tema 11: la capa de red en...
TRANSCRIPT

Adquisición y Tratamiento de Datos La capa de red en Internet
TEMA 11: La capa de red en Internet.
11.1 Introducción.
La capa de red en general, y la de Internet en particular, es la encargada de llevar los paquetes desde el origen hasta el destino. Es la primera capa desde el origen al destino, pues las capas anteriores tan solo se encargaban de que los datos llegaran correctamente de un extremo a otro de un enlace de comunicaciones, generalmente un cable. Llegar al destino puede requerir muchos saltos por dispositivos intermedios, generalmente routers.
Para lograr su cometido, la capa de red conoce la topología de la red de comunicaciones y escoge las trayectorias adecuadas a través de ella. También debe tener cuidado al escoger las rutas para evitar sobrecargar algunas líneas de comunicación y routers, mientras deja a otros sin trabajo. Además, si el origen y el destino están en redes diferentes, es misión de la capa de red el manejo de estas diferencias y la resolución de los problemas que causan.
La capa de red debe proporcionar un interfaz con la capa superior (la capa de transporte) de forma que:
1. Los servicios deben ser independientes de la tecnología de subred.
2. La capa de transporte debe estar aislada de la cantidad, tipo y topología de las subredes presentes.
3. Las direcciones de red disponibles para la capa de transporte deben seguir un plan de numeración uniforme, aun a través de varias LAN y WAN.
Con solo estos objetivos, la capa de red posee una gran libertad para especificar los servicios que ofrecerá a la capa de transporte.
11.2 Organización interna de la capa de red.
La libertad existente en la especificación de la capa de red, genera la posibilidad de que la capa de red proporcione servicio orientado o no orientado a conexión. Si el servicio es orientado a conexión, la complejidad de la comunicación la asume la capa de red, mientras que si es no orientado a conexión, la complejidad es asumida por la capa de transporte, que es propia de cada ordenador conectado a la red1.
La utilidad de la orientación a conexión se basa en evitar tener que escoger una ruta nueva para cada paquete enviado. Cuando se establece una conexión, se escoge y recuerda una ruta de la máquina de origen a la de destino como parte del establecimiento de la conexión. Esa ruta se usa para todo el tráfico que fluye por la conexión (circuito virtual).
1 Las conexiones son conocidas como circuitos virtuales, mientras que los paquetes independientes sin conexión son conocidos como datagramas.
Ciencias y Técnicas Estadísticas 1

Adquisición y Tratamiento de Datos La capa de red en Internet
Como los paquetes que fluyen por la conexión siempre siguen la misma ruta a través de la red, cada router debe recordar a dónde envía los paquetes para cada una de las conexiones que pasan por él. Por ello, cada router mantiene una tabla con una entrada por conexión abierta que pasa a través suyo. Al llegar un paquete al router, esté sabe la línea por la que llegó y el número del circuito virtual, con lo cual puede determinar la línea de salida correcta.
Por contra, en una red no orientada a conexión, no se determinan rutas por adelantado, aún en el caso de que el servicio en la capa de transporte esté orientado a conexión. Cada paquete se envía de manera independiente de sus antecesores, de forma que dos paquetes sucesivos pueden seguir rutas distintas. Esto hace las redes de datagramas más robustas y más adaptadas a posibles fallos, pero aumenta el trabajo que deben realizar.
En el caso de datagramas, los routers tienen una tabla que indica la línea de salida a usar para cada router de destino posible. Cada datagrama debe contener la dirección de destino completa, de forma que al llegar un paquete a un router, esté busca la línea de salida a usar y envía el paquete. El establecimiento y liberación de conexiones no requiere ningún trabajo especial por parte de los routers.
11.3 Algoritmos de encaminamiento.
Una función fundamental de la capa de red en los routers es decidir por que interfaz se manda el paquete recibido. Con datagramas esto se hace para cada paquete; con circuitos virtuales se hace sólo para cada nuevo circuito en el momento de efectuar la llamada. Los algoritmos que se encargan de decidir por donde se manda cada paquete recibido se conocen con el nombre de algoritmos de encaminamiento, pudiendo ser estáticos o dinámicos.
En el encaminamiento estático, las rutas están basadas en información de la topología obtenida previamente. Se fija cada posible ruta de antemano, según la capacidad de la línea, el tráfico esperado u otros criterios. En cada router se cargan sus tablas de rutas de forma estática, por lo que no necesita intercambiar ninguna información de encaminamiento con sus vecinos, y por tanto no requiere para su funcionamiento un protocolo de encaminamiento. Con el encaminamiento estático no es posible responder a situaciones cambiantes (por ejemplo saturación, exceso de tráfico o fallo de una línea), pero al realizar los cálculos a priori, es posible aplicar algoritmos muy sofisticados, aun cuando su cálculo sea muy costoso.
En el encaminamiento dinámico las rutas se fijan en cada momento, en función de información en tiempo real que los routers reciben del estado de la red. Se utilizan algoritmos autoadaptativos y es preciso utilizar un protocolo de encaminamiento que permita a los routers intercambiar continuamente información sobre el estado de la red. Los algoritmos no pueden ser demasiado complejos pues han de implementarse en los routers y ejecutarse cada poco tiempo.
Haciendo un símil podríamos decir que el encaminamiento estático consiste en fijar la ruta al planear un viaje en coche usando únicamente los mapas de carreteras,
Ciencias y Técnicas Estadísticas 2

