soporte para el diagnóstico de sepsis en adultos,...
TRANSCRIPT

Soporte Para el Diagnóstico De Sepsis En Adultos, Usando
Técnicas De Minería De Datos Supervisadas
Tesis
Maestría en Ingeniería – Sistemas e Informática
Autoría de:
Ing. ANDRÉS FELIPE RODRÍGUEZ ÁLVAREZ
Director:
Ph.D. CLAUDIA JIMÉNEZ RAMÍREZ
Codirector de investigación:
Ph.D. FABIÁN JAIMES
FACULTAD DE MINAS
UNIVERSIDAD NACIONAL DE COLOMBIA
SEDE MEDELLÍN
2014

i
AGRADECIMIENTOS
Le agradezco a Dios por haberme guiado durante mis estudios de posgrado, por darme fortaleza en momentos difíciles y por brindarme una vida llena
de aprendizajes y nuevas experiencias.
Le doy gracias a mi madre Eunice Álvarez por el apoyo incondicional, por los valores que me ha inculcado y por darme una excelente educación en el
transcurso de mi vida.
Le agradezco a la Doctora Claudia Jiménez, docente de la Universidad Nacional, quien me asesoró y dirigió durante el proceso de aprendizajes y
por haber compartido conmigo sus conocimientos y su amistad.
Adicionalmente, quiero agradecer al Doctor Fabián Jaimes docente, médico e investigador de la Universidad de Antioquia, por su disponibilidad, confianza, apoyo y por haberme brindado la oportunidad de desarrollar mi
tesis de Maestría.
Por último, quiero manifestar mis agradecimientos a la Universidad Nacional de Colombia, institución donde he recibido toda mi formación profesional.

ii
RESUMEN
La sepsis es una respuesta de un paciente a la infección, y es una causa
importante de morbilidad y mortalidad en todo el mundo. Este estudio
aborda el problema del diagnóstico de la sepsis aplicando la metodología del
descubrimiento del nuevo conocimiento en base de datos. Los datos
empleados fueron obtenidos de una investigación previa, en la cual se hizo
una serie de mediciones a los pacientes y éstos fueron clasificados por un
grupo de expertos.
Las técnicas de minería de datos utilizadas presentan un pobre desempeño
dado que muestran una precisión no mayor al 72.80%; sin embargo, se
puede observar que las características de los leucocitos, procalcitonina,
temperatura, presión arterial media y proteína C reactiva son las más
discriminantes.
Palabras Clave: Salud, inteligencia artificial, estadística,
epidemiologia clínica, red neuronal artificial, regresión logística, C4.5
y kappa.

iii
Abstract
Sepsis is a response of a patient to infection, and is an important
cause of morbidity and mortality worldwide. This study approaches
the problem of sepsis diagnosis using the methodology of discovery
of new knowledge based on data. Data used were obtained from
previous research, series of measurements were done to patients and
a group of experts classified these patients. Data mining techniques
used have performed poorly, they show an accuracy not greater than
72.80%; however, we can see that the characteristics of leukocytes,
procalcitonin, temperature, mean arterial pressure and C Reactive
Protein are the most discriminating.
Keywords: Health, artificial intelligence, statistics, clinical
epidemiology, artificial neural network, logistic regression, C4.5 and
kappa.

iv
CONTENIDO
1 PLANTEAMIENTO DEL PROBLEMA .................................................... 4
2 FUNDAMENTOS TEÓRICOS ............................................................. 7
2.1 Descubrimiento de Conocimiento en Bases de Datos (KDD, por sus
siglas en inglés) ............................................................................... 7
2.1.1 Concepto del KDD .............................................................. 7
2.1.2 El proceso de KDD ............................................................. 7
2.2 Fuentes de información ............................................................ 9
2.3 TECNICAS DE CLASIFICACIÓN .................................................. 9
2.3.1 K vecinos más cercanos (K nearest neighbors K-NN) .............. 9
2.3.2 Clasificador de Bayes Ingenuo (Naive Bayes) ........................ 10
2.3.3 Regresión Logística ........................................................... 10
2.3.4 Red neuronal artificial (artificial neural network - ANN) .......... 11
2.3.5 C4.5 ................................................................................ 12
2.4 Entrenamiento, Validación y Evaluación de los Modelos ............... 13
3 DESCRIPCIÓN DE LA BASE DE DATOS. ........................................... 15
4 METADATOS Y SELECCIÓN DE LOS ATRIBUTOS ............................... 18
5 PRE PROCESAMIENTO DE LOS DATOS ............................................ 48
6 ANÁLISIS DE LOS DATOS .............................................................. 52
7 APLICACIÓN DE LAS TECNICAS, MEJOR MODELO Y RESULTADOS. ..... 59
7.1 Modelos ................................................................................. 61
7.2 Resultados ............................................................................. 69
8 CONCLUSIONES Y RECOMENDACIONES .......................................... 71

v
LISTA DE TABLAS
Tabla 1. Clasificación Sin Infección (0), Infección Sin Sepsis (1), Sepsis(2) y
Sepsis Grave (3) ................................................................................ 17
Tabla 2. Metadatos Edad..................................................................... 18
Tabla 3. Metadatos VIH/SIDA .............................................................. 19
Tabla 4. Metadatos Trauma o Cirugía ................................................... 19
Tabla 5. Metadatos Drogadicción y/o Alcoholismo .................................. 20
Tabla 6. Metadatos Diabetes ............................................................... 20
Tabla 7. Metadatos Insuficiencia Cardiaca Congestiva ............................. 21
Tabla 8. Metadatos Esteroides ............................................................. 21
Tabla 9. Metadatos Enfermedad Pulmonar ............................................ 22
Tabla 10. Metadatos Cáncer ................................................................ 22
Tabla 11. Metadatos Insuficiencia renal ................................................ 23
Tabla 12. Metadatos Cirrosis ............................................................... 23
Tabla 13. Metadatos Paciente Trasplantado ........................................... 24
Tabla 14. Metadatos Presión Arterial del Oxigeno por la Fracción Inspirada
de Oxigeno ....................................................................................... 25
Tabla 15. Metadatos Plaquetas ............................................................ 26
Tabla 16. Presión Arterial Media .......................................................... 27
Tabla 17. Metadatos Bilirrubina ........................................................... 28
Tabla 18. Metadatos Creatinina ........................................................... 29
Tabla 19. Metadatos Temperatura ........................................................ 30
Tabla 20. Metadatos Frecuencia Cardiaca .............................................. 31
Tabla 21. Metadatos Frecuencia Respiratoria ......................................... 32
Tabla 22. Metadatos Potencial de Hidrógeno ......................................... 33
Tabla 23. Metadatos Nivel del Sodio Sérico ........................................... 34
Tabla 24. Metadatos Nivel de Potasio Sérico .......................................... 35
Tabla 25. Metadatos Hematocrito ......................................................... 36
Tabla 26. Metadatos Leucocitos ........................................................... 37
Tabla 27. Metadatos Tiempo de Protrombina ......................................... 38
Tabla 28. Metadatos Tiempo Parcial de Tromboplastina .......................... 39
Tabla 29. Metadatos Presión Arterial de Dióxido de Carbono.................... 40
Tabla 30. Metadatos Escala de Coma de Glasgow .................................. 41
Tabla 31. Metadatos Proteína C Reactiva Medición 1............................... 42
Tabla 32. Metadatos Procalcitonina Medición 1 ...................................... 43
Tabla 33. Metadatos Dímero-D ............................................................ 44
Tabla 34. Metadatos Proteína C Reactiva Medición 2............................... 45
Tabla 35. Metadatos Procalcitonina Medición 2 ...................................... 46
Tabla 36. Metadatos Dímero-D Medición 2 ............................................ 47
Tabla 37. Frecuencias Grupo Inmunosupresión ...................................... 48
Tabla 38. Frecuencias Grupo Enfermedad General ................................. 48
Tabla 39. Metadatos APACHE II ........................................................... 50
Tabla 40. Metadatos SOFA .................................................................. 51
Tabla 41. Resumen Prueba Diferencias de Medianas ............................... 55

vi
Tabla 42. Significancia Coeficientes ...................................................... 62
Tabla 43. Coeficientes Regresión Logística ............................................ 63
Tabla 44. Resultados Selección 1 de los Atributos .................................. 69
Tabla 45. Resultados Selección 2 de los Atributos .................................. 69
Tabla 46. Resultados Selección 3 de los Atributos .................................. 69

vii
LISTA DE FIGURAS
Figura 1. Proceso de KDD1 ................................................................... 8
Figura 2. Ejemplo Perceptrón Multicapa ................................................ 12
Figura 2. Gráfica de dispersión para Proteína C Reactiva Medición 1(Y) y
2(X) ................................................................................................. 53
Figura 3. Gráfica de dispersión para procalcitonina Medición 1(Y) y 2(X) ... 53
Figura 4. Gráfica de dispersión para Dímero-D Medición 1(Y) y 2(X) ......... 53
Figura 5. Gráfica de dispersión para Hematocrito (X) y T.P. Tromboplastina
(Y) ................................................................................................... 54
Figura 6. Gráfica de dispersión para Temperatura (X) y Nivel del sodio
sérico (Y) .......................................................................................... 54
Figura 7. Presión Arterial Media Literales A (Sepsis y No Sepsis) y Literales
B (No Infección y Sepsis Grave) .......................................................... 57
Figura 8. Proteína C reactiva Medición 1 Literales A (Sepsis y No sepsis) y
Literales B (No Infección y Sepsis Grave) .............................................. 57
Figura 9. Dímero-D (DD) Medición 1 Literales A (Sepsis y No sepsis) y
Literales B (No Infección y Sepsis Grave) .............................................. 58
Figura 10. Recuento de plaquetas Literales A (Sepsis y No sepsis) y Literales
B (No Infección y Sepsis Grave) .......................................................... 58
Figura 12. Interfaz RapidMiner Flujo de Trabajo ..................................... 60
Figura 13. Interfaz RapidMiner Flujo de Validación ................................. 60
Figura 14. Interfaz WEKA con Datos ..................................................... 61
Figura 15. Interfaz WEKA Resultados de la aplicación del algoritmo J48
(C4.5) .............................................................................................. 61

viii

1
INTRODUCCIÓN
La sepsis es la respuesta de un ser humano a la infección, usualmente de etiología bacteriana y de inicio agudo, y es una causa importante de
morbilidad y mortalidad en todo el mundo; por lo tanto es necesario abordar este tema de investigación utilizando técnicas novedosas. La definición clínica del concepto está estrechamente relacionada con el
Síndrome de Respuesta Inflamatoria Sistémica (SRIS), caracterizado por la alteración de al menos dos variables biológicas (temperatura, frecuencia
cardiaca, frecuencia respiratoria o leucocitos) en conjunto con una infección. Sin embargo, la simple combinación de los criterios de SRIS no es lo suficientemente específica ni sensible para ser útil en la toma de decisiones
médicas, en particular para el diagnóstico de la sepsis, y mucho menos para el diagnóstico temprano.
Como antecedente en Colombia, la Universidad de Antioquia mediante el proyecto de investigación “Hacia un Diagnóstico Efectivo en Sepsis: un
Análisis de Clases Latentes” iniciado en 2006, recolectó información de 805 pacientes adultos con sospecha de infección que ingresaron en el servicio de
urgencias entre los años 2007 y 2008. La finalidad fue hacer una investigación mediante el método de análisis de clases latentes con la intención de determinar si tres marcadores biológicos (la proteína C
reactiva, la procalcitonina y el dímero-D) podrían ser útiles para el diagnóstico temprano de la sepsis.
Es de anotar que de acuerdo con la información recolectada no se logró cumplir en su totalidad el objetivo deseado, y una de las razones para este
resultado parcial pudo ser el método de análisis empleado. Por consiguiente, el problema del diagnóstico aún persiste y la presente tesis
pretende utilizar las características medidas en dicha investigación para ajustar un método de clasificación de aprendizaje supervisado, que permita explicar razonablemente el fenómeno y contribuya en el diagnóstico
objetivo de la sepsis. Esta propuesta, por tanto, se enmarca en la nueva disciplina conocida bajo el nombre de Descubrimiento de Nuevo
Conocimiento en Bases de Datos. En esta investigación, la selección de los atributos fue hecha mediante la
colaboración de un médico experto, quien trabajó en el estudio anterior. Las técnicas de minería de datos que se utilizaron son el clasificador de bayes
ingenuo, la regresión logística, K-vecinos más cercanos, el árbol de decisión C4.5 y la red neuronal. Aunque los resultados no fueron los deseados, sí se
logró detectar algunas variables que en futuros trabajos se pueden tener en cuenta.
Acorde con lo expuesto, este documento se elaboró en capítulos siguiendo la metodología del descubrimiento de conocimiento en base de datos. Así,
se inicia con el planteamiento del problema, la presentación de los fundamentos teóricos de la metodología, la descripción de la base de datos,
los metadatos y selección de los atributos, pre procesamiento, análisis de

2
los datos, minería de datos, aplicación de las técnicas, modelos, evaluación
de los modelos, resultados, conclusiones y recomendaciones.

3
OBJETIVOS Y ALCANCE
OBJETIVO GENERAL
Ajustar un método de clasificación de aprendizaje supervisado con el conjunto o un subconjunto de variables de los pacientes adultos con
sospecha de infección, que permita explicar razonablemente el fenómeno y el diagnóstico objetivo de la sepsis, a partir de la base de datos obtenida en el proyecto de investigación Hacia un Diagnóstico Efectivo en Sepsis: un
Análisis de Clases Latentes realizado por Fabián Jaimes MD. MSc. PhD, Departamento de Medicina Interna, Universidad de Antioquia.
OBJETIVOS ESPECÍFICOS
Definir la estructura de metadatos de la base de datos y determinar
las propiedades de las características seleccionadas.
Identificar y corregir errores en la base datos.
Reducir el número de características o descriptores según criterios de importancia médica o redundancia de información, considerando la
parsimonia del modelo de clasificación que se quiere obtener.
Seleccionar las técnicas de minería de datos de las disponibles en la literatura para la discriminación y clasificación de objetos, que sean
adecuadas a las propiedades de los datos que se tiene disponibles.
Analizar y elegir los indicadores de ajuste más apropiados para
comparar las diferentes técnicas de minería de datos que se encuentran bajo estudio.
Evaluar los modelos de clasificación obtenidos con las distintas
técnicas bajo estudio usando los indicadores de ajuste elegidos.
ALCANCE DEL PROBLEMA DE INVESTIGACIÓN
Esta investigación cubre las técnicas de minería de datos de aprendizaje supervisado para la discriminación y la clasificación de objetos como árboles de decisión (C4.5) y redes neuronales. Al finalizar este estudio, se
descubrirá si existe un subconjunto de las variables de la base de datos que permitan una discriminación o clasificación de los nuevos pacientes entre los
que pueden desarrollar la sepsis y los que no. Se utilizaron algoritmos de técnicas estadísticas e inteligencia artificial, además no se recolectaron nuevas muestras dado el costo y el tiempo que consumirían.

4
1 PLANTEAMIENTO DEL PROBLEMA
La sepsis es una respuesta de un paciente a la infección, y es una causa importante de morbilidad y mortalidad en todo el mundo, en 2003 se estimaban 18 millones de casos nuevos cada año alrededor del mundo con
una mortalidad de casi un 30% (Slade, Tamber & Vincent, 2003). La incidencia ha aumentado con el envejecimiento de la población y con el
incremento en la frecuencia de condiciones de inmunosupresión, tales como el Síndrome de Inmunodeficiencia Adquirida (SIDA), la quimioterapia para cáncer y el uso de procedimientos invasivos (Martin, Mannino, Eaton &
Moss, 2003).
El concepto moderno de sepsis se ha centrado en la respuesta humana a los organismos invasores. En 1991 se introdujo la idea de que la sepsis es la respuesta inflamatoria del huésped a la infección. Para simplificar, de
acuerdo con el síndrome de respuesta inflamatoria sistémica (SRIS), se considera presente cuando hay más de uno de los siguientes cuatro
hallazgos clínicos: temperatura corporal (> 38° C o < 36° C), frecuencia cardiaca > 90 latidos por minuto, Hiperventilación (evidenciada por una frecuencia respiratoria > 20 respiraciones por minuto o PaCO2 < 32 mm Hg)
y/o conteo de Leucocitos > 12000 ó < 4000 células/microlitro o con > 10% de formas inmaduras. Estos criterios clínicos simples permitieron a los
investigadores y clínicos identificar a los pacientes con sospecha, algunos de los cuales sí desarrollaron la sepsis. Sin embargo, el enfoque de SRIS tiene
tres grandes problemas (Vincent, Opal, Marshall & Tracey, 2013) que se describirán a continuación:
Primero, los criterios de SRIS son tan sensibles que hasta el 90% de los pacientes ingresados a una unidad de cuidados intensivos cumplen con esos
criterios. El SRIS puede estar ocasionado por muchos procesos clínicos no infecciosos, como los traumatismos graves, las quemaduras, la pancreatitis y los episodios de reperfusión isquémica. Si la sepsis es definida por la
presencia de criterios de SRIS más una infección, y como casi todos los pacientes gravemente enfermos cumplen con los criterios de SRIS,
entonces la sepsis efectivamente es igual a la infección. Pero, a pesar de que todos los pacientes con sepsis tienen una infección, lo contrario no es necesariamente cierto (no todos los pacientes con infección tienen sepsis).
En segundo lugar, la infección se acompaña de una respuesta del huésped
(paciente) y de hecho, es un componente importante para diferenciar la infección de la mera colonización. Casi cualquier infección típicamente se asocia con fiebre y otras alteraciones como la taquicardia, cierto grado de
hiperventilación y leucocitosis. Esta respuesta del huésped tiene aspectos beneficiosos; la reducción o ausencia de dichos signos de respuesta podrían
sugerir que el individuo está inmunocomprometido. Así mismo, la presencia de estos signos o componentes en el organismo no necesariamente implican una respuesta de la magnitud suficiente para clasificar al paciente como
séptico.
Tercero, descifrar el papel de la infección en la patogénesis del SRIS ha sido difícil porque la inflamación estéril (presente, por ej., en el trauma grave, las quemaduras y la pancreatitis) y la infección pueden provocar signos

5
clínicos de inflamación sistémica aguda similares. Por otra parte, en
cualquier paciente podrían estar presentes simultáneamente varios factores de estrés.
En las tres últimas décadas, la sepsis ha sido llamada alternativamente septicemia (Pierce & Murray , 1986), síndrome de sepsis (Bone RC, Fisher
CJ Jr, Clemmer TP, Slotman GJ, Metz CA & Balk RA, 1989), o simplemente sepsis (American College of Chest Physicians, 1992); y en la práctica clínica
actual se insiste en la necesidad de la identificación temprana por parte del médico, con cualquier definición que utilice, de esos pacientes con infecciones lo suficientemente graves como para amenazar su vida.
En el 2003 la “campaña de supervivencia a la sepsis” hizo un llamado para
realizar una acción global contra la sepsis. La campaña definió como el reto fundamental en sepsis la dificultad en su diagnóstico (Slade et al., 2003). Ante la variación en la definición clínica para la sepsis; los médicos
frecuentemente, por falta de experiencia o por desconocimiento, retrasan o ignoran este diagnóstico. Esto es especialmente preocupante, ya que hay
evidencia de que el tratamiento temprano está asociado con un mayor éxito terapéutico (Rivers, Nguyen, Havstad, et al., 2001) (Vincent, Abraham E,
Annane, Bernard, Rivers & Van den Berghe, 2002). A pesar de la falta de criterios concluyentes para sepsis, las definiciones de
sepsis grave (infección más disfunción de un órgano o sistema) y choque séptico (infección más hipotensión que no mejora con el suministro de
líquidos endovenosos) son menos discutibles (Levy, Fink & Marshall JC, et al., 2003). Idealmente, deberían evaluarse y compararse “los hallazgos de sepsis” - síntomas, signos, marcadores biológicos - con una “prueba de oro”
(prueba que es 100% sensible y específica). En la práctica clínica general pocas veces existe este tipo de prueba perfecta, aunque a menudo hay al
menos una prueba lo suficientemente satisfactoria como para servir de estándar de referencia. Aún este escenario de un estándar aceptable es extremadamente difícil para el diagnóstico de sepsis, dado que la
microbiología no es lo suficientemente sensible y otras pruebas de laboratorio no son lo suficientemente específicas para ser usadas como
“prueba de oro”.
Con base en el conocimiento del papel de la inflamación y la coagulación en
la respuesta del ser humano a la infección (Marshall, Vincent, Fink, et al., 2000), se han estudiado tres potenciales marcadores biológicos con
presencia constante en las infecciones sistémicas: la proteína C reactiva (PCR) (Povoa, 2002), la procalcitonina (PCT) (Pettila, Hynninen, Takkunen, Kuusela & Valtonen, 2002) (Meisner, Tschaikowsky, Palmaers & Schmidt,
1999), y el dímero-D (DD) (Opal, Garber, LaRosa, et al., 2003) (Amaral, Opal & Vincent, 2004); este último como una señal inespecífica de la
activación de la coagulación. No obstante, hasta ahora, ningún estudio clínico apropiado ha confirmado la utilidad de alguno de ellos como un criterio único e independiente para el diagnóstico de sepsis.
En Colombia, la Universidad de Antioquia mediante el proyecto de
investigación “Hacia un Diagnóstico Efectivo en Sepsis: un Análisis de Clases Latentes” iniciado en 2006, recolectó información de 805 pacientes

6
adultos con sospecha de infección que ingresaron en el servicio de
urgencias entre los años 2007 y 2008. La finalidad fue hacer un análisis estadístico mediante el método de análisis de clases latentes con la
intención de estudiar si tres marcadores biológicos (la proteína C reactiva, la procalcitonina y el dímero-D) podían ser útiles para el diagnóstico temprano de la sepsis. Dicho estudio concluye que ninguno de los tres
biomarcadores capta diferencias significativas que ayuden a discriminar a los pacientes infectados de los no infectados, aunque la procalcitonina
puede discriminar a un grupo de pacientes con sepsis más grave de los otros infectados de mejor pronóstico (Jaimes, De La Rosa, Valencia, Arango, Gomez, Garcia, Ospina, Osorno & Henao, 2013).
Como se mencionó antes, dado que no existe un estándar de oro (prueba
que es 100% sensible y específica) para el diagnóstico temprano de sepsis, surge el interés de elaborar un análisis discriminante o de clasificación sobre la base de datos. Así mismo, el problema de clasificación de los pacientes es
complejo en el grado que las características medidas por si solas no son suficientes parar la discriminación de los pacientes, por lo tanto surge la
pregunta ¿será que existe un subconjunto de las características medidas en los pacientes que permita el diagnóstico de los mismos? por tal motivo se hace necesario explorar y analizar la base de datos y así mismo aplicar
clasificadores supervisados disponibles en la literatura de la minería de datos, que sean adecuados según los tipos de variables.

7
2 FUNDAMENTOS TEÓRICOS
2.1 Descubrimiento de Conocimiento en Bases de Datos (KDD, por
sus siglas en inglés)
El descubrimiento de la información oculta en las bases de datos es posible gracias a la Minería de Datos (Data Mining) (Fayyad, Piatetsky-Shapiro, & Smyth, 1996), la cual utiliza técnicas estadísticas e inteligencia artificial
para encontrar patrones y relaciones dentro de los datos, permitiendo la creación de modelos; es decir, representaciones abstractas de la realidad.
No obstante, se debe precisar que es el descubrimiento del conocimiento el que se encarga de la preparación de los datos y la interpretación de los resultados obtenidos, los cuales dan un significado a estos patrones
encontrados.
Para este caso, se espera obtener un modelo de clasificación que permita soportar el diagnóstico médico de la sepsis en pacientes adultos basados en datos obtenidos del paciente.
2.1.1 Concepto del KDD
De forma general, los datos son la materia prima bruta; en el momento que se le atribuyen algún significado especial a los datos pasan a ser
información. Cuando se elaboran o ajustan modelos o se hace una interpretación de la información, este modelo o interpretación representa un
valor agregado, entonces nos referimos al conocimiento. Como se expone en el planteamiento del problema, para este caso no existe un atributo o
combinación de los mismos que sirvan como criterio válido para la clasificación de los pacientes.
El Descubrimiento de Conocimiento en Bases de Datos (KDD) apunta a procesar automáticamente grandes cantidades de datos para encontrar
conocimiento útil en ellos, el KDD se define como un proceso no trivial de identificar patrones válidos, novedosos, potencialmente útiles y, en última instancia, comprensibles a partir de los datos (Fayyad, et al., 1996).
El objetivo fundamental del KDD es encontrar conocimiento útil, válido,
relevante y nuevo sobre un fenómeno o actividad mediante algoritmos eficientes; al mismo tiempo hay un profundo interés por presentar los resultados de manera visual o al menos de manera que su interpretación
sea muy clara.
2.1.2 El proceso de KDD
El proceso de KDD consiste en usar métodos de minería de datos (algoritmos) para extraer (identificar) lo que se considera como
conocimiento de acuerdo a la especificación de ciertos parámetros usando una base de datos junto con preprocesamientos y postprocesamientos. Se
estima que la extracción de patrones (minería) de los datos ocupa solo el 15% - 20% del esfuerzo total del proceso de KDD.

