una propuesta de mejora del algoritmo de optimización de
TRANSCRIPT

Universidad Central “Marta Abreu” de Las Villas
Facultad de Matemática, Física y Computación
Una propuesta de mejora del algoritmo de optimización
de consultas de PostgreSQL
Tesis en opción al título de Licenciado en Ciencia de la Computación
Autor: José Ramón Correa Rodríguez
Tutores: Dr. C. Carlos E. García González
Lic. Laura Pérez Triana
Santa Clara, 2013

Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central
“Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de
Ingeniería en Automática, autorizando a que el mismo sea utilizado por la Institución, para
los fines que estime conveniente, tanto de forma parcial como total y que además no podrá
ser presentado en eventos, ni publicados sin autorización de la Universidad.
Firma del Autor
Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo
de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un
trabajo de esta envergadura referido a la temática señalada.
Firma del Tutor Firma del Jefe del Laboratorio

Dedicatoria
DEDICATORIA
A mi familia, muy especialmente a mi mamá por su dedicación y por ser el motivo
del compromiso con mi carrera.
A mi amigo, compañero y esposo, por ser además mi profesor más exigente.
A todos mis amigos.

Agradecimientos
AGRADECIMIENTOS
A:
A mi mamá y mi papá, por su apoyo incondicional
A toda mi familia y amigo, pues todos de alguna forma posibilitaron la obtención de
esta tesis
A Laura , por su importante participación en el desarrollo de esta tesis
A mi tutor, por sus consejos y apoyo para la obtención de la tesis
A todos mis profesores, que ayudaron en mi formación durante los cinco años de la
carrera.

Resumen
RESUMEN
Obtener gradualmente la independencia tecnológica con respecto al uso del software en
nuestro país forma parte de la política de desarrollo del estado cubano, y en este sentido un
número creciente de instituciones y empresas han ido migrando sus entornos operativos y
aplicaciones hacia el software libre, y en los proyectos de desarrollo de software se utilizan
tecnologías y herramientas amparadas en las libertades que proporciona el software libre.
En esta investigación se da un primer paso hacia la obtención de un Sistema de Gestión de
Bases de Datos cubano, tomando como base al Sistema de Gestión de Bases de Datos
Objeto Relacional PostgreSQL, disponible bajo la licencia BSD.
En esta tesis se alcanzan dos resultados fundamentales: 1) se logra comprender cómo
funciona internamente el algoritmo genético utilizado por PostgreSQL para la optimización
de consultas que utilizan el operación de acople entre las tablas; 2) se propone sustituir el
algoritmo genético por un algoritmo basado en colonias de hormigas el cual mejora el
tiempo de optimización de la consulta.

Abstract
ABSTRACT
Get gradually technological independence with respect to the use of software in our
country is part of the development policy of the Cuban state. In this sense a growing
number of institutions and companies have been migrating their applications and
operating systems to free software, and the software development projects are being
using technologies and tools covered in the freedoms that provides the free software.
This research takes a first step towards to obtain a Cuban Management System
Database based in the Object Relational Management System Database PostgreSQL
available under the BSD license.
In this thesis two major results are achieved: 1) is gained to understand how work the
genetic algorithm used by PostgreSQL for query optimization that use the join
operation between tables, 2) is proposed to replace the genetic algorithm by an ant
colony algorithm which improves the time of query optimization.

Tabla de Contenidos
TABLA DE CONTENIDOS
Introducción ........................................................................................................................................................1
CAPÍTULO 1. Procesamiento de consultas. .....................................................................................................4
1.1. Panorama general del procesamiento de consultas. ..................................................................................4
1.2. Descomposición de la consulta. ................................................................................................................6
1.3. Optimización de la consulta. .....................................................................................................................9
1.4. Estimación de costes. ..............................................................................................................................12
1.5. Conclusiones parciales. ...........................................................................................................................13
CAPÍTULO 2. El procesamiento de consultas en PostgreSQL. ........................................................................14
2.1. Arquitectura de PostgreSQL ....................................................................................................................14
2.2. Procesamiento de consultas en PostgreSQL. ...........................................................................................16
2.2.1. El Catálogo de PostgreSQL. ..................................................................................................................17
2.2.2. Estimación de costes. ..........................................................................................................................19
2.2.3. Métodos de optimización de consultas en PostgreSQL ........................................................................21
2.2.3.1. Optimización de consultas utilizando búsqueda exhaustiva. ............................................................24
2.2.3.2. Optimización de consultas utilizando un algoritmo genético............................................................27
2.3. Conclusiones parciales. ..........................................................................................................................33
CAPÍTULO 3. Optimización de consultas utilizando un algoritmo basado en colonias de hormigas. ...............34
3.1. Algoritmo de optimización combinatoria basado en colonias de hormigas. .............................................34
3.2. Comparación del algoritmo genético implementado en PostgreSQL con al algoritmo de optimización
combinatoria basada en colonias de hormigas....................................................................................................35
3.3. Conclusiones parciales ............................................................................................................................38
Conclusiones ....................................................................................................................................................39
Recomendaciones ...........................................................................................................................................40
Bibliografía .......................................................................................................................................................41
Anexos ..............................................................................................................................................................43

Introducción
1
Introducción
Las Bases de Datos han estado en uso desde los primeros días de los ordenadores electrónicos. A
diferencia de los sistemas modernos, que se pueden aplicar a datos y necesidades muy diferentes, la
mayor parte de los sistemas originales estaban enfocados a bases de datos específicas y pensados
para ganar velocidad a costa de perder flexibilidad.
En la actualidad las bases de datos cuentan con un lugar privilegiado en el desarrollo empresarial,
por lo que la manipulación y mantenimiento de esta, tiene gran importancia para su desarrollo. Para
la realización de esta tarea existen programas llamados Sistemas de Gestión de Bases de Datos
(SGBD).
En nuestro país se ha alcanzado un notable desarrollo dentro de este campo, lo que brinda
indiscutibles facilidades en diferentes renglones de la economía, dirección del estado y empresarial,
no obstante, el bloqueo económico impuesto por EEUU (mayor promotor y líder mundial en este
campo) y lo cara que son estas tecnologías, hacen difícil adquirirlas de forma segura, por lo cual se
ve frustrado su desarrollo. Resultan conocidos los inconvenientes que trae aparejado el uso de
software propietario, que entre otros aspectos, crea una dependencia tecnológica que impide la
modificación del código existente y su adaptación a escenarios y contextos determinados. El
software libre es en estos momentos una brecha que permite de cierto modo obtener y crear
software, además de desarrollar la ciencia en el territorio nacional. En nuestro país se cuenta con
algunos productos desarrollados a partir de versiones libres tales como el Sistema Operativo Nova,
un módulo de seguridad para el paquete Open Office, un sistema operativo empotrado para su uso
en dispositivos, biblioteca de funciones para el Weka y un SGBD a partir de PostgreSQL.
PostgreSQL es uno de los SGBD más utilizados por la comunidad de desarrolladores, porque
además de ser libre, agrupa la mayoría de las funcionalidades que presentan los gestores privativos,
es uno de los más potentes y seguros entre los existentes a nivel mundial. Es un sistema de gestión
de bases de datos objeto-relacional (SGBDOR) capaz de manejar complejas rutinas y reglas.
Ejemplos de su avanzada funcionalidad son consultas SQL declarativas, control de concurrencia
multi-versión, soporte multi-usuario, optimización de consultas, herencia, entre otras facilidades. Es
liberado bajo la licencia BSD. Como muchos otros proyectos código abierto, su desarrollo no es

Introducción
2
manejado por una sola compañía sino que es dirigido por una comunidad de desarrolladores y
organizaciones comerciales las cuales trabajan en su desarrollo, dicha comunidad es denominada el
PGDG (PostgreSQL Global DevelopmentGroup). El estudio de este gestor brindaría experiencia y
capacitaría a los profesionales cubanos en la conformación de software de este tipo.
Debido al interés del Ministerio de las Fuerzas Armadas Revolucionarias de nuestro país en
desarrollar un SGBD propio usando como cimiento el PostgreSQL, surge la idea de hacer un
estudio del módulo de optimizador de consultas de este potente gestor de bases de datos, con el
propósito de entenderlo y posteriormente realizar modificaciones y mejoras al proceso de
optimización de consultas.
Objetivo General:
Diseñar un algoritmo que iguale o mejore al algoritmo genético que tiene implementado el módulo
de optimización de consultas de PostgreSQL.
Para su cumplimiento el objetivo general se desglosa en los siguientes objetivos específicos:
Objetivos Específicos:
1. Caracterizar y comprender el módulo de optimización de consultas de PostgreSQL, así como
determinar qué tipos de estructuras de datos están implicados en el proceso de optimización de
consultas.
2. Comprender el algoritmo genético utilizado por el módulo de optimización de consultas de
PostgreSQL.
3. Diseñar un nuevo algoritmo que tenga un rendimiento igual o mejor que el algoritmo genético
implementado en PostgreSQL.
Preguntas de investigación:
1. ¿Estará disponible dentro de la comunidad de PostgreSQL la información técnica relacionada
con las estructuras internas utilizadas en el gestor de bases de datos, en particular las referentes
al optimizador de consultas?
2. ¿Será posible mejorar la optimización de consultas que hace PostgreSQL utilizando otro
algoritmo?

Introducción
3
Justificación de la investigación:
Resulta estratégico para nuestro país disponer de un Sistema de Gestión de Bases de Datos propio
que pueda ser modificado y adaptado a diversas necesidades, garantizando en gran medida la
independencia tecnológico en este tipo de producto de software.

Capítulo 1
4
CAPÍTULO 1. Procesamiento de consultas.
En este capítulo describe cómo un SGBD lleva a cabo el procesamiento de las consultas. Para ello
la mayoría de los sistemas gestores de bases de datos se auxilian de técnicas y estrategias que les
permiten asegurar el llamado procesamiento de consultas. Este proceso ha transcurrido por
diferentes niveles dentro del desarrollo de la programación y la teoría de las bases de datos mismas
pues tiene que tener implícita una serie de etapas que le permitan al software entender y simplificar
peticiones que no siempre están bien redactadas o poseen determinadas complejidades que un
usuario común haría, para ello el gestor debe transformar la consulta a un lenguaje de menor nivel
que le facilite su manipulación interna y posterior ejecución, además del proceso de optimización al
cual debe ser sometida. “La evaluación de una consulta tiene dos componentes: optimizarla y
ejecutarla”(Chaudhuri, 1998). Entre todos los gestores existentes es muy difícil asegurar cual es el
mejor en ese proceso pues la mayoría; a pesar de sus diferencias en la implementación y
peculiaridades que tienen, hacen este proceso de formas similar a gran escala, pues existen
estrategias “clásicas” que son muy eficientes para hacerlas.
1.1. Panorama general del procesamiento de consultas.
Una consulta expresada en un lenguaje de alto nivel como SQL debe, en una primera fase, ser
explorada, analizada sintácticamente y validada. El analizador léxico identifica los elementos del
lenguaje como, por ejemplo, las palabras reservadas de SQL, los nombres de atributos y los
nombres de las relaciones, en el texto de la consulta, mientras que el analizador sintáctico
comprueba la sintaxis de la consulta para determinar si ha sido formulada en correspondencia con
las reglas de sintaxis del lenguaje de consultas. La consulta debe ser también ser validada,
comprobando que todos los nombres de atributos y de relaciones son permitidos y tienen
significado semántico dentro del esquema de la base de datos en particular sobre la cual se realiza la
consulta.
En la siguiente fase se crea una representación interna de la consulta; normalmente mediante una
estructura de datos en árbol denominada árbol de consultas. También es posible representar la
consulta utilizando una estructura de datos en grafo denominada grafo de consulta. Seguidamente,
el SGBD debe seguir una estrategia de ejecución para obtener el resultado de la consulta a partir de
los ficheros de la base de datos. Lo habitual es que en una consulta se disponga de muchas

Capítulo 1
5
estrategias distintas de ejecución; el proceso de elección de la estrategia más adecuada se conoce
como optimización de consultas (Navathe, 2007).
El optimizador de consultas se encarga de generar un plan de ejecución y el generador de código, de
generar el código para ejecutar dicho plan. El procesador de base de datos en tiempo de ejecución
tiene como función la ejecución del código, bien en modo compilado o bien en modo interpretado,
para generar el resultado de la consulta. Si se produce un error en tiempo de ejecución el procesador
de base de datos en tiempo de ejecución generará un mensaje de error.
El término optimización resulta, en realidad, inapropiado ya que en algunos casos el plan de
ejecución elegido no resulta ser la estrategia más óptima (se trata sólo de una estrategia
razonablemente eficiente para ejecutar la consulta). Por lo general, la búsqueda de la estrategia más
óptima consume demasiado tiempo excepto en el caso de las consultas más sencillas y es posible
que se necesite información sobre cómo están construidos los ficheros e incluso sobre el contenido
de los mismos (información que quizá no esté disponible por completo en el catálogo del SGBD).
Por tanto, la planificación de una estrategia de ejecución puede llegar a requerir una descripción
más detallada que en el caso de la optimización de consultas (Date, 2001) . El proceso de
optimización de consultas comprende varias fases, como se muestra en la Figura 1.1 y se describe
en (Ioannidis, 1995).