Adquisición y Tratamiento de Datos La capa de red en Internet
mientras que el encaminamiento dinámico supondría modificar nuestra ruta sobre la marcha en función de la información que recibimos sobre el estado de las carreteras, etc.
Estudiaremos a continuación algunos algoritmos de enrutamiento, pero antes, conviene enunciar un principio fundamental, que aunque parezca obvio, es necesario tener en cuenta. Este principio es conocido como principio de optimación y se enuncia como:
Si B está en la ruta óptima de A a C, entonces el camino óptimo de B a C está incluido en dicha ruta.
Una consecuencia importante de este principio es que todas las rutas óptimas para llegar a un punto determinado forman un árbol, con raíz en el punto de destino, sin bucles (spanning tree) y donde siempre es posible llegar al destino en un número finito de saltos.
11.3.1 Encaminamiento por el camino más corto.
Para elegir el camino más corto debemos definir, en primer lugar, que entendemos por distancia, pues es evidente que en redes de computadoras no tiene mucho sentido emplear la distancia física2. Normalmente, la distancia se mide como una combinación de los siguientes factores:
• La inversa de la capacidad del enlace (información estática).
• Tráfico medio (información estática y/o dinámica).
• Retardo (información dinámica medida a partir de los paquetes enviados).
• La inversa de la fiabilidad (información dinámica medida a partir de los paquetes enviados).
El peso relativo que se da a cada uno de los factores que intervienen en el cálculo de la distancia de la red se denomina métrica de la red. La métrica puede ser fijada o modificada al configurar los routers, aunque los parámetros que entran en juego y la fórmula que se utiliza para calcularla suelen estar muy relacionados con el algoritmo y el protocolo de encaminamiento utilizados. Cuando un trayecto está compuesto por varios tramos, la distancia del trayecto será igual a la suma de las distancias de los tramos que lo componen.
Existen diversos algoritmos que permiten calcular el camino más corto entre dos nodos de un grafo. Uno de los más conocidos es debido a Dijkstra, el cual se utiliza tanto en encaminamiento estático como dinámico.
Para explicar el algoritmo de Dijkstra, supongamos una red con los nodos y métrica indicada en la figura 11.3.1.1.
2 Ni siquiera tiene sentido emplear el número de routers por los que pasan los datos enviados, a no ser un caso muy particular y simple en el que todos los enlaces tienen la misma capacidad.
Ciencias y Técnicas Estadísticas 3
Adquisición y Tratamiento de Datos La capa de red en Internet
6
2
1
2
4
2
7
3
2 3
1
G H
F E
C B
D A
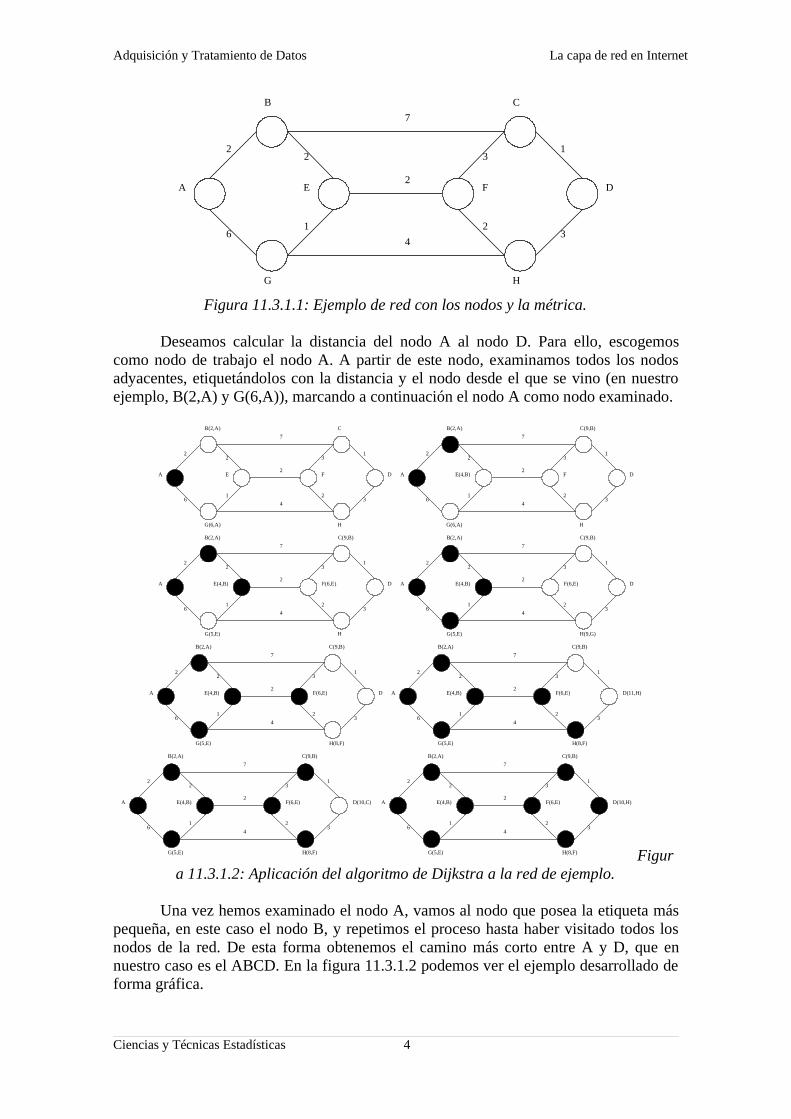
Figura 11.3.1.1: Ejemplo de red con los nodos y la métrica.
Deseamos calcular la distancia del nodo A al nodo D. Para ello, escogemos como nodo de trabajo el nodo A. A partir de este nodo, examinamos todos los nodos adyacentes, etiquetándolos con la distancia y el nodo desde el que se vino (en nuestro ejemplo, B(2,A) y G(6,A)), marcando a continuación el nodo A como nodo examinado.
6
2
1
2
4
2
7
3
2 3
1
G(6,A) H
F E
C B(2,A)
D A
6
2
1
2
4
2
7
3
2 3
1
G(6,A) H
F E(4,B)
C(9,B) B(2,A)
D A
6
2
1
2
4
2
7
3
2 3
1
G(5,E) H
F(6,E) E(4,B)
C(9,B) B(2,A)
D A
6
2
1
2
4
2
7
3
2 3
1
G(5,E) H(9,G)
F(6,E) E(4,B)
C(9,B) B(2,A)
D A
6
2
1
2
4
2
7
3
2 3
1
G(5,E) H(8,F)
F(6,E) E(4,B)
C(9,B) B(2,A)
D A
6
2
1
2
4
2
7
3
2 3
1
G(5,E) H(8,F)
F(6,E) E(4,B)
C(9,B) B(2,A)
D(11,H) A
6
2
1
2
4
2
7
3
2 3
1
G(5,E) H(8,F)
F(6,E) E(4,B)
C(9,B) B(2,A)
D(10,C) A
6
2
1
2
4
2
7
3
2 3
1
G(5,E) H(8,F)
F(6,E) E(4,B)
C(9,B) B(2,A)
D(10,H) A
Figura 11.3.1.2: Aplicación del algoritmo de Dijkstra a la red de ejemplo.
Una vez hemos examinado el nodo A, vamos al nodo que posea la etiqueta más pequeña, en este caso el nodo B, y repetimos el proceso hasta haber visitado todos los nodos de la red. De esta forma obtenemos el camino más corto entre A y D, que en nuestro caso es el ABCD. En la figura 11.3.1.2 podemos ver el ejemplo desarrollado de forma gráfica.
Ciencias y Técnicas Estadísticas 4

Adquisición y Tratamiento de Datos La capa de red en Internet
11.3.2 Encaminamiento por inundación.
Es un algoritmo muy simple consistente en enviar cada paquete por todas las líneas de salida posibles, excepto por la que se ha recibido. Produce un exceso de tráfico en la red, así como problemas en caso de existencia de bucles en la topología de la red.
Para limitar el problema de la existencia de bucles, se suele fijar un número máximo de saltos, que suele ser igual al número de saltos que hay entre los dos puntos más alejados de la red3.
Existe una variación de la inundación, conocida como inundación selectiva, en la cual el paquete se envía sólo por las líneas que, aparentemente, se encuentran en la dirección correcta; por ejemplo, si estamos en Madrid y el paquete va hacia Córdoba, se enviará solamente por las líneas que van al Sur.
11.3.3 Encaminamiento basado en el flujo.
Este algoritmo toma en cuenta la cantidad de tráfico medio que soportan las líneas y, con esta información, intenta optimizar el conjunto de las rutas para utilizar el camino menos congestionado en cada caso. Para aplicarlo se ha de conocer bastante bien el tráfico y éste ha de ser muy regular. Se pueden aplicar algoritmos relativamente sofisticados, ya que el cálculo de rutas se hace a priori y se carga en el router después.
Este algoritmo solo se aplica en algunos casos de encaminamiento estático, aunque puede ser útil para diseñar la topología de una red, como por ejemplo si se conectan una serie de oficinas y se dispone de un estudio con el tráfico previsto entre cada las diferentes oficinas.
11.3.4 Encaminamiento por vector distancia.
Este algoritmo se conoce como algoritmo de Bellman-Ford o Ford-Fulkerson, que fueron sus autores. En este encaminamiento, cada router mantiene una tabla que le indica la distancia mínima conocida hacia cada posible destino y la línea que debe utilizar para llegar a él.
La tabla se actualiza regularmente con la información obtenida de los routers vecinos, pues cada router manda la tabla completa de distancias a todos sus vecinos, y solo a ellos. Con la información que tiene y la recibida de sus vecinos, cada router puede calcular continuamente su tabla de distancias.
La métrica utilizada para medir las distancias puede ser el número de saltos, el retardo medio, los paquetes procesados, etc., o una combinación de estos u otros parámetros.
En éste algoritmo, las noticias buenas se propagan rápidamente, pero se reacciona lentamente a las malas. Esto se conoce como el problema de la cuenta a infinito. Se han ideado multitud de trucos para resolver este problema, pero para cada 3 El número máximo de saltos entre dos nodos de la red se conoce como tamaño o diámetro de la red.
Ciencias y Técnicas Estadísticas 5

Adquisición y Tratamiento de Datos La capa de red en Internet
nueva propuesta se ha encontrado una situación patológica en la que falla, no existiendo una solución definitiva a este problema.
11.3.5 Encaminamiento por el estado del enlace.
El encaminamiento basado en el estado del enlace apareció como un intento de resolver los problemas que planteaba el encaminamiento por vector distancia, fundamentalmente el de la cuenta a infinito. Se trata de un algoritmo más sofisticado y robusto, compuesto por cuatro fases:
• Descubrir los routers vecinos y averiguar sus direcciones.
• Medir el retardo o costo de llegar a cada vecino.
• Construir un paquete que resuma toda esta información, y enviarlo a todos los routers de la red.
• Calcular el camino mas corto a cada router.
Para cubrir estas fases los routers, cuando arrancan, envían paquetes de presentación (HELLO) por todas sus interfaces; los paquetes HELLO son respondidos con mensajes de identificación por los routers que los reciben. Además los routers envían paquetes de prueba (ECHO) que son respondidos por el router remoto y miden el tiempo de ida y vuelta.
Con la información obtenida el router construye un paquete de información y lo envía a todos los routers de la red. Para ello utiliza inundación. Los paquetes se numeran para detectar y descartar duplicados e ignorar paquetes obsoletos, por ejemplo si llega el paquete 26 después de haber recibido el 28 se descarta. Además, cada paquete tiene una vida limitada, al cabo de la cual es descartado. Con toda la información obtenida el router construye el árbol de expansión de las rutas óptimas a cada destino de la red aplicando el algoritmo de Dijkstra, obteniendo de esta forma la topología de la red.
La principal diferencia entre este encaminamiento y el encaminamiento por vector distancia, es que en el encaminamiento por vector distancia cada router envía información sólo a sus vecinos, pero esta información incluye a todos los nodos de la red. En cambio en el encaminamiento por el estado del enlace, cada router envía su paquete de información a toda la red, pero éste solo contiene la relativa a sus vecinos más próximos, permitiendo a cada router obtener el estado completo de la red, cosa que no es posible con el encaminamiento por vector distancia.
Entre los protocolos de encaminamiento que utilizan algoritmos basados en el estado del enlace destaca Open Shortest Path First, que es el protocolo estándar de encaminamiento en Internet. Otro protocolo de estado del enlace también utilizado en Internet y que proviene del mundo OSI es Intermediate System-Intermediate System. IS-IS es multiprotocolo, es decir, soporta múltiples protocolos de red por encima.
Ciencias y Técnicas Estadísticas 6

