universidad complutense de madrid econometr´ıa i -...
TRANSCRIPT

Dpto. de Economıa CuantitativaUniversidad Complutense de Madrid
Econometrıa ITema 1 Especificacion y Estimacion del Modelo Lineal General
Marcos Bujosa
Material de apoyo para el curso Econometrıa I
c© 2004–2007 Marcos Bujosa [email protected] el: 9 de octubre de 2007 Version 2.01
Copyright c© 2004–2007 Marcos Bujosa [email protected]
Algunos derechos reservados. Esta obra esta bajo una licencia Reconocimiento-CompartirIgual de CreativeCommons. Para ver una copia de esta licencia, visite http://creativecommons.org/licenses/by-sa/2.5/es/deed.es o envıe una carta a Creative Commons, 559 Nathan Abbott Way, Stanford, California94305, USA.Puede encontrar la ultima version de este material en:
http://www.ucm.es/info/ecocuan/mbb/index.html#ectr1
Indice
Indice 1
Especificacion y Estimacion del Modelo Lineal General 3
1. Introduccion 31.1. El punto de vista estadıstico: Regresion como descomposicion ortogonal . . . . . . . . . . . 31.2. El punto de vista del Analisis Economico: Regresion como modelo explicativo . . . . . . . . 4
2. Modelo Clasico de Regresion Lineal 52.1. Tres primeros supuestos en el Modelo Clasico de Regresion Lineal . . . . . . . . . . . . . . . 52.2. Variacion de los supuestos 2 y 3 en algunos casos especiales: . . . . . . . . . . . . . . . . . . 11
2.2.1. Supuestos del Modelo con Muestras Aleatorias . . . . . . . . . . . . . . . . . . . . . 112.2.2. Supuestos del Modelo con Regresores No Estocasticos . . . . . . . . . . . . . . . . . 12
3. Estimacion MCO (Mınimos Cuadrados Ordinarios) 123.1. Cuarto supuesto del Modelo Clasico de Regresion Lineal . . . . . . . . . . . . . . . . . . . . 133.2. Algunas expresiones que seran empleadas frecuentemente . . . . . . . . . . . . . . . . . . . 133.3. Algunos casos particulares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3.1. Modelo con solo una constante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.3.2. Modelo Lineal Simple . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153.3.3. Modelo con tres regresores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.3.4. Modelo Lineal General . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4. Propiedades algebraicas de la estimacion MCO 214.1. Propiedades basicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.2. Mas propiedades algebraicas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2.1. Proyecciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244.2.2. Regresion particionada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 254.2.3. Regresion en desviaciones respecto a la media . . . . . . . . . . . . . . . . . . . . . . 264.2.4. Anadiendo regresores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274.2.5. Correlaciones parciales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.3. Medidas de ajuste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29

2
5. Propiedades estadısticas de los estimadores MCO 325.1. Esperanza de los estimadores MCO β|x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 335.2. Varianza de los estimadores MCO β|x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345.3. Momentos de los valores ajustados y|x y de los errores e|x . . . . . . . . . . . . . . . . . . 36
6. Distribucion de los estimadores MCO bajo la hipotesis de Normalidad 376.1. Quinto supuesto del Modelo Clasico de Regresion Lineal . . . . . . . . . . . . . . . . . . . . 386.2. Estimacion de la varianza residual y la matriz de covarianzas . . . . . . . . . . . . . . . . . 396.3. Cota mınima de Cramer-Rao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
7. Estimacion por maxima verosimilitud 43
8. Ejercicios 43
9. Bibliografıa 44
10.Trasparencias 45
A. Geometrıa del modelo clasico de regresion lineal 46A.1. Geometrıa del estimador MCO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
B. Derivacion tradicional de las Ecuaciones Normales 48
C. Caso General 49C.1. Modelo Clasico de Regresion Lineal General . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
C.1.1. Ecuaciones normales en el Modelo Lineal General . . . . . . . . . . . . . . . . . . . . 50
D. Una expresion alternativa de las estimaciones MCO 50
. Soluciones a los Ejercicios 51
Este es un material de apoyo a las clases. En ningun caso sustituye a los libros de texto que figuran en elprograma de la asignatura; textos que el alumno debe estudiar para afrontar el examen final con ciertasgarantıas de exito.
Referencias recomendadas para la asignatura: Novales (1993), Wooldridge (2006), Verbeek (2004)
Otra referencia seguida en la elaboracion de este material es el capıtulo 1 de Hayashi (2000), que se puededescargar desde:http://www.pupress.princeton.edu/chapters/s6946.pdf

3
Especificacion y Estimacion del Modelo Lineal General
Capıtulos 1, 2 y 3 y secciones 4.1, 4.2, 6.2 y 6.3 de Wooldridge (2006)
Apendices E1, E2 y E3 de Wooldridge (2006)
1. Introduccion
Lease el Capıtulo 1 de Wooldridge (2006)
Otra referencia seguida en la elaboracion de este material es el capıtulo 1 de Hayashi (2000), que se puededescargar desde: http://www.pupress.princeton.edu/chapters/s6946.pdf
1.1. El punto de vista estadıstico: Regresion como descomposicion ortogonal
⇑ Descomposicion ortogonal y causalidad 1
Y = E(Y |D) + U
donde el conjunto de informacion es D : (X = x) ; por tanto
Y = E(Y |X) + U
donde E(Y | x) es una funcion arbitraria
lectura estadıstica: de izquierda a derecha.Siempre es cierta. No implica causalidad ni conclusiones teoricas
lectura teorica: de derecha a izquierda.Interpretacion puede ser falsa (regresiones espurias)
De Spanos (1999, Capıtulo 7, en particular la Seccion 7.5.3)
Sea Y una variable aleatoria con segundo momento finito, es decir, E(|Y|2
)< ∞, y un conjunto de
informacion D; entonces siempre podemos encontrar una descomposicion de Y como la siguiente:
Y = E(Y |D) + U (1.1)
dondeE(Y |D): es el componente sistematico 1
U: es el componente NO-sistematico
La existencia de dicha descomposicion2 esta garantizada siempre que E(|Y|2
)< ∞.
Ambos componentes de Y satisfacen las siguientes propiedades1. E(U | D) = 0
2. E(U2∣∣ D) = Var(Y | D) < ∞
3. E(U ·[E(Y |D)
])= 0 por tanto ambos componentes son ortogonales.
Supondremos que disponemos de una sucesion de variables aleatorias Yn (para n = 1, . . . , N) y de unamatriz de variables aleatorias X
[N×k]; y que nuestro conjunto de informacion D es
D : (X = x)
es decir, el conjunto de variables aleatorias X (en total N × k variables) ha tomado conjuntamente lamatriz de valores x.
Siendo ası, la descomposicion ortogonal para cada Yn queda como sigue:
Yn = E(Yn |X) + Un
1vea la Seccion ??, en la pagina˜??, del Tema 2 del curso de Introduccion a la Econometrıa de LECO2Si interpretamos las variables aleatorias con varianza finita como elementos de un espacio vectorial, entonces E(Y |D)
representa una proyeccion ortogonal, y la descomposicion (1.1) es analoga al teorema de proyeccion ortogonal (Luenberger,1968), con E(Y |D) como el mejor predictor en el sentido de la propiedad ECSV4 en la pagina˜?? del Tema 2 del curso deIntroduccion a la Econometrıa de LECO.

Seccion 1: Introduccion 4
Notese que esta es una descomposicion puramente estadıstica. Unicamente nos dice que si disponemosde cierta informacion acerca de las variables X, podemos descomponer la variable Yn en dos partes. Perono hay una teorıa economica detras; por tanto no dice si hay relaciones de causalidad entre las variables.Podrıa ocurrir que:
1. bien las variables X generaran parcialmente a Y (y por tanto, al conocer D : (X = x) sabemosque parte de Y es debida a X y que parte no)
2. o bien que Y causa (o genera) las variables X (y por tanto, al observar D : (X = x) sabemosque cabe esperar que ha ocurrido con la variable causante Y; como cuando vemos llover por laventana, y entonces sabemos que hay nubes en el cielo
3. o bien, que hay alguna otra causa comun (y quiza desconocida) que genera conjuntamente tanto aY como a X (y observar lo que ha ocurrido con X (la informacion D) nos indica que cabe esperarque ha ocurrido con Y (puesto que tienen un causante comun).
La descomposicion ortogonalYn = E(Yn |X) + Un
se lee de izquierda a derecha (es decir, “puedo descomponer Yn en las dos partes descritas a la derecha”),y no hay una teorıa detras.
1.2. El punto de vista del Analisis Economico: Regresion como modelo explicativo
Como economistas deseamos que la descomposicion estadıstica de mas arriba sea reflejo de las relacionesteoricas entre X y Y. En este sentido queremos leer la relacion de derecha a izquierda, es decir Y (porejemplo el consumo) esta generado por una funcion de las variables X (por ejemplo una funcion de larenta) junto a otras causas distintas de la renta (U).
Esta vision sugiere algunos de los nombres dados tanto para Y como para X. No obstante (y a pesarde los nombres), no debemos nunca perder de vista que la descomposicion ortogonal es una relacionestadıstica que siempre3 podemos encontrar; pero que en general no permite sacar conclusiones teoricasde ella (regresiones espurias). Solo en aquellos casos en que las variables situadas a derecha e izquierdaprovienen de un modelo teorico bien establecido, que nos sugiere que variables son causantes (y por ellolas situamos a derecha) y cuales son causadas (izquierda) quiza podamos sacar conclusiones. La palabra“quiza”, se debe a que con frecuencia los datos disponibles no miden aquellos conceptos empleados en losmodelos teoricos (consumo permanente, preferencias, nivel de precios, utilidades, aversion al riesgo, etc.),o bien a que los modelos no estan correctamente especificados (temas que se veran en otros cursos deeconometrıa).
⇑ Modelo de regresion 2
Yn = h(X)
+ Un = h(1, XH2, . . . , XHk
)+ Un
donde :
Yn: Vble. endogena, objetivo, explicada (o regresando)
X =[1, XH1, . . . ,XHk
]Vbles. exogenas, de control, explicativas (o regresores)
Un: factor desconocido o perturbacion
Suponemos que la variable aleatoria Y en el momento n, es decir, Yn es funcion del vector Xn. y de Un.Llamamos a Y vble. endogena (porque consideramos que se determina su valor o caracterısticas a traves
del modelo), vble. objetivo (porque es una magnitud que deseamos controlar, por ejemplo la inflacion sisomos la autoridad monetaria) o simplemente regresando.
La matriz X =[1, XH1, . . . ,XHk
]: esta constituida por k columnas de variables que llamamos
exogenas (porque consideramos que vienen dadas de manera externa al modelo), o vbles. de control (porquetenemos capacidad de alterar su valor para, a traves del modelo, controlar Y; por ejemplo fijar la ofertamonetaria o los tipos de interes en el ejemplo anterior), o simplemente regresores.
Un es el efecto conjunto de otras variables o circunstancias que influyen en la observacion de Yn, y quedecidimos no contemplar en el modelo por alguna razon (dificultad o imposibilidad de observarlas) o sen-cillamente que desconocemos. Tambien puede ser sencillamente un error cometido al medir Yn. Llamamosa Un perturbacion .
3siempre y cuando E“|Yn|2
”< ∞

5
⇑ Tipos de datos 3
Datos temporales (series de tiempo)
Seccion cruzada
Datos de panel
2. Modelo Clasico de Regresion Lineal
⇑ Modelo Clasico de Regresion Lineal 4
Modelo especial en el que la descomposicion ortogonal
Yn = E(Yn |X) + Un
es tal que E(Yn | x) es una funcion lineal de xn.
Var(Yn | x) es una constante (homocedasticidad)
¿QUE DEBO SUPONER PARA QUE ESTO SE CUMPLA?(¡al menos como lectura estadıstica!)
En el analisis de regresion estamos interesados en estimar los dos primeros momentos de Yn condicionadosa X = x, es decir, E(Yn | x) y Var(Yn | x).
El modelo Modelo Clasico de Regresion Lineal es un caso particular en el que E(Yn | x) es funcion linealde xn. (los regresores con subındice n, es decir, del instante n, o de la empresa n, o del paıs n, o delindividuo n, . . . ) y Var(Yn | x) es una funcion constante (por tanto Yn | x es homocedastica).
A continuacion, vamos a describir los tres supuestos de un modelo econometrico que garantizan la exis-tencia de una descomposicion ortogonal como la del modelo clasico de regresion lineal. El cuarto supuesto,que garantiza que la estimacion de la relacion lineal es unica, lo veremos en la seccion siguiente.
2.1. Tres primeros supuestos en el Modelo Clasico de Regresion Lineal
Capıtulos 2 y 3 de Wooldridge (2006)
Seccion 6.2 de Wooldridge (2006)
Apendice E1 de Wooldridge (2006)
⇑ Supuesto 1: linealidad 5
h(·) es lineal: Yn = h(Xn.
)+ Un = a1 + a2Xt2 + a3Xt3 + · · ·+ akXtk + Un
por lo tantoY1 = a1 + a2X12 + a3X13 + · · ·+ akX1k + U1
Y2 = a1 + a2X22 + a3X23 + · · ·+ akX2k + U2
· · · · · ·YN = a1 + a2XN2 + a3XN3 + · · ·+ akXNk + UN
oYn = Xn. β +Un
donde β = (a1, . . . , ak)′, y Xn. =[1 Xn2 Xn3 · · · Xnk
]es decir
Y[N×1]
= X[N×k]
β[k×1]
+ U[N×1]
dondeY =
[Y1, . . . , YN
]′, X =
[1, XH2, . . . , XHk
], U =
[U1, . . . , UN
]′es decir,
X =
1 X12 X13 . . . X1k
1 X22 X23 . . . X2k
. . . . . . . . . . . . . . . . . . .1 XN2 XN3 . . . XNk
;

Seccion 2: Modelo Clasico de Regresion Lineal 6
o bien X =
X1.
X2.
...XN.
=[1,XH2, . . . , XHk
]; donde XHj =
X1j
X2j
...XNj
por tanto
Y =[1,XH2, . . . , XHk
]β +U
=a1 + a2XH2 + a3XH3 + · · ·+ akXHk + U
es decir Y1
Y2
...YN
= a1 ·
11...1
+ a2 ·
X12
X22
...XN2
+ a3 ·
X13
X23
...XN3
+ · · ·+ ak ·
X1k
X2k
...XNk
+
U1
U2
...UN
⇑ Supuesto 1: linealidad 6
Modelo InterpretacionYn = βXn + Un β = dYn
dXnCambio esperado en nivel de
Yn cuando Xn aumenta una
unidad
ln(Yn) = β ln(Xn) + Un β = Xn
Yn
dYn
dXnCambio porcentual (en tan-
to por uno) esperado en Yn
cuando Xn aumenta un uno
por ciento (en tanto por uno,
ie, 0.01)
ln(Yn) = βXn + Un β = 1Yn
dYn
dXnCambio porcentual (en tan-
to por uno) esperado en
Yn cuando Xn aumenta una
unidad
Yn = β ln(Xn) + Un β = XndYn
dXnCambio esperado en el nivel
de Yn cuando Xn aumenta
un uno por ciento (en tanto
por uno)
Mas tipos de modelos lineales en Ramanathan (1998, Capıtulo 6, pp. 232 y siguientes) y en el materialpreparado por J. Alberto Mauricio http://www.ucm.es/info/ecocuan/jam/ectr1/Ectr1-JAM-Guion.pdf
Ejemplo 1. [funcion de consumo:]
CONn = β1 + β2RDn + Un
donde CONn y RDn son el consumo y la renta disponible del individuo n-esimo respectivamente, y Un
son otros factores que afectan al consumo del individuo n-esimo distintos a su renta disponible (activosfinancieros, estado de animo, etc.).
Aquı la variable exogena Y es el consumo (CON ), y los regresores son X1 =1 (una constante) y X2 larenta disponible (RD).
Ejemplo 2. [ecuacion de salarios:] Supongamos el siguiente modelo no-lineal en los parametros
SALARn = eβ1+β2EDUCn+β3ANTIGn+β4EXPERn+Un ;
donde SALARn es el salario del individuo n-esimo, EDUCn son sus anos de educacion, ANTIGn susanos de antiguedad en la empresa, y EXPERn sus anos de experiencia en el sector de la empresa.
Al tomar logaritmos tenemos un nuevo modelo para ln(SALARn) que es lineal en los parametros:
ln(SALARn) = β1 + β2EDUCn + β3ANTIGn + β4EXPERn + Un

Seccion 2: Modelo Clasico de Regresion Lineal 7
En este caso la interpretacion de un valor como β2 = 0.03 es que un ano adicional en la formacioneducativa implica un incremento esperado del salario del 3%.
Ejemplo 3. [funcion de produccion Cobb-Douglas:] Pensemos en la clasica funcion de produccion
Qn = cKnβ2Ln
β3
donde Qn es la produccion el el momento n, Kn es el capital empleado en el instante n; Ln el trabajoempleado en n. Supongamos, ademas, que hay un efecto aleatorio adicional νn debido a otras causas ofactores
Qn = cKnβ2Ln
β3νn;tomando logaritmos tenemos
lnQn = β1 + β2 lnKn + β3 lnLn + Un,
donde β1 = ln c, y Un = ln νn (es decir, νn = eUn . )En este caso, un valor como β2 = 0.05 es interpretado como que un incremento de capital del 1 % (0.01)
aumenta la produccion en un 5% (0.05).
Nota 1. Definimos la esperanza de una matriz X como la matriz de las esperanzas de sus elementos, esdecir
E(X) ≡ E
X11 X12 ··· X1N
X21 X22 ··· X2N
......
......
XN1 XN2 ··· XNN
≡
2666666666664
E(X11) E(X12) ··· E(X1N )
E(X21) E(X22) ··· E(X2N )
......
......
E(XN1) E(XN2) ··· E(XNN )
3777777777775
⇑ Supuesto 2: Esperanza condicional de U – Estricta exogeneidad 7
E(U | x) = 0[N×1]
es decir
E(U | x) =
E(U1 | x)E(U2 | x)
...E(UN | x)
=
00...0
E(Un | x) ≡ E(Un | xH2, . . . , xHk) ≡ E(Un | x1.; . . . ; xN.)para n = 1, . . . , N .
E(Un | x) ≡ E(Un | xH2, . . . , xHk) ≡ E
Un |
x1.
...xN.
para n = 1, . . . , N .
Ejemplo 4. [funcion de consumo: (continuacion del Ejemplo 1 en la pagina anterior)]Estricta exogeneidad implica que para el individuo n-esimo
E(Un | 1, rd) = E(Un | (rd2, rd3, · · · , rdk)) = 0,
es decir, la esperanza de la perturbacion n-esima, condicionada a todas y cada una de las rentas disponibles,es cero.
Ejemplo 5. [ecuacion de salarios: (continuacion del Ejemplo 2 en la pagina anterior)]Estricta exogeneidad implica que para el individuo n-esimo
E(Un | 1, educ, antig, exper) = 0,

