proyecto fin de carrera ingeniero de telecomunicaciones
TRANSCRIPT

Eugenia Ramírez Solano Página 1
Escuela Superior de Ingeniería
Universidad de Sevilla
Septiembre, 2013
Estudio de imágenes
dermatoscópicas para el
diagnóstico de lesiones de la
piel basado en análisis de
patrones
Autor: Eugenia Ramírez Solano
Tutor: Begoña Acha y Carmen Serrano
Proyecto Fin de Carrera
Ingeniero de Telecomunicaciones

Eugenia Ramírez Solano Página 2

Eugenia Ramírez Solano Página 3
ÍNDICE 1. INTRODUCCIÓN ..................................................................................................................... 5
1.1. Contexto del proyecto ................................................................................................... 5
1.2. Problema a resolver ...................................................................................................... 6
1.3. Metodología usada para la resolución del problema ................................................... 9
2. LESIONES PIGMENTADAS DE LA PIEL .................................................................................. 13
2.1. Incidencia del cáncer ................................................................................................... 13
2.2. Reglas clínicas para el diagnóstico .............................................................................. 14
2.3. Tipos de lesiones ......................................................................................................... 16
3. TRATAMIENTO DIGITAL DE IMÁGENES PARA CLASIFICACIÓN ............................................ 19
3.1. Estado del arte ............................................................................................................ 19
3.2. Algoritmo implementado ............................................................................................ 25
3.2.1. Estudio en escala de grises .................................................................................. 27
3.2.2. Estudio en color, Lab ........................................................................................... 30
4. RESULTADOS ....................................................................................................................... 35
4.1. Material usado ............................................................................................................ 35
4.2. Resultados ................................................................................................................... 36
5. CONCLUSIONES ................................................................................................................... 43
6. REFERENCIAS Y BIBLIOGRAFÍA ............................................................................................ 45

Eugenia Ramírez Solano Página 4

Eugenia Ramírez Solano Página 5
1. INTRODUCCIÓN
1.1. Contexto del proyecto En este proyecto desarrollaremos un algoritmo para el estudio de imágenes
dermatoscópicas basándonos en el análisis de patrones. Sin embargo, antes de
adentrarnos en esta materia sería interesante explicar algunos conocimientos médicos
que, aunque están fuera del objetivo de este proyecto, ayudarán a la contextualización
de nuestro trabajo.
Existen dos tipos fundamentales de cáncer de piel en función de la célula de la
cual se originen:
Melanoma: este cáncer surge en los melanocitos, que son células que forman
parte de la epidermis, la capa más superficial de la piel. El caso más típico de
esta patología es un lunar que degenera en melanoma. Este cáncer se da con
poca frecuencia pero es el más agresivo.
Actualmente supone un foco de atención desde el punto de vista médico ya
que en los años 80 se detectó un aumento de la enfermedad y desde entonces
la incidencia del melanoma no ha hecho más que aumentar por la base
genética que tiene.
Cáncer no melanoma: es debido a los queratinocitos que son células que, al
igual que en el caso anterior, forman parte de la epidermis. Hay dos tipos de
tumores dentro de este grupo:
- Carcinoma basocelular: es el cáncer de piel más frecuente. Suele
aparecer en la tercera edad, en pieles con un daño crónico por el sol,
aunque también puede aparecer en personas jóvenes con mucho
tiempo en exposición solar. En este tipo, la lesión aparece en piel
sana, a diferencia del melanoma que, como hemos comentado antes,
surge normalmente por la degeneración de lesiones benignas. El
carcinoma basocelular no da metástasis, (existen algunos casos pero
se consideran excepciones) crece célula a célula por contigüidad sin
invadir a distancia.

Eugenia Ramírez Solano Página 6
- Carcinoma espinocelular: aparece sobre todo en mucosas, es poco
frecuente y a diferencia del anterior puede producir metástasis. El
principal factor de la aparición de este cáncer es el sol aunque
también hay otros factores que crean mayor predisposición como los
genéticos, las radiaciones, algunas sustancias químicas, etc.
1.2. Problema a resolver En la actualidad, el número de casos de cáncer de piel diagnosticados, ha
aumentado significativamente debido tanto a la concienciación de la población como a
los avances hechos en la materia. Este incremento se ha producido principalmente en el
sector de población de jóvenes y mujeres por su mayor exposición al sol.
Para evitar desarrollar esta enfermedad, es muy importante la revisión de las
lesiones de la piel pudiendo conseguir una detección temprana. Con ese fin, se
desarrollan nuevos algoritmos y nuevas herramientas facilitadoras de la labor del
dermatólogo que le permitan obtener un diagnóstico precoz y fiable de esta patología.
La Dermatoscopia es la técnica no invasiva de diagnóstico que facilita el estudio
de las lesiones para poder realizar un tratamiento precoz. Utiliza un sistema de
magnificación con luz incidente que permite observar estructuras de la epidermis y la
dermis, las dos capas más superficiales de la piel, que a simple vista no son visibles. En
ningún momento hay que olvidar que esta técnica es una herramienta para
complementar al médico y contribuir a la eficiencia de su diagnóstico. Los avances
obtenidos en esta área nunca podrán sustituir al especialista.
Una vez obtenida la imagen de la lesión el siguiente paso es clasificarla. Para
realizar la evaluación dermatoscópica de la lesión cutánea es muy común usar el método
de diagnóstico en dos etapas. En el CNMD, el Consensus Net Meeting on Dermoscopy,
este procedimiento fue el usado por la mayoría de sus participantes para clasificar las
lesiones [3].
En la primera fase del procedimiento se cataloga la imagen en melanocítica o no
melanocítica. Para ello, se evalúa la presencia de una serie de características propias de
los tumores melanocíticos, quedando catalogada como lesión melanocíticas en caso de
detectarlos. Si estos criterios no se encuentran en la lesión se deberán evaluar las
características específicas de los tumores no melanocíticos. Si la lesión tampoco

Eugenia Ramírez Solano Página 7
presentara estas características se considerará lesión melanocítica. Esto se debe a que las
lesiones melanocíticas son las que podrían derivar en un melanoma, que como ya
dijimos anteriormente, es el cáncer más agresivo. Este es el motivo por el cual en caso
de no poder discernir entre un tipo u otro, la consideremos un posible melanoma,
minimizando así el riesgo de infradiagnóstico.
Una vez que esta clasificación es realizada se pasa a la siguiente etapa del
procedimiento. En la segunda fase, dentro del grupo de lesiones clasificadas
anteriormente como lesiones melanocíticas, se aplican algoritmos para diferenciar los
melanomas de las lesiones melanocíticas benignas. En este segundo paso se pueden usar
distintos algoritmos para el estudio de las lesiones. Los más comunes son:
- La regla de los 7 puntos
- La regla ABCD
- El método de Menzies
- Análisis de patrones
Además de las cuatro reglas clínicas mencionadas también existen más
algoritmos que han ido surgiendo conforme se profundizaba en la materia como pueden
ser el método ABCD(E) de Kittler o la lista de los 3 puntos de Soyer, etc.
En el CNMD, se evaluaron la especificidad y sensibilidad de los cuatro
algoritmos más comunes. De los resultados obtenidos se llegó a la conclusión de que
para el diagnóstico del melanoma el análisis de patrones era el más eficiente en términos
de especificidad y sensibilidad (83,4% y 83,7% respectivamente). El resto de algoritmos
a pesar de tener una sensibilidad similar a la del análisis de patrones, la especificidad era
menor (entre un 11,9% y un 13.4% menos) [3]. En este proyecto nos centraremos en el
estudio del análisis de patrones como algoritmo de clasificación de las lesiones
melanocíticas para implementar un método que detecte determinados patrones en las
imágenes.

