prediciendo el pbi: ¿quÉ aportan los … de economa... · o procedimiento requiere establecer un...
TRANSCRIPT

1
PREDICIENDO EL PBI: ¿QUÉ APORTAN LOS MÉTODOS CUANTITATIVOS?
Versión Preliminar
Julio de 2002
Elena Cuadrado∗∗∗∗
Fernando Lorenzo∗∗∗∗∗∗∗∗
Virginia Queijo∗∗∗∗∗∗∗∗∗∗∗∗
Abstract
En este trabajo se analizan las potencialidades y debilidades que presenta la predicción del
PBI trimestral de la economía uruguaya mediante el uso de métodos cuantitativos. Los
distintos procedimientos se distinguen de acuerdo al conjunto de información que utilizan.
Se tuvieron en cuenta varios tipos de modelos lineales de series temporales: i) univariantes,
ii) vectores autorregresivos (VAR), y iii) modelos econométricos de forma reducida. Cuando
se considera conjuntamente la precisión de las predicciones a distintos horizontes
temporales, se observa que ninguno de los esquemas de modelización considerados
muestra un predominio claro sobre los otros (en la métrica del error cuadrático medio). No
obstante, un modelo multivariante VAR con componentes del PBI parece ser el que genera
predicciones más precisas en el período analizado (1998-2001). La implementación de
contrastes de encompassing y de combinación de predicciones generadas por los diferentes
procedimientos, indica que una combinación lineal de las predicciones realizadas por el
modelo VAR con componentes del PBI con las provenientes de un modelo univariante naive
permite mejorar la precisión de las predicciones. El estudio revela que la predicción del PBI
trimestral de la economía uruguaya presenta elevados niveles de incertidumbre. Los
resultados obtenidos muestran que los modelos cuantitativos aplicados en el caso uruguayo
cometen errores de predicción más grandes que los utilizados en otros países.
Previsiblemente, este hecho se encuentra relacionado con el tamaño y el grado de apertura
de la economía considerada.
∗ Instituto de Economía, Facultad de Ciencias Económicas y Administración, Universidad de laRepública, Uruguay. E-mail: [email protected]∗∗ Centro de Investigaciones Económicas (CINVE), Uruguay. E-mail: [email protected]∗∗∗ Department of Economics and Institute for Latin American Studies, Stockholm University, Suecia.E-mail: [email protected]

2
1. INTRODUCCIÓN
El objetivo de este trabajo es realizar un ejercicio de predicción del Producto Bruto
Interno (PBI) trimestral de la economía uruguaya mediante el uso de métodos
cuantitativos para el período 1998-2001. El propósito de dicho ejercicio no es sólo
establecer cuál método presenta mejores resultados, sino también observar cuales
son los problemas que se presentan en la utilización regular de cada método, de
modo de extraer conclusiones sobre las ventajas e inconvenientes que se derivan de
su aplicación al caso concreto de la economía uruguaya.
El seguimiento de la evolución del PBI de una economía es de vital importancia, ya
que el mismo es un indicador sintético del bienestar general y representa la medición
de la actividad productiva de un país a nivel agregado más ampliamente difundida.
Por tanto, existe de parte de múltiples agentes económicos una preocupación
fundada por conocer por adelantado el comportamiento de este indicador.
En el caso de Uruguay, si bien existen algunos trabajos que aplican métodos
cuantitativos para contrastar relaciones económicas de interés referidas a la
determinación del PBI, no ha sido objeto de atención el desempeño predictivo de los
modelos. Este trabajo se propone avanzar en esta línea de investigación,
estudiando las ventajas e inconvenientes que enfrentan los analistas de coyuntura al
utilizar predicciones sobre el nivel de actividad generadas a partir de modelos
cuantitativos.
El uso de métodos cuantitativos para la elaboración de pronósticos económicos tiene
más de 70 años. La razón que motiva el desarrollo permanente de los
procedimientos de predicción radica en que cada vez resulta más importante para
los agentes económicos disponer de estimaciones, lo más precisas posibles, sobre
la evolución previsible de un amplio conjunto de indicadores económicos con el
objetivo de contribuir a la toma de decisiones.

3
Esta motivación ha originado el desarrollo de distintos procedimientos estadísticos y
econométricos, cada uno de los cuales presenta determinadas características,
ventajas y desventajas. Este trabajo pretende hacer una presentación sintética y
empírica de los métodos y procedimientos de predicción más usados en la
actualidad. Cabe advertir, sin embargo, que la presentación no pretende ser
exhaustiva, no abarcando modelos macroeconométricos estructurales ni métodos de
predicción basados en la utilización de modelos no lineales.
En cuanto al problema estricto de predicción, el uso de distintos modelos, así como
la incorporación de más o menos variables externas a la estructura del PBI derivan
en resultados dispares. Sin embargo, determinados métodos muestran ventajas
sobre otros.
Asimismo, importa resaltar que como las predicciones están sujetas a incertidumbre,
un buen ejercicio de predicción debe tener en cuenta los posibles errores que
pueden contener las predicciones. Esto lleva a que las predicciones puntuales
deban ir acompañadas por información que permita determinar el intervalo de
confianza de las estimaciones realizadas.
Por último, cabe resaltar que la predicción del PBI no puede entenderse como un
problema meramente estadístico, centrado exclusivamente en la utilización de
métodos que brinden predicciones lo más precisas posibles. La labor de predicción
de esta variable debe aportar una mejor comprensión sobre el funcionamiento de la
dinámica económica. Por lo tanto, explorar la capacidad de predicción de un modelo
o procedimiento requiere establecer un balance entre la precisión de las
predicciones y la racionalidad económica subyacente. Esto resulta fundamental a la
hora de elaborar el diagnóstico.
El trabajo se organiza de la siguiente manera. En el punto siguiente se presentan
las principales características de los distintos métodos de predicción considerados.
En la tercera sección se analizan diferentes criterios para evaluar el desempeño
predictivo de los modelos, destacándose aquellos que aportan información sobre la
constancia de los parámetros y los que permiten evaluar la precisión y contenido

4
informativo de las predicciones. Luego se presentan los principales resultados, y por
último, se realizan algunas consideraciones finales.
2. ASPECTOS METODOLOGICOS
A los efectos de este trabajo se optó por concentrar el esfuerzo en esquemas
cuantitativos para la predicción, ya que se considera que en la economía uruguaya
existe campo para mejorar la precisión de las predicciones utilizando modelos
cuantitativos. Asimismo, el estudio de los métodos de predicción desde un punto de
vista meramente formal, tiene la ventaja adicional de ser más fácil de comunicar y
aprender, ya que a diferencia de los métodos más intuitivos, estas técnicas
proporcionan una forma científica de contrastar las hipótesis con la evidencia
empírica y por ende, un procedimiento sistemático para avanzar en el conocimiento
de la realidad económica subyacente (Currie, 1994).
Los métodos cuantitativos para la realización de predicciones pueden distinguirse
según el conjunto de información que utilizan. A lo largo de este trabajo se
estudiarán principalmente varios tipos de modelos lineales de series temporales: i)
univariantes, ii) vectores autorregresivos (VAR), y iii) modelos econométricos de
forma reducida.
2.1. Modelos univariantes de series temporales
Entre los métodos considerados, los modelos univariantes de series temporales son
los que incorporan menor cantidad de información, ya que sólo usan la información
contenida en los retardos de la propia variable modelizada. La construcción de
estos modelos se realiza a partir del análisis de las propiedades estadísticas de los
datos, simplificando las relaciones de dependencia temporal de los mismos, y sin
incorporar ningún tipo de relación con otras variables.

5
El objetivo de los modelos univariantes no es lograr una representación apropiada
del funcionamiento de la economía, sino construir modelos simples que capturen las
propiedades de dependencia temporal de los datos, con el objetivo de proveer bases
adecuadas para los pronósticos.
La ventaja de estos modelos es que proveen de un enfoque simple y robusto al
problema de las predicciones, además de eliminar la posibilidad de realizar
pronósticos utilizando relaciones espurias entre variables. La desventaja que
presentan es que los mismos pueden ver deteriorada su capacidad predictiva al no
incorporar otra información disponible y relevante para pronosticar la variable de
interés (Hall, 1994).
En este trabajo se analizaron tres modelizaciones univariantes lineales dependiendo
de la aleatoriedad de los componentes básicos, tendencia y estacionalidad:
ARIMA A Crecimiento tendencial estable (determinista) y estacionalidad
estocástica
ARIMA B Crecimiento tendencial estocástico y estacionalidad estocástica
ARIMA C Crecimiento tendencial estable (determinista) y estacionalidad
determinista
tPp
iitit a
LLLL
Dy)()()()(
4
43
1 φφθθ
αµ ++=∆ ∑=
tPp
Qqt a
LLLL
y)()()()(
4
44
φφθθ
+=∆∆
tPp
Qqt a
LLLL
y)()()()(
4
44
φφθθ
µ +=∆

6
donde yt es el logaritmo del PBI, los polinomios en el operador de retardo L son de la
forma κr(L) = 1 - κ1L -.....- κrLr, o κr(L4) = 1 - κ1L4 -.....- κrL4r. Estos polinomios tienen
todas sus raíces estrictamente fuera del círculo unitario. El proceso estocástico at es
un ruido blanco con varianza finita y constante σ2a que representa la secuencia de
innovaciones que afectan a la serie de interés. Dit son variables dummies
estacionales que toman valor 1 cuando la observación t pertenece al trimestre i, -1
en el cuarto trimestre y 0 en los otros casos. Asimismo, se incluyeron variables de
intervención para modelizar los efectos sobre el nivel de la serie de todos los
eventos extraordinarios.
Este tipo de modelos puede estimarse de manera eficiente a partir de métodos de
máxima verosimilitud (Box y Jenkins, 1976). La aplicación de la metodología Box-
Jenkins permite especificar modelos ARIMA de manera simple.
2.2. Observaciones atípicas y su tratamiento estadístico
Una característica de las series de tiempo es que en general están contaminadas
por observaciones atípicas (outliers), consecuencia de eventos inusuales y no
repetitivos. En ese caso, la precisión de las predicciones se ve afectada por dos
vías: i) el efecto del outlier sobre los pronósticos puntuales, y ii) porque introduce un
sesgo en la estimación de los parámetros del modelo (Chen y Liu, 1993).
Los cuatro tipos fundamentales de observaciones atípicas considerados en la
literatura de series de tiempo son: atípico aditivo (additive outlier, AO), atípico
innovativo (innovative outlier, IO), cambio de nivel (level shift, LS), y cambio
transitorio (transitory change, TC)
Una vez que se ha identificado la localización y tipo de atípico, se corrigen los
mismos mediante el análisis de intervención propuesto originalmente por Box y Tiao
(1975). Este tipo de análisis no es más que una generalización del análisis con
variables cualitativas donde, finalmente, las variables de intervención se reducen a

7
dos tipos: i) impulsos para modelizar efectos transitorios de corto plazo, y ii)
escalones para modelizar efectos permanentes de largo plazo.
2.3. Modelo multivariante: VAR con componentes sectoriales del PBI
En este trabajo se consideró un desglose sectorial del IVF del PBI global a efectos
de construir un conjunto de modelos econométricos multivariantes de tipo VAR.
Estos modelos fueron utilizados para generar predicciones de los distintos IVF
sectoriales. La agregación de estos índices permitió construir predicciones del IVF
del PBI a partir de las predicciones de sus componentes sectoriales.
Este tipo de representación permite analizar los vínculos entre los comportamientos
de cada uno de los sectores, donde puede existir un sector cuyo comportamiento
incide sobre otros o donde pueden observarse causalidades bidireccionales que los
modelos univariantes son incapaces de capturar.
En concreto, se especificaron dos modelos VAR con componentes sectoriales del
PBI, con 4 y 5 retardos cada uno:
VAR A Crecimiento tendencial estable y estacionalidad estocástica
∆4Xt = µ + Λ(L) ∆4Xt-1 + εt
VAR B Crecimiento tendencial estable y estacionalidad determinista
∆Xt = µ + Λ(L) ∆Xt-1 + Σ3;i=1 α iDit + εt
donde las variables (endógenas) incluidas en el vector Xt son el logaritmo de
distintos componentes sectoriales del PBI, µ es un vector de constantes, Dit son
variables dummies estacionales, εt∼ IN(0, Ω), y Λ(L)Xt-1 = Λ1Xt-1 + ... + ΛpXt-p siendo Λi

8
matrices de n x n parámetros. Todas las raíces de In - Λ1L -...- ΛpLp = 0 se
encuentran estrictamente fuera del círculo unitario.
Por último, cabe mencionar que estos modelos también pueden incluir variables
dummies para corregir atípicos.
2.4. Modelo multivariante: VAR “econométrico”
En este trabajo se denomina VAR “econométrico” a un modelo multivariante donde
en el vector de variables endógenas se incluyen “variables explicativas” externas al
PBI y no los componentes sectoriales del mismo. Las variables consideradas
fueron los logaritmos de: PBI de Uruguay, PBI de Argentina, PBI de Brasil, inflación
en dólares en Uruguay, inflación en dólares en Argentina, inflación en dólares en
Brasil, relación de términos de intercambio (RTI)1, tasa de interés internacional2.
Asimismo, se incluyó en el modelo un conjunto de variables dummies para modelizar
la estacionalidad, así como un cierto número de variables cualitativas que capturan
los efectos de acontecimientos extraordinarios que afectaron a las distintas variables
en el período analizado.
La ventaja de introducir otras variables externas al PBI respecto a los modelos VAR
con componentes sectoriales, es que incorpora información disponible y relevante
para pronosticar la actividad económica. Las variables incorporadas son en general
variables que la teoría económica interpreta actúan sobre el PBI, y por lo tanto
podrían mejorar las predicciones.
Sin embargo, la introducción de estas variables podría presentar la desventaja de
generar relaciones espurias y así, perjudicar el desempeño predictivo de estos
modelos. 1 La RTI fue calculada como el cociente entre índices de precios de exportación y los precios
de importación, ambos en términos de dólares.

9
Asimismo, la modelización mediante vectores autorregresivos elimina el problema de
la precedencia temporal de las variables explicativas, permitiendo analizar la
existencia de interacciones dinámicas entre los datos. En este sentido, los modelos
VAR sin restricciones no necesitan que las variables incluidas en el vector
autorregresivo sean fuertemente exógenas para que el modelo sea válido con fines
predictivos.
2.5. Modelos econométricos de forma reducida
Los modelos econométricos hacen uso de la teoría económica incorporando, al igual
que en el caso anterior, información adicional a la que define la estructura sectorial
del PBI.
Por otra parte, los sistemas econométricos cumplen otras funciones a parte de ser
útiles para predecir. Por ejemplo, los mismos consolidan el conocimiento empírico y
teórico de cómo funcionan las economías, proveen un marco para una estrategia de
investigación futura y ayudan a explicar otras fallas. Asimismo, al igual que los
modelos de series de tiempo, se basan en modelos estadísticos y por lo tanto
permiten la derivación de medidas de incertidumbre de los pronósticos y los tests
asociados a la inadecuación de los mismos (Clements y Hendry, 1998).
Los modelos econométricos pueden especificarse como modelos macroeconómicos
generales o solamente bloques parciales. Los primeros son muy costosos, ya que
requieren de una gran cantidad de recursos técnicos y humanos para su uso. A los
efectos de este trabajo, solamente se considerarán modelos econométricos
uniecuacionales para la predicción del PBI.
2 Se consideró el logartimo de (1+ tasa de interés de los depósitos a 90 días en dólares).