Capítulo 1
6
Figura 1.1. Pasos habituales para procesar una consulta de alto nivel.
1.2. Descomposición de la consulta.
Descomponer la consulta es la primera fase del procesamiento de consultas. Los objetivos de la
descomposición de una consulta son transformar una consulta de alto nivel en una consulta del
álgebra relacional y comprobar que la consulta sea sintáctica y semánticamente correcta. Las etapas
típicas de la descomposición de consultas son el análisis, la normalización, el análisis semántico, la
simplificación y la reestructuración de la consulta (Connolly, 2005).
En la etapa del análisis, se analiza la consulta léxica y sintácticamente utilizando las técnicas de los
compiladores de los lenguajes de programación. Además, en esta etapa se verifica que las
relaciones y atributos especificados en la consulta están definidos en el catálogo del sistema. Se
verifica asimismo que todas las operaciones aplicadas a los objetos de la base de datos sean
apropiadas para el tipo de objeto. Por ejemplo, considere la siguiente consulta:
SELECT staffNumber FROM Staff WHERE position > 10;

Capítulo 1
7
Esta consulta sería rechazada por dos motivos:
(1) En la lista de selección, el atributo staffNumber no está definido para la relación Staff (debería
ser staffNo).
(2) En la cláusula WHERE, la comparación >10 es incompatible con el tipo de datos del atributo
position, que es una cadena de caracteres de longitud variable.
Completada esta etapa, la consulta de alto nivel se transforma en algún tipo de representación
interna más adecuada para su procesamiento. La forma interna que se suele elegir es algún tipo de
árbol de consulta, que se construye de la forma siguiente:
Se crea un nodo hoja para cada relación base de la consulta.
Se crea un nodo no hoja para cada relación intermedia producida por una operación de álgebra
relaciona.
La raíz del árbol representa el resultado de la consulta.
La secuencia de operaciones se dirige desde las hojas hacia la raíz.
La Figura 1.2 muestra el árbol de consulta correspondiente a la consulta mencionada anteriormente.
Este árbol se denomina árbol de álgebra relacional.
Figura 1.2. Ejemplo de un árbol de consulta de álgebra relacional.

Capítulo 1
8
La etapa de normalización del procesamiento de consulta convierte la consulta en una forma
normalizada que pueda manipularse más fácilmente. El predicado (en SQL, la condición WHERE),
que puede ser arbitrariamente complejo, puede convertirse a una de dos formas aplicando unas
pocas reglas de transformación (Jarke, 1984) .
Forma normal conjuntiva. Una secuencia de conjunciones conectadas mediante el operador /\
(AND). Cada conjunción contiene uno o más términos conectados mediante el operador v
(SELINGER P. ). Una selección conjuntiva contiene únicamente aquellas tuplas que satisfacen
todas las conjunciones.
Forma normal disyuntiva. Una secuencia de disyunciones conectadas mediante el operador v
(SELINGER P. ). Cada disyunción contiene uno o más términos conectados mediante el
operador /\ (AND). Una selección disyuntiva contiene todas las tuplas formadas por la unión de
todas las tuplas que satisfacen las disyunciones.
El objetivo del análisis semántico es rechazar las consultas normalizadas que estén incorrectamente
formuladas o que sean contradictorias. Una consulta estará incorrectamente formulada si sus
componentes no contribuyen a la generación del resultado, lo que puede suceder si faltan algunas
especificaciones de combinación.
Una consulta será contradictoria si su predicado no puede ser satisfecho por ninguna tupla. Los
objetivos de la etapa de simplificación son detectar las cualificaciones redundantes, eliminar las
subexpresiones comunes y transformar la consulta en otra consulta que sea semánticamente
equivalente pero que se pueda calcular de forma más fácil y eficiente. Normalmente, las
restricciones de acceso, las definiciones de vista y las restricciones de integridad se toman en
consideración en esta etapa, pudiendo algunas de esas restricciones y definiciones introducir
redundancia. Si el usuario no dispone de los derechos de acceso apropiados a todos los
componentes de la consulta, será necesario rechazar ésta. Suponiendo que el usuario tenga los
privilegios de acceso apropiados, una optimización inicial consiste en aplicar las muy conocidas
reglas de idempotencia de álgebra booleana. En la etapa final de la descomposición de una consulta,
la consulta se reestructura para obtener una implementación más eficiente.

Capítulo 1
9
1.3. Optimización de la consulta.
La optimización representa tanto un reto como una oportunidad para los sistemas relacionales. Es
un reto ya que si se desea que un sistema de esta naturaleza tenga un desempeño aceptable, será
necesario optimizarlo; y una oportunidad puesto que una de las ventajas del enfoque relacional es
precisamente que las expresiones relacionales están en un nivel semántico lo suficientemente alto
para que la optimización sea factible. Por el contrario, en un sistema no relacional donde las
peticiones de los usuarios están expresadas en un nivel semántico más bajo cualquier
"optimización" tiene que ser realizada en forma manual por el usuario.
La ventaja de la optimización automática no es únicamente que los usuarios no tienen que
preocuparse por formular sus consultas de la mejor manera (es decir, por como formular las
peticiones para obtener el mejor desempeño del sistema). El hecho es que existe una posibilidad
real de que el optimizador pueda hacerlo mejor que el usuario.
El objetivo de la optimización de consultas consiste en elegir aquella que minimice el uso de
recursos. Generalmente, se intenta reducir el tiempo total de ejecución de la consulta, que es la
suma de los tiempos de ejecución de todas las operaciones individuales que componen la consulta
(SELINGER P. , 1979). Sin embargo, el uso de recursos también podría medirse según el tiempo de
respuesta de la consulta, en cuyo caso se concentrará en maximizar el número de operaciones
paralelas (VALDURIEZ P., 1984). Ambos métodos de optimización de consultas dependen de las
estadísticas de la base de datos para evaluar apropiadamente las diferentes opciones disponibles, en
particular conocerá determinada información estadística tal como:
La cantidad de valores en cada dominio.
La cantidad actual de tuplas en cada varrel base.
La cantidad actual de valores distintos en cada atributo de cada varrel base.
La cantidad de veces que tales valores se dan en cada uno de esos atributos.
Por consecuencia, el optimizador deberá ser capaz de hacer una valoración más precisa de la
eficiencia de cualquier estrategia dada para implementar una petición en particular, y por lo tanto
será más probable que seleccione la implementación más eficiente. Luego se procede a aplicar
técnicas y artificios al proceso de optimización el cual tiene como datos de entrada un modelo más

Capítulo 1
10
sencillo y con mayor nivel de operatividad y se puede hacer uso de los conocimientos matemáticos
del algebra relacional que conducen a un proceso con mayor simplicidad por lo cual se pueden
utilizar reglas generales de transformación para las operaciones de álgebra relacional. Existen varias
reglas para transformar las operaciones de álgebra relacional en expresiones equivalentes, siendo de
interés el significado de las operaciones y de las relaciones resultantes. Según lo anterior, si dos
relaciones tienen el mismo conjunto de atributos en diferente orden pero representan la misma
información, se considerarán equivalentes. Existen algunas reglas de transformación que son útiles
en la optimización de consultas (Navathe, 2007).
La utilización de la heurística en la optimización de consultas hace más eficiente este proceso. Una
de las principales reglas heurísticas es aplicar las operaciones SELECT y PROJECT antes de
aplicar JOIN u otras operaciones binarias, ya que el tamaño del fichero resultante de una operación
binaria (como JOIN) es, por lo general, una función multiplicativa de los tamaños de los ficheros de
entrada. Las operaciones SELECT y PROJECT reducen el tamaño de un fichero y, por tanto,
deberían ser aplicadas antes de JOIN u otra operación binaria. Se utiliza un árbol de consultas para
representar una expresión en álgebra relacional o en álgebra relacional extendida, mientras que un
grafo de consultas se utiliza para representar una expresión de cálculo relacional. Un árbol de
consultas representa las relaciones de entrada a una consulta como los nodos hoja del árbol y las
operaciones del álgebra relacional como nodos internos. La ejecución del árbol de consultas
consiste en ejecutar una operación en un nodo interno siempre que estén disponibles sus operando y
después reemplazar ese nodo interno por la relación que resulta de la ejecución de la operación. La
ejecución finaliza cuando se ejecuta el nodo raíz y se genera la relación resultante de la consulta. Al
final este árbol es el que se debe optimizar haciendo podas o mejoras que provean una consulta
equivalente de menor costo computacional.
Para optimizar este árbol se ejecuta un algoritmo de optimización algebraica heurística que utiliza
algunas de las reglas descritas anteriormente para transformar un árbol de consultas inicial en un
árbol optimizado que se ejecute de forma más.
Existen dos opciones relativas a cuándo llevar a cabo las primeras tres fases del procesamiento de
una consulta. Una de las opciones consiste en llevar a cabo dinámicamente la descomposición y la
optimización cada vez que se ejecuta una consulta. La optimización dinámica de consultas tiene la
ventaja de que toda la información requerida para seleccionar una estrategia óptima estará

Capítulo 1
11
actualizada. Las desventajas son que la velocidad de la consulta se verá afectada debido a la
necesidad de analizar sintácticamente, validar y optimizar la consulta antes de poder ejecutarla.
Además, puede que sea necesario reducir el número de estrategias de ejecución que hay que
realizar, con el fin de conseguir que ese coste de procesamiento adicional sea aceptable, lo que a su
vez puede tener el efecto de que se seleccione una estrategia significativamente inferior a la óptima.
La opción alternativa consiste en efectuar una optimización estática de consultas, en la que las
consultas son analizadas sintácticamente, validadas y optimizadas una sola vez. Esta técnica es
similar a la que se utiliza cuando se ejecuta un compilador de un lenguaje de programación. Las
ventajas de la optimización estática son que se elimina el coste adicional de procesamiento en
tiempo de ejecución y que puede haber más tiempo disponible para evaluar un mayor número de
estrategias de ejecución, incrementándose así las posibilidades de encontrar una estrategia mejor.
Para las consultas que se ejecutan muchas veces, tomarse un cierto tiempo adicional para encontrar
un plan mejor puede proporcionar muchos beneficios. Las desventajas surgen del hecho de que la
estrategia de ejecución que se selecciona como óptima en el momento de compilar la consulta
puede haber dejado de ser óptima en el momento de ejecutarla. De todos modos, también puede
emplearse una técnica híbrida para evitar esta desventaja, técnica que consiste en reoptimizar la
consulta si el sistema detecta que las estadísticas de la base de datos han cambiado
significativamente desde la última vez que se compiló la consulta. Alternativamente, el sistema
podría compilar la consulta para la primera ejecución de cada sesión y luego almacenar en caché el
plan óptimo durante el resto de la sesión, de modo que el coste se distribuya entre toda la sesión del
SGBD (Connolly, 2005).
Estas estadísticas recopilan información acerca de las relaciones, atributos e índices. Por ejemplo, el
catálogo del sistema puede almacenar estadísticas que proporcionen la cardinalidad de las
relaciones, el número de valores distintos que tiene cada atributo y el número de niveles de un
índice multinivel. Mantener las estadísticas actualizadas puede llegar a ser problemático. Si el
SGBD actualizara las estadísticas cada vez que se inserta, actualiza o borra una tupla, esto tendría
un impacto significativo sobre el rendimiento durante los picos de carga de trabajo. Otra alternativa
generalmente preferible, consiste en actualizar las estadísticas de forma periódica, por ejemplo
todas las noches, o siempre que el sistema esté inactivo. Otra solución adoptada por algunos
sistemas consiste en asignar a los usuarios la responsabilidad de indicar cuándo hay que actualizar