Seccion 2: Modelo Clasico de Regresion Lineal 8
es decir, la esperanza de la perturbacion del individuo n-esimo, condicionada —no solo a los anos de edu-cacion, antiguedad y experiencia de dicho individuo sino a los anos de educacion, antiguedad y experienciade todos los trabajadores— es cero.
⇑ Supuesto 2: Esperanza condicional de U – Estricta exogeneidad 8
E(U | x) = 0[N×1]
⇒
E(Un X) = 0 ortogonalidad Un ⊥ X
E(Un) = 0
por tanto Cov(Un,X) = 0
(ortogonalidad entre lo que conozco X y lo que desconozco Un)
Comentario. En el caso de regresion con datos temporales, la exogeneidad estricta implica que losregresores son ortogonales a las perturbaciones pasadas, presentes y futuras. Esta es una restriccion muyfuerte, que no se cumple en general con datos temporales (se discutira en el segundo trimestre [EconometrıaII]).
A continuacion aparecen las demostraciones de la transparencia anterior T8 :Proposicion 2.1. Si E(Un | x) = 0, entonces E(Un X) = 0
[N×k]
Demostracion.
E(Un X) =∫· · ·∫
un x f (un,x) dun dxkN · · · dx11
=∫· · ·∫
un x f (un | x) f (x) dun dxkN · · · dx11
=∫
un
[∫· · ·∫
x f (x) dxkN · · · dx11
]f (un | x) dun
=∫
un [E(X)] f (un | x) dun
= [E(X)]∫
unf (un | x) dun
=E(X) · E(Un | x)=E(X) · 0 = 0
[N×k]por hipotesis
Una importante implicacion de E(Un | x) = 0, es que entonces E(Un) = 0 ya que
E(Un) =E(E(Un |x)) por el Ta de las esperanzas iteradas.=E(0) = 0 por ser E(Un | x) las realizaciones de E(Un |x)
Y de los dos resultados anteriores se deriva que
Cov(Un,X) = E(Un X)− E(Un) · E(X) = 0[N×k]
− 0 · E(X) = 0[N×k]
Ejercicio 6. [Relacion si y solo si entre la funcion de regresion lineal y los supuestos 1 y 2]Demuestre que los supuestos 1 y 2 implican la primera condicion del Modelo Clasico de Regresion Lineal,esto es, que la funcion de regresion de Yn sobre los regresores es lineal
E(Yn | x) = xn. β .
Recıprocamente, demuestre que si dicha condicion se verifica para todo n = 1, . . . , N , entonces necesaria-mente se satisfacen los supuestos 1 y 2.

Seccion 2: Modelo Clasico de Regresion Lineal 9
Solucion:
E(Yn | x) =E(Xn. β +Un | x) por el Supuesto 1= xn. β +E(Un | x) puesto que Xn. = xn.
= xn. β por el Supuesto 2.
Recıprocamente, suponga que E(Yn | x) = xn. β para todo n = 1, . . . , N. Definamos Un = Yn−E(Yn | x) .Entonces, por construccion el Supuesto 1 se satisface ya que Un = Yn −Xn. β . Por otra parte
E(Un | x) =E(Yn | x)− E(E(Yn |x) | x) por la definicion que aquı damos a Un
=0;
pues E(E(Yn |x) | x) = E(Yn | x) , ya que:
E(E(Yn |x) | x) =∫ [∫
ytf (Un | x) dun
]f (Un | x) dun
=∫ [∫
(Un + xn. β)f (Un | x) dun
]f (Un | x) dun
=xn. β +∫ [∫
Unf (Un | x) dun
]f (Un | x) dun
=xn. β +E(E(Un |x) | x)=xn. β +E(Un | x) = E(Xn. β +Un | x) = E(Yn | x)
Ejercicio 6
⇑ Supuesto 3: Perturbaciones esfericas 9
homocedasticidadE(Un
2∣∣ x) = σ2 para n = 1, 2, . . . , N
no autocorrelacion
E(UiUj | x) = 0 si i 6= j para i, j = 1, 2, . . . , N
Definicion 1. Definimos la matriz de varianzas y covarianzas de un vector columna Y como
Var(Y) ≡ E((
Y−E(Y))(
Y−E(Y))′)
(2.1)
Ejercicio 7. Demuestre que Var(Y) = E(Y Y′)− E(Y) E
(Y′) .
Nota 2. Por tanto la matriz de varianzas y covarianzas de un vector columna Y es de la forma
Var(Y) ≡Var
Y1
...YN
≡ E
(Y Y′)− E(Y) E
(Y′)
=
2666666666664
E(Y12) E(Y1Y2) ··· E(Y1YN )
E(Y22) ··· E(Y2YN )
......
E(YN2)
3777777777775−
2666666666664
[E(Y1)]2 E(Y1)E(Y2) ··· E(Y1)E(YN )
[E(Y2)]2 ··· E(Y2)E(YN )
......
[E(YN )]2
3777777777775
=
2666666666664
σ2Y1
σY1Y2 · · · σY1YN
σ2Y2
· · · σY2YN
. . ....
σ2YN
3777777777775
Aplicando la definicion de varianza al vector de perturbaciones, y teniendo en cuenta los dos supuestos

Seccion 2: Modelo Clasico de Regresion Lineal 10
anteriores, tenemos que la matriz de varianzas y covarianzas de las perturbaciones es
Var(U | x) =E(U U′ ∣∣ x)− E(U | x) E
(U′ ∣∣ x)
=E
U1
...UN
[U1 · · · UN
] ∣∣∣∣∣∣∣ x−
0...0
[0 · · · 0]
por el Supuesto 2
=
E(U1
2 |x) E(U1U2 |x) ... E(U1UN |x)
E(U2U1 |x) E(U22 |x) ... E(U2UN |x)
......
. . ....
E(UN U1 |x) E(UN U2 |x) ... E(UN2 |x)
−
0 0 · · · 00 0 · · · 0...
.... . .
...0 0 · · · 0
=
σ2 0 . . . 00 σ2 . . . 0...
.... . .
...0 0 . . . σ2
por el Supuesto 3
⇑ Supuestos 2 y 3: Implicacion conjunta 10
Var(U | x) =
Var(U1 |x) Cov(U1,U2 |x) ... Cov(U1,UN |x)
Cov(U2,U1 |x) Var(U2 |x) ... Cov(U2,UN |x)
......
. . ....
Cov(UN ,U1 |x) Cov(UN ,U2 |x) ... Var(UN |x)
=
σ2 0 . . . 00 σ2 . . . 0...
.... . .
...0 0 . . . σ2
= σ2 I[N×N]
El supuesto de que la matriz de varianzas y covarianzas de la perturbaciones (condicionada a x) es σ2
veces la matriz identidad (estructura denominada perturbaciones esfericas)
Σ =
σ2 0 0 . . . 00 σ2 0 . . . 00 0 σ2 . . . 0...
......
. . ....
0 0 0 . . . σ2
es una restriccion muy fuerte, ya que implica:
1. que la dispersion (la varianza) del efecto de termino perturbacion asociada a cada observacion (oa cada instante, o a cada individuo, etc) es identica a la de las demas (no sabemos exactamente aque se debe la perturbacion que afecta a cada Yn pero la dispersion (incertidumbre) de ese efecto esidentica para todos).Dicho de otra forma: las perturbaciones Un son hocedasticas, ya que
Var(Un | x) = σ2 para todo n = 1 : N.
2. que la covarianza entre las perturbaciones de observaciones distintas (o de instantes ,o individuosdiferentes) es cero. Dicho de otra forma: las perturbaciones no tienen correlacion serial, ya que
Cov(Ui, Uj | x) = 0 para i 6= j.
Esto anadido al supuesto de distribucion conjunta Normal(ver Supuesto 5 mas adelante T31
)significara que las perturbaciones son independientes para las distintas observaciones.
Ejemplo 8. [ecuacion de salarios: (continuacion del Ejemplo 2 en la pagina˜6)]Estricta exogeneidad y perturbaciones esfericas implican conjuntamente que: aunque el factor desco-
nocido Un de cada el individuo n-esimo es desconocido; la incertidumbre (la varianza) de dicho factor

Seccion 2: Modelo Clasico de Regresion Lineal 11
—condicionada a los anos de educacion, antiguedad y experiencia de todos los individuos— es la mismaen cada caso (¡Supuesto curioso! ¿no?).
Hay cierto factor que influye en los salarios de Pepito y Juanito; no se que es, pero la incertidumbreque tengo sobre el es la misma (la dispersion del efecto que tiene el factor desconocido es la misma) paraambos casos.
Nota 3 (Relacion entre la funcion cedastica contante y los supuestos 1 y 3). Notese que conlos supuestos 1 y 3 tambien se cumple la segunda condicion del modelo clasico de regresion lineal ya que
Var(Yn | x) = Var(β1 + β2Xn + Un | x) = Var(Un | x) = σ2
2.2. Variacion de los supuestos 2 y 3 en algunos casos especiales:
2.2.1. Supuestos del Modelo con Muestras AleatoriasSi (Y,X) es una muestra aleatoria simple, i.e.. {Yn,Xn.} es i.i.d. para n = 1, . . . , N ; entonces,
E(Un | x) =E(Un | xn.)
E(Un
2∣∣ x) =E
(Un
2∣∣ xn.
)y tambien E(UiUj | x) =E(Ui | xi.) E(Uj | xj.) para i 6= j
Con lo que los los supuestos 2 T7 y 3 T9 quedan reducidos asupuesto 2’: E(Un | xn.) = 0
supuesto 3’: E(Un
2∣∣ xn.
)= σ2 > 0
para todo n = 1, . . . , N(Notese que los regresores estan referidos exclusivamente a la observacion n-esima)En general este supuesto no es adecuado para modelos con datos de series temporales ya que las muestras
no son i.i.d. (no son muestras aleatorias simples puesto que suele haber correlacion entre los datos).
Ejemplo 9. [ecuacion de salarios: (continuacion del Ejemplo 2 en la pagina˜6)]Con muestras aleatorias, estricta exogeneidad implica que para el individuo n-esimo
E(Un | 1, educ, antig, exper) = E(Un | 1, educn, antign, expern) = 0,
es decir, la esperanza de la perturbacion del individuo n-esimo, condicionada —exclusivamente a los anosde educacion, antiguedad y experiencia de dicho individuo— es cero, independientemente de lo que ocurracon el resto de trabajadores. Por supuesto, tambien ocurre con la varianza condicionada:
Var(Un | 1, educ, antig, exper) = Var(Un | 1, educn, antign, expern) = σ2 I,
Ejercicio 10. Demuestre que
E(UiUj | x) = E(Ui | xi.) E(Uj | xj.) para i 6= j
para el caso de muestras aleatorias simples (m.a.s.)Pista.
E(UiUj | x) = E(E(Ui |X Uj) · Uj | x)debido a que {Ui,Xi.} es independiente de {Uj ,X1., . . . ,Xi−1., Xi+1., . . . ,XN.} para i 6= j, junto conel teorema de las esperanzas iteradas.

12
2.2.2. Supuestos del Modelo con Regresores No EstocasticosSi los regresores son no estocasticos, es decir son la matriz determinista x, entonces no es necesario
distinguir entre funciones de densidad condicionales, f (un | x) , e incondicionales, f (un) ; por tanto lossupuestos 2 T7 y 3 T9 quedan reducidos asupuesto 2”: E(Un) = 0
supuesto 3”: E(Un
2)
= σ2 > 0 y E(UiUj) = 0 para i 6= j
para todo n, i, j = 1, . . . , N(Estos son los supuestos empleados en la mayorıa de libros de texto, como por ejemplo en Novales
(1993))Este caso no puede suponerse con modelos autorregresivos o de ecuaciones simultaneas.
La interpretacion geometrica de estos supuestos aparece en la Seccion A en la pagina˜46 del Apendice.
Queda un cuarto supuesto acerca del rango de la matriz de regresores y un quinto supuesto acerca de ladistribucion conjunta de U que enunciaremos mas adelante (vease Supuesto 4 T13 y Supuesto 5 T31 )
3. Estimacion MCO (Mınimos Cuadrados Ordinarios)
Capıtulos 2 y 3 de Wooldridge (2006)
Apendice E1 de Wooldridge (2006)
⇑ Termino de error 11
Las perturbaciones Un no son observablesPero las podemos estimar para un hipotetico valor β de β y una muestra concreta {yn, xn.}N
n=1 de{Yn, Xn.}N
n=1.
en = yn − xn. β = yn − yn
Consideremos la Suma de los Residuos al Cuadrado para todo n
SRC(β) ≡N∑
n=1
(yn − xn. β
)2 = (y−xβ)′(y−xβ) = e′ e
⇑ Mınimos cuadrados ordinarios: Ecuaciones normales 12
El Supuesto 2 del modelo implica que Un ⊥ X (ortogonalidad).La SRC(β) es mınima para valores β tales que los errores
e = y−xβ
son ortogonales a los regresores de la muestra x
e ⊥ x ⇒ x′ e = 0 .
Asıx′ e = 0; ⇒ x′
(y − xβ
)= 0; ⇒ x′ y−x′ x β = 0
es decirx′ y =x′ x β (3.1)
Estimacion MCO es la solucion β a dichas ecuaciones
Proposicion 3.1. La suma de residuos al cuadrado SRC(β) es mınima para β = β .

Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 13
Demostracion. Sea β una estimacion de β, entonces
e′ e = (y−xβ)′(y−xβ) =(y−xβ +xβ−xβ)′(y−xβ +xβ−xβ) sumando y restando xβ
=(e + x(β − β)
)′ (e + x(β − β)
)=e′ e +(β− β)′ x′ x(β− β) ya que x′ e = 0 .
Y puesto que (β− β)′ x′ x(β− β) es una suma de cuadrados (por tanto semi-definido positivo), se deduceque
SRC(cualquier β) = e′ e ≥ e′ e = SRC(β).
Para una interpretacion geometrica, vease tambien la Seccion A.1 en la pagina˜47 del apendice.
La demostracion anterior es, para mi gusto, mas elegante que la que aparece en la mayorıa de los manuales(busqueda del mınimo de la suma residual igualando a cero las primeras derivadas). No obstante, en laSeccion B en la pagina˜48 del apendice se muestra la derivacion tradicional de las ecuaciones normales.
Para que la solucion al sistema de ecuaciones normales (3.1) sea unica es necesario que se cumpla uncuarto supuesto.
3.1. Cuarto supuesto del Modelo Clasico de Regresion Lineal
⇑ Supuesto 4: Independencia lineal de los regresores 13
El rango de X[N×k]
es k con probabilidad 1.
numero de observaciones ≥ k
Vectores columna 1, XH2, . . . , XHk linealmente indep.
Este supuesto implica que x′ x es de rango completo, es decir, que existe la matriz (x′ x)−1.Se dice que existe multicolinealidad perfecta cuando el Supuesto 4 NO se satisface; es decir, cuando hay
dependencia lineal entre los regresores, o lo que es lo mismo: hay multicolinealidad perfecta cuando algunode los coeficientes de correlacion lineal entre dos regresores es uno en valor absoluto.
El Supuesto 4 garantiza la unicidad de las soluciones. Si no se cumple no es posible encontrar “laestimacion” MCO de los parametros (pues hay infinitas soluciones posibles).
Ejemplo 11. [ecuacion de salarios: (continuacion del Ejemplo 2 en la pagina˜6)]¿Que pasa si todos los individuos de la muestra nunca han cambiado de empresa?Entonces anos de experiencia y anos de antiguedad coinciden. Por tanto no es posible discriminar el
efecto por separado de ambas variables; solo podemos calcular su efecto conjunto.
ln(SALARn) = β1 + β2EDUCn + (β3 + β4)EXPERn + Un
Volveremos sobre esto en la Seccion 3 sobre Multicolinealidad en la pagina˜8 del Tema 3
3.2. Algunas expresiones que seran empleadas frecuentemente
Las expresiones que aparecen a continuacion seran empleadas repetidamente durante el curso.
Denotamos a la media aritmetica de los elementos del vector y de orden N como:
y = (∑
yn)/N.

Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 14
Nota 4. Sean x e y vectores de orden N , entonces∑n
(xn − x)(yn − y) =∑
n
yn(xn − x) para n = 1, . . . , N.
Demostracion.∑n
(xn − x)(yn − y) =∑
n
yn(xn − x)− y∑
n
(xn − x)
=∑
n
yn(xn − x)− y · 0 =∑
n
yn(xn − x) para n = 1, . . . , N.
Nota 5. Sean x e y vectores de orden N , entonces∑n
(xn − x)(yn − y) =∑
n
ynxn −Ny x = y′ x−Ny x.
Ejercicio 12. Compruebe la igualdad de la nota anterior.
Ası pues, del ejercicio anterior, Nsx y =∑
n(xn − x)(yn − y) = y ′ x−Ny x, es decir
sx y =∑
n(xn − x)(yn − y)N
=y ′ x
N− y x; (3.2)
donde sx y es la covarianza muestral entre los elementos de x e y; por tanto, la expresion de mas arribaes el analogo muestral de Cov(X,Y) = E([X − E(X)][Y − E(Y)]) = E(XY)− E(X) E(Y) .
Nota 6. Sea z un vector de orden N , entonces∑
n(zn − z)2 =∑
n z2n −Nz2 = z ′ z −Nz2
Demostracion. De la Nota 4 sabemos que∑
n(zn − z)(yn − y) =∑
n yn(zn − z), por tanto, si y = z∑n
(zn − z)2 =∑
n
zn(zn − z)
=∑
n
z2n − z
∑n
zn =∑
n
z2n −Nz2 = z′ z−Nz2 para n = 1, . . . , N ;
Es decir,
s2z =
∑n(zn − z)2
N=
z ′ z
N− z2; (3.3)
donde s2z es la varianza muestral de los elementos de z; por tanto, la expresion anterior es el analogo
muestral de Var(Z) = E([Z − E(Z)]2
)= E
(Z2)− [E(Z)]2 .
3.3. Algunos casos particulares
3.3.1. Modelo con solo una constante
⇑ Modelo 1: No vbles explicativas 14
“Si no se nada (D : ∅)” ; Y = h(1) + U donde g(·) es lineal; por lo tanto
Yn = a · 1 + Un
E(Yn |conjunto de informacion vacıo ) = E(Yn) = aVeamos que nos da la estimacion MCO
x′ y = x′ x β
es decir1′ y = 1′ 1 a
y calculando los productos escalares,∑yn = N a; ⇒ a =
∑yn
N= y (3.4)

Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 15
Notese como la estimacion MCO consiste en sustituir el momentos teorico E(Yn) por su analogo muestral(la media aritmetica).
En este caso los residuos del modelo son las deviaciones de los datos respecto a su media, ya que
e = y− y = y−y. (3.5)
3.3.2. Modelo Lineal Simple
⇑ Modelo 2: Modelo Lineal Simple 15
“Si (D : XH = xH)” ; Y = h(1,XH) + U donde g(·) es lineal; por lo tanto
Yn = a + bXn + Un;
entonces
E(Yn | xn) =E(a + bXn + Un | xn)=a + bxn + E(Un | xn) = a + bxn.
Por lo tanto, es funcion lineal y
E(Yn | xn) = E(Y)− Cov(Y,X)Var(X)
E(X)︸ ︷︷ ︸a
+Cov(X,Y)Var(X)︸ ︷︷ ︸
b
·xn; (3.6)
para todo xn ∈ RX ,
Veanse las ecuaciones (??) y (??) Seccion ?? (??) del Tema 2 del curso de Introduccion a la Econometrıade LECO, pagina ??.
⇑ Modelo 2: Modelo Lineal Simple 16
Sea Yn = a + bXn + Un; entonces
y =
y1
y2
...yN
; x =
1 x1
1 x2
......
1 xN
; β =(
a
b
)
y loas ecuaciones normales sonx′ y = x′ x β
es decir (1 1 . . . 1x1 x2 . . . xN
)y1
y2
...yN
=(
1 1 . . . 1x1 x2 . . . xN
)1 x1
1 x2
......
1 xN
(
a
b
)
⇑ Modelo 2: Modelo Lineal Simple 17
∑yn = a N + b
∑xn∑
xnyn = a∑
xn + b∑
x2n
; (3.7)
dividiendo por N la primera igualdad, despejando a y sustituyendo en la segunda, y empleando (3.2) y(3.3)
y = a + b x
sx y = bs2x
(3.8)
es decirb =
sx y
s2x
(3.9)
ya = y − sx y
s2x
x = y − b x (3.10)
Supuesto 4 (independencia lineal de regresores) ⇒ solucion unica.

Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 16
Notese como las estimaciones MCO consisten en sustituir los momentos teoricos de la Ecuacion (3.6) porsus analogos muestrales.
Ejercicio 13. Empleando el sistema de ecuaciones (3.7), obtenga el segundo sistema (3.8) de la transpa-rencia anterior.
Ejercicio 14. ¿Como afectarıa al problema de estimacion que la variable x fuera un vector de constantesc?
Ejemplo 15. [precio de las viviendas:]
n Precio Superficie1 199.9 10652 228.0 12543 235.0 13004 285.0 15775 239.0 16006 293.0 17507 285.0 18008 365.0 18709 295.0 1935
10 290.0 194811 385.0 225412 505.0 260013 425.0 280014 415.0 3000
Cuadro 1: Superficie (en pies al cuadrado) y precio de venta de los pisos (en miles de dolares) (Ramanathan, 1998, pp. 78)
Planteamos el modelo Yn = a+bXn +Un, donde Yn es el precio del piso n-esimo, Xn es su superficie, y Un
son otros factores que influyen en el precio del piso, pero “ortogonales” al la superficie del mismo (situacion,estado de mantenimiento, servicios, etc.) Deseamos saber cual es el efecto marginal del incremento de lasuperficie de un piso en su precio. Por lo tanto necesitamos estimar el valor del parametro b.
Puesto que ∑n
xn = 26 753∑
n
x2n = 55 462 515
∑n
yn = 4 444.9∑
n
xnyn = 9 095 985.5
De 3.7 en la pagina anterior tenemos el sistema de ecuaciones lineales
4 444.9 = a · 14 + b · 26 7539 095 985.5 = a · 26 753 + b · 55 462 515
cuya solucion nos da la estimacion por mınimos cuadrados de a y b:
a = 52.3509 b = 0.13875;
que tambien podemos calcular a partir de (3.9) y (3.10) en la pagina anterior
a = y − xsx y
s2x
= 52.3509 b =sx y
s2x
= 0.13875

Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 17
Estimaciones MCO utilizando las 14 observaciones 1–14Variable dependiente: price
Variable Coeficiente Desv. tıpica Estadıstico t valor p
const 52,3509 37,2855 1,4041 0,1857sqft 0,138750 0,0187329 7,4068 0,0000
Media de la var. dependiente 317,493D.T. de la variable dependiente 88,4982Suma de cuadrados de los residuos 18273,6Desviacion tıpica de los residuos (σ) 39,0230R2 0,820522R2 corregido 0,805565Grados de libertad 12Criterio de informacion de Akaike 144,168Criterio de informacion Bayesiano de Schwarz 145,447
Salida del programa “libre” Gretl (Gnu Regression, Econometrics and Time-series Library)
price = 52, 3509(1,404)
+ 0, 138750(7,407)
sqft
N = 14 R2 = 0, 8056 F (1, 12) = 54, 861 σ = 39, 023(entre parentesis, los estadısticos t)
Por lo tanto, el precio de venta esperado de un piso con una superficie de 1800 pies cuadrados, E(Y | 1800),sera de
y7 = 52.3509 + 0.139 · 1800 = 302101.5sin embargo y7 = 285. Esta discrepancia (el error e7 puede deberse a que dicho piso esta en una malasituacion, dispone de pocos servicios, etc.)
n Precio Superficie Precio estimado ErrorE(P | superficie) be
1 199.9 1065 200.1200 -0.220002 228.0 1254 226.3438 1.656193 235.0 1300 232.7263 2.273684 285.0 1577 271.1602 13.839845 239.0 1600 274.3514 -35.351426 293.0 1750 295.1640 -2.163977 285.0 1800 302.1015 -17.101488 365.0 1870 311.8140 53.186009 295.0 1935 320.8328 -25.83278
10 290.0 1948 322.6365 -32.6365311 385.0 2254 365.0941 19.9058712 505.0 2600 413.1017 91.8982613 425.0 2800 440.8518 -15.8518014 415.0 3000 468.6019 -53.60187
Cuadro 2: Superficie (en pies al cuadrado), precio de venta (en miles de dolares), precio estimado, y errores estimados.

Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 18
⇑ Estimacion MCO: Interpretacion grafica 18
150
200
250
300
350
400
450
500
550
1500 2000 2500 3000
pri
ce
sqft
price versus sqft
E(P|superfic
ie)
y7
y12
E(P |2600) = y12
e > 0
“regresion a ojo” GNU Gretl (este ejemplo) “data list”Continuacion del ejemplo “precio de las viviendas” en la pagina 34
3.3.3. Modelo con tres regresores
Ejercicio 16. Repita los pasos dados en la transparencia T16 y llegue hasta el sistema de ecuacionesequivalente a ( 3.7 en la pagina˜15) para los siguientes modelos:(a) Yn = aX1n + bX2n + cX3n + Un
(b) Yn = a + bX2n + cX3n + Un
Ejercicio 17. Obtenga la siguiente solucion del segundo sistema de ecuaciones del ejercicio anterior.
a =y − b · x2 − c · x3 (3.11)
b =sx2 y · s2
x3− sx3 y · sx2 x3
s2x2· s2
x3−(sx2 x3
)2 (3.12)
c =sx3 y · s2
x2− sx2 y · sx2 x3
s2x2· s2
x3−(sx2 x3
)2 (3.13)
Notese que si la covarianza entre x2 y x3 es cero, la estimacion de b del modelo Yn = a+bX2n+cX3n+Un
coincide exactamente con la estimacion de b en el modelo restringido Yn = a + bX2n + Un en el que se haquitado el regresor X3n.
Ejercicio 18. Si la covarianza entre x2 y x3 es cero, ¿Con la estimacion de que modelo restringidocoincide la estimacion de c?
Nota 7. Si los regresores de una regresion multiple tienen correlacion muestral cero entre si (por tantoson ortogonales), entonces las estimaciones de las pendientes de la regresion multiple son las mismas quelas estimaciones de las pendientes de las regresiones simples.
Multicolinealidad perfecta: Ejercicio 19. ¿Como afectarıa al problema de estimacion que los regre-sores x2 y x3 tuvieran un coeficiente de correlacion muestral con valor absoluto igual a uno?
Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 19
Relacion entre los modelos de tres regresores y los de dos. Considere los siguientes modelos deregresion simple
1. Y = ayx2 + byx2 X2 +U : Regresion de Y sobre X2
2. Y = ayx3 + byx3 X3 +U∗ : Regresion de Y sobre X3
3. X2 = ax2x3 + bx2x3 X3 +U∗∗ : Regresion de X2 sobre X3
(Notese como los subındices de los coeficientes describen cada regresion)¿Que relacion tienen las estimaciones MCO de estos tres modelos con las estimaciones MCO del modelo
Y = a + b X2 +cX3 +U : Regresion de Y sobre X2 y X3
descritas en las ecuaciones (3.12) y (3.12)?Si multiplicamos y dividimos (3.12) y (3.12) por s2
x2· s2
x3obtenemos las siguientes expresiones en
terminos de los coeficientes MCO de las tres regresiones anteriores:
b =byx2 − byx3 bx2x3
1− r2x2x3
(3.14)
c =byx3 − byx2 bx2x3
1− r2x2x3
(3.15)
donde rx2x3es la correlacion muestral entre ambos regresores.
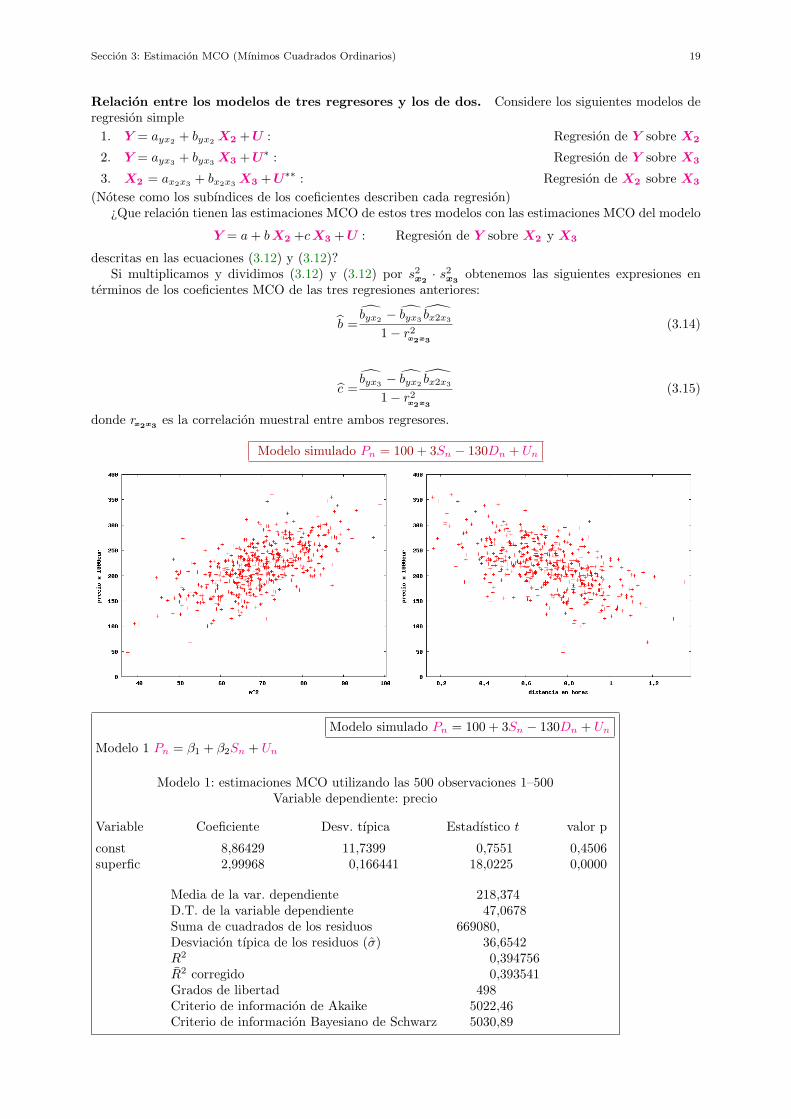
Modelo simulado Pn = 100 + 3Sn − 130Dn + Un
Modelo simulado Pn = 100 + 3Sn − 130Dn + Un
Modelo 1 Pn = β1 + β2Sn + Un
Modelo 1: estimaciones MCO utilizando las 500 observaciones 1–500Variable dependiente: precio
Variable Coeficiente Desv. tıpica Estadıstico t valor p
const 8,86429 11,7399 0,7551 0,4506superfic 2,99968 0,166441 18,0225 0,0000
Media de la var. dependiente 218,374D.T. de la variable dependiente 47,0678Suma de cuadrados de los residuos 669080,Desviacion tıpica de los residuos (σ) 36,6542R2 0,394756R2 corregido 0,393541Grados de libertad 498Criterio de informacion de Akaike 5022,46Criterio de informacion Bayesiano de Schwarz 5030,89
Seccion 3: Estimacion MCO (Mınimos Cuadrados Ordinarios) 20
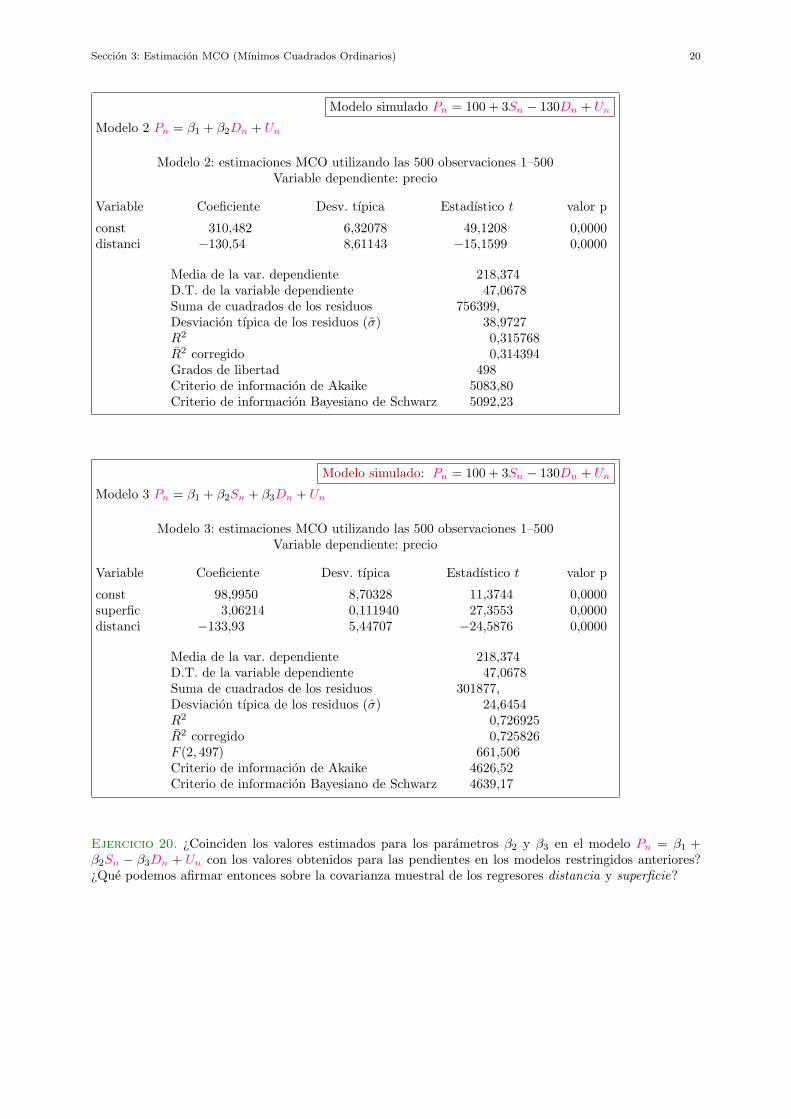
Modelo simulado Pn = 100 + 3Sn − 130Dn + Un
Modelo 2 Pn = β1 + β2Dn + Un
Modelo 2: estimaciones MCO utilizando las 500 observaciones 1–500Variable dependiente: precio
Variable Coeficiente Desv. tıpica Estadıstico t valor p
const 310,482 6,32078 49,1208 0,0000distanci −130,54 8,61143 −15,1599 0,0000
Media de la var. dependiente 218,374D.T. de la variable dependiente 47,0678Suma de cuadrados de los residuos 756399,Desviacion tıpica de los residuos (σ) 38,9727R2 0,315768R2 corregido 0,314394Grados de libertad 498Criterio de informacion de Akaike 5083,80Criterio de informacion Bayesiano de Schwarz 5092,23
Modelo simulado: Pn = 100 + 3Sn − 130Dn + Un
Modelo 3 Pn = β1 + β2Sn + β3Dn + Un
Modelo 3: estimaciones MCO utilizando las 500 observaciones 1–500Variable dependiente: precio
Variable Coeficiente Desv. tıpica Estadıstico t valor p
const 98,9950 8,70328 11,3744 0,0000superfic 3,06214 0,111940 27,3553 0,0000distanci −133,93 5,44707 −24,5876 0,0000
Media de la var. dependiente 218,374D.T. de la variable dependiente 47,0678Suma de cuadrados de los residuos 301877,Desviacion tıpica de los residuos (σ) 24,6454R2 0,726925R2 corregido 0,725826F (2, 497) 661,506Criterio de informacion de Akaike 4626,52Criterio de informacion Bayesiano de Schwarz 4639,17
Ejercicio 20. ¿Coinciden los valores estimados para los parametros β2 y β3 en el modelo Pn = β1 +β2Sn − β3Dn + Un con los valores obtenidos para las pendientes en los modelos restringidos anteriores?¿Que podemos afirmar entonces sobre la covarianza muestral de los regresores distancia y superficie?

