taller de programación i teoría -...
TRANSCRIPT

FACENA
UNNE
Taller de Programación I
Teoría
Autores: Expto. Oscar Zalazar, Expto. Pedro L. Alfonzo, Lic. Yanina Medina, Osvaldo P. Quintana, Lic. Lucía Salazar
5
Facultad de Ciencias Exactas y Naturales y Agrimensura- UNNE
Desarrollo de Aplicaciones Web
Año 2012
Expto. Oscar Zalazar - Expto. Pedro L. Alfonzo - Lic. Yanina Medina - Osvaldo P. Quintana - Lic. Lucía Salazar [2012]

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 6
Presentación
La popularidad de Internet ha obligado a que los programadores necesiten conocer y comprender las tecnologías más avanzadas para crear aplicaciones ejecutables sobre esta plataforma.
Un desarrollador de aplicaciones web necesita conocer una gran variedad de tecnologías: lenguajes de programación de páginas web, tecnologías de programación del lado del cliente y del lado del servidor, tecnologías de acceso a base de datos a través de Internet y otras tecnologías más complejas.
Esta asignatura pretende ofrecer al alumno una visión completa de las tecnologías utilizadas en el desarrollo de aplicaciones web. Partiendo del diseño de páginas estáticas y de las tecnologías orientadas a la presentación (CSS, JavaScript), repasa tecnologías de cliente para mostrar luego tecnologías de programación para servidores, completando el recorrido con una visión general del acceso a base de datos a través de Internet.
En este proceso se pretende consolidar en el alumno, las competencias requeridas para un analista programador, tales como el modelado (utilización de los conocimientos y la comprensión para el diseño y modelado de aplicaciones) y los métodos y herramientas (aplicar de manera apropiada teorías, prácticas, y herramientas para la especificación, diseño, implementación y evaluación de aplicaciones informáticas).

Índice
Licenciatura en Sistemas de Información 7
Conceptos teóricos
Tema 1: Introducción a las tecnologías Web.
Perspectiva histórica de Internet.
Es la red de redes. Es el Sistema mundial de redes de computadoras interconectadas. Fue concebida a fines de la década de 1960 por el Departamento de Defensa de los Estados Unidos; más precisamente, por la ARPA.
Se la llamó primero ARPAnet y fue pensada para cumplir funciones de investigación. Su uso se popularizó a partir de la creación de la World Wide Web. Actualmente es un espacio público utilizado por millones de personas en todo el mundo como herramienta de comunicación e información.
Historia de Internet
1957
La Unión Soviética lanza el Sputnik, el primer satélite artificial. En respuesta a este hecho, Estados Unidos crea el ARPA (Organismo de Proyectos de Investigación Avanzada) dentro del Ministerio de Defensa a fin de establecer su liderazgo en el área de la ciencia y la tecnología aplicada a las fuerzas armadas.
1965
El ARPA promueve un estudio sobre “Redes cooperativas de computadoras de tiempo compartido”.
- El TX-2 en el laboratorio Lincoln del MIT y el AN/FSQ-32 de la System Development Corporation quedan vinculadas directamente (sin conmutación por paquetes) por medio de una línea telefónica dedicada de 1200 bps; más tarde se agrega la computadora de la Digital Equipment Corporation (DEC) en ARPA y así conforma la red experimental.
1968
Se presenta la red conmutada por paquetes (PS - Network) ante el ARPA.
1969
Se ponen en servicio los nodos a medida que BBN construye cada IMP [Honeywell DDP-516 con 12 K de memoria]; AT&T provee líneas de 50 kpbs
El procesador de mensajes de interfaz (IMP) fue la de conmutación de paquetes nodo utiliza para interconectar las redes de los participantes a la ARPANET de los años 1960 a 1989. Fue la primera generación de gateways, que hoy se conocen como routers.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 8
Nodo 1: UCLA - Universidad de Los Ángeles, California. (30 de Agosto)
- Función: Centro de evaluación de redes.
- Sistema, Sistema operativo:SDS SIGMA 7,
Nodo 2: Instituto de Investigaciones de Stanford.(SRI) (1 de Octubre)
- Centro de Información de Redes (Network Information Center)(NIC)
- SDS 940/Genie
- Proyecto de Doug Engelbart sobre “Debate sobre el intelecto humano”.
Nodo 3: Universidad de California Santa Bárbara (UCSB) (1 de Noviembre)
- Matemática Interactiva de Culler - Fried.
- IBM 360/75, OS/MVT
Nodo 4: Universidad de Utah. (Diciembre)
- Gráficos.
- DEC PDP-10, Tenex
1971
15 nodos (23 hosts): UCLA, SRI, UCSB, Universidad de Utha, BBN, MIT, RAND, SDC, Harvard, Laboratorio Lincoln, Stanford, UIU©, CWRU, CMU, NASA/Ames.
Ray Tomlinson de BBN inventa un programa de correo electrónico para mandar mensajes en redes distribuidas. El programa original es producto de otros dos: un programa interno de correo electrónico (SENDMSG) y un programa experimental de transferencia de archivos (CPYNET).
1972
Ray Tomlinson modifica el programa de correo electrónico para ARPANET donde se transforma en un éxito. Se elige el signo @ entre los signos de puntuación de la máquina de teletipos Tomlinson Modelo 33 para representar el “en”.
Larry Roberts crea el primer programa de administración de correo electrónico para listar, leer selectivamente, guardar, re enviar y responder mensajes.
RFC 318: Especificación Telnet
1980
ARPANET deja de funcionar por completo el 27 de Octubre a raíz de una advertencia de virus propagada accidentalmente

Índice
Licenciatura en Sistemas de Información 9
1983
El servidor de nombres desarrollado en la Universidad de Wisconsin ya no requiere que el usuario conozca la ruta exacta para acceder a otros sistemas.
Paso de NCP a TCP/IP (1 Enero)
NCP: Protocolos de Control de Red de ARPANET
TCP/IP: Protocolo de Control de Transmisión / Protocolo de Internet
TCP/IP es un modelo de descripción de protocolos de red creado en la década de 1970 por DARPA. Desaparecen los IMPs Honeywell o Pluribus; los TIPs son reemplazados por TACs
1984
Se introduce el Domain Name System(DNS) (Sistema de nombre de dominio)
1986 Se crea la NSFNET (Con una velocidad principal de 56Kbps).
NSF establece 5 centros de super computadoras para proveer alto poder de proceso. (JVNC@Princeton, PSC@Pittsburgh, SDSC@UCSD, NCSA@UIUC, Theory Center@Cornell).
Esto permite una explosión de conexiones, especialmente por parte de las universidades.
1990
ARPANET deja de existir.
1991
CERN lanza la World-Wide Web (WWW)creada por Tim Berners - Lee.
1993
La Casa Blanca se conecta en línea ( http://www.whitehouse.gov/):
Presidente Bill Clinton: [email protected]
Vicepresidente Al Gore: [email protected]
Worms (gusanos) de una nueva clase aparecen en la Red - los Worms WWW (W4) a los que se les unen los Spiders (arañas) , Wanderers (vagabundos) , Crawlers (orugas) y Snakes (serpientes)…
Mosaic genera un crecimiento asombroso: la WWW crece a una tasa del 341.634% anual para el flujo de servicio. Gopher crece a una tasa del 997%.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 10
1995
Sun lanza JAVA el 23 de Mayo
Real Audio, una tecnología de audio, permite que los usuarios de la Red reciban el sonido casi en tiempo real.
WWW supera a ftp-data en Marzo y se transforma en el servicio de mayor flujo en la NSF Net? en base al conteo de paquetes y en Abril en base al conteo de bytes.
2000
El Controlador de tiempo de los EE. UU. (USNO) y otros pocos servicios de tiempo de todo el mundo reportan el nuevo año como 19100 el primero de Enero.
Un ataque de rechazo de servicio masivo es lanzado contra importantes sitios web, incluyendo a Yahoo, Amazon, y eBay a comienzos de Febrero.
El tamaño de la Web estimado por NEC-RI e Inktomi sobrepasa los mil millones de páginas susceptibles de ser catalogadas.
2011
En cuanto al número de URL´s creadas cada día, esta cifra ha crecido un 21% en los dos últimos años de 3.7 millones mensuales en 2009 a los 4.5 millones mensuales en el año 2011, con una media de 150.000 nuevas URL´s al día en Junio.
Protocolo http (protocolo de transferencia de hipertexto).
El Protocolo de Transferencia de HiperTexto (Hypertext Transfer Protocol) es un sencillo protocolo cliente-servidor que articula los intercambios de información entre los clientes Web y los servidores HTTP. La especificación completa del protocolo HTTP 1/0 está recogida en el RFC 1945. Fue propuesto por Tim Berners-Lee, atendiendo a las necesidades de un sistema global de distribución de información como el World Wide Web.
Desde el punto de vista de las comunicaciones, está soportado sobre los servicios de conexión TCP/IP, y funciona de la misma forma que el resto de los servicios comunes de los entornos UNIX: un proceso servidor escucha en un puerto de comunicaciones TCP (por defecto, el 80), y espera las solicitudes de conexión de los clientes Web. Una vez que se establece la conexión, el protocolo TCP se encarga de mantener la comunicación y garantizar un intercambio de datos libre de errores.
HTTP se basa en sencillas operaciones de solicitud/respuesta. Un cliente establece una conexión con un servidor y envía un mensaje con los datos de la solicitud. El servidor responde con un mensaje similar, que contiene el estado de la operación y su posible resultado. Todas las operaciones pueden adjuntar un objeto o recurso sobre el que actúan; cada objeto Web (documento HTML, fichero multimedia o aplicación CGI) es conocido por su URL.

Índice
Licenciatura en Sistemas de Información 11
Etapas de una transacción HTTP.
Cada vez que un cliente realiza una petición a un servidor, se ejecutan los siguientes pasos:
Un usuario accede a una URL, seleccionando un enlace de un documento HTML o introduciéndola directamente en el campo Location del cliente Web.
El cliente Web descodifica la URL, separando sus diferentes partes. Así identifica el protocolo de acceso, la dirección DNS o IP del servidor, el posible puerto opcional (el valor por defecto es 80) y el objeto requerido del servidor.
Se abre una conexión TCP/IP con el servidor, llamando al puerto TCP correspondiente. Se realiza la petición. Para ello, se envía el comando necesario (GET, POST, HEAD,…), la dirección del objeto requerido (el contenido de la URL que sigue a la dirección del servidor), la versión del protocolo HTTP empleada (casi siempre HTTP/1.0) y un conjunto variable de información, que incluye datos sobre las capacidades del browser, datos opcionales para el servidor,…
El servidor devuelve la respuesta al cliente. Consiste en un código de estado y el tipo de dato MIME de la información de retorno, seguido de la propia información.
Se cierra la conexión TCP.
Este proceso se repite en cada acceso al servidor HTTP. Por ejemplo, si se recoge un documento HTML en cuyo interior están insertadas cuatro imágenes, el proceso anterior se repite cinco veces, una para el documento HTML y cuatro para las imágenes.
El estándar HTTP/1.0 recoge únicamente tres comandos, que representan las operaciones de recepción y envío de información y chequeo de estado:
GET: Se utiliza para recoger cualquier tipo de información del servidor. Se utiliza siempre que se pulsa sobre un enlace o se teclea directamente a una URL. Como resultado, el servidor HTTP envía el documento correspondiente a la URL seleccionada, o bien activa un módulo CGI, que generará a su vez la información de retorno.
HEAD: Solicita información sobre un objeto (fichero): tamaño, tipo, fecha de modificación… Es utilizado por los gestores de cachés de páginas o los servidores proxy, para conocer cuándo es necesario actualizar la copia que se mantiene de un fichero.
POST: Sirve para enviar información al servidor, por ejemplo los datos contenidos en un formulario. El servidor pasará esta información a un proceso encargado de su tratamiento (generalmente una aplicación CGI). La operación que se realiza con la información proporcionada depende de la URL utilizada. Se utiliza, sobre todo, en los formularios.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 12
Un cliente Web selecciona automáticamente los comandos HTTP necesarios para recoger la información requerida por el usuario. Así, ante la activación de un enlace, siempre se ejecuta una operación GET para recoger el documento correspondiente. El envío del contenido de un formulario utiliza GET o POST, en función del atributo de <FORM METHOD="...">. Además, si el cliente Web tiene un caché de páginas recientemente visitadas, puede utilizar HEAD para comprobar la última fecha de modificación de un fichero, antes de traer una nueva copia del mismo.
Posteriormente se han definido algunos comandos adicionales, que sólo están disponibles en determinadas versiones de servidores HTTP, con motivos eminentemente experimentales. La última versión de HTTP, denominada 1.1, recoge estas y otras novedades, que se pueden utilizar, por ejemplo, para editar las páginas de un servidor Web trabajando en remoto.
Localizador Uniforme de Recursos (URL).
Un localizador uniforme de recursos, más comúnmente denominado URL (sigla en inglés de uniform resource locator), es una secuencia de caracteres, de acuerdo a un formato modélico y estándar, que se usa para nombrar recursos en Internet para su localización o identificación, como por ejemplo documentos textuales, imágenes, vídeos, presentaciones, presentaciones digitales, etc.
Los localizadores uniformes de recursos fueron una innovación fundamental en la historia de la Internet. Fueron usadas por primera vez por Tim Berners-Lee en 1991, para permitir a los autores de documentos establecer hiperenlaces en la World Wide Web. Desde 1994, en los estándares de la Internet, el concepto de URL ha sido incorporado dentro del más general de URI (uniform resource identifier, en español identificador uniforme de recurso), pero el término URL aún se utiliza ampliamente.
Aunque nunca fueron mencionadas como tal en ningún estándar, mucha gente cree que las iniciales URL significan universal resource locator (localizador universal de recursos). Esta interpretación puede ser debida al hecho de que, aunque la U en URL siempre ha significado "uniforme", la U de URI significó en un principio "universal", antes de la publicación del RFC 2396.
El URL es la cadena de caracteres con la cual se asigna una dirección única a cada uno de los recursos de información disponibles en la Internet. Existe un URL único para cada página de cada uno de los documentos de la World Wide Web, para todos los elementos de Gopher y todos los grupos de debate USENET, y así sucesivamente.
El URL de un recurso de información es su dirección en Internet, la cual permite que el navegador la encuentre y la muestre de forma adecuada. Por ello el URL combina el nombre del ordenador que proporciona la información, el directorio donde se encuentra, el nombre del archivo, y el protocolo a usar para recuperar los datos.
El formato general de un URL es:
esquema://máquina/directorio/archivo

Índice
Licenciatura en Sistemas de Información 13
También pueden añadirse otros datos:
esquema://usuario:contraseña@máquina:puerto/directorio/archivo
Por ejemplo: http://es.Wikipedia.org/
Esquema URL
Un URL se clasifica por su esquema, que generalmente indica el protocolo de red que se usa para recuperar, a través de la red, la información del recurso identificado. Un URL comienza con el nombre de su esquema, seguido por dos puntos, seguido por una parte específica del esquema'.
Algunos ejemplos de esquemas URL:
http - recursos HTTP
https - HTTP sobre SSL
ftp - File Transfer Protocol
mailto - direcciones de correo electrónico
ldap - búsquedas LDAP Lightweight Directory Access Protocol
file - recusos disponibles en el sistema local, o en una red local
news - grupos de noticias Usenet (newsgroup)
gopher - el protocolo Gopher (ya en desuso)
telnet - el protocolo telnet
data - el esquema para insertar pequeños trozos de contenido en los documentos Data: URL
Algunos de los esquemas URL, como los populares "mailto", "http", "ftp", y "file", junto a los de sintaxis general URL, se detallaron por primera vez en 1994, en el Request for Comments RFC 1630, sustituido un año después por los más específicos RFC 1738 y RFC 1808.
Algunos de los esquemas definidos en el primer RFC aún son válidos, mientras que otros son debatidos o han sido refinados por estándares posteriores. Mientras tanto, la definición de la sintaxis general de los URL se ha escindido en dos líneas separadas de especificación de URI: RFC 2396 (1998) y RFC 2732 (1999), ambos ya obsoletos pero todavía ampliamente referidos en las definiciones de esquemas URL.
El estándar actual es STD 66 / RFC 3986 (2005).
URL en el uso diario
Un HTTP URL combina en una dirección simple los cuatro elementos básicos de información necesarios para recuperar un recurso desde cualquier parte en la Internet:

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 14
El protocolo que se usa para comunicar,
El anfitrión (servidor) con el que se comunica,
El puerto de red en el servidor para conectarse,
La ruta al recurso en el servidor (por ejemplo, su nombre de archivo).
Un URL típico puede lucir como:
http://es.wikipedia.org:80/wiki/Special:Search?search=tren&go=Go
donde
http es el esquema,
es.wikipedia.org es el anfitrión,
80 es el número de puerto de red en el servidor (siendo 80 el valor por omisión para el protocolo HTTP, esta porción puede ser omitida por completo),
/wiki/Special:Search es la ruta de recurso,
?search=tren&go=Go es la cadena de búsqueda; esta parte es opcional.
Muchos navegadores web no requieren que el usuario ingrese "http://" para dirigirse a una página web, puesto que HTTP es el protocolo más común que se usa en navegadores web. Igualmente, dado que 80 es el puerto por omisión para HTTP, usualmente no se especifica. Normalmente uno sólo ingresa un URL parcial tal como www.wikipedia.org/wiki/Train. Para ir a una página principal se introduce únicamente el nombre de anfitrión, como www.wikipedia.org.
Qué es una aplicación Web.
En la ingeniería de software se denomina aplicación web a aquellas aplicaciones que los usuarios pueden utilizar accediendo a un servidor web a través de Internet o de una intranet mediante un navegador. En otras palabras, es una aplicación software que se codifica en un lenguaje soportado por los navegadores web en la que se confía la ejecución al navegador.
Las aplicaciones web son populares debido a lo práctico del navegador web como cliente ligero, a la independencia del sistema operativo, así como a la facilidad para actualizar y mantener aplicaciones web sin distribuir e instalar software a miles de usuarios potenciales. Existen aplicaciones como los webmails, wikis, weblogs, tiendas en línea, que son ejemplos bien conocidos de aplicaciones web.
Es importante mencionar que una página Web puede contener elementos que permiten una comunicación activa entre el usuario y la información. Esto permite que el usuario acceda a los datos de modo interactivo, gracias a que la página responderá a cada una de sus acciones, como por ejemplo rellenar y enviar formularios, participar en juegos diversos y acceder a gestores de base de datos de todo tipo.

