predicciÓn de la activaciÓn en redes …digital.csic.es/bitstream/10261/108207/1/pfm_...
TRANSCRIPT

MÁSTER EN INGENIERÍA QUÍMICA
PREDICCIÓN DE LA ACTIVACIÓN EN
REDES METABÓLICAS EMPLEANDO
OPTIMIZACIÓN DINÁMICA
PROYECTO FIN DE MÁSTER
Febrero 2011
María Gundián Martín de Hijas Liste
Directores:
Julio Rodriguez Banga (Instituto de Investigaciones Marinas, CSIC)
Eva Balsa-Canto (Instituto de Investigaciones Marinas, CSIC)
M. Asunción Longo Gonzalez (Universidad de Vigo)

Resumen
Los modelos matemáticos son fundamentales para el estudio de redes metabólicas
proporcionando nuevas formas de entender las funciones biológicas y ayudando en la
generación de nuevas hipótesis verificables. Los modelos metabólicos de tipo dinámico usan
ecuaciones diferenciales para describir las propiedades del sistema y su evolución en el tiempo.
Los estudios de optimización tratan de explicar las características de los sistemas metabólicos
(flujos, constantes cinéticas, etc) usando los principios de optimalidad, permitiendo entender
cómo y por qué un sistema funciona como lo hace.
El análisis de sistemas metabólicos mediante control óptimo, constituye un aspecto clave en la
ingeniería de bioprocesos. Numerosos autores han sugerido que los procesos de regulación en
sistemas metabólicos podrían seguir un principio de optimalidad (Klipp y col., 2002; Zaslaver y
col., 2004). Estas predicciones teóricas se verificaron con los datos experimentales obtenidos
para redes lineales responsables de la síntesis de aminoácidos (Zaslaver y col., 2004).
Para el estudio de estos sistemas se utiliza una combinación de optimización numérica y
modelos matemáticos dinámicos de dichas redes, para calcular los perfiles enzimáticos óptimos
para diferentes funciones objetivo como por ejemplo: la minimización del tiempo necesario para
alcanzar un determinado estado estacionario o para obtener una determinada cantidad de
producto. Más recientemente Oyarzún y col., (2009), dan una justificación analítica de los
perfiles de activación secuencial de las enzimas en redes lineales con restricciones en la
cantidad total de enzima disponible.
Si se consideran formulaciones más genéricas de estas redes (redes con ramificaciones o que
incorporen la dinámica de las enzimas), la aplicación de los métodos de control óptimo nos
conduce a problemas analíticamente intratables, y numéricamente muy complicados. En general
esta clase de problemas son muy complicados de resolver debido a su carácter no lineal y a la
presencia de restricciones en las concentraciones de los metabolitos y las enzimas, como
consecuencia de esto presentan varias soluciones subóptimas.
En este trabajo se aborda la solución de dichos problemas en el marco de una metodología de
optimización dinámica que permite considerar redes de complejidad y estructura arbitrarias.
Para obtener los perfiles óptimos de las redes consideradas se usará la aproximación de
parametrización de control combinada con métodos de optimización global e híbridos,
implementados en la herramienta DOTcvpSB (Hirmajer et al. 2009). Para ilustrar las

capacidades de esta aproximación se resolverán varios casos prácticos de redes metabólicas que
incluyen la dinámica de enzimas.

Índice de figuras
Figura 1.1. Respuesta de las diferentes redes celulares a un estímulo externo. ........................... 5
Figura 1.2. Mapa de las redes metabólicas de los seres vivos...................................................... 6
Figura 1.3. Pasos fundamentales de la FBA .............................................................................. 13
Figura 1.4. Esquema de las redes estudiadas por Klipp y Zaslaver ........................................... 15
Figura 2.1. Esquema de la parametrización de control (CVP) ................................................... 22
Figura 2.2. Esquema del proceso de resolución mediante parametrización de control. ............. 23
Figura 2.3. Comparación del procedimiento de busqueda del óptimo entre metodos
deterministas y estocásticos basados en poblaciones .................................................................. 25
Figura 2.4. Métodos globales más destacados ........................................................................... 26
Figura 2.5. Esquema del funcionamiento de un algoritmo genético .......................................... 27
Figura 2.6. Esquema del funcionamiento del método evolución diferencial ............................. 28
Figura 3.1. Red lineal de cuatro reacciones ............................................................................... 37
Figura 3.2. Histograma (500 puntos iniciales) para la red lineal ............................................... 37
Figura 3.3. Perfiles óptimos para la red lineal............................................................................ 38
Figura 3.4. Perfiles óptimos para la red lineal incluyendo la dinámica de las enzimas ............. 39
Figura 3.5. Red inspirada en la glicólisis ................................................................................... 40
Figura 3.6. Histograma (500 puntos iniciales) para la red inspirada en la glicólisis ................. 41
Figura 3.7. Perfiles óptimos para la matriz N1 .......................................................................... 42
Figura 3.8. Perfiles óptimos para la matriz N2 ........................................................................... 42
Figura 3.9. Perfiles óptimos para la matriz N1 incluyendo la dinámica de síntesis de las
enzimas. ....................................................................................................................................... 44
Figura 3.10. Perfiles óptimos para la matriz N2 incluyendo la dinámica de síntesis de las
enzimas ........................................................................................................................................ 44

Índice
Motivación .................................................................................................................................... 2
Parte I: Estudio de redes metabólicas ............................................................................................ 5
1. 1. Introducción: ..................................................................................................................... 5
1.2. Modelado de redes metabólicas ......................................................................................... 7
1.2.1 Modelado de reacciones químicas. ............................................................................... 8
1.2.2 Modelado de redes metabólicas. ................................................................................ 10
1.3. Aplicaciones de la optimización al estudio y análisis de redes metabólicas. ................... 12
Parte II. Métodos: Optimización dinámica.................................................................................. 16
2.1. Introducción a la optimización dinámica: ........................................................................ 17
2.2. Formulación del problema: .............................................................................................. 17
2.3. Métodos numéricos de optimización dinámica: ............................................................... 19
2.3.1 Programación dinámica: ............................................................................................. 19
2.3.2 Métodos indirectos: .................................................................................................... 19
2.3.3 Métodos directos: ....................................................................................................... 20
2.3.4 Comparación entre métodos ....................................................................................... 21
2.4. Parametrización de control: .............................................................................................. 22
2.5. Optimización no lineal ..................................................................................................... 24
2.5.1 Métodos numéricos de optimización no lineal: .......................................................... 24
2.6. Métodos numéricos de simulación ................................................................................... 28
2.7. DOTcvpSB toolbox .......................................................................................................... 29
Parte III. Casos prácticos. ............................................................................................................ 36
3.1. Caso práctico I: Red metabólica lineal ............................................................................. 36
3.2 Caso II: Red Metabólica inspirada en la glicolisis ............................................................ 39
Parte IV. Conclusión ................................................................................................................... 45
Anexo .......................................................................................................................................... 36
Bibliografía ................................................................................................................................. 55

2
Motivación
Una de las principales características de los organismos es su capacidad para “auto-regularse” y
mantener sus funciones en condiciones ambientales variables. Los mecanismos que permiten
esta robustez son complejos y desconocidos (Oyarzun 2009), el análisis del genoma humano
permitió que se empezara a comprender los mecanismos que gobiernan los sistemas biológicos.
La biología de sistemas es una aproximación integral al estudio de los sistemas biológicos que
no se centrará exclusivamente en el conocimiento de los genes y proteínas de un sistema, sino
en el comportamiento y las relaciones de los elementos que lo componen (Kitano, 2002).
Los procesos celulares se basan en arquitecturas regulatorias complejas, cada tarea que realiza
una célula implica diferentes niveles de organización celular, incluyendo genes, proteínas,…
Como consecuencia de esto, la descripción de las redes es de gran importancia para poder
entender los sistemas biológicos, no solo se necesita saber qué componentes intervienen, sino
cómo interaccionan. Para ello han de integrarse la experimentación, el procesamiento de los
datos, el modelado matemático y aquellas técnicas numéricas que permitan la resolución y
análisis de los modelos matemáticos así como técnicas de optimización que permitan: bien
mejorar la capacidad predictiva de los modelos (por ejemplo, estimando parámetros
desconocidos del modelo) bien optimizar algún aspecto del sistema de estudio (por ejemplo,
maximizar la producción de un determinado metabolito).
Uno de los aspectos más importantes de la biología de sistemas es el análisis de redes: redes de
genes, redes de interacción de proteínas, redes metabólicas, redes de señalización,... y la
interacción entre los componentes de las mismas (Raman y Chandra, 2009). Dentro de estas
diferentes posibilidades de estudio, este trabajo se va a centrar en el estudio de redes
metabólicas.
El modelado matemático nos permite entender la naturaleza interna, la dinámica de los sistemas
y realizar predicciones sobre su desarrollo, funcionamiento e interacción con el medio. Si bien
existen diversos tipos de aproximaciones matemáticas al estudio de redes biológicas, en el
contexto de redes metabólicas los modelos consisten habitualmente en ecuaciones diferenciales
ordinarias que representan los flujos o concentraciones de los elementos presentes en la red y
cómo evolucionan con el tiempo.
La calidad predictiva de un modelo dado dependerá del conocimiento disponible acerca del
sistema considerado y de la capacidad para traducir ese conocimiento en términos matemáticos.

3
En este sentido es frecuente que los modelos incorporen elementos desconocidos (constantes
cinéticas, flujos, concentraciones de enzimas, etc) y que no son accesibles experimentalmente.
El cálculo de constantes cinéticas desconocidas se realiza habitualmente resolviendo un
problema de estimación de parámetros (Banga y Balsa-Canto, 2008). El objetivo es calcular los
valores de las constantes cinéticas que minimizan la distancia entre las predicciones del modelo
y los datos experimentales.
Para el cálculo de flujos o la activación enzimática algunos autores (Klipp y col., 2002;
Mahadevan y col, 2002; Zaslaver y col., 2004, entre otros) han hipotetizado que los procesos de
regulación en sistemas metabólicos podrían seguir un principio de optimalidad. Esta hipótesis
ha permitido explicar el comportamiento observado experimentalmente para determinadas redes
metabólicas.En este sentido se han usado con éxito diferentes estrategias de optimización tanto
para explicar las propiedades de redes metabólicas como para predecir su comportamiento
(Heinrich y Schuster, 1996; Cornish-Bowden, 2004; Wagner y col., 2010).
Este trabajo se centra en el estudio de la activación enzimática. Como la mayoría de las
reacciones están catalizadas por enzimas, el desarrollo del metabolismo depende enormemente
de la disponibilidad de éstas. Por tanto la activación de una determinada ruta metabólica
requiere la coordinación con la ruta de síntesis de dicha enzima, y así poder obtener el producto
deseado.
La hipótesis de optimalidad se ha utilizado para descibir la regulación metábolica. En muchos
casos bajo el supuesto de que la concentración de las enzimas es un parámetro fijo del modelo.
Esta aproximación se debe a que la regulación genética y enzimática es más lenta que la
regulación metabólica (Oyarzun, 2009). Sin embargo, experimentalmente se han observado
patrones de distribución temporal de enzimas en la síntesis de distintos aminoácidos en redes
metabólicas lineales (Zaslaver y col., 2004), por ello será necesario el uso de estrategias de
optimización dinámica.
La optimización dinámica nos permite estudiar la evolución temporal o el comportamiento
cinético de las enzimas dentro de una red metabólica. Tabajos previos ilustran como el uso de
optimización dinámica produce un mejor ajuste a las observaciones experimentales (Klipp y
col., 2002; Zaslaver y col., 2004).
Quizá una de las preguntas clave tras el principio de optimalidad es la definición del objetivo de
optimización. Varios autores han considerado la resolución del problema utilizando objetivos de
optimización diferentes, tales como la minimización del tiempo o el consumo de enzima para
alcanzar un cierto estado estacionario (Oyarzún y col., (2009), Bartl y col., (2010)).

