resumen bd
DESCRIPTION
Resumen sobre consultas avanzadas de BDTRANSCRIPT

Unidad 1 Manipulación Avanzada de Datos
1 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Introducción En el sentido más amplio, se podría considerar que una base de datos es simplemente un conjunto de información
o tablas en donde se guardan un sinfín de datos, por ejemplo imágenes, videos información de usuarios etc., una
base de datos sencilla puede llevar datos de nuestros amigos que simplemente se registraran en ella, se utilizan
registros, campos, fichas, apartados, simplemente se utilizan para almacenar información que prácticamente
después se utilizaran en diferentes partes o formas por ejemplo páginas web, o para usuarios específicos oficinas.
Las BD son el método preferido para el almacenamiento estructurado de datos. Desde las grandes aplicaciones
multiusuario, hasta los teléfonos móviles y las agendas electrónicas utilizan tecnología de bases de datos para
asegurar la integridad de los datos y facilitar el trabajo tanto de usuarios como de los programadores que las
desarrollaron, desde la realización del primer modelo de datos, pasando por la administración del sistema gestor,
hasta llegar al desarrollo de la aplicación, los conceptos y la tecnología asociados son muchos y muy
heterogéneos. Sin embargo, es imprescindible conocer los aspectos clave de cada uno de estos temas para tener
éxito en cualquier proyecto que implique trabajar con bases de datos, en los primeros conceptos mencionados
en este reporte se describe como se utilizan las diferentes consultas en SQL.
Los primeros SGBD en los años sesenta todavía no se les denominaba así estaban orientados a facilitar la
utilización de grandes conjuntos de datos en los que las interacciones eran complejas. Al parecer los terminales
del teclado, conectados al ordenador central mediante una línea telefónica, se empiezan a construir grandes
aplicaciones los SGBD estaban íntimamente ligados al software de comunicaciones y de gestión de
transacciones, aunque para escribir los programas de aplicación se utilizaban lenguajes de alto nivel como se
disponía también de instrucciones y de subrutinas especializadas para tratar las BD que requerían que el
programador considera detalles del diseño físico, y que hacían que la programación fuese muy compleja, puesto
que los programas estaban relacionadas con el nivel físico, se deberían modificar continuamente cuando se
hacían cambios en el diseño y la organización de la BD, la preocupación básica era maximizar el rendimiento,
una base BD distribuida puede reducir el coste. En el caso de un sistema centralizado, todos los equipos usuarios
que pueden estar distribuidos por distintas y lejanas áreas geográficas, están concentradas el sistema central por
medio de líneas de comunicación, el coste total de las comunicaciones de puede reducir haciendo que un usuario
tenga más cerca los datos que utiliza con mayor frecuencia. El éxito de las BD, incluso en sistemas personales,
ha llevado a la operación de los Fourth Generación Lenguajes (4GL), especializados en el desarrollo de
aplicaciones fundamentales de BD, proporcionan muchas facilidades en el momento de definir, generalmente de
forma visual, diálogos para introducir, modificar y consultar datos en entornos. Hoy en día, los SGBD relacionales
estén en plena transformación para adaptarse a tres tecnologías de éxito reciente, frecuentemente relacionadas.
La incorporación de tecnologías multimedia- imagen y sonido- en los sistemas hace necesario que los SGBD
relacionales acepten atributos de estos tipos. Necesitan tipos complejos que el desarrollador pueda definir a

Unidad 1 Manipulación Avanzada de Datos
2 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
medida de la aplicación. En definitiva. Simplemente en la actualidad todo funciona con base de datos y es lo
primordial para nuestra carrera y futuro.

