resúmenes tablas 13 - home | universidad de granadabioest/mtrabajo/resumenesbioestadistica.pdf ·...
TRANSCRIPT

Estos Resúmenes y Tablas han sido extraídos del libro
40 ± 10 horas de BIOESTADÍSTICA (2013) publicado en esta misma Editorial y por los mismos autores
A. Martín Andrés y J. de D. Luna del Castillo
RESÚMENES y TABLAS de
BIOESTADÍSTICA 3ª edición (2013)
¡ATENCIÓN!
No puede escribirse nada en este cuadernillo,
salvo correcciones de erratas autorizadas por los profesores

2
© Antonio Martín Andrés Juan de Dios Luna del Castillo © EDICIONES CAPITEL, S.L. Europolis, C/ Bruselas 16B- 28232 LAS ROZAS ( Madrid) e-mail (editor): [email protected]. e-mail (autores): [email protected] y [email protected]. Reservados los derechos de edición, adaptación o reproducción para todos los países. No está permitida la reproducción total o parcial de este libro, ni su tratamiento in-formático, ni la transmisión de ninguna forma o por cualquier medio, ya sea electrónico, mecánico, por fotocopia, por registro u otros métodos, sin el permiso previo y por escri-to de los titulares del Copyright. ISBN: 978-84-8451-054-3. Depósito Legal: M-24.370-2013

INTRODUCCIÓN
1
RESUMEN DEL CAPÍTULO I
INTRODUCCIÓN
1.1 NECESIDAD Las Ciencias de la Salud se basan en el método inductivo (extensión al todo de las conclusiones obtenidas en una parte), siendo el Método Estadístico el úni-co modo de validarlo. Las razones que siguen son reflejo de la anterior: a) La variabilidad biológica de los individuos objeto de estudio origina que
sus datos sean impredecibles: el Método Estadístico lo controla. b) La naturaleza cuantitativa de las Ciencias de la Salud requiere del Método
Estadístico para analizar y poner orden en los datos que proporciona. c) La investigación en las Ciencias de la Salud requiere de la Estadística en sus
etapas de diseño, recopilación de datos y análisis de los resultados, permi-tiendo leer crítica y comprensivamente los resultados científicos ajenos.
d) La naturaleza del trabajo clínico es en esencia de tipo probabilístico o es-tadístico, disciplinas que dan rigor y objetividad a los clásicos procesos sub-jetivos de diagnóstico, pronóstico y tratamiento.
e) La perspectiva comunitaria de las Ciencias de la Salud requiere del uso de la Estadística para poder extrapolar las conclusiones desde la parte estudiada de la población a su globalidad.
1.2 DEFINICIÓN DE ESTADÍSTICA Es el conjunto de métodos necesarios para recoger, clasificar, representar y resumir datos, así como para hacer inferencias (extraer consecuencias) científi-cas a partir de ellos (Bioestadística alude a la aplicación teórica y/o práctica de la Estadística a las Ciencias de la Salud). De ahí que conste de dos partes: a) Estadística Descriptiva, cuyo fin es la recogida, clasificación, representa-
ción y resumen de los datos. b) Inferencia Estadística, cuyo fin es extender a toda la población las conclu-
siones obtenidas en una parte de ella (la muestra).
1.3 CONSIDERACIONES FINALES a) El método estadístico es un método riguroso para el análisis de datos. Su va-
lidez está condicionada por la verificación de ciertas hipótesis que no pueden ser violadas (y que, por tanto, deben ser comprobadas).
b) Es importante planificar adecuadamente la experiencia. Una planificación in-correcta puede hacer desaprovechable la experiencia o elevar indeseablemen-te el coste de la misma.
c) La Estadística Descriptiva no tiene valor inferencial alguno. Ella sólo descri-be lo que hay y sugiere posibles preguntas, pero no permite extraer conclu-siones ciertas sobre nada.
INTRODUCCIÓN
2
2
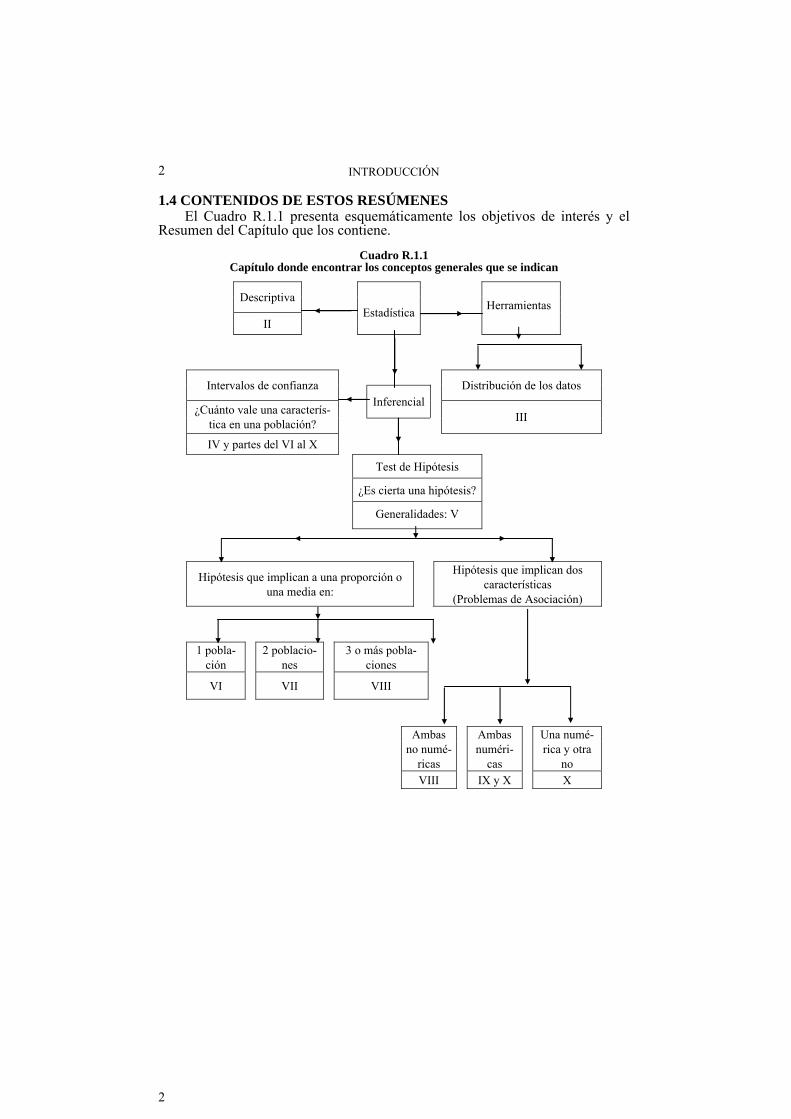
1.4 CONTENIDOS DE ESTOS RESÚMENES El Cuadro R.1.1 presenta esquemáticamente los objetivos de interés y el Resumen del Capítulo que los contiene.
Cuadro R.1.1
Capítulo donde encontrar los conceptos generales que se indican
Descriptiva
Herramientas
II
Estadística
Intervalos de confianza
Distribución de los datos
Inferencial¿Cuánto vale una caracterís-
tica en una población?
III
IV y partes del VI al X
Test de Hipótesis
¿Es cierta una hipótesis?
Generalidades: V
Hipótesis que implican a una proporción o una media en:
Hipótesis que implican dos características
(Problemas de Asociación)
1 pobla-ción
2 poblacio-nes
3 o más pobla-ciones
VI VII VIII
Ambas no numé-
ricas
Ambas numéri-
cas
Una numé-rica y otra
no
VIII IX y X X

ESTADÍSTICA DESCRIPTIVA
3
RESUMEN DEL CAPÍTULO II
ESTADÍSTICA DESCRIPTIVA
2.1 TIPOS DE DATOS Los datos obtenidos de un experimento pueden ser: a) Cuantitativos: Cuando su resultado es un número. Se dividen en:
i) Discretos: Si toman valores numéricos aislados (se “cuentan”). ii) Continuos: Si toman cualquier valor entre unos márgenes (se “miden”).
b) Cualitativos: Cuando su resultado no es un número. Pueden ser: i) Dicotómicos o Binarios: Si admiten solo dos posibilidades. ii) Multicotómicos o Policotómicos: Si admiten más de dos posibilidades.
Estos a su vez pueden ser ordinales (nominales) según que sus resultados sí (no) admitan una ordenación lógica.
2.2 PRESENTACIÓN TABULAR DE LOS DATOS a) Cuando los datos son discretos o cualitativos, con cada valor de los mismos
se forman las clases o modalidades del carácter. Cuando son continuos (o discretos con muchos valores posibles), con cada conjunto de valores de los mismos se forman los intervalos de clase (que deben tener igual longitud). En ambos casos, la primera y/o última clases pueden ser excepción.
b) Los intervalos de clase vienen definidos por dos números, el límite inferior LI y el límite superior LS; la diferencia de ellos es la longitud de clase L = LILS y la semisuma es la marca de clase (LI+LS)/2, valor que representa a toda ella.
c) A cada clase o intervalo de clase se le anota la frecuencia absoluta fi -o nú-mero de datos que pertenecen a la clase- y la frecuencia relativa hi = fi/n (con n = número total de datos). Sucederá que fi = n y hi = 1. Multiplicando hi por 100, 1.000,… se obtienen los % (tantos por ciento), 0/00 (tantos por mil),....
d) Toda tabla debe tener un enunciado claro, indicar las unidades de medida, contar con igual nº de decimales en cada columna, especificar el total de cada columna y “quedar bonita” (las fi deben crecer/decrecer razonablemente).
2.3 PRESENTACIÓN GRÁFICA DE LOS DATOS a) Histograma/Diagrama de barras: Si sobre cada punto (intervalo) del eje de
abscisas se levanta una barra (rectángulo) de tanta altura como frecuencia haya, se obtiene un diagrama de barras (histograma). Con frecuencia, la pa-labra “histograma” alude a ambas representaciones.
b) Polígono de frecuencias: Es la línea poligonal obtenida uniendo los puntos del plano que tienen por abscisa la clase o marca de clase y por ordenada la frecuencia.
c) Diagramas de sectores: Se obtiene si en un círculo se asigna a cada clase un sector de área proporcional a la frecuencia de la clase. El ángulo que lo deli-mita es 360hi (en grados).

ESTADÍSTICA DESCRIPTIVA
4
4
En los dos primeros casos la frecuencia puede ser absoluta o relativa. Las gráfi-cas deben verificar propiedades similares a las del resumen 2.2.d. 2.4 SÍNTESIS DE DATOS Para sintetizar la información de todos los datos de la muestra mediante uno o más números representativos de ella, se definen las medidas de una distribu-ción de frecuencias. Son de dos tipos: a) Medidas de posición: Describen cómo se encuentra el resto de la muestra
con respecto a ellas. i) Moda: La clase cuya frecuencia alcanza un máximo absoluto (si la cuali-
dad es nominal) o relativo (en otro caso). ii) Mediana: Es el valor que divide a la muestra ordenada (de menor a ma-
yor) en dos partes iguales; ocupa la posición (n+1)/2. iii) Percentil: El percentil pi es el nº que deja a su izquierda (incluido él mis-
mo) un "i%” de la muestra ordenada de menor a mayor (i = 1, 2,...., 99). iv) Cuartil: c1 = p25, c2 = p50, c3 = p75. v) Decil: d1 = p10, d2 = p20,..., d9 = p90. vi) Media aritmética (la importancia de cada dato la da su frecuencia):
Para datos no agrupados: x = xi / n. Para datos agrupados: x = fixi / n, con fi = n.
vii) Media ponderada (la importancia de cada dato la da su frecuencia y otro criterio): px =wixi /wi, con wi los pesos de ponderación.
b) Medidas de dispersión (describen cómo de dispersos son los datos): i) Recorrido, rango o amplitud: Es la diferencia entre los valores más grande
y más pequeño de la muestra. ii) Varianza o desviación cuadrática media: Es la medida de dispersión ade-
cuada cuando se utiliza la media como medida de posición. Se define co-mo la media de los cuadrados de las desviaciones a la media. Se obtiene mediante las fórmulas que siguen (en donde la primera fórmula es la defi-nición, la segunda es la apropiada para el cálculo y n =fi ):
Datos no agrupados: 2 2
2 1
1 1i i2
i
x x xs = x
n n n
Datos agrupados: 2 2
2
1i i i i2
i i
f x x f x1s = f x
n n 1 n
,
iii) Desviación típica o estándar: es la raíz cuadrada (s) de la varianza. iv) Rango intercuartílico: Es la medida de dispersión adecuada cuando se uti-
liza la mediana como medida de posición. Se define como RI = c3c1 (en un margen de RI unidades se encuentran el 50% de los datos).
v) Coeficiente de variación: Se utiliza para evaluar un método de medida. Como CV = (s/ x )100%, su interpretación es que por cada 100 unidades medidas, el método se equivoca en CV (en términos de s).

DISTRIBUCIONES DE PROBABILIDAD
5
RESUMEN DEL CAPÍTULO III
DISTRIBUCIONES DE PROBABILIDAD
3.1 DEFINICIONES a) Fenómeno aleatorio: aquel fenómeno cuyos resultados son impredecibles. b) Probabilidad (de un resultado dado de un fenómeno aleatorio): es el límite
de la frecuencia relativa del resultado cuando el número de experiencias (re-peticiones del fenómeno) tiende hacia infinito.
c) Variable aleatoria: es el resultado numérico de un fenómeno aleatorio y pueden ser: i) Discretas: se identifican por la función de probabilidad Pr (x) (regla que
asocia a cada valor x de la variable, su probabilidad Pr (x)). ii) Continuas: se identifican por la función de densidad f(x) (que indica cómo
de probable es que la variable caiga en los alrededores del valor x), cuya representación gráfica es la curva de densidad. El área bajo la curva de densidad entre dos valores a y b indica la probabilidad de que la variable x se encuentre entre dichos valores: Pr (a x b).
En general a ambas funciones se les llama distribución de probabilidad. d) Parámetros poblacionales: por contraposición a los parámetros muestrales
del resumen R.2.4 (que describen las muestras), se definen de modo similar los parámetros poblacionales (que describen las poblaciones o las variables aleatorias). Los paralelos a los parámetros muestrales x , s2, s y h = p son los parámetros poblacionales , 2, y p.
3.2 DISTRIBUCIONES DE PROBABILIDAD TEÓRICAS La mayoría de las variables de la Naturaleza siguen alguna de las siguientes (se excluyen las distribuciones en el muestreo que se ven más adelante): a) Distribución Normal:
i) Definición: una variable x sigue la distribución Normal (como la de la portada de este cuadernillo) si su curva de densidad tiene forma de cam-pana (campana de Gauss) con centro de simetría en (media, moda y mediana) y desviación típica (la distancia desde el eje vertical en al punto de inflexión de la curva). Por tanto x toma valores entre y +. Para aludirla se indicará x N(; ), con y los dos parámetros de la distribución.
ii) Tipificación: si x es una variable cualquiera de media y desviación , entonces (x)/, la variable x tipificada, tiene de media 0 y de desvia-ción 1. Cuando además x N(; ), entonces z = (x)/ N(0; 1) es la llamada Normal típica o estándar.
iii) Tabla 1: para cada probabilidad la tabla da el valor z de una N(0; 1) tal que Pr (z z +z) = 1. Por ello, si x N(; ), los intervalos x z, x + z2 y x z2 contienen al (1)100% de las ob-servaciones de la variable x.

DISTRIBUCIONES DE PROBABILIDAD
6
6
iv) Teorema Central del Límite: si x es una variable cualquiera de media y desviación típica , y si x es la media de una muestra de tamaño n 30, x se distribuye aproximadamente como una Normal: x N(; / n ), con / n el error estándar. Si x es Normal, lo anterior se verifica exac-tamente para cualquier valor de n.
b) Distribución Binomial: i) Definición: si de una población de tamaño (N) infinito, cuyos individuos ve-
rifican una cierta característica dicotómica con probabilidad p, se extrae una muestra de tamaño n, el número x de individuos de entre los n que verifican la característica sigue una distribución Binomial. Cuando N < , x sigue aproximadamente una Binomial si N > 40 y n/N (fracción de muestreo) 0,10. Por tanto 0 x n. Para aludirla se indicará x B(n; p), con n y p los dos parámetros de la distribución.
ii) Media y Varianza: son = np y 2 = npq respectivamente, con q = 1p. iii) Propiedad: Si n es suficientemente grande (np, nq > 5 suele bastar), la Bi-
nomial se aproxima a la Normal en el sentido de que la probabilidad de que la Binomial valga x es aproximadamente igual a la probabilidad de que la Normal valga entre x0,5 y x+0,5 (el valor 0,5 es la corrección por conti-nuidad o mitad del salto de la variable).
c) Distribución de Poisson: i) Identificación: Son variables x de Poisson (ley de los sucesos raros): i)
Aproximadamente, una Binomial con n grande y p pequeño; ii) El número de partículas por unidad de medio (si un gran número de partículas están re-partidas al azar en una gran cantidad de medio); iii) El número de sucesos que ocurren por unidad de tiempo (si estos suceden al azar e independien-temente entre sí). Por tanto 0 x < . Para aludirla se indicará x P(), con el único parámetro de la distribución.
ii) Media y Varianza: = 2 = en ambos casos. iii) Propiedad: Si es suficientemente grande, se aproxima a la Normal (en el
mismo sentido que el indicado para la Binomial).

INTERVALOS DE CONFIANZA
7
RESUMEN DEL CAPÍTULO IV
INTERVALOS DE CONFIANZA
4.1 MUESTREO ALEATORIO Las muestras deben tomarse al azar, de modo que todo individuo de la po-blación tenga igual probabilidad de ser seleccionado y que la selección de uno de ellos no condicione la selección de otro. El azar puede imitarse mediante da-dos, bolas en urna, etc., pero lo mejor es hacerlo a través de una Tabla de Números Aleatorios como la Tabla 2. Solo en ese caso la muestra es representa-tiva de la población y será válido todo lo que se indica en estos Resúmenes.
4.2 ESTIMACIÓN Los parámetros poblacionales no suelen ser conocidos y con frecuencia es imposible conocerlos exactamente. La Teoría de la Estimación es la parte de la Inferencia Estadística que sirve para determinar el valor de los parámetros po-blacionales en base al de los parámetros muestrales. La estimación puede ser: a) Por punto: si se asigna al parámetro desconocido () un único valor ( )
que será su valor aproximado y que es una función de los valores de la mues-tra. Antes de tomar la muestra se dice que es un estimador de ; después de tomarla, el valor de en ella es una estimación de . Usualmente es el parámetro muestral homónimo al parámetro poblacional a estimar ( ˆ x ,
2 = s2 y p = h). Es conveniente que el valor promedio de en todas las muestras posibles sea el verdadero valor a estimar; de ser así, es un es-timador insesgado o centrado de (los estimadores citados arriba lo son); en otro caso es un estimador sesgado o no centrado de .
b) Por intervalo: si se asigna al parámetro desconocido () un intervalo de va-lores (I; S) -dados por una fórmula- entre los cuales está con una cierta probabilidad 1. Al tomar una muestra y determinar I y S en base a ella, se obtiene el intervalo de confianza (I; S), con el error del intervalo y 1 la confianza del mismo: el investigador espera que este sea uno de los (1)100 intervalos de cada 100 que contienen realmente a (y no uno de los 100% de cada 100 que fallan).
4.3 INTERVALO DE CONFIANZA PARA UNA MEDIA a) Intervalo: si x es una variable aleatoria de media y varianza 2 desconoci-
das, y si x1, x2, ..., xn es una muestra aleatoria de ella con media x y desvia-ción típica s, entonces x ± ts/ n -con t en la Tabla 3 con (n1) gl y s/ n el llamado error estándar estimado- si: i) x es Normal. ii) x es cualquiera pero n 60. Cuando x es discreta (y saltando de 1 en 1), a
la expresión anterior hay que añadirle una corrección por continuidad: x ± [ts/ n +1/(2n)]
b) Tamaño de muestra: Si x N(; ), con y desconocidas, y se desea obtener un tamaño de muestra n tal que la media x de esa muestra verifique que x d x d, entonces: i) Si se conoce un valor máximo de 2: n = {z(Máx ) / d}2, con z en la
Tabla 1. ii) Si 2 es desconocida pero hay una muestra piloto: n = (ts/d)2, con t en
la Tabla 3 con ( n l) gl, n el tamaño de la muestra piloto y s2 su va-rianza.