Adquisición y Tratamiento de Datos La capa de red en Internet
11.3.6 Encaminamiento jerárquico.
El encaminamiento jerárquico es una traslación a la informática del encaminamiento que aplicamos a diario en nuestra vida a la hora de planificar un viaje. En un viaje en coche de Valencia a París, por ejemplo, utilizamos un mapa detallado de las zonas cercanas a Valencia y París, pero nos basta uno con las carreteras principales una vez nos alejamos del origen o del destino.
A medida que una red crece, la cantidad información de encaminamiento aumenta de forma exponencial, ya que cada router ha de calcular las rutas óptimas a todos los demás. Esto incrementa el tráfico, la memoria en los routers, y la complejidad de los cálculos necesarios para obtener las rutas óptimas. Como consecuencia de esto los algoritmos de encaminamiento no son escalables.
Para reducir este problema las redes se organizan en niveles jerárquicos; se divide la red en regiones, y sólo un número reducido de routers de cada región (los routers “interregionales”) puede comunicar con el exterior. Las rutas quizá no sean tan óptimas, pero se simplifica la gestión y el mantenimiento de las tablas de encaminamiento y se reduce el tráfico de gestión de la red.
11.4 Algoritmos de control de congestión.
Denominamos congestión a la circunstancia en la que el rendimiento de la red se degrada debido a la presencia de excesivo tráfico de paquetes en la red. Un ejemplo de congestión sería la situación en la que un router, con varias líneas de 2 Mb/s, recibe tráfico entrante por todas ellas dirigido a una sola. Inicialmente el router intentará salvar la situación utilizando sus buffers de almacenamiento, pero si ésta situación dura bastante tiempo, los buffers se llenarán y el router empezará a descartar paquetes Normalmente la congestión se produce por tráfico excesivo, pero también puede producirse por un router sobrecargado o de capacidad de proceso insuficiente para el tráfico que soporta.
11.4.1 Principios generales del control de congestión.
Para efectuar una estrategia de control de congestión caben dos planteamientos:
• Diseñar las cosas desde el principio para que la congestión no pueda llegar a ocurrir.
• Tomar medidas que permitan detectar la congestión y adoptar medidas correctoras en su caso.
La primera técnica es más segura, pero puede provocar ineficiencias si se aplican las limitaciones con demasiada severidad. La segunda permite aprovechar mejor la red, pero en caso de congestión puede ser difícil controlar la situación.
Una vez producida una congestión solo hay dos posibles medidas:
Ciencias y Técnicas Estadísticas 7

Adquisición y Tratamiento de Datos La capa de red en Internet
• Reducir el tráfico solicitando al emisor que pare de enviar, o que busque rutas alternativas.
• Aumentar la capacidad, a corto plazo esto puede hacerse por ejemplo activando canales RDSI, a más largo plazo será preciso contratar enlaces de más capacidad o nuevos enlaces.
11.4.2 Factores que pueden influir en la congestión.
La principal causa de la congestión es el tráfico a ráfagas. Si todos los ordenadores transmitieran siempre un flujo constante sería muy fácil evitar las congestiones.
Los perfiles de tráfico (traffic shaping) establecen unos márgenes máximos al tráfico a ráfagas. Suelen utilizarse para fijar una “calidad de servicio” (Quality of Service) entre el operador y el usuario, de forma que si el usuario respeta lo establecido, el operador se compromete a no descartar paquetes. El perfil de tráfico actúa como una especie de contrato entre las partes.
Se denomina vigilancia del tráfico (traffic policing) a la labor de monitorización o seguimiento del tráfico introducido por el usuario en la red para verificar que no excede el perfil pactado.
11.4.3 Algoritmo del pozal agujereado.
Uno de los sistemas mas utilizados para establecer perfiles de tráfico es el conocido como algoritmo del pozal agujereado (leaky bucket).
En este algoritmo, el ordenador puede enviar ráfagas, que son almacenadas en un buffer (pozal) de la interfaz, la cual envía a la red un caudal constante. Si la ráfaga es de tal intensidad o duración que el buffer se llena, los paquetes excedentes son descartados, o bien son enviados a la red con una marca especial que les identifica como de “segunda clase”, que hace que sean los primeros candidatos a descartar en caso de congestión.
Para definir un pozal agujereado se utilizan dos parámetros, el caudal ρ con que sale el flujo a la red, y la capacidad C del buffer. Si suponemos, por ejemplo, que ρ=10 Mbps y C=5 Mbits, si un ordenador envía una ráfaga de 5 Mbits en 50 mseg (equivalente a 100 Mbps), el pozal casi se llena. La ráfaga tardará en enviarse a la red 500 mseg, momento en el cual el pozal se habrá vaciado. Si el ordenador envía otra ráfaga de 5 Mbits antes de que el pozal se haya vaciado por completo, el buffer se llenará y se perderán los paquetes excedentes, o bien se enviarán marcados como descartables.
El pozal agujereado resuelve el problema de las ráfagas en la red, pero no estimula el ahorro, pues un usuario que esté continuamente transmitiendo con el caudal ρ del agujero mantendrá vacío su pozal, y a la hora de enviar una ráfaga estará en igualdad de condiciones respecto a otro usuario que no haya transmitido nada durante cierto tiempo. Para fomentar el ahorro se desarrollo el algoritmo del pozal con créditos
Ciencias y Técnicas Estadísticas 8

Adquisición y Tratamiento de Datos La capa de red en Internet
(token bucket), que compensa al usuario que alterna intervalos de tráfico con otros de inactividad, frente al que esta siempre transmitiendo.
El mecanismo que sigue para ello es el siguiente: cuando el ordenador no envía datos, el pozal va sumando créditos hasta un máximo igual a la capacidad del pozal. Los créditos acumulados pueden utilizarse después para enviar ráfagas con un caudal M mayor de lo normal hasta que se agoten los créditos, momento en el cual el caudal vuelve a su valor normal ρ y el algoritmo funciona como el del pozal agujereado. Podemos imaginar el pozal con crédito como dotado de dos agujeros, uno pequeño y uno grande, con un dispositivo mecánico que permite abrir uno u otro, pero no ambos a la vez; el agujero grande se abre cuando el usuario tiene créditos; el usuario acumula créditos cuando el pozal no está tirando líquido por el agujero pequeño, bien porque en el pozal no existe líquido que tirar, bien porque tenga abierto el agujero grande y cerrado el pequeño. Los parámetros que definen un pozal con créditos son la capacidad C del buffer, el caudal del agujero pequeño ρ y el caudal del agujero grande M4.
Supongamos, como ejemplo, que ρ=10 Mbps, C=5 Mbits y M=100 Mbps y que como en el ejemplo anterior el ordenador envía una ráfaga de 5 Mbits en 50 mseg. Existen ahora tres posibles situaciones en el pozal:
• El pozal esta lleno de créditos (5 Mbits), por lo cual la ráfaga es enviada a la red a 100 Mbps, la misma velocidad con la que envía el ordenador.
• El pozal esta vacío de créditos, por lo cual la ráfaga se comporta exactamente igual que en el pozal agujereado.
• El pozal esta parcialmente lleno de créditos (por ejemplo, tiene 2,5 Mbits de crédito iniciales). Dicha cantidad se incrementa a razón de 10 Mbps mientras está el agujero pequeño cerrado, y mientras está el agujero grande abierto se decrementa en 100 Mbps, por lo cual en un tiempo t los créditos son:
créditos totales = 2,5 Mbits + 10 Mbps *tcréditos consumidos = 100 Mbps *t
Igualando ambas expresiones tenemos 2,5+10t=100t, que despejando da un valor de t=2,5/90=0,0278 seg = 27,8 mseg. Por tanto, el pozal se vaciara a 100 Mbps durante 27,8 mseg y después se continuará vaciando a razón de 10 Mbps hasta completar la ráfaga.
11.4.4 Paquetes de asfixia.
Los paquetes de asfixia se pueden aplicar tanto en redes de circuitos virtuales como de datagramas. En esta técnica el router o conmutador comprueba regularmente cada una de sus líneas, analizando, por ejemplo, el grado de utilización, la longitud de la cola o la ocupación del buffer correspondiente. Cuando el parámetro inspeccionado supera un determinado valor considerado umbral de peligro se envía un paquete de asfixia ("choke packet”) al ordenador considerado "culpable" para que reduzca el ritmo.
4 El valor del caudal del agujero grande suele ser igual a la velocidad máxima de la interfaz física.
Ciencias y Técnicas Estadísticas 9