10
a) Modelo lineal general uniecuacional
Para exponer la formulación econométrica del modelo lineal general uniecuacional
se consideran k variables xk exógenas que tienen información relevante sobre la
evolución de la variable de interés yt (a efectos de este trabajo el logaritmo del PBI
uruguayo). Asimismo, se supone que tanto yt como las k variables exógenas son
procesos I(1), y que no existe una relación de cointegración entre ellas.
Bajo estas condiciones, el modelo lineal general puede expresarse en su
formulación de retardos racionales distribuidos como:
donde el cociente de polinomios en el operador de retardo aplicado sobre ∆xt,i
aproxima el efecto dinámico de la variable xi sobre ∆yt, mientras que el segundo
término representa una estructura ARMA (p,q) que resume la estructura de
dependencia temporal a través de la que las perturbaciones se transmiten a la serie
∆yt. Las raíces del polinomio δm,i(L) se encuentran todas estrictamente fuera del
círculo unitario, de tal modo que el cociente polinomial puede ser de orden infinito,
siendo la suma de sus coeficientes finita.
Se observa que en este tipo de modelización la parte predecible de la variable de
interés está formada por dos componentes: i) la contribución de las variables
exógenas y ii) la parte predecible del elemento residual.
Las variables “exógenas” incluidas en la especificación de los modelos
econométricos fueron3:
3 Otras variables como el tipo de cambio real bilateral con Argentina, la relación de términos de
intercambio y la tasa de interés internacional fueron dejadas de lado, ya que su inclusión en elmodelo no resultó estadísticamente significativa.
∆ ∆ ∆yLL
xLL
xLL
atn
mt
n k
m kt k
q
pt= + + +
ωδ
ωδ
θφ
,
,,
,
,,
( )( )
....( )( )
( )( )
1
11

11
Modelo A
• PBI de Argentina
• PBI de Brasil
Modelo B
• PBI de Argentina
• PBI de Brasil
• Tipo de cambio real bilateral con Brasil (TCR con Brasil)4
En los modelos estimados se incluyó una constante, variables dummies
estacionales, además de algunas variables cualitativas que captan los efectos de
algunos acontecimientos extraordinarios ocurridos durante el período muestral
considerado.
b) Exogeneidad de las variables explicativas
La validez de la utilización de los modelos de función de transferencia con fines
predictivos requiere que se verifiquen las condiciones de exogeneidad fuerte: i) que
la variable de interés no cause en el sentido de Granger a las variables exógenas
∆xt,i, y ii) que estas últimas sean además débilmente exógenas. La exogeneidad
débil es una condición necesaria para la validez de la inferencia acerca de los
parámetros del modelo uniecuacional5, mientras que la condición de exogeneidad
fuerte implica que no existe retroalimentación desde yt hacia xt.
Más formalmente, yt no causa en el sentido de Granger a xt si para todo s > 0 el
error cuadrático medio (MSE, Mean Square Error) del pronóstico de xt+s basado en
(xt, xt-1,…) es el mismo que el MSE del pronóstico de xt+s que usa ambos, (xt, xt+1, …)
y (yt, yt-1,…).
4 Los TCR bilaterales con Argentina y Brasil fueron calculados como la relación entre la
inflación en dólares en dichos países, respecto a la inflación en dólares en Uruguay.
5 El análisis de la hipótesis de exogeneidad débil se puede realizar a partir de la metodologíade contraste de Hausman (1978) y Engle (1982).

12
3. CRITERIOS PARA EVALUAR EL DESEMPEÑO DE LOS MODELOS
La constancia paramétrica y la evaluación de las predicciones basadas en el error
cuadrático medio son criterios frecuentemente usados para evaluar el desempeño de
los modelos. La verificación de ambos criterios es necesaria, pero no suficiente,
para seleccionar el modelo que predice mejor, dados los datos disponibles. El
contenido informativo de las distintas predicciones también debe ser tomado en
cuenta.
3.1. Constancia paramétrica
Un problema que enfrentan los modelos de predicción es que el proceso generador
de los datos (PGD) pocas veces es estable, lo que lleva a períodos de grandes
errores en las predicciones cuando se asiste a un cambio estructural. Cuando esto
ocurre, modelos que antes eran exitosos fallan en predecir las nuevas realizaciones
de los datos (Clements y Hendry, 1997).
La constancia paramétrica es esencial al diseño del modelo, tanto desde el punto de
vista estadístico como económico. Para que la inferencia sea válida los parámetros
deben ser estadísticamente estables. La práctica econométrica debe dirigirse a
identificar modelos que muestren una estructura paramétrica razonablemente
constante y que sigan siendo útiles cuando se producen cambios.
La teoría de la predicción ofrece un conjunto de instrumentos válidos para realizar la
inferencia cuando el modelo estimado coincide con el PGD. En este caso, los
pronósticos estimados como la esperanza condicional de la información pasada son
óptimos en el sentido de que son insesgados y eficientes. Sin embargo, en un
mundo cambiante y no estacionario, donde el modelo difiere del PGD, la teoría de
predicción enfrenta otros problemas.

13
En este sentido la constancia paramétrica es una propiedad estadística deseable de
los modelos y se encuentra íntimamente relacionada con el comportamiento en
predicción de los modelos. Ericsson (1994) demuestra que la constancia
paramétrica no es una condición necesaria y suficiente para minimizar el error
cuadrático medio de las predicciones entre un conjunto de modelos. Concretamente
la proposición demostrada por este autor establece que si un modelo tiene
empíricamente parámetros constantes, éste puede tener un error cuadrático medio
tanto inferior como superior al de otros modelos alternativos, que adolecen de
inestabilidad paramétrica. El autor demuestra, asimismo, que si un modelo tiene
parámetros no constantes, éste puede presentar un error cuadrático medio de las
predicciones tanto inferior como superior al de otro modelo con parámetros
constantes. Concluye que ambos criterios son necesarios pero no suficientes para
asegurar que un modelo sea adecuado para fines predictivos. Otros criterios, como
el de forecast encompassing, también son importantes para determinar la
adecuación del modelo.
Formalmente, la constancia paramétrica de un modelo puede evaluarse a partir de
procedimientos recursivos de estimación. A tales efectos, pueden utilizarse distintos
estadísticos, siendo el CUSUM propuesto por Brown, Durbin y Evans (1975) uno de
los más utilizados. El contraste CUSUM se basa en la suma acumulada de los
residuos recursivos estandarizados:
siendo et los errores de predicción un paso adelante, s la desviación estándar de los
residuos estandarizados calculados sobre toda la muestra, y τ el número de
predicciones post-muestrales.
La gráfica del CUSUM es útil para detectar inestabilidad paramétrica, ya que cuando
este estadístico cruza las líneas predeterminadas dadas por ±(a√τ + 2ah/√τ), donde
a=0.948 para un nivel de significancia de 5%, puede rechazarse la hipótesis nula de
τ,...,1,),(
1
0 1)(=
∑=
−
= ++n
s
enTCUSUM
n
j jT

14
estabilidad de la estructura paramétrica subyacente. El CUSUM es particularmente
útil para detectar situaciones en las que el modelo utilizado predice sistemáticamente
por debajo o por encima de las futuras realizaciones.
Otro contraste frecuentemente utilizado para evaluar la estabilidad del modelo en
predicción puede realizarse a partir del estadístico
donde s2 es la varianza estimada de las innovaciones muestrales y τ es el número
de predicciones “puras” un paso adelante (post-muestrales). Si el modelo está
correctamente especificado y asumiendo normalidad de los errores de predicción,
Box y Tiao (1976) demostraron que el estadístico ξ(τ) se distribuye F(τ, T-r) donde r
es el número de observaciones usadas como condiciones iniciales para la
estimación.
3.2. Evaluación de predicciones
La evaluación del desempeño de los pronósticos es un insumo importante en el
proceso de predicción, y en la medida en que proporciona información sobre la
performance futura, es de gran interés para los usuarios (Wallis, 1989). Asimismo,
es esencial informar de la medida de riesgo asociada a todo pronóstico puntual, así
como brindar la historia de los últimos errores de predicción. Esto es importante
porque permite al usuario conocer la incertidumbre futura, planear estrategias dentro
del rango posible de los pronósticos y establecer escenarios basados en distintos
supuestos sobre los acontecimientos futuros.
Cabe resaltar que detrás de los errores de predicción pueden existir distintos
problemas, como por ejemplo errores de especificación del modelo, errores en la
estimación de los parámetros, inestabilidad paramétrica, perturbaciones atípicas,
ζ ττ
τ
( )( )
=+ +
=
−
∑e
s
T jj
12
0
1
2

15
errores en las proyecciones de las variables exógenas y errores de medición de las
variables de interés.
a) Medidas de precisión
Los pronósticos macroeconómicos se expresan tradicionalmente como estimaciones
puntuales. Las evaluaciones retrospectivas de los mismos asumen usualmente que
la función de pérdida asociada a los errores de predicción aumenta con la magnitud
aritmética del error. Como resultado, distintas medidas descriptivas son a menudo
usadas para evaluar la performance de los pronósticos. Las más comunes son:
i. Error medio (Mean error, ME)
donde τ es el número de predicciones usadas en la comparación y h es el horizonte
temporal de los errores. El error de predicción, eT+h ,se define como la diferencia entre el
valor efectivamente observado de la variable de interés, yT+h, y la predicción condicional
realizada por el modelo correspondiente, y T+h, de modo que eT+h = yT+h – y T+h.
ii. Error absoluto medio (Mean absolute error, MAE)
iii. Raíz cuadrada del error cuadrático medio (Root mean square error, RMSE)
iv. Relación entre MAE y RMSE (x100)
v. Rango de los errores absolutos (Max AE – Min AE)
11τ
τ
e T i hi
( ),+=∑
11τ
τ
e T i hi
( ),+=∑
[ ]1 2
1τ
τ
e T i hi
( ),+=∑

16
Una crítica que enfrentan las medidas basadas en el MSE se refiere a la falta de
invarianza respecto a transformaciones de las variables para las cuales el modelo es
invariante (Clements y Hendry, 1995). Este problema se refiere a que un modelo A
puede mostrar un mejor desempeño que un modelo B en términos del MSE para
predecir la variable yT+h, pero la situación puede ser inversa cuando ambos modelos
predicen ∆yT+h. Clements y Hendry muestran que el uso del MSE carece de
ambigüedad para medir la precisión de las predicciones solamente en el caso de los
modelos univariantes y para las predicciones un paso adelante. En otras
circunstancias, estos autores recomiendan la utilización de la matriz de segundos
momentos de los errores de predicción. Sin embargo, los argumentos desarrollados
por Clements y Hendry van más allá del alcance de este trabajo y por tanto las
medidas de precisión utilizadas se basarán en el MSE. Por otra parte, la ventaja que
presenta el RMSE es que describe la magnitud del error en términos relativamente
fáciles y útiles para los usuarios de los pronósticos.
Otra dificultad que presentan estas medidas es que no existe un estándar absoluto
para evaluar la precisión, por lo cual se han desarrollado distintos procedimientos
comparativos. Una primera aproximación consiste en contrastar si la predicción
satisface ciertas propiedades de una predicción óptima, además de la minimización
del error cuadrático medio de las predicciones. Otra posibilidad es comparar el
desempeño predictivo de un cierto número de modelos alternativos.
b) Propiedades de las predicciones
Una predicción óptima es insesgada y eficiente, esto es, que el valor esperado de
los errores de predicción es nulo y no puede mejorarse la predicción a partir del
conjunto de información disponible (Wallis, 1989). Por lo tanto si la predicción es
óptima, debe ser insesgada y minimizar el MSE.
Considerando que los errores son independientes e idénticamente distribuidos, un
contraste simple de insesgamiento resulta de comparar la media muestral de los
errores de predicción un paso adelante con la desviación estándar de los errores
muestrales (estadístico t de la media de los errores de predicción).

17
Entonces, aceptando la hipótesis de insesgamiento de las predicciones, el criterio de
optimalidad a utilizar será el de minimizar el MSE de la predicción definido como:
MSE (y T,h) = E((yT+h – y T,h)2 / IT) = V(eT+h) + (E(eT+h))2
De lo anterior se desprende que para el caso de predicciones insesgadas, minimizar
el MSE es igual a minimizar la varianza de los errores de predicción h pasos
adelante.
3.3. Comparación entre modelos y combinación de predicciones
La comparación entre distintas predicciones concierne dos perspectivas: la precisión,
y el contenido informativo. Desde el punto de vista empírico, la primera pregunta
que corresponde plantearse es si existe en la métrica del error cuadrático medio
algún dominio claro de un método sobre otro. Cabe precisar que cuando se
comparan predicciones correspondientes a distintos procedimientos o modelos, es
necesario considerar todas las dimensiones (horizontes de predicción, niveles de
agregación) sobre las que se pretende que los modelos aporten información. El
ideal es que un modelo domine sobre sus competidores en todas las dimensiones
relevantes.6
Sin embargo, desde el momento que los distintos modelos comparten información, y
por lo tanto no son independientes, la significación estadística de las diferentes
medidas descriptivas no puede ser directamente contrastada entre los modelos. De
ahí se pasa al problema del contenido informativo de las predicciones realizadas
mediante distintos modelos, destacándose en la literatura dos enfoques: i) la
combinación de predicciones (cuando los errores de los modelos son
6 Öller y Tallbom (1996) señalan que muchas veces los datos con que trabajamos son también
estimaciones. Si el criterio para juzgar la adecuación de un método es comparando laspredicciones con los resultados se puede caer en la comparación de dos estimaciones.

