trabajo fin de grado - universidad de...
TRANSCRIPT

Equation Chapter 1 Section 1
Trabajo Fin de Grado
Grado en Ingeniería de Organización Industrial
Algoritmo genético para talleres de flujo híbrido con
ausencia de operaciones y minimización del
makespan. Influencia de las mejoras locales.
Autor: Manuel Burgos Martin
Tutor: Víctor Fernández Viagas
Dep. Organización Industrial y Gestión de Empresas I
Escuela Técnica Superior de Ingeniería
Universidad de Sevilla
Sevilla, 2017

2

3
Trabajo Fin de Carrera
Grado en Ingeniería de Organización Industrial
Algoritmo genético para talleres de flujo híbrido
con ausencia de operaciones y minimización del
makespan. Influencia de las mejoras locales.
Autor:
Manuel Burgos Martín
Tutor:
Víctor Fernández Viagas
Dep. de Organización Industrial y Gestión de Empresas I
Escuela Técnica Superior de Ingeniería
Universidad de Sevilla
Sevilla, 2017

4

5
Trabajo de Fin de Grado: Algoritmo genético para talleres de flujo híbrido con ausencia de operaciones y
minimización del makespan. Influencia de las mejoras locales.
El tribunal nombrado para juzgar el Proyecto arriba indicado, compuesto por los siguientes miembros:
Presidente:
Vocales:
Secretario:
Acuerdan otorgarle la calificación de:
Sevilla, 2017
Autor: Manuel Burgos Martín
Tutor: Víctor Fernández Viagas

6

7
A mi familia
A mis amigos
A mis maestros

8
Agradecimientos
Este trabajo va dedicado a mis padres, los cuales me han ayudado estos años de carrera, a Alba, que me ha
aguantado y dado fuerzas mientras realizaba el proyecto y a todos mis profesores, en especial a mi tutor.
Manuel Burgos Martin
Sevilla, 2017

9

10
Resumen
En este trabajo de Fin de Grado, abordaremos el problema del taller de flujo híbrido, con la restricción de
ausencia de operaciones. Resolveremos el problema del taller aplicando un método de resolución aproximada.
En nuestro caso, hemos decidido usar un algoritmo genético básico, que constara de un cruce de dos puntos y
una mutación de intercambio. El objetivo de este tipo de problemas de programación de la producción consiste
en determinar la secuencia de entrada que nos proporcione el mejor valor para una función objetivo
determinada; en nuestro caso buscaremos reducir el makespan.
Se crearán cinco variantes distintas del algoritmo genético para resolver el problema, aplicando a cada una
distintos tipos de mejoras locales, para poder evaluar la influencia de dichas mejoras en los resultados finales
de los modelos. La primera variante no constará de ningún tipo de mejora local. El resto de variantes las
podemos dividir en dos grupos, aquellas en las que se aplica la mejora local al mejor individuo de la población
final tras cada iteración y aquellas en que se aplica la mejora a todos los individuos de dicha población. A su
vez, dentro de cada grupo habrá dos variantes, una que use una mejora local por inserción y otra variante que
use una mejora local por intercambio.
Los problemas a resolver han sido generados aleatoriamente a partir de distintos parámetros característicos
para los talleres híbridos con ausencia de operaciones. Para cada combinación de parámetros se han generado
diez instancias, formando al final una batería de problemas con 360 instancias.

11
Abstract
In this work of End of Degree, we will approach the problem of the hybrid flowshop, with the restriction of
missing operation. We will solve the workshop problem by applying an approximate resolution method. In our
case, we have decided to use a basic genetic algorithm, consisting of a two-points crossover and an exchange
mutation. The goal of this type of production scheduling problem is to determine the input sequence that gives
us the best value for a given objective function; In our case, we will seek to reduce the makespan.
Five different variants of the genetic algorithm will be created to solve the problem, applying to each one
different types of local search methods in order to be able to evaluate their influence on the final results of the
models. The first variant is the traditional genetic algorithm without local search. The other variants can be
divided into two groups: those in which the local search is applied to the best individual of the final population
(after each iteration); and, those in which the local search is applied to all the individuals of the population. In
addition, within each group there will be two variants, one that uses an insertion phase as local search and
another variant that uses exchange.
The problems to be solved have been generated randomly from different parameters characteristic for the
hybrid flowshop with missing operation. For each combination of parameters, ten instances have been
generated, forming at the end a benchmark composed of 360 instances.

12

13
ÍNDICE
Agradecimientos 8
Resumen 10
Abstract 11
Índice 13
Índice de Tablas 15
Índice de figuras 16
1 Introducción 18
2 Programación de la producción 20
2.1 Notación 21
2.1.1 Clasificación de los problemas de los problemas de programación 22
3 Metaheurísticas: los algoritmos genéticos 26
3.1 Tipos de metaheurísticas 26
3.2 Características de las metaheurísticas 27
3.3 Los algoritmos genéticos 28
3.3.1 Parámetros de los algoritmos genéticos 29
3.3.2 Operaciones de los algoritmos genéticos 30
4 Descripción del problema 39
4.1 El objetivo del makespan 40
5 Algoritmo genético propuesto 42
5.1 Elementos del algoritmo genético 42
5.1.1 Individuos 42
5.1.2 Población inicial 43
5.2 Cruce de dos puntos 43
5.3 Mutación de intercambio 45
5.4 Reducción 46
5.5 Poblaciones intermedias 46
5.6 Criterios de parade 47
5.7 Población final y elección de solución final 48

14
5.8 Mejoras locales 50
5.8.1 Mejora local de inserción a un individuo 50
5.8.2 Mejora local de inserción a todos individuos 51
5.8.3 Mejora local de intercambio a un individuo 54
5.8.4 Mejora local de intercambio a todos los individuos 55
6 Comparación de resultados 58
6.1 Generación de problemas 58
6.2 Análisis de los resultados en función de los parámetros 60
6.2.1 Análisis de resultados en función del número de trabajos 62
6.2.2 Análisis de resultados en función del número de etapas 63
6.2.3 Análisis de resultados en función del porcentaje de missing 65
7 Conclusiones 68
8 Bibliografía 70
9 Anexos 73
9.1 Anexo A: Resultados en Excel 73
9.2 Anexo B: Códigos en C 82
9.2.1 Código metodo I: “Normal” 82
9.2.2 Código metodo II: “Inserción1” 101
9.2.3 Código metodo III: “Inserción10” 122
9.2.4 Código metodo IV: “Intercambio1” 143
9.2.5 Código metodo IV: “Intercambio10” 164

15
ÍNDICE DE TABLAS
Tabla 6-1: Ejemplo datos para problema propuesto 59
Tabla 6-2: Resultados clasificados por parámetros 61
Tabla 6-3: Resultados en función numjobs 62
Tabla 6-4: Resultados en función del número de etapas 64
Tabla 6-5: Resultados en función del % de missing 65
Tabla 7-1: Resultados finales 69

16
ÍNDICE DE FIGURAS
Figura 2-1: Ilustración del missing. Elaboración propia 25
Figura 3-1: Ilustración cromosoma y gen. Elaboración propia 29
Figura 3-3: Ilustración ruta mínima [www.ingenieriaindustrialonline.com] 32
Figura 3-4: Cruce de un punto. Elaboración propia 35
Figura 3-5: Cruce de dos puntos. Elaboración propia 36
Figura 2-2: Esquema del Floswshop Hibrido Flexible [Fernández-Viagas,2015] 39
Figura 4-1: Ejemplo individuo. Elaboración propia. 42
Figura 4-2: Ejemplo padres para cruce. Elaboración propia. 44
Figura 4-3: Padre e Hijo en cruce. Elaboración propia. 44
Figura 4-4: Hijo realizado por cruce. Elaboración propia. 45
Figura 4-5: Ejemplo mutación por intercambio. Elaboración propia. 46
Figura 4-6: Diagrama de flujo para modelo propuesto I: “Normal” . Elaboración propia. 49
Figura 4-7: Ejemplo Inserción I. Elaboración propia. 50
Figura 4-8: Ejemplo Inserción II. Elaboración propia. 51
Figura 4-9: Ejemplo Inserción III. Elaboración propia. 51
Figura 4-10: Diagrama de flujo para modelo propuesto II: “Inserción1” . Elaboración propia. 52
Figura 4-11: Diagrama de flujo para modelo propuesto III: “Inserción10” . Elaboración propia. 53
Figura 4-12: Ejemplo Intercambio I. Elaboración propia. 54

17
Figura 4-13: Ejemplo Intercambio II. Elaboración propia. 54
Figura 4-14: Ejemplo Intercambio III. Elaboración propia. 55
Figura 4-15: Diagrama de flujo para modelo propuesto IV: “Intercambio1” . Elaboración propia. 56
Figura 4-16: Diagrama de flujo para modelo propuesto V: “Intercambio10” . Elaboración propia. 57
Figura 6-1: Gráfica resultados en función numjobs. Elaboración propia. 62
Figura 6-2: Gráfica resultados en función número etapas. Elaboración propia. 64
Figura 6-3: Gráfica resultados en función del % de missing. Elaboración propia. 66

18
1 INTRODUCCIÓN
a Programación y Control de la Producción, está inscrita dentro de la Organización de la Producción. Se
trata de un proceso que ha tomado un papel muy importante en el sector industrial, tratando de alcanzar
unos elevados grados de productividad mediante la reducción de costes, aumentando así su
competitividad. Además de invertir en mejorar para los procesos de producción, las empresas deberán dedicar
parte de sus recursos en modernizar los métodos de gestión.
De acuerdo con lo que dice Colin R. Reevest (1995), no es una opción realista buscar soluciones óptimas
para los problemas combinatorios complejos, dada la gran cantidad de tiempo que necesitan los
ordenadores actuales para llegar hasta ellos. Por ello, la mayoría de los investigadores se han centrado en
la búsqueda de soluciones mediante algoritmos genéticos aproximados o heurísticos. Uno de dichos
problemas es el estudiado por Colin R. Reevest denotado como el programa de programación en talleres
de flujo regular, en el que n trabajos tienen que ser procesados en el mismo orden por m máquinas. El
objetivo de éste es encontrar la secuencia de trabajos que minimicen el makespan, es decir, el tiempo de
salida del último trabajo en la máquina m. A partir de las ideas desarrolladas por Holland (1975), Colin R.
Reevest decidió aplicarlos al problema del permutation flowshop. También Ogbu y Smith, (1990) y Ogbu
y Smith, (1991) han mostrado que el método del recocido simulado (Simulated Annealing) da resultados
de gran calidad para el problema del flowshop.
Ante la multitud de elementos que intervienen en los procesos productivos, las metaheurísticas aparecen para
ayudar en la resolución de problemas complejos, demostrando que aportan soluciones próximas al óptimo,
empleando para ello tiempos computacionales muy competitivos frente a otros métodos.
Visto los estudios realizados por Colin (1995), Ogbu y Smith(1990), hemos decidido aplicar una
metaheurística, como son los algoritmos genéticos, para resolver el problema del taller de flujo híbrido con
ausencia de operaciones (hybrid flowshop with missing opperation)1, para ver si también se consiguen
resultados de buena calidad al igual que al aplicarlos al permutation flowshop. Aplicándole después, a nuestra
metaheurística, diferentes tipos de mejora local y compararlas entre ellas, pudiendo así observar que tipo de
mejora local se adecua mejor a diferentes problemas.
Comenzaremos este trabajo describiendo la programación de la producción y su papel dentro de la
organización de la producción en la sección 2.En la sección 3 describiremos los tipos de problemas dentro de
1 En este trabajo utilizaremos las dos notaciones indistintamente.
L

19
la programación de la producción y en concreto el nuestro, el hybrid . A continuación, en la sección 4,
trataremos el tema de las metaheurísticas y especialmente los algoritmos genéticos que hemos usado para
resolver nuestro Hybrid Flowshop y las mejoras locales aplicadas. Seguiremos explicando en la sección 5 las
distintas metaheurísticas que hemos decidido implementar para resolver nuestro problema y las mejoras que
les hemos aplicado a ellas. Por último, en las secciones 6 y 7, hemos extraído los resultados obtenidos al
aplicar nuestras distintas metaheurísticas y hemos realizado un análisis de estos resultados en función de
distintos parámetros.

20
2 PROGRAMACIÓN DE LA PRODUCCIÓN
omo ya hemos dicho en la introducción, dentro de la Organización de la Producción (Production
Management), la programación de la producción es una etapa clave, donde se toman las decisiones de
carácter operativo a corto plazo. Podemos definirla como “la asignación de un conjunto de recursos en un
periodo de tiempo, para llevar a cabo un conjunto de tareas” (Phanden et al., 2012). Por tanto, se define la
Organización de la Producción como el proceso industrial, en el que, a partir de la toma de múltiples
decisiones, se intenta asegurar la entrega al cliente de los productos deseados con el mínimo coste, el mínimo
tiempo de entrega y la máxima calidad.
Se ha intentado caracterizar la producción desde distintos enfoques, tomando como referencia el enfoque
usado por Juan Camilo López Vargas (2013) en su tesis, Metodología de programación de la producción en
un flowshop híbrido flexible, en ella enfoca la producción como un conjunto jerarquico de decisiones con tres
niveles: el nivel estratégico, en táctico y el operativo.
a) Planificación estratégica:
Al usar una visión jerárquica, solo utilizaremos la información más importante para cada nivel.
Comenzaremos el proceso de producción estableciendo la estrategia, en ella se establecerán los criterios en los
que el departamento de producción tendrá que invertir sus esfuerzos y determinar las decisiones a largo plazo.
Dada la fluctuación constante de los mercados actuales en los costes de los productos, es muy importante tener
una fiabilidad alta a la hora de cumplir pedidos en el menor tiempo posible, con unos inventarios lo mas
reducios posibles.
b) Programación táctica:
Una vez definidas las estrategias de producción, se pueden analizar los aspectos tácticos y operativos. En el
táctico, se definirán el tamaño de los pedidos y las capacidades de las que disponemos para un horizonte
temporal determinado. El alcanze de dicha planificación será a medio plazo ya que en ella se establecerán las
políticas referentes al personal.
C

21
c) Programación Operativa
En este nivel se tomarán las decisiones a corto plazo, éstas son las relacionadas principalmente con la
disponibilidad de los recursos para poder cumplir los presupuestos de producción y ejecutar los programas
establecidos en los otros niveles.
Los objetivos más comunes que se buscan conseguir en la programación de la producción se pueden clasificar
en tres grandes grupos (Naderi et al., 2010):
1. La utilización eficiente de los recursos que está relacionado con el tiempo máximo de terminación,
también llamado makespan.
2. La reducción de los tiempos de entrega, es decir, minimizar el tiempo de respuesta a las demandas,
minimizando el tiempo de proceso (WIP)
3. El cumplimiento de los plazos de entrega, cuyos medidores son la tardanza total y el número de
trabajos retrasados.
2.1 Notación
Para este punto hemos tomado como referencia la notación explicada por Michael L. Pinedo (2008). Al igual
que él, en todos nuestros problemas el número de trabajos y de máquinas será finito, denotando el número de
trabajos con la letra n, el número de máquinas con la letra m y el número de etapas con la letra c. Usaremos el
subíndice j para los trabajos, el subindice i para las máquinas. Por tanto, al usar el par (i, j) nos referimos a un
proceso u operación del trabajo j en la máquina i. Cada trabajo podrá tener varios datos asociados como son:
-Tiempo de proceso (𝑝𝑖𝑗). Esto representará el tiempo que necesitará el trabajo j en la máquina i para terminar
de ser procesado. El subíndice i puede ser omitido si el tiempo de proceso del trabajo j no depende de la
maquina en que sea procesado o solo puede ser procesado en una máquina.
-Fecha de llegada (𝑟𝑗). Es el instante en que el trabajo j llega al sistema y puede empezar a procesarse.
-Fecha de entrega (𝑑𝑗) . Es la fecha máxima que tenemos para tener finalizado el trabajo, se puede acabar de
procesar el trabajo más tarde de esta fecha, pero se incurrirá en una penalización.

22
-Peso (𝑤𝑗). Es un factor para priorizar unos trabajos ante otros, es decir, es un factor que nos indica que
trabajos tenemos mas prioridad por finalizar primero, ya sea porque cueste mucho mantenerlos en el taller o
por otras causas.
En cuanto a las variables, necesarias especialmente a la hora de calcular los objetivos son:
Tiempo de finalización: el tiempo de finalización del trabajo j en la máquina i lo denotaremos como
𝐶𝑖𝑗 . Y al tiempo que j está en el sistema, es decir el tiempo en que el trabajo termina de ser procesado
en la última máquina se le llamará 𝐶𝑗
Retraso del trabajo o lateness (𝐿𝑗 = 𝐶𝑗 − 𝑑𝑗): es la diferencia entre la fecha en que hemos terminado
el trabajo y la fecha de entrega de dicho trabajo. Será positivo cuando el trabajo se acaba después de
su fecha límite y negativo cuando se termina antes de tiempo.
Tardanza del trabajo j o tardiness (𝑇𝑗 = max(𝐿𝑗 , 0): la tardanza indica si un trabajo se ha acabado con
retraso o no, siendo la tardanza 1 si se retrasó el trabajo y 0 si no.
Adelanto del trabajo o earliness (𝐸𝑗 = max(0, −𝐿𝑗): sería el contrario de la tardanza. Siendo 1 si se
acaba el trabajo con adelanto y 0 si se retrasa el trabajo.
Tiempo de flujo del trabajo j o flowtime (𝐹𝑗 = 𝐶𝑗 − 𝑟𝑗): tiempo que el trabajo esta en el entorno.
2.1.1 Clasificación de los problemas de los problemas de programación
Una de las clasificaciones más usadas es la descrita por Pinedo (2008), propuesta por Graham (1979).
Clasifica los problemas según tres parámetros: α | β | γ. El primer parámetro α indica el entorno de la máquina
y contiene solo una entrada. El segundo parámetro β contiene detalles de las características de proceso, este
campo puede constar de ninguna, una o varias entradas. El tercer parámetro γ describe el objetivo que debe ser
minimizado, normalmente tendrá una sola entrada.
Como ya hemos dicho antes el parámetro α contiene la información del entorno del problema. Nos indica la
estructura del taller en el que estamos trabajando, es decir, la distribución de las máquinas en el taller. Hay
varios tipos de entornos como son:

23
Single Machine (1). Una única máquina que procesa todos los trabajos. Es el caso más simple de
todos los posibles entornos y es un caso especial de otros más complicados.
Máquinas idénticas en paralelo (𝑃𝑚). Hay m máquinas idénticas en paralelo, los trabajos necesitan
solo una operación y pueden ser procesados en cualquiera de las máquinas. En todas las máquinas el
trabajo tardará lo mismo en ser procesado.
Máquinas en paralelo con distintas velocidades (𝑄𝑚). Hay m máquinas en paralelo con diferentes
velocidades. La velocidad de cada máquina se denota como 𝑣𝑖, y el tiempo que pasará un trabajo en
una máquina para ser procesado (𝑝𝑖𝑗) será igual a 𝑝𝑖/𝑣𝑖.
Máquinas en paralelo no relacionadas (𝑅𝑚). Es un caso generalizado a partir del anterior. En este caso
todas las máquinas son diferentes y el tiempo de proceso de cada trabajo depende de la máquina en
que sea procesado sin ninguna relación entre ellas. El tiempo de procesado de cada trabajo se denotará
como 𝑝𝑖𝑗.
Flow shop (𝐹𝑚). En este tipo de taller hay m máquinas en serie y cada trabajo tiene que ser procesado
en cada una de las m máquinas, y todos ellos tienen la misma ruta, es decir, primero deben ser
procesados en la máquina 1, cuando termine de ser procesado pasará a la máquina 2 y así
sucesivamente. En el campo β nos podemos encontrar la restricción de Prmu, lo que indica que en
cada máquina el orden de los trabajos ha de ser el mismo.
Job shop (𝐽𝑚). Es un caso muy parecido al anterior, la diferencia es que en este caso cada trabajo tiene
su propia ruta, no todos siguen la misma y cada trabajo puede ser procesado en alguna máquina más
de una vez.
Openshop (𝑂𝑚). Es el caso más complejo de todos. Hay m máquinas en paralelo y cada trabajo tiene
que ser procesado por todas las máquinas. En algunos casos el tiempo de proceso en alguna máquina
puede ser cero. Los trabajos no tienen una ruta determinada, al resolver el problema habrá que
determinar la ruta de cada trabajo j, pudiendo tener cada trabajo una ruta distinta.
El parámetro β, contiene las características del proceso, es decir, tiene las restricciones que tenemos que tener
en cuenta a la hora de resolver nuestro modelo. Alguno de los tipos de restricciones que nos podemos
encontrar son:
Fechas de llegada y de entrega (𝑟𝑗, 𝑑𝑗): como ya hemos explicado antes son fechas de llegada y de
entrega de los trabajos. Si aparecen en el campo β habrá que tenerlas en cuenta a la hora de resolver el
problema.

24
Interrupciones (Prmp): indica que están permitidas las interrupciones, es decir, no es necesario
mantener un trabajo en una máquina una vez iniciado hasta su finalización, sino que, podemos
interrumpir el procesado en cualquier momento. Hay tres tipos de interrupciones:
Non-resumable: se pierde el trabajo hecho de la tarea interrumpida, y se empieza
otra vez cuando se reinicia.
Semi-resumable: se pierde parte del trabajo realizado, es decir, se reinicia
parcialmente (una proporción del trabajo ya realizado)
Resumable: se reinicia por donde se había dejado tras la interrupción
Precedencia en los trabajos (Prec): indica que hay relaciones de preferencia entre operaciones de
diferentes trabajos. Puede aparecer en entornos de single machine o de máquinas en paralelo, indica
que uno o más trabajos tienen que ser finalizados antes de poder comenzar a procesar otro. Hay varios
tipos de relaciones de precedencia:
Chains (en serie): si cada trabajo tiene como máximo un predecesor y un sucesor.
Intree: cada trabajo tiene como máximo un sucesor.
Outtree: cada trabajo tiene como máximo un predecesor.
Tree: los trabajos no tienen un límite de predecesores o sucesores. Siguen un
esquema de árbol que será dado antes de resolver el problema.
Tiempos de setup (Setup): indica que existen tiempos de setup que hay que esperar entre operaciones.
Se denota como 𝑠𝑗𝑘 y representa el tiempo de setup necesario para procesar el trabajo k después del
trabajo j; 𝑠0𝑘 será el tiempo de Setup del trabajo k si éste es el primer trabajo en ser procesado, y 𝑠𝑘0
será el tiempo de clean-up, es decir, el tiempo de setup posterior si k es el último trabajo de la
secuencia. Si en el campo β no aparece setup consideraremos todos los tiempos cero.
Bloqueo (Block): Si un trabajo acaba de ser procesado y el buffer de la siguiente máquina está lleno el
trabajo deberá esperar en la máquina en la que ha sido procesado hasta que haya suficiente etapa en el
buffer para él. Los buffers de las maquinas pueden ser iguales todos o dependientes de cada máquina.
Máquina no ociosa (nwt): Indica que los trabajos no tienen permitido esperar entre dos máquinas
sucesivas, no podremos empezar a procesar un trabajo hasta estar seguros que puede recorrer todo el
flowshop sin tener que esperar en ninguna máquina.
Recirculación (rcrc): indica que algunos trabajos deberán ser procesados más de una vez en la misma
máquina o centro de trabajo.

25
Missing: La gran mayoría de las investigaciones de programación de la producción para los
problemas de los talleres híbridos flexibles, suponen que cada trabajo tiene que ser procesado en todas
las etapas, es decir, no consideran la restricción de missing. Sin embargo, en la vida real hay muchos
entornos de producción en los que existe missing. Esto consiste en trabajos que pueden saltarse una o
varias etapas de la cadena de producción.
Figura 2-1: Ilustración del missing. Elaboración propia
Y, por último, el parámetro γ. Todo problema de programación de la producción buscará dar una solución al
problema, minimizando uno o varios objetivos. Algunas de las funciones objetivos más usadas son:
- Makespan (𝐶𝑚𝑎𝑥): el makespan es definido como el máximo tiempo de finalización de los trabajos de
un entorno, es decir, el tiempo en que el último trabajo abandona el sistema. Cuando menor sea el
makespan mejor utilización se les habrán dado a las máquinas.
- Máximo retraso (𝐿𝑚𝑎𝑥): Es definido como el máximo de los retrasos,max( 𝐿1,…, 𝐿𝑛). Mide la peor
violación de las fechas de entregas.
- Tiempo de finalización total ponderado (∑𝑤𝑗𝐶𝑗 ): es la suma ponderada de todos los tiempos de
finalización.
- Número de trabajos tardíos (∑𝑈𝑗): indica cuantos trabajos hemos entregado con algún retraso
respecto a su fecha de entrega.

26
3 METAHEURÍSTICAS: LOS ALGORITMOS
GENÉTICOS
os métodos heurísticos proporcionan soluciones en las que se tiene cierta confianza que son factibles y
cercanas a la optimalidad. Pueden ser muy generales o específicas, teniendo las más generales ventajas
como: la sencillez, la adaptabilidad, la robustez, etc…
A partir de la década de los 70 han aparecido métodos de solución de problemas llamados técnicas
metaheurísticas. Dichas técnicas son definidas por Osman y Kelly (1996) como: “métodos aproximados
diseñados para resolver problemas de optimización combinatoria, en los que los heurísticos clásicos no son
efectivos. Los metaheurísticos proporcionan un marco general para crear nuevos algoritmos híbridos,
combinando diferentes conceptos derivados de la inteligencia artificial, la evolución biológica y los
mecanismos estadísticos.” Las técnicas metaheurísticas son útiles para aquellos problemas en que las técnicas
exactas no resultan eficientes o no se pueden aplicar. Las metaheurísticas a diferencia de las heurísticas poseen
mecanismos para escapar de las soluciones óptimas locales y continuar en la búsqueda del óptimo global,
aunque ninguna metaheurística puede garantizar el óptimo global. Es decir, las metaheurísticas encuentran
soluciones muy superiores a las heurísticas con esfuerzos computacionales mayores pero aceptables desde el
punto de vista práctico.
3.1 Tipos de metaheurísticas
Las metaheurísticas se pueden clasificar de diversas formas. Una de las posibles clasificaciones, dado que las
metaheurísticas son usadas para plantear otros procedimientos heurísticos, es clasificarlas dependiendo de la
clase de procedimiento a los que se refieran:
a) Metaheurísticas para los procesos de relajación: Las metaheurísticas de relajación hacen referencia a
aquellos métodos que usan relajaciones del original, es decir, modifica el modelo original para que
éste sea más sencillo de resolver.
L

27
b) Metaheurísticas para los procesos constructivos: Las metaheurísticas constructivas, son aquellas en las
que los procedimientos tratan de obtener nuevas soluciones a partir del análisis y selección paulatina
de los componentes que forman dichas soluciones.
c) Metaheurísticas para las búsquedas de entorno: Las metaheurísticas de búsqueda son las más
importantes, establecen estrategias para recorrer el espacio de soluciones del problema transformando
iterativamente las soluciones de partida.
d) Metaheurísticas para los procedimientos evolutivos: Las metaheurísticas evolutivas están enfocadas
en procedimientos que comienzan en un conjunto de soluciones que van evolucionando sobre el
espacio de soluciones. Su aspecto fundamental consiste en la iteración entre los miembros, a
diferencia de otro métodos de búsqueda, que toman como patrón la información de cada solución por
separado.
e) Otros tipos: Otras metaheurísticas surgen combinando varias de distintos tipos, como las GRASP
(Greedy Randomized Adaptative Search Procedure) que une una fase constructiva con otra de
búsqueda de mejora.
3.2 Características de las metaheurísticas
Todas las técnicas metaheurísticas tienen una serie de características comunes:
- Son técnicas que no se detendrán cuando lleguen a la solución óptima ya que no saben diferenciar la
óptima de una óptima local. Debido a eso deberemos determinar los criterios de parada para indicar
cuando debe finalizar el algoritmo.
- Son algoritmos aproximativos, y por tanto no garantizan que se llegue a la solución óptima.
- A veces realizan malos movimientos, es decir, en estas técnicas no toda nueva solución es mejor que
la anterior en términos de la función objetivo. A veces incluso crean soluciones no factibles pero que
sirven como etapa intermedia para llegar a nuevas regiones que no han sido analizadas.
- Son por lo general sencillas, lo único necesario para comenzar es una muestra del campo en el que
buscaremos las soluciones, un punto en el que comenzar, es decir, una o varias soluciones iniciales, y
un procedimiento determinado que nos permita ir explorando todo el espacio de soluciones.
- Son muy genéricas, permitiendo así su aplicación a cualquier problema de optimización combinatorio.

