trabajo investigacion de algoritmos
DESCRIPTION
En esta presente investigación contiene los temas: Estructura de datos Externas, Archivos, Búsqueda y ordenamiento y Programación de aplicaciones.TRANSCRIPT

TEORÍA DE ALGORITMOS II VILLALOBOS ESTUDILLO WILLIAM
PROFRA.: PÉREZ VILLANUEVA JUANA
10/07/2016
CENTRO UNIVERSITARIO SALINA CRUZ

Contenido 1. ESTRUCTURA DE DATOS EXTERNOS, ARCHIVOS ................................................................................... 3
1.1 Conceptos y Definiciones .................................................................................................................... 3
1.2 Características ..................................................................................................................................... 3
2.2.1 Residencia ..................................................................................................................................... 3
2.2.2 Permanencia ................................................................................................................................. 3
2.2.3 Portabilidad .................................................................................................................................. 3
1.2.3 Capacidad ..................................................................................................................................... 4
1.3 Clasificación ......................................................................................................................................... 9
1.3.1 Permanentes ............................................................................................................................... 9
1.3.1.1 De constantes .......................................................................................................................... 9
1.3.1.2 De situación: ............................................................................................................................ 9
1.3.1.2 Maestros: ................................................................................................................................... 9
1.3.1.3 Históricos: ................................................................................................................................. 9
1.3.2 De movimientos .......................................................................................................................... 9
1.3.3 De trabajo: .................................................................................................................................. 9
1.4 Organización ........................................................................................................................................ 9
1.4.1 Secuencia ..................................................................................................................................... 9
1.4.2 Random o directo ....................................................................................................................... 10
1.4.3 Indexada ..................................................................................................................................... 10
2. Búsqueda y Ordenamiento ...................................................................................................................... 10
2.1 Algoritmo de búsqueda ..................................................................................................................... 10
2.1.1 Secuencial ................................................................................................................................... 11
2.1.2 Binaria ......................................................................................................................................... 11
2.1.3 Cálculo de dirección ................................................................................................................... 12
2.2 Ordenamiento ................................................................................................................................... 14
2.2.1 Optimo teórico para ordenamiento de tablas ........................................................................... 17
2.2.2 Intercambio simple ..................................................................................................................... 18
2.2.3 Algoritmo de la burbuja.............................................................................................................. 19
2.2.4 Shell sort ..................................................................................................................................... 22
2.2.5 Quick sort................................................................................................................................... 23
2.2.6 Tree sort o Heap sort .................................................................................................................. 25
2.2.7 Ordenamiento pot intercalation ................................................................................................ 26

2.2.8 Ordenamiento por distribución .................................................................................................. 28
2.3 Ordenamiento externo ...................................................................................................................... 28
2.3.1 El torneo de tenis para ordenamiento externo .......................................................................... 28
2.3.2 Interacción con lotes. Algoritmo balanceado............................................................................. 29
2.3.3 El algoritmo poli fase para interacción por lote ......................................................................... 29
2.3.4 El algoritmo de cascada .............................................................................................................. 30
2.4 Árboles balanceados ......................................................................................................................... 30
2.4.1 Definiciones ................................................................................................................................ 30
2.4.2 Árboles AVL ................................................................................................................................ 33
2.4.3 Árboles tipo B ............................................................................................................................. 37
2.5 Dispersión al azar desmenuzamiento o hassing................................................................................ 45
2.5.1 Algoritmos .................................................................................................................................. 46
2.5.2 Funciones de dispersión ............................................................................................................. 47
2.5.3 Manejo de colisiones .................................................................................................................. 47
2.5.4 Manejo de sobre flujo ................................................................................................................ 48
2.5.5 Un corrector de ortografía ......................................................................................................... 49
3. Programación de aplicaciones ................................................................................................................. 49
3.1 Descripción del lenguaje a utilizar ..................................................................................................... 49
3.1.1 Estructura de un programa y reglas sintácticas ......................................................................... 50
3.1.2 Palabras reservadas .................................................................................................................... 53
3.1.3 Tipos de datos y variables .......................................................................................................... 54
3.1.4 Instrucciones asociadas a: .......................................................................................................... 56
3.1.4.1 Operaciones primitivas ............................................................................................................ 56
3.1.4.2 Estructuras de control ............................................................................................................. 57
3.1.4.3 Operaciones aritméticas.......................................................................................................... 57
3.1.4.4 Funciones matemáticas ........................................................................................................... 58
3.1.4.5 Manejo de caracteres .............................................................................................................. 59
3.1.4.7 Estructura de datos ................................................................................................................. 61
3.1.4.7 Operaciones especiales ........................................................................................................... 61
3.1.5 Subrutinas / procedimientos ...................................................................................................... 61
3.2.1 Funciones.................................................................................................................................... 62
3.2 Estructura de los datos internos ....................................................................................................... 64
3.2.1 Vectores ...................................................................................................................................... 65
3.2.2 Matrices ...................................................................................................................................... 70
3.2.3 Poliedros ..................................................................................................................................... 70

1. ESTRUCTURA DE DATOS EXTERNOS, ARCHIVOS
1.1 Conceptos y Definiciones
Concepto:
Archivo: Para poder acceder a determinada información en cualquier momento, se
necesitará que ella esté depositada en soportes físicos los cuales la almacenan en forma
permanente. Este es el caso de la memoria externa o auxiliar como ser disquete, disco
duro, cinta magnética, etc.-, en las cuales sin necesidad de estar conectadas a la corriente
eléctrica, la información permanece allí. La forma de guardar los datos en estos
dispositivos auxiliares es mediante unas estructuras llamadas archivos o ficheros.
Definición:
“Es una estructura externa de datos, constituida por un conjunto de elementos
todos del mismo tipo, organizados en unidades de acceso, llamadas registros.”
1.2 Características
Residen en soporte de almacenamiento externo.
La información se almacena de forma permanente.
Alta capacidad de almacenamiento de datos.
Independencia de la información que guardan respecto a los programas
que los usan.
2.2.1 Residencia
La forma de guardar los datos en estos dispositivos auxiliares es mediante unas
estructuras llamadas archivos o ficheros.
2.2.2 Permanencia
Para poder acceder a determinada información en cualquier momento, se
necesitará que ella esté depositada en soportes físicos los cuales la almacenan en
forma permanente.
2.2.3 Portabilidad
Este es el caso de la memoria externa o auxiliar como ser disquete, disco duro,
cinta magnética, etc.-, en las cuales sin necesidad de estar conectadas a la
corriente eléctrica, la información permanece allí. La forma de guardar los datos
en estos dispositivos auxiliares es mediante unas estructuras llamadas archivos o
ficheros.
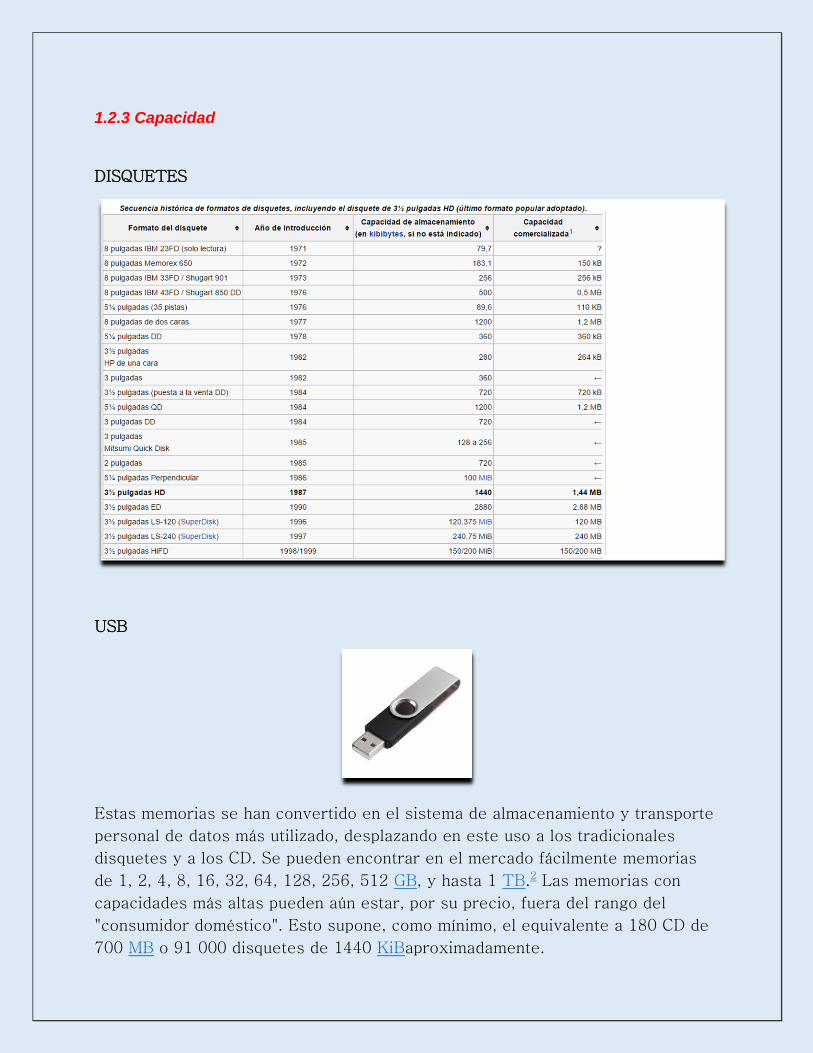
1.2.3 Capacidad
DISQUETES
USB
Estas memorias se han convertido en el sistema de almacenamiento y transporte
personal de datos más utilizado, desplazando en este uso a los tradicionales
disquetes y a los CD. Se pueden encontrar en el mercado fácilmente memorias
de 1, 2, 4, 8, 16, 32, 64, 128, 256, 512 GB, y hasta 1 TB.2 Las memorias con
capacidades más altas pueden aún estar, por su precio, fuera del rango del
"consumidor doméstico". Esto supone, como mínimo, el equivalente a 180 CD de
700 MB o 91 000 disquetes de 1440 KiBaproximadamente.

DISCO DURO
Capacidad.- La capacidad de almacenamiento de los discos duros ha ido
aumentando a través de los años, desde unos cuantos megabytes hasta llegar en
la actualidad a estandarizarse en varios cientos de gigabytes e incluso terabytes.

CD
DVD
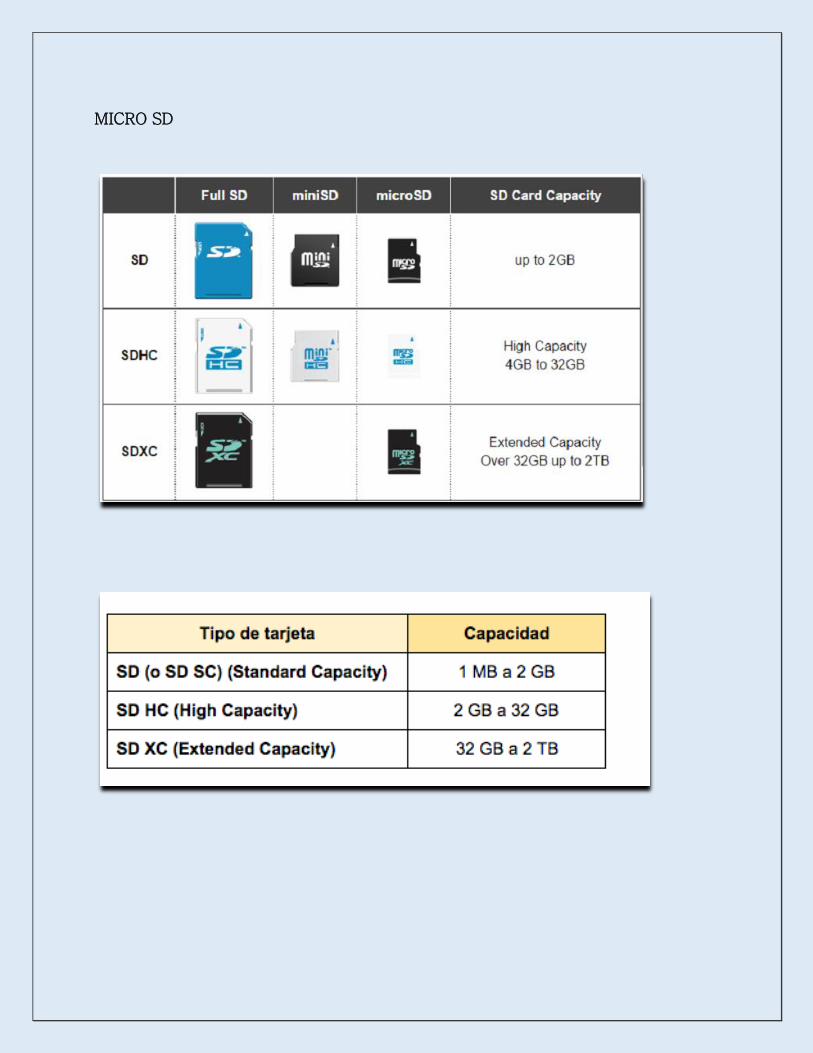
MICRO SD

MEMORY STICK
Las capacidades comerciales actuales en nuestro país son:
Formato de
memoria Capacidades en MB / GB
Memory Stick 64 Megabytes (MB), 128 MB
MS Pro Duo 512 MB, 1 Gigabyte (GB), 2 GB, 4 GB, 8 GB, 16 GB, 32 GB
MS Pro Magic Gate 256 MB, 512 MB, 1 GB, 2 GB, 4 GB
MS micro - M2 512 MB, 1 GB, 2 GB, 4 GB, 8 GB, 16 GB
BLU-RAY
Normalmente una capa de disco Blu-Ray puede almacenar cerca de 25 GB de
información, habiendo discos ópticos de esa tecnología que disponen cuatro capas
y que por tanto llegan a almacenar 100 GB de información total. La velocidad actual
de transferencia de datos que tienen estos discos viene a ser de 36 mbps,
analizándose la posibilidad de aumentar esta velocidad a unos 82 mbps.