18
independientes), y ii) el encompassing (cuando se admite que las predicciones con
un período de antelación de un modelo pueden estar contenidas en otro).
Algunos autores piensan que estos procedimientos son superiores a la simple
comparación del RMSE. Si dos modelos presentan RMSE similares nada se puede
decir sobre la conveniencia de utilizar uno u otro. Además, si un modelo presenta un
RMSE inferior al de otro, esto no quiere decir que éste último no aporte información
útil sobre el funcionamiento del fenómeno analizado.
a) Combinación de predicciones
La combinación de predicciones es un procedimiento alternativo que permite
contrastar ex-post el desempeño de distintas predicciones y al mismo tiempo puede
contribuir a la mejora de las predicciones ex-ante (considerando las predicciones con
un período de antelación).
En general, se espera que diferentes predicciones basadas en distintos conjuntos de
información, modelos, o aún distintos enfoques del análisis de los datos, contribuyan
de manera distinta al problema de predicción. Por lo tanto, la combinación de
pronósticos diferentes podría ser más precisa que la aportada por cualquiera de los
modelos por separado (Wallis, 1989). La ventaja de combinar predicciones consiste
en que no se descartan los pronósticos con peor desempeño, ya que los mismos
podrían contener información útil.
Si dos predicciones individuales son insesgadas7, una predicción compuesta tiene la
siguiente forma:
Ct = kt y 1t + (1-kt) y 2t
7 Esta condición se impone a todas las predicciones individuales. En caso que las mismas
sean sesgadas, son corregidas por el sesgo.

19
Existen distintos procedimientos para escoger k. El más simple es utilizar la media
aritmética8, pero en términos generales corresponde otorgar mayor ponderación a
los pronósticos que presentan menor MSE. Un ejemplo de cómo escoger k sería
kt = MSET-1;2MSET-1;1 +MSET-2;2
donde el subíndice 1 y 2 corresponde a dos modelos distintos y k1 = 0,5 (Bates y
Granger, 1969).
En general se puede decir que si los errores de una combinación tienen una
varianza significativamente menor que la de los errores de los pronósticos
individuales, esto estaría evidenciando que los modelos considerados han sido mal
especificados y que los mismos no están usando de manera óptima toda la
información disponible. Esto sugiere que podría encontrarse un modelo más
general, el cual incluya las características de los modelos combinados que mejoraría
las predicciones.
Sobre este aspecto, Diebold (1989) considera que, aunque muchos econometras
están en desacuerdo, la combinación de predicciones constituye una vía útil y
productiva para el mejoramiento de las predicciones. Obviamente, si la información
puede ser combinada rápidamente y sin coste, no existe posibilidad de extraer
beneficios de la combinación de predicciones. Es mejor combinar conjuntos de
información y no predicciones.
Sin embargo, a pesar que la combinación de predicciones es una estrategia
ineficiente frente a la combinación de conjuntos de información, en determinadas
circunstancias las restricciones de costos o de tiempo se convierten en un obstáculo
para la implementación de la combinación de conjuntos de información. La
combinación de predicciones aparece, entonces, como una solución pragmática ante
el costo que implicaría combinar conjuntos de información.
8 Diebold (1989) señala que los beneficios de imponer ponderadores iguales muchas veces
superan los costos, y que los resultados de las predicciones resultantes son mejores.

20
b) Forecast-encompassing
La propiedad de forecast-encompassing se relaciona con el problema de determinar
si las predicciones con un período de antelación realizadas por un modelo aportan
información útil para explicar los errores de predicción de otro modelo. El contraste
estadístico de esta propiedad fue desarrollado por Chong y Hendry (1986), quienes
establecieron que la necesidad de combinar pronósticos surge como consecuencia
de la mala especificación de los modelos (Clements y Hendry, 1993)9. La meta final
sería encontrar modelos que contengan a sus competidores mediante mejores
pronósticos que sus rivales (forecast-encompassing).
Desde el punto de vista de la implementación empírica, y considerando que existe
autocorrelación entre los sucesivos errores de predicción a distintos horizontes, este
concepto solamente puede hacerse operacional para pronósticos un paso adelante.
Un contraste de encompassing se puede realizar estimando por mínimos cuadrados
ordinarios las siguientes regresiones:10
eT+i,1 = β1 (y T+i,2 - y T+i,1) + uT+i,1
eT+i,2 = β2 (y T+i,1 - y T+i,2) + uT+i,2
donde i =1,..., τ, eT+i, j son los errores de predicción un paso adelante del modelo j, y
y T+i, j son las predicciones un paso adelante del modelo j. La hipótesis nula a
contrastar es Ho: βj = 0, lo que significa que la diferencia de las predicciones de los
modelos no puede explicar los errores cometidos por uno de los modelos
considerados (se dice que el modelo j “encompasses” al otro modelo). En el caso
que βj sea distinto de 0, entonces ambos modelos son valiosos para predecir yt pero
ninguno es suficiente. 9 Diebold (1989) reconcilia estos dos enfoques estableciendo que la combinación de
pronósticos es útil en el corto plazo, cuando combinar conjuntos de información resulta muycostoso.
10 Este contraste puede realizarse de igual manera en diferencias por la homegeneidad quepresentan las ecuaciones.

21
Analizando la primera ecuación, se observa que en el caso que las predicciones del
modelo 2 contengan toda la información aportada por el modelo 1, y cierta
información adicional, el parámetro estimado debe converger a la unidad (β1 = 1).
En este caso, las técnicas de combinación de predicciones carecen de sentido
porque toda la información aportada por el modelo 1 estaría comprendida en el
segundo modelo11.
Desde el punto de vista de la implementación empírica, la propiedad de forecast-
encompassing es formalmente equivalente a la definición de eficiencia condicional
propuesta por Granger y Newbold (1973). Un pronóstico es condicionalmente
eficiente si la varianza del error de predicción de una combinación del mismo con
otro pronóstico no es significativamente menor que la del modelo considerado. En
esta definición nuevamente se observa que bajo las condiciones de forecast-
encompassing, la combinación de pronósticos no mejora las predicciones.
4. RESULTADOS
Los datos utilizados en este trabajo corresponden a la serie trimestral del Índice de
Volumen Físico (IVF) del PBI uruguayo que elabora el Banco Central del Uruguay.
El período analizado abarca desde el primer trimestre de 1978 hasta el último
trimestre del año 2001. Las observaciones correspondientes a los últimos cuatro
años fueron en un principio dejadas de lado en el proceso de estimación de los
11 Considerando la primera ecuación:
eT+i,1 = yT+i -y T+i, 1 = β1 (y T+i, 2 - y T+i, 1 ) + uT+i,1
entoncesyT+i = (1-β1) y T+i, 1 + β1 y T+i, 2+ uT+i,1
Se observa que en el caso que β1 converja a uno, el mejor pronóstico va a ser y T+i,2 y no unacombinación de ambos.Además, considerando que ambas predicciones son insesgadas, se deriva
eT+i,2 = yT+i - y T+i,2 = (1-β1) (y T+i, 1 -y T+i,,2) + uT+i,2 = β2 (y T+i, 1 -y T+i, 2) + uT+i,2por lo cual β1=1 implica β2=0, verificándose que existe forecast encompassing en el segundomodelo. Lo mismo ocurre si se considera la segunda ecuación.

22
modelos para ser utilizadas en la evaluación de la capacidad predictiva de los
mismos.
Cabe resaltar que el período de evaluación de las predicciones ha sido un período
particularmente inestable para la economía uruguaya, particularmente afectado por
los efectos de la devaluación de la moneda brasileña en enero de 1999 y por la
ausencia de dinamismo e inestabilidad reinante en la economía argentina.
4.1. Modelos univariantes de series temporales
En primer lugar se observa que la serie del PBI uruguayo presenta tendencia de
largo plazo y oscilaciones estacionales (Gráfico 1). Luego se pasó a estimar los
modelos con el programa Eviews (Econometric Views versión 3). Las estimaciones
se realizaron con datos correspondientes al período comprendido entre el primer
trimestre de 1979 y el cuarto trimestre de 1997. Las observaciones de los cuatro
últimos años fueron “reservadas” para evaluar el desempeño predictivo de los
modelos estimados.
En los tres modelos estimados se incluyó un Análisis de Intervención para modelizar
cuatro observaciones atípicas (outliers) detectadas en el transcurso del proceso de
modelización: 1981.4 y 1982.3 escalón, 1985.1 y 1995.3 impulso.
Las estimaciones se realizaron utilizando un procedimiento recursivo (rolling
estimation) que consiste en volver a estimar todos los parámetros del modelo cada
vez que se incorpora un nuevo dato. Con los nuevos parámetros se realizan las
predicciones correspondientes y así se calculan los errores de predicción
(recursivos). El proceso de estimación recursiva se reiteró hasta el tercer trimestre
de 200112.
12 En el Cuadro A2 del Anexo se presentan las primeras estimaciones del modelo ARIMA C.

23
Cuadro 1Evaluación de los errores de predicción: Modelos univariantes
Período: 1998.01 – 2001.4
ARIMA A ARIMA B ARIMA C ME -0,0178 -0,0131 -0,0104
1 trimestre MAE 0,0228 0,0200 0,0193de Min 0,0007 0,0005 0,0005
antelación Max 0,0646 0,0523 0,0457 RMSE 0,0302 0,0262 0,0245
ME -0,0356 -0,0277 -0,0225
2 trimestres MAE 0,0415 0,0343 0,0306de Min 0,0000 0,0030 0,0008
antelación Max 0,1031 0,0837 0,0720 RMSE 0,0498 0,0419 0,0371
ME -0,0494 -0,0389 -0,0323
3 trimestres MAE 0,0556 0,0401 0,0364de Min 0,0185 0,0002 0,0021
antelación Max 0,1108 0,0894 0,0815 RMSE 0,0624 0,0497 0,0447
ME -0,0621 -0,0501 -0,0437
4 trimestres MAE 0,0656 0,0509 0,0454de Min 0,0158 0,0052 0,0115
antelación Max 0,1125 0,0965 0,0939 RMSE 0,0723 0,0567 0,0523
Elaboración propia
Cabe resaltar que a lo largo de este trabajo, los errores de predicción se calcularon
sobre el logaritmo del IVF del PBI trimestral, por lo que los mismos pueden
considerarse como una medida aproximada de la diferencia porcentual entre el valor
estimado y el verdadero valor del índice (expresada en tanto por uno).
Los resultados obtenidos en materia de desempeño predictivo se exponen en el
Cuadro 1. Los datos sombreados representan al modelo que muestra mejor
desempeño predictivo. Puede apreciarse que el modelo ARIMA C es el que mejor
se comporta, ya que presenta menores RMSE y MAE en todos los horizontes
temporales considerados, por lo cual los resultados correspondientes a este modelo

24
serán utilizados como punto de referencia para evaluar los otros procedimientos de
predicción.
Por otra parte, al analizar los errores de predicción con un trimestre de antelación se
observa que a partir del cuarto trimestre de 1998 los tres modelos cometen una
secuencia de errores negativos. Esto estaría indicando que los modelos
univariantes estimados tardan un tiempo en “adaptarse” al escenario recesivo que se
instaló en ese entonces en la economía uruguaya (véase Gráfico 2).
Se observa que los mayores errores absolutos de predicción en el período
considerado ocurrieron en el tercer trimestre de 1999, y en los dos últimos trimestres
de 2001 para todos los horizontes considerados.
Por su parte, los contrastes realizados sobre los residuos recursivos de los
pronósticos mostraron cierta evidencia de inestabilidad en la estructura paramétrica
solamente en el caso del modelo ARIMA A. Los mismo resultados se observan
mediante los estadísticos de Box y Tiao (véase Cuadro A9). Sin embargo,
realizando contrastes sobre los residuos recursivos de toda la muestra no se
rechaza la hipótesis de estabilidad de los parámetros en los tres modelos.
4.2. Modelo multivariante: VAR con componentes sectoriales del PBI
El IVF del PBI es un índice Laspeyres, donde los ponderadores sectoriales
corresponden a la distribución del Valor Agregado Bruto generado por cada sector
en el año 1983. Los siete sectores de actividad económica en que puede
descomponerse el PBI son13: Agropecuario (AGRO), Industria Manufacturera
(INDU), Electricidad, gas y agua (ELEC), Construcción (CONS), Comercio,
restaurantes y hoteles (COME), Transporte y comunicaciones (TRAN), y Otros
sectores (OTRO). 13 Estos son a su vez índices de Laspeyres construidos a partir de información más
desagregada. La fórmula del agregado es la siguiente: PBIt = 0,131*AGROt + 0,254*INDUt +0,032*ELECt + +0,043*CONSt + 0,108*COMEt + 0,061*TRANt + 0,372*OTROt

25
Sin embargo, para la estimación de los modelos VAR en este trabajo seconsideraron solamente cinco sectores14.
Los cinco componentes del VAR fueron incluidos con una diferencia, ya que
realizados los contrastes de raíz unitaria (test de Dickey y Fuller Aumentado) no se
pudo rechazar la hipótesis nula de existencia de una raíz unitaria al 95% de
confianza. Por otra parte, sí se rechazó la existencia de dos raíces unitarias (véase
Cuadro A8).
Los modelos VAR fueron estimados con datos correspondientes al período
comprendido entre el primer trimestre de 1983 y el cuarto trimestre de 1997, usando
el programa PC GIVE, en su versión para sistemas de ecuaciones (PC FIML). Se
estimaron modelos con cuatro y cinco retardos de las variables endógenas15.
Estudiando los residuos de cada uno de los modelos, se identificaron algunas
observaciones atípicas, por lo cual se procedió a diseñar un esquema de
intervención apropiado. Los residuos de cada uno de los modelos fueron sometidos
a contrastes de normalidad y autocorrelación16. Las intervenciones realizadas
variarion según cada modelo17.
14 Las ponderaciones utilizadas para recomponer el IVF del PBI fueron las siguientes:
i) Agro = 0,131ii) Industria Manufacturera = 0,254iii) Construcción = 0,043iv) Comercio, restaurantes y hoteles = 0,108v) Resto = 0,465
15 En el Cuadro A3 del Apéndice se presenta la estimación del modelo VAR A con 5 retardospara el período 1983.1-1997.4.
16 Se verificó que los residuos de cada una de las ecuaciones fueran normales y satisfacieran elestadístico de Ljung-Box luego de realizadas las intervenciones.
17 Las intervenciones realizadas fueron:- VAR A con 4 lags: 1985.2, 1993.2 y 1995.3 impulso, 1999.3 escalón- VAR A con 5 lags: 1993.2 y 1995.3 impulso, 1999.2 y 1999.3 escalón- VAR B con 4 lags: 1985.1 impulso, 1995.3, 2000.2 y 2001.2 escalón- VAR B con 5 lags: 1985.1 impulso, 1995.3, 2000.2 y 2001.2 escalón