28
Por ello es importante escoger una técnica que se adecue bien al problema considerado y que tengan
relación con este, para que sean lo más eficientes posibles.
- Las reglas de selección dependen del instante del proceso y de la historia de la técnica hasta dicho
instante. Así, en dos iteraciones determinadas en las que se obtiene la misma solución, la nueva
solución de la siguiente iteración no tiene por qué ser la misma en ambos casos.
3.3 Los algoritmos genéticos
Los algoritmos genéticos son técnicas de búsqueda basada en el comportamiento de los seres vivos, que junto
con otras técnicas conforman los llamados algoritmos evolutivos.
Fueron desarrollados por John Holland y Rechemberg, (1975), en la década de los 60, los cuales a partir del
comportamiento de la naturaleza crearon estos algoritmos de optimización. Su estructura se diseña a partir de
comportamientos de la propia naturaleza con la esperanza de que así se consigan resultados similares a la
capacidad de adaptación a un amplio número de ámbitos diferentes. Los algoritmos genéticos son muy
flexibles, es decir se pueden adaptar a multitud de diferentes casos tanto en ingeniería como en otros campos
como la química, la medicina o en el ámbito empresarial.
Nacen a partir de la biología y en concreto con Charles Darwin y su publicación El origen de las especies
(1859), en el que habla de los principios de la selección natural. A partir de las leyes de la naturaleza descritas
por Darwin podemos definir los fundamentos esenciales de los algoritmos genéticos.
En la naturaleza, son los cromosomas son los que contienen la información, es decir los genes. Los organismos
se agrupan en poblaciones, y los que estén mejor preparados para adaptarse son los que sobrevivirán y se
reproducirán. Algunos de estos supervivientes serán cruzados y se generara una nueva generación de
individuos. Los genes también pueden sufrir pequeñas modificaciones, denominadas mutaciones.
Los individuos, que son las posibles soluciones del problema, están formados por un grupo de parámetros a los
que llamaremos genes, dichos genes se pueden agrupar en forma de una secuencia de valores.

29
Figura 3-1: Ilustración cromosoma y gen. Elaboración propia.
3.3.1 Parámetros de los algoritmos genéticos
A continuación, pasaremos a describir los parámetros principales de los algoritmos genéticos:
3.3.1.1 Población
-Tamaño de la población
Una de las cuestiones que tendremos que valorar es el tamaño adecuado de la población. Parece lógico pensar
que cuánto más pequeña sea la población menor será la garantía de recorrer de forma adecuada el espacio de
búsqueda y dejar fuera de él posibles soluciones, mientras que si la población es demasiado grande tendremos
problemas relacionados con el costo computacional de resolver el problema, el cual será muy elevado.
Goldberg (1989), realizó un estudio teórico obteniendo como conclusión que el tamaño óptimo de la población
para secuencias de longitud l, con codificación binaria, crece exponencialmente según el tamaño de dicha
secuencia. Alander (1992), basándose en pruebas empíricas con los algoritmos genéticos sugirió que las
poblaciones con unas dimensiones entre l y 2l eran suficientes para resolver adecuadamente los problemas que
él había abordado.

30
-Población inicial
La población inicial será aquella de la que se parta en cada iteración y a la que se le irán aplicando
modificaciones hasta alcanzar nuestra solución final. Habitualmente, se generará la población inicial de forma
aleatoria, pudiendo contener cada gen uno de los posibles valores, teniendo todos una probabilidad uniforme.
Hay algunos estudios, aunque son pocos, en los que se preguntan si obteniendo la población inicial mediante
algún tipo de técnica se obtendrían mejores resultados. En ellos se llega a la conclusión que generando la
población inicial de forma no aleatoria se puede conseguir que converja antes, aunque eso puede llegar a ser
un problema ya que al converger demasiado pronto se podría no haber recorrido el espacio de soluciones
completamente, y caer en óptimos locales.
3.3.1.2 Probabilidad de cruce
Nos indicara la asiduidad con la que se producirán cruces en los padres, es decir, que se reproduzcan y se
formen nuevos individuos. En el caso que no halla cruce ya que la probabilidad así lo indique, hay dos
posibilidades dependiendo de cada autor, algunos si no hay reproducción no crean nuevos individuos y otros
deciden que los hijos sean copias exactas de los padres, aunque podría parecer redundante tener dos individuos
iguales al aplicarles la mutación tendremos dos nuevos individuos diferentes aumentando así el espacio de
búsqueda.
3.3.1.3 Probabilidad de mutación
Nos indica que porcentaje de individuos de nuestra población mutaremos. Si la probabilidad es de cero todos
los individuos tras la mutación serán los mismos.
3.3.2 Operaciones de los algoritmos genéticos
Tras determinar los parámetros de nuestro algoritmo genético, pasaremos a aplicar una serie de operadores a
nuestros individuos. Aunque los algoritmos genéricos son independientes del problema al que se están
aplicando, el proceso de resolución del problema ira contenido en él, eso hace a los algoritmos una
herramienta muy interesante ya que resultan de gran utilidad en multitud de entornos, aunque no esté
especializado en ninguno. Las soluciones compiten para ver cuál es la mejor, y las mejores irán guiando al
resto de soluciones de forma que vayan mejorando en una dirección concreta y al final solo las más adecuadas
sobrevivan.

31
Por tanto, la clave de un algoritmo genético estará en determinar de forma adecuada los parámetros del
problema, la manera de codificarlos y la forma en que aplicaremos los operadores.
Los individuos, que son las posibles soluciones, estarán formados por una serie de parámetros llamados genes,
estos estarán agrupados en forma de secuencias, a las que llamaremos cromosomas.
3.3.2.1 Codificación de las variables
Debemos hacer que los cromosomas contengan información acerca de la solución que representan. Para ello
hay varias formas de llevarla a cabo: la más extendida es creando una secuencia binaria, aunque también
podría realizarse con números enteros o caracteres, elegiremos una u otra opción dependiendo cual se adecue
más a nuestro tipo de problema.
A) Codificación binaria
Es la que fue usada en los inicios de los algoritmos, por ello es la más frecuente. Cada cadena de
cromosomas es una serie de unos y ceros. Tiene como ventaja que podemos incluir multitud de cromosomas
con solo unos pocos genes. Aunque para muchos problemas no es una buena codificación y en algunos casos
será necesario aplicar correcciones tras usar los operadores.
Este tipo es utilizado para problemas como el de la mochila. En el cual consideramos una mochila con un
volumen determinado y una lista de objetos, los cuales tendrán un peso y un beneficio asignado. El volumen
de la mochila será menor al total de los pesos de los objetos. Se intentará determinar qué conjunto de objetos
nos reportará mayor beneficio mientras su suma de pesos no sobrepase el volumen permitido.
B) Codificación numérica
En este caso utilizaremos series de números que indica la cardinalidad dentro de en una secuencia. Es utilizada
generalmente cuando necesitamos ordenar una serie de elementos. Aunque, al igual que en la binaria a veces
será necesario realizar correcciones tras el cruce o la mutación.
Un ejemplo en el que es muy útil aplicarla es en el problema del viajero. En él tenemos un conjunto de
ciudades que el viajero deberá visitar y las distancias existentes entre cada una.Se busca determinar la ruta que
deberá recorrer el comerciante para que iniciando la ruta en una ciudad pase por el resto de ellas, recorriendo el

32
mínimo número de kilómetros
Figura 3-2: Ilustración ruta mínima [www.ingenieriaindustrialonline.com]
C) Codificación por valor directo
Esta codificación la utilizaremos en casos de resolución de problemas en el que se requiera el uso de
valores de cifrado complicados como sería el uso de números reales, ya que codificar números reales en
binario sería muy complejo. Cada cromosoma representa una serie de valores, los cuales pueden ser
números, ya sean enteros o binarios, o caracteres. Es muy útil para casos específicos, aunque para
utilizarla normalmente será imprescindible determinar una serie de métodos de reproducción y mutación
específicos para el problema, lo cual aumentara la complejidad del algoritmo genético bastante.
Por ejemplo, una aplicación de esta codificación será en la resolución de problemas para la búsqueda de
pesos para las redes neuronales. En ellos trataremos de encontrar el peso de las neuronas para ciertas
entradas y así entrenar a la red para obtener la salida deseada. El valor del peso de las entradas vendrá
representado en el propio cromosoma.
D) Codificación en árbol
Este último tipo, se utiliza principalmente en el desarrollo de programas o expresiones para programación
genética. En este caso, cada cromosoma será un árbol con ciertos objetos.
En este método, los cambios aleatorios se podrían generar cambiando el operador, variando los valores de

33
los nodos de los árboles o sencillamente cambiando un árbol por otro.
3.3.2.2 Selección
En los algoritmos genéticos, necesitaremos seleccionar los individuos mejor preparados, es decir, los que
mejor solución aporten a nuestro problema, para que estos sean los que más se reproduzcan, al igual que en la
naturaleza, en la cual los más capacitados son los que sobreviven y crean unos descendientes más capaces.
Por tanto, una vez evaluados todos los individuos y obtenido el resultado que nos proporciona a nuestro
problema, crearemos una nueva población intentando que los buenos rasgos de los mejores pasen a dicha
población.
A continuación, nombramos algunas de las formas de cómo podremos realizar dicha selección, aunque hay
multitud de posibilidades, pueden ser:
1) Selección por rueda de ruleta: En este caso, crearemos una ruleta con los cromosomas de la
generación, y cada uno de ellos contendrá una porción de la ruleta relativa a su valor para la función
objetivo. Tras crear la ruleta, seleccionaremos aleatoriamente un cromosoma de ella. Los cromosomas
con mayor puntuación saldrán con mayor probabilidad, lo que puede dar problemas ya que, si uno
tiene el 85% de oportunidad de salir, los otros casi nunca serán escogidos y reduciremos la diversidad
de la muestra.
2) Selección por rango: En este método, haremos un ranking de los cromosomas dependiendo de su
aptitud, y a cada posición en el ranking le asignaremos un % de ruleta, dándole a los de mayor ranking
más proporción de la ruleta. Así conseguiremos solucionar el problema de que un solo cromosoma
tenga la mayoría de la ruleta y tendremos mucha más diversidad, aunque el principal incinveniente de
este caso es que se tarda mas en llegar a converger.
3) Selección elitista: En algunas circunstancias, tras aplicar los operadores podemos perder el
cromosoma mas adaptado. Aplicando esta selección conseguiremos evitar eso, ya que copiaremos
dicho cromosoma u otro de entre los mejores directamente a la nueva generación. El resto se realizará
de alguna de las formas vistas anteriormente. Una variación, es que copiemos el mejor cromosoma en
la nueva generación, solo si tras el cruce y la mutación no hayamos creado un cromosoma mejor.

34
4) Selección por torneo: Es uno de los procesos de selección de padres mas usados, consiste en tomar un
grupo de elementos al azar de la población, seleccionar al mejor de dicho grupo e ir repitiendo el
proceso, hasta que el número de individuos seleccionados coincida con el tamaño de la población.
5) Selección jerárquica: En esta los elementos irán atravesando varias fases de selección en cada
iteración. Las primeras rondas, evaluaran de forma rápida y no tan rigurosamente, pero conforme
avance y se llegue a fases mas avanzadas se volverá mas electiva, reduciendo así los tiempos
computacionales ya que en las primeras rondas eliminamos de manera rápida a la mayoría de los
individuos que se muestren poco capaces, y solo evaluaremos de forma más estricta, que requiere más
costos computacionales, a las soluciones más prometedoras.
3.3.2.3 Cruce o crossover
Se denomina cruce a la forma de crear un nuevo individuo a partir de dos padres. Los cruces podrán realizarse
de dos formas distintas: una tomando una estrategia destructiva, es decir, los descendientes sustituirán a los
padres en la población nueva, o por el contrario se puede tomar una no destructiva en la que los nuevos
individuos se trasladaran a la nueva generación si están mejor adaptados al problema que los individuos que
debe sustituir.
La idea en la que se basan los cruces es que, tomando dos individuos correctamente adaptados al problema, si
obtenemos un individuo que sea hijo de los dos, existe la posibilidad de que herede los genes causantes de la
buena adaptación de los padres. Al compartir los genes de los padres la descendencia, o por lo menos parte de
ella, debería adaptarse mejor que los padres, ya que tendrá los genes buenos de ambos. Aunque obtengamos
hijos peor adaptados, eso no evidencia que estemos retrocediendo en nuestra resolución ya que los genes de los
padres seguirán en ellos, aunque de forma más dispersa, y en posteriores cruces podrán volver a ser útiles y
obtener una futura descendencia mejor.
La elección del tipo de cruce, determinará en gran medida como va a evolucionar nuestra población.Hay
diversos tipos, algunos de los más importantes son:
1) Cruce básico o de un punto
Tomaremos el par de individuos que harán de padres, en uno de ellos seleccionaremos una posición, para

35
después permutar las secciones que estén a la derecha de dicha posición. Por tanto, los genes del padre 1 a la
izquierda del punto de corte forman parte del hijo 1 y los situados a la derecha formaran parte del hijo 2,
mientras que con el padre 2 ocurrirá lo opuesto.
Figura 3-3: Cruce de un punto. Elaboración propia.
2) Cruce multipunto
Se realizarán igual que el anterior, pero tomaremos varios puntos a la hora de cruzar. Es el usado en nuestro
algoritmo propuesto, pero con una pequeña modificación, ya que al ser los genes secuencias de trabajos, no
podrá haber dos genes con el mismo valor. Por tanto, tomaremos dos puntos de cruce, y los genes entre dichos
puntos en el padre 1 pasaran al hijo 1, e igual con el padre 2 y el hijo 2. Tras esto, rellenaremos los genes del
hijo 1, con los genes en el mismo orden en que estén colocados en el padre 2, pero saltándonos los genes
repetidos.

36
Figura 3-4: Cruce de dos puntos. Elaboración propia.
3) Cruce uniforme
En este caso, cada gen del hijo tiene una probabilidad de que pertenezca a un padre o al otro.
4) Cruce PMX o de mapeamiento parcial
Tomamos una sección del padre 1 y lo colocamos en el hijo, en igual orden y posición, después rellenamos
con la madre, de forma que se parezca lo máximo posible a esta.
3.3.2.4 Mutación
La mutación modifica aleatoriamente parte de un individuo para crear uno parecido, pero no igual, variando
uno o varios genes de manera aleatoria. La mutación nos permitirá, si estamos atrapados en un mínimo, salir
de éste dando un salto a un nuevo subespacio de soluciones y así ampliar la zona de búsqueda. El
inconveniente es que si tenemos una tasa de mutación muy alta podemos tener una deriva genética, es decir, se
homogeneizará mucho la población alrededor de un mínimo y acabaremos con muchas soluciones idénticas en
un mínimo, que puede que sea no muy bueno. Para solucionar esto, una buena estrategia sería aplicar un alto
índice de mutación al principio para diversificar mucho el espacio de búsqueda e ir reduciendo dicha tasa a

37
medida que vamos avanzando en el algoritmo.
Aunque podremos escoger elementos de la población que se esté usando y mutarlos para introducirlos
posteriormente en una nueva población, lo más común es usar la mutación conjuntamente con algún tipo de
cruce. Si se determina que hay un cruce, pasaremos a mutar uno o varios de los descendientes dependiendo de
la probabilidad de cruce. Al igual que en el comportamiento de la propia naturaleza, ya que al crearse cierta
transcendencia se obtienen leves diferencias en el paso de la carga genética de padres a hijos.
Algunos tipos de mutaciones son:
a. Mutación bit a bit: Hay una posibilidad de que se dé una mutación en algún bit, si
efectivamente se produce tomaremos dicho bit e invertiremos su valor.
b. Mutación multibit: en este caso cada bit tiene una probabilidad de mutar, pudiendo mutar
varios bits a la vez.
c. Mutación de gen: de la misma manera que en la bit a bit cada elemento tendrá una
probabilidad de mutar, pero a diferencia de esa se mutaran genes enteros.
d. Mutación multigen: de la misma forma que en la bit a bit, pero cambiaremos conjuntos de
genes en vez de un conjunto de bits.
e. Mutación de intercambio: habrá una cierta posibilidad de que haya mutación, de haberla, en
dicha mutación tomaremos dos bits o genes al azar, dependiendo del caso, y los
intercambiaremos.
f. Mutación de barajado: teniendo una probabilidad de mutación, si se realiza mutación
tomaremos un par de elementos, y serán mezclados aleatoriamente los elementos que se
encuentren entre ellos

38
3.3.2.5 Reducción
Una vez obtenidos, los individuos descendientes tras los cruces y/o mutaciones de una población, en un
periodo de tiempo determinado, seleccionaremos los λ individuos que formarán parte de la nueva población de
entre todos los resultantes. Los dos métodos usados generalmente para realizar la reducción son:
a) Reducción simple: Escogeremos los λ elementos que conformen parte de la población en un
instante t+1 determinado.
b) Reducción elitista: Una vez obtenidos todos los descendientes, elegir de entre ellos los λ
individuos más adaptados al problema.

39
4 DESCRIPCIÓN DEL PROBLEMA
l flow shop es considerada como un caso particular del job shop, en el que como hemos dicho antes, se
tratará de secuenciar una cantidad de n trabajos, todos con la misma ruta, en una serie de m máquinas. Se
trata de un problema NP-hard para más de dos máquinas. Para un número no muy grande de trabajos, el
número de secuencias posibles es muy elevado y evaluarlas todas no sería posible.
Un caso especial del flowshop sería el flowshop hibrido flexible, que posee un grupo de n trabajos con la
diferencia que hay c etapas y en cada una de ellas hay 𝑚𝑖 máquinas en paralelo. Al menos una de las etapas
tiene 𝑚𝑖 máquinas mayor que uno, y se busca optimizar el proceso para cierta función objetivo. La solución
del problema es la secuencia de trabajos a la entrada de cada máquina para minimizar la función objetivo.
Figura 4-1: Esquema del Floswshop Hibrido Flexible [Fernández-Viagas,2015].
En general, el flujo de productos tendrá una única dirección y cada trabajo tendrá que pasar por todas las
etapas antes de terminar de ser procesado. Todos los trabajos tendrán la misma ruta, es decir, deberán pasar
primero por la etapa 1, después por la etapa 2, hasta la etapa m. Como proponen Zandieh y Karimi (2013), el
concepto de flexibilidad de un flowshop indica que no todos los trabajos tendrán porque ser procesados en
todas las etapas, es decir, que algunos trabajos podrán saltarse alguna etapa. Esto no influye en lo que hemos
E

40
indicado anteriormente sobre las rutas, todos los trabajos seguirán teniendo la misma ruta, aunque algunos se
salten determinadas etapas.
Como hemos dicho en el apartado 2, el campo β nos indica las restricciones del taller en estudio, para nuestro
problema solo consideraremos la restricción de missing.
Adicionalmente este tipo de entornos conllevan las siguientes restricciones comunes:
- Todos los trabajos están disponibles al principio del horizonte de programación, no tienen fecha de
llegada.
- Todas las máquinas de una etapa son idénticas.
- Cada máquina solo puede procesar un trabajo en cada instante de tiempo, es decir, cada máquina tiene
que procesar los trabajos de uno en uno. Y cada trabajo solo puede ser procesado en una maquina a la
vez y solo en una maquina en cada etapa.
- Cada trabajo está compuesto por varias operaciones que deben ser ejecutadas en un orden predefinido
- Tampoco se puede interrumpir trabajos, una vez que se inicie un trabajo no se puede parar la maquina
hasta que haya finalizado con el trabajo en curso.
- Los tiempos de proceso son conocidos e independientes de la secuencia
- Las maquinas siempre que no estén procesando un trabajo están libres, no habrá tiempos de set-up, ni
necesitan ningún mantenimiento.
- El buffer entre máquinas es infinito, esto es el número de trabajos que acaban de salir de una máquina
y están esperando a ser procesados en otra.
- El tiempo de transporte entre máquina y máquina lo suponemos despreciable o igual entre todas las
máquinas, por tanto, no tendremos que tenerlo en cuenta a la hora de resolver el problema.
4.1 El objetivo del makespan
Hay multitud de objetivos que se pueden optimizar en el estudio de los flow shop híbridos, como pueden ser:
la reducción del WIP, maximizar el número de trabajos entregados a tiempo reducir la suma de penalizaciones
por entregas tardías. Pero uno de los más usados en la literatura, es la búsqueda de la utilización eficiente de
los recursos, medida mediante el makespan.

41
Se puede definir el makespan según Hojjati y Sahraeyan (2009) como, el tiempo que transcurre entre el inicio
del primer trabajo en la primera máquina y la terminación del último trabajo en la última máquina. También se
conoce como 𝐶𝑚𝑎𝑥 ya que por definición el makespan es igual al máximo tiempo de terminación de los
trabajos. Hekmatfar et al. (2011) consideran que minimizar el makespan, estaríamos maximizando la
utilización de las máquinas, ya que se reducen los tiempos en que las máquinas están ociosas.

42
5 ALGORITMO GENÉTICO PROPUESTO
n esta sección describiremos el algoritmo genético destinado a resolver nuestro problema de Hybrid
Flowshop con Missing Operation, explicando su funcionamiento y sus elementos, que clasificaremos
en individuos, población inicial, operadores de creación de nuevos individuos, poblaciones
intermedias, criterios de parada y la solución con su criterio de selección final.
5.1 Elementos del algoritmo genético
5.1.1 Individuos
Llamaremos individuos, a los elementos básicos del algoritmo genético. Los individuos tienen tantos
elementos como trabajos tenga nuestro problema, e indican, al mismo tiempo, el orden en el que irán entrando
en el taller. Es necesario remarcar que, dentro de cada individuo, no podrá estar repetido ninguno de los
trabajos antes mencionados, ni tampoco podrá faltar ninguno de ellos.
Figura 5-1: Ejemplo individuo. Elaboración propia.
E
Población inicial
Cuce de dos puntos
Mutación por intercambio
Mejora Local

43
Cada individuo tiene asignado un makespan, que indica el tiempo que tarda dicha cadena de trabajos en
procesarse en el taller, usando como secuencia inicial dicho individuo
Podemos distinguir tres tipos de individuos:
a) Individuos iniciales:
Son los individuos con los que se pone en marcha el algoritmo; son obtenidos de forma aleatoria a partir de un
número de trabajos, estando todos presentes y sin repetición de ninguno de ellos.
b) Individuos nuevos:
Son los individuos obtenidos a partir de los padres, antes citados, mediante crossover y mutación.
c) Individuos de salida o solución
Son aquellos individuos resultantes tras aplicar los procesos de crossover, mutación y reducción, es decir,
aquellos con menor makespan entre los nuevos individuos y los iniciales.
5.1.2 Población inicial
El número de individuos iniciales, que integrarán la población inicial, es un parámetro de nuestro algoritmo
que podemos modificar, siempre teniendo en cuenta que el tamaño de esta debe ser par. En nuestro caso,
hemos decidido que dicho tamaño sea de 10 individuos iniciales.
5.2 Cruce de dos puntos
Usaremos un cruce de dos puntos, para el cual partiremos de la población inicial, en nuestro caso formada por
los 10 individuos generados anteriormente, e iremos seleccionándolos por parejas de forma aleatoria. Cada
pareja tiene una probabilidad de cruce del 80%, así que, para cada pareja primero comprobaremos si se cruza o
no, si no se cruzan la pareja de padres no tendrá descendiente, si por el contrario si se cruzan daremos

44
comienzo al cruce, primero tomando como padre 1 un individuo y después repitiendo el proceso tomando
como padre 2 el otro individuo, así obtendremos dos hijos por cada pareja.
Los pasos del cruce de dos puntos son los siguientes:
1º- Seleccionamos la pareja de individuos a la cual queremos aplicar el cruce, y decidimos que individuo va a
ser el padre 1 y cual el padre 2.
Figura 5-2: Ejemplo padres para cruce. Elaboración propia.
Una vez decidido que individuo será cada padre, tomamos el padre 1 y dividimos dicho padre por don puntos.
Tomaremos los trabajos que se encuentren entre dichos puntos y con ellos generaremos el hijo 1, colocando en
el hijo 1 dichos trabajos en el mismo orden y en las mismas posiciones que en el padre 1.
Figura 5-3: Padre e Hijo en cruce. Elaboración propia.

45
A continuación, tomaremos el padre 2, e iremos tomando los trabajos de uno en uno en el orden en que están
colocados en el padre 2 y los colocaremos en las posiciones libres del hijo 1. Teniendo en cuenta que no
podemos repetir ningún trabajo. De esta manera ya tendremos formado el hijo 1.
Figura 5-4: Hijo realizado por cruce. Elaboración propia.
5.3 Mutación de intercambio
El otro método que usaremos para obtener nuevos individuos a partir de los que tenemos, es la mutación.
Iremos tomando uno a uno los individuos de la población actual, formada por los padres y por los hijos
obtenidos a partir de estos tras el cruce, y para cada uno comprobaremos la probabilidad de mutación, si sale
positiva procederemos a mutar al individuo y si no el individuo no mutará.
Dicha mutación consiste en tomar dos genes aleatoriamente del individuo, en nuestro caso dichos genes serán
dos posiciones, e intercambiar los trabajos de dichas posiciones. Tras esto, obtendremos un nuevo individuo
por cada individuo al que le apliquemos la mutación.

46
Figura 5-5: Ejemplo mutación por intercambio. Elaboración propia.
5.4 Reducción
Para nuestro problema, hemos decidido usar una reducción elitista, que como hemos explicado antes, consiste
en tomar de la población intermedia los λ individuos más adaptados y tomarlos como población inicial para la
siguiente iteración.
Tomaremos los 10 individuos mejor preparados ya que es el tamaño de nuestra población inicial, y como
criterio de adaptación tomaremos el makespan ya que es nuestra función objetivo, tomando así los 10
individuos con menor makespan de la población intermedia.
5.5 Poblaciones intermedias
Partiendo de nuestra población inicial explicada anteriormente, formada por 10 individuos, comenzaremos la
primera iteración, tras aplicarle a dicha población el cruce de dos puntos y la mutación, nuestra población
constara de los individuos iniciales, más aquellos resultantes tras dichas operaciones.
Una vez obtenida dicha población, evaluaremos todos los individuos y veremos el makespan de cada
individuo para nuestro problema, y tomaremos los 10 individuos con mejor makespan y con ellos formaremos

47
una nueva población que usaremos en la siguiente iteración como población inicial.
En cada iteración repetiremos este proceso para obtener la población inicial de la siguiente iteración.
5.6 Criterios de parade
Tendremos 3 criterios de parada que se evaluaran tras cada iteración, si se cumple alguno de los 3 criterios tras
dicha iteración y con de la población final de dicha iteración obtendremos la solución final.
Los tres criterios de parada serán:
a) Número de iteraciones: pondremos un número máximo de iteraciones que queremos que se
realicen. Si no se cumple ninguno de los otros dos criterios y se ha llegado al número máximo de
iteraciones pararemos el algoritmo.
b) Tiempo de ejecución: al iniciar el programa se comenzará a contar el tiempo que está
ejecutándose el algoritmo y tras cada iteración comprobaremos el tiempo que lleva ejecutándose y
comprobando si hemos superado el tiempo de ejecución.
c) Número de iteraciones sin mejorar solución actual: tras cada iteración comprobaremos si en dicha
iteración hemos mejorado la mejor solución obtenida en la anterior iteración, si la hemos
mejorado pondremos el contador a cero, sino aumentaremos el contador en 1 y comprobaremos si
hemos superado el número de iteraciones sin mejorar permitido.
Dichos criterios serán tres variables que determinaremos antes de comenzar el algoritmo, tendremos que tener
en cuenta nuestros objetivos y recursos disponibles. Para algunos casos, nos convendrá obtener la solución
óptima y para otros igual nos vale con una solución buena pero no necesariamente la óptima. Como es lógico,
obtener la solución óptima, nos llevara más tiempo, por tanto, tendremos que buscar un punto de equilibrio
entre ambos.

