tÓpicos de base de datos · 2019. 6. 4. · migración de mysql a sql server tenemos una base de...
TRANSCRIPT

Instituto Tecnológico Superior de Teziutlán
TÓPICOS DE BASE DE DATOS
ACTIVIDAD: Investigación
ALUMNOS: González Calleja Gabriel Abelardo
Orlando Cárcamo Máximo
Luis Manuel Aguilar López
UNIDAD 4
NOMBRE DE LA ACTIVIDAD:
(investigación sobre La Migración en Base de
Datos)
FECHA: 27/05/2019

Introducción
Habitualmente, un proyecto de migración de datos se lleva a cabo para reemplazar o actualizar servidores o equipos de almacenamiento, para una consolidación de un sitio web, para llevar a cabo el mantenimiento de un servidor o para reubicar un centro de datos. Usando un software basado en matriz, que es la mejor opción para el movimiento de datos entre sistemas similares. Apoyándose en un software basado en el host: que sería la opción más recomendable para las migraciones específicas de la aplicación. Es el caso de la copia de archivos, las actualizaciones de la plataforma o la replicación de la base de datos. Empleando los dispositivos de red. De esta manera, se migran volúmenes, archivos o bloques de datos del modo más apropiado, en función de su configuración.

Migración de MySQL a SQL Server
Tenemos una base de datos en MySQL como vemos en la siguiente imagen:
La idea es poder migrar esa base de datos a SQL Server, como les mencioné partiré de que ya instalaron el programa, lo que seguirá es crear una base de datos en SQL Server que será donde se migren los datos, para eso la crearemos desde el Managment Studio. CREATE DATABASE pronosticos2 USE pronosticos2 Una vez que tenemos creada la base de datos, que tiene que ser con el mismo nombre que en MySQL, procederemos a abrir el programa de Migración que instalamos previamente y daremos clic en el botón de Nuevo
Como segundo paso, configuraremos el proyecto y seleccionaremos la versión del SQL Server a la que vamos a migrar, en mi caso 2012, así como el nombre del proyecto.

Una vez configurado, nos vamos a conectar a MySQL y a SQL Server, para realizar eso, en la parte de arriba, en los menús vienen los botones para realizarlo. Primero me conectare a MySQL como se muestra en la siguiente imagen:
Ahora una vez conectado, nos vamos a conectar a SQL Server como se muestra en la siguiente imagen:

Una vez conectados los dos servidores procederemos a crear el schema, que será algo parecido al script que se va a exportar, eso lo tendremos que hacer en la base de datos de MySQL, para que lo pueda convertir a MySQL, lo haremos dando clic con el botón derecho del mouse y seleccionando la opción Convert Schema como se muestra en la siguiente imagen:
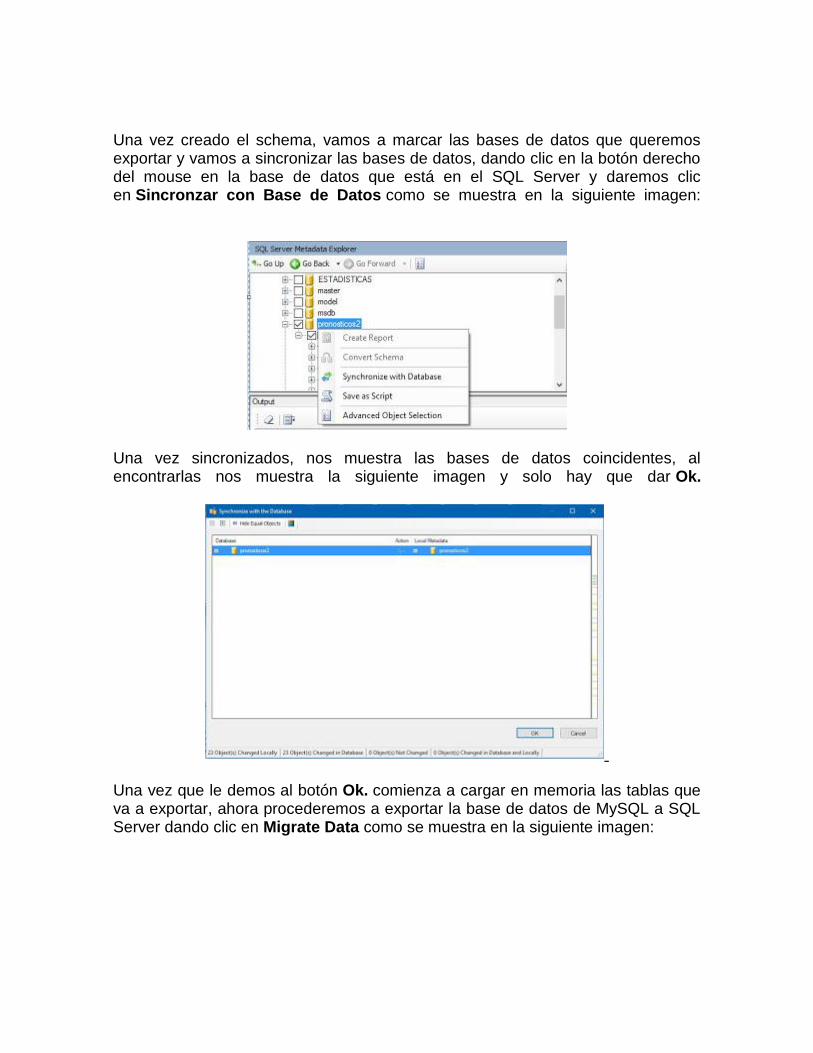
Una vez creado el schema, vamos a marcar las bases de datos que queremos exportar y vamos a sincronizar las bases de datos, dando clic en la botón derecho del mouse en la base de datos que está en el SQL Server y daremos clic en Sincronzar con Base de Datos como se muestra en la siguiente imagen:
Una vez sincronizados, nos muestra las bases de datos coincidentes, al encontrarlas nos muestra la siguiente imagen y solo hay que dar Ok.
Una vez que le demos al botón Ok. comienza a cargar en memoria las tablas que va a exportar, ahora procederemos a exportar la base de datos de MySQL a SQL Server dando clic en Migrate Data como se muestra en la siguiente imagen:

Al terminar la migración nos mostrará un reporte de los datos migrados con el nombre de la tabla y los registros como se muestra en la siguiente imagen:
Listo, terminamos, ahora vamos a probar que realmente se pasaron los datos, para eso, vamos a SQL SERVER con el Managment Studio y lo comprobaremos como se muestra en la imagen:

Tambien se pasaron los procedimientos almacenados

Migración de MySQL a PostgreSQL
Cualquiera sea la razón, migrar de MySQL a PostgreSQL no es muy complicado si se tienen a la mano algunos scripts que hagan el trabajo sucio por nosotros, pero aun así hay que hacer modificaciones manuales durante la migración.
El problema radica en la diferencia que hay en la sintaxis del lenguaje SQL de ambos, se parecen mucho pero no son iguales, yo creo que lo más complicado es migrar los campos que están señalados como AUTO_INCREMENT en MySQL, en PostgreSQL no existe AUTO_INCREMENT como atributo de campo, para ello es necesario crear una secuencia y enlazarlo al campo.
Paso 1. Generar un respaldo de la ESTRUCTURA de la
base de datos MySQL
El primer paso para migrar nuestra base de datos MySQL a PostgreSQL es generar una copia de seguridad mediante mysqldump de la siguiente forma:
1. mysqldump -u [usuario] -p [base_de_datos] --no-data > [archivo_salida].sql
Donde:
[usuario] el el nombre de usuario con el que accedemos a la base de datos (usualmente root)
[base_de_datos] es el nombre de la base de datos que vamos a migrar (en este caso la base de datos de ejemplo World).
[archivo_salida] es el nombre de nuestro archivo de salida que contendrá los comandos SQL generados por mysqldump
El parámetro -p es para que mysqldump nos pregunte por la contraseña del usuario, si no hay contraseña de base de datos entonces obviar este parametro.
El parámetro –no-data omitirá los datos, por que sólo necesitamos la estructura de las tablas, una vez migrada la estructura seguimos con los datos más adelante.
El comando se vería de la siguiente forma:
mysqldump -u root -p world –no-data > world-mysql.sql
El comando producirá un archivo parecido al siguiente:

1. -- MySQL dump 10.13 Distrib 5.1.54, for debian-linux-gnu (i686)
2. --
3. -- Host: localhost Database: world
4. -- ------------------------------------------------------
5. -- Server version 5.1.54-1ubuntu4
6.
7. --
8. -- Table structure for table `City`
9. --
10.
11. DROP TABLE IF EXISTS `City`;
12. /*!40101 SET @saved_cs_client = @@character_set_client */;
13. /*!40101 SET character_set_client = utf8 */;
14. CREATE TABLE `City` (
15. `ID` int(11) NOT NULL AUTO_INCREMENT,
16. `Name` char(35) NOT NULL DEFAULT '',
17. `CountryCode` char(3) NOT NULL DEFAULT '',
18. `District` char(20) NOT NULL DEFAULT '',
19. `Population` int(11) NOT NULL DEFAULT '0',
20. PRIMARY KEY (`ID`)
21. ) ENGINE=MyISAM AUTO_INCREMENT=4080 DEFAULT CHARSET=latin1;
22. /*!40101 SET character_set_client = @saved_cs_client */;
23.
24. --
25. -- Table structure for table `Country`
26. --
27.
28. DROP TABLE IF EXISTS `Country`;
29. /*!40101 SET @saved_cs_client = @@character_set_client */;
30. /*!40101 SET character_set_client = utf8 */;
31. CREATE TABLE `Country` (
32. `Code` char(3) NOT NULL DEFAULT '',
33. `Name` char(52) NOT NULL DEFAULT '',
34. `Continent` enum('Asia','Europe','North America','Africa','Oceania','Antarctica','South America') NOT NULL
DEFAULT 'Asia',
35. `Region` char(26) NOT NULL DEFAULT '',
36. `SurfaceArea` float(10,2) NOT NULL DEFAULT '0.00',
37. `IndepYear` smallint(6) DEFAULT NULL,
38. `Population` int(11) NOT NULL DEFAULT '0',
39. `LifeExpectancy` float(3,1) DEFAULT NULL,
40. `GNP` float(10,2) DEFAULT NULL,
41. `GNPOld` float(10,2) DEFAULT NULL,
42. `LocalName` char(45) NOT NULL DEFAULT '',
43. `GovernmentForm` char(45) NOT NULL DEFAULT '',
44. `HeadOfState` char(60) DEFAULT NULL,
45. `Capital` int(11) DEFAULT NULL,
46. `Code2` char(2) NOT NULL DEFAULT '',
47. PRIMARY KEY (`Code`)
48. ) ENGINE=MyISAM DEFAULT CHARSET=latin1;
49. /*!40101 SET character_set_client = @saved_cs_client */;
50.
51. --
52. -- Table structure for table `CountryLanguage`

53. --
54.
55. DROP TABLE IF EXISTS `CountryLanguage`;
56. /*!40101 SET @saved_cs_client = @@character_set_client */;
57. /*!40101 SET character_set_client = utf8 */;
58. CREATE TABLE `CountryLanguage` (
59. `CountryCode` char(3) NOT NULL DEFAULT '',
60. `Language` char(30) NOT NULL DEFAULT '',
61. `IsOfficial` enum('T','F') NOT NULL DEFAULT 'F',
62. `Percentage` float(4,1) NOT NULL DEFAULT '0.0',
63. PRIMARY KEY (`CountryCode`,`Language`)
64. ) ENGINE=MyISAM DEFAULT CHARSET=latin1;
65. /*!40101 SET character_set_client = @saved_cs_client */;
66. /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
67.
68. -- Dump completed on 2011-09-17 11:36:57
Paso 2. Traducir SQL de MySQL a SQL de PostgresSQL
utilizando mysql2pgsql.perl
mysql2pgsql.perl es un script escrito en Perl que «traduce» la sintaxis del código SQL de MySQL a un SQL que pueda entender PostgreSQL, es muy fácil de usar:
1. perl mysql2pgsql.perl [opciones] sql_formato_mysql.sql sql_formato_postgresql.sql
Para nuestro caso, el comando que ejecutamos es:
1. perl mysql2pgsql.perl --nodrop world-mysql.sql world-postgresql.sql
Dónde: La opción –nodrop hace que el script no incluya los comandos DROP TABLE antes de crear las tablas.
Puedes descargar mysql2pgsql.perl de http://pgfoundry.org/projects/mysql2pgsql/
El archivo world-postgresql.sql generado por el script se verá asi:

1. --
2. -- Generated from mysql2pgsql.perl
3. -- http:// gborg.postgresql.org/project/mysql2psql/
4. -- (c) 2001 - 2007 Jose M. Duarte, Joseph Speigle
5. --
6.
7. -- warnings are printed for drop tables if they do not exist
8. -- please see http:// archives.postgresql.org/pgsql-novice/2004-10/msg00158.php
9.
10. -- ##############################################################
11.
12. -- MySQL dump 10.13 Distrib 5.1.54, for debian-linux-gnu (i686)
13. --
14. -- Host: localhost Database: world
15. -- ------------------------------------------------------
16. -- Server version 5.1.54-1ubuntu4
17.
18.
19. --
20. -- Table structure for table City
21. --
22.
23. DROP SEQUENCE "city_id_seq" CASCADE ;
24.
25. CREATE SEQUENCE "city_id_seq" START WITH 4080 ;
26.
27. CREATE TABLE "city" (
28. "id" integer DEFAULT nextval('"city_id_seq"') NOT NULL,
29. "name" char(35) NOT NULL DEFAULT '',
30. "countrycode" char(3) NOT NULL DEFAULT '',
31. "district" char(20) NOT NULL DEFAULT '',
32. "population" int NOT NULL DEFAULT '0',
33. primary key ("id")
34. ) ;
35. /*!40101 SET character_set_client = @saved_cs_client */;
36. /*!40101 SET @saved_cs_client = @@character_set_client */;
37. /*!40101 SET character_set_client = utf8 */;
38.
39. --
40. -- Table structure for table Country
41. --
42.
43. CREATE TABLE "country" (
44. "code" char(3) NOT NULL DEFAULT '',
45. "name" char(52) NOT NULL DEFAULT '',
46. "continent" varchar CHECK ("continent" IN ( 'Asia','Europe','North
America','Africa','Oceania','Antarctica','South America' )) NOT NULL DEFAULT 'Asia',
47. "region" char(26) NOT NULL DEFAULT '',
48. "surfacearea" double precision NOT NULL DEFAULT '0.00',
49. "indepyear" smallint DEFAULT NULL,
50. "population" int NOT NULL DEFAULT '0',
51. "lifeexpectancy" double precision DEFAULT NULL,
52. "gnp" double precision DEFAULT NULL,

53. "gnpold" double precision DEFAULT NULL,
54. "localname" char(45) NOT NULL DEFAULT '',
55. "governmentform" char(45) NOT NULL DEFAULT '',
56. "headofstate" char(60) DEFAULT NULL,
57. "capital" int DEFAULT NULL,
58. "code2" char(2) NOT NULL DEFAULT '',
59. primary key ("code")
60. ) ;
61. /*!40101 SET character_set_client = @saved_cs_client */;
62. /*!40101 SET @saved_cs_client = @@character_set_client */;
63. /*!40101 SET character_set_client = utf8 */;
64.
65. --
66. -- Table structure for table CountryLanguage
67. --
68.
69. CREATE TABLE "countrylanguage" (
70. "countrycode" char(3) NOT NULL DEFAULT '',
71. "language" char(30) NOT NULL DEFAULT '',
72. "isofficial" varchar CHECK ("isofficial" IN ( 'T
73. ','F' )) NOT NULL DEFAULT 'F',
74. "percentage" double precision NOT NULL DEFAULT '0.0',
75. primary key ("countrycode", "language")
76. ) ;
Notar el cambio en la forma de declarar los campos y la creación de secuencias. Los comentarios en PostgreSQL son solo eso comentarios.
Paso 3: Enviar los datos generados desde MySQL a
PostgreSQL
Ahora debemos volcar el contenido del archivo generado hacia postgresql, para ello nos logueamos con el usuario postgres y ejecutamos los comandos necesarios:
1. $su postgres
2.
3. createdb world
4.
5. psql -f world_postgresql.sql -u usuario-db word
Ya casi todo esta listo, ahora solo nos queda migrar los datos. Al igual que en el paso 1, tenemos que sacar un respaldo pero esta vez solamente de los datos sin la creación de la estructura de las tablas, para ellos utilizamos el siguiente comando:
1. mysqldump -u root -p world --no-create-info --complete-insert --skip-add-locks > world-mysql-data.sql