Índice
Licenciatura en Sistemas de Información 15
Cliente web. Servidor Web.
La arquitectura cliente-servidor es un modelo de aplicación distribuida en el que las tareas se reparten entre los proveedores de recursos o servicios, llamados servidores, y los demandantes, llamados clientes. Un cliente realiza peticiones a otro programa, el servidor, que le da respuesta. Esta idea también se puede aplicar a programas que se ejecutan sobre una sola computadora, aunque es más ventajosa en un sistema operativo multiusuario distribuido a través de una red de computadoras.
En esta arquitectura la capacidad de proceso está repartida entre los clientes y los servidores, aunque son más importantes las ventajas de tipo organizativo debidas a la centralización de la gestión de la información y la separación de responsabilidades, lo que facilita y clarifica el diseño del sistema.
La separación entre cliente y servidor es una separación de tipo lógico, donde el servidor no se ejecuta necesariamente sobre una sola máquina ni es necesariamente un sólo programa. Los tipos específicos de servidores incluyen los servidores web, los servidores de archivo, los servidores del correo, etc. Mientras que sus propósitos varían de unos servicios a otros, la arquitectura básica seguirá siendo la misma.
Una disposición muy común son los sistemas multicapa en los que el servidor se descompone en diferentes programas que pueden ser ejecutados por diferentes computadoras aumentando así el grado de distribución del sistema.
La arquitectura cliente-servidor sustituye a la arquitectura monolítica en la que no hay distribución, tanto a nivel físico como a nivel lógico.
La red cliente-servidor es aquella red de comunicaciones en la que todos los clientes están conectados a un servidor, en el que se centralizan los diversos recursos y aplicaciones con que se cuenta; y que los pone a disposición de los clientes cada vez que estos son solicitados. Esto significa que todas las gestiones que se realizan se concentran en el servidor, de manera que en él se disponen los requerimientos provenientes de los clientes que tienen prioridad, los archivos que son de uso público y los que son de uso restringido, los archivos que son de sólo lectura y los que, por el contrario, pueden ser modificados, etc. Este tipo de red puede utilizarse conjuntamente en caso de que se este utilizando en una red mixta.
Ejemplo:
La mayoría de los servicios de Internet son tipo de cliente-servidor. La acción de visitar un sitio web requiere una arquitectura cliente-servidor, ya que el servidor web sirve las páginas web al navegador (al cliente). Al leer este artículo en Wikipedia, la computadora y el navegador web del usuario serían considerados un cliente; y las computadoras, las bases de datos, y los usos que componen Wikipedia serían considerados el servidor. Cuando el navegador web del usuario solicita un artículo particular de Wikipedia, el servidor de Wikipedia recopila toda la información a mostrar en la base de datos de Wikipedia, la articula en una página web, y la envía de nuevo al navegador web del cliente.
Otro ejemplo podría ser el funcionamiento de un juego online. Si existen dos servidores de juego, cuando un usuario lo descarga y lo instala en su computadora pasa a ser un cliente. Si tres personasj juegan en un solo computador existirían

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 16
dos servidores, un cliente y tres usuarios. Si cada usuario instala el juego en su propio ordenador existirían dos servidores, tres clientes y tres usuarios.
Transferencia de páginas web.
FTP (siglas en inglés de File Transfer Protocol, 'Protocolo de Transferencia de Archivos') en informática, es un protocolo de red para la transferencia de archivos entre sistemas conectados a una red TCP (Transmission Control Protocol), basado en la arquitectura cliente-servidor. Desde un equipo cliente se puede conectar a un servidor para descargar archivos desde él o para enviarle archivos, independientemente del sistema operativo utilizado en cada equipo.
El servicio FTP es ofrecido por la capa de aplicación del modelo de capas de red TCP/IP al usuario, utilizando normalmente el puerto de red 20 y el 21. Un problema básico de FTP es que está pensado para ofrecer la máxima velocidad en la conexión, pero no la máxima seguridad, ya que todo el intercambio de información, desde el login y password del usuario en el servidor hasta la transferencia de cualquier archivo, se realiza en texto plano sin ningún tipo de cifrado, con lo que un posible atacante puede capturar este tráfico, acceder al servidor y/o apropiarse de los archivos transferidos.
Para solucionar este problema son de gran utilidad aplicaciones como scp y sftp, incluidas en el paquete SSH, que permiten transferir archivos pero cifrando todo el tráfico.
Entornos web: Internet, Intranet, Extranet.
La definición original de Internet es "Red de todos los sistemas de redes", y a pesar que Internet está cambiando día a día, el concepto parece acentuarse. Por esto es importante recordar que la Web esta hecha de varios medios de comunicación que incluyen una diferentes tipos de sistemas.
Actualmente, la Web no se refiere solamente a Internet, sino también a muchos de los sistemas de redes que se están extendiendo por todos los rincones del globo. Las redes más comunes para los usuarios empresariales son las Intranets, y las Extranets.
Estos sistemas variados son comunicaciones online, que al mismo tiempo pueden ser extendidas y limitadas. Decimos que son amplias y que se extienden porque combinan a Internet con sistemas de redes menos abiertos y más localizados; y decimos que son limitados porque, como en el caso de las Intranet y las Extranet, el acceso es exclusivo a una audiencia específica, brindando más seguridad.
Lo importante para recordar mientras Internet sigue evolucionando es que se convirtió en mucho más que una simple tecnología que permite compartir los mensajes del correo electrónico; ya que, en realidad, es una nueva dinámica que cambió por completo la naturaleza de la computación.
Desde el impacto del desarrollo de la Web en sí, hasta el progreso apoyado por la computación basada en el sistema cliente-servidor; la evolución de los sistemas de redes, y del método de compartir los recursos, están cambiando nuestro mundo electrónico.

Índice
Licenciatura en Sistemas de Información 17
Conceptos
En el mundo electrónico hay muchas palabras que generalmente no entendemos pero que siempre utilizamos. Por ejemplo, LAN (Local Área Network, o Sistemas de Redes de Área Local) y WAN (Wide Area Network, Sistema de Redes de Area Extensa) definen los alcances y características de algunos sistemas de redes, como por ejemplo la Internet, Intranet, y Extranet. Si no sabes distinguir entre estos tres conceptos no debes preocuparte, nosotros te los explicaremos más detalladamente. Para que todo te quede más claro, piensa que Internet es la madre de todos los sistemas de redes del mundo, es la red de redes. Abarca la mayoría de las zonas del globo y es utilizada por muchos, desde individuos que navegan un rato en sus hogares, hasta las pequeñas empresas o las organizaciones multinacionales.
El término Intranet se refiere a todas aquellas redes que utilizan el protocolo TCP para promocionar sitios web internos y contenido relacionado, que se publica sólo dentro de una institución, una empresa, o una universidad.
Y las Extranets combinan la accesibilidad y el alcance universal de Internet con las funcionalidades más focalizadas de las Intranets. Una Extranet ofrece el tipo de contenidos exclusivos que normalmente estaría disponible sólo para los consumidores internos en una Intranet, a participantes externos. Estas personas podrían ser empleados que estén en algún viaje, o que trabajen en localidades remotas, o consumidores estratégicos que necesiten chequear proyectos internos.
¿En qué se los utiliza?
Internet: Internet es un nuevo mundo, pero no es solo un par de páginas con unas fotos bonitas y algunas canciones de moda, es toda una nueva tecnología. Una innovadora metodología para la comunicación que provee conectividad a cualquiera que tenga una computadora y una línea telefónica. Internet es el avance más amplio con respecto a los sistemas de redes, que incluye todo lo que alguna vez podrías haber soñado tener, desde la capacidad de mandar mensajes instantáneamente, hasta poder realizar transacciones entre individuos y compañías. Ya no sólo se dedica al intercambio de información, sino también a grandes y complejas operaciones comerciales.
Algunas de las consecuencias más importantes de esta nueva forma de comunicación son el desarrollo de un nuevo método de comercio, conexiones más rápidas y eficaces entre los individuos y las empresas, recursos y caminos diferentes para las noticias y la investigación, y oportunidades de aplicar otros métodos para la promoción y la distribución de los productos y de la información. Pero, no todo es tan bueno como parece, ya que al tener un alcance tan amplio, también pierde la privacidad y seguridad necesaria para los trabajos internos de las organizaciones empresariales.
Intranets: Estas son una especie de sistemas de redes internos. Piensa en "Intra" como algo que puede ser interno, o "entre", y te será más fácil entender el concepto. Este tipo de redes son utilizadas para lograr una comunicación y una conectividad más privada entre diferentes grupos de trabajo y grandes corporaciones. Por ejemplo, algunas compañías utilizan una Intranet para ofrecer diferentes servicios empresariales, tales como programas de beneficio, y otro tipo de comunicaciones;

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 18
y además permiten compartir la información facilitando la comunicación entre los empleados.
Las Intranet ofrecen más ancho de banda, debido al rango limitado de su alcance. Y a raíz de esta capacidad también se aprovechan mejor algunas herramientas de multimedia y video, además de disfrutar de un mejor control tecnológico. Por ejemplo, una empresa puede determinar el navegador y la versión de él, que quiere que utilizar en su Intranet.
Extranets: Estas implican un tipo de implementación más completa del mundo cableado, ya que pueden utilizarse para favorecer a aquellos empleados que están trabajando a distancia, o a quienes están en un viaje, y hasta incluso a los que están sentados detrás del escritorio. Además también son un medio útil para los proveedores, o vendedores que necesiten tener un contacto permanente con la empresa. Por esto la Extranet provee estos puentes tan importantes combinando la seguridad y privacidad de una Intranet, con el alcance de la Web.
Por eso, tratando de combinar un sistema con otro se logró unificar lo mejor de ambos mundos, la movilidad y la exclusividad. Además este sistema requiere aplicaciones especializadas para proteger la información. Por ejemplo, pueden crearse bases de datos que tengan el acceso habilitado sólo para los miembros de la empresa, y que no sean visibles para los competidores. Por otro lado, utilizan la encriptación ya que los passwords no son un medio suficientemente seguro.
Pero a diferencia de las Intranets, no se utilizan aplicaciones de videos o multimedia debido al ancho de banda limitado de los usuarios remotos que generalmente utilizan conexiones de módems mediante las líneas telefónicas para acceder a la red.
Groupware: Tanto las Intranets como las Extranets habilitan el uso de grupos de aplicaciones comúnmente conocidas como groupware o software de grupo. La aplicación más famosa de estas es el Lotus Notes, pero hay otras que incluyen sitios Web internos que se manejan por bases de datos que permiten a los usuarios ingresar información. Uno de los ejemplos típicos en los que se utilizan este tipo de herramientas es en un equipo de proyecto para compartir información. Lo que se debe hacer en este caso es avisar que se envió el proyecto a la base datos y actualizar la información constantemente, y de esta manera se evita el tráfico de varios mails o memos a través de la Web.
Ejemplos de Groupware
Sironta, aplicación P2P para el intercambio, creación y edición de documentos que requieren trabajo en grupo.
Workflux.net solución para administración, distribución y control de archivos y proyectos empresariales en español.
eGroupWare solución de trabajo en grupo vía web, de código abierto.
OpenGroupWare solución de trabajo en grupo vía web, de código abierto

Índice
Licenciatura en Sistemas de Información 19
Tema 2: Arquitecturas Cliente - Servidor
Arquitectura Cliente – Servidor.
La World Wide Web, o simplemente la web, consiste de varios componentes que trabajan en conjunto para traer una página web al navegador a través de Internet.
Las aplicaciones web (WebApp) utilizan la arquitectura cliente-servidor. Esta arquitectura está compuesta por servidores que comparten recursos con los clientes a través de una red.
Separación de Funciones. Lógica de presentación, de negocio o de aplicación y de datos.
La arquitectura cliente/servidor nos permite la separación de funciones en tres niveles:
La lógica de presentación: Se encarga de la entrada y salida de la aplicación con el usuario. Sus principales tareas son: obtener información del usuario, enviar la información del usuario a la lógica de negocio para su procesamiento, recibir los resultados del procesamiento de la lógica de negocio y presentar estos resultados al usuario.
Lógica de negocio (o aplicación): Se encarga de gestionar los datos a nivel de procesamiento. Actúa de puente entre el usuario y los datos. Sus principales tareas son: recibir la entrada del nivel de presentación, interactuar con la lógica de datos, para ejecutar las reglas de negocios (business rules) que tiene que cumplir la aplicación (facturación, cálculo de nóminas, control de inventarios, etc.) y enviar el resultado del procesamiento al nivel de presentación.
Lógica de datos: Se encarga de gestionar los datos a nivel de almacenamiento. Sus principales tareas son: almacenar los datos, recuperar los datos, mantener los datos y asegurar la integridad de los mismos.
Si un sistema distribuido se diseña correctamente, los tres niveles anteriores pueden distribuirse y redistribuirse independientemente sin afectar al funcionamiento de la aplicación.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 20
Modelos de Distribución en aplicaciones Cliente / Servidor. Presentación Distribuida. Aplicación Distribuida. Datos Distribuidos.
Según como se distribuyan las tres funciones básicas de una aplicación (presentación, negocio y datos) entre el cliente y el servidor, podemos contemplar tres modelos:
Presentación distribuida: El cliente solo mantiene la presentación, el resto de la aplicación se ejecuta remotamente. La presentación distribuida, en su forma más simple, es una interfaz gráfica de usuario a la que se le pueden acoplar controles de validación de datos, para evitar la validación de los mismos en el servidor.
Aplicación distribuida: Es el modelo que proporciona máxima flexibilidad, puesto que permite tanto a servidor como a cliente mantener la lógica de negocio realizando cada uno las funciones que le sean más propias, ya sea por organización, o por mejora en el rendimiento del sistema.
Datos distribuidos: Los datos son los que se distribuyen, por lo que la lógica de datos es lo que queda separado del resto de la aplicación. Se puede dar de dos formas: ficheros distribuidos o bases de datos distribuidas.
Arquitecturas de dos y tres niveles.
La diferencia entre las arquitecturas de dos y tres niveles (capas) estriba en la forma de distribución de la aplicación entre el cliente y el servidor.
Aunque todos los modelos de distribución en aplicaciones cliente/servidor se basan en arquitecturas de dos capas, normalmente cuando se habla de aplicaciones de dos niveles se está haciendo referencia a una aplicación donde el cliente mantiene la lógica de presentación, de negocio y de acceso a datos., y el servidor únicamente gestiona los datos. Suelen ser aplicaciones cerradas que supeditan la lógica de los procesos cliente al gestor de base de datos que se está usando.
En las arquitecturas de tres niveles, la lógica de presentación, la lógica de negocios y la lógica de datos están separadas, de tal forma que mientras la lógica de presentación se ejecutará normalmente en la estación cliente, la lógica de negocio y la de datos pueden estar repartidas entre distintos procesadores. En este tipo de aplicaciones suelen existir dos servidores: uno contiene la lógica de negocio y otro la lógica de datos.
Descripción de un sistema Cliente – Servidor.
La arquitectura cliente-servidor es un modelo de aplicación distribuida en el que las tareas se reparten entre los proveedores de recursos o servicios, llamados servidores, y los demandantes, llamados clientes. Un cliente realiza peticiones a otro programa, el servidor, que le da respuesta. Esta idea también se puede aplicar a programas que se ejecutan sobre una sola computadora, aunque es más ventajosa en un sistema operativo multiusuario distribuido a través de una red de computadoras.
En esta arquitectura la capacidad de proceso está repartida entre los clientes y los servidores, aunque son más importantes las ventajas de tipo organizativo debidas a la centralización de la gestión de la información y la separación de responsabilidades, lo que facilita y clarifica el diseño del sistema.
La separación entre cliente y servidor es una separación de tipo lógico, donde el servidor no se ejecuta necesariamente sobre una sola máquina ni es necesariamente un sólo programa. Los tipos específicos de servidores incluyen los