La superficie de la que consta el Blu-Ray es resistente a todo tipo de rayaduras
debido a un material llamado como Durabis que viene a formar la última capa de
protección física de estos discos
1.3 Clasificación
Según su función o uso que se hace de ellos:
1.3.1 Permanentes: Su información varía poco en el tiempo
1.3.1.1 De constantes: Consultas. Baja o nula modificación (Códigos
Postales).
1.3.1.2 De situación: estado actual de la información (F. maestros)
1.3.1.2 Maestros: Estos contienen información que varía poco. En algunos casos
es preciso actualizarlos periódicamente.
1.3.1.3 Históricos: Nunca se modifican (Rentas de años anteriores)
1.3.2 De movimientos: Información para actualizar ficheros permanentes
(compra-ventas diarias).
1.3.3 De trabajo: Tienen una vida limitada, normalmente menor que la duración
de la ejecución de un programa. Su utilizan como auxiliares de los anteriores.
1.4 Organización
Organización de Archivos: La organización de un archivo define la forma en la que
los registros se disponen sobre el soporte de almacenamiento, o también se define
la organización como la forma en que se estructuran los datos en un archivo. En
general, se consideran tres organizaciones fundamentales:
•Organización secuencial
•Organización directa o aleatoria (random)
•Organización secuencial indexada
Obs: En Pascal estándar los archivos son de Org. Secuencial Turbo Pascal
permite el acceso aleatorio o directo en todos los archivos (excepto en archivos
de textos).
1.4.1 Secuencia
Organización secuencial No es más que una sucesión de registros almacenados en
forma consecutiva sobre un soporte externo. Los registros están ubicados
físicamente en una secuencia usualmente fijada por uno o más campos de control
contenidos dentro de cada registro, en forma ascendente o descendente. Esta
organización tiene el último registro en particular, contiene una marca (en general

un asterisco) de fin de archivo, la cual se detecta con funciones tipo EOF (end of
file) o FDA (Fin de Archivo).
1.4.2 Random o directo
Los datos se colocan y se acceden aleatoriamente mediante su posición, es decir,
indicando el lugar relativo que ocupan dentro del conjunto de posiciones posibles.
En esta organización se pueden leer y escribir registros, en cualquier orden y en
cualquier lugar. Inconvenientes:
a) Establecer la relación entre la posición que ocupa un registro y su contenido.
b) Puede desaprovecharse parte del espacio destinado al archivo. Ventaja:
Rapidez de acceso a un registro cualquiera.
1.4.3 Indexada
Un archivo con esta organización consta de tres áreas: Área de índices Área
primaria Área de excedentes (overflow)
Ventaja:
a) Rápido acceso, y, además, el sistema se encarga de relacionar la posición de
cada registro con su contenido por medio del área de índices.
b) Gestiona las áreas de índices y excedentes.
Desventajas:
a) Necesidad de espacio adicional para el área de índices.
b) el desaprovechamiento de espacio que resulta al quedar huecos intermedios
libres después de sucesivas actualizaciones.
2. Búsqueda y Ordenamiento
2.1 Algoritmo de búsqueda
Con mucha frecuencia los programadores trabajan con grandes cantidades de
datos almacenados en arrays y registros, y por ello será necesario determinar si
un array contiene un valor que coincida con un cierto valor clave. El proceso de
encontrar un elemento específico de un array se denomina búsqueda. En esta
sección se examinarán dos técnicas de búsqueda: búsqueda lineal o secuencial, la
técnica más sencilla, y búsqueda binaria o dicotómica, la técnica más eficiente.

2.1.1 Secuencial
La búsqueda secuencial busca un elemento de una lista utilizando un valor destino
llamado clave.
En una búsqueda secuencial (a veces llamada búsqueda lineal), los elementos de
una lista o vector se exploran (se examinan) en secuencia, uno después de otro.
La búsqueda secuencial es necesaria, por ejemplo, si se desea encontrar la
persona cuyo número de teléfono es 958-220000 en un directorio o listado
telefónico de su ciudad. Los directorios de teléfonos están organizados
alfabéticamente por el nombre del abonado en lugar de por números de teléfono,
de modo que deben explorarse todos los números, uno después de otro, esperando
encontrar el número 958-220000.
El algoritmo de búsqueda secuencial compara cada elemento del array con la clave
de búsqueda.
Dado que el array no está en un orden prefijado, es probable que el elemento a
buscar pueda ser el primer elemento, el último elemento o cualquier otro. De
promedio, al menos el programa tendrá que comparar la clave de búsqueda con la
mitad de los elementos del array. El método de búsqueda lineal funcionará bien
con arrays pequeños o no ordenados. La eficiencia de la búsqueda secuencial es
pobre, tiene complejidad lineal, O(n).
2.1.2 Binaria
La búsqueda secuencial se aplica a cualquier lista. Si la lista está ordenada, la
búsqueda binaria proporciona una técnica de búsqueda mejorada. Una búsqueda
binaria típica es la búsqueda de una palabra en un diccionario. Dada la palabra, se
abre el libro cerca del principio, del centro o del final dependiendo de la primera
letra del primer apellido o de la palabra que busca. Se puede tener suerte y acertar
con la página correcta; pero, normalmente, no será así y se mueve el lector a la
página anterior o posterior del libro. Por ejemplo, si la palabra comienza con «J» y
se está en la «L» se mueve uno hacia atrás. El proceso continúa hasta que se
encuentra la página buscada o hasta que se descubre que la palabra no está en la
lista.
Una idea similar se aplica en la búsqueda en una lista ordenada. Se sitúa la lectura
en el centro de la lista y se comprueba si la clave coincide con el valor del
elemento central. Si no se encuentra el valor de la clave, se sigue la búsqueda uno
en la mitad inferior o superior del elemento central de la lista. En general, si los
datos de la lista están ordenados se puede utilizar esa información para acortar el
tiempo de búsqueda.

2.1.3 Cálculo de dirección
ALGORITMO DE ORDENAMIENTO POR CALCULO DE DIRECCIONES
PROCEDURE HASH;
TYPE
TIPO.NODO=RECORD;
NEXT,INFO: INTEGER;
END;
VAR
NODO:ARRAY [1...N] OF TIPO.NODO
F: ARRAY [O...9] OF INTEGER
P,PRIM,Q,I,J,AVAIL,Y:INTEGER;
BEGIN
FOR I:=1 TO N-1 DO
BEGIN
NODO[I].INFO:=X[I];
NODO[1].NEXT:=I+1;
END;
NODO[N].INFO:=X[N];
NODO[N].NEXT:=0;
FOR I:=0 TO 9 DO
F[I]:=0;
FOR I:=1 TO N DO
BEGIN
Y:=X[I]; PRIM:=Y DIV 10;
INSERT_LISTA (F(PRIM),Y);
END;
I:=0;

FOR J:=0 TO N DO
BEGIN
P:=F[J];
WHILE P <> 0 DO
BEGIN
I:=I+1;
X[I]:=NODO[P].INFO;
P:=NODO[P].NEXT;
END;
END;
END;
1 [56] J=-->0 [0]=0
2 [28] 1 [1]=0->[14|]
3 [32] 2 [2]=0->[28|]
4 [14] 3 [3]=0->[32|]
5 [51] 4 [4]=0
5 [5]=0->[51|]-->[56|]-¬
6 [6]=0
7 [7]=0
8 [8]=0
9 [9]=0
NODO
INFO NEXT
[56 | 2 ] 1=1 [14]
[28 | 3 ] 2 [28]
[32 | 4 ] 3 [32]

[14 | 5 ] 4 [51]
[51 | 0 ] 5 [56]
I=1,2,3,4,5
Y=56,28,32,14,51
PRIM=5,2,3,1,5
P=0,4,0,2,0,3,0,0,5,1,0,0,0,0,0
2.2 Ordenamiento
La ordenación o clasificación de datos (sort, en inglés) es una operación consistente
en disponer un conjunto —estructura— de datos en algún determinado orden con
respecto a uno de los campos de elementos del conjunto. Por ejemplo, cada
elemento del conjunto de datos de una guía telefónica tiene un campo nombre, un
campo dirección y un campo número de teléfono; la guía telefónica está dispuesta
en orden alfabético de nombres; los elementos numéricos se pueden ordenar en
orden creciente o decreciente de acuerdo al valor numérico del elemento. En
terminología de ordenación, el elemento por el cual está ordenado un conjunto de
datos (o se está buscando) se denomina clave.
Una colección de datos (estructura) puede ser almacenada en un archivo, un array (vector o tabla), un array de registros, una lista enlazada o un árbol. Cuando los
datos están almacenados en un array, una lista enlazada o un árbol, se denomina
ordenación interna. Si los datos están almacenados en un archivo, el proceso de
ordenación se llama ordenación externa. Una lista se dice que está ordenada por la clave k si la lista está en orden
ascendente o descendente con respecto a esta clave. La lista se dice que está en
orden ascendente si:
i < j implica que k[i] <= k[j]
y se dice que está en orden descendente si:
i > j implica que k[i] <= k[j]
Para todos los elementos de la lista. Por ejemplo, para una guía telefónica, la lista
está clasificada en orden ascendente por el campo clave k, donde k[i] es el nombre
del abonado (apellidos, nombre).
4 5 14 21 32 45 orden ascendente 75 70 35 16 14 12 orden descendente Zacarias Rodriguez Martinez Lopez Garcia orden descendente