8
El proceso de descubrimiento de conocimiento en bases de datos involucra varios pasos (Fayyad, et al., 1996) (ver Figura 1):
Determinar las fuentes de información: que pueden ser útiles y
dónde conseguirlas.
Diseñar el esquema de un almacén de datos (Data Warehouse): que consiga unificar de manera operativa toda la
información recogida. Implantación del almacén de datos: que permita la navegación y
visualización previa de sus datos, para discernir qué aspectos puede
interesar que sean estudiados. Esta es la etapa que puede llegar a consumir el mayor tiempo.
Selección, limpieza y transformación de los datos que se van a analizar: Esto incluye la selección de los datos que son influyentes en el fenómeno de estudio (para este caso según criterio médico), se
limpian y se transforman las variables que sean necesarias con el fin de generar un buen modelo. Esta es la etapa que demanda más
tiempo y la más importante del estudio ya que de la calidad de los datos depende la calidad del modelo.
Seleccionar y aplicar el método de minería de datos apropiado: Para esta investigación se incluyen solo métodos de clasificación supervisada. La transformación de los datos al formato
requerido por el algoritmo específico de minería de datos. Evaluación, interpretación, transformación y representación
de los patrones extraídos: Interpretar los resultados y posiblemente regresar a los pasos anteriores. Esto puede involucrar repetir el proceso, quizás con otros datos, otros algoritmos, otras
metas y otras estrategias. Este es un paso crucial en donde se requiere tener conocimiento del dominio. La interpretación puede
beneficiarse de procesos de visualización, y sirve también para borrar patrones redundantes y/o relevantes.
Difusión y uso del nuevo conocimiento: Incorporar el
conocimiento descubierto al sistema (normalmente para mejorarlo) lo cual puede incluir resolver conflictos potenciales con el conocimiento
existente.
Figura 1. Proceso de KDD1
1 Tomado de Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. From Data Mining to Knowledge Discovery in Databases. American Association for Artificial Intelligence. 0738-4602-1996: 17-54

9
El conocimiento se obtiene para realizar acciones, ya sea incorporándolo
dentro de un sistema de desempeño o simplemente para almacenarlo y reportarlo a las personas interesadas.
En este sentido, KDD implica un proceso interactivo e iterativo involucrando la aplicación de varios algoritmos de minería de datos.
En la literatura se encuentran varios casos exitosos donde la minería de datos ha logrado obtener muy buenos resultados para el análisis y
diagnóstico de otras enfermedades, así mismo logra dar soporte a las decisiones médicas (Glover, Rivers, Asoh, Piper & Murph, 2010).
2.2 Fuentes de información
La base de datos fue suministrada por el Doctor Fabián Jaimes, quien hizo
parte activa de la investigación previa en el proyecto “Hacia un Diagnóstico
Efectivo en Sepsis: un Análisis de Clases Latentes”de la Universidad de
Antioquia financiado por Colciencias. Los datos fueron almacenados en el
sistema de información de los hospitales San Vicente de Paul y Pablo Tobón
Uribe en le ciudad de Medellín. Cabe anotar que la depuración fue trabajo
del grupo de investigación de la Universidad de Antioquia.
2.3 TECNICAS DE CLASIFICACIÓN
En este capítulo se describen las técnicas de clasificación supervisadas. Se entiende por supervisada que se parte de un conjunto de clases conocido a
priori. Estas clases deben caracterizarse en función del conjunto de variables mediante la medición de las mismas en individuos cuya
pertenencia a una de las clases no presente dudas. La descripción de las técnicas que se aplicaron en esta investigación se presenta a continuación:
2.3.1 K vecinos más cercanos (K nearest neighbors K-NN)
En el método K vecinos más cercanos es un método de clasificación
supervisada no paramétrica, la cual se basa en utilizar todos los datos de la etapa de entrenamiento y para validar se selecciona un subconjunto de
ellos. Las observaciones nuevas se clasifican según un criterio de distancia. Cuando un nuevo dato se presenta al sistema de aprendizaje, éste se clasifica según el comportamiento de las K observaciones más cercanas
(Aha, Kibler & Albert, 1991).
Los datos de entrenamiento se guardan en vectores o matrices, buscando eficiencia en un espacio característico multidimensional, cada tupla está
descrita en términos 𝐴 atributos y considerando la clase para la
clasificación.
El criterio de distancia que se utiliza generalmente es la distancia euclidiana:

10
𝑑(𝑥𝑖, 𝑥𝑗) = √∑(𝑥𝑖𝑟 − 𝑥𝑗𝑟)2
𝐴
𝑟=1
La fase de entrenamiento del algoritmo consiste en almacenar los datos y las etiquetas de las clases del conjunto de entrenamiento. En la fase de
clasificación, la evaluación de una nueva entrada (no se conoce su clase) es representada por un vector en el espacio característico. Se calcula la distancia entre los vectores almacenados y el nuevo vector, y se
seleccionan los k ejemplos más cercanos. El nuevo ejemplar es clasificado en la clase que más se repite en los vectores seleccionados. Esta técnica
tiene como ventaja la simplicidad y la desventaja es que cuando se cuenta con muestras muy grandes, se incrementa el tiempo de respuesta.
2.3.2 Clasificador de Bayes Ingenuo (Naive Bayes)
El clasificador bayesiano ingenuo es un clasificador probabilístico sencillo basado en aplicar el teorema de Bayes (estadística bayesiana) con hipótesis de independencia entre las variables (de ahí, la “ingenuidad). En términos
simples, el clasificador de Bayes ingenuo asume que la presencia (o ausencia) de una característica particular de una clase (es decir atributo) no
está relacionada con la presencia (o ausencia) de cualquier otra característica. Por ejemplo, una fruta puede ser considerada como una
manzana si es de color rojo, redondo, y de aproximadamente 4 pulgadas de diámetro. Aunque estas características pueden depender unas de otras o de la existencia de las otras características, un clasificador bayesiano considera
todas estas propiedades para contribuir de forma independiente a la probabilidad de que esta fruta sea una manzana. Para mayor información
sobre el modelo probabilístico y la estimación de parámetros ver Machine Learning: ECML-98 (Lewis, 1998).
La ventaja del clasificador de Bayes ingenuo es que sólo se requiere una pequeña cantidad de datos de entrenamiento para estimar las medias y las
varianzas de las variables necesarias para la clasificación. Debido a que se supone que los atributos son independientes, sólo las varianzas de las variables para cada etiqueta necesitan ser determinadas y no toda la matriz
de covarianza.
2.3.3 Regresión Logística
La regresión logística es un tipo de análisis de regresión utilizado para
predecir el resultado de una variable categórica (binaria o dicotómica) en función de las variables independientes o predictoras. Esta es útil para
modelar la probabilidad de un evento como función de otros factores (Hosmer, David, Lemeshow & Stanley, 2000). La ecuación del modelo de regresión logística es la siguiente:
𝑃(𝑦 = 1|𝑥)
1 − 𝑃(𝑦 = 1|𝑥)= 𝑒𝑏0+𝑏1𝑥1+𝑏2𝑥2+⋯+𝑏𝑎𝑥𝑎

11
Esta técnica tiene una gran ventaja frente a otras, puesto que el modelo es interpretable y permite cuantificar como es la influencia de cada variable en
la respuesta.
2.3.4 Red neuronal artificial (artificial neural network - ANN)
Una red neuronal artificial, generalmente llamada redes neuronales (NN), es
un modelo matemático o un modelo computacional que se inspira en la estructura y los aspectos funcionales de las redes neuronales biológicas.
Una red neuronal se compone de un grupo interconectado de neuronas artificiales y procesa la información utilizando un enfoque conexionista a la computación (el principio conexionista central es que los fenómenos
mentales pueden ser descritos por las redes interconectadas de forma sencilla conformadas por unidades simples e iguales). En la mayoría de los
casos una ANN es un sistema adaptativo que cambia su estructura con base a la información externa o interna que fluye a través de la red durante la fase de aprendizaje. Redes neuronales modernas se utilizan generalmente
para modelar relaciones complejas entre entradas y salidas o para encontrar patrones en los datos.
Una NN feed-forward es una red neuronal artificial donde las conexiones entre las unidades no forman un ciclo. En esta red la información se mueve
en una sola dirección, hacia adelante, a partir de los nodos de entrada, a través de los nodos ocultos (si los hay) a los nodos de salida. No hay ciclos
o bucles en la red. Back propagation es un método de aprendizaje supervisado, que puede
dividirse en dos fases: la propagación y la actualización de los pesos. Las dos fases se repiten hasta que el rendimiento de la red es lo
suficientemente bueno. En los algoritmos de Back propagation los valores de salida se comparan con la respuesta correcta para calcular el valor de alguna función de error predefinida (usualmente se usa el error cuadrático
de la media - MSE). Con esta estrategia se calcula el error a través de la red. Usando esta información el algoritmo ajusta los pesos de cada
conexión, con el fin de reducir el valor de la función de error por una pequeña cantidad. Después de repetir este proceso para un número suficientemente grande de ciclos de formación, la red suele converger a un
estado en el que el error de los cálculos es pequeño.
Un perceptrón multicapa (multilayer perceptron - MLP) es un modelo NN feed-forward de red que asigna conjuntos de datos de entrada en un conjunto de salida apropiado. Un MLP se compone de varias capas de nodos
de un grafo dirigido, con cada capa totalmente conectado a la siguiente. Excepto para los nodos de entrada, cada nodo es una neurona (o elemento
de procesamiento) con una función de activación no lineal. MLP utiliza back propagation para entrenar la red (Sathyanarayana, 2014). En muchas
aplicaciones de las unidades de estas redes se aplican una función sigmoidea como una función de activación.

12
En este caso la función sigmoide habitual se utiliza como la función de
activación o trasferencia. Por lo tanto, los rangos de valores de los atributos deben ser escalados a -1 y 1. Esto se puede hacer mediante una
normalización. El tipo de nodo de salida es sigmoide. A continuación en la Figura 6 se muestra un ejemplo de un grafo de un perceptrón multicapa (Rosenblatt, 1961).
Figura 2. Ejemplo Perceptrón Multicapa
Una desventaja considerable del perceptrón multicapa es la imposibilidad de
interpretar los pesos asignados en las conexiones.
2.3.5 C4.5
C4.5 es un algoritmo usado para generar un árbol de decisión desarrollado
por Ross Quinlan. (Quinlan, 1993) Este algoritmo genera un árbol de decisión a partir de los datos mediante particiones realizadas
recursivamente. El árbol se construye mediante la estrategia de profundidad-primero (depth-first).
Para cada atributo discreto, se considera una prueba con n resultados, siendo n el número de valores posibles que puede tomar el atributo. Para
cada atributo continuo se realiza una prueba binaria sobre cada uno de los valores que toma el atributo en los datos. En cada nodo el sistema debe decidir cuál prueba selecciona para dividir los datos.
Los tres tipos de pruebas posibles propuestas por el C4.5 son:
La prueba "estándar" para las variables discretas con un resultado y una rama para cada valor posible de la variable.
Una prueba más compleja basada en una variable discreta, en donde los
valores posibles son asignados a un número variable de grupos con un resultado posible para cada grupo, en lugar de para cada valor.

13
Si una variable A tiene valores numéricos continuos, se realiza una prueba binaria con resultados A <= Z y A > Z, para lo cual debe determinarse el
valor límite Z. Todas estas pruebas se evalúan de la misma manera, mirando el resultado
de la proporción de ganancia (gain ratio), o alternativamente, el de la ganancia resultante de la división que produce. Ha sido útil agregar una
restricción adicional: para cualquier división, al menos dos de los subconjuntos Ci deben contener un número razonable de casos. Esta restricción, que evita las subdivisiones casi triviales, es tenida en cuenta
solamente cuando el conjunto C es pequeño.
2.4 Entrenamiento, Validación y Evaluación de los Modelos
La validación cruzada es una herramienta estándar de análisis que resulta muy útil a la hora de desarrollar y ajustar los modelos de minería de datos. La validación cruzada es un método estadístico de evaluación y comparación
de algoritmos de aprendizaje por los datos que se dividen en dos segmentos: uno se utiliza para entrenar un modelo y el otro se utiliza para
validar el modelo. En la validación cruzada típica, los conjuntos de entrenamiento y validación son cruzados en rondas sucesivas, de tal manera que cada segmento de observaciones tiene una oportunidad de ser
validados.(Refaeilzadeh, Tang & Liu, 2008.)
Para evaluar los modelos anteriores se utilizará El Coeficiente Kappa de Cohen, el cual es una medida estadística que ajusta el efecto del azar en la proporción de la concordancia observada para los elementos cualitativos
(variables categóricas). En general se cree que es una medida más robusta que el simple cálculo del porcentaje de concordancia (Jean, 1996).
La ecuación para kappa es:
𝑘 =𝑃𝑟(𝑎) − 𝑃𝑟(𝑒)
1 − 𝑃𝑟(𝑒)
Donde 𝑃𝑟(𝑎) es la proporción de veces que los evaluadores están de
acuerdo, y 𝑃𝑟(𝑒) la proporción de veces que se espera que ellos estén de
acuerdo por azar. Si los evaluadores son completamente de acuerdo
entonces 𝑘 = 1 y si no hay acuerdo entre los calificadores 𝑘 = 0. Adicional al Coeficiente Kappa, se contará con la precisión (accuracy), es
decir el número relativo de ejemplos clasificados correctamente o en otras palabras el porcentaje de predicciones correctas. Así mismo, se contará con el error de clasificación, es decir el número relativo de observaciones mal
clasificadas o en otras palabras el porcentaje de predicciones incorrectas. Además con el error absoluto medio (Mean absolute error), es decir
desviación absoluta media de la predicción del valor real.

14

15
3 DESCRIPCIÓN DE LA BASE DE DATOS.
En el año 2006 se inicia el Proyecto “Hacia un Diagnóstico Efectivo en Sepsis: un Análisis de Clases Latentes”, en el cual se conformó una base de
datos con características descriptivas, clínicas y posibles marcadores biológicos de sepsis en los pacientes mayores de edad admitidos por urgencias con sospecha de infección (Jaimes, et al., 2013). El total de la
muestra fue de 805 participantes (número determinado con base en algunas estimaciones de tamaño de muestra para obtener una precisión
estadística del 95%) recolectados entre el 2007 y el 2008; pacientes que fueron evaluados y diagnosticados por expertos, los cuales mediante consenso los agruparon en: sin infección, con infección sin sepsis y con
sepsis.
La base de datos cuenta con características informativas como son el número del formulario para identificar pacientes, fecha y hora de ingreso a la institución, letras de las iniciales del nombre y apellidos del paciente,
número de la historia clínica, género, edad, teléfono del paciente, teléfono familiar y teléfono celular. Adicional se cuenta información sobre el criterio
de inclusión del paciente al estudio antes mencionado.
Las características descriptivas tomadas de la población de estudio son
entre otras, las siguientes: la sospecha de infección (infección que se sospecha que tiene), fiebre, alteraciones en el estado mental, hipotensión de causa no explicada, insuficiencia cardiaca descompensada, enfermedad
pulmonar obstructiva crónica descompensada, diabetes descompensada, síndrome de dificultad respiratoria aguda, falla o disfunción orgánica
múltiple, dolor abdominal y tipo de infección. Estas características solo se tomaron para determinar si se incluía o no un paciente al estudio, pero no
hacen parte de las características determinantes del fenómeno bajo estudio.
Además se consideraron los antecedentes de la historia clínica del
paciente, como son: VIH/SIDA, traumas o cirugías hace menos de 30 días, drogadicción/alcoholismo, diabetes, insuficiencia cardiaca congestiva, antecedentes de esteroides, enfermedad pulmonar obstructiva crónica,
insuficiencia cardiaca, cáncer, cirrosis, paciente trasplantado e insuficiencia renal crónica y/o diálisis crónica.
Las características de laboratorio y exámenes. Los atributos registrados del paciente son: la presión arterial del oxígeno por la fracción
inspirada de oxígeno, el recuento de plaquetas, presión arterial media, bilirrubina total, creatinina, temperatura al momento del ingreso, frecuencia
cardiaca, frecuencia respiratoria, potencial de hidrógeno, nivel del sodio sérico, nivel de potasio sérico, hematocrito, leucocitos, tiempo de protrombina, tiempo parcial de tromboplastina, presión arterial de dióxido
de carbono y escala de coma de Glasgow; adicionalmente los seis potenciales marcadores biológicos: la proteína C reactiva (PCR), la
procalcitonina (PCT), el dímero-D (DD), el receptor CD64, receptor soluble ‘desencadenador’ expresado en células mieloides (sTREM-1) y la proteína del grupo Box-1 de alta movilidad (HMGB-1).
De las variables anteriores, la escala de coma de Glasgow es una valoración
del nivel de conciencia consistente en la evaluación de tres criterios de

16
observación clínica (la respuesta ocular, la respuesta verbal y la respuesta
motora) y presión arterial del oxígeno por la fracción inspirada de oxígeno, la cual es una relación entre dos variables; sin embargo, el registro de dicho
atributo fue ingresado directamente. Para los marcadores biológicos proteína C reactiva (PCR), la procalcitonina
(PCT), el dímero-D (DD) se hizo una primera medición en el momento del ingreso del paciente y una segunda medición 24 horas después.
Las características de tratamiento y seguimiento. Estas características incluyen: estado vital, antibióticos, esteroides, dopamina, adrenalina,
norepinefrina, dobutamina, vasopresina, hospitalización en UCI (Unidad de Cuidados Intensivos), Ventilación mecánica, temperatura máxima,
temperatura mínima, frecuencia cardiaca máxima y frecuencia cardiaca mínima. Estas últimas características con máximos y mínimos no son tomadas en el momento del ingreso, sino durante la estadía del paciente en
el hospital. Estas características no son consideradas dado que no hacen parte del enfoque diagnóstico inicial.
Características de muestras microbiológicas. Estas características son:
solicitud de muestra de hemocultivo, solicitud de muestra de líquido pleural, solicitud de muestra de piel y tejidos, solicitud de muestra de líquido cefalorraquídeo (LCR). Para cada solicitud se incluyen fecha de la solicitud,
microorganismos de los cultivos, clasificación de los cultivos. Adicional solicitud de muestra de orina con su respectivo tipo. Estas características
están excluidas dado que los exámenes practicados tardan en dar los resultados.
Características derivadas, duplicadas y de análisis anteriores. Como se mencionaba en el proyecto “Hacia un Diagnóstico Efectivo en Sepsis: un
Análisis de Clases Latentes”, se hizo uso de los datos recolectados y durante su desarrollo se duplicaron, derivaron o discretizaron algunas características, las cuales quedaron registradas dentro de la base de datos.
La clasificación de los pacientes realizada por los médicos expertos es
mediante un consenso, el cual a cada paciente se le etiqueta en paciente con sepsis y paciente sin sepsis (no sepsis); es de anotar que los pacientes sin sepsis pueden ser pacientes sin infección o pacientes con
infección, pero sin sepsis. De la muestra tomada 541 pacientes fueron clasificados con sepsis (67%) y 264 pacientes fueron clasificados sin sepsis
(33%). La clasificación de los pacientes se complementó con el criterio de sepsis
grave según el puntaje de evaluación de disfunción de órganos (SOFA), el cual se considera con sepsis grave cuando el paciente tiene sepsis y el SOFA
es mayor o igual a dos. Ver más detalles en Pre procesamiento página 42. La clasificación complementada consta de cuatro etiquetas, la cuales son:
paciente sin infección, paciente con infección sin sepsis, paciente con sepsis y paciente con sepsis grave. En la tabla siguiente se presenta la cantidad de
pacientes clasificados en cada categoría.

17
Tabla 1. Clasificación Sin Infección (0), Infección Sin Sepsis (1), Sepsis(2) y Sepsis
Grave (3)
Clasificación 0 1 2 3
Cantidad
19%
(152)
14%
(112)
21%
(170)
46%
(371)
Total 33% (264) 67% (541)
El procedimiento de la toma de los datos e ingreso al sistema de información y/o bases de datos se presenta en anexo A.
Durante la toma de los datos las cinco infecciones más recurrentes fueron:
neumonía adquirida en la comunidad con 21% (169 pacientes), infección urinaria sintomática con 15% (124 pacientes), infección de tejidos blandos con 15% (122 pacientes), sepsis clínica con 13% (102 pacientes) e
infección intra-abdominal con 9% (75 pacientes). Adicional 11 pacientes sufrieron choque séptico.
En total se tienen 612 columnas (atributos) con las características antes mencionadas y 805 tuplas (pacientes).
18
4 METADATOS Y SELECCIÓN DE LOS ATRIBUTOS
Los metadatos son importantes porque dan información sobre los datos, sirven para dar interpretación de los resultados otorgados por los distintos métodos de la minería de datos; también para detectar errores de digitación
y para integrar datos, entre otros asuntos.
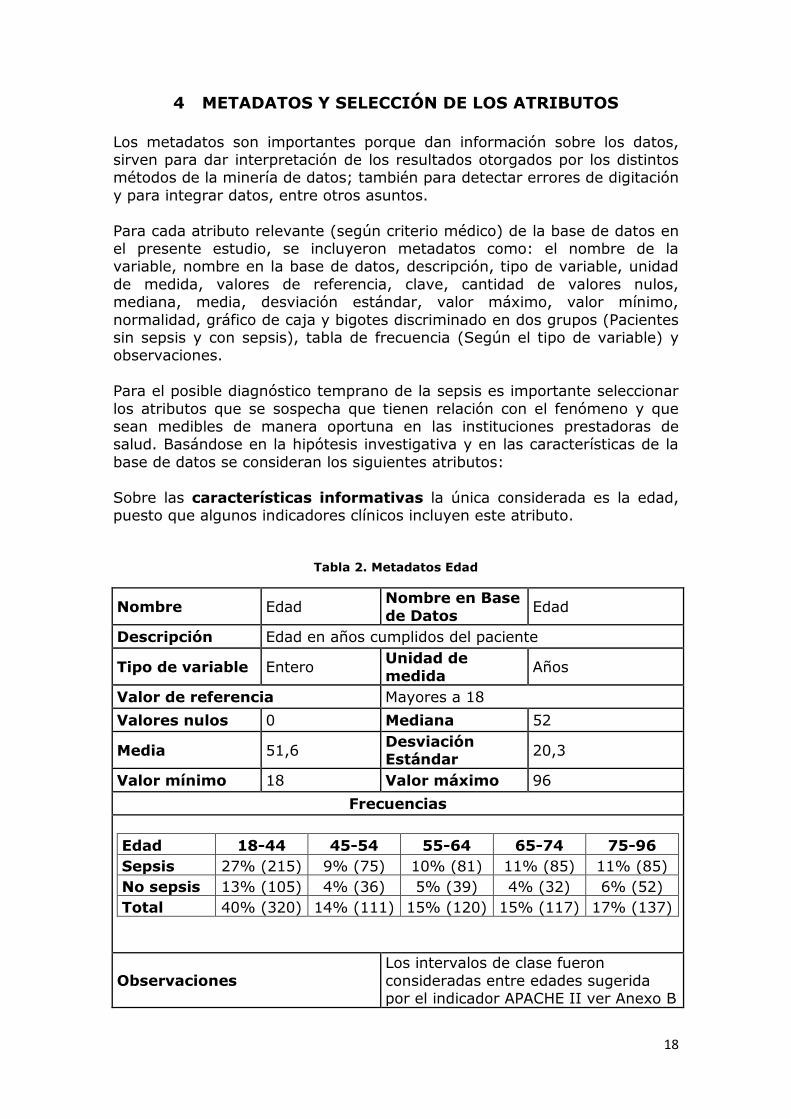
Para cada atributo relevante (según criterio médico) de la base de datos en el presente estudio, se incluyeron metadatos como: el nombre de la variable, nombre en la base de datos, descripción, tipo de variable, unidad
de medida, valores de referencia, clave, cantidad de valores nulos, mediana, media, desviación estándar, valor máximo, valor mínimo,
normalidad, gráfico de caja y bigotes discriminado en dos grupos (Pacientes sin sepsis y con sepsis), tabla de frecuencia (Según el tipo de variable) y observaciones.
Para el posible diagnóstico temprano de la sepsis es importante seleccionar
los atributos que se sospecha que tienen relación con el fenómeno y que sean medibles de manera oportuna en las instituciones prestadoras de salud. Basándose en la hipótesis investigativa y en las características de la
base de datos se consideran los siguientes atributos:
Sobre las características informativas la única considerada es la edad, puesto que algunos indicadores clínicos incluyen este atributo.
Tabla 2. Metadatos Edad
Nombre Edad Nombre en Base
de Datos Edad
Descripción Edad en años cumplidos del paciente
Tipo de variable Entero Unidad de
medida Años
Valor de referencia Mayores a 18
Valores nulos 0 Mediana 52
Media 51,6 Desviación Estándar
20,3
Valor mínimo 18 Valor máximo 96
Frecuencias
Edad 18-44 45-54 55-64 65-74 75-96
Sepsis 27% (215) 9% (75) 10% (81) 11% (85) 11% (85)
No sepsis 13% (105) 4% (36) 5% (39) 4% (32) 6% (52)
Total 40% (320) 14% (111) 15% (120) 15% (117) 17% (137)
Observaciones
Los intervalos de clase fueron
consideradas entre edades sugerida por el indicador APACHE II ver Anexo B
19
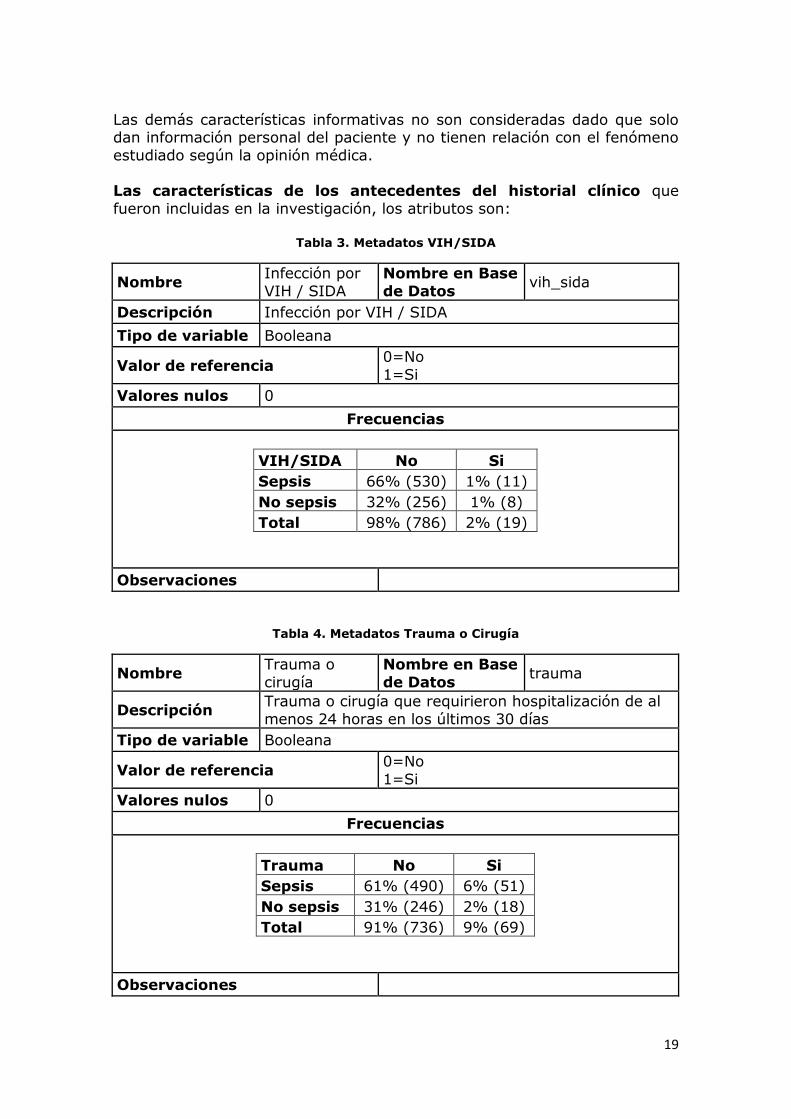
Las demás características informativas no son consideradas dado que solo dan información personal del paciente y no tienen relación con el fenómeno
estudiado según la opinión médica. Las características de los antecedentes del historial clínico que
fueron incluidas en la investigación, los atributos son:
Tabla 3. Metadatos VIH/SIDA
Nombre Infección por
VIH / SIDA
Nombre en Base
de Datos vih_sida
Descripción Infección por VIH / SIDA
Tipo de variable Booleana
Valor de referencia 0=No
1=Si
Valores nulos 0
Frecuencias
VIH/SIDA No Si
Sepsis 66% (530) 1% (11)
No sepsis 32% (256) 1% (8)
Total 98% (786) 2% (19)
Observaciones
Tabla 4. Metadatos Trauma o Cirugía
Nombre Trauma o
cirugía
Nombre en Base
de Datos trauma
Descripción Trauma o cirugía que requirieron hospitalización de al
menos 24 horas en los últimos 30 días
Tipo de variable Booleana
Valor de referencia 0=No
1=Si
Valores nulos 0
Frecuencias
Trauma No Si
Sepsis 61% (490) 6% (51)
No sepsis 31% (246) 2% (18)
Total 91% (736) 9% (69)
Observaciones
20
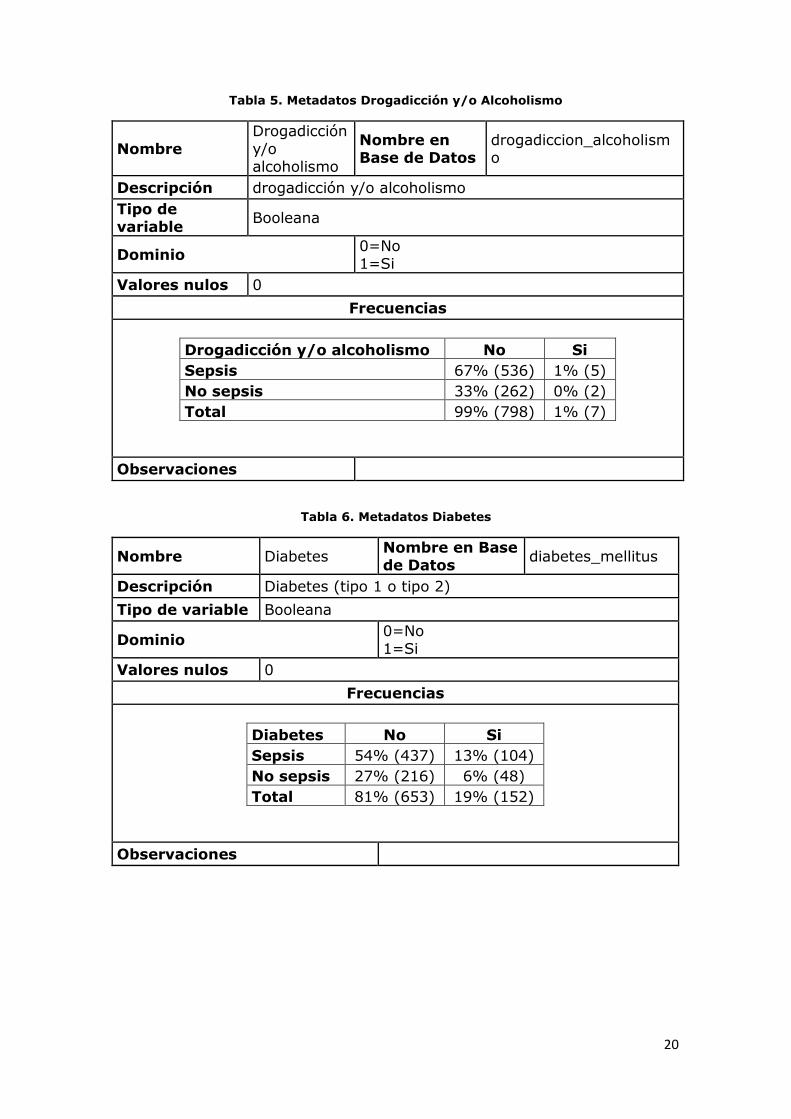
Tabla 5. Metadatos Drogadicción y/o Alcoholismo
Nombre
Drogadicción
y/o alcoholismo
Nombre en Base de Datos
drogadiccion_alcoholismo
Descripción drogadicción y/o alcoholismo
Tipo de variable
Booleana
Dominio 0=No 1=Si
Valores nulos 0
Frecuencias
Drogadicción y/o alcoholismo No Si
Sepsis 67% (536) 1% (5)
No sepsis 33% (262) 0% (2)
Total 99% (798) 1% (7)
Observaciones
Tabla 6. Metadatos Diabetes
Nombre Diabetes Nombre en Base de Datos
diabetes_mellitus
Descripción Diabetes (tipo 1 o tipo 2)
Tipo de variable Booleana
Dominio 0=No 1=Si
Valores nulos 0
Frecuencias
Diabetes No Si
Sepsis 54% (437) 13% (104)
No sepsis 27% (216) 6% (48)
Total 81% (653) 19% (152)
Observaciones
21
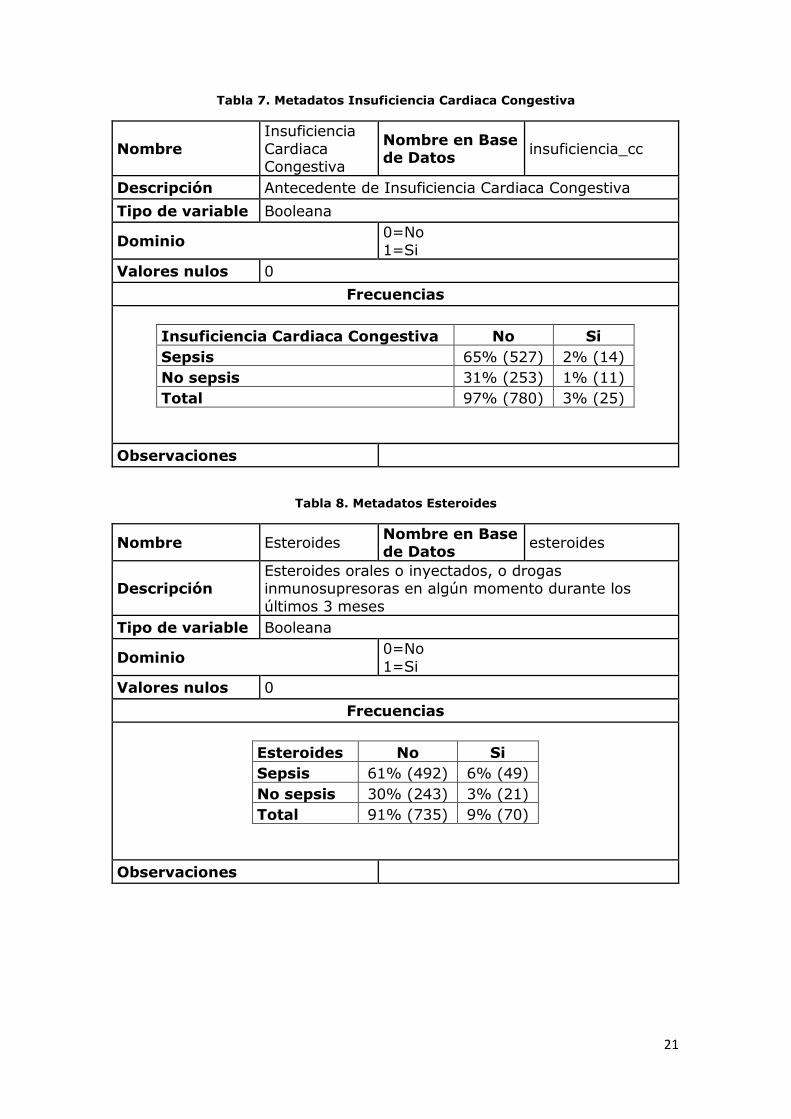
Tabla 7. Metadatos Insuficiencia Cardiaca Congestiva
Nombre
Insuficiencia
Cardiaca Congestiva
Nombre en Base de Datos
insuficiencia_cc
Descripción Antecedente de Insuficiencia Cardiaca Congestiva
Tipo de variable Booleana
Dominio 0=No
1=Si
Valores nulos 0
Frecuencias
Insuficiencia Cardiaca Congestiva No Si
Sepsis 65% (527) 2% (14)
No sepsis 31% (253) 1% (11)
Total 97% (780) 3% (25)
Observaciones
Tabla 8. Metadatos Esteroides
Nombre Esteroides Nombre en Base de Datos
esteroides
Descripción Esteroides orales o inyectados, o drogas inmunosupresoras en algún momento durante los
últimos 3 meses
Tipo de variable Booleana
Dominio 0=No
1=Si
Valores nulos 0
Frecuencias
Esteroides No Si
Sepsis 61% (492) 6% (49)
No sepsis 30% (243) 3% (21)
Total 91% (735) 9% (70)
Observaciones