Donde:
–no-create-info Omite los scripts de creación de tabla (no las necesitamos) –complete-insert Hace que los comandos INSERT contengan también los
nombres de las columnas, PostgreSQL no permite comandos INSERT sin los nombres de las columnas.
–skip-add-locks omite el comando LOCK TABLE … ese comando también es diferente en PostgreSQL.
Como resultado tendremos el archivo world-mysql-data.sql, va a ser algo parecido a esto:
1. -- MySQL dump 10.13 Distrib 5.1.54, for debian-linux-gnu (i686)
2. --
3. -- Host: localhost Database: world
4. -- ------------------------------------------------------
5. -- Server version 5.1.54-1ubuntu4
6.
7. --
8. -- Dumping data for table `City`
9. --
10.
11. INSERT INTO `City` (`ID`, `Name`, `CountryCode`, `District`, `Population`)
12. VALUES (1,'Kabul','AFG','Kabol',1780000),
13. (2,'Qandahar','AFG','Qandahar',237500),
14. (3,'Herat','AFG','Herat',186800)
15. ...
16.
17. --
18. -- Dumping data for table `Country`
19. --
20.
21.
22. INSERT INTO `Country` ( `Code`, `Name`, `Continent`, `Region`, `SurfaceArea`, `IndepYear`,
23. `Population`, `LifeExpectancy`, `GNP`, `GNPOld`, `LocalName`, `GovernmentForm`,
24. `HeadOfState`, `Capital`, `Code2`)
25. VALUES ('ABW','Aruba','North America','Caribbean',193.00,NULL,103000,78.4,828.00,793.00,
26. 'Aruba','Nonmetropolitan Territory of The Netherlands','Beatrix',129,'AW'),
27. ('AFG','Afghanistan','Asia','Southern and Central Asia',652090.00,1919,22720000,
28. 45.9,5976.00,NULL,'Afganistan/Afqanestan','Islamic Emirate','Mohammad Omar',1,'AF'),
29. ('AGO','Angola','Africa','Central Africa',1246700.00,1975,12878000,38.3,6648.00,7984.00,
30. 'Angola','Republic','José Eduardo dos Santos',56,'AO'),
31. ('AIA','Anguilla','North America','Caribbean',96.00,NULL,8000,76.1,63.20,NULL,
32. 'Anguilla','Dependent Territory of the UK','Elisabeth II',62,'AI'),
33. ('ALB','Albania','Europe','Southern Europe',28748.00,1912,3401200,71.6,3205.00,2500.00,
34. 'Shqipëria','Republic','Rexhep Mejdani',34,'AL'),
35. ...
36.
37. --
38. -- Dumping data for table `CountryLanguage`
39. --
40.

41. INSERT INTO `CountryLanguage` (`CountryCode`, `Language`, `IsOfficial`, `Percentage`)
42. VALUES ('ABW','Dutch','T',5.3),
43. ('ABW','English','F',9.5),
44. ('ABW','Papiamento','F',76.7),
45. ('ABW','Spanish','F',7.4)
46. ...
47.
48. -- Dump completed on 2011-09-18 17:41:21
49.
Es probable que tengas problemas con el caracter `, para ello vamos a reemplazar el caracter con la doble comilla » utilizando:
1. sed -i 's/`/'"'/g' world-mysql-data.sql
Pueden también utilizar el editor de texto de tu preferencia y reemplazar el carácter,
el resultado debe ser el siguiente:
1. -- MySQL dump 10.13 Distrib 5.1.54, for debian-linux-gnu (i686)
2. --
3. -- Host: localhost Database: world
4. -- ------------------------------------------------------
5. -- Server version 5.1.54-1ubuntu4
6.
7. --
8. -- Dumping data for table "City"
9. --
10.
11. INSERT INTO "City" ("ID", "Name", "CountryCode", "District", "Population")
12. VALUES (1,'Kabul','AFG','Kabol',1780000),
13. (2,'Qandahar','AFG','Qandahar',237500),
14. (3,'Herat','AFG','Herat',186800)
15. ...
16.
17. --
18. -- Dumping data for table "Country"
19. --
20.
21.
22. INSERT INTO "Country" ( "Code", "Name", "Continent", "Region", "SurfaceArea", "IndepYear",
23. "Population", "LifeExpectancy", "GNP", "GNPOld", "LocalName", "GovernmentForm",
24. "HeadOfState", "Capital", "Code2")
25. VALUES ('ABW','Aruba','North America','Caribbean',193.00,NULL,103000,78.4,828.00,793.00,
26. 'Aruba','Nonmetropolitan Territory of The Netherlands','Beatrix',129,'AW'),
27. ('AFG','Afghanistan','Asia','Southern and Central Asia',652090.00,1919,22720000,
28. 45.9,5976.00,NULL,'Afganistan/Afqanestan','Islamic Emirate','Mohammad Omar',1,'AF'),
29. ('AGO','Angola','Africa','Central Africa',1246700.00,1975,12878000,38.3,6648.00,7984.00,
30. 'Angola','Republic','José Eduardo dos Santos',56,'AO'),
31. ('AIA','Anguilla','North America','Caribbean',96.00,NULL,8000,76.1,63.20,NULL,
32. 'Anguilla','Dependent Territory of the UK','Elisabeth II',62,'AI'),
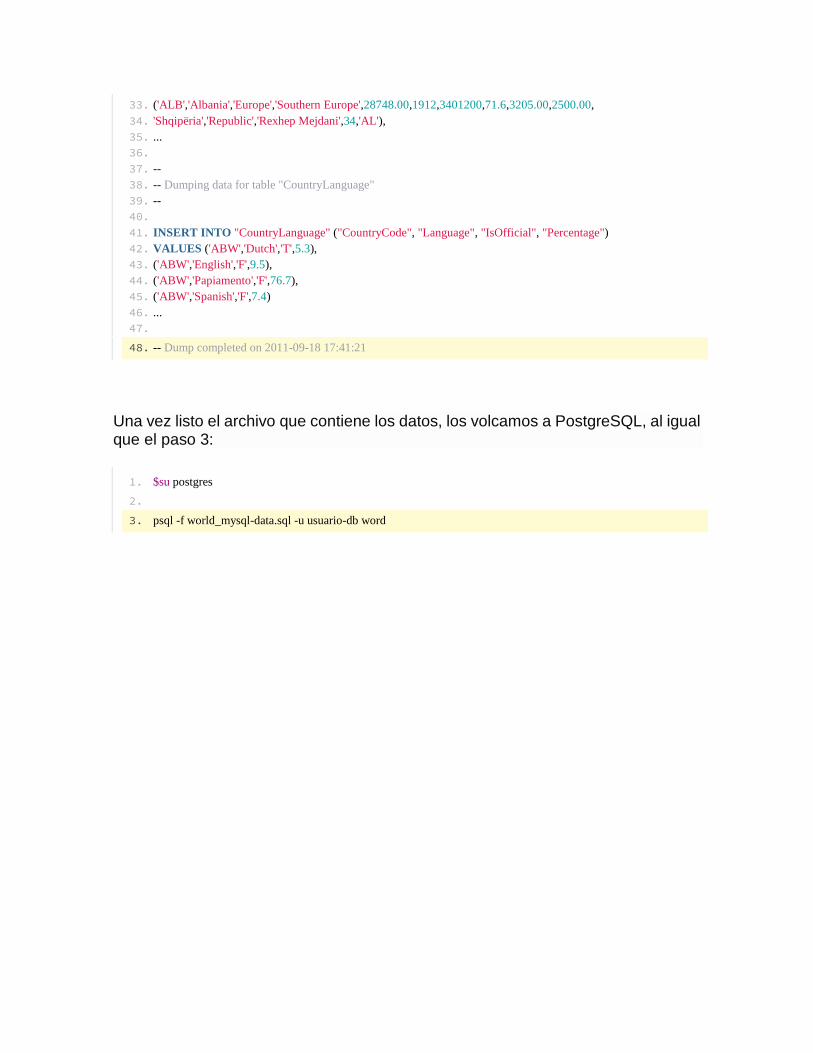
33. ('ALB','Albania','Europe','Southern Europe',28748.00,1912,3401200,71.6,3205.00,2500.00,
34. 'Shqipëria','Republic','Rexhep Mejdani',34,'AL'),
35. ...
36.
37. --
38. -- Dumping data for table "CountryLanguage"
39. --
40.
41. INSERT INTO "CountryLanguage" ("CountryCode", "Language", "IsOfficial", "Percentage")
42. VALUES ('ABW','Dutch','T',5.3),
43. ('ABW','English','F',9.5),
44. ('ABW','Papiamento','F',76.7),
45. ('ABW','Spanish','F',7.4)
46. ...
47.
48. -- Dump completed on 2011-09-18 17:41:21
Una vez listo el archivo que contiene los datos, los volcamos a PostgreSQL, al igual que el paso 3:
1. $su postgres
2.
3. psql -f world_mysql-data.sql -u usuario-db word