Eugenia Ramírez Solano Página 8
Este proceso de clasificación que acabamos de explicar queda recogido en la
siguiente figura. Este algoritmo es conocido en el entorno médico por “Algoritmos de
diagnóstico”. (Nótese que, como ya hemos comentado, en el caso de no poder discernir
entre melanocítica o no melanocítica, la lesión se cataloga como melanocítica como
medida preventiva para así, contemplar la posibilidad de que sea el cáncer más
agresivo).
Ilustración 1 – Algoritmos de diagnóstico en 2 etapas

Eugenia Ramírez Solano Página 9
1.3. Metodología usada para la resolución del problema Como ya hemos comentado, el análisis de patrones es un método muy usado
para la detección de melanomas, de ahí que nos centremos en su estudio ya que es el
preferido por los dermatólogos profesionales, como apuntaron los participantes del
CNMD.
Este método se basa en buscar patrones determinados en la lesión bajo estudio
que guíen al dermatólogo al emitir el diagnóstico de la misma. Dentro de los múltiples
patrones que hay, los criterios establecen que lesiones con patrones globular,
empedrado, homogéneo o estrellado están asociadas a diagnósticos de lesiones
melanocíticas benignas mientras que el patrón paralelo y el multicomponente están
relacionados con el melanoma [3].
En nuestro trabajo, en primer lugar, se implementó un método que, basándose en
la textura de la imagen detectara 4 patrones: reticulado, paralelo, homogéneo y
empedrado. Este método se basa en la idea de que cada textura tiene un patrón que se
repite entre un píxel y su conjunto de vecinos. Es decir, si subdividimos la imagen de la
lesión en vecindarios estos guardarán cierto parecido en función del patrón de la imagen
bajo observación.
Por ejemplo, en el caso del homogéneo si tomamos un píxel cualquiera de
referencia y su vecindario 3x3 todos estos píxeles tendrán el mismo color o un color
muy similar por lo que los valores de los píxeles de dicho vecindario serán muy
parecidos. De esta forma una imagen con patrón homogéneo estará formada por un
conjunto de vecindarios cuya característica común será que los píxeles tienen un valor
similar. En la siguiente figura podemos observar una imagen de una lesión de la cual se
han extraído tres regiones a modo de vecindarios para representar lo explicado. Como se
puede comprobar las tres se caracterizan por tener un color similar, es decir, todos los
píxeles tienen un valor parecido.
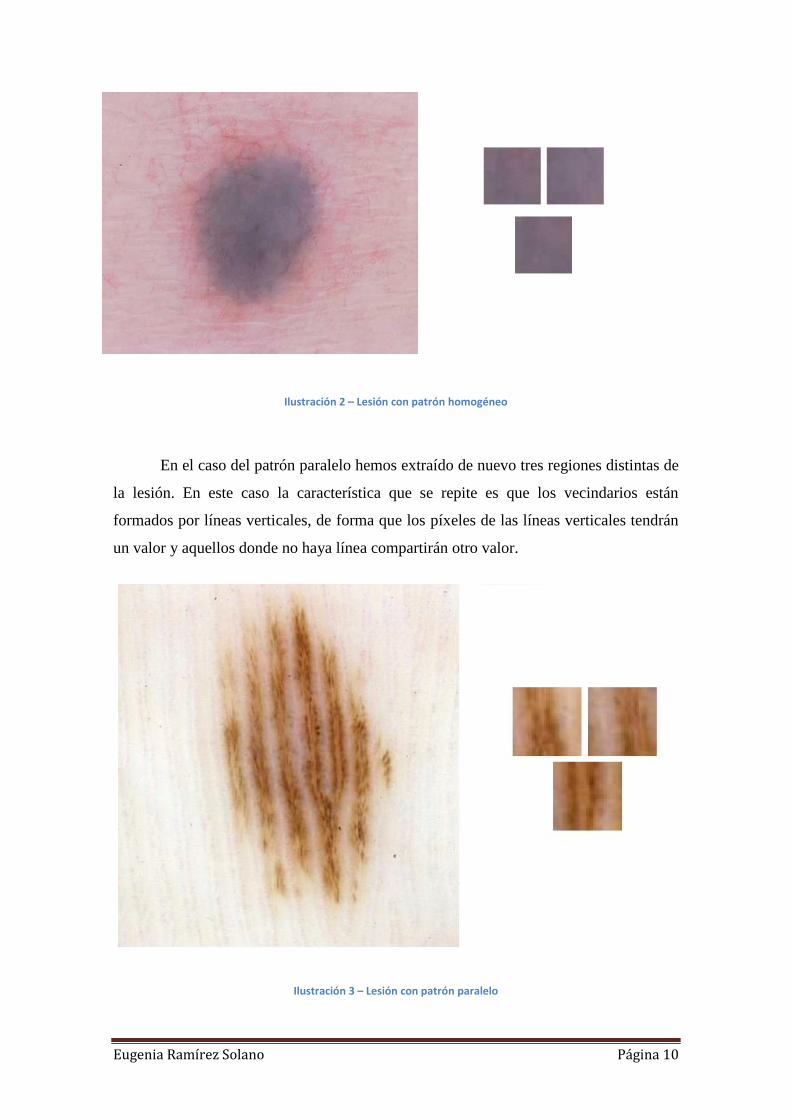
Eugenia Ramírez Solano Página 10
Ilustración 2 – Lesión con patrón homogéneo
En el caso del patrón paralelo hemos extraído de nuevo tres regiones distintas de
la lesión. En este caso la característica que se repite es que los vecindarios están
formados por líneas verticales, de forma que los píxeles de las líneas verticales tendrán
un valor y aquellos donde no haya línea compartirán otro valor.
Ilustración 3 – Lesión con patrón paralelo

Eugenia Ramírez Solano Página 11
Así pues se implementó un algoritmo que extrajera esta característica que
comparten las imágenes de un mismo patrón y usara el resultado obtenido para formar
un modelo con el que poder clasificar imágenes nuevas.
Posteriormente con la intención de mejorar los resultados obtenidos por este
primer método se incluyó el color en el algoritmo de forma que caracterizamos los
patrones por textura y color en lugar de trabajar en grises como se hacía en el primer
método.
En este documento se profundizará sobre ambos algoritmos y se mostrarán los
resultados obtenidos en los experimentos llevados a cabo.

Eugenia Ramírez Solano Página 12

Eugenia Ramírez Solano Página 13
2. LESIONES PIGMENTADAS DE LA
PIEL
2.1. Incidencia del cáncer Según la AECC, Asociación Española contra el Cáncer, actualmente se
diagnostican unos 160.000 casos de melanomas al año en todo el mundo (79.000
hombres y 81.000 mujeres).
En Europa este cáncer es más frecuente entre las mujeres mientras que en el
resto del mundo es al contrario. La mayor incidencia se registra en países con fuerte
irradiación solar y con una población blanca no autóctona, como puede ser en Australia,
Nueva Zelanda, USA y Sudáfrica. En Europa es más frecuente en el norte y en el oeste
(población con piel muy blanca, expuesta al sol sobre todo en verano). Pero mientas que
en todas estas zonas la frecuencia del melanoma tiende a estabilizarse e incluso a
disminuir, sigue aumentando en el sur y el este de nuestro continente.
En España se diagnostican unos 3.600 casos anuales y al igual que en el resto de
Europa, es un tumor más frecuente entre las mujeres (2,7% de los cánceres femeninos)
que entre los hombres (1,5%). La incidencia en nuestro país se puede considerar alta
(tasa ajustada mundial en 2002: 5,3 nuevos casos/100.000 habitantes/año en hombres y
5,5 en mujeres), con un ascenso muy importante, especialmente desde los años 90.
En lo que respecta a la edad en la que se detectan los tumores se registran casos
prácticamente a cualquier edad, aunque la mayoría se diagnostican entre los 40 y los 70
años.
El carcinoma espinocelular supone el 20-25% de los tumores malignos. Al tener
una estrecha relación con la exposición solar esta incidencia ha aumentado en casi todos
los países. En el caso del carcinoma basocelular la incidencia está aumentando en un
10% anual y supone el 80% de los casos de cáncer de piel.

Eugenia Ramírez Solano Página 14
2.2. Reglas clínicas para el diagnóstico Desde el punto de vista clínico, el médico puede usar distintos métodos para
evaluar si una lesión melanocítica es benigna o es un melanoma. Hay muchas reglas
clínicas para diagnosticar el melanoma que han ido surgiendo conforme se ha
profundizado en la materia, sin embargo, aquí solo daremos una breve explicación de
las 4 reglas más comunes.
- 7-point checklist: En este método, también conocido como la regla de los 7
puntos, se definen 7 criterios: Athypical pigment network, Blue-whitish veil,
Atypical vascular pattern, Irregular streaks, Irregular gobules, Irregular blotches.
Las definiciones de estas características se recogen en la siguiente tabla:
Ilustración 4 - Criterios de la regla de los 7 puntos
Los tres primeros criterios se consideran los criterios principales y les
corresponden dos puntos a cada uno mientras que los restantes se consideran
secundarios y tienen asignados un punto para cada uno de ellos. De esta forma
cuando el médico analiza la lesión, evalúa si esta presenta alguno de los 7
criterios definidos y en caso de tenerlos suma los puntos correspondientes. Si al
terminar la evaluación la lesión tiene una puntuación de 3 o superior el
diagnostico estará asociado a un melanoma. Si por el contrario es menor, se
considerará una lesión melanocítica benigna.

Eugenia Ramírez Solano Página 15
- Menzies method: En este método se definen 2 características llamadas
“Negative features” y otras 9 características llamadas “Positive feautures”. La
definición de todas ellas se recoge en la tabla que se muestra a continuación:
Ilustración 5 - Características de Menzies
La lesión será diagnosticada como un melanoma si no aparece ninguno de los
dos criterios negativos y aparece al menos uno de los 9 criterios positivos.