Unidad 1 Manipulación Avanzada de Datos
3 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Recuperación Básica consultas en SQL
Con las consultas en SQL pueden ser muy complejas. Pueden ir de menor grado de complejidad hasta un mayor
grado.
Por ejemplo el comando más utilizado es la instrucción SELECT a veces llamado un mapeo o un select-from-en
bloque, que se utiliza para recuperar los datos y la sintaxis es:
SELECT <lista de atributos>
FROM <lista de tabla>
DONDE <condición>;
Donde tiene una:
Lista de atributos es una lista de nombres de atributos cuyos valores son para ser recuperado por la consulta.
Lista de tabla es una lista de los nombres de relaciones necesarias para procesar la consulta.
Condición es una expresión condicional (booleano) que identifica las tuplas para ser recuperado por la consulta.
Con ayuda de los operadores de comparación lógicos básicos para la comparación de valores de atributos con
entre sí y con las constantes literales son =, <, <=,>,> = y <>.
Para ver un ejemplo más claro podemos ver el siguiente ejemplo en la figura 1:
Figura 1 Ejemplo de la instrucción SELECT.

Unidad 1 Manipulación Avanzada de Datos
4 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Nombres de atributos ambiguos, uso de alias, cambio de nombre y variables tupla
Cuando el mismo nombre puede ser utilizado para dos o más atributos y cuando estos están en diferentes
relaciones en una consulta de varias tablas refiriéndose a dos atributos con el mismo nombre hay que realizar lo
siguiente para evitar la ambigüedad se tiene que anteponer el nombre de relación con el nombre del atributo y la
separación de los dos por un punto. Para dar un ejemplo de esto podemos observar la siguiente consulta:
SELECT Fnombre, EMPLOYEE.Name, Dirección
FROM EMPLEADO, DEPARTAMENTO
WHERE DEPARTMENT.Name = 'Investigación' Y
DEPARTMENT.Dnumber = EMPLOYEE.Dnumber;
El el siguiente ejemplo tenemos una situación totalmente diferente:
SELECT E.Fname, E.Lname, S.Fname, S.Lname
FROM EMPLEADO COMO E, EMPLEADO COMO S
WHERE E.Super_ssn = S.Ssn;
En este caso, tenemos la obligación de declarar los nombres de relación alternativa E y S, llamados alias o
variables de tupla, para la relación EMPLEADO. Un alias puede seguir la palabra clave AS, como se muestra en
la consulta, o puede seguir directamente el ejemplo de nombre para la relación.
Podemos ver otro ejemplo en la figura 1.2.