Migración de MySQL a Oracle
Características de Conversión de MySQL a Oracle
La herramienta migra los siguientes objetos de base de datos y propiedades de MySQL a Oracle:
Tablas y Datos
o Convierte definiciones de columnas - tipos de datos, valores por defecto, restricciones NOT NULL, propiedades de incremento automático
o Convierte las restricciones de integridad - claves primarias y externas, restricciones únicas y de verificación
o Convierte los comentarios
o Resuelve las palabras reservadas y conflictos de identificadores
o Transfiere datos
Índices y Vistas
Procedimientos Almacenados, Funciones y Triggers
Además de lógica de negocio de servidor, Ispirer MnMTK también convierte las consultas SQL en las aplicaciones front-end y guiones para ajustar a la sintaxis SQL de Oracle.
Características de Herramientas de Ispirer MnMTK para la Migración de MySQL a Oracle
Conversión Rápida y Útil de SQL Guiones - Usted puede fácilmente comenzar la conversión de existentes SQL Guiones - sentencias DDL, bases de datos SQL dump, consultas SQL, etc.
Conversión con Conexión de Base de Datos - Ispirer MnMTK puede juntarse a MySQL, extraer y convertir la base de datos entera o sólo objetos y esquemas especificados
Genera SQL guiones en la sintaxis de Oracle
Genera archivos de control y comandos de SQL * Loader para importar datos a Oracle (LOBs son soportados)
Soporte de Línea de Comandos puede ayudar a automatizar el proceso de migración
Validación de Migración - La herramienta puede comparar el número de tablas, el número de filas, y realizar la validación de datos para todas o seleccionadas columnas (basadas en las claves primarias o la cláusula de orden especificada)

Migración de SQL Server a MySQL
Para eso tenemos en SQL Server una base de Datos llamada Migración con dos Tablas, una llamada Persona y otra llamada Animal, como se muestra en la siguiente imagen:
Base de Datos llamada Migración
Esa base de datos tambien tiene las tablas llenas con algunos datos, tiene dos registros tanto en la tabla Persona como en la tabla animal, como se muestra en las siguientes imagenes:
Tabla Personas

Tabla Animales
Lo primero que tenemos que hacer es crear el DSN de conexión, es decir el ODBC, y para eso nos iremos a las Herramientas Administrativas / Origenes de Datos ODBC y Agregar, procederemos a crear la conexión a SQL Server
Le damos clic en Agregar para crear la conexión a SQL SERVER

Llenamos los datos, como el nombre, la descripción y el servidor SQL y damos clic en Siguiente
Seleccionamos el método de conexión, si es con seguridad de SQL o seguridad Windows, en este caso utilizaré la seguridad de Windows y damos clic en Siguiente

Establecemos la base de Datos que vamos a migrar como predeterminada y damos clic en Siguiente
Seleccionamos el idioma, en este caso Spanish y damos clic en Finalizar

Damos clic en "Probar origen de Datos" y comprobamos que se completen correctamente
Una vez que tengamos guardado el DSN, vamos a abrir el WorkBench, que es un manejador de MySQL Server y trae las opciones para la migración de Datos
Daremos clic en la opción Migration Wizard
Damos clic en el botón Start Migration

Seleccionar el DSN que habíamos guardado, dar clic en TEST Connection y damos Clic en Next
Seleccionamos el destino de la base de Datos, que será nuesto servidos MySQL, probamos la conexión y damos clic en Siguiente
Después de unos momentos el programa estará listo para exportar la base de Datos, tal como se muestra en la siguiente imagen:
Damos clic en Siguiente para comenzar a configurar la migración

Seleccinaremos la base de Datos de SQL que vamos a migrar, en este caso será la base Migracion y damos clic en Siguiente
Una vez que seleccionamos la base de Datos a Migrar, el sistema realiza algunas tareas y nos prepara para el siguiente paso, mediante esta pantalla a la que le daremos clic en Siguiente
Ahora vamos a indicarle que tablas vamos a exportar, mediante la siguiente interface:
Nos preguntará que tablas queremos exportar, en mi caso exportaré las dos tablas y damos clic en Siguiente

Una vez seleccionadas las tablas, damos clic en Siguiente
Posteriormente a esto, nos mostrará los errores encontrados en la migración del lado del origen, es decir del lado de SQL Server como se muestra en la siguiente imagen:
En este caso no hay ningun error, así que presionamos Siguiente
Ahora vamos a configurar el destino, que en este caso es MySQL y lo haremos mediante esta interface:

En este caso dejare esas opciones, pero como pueden ver, pueden seleccionar un archivo .sql de destino con el Script de los Datos, damos clic en el botón de Siguiente
Ya tenemos configuradas algunas opciones y el sistema nos lo hace saber mediante la siguiente pantalla:
Damos Clic en Siguiente
Nos mostrará los scripts de las tablas que se van a migrar y presionamos el botón Siguiente

Dejaremos las opciones así como están, pero como pueden ver son algunas opciones de la misma migración, para que, si queremos Migrar después ya sin hacer tantos pasos. Damos Clic en Siguiente
En este paso, el sistema esta realizando la migración, como ven, sin ningún error. Damos clic en Siguiente para ver el reporte de la migración
Vemos en este caso que no hay ningun error y la migración esta realizada. Damos clic en Finalizar
Una vez que hemos realizado los pasos nos dirigiremos a MySQL para corroborar que efectivamente, la Base de Datos fue migrada de manera satisfactoria

Vemos como si aparece la Base de Datos migracion y sus dos tablas, pueden ustedes realizar el select para comprobar que si se pasaron los datos
Yo utilizo el gestor de HeidiSQL para manipular MySQL (MariaDB) pero la
exportación la hice con Workbench ya que ese programa nos provee la herramienta,
los Procedimientos Almacenados y los Disparadores si los migra, pero no siempre
funcionan, así que es recomendable, tener en cuenta que se tendrán que volver a
crear.

Migración de SQL Server a PostgreSQL
Los datos son los datos. Es traído en forma de texto y se moldea en su forma
correcta de la base de datos de acuerdo a los tipos de datos que utilizó en la
creación de las tablas. Si usted tiene datos binarios, yo soy el tipo equivocado para
preguntar.
Hay un par de error aquí también, por supuesto. Desde que utilizamos el comando
COPY, y se interpreta como un salto de línea al final de una tupla, es necesario
limpiar todos los saltos de línea al acecho en los campos de texto en MS SQL
Server. Esto es bastante fácil de hacer. Además, el volcado de datos de MS SQL
Server utiliza el estándar CR / LF terminador de línea, que debe ser cambiado a LF
o que causará estragos en las comparaciones de cadenas, entre otros problemas.
Lo hice el camino más fácil, la descarga de los vertederos a mi máquina con mi
favorito de Unix-como sistema operativo a través de FTP, lo que hace la traducción
para usted.
El primer paso en el volcado de los datos de MS SQL Server es escribir todos los
nombres de sus campos en un archivo de texto en la máquina Win32. Puedes hacer
trampa y número:
select name from sysobjects WHERE type = 'U'
en el Analizador de consultas (ISQL-W) para obtener la lista, y luego guardar los
resultados en un archivo. Luego, escribir un pequeño script muy útil para llamar a
BCP, el programa de copia masiva. Minas tiene este aspecto:
conjunto de archivos [Open "C: \ \ inetpub \ \ ftproot \ \ tablelist.txt" r], mientras que ([eof $ file]) ( cuadro [gets $ file] Exec bcp .. mesa $ out $ table-c-k-S192.168.100.1-Usa-Ppassword-R ~ ) cerca de $ archivo
Esto volcado todos los cuadros que figuran en los archivos del mismo nombre en el
directorio actual. La opción-c medios para utilizar el formato de caracteres sin
formato. El flag-k dice bcp para "mantener los nulos". Esto es importante, más
adelante, cuando la importación de los datos. El-R es el "terminador de la fila". Para
hacer la limpieza de los retornos más fácil el transporte, uso este para indicar el final

de una fila. Pongo esta secuencia de comandos en el directorio C: \ Inetpub \ ftproot,
así que puedes ir al siguiente paso.
De la máquina Unix, ftp de inicio y obtener el archivo de lista que creó anteriormente.
Ponlo en un directorio de trabajo. Cambie al directorio nuevo trabajo y conseguir los
archivos:
ftp> lcd / home / Homer / local workdir ahora / home / Homer / workdir ftp> fget tablelist.txt
Esto debe descargar todos los archivos de datos en el directorio de trabajo,
mágicamente convertir terminadores de línea a formato compatible con Unix. Si
usted no puede usar FTP, hay otras maneras de obtener los archivos de aquí para
allá. Sólo tenga en cuenta que es posible que tenga una secuencia de comandos
sed poco para solucionar el CR / LF problema.
Ahora, vamos a solucionar el problema incrustado avance de línea.
#! / usr / pkg / bin / tclsh conjunto de archivos [tblnames abierto r] flist conjunto [lectura nonewline $ file] cerca de $ archivo flist conjunto [$ split flist \ n] flist foreach f $ ( conjunto de archivos [Open $ f r] conjunto de datos [read-nonewline $ file] cerca de $ archivo regsub-all (\ 000) () $ data de datos regsub-all (\ n) $ data \ \ \ n datos regsub todo ~) ($ datos \ n datos conjunto de archivos [Open $ f w] pone-nonewline $ file $ datos cerca de $ archivo )
Las líneas son regsub donde se realiza el trabajo. Que reemplazar todos los valores
nulos (\ 000) con una cadena vacía, entonces todos avances de línea con un literal
"\ n" que le dirá a copiar lo que hacemos al importar el archivo, entonces mi
terminadores de línea se reemplazan con un salto de línea, que es lo COPIA está
esperando. Hay formas más limpias y más fácil de hacer esto, pero usted consigue
el punto.