Adquisición y Tratamiento de Datos La capa de red en Internet
Normalmente los paquetes de asfixia se envían a los ordenadores que generan el tráfico, ya que son éstos y no los routers los verdaderos causantes de la congestión. Los ordenadores, cuando reciben estos paquetes, suelen reducir, por ejemplo a la mitad, la velocidad con la que envían datos a la red. Esto lo pueden hacer de varias maneras, por ejemplo, reduciendo el tamaño de ventana del protocolo a nivel de transporte o cambiando los parámetros del pozal agujereado o del pozal con crédito, si utilizan alguno de estos algoritmos para controlar el flujo. En una situación de congestión normalmente muchos ordenadores recibirán este tipo de paquetes.
En ocasiones interesa que los paquetes de asfixia tengan un efecto inmediato en cada uno de los routers que atraviesan en su camino hacia el ordenador que genera el tráfico; esto es especialmente importante cuando se trata de una conexión de alta velocidad y elevado retardo. De esta forma la congestión se reduce de forma inmediata, distribuyendo el tráfico en ruta entre los buffers de los routers que hay en el camino mientras el mensaje de alerta llega al ordenador que genera el tráfico.
Por desgracia la obediencia a los paquetes de asfixia es completamente voluntaria. Si un ordenador obedece las indicaciones y reduce su ritmo, mientras otro no lo hace, el primero saldrá perjudicado pues obtendrá una parte aún menor de la ya escasa capacidad disponible. No es posible obligar a los ordenadores a obedecer las indicaciones de los paquetes de asfixia.
En situaciones de saturación se plantea el problema de como repartir la capacidad disponible de forma justa entre los usuarios. Existen varios algoritmos que intentan resolver este problema, por ejemplo:
• Encolamiento justo (fair queuing): el router mantiene una cola independiente por cada ordenador y envía los paquetes en turno rotatorio ("round robin"). En este caso se da el problema de que al ser el reparto equilibrado en paquetes por ordenador y unidad de tiempo, los usuarios o aplicaciones que manejan paquetes grandes obtienen mas recursos que los que manejan paquetes pequeños. Una versión mejorada de este algoritmo intenta hacer un reparto homogéneo en número de bytes (o bits) transmitidos por ordenador y por unidad de tiempo.
• Encolamiento justo ponderado (weighted fair queuing): es similar al anterior, pero permite además establecer prioridades, ya que en ocasiones interesa dar mas prioridad a algunas máquinas (por ejemplo servidores) o a algunos servicios (aplicaciones interactivas, por ejemplo). La prioridad se puede establecer por direcciones, por tipo de aplicación o por una combinación de estos u otros factores. Además de prioridades también se pueden reservar capacidades para ciertas direcciones o aplicaciones, por ejemplo "reservar el 30% de la capacidad para el servidor de FTP" o "reservar el 20% de la capacidad para paquetes provenientes de la dirección IP 147.156.1.1".
11.4.5 Derramamiento de la carga.
El último recurso para resolver un problema de congestión es descartar paquetes. En ocasiones, los paquetes llevan alguna indicación de su grado de importancia, en cuyo
Ciencias y Técnicas Estadísticas 10

Adquisición y Tratamiento de Datos La capa de red en Internet
caso los routers intentan descartar los menos importantes primero. Por ejemplo, sería bastante grave si un router para resolver una situación de congestión descartara paquetes de asfixia.
A veces el nivel de aplicación puede dar información sobre la prioridad de descarte de los paquetes. Por ejemplo en aplicaciones isócronas (audio y vídeo en tiempo real) suele ser preferible descartar el paquete viejo al nuevo ya que el viejo seguramente es inútil, mientras que en transferencia de ficheros ocurre al contrario pues el receptor necesita recibirlos todos y el más antiguo causará antes retransmisión por timeout. En los ficheros MPEG (formato de compresión de vídeo en Internet), debido a la técnica de compresión utilizada algunos fotogramas son completos (los denominados fotogramas intra) y otros son diferencias respecto a los anteriores y/o posteriores (llamados fotogramas predictivos y bidireccionales); descartar un paquete perteneciente a un fotograma intra es más perjudicial para la calidad de la imagen que descartar uno de un fotograma predictivo o bidireccional, ya que el defecto repercute en todos los fotogramas que derivan de él.
En algunos casos el paquete transmitido por la red es parte de una secuencia correspondiente a otro paquete de mayor tamaño que viaja fragmentado. En estos casos si se descarta un paquete cualquiera de una secuencia se tendrá que reenviar todo el grupo, por lo que al descartar uno es conveniente descartar todos los demás ya que son tráfico inútil.
11.5 La capa de red en Internet.
Internet es un compendio de redes diferentes que comparten un protocolo, o pila de protocolos comunes (IP a nivel de red y sobre todo TCP a nivel de transporte); cada una de estas redes es administrada por una entidad diferente: universidades, redes académicas nacionales, proveedores comerciales (Internet Service Providers), operadores, multinacionales, etc. Como consecuencia de esto las políticas de uso son muy variadas.
La red Internet tiene como protocolo principal al protocolo IP pero dentro de ella encontramos otros auxiliares que se emplearán para determinadas funciones que debe realizar esta capa. Técnicamente a nivel de red la Internet puede definirse como un conjunto de redes o sistemas autónomos conectados entre sí que utilizan el protocolo de red IP.
IP es una red de datagramas, no orientada a conexión, con calidad de servicio “best effort”, es decir, no hay calidad de servicio; no se garantiza la entrega de los paquetes ya que en momentos de congestión éstos pueden ser descartados sin previo aviso por los routers que se encuentren en el trayecto.
11.6 El protocolo IP.
Toda información en una red IP ha de viajar en datagramas IP. Esto incluye tanto las TPDUs (Transport Protocol Data Units) de TCP y UDP, como cualquier
Ciencias y Técnicas Estadísticas 11

Adquisición y Tratamiento de Datos La capa de red en Internet
información de routing que se intercambie en la red (paquetes ECHO, HELLO, PRUNE, de asfixia, etc.).
El datagrama tiene dos partes: cabecera y texto; la cabecera tiene una parte fija de 20 bytes y una opcional de entre 0 y 40 bytes (siempre múltiplo de 4). La estructura de la cabecera es la que se muestra en la figura 11.6.1.
311916840
Versión IHL Tipo de servicio Longitud total
Identificación Desplazamiento del fragmento
Tiempo de vida Protocolo Suma de comprobación de la cabecera
Dirección de origen
Dirección de destino
Opciones IP (0 o más palabras)
Flags
Datos (Opcional)
Figura 11.6.1: Campos del Datagrama IP.
El campo versión permite que coexistan en la misma red sin ambigüedad paquetes de distintas versiones; la versión actualmente utilizada de IP (que corresponde a la estructura de datagrama que estamos estudiando) es la 4. Actualmente está en fase de desarrollo e introducción una nueva versión (la versión 6) con una estructura de datagrama diferente.
El campo IHL especifica la longitud de la cabecera, en palabras de 32 bits, ya que ésta puede variar debido a la presencia de campos opcionales. Se especifica en palabras de 32 bits. La longitud mínima es 5 y la máxima 15, que equivale a 40 bytes de información opcional. La longitud de la cabecera siempre ha de ser un número entero de palabras de 32 bits, por lo que si la longitud de los campos opcionales no es un múltiplo exacto de 32 bits se utiliza un campo de relleno al final de la cabecera.
El campo tipo de servicio tiene la siguiente estructura:
Subcampo Longitud (bits)Precedencia (o prioridad) 3TOS (Type Of Service) 4Reservado 1Figura 11.6.2: Estructura del campo “Tipo de servicio”.
La precedencia permiten especificar una prioridad entre 0 y 7 para cada datagrama, pudiendo así marcar los paquetes normales con prioridad 0 y los importantes (por ejemplo paquetes de asfixia) con prioridad 7. La prioridad actúa alterando el orden de los paquetes en cola en los routers, pero no modifica la ruta de éstos. Dada la actual abundancia de ordenadores personales y estaciones de trabajo gestionadas por el usuario final, muchos equipos ignoran este campo y cuando hacen uso de él es únicamente para datagramas transmitidos entre routers, que se supone que están libres de esta sospecha. Los cuatro bits siguientes actúan como flags denominados D, T, R y C respectivamente. El primero indica que se desea un servicio de bajo retardo (D=Delay); el segundo que se quiere elevado rendimiento (T=Throughput), el tercero que se quiere una elevada
Ciencias y Técnicas Estadísticas 12