Unidad 1 Manipulación Avanzada de Datos
5 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Figura 2 Ejemplo del uso de Alias
Sin especificar cláusula WHERE y Uso del asterisco
La cláusula WHERE indica que no hay condición en la selección tupla; por lo tanto, todas las tuplas de la relación
especificada en la FROM cláusula califica y se seleccionan para el resultado de la consulta. Si se especifica más
de una relación en la cláusula FROM y no hay cláusula WHERE es, entonces la CRUZA PRODUCTOS - todas
las combinaciones posibles de tupla -de estas relaciones se selecciona.
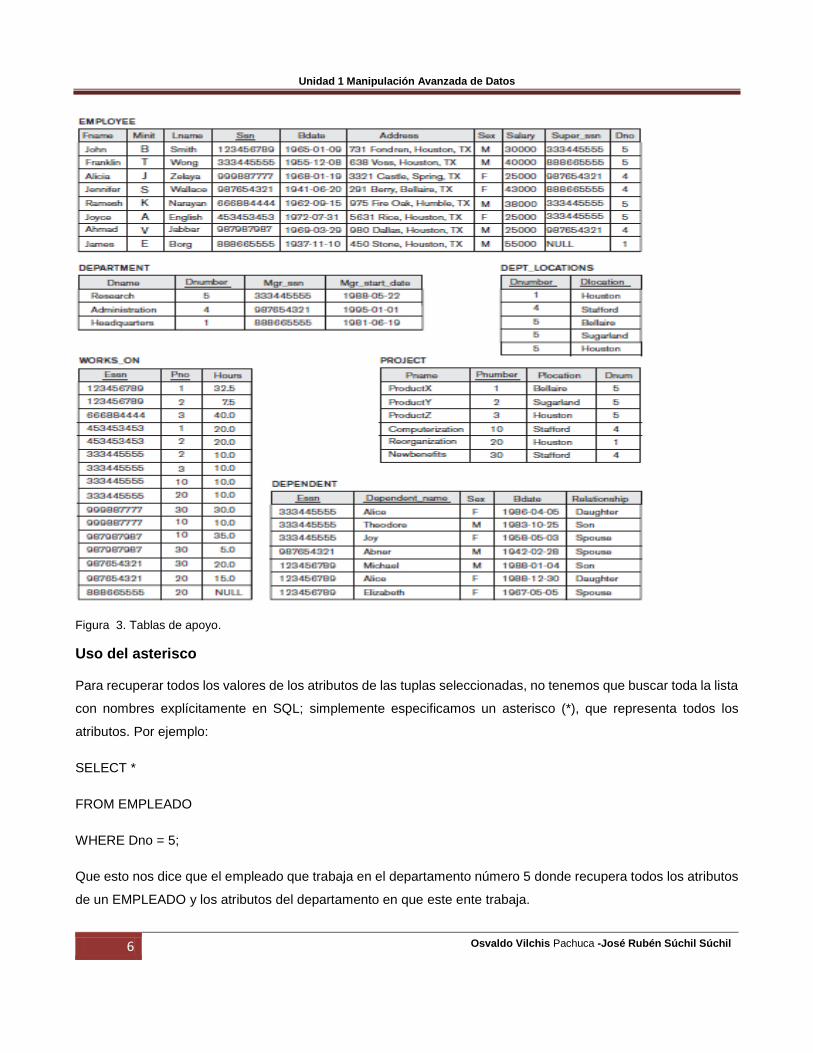
Como podemos ver esto se puede observar en la siguiente consulta y en la figura 3:
A) SELECT Ssn
FROM EMPLEADO;
B) SELECT Ssn, Dname
FROM EMPLEADO, DEPARTAMENTO;
Unidad 1 Manipulación Avanzada de Datos
6 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Figura 3. Tablas de apoyo.
Uso del asterisco
Para recuperar todos los valores de los atributos de las tuplas seleccionadas, no tenemos que buscar toda la lista
con nombres explícitamente en SQL; simplemente especificamos un asterisco (*), que representa todos los
atributos. Por ejemplo:
SELECT *
FROM EMPLEADO
WHERE Dno = 5;
Que esto nos dice que el empleado que trabaja en el departamento número 5 donde recupera todos los atributos
de un EMPLEADO y los atributos del departamento en que este ente trabaja.

Unidad 1 Manipulación Avanzada de Datos
7 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Tablas Conjuntos en SQL
SQL generalmente trata de multiconjuntos; duplicar tuplas puede aparecer más de una vez en el resultado de una
consulta.
Una tabla de SQL con una clave se limita a ser un conjunto, ya que el valor de la clave debe ser distinto en cada
tupla. Si nosotros queremos eliminar tuplas duplicadas del resultado de una consulta SQL, se utiliza la palabra
clave DISTINCT en la cláusula SELECT, lo que significa que sólo tuplas distintas deben permanecer en el
resultado. En general, una consulta con SELECT DISTINCT elimina duplicados, mientras que una consulta con
SELECT TODO no lo hace. Podemos verlo en la siguiente consulta:
SELECT ALL Salario
FROM EMPLEADO;
Si estamos interesados sólo en los valores distintos y queremos que cada valor que aparezca una sola vez,
independientemente de cual se la condición sea. Se realiza mediante el uso de la palabra clave DISTINCT como
en la siguiente consulta:
SELECT DISTINCT Salario
FROM EMPLEADO;
La intersección set (INTERSECT) Operaciones (UNION), diferencia set (EXCEPT). Las relaciones que resulten
de estas operaciones de conjuntos son conjuntos de tuplas; es decir, duplicar las tuplas son eliminadas del
resultado. Por ejemplo: Consulta que haga una lista de todos los números de proyecto para proyectos que
impliquen un empleado cuyo apellido es 'Smith', ya sea como trabajador o como gerente de la departamento que
controla el proyecto.
(SELECT DISTINCT Pnumber
FROM PROYECTO, DEPARTAMENTO, EMPLEADO
WHERE NUMD = NUMEROD Y Mgr_ssn = Ssn
AND Lname = 'Smith')
UNIÓN
(SELECT DISTINCT Pnumber