Capítulo 1
12
las estadísticas (Connolly, 2005). Cualquiera de las formas de actualización de las estadísticas
tienen la responsabilidad de brindad información confiable para los posteriores cálculos de costes
de procesamiento de consulta.
1.4. Estimación de costes.
Un SGBD puede tener muchas formas distintas de implementar las operaciones del álgebra
relacional. Un optimizador de consultas no debería basarse exclusivamente en reglas heurísticas;
también debería calcular y comparar los costes de ejecución de una consulta utilizando diferentes
estrategias de ejecución y debería elegir la estrategia con el menor coste estimado. Para que
funcione este modelo se necesitan estimaciones de coste precisas para que la comparación entre las
diferentes estrategias se realice con ecuanimidad y de forma real (Jarke, 1984). Además, se debe
limitar el número de estrategias a tener en cuenta ya que, en caso contrario, se perdería demasiado
tiempo haciendo estimaciones de coste para un número tan elevado de estrategias de ejecución
posibles. De acuerdo con esto, este modelo es más adecuado en consultas compiladas en las cuales
la optimización se realiza en tiempo de compilación, y el código para la estrategia de ejecución
resultante se almacena y se ejecuta directamente en tiempo de ejecución. En el caso de las consultas
interpretadas en las cuales todo el proceso se realiza en tiempo de ejecución, una optimización a
gran escala podría ralentizar el tiempo de respuesta. La optimización más elaborada está indicada en
el caso de las consultas compiladas, mientras que una optimización parcial que requiera menos
tiempo funciona mejor en el caso de las consultas interpretadas.
El coste de ejecución de una consulta incluye los siguientes componentes:
1. Coste de acceso al almacenamiento secundario. Es el coste de la búsqueda, lectura y escritura de
bloques de datos que residen en almacenamiento secundario, principalmente en disco. El coste
de la búsqueda de registros en un fichero depende del tipo de las estructuras de acceso a dicho
fichero, como, por ejemplo, la ordenación, la dispersión y los índices primarios y secundarios.
Aparte de esto, factores como la ubicación contigua de los bloques del fichero en el mismo
cilindro del disco o diseminados por el disco afectan al coste de acceso.
2. Coste de almacenamiento. Es el coste de almacenamiento de los ficheros intermedios generados
por una estrategia de ejecución de la consulta.

Capítulo 1
13
3. Coste computacional. Es el coste de la ejecución de operaciones en memoria sobre los búferes
de datos durante la ejecución de la consulta. Este tipo de operaciones incluye la búsqueda y la
ordenación de los registros, la mezcla de registros durante una concatenación y la ejecución de
cálculos sobre valores de los campos.
4. Coste de uso de memoria. Es el coste relativo al número de búferes de memoria que se necesitan
durante la ejecución de la consulta.
5. Coste de comunicaciones. Es el coste del envío de la consulta y de sus resultados desde el sitio
donde se ubica la base de datos hasta el sitio o el terminal donde se originó la consulta.
En el caso de bases de datos de gran tamaño, el objetivo principal es minimizar el coste de acceso al
almacenamiento secundario. Las funciones de coste sencillas ignoran otro tipo de factores y
comparan las diferentes estrategias de ejecución en función del número de transferencias de bloque
entre el disco y la memoria principal.
En el caso de bases de datos de menor tamaño, en las que se puede almacenar en memoria la
mayoría de los datos de los ficheros implicados en la consulta, el objetivo principal es minimizar el
coste computacional.
En el caso de bases de datos distribuidas en las que se encuentran implicadas varias ubicaciones
físicas también se debe minimizar el coste de las comunicaciones. Resulta difícil incluir todos los
componentes de coste en una función (ponderada) de coste debido a la dificultad de asignar los
pesos adecuados a los componentes de coste. Ésta es la razón por la que algunas funciones de coste
tienen en cuenta un único factor: el acceso a disco (Navathe, 2007).
1.5. Conclusiones parciales.
El procesamiento de consultas es un proceso muy complejo, el cual puede dividirse en cuatro
partes principales: descomposición (análisis sintáctico y validación), optimización, generación de
código y ejecución. Uno de los aspectos más importante dentro del procesamiento de la consulta es
la optimización debido a que permite transformar la consulta inicial en una equivalente que propicie
un mejor rendimiento y eficiencia del SGBD en la ejecución de la misma.
Los aspectos tratados en este capítulo permiten abordar el estudio y comprensión del proceso de
optimización de consultas que realiza el SGBD PostgreSQL, lo cual constituye el objetivo
fundamental del próximo capítulo.

Capítulo 2
14
CAPÍTULO 2. El procesamiento de consultas en PostgreSQL.
Para la obtención de un Sistema de Gestión de Bases de Datos (SGBD) cubano, partiendo de
PostgreSQL, se ha identificado la optimización del procesamiento de consulta como punto de
partida del proyecto, con el objetivo de realizar cambios en dicho módulo que mejoren su
rendimiento e ir particularizando así al gestor.
En este capítulo se describe la arquitectura interna de PostgreSQL y se particulariza en el proceso
de optimización de consultas, describiendo las estructuras de datos involucradas en este proceso así
como el uso del catálogo.
2.1. Arquitectura de PostgreSQL
PostrgreSQL es un proyecto con más de 15 años de vida. Se inició en la Universidad de Berkeley
en 1977 bajo el nombre Ingres como un ejercicio de aplicación de las teorías de las Sistemas
Gestores de Bases de Datos Relacional. Está escrito en lenguaje C, es un servidor de base de datos
objeto relacional liberado bajo la licencia BSD. Incluye características de la orientación a objetos,
como la herencia, tipos de datos, funciones, restricciones, disparadores, reglas e integridad
transaccional. Como muchos otros proyectos de código abierto, el desarrollo de PostgreSQL no es
manejado por una sola compañía sino que es dirigido por una comunidad de desarrolladores y
organizaciones comerciales las cuales trabajan en su desarrollo. Posee todas las ventajas de todos
los programas libres, entre ellas brindar su código al usuario y poder ser estudiado con detalles, para
poder descubrir cómo funciona.
PostgreSQL utiliza un modelo cliente/servidor de un proceso por usuario. Una sesión de
PostgreSQL consiste en los siguientes procesos, como se muestra en la Figura 2.1:
Aplicación cliente: Esta es la aplicación cliente que utiliza PostgreSQL como administrador de
bases de datos. La conexión puede ocurrir vía TCP/IP ó sockets locales.
Demonio postmaster: Este es el proceso principal de PostgreSQL. Es el encargado de escuchar por
un puerto/socket por conexiones entrantes de clientes. También es el encargado de crear los procesos
hijos que se encargaran de autentificar estas peticiones, gestionar las consultas y mandar los
resultados a las aplicaciones clientes.
Ficheros de configuracion: Los tres ficheros principales de configuración utilizados por
PostgreSQL, postgresql.conf, pg_hba.conf y pg_ident.conf.

Capítulo 2
15
Procesos hijos postgres: Procesos hijos que se encargan de autentificar a los clientes, de gestionar
las consultas y mandar los resultados a las aplicaciones clientes.
PostgreSQL share buffer cache: Memoria compartida usada por POstgreSQL para almacenar datos
en caché.
Write-Ahead Log (WAL): Componente del sistema encargado de asegurar la integridad de los
datos (recuperación de tipo REDO)
Kernel disk buffer cache: Caché de disco del sistema operativo
Disco: Disco físico donde se almacenan los datos y toda la información necesaria para que
PostgreSQL funcione.
Figura 2.1. Arquitectura de PostgreSQL.
Un único postmaster maneja una colección de bases de datos en un servidor, esta colección se
denomina instalación. Las aplicaciones de frontend que acceden a una base de datos en una
instalación realizan llamadas a la librería. La librería envía el requerimiento del usuario a través de

Capítulo 2
16
la red al postmaster. A partir de aquí, el proceso cliente y el servidor se comunican entre ellos sin
intervención del postmaster. En consecuencia, el proceso postmaster está siempre corriendo,
esperando llamadas, mientras que los procesos cliente y servidor vienen y van. La librería libpq
permite a un único proceso cliente tener múltiples conexiones con procesos servidores. Una
implicación de esta arquitectura es que el postmaster y los servidores siempre corren en la misma
máquina (el servidor de base de datos), mientras que el cliente puede correr en cualquier sitio. El
proceso postmaster y los servidores postgres corren bajo el identificador del "superusuario" de
Postgres. Nótese que el superusuario de PostgreSQL no tiene por qué ser un usuario especial (es
decir, un usuario llamado "postgres"), aunque en muchos sistemas esté instalado así.
2.2. Procesamiento de consultas en PostgreSQL.
PostgreSQL es un sistema gestor de base de datos que aproxima los datos a un modelo objeto
relacional, y es capaz de manejar complejas rutinas y reglas. Ejemplos de su avanzada
funcionalidad son consultas SQL declarativas, control de concurrencia multi-versión, soporte multi-
usuario, transacciones, optimización de consultas, herencia, y arreglos. El procesamiento de
consultas pasa por una serie de fases las cuales se resumen en la Figura 2.2.
Figura 2.1. Arquitectura del procesamiento de consulta en el servidor PostgreSQL.

Capítulo 2
17
Parser (Reconocedor): Este es el primer módulo por donde transita una consulta, este módulo es el
encargado de reconocer los identificadores y palabras claves del lenguaje SQL, realizar la
interpretación semántica necesaria para comprender que tablas, funciones y operadores son
referenciados en la consulta y además construye el árbol de traducción.
Rewriter (Re-escritor): PostgreSQL: Soporta un poderoso sistema de reglas para la especificación
de vistas y vistas actualizables. El sistema de reglas de PostgreSQLse concibe en el Rewriter. Este
es un módulo en el cual se toma el árbol devuelto por el Parser y se realiza la búsqueda de reglas
presentes dentro de la consulta. Si se encuentra alguna regla dentro de la consulta, la estructura del
árbol se transforma en una expresión equivalente.
Planner/Optimizer (Planificador/Optimizador): La tarea de este módulo es crear un plan de
ejecución óptimo. Primero, combina las posibles formas de recorrer y unir las relaciones que
aparecen en la consulta (caminos). Todos los caminos creados llevan al mismo resultado y la tarea
del optimizador es estimar el costo de ejecución de cada camino y encontrar cuál de éstos es el más
barato.
Executor (Ejecutor): Ejecuta la consulta utilizando el plan elegido por el Planner/Optimizer, este
plan representa lógicamente los pasos necesarios para satisfacer la consulta, y físicamente es un
árbol cuyos nodos representan operaciones básicas.
Cada uno de estos módulos se auxilia de información estadística que necesita para la toma de
decisiones, estimación de costes y otras funciones necesarias para el procesamiento. Toda esta
información se puede encontrar en los catálogos del SGBD.
2.2.1. El Catálogo de PostgreSQL.
El Sistema de Catálogo es el lugar donde un SGBD almacena esquemas de meta-datos, así como
información sobre tablas y columnas, e información estadística. El sistema de catálogos de
PostgreSQL son tablas normales, se puede borrar y recrear las tablas, agregar columnas, insertar y
actualizar valores. Normalmente no se debería acceder directamente al sistema de catálogos, existen
comandos SQL para hacerlo.

