unidad2 espiralapers
TRANSCRIPT

UNIDAD 2: Tercera década de la web y aplicaciones en educación,
Educación como servicio.
2.1 Herramientas de la web semántica
2.1.1: Herramientas semánticas de recomendación contextual:
2.1.2: Redes sociales
2.1.3: Buscadores:
2.2 Linked data web: Aplicaciones en educación.
2.2.1 Explorador de datos públicos de Google, Google Charts.
2.2.2 Iniciativas gubernamentales entre la web participativa y la Semweb: Show us a better way
2.3 Web contextual, Personalización, Educación como Servicio.
2.3.1 Educación como servicio y Entornos Personalizados de Aprendizaje.
Dolors Reig Hernández, Consultora y Profesora (UOC, URL, Organizaciones), experta en
tendencias TIC, Comunidades, Social Media.

2. 1 Herramientas de la web semántica:
2.1.1 Herramientas semánticas de recomendación contextual
Hemos visto la aplicación de lenguajes semánticos a las recomendaciones contextuales al
hablar de publicidad. Veámos ahora otras herramientas útiles en educación y que nos
ayudarán a entender los conceptos vistos en la Unidad 1:
2.1.1.1: Evri
Evri, que recientemente adquiría Twine (la primera red social semántica, hoy
desaparecida), está entre los entornos más potentes de análisis y recomendación
contextual - automatizada de contenidos.
Evri supone un nuevo acercamiento a la web semántica, en el ámbito de las búsquedas y
el blogging. Su slogan, “Search less, understand more” (busca menos, entiende más),
intenta definir lo que puede ofrecernos, tanto si somos creadores de contenidos para la
web como si queremos realizar búsquedas avanzadas de información.
¿Qué hace?
Evri crea un mapa de conexiones entre personas, lugares y cosas (que reconoce
mediante los marcadores semánticos explicados) en la web.
Sobre este mapa podremos encontrar las cosas en las que estamos interesados.
En lugar de buscar a partir de keywords y resultados relevantes, Evri nos llevará a
artículos, imágenes y vídeos relevantes basados en nuestras lecturas.
¿De dónde extrae la información?
Evri busca en la WWW y recopila contenido de tantos sitios como puede. Su base de
datos crece día a día y aumenta exponencialmente su importancia a partir de la compra
de Twine.
Quizás lo más atractivo no sean sus búsquedas sinó los widgets para blogs y otros
sistemas de publicación de contenidos. Al estilo de Sphere related content (una
herramienta similar) y si lo instalamos en nuestros espacios, despliega una ventana (pop-
up) sobre contenidos relacionados con el artículo o página en cuestión como la que
podéis ver en la siguiente imagen:

2.1.1.2 Calais, Zemanta:
Tenéis en el gráfico otras herramientas de la web semántica con funciones similares:
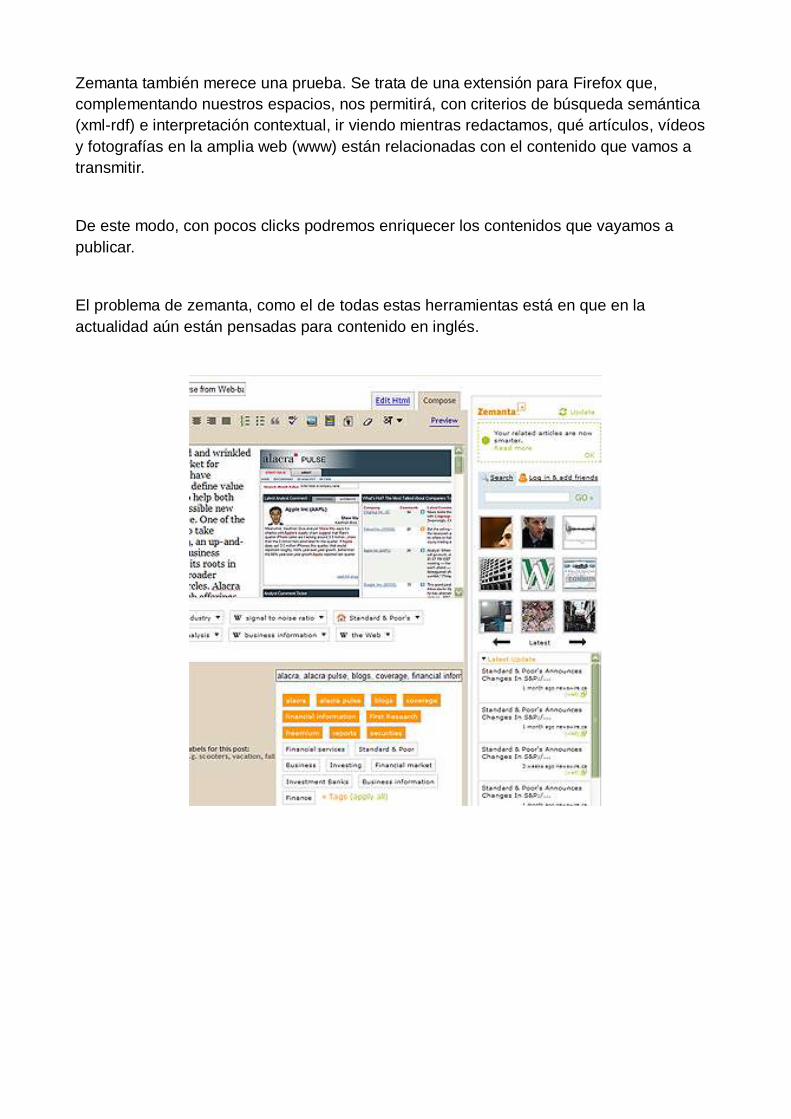
Zemanta también merece una prueba. Se trata de una extensión para Firefox que,
complementando nuestros espacios, nos permitirá, con criterios de búsqueda semántica
(xml-rdf) e interpretación contextual, ir viendo mientras redactamos, qué artículos, vídeos
y fotografías en la amplia web (www) están relacionadas con el contenido que vamos a
transmitir.
De este modo, con pocos clicks podremos enriquecer los contenidos que vayamos a
publicar.
El problema de zemanta, como el de todas estas herramientas está en que en la
actualidad aún están pensadas para contenido en inglés.

