuviera los mejores resultados. Este análisis se basó únicamente en ladetección visual de las masas por parte de radiólogos expertos y estudiantes. Llegaron a laconclusión de que estos están relacionado de la siguiente manera:
HIW > IW ≥ sinpreprocesar = CLAHE
Cabe destacar la importancia que tiene la elección de parámetros, ya que solo un conjunto deparámetros obtuvo mejores resultados que las imágenes originales. En el caso del algoritmoHIW los mejores resultados se obtuvieron fijando el percentil mínimo a 20%, mientras queen el caso de CLAHE no se encontró una combinación de parámetros capaz de superar lasimágenes sin preprocesador, pero si igualarlo [33]. Los resultados de las pruebas realizadasen este TFG no concuerdan con los ofrecidos por dicho estudio.
En la tabla 4.9 se recogen los datos de precisión y errores obtenidos en cada una de laspruebas. En la prueba0, considerada la prueba de referencia por haber sido realizada conlas imágenes originales, se obtuvo una precisión total del 75%. A partir de este dato seconsidera que las demás pruebas son positivas si el resultado obtenido en la precisión totales superior al de referencia o por el contrario negativas, si el dato obtenido es inferior.
PRUEBA PRECISIÓN (%)Prueba0 75Prueba1 67Prueba2 64Prueba3 74Prueba4 78Prueba5 80Prueba6 81
Tabla 4.9: Precisión y error obtenido en cada una de las pruebas
La primera prueba presenta un 67% de precisión total. Es una prueba negativa puesto queel algoritmo HIW con los parámetros establecidos en esta prueba no mejora la clasificación
40

automática llevada a cabo por el sistema, si no que por el contrario lo reduce. En la imagen4.2a se puede observar como al realzar los tejidos denso y patológico se generan imágenesque presentan una diferencia de contraste alta en cuanto a las microcalcificaciones y másbaja en relación a las masas. A pesar de esto, los valores de intensidad obtenidos en laimagen resultado están, por lo general, más próximos al 0 que al 1 dando lugar a imágenesde baja intensidad con poco contraste entre la mama y el fondo. Esto podría explicar elhecho de que la precisión total sea menor que la de referencia.
La segunda prueba también se considera negativa, ya que la precisión total obtenida esde un 64%. A diferencia de la prueba anterior, en este caso se calculan tres umbrales enlugar de cuatro con el objetivo de realzar el tejido patológico de alta intensidad junto conel de intensidad similar, el tejido denso, pertenecientes ambos a la región situada entre eltercer y el cuarto umbral. Se vuelve a seleccionar como valor inferior el segundo umbral ycomo superior la máxima intensidad. De esta forma quedan realzados los tejidos fibrosos ograsos, los densos y las patologías. Como se puede observar en la imagen 4.3a en este casola diferencia de contraste es menor entre los diferentes tejidos. Este hecho queda reflejadoen las precisiones individuales de las masas benignas y masas malignas, que en este casoson menores que en la prueba anterior y que la prueba de referencia. Además, el rango deintensidades de la imagen está más próximo al valor máximo para toda la mama, lo queimplica un contraste bajo entre las estructuras.
De la misma forma que las dos pruebas anteriores llevadas a cabo con el algoritmo HIW,la tercera prueba tambien presenta una precisión total inferior a la de referencia, pero eneste caso muy poco significativa, un 74% frente a un 75%. En la imagen 4.4a se puedever un ejemplo de mamografía realzada en esta prueba. En este caso, el límite inferior seestablece en el primer umbral y el superior en el valor máximo nuevamente. Debido a esto,únicamente las estructuras de menor intensidad quedan sin realzar, mientras que el restode estructuras, incluyendo todos los tipos de tejido, son realzadas.
En la cuarta prueba se ha empleado el algoritmo CLAHE, obteniendo una precisión total de78%. En la imagen 4.5a se puede observar como se consigue un aumento de los tejidos másdensos, aumentando las precisiones individuales de las masas benignas y las masas malignas.Por otro lado, las microcalcificaciones quedan completamente realzadas manteniendo valoresde intensidad muy próximos a 1. A pesar de esto, también se ven realzas las estructurasde tejido fibroso, lo cual puede complicar la autoclasificación. A la vista de los resultados,y dado el tamaño de regiones 8x8 es posible que el algoritmo esté teniendo en cuentaun número de píxeles vecinos superior al necesario para obtener un realce y aumento decontraste buenos.
La quinta prueba alcanza un 80% de precisión. Con respecto a la prueba anterior se mantieneel mismo factor límite, pero se modifica el tamaño de las regiones estableciéndolas en 3x3.Como se puede observar en la imagen 4.6a el contraste entre las estructuras más densas y elresto de tejido mamario aumenta. A pesar de esto, también se ven realzados los bordes de lamama con un pequeño aumento de los valores de intensidad que hace que sean más próximasa las intensidades del tejido mamario, pudiendo dificultar el proceso de clasificación de lared. En cuanto a las microcalcificaciones, continúan teniendo valores de intensidad muyaltos y debido al contraste con el resto de los tejidos.