4
En lo relativo a las métodos elegidos para la resolución de los problemas, Klipp y col. 2002,
utilizaron un método basado en la discretización de los perfiles de activación enzimática en
combinación con un método de optimización no lineal local. Oyarzún y col., (2009) y Bartl y
col., (2010) utilizan en cambio el principio máximo de Pontriagyn para obtener la solución
analítica al problema.
Sin embargo, el trabajo desarrollado en esta área hasta ahora se encuentra limitado por la
imposibilidad de resolver de forma analítica casos más realistas, ya que la aplicación de los
métodos de control óptimo a redes más genéricas nos conduce a problemas analíticamente
intratables, numéricamente muy complicados y que frecuentemente presentan, debido a las
restricciones en los metabolitos y la concentración de enzimas, varias soluciones subóptimas.
Todo esto hace necesario aplicar nuevas técnicas de optimización, que ya se han usado con éxito
para resolver otros problemas de optimización dinámica de tipo biológico (Banga y col., 2005).
En este trabajo se van a considerar formulaciones más genéricas de estas redes (redes con
ramificaciones o que incorporen la dinámica de las enzimas). Para obtener los perfiles óptimos
de las redes consideradas se usará la aproximación de parametrización de control combinada
con métodos de optimización global, tal como está implementado en DOTcvpSB (Hirmajer y
col., 2009), una herramienta de MATLAB® desarrollada para resolver problemas de
optimización dinámica en sistemas biológicos. Para demostrar las posibilidades de esta
aproximación se resolverán diferentes casos prácticos de redes metabólicas, con bifurcaciones e
incluyendo la dinámica de la síntesis de las enzimas.

Parte I: Estudio de redes metabólicas
5
Parte I: Estudio de redes metabólicas Equation Chapter 1 Section 1
1. 1. Introducción:
La actividad celular está determinada por la interacción entre una gran cantidad de especies
químicas. Estas reacciones químicas no ocurren aisladamente y están interconectadas ya que
comparten reactivos y productos. A estos grupos de reacciones se les conoce como redes
bioquímicas y están formadas por una gran variedad de componentes y los más abundantes son
las proteínas. Las proteínas contribuyen a todas las funciones celulares y se sintetizan mediante
la expresión génica de acuerdo con la información contenida en el ADN (Lehninger y col.,
2008).
Muchas de las funciones celulares ocurren en respuesta a diferentes estímulos externos, este
estímulo será captado por los receptores en la membrana celular que iniciará la transmisión de la
señal al núcleo, donde la información genética modula la respuesta celular (Alberts y col.,
2007).
Figura 1. 1. Respuesta de las diferentes redes celulares a un estímulo externo.
La interacción entre las diferentes redes bioquímicas, que se muestra en la figura 1. 1 , es lo que
permite la regulación de la actividad celular según los diferentes estímulos que recibe el
sistema. Las redes de señalización implican la transmisión de una señal, desde el exterior de la
célula al interior, ya sea al núcleo, o a otras partes de la célula. Las redes de regulación genética

Parte I: Estudio de redes metabólicas
6
son muy complejas y son las responsables de la respuesta celular, según la información que
éstas reciban unos u otros genes se expresaran en respuesta al estímulo (Palsson, 2006).
En este trabajo nos centraremos en las redes de tipo metabólicas. Las redes metabólicas
convierten los nutrientes en energía útil y sintetizan un gran número de especies necesarias para
la célula. Cada sustrato va a seguir un camino determinado para formar nuevos productos a
través de una serie de especies intermedias.
Las especies químicas, reactivos, intermedios y productos, implicados en las redes metabólicas
se conocen como metabolitos. Las reacciones metabólicas están catalizadas por enzimas, éstas
se definen como sustancias proteicas que tienen como función catalizar reacciones específicas
necesarias para el mantenimiento de la vida. Existen más 2000 reacciones metabólicas, cada una
catalizada por una enzima.
Debido a que la mayoría de las reacciones están catalizadas por enzimas, la activación de una
determinada red metabólica dependerá de la coordinación con la red de síntesis de la enzima, a
través de las redes de transcripción genética.
Las redes metabólicas son complejas, ya que se encuentran interconectadas unas con otras por
lo que es corriente dividir el metabolismo en series más sencillas, facilitando así su comprensión
y análisis. En la figura 1.2 se ilustra la complejidad del metabolismo de los seres vivos.
Figura 1.2. Mapa de las redes metabólicas de los seres vivos (Roche Biochemical Pathways)

Parte I: Estudio de redes metabólicas
7
Dada esta complejidad, no se cree que se pueda llegar a entender como fue el proceso de
evolución que llevó al metabolismo a su estado actual, ya que en la mayoría de los casos no
quedan trazas de la información genética anterior (Cornish-Bowden, 2004).
Numerosas observaciones sugieren que los procesos de mutación y selección pueden modificar
los organismos, células, redes e incluso constantes cinéticas, para lograr un mejor y más
eficiente funcionamiento del sistema biológico (Klipp y col., 2010).
Mediante los estudios de optimización en sistemas metabólicos se trata de explicar las
características de estos (estructura, flujos, valores de parámetros cinéticos) usando un principio
de optimalidad. Para ello se describirá el sistema desde un punto de vista matemático y eso se
realiza a través de modelos.
1.2. Modelado de redes metabólicas
Los modelos de redes metabólicas son como en cualquier sistema físico una aproximación a la
realidad del sistema y la precisión de estos depende de las suposiciones que se hagan a la hora
de construir el modelo.
Una red metabólica puede ser representada por un esquema gráfico donde solo se muestren los
metabólitos mediante puntos y las reacciones usando flechas. Esa misma red puede ser descrita
empleando un sistema de ecuaciones diferenciales ordinarias (Ordinary Differential Equations,
ODE), lo que permite simular y predecir el comportamiento dinámico de la red.
Los modelos dinámicos usados en biología de sistemas consisten en elementos matemáticos
(variables y constantes) que describen las propiedades del sistema biológico y su evolución con
el tiempo. Un modelo solo puede describir ciertos aspectos del sistema, otras propiedades se
simplifican o se desprecian (sustancias que no intervienen en el proceso a estudiar o medio
celular), siendo de vital importancia no eliminar propiedades que comprometan los resultados
del modelo.
Los modelos dinámicos usados generalmente para describir redes metabólicos utilizan ODE´s
(Klipp y col., 2005, Klipp y col., 2010; Chen y col., 2010). Estos modelos están basados en la
Ley de Acción de Masas. Se pueden distinguir dos tipos: estequiométricos, que solo describen la
topología de la red y cinéticos, que tienen en cuenta la posible no linealidad de las reacciones.

Parte I: Estudio de redes metabólicas
8
1.2.1 Modelado de reacciones químicas.
La cinética de las reacciones bioquímicas se basa en la ley de acción de masas, que fue
desarrollada por Guldberg y Waage en el siglo XIX. (Guldberg y Waage, 1879). Su enunciado
nos dice que “la velocidad de reacción es proporcional a la probabilidad de choque entre los
reactivos”, esto resulta proporcional a la concentración de los reactantes elevado a la
molecularidad. Para una reacción reversible con n reactivos y m productos.
1 1
n n
i i i ii i
R P (1.1)
Su expresión general sería:
1 1
( , ) ( ) ( ) i i
n m
i ii i
R P R P k R k P (1.2)
La velocidad de reacción se puede descomponer en velocidad de reacción del proceso directo
(de reactivos a productos), ν+ y de la reacción inversa ν+.
Donde: αi y βi son constantes que denotan los coeficientes estequiométricos de los reactivos y
productos respectivamente. Las variables dependientes del tiempo serían Ri y Pi , que son las
concentraciones de las diferentes especies presentes, y la velocidad de reacción (ν). Esta
también puede ser expresada en función de la concentración de las especies, es decir
( , )R P , por tanto la velocidad de cambio en las concentraciones vendría dada por:
( , ) 1,2, ,
( , ) 1,2, ,
ii
ii
dRR P for i n
dt
dPR P for i m
dt
(1.3)
Las constante y se conocen como constantes cinéticas directa e inversa, respectivamente.
Cuando la velocidad de reacción es cero ( =0), se dice que la reacción está en equilibrio
químico y se define:
1
1
i
i
m
i eqi
eq n
i eqi
Pk
Kk
R
(1.4)
k
k

Parte I: Estudio de redes metabólicas
9
Keq se denomina constante de equilibrio de reacción, Rieq y Pieq son las concentraciones de las
especies en el equilibrio. El equilibrio debe entenderse desde el sentido que las constantes de la
reacción directa e inversa son iguales y por ello la velocidad total es cero. Cuando es
mucho mayor que uno la reacción directa (de reacctivos a productos) está muy favorecida, en
ese caso se dice que la reacción es irreversible y se asume que la velocidad del proceso inverso
es igual a cero, el sistema pasaría a escribirse como:
1 1
n n
i i i ii i
R P (1.5)
Y la velocidad de reacción:
1
( ) i
n
ii
R k R (1.6)
Un amplio rango de reacciones bioquímicas pueden estudiarse usando la ley de acción de
masas. Para obtener el comportamiento dinámico de la reacción se debe resolver el sistema de
ecuaciones diferenciales de (1.3) para unas condiciones iniciales dadas. Para el estudio de
reacciones metabólicas nos interesa un tipo específico de reacciones que son las reacciones
enzimáticas, estas reacciones se caracterizan por la presencia de una proteína denominada
enzima, que tienen como una de sus principales características acelerar el proceso sin
transformarse. Para una reacción enzimática irreversible, el modelo que describe el sistema
sería:
(1.7)
La reacción (1.7) es una reacción irreversible unimolecular que convierte un sustrato S en un
producto P y es catalizada por una enzima E. Dado que la concentración de E no se ve afectada
por la reacción, el modelo para (1.7) se puede escribir como:
( )
( )
dSS
dt
dPS
dt
(1.8)
Y ( )T
E t E es la concentración constante de enzima. Usando la ley de acción de masas
podemos escribir la velocidad de reacción como función lineal del sustrato.
E S E P

Parte I: Estudio de redes metabólicas
10
1
( )T
S k E S (1.9)
Pero este modelo falla a la hora de describir reacciones enzimáticas debido a que no tiene en
cuenta la saturación de las enzimas. Un modelo más adecuado sería el Modelo de Michaelis-
Menten (Brown, 1902) que describe la velocidad de reacción como:
2
( )T
M
SS k E
S K
(1.10)
La descripción de Michaelis-Menten es una de las más empleadas en el modelado de reacciones
bioquímicas, pero dependiendo de las propiedades particulares de la enzima, se han desarrollado
diferentes expresiones (Klipp, 2010), generalmente no lineales respecto a la concentración de
reactivos. Por ejemplo para enzimas cooperativas se ha desarrollado el modelo de Hill.
( )n
i ii i n
i i
k xg x
K x (1.11)
1.2.2 Modelado de redes metabólicas.
Los modelos dinámicos empleados para el estudio de redes metabólicas se clasifican
principalmente en dos tipos, modelos estequiométricos y modelos cinéticos. Los modelos
estequiométricos describen únicamente la topología de la red, mientras que los modelos
cinéticos combinan información sobre el proceso celular específico con la estequiometría del
sistema, estos modelos permiten capturar la dinámica del sistema. (Patil y col., 2004)
Si consideramos una red formada por n metabolitos y m reacciones, la ecuación de balance de
masas para el sustrato si vendría dada por:
1
mi
ij jj
dsn
dt
(1.12)
Los valores de nij son los coeficientes estequiométricos del metabolito i en la reacción j. Esta
expresión se puede escribir en forma vectorial.
ds
Ndt
(1.13)
Donde 21...
ns s s s y 21
...n
y N es la matriz estequiométrica que
contiene la información de la estructura de la red y combina los coeficientes estequiométricos
con las reacciones. En la tabla 1 se muestran las matrices estequiométricas de diferentes redes.
La ecuación (1.13) es lo que se conoce como modelo estequiométrico.