Capítulo 2
18
La mayoría de los sistemas de catálogos son copiados desde la base datos plantilla durante la
creación de la base de datos y son más tarde específicos de la base de datos. Algunos catálogos son
físicamente compartidos a través de todas las base de datos en un cluster; estos son notificados en la
descripción de los catálogos individuales.
Figura 2.3. El principal sistema de catálogos de PostgreSQL.
El catálogo pg_aggregate almacena información sobre funciones agregadas. Una función agregada
es una función que opera en un conjunto de valores y devuelve un simple valor calculado a partir de
todos esos valores (SUM, COUNT y MAX). Cada entrada en pg_aggregate es una extensión de una
entrada en pg_proc. La entrada pg_proc porta el nombre del agregado, tipos de datos de entrada y
salida y otra información similar a funciones usuales.
El catálogo pg_am almacena información sobre métodos de acceso a índices. Hay una fila por cada
método de acceso a índice soportado por el sistema. Una panorámica más detallada del catálogo se
muestra en el ANEXO I.
Para elegir el plan con menor costo, el planificador estima el costo que tendrá ejecutar la consulta
con cada uno de los planes y luego elige el de menor costo, para ello utiliza las estadísticas
almacenadas en el Sistema de Catálogos. De esta información los datos más utilizados para estimar
el costo son el número total de entradas en cada tabla e índice, el número de bloques de disco

Capítulo 2
19
ocupados por cada tabla e índice, lista de valores más comunes de los campos, entre otros. Toda
esta información está almacenada específicamente en pg_class y pg_statistic.
Las entradas en pg_statistic son actualizados por los comandos ANALYZE y VACUUM
ANALYZE, y son siempre aproximaciones aun cuando se actualizaron recientemente.
2.2.2. Estimación de costes.
PostgreSQL hace uso de la estimación de costes dentro de varios módulos. El
Planificador/Optimizador es en el que más se evidencia su uso, calculando las estadísticas usadas
para elegir el plan menos costoso o relativamente eficiente dentro de los generados con los que se
puede ejecutar una consulta dada.
Los costos son medidos en unidades arbitrarias, tradicionalmente equivale a la cantidad de páginas
leídas desde el disco.
La herramienta pgAdmin de PostrgreSQL brinda información detallada del plan elegido por el
Planificador, para obtener esta información se utiliza el comando EXPLAIN o EXPLAIN
ANALYZE.
La salida del comando EXPLAIN tiene una línea para cada nodo en el árbol del plan, que muestra
el tipo de nodo y las estimaciones de costos que el planificador hizo para la ejecución de este. La
primera línea (nodo superior) tiene el costo total estimado de ejecución del plan, y es este número el
que el Planificador/Optimizador busca minimizar. A continuación se muestra en la Figura 2.4 un
ejemplo en el cual se calculan los costos.

Capítulo 2
20
Figura 2.4. Ejemplo del cálculo de costos en PostgrSQL.
Los números que se señalan representan:
cost: Costo total estimado
rows: Número estimado de filas de salida del nodo
width: Ancho medio estimado (en bytes) de las filas de salida de este nodo.
El costo total estimado para este ejemplo fue calculado como:
(cantidad de páginas leídas en disco*seq_page_cost) + (cantidad de filas examinadas
*cpu_tuple_cost)
seq_page_cost y cpu_tuple_cost son variables de costo medidas en una escala arbitraria. Por
defecto estas variables de costo están basadas en seq_page_cost y las demás variables de costo son

Capítulo 2
21
fijadas en relación a esta. Estas variables tienen un valor por defecto que propicia un
funcionamiento de rendimiento medio a la base de datos. Como se mostró en el ejemplo anterior
una de las cosas que el Planificador necesita estimar es el número de filas que recuperará una
consulta dada (Group, 2012).
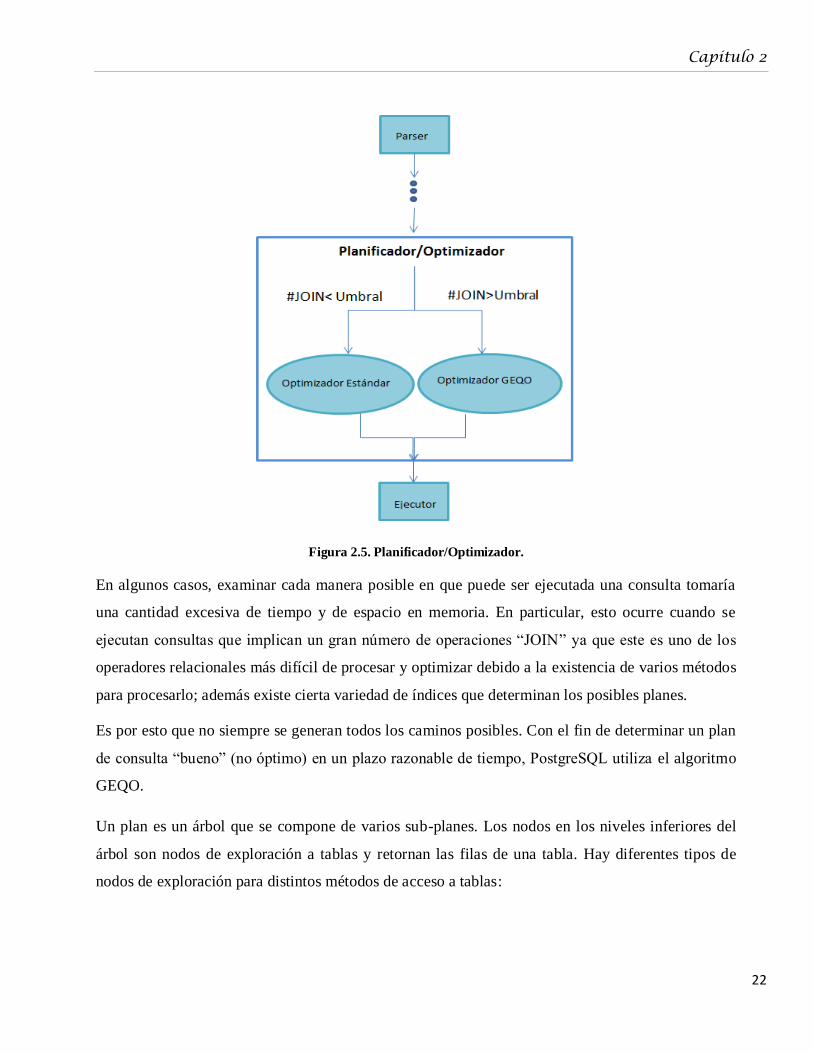
2.2.3. Métodos de optimización de consultas en PostgreSQL
El Planificador/Optimizador es el módulo de PostgreSQL encargado de generar los posibles planes
con los que se puede ejecutar una consulta dada y de elegir el menos costoso o relativamente
eficiente. Siempre existe la posibilidad de realizar una búsqueda secuencial en una relación, por lo
que siempre se crea un plan de exploración secuencial.
En el módulo Planificador/Optimizador se hacen básicamente dos tipos de optimizaciones
siguiendo diferentes estrategias. Para consultas simples sigue una estrategia de ejecución directa,
pues tardaría más buscando posibles soluciones óptimas y ejecutar resultados posteriormente que
desechar la optimización y ejecutarlas directamente. Otras consultas con un mayor grado de
complejidad son procesadas por un módulo de optimización llamado Optimizador Normal o
Estándar cuando la cantidad de acoples es inferior a un umbral, de lo contrario la consulta pasa al
Optimizador Genético de Consulta (GEQO, por sus siglas en inglés), este módulo hace una
búsqueda heurística utilizando un algoritmo genético.
En la Figura 2.5 se muestra un esquema general de los tipos de optimizadores del
Planificador/Optimizador.
Capítulo 2
22
Figura 2.5. Planificador/Optimizador.
En algunos casos, examinar cada manera posible en que puede ser ejecutada una consulta tomaría
una cantidad excesiva de tiempo y de espacio en memoria. En particular, esto ocurre cuando se
ejecutan consultas que implican un gran número de operaciones “JOIN” ya que este es uno de los
operadores relacionales más difícil de procesar y optimizar debido a la existencia de varios métodos
para procesarlo; además existe cierta variedad de índices que determinan los posibles planes.
Es por esto que no siempre se generan todos los caminos posibles. Con el fin de determinar un plan
de consulta “bueno” (no óptimo) en un plazo razonable de tiempo, PostgreSQL utiliza el algoritmo
GEQO.
Un plan es un árbol que se compone de varios sub-planes. Los nodos en los niveles inferiores del
árbol son nodos de exploración a tablas y retornan las filas de una tabla. Hay diferentes tipos de
nodos de exploración para distintos métodos de acceso a tablas:

Capítulo 2
23
Escaneo secuencial: leer toda la tabla y chequear cada fila.
Escaneo con índice: leer el índice que coincida con lo que se busca e ir a la tabla para la
lectura de la fila. es importante saber que PostgreSQL siempre tiene que visitar la tabla para
comprobar si una fila se puede ver en la transacción actual.
Escaneo de índice de mapa de bits: analiza que el índice que coincida con lo que se busca,
guardar los resultados en un mapa de bits en la memoria, ordena el mapa de bits en el orden
de la tabla (es ordenado por números de bloques) y lee la tabla. Esto elimina los saltos entre
el índice y la tabla.
Para procesar el operador JOIN el planificador/Optimizador sigue tres posibles estrategias:
bucle anidado: La relación de la derecha se explora una sola vez por cada fila encontrada en
la relación de la izquierda. Esta estrategia es fácil de implementar, pero puede tomar mucho
tiempo. Si la relación de la derecha se puede explorar con un índice, esto puede ser una
buena estrategia ya que es posible usar los valores de la fila actual de la relación izquierda
como claves para la exploración de índice de la derecha.
ordenamiento por mezcla: Cada relación está ordenada sobre los atributos del JOIN.
Entonces las dos relaciones se exploran en paralelo, y las filas coincidentes se combinan
para formar las filas del acople. Este tipo de unión es más atractiva, ya que cada relación es
explorarda una sola vez. El ordenamiento requerido puede lograrse ya sea mediante una
etapa de ordenamiento explícito, o mediante la exploración de la relación en el orden
correcto mediante un índice sobre la clave de combinación.
hash: la relación de la derecha se explora primero y se carga en una tabla hash, utilizando
sus atributos del acople como claves hash. A continuación, la relación izquierda se explora y
los valores correspondientes de cada fila se utilizan como claves hash para localizar las filas
coincidentes en la tabla.
Cuando la consulta incluye más de dos relaciones, el planificador examina diferentes secuencias de
acoples posibles para encontrar la menos costosa. Resulta evidente que uno de los operadores más
costoso en su procesamiento es el acople, debido a que el número de vías alternativas para
responder a una consulta crece exponencialmente con el número de uniones incluidas en ella. El
esfuerzo adicional de optimización está causado por la existencia de una variedad de métodos de

Capítulo 2
24
acople para procesar acoples individuales (e.g.,nestedloop, hash join, mergejoin) y de una gran
variedad de índices (B-tree, hash, GiST and GIN) como camino de acceso para las relaciones.
2.2.3.1. Optimización de consultas utilizando búsqueda exhaustiva.
PostgreSQL cuenta con diversas estrategias para optimizar una consulta. La consulta es procesada
hasta llegar al módulo de Planificador/Optimizador, donde puede tomar varias decisiones respecto a
cuál estrategia de optimización utilizar. La estrategia de búsqueda exhaustiva tiene entre sus
ventajas la simplicidad de implementación y rapidez de respuesta en casos de poca complejidad, por
lo que al procesar una consulta con un nivel de simplicidad determinado (estimado por la cantidad
de acoples que contiene la consulta objetivo) hace este tipo de optimización, llamada optimización
normal o estándar, la cual sigue una estrategia de búsqueda exhaustiva de posibles caminos y de
ellos toma la óptima haciendo un cubrimiento total de espacio de búsqueda lo cual le confiere un
alto costo computacional. Este módulo es utilizado cuando la cantidad de acoples que intervienen
en la consulta no sobrepasa un umbral predefinido llamado geqo_threshold que por defecto es 12. A
continuación se muestra en la Figura 2.6 los resultados de una comparación realizada en (Petkovié,
2011) donde se evidencia la justificación del valor de este parámetro.
Figura 2.6. Comparación entre GEQO y el algoritmo de programación dinámica.

