presentación de powerpoint - profesor ezequiel ruiz ... · tratamiento de valores de variables...
TRANSCRIPT

Selección de fuentes de datos y
calidad de datos
ESCUELA COMPLUTENSE DE VERANO 2014
MINERIA DE DATOS CON SAS E INTELIGENCIA DE NEGOCIO
Juan F. Dorado
José María Santiago

. Valores atípicos
. Valores faltantes
. Valores erróneos
. Eliminación
. Corrección
ó…
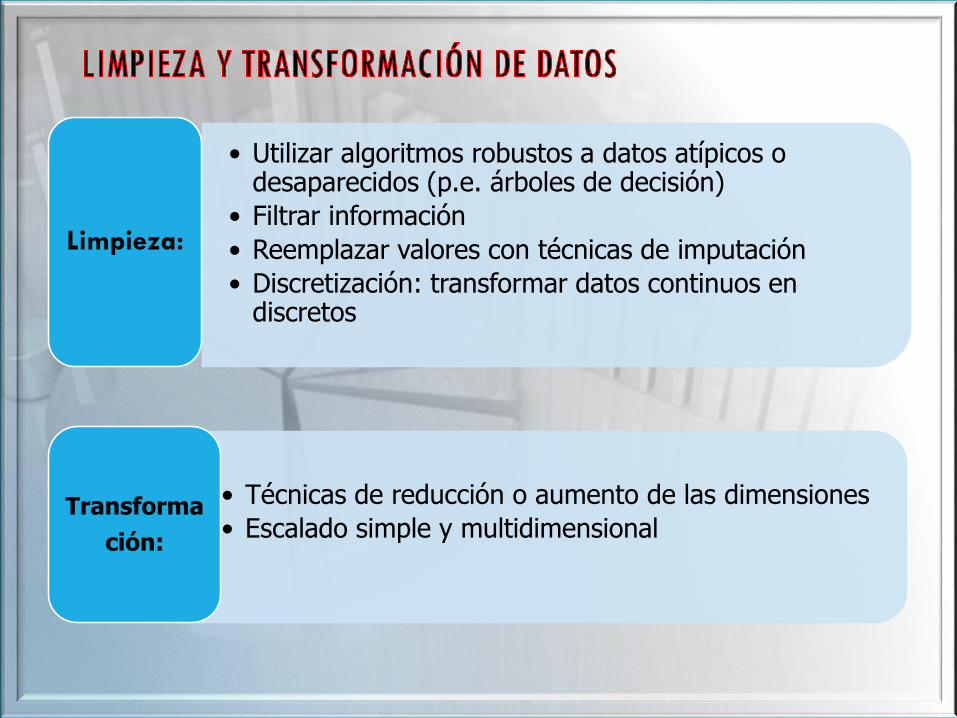
• Utilizar algoritmos robustos a datos atípicos o desaparecidos (p.e. árboles de decisión)
• Filtrar información
• Reemplazar valores con técnicas de imputación
• Discretización: transformar datos continuos en discretos
Limpieza:
• Técnicas de reducción o aumento de las dimensiones
• Escalado simple y multidimensionalTransforma
ción:

• Puntuación extrema en una variable
• Produce distorsiones en los análisis
• Alejados del promedio de observaciones
Características
• Errores de procedimiento: codificación, grabación, entrada de datos…(Acción: Filtrado, eliminación, recodificación a ausentes…)
• Observaciones extraordinarias, con explicación (se retienen si no anecdóticas)
• Observaciones extraordinarias, sin explicación (Eliminación)
• Observaciones fuera de rango ordinario de valores de la variable (Eliminación)
• * Los casos atípicos hay que analizarlos desde perspectiva multivariante, considerarse en el conjunto de todas las variables
Causas:

• Análisis exploratorio univariante: Gráficos de caja y bigotes.
• Diagramas de control
• Estadisticos robustos de la variable y ver diferencias respecto de no robustos:
• Media truncada: quita 15% de los valores en cada extremo
• .Media winsorizada: sustituye ese 15% por valores del centro de la distribución.
• variación media respecto de la mediana
• desviación típica truncada
• desviación típica winsorizada
• ***Si no hay valores atípicos los estadísticos robustos y los normales no difieren mucho.
• Contraste formal estadístico par detectar valores atípicos: Test de Dixon, Test de Grubs
Detección:

• Gráfico de caja y bigotes múltiple (distintos gráficos de
una variable para diferentes niveles de la otra).
• Gráficos de dispersión por pares de variables.
Análisis Bivariante:
• Análisis de Influencia (leverage) de cada observación
• D2 (Distancia de Mehalanobis): distancia media cuadrática de cada observación respecto del centro medio de las observaciones.
• DFITS: influencias de cada observación en caso de ser eliminada del análisis.
Análisis Multivariante:

• Inexistencia de información para determinadas observaciones y variables
Características
• Registro defectuoso
• Ausencia natural de información
• Falta de respuesta (total o parcial)
• Unión o actualización de base de datos
Causas:

• Tabla de frecuencias de valoresperdidos, para cada variable, paratener idea de su magnitud.
• Comprobar si se distribuyenaleatoriamente en todo el conjuntode datos (para cada variable enrelación a las demás variables).
• Matriz de correlaciones dicotomizadas
Evaluación:

• Supresión según lista (por defecto): se quitan lasfilas (casos) con valores faltantes en algunavariable.
• Inconvenientes: si muchos valoresperdidos=reducción drástica de ficheros y análisisno representativos.
• Supresión de casos según pareja, en análisis bivariante: se suprimen solo los casos con información faltante en cada par de variables en análisis, con independencia de lo que ocurra con otras variables.
• Se elimina menos información que con anterior.
Tratamiento 1:

• Suprimir casos (filas) o variables (columnas) quepeor se comporten respecto de datos ausentes.
• Balancear lo que se gana o pierde con la supresión.
• Imputación de la información faltante. Estimación devalores en base a valores válidos de otras variableso casos.
Tratamiento 2:

• Imputación NO de valores, sino de caracteristicas dedistribución: desviación típica, correlaciones…
Enfoque de disponibilidad
completa:
• 1. Sustitución del caso: cuando casos con casi o todala información ausente, se sustituye todo el caso poruno nuevo, ajeno a la muestra.
Sustitución de valores ausentes
por estimados:

• 2. Sustitución por la media: los valores ausentes sesustituyen por la media de los valores válidos de lavariable correspondiente.
• Fácil, pero altera correlaciones e invalidaestimaciones de la varianza.
• 3. Sustitución por la mediana: cuando valores másextremos en variable se usa mediana (+robusta) yno media.
• 4. Sustitución por interpolación de valoresadyacentes (media o moda da un cierto nº devalores adyacentes.
Sustitución de valores ausentes
por estimados:

• 5. Sustitución por valor constante, derivado defuentes externas, juicio de expertos o investigaciónprevia.
• 6. Imputación por regresión: predicción del valor apartr de una ecuación de regresión con otrasvariables.
• Originará correlaciones más elevadas con variablesde las que proviene.
• 7. Imputación múltiple: combinación de variosmétodos anteriores.
Sustitución de valores ausentes
por estimados:

Detección y tratamiento de valores en las variables cualitativas
Detección y tratamiento de valores en variables cuantitativas
Tratamientos de valores perdidos
Puntos a tratar
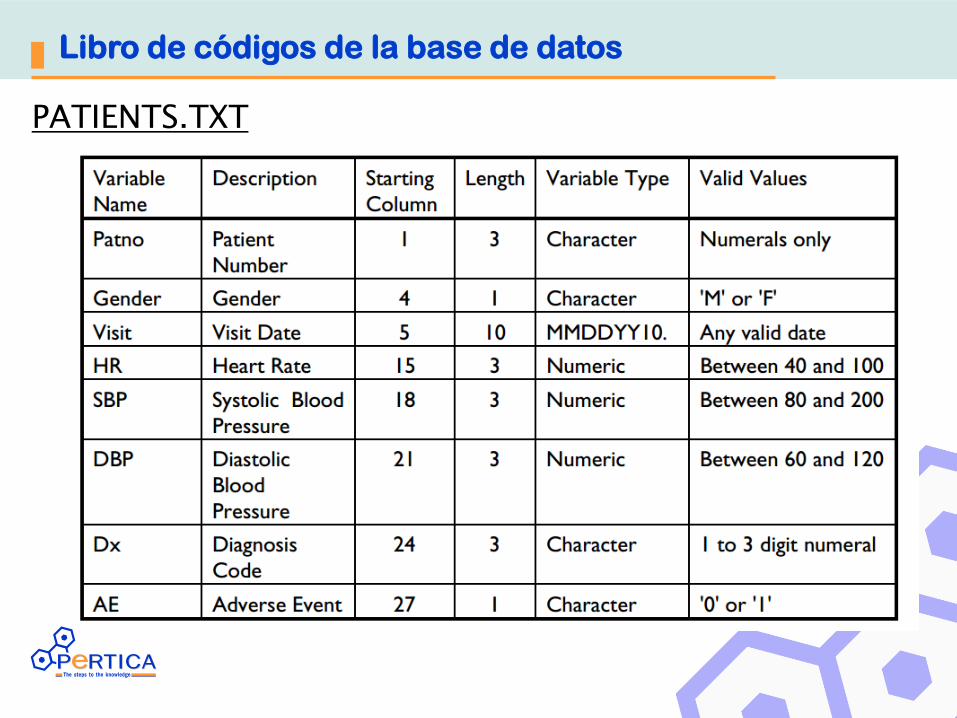
Libro de códigos de la base de datos
PATIENTS.TXT