Parte I: Estudio de redes metabólicas
11
Tabla 1 Matrices estequiométricas para diferentes redes
Red Matriz estequiométrica
En estos modelos la velocidad de reacción es una constante, si consideramos que el vector
depende de los metabolitos y enzimas de la red, la ecuación (1.13) se transforma en:
( , )ds
N s edt
(1.14)
Donde:
(1.15)
La ecuación (1.14) representa un modelo cinético, donde 21...
T
ne e e e denota la
concentración de cada enzima que cataliza la reacción i y G(s) es la matriz diagonal de las
velocidades de reacción 21( ) ...
nG s diag g g g . Cada velocidad de reacción
individual, gi, podrá expresarse usando el modelo cinético más adecuado.
( )i i i i
g x k x (Acción de Masas)
( ) i ii i
i i
k xg x
K x
(Michaelis-Menten)
( )n
i ii i n
i i
k xg x
K x
(Hill) donde n es un número entero
( ) c
i i i ig x k x (Ley de la potencia) donde c es un número real
( , ) ( )s e G s e

Parte I: Estudio de redes metabólicas
12
1.3. Aplicaciones de la optimización al estudio y análisis de
redes metabólicas.
Numerosas observaciones sugieren que los procesos de mutación y selección pueden modificar
los organismos, células, redes e incluso constantes cinéticas para lograr un mejor y más eficiente
funcionamiento del sistema biológico (Klipp y col., 2010). Por ejemplo Dekel y Alon (2005)
observaron que el metabolismo de las bacterias funcionaba tratando de maximizar el
crecimiento celular.
Para sintetizar un mismo producto, el metabolismo puede tomar diferentes rutas, pero se
desconoce por qué el sistema prefiere una ruta frente a otras (Savageau, 1985), esto es lo que
lleva a pensar que los sistemas metabólicos funcionan siguiendo algún criterio de optimización
(Heinrich y col., 1991; Heinrich y Schuster, 1996; Cornish-Bowden, 2004; Wagner y col.,
2010).
Mediante los estudios de optimización en sistemas metabólicos se trata de explicar las
características de los mismos (estructura, flujos, valores de parámetros cinéticos) utilizando un
principio de optimalidad. La optimización nos puede ayudar a entender cómo y por qué un
sistema metabólico ha evolucionado de la forma que lo ha hecho.
La optimización se ha venido usando en diferentes áreas del estudio de redes metabólicas,
ingeniería metabólica, ingeniería inversa, estimación de parámetros y diseño experimental. El
uso de las técnicas de optimización en el estudio de redes metabólicas se realiza con dos
objetivos principalmente: el primero sería entender la estructura y la dinámica del sistema
metabólico y el segundo sería el diseño de redes metabólicas para fines biotecnológicos.
En la bibliografía se pueden encontrar un gran número de técnicas y aplicaciones donde se
utiliza la optimización para el estudio y análisis de redes metabólicas (Banga, 2008). Estos
estudios difieren en el tipo de herramienta matemática empleada para resolver el problema. En
la tabla 2 se muestran diferentes tipos de problemas de optimización relacionados con el estudio
y análisis de redes metabólicas.

Parte I: Estudio de redes metabólicas
13
Tabla 2
Ejemplo Definición Formulación Matemática
Estimación de
parámetros
Cálculo de parámetros del modelo que
minimizan la distancia entre la predicción del
modelo y los datos experimentales
Programación no lineal (Nonlinear
programming, NLP)
+restricciones dinámicas
+restricciones algebraicas
FBA Calcular flujos en el estado estacionario para
maximizar/ minimizar una determinada
función objetivo
Programación lineal
(Linear programming, LP)
DFBA Calcular flujos como funciones del tiempo
para maximizar/minimizar un determinado
funcional objetivo
Optimización dinámica: NLP
+restricciones dinámicas
+restricciones algebraicas
Activación
optima de
enzimas
Calculo de concentraciones de enzimas como
funciones del tiempo para
maximizar/minimizar un determinado
funcional objetivo
Optimización dinámica : NLP
+restricciones dinámicas
+restricciones algebraicas
Una de las técnicas de optimización más usadas para el estudio de sistemas metabólicos es Flux
Balances Analysis (FBA). Se centra en el uso de la programación lineal para determinar la
distribución de flujo de una red en el estado estacionario, maximizando una función objetivo
(Varma y Palsson, 1994). En la figura 1.3 se pueden observar los pasos fundamentales para
resolver un problema de FBA:
Figura 1. 3 : Pasos FBA: (1) Definir el sistema (2) Aplicar balance de masas. (3) Añadir restricciones y definir
la función objetivo (4) Optimización. (Datos de Lee y col., 2006)
Esta técnica se emplea para resolver un gran número de problemas, obteniéndose las
distribuciones de flujo que permiten reproducir datos experimentales (Raman y Chandra, 2009),
además se han desarrollado un gran número de variantes y extensiones. Algunos autores han
incorporado restricciones termodinámicas (Beard y col., 2002), otros información regulatoria
(regulatory flux balance analysis, r-FBA)(Covert y col., 2001). Gadkar y col. (2005) combinan
FBA con una estrategia de optimización de dos niveles (Bilevel optimization, BLO), en la que
resuelven un problema con restricciones que surge de resolver otro problema.
Otra técnica que tiene gran importancia es la formulación S-system, que se desarrolló como una
herramienta sistemática para el modelado de redes bioquímicas (Savageau, 1985). En esta caso

Parte I: Estudio de redes metabólicas
14
el modelo matemático se basa en el uso de potencias y bajo la asunción de estado estacionario
se resuelve un problema de optimización para el cálculo de los parámetros cinéticos (constantes
cinéticas y órdenes cinéticos). Este método se ha usado para resolver un gran número de
problemas, empleando diferentes formulaciones del problema, sobre todo con fines
biotecnológicos, por ejemplo aumentar el rendimiento que se obtiene de determinados
metabolitos (Torres y Voit, 2002). Se ha combinado la formulación S-system con restricciones
específicas para forzar la estabilidad del sistema y para resolver el problema se utiliza una
estrategia de dos niveles (Bilevel optimization, BLO) (Chang y Sahinidis, 2005).
Con el fin de diseñar rutas metabólicas se formula el problema tanto como programación lineal
mixta entera (Mixed integer linear programming, MILP), en donde se resuelve un problema no
lineal con variables de decisión enteras y reales (Vital-Lopez y col., 2006) o como
programación no lineal mixta entera (Mixed integer nonlinear programming, MINLP) en donde
se resuelve un problema no lineal con variables de decisión enteras y reales. Esta estrategia
también se ha usado para aumentar la enantioselectividad de una ruta (Hatzimanikatis y col.,
1996). Lee y col. (2000) combinan una estrategia de optimización MILP con espectroscopía de
13C y así poder predecir espectros de la red metabólica.
Una característica de las aproximaciones vistas hasta ahora es que consideran el
comportamiento de la red bajo unas condiciones fijas de enzimas, pero se han encontrado
evidencias experimentales de patrones de distribuciones temporales de enzimas en rutas lineales
responsables de la síntesis de aminoácidos como la Serina, Metionina y Arginina (Zaslaver y
col., 2004). Estos descubrimientos pueden entenderse desde los principios de optimalidad, por
ello la optimización dinámica será una herramienta muy útil para el estudio de las rutas
metabólicas. Diferentes autores la han utilizado para explicar las propiedades de los sistemas
metabólicos.
Por ejemplo: Leng y Muller, 2006 y van Riel y col., 2000 emplearon un algoritmo de
optimización dinámica para estudiar la regulación homeostática del metabolismo central del
nitrógeno en la S. cerevisiae. Otro ejemplo destacable sería la versión dinámica de la FBA.
Mahadevan y col. (2002) desarrollaron dos algoritmos diferentes para calcular la distribución
temporal de los flujos en la E. Coli. Adiwijaya y col. (2006) usan la optimización dinámica para
diseñar redes y Lebiedz (2005) para el diseño experimental.
En todos estos ejemplos se están considerando los metabolitos como variables de estado y las
velocidades de reacción como variables a optimizar, el problema de este enfoque es que la
velocidad de reacción es función no lineal de la concentración, como se puede observar tanto en
el modelo de Michaelis-Menten como en el de Hill, una posibilidad más adecuada es el
considerar la concentración de las enzimas como variables de decisión.

Parte I: Estudio de redes metabólicas
15
La optimización dinámica de las concentraciones de las enzimas fue utilizada por primera vez
por Klipp y col (2002), que consideran el caso de una red lineal (figura 1.4) con cinética de
acción de masas bajo una restricción en la cantidad total de enzima con el fin de ilustrar que los
perfiles tipo todo-nada conducen a un tiempo mínimo de transición.
Las predicciones teóricas realizadas por Klipp y col. fueron verificadas experimentalmente por
Zaslaver y col. (2004). Experimentalmente encontraron que la célula sintetiza la enzima en el
momento que la necesita (just-in-time). Para explicar los resultados desarrollaron su propio
modelo para una red lineal de tres reacciones con cinética de Michaelis-Menten (figura 1.4), en
este modelo tuvieron en cuenta la transcripción de las enzimas y los efectos de dilución que se
producen con el crecimiento celular.
Estos resultados apoyan la idea de que la regulación genética en redes metabólicas se realiza
siguiendo un cierto comportamiento óptimo, estos resultados motivan el desarrollo de
aproximaciones eficientes de optimización.
Figura 1. 4: Esquema de las redes estudiadas por Klipp y col., (2002) y Zaslaver y col., (2004).
Oyarzun y col. (2009), extenderán los trabajos anteriores aplicando la teoría del control óptimo
para resolver este tipo de problemas, dando una justificación analítica de la activación
secuencial. Usando el principio máximo Pontryagin minimiza una función objetivo formada por
dos términos: el tiempo de transición necesario para que el sistema alcance un estado
estacionario prefijado y la cantidad de enzima necesaria, en una red lineal bajo una restricción
en la cantidad total de enzima.
Posteriormente Bartl y col. (2010) generalizan los resultados para el caso de cinéticas lineales
usando también el principio máximo Pontryagin y en otro trabajo posterior (Barl y col., 2010) lo
amplían para sistemas con cinética de Michaelis-Menten. Pero en ambos trabajos remarcan la
dificultad de resolver analíticamente casos más realistas, como aquellos que consideran
expresiones no lineales para la dinámica de enzimas o redes complejas, esto unido a la

Parte I: Estudio de redes metabólicas
16
multimodalidad que presentan este tipo de problemas hace necesario aplicar nuevas técnicas de
optimización que ya se han usado con éxito para resolver otros problemas de tipo biológico
(Banga y col., 2005).
Equation Section (Next)