Capítulo 2
25
El optimizador genera planes de consulta óptimos haciendo una búsqueda exhaustiva dentro de las
formas de ejecutar la consulta. El mejor árbol que se almacena en la estructura Path es encontrado
por un proceso recursivo, que se caracteriza por tomar cada relación base en la consulta, y crear una
estructura RelOptInfo, para así en una primera fase encontrar formas de acceder a la relación
(incluyendo escaneo secuencial y escaneo de índices) y hacer caminos representados de esas
formas. En una segunda fase, se tiene un problema de planificación que contiene listas de relaciones
a ser asociadas en cualquier orden, donde cualquier elemento individual puede ser una sub-lista que
tienen que ser validadas antes que se puede considerar asociar este a sus hermanos. Se procesan
estos sub-problemas recursivamente utilizando el método bottom-up.
El planificador estándar (non-GEQO) construye una estructura RelOptInfo para cada relación base
en la consulta. Las relaciones base son cualquier tabla primitiva o subconsulta que son planificadas
mediante una separada invocación recursiva del Planificador. Un RelOptInfo también se construye
para cada relación de acople que es considerada durante la planificación. Una relación de acople es
simplemente una combinación de relaciones bases. Se considera asociar cada RelOptInfo a cada
una de las otras RelOptInfo para la cual hay una cláusula utilizable, y genera un camino para cada
posible método de acople y para cada una de las parejas. Si se tiene una RelOptInfo sin cláusula de
acople, no hay más opción que generar un acople de producto cartesiano sin cláusula. Si solo se
encuentran dos relaciones en la lista, se elige el camino más barato para su acople, en caso de
encontrar más de dos relaciones se consideran formas de acoplamiento para cada una de estas
relaciones.
El árbol de acoples se crea usando un algoritmo de programación dinámica: en el primer paso
consideramos las formas de crear relaciones de acoples representando exactamente dos elementos
en la lista. El segundo paso considera las formas de hacer relaciones de acoples que representen
exactamente tres elementos de la lista; el siguiente paso, cuatro elementos, y así sucesivamente. El
último paso considera como hacer la relación de acople final que incluya todos los elementos de la
lista, en este último nivel solo puede estar una relación de acople, mientras que pueden estar más de
una relación de acople en niveles más bajos. En cada nivel usamos acoples que sigan cláusulas de
acoples disponibles, si es posible. Por ejemplo, considere un acople entre las tablas tab1, tab2,
tab3y tab4 por el atributo común col:

Capítulo 2
26
SELECT *
FROM tab1, tab2, tab3, tab4
WHERE tab1.col = tab2.col AND tab2.col = tab3.col AND tab3.col = tab4.col
La tablas 1, 2, 3 y 4 serán acopladas de la siguiente manera:
{1 2}, {2 3}, {3 4}
{1 2 3}, {2 3 4}
{1 2 3 4}
SELECT *
FROM tab1, tab2, tab3, tab4
WHERE tab1.col = tab2.col AND tab1.col = tab3.col AND tab1.col = tab4.col
Las tablas 1, 2, 3, y 4 serán acopladas de la siguiente manera:
{1 2}, {1 3}, {1 4}
{1 2 3}, {1 3 4}, {1 2 4}
{1 2 3 4}
En cuanto se tenga construido la relación de acople final, se usará cualquier camino más barato para
este, o el camino más barato con el ordenamiento deseado.
En consultas con un grado de complejidad mayor opta por estrategias de otra categoría, como son
las estrategias heurísticas. El optimizador emplea un tiempo considerable en el orden de las tuplas
retornadas por un camino. Esto es útil porque conociendo el tipo de ordenamiento de un camino, se
puede estar capacitado para usar este camino como entradas izquierda o derecha de un mergejoin y
evita un paso de ordenar explícito.
Cuando se generan caminos para un RelOptInfo particular, se descarta un camino si este es más
caro que otro camino conocido que tiene el mismo tipo de orden. Nunca se descartará un camino
que es la única forma conocida de lograr un tipo de orden (sin un orden explícito).

Capítulo 2
27
2.2.3.2. Optimización de consultas utilizando un algoritmo genético.
Dentro del código fuente de PostgreSQL, el módulo GEQO se utiliza para la optimización de
consultas similares al problema del viajero (TSP por sus siglas en ingles). El módulo GEQO
transforma el problema de procesar una consulta a un problema TSP, donde las tablas que forman
la consulta son codificadas con números enteros y se ordena de acuerdo al orden de los acople. Este
orden las tablas son interpretadas como cromosomas. El problema de ordenamiento de la
operaciones de acople ha sido discutido en varios artículos. La primera implementación de este
problema se hizo en System R (Astrahan, 1979). Cada una de las tablas que van a ser acopladas
(JOIN) son enumeradas por un entero comenzando por el 1, así un posible plan con 5 tablas a
acoplar podría codificarse como 1-2-3-4-5. Por ejemplo para el árbol de consulta:
Este está codificado por la cadena de enteros ’4-1-3-2’, que significa, la primera relación de unión
’4’ y ’1’, después ’3’, y después ’2’, donde 1, 2, 3, 4 son identificadores de las tablas en
PostgreSQL.
GEQO comienza creando aleatoriamente planes de ejecución. Entonces este evalúa cada uno de
estos para la adaptabilidad, específicamente cuán grande es el costo de ejecución por cada uno de
ellos. Los mejores planes son guardados y los peores son desechados, se hacen algunos cambios en
los planes (mutación) y el proceso se repite por cierto número de generaciones.
Debido a que se obtienen muchos valores aleatorios en este proceso, no se puede esperar que el plan
devuelto por GEQO sea el mismo en cada momento, incluso dado las mismas estadísticas y la
misma consulta de entrada. La ejecución de GEQO depende del parámetro geqo_threshold, el cual
por defecto es 12.
El módulo GEQO está previsto para solucionar el problema de optimización de consultas similares
al problema del viajante (PV).

Capítulo 2
28
El algoritmo genético (AG) es un método de búsqueda heurística que opera mediante búsqueda
determinada y aleatoria. El conjunto de soluciones posibles para el problema de la optimización se
considera como una población de individuos. El grado de adaptación de un individuo en su entorno
está determinado por su adaptabilidad.
Las coordenadas de un individuo en el espacio de búsqueda están representadas por los
cromosomas, en esencia un conjunto de cadenas de caracteres. Un gen es una subsección de un
cromosoma que codifica el valor de un único parámetro que ha de ser optimizado. Las
codificaciones típicas para un gen pueden ser binarias o enteras. “Un algoritmo genético es un
proceso iterativo en que los cromosomas son reorganizados en cada momento para conseguir una
solución óptima” (Goldberg, 1989).
Mediante la simulación de operaciones evolutivas recombinación, mutación, y selección se
encuentran nuevas generaciones de puntos de búsqueda, los cuales muestran un mayor nivel de
adaptabilidad que sus antecesores.
Seudocódigo del algoritmo genético de optimización de consultas de PostgreSQL:
P(t) generación de una población inicial en un tiempo t. // se generan individuos de forma
aleatoria que cumplan con los requisitos de la población.
P”(t) generar descendientes de esta población inicial en un tiempo t
INICIALIZAR t := 0
INICIALIZAR P (t)
Evaluar APTITUD de P (t) //calidad de los individuos
mientras ( no se cumpla el Criterio de Parada ) //número de generaciones
hacer
P’(t) := Recombinación{P(t)}
P”(t) := Mutación{P’(t)}
P(t+1) := Selección{P”(t) + P(t)}
Evaluar APTITUD de P” (t) //calidad de los individuos
t := t + 1

Capítulo 2
29
Comentarios del seudocódigo del algoritmo genético:
El uso de un algoritmo genético en estado constante (remplazo de los individuos con menor
adaptación de la población, no el reemplazo total de un generación) permite converger
rápidamente hacia planes mejorados de consulta. Esto es esencial para el manejo de la
consulta en un tiempo razonable.
El criterio de parada es la cantidad de generaciones que se desean obtener, pues este
algoritmo tiene como objetivo ir mejorando los individuos en el transcurso del tiempo t.
El uso de cruce de recombinación limitada que esta especialmente adaptado para quedarse
con el límite menor de pérdidas para la solución del PV por medio de un AG;
La mutación como operación genética se recomienda a fin de que no sean necesarios
mecanismos de reparación para generar viajes legales del PV. El operador de Mutación al
estilo del operador natural realiza la mutación de un gen dentro de un cromosoma o cadena a
sus diferentes formas alelomorfas.
El operador de selección realiza la selección de las cadenas de acuerdo a su adaptabilidad
para el posterior apareamiento.
Las características específicas de la implementación de GEQO son:
El uso de un AG en estado constante (remplazo de los individuos con menor adaptación de la
población, no el reemplazo total de una generación) permite converger rápidamente hacia planes
mejorados de consulta. Esto es esencial para el manejo de la consulta en un tiempo razonable;
El uso de cruce de recombinación limitada que está especialmente adaptado para quedarse con
el límite menor de pérdidas para la solución del PV por medio de un AG.
La mutación como operación genética se recomienda a fin de que no sean necesarios
mecanismos de reparación para generar viajes legales del PV.
El módulo GEQO proporciona los siguientes beneficios para la DBMS PostgresSQL comparado
con la implementación del optimizador de consultas de GEQO:
El manejo de grandes consultas de tipo unión a través de una búsqueda no-exhaustiva;

Capítulo 2
30
Es necesario una mejora en la aproximación del tamaño del coste de los planes de consulta
desde la fusión del plan más corto (el módulo GEQO evalúa el coste de un plan de consulta
como un individuo).
2.2.4. Generación de posibles planes de ejecución
En la etapa inicial el código de GEQO simplemente genera posibles secuencias de acoples (JOIN)
de forma aleatoria. Por cada secuencia JOIN considerada, el código del planificador estándar es
llamado para estimar el costo de ejecutar la consulta con esa secuencia. Para cada paso de la
secuencia JOIN, las tres estrategias posibles son consideradas y todos los planes de escaneo a
relaciones inicialmente-determinado están disponibles. El costo estimado es el más barato de esas
posibilidades. Las secuencias JOIN con el costo estimado más bajo son consideradas más
adaptadas. El algoritmo genético descarta los candidatos menos adaptados. Entonces los nuevos
candidatos son generados por combinación de genes de los candidatos más adaptados.
Este proceso es esencialmente no determinista, porque se hace aleatoria la selección de la población
inicial y la subsecuente mutación de los mejores candidatos. Para evitar cambios sorpresivos del
plan seleccionado, cada corrida del algoritmo de GEQO reinicia el generador de números aleatorios
con el parámetro “guc-geqo-seed”.
2.2.5. Estructuras de datos utilizadas por el algoritmo
Cuando PostgreSQL procesa la consulta, en el módulo Parser se convierte la petición del usuario en
un árbol de consulta o estructura de datos llamada Query (C/A, 1999). La definición de dicha
estructura se muestra en el ANEXO II. A continuación se describen los atributos más importantes
de Query.
struct Query
{
CmdType commandType;
int resultRelation;
List *rtable;
List *targetList;
…
} Query;