26
Posteriormente, con los modelos estimados se hicieron predicciones a distintos
horizontes temporales para cada uno de los sectores de actividad. A partir de las
predicciones sectoriales se reconstruyó la predicción del PBI agregado. A
continuación se incluyó la observación del primer trimestre de 1998 en la muestra de
observaciones utilizadas en la estimación de los modelos y se procedió a la
reestimación del modelo (rolling estimation) manteniendo incambiada la estructura
paramétrica. Este proceso se repitió hasta el último trimestre del año 2001.
Los resultados obtenidos muestran que las peores predicciones se obtienen para los
sectores de Agro y Construcción (véase Cuadro A4).
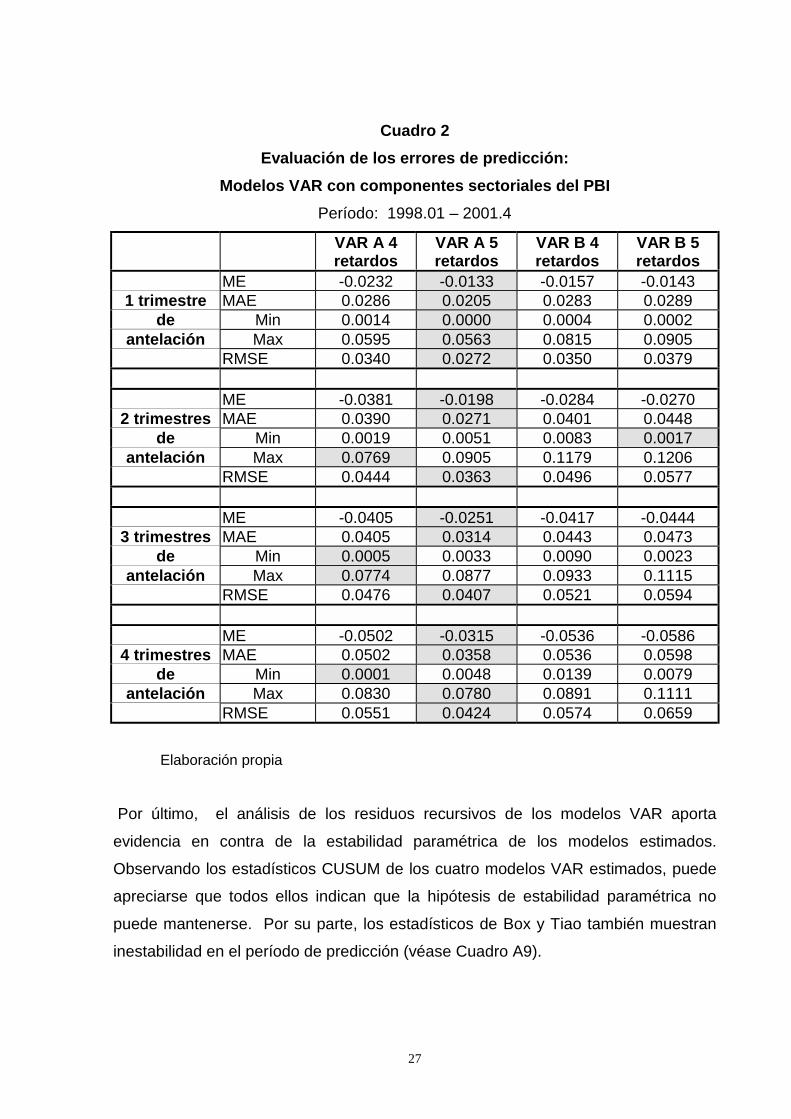
El análisis del desempeño predictivo de los modelos estimados puede realizarse a
partir de la información expuesta en el Cuadro 2. Puede apreciarse que el modelo
Var A con 5 retardos domina en todos los horizontes temporales considerados.
El análisis de los estadísticos expuestos en el Cuadro 2 muestra que la modelización
del PBI agregado a partir de un desglose en sus principales componentes
sectoriales implica una mejora en la precisión de las predicciones. Sin embargo, en
el caso de los errores de predicción con un trimestre de antelación el desempeño
predictivo es peor que el observado en los modelos univariantes. A medida que se
consideran horizontes de predicción más extensos, los modelos VAR sectoriales
ofrecen ciertas ventajas respecto a las representaciones univariantes.
Un aspecto a subrayar es que, si bien la utilización de estos modelos aporta un
ajuste más preciso al comportamiento del PBI en el período muestral, respecto a
técnicas más naive como son los modelos ARIMA, las predicciones “puras”
resultantes son peores (con un trimestre de antelación). En definitiva, los modelos
VAR aportan una mejor representación del comportamiento histórico del IVF del PBI
uruguayo, pero la mejor comprensión del fenómeno no se traduce directamente al
desempeño predictivo.
Otro punto a resaltar es que al igual que en el análisis univariante, los errores de
predicción muestran en los tres modelos una secuencia de errores negativos.
27
Cuadro 2Evaluación de los errores de predicción:
Modelos VAR con componentes sectoriales del PBIPeríodo: 1998.01 – 2001.4
VAR A 4retardos
VAR A 5retardos
VAR B 4retardos
VAR B 5retardos
ME -0.0232 -0.0133 -0.0157 -0.01431 trimestre MAE 0.0286 0.0205 0.0283 0.0289
de Min 0.0014 0.0000 0.0004 0.0002antelación Max 0.0595 0.0563 0.0815 0.0905
RMSE 0.0340 0.0272 0.0350 0.0379
ME -0.0381 -0.0198 -0.0284 -0.02702 trimestres MAE 0.0390 0.0271 0.0401 0.0448
de Min 0.0019 0.0051 0.0083 0.0017antelación Max 0.0769 0.0905 0.1179 0.1206
RMSE 0.0444 0.0363 0.0496 0.0577
ME -0.0405 -0.0251 -0.0417 -0.04443 trimestres MAE 0.0405 0.0314 0.0443 0.0473
de Min 0.0005 0.0033 0.0090 0.0023antelación Max 0.0774 0.0877 0.0933 0.1115
RMSE 0.0476 0.0407 0.0521 0.0594
ME -0.0502 -0.0315 -0.0536 -0.05864 trimestres MAE 0.0502 0.0358 0.0536 0.0598
de Min 0.0001 0.0048 0.0139 0.0079antelación Max 0.0830 0.0780 0.0891 0.1111
RMSE 0.0551 0.0424 0.0574 0.0659
Elaboración propia
Por último, el análisis de los residuos recursivos de los modelos VAR aporta
evidencia en contra de la estabilidad paramétrica de los modelos estimados.
Observando los estadísticos CUSUM de los cuatro modelos VAR estimados, puede
apreciarse que todos ellos indican que la hipótesis de estabilidad paramétrica no
puede mantenerse. Por su parte, los estadísticos de Box y Tiao también muestran
inestabilidad en el período de predicción (véase Cuadro A9).

28
En términos generales, puede afirmarse que la inestabilidad de los modelos en el
plano predictivo puede atribuirse a dos fenómenos: i) la presencia de
observaciones atípicas (la modelización de las anomalías a través de Análisis de
Intervención debería eliminar los problemas de inestabilidad), ii) la ocurrencia de un
cambio estructural (la inestabilidad paramétrica es “genuina” y las aproximaciones
lineales al fenómeno analizado pierden validez empírica).
Un análisis minucioso de los errores de predicción con un trimestre de antelación
cometidos por los modelos VAR indica que los problemas de inestabilidad
paramétrica pueden estar relacionados con la presencia de observaciones atípicas
ocurridas durante el período de predicción (1998-2001).
En el caso de los modelos considerados, el tratamiento de las observaciones
atípicas ocurridas en el período de predicción mediante el Análisis de Intervención
provoca una reducción considerable del valor del estadístico RMSE calculado a
partir de los residuos correspondientes a dicho período. Los resultados de este
ejercicio se comentan más adelante, pero desde ya puede adelantarse que la
evidencia encontrada apunta a que el tipo de inestabilidad observada en los errores
de predicción de los modelos VAR estimados podría estar atribuida básicamente a la
presencia de anomalías y no a problemas de cambio estructural (modificación de la
estructura paramétrica).
En este sentido, si se estudia la estabilidad paramétrica del modelo incorporando
todos los datos (inclusive hasta el último trimestre de 2001), se observa que
mediante el estudio de los residuos recursivos de toda la muestra, en particualar a
través de estadísticos CUSUM, no se rechaza la hipótesis de estabilidad. Esto
significa, que interveniendo las estimaciones en el período de predicción la
inestabilidad observada en los errores de predicción corresponde únicamente a la
presencia de observaciones atípicas.
Esta evidencia indica, por su parte, que la utilización de modelos VAR como los aquí
considerados en la labor de predicción del PBI trimestral de la economía uruguaya,
requiere un esfuerzo sistemático de monitoreo por parte del experto y un análisis

29
riguroso de los errores de predicción observados en las ecuaciones
correspondientes a cada uno de los sectores productivos, lo cual puede resultar
costoso para el usuario.
Parece ser, entonces, que los modelos univariantes y los VAR reaccionan de
manera muy diferente ante acontecimientos extraordinarios. Por otra parte, la
presencia de perturbaciones de gran magnitud, parece deteriorar la capacidad
predictiva de los VAR fundamentalmente a corto plazo. Cuando se consideran
horizontes de predicción más alejados en el tiempo, los modelos VAR logran un
mejor desempeño que los modelos univariantes.
4.3. Modelo multivariante: VAR “econométrico”
En la especificación de los modelos VAR “econométricos” se consideraron datos
correspondientes al período comprendido entre el primer trimestre de 1979 y el
cuarto trimestre de 1997. Al igual que en los casos anteriores, se reservaron las
observaciones del período 1998-2001 para la evaluación del desempeño predictivo.
En primer lugar se realizaron contrastes de raíces unitarias con el objetivo de
establecer cómo serían incluidas las variables del vector autorregresivo. Los
contrastes fueron realizados sobre las transformaciones logarítmicas de los datos
originales18. Los resultados del test de Dickey y Fuller Aumentado (véase Cuadro
A8) muestran que todas las variables endógenas incluidas en el VAR son integradas
de orden 1, por lo cual se trabajó con las primeras diferencias de las
transformaciones logarítmicas de los datos.
18 En el caso de la tasa de interés, la variable considerada fue la diferencia primera del
logaritmo de (1 + tasa de interés).

30
Luego de realizarse un análisis de intervención19, se especificaron modelos VAR con
cuatro y cinco retardos de las variables endógenas20. Es importante subrayar que
los parámetros estimados indican que un shock en Argentina repercute más
rápidamente en el nivel de actividad uruguaya que uno proveniente de Brasil21. No
obstante, la evolución del nivel de actividad en las dos economías vecinas aporta
valiosa información para comprender la dinámica del PBI trimestral uruguayo.
Luego de estimados los modelos, se procedió a predecir el PBI uruguayo para los
cuatro trimestres siguientes, repitiéndose esta operación hasta incorporar el dato del
tercer trimestre del año 2001.
El análisis de la información incluida en el Cuadro 3 muestra que el VAR estimado
con 4 retardos de las variables endógenas muestra, en general, un mejor
desempeño predictivo, excepto en la predicción con un trimestre de antelación. Un
problema que presentó este modelo fue que se requirió un mayor número de
variables cualitativas para modelizar los eventos extraordinarios. Este hecho
muestra que este tipo de modelos puede ser peor en épocas de crisis.
Por otra parte, al igual que en el caso del VAR con componentes sectoriales del PBI,
se observa que los errores de predicción más importantes varían según el horizonte
temporal considerado y el número de retardos incluidos para modelizar la
dependencia temporal observada en los datos.
Lo cierto es que este tipo de modelo no ofrece mejoras en materia de precisión de
las predicciones respecto a los VAR construidos a partir de un desglose sectorial del
19 El Análisis de Intervención se realizó mediante las siguientes variables dummies: 1982.3 y
1999.1 escalón, 1989.1 y 1994.1 impulso. Además, en el caso de 4 lags, se incluyeron:1980.2, 1981.2 y 1982.4 escalón, 2001.3 impulso.
20 Los resultados del modelo con 4 retardos se presentan en el Cuadro A3.
21 Corresponde la advertencia de que una parte de las correlaciones que se observan entre laevolución del PBI de Uruguay y sus vecinos podría deberse a shocks originados en elcontexto extra-regional, que generan un efecto del mismo signo (simétrico) en los dos sociosprincipales de la economía uruguaya (Masoller, 1998).

31
PBI. Respecto a los modelos univariantes, los resultados varían de acuerdo al
horizonte temporal.
Cuadro 3Evaluación de los errores de predicción: Modelo VAR “econométrico”
Período: 1998.1 – 2001.4
Elaboración propia
En este caso también importa señalar que, al igual que en el caso anterior, los
modelos VAR aportan una mejor representación del comportamiento histórico del
PBI uruguayo, pero la mejor comprensión del fenómeno no se traduce directamente
al desempeño predictivo.
En este sentido, no se puede concluir a partir de estos resultados que la información
aportada por las variables del entorno económico nacional y regional no son
relevantes a la hora de elaborar un diagnóstico sobre el desempeño productivo
previsible de la economía uruguaya, ya que al considerar modelos que incluyen
4 lags 5 lagsME -0.0119 -0.0076
1 trimestre MAE 0.0246 0.0219de min 0.0048 0.0066
antelación max 0.0761 0.0545RMSE 0.0313 0.0253
ME -0.0165 -0.01712 trimestres MAE 0.0294 0.0319
de min 0.0006 0.0056antelación max 0.0840 0.0851
RMSE 0.0376 0.0380
ME -0.0259 -0.02913 trimestres MAE 0.0384 0.0415
de min 0.0063 0.0002antelación max 0.0881 0.0825
RMSE 0.0441 0.0473
ME -0.0360 -0.04334 trimestres MAE 0.0429 0.0526
de min 0.0146 0.0131antelación max 0.0680 0.1240
RMSE 0.0460 0.0601

32
estas variables se obtiene un mejor ajuste (este resultado se comenta más
adelante). El problema que se presenta aquí deriva de cómo se predicen el resto de
las variables incluidas en el VAR. En particular, en esta sección las variables
externas al PBI fueron predichas a partir del modelo VAR, cuando podría ser más
eficiente usar pronósticos externos al sistema. Es de esperar que en dicho caso,
usando mejores proyecciones de las otras variables, las predicciones de este
modelo en el caso concreto del PBI uruguayo presenten menor RMSE.
Por otra parte, la información aportada por los estadísticos CUSUM de los errores de
predicción del PBI, parece indicar que el modelo es estable con cinco retardos, pero
presenta algún síntoma de inestabilidad con 4 retardos. Asimismo, el estadístico de
Box y Tiao rechaza la hipótesis de estabilidad paramétrica para un nivel de confianza
de 95% (véase Cuadro A9). Este último resultado indica que los modelos estimados
presentan algunos síntomas de inestabilidad paramétrica. Este aspecto será
retomado más adelante, pero puede adelantarse que cuando se estudian los
residuos recursivos de toda la muestra, los estadísticos CUSUM permanecen dentro
de las bandas de confianza, con lo cual no se rechaza la hipótesis de estabilidad
paramétrica en todo el período analizado.
4.4. Modelo lineal general uniecuacional
Los modelos econométricos uniecuacionales que se presentan en esta sección
fueron estimados a partir del programa Eviews. El período muestral utilizado para las
estimaciones iniciales fue el mismo que en la sección anterior. La variable
dependiente del modelo fue la primera diferencia del logaritmo del PBI uruguayo.
El proceso de especificación de los modelos comenzó con la realización de
contrastes de raíces unitarias de tipo Dickey y Fuller Aumentado. Los contrastes
fueron realizados sobre las transformaciones logarítmicas de los datos originales.
Los resultados de los contrastes muestran que no es posible rechazar la hipótesis
nula de existencia de una raíz unitaria, mientras que sí se puede rechazar al 95% de
confianza la presencia de dos raíces unitarias (véase Cuadro A8). Teniendo en