Unidad 1 Manipulación Avanzada de Datos
8 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
FROM PROYECTO, TRABAJA_EN, EMPLEADO
WHRE Pnumber = Pno Y ESSN = Ssn
AND Lname = 'Smith');
Substring Matching Patrón y operadores aritméticos.
El operador LIKE permite la comparación de condiciones en partes de una cadena de caracteres se puede usar
para el patrón de cadena coincidente. Cadenas parciales se especifican usando dos caracteres reservados: %
reemplaza un número arbitrario de cero o más personajes y el guión bajo (_) sustituye a un solo carácter. Por
ejemplo, Recuperar todos los empleados cuya dirección se encuentra en Houston, Texas.
SELECT Fnombre, Lname
DE EMPLEADO
DONDE Dirección LIKE '% Houston, TX%';
Resultados de la consulta
SQL permite al usuario ordenar las tuplas en el resultado de una consulta por los valores de una o más de los
atributos que aparecen en el resultado de la consulta, mediante el ORDER BY cláusula.
Ejemplo: una consulta que me muestre una lista de los empleados y los proyectos que están trabajando en,
ordenado por departamento y, dentro de cada departamento, ordenada alfabéticamente por apellido, luego el
nombre.
SELECT D.Dname, E.Lname, E.Fname, P.Pname
FROM DEPARTAMENTO D, EMPLEADO E, TRABAJA_EN W,
PROYECTO P
WHERE D.Dnumber = E.Dno Y E.Ssn = W.Essn Y
W.Pno = P.Pnumber
ORDER BY D.Dname, E.Lname, E.Fname;

Unidad 1 Manipulación Avanzada de Datos
9 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Resumen de las consultas
Una consulta de recuperación sencilla en SQL puede constar de hasta cuatro cláusulas, pero sólo el primero dos
SELECT y FROM -son obligatorio.
SELECT <lista de atributos>
FROM <lista de tabla>
[WHERE <condición>]
[ORDER BY <lista de atributos>];
La cláusula SELECT lista los atributos para ser recuperados y el FROM especifica la cláusula todas las relaciones
(tablas) necesarios en la simple consulta. La cláusula WHERE identifica las condiciones para la selección de las
tuplas de estas relaciones, incluyendo condiciones de unión si seanecesario. ORDER BY especifica un orden
para la visualización de los resultados de una consulta.
Las declaraciones en SQL
El comando insert
El comando insert se usa para La cláusula SELECT lista los atributos para ser recuperados y el DE especifica la
cláusula todas las relaciones (tablas) necesarios en la simple consulta. La cláusula WHERE identifica las
condiciones para la selección de las tuplas de estas relaciones, incluyendo condiciones de unión si seanecesario.
Por ejemplo:
INSERT INTO EMPLEADO
VALUES ('Richard', 'K', 'Marini', '653 298 653', '30/12/1962', '98
Oak Forest, Katy, TX ',' M ', 37000:' 653298653 ', 4);
Esto variara según el tipo de datos que se tenga en la tabla EMPLEADO o ya sea en otra ya que puede tener
distintos tipos de datos.
El comando DELETE
El comando DELETE elimina tuplas de una relación. Incluye una cláusula WHERE, similar a la utilizada en una
consulta SQL, para seleccionar las tuplas que desea eliminar.