Eugenia Ramírez Solano Página 16
- ABCD Rule: en este método se establecen cuatro criterios: la asimetría, los
bordes, el color y las estructuras dermatoscópicas. Estos criterios se definen a
continuación:
Ilustración 6 - Regla ABCD
El médico, según las calificaciones de la tabla anterior, puntuará los criterios que
se observen en la lesión y con la ayuda de una fórmula, se estimará la
puntuación total de la misma. Si el valor obtenido es menor que 4.75 la lesión
melanocítica es benigna; si pertenece al intervalo [4.8-5.45] la lesión se
considerará sospechosa y se recomienda su extirpación o seguimiento;
finalmente si el valor es mayor que 5.45 se considera posible melanoma.
- Análisis de patrones: como ya se ha comentado esta técnica es la más usada por
los médicos experimentados en la materia. Existen dos modalidades en función
de si se detectan patrones globales o patrones locales. Los patrones globales son
aquellos que cubren la mayor parte de la lesión permitiendo una categorización
preliminar rápida. Por otra parte, los patrones locales son aquellas estructuras
individuales presentes en distintas regiones de la lesión. Aquel patrón local que
sea predominante será el que determine el patrón global.
2.3. Tipos de lesiones Las lesiones con las que trabajaremos en este proyecto serán, como ya hemos
comentado, aquellas que tengan patrones globales, es decir, lesiones que presenten un
patrón que cubra la mayor parte de la lesión. A pesar de que existen muchos patrones
globales en este trabajo nos hemos centrado en el estudio de cuatro en particular: el
“Reticular pattern”, “Cobblestone pattern”, “Homogeneus pattern” y “Parallel pattern”.
Las características de estos patrones se detallan a continuación:

Eugenia Ramírez Solano Página 17
Reticular: se caracteriza por una red pigmentada que cubre la mayor parte de la
lesión. La red suele estar formada por finas líneas de color marrón. Este patrón
es común en las lesiones melanocíticas y suele conllevar el diagnóstico de
“Melanocytic nevus”, que es una lesión melanocítica benigna.
Ilustración 7 – Patrones reticulados
Cobbestone: esta textura está formada por glóbulos grandes muy cercanos. Su
traducción al español podría ser “empedrado” lo cual nos da una idea de su
aspecto. En este caso el diagnostico asociado sería “Dermal nevus”.
Ilustración 8 – Patrones empedrados

Eugenia Ramírez Solano Página 18
Homogeneous: en este caso la lesión presenta una superficie homogénea y no
presenta otras características locales. En este caso el diagnóstico es
“Melanocytic nevus”. Si el color de la lesión es azulino, tendremos un “Blue
nevus”.
Ilustración 9 – Patrones homogéneos
Parallel: este patrón es encontrado en las palmas de las manos y de los pies por
la particular anatomía de esas zonas de nuestro cuerpo (la piel ya tiene surcos de
por sí). El diagnóstico de este patrón puede estar asociado tanto a un “Acral
nevus” como a un “Melanoma”.
Ilustración 10 – Patrones paralelos

Eugenia Ramírez Solano Página 19
3. TRATAMIENTO DIGITAL DE
IMÁGENES PARA CLASIFICACIÓN
3.1. Estado del arte En las últimas décadas muchos han sido los autores que se han centrado en
desarrollar algoritmos de detección de patrones en las lesiones pigmentadas de la piel
por ser el método más usados por los dermatólogos. Los patrones pueden ser globales o
locales en función de si cubren la mayor parte de la lesión o de si están repartidos por
distintas regiones de la misma [14].
La red pigmentada, los puntos y glóbulos irregulares, el velo azul-blanquecino,
las estructuras de regresión o las estructuras vasculares son algunos de los patrones
locales que se detectan en los métodos desarrollados. El patrón local más estudiado es la
red pigmentada ya que es muy típico de las lesiones melanocíticas por lo que su
detección contribuye a la primera fase del procedimiento en dos etapas, la
diferenciación entre lesión melanocítica y no melanocítica. Además, si la red no es
regular el diagnóstico estará asociado al melanoma. Así pues gracias a toda la
información que aporta este patrón, los especialistas se han centrado en su detección.
Anantha et al. [6] trabajaron con dos algoritmos de identificación de texturas
llamados NGLDM y LAWS para la detección de la red pigmentada. Los resultados que
se obtuvieron en la correcta clasificación de las imágenes fueron de un 78% y un 65%
respectivamente sobre 155 lesiones a estudiar.
Sadegui et al. [9] desarrollaron un método basado en la detección de borde y la
búsqueda de estructuras cíclicas y mallas. La imagen se pasa por un filtro LOG el cual
detecta los cambios de intensidad dando como resultado una imagen binaria. En esta
imagen binaria se buscan estructuras circulares y en función de la densidad de la imagen
obtenida se decide si la imagen presenta una red pigmentada o no (Presento or Absent).
Un ejemplo de este proceso se recoge en la siguiente figura.
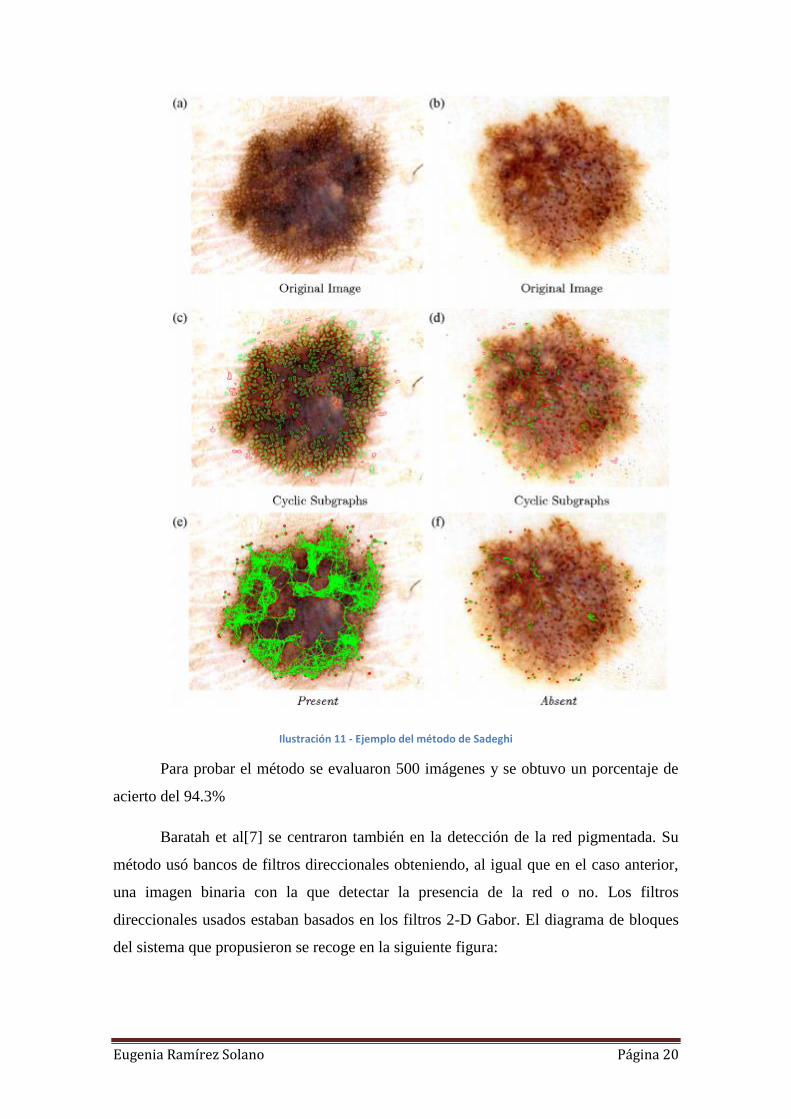
Eugenia Ramírez Solano Página 20
Ilustración 11 - Ejemplo del método de Sadeghi
Para probar el método se evaluaron 500 imágenes y se obtuvo un porcentaje de
acierto del 94.3%
Baratah et al[7] se centraron también en la detección de la red pigmentada. Su
método usó bancos de filtros direccionales obteniendo, al igual que en el caso anterior,
una imagen binaria con la que detectar la presencia de la red o no. Los filtros
direccionales usados estaban basados en los filtros 2-D Gabor. El diagrama de bloques
del sistema que propusieron se recoge en la siguiente figura:
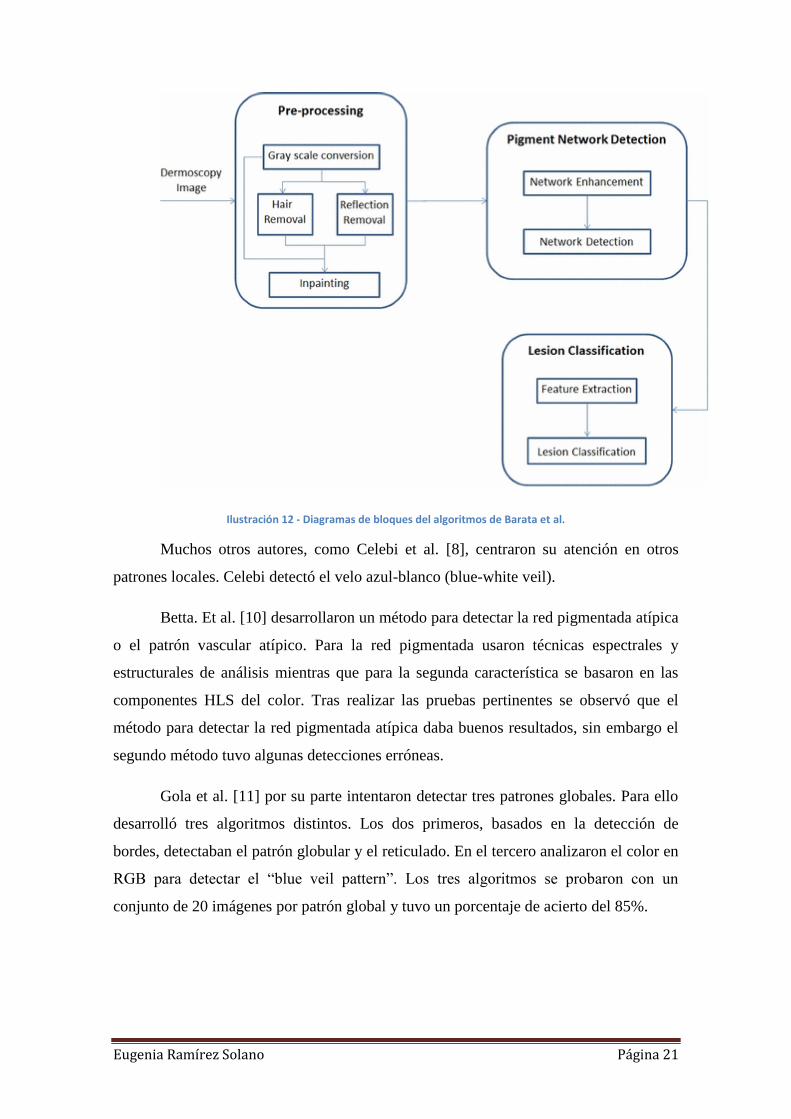
Eugenia Ramírez Solano Página 21
Ilustración 12 - Diagramas de bloques del algoritmos de Barata et al.
Muchos otros autores, como Celebi et al. [8], centraron su atención en otros
patrones locales. Celebi detectó el velo azul-blanco (blue-white veil).
Betta. Et al. [10] desarrollaron un método para detectar la red pigmentada atípica
o el patrón vascular atípico. Para la red pigmentada usaron técnicas espectrales y
estructurales de análisis mientras que para la segunda característica se basaron en las
componentes HLS del color. Tras realizar las pruebas pertinentes se observó que el
método para detectar la red pigmentada atípica daba buenos resultados, sin embargo el
segundo método tuvo algunas detecciones erróneas.
Gola et al. [11] por su parte intentaron detectar tres patrones globales. Para ello
desarrolló tres algoritmos distintos. Los dos primeros, basados en la detección de
bordes, detectaban el patrón globular y el reticulado. En el tercero analizaron el color en
RGB para detectar el “blue veil pattern”. Los tres algoritmos se probaron con un
conjunto de 20 imágenes por patrón global y tuvo un porcentaje de acierto del 85%.