Los métodos (algoritmos) de ordenación son numerosos, por ello se debe prestar
especial atención en su elección. ¿Cómo se sabe cuál es el mejor algoritmo? La
eficiencia es el factor que mide la calidad y rendimiento de un algoritmo. En el
caso de la operación de ordenación, dos criterios se suelen seguir a la hora de
decidir qué algoritmo —de entre los que resuelven la ordenación— es el más
eficiente: 1) tiempo menor de ejecución en computadora; 2) menor número de instrucciones.
Sin embargo, no siempre es fácil efectuar estas medidas: puede no disponerse de
instrucciones para medida de tiempo —aunque no sea éste el caso del lenguaje
C—, y las instrucciones pueden variar, dependiendo del lenguaje y del propio estilo
del programador. Por esta razón, el mejor criterio para medir la eficiencia de un
algoritmo es aislar una operación específica clave en la ordenación y contar el
número de veces que se realiza. Así, en el caso de los algoritmos de ordenación,
se utilizará como medida de su eficiencia el número de comparaciones entre
elementos efectuados. El algoritmo de ordenación A será más eficiente que el B,
si requiere menor número de comparaciones.
Así, en el caso de ordenar los elementos de un vector, el número de comparaciones
será función del número de elementos (n) del vector (array). Por consiguiente, se
puede expresar el número de comparaciones en términos de n (por ejemplo, n+4,
o bien n2 en lugar de números enteros (por ejemplo, 325).
En todos los métodos de este capítulo, normalmente —para comodidad del lector—
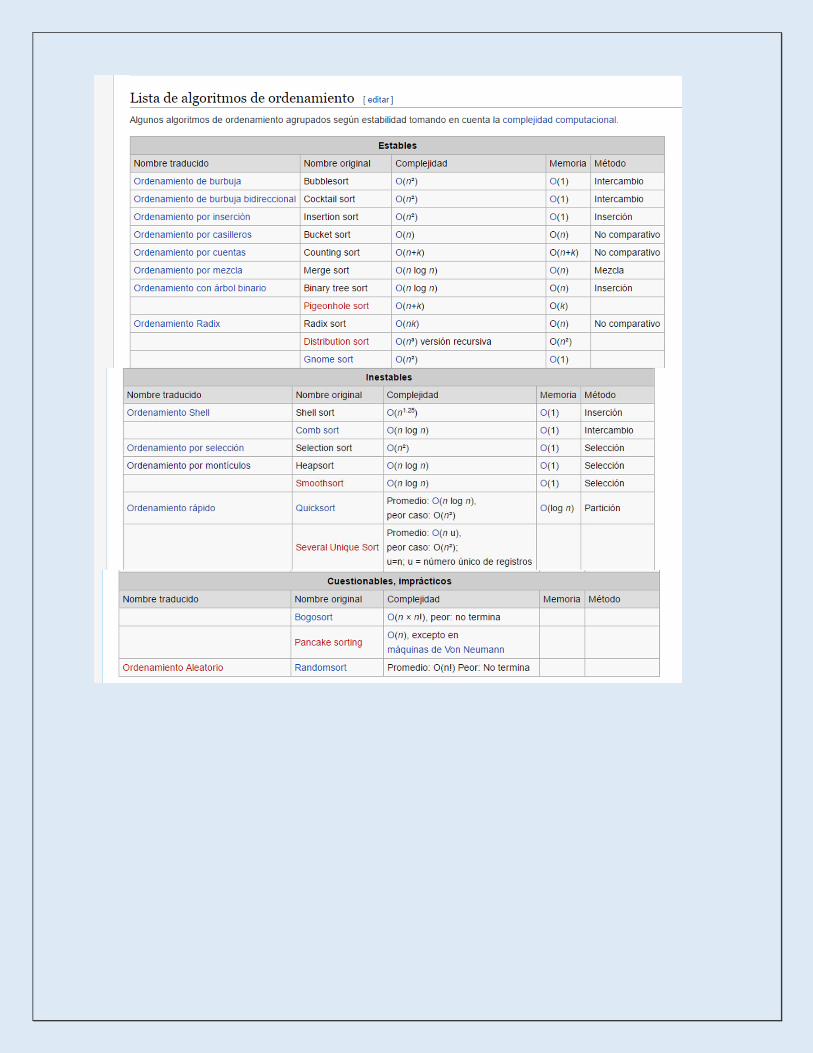
se utiliza el orden ascendente sobre vectores o listas (arrays unidimensionales). Los métodos de ordenación se suelen dividir en dos grandes grupos:
• Directos burbuja, selección, inserción • Indirectos (avanzados) Shell, ordenación rápida, ordenación por mezcla, Radixsort En el caso de listas pequeñas, los métodos directos se muestran eficientes, sobre
todo porque los algoritmos son sencillos; su uso es muy frecuente. Sin embargo,
en listas grandes estos métodos se muestran ineficaces y es preciso recurrir a los
métodos avanzados.

2.2.1 Optimo teórico para ordenamiento de tablas
INTRODUCCIÓN:
A la hora de tratar datos, muchas veces nos conviene que estén ordenados. Estos
métodos nos pueden resultar eficientes cuando hacemos las búsquedas.
ORDENACIÓN:
Consiste en organizar un conjunto de datos en un orden determinado según un
criterio.
La ordenación puede ser interna o externa:
Interna: La hacemos en memoria con arryas. Es muy rápida.
Externa: La hacemos en dispositivos de almacenamiento externo con
ficheros.
Para determinar lo bueno que es un algoritmo de ordenación hay que ver la
complejidad del algoritmo (cantidad de trabajo de ese algoritmo), se mide en el
número de operaciones básicas que realiza un algoritmo. La operación básica de
un algoritmo es la operación fundamental, que es la comparación.
Existen diferentes algoritmos de ordenación elementales o básicos cuyos detalles
de implementación se pueden encontrar en diferentes libros de algoritmos. La
enciclopedia de referencia es [KNUTH 1973]1 y sobre todo la 2.a edición
publicada en el año 1998 [KNUTH 1998]2. Los algoritmos presentan diferencias
entre ellos que los convierten en más o menos eficientes y prácticos según sea la
rapidez y eficiencia demostrada por cada uno de ellos. Los algoritmos básicos de
ordenación más simples y clásicos son:
• Ordenación por selección.
• Ordenación por inserción.
• Ordenación por burbuja.
Los métodos más recomendados son: selección e inserción, aunque se estudiará el
método de burbuja, por aquello de ser el más sencillo aunque a la par también es
el más ineficiente; por esta causa no recomendamos su uso, pero sí conocer su
técnica.
Los datos se pueden almacenar en memoria central o en archivos de datos
externos guardados en unidades de almacenamiento magnético (discos, cintas,
disquetes, CD-ROM, DVD, discos flash USB, etc.) Cuando los datos se guardan en
listas y en pequeñas cantidades, se suelen almacenar de modo temporal en arrays
y registros; estos datos se almacenan exclusivamente para tratamientos internos
que se utilizan en gestión masiva de datos y se guardan en arrays de una o varias
dimensiones.
Los datos, sin embargo, se almacenan de modo permanente en archivos y bases
de datos que se guardan en discos y cintas magnéticas.

2.2.2 Intercambio simple
El algoritmo de ordenación tal vez más sencillo sea el denominado de intercambio que ordena los elementos de una lista en orden ascendente. Este algoritmo se basa
en la lectura sucesiva de la lista a ordenar, comparando el elemento inferior de la
lista con los restantes y efectuando intercambio de posiciones cuando el orden
resultante de la comparación no sea el correcto.
El algoritmo se ilustra con la lista original 8, 4, 6, 2 que ha de convertirse en la
lista ordenada 2, 4, 6, 8. El algoritmo realiza n − 1 pasadas (3 en el ejemplo),
siendo n el número de elementos, y ejecuta las siguientes operaciones.
El elemento de índice 0 (a[0]) se compara con cada elemento posterior de la lista
de índices 1, 2 y 3. En cada comparación se comprueba si el elemento siguiente
es más pequeño que el elemento de índice 0, en ese caso se intercambian. Después
de terminar todas las comparaciones, el elemento más pequeño se localiza en el
índice 0.
Pasada 1 El elemento más pequeño ya está localizado en el índice 0, y se considera la
sublista restante 8, 6, 4. El algoritmo continúa comparando el elemento de índice
1 con los elementos posteriores de índices 2 y 3. Por cada comparación, si el
elemento mayor está en el índice 1 se intercambian los elementos. Después de
hacer todas las comparaciones, el segundo elemento más pequeño de la lista se
almacena en el índice 1.

Pasada 2 La sublista a considerar ahora es 8, 6 ya que 2, 4 está ordenada. Una comparación
única se produce entre los dos elementos de la sublista
2.2.3 Algoritmo de la burbuja
El método de ordenación por burbuja es el más conocido y popular entre
estudiantes y aprendices de programación, por su facilidad de comprensión y
programación; por el contrario, es el menos eficiente y por ello, normalmente, se
aprende su técnica pero no suele utilizarse.
La técnica utilizada se denomina ordenación por burbuja u ordenación por hundimiento debido a que los valores más pequeños «burbujean» gradualmente
(suben) hacia la cima o parte superior del array de modo similar a como suben las
burbujas en el agua, mientras que los valores mayores se hunden en la parte
inferior del array. La técnica consiste en hacer varias pasadas a través del array.
En cada pasada, se comparan parejas sucesivas de elementos. Si una pareja está
en orden creciente (o los valores son idénticos), se dejan los valores como están.
Si una pareja está en orden decreciente, sus valores se intercambian en el array.

Algoritmo de la burbuja
En el caso de un array (lista) con n elementos, la ordenación por burbuja requiere
hasta n − 1 pasadas.
Por cada pasada se comparan elementos adyacentes y se intercambian sus valores
cuando el primer elemento es mayor que el segundo elemento. Al final de cada
pasada, el elemento mayor ha «burbujeado» hasta la cima de la sublista actual. Por
ejemplo, después que la pasada 0 está completa, la cola de la lista A[n − 1] está
ordenada y el frente de la lista permanece desordenado. Las etapas del algoritmo
son:
• En la pasada 0 se comparan elementos adyacentes:
(A[0],A[1]),(A[1],A[2]),(A[2],A[3]),...(A[n-2],A[n-1])
Se realizan n − 1 comparaciones, por cada pareja (A[i],A[i+1]) se intercambian
los valores si A[i+1] < A[i]. Al final de la pasada, el elemento mayor de la lista
está situado en A[n-1].
• En la pasada 1 se realizan las mismas comparaciones e intercambios, terminando
con el elemento segundo mayor valor en A[n-2].
• El proceso termina con la pasada n − 1, en la que el elemento más pequeño se
almacena enA[0].
El algoritmo tiene una mejora inmediata, el proceso de ordenación puede terminar
en la pasada n − 1, o bien antes, si en una pasada no se produce intercambio
alguno entre elementos del vector es porque ya está ordenado, entonces no es
necesario más pasadas.
El ejemplo siguiente ilustra el funcionamiento del algoritmo de la burbuja con un
array de 5 elementos (A = 50, 20, 40, 80, 30), donde se introduce una variable
interruptor para detectar si se ha producido intercambio en la pasada.

En la pasada 3, se hace una única comparación de 20 y 30, y no se produce
intercambio:
En consecuencia, el algoritmo de ordenación de burbuja mejorado contempla dos
bucles anidados: el bucle externo controla la cantidad de pasadas (al principio de
la primera pasada todavía no se ha producido ningún intercambio, por tanto la
variable interruptor se pone a valor falso (0); el bucle interno controla cada pasada
individualmente y cuando se produce un intercambio, cambia el valor de interruptor
a verdadero (1).
El algoritmo terminará, bien cuando se termine la última pasada (n − 1) o bien
cuando el valor del interruptor sea falso (0), es decir, no se haya hecho ningún
intercambio. La condición para realizar una nueva pasada se define en la expresión
lógica
(pasada < n-1) && interruptor

2.2.4 Shell sort
La ordenación Shell debe el nombre a su inventor, D. L. Shell. Se suele denominar
también ordenación por inserción con incrementos decrecientes. Se considera que
el método Shell es una mejora de los métodos de inserción directa. En el algoritmo de inserción, cada elemento se compara con los elementos
contiguos de su izquierda, uno tras otro. Si el elemento a insertar es el más
pequeño hay que realizar muchas comparaciones antes de colocarlo en su lugar
definitivo.
El algoritmo de Shell modifica los saltos contiguos resultantes de las
comparaciones por saltos de mayor tamaño y con ello se consigue que la
ordenación sea más rápida. Generalmente se toma como salto inicial n/2 (siendo n el número de elementos), luego se reduce el salto a la mitad en cada
Repetición hasta que el salto es de tamaño 1. El Ejemplo 6.1 ordena una lista de
elementos siguiendo paso a paso el método de Shell.
Ejemplo 6.1
Obtener las secuencias parciales del vector al aplicar el método Shell para ordenar
en orden creciente la lista:
6 1 5 2 3 4 0
El número de elementos que tiene la lista es 6, por lo que el salto inicial es 6/2 =
3. La siguiente tabla muestra el número de recorridos realizados en la lista con los
saltos correspondiente.
Algoritmo de ordenación Shell
Los pasos a seguir por el algoritmo para una lista de n elementos son:
1. Dividir la lista original en n/2 grupos de dos, considerando un incremento o salto
entre los elementos de n/2.
2. Clarificar cada grupo por separado, comparando las parejas de elementos, y si
no están ordenados, se intercambian
3. Se divide ahora la lista en la mitad de grupos (n/4), con un incremento o salto
entre loselementos también mitad (n/4), y nuevamente se clasifica cada grupo por
separado.

4. Así sucesivamente, se sigue dividiendo la lista en la mitad de grupos que en el
recorrido anterior con un incremento o salto decreciente en la mitad que el salto
anterior, y luego clasificando cada grupo por separado.
5. El algoritmo termina cuando se consigue que el tamaño del salto es 1. Por
consiguiente, los recorridos por la lista están condicionados por el bucle,
En el código anterior se observa que se comparan pares de elementos indexados
por j y k, (a[j],a[k]), separados por un salto, intervalo. Así, si n = 8 el primer valor
de intervalo = 4, y los índices i =5, j =1, k =6. Los siguientes valores de los índices
son i = 6, j = 2, k = 7, y así hasta recorrer la lista.
Para realizar un nuevo recorrido de la lista con la mitad de grupos, el intervalo se
hace la mitad:
Intervalo v intervalo / 2 así se repiten los recorridos por la lista, mientras intervalo > 0.
2.2.5 Quick sort
El algoritmo conocido como quicksort (ordenación rápida) recibe el nombre de su
autor, Tony Hoare. La idea del algoritmo es simple, se basa en la división en
particiones de la lista a ordenar, por lo que se puede considerar que aplica la
técnica divide y vencerás. El método es, posiblemente, el más pequeño de código,
más rápido, más elegante, más interesante y eficiente de los algoritmos de
ordenación conocidos. El método se basa en dividir los n elementos de la lista a
ordenar en dos partes o particiones separadas por un elemento: una partición izquierda, un elemento central denominado pivote o elemento de partición, y una
partición derecha. La partición o división se hace de tal forma quetodos los
elementos de la primera sublista (partición izquierda) son menores que todos los

elementos de la segunda sublista (partición derecha). Las dos sublistas se ordenan
entonces independientemente.
Para dividir la lista en particiones (sublistas) se elige uno de los elementos de la
lista y seutiliza como pivote o elemento de partición. Si se elige una lista cualquiera
con los elementos en orden aleatorio, se puede seleccionar cualquier elemento de
la lista como pivote, por ejemplo, el primer elemento de la lista. Si la lista tiene
algún orden parcial conocido, se puede tomar otra
decisión para el pivote. Idealmente, el pivote se debe elegir de modo que se divida
la lista exactamente por la mitad, de acuerdo al tamaño relativo de las claves. Por
ejemplo, si se tiene una lista de enteros de 1 a 10, 5 o 6 serían pivotes ideales,
mientras que 1 o 10 serían elecciones «pobres» de pivotes.
Una vez que el pivote ha sido elegido, se utiliza para ordenar el resto de la lista
en dos sublistas: una tiene todas las claves menores que el pivote y la otra, todos
los elementos (claves) mayores que o iguales que el pivote (o al revés). Estas dos
listas parciales se ordenan recursivamente utilizando el mismo algoritmo; es decir,
se llama sucesivamente al propio algoritmo quicksort. La lista final ordenada se
consigue concatenando la primera sublista, el pivote y la segunda lista, en ese
orden, en una única lista. La primera etapa de quicksort es la división o
«particionado» recursivo de la lista
hasta que todas las sublistas constan de sólo un elemento.