Adquisición y Tratamiento de Datos La capa de red en Internet
fiabilidad (R=Reliability), y el cuarto que se quiere un bajo costo (C=Cost). Las combinaciones válidas del subcampo TOS son las siguientes:
Valor TOS Descripción0000 Valor por defecto0001 Mínimo costo0010 Máxima fiabilidad0100 Máximo rendimiento1000 Mínimo retardo1111 Máxima seguridad
Figura 11.6.3: Combinaciones válidas del campo TOS.
Para cada aplicación existe un valor de TOS recomendado. Por ejemplo, para telnet se recomienda 1000 (mínimo retardo), para FTP 0100 (máximo rendimiento) y para NNTP (news) 0001 (mínimo costo).
Algunos routers utilizan el subcampo TOS para encaminar los paquetes por la ruta óptima en función del valor especificado (podrían tener una ruta diferente según se desee mínimo retardo o mínimo costo, por ejemplo); también pueden utilizar el valor del campo TOS para tomar decisiones sobre que paquetes descartar en situaciones de congestión (por ejemplo descartar antes un paquete con mínimo costo que uno con máxima fiabilidad). Algunos routers simplemente ignoran este subcampo.
Protocolo a nivel de enlace MTU(bytes)PPP (valor por defecto) 1500PPP (bajo retardo) 296SLIP 1006 (límite original)X.25 1600 (varía según las redes)Frame relay Al menos 1600 normalmenteSMDS 9235Ethernet versión 2 1500IEEE 802.3/802.2 1492IEEE 802.4/802.2 8166Token Ring IBM 16 Mbps 17914 máximoIEEE 802.5/802.2 4 Mbps 4464 máximoFDI 4352Hyperchannel 65535ATM 9180
Figura 11.6.4: Valor de MTU para los protocolos más comunes a nivel de enlace.
El campo longitud total especifica la longitud del datagrama completo (cabecera incluida) en bytes. Su tamaño se especifica en un campo de dos bytes, por lo que su valor máximo es de 65535 bytes, pero muy pocas redes admiten este valor. Normalmente el nivel de enlace no fragmenta, por lo que el nivel de red adapta el tamaño de cada paquete para que viaje en una trama; con lo que en la práctica el tamaño máximo de paquete viene determinado por el tamaño máximo de trama característico de la red utilizada. Este tamaño máximo de paquete se conoce como MTU (Maximum Transfer Unit). En la tabla 11.6.4 se dan algunos ejemplos de valores de MTU característicos de las redes más habituales.
Ciencias y Técnicas Estadísticas 13

Adquisición y Tratamiento de Datos La capa de red en Internet
Es bastante normal utilizar 1500 como valor de MTU. Cualquier red debe soportar como mínimo un MTU de 68 bytes.
El campo identificación lo usa el emisor para marcar en origen cada datagrama emitido, y permite al receptor reconocer las partes correspondientes en caso de que se haya producido fragmentación por el camino (dado que se pueden tener que atravesar varias redes puede ocurrir que ya estando el datagrama de camino se encuentre una red con un tamaño menor de MTU, por lo que el router de turno deberá fragmentar el datagrama).
Dentro de los flags el bit más significativo está reservado. El siguiente bit, el bit DF (Don't Fragment), cuando está a 1 indica a los routers que no fragmenten el paquete, ya que el receptor no está capacitado para reensamblarlo. Por ejemplo, si un ordenador arranca su sistema operativo a través de la red solicitará que el ejecutable correspondiente se le envíe desde algún servidor a través de la red como un único datagrama (ya que en ese estado él aun no está capacitado para reensamblar datagramas). Si un datagrama con el bit DF puesto no puede pasar por una red el router lo rechazará con un mensaje de error al emisor. Existe una técnica para averiguar el MTU de una ruta (denominada “path MTU discovery”) que consiste en enviar un datagrama grande con el bit DF puesto al destino deseado; si se recibe un mensaje de error se envía otro mas pequeño, hasta que el emisor averigua a base de tanteos cual es el valor de MTU de la ruta correspondiente, y a partir de ahí puede utilizarla para todos los datagramas sin riesgo de que sean fragmentados en el camino (siempre y cuando la ruta no cambie sobre la marcha).
El otro flag corresponde al bit MF (More Fragments) y puesto a 1 especifica que este datagrama es realmente un fragmento de un datagrama mayor, y que no es el último. Si está a 0 indica que este es el último fragmento (o bien que el datagrama original no esta fragmentado).
El campo desplazamiento del fragmento (fragment offset) sirve para indicar, en el caso de que el datagrama sea un fragmento de un datagrama mayor, en que posición del datagrama mayor empieza este fragmento. Los cortes siempre se realizan en frontera múltiplo de 8 bytes (la unidad elemental de fragmentación), por lo que este campo en realidad cuenta los bytes de 8 en 8. Al ser su longitud de 13 bits el número máximo de fragmentos es de 8192, que da cabida a la longitud máxima de un datagrama (8192 x 8 = 65536). Los fragmentos pueden llegar desordenados, por lo que el último fragmento puede llegar al receptor sin que haya recibido aun todos los fragmentos; la información fragment offset junto con longitud del último fragmento (identificado porque tiene el bit MF a 0) le permite al receptor calcular la longitud total del datagrama original (que sería fragment_offset*8 + longitud).
El campo tiempo de vida (TTL) permite descartar un datagrama cuando ha pasado un tiempo excesivo viajando por la red y es presumiblemente inútil. En el diseño original se pretendía que el valor de este campo (que inicialmente podía valer por ejemplo 64) disminuyera en cada router en un valor igual al tiempo en segundos que el paquete había empleado en esa parte del trayecto, restando como mínimo 1 en cualquier caso. En la práctica medir tiempos en una red es mucho más difícil de lo que parece (los relojes de los routers han de estar muy bien sincronizados, cosa que hoy en día no
Ciencias y Técnicas Estadísticas 14
Adquisición y Tratamiento de Datos La capa de red en Internet
ocurre), por lo que todas las implementaciones se limitan sencillamente a restar 1 al valor de TTL de cada paquete que pasa por ellos, sin analizar el tiempo que el paquete ha invertido en el salto. Como de cualquier forma hoy en día es muy raro que un paquete tarde más de un segundo en cada salto esto está aproximadamente de acuerdo con el diseño original. El valor inicial de TTL de un paquete fija el número máximo de saltos que podrá dar, y por tanto debería ser suficientemente grande como para que pueda llegar a su destino. El TTL evita que por algún problema de rutas se produzcan bucles y un datagrama pueda permanecer “flotando” indefinidamente en la red.
El campo protocolo especifica a que protocolo del nivel de transporte corresponde el datagrama. La tabla de protocolos válidos y sus correspondientes números son controlados por el IANA (Internet Assigned Number Authority) y se especifican (junto con muchas otras tablas de números) en un RFC muy especial, denominado “Assigned Numbers”, que se actualiza regularmente; el vigente actualmente es el RFC 1700. Algunos de los posibles valores del campo protocolo son los siguientes:
Valor Protocolo Descripción0 Reservado1 ICMP Internet Control Message Protocol2 IGMP Internet Group Management Protocol3 GGP Gateway-to-Gateway Protocol4 IP IP en IP (encapsulado)5 ST Stream6 TCP Transmission Control Protocol8 EGP Exterior Gateway Protocol17 UDP User Datagram Protocol29 ISO-TP4 ISO Transport Protocol Clase 438 IDRP-CMTP IDRP Control Message Transport Protocol80 ISO-IP ISO Internet Protocol (CLNP)88 IGRP Internet Gateway Routing Protocol (Cisco)89 OSPF Open Shortest Path First255 Reservado
Figura 11.6.5: Ejemplo de valores y significados del campo protocolo en un datagrama.
Obsérvese que el valor 4 está reservado al uso de IP para transportar IP, es decir al encapsulado de un datagrama IP dentro de otro.
El campo suma de comprobación de la cabecera (checksum) sirve para detectar errores producidos en la cabecera del datagrama; la suma de comprobación es el complemento a uno en 16 bits de la suma complemento a uno de toda la cabecera (incluidos los campos opcionales si los hubiera), tomada en campos de 16 bits; para el cálculo el campo suma de comprobación se pone a sí mismo a ceros. Este campo permite salvaguardar a la red de un router que alterara los campos de cabecera de un datagrama, por ejemplo por un problema hardware. El campo suma de comprobación se ha de recalcular en cada salto, ya que al menos el TTL cambia. Esto supone un serio inconveniente desde el punto de vista de rendimiento en routers con mucho tráfico.
Ciencias y Técnicas Estadísticas 15