21
3.3.4. Modelo Lineal General
⇑ Modelo Lineal General 19
En general tenemos mas de una variable exogena por lo que “ (D : X = x)”;
Yn = Xn. β +Un =[1, Xn2, . . . , Xnk
]β
[k×1]
+Un;
entoncesE(Yn | xn.) = E
([1, Xn2, . . . , Xnk
]β +Un
∣∣ xn.
)=
= E([
1, xt2, . . . , xtk
]β +Un
∣∣ xn.
)=
= E(a1 + a2xn2 + · · ·+ akxnk + Un | xn.) == a1 + a2xn2 + · · ·+ akxnk + E(Un | xn.)= a1 + a2xn2 + · · ·+ akxnk = xn. β;
donde xn. = (1, xn2, . . . , xnk).Necesitamos conocer el valor de los elementos de β,
(a1, a2, · · · , ak).
que dependen de las varianzas y covarianzas de[Yn, Xn.
].
(Vease la Seccion C.1 del apendice)
La expresion general de las ecuaciones normales es
x′ y = x′ x β .
El Supuesto 4 garantiza (con probabilidad 1) que la matriz x′ x es invertible. Por tanto la estimacion MCOdel vector β se puede expresar como
β = (x′ x)−1x′ y .
(Vease la Seccion D para una interpretacion de esta expresion.)
4. Propiedades algebraicas de la estimacion MCO
4.1. Propiedades basicas
Capıtulos 2 y 3 de Wooldridge (2006)
Apendice E1 de Wooldridge (2006)
⇑ Mınimos cuadrados ordinarios: Propiedades algebraicas 20
El vector de residuos evaluado en β = β es
e[N×1]
= y−x β
Reordenando las ecuaciones normales x′ y = x′ x β tenemos
x′(y−x β) = 0; ⇒ x′ e =0 ⇒ y ′ e =0 (4.1)
La propiedadx′ e = 0
es el analogo muestral de las condiciones de ortogonalidad derivadas del Supuesto 2 T8 (recuerdese quedos vectores de numeros a y b son ortogonales si a′ b =
∑aibi = 0.)
Esta propiedad indica que el termino de error estimado, e, es ortogonal a todos y cada uno de losregresores.
Del mismo modo que hemos definido e como e = y−x β, definimos los valores ajustados y como
y = x β;
entonces y′ = β′x′, y por tanto
y′ e = β′x′ e = β′0 = 0.
Practica 21. Con algun programa econometrico estime un modelo del tipo
Yn = β1 + β2Xn2 + β3Xn3 + Un.

Seccion 4: Propiedades algebraicas de la estimacion MCO 22
Obtenga los residuos e y los valores ajustados y. Compruebe que
x1′ e =0
x2′ e =0
y′ e =0
Calcule los valores medios de e, y e y. Explique los resultados. Anadir script de Gretl
⇑ Mınimos cuadrados ordinarios: Mas propiedades algebraicas 21
y ′ y = y ′ y + e ′ e (Ta Pitagoras T46 ) (4.2)
Ya que
y′ y = (y + e)′ (y + e) puesto que e = y− y
=y′ y + 2 y′ e + e′ e desarrollando el producto
=y′ y + e′ e ya que de (4.1) y′ e = 0
⇑ Sumas de cuadrados 22
SRC ≡N∑
n=1
en2 = e′ e
STC ≡N∑
n=1
(yn − y)2 = y′ y−Ny2
SEC ≡N∑
n=1
(yn − y)2 = y′ y +Ny2 − 2Nyy
Por tanto, STC = Ns2y donde s2
y es la varianza muestral de y; por el contrario, las sumas SRC y SECno son necesariamente N veces las varianzas de e y y (aunque veremos que ası ocurre si el modelo tienetermino cte.).
Ejercicio 22. Verifique las igualdades de la transparencia anterior.
Caso especial (Modelos con termino constante). Cuando hay termino constante en el modelo (elprimer regresor es un vector de unos — tal y como hemos presentado el modelo aquı) se verifica que
1′ e = 0; ⇒N∑
n=1
en = 0 ⇒ e =0 .
Y puesto que para cada n, se verifica que yn = yn + en , entonces sumando para n = 1, . . . , NN∑
n=1
yn =N∑
n=1
yn + 0 o bien 1′ y = 1′ y ⇒ y =y
Ademas, de (4.2) ∑y2
n =∑
yn2 +
∑e2;
restando a derecha e izquierda Ny2 (que es igual a Ny2),∑
y2n −Ny2 =
∑yn
2 −Ny2
+∑
e2;
y empleando el resultado de la Nota 6 en la pagina˜14N∑
n=1
(yn − y)2 =N∑
n=1
(yn − y)2 +N∑
n=1
en2 o bien (y−y)′ (y−y) = (y−y)′ (y−y) + e′ e .

Seccion 4: Propiedades algebraicas de la estimacion MCO 23
Dividiendo por N tenemoss2
y =s2by +s2beya que e = 0; y donde s2
z es la varianza muestral de z.
Ejercicio 23. Demuestre que y ′ y = y ′ y ; es decir,∑
yn2 =
∑ynyn.
Caso especial (Modelos con termino constante). La suma explicada de cuadrados, SEC, se puedeexpresar como:
SEC =y′ y +Ny2 − 2Nyy
=y′ y−Ny2 ya que y = y por haber termino cte.
=Ns2by por la Nota 6
otras expresiones son:
= β′ x′ x β−Ny2 sustituyendo y por x β
=y′ y−Nyy por Ejercicio 23 y por y = y
=Nsby y por la Nota 4
Ademas, en este caso en particular, la suma total de cuadrados, STC, se puede descomponer en lasuma:
STC = SEC + SRC
ya que
y′ y =y′ y +e′ e de (4.2) (pagina 22)
y′ y−Ny2 =y′ y−Ny2 + e′ e restando a ambos lados Ny2
STC =y′ y−Ny2 + SRC por definicion de STC y SRC
STC =SEC + SRC por haber termino constante y = y
Esta relacion sugiere el nombre de “suma explicada de cuadrados”, ya que descomponemos la variabilidadde la variable que queremos estudiar (y) en dos partes: SRC es la variabilidad de los residuos (aquello queel modelo no “explica”) y SEC es la variabilidad de y, que es la estimacion de la esperanza condicionadaa los datos (aquello que “explica” el modelo).
En esta discusion se debe tener presente que el termino “explicacion” es enganoso. En el ejemplo delprecio de las viviendas y su superficie, es sensato suponer que los precios dependen de las caracterısticasde las viviendas, y en particular, que parte de las variaciones de los precios se deben a la variacion en lasuperficie de las viviendas; por ello, el nombre de “suma explicada de cuadrados” toma todo su sentido.
Ahora bien, suponga que estima el modelo:
Sn = β1 + β2Pn + Un.
En este modelo, la superficie es funcion del precio de la vivienda, y por ser un modelo lineal con terminoconstante, la relacion algebraica STC = SEC + SRC se cumple. Pero no tiene sentido suponer quelas caracterısticas de la vivienda se deben al precio; de lo contrario podrıamos suponer que si el pisoexperimenta un alza en su precio, entonces, en consecuencia su superficie aumentara. Esto es absurdo, ypodemos concluir que la relacion STC = SEC + SRC es puramente algebraica, y que su interpretacionsolo es posible cuando el modelo estimado “tiene sentido” desde el punto de vista de la Teorıa Economica.
La unica interpretacion posible a las estimaciones es de caracter puramente estadıstico (y no de TeorıaEconomica): si un piso tiene un precio muy elevado, cabe “esperar” que el piso sea grande. (Este es unbuen momento para que lea de nuevo la Introduccion a este Tema 1 en la pagina˜3).

Seccion 4: Propiedades algebraicas de la estimacion MCO 24
4.2. Mas propiedades algebraicas.
4.2.1. ProyeccionesSi se cumple el cuarto supuesto, entonces x′ x es de rango completo y existe la matriz (x′ x)−1. Solo
entonces, es posible “despejar” β en las ecuaciones normales (3.1) para obtener la expresion:
β = (x′ x)−1x′ y .
Llamamos estimacion MCO de y ay = xβ
que es igual ay = xβ = x(x′ x)−1x′ y .
Por otra parte,
e =y−y = y−xβ
=y−x(x′ x)−1x′ y
=(I−x(x′ x)−1x′) y
Si llamamos p ≡ x(x′ x)−1x′ y m ≡ I−p, entonces
y = py ≡ y⊂x; e = my ≡ y⊥x .
donde y⊂x es la parte de y que se puede expresar como funcion lineal de las x; e y⊥x es la parte de y que nose puede expresar como funcion lineal de las x, es decir, la parte de y ortogonal a las x.
Ademas sabemos que y = y + e, por tanto
y = py +my = y⊂x+y⊥x .
(vease la figura de la Transparencia T46); y p+m = I .
Nota 8. La inversa de una matriz simetrica es simetrica, ası pues, (x′ x)−1 es una matriz simetrica, y portanto
[(x′ x)−1
]′ = (x′ x)−1. La traspuesta de un producto de matrices a y b es [ab]′ = b′ a′ .
Ejercicio 24. Cual sera la expresion de la traspuesta del producto de tres matrices (abc)′?
Ejercicio 25. Demuestre que p′ m = p′(I−p) = 0 .
Se puede verificar (empleando el resultado del ejercicio anterior) que y ′ e = 0, pues
y′ e = (py)′ my = y′ p′ my = y′ 0y = 0;
resultado que ya vimos en la Ecuacion 4.1 en la pagina˜21. Por tanto, podemos concluir que:La estimacion MCO separa el vector y en dos componentes, y y e, ortogonales entre si
(perpendiculares). La primera componente y es una combinacion lineal de los regresores (laparte de y que se puede describir mediante un modelo lineal con las variables explicativas). Lasegunda componente es la parte de y ortogonal a los regresores (lo que no se puede describirlinealmente con los regresores, ni siquiera de manera aproximada).
Ejercicio 26. Demuestre que m′ = m y que m′ m = m,
De los ejercicios y resultados anteriores, se deduce que
y′ y =(py +my)′ (py +my)
=y′ p′ py +y′ m′ my pues p′ m = pm′ = 0
=y′ y +e′ e (expresion que ya obtuvimos en (4.2); T. de Pitagoras)
(vease la figura de la Transparencia T46).La estimacion MCO de y, es decir el vector y = py, se obtiene proyectando y sobre el conjunto de
todas las combinaciones lineales de los regresores (todos los posibles modelos lineales generados con losregresores x), para seleccionar aquel cuya suma de residuos al cuadrado e ′ e es menor. (compare la figurade la Transparencia T46 con la figura inmediatamente anterior).

Seccion 4: Propiedades algebraicas de la estimacion MCO 25
De manera analoga, los residuos e = my son la proyeccion del vector y sobre el espacio ortogonal alanterior (al de los modelos lineales obtenidos como combinaciones lineales de los regresores x). Es decir,e es la parte de y que no es expresable en funcion de un modelo lineal de x (o lo que es lo mismo, no esexplicable como combinacion lineal de los regresores).
Por tanto, la matriz p es una aplicacion lineal que “proyecta” el vector y sobre las x (sobre el espaciovectorial expandido por las columnas —los regresores— de la matriz x); y la matriz m es una aplicacionlineal que “proyecta” el vector y sobre el espacio ortogonal a las x (sobre el espacio vectorial ortogonal alexpandido por las columnas de la matriz x);
Proyectores ortogonalesDefinicion 2. Decimos que una matriz q es simetrica si se verifica que q′ = q .
Definicion 3. Decimos que una matriz q es idempotente si se verifica que qq = q .
Definicion 4. Sea q una matriz idempotente (qq = q). Si ademas la matriz es simetrica (q = q′),entonces se dice que la matriz q es un proyector ortogonal.
Ejercicio 27. Verifique que p y m son proyectores ortogonales.
4.2.2. Regresion particionadaWooldridge (paginas 85 y ejercicio 3.17 de la pagina 119 2006). Pero mejor en:
Johnston y Dinardo (paginas 88 a 95 y 116 a 118 2001)
Novales (paginas 85 a 86 1993)
Pena (paginas 390 a 392 2002)
En la parte de contrastacion de hipotesis sera necesario, en ocasiones, tener expresiones explıcitas desub-vectores de β
β =
β1
· · ·β2
Para ello vamos a reescribir el modelo lineal de la forma Y =X1 β1 +X2 β2 +U y tambien las ecuacionesnormales 3.1 en la pagina˜12 del siguiente modo[(
x1′
x2′
)[x1 x2
]] [β1
β2
]=[x1
′ yx2
′ y
]o mejor aun
x1′ x1 β1 +x1
′ x2 β2 = x1′ y
x2′ x1 β1 +x2
′ x2 β2 = x2′ y
(4.3)
donde x =[x1
...x2
], es decir, hemos dividido la matriz de regresores en dos conjuntos de columnas, cada
uno asociado a los parametros de los vectores β1 y β2 .Si pre-multiplicamos la primera de las ecuaciones por x2
′ x1(x1′ x1)−1 y la restamos de la segunda,
tenemos (x2
′ x2−x2′ x1(x1
′ x1)−1x1′ x2
)β2 = x2
′ y−x2′ x1(x1
′ x1)−1x1′ y (4.4)
Vamos ha definir los proyectores
p1 = x1(x1′ x1)−1x1
′ y m1 = I−p1
El primero de ellos es una aplicacion lineal que “proyecta” cualquier vector z sobre el primer conjuntode regresores x1, y el segundo lo “proyecta” sobre el espacio ortogonal al primero. Por tanto p1z realiza laregresion MCO del vector z sobre los regresores x1 y m1z son los residuos (los errores) de dicha regresion.
Sustituyendo p1 y m1 en (4.4) tenemos
β2 = (x2′ m1 x2)−1 x2
′ m1y (4.5)
y sustituyendo esta expresion en las ecuaciones normales (4.3)
β1 = (x1′ x1)−1x1
′(y−x2β2) (4.6)

Seccion 4: Propiedades algebraicas de la estimacion MCO 26
Es sencillo verificar que, de nuevo, m1′ = m1 . y que m1
′ m1 = m1 . Por lo que (4.5) se puede escribircomo
β2 = (x2′ m1
′ m1 x2)−1 x2′ m1
′ m1 y
En esta expresion, m1y son los residuos obtenidos al realizar la regresion de y sobre el subconjunto deregresores x1 (la parte de y ortogonal a x1). Y m1x2 es una matriz cuyas columnas son los residuosobtenidos realizando la regresion de cada una de las columnas de x2 sobre x1 (la parte de x2 ortogonal ax1).
Notese que si llamamos y⊥x1= m1y a los residuos de la primera regresion, y x2⊥x1
= m1x2 a la matrizde residuos de las regresiones de las columnas de x2, entonces (4.5) se puede escribir como
β2 = (x2⊥x1
′ x2⊥x1)−1x2⊥x1
′ y⊥x1
Este resultado nos indica que podemos estimar β2 mediante regresiones auxiliares:1. Realizamos la regresion de y sobre el primer conjunto de regresores x1 y obtenemos el vector de
residuos y⊥x1
2. Realizamos las regresiones de cada una de las columnas de x2 sobre las variables x1, almacenandolos residuos de cada regresion en las columnas de x2⊥x1
.
3. por ultimo, β2 se obtiene de la regresion de y⊥x1sobre x2⊥x1
, es decir, β2 = (x2⊥x1
′ x2⊥x1)−1x2⊥x1
′ y⊥x1
4. las estimaciones de β1 se pueden recuperar de (4.6)
Notese que si β2 = β2; es decir, si el sub-vector se reduce a un escalar (un unico parametro), entonces laexpresion (4.5) se reduce a
β2 = β2 = ( x′2
[1×N]
m1[N×N]
x2[N×1]
)−1x2′ m1y =
x2′ m1y
x′2
[1×N]
m1[N×N]
x2[N×1]
(4.7)
Regresion ortogonal particionada. Suponga que ambos grupos de regresores[x1
...x2
], son ortogo-
nales entre si (x1′ x2 = 0), es decir, estan incorrelados. En este caso, las ecuaciones 4.3 en la pagina
anterior se reducen a
x1′ x1 β1 = x1
′ y
x2′ x2 β2 = x2
′ y;
y por lo tanto los vectores de coeficientes β1 y β2 se pueden estimar por separado mediante las regresionesde Y sobre X1 , y de Y sobre X2 . Esta es una generalizacion de la Nota 7 en la pagina˜18.
4.2.3. Regresion en desviaciones respecto a la mediaWooldridge (paginas 63, 64, 90 2006). Pero mejor:
Novales (paginas 86 a 91 1993)
Johnston y Dinardo (paginas 84 a 88 2001)
Gujarati (Seccion 6.1 2003, hay version castellana de este manual)
Un caso particular de la regresion particionada es que el primer grupo de regresores se limite a la columna
de unos. Es decir x =[1
...x2
], donde x1 = 1 . En este caso
p1 = x1(x1′ x1)−1x1
′ = 1(1′ 1)−11′ =11′
N=
1N
1N · · · 1
N
1N
1N · · · 1
N
· · · · · ·. . .
...1N
1N · · · 1
N
por lo que
m1y = (I−p1) y =
y1 − yy2 − y
...yN − y
= y ≡ y⊥1

Seccion 4: Propiedades algebraicas de la estimacion MCO 27
es decir, y = m1y son las desviaciones de los elementos del vector columna y respecto de su media muestraly (son los residuos y⊥x1
≡ y⊥1 de la primera regresion en el paso 1; aquı x1 = 1. Vease la Ecuacion 3.5 enla pagina˜15). De manera similar, m1x2 da como resultado una matriz x2⊥1 ≡ x2 en la que aparecen lasdesviaciones de los datos de cada una de las columnas de X2 respecto de sus respectivas medias (son losresiduos de las regresiones auxiliares del paso 2).
Ahora es inmediato estimar β2 como (paso 3)
β2 = (x′2 x2)−1x′
2 y (4.8)
es decir, en un modelo con termino constante, la estimacion de todos los parametros excepto el de laconstante. se pueden obtener mediante la regresion de las variables del modelo en desviaciones respecto asu media. Por ultimo (paso 4)
β1 = (1′ 1)−11′(y−x2β2) =1′(y−x2β2)
N= y − β2x2 − β3x3 − · · · − βkxk (4.9)
En definitiva, si en el modelo Yn = β1 + β2X2n + · · ·+ βkXkn deseamos estimar por MCO solo β2, β3,. . . , βk. Basta restar la media muestral a cada una de las variables del modelo, y realizar la regresion en unnuevo modelo sin termino constante y con las nuevas variables transformadas. Yn = β2X2n + · · ·+ βkXkn.
Practica 28. Verifique con un programa econometrico la afirmacion anterior.
Notese ademas, que la expresion (4.8) se puede reescribir como:
β2 =(
1N
x′2 x2
)−1( 1N
x′2 y
);
donde 1N x′
2 x2 es la matriz de covarianzas muestrales de los regresores, y 1N x′
2 y es el vector de covarianzasmuestrales entre los regresores y el regresando (que es la contrapartida muestral de la Ecuacion C.1 en lapagina˜49).
4.2.4. Anadiendo regresores
Suponga que ha estimado por MCO el siguiente modelo
Y = Xβ +U .
Posteriormente decide incluir como regresor adicional la variable Z; entonces el nuevo modelo ampliadosera:
Y = Xβ∗ +cZ +U∗ .
Podemos aplicar los resultados de la regresion particionada para obtener el coeficiente, c, asociado al nuevoregresor Z del siguiente modo (de 4.5 en la pagina˜25):
c = (z′ m z)−1z′ my = (z⊥x′ z⊥x)−1z⊥x
′ y⊥x; (4.10)
donde y⊥x son los residuos de la regresion MCO de y sobre x (la parte de y que no se puede expresar comofuncion lineal de las x, es decir, la parte de y ortogonal a las x), y z⊥x son los residuos de la regresion MCOde z sobre x (la parte de z ortogonal a las x), es decir z⊥x = mz, e y⊥x =my; donde m =
[I−x(x′ x)−1x′ ].
Practica 29. Verifique con un programa econometrico la afirmacion anterior. Los pasos a seguir son1. Calcule los residuos MCO con el modelo reducido.
2. Calcule los coeficientes estimados en el modelo ampliado. Fıjese en el valor obtenido para el coeficientec asociado al nuevo regresor4.
3. Calcule los residuos en la regresion de la nueva variable explicativa z sobre los antiguos regresoresx.
4. Calcule por MCO la regresion de los residuos del punto 3 sobre los residuos del punto 1; y compareel valor estimado con el obtenido en el punto 2.
4Notese que el resto de coeficientes puede diferir respecto de los obtenidos en la nueva regresion. Esto sera ası siempreque el nuevo regresor tenga correlacion con los del modelo inicial.