48
Para nuestro problema hemos decidido poner un numero de iteraciones y de iteraciones de no mejora muy alto
para que el programa no pare por ninguno de estos dos criterios. Y hemos calculado el tiempo de parada a
partir del tamaño del problema, es decir, para problemas más grandes (con mayor número de trabajos y etapas)
tendremos un tiempo de parada más alto que si el problema es más simple.
𝑇𝑚𝑎𝑥 =𝑁𝑢𝑚. 𝑡𝑟𝑎𝑏𝑎𝑗𝑜𝑠 ∗ 𝑁𝑢𝑚. 𝑒𝑡𝑎𝑝𝑎𝑠
2 ∗ 10
5.7 Población final y elección de solución final
Como ya hemos dicho, tras cada iteración obtendremos una población final de diez individuos, que serán los
mejores obtenidos hasta el momento. En la última iteración, tomaremos la población final de dicha iteración y
en ella buscaremos la mejor, es decir, aquella con menor makespan de entre todas, y esta será la solución final
de nuestro problema.
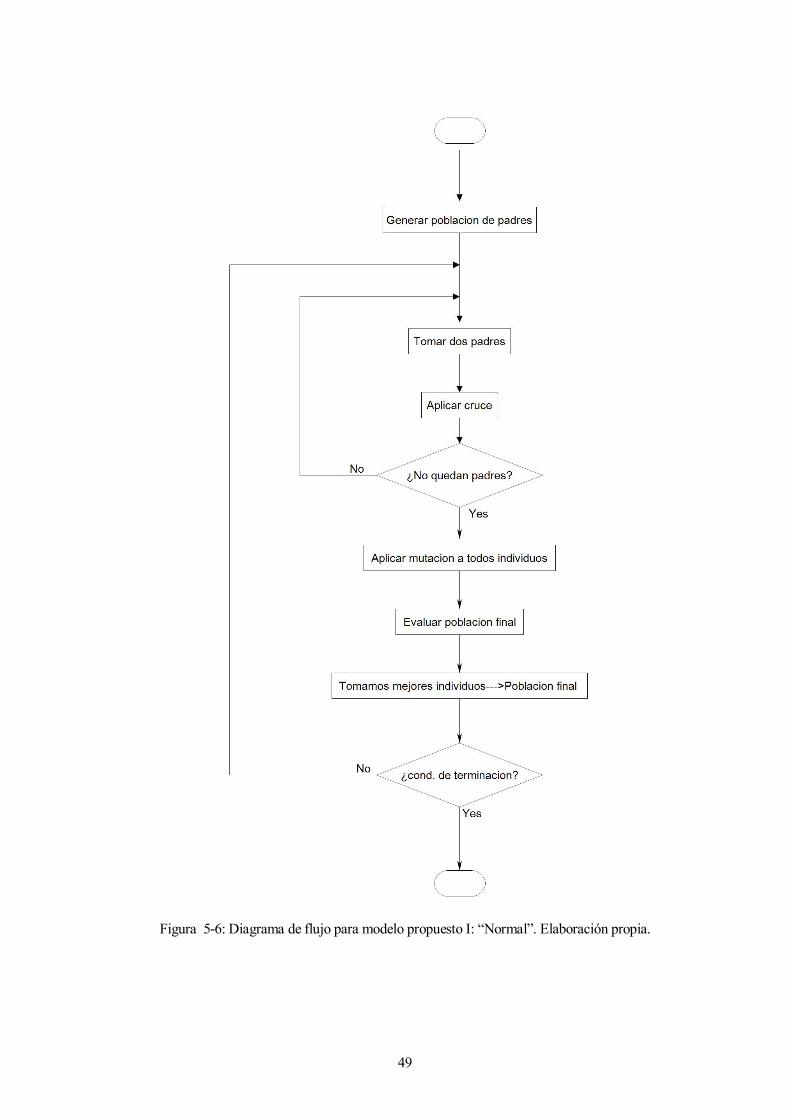
49
Figura 5-6: Diagrama de flujo para modelo propuesto I: “Normal”. Elaboración propia.

50
5.8 Mejoras locales
Anteriormente hemos explicado el funcionamiento del programa general, a parte de ese hemos añadido cuatro
variantes más añadiéndole en cada caso un tipo de mejora local a la población final de cada iteración. Así
podremos comparar resultados entre las variantes y ver para nuestro problema, cual obtiene mejores resultados
y comparar para que tamaños del problema funciona mejor una mejora local que otra.
Estas son las cuatro mejoras locales que hemos decidido implementar:
5.8.1 Mejora local de inserción a un individuo
Una vez obtenemos nuestra población final, al mejor individuo de dicha población, es decir el de menor
makespan, le aplicaremos una mejora local de inserción.
La mejora local consistirá en ir insertando cada trabajo en distintas posiciones obteniendo así nuevos
individuos y evaluaremos cada nuevo individuo quedándonos con el mejor tras insertar todos los trabajos en
todas las posiciones.
1º-Tomamos trabajo que vamos a insertar:
Figura 5-7: Ejemplo Inserción I. Elaboración propia.

51
2º- Insertamos en trabajo en la posición escogida:
Figura 5-8: Ejemplo Inserción II. Elaboración propia.
3º- Obtenemos el nuevo individuo y lo evaluamos, si es mejor que el mejor hasta el momento, lo guardamos
como el mejor, sino se desechara.
Figura 5-9: Ejemplo Inserción III. Elaboración propia.
4º-Iremos repitiendo el proceso para todos los trabajos en todas las posiciones y nos quedaremos con el mejor
que sustituirá a nuestro mejor individuo de la población final que habíamos obtenido.
5.8.2 Mejora local de inserción a todos individuos
Es el mismo tipo de mejora que la anterior solo que repetiremos el proceso para todos los individuos de
nuestra población final, en vez de solo aplicarle la mejora al mejor de todos.
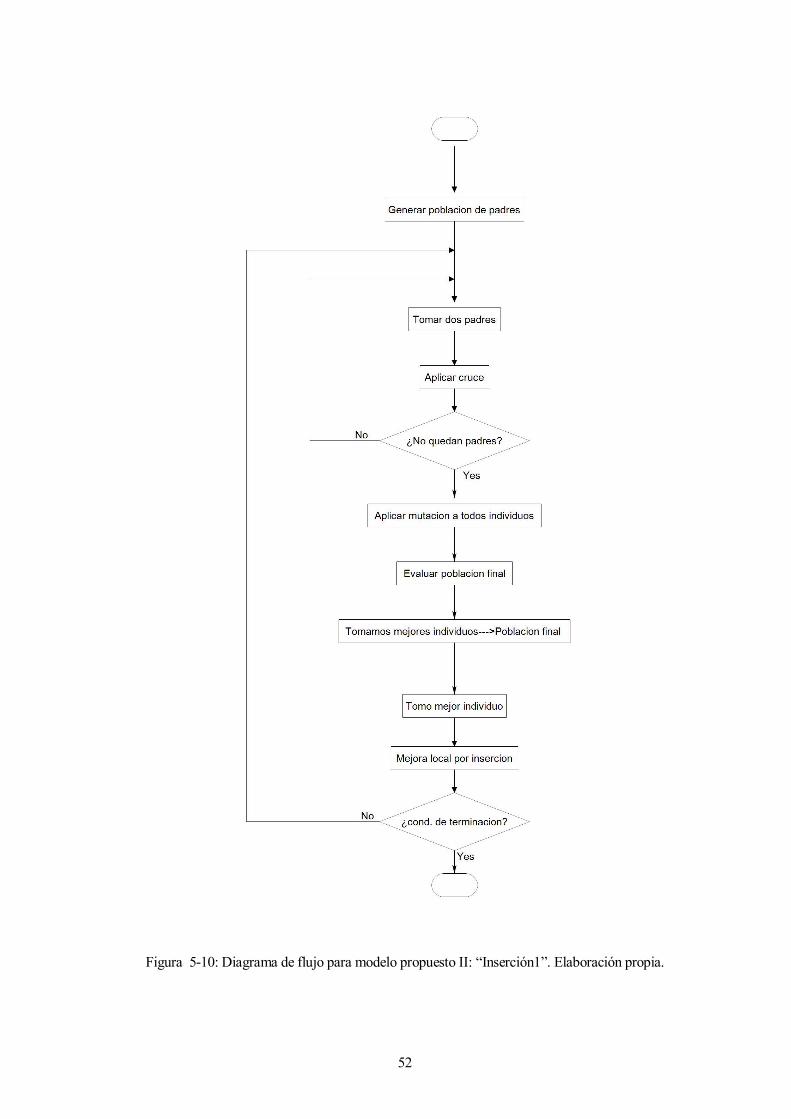
52
Figura 5-10: Diagrama de flujo para modelo propuesto II: “Inserción1”. Elaboración propia.
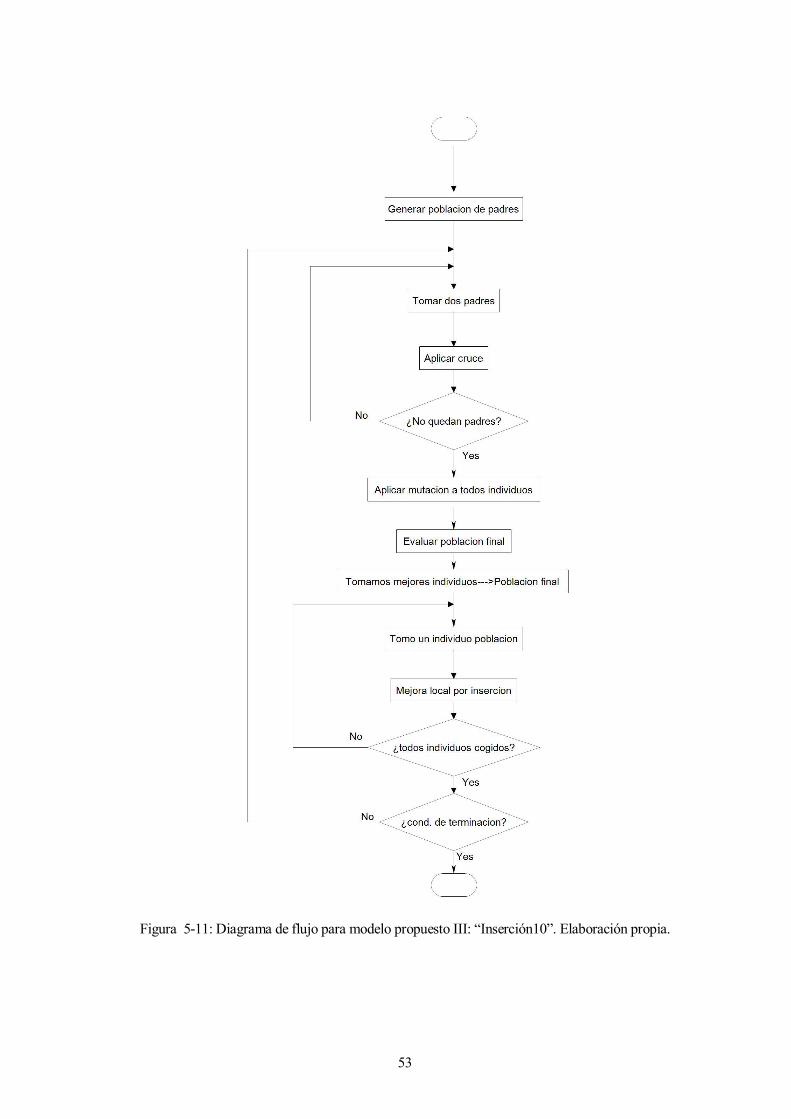
53
Figura 5-11: Diagrama de flujo para modelo propuesto III: “Inserción10”. Elaboración propia.

54
5.8.3 Mejora local de intercambio a un individuo
Al igual que en la mejora de inserción tomaremos al mejor individuo de la población final y a este le
aplicaremos la mejora local.
En este caso, en vez de ir insertando trabajos iremos intercambiándolos, es decir, tomaremos un trabajo y lo
intercambiaremos con el primer trabajo de la secuencia y evaluaremos el nuevo individuo. Repetiremos el
proceso intercambiando nuestro trabajo con todos los demás y evaluando las nuevas soluciones, quedándonos
al final con el individuo que nos proporciones la mejor solución.
1º-Tomamos trabajo que vamos a intercambiar
Figura 5-12: Ejemplo Intercambio I. Elaboración propia.
2º- Intercambiamos el trabajo escogido con otro:
Figura 5-13: Ejemplo Intercambio II. Elaboración propia.
3º- Tras el intercambio obtendremos un nuevo individuo que evaluaremos y guardaremos como mejor, si
mejora al mejor actual que teníamos.

55
Figura 5-14: Ejemplo Intercambio III. Elaboración propia.
4º- Intercambiaremos el trabajo con todo el resto de trabajo y así iremos obteniendo nuevos individuos de los
cuales nos quedaremos con el mejor, tras intercambiarlo con todos pasaremos al siguiente trabajo y
volveremos a intercambiarlo con todos e iremos repitiendo el proceso hasta que lo hayamos hecho con todos.
5.8.4 Mejora local de intercambio a todos los individuos
Esta mejora consiste en repetir el mismo proceso que en anterior punto, pero haciéndolo para todos los
individuos no solo para el mejor de la población final.
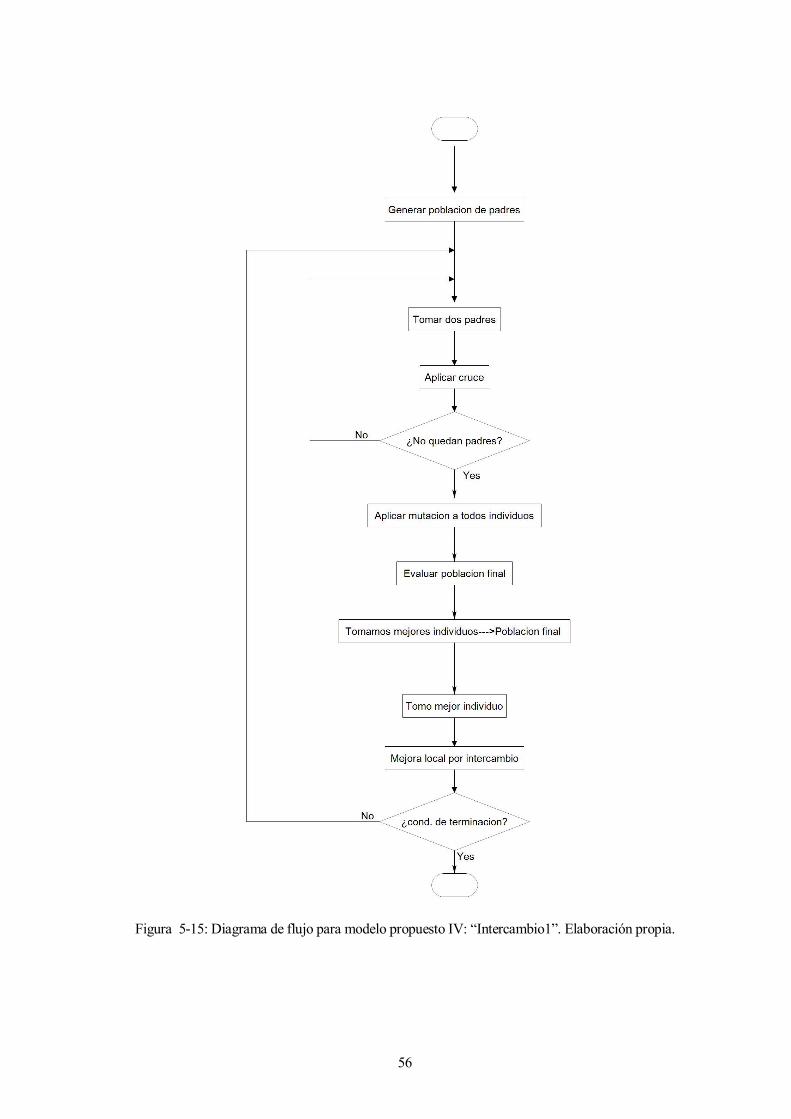
56
Figura 5-15: Diagrama de flujo para modelo propuesto IV: “Intercambio1”. Elaboración propia.
57
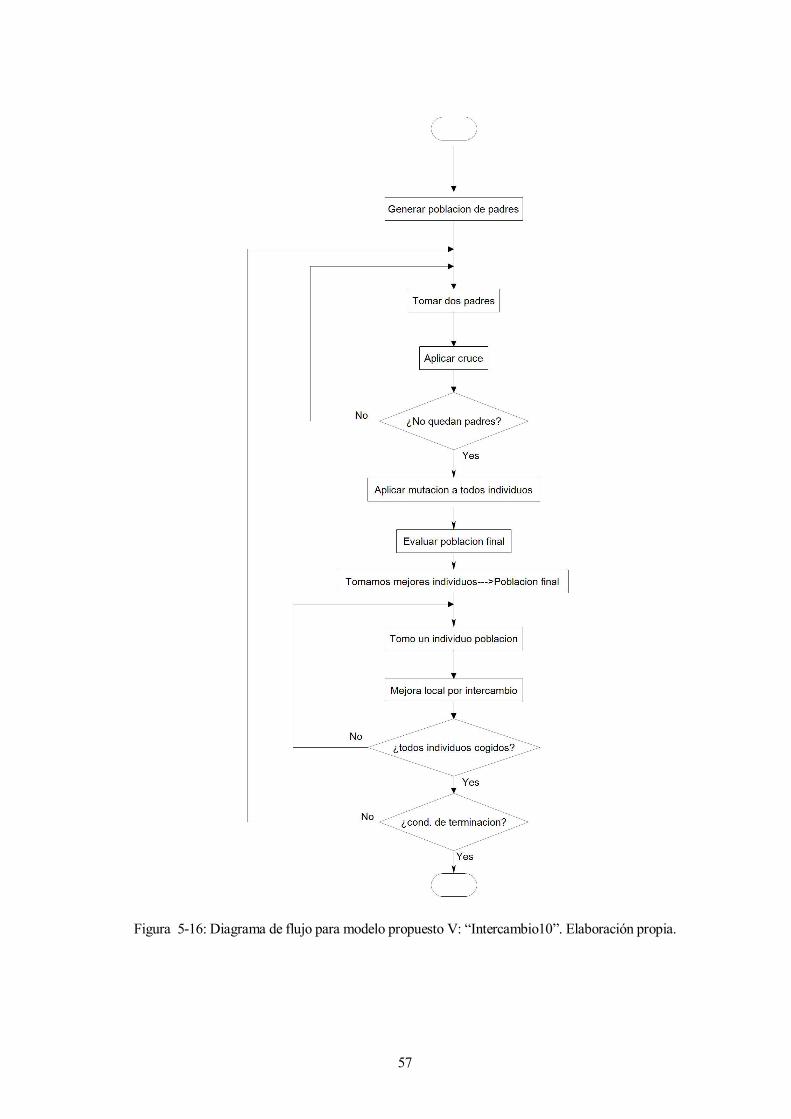
Figura 5-16: Diagrama de flujo para modelo propuesto V: “Intercambio10”. Elaboración propia.

58
6 COMPARACIÓN DE RESULTADOS
n este capítulo procederemos a analizar los resultados obtenidos mediante los distintos métodos,
ayudándonos de gráficos que ayuden a visualizar los datos más destacados
6.1 Generación de problemas
La primera fase de los experimentos consiste en la generación aleatoria de una batería de problemas. Los
parámetros que se tuvieron en cuenta en para la generación fueron: el número de trabajos que tendremos que
procesar, el número de etapas por el que tendrán que pasar y el % de missing, es decir, el porcentaje de
operaciones que se saltaran los trabajos.
Los números de trabajos considerados fueron 20, 50 y 100. El número de etapas fue 5,10 y 20. Y los
porcentajes de missing tomados fueron 0%, 20%, 40% y 60%. Para cada combinación de parámetros se
generaron 10 instancias, por lo que el número total de problemas considerados fue de 360.
En la siguiente tabla se muestra un ejemplo de uno de los problemas generados:
E
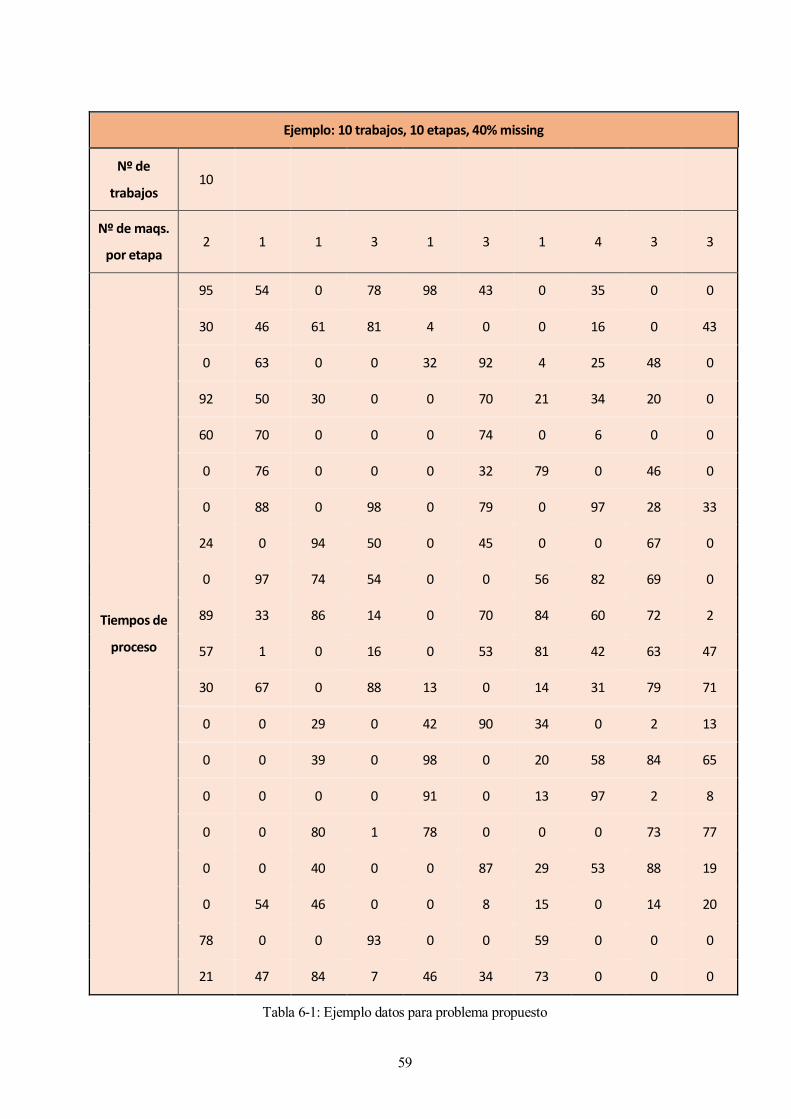
59
Ejemplo: 10 trabajos, 10 etapas, 40% missing
Nº de
trabajos 10
Nº de maqs.
por etapa 2 1 1 3 1 3 1 4 3 3
Tiempos de
proceso
95 54 0 78 98 43 0 35 0 0
30 46 61 81 4 0 0 16 0 43
0 63 0 0 32 92 4 25 48 0
92 50 30 0 0 70 21 34 20 0
60 70 0 0 0 74 0 6 0 0
0 76 0 0 0 32 79 0 46 0
0 88 0 98 0 79 0 97 28 33
24 0 94 50 0 45 0 0 67 0
0 97 74 54 0 0 56 82 69 0
89 33 86 14 0 70 84 60 72 2
57 1 0 16 0 53 81 42 63 47
30 67 0 88 13 0 14 31 79 71
0 0 29 0 42 90 34 0 2 13
0 0 39 0 98 0 20 58 84 65
0 0 0 0 91 0 13 97 2 8
0 0 80 1 78 0 0 0 73 77
0 0 40 0 0 87 29 53 88 19
0 54 46 0 0 8 15 0 14 20
78 0 0 93 0 0 59 0 0 0
21 47 84 7 46 34 73 0 0 0
Tabla 6-1: Ejemplo datos para problema propuesto

60
Los tiempos de proceso asignados para cada uno de los trabajos en cada etapa fueron generados aleatoriamente
entre un intervalo de [0,100], siendo 0 el porcentaje de tiempos considerado por el % de missing.
6.2 Análisis de los resultados en función de los parámetros
En este apartado procederemos a analizar los resultados de los diferentes métodos que usamos buscando cual
se ajusta mejor a cada variante de los parámetros.
Para esto vamos a usar el DPRA, desvío porcentual relativo aceptable, aunque normalmente se le conoce por
su nombre en inglés, ARPD (Average relative percentage deviation). El ARPD es una medida estadística que
describe la propagación de los datos con respecto a la media y el resultado se expresa como un porcentaje.
El ARPD se calcula como:
ARPD = (𝐹 − 𝐹𝑏𝑒𝑠𝑡)/𝐹𝑏𝑒𝑠𝑡
Siendo F el resultado del método para el que estamos calculando el ARPD y 𝐹𝑏𝑒𝑠𝑡 el mejor resultado
encontrado de entre todos los métodos para el problema dado.
En la siguiente tabla recogemos todos los resultados obtenidos por los distintos métodos en función de los
distintos parámetros de los problemas. Los datos para cada caso son una media de los ARPD obtenidos para
las 10 instancias de cada tipo de problema.
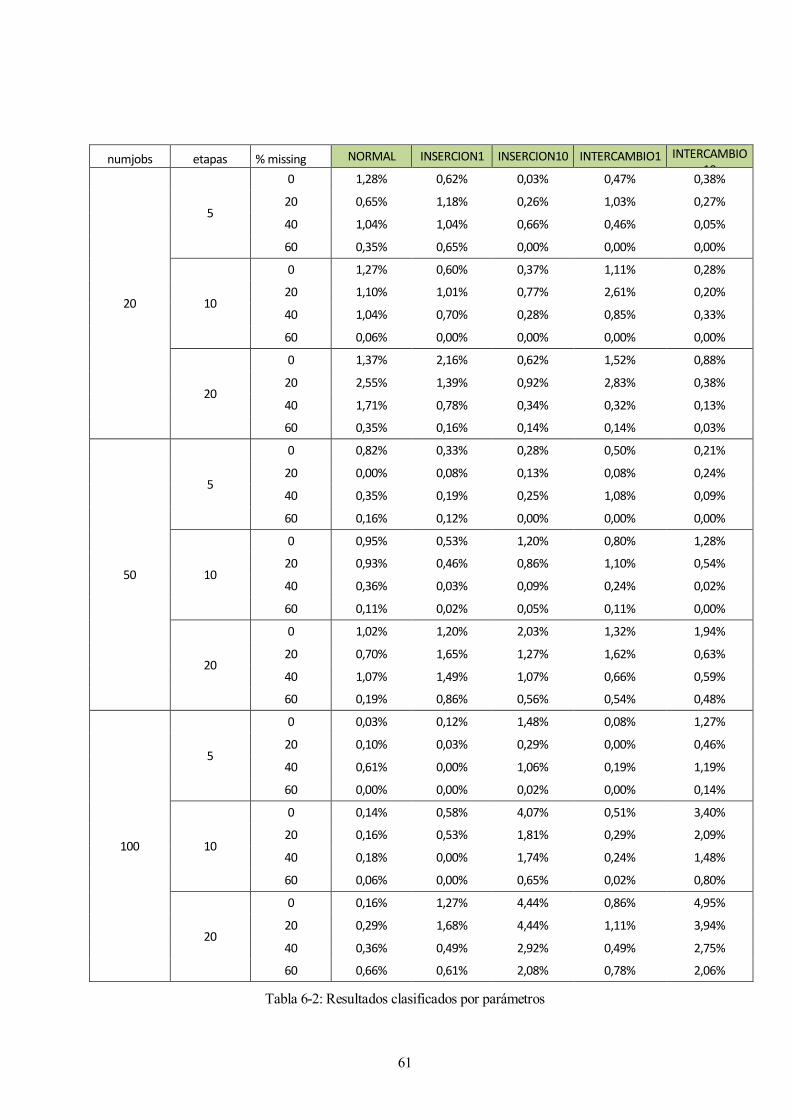
61
numjobs etapas % missing NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO 10
20
5
0 1,28% 0,62% 0,03% 0,47% 0,38%
20 0,65% 1,18% 0,26% 1,03% 0,27%
40 1,04% 1,04% 0,66% 0,46% 0,05%
60 0,35% 0,65% 0,00% 0,00% 0,00%
10
0 1,27% 0,60% 0,37% 1,11% 0,28%
20 1,10% 1,01% 0,77% 2,61% 0,20%
40 1,04% 0,70% 0,28% 0,85% 0,33%
60 0,06% 0,00% 0,00% 0,00% 0,00%
20
0 1,37% 2,16% 0,62% 1,52% 0,88%
20 2,55% 1,39% 0,92% 2,83% 0,38%
40 1,71% 0,78% 0,34% 0,32% 0,13%
60 0,35% 0,16% 0,14% 0,14% 0,03%
50
5
0 0,82% 0,33% 0,28% 0,50% 0,21%
20 0,00% 0,08% 0,13% 0,08% 0,24%
40 0,35% 0,19% 0,25% 1,08% 0,09%
60 0,16% 0,12% 0,00% 0,00% 0,00%
10
0 0,95% 0,53% 1,20% 0,80% 1,28%
20 0,93% 0,46% 0,86% 1,10% 0,54%
40 0,36% 0,03% 0,09% 0,24% 0,02%
60 0,11% 0,02% 0,05% 0,11% 0,00%
20
0 1,02% 1,20% 2,03% 1,32% 1,94%
20 0,70% 1,65% 1,27% 1,62% 0,63%
40 1,07% 1,49% 1,07% 0,66% 0,59%
60 0,19% 0,86% 0,56% 0,54% 0,48%
100
5
0 0,03% 0,12% 1,48% 0,08% 1,27%
20 0,10% 0,03% 0,29% 0,00% 0,46%
40 0,61% 0,00% 1,06% 0,19% 1,19%
60 0,00% 0,00% 0,02% 0,00% 0,14%
10
0 0,14% 0,58% 4,07% 0,51% 3,40%
20 0,16% 0,53% 1,81% 0,29% 2,09%
40 0,18% 0,00% 1,74% 0,24% 1,48%
60 0,06% 0,00% 0,65% 0,02% 0,80%
20
0 0,16% 1,27% 4,44% 0,86% 4,95%
20 0,29% 1,68% 4,44% 1,11% 3,94%
40 0,36% 0,49% 2,92% 0,49% 2,75%
60 0,66% 0,61% 2,08% 0,78% 2,06%
Tabla 6-2: Resultados clasificados por parámetros
62
6.2.1 Análisis de resultados en función del número de trabajos
En este apartado analizaremos los resultados obtenidos por los distintos métodos para distintos valores del
número de trabajos, comparándolos entre ellos.
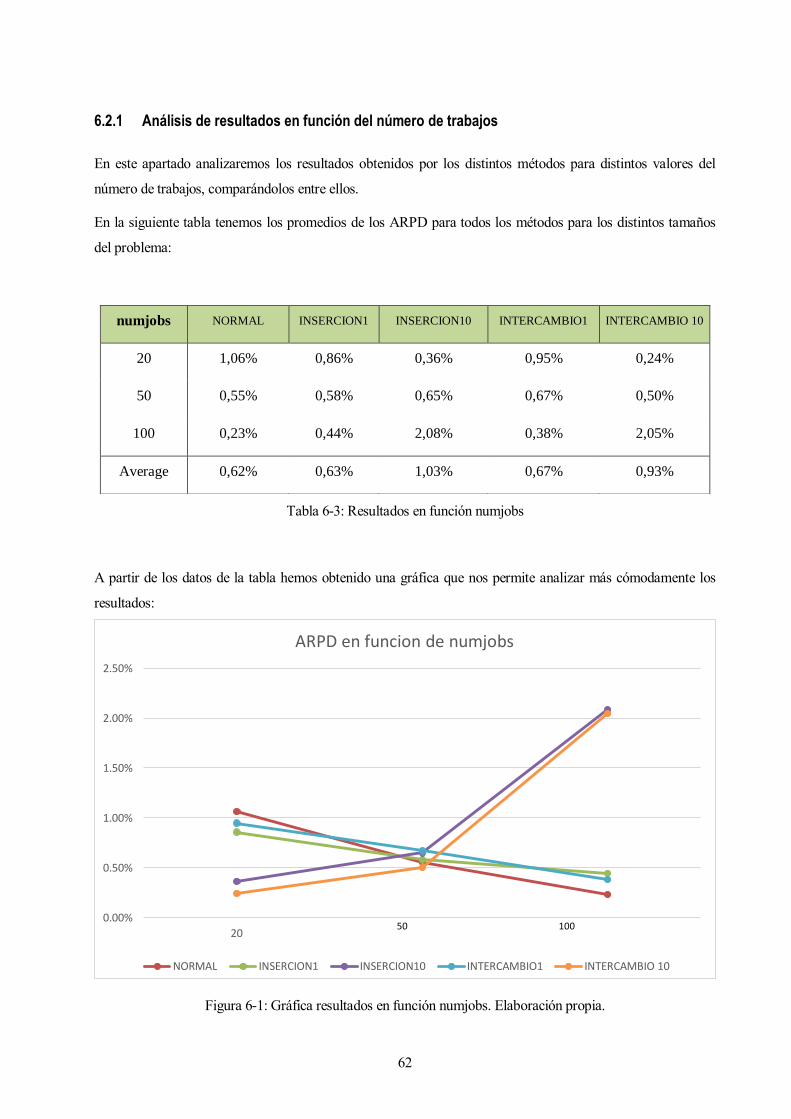
En la siguiente tabla tenemos los promedios de los ARPD para todos los métodos para los distintos tamaños
del problema:
A partir de los datos de la tabla hemos obtenido una gráfica que nos permite analizar más cómodamente los
resultados:
Figura 6-1: Gráfica resultados en función numjobs. Elaboración propia.
0.00%
0.50%
1.00%
1.50%
2.00%
2.50%
20
ARPD en funcion de numjobs
NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO 10
50 100
numjobs NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO 10
20 1,06% 0,86% 0,36% 0,95% 0,24%
50 0,55% 0,58% 0,65% 0,67% 0,50%
100 0,23% 0,44% 2,08% 0,38% 2,05%
Average 0,62% 0,63% 1,03% 0,67% 0,93%
Tabla 6-3: Resultados en función numjobs