Adquisición y Tratamiento de Datos La capa de red en Internet
Los campos dirección de origen y dirección de destino corresponden a direcciones IP según el formato que veremos con posterioridad.
Los campos opcionales de la cabecera no siempre están soportados en los routers y se utilizan muy raramente; de estos podemos destacar los siguientes:
• Record route: Esta opción pide a cada router por el que pasa este datagrama que anote en la cabecera su dirección, con lo que se dispone de una traza de la ruta seguida para fines de prueba o diagnóstico de problemas (es como si el router estampara su sello en el datagrama antes de reenviarlo). Debido a la limitación en la longitud de la cabecera como máximo pueden registrarse 9 direcciones, lo cual es insuficiente en algunos casos.
• Source routing: permite al emisor especificar la ruta que debe seguir el datagrama hasta llegar a su destino. Existen dos variantes: “strict source routing” permite especificar la ruta exacta salto a salto, de modo que si algún paso de la ruta no es factible por algún motivo se producirá un error. Con “loose source routing” no es preciso detallar todos los saltos, puede haber pasos intermedios no especificados.
• Timestamp: esta opción actúa de manera similar a “record route”, pero además de anotar la dirección IP de cada router atravesado se anota en otro campo de 32 bits el instante en que el datagrama pasa por dicho router. El uso de dos campos de 32 bits acentúa aún mas el problema antes mencionado del poco espacio disponible para grabar esta información.
De estos el más utilizado es “source routing”, y aún éste se usa poco por el problema del espacio en la cabecera; generalmente se prefiere usar en su lugar encapsulado IP en IP, que es más eficiente.
11.7 Direcciones IP.
Cada interfaz de red de cada nodo (ordenador o router) en una red IP se identifica mediante una dirección única de 32 bits. Sin embargo, y dado que representar las direcciones en binario es confuso, las direcciones IP se suelen representar por cuatro números decimales separados por puntos, donde cada valor decimal corresponde a la representación en decimal del valor binario de 8 bits (1 byte). Así, por ejemplo, la dirección IP dada por 10010011100111001101111001000001 se suele representar como 147.156.222.65.
Si un nodo dispone de varias interfaces físicas5, cada una de ellas deberá tener necesariamente una dirección IP distinta si se desea que sea accesible para este protocolo. Es posible además, y en algunas situaciones resulta útil, definir varias direcciones IP asociadas a una misma interfaz física.
Las direcciones IP tienen una estructura jerárquica. Una parte de la dirección corresponde a la red, y la otra al ordenador dentro de la red. Cuando un router recibe un
5 De forma general los routers y cualquier otro dispositivo de encaminamiento poseen más de un interfaz físico de red.
Ciencias y Técnicas Estadísticas 16

Adquisición y Tratamiento de Datos La capa de red en Internet
datagrama por una de sus interfaces compara la parte de red de la dirección con las entradas contenidas en sus tablas6 y envía el datagrama por la interfaz correspondiente.
En el diseño inicial de la Internet se reservaron los ocho primeros bits para la red, dejando los 24 restantes para el ordenador; se creía que con 254 redes habría suficiente para una red experimental que era fruto de un proyecto de investigación del Departamento de Defensa americano. Sin embargo, en 1980 se vio que esto resultaba insuficiente, por lo que se reorganizó el espacio de direcciones reservando una parte para poder definir redes más pequeñas. Con el fin de proporcionar mayor flexibilidad y permitir diferentes tamaños se optó por dividir el rango de direcciones en tres partes adecuadas para redes grandes, medianas y pequeñas, conocidas como redes de clase A, B y C respectivamente:
• Una red de clase A (que corresponde a las redes originalmente diseñadas) se caracteriza por tener a 0 el primer bit de dirección; el campo red ocupa los 7 bits siguientes y el campo ordenador los últimos 24 bits. Puede haber hasta 126 redes de clase A con 16 millones de ordenadores cada una.
• Una red de clase B tiene el primer bit a 1 y el segundo a 0; el campo red ocupa los 14 bits siguientes, y el campo ordenador los 16 últimos bits. Puede haber 16382 redes clase B con 65534 ordenadores cada una.
• Una red clase C tiene los primeros tres bits a 110; el campo red ocupa los siguientes 21 bits, y el campo ordenador los 8 últimos. Puede haber hasta dos millones de redes clase C con 254 ordenadores cada una.
Existe además direcciones (no redes) clase D cuyos primeros cuatro bits valen 1110, que se utilizan para definir grupos multicast (el grupo viene definido por los 28 bits siguientes).
Por último, la clase E, que corresponde al valor 11110 en los primeros cinco bits, está reservada para usos futuros.
De los valores de los primeros bits de cada una de las clases antes mencionadas se puede deducir el rango de direcciones que corresponde a cada una de ellas. Así pues, en la práctica es inmediato saber a que clase pertenece una dirección determinada sin más que saber el primer byte de su dirección. La figura 11.7.1 resume la información esencial sobre los tipos de direcciones de Internet.
6 Estas entradas contienen solo la identificación de la red, y no de un ordenador particular de la red.
Ciencias y Técnicas Estadísticas 17

Adquisición y Tratamiento de Datos La capa de red en Internet
2416 3180
Clase D
Clase C
Clase B
Clase A
224.0.0.0 … 239.255.255.0
192.0.0.0 … 223.255.255.0
128.0.0.0 … 191.255.0.0
0.1.0.0 … 126.0.0.0
0| Red
Host
1110
Host
10| Red
110| Red
Dirección multicast
Host
Figura 11.7.1: Clases de direcciones Internet y sus principales características.
La asignación de direcciones válidas de Internet la realizan los NICs (Network Information Center). Al principio había un NIC para toda la Internet, pero luego se crearon NICs regionales (por continentes); actualmente muchos países tienen un NIC propio; en España el NIC es administrado por RedIRIS.
Existen unas reglas y convenios en cuanto a determinadas direcciones IP que es importante conocer:
1. La dirección 255.255.255.255 y la que posee el campo ordenador todo a 1 se utiliza para indicar un datagrama broadcast7.
2. La dirección con el campo del ordenador todo a ceros se utiliza para indicar la red misma y, por tanto, no identifica a ningún ordenador.
3. La dirección 0.0.0.0 identifica siempre al ordenador actual.
4. La dirección con el campo de red todo a ceros identifica siempre a un ordenador dentro de la propia red.
5. Las redes 127.0.0.0, 128.0.0.0, 191.255.0.0, 192.0.0.0 y el rango de 240.0.0.0 en adelante están reservados y no deben utilizarse.
6. La dirección 127.0.0.1 se utiliza para pruebas de “loopback”; todas las implementaciones de IP devuelven a la dirección de origen los datagramas enviados a esta dirección, sin intentar enviarlos a ninguna parte.
7. Las redes 10.0.0.0, 172.16.0.0 a 172.31.0.0, y 192.168.0.0 a 192.168.255.0 están reservadas para “intranets” (redes privadas) por el RFC 1918, por lo que estos números no se asignan a ninguna dirección válida en Internet y pueden utilizarse para construir redes, por ejemplo detrás de un cortafuego, sin riesgo de entrar en conflicto de acceso a redes válidas de la Internet.
7 Un datagrama broadcast es aquel datagrama que debe ser enviado a todos los ordenadores de una red.
Ciencias y Técnicas Estadísticas 18