Eugenia Ramírez Solano Página 22
Existen también muchos trabajos que usan bancos de filtros para el estudio de la
textura, formando distribuciones de entrenamiento a partir de las representaciones
estadísticas de las respuestas de los filtros.
En este campo, a pesar de aunque hay varios autores que trabajaron en él, se ha
cogido el clasificador VZ de Varma y Zisserman [2] como referente.
El clasificador VZ, como es habitual, se divide en dos etapas. En la primera
etapa de aprendizaje se crean los modelos de las texturas a partir de las respuestas a los
bancos de filtros de las imágenes de entrenamiento. En la segunda etapa una imagen
nueva se clasificará comparando su distribución con las de los modelos del
entrenamiento.
En la fase de entrenamiento las imágenes de entrenamiento son convolucionadas
con los bancos de filtros. El número de filtros del banco era normalmente 50 por lo que
para cada píxel de cada imagen se obtendrían 50 respuestas distintas, es decir, un píxel
quedaría representado por Nfil respuestas, siendo Nfil el número de filtros del banco.
En este punto habría que preguntarse si realmente es útil toda la información
obtenida ya que si cada píxel está representado por Nfil respuestas tendremos una
cantidad elevada de datos que manejar. Repasando nuestro objetivo y el explicado hasta
ahora, nuestra intención es ser capaz de clasificar imágenes según su textura. La textura
es una propiedad de los materiales que no se puede medir, es algo intuitivo.
Observemos las siguientes imágenes de texturas:
Ilustración 13 – Ejemplos de texturas

Eugenia Ramírez Solano Página 23
La mayoría de la gente coincidiría en que la primera sería una textura granulada,
y la segunda una textura rugosa, por lo que aunque no tenemos forma de cuantificar la
textura sí somos capaces de diferenciar entre ambas. Esto se debe a que los píxeles de
cada imagen guardan una relación entre sí que los caracteriza. En el primer ejemplo la
imagen está compuesta de mucho gránulos, en el caso de que tuviéramos una imagen
lisa todos los píxeles serían iguales y así con cada tipo de textura. Se deja ver pues, que
una textura tiene ciertas propiedades espaciales que se repiten, es decir, contiene mucha
información redundante en sí misma.
Retomando la pregunta que nos hacíamos anteriormente, ¿toda la información
que obtenemos de los bancos de filtros es necesaria? La respuesta obviamente es
negativa por la explicación que acabamos de dar. Así pues, tras procesar todos los
píxeles de todas las imágenes tendríamos Nfil componentes por cada píxel procesado
como comentamos anteriormente. Sin embargo, al tener información redundante surgió
la idea del “clustering”, que se basa en reducir la información obtenida a un conjunto
pequeño de prototipos de respuesta a los filtros. Estos prototipos son conocidos como
textons. El algoritmo de cuantización usado normalmente es el K-means.
Antes de explicar los fundamentos del k-means explicaremos un par de
conceptos que nos ayudarán a entender el método. Llamamos “cluster”, o grupo, a un
conjunto de objetos que son similares entre ellos y diferentes de los objetos que
pertenecen a otro “cluster”. De esta forma cuando hablamos de “clustering” estamos
hablando de subdividir el conjunto de datos que tenemos en grupos que guarden
similitudes entre sí.
El k-means, como hemos dicho, es el algoritmo de clustering más usado y
conocido. Su nombre se debe a que representa cada uno de los cluster por la media de
sus puntos, es decir, por el centroide del grupo. El método se inicia con K cluster
iniciales. A continuación se asignan los datos al cluster más cercano. Cuando todos los
datos tienen un centroide asociado se recalcula el centroide formado por el conjunto de
puntos y de nuevo se vuelven a reasignar los puntos. Este proceso se repetirá hasta que
el sistema converja y obtengamos los cluster definitivos o textons. Un ejemplo del K-
means se muestra en la siguiente figura:

Eugenia Ramírez Solano Página 24
Ilustración 14 - Ejemplo de Clustering
En el ejemplo vemos cómo se han dibujado un elevado número de puntos. Sin
embargo como están localizados por zonas podemos quedarnos con los centroides de
esas nubes. En nuestro algoritmo haremos lo mismo para reducir puntos pero en un
espacio 8-dimensional.
Así pues, continuando con el clasificador VZ, para simplificar los resultados
obtenidos del banco de filtros se aplicó k-means. Los centroides de los clusters, o
textons, obtenidos formaron la base del diccionario de modelos de texturas. Una vez que
se obtuvo este diccionario de textons se pasó a formar los modelos de las imágenes de
entrenamiento. Para ello, se asignó cada píxel de una imagen al centroide más cercano.
Estos datos quedaron recogidos en un histograma que sería el modelo de la imagen. Este
histograma por tanto estaría compuesto por tantos bins como componentes tuviera el
banco de filtros.
Este proceso se repitió para todas las imágenes que formaron el entrenamiento
por lo que cada textura quedó representada por tantos modelos como imágenes de
entrenamiento hubiera de dicha textura en el conjunto.
Para catalogar una imagen nueva, en la etapa de clasificación se compararía el
modelo de dicha imagen con los modelos aprendidos anteriormente. Para ello la imagen
nueva se convolucionaría con el banco de filtros de nuevo obteniendo las respuestas