63
Como podemos observar los métodos que mejoran localmente todas las soluciones finales de los problemas,
Insercion10 e Intercambio10, son los mejores para tamaños de poblaciones pequeños ya que al no haber
muchos trabajos llegan a una solución muy buena antes de que finalice el tiempo de ejecución, consiguiendo
de un 0,36% el método de Inserción10 y de un 0,24% el de Intercambio10, llegando a mejorar a los otros
métodos entre un 200% y un 300%. Conforme el número de trabajos aumenta empiezan a empeorar dichos
métodos, ya que al tener que mejorar todas las soluciones y al tener estos tantos trabajos, no les da tiempo a
llegar a una buena solución antes de terminar el tiempo de ejecución, consiguiendo para los problemas de 50
trabajos resultados muy parecidos al resto de métodos, pero para los problemas de 100 trabajos consiguen
resultados mucho peores.
Los métodos que solo mejoran una solución, Inserción1 y Intercambio1, como ya hemos dicho antes son
peores que los nombrados anteriormente para problemas pequeños ya que al ir mejorando solo una solución
por iteración, aunque cada iteración tarda mucho menos tiempo que en los casos anteriores no realizan
suficientes iteraciones en el tiempo de ejecución para llegar a soluciones tan buenas como los otros. Pero para
problemas de mayor tamaño al tardar menos tiempo cada iteración consiguen resultados de 0,44% y de 0,38%
mejorando a los métodos de mejora de 10 soluciones en casi un 400%.
El método Normal es el que mejores resultados consigue cuando los problemas de 100 trabajos, con lo que
podemos concluir que al poder realizar más número de iteraciones consigue diversificarse más aunque no
profundice tanto en ellas y obtiene mejores resultados.
6.2.2 Análisis de resultados en función del número de etapas
A partir de la tabla y la gráfica siguiente procederemos a analizar en función del segundo parámetro de nuestro
problema, el número de etapas.
Al igual que en el caso anterior hemos realizado una tabla con los promedios de los ARPD obtenidos tras
resolver los problemas:
64
A partir de los datos de la tabla hemos obtenido esta gráfica:
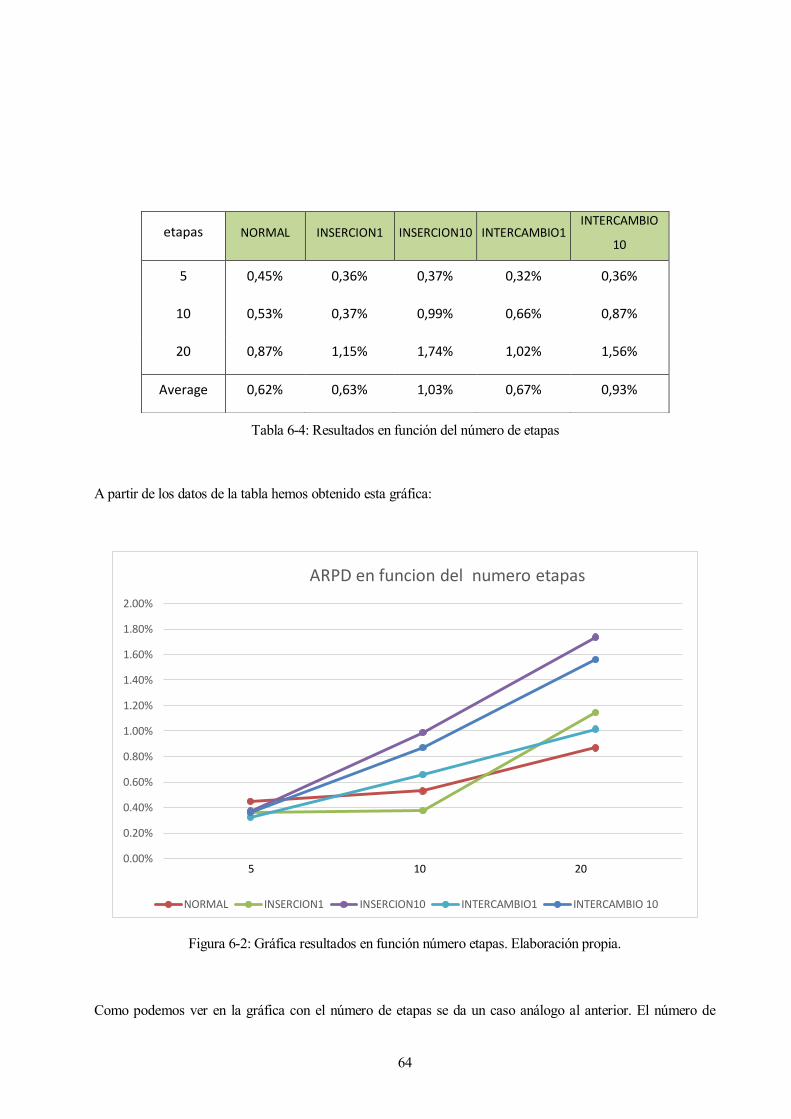
Figura 6-2: Gráfica resultados en función número etapas. Elaboración propia.
Como podemos ver en la gráfica con el número de etapas se da un caso análogo al anterior. El número de
0.00%
0.20%
0.40%
0.60%
0.80%
1.00%
1.20%
1.40%
1.60%
1.80%
2.00%
ARPD en funcion del numero etapas
NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO 10
5 10 20
etapas NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO
10
5 0,45% 0,36% 0,37% 0,32% 0,36%
10 0,53% 0,37% 0,99% 0,66% 0,87%
20 0,87% 1,15% 1,74% 1,02% 1,56%
Average 0,62% 0,63% 1,03% 0,67% 0,93%
Tabla 6-4: Resultados en función del número de etapas
65
etapas incide de la misma forma que el número de trabajos, aunque de forma más leve, no habiendo tanta
diferencia entre los resultados como en el caso anterior, ya que para 5 etapas consiguen los 5 métodos casi
idénticos resultados. Aunque a diferencia que en el caso anterior los resultados siempre van empeorando
conforme aumentamos el número de etapas, aunque los de mejora de 10 empeoran más rápido, los de mejora
de 1 y el normal también empeoran al aumentar el número de etapas no como con el número de trabajos que
conforme añadíamos más trabajos mejorábamos los resultados.
En resumen, los métodos Normal, Inserción1 e Intercambio1 consiguen resultados de 0,62%, 0,63% y de
0,67%, mejorando a los métodos de Inserción10 e Intercambio10 que consiguen 1,03% y 0,93%
respectivamente. Como podemos ver, aunque hay diferencias al igual que cuando variábamos el numero de
trabajos las diferencias son muchos menores.
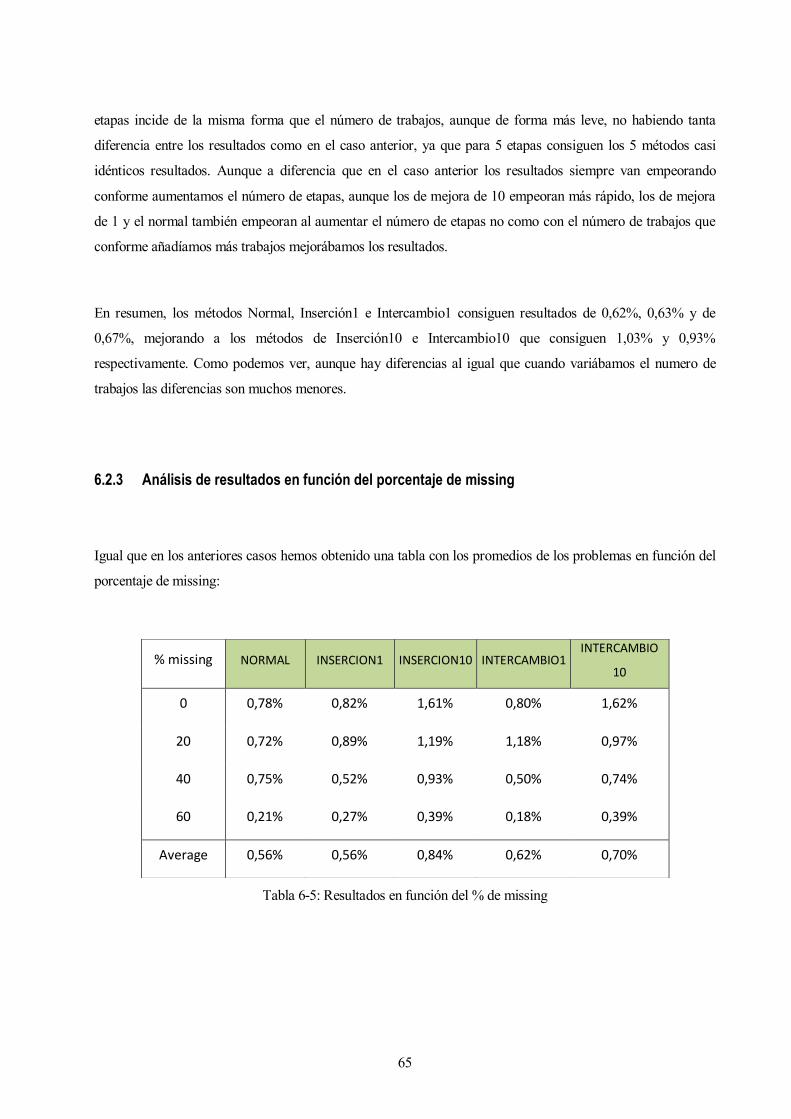
6.2.3 Análisis de resultados en función del porcentaje de missing
Igual que en los anteriores casos hemos obtenido una tabla con los promedios de los problemas en función del
porcentaje de missing:
% missing NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO
10
0 0,78% 0,82% 1,61% 0,80% 1,62%
20 0,72% 0,89% 1,19% 1,18% 0,97%
40 0,75% 0,52% 0,93% 0,50% 0,74%
60 0,21% 0,27% 0,39% 0,18% 0,39%
Average 0,56% 0,56% 0,84% 0,62% 0,70%
Tabla 6-5: Resultados en función del % de missing
66
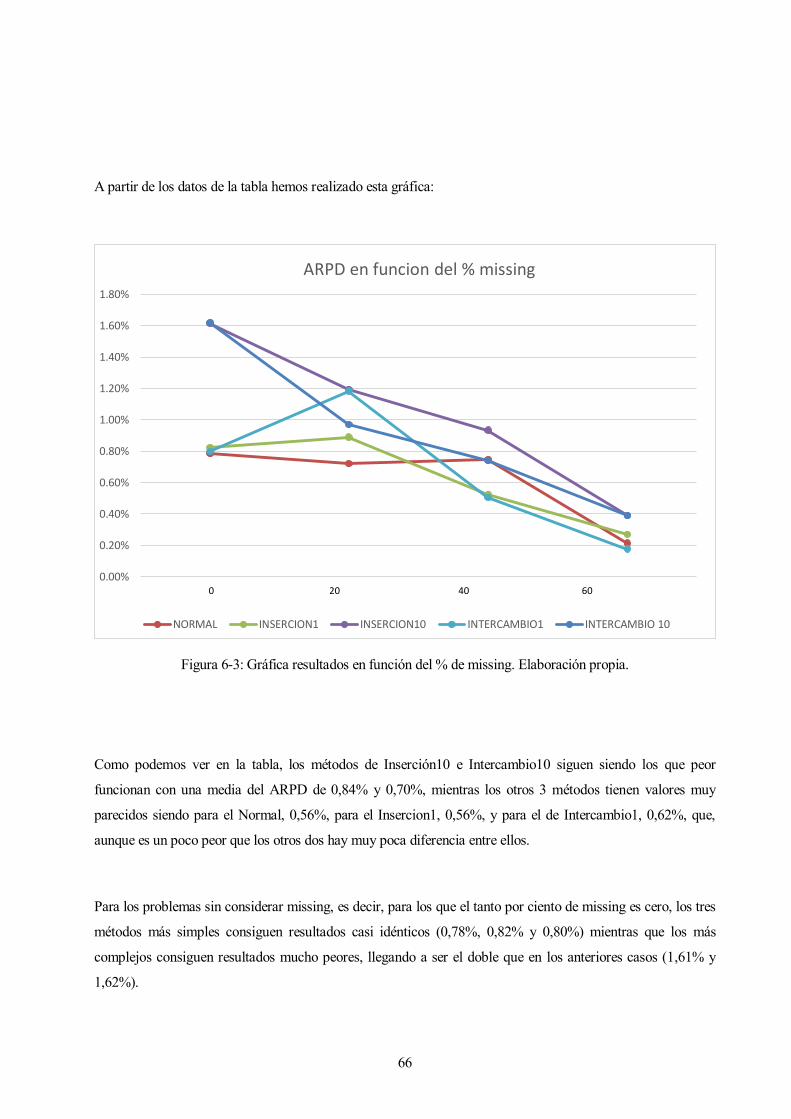
A partir de los datos de la tabla hemos realizado esta gráfica:
Figura 6-3: Gráfica resultados en función del % de missing. Elaboración propia.
Como podemos ver en la tabla, los métodos de Inserción10 e Intercambio10 siguen siendo los que peor
funcionan con una media del ARPD de 0,84% y 0,70%, mientras los otros 3 métodos tienen valores muy
parecidos siendo para el Normal, 0,56%, para el Insercion1, 0,56%, y para el de Intercambio1, 0,62%, que,
aunque es un poco peor que los otros dos hay muy poca diferencia entre ellos.
Para los problemas sin considerar missing, es decir, para los que el tanto por ciento de missing es cero, los tres
métodos más simples consiguen resultados casi idénticos (0,78%, 0,82% y 0,80%) mientras que los más
complejos consiguen resultados mucho peores, llegando a ser el doble que en los anteriores casos (1,61% y
1,62%).
0.00%
0.20%
0.40%
0.60%
0.80%
1.00%
1.20%
1.40%
1.60%
1.80%
ARPD en funcion del % missing
NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO 10
0 20 40 60

67
Conforme vamos aumentando el porcentaje de missing los resultados van convergiendo, aunque los métodos
más complejos siempre siguen siendo los peores. Excepto para el 20% de missing en el que el método de
Intercambio1 da los peores resultados junto con el método de Insercion10.

68
7 CONCLUSIONES
n este Trabajo de Fin de Grado se ha estudiado el problema de programación de la producción del
Hybrid Flowshop con missing operation. Para ello hemos realizado una metaheurística en C que
comienza con una secuencia inicial que nos indica el orden en que entran los trabajos al taller,
posteriormente se le aplican diversos operadores de los algoritmos genéticos como son en nuestro caso: el
cruce de dos puntos y una mutación de intercambio para obtener así diversas secuencias de entrada al
problema. Tras obtener las secuencias iniciales hemos resuelto el problema obteniendo el makespan para cada
una de ellas. Una vez que tenemos todas las soluciones nos quedamos con las mejores y seguimos repitiendo
el proceso hasta alcanzar alguno de los tres criterios de parada, en nuestro caso decidimos poner dos criterios
de parada, el número de iteraciones y el número de iteraciones en las que no mejoramos la solución inicial de
la iteración, con valores muy altos para que el programa solo parase por el criterio del tiempo de ejecución.
Una vez resuelto los problemas, mediante este método, se le aplican distintas mejoras locales a este para ver si
aplicando dichas mejoras podíamos conseguir mejores resultados en el mismo tiempo de ejecución. Para ello
decidimos aplicar las mejoras a las secuencias finales tras cada iteración, que son las usadas como secuencias
iniciales en la siguiente iteración, intentando así llegar a mejores resultados en menos tiempo. Las distintas
mejoras que hemos aplicados se pueden dividir en dos grupos, unas solo mejoran la mejor solución de la
iteración, así conseguimos profundizar en el camino de la óptima, reduciendo así la diversificación y los
tiempos de cálculo ya que se llegará a un óptimo de manera rápida al ir descartando el resto de caminos, pero
pudiendo caer así en óptimos locales al solo profundizar en un sentido. El otro grupo de métodos mejora todas
las soluciones tras cada iteración, consiguiendo diversificar mucho el espacio de búsqueda de soluciones, pero
al aumentar este la carga de trabajo será mucho mayor no consiguiendo profundizar tanto en todas las
direcciones como el resto de métodos.
En los capítulos 1,2 y 3 se contextualiza nuestro problema dentro de la Organización de la Producción y de la
Planificación de la Producción. También se han desarrollado los conocimientos teóricos necesarios para
entender los métodos aplicados en la resolución de los problemas, explicando las características de los
entornos de producción, los objetivos que buscamos mejorar con nuestro trabajo y las restricciones que se
tienen.
E
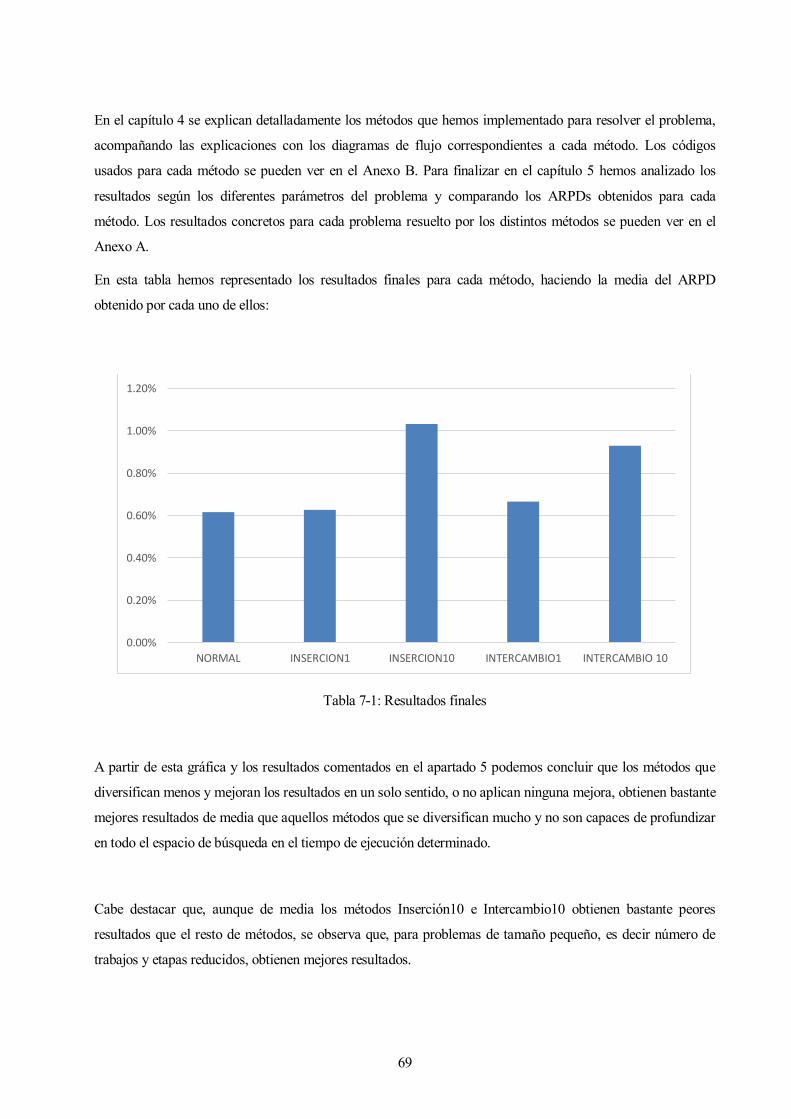
69
En el capítulo 4 se explican detalladamente los métodos que hemos implementado para resolver el problema,
acompañando las explicaciones con los diagramas de flujo correspondientes a cada método. Los códigos
usados para cada método se pueden ver en el Anexo B. Para finalizar en el capítulo 5 hemos analizado los
resultados según los diferentes parámetros del problema y comparando los ARPDs obtenidos para cada
método. Los resultados concretos para cada problema resuelto por los distintos métodos se pueden ver en el
Anexo A.
En esta tabla hemos representado los resultados finales para cada método, haciendo la media del ARPD
obtenido por cada uno de ellos:
Tabla 7-1: Resultados finales
A partir de esta gráfica y los resultados comentados en el apartado 5 podemos concluir que los métodos que
diversifican menos y mejoran los resultados en un solo sentido, o no aplican ninguna mejora, obtienen bastante
mejores resultados de media que aquellos métodos que se diversifican mucho y no son capaces de profundizar
en todo el espacio de búsqueda en el tiempo de ejecución determinado.
Cabe destacar que, aunque de media los métodos Inserción10 e Intercambio10 obtienen bastante peores
resultados que el resto de métodos, se observa que, para problemas de tamaño pequeño, es decir número de
trabajos y etapas reducidos, obtienen mejores resultados.
0.00%
0.20%
0.40%
0.60%
0.80%
1.00%
1.20%
NORMAL INSERCION1 INSERCION10 INTERCAMBIO1 INTERCAMBIO 10

70
8 BIBLIOGRAFÍA
F. A. Ogbu and D. K. Smith, “The application of the simulated annealing algorithm to the solution of the
n/m/Cmax flowshop problem”, 1990.
J. H. Holland, “Adaptation in Natural and Artificial Systems”. Univ. of Michigan Press, Ann Arbor, 1976.
F. A. Ogbu and D. K. Smith, “Simulated annealing for the permutation flow-shop problem”. 1991
C. R. Reeves, “An introduction to genetic algorithms” en Operational Research Tutorial Papers ,1991.
C. R. Reeves, “A genetic algorith for flowshop sequencing” en Computer and Operations Research, 1995.
M. Zandieh, and N. Karimi, “An adaptive multi-population genetic algorithm to solve the multi-objective
group scheduling problem in hybrid flexible flowshop with sequence-dependent setup times”, en Journal of
Intelligent Manufacturing, 2010
S. M. H. Hojjati, and A. Sahraeyan, “Minimizing makespan subject to budget limitation in hybrid flow shop”,
en International Conference on Computers & Industrial Engineering, 2009.
Juan C. Lopez, Jaime A. Giraldo and Jaime A. Arango, “Reducción del Tiempo de Terminación en la
Programación de la Producción de una Línea de Flujo Híbrida Flexible (HFS)”, versión online, 2005.
Saravanan, M., Sridhar, S. and Harikannan, N. “Application of meta-heuristics for minimization of makespan
in multi-stage hybrid flow shop scheduling problems with missing operations” en International Review of
mechanical engineering, 2014.
Rubén Ruiz and Jose Antonio Vázquez-Rodríguez, “The hybrid flow shop scheduling problem”, en European
Journey of Operational Research,2010.