Capítulo 2
31
commandType: Este es un valor sencillo que nos dice el comando que produjo el árbol de traducción.
resultRelation: Un índice a la tabla de rango que identifica la relación donde irán los resultados de
la query. Las queries SELECT normalmente no tienen una relación resultado. El caso especial de
una SELECT INTO es principalmente idéntica a una secuencia CREATE TABLE, INSERT...
SELECT. En las consultas INSERT, UPDATE y DELETE la relación resultado es la tabla (o vista)
donde tendrán efecto los cambios.
rtable: La tabla de rango es una lista de las relaciones que se utilizan en la query. En una
instrucción SELECT, son las relaciones dadas tras la palabra clave FROM. Toda entrada en la tabla
del rango identifica una tabla o vista, y nos dice el nombre por el que se la identifica en las otras
partes de la query. En un árbol de query, las entradas de la tabla de rango se indican por un índice
en lugar de por su nombre como estarían en una instrucción SQL. Esto puede ocurrir cuando se han
mezclado las tablas de rangos de reglas. Los ejemplos de este documento no muestran esa situación.
targetList: La lista objetivo es una lista de expresiones que definen el resultado de la consulta. En
el caso de una SELECT, las expresiones son las que se construyen la salida final de la consulta.
Las sentencias DELETE no necesitan una lista objetivo porque no producen ningún resultado. De
hecho, el optimizador añadirá una entrada especial para una lista objetivo vacía. Para el sistema de
reglas, la lista objetivo está vacía. En consultas INSERT la lista objetivo describe las nuevas filas
que irán a la relación resultado. Las columnas que no aparecen en la relación resultado serán
añadidas por el optimizador con una expresión constante NULL. Son las expresiones de la cláusula
VALUES y las de la cláusula SELECT en una INSERT.... SELECT.
En consultas UPDATE, describe las nuevas filas que reemplazarán a las anteriores. Ahora el
optimizador añadirá las columnas que no aparecen insertando expresiones que recuperan los valores
de las filas anteriores en las nuevas. Y añadirá una entrada especial como lo hace DELETE. Es la
parte de la consulta que recoge las expresiones del atributo SET atributo = expresión. Cada entrada
de la lista objetivo contiene una expresión que puede ser un valor constante, una variable apuntando
a un atributo de una de las relaciones en la tabla de rango, un parámetro o un árbol de expresiones
hecho de llamadas a funciones, constantes, variables, operadores, etc.
En el directorio \optimizer se toma la estructura de la consulta retornada por el parse y genera un
plan usado por el executor. El directorio \plan genera el actual plan de salida, el código de \plan

Capítulo 2
32
genera todas las posibles formas de unir (join) las tablas, y \prep, maneja varios pasos de pre-
procesamiento para casos especiales. El directorio \útil son cosas de utilidad. El directorio \geqo,
hace una búsqueda semi-aleatoria dentro del espacio del árbol de consulta (join), en lugar de
exhaustivamente considerar todos los posibles arboles de consultas. Pero cada acople considerado
por \geqo es dado a \path para crearle caminos, así se considera todos los caminos posibles de
implementación para cada par de acoples específicos aún en el módulo GEQO. Las siguientes
estructuras son utilizadas en el módulo de optimización:
RelOptInfo: esta estructura es utilizada para almacenar información referente a la construcción de
arboles de consultas y almacena datos tales como lista de caminos, mejor costo para un camino
almacenado, entre otros datos que se almacena en el transcurso de la optimización, esta estructura
se construye dentro del módulo.
PlannerInfo: esta estructura es utilizada para almacenar información referente a la consulta,
contiene un campo de tipo RelOptInfo para el proceso de optimización, además de tener la
información referente al plan de consultas de forma general, este tipo de estructuras es construida
por el planificador.
Otras estructuras de datos utilizadas por GEQO son:
Gene: este tipo de dato es la interpretación de una tabla codificada dentro de la optimización
genética.
Chromosome: es la representación de un cromosoma, que no es más que una ordenación de tablas
codificadas como números enteros, también guarda información referente a la cantidad de
relaciones que intervienen en la consulta objetivo así como el costo de ejecución.
Pool: es la población n del algoritmo genético, esta almacena información referente a los individuos
en cada generación, así como su calidad, pues estos están ordenados por costo.

Capítulo 2
33
2.3. Conclusiones parciales.
El estudio realizado en este capítulo sobre el procesamiento de consultas que lleva a cabo
PostgreSQL y en particular lo concerniente al módulo de optimización de consultas, ha posibilitado
comprender, a partir de la información técnica y del código fuente, la manera en que procesan y
optimizan las consultas. Esto permite estar en condiciones de proponer cambios en el módulo de
optimización con el objetivo de mejorar su rendimiento. En el próximo capítulo se hace la
propuesta de utilizar otro algoritmo heurístico en lugar del algoritmo genético descrito
anteriormente.

Capítulo 3
34
CAPÍTULO 3. Optimización de consultas utilizando un algoritmo
basado en colonias de hormigas.
Resulta importante en el desarrollo de este proyecto tener en cuenta las dependencias y normas de
programación existente entre los módulos del software en estudio, además de hacer una valoración
de los resultados comparativos entre el algoritmo de optimización existente en estos momentos en
PostgreSQL y posibles candidatos para poder dar una idea de mejora sustancial en función de
parámetros significativos en los resultados tales como calidad de la solución y número de
iteraciones u otros parámetros.
En este capítulo se muestran comparaciones entre la propuesta de algoritmo basado en colonias de
hormigas y el algoritmo genético implementado, así como posibles formas de cálculo de los costos
para la introducción o modificación en el módulo de optimización del algoritmo propuesto.
3.1. Algoritmo de optimización combinatoria basado en colonias de
hormigas.
Los algoritmos de Ant Colony Optimization (ACO, optimización basada en colonias de hormigas
por su traducción al español) fueron desarrollados para solucionar problemas de optimización
combinatoria. Se basan en el comportamiento de las hormigas naturales, que trabajan de manera
cooperativa y se comunican mediante rastros de feromona (Dorigo, 1996; Dorigo, 1997a).
Los algoritmos de ACO son esencialmente algoritmos constructivos: en cada iteración del método,
cada hormiga construye una solución al problema recorriendo un grafo de construcción G. Este
movimiento está influenciado por dos tipos de información: 1) la información heurística (se denota
por ηrs y no se modifica), mide la preferencia heurística de moverse desde el nodo r hasta el nodo s
y 2) la información de los rastros artificiales de feromona (se denota por τrs y sí se modifica), mide
la “deseabilidad aprendida” del movimiento del estado r al s. Cada algoritmo ACO presenta una
forma de actualizar los rastros de feromona. También los algoritmos de ACO incluyen dos
procedimientos adicionales, la evaporación de los rastros de feromona y las acciones del demonio
(Dorigo, 2004). Existen diversos algoritmos de ACO entre los que se encuentran el Sistema de
Hormigas (Ant System, AS) (Dorigo, 1996), el Sistema de Colonia de Hormigas (Ant Colony
System, ACS) (Dorigo, 1997b) y el Sistema de Hormigas Máximo-Mínimo (Max-Min Ant System,
MMAS) (Stützle, 2000).

Capítulo 3
35
3.2. Comparación del algoritmo genético implementado en
PostgreSQL con al algoritmo de optimización combinatoria
basada en colonias de hormigas.
El problema del viajero vendedor (Traveling Salesman Problem – TSP) es un problema típico de
optimización. Existen algunas técnicas heurísticas de optimización (Algoritmos Genéticos,
Recosido simulado, Colonia de Hormigas, Búsqueda Tabú) aplicadas a la solución de este
problema. La solución al problema consiste en encontrar la ruta óptima para recorrer n ciudades sin
repetirlas finalizando en la ciudad de origen. Existe evidencia científica, (Ricardo Alberto Hincapié
Isaza, 2004) que apunta a que el algoritmo que ofrece mejores prestaciones es Colonia de
Hormigas, con relación a algoritmos genéticos debido a que es más fácil de implementar y
convergen con el menor número de iteraciones.
En el estudio del proceso de optimización de consultas en PostgreSQL se encontraron evidencias
de que, en la fase de optimización genética se modela el problema de optimización de consulta
similar al problema del viajero vendedor.
Esto motivó la idea de hacer comparaciones para verificar dicha aseveración, pues no se puede
asegurar que todos los algoritmos genéticos tienen un peor desempeño que los algoritmos basados
en colonias de hormigas, pues esto depende de su implementación y en gran medida del tipo de
problema que resuelven, inclusive hasta las instancias a las que se enfrentan en su trabajo de
resolución.
Tras esta idea se decidió extraer el algoritmo genético de PostgreSQL, independizarlo del software
y realizar algunas transformaciones para que en lugar de resolver la optimización de una consulta,
simplemente resuelva un problema del viajero vendedor, y así poder comparar con el algoritmo
propuesto, que resuelve este tipo de problema también. Este algoritmo toma como parámetro una
matriz con los costos asociados del viaje de una ciudad a otra, el camino óptimo, y la cantidad
máxima de iteraciones.
Al contar con una implementación en Java de un algoritmo basado en colonias de hormigas llamado
Hormigas Max-Min, se tiene el problema de comparar dos algoritmos implementados en lenguajes

Capítulo 3
36
diferentes (Java y C) , por lo que comparaciones en función de tiempo no serían justas pues las
prestaciones del lenguaje C en su desempeño en relación al tiempo es indiscutible al compararlo
con Java que es un lenguaje interpretado, por lo que para posibles comparaciones se tendría que
tomar en cuenta otros aspectos.
Como la principal característica de estos algoritmos es la búsqueda heurística de soluciones
candidatas al problema en cuestión, se caracterizan ambos por hacer una determinada cantidad de
iteraciones para conformar su solución. Estas iteraciones están definidas en los algoritmos genéticos
por la inspección de calidad de todos los individuos de una generación completa, y en las colonias
de hormigas cuando todas las hormigas del enjambre encuentran una solución candidata (tomando
la cantidad de veces que se evalúa la función objetivo como parámetro a medir), tras la similitud
existente en cuanto a costo computacional nos referimos, esta variable a comparar daría un
estimado de rendimiento al enfrentarse ambos algoritmos a la solución de instancias similares, por
lo que una buena idea será compararlos en función de la cantidad de iteraciones que efectúan para
lograr una buena solución, otros parámetro comparativo seria la calidad de la solución encontrada
según iteraciones, esto daría una medida de calidad de las estrategias de enfrentamiento. Para más
información sobre el funcionamiento de algoritmos basados en colonias de hormigas y posibles
comparaciones con algoritmos genético consultar (Amilkar Puris, 2007), (Petkovié, 2011), (Dorigo,
1997a), (Dorigo, 1996).
Para la comparación de los algoritmos se utilizaron 23 instancias del problema del Viajero
Vendedor de la biblioteca LIBTSP(Skorobohatyj, 1999). La mayoría de estas instancias tienen un
tamaño relativamente pequeño debido a que el problema de optimización de consulta que se quiere
resolver, considera que 12 tablas o ciudades es un tamaño considerable para complejizar la
optimización.