Por último, la sexta prueba ha obtenido un 81%, lo que supone el mejor valor obtenidodurante las pruebas, 81%. En este caso, se emplea nuevamente el algoritmo CLAHE conel tamaño de las regiones 8x8, al igual que en la prueba4, pero aumentando el límite deintensidad a 0.05. Como se puede observar en la imagen 4.7a el contraste aumenta muy
41
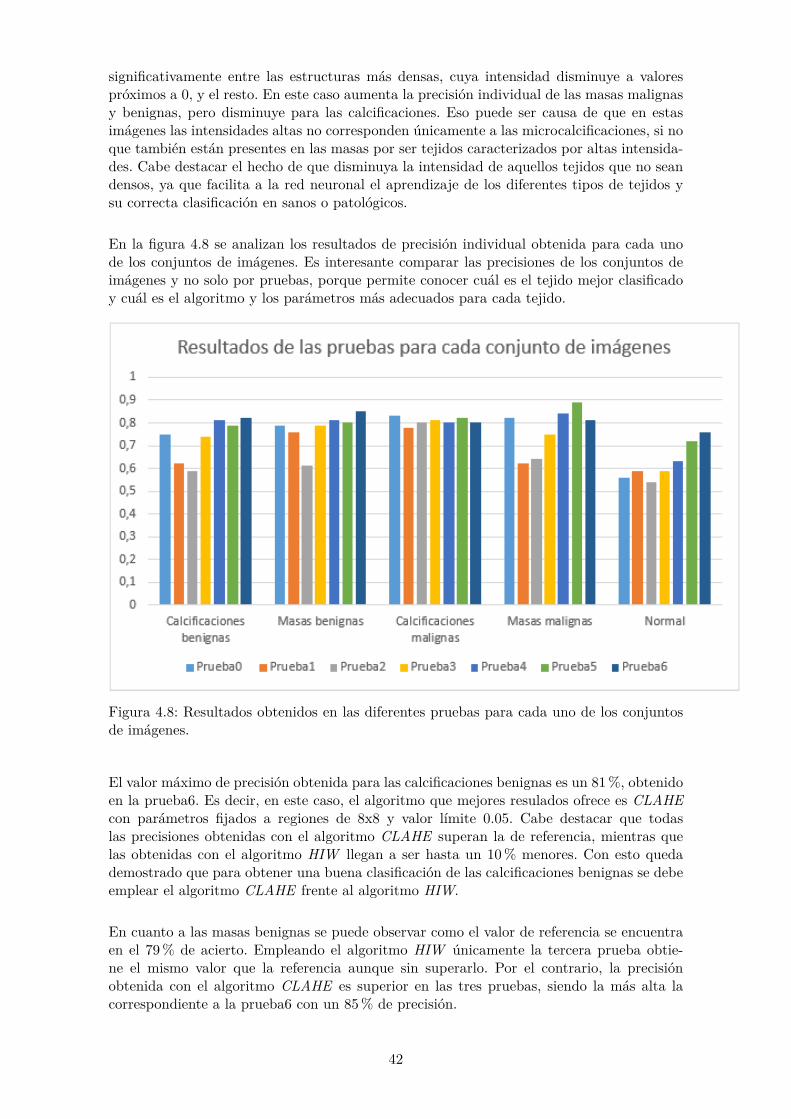
significativamente entre las estructuras más densas, cuya intensidad disminuye a valorespróximos a 0, y el resto. En este caso aumenta la precisión individual de las masas malignasy benignas, pero disminuye para las calcificaciones. Eso puede ser causa de que en estasimágenes las intensidades altas no corresponden únicamente a las microcalcificaciones, si noque también están presentes en las masas por ser tejidos caracterizados por altas intensida-des. Cabe destacar el hecho de que disminuya la intensidad de aquellos tejidos que no seandensos, ya que facilita a la red neuronal el aprendizaje de los diferentes tipos de tejidos ysu correcta clasificación en sanos o patológicos.
En la figura 4.8 se analizan los resultados de precisión individual obtenida para cada unode los conjuntos de imágenes. Es interesante comparar las precisiones de los conjuntos deimágenes y no solo por pruebas, porque permite conocer cuál es el tejido mejor clasificadoy cuál es el algoritmo y los parámetros más adecuados para cada tejido.
Figura 4.8: Resultados obtenidos en las diferentes pruebas para cada uno de los conjuntosde imágenes.