33
cuenta estos resultados se incluyeron las diferencias primeras del logaritmo de estas
variables en los modelos econométricos estimados. Además, se procedió a
intervenir los modelos cuando se percibieron observaciones atípicas22.
En el primer modelo estimado (Modelo A) se observa que para el PBI brasileño
fueron significativos los coeficientes correspondientes al tercer y cuarto retardo,
mientras que en el caso del PBI argentino el único coeficiente estadísticamente
distinto de cero es el correspondiente al primer retardo. En el segundo modelo
(Modelo B) se repiten los resultados respecto al PBI de Argentina y Brasil, siendo
además significativos los coeficientes correspondientes a uno y tres trimestres de
retraso en el caso del TCR bilateral con Brasil.
Cabe precisar, por otra parte, que como en todos los casos las variables explicativas
tienen efectos retrasados sobre la variable de interés -no existe correlación
contemporánea- carece de sentido realizar los contrastes de exogeneidad fuerte
para validar la utilización de estos modelos con fines predictivos.
Luego de especificados los dos modelos, se obtuvieron predicciones recursivas. Por
su parte, las predicciones de las variables exógenas se realizaron a partir de
modelos ARIMA para cada una de las mismas, estimados en el programa
DEMETRA. La utilización de este tipo de predicciones puede implicar una pérdida
de precisión en la predicción de la variable de interés, respecto al modelo VAR
considerado en la sección anterior.
En el caso del PBI de Brasil, la dinámica de esta variable fue ajustada por un modelo
ARIMA(2 1 0)×(0 1 1) en el período entre 1979.1 a 1997.4. En esta serie se detectó
un dato atípico en el segundo trimestre de 1990, que fue intervenido con una
variable impulso. En el caso del PBI de Argentina el modelo ajustado fue un
ARIMA(010)×(012). En el TCR bilateral con Brasil se especificó un modelo ARIMA
22 Fueron introducidas cuatro intervenciones en las siguientes fechas 1981.4 y 1995.3 escalón,
1982.3 y 1985.1 impulso. Ellas corresponden a las mismas fechas intervenidas en el modelounivariante, aunque ha variado el tipo de outlier identificado.

34
(010)×(011) con cinco intervenciones23. Por último, el TCR bilateral con Argentina
no fue necesario proyectarlo, ya que dicha variable no ftuvo efectos
estadísticamente significativos.
Las predicciones de todas estas variables fueron realizadas a partir de un
procedimiento recursivo. Las características de los errores de predicción obtenidos
a través de este procedimiento para cada una de las variables exógenas se
describen en el Cuadro A7.
Cuadro 4Evaluación de los errores de predicción:Modelos econométricos uniecuacionales
Período: 1998.1 – 2001.4
Elaboración propia
23 1979.4, 1982.4 y 1990.1 impulso, 1994.3 y 1999.1 escalón.
Modelo A Modelo B ME -0,0093 -0,0113
1 trimestre MAE 0,0171 0,0191de min 0,0008 0,0001
antelación max 0,0567 0,0567 RMSE 0,0233 0,0240
ME -0,0224 -0,0249
2 trimestres MAE 0,0317 0,0328de min 0,0053 0,0053
antelación max 0,0826 0,0853 RMSE 0,0388 0,0405
ME -0,0329 -0,0362
3 trimestres MAE 0,0375 0,0408de min 0,0081 0,0093
antelación max 0,0958 0,1014 RMSE 0,0458 0,0487
ME -0,0442 -0,0473
4 trimestres MAE 0,0460 0,0490de min 0,0114 0,0109
antelación max 0,0793 0,0826 RMSE 0,0508 0,0528

35
Los resultados de la evaluación del desempeño predictivo de los modelos
observados se exponen en el Cuadro 4. Puede apreciarse que el denominado
Modelo A, que sólo incluye como variables explicativas al PBI de Argentina y Brasil
muestra un mejor desempeño predictivo en todos los horizontes de predicción
considerados. Esto puede deberse en cierta medida a que la inclusión del TCR
bilateral con Brasil agrega “incertidumbre”, ya que las predicciones univariantes de
esta variable ha sido de muy baja calidad en el período analizado.
Por otra parte, al comparar las predicciones de este modelo con los anteriores, se
observa que las mismas mejoran un trimestre adelante, pero son superadas por los
modelos VAR en el resto de los horizontes temporales. Como se mencionara
anteriormente, esto puede ser consecuencia de la inclusión de variables exógenas
que a su vez deben ser predichas. En particular, es de esperar que usando otro tipo
de proyecciones de las variables exógenas, más sofisticadas que los modelos
ARIMA, los resultados sean más eficientes.
Asimismo, al igual que en varios de los casos anteriores, se observa una secuencia
de errores de predicción negativos desde principios de 1999. Esta observación se
encuentra directamente vinculada a los efectos de la devaluación brasileña de enero
de 1999, que supuso un cambio importante en el mecanismo de generación de los
datos del tipo de cambio real brasileño.
Por último, el análisis de estabilidad de los dos modelos en base al estadístico
CUSUM indica que las predicciones son estables. En este caso, los estadísticos de
Box y Tiao concuerdan con este resultado, no rechazándose la hipótesis de
estabilidad de las predicciones generadas por los dos modelos (véase Cuadro A9).
Asimismo, no se rechaza la hipótesis de estabilidad cuando se consideran los
residuos recursivos de toda la muestra.

36
4.5. Consideraciones sobre el desempeño predictivo de los modelosestimados
Antes de abordar un análisis comparativo de las predicciones generadas a partir de
los distintos modelos estimados en este trabajo, se entendió conveniente calcular el
RMSE considerando los residuos de cada uno de los modelos especificados, pero
estimando los parámetros con una muestra que abarca todas las observaciones
disponibles, o sea incluyendo los datos hasta el cuarto trimestre del año 2001. El
propósito de este ejercicio es comprender mejor los problemas que presentan las
predicciones de los distintos modelos y avanzar en la comprensión de la naturaleza
de la inestabilidad observada en varios de los modelos estimados.
En el Cuadro 5 se presentan los RMSE calculados sobre los residuos de los
modelos para todo el período analizado y para dos sub-períodos. El primer sub-
período se extiende hasta el cuarto trimestre de 1997, mientras que el segundo
abarca los 16 trimestres comprendidos entre el primer trimestre de 1998 y el último
trimestre de 2001. Asimismo, los mismos modelos fueron reestimados interviniendo
las observaciones atípicas detectadas en el segundo sub-período. Los residuos de
estas nuevas estimaciones se utilizaron para reestimar los RMSE. Esta información
se presenta también en el Cuadro 5.
El análisis de la información incluida en este cuadro muestra, en primer lugar, que
los dos modelos VAR formulados sobre los componentes sectoriales del PBI
uruguayo dejan de exhibir problemas de estabilidad, una vez que se eliminan los
efectos distorsionantes de las anomalías detectadas en el período considerado en la
evaluación de predicciones. Las estimaciones realizadas revelan por otra parte, que
la modelización a nivel sectorial ofrece una representación bastante más precisa que
la univariante respecto al comportamiento dinámico del IVF del PBI trimestral
uruguayo.

37
Cuadro 5RMSE calculado sobre los residuos de los modelos
Parámetros estimados con datos hasta 2001.4
Elaboración propia
En el caso de los modelos VAR que incluyen información sobre variables externas al
PBI uruguayo, el cálculo del RMSE considerando los residuos en el período de
predicción no difiere mucho al de todo el período, por lo cual se elimina toda
hasta 1997.4 1998.1 - 2001.4 hasta 2001.4
ARIMA A 0.0232 0.0254 0.0237
ARIMA B 0.0238 0.0253 0.0241
ARIMA C 0.0241 0.0229 0.0239
VAR A (con componentes del PBI)4 lags 0.0146 0.0236 0.01715 lags 0.0126 0.0202 0.0148
Con intervencion en período de predicción4 lags (99.3 escalón) 0.0142 0.0200 0.0158
5 lags (99.2 y 99.3 escalón) 0.0119 0.0129 0.0121
VAR B (con componentes del PBI)4 lags 0.0151 0.0217 0.01695 lags 0.0144 0.0204 0.0160
Con intervencion en período de predicción4 lags (00.2 y 01.2 escalón) 0.0136 0.0148 0.01395 lags (00.2 y 01.2 escalón) 0.0124 0.0126 0.0125
MODELO ECONOMETRICO A 0.0215 0.0224 0.0217
MODELO ECONOMETRICO B 0.0204 0.0228 0.0208
VAR ECONOMETRICO4 lags 0.0156 0.0189 0.01635 lags 0.0154 0.0167 0.0157
Con intervencion en período de predicción4 lags (99.1 escalón, 01.3 impulso) 0.0155 0.0169 0.0158
5 lags (99.1 escalón) 0.0154 0.0158 0.0155
En el períodoMODELO

38
evidencia de inestabilidad en dicho período. Asimismo, se observa que estos
modelos presentan un mejor ajuste que los modelos ARIMA o los modelos
econométricos uniecuacionales.
Por su parte, los modelos econométricos uniecuaciones de forma reducida se
muestran como un instrumento relativamente menos preciso que los dos tipos de
representaciones VAR consideradas en este trabajo.
El análisis comparativo de las predicciones tuvo varias etapas. En la primera se
realizaron contrastes de insesgamiento de las predicciones generadas por cada uno
de los modelos. En el Cuadro 6 se presenta información sobre el valor medio de los
errores de predicción, los que comparados con las desviaciones típicas residuales
muestran claramente que no es posible rechazar la hipótesis nula de insesgamiento
de las predicciones realizadas por los distintos modelos24.
Es importante observar, no obstante, que la estimación puntual del valor medio de
los errores de predicción presenta signo negativo para todos los horizontes
temporales considerados. Esto está indicando una tendencia sistemática de las
predicciones a ubicarse por encima de las realizaciones del PBI a lo largo de todo el
período considerado.
En segundo lugar, se realizó un análisis comparativo de la precisión de las
predicciones. La información del Cuadro 6 muestra que en la métrica del error
cuadrático medio no existe ningún modelo que muestre un dominio claro sobre el
resto de los modelos estimados. Esto pone en evidencia que no es una tarea fácil
escoger un método sobre otro para pronosticar el comportamiento futuro del PBI.
Todos los modelos se basan en supuestos simplificadores, y por lo tanto, es posible
24 Los t-valores de los errores medios un trimestre de antelación de cada modelo fueron:
- Modelo ARIMA C : -1,64- VAR A con 5 retardos: -1,90- VAR “econométrico” con 4 retardos: -1,48- Modelo econométrico A: -1,69
Por lo cual en los 4 casos, no se rechaza la hipótesis nula de que el valor medio de loserrores de predicción es igual a cero (las predicciones son insesgadas).

39
que unos sean mejores en determinadas circunstancias y otros sean más
apropiados en otras.
Cuadro 6Evaluación de los errores de predicción
Período: 1998.1 – 2001.4
Nota: Las denominaciones de modelo ARIMA, VAR con componentes del PBI, VAR econométrico yModelo econométrico uniecuacional se refieren respectivamente a los modelos ARIMA C, VAR A con5 retardos, VAR econométrico con 4 retardos y Modelo econométrico A.
Elaboración propia
Un aspecto, particularmente importante es conocer los rasgos fundamentales de los
distintos métodos y la forma como cada uno reacciona ante la presencia de
observaciones atípicas (acontecimientos extraordinarios). Por ejemplo, dada la
inestabilidad que presentaron los modelos VARs, y teniendo en cuenta que el
período de predicción se caracterizó por la presencia de observaciones atípicas, las
VAR con VAR Modelocomponentes econométrico econométrico
del PBI uniecuacionalME -0,0104 -0,0133 -0,0119 -0,0093
1 trimestre MAE 0,0193 0,0205 0,0246 0,0171de min 0,0005 0,0000 0,0048 0,0008
antelación max 0,0457 0,0563 0,0761 0,0567RMSE 0,0245 0,0272 0,0313 0,0233
ME -0,0225 -0,0198 -0,0165 -0,02242 trimestres MAE 0,0306 0,0271 0,0294 0,0317
de min 0,0008 0,0051 0,0006 0,0053antelación max 0,0720 0,0905 0,0840 0,0826
RMSE 0,0371 0,0363 0,0376 0,0388
ME -0,0323 -0,0251 -0,0259 -0,03293 trimestres MAE 0,0364 0,0314 0,0384 0,0375
de min 0,0021 0,0033 0,0063 0,0081antelación max 0,0815 0,0877 0,0881 0,0958
RMSE 0,0447 0,0407 0,0441 0,0458
ME -0,0437 -0,0315 -0,0360 -0,04424 trimestres MAE 0,0454 0,0358 0,0429 0,0460
de min 0,0115 0,0048 0,0146 0,0114antelación max 0,0939 0,0780 0,0680 0,0793
RMSE 0,0523 0,0424 0,0460 0,0508
ARIMA

40
predicciones generadas por este tipo de modelización pueden resultar menos
precisas a corto plazo, pero tener mejores propiedades que las de los modelos
univariantes cuando se consideran horizontes de predicción más amplios.
De la información contenida en el Cuadro 6 parece surgir que el modelo VAR con
componentes de oferta es el que exhibe un mejor desempeño predictivo: presenta el
menor RMSE en tres de los cuatro horizontes temporales considerados y en el
restante caso exhibe un nivel de precisión cercano al mejor de las otras alternativas.
Sin embargo, este modelo es el que presenta los mayores problemas de
inestabilidad, hecho a tener en cuenta a la hora de evaluar.
4.6. Combinación de predicciones y encompassing
Un último aspecto a considerar tiene que ver con el contenido informativo de los
modelos, para lo cual se realizaron contrastes de encompassing. Los resultados de
los mismos se exponen en el Cuadro 7. En primer lugar, se observa que el VAR
especificado sobre sobre variables externas al PBI no agrega información adicional a
los otros modelos (los otros tres modelos engloban al VAR “econométrico”).
Por otra parte, se observa que el modelo uniecuacional engloba tanto al VAR con
componentes del PBI como al VAR “econométrico”. Sin embargo, al comparar este
modelo con el modelo univariante los resultados son ambiguos. Lo mismo ocurre
cuando se compara al VAR con componentes del PBI con el modelo univariante.
Para analizar las implicaciones de estos resultados se desarrolló un ejercicio de
combinar predicciones, con el propósito de evaluar si la combinación ofrece mejores
predicciones que cada modelo por separado.
En primer lugar se combinaron las predicciones del modelo ARIMA y el modelo
uniecuacional econométrico usando como ponderadores ki = 0,5 en una primera
combinación y ki = MSEj / (MSEi + MSEj) en una segunda. Los resultados muestran
que combinando estos dos modelos se podrían mejoran muy levemente las