71
Imma Ribas Vila and Ramon Companys Pascual, “Programación de la Producción en un sistema flow shop
híbrido sin esperas y tiempos de preparación dependientes de la secuencia”, Working Paper del Departament
d’Organització D’empreses de la Universitat Politècnica de Catalunya, 2010.
M.K. Marichelvam, “Performance evaluation of an improved hybrid genetic scatter search (IHGSS)
algorithm for multistage hybrid flow shop scheduling problems with missing operations”, en Int. J. Industrial
and Systems Engineering,2014.
Jose M Framinan, Rainer Leisten, Rubén Ruiz, “Manufacturing Scheduling Systems”, 2013.
Michael L. Pinedo, “Scheduling Theory, Algorithms and systems”, 2008.
Marcos Gestal, Daniel Rivero, Juan Ramón Rabuñal, Julián Dorado and Alejandro Pazos, “Introducción a los
Algoritmos Genéticos y la Programación Genética”,2010
Javier Santos García, “Organización de la Producción II Planificación de procesos productivos”,2010.
Chao-Tang Tseng, Ching-Jong Liao, Tai-Xiang Liao. “A note on two-stage hybrid flowshop scheduling with
missing operations”, in Computers & Industrial Engineering,2008.
Nakano, R., and Yamada, T. “Conventional genetic algorithm for job-shop problems”, en 4th International
Conference on Genetic Algorithms and their Applications,1991.
Osman, I. H. and Kelly J. P. “Meta-Heuristics: theory and applications”. Boston: Kluwer Academic, 1996.
Juan Camilo Lopez Vargas. “Metodología de Programación de Producción en un Flow Shop Híbrido
Flexible con el Uso de Algoritmos Genéticos para Reducir el Makespan. Aplicación en la Industria
Textil, Tesis de Maestría, 2013.
Jose M Framinan, Paz Perez-Gonzalez, Víctor Fernandez-Viagas “Tema 1: Introducción a la
Programación y Control de la Producción”, 2015
Jose M Framinan, Paz Perez-Gonzalez, Víctor Fernandez-Viagas “Tema 2: Programación de la Producción:
Introducción y Objetivos”, 2015
Jose M Framinan, Paz Perez-Gonzalez, Víctor Fernandez-Viagas “Tema 3: Modelos de Programación de la

72
Producción: Entornos”, 2015
Jose M Framinan, Paz Perez-Gonzalez, Víctor Fernandez-Viagas “Tema 4: Modelos de Programación de la
Producción: Restricciones”, 2015
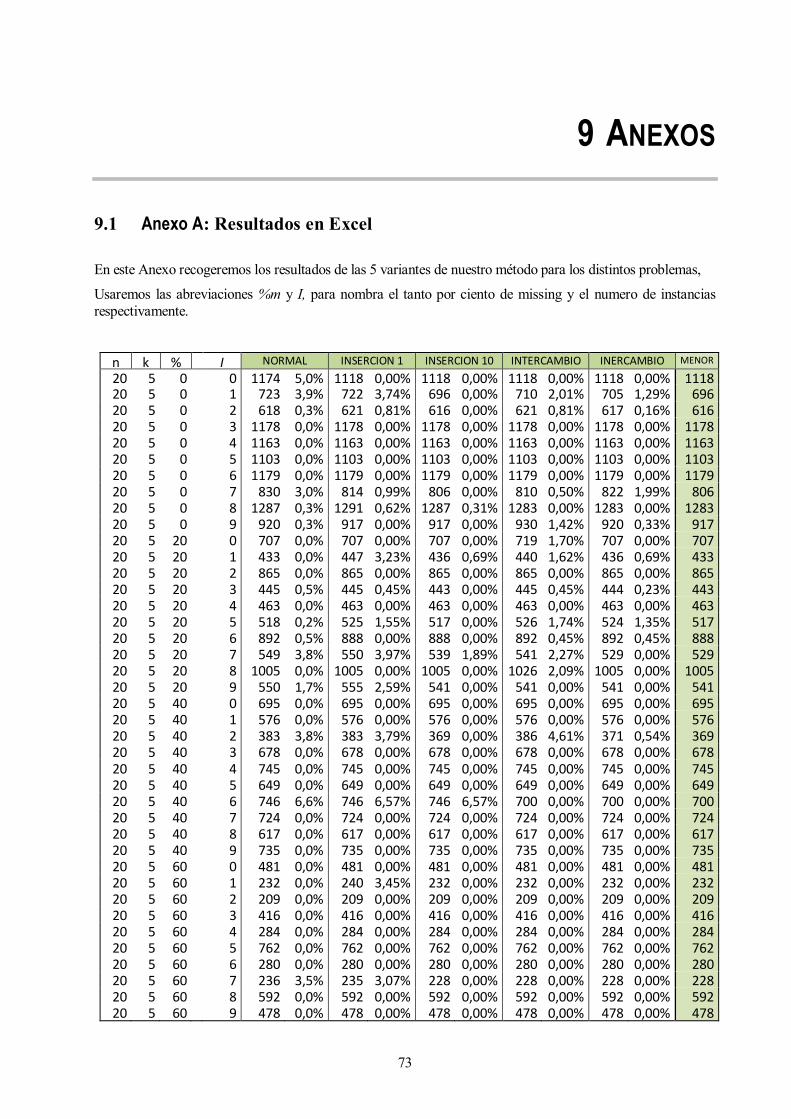
73
9 ANEXOS
9.1 Anexo A: Resultados en Excel
En este Anexo recogeremos los resultados de las 5 variantes de nuestro método para los distintos problemas,
Usaremos las abreviaciones %m y I, para nombra el tanto por ciento de missing y el numero de instancias
respectivamente.
n k %
m
I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
20 5 0 0 1174 5,0% 1118 0,00% 1118 0,00% 1118 0,00% 1118 0,00% 1118 20 5 0 1 723 3,9% 722 3,74% 696 0,00% 710 2,01% 705 1,29% 696 20 5 0 2 618 0,3% 621 0,81% 616 0,00% 621 0,81% 617 0,16% 616 20 5 0 3 1178 0,0% 1178 0,00% 1178 0,00% 1178 0,00% 1178 0,00% 1178 20 5 0 4 1163 0,0% 1163 0,00% 1163 0,00% 1163 0,00% 1163 0,00% 1163 20 5 0 5 1103 0,0% 1103 0,00% 1103 0,00% 1103 0,00% 1103 0,00% 1103 20 5 0 6 1179 0,0% 1179 0,00% 1179 0,00% 1179 0,00% 1179 0,00% 1179 20 5 0 7 830 3,0% 814 0,99% 806 0,00% 810 0,50% 822 1,99% 806 20 5 0 8 1287 0,3% 1291 0,62% 1287 0,31% 1283 0,00% 1283 0,00% 1283 20 5 0 9 920 0,3% 917 0,00% 917 0,00% 930 1,42% 920 0,33% 917 20 5 20 0 707 0,0% 707 0,00% 707 0,00% 719 1,70% 707 0,00% 707 20 5 20 1 433 0,0% 447 3,23% 436 0,69% 440 1,62% 436 0,69% 433 20 5 20 2 865 0,0% 865 0,00% 865 0,00% 865 0,00% 865 0,00% 865 20 5 20 3 445 0,5% 445 0,45% 443 0,00% 445 0,45% 444 0,23% 443 20 5 20 4 463 0,0% 463 0,00% 463 0,00% 463 0,00% 463 0,00% 463 20 5 20 5 518 0,2% 525 1,55% 517 0,00% 526 1,74% 524 1,35% 517 20 5 20 6 892 0,5% 888 0,00% 888 0,00% 892 0,45% 892 0,45% 888 20 5 20 7 549 3,8% 550 3,97% 539 1,89% 541 2,27% 529 0,00% 529 20 5 20 8 1005 0,0% 1005 0,00% 1005 0,00% 1026 2,09% 1005 0,00% 1005 20 5 20 9 550 1,7% 555 2,59% 541 0,00% 541 0,00% 541 0,00% 541 20 5 40 0 695 0,0% 695 0,00% 695 0,00% 695 0,00% 695 0,00% 695 20 5 40 1 576 0,0% 576 0,00% 576 0,00% 576 0,00% 576 0,00% 576 20 5 40 2 383 3,8% 383 3,79% 369 0,00% 386 4,61% 371 0,54% 369 20 5 40 3 678 0,0% 678 0,00% 678 0,00% 678 0,00% 678 0,00% 678 20 5 40 4 745 0,0% 745 0,00% 745 0,00% 745 0,00% 745 0,00% 745 20 5 40 5 649 0,0% 649 0,00% 649 0,00% 649 0,00% 649 0,00% 649 20 5 40 6 746 6,6% 746 6,57% 746 6,57% 700 0,00% 700 0,00% 700 20 5 40 7 724 0,0% 724 0,00% 724 0,00% 724 0,00% 724 0,00% 724 20 5 40 8 617 0,0% 617 0,00% 617 0,00% 617 0,00% 617 0,00% 617 20 5 40 9 735 0,0% 735 0,00% 735 0,00% 735 0,00% 735 0,00% 735 20 5 60 0 481 0,0% 481 0,00% 481 0,00% 481 0,00% 481 0,00% 481 20 5 60 1 232 0,0% 240 3,45% 232 0,00% 232 0,00% 232 0,00% 232 20 5 60 2 209 0,0% 209 0,00% 209 0,00% 209 0,00% 209 0,00% 209 20 5 60 3 416 0,0% 416 0,00% 416 0,00% 416 0,00% 416 0,00% 416 20 5 60 4 284 0,0% 284 0,00% 284 0,00% 284 0,00% 284 0,00% 284 20 5 60 5 762 0,0% 762 0,00% 762 0,00% 762 0,00% 762 0,00% 762 20 5 60 6 280 0,0% 280 0,00% 280 0,00% 280 0,00% 280 0,00% 280 20 5 60 7 236 3,5% 235 3,07% 228 0,00% 228 0,00% 228 0,00% 228 20 5 60 8 592 0,0% 592 0,00% 592 0,00% 592 0,00% 592 0,00% 592 20 5 60 9 478 0,0% 478 0,00% 478 0,00% 478 0,00% 478 0,00% 478

74
n k %
m
I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
20 10 0 0 1508 4,3% 1508 4,29% 1446 0,00% 1508 4,29% 1481 2,42% 1446
20 10 0 1 1369 0,0% 1369 0,00% 1395 1,90% 1369 0,00% 1369 0,00% 1369
20 10 0 2 1445 0,0% 1445 0,00% 1445 0,00% 1445 0,00% 1445 0,00% 1445
20 10 0 3 1540 0,1% 1540 0,13% 1538 0,00% 1540 0,13% 1538 0,00% 1538
20 10 0 4 1550 2,0% 1520 0,00% 1520 0,00% 1525 0,33% 1520 0,00% 1520
20 10 0 5 1180 0,9% 1180 0,94% 1180 0,94% 1169 0,00% 1169 0,00% 1169
20 10 0 6 1174 1,3% 1159 0,00% 1159 0,00% 1159 0,00% 1159 0,00% 1159
20 10 0 7 1243 1,6% 1223 0,00% 1223 0,00% 1243 1,64% 1223 0,00% 1223
20 10 0 8 1304 0,0% 1313 0,69% 1315 0,84% 1313 0,69% 1309 0,38% 1304
20 10 0 9 1262 2,4% 1232 0,00% 1232 0,00% 1282 4,06% 1232 0,00% 1232
20 10 20 0 1066 0,0% 1066 0,00% 1066 0,00% 1066 0,00% 1066 0,00% 1066
20 10 20 1 1158 0,0% 1158 0,00% 1158 0,00% 1158 0,00% 1158 0,00% 1158
20 10 20 2 726 4,3% 741 6,47% 731 5,03% 733 5,32% 696 0,00% 696
20 10 20 3 1056 1,3% 1053 1,06% 1042 0,00% 1068 2,50% 1042 0,00% 1042
20 10 20 4 1150 0,3% 1147 0,09% 1146 0,00% 1147 0,09% 1147 0,09% 1146
20 10 20 5 1041 3,9% 1003 0,10% 1002 0,00% 1091 8,88% 1005 0,30% 1002
20 10 20 6 1164 1,1% 1165 1,22% 1165 1,22% 1168 1,48% 1151 0,00% 1151
20 10 20 7 1078 0,0% 1078 0,00% 1078 0,00% 1078 0,00% 1078 0,00% 1078
20 10 20 8 968 0,0% 968 0,00% 968 0,00% 968 0,00% 968 0,00% 968
20 10 20 9 698 0,0% 706 1,15% 708 1,43% 753 7,88% 709 1,58% 698
20 10 40 0 1003 2,8% 1003 2,77% 976 0,00% 1003 2,77% 1003 2,77% 976
20 10 40 1 762 0,0% 762 0,00% 762 0,00% 762 0,00% 762 0,00% 762
20 10 40 2 587 3,3% 587 3,35% 580 2,11% 585 2,99% 568 0,00% 568
20 10 40 3 985 0,0% 985 0,00% 985 0,00% 985 0,00% 985 0,00% 985
20 10 40 4 893 0,0% 893 0,00% 893 0,00% 893 0,00% 893 0,00% 893
20 10 40 5 768 0,0% 775 0,91% 773 0,65% 768 0,00% 772 0,52% 768
20 10 40 6 899 4,3% 862 0,00% 862 0,00% 884 2,55% 862 0,00% 862
20 10 40 7 740 0,0% 740 0,00% 740 0,00% 740 0,00% 740 0,00% 740
20 10 40 8 708 0,0% 708 0,00% 708 0,00% 708 0,00% 708 0,00% 708
20 10 40 9 891 0,0% 891 0,00% 891 0,00% 893 0,22% 891 0,00% 891
20 10 60 0 701 0,6% 697 0,00% 697 0,00% 697 0,00% 697 0,00% 697
20 10 60 1 475 0,0% 475 0,00% 475 0,00% 475 0,00% 475 0,00% 475
20 10 60 2 525 0,0% 525 0,00% 525 0,00% 525 0,00% 525 0,00% 525
20 10 60 3 382 0,0% 382 0,00% 382 0,00% 382 0,00% 382 0,00% 382
20 10 60 4 548 0,0% 548 0,00% 548 0,00% 548 0,00% 548 0,00% 548
20 10 60 5 687 0,0% 687 0,00% 687 0,00% 687 0,00% 687 0,00% 687
20 10 60 6 558 0,0% 558 0,00% 558 0,00% 558 0,00% 558 0,00% 558
20 10 60 7 687 0,0% 687 0,00% 687 0,00% 687 0,00% 687 0,00% 687
20 10 60 8 494 0,0% 494 0,00% 494 0,00% 494 0,00% 494 0,00% 494
20 10 60 9 532 0,0% 532 0,00% 532 0,00% 532 0,00% 532 0,00% 532

75
n k %m I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
20 20 0 0 1848 0,9% 1884 2,84% 1832 0,00% 1929 5,29% 1841 0,49% 1832
20 20 0 1 1974 0,0% 2019 2,28% 1993 0,96% 2046 3,65% 1974 0,00% 1974
20 20 0 2 2056 3,3% 2029 1,96% 1990 0,00% 2041 2,56% 2053 3,17% 1990
20 20 0 3 2010 1,5% 1986 0,25% 1982 0,05% 1985 0,20% 1981 0,00% 1981
20 20 0 4 1820 1,6% 1923 7,37% 1853 3,46% 1791 0,00% 1801 0,56% 1791
20 20 0 5 2058 0,8% 2088 2,30% 2069 1,37% 2041 0,00% 2066 1,22% 2041
20 20 0 6 2100 1,0% 2083 0,19% 2079 0,00% 2100 1,01% 2085 0,29% 2079
20 20 0 7 1786 0,0% 1786 0,00% 1786 0,00% 1786 0,00% 1786 0,00% 1786
20 20 0 8 1925 1,2% 1903 0,00% 1909 0,32% 1927 1,26% 1947 2,31% 1903
20 20 0 9 1737 3,4% 1754 4,40% 1680 0,00% 1701 1,25% 1692 0,71% 1680
20 20 20 0 1574 8,3% 1523 4,75% 1476 1,51% 1566 7,70% 1454 0,00% 1454
20 20 20 1 1361 0,0% 1363 0,15% 1369 0,59% 1374 0,96% 1361 0,00% 1361
20 20 20 2 1494 1,7% 1498 1,97% 1469 0,00% 1542 4,97% 1503 2,31% 1469
20 20 20 3 1620 1,6% 1620 1,63% 1620 1,63% 1614 1,25% 1594 0,00% 1594
20 20 20 4 1460 1,7% 1449 0,98% 1508 5,09% 1503 4,74% 1435 0,00% 1435
20 20 20 5 1541 2,5% 1531 1,86% 1503 0,00% 1540 2,46% 1520 1,13% 1503
20 20 20 6 1651 0,2% 1648 0,00% 1648 0,00% 1665 1,03% 1648 0,00% 1648
20 20 20 7 1677 2,9% 1629 0,00% 1629 0,00% 1639 0,61% 1634 0,31% 1629
20 20 20 8 1846 2,3% 1829 1,39% 1804 0,00% 1837 1,83% 1804 0,00% 1804
20 20 20 9 1654 4,2% 1607 1,20% 1594 0,38% 1631 2,71% 1588 0,00% 1588
20 20 40 0 1234 6,0% 1164 0,00% 1164 0,00% 1172 0,69% 1164 0,00% 1164
20 20 40 1 1131 0,0% 1131 0,00% 1131 0,00% 1131 0,00% 1131 0,00% 1131
20 20 40 2 1380 0,7% 1387 1,17% 1371 0,00% 1387 1,17% 1371 0,00% 1371
20 20 40 3 1488 1,1% 1500 1,90% 1472 0,00% 1472 0,00% 1472 0,00% 1472
20 20 40 4 1059 1,3% 1059 1,34% 1067 2,11% 1045 0,00% 1045 0,00% 1045
20 20 40 5 1254 5,6% 1203 1,35% 1193 0,51% 1187 0,00% 1203 1,35% 1187
20 20 40 6 1297 0,0% 1297 0,00% 1297 0,00% 1297 0,00% 1297 0,00% 1297
20 20 40 7 1124 2,2% 1109 0,82% 1109 0,82% 1109 0,82% 1100 0,00% 1100
20 20 40 8 1428 0,1% 1444 1,26% 1426 0,00% 1434 0,56% 1426 0,00% 1426
20 20 40 9 1383 0,0% 1383 0,00% 1383 0,00% 1383 0,00% 1383 0,00% 1383
20 20 60 0 1061 0,9% 1052 0,00% 1052 0,00% 1052 0,00% 1052 0,00% 1052
20 20 60 1 957 1,2% 957 1,16% 957 1,16% 957 1,16% 946 0,00% 946
20 20 60 2 1011 0,0% 1011 0,00% 1011 0,00% 1011 0,00% 1011 0,00% 1011
20 20 60 3 784 0,0% 786 0,26% 786 0,26% 786 0,26% 786 0,26% 784
20 20 60 4 754 0,0% 754 0,00% 754 0,00% 754 0,00% 754 0,00% 754
20 20 60 5 848 0,6% 843 0,00% 843 0,00% 843 0,00% 843 0,00% 843
20 20 60 6 916 0,9% 910 0,22% 908 0,00% 908 0,00% 908 0,00% 908
20 20 60 7 791 0,0% 791 0,00% 791 0,00% 791 0,00% 791 0,00% 791
20 20 60 8 1003 0,0% 1003 0,00% 1003 0,00% 1003 0,00% 1003 0,00% 1003
20 20 60 9 833 0,0% 833 0,00% 833 0,00% 833 0,00% 833 0,00% 833

76
n k %m I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
50 5 0 0 2392 0,0% 2393 0,04% 2392 0,00% 2392 0,00% 2392 0,00% 2392
50 5 0 1 2693 0,6% 2693 0,64% 2676 0,00% 2676 0,00% 2693 0,64% 2676
50 5 0 2 1037 2,5% 1025 1,28% 1012 0,00% 1029 1,68% 1014 0,20% 1012
50 5 0 3 2638 0,3% 2630 0,00% 2630 0,00% 2635 0,19% 2630 0,00% 2630
50 5 0 4 2578 0,0% 2580 0,08% 2578 0,00% 2578 0,00% 2578 0,00% 2578
50 5 0 5 2604 0,0% 2604 0,00% 2604 0,00% 2604 0,00% 2604 0,00% 2604
50 5 0 6 1440 1,3% 1432 0,77% 1431 0,70% 1432 0,77% 1421 0,00% 1421
50 5 0 7 1020 2,9% 991 0,00% 1012 2,12% 1014 2,32% 1004 1,31% 991
50 5 0 8 2841 0,5% 2841 0,50% 2827 0,00% 2827 0,00% 2827 0,00% 2827
50 5 0 9 2946 0,0% 2946 0,00% 2946 0,00% 2946 0,00% 2946 0,00% 2946
50 5 20 0 2205 0,0% 2205 0,00% 2205 0,00% 2205 0,00% 2205 0,00% 2205
50 5 20 1 2006 0,0% 2006 0,00% 2006 0,00% 2006 0,00% 2006 0,00% 2006
50 5 20 2 2203 0,0% 2203 0,00% 2203 0,00% 2203 0,00% 2203 0,00% 2203
50 5 20 3 2281 0,0% 2281 0,00% 2281 0,00% 2281 0,00% 2281 0,00% 2281
50 5 20 4 2247 0,0% 2247 0,00% 2247 0,00% 2247 0,00% 2247 0,00% 2247
50 5 20 5 2247 0,0% 2264 0,76% 2277 1,34% 2264 0,76% 2300 2,36% 2247
50 5 20 6 2534 0,0% 2534 0,00% 2534 0,00% 2534 0,00% 2534 0,00% 2534
50 5 20 7 1269 0,0% 1269 0,00% 1269 0,00% 1269 0,00% 1269 0,00% 1269
50 5 20 8 2052 0,0% 2052 0,00% 2052 0,00% 2052 0,00% 2052 0,00% 2052
50 5 20 9 1807 0,0% 1807 0,00% 1807 0,00% 1807 0,00% 1807 0,00% 1807
50 5 40 0 1578 0,0% 1578 0,00% 1578 0,00% 1578 0,00% 1578 0,00% 1578
50 5 40 1 1393 0,0% 1393 0,00% 1393 0,00% 1393 0,00% 1393 0,00% 1393
50 5 40 2 1344 0,0% 1344 0,00% 1344 0,00% 1344 0,00% 1344 0,00% 1344
50 5 40 3 978 3,2% 959 1,16% 948 0,00% 964 1,69% 948 0,00% 948
50 5 40 4 1828 0,3% 1822 0,00% 1822 0,00% 1822 0,00% 1822 0,00% 1822
50 5 40 5 2172 0,0% 2172 0,00% 2172 0,00% 2172 0,00% 2172 0,00% 2172
50 5 40 6 1416 0,0% 1416 0,00% 1416 0,00% 1416 0,00% 1416 0,00% 1416
50 5 40 7 1751 0,0% 1751 0,00% 1751 0,00% 1751 0,00% 1751 0,00% 1751
50 5 40 8 559 0,0% 563 0,72% 573 2,50% 610 9,12% 564 0,89% 559
50 5 40 9 1530 0,0% 1530 0,00% 1530 0,00% 1530 0,00% 1530 0,00% 1530
50 5 60 0 870 0,0% 870 0,00% 870 0,00% 870 0,00% 870 0,00% 870
50 5 60 1 933 0,0% 933 0,00% 933 0,00% 933 0,00% 933 0,00% 933
50 5 60 2 1454 0,0% 1454 0,00% 1454 0,00% 1454 0,00% 1454 0,00% 1454
50 5 60 3 1021 0,0% 1021 0,00% 1021 0,00% 1021 0,00% 1021 0,00% 1021
50 5 60 4 889 0,0% 889 0,00% 889 0,00% 889 0,00% 889 0,00% 889
50 5 60 5 652 1,2% 652 1,24% 644 0,00% 644 0,00% 644 0,00% 644
50 5 60 6 584 0,3% 582 0,00% 582 0,00% 582 0,00% 582 0,00% 582
50 5 60 7 893 0,0% 893 0,00% 893 0,00% 893 0,00% 893 0,00% 893
50 5 60 8 661 0,0% 661 0,00% 661 0,00% 661 0,00% 661 0,00% 661
50 5 60 9 847 0,0% 847 0,00% 847 0,00% 847 0,00% 847 0,00% 847

77
n k %m I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
50 10 0 0 2738 0,0% 2747 0,33% 2747 0,33% 2754 0,58% 2742 0,15% 2738
50 10 0 1 2586 1,7% 2543 0,00% 2580 1,45% 2605 2,44% 2581 1,49% 2543
50 10 0 2 2923 1,1% 2890 0,00% 2926 1,25% 2899 0,31% 2943 1,83% 2890
50 10 0 3 2612 0,0% 2612 0,00% 2612 0,00% 2612 0,00% 2615 0,11% 2612
50 10 0 4 2913 1,3% 2875 0,00% 2896 0,73% 2875 0,00% 2903 0,97% 2875
50 10 0 5 1439 2,3% 1416 0,64% 1429 1,56% 1407 0,00% 1426 1,35% 1407
50 10 0 6 2831 0,0% 2831 0,00% 2831 0,00% 2831 0,00% 2831 0,00% 2831
50 10 0 7 2732 0,0% 2841 3,99% 2788 2,05% 2768 1,32% 2820 3,22% 2732
50 10 0 8 1686 3,1% 1635 0,00% 1708 4,46% 1672 2,26% 1688 3,24% 1635
50 10 0 9 2767 0,0% 2776 0,33% 2771 0,14% 2797 1,08% 2778 0,40% 2767
50 10 20 0 2267 2,1% 2226 0,23% 2244 1,04% 2221 0,00% 2221 0,00% 2221
50 10 20 1 1932 3,9% 1895 1,94% 1932 3,93% 1859 0,00% 1860 0,05% 1859
50 10 20 2 2157 0,0% 2157 0,00% 2157 0,00% 2157 0,00% 2157 0,00% 2157
50 10 20 3 2229 0,0% 2254 1,12% 2263 1,53% 2277 2,15% 2277 2,15% 2229
50 10 20 4 2191 1,9% 2151 0,00% 2157 0,28% 2196 2,09% 2191 1,86% 2151
50 10 20 5 2065 0,3% 2058 0,00% 2058 0,00% 2106 2,33% 2058 0,00% 2058
50 10 20 6 2039 0,4% 2031 0,00% 2031 0,00% 2039 0,39% 2031 0,00% 2031
50 10 20 7 2330 0,7% 2314 0,00% 2314 0,00% 2314 0,00% 2330 0,69% 2314
50 10 20 8 2189 0,0% 2189 0,00% 2189 0,00% 2189 0,00% 2189 0,00% 2189
50 10 20 9 1224 0,0% 1240 1,31% 1246 1,80% 1273 4,00% 1232 0,65% 1224
50 10 40 0 1757 0,0% 1757 0,00% 1757 0,00% 1757 0,00% 1757 0,00% 1757
50 10 40 1 1811 0,0% 1811 0,00% 1811 0,00% 1811 0,00% 1811 0,00% 1811
50 10 40 2 1704 0,4% 1698 0,00% 1709 0,65% 1709 0,65% 1698 0,00% 1698
50 10 40 3 1526 1,1% 1509 0,00% 1509 0,00% 1534 1,66% 1509 0,00% 1509
50 10 40 4 1542 0,9% 1529 0,00% 1529 0,00% 1529 0,00% 1529 0,00% 1529
50 10 40 5 1859 0,0% 1859 0,00% 1859 0,00% 1859 0,00% 1859 0,00% 1859
50 10 40 6 1687 0,9% 1677 0,30% 1676 0,24% 1672 0,00% 1676 0,24% 1672
50 10 40 7 1521 0,0% 1521 0,00% 1521 0,00% 1521 0,00% 1521 0,00% 1521
50 10 40 8 1663 0,4% 1657 0,00% 1657 0,00% 1657 0,00% 1657 0,00% 1657
50 10 40 9 2017 0,0% 2017 0,00% 2017 0,00% 2019 0,10% 2017 0,00% 2017
50 10 60 0 1309 0,0% 1309 0,00% 1309 0,00% 1309 0,00% 1309 0,00% 1309
50 10 60 1 834 1,1% 825 0,00% 829 0,48% 834 1,09% 825 0,00% 825
50 10 60 2 1547 0,0% 1547 0,00% 1547 0,00% 1547 0,00% 1547 0,00% 1547
50 10 60 3 1547 0,0% 1547 0,00% 1547 0,00% 1547 0,00% 1547 0,00% 1547
50 10 60 4 1250 0,0% 1250 0,00% 1250 0,00% 1250 0,00% 1250 0,00% 1250
50 10 60 5 1083 0,0% 1083 0,00% 1083 0,00% 1083 0,00% 1083 0,00% 1083
50 10 60 6 1088 0,0% 1088 0,00% 1088 0,00% 1088 0,00% 1088 0,00% 1088
50 10 60 7 1338 0,0% 1341 0,22% 1338 0,00% 1338 0,00% 1338 0,00% 1338
50 10 60 8 1189 0,0% 1189 0,00% 1189 0,00% 1189 0,00% 1189 0,00% 1189
50 10 60 9 1249 0,0% 1249 0,00% 1249 0,00% 1249 0,00% 1249 0,00% 1249