Ahora, vuelve a el archivo sql modificó para crear su base de datos de objetos.
Supongo que está en el cuadro de Unix en este punto. Debe tener una serie de
comandos CREATE TABLE, seguido de ALTER TABLE y CREATE INDEX, etc
declaraciones. Lo que tenemos que hacer ahora es decirle que queremos cargar los
datos después de que se crean las tablas, pero antes que nada.
Para cada comando CREATE TABLE, siga con una declaración COPY. Algo como:
COPY FROM TableName "/ home / Homer / workdir / NombreDeTabla con nula como;
Una vez que haya hecho esto, ejecutar en contra de su base de datos PostgreSQL,
algo así como
Newdb $ psql <modifiedscript.sql &> OUTFILE
debería funcionar. El archivo de salida es bueno tener para buscar problemas. Se
vuelve tan desordenado:
OUTFILE $ cat | grep ERROR
puede dar una idea de cómo iban las cosas. Te garantizo que tienen que hacer
algunos ajustes.
Vistas == ==
Las opiniones están bastante fácil, mientras que no ha utilizado demasiadas
funciones en ellos. Una de mis favoritas es IsNull (). Como la mayoría de las
funciones, tiene una contrapartida de PostgreSQL, se unen (). Un número
sorprendente de funciones funcionará bien. Por ejemplo, round () es exactamente
el mismo. DatePart () se convierte en date_part (), pero los argumentos son los
mismos, a pesar de PostgreSQL puede ser más concreto sobre las cadenas de
formato. Por ejemplo, SQL Server aceptará DatePart (aaaa, myDateField), así como
DatePart (año, myDateField). PostgreSQL quiere ver date_part ( 'año', myDateField)
(nótese las comillas simples).
SQL para la generación de puntos de vista es más o menos lo mismo que para las
tablas. Desde el Administrador de Empresa, haga clic derecho sobre la base de
datos y seleccionar "Generar Todas las tareas 'y luego' secuencias de comandos

SQL en el menú de contexto. Desactive la opción "Todos los objetos de secuencias
de comandos", y seleccione "Todas las vistas". En el 'formato' la ficha, de-seleccione
"Generar el ...'. En la pestaña "Opciones", se comprueba Seleccione el formato de
archivo de MS-DOS, y asegúrese de que "Crear un archivo". Haga clic en Aceptar,
darle un nombre, y ponerlo en algún sitio donde pueda encontrarlo.
Ejecute este archivo a través del mismo guión que ha creado para limpiar el SQL
para sus tablas, y ver si funciona en PostgreSQL. Si no, tendrá que hacer algunas
de las funciones de fijación.

Migración de SQL Server a Oracle
Para empezar con la instalación descargaremos de este enlace el instalador. Una vez descargado el fichero .zip lo descomprimimos y ejecutamos el fichero SSMA for Oracle 5.2.exe para realizar la primera parte.
La segunda parte de la instalación consiste en copiar el segundo instalador, SSMA for Oracle 5.2 Extension Pack en el servidor SQL Server destino y ejecutarlo para completar todo el proceso. Este último crea una base de datos para uso propio de la aplicación y copia algunas librerías en la instalación de SQL Server. Durante alguno de los pasos nos pedirá un usuario de la base de datos con permisos para crear base de datos.
En nuestra primera ejecución nos pedirá el fichero de licencia. Pese a ser una aplicación gratuita, Ms nos pide tener en una ubicación un fichero de licencia para la versión concreta de nuestra aplicación. En el caso de la versión 5.2, independientemente de la versión de la base de datos origen nos la podemos descargar de este enlace.
Empezando a usarlo
Para ejecutarlo basta con buscarlo en el menú inicio. Nada más abrirlo, seleccionaremos del Menú File > New Project, donde elegiremos la ruta donde guardar el proyecto y seleccionamos la versión de SQL Server destino.

Las primeras pruebas son interesantes para hacerlas con los entornos de test o desarrollo que estén a nuestra disposición y en el peor de los casos, si solo tenemos entornos de producción probaremos con esquemas pequeños.
Primero nos conectaremos a Oracle, el origen de los datos. En el dialogo elegimos entre el cliente Oracle Client provider o el proveedor OleDb y luego desplegaremos el Mode para especificar de distintas maneras los datos del servidor origen ya sea mediante cadena de conexión, TNSNAMES o Standard (campo a campo).
Una vez lo hagamos, la aplicación se conecta y descarga los metadatos para mostrarnos los esquemas visibles. Por cuestión clara de permisos, según el usuario que especifiquemos en la conexión veremos más o menos. Si queremos hacer una migración de todo podemos necesitar al usuario system de Oracle.
El siguiente paso puede ser conectarnos al servidor destino. Para hacerlo elegimos la opción Connect to SQL Server de debajo del menú.
Por cierto, es posible que por algún motivo nos despistemos y no hayamos instalado en el servidor el "Extension Pack". Lo instalamos y solucionado. El error que veremos será como el de la siguiente imagen:
Una vez conectados al servidor origen y destino es momento de empezar a jugar. En la parte superior tenemos primero el Oracle Metadata Explorer y una pestaña a su derecha que nos muestra la información relativa al origen. En la parte inferior tenemos el SQL Server Metadata Explorer que muestra lo mismo para el servidor destino. El "Metadata Explorer" es el árbol de objetos de cada servidor. Es como un Explorador de objetos para las dos bases de datos. Lo único a tener en cuenta es que mientras en Oracle hablamos de diferentes esquemas para una misma base de datos, en MS SQL Server vemos las diferentes bases de datos y los esquemas de seguridad que contiene cada una de ellas.

Migración de Oracle a MySQL
Descargarnos el fichero (a la hora de escribir esto mi version era: mysql-gui-tools-5.0r11-linux-i386.tar.gz)
* Descomprimimos el fichero mysql-gui-tools-5.0r11-linux-i386.tar.gz
Y nos metemos dentro de la carpeta creada.
cd mysql-gui-tools-5.0
En ella, Hay dos utilidades que nos permiten por un lado administrar la base de datos MySQL y por el otro utilizar un cliente de SQL.
Vamos a ejecutar el administrador:
./mysql-administrator
* Al ejecutar nos da este error:
root@soledad:~/Desktop/mysql-gui-tools-5.0# ./mysql-administrator Error starting ./mysql-administrator. The actual installation path of mysql-administrator is different from the expected one. Please run ./mysql-administrator --update-paths (as the root user, if needed) to have the installation directory updated.
Pues como nos dice, Actualizamos los paths:
root@soledad:~/Desktop/mysql-gui-tools-5.0# ./mysql-administrator --update-paths Updating mysql-administrator installation paths... Done.
Lo lanzamos, y ahora si que nos muestra la ventana de login:
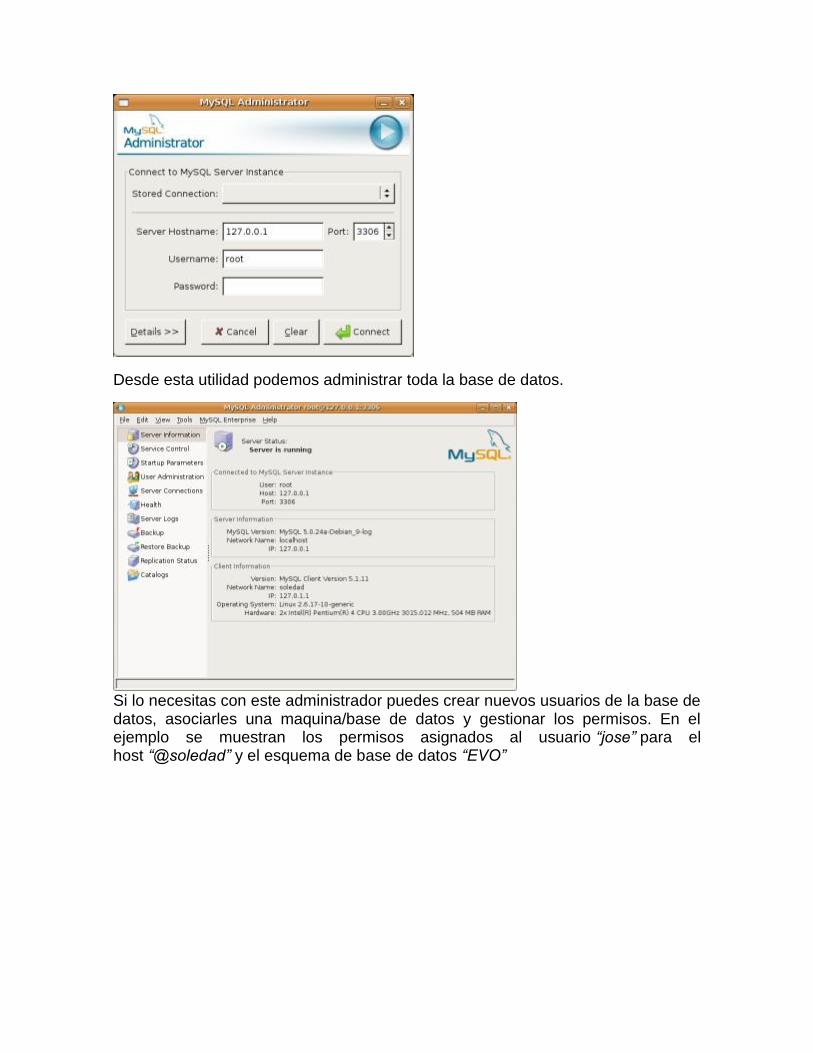
Desde esta utilidad podemos administrar toda la base de datos.
Si lo necesitas con este administrador puedes crear nuevos usuarios de la base de datos, asociarles una maquina/base de datos y gestionar los permisos. En el ejemplo se muestran los permisos asignados al usuario “jose” para el host “@soledad” y el esquema de base de datos “EVO”