INTERVALOS DE CONFIANZA
8
8
iii) En otro caso: Hacer d = K y n = (z/K)2, con z en la Tabla 1. Si el n resultante es grande ( 60), las fórmulas anteriores también valen, aproximadamente, si x es no Normal. Los casos i) e ii) requieren comprobar que la muestra del tamaño n acon-sejado verifica las especificaciones: tomada la muestra y obtenido el intervalo de confianza (I; S) en base a ella, debe ocurrir que (SI)/2 d (de no ser así hay que volver a determinar el tamaño de muestra).
4.4 INTERVALO DE CONFIANZA PARA UNA PROPORCIÓN p Sea x B(n; p) y x una observación (en lo que sigue z siempre en la Tabla 1):
a) Intervalo: i) Método de Wilson con cpc: si x, nx > 5:
2 2
20 50 5 0 5 1
2 4z z x ,
p x , z x , n z n
(del símbolo , usar el para el extremo inferior y el + para el superior), expresión que se simplifica en el clásico método de Wald con cpc (el de casi todos los libros) si x > 20 y nx > 20 (en ella p = x/n y 1ˆ ˆq p ):
10 5
2
x n xˆ ˆpqˆp p z = x z , n
nn n
El método de Wilson es siempre mejor que el de Wald. ii) Método de Wald ajustado: válido siempre pero peor que el de Wilson (uti-
lizar solo si el anterior no es válido)
2 22 4
4
x n x+p x z n+
n
b) Tamaño de muestra: Si se desea obtener un tamaño de muestra n tal que la proporción p de ella verifique que p p d p p d, entonces: i) Con información: Si en base a una información previa -bibliográfica o de
muestra piloto- se conoce que p (pI; pS), n = (z/d)2pq, con p el valor de dicho intervalo que esté más cercano a 0,5 y q = 1p.
ii) Sin información: n = (z/2d)2. En el primer caso hace falta comprobar al final que la muestra del tamaño n aconsejado verifica las especificaciones: tomada la muestra y obtenido el in-tervalo de confianza p (pI; pS) y el valor de p en base a ella, debe ocurrir que Ip p d y Sp p d (de no ser así hay que volver a determinar el tamaño de muestra).
4.5 GENERALIDADES SOBRE LOS INTERVALOS DE CONFIANZA Lo que sigue es válido para todos los intervalos de confianza:
a) Los intervalos de confianza de estos Resúmenes son siempre de dos colas -es decir del tipo (I; S)- con una confianza de 1. Cuando se desee un intervalo de confianza de una cola, obtener el extremo que interese (I o S) al error 2. El intervalo será S o I.
b) Las fórmulas de tamaño de muestra son válidas para un intervalo de confian-za de dos colas al error . Cuando se le desee de una cola, cambiar en ellas por 2.

CONCEPTO GENERAL DE TEST DE HIPÓTESIS
9
RESUMEN DEL CAPÍTULO V
CONCEPTO GENERAL DE TEST DE HIPÓTESIS
5.1 OBJETIVO Un test o contraste de hipótesis es un conjunto de reglas tendentes a decidir cuál de dos hipótesis -H0 (hipótesis nula) o H1 (hipótesis alternativa)- debe aceptarse en base al resultado obtenido en una muestra.
5.2 TIPOS a) Test bilateral o de dos colas: Si H1 es la negación total de H0. b) Test unilateral o de una cola: Si H1 es una parte de la negación de H0.
5.3 ELECCIONES PREVIAS Antes de realizar un test, el investigador debe decidir: a) H0: Hipótesis formulada como una igualdad o una afirmación positiva. Una
conclusión por ella no implica seguridad alguna acerca de su certeza (salvo que se fije de antemano el tamaño de la muestra).
b) H1: Es la hipótesis que se quiere demostrar fuera de toda duda, es decir aque-lla que, de concluirse, se quiere estar prácticamente seguro de que es cierta. Puede ser una parte de la negación de H0 (test de una cola) si la otra parte im-plica una conclusión/acción equivalente a la que proporcionaría una acepta-ción de H0.
c) : Es un valor tanto más pequeño cuantas más garantías se precisen de que una decisión por H1 sea correcta. Usualmente = 5% .
d) Estadístico de contraste: Es la variable que se va a utilizar para realizar el test; viene dada por una función de los valores de la muestra que resume toda la información relevante de ella respecto del test a realizar.
e) Tamaño de muestra n (opcional): Si se desea que una conclusión por H0 sea también fiable (ver los detalles en R.5.7).
5.4 MÉTODO Para tomar la decisión debe obtenerse un intervalo de valores del estadísti-co de contraste cuya probabilidad, bajo H0, sea 1. El intervalo -que será de dos colas en los tests bilaterales y de una cola (con la desigualdad en sentido opuesto al indicado por H1) en los unilaterales- se denomina región de acepta-ción; los valores que están fuera de él se denominan región crítica o región de rechazo. Obtenida la muestra, si el valor que toma en ella el estadístico de con-traste está en la región de aceptación se acepta H0; si está fuera (es decir, en la región de rechazo) se acepta H1. En el primer caso se dice que el test (o el resul-tado) es estadísticamente no significativo; en el segundo se dice que el test (o el resultado) es estadísticamente significativo (ambos para un test realizado al error ).

CONCEPTO GENERAL DE TEST DE HIPÓTESIS
10
10
5.5 ERRORES ASOCIADOS A LA CONCLUSIÓN DE UN TEST a) Definiciones: Toda decisión de un test de hipótesis puede ser errónea. Las
dos posibilidades de error se denominan: i) Si se concluye H1: error = error de Tipo I = nivel de significación =
= Pr (decidir H1es cierta H0). ii) Si se concluye H0: error = error de Tipo II =
= Pr (decidir H0es cierta H1). b) Consecuencias:
i) El error está controlado, pues se fija de antemano y es tan pequeño co-mo se desee; de ahí que una decisión por H1 es siempre fiable.
ii) El error no está controlado de antemano, pudiendo ser grande; de ahí que una decisión por H0 no sea fiable (lo único que indica es que no se ha podido demostrar que es falsa).
iii) El error es un único número (puesto que H0 alude a un único valor, al venir dada por una igualdad), pero el error alude a muchos números (puesto que depende de la alternativa H1 que se considere).
iv) El error disminuye conforme aumenta , conforme H1 se aleja de H0 y conforme aumenta el tamaño n de la muestra (si todo lo demás permane-ce constante).
5.6 POTENCIA DE UN TEST Se llama potencia a la capacidad que tiene un test para detectar las hipó-tesis alternativas verdaderas, es decir:
= 1 = Pr (decidir H1es cierta H1) Como también depende de la hipótesis alternativa, ella alude a muchos núme-ros que, en el caso de tests acerca de parámetros, dan lugar a una representación gráfica llamada curva de potencia (de vs. H1). Un test es tanto mejor cuanto más potente sea.
5.7 TAMAÑO DE MUESTRA Determinando el tamaño de muestra n de antemano, las conclusiones por H0 también son fiables (las conclusiones por H1 siempre lo son) pues su error asociado también está controlado (como lo estaba ). Si H0: = 0 (con el parámetro de interés), para determinar n hace falta especificar: a) El error del test; b) La primera alternativa de interés o primera H1 (digamos 1) que se desea
diferenciar de H0. Esto es equivalente a fijar la mínima diferencia de interés =10, pues la primera alternativa de interés será 1 = 0 + (para H1: > 0), 1 = 0 (para H1: < 0) o 1 = 0 (para H1: 0).
c) El error (o la potencia = 1) para tal alternativa. El n obtenido garantiza que el test realizado con tal muestra (al error ) dará significativo el (1)100% de las veces en que la verdadera hipótesis H1 se diferencie de H0 en la cantidad especificada (o más veces si la diferencia es mayor, o menos veces si es menor).

CONCEPTO GENERAL DE TEST DE HIPÓTESIS
11
5.8 INTERVALOS DE CONFIANZA TRAS UN TEST DE HIPÓTESIS Tras realizar un test de hipótesis acerca de un parámetro usualmente es con-veniente obtener un intervalo de confianza para el mismo, tanto si se concluye H0 (para ver si la conclusión es fiable o debería aumentarse la muestra) como si se concluye H1 (para así indicar cuánto de falsa es H0). Las reglas son: a) Cuando el test es de dos colas, el intervalo será de dos colas:
i) Si se concluyó H1: al error . ii) Si se concluyó H0: al error 2.
b) Cuando el test es de una cola, el intervalo será de una cola: i) Si se concluyó H1: al error y con la desigualdad en el sentido que indica
H1. ii) Si se concluyó H0: al error y con la desigualdad en el sentido contrario
al que indica H1. c) En ambos casos, si se concluye H0:
i) Si n fue fijado de antemano: la conclusión es fiable y no es preciso obte-ner el intervalo.
ii) Si n no fue fijado de antemano: la conclusión es fiable solo si el intervalo obtenido no contiene a la/s primera/s alternativa/s de interés. En otro caso la conclusión no es fiable, debe aumentarse n y repetirse el test.
d) En ambos casos, si se concluye H1: el intervalo obtenido (que sirve para ver cuánto de falsa es H0) no debe contener al valor del parámetro bajo H0.
Adicionalmente, cuando se concluye H1 puede interesar conocer si también hay significación biológica: la hay si el intervalo al error (de dos colas si el test es de dos colas; de una cola, con la desigualdad en sentido contrario al que indica H1, si el test es de una cola) contiene a algún valor relevantemente distin-to del valor del parámetro bajo H0.
5.9 VALOR P a) Definición: El valor P, nivel crítico P o nivel mínimo de significación es
i) El mínimo error al cual un resultado es significativo. ii) La probabilidad de obtener un resultado tan extraño o más que el obtenido
cuando H0 es cierta. b) Consecuencias:
i) P mide las evidencias que hay en contra de H0 (pero no mide cuánto de falsa es H0).
ii) El valor P de un test de una cola (con H1 en la dirección a que apuntan los datos) suele ser la mitad del valor P del test de dos colas.
iii) Fijado un valor de : si P se decide H1; si P > se decide H0.
5.10 REGLAS PARA TOMAR LA DECISIÓN a) Regla usual para un error dado (generalmente = 5%):
i) Si P % se concluye H1 (la decisión es fiable); ii) Si P > % se concluye H0 (la decisión será fiable si se verifica 5.8.c).

CONCEPTO GENERAL DE TEST DE HIPÓTESIS
12
12
b) Regla Automática de Decisión para el caso de = 5%: i) Si P 5%: se concluye H1; ii) Si P > 15%: se concluye H0; iii) En otro caso: Se concluye H0, indicando que hay indicios de significa-
ción (en realidad conviene ampliar la muestra y repetir el test).
5.11 PRESENTACIÓN DE LAS CONCLUSIONES a) Las tablas estadísticas generalmente no permiten conocer el valor exacto de
P, sino una cota del mismo. Las conclusiones entonces suelen ser del tipo: H1 (P < 2%) o H0 (P 30%) por ejemplo.
b) Cuando P es “> 5%, 5%, 1% o 1‰” se dice que el test o el resultado es “no significativo, significativo, muy significativo o altamente significativo” respectivamente. En otras ocasiones encima del valor experimental se coloca “nada, *, ** o ***” respectivamente (para indicar que P toma los valores re-señados arriba).
5.12 CRITERIOS GENERALES PARA TODOS LOS TESTS a) Tests de dos colas realizados a un error : Calcular una cantidad experi-
mental Cexp a partir de los datos y compararla con la/s cantidad/es teórica/s C que indique/n la Tabla del Apéndice apropiada (al error ), decidiendo como sigue: i) Si la tabla proporciona dos límites CI y CS (como en las Tablas 4, 6 y 7):
0
1
Si aceptar al error
Si o aceptar con error
I exp S
exp I exp S
C C C H
C C C C H
ii) Si la tabla proporciona solo un límite C:
0
1
Si aceptar al error
Si aceptar con error
exp
exp
C C H
C C H
b) Cálculo de P y test de dos colas en base al mismo: Localizar en la Tabla del Apéndice apropiada los dos valores 1 y 2 consecutivos (con 1 < 2) en los que el test pasa de concluir H0 a concluir H1; entonces 1 < P 2 y la decisión se toma del modo indicado en el Resumen 5.10.
c) Tests de una cola al error : Comprobar si el resultado experimental es conforme con H1 y entonces: i) Si NO es conforme con H1: Decidir H0 sin más operaciones (P 50%). ii) Si SÍ es conforme con H1: Actuar como en a), pero en base al error 2, o
como en b), pero con el P obtenido dividido por 2: 1/2 < P 2/2. d) Tamaño de muestra: Las fórmulas de tamaño de muestra que se verán sir-
ven para determinar el mínimo tamaño de muestra preciso para que un test de dos colas al error dé significativo el (1)100% de las veces en que la verdadera hipótesis H1 se diferencie de H0 en la cantidad que se especifique (o más veces si la diferencia es mayor, o menos veces si es menor). En todo caso, cuando el test es de una cola hay que cambiar en la fórmula por 2.

TESTS CON UNA MUESTRA
13
RESUMEN DEL CAPÍTULO VI
TESTS CON UNA MUESTRA
6.1 TEST DE NORMALIDAD DE D’AGOSTINO (H0: “La muestra proviene de una variable aleatoria Normal”)
Si x1, x2, ..., xn es una muestra aleatoria (ordenada de menor a mayor) de una variable aleatoria x, comparar con una D de la Tabla 4 (por el modo allí indicado) la cantidad:
2
2
12i i
exp
ii
nix x
D = x
n n xn
6.2 TEST DE HIPÓTESIS PARA UNA PROPORCIÓN (H0: p = p0) Sea xB(n; p), con p desconocido: a) Test: Si x es una observación de ella y ocurre que np0 > 5 y nq0 > 5, con q0 =
1p0, comparar zexp = (xnp00,5) / 0 0np q con una z de la Tabla 1. b) Tamaño de la muestra: Para detectar alternativas p1, con p1p0= :
2
0 0 2 1 1z p q z p qn =
con q1 = 1p1, las cantidades z en la Tabla 1 y: i) En tests de una cola: p1 = p0 para H1: p < p0; p1 = p0+ para H1: p > p0
(además de cambiar por 2 como es tradicional); ii) En tests de dos colas: p1 el valor más cercano a 0,5 de entre los p0 .

TESTS DE HOMOGENEIDAD CON DOS MUESTRAS
14
14
RESUMEN DEL CAPÍTULO VII
TESTS DE HOMOGENEIDAD CON DOS MUESTRAS
7.1 GENERALIDADES VÁLIDAS PARA EL RESUMEN ACTUAL a) Muestras: Dos muestras son independientes cuando cada individuo de las
mismas proporciona una única observación. Son apareadas, relacionadas o dependientes cuando cada individuo proporciona dos observaciones (los da-tos se obtienen por parejas). Cuando la asociación entre esas parejas de datos es positiva, el muestreo apareado es preferible al independiente.
b) Test: Las comprobaciones previas a un test de una cola (H1: 1 < 2 o H1: p1 < p2 por ejemplo) son las lógicas ( 1 2x x o 1 2
ˆ ˆp p ). c) Intervalos de confianza: Todos están construidos como de dos colas. Para
una cola cambiar por 2 y conservar sólo el extremo apropiado. d) Tamaños de muestra: En las fórmulas debe entenderse que:
i) El tamaño pronosticado alude al tamaño de cada una de las dos muestras (n = n1 = n2) cuando estas se planifican como iguales.
ii) Aluden a un test de dos colas: cuando sea de una cola cambiar por 2. iii) La mínima diferencia importante alude al primer valor de 12 o
de p1p2 a diferenciar del valor 0. Si el test es de una cola, lo anterior es válido sin el valor absoluto.
7.2 TESTS PARAMÉTRICOS PARA COMPARAR DOS MEDIAS DE VARIABLES NORMALES (H0: 1 = 2)
a) Test para muestras independientes: Si las muestras -de tamaños n1 y n2, medias 1x y 2x y varianzas 2
1s y 22s - provienen de variables de medias 1 y
2 y varianzas 21 y 2
2 desconocidas, obtener Fexp = 21s / 2
2s , con 2 21 2s s , y
compararla con F0,10 [n11; n21] de la Tabla 5; entonces: i) Si Fexp < F0,10 (Varianzas iguales: 2 2 2
1 2 ) (Test de Student): Com-parar con una t(n1+n22) de la Tabla 3 la cantidad:
1 2
2 1 2
1 2
exp
x xt =
n ns
n n
, con
2 21 1 2 22
1 2
1 1
2
n s n ss =
n n
ii) Si Fexp F0,10 (Varianzas distintas: 2 21 2 ) (Test de Welch): Comparar
con una t(f) de la Tabla 3 la cantidad:
1 2exp
x xt =
A B
, con A =
21
1
s
n, B =
22
2
s
n y
2
2 2
1 21 1
A Bf =
A Bn n
b) Test para muestras apareadas (Test de Student): Dadas dos variables (x1 y x2 de medias 1 y 2 respectivamente) y n parejas de datos (x1i; x2i) de las mismas, con i = 1, 2, …, n, obtener sus diferencias di = x1ix2i y la media ( d ) y varianza ( 2
ds ) de las mismas. El test consiste en comparar:
texp = 2d
d
s / n vs. t(n1) de la Tabla 3

TESTS DE HOMOGENEIDAD CON DOS MUESTRAS
15
c) Intervalo de confianza para la diferencia de medias: La siguiente expre-sión es válida para los tres casos citados en a) y b), con la misma notación, condiciones y alusiones de entonces: 12(numerador de la texp sin valor absoluto) t(denominador de la texp)
d) Tamaño de muestra: Con igual notación que en a) y b), para detectar una diferencia 12= (en lo que sigue zx se mira en la Tabla 1 y tx en la Ta-bla 3 con f gl): i) Muestras independientes (Varianzas iguales): n1 = n2 = n, con:
2
222z z
n
, 2
222t t
n = s
,
2
2z zn = 2
K
la primera expresión se utiliza cuando 2 (o su valor máximo) es conoci-do, la segunda cuando hay muestras piloto de tamaños in y varianza común 2s (con f = 1 2 2n n ) y la tercera cuando = K (con K un va-lor dado de antemano que usualmente verifica 0 K 0,5).
ii) Muestras apareadas: 2
2 2d
z zn =
, 2
2 2d
t tn = s
, 2
2z zn =
K
la primera expresión se utiliza cuando 2d (o su valor máximo) es conoci-
do, la segunda cuando hay una muestra piloto de tamaño n y varianza 2s (con f = n 1 gl), la tercera cuando 12= Kd.
7.3 TESTS PARAMÉTRICOS PARA COMPARAR DOS MEDIAS DE VARIABLES CUALESQUIERA (H0: 1 = 2)
Si, en las condiciones y notación del Resumen 7.2, las variables implicadas (x o d) no son Normales, gran parte de lo indicado allí es aproximadamente váli-do si las muestras son grandes (mayores que 60 si las variables son marcada-mente no Normales). Las reglas aconsejadas son las siguientes:
a) Test e intervalo para muestras independientes: Aplicar el test de Welch del Resumen 7.2.a.ii) y el intervalo del Resumen 7.2.c.
b) Test e intervalo para muestras apareadas: Aplicar el test de Student del Resumen 7.2.a.i) y el intervalo del Resumen 7.2.c.
c) Tamaño de muestra: Es válido lo indicado en el Resumen 7.2.d si el n final predicho es superior a 60.
d) Variables discretas: En los casos a) y b), si la variable implicada es discreta y saltando de 1 en 1 conviene efectuar una cpc consistente en sumar al radio del intervalo de confianza la cantidad c (o restar al numerador de la texp la cantidad c) con: i) Muestras independientes: c = (n1+n2)/2n1n2. ii) Muestras apareadas: c = 1/2n.