2.1.1.3 Ubiquity:
Ubiquity también es una extensión de Firefox, destinada a formar parte esencial del
navegador en un futuro y que ofrece tecnología contextual (semántica) mediante texto
(lo que ellos denominan “verbos”) en una línea de comando.
Estos serían sus fundamentos:
Las aplicaciones web, como muchas de las de escritorio, parecen en ocasiones
ciudades aisladas, sin demasiados puentes o posibilidades para el intercambio de
información.
Cada vez son más esos puentes. Así, podemos con Ubiquity, mediante textos
simples, desde añadir eventos de forma simple a Google Calendar, hasta añadir
marcadores a Twine / Evri, Ping-fm, convertir selecciones a pdf, rtf o html, pasando
por definir, traducir, localizar en Google Maps, convertir enlaces a tinyURLs, etc…
Comentar para terminar que es muy probable, como decíamos, que en este caso, la
extensión forme parte de la próxima versión de Firefox.
2.1.2: Redes sociales: GNOSS:

Gnoss es, desaparecido Twine, una de las pocas redes sociales semánticas existentes en
la actualidad.
Se definen, mejor, como red de intereses profesionales, red vertical, en este artículo
publicado en El País:
“Para ligar, Meetic; para el chismorreo con los amigos, Facebook; para la profesión,
Linkedin; para mis excursiones Wikiloc... Cada red social ha acabado por especializarse
en una actividad, incluso por profesiones, de tal forma que, por ejemplo, en España los
internautas pertenecen a más de dos redes sociales de media, con el consiguiente lío de
mensajes, actualizaciones y perfiles. Gnoss quiere acabar con esa esquizofrenia y aspira
a ser la red social para profesionales.
El profesional, la empresa o la organización disponen en Gnoss de un espacio propio para
sus recursos, herramientas para la creación y almacenamiento de blogs, búsqueda de
personas y documentos y acceso a otras comunidades de interés.
2. 1. 3 Los buscadores están entre las herramientas más conocidas:
Me gusta pensar la web semántica como el esperanto de la red, que hace comprensibles los
contenidos, independientemente de su posición en Google o la plataforma en
que estén construidos.
Los buscadores que veremos a continuación consiguen este efecto, al aplicar coherencia y
naturalización a los resultados. Hemos visto algún ejemplo en la primera Unidad pero no
queríamos dejar de recomendar otras opciones útiles en educación:
Dbpedia, motor de búsqueda auxiliar a Wikipedia, por ejemplo, es capaz de responder a
preguntas como esta: “Jugadores de futbol que llevan el número 11, juegan en un equipo
con un estadio de más de 40000 espectadores y han nacido en un país con más de 10
millones de habitante” ofreciendo el siguiente resultado:

2.1.3.1 CLUZZ ofrece ventajas a la hora de representar los resultados de forma
gráfica:
Cluuz (http://www.cluuz.com) es un buscador de nueva generación que integra, además
de resultados, la visualización gráfica de relaciones entre ellos. Para un determinado
término, extrae elementos de importancia y los apila en forma de gráfica (gráfico
semántico).
Ofrece distintas opciones de búsqueda, desde resultados textuales, gráficos, listas en
flash, pilas de datos, etc…, generando en todos los casos enlaces activos.
Se trata, en realidad, de un metabuscador, que integra búsquedas en los siguientes
servicios: Yahoo Search Web Service, Microsoft Live Search, Alexa Web Search,
Technorati Search API.
Merece la pena dedicarle una revisión. Para un determinado término, persona, blog o lo
que queráis imaginar o explorar, el gráfico que devuelve es extremadamente fiel a la
realidad.
Al estilo de los mapas conceptuales y para saber, por ejemplo, de qué hablamos en El
caparazón, Cluuz extrae información de todos los enlaces y devuelve el gráfico que os
dejo en esta captura de pantalla:

2.1.3.2 Wolfram Alpha.
Sin cumplir con los estándares semánticos pero sí mediante algoritmos derivados de
inteligencia artificial, Wolfram Alpha, una herramienta de autor con un equipo y años de
trabajo, se presentaba en su momento como el nuevo “Google Killer” .
Más allá de esta presentación, excesivamente comercial, lo que sí es cierto acerca de
Wolfram Alpha es que:
-No es un buscador general.
-No compite con Google en su punto fuerte fundamental: la sencillez de uso. En este caso
requiere de un proceso de aprendizaje importante.
-Resulta un motor de conocimiento computacional muy adecuado para datos de tipo
enciclopédico.
Sus creadores nos dejan algunos consejos útiles para obtener resultados:

Probar distintas formas de decir lo mismo, incluso distintas combinaciones de
mayúsculas-minúsculas pueden marcar la diferencia.
Probar con búsquedas que puedan estar en ámbitos conceptuales cerrados (altura
de una montaña, fórmulas químicas, estadísticas de población, planetas, etc…) .
Probar combinación de dos búsquedas. Funciona muy bien en eso.
Trabaja bien con problemas matemáticos, comidas, medicamentos, etc…
Vale la pena probarlo en educación y creo que puede ser bastante útil, tanto en
investigación como en enseñanza. Probad los cómputos, problemas predefinidos que
ellos mismos proponen en la sección de Ejemplos.
Un experimento curioso consiste en preguntarle nuestra edad. Tengo 13720 días. Qué
mayor estoy….;)

2.1.3.3: Retrievr, buscador de imágenes.
Retrievr es un experimento curioso de inteligencia artificial que juega con las imágenes y
las formas que nosotros queramos para ofrecernos resultados de flickr inspirados en ellas.
Podemos determinar como criterios de búsqueda formas, colores, etc…
Pulsando “Retrievr Search” aparecerán imágenes de flickr que tengan una composición
similar. Con imaginación se puede atinar bastante y encontrar imágenes que sólo
teníamos pensadas conceptualmente, lo cual no deja de ser incluso útil para algunas
pequeñas tareas de diseño.
2.2 Linked data web: Aplicaciones en educación.
Hablábamos en la primera unidad de la Web de los datos enlazados. Estados Unidos, UK
se unían recientemente al proyecto de Reutilización de datos gubernamentales, públicos.

En España, País Vasco, Asturias o Cataluña también apuestan por la apertura de APIs a
disposición del público general para operar, crear aplicaciones o Mashups con los datos
estructurados de la Linked Data Web.
Todo ello tiene aplicaciones, especialmente en cuanto al desarrollo del conocimiento libre
mediante la creación de “Mashups” diversos (ampliaremos este concepto en la Unidad 4)
2.2.1: Explorador de datos públicos de Google, Google Charts:
Muestra de sus posibles aplicaciones son también, tanto el Explorador de datos
públicos de Google, abierto últimamente a todo el que quiera explorarlo o utilizar su API
para crear nuevas aplicaciones como Google Charts, aplicación que permitirá crear
interesantes gráficos a partir de los datos abiertos.
Podemos ahora, como vemos en el ejemplo, embeber gráficos, tablas y otras
herramientas de representación visual en nuestros sitios. Su carácter dinámico hará que
si los datos se actualizan, también lo haga el gráfico.
Datos metereológicos, de estadística oficial, de turismo, accidentes de tráfico, pasajeros
de aviación, agricultura, resultados escolares, etc… son indexados desde hace un año por
Google y pueden formar parte ahora de su explorador de datos públicos.
Lo que hay en este momento (inicios 2010) son 13 datasets (bases de datos, conjuntos)
disponibles, desde las estadísticas de educación en California a indicadores de desarrollo
en el mundo desde el World Bank. También los datos públicos del U.S. Center for Disease
Control (recordemos las Flu Trends, la evolución de la enfermedad que nos ofrecía
Google), el U.S. Bureau of Economic Analysis, Eurostat, la Organización para la
cooperación económica y el desarrollo y el departamento de educación de California.
El propósito de la nueva herramienta es hacer de los grandes datasets más o menos
estructurados, entornos de fácil exploración, visualización y comunicación.
El tema puede ser útil para pequeñas organizaciones sin recursos para crear sistemas
más complejos pero que tienen la necesidad de visualizar distintos datos y tendencias.
Puede ser una buena herramienta, en este sentido (como Youtube direct), para pequeñas
empresas periodísticas que quieran competir con los grandes medios. También, por
supuesto, puede significar la posibilidad de distintas investigaciones independientes.