Parte II: Métodos: Optimización dinámica
17
Parte II. Métodos: Optimización dinámica
2.1. Introducción a la optimización dinámica:
Los problemas de optimización dinámica, también llamados de control óptimo en lazo abierto
(Bryson, 1999), consisten en calcular las trayectorias temporales que deben seguir ciertas
variables manipulables, conocidas como controles, para alcanzar un cierto objetivo,
generalmente formulado como la maximización o minimización de una función de coste, sujeto
a una serie de condiciones que deben cumplirse, denominadas restricciones.
El origen de la optimización dinámica data del siglo XVII y se basa en el cálculo de variaciones
(Fernat, Newton, Liebnitz y los hermanos Bernouilli), que fue posteriormente desarrollado en el
siglo XVIII por Euler y Lagrange y en el siglo XIX por Legrende, Jacobi, Hamilton y
Weierstrass. Ya en el siglo XX, en 1957, Bellman aporta una nueva visión de la teoría de
Hamilton-Jacobi que llamó programación dinámica. En aquellos años, Pontryagin y sus
colaboradores (1962) extendieron el cálculo de variaciones para poder manipular restricciones
de desigualdad con variables de control. Además, Pontryagin enunció el principio máximo que
lleva su nombre, que permite resolver el problema de tiempo mínimo usando una función de
control de tipo todo/nada, basándose en el cálculo de variaciones desarrollado por Euler.
Los métodos de optimización de Belman y Pontryagin, dan origen a lo que se conoce como
teoría moderna de control o teoría del control óptimo, basada en la descripción de un sistema
según el enfoque del espacio de los estados. El elemento fundamental para la expansión y el uso
de la teoría de control óptimo fue el desarrollo del ordenador digital, que comenzó a estar
disponible comercialmente en los años 50. Estos nuevos avances y sus aplicaciones no solo se
centraban en el campo de la ingeniería, sino también en la economía, biología, medicina,
ciencias sociales y en el programa espacial americano.
2.2. Formulación del problema:
La optimización dinámica de un proceso consiste en el cálculo de las variables de control o
políticas de control, junto con otros parámetros de diseño que optimizan un cierto criterio sujeto
a un conjunto de condiciones que deben cumplirse. De forma general, esto puede expresarse
como:

Parte II: Métodos: Optimización dinámica
18
Encontrar los controles u(t) a lo largo del tiempo 0
[ , ]f
t t t y los parámetros υ que maximicen
o minimicen la función objetivo J:
0
[ ( ), ] [ ( ), ( ), , ]ft
f ft
J x t t L t t t dt x u ω (2.1)
Donde x(t) representa las variables de estado dependientes del tiempo, u(t) es el vector de las
variables de control, t denota el tiempo, tf el tiempo final que puede ser libre o fijado y ω es el
vector de parámetros invariantes con el tiempo.
Sujeto a la dinámica del sistema:
0 0
( ), ( ), , , ( )d
t xdt
t t t x
xx u (2.2)
Y a una serie de restricciones que se imponen en las variables y parámetros del sistema con el
objetivo de que cumplan determinadas condiciones biológicas. Estas condiciones se pueden
clasificar en:
- Restricciones de camino (path constraints), que se deben satisfacer durante todo el
tiempo que dure el proceso, por ejemplo, que la concentración de un metabolito sea
inferior a un determinado valor.
( ), ( ) 0
0
, ,
( ), ( ), ,
eq
ineq
t t t
t t
h
th
x u
x u
(2.3)
- Restricciones puntuales (point constraints), que se deben cumplir en un determinado
instante del proceso. Si tk=tf se denominan restricciones a tiempo final (end point
constraints).
( ), ( ), ,
( ), ( )
0
, , 0
eq
i
k k
neq
k
k k k
t t t
t t
g
g t
x u
x u
(2.4)
Las variables de control y los parámetros pueden tener limitados sus valores, por ejemplo, la
cantidad de enzima no puede superar el valor máximo.
( )
( )
L U
L U
L U
t
t
x x x
u u u
(2.5)

Parte II: Métodos: Optimización dinámica
19
El funcional J está compuesto por dos términos, la función escalar , denominada término de
Mayer y el componente integral donde se sitúa la función escalar L, conocida por término
Lagrangiano.
2.3. Métodos numéricos de optimización dinámica:
Para resolver el problema de optimización dinámica descrito anteriormente, salvo para casos
sencillos, es necesario usar una aproximación numérica. Los métodos numéricos para la
resolución de problemas de optimización dinámica se clasifican en tres grandes grupos: la
programación dinámica, los métodos indirectos y los métodos directos.
2.3.1 Programación dinámica:
Los métodos de programación dinámica se basan en el principio de optimalidad de Bellman:
“Las partes de una trayectoria óptima son también óptimas”, es decir para encontrar la solución
óptima se deben encontrar las soluciones óptimas de un número de etapas sucesivas. Estos
métodos se desarrollaron inicialmente para resolver problemas estacionarios. Su aplicación a
sistemas dinámicos surge del uso de la ecuación de Hamilton-Jacobi-Bellman, una ecuación no
lineal en derivadas parciales que no tiene generalmente solución analítica (Bellman, 1957).
En sus orígenes, estos métodos fueron muy populares, ya que suponían la primera forma
sistemática para resolver problemas de optimización dinámica. Pero su uso está limitado ya que
no se puede aplicar a problemas no lineales de tamaño real, puesto que supondría unos tiempos
de computación muy elevados. Para intentar solventar estas limitaciones se desarrolló una
variante conocida como programación dinámica iterativa (IDP), que se aplicó para la resolución
de problemas de optimización de fermentadores (Luus, 1992) y reactores semicontinuos
(Guntern y col., 1998) pero sigue siendo muy costoso en términos de esfuerzo computacional
sobre todo en sistemas con gran número de ecuaciones diferenciales.
2.3.2 Métodos indirectos:
Los métodos indirectos resuelven el problema de optimización dinámica aplicando el principio
máximo de Pontryagin (PMP). Estos métodos se basan en calcular el Hamiltoniano (H) del
sistema, que depende de la función objetivo y de las restricciones, incluyendo la dinámica del
sistema, asociada al objetivo a través de las llamadas variables adjuntas.
La solución al problema pasa por resolver las condiciones de optimalidad con respeto a las
variables de control (Bryson y Ho, 1988) resultando un problema de condiciones iniciales para
los estados finales y/o para las denominadas variables adjuntas (TPBVP, Two Point Boundary

Parte II: Métodos: Optimización dinámica
20
Value Problem, Bryson y Ho, 1988). Si el problema presenta restricciones de camino o
puntuales o en problemas de tiempo final libre, será necesario imponer condiciones adicionales,
lo que tiene como resultado problemas de fronteras múltiples (MPBVP, Multi Point Boundary
Value Problem) (Cervantes y Beigler., 2000). Existen diferentes métodos numéricos para
realizar esta tarea, entre los que destacan: el método shooting (Bryson y Ho, 1975) y el método
del gradiente (Srinivasan y col., 2003).
El PMP ha sido utilizado en la esterilización térmica de alimentos envasados (Bermúdez y
Martínez, 1994), procesos de secado (Chang y Ma, 1985), así como en el estudio de redes
metabólicas (Oyarzun y col., 2009, Bartl y col., 2010). Para poder aplicar este principio, se
necesitan cálculos analíticos previos, lo que hace que sea bastante difícil usarlo en aplicaciones
prácticas. En general, la comunidad científica usa el principio máximo para analizar las
propiedades del sistema.
2.3.3 Métodos directos:
Estos métodos transforman el problema original de optimización dinámica de dimensión infinita
en un problema de optimización no lineal de dimensión finita (nonlinear programming
problem, NLP) que puede ser resuelto con un método de optimización no lineal estándar. Para
llevar a cabo esta trasformación discretizarán las variables de estado y las de control, o sólo las
de control mediante las denominadas parametrización total (CP) y parametrización de control
(CVP), respectivamente.
En el caso de la parametrización de control (CVP), o aproximación secuencial, para un
determinado nivel de discretización (ρ) aproximarán las variables de control en cada elemento
empleando diferentes funciones base, como por ejemplo polinomios de orden cero, dando lugar
a perfiles en forma de escalones (PC, Piecewise Constant) o polinomios de orden uno, dando
lugar a rampas continuas (PL, Piecewise Linear). Como resultado de este proceso, obtenemos
un problema de optimización no lineal (NLP) de dimensión relativamente pequeña
(directamente relacionada con el nivel de discretización elegido para las variables de control y el
número de éstas) y un problema de valor inicial (IVP), que tiene que ser resuelto cada vez que
se evalúe la función objetivo.
La parametrización de control se ha usado con éxito en varias aplicaciones de interés industrial,
como por ejemplo en destilación (Furlonge y col., 1999, Pollard y Sargent, 1970), en
producción de polímeros (Ishikawa y col., 1997) y en biorreactores (Banga y col., 2005). Este
método también ha sido empleado para resolver problemas de control óptimo de dimensión
elevada o asociados a procesos en parámetros distribuidos, obteniendo buenas soluciones en
tiempos de cálculo moderados ( Balsa-Canto y col., 2004, Banga y col., 1994b).

Parte II: Métodos: Optimización dinámica
21
En la parametrización total (CP), o estrategia simultánea, se parametrizarán tanto las variables
de estado como los controles (Biegler, 2007). Esta parametrización se realiza mediante una
estrategia directa, como la colocación ortogonal. El siguiente paso sería seleccionar un perfil
inicial para las variables de decisión y realizar una resolución iterativa del problema utilizando
un método NLP. Este método genera problemas NLP de elevada dimensión con restricciones
que van a requerir métodos numéricos eficientes, además será necesario imponer restricciones
de igualdad para garantizar la continuidad en el óptimo. Sin embargo no precisa resolver un
problema de valor inicial para cada perfil de control. Esta estrategia se ha empleado en la
optimización dinámica de fermentadores (Kameswaran y Beigler., 2006) y biorreactores (Balsa-
Canto y col., 2000; Banga y Seider, 1996; Banga y col., 2003a; Riascos y col., 2004), reactores
de polimerización (Flores-Tlacuahuac y col., 2005), separadores de membrana (Eliceche y col.,
2005), cristalizadores (Lang y col., 1998).
Existe otro método, un híbrido entre las dos estrategias anteriores, denominado método directo
de disparo múltiple (multiple shooting, MS), esta aproximación va a dividir el horizonte de
tiempo en una serie de elementos, en cada uno de los cuales se resuelve el problema de valor
inicial. Salvo para el primer tramo, las condiciones iniciales se consideran variables de decisión.
Además, existen restricciones de continuidad que obligan a los estados iniciales de cada tramo a
coincidir con los finales del tramo precedente. Esta estrategia se ha empleado en la resolución
de problemas de control óptimo relacionados con bio-sistemas y procesos distribuidos (Lebiedz,
2005; Lebiedz y Maurer, 2004; Serban y col., 2003).
2.3.4 Comparación entre métodos
La programación dinámica funcionaba bien para problemas pequeños, pero no resultaba
eficiente si se comparaba con otros métodos. En su versión iterativa se utilizó para diferentes
problemas (Luus, 1992) pero estos métodos eran muy costosos computacionalmente
especialmente para resolver problemas con un gran número de ecuaciones diferenciales. El
problema de los métodos variacionales, es que son complicados de usar en la práctica, sobre
todo cuando existen restricciones en las variables de estado, como ocurre cuando se formulan
problemas de sistemas metabólicos.
La otra posible alternativa será el uso de métodos indirectos, en general la parametrización de
control es más sencilla de utilizar y se puede adaptar mejor a los diferentes tipos de problemas,
es un método eficiente y robusto (Balsa-Canto, 2001). La parametrización total al discretizar
tanto los controles como las variables de estado requiere la solución de un NLP con
restricciones de gran tamaño, para las que es necesarios usar métodos numéricos muy eficientes