Capítulo 3
37
A continuación se muestra en la Tabla 3.1 los resultados de las corridas de ambos algoritmo,
Instancias Algoritmo Genético Algoritmo Basado en Colonias de
Hormigas
Nro.
Iteraciones
Solución Nro.
Iteraciones
Solución
bays29 4143 2097 140 2027
gr24 2947 1272 102 1272 gr120 31593 10190 140 7249
rd100 21884 11802 125 8126
st70 12964 968 132 735 tsp255 45581 8693 153 4174
gr23 2694 1236 86 1236
gr22 2477 1224 82 1216
gr21 2988 1216 56 1218 gr20 3085 1188 105 1189
gr19 1989 1159 95 1159
gr18 1806 1233 79 1159 gr17 1856 1051 56 1051
gr16 2247 1011 30 1011
gr15 1889 1014 39 1014 gr14 1051 928 28 928
gr13 887 928 17 928
gr12 938 928 29 928 gr11 957 922 10 922
gr10 470 846 1 846
gr9 424 832 2 832 gr8 0 692 56 693
gr7 113 683 1 683
Tabla 3.1. Resultados de las corridas de los algoritmos Genético y Hormigas Max-Min.
donde Nro. Iteraciones es la cantidad de iteraciones transcurridas para la búsqueda de la mejor
solución mostrada en la columna Solución.

Capítulo 3
38
En la Figura 3.1 se muestra un gráfico a partir de los datos tabulados en la Tabla 3.1.
Figura 3.1. Gráfico comparativo en función del número de iteraciones.
En la Figura 3.1, el eje horizontal representa el número de ciudades y en el eje vertical la cantidad
de iteraciones en la que encuentra la mejor solución. Como se puede observar, el algoritmo basado
en colonias de hormigas muestra un mejor comportamiento en comparación con el algoritmo
genético. Nótese que cuando el número de ciudades aumenta el algoritmo genético se dispara de
forma notable a partir de las 70 ciudades, dando resultados peores en comparación con el algoritmo
basado en colonias de hormigas.
3.3. Conclusiones parciales
De los resultados comparativos mostrados en este capítulo, se puede concluir que el algoritmo
Hormigas Max-Min exhibe mejores prestaciones en cuanto a número de iteraciones en comparación
con el algoritmo genético de PostgreSQL, lo cual supone obtener una solución suficientemente
buena en menor tiempo. Este comportamiento avala la propuesta de utilizar el algoritmo basado en
colonias de hormigas Max-Min para la optimización de consultas cuando el número de acoples sea
mayor que el umbral mencionado en el capítulo 2.
0
1000
2000
3000
4000
5000
6000
7 10 12 14 16 18 20 22 24 70 120
Iter
acio
nes
Numero de Ciudades
Gráfico Comparativo
Hormigas
Genetico

Conclusiones
39
Conclusiones
Como resultado de esta investigación, se ha arribado a las conclusiones siguientes:
1. A partir del código fuente de PostgreSQL, se hizo un estudio del proceso de optimización de
consultas que lleva a cabo este SGBD, en particular, se hizo énfasis en la comprensión del
algoritmo genético utilizado para optimizar consultas donde el número de acoples supera un
determinado umbral.
2. El estudio del código fuente permitió determinar las estructuras de datos utilizadas por el
proceso de optimización de consultas que realiza PostgreSQL.
3. Se hizo un estudio comparativo, en cuanto a número de iteraciones, entre el algoritmo
genético de PostgreSQL y la propuesta de un algoritmo basado en colonias de hormigas.
4. Como resultado de esta tesis, se propone utilizar el algoritmo basado en colonias de
hormigas Max-Min para la optimización de consultas complejas en PostgreSQL.

Recomendaciones
40
Recomendaciones
Derivadas de la investigación realizada, así como de las conclusiones generales emanadas de la
misma, se recomienda:
1. Sustituir el código del algoritmo genético por el código del algoritmo basado en colonias de
hormigas.
2. Probar la propuesta de algoritmo dentro de PostgreSQL con consultas características que
permitan comparar el rendimiento con la versión anterior.

Bibliografía
41
Bibliografía
Amilkar Puris, R. B., Yailen Martínez and Ann Nowe (2007). Two-Stage Ant Colony Optimization for
solving the Traveling Salesman Problem. pp 1-10.
Astrahan, M. M. (1979): Access Path Selection in a Relational Database Management System.Boston. p
1360.
C/A (1999): Guia del Programador de PostgreSQL. Thomas Lockhart.
Chaudhuri, S. (1998): An Overview of Query Optimization in Relational Database Systems.Seattle. p
400.
Connolly, T. M. B., C. E. (2005): SISTEMAS DE BASES DE DATOS, 4 ed., Pearson Educación S.A.,.Madrid.
p 1320.
Date, C. J. (2001): Introducción a los Sistemas de Bases de Datos, 7ma ed., Pearson Educación. p 960.
Dorigo, M., Maniezzo, V. And Colorni, A. (1996): Ant System: Optimization by a Colony of Cooperating
Agents. Man and Cybernetics-Part B. Vol. 26. No. 1. pp 1-13.
Dorigo, M. a. G., L.M.. (1997a): Ant colonies for the traveling salesman problem. BioSystems. Vol. 26.
No. 43. pp 73-81.
Dorigo, M. y. L. M. G. (1997b): Ant Colony System: A cooperative learning approach to the traveling
salesman problem. IEEE Transactions on Evolutionary Computation. Vol. No. 1. pp 53-66.
Dorigo, M. y. T. S. (Ed.) (2004) Ant Colony Optimization, MIT Press.
Goldberg, D. E. (1989): Genetic Algorithms in Search, Addison Wesley. p 653.
Group, T. P. G. D. (2012): PostgreSQL 9.2.1 Documentation. http://www.postgresql.org/. Retrieved:
Ioannidis, Y. E. (1995): Query Optimization. University of Wisconsin, Madison.
Jarke, M. K., J. (1984): Query Optimization in Database Systems. ACM Computing Survery.
Navathe, R. E. S. B. (2007): Fundamentos de Sistemas de Bases de Datos, 5 ed., PEARSON EDUCACIÓN
S.A.,Madrid. p 1320.
Petkovié, D. (2011). Dynamic Programming Algorithm vs. Genetic Algorithm: Which is Faster? , pp 15-
22.

Bibliografía
42
Ricardo Alberto Hincapié Isaza, C. A. R. P., Ramón Alfonso Gallego R, (2004). TÉCNICAS HEURÍSTICAS
APLICADAS AL PROBLEMA DEL CARTERO VIAJANTE (TSP). pp 53-128.
SELINGER P. , A. M. M., LORIE R.A. (1979): Acces path selection in a ralational database management
system, PRICE T.G.Boston. p 1200.
Skorobohatyj, G. (1999). The TSPLIB Symmetric Traveling Salesman Problem Instances,. pp 11-56.
Stützle, T. y. H. H. (2000). MAX-MIN Ant System. Future Generation Computer Systems. pp 421-481.
VALDURIEZ P., G. G. (1984): Join and semi-join algorithms for a multi-processor database machine. p
1214.

Anexos
43
Anexos
ANEXO I. Estructura del catálogo de PostgreSQL.

Anexos
44
Anexo II. Definición de las estructuras de datos
En include/optimizer/geqo_gene.h
typedef int Gene;
typedef struct Chromosome {
Gene *string; Cost worth;
} Chromosome;
typedef struct Pool {
Chromosome *data; int size; int string_length;
} Pool;
typedef struct {
RelOptInfo *joinrel; /* joinrel para el conjunto de las relaciones*/ int size; /* número de relaciones de entrada en grupo */
} Clump;
Estado privado a correr GEQO accesible a través de la raíz-> join_search_privatetypedef struct {
List *initial_rels; /* las relaciones bajas que nosotros estamos uniendo */ unsigned short random_state[3]; /* el estado para el pg_erand48 () */
} GeqoPrivateData;
El primer campo de un nodo de cualquier tipo se garantiza que sea la NodeTag. Por lo tanto el tipo de cualquier nodo puede ser obtenido por colada a nodo. Declarar una variable como del Nodo * (en lugar de void *) también puede facilitar la depuración.typedef struct Node {
NodeTag type; } Node;
typedef struct RelOptInfo {
NodeTag type; RelOptKind reloptkind;

Anexos
45
/* todas las relaciones incluidas en este RelOptInfo */ Relids relids; /* conjunto de relids base (índices tabla de rango)*/ /* estimaciones del tamaño generadas por proyectista */ double rows; /* el número estimado de tuplas del resultado */ int width; /* la tamaño del avg estimada de tuplas del resultado */ /* la información de la materialización */ List *reltargetlist; /* Variable de salida para scanear la relacion */ List *pathlist; /* Structura del Camino */ List *ppilist; /* ParamPathInfos usada en pathlist */ struct Path *cheapest_startup_path; struct Path *cheapest_total_path; struct Path *cheapest_unique_path; List *cheapest_parameterized_paths; /* informacion relacionada con la relación base */ Index relid; Oid reltablespace; /* el tablespace conteniendo */ RTEKind rtekind; /* RELATION, SUBQUERY, or FUNCTION */ AttrNumber min_attr; /* el attrno más pequeño de la relación (often <0) */ AttrNumber max_attr; /* el attrno más grande de la relación */ Relids *attr_needed; /* la serie puso en un índice [min_attr .. max_attr] */ int32 *attr_widths; /* la serie puso en un índice [min_attr .. max_attr] */ List *indexlist; /* lista deIndexOptInfo */ BlockNumber pages; /* las estimaciones del tamaño derivaron de pg_class */ double tuples; double allvisfrac; /* usa "struct Plan" para evitar incluso plannodes.h aquí */ struct Plan *subplan; /* si es subquery */ PlannerInfo *subroot; /* si es subquery */ /* use "el struct FdwRoutine" para evitar incluso fdwapi.h aquí */ struct FdwRoutine *fdwroutine; /* la table extrangera */ void *fdw_private; /* la table extrangera */ /* usado por varios examina y une: */ List *baserestrictinfo; /* RestrictInfo estructura (si el rel bajo) */ QualCost baserestrictcost; /* el costo de evaluar el anterior */ List *joininfo; /* RestrictInfo estructura para una cláusulas que involucran este rel*/ bool has_eclass_joins; /* T quiere decir que el joininfo está incompleto */
} RelOptInfo;
/*Tipo que "Camino" se usa como-es para secuencial-examine los caminos, así como algún otro * los tipos del plan simples que nosotros no necesitamos información extra en el camino para. * Para otros tipos del camino es el primer componente de un struct más grande. * "pathtype" es el NodeTag del nodo del Plan que nosotros podríamos construir de este Camino.