Unidad 1 Manipulación Avanzada de Datos
10 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Un ejemplo de esto tenemos lo siguiente:
DELETE FROM EMPLEADO
DONDE Lname = 'Brown';
Con esta consulta se eliminaran todas las tuplas de la tabla empleado.
El comando UPDATE
El comando UPDATE se utiliza para modificar los valores de atributo de uno o más seleccionados tuplas. Al igual
que en el comando DELETE, una cláusula WHERE en el comando UPDATE se selecciona las tuplas que serán
modificadas de una sola relación.
Por ejemplo:
UPDATE FROM PROYECTO
SET Plocation = 'Bellaire', NUMD = 5
WHERE Pnumber = 10;
Ejercicios
4.10. Especifique las siguientes consultas en SQL en la EMPRESA base de datos relacional esquema se muestra
en la Figura 3.5. Mostrar el resultado de cada consulta si se aplica a la EMPRESA base de datos en la Figura 3.6.
a. Recuperar los nombres de todos los empleados en el departamento 5 que trabajan más de 10 horas por
semana en el proyecto productoX.
SELECT Fname, Dnumber, Hours, Pname
FROM EMPLOYEE INNER JOIN DEPARTMENT ON Dnumber=Dnum INNER JOIN (SELECT FROM PROJECT)
ON Dnum=Pname
WHERE Pname= ProductX and Hours>10
b. Anote los nombres de todos los empleados que tienen un dependiente con el mismo primero nombrar como
ellos mismos.
SELECT Fname, Dependent_name
FROM EMPLOYEE INNER JOIN DEPENDET

Unidad 1 Manipulación Avanzada de Datos
11 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
WHERE ALICE=Alice AND Theodore=Theodore AND Joy=Joy AND Abner=Abner AND Michael=Michael
4.12. Especifique las siguientes consultas en SQL en el esquema de base de la figura 1.2.
a. Recuperar los nombres de todos los estudiantes del último año que se especializan en 'CS' (informática).
SELECT Name, Year, Course_name
FROM STUDENT INNER JOIN COURSE ON SECTION Course_number= Course_number
WHERE Course_name= Course Science
b. Recuperar los nombres de todos los cursos impartidos por el profesor King en 2007 y
2008.
SELEC Course_name, Istructor
FROM COURSE INNER JOIN SECTION ON Course_number= Course_number
WHERE Instructor=King
Recuperación de consultas más complejas
Comparaciones que involucran NULL
SQL tiene varias reglas para tratar con valores NULL NULL se utiliza para representar un valor perdido, pero que
por lo general tiene una de tres diferentes existe desconocido interpretaciones valor (existe pero no se conoce),
el valor no está disponible.
A continuación algunos ejemplos que se usan para comprender los significados del NULL.
Valor Desconocido. Fecha de nacimiento de una persona no se conoce, por lo que se representa por NULL en la
base de datos.
Valor no disponible o retenido. Una persona tiene un teléfono de casa, pero no lo hace quiere que sea en la lista,
por lo que se retiene y representa como NULL en la base de datos.
Atributo No aplicable. Un atributo sería NULL para una persona que no tiene un título universitario, ya que no se
aplica a esa persona.
Consultas anidadas

Unidad 1 Manipulación Avanzada de Datos
12 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Algunas consultas requieren que los valores existentes en la base de datos se obtengan y luego se usa en una
condición de comparación. Tales consultas se pueden formulan convenientemente mediante el uso de consultas
anidadas, que son de selección-de-donde los bloques completos dentro del DONDE cláusula de otra consulta.
Un ejemplo de esto es el siguiente:
SELECT DISTINCT Pnumber
FROM PROYECTO
WHERE Pnumber IN
(SELECT Pnumber
FROM PROYECTO, DEPARTAMENTO, EMPLEADO
WHERE NUMD = NUMEROD AND
Mgr_ssn = SSN y Lname = 'Smith')
Oregón
Pnumber IN
(SELECT Pno
FROM TRABAJA_EN, EMPLEADO
WHERE ESSN = SSN y Lname = 'Smith');
Si una consulta anidada devuelve un solo atributo y una sola tupla, el resultado de la consulta será una sola
(escalar) de valor. En tales casos, se permite utilizar = en lugar de IN para el operador de comparación. En
general, la consulta anidada volverá una tabla.
Consultas Anidadas Correlacionadas
Cada vez que una condición en la cláusula WHERE de una consulta anidada hace referencia a algún atributo de
una relación declarado en la consulta externa, se dice que están correlacionadas las dos consultas.
Podemos entender una consulta correlacionada mejor al considerar que la consulta anidada es evaluado una vez
por cada tupla (o combinación de tuplas) en la consulta externa. Por ejemplo
SELECT E.Fname, E.Lname