Índice
Licenciatura en Sistemas de Información 21
servidores web, los servidores de archivo, los servidores del correo, etc. Mientras que sus propósitos varían de unos servicios a otros, la arquitectura básica seguirá siendo la misma.
Una disposición muy común son los sistemas multicapa en los que el servidor se descompone en diferentes programas que pueden ser ejecutados por diferentes computadoras aumentando así el grado de distribución del sistema.
La arquitectura cliente-servidor sustituye a la arquitectura monolítica en la que no hay distribución, tanto a nivel físico como a nivel lógico.
La red cliente-servidor es aquella red de comunicaciones en la que todos los clientes están conectados a un servidor, en el que se centralizan los diversos recursos y aplicaciones con que se cuenta; y que los pone a disposición de los clientes cada vez que estos son solicitados. Esto significa que todas las gestiones que se realizan se concentran en el servidor, de manera que en él se disponen los requerimientos provenientes de los clientes que tienen prioridad, los archivos que son de uso público y los que son de uso restringido, los archivos que son de sólo lectura y los que, por el contrario, pueden ser modificados, etc. Este tipo de red puede utilizarse conjuntamente en caso de que se esté utilizando en una red mixta.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 22
Tema 3: HTML (Hyper Text Markup Language)
Introducción al HTML.
Las páginas web pueden acomodar diferentes tipos de contenidos tales como texto, gráficos, audio y video.
Cada sitio web es distinto, pero todos tienen una cosa en común: el Lenguaje de Marcas de Hipertexto (Hipertext Markup Language o HTML)
Los archivos HTML que producen una página web son simplemente archivos de texto, como son (X)HTML o CSS. Pero las páginas web, no son simplemente documentos de texto, estos archivos de texto especifican como se presenta y se comporta la página.
HTML es utilizado para definir el contenido y la estructura de una página web y XHTML es una versión mejorada de HTML basada en el Lenguaje Extensible de Marcado de Hipertexto (eXtensible Markup Languaje o XML) que soporta las mismas características de HTML pero utiliza una sintaxis más estricta. Ambos, HTML y XHTML tienen tres tipos de componentes:
• Elementos: que identifican diferentes partes de un documento HTML por medio de etiquetas (tags)
• Atributos: información de la instancia de un elemento
• Entidades: caracteres de texto NO ASCII, como símbolos de copyright (©) o caracteres acentuados (È). Estas entidades provienen del Estándar de Lenguaje de Marcado Generalizado (Standar Generic Markup Language o SGML)
Evolución de HTML.
Elementos del lenguaje HTML.
Hipertexto: Instrucciones especiales en HTML permite a líneas de texto apuntar hacia algún lugar en el cyberespacio (links). Estos apuntadores son llamados hipervínculos (hyperlinks). Estos hipervínculos son el pegamento que mantiene a la World Wide Web unida
Marcas: Los navegadores web se crearon específicamente con el propósito de interpretar instrucciones conocidas como marcado (markup). El marcado está en archivos de texto, junto con el contenido, para dar órdenes al navegador. El navegador web sabe como desplegar las marcas y el contenido de la página gracias a las marcas HTML (HTML markup)

Índice
Licenciatura en Sistemas de Información 23
Estructura de una página.
Lo primero que se debe tener claro es qué contenidos va a tener una página. Por ejemplo, si se va a hacer una página sobre un Instituto, ¿qué se va a incluir?: las enseñanzas que se cursan, los proyectos que están llevando a cabo, un poco de historia del pueblo o ciudad donde esté enclavado el centro, las actividades extraescolares que realiza el centro, etc.
Una vez decidido esto ¿qué se necesita?
Un navegador.
Un editor de Html o bien escribir todo el código a mano.
Imágenes que se quieran incluir
Espacio en un servidor que albergue la página.
Un programa para subir la página al servidor
Dar de alta la página en algunos buscadores
Y tiempo para el mantenimiento de la página: comprobar los enlaces,
actualizar las fotos, el contenido, etc.
<HTML>
<HEAD>
<TITLE>Título de la página</TITLE>
...
</HEAD>
<BODY>
Aquí iría el contenido de la página
</BODY>
</HTML>
Entre las etiquetas <html> y <head> se suelen colocar otras opcionales, como por ejemplo:
<meta name="description" content="Información sobre el Centro, las enseñanzas que se pueden cursar, los departamentos didácticos">
<meta name="keywords" content="educación, enseñanza, instituto, profesores, alumnos">
En este caso las etiquetas le indican a los buscadores el contenido de nuestras páginas (description) y algunas palabras clave (keywords) para su localización.
Cabecera.
Es la sección comprendida entre <head> y </head>. En ella se encuentra necesariamente el título (entre las etiquetas <title> y </title>).

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 24
El título de la página debe describir su contenido por ejemplo: <TITLE> Colegio Público Nº 150 </TITLE> no valdría en cambio <TITLE>Página de Inicio</TITLE> ya que esto no dice nada por sí solo.
Cuerpo.
Es aquí donde debemos colocar el contenido de nuestra página: texto, fotos, etc.
El cuerpo está delimitado por las etiquetas <body> y </body>
La etiqueta <body> suele contener algunos atributos, a saber:
BGCOLOR: parámetro usado para especificar el color de fondo de la
página. El color se define como una terna de números (#rrggbb) en base
hexadecimal en el orden rojo, verde, azul (Red, Green, Blue). También se
puede usar el nombre en inglés de los colores predefinidos en los
navegadores.
Sintaxis: <BODY BGCOLOR=#0000FF> o <BODY BGCOLOR=blue>
TEXT: parámetro usado para definir el color del texto por omisión. Su
formato es el mismo que el de BGCOLOR. Si no se pone nada es negro.
LINK, VLINK, ALINK: parámetros usados para especificar el color por
omisión de: texto con enlace, enlace ya visitado y enlace activo. Los
colores por omisión son LINK=blue, VLINK=purple y ALINK=red. El
formato es el mismo que BGCOLOR.
BACKGROUND: parámetro usado para especificar la ruta y nombre de un
archivo (URL) de la imagen que será usada como fondo del documento.
Esta se verá como mosaico para cubrir toda la ventana si es pequeña (lo
habitual).
Sintaxis: <BODY BACKGROUND="ruta/archivo.gif">
Metadatos
El HTML permite a los autores especificar metadatos, información sobre un documento más que contenido del propio documento de diferentes de maneras.
Por ejemplo, para especificar el autor de un documento, puede utilizarse el elemento META de la siguiente manera:
<META name="Author" content="Yanina">
El elemento META especifica una propiedad (aquí "Author") y le asigna un valor (aquí "Yanina").

Índice
Licenciatura en Sistemas de Información 25
Esta especificación no define un conjunto de propiedades legales de metadatos. El significado de una propiedad y el conjunto de valores legales para esa propiedad debería estar definido en un diccionario de referencia llamado perfil. Por ejemplo, un perfil diseñado para ayudar a los motores de búsqueda a indexar documentos podría definir propiedades tales como "author", "copyright", "keywords", etc.
Etiquetas.
Por medio de ellas se pueden controlar los elementos tipográficos del texto: tipo, color y tamaño de las fuentes, el estilo ( negrita, cursiva, etc ), así como también la inclusión de tablas, listas, formularios, la inserción de fotos, sonidos, fondos, los enlaces mencionados anteriormente. etc. Las etiquetas se pueden modificar por medio de sus atributos, éstos son del tipo atributo="valor" y se colocan detrás del nombre de la etiqueta El nombre de la etiqueta y sus atributos se colocan entre los símbolos < y > y normalmente se usan dos, una de inicio y otra final, para conseguir el efecto deseado.
Por ejemplo si escribimos
<FONT COLOR="#ff0000" size="2">
El texto se verá rojo y en tamaño un poco menor de lo normal.
Formato del texto.
Las propiedades del texto pueden modificarse a través de la etiqueta <font>. Para ello, podemos insertar el texto entre las etiquetas <font> y </font>, especificando algunos de los atributos de la etiqueta:
Atributo Significado Posibles valores
face fuente nombre de la fuente, o fuentes
color color del texto número hexadecimal o texto predefinido
size tamaño del texto valores del 1 al 7, siendo por defecto el 3,
o desplazamiento respecto al tamaño por defecto, añadiendo + o - delante del valor
Resaltado del texto <b>
Existen una serie de etiquetas que permiten aplicar diferentes estilos al texto que se encuentra entre ellas, y generalmente se utilizan para resaltarlo. Estos estilos pueden agruparse según vayan asociados al tipo de letra o a la información que represente el texto. No hay que olvidar que todas estas etiquetas necesitan una etiqueta de cierre, y que pueden aplicarse varias etiquetas al mismo texto.
A continuación se muestran algunas etiquetas asociadas al tipo de letra:
Etiqueta Significado Ejemplo
<b> negrita Taller de Programación I
<i> cursiva Taller de Programación I
<u> subrayado Taller de Programación I
Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 26
<s> tachado Taller de Programación I
<tt> teletipo (máquina de escribir) Taller de Programación I
<big> aumenta el tamaño de la fuente Taller de Programación I
<small> disminuye el tamaño de la fuente Taller de Programación I
A continuación se muestran algunas etiquetas asociadas al tipo de información:
Etiqueta Significado Ejemplo
<cite> cita Taller de Programación I
<code> ejemplo de código Taller de Programación I
<dfn> definición Taller de Programación I
<del> eliminado Taller de Programación I
<em> énfasis Taller de Programación I
<ins> insertado Taller de Programación I
<kbd> teclado Taller de Programación I
<samp> muestra Taller de Programación I
<strong> destacado Taller de Programación I
<sub> subíndice Taller de Programación I
<sup> superíndice Taller de Programación I
<var> variable Taller de Programación I
El resultado de aplicar las etiquetas <b> y <strong> es el mismo. Incluso a veces algunos estilos asociados al tipo de información pueden representarse de forma distinta según el navegador.
Párrafos <p>
El texto de una página puede agruparse en párrafos. Para ello, el texto de cada
uno de los párrafos debe insertarse entre las etiquetas <p> y </p>.
No es necesario insertar la etiqueta <br> para que un nuevo párrafo aparezca
debajo del anterior, ya que las etiquetas <p> y </p> hacen que se cambie de línea automáticamente.
También es posible cambiar la alineación del texto de cada párrafo. Para ello se
modifica el valor del atributo align, cuyos valores pueden
ser left (izquierda), right (derecha), center (centrado) o justify (justificado).
Otra forma de cambiar la alineación del texto es mediante las
etiquetas <div> y </div>, para las que también existe el atributo align. La
etiqueta <div>, al igual que la etiqueta <p>, se utiliza para agrupar bloques de texto, pero con la diferencia de que la separación entre ellos es menor.
También es posible insertar el texto entre las
etiquetas <center> y </center> para que aparezca centrado.

Índice
Licenciatura en Sistemas de Información 27
Otro par de etiquetas que permiten agrupar bloques de texto, pero que no
implican el cambio de línea (como en el caso de <p> y <div>), son las
etiquetas <span> y </span> volveremos a hablar de estas etiquetas cuando veamos las hojas de estilo.
Encabezados <h1>
Existen una serie de encabezados que suelen utilizarse para
establecer títulos dentro de una página. La diferencia entre los distintos tipos de
encabezado es el tamaño de la letra, el tipo de resaltado, y la separación existente entre el texto y los elementos que tiene encima y debajo de él. Hay que tener en cuenta que el navegador del usuario es el que aplicará el estilo del encabezado por lo que el mismo título se puede visualizar de forma diferente según el navegador.
Existen seis etiquetas que representan seis tipos de cabeceras distintas. Todas estas etiquetas precisan una etiqueta de cierre.
A continuación se muestran los distintos encabezados existentes:
Etiqueta Ejemplo
<H1> Título 1: HTML <H2> Título 2: HTML <H3> Título 3: HTML
<H4> Título 4: HTML
<H5> Título 5: HTML
<H6> Título 6: HTML
Colores
Los colores se forman a partir de tres básicos, que son el rojo, verde y azul.
La intensidad de cada componente se expresa como un número hexadecimal del 00 al FF (del 0 al 255 en base diez) Los números hexadecimales, se forman utilizando 16 dígitos (en lugar de los diez de la numeración decimal habitual o dos en la binaria).
Estos dígitos son: 0 1 2 3 4 5 6 7 8 9 A B C D E F Así, por ejemplo, el color rojo se representa como #FF0000, porque tiene toda la intensidad de rojo y nada de verde y azul.
#FF0000 - Rojo
#00FF00 - Verde
#0000FF – Azul
Otros colores son:

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 28
#FFFFFF - Blanco
#000000 - Negro
#FFFF00 - Amarillo
Para hacer un color más oscuro, reduce la intensidad del componente, dejando los otros dos iguales. Así, el rojo (#FF0000) se hace más oscuro así: #CC0000, #990000, #660000, #330000 etc
Para hacer que un color más pastel, simplemente variar los otros dos colores dejando igual el principal. Así, el rojo (#FF0000) se hace más claro asi: #FF3333, #FF6666, #FF9999, #FFCCCC etc
Ejemplo 1: <FONT SIZE=+2 COLOR=#FF00FF>Esto está en color fucsia</FONT>
Ejemplo 2: Este color es #C1E1F8
Enlaces
Un hiperenlace, hipervínculo, o vínculo, no es más que un enlace, que al ser pulsado lleva de una página o archivo.
Aquellos elementos (texto, imágenes, etc.) sobre los que se desee insertar un enlace han de encontrarse entre las etiquetas <a> y </a>.
A través del atributo href se especifica la página a la que está asociado el enlace, la página que se visualizará cuando el usuario haga clic en el enlace.
Por ejemplo, para insertar el enlace:
¡Error! Referencia de hipervínculo no válida.
Habría que escribir:
<a href="http://www.unne.edu.ar”>Visita ¡Error! Referencia de
hipervínculo no válida.>
Destino del enlace
El destino del enlace determina en qué ventana va a ser abierta la página
vinculada, se especifica a través del atributo target al que se le puede asignar
los siguientes valores:
1. _blank: Abre el documento vinculado en una ventana nueva del navegador.
2. _parent: Abre el documento vinculado en la ventana del marco que contiene el vínculo o en el conjunto de marcos padre.

Índice
Licenciatura en Sistemas de Información 29
3. _self: Es la opción predeterminada. Abre el documento vinculado en el mismo marco o ventana que el vínculo.
4. _top:Abre el documento vinculado en la ventana completa del navegador.
Los colores de los vínculos pueden especificarse a través de las propiedades
de la página, en la etiqueta <body>. Estos colores se asignan a través de los
atributos link (vínculo), alink(vínculo activo), y vlink (vínculo visitado).
link permite determinar el color de los enlaces sin visitar (enlace que
no ha sido pulsado ninguna vez).
alink permite determinar el color del enlace activo (enlace que acaba
de ser pulsado).
vlink permite determinar el color de los enlaces visitados (enlaces que
ya han sido pulsados).
Por ejemplo, al insertar el siguiente código:
<body link="#FF0000" vlink="#FF0099" alink="#FF9900">
<a href="http://www.unne.edu.ar" target ="_blank">¡Error! Referencia de
hipervínculo no válida.>
Correo electrónico
Abre la aplicación Outlook Express para escribir un correo electrónico, cuyo destinatario será el especificado en el enlace. Para ello la referencia del vínculo
debe ser "mailto:direcciondecorreo".
Por ejemplo, para insertar un enlace que permita enviar un correo electrónico a misitio, tal como este:
e-mail para misitio
Habría que escribir:
<a href="mailto:[email protected]">e-mail para misitio</a>
Después de hacer clic en el enlace se abrirá el Outlook Express (si el usuario lo tiene instalado) con la pantalla para redactar un nuevo mensaje y con el campo destinatario rellenado con la direcciondecorreo. Podemos hacer que esté rellenado algún campo más como es el asunto. En este caso habría que escribir:
<a href="mailto:[email protected]?subject=el asunto del mensaje">e-mail para misitio</a>
Vínculo a ficheros para descarga:
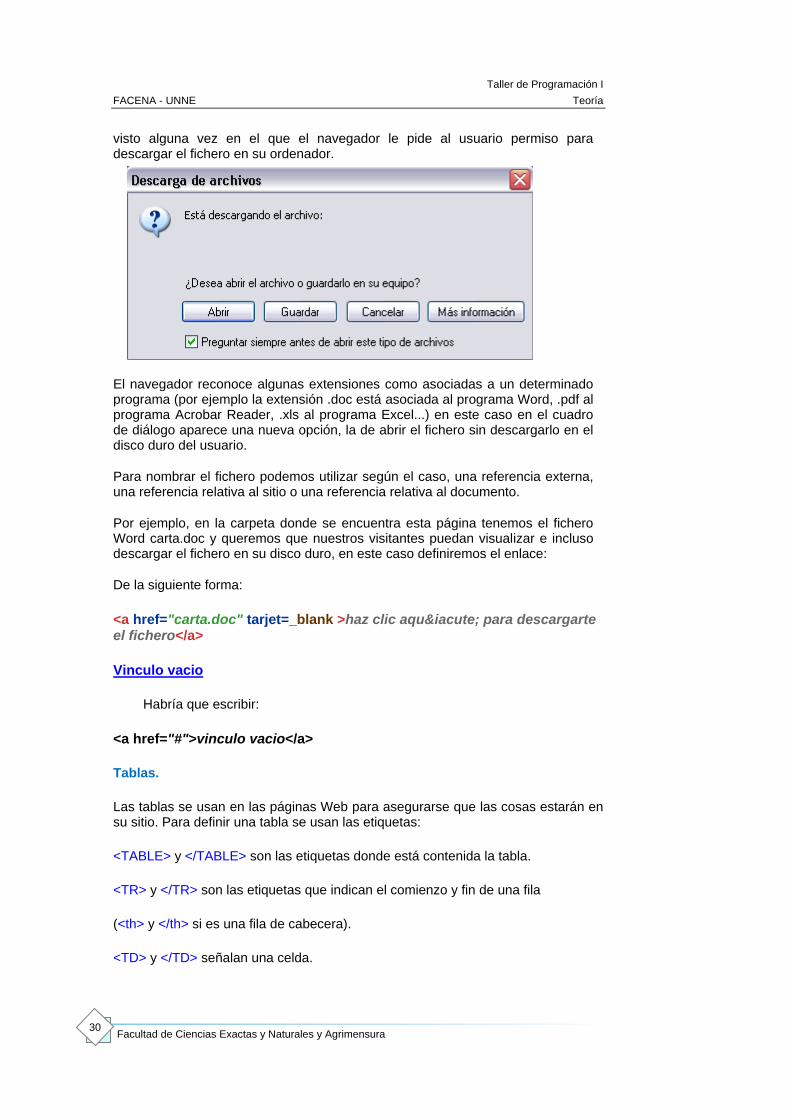
El valor del atributo href normalmente será una página web (con extensión htm, html, asp, php...) pero también puede ser un fichero comprimido, una hoja de Excel, un documento Word, un documento con extensión pdf. Cuando el enlace no es a una página Web nos aparecerá el cuadro de diálogo que seguro habrás
Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 30
visto alguna vez en el que el navegador le pide al usuario permiso para descargar el fichero en su ordenador.
El navegador reconoce algunas extensiones como asociadas a un determinado programa (por ejemplo la extensión .doc está asociada al programa Word, .pdf al programa Acrobar Reader, .xls al programa Excel...) en este caso en el cuadro de diálogo aparece una nueva opción, la de abrir el fichero sin descargarlo en el disco duro del usuario.
Para nombrar el fichero podemos utilizar según el caso, una referencia externa, una referencia relativa al sitio o una referencia relativa al documento.
Por ejemplo, en la carpeta donde se encuentra esta página tenemos el fichero Word carta.doc y queremos que nuestros visitantes puedan visualizar e incluso descargar el fichero en su disco duro, en este caso definiremos el enlace:
De la siguiente forma:
<a href="carta.doc" tarjet=_blank >haz clic aquí para descargarte el fichero</a>
Vinculo vacio
Habría que escribir:
<a href="#">vinculo vacio</a>
Tablas.
Las tablas se usan en las páginas Web para asegurarse que las cosas estarán en su sitio. Para definir una tabla se usan las etiquetas:
<TABLE> y </TABLE> son las etiquetas donde está contenida la tabla.
<TR> y </TR> son las etiquetas que indican el comienzo y fin de una fila
(<th> y </th> si es una fila de cabecera).
<TD> y </TD> señalan una celda.