El valor máximo de precisión obtenida para las calcificaciones benignas es un 81%, obtenidoen la prueba6. Es decir, en este caso, el algoritmo que mejores resulados ofrece es CLAHEcon parámetros fijados a regiones de 8x8 y valor límite 0.05. Cabe destacar que todaslas precisiones obtenidas con el algoritmo CLAHE superan la de referencia, mientras quelas obtenidas con el algoritmo HIW llegan a ser hasta un 10% menores. Con esto quedademostrado que para obtener una buena clasificación de las calcificaciones benignas se debeemplear el algoritmo CLAHE frente al algoritmo HIW.
En cuanto a las masas benignas se puede observar como el valor de referencia se encuentraen el 79% de acierto. Empleando el algoritmo HIW únicamente la tercera prueba obtie-ne el mismo valor que la referencia aunque sin superarlo. Por el contrario, la precisiónobtenida con el algoritmo CLAHE es superior en las tres pruebas, siendo la más alta lacorrespondiente a la prueba6 con un 85% de precisión.
42
El conjunto de calcificaciones malignas es el único donde no se ve superada la precisión dereferencia por ninguna de las seis pruebas. Todos los resultados obtenidos rondan el 80%pero ninguno llega al 83% de referencia, quedándose el más próximo el de la prueba cincocon un 82% de precisión. Por lo tanto, en cuanto al conjunto de calcificaciones malignas sepuede afirmar que la mejor opción es no aplicar ningún algoritmo a las mamografías.
En cuanto las masas malignas, la precisión obtenida con los algoritmos HIW es significati-vamente inferior en las tres pruebas llegando a alcanzar hasta un 20% menos. En relacióna los resultados de las pruebas correspondientes al algoritmo CLAHE, excepto la pruebaseis que iguala a la referencia, todas superan esta precisión, alcanzando el 89% la quintaprueba. Por lo tanto, con el algoritmo CLAHE se obtiene un aumento de la precisión, quees mayor con los parámetros fijados en la prueba cinco.
Por último, se puede observar como la precisión obtenida en el conjunto de imágenes sanases muy inferior al resto de conjuntos. A pesar de esto, exceptuando la segunda prueba, todassuperan la referencia que tiene un valor de 56%. El algoritmo HIW obtiene una precisiónligeramente mayor, mientras que el algoritmo CLAHE llega a alcanzar un 76%.
La tabla 4.10 recoge cual ha sido la prueba con la que se ha obtenido una mejor precisiónde forma individual para cada uno de los conjuntos, junto con el algoritmo y los parámetrosque se han empleado.
CONJUNTO DE IMÁGENES MEJOR RESULTADO ParámetrosCalcificaciones benignas Prueba6: CLAHE [8 8]
0.05Masas benignas Prueba6: CLAHE [8 8]
0.05Calcificaciones benignas Prueba0: referencia
Masas malignas Prueba5: CLAHE [3 3]0.01
Tejido sano Prueba6: CLAHE [8 8]0.05
Tabla 4.10: Prueba que mejor precisión ofrece para cada uno de los conjuntos de imágenes,indicando el algoritmo y sus parámetros.
En la tabla 4.10 se puede observar como en tres de los cinco conjuntos de imágenes, laprueba seis obtiene los mejores resultados. Por lo tanto, a la hora de implementar un siste-ma CAD de clasificación automática, los mejores resultados se obtendría con el algoritmoCLAHE especificando los parámetros de tamaño de regiones y valor límite a 8x8 y 0.05respectivamente. De esta manera, los conjuntos: calcificaciones benignas, masas benignas ytejido sano obtendrían la máxima precisión. Por otro lado, los conjuntos masas malignas ycalcificaciones malignas, a pesar de que no estarían siendo preprocesados con el algoritmocon el que obtienen un mejor resultado, la diferencia es poco significativa, ya que en amboscasos se supera el 80% de precisión individual. Además, la mejor precisión global también seha obtenido con la prueba seis, lo cual apoya la implementación del sistema CAD empleandoen su fase de preprocesamiento dicho algoritmo. Esto permitiría obtener una herramientacon una precisión global de 81%, y cuyas precisiones individuales para todos los conjuntosse situan al rededor del 80%.
43

Capítulo 5
Conclusiones
En este trabajo se han comparado dos algoritmos de realce de contraste basados en histogra-ma: HIW y CLAHE, con el fin de estudiar su rendimiento de cara a incluirlos en un sistemaCAD de clasificación automática. Existen numerosos parámetros que intervienen en el re-sultado, desde la selección del tipo de mamografías de la base de datos hasta los parámetrosempleados en cada uno de los algoritmos. El proceso de evaluación se puede dividir en cincoetapas diferentes. En primer lugar, hay que elegir el conjunto de imágenes a analizar de labase de datos conociendo sus características y patología si la presentan. En segundo lugar,es necesario realizar un tratamiento de la imagen antes de aplicar el algoritmo de realcecon el fin de obtener solo el tejido de interés, es decir la mama, eliminando la etiqueta ylos bordes. Para ello se extrae una silueta de la mama y a partir de ella una nueva imagenque contiene únicamente tejido mamario. A continuación se aplica el algoritmo de realcefijando los parámetros en función de las características de la mamografía. Una vez aplicadoel algoritmo, hay que diferenciar entre el tejido sano mamario y el tejido patológico. Paraesto se emplean las máscaras creadas por radiólogos expertos. Tras esto es necesario recor-tar las imágenes y organizarlas en carpetas para permitir el aprendizaje de la red neuronalconvolucional y obtener así una clasificación correcta. Por último, se introducen los recortesen la red y se analizan los resultados obtenidos, que son presentados en forma de matriz deconfusión y tabla de precisiones global e individuales. Cualquier modificación en alguna delas etapas introduce cambios en la clasificación final.