22
Tabla 9. Metadatos Enfermedad Pulmonar
Nombre
Enfermedad
Pulmonar Obstructiva Crónica
Nombre en Base de Datos
epoc
Descripción Antecedente de Enfermedad Pulmonar Obstructiva
Crónica
Tipo de variable Booleana
Dominio 0=No
1=Si
Valores nulos 0
Frecuencias
Enfermedad Pulmonar No Si
Sepsis 59% (475) 8% (66)
No sepsis 29% (233) 4% (31)
Total 88% (708) 12% (97)
Observaciones
Tabla 10. Metadatos Cáncer
Nombre Cáncer Nombre en Base
de Datos Cáncer
Descripción Diagnóstico de cualquier tipo de cáncer en el último año
Tipo de variable Booleana
Dominio 0=No 1=Si
Valores nulos 0
Frecuencias
Cáncer No Si
Sepsis 61% (492) 6% (49)
No sepsis 31% (246) 2% (18)
Total 92% (738) 8% (67)
Observaciones
23
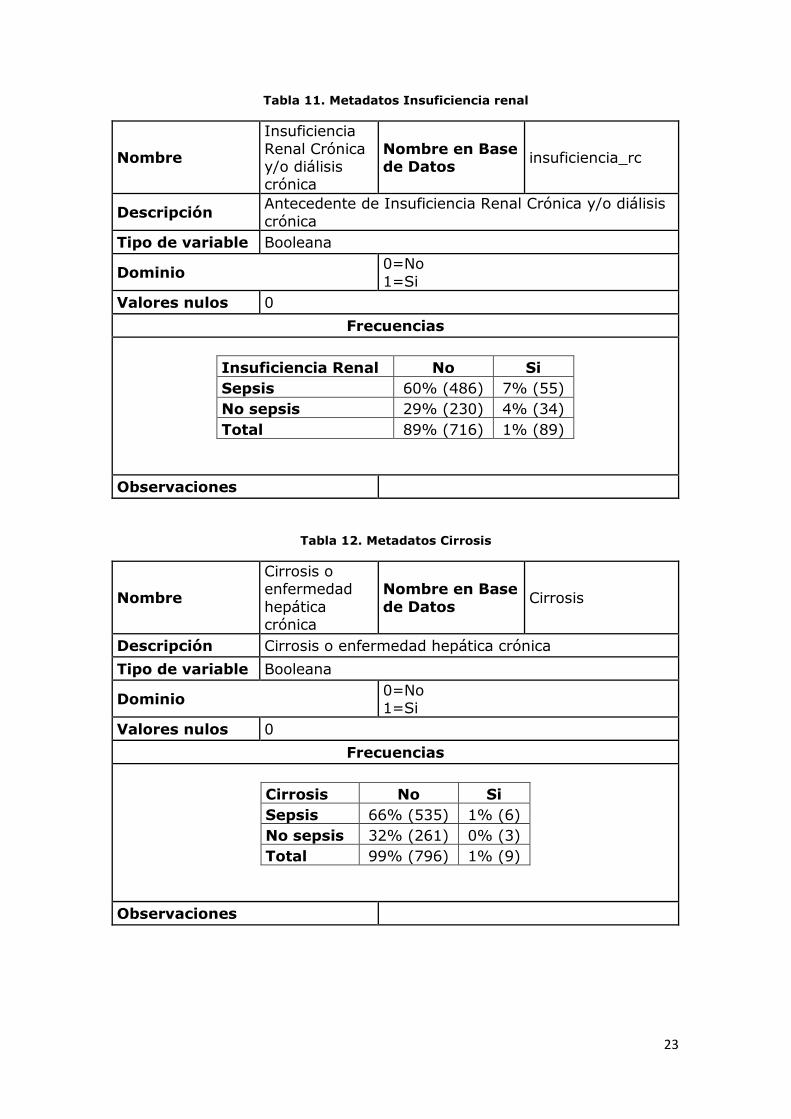
Tabla 11. Metadatos Insuficiencia renal
Nombre
Insuficiencia
Renal Crónica y/o diálisis crónica
Nombre en Base de Datos
insuficiencia_rc
Descripción Antecedente de Insuficiencia Renal Crónica y/o diálisis
crónica
Tipo de variable Booleana
Dominio 0=No
1=Si
Valores nulos 0
Frecuencias
Insuficiencia Renal No Si
Sepsis 60% (486) 7% (55)
No sepsis 29% (230) 4% (34)
Total 89% (716) 1% (89)
Observaciones
Tabla 12. Metadatos Cirrosis
Nombre
Cirrosis o enfermedad
hepática crónica
Nombre en Base
de Datos Cirrosis
Descripción Cirrosis o enfermedad hepática crónica
Tipo de variable Booleana
Dominio 0=No 1=Si
Valores nulos 0
Frecuencias
Cirrosis No Si
Sepsis 66% (535) 1% (6)
No sepsis 32% (261) 0% (3)
Total 99% (796) 1% (9)
Observaciones
24
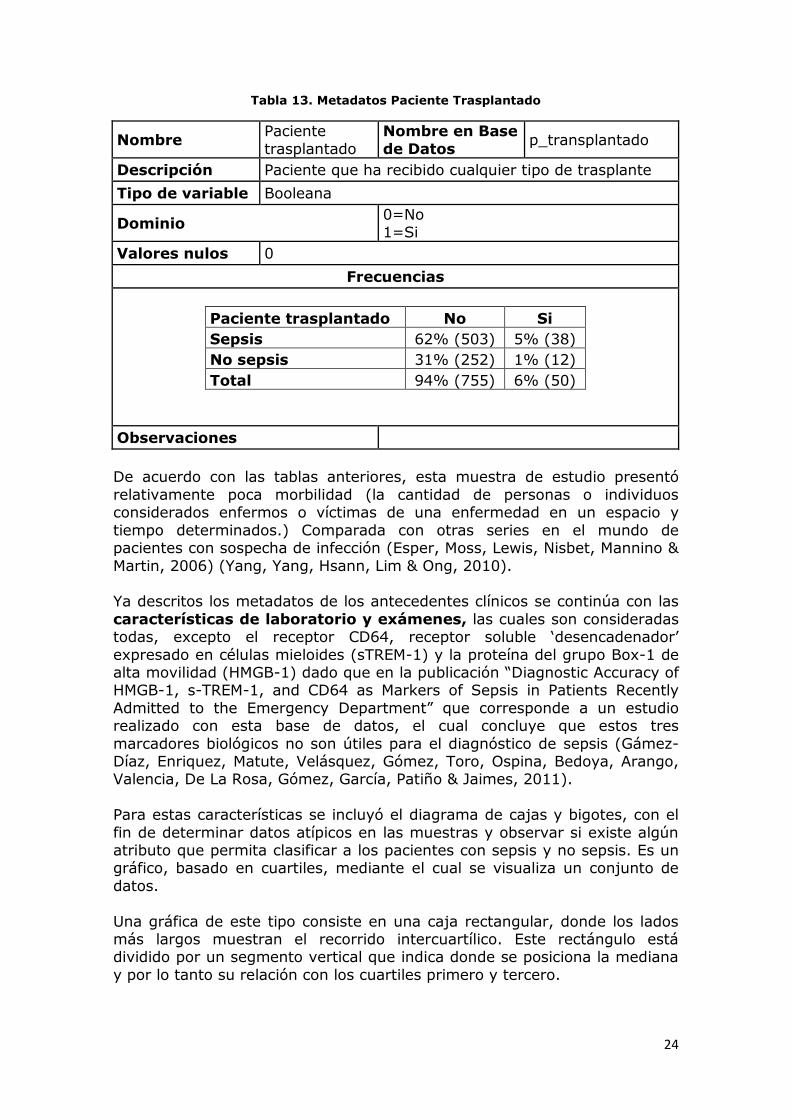
Tabla 13. Metadatos Paciente Trasplantado
Nombre Paciente
trasplantado
Nombre en Base
de Datos p_transplantado
Descripción Paciente que ha recibido cualquier tipo de trasplante
Tipo de variable Booleana
Dominio 0=No 1=Si
Valores nulos 0
Frecuencias
Paciente trasplantado No Si
Sepsis 62% (503) 5% (38)
No sepsis 31% (252) 1% (12)
Total 94% (755) 6% (50)
Observaciones
De acuerdo con las tablas anteriores, esta muestra de estudio presentó
relativamente poca morbilidad (la cantidad de personas o individuos considerados enfermos o víctimas de una enfermedad en un espacio y
tiempo determinados.) Comparada con otras series en el mundo de pacientes con sospecha de infección (Esper, Moss, Lewis, Nisbet, Mannino &
Martin, 2006) (Yang, Yang, Hsann, Lim & Ong, 2010). Ya descritos los metadatos de los antecedentes clínicos se continúa con las
características de laboratorio y exámenes, las cuales son consideradas todas, excepto el receptor CD64, receptor soluble ‘desencadenador’
expresado en células mieloides (sTREM-1) y la proteína del grupo Box-1 de alta movilidad (HMGB-1) dado que en la publicación “Diagnostic Accuracy of HMGB-1, s-TREM-1, and CD64 as Markers of Sepsis in Patients Recently
Admitted to the Emergency Department” que corresponde a un estudio realizado con esta base de datos, el cual concluye que estos tres
marcadores biológicos no son útiles para el diagnóstico de sepsis (Gámez-Díaz, Enriquez, Matute, Velásquez, Gómez, Toro, Ospina, Bedoya, Arango, Valencia, De La Rosa, Gómez, García, Patiño & Jaimes, 2011).
Para estas características se incluyó el diagrama de cajas y bigotes, con el
fin de determinar datos atípicos en las muestras y observar si existe algún atributo que permita clasificar a los pacientes con sepsis y no sepsis. Es un gráfico, basado en cuartiles, mediante el cual se visualiza un conjunto de
datos.
Una gráfica de este tipo consiste en una caja rectangular, donde los lados más largos muestran el recorrido intercuartílico. Este rectángulo está dividido por un segmento vertical que indica donde se posiciona la mediana
y por lo tanto su relación con los cuartiles primero y tercero.