Parte II: Métodos: Optimización dinámica
22
de carácter local (Biegler, 2007). Por otro lado, la parametrización total puede ser inadecuada
para abordar problemas en los que la dinámica es rígida.
Los problemas de optimización de sistemas metabólicos, cuando se estudian redes con
bifurcaciones o se tiene en cuenta la transcripción de las enzimas son problemas analíticamente
intratables y numéricamente muy complicados. Por ello la estrategia más adecuada para
resolverlos será la parametrización de control ya que permite manejar problemas de control
óptimo de gran tamaño sin tener que resolver NLP´s excesivamente grandes (Balsa-Canto y
col., 2004a; Banga y col., 2005; Banga, 2008).
2.4. Parametrización de control:
Como ya se indicó anteriormente, la parametrización de control (Vassiliadis, 1993; Vassiliadis y
col., 1994) consiste en transformar el problema original de dimensión infinita en un problema
de optimización no lineal de dimensión finita. Para ello el horizonte temporal del proceso se
divide en un número de intervalos ρ y las variables de control u=u() se aproximan utilizando
polinomios de Lagrange en cada intervalo, generalmente de orden bajo. (figura 2.1).
Figura 2. 1: Esquema de la parametrización de control (CVP)
Matemáticamente, las variables de control están expresadas en función de nuevos parámetros
independientes del tiempo, que son los coeficientes polinómicos. Para una variable de control uj
en uno de los elementos i, la aproximación polinómica de orden Mj viene dada por:
(( ) ( ))
11
( ) ( ) [ , ]j
j
MMi i
ijk k i ik
u t u l t t t
(2.6)

Parte II: Métodos: Optimización dinámica
23
Siendo τ el tiempo normalizado en el elemento i:
( ) 1
1
i i
i i
t t
t t
(2.7)
y los polinomios de Lagrange de orden Mj
( ) ´
´ 1, 1 ´
1 1
( ) 2j
MM k
kk k k k
si M
l si M
(2.8)
con i=1,…, ρ, y k=1,…,Mj.
El problema de optimización dinámica de elevada dimensión se transforma en uno de NLP en el
que las variables son, ahora, el conjunto formado por los parámetros invariantes en el tiempo y
los coeficientes de las aproximaciones polinómicas. Por tanto el vector de variables de
optimización será:
ijk
u (2.9)
El esquema general del proceso de resolución del nuevo problema de optimización se puede ver
en la figura 2.2. Dicho algoritmo consta de dos iteraciones: una externa que resuelve el NLP y
una interna que se encarga de calcular el valor de la función objetivo y las posibles restricciones
resolviendo el IVP.
Solución
Sí
Objetivos y
restricciones
Resolución del NLP
(iteración externa)
Convergencia
Dinámica del
sistema
Resolución del IVP
(Iteración interna)
Є R ρ
No
Figura 2. 2: Esquema de la solución del problema de optimización no lineal (NLP) resultante de la
parametrización de control.

Parte II: Métodos: Optimización dinámica
24
Para resolver el problema de optimización dinámica deberemos resolver tanto la iteración
externa (NLP) como la interna (IVP). De ahí que en la mayoría de los casos necesitaremos
métodos numéricos de optimización y de simulación para poder resolver este tipo de problemas.
2.5. Optimización no lineal
Los problemas de optimización no lineal (NLP) se basan en encontrar el vector de variables de
decisión v que minimiza la función
( )J (2.10)
y que verifica las restricciones:
( ) 0
( ) 0i
i
h i E
g i I
(2.11)
Donde J es una función escalar de varias variables que se denominará función objetivo o de
coste. hi e gi son también funciones escalares que determinan el espacio de valores posibles para
v, son las denominadas restricciones de igualdad o desigualdad.
El problema de interés en la mayoría de las situaciones reales será un NLP con restricciones, es
decir, tanto la función objetivo como las restricciones son no lineales. En la mayoría de los
casos no será posible encontrar una solución analítica al problema o será extremadamente
complicada. Es por ello que se requiere el uso de técnicas numéricas para la resolución de este
tipo de problemas.
2.5.1 Métodos numéricos de optimización no lineal:
Para resolver el problema de optimización no lineal, se necesitan habitualmente métodos
numéricos. Estos son procedimientos iterativos que parten de un valor inicial para las variables
de decisión (vk) y generan una secuencia de valores, llamada generalmente mapa del algoritmo
que minimiza la función objetivo hasta alcanzar la solución dentro de una tolerancia definida
previamente. El método de iteración se suele expresar de la siguiente forma
1k k k
d (2.12)

Parte II: Métodos: Optimización dinámica
25
Donde k+1 es el valor actual de aproximación al óptimo y dk una función que dependerá de la
dirección de búsqueda, siendo la manera en que se calcula dk la que crea la diferencia entre los
métodos de optimización. Básicamente, se dividen en dos grupos: deterministas o estocásticos.
Los métodos deterministas calculan la dirección de búsqueda de forma sistemática, mientras que
los estocásticos se caracterizan por utilizar secuencias pseudo-aleatorias y valores previos de la
función objetivo para calcular la dirección de búsqueda.
Atendiendo a la naturaleza de la función objetivo, los métodos numéricos de optimización
también pueden clasificarse en locales y globales. Los métodos locales, que se desarrollaron
inicialmente para problemas sin restricciones, son aquellos que buscan un vector p* tal que
J(v*) < J(v) para todos los valores de v cercanos a v*. En el caso de los métodos globales el
objetivo es más ambicioso y se pretende encontrar el valor v* de entre todos los posibles valores
de v.
Los métodos locales, que a su vez son deterministas, convergerán al mínimo más cercano al
punto inicial de búsqueda, encontrando rápidamente la solución, pero la solución que
encuentran no tiene por qué ser el óptimo global o estar cerca de él, pudiendo ser un óptimo
local. En el contexto de la optimización dinámica, los más habituales son los métodos de
programación cuadrática sucesiva (Successive Quadratic Programming, SQP). Estos métodos
transformarán el problema original en una sucesión de problemas cuadráticos con restricciones
lineales (Gill y col., 1981).
La necesidad de los métodos globales, que pueden ser deterministas, estocásticos o híbridos,
surge de la multimodalidad de las aplicaciones reales. Es decir, en los problemas reales suelen
existir varios mínimos o máximos y, por tanto, necesitamos métodos más eficientes que nos
permitan encontrar el óptimo global del problema.
Figura 2. 3: Comparación entre procedimiento determinista y estocástico basado en poblaciones (Balsa-Canto
2010)
Los métodos globales deterministas usan la información del sistema (función objetivo,
gradiente o el gradiente y el Hessiano) para asegurarse la convergencia al óptimo global (Horst
y Pardalos, 1995). Estas propiedades teóricas de convergencia global solo se cumplen en

Parte II: Métodos: Optimización dinámica
26
algunos problemas ideales, pero rara vez se cumplen en aplicaciones reales (Guus y col, 1995).
Además, el tiempo de cálculo se incrementa rápidamente con el tamaño del problema, Floudas
(1999) estudió un sistema de 3 ODE´s comparando diferentes métodos globales y comprobó las
elevadas necesidades computacionales de los métodos deterministas. De todo esto se deriva que
el uso de estos métodos en procesos o aplicaciones reales es muy complicado y actualmente
intratable desde el punto de vista computacional.
Los métodos globales estocásticos se basan en procedimientos de naturaleza probabilística. Su
principal limitación procede del carácter aleatorio que imposibilita, en general, asegurar la
convergencia global. Aún así, estos métodos alcanzan soluciones de alta calidad en bajos
tiempos de cálculo, siendo además fáciles de implementar y usar. Se pueden clasificar según
que usen un solo punto de partida para la búsqueda (métodos secuenciales), y los que usan un
conjunto de puntos (métodos basados en poblaciones). En la figura 2.4 se muestra una posible
clasificación de los métodos globales estocásticos más destacados:
Figura 2. 4: Métodos globales más destacados (Balsa-Canto 2010)
Dentro de los algoritmos Secuenciales Adaptativos, nos encontramos con métodos de búsqueda
aleatoria que generan al azar secuencias de búsqueda, como son Controled random search
(CRS) (Goulcher y Casares, 1978) y Dynamic Hill climbing (DHC) (Luus y Jaakola, 1973).
También se encuentra en este grupo Simulated Annealing (Kirkpatrick y col., 1983, Laarhoven y
Aarts ,1987) que se basa en el fenómeno físico del enfriamiento.
Dentro de los métodos basados en poblaciones, se encuentran las estrategias evolutivas (ES,
Evolution Strategies), que se caracterizan por tener una base teórica firme (Rechenberg, 1973;
Schwefel, 1995) y que son uno de los métodos estocásticos más empleados gracias a su
eficiencia y robustez (Banga y col., 2003a).

Parte II: Métodos: Optimización dinámica
27
El método de optimización por colonia de hormigas (Ant Colony Optimization ACO) fue
desarrollado por Dorigo (1996) para la optimización combinatoria y fue ampliado por Dréo y
Siarry (2006) y Dorigo y Stützle (2003) para el estudio de problemas continuos. Su base
biológica es la comunicación entre las hormigas cuando buscan comida, las hormigas modifican
las condiciones ambientales secretando feromonas en su camino y marcando así las rutas más
cortas hacia la comida, para que esa ruta pueda ser usada por otro miembro de su comunidad. El
algoritmo utilizado seleccionará las mejores soluciones del espacio de búsqueda, para construir
las feromonas correspondientes y coger nueva información basándose en la información de las
feromonas para así seleccionar otro grupo de soluciones. Este proceso se repetirá hasta que se
llegue al criterio de convergencia.
Mientras que el método de optimización con enjambre de partículas (Particle Swarm
Optimization, PSO) emula el comportamiento del colectivo a partir de la interacción de sus
miembros (Kennedy y Eberhart, 2003, 1999)
Los algoritmos genéticos/evolutivos (Genetic Algorithms, Gas) usan técnicas inspiradas en la
evolución como la mutación, selección e intercambio. Estos algoritmos empiezan con la
generación de una población aleatoria de candidatos a soluciones. El mejor sub-grupo de
candidatos (padres) en términos de función de coste se selecciona para crear los vástagos
mediante recombinación y/o mutación. Los nuevos candidatos compiten con los antiguos por su
sitio en la nueva generación. En la figura 2.5 se puede ver un esquema de este proceso. Un
ejemplo de este método es SRES (Stochastic Ranking Evolutionary Search) (Runarsson, 2000).
Figura 2. 5: Esquema del funcionamiento de un algoritmo genético (Balsa-Canto 2010)
Finalmente el método de evolución diferencial (Differential Evolution, DE) generará un nuevo
candidato añadiendo a los candidatos padres la diferencia ponderada entre otros dos candidatos.
Se forma una mezcla entre los candidatos nuevos y los antiguos (Storn y Price, 1997) como se
puede ver en la figura 2.6.