En relación a la selección de las mamografías se debe de tener en cuenta que tanto losespecialistas como diferentes estudios han demostrado las complicaciones del análisis demamografías que presentan gran cantidad de tejido denso. A mayor densidad de la mamamenor es el contraste entre los diferentes tejidos y entre las diferentes estructuras, ya que lostejidos de elevada densidad se caracterizan por presentar valores elevados de intensidad enlas mamografías. Las estructuras patológicas, tanto las microcalcificaciones como las masastambién presentan valores de intensidad elevados, las primeras por ser acumulaciones decalcio que absorben mucha radiación y las segundas por ser tejido muy compacto y denso.Los niveles de intensidad tan similares introducen dificultades a la hora de diferenciar lasestructuras. Actualmente este hecho supone un gran inconveniente, ya que puede dar lugar apruebas invasivas innecesarias como puede ser la biopsia o, lo que es peor, pasar inadvertidasen los estudios de mama. Este inconveniente se puede solventar, o bien mejorando la calidadde las imágenes en la toma usando equipos de última generación, o bien aumentando elcontraste entre las estructuras una vez tomada la imagen con métodos de preprocesadocomo los algoritmos de realce. Otro aspecto relacionado con las mamografías es el tipo devista. Mientras que en las vistas cráneo-caudal únicamente se obtiene tejido mamario, en lavista medio-lateral en numerosas ocasiones se coge parte del brazo junto con la mama. Estose debería tener en cuenta a la hora de aplicar algoritmos de realce de contraste basados enhistograma ya que el tejido del brazo es similar al tejido mamario y puede ocurrir que al
44

intentar realzar estructuras patológicas quede realzado el brazo en lugar de la mama. Comolos algoritmos que se han empleado son de realce de contraste, a las imágenes mamográficasseleccionadas es necesario aplicarlas un tratamiento para aislar en ellas el tejido mamario.Este tratamiento permite eliminar las etiquetas y los bordes de la imagen, incluido el brazo,y obtener así un histograma que solo contenga información de la mama.
Una vez obtenidas las imágenes que contienen solo tejido mamográfico se aplican los algo-ritmos de realce. En este trabajo se han estudiado dos algoritmos basados en el histograma:HIW (histogram intensity windowing) y CLAHE (contrast limited adaptative histgoramequalization) .
El primero consiste en la división del histograma en los diferentes tipos de tejidos: fondo,graso, denso y patológico, y el posterior realce del tejido de interés, en nuestro caso el pa-tológico. Para ello, se calculan los umbrales que separan la imagen en los distintos tejidosy se aumenta el contraste de los tejidos seleccionados. Este algoritmo permite modificar elnúmero de umbrales con los que se quiere dividir la imagen, los valores impuestos comopercentil mínimo y máximo que permiten seleccionar los tejidos y el rango de valores al quese mapea. Tras analizar los resultados de las pruebas realizadas en la sección 4.2 se puedeconcluir que la modificación de ambos parámetros varía significativamente la precisión de laclasificación automática. Aumentando el número de umbrales crece la división del histogra-ma. El valor máximo empleado ha sido cuatro, dividiendo el histograma en cinco regionesdiferentes. En cuanto a los percentiles seleccionados como máximo y mínimo también varíanla clasificación porque a medida que disminuye el valor del percentil mínimo más tipos detejidos se verán realzados. Cuanto más próximos estén los valores máximo y mínimo se real-zará menos tejido. Se ha demostrado que seleccionado rango del histograma pequeño, conel percentil mínimo en el tercer umbral y el máximo con valor uno se obtienen resultadospeores en la clasificación que con intervalos más grandes como el caso de fijar el percentilmínimo en el primer umbral y el máximo en la máxima intensidad. Lo mismo ocurre con elrango del valores al que se mapea por lo que es conveniente mapear el rango de la imagende interés al rango máximo posible, es decir entre [0 1] para obtener el mayor contrastedisponible. Las pruebas han demostrado que en general este algoritmo no da resultadosútiles en la clasificación ya que la precisión máxima obtenida es de 74%, que se encuentrapor debajo de la obtenida con las imágenes originales.