25
Esta caja se ubica a escala sobre un segmento que tiene como extremos los
valores mínimo y máximo de la variable. Las líneas que sobresalen de la caja se llaman bigotes. Estos bigotes tienen un límite de prolongación, de
modo que cualquier dato o caso que no se encuentre dentro de este rango es marcado e identificado individualmente (dato atípico). Las características incluidas son las que se enuncian a continuación:
Tabla 14. Metadatos Presión Arterial del Oxigeno por la Fracción Inspirada de
Oxigeno
Nombre
Presión arterial
del oxígeno por la fracción inspirada de oxígeno
Nombre en Base de Datos
valor__pao2_fio2
Descripción
Dividir la Presión Arterial de Oxígeno (PaO2) por la
Fracción Inspirada de Oxígeno que tiene el paciente (FiO2). En caso que el paciente no tenga suministro complementario de oxígeno, la FiO2 es de 0.21; por cada
litro que se suministre por cánula nasal se adiciona 0.03 al 0.21 previo, hasta máximo 0.09 (O2 por máscara
nasal a 3 litros corresponde a una FiO2 de 0.30). Cuando se suministra oxígeno por ventury al 35%, se brinda FiO2 de 0.35, y si el ventury es al 50% la FiO2 es 0.50.
Tipo de
variable Real Entera
Unidad de
medida No tiene
Valor de referencia Se considera sano valores mayores a
300
Valores nulos 27 Mediana 310
Media 299,02 Desviación
Estándar 108,38
Valor mínimo 50 Valor máximo 500
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 50-500
26
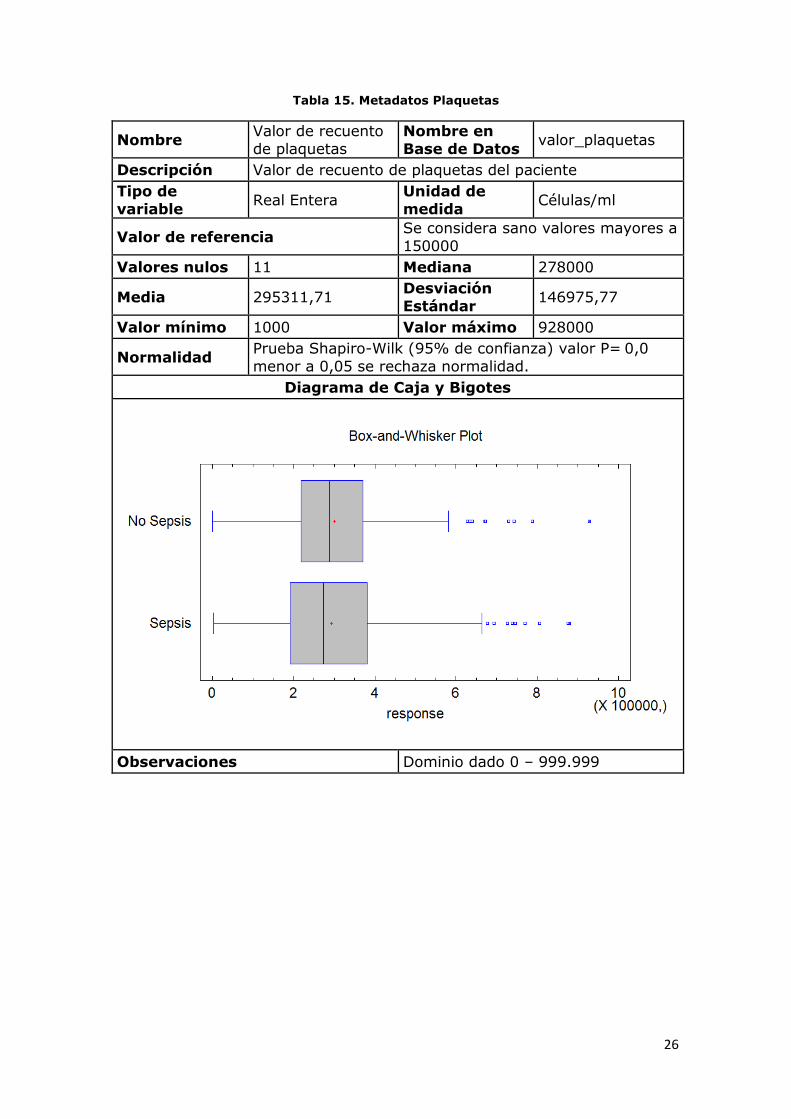
Tabla 15. Metadatos Plaquetas
Nombre Valor de recuento
de plaquetas
Nombre en
Base de Datos valor_plaquetas
Descripción Valor de recuento de plaquetas del paciente
Tipo de
variable Real Entera
Unidad de
medida Células/ml
Valor de referencia Se considera sano valores mayores a
150000
Valores nulos 11 Mediana 278000
Media 295311,71 Desviación
Estándar 146975,77
Valor mínimo 1000 Valor máximo 928000
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 0 – 999.999
27
Tabla 16. Presión Arterial Media
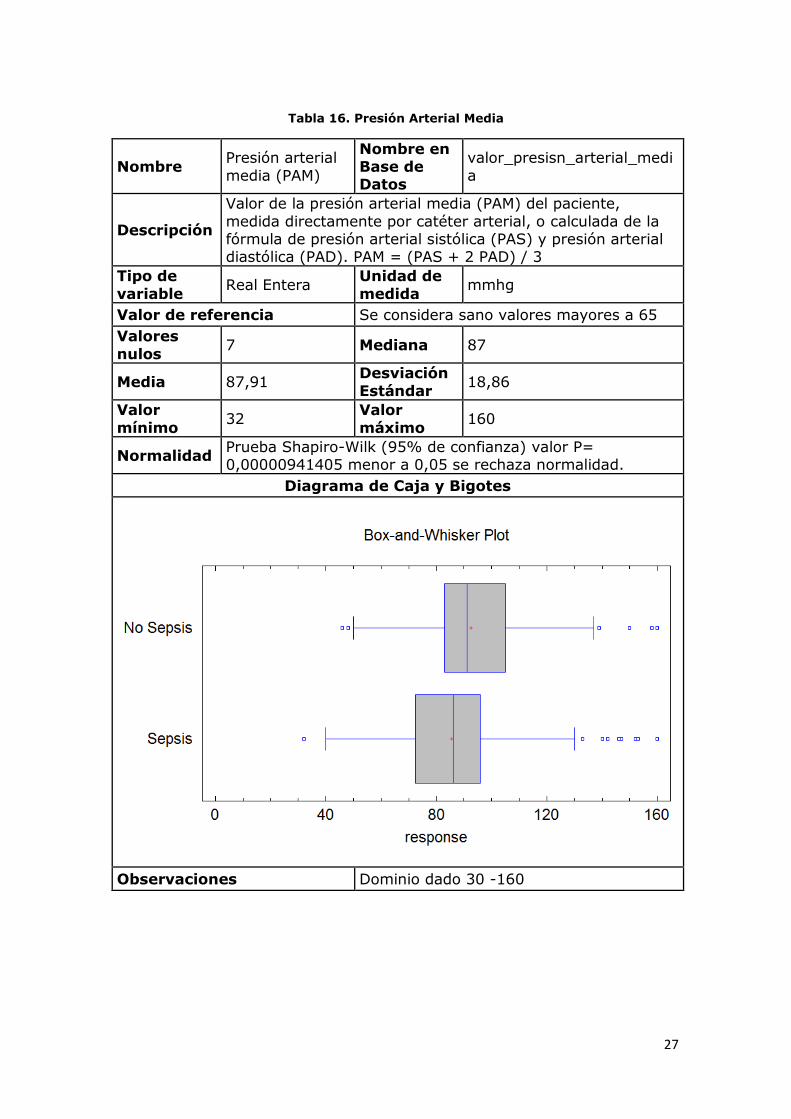
Nombre Presión arterial
media (PAM)
Nombre en Base de Datos
valor_presisn_arterial_medi
a
Descripción
Valor de la presión arterial media (PAM) del paciente,
medida directamente por catéter arterial, o calculada de la fórmula de presión arterial sistólica (PAS) y presión arterial diastólica (PAD). PAM = (PAS + 2 PAD) / 3
Tipo de
variable Real Entera
Unidad de
medida mmhg
Valor de referencia Se considera sano valores mayores a 65
Valores
nulos 7 Mediana 87
Media 87,91 Desviación
Estándar 18,86
Valor
mínimo 32
Valor
máximo 160
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,00000941405 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 30 -160
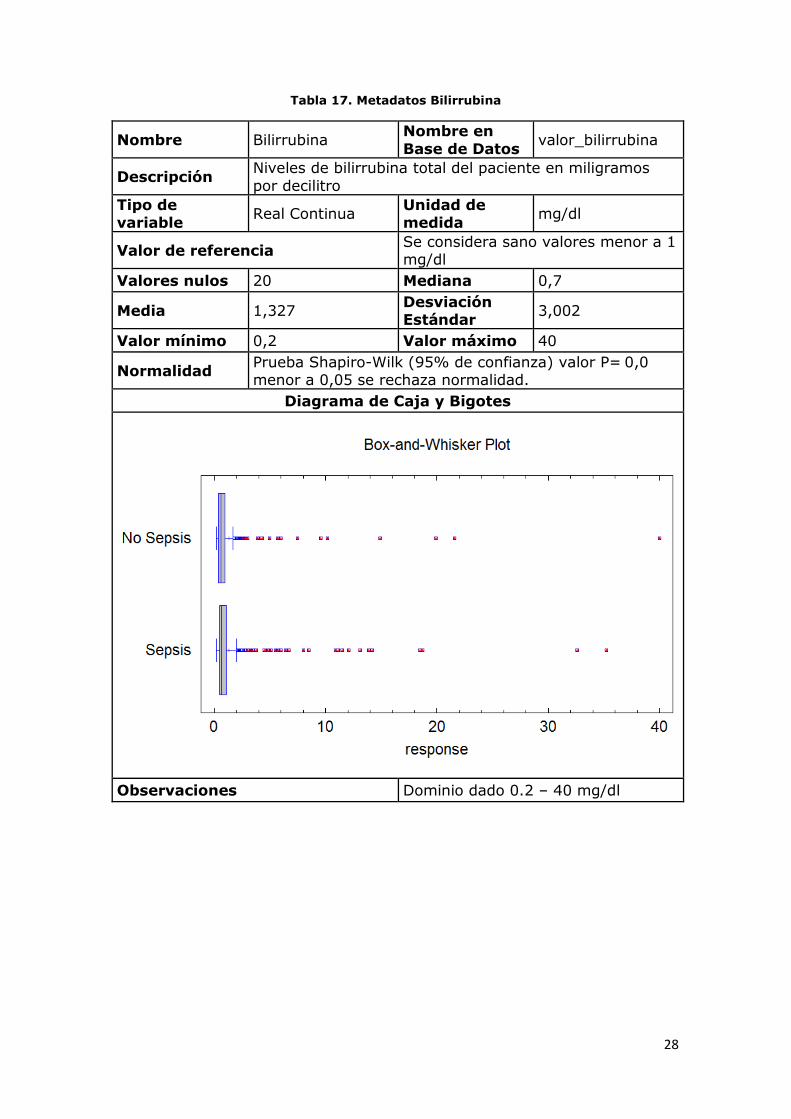
28
Tabla 17. Metadatos Bilirrubina
Nombre Bilirrubina Nombre en
Base de Datos valor_bilirrubina
Descripción Niveles de bilirrubina total del paciente en miligramos
por decilitro
Tipo de variable
Real Continua Unidad de medida
mg/dl
Valor de referencia Se considera sano valores menor a 1 mg/dl
Valores nulos 20 Mediana 0,7
Media 1,327 Desviación Estándar
3,002
Valor mínimo 0,2 Valor máximo 40
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 0.2 – 40 mg/dl
29
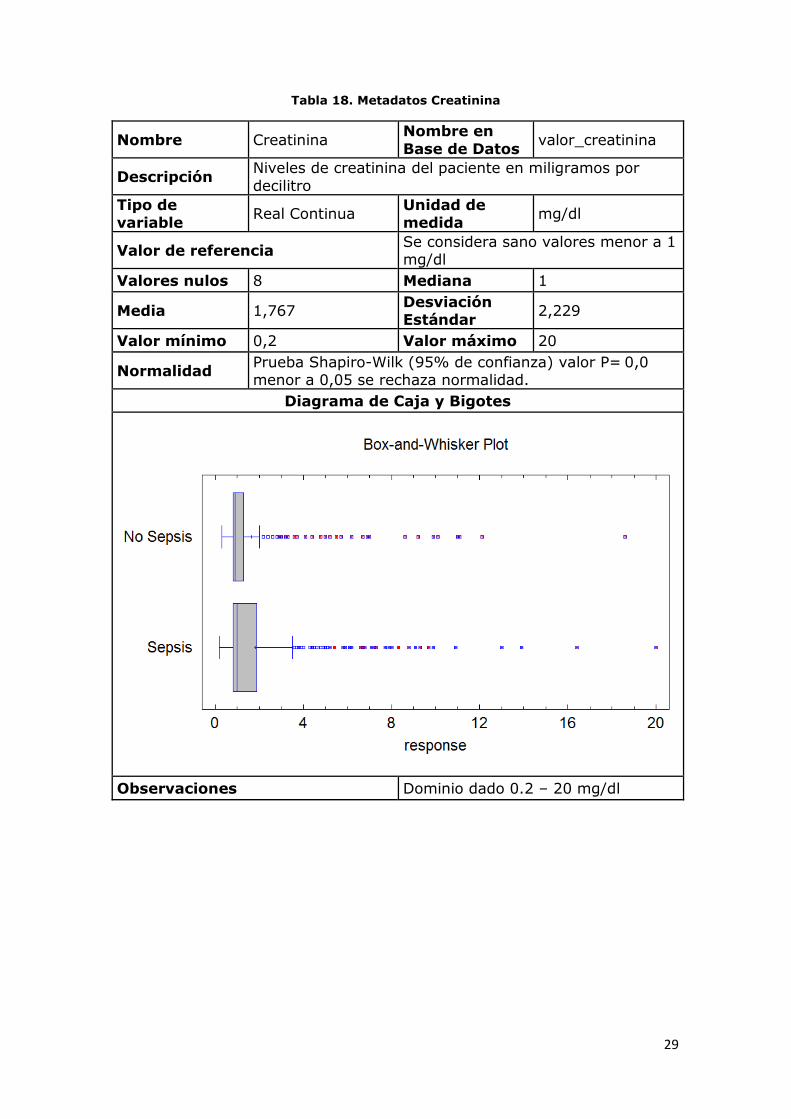
Tabla 18. Metadatos Creatinina
Nombre Creatinina Nombre en
Base de Datos valor_creatinina
Descripción Niveles de creatinina del paciente en miligramos por
decilitro
Tipo de variable
Real Continua Unidad de medida
mg/dl
Valor de referencia Se considera sano valores menor a 1 mg/dl
Valores nulos 8 Mediana 1
Media 1,767 Desviación Estándar
2,229
Valor mínimo 0,2 Valor máximo 20
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 0.2 – 20 mg/dl
30
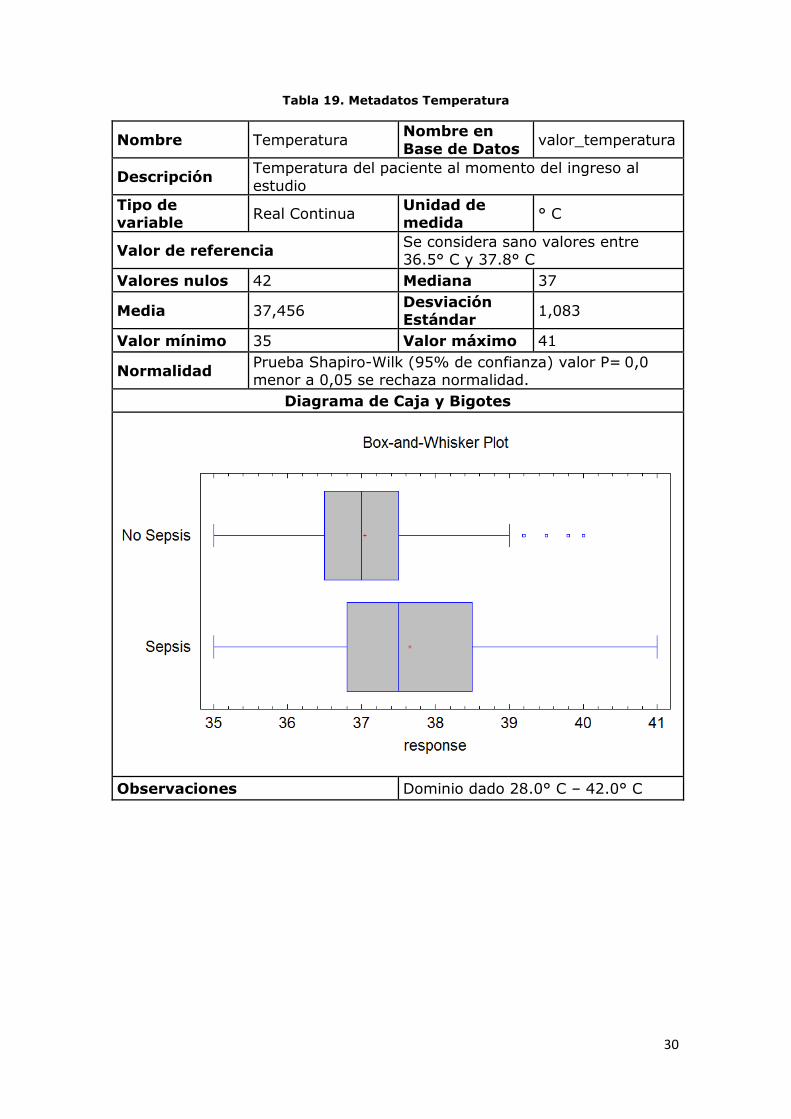
Tabla 19. Metadatos Temperatura
Nombre Temperatura Nombre en
Base de Datos valor_temperatura
Descripción Temperatura del paciente al momento del ingreso al
estudio
Tipo de variable
Real Continua Unidad de medida
° C
Valor de referencia Se considera sano valores entre 36.5° C y 37.8° C
Valores nulos 42 Mediana 37
Media 37,456 Desviación Estándar
1,083
Valor mínimo 35 Valor máximo 41
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 28.0° C – 42.0° C
31
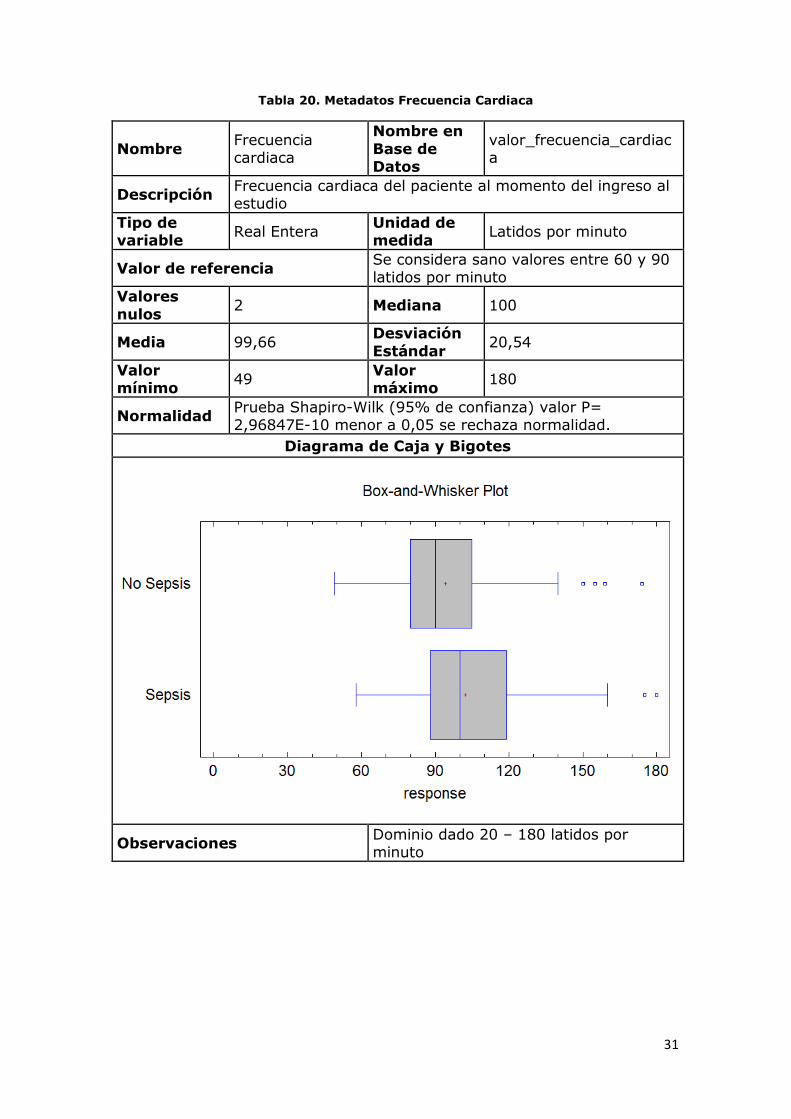
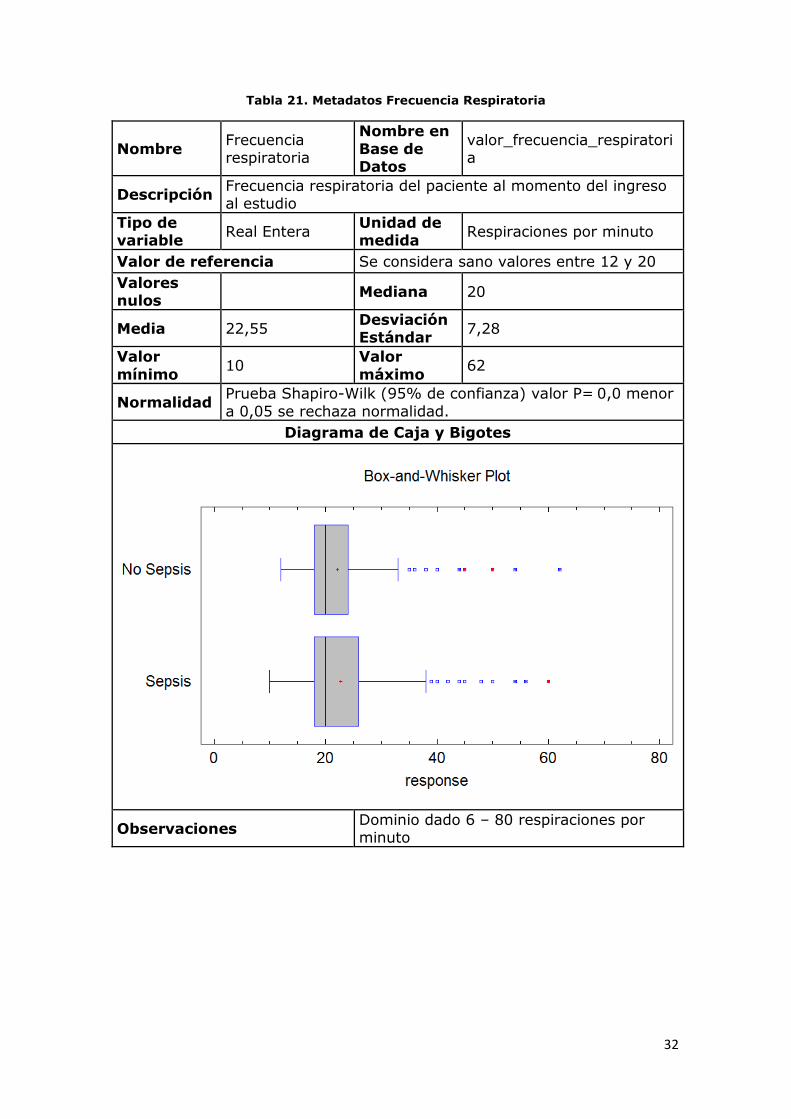
Tabla 20. Metadatos Frecuencia Cardiaca
Nombre Frecuencia cardiaca
Nombre en
Base de Datos
valor_frecuencia_cardiaca
Descripción Frecuencia cardiaca del paciente al momento del ingreso al estudio
Tipo de variable
Real Entera Unidad de medida
Latidos por minuto
Valor de referencia Se considera sano valores entre 60 y 90 latidos por minuto
Valores
nulos 2 Mediana 100
Media 99,66 Desviación
Estándar 20,54
Valor mínimo
49 Valor máximo
180
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 2,96847E-10 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 20 – 180 latidos por minuto
32
Tabla 21. Metadatos Frecuencia Respiratoria
Nombre Frecuencia respiratoria
Nombre en
Base de Datos
valor_frecuencia_respiratoria
Descripción Frecuencia respiratoria del paciente al momento del ingreso al estudio
Tipo de variable
Real Entera Unidad de medida
Respiraciones por minuto
Valor de referencia Se considera sano valores entre 12 y 20
Valores nulos
Mediana 20
Media 22,55 Desviación Estándar
7,28
Valor
mínimo 10
Valor
máximo 62
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor
a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 6 – 80 respiraciones por minuto
33
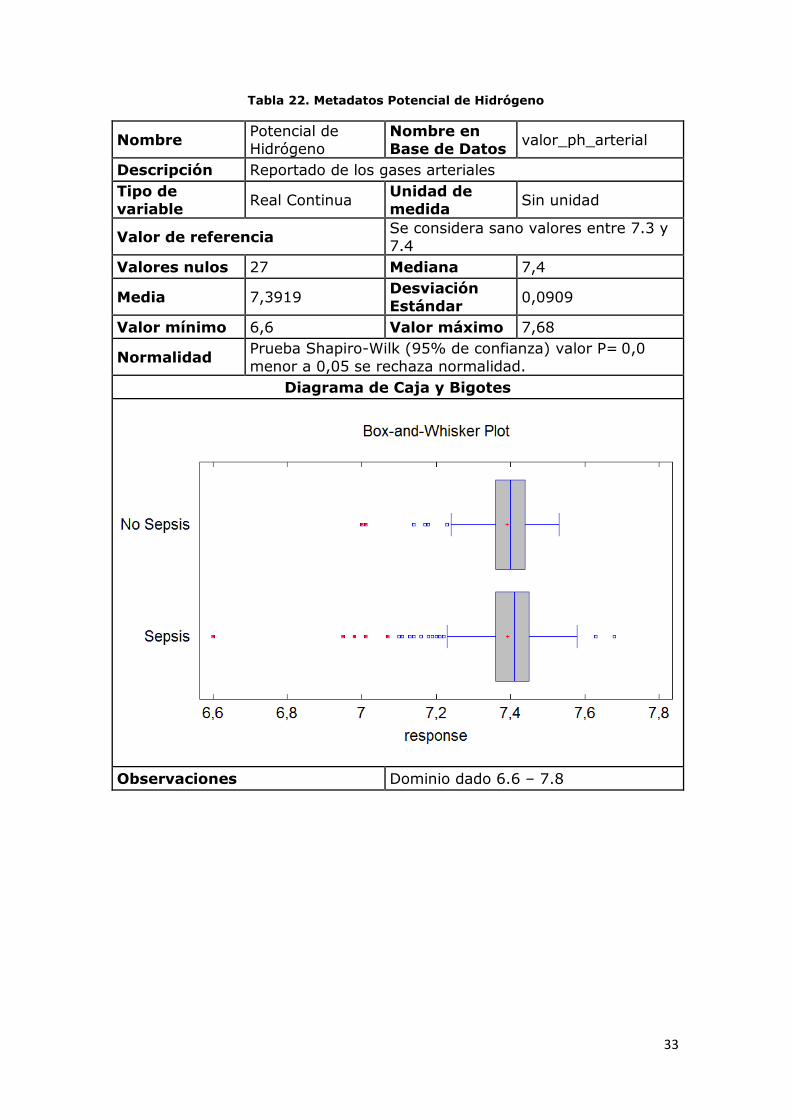
Tabla 22. Metadatos Potencial de Hidrógeno
Nombre Potencial de
Hidrógeno
Nombre en
Base de Datos valor_ph_arterial
Descripción Reportado de los gases arteriales
Tipo de
variable Real Continua
Unidad de
medida Sin unidad
Valor de referencia Se considera sano valores entre 7.3 y
7.4
Valores nulos 27 Mediana 7,4
Media 7,3919 Desviación
Estándar 0,0909
Valor mínimo 6,6 Valor máximo 7,68
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 6.6 – 7.8
34
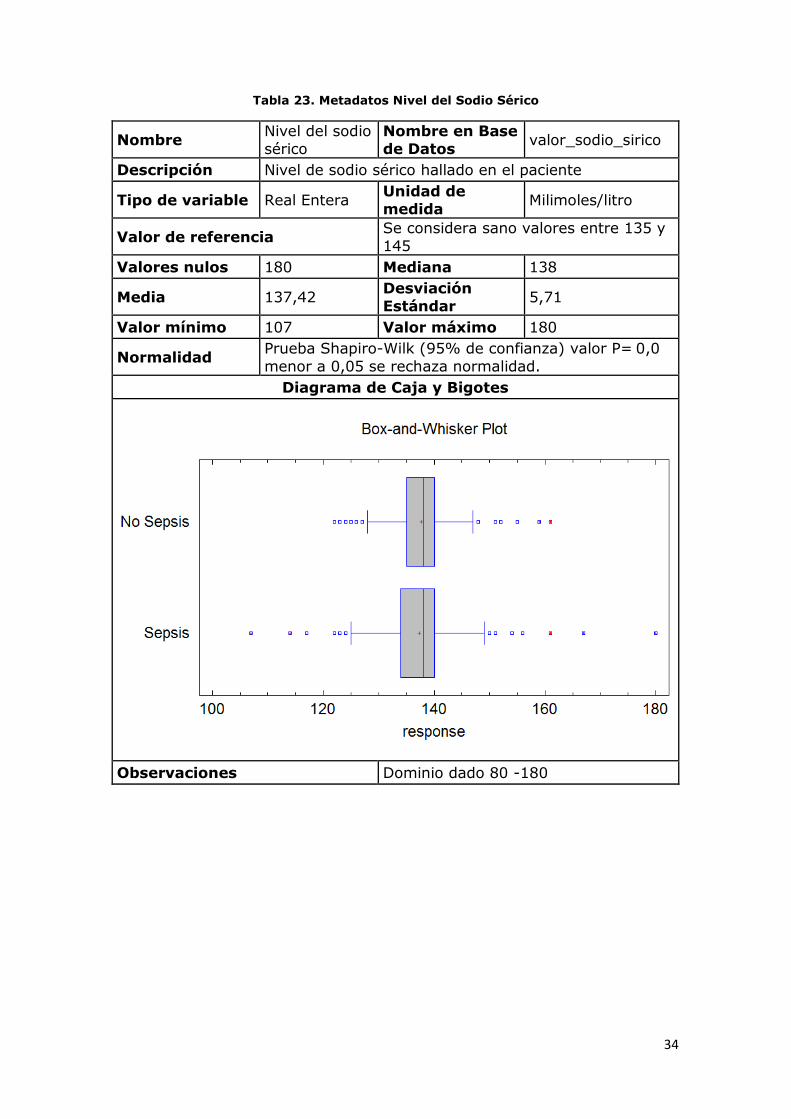
Tabla 23. Metadatos Nivel del Sodio Sérico
Nombre Nivel del sodio
sérico
Nombre en Base
de Datos valor_sodio_sirico
Descripción Nivel de sodio sérico hallado en el paciente
Tipo de variable Real Entera Unidad de
medida Milimoles/litro
Valor de referencia Se considera sano valores entre 135 y
145
Valores nulos 180 Mediana 138
Media 137,42 Desviación
Estándar 5,71
Valor mínimo 107 Valor máximo 180
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 80 -180