Detección y tratamiento de valores en las variables cualitativas
Detección y tratamiento de valores en variables cuantitativas
Tratamientos de valores perdidos
Puntos a tratar

Detección y tratamiento de valores en las
variables cualitativas
Exploración de variables
El objetivo es detectar valores ausentes y detectar
errores en la codificación de las variables
Generación de tablas de frecuencias. Buscamos los
diferentes valores repetidos en la variable
categórica.
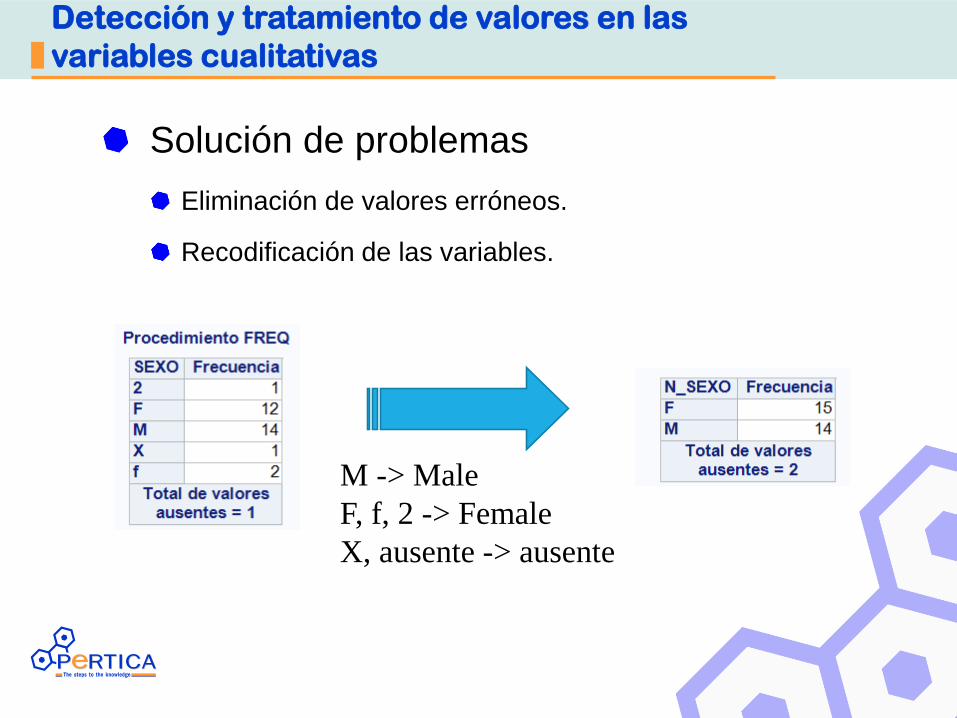
Detección y tratamiento de valores en las
variables cualitativas
Solución de problemas
Eliminación de valores erróneos.
Recodificación de las variables.
M -> Male
F, f, 2 -> Female
X, ausente -> ausente

Detección y tratamiento de valores en las variables cualitativas
Detección y tratamiento de valores en variables cuantitativas
Tratamientos de valores perdidos
Puntos a tratar