Seccion 4: Propiedades algebraicas de la estimacion MCO 28
Suma de residuos: Cuando se anaden regresores a un modelo, la suma de residuos al cuadrado nuncacrece; de hecho suele disminuir. Esto se cumple incluso si la variable anadida no tiene ningun sentidodentro del modelo (ninguna relacion teorica). Veamoslo:
Del modelo inicial obtendremos los residuos
e = y−xβ;
por otra parte, los residuos con el modelo ampliado son
e∗ = y−xβ∗ −z c.
(notese que si x′ z 6= 0 entonces β 6= β∗ ; y que si c 6= 0 entonces e 6= e∗ .)De (4.6) sabemos que
β∗ = (x′ x)−1x′(y−z c) = β − (x′ x)−1x′ z c.
Sustituyendo β∗ en e∗ obtenemos
e∗ =y−xβ +x(x′ x)−1x′ z c − z c
= e−mz c
= e−z⊥x c de (4.10)
Ası pues,e∗′ e∗ = e′ e +c2
(z⊥x
′ z⊥x
)− 2cz⊥x
′ e
Teniendo en cuenta que de (4.10) c = (z⊥x′ z⊥x)−1z⊥x
′ y⊥x y que e = my = y⊥x tenemos
c2(z⊥x
′ z⊥x
)= c(z⊥x
′ z⊥x
)c = c
(z⊥x
′ z⊥x
)(z⊥x
′ z⊥x)−1z⊥x′ y⊥x = cz⊥x
′ y⊥x = cz⊥x′ e .
Por lo que finalmentee∗′ e∗︸ ︷︷ ︸SRC∗
= e′ e︸︷︷︸SRC
− c2(z⊥x
′ z⊥x
)︸ ︷︷ ︸
≥0
(4.11)
por lo que la suma de residuos al cuadrado del modelo ampliado SRC∗ nunca sera mayor que la del modeloreducido SRC.
4.2.5. Correlaciones parciales
Suponga que tiene tres variables; por ejemplo, la renta r, la edad e y el numero de anos de estudio oformacion f de una serie de individuos.
Rn = β1 + β2Fn + β3En + Un
Querrıamos saber el grado de relacion lineal entre dos de ellas, una vez “descontado” la relacion lineal quela tercera tiene con ellas. En nuestro ejemplo nos podrıa interesar conocer el grado de relacion lineal de larenta con la formacion, una vez “descontado el efecto lineal” que la edad tiene con ambas (notese que tantopara formarse como para generar rentas es necesario el transcurso del tiempo, por lo que generalmentehay una relacion directa entre la edad y las otras dos variables).
La solucion es “tomar” la parte de ambas variables, “renta” y “educacion”, ortogonal a la tercera,la“edad”; y observar la correlacion de dichas partes (que ya no mantienen relacion lineal ninguna con lavariable “edad”).
El modo de hacerlo es sencillo una vez visto lo anterior:1. Se toman los residuos de la regresion de la variable renta r sobre la variable edad e y la constante
(modelo lineal simple); es decir, se obtiene r⊥e.
2. Se toman los residuos de la regresion de la variable formacion f sobre la variable edad e y la constante(modelo lineal simple); es decir, se obtiene f⊥e.
3. Por ultimo se calcula el coeficiente de correlacion simple de ambos residuos rr⊥ef⊥e.Dicho coeficiente es la correlacion parcial de la variable renta r con la variable formacion f , una vez“descontado” el efecto de la edad e sobre ambas variables. Notese que ambos residuos tiene media ceropor ser residuos de un modelo con termino constante.
Suponga por tanto que dividimos la matriz de regresores x en dos columnas; por ejemplo la primeravariable no cte. x2 y el resto de k − 1 regresores (incluyendo el termino cte.) w.
x =[x2
... w]

Seccion 4: Propiedades algebraicas de la estimacion MCO 29
entonces el coeficiente de correlacion parcial de y con x2 una vez descontado el efecto de las demas variables(incluida la constante) w es
r(y,x2)⊥z
=y′ mw x2√
y′ mw y√
x2′ mw x2
=sy
⊥wx2⊥w√s2
y⊥w
√s2
x2⊥w,
donde mw = I−w(w′ w)−1w′ .
Ejercicio 30. Resuelva el ejercicio propuesto no 2 del profesor Jose Alberto Mauricio.http://www.ucm.es/info/ecocuan/ectr1/index.html#Material.
Ejercicio 31. Resuelva el ejercicio propuesto no 3 del profesor Jose Alberto Mauricio.http://www.ucm.es/info/ecocuan/ectr1/index.html#Material.
4.3. Medidas de ajuste
Las medidas de ajuste sirven paraCuantificar la reduccion de incertidumbre que proporciona el modelo estimado.
Comparar la bondad de modelos alternativos para la misma muestra
⇑ Medidas de ajuste: Coeficiente de determinacion R2 23
R2 ≡ 1− SRC
STC; R2 ≤ 1 (no acotado inferiormente)
Cuando hay termino constante
R2 =SEC
STC; 0 ≤ R2 ≤ 1 (acotado)
Coeficiente de Determinacion o R2 es una medida de ajuste frecuente. Cuando el modelo contieneun regresor constante, muestra el poder explicativo de los regresores no constantes. Se define como
R2 ≡ 1− SRC
STC;
y puesto que SRC y STC son siempre mayores o iguales a cero, R2 ≤ 1.Cuando el modelo no tiene cte. SRC puede ser mayor que STC, por lo que R2 no esta acotado
inferiormente.
GNU Gretl: ejemplo simulado
Caso especial (Modelos con termino constante). Si el modelo tiene termino constante, el coeficienteR2 mide el porcentaje de variacion de y “explicado” por los regresores no constantes del modelo; ya que
R2 = 1− SRC
STC=
STC − SRC
STC=
SEC
STC
y por tanto 0 ≤ R2 ≤ 1.Notese ademas que
R2 =SEC
STC=
SEC2
STC × SEC=
(Nsby y
)2Ns2
y ×Ns2by =N2
N2
sby y√s2
y × s2by
2
=(rby y
)2, (4.12)

Seccion 4: Propiedades algebraicas de la estimacion MCO 30
donde rby y = s by y
s by×syes el coeficiente de correlacion lineal simple entre y y y.
Ejercicio 32. Calcule el coeficiente de determinacion R2 para el el ejemplo del precio de las viviendas
Ejercicio 33. Calcule el coeficiente de determinacion para el Modelo 1: Yn = a + Un
Pista. piense cuanto vale SEC en este caso.
Ejercicio 34. Verifique que, para el caso del Modelo Lineal Simple Yn = a + bXn + Un, el coeficiente dedeterminacion R2 es el cuadrado del coeficiente de correlacion simple entre el regresando y y el regresorx; es decir, que en este caso R2 = r2
y x. (Notese que este resultado es diferente de (4.12)).
El coeficiente de determinacion R2 tiene algunos problemas al medir la bondad del ajuste.anadir nuevas variables al modelo (cuales quiera que sean) nunca hace crecer SRC pero esta sumasi pude disminuir (vease la Seccion 4.2.4)Por tanto el R2 del modelo ampliado nunca puede ser menor que el del modelo inicial.Para evitar este efecto se emplea el coeficiente de determinacion corregido (o ajustado) R2
El coeficiente de determinacion corregido R2 de define como
R2 ≡ 1−SRCN−kSTCN−1
; = 1−s2bes2y
es decir, uno menos la fraccion de la cuasivarianza de los errores con la cuasivarianza muestral del regre-sando. Por ello tambien es siempre menor o igual a uno.
1. compara estimadores insesgados de la varianza residual y de la varianza de la variable dependiente
2. penaliza modelos con un elevado numero de parametros, al corregir por el numero de grados delibertad N − k.
⇑ Otras medidas de ajuste 24
R2 corregido (mejor cuanto mas elevado)
R2 ≡ 1−SRCN−kSTCN−1
= 1− N − 1N − k
(1−R2) ≤ 1
Criterios de informacion de Akaike y de Schwartz (mejor cuanto mas bajos)
AIC =N ln(2π) + N ln(
e ′ e
N
)+ N + 2(k + 1)
SBC =N ln(2π) + N ln(
e ′ e
N
)+ N + (k + 1) ln(N)
Volver al recuadro del ejemplo del precio de las viviendas (pagina 17).
Otras medidas de la bondad del ajuste son los criterios de informacion de Akaike y de Schwartz (mejorcuanto mas bajos)Akaike prima la capacidad predictiva del modelo (pero tiende a sobreparametrizar)
Schwartz prima la correcta especificacion
El programa Gretl (Gnu Regression, Econometrics and Time-series Library) realiza un calculo especialde R2 cuando el modelo no tiene termino cte. En este caso el R-cuadrado es calculado como el cuadradode la correlacion entre los valores observado y ajustado de la variable dependiente (Vease Ramanathan,1998, Seccion 4.2).
Los coeficientes de determinacion nos dan informacion sobre el grado de ajuste del modelo, pero ¡ojo! nospueden conducir a enganos. No es recomendable darles demasiada importancia, hay otras cuestiones sobreel modelo de mayor relevancia a la hora de valorarlo. . .

Seccion 4: Propiedades algebraicas de la estimacion MCO 31
Ejemplo 35. [peso de ninos segun su edad:]
n Peso Kg Edad1 39 72 40 73 42 84 49 105 51 106 54 117 56 128 58 14
Cuadro 3: Peso (en kilogramos) y edad (en anos)
(Modelo 1 Pn = β1 + β2EDADn + Un)
40
45
50
55
60
7 8 9 10 11 12 13 14
Peso
Edad
Peso con respecto a Edad
E(P | e) = a + b · eajustado
observado
Peso Kg = 19, 6910(6,999)
+ 2, 93003(10,564)
Edad
T = 8 R2 = 0, 9405 F (1, 6) = 111, 6 σ = 1, 8161(entre parentesis, los estadısticos t)
(Modelo 2 Pn = β1 + β2EDADn + β3EDADn2 + Un)
40
45
50
55
60
7 8 9 10 11 12 13 14
Peso
Edad
Peso con respecto a Edad
E(P | e) = a + b · e + c · e2
ajustadoobservado
Peso Kg = −5, 11497(−0,664)
+ 8, 06835(5,159)
Edad− 0, 252102(−3,305)
Edad2
T = 8 R2 = 0, 9776 F (2, 5) = 153, 57 σ = 1, 1148(entre parentesis, los estadısticos t)

32
(Modelo 3 Pn = β1 + β2EDADn + β3EDADn2 + β4EDADn
3 + Un)
40
45
50
55
60
7 8 9 10 11 12 13 14
Peso
Edad
Peso con respecto a Edad
E(P | e) = a + b · e + c · e2 + d · e3
ajustadoobservado
Peso Kg = 81, 7714(1,904)
− 18, 5964(−1,419)
Edad + 2, 37778(1,845)
Edad2− 0, 0836541(−2,043)
Edad3
T = 8 R2 = 0, 9863 F (3, 4) = 168, 75 σ = 0, 87188(entre parentesis, los estadısticos t)
5. Propiedades estadısticas de los estimadores MCO
Capıtulos 2 y 3 de Wooldridge (2006)
Apendice E2 de Wooldridge (2006)
⇑ Estimador MCO bβ| x 25
Los coeficientes estimados verificanx′ y = x′ x β
por Supuesto 4 T13 de independencia lineal podemos despejar β:
β = (x′ x)−1x′ y
que es una estimacion.El estimador de los coeficientes es β = (X′ X)−1X′ Y o bien
β|x ≡ β∣∣∣ x = (x′ x)−1x′ Y = aY = β +aU
donde Y = xβ +U suponiendo conocidas las realizaciones de los regresores.
Nota 9. Notese las dimensiones de la matriz:
a[k×N]
≡ (x′ x)−1x′ =
a11 a12 · · · a1N
a21 a22 · · · a2N
......
. . ....
ak1 ak2 · · · akN
;
por lo tanto, β son k combinaciones lineales de los N datos del vector y, donde los coeficientes especıficosde cada combinacion son los elementos de cada una de las filas de la matriz (x′ x)−1 x′.
Del mismo modo, cada uno de los elementos del vector aleatorio β es una combinacion lineal de las Nvariables aleatorias Yn.
Notese ademas que
β|x ≡ β∣∣∣ x = aY
= a[xβ +U
]= β +aU
= β +(x′ x)−1x′ U
es decir:β|x es igual al verdadero valor de los parametros mas una combinacion lineal (o suma ponde-rada) de las perturbaciones determinada por los coeficientes aij de la matriz a.

Seccion 5: Propiedades estadısticas de los estimadores MCO 33
5.1. Esperanza de los estimadores MCO β|x
⇑ Esperanza del estimador MCO bβ| x 26
Denotemos (X′ X)−1X′ por A[k×N]
E(
β∣∣∣ x) =E(β +AU | x)
=E(β +aU | x)=β +a ·E(U | x)=β
por lo tanto es un estimador insesgado.
Si los regresores son NO estocasticos, la demostracion es mas sencilla aun
E(β)
=E(β +aU)
=β +a ·E(U)=β
Modelo 2. [Modelo Lineal Simple (caso particular T16 ).]De 3.7 en la pagina˜15 resulta
b =∑
n(xn − x)(yn − y)∑n (xn − x)2
=∑
n yn(xn − x)∑n (xn − x)2
.
es decir,b =
∑n
mnyn, (5.1)
dondemn =
xn − x∑n (xn − x)2
.
Por tanto, b es una combinacion lineal de los datos yn (donde mn son los coeficientes de dicha combi-nacion); y entonces a tambien es combinacion lineal de los datos yn (vease 3.10 en la pagina˜15).
Por 5.1 sabemos que b|x =∑
mnYn, donde
mn =xn − x∑(xn − x)2
.
Se puede verificar que1.
∑mn = 0
2.∑
m2n = 1P
x2n
= 1P(xn−x)2 = 1
Ns2x
3.∑
mn(xn − x) =∑
mnxn = 1.Entonces,
b|x =∑
mn(a + bxn + Un)
=a∑
mn + b∑
mnxn +∑
mnUn = b +∑
mnUn
yE(
b∣∣∣ x) = b +
∑mnE(Un | x) = b.
(Novales, 1997; Gujarati, 2003, pag. 488–491 y pag. 100 respectivamente).Por otra parte, de 3.10 en la pagina˜15 sabemos que
a = y − b x =1N
∑yn − b
1N
∑xn.
Por lo tanto el estimador condicionado es
a|x =1N
∑Yn −
(b|x
) 1N
∑xn

Seccion 5: Propiedades estadısticas de los estimadores MCO 34
cuya esperanza es
E( a | x) =1N
∑E(Yn | x)− E
(b∣∣∣ x) 1
N
∑xn
=1N
∑E(Yn | x)− b
1N
∑xn
=1N
∑E(a + bxn + Un | x)− b
1N
∑xn
=1N
∑a + b
1N
∑xn +
1N
∑E(Un | x)− b
1N
∑xn
= a.
Ejercicio 36. Verifique que el estimador MCO del parametro a del Modelo 1 (constante como unicoregresor) es insesgado.
5.2. Varianza de los estimadores MCO β|x
⇑ Varianza del estimador MCO bβ| x 27
Aplicando la def. de la Ecuacion (1) tenemos:
Var(
β∣∣∣ x) =E
((β −β
)(β −β
)′ ∣∣∣∣ x)=E(
(x′ x)−1x′ U U′ x(x′ x)−1∣∣∣ x)
=(x′ x)−1x′ E(U U′ ∣∣ x)x(x′ x)−1
=σ2(x′ x)−1
Modelo 2. [Modelo Lineal Simple] Sabemos de (3.7) en la pagina˜15 que x′ x =(
NP
xnPxn
Px2
n
)cuyo
determinante esdetx′ x ≡ |x′ x| = N
∑x2
n −(∑
xn
)2 = N∑
(xn − x)2;
Por tanto la matriz de varianzas y covarianzas del estimador es:
σ2(x′ x)−1 =σ2
N∑
(xn − x)2·( ∑
x2n −
∑xn
−∑
xn N
).
Notese que ∑(xn − x)2 = N · s2
x.
Ası pues, podemos deducir que
Var( a | x) =σ2∑
x2n
N∑
(xn − x)2=
σ2x2
N · s2x
; y Var(
b∣∣∣ x) =
σ2∑(xn − x)2
=σ2
N · s2x
. (5.2)
Ademas, ambos estimadores tienen una covarianza igual a
Cov(
a, b∣∣∣ x) =
−σ2∑
xn
N∑
(xn − x)2=−σ2 · xN · s2
x
(5.3)
Ejemplo 37. [continuacion de “precio de las viviendas”:]Podemos calcular la inversa de x′ x:
(x′ x)−1 =[
9.1293e− 01 −4.4036e− 04−4.4036e− 04 2.3044e− 07
];