Parte II: Métodos: Optimización dinámica
28
Figura 2. 6: Esquema del funcionamiento del método evolución diferencial (Balsa-Canto 2010)
Este algoritmo usa dos operadores: el primero se encarga de modificar el vector de población
añadiendo la diferencia entre otros dos vectores de población, el segundo operador intercambia
algunos valores de las variables de decisión entre el vector original y otros dos candidatos. Este
método se ha usado en numerosos problemas de ingeniería de procesos (Wang y col., 2001;
Banga y col., 2003a; Angira y Santosh, 2007)
Los métodos estocásticos pueden suponer un exceso de esfuerzo computacional, sobre todo
cuando el número de variables es elevado. Para resolver este problema se proponen los métodos
híbridos, que intentan combinar las ventajas de los distintos métodos presentados.
Una de las estrategias que se ha usado con más éxito es la combinación de métodos globales
estocásticos con métodos locales. Los primeros cubrirán todo el espacio de búsqueda
permitiendo acercarse a las proximidades del óptimo para, posteriormente, usar un método local
para aproximar la solución. De las diferentes combinaciones entre métodos globales y locales se
puede destacar ACOmi, que combina una estrategia de búsqueda basada en el movimiento de
las hormigas con un método local SQP (Shlüter y col., 2009). O MITS que combina un
algoritmo de búsqueda de tabú con un método local SPQ (Exler y col., 2008). Varios autores
han usado esta estrategia para resolver con éxito diferentes problemas de optimización dinámica
(Balsa-Canto y col., 2005; Banga y col., 2005).
2.6. Métodos numéricos de simulación
Como se muestra en la figura 2.2, en cada interacción externa necesitaremos simular la
dinámica del sistema. Para ello necesitamos el modelo matemático del proceso, que consiste en
la definición de un conjunto de ecuaciones que pretenden aproximar el comportamiento real del
mismo.
Se pretende resolver la dinámica del siguiente problema de valor inicial (IVP)
( ,t)y f y (2.13)
Para [ , ]o f
t t t y con las siguientes condiciones iniciales

Parte II: Métodos: Optimización dinámica
29
0 0
( )t y y (2.14)
Donde , nyRy y son las variables de estado resultantes y sus derivadas temporales,
respectivamente. En muchos casos este problema de valor inicial no se puede resolver
analíticamente, por lo que se necesitan métodos numéricos para aproximar la solución. En
general estos métodos consisten en resolver la expresión que resulta de integrar (2.14) y
despejar la variable dependiente.
0
0
ft
t( ,t)dt y y f y (2.15)
Para ello se divide el dominio del tiempo en intervalos y se calcularán las variables
dependientes en un intervalo en función de los intervalos adyacentes. Para ello se usa la
siguiente formula general:
1 1 1 1 1
( , , , , , , , , )i i i i i i i i i m i m
t t t t t y y y y y y (2.16)
Existen muchos métodos para la solución de sistemas EDO´s (Butcher, 2000), los cuales se
clasifican en implícitos y explícitos (métodos de un paso y métodos multipaso). Los métodos
explícitos se caracterizan porque la función solo depende de los puntos temporales anteriores,
y los implícitos porque además de depender de los puntos anteriores también depende del punto
que se está considerando. Dentro de los métodos explícitos destacan: los métodos Runge-Kutta
y los métodos de Adams. Entre los implícitos destacan los métodos BDF, que permiten además
el cálculo de sensibilidades paramétricas muy útiles para el cálculo del gradiente de la función
objectivo con respecto a las variables de decisión.
2.7. DOTcvpSB toolbox
Es una herramienta de optimización dinámica desarrollada en MATLAB® con una interfaz
gráfica amigable, que permite la resolución de problemas de optimización dinámica con
restricciones. La herramienta ha sido desarrollada por el grupo de ingeniería de procesos del
Instituto de Investigaciones Marinas (CSIC) y está disponible online
(http://www.iim.csic.es/~dotcvpsb/)..
DOTcvpSB se basa en el uso de la aproximación de la parametrización de control y cuenta con
diversos numéricos tanto de simulación como de optimización lo que permite abordar la
resolución de un amplio rango de problemas de optimización dinámica.

Parte II: Métodos: Optimización dinámica
30
En lo relativo a la resolución del modelo dinámico (IVP) DOTcvpSB ofrece acceso al método
de Adams y al método BDF (implícitos) incorporados en SUNDIALS, en concreto en CVODES
(Hindmarsh y col., 2005).
En lo relativo a métodos de optimización, la herramienta incorpora tanto métodos locales como
globales e híbridos tal y como se detalla en la Tabla 3.
Tabla 3: Solver implementados en DOTcvpSB.
Solver Descripción
FMINCON Find minimum of constrained nonlinear multivariable function (Coleman y col, 1998)
MISQP Mixer-Integer Sequential Quadratic Programming (Exler y Schtkowski 2007)
DE Differential evolution (Storn y Price, 1997)
SRES Stochastic ranking for constrained evolutionary optimization (Runarsson y Yao 2000).
ACOmi Extended ant colony optimization for non-convex mixed integer nonlinear
programming. (Schülter, y col. 2009).
MITS A tabu search-based algorithm for mixed-integer nonlinear problems and its
application to integrated process and control system design, Computers and Chemical
Engineering (Exler y col 2008).
Los problemas a resolver se implementan fácilmente empleando ficheros de texto o una interfaz
gráfica.
La interfaz gráfica nos permite introducir el problema de una forma sencilla, simplemente
siguiendo, los pasos que nos indica la pantalla del ordenador. En las siguientes imágenes se
pueden ver los pasos a seguir para implementar el problema.
Paso 1:

Parte II: Métodos: Optimización dinámica
31
Paso 2:
En el primero se creará un nuevo problema, en el segundo se realiza la formulación del NLP
fijando: la función objetivo, el número de intervalos que vamos a utilizar para aproximar la
solución, los límites de las variables de control, si el problema es de tiempo final libre y el
solver a utilizar.
En el tercer paso se establecen los parámetros para iniciar NLP y el IVP, se fijan entre otros
valores, el número de variables de control, y tanto el tiempo inicial como final. En el paso
cuarto se definen las ecuaciones diferenciales que describen el sistema.
Paso 3:
Función objetivo
Solver
Variables a optimizar
Limites u(t)
Nº variables de control

Parte II: Métodos: Optimización dinámica
32
Paso 4:
En el quinto paso se establecen las restricciones del sistema, tanto de igualdad como de
desigualdad y se les asigna el intervalo de tiempo donde deben cumplirse. En el paso seis se
definen los solvers a emplear, tanto el lineal como el no lineal y el método de simulación. En el
último paso se establecen los valores de salida.
Paso 5:
ODE´s del sistema
Restricciones de igualdad
Restricciones de desigualdad

Parte II: Métodos: Optimización dinámica
33
Paso 6:
Paso 7:
La otra posibilidad es introducir esta misma, información mediante un archivo de entrada
MATLAB®, un archivo típico de DOTcvpSB seria:
clear mex; clear all; close all;
% --------------------------------------------------- %
% Initialization:
% --------------------------------------------------- %
data.name = 'Red_lineal';
data.compiler = 'None'; %['None'|'FORTRAN']
% --------------------------------------------------- %
% Settings for IVP (ODEs, sensitivities):
% --------------------------------------------------- %
data.odes.Def_FORTRAN = {};
data.odes.parameters = {};
data.odes.Def_MATLAB = {};

Parte II: Métodos: Optimización dinámica
34
data.odes.res(1) = {'((5)/(1+5))*u(1)-((2*y(1))/(1+y(1)))*u(2)'};
data.odes.res(2) = {'((2*y(1))/(1+y(1)))*u(2)- ((4*y(2))/(1+y(2)))*u(3)'};
data.odes.res(3) = {'((4*y(2))/(1+y(2)))*u(3)-((3*y(3))/(1+y(3)))*u(4)'};
data.odes.res(4) = {'(1+u(1)+u(2)+u(3)+u(4))'}
data.odes.black_box = {'None','1','FunctionName'};
data.odes.ic = [0.0 0.0 0.0 0.0];
data.odes.NUMs = size(data.odes.res,2);
data.odes.t0 = 0.0;
data.odes.tf = 5;
data.odes.NonlinearSolver = 'Newton';
data.odes.LinearSolver = 'Dense';
data.odes.LMM = 'Adams';
data.odes.MaxNumStep = 500;
data.odes.RelTol = 1*10^(-9);
data.odes.AbsTol = 1*10^(-9);
data.sens.SensAbsTol = 1*10^(-9);
data.sens.SensMethod = 'Staggered';
data.sens.SensErrorControl= 'on';
% --------------------------------------------------- %
% NLP definition:
% --------------------------------------------------- %
data.nlp.RHO = 4;
data.nlp.problem = 'min';
data.nlp.J0 = 'y(4)';
data.nlp.u0 = [0.1 0.1 0.1 0.1]
data.nlp.lb = [0.0 0.0 0.0 0.0];
data.nlp.ub = [1.0 1.0 1.0 1.0];
data.nlp.p0 = [];
data.nlp.lbp = [];
data.nlp.ubp = [];
data.nlp.solver = 'DE';
data.nlp.SolverSettings = 'None';
data.nlp.NLPtol = 1*10^(-7);
data.nlp.GradMethod = 'SensitivityEq';
data.nlp.MaxIter = 1000;
data.nlp.MaxCPUTime = 60*60*0.25;
data.nlp.approximation = 'PWC';
data.nlp.FreeTime = 'on';
data.nlp.t0Time = [data.odes.tf/data.nlp.RHO]
data.nlp.lbTime = 0.01;
data.nlp.ubTime = data.odes.tf;
data.nlp.NUMc = size(data.nlp.u0,2);
data.nlp.NUMi = 0;
data.nlp.NUMp = size(data.nlp.p0,2); (p)
% --------------------------------------------------- %
% Equality constraints (ECs):
% --------------------------------------------------- %
data.nlp.eq.status = 'on';
data.nlp.eq.NEC = 5;
data.nlp.eq.eq(1) = {'(5/(1+5))*u(1)-0.2'};
data.nlp.eq.eq(2) = {'((2*y(1))/(1+y(1)))*u(2)-0.2'};
data.nlp.eq.eq(3) = {'((4*y(2))/(1+y(2)))*u(3)-0.2'};
data.nlp.eq.eq(4) = {'((3*y(3))/(1+y(3)))*u(4)-0.2'};
data.nlp.eq.eq(5) = {'u(1)+u(2)+u(3)+u(4)-1.0'}
data.nlp.eq.time(1) = data.nlp.RHO;
data.nlp.eq.time(2) = data.nlp.RHO;
data.nlp.eq.time(3) = data.nlp.RHO;
data.nlp.eq.time(4) = data.nlp.RHO;
data.nlp.eq.time(5) = data.nlp.RHO;
data.nlp.eq.PenaltyFun = 'on';
data.nlp.eq.PenaltyCoe = [100.0 100.0 100.0 100.0 100.0];
% --------------------------------------------------- %
% Inequality /path/ constraints (INECs):
% --------------------------------------------------- %
data.nlp.ineq.status = 'on';
data.nlp.ineq.NEC = 1;
data.nlp.ineq.InNUM = 0;
data.nlp.ineq.eq(1) = {'u(1)+u(2)+u(3)+u(4)-1.0'};
data.nlp.ineq.Tol = 0.0005;
data.nlp.ineq.PenaltyFun = 'on';
data.nlp.ineq.PenaltyCoe = [1000.0];
% --------------------------------------------------- %
% Options for setting of the final output:

Parte II: Métodos: Optimización dinámica
35
% --------------------------------------------------- %
data.options.intermediate = 'on';
data.options.display = 'on';
data.options.title = 'on';
data.options.state = 'on';
data.options.control = 'on';
data.options.ConvergCurve = 'on';
data.options.Pict_Format = 'eps';
data.options.report = 'on';
data.options.commands = {''};
data.options.trajectories = data.odes.NUMs;
data.options.profiler = 'off';
data.options.multistart = 1;
data.options.action = 'single-optimization';
% --------------------------------------------------- %
% Call of the main function (you do not change this!):
% --------------------------------------------------- %
[data]=dotcvp_main(data);