35
Tabla 24. Metadatos Nivel de Potasio Sérico
Nombre Nivel de
potasio sérico
Nombre en Base
de Datos valor_potasio_sirico
Descripción Nivel de potasio sérico hallado en el paciente
Tipo de variable Real Entera Unidad de
medida Milimoles/litro
Valor de referencia Se considera sano valores entre 3.5 y 5
Valores nulos 180 Mediana 4
Media 4,2 Desviación Estándar
0,89
Valor mínimo 1,5 Valor máximo 9,9
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 1.5 – 9.9
36
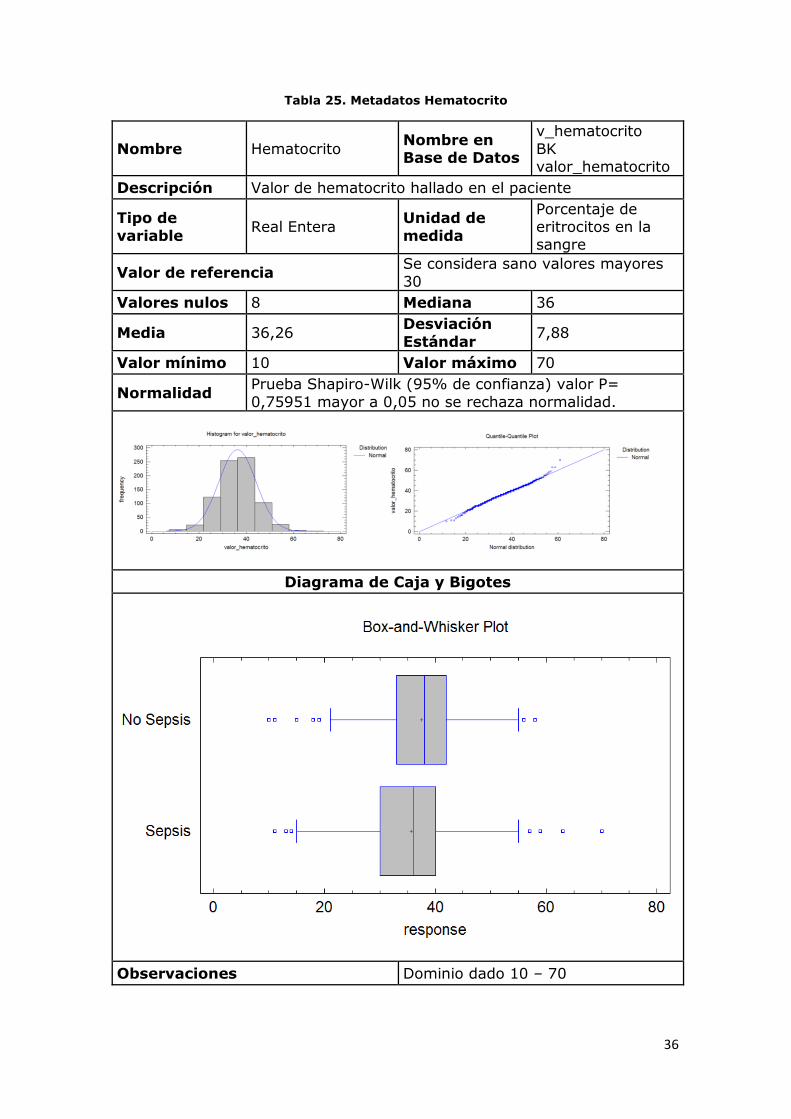
Tabla 25. Metadatos Hematocrito
Nombre Hematocrito Nombre en Base de Datos
v_hematocrito
BK valor_hematocrito
Descripción Valor de hematocrito hallado en el paciente
Tipo de
variable Real Entera
Unidad de
medida
Porcentaje de eritrocitos en la sangre
Valor de referencia Se considera sano valores mayores
30
Valores nulos 8 Mediana 36
Media 36,26 Desviación
Estándar 7,88
Valor mínimo 10 Valor máximo 70
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,75951 mayor a 0,05 no se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 10 – 70
37
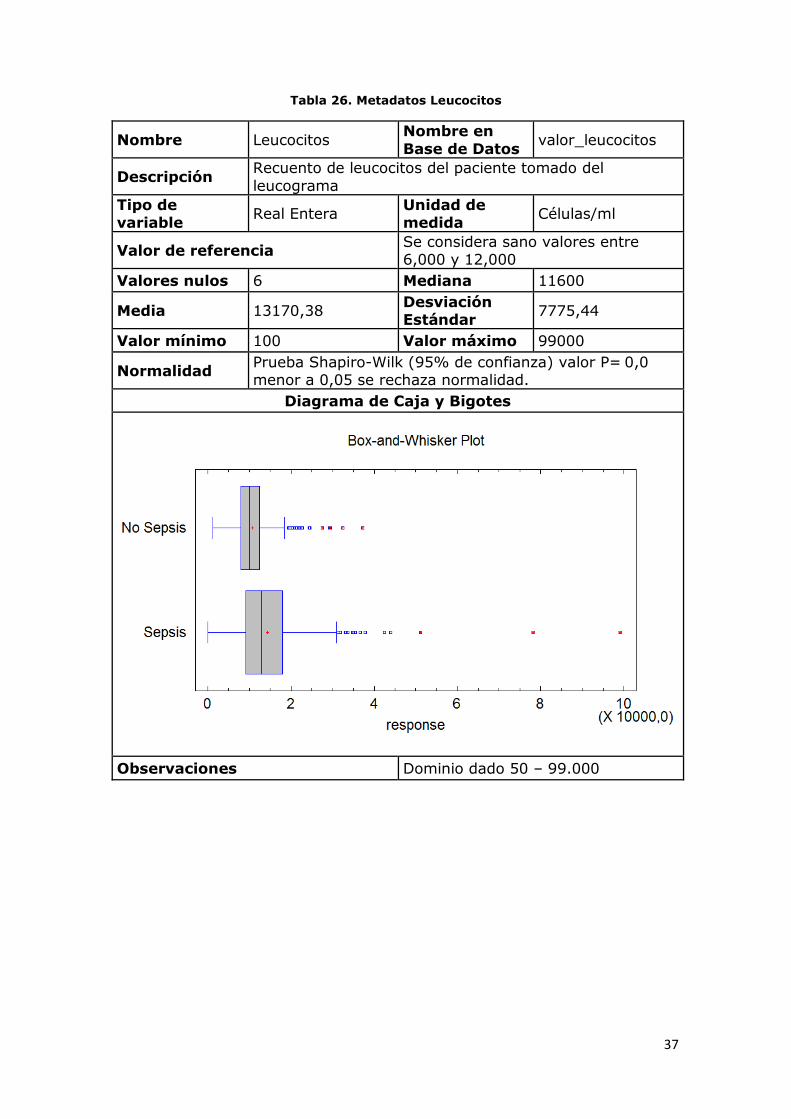
Tabla 26. Metadatos Leucocitos
Nombre Leucocitos Nombre en
Base de Datos valor_leucocitos
Descripción Recuento de leucocitos del paciente tomado del
leucograma
Tipo de variable
Real Entera Unidad de medida
Células/ml
Valor de referencia Se considera sano valores entre 6,000 y 12,000
Valores nulos 6 Mediana 11600
Media 13170,38 Desviación Estándar
7775,44
Valor mínimo 100 Valor máximo 99000
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 50 – 99.000
38
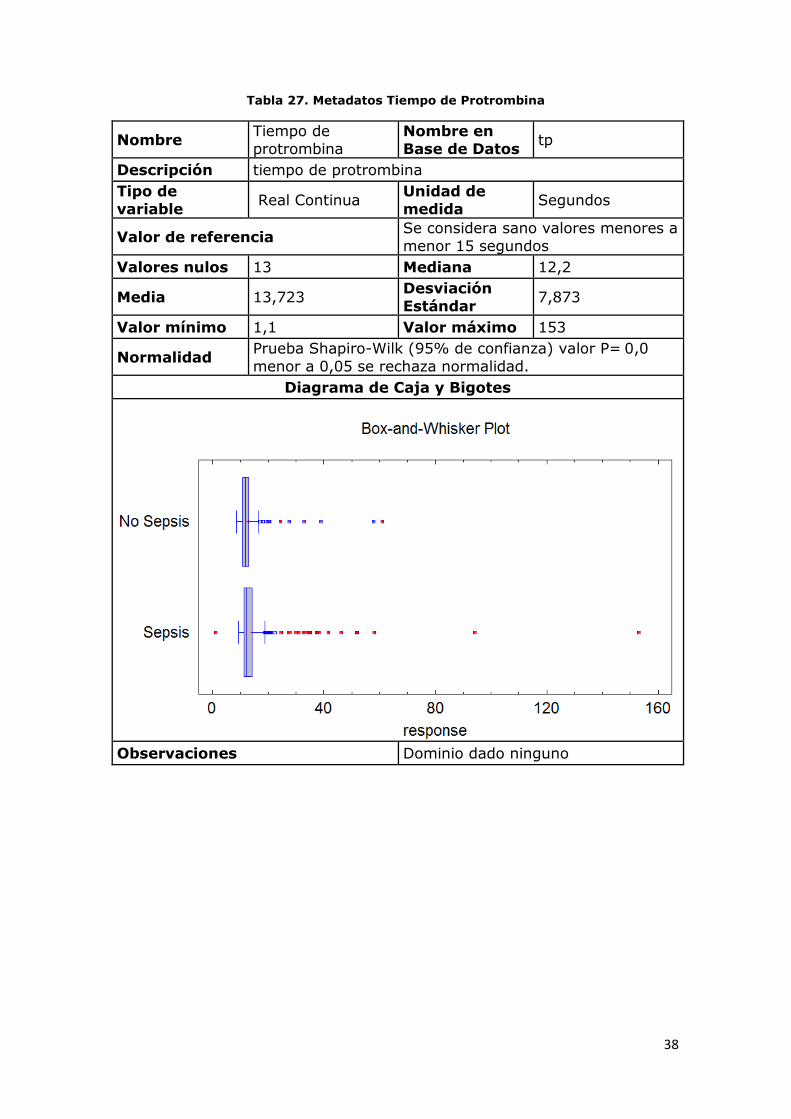
Tabla 27. Metadatos Tiempo de Protrombina
Nombre Tiempo de
protrombina
Nombre en
Base de Datos tp
Descripción tiempo de protrombina
Tipo de
variable Real Continua
Unidad de
medida Segundos
Valor de referencia Se considera sano valores menores a
menor 15 segundos
Valores nulos 13 Mediana 12,2
Media 13,723 Desviación
Estándar 7,873
Valor mínimo 1,1 Valor máximo 153
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
39
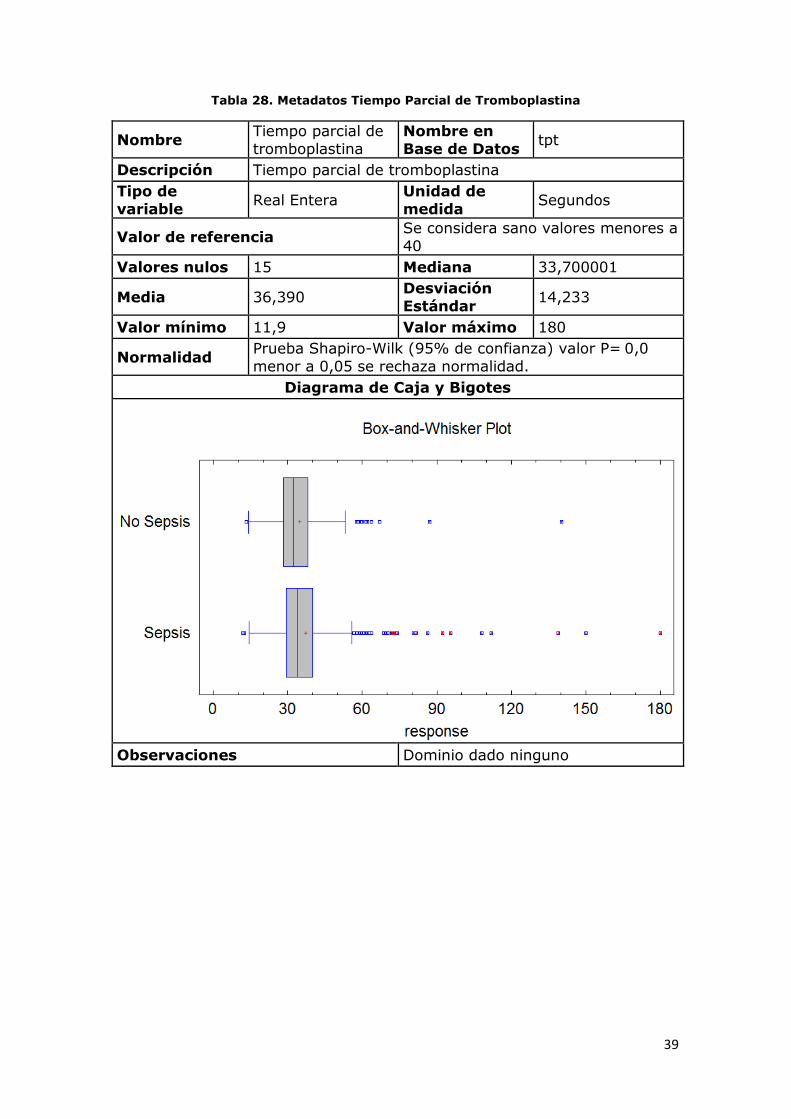
Tabla 28. Metadatos Tiempo Parcial de Tromboplastina
Nombre Tiempo parcial de
tromboplastina
Nombre en
Base de Datos tpt
Descripción Tiempo parcial de tromboplastina
Tipo de
variable Real Entera
Unidad de
medida Segundos
Valor de referencia Se considera sano valores menores a
40
Valores nulos 15 Mediana 33,700001
Media 36,390 Desviación
Estándar 14,233
Valor mínimo 11,9 Valor máximo 180
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
40
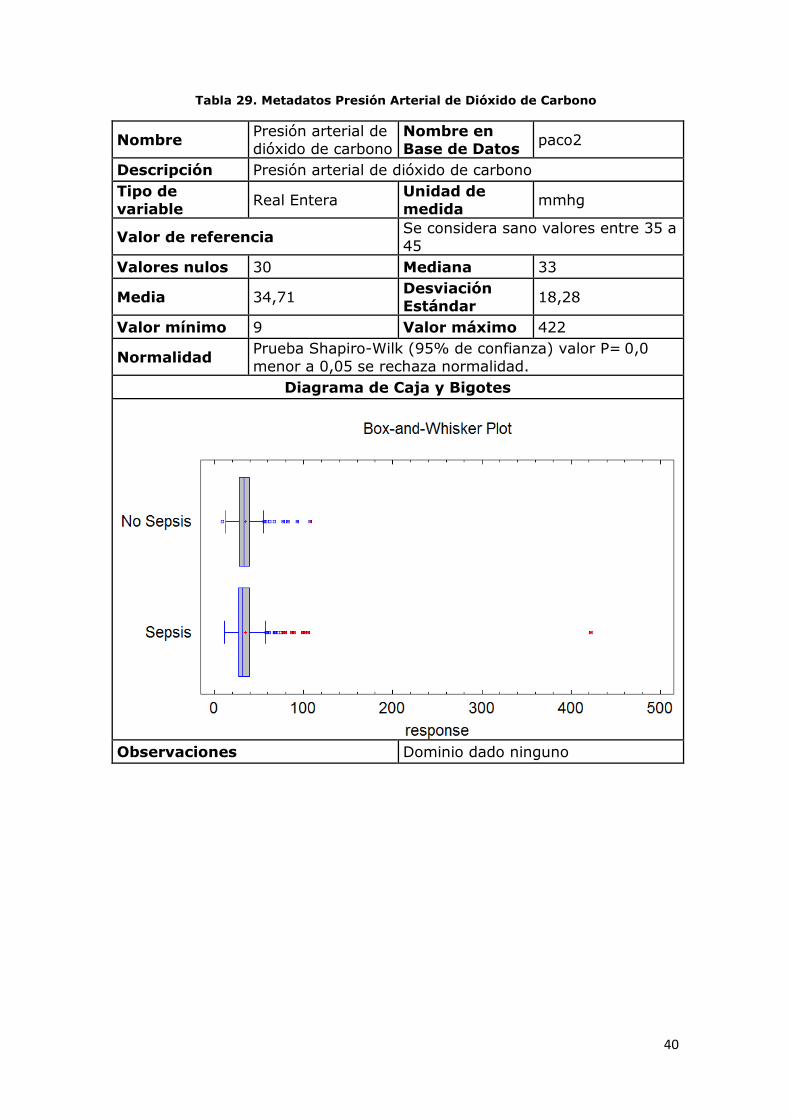
Tabla 29. Metadatos Presión Arterial de Dióxido de Carbono
Nombre Presión arterial de
dióxido de carbono
Nombre en
Base de Datos paco2
Descripción Presión arterial de dióxido de carbono
Tipo de
variable Real Entera
Unidad de
medida mmhg
Valor de referencia Se considera sano valores entre 35 a
45
Valores nulos 30 Mediana 33
Media 34,71 Desviación
Estándar 18,28
Valor mínimo 9 Valor máximo 422
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
41
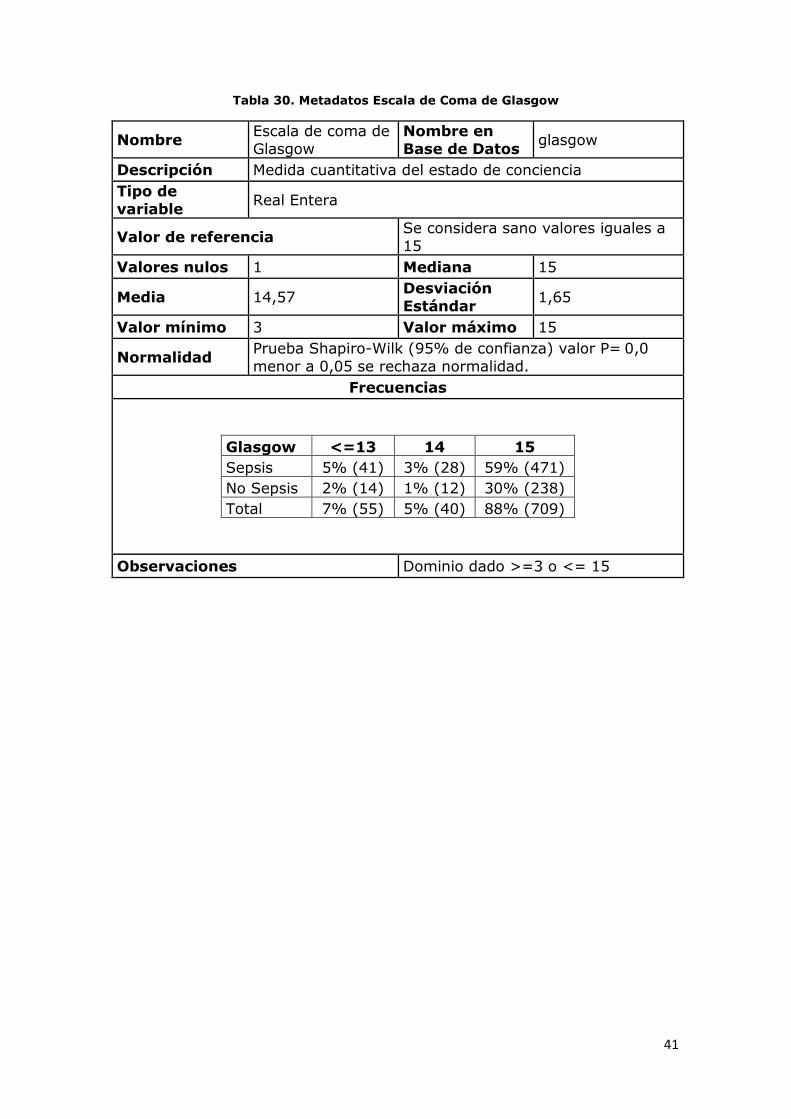
Tabla 30. Metadatos Escala de Coma de Glasgow
Nombre Escala de coma de
Glasgow
Nombre en
Base de Datos glasgow
Descripción Medida cuantitativa del estado de conciencia
Tipo de
variable Real Entera
Valor de referencia Se considera sano valores iguales a
15
Valores nulos 1 Mediana 15
Media 14,57 Desviación
Estándar 1,65
Valor mínimo 3 Valor máximo 15
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Frecuencias
Glasgow <=13 14 15
Sepsis 5% (41) 3% (28) 59% (471)
No Sepsis 2% (14) 1% (12) 30% (238)
Total 7% (55) 5% (40) 88% (709)
Observaciones Dominio dado >=3 o <= 15
42
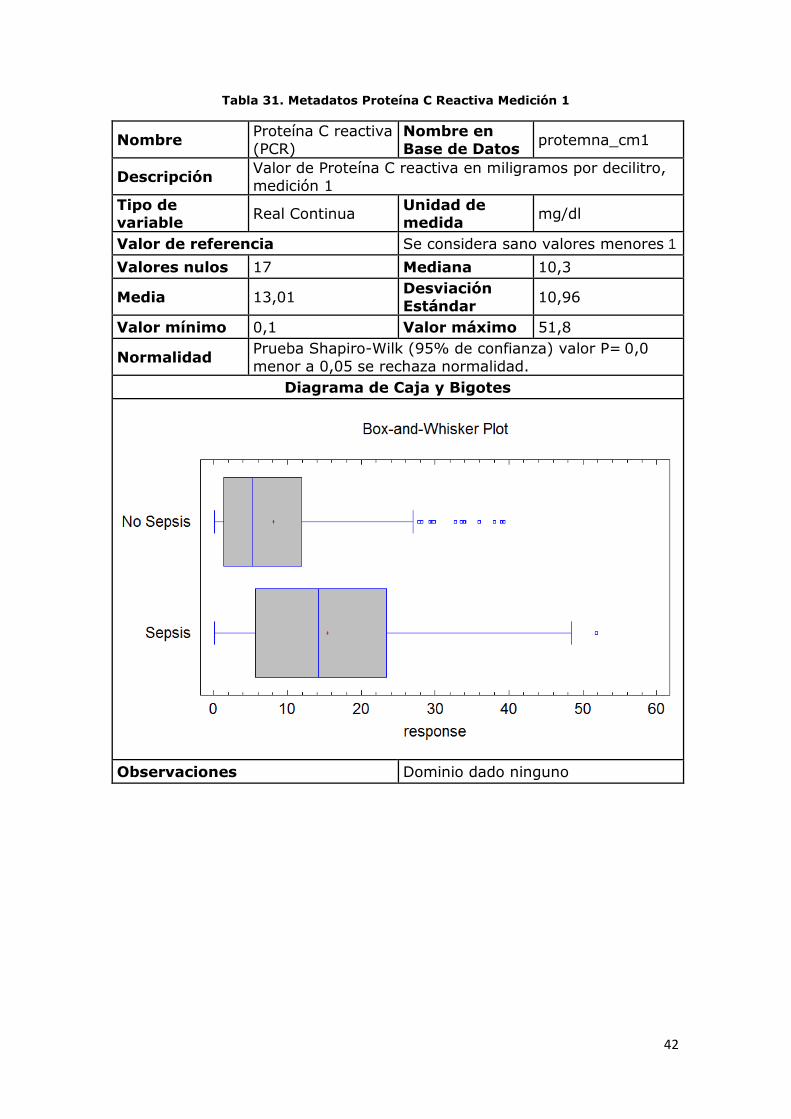
Tabla 31. Metadatos Proteína C Reactiva Medición 1
Nombre Proteína C reactiva
(PCR)
Nombre en
Base de Datos protemna_cm1
Descripción Valor de Proteína C reactiva en miligramos por decilitro,
medición 1
Tipo de variable
Real Continua Unidad de medida
mg/dl
Valor de referencia Se considera sano valores menores 1
Valores nulos 17 Mediana 10,3
Media 13,01 Desviación
Estándar 10,96
Valor mínimo 0,1 Valor máximo 51,8
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
43
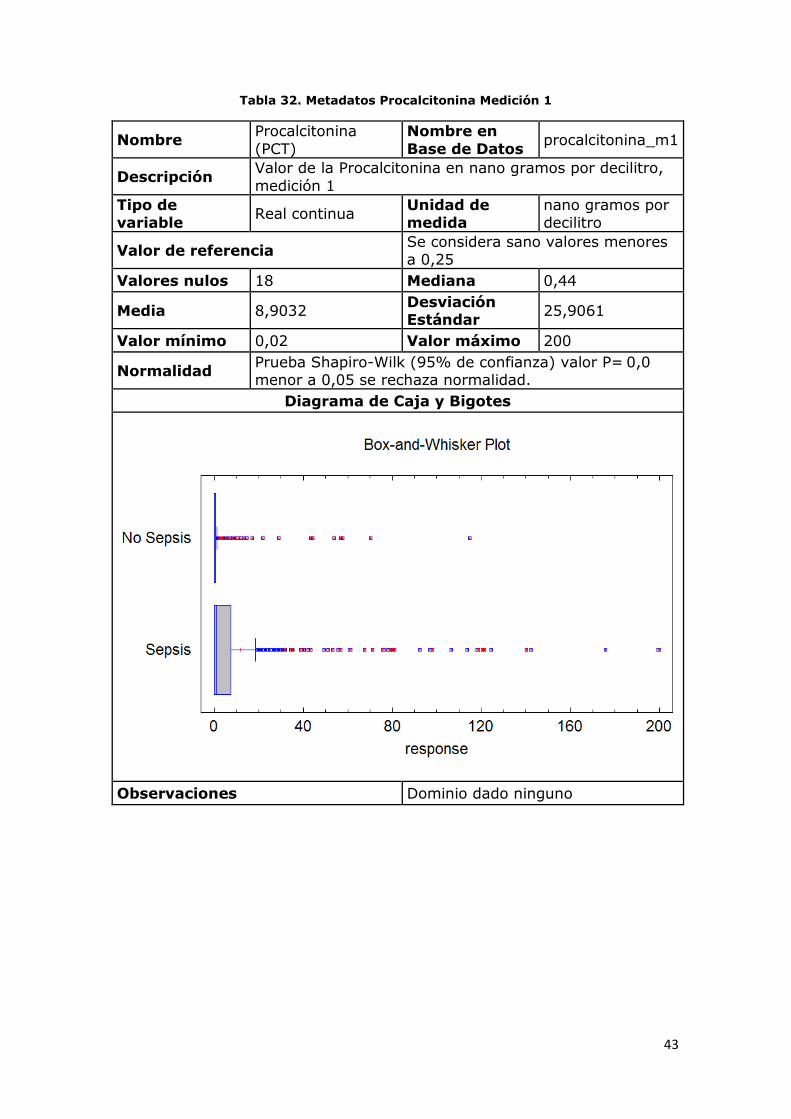
Tabla 32. Metadatos Procalcitonina Medición 1
Nombre Procalcitonina
(PCT)
Nombre en
Base de Datos procalcitonina_m1
Descripción Valor de la Procalcitonina en nano gramos por decilitro,
medición 1
Tipo de variable
Real continua Unidad de medida
nano gramos por decilitro
Valor de referencia Se considera sano valores menores a 0,25
Valores nulos 18 Mediana 0,44
Media 8,9032 Desviación Estándar
25,9061
Valor mínimo 0,02 Valor máximo 200
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
44
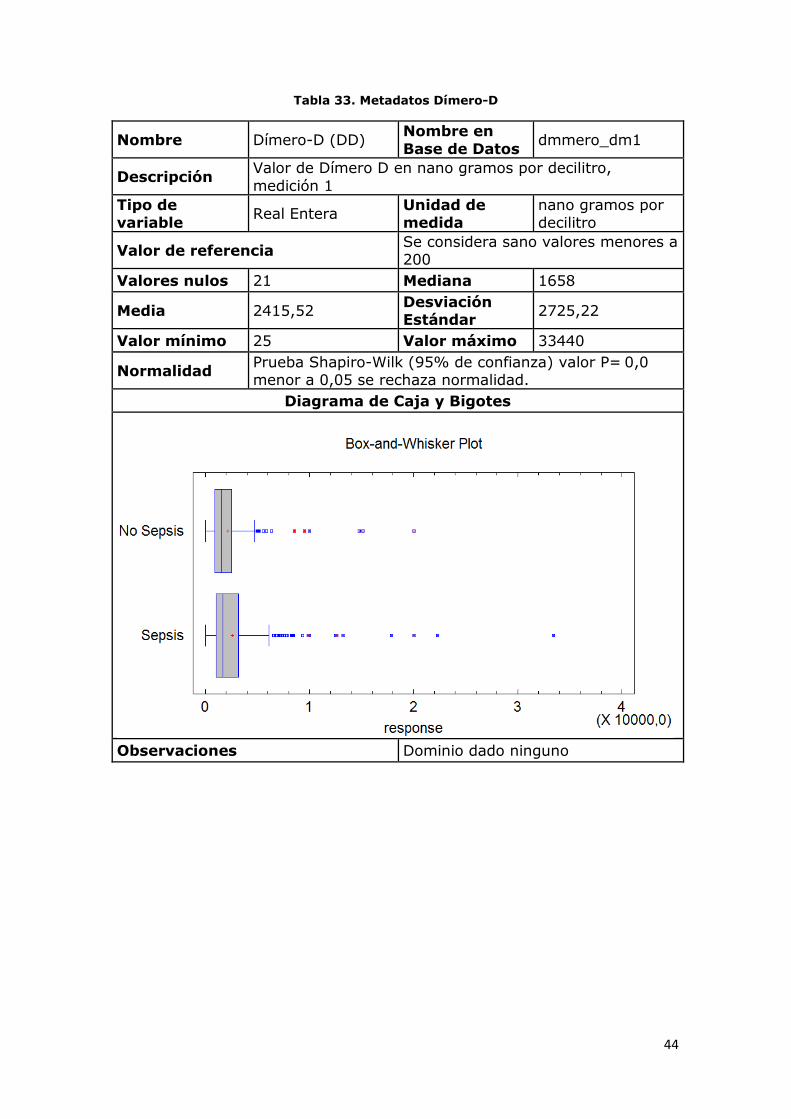
Tabla 33. Metadatos Dímero-D
Nombre Dímero-D (DD) Nombre en
Base de Datos dmmero_dm1
Descripción Valor de Dímero D en nano gramos por decilitro,
medición 1
Tipo de variable
Real Entera Unidad de medida
nano gramos por decilitro
Valor de referencia Se considera sano valores menores a 200
Valores nulos 21 Mediana 1658
Media 2415,52 Desviación Estándar
2725,22
Valor mínimo 25 Valor máximo 33440
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
45
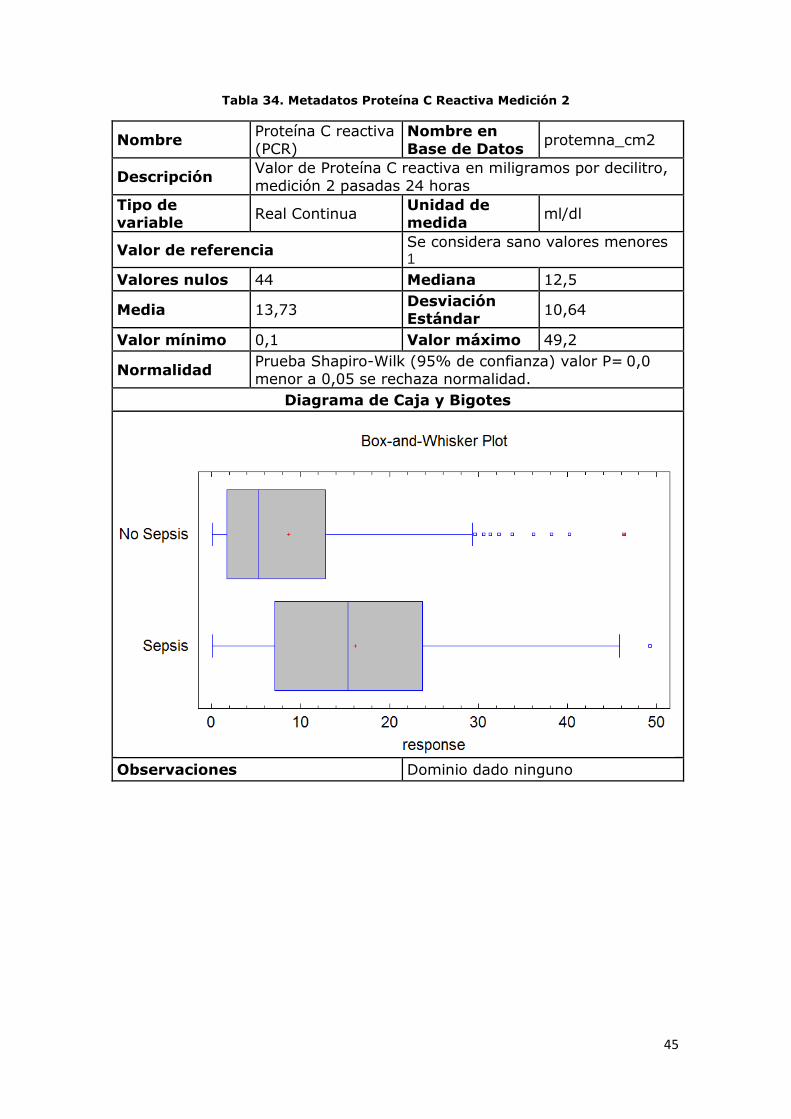
Tabla 34. Metadatos Proteína C Reactiva Medición 2
Nombre Proteína C reactiva
(PCR)
Nombre en
Base de Datos protemna_cm2
Descripción Valor de Proteína C reactiva en miligramos por decilitro,
medición 2 pasadas 24 horas
Tipo de variable
Real Continua Unidad de medida
ml/dl
Valor de referencia Se considera sano valores menores 1
Valores nulos 44 Mediana 12,5
Media 13,73 Desviación Estándar
10,64
Valor mínimo 0,1 Valor máximo 49,2
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno

46
Tabla 35. Metadatos Procalcitonina Medición 2
Nombre Procalcitonina
(PCT)
Nombre en
Base de Datos procalcitonina_m2
Descripción Valor de la Procalcitonina en nano gramos por decilitro,
medición 2 pasadas 24 horas
Tipo de variable
Real continua Unidad de medida
nano gramos por decilitro
Valor de referencia Se considera sano valores menores a 0,25
Valores nulos 58 Mediana 0,43
Media 7,7847 Desviación Estándar
26,7003
Valor mínimo 0,01 Valor máximo 464
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
47
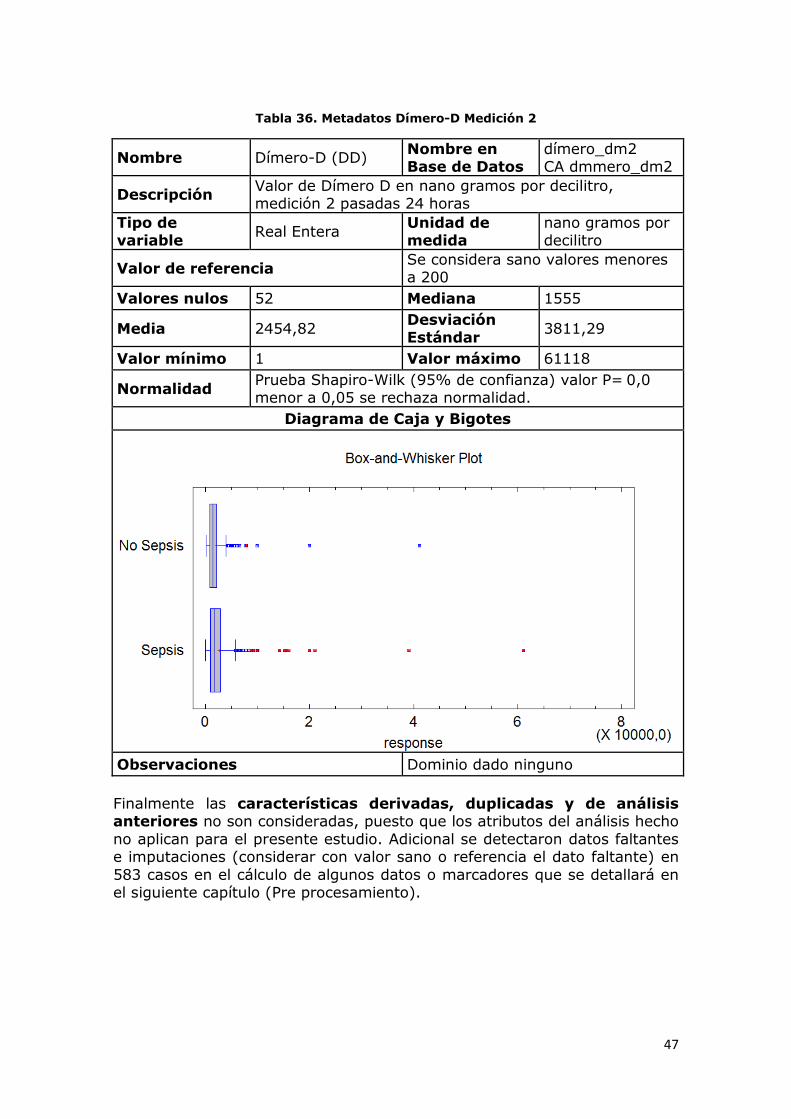
Tabla 36. Metadatos Dímero-D Medición 2
Nombre Dímero-D (DD) Nombre en Base de Datos
dímero_dm2 CA dmmero_dm2
Descripción Valor de Dímero D en nano gramos por decilitro, medición 2 pasadas 24 horas
Tipo de variable
Real Entera Unidad de medida
nano gramos por decilitro
Valor de referencia Se considera sano valores menores a 200
Valores nulos 52 Mediana 1555
Media 2454,82 Desviación Estándar
3811,29
Valor mínimo 1 Valor máximo 61118
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado ninguno
Finalmente las características derivadas, duplicadas y de análisis anteriores no son consideradas, puesto que los atributos del análisis hecho
no aplican para el presente estudio. Adicional se detectaron datos faltantes e imputaciones (considerar con valor sano o referencia el dato faltante) en
583 casos en el cálculo de algunos datos o marcadores que se detallará en el siguiente capítulo (Pre procesamiento).