Índice
Licenciatura en Sistemas de Información 31
La tabla se va definiendo declarando una fila y a continuación las celdas que contiene esa fila, luego otra fila y sus celadas, etc. No es necesario que todas las filas contengan el mismo número de celdas.
La tabla (2x2) más sencilla que podemos hacer es la siguiente
Escribimos: Visualizamos
<TABLE > <TR> <TD>1 </TD> <TD> 2 </TD> </TR> <TR> <TD>3 </TD> <TD> 4</TD> </TR> </TABLE>
1 2
3 4
Atributos de la etiqueta TABLE
Todos los atributos son opcionales.
BORDER="4". Indica el tamaño del borde en píxels, en este caso 4. Si no se
indica nada carece de borde.
WIDTH="5" o WIDTH="50%". Es el ancho de la tabla, puede especificarse en valor
absoluto (5 píxels) o como un porcentaje (50% del ancho disponible).
CELLSPACING="2". Es el espacio entre las celdas, por defecto es 2.
CELLPADDING="5". Es el espacio entre el contenido de las celdas y el borde de
las mismas, por defecto es 1.
ALIGN=" left", "right", "center". Alinea la tabla a la izquierda, derecha o en el centro.
Otro ejemplo:
Escribimos: Visualizamos
<TABLE BORDER="3" CELLSPACING="5" WIDTH="150"> <TR> <TD>1 </TD> <TD> 2 </TD> </TR> <TR> <TD>3 </TD> <TD> 4</TD> </TR> </TABLE>
1 2
3 4

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 32
Atributos de las etiquetas de fila y celda
Las etiquetas que soportan las filas y las celdas son
WIDTH="30". Ancho de toda la fila o celda. También se puede dar en %.
ALIGN=" left", "right", "center". Alinea el contenido a la izquierda, derecha o centro.
VALIGN="top”, "middle" o "bottom". Alinea el contenido verticalmente arriba, en medio o abajo.
BGCOLOR="#AACCEE". Pone un fondo del color especificado a la celda o fila.
COLSPAN=3. Especifica el número de columnas que abarca la fila.
ROWSPAN=2. Especifica el número de filas que abarca la columna.
Ejemplo: Obsérvese que la etiqueta TH, que sustituye a TR, resalta su contenido con negrita, por eso se usa para los títulos
Escribimos: Visualizamos
<TABLE BORDER="3" CELLSPACING="5" WIDTH="200"> <TH COLSPAN=2 BGCOLOR="#6D8FFF> Este es el título</TH> <TR align="center"> <TD>Esta es la celda de la 1ª fila y de la 1ª columna</TD> <TD> Esta es de la 1ª fila y de la 2ª columna</TD> </TR> <TR BGCOLOR="#6D8FFF> <TD>Esto está con un fondo azul</TD> <TD align="right" valign="bottom">Y esto también</TD> </TR> </TABLE>
Este es el título
Esta es la celda de la 1ª fila y de la 1ª
columna
Esta es de la 1ª fila y de la 2ª columna
Esto está con un fondo azul
Y esto también
Como se observa, se pueden ir modificando los comandos básicos para obtener la tabla que deseemos.
Es frecuente no escribir las etiquetas de cierre de fila y celda, los navegadores presentan la tabla igual y nos ahorramos unas cuantas pulsaciones de teclas.
Formularios.
Un formulario es un elemento que permite recoger datos introducidos por el usuario.

Índice
Licenciatura en Sistemas de Información 33
Los formularios se utilizan para conocer las opiniones, dudas, y otra serie de datos sobre los usuarios, para introducir pedidos a través de la red, tienen multitud de aplicaciones.
Un formulario está formado, entre otras cosas, por etiquetas, campos de texto, menús desplegables, y botones.
Es muy recomendable utilizar tablas para organizar los elementos de los formularios. Utilizando tablas se consigue una mejor distribución de los elementos del formulario, lo que facilita su comprensión y mejora su apariencia.
Los formularios se insertan a través de las etiquetas <form> y </form>. Entre dichas etiquetas habrá que insertar los diferentes objetos que formarán el formulario. La etiqueta <form>tiene los siguientes atributos:
El atributo action indica una dirección de correo electrónico a la que mandar el formulario, o la dirección del programa que se encargará de procesar el contenido del formulario.
El atributo enctype indica el modo en que será cifrada la información para su envío. Por defecto tiene el valor application/x-www-form-urlencoded.
El atributo method indica el método mediante el que se transferirán las variables
del formulario. Su valor puede ser get o post.
El valor get se utiliza cuando no se van a producir cambios en ningún documento o programa que no sea el navegador del usuario que pretende mandar el formulario, como ocurre cuando se realizan consultas sobre una base de datos.
El valor post se utiliza cuando sí se van a producir cambios, como ocurre cuando el usuario manda datos que deben ser almacenados en una base de
datos. Se recomienda utilizar el valor post.
Por ejemplo, podríamos insertar un formulario escribiendo el siguiente código: <form action="mailto:[email protected]" method="post" enctype="text/plain" > ... </form>
ELEMENTOS DE ENTRADA <Input>
Para insertar un elemento de entrada es necesario incluir la
etiqueta <input> entre las etiquetas <form> y </form> del formulario.
El atributo name indica el nombre que se desea dar al elemento de entrada,
mediante el cual será evaluado, y el atributo type indica el tipo de elemento de entrada.
Tipos de elementos de entrada y atributos que pueden definirse para cada uno de ellos.
Campo de texto: Para insertar un campo de texto, el atributo type debe tener
el valor text.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 34
El atributo size indica el número de caracteres que podrán ser visualizados en el campo de texto, determina el ancho de la caja.
El atributo maxlenght indica el número de caracteres que podrán ser insertados en el campo de texto.
El atributo value indica el valor inicial del campo de texto.
Por ejemplo, para insertar el campo de texto:
Habría que escribir:
<input name="campo" type="text" value="Campo de texto" size="20" maxlength="15">
Campo de contraseña: Para insertar un campo de contraseña, el
atributo type debe tener el valor password.
El resto de atributos son los mismos que para un campo de texto normal. La única diferencia es que todas las letras escritas en el campo de contraseña serán visualizadas como asteriscos.
Por ejemplo, para insertar el campo de contraseña:
<input name="contra" type="password" value="contraseña" size="20" maxlength="15">
Botón: Para insertar un botón, el atributo type debe tener el
valor submit, restore o button.
Si el valor es submit, al pulsar sobre el botón se enviará el formulario.
Si el valor es restore, al pulsar sobre el botón se restablecerá el formulario, borrándose todos los campos del formulario que hayan sido modificados y adquiriendo su valor inicial.
Si el valor es button, al pulsar sobre el botón no se realizará ninguna acción.
El atributo value indica el texto que mostrará el botón.
Habría que escribir:
<input name="boton" type="submit" value="Enviar">
Botón de opción: Para insertar un botón de opción, el atributo type debe tener
el valor radio.
Campo de texto
**********

Índice
Licenciatura en Sistemas de Información 35
El atributo value indica el valor asociado al botón de opción. Es necesario poner este atributo, aunque el usuario no pueda ver su valor. Es el valor a enviar.
La aparición del atributo checked indica que el botón aparecerá activado inicialmente. Este atributo no toma valores.
Los botones de opción se utilizan cuando se desea que una variable del formulario pueda tomar un solo valor de entre varios posibles. Para ello, se insertan varios botones de opción con el mismo nombre (que indica la variable) y con distintos valores. Solamente uno de estos botones podrá estar activado, el que esté activado cuando se envía el formulario, su valor será el que tendrá la variable.
Por ejemplo, para insertar los botones de opción:
Habría que escribir:
<input name="prefiere" type="radio" value="estudiar" checked> <input name="prefiere" type="radio" value="trabajar">
Cuando se envíe el formulario, si el primer botón está activado la
variable prefiere será igual a estudiar, si es el segundo el activado, la
variable prefiere valdrá trabajar. Observa que lo que ponemos como valor no aparece escrito en la página es un dato interno.
CAMPOS DE SELECCIÓN <select>
Los campos de selección se utilizan para insertar menús y listas desplegables.
Para insertar uno de estos menús o listas es necesario insertar las
etiquetas <select> y </select> en un formulario.
El atributo name indica el nombre del menú o lista será el nombre de la variable que contendrá el valor seleccionado.
El atributo size indica el número de elementos de la lista que pueden ser visualizados al mismo tiempo, determina el alto de la lista.
La aparición del atributo multiple indica que el usuario podrá seleccionar varios elementos de la lista al mismo tiempo, ayudándose de la tecla Ctrl. Este atributo no toma valores.
La aparición del atributo disabled indica que la lista estará desactivada, por lo que el usuario no podrá seleccionar sus elementos. Este atributo tampoco toma valores.
Cada uno de los elementos de la lista ha de insertarse entre las
etiquetas <option> y </option>.
Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 36
El atributo value indica el valor a enviar si se selecciona el elemento. Si no se especifica este atributo, se enviará el texto de la opción, que se encuentra entre
las etiquetas <option> y</option>.
La aparición del atributo selected indica que el elemento aparecerá seleccionado. Este atributo no toma valores.
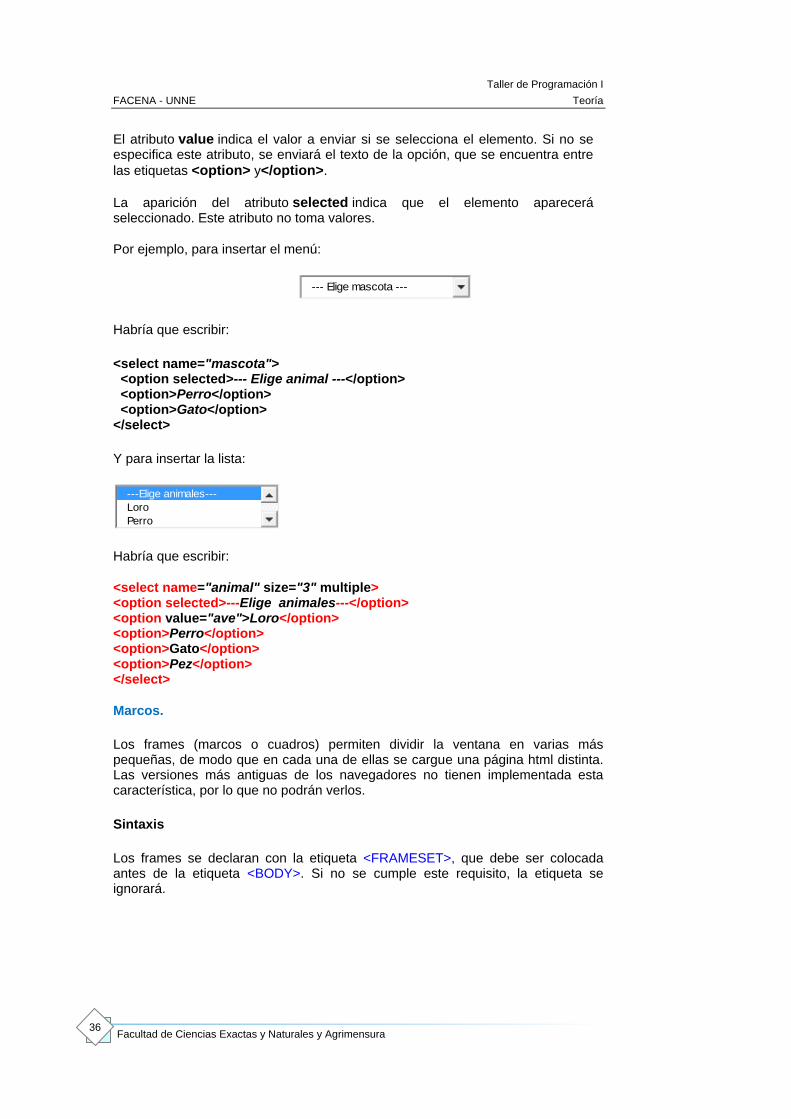
Por ejemplo, para insertar el menú:
Habría que escribir:
<select name="mascota"> <option selected>--- Elige animal ---</option> <option>Perro</option> <option>Gato</option> </select>
Y para insertar la lista:
Habría que escribir:
<select name="animal" size="3" multiple> <option selected>---Elige animales---</option> <option value="ave">Loro</option> <option>Perro</option> <option>Gato</option> <option>Pez</option> </select>
Marcos.
Los frames (marcos o cuadros) permiten dividir la ventana en varias más pequeñas, de modo que en cada una de ellas se cargue una página html distinta. Las versiones más antiguas de los navegadores no tienen implementada esta característica, por lo que no podrán verlos.
Sintaxis
Los frames se declaran con la etiqueta <FRAMESET>, que debe ser colocada antes de la etiqueta <BODY>. Si no se cumple este requisito, la etiqueta se ignorará.
--- Elige mascota ---
---Elige animales---
Loro
Perro
Índice
Licenciatura en Sistemas de Información 37
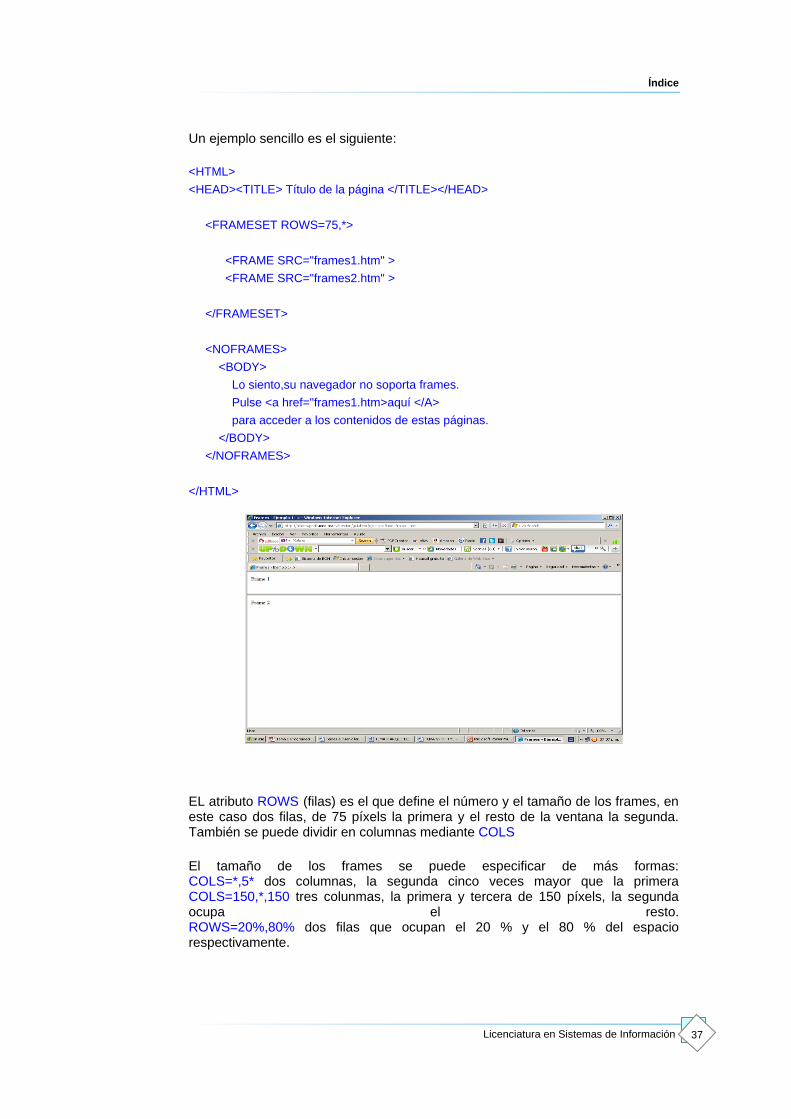
Un ejemplo sencillo es el siguiente:
<HTML>
<HEAD><TITLE> Título de la página </TITLE></HEAD>
<FRAMESET ROWS=75,*>
<FRAME SRC="frames1.htm" >
<FRAME SRC="frames2.htm" >
</FRAMESET>
<NOFRAMES>
<BODY>
Lo siento,su navegador no soporta frames.
Pulse <a href="frames1.htm>aquí </A>
para acceder a los contenidos de estas páginas.
</BODY>
</NOFRAMES>
</HTML>
EL atributo ROWS (filas) es el que define el número y el tamaño de los frames, en este caso dos filas, de 75 píxels la primera y el resto de la ventana la segunda. También se puede dividir en columnas mediante COLS
El tamaño de los frames se puede especificar de más formas: COLS=*,5* dos columnas, la segunda cinco veces mayor que la primera COLS=150,*,150 tres colunmas, la primera y tercera de 150 píxels, la segunda ocupa el resto. ROWS=20%,80% dos filas que ocupan el 20 % y el 80 % del espacio respectivamente.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 38
Las etiquetas NOFRAMES y BODY solamente se usan por cortesía, de hecho se pueden suprimir.
Las etiquetas FRAME SRC="frames.htm" cargan las página indicadas en el frame correspondiente.
También es posible anidar frames, llamando a una página que tenga de nuevo frames o bien declarándolo explícitamente.
<FRAMESET COLS=20%,*>
<FRAME SRC="frames1.htm">
<FRAMESET ROWS=20%,*>
<FRAME SRC="frames2.htm">
<FRAME SRC="frames3.htm">
</FRAMESET>
</FRAMESET>
Este código divide la ventana en dos columnas, la primera del 20 % del ancho total, y la segunda queda dividida a su vez en dos filas, siendo la primera de ellas un 20 % del total.
El atributo TARGET
Lo más interesante de los frames es la posibilidad que tienen de interactuar entre si, es decir pulsar un enlace en el frame 1 y cargar el contenido en el frame 2. Para conseguir esto hay que darle un nombre a los frames y luego indicar en el enlace donde se va a cargar mediante el atributo TARGET. Veamos un ejemplo:
<HTML>
<HEAD><TITLE> Frames --Ejemplo 3--</TITLE></HEAD>
<FRAMESET COLS=150,*>