Detección y tratamiento de valores en las
variables numéricas
Exploración de variables
El objetivo es detectar, no solamente valores
ausentes, sino también, detectar valores extremos o
fuera de rango
Utilización de estadísticos descriptivos para detectar
esta información
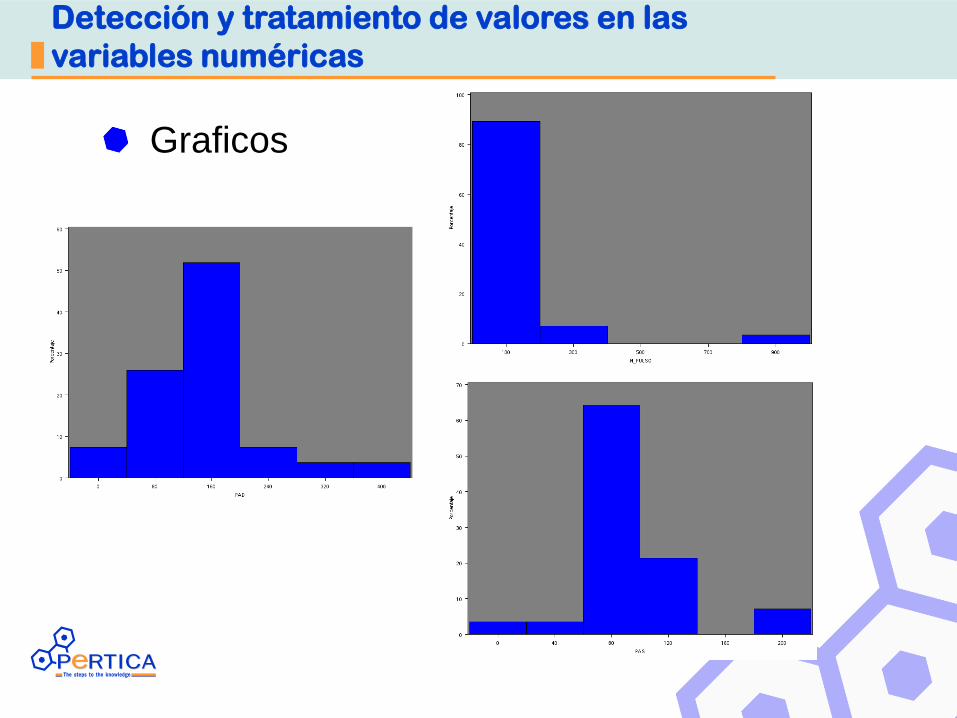
Detección y tratamiento de valores en las
variables numéricas
Graficos