TESTS DE HOMOGENEIDAD CON DOS MUESTRAS
16
16
7.4 TESTS NO PARAMÉTRICOS (TESTS DE WILCOXON) PARA COMPARAR DOS MUESTRAS DE VARIABLES CUALESQUIERA (H0: La primera población no tiende a dar valores más altos o más bajos que la segunda, lo que es prácticamente equivalente a afirmar que 1 = 2)
a) Asignación de rangos: En lo que sigue se hablará de “asignar rangos a una muestra ordenada”. Por tal se entiende al proceso de, dada una muestra orde-nada de menor a mayor (x1 x2 ... xn), asignar el rango 1 al elemento x1, el rango 2 al elemento x2, ..., el rango n al elemento xn. Cuando haya varios ele-mentos xi consecutivos iguales (empates) a cada uno de ellos se le asigna el rango promedio que tendrían si fueran distintos; por ejemplo, si xr = xr+1 = ... = xs, a cada elemento se le asigna el rango promedio (r+s)/2.
b) Muestras independientes (test de Wilcoxon): Dadas dos muestras indepen-dientes de tamaños n1 y n2 (n1 n2 por convenio), unir las dos muestras en una sola, ordenarla de menor a mayor, asignarle rangos a sus elementos y calcular las sumas de rangos (R1 y R2) de los elementos de cada una de las muestras. Deberá suceder que R1+R2 = (n1+n2)(n1+n2+1)/2. Llamar por Rexp a la suma de rangos (R1) de la muestra de menor tamaño y entonces: i) Si n1+n2 30: Comparar Rexp con el valor R de la Tabla 6 por el modo
allí indicado. ii) Si n1+n2 >30: Comparar con el valor z de la Tabla 1 la cantidad (en lo
que sigue no se tiene en cuenta la posible existencia de empates):
zexp=0 5expR ,
, con = 1 2 11
2
n n n y 2 = 2
6
n
La verificación del sentido de la significación se hace en base a los rangos médios iR = Ri/ni de cada muestra: si 1R < 2R entonces 1 < 2.
c) Muestras apareadas (test de Wilcoxon): Dadas n' parejas de datos, obtener las n' diferencias entre ellas, rechazar las que sean cero, ordenar el resto (n) de menor a mayor valor de sus valores absolutos, asignarles rangos y calcular las sumas de rangos -R(+) y R()- de las diferencias positivas y negativas. Deberá suceder que R(+) + R() = n(n+1)/2. Entonces: i) Si n 25: Comparar R(+) -o R(), es lo mismo- con el valor R de la Ta-
bla 7 por el modo allí indicado. ii) Si n > 25: Comparar con el valor z de la Tabla 1 la cantidad (en lo que
sigue no se tiene en cuenta la posible existencia de empates):
zexp = 0 5R ,
, con = 1
4
n n y 2 = 2 1
6
n
La verificación del sentido de la significación se hace en base a los rangos: si R(+) < R() entonces 1 < 2.
7.5 TESTS DE COMPARACIÓN DE DOS PROPORCIONES (MUES-TRAS INDEPENDIENTES) (H0: p1 = p2)
Si xi B(ni; pi) -con i = 1, 2- son independientes y si de cada una de ellas se obtiene una muestra en el formato de la Tabla R.7.1, entonces, llamando por
ip =xi/ni, p =a1/N, iq =1 ip y 1ˆ ˆq p (en lo que sigue las cantidades zx siem-pre en la Tabla 1, pues se utiliza la aproximación de la Binomial a la Normal):

TESTS DE HOMOGENEIDAD CON DOS MUESTRAS
17
Tabla R.7.1 Tabla R.7.2 Presentación de datos cuando se comparan
dos proporciones independientes Presentación de datos cuando se comparan
dos proporciones apareadas
Característica
Muestras
SÍ
NO
Totales
B
A
SÍ
NO
Total
1 x1 y1 n1 SÍ n11 n12 2 x2 y2 n2 NO n21 n22
Totales a1 a2 N Total n
a) Test: Sea E = Mín (a1; a2)Mín (n1; n2)/N. El test incondicionado consiste en comparar:
1 2 1 2
1 2 1 21 2
1 sicon
2 siexp 1 2
/n n n nNˆ ˆ ˆ ˆz = p p c pq , c=
/n n n nn n
vs. z
siendo válido si E 14,9 (aunque cuando N 500, basta con que E 7,7). Más conservador es el test condicionado clásico con la cpc de Yates que se obtiene haciendo arriba c = N/2n1n2, el cual suele decirse (erróneamente) que es válido si E > 5.
b) Intervalo de confianza para la diferencia de proporciones: i) Método de Wald (clásico): Si x1, x2, y1, y2 son todos mayores que 5:
1 2p p ( 1 2ˆ ˆp p ) 1 1 2 2
1 2
ˆ ˆ ˆ ˆp q p qz c
n n
con c como arriba
ii) Método de Agresti-Caffo (mejor que el anterior): Si h = 2 4z :
p1p2 1 2
1 22 2
x h x h
n h n h
1 1 2 23 31 2
x h y h x h y hz
n n
(el método de Wald, para c = 0 y con los datos incrementados en 2 4z ).
c) Tamaño de muestra: Para detectar una diferencia = p1p2: i) Con información (sobre las pi):
2
2 1 1 2 22z pq z p q p qn
,
con p = (p1+p2)/2, q = 1p, qi = 1pi y las p1 y p2 lo más cercanas posibles a 0,5 /2, compatibles con la información que se posea sobre ellas y ta-les que p1 p2 = .
ii) Sin información: haciendo pi = 0,5 /2 arriba:
n =
22
2 11
2
z z

TESTS DE HOMOGENEIDAD CON DOS MUESTRAS
18
18
7.6 TEST DE COMPARACIÓN DE DOS PROPORCIONES (MUES-TRAS APAREADAS) (H0: p1 = p2)
Si los n individuos de una muestra son clasificados según que presenten (SÍ) o no (NO) una determinada característica tras la aplicación de un tratamien-to A (entendido de modo genérico: no tiene porqué ser un tratamiento médico) y lo mismo tras la aplicación de otro tratamiento B, los datos pueden presentarse como en la Tabla R.7.2. Si p1 y p2 son las proporciones de respuestas SÍ a cada tratamiento (en lo que sigue zx siempre en la Tabla 1): a) Test de McNemar: Si n12+n21 > 10, comparar
zexp = 12 21
12 21
0 5n n ,
n n
vs. z.
b) Intervalo de confianza para la diferencia de proporciones:
i) Método de Wald (clásico): Si n12, n21 > 5:
2
211 2 21 21 0 512
12 12
n np p n n z n n , n
n
ii) Método de Agresti-Min (mejor que el anterior): Equivalente a aplicar el anterior omitiendo el 0,5 e incrementando los datos en 0,5:
212 21
12 21 12 21
1 2
( )( ) ( +1)
22
n nn n z n n
np pn
c) Tamaño de muestra: Para valores , y =p1p2=p12p21:
i) Con información (sobre las pi): hacer (p12+p21) () lo máximo posible en:
22
12 21 2 12 21 = n z p p z p p
ii) Sin información: n = 22
2 1z z
7.7 COMPARACIONES MÚLTIPLES: Método de Bonferroni
Cuando deban hacerse K tests de hipótesis sobre los que se desea un error global de , el nivel de error a utilizar en cada test individual debe ser de /K. La Tabla 8 ayuda a obtener las cantidades teóricas t/K (f gl) y z/K (la de antes en f = ).

TEST CHI-CUADRADO Y TABLAS 22
19
RESUMEN DEL CAPÍTULO VIII
TEST CHI-CUADRADO Y TABLAS 22
8.1 TESTS EN TABLAS rs DISTINTAS DE 22 a) Test de homogeneidad de varias muestras cualitativas (H0: La proporción
de individuos que caen en una determinada clase es la misma para todas las poblaciones y esto vale para todas las clases Todas las muestras provienen de igual población).
Tabla R.8.1: Tabla de contingencia rs
Columnas Oij
1 2 · · · s Totales
1 O11 O12 · · · O1s F1
2 O21 O22 · · · O2s F2
· · · · · · · · · · · · · · · · · ·
Filas
r Or1 Or2 · · · Ors Fr
Totales C1 C2 · · · Cs T
i) Presentación de los datos: Dadas r muestras cuyos individuos se clasifi-can en s clases como en la Tabla R.8.1 (muestras = filas; clases = colum-nas), se define: Oij = Nº de individuos de la muestra i que caen en la clase j = Cantidades Observadas; Fi = Total de la fila i = nº total de individuos de la muestra i = jOij; Cj = Total de la columna j = nº total de individuos de la clase j =iOij; T = Gran total = nº total de individuos = Fi = Cj =Oij.
ii) Realización del test: Calcular las Cantidades Esperadas Eij = FiCj/T (cuyos totales de fila y de columna han de ser las Fi y Cj de antes) y en-tonces, si ninguna Eij es inferior a 1 y no más del 20% de ellas son infe-riores o iguales que 5, comparar
2
22 ij ij ijexp
i , j i , jij ij
O E OT
E E
vs. 2
{gl = (r1)(sl)} de la Tabla 9,
La cantidad experimental anterior se denomina estadístico chi-cuadrado de Pearson (su segunda expresión es la más apropiada para el cálculo).
iii) Búsqueda de la significación (si ocurre): A través de los % por filas. b) Test de independencia entre dos cualidades (H0: Los caracteres A y B son
independientes no están asociados no están relacionados). Si en los T individuos de una muestra aleatoria se determinan dos caracte-
res cualitativos A y B, el primero dividido en r clases y el segundo en s cla-ses, y se les clasifica en base a ello en una tabla como la Tabla R.8.1 (con “fi-las” y “columnas” cambiadas por “clases del carácter A” y “clases del carác-ter B” respectivamente) proceder como en el Resumen a) anterior. Ahora las causas de la significación se pueden buscar por filas o columnas.

TEST CHI-CUADRADO Y TABLAS 22
20
20
8.2 TESTS EN TABLAS 22 Con la misma notación y objetivos de la sección anterior, para todo lo que sigue se define E = Mín (F1 ; F2)Mín (C1; C2) / T = mínima cantidad esperada de la tabla. La cantidad teórica para el test es siempre 2
{gl = l} de la Tabla 9. a) Tests clásicos para cualquier tabla 22: (NO USAR)
i)Test chi-cuadrado de Pearson = test chi-cuadrado sin corrección por con-tinuidad: Si E > 5, aplicar el estadístico del Resumen 8.1 que es igual a:
2
2
1 2 1 2
11 22 12 21P
O O O O= T
F F C C
ii) Test chi-cuadrado de Yates = test chi-cuadrado con la corrección por continuidad de Yates: Si E 20,7 (aunque si N 500 basta con E 8,8), aplicar el estadístico del Resumen 8.1 con la cpc de Yates:
2
211 22 12 21
2
1 2 1 2
O O O O0 5 2 ij ij
Yij
TO E ,
TE F F C C
b) Test (óptimo) de homogeneidad en tablas 22: (SÍ USAR) Si E 14,9 (aunque cuando N 500, basta con que E 7,7):
2
1 22
1 21 2 1 2
1 sicon
2 si11 22 12 21
exp
O O O O c F F = T , c=
F FF F C C
c) Test (óptimo) de independencia en tablas 22: (SÍ USAR) Si E 6,2 (aun-que cuando N 500, basta con que E 3,9):
2
2
1 2 1 2
0 511 22 12 21
exp
O O O O , = T
F F C C
8.3 ASIGNACIÓN DE VALORES CUANTITATIVOS ARBITRARIOS a) Los métodos basados en datos cuantitativos (como los tests de Student) son
preferibles a los basados en datos cualitativos (como el test 2), pues dan lu-gar a tests más potentes.
b) Si una característica cualitativa es ordinal, es posible y preferible asignarle valores numéricos a sus clases y analizar los nuevos datos por la técnica cuantitativa apropiada (en lugar de por el test chi-cuadrado).
c) La asignación puede hacerse si el fenómeno estudiado hubiera podido medir-se en una escala continua (de haber dispuesto de los instrumentos adecuados) y si las clases obtenidas pueden considerarse como un agrupamiento de tal escala por medio de otra más burda formada por sus valores redondeados.
8.4 MEDIDAS DE ASOCIACIÓN EN TABLAS 22 Con frecuencia los dos caracteres dicotómicos estudiados (E y FR) suelen aludir a la presencia o no de una enfermedad o efecto indeseado (E o E ) y a la presencia o no de un factor de riesgo (FR o FR ). En lo que sigue se asume que la enfermedad se ubica en filas, el factor de riesgo en columnas y el SÍ en pri-mer lugar, obteniendo así unos datos como los de la Tabla R.8.2. a) Tipos de muestreo y tipos de estudio (epidemiológico): Para estudiar la
asociación entre E y FR los tipos de muestreo pueden ser dos y los tipos de

TEST CHI-CUADRADO Y TABLAS 22
21
estudio tres (en lo que sigue se utiliza el nombre que está subrayado): Tabla R.8.2
Formato estándar para los estudios epidemiológicos
Factor de riesgoEnfermedad SÍ = FR NO = FR Totales
SÍ = E
NO = E
O11 O21
O12 O22
F1 F2
Totales C1 C2 T
i) Muestreo de Tipo I (Estudio Transversal): Tomar T individuos al azar y clasificarlos en base a E y FR.
ii) Muestreo de Tipo II (Preferible al de Tipo I si las Fi o las Cj se planifican como iguales): Estudio Prospectivo, Longitudinal o de Seguimiento: Tomar C1 y C2 in-
dividuos al azar y clasificarlos en base a E. Estudio Retrospectivo o de Caso-Control: Tomar F1 y F2 individuos al
azar y clasificarlos en base a FR. Desde un punto de vista estadístico, el diseño óptimo consiste en tomar muestras de igual tamaño de los niveles de la característica cuya frecuencia dista más de 0,5 (en general la enfermedad: estudio retrospectivo).
b) Test apropiado (H0: E y FR son independientes): i) En el muestreo de Tipo I: Si E 6,2 (basta con E 3,9 si N 500):
2
2
1 2 1 2
0 511 22 12 21
exp
O O O O , = T
F F C C
ii) En el muestreo de Tipo II: Si E 14,9 (basta con E 7,7 si N 500):
2
2
1 2 1 2
11 22 12 21exp
O O O O c = T
F F C C
con:
Si Retrospectivo: 1 2
1 2
1 si
2 si
F Fc=
F F
; Si Prospectivo: 1 2
1 2
1 si
2 si
C Cc=
C C
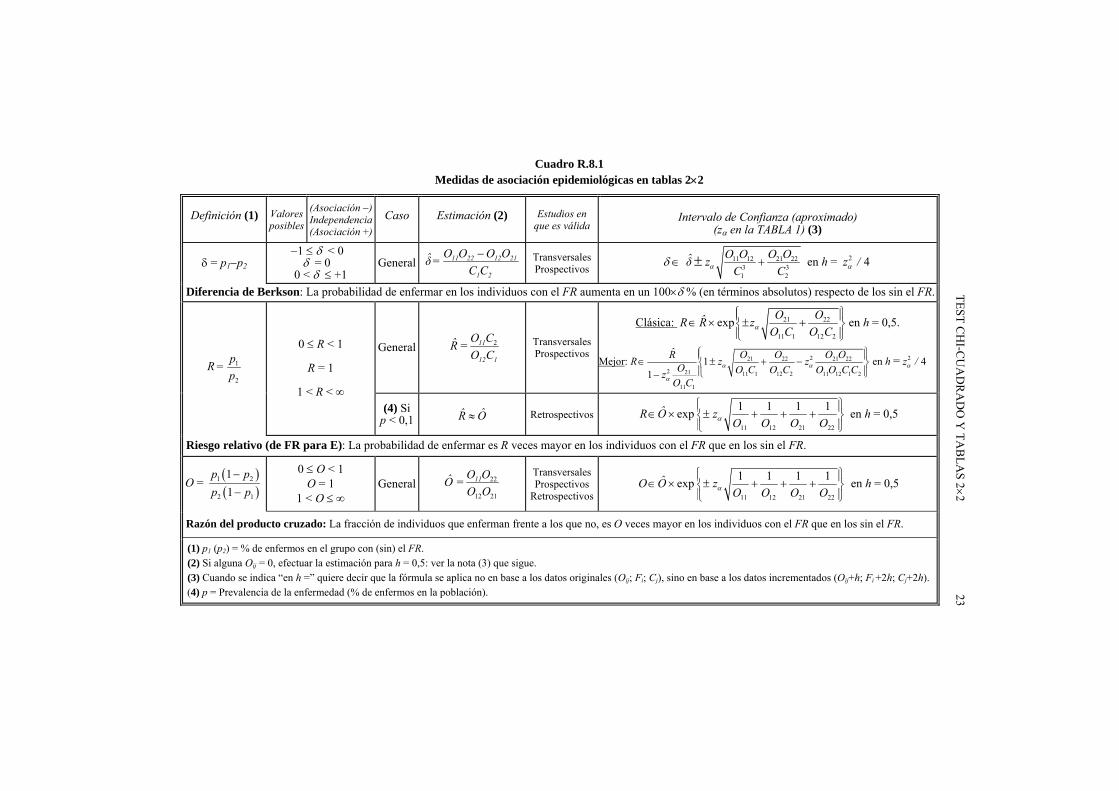
c) Medidas de asociación: Una medida de asociación es un número que indica el grado de dependencia existente entre los dos caracteres E y FR estudiados, pero la medida a usar depende del fin perseguido y su cálculo será lícito o no en función del muestreo utilizado. El Cuadro R.8.1 las resume (pero él es aplicable solo a datos en el formato de la Tabla R.8.2).
8.5 EVALUACIÓN DE UN MÉTODO DE DIAGNÓSTICO BINARIO Si en la Tabla R.8.2 se entiende que FR alude a que un test diagnóstico ha dado positivo (suceso D), se obtiene entonces la Tabla R.8.3. El objetivo es eva-luar la bondad del test. a) Tipos de muestreo: La tabla puede haberse obtenido de dos modos: i) Muestreo de Tipo I: T individuos al azar se clasifican en base a su estado real
y al resultado del test (estudio transversal del Resumen 8.4). ii) Muestreo de Tipo II: F1 enfermos y F2 sanos se clasifican en base al resulta-
do del test (estudio retrospectivo del Resumen 8.4).