48
5 PRE PROCESAMIENTO DE LOS DATOS
En este capítulo se explica el manejo de los datos atípicos, los valores nulos, se hace uso de los antecedente clínicos para conformar dos grupos y
se adoptan los puntajes APACHE II y SOFA con el fin de reducir la cantidad de atributos que alimentarán posteriormente las técnicas de clasificación de minería de datos, dichos puntajes involucran un subconjunto de mediciones.
La aparición de los datos atípicos puede ser debida a la sospecha que se
tiene sobre el fenómeno de la sepsis; es decir, para valores alterados por ser más altos o más bajos se espera que el paciente tenga mayor probabilidad de desarrollar sepsis.
Dada la naturaleza del problema y la metodología del descubrimiento de
nuevo conocimiento en bases de datos, el manejo de los datos nulos dependerá de las técnicas de minería de datos que se utilicen, dado el caso
en que la técnica no soporte valores nulos, el tratamiento más recomendado es la eliminación de las tuplas que contengan dichos valores. En el caso de la eliminación de las tuplas con valores nulos, las
implicaciones es que no se puede garantizar la confianza del 95% del proyecto de investigación anterior.
De acuerdo con el antecedente del historial clínico se identificaron los pacientes con bajas defensas (inmunosupresión), es decir, pacientes que
vienen con una condición que afecta negativamente el sistema inmunológico. Dicho grupo cobija a los que padecen VIH/SIDA, con
antecedentes de esteroides o quimioterapia, cáncer, cirrosis o pacientes trasplantados como se muestra en la siguiente Tabla 37:
Tabla 37. Frecuencias Grupo Inmunosupresión
Inmunosupresión Si No
Sepsis 15% (117) 53% (424)
No Sepsis 6% (51) 26% (213)
Total 21% (168) 79% (637)
El segundo grupo con enfermedad general que concentra los atributos:
trauma, drogadicción o alcoholismo, diabetes, insuficiencia cardiaca, enfermedad pulmonar e insuficiencia renal crónica. Este grupo representa a los pacientes que tienen enfermedades que no comprometen el sistema
inmunológico. A continuación en la Tabla 38 se muestran las frecuencias correspondientes a este grupo.
Tabla 38. Frecuencias Grupo Enfermedad General
Enfermedad General Si No
Sepsis 24% (190) 44% (351)
No Sepsis 11% (92) 21% (172)
Total 35% (282) 65% (523)

49
Entre los grupos inmunosupresión y enfermedad general son excluyentes,
es decir si un paciente presenta un antecedente de inmunosupresión y al mismo tiempo uno de enfermedad general, se considera que pertenece al
grupo inmunosupresión y no al de enfermedad general. Lo anterior se da porque es más importante considerar el estado de inmunosupresión que el estado de enfermedad general. Utilizar estos dos nuevos atributos en vez
de los 11, mejora la parsimonia del modelo, es decir, el grupo inmunosupresión y enfermedad general contiene la información relevante
de las 11 características de los antecedentes clínicos para esta investigación.
El puntaje APACHE II es un reconocido y validado indicador de severidad y riesgo de mortalidad en pacientes críticamente enfermos. Esta variable es
necesaria para una adecuada caracterización de la población, y fue determinada de manera estándar por los asistentes de investigación en todos los pacientes admitidos al estudio.
El puntaje APACHE II incluye los atributos de temperatura, presión arterial
media, frecuencia cardiaca, frecuencia respiratoria, presión arterial del oxígeno por la fracción inspirada de oxígeno, potencial de hidrógeno, nivel
del sodio sérico, nivel de potasio sérico, creatinina, hematocrito, leucocitos, escala de coma de Glasgow, edad y algunas características de antecedentes.
En el APACHE II puede usarse un tipo particular de imputación que consiste
en asumir sanos los datos faltantes de las características presión arterial del oxígeno por la fracción inspirada de oxígeno, potencial de hidrógeno, nivel
del sodio sérico y nivel de potasio sérico. Los restantes atributos no son adecuados imputar ya que son medidas directas sobre el paciente o son exámenes clínicos comunes y no deberían de faltar.
En el Anexo B se presenta el cálculo del puntaje APACHE II, a continuación
la estructura de los Metadatos para el APACHE II:

50
Tabla 39. Metadatos APACHE II
Nombre APACHE II Nombre en
Base de Datos total_apache_ii
Descripción Indicador de severidad y riesgo de mortalidad en
pacientes críticamente enfermos
Tipo de variable
Real Entera Unidad de medida
Valor de referencia Se considera sano valores iguales a cero
Valores nulos 76 Mediana 10
Media 10,41 Desviación Estándar
6,281
Valor mínimo 0 Valor máximo 37
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0 menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 0 -67
El puntaje SOFA es un indicador de la frecuencia y magnitud de la
disfunción de órganos o sistemas. Adicionalmente, sus valores permiten estimar la gravedad de la condición clínica y por consiguiente el riesgo de
muerte. En el Anexo C, se muestra el cálculo del SOFA.
El indicador SOFA incluye los atributos de presión arterial del oxígeno por la fracción inspirada de oxígeno, plaquetas, presión arterial media, escala de coma de Glasgow, bilirrubina y creatinina.
De manera similar al APACHE II en el SOFA puede usarse el mismo tipo de
imputación sobre las siguientes características: presión arterial del oxígeno por la fracción inspirada de oxígeno y bilirrubina. Los restantes atributos no son adecuados imputar.
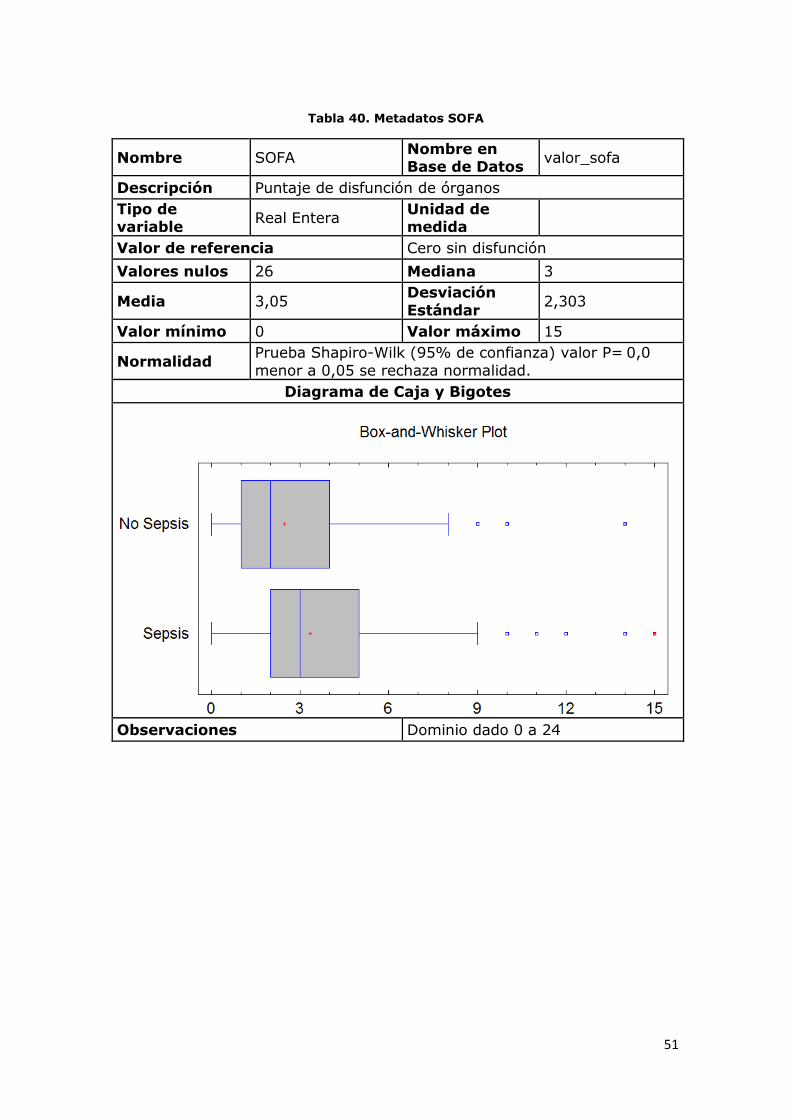
51
Tabla 40. Metadatos SOFA
Nombre SOFA Nombre en Base de Datos
valor_sofa
Descripción Puntaje de disfunción de órganos
Tipo de variable
Real Entera Unidad de medida
Valor de referencia Cero sin disfunción
Valores nulos 26 Mediana 3
Media 3,05 Desviación
Estándar 2,303
Valor mínimo 0 Valor máximo 15
Normalidad Prueba Shapiro-Wilk (95% de confianza) valor P= 0,0
menor a 0,05 se rechaza normalidad.
Diagrama de Caja y Bigotes
Observaciones Dominio dado 0 a 24

52
6 ANÁLISIS DE LOS DATOS
En este capítulo se analiza las variables incluidas en el presente estudio, con el fin de determinar si alguna de ellas por sí sola sirve como criterio para clasificar a los pacientes con sepsis y no sepsis; incluye relación entre
las variables, diferencias de medias y medianas de cada variable entre los grupos sepsis y no sepsis; además se considera el uso de las etiquetas sin
infección, infección sin sepsis, sepsis y sepsis grave. De manera general, se observa que los grupos etiquetados en No Sepsis
(Sin infección e infección sin sepsis) y Sepsis (sepsis y sepsis grave) en todos los atributos se traslapan en las gráficas de cajas y bigotes; las cuales
se constatan en las tablas de los metadatos (entre Tabla 15 y Tabla 38). Adicionalmente se ve que los valores medios aparentemente son similares o cercanos en: plaquetas, frecuencia respiratoria, potencial de hidrógeno,
nivel del sodio sérico y nivel de potasio sérico. Sin embargo en casos como en los atributos presión arterial del oxígeno por la fracción inspirada de
oxígeno, presión arterial media, temperatura, frecuencia cardiaca, hematocrito, leucocitos, proteína C reactiva medición 1 y proteína C reactiva medición 2, aparentemente hay diferencias en los valores medios,
esto se complementará con pruebas estadísticas.
En otros atributos no se logra observar con claridad diferencias o similitudes en los valores medios dada a la presencia de valores extremos, dichos
atributos son: bilirrubina, creatinina, tiempo de protrombina, tiempo parcial de tromboplastina, presión arterial de dióxido de carbono, procalcitonina medición 1, dímero-D medición 1, procalcitonina medición 2 y dímero-D
medición 2.
Adicional se evidenció en todas las variables una mayor variabilidad o dispersión en el grupo de pacientes que presentaron sepsis. Sin embargo se debe recordar que las muestras son dispares ya que la clase sepsis
representa el 67% de la muestra y no sepsis 33% de la muestra. Intuitivamente se espera mayor dispersión en una muestra mayor y menor
dispersión en una muestra menor. Por esto, la dispersión no se puede atribuir únicamente a la sepsis.
Por otro lado, observando la matriz de dispersión, se determinó que no existe relación aparente entre las variables, excepto entre las mediciones 1
y 2 de los biomarcadores. A continuación, a manera de ilustración, se muestran algunas gráficas de
dispersión diferenciando entre Sepsis (Azul) y No Sepsis (Rojo).
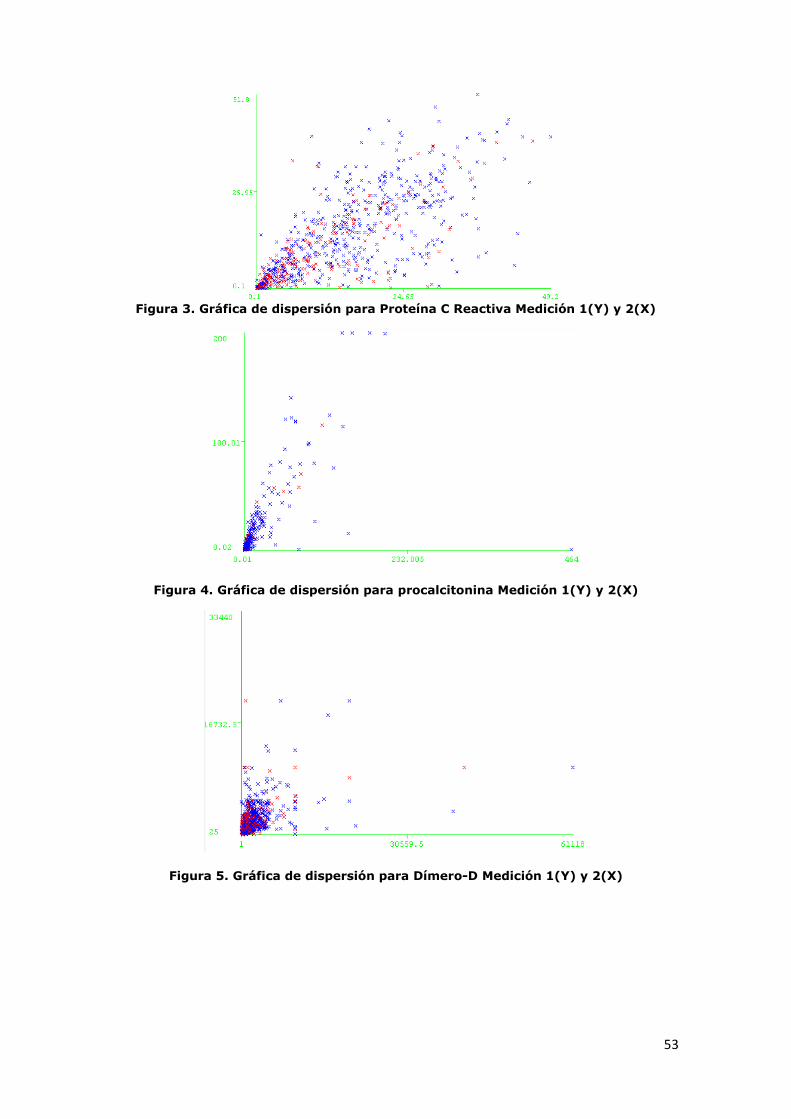
53
Figura 3. Gráfica de dispersión para Proteína C Reactiva Medición 1(Y) y 2(X)
Figura 4. Gráfica de dispersión para procalcitonina Medición 1(Y) y 2(X)
Figura 5. Gráfica de dispersión para Dímero-D Medición 1(Y) y 2(X)
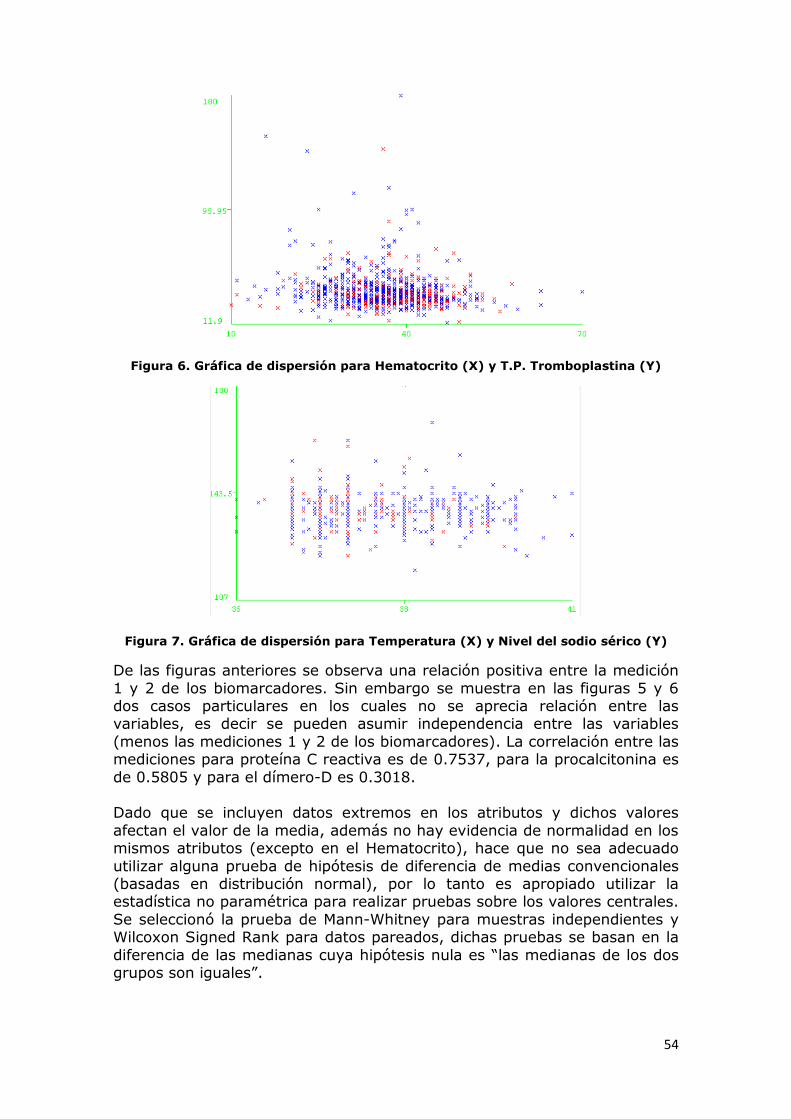
54
Figura 6. Gráfica de dispersión para Hematocrito (X) y T.P. Tromboplastina (Y)
Figura 7. Gráfica de dispersión para Temperatura (X) y Nivel del sodio sérico (Y)
De las figuras anteriores se observa una relación positiva entre la medición
1 y 2 de los biomarcadores. Sin embargo se muestra en las figuras 5 y 6 dos casos particulares en los cuales no se aprecia relación entre las variables, es decir se pueden asumir independencia entre las variables
(menos las mediciones 1 y 2 de los biomarcadores). La correlación entre las mediciones para proteína C reactiva es de 0.7537, para la procalcitonina es
de 0.5805 y para el dímero-D es 0.3018. Dado que se incluyen datos extremos en los atributos y dichos valores
afectan el valor de la media, además no hay evidencia de normalidad en los mismos atributos (excepto en el Hematocrito), hace que no sea adecuado
utilizar alguna prueba de hipótesis de diferencia de medias convencionales (basadas en distribución normal), por lo tanto es apropiado utilizar la estadística no paramétrica para realizar pruebas sobre los valores centrales.
Se seleccionó la prueba de Mann-Whitney para muestras independientes y Wilcoxon Signed Rank para datos pareados, dichas pruebas se basan en la
diferencia de las medianas cuya hipótesis nula es “las medianas de los dos grupos son iguales”.

55
Para esto se utilizó el software R (versión 3.1.1) y se utilizó el comando
wilcox.test con 95% de confianza, parámetro de datos pareados (falso o verdadero según el caso) e hipótesis alternativa medianas diferentes. Con el
fin de determinar si es posible eliminar una de las dos mediciones en el caso en que la hipótesis nula se acepte.
Se aplicaron las pruebas de diferencia de medianas para datos pareados entre las mediciones uno y dos, discriminando entre la clasificación sepsis y
no sepsis para cada biomarcador: proteína C reactiva, procalcitonina y dímero-D.
Dichas pruebas dieron como resultado que las medianas eran iguales para la proteína C reactiva y el Dímero-D en las mediciones 1 y 2. Los resultados
para la procalcitonina entre las mediciones uno y dos es valor P igual a 1.329E-11 menor a 0,05 por lo tanto hay suficiente evidencia para rechazar la hipótesis nula, es decir se rechaza que las medianas son estadísticamente
iguales.
Ahora entre las subcategoría Sepsis medición uno y Sepsis medición dos es valor P igual a 1.007E-09 menor a 0,05 por lo tanto hay suficiente evidencia para rechazar la hipótesis nula, es decir se rechaza que las medianas son
estadísticamente iguales.
Y las subcategoría No Sepsis medición uno y No Sepsis medición dos es el valor P igual a 0.005014 menor a 0,05 por lo tanto hay suficiente evidencia para rechazar la hipótesis nula, es decir se rechaza que las medianas son
estadísticamente iguales.
Los resultados anteriores muestran que solo la procalcitonina evidencia
cambios en el tiempo de manera general y entre las subcategorías. Para los otros dos biomarcadores se puede eliminar la medición 2, dado que no
presentan cambios en el tiempo.
Para determinar si hay cambios al nivel de la mediana entre los grupos de
clasificación Sepsis y No sepsis se aplicó la prueba Mann-Whitney para cada atributo, excepto para el hematocrito, dado que se ajusta a una distribución
normal. Se utilizó la prueba T de Student con 95% de confianza (comando en R: t.test). En la Tabla 41 se presenta una sinopsis de las pruebas practicadas.
Tabla 41. Resumen Prueba Diferencias de Medianas
Atributo Mediana
No Sepsis
Mediana
Sepsis
Valor P Conclusión
Medianas
Presión A. del oxígeno por
la fracción inspirada de O.
339 298 1.809E-06 Diferentes
Valor de recuento de
plaquetas
289000 273000 0.3188 Iguales
Presión arterial media 91 86 7.491E-08 Diferentes
Bilirrubina 0,6 0,7 0.08673 Iguales
Creatinina 0,9 1 0.0308 Diferentes
Temperatura 37 37,5 2.007E-12 Diferentes
Frecuencia cardiaca 90 100 2.785E-08 Diferentes
Frecuencia respiratoria 20 20 0.0902 Iguales
Potencial de Hidrógeno 7,4 7,41 0.2392 Iguales
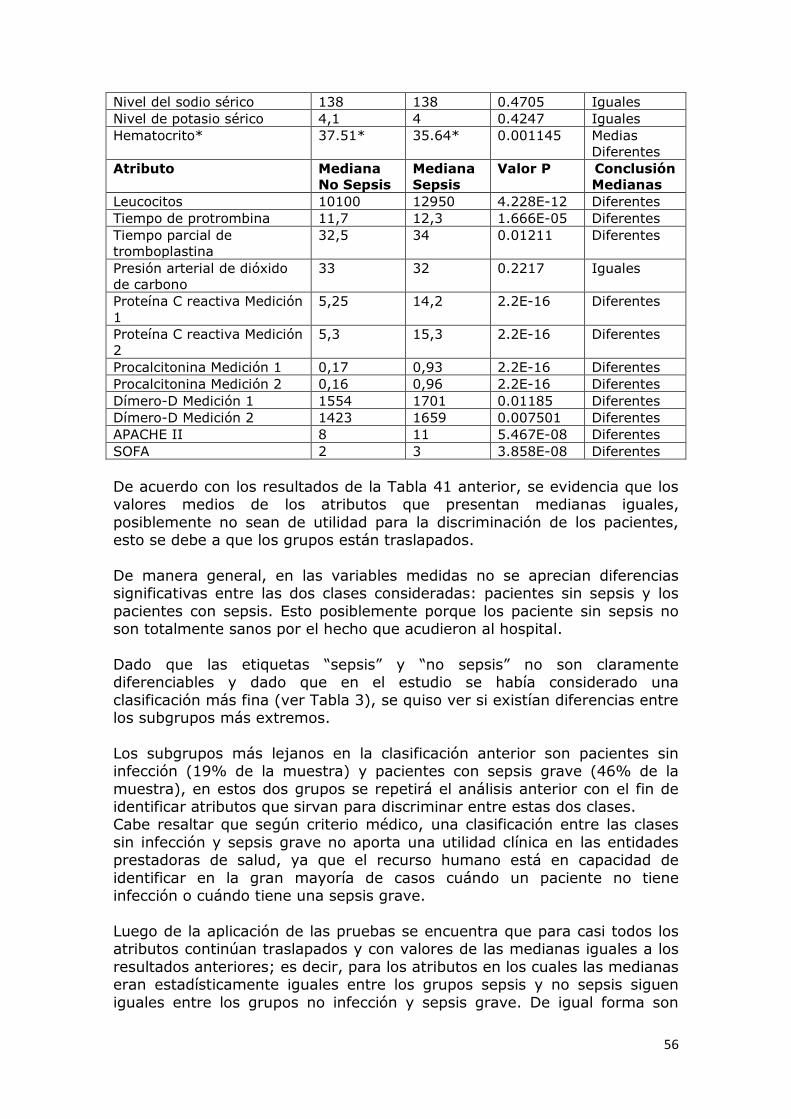
56
Nivel del sodio sérico 138 138 0.4705 Iguales
Nivel de potasio sérico 4,1 4 0.4247 Iguales
Hematocrito* 37.51* 35.64* 0.001145 Medias
Diferentes
Atributo Mediana
No Sepsis
Mediana
Sepsis
Valor P Conclusión
Medianas
Leucocitos 10100 12950 4.228E-12 Diferentes
Tiempo de protrombina 11,7 12,3 1.666E-05 Diferentes
Tiempo parcial de
tromboplastina
32,5 34 0.01211 Diferentes
Presión arterial de dióxido
de carbono
33 32 0.2217 Iguales
Proteína C reactiva Medición
1
5,25 14,2 2.2E-16 Diferentes
Proteína C reactiva Medición
2
5,3 15,3 2.2E-16 Diferentes
Procalcitonina Medición 1 0,17 0,93 2.2E-16 Diferentes
Procalcitonina Medición 2 0,16 0,96 2.2E-16 Diferentes
Dímero-D Medición 1 1554 1701 0.01185 Diferentes
Dímero-D Medición 2 1423 1659 0.007501 Diferentes
APACHE II 8 11 5.467E-08 Diferentes
SOFA 2 3 3.858E-08 Diferentes
De acuerdo con los resultados de la Tabla 41 anterior, se evidencia que los valores medios de los atributos que presentan medianas iguales,
posiblemente no sean de utilidad para la discriminación de los pacientes, esto se debe a que los grupos están traslapados.
De manera general, en las variables medidas no se aprecian diferencias significativas entre las dos clases consideradas: pacientes sin sepsis y los
pacientes con sepsis. Esto posiblemente porque los paciente sin sepsis no son totalmente sanos por el hecho que acudieron al hospital.
Dado que las etiquetas “sepsis” y “no sepsis” no son claramente diferenciables y dado que en el estudio se había considerado una
clasificación más fina (ver Tabla 3), se quiso ver si existían diferencias entre los subgrupos más extremos.
Los subgrupos más lejanos en la clasificación anterior son pacientes sin infección (19% de la muestra) y pacientes con sepsis grave (46% de la
muestra), en estos dos grupos se repetirá el análisis anterior con el fin de identificar atributos que sirvan para discriminar entre estas dos clases. Cabe resaltar que según criterio médico, una clasificación entre las clases
sin infección y sepsis grave no aporta una utilidad clínica en las entidades prestadoras de salud, ya que el recurso humano está en capacidad de
identificar en la gran mayoría de casos cuándo un paciente no tiene infección o cuándo tiene una sepsis grave.
Luego de la aplicación de las pruebas se encuentra que para casi todos los atributos continúan traslapados y con valores de las medianas iguales a los
resultados anteriores; es decir, para los atributos en los cuales las medianas eran estadísticamente iguales entre los grupos sepsis y no sepsis siguen
iguales entre los grupos no infección y sepsis grave. De igual forma son
57
para los atributos con medianas estadísticamente diferentes. A continuación
se presentan algunos casos particulares en las Figuras 7, 8 y 9.
Figura 8. Presión Arterial Media Literales A (Sepsis y No Sepsis) y Literales B (No Infección y Sepsis Grave)
Figura 9. Proteína C reactiva Medición 1 Literales A (Sepsis y No sepsis) y Literales B (No Infección y Sepsis Grave)

58
Figura 10. Dímero-D (DD) Medición 1 Literales A (Sepsis y No sepsis) y Literales B
(No Infección y Sepsis Grave)
Considerando los subgrupos más extremos, el único atributo que cambió fue el recuento de plaquetas en el resultado de la aplicación de la prueba de diferencia de medianas la cual se aceptaba la hipótesis nula de medianas
iguales y pasó a rechazar dicha hipótesis, sin embargo como se muestra en la Figura 10 se evidencia que continua traslapada y a simple vista no hay un
cambio considerable.
Figura 11. Recuento de plaquetas Literales A (Sepsis y No sepsis) y Literales B (No
Infección y Sepsis Grave)
Finalmente, del análisis se puede concluir que ningún atributo por sí solo
logra separar claramente los subgrupos de no infección y sepsis grave, mucho menos los grupos sepsis y no sepsis; se intuye que solo los atributos cuyas medianas sean diferentes pueden ser de utilidad para la clasificación
de los pacientes.

59
7 APLICACIÓN DE LAS TECNICAS, MEJOR MODELO Y
RESULTADOS.
Para la aplicación de las técnicas se filtró los atributos para alimentar los
modelos. La primera selección consta de todos los atributos en bruto, es decir se consideran todas las variables, excepto los puntajes APACHE II y
SOFA. La segunda selección incluye todas las características en bruto cuyo resultado de diferencia de medianas es estadísticamente diferente, dichas características son las que se sospechan que ayudan a la clasificación de los
pacientes. Y la tercera incluye a los puntajes APACHE II y SOFA, así mismo todas las demás variables que no estén incluidas en dichos puntajes. Las
selecciones fueron:
1. Todos los atributos, excepto los indicadores APACHE II y SOFA.
2. Todos los atributos cuya diferencia de medianas es significativa, es decir los siguientes atributos: edad, presión arterial del oxígeno por
la fracción inspirada de oxígeno, presión arterial media, creatinina, temperatura, frecuencia cardiaca, hematocrito, leucocitos, tiempo de protrombina, tiempo parcial de tromboplastina, escala de coma de
Glasgow, proteína C reactiva medición 1, procalcitonina medición 1, procalcitonina medición 2, dímero-D medición 1, grupo
inmunosupresión y grupo enfermedad general. 3. Los indicadores APACHE II, SOFA y atributos que no estén incluidos
completamente en dichos indicadores, es decir las siguientes
variables: APACHE II, SOFA, tiempo de protrombina, tiempo parcial de tromboplastina, proteína C reactiva medición 1, procalcitonina
medición 1, procalcitonina medición 2, dímero-D medición 1, grupo inmunosupresión y grupo enfermedad general.
La clasificación utilizada es sepsis y no sepsis.
Los modelos en el presente estudio fueron entrenados y validados mediante la validación cruzada con 10 segmentos de igual tamaño cada uno,
seleccionados de manera lineal. Para cada validación se calculó la exactitud, el error de clasificación, el error absoluto medio y el coeficiente de Kappa.
El criterio para seleccionar el “mejor” modelo es el coeficiente de Kappa, el cual se interpreta con valores cercanos a 1 como mejores modelos y valores
cercanos a 0 como peores modelos. Los métodos K vecinos más cercanos, Bayes ingenuo y Perceptrón
multicapa se ejecutaron en el software RapidMiner (versión 5.3.015). Los métodos Regresión Logística y el C4.5 se ejecutaron en el software WEKA
(versión 3.6.11). En la Figura 12 se muestra el flujo en RapidMiner el cual cuenta con los
datos que alimentan el modelo y el módulo de entrenamiento, cuyas salidas son el modelo (coeficientes o pesos estimados) y los criterios seleccionados
para evaluar los métodos.
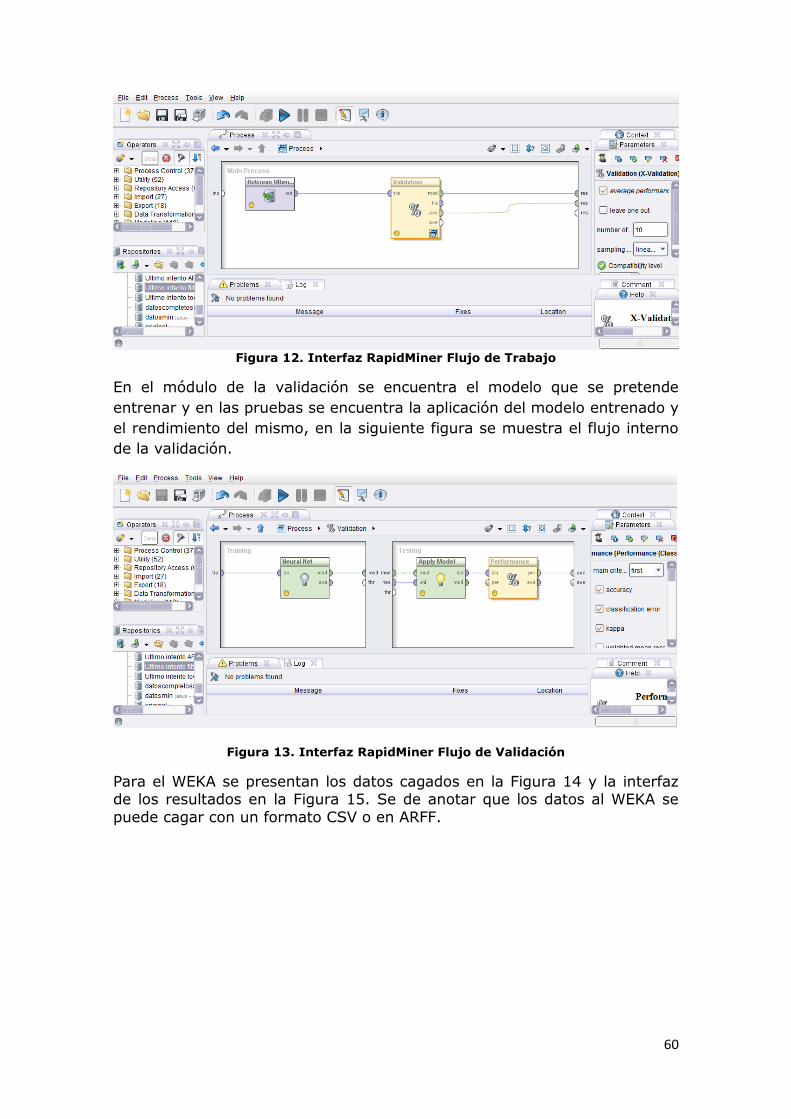
60
Figura 12. Interfaz RapidMiner Flujo de Trabajo
En el módulo de la validación se encuentra el modelo que se pretende
entrenar y en las pruebas se encuentra la aplicación del modelo entrenado y
el rendimiento del mismo, en la siguiente figura se muestra el flujo interno
de la validación.
Figura 13. Interfaz RapidMiner Flujo de Validación
Para el WEKA se presentan los datos cagados en la Figura 14 y la interfaz de los resultados en la Figura 15. Se de anotar que los datos al WEKA se
puede cagar con un formato CSV o en ARFF.