En cuanto al algoritmo CLAHE, cabe destacar que realiza una ecualización del histograma,y por tanto, no es necesario segmentar la imagen en diferentes tejidos. Los parámetrosque han demostrado introducir cambios significativos en la clasificación automática son eltamaño de las regiones vecindario empleadas para ecualizar y el valor límite. Este límiteevita la aparición del efecto de sombras así como el realce del ruido. En cuanto al valorlímite este permite evitar el realce del ruido presente en la imagen pero sin descartar lospíxeles que superan dicho valor, ya que la función los redistribuye por debajo de dicholímite. Es decir, no se pierden píxeles y por tanto no se pierde información y a su vez secontrola el realce del ruido. Si el valor límite es alto aumenta el contraste entre las diferentesestructuras pero aumenta también el realce del ruido y viceversa. En este caso, es necesariollegar a un compromiso entre el realce máximo que se quiere obtener y el ruido realzado.Aumentando el tamaño de las regiones se consigue que la modificación de contraste de unpixel dependa de un número mayor de píxeles vecinos. Es necesario encontrar el tamañoóptimo de estas regiones ya que si se emplea un número muy bajo el cada pixel dependeráde un número muy pequeño de píxeles vecinos dando lugar a poco aumento de contraste.Por el contrario, si el número es alto, la intensidad del pixel se verá influida por un grannúmero de intensidades vecinas pudiendo dar lugar a cambios de intensidad muy brusco.Analizando las pruebas se puede observar como tienen mejores resultados las regiones de
45

mayor tamaño y el valor límite más elevado. Las tres pruebas realizadas con este algoritmoobtienen una precisión en torno al 80%, superando todas ellas la precisión de referencia.
Comparando los resultados obtenidos con los dos algoritmos se puede comprobar cómo elalgoritmo CLAHE obtiene una precisión mayor, superando la precisión de referencia. Estose puede deber a que el algoritmo HIW además de no tener en cuenta el ruido presenteen la imagen realza únicamente determinados tipos de tejidos, mientras que CLAHE realzatoda la imagen, aumentando el contraste entre las diferentes estructuras. Por otro lado,cabe destacar que no todos los subconjuntos de imágenes se ven igual de afectados por losalgoritmos. El mejor resultado obtenido para las microcalcificaciones malignas es con laimagen sin realzar, mientras que para las masas benignas, las masas malignas, las micro-calcificaciones benignas y el tejido sano la precisión es mayor realzándolas con el algoritmoCLAHE. Con esto queda demostrado que en función del tipo de patología que se quieradetectar es más conveniente emplear el algoritmo CLAHE o no emplearlo.
A la vista de los resultados obtenidos a lo largo del trabajo, se puede afirmar que el prepro-cesado de las imágenes mamográficas empleando algoritmos de realce de contraste basadosen histograma puede aportar numerosas mejoras en la etapa de preprocesado de un sistemaCAD mediante redes neuronales convolucionales, dando lugar a una herramienta capaz dedetectar y clasificar anormalidades en el tejido mamario. Por otro lado, se ha demostrado lainfluencia de diferentes factores, no solo relacionados con los algoritmos, si no con el procesocompleto hasta obtener en resultado del sistema CAD. A pesar de esto es necesario seguirestudiando estos factores con el fin de encontrar la mejor combinación de ellos posible paraaumentar la precisión de la red.
Para concluir, se quiere destacar que los resultados obtenidos en este TFG, abren una nuevavía de estudio que permita mejorar el sistema CAD, facilitando la detección y clasificacióndel cáncer. De esta forma, el sistema podría constituir una herramienta fundamental deayuda a los facultativos, que les sirva de ayuda en la toma de decisiones. Así es posibleaumentar la posibilidad de tratar el cáncer en estadios iniciales, mejorando la calidad devida de los pacientes que lo sufren y, en definitiva, reduciendo la mortalidad producida poresta enfermedad.
46

Capítulo 6
Líneas futuras
Este TFG puede servir como base de otros estudios relacionados con el desarrollo o la mejorade un sistema CAD de apoyo a los facultativos que sea capaz de extraer las característicasde la imagen de la mejor forma posible.
En primer lugar, se podría estudiar cómo afecta la combinación de ambas técnicas a lasmamografías. Como ha quedado demostrado, algunos subconjuntos de imágenes dan mejoresresultados con unos algoritmos y parámetros concretos que con otros. Se podría pensar unafunción que aplicara el algoritmo CLAHE con diferentes parámetros dependiendo de lascaracterísticas de la imagen de entrada. Es decir, automatizar el sistema para los diferentestipos de mamografía, evitando así las complicaciones que causan las imágenes con grancantidad de tejido denso. En segundo lugar sería interesante modificar no solo parámetrosde los algoritmos, si no parámetros de la red, como por ejemplo aumentar el número derecortes que la red emplea para el aprendizaje o modificar el tamaño de estos recortes.