Ejecutemos ahora el cliente SQL:
root@soledad:~/Desktop/mysql-gui-tools-5.0# ./mysql-query-browser
Con el cliente podemos lanzar consultas y scripts SQL:
Bien, esto solo era para ver un poco por encima estas herramientas adicionales. Pasemos ahora a la buena, la encargada de migrar entre las bases de datos. MIGRANDO LA BASE DE DATOS ORACLE A MYSQL
Nos cambiamos al directorio migration-tool-script que es donde se encuentra la utilidad de migracion:
cd migration-tool-script Hay 2 versiones: run_migration (que emplea un interface grafico) y run_migration_simple (que usa la consola)
Ejecutamos la de terminal grafico:

root@soledad:~/Desktop/mysql-gui-tools-5.0/migration-tool-script# ./run_migration JRE not found. Please make sure JRE (1.6.0 recommended) is installed and update the ./run_migration script to point to the correct path Nos da un error porque no encuentra el JRE, para solucinarlo, actualizamos el contenido del script run_migration pasando la ruta donde esta el JRE 1.6 (dependera de donde lo tengas instalado) y tambien indicandole, la ruta del fichero del fichero libjvm.so en la siguiente linea: export GRT_JVM_PATH="/usr/lib/jvm/java-6-sun/jre/lib/i386/server/libjvm.so":
En mi caso,Queda asi:
#!/bin/sh # Change the following paths to your local installation of JRE 1.6 if test "x$JRE_LIB_BASE" = x; then #JRE_LIB_BASE="/usr/java/jdk1.6.0/jre/lib//" JRE_LIB_BASE="/usr/lib/jvm/java-6-sun/jre/lib//" fi if [ ! -d $JRE_LIB_BASE ]; then echo "JRE not found. Please make sure JRE (1.6.0 recommended) is installed and update the $0 script to point to the correct path" exit 1 fi JRE_LIB_PATHS="$JRE_LIB_BASE:$JRE_LIB_BASE/server" LD_LIBRARY_PATH="java:$JRE_LIB_PATHS:$LD_LIBRARY_PATH" export LD_LIBRARY_PATH #export GRT_JVM_PATH="$JRE_LIB_BASE/server/libjvm.so" export GRT_JVM_PATH="/usr/lib/jvm/java-6-sun/jre/lib/i386/server/libjvm.so" ./grtsh -x scripts/TextMigrationScript.lua
Lo ejecutamos ahora:
./run_migration
Y mas sorpresas…
root@soledad:~/Desktop/mysql-gui-tools-5.0/migration-tool-script# ./run_migration Opening script file lua/_textforms.lua ... Executing script file lua/_textforms.lua ... Execution finished. Initializing migration environment... Initialisation complete. error executing script: scripts/TextMigrationScript.lua:1123: attempt to index global

`dlg' (a nil value) root@soledad:~/Desktop/mysql-gui-tools-5.0/migration-tool-script# Ocurre un Error, aqui no hay nada que hacer, es un Bug que todavia no esta solucionado (en Ubuntu, no podremos por tanto emplear el Asistente grafico). Sin embargo la version de Windows si que funciona:
No importa, usaremos la version simple, la del texto:
Lo mismo que antes. Editamos el fichero run_migration_simple y cambiamos path del JRE 1.6 y ruta de libjvm.so: #!/bin/sh # Change the following paths to your local installation of JRE 1.6 if test "x$JRE_LIB_BASE" = x; then # JRE_LIB_BASE="/usr/java/jdk1.6.0/jre/lib//" JRE_LIB_BASE="/usr/lib/jvm/java-6-sun/jre/lib//" fi if [ ! -d $JRE_LIB_BASE ]; then echo "JRE not found. Please make sure JRE (1.6.0 recommended) is installed and update the $0 script to point to the correct path" exit 1 fi JRE_LIB_PATHS="$JRE_LIB_BASE:$JRE_LIB_BASE/server" LD_LIBRARY_PATH="java:$JRE_LIB_PATHS:$LD_LIBRARY_PATH" export LD_LIBRARY_PATH #export GRT_JVM_PATH="$JRE_LIB_BASE/server/libjvm.so" export GRT_JVM_PATH="/usr/lib/jvm/java-6-sun/jre/lib/i386/server/libjvm.so" #CLASSPATH="/home/jose/Desktop/mysql-gui-tools-5.0/migration-tool-script/ojdbc14.jar"

#export CLASSPATH ./grtsh -x scripts/MigrationScript.lua
Lo ejecutamos: ./run_migration_simple
root@soledad:~/Desktop/mysql-gui-tools-5.0/migration-tool-script# ./run_migration_simple MySQL Migration Toolkit - Script Version 1.1.9exp ------------------------------------------------- Initializing migration environment... Initialisation complete. ******************************* * Source database connection. * ******************************* Please choose a database system: -------------------------------- 1. MS Access 2. Generic Jdbc 3. MaxDB Database Server 4. MS SQL Server 5. MySQL Server 6. Oracle Database Server 7. Sybase Server 0. Abort Source Database System:
Perfecto, funciona!!!, pero pulsamos 0 para salir. Antes tengo que comentarte unas cosas:
COSAS PREVIAS A HACER Para que no nos de errores del tipo “Class not Found”, copiaremos los ficheros .jar con el driver JDBC en la subcarpeta migration-tool-script/java/lib P.ej el ORACLE Thin driver que es: “ojdbc14.jar” $ cp <ruta_driver>/ojdbc14.jar $HOME/Desktop/migration-tool-script/java/lib
El driver JDBC de MySQL no es necesario porque ya va incluido.
Mas cosas:
Esto es MUY IMPORTANTE. Da igual que el asistente te pida user y password no lo tiene en cuenta, perdi mucho tiempo hasta que me di cuenta de que para que te coja la conexion tienes que pasarselos en la URL. Por ejemplo para ORACLE la url es de la forma: jdbc:oracle:thin:<user>/<pass>@<server>:<port>:<sid>

Ejemplo: jdbc:oracle:thin:demo/demo@repositorio:1521:DESARROLLO
y para MySQL es de la forma:
jdbc:mysql://<server>:<port>/?user=<user>&password=<pass> Ejemplo: jdbc:mysql://localhost:3306/?user=jose&password=jose
Tampoco migres directamente de una base de datos a otra, a mi me dio error (es otro bug) lo que si hice es generar los Scripts de Migracion de la base de datos y luego conectarme a la base de datos destino y lanzarlos. la migracion directa no la recomiendo.
Y poco mas, vamos a ver un ejemplo completo, muy completito:
./run_migration_simple Pego incluso los errores que tuve (cuando no ponia las URLS como he comentado antes): Es muy largo pero te puede servir de ayuda. Lo que hace el asistente es ir pidiendote datos, primero la conexion origen, despues la de destino, que esquemas quieres copiar y si quieres o no generar scripts de migracion. En el ejemplo lo puedes ver mejor. Por cierto, he capado los nombres reales, por **** pero te sirve igual para darte una idea.