Parte III: Casos prácticos
36
Parte III. Casos prácticos. Equation Section (Next)
3.1. Caso práctico I: Red metabólica lineal
En este ejemplo se considera una red simple lineal con cinética de Michaelis-Menten (Oyarzun
y col., 2009). La red (figura 3.1) consiste en cuatro reacciones consecutivas cada una catalizada
por una enzima. El objetivo del problema es minimizar la suma del tiempo necesario para
alcanzar un determinado estado estacionario caracterizado por la presencia de restricciones a
tiempo final y por una cantidad de enzima fijada previamente. La formulación matemática del
problema sería la siguiente:
Figura 3. 1: Red lineal de cuatro reacciones.
Encontrar las políticas óptimas de control E(t) pertenecientes a t[t0,tf]que minimicen:
3
00
1 ( )
ft
i
i
J e t (3.1)
Sujeto a la dinámica del sistema:
1 1 1( ), ( ) ( ), ( ) 1, ,3 ii i i i i i
dt t t t i
dt
SS e S e (3.2)
( )
( ), ( ) ( )( )
cat i i
i i i i
M i
k tt t t
K t
SS e e
S (3.3)
Con las siguientes restricciones a tiempo final:
; 0,1, ,3i fV para t t i (3.4)
Y la siguiente restricción de camino:
3
0
( )
i T
i
te E (3.5)
S
0
S1 S2 S3
e2 e1 e3 e0

Parte III: Casos prácticos
37
Con : kcat0=1s-1
, kcat1=2s-1
, kcat2=4s-1
, kcat3=3s-1
, Kmi=1mM, S0=5mM, Si=0 for i=1,…3, ET=1mM,
V=0.2
El carácter no lineal de los modelos a tratar, junto con la presencia de restricciones de camino y
restricciones a tiempo final relacionadas con la concentración de los metabolitos y enzimas o los
flujos induce generalmente a multi-modalidad. Para ilustrar este punto se resolverá la red
metabólica del caso práctico número uno usando un método local.
De quinientos cálculos lanzados el método local SQP solo fue capaz de converger a soluciones
factibles en 48 casos y todas las soluciones obtenidas fueron soluciones sub-óptimas (Figura
3.3).
Figura 3. 2: Resultado del cálculo con 500 puntos iniciales para la red del caso I con un local SQP
Por tanto en este tipo de sistemas se necesitan métodos de optimización robustos y eficientes
para poder alcanzar la mejor solución posible. En este caso se emplea un método híbrido,
ACOmi, para obtener los perfiles óptimos, en el anexo se pueden ver los archivos de entrada de
DOTcvpSB.
La solución óptima corresponde con un perfil tipo bang-bang (todo-nada) donde cada enzima
sigue una secuencia temporal que encaja con la topología de la red metabólica (figura 3.3),
salvo en el último intervalo. Hay que destacar que a tiempo final se requieren ciertos niveles de
enzima para así alcanzar el estado estacionario fijado por las restricciones a tiempo final.
Debido a la minimización de la cantidad de enzima usada junto con la restricción en la cantidad
total de enzima, el substrato inicial no queda totalmente convertido en producto final.
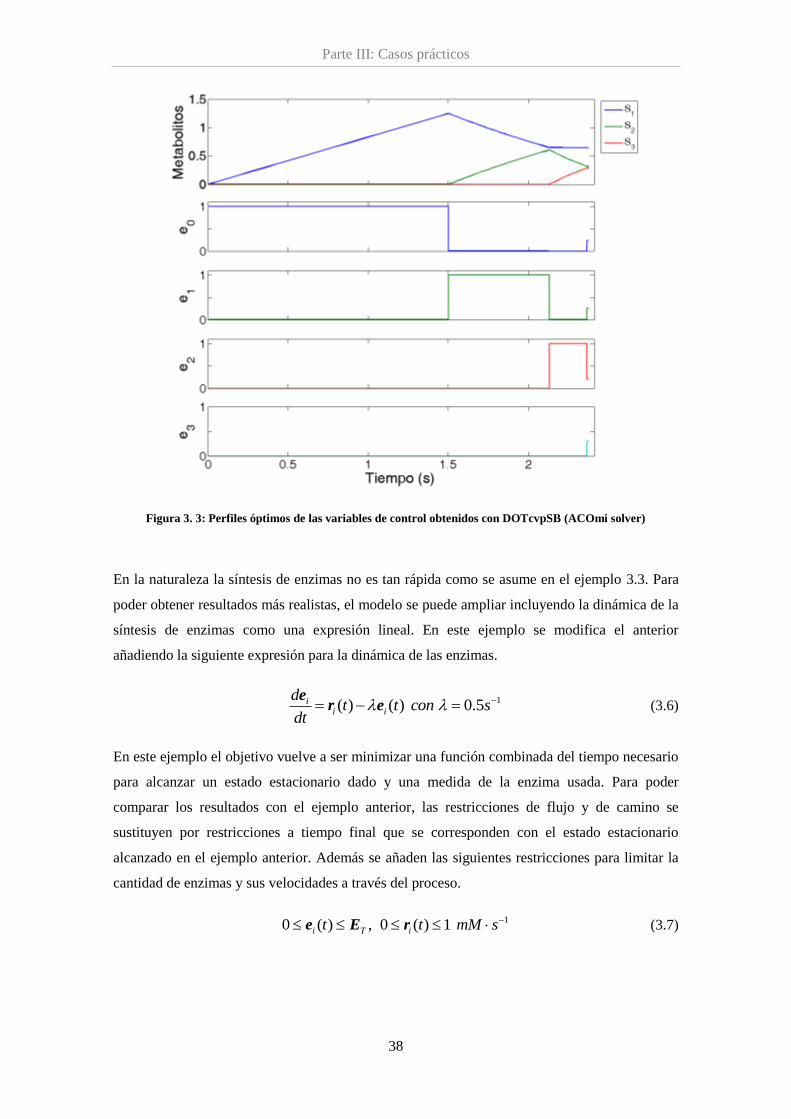
Parte III: Casos prácticos
38
Figura 3. 3: Perfiles óptimos de las variables de control obtenidos con DOTcvpSB (ACOmi solver)
En la naturaleza la síntesis de enzimas no es tan rápida como se asume en el ejemplo 3.3. Para
poder obtener resultados más realistas, el modelo se puede ampliar incluyendo la dinámica de la
síntesis de enzimas como una expresión lineal. En este ejemplo se modifica el anterior
añadiendo la siguiente expresión para la dinámica de las enzimas.
1( ) ( ) 0.5 i
i i
dt t con s
dt
er e (3.6)
En este ejemplo el objetivo vuelve a ser minimizar una función combinada del tiempo necesario
para alcanzar un estado estacionario dado y una medida de la enzima usada. Para poder
comparar los resultados con el ejemplo anterior, las restricciones de flujo y de camino se
sustituyen por restricciones a tiempo final que se corresponden con el estado estacionario
alcanzado en el ejemplo anterior. Además se añaden las siguientes restricciones para limitar la
cantidad de enzimas y sus velocidades a través del proceso.
10 ( ) , 0 ( ) 1 i T it t mM se E r (3.7)
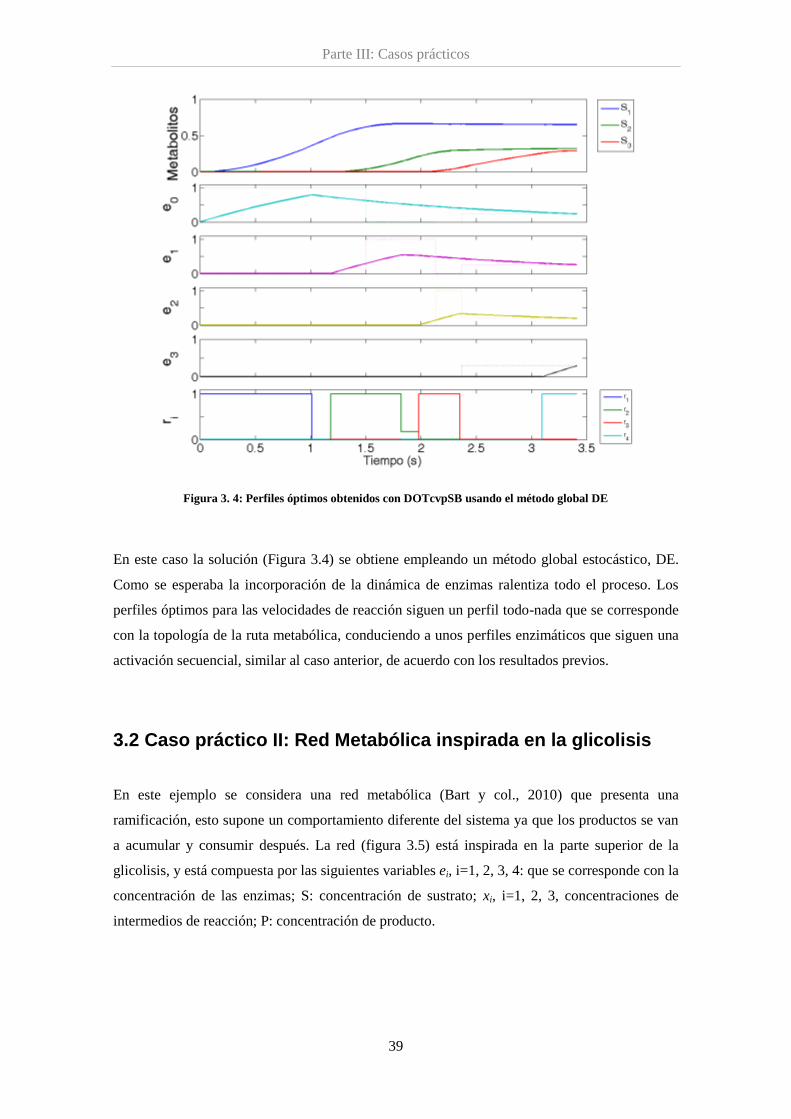
Parte III: Casos prácticos
39
Figura 3. 4: Perfiles óptimos obtenidos con DOTcvpSB usando el método global DE
En este caso la solución (Figura 3.4) se obtiene empleando un método global estocástico, DE.
Como se esperaba la incorporación de la dinámica de enzimas ralentiza todo el proceso. Los
perfiles óptimos para las velocidades de reacción siguen un perfil todo-nada que se corresponde
con la topología de la ruta metabólica, conduciendo a unos perfiles enzimáticos que siguen una
activación secuencial, similar al caso anterior, de acuerdo con los resultados previos.
3.2 Caso práctico II: Red Metabólica inspirada en la glicolisis
En este ejemplo se considera una red metabólica (Bart y col., 2010) que presenta una
ramificación, esto supone un comportamiento diferente del sistema ya que los productos se van
a acumular y consumir después. La red (figura 3.5) está inspirada en la parte superior de la
glicolisis, y está compuesta por las siguientes variables ei, i=1, 2, 3, 4: que se corresponde con la
concentración de las enzimas; S: concentración de sustrato; xi, i=1, 2, 3, concentraciones de
intermedios de reacción; P: concentración de producto.