Seccion 5: Propiedades estadısticas de los estimadores MCO 35
ası pues, las desviaciones tıpicas de a|x y b|x son (vease 5.2 en la pagina anterior)
Dt( a | x) =√
σ2 · (9.1293e− 01) =
√σ2x2
N · s2x
Dt(
b∣∣∣ x) =
√σ2 · (2.3044e− 07) =
√σ2
N · s2x
.
Pero no conocemos σ2Un
.
Continuacion del ejemplo “precio de las viviendas” en la pagina 41
Practica 38. Observe los resultados de las estimaciones del ejemplo del “precio de las viviendas”. ¿Que es-timacion cree que es mas fiable, la de la pendiente o la de la constante? Con los datos del ejemplo del“precio de las viviendas”, repita la regresion pero con las siguientes modificaciones:
1. con todos los datos excepto los de la ultima vivienda
2. con todos los datos excepto los de las ultimas dos viviendas
3. con todos los datos excepto los de la primera y la ultima viviendas¿Confirman los resultados de estas regresiones su respuesta a la primera pregunta?ejemplo del “precio de las viviendas’ en GNU Gretl
Nota 10. Sea a[m×N]
, entonces, aplicando la definicion de la Nota 2
Var(aY) =E(aY Y′a′)− E(aY) E
(Y′a′)
=a[E(Y Y′)− E(Y) E
(Y′)]a′ sacando factores comunes
=aVar(Y)a′
Nota 11. Sean q[n×N]
y r[m×N]
matrices, y v y w vectores de orden n y m respectivamente. Entonces
E(qU +v) = E(qU) + E(v) = qE(U) + v,
yVar(qU +v) = Var(qU) = qVar(U)q′,
ademasCov(qU +v, rU +w) = Cov(qU, rU) = qCov(U,U) r′ = qVar(U) r′
Nota 12. Sean Q[n×N]
= f(X) y R[m×N]
= g(X) matrices, y v y w vectores de orden n y m respectivamente;
sea ademas X = x, por lo que q = f(x) y r = g(x). Entonces
E(QU +v | x) = E(qU | x) + E(v | x) = qE(U | x) + v,
yVar(QU +v | x) = Var(qU | x) = qVar(U | x)q′;
ademasCov(QU +v,RU +w | x) = Cov(qU, rU | x) = qVar(U | x) r′
Ejercicio 39. Denotemos (X′ X)−1X′ por A[k×N]
. Sabiendo que β = β +AU, calcule de nuevo la ex-
presion de Var(
β∣∣∣ x) empleando las propiedades de la esperanza y la varianza de vectores de las notas
anteriores.

Seccion 5: Propiedades estadısticas de los estimadores MCO 36
⇑ Eficiencia del estimador MCO bβ ˛x: Ta de Gauss-Markov 28
Con los supuestos 1 a 4,β|x eficiente entre estimadores lineales e insesgados
es decir, para cualquier estimador lineal insesgado β|x
Var(
β∣∣∣ x) ≥ Var
(β∣∣∣ x)
en sentido matriciala
Entonces se dice ELIO (BLUE en ingles).
aLa matrizhVar
“ eβ ˛x
”−Var
“ bβ ˛x
”ies definida positiva
De hecho el Ta arriba mencionado implica que
Var(
βj
∣∣∣ x) ≥ Var(
βj
∣∣∣ x) para j = 1, . . . , k.
es decir, la relacion es cierta para cada uno de los estimadores de cada uno de los parametros individuales.Teorema 5.1 (Gauss-Markov). Sea β|x el estimador MCO de β, y sea β|x otro estimador lineal e
insesgado de β; entonces bajo los supuestos 1 a 4, para cualquier v[k×1]
se verifica que Var(
v ′ β∣∣∣ x) ≥
Var(
v ′ β∣∣∣ x)
Demostracion. Puesto que β|x = fY es un estimador insesgado, E(
β∣∣∣ x) = f ·E(Y | x) = f xβ = β . Por
tanto la insesgadez implica necesariamente que fx = I . Sea g = a+ f , donde a = (x′ x)−1x′ ; entoncesgx = 0 (y por tanto g a′ = 0
[k×k]y, trasponiendo, ag′ = 0′
[k×k]). Puesto que Var(Y | x) = Var(U | x) = σ2 I
se deduce que:
Var(
β∣∣∣ x) = f Var(Y | x) f ′ = σ2
[a+g
] [a′ +g′] = σ2
[aa′ +ag′ +g a′ +g g′] = σ2(x′ x)−1︸ ︷︷ ︸
Var( cβj |x)
+σ2 g g′,
donde g g′ es semi-definida positiva.Por tanto, para cualquier vector v de orden k
Var(
v′ β
∣∣∣∣ x) =v′Var(
β∣∣∣ x)v′
=Var(
v′ β
∣∣∣∣ x)+ σ2v′ g g′ v;
que implica
Var(
v′ β
∣∣∣∣ x) ≥ Var(
v′ β
∣∣∣∣ x) .
Ejercicio 40. En particular ¿que implica el Teorema de Gauss-Markov para el caso particular de unvector v =
[0 . . . 0 1 0 . . . 0
]; es decir, con un 1 en la posicion j-esima y ceros en el resto?
5.3. Momentos de los valores ajustados y|x y de los errores e|x
Recuerde las definiciones que aparecen al final de la Subseccion 4.2.1 en la pagina˜25; y resuelva elsiguiente ejercicio:
Ejercicio 41. Denotemos x (x′ x)−1 x′ por p.Notese que
p ≡ x (x′ x)−1x′ = xa .
Verifique que px = x . Demuestre ademas que p′ = p y que pp = p; es decir, que p es simetrica eidempotente.

37
⇑ Primeros momentos de los valores ajustados por MCO 29
Denotemos x (x′ x)−1 x′ por p, entonces
y|x = x β| x =x[β +(x′ x)−1x′ U
]=xβ +x(x′ x)−1x′ U = xβ +pU T47
ası pues:E( y | x) = xβ por el Supuesto 2 T7
Var( y | x) =pVar(U | x)p′
=σ2 pp′ = σ2 p por el Supuesto 3 T9
Donde hemos empleado los resultados de la Nota 11 en la pagina˜35.
Notese que la matriz de varianzas y covarianzas es (en general) una matriz “llena” (al contrario que lamatriz identidad) por tanto los valores ajustados son autocorrelados y heterocedasticos.
Ejercicio 42. Denotemos I−x(x′ x)−1x′ por m.Notese que
m ≡ I−x(x′ x)−1x′ = I−p = I−xa .
Verifique que mx = 0, y que am = 0 . Demuestre ademas que m = m′ y que mm = m; es decir, que mes simetrica e idempotente.
⇑ Primeros momentos de los errores MCO 30
Denotemos I−x(x′ x)−1x′ por m, entonces
e|x = Y|x − y|x =[xβ +U
]− x
[β +(x′ x)−1x′ U
]=[I−x(x′ x)−1x′]U = mU T47
por tanto,E( e | x) = 0 por el Supuesto 2 T7
y
Var( e | x) =mVar(U | x)m′
=σ2 mm′ = σ2 m por Supuesto 3 T9
Notese que la matriz de varianzas y covarianzas es (en general) una matriz “llena” (al contrario que lamatriz identidad) por tanto los valores ajustados son autocorrelados y heterocedasticos.
Ejercicio 43. Demuestre que el estimador de la suma residual es SRC|x = U′ mU .
6. Distribucion de los estimadores MCO bajo la hipotesis de Normalidad
Secciones 4.1 y 4.2 de Wooldridge (2006)
Apendice E3 de Wooldridge (2006)
Nota 13. Distribucion conjunta normal implica1. distribucion queda completamente determinada por el vector de esperanzas y la matriz de varianzas
y covarianzas (lo que ya hemos calculado).
2. Correlacion cero implica independencia
3. Cualquier transformacion lineal tambien es conjuntamente normal

Seccion 6: Distribucion de los estimadores MCO bajo la hipotesis de Normalidad 38
6.1. Quinto supuesto del Modelo Clasico de Regresion Lineal
⇑ Supuesto 5: Distribucion Normal de las perturbaciones 31
Para conocer la distribucion completa necesitamos un supuesto mas sobre la distribucion conjunta de U:
U|x ∼ N(0 , σ2 I
)⇒ Y|x ∼ N
(xβ , σ2 I
)donde I es la matriz identidad.Puesto que
β|x = β +(x′ x)−1x′ U = β +AU
es funcion lineal de U, entonces β|x tiene distribucion normal multivariante.
β|x ∼ N(β , σ2(x′ x)−1
)β|x ∼ N
(β , σ2(x′ x)−1
)es decir (y si el modelo tiene termino constante)
β1
β2
...
βk
|x
∼ N
β1
β2
...
βk
, σ2
1′ 1 1′ xH2 · · · 1′ xHk
xH2′ 1 xH2
′ xH2 · · · xH2′ xHk
......
. . ....
xHk′ 1 xHk
′ xH2 · · · xHk′ xHk
−1⇑ Distribucion del estimador MCO bβ| x 32
Ası pues,βj |x ∼ N
(βj , σ2
[(x′ x)−1
]jj
)donde
[(x′ x)−1
]jj
es el elemento (j, j) de la matriz (x′ x)−1.
yβj |x − βj
Dt(
βj
∣∣∣ x) ∼ N (0 , 1)
(a partir de ahora tambien denotaremos los estadısticos condicionados, i.e., bβ| x o be| x sencillamente como bβ ybe)
Modelo 2. [Modelo Lineal Simple.] De la transparencia anterior y de 5.2 en la pagina˜34 podemosafirmar que bajo todos los supuestos del MLS
a|x ∼ N
(a ,
σ2x2
N · s2x
)y b|x ∼ N
(b ,
σ2
N · s2x
). (6.1)
⇑ Distribucion de los estimadores de valores ajustados y residuos 33
Ambos estimadores son transformaciones lineales de U ∼ N; y vistos sus primeros momentos T29 yT30 :
y|x ∼N(xβ , σ2 p
)pues y|x = xβ +pU
e|x ∼N(0 , σ2 m
)pues e|x = mU
donde p = x(x′ x)−1x′; y m = I−x(x′ x)−1x′

Seccion 6: Distribucion de los estimadores MCO bajo la hipotesis de Normalidad 39
6.2. Estimacion de la varianza residual y la matriz de covarianzas
Nota 14. Llamamos “traza” a la suma de los elementos de la diagonal de una matriz.El operador traza es un operador lineal con la siguiente propiedad: Sean a y b dos matrices cuadradas,
entoncestraza (ab) = traza (ba)
Proposicion 6.1. traza (m) = N − k;
Demostracion.
traza (m) = traza
(I
[N×N]− p
[N×N]
)puesto que m ≡ I−p
=traza (I)− traza (p) puesto que traza es lineal=N − traza (p)
y
traza (p) = traza(x(x′ x)−1x′) puesto que p ≡ x(x′ x)−1x′ = xa
=traza((x′ x)−1x′ x
)puesto que traza (xa) = traza (ax)
= traza(
I[k×k]
)= k
Por tanto traza (m) = N − k.
Proposicion 6.2. E(e ′ e
∣∣ x) = (N − k)σ2
Demostracion. En T30 vimos que e|x = mU; por tanto
E(
e ′ e
∣∣∣∣ x) =E(U ′ m′ mU
∣∣ x) = E(U ′ mU
∣∣ x) por ser m idempotente
=N∑
i=1
N∑j=1
mijE(UiUj | x) pues el operador esperanza es lineal
=N∑
i=1
miiσ2 por el supuesto 3 T9
=σ2 traza (m) = σ2(N − k) por la Nota 14 (Pag. 39) y Proposicion 6.1
Por tanto, s2be ≡ be ′ beN−k es un estimador insesgado de σ2. Consecuentemente emplearemos como estimador
de la matriz de varianzas y covarianzas la expresion (6.2) de mas abajo.
⇑ Estimacion de la varianza residual 34
El parametro σ2 es desconocido T9La cuasivarianza de e
s2be ≡ e ′ e
N − k
es un estimador insesgado de σ2 puesto que
E(
s2be∣∣∣ x) = E
(e ′ e
N − k
∣∣∣∣ x) =σ2(N − k)
N − k= σ2
Estimador de la matriz de varianzas y covarianzas de β|x
Var(β|x
)= s2be · (x′ x)−1 (6.2)
Proposicion 6.3. Si una matriz cuadrada q es idempotente entonces rango (q) = traza (q) .
Demostracion. (Demostracion en Rao, 2002, pp. 28)

Seccion 6: Distribucion de los estimadores MCO bajo la hipotesis de Normalidad 40
Proposicion 6.4. Sea el vector Z ∼ N (0 , I) , y sea q una matriz simetrica e idempotente, entoncesZ′ qZ ∼ χ2
(rango(q)).
Demostracion. (Demostracion en Mittelhammer, 1996, pp. 329)
⇑ Distribucion cuando la varianza de U es desconocida 35
βj − βj√σ2((x′ x)−1
)jj
∼ N (0 , 1)
sustituyendo σ2 por su estimador, s2be , tenemos el estadıstico T del parametro j -esimo:
βj − βj√s2be ((x′ x)−1
)jj
=βj − βj√[Var
(β)]
jj
≡ T j ∼ tN−k (6.3)
Proposicion 6.5. N−kσ2 s2be = be ′ be
σ2 ∼ χ2(N−k)
Demostracion.N − k
σ2s2be =
N − k
σ2
e ′ e
N − k=
e ′ e
σ2=
1σ
e ′ e1σ
=1σ
U′m′ mU1σ
ya que e = mU
=1σ
U′ mU1σ∼ χ2
(N−k)
puesto que m es idempotente, U|x ∼ N(0 , σ2 I
), por las proposiciones 6.3 y 6.4 y la Proposicion 6.1 en
la pagina anterior.
Ejercicio 44. Teniendo en cuenta que si una v.a. X ∼ χ2N−k entonces E(X) = N − k y Var(X) =
2(N − k), y puesto que s2be es una variable aleatoria χ2N−k multiplicada por σ2
N−k ; calcule la esperanza y
la varianza de s2beProposicion 6.6. Las variables aleatorias
(β − β
)|x y e|x son independientes.
Demostracion. Puesto que(β − β
)|x = aU y e|x = mU, ambas variables son transformaciones
lineales de U, y por tanto ambas tienen distribucion conjunta normal condicionada a x (Nota 13 en lapagina˜37)
Basta, por tanto, demostrar que ambas variables tienen covarianza nula
Cov(aU,mU | x) = aVar(U | x)m′ por el supuesto 2 y la Nota 12 (Pagina 35)
= aσ2 Im′ por el supuesto 3
= σ2 am = σ2 0 = 0
Nota 15. Si dos variables aleatorias X e Y son independientes, entonces transformaciones de ellas, h(X)y g(Y), tambien son independientes.
Proposicion 6.7. El estadıstico T j de distribuye como una t con N − k grados de libertad, es decir,T j ∼ tN−n
Demostracion.
βj − βj√s2be ((x′ x)−1
)jj
=βj − βj√
σ2((x′ x)−1
)jj
·
√√√√σ2
s2be =Z√cs2beσ2
=Z√ be ′ be /σ2
N−k

Seccion 6: Distribucion de los estimadores MCO bajo la hipotesis de Normalidad 41
donde la parte de numerador es funcion de(β −β
)|x y la del denominador es funcion de e|x. Ası pues,
por la Nota 15 en la pagina anterior y la Proposicion 6.6 en la pagina anterior el numerador y eldenominador son independientes.
Ademas, en numerador tiene distribucion N (0 , 1). Por tanto tenemos una N (0 , 1) dividida por la raızcuadrada de un χ2 dividida por sus grados de libertad; este cociente tiene distribucion t de Student conN − k grados de libertad.
Ejemplo 45. [continuacion de “precio de las viviendas”:]La inversa de x′ x es:
(x′ x)−1 =[
9.1293e− 01 −4.4036e− 04−4.4036e− 04 2.3044e− 07
];
ası pues, las desviaciones tıpicas de a y b son (vease 5.2 en la pagina˜34)
Dt(a) =√
σ2 · (9.1293e− 01) =
√σ2∑
x2n
N∑
(xn − x)2
Dt(b)
=√
σ2 · (2.3044e− 07) =
√σ2∑
(xn − x)2.
No conocemos σ2Un
; pero podemos sustituirla por la la cuasi-varianza:
Dt(a) =√
(1522.8) · (9.1293e− 01) =
√(1522.8)
∑x2
n
N∑
(xn − x)2= 37.285;
Dt(b)
=√
(1522.8) · (2.3044e− 07) =
√(1522.8)∑(xn − x)2
= 0.01873
puesto que s2be = be ′ beN−n = 18273.6
14−2 = 1522.8.
Vease los resultados de estimacion en el ejemplo del precio de las viviendas (pagina 17).
Por otra parte, Cov(a, b)
= (1522.8) ∗ (−4.4036e− 04) =−cs2be P
xn
NP
(xn−x)2 = −0.671(vease 5.3 en la pagina˜34).
6.3. Cota mınima de Cramer-Rao
⇑ Matriz de Informacion 36
Funcion de verosimilitud
`(θ;y,x) = (2πσ2)−n2 exp
[− 1
2σ2(y − xβ)′ (y − xβ)
]= f (y,x;θθθ) ;
donde θ =[
βσ2
]Matriz de Informacion para θ
I(θ) = −E(
∂2 ln `(θ;Y,X)∂ θ ∂θ′
∣∣∣∣ x)