78
n k %m I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
50 20 0 0 3178 0,9% 3214 2,06% 3187 1,21% 3149 0,00% 3160 0,35% 3149
50 20 0 1 3420 0,6% 3447 1,44% 3437 1,15% 3461 1,85% 3398 0,00% 3398
50 20 0 2 3427 0,0% 3469 1,23% 3427 0,00% 3455 0,82% 3499 2,10% 3427
50 20 0 3 3544 0,1% 3615 2,09% 3663 3,45% 3541 0,00% 3659 3,33% 3541
50 20 0 4 3462 1,4% 3472 1,67% 3496 2,37% 3415 0,00% 3517 2,99% 3415
50 20 0 5 3463 2,4% 3382 0,00% 3464 2,42% 3405 0,68% 3460 2,31% 3382
50 20 0 6 3293 2,3% 3301 2,55% 3333 3,54% 3219 0,00% 3354 4,19% 3219
50 20 0 7 3578 1,0% 3543 0,00% 3589 1,30% 3641 2,77% 3573 0,85% 3543
50 20 0 8 3378 1,5% 3327 0,00% 3393 1,98% 3373 1,38% 3370 1,29% 3327
50 20 0 9 3140 0,0% 3169 0,92% 3230 2,87% 3320 5,73% 3201 1,94% 3140
50 20 20 0 2779 1,2% 2821 2,69% 2782 1,27% 2834 3,17% 2747 0,00% 2747
50 20 20 1 2879 0,0% 2896 0,59% 2879 0,00% 2879 0,00% 2879 0,00% 2879
50 20 20 2 2867 0,0% 2904 1,29% 2922 1,92% 2867 0,00% 2882 0,52% 2867
50 20 20 3 2679 0,0% 2710 1,16% 2799 4,48% 2689 0,37% 2697 0,67% 2679
50 20 20 4 2779 0,0% 2779 0,00% 2779 0,00% 2779 0,00% 2779 0,00% 2779
50 20 20 5 2998 2,7% 3126 7,13% 2918 0,00% 3025 3,67% 2929 0,38% 2918
50 20 20 6 2633 3,0% 2558 0,04% 2577 0,78% 2590 1,29% 2557 0,00% 2557
50 20 20 7 2858 0,1% 2854 0,00% 2895 1,44% 2991 4,80% 2868 0,49% 2854
50 20 20 8 2766 0,0% 2841 2,71% 2802 1,30% 2830 2,31% 2883 4,23% 2766
50 20 20 9 2740 0,0% 2764 0,88% 2781 1,50% 2755 0,55% 2740 0,00% 2740
50 20 40 0 2063 1,5% 2052 0,98% 2055 1,13% 2032 0,00% 2063 1,53% 2032
50 20 40 1 2359 2,7% 2377 3,48% 2350 2,31% 2367 3,05% 2297 0,00% 2297
50 20 40 2 1907 0,2% 1907 0,21% 1903 0,00% 1903 0,00% 1906 0,16% 1903
50 20 40 3 2231 0,0% 2240 0,40% 2233 0,09% 2243 0,54% 2233 0,09% 2231
50 20 40 4 2202 0,0% 2255 2,41% 2229 1,23% 2229 1,23% 2229 1,23% 2202
50 20 40 5 2445 1,2% 2489 3,02% 2445 1,20% 2416 0,00% 2445 1,20% 2416
50 20 40 6 1711 0,3% 1706 0,00% 1734 1,64% 1736 1,76% 1710 0,23% 1706
50 20 40 7 2142 2,4% 2140 2,34% 2107 0,77% 2091 0,00% 2101 0,48% 2091
50 20 40 8 2356 0,0% 2356 0,00% 2356 0,00% 2356 0,00% 2356 0,00% 2356
50 20 40 9 1957 2,4% 1951 2,04% 1957 2,35% 1912 0,00% 1931 0,99% 1912
50 20 60 0 1621 0,0% 1630 0,56% 1621 0,00% 1621 0,00% 1621 0,00% 1621
50 20 60 1 1529 0,0% 1557 1,83% 1543 0,92% 1536 0,46% 1538 0,59% 1529
50 20 60 2 1395 0,0% 1457 4,44% 1440 3,23% 1457 4,44% 1440 3,23% 1395
50 20 60 3 1524 0,0% 1524 0,00% 1524 0,00% 1524 0,00% 1524 0,00% 1524
50 20 60 4 1338 0,0% 1338 0,00% 1338 0,00% 1338 0,00% 1338 0,00% 1338
50 20 60 5 1399 1,5% 1394 1,16% 1378 0,00% 1385 0,51% 1379 0,07% 1378
50 20 60 6 1194 0,0% 1201 0,59% 1207 1,09% 1194 0,00% 1201 0,59% 1194
50 20 60 7 1528 0,0% 1528 0,00% 1528 0,00% 1528 0,00% 1528 0,00% 1528
50 20 60 8 1099 0,0% 1099 0,00% 1099 0,00% 1099 0,00% 1099 0,00% 1099
50 20 60 9 1218 0,3% 1214 0,00% 1218 0,33% 1214 0,00% 1218 0,33% 1214
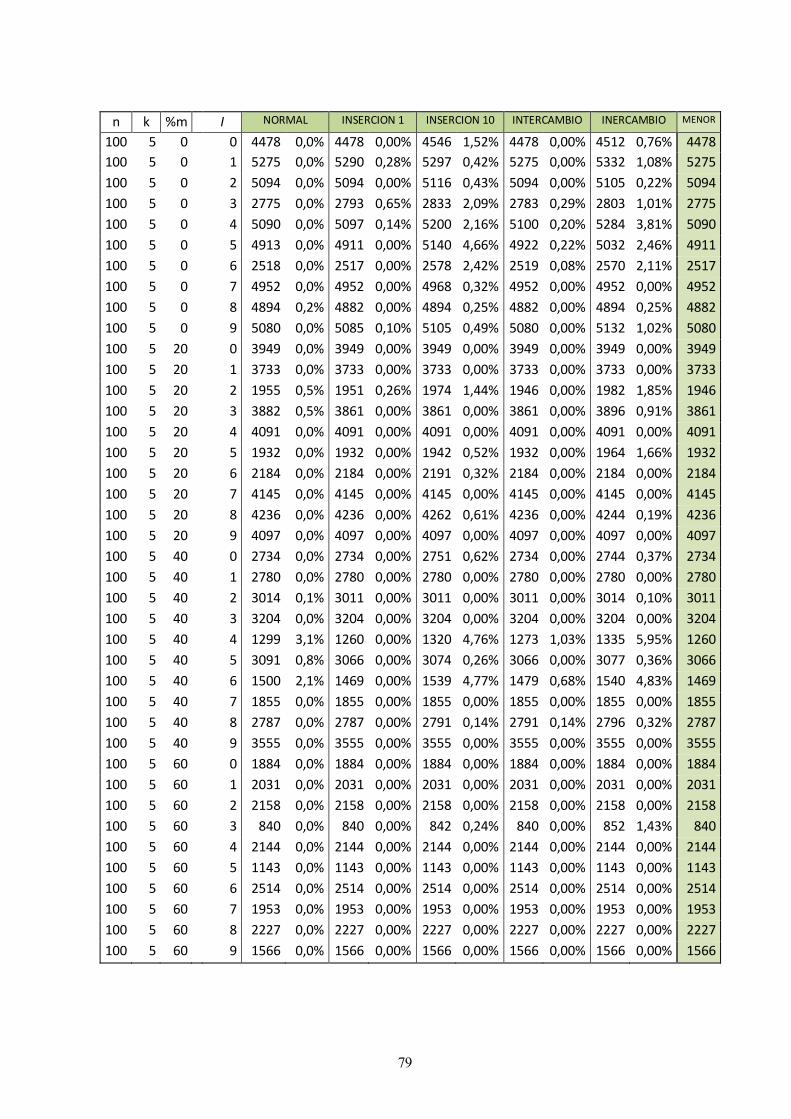
79
n k %m I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
100 5 0 0 4478 0,0% 4478 0,00% 4546 1,52% 4478 0,00% 4512 0,76% 4478
100 5 0 1 5275 0,0% 5290 0,28% 5297 0,42% 5275 0,00% 5332 1,08% 5275
100 5 0 2 5094 0,0% 5094 0,00% 5116 0,43% 5094 0,00% 5105 0,22% 5094
100 5 0 3 2775 0,0% 2793 0,65% 2833 2,09% 2783 0,29% 2803 1,01% 2775
100 5 0 4 5090 0,0% 5097 0,14% 5200 2,16% 5100 0,20% 5284 3,81% 5090
100 5 0 5 4913 0,0% 4911 0,00% 5140 4,66% 4922 0,22% 5032 2,46% 4911
100 5 0 6 2518 0,0% 2517 0,00% 2578 2,42% 2519 0,08% 2570 2,11% 2517
100 5 0 7 4952 0,0% 4952 0,00% 4968 0,32% 4952 0,00% 4952 0,00% 4952
100 5 0 8 4894 0,2% 4882 0,00% 4894 0,25% 4882 0,00% 4894 0,25% 4882
100 5 0 9 5080 0,0% 5085 0,10% 5105 0,49% 5080 0,00% 5132 1,02% 5080
100 5 20 0 3949 0,0% 3949 0,00% 3949 0,00% 3949 0,00% 3949 0,00% 3949
100 5 20 1 3733 0,0% 3733 0,00% 3733 0,00% 3733 0,00% 3733 0,00% 3733
100 5 20 2 1955 0,5% 1951 0,26% 1974 1,44% 1946 0,00% 1982 1,85% 1946
100 5 20 3 3882 0,5% 3861 0,00% 3861 0,00% 3861 0,00% 3896 0,91% 3861
100 5 20 4 4091 0,0% 4091 0,00% 4091 0,00% 4091 0,00% 4091 0,00% 4091
100 5 20 5 1932 0,0% 1932 0,00% 1942 0,52% 1932 0,00% 1964 1,66% 1932
100 5 20 6 2184 0,0% 2184 0,00% 2191 0,32% 2184 0,00% 2184 0,00% 2184
100 5 20 7 4145 0,0% 4145 0,00% 4145 0,00% 4145 0,00% 4145 0,00% 4145
100 5 20 8 4236 0,0% 4236 0,00% 4262 0,61% 4236 0,00% 4244 0,19% 4236
100 5 20 9 4097 0,0% 4097 0,00% 4097 0,00% 4097 0,00% 4097 0,00% 4097
100 5 40 0 2734 0,0% 2734 0,00% 2751 0,62% 2734 0,00% 2744 0,37% 2734
100 5 40 1 2780 0,0% 2780 0,00% 2780 0,00% 2780 0,00% 2780 0,00% 2780
100 5 40 2 3014 0,1% 3011 0,00% 3011 0,00% 3011 0,00% 3014 0,10% 3011
100 5 40 3 3204 0,0% 3204 0,00% 3204 0,00% 3204 0,00% 3204 0,00% 3204
100 5 40 4 1299 3,1% 1260 0,00% 1320 4,76% 1273 1,03% 1335 5,95% 1260
100 5 40 5 3091 0,8% 3066 0,00% 3074 0,26% 3066 0,00% 3077 0,36% 3066
100 5 40 6 1500 2,1% 1469 0,00% 1539 4,77% 1479 0,68% 1540 4,83% 1469
100 5 40 7 1855 0,0% 1855 0,00% 1855 0,00% 1855 0,00% 1855 0,00% 1855
100 5 40 8 2787 0,0% 2787 0,00% 2791 0,14% 2791 0,14% 2796 0,32% 2787
100 5 40 9 3555 0,0% 3555 0,00% 3555 0,00% 3555 0,00% 3555 0,00% 3555
100 5 60 0 1884 0,0% 1884 0,00% 1884 0,00% 1884 0,00% 1884 0,00% 1884
100 5 60 1 2031 0,0% 2031 0,00% 2031 0,00% 2031 0,00% 2031 0,00% 2031
100 5 60 2 2158 0,0% 2158 0,00% 2158 0,00% 2158 0,00% 2158 0,00% 2158
100 5 60 3 840 0,0% 840 0,00% 842 0,24% 840 0,00% 852 1,43% 840
100 5 60 4 2144 0,0% 2144 0,00% 2144 0,00% 2144 0,00% 2144 0,00% 2144
100 5 60 5 1143 0,0% 1143 0,00% 1143 0,00% 1143 0,00% 1143 0,00% 1143
100 5 60 6 2514 0,0% 2514 0,00% 2514 0,00% 2514 0,00% 2514 0,00% 2514
100 5 60 7 1953 0,0% 1953 0,00% 1953 0,00% 1953 0,00% 1953 0,00% 1953
100 5 60 8 2227 0,0% 2227 0,00% 2227 0,00% 2227 0,00% 2227 0,00% 2227
100 5 60 9 1566 0,0% 1566 0,00% 1566 0,00% 1566 0,00% 1566 0,00% 1566

80
n k %m I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
100 10 0 0 5182 0,0% 5216 0,66% 5424 4,67% 5245 1,22% 5474 5,63% 5182
100 10 0 1 5604 0,2% 5598 0,09% 5793 3,58% 5593 0,00% 5740 2,63% 5593
100 10 0 2 5749 0,0% 5778 0,50% 6228 8,33% 5772 0,40% 6136 6,73% 5749
100 10 0 3 5436 0,9% 5387 0,00% 5431 0,82% 5466 1,47% 5479 1,71% 5387
100 10 0 4 5053 0,0% 5161 2,14% 5426 7,38% 5066 0,26% 5304 4,97% 5053
100 10 0 5 5505 0,0% 5589 1,53% 5829 5,89% 5535 0,54% 5756 4,56% 5505
100 10 0 6 5173 0,0% 5214 0,79% 5376 3,92% 5173 0,00% 5278 2,03% 5173
100 10 0 7 5285 0,3% 5271 0,00% 5443 3,26% 5298 0,51% 5383 2,12% 5271
100 10 0 8 4908 0,0% 4915 0,14% 5017 2,22% 4936 0,57% 5000 1,87% 4908
100 10 0 9 5643 0,0% 5643 0,00% 5676 0,58% 5651 0,14% 5744 1,79% 5643
100 10 20 0 4107 0,1% 4117 0,39% 4164 1,54% 4101 0,00% 4183 2,00% 4101
100 10 20 1 3753 0,0% 3753 0,00% 3753 0,00% 3753 0,00% 3753 0,00% 3753
100 10 20 2 4035 0,2% 4028 0,00% 4060 0,79% 4035 0,17% 4055 0,67% 4028
100 10 20 3 4465 0,1% 4462 0,00% 4505 0,96% 4465 0,07% 4544 1,84% 4462
100 10 20 4 4558 0,4% 4542 0,00% 4747 4,51% 4552 0,22% 4740 4,36% 4542
100 10 20 5 4632 0,0% 4632 0,00% 4632 0,00% 4632 0,00% 4632 0,00% 4632
100 10 20 6 4356 0,0% 4356 0,00% 4372 0,37% 4372 0,37% 4372 0,37% 4356
100 10 20 7 3721 0,6% 3698 0,00% 3796 2,65% 3743 1,22% 3805 2,89% 3698
100 10 20 8 3965 0,2% 3956 0,00% 4063 2,70% 3956 0,00% 4089 3,36% 3956
100 10 20 9 4408 0,0% 4625 4,92% 4608 4,54% 4445 0,84% 4646 5,40% 4408
100 10 40 0 3581 0,0% 3581 0,00% 3600 0,53% 3581 0,00% 3600 0,53% 3581
100 10 40 1 3415 0,0% 3415 0,00% 3417 0,06% 3415 0,00% 3415 0,00% 3415
100 10 40 2 3442 0,3% 3433 0,00% 3459 0,76% 3442 0,26% 3516 2,42% 3433
100 10 40 3 3237 0,0% 3237 0,00% 3283 1,42% 3237 0,00% 3268 0,96% 3237
100 10 40 4 3195 1,5% 3147 0,00% 3214 2,13% 3147 0,00% 3251 3,30% 3147
100 10 40 5 3014 0,0% 3014 0,00% 3154 4,64% 3014 0,00% 3073 1,96% 3014
100 10 40 6 1622 0,1% 1621 0,00% 1649 1,73% 1621 0,00% 1652 1,91% 1621
100 10 40 7 3166 0,0% 3166 0,00% 3208 1,33% 3167 0,03% 3189 0,73% 3166
100 10 40 8 3320 0,0% 3320 0,00% 3320 0,00% 3320 0,00% 3320 0,00% 3320
100 10 40 9 1120 0,0% 1120 0,00% 1174 4,82% 1144 2,14% 1154 3,04% 1120
100 10 60 0 2321 0,0% 2321 0,00% 2352 1,34% 2321 0,00% 2343 0,95% 2321
100 10 60 1 2144 0,3% 2137 0,00% 2141 0,19% 2137 0,00% 2138 0,05% 2137
100 10 60 2 2099 0,0% 2099 0,00% 2099 0,00% 2099 0,00% 2099 0,00% 2099
100 10 60 3 2000 0,0% 2000 0,00% 2042 2,10% 2000 0,00% 2000 0,00% 2000
100 10 60 4 2386 0,0% 2387 0,04% 2387 0,04% 2386 0,00% 2422 1,51% 2386
100 10 60 5 2792 0,0% 2792 0,00% 2792 0,00% 2792 0,00% 2792 0,00% 2792
100 10 60 6 2387 0,0% 2386 0,00% 2407 0,88% 2386 0,00% 2401 0,63% 2386
100 10 60 7 2623 0,2% 2617 0,00% 2623 0,23% 2623 0,23% 2724 4,09% 2617
100 10 60 8 2377 0,0% 2377 0,00% 2377 0,00% 2377 0,00% 2377 0,00% 2377
100 10 60 9 2479 0,0% 2479 0,00% 2521 1,69% 2479 0,00% 2498 0,77% 2479
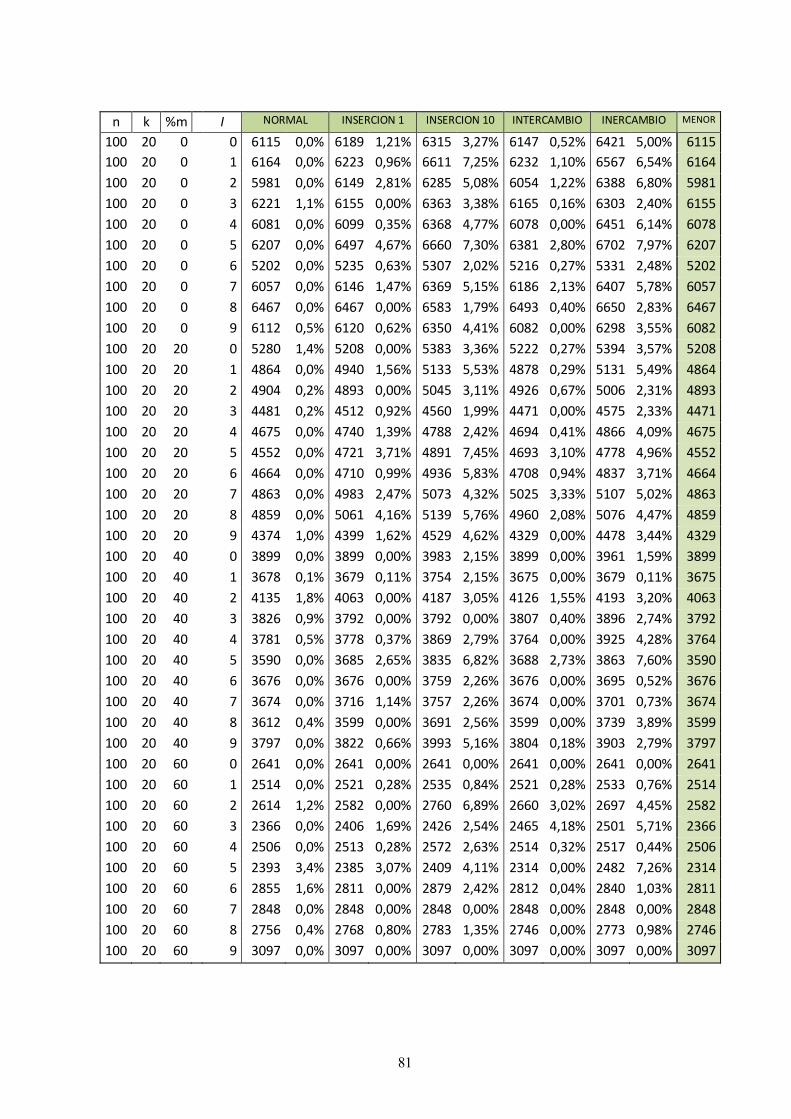
81
n k %m I NORMAL INSERCION 1 INSERCION 10 INTERCAMBIO
1
INERCAMBIO
10
MENOR
100 20 0 0 6115 0,0% 6189 1,21% 6315 3,27% 6147 0,52% 6421 5,00% 6115
100 20 0 1 6164 0,0% 6223 0,96% 6611 7,25% 6232 1,10% 6567 6,54% 6164
100 20 0 2 5981 0,0% 6149 2,81% 6285 5,08% 6054 1,22% 6388 6,80% 5981
100 20 0 3 6221 1,1% 6155 0,00% 6363 3,38% 6165 0,16% 6303 2,40% 6155
100 20 0 4 6081 0,0% 6099 0,35% 6368 4,77% 6078 0,00% 6451 6,14% 6078
100 20 0 5 6207 0,0% 6497 4,67% 6660 7,30% 6381 2,80% 6702 7,97% 6207
100 20 0 6 5202 0,0% 5235 0,63% 5307 2,02% 5216 0,27% 5331 2,48% 5202
100 20 0 7 6057 0,0% 6146 1,47% 6369 5,15% 6186 2,13% 6407 5,78% 6057
100 20 0 8 6467 0,0% 6467 0,00% 6583 1,79% 6493 0,40% 6650 2,83% 6467
100 20 0 9 6112 0,5% 6120 0,62% 6350 4,41% 6082 0,00% 6298 3,55% 6082
100 20 20 0 5280 1,4% 5208 0,00% 5383 3,36% 5222 0,27% 5394 3,57% 5208
100 20 20 1 4864 0,0% 4940 1,56% 5133 5,53% 4878 0,29% 5131 5,49% 4864
100 20 20 2 4904 0,2% 4893 0,00% 5045 3,11% 4926 0,67% 5006 2,31% 4893
100 20 20 3 4481 0,2% 4512 0,92% 4560 1,99% 4471 0,00% 4575 2,33% 4471
100 20 20 4 4675 0,0% 4740 1,39% 4788 2,42% 4694 0,41% 4866 4,09% 4675
100 20 20 5 4552 0,0% 4721 3,71% 4891 7,45% 4693 3,10% 4778 4,96% 4552
100 20 20 6 4664 0,0% 4710 0,99% 4936 5,83% 4708 0,94% 4837 3,71% 4664
100 20 20 7 4863 0,0% 4983 2,47% 5073 4,32% 5025 3,33% 5107 5,02% 4863
100 20 20 8 4859 0,0% 5061 4,16% 5139 5,76% 4960 2,08% 5076 4,47% 4859
100 20 20 9 4374 1,0% 4399 1,62% 4529 4,62% 4329 0,00% 4478 3,44% 4329
100 20 40 0 3899 0,0% 3899 0,00% 3983 2,15% 3899 0,00% 3961 1,59% 3899
100 20 40 1 3678 0,1% 3679 0,11% 3754 2,15% 3675 0,00% 3679 0,11% 3675
100 20 40 2 4135 1,8% 4063 0,00% 4187 3,05% 4126 1,55% 4193 3,20% 4063
100 20 40 3 3826 0,9% 3792 0,00% 3792 0,00% 3807 0,40% 3896 2,74% 3792
100 20 40 4 3781 0,5% 3778 0,37% 3869 2,79% 3764 0,00% 3925 4,28% 3764
100 20 40 5 3590 0,0% 3685 2,65% 3835 6,82% 3688 2,73% 3863 7,60% 3590
100 20 40 6 3676 0,0% 3676 0,00% 3759 2,26% 3676 0,00% 3695 0,52% 3676
100 20 40 7 3674 0,0% 3716 1,14% 3757 2,26% 3674 0,00% 3701 0,73% 3674
100 20 40 8 3612 0,4% 3599 0,00% 3691 2,56% 3599 0,00% 3739 3,89% 3599
100 20 40 9 3797 0,0% 3822 0,66% 3993 5,16% 3804 0,18% 3903 2,79% 3797
100 20 60 0 2641 0,0% 2641 0,00% 2641 0,00% 2641 0,00% 2641 0,00% 2641
100 20 60 1 2514 0,0% 2521 0,28% 2535 0,84% 2521 0,28% 2533 0,76% 2514
100 20 60 2 2614 1,2% 2582 0,00% 2760 6,89% 2660 3,02% 2697 4,45% 2582
100 20 60 3 2366 0,0% 2406 1,69% 2426 2,54% 2465 4,18% 2501 5,71% 2366
100 20 60 4 2506 0,0% 2513 0,28% 2572 2,63% 2514 0,32% 2517 0,44% 2506
100 20 60 5 2393 3,4% 2385 3,07% 2409 4,11% 2314 0,00% 2482 7,26% 2314
100 20 60 6 2855 1,6% 2811 0,00% 2879 2,42% 2812 0,04% 2840 1,03% 2811
100 20 60 7 2848 0,0% 2848 0,00% 2848 0,00% 2848 0,00% 2848 0,00% 2848
100 20 60 8 2756 0,4% 2768 0,80% 2783 1,35% 2746 0,00% 2773 0,98% 2746
100 20 60 9 3097 0,0% 3097 0,00% 3097 0,00% 3097 0,00% 3097 0,00% 3097

82
9.2 Anexo B: Códigos en C
9.2.1 Código metodo I: “Normal”
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<string>
#define M 10000
#define pc 80
#define pm 20
#define numpadres 10
#define numiteraciones 100000
#define numnomejoras 100000
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100]);
void transponerM (int numjobs, int numS,int tproceso[100][100]);
void ordenar2V(int tam,int v1[],int v2[]);
int buscarmayorv(int tamv ,int v[]);
int buscarmenor(int fila, int tamfila ,int matriz[100][100]);
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100]);
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int v[]);
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100]);
void ordenpadre(int numjobs,int orden[numpadres]);
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100]);
int mutacion(int tam,int fila,int contmutaciones, int secuencias[numpadres*4][100]);
int GA (int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100]);
int todo(int tacumulado,char frase[100]);
int main()
{
int vJ[3]={20,50,100};
int vS[3]={5,10,20};
int vM[4]={0,20,40,60};
int vI[10]={0,1,2,3,4,5,6,7,8,9};
int cJ,cS,cM,cI;

83
int tacumulado=0;
int t;
char barra[2]="_";
char problem[13]="_problem.txt";
char frase[100];
char s1[10];
for(cJ=0;cJ<3;cJ++)
{
for(cS=0;cS<3;cS++)
{
for(cM=0;cM<4;cM++)
{
for(cI=0;cI<10;cI++)
{
memset (frase,'\0',100);
itoa(vJ[cJ],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vS[cS],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vM[cM],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vI[cI],s1,10);
strcat(frase, s1);
strcat(frase, problem);
printf("%s \n",frase);
t = todo(tacumulado,frase);
tacumulado=t;
memset (frase,'\0',100);
}
}
}

84
}
printf("%d FIN\n",tacumulado);
system ("pause");
}
//--------------------------------------PROGRAMA PRINCIPAL----------------------------
void transponerM (int numjobs, int numS,int tproceso[100][100])
{
int auxM[100][100];
int i,j;
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
auxM[i][j]=tproceso[i][j];
}
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
tproceso[j][i]=auxM[i][j];
}
}
}
void ordenar2V(int tam,int v1[],int v2[])
{
int i,j;
int sec,temp;
for (j=tam-1;j>0;j--)
{
for (i=0;i<j;i++)
{

85
if (v1[i] > v1[i+1])
{
temp = v1[i];
sec=v2[i];
v1[i] = v1[i+1];
v2[i]=v2[i+1];
v1[i+1] = temp;
v2[i+1]=sec;
}
}
}
}
int buscarmenor(int fila, int tamfila ,int matriz[100][100])/*Lo hace bien*/
{
int menor=10000;
int i,posicion;
for(i=0;i<tamfila;i++)
{
if(menor>matriz[fila][i])
{
menor=matriz[fila][i];
posicion=i;
}
}
return posicion;
}
int buscarmayorv(int tamv ,int v[])
{
int mayor=0;
int i;
for(i=0;i<tamv;i++)

86
{
if(mayor<v[i])
{
mayor=v[i];
}
}
return mayor;
}
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100])
{
int mayor=0;
int i;
int fila=numS-1;
for(i=0;i<numjobs;i++)
{
if(mayor<v[fila][i])
{
mayor=v[fila][i];
}
}
return mayor;
}
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int jobs[])
{
int a,b;
int i,j,l;
int posicion,aux;
if(fila>0)
{
for (j=tam-1;j>0;j--)
{
for (i=0;i<j ;i++)

87
{
if (Q[fila-1][i] >= Q[fila-1][i+1])
{
a=Q[fila-1][i];
Q[fila-1][i]=Q[fila-1][i+1];
Q[fila-1][i+1]=a;
b=jobs[i];
jobs[i]=jobs[i+1];
jobs[i+1]=b;
}
}
}
}
for(i=tam-1;i>=0;i--)
{
if(tproceso[fila][jobs[i]]==0)
{
posicion=i;
aux=jobs[i];
for(j=posicion;j>0;j--)
{
jobs[j]=jobs[j-1];
}
jobs[0]=aux;
}
}
}
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100])
{
int j,k,l,i;
int maq;
int jobs[numjobs];

88
int aux[100][100];
int aux1;
int posicion;
int makespan;
int t[100][100];
int Q[100][100];
for(k=0;k<numS;k++)
{
for(j=0;j<maxmaq;j++)
{
if(j<L[k])
{
t[k][j]=0;
}
else
{
t[k][j]=M;
}
}
}
for(k=0;k<numS;k++)
{
for(j=0;j<numjobs;j++)
{
Q[k][j]=0;
}
}
for(i=0;i<numjobs;i++)
{
jobs[i]=secuencia[i];
}

89
for(k=0;k<numS;k++)
{
for(i=0;i<numS;i++)
{
for(l=0;l<numjobs;l++)
{
aux[i][l]=Q[i][l];
}
}
if(k!=0)
{
for(i=0;i<numjobs;i++)
{
jobs[i]=i;
}
}
ordenarVsegunM(numjobs,k,aux,tproceso,jobs);
for (j=0;j<numjobs;j++)
{
maq = buscarmenor(k,maxmaq,t);
if(tproceso[k][jobs[j]]>0)
{
if(k==0)
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
if(t[k][maq]>Q[k-1][jobs[j]])
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}

90
else
{
t[k][maq]=Q[k-1][jobs[j]]+tproceso[k][jobs[j]];
}
}
}
if(k==0)
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[0][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
else
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[k-1][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
}
}
makespan=buscarmayorMatriz(numS,numjobs,Q);
return makespan;
}
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100])

91
{
int i,j,k;
int num;
int repite=0;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
num = rand()% (numjobs) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(matrizpadres[i][k]==num)
{
repite=1;
}
}
if(repite==0)
{
matrizpadres[i][j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
}
void ordenpadre(int numjobs,int orden[numpadres])
{
int num;
int k,j;
int repite;

92
for(j=0;j<numpadres;j++)
{
num = rand()% (numpadres) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(orden[k]==num)
{
repite=1;
}
}
if(repite==0)
{
orden[j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100])
{
int i,j,aux;
int P1,P2;
int posicion;
int esta;
int a;
int aux1[100];
int aux2[100];
a=rand()% 101 + 0;