Unidad 1 Manipulación Avanzada de Datos
13 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
FROM EMPLEADO COMO E, dependiente como D
WHERE E.Ssn = D.Essn Y E.Sex = D.Sex
AND E.Fname = D.Dependent_name;
De la consulta se puede decir lo siguiente: Para cada tupla EMPLEADO, evaluar la anidada consulta, que
recupera los valores ESSN para todas las tuplas DEPENDIENTES con el mismo sexo y el nombre como la tupla
EMPLEADO; si el valor Ssn de la tupla EMPLEADO está en el resultado de la consulta anidada, a continuación,
seleccione que tupla EMPLEADO.
Funciones únicas en SQL
El EXISTS función en SQL se utiliza para comprobar si el resultado de una correlacionado consulta anidada está
vacía (no contiene tuplas) o no. El resultado de EXISTS es un booleano valor TRUE si el resultado de la consulta
anidada contiene al menos una tupla, o FALSE si el resultado de la consulta anidada no contiene tuplas. Un
ejemplo de esto es el siguiente:
SELECT E.Fname, E.Lname
FROM EMPLEADO COMO E
WHERE EXISTE (SELECCIONAR *
FROM COMO DEPENDIENTE D
WHERE E.Ssn = D.Essn Y E.Sex = D.Sex
AND E.Fname = D.Dependent_name);
Tablas acumulados en SQL
El concepto de una tabla unida (o relación unido) fue incorporado en SQL para permitir a los usuarios especificar
una tabla resultante de una operación de combinación en la cláusula FROM de una consulta.
Un ejemplo de esto es el siguiente:
SELECT Fnombre, Lname, Dirección
FROM (EMPLEADO ÚNETE DEPARTAMENTO EN Dno = NUMEROD)
WHERE Dname = 'Investigación';

Unidad 1 Manipulación Avanzada de Datos
14 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
La cláusula de FROM en la consulta contiene una sola tabla unida. Los atributos de una tabla de este tipo son
todos los atributos de la primera tabla, EMPLEADO, seguidos de todos los atributos de la segunda tabla,
DEPARTAMENTO. El concepto de una tabla unida también permite al usuario especificar diferentes tipos de
unión.
Funciones de Agregación.
Las funciones de agregación se utilizan para resumir la información a partir de múltiples tuplas en un resumen de
una sola tupla. Agrupación se utiliza para crear subgrupos de tuplas antes de resumen. Agrupación y agregación
son necesarias en muchas aplicaciones de bases de datos, y vamos a introducir su uso en SQL a través de
ejemplos.
Una serie de funciones integradas de agregados existir: COUNT, SUM, MAX, MIN, y AVG.
Un ejemplo más claro de esto es lo siguiente:
Encuentre la suma de los salarios de todos los empleados, el salario máximo, el salario mínimo y el salario
promedio.
SELECT SUM (salario), MAX (Sueldo), MIN (Sueldo), AVG (Sueldo)
DEL EMPLEADO;
Si queremos obtener los valores de la función anterior para empleados de una Department- específica.
Group by y Having
En muchos casos, queremos aplicar las funciones de agregado a subgrupos de tuplas en una relación, donde los
subgrupos se basan en algunos valores de atributos. Por ejemplo, podemos puede que desee encontrar el salario
promedio de los empleados en cada departamento o el número de los empleados que trabajan en cada proyecto.
En estos casos tenemos que dividir la relación en subconjuntos no superpuestos (o grupos) de tuplas.
Un ejemplo de cómo utilizar esto es el siguiente:
SELECT Dno, COUNT (*), AVG (Sueldo)
FROM EMPLEADO
GROUP BY Dno;