Adquisición y Tratamiento de Datos La capa de red en Internet
11.8 Subredes y superredes.
Existen determinados casos en que es necesario separar una red en subredes o bien, unir varias redes menores en una red de mayor tamaño. Un ejemplo del primer caso es cuando se tiene una red muy grande y desea dividirse en redes de menor tamaño, con el fin de facilitar la localización de los ordenadores y, con ello, las tablas de encaminamiento de los routers8; mientras que un ejemplo del segundo caso sería cuando se necesita una red para 500 ordenadores pues, en este caso, una red de clase B tiene un número excesivo de IPs, mientras que serían necesarias dos redes de clase C para cubrir su demanda. Para permitir la separación o unión de redes surgió el concepto de máscara.
Podemos definir la máscara de una red como un conjunto de números binarios que indican que bits de una dirección de red indican la red (bits con valor 1) y que bits de la red indican el ordenador (bits con valor 0). Además, existe la restricción de que los bits que indicaban la red deben ser los primeros y deben ser contiguos, de forma que una máscara es un grupo de bits con valor 1 seguido de otro grupo de bits con valor 0, teniendo una longitud de 32 bits.
Por ejemplo, son máscaras válidas las siguientes:
11111111000000000000000000000000111111111111111100000000000000001111111111111111111111110000000011111111111111111111111000000000
Mientras que no son máscaras válidas las siguientes:
1111111100000000111111110000000000000000000000001111111111111111
Como norma general, y para no escribir las máscaras en formato binario, suelen agruparse de 8 en 8 bits, convirtiendo ese valor en su representación decimal, y separando los grupos mediante un punto. Así, las máscaras válidas anteriores se escribirían como:
255.0.0.0255.255.0.0255.255.255.0255.255.254.0
En la actualidad, y teniendo en cuenta el hecho de que los bits con valor 1 son contiguos a la izquierda y el resto, hasta 32 bits, tienen valor 0, se suele emplear una notación consistente en escribir, en decimal, el número de bits que tienen valor 1. Así, las máscaras anteriores se representarían como 8, 16, 24 y 23, respectivamente.
El concepto de máscara puede aplicarse a cualquier red, aunque esta no sea una subred o una superred, siendo por tanto, 255.0.0.0 la máscara de una red de clase A, 255.255.0.0 la máscara de una red de clase B y 255.255.255.0 la de una red de clase C.
8 Un ejemplo de esto lo proporciona la propia red de la UV, en la cual se ha dividido la red de clase B 147.156.0.0 en subredes de mayor o menor tamaño según su localización geográfica en los distintos campús y edificios.
Ciencias y Técnicas Estadísticas 19

Adquisición y Tratamiento de Datos La capa de red en Internet
Es importante resaltar que la definición de máscara implica que, en una red, subred o superred, todos los bits que tengan valor 1 en la máscara, deben tener el mismo valor en la identificación de la red, de forma que, por ejemplo, si tenemos la máscara 255.255.255.252, que indica una subred de 4 direcciones IP, todas esas direcciones IP deben tener igual sus primeros 30 bits, pudiendo variar tan solo sus 2 últimos bits, por lo que, por ejemplo, las direcciones 192.168.1.4, 192.168.1.5, 192.168.1.6 y 192.168.1.7 pueden pertenecer a la misma red, mientras que las direcciones 192.168.1.6, 192.168.1.7, 192.168.1.8 y 192.168.1.9 no9.
11.8.1 Subredes.
Supongamos que deseamos utilizar la red de clase B 172.16.0.010 para asignar a un conjunto de ordenadores, y que dicho conjunto de ordenadores se encuentra disperso en diferentes edificios, tal y como sucede, por ejemplo, en un campús universitario.
En esta situación, suele ser muy conveniente dividir la red de clase B en redes de menor tamaño, pues esto nos permite, por ejemplo, separar el tráfico por edificios, disminuyendo el flujo de información por la red y mejorando sus prestaciones.
Para ello, supongamos que deseamos dividir la red de clase B en cuatro subredes11 iguales para los edificios Norte, Sur, Este y Oeste. Esta división se puede realizar mediante la máscara:
11111111111111111100000000000000 = 255.255.192.0
Con lo que obtenemos cuatro subredes que vendrán identificadas por los valores 172.16.0.0, 172.16.64.0, 172.16.128.0 y 172.16.192.0.
Si ahora deseamos dividir alguna de esas subredes, por ejemplo la 172.16.64.0 por la mitad, para dividir el tráfico de red entre dos edificios del Sur, podemos realizarlo mediante una nueva máscara que se aplicará a esa subred. Esta máscara será:
11111111111111111110000000000000 = 255.255.224.0
De forma que ahora tendremos un total de cinco subredes identificadas por los valores 172.16.0.0, 172.16.64.0, 172.16.96.0, 172.16.128.0 y 172.16.192.0.
11.8.2 Superredes.
El concepto de superred es contrario al de subred. Mientras que en una subred dividimos una red en redes de menor tamaño, en una superred unimos redes en una red de mayor tamaño mediante el uso de una máscara.
9 Téngase en cuenta la representación en binario de estos valores decimales.10 En los ejemplos utilizaremos direcciones pertenecientes a intranets y que por tanto no existen en Internet, tal y como indicamos en el apartado 11.7.11 Las divisiones solo pueden realizarse en potencias de 2, esto es, en 2, 4, 8, ..., partes iguales.
Ciencias y Técnicas Estadísticas 20

Adquisición y Tratamiento de Datos La capa de red en Internet
Para ello, supongamos que tenemos necesidad de crear una red para 500 ordenadores, pero solo se nos permite utilizar dos redes de clase C, por ejemplo, las redes 192.168.0.0 y 192.168.1.012. Entonces, podemos especificar una superred uniendo esas dos redes mediante la máscara:
11111111111111111111111000000000 = 255.255.254.0
Que indica que tenemos la superred 192.168.0.0/23, formada por 512 direcciones de red, donde 192.168.0.0 representa a la superred, 192.168.1.255 representa el broadcast de la superred y el resto de direcciones IP pueden ser asignadas a los ordenadores o dispositivos de red que se deseen conectar.
11.9 Configuración básica de una red.
Desarrollaremos a continuación unas sencillas explicaciones y un sencillo ejemplo que permitan aprender a configurar redes de ordenadores muy sencillas13. Para ello, utilizaremos siempre la red 192.168.0.0/24, correspondiente a una intranet, y consideraremos que tenemos acceso a Internet mediante una dirección IP que designaremos como A.B.C.D. Además, debemos introducir previamente algunos conceptos que todavía no hemos visto.
El primero de esos conceptos necesarios es la puerta de enlace14. Una puerta de enlace es el dispositivo de red, generalmente un router u ordenador, que nos permite acceder desde nuestra subred a una red más amplía. Como ejemplo, supóngase que una red es una habitación el la cual existe una puerta. Si deseamos ver a una persona que se encuentra fuera de la habitación, debemos salir por la puerta, mientras que si tan solo deseamos ver a una persona de la habitación no es necesario salir por la puerta. Por último, comentar que la puerta de enlace debe pertenecer a la red en la que se encuentra el dispositivo al que sirve como puerta de enlace, de igual forma que la puerta de nuestro ejemplo debe pertenecer a nuestra habitación y no a otra habitación distinta.
Otro concepto que es necesario conocer es el del servidor de nombres o DNS (Domain Name Server). El DNS no es más que un ordenador capaz de convertir los nombres con los que nos referimos a los ordenadores, en las direcciones IP correspondientes. Por ejemplo, cuando un usuario escribe en su navegador web el nombre www.uv.es, ese nombre debe traducirse en la dirección IP 147.156.1.46, que corresponde al ordenador en el que se encuentran esas páginas web.
Una vez introducidos estos conceptos, supongamos la siguiente configuración física de una red formada por dos ordenadores (figura 11.9.1). En ella, podemos ver dos ordenadores A y B conectados entre si mediante una intranet a un interfaz de red en cada ordenador. Además uno de ellos, el ordenador A, tiene un segundo interfaz de red que le permite acceder a Internet a través del mismo.
12 Téngase en cuenta que no es posible utilizar cualquiera dos redes clase C, pues estas deben ser tal que, al aplicar la máscara, todos los bits de red sean iguales, tal y como se ha indicado con anterioridad.13 Estas redes serán las típicas redes que un usuario particular puede tener en su domicilio.14 La puerta de enlace es también conocida con los nombres de puerta de acceso, pasarela y gateway.
Ciencias y Técnicas Estadísticas 21