Por otro lado, también sería interesante la combinación de algoritmos de realce de contrastecon otros como puede ser la detección de bordes. De esta forma se conseguiría delimitartodas las estructuras presentes en la mama, incluido el tejido patológico, introduciendonueva información a la red neuronal que podría facilitar su aprendizaje, dando lugar amejores precisiones en la clasificación.
47

Índice de figuras
1.1. Las cifras del cáncer en España en 2014 [4] . . . . . . . . . . . . . . . . . . 7
1.2. Vistas CC y MLO de mama . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1. Esquema de un sistema CAD genérico. Modificado de [15] . . . . . . . . . . 10
2.2. Técnicas de segmentación más empleadas. Modificado de [15]. . . . . . . . . 11
2.3. Técnicas de extracción de características más empleadas basadas en textura.Modificado de [15]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.4. Técnicas de extracción de características más empleadas basadas en la forma.Modificado de [15]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.5. Técnicas de clasificación más empleadas. Modificado de [15]. . . . . . . . . . 12
2.6. Ejemplo de un caso de la DDSM. Fuente [26] . . . . . . . . . . . . . . . . . 15
2.7. Técnicas de realce mamográfico en sistemas CAD. Modificado de [27]. . . . 16
3.1. Redes neuronales: ANN y CNN. Fuentes:[30] [31] . . . . . . . . . . . . . . . 19
3.2. Estructura de la red neuronal convolucional utilizada en este trabajo. Cadauna de las capas se muestra acompañada de la dimensionalidad de los datosde entrada y salida. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3. Esquema del procedimiento de obtención de los recortes . . . . . . . . . . . 20
3.4. Imágenes obtenidas durante la formación del TrainingSet . . . . . . . . . . 21
3.5. Percentiles del histograma de una mamografía y resultado del mapeo HIWen función de la intensidad que permite el dispositivo. El valor más bajo deHIW corresponde con el percentil 20. Fuente: [34]. . . . . . . . . . . . . . . 23
3.6. Resultados de la comparación entre imágenes sin procesar e imágenes proce-sadas con valores de intensidad mínimos fijados por 4 percentiles diferentes.La línea de referencia corresponde con una ventana IW prefijada de contras-te fijo considerada como control. El valor 0.0 corresponde con la ausencia dediferencia significativas entre la imagen sin procesar y la imagen procesada.Modificado de: [33]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.7. Histogramas de mamografías en vista CC (izquierda) y MLO (derecha). . . 26
3.8. Umbrales sobre el histograma de una imagen mamográfica en vista CC ytejidos que forman la imagen. . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.9. Regiones que afectan a cada parte de la imagen: parte central, esquinas ybordes [36]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
48

3.10. Proceso de la técnica CLAHE donde se muestra la función de transformacióndel histograma sin aplicar el valor límite en comparación con la función detransformación que se aplica tras la ecualización adaptativa [37]. . . . . . . 29
3.11. Variación del número de barras del histograma en la función CLAHE y sushistogramas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.12. Distribuciones disponibles en la función CLAHE y sus histogramas. De iz-quierda a derecha uniforme, Rayleigh y exponencial. . . . . . . . . . . . . . 32
3.13. Rangos disponibles en la función CLAHE y sus histogramas. De izquierda aderecha: completo y original. . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.1. Resultados obtenidos durante la prueba0 . . . . . . . . . . . . . . . . . . . . 34
4.2. Resultados obtenidos durante la prueba1 . . . . . . . . . . . . . . . . . . . . 35
4.3. Resultados obtenidos durante la prueba2 . . . . . . . . . . . . . . . . . . . . 36
4.4. Resultados obtenidos durante la prueba3 . . . . . . . . . . . . . . . . . . . . 37
4.5. Resultados obtenidos durante la prueba4 . . . . . . . . . . . . . . . . . . . . 38
4.6. Resultados obtenidos durante la prueba5 . . . . . . . . . . . . . . . . . . . . 39
4.7. Resultados obtenidos durante la prueba6 . . . . . . . . . . . . . . . . . . . . 40
4.8. Resultados obtenidos en las diferentes pruebas para cada uno de los conjuntosde imágenes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
49

Índice de tablas
1.1. Tasa de supervivencia en función del estadio. . . . . . . . . . . . . . . . . . 6
2.1. Resultados obtenidos en el estudio del sistema CAD. Modificado de [17]. . . 13
3.1. Resultados de la comparación entre los parámetros de los algoritmos IW yHIW. Modificado de: [33]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2. Relación entre el tamaño de las regiones y el valor límite [37]. . . . . . . . . 29