4 opciones de visualización, selección de criterios y variables dinámica son algunas de las
cosas que podéis testear. El siguiente gráfico dinámico refleja, por ejemplo, la evolución
de los datos de desempleo en Europa:
2.2.2.: Iniciativas gubernamentales entre la web participativa y la Semweb: Show us
a better way
Otro ejemplo de aplicación de la Linked Data Web a los nuevos enfoques Experimentales
sobre el Aprendizaje (que veremos en la Unidad 4) es la iniciativa “Show us a better way”
(Muéstranos una forma mejor –de hacer las cosas-)
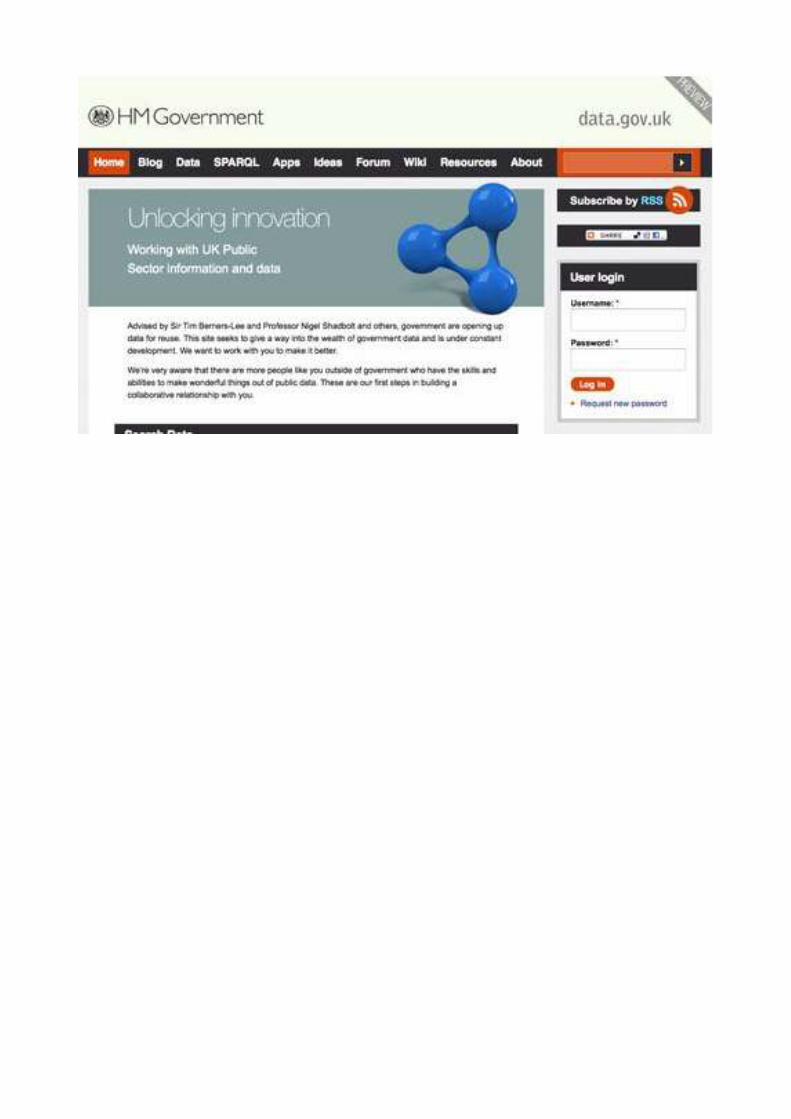
El gobierno de UK ha sido pionero en innovación basada en el análisis de datos públicos
abiertos. Esponsorizaba incluso, hace poco , ejemplificando la combinación de web social
(participativa) y semántica, un concurso: Show Us a Better Way que premia las mejores
ideas para mashups que serían creados si se tuviera acceso a los datos gubernamentales
que también allí se determinan. Tenéis su portada en la imagen:

2.3 Web contextual, Personalización, “Content Curation”, Educación como Servicio:
Hemos hablado de web semántica como de uno de los caminos hacia una futura web más
organizada. Las herramientas semánticas son solo una de las derivaciones de la web
contextual, esa que personalizará la experiencia del usuario en la web. El futuro de la web
está, hemos dicho en otras ocasiones, en esa personalización.
.
Puede ayudarnos a entener la importancia del aspecto social, la batalla por el dominio
del grafo social, de nuestro árbol de relaciones, por parte de Facebook, Google, etc...
Como veremos en apartados posteriores, buscamos, cada vez más entre nuestros
pares, consejo tanto acerca de lo que debemos aprender como sobre lo que debemos
comprar.
El término “Social Media” o la emergencia de lo social como fuente de información
que viene a completar o sustituir el monopolio informativo de los medios tradicionales
(periódicos, televisión), como vemos en la imagen siguiente, va en el mismo sentido.

2.3.1 Web semàntica, Web contextual, Educación como servicio y Entornos
Personalizados de Aprendizaje:
La idea es, a partir de una web más inteligente, capaz de aplicar criterios de los
distintos contextos para personalizar la experiencia educativa, llegar a una educación
permanente, “curada” desde la web. Dicho de otro modo, la Educación puede resultar,
también, un nuevo servicio web.
Veremos en la tercera Unidad esta importante característica de la web futura, que
viene imponiéndose desde hace un tiempo y destacaba O´Reilly, hace pocos días
(2010): la tendencia de los servicios “en la nube” a imponerse a las aplicaciones
tradicionales.

Imagen propia: Podemos entender los distintos contextos hasta crear Entornos Personalizados de
Aprendizaje como diques al mar de conocimiento que fluye constantemente en la web.

Fuentes Biblio – Web gráficas:
-ABC, redacción (2010): “Content Curators, los nuevos brokers del conocimiento”, en
Diario ABC, Sección Medios y Redes: http://www.abc.es/20100112/medios-redes-
web/nuevo-intermediariomedios-201001121104.html, Recuperado, 12 de marzo de 2010.
-Berners Lee, Tim (2009): Putting Government Data online
http://www.w3.org/DesignIssues/GovData Recuperado 12/1/2010 Recuperado 12/1/2010
-O´Reilly, T. (2010) The State of the Internet Operating System,
http://radar.oreilly.com/2010/03/state-of-internet-operating-system.html Recuperado 16 de
mayo 2010.
-Reig Hernández, D. (2009). Valores generativos y excelencia en Aprendizaje. Congreso
para la Cibersociedad: http://www.cibersociedad.net/congres2009/es/coms/nuevos-
modelos-deexcelencia-y-negocio-en-elearning-en-la-epoca-de-la-freenomics-en-
educacio/408/. Recuperado, 12 de marzo de 2010.
-Reig Hernández, D. (2010): Entornos Personales / Profesionales de Aprendizaje para
Organizaciones. El caso del programa Compartim. Comunicación – Ponencia –
Comunicación presentada al Congreso Internacional EDO 2010: ”Nuevas estrategias
formativas para las Organizaciones”. Barcelona.
-Reig Hernández, D. (2010): Un mundo de medios sin fin. Cambios en aprendizaje,
Facebook y la apoteosis de las aplicaciones expresivas. En Piscitelli et al. El Proyecto
Facebook y la posuniversidad. Sistemas operativos sociales y entornos abiertos de
aprendizaje. Fundación telefónica 2010, Buenos Aires.
-Reig Hernández, Dolors (2009): http://www.dreig.eu/caparazon/2009/07/12/web-
semantica-linked-data-web-ultimos-conceptos-tendencias-y-aplicaciones Recuperado
12/1/2010
-Reig Hernández, Dolors (2009): Seminario – Taller web 3.0 – Semántica Virtual Educa
Buenos Aires, 2009. http://www.slideshare.net/dreig/seminariotaller-web-30 Recuperado
12/1/2010
-Reig Hernández, Dolors (2009): Vídeos para entender la web 3.0
http://www.dreig.eu/caparazon/2009/04/12/4-videos-imprescindibles-para-entender-la-
web-30/ Recuperado 12/1/2010
-Varios autores, Fundación Telefónica. (2009). Informe Sociedad de la Información 2009.
http://elibros.fundacion.telefonica.com/sie09/ Recuperado, 12 de marzo de 2010.