Índice
Licenciatura en Sistemas de Información 39
<FRAME SRC="frames4.htm" NAME=margen>
<FRAME SRC="frames5.htm" NAME=principal>
</FRAMESET>
</HTML>
Los enlaces de la página frames4.htm, que es la que se carga en el margen izquierdo, se escriben de la forma: <A HREF="frames1.htm" TARGET=principal>Frame 1 </A>
Hay ciertos valores reservados para TARGET, estos son
TARGET=_top, hace que la página se cargue en la ventana completa del navegador.
TARGET=_self, hace que la página se cargue en la misma ventana del frame actual.
TARGET=_parent, hace que la página se cargue en el frame "padre", del que desciende el actual.
TARGET=_blank, hace que la página se cargue en una nueva ventana.
TARGET=nombre, hace que la página se cargue en el frame llamado nombre. Si no existe se carga en una ventana nueva.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 40
Atributos de FRAME
En los frames se pueden modificar algunas de sus características por medio de las etiquetas que siguen:
SCROLLING= yes, no, auto. Indica si el frame llevará siempre, nunca o cuando lo necesite, barra de deslizamiento vertical
BORDERCOLOR="color”. Indica el color del borde
MARGINWIDTH=n. Indica el margen horizontal, tanto derecho como izquierdo, en píxels
MARGINHEIGHT=n. Indica el margen vertical, tanto superior como inferior, en píxels
NORESIZE. Indica que el frame no se puede redimensionar. Si no se pone este atributo colocando el cursor en el borde del frame, permitiría su deslizamiento
Atributo de FRAMESET
FRAMEBORDER=yes, no. Indica si los frames tendrán bordes o no.
Puedes ver un ejemplo más de frames.
Guías de estilo.
Los estilos CSS (Cascading Style Sheets) son hojas de estilo de actualización
automática.
Se usan principalmente para definir estilos que luego se aplicarán a las páginas de nuestro sitio, incluso a veces permiten definir características que nos permiten definir los estilos HTML, como el color de fondo para el texto por ejemplo.
Al estar la definición de los estilos en un archivo externo a las páginas y común a todas las páginas del sitio (es recomendable) el aspecto de nuestras páginas será más homogéneo y además podremos cambiar ese aspecto de manera segura e inmediata cambiando únicamente la hoja de estilos.
Se pueden definir estilos independientes o estilos asociados a determinadas
etiquetas por ejemplo a la etiqueta <a> (que corresponde a los hiperenlaces). De
este modo, todos los hiperenlaces de la página o del sitio adquirirían la apariencia definida en ese estilo y con un sólo cambio en la hoja de estilos podemos cambiar de golpe el estilo de todos los enlaces en todas las páginas vinculadas a este estilo.
El inconveniente que tiene trabajar con hojas de estilos es que algunos navegadores no las soportan y las ignoran, aunque estos navegadores suelen ser versiones antiguas, por lo que ocurrirá en pocos casos.
Las hojas de estilo pueden crearse con cualquier editor de texto, como puede ser el Bloc de notas, eclipse u algún otro y pueden guardarse con la extensión TXT.

Índice
Licenciatura en Sistemas de Información 41
VINCULAR HOJAS DE ESTILO
Para poder incluir las propiedades de una hoja de estilo en un documento, hay que vincularla a él. Un documento puede tener varias hojas de estilo vinculadas.
Para vincular una hoja de estilo a un documento es necesario insertar la
etiqueta <link> en el documento, entre las etiquetas <head> y </head>. Esta etiqueta no necesita etiqueta de cierre.
A través del atributo href se especifica la hoja de estilo que se va a vincular al documento.
A través del atributo rel se tiene que especificar que se está vinculando una hoja
de estilo, por lo que su valor ha de ser stylesheet.
A través del atributo type se tiene que especificar que el archivo es de texto, con
sintaxis CSS, por lo que su valor ha de ser text/css.
Por ejemplo, podríamos vincular una hoja de estilo escribiendo el siguiente código.
<link href="misestilos.txt" rel="stylesheet" type="text/css" >
SINTAXIS DE LAS HOJAS DE ESTILO
Todas las propiedades se especifican a través del atributo style, y aparecen entre comillas dobles, con un punto y coma detrás de cada una. Para asignar los valores a las propiedades no se utiliza el símbolo = (igual), sino que se utiliza el símbolo: (dos puntos).
Esto es debido a que se está especificando un estilo, pero sin vincular ninguna hoja de estilo a la página.
Para especificar las propiedades dentro de una hoja de estilo, la sintaxis es muy similar.
En primer lugar se pone el nombre del estilo, y entre llaves se especifica la lista de propiedades (en minúsculas) que se corresponden con dicho estilo. Cada una de estas propiedades tiene que tener un punto y coma detrás, y los valores se asignan con el símbolo : (dos puntos).
El nombre del estilo puede ser un nombre inventado por nosotros, o el nombre de una etiqueta HTML. Para poder utilizar un nombre inventado, tiene que estar precedido por un punto, o por el nombre de una etiqueta seguida de un punto.
Por ejemplo, en una hoja de estilo podríamos tener lo siguiente:
body {background-color: #006699; font-family: Arial,Helvetica;}
.mitexto {font-family: Arial,Helvetica; font-size:18px;}

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 42
Si vinculáramos esta hoja de estilo a un documento, se aplicarían directamente
las propiedades especificadas para la etiqueta <body>.
En cambio, no existe ninguna etiqueta <mitexto>, por lo que para aplicar este estilo a algún elemento de la página habría que indicarlo de algún modo.
Para aplicar este estilo a un elemento, habría que insertar el atributo class en su etiqueta.
Por ejemplo, para aplicar ese estilo al siguiente párrafo del documento:
<p>texto con estilo</p>
Habría que escribir:
<p class="mitexto">texto con estilo</p>
Pero para aplicar el estilo únicamente a una parte del contenido de la etiqueta, como podría ser en este caso una palabra del párrafo, sería necesario incluir la
etiqueta <span> (que agrupa bloques, sin producir un cambio de línea). Por
ejemplo, para aplicar el estilo únicamente a la palabra estilo, habría que escribir:
<p>texto con <span class="mitexto">estilo</span></p>
Cuando queremos aplicar estilos a un bloque que creamos nosotros, antes del nombre tenemos que insertar un “#”, imaginemos que creamos un bloque (capa) llamado “cabecera” donde queremos asignarle un tamaño de 780px de ancho, lo hacemos así:
#cabecera{
width:780px;
}
LAS PROPIEDADES
Familia de la fuente:
La propiedad es font-family.
Puede tomar como valor varios nombres de fuentes, separados por comas, como pueden
ser arial, helvetica, etc. La ventaja de definir una familia de fuentes es que si el ordenador del visitante no tiene instalada la primera fuente, entonces se aplicará la segunda, así sucesivamente hasta encontrar una de las fuentes.
Por ejemplo:
body {
font-family:Arial,Times New Roman,Verdana;
}
Grosor del texto:
La propiedad es font-weight.
Sus valores pueden ser: bold (negrita), bolder (mas negrita), lighter (ligera) o
un número del 100 al 900

Índice
Licenciatura en Sistemas de Información 43
Tamaño de la fuente:
La propiedad es font-size.
Puede tomar como valor un número por ejemolo:
body{
font-size:16px;
}
Espacio entre líneas:
La propiedad es line-height, establece la altura de cada línea que forma el contenido de texto de un elemento, por lo que se emplea para controlar el interlineado del texto. El uso de line-height es imprescindible cuando se quiere facilitar la lectura de los contenidos de una página.
Puede tomar como valor un número.Si se utilizan porcentajes, el valor que se toma como referencia es el tamaño de letra del texto, por lo que line-height: 130% significa que el tamaño de cada línea debe ser un 30% superior al tamaño de la letra.
Espacio entre caracteres:
La propiedad es letter-spacing.
Puede tomar como valor un número. El valor normal indica que el navegador se encarga de determinar la separación óptima entre las letras del texto. Esta separación se hace más evidente cuando se justifica el texto con la propiedad text-align:
Estilo de la fuente:
La propiedad es font-style, permite establecer el estilo con el que se muestra el tipo de letra seleccionado mediante la propiedad font-family. Los tres estilos disponibles son: normal (normal), itálico (italic) y oblicuo (oblique).
Por ejemplo:
body{
font-family: Arial, Helvetica, sans-serif;
font-size: 12px;
font-style: italic;
}
Decoración de la fuente:
La propiedad es text-decoration, establece la decoración que se aplica al texto de un elemento.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 44
El estándar CSS 2.1 define los siguientes cinco tipos de decoraciones:
underline: se muestran subrayadas todas las líneas de texto.
overline: similar al valor underline, pero en este caso el subrayado se muestra en la parte superior de cada línea.
line-through: todas las líneas de texto se muestran tachadas mediante una línea continua en el medio de cada línea.
blink: el texto parpadea apareciendo y desapareciendo de forma alternativa.
none: el texto no muestra ninguna decoración, por lo que se eliminan todas las decoraciones que puede haber heredado el elemento.
Si se aplica none a los hiperenlaces, puede evitarse que aparezcan subrayados.
Transformar el texto:
La propiedad es text-transform, permite transformar el texto de un elemento para mostrarlo en mayúsculas, minúsculas o una mezcla de ambas. Los cuatro valores definidos por esta propiedad son los siguientes:
lowercase: muestra todo el texto del elemento con letras minúsculas.
uppercase: muestra todo el texto del elemento con letras mayúsculas.
capitalize: muestra la primera letra de cada palabra en mayúscula y el resto de letras en minúsculas.
none: muestra el texto tal y como está escrito, respetando todas las
mayúsculas y minúsculas.
La propiedad text-transform también tiene en cuenta el texto generado
dinámicamente mediante propiedades como content: Ejemplo
p {
text-transform: capitalize;
}
p:before {
content: "texto generado dinámicamente ";
}
<p>Lorem ipsum dolor sit amet...</p>
Alineación del texto:
La propiedad es text-align.
Puede tomar como valor center (centrado), left (izquierda), right (derecha) o justify (justificado).
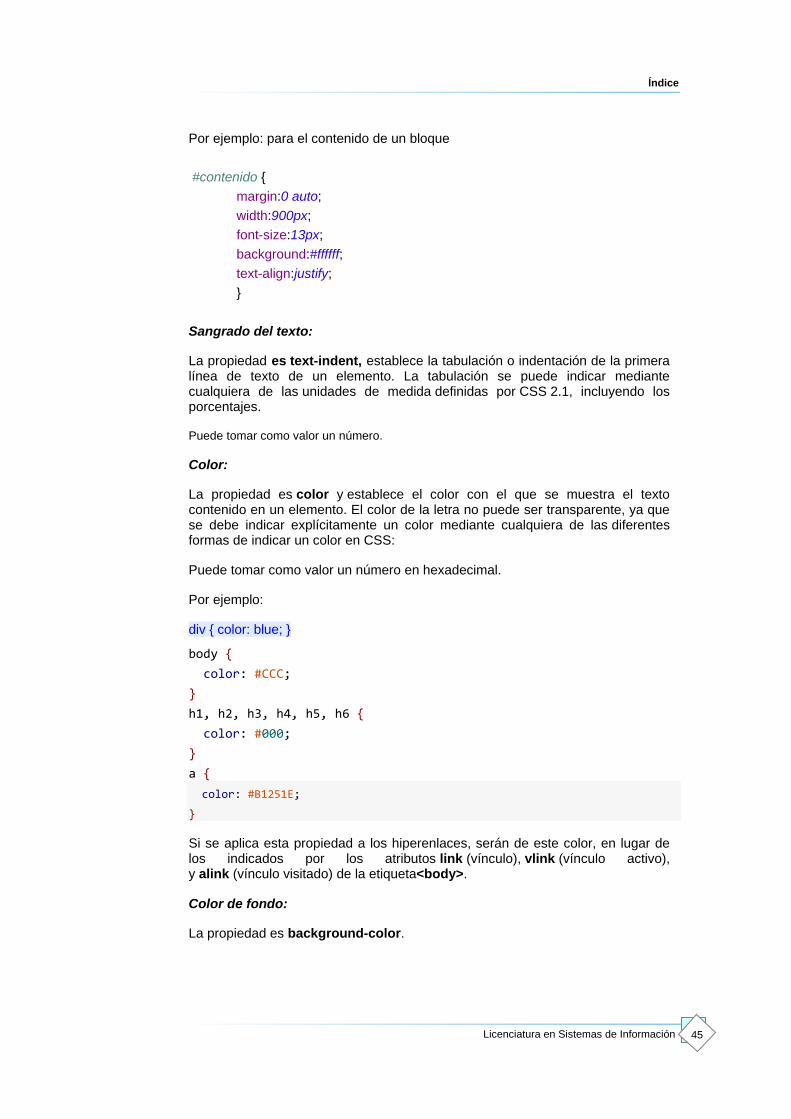
Índice
Licenciatura en Sistemas de Información 45
Por ejemplo: para el contenido de un bloque
#contenido {
margin:0 auto;
width:900px;
font-size:13px;
background:#ffffff;
text-align:justify;
}
Sangrado del texto:
La propiedad es text-indent, establece la tabulación o indentación de la primera línea de texto de un elemento. La tabulación se puede indicar mediante cualquiera de las unidades de medida definidas por CSS 2.1, incluyendo los porcentajes.
Puede tomar como valor un número.
Color:
La propiedad es color y establece el color con el que se muestra el texto contenido en un elemento. El color de la letra no puede ser transparente, ya que se debe indicar explícitamente un color mediante cualquiera de las diferentes formas de indicar un color en CSS:
Puede tomar como valor un número en hexadecimal.
Por ejemplo:
div { color: blue; }
body {
color: #CCC;
}
h1, h2, h3, h4, h5, h6 {
color: #000;
}
a {
color: #B1251E;
}
Si se aplica esta propiedad a los hiperenlaces, serán de este color, en lugar de los indicados por los atributos link (vínculo), vlink (vínculo activo), y alink (vínculo visitado) de la etiqueta<body>.
Color de fondo:
La propiedad es background-color.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 46
Gracias a la propiedad background se puede establecer de forma directa el color de fondo (background-color), la imagen de fondo (background-image), su posición (background-position), si la imagen es fija o no (background-attachment) y/o si la imagen se repite o no (background-repeat).
En ocasiones, la propiedad background se utiliza simplemente para establecer el color de fondo de un elemento, ya que es más corto de escribir que la propiedad background-color. De esta forma, las dos reglas CSS siguientes producen el mismo efecto:
Puede tomar como valor un número en hexadecimal.
Por ejemplo para el bloque div:
div {
background-color: #CCC;
}
div {
background: #CCC;
}
Como el orden de cada propiedad individual dentro de background es indiferente, todas las declaraciones CSS siguientes son correctas y equivalentes: Imagen de fondo:
background: url("images/imagen_pequena.png") no-repeat 2em 1.5cm
fixed;
background: fixed url("images/imagen_pequena.png") no-repeat 2em
1.5cm;
background: no-repeat fixed url("images/imagen_pequena.png") 2em
1.5cm;
background: 2em 1.5cm url("images/imagen_pequena.png") no-repeat
fixed;
background: no-repeat 2em 1.5cm fixed
url("images/imagen_pequena.png");
background: 2em 1.5cm url("images/imagen_pequena.png") fixed no-
repeat;
background: no-repeat url("images/imagen_pequena.png") 2em 1.5cm
fixed;
background: fixed 2em 1.5cm url("images/imagen_pequena.png") no-
repeat;
Imagen de fondo
La propiedad es background-image.
La propiedad background-image se emplea para establecer la imagen de fondo de cada elemento. La imagen se muestra en la zona que ocupan el contenido y el relleno del elemento, justo hasta su borde.