3.3. Comparaciones llevadas a cabo entre imágenes preprocesadas con CLAHE ysin preprocesar [37] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.4. Parámetros modificables en el algoritmo. . . . . . . . . . . . . . . . . . . . . 31
4.1. Descripción de las pruebas realizadas. . . . . . . . . . . . . . . . . . . . . . 33
4.2. Resultados obtenidos durante la prueba0. Se muestra la precisión total juntoa las precisiones individuales de cada conjunto de imágenes por separado. . 34
4.3. Resultados obtenidos durante la prueba1. Se muestra la precisión total juntoa las precisiones individuales de cada conjunto de imágenes por separado. . 35
4.4. Resultados obtenidos durante la prueba2. Se muestra la precisión total juntoa las precisiones individuales de cada conjunto de imágenes por separado. . 36
4.5. Resultados obtenidos durante la prueba3. Se muestra la precisión total juntoa las precisiones individuales de cada conjunto de imágenes por separado. . 36
4.6. Resultados obtenidos durante la prueba4. Se muestra la precisión total juntoa las precisiones individuales de cada conjunto de imágenes por separado. . 37
4.7. Resultados obtenidos durante la prueba5. Se muestra la precisión total juntoa las precisiones individuales de cada conjunto de imágenes por separado. . 38
4.8. Resultados obtenidos durante la prueba6. Se muestra la precisión total juntoa las precisiones individuales de cada conjunto de imágenes por separado. . 39
4.9. Precisión y error obtenido en cada una de las pruebas . . . . . . . . . . . . 40
4.10. Prueba que mejor precisión ofrece para cada uno de los conjuntos de imáge-nes, indicando el algoritmo y sus parámetros. . . . . . . . . . . . . . . . . . 43
50

Glosario
ACS: American Cancer Society
AECC: Asociación Española contra el Cáncer
AHE: Adaptative Histogram Equalization
AMDI: Indexed Atlas of Digital Mammograms
ANN: Artificial Neural Network
B-SCREEN: Bayesian Decision Support in Medical Screening
BI-RADS: Breast Imaging Reporting and Data System
CAD: Computer Aided diagnosis.
CC: Cráneo-Caudal
CLAHE: Clip-Limited Adaptative Histogram Equalization
CNN: Convolutional Neuronal Network
DDSM: Digital Database for Screening Mammography
HIW: Histogram Intensity Windowing.
IRMA: Image Retrieval in Medical Applications
IW: Intensity Windowing
MIAS: Mammography Database
MLO: Medio-Lateral Oblícua
OMS: Organización Mundial de la Salud
RSNA: Radiological Society of North America
SEOM: Sociedad Española de Oncología
51

Bibliografía
[1] Ahmedin Jemal, Rebecca Siegel, Jiaquan Xu, and Elizabeth Ward. Cancer statistics,2010. CA: a cancer journal for clinicians, 60(5):277–300, 2010.
[2] World Health Organization. Women and health: today’s evidence tomorrow’s agenda.World Health Organization, 2009.
[3] http://www.who.int/topics/cancer/breastcancer/es/.
[4] https://www.aecc.es/sobreelcancer/cancerporlocalizacion/cancerdemama.aspx.
[5] SEOM. Las cifras del cancer en España 2014. PhD thesis, Sociedad espanola deoncología medica, 2014.
[6] http://www.breastcancer.org/es/sintomas/diagnostico/estadios.
[7] http://www.cancer.org/cancer/breastcancer/.
[8] A Cabanes, E Vidal, N Aragonés, B Pérez-Gómez, M Pollán, V Lope, and G Lopez-Abente. Cancer mortality trends in spain: 1980–2007. Annals of Oncology, 21(suppl3):iii14–iii20, 2010.
[9] L Nystrom, S Wall, LE Rutqvist, A Lindgren, M Lindqvist, S Ryden, J Andersson,N Bjurstam, G Fagerberg, J Frisell, et al. Breast cancer screening with mammography:overview of swedish randomised trials. The Lancet, 341(8851):973–978, 1993.
[10] Jose Avelino Manzano Lizcano. Sistemas de ayuda al diagnóstico y reconocimiento demicrocalcificaciones en mamografía mediante descriptores de escala y redes jerárquicas.PhD thesis, Escuela técnica superior de Ingenieros de Telecomunicación, 2015.
[11] Jae Young Choi, Dae Hoe Kim, Konstantinos N Plataniotis, and Yong Man Ro.Computer-aided detection (cad) of breast masses in mammography: combined detec-tion and ensemble classification. Physics in medicine and biology, 59(14):3697, 2014.
[12] Nedhal A Al-Saiyd and Sameera M Talafha. Mammographic image enhancementtechniques-a survey.
[13] Juana Gonzalez Bueno Puyal. Desarrollo de una herramienta para la detección detejidos anómalos en mamografías digitales mediante redes neuronales convoluciones.PhD thesis, Escuela técnica superior de Ingenieros de Telecomunicación, 2015.
[14] Timothy W Freer and Michael J Ulissey. Screening mammography with computer-aided detection: prospective study of 12,860 patients in a community breast center 1.Radiology, 220(3):781–786, 2001.
[15] Nadia El Atlas, Mohammed El Aroussi, and Mohammed Wahbi. Computer-aidedbreast cancer detection using mammograms: A review. In Complex Systems (WCCS),2014 Second World Conference on, pages 626–631. IEEE, 2014.