Anexos
46
* Es parcialmente redundante con el NodeTag del Camino, pero nos permite usar * el mismo tipo del Camino para los tipos del Plan múltiples cuando no hay necesidad a * distinga el tipo del Plan durante el proceso del camino. * *"param_info", if not NULL, links to a ParamPathInfo that identifies outer *el relation(s) eso proporciona los valores del parámetro a cada uno examine de este camino. *Eso significa que este camino sólo puede unirse a esos rels por medio del nestloop * une con este camino en el interior. También la nota que un camino del parameterized * es responsable para probar todos "movible" joinclauses que involucra este rel * y el rel(s exterior especificado). * "filas" son igual que padre->rows en los caminos simples, pero en el parameterized * los caminos y UniquePaths puede ser menos de padre->rows, reflejando el *el hecho que nosotros nos hemos filtrado por el extra una condiciones o los duplicados alejados. * "pathkeys" es una Lista de nodos de PathKey (vea anteriormente), describiendo la clase * pidiendo de las filas del rendimiento del camino. */
typedef struct Path {
NodeTag type; NodeTag pathtype; /* etiqueta que identifica el método del scan/join */ RelOptInfo *parent; /* la relación que este camino puede construir */ ParamPathInfo *param_info; /* el info del parameterization, o NULO si ninguno */ /* el size/costs estimado para el camino (vea costsize.c para más info)*/ double rows; /* el número estimado de tuples del resultado */ Cost startup_cost; /* el costo expendió antes de sacar cualquier tuples */ Cost total_cost; /* el costo total (asumiendo todo el tuples sacado) */ List *pathkeys; /* la clasificación de la clase del rendimiento de camino */ /* el pathkeys es una Lista de nodos de PathKey; vea anteriormente */
} Path;
La estimación del costo producida por el cost_qual_eval () incluye ambos un uno-tiempo (el startup) el
costo, y un por-tuple el costo.typedef struct QualCost {
Cost startup; /* one-time costo */ Cost per_tuple; /* per-evaluation costo */
} QualCost;
Costando la ejecución de la función agregado requiere estas estadísticas sobre los agregados a ser ejecutados por un nodo de Agg dado. La nota que el transCost incluye los costos de la ejecución de las expresiones de la entrada de los agregados.typedef struct AggClauseCosts
{ int numAggs; /* el número total de funciones agregado */

Anexos
47
int numOrderedAggs; /* número que usa DISTINTO o PIDE POR */ QualCost transCost; /* los costos de ejecución de por-entrada-fila totales */ Cost finalCost; /* los costos del total de agg las funciones finales */ Size transitionSpace;/* el espacio para los datos de transición de paso-por-ref */
} AggClauseCosts;
PlannerGlobal La información global para el planning/optimizationPlannerGlobal holds state for an entire planner la invocación; este estado es compartido por todos los niveles de subalterno-pregunta que existen en el ser del orden planeados. typedef struct PlannerGlobal {
NodeTag type; ParamListInfo boundParams; /* Param valora proporcionado a proyectista () */ List *paramlist; /* para guardar huella de Params cruz-nivelado */ List *subplans; /* Los planes para los nodos de SubPlan */ List *subroots; /* PlannerInfos para los nodos de SubPlan */ Bitmapset *rewindPlanIDs; /* el indices de subplans que requiere el REBOBINADO */ List *finalrtable; /* "flat" el rangetable para el ejecutor */ List *finalrowmarks; /* "flat" lista para PlanRowMarks */ List *resultRelations; /* "flat" la lista de entero los índices de RT */ List *relationOids; /* OIDs de relaciones de que el plan depende */ List *invalItems; /* otras dependencias, como PlanInvalItems, */ Index lastPHId; /* PlaceHolderVar ID más alto asignó */ Index lastRowMarkId; /* PlanRowMark ID más alto asignó */ bool transientPlan; /* ¿los redo planean cuándo los cambios de TransactionXmin? */
} PlannerGlobal; typedef struct PlannerInfo
{ NodeTag type; Query *parse; /* el ser de la Pregunta planeó */ PlannerGlobal *glob; /* el info global para la carrera del proyectista actual */ Index query_level; /* 1 a la Pregunta extrema */ struct PlannerInfo *parent_root; /* NULO a la Pregunta extrema */ /*el simple_rel_array sostiene los indicadores a "rels bajo" y "otro rels" (vea * los comentarios para RelOptInfo para más info). se pone en un índice por el rangetable * el índice (para que entrada 0 siempre se gasta). las Entradas pueden ser NULAS cuando un RTE * no corresponda a una relación baja, como un una RTE o un * los unreferenced ven RTE; o si el RelOptInfo no ha sido todavía hecho. * / struct RelOptInfo **simple_rel_array; /* Todos los 1-rel RelOptInfos */ int simple_rel_array_size; /* el tamaño asignado de serie */ /* el simple_rte_array es la misma longitud como los simple_rel_array y sostenimientos los indicadores a las entradas del rangetable asociadas. Esto nos permite evitar el rt_fetch () que puede ser lentamente una vez un pedazo los juegos de herencia grandes tiene se extendido. */

Anexos
48
RangeTblEntry **simple_rte_array; /* rangetable as an array */ /* * el all_baserels es un juego de Relids de todo el relids de la base (pero no "otro" *el relids) en la pregunta; es decir, el identificador de Relids del examen final une *nosotros necesitamos formar. */ Relids all_baserels; /* * el join_rel_list es una lista de toda la unir-relación RelOptInfos que nosotros tenemos * consideró en esta carrera de la planificación. Para los problemas pequeños nosotros examinamos *apenas el * la lista para hacer el lookups, pero cuando hay que muchos unen las relaciones nosotros *construimos un * la mesa de picadillo para el lookups más rápido. La mesa de picadillo está presente y válida * cuando el join_rel_hash no es NULO. La nota que nosotros todavía mantenemos la lista * incluso al usar la mesa de picadillo para el lookups; esto simplifica la vida para * GEQO. */ List *join_rel_list; /* la lista de unir-relación RelOptInfos */ struct HTAB *join_rel_hash; /* el hashtable optativo para una las relaciones */ /* * Cuando haciendo un dinámico-programación-estilo unen la búsqueda, el join_rel_level[k] * es una lista de toda la unir-relación RelOptInfos de k nivelado, y * el join_cur_level es el nivel actual. Nueva unir-relación que RelOptInfos son * automáticamente agregó al join_rel_level[join_cur_level] la lista. * el join_rel_level es NULO si no en el uso. */ List **join_rel_level; /* las listas de unir-relación RelOptInfos */ int join_cur_level; /* el índice de lista que está extendido */ List *init_plans; /* el init SubPlans para la pregunta */ List *cte_plan_ids; /* la lista del por-CTE-artículo de subplan IDs */ List *eq_classes; /* la lista de EquivalenceClasses activo */ List *canon_pathkeys; /* la lista de "canónico" PathKeys */ List *left_join_clauses; /* la lista de R estrictInfos para
* el mergejoinable exterior una las cláusulas * el var del w/nonnullable en la izquierda * /
List *right_join_clauses; /* la lista de RestrictInfos para * el mergejoinable exterior una las cláusulas * el var del w/nonnullable en el derecho * /
List *full_join_clauses; /* la lista de RestrictInfos para los mergejoinable abatanan una las cláusulas * /
List *join_info_list; /* la lista de SpecialJoinInfos * / List *append_rel_list; /* Lista de AppendRelInfos */ List *rowMarks; /* lista de PlanRowMarks */ List *placeholder_list; /* lista de PlaceHolderInfos */ List *query_pathkeys; /* el pathkeys deseado para el query_planner (), y
* el pathkeys real después */ List *group_pathkeys; /* el pathkeys del groupClause, si cualquiera */ List *window_pathkeys; /* el pathkeys de ventana del fondo, si cualquiera */

Anexos
49
List *distinct_pathkeys; /* el pathkeys del distinctClause, si cualquiera */ List *sort_pathkeys; /* el pathkeys del sortClause, si cualquiera */ List *minmax_aggs; /* lista de MinMaxAggInfos */ List *initial_rels; /* RelOptInfos que nosotros estamos intentando unir ahora */ MemoryContext planner_cxt; /* contexto que sostiene PlannerInfo */ double total_table_pages; /* #de páginas en todas las mesas de pregunta */ double tuple_fraction; /* los tuple_fraction pasaron al query_planner */ double limit_tuples; /* los limit_tuples pasaron al query_planner */ bool hasInheritedTarget; /* verdadero si analizar->resultRelation es un
* el rel de niño de herencia */ bool hasJoinRTEs; /* verdadero si cualquier RTEs es el tipo de RTE_JOIN */ bool hasHavingQual; /* verdadero si el havingQual fuera non-nulo */ bool hasPseudoConstantQuals; /* verdadero si cualquier RestrictInfo tiene
*el pseudoconstant = verdadero * / bool hasRecursion; /* true if planning a recursive WITH item */ /* Estos campos sólo se usan cuando el hasRecursion es verdad: */ int wt_param_id; /* PARAM_EXEC ID para la mesa de trabajo */ struct Plan *non_recursive_plan; /* el plan para el término del non-recursive */ /* Estos campos son los workspace para createplan.c */ Relids curOuterRels; /* el rels exterior sobre el nodo actual */ List *curOuterParams; /* NestLoopParams no-todavía-asignado */ /* por ejemplo, datos privados optativos para el join_search_hook GEQO */ void *join_search_private;
} PlannerInfo; /* * IndexOptInfo * La información del por-índice para el planning/optimization * el indexkeys [], indexcollations [], opfamily [], y opcintype [] * cada uno tiene las entradas del ncolumns. * el sortopfamily [], reverse_sort [], y nulls_first [] igualmente tiene * las entradas del ncolumns, si el índice se pide; pero si es el unordered, * esos indicadores son NULOS. * Zeroes en el indexkeys [] la serie indica columnas del índice que son * las expresiones; hay un elemento en el indexprs para cada tal columna. * Para un índice pedido, reverse_sort [] y nulls_first [] describa el * la clasificación de la clase de un indexscan delantero; nosotros también podemos considerar un dirigido hacia atrás * indexscan que generará la clasificación inversa. * Los indexprs y expresiones del indpred se han atravesado * prepqual.c y eval_const_expressions () para la facilidad de emparejar a * DONDE las cláusulas. el indpred es en implícito-y forma. * el indextlist es una lista de TargetEntry que representa las columnas del índice. * Mantiene una base-relación equivalente Var cada columna simple, * y eslabones al elemento del indexprs emparejando para cada columna de la expresión. * /

Anexos
50
typedef struct IndexOptInfo {
NodeTag type; Oid indexoid; / * OID de la relación del índice */ Oid reltablespace; /* el tablespace de índice (no la tabla) */ RelOptInfo *rel; /* el parte de atrás-eslabón a la mesa de índice */ /* statistics from pg_class */ BlockNumber pages; / * el número de páginas del disco en el índice */ double tuples; /* el número de tuples del índice en el índice */ /* ponga en un índice la información del descriptor */ int ncolumns; /* el número de columnas en el índice */ int *indexkeys; /* la columna numera de las llaves de índice, o 0 */ Oid *indexcollations;/* OIDs de comparaciones de columnas del índice */ Oid *opfamily; /* OIDs de familias del operador para las columnas */ Oid *opcintype; /* OIDs de opclass declaró los tipos de datos de entrada */ Oid *sortopfamily;/* IDs de opfamilies del btree, si el orderable */ bool *reverse_sort; /* ¿el clase orden descender es? */ bool *nulls_first; /* ¿NULLs entran primero en el orden de la clase? */ Oid relam; /* OID del método de acceso (en el pg_am) */ RegProcedure amcostestimate; /* OID del fcn del costo del método de acceso */ List *indexprs; /* las expresiones para las columnas del índice non-simples */ List *indpred; /* el predicado si un índice parcial, el NADA del resto, */ List *indextlist; /* targetlist que representa las columnas del índice * / bool predOK; /* verdadero si el predicado empareja la pregunta */ bool unique; /* verdadero si un único índice */ bool immediate; /* ¿la singularidad se da fuerza a inmediatamente? */ bool hypothetical; /* verdadero si el índice realmente no existe */ bool canreturn; /* ¿puede poner en un índice devuelva IndexTuples? */ bool amcanorderbyop; /* ¿hace el orden de apoyo ESTÁ por el resultado del operador? */ bool amoptionalkey; /* ¿puede preguntar omita la llave para la primera columna? */ bool amsearcharray; /* ¿la lata el asa el quals de ScalarArrayOpExpr ES? */ bool amsearchnulls; /* ¿la lata la búsqueda ES para NULL/NOT las entradas NULAS? */ bool amhasgettuple; /* ¿hace ES tiene la interface del amgettuple? */ bool amhasgetbitmap; /* ¿hace ES tiene la interface del amgetbitmap? */
} IndexOptInfo;