Seccion 6: Distribucion de los estimadores MCO bajo la hipotesis de Normalidad 42
⇑ Cota mınima de Cramer-Rao 37
I(θ) =[
x′ xσ2 00′ N
2σ4
]Cota mınima es la inversa de la Matriz de Informacion
I(θ)−1 =[σ2(x′ x)−1 0
0′ 2σ4
N
]Matriz de varianzas y covarianzas de los estimadores MCO
Σbβ| x,cs2be =[σ2(x′ x)−1 0
0′ 2σ4
N−k
]
I(θ) =− E
−x′ xσ2 −
[x′ Y −x′ x β
]σ4
−[x′ Y −x′ x β
]′σ4
N2σ4 − 1
σ6
[Y−xβ
]′ [Y−xβ
] ∣∣∣∣∣∣ x
=[
x′ xσ2 00′ N
2σ4
]1. La matriz de varianzas y covarianzas Σbβ| x
alcanza la cota mınima de Cramer-Rao. Es decir es elestimador insesgado de mınima varianza (resultado mas fuerte que Ta de Gauss-Markov)
2. La varianza del estimador s2be no alcanza la cota mınima de Cramer-Rao. No obstante, no existe
ningun estimador insesgado de σ2 con varianza menor a 2σ4
N .
Ejercicio 46. Revise el ejercicio numerico no1 del profesor Jose Alberto Mauriciohttp://www.ucm.es/info/ecocuan/jam/ectr1/index.html#Material.
Ejercicio 47. Resuelva el ejercicio propuesto no 1 del profesor Jose Alberto Mauricio.http://www.ucm.es/info/ecocuan/jam/ectr1/index.html#Material.
Para los ejercicios practicos con ordenador le puede ser utilEl programa gratuito GRETL. (http://gretl.sourceforge.net/gretl_espanol.html)Tiene documentacion en castellano• Guıa del usuario• Guıa de instrucciones
Tambien puede obtener los datos del libro de texto (Wooldridge, 2006) desde http://gretl.sourceforge.net/gretl_data.html
la guia de Eviews del profesor Jose Alberto Mauricio (material extenso)(http://www.ucm.es/info/ecocuan/jam/ectr1/Ectr1-JAM-IntroEViews.pdf).
Ejercicio 48. AnscombeGNU Gretl: ejemplo Anscombe
Ejercicio 49. Replique con el ordenador la practica con ordenador propuesta por el profesor Miguel Jerezhttp://www.ucm.es/info/ecocuan/mjm/ectr1mj/.
GNU Gretl MLG peso bbs

43
7. Estimacion por maxima verosimilitud
⇑ funcion de verosimilitud vs funcion de densidad 38
Los supuestos 1, 2, 3 y 5, implican que
Y | x∼ N(xβ , σ2 I
[N×N]
)por tanto, la funcion de densidad de Y dado x es
f (y | x) = (2πσ2)−n/2 exp[− 1
2σ2(y − xβ)′ (y − xβ)
]donde los parametros
(β, σ2
)son desconocidos.
⇑ Estimacion por Maxima Verosimilitud 39
Sustituyendo el vector desconocido(β, σ2
)por un hipotetico
(β, σ2
)y tomando logsa obtenemos
funcion de verosimilitud logarıtmica
ln `(β, σ2) = −n
2ln(2π)− n
2ln(σ2)− 1
2σ2(y−xβ)′(y−xβ)
Maximizandomaxeβ,eσ2
ln `(β, σ2)
obtenemos estimaciones maximo verosımiles de(β, σ2
).
atransformacion monotona
⇑ Estimacion por Maxima Verosimilitud: derivacion 40
Cond. primer orden en maximizacion:
∂ ln `(β, σ2)
∂β′= 0 =⇒ − 1
2eσ2∂
∂ eβ′ (y−xβ)′(y−xβ) = 0
β′MV = (x′ x)−1x′ y
∂ ln `(β, σ2)∂σ2
= 0 =⇒ − n2eσ2 + 1
2eσ4 (y−xβ)′(y−xβ) = 0
σ2MV = be ′ be
N = s2be = N−kN s2be
Por tanto:la estimacion de β coincide con el MCOla estimacion de σ2 es sesgada
Ejercicio 50.(a) Calcule la esperanza de σ2
MV . ¿Es un estimador insesgado de σ2?(b) Calcule la varianza de σ2
MV
(c) Compare su resultado con la cota mınima de Cramer-Rao. Pero ¿es aplicable esta cota a este estimador?
8. Ejercicios
Ejercicio 51. Demuestre que en el modelo de regresion simple Yn = a+bXn+Un el supuesto E(Un | x) = 0implica E(Yn | x) = a + bXn; donde los regresores son no-estocasticos, y Ues la perturbacion aleatoria delmodelo.

44
Ejercicio 52. (Consta de 5 apartados)Sean los siguientes datos:
Empresa yi xi xiyi x2i
A 1 1 1 1B 3 2 6 4C 4 4 16 16D 6 4 24 16E 8 5 40 25F 9 7 63 49G 11 8 88 64H 14 9 126 81
sumas 56 40 364 256
Cuadro 4:
donde y son beneficios, y x son gastos en formacion de personal de una empresa.Ademas se sabe que las varianzas y covarianzas muestrales son tales que:
N · s2y =
∑(yi − y)2 = 132,
N · s2x =
∑(xi − x)2 = 56,
N · sx y =∑
(xi − x)(yi − y) = 84,
donde N es el tamano muestral.Suponga que se plantea el siguiente modelo
Yi = a + bxi + Ui,
donde Ui son otros factores que afectan a los beneficios distintos de sus gastos en formacion (el terminode error). Se sabe que la distribucion conjunta de dichos factores es:
U ∼ N(0, σ2 I),
donde I es una matriz identidad de orden 8, y σ2 es la varianza de Ui, cuyo valor es desconocido.(a) Estime por MCO los parametros a y b del modelo.(b) ¿Cual es el beneficio esperado para una empresa que incurriera en unos gastos de formacion de personal
de 3?(c) Calcule los residuos de la empresa E y F. ¿Que indica en este caso el signo de los residuos? La
comparacion de los residuos para estas empresas ¿contradice el hecho de que F tiene mayores beneficiosque E? Justifique su respuesta.(Los siguientes apartados solo tras haber estudiado el tema siguiente)
(d) Estime por MCO un intervalo de confianza del 95 % para el parametro b del modelo, sabiendo que lasuma de los residuos al cuadrado es 6.
(e) Contraste la hipotesis de que “la pendiente del modelo es uno” frente a que “es menor que uno” conun nivel de significacion del 10 %. ¿Cual es el p-valor de la estimacion de “dicha pendiente”?
9. Bibliografıa
Gujarati, D. N. (2003). Basic Econometrics. McGraw-Hill, cuarta ed. ISBN 0-07-112342-3. Internationaledition. 26, 33
Hayashi, F. (2000). Econometrics. Princeton University Press, Princeton, New Jersey. ISBN 0-691-01018-8.2, 3
Johnston, J. y Dinardo, J. (2001). Metodos de Econometrıa. Vicens Vives, Barcelona, Espana, primeraed. ISBN 84-316-6116-x. 25, 26
Luenberger, D. G. (1968). Optimization by vector space methods. Series in decision and control. JohnWiley & Sons, Inc., New York. 3
Mittelhammer, R. C. (1996). Mathematical Statistics for Economics and Business. Springer-Verlag, NewYork, primera ed. ISBN 0-387-94587-3. 40
Novales, A. (1993). Econometrıa. McGraw-Hill, segunda ed. 2, 12, 25, 26

45
Novales, A. (1997). Estadıstica y Econometrıa. McGraw-Hill, Madrid, primera ed. ISBN 84-481-0798-5.33
Pena, D. (2002). Regresion y diseno de experimentos. Alianza Editorial, Madrid. ISBN 84-206-8695-6. 25
Ramanathan, R. (1998). Introductory Econometrics with Applications. Harcourt College Publisher, Or-lando. 6, 16, 30
Rao, C. R. (2002). Linear Statistical Inference and Its Applications. Wiley series in probability andstatistics. John Wiley & Sons, Inc., New York, segunda ed. ISBN 0-471-21875-8. 39
Spanos, A. (1999). Probability Theory and Statistical Inference. Econometric Modeling with ObservationalData. Cambridge University Press, Cambridge, UK. ISBN 0-521-42408-9. 3
Verbeek, M. (2004). A Guide to Modern Econometrics. John Wiley & Sons, Inc., segunda ed. 2
Wooldridge, J. M. (2006). Introduccion a la econometrıa. Un enfoque moderno. Thomson Learning, Inc.,segunda ed. 2, 3, 5, 12, 21, 25, 26, 32, 37, 42
10. Trasparencias
Lista de Trasparencias
1 [Descomposicion ortogonal y causalidad]
2 [Modelo de regresion]
3 [Tipos de datos]
4 [Modelo Clasico de Regresion Lineal]
5 [Supuesto 1: linealidad]
6 [Supuesto 1: linealidad]
7 [Supuesto 2: Esperanza condicional de U– Estricta exogeneidad]
8 [Supuesto 2: Esperanza condicional de U– Estricta exogeneidad]
9 [Supuesto 3: Perturbaciones esfericas]
10 [Supuestos 2 y 3: Implicacion conjunta]
11 [Termino de error]
12 [Mınimos cuadrados ordinarios: Ecuaciones normales]
13 [Supuesto 4: Independencia lineal de los regresores]
14 [Modelo 1: No vbles explicativas]
15 [Modelo 2: Modelo Lineal Simple]
16 [Modelo 2: Modelo Lineal Simple]
17 [Modelo 2: Modelo Lineal Simple]
18 [Estimacion MCO: Interpretacion grafica]
19 [Modelo Lineal General]
20 [Mınimos cuadrados ordinarios: Propiedades algebraicas]
21 [Mınimos cuadrados ordinarios: Mas propiedades algebraicas]
22 [Sumas de cuadrados]
23 [Medidas de ajuste: Coeficiente de determinacion R2]
24 [Otras medidas de ajuste]
25 [Estimador MCO bβ| x ]
26 [Esperanza del estimador MCO bβ| x ]
27 [Varianza del estimador MCO bβ| x ]
28 [Eficiencia del estimador MCO bβ ˛x: Ta de Gauss-Markov]
29 [Primeros momentos de los valores ajustados por MCO]
30 [Primeros momentos de los errores MCO]
31 [Supuesto 5: Distribucion Normal de las perturbaciones]
32 [Distribucion del estimador MCO bβ| x ]
33 [Distribucion de los estimadores de valores ajustados y residuos]
34 [Estimacion de la varianza residual]
35 [Distribucion cuando la varianza de U es desconocida]
36 [Matriz de Informacion]
37 [Cota mınima de Cramer-Rao]
38 [funcion de verosimilitud vs funcion de densidad]
39 [Estimacion por Maxima Verosimilitud]
40 [Estimacion por Maxima Verosimilitud: derivacion]
41 [Geometrıa del Modelo lineal]
42 [Supuesto 2’: Regresores no estocasticos]

46
43 [Geometrıa del Modelo lineal: regresores no estocasticos]
44 [Estimacion de la esperanza condicional: MCO]
45 [Estimacion modelo lineal: geometrıa MCO]
46 [Modelo lineal estimado: geometrıa MCO]
47 [Geometrıa del estimador]
48 [Mınimos cuadrados ordinarios: Ecuaciones normales (Tradicional)]
A. Geometrıa del modelo clasico de regresion lineal
⇑ Geometrıa del Modelo lineal 41
X =[1, XH2
]; β =
[ab
]; Y = X β +U
Vision en 3D interactiva
⇑ Supuesto 2’: Regresores no estocasticos 42
Suponemos que realmente disponemos de una unica realizacion de X que denotamos por x.Es decir, condicionamos a que
X = x
Bajo este supuesto, se mantiene que
E(xijUn) = 0 para n, i = 1, . . . , N ; y j = 1, . . . , k.
Esto significa que, como en el caso general, los regresores son ortogonales a los terminos de perturbacionde todas las observaciones
E(xijUn) = xijE(Un) = 0 para todo i, n = 1, . . . , N ; y j = 1, . . . , k.
por lo queE(xi.Un) = xi. · E(Un) = xi. · 0 = 0
[1×k]para todo i, n = 1, . . . , N.
Y la correlacion entre los regresores y las perturbaciones es cero, ya que
Cov(Un, xij) =E(xijUn)− E(xij) E(Un)=xijE(Un)− xijE(Un) = 0
es decir, regresores no estocasticos en un caso particular del caso general: Supuesto 2 T7 (vease tambienla Seccion 2.2.2 en la pagina˜12, Pagina 12)
Seccion A: Geometrıa del modelo clasico de regresion lineal 47
⇑ Geometrıa del Modelo lineal: regresores no estocasticos 43
x =[1, xH2
]; β =
[ab
]; Y = xβ +U
Vision en 3D interactiva
A.1. Geometrıa del estimador MCO
⇑ Estimacion de la esperanza condicional: MCO 44
Tenemos realizaciones de Y y X; es decir, disponemos de
y =
y1
y2
...yN
x =
1 x1
1 x2
......
1 xN
y buscamos β =
(a
b
)tales que
y = x β + e
y e sea pequeno.
⇑ Estimacion modelo lineal: geometrıa MCO 45
1
y
X H2
e
a1
y = X β
bX H2
x =[1, xH2
]; β =
[a
b
]; y = y +e; y = xβ;
e = y− y

48
⇑ Modelo lineal estimado: geometrıa MCO 46
a1
1
y
X H2
bX H2
e
y = X β
x =[1, xH2
]; β =
[a
b
]; y = y +e; y = xβ;
e = y− y
⇑ Geometrıa del estimador 47
Vision en 3D interactiva
B. Derivacion tradicional de las Ecuaciones Normales
⇑ Mınimos cuadrados ordinarios: Ecuaciones normales (Tradicional) 48
SRC(β) = y′ y−2β′ x′ y +β′ x′ x β
Buscamos un vector β que minimice SRC
mınbβ SRC(β)
∂SRC(β)
∂ β= 0; −2x′ y +2x′ x β = 0
con lo que obtenemos las ecuaciones normales
x′ y = x′ x β (B.1)
Estimacion MCO es la solucion a dichas ecuaciones

49
SRC(β) =(y−xβ)′(y−xβ)
=(y′ − β′x′ ) (y − xβ) puesto que (xβ)′ = β′x′
=y′ y−β′x′ y−y′ x β +β′x′ xβ
=y′ y−2y′ x β +β′ x′ x β
ya que el escalar β′x′ y es igual a su traspuesta y′ xβ (por ser escalar)
Renombremos algunos terminos. . . por una parte definimos a ≡ y′ x y por otra c ≡ x′ x, entonces
SRC(β) = y′ y−2 a β + β′ c β .
Puesto que y ′ y no depende de β la diferencial de SRC(β) respecto de β es
∂SRC(β)
∂ β=− 2 a+2 c β por las propiedades de derivacion matricial
=− 2x′ y +2x′ x β sustituyendo a y c;
que igualando a cero nos da
−2x′ y +2x′ x β = 0 ⇒ x′ x β = x′ y
Las condiciones de segundo orden son:
∂SRC(β)
∂ β ∂β′= 2x′ x que es una matriz definida positiva.
C. Caso General
Sean Yn, y X∗n. ≡
[Xn2, . . . , Xnk
]con matriz de varianzas y covarianzas
Var([
Yn, X∗n.
])=[
σ2Yn
σYnX∗n.
σX∗′n.Yn
ΣX∗n.
]entonces siempre podemos encontrar unos parametros β1 y β∗ =
[β2, . . . , βk
], tales que
Yn = β1 + X∗n. β∗ +Un
donde E(Un) = 0, y Var(Un) = σYnX∗n. Σ−1
X∗n.
σX∗′n.Yn
Dichos parametros resultan serβ∗ = Σ−1
X∗n.
σX∗′n.Yn
; (C.1)(es decir, las covarianzas pre-multiplicadas por la inversa de matriz de varianzas de los regresores) y
β1 = E(Yn)− β∗′E(X∗n.) . (C.2)
Estos parametros son la solucion a las ecuaciones normales
E(X′ Y
)= E
(X′ X
)(β1
β∗
)donde la primera columna de X esta exclusivamente compuesta por unos.
Notese como los parametros a y b de la Ecuacion (3.6) en la pagina˜15 son un caso particular, dondea = β1 y b = β2.
Llamamos a β1 +X∗n. β∗ el mejor predictor lineal de Yn dado X∗′
n.; puesto que se puede demostrarque β1 y β∗ son los valores de b1 y b∗ que minimizan
E([
Yn − b1 −X∗′n. b∗
]2)En este contexto, llamamos a Un = Yn −
[β1 + X∗
n. β∗]
el error de prediccion.Podemos estimar por MCO los parametros desconocidos, β1 y β∗, sustituyendo, en las expresiones
anteriores, los momentos poblacionales por sus equivalentes muestrales (vease la Subseccion D en la paginasiguiente). Pero, puesto que aquı no estamos imponiendo las restricciones del Modelo Clasico de RegresionLineal, no podemos, siquiera, conocer la esperanza del estimador. Para ello es necesario especificar algomas sobre la relacion entre X∗
n. e Yn.

50
C.1. Modelo Clasico de Regresion Lineal General
El modelo lineal general es mas restrictivo precisamente es este sentido; puesto que supone que laesperanza condicional E(Yn | X∗
n.) sea funcion lineal de X∗n..
Bajo esta hipotesis clasica el predictor lineal de mas arriba se convierte en el mejor predictor posibleen el sentido de que
E([
Yn − E(Yn | X∗n.)]2)
≤ E([
Yn − g(X∗n.)]2)
para cualquier funcion g(·).
C.1.1. Ecuaciones normales en el Modelo Lineal General
Las matrices y vectores de las ecuaciones normales x′ y = x′ x β en el caso general (k regresores) quedandel siguiente modo
x′ x[k×k]
=
1′ 1 1′ xH2 · · · 1′ xHk
xH2′ 1 xH2
′ xH2 · · · xH2′ xHk
......
. . ....
xHk′ 1 xHk
′ xH2 · · · xHk′ xHk
donde cada elemento de la matriz x′ x es de la forma
xHi′ xHj =
(x1i x2i · · · xNi
)x1j
x2j
· · ·xNj
=∑N
n=1 xnixnj
Ademas, 1′ 1 = N y 1′ xHi =∑N
n=1 xni. Por otra parte, el vector x′ y es de la forma
x′ y[N×1]
=
xH1′ y
xH2′ y
...
xHk′ y
donde cada elemento es xHi
′ y =(x1i x2i · · · xNi
)y1
y2
· · ·yN
=∑N
n=1 xniyn
D. Una expresion alternativa de las estimaciones MCO
Si suponemos que la matriz (x′ x) es invertible, entonces se puede despejar β en las ecuaciones normalespara obtener
β = (x′ x)−1x′ y;y puesto que
(x′ x)−1x′ y = (x′ x /n)−1 x′ y /n
las estimaciones MCO se pueden escribir como
β =(S2x
)−1Sxy (D.1)
donde
S2x
=x′ xn
; y Sxy =x′ y
n;
Compare (D.1) con (C.1) y resuelva el ejercicio de mas abajo.Por ejemplo, para k = 2
S2x
=[1 xx 1
N
∑x2
n
]; y Sxy =
[y
1N
∑ynxn
]Ejercicio 53.(a) Verifique las dos igualdades anteriores(b) Empleando la expresion (D.1) obtenga las expresiones de las ecuaciones (3.9) y (3.10) de la pagina 15.