Eugenia Ramírez Solano Página 25
correspondientes. Estas se compararían con los textons del diccionario quedando otra
vez cada píxel de la imagen de prueba asociado a un texton y dando lugar al histograma
propio de la imagen de test. El último paso sería comparar este histograma con los
modelos formados en la etapa de entrenamiento. La imagen de test pertenecerá a la
textura del modelo más cercano al histograma de test. Para medir la distancia entre los
histogramas y poder realizar la comparación Varma usó la medida de distancia χ².
3.2. Algoritmo implementado Tras investigar los algoritmos implementados para el análisis de patrones
centramos nuestro proyecto en Varma y Zisserman y su algoritmo basado en el conjunto
de vecinos [2]
Al desarrollar el clasificador VZ basado en bancos de filtros, Varma y Zisserman
se centraron en reducir la carga computacional que este requería. Es por ello que se
comenzó a investigar sobre cómo extraer la información que caracteriza la textura sin
tener redundancia. Finalmente demostraron que, en lugar de trabajar con un banco de
filtros, se podría trabajar con el conjunto de vecinos de cada píxel ya que en ellos se
encontraba el patrón que definiría la textura, ahorrando tener tanta información
redundante y tanto coste computacional [1]. Implementaron varios algoritmos basados
en esta idea que explicaremos a continuación.
Este algoritmo, es prácticamente igual al clasificador VZ con la salvedad de que
se sustituye el banco de filtros y en su lugar se trabaja con el vecindario de cada píxel de
la imagen. De esta forma, para cada píxel, se cogía su conjunto de vecinos (NxN, en
nuestro caso 3x3), se reordenaba y se almacenaba en un vector formando un espacio N²
dimensional. De esta forma, el algoritmo procesaba, por cada imagen de una textura, el
píxel central y sus vecinos y los iba guardando en una matriz. Aplicando k-means a esta
matriz se obtendrían los centroides, o más comúnmente, los textons que se usarían para
formar el modelo de cada imagen de entrenamiento. Estos textons estarían en un espacio
N-dimensional, es decir, cada texton tendría N componentes. Para el caso de un
vecindario de 3x3, los textons serían puntos de 9 coordenadas.
Varma y Zisserman demostraron en su estudio que había suficiente información
en la distribución de probabilidad conjunta de los 9 valores (el píxel central y sus 8
vecinos) para poder discriminar entre tipos de texturas. Este clasificador recibió el
nombre de Joint Classifier.

Eugenia Ramírez Solano Página 26
A continuación estudiaron las relaciones entre el píxel central y el conjunto de
vecinos y cómo de significante era la distribución de probabilidad conjunta para la
clasificación. Se llegó a la conclusión de que aunque el píxel central es significativo la
probabilidad estaba condicionada realmente por el conjunto de vecinos por lo que
eliminaron el píxel central y trabajaron únicamente con el vecindario. De esta forma en
lugar de almacenar el píxel central con sus 8 vecinos se quedaron con estos últimos. En
este caso los textons pasaron a tener N-1 componentes. Los resultados obtenidos con
este método fueron muy similares a los del Joint Classifier. Este método recibió el
nombre de Neighbourhood classifier.
Finalmente, se pasó al otro extremo y se estudió la distribución del píxel central
condicionada por sus vecinos. Para ello, en primer lugar se obtuvieron los textons
teniendo en cuenta solamente los 8 vecinos, como se hizo en el Neighbourhood
classifier. A continuación se asignaron los píxeles de las imágenes a los textons más
próximos, como se hacía en los anteriores clasificadores. Sin embargo en este
algoritmo, para cada texton, para los píxeles asociados, se tuvo en cuenta el valor de
cada uno de ellos obteniendo así un histograma. El modelo por tanto ahora estaba
formado por tantos histogramas como textons hubiera, y cada histograma tendría tantos
bins como intervalos de intensidad del píxel central se consideraran.
Resumiendo, el modelo de una imagen de entrenamiento sería un conjunto de
histogramas unidimensionales, uno por cada textons, en el cual se indicaría el valor de
los píxeles centrales asociados al textons en cuestión. Este clasificador se denominó
MRF (Markov Random Field) Classifier. Los resultados obtenidos en la clasificación de
imágenes nuevas fueron mejores que con los dos algoritmos anteriores como
demostraron VZ en sus pruebas [2].
A continuación explicaremos con algo más de detalle los algoritmos
desarrollados en nuestro caso.

Eugenia Ramírez Solano Página 27
3.2.1. Estudio en escala de grises
Como ya se ha comentado en este proyecto nos hemos centrado en detectar
cuatro texturas: homogéneo, paralelo, reticulado y empedrado. El primer paso es crear
el diccionario de textons para formar los modelos de las texturas. Estos modelos serán
comparados con los modelos de las imágenes a clasificar pudiendo clasificar así dichas
imágenes.
Tras estudiar los tres algoritmos de Varma y Zisserman se decidió implementar
el MRF Classifier por ser el más eficiente.
En primer lugar, se cargaron las imágenes en escala de grises de forma que cada
píxel podía tener un valor de intervalo [0,255]. A continuación se recorrió el conjunto
de imágenes de cada textura reordenando los píxeles de la imagen. Para ello por cada
píxel se tomó su vecindario 3x3 formando un vector en un espacio 8-dimensional.
Todos los vectores se almacenaron en una matriz de dimensiones [Nº píxel totales, 8].
Para reducir la gran cantidad de puntos obtenidos, y recordando que tenemos
redundancia en los datos, se aplicó k-means para quedarnos solo con 10 centroides.
Este proceso se realizó para las cuatro texturas por lo que finalmente se
obtuvieron 40 textons, 10 por cada textura, que formaron el diccionario de textons. Una
vez obtenidos los textons, se asignó cada punto 8-dimensional (el vecindario) al
centroide más cercano al mismo (este proceso lo hace internamente el k-means).
Finalmente solo quedaría calcular la distribución del píxel central condicionada
por sus vecinos para obtener el modelo de la imagen de entrenamiento. Para ello, se
formó un histograma unidimensional por cada centroide con tantos bins como
particiones se hubieran tomado en el intervalo [0,255]. Así pues la búsqueda que se
llevó a cabo fue, por cada imagen, por cada centroide, por cada píxel central asociado a
dicho centroide, a qué intervalo del rango [0,255] pertenecía. De esta forma, el modelo
de cada imagen de entrenamiento estaría formado por 40 histogramas (uno por cada
centroide), cada uno de los cuales representaría el valor del píxel central para los
conjuntos de vecinos asociados al centroide del histrograma.
Repitiendo este proceso de formación de histogramas para cada una de las
imágenes de entrenamiento obtuvimos el “Diccionario de texturas”. A continuación se
muestra el diagrama de bloques del algoritmo implementado:
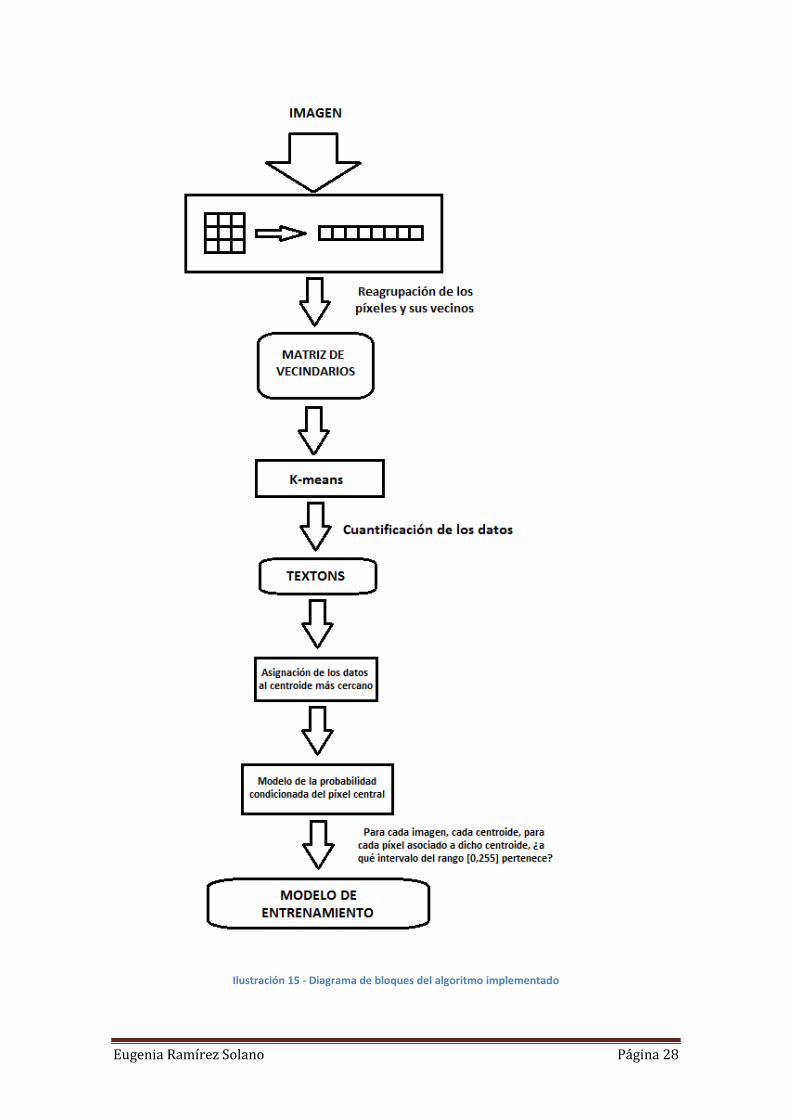
Eugenia Ramírez Solano Página 28
Ilustración 15 - Diagrama de bloques del algoritmo implementado