93
if(a<=pc)
{
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P2;i<tam;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P1;i<P2;i++)
{
aux1[i]=-1;
}
posicion=P1;
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila2][i]==aux1[j])
{
esta=1;

94
}
}
if(esta==0)
{
aux1[posicion]=secuencias[fila2][i];
posicion++;
}
esta=0;
}
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P2;i<tam;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P1;i<P2;i++)
{
aux2[i]=-1;
}
posicion=P1;

95
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila1][i]==aux2[j])
{
esta=1;
}
}
if(esta==0)
{
aux2[posicion]=secuencias[fila1][i];
posicion++;
}
esta=0;
}
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux1[i];
}
contposicion++;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux2[i];
}
contposicion++;
}
return contposicion;
}
int mutacion(int tam,int fila,int contmutaciones,int secuencias[numpadres][100])
{
int i;

96
int a,b;
int c;
int muta=0;
c=rand()% 101 + 0;
if(c<=pm)
{
muta=1;
a=rand()% (tam) + 0;
b=rand()% (tam) + 0;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contmutaciones][i]=secuencias[fila][i];
}
secuencias[numpadres+contmutaciones][a]=secuencias[fila][b];
secuencias[numpadres+contmutaciones][b]=secuencias[fila][a];
}
return muta;
}
int GA(int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100])
{
int i,j;
int fila1,fila2;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
secuencias[i][j]=matrizpadres[orden[i]][j];
}
}

97
int contposicion=0;
for(i=0;i<numpadres;i=i+2)
{
fila1=i;
fila2=i+1;
contposicion=crossover(numjobs,fila1,fila2,contposicion,secuencias);
}
int contmutaciones=contposicion;
int muta=0;
for(j=0;j<numpadres;j++)
{
muta=mutacion(numjobs,j,contmutaciones,secuencias);
contmutaciones=contmutaciones+muta;
}
return contmutaciones;
}
int todo(int tacumulado,char frase[100])
{
int numjobs;
int numS;
int tproceso[100][100];
int jobs[100];
int L[100];
int k,j,l,i;
int aux;
int secuencia[100];
int makespan;
int makespans[numpadres*4];
int matrizpadres[numpadres][100];
int orden[numpadres];
int secuencias[numpadres*4][100];
int posiciones[numpadres*4];

98
int salida=0;
/*LECTURA DE DATOS DEL PROBLEMA*/
FILE *datos=NULL;
datos=fopen(frase,"r");
if(datos==NULL)
printf("el fichero no existe");
fscanf(datos,"%d",&numjobs);
fscanf(datos,"%d",&numS);
for(i=0;i<numS;i++)
{
fscanf(datos,"%d",&L[i]);
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
fscanf(datos,"%d",&tproceso[i][j]);
}
}
fclose(datos);
transponerM(numjobs,numS,tproceso);
int maxmaq;
maxmaq=buscarmayorv(numS,L);
/*FIN DATOS*/
int bestmakespan=M;
clock_t tiempo;
tiempo=clock();

99
double tmax=(double)(numjobs*numS)/(double)(10);
clock_t tiempoFinal=clock();
double tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
int tam;
int contmutaciones=0;
creamatrizpadres(numjobs,matrizpadres);
for(k=0;k<numiteraciones && salida<numnomejoras && tiempoTranscurrido<tmax;k++)
{
for(i=0;i<numpadres;i++)
{
orden[i]=0;
}
ordenpadre(numjobs,orden);
contmutaciones=GA(numjobs,orden,matrizpadres,secuencias);
tam=numpadres+contmutaciones;
for(i=0;i<tam;i++)
{
for(j=0;j<numjobs;j++)
{
secuencia[j]=secuencias[i][j];
}
makespan=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
makespans[i]=makespan;
}
for(i=0;i<tam;i++)
{
posiciones[i]=i;
}

100
ordenar2V(tam,makespans,posiciones);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
matrizpadres[i][j]=secuencias[posiciones[i]][j];
}
}
if(makespans[0]<bestmakespan)
{
bestmakespan=makespans[0];
salida=0;
}
else
{
salida=salida+1;
}
tiempoFinal=clock();
tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
printf("Iteracion %d:\n ",k);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
printf("%d ",matrizpadres[i][j]);
}
printf(" :%d\n ",makespans[i]);
}
printf("\n");
}
FILE *resultados;
resultados= fopen("ResultadosNormal.txt","a");
fprintf(resultados, "%d\n", makespans[0]);

101
fclose(resultados);
return tmax;
}
9.2.2 Código metodo II: “Inserción1”
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<string>
#define M 10000
#define pc 80
#define pm 20
#define numpadres 10
#define numiteraciones 100000
#define numnomejoras 100000
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100]);
void transponerM (int numjobs, int numS,int tproceso[100][100]);
void ordenar2V(int tam,int v1[],int v2[]);
int buscarmayorv(int tamv ,int v[]);
int buscarmenor(int fila, int tamfila ,int matriz[100][100]);
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100]);
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int v[]);
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100]);
void ordenpadre(int numjobs,int orden[numpadres]);
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100]);
int mutacion(int tam,int fila,int contmutaciones, int secuencias[numpadres*4][100]);
int GA (int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100]);
int buscarNenM(int fila,int N,int numjobs,int matrizpadres[numpadres][100]);
void insercion (int tam,int secuencia[],int posinicio, int posfinal);
void mejoralocalinsercion (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int
maxmaq,int L[100], int tproceso[100][100]);
int todo(int tacumulado,char frase[100]);

102
int main()
{
int vJ[3]={20,50,100};
int vS[3]={5,10,20};
int vM[4]={0,20,40,60};
int vI[10]={0,1,2,3,4,5,6,7,8,9};
int cJ,cS,cM,cI;
int tacumulado=0;
int t;
char barra[2]="_";
char problem[13]="_problem.txt";
char s1[10];
char frase[100];
for(cJ=0;cJ<3;cJ++)
{
for(cS=0;cS<3;cS++)
{
for(cM=0;cM<4;cM++)
{
for(cI=0;cI<10;cI++)
{
memset (frase,'\0',100);
itoa(vJ[cJ],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vS[cS],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vM[cM],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vI[cI],s1,10);
strcat(frase, s1);
strcat(frase, problem);

103
printf("%s \n",frase);
t = todo(tacumulado,frase);
tacumulado=t;
memset (frase,'\0',100);
}
}
}
}
printf("%d FIN\n",tacumulado);
system ("pause");
}
//--------------------------------------PROGRAMA PRINCIPAL----------------------------
void transponerM (int numjobs, int numS,int tproceso[100][100])
{
int auxM[100][100];
int i,j;
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
auxM[i][j]=tproceso[i][j];
}
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
tproceso[j][i]=auxM[i][j];
}
}
}
void ordenar2V(int tam,int v1[],int v2[])

104
{
int i,j;
int sec,temp;
for (j=tam-1;j>0;j--)
{
for (i=0;i<j;i++)
{
if (v1[i] > v1[i+1])
{
temp = v1[i];
sec=v2[i];
v1[i] = v1[i+1];
v2[i]=v2[i+1];
v1[i+1] = temp;
v2[i+1]=sec;
}
}
}
}
int buscarmenor(int fila, int tamfila ,int matriz[100][100])/*Lo hace bien*/
{
int menor=10000;
int i,posicion;
for(i=0;i<tamfila;i++)
{
if(menor>matriz[fila][i])
{
menor=matriz[fila][i];
posicion=i;
}
}
return posicion;
}

105
int buscarmayorv(int tamv ,int v[])
{
int mayor=0;
int i;
for(i=0;i<tamv;i++)
{
if(mayor<v[i])
{
mayor=v[i];
}
}
return mayor;
}
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100])
{
int mayor=0;
int i;
int fila=numS-1;
for(i=0;i<numjobs;i++)
{
if(mayor<v[fila][i])
{
mayor=v[fila][i];
}
}
return mayor;
}
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int jobs[])
{
int a,b;
int i,j,l;

106
int posicion,aux;
if(fila>0)
{
for (j=tam-1;j>0;j--)
{
for (i=0;i<j ;i++)
{
if (Q[fila-1][i] >= Q[fila-1][i+1])
{
a=Q[fila-1][i];
Q[fila-1][i]=Q[fila-1][i+1];
Q[fila-1][i+1]=a;
b=jobs[i];
jobs[i]=jobs[i+1];
jobs[i+1]=b;
}
}
}
}
for(i=tam-1;i>=0;i--)
{
if(tproceso[fila][jobs[i]]==0)
{
posicion=i;
aux=jobs[i];
for(j=posicion;j>0;j--)
{
jobs[j]=jobs[j-1];
}
jobs[0]=aux;
}
}

107
}
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100])
{
int j,k,l,i;
int maq;
int jobs[numjobs];
int aux[100][100];
int aux1;
int posicion;
int makespan;
int t[100][100];
int Q[100][100];
for(k=0;k<numS;k++)
{
for(j=0;j<maxmaq;j++)
{
if(j<L[k])
{
t[k][j]=0;
}
else
{
t[k][j]=M;
}
}
}
for(k=0;k<numS;k++)
{
for(j=0;j<numjobs;j++)
{
Q[k][j]=0;
}
}

108
for(i=0;i<numjobs;i++)
{
jobs[i]=secuencia[i];
}
for(k=0;k<numS;k++)
{
for(i=0;i<numS;i++)
{
for(l=0;l<numjobs;l++)
{
aux[i][l]=Q[i][l];
}
}
if(k!=0)
{
for(i=0;i<numjobs;i++)
{
jobs[i]=i;
}
}
ordenarVsegunM(numjobs,k,aux,tproceso,jobs);
for (j=0;j<numjobs;j++)
{
maq = buscarmenor(k,maxmaq,t);
if(tproceso[k][jobs[j]]>0)
{
if(k==0)
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else

109
{
if(t[k][maq]>Q[k-1][jobs[j]])
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
t[k][maq]=Q[k-1][jobs[j]]+tproceso[k][jobs[j]];
}
}
}
if(k==0)
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[0][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
else
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[k-1][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
}
}
makespan=buscarmayorMatriz(numS,numjobs,Q);

110
return makespan;
}
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100])
{
int i,j,k;
int num;
int repite=0;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
num = rand()% (numjobs) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(matrizpadres[i][k]==num)
{
repite=1;
}
}
if(repite==0)
{
matrizpadres[i][j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
}
void ordenpadre(int numjobs,int orden[numpadres])
{

111
int num;
int k,j;
int repite;
for(j=0;j<numpadres;j++)
{
num = rand()% (numpadres) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(orden[k]==num)
{
repite=1;
}
}
if(repite==0)
{
orden[j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100])
{
int i,j,aux;
int P1,P2;
int posicion;
int esta;
int a;
int aux1[100];
int aux2[100];

112
a=rand()% 101 + 0;
if(a<=pc)
{
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P2;i<tam;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P1;i<P2;i++)
{
aux1[i]=-1;
}
posicion=P1;
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila2][i]==aux1[j])
{
esta=1;
}
}

113
if(esta==0)
{
aux1[posicion]=secuencias[fila2][i];
posicion++;
}
esta=0;
}
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P2;i<tam;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P1;i<P2;i++)
{
aux2[i]=-1;
}
posicion=P1;
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)

114
{
if(secuencias[fila1][i]==aux2[j])
{
esta=1;
}
}
if(esta==0)
{
aux2[posicion]=secuencias[fila1][i];
posicion++;
}
esta=0;
}
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux1[i];
}
contposicion++;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux2[i];
}
contposicion++;
}
return contposicion;
}
int mutacion(int tam,int fila,int contmutaciones,int secuencias[numpadres][100])
{
int i;
int a,b;
int c;
int muta=0;
c=rand()% 101 + 0;
if(c<=pm)

115
{
muta=1;
a=rand()% (tam) + 0;
b=rand()% (tam) + 0;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contmutaciones][i]=secuencias[fila][i];
}
secuencias[numpadres+contmutaciones][a]=secuencias[fila][b];
secuencias[numpadres+contmutaciones][b]=secuencias[fila][a];
}
return muta;
}
int GA(int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100])
{
int i,j;
int fila1,fila2;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
secuencias[i][j]=matrizpadres[orden[i]][j];
}
}
int contposicion=0;
for(i=0;i<numpadres;i=i+2)
{
fila1=i;
fila2=i+1;
contposicion=crossover(numjobs,fila1,fila2,contposicion,secuencias);

116
}
int contmutaciones=contposicion;
int muta=0;
for(j=0;j<numpadres;j++)
{
muta=mutacion(numjobs,j,contmutaciones,secuencias);
contmutaciones=contmutaciones+muta;
}
return contmutaciones;
}
int todo(int tacumulado,char frase[100])
{
int numjobs;
int numS;
int tproceso[100][100];
int jobs[100];
int L[100];
int k,j,l,i;
int aux;
int secuencia[100];
int makespan;
int makespans[numpadres*4];
int matrizpadres[numpadres][100];
int orden[numpadres];
int secuencias[numpadres*4][100];
int posiciones[numpadres*4];
int salida=0;
/*LECTURA DE DATOS DEL PROBLEMA*/
FILE *datos=NULL;
datos=fopen(frase,"r");
if(datos==NULL)
printf("el fichero no existe");

117
fscanf(datos,"%d",&numjobs);
fscanf(datos,"%d",&numS);
for(i=0;i<numS;i++)
{
fscanf(datos,"%d",&L[i]);
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
fscanf(datos,"%d",&tproceso[i][j]);
}
}
fclose(datos);
transponerM(numjobs,numS,tproceso);
int maxmaq;
maxmaq=buscarmayorv(numS,L);
/*FIN DATOS*/
int bestmakespan=M;
clock_t tiempo;
tiempo=clock();
double tmax=(double)(numjobs*numS)/(double)(10);
clock_t tiempoFinal=clock();
double tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
int tam;
int contmutaciones=0;
creamatrizpadres(numjobs,matrizpadres);
for(k=0;k<numiteraciones && salida<numnomejoras && tiempoTranscurrido<tmax;k++)
{

118
for(i=0;i<numpadres;i++)
{
orden[i]=0;
}
ordenpadre(numjobs,orden);
contmutaciones=GA(numjobs,orden,matrizpadres,secuencias);
tam=numpadres+contmutaciones;
for(i=0;i<tam;i++)
{
for(j=0;j<numjobs;j++)
{
secuencia[j]=secuencias[i][j];
}
makespan=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
makespans[i]=makespan;
}
for(i=0;i<tam;i++)
{
posiciones[i]=i;
}
ordenar2V(tam,makespans,posiciones);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
matrizpadres[i][j]=secuencias[posiciones[i]][j];
}
}
int fila=0;
mejoralocalinsercion(fila,numjobs,makespans,matrizpadres,numS,maxmaq,L,tproceso);

119
if(makespans[0]<bestmakespan)
{
bestmakespan=makespans[0];
salida=0;
}
else
{
salida=salida+1;
}
tiempoFinal=clock();
tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
printf("Iteracion %d:\n ",k);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
printf("%d ",matrizpadres[i][j]);
}
printf(" :%d\n ",makespans[i]);
}
printf("\n");
}
FILE *resultados;
resultados= fopen("ResultadosInsercion1.txt","a");
fprintf(resultados, "%d\n", makespans[0]);
fclose(resultados);
return tmax;
}
int buscarNenM(int fila ,int N ,int numjobs ,int matrizpadres[numpadres][100] )
{
int i;
int posicion;

120
for(i=0;i<numjobs;i++)
{
if(matrizpadres[fila][i]==N)
{
posicion=i;
}
}
return posicion;
}
void insercion(int tam,int secuencia[],int posinicio, int posfinal)
{
int aux;
int k,i;
if(posinicio>posfinal)
{
aux=secuencia[posinicio];
for(k=posinicio;k>posfinal;k--)
{
secuencia[k]=secuencia[k-1];
}
secuencia[posfinal]=aux;
}
else
{
aux=secuencia[posinicio];
for(k=posinicio;k<posfinal;k++)
{
secuencia[k]=secuencia[k+1];
}
secuencia[posfinal]=aux;
}
}

121
void mejoralocalinsercion (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int
maxmaq,int L[100], int tproceso[100][100])
{
int posicion;
int i,j,k,l,a,b;
int job;
int makespanbest,makespannuevo;
int secuencia[numjobs];
int secuenciabest[numjobs];
int cambio;
int aux[100];
makespanbest=makespans[fila];
cambio=0;
for(job=0;job<numjobs;job++)
{
posicion=buscarNenM(fila,job,numjobs,matrizpadres);
for(k=0;k<numjobs;k++)
{
if(k!=posicion)
{
for(i=0;i<numjobs;i++)
{
aux[i]=matrizpadres[fila][i];
}
insercion(numjobs,aux,posicion,k);
for(i=0;i<numjobs;i++)
{
secuencia[i]=aux[i];
}
makespannuevo=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
if(makespannuevo<makespanbest)

122
{
for(i=0;i<numjobs;i++)
{
secuenciabest[i]=secuencia[i];
}
makespanbest=makespannuevo;
cambio=1;
}
}
}
}
if(cambio==1)
{
makespans[fila]=makespanbest;
for(i=0;i<numjobs;i++)
{
matrizpadres[fila][i]=secuenciabest[i];
}
}
}
9.2.3 Código metodo III: “Inserción10”
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<string>
#define M 10000
#define pc 80 //entre 0 y 100 no entre 0 y 1
#define pm 20 //entre 0 y 100 no entre 0 y 1
#define numpadres 10
#define numiteraciones 100000
#define numnomejoras 100000
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100]);

123
void transponerM (int numjobs, int numS,int tproceso[100][100]);
void ordenar2V(int tam,int v1[],int v2[]);
int buscarmayorv(int tamv ,int v[]);
int buscarmenor(int fila, int tamfila ,int matriz[100][100]);
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100]);
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int v[]);
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100]);
void ordenpadre(int numjobs,int orden[numpadres]);
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100]);
int mutacion(int tam,int fila,int contmutaciones, int secuencias[numpadres*4][100]);
int GA (int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100]);
int buscarNenM(int fila,int N,int numjobs,int matrizpadres[numpadres][100]);
void insercion (int tam,int secuencia[],int posinicio, int posfinal);
void mejoralocalinsercion (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int maxmaq,int L[100], int tproceso[100][100]);
int todo(int tacumulado,char frase[100]);
int main()
{
int vJ[3]={20,50,100};
int vS[3]={5,10,20};
int vM[4]={0,20,40,60};
int vI[10]={0,1,2,3,4,5,6,7,8,9};
int cJ,cS,cM,cI;
int tacumulado=0;
int t;
char barra[2]="_";
char problem[13]="_problem.txt";
char s1[10];
char frase[100];
for(cJ=0;cJ<3;cJ++)
{
for(cS=0;cS<3;cS++)
{
for(cM=0;cM<4;cM++)
{

124
for(cI=0;cI<10;cI++)
{
srand (time(NULL));
memset (frase,'\0',100);
itoa(vJ[cJ],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vS[cS],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vM[cM],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vI[cI],s1,10);
strcat(frase, s1);
strcat(frase, problem);
printf("%s \n",frase);
t = todo(tacumulado,frase);
tacumulado=t;
memset (frase,'\0',100);
}
}
}
}
printf("%d FIN\n",tacumulado);
system ("pause");
}
//--------------------------------------PROGRAMA PRINCIPAL----------------------------
void transponerM (int numjobs, int numS,int tproceso[100][100])
{
int auxM[100][100];
int i,j;
for(i=0;i<numjobs;i++)

125
{
for(j=0;j<numS;j++)
{
auxM[i][j]=tproceso[i][j];
}
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
tproceso[j][i]=auxM[i][j];
}
}
}
void ordenar2V(int tam,int v1[],int v2[])
{
int i,j;
int sec,temp;
for (j=tam-1;j>0;j--)
{
for (i=0;i<j;i++)
{
if (v1[i] > v1[i+1])
{
temp = v1[i];
sec=v2[i];
v1[i] = v1[i+1];
v2[i]=v2[i+1];
v1[i+1] = temp;
v2[i+1]=sec;
}
}
}
}
int buscarmenor(int fila, int tamfila ,int matriz[100][100])/*Lo hace bien*/

126
{
int menor=10000;
int i,posicion;
for(i=0;i<tamfila;i++)
{
if(menor>matriz[fila][i])
{
menor=matriz[fila][i];
posicion=i;
}
}
return posicion;
}
int buscarmayorv(int tamv ,int v[])
{
int mayor=0;
int i;
for(i=0;i<tamv;i++)
{
if(mayor<v[i])
{
mayor=v[i];
}
}
return mayor;
}
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100])
{
int mayor=0;
int i;
int fila=numS-1;
for(i=0;i<numjobs;i++)

127
{
if(mayor<v[fila][i])
{
mayor=v[fila][i];
}
}
return mayor;
}
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int jobs[])
{
int a,b;
int i,j,l;
int posicion,aux;
if(fila>0)
{
for (j=tam-1;j>0;j--)
{
for (i=0;i<j ;i++)
{
if (Q[fila-1][i] >= Q[fila-1][i+1])
{
a=Q[fila-1][i];
Q[fila-1][i]=Q[fila-1][i+1];
Q[fila-1][i+1]=a;
b=jobs[i];
jobs[i]=jobs[i+1];
jobs[i+1]=b;
}
}
}
}
for(i=tam-1;i>=0;i--)
{
if(tproceso[fila][jobs[i]]==0)

128
{
posicion=i;
aux=jobs[i];
for(j=posicion;j>0;j--)
{
jobs[j]=jobs[j-1];
}
jobs[0]=aux;
}
}
}
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100])
{
int j,k,l,i;
int maq;
int jobs[numjobs];
int aux[100][100];
int aux1;
int posicion;
int makespan;
int t[100][100];
int Q[100][100];
for(k=0;k<numS;k++)
{
for(j=0;j<maxmaq;j++)
{
if(j<L[k])
{
t[k][j]=0;
}
else
{
t[k][j]=M;

129
}
}
}
for(k=0;k<numS;k++)
{
for(j=0;j<numjobs;j++)
{
Q[k][j]=0;
}
}
for(i=0;i<numjobs;i++)
{
jobs[i]=secuencia[i];
}
for(k=0;k<numS;k++)
{
for(i=0;i<numS;i++)
{
for(l=0;l<numjobs;l++)
{
aux[i][l]=Q[i][l];
}
}
if(k!=0)
{
for(i=0;i<numjobs;i++)
{
jobs[i]=i;
}
}
ordenarVsegunM(numjobs,k,aux,tproceso,jobs);
for (j=0;j<numjobs;j++)
{
maq = buscarmenor(k,maxmaq,t);

130
if(tproceso[k][jobs[j]]>0)
{
if(k==0)
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
if(t[k][maq]>Q[k-1][jobs[j]])
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
t[k][maq]=Q[k-1][jobs[j]]+tproceso[k][jobs[j]];
}
}
}
if(k==0)
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[0][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
else
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[k-1][jobs[j]];
}

131
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
}
}
makespan=buscarmayorMatriz(numS,numjobs,Q);
return makespan;
}
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100])
{
int i,j,k;
int num;
int repite=0;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
num = rand()% (numjobs) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(matrizpadres[i][k]==num)
{
repite=1;
}
}
if(repite==0)
{
matrizpadres[i][j]=num;
}
if(repite==1)

132
{
j=j-1;
}
}
}
}
void ordenpadre(int numjobs,int orden[numpadres])
{
int num;
int k,j;
int repite;
for(j=0;j<numpadres;j++)
{
num = rand()% (numpadres) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(orden[k]==num)
{
repite=1;
}
}
if(repite==0)
{
orden[j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100])
{

133
int i,j,aux;
int P1,P2;
int posicion;
int esta;
int a;
int aux1[100];
int aux2[100];
a=rand()% 101 + 0;
if(a<=pc)
{
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P2;i<tam;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P1;i<P2;i++)
{
aux1[i]=-1;
}
posicion=P1;
esta=0;

134
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila2][i]==aux1[j])
{
esta=1;
}
}
if(esta==0)
{
aux1[posicion]=secuencias[fila2][i];
posicion++;
}
esta=0;
}
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P2;i<tam;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P1;i<P2;i++)
{

135
aux2[i]=-1;
}
posicion=P1;
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila1][i]==aux2[j])
{
esta=1;
}
}
if(esta==0)
{
aux2[posicion]=secuencias[fila1][i];
posicion++;
}
esta=0;
}
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux1[i];
}
contposicion++;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux2[i];
}
contposicion++;
}
return contposicion;
}
int mutacion(int tam,int fila,int contmutaciones,int secuencias[numpadres][100])
{

136
int i;
int a,b;
int c;
int muta=0;
c=rand()% 101 + 0;
if(c<=pm)
{
muta=1;
a=rand()% (tam) + 0;
b=rand()% (tam) + 0;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contmutaciones][i]=secuencias[fila][i];
}
secuencias[numpadres+contmutaciones][a]=secuencias[fila][b];
secuencias[numpadres+contmutaciones][b]=secuencias[fila][a];
}
return muta;
}
int GA(int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100])
{
int i,j;
int fila1,fila2;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
secuencias[i][j]=matrizpadres[orden[i]][j];
}
}
int contposicion=0;
for(i=0;i<numpadres;i=i+2)

137
{
fila1=i;
fila2=i+1;
contposicion=crossover(numjobs,fila1,fila2,contposicion,secuencias);
}
int contmutaciones=contposicion;
int muta=0;
for(j=0;j<numpadres;j++)
{
muta=mutacion(numjobs,j,contmutaciones,secuencias);
contmutaciones=contmutaciones+muta;
}
return contmutaciones;
}
int todo(int tacumulado,char frase[100])
{
int numjobs;
int numS;
int tproceso[100][100];
int jobs[100];
int L[100];
int k,j,l,i;
int aux;
int secuencia[100];
int makespan;
int makespans[numpadres*4];
int matrizpadres[numpadres][100];
int orden[numpadres];
int secuencias[numpadres*4][100];
int posiciones[numpadres*4];
int salida=0;

138
/*LECTURA DE DATOS DEL PROBLEMA*/
FILE *datos=NULL;
datos=fopen(frase,"r");
if(datos==NULL)
printf("el fichero no existe");
fscanf(datos,"%d",&numjobs);
fscanf(datos,"%d",&numS);
for(i=0;i<numS;i++)
{
fscanf(datos,"%d",&L[i]);
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
fscanf(datos,"%d",&tproceso[i][j]);
}
}
fclose(datos);
transponerM(numjobs,numS,tproceso);
int maxmaq;
maxmaq=buscarmayorv(numS,L);
/*FIN DATOS*/
int bestmakespan=M;
clock_t tiempo;
tiempo=clock();
double tmax=(double)(numjobs*numS)/(double)(10);
clock_t tiempoFinal=clock();
double tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;

139
int tam;
int contmutaciones=0;
creamatrizpadres(numjobs,matrizpadres);
for(k=0;k<numiteraciones && salida<numnomejoras && tiempoTranscurrido<tmax;k++)
{
for(i=0;i<numpadres;i++)
{
orden[i]=0;
}
ordenpadre(numjobs,orden);
contmutaciones=GA(numjobs,orden,matrizpadres,secuencias);
tam=numpadres+contmutaciones;
for(i=0;i<tam;i++)
{
for(j=0;j<numjobs;j++)
{
secuencia[j]=secuencias[i][j];
}
makespan=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
makespans[i]=makespan;
}
for(i=0;i<tam;i++)
{
posiciones[i]=i;
}
ordenar2V(tam,makespans,posiciones);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
matrizpadres[i][j]=secuencias[posiciones[i]][j];
}
}
int fila;

140
for(fila=0;fila<numpadres;fila++)
{
mejoralocalinsercion(fila,numjobs,makespans,matrizpadres,numS,maxmaq,L,tproceso);
}
if(makespans[0]<bestmakespan)
{
bestmakespan=makespans[0];
salida=0;
}
else
{
salida=salida+1;
}
tiempoFinal=clock();
tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
printf("Iteracion %d:\n ",k);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
printf("%d ",matrizpadres[i][j]);
}
printf(" :%d\n ",makespans[i]);
}
printf("\n");
}
FILE *resultados;
resultados= fopen("ResultadosInsercion10.txt","a");
fprintf(resultados, "%d\n", makespans[0]);
fclose(resultados);
return tmax;
}
int buscarNenM(int fila ,int N ,int numjobs ,int matrizpadres[numpadres][100] )
{

141
int i;
int posicion;
for(i=0;i<numjobs;i++)
{
if(matrizpadres[fila][i]==N)
{
posicion=i;
}
}
return posicion;
}
void insercion(int tam,int secuencia[],int posinicio, int posfinal)
{
int aux;
int k,i;
if(posinicio>posfinal)
{
aux=secuencia[posinicio];
for(k=posinicio;k>posfinal;k--)
{
secuencia[k]=secuencia[k-1];
}
secuencia[posfinal]=aux;
}
else
{
aux=secuencia[posinicio];
for(k=posinicio;k<posfinal;k++)
{
secuencia[k]=secuencia[k+1];
}
secuencia[posfinal]=aux;
}
}