41
predicciones con un trimestre de antelación, pasando el RMSE de 0,0233 a 0,231
(véase Cuadro A10).
Cuadro 7Test de encompassing
Variable dependiente: Errores del modelo en 1
Variable independiente: Predicciones del modelo en 2 –predicciones del modelo en 1
Nota: Las denominaciones de modelo ARIMA, VAR con componentes del PBI,VAR “econométrico” y Modelo econométrico uniecuacional se refierenrespectivamente a los modelos ARIMA C, VAR A con 5 retardos, VAR econométricocon 4 retardos y Modelo econométrico A.Los coeficientes estadísticamente no distintos de cero indican la existencia deencompassing, o sea que el modelo que se considera como variable dependienteengloba al otro modelo.
Elaboración propia
En segundo lugar, se combinaron las predicciones del modelo ARIMA y VAR con
componentes del PBI. En este caso, también se observa que la combinación de
predicciones mejora los pronósticos con un trimestre de antelación: el RMSE de las
predicciones pasó de 0,0245 a 0,0239.
Estos resultados apoyan la idea de que el VAR con componentes del PBI el que
posee el mejor desempeño predictivo, pero que podría ser una buena estrategia
1 2 Coef. Std. Error t-Statistic Prob.
VAR con comp. del PBI 0.40 0.27 1.47 0.16Modelo econométrico 0.76 0.60 1.26 0.23Var "econométrico" 0.21 0.26 0.81 0.43
VAR con Arima 0.56 0.29 1.93 0.07componentes Modelo econométrico 0.61 0.22 2.72 0.02
del PBI Var "econométrico" 0.34 0.24 1.44 0.17
Modelo Arima 0.00 0.60 0.00 1.00econométrico VAR con comp. del PBI 0.33 0.22 1.50 0.15uniecuacional Var "econométrico" 0.09 0.25 0.37 0.71
VAR Arima 0.80 0.26 3.04 0.01"econométrico" VAR con comp. del PBI 0.66 0.24 2.80 0.01
Modelo econométrico 0.85 0.26 3.25 0.01
ARIMA

42
combinar dicho modelo con un modelo más naive como el ARIMA (esto sólo es
válido en el caso de las predicciones con un trimestre de antelación).
4.7. Comparación a nivel internacional
Los resultados obtenidos en el presente trabajo muestran que los errores de
predicción en el caso de Uruguay son en general mayores que en otros países.
Sobre este aspecto, un estudio realizado por Peña (1995) para 7 países25 muestra
que el RMSE de las predicciones con un año de antelación alcanza un mínimo en
promedio de 0,016, mientras que en el caso uruguayo considerando las predicciones
tan solo con un trimestre de antelación dicha medida alcanza 0,023 en el mejor de
los modelos estudiados en este trabajo. Del mismo modo, mientras las predicciones
del PBI uruguayo con cuatro trimestres de antelación mostraron un RMSE de 0,042
en el mejor de los casos, el promedio de los 7 países estudiados fue de 0,044 con
tres años de antelación.
Esto muestra que la predicción del PBI está sujeta a mayor incertidumbre en el caso
uruguayo. Detrás de este hecho pueden existir razones de índole económicas, ya
que al ser la economía uruguaya una economía pequeña y abierta, es más sensible
que otros países a los shocks tanto internos como externos. Asimismo, la reducida
diversificación productiva que presenta la economía uruguaya podría contribuir a
explicar la mayor inestabilidad.
Otro aspecto a considerar tiene que ver con al período durante el cual se evaluaron
las predicciones en este trabajo. Como se mencionó anteriormente, éste fue un
período particularmente inestable, especialmente afectado por la situación crítica
que se ha instalado en la región después de la devaluación del real a principios de
1999 y la inestabilidad presentada por la economía argentina.
25 Francia, Italia, Reino Unido, Alemania, España, Japón y Estados Unidos (véase Cuadro A11).

43
5. CONSIDERACIONES FINALES
A lo largo de este trabajo se consideraron las potencialidades y debilidades que
presentan cuatro esquemas de modelización para predecir la evolución del PBI
uruguayo. En primera instancia se utilizaron modelos univariantes de series
temporales. Si bien este tipo de modelos presenta la ventaja de su sencillez, la
evaluación de los errores de predicción muestra una menor precisión que otros
esquemas. El deterioro de la capacidad predictiva de este tipo de modelos se
vuelve más evidente a medida que se extiende el horizonte de predicción (con un
trimestre de antelación, las predicciones del modelo univariante tienen un
desempeño comparable al de modelos que incorporan información sobre variables
externas al PBI).
En segundo lugar, se consideraron modelos VAR especificados sobre componentes
sectoriales del PBI. Si bien este tipo de modelos presenta una mejor representación
del comportamiento histórico del IVF del PBI trimestral, respecto a los modelos
univariantes, esto no se traduce a un mejor desempeño predictivo a corto plazo. Sin
embargo, cuando se consideran predicciones más alejadas en el tiempo son los que
tuvieron el mejor desempeño. Por otra parte, estos modelos presentan problemas en
presencia de acontecimientos extraordinarios, por lo cual su uso requiere un
esfuerzo sistemático de monitoreo y un análisis riguroso de los errores de predicción
observados en cada una de las ecuaciones.
En tercer lugar, se estimaron modelos VAR en los que entre las variables endógenas
se incluyó el IVF del PBI uruguayo y un conjunto de variables que aportan
información sobre el entorno macroeconómico en el que se desenvuelve la
economía uruguaya. Este tipo de representación no presentó un buen desempeño
predictivo, además de tener otros problemas: incorporó un elevado número de
observaciones atípicas y los test de encompassing revelaron que no agrega
información al resto de los modelos considerados en este estudio. Sin embargo, y
dado que estos modelos presentaron un mejor ajuste muestral, es de esperar que
usando predicciones más eficientes de las variables externas al PBI (a través de

44
pronósticos generados fuera del modelo), las predicciones del PBI uruguayo
presenten menor RMSE.
Por último, se especificaron modelos econométricos uniecuacionales que incluyeron
variables explicativas exógenas. Este tipo de modelos fue el que generó
predicciones más precisas con un trimestre de antelación. Sin embargo, las
predicciones de las variables exógenas mediante modelos univariantes aportaron un
factor adicional de incertidumbre, lo que lleva a que las predicciones sean menos
precisas considerando horizontes temporales más largos.
Corresponde ahora realizar algunas consideraciones generales relativas al ejercicio
de predicción que se desarrolló en este trabajo. Por un lado, deben tenerse en
cuenta las dificultades que ha presentado la predicción del PBI uruguayo en el
período más reciente (afectado por consecuencias derivadas de la devaluación del
real en 1999, la posterior contracción de las exportaciones hacia Brasil y los
problemas macroeconómicos que ha enfrentado la economía argentina). En buena
medida, la magnitud de los errores de predicción detectados puede atribuirse al
turbulento entorno en que se generaron los datos más recientes del PBI uruguayo.
Por otra parte, y a pesar que los pronósticos del PBI uruguayo no parecen ser muy
precisos, no debe perderse de vista que los mismos pueden ser mejorados mediante
la incorporación de información externa a los modelos (cuantitativa y no cuantitativa).
En general es una práctica común de quienes realizan pronósticos ajustar sus
predicciones tanto sobre bases subjetivas como objetivas (considerando los errores
del pasado).
Asimismo, existe un vasto campo de investigación por explorar no abordado en este
trabajo que podría derivar en resultados más precisos. Algunas de las posibles vías
de futuro análisis son:
• Utilización de modelos no lineales. Estos modelos son especialmente útiles en
épocas afectadas por acontecimientos extraordinarios (épocas de crisis), cuando
en la dinámica de los datos existen asimetrías cíclicas o situaciones anormales

45
localmente. Sin embargo, no es seguro que los modelos no lineales generen
mejores predicciones que los modelos lineales.
• Consideración de relaciones de cointegración. Los métodos expuestos en este
trabajo no consideran la existencia de relaciones de equilibrio de largo plazo
(cointegración) entre los datos, lo que constituye una limitación. Sin embargo,
dada la naturaleza cambiante en las relaciones de equilibrio al interior del
proceso de integración regional, la exclusión de dichas relaciones podría estar
justificada.
• Introducción de nuevas variables. Tanto en los modelos especificados en este
trabajo como en otro tipo de modelos, se podrían agregar nuevas variables al
análisis. Algunas alternativas podrían ser variables que representen la demanda
mundial como el PBI de Estados Unidos u otros países de la Unión Europea,
variables de los mercados financieros, etc.
• Utilización de indicadores adelantados. El uso de indicadores adelantados
podría ser una herramienta que complemente los métodos aquí descriptos. La
filosofía que subyace detrás del uso de este tipo de indicadores en la predicción
es que las economías de mercado se caracterizan por tener ciclos que se
manifiestan de manera anticipada en una variedad de series económicas. Estas
series, conocidas como indicadores adelantados, se caracterizan porque sus
puntos de giro históricamente preceden a los puntos de giro de la variable de
referencia. De esta forma, los indicadores adelantados brindan señales
tempranas de potenciales recesiones o expansiones de la actividad económica
agregada. En este sentido, se podría explotar información que hasta el momento
no ha sido sistemáticamente usada en el país con fines predictivos como son las
series de importaciones en admisión temporaria, solicitudes de exportación,
consumo industrial de energía, ventas de autos 0 km., gastos del turismo, etc.
Un último comentario sobre los resultados de este trabajo se refiere al alto nivel de
incertidumbre que presentaron las predicciones del PBI. Conocer más sobre las
causas que generan esta incertidumbre es clave. Como se mencionara

46
anteriormente, esto puede atribuirse a causas económicas, pero también podría
estar relacionado con causas metodológicas.
En este plano, debe tenerse en cuenta el proceso de construcción de los datos y los
mecanismos de revisión de los mismos, ya que el proceso de revisión podría actuar
como un factor adicional de incertidumbre sobre las predicciones.26
26 Este aspecto fue analizado con mayor profundidad en Cuadrado, Lorenzo y Queijo (2002).

47
REFERENCIAS
Bates, J. M. y Granger, C. W. (1969). “The Combination of Forecasts”. Operational ResearchQuarterly, vol. 20, 451-468.
Box, G. E. P., y Jenkins G. M. (1976). “Time series analysis: Forecasting and Control”.Edición revisada, Holden-Day, San Francisco.
Box, G. E. P., y Tiao, G. C. (1975). “Intervention Analysis with applications to Economic andEnvironmental problems”. Journal of the American Statistic Association 70, 70-79.
Box, G. E. P., y Tiao, G. C. (1976). “Comparison of Forecast and Actuality”. Applied Statistics25, nº 3, 195-200.
Chen, C. y Liu, L. (1993). “Forecasting Time Series with Outliers”. Journal of Forecasting 12,13-35.
Chong, Y. Y., y Hendry D. F. (1986). “Econometric Evaluation of Linear MacroeconomicModels”. Review of Economic Studies 53, 671-690.
Clements, M. P. y Hendry, D. F. (1993). “On the limitations of comparing Mean SquaredForecast Errors“. Journal of Forecasting, 12, 617-637.
Clements, M. P. y Hendry, D. F. (1995). “Towards a Theory of Economic Forecasting”.Nonstationary time series analysis and cointegration, edited by Colin P. Hargreaves,Oxford University Press, 9-52.
Clements, M. P. y Hendry, D. F. (1997). “Forecasting Economic Processes“, mimeo.
Clements, M. P. y Hendry, D. F. (1998). “Forecasting Economic Time Series“. CambridgeUniversity Press.
Cuadrado, E. y Queijo, V. (2001). “Utilización de métodos cuantitativos para predecir el PBIuruguayo”. Trabajo monográfico, Facultad de Ciencias Económicas y Administración,Universidad de la República, Uruguay.
Cuadrado, E., Lorenzo, F. y Queijo, V. (2002). “Características y regularidades empíricas delas estimaciones preliminares del PBI uruguayo”. Trabajo presentado para las XVIIJornadas Anuales de Economía, Banco Central del Uruguay.
Currie, D. (1994). “Economic Forecasts: Their relevance and use”. Applied economicforecasting techniques, London Business School, 1-8.
Diebold, F. X. (1989). “Forecasting Combination and Encompassing: Reconciling twodivergent literatures”. International Journal of Forecasting 5, 589-592.
Ericsson, N. R. (1994). “Parameter constancy, Mean square forecast errors, and Measuringforecast performance: An exposition, extensions, and illustrarion”. Testing Exogeneity,editado por Ericsson y Irons, Oxford University Press, 311-339.
Granger, C. W. J. y Newbold, P. (1973). “Some Comments on the Evaluation of EconomicForecasts”. Applied Economics 5, 35-47.