Eugenia Ramírez Solano Página 29
Una vez obtenidos los modelos de las imágenes de aprendizaje se pasa a la etapa
de clasificación en la cual se compara el modelo de la imagen a clasificar con los
modelos del entrenamiento por lo que lo primero que había que hallar era el modelo de
la imagen de test. Para obtener este modelo se cargó la imagen en escala de grises y se
procesó de la misma forma que las imágenes de aprendizaje, guardando los vecindarios
de cada píxel en una matriz. A continuación se asignó el centroide más cercanos de los
40 del diccionario a cada uno de los puntos 8-dimensionales almacenados. Finalmente
se hallaron los histogramas para cada centroide según el valor del píxel central de cada
conjunto de vecinos. Este proceso se llevaba a cabo respondiendo a la siguiente
pregunta: por cada centroide, para cada píxel central asociado a ese centroide, ¿a qué
intervalo pertenecía? De esta forma ya tendríamos formado el modelo de la imagen y
estaríamos en disposición de comparar con los modelos del entrenamiento con el nuevo
modelo formado.
En un principio se usaron varios algoritmos de medición de distancias entre
histogramas para realizar estas comparaciones: batthacharyya distance, χ² y The Earth
Mover's Distance (EMD).
Los dos primeros son del tipo “bin-to-bin” porque se asume que los histogramas
ya están alineados de forma que el bin de un histograma es comparado con el
correspondiente bin del otro histograma. Estas distancias se definen a continuación
[12],[13]:
( )
∑
( )
√ ∑√
En el caso del EMD la comparación es “cross-bin”, es decir, una comparación
global entre bins, sin suponer que los histogramas están alineados. El EMD se basa en la
solución de un problema de transporte calculando los costes que suponen los transportes
en el histograma para igualarlos. La distancia EMD se muestra a continuación y se
observa como en este caso sí que se tiene en cuenta las relaciones entre bins distintos.

Eugenia Ramírez Solano Página 30
( ) ∑ ∑
∑ ∑ donde {
Tras hacer pruebas para comprobar cuál era el más eficiente y más apropiado
para nuestro caso, nos quedamos con el EMD, como era de esperar al ser “cross-bin”.
El algoritmo implementado nos devolvía la imagen de entrenamiento a la que
más se parecía la imagen a catalogar, por lo que comprobando a qué textura pertenecía
el modelo de entrenamiento señalado ya teníamos la imagen clasificada.
3.2.2. Estudio en color, Lab
En un intento de mejorar el algoritmo anterior, se contempló la idea de
introducir el color en lugar de trabajar en escala de grises. El fundamento del algoritmo
es exactamente igual que el explicado en el apartado anterior.
El primer paso sería leer la imagen en Lab, que es el espacio de color en el que
vamos a trabajar. Sin embargo en este caso tendríamos por cada píxel, tres componentes
(Lab) en lugar de un valor del rango [0,255] como teníamos antes.
Así pues, al trabajar en color, necesitamos un pre-procesado de la imagen antes
de poder estudiar la textura para conseguir tener un único valor por píxel en lugar de
tres componentes. La solución está en la línea de lo hecho hasta el momento.
Al leer las imágenes tendremos por cada píxel, un vector de tres componentes
correspondientes a las componentes “L”, ”a” y ”b” que forman el color del píxel. De
esta forma leeremos todos los píxeles de todas las imágenes y almacenaremos su color
en una matriz. De nuevo podemos intuir que en esta matriz de colores habrá muchos de
ellos repetidos, ya que algunos formarán parte de la misma imagen e incluso, los colores
de las distintas lesiones son similares. Además las lesiones de la piel suelen tener
colores marrones, negros, azules y rara vez aparecerán colores como el rosa, el naranja,
etc. Es por ello que cuantificaremos los colores aplicando de nuevo k-means. De esta
forma pasaremos de tener colores a tener el número de colores que le indiquemos al
kmeans.
Pondremos un ejemplo aclaratorio. Supongamos que los colores recogidos de los
píxeles de las imágenes son los que se muestran en la siguiente figura (sabemos que esto
no es así porque ya hemos comentado que hay algunos colores que no se darán en las
lesiones pigmentadas de la piel):

Eugenia Ramírez Solano Página 31
Ilustración 16 - Ejemplo del k-means del color
En la imagen comprobamos que tenemos una cantidad muy elevada de colores
con la cual es difícil trabajar. Si aplicamos k-means podríamos reducir dichos colores a
tantos como nº de centroides le indiquemos al k-means. De esta forma, si
introdujéramos K=9, obtendríamos los centroides de 9 nubes de puntos, unificando los
colores de tonalidades similares y quedándonos finalmente con 9. La reducción de los
datos se puede apreciar en la siguiente figura:

Eugenia Ramírez Solano Página 32
Una vez que tengamos los centroides de los colores, debemos indexar dichos
colores. De esta forma haremos corresponder cada píxel, definido por un color en Lab
de tres componentes, con el índice del color más cercano. De este modo ya tendremos
los píxeles de las imágenes definidos por un único valor, el índice del color asociado.
En esta situación nos encontramos ya en el punto de partida del algoritmo en
escala de grises. Los píxeles de la imagen serán un único valor, si bien en el caso
anterior este valor era un número en la escala de grises [0,255], ahora será el índice del
centroide, es decir, del color, al que está asignado el píxel.
Ilustración 17 – Ejemplo del k-means para k=9

Eugenia Ramírez Solano Página 33
El procesamiento de las imágenes, junto con el desarrollo del algoritmo serán
iguales que en el estudio en escala de grises excepto al calcular los centroides asociados
a la textura.
En escala de grises almacenábamos el vecindario de cada píxel en una matriz y a
ese conjunto de puntos 8-dimensionales (el vecindario) le aplicábamos k-means para
obtener los centroides que definirían la textura. Los valores de los puntos eran números
de [0,255] correspondientes a la escala de grises. En el caso que nos ocupa los valores
de los puntos serían un valor del intervalo [1-nº de centroides], es decir, el índice del
color asociado. El k-means basa su funcionamiento en el cálculo de distancias entre
puntos, en el caso de grises calculaba la diferencia entre distintos grados de grises. En
este caso ha habido que modificar el k-means para que en lugar de realizar la distancia
entre índices de colores, que es el dato que recibe, calculara la distancia entre los
colores indexados por dichos índices. Explicaremos esto con un ejemplo sencillo.
Supongamos que los índices [34, 50, 35, 52, 40] corresponden con los colores [negro,
verdoso, amarillo, rosa, rojo] respectivamente. Supongamos también que el k-means
recibe, entre otros puntos, los dos siguientes: [34, 50, 35] y [35, 52, 40]. Al aplicar k-
means a estos vectores, este se basaría en las distancias entre dichos números, sin
embargo estos índices no se corresponden realmente con la posición que tienen los
colores a los que indexan en el espacio (índices cercanos no significa colores cercanos).
Para solucionar esta situación hubo que modificar el k-means para que no
subdividiera el conjunto de datos en función del índice del color al que estaban
asociados. Para definir los centroides a los que asociar los vecindarios compararía los
colores en sí de los puntos y no sus índices, es decir, calcularía la distancia euclídea
entre los colores representados por esos índices.
Una vez obtenidos los textons de la textura se hallaron los histogramas como se
hizo en el algoritmo en escala de grises, basándonos en el MRF classifier. Una vez que
se obtuvieron los modelos se implementó la etapa de clasificación.
En esta fase también se realizaron algunas modificaciones respecto al trabajo en
grises. La imagen a clasificar se cargó en Lab y a continuación se asoció el color de
cada píxel con el centroide de color más cercano de los obtenidos en la etapa de
entrenamiento. Una vez que los píxel de la imagen estaban definidos por el índice de un
color se aplicaba el k-means modificado y se formaban los histogramas del modelo.

Eugenia Ramírez Solano Página 34
Finalmente, había que comparar el modelo de la imagen de test con los modelos
de entrenamiento para poder catalogar la imagen con la textura del modelo al que
guardara más parecido. En este caso también hubo que modificar el EMD para que
calculara la distancia euclídea entre los colores indexados y no entre los índices en sí.

Eugenia Ramírez Solano Página 35
4. RESULTADOS
Para probar la validez de los algoritmos desarrollados se formó una base de
imágenes con la que poder trabajar. En primera instancia la formación de la misma
puede parecer algo trivial sin embargo la inmensa variabilidad de las lesiones, la calidad
del aparato con que se obtienen las imágenes e incluso las condiciones bajo las que estas
fueron tomadas hace que la elección de las imágenes requiera un gran trabajo.
Especialmente a la hora de elegir las imágenes de entrenamiento hubo que realizar un
trabajo minucioso ya que debían ser imágenes con el menor ruido posible y que
plasmaran claramente los patrones en base a los cuales se realizaría la clasificación
posteriormente.
4.1. Material usado Las imágenes que se han usado en este proyecto son del “Dermoscopy an
Interactive Atlas” [15]. Este atlas cuenta con muchísimas imágenes de lesiones sin
embargo con solo observar el atlas queda patente que las imágenes no fueron
conseguidas bajo condiciones similares. De esta forma hay muchas diferencias entre dos
imágenes que, por diagnóstico, debían presentar más similitudes que las observadas.
Este ha sido un gran problema a la hora de formar la base ya que tanta variabilidad
impide que el programa pueda establecer patrones regulares con los que poder catalogar
las imágenes.
Se ha trabajado con distintas bases de imágenes variando el tamaño de las
mismas (se ha trabajo con imágenes de 40x40, 50x50 y 81x81) o el número de
imágenes de la base. El conjunto de trabajo quedó finalmente formado por 78 imágenes
correspondientes a 4 texturas distintas: 20 de paralelo, 20 de reticulado, 18 de
empedrado y 20 homogéneo. El tamaño elegido de las imágenes fue 50x50 porque en
los conjuntos de 81x81 la carga computacional al tener tantos píxeles por imagen era
muy elevada y los tiempos de simulación llegaban a ser demasiado altos para los
medios de trabajo de los que se disponían.