Índice
Licenciatura en Sistemas de Información 47
Para indicar la imagen que se muestra como fondo de un elemento, se utiliza una URL. Los navegadores no restringen el tipo de URL que se pueden utilizar, por lo que pueden ser URL externas/internas y URLrelativas/absolutas.
La URL de la imagen que se quiere mostrar se incluye dentro de los paréntesis de la palabra url(). De forma opcional, el valor de la URL se puede encerrar entre comillas simples o entre comillas dobles. Ejemplo
div {
background-image:
url(http://www.librosweb.es/website/css/images/logo.gif);
}
h1, h2, h3 {
background-image: url("imagenes/fondo.png");
}
ul li {
background-image: url('../comun/imagenes/icono.gif');
}
La ruta y el nombre de la imagen han de aparecer entre paréntesis, después de la palabra url.
Si la imagen de fondo es más grande que el sitio disponible para mostrarla, el navegador sólo muestra la parte visible que resulta de colocar la esquina superior izquierda de la imagen en la esquina superior izquierda del espacio que ocupa el elemento.
Por el contrario, si la imagen es más pequeña que el sitio disponible, el navegador repite la misma imagen en todas las direcciones hasta cubrir completamente el espacio que ocupa el elemento.
Se recomienda establecer un color de fondo siempre que se utilice una imagen de fondo. Como las imágenes se indican mediante URL y el navegador las tiene que descargar, es posible que se produzcan errores y la descarga de la imagen no se pueda realizar.
El estándar CSS no permite modificar el tamaño con el que se muestra la imagen de fondo. Sin embargo, es posible modificar opciones como si la imagen se repite o no (background-repeat), si la imagen permanece fija o no (background-attachment) y modificar su posición por defecto (background-position).
Por último, no se pueden establecer dos o más imágenes diferentes sobre un mismo elemento. Si se quieren mostrar dos imágenes diferentes como fondo de una página web, se puede establecer la primera imagen sobre el selector html y la segunda imagen sobre el selector body:

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 48
Ejemplo:
html {
background-image: url("imagenes/primera_imagen.png"); }
body { background-image: url("imagenes/segunda_imagen.png"); }
Márgenes:
Las propiedades son margin-top (margen superior), margin-right (margen derecho), margin-bottom (margen inferior), margin-left (margen izquierdo), o margin (los valores de los márgenes superior, derecho, inferior e izquierdo, separados por espacios).
Pueden tomar como valor un número (cuatro números separados por espacios en el caso de margin).
La propiedad margin es tan poderosa que permite establecer uno, dos, tres o los cuatro márgenes de forma simultánea.
Si se indican dos valores, el primero hace referencia a los márgenes verticales y el segundo es el valor de los márgenes horizontales, de modo que las siguientes reglas CSS son equivalentes:
Ejemplos:
div {
margin: 10px 20px;
}
div {
margin-top: 10px;
margin-right: 20px;
margin-bottom: 10px;
margin-left: 20px;
}
Ancho de bordes:
La propiedad es border-width. permite establecer el grosor de uno, dos, tres o los cuatro bordes de forma simultánea.
Puede tomar como valor un número. Por ejemplo:
div {
border-top-width: 3px; border-right-width: 3px; border-bottom-width: 3px;
border-left-width: 3px; }

Índice
Licenciatura en Sistemas de Información 49
Color del borde:
La propiedad es border-color. permite establecer el color de uno, dos, tres o los cuatro bordes de forma simultánea.
Puede tomar como valor un número en hexadecimal.
No hay que olvidar, en el caso de los valores numéricos, especificar la unidad de medida a utilizar: cm (centímetros), pt (puntos), px (píxeles), o % (porcentaje).
Por ejemplo:
#pie {
clear:both;
border-top: 5px solid #ffd700;
}
O para el bloque div
div {
border-top-color: red;
border-right-color: blue;
border-bottom-color: green;
border-left-color: blue;
}
O también es correcto: div { border-color: red #080; }
El modelo de cajas
– Cuando el navegador despliega la página, ubica cada elemento HTML de bloque en una caja.
– Esto facilita el control del espacio, bordes, rellenos y otros elementos para dar formatos como las divisiones, encabezados y párrafos.
– También algunos elementos de línea, como imágenes y enlaces, se colocan en cajas.
Para trabajar con estas cajas se utiliza el modelo de cajas
El modelo de cajas de CSS
– Permite trabajar con cajas que el navegador coloca alrededor de elementos de bloque y algunos elementos de línea.
– Por defecto, la caja para un elemento de bloque es del ancho como el bloque que contiene y del alto como debe ser en función de su contenido.
– Para especificar el ancho y el alto del área de contenido para un elemento de bloque se utilizan las propiedades width y heigth.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 50
– Otras propiedades para elementos de bloques son margin, borders y padding. Estas propiedades se agregan al alto y ancho del área de contenido para determinar las propiedades height y width de la caja.
Una primera aproximación visual
Para entrar en tema, vamos a construir un sencillo ejemplo utilizando un único
elemento <div> al que aplicaremos un estilo. El resultado producido será analizado
con la ayuda de una figura en la que hemos modelado el orden de apilado de los
elementos del <div> en una disposición tridimensional que nos ayudará a
comprenderlo.
Supongamos el siguiente código (lo mostramos fuera de su contexto,
restringiéndonos a lo significativo para el ejemplo):
El elemento <div>
<div>
<p>Este es el contenido de nuestra caja.</p>
<p>Este es el contenido de nuestra caja.</p>
<p>Este es el contenido de nuestra caja.</p>
<p>Este es el contenido de nuestra caja.</p>
</div>
El estilo
div {
background-color: #be4061; /*color bordó para el
fondo*/
background-image: url('cabeza.jpg');
border: 10px solid #e7a219; /*color naranja para el
borde*/
margin: 10px;
padding: 20px;
}
p {
margin: 0 0 20px 0; /*margen inferior de 20 px para el
párrafo*/
padding: 0;
}
El código anterior generará una caja como la que muestra la figura siguiente, en la
que adicionalmente se ha dado color a los elementos transparentes (margen y
relleno) solo para hacerlos visibles.
Un detalle interesante que puede apreciarse en la representación tridimensional en
que la capa superior del apilamiento no es el borde, como podría suponerse
intuitivamente.

Índice
Licenciatura en Sistemas de Información 51
La capa situada encima de todas las demás es la de Contenido.
Aunque el caso específico sea materia de otro artículo, comentaremos que esta
disposición fue utilizada por el diseñador Douglas Bowman de Stopdesign para el
rediseño del sitio de Blogger , logrando las armoniosas líneas curvas de sus
páginas mediante CSS, ubicando imágenes en la capa de Contenidos de modo
que oculten el borde anguloso de las cajas.
Áreas y propiedades
Cada caja en CSS posee, además de su área de Contenido, otras tres áreas opcionales:
Área de Margen - Margin
Área de Relleno - Padding
Área de Borde - Border
Cada área, a su vez, puede dividirse en cuatro segmentos según su posición: izquierdo (left), derecho (right), superior (top) e inferior (bottom).
El tamaño de cada área o de sus segmentos está dado por el valor de las
respectivas propiedades, definidas en forma global o discriminada por segmento.
Por ejemplo, la siguiente sentencia asignará un margen homogéneo de 20 píxeles
alrededor de la caja:
div { margin: 20px }
Si en cambio se desea asignar valores distintos a cada uno de los segmentos,
pueden reflejarse los cuatro valores numéricos siguiendo el orden top - right -
bottom - left.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 52
El siguiente ejemplo asigna 10 píxeles arriba, 5 a la derecha, 20 abajo y nada a la
izquierda:
div { margin: 10px 5px 20px 0 }
Pueden especificarse valores también con la siguiente notación, en la que ya no
es necesario mantener el orden:
div {
margin-top: 10px ;
margin-right: 5px ;
margin-bottom: 20px ;
}
En cualquier caso puede obviarse el valor 0 ya que es el valor que toman las
propiedades por defecto.
La lista completa de propiedades es la siguiente:
Propiedades del Margen
"margin-top", "margin-right", "margin-bottom", "margin-left" y "margin"
Propiedades del Relleno
"padding-top", "padding-right", "padding-bottom", "padding-left" y "padding"
Propiedades del Borde
1) Ancho (width)
"border-top-width", "border-right-width", "border-bottom-width", "border-left-width" y
"border-width". Pueden ser valores específicos o los valores "thin" (fino), "medium"
(medio) y "thick" (grueso)
2) Color (color)
"border-top-color", "border-right-color", "border-bottom-color", "border-left-color" y
"border-color"
3) Estilo (style)
"border-top-style", "border-right-style", "border-bottom-style", "border-left-style" and
"border-style". Toma una serie de posibles valores, tales como: none, hidden,
dotted, dashed, solid, double, groove, ridge, inset y outset. Es una propiedad algo
conflictiva ya que no todos los navegadores interpretan sus valores de la misma
manera.
Como corolario de esta aproximación al modelo de caja resta analizar qué es lo
que se verá en cada área cuando la página se muestre en un navegador:

Índice
Licenciatura en Sistemas de Información 53
En el área de Contenido y en la de Relleno se verá aquello que se
determine en la propiedad "background" del elemento (un color o una
imagen, según el orden de apilado).
En el área de Borde se verá aquello que se determine en las propiedades
del Borde (ancho, color y estilo).
El área de Margen es siempre transparente.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 54
Tema 4: Desarrollo de aplicaciones Web
Arquitectura de las aplicaciones Web.
En la ingeniería de software se denomina aplicación web a aquellas aplicaciones que los usuarios pueden utilizar accediendo a un servidor web a través de Internet o de una intranet mediante un navegador. En otras palabras, es una aplicación software que se codifica en un lenguaje soportado por los navegadores web en la que se confía la ejecución al navegador.
Las aplicaciones web son un tipo especial de aplicaciones cliente/ servidor. Las aplicaciones web (WebApp) utilizan la arquitectura cliente-servidor (Figura 1)
Figura 1. Arquitectura cliente-servidor
Cliente/servidor es una arquitectura de red1 en la que cada ordenador o proceso
en la red es cliente o servidor2.
Normalmente los servidores son ordenadores potentes dedicados a gestionar unidades de disco (servidor de ficheros), impresoras (servidor de impresoras), tráfico de red (servidor de red), datos (servidor de base de datos), o incluso aplicaciones (servidor de aplicaciones), mientras que los clientes son máquinas menos potentes y usan los recursos que ofrecen los servidores.
Dentro de los clientes se suelen distinguir dos clases: los clientes inteligentes (rich client) y los clientes tontos (thin client). Los primeros son ordenadores completos, con todo el hardware y software necesarios para funcionar de forma independiente.
Los segundos son terminales que no pueden funcionar de forma independiente, ya que necesitan de un servidor para ser operativos.
Esta arquitectura implica la existencia de una relación entre procesos que solicitan servicios (clientes) y procesos que responden a estos servicios (servidores). Estos dos tipos de procesos pueden ejecutarse en el mismo servidor o en distintos.
La arquitectura cliente/ servidor1 permite la creación de aplicaciones distribuidas.
La principal ventaja de esta arquitectura es que facilita la separación de las funciones según su servicio, permitiendo situar cada función en la plataforma más adecuada para su ejecución. Además presenta también las siguientes ventajas:
1. Otro tipo de arquitectura de red es peer- to- peer (entre pares o de igual a igual), en la que cada
ordenador de la red posee responsabilidades equivalentes.
2. Aunque un mismo ordenador puede ser cliente y servidor simultáneamente se establece una separación
lógica según las funciones que realiza.