TEST CHI-CUADRADO Y TABLAS 22
22
22
Tabla R.8.3 Resultados de un test diagnóstico en función del estado real del individuo
Resultado del test + ( D ) ( D )
Presencia de la enfermedad
SÍ (E) NO ( E )
O11 O21
O12 O22
F1 F2
C1 C2 T
b) Evaluación de la calidad de un test: Se basa en los porcentajes de aciertos SN y EP al diagnosticar a los enfermos y sanos respectivamente: SN = Sensibilidad = % de enfermos diagnosticados positivamente; FN = Falsos Negativos = % de enfermos diagnosticados negativamente; EP = Especificidad = % de sanos diagnosticados negativamente; FP = Falsos Positivos = % de sanos diagnosticados positivamente; en donde SN+FN=EP+FP = 100 (FP y FN aluden a fallos en el diagnóstico).
Tales parámetros son proporciones binomiales que se estiman puntual-mente (bajo cualquiera de los dos muestreos) por:
11 12 22 21
1 1 2 2
O O O OSN , FN = , E P , FP
F F F F
y por intervalo de confianza como en el Resumen 4.4.a). En base a ellos: i) Si EP es alta: el test es útil para afirmar la enfermedad (conviene aplicarlo
a individuos sospechosos de poseerla). ii) Si SN es alta: el test es útil para descartar la enfermedad (conviene apli-
carlo como procedimiento de rutina para el diagnóstico precoz de ella). c) Evaluación de la utilidad clínica de un test: Se basa en los % de aciertos de
los diagnósticos positivo o negativo (los de interés para el enfermo): VPP = Valor Predictivo Positivo = % de diagnósticos positivos que son correctos, VPN = Valor Predictivo Negativo = % de los diagnósticos negativos que son correctos,
cuyos valores que dependen de SN, EP y de la prevalencia p (% de enfermos) de la población a la que se esté aludiendo. Para estimarlos hay que contem-plar dos situaciones: i) Muestreo de Tipo I: Como son proporciones binomiales, se estiman por
intervalo de confianza como en el Resumen 4.4.a) y puntualmente por:
11 22
1 2
O OVPP , VPN =
C C
ii) Muestreo de Tipo II: No se pueden estimar hasta conocer la prevalencia p
de la población de interés, en cuyo caso (S y EP como en i)):
1 p EPp S
VPP = , VPN = p SN + 1 p 1 EP 1 p EP + p 1 SN
En base a tales valores (y para la prevalencia asumida): i) Si VPP es alto: el test es útil para afirmar la enfermedad. ii) Si VPN es alto: el test es útil para descartar la enfermedad.
TE
ST
CH
I-CU
AD
RA
DO
Y T
AB
LA
S 22 23
Cuadro R.8.1 Medidas de asociación epidemiológicas en tablas 22
Definición (1) Valores posibles
(Asociación )Independencia(Asociación +)
Caso Estimación (2) Estudios en que es válida
Intervalo de Confianza (aproximado) (z en la TABLA 1) (3)
= p1p2 1 < 0 = 0
0 < +1 General 11 22 12 21
1 2
O O O Oδ = C C
Transversales Prospectivos
δ 11 12 21 223 31 2
O O O Oz
C C en h = 2 4z /
Diferencia de Berkson: La probabilidad de enfermar en los individuos con el FR aumenta en un 100 % (en términos absolutos) respecto de los sin el FR.
General 211
12 1
O Cˆ R =O C
Transversales Prospectivos
Clásica: 21 22
11 1 12 2
expO OˆR R z
O C O C
en h = 0,5.
Mejor: 221 22 21 22
2 21 11 1 12 2 11 12 1 2
11 1
11
R O O O OR z z
O O C O C O O C CzO C
en h = 2 4z / 1
2
pR =
p
0 R < 1
R = 1
1 < R < (4) Si
p < 0,1ˆR O Retrospectivos
11 12 21 22
1 1 1 1expˆR O z
O O O O
en h = 0,5
Riesgo relativo (de FR para E): La probabilidad de enfermar es R veces mayor en los individuos con el FR que en los sin el FR.
O =
1 2
2 1
1
1
p p
p p
0 O < 1
O = 1 1 < O
General 22
12 21
11O OO =
O O
Transversales Prospectivos
Retrospectivos 11 12 21 22
1 1 1 1expˆO O z
O O O O
en h = 0,5
Razón del producto cruzado: La fracción de individuos que enferman frente a los que no, es O veces mayor en los individuos con el FR que en los sin el FR.
(1) p1 (p2) = % de enfermos en el grupo con (sin) el FR. (2) Si alguna Oij = 0, efectuar la estimación para h = 0,5: ver la nota (3) que sigue. (3) Cuando se indica “en h =” quiere decir que la fórmula se aplica no en base a los datos originales (Oij; Fi; Cj), sino en base a los datos incrementados (Oij+h; Fi +2h; Cj+2h). (4) p = Prevalencia de la enfermedad (% de enfermos en la población).

24
TE
ST
CH
I-CU
AD
RA
DO
Y T
AB
LA
S 22
23
RESUMEN DEL CAPÍTULO IX
REGRESIÓN LINEAL SIMPLE
9.1 INTRODUCCIÓN a) Objetivos: Dadas dos variables cuantitativas x e y medidas en los mismos in-
dividuos, la técnica de regresión puede perseguir tres objetivos: i) Estudiar si ambas variables están relacionadas o si son independientes. ii) Estudiar el tipo de relación que las liga (si existe). iii) Predecir los valores de una de ellas a partir de los de la otra.
b) Relaciones deterministas y aleatorias: En las Ciencias Exactas la relación entre dos variables es determinista (conocido el valor de una de ellas se co-noce exactamente el de la otra), pero en las Ciencias de la Salud la relación es aleatoria (conocido el valor de una variable se conoce el de la otra sólo de un modo aproximado). Ello sucede por dos causas: i) La variabilidad biológica de los individuos a estudiar. ii) La variabilidad aleatoria de los métodos utilizados al medir las dos varia-
bles implicadas. c) Sobre la existencia de regresión: Dadas n parejas de valores (xi; yi) obteni-
dos de una muestra, su representación por puntos en el plano cartesiano da lugar a una nube de puntos. Si a ella se ajusta alguna curva, se dice que existe regresión, a la curva se le llama línea de regresión y a la función que la re-presenta se le llama función de regresión. A la variable ubicada en el eje horizontal (usualmente x) se le llama variable independiente o controlada; a la ubicada en el eje vertical (usualmente y) se le llama variable dependiente.
d) Tipos de regresión: i) Regresión lineal simple (la de este capítulo): Si hay solo dos variables, x
e y, relacionadas entre sí mediante una línea recta. ii) Regresión curvilínea: Si hay sólo dos variables, x e y, relacionadas entre
sí mediante una línea curva. iii) Regresión múltiple: Si hay una variable objetivo y a relacionar con más
de una variable de apoyo x1, x2, … e) Asociación y causalidad: La demostración estadística de que dos variables
están asociadas no constituye una prueba de que una de ellas sea causa de la otra. Puede ocurrir: i) Que x sea realmente la causa de y. ii) Que ambas variables se influyan mutuamente. iii) Que ambas variables dependan de una causa común (una tercera variable
z no contemplada).

REGRESIÓN LINEAL SIMPLE
25
9.2 MODELO DE REGRESIÓN LINEAL SIMPLE Y SUS CONSE-CUENCIAS
a) Modelo: Para cada valor de x, la variable y sigue una distribución Normal de media x = +x y de varianza 2 constante (independiente de x). A x = +x se le llama recta de regresión poblacional, a altura en el origen po-blacional (altura en que corta la recta al eje vertical, es decir cuando x = 0), a pendiente poblacional (lo que aumenta la media de y cuando x aumenta en una unidad) y a 2 varianza de regresión poblacional (variabilidad de y alre-dedor de la recta de regresión). Las claves del modelo son pues: Normalidad, linealidad y homogeneidad de varianzas. Los parámetros poblacionales anteriores se estimarán por sus correspon-dientes parámetros muestrales = a (altura en el origen muestral), = b (pendiente muestral), 2 = s2 (varianza de regresión muestral) e y = a+bx (recta de regresión muestral), en donde el término “muestral” puede susti-tuirse por “experimental” o por “estimada”.
b) Predicciones y residuales: y = a+bx proporciona la predicción de y en ca-da valor de x, siendo di = yi iy los residuos o residuales (o error de la pre-dicción).
c) ¿Quién sobre quién?: Los parámetros anteriores se entiende que son ay·x, by·x y 2
y xs por haber sido obtenidos de la regresión de “y sobre x” (y en el eje ver-
tical; x en el horizontal). Los resultados no son los mismos (ax·y, bx·y y 2x ys ) si
en el eje horizontal se pone a la variable y y en el vertical la variable x (regre-sión de “x sobre y”). Se realizará la regresión de “y sobre x” cuando el objeti-vo sea predecir y a partir de x.
d) Tipos de muestreo: La obtención de las n parejas (xi; yi) pueden hacerse me-diante dos tipos de muestreo (es preferible el segundo), siendo la clave que los valores de yi deben obtenerse siempre al azar: i) Muestreo de Tipo I: Tomar n individuos al azar y anotar sus valores de x
e y. ii) Muestreo de Tipo II: Tomar n valores de x elegidos de antemano (que no
tienen porqué ser todos distintos) y obtener un valor de y al azar en cada uno de ellos.
El muestreo de Tipo I permite hacer las dos regresiones; el de Tipo II (que es preferible por controlar la variabilidad de los valores xi, que conviene que sea grande) sólo la de “y sobre x”. La predicción puntual de x en este último caso se hace por calibración lineal: x y / b a / b . En todo ca-so, las predicciones solo son válidas dentro del rango de muestreo (entre el valor mínimo y el valor máximo de xi).
e) Comprobación del modelo: Sea la nube de puntos normal que se obtiene al representar en el plano las n parejas de valores (xi, yi). Sea la nube de puntos de residuales que se obtiene al representar di = yi iy (en el eje vertical) con-tra iy (en el eje horizontal). Las tres condiciones del modelo de regresión se pueden verificar del siguiente modo (el basado en los residuales es mejor): i) Normalidad: No se verifica si la variable y es discreta o si el test de Nor-
malidad es significativo al aplicarlo a cada conjunto de observaciones y

26
TE
ST
CH
I-CU
AD
RA
DO
Y T
AB
LA
S 22
23
en cada x (lo que requiere de un muestreo con observaciones repetidas). ii) Linealidad: La nube de puntos normal ha de mostrar una tendencia ex-
clusivamente lineal. La de residuales ha de ser paralela al eje horizontal. Cuando esto no es así, a veces un cambio de escala apropiado puede convertir la curva en recta (linealización): cambiar x por log x, 1/x,
,x etc. y/o similarmente con y. iii) Homogeneidad de varianzas: La nube de puntos normal ha de ser ovala-
da, sin mostrar tendencia a ser más ancha o más estrecha con el aumento de x. La de residuales igual con el aumento de y .
9.3 ESTIMACIÓN DE LOS PARÁMETROS DEL MODELO DE RE-GRESIÓN LINEAL
Si (xi; yi), con i = 1, 2, ..., n, son n parejas de valores de (x; y) obtenidos por alguno de los tipos de muestreo anteriores, los estimadores a de y b de que dan lugar a la recta de regresión estimada y = a+bx se determinan por el princi-pio de los mínimos cuadrados, es decir haciendo que la suma de los cuadrados de las diferencias entre lo real (y) y lo estimado ( y ) -(yi y )2= (yiabxi)
2- sea lo más pequeña posible. El criterio ocasiona que tales estimadores y el esti-mador s2 de 2 sean:
b = xy
xx, a = y bx y 2 1
2
xys yy
n xx)
con:
(xx) = (xi x )2 = 2ix
2Σ ix
n
(yy) = (yi y )2 = 2iy
2Σ iy
n
(xy) = (xi x )(yi y ) = xiyi Σ Σi ix y
n
en donde la segunda expresión es la definición, la tercera su método abreviado de cálculo y la primera su símbolo corto para referencias.
9.4 INFERENCIAS EN REGRESIÓN LINEAL SIMPLE En los dos casos que siguen, t se busca en la Tabla 3 con (n2) g1:
a) Intervalo de confianza para la pendiente:
2sb t
xx .
b) Test de independencia (H0: = 0): Si la relación es lineal, comparar texp =
b
2
xx
s vs. t.

CORRELACIÓN
27
RESUMEN DEL CAPÍTULO X
CORRELACIÓN
10.1 INTRODUCCIÓN a) Objetivos: Dadas dos variables cuantitativas x e y cuyos valores (xi; yi) se
miden en los n individuos de una muestra, con i = 1,..., n, se trata de: i) Medir la fuerza con ambas variables que están relacionadas: mediante el
coeficiente de correlación. ii) Realizar el test de independencia entre ambas: mediante el contraste de
H0: “x e y son independientes” vs. H1: “x e y son dependientes”. b) Muestreo válido:
i) Para medir la fuerza: de Tipo I (los valores xi e yi se eligen al azar). ii) Para el test de independencia: de Tipo I o de Tipo II (los valores de xi o yi
están dados de antemano).
10.2 COEFICIENTE DE CORRELACIÓN LINEAL SIMPLE (O DE PEARSON): CORRELACIÓN PARAMÉTRICA a) Modelo, comprobación del modelo y valores de (xx), (xy) e (yy): Como en
los Resúmenes 9.2.a) y e) y 9.3. b) Estimación: La fuerza con que las dos variables están ligadas se mide me-
diante el coeficiente de correlación poblacional (lineal simple) , el cual se estima (en el muestreo I) por el coeficiente de correlación muestral ( = r):
xyr
xx yy .
c) Propiedades de (lo que sigue es válido también para r): i) 1 +1 es un número adimensional que no depende de las unidades
de medida ni del orden en que se enuncien las variables (xy=yx). ii) 2 es la proporción de la variabilidad total de y que está explicada por su
regresión lineal en x (el resto, 12, es la parte no explicada que depende de otras variables no contempladas en el problema).
iii) El valor absoluto mide la fuerza de relación entre x e y (a más más fuerza), en tanto que el signo de indica el sentido de la misma: po-sitiva si > 0 (a más x, más y), negativa si < 0 (a más x, menos y) o nu-la (es decir, x e y son independientes) si = 0.
iv) Cuanto más aplastada es una nube de puntos respecto de una misma recta de regresión, más grande es . Cuando tiene forma circular o es para-lela a uno de los ejes entonces = 0.
d) Test de independencia entre x e y (H0: = 0): Cualquiera que sea el mues-treo utilizado, comparar (test idéntico al del Resumen 9.4.b):
2
21exp
n rt =
r
vs. t (n2 gl) de la Tabla 3
e) ¿Regresión o correlación? Dadas dos variables (x, y) se utilizará la técnica de correlación si el único objetivo es saber si ambas están relacionadas y con qué fuerza. Se utilizará la técnica de regresión si lo que se desea es saber si están relacionadas y efectuar predicciones de una variable a partir de la otra. Es muy habitual simultanear ambos resultados.

CORRELACIÓN
28
28
10.3 COEFICIENTE DE CORRELACIÓN DE SPEARMAN: CORRE-LACIÓN NO PARAMÉTRICA
a) Objetivo: Medir la asociación entre dos variables cuantitativas cualesquiera. b) Modelo: Las dos variables pueden ser cualesquiera, pero la asociación entre
las mismas ha de ser monotónica (una variable siempre crece o siempre de-crece con la otra), lo que puede comprobarse a través de la nube de puntos.
c) Estimación: La fuerza de la asociación la mide el coeficiente de correlación poblacional de Spearman S, el cual se estima (en el muestreo I) por el coefi-ciente de correlación muestral S = rS que se obtiene como sigue:
(1) Obtener una muestra de n parejas de valores (xi; yi). (2) Ordenar de menor a mayor los valores de xi y asignarles rangos Ri como en
el Resumen 7.4.a). (3) Proceder igual con los valores de yi asignándoles rangos iR . (4) Anotar las parejas (Ri; iR ) correspondientes a las parejas (xi; yi) originales,
comprobando que Ri = iR = n(n+1)/2. (5) Obtener el coeficiente de correlación lineal simple para las n parejas de ran-
gos, es decir, y con igual convenio que en el Resumen 9.3,
S
RRr
RR R R
Cuando no hay empates, la fórmula anterior se simplifica en la siguiente:
2
1 61 1
i iS
R Rr =
n n n+
d) Propiedades: Como en el Resumen 10.2.c), pero relativas a los rangos. e) Test de independencia entre x e y (H0: S = 0): con cualquier muestreo:
i) Si n 30: Comparar rS con r de la Tabla 10 por el modo allí indicado. ii) Si n > 30: Comparar con z de la Tabla 1 la cantidad zexp = rS 1n .
10.4 TEST DE INDEPENDENCIA CON VARIABLES MIXTAS (H0: Los valores de un individuo con respecto a una variable cuantitativa x son in-dependientes de la clase a que este pertenece respecto de una cualidad C).
Sea x una variable cuantitativa cualquiera y C una cualidad con s clases. Si se toma una muestra de n individuos se obtendrán n parejas de valores (x; C) a partir de las cuales hay que contrastar H0. Los métodos para ello son: a) Si C es una cualidad ordinal: Convertir la cualidad en cantidad (asignándo-
le a sus clases valores cuantitativos arbitrarios y por el método del Resumen 8.3) y aplicar a las parejas (xi; yi) así obtenidas los Resúmenes 10.2 o 10.3.
b) Si C es una cualidad no ordinal: i) Si s = 2: Comparar los valores medios de x (1 y 2) en las dos clases de
C por el procedimiento de los Resúmenes 7.2.a), 7.3.a) o 7.4.b). ii) Si s > 2: Comparar los valores medios de x (1, 2, ..., s) en las s clases de
C por el procedimiento del análisis de la varianza (no contemplado en es-tos Resúmenes). Alternativamente, convertir la cantidad x en cualidad (definiendo r intervalos de clase arbitrarios), formar la tabla contingencia rs que ello produce y analizarla por la técnica de 2 del Resumen 8.1 (aunque ello conlleva una gran pérdida de potencia).