Adquisición y Tratamiento de Datos La capa de red en Internet
A B
Figura 11.9.1: Red formada por dos ordenadores.
La configuración de los dos ordenadores deberá permitir que ambos ordenadores, A y B, sean capaces de comunicarse entre si y, además, que ambos puedan acceder a Internet.
Para ello, comenzaremos asignando direcciones IP a los interfaces de la intranet. Si recordamos que hemos escogido la red 192.68.0.0/24 para las direcciones IP de la intranet, podemos elegir, por ejemplo, la dirección 192.168.0.1 para el interfaz de la intranet del ordenador A y 192.168.0.2 para el interfaz del ordenador B15. Una vez asignadas las direcciones, procederemos a asignar las máscaras, que en ambos casos son iguales y con valor 255.255.255.0.
Una vez configuradas las direcciones IP de los interfaces de la intranet, procederemos a configurar las direcciones IP del interfaz del ordenador A que da acceso a Internet. Para ello, le asignaremos la dirección A.B.C.D, con la máscara adecuada según la red en la que se encuentre dicha dirección16.
Por tanto, en este momento tenemos la siguiente configuración en los ordenadores:
A B
IP: 192.168.0.1 Máscara: 255.255.255.0
IP: 192.168.0.2 Máscara: 255.255.255.0
IP: A.B.C.D Máscara: X.Y.Z.T
Figura 11.9.2: Configuración básica de la conexión de dos ordenadores.
En este momento podemos comprobar la misión fundamental que realiza la capa de red. Para ello, supongamos que el ordenador A desea enviar información al
15 Es necesario recordar que la dirección 192.168.0.0 identifica a la red, mientras que la dirección 192.168.0.255 identifica el broadcast de la red, por lo que no pueden utilizarse para identificar un ordenador de la red.16 Estos valores pueden ser asignados dinámicamente por el proveedor de acceso a Internet por lo que en esos casos no es necesario asignarlos manualmente, sino que es necesario indicar que la asignación se realizará mediante el protocolo DHCP (Dynamic Host Configuration Protocol). Además de estos valores, DHCP suele proveer también la dirección de la puerta de enlace y del servidor de DNS.
Ciencias y Técnicas Estadísticas 22

Adquisición y Tratamiento de Datos La capa de red en Internet
ordenador B. En este momento, la capa de red analiza los dos interfaz del ordenador A y determina que el ordenador B pertenece a la red del interfaz de la intranet, enviando la información por dicho interfaz. Sin embargo, si A desea enviar la información a la red de Internet, la capa de red decidirá enviarla por el otro interfaz que da acceso a Internet.
Sin embargo, a pesar de que en este punto los ordenadores A y B pueden comunicarse entre sí, pudiendo, además, el ordenador A acceder a Internet y llegar a todos los ordenadores de su red, sucede que el ordenador B no es capaz de acceder a Internet, mientras que el ordenador A no es capaz de acceder a ordenadores fuera de su red de Internet.
El motivo es que tanto en A como en B no se ha configurado la puerta de enlace, de forma que la capa de red de B no conoce por donde debe enviar los datos que no tengan como destino el ordenador A, mientras que A no conoce por donde debe enviar los datos que deban salir de su “trozo de red Internet”.
La configuración de las puertas de enlace es sencilla. La puerta de enlace de B es el interfaz de la intranet del ordenador A, mientras que la puerta de enlace de A con el resto de Internet debe ser facilitada por el proveedor de acceso a Internet, por ejemplo, A’.B’.C’.D’. Con esto, la configuración queda como
A B
IP: . . .1921680 1 Máscara: . . .2552552550
IP: . . .1921680 2 Máscara: . . .2552552550 Puerta: . . .1921680 1
IP: A.B.C.D Máscara: X.Y.Z.T Puerta: A’.B’.C’.D’
Figura 11.9.3: Configuración con puertas de enlace de dos ordenadores.
Con esta configuración, si el ordenador B desea enviar un paquete a un ordenador cualquiera de Internet, su capa de red observa que no pertenece a su red, por lo que comprueba que ordenador de su red es la puerta de enlace, enviando el paquete a la puerta de enlace para que esta lo reenvíe por el enlace adecuado. De igual forma, si A desea enviar un paquete fuera de su “trozo de red Internet”, o bien recibe un paquete de B con idéntico destino, procederá a enviarlo a la puerta de enlace de su interfaz de Internet, para que la puerta de enlace proceda de forma adecuada.
Por último, solo nos queda por configurar los DNS, pues ambos ordenadores son en este instante capaces de enviar y recibir paquetes de Internet, pero no son capaces de convertir ningún nombre de ordenador en la dirección IP correspondiente.
Esto se resuelve mediante la asignación de las direcciones de los servidores de DNS. Para ello, supongamos que la dirección IP del servidor de DNS que nos ha facilitado el proveedor de Internet es A’’.B’’,C’’.D’’. Entonces, podemos configurar el ordenador A indicando que el DNS es A’’.B’’.C’’.D’’. Sin embargo, en el ordenador B
Ciencias y Técnicas Estadísticas 23

Adquisición y Tratamiento de Datos La capa de red en Internet
tenemos dos posibilidades. La primera implica poner como servidor de DNS la misma dirección que en A, esto es A’’.B’’.C’’.D’’. La otra, consiste en poner como servidor de DNS en B la dirección de la intranet de A, esto es, 192.168.0.1, pues cuando la petición llegue al ordenador A, este verá que es una petición de DNS y, como conoce quién es el DNS, reenvía dicha petición al DNS17.
Por tanto, la configuración final de los ordenadores puede verse en la figura siguiente:
A B
IP: 192.168.0.1 Máscara: 255.255.255.0
IP: 192.168.0.2 Máscara: 255.255.255.0 Puerta: 192.168.0.1 DNS: 192.168.0.1
IP: A.B.C.D Máscara: X.Y.Z.T Puerta: A’.B’.C’.D’ DNS: A’’.B’’.C’’.D’’
Figura 11.9.4: Configuración de red de dos ordenadores.
11.10 Ejercicios.
11.10.1 Ejercicio.
Aplicando el algoritmo de Dijkstra, calcular el camino más corto entre los nodos A y J del siguiente grafo, que representa una red de comunicaciones, donde los valores entre los nodos del grafo indican la distancia existente en función de la métrica.
1
1
2
3
4
3
2
5
8
5
6
6
2
1
3
4
5
2
1
J
I
H
G
F
E
D
C
B
A
17 Si el proveedor de acceso a Internet facilita los datos mediante DHCP, debe utilizarse siempre esta segunda forma, pues no podemos asegurar que el servidor de DNS no cambie su IP en cada nueva asignación de dirección a nuestro ordenador.
Ciencias y Técnicas Estadísticas 24

Adquisición y Tratamiento de Datos La capa de red en Internet
11.10.2 Ejercicio.
Utilizando el algoritmo del pozal agujerado, calcular el tiempo que tardará en transmitirse una ráfaga de 10 Mbits en 50 msegs si =10 Mbps, C=5 Mbits y M=100 Mbps y el pozal está inicialmente lleno de créditos.
11.10.3 Ejercicio
Un pozal agujereado posee los valores de =10 Mbps y M=1 Gbps. Sabemos que si el pozal esta vacío y los créditos a la mitad de su valor máximo, que recordemos es la capacidad total del pozal C, es capaz de enviar tráfico de red a la velocidad de 1 Gbps durante 0,01 segundos. Calcular la capacidad del pozal.
11.10.4 Ejercicio.
Queremos enviar por una red una serie de 1000 datos bajo el protocolo de red IP. Especificar los campos longitud total, identificación, MF y desplazamiento del fragmento si la capacidad de envió por la red es:
a) Toda la red entre origen y destino admite paquetes de 256 bytes como máximo.
b) El principio de la red admite paquetes de 512 bytes como máximo y, a partir de cierto nodo, solo paquetes de 256 bytes como máximo.
11.10.5 Ejercicio.
Deseamos enviar 1000 bytes del ordenador 147.156.1.1 al ordenador 147.156.160.55. La red admite datagramas IP de 576 bytes. Escribir los datagramas que se enviarán, especificando toda la información posible.
11.10.6 Ejercicio.
Nos han asignado una red de clase C para dar soporte a un edificio de 4 plantas, de forma que queremos asignar 64 ordenadores a la 1ª planta, 32 a la 2ª y 3ª plantas y 128 a la 4ª planta. ¿Cuales son la direcciones IP y las mascaras de subred de cada una de las plantas?.
11.10.7 Ejercicio.
Deseamos crear una superred de 1024 direcciones y nos permiten elegir cualquier subred en el rango XXX.YYY.14.0 y XXX.YYY.21.0. ¿Cuál es el rango a elegir?.
Ciencias y Técnicas Estadísticas 25