Eugenia Ramírez Solano Página 36
4.2. Resultados Como ya se ha comentado anteriormente se ha trabajado con distintas bases con
características diferentes cada una. Es por ello que los resultados que se han obtenido
para cada base variaban según las propiedades de la misma. Cuanto mayor fuera el
número de imágenes con las que se trabajara mejores eran los resultados obtenidos. Sin
embargo en este apartado solo reflejaremos los resultados para la base definitiva.
Para probar los algoritmos se ha trabajado primero con un conjunto de imágenes
de entrenamiento a partir del cual se obtenían los textons necesarios para clasificar. Este
entrenamiento se realizaba con 15 imágenes de cada textura. A continuación se usaba el
conjunto de imágenes de test. Estas eran clasificadas comparando sus histogramas con
los obtenidos en el entrenamiento. De las texturas homogénea, paralelo y reticulado se
usaron 5 imágenes de test por cada una de ella sin embargo del patrón empedrado solo
se escogieron 3 imágenes de test.
Una vez realizada la primera prueba, las imágenes de test se incluían en el
conjunto de entrenamiento y de este se extraían el siguiente conjunto de imágenes para
clasificar. Este proceso se repitió en total 4 veces de forma que al final se clasificaron
20 imágenes de las texturas paralelo, empedrado y homogéneo y solo 12 imágenes de la
textura empedrada. Esta técnica es conocida como “Cross Fold Validation”

Eugenia Ramírez Solano Página 37
En el caso del algoritmo en escala de grises se hicieron dos pruebas. En primer
lugar se formó la base de entrenamiento con histogramas de 8 bins. El porcentaje de
acierto al clasificar las texturas fue de un 51,3889%. En la tabla que se muestra a
continuación podemos ver los resultados obtenidos con más detalle.
Ilustración 18 - Resultados en gris para histogramas con 8 bins
Eugenia Ramírez Solano Página 38
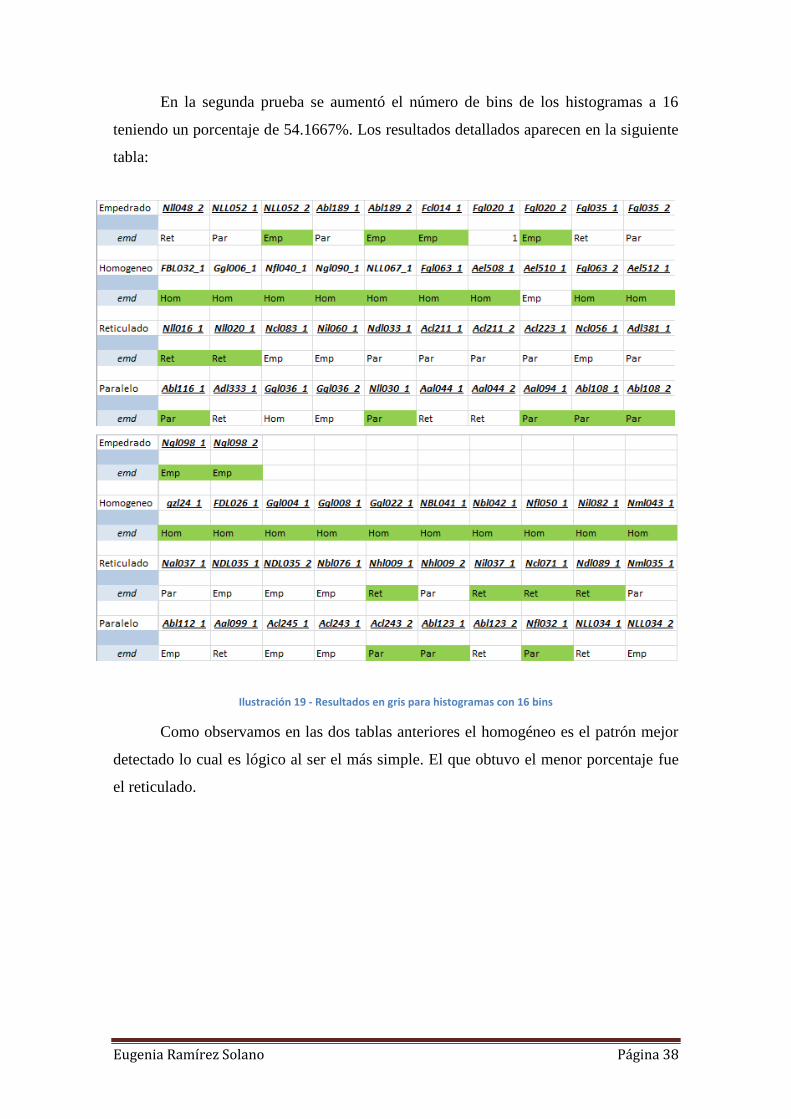
En la segunda prueba se aumentó el número de bins de los histogramas a 16
teniendo un porcentaje de 54.1667%. Los resultados detallados aparecen en la siguiente
tabla:
Ilustración 19 - Resultados en gris para histogramas con 16 bins
Como observamos en las dos tablas anteriores el homogéneo es el patrón mejor
detectado lo cual es lógico al ser el más simple. El que obtuvo el menor porcentaje fue
el reticulado.

Eugenia Ramírez Solano Página 39
Para los algoritmos en color el porcentaje de acierto aumentaba conforme
aumentaba el número de colores tenidos en cuenta durante el algoritmo por lo que se
hicieron de nuevos dos pruebas. En primer lugar se tomaron 15 colores y se obtuvo un
porcentaje del 59.7222%. Los resultados detallados muestran en la siguiente tabla:
Ilustración 20 - Resultados para 15 colores
Eugenia Ramírez Solano Página 40
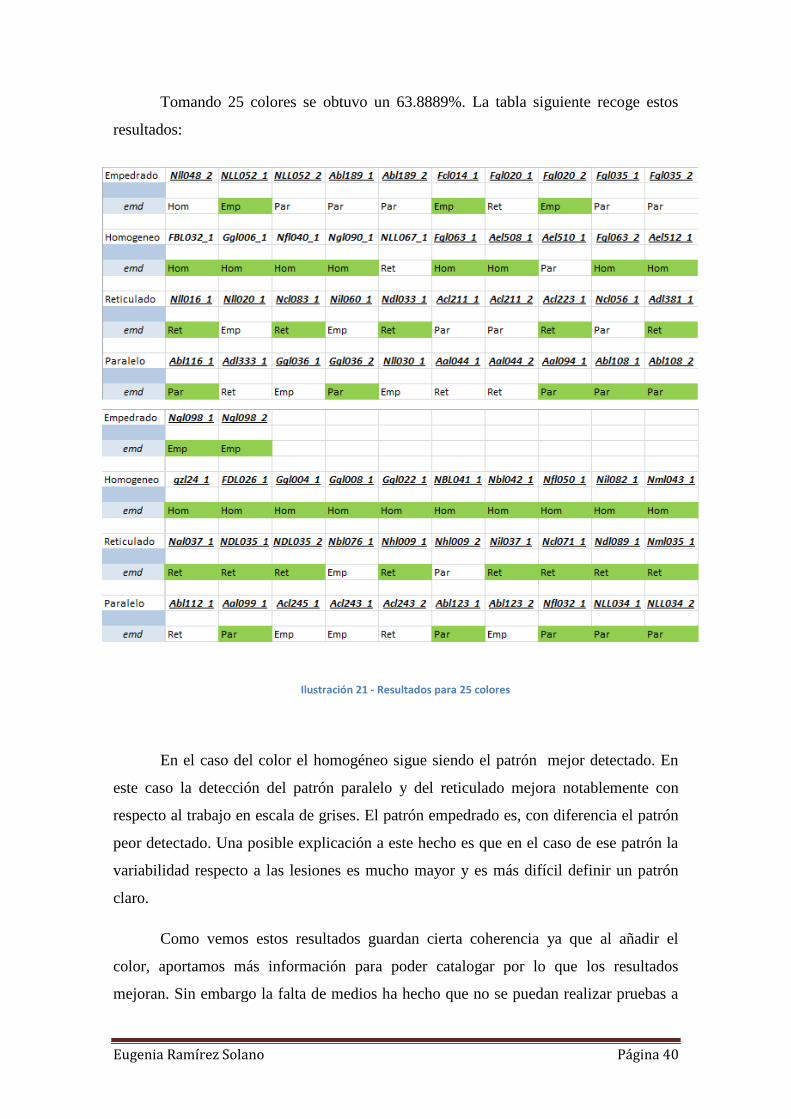
Tomando 25 colores se obtuvo un 63.8889%. La tabla siguiente recoge estos
resultados:
En el caso del color el homogéneo sigue siendo el patrón mejor detectado. En
este caso la detección del patrón paralelo y del reticulado mejora notablemente con
respecto al trabajo en escala de grises. El patrón empedrado es, con diferencia el patrón
peor detectado. Una posible explicación a este hecho es que en el caso de ese patrón la
variabilidad respecto a las lesiones es mucho mayor y es más difícil definir un patrón
claro.
Como vemos estos resultados guardan cierta coherencia ya que al añadir el
color, aportamos más información para poder catalogar por lo que los resultados
mejoran. Sin embargo la falta de medios ha hecho que no se puedan realizar pruebas a
Ilustración 21 - Resultados para 25 colores