TABLAS
29
TABLAS DE BIOESTADÍSTICA
Pág.
Tabla 1 .... Distribución Normal típica (dos colas) ............................... 30
Tabla 2 .... 2.500 números aleatorios ..................................................... 31
Tabla 3 .... Distribución t de Student ...................................................... 32
Tabla 4 .... Límites de significación para el test de Normalidad deD’Agostino ........................................................................... 33
Tabla 5 .... Distribución F de Snedecor .................................................. 34
Tabla 6 .... Límites de significación para el test de Wilcoxon (dos muestras independientes) ............................................. 35
Tabla 7 .... Límites de significación para el test de Wilcoxon (dos muestras apareadas) ...................................................... 36
Tabla 8 .... Distribución de Bonferroni .................................................. 37
Tabla 9 .... Distribución 2 ..................................................................... 38
Tabla 10 .... Límites de significación para el coeficiente de correlación de Spearman ......................................................................... 39
REFERENCIAS
D'Agostino, R.B. and Stephens, M.A. (Eds) (1986). Goodness-of-fit Techniques. Marcel Dekker, Inc. New York.
Glasser, G.J. and Winter, R.E. (1961). Critical values of the coefficient of rank correla-tion for testing the hypothesis of independence. Biometrika 48, 444-448.
Ríos, S. (1967). Métodos estadísticos. Ediciones del Castillo. Madrid. Tukey, J.W. (1949). The simplest signed rank tests. Memorandum report nº 17 Statisti-
cal Research group. Princeton. New Jersey. White, C. (1952). The use of ranks in a test of significance for comparing two treat-
ments. Biometrics 8, 33-40.
TABLAS
30
30
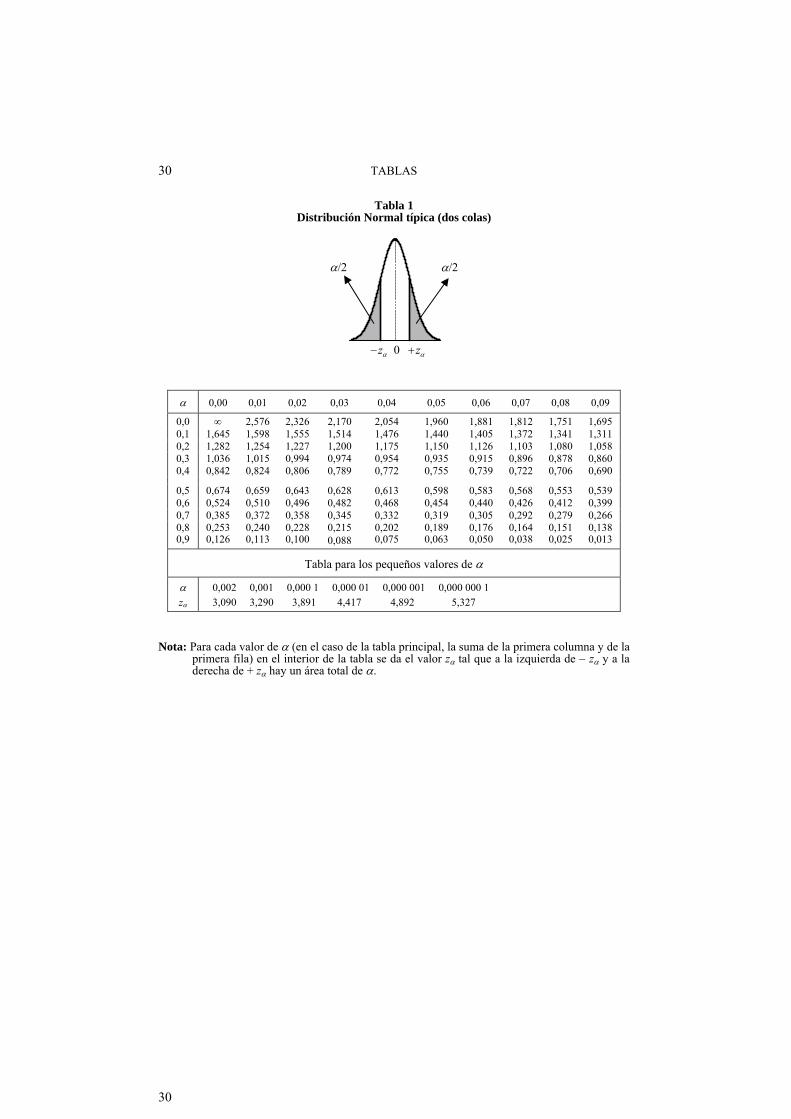
Tabla 1 Distribución Normal típica (dos colas)
0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
0,0 2,576 2,326 2,170 2,054 1,960 1,881 1,812 1,751 1,695 0,1 1,645 1,598 1,555 1,514 1,476 1,440 1,405 1,372 1,341 1,311 0,2 1,282 1,254 1,227 1,200 1,175 1,150 1,126 1,103 1,080 1,058 0,3 1,036 1,015 0,994 0,974 0,954 0,935 0,915 0,896 0,878 0,860 0,4 0,842 0,824 0,806 0,789 0,772 0,755 0,739 0,722 0,706 0,690
0,5 0,674 0,659 0,643 0,628 0,613 0,598 0,583 0,568 0,553 0,539 0,6 0,524 0,510 0,496 0,482 0,468 0,454 0,440 0,426 0,412 0,399 0,7 0,385 0,372 0,358 0,345 0,332 0,319 0,305 0,292 0,279 0,266 0,8 0,253 0,240 0,228 0,215 0,202 0,189 0,176 0,164 0,151 0,138 0,9 0,126 0,113 0,100 0,088 0,075 0,063 0,050 0,038 0,025 0,013
Tabla para los pequeños valores de
0,002 0,001 0,000 1 0,000 01 0,000 001 0,000 000 1
z 3,090 3,290 3,891 4,417 4,892 5,327
Nota: Para cada valor de (en el caso de la tabla principal, la suma de la primera columna y de la primera fila) en el interior de la tabla se da el valor z tal que a la izquierda de z y a la derecha de + z hay un área total de .
z 0 z
/2 /2
TABLAS
31
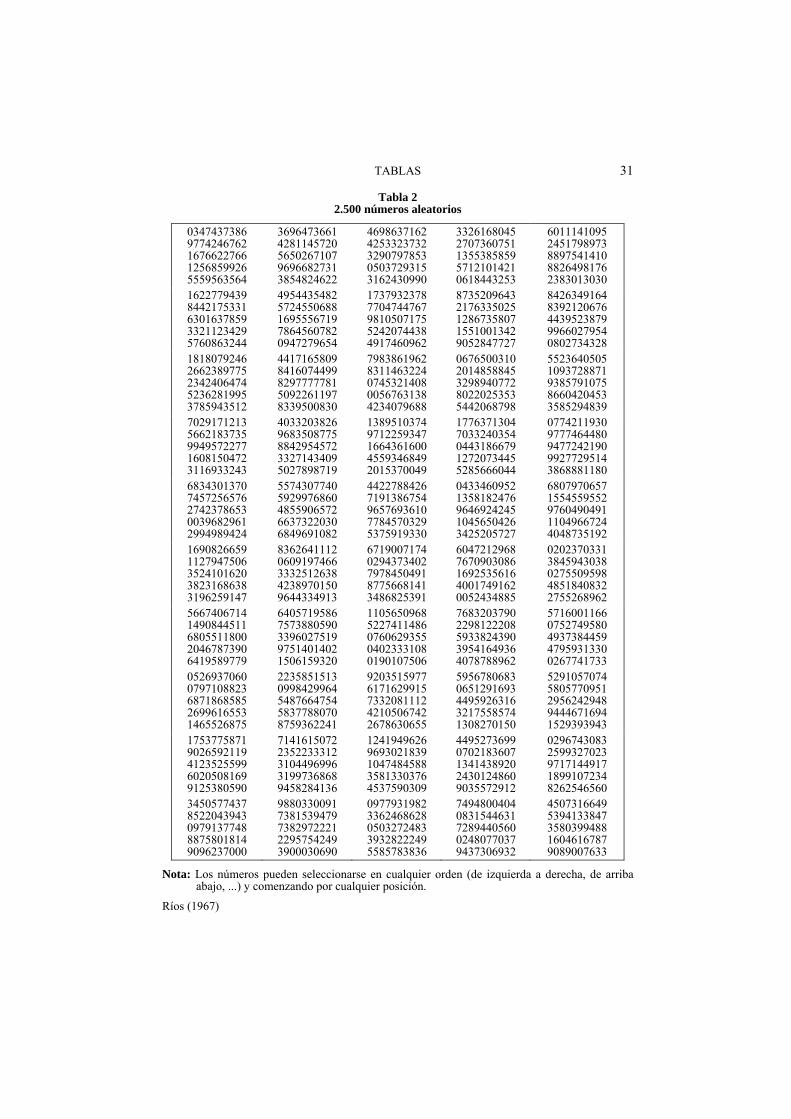
Tabla 2 2.500 números aleatorios
0347437386 9774246762 1676622766 1256859926 5559563564
3696473661 4281145720 5650267107 9696682731 3854824622
4698637162 4253323732 3290797853 0503729315 3162430990
3326168045 2707360751 1355385859 5712101421 0618443253
6011141095 2451798973 8897541410 8826498176 2383013030
1622779439 8442175331 6301637859 3321123429 5760863244
4954435482 5724550688 1695556719 7864560782 0947279654
1737932378 7704744767 9810507175 5242074438 4917460962
8735209643 2176335025 1286735807 1551001342 9052847727
8426349164 8392120676 4439523879 9966027954 0802734328
1818079246 2662389775 2342406474 5236281995 3785943512
4417165809 8416074499 8297777781 5092261197 8339500830
7983861962 8311463224 0745321408 0056763138 4234079688
0676500310 2014858845 3298940772 8022025353 5442068798
5523640505 1093728871 9385791075 8660420453 3585294839
7029171213 5662183735 9949572277 1608150472 3116933243
4033203826 9683508775 8842954572 3327143409 5027898719
1389510374 9712259347 1664361600 4559346849 2015370049
1776371304 7033240354 0443186679 1272073445 5285666044
0774211930 9777464480 9477242190 9927729514 3868881180
6834301370 7457256576 2742378653 0039682961 2994989424
5574307740 5929976860 4855906572 6637322030 6849691082
4422788426 7191386754 9657693610 7784570329 5375919330
0433460952 1358182476 9646924245 1045650426 3425205727
6807970657 1554559552 9760490491 1104966724 4048735192
1690826659 1127947506 3524101620 3823168638 3196259147
8362641112 0609197466 3332512638 4238970150 9644334913
6719007174 0294373402 7978450491 8775668141 3486825391
6047212968 7670903086 1692535616 4001749162 0052434885
0202370331 3845943038 0275509598 4851840832 2755268962
5667406714 1490844511 6805511800 2046787390 6419589779
6405719586 7573880590 3396027519 9751401402 1506159320
1105650968 5227411486 0760629355 0402333108 0190107506
7683203790 2298122208 5933824390 3954164936 4078788962
5716001166 0752749580 4937384459 4795931330 0267741733
0526937060 0797108823 6871868585 2699616553 1465526875
2235851513 0998429964 5487664754 5837788070 8759362241
9203515977 6171629915 7332081112 4210506742 2678630655
5956780683 0651291693 4495926316 3217558574 1308270150
5291057074 5805770951 2956242948 9444671694 1529393943
1753775871 9026592119 4123525599 6020508169 9125380590
7141615072 2352233312 3104496996 3199736868 9458284136
1241949626 9693021839 1047484588 3581330376 4537590309
4495273699 0702183607 1341438920 2430124860 9035572912
0296743083 2599327023 9717144917 1899107234 8262546560
3450577437 8522043943 0979137748 8875801814 9096237000
9880330091 7381539479 7382972221 2295754249 3900030690
0977931982 3362468628 0503272483 3932822249 5585783836
7494800404 0831544631 7289440560 0248077037 9437306932
4507316649 5394133847 3580399488 1604616787 9089007633
Nota: Los números pueden seleccionarse en cualquier orden (de izquierda a derecha, de arriba abajo, ...) y comenzando por cualquier posición.
Ríos (1967)
TABLAS
32
32
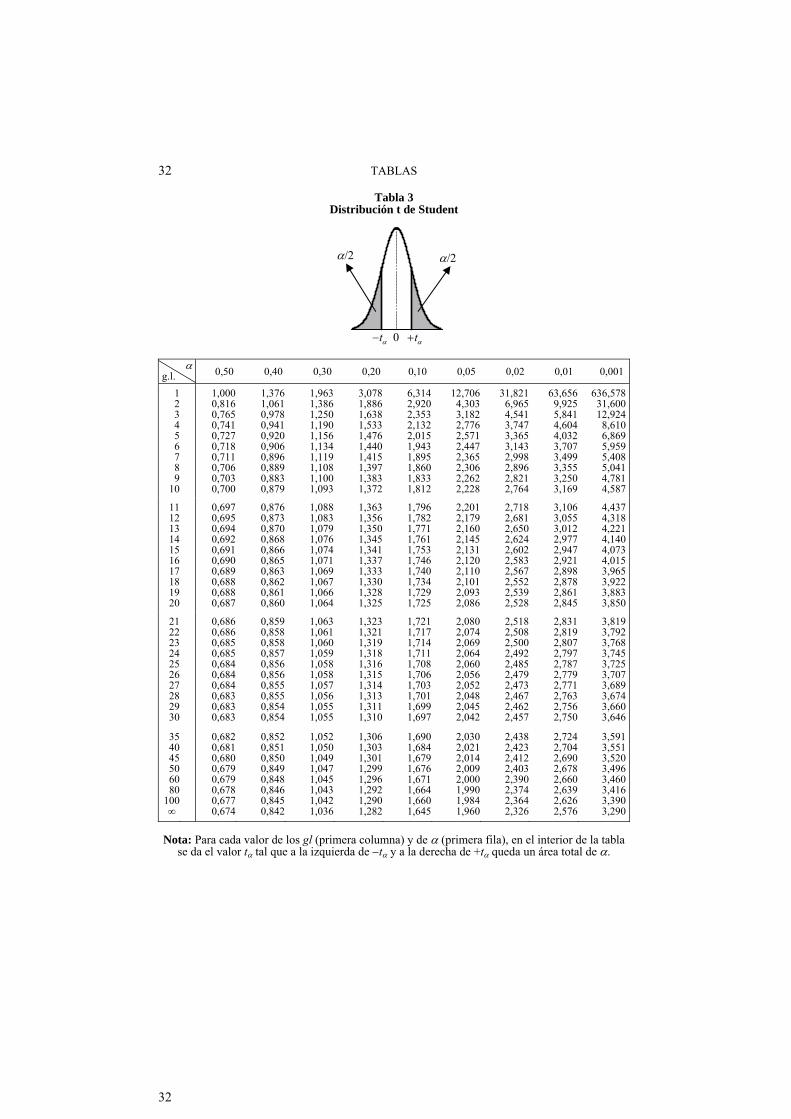
Tabla 3 Distribución t de Student
g.l. 0,50 0,40 0,30 0,20 0,10 0,05 0,02 0,01 0,001
1 2 3 4 5 6 7 8 9
10
1,0000,8160,7650,7410,7270,7180,7110,7060,7030,700
1,376 1,061 0,978 0,941 0,920 0,906 0,896 0,889 0,883 0,879
1,9631,3861,2501,1901,1561,1341,1191,1081,1001,093
3,0781,8861,6381,5331,4761,4401,4151,3971,3831,372
6,3142,9202,3532,1322,0151,9431,8951,8601,8331,812
12,7064,3033,1822,7762,5712,4472,3652,3062,2622,228
31,8216,9654,5413,7473,3653,1432,9982,8962,8212,764
63,656 9,925 5,841 4,604 4,032 3,707 3,499 3,355 3,250 3,169
636,578 31,600 12,924
8,610 6,869 5,959 5,408 5,041 4,781 4,587
11 12 13 14 15 16 17 18 19 20
0,6970,6950,6940,6920,6910,6900,6890,6880,6880,687
0,876 0,873 0,870 0,868 0,866 0,865 0,863 0,862 0,861 0,860
1,0881,0831,0791,0761,0741,0711,0691,0671,0661,064
1,3631,3561,3501,3451,3411,3371,3331,3301,3281,325
1,7961,7821,7711,7611,7531,7461,7401,7341,7291,725
2,2012,1792,1602,1452,1312,1202,1102,1012,0932,086
2,7182,6812,6502,6242,6022,5832,5672,5522,5392,528
3,106 3,055 3,012 2,977 2,947 2,921 2,898 2,878 2,861 2,845
4,437 4,318 4,221 4,140 4,073 4,015 3,965 3,922 3,883 3,850
21 22 23 24 25 26 27 28 29 30
0,6860,6860,6850,6850,6840,6840,6840,6830,6830,683
0,859 0,858 0,858 0,857 0,856 0,856 0,855 0,855 0,854 0,854
1,0631,0611,0601,0591,0581,0581,0571,0561,0551,055
1,3231,3211,3191,3181,3161,3151,3141,3131,3111,310
1,7211,7171,7141,7111,7081,7061,7031,7011,6991,697
2,0802,0742,0692,0642,0602,0562,0522,0482,0452,042
2,5182,5082,5002,4922,4852,4792,4732,4672,4622,457
2,831 2,819 2,807 2,797 2,787 2,779 2,771 2,763 2,756 2,750
3,819 3,792 3,768 3,745 3,725 3,707 3,689 3,674 3,660 3,646
35 40 45 50 60 80
100
0,6820,6810,6800,6790,6790,6780,6770,674
0,852 0,851 0,850 0,849 0,848 0,846 0,845 0,842
1,0521,0501,0491,0471,0451,0431,0421,036
1,3061,3031,3011,2991,2961,2921,2901,282
1,6901,6841,6791,6761,6711,6641,6601,645
2,0302,0212,0142,0092,0001,9901,9841,960
2,4382,4232,4122,4032,3902,3742,3642,326
2,724 2,704 2,690 2,678 2,660 2,639 2,626 2,576
3,591 3,551 3,520 3,496 3,460 3,416 3,390 3,290
Nota: Para cada valor de los gl (primera columna) y de (primera fila), en el interior de la tabla
se da el valor t tal que a la izquierda de t y a la derecha de +t queda un área total de .
t 0 t
/2 /2