Migración de Oracle a PostgreSQL
Paso 1: Instalar los controladores de SQL y AWS
Schema Conversion Tool en su equipo local
Instale los controladores de SQL y AWS Schema Conversion Tool (AWS SCT) en
su equipo local.
Para instalar el software de cliente SQL
1. Descargue el controlador JDBC correspondiente a su versión de base de
datos de Oracle. Para obtener más información,
visite https://www.oracle.com/jdbc.
2. Descargue el controlador PostgreSQL (postgresql-42.1.4.jar).
3. Instale AWS SCT y los controladores JDBC necesarios.
a. Descargue AWS SCT desde Instalar y actualizar AWS Schema
Conversion Tool en la Guía del usuario de AWS Schema Conversion
Tool.
b. Iniciar AWS SCT.
c. En AWS SCT elija Global Settings en Settings.
d. En Global Settings elija Driver y, a continuación,
seleccione Browse para Oracle Driver Path. Busque el controlador
JDBC de Oracle y seleccione OK.
e. Elija Browse para PostgreSQL Driver Path. Busque el controlador
JDBC de PostgreSQL y seleccione OK.

f. Seleccione OK para cerrar el cuadro de diálogo.
Paso 2: Configurar la base de datos de origen de
Oracle
Para utilizar Oracle como origen para AWS Database Migration Service (AWS
DMS), primero debe asegurarse de que está en ARCHIVELOG MODE para
proporcionar información a la LogMiner. AWS DMS utiliza LogMiner para leer
información de los registros de archivo para que AWS DMS pueda capturar los
cambios.
Para que AWS DMS lea esta información, asegúrese de que los registros de archivo
se conservan en el servidor de la base de datos mientras AWS DMS los necesite.
Si configura su tarea para empezar a capturar los cambios de forma inmediata, solo
deberá conservar los logs de archivo un poco más de la duración de la transacción
cuya ejecución sea más larga. Normalmente basta con retener los registros de
archivo durante 24 horas. Si configura su tarea para empezar desde un momento
dado en el pasado, los logs de archivo deben estar disponibles desde ese momento.
Para obtener más instrucciones específicas para activar ARCHIVELOG MODE y

garantizar la retención de los logs para la base de datos de Oracle local, consulte
la documentación de Oracle.
Para capturar los cambios en los datos, AWS DMS precisa que el registro
suplementario esté activado en la base de datos de origen. Debe activar el registro
suplementario mínimo en el nivel de base de datos. AWS DMS también requiere
que el registro de claves de identificación esté activado. Esta opción hace que la
base de datos coloque todas las columnas de la clave principal de una fila en el
archivo de log REDO cada vez que se actualiza una fila que contiene una clave
principal. Este resultado se produce incluso si ningún valor de la clave principal ha
cambiado. Puede configurar esta opción en el nivel de la base de datos o de la tabla.
Para configurar la base de datos de origen de Oracle
1. Cree o configure una cuenta de base de datos para que la use AWS DMS.
Le recomendamos que utilice una cuenta con los privilegios mínimos exigidos
por AWS DMS para la conexión a AWS DMS. AWS DMS requiere los
privilegios siguientes.
2. 3. 4. CREATE SESSION 5. SELECT ANY TRANSACTION 6. SELECT on V_$ARCHIVED_LOG 7. SELECT on V_$LOG 8. SELECT on V_$LOGFILE 9. SELECT on V_$DATABASE 10. SELECT on V_$THREAD 11. SELECT on V_$PARAMETER 12. SELECT on V_$NLS_PARAMETERS 13. SELECT on V_$TIMEZONE_NAMES 14. SELECT on V_$TRANSACTION 15. SELECT on ALL_INDEXES 16. SELECT on ALL_OBJECTS 17. SELECT on ALL_TABLES 18. SELECT on ALL_USERS 19. SELECT on ALL_CATALOG 20. SELECT on ALL_CONSTRAINTS 21. SELECT on ALL_CONS_COLUMNS 22. SELECT on ALL_TAB_COLS 23. SELECT on ALL_IND_COLUMNS 24. SELECT on ALL_LOG_GROUPS 25. SELECT on SYS.DBA_REGISTRY

26. SELECT on SYS.OBJ$ 27. SELECT on DBA_TABLESPACES 28. SELECT on ALL_TAB_PARTITIONS 29. SELECT on ALL_ENCRYPTED_COLUMNS 30. * SELECT on all tables migrated 31.
Si desea capturar y aplicar cambios (CDC), también necesitará los siguientes
privilegios.
EXECUTE on DBMS_LOGMNR SELECT on V_$LOGMNR_LOGS SELECT on V_$LOGMNR_CONTENTS LOGMINING /* For Oracle 12c and higher. */ * ALTER for any table being replicated (if you want AWS DMS to add supplemental logging)
Para versiones de Oracle previas a 11.2.0.3, necesitará los siguientes
privilegios.
SELECT on DBA_OBJECTS /* versions before 11.2.0.3 */ SELECT on ALL_VIEWS (required if views are exposed)
32. Si la base de datos de Oracle es una base de datos de AWS RDS, conéctese
a ella como usuario administrativo y ejecute el siguiente comando para
garantizar que los logs de archivo se conserven en el RDS de origen durante
24 horas:
33. 34. 35. exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention
hours',24); 36.
Si el origen de Oracle es una base de datos de AWS RDS, se pondrá en
ARCHIVELOG MODE si, y solo si, activa los backups.
37. Ejecute el siguiente comando para activar el registro suplementario en el nivel
de base de datos que requiere AWS DMS:
En Oracle SQL:

ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
En RDS:
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD');
38. Utilice el siguiente comando para activar el registro suplementario de claves
de identificación en el nivel de la base de datos. AWS DMS requiere un
registro adicional de claves en el nivel de base de datos. Hay una excepción:
si permite a AWS DMS que añada automáticamente el registro suplementario
cuando sea necesario o active el registro suplementario de nivel de la clave
en el nivel de tabla:
En Oracle SQL:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY
KEY) COLUMNS;
En RDS:
exec
rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD','PRIMARY KEY');
La base de datos de origen incurre en pequeños gastos adicionales si
el registro suplementario del nivel de la clave está activado. Por lo
tanto, si migra únicamente un subconjunto de tablas, es posible que le
interese activar el registro suplementario de nivel de la clave en el nivel
de la tabla.
39. Para activar el registro suplementario del nivel de la clave en el nivel de la
tabla, utilice el siguiente comando.
ALTER TABLE table_name ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
Si una tabla no tiene una clave principal tiene dos opciones.

Puede agregar el registro suplementario en todas las columnas
implicadas en el primer índice único de la tabla (ordenadas por nombre
de índice).
Puede agregar el registro suplementario a todas las columnas de la
tabla.
Para añadir el registro suplementario a un subconjunto de columnas de una
tabla como, por ejemplo, las columnas implicadas en un índice único, ejecute
el siguiente comando.
ALTER TABLE table_name ADD SUPPLEMENTAL LOG GROUP example_log_group (column_list) ALWAYS;
Para añadir el registro suplementario a todas las columnas de una tabla,
ejecute el siguiente comando.
ALTER TABLE table_name ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
40. Cree un usuario para AWS SCT.
41. 42. CREATE USER oracle_sct_user IDENTIFIED BY password; 43. 44. GRANT CONNECT TO oracle_sct_user; 45. GRANT SELECT_CATALOG_ROLE TO oracle_sct_user;
GRANT SELECT ANY DICTIONARY TO oracle_sct_user;
Paso 3: Configurar la base de datos de destino
PostgreSQL
1. Si los esquemas que va a migrar no existen en la base de datos de
PostgreSQL cree los esquemas.

2. Cree el usuario de AWS DMS para conectarse a la base de datos de destino
y conceda privilegios de superusuario o los privilegios individuales
necesarios (o use el nombre de usuario maestro para RDS).
3. 4. 5. CREATE USER postgresql_dms_user WITH PASSWORD 'password'; 6. ALTER USER postgresql_dms_user WITH SUPERUSER; 7.
8. Cree un usuario para AWS SCT.
9. 10. 11. CREATE USER postgresql_sct_user WITH PASSWORD 'password'; 12. 13. GRANT CONNECT ON DATABASE database_name TO
postgresql_sct_user; 14. GRANT USAGE ON SCHEMA schema_name TO postgresql_sct_user; 15. GRANT SELECT ON ALL TABLES IN SCHEMA schema_name TO
postgresql_sct_user;
GRANT ALL ON SEQUENCES IN SCHEMA schema_name TO postgresql_sct_user;
Paso 4: Utilizar AWS Schema Conversion Tool (AWS
SCT) para convertir los esquemas de Oracle a
PostgreSQL
Antes de migrar datos a PostgreSQL debe convertir el esquema de Oracle en un
esquema de PostgreSQL.
Para convertir un esquema de Oracle en un esquema de PostgreSQL con AWS
SCT
1. Iniciar AWS SCT. En AWS SCT seleccione File y, a continuación, elija New
Project. Cree un nuevo proyecto llamado AWS Schema Conversion Tool
Oracle to PostgreSQL. Indique la siguiente información en la ventana New
Project y, a continuación, seleccione OK.
Parámetro Descripción

Project Name Escriba AWS Schema Conversion Tool Oracle to
PostgreSQL.
Ubicación Utilice la carpeta Projects predeterminada y la
opción Transactional Database
(OLTP) predeterminada.
Source
Database
Engine
Seleccione Oracle.
Target
Database
Engine
Seleccione Amazon RDS for PostgreSQL.
2.
3. Elija Connect to Oracle. En el cuadro de diálogo Connect to Oracle escriba
la información siguiente y, a continuación, elija Test Connection.
Parámetro Descripción
Type Elija SID.
Server name Escriba el nombre del servidor.

