r-studio, diferencia estadísticamente significativa 2
TRANSCRIPT

Pasos para el análisis de datos a través de R-Studio.

En el presente análisis muestro los pasos que tuve que dar para poder evaluar si
existía una diferencia estadísticamente significativa entre las calificaciones que
obtuvieron los estudiantes de un grupo de 40 personas, el cual fue dividido en partes
iguales para trabajar en dos entornos virtuales de aprendizaje distintos (uno
Moodle y el otro Google Apps).

Este estudio se realizó por 2 años consecutivos; los datos evaluados a
continuación corresponden al segundo año.

Abrimos R-Studio.

Nos abrirá esta interfaz.

En la ventana superior derecha hacemos clic en la pestaña Import Dataset, y luego en
la opción Text File.

Buscamos y seleccionamos el archivo(Notas-2grupos-v2.csv).

En la imagen siguiente podremos ver en la parte superior de la ventana un cuadro de texto (Input File) el cual muestra los datos
como están originalmente en el archivo, y en la parte inferior en otro cuadro de texto
(Data Frame) vemos los datos como serán mostrados luego de ser cargados a R-Studio.
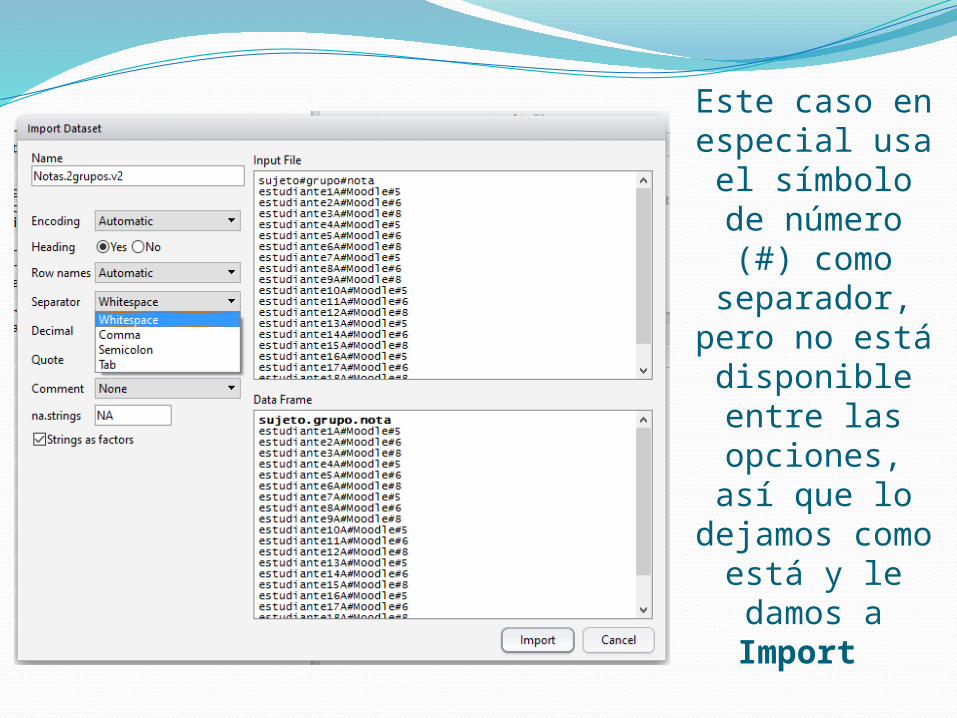
Este caso en especial usa el
símbolo de número (#)
como separador, pero
no está disponible entre las opciones, así que lo dejamos como está y le
damos a Import
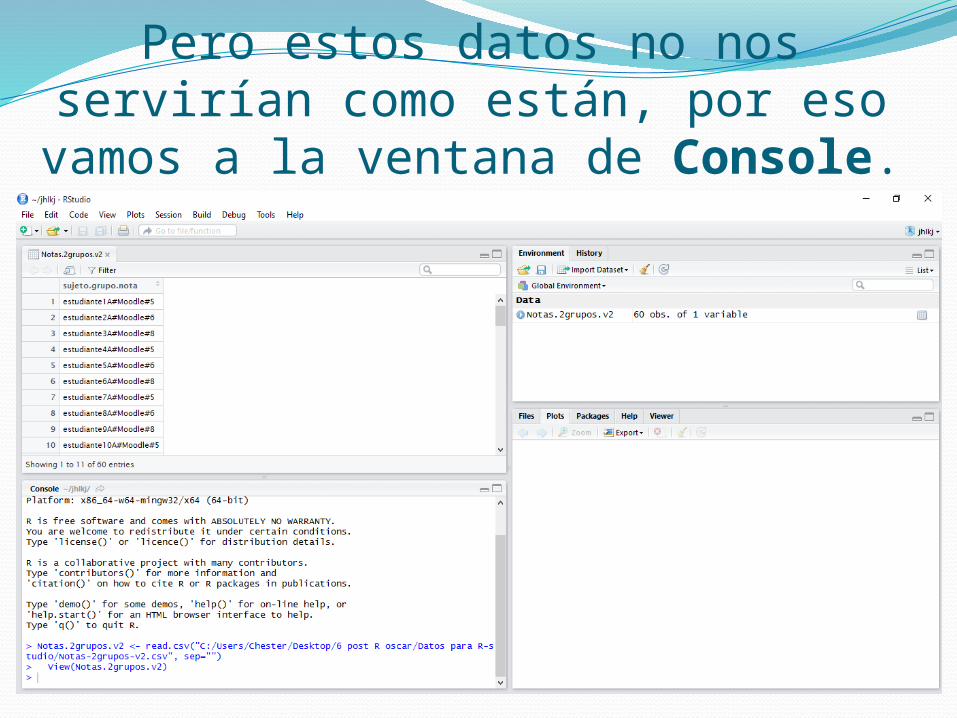
Pero estos datos no nos servirían como están, por eso vamos a la ventana de Console.
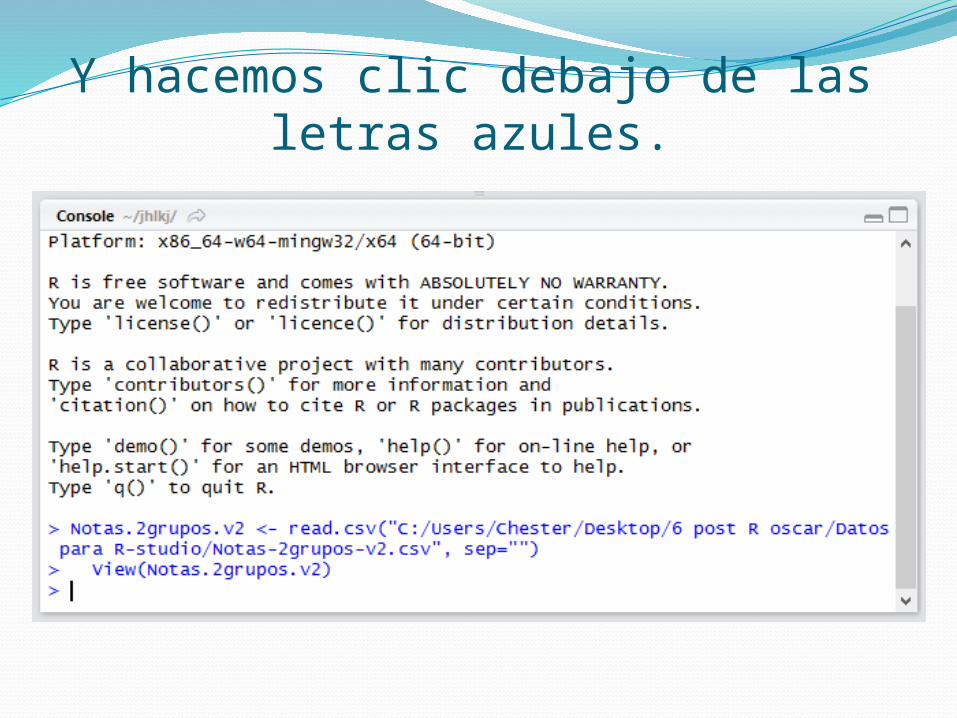
Y hacemos clic debajo de las letras azules.