Unidad 1 Manipulación Avanzada de Datos
15 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
En la consulta, las tuplas de EMPLEADO se dividen en grupos, cada grupo que tiene el mismo valor para la
agrupación de atributos Dno. Por lo tanto, cada grupo contiene el los empleados que trabajan en el mismo
departamento.
Vistas
Una vista en la terminología de SQL es una sola tabla que se deriva de otras tablas. Estos otras tablas pueden
ser tablas base o puntos de vista previamente definidos. Una vista no necesariamente existir en forma física; se
considera para ser una tabla virtual, en contraste con tablas de base, cuya tuplas siempre están almacenados
físicamente en la base de datos. Esto limita la posible las operaciones de actualización que se pueden aplicar a
las vistas, pero no proporciona ningún tipo de limitaciones en la consulta de una vista.
Un ejemplo de estas so el siguiente:
CREATE VIEW WORKS_ON1
AS SELECT Fnombre , Lname , Pname , Horas
FROM EMPLEADO, PROYECTO, TRABAJA_EN
WHERE Ssn = ESSN Y Pno = Pnumber ;
En la consulta, no especificamos nuevos nombres de atributos de la vista WORKS_ON1 (Aunque podríamos
tener); en este caso, WORKS_ON1 hereda los nombres de la vista atributos de la definición de tablas
EMPLEADO, PROYECTO, y TRABAJA_EN.
Ejercicios.
Especifique las siguientes consultas en la base de datos en la Figura 3.5 en SQL. Mostrar los resultados de la
consulta, si cada consulta se aplica a la base de datos en la Figura 3.6.
a. Para cada instancia cuya media de empleados salario es más de $ 30,000, recuperar el nombre del
departamento y el número de empleados que trabajan para ese departamento.
(a) SELECT DNAME, COUNT (*)
FROM DEPARTMENT, EMPLOYEE
WHERE DNUMBER=DNO
GROUP BY DNAME

Unidad 1 Manipulación Avanzada de Datos
16 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
HAVING AVG (SALARY) > 30000
Result:
DNAME DNUMBER COUNT (*)
Research 5 4
Administration 4 3
Headquarters 1 1
b. Supongamos que queremos que el número de empleados de sexo masculino en cada departamento que ganan
más de 30.000 dólares, en lugar de todos los empleados (como en 5.4a Ejercicio). ¿Podemos especificar esta
consulta en SQL? ¿Por qué o por qué no?
(b) The query may still be specified in SQL by using a nested query as follows (not all implementations may support
this type of query):
SELECT DNAME, COUNT (*)
FROM DEPARTMENT, EMPLOYEE
WHERE DNUMBER=DNO AND SEX='M' AND DNO IN ( SELECT DNO
FROM EMPLOYEE
GROUP BY DNO
HAVING AVG (SALARY) > 30000)
GROUP BY DNAME
Result:
DNAME DNUMBER COUNT (*)
Research 5 3
Administration 4 1

Unidad 1 Manipulación Avanzada de Datos
17 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Headquarters 1 1
In SQL, specify the following queries on the database in Figure 3.5 using the concept of nested queries and
concepts described in this chapter.
a. Retrieve the names of all employees who work in the department that has the employee with the highest salary
among all employees.
SELECT LNAME FROM EMPLOYEE WHERE DNO =
(SELECT DNO FROM EMPLOYEE WHERE SALARY =
(SELECT MAX (SALARY) FROM EMPLOYEE) )
b. Retrieve the names of all employees whose supervisor’s supervisor has ‘888665555’ for Ssn.
SELECT LNAME FROM EMPLOYEE WHERE SUPERSSN IN
(SELECT SSN FROM EMPLOYEE WHERE SUPERSSN = ‘888665555’)
c. Retrieve the names of employees who make at least $10,000 more than the employee who is paid the least in
the company.
SELECT LNAME FROM EMPLOYEE WHERE SALARY >= 10000 +
(SELECT MIN (SALARY) FROM EMPLOYEE)