61
Figura 14. Interfaz WEKA con Datos
Figura 15. Interfaz WEKA Resultados de la aplicación del algoritmo J48 (C4.5)
7.1 Modelos
A continuación se presentan los modelos mejor ajustados según el coeficiente de Kappa, así mismo los parámetros utilizados para el ajuste. Se
debe resaltar que se entrenó cada modelo con los tres subconjuntos de las variables.
K vecinos más cercanos (KNN): para esta técnica se probó con diferentes valores enteros e impares entre 1 y 15 para cada selección de atributos. Para la selección 1 el mejor resultado según el coeficiente de
Kappa es K=13, para la selección 2 el mejor resultado según el coeficiente de Kappa es k=7 y para la selección 3 el mejor resultado según el

62
coeficiente de Kappa es K=1. Esta técnica no presenta en modelo
matemático.
Clasificador de Bayes Ingenuo (Naive Bayes): esta técnica no presenta ningún parámetro especial de ensayo y error, sin embargo cabe resaltar que los supuestos de esta técnica no se cumplen. El modelo que se obtiene
es:
Donde
(Supuesto de normalidad no se cumple)
Cada 𝜇𝑐 y 𝜎𝑐2 es estimación de la media y de la varianza correspondiente de
cada atributo en cada clase (sepsis y no sepsis).
Regresión logística: esta técnica no presenta ningún parámetro especial
de ensayo y error, además la selección 1 de las variables no cumplen con el supuesto de independencia (se incluyen las mediciones 1 y 2 de la proteína
C reactiva y el Dímero-D).
Para este caso se muestra el mejor modelo entre los tres realizados con casa selección de variables.
Tabla 42. Significancia Coeficientes

63
Tabla 43. Coeficientes Regresión Logística
Para un paciente nuevo, la probabilidad de clasificación en el grupo de
sepsis, de acuerdo con el modelo ajustado, sería:
𝑃(𝑌 = 𝑆𝑒𝑝𝑠𝑖𝑠) =𝑒−21.54−0.0031∗𝑣𝑎𝑙𝑜𝑟_𝑝𝑎𝑜2_𝑓𝑖𝑜2+⋯+0.0338∗𝑝𝑟𝑜𝑡𝑒𝑚𝑛𝑎_𝑐𝑚1
1 + 𝑒−21.54−0.0031∗𝑣𝑎𝑙𝑜𝑟_𝑝𝑎𝑜2_𝑓𝑖𝑜2+⋯+0.0338∗𝑝𝑟𝑜𝑡𝑒𝑚𝑛𝑎_𝑐𝑚1
El porcentaje de ajuste de dicho modelo es solo 44.17% valor que indica
que no hay un buen ajuste al modelo.
La interpretación del modelo: los signos de los coeficientes indican el
incremento de la probabilidad de que ocurra el suceso, es decir, si el
coeficiente p-ésimo es negativo indica que a media que dicha variable va
aumentando va a ir disminuyendo el logaritmo del cociente de
probabilidades y al revés si es positivo.
Los resultados que se muestran en la Tabla 43 muestran que a medida que
aumenta la presión arterial del oxígeno por la fracción inspirada de oxígeno
y la presión arterial media, la probabilidad del paciente a desarrollar sepsis
es menor; para las demás variables la probabilidad crece a medida que
aumentan los valores dichas variables.
Perceptrón multicapa: para la selección 1 se probó con 1 capa oculta con un número de neuronas entre 21 y 31. Según el coeficiente de Kappa el
mejor es de 28 neuronas. Para la selección 2 se probó con 1 capa oculta con un número de neuronas entre 12 y 22. Según el coeficiente de Kappa el
mejor es de 17 neuronas. Para la selección 3 se probó con 1 capa oculta con un número de neuronas entre 5 y 15. Según el coeficiente de Kappa el
mejor es de 10 neuronas. Los parámetros para el entrenamiento de todos los casos son: ciclos de entrenamiento=500, taza de aprendizaje=0.3, momentun=0.2 y épsilon=1.0E-5.
En el en el Anexo D se encuentra los pesos de cada conexión entre los
nodos en la selección 2 de atributos. C4.5: el J48 no presenta ningún parámetro especial de ensayo y error. La
mejor subconjunto de datos fue la selección 2.

64
Como resultado notable se tiene que las características de Leucocitos,
procalcitonina medición 1, temperatura, presión arterial media y proteína C
reactiva medición 1 son los más discriminantes como se muestra en la
siguiente gráfica.
Las reglas generadas por al C4.5 con la Selección 2 de variables se
muestran a continuación, dichas reglas son utilizadas para la clasificación de
los pacientes nuevos:
valor_leucocitos <= 13300
| procalcitonina_m1 <= 0.76
| | valor_temperatura <= 38.099998
| | | valor_presisn_arterial_media <= 70
| | | | glasgow <= 14: S (3.0)
| | | | glasgow > 14
| | | | | inmunosupresion <= 0
| | | | | | valor_temperatura <= 37.5
| | | | | | | valor_leucocitos <= 5200: N (3.01/1.01)
| | | | | | | valor_leucocitos > 5200: S (16.57/2.08)
| | | | | | valor_temperatura > 37.5: N (2.02/0.01)
| | | | | inmunosupresion > 0
| | | | | | protemna_cm1 <= 3.5: S (2.0)
| | | | | | protemna_cm1 > 3.5: N (3.67)
| | | valor_presisn_arterial_media > 70
| | | | inmunosupresion <= 0
| | | | | valor_frecuencia_cardiaca <= 97
| | | | | | valor__pao2_fio2 <= 316

65
| | | | | | | Enfermedad General <= 0
| | | | | | | | valor_temperatura <= 36.700001
| | | | | | | | | protemna_cm1 <= 1.3: N (2.79)
| | | | | | | | | protemna_cm1 > 1.3
| | | | | | | | | | valor_temperatura <= 36.400002
| | | | | | | | | | | valor_hematocrito <= 35: S (3.0)
| | | | | | | | | | | valor_hematocrito > 35: N (3.06/0.2)
| | | | | | | | | | valor_temperatura > 36.400002: S (3.8/0.12)
| | | | | | | | valor_temperatura > 36.700001: N (17.8/2.07)
| | | | | | | Enfermedad General > 0
| | | | | | | | procalcitonina_m1 <= 0.29
| | | | | | | | | valor__pao2_fio2 <= 163: N (5.45/1.15)
| | | | | | | | | valor__pao2_fio2 > 163
| | | | | | | | | | glasgow <= 14
| | | | | | | | | | | valor__pao2_fio2 <= 284: S (2.0)
| | | | | | | | | | | valor__pao2_fio2 > 284: N (2.0)
| | | | | | | | | | glasgow > 14: S (14.52/1.01)
| | | | | | | | procalcitonina_m1 > 0.29: N (6.06/0.06)
| | | | | | valor__pao2_fio2 > 316
| | | | | | | glasgow <= 14
| | | | | | | | valor_frecuencia_cardiaca <= 79: N (2.0)
| | | | | | | | valor_frecuencia_cardiaca > 79: S (2.0)
| | | | | | | glasgow > 14: N (74.67/12.15)
| | | | | valor_frecuencia_cardiaca > 97
| | | | | | Enfermedad General <= 0
| | | | | | | valor_frecuencia_cardiaca <= 104
| | | | | | | | valor_hematocrito <= 39: S (7.09/0.09)
| | | | | | | | valor_hematocrito > 39: N (4.0/1.0)
| | | | | | | valor_frecuencia_cardiaca > 104
| | | | | | | | valor__pao2_fio2 <= 205

66
| | | | | | | | | valor_temperatura <= 36.599998: N (3.0/1.0)
| | | | | | | | | valor_temperatura > 36.599998: S (3.0)
| | | | | | | | valor__pao2_fio2 > 205: N (13.69/0.86)
| | | | | | Enfermedad General > 0
| | | | | | | glasgow <= 14: S (3.0)
| | | | | | | glasgow > 14
| | | | | | | | procalcitonina_m2 <= 0.25
| | | | | | | | | valor__pao2_fio2 <= 192: S (7.78/1.0)
| | | | | | | | | valor__pao2_fio2 > 192
| | | | | | | | | | procalcitonina_m1 <= 0.05: N (4.87)
| | | | | | | | | | procalcitonina_m1 > 0.05
| | | | | | | | | | | edad <= 73
| | | | | | | | | | | | valor_frecuencia_cardiaca <= 112: S (5.78/0.78)
| | | | | | | | | | | | valor_frecuencia_cardiaca > 112: N (2.67/0.67)
| | | | | | | | | | | edad > 73: N (3.34)
| | | | | | | | procalcitonina_m2 > 0.25: S (6.81/0.41)
| | | | inmunosupresion > 0
| | | | | procalcitonina_m2 <= 0.31
| | | | | | valor_creatinina <= 1.5
| | | | | | | dmmero_dm1 <= 366: S (4.86)
| | | | | | | dmmero_dm1 > 366: N (32.31/5.9)
| | | | | | valor_creatinina > 1.5
| | | | | | | valor_presisn_arterial_media <= 109: S (10.9/1.0)
| | | | | | | valor_presisn_arterial_media > 109: N (2.26)
| | | | | procalcitonina_m2 > 0.31: S (5.39/0.19)
| | valor_temperatura > 38.099998
| | | valor_frecuencia_cardiaca <= 120
| | | | tpt <= 40.200001
| | | | | edad <= 81: S (23.14/3.22)
| | | | | edad > 81: N (2.0)

67
| | | | tpt > 40.200001: N (8.41/2.27)
| | | valor_frecuencia_cardiaca > 120: S (13.86/0.04)
| procalcitonina_m1 > 0.76
| | valor_presisn_arterial_media <= 82
| | | tp <= 12
| | | | valor_frecuencia_cardiaca <= 99
| | | | | edad <= 49: S (4.33/1.0)
| | | | | edad > 49: N (4.0)
| | | | valor_frecuencia_cardiaca > 99: S (12.33/0.33)
| | | tp > 12: S (53.0/0.33)
| | valor_presisn_arterial_media > 82
| | | Enfermedad General <= 0
| | | | procalcitonina_m2 <= 14.54
| | | | | inmunosupresion <= 0
| | | | | | valor_creatinina <= 0.8: S (11.1/1.75)
| | | | | | valor_creatinina > 0.8
| | | | | | | dmmero_dm1 <= 2138: N (7.05/1.0)
| | | | | | | dmmero_dm1 > 2138: S (7.97/2.17)
| | | | | inmunosupresion > 0
| | | | | | valor__pao2_fio2 <= 286: S (7.0/1.0)
| | | | | | valor__pao2_fio2 > 286
| | | | | | | valor_leucocitos <= 10300: N (3.8)
| | | | | | | valor_leucocitos > 10300
| | | | | | | | edad <= 39: N (3.0/1.0)
| | | | | | | | edad > 39: S (3.0)
| | | | procalcitonina_m2 > 14.54: S (10.94/0.2)
| | | Enfermedad General > 0: S (35.65/15.33)
valor_leucocitos > 13300
| protemna_cm1 <= 2.7
| | valor_temperatura <= 36.700001: N (9.51/0.4)

68
| | valor_temperatura > 36.700001
| | | glasgow <= 14: N (4.0/1.0)
| | | glasgow > 14
| | | | Enfermedad General <= 0
| | | | | tpt <= 38.200001
| | | | | | dmmero_dm1 <= 1076: S (4.21/0.1)
| | | | | | dmmero_dm1 > 1076: N (4.1/0.1)
| | | | | tpt > 38.200001: S (7.31)
| | | | Enfermedad General > 0: S (2.7)
| protemna_cm1 > 2.7
| | valor_temperatura <= 37
| | | Enfermedad General <= 0
| | | | tp <= 14.4
| | | | | procalcitonina_m2 <= 3.58
| | | | | | valor_creatinina <= 0.9
| | | | | | | valor_temperatura <= 36.900002: N (13.54/3.38)
| | | | | | | valor_temperatura > 36.900002: S (13.57/3.96)
| | | | | | valor_creatinina > 0.9
| | | | | | | edad <= 32: N (4.35/1.02)
| | | | | | | edad > 32: S (12.1/0.67)
| | | | | procalcitonina_m2 > 3.58: S (21.41/1.22)
| | | | tp > 14.4: S (20.21/0.24)
| | | Enfermedad General > 0
| | | | valor__pao2_fio2 <= 413
| | | | | valor_hematocrito <= 52: S (34.83)
| | | | | valor_hematocrito > 52: N (3.0/1.0)
| | | | valor__pao2_fio2 > 413
| | | | | edad <= 50: S (2.0)
| | | | | edad > 50: N (3.47)
| | valor_temperatura > 37: S (143.95/4.11)
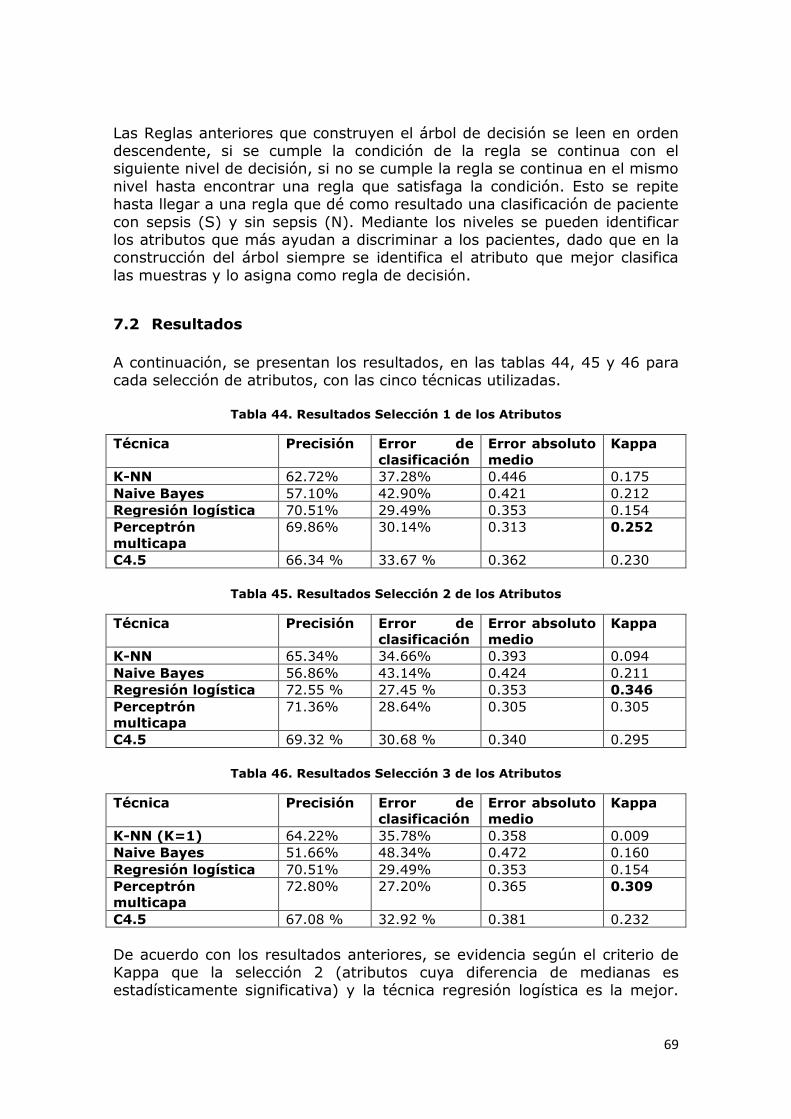
69
Las Reglas anteriores que construyen el árbol de decisión se leen en orden descendente, si se cumple la condición de la regla se continua con el siguiente nivel de decisión, si no se cumple la regla se continua en el mismo
nivel hasta encontrar una regla que satisfaga la condición. Esto se repite hasta llegar a una regla que dé como resultado una clasificación de paciente
con sepsis (S) y sin sepsis (N). Mediante los niveles se pueden identificar los atributos que más ayudan a discriminar a los pacientes, dado que en la construcción del árbol siempre se identifica el atributo que mejor clasifica
las muestras y lo asigna como regla de decisión.
7.2 Resultados
A continuación, se presentan los resultados, en las tablas 44, 45 y 46 para cada selección de atributos, con las cinco técnicas utilizadas.
Tabla 44. Resultados Selección 1 de los Atributos
Técnica Precisión Error de
clasificación
Error absoluto
medio
Kappa
K-NN 62.72% 37.28% 0.446 0.175
Naive Bayes 57.10% 42.90% 0.421 0.212
Regresión logística 70.51% 29.49% 0.353 0.154
Perceptrón
multicapa
69.86% 30.14% 0.313 0.252
C4.5 66.34 % 33.67 % 0.362 0.230
Tabla 45. Resultados Selección 2 de los Atributos
Técnica Precisión Error de
clasificación
Error absoluto
medio
Kappa
K-NN 65.34% 34.66% 0.393 0.094
Naive Bayes 56.86% 43.14% 0.424 0.211
Regresión logística 72.55 % 27.45 % 0.353 0.346
Perceptrón
multicapa
71.36% 28.64% 0.305 0.305
C4.5 69.32 % 30.68 % 0.340 0.295
Tabla 46. Resultados Selección 3 de los Atributos
Técnica Precisión Error de
clasificación
Error absoluto
medio
Kappa
K-NN (K=1) 64.22% 35.78% 0.358 0.009
Naive Bayes 51.66% 48.34% 0.472 0.160
Regresión logística 70.51% 29.49% 0.353 0.154
Perceptrón
multicapa
72.80% 27.20% 0.365 0.309
C4.5 67.08 % 32.92 % 0.381 0.232
De acuerdo con los resultados anteriores, se evidencia según el criterio de Kappa que la selección 2 (atributos cuya diferencia de medianas es estadísticamente significativa) y la técnica regresión logística es la mejor.

70
Además se corrobora que los demás indicadores de la calidad de modelos
ajustados son relativamente buenos.
Cabe resaltar que aunque la regresión logística con la selección 2 de atributos es la mejor, ésta presenta un pobre desempeño, dado que el coeficiente de Kappa obtenido es de solo 0.346 muy alejado del valor 1 que
sería el ideal. Además, la precisión es solo el 69.86% y el error de clasificación es 27.45%, valores que en la práctica hacen que estos modelos
no sean adecuados.

71
8 CONCLUSIONES Y RECOMENDACIONES
La investigación presentada en esta tesis para el soporte del diagnóstico de la sepsis en pacientes adultos, se enfocó en los siguientes aspectos: la naturaleza de la enfermedad, los atributos que explicarían la clasificación, el
análisis de dichos atributos, la aplicación de técnicas de clasificación supervisadas de minería de datos, la evaluación de las técnicas y selección
de la mejor. La elaboración de la presente investigación afrontó como principal obstáculo
comprender la naturaleza del problema y tener todos los metadatos; para incluir esta información de debió hacer una serie de reuniones con el
codirector el Doctor Fabián Jaimes, experto en el tema. Esto con el fin de entender las variables y la naturaleza del problema.
Esta investigación contó con el problema de considerar los datos atípicos o extremos los cuales afectan directamente los resultados arrojados por las
técnicas de clasificación. La inclusión de dichos valores se debe al fenómeno de estudio, el cual por tratarse de una situación biológica y bioquímica de la realidad presenta una gran variabilidad en los datos medidos.
Del análisis de los datos se puede mencionar que son independientes entre
ellos, sin embargo cabe anotar que algunos atributos miden características comunes como por ejemplo PT y TPT que están relacionados con la
coagulación en el cuerpo, no obstante según los datos medidos no tienen relación alguna. Es interesante recordar que solo el hematocrito sigue una distribución normal en la muestra.
Sobre las mediciones tomadas en el tiempo (24 horas) de los
biomarcadores: proteína C reactiva, la procalcitonina y el dímero-D se puede decir que sólo la procalcitonina presenta cambios en este período de tiempo. Los valores máximos y mínimos para la proteína C reactiva es 0.1 y
51,8 miligramos por decilitro, para la procalcitonina es 0.01 y 464 nanogramos por decilitro y para el dímero-D es 1 y 61118 nanogramos por
decilitro. Respecto a los atributos se puede constatar que ninguna combinación ni
mucho menos solos sirven para discriminar de una manera adecuada a los pacientes. Es importante recordar que los pacientes de la muestra
etiquetados como no sepsis padecían alguna enfermedad. La selección o filtrado de algunos atributos mejoró el desempeño de las técnicas aplicadas. La inclusión del puntaje APACHE II y SOFA no representa una mejora
significativa para la clasificación. Los leucocitos, procalcitonina medición 1, temperatura, presión arterial media y proteína C reactiva medición 1 son las
más discriminantes según el C4.5. Por último, las técnicas de minería de datos aplicadas mostraron un pobre
desempeño ya que el coeficiente de kappa máximo es solo 0.346, la máxima exactitud es 72.80%, el mínimo error de clasificación es de 27.20%
y el mínimo error absoluto medio es 0.305; debido a que los atributos no discriminan a los pacientes. Para este caso, la regresión logística tuvo el mejor desempeño según el coeficiente de Kappa.

72
Para trabajos futuros en el campo médico para el diagnóstico de sepsis en pacientes adultos, se recomienda investigar otros posibles biomarcadores
que permitan la discriminación de los mismos. También se recomienda la inclusión de un grupo de control que permita una mejor comprensión en el cambio de los atributos para el presente fenómeno.
Es importante continuar con la aplicación del descubrimiento del nuevo
conocimiento en bases de datos en el campo médico, con el fin de ayudar al personal en la toma de decisiones en la cotidianidad. Esto se puede lograr gracias a la creación de grupos interdisciplinarios interesados en la
investigación y desarrollo de las tecnologías.
Es de anotar que aunque no se logró detectar características que permitan
clasificar adecuadamente a los pacientes y no se obtuvo un buen modelo,
cabe resaltar que esta investigación me permitió un crecimiento a nivel
personal y profesional; igualmente adquirí nuevos conocimientos y
aprendizajes significativos.

73
BIBLIOGRAFIA
Aha D. W., Kibler D. & Albert M. K. (1991). Instance-Based Learning
Algorithms. Machine Learning, 6, 37-66.
Amaral A., Opal S. M. & Vincent J. L. (2004) Coagulation in sepsis.
Intensive Care Med. 30(6):1032-40.
American College of Chest Physicians/Society of Critical Care Medicine
Consensus Conference. (1992). Definitions for sepsis and organ failure and
guidelines for the use of innovative therapies in sepsis. Crit Care Med.
20:864-874.
Bone R. C., Fisher C. J. Jr, Clemmer T. P., Slotman G. J., Metz C. A. & Balk
R. A. (1989). Sepsis syndrome: a valid clinical entity. Methylprednisolone
Severe Sepsis Study Group. Crit Care Med. 5:389-393.
Esper A.M., Moss M., Lewis C.A., Nisbet R., Mannino D.M., Martin G.S.
(2006). The role of infection and comorbidity: Factors that influence
disparities in sepsis. Crit Care Med, Vol. 34, No. 10, 2576-2582.
Fayyad U., Piatetsky-Shapiro G. & Smyth P. (1996). From Data Mining to
Knowledge Discovery in Databases. American Association for Artificial
Intelligence. 0738-4602-1996: 17-54.
Gámez-Díaz L. Y., Enriquez L. E., Matute J. D., Velásquez S., Gómez I. D.,
Toro F, Ospina S.,Bedoya V., Arango C. M., Valencia M. L., De La Rosa G.,
Gómez C. I., García A., Patiño P. J. & Jaimes F. A. (2011). Diagnostic
Accuracy of HMGB-1, s-TREM-1, and CD64 as Markers of Sepsis in Patients
Recently Admitted to the Emergency Department. the Society for Academic
Emergency Medicine. 807-815.
Glover S., Rivers P. A., Asoh D. A., Piper C. N. & Keva Murph K. (2010).
Data mining for health executive decision support: an imperative with a
daunting future! Health services management research: an official journal
of the Association of University Programs in Health Administration / HSMC,
AUPHA.; Vol 23, 1; 42-46.
Hosmer, David W., Lemeshow, Stanley (2000). Applied Logistic Regression,
segunda edición.
Jaimes F. A., De La Rosa G. D., Valencia M. L., Arango C. M., Gomez C. I.,
Garcia A., Ospina S., Osorno S. C. & Henao A. I. (2013). A latent class
approach for sepsis diagnosis supports use of procalcitonin in the
emergency room for diagnosis of severe sepsis. BMC Anesthesiology, 13:23,
1-10.

74
Jean C. (1996). Assessing agreement on classification tasks: the kappa
statistic. Computational Linguistics, 22, 2. 1-6.
Levy M. M., Fink M. P., Marshall J. C., et al. (2003). 2001
SCCM/ESICM/ACCP/ATS/SIS International Sepsis Definitions Conference.
Crit Care Med. 31:1250-1256.
Lewis D. D. (1998). Naive (Bayes) at forty: The independence assumption
in information retrieval. Machine Learning: ECML-98, 1398, 4-15
Marshall J. C., Vincent J-L., Fink M. P. , et al. (2003). Measures, markers,
and mediators: Toward a staging system for clinical sepsis. A report of the
Fifth Toronto Sepsis Roundtable, Toronto, Ontario, Canada, October 25-26,
2000. Crit Care Med. 31:1560-1567.
Martin G.S., Mannino D.M., Eaton S. & Moss M. (2003) The epidemiology of
sepsis in the United Sates from 1979 through 2000. N Engl J Med. 348.
1546-1554.
Meisner M., Tschaikowsky K., Palmaers T. & Schmidt J. (1999). Comparison
of procalcitonin (PCT) and C-reactive protein (CRP) plasma concentrations
at different SOFA scores during the course of sepsis and MODS. Crit Care
(Lond). 3(1):45-50.
Opal S., Garber G. E., LaRosa S. P., et al. (2003) Systemic host responses
in severe sepsis analyzed by causative microorganism and treatment effects
of Drotrecogin Alfa (activated). Clin Infect Dis. 37:50-58.
Pettila V., Hynninen M., Takkunen O., Kuusela P. & Valtonen M. (2002).
Predictive value of procalcitonin and interleukin 6 in critically ill patients
with suspected sepsis. Intensive Care Med. 28(9):1220-5.
Pierce G. & Murray P. R. (1986) Current controversies in the detection of
septicemia. Eur J Clin Microbiol. 5:487-491.
Povoa P. (2002). C-reactive protein: a valuable marker of sepsis. Intensive
Care Med. 28(3):235-43.
Quinlan, J. R. C4.5: Programs for Machine Learning. Morgan Kaufmann
Publishers, 1993.
Refaeilzadeh P., Tang L., Liu H. (2008). Cross-Validation. Computer Science
& Engineering at Arizona State University. 1-6.
Rivers E., Nguyen B., Havstad S., et al. (2001). Early goal-directed therapy
in the treatment of severe sepsis and septic shock. N Engl J Med. 345:1368-
1377.
Rosenblatt F.(1961). Principles of Neurodynamics: Perceptrons and the
Theory of Brain Mechanisms. Spartan Books, Washington DC.