2.2.6 Tree sort o Heap sort
El ordenamiento por montículos (heapsort en inglés) es
un algoritmo de ordenamiento no recursivo, no estable, concomplejidad
computacional
Este algoritmo consiste en almacenar todos los elementos del vector a ordenar en
un montículo (heap), y luego extraer el nodo que queda como nodo raíz del
montículo (cima) en sucesivas iteraciones obteniendo el conjunto ordenado. Basa
su funcionamiento en una propiedad de los montículos, por la cual, la cima contiene
siempre el menor elemento (o el mayor, según se haya definido el montículo) de
todos los almacenados en él. El algoritmo, después de cada extracción, recoloca
en el nodo raíz o cima, la última hoja por la derecha del último nivel. Lo cual
destruye la propiedad heap del árbol. Pero, a continuación realiza un proceso de
"descenso" del número insertado de forma que se elige a cada movimiento el mayor
de sus dos hijos, con el que se intercambia. Este intercambio, realizado
sucesivamente "hunde" el nodo en el árbol restaurando la propiedad montículo del
arbol y dejándo paso a la siguiente extracción del nodo raíz.
El algoritmo, en su implementación habitual, tiene dos fases. Primero una fase de
construcción de un montículo a partir del conjunto de elementos de entrada, y
después, una fase de extracción sucesiva de la cima del montículo. La
implementación del almacén de datos en el heap, pese a ser conceptualmente un
árbol, puede realizarse en un vector de forma fácil. Cada nodo tiene dos hijos y
por tanto, un nodo situado en la posición i del vector, tendrá a sus hijos en las
posiciones 2 x i, y 2 x i +1 suponiendo que el primer elemento del vector tiene un

índice = 1. Es decir, la cima ocupa la posición inicial del vector y sus dos hijos la
posición segunda y tercera, y así, sucesivamente. Por tanto, en la fase de
ordenación, el intercambio ocurre entre el primer elemento del vector (la raíz o
cima del árbol, que es el mayor elemento del mismo) y el último elemento del
vector que es la hoja más a la derecha en el último nivel. El árbol pierde una hoja
y por tanto reduce su tamaño en un elemento. El vector definitivo y ordenado,
empieza a construirse por el final y termina por el principio.
Descripción
He aquí una descripción en pseudocódigo del algoritmo. Se pueden encontrar
descripciones de las
operaciones insertar_en_monticulo y extraer_cima_del_monticulo en el artículo
sobre montículos.
2.2.7 Ordenamiento pot intercalation
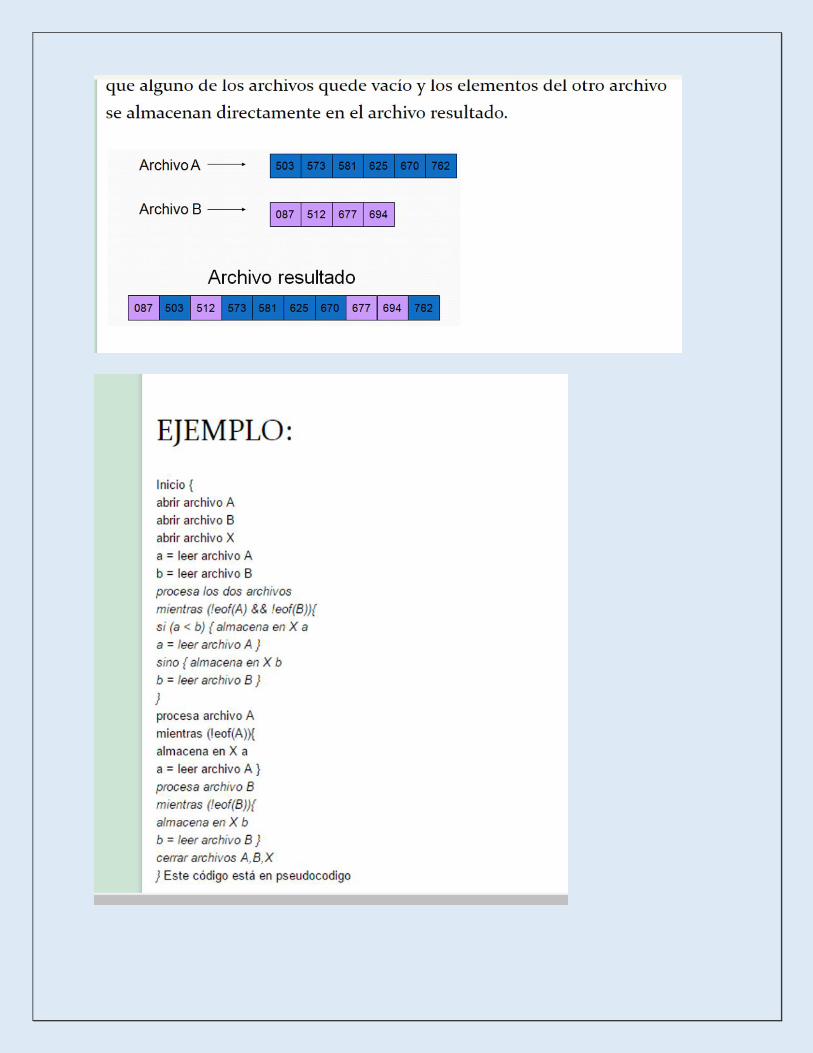
En este método de ordenamiento existen dos archivos con llaves ordenadas, los
cuales se mezclan para formar un solo archivo.
1.-La longitud de los archivos puede ser diferente.
2.-El proceso consiste en leer un registro de cada archivo y compararlos, el menor
es almacenando en el archivo de resultado y el otro se compara con el siguiente
elemento del archivo si existe. El proceso se repite hasta que alguno de los
archivos quede vacío y los elementos del otro archivo se almacenan directamente
en el archivo resultado.

2.2.8 Ordenamiento por distribución
Un problema que se presenta con frecuencia es el siguiente: "Ordenar un archivo
con N registros cuyas llaves son enteros comprendidos entre 0 y M-1". SiM no es
muy grande, se puede usar el algoritmo de distribución por conteo. La idea básica
es contar el número de veces que se repite cada llave diferente y en una segunda
pasada utilizar el conteo para posicionar los registros en el archivo.
2.3 Ordenamiento externo
Ordenamiento externo es un término genérico para los algoritmos de
ordenamiento que pueden manejar grandes cantidades de información. El
ordenamiento externo se requiere cuando la información que se tiene que ordenar
no cabe en la memoria principal de una computadora (típicamente la RAM) y un
tipo de memoria más lenta (típicamente un disco duro) tiene que utilizarse en el
proceso.
Un ejemplo de ordenamiento externo es el algoritmo de ordenamiento por mezcla.
Supongamos que 900 MB de información deben ser ordenados utilizando
únicamente 100 MB de RAM.
1. Leanse 100MB de información en la memoria principal y ordenense
utilizando un algoritmo tradicional (típicamente quicksort).
2. Escríbase la información ordenada en el disco.
3. Repítanse los pasos 1 y 2 hasta que toda la información esté ordenada en
pedazos de 100 MB. Ahora se deben mezclar todos los pedazos ordenados.
4. Léanse los primeros 10MB de cada pedazo ordenado a la memoria principal
(total de 90 MB) y destínense los 10 MB restantes para el buffer de salida.
5. Ordénense los nueve pedazos mezclándolos y grábese el resultado en el
buffer de salida. Si el buffer de salida está lleno, escríbase al archivo destino
final. Si cualquiera de los 9 buffers leídos queda vacío, se llena con los
siguientes 10 MB de su pedazo original de 100 MB o se marca este como
completado si ya no hay registros remanentes.
Otro ejemplo es el algoritmo de ordenamiento por mezcla equilibrada, que es una
optimización del anterior.
2.3.1 El torneo de tenis para ordenamiento externo
La técnica de dividir para vencer tiene varias aplicaciones. No sólo en el diseño
de algoritmos. Si no también en el diseño de circuitos, construcción de
demostraciones matemáticas y en otros campos del quehacer humano. Se brinda
un ejemplo para ilustrar esto. Considérese el diseño del programa de un torneo de
tenis para n =Zk jugadores. Cada jugador debe enfrentarse a todos los demás. Y

debe tener un encuentro diario durante n - I días, que es el número mínimo de días
necesarios para completar el torneo. El programa del torneo es una tabla de n filas
por n - 1 columnas cuya posición en fila i y columna j es el jugador con quien debe
contender i el j-ksimo día. El enfoque dividir para vencer construye un programa
para la mitad de los jugadores. Que está diseñado por una aplicación recursiva del
algoritmo buscando un programa para una mitad de esos jugadores, y así
sucesivamente. Cuando se llega hasta dos jugadores, se tiene el caso base y
simplemente se emparejan. Supóngase que hay ocho jugadores. El programa para
los jugadores 1 a 4 ocupa la esquina superior izquierda (4 filas por 3 columnas)
del programa que se está consumiendo. La esquina inferior izquierda (4 filas por 3
columnas) debe enfrentar a los jugadores con numeración más alta (5 a 8). Este
subprograma se obtiene agregando 4 a cada entrada de la esquina superior
izquierda. Ahora se ha simplificado el problema, y lo único que falta es enfrentar
a los jugadores de baja numeración con los de alta numeración. Esto es fácil si los
jugad* res 1 a 4 contienden con los 5 a 8, respectivamente, en el día 4, y se
permutan cíclicamente 5 a 8 en los días siguientes. El proceso se ilustra en la
figura 10.4.
2.3.2 Interacción con lotes. Algoritmo balanceado
Los árboles AVL están siempre equilibrados de tal modo que para todos los nodos,
la altura de la rama izquierda no difiere en más de una unidad de la altura de la
rama derecha o viceversa. Gracias a esta forma de equilibrio (o balanceo), la
complejidad de una búsqueda en uno de estos árboles se mantiene siempre en
orden de complejidad O(log n).
2.3.3 El algoritmo poli fase para interacción por lote
La ordenación de datos por intercalación es un proceso muy frecuente en
programación. Esta operación es también un proceso que las personas encuentran
comúnmente en sus rutinas diarias. Por ejemplo, cada elemento de la colección de
datos de una agenda telefónica tiene un campo nombre, dirección y un número de
teléfono. Una colección de datos clasificados se puede almacenar en un archivo,
un vector o tabla, una lista enlazada o un árbol. Cuando los datos están
almacenados en vectores, tablas (arrays), listas enlazadas o árboles, la ordenación
se denomina ordenación interna. Cuando los datos a clasificar se encuentran
almacenados en archivos, en soporte de almacenamiento masivo (cintas o discos)
el proceso de ordenación se denomina ordenación externa.