Índice
Licenciatura en Sistemas de Información 55
a- Las redes de ordenadores permiten que múltiples ordenadores puedan ejecutar partes distribuidas de una misma aplicación, logrando concurrencia de procesos.
b- Existe la posibilidad de migrar aplicaciones de un procesador a otro con modificaciones mínimas en los programas.
c- Se obtiene una escalabilidad de la aplicación. Permite la ampliación horizontal o vertical de las aplicaciones. La escalabilidad horizontal se refiere a la capacidad de añadir o suprimir estaciones de trabajo que hagan uso de la aplicación (clientes), sin que afecte sustancialmente al rendimiento general. La estrategia más sencilla para escalar una aplicación web es simplemente comprar hardware mejor y más caro. Si nuestro hardware actual puede servir 100 peticiones por segundo, cuando alcancemos ese límite podemos actualizar la máquina a una con más potencia y así servir más peticiones. Esto se conoce como escalabilidad vertical. La sabiduría popular nos dice que la escalabilidad vertical tiene un límite: llegados a cierto punto, simplemente no hay máquinas más caras, por lo que no se puede seguir escalando verticalmente. Además, el precio de las máquinas suele aumentar exponencialmente con su potencia, por lo que la escalabilidad vertical suele ser una opción cara.
La escalabilidad vertical se refiere a la capacidad de migrar hacia servidores de mayor capacidad o velocidad, o de un tipo distinto de arquitectura sin que afecte a los clientes. El mejor ejemplo de este paradigma es la arquitectura de Google. La plataforma en la que corre el famoso buscador está compuesta de decenas de miles de máquinas de hardware utilitario. Entre tanto hardware barato es normal que cada día decenas de máquinas dejen de funcionar por problemas de hardware, pero eso no supone un problema grave: el sistema es capaz de redirigir automáticamente el tráfico de un nodo caído a los nodos sanos y seguir funcionando como si tal cosa. Para aumentar su capacidad, Google sólo tiene que comprar más máquinas y ponerlas a funcionar. Posibilita el acceso a los datos independientemente de donde se encuentre el usuario.
Separación de funciones
La arquitectura cliente/servidor nos permite la separación de funciones en tres niveles:
La lógica de presentación: Se encarga de la entrada y salida de la aplicación con el usuario. Sus principales tareas son: obtener información del usuario, enviar la información del usuario a la lógica de negocio para su procesamiento, recibir los resultados del procesamiento de la lógica de negocio y presentar estos resultados al usuario.
Lógica de negocio (o aplicación): Se encarga de gestionar los datos a nivel de procesamiento. Actúa de puente entre el usuario y los datos. Sus principales tareas son: recibir la entrada del nivel de presentación, interactuar con la lógica de datos, para ejecutar las reglas de negocios (business rules) que tiene que cumplir la aplicación (facturación, cálculo de nóminas, control de inventarios, etc.) y enviar el resultado del procesamiento al nivel de presentación.
Lógica de datos: Se encarga de gestionar los datos a nivel de almacenamiento. Sus principales tareas son: almacenar los datos, recuperar los datos, mantener los datos y asegurar la integridad de los mismos.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 56
Si un sistema distribuido se diseña correctamente, los tres niveles anteriores pueden distribuirse y redistribuirse independientemente sin afectar al funcionamiento de la aplicación.
Modelos de distribución en aplicaciones cliente/servidor
Según como se distribuyan las tres funciones básicas de una aplicación (presentación, negocio y datos) entre el cliente y el servidor, podemos contemplar tres modelos:
Presentación distribuida: El cliente solo mantiene la presentación, el resto de la aplicación se ejecuta remotamente. La presentación distribuida, en su forma más simple, es una interfaz gráfica de usuario a la que se le pueden acoplar controles de validación de datos, para evitar la validación de los mismos en el servidor.
Aplicación distribuida: Es el modelo que proporciona máxima flexibilidad, puesto que permite tanto a servidor como a cliente mantener la lógica de negocio realizando cada uno las funciones que le sean más propias, ya sea por organización, o por mejora en el rendimiento del sistema.
Datos distribuidos: Los datos son los que se distribuyen, por lo que la lógica de datos es lo que queda separada del resto de la aplicación. Se puede dar de dos formas: ficheros distribuidos o bases de datos distribuidas.
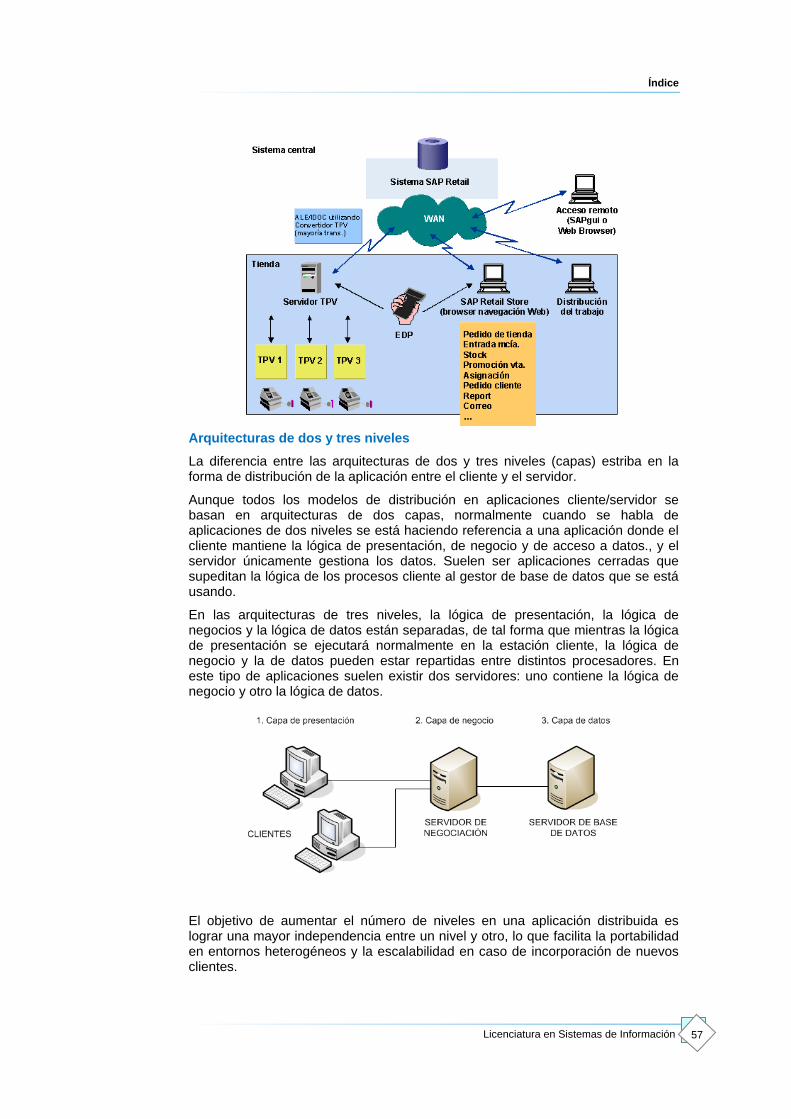
Índice
Licenciatura en Sistemas de Información 57
Arquitecturas de dos y tres niveles
La diferencia entre las arquitecturas de dos y tres niveles (capas) estriba en la forma de distribución de la aplicación entre el cliente y el servidor.
Aunque todos los modelos de distribución en aplicaciones cliente/servidor se basan en arquitecturas de dos capas, normalmente cuando se habla de aplicaciones de dos niveles se está haciendo referencia a una aplicación donde el cliente mantiene la lógica de presentación, de negocio y de acceso a datos., y el servidor únicamente gestiona los datos. Suelen ser aplicaciones cerradas que supeditan la lógica de los procesos cliente al gestor de base de datos que se está usando.
En las arquitecturas de tres niveles, la lógica de presentación, la lógica de negocios y la lógica de datos están separadas, de tal forma que mientras la lógica de presentación se ejecutará normalmente en la estación cliente, la lógica de negocio y la de datos pueden estar repartidas entre distintos procesadores. En este tipo de aplicaciones suelen existir dos servidores: uno contiene la lógica de negocio y otro la lógica de datos.
El objetivo de aumentar el número de niveles en una aplicación distribuida es lograr una mayor independencia entre un nivel y otro, lo que facilita la portabilidad en entornos heterogéneos y la escalabilidad en caso de incorporación de nuevos clientes.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 58
Lenguajes de programación del lado del cliente.
Estos programas residen junto a la página web en el servidor pero son transferidos al cliente para que este los ejecute.
Java, JavaScript, VBScript son lenguajes del lado del cliente.
Lenguajes de programación del lado del servidor.
Los lenguajes son ejecutados por el servidor y lo que se envía al cliente es la respuesta o el resultado de dicha ejecución.
Lenguajes como PHP o Perl pertenecen a esta categoría.
Ambientes para el desarrollo de aplicaciones Web.
Los IDE (ambientes integrados de desarrollo) para aplicaciones Web son muy numerosos. Algunos son específicos para lenguajes del lado del servidor. Por ejemplo, Visual Studio solo soporta ASP.NET del lado del servidor.
Existen IDE’s en buena cantidad, libres y gratuitos de buena calidad. Algunos ejemplos de IDE para Web son:
Microsoft Visual Studio.
Microsoft Web Developer Express.
Mono (para ASP.NET).
NetBeans.
Jbuilder.
Eclipse.

Índice
Licenciatura en Sistemas de Información 59
Metodologías para el desarrollo de aplicaciones Web.
Las distintas metodologías se pueden dividir en tres generaciones, en base a su nivel de sofisticación, y en dos familias, las derivadas de modelos clásicos de datos (E/R) y las derivadas de modelos Orientados a Objetos (OMT y UML).
La primera generación: (primera mitad de los 90’s). Sienta las bases de la Ingeniería Web al incluir conceptos como constructores de navegación, o promover la separación entre estructuras de navegación y el contenido durante el proceso de desarrollo.
La segunda generación: (segunda mitad de los 90’s). Refina los primeros modelos e incluye conceptos como los soportes de funcionalidad básica, y los primeros esbozos de proceso donde se delimitan los modelos conceptual, lógico y físico.
La tercera generación: (2000-2002). Profundiza en el soporte para la funcionalidad, se enfatiza el artículo del usuario en los métodos, y se producen avances hacia la estandarización de notaciones, procesos y lenguajes textuales de especificación.
Debido al gran auge que ha tenido en el ámbito mundial el uso y navegación por Internet y la economía electrónica, los diseñadores de sitios Web y quienes los contratan para la construcción de sus portales, se han preocupado por las razones que implican que un usuario regrese o no al sitio; pues en el comercio electrónico, el usuario primero se enfrenta a la usabilidad y después hace el pago.
La evaluación o diagnóstico de usabilidad consiste en las metodologías que miden los aspectos de usabilidad de una interfaz utilizada por un sistema e identificar problemas específicos; siendo una parte importante del proceso total del diseño de la interfaz de usuario, que consiste en ciclos iterativos de diseñar, de prototipos y de la evaluación. No obstante la popularidad de UML, no se han contemplado la inclusión de características para el desarrollo en Web, tanto así que ha surgido una nueva rama de la ingeniería de software denominada “Ingeniería Web”, en la cual se trata de cubrir los aspectos importantes de las aplicaciones enfocadas a la Web.
UWE (Ingeniería Web basada en UML)
La ingeniería Web basada en UML (UWE) fue presentada por Nora Koch en el 2000. Esta metodología utiliza un paradigma orientado a objetos, y está orientada al usuario. Está basada en los estándares UML y UP (Proceso Unificado), cubre todo el ciclo de vida de este tipo de aplicaciones centrando además su atención en aplicaciones personalizadas.
UWE propone una extensión de UML que se divide en 4 pasos:
1. Análisis de requisitos. Su objetivo es encontrar los requisitos funcionales de la aplicación Web para representarlos como casos de uso. Da lugar a un diagrama de casos de uso.
2. Diseño conceptual. Su objetivo es construir un modelo conceptual del dominio de la aplicación considerando los requisitos reflejados en los casos de uso. Da como resultado un diagrama de clases de dominio.
3. Diseño navegacional. Se obtienen el modelo de espacio de navegación y modelo de estructura de navegación, que muestra cómo navegar a través del

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 60
espacio de navegación. Se obtienen diagramas de clases que representan estos modelos.
4. Diseño de presentación. De este paso se obtienen una serie de vistas de interfaz de usuario que se presentan mediante diagramas de interacción UML. Los aspectos principales de esta metodología son:
Uso de una notación estándar, como es la notación UML.
Definición precisa del método, una serie de pasos para seguir la construcción de los modelos.
La especificación de restricciones, la metodología recomienda el uso de restricciones escritas en el Lenguaje de Restricciones de Objetos (OCL) para aumentar la precisión de los modelos.
WAE (Extensión de Aplicaciones Web para UML)
UML tiene definido un mecanismo para permitir cierto dominio para extender la semántica del modelo de elementos específicos, el mecanismo de extensión permite incluir nuevos atributos, diferente semántica y restricciones adicionales.
El conjunto de extensión de UML propuesto por Jim Conallen está formado por Valores etiquetados, estereotipos y restricciones (Tagged Values, Stereotypes and Constraints).
La parte del mecanismo de la extensión de UML es la habilidad de asignar iconos diferentes a las clases estereotipadas. El problema de una página Web es que tiene diferentes scripts y variables que se ejecutan en el servidor o del lado del cliente, este problema se puede resolver de dos formas:
El primero sería definir los estereotipos; método del servidor y método del cliente. En un objeto de la página un método que ejecuta en el servidor se estereotipará como «server method» y las funciones que corren en el cliente «client method». Esto resuelve el problema de distinguir los atributos y métodos de un objeto de la página, sin embargo todavía es un poco confuso. Una complicación extensa se levanta después cuando se hacen asociaciones a otros componentes en el modelo. No está claro que algunas de estas relaciones sólo son válidas en el contexto de los métodos y atributos del servidor o en los del cliente.
Metodologías Basadas en Hipermedia y Orientadas a Objetos.
¿Qué es Multimedia?
Multimedia: también denominada integración de medios digitales, consiste en un sistema que utiliza información almacenada o controlada digitalmente (texto, gráficos, animación, voz y vídeo) que se combinan en la computadora para formar una única presentación. La multimedia se pude definir, como una combinación de informaciones de naturaleza diversa, coordinada por la computadora y con la que el usuario puede interactuar. Se podrá emplear para realzar y optimizar el flujo de información, incrementando la eficacia de la comunicación entre el usuario final y la computadora.
La utilización de medios digitales de forma interactiva permitirá crear un entorno de comunicación más participativo, ya que combina información de diversos medios

Índice
Licenciatura en Sistemas de Información 61
en una única corriente de conocimiento, aumentando el impacto que se produciría en los usuarios si se emplea de manera separada, los medios digitales que se incluyen en una computadora son Animación, Gráficos, Sonido y Vídeo.
¿Qué es la Hipermedia?
La hipermedia es el resultado de combinación de hipertexto y la multimedia. Tradicionalmente, la idea de hipertexto se ha asociado con la documentación puramente textual, o en todo caso gráfico, por lo que la inclusión de otros tipos de información (vídeo, música, etc.) suele recogerse con el nombre de hipermedia. Por una parte, el hipertexto permite representar una estructura asociativa en la que nodos o conceptos pueden enlazarse automáticamente. Las aplicaciones multimedia permiten integrar diferentes medios bajo una presentación interactiva, para lo que pueden ofrecer dos tipos de accesos a la información:
El mecanismo mayoritariamente utilizado, consiste en un control de usuario similar al de un reproductor de vídeo o sonido que avanza siguiendo el eje de coordenadas temporal.
En algunos casos, se permite realizar saltos a un determinado instante dentro de una presentación, como suele hacerse en muchos reproductores de discos compactos. Esta facilidad tan sólo permite al usuario que, indicando el momento exacto en que debería aparecer un contenido, se pueda llevar a cabo un rápido movimiento hasta alcanzar dicho punto. A diferencia de los enlaces hipertextuales, estos saltos no dan lugar a ningún tipo de estructura concreta en la que navegar a través de la información.
Las ventajas de la hipermedia
En primer lugar, la hipermedia ofrece un medio adecuado para representar aquella información poco o nada estructurada que no puede ajustarse a los rígidos esquemas de las bases de datos tradicionales. Además, permite estructurar la información, jerárquicamente o no, de tal modo que también resulta útil en sistemas de documentación de textos tradicionales que poseen una marcada organización.
Esta tecnología, que se caracteriza por sus ergonómicos interfaces de usuario, muy intuitivos, pues imitan el funcionamiento de la memoria humana, hace que el usuario no tenga que realizar grandes esfuerzos para conseguir resultados rápidamente.
Estructura de los sistemas Hipermedia
Propiedades fundamentales en un sistema hipermedia hoy en día son:
1. El proceso de ligado entre dos ítems, dando una elevación al paradigma básico de nodo y liga.
2. La selección por asociación, dando una elevación al soporte de ligas que permite el recorrido de una red de nodos en una manera directa. Un sistema hipermedia esta hecho de nodos (conceptos) y ligas (relaciones). Los nodos están conectados a otros nodos por ligas. El nodo del cual una liga origina es llamado referencia y el nodo en el cual la liga termina es llamado referente. Ellos son también referidos como anclas. El contenido de un nodo es desplegado por ligas

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 62
activas. Aparte de esta arquitectura nodo-liga, los sistemas hipermedia tienen una estructura irregular.
Balasubramanian lista los componentes básicos de un sistema hipermedia como sigue:
1. Una interfaz de usuario gráfica con navegadores y diagramas generales para ayudar a los usuarios a navegar a través de una gran cantidad de información dispersa, posiblemente interconectada, unida por ligas activas.
2. Un sistema con herramientas para crear y manejar nodos y ligas.
3. Mecanismos de recuperación de información tradicional (tales como búsquedas por palabra clave, búsqueda por autor, etc.)
4. Una ingeniería hipermedia para manejar información acerca de nodos y ligas.
5. Un sistema de almacenaje el cual puede ser un sistema de archivos o una base de conocimiento o un tradicional DBMS.
Diseñando Sistemas Hipermedia
El proceso de desarrollo de un sistema hipermedia puede ser modelado a un cierto grado sobre los procesos de ingeniería de software. Por ejemplo, diseñar el modelo de datos conceptual y el modelo abstracto de navegación puede beneficiarse directamente de las propuestas de ingeniería de software. Las técnicas de diseño formal perfeccionan la consistencia de los documentos hipermedia y proveen líneas de guía. Sin embargo, para los procesos de ingeniería de software, no se requiere tomar en cuenta aspectos estéticos y cognoscitivos, los cuales son dos aspectos importantes del desarrollo hipermedia. Esto implica que las propuestas de ingeniería de software tradicional no son completamente adecuadas para el diseño de sistemas hipermedia. Nanard y Nanard sugiere que las aplicaciones hipermedia pueden ser mejor desarrolladas no siguiendo los pasos secuénciales de las metodologías formales tan correctamente.
SOHDM (Metodología de Diseño Hipermedia Orientado a Objetos y basada en escenarios)
Esta propuesta presenta la necesidad de disponer de un proceso que permita capturar las necesidades del sistema. Para ello, propone el uso de escenarios. El proceso de definición de requisitos parte de la realización de un diagrama de contexto tal y como se propone en diagrama de flujos de datos (DFD) de Yourdon. En este diagrama de contexto se identifican las entidades externas que se comunican con el sistema, así como los eventos que provocan esa comunicación. Las lista de eventos es una tabla que indica en qué eventos puede participar cada entidad. Por cada evento diferente SOHDM propone elaborar un escenario. Éstos son representados gráficamente mediante los denominados SACs (Scenario Activity Chart). Cada escenario describe el proceso de interacción entre el usuario y el sistema cuando se produce un evento determinado especificando el flujo de actividades, los objetos involucrados y las transacciones realizadas. SOHDM propone un proceso para conseguir a partir de estos escenarios el modelo conceptual del sistema que es representado mediante un diagrama de clases. El proceso de SOHDM continúa reagrupando estas clases para conseguir un modelo de clases navegacionales del sistema.