75
Sathyanarayana S. (2014). A Gentle Introduction to Backpropagation.
Numeric Insight, 1-15.
Slade E., Tamber P. S. & Vincent J.L. (2003). The Surviving Sepsis
Campaign: raising awareness to reduce mortality. Crit Care. 7(1). 1-2.
Vincent J-L, Abraham E., Annane D., Bernard G. R., Rivers E., Van den
Berghe G. (2002) Reducing mortality in sepsis: new directions. Critical Care.
6(Suppl 3):1-8.
Vincent JL., Opal S. M., Marshall J. C. & Tracey K. J. (2013). Sepsis
definitions: time for change, The Lancet, 381, Issue 9868, 774 – 775.
Yang Y., Yang K.S., Hsann Y.M., Lim V., Ong B.C. (2010). The effect of
comorbidity and age on hospital mortality and length of stay in patients with
sepsis. Critical Care, 25, 398–405.

1
Anexo A Selección de pacientes elegibles o candidatos para el estudio
Los pacientes elegibles serán detectados en el servicio de urgencias del HUSVP y serán
considerados como candidatos para el estudio los siguientes:
1. Hospitalizados por razón de su tratamiento (no entran pacientes que estén solamente en observación) dentro de las 24 horas anteriores al ingreso del estudio.
2. Edad igual o mayor a 18 años 3. Registro en la historia clínica, en el día en que se hace la evaluación, de cualquiera de los
siguientes problemas: Sospecha o confirmación de infección de cualquier tipo, etiología o severidad. Si el
diagnòstico de infecciòn no està claro se ingresarà de acuerdo con el criterio del investigador o de la evaluaciòn por las especialidades.
Si el paciente no tiene sospecha de infección como principal diagnóstico pero tiene alguno de los siguientes diagnósticos no explicados por una causa no infecciosa:
i. Al menos un episodio de fiebre en las últimas 24 horas (mayor a 38° C.) ii. Cambios en el estado mental (somnolencia, confusión, obnubilación o
cualquier hallazgo mental nuevo) que aparecen en las últimas 24 horas. iii. Insuficiencia cardiaca descompensada (ICC), enfermedad pulmonar
obstructiva crónica (EPOC) descompensada, diabetes descompensada (Cetoacidosis o estado hiperosmolar)
iv. Presión arterial sistólica menor de 90 mm Hg., o disminución mayor de 40 mm Hg. con respecto a valores previos o presión arterial media menor de 70 mm Hg que aparece en las últimas 24 horas y no es explicada por sangrado u otra pérdida de líquidos
v. Síndrome de Dificultad Respiratoria Agudo (SDRA) vi. Falla o disfunción orgánica múltiple
vii. Dolor abdominal
4. Criterios de exclusión:
Negativa del paciente, sus familiares o del médico tratante para participar en el estudio.
Alta hospitalaria o remisión a otra institución en las primeras 24 horas posteriores al ingreso al estudio.
.Remisión de otra institución en donde haya recibido algún tipo de tratamiento antimicrobiano
Más de 24 horas de hospitalización Sin domicilio fijo o telèfono disponible.
Si el paciente cumple los criterios de ingreso al estudio y no tiene criterios de exclusión se le
explicará de forma clara la invitación a participar en una investigación y se solicitará el

2
consentimiento informado de forma verbal. Si el paciente o familiares están de acuerdo, se
procede con el ingreso al estudio.
1. Se le avisa a la enfermera encargada del paciente y se ordenaran en la historia clínica los
siguientes exámenes (Se agregaran sólo los que el médico tratante no haya solicitado):
1. Procalcitonina 2. PCR 3. Dimero D, 4. Acido láctico, 5. Plaquetas, 6. TP, 7. TPT, 8. Gases arteriales, 9. Bilirrubina total, 10. Creatinina.
Se dejarán ordenados los exámenes de Procalcitonina, Dimero D. Y PCR para tomar a las 24
horas de ingreso al estudio.
2. Se llena el formulario de la siguiente forma:
Pàgina 1: tamización
1. Número de formulario: este es un número interno del estudio, y se asigna de manera secuencial desde 0001 en el orden de llegada de los potenciales participantes. El mismo número identificará cada una de las páginas del formulario.
2. Fecha de ingreso al hospital, día, mes, año, hora militar: la que aparece impresa en la hoja de identificación.
3. Iniciales del paciente: para el primer nombre, primer apellido y segundo apellido. Para pacientes con solo un apellido se llenaran solo las dos primeras casillas, al igual que para aquellos identificados como N.N. Estas mismas iniciales identificarán cada una de las páginas del formulario. Si posteriormente se conoce el nombre, este se debe cambiar con las iniciales correspondientes
4. Número de historia clínica: es el número asignado por la institución a cada registro de atención, usualmente corresponde a la cédula o documento de identidad del paciente, y está disponible en la hoja de identificación administrativa que se hace para cada historia. Este número está impreso en esa hoja de identificación o en un adhesivo de la misma. Los números que se transcriben a mano en las hojas médicas o de enfermería pueden tener inconsistencias y no son una fuente confiable. Cuando el número sea menor al número de casillas, este se registrará con ceros en las casillas iniciales hasta completar el número total de casillas. El mismo número identificará cada una de las secciones del formulario

3
5. Sexo: marcar 1 si es masculino ò 2 si es Femenino. 6. Edad en años cumplidos, tomar el valor registrado en la historia clínica. 7. Teléfono del paciente 8. Teléfono del familiar 9. Teléfono celular
Se deben anotar todos los teléfonos posibles y se deben confirmar realizando una
llamada cuando el paciente aún se encuentre hospitalizado.
10. Proceso de reclutamiento: las preguntas 10.1 y 10.2. son las que definen si el paciente es candidato para entrar a la investigación. Todas ellas pueden verificarse en la evolución médica y las notas de enfermería de cada día. Si la respuesta 10.1 es afirmativa, las siguientes preguntas 10.2.1 a 10.2.7 deberán ser respondidas de forma negativa. Si la respuesta 10.1 es negativa y una de las del 10.2 es positiva se debe revisar la evolución médica y verificar que los síntomas o diagnósticos del 10.2.1 al 10.2.7. no son explicados por una causa diferente de infección. Si el diagnóstico de infección no está claro se ingresará de acuerdo con el criterio del investigador o de la evaluación por las especialidades. El paciente debe tener al menos una de las preguntas con respuesta 1 (si) para poder continuar con la pregunta 11.
11. Criterios de exclusión: en caso de tener una respuesta si en una de las preguntas, se finaliza el diligenciamiento y el paciente queda sòlo tamizado..
Pàgina 2: Ingreso y evaluación inicial
12. Fecha de ingreso al estudio: corresponde al día, mes y año del momento en que se ordenan en la historia clínica, los exámenes de ingreso al estudio.
13. Hora militar del momento en que ordenan los exámenes del estudio en la historia clínica.
14. Tiempo de evolución de los síntomas en horas se anotará en horas y se tomará de la historia clínica o interrogando al paciente.
15. Escala de coma de Glasgow (sistema neurológico): aplicar la escala anotada en el formulario. Para pacientes que estén bajo el efecto de medicamentos sedantes o depresores del sistema nervioso, o que se encuentren hospitalizados en Unidad de Cuidados Intensivos (UCI), se calculará la escala de coma de Glasgow con base en los registros en la historia clínica del estado neurológico previo al evento o al medicamento sedante. El 15.1, 15.2 y 15.3 el valor de cada parámetro y el 15.4 la suma de los tres parámetros.
16. SOFA: Aplicar la escala anotada en el formulario. Anotar el valor correspondiente a cada parámetro, En el 16.1 al 16.6 anotar el valor de cada parámetro, del 16.7 al 16.12 anotar el puntaje y en el 16.13 anotar la suma de los parámetros.
Índice PaO2 / FiO2 (sistema respiratorio): es el resultado de dividir el valor de la presión arterial de oxígeno (PaO2 de los gases arteriales) por el valor de la fracción inspirada de oxígeno. Esta última puede oscilar desde 0.21 si el paciente está respirando aire ambiente, a 1 si el paciente está en ventilación mecánica con máximo flujo de oxígeno. Los valores de FiO2 se encuentran registrados en las órdenes médicas o notas de enfermería, de acuerdo con el sistema de flujo de oxígeno que reciba el paciente: aire ambiente (0.21), oxígeno por cánula nasal o gafitas (entre 0.24 y 0.4: 1 litro 0.24, 2 litros 0.28, 3

4
litros 0.32, 4 litros 0.36, 5 litrso 0.4), oxígeno por sistema vénturi (entre 0.28 y 0.5) o ventilación mecánica con respirador artificial (entre 0.21 y 1).
Plaquetas (sistema hematológico): recuento de células por mm3 de sangre Cardiovascular: los puntos se asignan de acuerdo con los valores de presión
arterial media (PAM) o uso de medicamentos venosos de acción específica en el sistema cardiovascular (dopamina en dosis ascendentes en mcg/kg/min, cualquier dosis de dobutamina y norepinefrina o adrenalina en dosis en mcg/kg/min).
Glasgow: el valor resultante del cálculo según el item anterior. Bilirrubina sérica (sistema hepático): resultado de laboratorio reportado en
miligramos por decilitro (mg/dL) Creatinina sérica (sistema renal): resultado de laboratorio reportado en
miligramos por decilitro (mg/dL). O si el gasto urinario està disminuido en mL/dìa.
17. Puntaje de APACHE II. Este puntaje debe ser determinado directamente en los pacientes de manera estándar por los asistentes de investigación. Todos los resultados de laboratorio (gases arteriales, sodio y potasio sérico, creatinina, hematocrito y glóbulos blancos), son tomados de exámenes que deben ser ordenados en las primeras 24 horas de ingreso al estudio y se debe anotar el peor valor cuando se encuentre màs de un exàmen. Se debe anotar el valor de cada parámetro utilizado para la asignación de los puntajes. 17.1.: anotar el peor valor de temperatura y asigne el puntaje correspondiente. 17.2: anotar el peor valor de la presion arterial media si esta està registrada en la historia clìnica y si no se encuentra este valor, se debe calculara asi: multiplicar por 2 la presión diastólica y sumarla con la presión sistólica, para dividir todo ese total por 3; 17.3 y 17.4: anotar los peores valores registrados. 17.5: anotar el peor valor de oxigenación (presión arterial de oxígeno) que deben ser tomados de una muestra para gases arteriales; si la FiO2 es igual o menor de 0.5 se utilizara el puntaje correspondiente al valor de PaO2, ubicado en la parte derecha de la tabla; si la FiO2 es mayor de 0.5 se debe calcular el gradiente alveolo arterial de oxigeno (D(A-a)O2) y esta se obtiene calculando la presion alveolar de oxigeno que es igual a la FiO2 x 640 (Presiòn barometrica de Medellín) menos la PaCO2 entre 0.8. (PAO2 = FiO2 x 640 – PaCO2/0.8); a esta presiòn alveolar se le resta la PaO2 obtenida en los gases arteriales y a este resultado se le asigna el puntaje correspondiente en el lado izquierdo de la tabla. 17.6: anote el peor pH de los gases arteriales, 17.7 a 17.11: anotar el peor valor de los exàmenes correspondientes. 17.12: restar de 15 el Glasgow calculado previamente. 17.13: anotar la suma de todos los puntaje en cada columna. 17.14. El total del puntaje APS: sumar los valores de la fila 17.13. Los puntajes por edad (pregunta 17.15) y por estado de salud previo (pregunta 17.16) se explican en el formulario. 17.17. Puntaje total APACHE II, es la suma de los puntajes APS, edad e insuficiencia orgánica crónica: 17.14 + 17.15 + 17.16.
18. Diagnósticos. Corroborar el diagnóstico con los criterios del anexo No. 1. 19. Exámenes al ingreso: proteina C reactiva en mg/dl: anotar un decimal, Dimero D en
ng/ml: anotar sin decimales, Procalcitonina: anotar dos decimales. Valores del ingreso al estudio (mediciòn 1) y a las 24 horas (mediciòn 2): se anotaran los valores de examenes solicitados y las horas que transcurrieron entre la hora de ingreso al estudio y la hora de la toma de las muestras.
20. Ingreso a UCI: anotar 1 si ingreso y 2 si no ingresò 21. Fecha de egreso del hospital: anotar el dìa, mes y año del egreso. 22. Estado vital al egreso: anotar 1 si egresa muerto y 2 si egresa vivo del hospital.

5
23. Fecha de estado vital a los 28 dìas: anotar el dìa, mes y año de la fecha de verificación del estado vital a los 28 dìas.
24. Estado vital a los 28 dìas. Anotar 1 si està muerto y 2 si està vivo. 25. Nombre y apellido del asistente de investigación que llena el formulario. 26. Nombre y apellido del investigador que revisa el formulario
6
Anexo B
PUNTAJE APACHE II
ACUTE PHYSIOLOGY POINTS (APS)
Physiologic variable +4 +3 +2 +1 0 +1 +2 +3 +4
Temperature (ºC) ≥ 41 39-40.9
38.5-38.9
36-38.4 34-35.9
32-33.9 30-31.9 ≤ 29.9
Mean arterial pressure ([SBP+2DBP]/3)
> 160 130-159
110-129
70-109 50-69 ≤ 49
Heart rate ≥ 180 140-179
110-139
70-109 55-69 40-54 ≤ 39
Respiratory rate ≥ 50 35-49 25-34 12-24 10-11 6-9 ≤ 5
Oxygenation (PaO2) > 70 61-70 55-60 < 55
Arterial pH ≥ 7.7 7.6-7.69
7.5-7.59
7.33-7.49
7.25-7.32
7.15-7.24
< 7.15
FERUM sodium (mM/dL) ≥ 180 160-179
155-159
150-154
130-149
120-129
111-119
≤ 110
Serum potassium (mM/dL) ≥ 7 6-6.9 5.5-5.9 3.5-5.4 3-3.4 2.5-2.9 ≤ 2.5
Serum creatinine (mg/dL) ≥ 3.5 2-3.4 1.5-1.9 0.6-1.4 < 0.6
Hematocrit (%) ≥ 60 50-59.9
46-49.9 30-45.9 20-29.9 < 20
White Blood Count x 1,000 ≥ 40 20-39.9
15-19.9 3-14.9 1-2.9 < 1
15 minus actual Glasgow coma score
7.1. Total APS Score
AGE POINTS Assign points to age as follows: Age (years) Points ≤ 44 0 45-54 2 55-64 3 65-74 5 ≥ 75 6
CHRONIC HEALTH POINTS If the patient has a history of severe organ insufficiency or is immunocompromised (see definitions below) , assigns points as follows:
A. Nonoperative or emergency post-operative: 5 points B. Elective post-operative: 2 points
LIVER: biopsy proven cirrhosis and documented portal hypertension; episodes of past upper GI bleeding attributed to portal hypertension; or prior episodes of hepatic failure / encephalopathy / coma. CARDIOVASCULAR: New York Heart Association Class IV. RESPIRATORY: chronic restrictive, obstructive, or vascular disease resulting in severe exercise restriction, i.e., unable to climb stairs or perform household duties; or documented chronic hypoxia, hypercapnia, secondary polycythemia, severe pulmonary hypertension (> 40 mm Hg), or respirator dependency. RENAL: receiving chronic dialysis IMMUNOCOMPROMISED: has received therapy that suppresses resistance to infection, e.g., immunosuppressant, chemotherapy, radiation, long term or recent high dose steroids, or has a disease that is sufficiently advanced to suppress resistance to infection (e.g. leukemia, lymphoma, AIDS).
7.2. Age points 7.3. Chronic health points
8. Total APACHE II score (7.1 + 7.2 + 7.3)

7
Anexo C PUNTAJE SOFA
p_pao2_fio2 ≥ 400 = 0
< 400 = 1
< 300 = 2
< 200 y ventilación mecánica = 3
< 100 y ventilación mecánica = 4
p_plaquetas ≥ 150.000 = 0
< 150.000 = 1
< 100.000 = 2
< 50.000 = 3
< 20.000 = 4
p_cardiovascular PAM ≥ 70 = 0
PAM < 70 = 1
Dopamina < 5 mcg/kg/min o dobutamina en cualquier dosis = 2
Dopamina > 5, o epinefrina (E) o norepinefrina (N) < 0.1 mcg/kg/min = 3
Dopamina > 15, o E o N > 0.1 mcg/kg/min = 4
p_glasgow Valor correspondiente al parámetro anteriormente anotado
p_bilirribuna Valor correspondiente al parámetro anteriormente anotado
p_creatinina < 1.2 mg/dl = 0
1.2 – 1.9 mg/dl = 1
2.0 – 3.4 mg/dl = 2
3.5 – 4.9 mg/dl ó < 500 cc de diuresis diaria = 3
> 5 mg/dl o < 200 cc de diuresis diaria = 4
valor_total_sofa Es la sumatoria de los seis sistemas que evalúa el puntaje SOFA: Respiratorio (índice PaO2/FiO2), Hematológico (plaquetas), Cardiovascular (PAM o necesidad de vasopresores), Neurológico (Glasgow), Hepático (bilirrubina) y Renal (creatinina o gasto urinario)

8
Anexo D
Pesos red neuronal Hidden 1 ======== Node 1 (Sigmoid) ---------------- edad: 1.665 valor__pao2_fio2: -4.533 valor_presisn_arterial_media: -11.179 valor_creatinina: -0.658 valor_temperatura: -8.922 valor_frecuencia_cardiaca: -2.449 valor_hematocrito: 2.849 valor_leucocitos: 3.401 protemna_cm1: 1.174 procalcitonina_m1: 2.848 dmmero_dm1: -7.508 procalcitonina_m2: 2.381 tp: 0.572 tpt: 5.099 glasgow: -1.437 inmunosupresion: 8.485 Enfermedad General: -0.772 Bias: -0.625 Node 2 (Sigmoid) ---------------- edad: 3.586 valor__pao2_fio2: 7.230 valor_presisn_arterial_media: -3.627 valor_creatinina: 2.442 valor_temperatura: -4.332 valor_frecuencia_cardiaca: 4.805 valor_hematocrito: 2.638 valor_leucocitos: 4.000 protemna_cm1: -1.895 procalcitonina_m1: 2.008 dmmero_dm1: -1.459 procalcitonina_m2: 3.302 tp: 1.015 tpt: 1.754 glasgow: -1.177 inmunosupresion: -0.498 Enfermedad General: 3.999 Bias: -1.779 Node 3 (Sigmoid) ---------------- edad: 0.355 valor__pao2_fio2: 0.798 valor_presisn_arterial_media: -3.533 valor_creatinina: 2.276 valor_temperatura: -0.995 valor_frecuencia_cardiaca: -0.740 valor_hematocrito: 3.029 valor_leucocitos: 1.739 protemna_cm1: 0.003

9
procalcitonina_m1: 1.858 dmmero_dm1: 1.203 procalcitonina_m2: 1.691 tp: 0.182 tpt: 0.218 glasgow: 0.040 inmunosupresion: -0.169 Enfermedad General: 2.328 Bias: 0.137 Node 4 (Sigmoid) ---------------- edad: 1.526 valor__pao2_fio2: -3.688 valor_presisn_arterial_media: -3.095 valor_creatinina: -4.969 valor_temperatura: -8.746 valor_frecuencia_cardiaca: 3.045 valor_hematocrito: 3.795 valor_leucocitos: 16.767 protemna_cm1: -3.186 procalcitonina_m1: -3.876 dmmero_dm1: -1.020 procalcitonina_m2: 2.971 tp: -0.518 tpt: 1.826 glasgow: -3.202 inmunosupresion: 2.169 Enfermedad General: 10.410 Bias: -2.011 Node 5 (Sigmoid) ---------------- edad: -1.614 valor__pao2_fio2: -0.495 valor_presisn_arterial_media: -0.053 valor_creatinina: 2.652 valor_temperatura: -0.370 valor_frecuencia_cardiaca: -1.702 valor_hematocrito: 0.984 valor_leucocitos: 1.520 protemna_cm1: -5.355 procalcitonina_m1: 1.972 dmmero_dm1: -1.027 procalcitonina_m2: 1.991 tp: 0.530 tpt: 0.276 glasgow: -0.575 inmunosupresion: 3.149 Enfermedad General: -0.491 Bias: -0.355 Node 6 (Sigmoid) ---------------- edad: -2.194 valor__pao2_fio2: -2.812 valor_presisn_arterial_media: -0.442 valor_creatinina: 2.066 valor_temperatura: -0.367

10
valor_frecuencia_cardiaca: -2.707 valor_hematocrito: 1.685 valor_leucocitos: -0.598 protemna_cm1: 0.871 procalcitonina_m1: 0.595 dmmero_dm1: 2.900 procalcitonina_m2: 0.783 tp: -0.481 tpt: 1.703 glasgow: -1.332 inmunosupresion: -0.222 Enfermedad General: -1.598 Bias: 0.950 Node 7 (Sigmoid) ---------------- edad: -5.680 valor__pao2_fio2: -1.083 valor_presisn_arterial_media: -8.085 valor_creatinina: 0.639 valor_temperatura: 4.239 valor_frecuencia_cardiaca: -5.995 valor_hematocrito: 4.763 valor_leucocitos: -2.404 protemna_cm1: 1.717 procalcitonina_m1: 4.483 dmmero_dm1: 0.230 procalcitonina_m2: 3.016 tp: -0.852 tpt: 1.800 glasgow: 0.632 inmunosupresion: -0.877 Enfermedad General: -3.392 Bias: -0.732 Node 8 (Sigmoid) ---------------- edad: -3.798 valor__pao2_fio2: 8.063 valor_presisn_arterial_media: -7.331 valor_creatinina: -0.195 valor_temperatura: -5.796 valor_frecuencia_cardiaca: 4.546 valor_hematocrito: -3.323 valor_leucocitos: 9.770 protemna_cm1: 2.969 procalcitonina_m1: -4.218 dmmero_dm1: -4.594 procalcitonina_m2: 2.828 tp: 0.522 tpt: 4.425 glasgow: 0.799 inmunosupresion: -7.977 Enfermedad General: -1.862 Bias: -3.390 Node 9 (Sigmoid) ---------------- edad: -1.043

11
valor__pao2_fio2: 2.775 valor_presisn_arterial_media: 5.186 valor_creatinina: 3.499 valor_temperatura: -1.683 valor_frecuencia_cardiaca: -0.480 valor_hematocrito: 0.850 valor_leucocitos: 3.701 protemna_cm1: -8.109 procalcitonina_m1: 3.211 dmmero_dm1: -2.229 procalcitonina_m2: 3.137 tp: 0.689 tpt: 2.109 glasgow: 1.172 inmunosupresion: 4.894 Enfermedad General: -0.677 Bias: -1.355 Node 10 (Sigmoid) ----------------- edad: -6.295 valor__pao2_fio2: -2.448 valor_presisn_arterial_media: -7.206 valor_creatinina: 2.443 valor_temperatura: 19.695 valor_frecuencia_cardiaca: 3.368 valor_hematocrito: -3.184 valor_leucocitos: 3.360 protemna_cm1: -1.412 procalcitonina_m1: 0.791 dmmero_dm1: -6.538 procalcitonina_m2: 3.795 tp: 6.218 tpt: -2.980 glasgow: 0.550 inmunosupresion: -4.441 Enfermedad General: 0.177 Bias: -5.067 Node 11 (Sigmoid) ----------------- edad: 2.072 valor__pao2_fio2: -1.450 valor_presisn_arterial_media: -2.772 valor_creatinina: 3.008 valor_temperatura: 1.653 valor_frecuencia_cardiaca: 0.399 valor_hematocrito: 13.505 valor_leucocitos: -2.181 protemna_cm1: 0.953 procalcitonina_m1: 1.441 dmmero_dm1: 3.403 procalcitonina_m2: 4.630 tp: 1.241 tpt: -3.124 glasgow: -0.143 inmunosupresion: -2.619 Enfermedad General: -1.697 Bias: -0.588

12
Node 12 (Sigmoid) ----------------- edad: 0.902 valor__pao2_fio2: 1.203 valor_presisn_arterial_media: -3.201 valor_creatinina: -1.392 valor_temperatura: 4.141 valor_frecuencia_cardiaca: 9.010 valor_hematocrito: -4.756 valor_leucocitos: 1.779 protemna_cm1: 3.998 procalcitonina_m1: 4.712 dmmero_dm1: -2.368 procalcitonina_m2: 1.614 tp: 0.312 tpt: 3.959 glasgow: 0.495 inmunosupresion: 4.469 Enfermedad General: -1.989 Bias: 1.962 Node 13 (Sigmoid) ----------------- edad: 1.434 valor__pao2_fio2: -1.172 valor_presisn_arterial_media: 11.444 valor_creatinina: 2.070 valor_temperatura: -7.640 valor_frecuencia_cardiaca: 3.240 valor_hematocrito: -6.586 valor_leucocitos: -3.351 protemna_cm1: -4.848 procalcitonina_m1: -0.134 dmmero_dm1: 1.418 procalcitonina_m2: 0.426 tp: 3.039 tpt: 7.983 glasgow: -3.361 inmunosupresion: -0.814 Enfermedad General: -1.484 Bias: 0.100 Node 14 (Sigmoid) ----------------- edad: 3.010 valor__pao2_fio2: 3.747 valor_presisn_arterial_media: 5.088 valor_creatinina: -0.028 valor_temperatura: -2.217 valor_frecuencia_cardiaca: 1.304 valor_hematocrito: -2.146 valor_leucocitos: -1.569 protemna_cm1: -3.819 procalcitonina_m1: 4.304 dmmero_dm1: 3.484 procalcitonina_m2: 3.078 tp: 1.502 tpt: -0.545

13
glasgow: 0.893 inmunosupresion: -3.828 Enfermedad General: -5.878 Bias: -2.058 Node 15 (Sigmoid) ----------------- edad: -1.138 valor__pao2_fio2: -12.798 valor_presisn_arterial_media: 4.804 valor_creatinina: -12.446 valor_temperatura: 13.770 valor_frecuencia_cardiaca: -7.159 valor_hematocrito: -7.351 valor_leucocitos: 10.502 protemna_cm1: -2.491 procalcitonina_m1: -5.338 dmmero_dm1: -0.042 procalcitonina_m2: 1.903 tp: -0.477 tpt: 9.021 glasgow: 0.227 inmunosupresion: -0.669 Enfermedad General: 4.415 Bias: -4.365 Node 16 (Sigmoid) ----------------- edad: 3.070 valor__pao2_fio2: -9.429 valor_presisn_arterial_media: -12.842 valor_creatinina: -4.475 valor_temperatura: 2.956 valor_frecuencia_cardiaca: -7.035 valor_hematocrito: -0.313 valor_leucocitos: 8.374 protemna_cm1: 14.907 procalcitonina_m1: -0.903 dmmero_dm1: 12.202 procalcitonina_m2: -1.044 tp: 0.389 tpt: -13.038 glasgow: 2.256 inmunosupresion: -2.703 Enfermedad General: -1.158 Bias: 2.367 Node 17 (Sigmoid) ----------------- edad: -0.907 valor__pao2_fio2: 8.929 valor_presisn_arterial_media: 8.906 valor_creatinina: 0.894 valor_temperatura: 15.868 valor_frecuencia_cardiaca: -3.159 valor_hematocrito: 0.734 valor_leucocitos: 7.524 protemna_cm1: 5.728 procalcitonina_m1: -0.305

14
dmmero_dm1: -0.679 procalcitonina_m2: 0.164 tp: 1.553 tpt: -3.986 glasgow: 1.184 inmunosupresion: 1.327 Enfermedad General: 3.350 Bias: -0.158 Output ====== Class 'S' (Sigmoid) ------------------- Node 1: 7.142 Node 2: 6.531 Node 3: 1.860 Node 4: 4.758 Node 5: 1.988 Node 6: 2.440 Node 7: 3.021 Node 8: 5.302 Node 9: 4.217 Node 10: 7.340 Node 11: 6.150 Node 12: 6.891 Node 13: 5.263 Node 14: 2.631 Node 15: 6.684 Node 16: 4.558 Node 17: 8.766 Threshold: -10.585 Class 'N' (Sigmoid) ------------------- Node 1: -7.141 Node 2: -6.528 Node 3: -1.873 Node 4: -4.757 Node 5: -1.990 Node 6: -2.428 Node 7: -3.023 Node 8: -5.302 Node 9: -4.215 Node 10: -7.341 Node 11: -6.151 Node 12: -6.891 Node 13: -5.264 Node 14: -2.631 Node 15: -6.684 Node 16: -4.559 Node 17: -8.767 Threshold: 10.585