Es un proceso utilizado en sistema de actualización, y en casos en que es necesario
varias listas ordenadas. También es la única forma que hay para el ordenamiento
de archivos, debido a la imposibilidad de almacenarlos en memoria y a limitaciones
en el tiempo, por la cantidad de elementos a ordenar.
El método de ordenación por intercalación es utilizado por los jugadores de cartas
o naipes para ordenar sus barajas. Consiste en mirar las cartas una a una y cuando
se ve cada nueva carta se inserta en el lugar adecuado. Para desarrollar el
algoritmo imaginemos que las cartas se encuentran situadas en una fila encima del
tapete; a medida que se ve una carta nueva, ésta se compara con la fila y se debe
empujar alguna de ellas a la derecha para dejar espacio e insertar la nueva.
Consideremos un vector de n posiciones. Comencemos con el subíndice i en la
segunda posición incrementando en 1, el elemento del subíndice del vector se
elimina de la secuencia y se reinserta en el vector en la posición adecuada.
2.3.4 El algoritmo de cascada
En numerosos casos en el desarrollo de la solución de problemas, encontramos
que luego de tomar una decisión y marcar el camino correspondiente a seguir, es
necesario tomar otra decisión. Luego de evaluar las condiciones, se señala
nuevamente la rama correspondiente a seguir y nuevamente podemos tener que
tomar otra decisión. El proceso puede repetirse numerosas veces. En el siguiente
ejemplo tenemos una estructura selectiva SI ENTONCES que contiene dentro de
ella otra estructura selectiva SI ENTONCES / SINO.
2.4 Árboles balanceados
2.4.1 Definiciones
Árboles en General
Un árbol se puede definir como una estructura jerárquica aplicada sobre una
colección de elementos u objetos llamados nodos, uno de los cuales es conocido
como raíz. Además se crea una relación o parentesco entre los nodos dando lugar
a términos como padre, hijo, hermano, antecesor, sucesor, ancestro, etc.
Formalmente se define un árbol de tipo T como una estructura homogénea
resultado de la concatenación de un elemento de tipo T con un número finito de
árboles disjuntos, llamados subárbols. Una forma particular de árbol es el árbol
vacío.

Los árboles son estructuras recursivas, ya que cada subárbol es a su vez un árbol.
Los árboles se pueden aplicar para la solución de una gran cantidad de problemas
Por ejemplo, se pueden utilizar para representar fórmulas matemáticas, para
registrar la historia de un campeonato de tenis, para construir un árbol
genealógico, para el análisis de circuitos eléctricos y para enumerar los capítulos
y secciones de un libro.
¿Balance?
Las operaciones de insertar y remover claves modifican la forma del árbol. La
garantía de tiempo de acceso O (log n ) está solamente válida a árboles
balanceados.
Balanceo perfecto
Un árbol está perfectamente balanceado si su estructura es óptima con respeto al
largo del camino de la raíz a cada hoja: Todas las hojas están en el mismo nivel,
es decir, el largo máximo de tal camino es igual al largo mínimo de tal camino
sobre todas las hojas. Esto es solamente posible cuando el número de hojas es 2
k para k ∈ Z +, en que caso el largo de todos los caminos desde la raíz hasta las
hojas es exactamente k.
Rotaciones
Necesitamos operaciones para “recuperar” la forma balanceada después de
inserciones y eliminaciones de elementos, aunque no cada operación causa una
falta de balance en el árbol. Estas operaciones se llaman rotaciones.
Rotaciones básicas

Elección de rotación
La rotación adecuada está elegida según las alturas de los ramos que están fuera
de balance, es decir, tienen diferencia de altura mayor o igual a dos. Si se balancea
después de cada inserción y eliminación siempre y cuando es necesario, la
diferencia será siempre exactamente dos.
¿Por qué dos?

Punto de rotación
Con esas rotaciones, ninguna operación va a aumentar la altura de un ramo, pero
la puede reducir por una unidad. La manera típica de encontrar el punto de rotación
t es regresar hacía la raíz después de haber operado con una hoja para verificar
si todos los vértices en camino todavía cumplan con la condición de balance.
Análisis de las rotaciones
2.4.2 Árboles AVL
La estructura de datos más vieja y mejor conocida para árboles balanceados es el
árbol AVL. Su propiedad es que la altura de los subárboles de cada nodo difiere
en no mas de 1. Para mantenerlo balanceado es necesario saber la altura o la
diferencia en alturas de todos los subárboles y eso provoca que tengamos que
guardar información adicional en cada nodo, un contador de la diferencia entre las
alturas de sus dos subárboles.
Los árboles AVL fueron nombrados por sus desarrolladores Adel'son-Vel'skii y
Landis.
Probablemente la principal característica de los árboles AVL es su excelente
tiempo de ejecución para las diferentes operaciones (búsquedas, altas y bajas).
En las siguientes dos figuras la primera es un árbol AVL y la segunda no lo es ya
que los subárboles del nodo 'L' difieren en altura por más de 1. }
Árbol AVL: El árbol a es un árbol AVL, mientras que el árbol b no lo es

Rotaciones simples de nodos
Los reequilibrados se realizan mediante rotaciones, en el siguiente punto veremos
cada caso.
Rotación simple a la derecha (SD):
Esta rotación se usará cuando el subárbol izquierdo de un nodo sea 2 unidades más
alto que el derecho, es decir, cuando su FE sea de -2. Y además, la raíz del
subárbol izquierdo tenga una FE de -1, es decir, que esté cargado a la izquierda.
Procederemos del siguiente modo:
Llamaremos P al nodo que muestra el desequilibrio, el que tiene una FE de -2. Y
llamaremos Q al nodo raíz del subárbol izquierdo de P. Además, llamaremos A al
subárbol izquierdo de Q, B al subárbol derecho de Q y C al subárbol derecho de P.
En el gráfico que puede observar que tanto B como C tienen la misma altura (n), y
A es una unidad mayor (n+1). Esto hace que el FE de Q sea -1, la altura del
subárbol que tiene Q como raíz es (n+2) y por lo tanto el FE de P es -2.
1. Pasamos el subárbol derecho del nodo Q como subárbol izquierdo de P. Esto
mantiene el árbol como ABB, ya que todos los valores a la derecha de Q siguen
estando a la izquierda de P.
2. El árbol P pasa a ser el subárbol derecho del nodo Q.

3. Ahora, el nodo Q pasa a tomar la posición del nodo P, es decir, hacemos que la
entrada al árbol sea el nodo Q, en lugar del nodo P. Previamente, P puede que
fuese un árbol completo o un subárbol de otro nodo de menor altura.
En el árbol resultante se puede ver que tanto P como Q quedan equilibrados en
cuanto altura. En el caso de P porque sus dos subárboles tienen la misma altura
(n), en el caso de Q, porque su subárbol izquierdo A tiene una altura (n+1) y su
subárbol derecho también, ya que a P se añade la altura de cualquiera de sus
subárboles.
Rotación simple a la izquierda (SI):
Se trata del caso simétrico del anterior. Esta rotación se usará cuando el subárbol
derecho de un nodo sea 2 unidades más alto que el izquierdo, es decir, cuando su
FE sea de 2. Y además, la raíz del subárbol derecho tenga una FE de 1, es decir,
que esté cargado a la derecha.
Procederemos del siguiente modo:

Llamaremos P al nodo que muestra el desequilibrio, el que tiene una FE de 2. Y
llamaremos Q al nodo raíz del subárbol derecho de P. Además, llamaremos A al
subárbol izquierdo de P, B al subárbol izquierdo de Q y C al subárbol derecho de
Q.
En el gráfico que puede observar que tanto A como B tienen la misma altura (n), y
C es una unidad mayor (n+1). Esto hace que el FE de Q sea 1, la altura del subárbol
que tiene Q como raíz es (n+2) y por lo tanto el FE de P es 2.
1. Pasamos el subárbol izquierdo del nodo Q como subárbol derecho de P. Esto
mantiene el árbol como ABB, ya que todos los valores a la izquierda de Q siguen
estando a la derecha de P.
2. El árbol P pasa a ser el subárbol izquierdo del nodo Q.
3. Ahora, el nodo Q pasa a tomar la posición del nodo P, es decir, hacemos que la
entrada al árbol sea el nodo Q, en lugar del nodo P. Previamente, P puede que
fuese un árbol completo o un subárbol de otro nodo de menor altura.
En el árbol resultante se puede ver que tanto P como Q quedan equilibrados en
cuanto altura. En el caso de P porque sus dos subárboles tienen la misma altura
(n), en el caso de Q, porque su subárbol izquierdo A tiene una altura (n+1) y su
subárbol derecho también, ya que a P se añade la altura de cualquiera de sus
subárboles.

2.4.3 Árboles tipo B
Arboles B ´ Los ´arboles B 14 constituyen una categoría muy importante de
estructuras de datos, que permiten una implementación eficiente de conjuntos y
diccionarios, para operaciones de consulta y acceso secuencial. Existe una gran
variedad de ´arboles B: los ´arboles B, B+ y B*; pero todas ellas están basadas en
la misma idea, la utilización de ´árboles de búsqueda no binarios y con condición
de balanceo. En concreto, los ´arboles B+ son ampliamente utilizados en la
representación de ́ índices en bases de datos. De hecho, este tipo de ́ arboles están
diseñados específicamente para aplicaciones de bases de datos, donde la
característica fundamental es la predominancia del tiempo de las operaciones de
entrada/salida de disco en el tiempo de ejecución total. En consecuencia, se busca
minimizar el número de operaciones de lectura o escritura de bloques de datos del
disco duro o soporte físico.
Árboles de búsqueda no binarios
En cierto sentido, los ´arboles B se pueden ver como una generalización de la idea
de árbol binario de búsqueda a árboles de búsqueda no binarios. Consideremos la
representación de árboles de búsqueda binarios y n-arios de la figura 4.23. En un
ABB (figura 4.23a) si un nodo x tiene dos hijos, los nodos del subárbol izquierdo
contienen claves menores que x y los del derecho contienen claves mayores que
x. En un árbol de búsqueda no binario (figura 4.23b), cada nodo interno puede
contener q claves x1, x2, ..., xq, y q+1 punteros a hijos que están “situados” entre
cada par de claves y en los dos extremos. Las claves estarán ordenadas de menor
a mayor: x1 < x2 <...< xq. Además, el hijo más a la izquierda contiene claves
menores que x1; el hijo entre x1 y x2 contiene claves mayores que x1 y menores
que x2; y as´ı sucesivamente hasta el hijo más a la derecha que contiene claves
mayores que xq.

Definición de árbol B.
Un árbol B de orden p es básicamente un árbol de búsqueda n-ario donde los nodos
tienen p hijos como máximo, y en el cual se añade la condición de balanceo de que
todas las hojas estén al mismo nivel. La definición formal de árbol B es la siguiente.
Definición 4.6 Un árbol B de orden p, siendo p un entero mayor que 2, es un árbol
con las siguientes características: 1. Los nodos internos son de la forma (p1, x1,
p2, x2, ..., xq−1, pq), siendo pi punteros a nodos hijos y xi claves, o pares (clave,
valor) en caso de representar diccionarios. 2. Si un nodo tiene q punteros a hijos,
entonces tiene q − 1 claves.

3. Para todo nodo interno, excepto para la raíz, p/2 ≤ q ≤ p. Es decir, un nodo
puede tener como mínimo p/2 hijos y como máximo p. El valor p/2 − 1 indicaría el
mínimo número de claves en un nodo interno y se suele denotar por d.
4. La raíz puede tener 0 hijos (si es el único nodo del ´árbol) o entre 2 y p.
5. Los nodos hoja tienen la misma estructura, pero todos sus punteros son nulos.
6. En todos los nodos se cumple: x1 < x2 <...< xq−1.
7. Para todas las claves k apuntadas por un puntero pi de un nodo se cumple:
8. Todos los nodos hoja están al mismo nivel en el ´árbol. Los ´arboles B+ son una
variante de los ´arboles B, que se utiliza en representación de diccionarios. La
estructura de los nodos hoja es distinta de la de los nodos internos. En esencia, la
modificación consiste en que en los nodos internos solo aparecen claves, mientras
en los nodos hoja aparecen las asociaciones (clave, valor). Por otro lado, tenemos
la variante de los ´arboles B*. Su principal característica es que si en los ´arboles
B –teniendo en cuenta la anterior definición– los nodos deben estar ocupados como
mínimo hasta la mitad, en los B* tienen que estar ocupados más de dos tercios del
máximo. En adelante nos centraremos en el estudio de los ´arboles B. En la figura
4.24 se muestra un ejemplo de árbol B de orden p = 5.

Representación del tipo árbol B
Pasando ahora a la implementación de ´arboles B de cierto orden p, lo normal es
reservar espacio de forma fija para p hijos y p − 1 elementos. La definición,
suponiendo que el tipo almacenado es T, podría ser como la siguiente. Tipo

Inserción en un árbol B
Además de mantener la estructura de árbol de búsqueda, el procedimiento de
inserción en un árbol B debe asegurar la propiedad que impone que todas las hojas
estén al mismo nivel. La nueva entrada debe insertarse siempre en un nodo hoja
15. Si hay sitio en la hoja que le corresponde, el elemento se puede insertar
directamente. En otro caso aplicamos un proceso de partición de nodos, que es
mostrado en la figura 4.25. El proceso consiste en lo siguiente: con las p − 1
entradas de la hoja donde se hace la inserción más la nueva entrada, se crean dos
nuevas hojas con (p − 1)/2 y (p−1)/2 entradas. La entrada m que está en la
mediana aparece como una nueva clave de nivel superior, y tiene como hijas las
dos hojas recién creadas. El proceso se repite recursivamente en el nivel superior,
en el que habrá que insertar m. Si m cabe en el nodo interno correspondiente, se
inserta. En otro caso, se parte el nodo interno y se repite el proceso hacia arriba.