TABLAS
33
Tabla 4
Límites de significación para el test de Normalidad de D’Agostino
n
0,20 0,10 0,05 0,02 0, 01
10 12 14 16 18
0,2632 - 0,2835 0,2653 - 0,2841 0,2669 - 0,2846 0,2681 - 0,2848 0,2690 - 0,2850
0,2573 - 0,2843 0,2598 - 0,2849 0,2618 - 0,2853 0,2634 - 0,2855 0,2646 - 0,2857
0,2513 - 0,2849 0,2544 - 0,2854 0,2568 - 0,2858 0,2587 - 0,2860 0,2603 - 0,2862
0,2436 - 0,2855 0,2473 - 0,2859 0,2503 - 0,2862 0,2527 - 0,2865 0,2547 - 0,2866
0,2379 - 0,2857 0,2420 - 0,2862 0,2455 - 0,2865 0,2482 - 0,2867 0,2505 - 0,2868
20 22 24 26 28
0,2699 - 0,2852 0,2705 - 0,2853 0,2711 - 0,2853 0,2717 - 0,2854 0,2721 - 0,2854
0,2657 - 0,2859 0,2667 - 0,2860 0,2675 - 0,2861 0,2682 - 0,2861 0,2688 - 0,2861
0,2617 - 0,2863 0,2629 - 0,2864 0,2639 - 0,2865 0,2647 - 0,2866 0,2655 - 0,2866
0,2564 - 0,2867 0,2579 - 0,2869 0,2591 - 0,2869 0,2603 - 0,2870 0,2612 - 0,2870
0,2525 - 0,2869 0,2542 - 0,2870 0,2557 - 0,2871 0,2570 - 0,2872 0,2581 - 0,2873
30 32 34 36 38
0,2725 - 0,2854 0,2729 - 0,2854 0,2732 - 0,2854 0,2735 - 0,2854 0,2738 - 0,2854
0,2693 - 0,2862 0,2698 - 0,2862 0,2703 - 0,2862 0,2707 - 0,2862 0,2710 - 0,2862
0,2662 - 0,2866 0,2668 - 0,2867 0,2674 - 0,2867 0,2679 - 0,2367 0,2683 - 0,2867
0,2622 - 0,2871 0,2630 - 0,2871 0,2636 - 0,2871 0,2643 - 0,2871 0,2649 - 0,2871
0,2592 - 0,2872 0,2600 - 0,2873 0,2609 - 0,2873 0,2617 - 0,2873 0,2623 - 0,2873
40 42 44 46 48
0,2740 - 0,2854 0,2743 - 0,2854 0,2745 - 0,2854 0,2747 - 0,2854 0,2749 - 0,2854
0,2714 - 0,2862 0,2717 - 0,2861 0,2720 - 0,2861 0,2722 - 0,2861 0,2725 - 0,2861
0,2688 - 0,2867 0,2691 - 0,2867 0,2695 - 0,2867 0,2698 - 0,2866 0,2702 - 0,2866
0,2655 - 0,2871 0,2659 - 0,2871 0,2664 - 0,2871 0,2668 - 0,2871 0,2672 - 0,2871
0,2630 - 0,2874 0,2636 - 0,2874 0,2641 - 0,2874 0,2646 - 0,2874 0,2651 - 0,2874
50 60 70 80 90
0,2751 - 0,2853 0,2757 - 0,2852 0,2763 - 0,2851 0,2768 - 0,2850 0,2771 - 0,2849
0,2727 - 0,2861 0,2737 - 0,2860 0,2744 - 0,2859 0,2750 - 0,2857 0,2756 - 0,2856
0,2705 - 0,2866 0,2717 - 0,2865 0,2726 - 0,2864 0,2734 - 0,2863 0,2741 - 0,2861
0,2676 - 0,2871 0,2692 - 0,2870 0,2704 - 0,2869 0,2713 - 0,2868 0,2721 - 0,2866
0,2655 - 0,2874 0,2673 - 0,2873 0,2687 - 0,2872 0,2698 - 0,2871 0,2707 - 0,2870
100 120 140 150 160 180
0,2774 - 0,2849 0,2779 - 0,2847 0,2782 - 0,2846 0,2784 - 0,2845 0,2785 - 0,2845 0,2787 - 0,2844
0,2759 - 0,2855 0,2765 - 0,2853 0,2770 - 0,2852 0,2772 - 0,2851 0,2774 - 0,2851 0,2777 - 0,2850
0,2745 - 0,2860 0,2752 - 0,2858 0,2758 - 0,2856 0,2761 - 0,2856 0,2763 - 0,2855 0,2767 - 0,2854
0,2727 - 0,2865 0,2737 - 0,2863 0,2744 - 0,2862 0,2747 - 0,2861 0,2750 - 0,2860 0,2755 - 0,2859
0,2714 - 0,2869 0,2725 - 0,2866 0,2734 - 0,2865 0,2737 - 0,2864 0,2741 - 0,2863 0,2745 - 0,2862
200 250 300 350 400 450
0,2789 - 0,2843 0,2793 - 0,2841 0,2796 - 0 2840 0,2798 - 0:2839 0,2799 - 0,2838 0,2801 - 0,2837
0,2779 - 0,2848 0,2784 - 0,2846 0,2788 - 0,2844 0,2791 - 0,2843 0,2793 - 0,2842 0,2795 - 0,2841
0,2770 - 0,2853 0,2776 - 0,2850 0,2781 - 0,2847 0,2784 - 0,2847 0,2787 - 0,2845 0,2789 - 0,2844
0,2759 - 0,2857 0,2767 - 0,2855 0,2772 - 0,2853 0,2776 - 0,2851 0,2780 - 0,2849 0,2782 - 0,2848
0,2751 - 0,2860 0,2760 - 0,2857 0,2766 - 0,2855 0,2771 - 0,2853 0,2775 - 0,2852 0,2778 - 0,2850
500 550 600 650 700 750
0,2802 - 0,2836 0,2803 - 0,2835 0,2804 - 0,2835 0,2804 - 0,2834 0,2805 - 0,2834 0,2806 - 0,2834
0,2796 - 0,2840 0,2797 - 0,2839 0,2799 - 0,2839 0,2799 - 0,2838 0,2800 - 0,2837 0,2801 - 0,2837
0,2791 - 0,2843 0,2792 - 0,2842 0,2794 - 0,2842 0,2795 - 0,2841 0,2796 - 0,2840 0,2797 - 0,2840
0,2785 - 0,2847 0,2787 - 0,2846 0,2788 - 0,2845 0,2790 - 0,2844 0,2791 - 0,2844 0,2792 - 0,2843
0,2780 - 0,2849 0,2782 - 0,2848 0,2784 - 0,2847 0,2786 - 0,2846 0,2787 - 0,2846 0,2789 - 0,2845
800 850 900 950
0,2806 - 0,2833 0,2807 - 0,2833 0,2807 - 0,2833 0,2807 - 0,2832
0,2802 - 0,2837 0,2802 - 0,2836 0,2803 - 0,2836 0,2803 - 0,2835
0,2798 - 0,2839 0,2799 - 0,2839 0,2799 - 0,2838 0,2800 - 0,2838
0,2793 - 0,2842 0,2794 - 0,2842 0,2795 - 0,2841 0,2796 - 0,2841
0,2790 - 0,2844 0,2791 - 0,2844 0,2792 - 0,2843 0,2793 - 0,2843
1000 1250 1500 1750 2000
0,2808 - 0,2832 0,2809 - 0,2831 0,2810 - 0,2830 0,2811 - 0,2830 0,2812 - 0,2829
0,2804 - 0,2835 0,2806 - 0,2834 0,2807 - 0,2833 0,2808 - 0,2832 0,2809 - 0,2831
0,2800 - 0,2838 0,2803 - 0,2836 0,2805 - 0,2835 0,2806 - 0,2834 0,2807 - 0,2833
0,2796 - 0,2840 0,2799 - 0,2839 0,2801 - 0,2837 0,2803 - 0,2836 0,2804 - 0,2835
0,2793 - 0,2842 0,2797 - 0,2840 0,2799 - 0,2839 0,2801 - 0,2838 0,2802 - 0,2837
Nota: Para cada tamaño de muestra n (primera columna) y para cada nivel de significación (primera fila), en el interior de la tabla se dan dos números (DI - DS) tales que si el estadístico Dexp de D’Agostino verifica que Dexp DI o Dexp DS, entonces se rechaza la hipótesis nula de Normalidad.
D’Agostino and Stephens (1986).
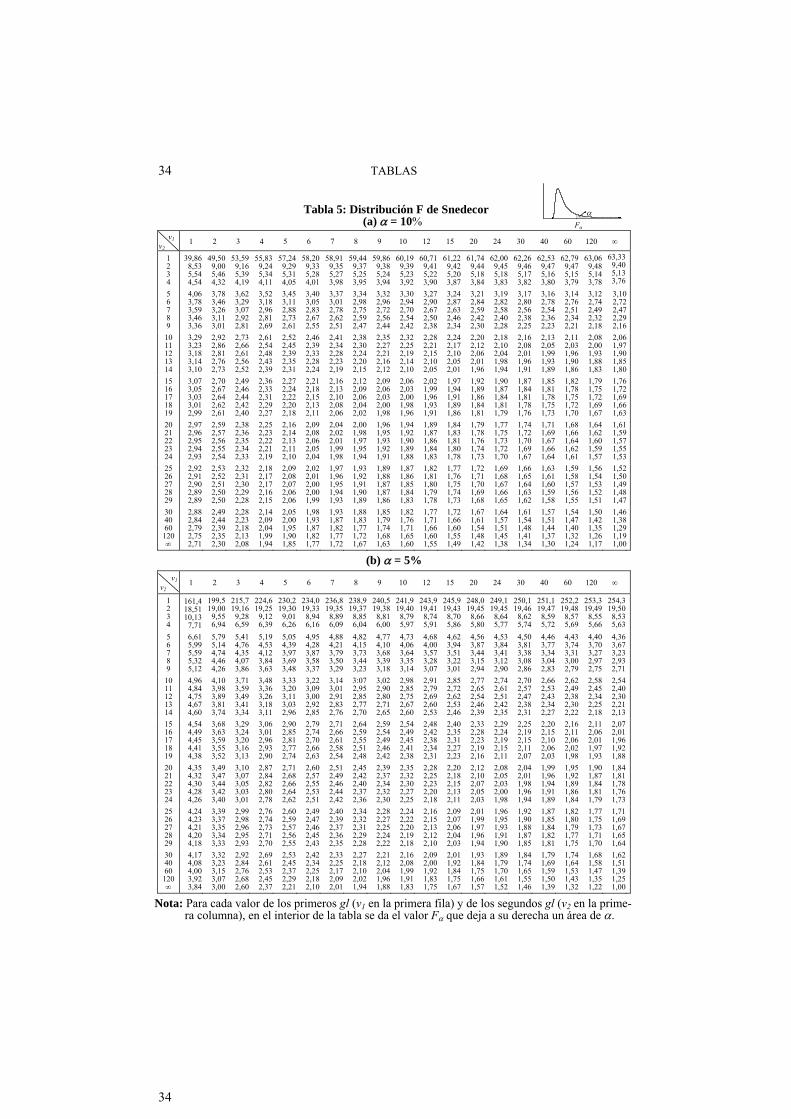
TABLAS
34
34
Tabla 5: Distribución F de Snedecor
(a) = 10%
v1
v2 1 2 3 4 5 6 7 8 9 10 12 15 20 24 30 40 60 120
1 2 3 4
39,86 8,53 5,54 4,54
49,50 9,00 5,46 4,32
53,59 9,16 5,39 4,19
55,83 9,24 5,34 4,11
57,24 9,29 5,31 4,05
58,20 9,33 5,28 4,01
58,919,355,273,98
59,449,375,253,95
59,869,385,243,94
60,199,395,233,92
60,719,415,223,90
61,229,425,203,87
61,749,445,183,84
62,009,455,183,83
62,269,465,173,82
62,539,475,163,80
62,79 9,47 5,15 3,79
63,06 9,48 5,14 3,78
63,33 9,40 5,13 3,76
5 6 7 8 9
4,06 3,78 3,59 3,46 3,36
3,78 3,46 3,26 3,11 3,01
3,62 3,29 3,07 2,92 2,81
3,52 3,18 2,96 2,81 2,69
3,45 3,11 2,88 2,73 2,61
3,40 3,05 2,83 2,67 2,55
3,373,012,782,622,51
3,342,982,752,592,47
3,322,962,722,562,44
3,302,942,702,542,42
3,272,902,672,502,38
3,242,872,632,462,34
3,212,842,592,422,30
3,192,822,582,402,28
3,172,802,562,382,25
3,162,782,542,362,23
3,14 2,76 2,51 2,34 2,21
3,12 2,74 2,49 2,32 2,18
3,102,722,472,292,16
10 11 12 13 14
3,29 3,23 3,18 3,14 3,10
2,92 2,86 2,81 2,76 2,73
2,73 2,66 2,61 2,56 2,52
2,61 2,54 2,48 2,43 2,39
2,52 2,45 2,39 2,35 2,31
2,46 2,39 2,33 2,28 2,24
2,412,342,282,232,19
2,382,302,242,202,15
2,352,272,212,162,12
2,322,252,192,142,10
2,282,212,152,102,05
2,242,172,102,052,01
2,202,122,062,011,96
2,182,102,041,981,94
2,162,082,011,961,91
2,132,051,991,931,89
2,11 2,03 1,96 1,90 1,86
2,08 2,00 1,93 1,88 1,83
2,061,971,901,851,80
15 16 17 18 19
3,07 3,05 3,03 3,01 2,99
2,70 2,67 2,64 2,62 2,61
2,49 2,46 2,44 2,42 2,40
2,36 2,33 2,31 2,29 2,27
2,27 2,24 2,22 2,20 2,18
2,21 2,18 2,15 2,13 2,11
2,162,132,102,082,06
2,122,092,062,042,02
2,092,062,032,001,98
2,062,032,001,981,96
2,021,991,961,931,91
1,971,941,911,891,86
1,921,891,861,841,81
1,901,871,841,811,79
1,871,841,811,781,76
1,851,811,781,751,73
1,82 1,78 1,75 1,72 1,70
1,79 1,75 1,72 1,69 1,67
1,761,721,691,661,63
20 21 22 23 24
2,97 2,96 2,95 2,94 2,93
2,59 2,57 2,56 2,55 2,54
2,38 2,36 2,35 2,34 2,33
2,25 2,23 2,22 2,21 2,19
2,16 2,14 2,13 2,11 2,10
2,09 2,08 2,06 2,05 2,04
2,042,022,011,991,98
2,001,981,971,951,94
1,961,951,931,921,91
1,941,921,901,891,88
1,891,871,861,841,83
1,841,831,811,801,78
1,791,781,761,741,73
1,771,751,731,721,70
1,741,721,701,691,67
1,711,691,671,661,64
1,68 1,66 1,64 1,62 1,61
1,64 1,62 1,60 1,59 1,57
1,611,591,571,551,53
25 26 27 28 29
2,92 2,91 2,90 2,89 2,89
2,53 2,52 2,51 2,50 2,50
2,32 2,31 2,30 2,29 2,28
2,18 2,17 2,17 2,16 2,15
2,09 2,08 2,07 2,06 2,06
2,02 2,01 2,00 2,00 1,99
1,971,961,951,941,93
1,931,921,911,901,89
1,891,881,871,871,86
1,871,861,851,841,83
1,821,811,801,791,78
1,771,761,751,741,73
1,721,711,701,691,68
1,691,681,671,661,65
1,661,651,641,631,62
1,631,611,601,591,58
1,59 1,58 1,57 1,56 1,55
1,56 1,54 1,53 1,52 1,51
1,521,501,491,481,47
30 40 60 120
2,88 2,84 2,79 2,75 2,71
2,49 2,44 2,39 2,35 2,30
2,28 2,23 2,18 2,13 2,08
2,14 2,09 2,04 1,99 1,94
2,05 2,00 1,95 1,90 1,85
1,98 1,93 1,87 1,82 1,77
1,931,871,821,771,72
1,881,831,771,721,67
1,851,791,741,681,63
1,821,761,711,651,60
1,771,711,661,601,55
1,721,661,601,551,49
1,671,611,541,481,42
1,641,571,511,451,38
1,611,541,481,411,34
1,571,511,441,371,30
1,54 1,47 1,40 1,32 1,24
1,50 1,42 1,35 1,26 1,17
1,461,381,291,191,00
(b) = 5% v1
v2 1 2 3 4 5 6 7 8 9 10 12 15 20 24 30 40 60 120
1 2 3 4
161,4 18,51 10,13 7,71
199,5 19,00 9,55 6,94
215,7 19,16 9,28 6,59
224,6 19,25 9,12 6,39
230,2 19,30 9,01 6,26
234,0 19,33 8,94 6,16
236,819,358,896,09
238,919,378,856,04
240,519,388,816,00
241,919,408,795,97
243,919,418,745,91
245,919,438,705,86
248,019,458,665,80
249,119,458,645,77
250,119,468,625,74
251,119,478,595,72
252,2 19,48 8,57 5,69
253,3 19,49 8,55 5,66
254,3 19,50 8,53 5,63
5 6 7 8 9
6,61 5,99 5,59 5,32 5,12
5,79 5,14 4,74 4,46 4,26
5,41 4,76 4,35 4,07 3,86
5,19 4,53 4,12 3,84 3,63
5,05 4,39 3,97 3,69 3,48
4,95 4,28 3,87 3,58 3,37
4,884,213,793,503,29
4,824,153,733,443,23
4,774,103,683,393,18
4,734,063,643,353,14
4,684,003,573,283,07
4,623,943,513,223,01
4,563,873,443,152,94
4,533,843,413,122,90
4,503,813,383,082,86
4,463,773,343,042,83
4,43 3,74 3,31 3,00 2,79
4,40 3,70 3,27 2,97 2,75
4,36 3,67 3,23 2,93 2,71
10 11 12 13 14
4,96 4,84 4,75 4,67 4,60
4,10 3,98 3,89 3,81 3,74
3,71 3,59 3,49 3,41 3,34
3,48 3,36 3,26 3,18 3,11
3,33 3,20 3,11 3,03 2,96
3,22 3,09 3,00 2,92 2,85
3,143,012,912,832,76
3:072,952,852,772,70
3,022,902,802,712,65
2,982,852,752,672,60
2,912,792,692,602,53
2,852,722,622,532,46
2,772,652,542,462,39
2,742,612,512,422,35
2,702,572,472,382,31
2,662,532,432,342,27
2,62 2,49 2,38 2,30 2,22
2,58 2,45 2,34 2,25 2,18
2,54 2,40 2,30 2,21 2,13
15 16 17 18 19
4,54 4,49 4,45 4,41 4,38
3,68 3,63 3,59 3,55 3,52
3,29 3,24 3,20 3,16 3,13
3,06 3,01 2,96 2,93 2,90
2,90 2,85 2,81 2,77 2,74
2,79 2,74 2,70 2,66 2,63
2,712,662,612,582,54
2,642,592,552,512,48
2,592,542,492,462,42
2,542,492,452,412,38
2,482,422,382,342,31
2,402,352,312,272,23
2,332,282,232,192,16
2,292,242,192,152,11
2,252,192,152,112,07
2,202,152,102,062,03
2,16 2,11 2,06 2,02 1,98
2,11 2,06 2,01 1,97 1,93
2,07 2,01 1,96 1,92 1,88
20 21 22 23 24
4,35 4,32 4,30 4,28 4,26
3,49 3,47 3,44 3,42 3,40
3,10 3,07 3,05 3,03 3,01
2,87 2,84 2,82 2,80 2,78
2,71 2,68 2,66 2,64 2,62
2,60 2,57 2,55 2,53 2,51
2,512,492,462,442,42
2,452,422,402,372,36
2,392,372,342,322,30
2,352,322,302,272,25
2,282,252,232,202,18
2,202,182,152,132,11
2,122,102,072,052,03
2,082,052,032,001,98
2,042,011,981,961,94
1,991,961,941,911,89
1,95 1,92 1,89 1,86 1,84
1,90 1,87 1,84 1,81 1,79
1,84 1,81 1,78 1,76 1,73
25 26 27 28 29
4,24 4,23 4,21 4,20 4,18
3,39 3,37 3,35 3,34 3,33
2,99 2,98 2,96 2,95 2,93
2,76 2,74 2,73 2,71 2,70
2,60 2,59 2,57 2,56 2,55
2,49 2,47 2,46 2,45 2,43
2,402,392,372,362,35
2,342,322,312,292,28
2,282,272,252,242,22
2,242,222,202,192,18
2,162,152,132,122,10
2,092,072,062,042,03
2,011,991,971,961,94
1,961,951,931,911,90
1,921,901,881,871,85
1,871,851,841,821,81
1,82 1,80 1,79 1,77 1,75
1,77 1,75 1,73 1,71 1,70
1,71 1,69 1,67 1,65 1,64
30 40 60 120
4,17 4,08 4,00 3,92 3,84
3,32 3,23 3,15 3,07 3,00
2,92 2,84 2,76 2,68 2,60
2,69 2,61 2,53 2,45 2,37
2,53 2,45 2,37 2,29 2,21
2,42 2,34 2,25 2,18 2,10
2,332,252,172,092,01
2,272,182,102,021,94
2,212,122,041,961,88
2,162,081,991,911,83
2,092,001,921,831,75
2,011,921,841,751,67
1,931,841,751,661,57
1,891,791,701,611,52
1,841,741,651,551,46
1,791,691,591,501,39
1,74 1,64 1,53 1,43 1,32
1,68 1,58 1,47 1,35 1,22
1,62 1,51 1,39 1,25 1,00
Nota: Para cada valor de los primeros gl (v1 en la primera fila) y de los segundos gl (v2 en la prime-ra columna), en el interior de la tabla se da el valor F que deja a su derecha un área de .
Fα
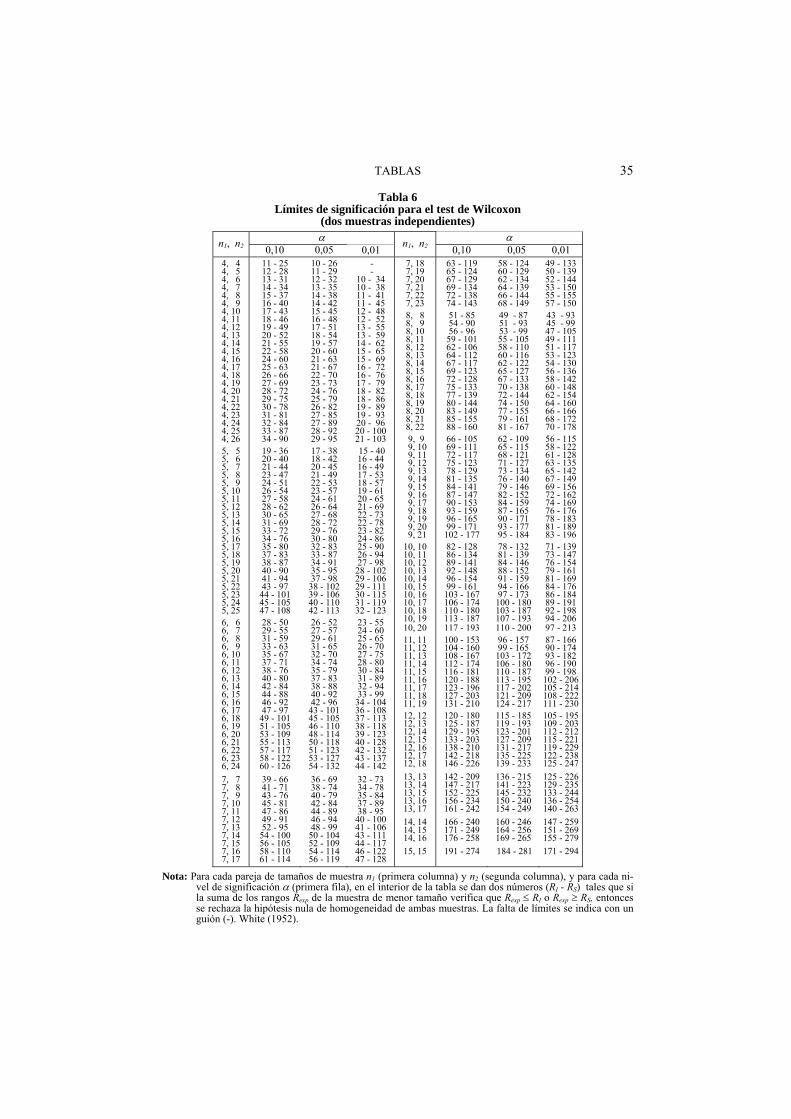
TABLAS
35
Tabla 6 Límites de significación para el test de Wilcoxon
(dos muestras independientes)
n1, n2 0,10 0,05 0,01 n1, n2 0,10 0,05 0,01
4, 4 4, 5 4, 6 4, 7 4, 8 4, 9 4, 10 4, 11 4, 12 4, 13 4, 14 4, 15 4, 16 4, 17 4, 18 4, 19 4, 20 4, 21 4, 22 4, 23 4, 24 4, 25 4, 26 5, 5 5, 6 5, 7 5, 8 5, 9 5, 10 5, 11 5, 12 5, 13 5, 14 5, 15 5, 16 5, 17 5, 18 5, 19 5, 20 5, 21 5, 22 5, 23 5, 24 5, 25 6, 6 6, 7 6, 8 6, 9 6, 10 6, 11 6, 12 6, 13 6, 14 6, 15 6, 16 6, 17 6, 18 6, 19 6, 20 6, 21 6, 22 6, 23 6, 24
7, 7 7, 8 7, 9 7, 10 7, 11 7, 12 7, 13 7, 14 7, 15 7, 16 7, 17
11 - 25 12 - 28 13 - 31 14 - 34 15 - 37 16 - 40 17 - 43 18 - 46 19 - 49 20 - 52 21 - 55 22 - 58 24 - 60 25 - 63 26 - 66 27 - 69 28 - 72 29 - 75 30 - 78 31 - 81 32 - 84 33 - 87 34 - 90 19 - 36 20 - 40 21 - 44 23 - 47 24 - 51 26 - 54 27 - 58 28 - 62 30 - 65 31 - 69 33 - 72 34 - 76 35 - 80 37 - 83 38 - 87 40 - 90 41 - 94 43 - 97 44 - 101 45 - 105 47 - 108 28 - 50 29 - 55 31 - 59 33 - 63 35 - 67 37 - 71 38 - 76 40 - 80 42 - 84 44 - 88 46 - 92 47 - 97 49 - 101 51 - 105 53 - 109 55 - 113 57 - 117 58 - 122 60 - 126
39 - 66 41 - 71 43 - 76 45 - 81 47 - 86 49 - 91 52 - 95 54 - 100 56 - 105 58 - 110 61 - 114
10 - 26 11 - 29 12 - 32 13 - 35 14 - 38 14 - 42 15 - 45 16 - 48 17 - 51 18 - 54 19 - 57 20 - 60 21 - 63 21 - 67 22 - 70 23 - 73 24 - 76 25 - 79 26 - 82 27 - 85 27 - 89 28 - 92 29 - 95 17 - 38 18 - 42 20 - 45 21 - 49 22 - 53 23 - 57 24 - 61 26 - 64 27 - 68 28 - 72 29 - 76 30 - 80 32 - 83 33 - 87 34 - 91 35 - 95 37 - 98 38 - 102 39 - 106 40 - 110 42 - 113 26 - 52 27 - 57 29 - 61 31 - 65 32 - 70 34 - 74 35 - 79 37 - 83 38 - 88 40 - 92 42 - 96 43 - 101 45 - 105 46 - 110 48 - 114 50 - 118 51 - 123 53 - 127 54 - 132
36 - 69 38 - 74 40 - 79 42 - 84 44 - 89 46 - 94 48 - 99 50 - 104 52 - 109 54 - 114 56 - 119
- -