Pulsamos la tecla de dirección arriba.

Luego nos dirigimos a la parte subrayada por una línea roja, donde dice sep="")

E ingresamos el símbolo de número (#) y pulsamos la tecla Enter.

Ya podemos ver una tabla con los datos cargados y organizados.

Ahora vamos a la ventana Console e ingresamos los siguientes códigos para filtrar los datos de la
tabla y crear una nueva a partir del elemento (Moodle o Google Apps).
datosMoodle <- subset(Notas.2grupos.v2, grupo=="Moodle")
Como resultado de ingresar esta línea de código nos arroja una tabla con 20 elementos filtrados
a partir del elemento Google Apps.

Notas.2grupos.v2 es el nombre de la tabla original de la cual filtramos los datos y creamos
la nueva tabla llamada datosMoodle

Si utilizáramos este código para otros datos tendríamos que cambiar las siguientes partes:
datosMoodle: es el nombre de la tabla nueva que vamos a crear. Notas.2grupos.v2: es el nombre de la tabla que cargamos previamente y de donde haremos el filtrado. grupo=="Moodle": (grupo) es el nombre de la columna y (Moodle) es el elemento que filtrará.

Ahora ingresamos otra línea de código.
datosGoogleApps <- subset(Notas.2grupos.v2, grupo=="Google Apps")
Que nos dará como resultado otra tabla con 20 elementos pero con la diferencia de que estos fueron filtrados a partir del elemento Google
Apps.

De nuevo (Notas.2grupos.v2) es el nombre de la tabla original de la cual filtramos los datos y
creamos la nueva tabla llamada datosGoogleApps

Ahora vamos a hacer la representación gráfica, y para ello
ingresamos el siguiente código.
plot(Notas.2grupos.v2$grupo, Notas.2grupos.v2$nota,
xlab="Grupos", ylab="Notas", type="n")


Ahora el análisis diferencial entre grupos y para ello usamos el siguiente código.
with(Notas.2grupos.v2, tapply(nota, list(grupo), mean))

Aquí podemos ver que la nota media de los estudiantes que utilizaron la interfaz virtual de Google Apps fue de (7.25) y del grupo
de Moodle fue de (6.55).

y ya para el final analizaremos si existe una diferencia estadísticamente significativa
entre las calificaciones.
Para lo cual ingresaremos el siguiente código.
t.test(datosMoodle$nota, datosGoogleApps$nota)


y como resultado obtenemos que P-value = 0.08832
Al llevar este valor a porcentaje nos arroja: 0.08832 * 100 = 8.832%
Por consiguiente, como conclusión podemos decir que no existe una diferencia
estadísticamente significativa entre las notas de los dos grupos.