Si se produce la partición a nivel de la raíz entonces tenemos el caso donde la
profundidad del árbol aumenta en uno. En definitiva, el esquema del algoritmo de
inserción de una clave x en un árbol B de orden p seria el siguiente.
1. Buscar el nodo hoja donde se debería colocar x, usando un procedimiento
parecido a la operación Miembro. Si el elemento ya está en el árbol, no se vuelve
a insertar.
2. Si la hoja contiene menos de p − 1 entradas, entonces quedan sitios libres.
Insertar x en esa hoja, en la posición correspondiente.
3. Si no quedan sitios libres, cogemos las p − 1 entradas de la hoja y x. La mediana
m pasa al nodo padre, así como los punteros a sus nuevos hijos: los valores
menores que m forman el nodo hijo de la izquierda y los valores mayores que m
forman el nodo hijo de la derecha.
4. Si el nodo padre está completo, se dividirá a su vez en dos nodos, propagándose
el proceso de partición hasta la raíz.
El algoritmo garantiza las propiedades de árbol B: todas las hojas están al mismo
nivel y los nodos internos (excepto, posiblemente, la raíz) están llenos como
mínimo hasta la mitad. Por otro lado, el tiempo de ejecución depende de la altura
del árbol. Pero, además, el tiempo en cada nivel no es constante; el proceso de
partición tardará un O(p) en el peor caso. No obstante, ya hemos visto que
realmente el factor a considerar es el número de nodos tratados, más que las
operaciones que se realicen dentro de cada nodo.
Eliminación en un árbol B
Igual que la inserción en un árbol B hace uso de la partición de un nodo en dos, la
eliminación se caracteriza por el proceso de unión de dos nodos en uno nuevo, en
caso de que el nodo se vacíe hasta menos de la mitad. No obstante, hay que tener
en cuenta todas las situaciones que pueden ocurrir en la supresión.
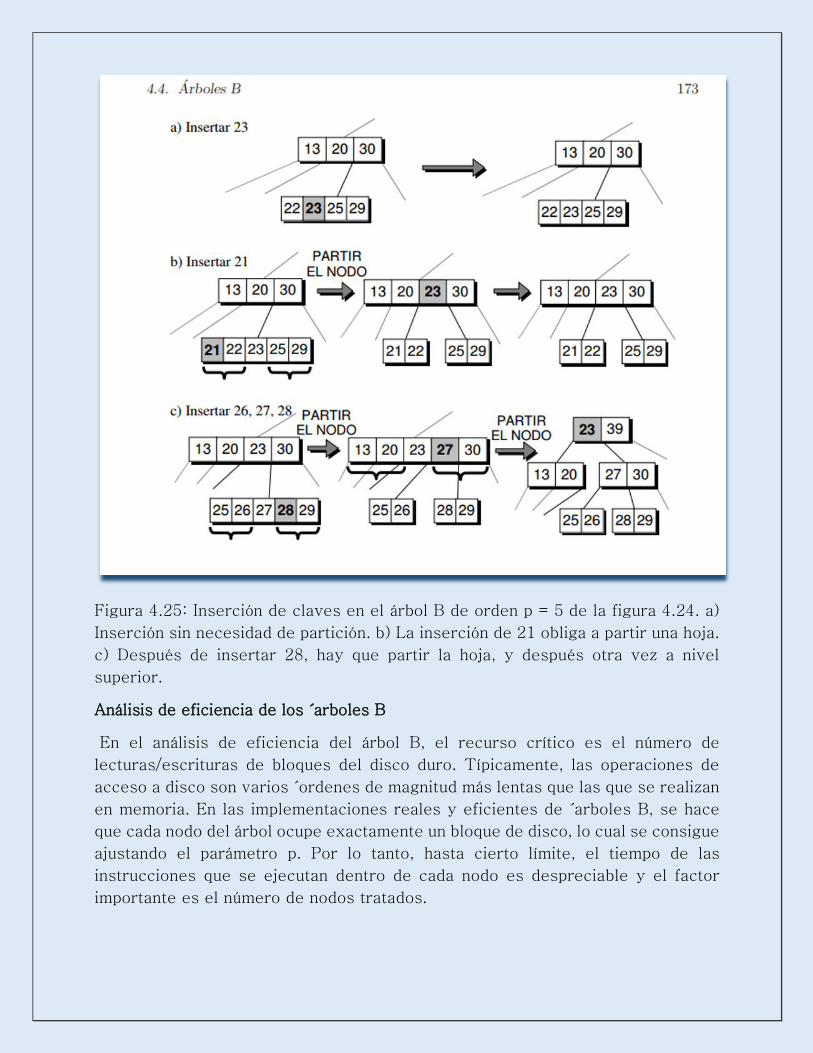
Figura 4.25: Inserción de claves en el árbol B de orden p = 5 de la figura 4.24. a)
Inserción sin necesidad de partición. b) La inserción de 21 obliga a partir una hoja.
c) Después de insertar 28, hay que partir la hoja, y después otra vez a nivel
superior.
Análisis de eficiencia de los ´arboles B
En el análisis de eficiencia del árbol B, el recurso crítico es el número de
lecturas/escrituras de bloques del disco duro. Típicamente, las operaciones de
acceso a disco son varios ´ordenes de magnitud más lentas que las que se realizan
en memoria. En las implementaciones reales y eficientes de ´arboles B, se hace
que cada nodo del árbol ocupe exactamente un bloque de disco, lo cual se consigue
ajustando el parámetro p. Por lo tanto, hasta cierto límite, el tiempo de las
instrucciones que se ejecutan dentro de cada nodo es despreciable y el factor
importante es el número de nodos tratados.
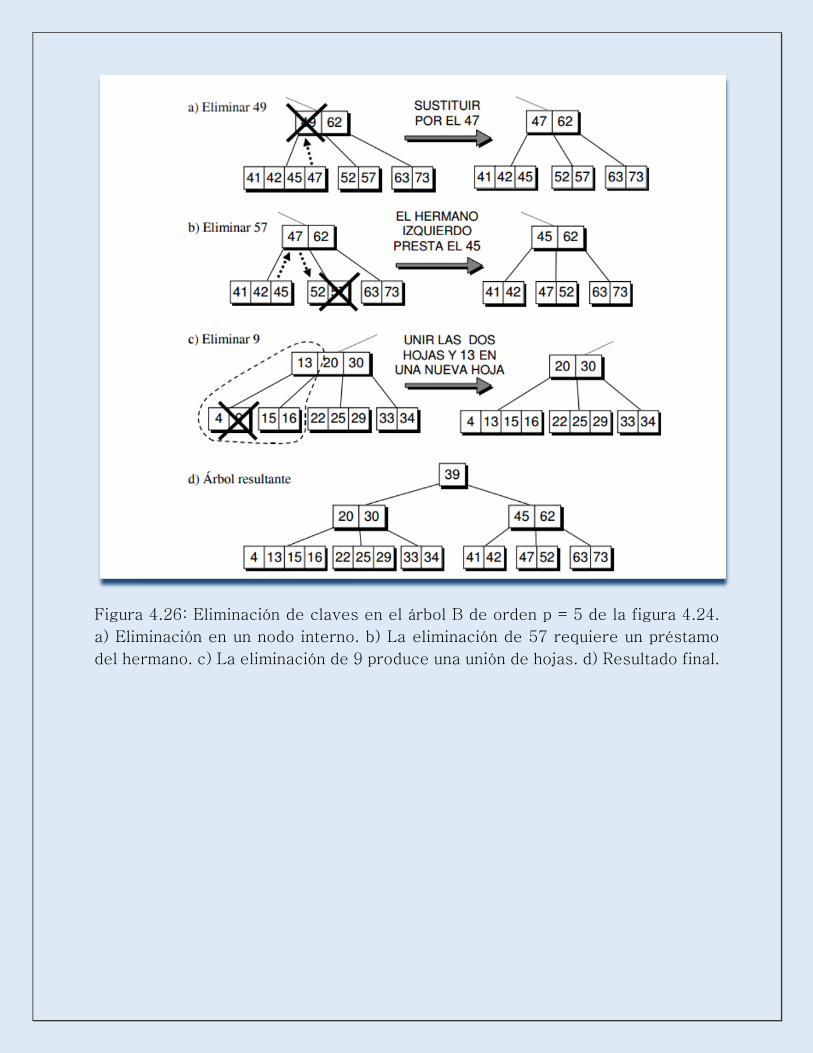
Figura 4.26: Eliminación de claves en el árbol B de orden p = 5 de la figura 4.24.
a) Eliminación en un nodo interno. b) La eliminación de 57 requiere un préstamo
del hermano. c) La eliminación de 9 produce una unión de hojas. d) Resultado final.

2.5 Dispersión al azar desmenuzamiento o hassing.

2.5.1 Algoritmos
CONCEPTO DE ALGORITMO:
El algoritmo trata de resolver problemas mediante programas.
Fases:
Análisis preliminar o evaluación del problema: Estudiar el problema en
general y ver que parte nos interesa.
Definición o análisis del problema: Ver que es lo que entra y que es lo que
sale, las posibles condiciones o restricciones, ...
Diseño del algoritmo: Diseñar la solución.
El programa: Codificación del algoritmo en un lenguaje de programación.
Ejecución del programa y las pruebas: Ver si el programa hace lo que
queríamos.
¿Qué es un algoritmo?:
Es una fórmula para resolver un problema. Es un conjunto de acciones o
secuencia de operaciones que ejecutadas en un determinado orden resuelven el
problema. Existen algoritmos, hay que coger el más efectivo.
Características:

Tiene que ser preciso.
Tiene que estar bien definido.
Tiene que ser finito.
La programación es adaptar el algoritmo al ordenador.
El algoritmo es independiente según donde lo implemente.
2.5.2 Funciones de dispersión
Una tabla hash, matriz asociativa, mapa hash, tabla de dispersión o tabla
fragmentada es una estructura de datos que
asocia llaves o claves con valores. La operación principal que soporta de
manera eficiente es la búsqueda: permite el acceso a los elementos
(teléfono y dirección, por ejemplo) almacenados a partir de una clave
generada (usando el nombre o número de cuenta, por ejemplo). Funciona
transformando la clave con una función hash en un hash, un número que
identifica la posición (casilla o cubeta) donde la tabla hash localiza el valor
deseado.
Un ejemplo práctico para ilustrar que es una tabla hash es el siguiente: Se
necesita organizar los periódicos que llegan diariamente de tal forma que
se puedan ubicar de forma rápida, entonces se hace de la siguiente forma
- se hace una gran caja para guardar todos los periódicos (una tabla), y se
divide en 31 contenedores (ahora es una "hash table" o tabla fragmentada),
y la clave para guardar los periódicos es el día de publicación (índice).
Cuando se requiere buscar un periódico se busca por el día que fue
publicado y así se sabe en que zócalo (bucket) está. Varios periódicos
quedarán guardados en el mismo zócalo (es decir colisionan al ser
almacenados), lo que implica buscar en la sub-lista que se guarda en cada
zócalo. De esta forma se reduce el tamaño de las búsquedas de O(n) a, en
el mejor de los casos, O(1) y, en el peor, a O(log(n)).
2.5.3 Manejo de colisiones