52

[16] Kavita Ganesan, URajendra Acharya, Chua Kuang Chua, Lim Choo Min, K ThomasAbraham, and Kung Bo Ng. Computer-aided breast cancer detection using mammo-grams: a review. Biomedical Engineering, IEEE Reviews in, 6:77–98, 2013.
[17] Corinne Balleyguier, Karen Kinkel, Jacques Fermanian, Sebastien Malan, GermaineDjen, Patrice Taourel, and Olivier Helenon. Computer-aided detection (cad) in mam-mography: does it help the junior or the senior radiologist? European journal of radio-logy, 54(1):90–96, 2005.
[18] Michael Heath, Kevin Bowyer, Daniel Kopans, Richard Moore, and W Philip Kegel-meyer. The digital database for screening mammography. In Proceedings of the 5thinternational workshop on digital mammography, pages 212–218. Citeseer, 2000.
[19] Denise Guliato, RS Bôaventura, EV Melo, and Rangaraj M Rangayyan. Amdi: anindexed atlas of digital mammograms that integrates case studies, e-learning, and re-search systems via the web. Recent Advances in Breast Imaging, Mammography, andComputer-aided Diagnosis of Breast Cancer. Bellingham, WA: SPIE, pages 529–555,2006.
[20] http://www.mammoimage.org/databases/.
[21] Susan G Orel, Nicole Kay, Carol Reynolds, and Daniel C Sullivan. Bi-rads categoriza-tion as a predictor of malignancy 1. Radiology, 211(3):845–850, 1999.
[22] http://peipa.essex.ac.uk/info/mias.html.
[23] S Tangaro, Roberto Bellotti, Francesco De Carlo, Gianfranco Gargano, E Lattanzio,Pietro Monno, Raffaella Massafra, Pasquale Delogu, Maria Evelina Fantacci, Alessan-dra Retico, et al. Magic-5: an italian mammographic database of digitised images forresearch. La radiologia medica, 113(4):477–485, 2008.
[24] http://marathon.csee.usf.edu/Mammography/Database.html.
[25] Juan Antonio Solves Llorens. Análisis de la densidad de mama asistido por ordenador.2012.
[26] http://www rayos.medicina.uma.es/Rmf/RadiolDigital/DDSM.htm.
[27] Etta D Pisano, Jayanthi Chandramouli, Bradley M Hemminger, Deb Glueck, R Euge-ne Johnston, Keith Muller, M Patricia Braeuning, Derek Puff, William Garrett, andStephen Pizer. The effect of intensity windowing on the detection of simulated massesembedded in dense portions of digitized mammograms in a laboratory setting. Journalof digital imaging, 10(4):174–182, 1997.
[28] Patrice Y Simard, David Steinkraus, and John C Platt. Best practices for convolutionalneural networks applied to visual document analysis. In ICDAR, volume 3, pages 958–962, 2003.
[29] Sun-Chong Wang. Artificial neural network. In Interdisciplinary Computing in JavaProgramming, pages 81–100. Springer, 2003.
[30] https://inovancetech.com/ann.html.
[31] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification withdeep convolutional neural networks. In Advances in neural information processingsystems, pages 1097–1105, 2012.
[32] Paulo J Lisboa and Azzam FG Taktak. The use of artificial neural networks in decisionsupport in cancer: a systematic review. Neural networks, 19(4):408–415, 2006.
53

[33] Bradley M Hemminger, Shuquan Zong, Keith E Muller, Christopher S Coffey, Marla CDeLuca, R Eugene Johnston, and Etta D Pisano. Improving the detection of simulatedmasses in mammograms through two different image-processing techniques. Academicradiology, 8(9):845–855, 2001.
[34] Etta D Pisano, Elodia B Cole, Bradley M Hemminger, Martin J Yaffe, Stephen RAylward, Andrew DA Maidment, R Eugene Johnston, Mark B Williams, Loren T Ni-klason, Emily F Conant, et al. Image processing algorithms for digital mammography:A pictorial essay 1. Radiographics, 20(5):1479–1491, 2000.
[35] Burçin Kurt, Vasif V Nabiyev, and Kemal Turhan. Medical images enhancementby using anisotropic filter and clahe. In Innovations in Intelligent Systems andApplications (INISTA), 2012 International Symposium on, pages 1–4. IEEE, 2012.
[36] CJ Vicente Peña. Ahe ecualización del histograma adaptativo, 1998.
[37] Etta D Pisano, Shuquan Zong, Bradley M Hemminger, Marla DeLuca, R Eugene Johns-ton, Keith Muller, M Patricia Braeuning, and Stephen M Pizer. Contrast limitedadaptive histogram equalization image processing to improve the detection of simu-lated spiculations in dense mammograms. Journal of Digital imaging, 11(4):193–200,1998.
54