Server port Escriba el número de puerto de Oracle. El valor
predeterminado es 1521.
Oracle SID Escriba el SID de la base de datos.
Nombre de
usuario
Escriba el nombre de usuario administrador de Oracle.
Contraseña Especifique la contraseña para el usuario administrador.
4.
5. Seleccione OK para cerrar la alerta y, a continuación, seleccione OK para
cerrar el cuadro de diálogo y comenzar la conexión a la instancia de base de
datos de Oracle. A continuación se muestra la estructura de base de datos
en la instancia de base de datos de Oracle.
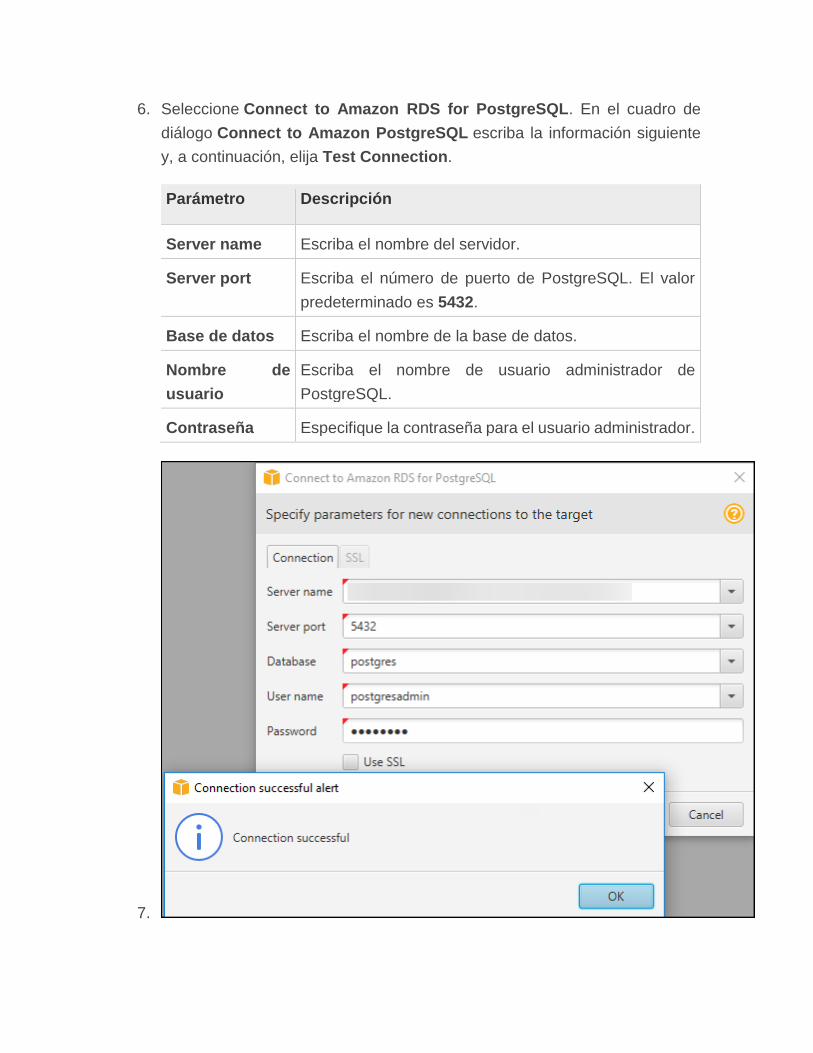
6. Seleccione Connect to Amazon RDS for PostgreSQL. En el cuadro de
diálogo Connect to Amazon PostgreSQL escriba la información siguiente
y, a continuación, elija Test Connection.
Parámetro Descripción
Server name Escriba el nombre del servidor.
Server port Escriba el número de puerto de PostgreSQL. El valor
predeterminado es 5432.
Base de datos Escriba el nombre de la base de datos.
Nombre de
usuario
Escriba el nombre de usuario administrador de
PostgreSQL.
Contraseña Especifique la contraseña para el usuario administrador.
7.

8. Seleccione OK para cerrar la alerta y, a continuación, seleccione OK para
cerrar el cuadro de diálogo y comenzar la conexión a la instancia de base de
datos de PostgreSQL.
9. Abra el menú contextual (haga clic con el botón derecho) del esquema que
va a migrar y seleccione Convert schema.
10. Seleccione Yes para el mensaje de confirmación. AWS SCT convierte los
esquemas al formato de la base de datos de destino.

AWS SCT analiza el esquema y crea un informe de evaluación de la
migración de la base de datos para la conversión a PostgreSQL.
11. Seleccione Assessment Report View en View para comprobar el informe.
El informe se desglosa por cada tipo de objeto y por la cantidad de cambios
manuales que son necesarios para realizar la conversión correctamente.

Por lo general, los paquetes, los procedimientos y las funciones son los
elementos con más probabilidades de tener problemas que deben
resolverse, ya que contienen la mayor parte del código PL/SQL
personalizado. AWS SCT también ofrece consejos para solucionar los
problemas de estos objetos.
12. Haga clic en la pestaña Action Items.

La pestaña Action Items muestra cada uno de los problemas de cada objeto
que precisan atención.
Por cada problema de conversión, puede realizar una de las siguientes
acciones:
Modificar los objetos en la base de datos de Oracle de origen para que
AWS SCT pueda convertir los objetos a la base de datos de
PostgreSQL de destino.
a. Modifique los objetos en la base de datos de Oracle de origen.
b. Repita los pasos anteriores para convertir el esquema y
comprobar el informe de evaluación.
c. Si es necesario, repita este proceso hasta que no haya
problemas de conversión.
d. Elija Main View en View, abra el menú contextual (haga clic
con el botón derecho) del esquema PostgreSQL de destino y
elija Apply to database para aplicar los cambios de esquema
en la base de datos de PostgreSQL.

En lugar de modificar el esquema de origen, modifique los scripts
generados por AWS SCT antes de aplicar los scripts en la base de
datos de PostgreSQL de destino.
a. Abra el menú contextual (haga clic con el botón derecho) del
nombre de esquema de PostgreSQL de destino y
seleccione Save as SQL. A continuación, elija un nombre y un
destino para el script.
b. En el script modifique los objetos para corregir los problemas
de conversión.
c. Ejecute el script en la base de datos de PostgreSQL de destino.
Para obtener más información, consulte Conversión de esquemas de bases
de datos a Amazon RDS con AWS Schema Conversion Tool en la Guía del
usuario de AWS Schema Conversion Tool.
13. Utilice AWS SCT para crear reglas de mapeo.
a. En Settings seleccione Mapping Rules.

b. Además de las dos reglas de mapeo predeterminadas que convierten los
nombres de esquemas y de tablas en minúsculas, cree reglas de mapeo adicionales
necesarias en función de los elementos de acción.
c. Guarde las reglas de mapeo.
d. Haga clic en Export script for DMS (Exportar script para DMS) para
exportar un formato JSON de todas las transformaciones que la tarea AWS DMS
utilizará para determinar qué objeto del origen corresponde a qué objeto del destino.
Haga clic en Guardar.

Conclusiones
El proceso de migración de un sistema de automatización hacia otro es complejo y lento; sin embargo, los resultados y beneficios obtenidos han mostrado que se justifica su implementación. SQL Server Migration Assistant (SSMA) para MySQL es un entorno completo que le permite migrar rápidamente bases de datos MySQL a SQL Server o SQL Azure. Mediante el uso de SSMA para MySQL, puede revisar los datos y objetos de base de datos, evaluar las bases de datos para la migración, migrar objetos de base de datos a SQL Server o SQL Azure y, a continuación, migrar datos a SQL Server o SQL Azure.

Bibliografía
http://www.respuestasit.com.mx/2017/01/migrar-base-de-datos-de-mysql-sql-
server.html
http://www.latindevelopers.com/articulo/migrar-de-mysql-a-postgresql/
https://www.ispirer.es/products/mysql-to-oracle-migration
http://www.respuestasit.com.mx/2017/06/migrar-base-de-datos-de-sql-server.html
https://wiki.postgresql.org/wiki/Migraci%C3%B3n_de_Microsoft_SQL_Server_a_Po
stgreSQL_por_Ian_Harding
http://www.dataprix.com/blog-it/bases-datos/como-migrar-oracle-sql-server-
usando-sql-server-migration-assistant-oracle
https://ubuntulife.wordpress.com/2007/04/20/migrar-de-oracle-a-mysql-empleando-
mysql-migration-toolkit/
https://docs.aws.amazon.com/es_es/dms/latest/sbs/CHAP_RDSOracle2PostgreS
QL.Steps.ConvertSchema.html