Unidad 1 Manipulación Avanzada de Datos
18 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Conclusión
Luego de haber concluido este trabajo de investigación sobre bases de datos fueron muchos los esfuerzos y
conocimientos adquiridos durante dicha elaboración. Algunos de los aspectos aprendidos y que de gran peso es
la base de datos su definición, requerimiento, ventajas y características donde podemos decir que la base de
datos: Es una colección de datos o información usados para dar servicios a muchas aplicaciones al mismo tiempo.
En cuanto al requerimiento podemos decir que cumple las mismas tareas de análisis que del software y tiene
como característica relacionar la información como vía organización y asociación donde la base de datos tiene
una ventaja que es utilizar la plataforma para el desarrollo del sistema de aplicación. Los sistemas de bases de
datos requieren que la institución reconozca el papel estratégico de la información y comience activamente a
administrar y planear la información como recurso corporativo. Esto significa que la institución debe desarrollar la
función de administración de datos con el poder de definir los requerimientos de la información para toda la
empresa y con acceso directo a la alta dirección. El director de la información (DI) o vicepresidentes de la
información es el primero que aboga en la institución por los sistemas de bases de datos. Luego de haber
concluido este trabajo de investigación sobre bases de datos fueron muchos los esfuerzos y conocimientos
adquiridos durante dicha elaboración. Algunos de los aspectos aprendidos y que de gran peso es la base de
datos su definición, requerimiento, ventajas y características donde podemos decir que la base de datos: Es una
colección de datos o información usados para dar servicios a muchas aplicaciones al mismo tiempo. En cuanto
al requerimiento podemos decir que cumple las mismas tareas de análisis que del software y tiene como
característica relacionar la información como vía organización y asociación donde la base de datos tiene una
ventaja que es utilizar la plataforma para el desarrollo del sistema de aplicación en las organizaciones. Otro
aspectos importante sería el diseño y creación de la base de datos, donde existen distintos modos de organizar
la información y representar las relaciones entre por datos los tres modelos lógicos principales dentro de una base
de datos son el jerárquico, de redes y el relacional, los cuales tiene ciertas ventajas de procesamiento y de
negocios.
Otro punto necesario es la clase de bases de datos las cuales son, base de dato documental, base de datos
distribuidas y base de datos orientadas a objetos e hipermedia y tienen como función derivar, almacenar y
procesar datos dentro de una información. Los gráficos y tablas nos sirven para resumir en un dibujo toda una
serie de datos mucho más explícito y fácil de asimilar, los tipos de gráficos que se pueden utilizar en una base de
datos son: gráficos de pastel, barra y discretos. Sistemas de gestión, es un sistema de desarrollo que hace posible
ascender a datos integrados funcionales y organizacionales de una empresa.
Otro punto importante sería la creación de un informe y consultas dentro de una base de datos. Los informe de
base de datos están definidos por bandas de informe, estas bandas de informe se definen cinco tipos de diferentes

Unidad 1 Manipulación Avanzada de Datos
19 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
función en el informe, por ejemplo la cabecera que aparece en la parte superior de cada página, líneas de detalle
y resumen de informe. El informe se pueda crear rápido y personalizado. La creación de consultas de base de
datos consta de archivos que permiten realizar muchas tareas diferentes con los datos que se pueden ver.
También se pueden utilizar para controlar los registros que visualiza Dbase la consulta no contiene información
de base de datos, si no tan solo las instrucciones necesarias para seleccionar los registros y campos requeridos
de una base de datos.

Unidad 1 Manipulación Avanzada de Datos
20 Osvaldo Vilchis Pachuca -José Rubén Súchil Súchil
Bibliografía
Fundamentals of Database Systems(Elmasri,Navathe) 6th Edition