En informática, una colisión de hash es una situación que se produce
cuando dos entradas distintas a una función de hash producen la
misma salida.
Es matemáticamente imposible que una función de hash carezca de
colisiones, ya que el número potencial de posibles entradas es mayor que
el número de salidas que puede producir un hash. Sin embargo, las
colisiones se producen más frecuentemente en los malos algoritmos. En
ciertas aplicaciones especializadas con un relativamente pequeño número
de entradas que son conocidas de antemano es posible construir
una función de hash perfecta, que se asegura que todas las entradas
tengan una salida diferente. Pero en una función en la cual se puede
introducir datos de longitud arbitraria y que devuelve un hash de tamaño
fijo (como MD5), siempre habrá colisiones, debido a que un hash dado
puede pertenecer a un infinito número de entradas.
2.5.4 Manejo de sobre flujo
Un diagrama de flujo es una representación esquemática de los distintos
pasos de un programa. Constituyen pues, otra forma de representar
algoritmos distintos al pseudocódigo, pero que nos sirve de forma
complementaria en el proceso de creación de la estructura del programa
antes de ponernos delante del ordenador.
El diagrama de flujo goza de ventajas como el ser altamente intuitivo, fácil de
leer, claro y preciso. Su interés para nosotros, sin desdeñar su utilidad
profesional, radica en su valor didáctico. Lo consideraremos una herramienta
muy potente de cara a comenzar a programar ya que su contenido gráfico lo
hace menos árido que el pseudocódigo.
Las limitaciones principales de los diagramas de flujo derivan precisamente
de su carácter de dibujo. No resultan tan fáciles de crear o de mantener como
el texto del pseudocódigo (que podemos trabajar en un procesador de textos
cualquiera) y pueden requerir utilizar papeles tipo plano (más grande de lo

normal) cuando los programas son de cierta longitud. Gráficamente podemos
verlo de la siguiente manera: si tenemos por ejemplo siete páginas de
pseudocódigo bastará con numerarlas y ponerlas una detrás de otra.
2.5.5 Un corrector de ortografía
Implementación:
Podrías implementar un sencillo corrector ortográfico con un árbol binario de
búsqueda (ABB), aunque si te sientes con energía puedes implementar un árbol
balanceado (AVL). Generalmente en los árboles se suele buscar/insertar a partir
de una clave. Como te interesa buscar el nodo por la palabra no te servira el < >
=, pero puedes aprovechar la caracteristica del strcmp (cadena1, cadena2) que
devuelve <0 si cadena1 es menor que cadena2, >0 si cadena1 es mayor que
cadena2 y 0 si son iguales.
La búsqueda en árboles apenas son 3 líneas (ya q es un procedimiento recursivo)
por lo que no te costará implementarlo.
Idea general:
Podrías comenzar con el árbol vacío y a medida que escribes las palabras, al no
encontrarse, dar la opción de añadirla. Y si está no hace nada.
Otra manera:
Sería implementar un árbol trie o patricia, estos árboles tienen al menos 26
punteros (uno por cada letra del abecedario) como imagino que querrás contemplar
los acentos y la ñ pues más punteros. El orden de complejidad es O(n) tanto en la
inserción como en la busqueda. Los árboles ABB tienen una complejidad Ω(log n)
y Θ(log n) aunque podría tener O(n) (si por ejemplo si todas las claves son mayores
o menores que el nodo anterior, produciéndose una lista enlazada en vez de un
árbol) Los AVL son de O(log n) el inconveniente es que hay q usar un código más
elaborado y corregir los desbalanceo.
3. Programación de aplicaciones
3.1 Descripción del lenguaje a utilizar
La interfaz de programación de aplicaciones, abreviada como API (del inglés:
Aplication Programming interface). Es el conjunto de subrutinas, funciones y

procedimientos (o métodos, en la programación orientada a objetos) que ofrece
cierta biblioteca para ser utilizado por otro software como una capa de abstracción.
3.1.1 Estructura de un programa y reglas sintácticas
CONCEPTO DE PROGRAMA:
Un programa es un conjunto de instrucciones que al ser ejecutadas resuelven un
problema.
Un programa tiene 3 partes:
Entrada de datos: Normalmente se va a ejecutar a través de instrucciones de
lectura, y en lo que se le pide al usuario la información que el programa va a
necesitar para ejecutarse y se hace a través de lecturas.
Acciones de un algoritmo: Parte en la que se resuelve el problema usando los
datos de entrada.
Salida: Mostrar en un dispositivo de salida los resultados de las acciones
anteriormente realizadas. Son acciones de escritura.
En la parte de las acciones a ejecutar se distinguirán dos partes:
Declaración de variables.
Instrucciones del programa.
INSTRUCCIONES Y TIPOS:
Para que una instrucción se ejecute tiene que ser llevada a memoria. En cuanto al
orden de ejecución de las instrucciones, el programa puede ser de dos tipos:
Programas lineales: Se va ejecutando una instrucción más otra y el orden de
ejecución es igual al orden de escritura.
Programas no lineales: Las instrucciones no se ejecutan en el mismo orden
en el que aparecen escritas, sino que se realizan saltos que nos mandan de
unas instrucciones a otras.
Nunca se deben hacer saltos no lineales.
Tipos de instrucciones:
Inicio y fin.

es de bifurcación: Alternan el orden de ejecución del programa. Salto
a otra instrucción que no es la siguiente.
esa instrucción: Goto Ir a.
cutan un conjunto de instrucciones u otras
dependiendo del valor devuelto al evaluar una condición.
Es la que vamos a usar.
ELEMENTOS BÁSICOS DE UN PROGRAMA:
¿Qué es la sintaxis de un lenguaje?:
Conjunto de reglas que tenemos que seguir a la hora de escribir un programa en
ese lenguaje tal que si no seguimos esas reglas de sintaxis el compilador da
errores.
Elementos del lenguaje de programación:
Palabras reservadas: Son un conjunto de palabras especiales que nos sirven
para definir la estructura del programa, y solo se pueden usar para el fin para el
que están reservadas.
Identificadores: Son los nombres que aparecen en el programa dados por el
usuario. Son por tanto los nombres de variables, de constantes, de subprogramas
y nombres de tipos creados por el usuario.
Caracteres especiales: Sirven como separadores entre sentencias, por ejemplo
el ;.
Instrucciones: De 3 tipos, secuenciales, repetitivas y selectivas, y pueden
aparecer elementos especiales (bucles, contadores, interruptores y
acumuladores).
Bucle: Un conjunto de instrucciones que se repiten un número finito de
veces. Lleva asociado aparte de las instrucciones una condición que es la
que determina cuando se termina un bucle. Ejecución de un bucle
(iteración). Los bucles se pueden anidar unos dentro de otros, y puede
haber varios bucles al mismo nivel, pero nunca se entrelazan.

Contador: Un elemento cuyo valor se incrementa o decrementa en un valor
constante en cada iteración de un bucle, y se utiliza para controlar la
condición del bucle.
Acumulador: Es una variable que también se suele usar en los bucles y que
se incrementa o decrementa en cada iteración del bucle, pero no en una
cantidad constante.
Algoritmo ejemplo
Var cont, num, sum: entero
Inicio
Cont 0
Sum 0
Mientras cont <> 3
Leer num
Sum sum + num
Cont cont +1
Fin mientras
Escribir suma
End
Interruptor (marca, bandera o flag): Es una variable que sirve como
indicador de una determinada información y que solo puede tomar uno de
dos valores. El valor de la variable tiene asociado un signo y puede variar
a lo largo de la ejecución.
Algoritmo ejemplo:
Var cont, num, suma: entero
Neg: boolean
Inicio
Cont 0
Sum 0

Neg falso
Mientras cont <>3
Leer num
Si num < 0
Entonces neg verdadero
Fin si
Sum sum + num
Cont cont + 1
Fin mientras
Si neg=verdadero
Entonces escribir (“Se ha leído negativos”)
Sino escribir (“No negativos”)
Fin si
Fin
Si es leer un número negativo o hasta 3 números:
Mientras (cont <> 3) y (neg = verdadero)
3.1.2 Palabras reservadas
Las Palabras clave son palabras “reservadas” para utilizar dentro del
lenguaje que tienen un significado especial y no pueden ser utilizadas como
nombres de variables o identificadores (salvo que se fuerce mediante la
utilización de corchetes “[ ] “).
Rem: Nos permite incluir comentarios sobre el programa en medio del
código, la sintaxis es:
Rem Comentario
Además, se puede conseguir lo mismo sin necesidad de escribir Rem,
utilizando la comilla simple, es decir, la anterior orden es equivalente a:
'Comentario
Observaremos como el editor de código reconoce los comentarios ya que
les aplica como color del texto el verde.

Exit Sub: Nos permite acabar la ejecución del procedimiento en el que lo
pongamos, y en punto del mismo donde se halle situado.
End: Nos permite acabar la ejecución del programa en el punto del mismo
donde se halle situado.
3.1.3 Tipos de datos y variables
- Dato: Es un objeto o elemento que tratamos a lo largo de diversas
operaciones.
Tienen 3 características:
Un nombre que los diferencia del resto.
Un tipo que nos determina las operaciones que podemos hacer con ese dato.
Un valor que puede variar o no a lo largo de la operación.
Existen diferentes tipos de datos.
- Características de los tipos:
Cada tipo se representa o almacena de forma diferente en la computadora.
Bit:1/0; Byte=8 bits.
Un tipo agrupa a los valores que hacen las mismas operaciones.
Si tiene definida una relación de orden es un tipo escalar.
Cardinalidad de un tipo: Número de valores distintos que puede tomar un
tipo.
Pueden ser finitos (caracteres), y si son infinitos el ordenador los toma como
finitos porque está limitado por el tamaño de los bytes en el que la cifra es
almacenada.
- Los datos pueden ser:
Simples: Un elemento.
Compuestos: Varios elementos.
- Los tipos pueden ser:
Estándar: Que vienen en el sistema por defecto.
No estándar: Son los que crea el usuario.
- Los tipos simples más importantes son:
Numéricos.

Lógicos.
Caracteres.
Numéricos:
Entero: Subconjunto finito del conjunto matemático de los números enteros.
No tiene parte decimal. El rango de los valores depende del tamaño que se
les da en memoria.
Real: Subconjunto finito del conjunto matemático de los números reales.
Llevan signo y parte decimal. Se almacenan en 4 Bytes (dependiendo de los
modificadores). Si se utilizan números reales muy grandes, se puede usar
notación científica que se divide en mantisa, base y exponente; tal que el
valor se obtiene multiplicando la mantisa por la base elevada al exponente.
Lógicos o booleanos:
Aquel que sólo puede tomar uno de los dos valores, verdadero o falso (1/0).
Carácter:
Abarca al conjunto finito y ordenado de caracteres que reconoce la
computadora (letras, dígitos, caracteres especiales, ASCII).
Tipo de cadena o String: Conjunto de caracteres, que van a estar entre “”.
El propio lenguaje puede añadir más tipos, o se pueden añadir modificadores.
Entero : Int Long int
En algunos lenguajes se definen tipos especiales de fecha y hora, sobre todo
en los más modernos.
CONSTANTES Y VARIABLES:
Constantes: Tienen un valor fijo que se le da cuando se define la constante
y que ya no puede ser modificado durante la ejecución.
Variables: El valor puede cambiar durante la ejecución del algoritmo, pero
nunca varía su nombre y su tipo.
Antes de usar una variable hay que definirla o declararla, al hacerlo hay que
dar su nombre y su tipo. El nombre que le damos tiene que ser un nombre
significativo, va a ser un conjunto de caracteres que dependiendo del

lenguaje hay restricciones. Tiene que empezar por una letra, y el tamaño
depende del lenguaje.
Identificador: Palabra que no es propia del lenguaje.
El valor de la variable si al declararla no se la inicializa, en algunos lenguajes
toma una por defecto. En cualquier caso el valor de la variable podemos
darle uno inicial o podemos ir variándolo a lo largo de la ejecución.
Las constantes pueden llevar asociados un nombre o no, si no lo llevan, se
llaman literales. Su valor hay que darlo al definir la constante y ya no puede
cambiar a lo largo de la ejecución, y en cuanto al tipo, dependiendo de los
lenguajes en algunos hay que ponerlo, y en otros no hace falta ponerlo
porque toma el tipo del dato que se le asigna. Const PI=3,1416.
Hay que inicializar todas las variables.
< > Hay que poner algo obligatoriamente.
[ ] Puede llevar algo o no llevarlo.
La ventaja de usar constantes con nombre es que en cualquier lugar donde
quiera que vaya la constante, basta con poner su nombre y luego el
compilador lo sustituirá por su valor.
Las constantes sin nombres son de valor constante: 5, 6, `a', “hola”.
Cuando una cadena es de tipo carácter, se encierra entre `' `a'.
Relación entre variables y constantes en memoria:
Al detectar una variable o una constante con nombre, automáticamente se
reserva en memoria espacio para guardar esa variable o constante. El
espacio reservado depende del tipo de la variable.
En esa zona de memoria es en la que se guarda el valor asociado a la variable
o constante y cuando el programa use esa variable, ira a esa zona de
memoria a buscar su valor.
3.1.4 Instrucciones asociadas a:
3.1.4.1 Operaciones primitivas
Operaciones primitivas elementales. Son las acciones básicas que la
computadora “sabe hacer”, y que se ejecutan sobre los datos para darles
entrada, transformarlos y darles salida convertidos en información.

3.1.4.2 Estructuras de control
Estructuras de control. Son las formas lógicas de funcionamiento de la
computadora mediante las que se dirige el orden en que deben ejecutarse las
instrucciones del programa. Las estructuras de control son: La secuenciación,
que es la capacidad de ejecutar instrucciones secuenciales una tras otra. La
selección es la capacidad de escoger o seleccionar si algo se ejecuta o no, optar
por una de dos o más alternativas, y la repetición, que es la capacidad de realizar
en más de una ocasión (es decir, varias veces) una acción o conjunto de
acciones.
3.1.4.3 Operaciones aritméticas
Una expresión es una combinación de constantes, variables, signos de
operación, paréntesis y nombres especiales (nombres de funciones
estándar), con un sentido unívoco y definido y de cuya evaluación resulta un
único valor.
Toda expresión tiene asociada un tipo que se corresponde con el tipo del
valor que devuelve la expresión cuando se evalúa, por lo que habrá tantos
tipos de expresiones como tipos de datos. Habrá expresiones numéricas y
lógicas.
Numéricas: Operadores aritméticos.
Son los que se utilizan en las expresiones numéricas (una combinación de
variables y/o constantes numéricas con operadores aritméticos y que al
evaluarla devuelve un valor numérico.
+, -, *, /.
Operación resto: Lo que devuelve es el resto de una división entera.
Mod: Pascal. 5 mod 3 = 2
%: C.
División entera: Nos devuelve el cociente de una división entera (en la que
no se sacan decimales).
Div: Pascal. 5 div 3 = 1
\: C.
Potencia: ^ 5^2.