48
Hall, S. G. (1994). “Time series Forecasting”. Applied economic forecasting techniques,London Business School, 9-28.
Masoller, A. (1998). “Shocks regionales y el comportamiento de la economía uruguaya entre1974 y 1997”. Revista de Economía, Banco Central del Uruguay, vol. 5, nº 1, SegundaEpoca, 141-214.
Peña, D. (1995). “Forecasting growth with Time series models”. Journal of Forecasting,vol.14, 97-105.
Wallis, K. F. (1989). “Macroeconomic Forecasting: A Survey”, The Economic Journal 99,28-61.
Öller, L. E. y Tallbom, C. (1996). “Smooth and timely Business cycle indicators for noisySwedish data”. Journal of Forecasting 12, 389-402.
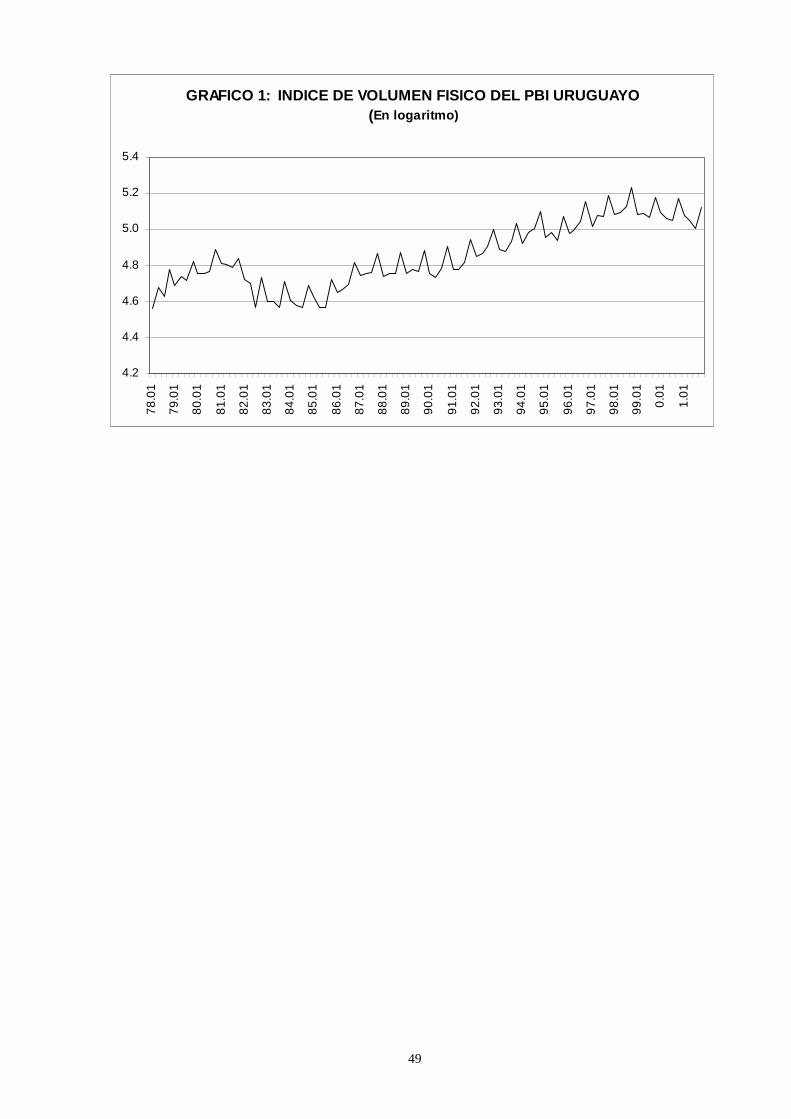
49
GRAFICO 1: INDICE DE VOLUMEN FISICO DEL PBI URUGUAYO(En logaritmo)
4.2
4.4
4.6
4.8
5.0
5.2
5.478
.01
79.0
1
80.0
1
81.0
1
82.0
1
83.0
1
84.0
1
85.0
1
86.0
1
87.0
1
88.0
1
89.0
1
90.0
1
91.0
1
92.0
1
93.0
1
94.0
1
95.0
1
96.0
1
97.0
1
98.0
1
99.0
1
0.01
1.01

50
Nota: Las denominaciones de ARIMA, VAR oferta, Modelo eco. y VAR eco., se refieren a los modelos ARIMA C, VAR A con 5 lags, Modelo econométrico A y VAR econométrico con 4 lags respectivamente.
Elaboración propia
GRAFICO 2: ERRORES DE PREDICCION
Errores de predicción con 1 trimestre de antelación
-0.09
-0.06
-0.03
0.00
0.03
0.06
I/98 II/98 III/98 IV/98 I/99 II/99 III/99 IV/99 I/00 II/00 III/00 IV/00 I/01 II/01 III/01 IV/01
ARIMA VAR oferta Modelo Eco. VAR Eco.
Errores de predicción con 2 trimestres de antelación
-0.12
-0.09
-0.06
-0.03
0.00
0.03
0.06
II/98 III/98 IV/98 I/99 II/99 III/99 IV/99 I/00 II/00 III/00 IV/00 I/01 II/01 III/01 IV/01
ARIMA VAR oferta Modelo Eco. VAR Eco.
Errores de predicción con 3 trimestres de antelación
-0.12
-0.09
-0.06
-0.03
0.00
0.03
0.06
III/98 IV/98 I/99 II/99 III/99 IV/99 I/00 II/00 III/00 IV/00 I/01 II/01 III/01 IV/01
ARIMA VAR oferta Modelo Eco. VAR Eco.
Errores de predicción con 4 trimestres de antelación
-0.12
-0.09
-0.06
-0.03
0.00
0.03
0.06
IV/98 I/99 II/99 III/99 IV/99 I/00 II/00 III/00 IV/00 I/01 II/01 III/01 IV/01
ARIMA VAR oferta Modelo Eco. VAR Eco.

51
Elaboración propia
GRAFICO 3: CUSUM DE LOS RESIDUOS DE LOS MODELOSPeríodo: 1998.1-2001.4
CUSUM de los residuos del Modelo ARIMA C
-15
-10
-5
0
5
10
15
CUSUM de los residuos del Modelo VAR A con 5 lags
-20
-15
-10
-5
0
5
10
15
CUSUM de los residuos del VAR Econométrico con 4 lags
-15
-10
-5
0
5
10
15
CUSUM de los residuos del Modelo Econométrico A
-15
-10
-5
0
5
10
15

52
Cuadro A1Especificación de los modelos ARIMA
Período: 1979.1 - 1997.4
Modelo Parámetro T-valor
ARIMA A AR(1) 0.770 9.368 MA(4) -0.886 -2.395 ARIMA B MA(4) -0.816 -14.792 ARIMA C AR(4) 0.271 2.171
Elaboración propia en base al programa Eviews

53
Var. Independiente Coef. Std. Error
Constante 0.008 0.004 2.033D1 -0.118 0.007 -17.070D2 0.000 0.007 0.061D3 0.004 0.007 0.647I814 -0.084 0.024 -3.552I823 -0.131 0.024 -5.466I851 0.050 0.017 2.960I953 -0.044 0.017 -2.608AR(4) 0.271 0.125 2.171
R-squared 0.929S.E. of regression 0.024Sum squared resid 0.037
Q(10) 12.506 prob 0.186Q(14) 17.574 prob 0.174
Jarque Vera 2.827 prob 0.243
Nota: Di son variables deterministas estacionales.I814 e I823 son variables dummies para modelizar un cambio de nivel en 1981.4 y 1982.3.Por otra parte, I851 y I953 modelizan dos outliers de tipo aditivo en 1985.1 y 1995.3
Elaboración propia en base al programa Eviews
t-statistic
Cuadro A2Estimación del modelo univariante
Variable dependiente: ∆y = ln PBIt - ln PBIt-1Período: 1979.1 - 1997.4
Modelo ARIMA C

54
Coef. t-Stat. Coef. t-Stat. Coef. t-Stat. Coef. t-Stat. Coef. t-Stat.
Agro (-1) 0.54 2.59 0.07 0.71 0.18 0.78 0.01 0.07 0.00 0.10Agro (-2) -0.07 -0.29 -0.12 -1.15 0.10 0.37 0.08 0.77 0.06 1.49Agro (-3) -0.22 -0.86 -0.03 -0.29 0.05 0.18 -0.13 -1.12 -0.02 -0.56Agro (-4) 0.00 -0.02 0.03 0.20 -0.09 -0.30 -0.05 -0.35 -0.01 -0.15Agro (-5) -0.05 -0.19 0.02 0.22 0.11 0.40 0.20 1.80 0.11 2.68Industria (-1) 0.36 1.05 0.34 2.14 0.05 0.12 -0.44 -2.75 -0.07 -1.11Industria (-2) -0.11 -0.29 -0.01 -0.03 -0.53 -1.23 -0.12 -0.70 0.02 0.38Industria (-3) -0.46 -1.10 0.15 0.75 -0.15 -0.31 -0.06 -0.30 0.03 0.35Industria (-4) -0.07 -0.16 -0.39 -1.86 -0.72 -1.39 -0.16 -0.74 -0.14 -1.80Industria (-5) 0.29 0.80 0.34 2.04 0.77 1.86 0.23 1.35 0.06 0.98Construcción (-1) -0.27 -0.67 -0.55 -2.92 -0.25 -0.55 0.56 2.93 0.08 1.11Construcción (-2) 0.01 0.02 0.01 0.05 0.10 0.15 -0.35 -1.30 -0.23 -2.26Construcción (-3) 0.29 0.47 0.41 1.43 -0.19 -0.27 0.14 0.47 0.13 1.21Construcción (-4) -0.65 -1.01 0.01 0.02 -0.33 -0.45 0.35 1.16 0.27 2.42Construcción (-5) 0.41 0.93 -0.13 -0.61 -0.17 -0.34 -0.32 -1.56 -0.19 -2.39Comercio (-1) -0.12 -0.69 0.12 1.48 0.66 3.43 0.09 1.11 0.04 1.51Comercio (-2) -0.05 -0.26 -0.10 -1.05 -0.15 -0.66 -0.02 -0.24 -0.03 -0.81Comercio (-3) 0.32 1.56 -0.01 -0.14 0.43 1.80 0.00 0.00 -0.05 -1.28Comercio (-4) -0.20 -0.93 -0.03 -0.31 -0.46 -1.91 -0.14 -1.38 0.03 0.78Comercio (-5) 0.09 0.63 -0.09 -1.32 0.01 0.05 -0.02 -0.24 -0.06 -2.25Resto (-1) 0.71 0.68 1.24 2.53 1.78 1.47 0.69 1.39 0.42 2.27Resto (-2) -0.04 -0.04 -0.13 -0.26 0.05 0.04 1.15 2.32 0.60 3.22Resto (-3) 0.44 0.40 -0.20 -0.40 0.19 0.15 -0.43 -0.84 -0.34 -1.75Resto (-4) 0.06 0.06 0.07 0.15 1.59 1.29 -0.52 -1.03 -0.43 -2.27Resto (-5) -0.52 -0.52 -0.01 -0.02 0.23 0.20 0.57 1.23 0.35 2.01Constant 0.00 0.07 -0.02 -1.02 -0.12 -2.34 -0.03 -1.43 0.01 1.63I932 -0.04 -0.50 -0.12 -3.56 -0.05 -0.58 -0.01 -0.27 -0.02 -1.79I953 -0.01 -0.11 -0.10 -2.53 0.06 0.61 -0.14 -3.63 -0.05 -3.35
Q(10) 5.43 18.27 5.20 6.96 7.21 prob 0.86 0.05 0.88 0.73 0.71Q(14) 7.40 20.78 6.16 8.25 14.23 prob 0.92 0.11 0.96 0.88 0.43
Jarque Vera 2.57 1.13 0.14 0.61 0.39 prob 0.28 0.57 0.93 0.74 0.82
Nota: Todas las variables fueron incluidas como la diferencia primera del logaritmo."Resto" incluye: Pesca, Electricidad, gas y agua, Transporte y comunicaciones y Otros.Di son variables determinísticas estacionales.I932, I953 son variables dummies para modelizar outliers en esas fechas.
Elaboración propia en base al programa PC FIML
RestoVariable Dependiente
Var. Independiente Agro Industria Construcción Comercio
VAR A con 5 retardos
Cuadro A3Estimación del modelo VAR con componentes sectoriales del PBI
Período: 1983.1 - 1997.4
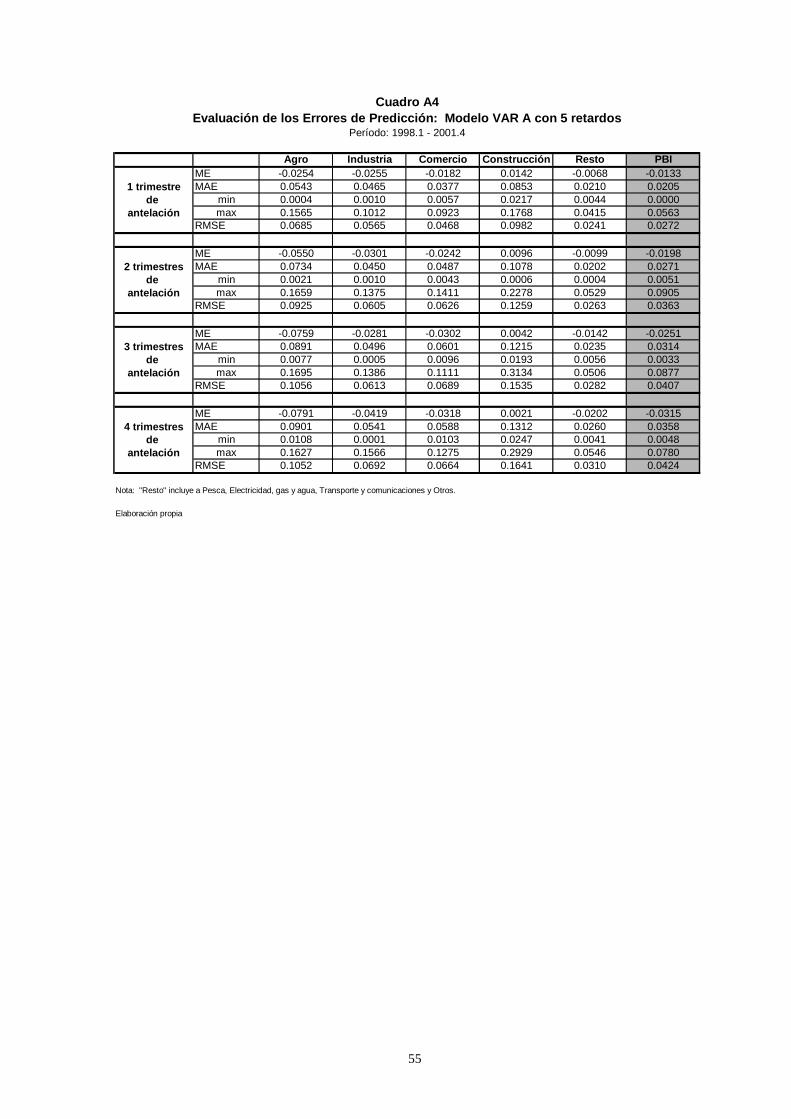
55
Agro Industria Comercio Construcción Resto PBIME -0.0254 -0.0255 -0.0182 0.0142 -0.0068 -0.0133
1 trimestre MAE 0.0543 0.0465 0.0377 0.0853 0.0210 0.0205de min 0.0004 0.0010 0.0057 0.0217 0.0044 0.0000
antelación max 0.1565 0.1012 0.0923 0.1768 0.0415 0.0563RMSE 0.0685 0.0565 0.0468 0.0982 0.0241 0.0272
ME -0.0550 -0.0301 -0.0242 0.0096 -0.0099 -0.01982 trimestres MAE 0.0734 0.0450 0.0487 0.1078 0.0202 0.0271
de min 0.0021 0.0010 0.0043 0.0006 0.0004 0.0051antelación max 0.1659 0.1375 0.1411 0.2278 0.0529 0.0905
RMSE 0.0925 0.0605 0.0626 0.1259 0.0263 0.0363
ME -0.0759 -0.0281 -0.0302 0.0042 -0.0142 -0.02513 trimestres MAE 0.0891 0.0496 0.0601 0.1215 0.0235 0.0314
de min 0.0077 0.0005 0.0096 0.0193 0.0056 0.0033antelación max 0.1695 0.1386 0.1111 0.3134 0.0506 0.0877
RMSE 0.1056 0.0613 0.0689 0.1535 0.0282 0.0407
ME -0.0791 -0.0419 -0.0318 0.0021 -0.0202 -0.03154 trimestres MAE 0.0901 0.0541 0.0588 0.1312 0.0260 0.0358
de min 0.0108 0.0001 0.0103 0.0247 0.0041 0.0048antelación max 0.1627 0.1566 0.1275 0.2929 0.0546 0.0780
RMSE 0.1052 0.0692 0.0664 0.1641 0.0310 0.0424
Nota: "Resto" incluye a Pesca, Electricidad, gas y agua, Transporte y comunicaciones y Otros.
Elaboración propia
Evaluación de los Errores de Predicción: Modelo VAR A con 5 retardosPeríodo: 1998.1 - 2001.4
Cuadro A4