142
void mejoralocalinsercion (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int
maxmaq,int L[100], int tproceso[100][100])
{
int posicion;
int i,j,k,l,a,b;
int job;
int makespanbest,makespannuevo;
int secuencia[numjobs];
int secuenciabest[numjobs];
int cambio;
int aux[100];
makespanbest=makespans[fila];
cambio=0;
for(job=0;job<numjobs;job++)
{
posicion=buscarNenM(fila,job,numjobs,matrizpadres);
for(k=0;k<numjobs;k++)
{
if(k!=posicion)
{
for(i=0;i<numjobs;i++)
{
aux[i]=matrizpadres[fila][i];
}
insercion(numjobs,aux,posicion,k);
for(i=0;i<numjobs;i++)
{
secuencia[i]=aux[i];
}
makespannuevo=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
if(makespannuevo<makespanbest)
{
for(i=0;i<numjobs;i++)
{
secuenciabest[i]=secuencia[i];

143
}
makespanbest=makespannuevo;
cambio=1;
}
}
}
}
if(cambio==1)
{
makespans[fila]=makespanbest;
for(i=0;i<numjobs;i++)
{
matrizpadres[fila][i]=secuenciabest[i];
}
}
}
9.2.4 Código metodo IV: “Intercambio1”
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<string>
#define M 10000
#define pc 80
#define pm 20
#define numpadres 10
#define numiteraciones 100000
#define numnomejoras 100000

144
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100]);
void transponerM (int numjobs, int numS,int tproceso[100][100]);
void ordenar2V(int tam,int v1[],int v2[]);
int buscarmayorv(int tamv ,int v[]);
int buscarmenor(int fila, int tamfila ,int matriz[100][100]);
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100]);
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int v[]);
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100]);
void ordenpadre(int numjobs,int orden[numpadres]);
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100]);
int mutacion(int tam,int fila,int contmutaciones, int secuencias[numpadres*4][100]);
int GA (int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100]);
int buscarNenM(int fila,int N,int numjobs,int matrizpadres[numpadres][100]);
void intercambioAconB(int fila,int posicion1,int posicion2,int numjobs,int matrizpadres[numpadres][100]);
void mejoralocalintercambio (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int
maxmaq,int L[100], int tproceso[100][100]);
int todo(int tacumulado,char frase[100]);
int main()
{
int vJ[3]={20,50,100};
int vS[3]={5,10,20};
int vM[4]={0,20,40,60};
int vI[10]={0,1,2,3,4,5,6,7,8,9};
int cJ,cS,cM,cI;
int tacumulado=0;
int t;
char barra[2]="_";
char problem[13]="_problem.txt";
char s1[10];
char frase[100];
for(cJ=0;cJ<3;cJ++)
{
for(cS=0;cS<3;cS++)
{
for(cM=0;cM<4;cM++)

145
{
for(cI=0;cI<10;cI++)
{
memset (frase,'\0',100);
itoa(vJ[cJ],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vS[cS],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vM[cM],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vI[cI],s1,10);
strcat(frase, s1);
strcat(frase, problem);
printf("%s \n",frase);
t = todo(tacumulado,frase);
tacumulado=t;
memset (frase,'\0',100);
}
}
}
}
printf("%d FIN\n",tacumulado);
system ("pause");
}
//--------------------------------------PROGRAMA PRINCIPAL----------------------------
void transponerM (int numjobs, int numS,int tproceso[100][100])
{
int auxM[100][100];
int i,j;
for(i=0;i<numjobs;i++)

146
{
for(j=0;j<numS;j++)
{
auxM[i][j]=tproceso[i][j];
}
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
tproceso[j][i]=auxM[i][j];
}
}
}
void ordenar2V(int tam,int v1[],int v2[])
{
int i,j;
int sec,temp;
for (j=tam-1;j>0;j--)
{
for (i=0;i<j;i++)
{
if (v1[i] > v1[i+1])
{
temp = v1[i];
sec=v2[i];
v1[i] = v1[i+1];
v2[i]=v2[i+1];
v1[i+1] = temp;
v2[i+1]=sec;
}
}
}
}
int buscarmenor(int fila, int tamfila ,int matriz[100][100])

147
{
int menor=10000;
int i,posicion;
for(i=0;i<tamfila;i++)
{
if(menor>matriz[fila][i])
{
menor=matriz[fila][i];
posicion=i;
}
}
return posicion;
}
int buscarmayorv(int tamv ,int v[])
{
int mayor=0;
int i;
for(i=0;i<tamv;i++)
{
if(mayor<v[i])
{
mayor=v[i];
}
}
return mayor;
}
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100])
{
int mayor=0;
int i;
int fila=numS-1;
for(i=0;i<numjobs;i++)
{

148
if(mayor<v[fila][i])
{
mayor=v[fila][i];
}
}
return mayor;
}
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int jobs[])
{
int a,b;
int i,j,l;
int posicion,aux;
if(fila>0)
{
for (j=tam-1;j>0;j--)
{
for (i=0;i<j ;i++)
{
if (Q[fila-1][i] >= Q[fila-1][i+1])
{
a=Q[fila-1][i];
Q[fila-1][i]=Q[fila-1][i+1];
Q[fila-1][i+1]=a;
b=jobs[i];
jobs[i]=jobs[i+1];
jobs[i+1]=b;
}
}
}
}
for(i=tam-1;i>=0;i--)
{
if(tproceso[fila][jobs[i]]==0)
{

149
posicion=i;
aux=jobs[i];
for(j=posicion;j>0;j--)
{
jobs[j]=jobs[j-1];
}
jobs[0]=aux;
}
}
}
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100])
{
int j,k,l,i;
int maq;
int jobs[numjobs];
int aux[100][100];
int aux1;
int posicion;
int makespan;
int t[100][100];
int Q[100][100];
for(k=0;k<numS;k++)
{
for(j=0;j<maxmaq;j++)
{
if(j<L[k])
{
t[k][j]=0;
}
else
{
t[k][j]=M;
}

150
}
}
for(k=0;k<numS;k++)
{
for(j=0;j<numjobs;j++)
{
Q[k][j]=0;
}
}
for(i=0;i<numjobs;i++)
{
jobs[i]=secuencia[i];
}
for(k=0;k<numS;k++)
{
for(i=0;i<numS;i++)
{
for(l=0;l<numjobs;l++)
{
aux[i][l]=Q[i][l];
}
}
if(k!=0)
{
for(i=0;i<numjobs;i++)
{
jobs[i]=i;
}
}
ordenarVsegunM(numjobs,k,aux,tproceso,jobs);
for (j=0;j<numjobs;j++)
{

151
maq = buscarmenor(k,maxmaq,t);
if(tproceso[k][jobs[j]]>0)
{
if(k==0)
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
if(t[k][maq]>Q[k-1][jobs[j]])
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
t[k][maq]=Q[k-1][jobs[j]]+tproceso[k][jobs[j]];
}
}
}
if(k==0)
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[0][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
else
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[k-1][jobs[j]];
}

152
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
}
}
makespan=buscarmayorMatriz(numS,numjobs,Q);
return makespan;
}
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100])
{
int i,j,k;
int num;
int repite=0;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
num = rand()% (numjobs) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(matrizpadres[i][k]==num)
{
repite=1;
}
}
if(repite==0)
{
matrizpadres[i][j]=num;
}
if(repite==1)
{

153
j=j-1;
}
}
}
}
void ordenpadre(int numjobs,int orden[numpadres])
{
int num;
int k,j;
int repite;
for(j=0;j<numpadres;j++)
{
num = rand()% (numpadres) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(orden[k]==num)
{
repite=1;
}
}
if(repite==0)
{
orden[j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100])
{
int i,j,aux;

154
int P1,P2;
int posicion;
int esta;
int a;
int aux1[100];
int aux2[100];
a=rand()% 101 + 0;
if(a<=pc)
{
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P2;i<tam;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P1;i<P2;i++)
{
aux1[i]=-1;
}
posicion=P1;
esta=0;

155
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila2][i]==aux1[j])
{
esta=1;
}
}
if(esta==0)
{
aux1[posicion]=secuencias[fila2][i];
posicion++;
}
esta=0;
}
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P2;i<tam;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P1;i<P2;i++)
{

156
aux2[i]=-1;
}
posicion=P1;
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila1][i]==aux2[j])
{
esta=1;
}
}
if(esta==0)
{
aux2[posicion]=secuencias[fila1][i];
posicion++;
}
esta=0;
}
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux1[i];
}
contposicion++;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux2[i];
}
contposicion++;
}
return contposicion;
}

157
int mutacion(int tam,int fila,int contmutaciones,int secuencias[numpadres][100])
{
int i;
int a,b;
int c;
int muta=0;
c=rand()% 101 + 0;
if(c<=pm)
{
muta=1;
a=rand()% (tam) + 0;
b=rand()% (tam) + 0;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contmutaciones][i]=secuencias[fila][i];
}
secuencias[numpadres+contmutaciones][a]=secuencias[fila][b];
secuencias[numpadres+contmutaciones][b]=secuencias[fila][a];
}
return muta;
}
int GA(int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100])
{
int i,j;
int fila1,fila2;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
secuencias[i][j]=matrizpadres[orden[i]][j];
}
}

158
int contposicion=0;
for(i=0;i<numpadres;i=i+2)
{
fila1=i;
fila2=i+1;
contposicion=crossover(numjobs,fila1,fila2,contposicion,secuencias);
}
int contmutaciones=contposicion;
int muta=0;
for(j=0;j<numpadres;j++)
{
muta=mutacion(numjobs,j,contmutaciones,secuencias);
contmutaciones=contmutaciones+muta;
}
return contmutaciones;
}
int todo(int tacumulado,char frase[100])
{
int numjobs;
int numS;
int tproceso[100][100];
int jobs[100];
int L[100];
int k,j,l,i;
int aux;
int secuencia[100];
int makespan;
int makespans[numpadres*4];
int matrizpadres[numpadres][100];
int orden[numpadres];
int secuencias[numpadres*4][100];
int posiciones[numpadres*4];
int salida=0;

159
/*LECTURA DE DATOS DEL PROBLEMA*/
FILE *datos=NULL;
datos=fopen(frase,"r");
if(datos==NULL)
printf("el fichero no existe");
fscanf(datos,"%d",&numjobs);
fscanf(datos,"%d",&numS);
for(i=0;i<numS;i++)
{
fscanf(datos,"%d",&L[i]);
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
fscanf(datos,"%d",&tproceso[i][j]);
}
}
fclose(datos);
transponerM(numjobs,numS,tproceso);
int maxmaq;
maxmaq=buscarmayorv(numS,L);
/*FIN DATOS*/
int bestmakespan=M;
clock_t tiempo;
tiempo=clock();
double tmax=(double)(numjobs*numS)/(double)(10);
clock_t tiempoFinal=clock();
double tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;

160
int tam;
int contmutaciones=0;
creamatrizpadres(numjobs,matrizpadres);
for(k=0;k<numiteraciones && salida<numnomejoras && tiempoTranscurrido<tmax;k++)
{
for(i=0;i<numpadres;i++)
{
orden[i]=0;
}
ordenpadre(numjobs,orden);
contmutaciones=GA(numjobs,orden,matrizpadres,secuencias);
tam=numpadres+contmutaciones;
for(i=0;i<tam;i++)
{
for(j=0;j<numjobs;j++)
{
secuencia[j]=secuencias[i][j];
}
makespan=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
makespans[i]=makespan;
}
for(i=0;i<tam;i++)
{
posiciones[i]=i;
}
ordenar2V(tam,makespans,posiciones);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
matrizpadres[i][j]=secuencias[posiciones[i]][j];

161
}
}
int fila=0;
mejoralocalintercambio (fila,numjobs,makespans,matrizpadres,numS,maxmaq,L,tproceso);
if(makespans[0]<bestmakespan)
{
bestmakespan=makespans[0];
salida=0;
}
else
{
salida=salida+1;
}
tiempoFinal=clock();
tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
printf("Iteracion %d:\n ",k);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
printf("%d ",matrizpadres[i][j]);
}
printf(" :%d\n ",makespans[i]);
}
printf("\n");
}
FILE *resultados;
resultados= fopen("ResultadosInterccambio1.txt","a");
fprintf(resultados, "%d\n", makespans[0]);
fclose(resultados);
return tmax;
}

162
int buscarNenM(int fila ,int N ,int numjobs ,int matrizpadres[numpadres][100] )
{
int i;
int posicion;
for(i=0;i<numjobs;i++)
{
if(matrizpadres[fila][i]==N)
{
posicion=i;
}
}
return posicion;
}
void intercambioAconB(int fila,int posicion1,int posicion2,int numjobs,int matrizpadres[numpadres][100])
{
int aux;
int k;
aux=matrizpadres[fila][posicion1];
matrizpadres[fila][posicion1]=matrizpadres[fila][posicion2];
matrizpadres[fila][posicion2]=aux;
}
void mejoralocalintercambio (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int
maxmaq,int L[100], int tproceso[100][100])
{
int posicion;
int i,k;
int job;
int makespanbest;
int makespannuevo;
int secuencia[100];
int secuenciabest[100];
int cambio;
makespanbest=makespans[fila];

163
makespannuevo=makespans[fila];
cambio=0;
for(job=0;job<numjobs;job++)
{
posicion=buscarNenM(fila,job,numjobs,matrizpadres);
for(k=0;k<numjobs;k++)
{
if(k!=posicion)
{
intercambioAconB(fila,posicion,k,numjobs,matrizpadres);
for(i=0;i<numjobs;i++)
{
secuencia[i]=matrizpadres[fila][i];
}
makespannuevo=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
if(makespannuevo<makespanbest)
{
for(i=0;i<numjobs;i++)
{
secuenciabest[i]=secuencia[i];
}
makespanbest=makespannuevo;
cambio=1;
}
intercambioAconB(fila,k,posicion,numjobs,matrizpadres);
}
}
}
if(cambio==1)
{
makespans[fila]=makespanbest;
for(i=0;i<numjobs;i++)
{
matrizpadres[fila][i]=secuenciabest[i];
}

164
}
}
9.2.5 Código metodo IV: “Intercambio10”
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<string>
#define M 10000
#define pc 80
#define pm 20
#define numpadres 10
#define numiteraciones 100000
#define numnomejoras 100000
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100]);
void transponerM (int numjobs, int numS,int tproceso[100][100]);
void ordenar2V(int tam,int v1[],int v2[]);
int buscarmayorv(int tamv ,int v[]);
int buscarmenor(int fila, int tamfila ,int matriz[100][100]);
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100]);
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int v[]);
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100]);
void ordenpadre(int numjobs,int orden[numpadres]);
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100]);
int mutacion(int tam,int fila,int contmutaciones, int secuencias[numpadres*4][100]);
int GA (int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100]);
int buscarNenM(int fila,int N,int numjobs,int matrizpadres[numpadres][100]);
void intercambioAconB(int fila,int posicion1,int posicion2,int numjobs,int matrizpadres[numpadres][100]);
void mejoralocalintercambio (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int maxmaq,int L[100], int tproceso[100][100]);
int todo(int tacumulado,char frase[100]);
int main()

165
{
int vJ[3]={20,50,100};
int vS[3]={5,10,20};
int vM[4]={0,20,40,60};
int vI[10]={0,1,2,3,4,5,6,7,8,9};
int cJ,cS,cM,cI;
int tacumulado=0;
int t;
char barra[2]="_";
char problem[13]="_problem.txt";
char s1[10];
char frase[100];
for(cJ=0;cJ<3;cJ++)
{
for(cS=0;cS<3;cS++)
{
for(cM=0;cM<4;cM++)
{
for(cI=0;cI<10;cI++)
{
memset (frase,'\0',100);
itoa(vJ[cJ],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vS[cS],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vM[cM],s1,10);
strcat(frase, s1);
strcat(frase, barra);
itoa(vI[cI],s1,10);
strcat(frase, s1);
strcat(frase, problem);
printf("%s \n",frase);
t = todo(tacumulado,frase);

166
tacumulado=t;
memset (frase,'\0',100);
}
}
}
}
printf("%d FIN\n",tacumulado);
system ("pause");
}
//--------------------------------------PROGRAMA PRINCIPAL----------------------------
void transponerM (int numjobs, int numS,int tproceso[100][100])
{
int auxM[100][100];
int i,j;
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
auxM[i][j]=tproceso[i][j];
}
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
tproceso[j][i]=auxM[i][j];
}
}
}
void ordenar2V(int tam,int v1[],int v2[])
{
int i,j;
int sec,temp;
for (j=tam-1;j>0;j--)

167
{
for (i=0;i<j;i++)
{
if (v1[i] > v1[i+1])
{
temp = v1[i];
sec=v2[i];
v1[i] = v1[i+1];
v2[i]=v2[i+1];
v1[i+1] = temp;
v2[i+1]=sec;
}
}
}
}
int buscarmenor(int fila, int tamfila ,int matriz[100][100])
{
int menor=10000;
int i,posicion;
for(i=0;i<tamfila;i++)
{
if(menor>matriz[fila][i])
{
menor=matriz[fila][i];
posicion=i;
}
}
return posicion;
}
int buscarmayorv(int tamv ,int v[])
{
int mayor=0;
int i;
for(i=0;i<tamv;i++)

168
{
if(mayor<v[i])
{
mayor=v[i];
}
}
return mayor;
}
int buscarmayorMatriz(int numS,int numjobs ,int v[100][100])
{
int mayor=0;
int i;
int fila=numS-1;
for(i=0;i<numjobs;i++)
{
if(mayor<v[fila][i])
{
mayor=v[fila][i];
}
}
return mayor;
}
void ordenarVsegunM(int tam,int fila, int Q[100][100],int tproceso[100][100], int jobs[])
{
int a,b;
int i,j,l;
int posicion,aux;
if(fila>0)
{
for (j=tam-1;j>0;j--)
{
for (i=0;i<j ;i++)
{
if (Q[fila-1][i] >= Q[fila-1][i+1])

169
{
a=Q[fila-1][i];
Q[fila-1][i]=Q[fila-1][i+1];
Q[fila-1][i+1]=a;
b=jobs[i];
jobs[i]=jobs[i+1];
jobs[i+1]=b;
}
}
}
}
for(i=tam-1;i>=0;i--)
{
if(tproceso[fila][jobs[i]]==0)
{
posicion=i;
aux=jobs[i];
for(j=posicion;j>0;j--)
{
jobs[j]=jobs[j-1];
}
jobs[0]=aux;
}
}
}
int resolver(int numjobs,int numS,int maxmaq,int secuencia[100],int L[100], int tproceso[100][100])
{
int j,k,l,i;
int maq;
int jobs[numjobs];
int aux[100][100];
int aux1;
int posicion;

170
int makespan;
int t[100][100];
int Q[100][100];
for(k=0;k<numS;k++)
{
for(j=0;j<maxmaq;j++)
{
if(j<L[k])
{
t[k][j]=0;
}
else
{
t[k][j]=M;
}
}
}
for(k=0;k<numS;k++)
{
for(j=0;j<numjobs;j++)
{
Q[k][j]=0;
}
}
for(i=0;i<numjobs;i++)
{
jobs[i]=secuencia[i];
}
for(k=0;k<numS;k++)
{
for(i=0;i<numS;i++)
{
for(l=0;l<numjobs;l++)
{
aux[i][l]=Q[i][l];

171
}
}
if(k!=0)
{
for(i=0;i<numjobs;i++)
{
jobs[i]=i;
}
}
ordenarVsegunM(numjobs,k,aux,tproceso,jobs);
for (j=0;j<numjobs;j++)
{
maq = buscarmenor(k,maxmaq,t);
if(tproceso[k][jobs[j]]>0)
{
if(k==0)
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
if(t[k][maq]>Q[k-1][jobs[j]])
{
t[k][maq]=t[k][maq]+tproceso[k][jobs[j]];
}
else
{
t[k][maq]=Q[k-1][jobs[j]]+tproceso[k][jobs[j]];
}
}
}
if(k==0)
{
if(tproceso[k][jobs[j]]==0)
{

172
Q[k][jobs[j]]=Q[0][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
else
{
if(tproceso[k][jobs[j]]==0)
{
Q[k][jobs[j]]=Q[k-1][jobs[j]];
}
else
{
Q[k][jobs[j]]=t[k][maq];
}
}
}
}
makespan=buscarmayorMatriz(numS,numjobs,Q);
return makespan;
}
void creamatrizpadres(int numjobs,int matrizpadres[numpadres][100])
{
int i,j,k;
int num;
int repite=0;
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
num = rand()% (numjobs) + 0;
repite=0;

173
for(k=0;k<j;k++)
{
if(matrizpadres[i][k]==num)
{
repite=1;
}
}
if(repite==0)
{
matrizpadres[i][j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
}
void ordenpadre(int numjobs,int orden[numpadres])
{
int num;
int k,j;
int repite;
for(j=0;j<numpadres;j++)
{
num = rand()% (numpadres) + 0;
repite=0;
for(k=0;k<j;k++)
{
if(orden[k]==num)
{
repite=1;
}
}

174
if(repite==0)
{
orden[j]=num;
}
if(repite==1)
{
j=j-1;
}
}
}
int crossover(int tam,int fila1,int fila2,int contposicion,int secuencias[numpadres*2][100])
{
int i,j,aux;
int P1,P2;
int posicion;
int esta;
int a;
int aux1[100];
int aux2[100];
a=rand()% 101 + 0;
if(a<=pc)
{
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;
}
for(i=0;i<P1;i++)
{
aux1[i]=secuencias[fila1][i];

175
}
for(i=P2;i<tam;i++)
{
aux1[i]=secuencias[fila1][i];
}
for(i=P1;i<P2;i++)
{
aux1[i]=-1;
}
posicion=P1;
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila2][i]==aux1[j])
{
esta=1;
}
}
if(esta==0)
{
aux1[posicion]=secuencias[fila2][i];
posicion++;
}
esta=0;
}
P1=rand()% (tam) + 0;
P2=rand()% (tam) + 0;
if(P1>P2)
{
aux=P1;
P1=P2;
P2=aux;

176
}
for(i=0;i<P1;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P2;i<tam;i++)
{
aux2[i]=secuencias[fila2][i];
}
for(i=P1;i<P2;i++)
{
aux2[i]=-1;
}
posicion=P1;
esta=0;
for(i=0;i<tam;i++)
{
for(j=0;j<tam;j++)
{
if(secuencias[fila1][i]==aux2[j])
{
esta=1;
}
}
if(esta==0)
{
aux2[posicion]=secuencias[fila1][i];
posicion++;
}
esta=0;
}
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux1[i];
}
contposicion++;

177
for(i=0;i<tam;i++)
{
secuencias[numpadres+contposicion][i]=aux2[i];
}
contposicion++;
}
return contposicion;
}
int mutacion(int tam,int fila,int contmutaciones,int secuencias[numpadres][100])
{
int i;
int a,b;
int c;
int muta=0;
c=rand()% 101 + 0;
if(c<=pm)
{
muta=1;
a=rand()% (tam) + 0;
b=rand()% (tam) + 0;
for(i=0;i<tam;i++)
{
secuencias[numpadres+contmutaciones][i]=secuencias[fila][i];
}
secuencias[numpadres+contmutaciones][a]=secuencias[fila][b];
secuencias[numpadres+contmutaciones][b]=secuencias[fila][a];
}
return muta;
}
int GA(int numjobs,int orden[],int matrizpadres[numpadres][100],int secuencias[numpadres*4][100])
{
int i,j;
int fila1,fila2;

178
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
secuencias[i][j]=matrizpadres[orden[i]][j];
}
}
int contposicion=0;
for(i=0;i<numpadres;i=i+2)
{
fila1=i;
fila2=i+1;
contposicion=crossover(numjobs,fila1,fila2,contposicion,secuencias);
}
int contmutaciones=contposicion;
int muta=0;
for(j=0;j<numpadres;j++)
{
muta=mutacion(numjobs,j,contmutaciones,secuencias);
contmutaciones=contmutaciones+muta;
}
return contmutaciones;
}
int todo(int tacumulado,char frase[100])
{
int numjobs;
int numS;
int tproceso[100][100];
int jobs[100];
int L[100];
int k,j,l,i;
int aux;
int secuencia[100];
int makespan;

179
int makespans[numpadres*4];
int matrizpadres[numpadres][100];
int orden[numpadres];
int secuencias[numpadres*4][100];
int posiciones[numpadres*4];
int salida=0;
/*LECTURA DE DATOS DEL PROBLEMA*/
FILE *datos=NULL;
datos=fopen(frase,"r");
if(datos==NULL)
printf("el fichero no existe");
fscanf(datos,"%d",&numjobs);
fscanf(datos,"%d",&numS);
for(i=0;i<numS;i++)
{
fscanf(datos,"%d",&L[i]);
}
for(i=0;i<numjobs;i++)
{
for(j=0;j<numS;j++)
{
fscanf(datos,"%d",&tproceso[i][j]);
}
}
fclose(datos);
transponerM(numjobs,numS,tproceso);
int maxmaq;
maxmaq=buscarmayorv(numS,L);
/*FIN DATOS*/

180
int bestmakespan=M;
clock_t tiempo;
tiempo=clock();
double tmax=(double)(numjobs*numS)/(double)(10);
clock_t tiempoFinal=clock();
double tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
int tam;
int contmutaciones=0;
creamatrizpadres(numjobs,matrizpadres);
for(k=0;k<numiteraciones && salida<numnomejoras && tiempoTranscurrido<tmax;k++)
{
for(i=0;i<numpadres;i++)
{
orden[i]=0;
}
ordenpadre(numjobs,orden);
contmutaciones=GA(numjobs,orden,matrizpadres,secuencias);
tam=numpadres+contmutaciones;
for(i=0;i<tam;i++)
{
for(j=0;j<numjobs;j++)
{
secuencia[j]=secuencias[i][j];
}
makespan=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
makespans[i]=makespan;
}
for(i=0;i<tam;i++)
{
posiciones[i]=i;
}
ordenar2V(tam,makespans,posiciones);
for(i=0;i<numpadres;i++)

181
{
for(j=0;j<numjobs;j++)
{
matrizpadres[i][j]=secuencias[posiciones[i]][j];
}
}
int fila;
for(fila=0;fila<numpadres;fila++)
{
mejoralocalintercambio (fila,numjobs,makespans,matrizpadres,numS,maxmaq,L,tproceso);
}
if(makespans[0]<bestmakespan)
{
bestmakespan=makespans[0];
salida=0;
}
else
{
salida=salida+1;
}
tiempoFinal=clock();
tiempoTranscurrido=(double)(tiempoFinal-tiempo)/CLOCKS_PER_SEC;
printf("Iteracion %d:\n ",k);
for(i=0;i<numpadres;i++)
{
for(j=0;j<numjobs;j++)
{
printf("%d ",matrizpadres[i][j]);
}
printf(" :%d\n ",makespans[i]);
}
printf("\n");
}
FILE *resultados;

182
resultados= fopen("ResultadosInterccambio10.txt","a");
fprintf(resultados, "%d\n", makespans[0]);
fclose(resultados);
return tmax;
}
int buscarNenM(int fila ,int N ,int numjobs ,int matrizpadres[numpadres][100])
{
int i;
int posicion;
for(i=0;i<numjobs;i++)
{
if(matrizpadres[fila][i]==N)
{
posicion=i;
}
}
return posicion;
}
void intercambioAconB(int fila,int posicion1,int posicion2,int numjobs,int matrizpadres[numpadres][100])
{
int aux;
int k;
aux=matrizpadres[fila][posicion1];
matrizpadres[fila][posicion1]=matrizpadres[fila][posicion2];
matrizpadres[fila][posicion2]=aux;
}
void mejoralocalintercambio (int fila,int numjobs,int makespans[100],int matrizpadres[100][100], int numS,int
maxmaq,int L[100], int tproceso[100][100])
{
int posicion;
int i,k;
int job;
int makespanbest;
int makespannuevo;
int secuencia[100];
int secuenciabest[100];

183
int cambio;
makespanbest=makespans[fila];
makespannuevo=makespans[fila];
cambio=0;
for(job=0;job<numjobs;job++)
{
posicion=buscarNenM(fila,job,numjobs,matrizpadres);
for(k=0;k<numjobs;k++)
{
if(k!=posicion)
{
intercambioAconB(fila,posicion,k,numjobs,matrizpadres);
for(i=0;i<numjobs;i++)
{
secuencia[i]=matrizpadres[fila][i];
}
makespannuevo=resolver(numjobs,numS,maxmaq,secuencia,L,tproceso);
if(makespannuevo<makespanbest)
{
for(i=0;i<numjobs;i++)
{
secuenciabest[i]=secuencia[i];
}
makespanbest=makespannuevo;
cambio=1;
}
intercambioAconB(fila,k,posicion,numjobs,matrizpadres);
}
}
}
if(cambio==1)
{
makespans[fila]=makespanbest;

184
for(i=0;i<numjobs;i++)
{
matrizpadres[fila][i]=secuenciabest[i];
}
}
}