51
Soluciones a los Ejercicios
Ejercicio 7.
Var(Y) =E((
Y−E(Y))(
Y−E(Y))′)
=E(
Y Y′ − Y E(Y′)− E(Y) Y′ + E(Y) E
(Y′) ) desarollando el producto
=E(Y Y′)− E
(Y E
(Y′) )− E
(E(Y) Y′
)+ E
(E(Y) E
(Y′) )
=E(Y Y′)− E(Y) E
(Y′)− E(Y) E
(Y′)+ E(Y) E
(Y′) pues E
(Y′) es constante
=E(Y Y′)− E(Y) E
(Y′)
Ejercicio 7
Ejercicio 10. Puesto que {Ui,Xi.} es independiente de {Uj ,X1., . . . ,Xi−1., Xi+1., . . . ,XN.}; tenemosque E(Ui | xuj) = E(Ui | xi.) . Ası
E(UiUj | x) = E(E(UiUj |X Uj) · Uj | x) por Teorema esperanzas iteradas= E(E(Ui |X Uj) · Uj | x) por linealidad de la esperanza condicional= E(E(Ui |xi.) · Uj | x) por ser m.a.s.= E(Ui | xi.) E(Uj | xj.) por ser m.a.s.
Ejercicio 10
Ejercicio 12. Por la Nota 4 en la pagina˜14 sabemos que∑
n(xn − x)(yn − y) =∑
n yn(xn − x); portanto, operando ∑
n
(xn − x)(yn − y) =∑
n
yn(xn − x)
=∑
n
ynxn − x∑
n
yn
=∑
n
ynxn −Ny x
= y′ x−Ny x.
Ejercicio 12
Ejercicio 13. Por una parte, dividiendo la primera ecuacion de (3.7) por N obtenemos directamente
y = a + b x ; por lo que a = y − b x.
Por otra parte, dividiendo la segunda por N tenemos∑xnyn
N= a x + b
∑x2
n
N
o lo que es lo mismo, tenemos
x′ y
N= a x + b
x′ x
Nexpresando los sumatorios como productos escalares
=(y − b x
)x + b
x′ x
Nsustituyendo a
= x · y − b x2 + bx′ x
Noperando en el parentesis
= x · y + b(x′ x
N− x2
)sacando b factor comun
es decirx′ y
N− x · y = b
(x′ x
N− x2
)por lo que empleando (3.2) y (3.3) tenemos la segunda ecuacion sx y = b s2
x
Ejercicio 13
Ejercicio 14. Entonces el Supuesto 4 no se cumplirıa, pues x serıa conbinacion lineal del vector de unosya que x = c1 .

Soluciones a los Ejercicios 52
En tal situacion el sistema de ecuaciones normales (3.7) se reducirıa a:∑yn = a N + b
∑xn
c ·∑
yn = c · a N + c · b∑
xn
donde la segunda ecuacion es c veces la primera, por lo que realmente tenemos una sola ecuacion con dosincognitas.
Ademas, la varianza de un vector constante es cero, por lo que s2x = 0 y tambien sx y = y ′ x
N − y x =cy ′ 1
N − cy = 0; por lo que la estimacion de b esta indeterminada, ya que
b =sx y
s2x
=00.
Ejercicio 14
Ejercicio 16(a) ∑x1nyn =a
∑x1
2n + b
∑x1nx2n + c
∑x1nx3n∑
x2nyn =a∑
x2nx1n + b∑
x22n + c
∑x2nx3n∑
x3nyn =a∑
x3nx1n + b∑
x3nx2n + c∑
x32n
�
Ejercicio 16(b) ∑yn =aN + b
∑x2n + c
∑x3n∑
x2nyn =a∑
x2n + b∑
x22n + c
∑x2nx3n∑
x3nyn =a∑
x3n + b∑
x3nx2n + c∑
x32n
�
Ejercicio 17. Dividiendo la primera ecuacion del sistema anterior por N obtenemos
y = a + b · x2 + c · x3
esta ecuacion indica que el plano de regresion para por el punto de los valores medios de las variables delsistema.
Despejando a tenemosa = y − b · x2 − c · x3
que se puede sustituir en las otras dos ecuaciones del sistema:∑x2nyn =
(y − bx2 − cx3
)∑x2n + b
∑x2
2n + c
∑x2nx3n∑
x3nyn =(y − bx2 − cx3
)∑x3n + b
∑x3nx2n + c
∑x3
2n;
operando ∑x2nyn =y
∑x2n − bx2
∑x2n − cx3
∑x2n + b
∑x2
2n + c
∑x2nx3n∑
x3nyn =y∑
x3n − bx2
∑x3n − cx3
∑x3n + b
∑x3nx2n + c
∑x3
2n;
puesto que∑
x2n = Nx2 y∑
x3n = Nx3, sustituyendo∑x2nyn =Ny · x2 −Nb · x2 · x2 −Nc · x3 · x2 + b
∑x2
2n + c
∑x2nx3n∑
x3nyn =Ny · x3 −Nb · x2 · x3 −Nc · x3 · x3 + b∑
x3nx2n + c∑
x32n;
sustituyendo los sumatorios que restan por productos escalares:
x2′ y =Ny · x2 −Nb · x2 · x2 −Nc · x3 · x2 + b · x2
′ x2 +c · x2′ x3
x3′ y =Ny · x3 −Nb · x2 · x3 −Nc · x3 · x3 + b · x3
′ x2 +c · x3′ x3;

Soluciones a los Ejercicios 53
reordenando terminos:
x2′ y−Ny · x2 =b ·
(x2
′ x2−Nx22)
+ c ·(x2
′ x3−Nx3 · x2
)x3
′ y−Ny · x3 =b ·(x3
′ x2−Nx2 · x3
)+ c ·
(x3
′ x3−Nx32);
y teniendo en cuenta las notas 4 a 6 en la pagina˜14
Nsx2 y =b ·Ns2x2
+ c ·Nsx2 x3
Nsx3 y =b ·Nsx2 x3 + c ·Ns2x3
;
o bien; ∑n
yn(x2n − x2) =b ·∑
n
x2n(x2n − x2) + c ·∑
n
x3n(x2n − x2)∑n
yn(x3n − x3) =b ·∑
n
x3n(x2n − x2) + c ·∑
n
x3n(x3n − x3);
por tanto, resolviendo el sistema, obtenemos los dos ultimos resultados
b =sx2 y · s2
x3− sx3 y · sx2 x3
s2x2· s2
x3−(sx2 x3
)2c =
sx3 y · s2x2− sx2 y · sx2 x3
s2x2· s2
x3−(sx2 x3
)2Ejercicio 17
Ejercicio 18. Con la estimacion de la pendiente en el modelo Yn = a + cX3n + Un
Ejercicio 18
Ejercicio 19. Un coeficiente de correlacion muestral con valor absoluto igual a uno significa que hay unadependencia lineal entre los regresores, por lo que el Supuesto 4 deja de cumplirse; y por tanto el sistemade ecuaciones normales tiene infinitas soluciones.
En tal caso las expresiones (3.11), (3.12) y (3.13) dejan de estar definidas ya que, en este caso
|ρx2x3| =
∣∣∣∣∣ sx2 x3√s2
x2s2
x3
∣∣∣∣∣ = 1,
lo que implica que |sx2 x3 | =∣∣√s2
x2s2
x3
∣∣ y por tanto s2x2· s2
x3=(sx2 x3
)2; y los denominadores de de lasexpresiones (3.12) y (3.13) son cero.
Ejercicio 19
Ejercicio 20. Los valores estimados en los modelos restringidos y sin restringir difieren. Por lo tanto,podemos afirmar que la covarianza muestral entre los regresores Sn y Dn en esta simulacion es distinta decero.
Ejercicio 20
Ejercicio 22. La primera es inmediata. La segundad tambien lo es por la Nota 6 en la pagina˜14. Latercera en un poco mas complicada (pero no mucho):Pista. Transforme el producto escalar en un sumatorio. Opere dentro del sumatorio y tenga en cuentaque las medias muestrales son constantes que se pueden sacar fuera de los sumatorios como un “factorcomun”.
Ejercicio 22
Ejercicio 23.Pista.
y = y− ey ′ e = 0
Ejercicio 23
Ejercicio 24.(abc)′ = ((ab) c)′ = c′ (ab)′ = c′ b′ a′ .
Ejercicio 24

Soluciones a los Ejercicios 54
Ejercicio 25. Por la Nota 8 en la pagina˜24 sabemos que
p′ =[(x(x′ x)−1)x′]T = x
(x(x′ x)−1
)T= x(x′ x)−1x′ = p
y entonces
p′ m =p(I−p) = p−pp
=p−x(x′ x)−1x′ x(x′ x)−1︸ ︷︷ ︸I
x′
=p−x(x′ x)−1x′ = p−p = 0
Ejercicio 25
Ejercicio 26.1.
m′ =[I−p
]′ = I′−p′ = I−p = m
2.mm′ mm = mm =
[I−p
] [I−p
]= I−p−p+pp = I−p−p+p = I−p = m
Ejercicio 26
Ejercicio 32.Pista. Calcule el coeficiente de correlacion lineal simple entre y y y y elevelo al cuadrado.
Solucion numerica en el recuadro del ejemplo del precio de las viviendas (pagina 17).Ejercicio 32
Ejercicio 33. Por una parte, SEC =∑
(yn − y)2; pero en este modelo los valores ajustados son constantesiguales a la media muestral de y, es decir yn = y. Por tanto SEC = 0.
Por otra parte, este modelo tiene termino cte. y, entonces, R2 = SECSTC = 0.
Es decir, un modelo que consiste unicamente en un constante, no tiene ninguna capacidad de “explicar”las variaciones de la variable dependiente.
Otra forma de verlo es la siguiente. En este modelo sabemos que yn = y. Ası que
SEC =∑
(yn − y)2 = y′ y +Ny2 − 2Nyy por T22
= y′ y−Ny2
pues en este caso y = y
=y · 1′ y −Ny2
pues y es un vector de constantes y
=Ny2 −Ny
2pues en este caso y = y
Ejercicio 33
Ejercicio 34. En este casob =
sx y
s2x
y a = y − xb,
por tantoyn = a + bxn = y + b(xn − x); ⇒ yn − y = b(xn − x).
EntoncesSEC =
∑(yn − y)2 = b2
∑(xn − x)2
y consiguientemente (por tener un termino constante el Modelo Lineal General)
R2 =SEC
STC=
b2∑
(xn − x)2∑(yn − y)2
=
(sx y
)2(s2
x
)2 · Ns2x
Ns2y
=
(sx y
)2s2
xs2y
= r2y x
Ejercicio 34
Ejercicio 39.
Var(
β∣∣∣ x) =Var
(β −β
∣∣∣ x) ya que β es cte.
=Var(AU | x) ya que β = β +AU
=E(AU U′A′ ∣∣ x) pues E(AU | x) = 0
=aVar(U | x)a′ pues a cte. si X = x
=aσ2 I a′ por los supuestos 2 y 3 T10
=σ2 aa′ = σ2(x′ x)−1

Soluciones a los Ejercicios 55
puesto que aa′ = (x′ x)−1x′ x(x′ x)−1 = (x′ x)−1.Si los regresores son NO estocasticos: denotemos (x′ x)−1x′ por a
[k×N]
Var(β)
=Var(β −β
)ya que β es cte.
=Var(aU) ya que β = β +aU
=aVar(U)a′ ya que a es una matriz cte.
=aσ2 I a′ por los supuestos 2 y 3
=σ2 aa′
=σ2(x′ x)−1
Ejercicio 39
Ejercicio 40. En este caso seleccionamos la componente j-esima del vector β , por tanto
Var(
v′ β
∣∣∣∣ x) = Var(
βj
∣∣∣ x) ≥ Var(
βj
∣∣∣ x) = Var(
v′ β
∣∣∣∣ x) .
Es decir, el teorema de Gauss-Markov implica que la varianza del estimador de cada parametro j-esimoVar
(βj
∣∣∣ x) es mayor o igual que la del estimador MCO Var(
βj
∣∣∣ x).Ejercicio 40
Ejercicio 41.1. px = x (x′ x)−1x′ x︸ ︷︷ ︸
I
= x
2.
p′ =[x(x′ x)−1x′]′
=[(x′ x)−1x′]′ x′ pues
[xa]′ = a′ x′
=x[(x′ x)−1
]′x′ identica regla de trasposicion sobre el corchete
=x(x′ x)−1x′ = p pues (x′ x)−1 es simetrica
3.
pp =pxa
=xa = p pues px = x
Ejercicio 41
Ejercicio 42.1.
mx =[I−p
]x = x−px = x−x = 0
2.am = a
[I−p
]= a−(x′ x)−1x′ x (x′ x)−1x′ = a−a = 0
3.m′ =
[I−p
]′ = I′−p′ = I−p = m
4.mm =
[I−p
] [I−p
]= I−p−p+pp = I−p−p+p = I−p = m
Ejercicio 42
Ejercicio 43.SRC|x = e| x
′ e| x = U′m′ mU = U mU
por ser m simetrica e idempotente.Ejercicio 43
Ejercicio 44.
E(
s2be∣∣∣x) =
σ2
N − k· (N − k) = σ2 y Var
(s2be∣∣∣x) =
(σ2
N − k
)2
· 2(N −K) = 2σ4
(N − k).
Ejercicio 44

Soluciones a los Ejercicios 56
Ejercicio 50(a)
E(σ2
MV
∣∣x) = E(
s2be∣∣∣x) =
(σ2
N
)· (N −K) =
(N − k)σ2
(N).
�
Ejercicio 50(b)
Var(σ2
MV
∣∣x) = Var(
s2be∣∣∣x) =
(σ2
N
)2
· 2(N −K) =2σ4
(N).
�
Ejercicio 50(c) La varianza coincide con la cota mınima, pero esto no quiere decir nada; esta cota soloes aplicable a estimadores insesgados, y este estimador es sesgado.
�
Ejercicio 51. Ya que
E(Yn | x) =E(a + bXn + Un | x)=a + bXn + E(Un | x) pues a, b, y Xn son ctes=a + bXn por el supuesto: E(Un | x) = 0
Ejercicio 51
Ejercicio 52(a)1. Por una parte:
b =sx y
s2x
=8456
= 1.5
por otra, las medias muestrales son
x =∑
xi
8=
408
= 5; y =∑
yi
8=
568
= 7;
por lo quea = y − b · x = 7− 1.5 · 5 = −0.5.
�
Ejercicio 52(b) Segun el modelo estimado, una empresa que incurra en unos gastos de 3 deberıa tenerunos beneficios de
y = a + bx = −0.5 + 1.5 · 3 = 4�
Ejercicio 52(c) Los residuos de la empresa E seran:
yE − yE = yE −(a + bxE
)= 8−
(− 0.5 + 1.5 · 5) = 8− 7 = 1
y los de la empresa F:
yF − yF = yF −(a + bxF
)= 9−
(− 0.5 + 1.5 · 7) = 9− 10 = −1.
Puesto quey = E(Y | xf.) ,
un signo positivo para el residuo de cierta empresa significa que esta ha logrado unos beneficios mayoresque los esperados (dado su nivel de gasto en formacion de personal, x). Por el contrario, un residuo negativosignifica que la empresa ha obtenido unos beneficios menores de los esperados por el modelo (dado su gastoen formacion).
La comparacion entre empresas con distinta inversion en formacion no es apropiada para valorar losdatos sobre beneficios (solo lo es entre empresas con mismo nivel de gasto en formacion). La empresaF tiene mayores beneficios que los de E, pero, dado su nivel de gasto en formacion (7), estos beneficiosdeberıan haber sido aun mayores (el valor esperado es 10).
�
Ejercicio 52(d) El estimador MCO se distribuye Normal con esperanza igual al verdadero valor de losparametros estimados, y varianza desconocida.

Soluciones a los Ejercicios 57
Buscamos los valores A y B tales que
P
A ≤ bb−bs cs2beP
(xi−x)2
≤ B
= (1− α)
Donde bb−bs cs2beP
(xi−x)2
se distribuye como una t de Student con N − 2 grados de libertad; por tanto A y
B son los valores que aparecen en las tablas, y que determinan un intervalo centrado en cero con unaprobabilidad asociada del 95 %; es decir, A = −2.447, y B = 2.447, y s2be = 6/(N − 2) = 1. Ası pues,la estimacion del intervalo de confianza de parametro desconocido b es
ICb0.95(w) =
[1.5± 2.447 ·
√1/56
]�
Ejercicio 52(e) Las hipotesis son:
H0 : b = 1H1 : b < 1
La region critica de una sola cola es
RC =
x
∣∣∣∣∣∣∣∣b − 1√ cs2beP
(xi−x)2
< k
,
donde k es el valor de la tablas para una t de Student de seis grados de libertad, ya que el estadıstico de laparte izquierda de la desigualdad tiene dicha distribucion. Para α = 0.1, tenemos que k = t6, 0.1 = −1.44.Sustituyendo tenemos que
1.5− 1√1/56
= 3.74 > k = t6,0.1 = −1.44
por lo que no rechazamos H0.El p-valor es la probabilidad de
P(
b ≤ 1.5∣∣∣ H0
)=P
b − b√ cs2beP(xi−x)2
≤ 1.5− b√ cs2beP(xi−x)2
∣∣∣∣∣∣∣∣ H0
=P
(W ≤ 1.5− 1√
1/56= 3.74
)' 0.999
donde W se distribuye como una t de Student con seis grados de libertad.