10 - 34 10 - 38 11 - 41 11 - 45 12 - 48 12 - 52 13 - 55 13 - 59 14 - 62 15 - 65 15 - 69 16 - 72 16 - 76 17 - 79 18 - 82 18 - 86 19 - 89 19 - 93 20 - 96 20 - 100 21 - 103 15 - 40 16 - 44 16 - 49 17 - 53 18 - 57 19 - 61 20 - 65 21 - 69 22 - 73 22 - 78 23 - 82 24 - 86 25 - 90 26 - 94 27 - 98 28 - 102 29 - 106 29 - 111 30 - 115 31 - 119 32 - 123 23 - 55 24 - 60 25 - 65 26 - 70 27 - 75 28 - 80 30 - 84 31 - 89 32 - 94 33 - 99 34 - 104 36 - 108 37 - 113 38 - 118 39 - 123 40 - 128 42 - 132 43 - 137 44 - 142
32 - 73 34 - 78 35 - 84 37 - 89 38 - 95 40 - 100 41 - 106 43 - 111 44 - 117 46 - 122 47 - 128
7, 18 7, 19 7, 20 7, 21 7, 22 7, 23 8, 8 8, 9 8, 10 8, 11 8, 12 8, 13 8, 14 8, 15 8, 16 8, 17 8, 18 8, 19 8, 20 8, 21 8, 22 9, 9
9, 10 9, 11 9, 12 9, 13 9, 14 9, 15 9, 16 9, 17 9, 18 9, 19 9, 20 9, 21 10, 10 10, 11 10, 12 10, 13 10, 14 10, 15 10, 16 10, 17 10, 18 10, 19 10, 20 11, 11 11, 12 11, 13 11, 14 11, 15 11, 16 11, 17 11, 18 11, 19 12, 12 12, 13 12, 14 12, 15 12, 16 12, 17 12, 18
13, 13 13, 14 13, 15 13, 16 13, 17
14, 14 14, 15 14, 16
15, 15
63 - 119 65 - 124 67 - 129 69 - 134 72 - 138 74 - 143 51 - 85 54 - 90 56 - 96 59 - 101 62 - 106 64 - 112 67 - 117 69 - 123 72 - 128 75 - 133 77 - 139 80 - 144 83 - 149 85 - 155 88 - 160 66 - 105 69 - 111 72 - 117 75 - 123 78 - 129 81 - 135 84 - 141 87 - 147 90 - 153 93 - 159 96 - 165 99 - 171 102 - 177 82 - 128 86 - 134 89 - 141 92 - 148 96 - 154 99 - 161 103 - 167 106 - 174 110 - 180 113 - 187 117 - 193 100 - 153 104 - 160 108 - 167 112 - 174 116 - 181 120 - 188 123 - 196 127 - 203 131 - 210 120 - 180 125 - 187 129 - 195 133 - 203 138 - 210 142 - 218 146 - 226
142 - 209 147 - 217 152 - 225 156 - 234 161 - 242
166 - 240 171 - 249 176 - 258
191 - 274
58 - 124 60 - 129 62 - 134 64 - 139 66 - 144 68 - 149 49 - 87 51 - 93 53 - 99 55 - 105 58 - 110 60 - 116 62 - 122 65 - 127 67 - 133 70 - 138 72 - 144 74 - 150 77 - 155 79 - 161 81 - 167 62 - 109 65 - 115 68 - 121 71 - 127 73 - 134 76 - 140 79 - 146 82 - 152 84 - 159 87 - 165 90 - 171 93 - 177 95 - 184 78 - 132 81 - 139 84 - 146 88 - 152 91 - 159 94 - 166 97 - 173 100 - 180 103 - 187 107 - 193 110 - 200 96 - 157 99 - 165 103 - 172 106 - 180 110 - 187 113 - 195 117 - 202 121 - 209 124 - 217 115 - 185 119 - 193 123 - 201 127 - 209 131 - 217 135 - 225 139 - 233
136 - 215 141 - 223 145 - 232 150 - 240 154 - 249
160 - 246 164 - 256 169 - 265
184 - 281
49 - 133 50 - 139 52 - 144 53 - 150 55 - 155 57 - 150 43 - 93 45 - 99 47 - 105 49 - 111 51 - 117 53 - 123 54 - 130 56 - 136 58 - 142 60 - 148 62 - 154 64 - 160 66 - 166 68 - 172 70 - 178 56 - 115 58 - 122 61 - 128 63 - 135 65 - 142 67 - 149 69 - 156 72 - 162 74 - 169 76 - 176 78 - 183 81 - 189 83 - 196 71 - 139 73 - 147 76 - 154 79 - 161 81 - 169 84 - 176 86 - 184 89 - 191 92 - 198 94 - 206 97 - 213 87 - 166 90 - 174 93 - 182 96 - 190 99 - 198 102 - 206 105 - 214 108 - 222 111 - 230 105 - 195 109 - 203 112 - 212 115 - 221 119 - 229 122 - 238 125 - 247
125 - 226 129 - 235 133 - 244 136 - 254 140 - 263
147 - 259 151 - 269 155 - 279
171 - 294
Nota: Para cada pareja de tamaños de muestra n1 (primera columna) y n2 (segunda columna), y para cada ni-vel de significación (primera fila), en el interior de la tabla se dan dos números (RI - RS) tales que si la suma de los rangos Rexp de la muestra de menor tamaño verifica que Rexp RI o Rexp RS, entonces se rechaza la hipótesis nula de homogeneidad de ambas muestras. La falta de límites se indica con un guión (-). White (1952).
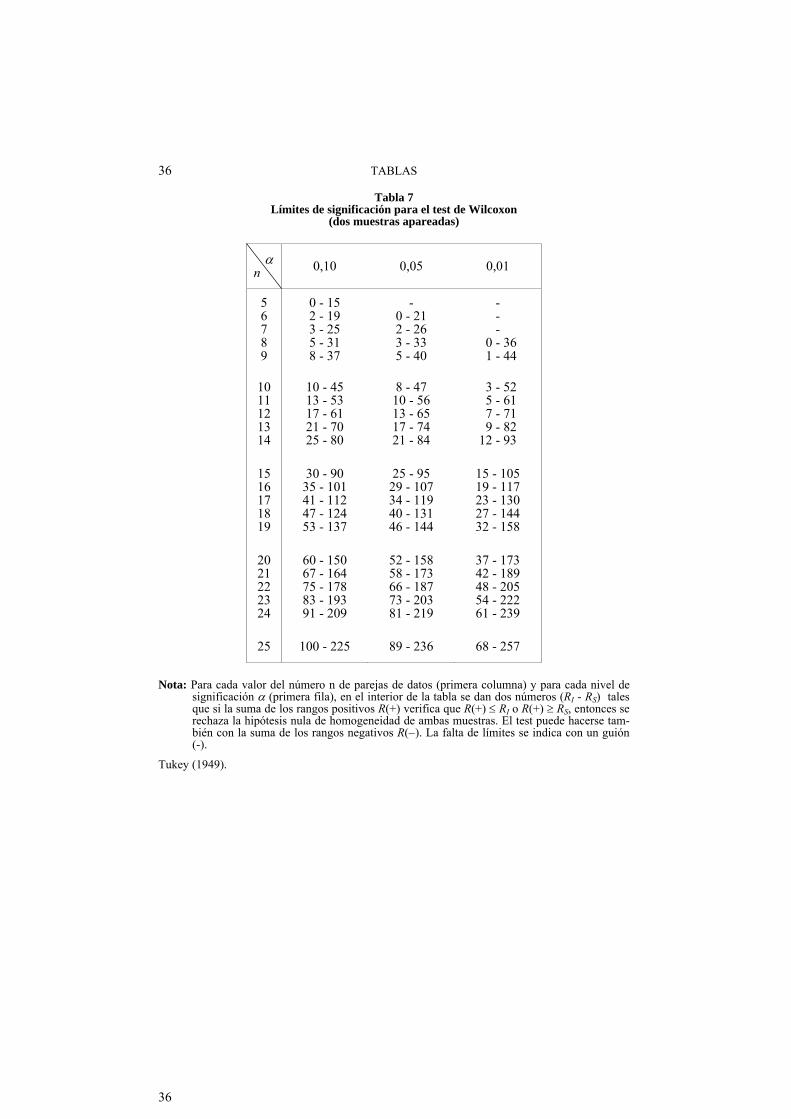
TABLAS
36
36
Tabla 7 Límites de significación para el test de Wilcoxon
(dos muestras apareadas)
n 0,10 0,05 0,01
5 6 7 8 9
0 - 15 2 - 19 3 - 25 5 - 31 8 - 37
- 0 - 21 2 - 26 3 - 33 5 - 40
- - -
0 - 36 1 - 44
10 11 12 13 14
10 - 45 13 - 53 17 - 61 21 - 70 25 - 80
8 - 47 10 - 56 13 - 65 17 - 74 21 - 84
3 - 52 5 - 61 7 - 71 9 - 82 12 - 93
15 16 17 18 19
30 - 90 35 - 101 41 - 112 47 - 124 53 - 137
25 - 95 29 - 107 34 - 119 40 - 131 46 - 144
15 - 105 19 - 117 23 - 130 27 - 144 32 - 158
20 21 22 23 24
60 - 150 67 - 164 75 - 178 83 - 193 91 - 209
52 - 158 58 - 173 66 - 187 73 - 203 81 - 219
37 - 173 42 - 189 48 - 205 54 - 222 61 - 239
25 100 - 225 89 - 236 68 - 257
Nota: Para cada valor del número n de parejas de datos (primera columna) y para cada nivel de significación (primera fila), en el interior de la tabla se dan dos números (RI - RS) tales que si la suma de los rangos positivos R(+) verifica que R(+) RI o R(+) RS, entonces se rechaza la hipótesis nula de homogeneidad de ambas muestras. El test puede hacerse tam-bién con la suma de los rangos negativos R(). La falta de límites se indica con un guión (-).
Tukey (1949).
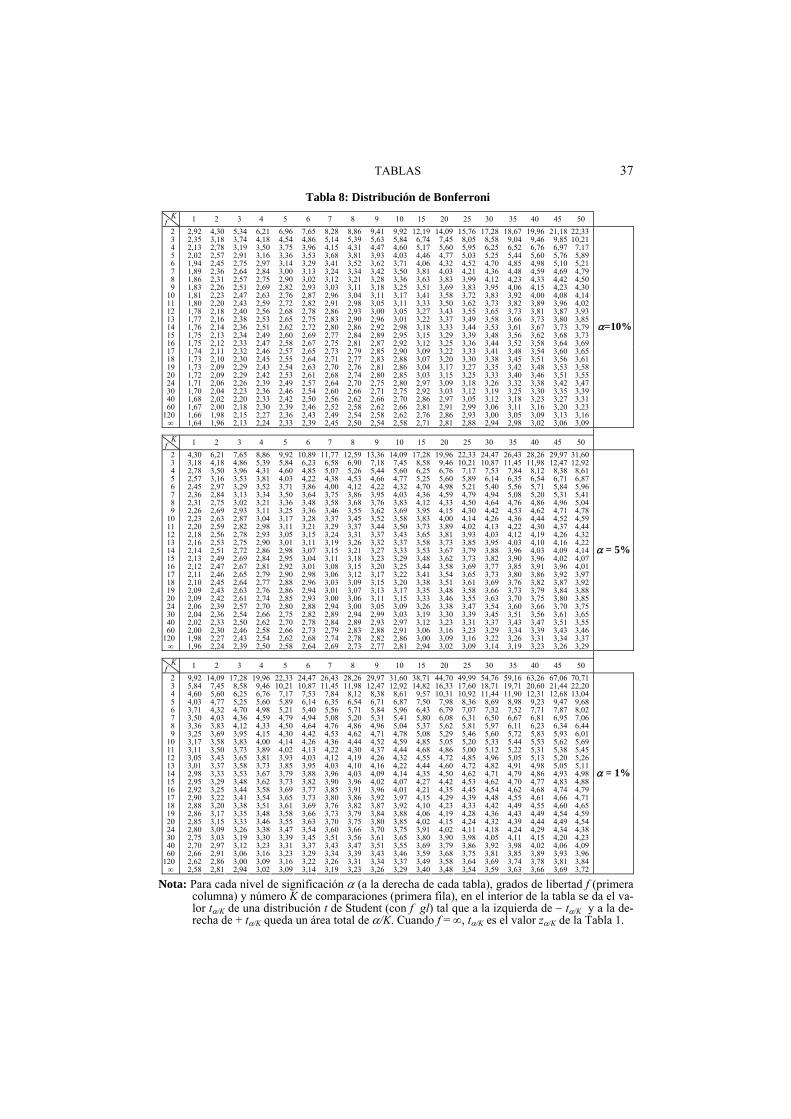
TABLAS
37
Tabla 8: Distribución de Bonferroni
K f 1 2 3 4 5 6 7 8 9 10 15 20 25 30 35 40 45 50
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 24 30 40 60
120
2,92 2,35 2,13 2,02 1,94 1,89 1,86 1,83 1,81 1,80 1,78 1,77 1,76 1,75 1,75 1,74 1,73 1,73 1,72 1,71 1,70 1,68 1,67 1,66 1,64
4,30 3,18 2,78 2,57 2,45 2,36 2,31 2,26 2,23 2,20 2,18 2,16 2,14 2,13 2,12 2,11 2,10 2,09 2,09 2,06 2,04 2,02 2,00 1,98 1,96
5,34 3,74 3,19 2,91 2,75 2,64 2,57 2,51 2,47 2,43 2,40 2,38 2,36 2,34 2,33 2,32 2,30 2,29 2,29 2,26 2,23 2,20 2,18 2,15 2,13
6,21 4,18 3,50 3,16 2,97 2,84 2,75 2,69 2,63 2,59 2,56 2,53 2,51 2,49 2,47 2,46 2,45 2,43 2,42 2,39 2,36 2,33 2,30 2,27 2,24
6,96 4,54 3,75 3,36 3,14 3,00 2,90 2,82 2,76 2,72 2,68 2,65 2,62 2,60 2,58 2,57 2,55 2,54 2,53 2,49 2,46 2,42 2,39 2,36 2,33
7,65 4,86 3,96 3,53 3,29 3,13 3,02 2,93 2,87 2,82 2,78 2,75 2,72 2,69 2,67 2,65 2,64 2,63 2,61 2,57 2,54 2,50 2,46 2,43 2,39
8,285,144,153,683,413,243,123,032,962,912,862,832,802,772,752,732,712,702,682,642,602,562,522,492,45
8,865,394,313,813,523,343,213,113,042,982,932,902,862,842,812,792,772,762,742,702,662,622,582,542,50
9,415,634,473,933,623,423,283,183,113,053,002,962,922,892,872,852,832,812,802,752,712,662,622,582,54
9,925,844,604,033,713,503,363,253,173,113,053,012,982,952,922,902,882,862,852,802,752,702,662,622,58
12,196,745,174,464,063,813,633,513,413,333,273,223,183,153,123,093,073,043,032,972,922,862,812,762,71
14,097,455,604,774,324,033,833,693,583,503,433,373,333,293,253,223,203,173,153,093,032,972,912,862,81
15,768,055,955,034,524,213,993,833,723,623,553,493,443,393,363,333,303,273,253,183,123,052,992,932,88
17,288,586,255,254,704,364,123,953,833,733,653,583,533,483,443,413,383,353,333,263,193,123,063,002,94
18,679,046,525,444,854,484,234,063,923,823,733,663,613,563,523,483,453,423,403,323,253,183,113,052,98
19,969,466,765,604,984,594,334,154,003,893,813,733,673,623,583,543,513,483,463,383,303,233,163,093,02
21,18 9,85 6,97 5,76 5,10 4,69 4,42 4,23 4,08 3,96 3,87 3,80 3,73 3,68 3,64 3,60 3,56 3,53 3,51 3,42 3,35 3,27 3,20 3,13 3,06
22,33 10,21 7,17 5,89 5,21 4,79 4,50 4,30 4,14 4,02 3,93 3,85 3,79 3,73 3,69 3,65 3,61 3,58 3,55 3,47 3,39 3,31 3,23 3,16 3,09
=10%
K f 1 2 3 4 5 6 7 8 9 10 15 20 25 30 35 40 45 50
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 24 30 40 60
120
4,30 3,18 2,78 2,57 2,45 2,36 2,31 2,26 2,23 2,20 2,18 2,16 2,14 2,13 2,12 2,11 2,10 2,09 2,09 2,06 2,04 2,02 2,00 1,98 1,96
6,21 4,18 3,50 3,16 2,97 2,84 2,75 2,69 2,63 2,59 2,56 2,53 2,51 2,49 2,47 2,46 2,45 2,43 2,42 2,39 2,36 2,33 2,30 2,27 2,24
7,65 4,86 3,96 3,53 3,29 3,13 3,02 2,93 2,87 2,82 2,78 2,75 2,72 2,69 2,67 2,65 2,64 2,63 2,61 2,57 2,54 2,50 2,46 2,43 2,39
8,86 5,39 4,31 3,81 3,52 3,34 3,21 3,11 3,04 2,98 2,93 2,90 2,86 2,84 2,81 2,79 2,77 2,76 2,74 2,70 2,66 2,62 2,58 2,54 2,50
9,92 5,84 4,60 4,03 3,71 3,50 3,36 3,25 3,17 3,11 3,05 3,01 2,98 2,95 2,92 2,90 2,88 2,86 2,85 2,80 2,75 2,70 2,66 2,62 2,58
10,89 6,23 4,85 4,22 3,86 3,64 3,48 3,36 3,28 3,21 3,15 3,11 3,07 3,04 3,01 2,98 2,96 2,94 2,93 2,88 2,82 2,78 2,73 2,68 2,64
11,776,585,074,384,003,753,583,463,373,293,243,193,153,113,083,063,033,013,002,942,892,842,792,742,69
12,596,905,264,534,123,863,683,553,453,373,313,263,213,183,153,123,093,073,063,002,942,892,832,782,73
13,367,185,444,664,223,953,763,623,523,443,373,323,273,233,203,173,153,133,113,052,992,932,882,822,77
14,097,455,604,774,324,033,833,693,583,503,433,373,333,293,253,223,203,173,153,093,032,972,912,862,81
17,288,586,255,254,704,364,123,953,833,733,653,583,533,483,443,413,383,353,333,263,193,123,063,002,94
19,969,466,765,604,984,594,334,154,003,893,813,733,673,623,583,543,513,483,463,383,303,233,163,093,02
22,3310,217,175,895,214,794,504,304,144,023,933,853,793,733,693,653,613,583,553,473,393,313,233,163,09
24,4710,877,536,145,404,944,644,424,264,134,033,953,883,823,773,733,693,663,633,543,453,373,293,223,14
26,4311,457,846,355,565,084,764,534,364,224,124,033,963,903,853,803,763,733,703,603,513,433,343,263,19
28,2611,988,126,545,715,204,864,624,444,304,194,104,033,963,913,863,823,793,753,663,563,473,393,313,23
29,97 12,47 8,38 6,71 5,84 5,31 4,96 4,71 4,52 4,37 4,26 4,16 4,09 4,02 3,96 3,92 3,87 3,84 3,80 3,70 3,61 3,51 3,43 3,34 3,26
31,60 12,92 8,61 6,87 5,96 5,41 5,04 4,78 4,59 4,44 4,32 4,22 4,14 4,07 4,01 3,97 3,92 3,88 3,85 3,75 3,65 3,55 3,46 3,37 3,29
= 5%
K f 1 2 3 4 5 6 7 8 9 10 15 20 25 30 35 40 45 50
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 24 30 40 60
120
9,92 5,84 4,60 4,03 3,71 3,50 3,36 3,25 3,17 3,11 3,05 3,01 2,98 2,95 2,92 2,90 2,88 2,86 2,85 2,80 2,75 2,70 2,66 2,62 2,58
14,09 7,45 5,60 4,77 4,32 4,03 3,83 3,69 3,58 3,50 3,43 3,37 3,33 3,29 3,25 3,22 3,20 3,17 3,15 3,09 3,03 2,97 2,91 2,86 2,81
17,28 8,58 6,25 5,25 4,70 4,36 4,12 3,95 3,83 3,73 3,65 3,58 3,53 3,48 3,44 3,41 3,38 3,35 3,33 3,26 3,19 3,12 3,06 3,00 2,94
19,96 9,46 6,76 5,60 4,98 4,59 4,33 4,15 4,00 3,89 3,81 3,73 3,67 3,62 3,58 3,54 3,51 3,48 3,46 3,38 3,30 3,23 3,16 3,09 3,02
22,33 10,21 7,17 5,89 5,21 4,79 4,50 4,30 4,14 4,02 3,93 3,85 3,79 3,73 3,69 3,65 3,61 3,58 3,55 3,47 3,39 3,31 3,23 3,16 3,09
24,47 10,87 7,53 6,14 5,40 4,94 4,64 4,42 4,26 4,13 4,03 3,95 3,88 3,82 3,77 3,73 3,69 3,66 3,63 3,54 3,45 3,37 3,29 3,22 3,14
26,4311,457,846,355,565,084,764,534,364,224,124,033,963,903,853,803,763,733,703,603,513,433,343,263,19
28,2611,988,126,545,715,204,864,624,444,304,194,104,033,963,913,863,823,793,753,663,563,473,393,313,23
29,9712,478,386,715,845,314,964,714,524,374,264,164,094,023,963,923,873,843,803,703,613,513,433,343,26
31,6012,928,616,875,965,415,044,784,594,444,324,224,144,074,013,973,923,883,853,753,653,553,463,373,29
38,7114,829,577,506,435,805,375,084,854,684,554,444,354,274,214,154,104,064,023,913,803,693,593,493,40
44,7016,3310,317,986,796,085,625,295,054,864,724,604,504,424,354,294,234,194,154,023,903,793,683,583,48
49,9917,6010,928,367,076,315,815,465,205,004,854,724,624,534,454,394,334,284,244,113,983,863,753,643,54
54,7618,7111,448,697,326,505,975,605,335,124,964,824,714,624,544,484,424,364,324,184,053,923,813,693,59
59,1619,7111,908,987,526,676,115,725,445,225,054,914,794,704,624,554,494,434,394,244,113,983,853,743,63
63,2620,6012,319,237,716,816,235,835,535,315,134,984,864,774,684,614,554,494,444,294,154,023,893,783,66
67,06 21,44 12,68 9,47 7,87 6,95 6,34 5,93 5,62 5,38 5,20 5,05 4,93 4,83 4,74 4,66 4,60 4,54 4,49 4,34 4,20 4,06 3,93 3,81 3,69
70,71 22,20 13,04 9,68 8,02 7,06 6,44 6,01 5,69 5,45 5,26 5,11 4,98 4,88 4,79 4,71 4,65 4,59 4,54 4,38 4,23 4,09 3,96 3,84 3,72
= 1%
Nota: Para cada nivel de significación (a la derecha de cada tabla), grados de libertad f (primera columna) y número K de comparaciones (primera fila), en el interior de la tabla se da el va-lor t/K de una distribución t de Student (con f gl) tal que a la izquierda de t/K y a la de-recha de + t/K queda un área total de /K. Cuando f = , t/K es el valor z/K de la Tabla 1.
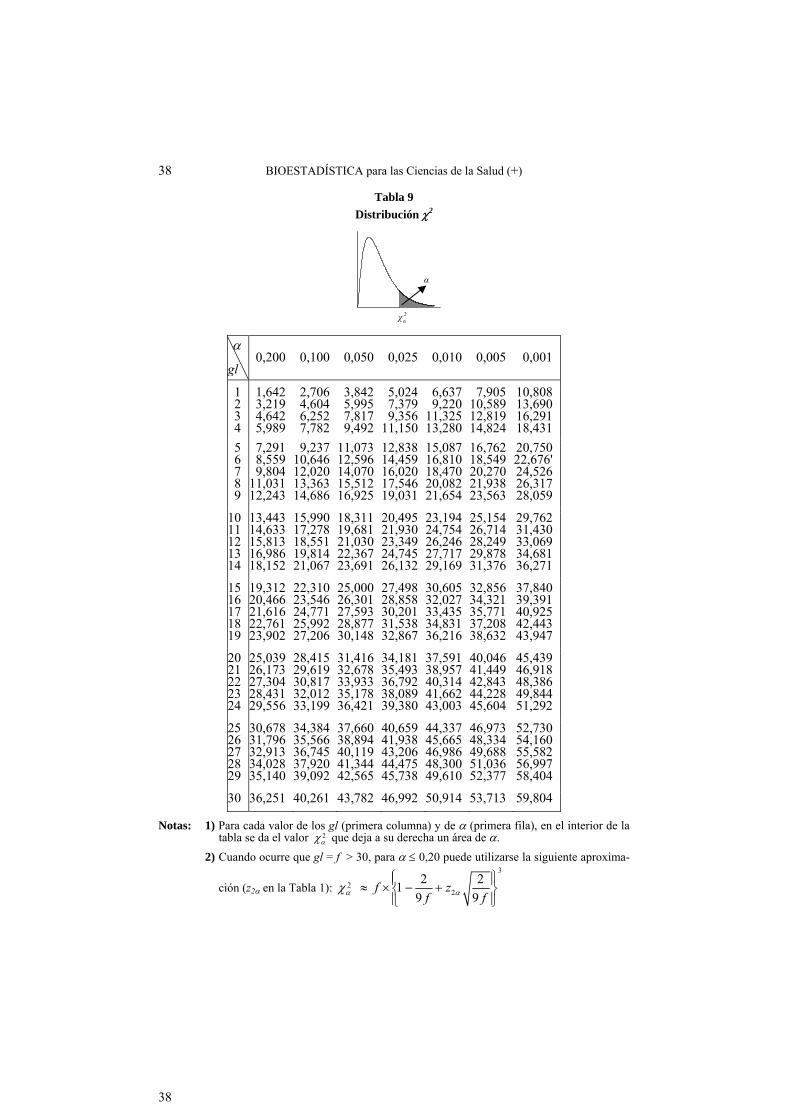
BIOESTADÍSTICA para las Ciencias de la Salud (+)
38
38
Tabla 9
Distribución 2
gl
0,200 0,100 0,050 0,025 0,010 0,005 0,001
1 2 3 4
1,642 3,219 4,642 5,989
2,706 4,604 6,252 7,782
3,842 5,995 7,817 9,492
5,024 7,379 9,356
11,150
6,637 9,220
11,325 13,280
7,905 10,589 12,819 14,824
10,808 13,690 16,291 18,431
5 6 7 8 9
7,291 8,559 9,804
11,031 12,243
9,237 10,646 12,020 13,363 14,686
11,073 12,596 14,070 15,512 16,925
12,838 14,459 16,020 17,546 19,031
15,087 16,810 18,470 20,082 21,654
16,762 18,549 20,270 21,938 23,563
20,750 22,676' 24,526 26,317 28,059
10 11 12 13 14
13,443 14,633 15,813 16,986 18,152
15,990 17,278 18,551 19,814 21,067
18,311 19,681 21,030 22,367 23,691
20,495 21,930 23,349 24,745 26,132
23,194 24,754 26,246 27,717 29,169
25,154 26,714 28,249 29,878 31,376
29,762 31,430 33,069 34,681 36,271
15 16 17 18 19
19,312 20,466 21,616 22,761 23,902
22,310 23,546 24,771 25,992 27,206
25,000 26,301 27,593 28,877 30,148
27,498 28,858 30,201 31,538 32,867
30,605 32,027 33,435 34,831 36,216
32,856 34,321 35,771 37,208 38,632
37,840 39,391 40,925 42,443 43,947
20 21 22 23 24
25,039 26,173 27,304 28,431 29,556
28,415 29,619 30,817 32,012 33,199
31,416 32,678 33,933 35,178 36,421
34,181 35,493 36,792 38,089 39,380
37,591 38,957 40,314 41,662 43,003
40,046 41,449 42,843 44,228 45,604
45,439 46,918 48,386 49,844 51,292
25 26 27 28 29
30,678 31,796 32,913 34,028 35,140
34,384 35,566 36,745 37,920 39,092
37,660 38,894 40,119 41,344 42,565
40,659 41,938 43,206 44,475 45,738
44,337 45,665 46,986 48,300 49,610
46,973 48,334 49,688 51,036 52,377
52,730 54,160 55,582 56,997 58,404
30 36,251 40,261 43,782 46,992 50,914 53,713 59,804
Notas: 1) Para cada valor de los gl (primera columna) y de (primera fila), en el interior de la tabla se da el valor 2
que deja a su derecha un área de .
2) Cuando ocurre que gl = f > 30, para 0,20 puede utilizarse la siguiente aproxima-
ción (z2 en la Tabla 1):
3
22 f z
f f
2αχ
α