Índice
Licenciatura en Sistemas de Información 63
OOHDM (Método de Diseño Hipermedia Orientado a Objetos)
OOHDM propone el desarrollo de aplicaciones hipermedia a través de un proceso compuesto por cuatro etapas:
1. Diseño conceptual
2. Diseño navegacional
3. Diseño de interfaces abstractas
4. Implementación
Diseño conceptual: durante esta actividad se construye un esquema conceptual representado por los objetos del dominio, las relaciones y colaboraciones existentes establecidas entre ellos. En las aplicaciones hipermedia convencionales, cuyos componentes de hipermedia no son modificados durante la ejecución, se podría usar un modelo de datos semántica estructural (como el modelo E/R). De este modo, en los casos en que la información base pueda cambiar dinámicamente o se intente ejecutar cálculos complejos, se necesitará enriquecer el comportamiento del modelo de objetos.
En OOHDM el esquema conceptual está construido por clases, relaciones y subsistemas. Las clases son descritas como en los modelos orientados a objetos tradicionales. Sin embargo, los atributos pueden ser de múltiples tipos para representar perspectivas diferentes de las mismas entidades del mundo real. Se usa una notación similar a UML y tarjetas de clases y relaciones similares a las tarjetas CRC (Clase Responsabilidad Colaboración).
El esquema de las clases consiste en un conjunto de clases conectadas por relaciones.
Los objetos son instancias de las clases. Las clases son usadas durante el diseño navegacional para derivar nodos, y relaciones que son usadas para construir enlaces.
Diseño navegacional: en OOHDM la navegación es considerada un paso crítico en el diseño de aplicaciones. Un modelo navegacional es construido como una vista sobre un diseño conceptual, admitiendo la construcción de modelos diferentes de acuerdo con los diferentes perfiles de usuarios. Cada modelo navegacional provee una vista subjetiva del diseño conceptual.
En OOHDM existen un conjunto de tipo predefinidos de clases navegacionales: nodos, enlaces y estructuras de acceso. La semántica de los nodos y los enlaces son las tradicionales aplicaciones hipermedia, y las estructuras de acceso, tales como índices o recorridos guiados, representan los posibles caminos de acceso a los nodos. Los nodos son enriquecidos con un conjunto de clases especiales que permiten de un nodo observar y presentar atributos (incluidos los links), así como métodos cuando se navega en un particular contexto.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 64
Diseño de interfaz abstracta: en OOHDM se utiliza el diseño de interfaz abstracta para describir la interfaz de usuario de aplicación de hipermedia. El modelo de interfaz ADVs (Vista de Datos Abstracta) especifica la organización y comportamiento de la interfaz, pero la apariencia física real o de los atributos, y la disposición de las propiedades de las ADVs. en la pantalla real son hechas en fase de implementación.
Implementación: en esta fase, el diseñador debe implementar el diseño. Hasta ahora, todos los modelos fueron construidos en forma independiente de la plataforma de implementación; en esta fase es tenido en cuenta el entorno particular en el cual se va a correr la aplicación.
Al llegar a esta fase, el primer paso que debe realizar el diseñador es definir los ítems de información que son parte del dominio del problema. Debe identificar también, cómo son organizados los ítems de acuerdo con el perfil del usuario y su tarea; decidir qué interfaz debería ver y como debería comportarse. A fin de implementar todo en un entorno Web, el diseñador debe decidir además que información debe ser almacenada.
W2000
Supone una propuesta que amplía la notación UML con conceptos para modelar elementos de multimedia heredados de la propuesta HDM (Método de Diseño Hipermedia). El proceso de desarrollo de W2000 se divide en tres etapas:
1. Análisis de requisitos.
2. Diseño de hipermedia.
3. Diseño funcional.
La especificación de requisitos en W2000 se divide en dos subactividades: análisis de requisitos funcionales y análisis de requisitos navegacionales. La especificación de requisitos comienza haciendo un estudio de los diferentes roles de usuario que van a interactuar con el sistema. Cada actor potencialmente distinto tendrá su modelo de requisitos de navegación y de requisitos funcionales.
El modelo de requisitos funcionales es representado como un modelo de casos de uso tal y como se propone en UML. En él se representa la funcionalidad principal asociada a cada rol y las interacciones que se producen entre el sistema y cada rol. El segundo modelo consiste en otro diagrama de casos de uso pero que no representa funcionalidad sino posibilidades de navegación de cada actor. La representación gráfica es realizada con una extensión de UML.
EORM (Metodología de Relaciones de Objetos Mejorada)
En esta metodología, propuesta por D. Lange, el proceso de desarrollo de un Sistema de Información Hipermedial (Hiperdocumento) comprendería una primera fase de Análisis Orientada a Objetos del sistema, sin considerar los aspectos hipermediales del mismo, obteniendo un Modelo de Objetos con la misma notación utilizada en OMT, que refleje la estructura de la información (mediante clases de objetos con atributos y relaciones entre las clases) y el comportamiento del sistema (a través de los métodos asociados a las clases de objetos).

Índice
Licenciatura en Sistemas de Información 65
La idea fundamental de esta metodología es considerar una segunda fase, de Diseño, durante la cual se proceda a modificar el modelo de objetos obtenido durante el análisis añadiendo la semántica apropiada a las relaciones entre las de objetos para convertirlas en enlaces hipermedia, obteniendo finalmente un modelo enriquecido, que su autor denomina EORM (Enhanced Object-Relationship Model), en el que se refleje tanto la estructura de la información (modelo abstracto hipermedial compuesto de nodos y enlaces) como las posibilidades de navegación ofrecidas por el sistema. Sobre dicha estructura, para lo cual existirá un repositorio o librería de clases de enlaces, donde se especifican las posibles operaciones asociadas a cada enlace de un hiperdocumento, que serán de tipo crear, eliminar, atravesar, siguiente, previo etc., así como sus posibles atributos (fecha de creación del enlace, estilo de presentación en pantalla, restricciones de acceso, etc.).
El desarrollo del Sistema concluiría con una última fase de Construcción, durante la que se generaría el código fuente (por ejemplo en C++) correspondiente a cada clase, y se prepararía la Interfaz Gráfica de Usuario. La adopción del enfoque orientado a objetos OMT garantiza todas las ventajas reconocidas para esta técnica de modelado, como la flexibilidad (posible existencia de múltiples formas de relaciones entre nodos) y la reutilización, por la existencia de una librería de clases de enlaces que pueden ser reutilizados en diferentes proyectos de desarrollo hipermedial.
Para automatizar la aplicación de la metodología EORM, su autor ha desarrollado, en los laboratorios de investigación de IBM, una herramienta denominada ODMTool que, junto a un generador comercial de Interfaces Gráficas de Usuario denominado ONTOS Studio y un Sistema de Gestión de Base de Datos Orientado a Objetos (SGBDOO), permite el diseño interactivo de esquemas EORM y la generación de código fuente, inicialmente en C++, de las clases incluidas en estos esquemas. El SGBDOO ofrece un repositorio de objetos que permite compartir la información de los esquemas entre las herramientas (ODMTool, ONTOS Studio) y las aplicaciones hipermediales desarrolladas.
Aspectos de seguridad.
Introducción a la Seguridad en Sistemas Web
Un efecto secundario del crecimiento exponencial que ha tenido el Internet es la privacidad de información tanto personal como profesional. En Internet encontramos funcionando a tiendas en línea, negocios que mueven grandes cantidades de dinero, redes de los servicios que habilitan el comercio a nivel internacional así como sitios de redes sociales que contienen información muy delicada de la vida privada de sus miembros.
Mientras más se conecta el mundo, la necesidad de seguridad en los procedimientos usados para compartir la información se vuelve más importante. Desde muchos puntos de vista, podemos creer sin dudar que el punto más crítico de la seguridad del Internet, lo tienen las piezas que intervienen de forma directa con las masas de usuarios, los servidores web.
Respecto a los servidores web, es común escuchar sobre fallas en los sistemas de protección de los servidores más frecuentemente utilizados (Apache, IIS, etc.), o en los lenguajes de programación en los que son escritas las aplicaciones que son ejecutadas por estos servidores. Pero es un hecho, que la mayoría de los problemas detectados en servicios web no son provocados por fallas intrínsecas

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 66
de ninguna de estas partes, ya que una gran cantidad de los problemas se generan por malos usos por parte de los programadores.
Ahora que sabemos que la mayoría de los problemas de seguridad en los sitios web se encuentran a nivel aplicación y que son el resultado de escritura defectuosa de código, debemos entender que programar aplicaciones web seguras no es una tarea fácil, ya que requiere por parte del programador, no únicamente mostrar atención en cumplir con el objetivo funcional básico de la aplicación, sino una concepción general de los riesgos que puede correr la información contenida, solicitada y recibida por el sistema. En la actualidad, aunque existen muchas publicaciones que permiten formar un criterio sobre el tema, no existen acuerdos básicos sobre lo que se debe o no se debe hacer, y lo que en algunas publicaciones se recomienda, en otras es atacado.
Problemas principales en la Programación de Sistemas Web
Una gran parte de los problemas de seguridad en las aplicaciones web son causados por la falta de seguimiento por parte del programador en los siguientes aspectos:
Entradas al sistema
Salidas del sistema
Quizás uno de los consejos de seguridad en PHP más conocido en cualquier foro de Internet es el uso del parámetro register_globals que es considerado a priori por muchos administradores como un defecto en la configuración y muy probablemente sin entender con cabalidad que es lo que implica esta configuración. El tener habilitado este parámetro oculta el origen de los datos. Si se encuentra habilitado, no podemos saber cómo es que una variable entró al sistema (si lo hizo por medio de una petición GET o POST por ejemplo) y contribuye a la pérdida del control por parte del programador sobre los procesos a los que se ha sometido cada variable para librarla de riesgos potenciales para la aplicación.
Otro aspecto importante además de los procesos de verificación que se deben de tener para con las entradas y salidas del sistema lo representa la fuga de información útil para un posible ataque sobre nuestro sistema. En este punto, los mensajes de error enviados por el servidor, que suelen ser de gran utilidad durante el proceso de desarrollo de la aplicación, se vuelven contra nosotros cuando siguen apareciendo en una aplicación que se encuentra en la etapa de producción, por lo que es necesario deshabitar todos estos mensajes y editar algunos otros (como los que se envían cuando el servidor no encuentra algún archivo en particular) que también pueden ser utilizados por los atacantes para obtener información sobre nuestro sistema.
Practicas básicas de Seguridad Web
Balancear Riesgo y Usabilidad: La recomendación inicial sería tratar de usar medidas de seguridad que sean transparentes a los usuarios. Por ejemplo, la solicitud de un nombre de usuario y una contraseña para registrarse en un sistema son procedimientos esperados y lógicos por parte del usuario.
Rastrear el paso de los Datos: Particularmente para PHP existen arreglos superglobales como $_GET, $_POST y $_COOKIE entre otros que sirven para

Índice
Licenciatura en Sistemas de Información 67
identificar de forma clara las entradas enviadas por el usuario. Si esto lo combinamos con una convención estricta para el nombrado de las variables podemos así tener un control sobre el origen de los datos usados en el código.
Además de entender los orígenes de la información, tiene también igual importancia entender cuáles son las salidas que tiene ésta de la aplicación.
Filtrar Entradas: El filtrado es una de las piedras angulares de la seguridad en aplicaciones web. Es el proceso por el cual se prueba la validez de los datos. Si nos aseguramos que los datos son filtrados apropiadamente al entrar, podemos eliminar el riesgo de que datos contaminados y que reciben confianza indebida sean usados para provocar funcionamientos no deseados en la aplicación.
Escapar salidas: El proceso de escapado debe estar compuesto a su vez por los siguientes pasos: Identificar las salidas, escapar las salidas y distinguir entre datos escapados y no escapados. Para escapar las salidas, primero debemos identificarlas. En PHP una forma de identificar salidas hacia el cliente es buscar por líneas como: echo, print, printf, <?=
Clasificación de Ataques
Ataques URL de tipo Semántico: Este tipo de ataques involucran a un usuario modificando la URL a modo de descubrir acciones a realizar originalmente no planeadas para él. Los parámetros que son enviados directamente desde la URL son enviados con el método GET y aunque los parámetros que son enviados con este método sólo son un poco más fáciles de modificar que los enviados en forma oculta al usuario en el navegador, esta exposición adicional de los parámetros tiene consecuencias, como cuando queda registrada la URL con todo y estos parámetros quizás privados en buscadores como Google.
Ataques al subir archivos: Existen algunos ataques que aprovechan la posibilidad de la aplicación de subir archivos al servidor. Generalmente PHP almacena los archivos subidos en un carpeta temporal, sin embargo es común en las aplicaciones cambiar la localización del archivo subido a una carpeta permanente y leerlo en la memoria. Al hacer este tipo de procedimientos debemos revisar el parámetro que hará referencia al nombre del archivo, ya que puede ser truqueado a modo de apuntar a archivos de configuración del sistema (como /etc/passwd en sistemas Unix).
Ataques de Cross−Site Scripting: XSS es un tipo de vulnerabilidad de seguridad informática típicamente encontrada en aplicaciones web que permiten la inyección de código por usuarios maliciosos en páginas web vistas por otros usuarios. Los atacantes típicamente se valen de código HTML y de scripts ejecutados en el cliente. Desde la liberación del lenguaje JavaScript, se previeron los riesgos de permitir a un servidor Web enviar código ejecutable al navegador. Un problema se presenta cuando los usuarios tienen abiertos varias ventanas de navegador, en algunos casos un script de una página podría acceder datos en otra página u objeto, observando el peligro de que un sitio malicioso intentara acceder datos sensibles de esta forma. Por ello se introdujo la política same−origin. Esencialmente esta política permite la interacción entre objetos y páginas, mientras estos objetos provengan del mismo dominio y en el mismo protocolo. Evitando así que un sitio malicioso tenga acceso a datos sensibles en otra ventana del navegador vía JavaScript.

Taller de Programación I
FACENA - UNNE Teoría
Facultad de Ciencias Exactas y Naturales y Agrimensura 68
Cross−Site Request Forgeries: Este tipo de ataque permite al atacante enviar peticiones HTTP a voluntad desde la máquina de la víctima. Por la naturaleza de este tipo de ataques, es difícil determinar cuándo una petición HTML se ha originado por un ataque de este tipo.
Envío de Formas falsificadas: Falsificar una forma es casi tan fácil como manipular una URL. Un atacante podría copiar el código fuente de una página, salvarla en su equipo, y modificar el atributo de la acción que realizará la forma incluyendo ahora la ruta absoluta de la página originalmente deseada. Ahora el atacante puede quitar restricciones originales que se hubieran ejecutado en el cliente, como el tamaño máximo de un archivo adjunto, desactivar la validación de datos en el lado del cliente, alterar los elementos ocultos o los tipos de datos de los elementos de la forma. Operando de esta forma podemos enviar datos arbitrarios al servidor, de una manera sencilla y sin el uso de herramientas sofisticadas. Este tipo de falsificaciones es algo que no podemos prevenir, pero es algo que debemos tomar en cuenta. Mientras tengamos el poder de filtrar las entradas, los usuarios deben jugar con nuestras reglas.
Peticiones HTTP Falsificadas: Un ataque más sofisticado que el anterior es enviar peticiones falsas empleando herramientas especiales para este propósito. La existencia de este tipo de ataques es una prueba determinante de que los datos enviados por los usuarios no son dignos de ninguna confianza.
Los dos últimos tipos de ataques mencionados son una muestra de que el usuario no está obligado a enviar la información siguiendo las reglas que han sido definidas en la aplicación. En realidad un atacante puede confeccionar a gusto sus peticiones HTTP, la fortaleza de nuestro sistema será medible por su capacidad de detectar que peticiones recibidas deben ser escuchadas y procesadas de acuerdo a los parámetros y valores de éstos que son esperables recibir.
Como conclusión general podemos decir que la seguridad en aplicaciones Web involucra principalmente al desarrollador, aunque con gran frecuencia se encuentran defectos que pueden ser aprovechados por atacantes en las tecnologías en que se basan los sistemas web (Sistemas Operativos, Servidores Web, Servidor Base de Datos, etc.) la atención principal debe dirigirse a los defectos propios al desarrollo nuestras aplicaciones. A menudo, los desarrolladores desconocen a detalle el funcionamiento de los sistemas web y no consideran todas las posibilidades de uso o mal uso al que un sistema web puede someterse cuando se conoce con mayor detalle el protocolo HTTP y las herramientas que permiten aprovecharlo de otra manera, es decir, los programadores con frecuencia desconocen que las aplicaciones pueden ser accedidas con herramientas diferentes al puro navegador web, o incluso la existencia de aditamentos a los navegadores que potencializan su uso de manera diferente al navegador común.
Entendiendo lo anterior, todo programador debe estar consciente de que de él depende el rechazar o filtrar las peticiones recibidas en que los datos o variables recibidas no cumplan con las características esperadas o predefinidas. Ninguna entrada al sistema debe ser digna de una confianza plena, todas de preferencia deben pasar por el filtrado de los datos contenidos para confirmar su usabilidad.
Otro aspecto importante a considerar son los procesos de salida de la información del sistema. Es importante siempre considerar el significado que pueda tener la información enviada en su nuevo contexto, y en el caso de poder crear problemas de interpretación de las salidas escapar las salidas para preservarlas. Al igual que

Índice
Licenciatura en Sistemas de Información 69
en el proceso de filtrado, es importante mantener un control sobre la codificación que tienen los datos antes de enviarlos a su nuevo contexto.
Otro tipo de problemas, como los procesos de autenticación tienen consideraciones propias que debemos implementar para hacer más robusta y confiable nuestra aplicación.
2
2 Aspectos Básicos de la Seguridad en Aplicaciones Web.
http://www.seguridad.unam.mx