Detección y tratamiento de valores en las
variables numéricas
BOX-PLOT

Detección y tratamiento de valores en las
variables numéricas
Listado de valores fuera de rango
Errores de transcripción de la informacion
Valores ausentes “especiales”
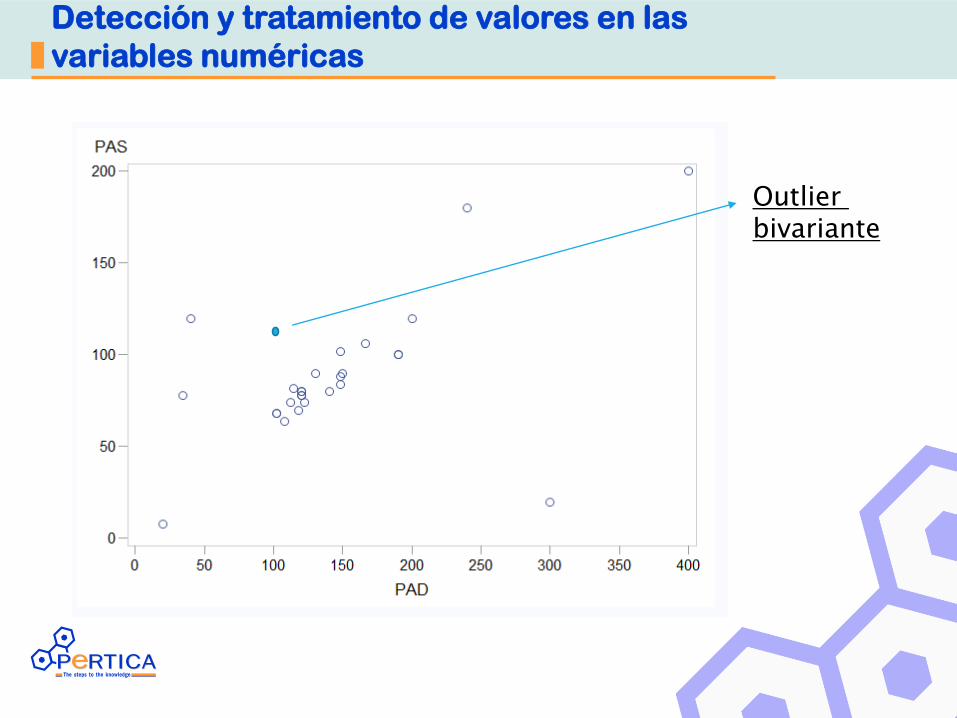
Detección y tratamiento de valores en las
variables numéricas
Outlier
bivariante
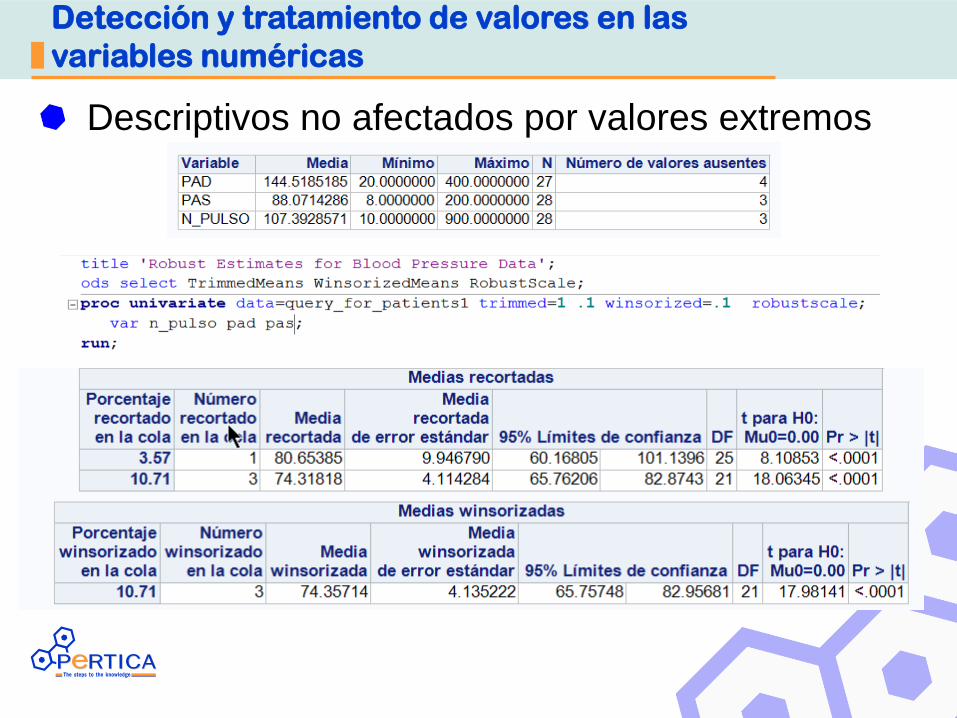
Detección y tratamiento de valores en las
variables numéricas
Descriptivos no afectados por valores extremos

Detección y tratamiento de valores en las variables cualitativas
Detección y tratamiento de valores en variables cuantitativas
Tratamiento de valores perdidos
Puntos a tratar

Tratamiento de valores perdidos
¿Por qué es importante tratar los valores
perdidos?
Determinados modelos matemáticos (modelos lineales,
como la regresión lineal o la regresión de poison) no
permiten la existencia de valores perdidos,
produciéndose la perdida del caso entero para el modelo.
Pueden inutilizar el poder predictivo de una variable sobre
otra.

Tratamiento de valores perdidos
Forma de tratar los valores perdidos
Eliminación de casos con valores perdidos
Eliminación de variables con demasiado valores perdidos
Imputación de valores
Tratamiento de valores de variables cuantitativas por
medio de la categorización de la variable, y dejando una
categoría mas con todos los valores perdidos.

Tratamiento de valores perdidos
Imputación a través de valores de la variable
A través de los estadísticos de la distribución como la media, la
mediana, máximo. Minimo. Inconveniente: Modificamos la
variabilidad de la variable.
A través de los valores de otras variables
Utilización de los valores de otras variables para calcular un
modelo predictivo que nos de el valor de la variable en el caso
de que esta contenga un valor perdido.

Cody, Ron. 2008. Cody’s Data Cleaning Techniques Using SAS®, Second Edition. Cary,
NC: SAS Institute Inc.
Bibliografía recomendada

MUCHAS GRACIAS