56
Var. Independiente Coef. Std. Error t-Statistic Prob.
PBI Uru (-1) -0.54 0.16 -3.45 0.00PBI Uru (-2) -0.08 0.16 -0.50 0.62PBI Uru (-3) -0.34 0.17 -1.99 0.06PBI Uru (-4) -0.02 0.15 -0.16 0.87PBI Arg (-1) 0.38 0.14 2.61 0.01PBI Arg (-2) 0.19 0.15 1.27 0.21PBI Arg (-3) 0.00 0.16 -0.01 0.99PBI Arg (-4) -0.11 0.18 -0.60 0.55PBI Br (-1) 0.18 0.13 1.45 0.16PBI Br (-2) -0.03 0.13 -0.20 0.84PBI Br (-3) 0.30 0.12 2.44 0.02PBI Br (-4) 0.14 0.13 1.04 0.31IPC/TC Uru (-1) 0.00 0.04 -0.05 0.96IPC/TC Uru (-2) 0.09 0.04 1.99 0.06IPC/TC Uru (-3) 0.10 0.05 2.04 0.05IPC/TC Uru (-4) -0.01 0.04 -0.36 0.72IPC/TC Arg (-1) 0.00 0.02 -0.22 0.83IPC/TC Arg (-2) 0.01 0.02 0.23 0.82IPC/TC Arg (-3) 0.02 0.02 0.69 0.49IPC/TC Arg (-4) 0.00 0.02 0.14 0.89IPC/TC Br (-1) -0.03 0.06 -0.57 0.58IPC/TC Br (-2) 0.05 0.05 0.95 0.35IPC/TC Br (-3) 0.07 0.04 1.64 0.11IPC/TC Br (-4) -0.06 0.04 -1.57 0.13RTI (-1) -0.01 0.05 -0.29 0.77RTI (-2) -0.03 0.05 -0.60 0.56RTI (-3) 0.05 0.05 1.11 0.28RTI (-4) 0.06 0.05 1.22 0.23Tasa de interés (-1) 0.03 0.03 1.10 0.28Tasa de interés (-2) 0.00 0.03 -0.03 0.98Tasa de interés (-3) -0.07 0.03 -2.58 0.02Tasa de interés (-4) -0.09 0.04 -2.67 0.01Constante 0.00 0.00 0.92 0.36D1 -0.08 0.02 -3.20 0.00D2 -0.02 0.03 -0.60 0.55D3 0.03 0.03 1.01 0.32I802 -0.01 0.03 -0.33 0.74I812 0.00 0.04 -0.01 0.99I823 -0.17 0.04 -4.93 0.00I824 -0.06 0.05 -1.28 0.21I891 -0.01 0.02 -0.59 0.56I941 -0.04 0.02 -1.97 0.06
sigma = 0.0230 RSS = 0.0153Q(10) 11.38 Jarque Vera 0.57 prob 0.33 prob 0.75Q(14) 11.77 prob 0.63
Nota: No se incluyeron aquí los resultados obtenidos para el resto de las variables dependientes queconforman al VAR. Dichos resultados están a disposición por parte de los autores.Todas las variables fueron incluidas como la diferencia primera del logaritmo, exepto la tasa deinterés que se consideró la diferencia primera de (1+tasa). Di son variables determinísticas estacionales.I802, I812, I823 e I824 son variables dummies para modelizar un cambio de nivel en esas fechas.I891 e I941 son variables dummies para modelizar un cambio transitorio en esas fechas.
Elaboración propia en base al programa PC FIML
Cuadro A5Estimación del modelo VAR "econométrico"
Variable dependiente: ∆y = ln PBIt - ln PBIt-1Período: 1979.1 - 1997.4
VAR Econométrico con 4 retardos

57
Var. Independiente Coef. Std. Error t-Statistic Prob.
Constante 0.004 0.003 1.337 0.186PBI Arg (-1) 0.160 0.052 3.057 0.003PBI Br (-3) 0.218 0.085 2.572 0.013PBI Br (-4) 0.151 0.054 2.813 0.007D1 -0.125 0.006 -19.304 0.000I814 -0.061 0.024 -2.594 0.012I823 -0.087 0.017 -5.062 0.000I851 0.048 0.017 2.797 0.007I953 -0.068 0.024 -2.892 0.005
R-squared 0.94 Mean dependent var 0.01Adjusted R-squared 0.93 S.D. dependent var 0.09S.E. of regression 0.02 Akaike info criterion -4.60Sum squared resid 0.03 Schwarz criterion -4.31Log likelihood 174.49 F-statistic 117.40Durbin-Watson stat 1.90 Prob(F-statistic) 0.00
Q(10) 4.70 prob 0.91Q(14) 8.11 prob 0.88
Jarque Vera 0.59 prob 0.75
Nota: Todas las variables fueron incluidas como la diferencia primera del logaritmo.D1 es una variable dummy que marca la estacionalidad en el primer trimestre del año. I814 e I953son variables dummies para modelizar un cambio de nivel en 1981.4 y 1995.3. Por otra parte, I823 e I851modelizan outliers de tipo aditivo en 1982.3 y 1985.1.
Elaboración propia en base al programa Eviews
Cuadro A6Estimación del modelo lineal uniecuacional
Variable dependiente: ∆y = ln PBIt - ln PBIt-1Período: 1979.1 - 1997.4
Modelo econométrico A
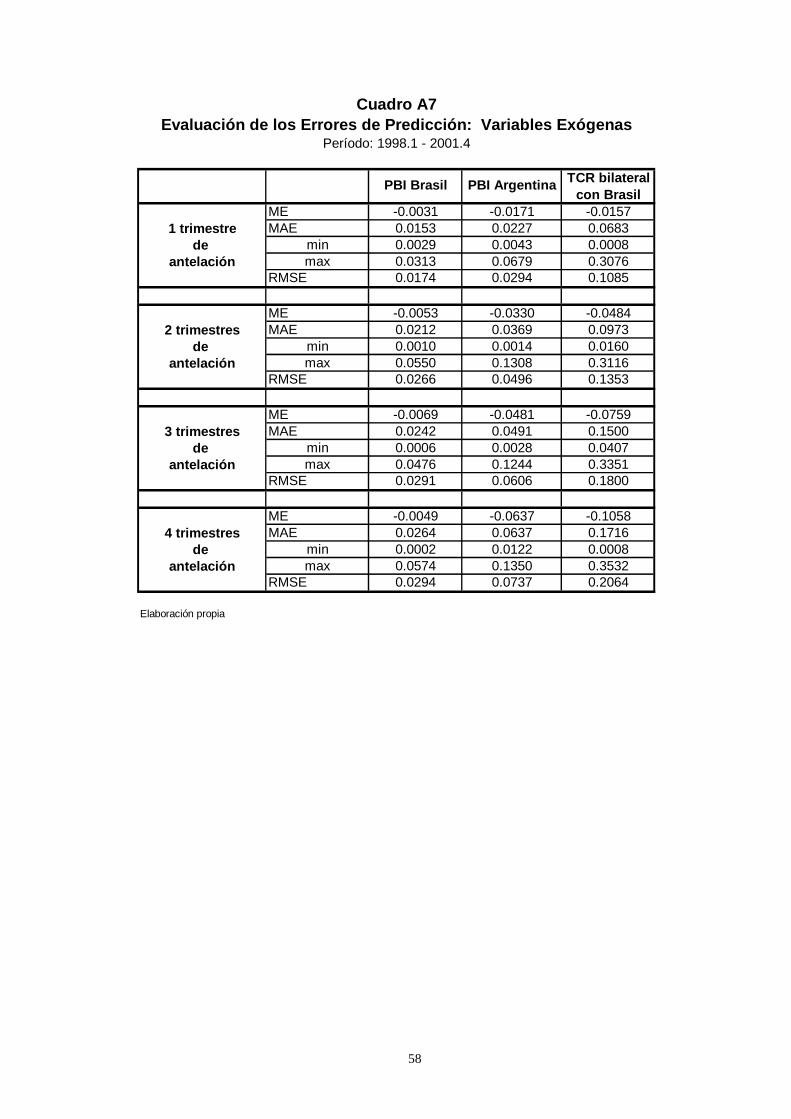
58
TCR bilateralcon Brasil
ME -0.0031 -0.0171 -0.01571 trimestre MAE 0.0153 0.0227 0.0683
de min 0.0029 0.0043 0.0008antelación max 0.0313 0.0679 0.3076
RMSE 0.0174 0.0294 0.1085
ME -0.0053 -0.0330 -0.04842 trimestres MAE 0.0212 0.0369 0.0973
de min 0.0010 0.0014 0.0160antelación max 0.0550 0.1308 0.3116
RMSE 0.0266 0.0496 0.1353
ME -0.0069 -0.0481 -0.07593 trimestres MAE 0.0242 0.0491 0.1500
de min 0.0006 0.0028 0.0407antelación max 0.0476 0.1244 0.3351
RMSE 0.0291 0.0606 0.1800
ME -0.0049 -0.0637 -0.10584 trimestres MAE 0.0264 0.0637 0.1716
de min 0.0002 0.0122 0.0008antelación max 0.0574 0.1350 0.3532
RMSE 0.0294 0.0737 0.2064
Elaboración propia
Cuadro A7Evaluación de los Errores de Predicción: Variables Exógenas
Período: 1998.1 - 2001.4
PBI Brasil PBI Argentina

59
Período: 1979.1 - 1997.4Ho = Existencia de raíz unitaria
Valor del nº de Rech Ho Valor del nº de Rech Hoestadístico rezagos al 95% estadístico rezagos al 95%En niveles Primera dif.
PBI Uruguay -2.52 4 no -3.05 3 si
Sectores del PBI
Agro -3.28 4 no -5.25 6 si
Industria -2.18 4 no -3.69 3 si
Construcción -3.27 3 no -5.69 2 si
Comercio, rest. y hoteles -3.19 4 no -2.97 4 si
Resto -3.21 4 no -3.26 5 si
Var. externas al PBI
PBI Brasil -2.57 4 no -3.98 3 si
PBI Argentina -1.38 7 no -3.32 4 si
Inflación en dól. Uruguay -2.42 5 no -5.32 2 si
Inflación en dól. Argentina -2.49 1 no -6.74 1 si
Inflación en dól. Brasil -2.30 4 no -3.30 3 si
Tasa de interés -2.19 8 no -3.56 7 si
Términos del Intercambio -2.94 2 no -8.28 1 si
TCR bilateral con Brasil -2.09 3 no -6.60 2 si
TCR bilateral con Argentina -3.45 3 no -7.65 1 si
Nota: Todas las variables, excepto la tasa de interés, fueron consideradas en logaritmos.El número de rezagos a incluir se eligió según el Akaike Information Criterion.En el caso de las variables en niveles se consideró tendencia y constante y en el caso de las diferenciassolamente la constante.En el caso de los sectores del PBI el período fue: 1983.1 - 1997.4.
Elaboración propia en base al programa Eviews
Test de raíz unitariaDickey - Fuller Aumentado
Variables
Cuadro A8

60
Período: 1998.1 - 2001.4Ho = Estabilidad de las predicciones
Estadístico ValorBox y Tiao crítico (5%)
ARIMA A 1.81 1.79 0.05
ARIMA B 1.21 1.79 0.28
ARIMA C 1.07 1.79 0.40
VAR A (con componentes del PBI)4 retardos 8.20 1.84 0.005 retardos 5.91 1.85 0.00
VAR B (con componentes del PBI)4 retardos 8.85 1.83 0.005 retardos 12.28 1.84 0.00
VAR "econométrico"4 retardos 4.48 1.79 0.005 retardos 3.39 1.79 0.00
Modelo econométrico A 1.17 1.79 0.32
Modelo econométrico B 1.40 1.79 0.17
Nota: El estadístico de Box y Tiao se destribuye F(16, T-r) , siendo r el número de observacionesusadas como condiciones iniciales para la estimación. Debido a que según el modelo, tantoT como r varían, también cambia el valor crítico.
Elaboración propia
Modelo
Cuadro A9Test de estabilidad paramétrica de Box y Tiao
Prob.

61
ARIMA Modelo Eco Comb. 1 Comb. 2ME -0.0104 -0.0093 -0.0100 -0.0095
1 trimestre MAE 0.0193 0.0171 0.0183 0.0173de min 0.0005 0.0008 0.0005 0.0001
antelación max 0.0457 0.0567 0.0512 0.0521RMSE 0.0245 0.0233 0.0238 0.0231
Nota: Las denominaciones de ARIMA y Modelo Econométrico se refieren al modelo ARIMA C y Modelo Econométrico Arespectivamente. La combinación 1 se realizó utilizando ambos modelos con un ponderador k =0,5, mientrasen la combinación 2 ki=MSEj / (MSEi + MSEj)
ARIMA VAR oferta Comb. 1 Comb. 2ME -0.0104 -0.0133 -0.0120 -0.0126
1 trimestre MAE 0.0193 0.0205 0.0203 0.0213de min 0.0005 0.0000 0.0054 0.0048
antelación max 0.0457 0.0563 0.0461 0.0460RMSE 0.0245 0.0272 0.0239 0.0253
Nota: Las denominaciones de ARIMA y VAR oferta se refieren al modelo ARIMA C y VAR A con 5 retardosrespectivamente. La combinación 1 se realizó utilizando ambos modelos con un ponderador k =0,5, mientrasen la combinación 2 ki=MSEj / (MSEi + MSEj)
Elaboración propia
Cuadro A10Evaluación de los Errores de Predicción:
Modelo univariante - VAR con componentes de oferta
Modelo univariante - Modelo econométrico
Combinación de predicciones con 1 trimestre de antelaciónPeríodo: 1998.1 - 2001.4

62
Datos PBI anuales: 1960-1991Período de predicción: 1980-1991
1 año adelante 2 años adelante 3 años adelante
Francia 0.010 0.022 0.032Alemania 0.014 0.033 0.049Italia 0.014 0.033 0.050Japón 0.010 0.020 0.028España 0.014 0.026 0.044Reino Unido 0.022 0.044 0.055Estados Unidos 0.026 0.039 0.049
Promedio 0.016 0.031 0.044
En base a un trabajo de Daniel Peña (1995), donde se trabaja con 4 modelos de series de tiempopara pronosticar el crecimiento anual del PBI en 7 países.
RMSE de las predicciones del PBI en 7 países
Mínimo RMSEPaíses
Cuadro A11