Eugenia Ramírez Solano Página 41
gran escala con mayor número de imágenes y más colores. Sería interesante llevar estas
pruebas a cabo para reafirmar la validez de los algoritmos y una vez comprobado añadir
más texturas al clasificador aunque para ello habría que disponer medios que soporten la
elevada carga computacional que requiere manejar tantos píxeles y trabajar en espacios
tan grandes (8-dimensional que es el mínimo que obtenemos con un vecindario 3x3).

Eugenia Ramírez Solano Página 42

Eugenia Ramírez Solano Página 43
5. CONCLUSIONES Tras estudiar los distintos métodos seguidos por los autores para análisis de
patrones se implementó un clasificador basado en el MRF Classifier de Varma y
Zisserman. Así pues desarrollamos el algoritmo para que detectara 4 de los patrones
comunes: el reticulado, el paralelo, el empedrado y el homogéneo. El funcionamiento se
comenta en líneas generales a continuación:
Etapa de aprendizaje
Leer las imágenes en escala de grises.
Reordenar la imagen, almacenando en vectores 8-dimensionales los vecinos de
cada píxel central, considerando un vecindario 3x3.
Reducir todos los puntos 8-dimensionales obtenidos aplicando k-means a 10
centroides por textura, 40 en total.
Asignar cada punto 8-dimensional al centroide más cercano obtenido en el k-
means.
Formar el modelo de la probabilidad condicionada del píxel central, esto es, para
cada imagen, cada centroide, para cada píxel asociado a dicho centroide, ¿a qué
intervalo del rango [0,255] pertenece? De esta forma se obtienen todos los
modelos de las imágenes de entrenamiento.
Etapa de clasificación
Se lee la imagen a clasificar en escala de grises.
Se reordena guardando por filas, el vecindario de cada píxel central.
Se asigna cada punto definido en el paso central al centroide más cercano
hallado en la etapa de entrenamiento.
Se forma el modelo siguiendo el mismo procedimiento que con las imágenes de
aprendizaje.
Se compara este modelo obtenido con los calculados en la fase anterior. Para
ello, se halla la distancia entre histogramas usando el método EMD, que es del
tipo cross-bin, (establece comparaciones globales entre histogramas).

Eugenia Ramírez Solano Página 44
En un intento de innovar y mejorar los resultados del algoritmo anterior se
contempló la idea de trabajar en color en lugar de en escala de grises. Así pues se
modificó el código anterior para poder trabajar en color como hemos explicado en la
sección 3.2.2.
Efectivamente, en los resultados de las pruebas realizadas se comprobó que el
algoritmo en color mejoraba los resultados obtenidos por el algoritmo en escala de
grises.
Sería muy interesante en el futuro seguir mejorando ambos clasificadores
aumentando el tamaño del vecindario escogido o considerando más colores. También
para reafirmar el buen funcionamiento de los clasificadores se podrían incluir más
texturas a detectar además de las cuatro con las que ya trabajamos.

Eugenia Ramírez Solano Página 45
6. REFERENCIAS Y BIBLIOGRAFÍA
[1] M. Varma, A. Zisserman. “Texture classification: Are Filter Banks Necessary?” Proc IEEE
Conf. Computer Vision and Pattern Recognition, vol.2, June 2003.
[2] M. Varma, A. Zisserman. “A Statistical Approach to Material Classification Using Imagen Patch
Exemplars” IEEE Transactions on pattern analysis and machine intelligence, vol. 31. November
2009.
[3] Argenziano G, Soyer HP, Chimenti S et al. “Dermoscopy of pigmented skin lesions: results of a
consensus meeting via the Internet”, J Am Acad Dermatol, 2003.
[4] T. Leung and J.Malik, “Representing and Recognizing the Visual Appearance of Materials using
Three-dimensional Textons”, Int’l J.Computer Vision, vol.43, June 2001
[5] Sadeghi, M., Lee, T.K., McLean, D., Lui, H., Atkins, M.S.: Global pattern analysis and
classification of dermoscopic images using textons. Progress in Biomedical Optics and Imaging
Proceedings of SPIE 8314, art. No. 83144X, 2012.
[6] Anantha, M., Moss, R.H., Stoecker, W.V.: Detection of pigment network in dermatoscopy
images using texture analysis. Computerized Medical Imaging and Graphics, 2004.
[7] Barata, C., Maques, J.S., Rozeira, J.: A system for the detection of pigment network in
dermoscopy images using directional filters. IEEE Transactions on Biomedical Engineering 59,
art. No. 10, 2012.
[8] Celebi, M.E., Iyatomi, H., Stoecker, W.V., Moss, R.H., Rabinovitz, H.S., Argenziano, G., Soyer,
H.P.: Automatic detection of blue-white veil and related structures in dermoscopy images.
Computerized Medical Imaging and Graphics 32, 2008.
[9] Sadeghi, M., Razmara, M., Lee, T.K., Atkins, M.S.: A novel method for detection of pigment
network in dermoscopic images using graphs. Computerized Medical Imaging and Graphics ,
2011.
[10] Betta, G., Di Leo, G., Fabbrocini, G., Paolillo, A., Sommella, P.: Dermoscopic image-analysis
system: estimation of atypical pigment network and atypical vascular pattern. IEEE International
Workshop on Medical Measurement and Applications, 2006.
[11] Gola Isasi, A., Garca Zapirain, B., Mndez Zorrilla, A.: Melanomas non-invasive diagnosis
application based on the ABCD rule and pattern recognition image processing algorithms.
Computers in Biology and Medicine, 2011.
[12] S. Dubuisson. The computation of the Bhattacharyya distance between histograms without
histograms. In International Conference on Image Processing Theory, Tools and Applications
(IPTA'10). Paris, France, July 7-10 2010.
[13] H. Ling and K. Okada, Diffusion Distance for Histogram Comparison, IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), Vol. I, pp. 246-253, 2006.
[14] A.Saez, C.Serrano, B. Acha. Pattern analysis in dermoscopic images. In Computer Vision
Techniques for the Diagnosis Skin Cancer, Springer, 2013.

Eugenia Ramírez Solano Página 46
[15] G-Argenziano, H. Soyer, et al., “Interactive atlas of dermoscopy”, EDRA-Medical Publishing
and New Media, Milan, 2000.
[16] www.aecc.es, Asociación Española contra el Cáncer.
[17] www.cancer.org

Eugenia Ramírez Solano Página 47
Tabla de figuras Ilustración 1 – Algoritmos de diagnóstico en 2 etapas ................................................................. 8
Ilustración 2 – Lesión con patrón homogéneo ............................................................................ 10
Ilustración 3 – Lesión con patrón paralelo .................................................................................. 10
Ilustración 4 - Criterios de la regla de los 7 puntos ..................................................................... 14
Ilustración 5 - Características de Menzies ................................................................................... 15
Ilustración 6 - Regla ABCD ........................................................................................................... 16
Ilustración 7 – Patrones reticulados ............................................................................................ 17
Ilustración 8 – Patrones empedrados ......................................................................................... 17
Ilustración 9 – Patrones homogéneos ......................................................................................... 18
Ilustración 10 – Patrones paralelos ............................................................................................. 18
Ilustración 11 - Ejemplo del método de Sadeghi ........................................................................ 20
Ilustración 12 - Diagramas de bloques del algoritmos de Barata et al. ...................................... 21
Ilustración 13 – Ejemplos de texturas ......................................................................................... 22
Ilustración 14 - Ejemplo de Clustering ........................................................................................ 24
Ilustración 15 - Diagrama de bloques del algoritmo implementado .......................................... 28
Ilustración 16 - Ejemplo del k-means del color ........................................................................... 31
Ilustración 17 – Ejemplo del k-means para k=9 .......................................................................... 32
Ilustración 18 - Resultados en gris para histogramas con 8 bins ................................................ 37
Ilustración 19 - Resultados en gris para histogramas con 16 bins .............................................. 38
Ilustración 20 - Resultados para 15 colores ................................................................................ 39
Ilustración 21 - Resultados para 25 colores ................................................................................ 40