Todos estos operadores son binarios (el operador se sitúa en medio), el
menos también puede ser unario (lleva un único operando) y significa signo
negativo.
Reglas de precedencia:
El problema es cuando una expresión entera según como la evalué pueda
dar diferentes valores.
7*3+4 25
49
La solución es aplicar prioridad entre los operadores, de modo que ante la
posibilidad de usar varios siempre aplicaremos primero el de mayor
prioridad.
Cada lenguaje puede establecer sus propias reglas de prioridad o
precedencia de operadores. Si no nos acordamos, siempre podemos poner (
).
1ª) ^
2ª) * / div mod
3ª) + -
Entre dos operaciones que tienen la misma precedencia para resolver la
ambigüedad, hay que usar la regla de la asociatividad. La más normal es la
de la asociatividad a izquierdas (primero lo de la izquierda).
3.1.4.4 Funciones matemáticas
FUNCIONES INTERNAS:
Son funciones matemáticas diferentes de las operaciones básicas pero que
se incorporan al lenguaje y que se consideran estándar. Dependen del
lenguaje. Normalmente se encuentran en la librería de matemáticas del
lenguaje de programación.
Fórmulas:
Abs (x)
Arctan (x)
Cos (x)
Sen (x)

Exp (x)
Ln (x)
Log 10 (x)
Redondeo (x)
Trunc (x)
Cuadrado (x)
Raíz (x)
3.1.4.5 Manejo de caracteres
JUEGO DE CARACTERES:
En principio se programaba todo con 0 y 1, pero como esto costaba mucho,
apareció la necesidad de crear un lenguaje semejante al humano para
entendernos más fácilmente con la computadora, y para ello aparecen los
juegos de caracteres.
El juego de caracteres es una especie de alfabeto que usa la máquina.
Hay 2 juegos de caracteres principales:
ASCII: El que más se usa.
EBCDIC: Creado por IBM.
Hay 2 tipos de ASCII, el básico y el extendido.
En el ASCII básico, cada carácter se codifica con 7 bits, por lo que existen
2^7=128 caracteres.
En el ASCII extendido, cada carácter ocupa 8 bits (1 byte) por lo que
existirán 2^8= 256 caracteres, numerados del 0 al 255.
En el EBCDIC, cada carácter ocupa también 8 bits.
En cualquiera de los 2 juegos, existen 4 tipos de caracteres:
Alfabéticos: Letras mayúsculas y minúsculas.
Numéricos: Números.
Especiales: Todos los que no son letras y números, que vienen en el teclado.

Control: No son imprimibles y tienen asignados caracteres especiales.
Sirven para determinar el fin de línea, fin de texto. Van del 128 al 255.
Un juego de caracteres es una tabla que a cada número tiene asociado un
número.
CADENA DE CARACTERES:
Es un conjunto de 0 ó más caracteres. Entre estos caracteres puede estar
incluido el blanco.
En pseudocódigo, el blanco es el b. Las cadenas de caracteres se delimitan
con dobles comillas “ “, pero en algunos lenguajes se delimitan con ` `.
Las cadenas de caracteres se almacenan en posiciones contiguas de
memoria.
La longitud de una cadena es el número de caracteres de la misma. Si
hubiese algún carácter que se utilizara como especial para señalar el fin de
cadena, no se consideraría en la longitud.
Si una cadena tiene longitud 0, la llamamos cadena nula por lo que no tiene
ningún carácter, pero esto no quiere decir que no tenga ningún carácter
válido, por que puede haber algún carácter especial no imprimible que forme
parte de la cadena.
Una subcadena es una cadena extraída de otra.
DATOS DE TIPO CARÁCTER:
Constantes: Una constante de tipo cadena es un conjunto de 0 o más
caracteres encerrados entre “ “.
Si dentro de la cadena quiero poner como parte de la cadena las “, las pongo
2 veces. Esto depende del lenguaje.
“Hola””Adios” Hola”Adios
En algunos lenguajes hay un carácter de escape. En C, el carácter de escape
es la \.
Una constante de tipo carácter es un solo carácter encerrado entre comillas
simples.
variable de tipo cadena, el contenido de una variable de tipo cadena es un
conjunto de 0 ó más caracteres encerrados entre “ “, mientras que una
variable de tipo carácter es un solo carácter encerrado entre ` `.

3.1.4.7 Estructura de datos
Estructuras de datos. Son las formas de representación interna de la
computadora. Los hechos reales, representados en forma de datos, pueden
estar organizados de diferentes maneras llamadas estructuras de datos.
3.1.4.7 Operaciones especiales
Cadenas de caracteres, Operaciones muy especiales
Las cadenas de caracteres como ya mencionamos, son tipos de datos muy
especiales, ya que se trata de caracteres arreglados con un orden específico
para formar las palabras. Por este motivo es que muchos lenguajes de
programación dedican una serie de operaciones muy especiales para
manejar estas cadenas de caracteres, en los manuales de usuario de cada
lenguaje explican si disponen de funciones especiales para el manejo de este
tipo de variables.
Carátula del Programa, Formatos de Entrada y Salida
Al estructurar un programa hay un momento en el que es necesario mostrar
o pedir información al usuario, es necesario definir dos situaciones:
La computadora espera datos por parte del usuario, se dice que la
computadora espera leer datos del usuario
La computadora muestra datos al usuario, se dice que la
computadora escribe datos al usuario.
Estas dos situaciones tienden a confundir a los programadores novatos, un
ejemplo de esta confusión es cuando se requiere que la computadora lea
datos por parte del usuario colocan escribir datos, es cierto que el usuario
tiene que escribir datos, pero la computadora debe leer los datos que le
suministra usuario. El programa de aplicación es un conjunto de
instrucciones para la computadora, no para el usuario. Es buena costumbre
que en el momento de solicitar datos al usuario se le muestre un mensaje
de que es lo que debe introducir, esto hace que nuestro programa tenga una
carátula amena al usuario y despierte interés en continuar el uso de nuestro
programa.
3.1.5 Subrutinas / procedimientos

INTRODUCCIÓN A LOS SUBPROGRAMAS O SUBALGORITMOS:
La programación modular es una de las técnicas fundamentales de la programación.
Se apoya en el diseño descendente y en la filosofía de “divide y vencerás”, es
decir se trata de dividir el problema dado, en problemas más simples en que cada
uno de los cuales lo implementaremos en un módulo independiente. A cada uno de
estos módulos es a lo que llamamos subalgoritmos o subprogramas.
Siempre existirá un módulo o programa principal que es con el que comienza la
ejecución de todo el programa, y a partir de él iremos llamando al resto.
Cada vez que se llama a un subprograma se le pasa la información que necesita en
la llamada, a continuación comienza a ejecutarse el subprograma llamado, y cuando
termine su ejecución, devuelve el control a la siguiente instrucción a la de llamada
en el programa que lo llamó.
En cuanto a la estructura de un subprograma es igual a la estructura de un
programa, va a tener una información de entrada que es la que le pasamos al hacer
la llamada y que se coloca junto al nombre del subprograma. Después va a tener
un conjunto de acciones, declarar otras variables propias del subprograma, y al
terminar la ejecución puede que devuelva o no resultados al programa que lo llamó.
Hay dos tipos fundamentales de subprogramas: Funciones y procedimientos.
3.2.1 Funciones
Desde el punto de vista matemático, una función es una operación que toma uno o
varios operando, y devuelve un resultado. Y desde el punto de vista algorítmico,
es un subprograma que toma uno o varios parámetros como entrada y devuelve a
la salida un único resultado.
Pascal: En las funciones se puede devolver más de un único resultado mediante
parámetros.
C: Se devuelve todo por parámetros.
Este único resultado irá asociado al nombre de la función. Hay dos tipos de
funciones:
Internas: Son las que vienen definidas por defecto en el lenguaje.
Externas: Las define el usuario y les da un nombre o identificador.
Para llamar a una función se da su nombre, y entre paréntesis van los argumentos
o parámetros que se quieren pasar.
Declaración de una función:
La estructura de una función es semejante a la de cualquier subprograma. Tendrá
una cabecera (con el nombre y los parámetros) y un cuerpo (con la declaración de
los parámetros de la función y las instrucciones).
Sintaxis:

Función <nombre_funcion> (n_parametro: tipo, n_parametro: tipo): tipo función
Var <variables locales función>
Inicio
<acciones>
retorno <valor>
fin <nombre_funcion>
La lista de parámetros es la información que se le tiene que pasar a la función. Los
parámetros luego dentro de la función los podemos utilizar igual que si fueran
variables locales definidas en la función y para cada parámetro hay que poner su
nombre y tipo.
El nombre de la función lo da al usuario y tiene que ser significativo.
En las variables locales se declaran las variables que se pueden usar dentro de la
función.
Entre las acciones tendrá que existir entre ellas una del tipo retorno <valor>. Esta
sentencia pondrá fin a la ejecución de la función y devolverá el valor de la función,
es decir, como valor asociado al nombre de mismo tipo que el tipo de datos que
devuelve a la función, este valor por tanto tiene que ser del mismo tipo que el tipo
de datos que devuelve la función, que es el que habremos indicado al declarar la
función en la parte final de la cabecera.
No se permiten funciones que no devuelvan nada.
Los parámetros que aparecen en la declaración de la función se denominan
parámetros formales, y los parámetros que yo utilizo cuando llamo a la función se
denominan parámetros actuales o reales.
Invocación de una función:
Para llamar a una función se pone el nombre de la función, y entre paréntesis los
parámetros reales, que podrán ser variables, expresiones, constantes,... pero
siempre del mismo tipo que los parámetros normales asociados
<nombre_funcion> (parámetros reales)
La función puede ser llamada desde el programa principal o desde cualquier otro
subprograma.
Para llamar a la función desde cualquier parte, implica el conocimiento previo de
que ésta función existe.
A través de los parámetros reales de la llamada se proporciona a la función la
información que necesita, para ello, al hacer la llamada lo que se produce es una
asociación automática entre parámetros reales y parámetros formales. Esta
asociación se realiza según el orden de la aparición y de izquierda y derecha.
Si el parámetro formal y real no es del mismo tipo, en Pascal se produce un error,
y en C se transforman los tipos si es posible.
La llamada a una función, siempre va a formar parte de una expresión, de cualquier
expresión en la que en el punto en la que se llama a la función, pudiera ir colocado
cualquier valor del tipo de datos que devuelve la función, esto se debe a que el
valor que devuelve una función está asociado a su nombre.
Pasos para hacer la llamada a una función:

cada parámetro real a cada parámetro formal asociado, siempre por orden de
aparición y de izquierda a derecha, por lo que siempre que no coincidan los tipos
y el número de parámetros formales y reales, se produce un error.
a una de tipo retorno <valor> que pondrá fin a la ejecución. Pueden existir varias
sentencias de retorno en la misma función, pero en cada llamada solo se podrá
ejecutar uno.
al subprograma que hizo la llamada pero sustituyendo el nombre de la función por
el valor devuelto.
Otra forma de especificar el retorno de una función:
Se le asigna el valor devuelto al nombre de la función.
Función valor
3.2 Estructura de los datos internos
Operaciones Con Arreglos
Las operaciones en arreglos pueden clasificarse de la siguiente forma: • Lectura •
Escritura • Asignación • Actualización • Ordenación • Búsqueda
a) LECTURA Este proceso consiste en leer un dato de un arreglo y asignar un
valor a cada uno de sus componentes. La lectura se realiza de la siguiente manera:
para i desde 1 hasta N haz x<--arreglo[i]
b) ESCRITURA Consiste en asignarle un valor a cada elemento del arreglo. La
escritura se realiza de la siguiente manera: para i desde 1 hasta N haz arreglo[i]<-
-x
c) ASIGNACIÓN No es posible asignar directamente un valor a todo el arreglo, por
lo que se realiza de la manera siguiente: para i desde 1 hasta N haz arreglo[i]<--
algún_valor
d) ACTUALIZACIÓN Dentro de esta operación se encuentran las operaciones de
eliminar, insertar y modificar datos. Para realizar este tipo de operaciones se debe
tomar en cuenta si el arreglo está o no ordenado.

3.2.1 Vectores





3.2.2 Matrices
3.2.3 Poliedros