39
Tabla 10
Límites de significación para el coeficiente de correlación de Spearman
n
0,10 0,05 0,01 0,001
5 6 7 8 9
10
0,9000 0,8286 0,7143 0,6429 0,6000 0,5636
1,0000 0,8857 0,7857 0,7381 0,6833 0,6485
-- 1,0000 0,9286 0,8810 0,8333 0,7939
-- --
1,0000 0,9762 0,9333 0,9030
11 12 13 14 15 16 17 18 19 20
0,5294 0,4973 0,4748 0,4562 0,4396 0,4247 0,4112 0,3989 0,3877 0,3774
0,6194 0,5910 0,5658 0,5436 0,5238 0,5061 0,4900 0,4754 0,4620 0,4496
0,7724 0,7509 0,7294 0,7080 0,6865 0,6650 0,6440 0,6247 0,6071 0,5909
0,8875 0,8720 0,8565 0,8410 0,8255 0,8100 0,7945 0,7790 0,7635 0,7480
21 22 23 24 25 26 27 28 29 30
0,3678 0,3589 0,3507 0,3430 0,3358 0,3290 0,3226 0,3166 0,3108 0,3054
0,4383 0,4277 0,4179 0,4087 0,4001 0,3920 0,3844 0,3772 0,3704 0,3640
0,5760 0,5621 0,5492 0,5371 0,5258 0,5152 0,5052 0,4957 0,4868 0,4783
0,7325 0,7170 0,7015 0,6861 0,6717 0,6581 0,6453 0,6333 0,6219 0,6110
Nota: Para cada número n de parejas de datos (primera columna) y para cada nivel de significa-ción (primera fila), en el interior de la tabla se da un valor r tal que si el coeficiente de correlación de Spearman rS verifica que rS r, entonces se rechaza la hipótesis nula de independencia. Las casillas con -- indican que para esos valores de n y el test no puede dar significativo.
Glasser and Winter (1961).