Parte III: Casos prácticos
40
Figura 3. 5. Red metabólica inspirada en la glicolisis
La formulación matemática del problema sería la siguiente. Encontrar e(t) en el intervalo
t[t0,tf] de forma que minimice:
( ),
minf
fu t t
J t (3.8)
Sujeto a la dinámica del sistema:
0 0( ( ), ( )), ( )d
t t tdt
x
N x e x x (3.9)
Donde:
( )
( ( ), ( )) ( ), 1, ,4.( )
cat kk
M k
k tt t t k
K t
xx e e
x (3.10)
1 2
1 0 0 0 0 0 0 0
1 1 0 0 1 1 0 0
,0 1 1 0 0 1 1 0
0 1 1 1 0 1 1 1
0 0 0 1 0 0 0 1
N N (3.11)
Con las siguientes restricciones de camino:
4
1
( ) 1k
k
t
e (3.12)
( ) 0, 1, ,4k t k e (3.13)
Y la siguiente restricción a tiempo final:
S
x1
e1
x2
e2
e3
e4
P
x3

Parte III: Casos prácticos
41
5 ( ) 0.75fx t (3.14)
El objetivo de este problema es minimizar el tiempo que tarda en formarse una determinada
cantidad de producto a partir del sustrato. Esto representa una situación biológica donde el
producto no se necesita en la máxima concentración pero si es esencial en una determinada
cantidad.
En este problema se consideran dos situaciones, la matriz estequiométrica N1 representa la
situación donde el sustrato se consume a medida que se forma el intermedio de reacción x1. La
matriz N2 representa la situación donde el sustrato se puede considerar una constante, esta
situación también es interesante ya es una situación que se considera normalmente en el
modelado metabólico (Heinrich y Shuster, 1996), se aplica por ejemplo en el caso de un medio
de cultivo constante para el crecimiento de un microorganismo.
Primero se resuelve el problema usando un método local SQP, de un cálculo con 500 puntos
iniciales, en 465 el método local logra obtener una solución, pero todas las soluciones obtenidas
son subóptimas, como se puede ver en la figura 3.6.
Figura 3. 6. Calculo con 500 puntos iniciales para la matriz N2
Para resolver el problema utilizará un método global estocástico, DE. Como se puede observar
en las figuras 3.7 y 3.8, la solución se corresponde también con un perfil tipo todo-nada (Bang-
Bang), donde cada una de las enzimas se activa tras desactivarse la anterior en un orden que
coincide con la topología del sistema.

Parte III: Casos prácticos
42
Figura 3. 7 Perfiles óptimos para la matriz N1
Figura 3. 8 Perfiles óptimos para la matriz N2
Si comparamos los dos casos se puede observar que cuando la concentración de sustrato se
considera una constante, es decir no se consume, el tiempo que tarda el sistema en alcanzar la
cantidad de producto fijada es menor. Así mismo, también se observan variaciones en los

Parte III: Casos prácticos
43
tiempos que las diferentes enzimas se encuentran activadas, por ejemplo para el caso de la
matriz N2 el tiempo en que se encuentra activada la tercera enzima es menor.
Como en el ejemplo del caso anterior, es interesante considerar la dinámica de la síntesis de
enzimas, ya que ésta en la naturaleza no ocurre tan rápido como muestran los perfiles de tipo
bang-bang. Para ello cada una de las enzimas estará descrita por la siguiente ecuación:
1( ) ( ) 0.5i
i i
dt t con s
dt
er e (3.15)
La formulación del problema no se modifica salvo que la restricción en la cantidad total de
enzima (ecuación 3.2) se sustituirá por la siguiente:
1 1
1
( )( )
( )
n ni
i T
i i
n
i T tot
i
r tt
r t c
e E
E
(3.16)
Esto indica que para la velocidad de conversión ctot la suma de todas las velocidades de
producción es igual al total de enzima multiplicado por la velocidad de degradación de las
enzimas.
El método de optimización usado para obtener los perfiles óptimos, es un métodos global
estocástico, DE. En la figuras 3.9 y 3.10, podemos observar que nuevamente la inclusión de la
dinámica de las enzimas ralentiza todo el proceso, las enzimas se van activando sucesivamente
siguiendo la topología de la red, también observamos que cuando empieza la degradación de
una enzima, empieza la síntesis de la siguiente. Al incluir la dinámica de las enzimas los perfiles
tipo bang-bang se pueden observar ahora en las velocidades de expresión de las enzimas.

Parte III: Casos prácticos
44
Figura 3. 9: Perfiles óptimos para la matriz N1 si se incluye la dinámica de síntesis de las enzimas.
Figura 3. 10: Perfiles óptimos para la matriz N2 si se incluye la dinámica de síntesis de las enzimas

Parte IV: Conclusión
45
Parte IV. Conclusión
Este trabajo parte de la hipótesis de optimalidad del proceso de activación enzimática en redes
metabólicas y que asume que esta activación se produce de forma que se minimice un
determinado funcional relacionado con el tiempo de transición o la cantidad de enzima
necesaria para alcanzar un cierto estado estacionario.
Bajo esta hipótesis, la optimización dinámica es un método eficiente para predecir o explicar los
patrones temporales de regulación en redes metabólicas. Los perfiles de distribución de enzimas
obtenidos tienen sentido desde un punto de vista biológico, permitiendo a la célula funcionar
eficientemente con un número limitado de recursos. Pero como se ha estudiado los perfiles tipo
todo-nada no representan de una manera realista las necesidades de la célula, por eso los
modelos deben ampliarse teniendo en cuenta la dinámica del proceso de síntesis de las enzimas.
Los problemas de optimización en redes metabólicas son complejos debido a que presentan
restricciones tanto en los estados como en los controles y los modelos tienen un alto carácter no
lineal, por lo cual los métodos de optimización local fallan, obteniendo soluciones subóptimas.
Por ello será necesario combinar técnicas de optimización robusta y eficiente, como la
parametrización de control combinada con métodos de optimización global e híbridos para
poder obtener las políticas de control óptimas.
En este trabajo se ha ilustrado como la herramienta DOTcvpSB, que combina el método de
parametrización de control con métodos de optimización global e híbridos, permite resolver
estos problemas de forma eficiente y evitando la convergencia a soluciones locales (subóptimas)
para redes metabólicas de complejidad creciente, permitiendo en el futuro abordar la resolución
de problemas más complejos como puede ser el metabolismo central de la bacteria B. subilis.

Anexo
46
Anexo
Código correspondiente a la implementación de Matlab del caso I
clear mex; clear all; close all;
% --------------------------------------------------- %
% Initialization:
% --------------------------------------------------- %
data.name = 'Red_lineal';
data.compiler = 'None'; %['None'|'FORTRAN']
% --------------------------------------------------- %
% Settings for IVP (ODEs, sensitivities):
% --------------------------------------------------- %
data.odes.Def_FORTRAN = {};
data.odes.parameters = {};
data.odes.Def_MATLAB = {};
data.odes.res(1) = {'((5)/(1+5))*u(1)-((2*y(1))/(1+y(1)))*u(2)'};
data.odes.res(2) = {'((2*y(1))/(1+y(1)))*u(2)- ((4*y(2))/(1+y(2)))*u(3)'};
data.odes.res(3) = {'((4*y(2))/(1+y(2)))*u(3)-((3*y(3))/(1+y(3)))*u(4)'};
data.odes.res(4) = {'(1+u(1)+u(2)+u(3)+u(4))'}
data.odes.black_box = {'None','1','FunctionName'};
data.odes.ic = [0.0 0.0 0.0 0.0];
data.odes.NUMs = size(data.odes.res,2);
data.odes.t0 = 0.0;
data.odes.tf = 5;
data.odes.NonlinearSolver = 'Newton';
data.odes.LinearSolver = 'Dense';
data.odes.LMM = 'Adams';
data.odes.MaxNumStep = 500;
data.odes.RelTol = 1*10^(-9);
data.odes.AbsTol = 1*10^(-9);
data.sens.SensAbsTol = 1*10^(-9);
data.sens.SensMethod = 'Staggered';
data.sens.SensErrorControl= 'on';
% --------------------------------------------------- %
% NLP definition:
% --------------------------------------------------- %
data.nlp.RHO = 4;
data.nlp.problem = 'min';
data.nlp.J0 = 'y(4)';
data.nlp.u0 = [0.1 0.1 0.1 0.1]
data.nlp.lb = [0.0 0.0 0.0 0.0];
data.nlp.ub = [1.0 1.0 1.0 1.0];
data.nlp.p0 = [];
data.nlp.lbp = [];
data.nlp.ubp = [];
data.nlp.solver = 'ACOMI';
data.nlp.SolverSettings = 'None';
data.nlp.NLPtol = 1*10^(-7);
data.nlp.GradMethod = 'SensitivityEq';
data.nlp.MaxIter = 1000;
data.nlp.MaxCPUTime = 60*60*0.25;
data.nlp.approximation = 'PWC';
data.nlp.FreeTime = 'on';
data.nlp.t0Time = [data.odes.tf/data.nlp.RHO]
data.nlp.lbTime = 0.01;
data.nlp.ubTime = data.odes.tf;
data.nlp.NUMc = size(data.nlp.u0,2);
data.nlp.NUMi = 0;
data.nlp.NUMp = size(data.nlp.p0,2); (p)
% --------------------------------------------------- %
% Equality constraints (ECs):
% --------------------------------------------------- %
data.nlp.eq.status = 'on';
data.nlp.eq.NEC = 5;
data.nlp.eq.eq(1) = {'(5/(1+5))*u(1)-0.2'};
data.nlp.eq.eq(2) = {'((2*y(1))/(1+y(1)))*u(2)-0.2'};
data.nlp.eq.eq(3) = {'((4*y(2))/(1+y(2)))*u(3)-0.2'};
data.nlp.eq.eq(4) = {'((3*y(3))/(1+y(3)))*u(4)-0.2'};

Anexo
47
data.nlp.eq.eq(5) = {'u(1)+u(2)+u(3)+u(4)-1.0'}
data.nlp.eq.time(1) = data.nlp.RHO;
data.nlp.eq.time(2) = data.nlp.RHO;
data.nlp.eq.time(3) = data.nlp.RHO;
data.nlp.eq.time(4) = data.nlp.RHO;
data.nlp.eq.time(5) = data.nlp.RHO;
data.nlp.eq.PenaltyFun = 'on';
data.nlp.eq.PenaltyCoe = [100.0 100.0 100.0 100.0 100.0];
% --------------------------------------------------- %
% Inequality /path/ constraints (INECs):
% --------------------------------------------------- %
data.nlp.ineq.status = 'on';
data.nlp.ineq.NEC = 1;
data.nlp.ineq.InNUM = 0;
data.nlp.ineq.eq(1) = {'u(1)+u(2)+u(3)+u(4)-1.0'};
data.nlp.ineq.Tol = 0.0005;
data.nlp.ineq.PenaltyFun = 'on';
data.nlp.ineq.PenaltyCoe = [1000.0];
% --------------------------------------------------- %
% Options for setting of the final output:
% --------------------------------------------------- %
data.options.intermediate = 'on';
data.options.display = 'on';
data.options.title = 'on';
data.options.state = 'on';
data.options.control = 'on';
data.options.ConvergCurve = 'on';
data.options.Pict_Format = 'eps';
data.options.report = 'on';
data.options.commands = {''};
data.options.trajectories = data.odes.NUMs;
data.options.profiler = 'off';
data.options.multistart = 1;
data.options.action = 'single-optimization';
% --------------------------------------------------- %
% Call of the main function (you do not change this!):
% --------------------------------------------------- %
[data]=dotcvp_main(data);
Código correspondiente a la implementación de Matlab del caso I incluyendo la dinámica
de las enzimas
clear mex; clear all; close all;
% --------------------------------------------------- %
% Initialization:
% --------------------------------------------------- %
data.name = 'Red_lineal_Dinámica';
data.compiler = 'None'; %['None'|'FORTRAN']
% --------------------------------------------------- %
% Settings for IVP (ODEs, sensitivities):
% --------------------------------------------------- %
data.odes.Def_FORTRAN = {};
data.odes.parameters = {};
data.odes.Def_MATLAB = {};
data.odes.res(1) = {'((5)/(1+5))*y(4)-((2*y(1))/(1+y(1)))*y(5)'};
data.odes.res(2) = {'((2*y(1))/(1+y(1)))*y(5)- ((4*y(2))/(1+y(2)))*y(6)'};
data.odes.res(3) = {'((4*y(2))/(1+y(2)))*y(6)-((3*y(3))/(1+y(3)))*y(7)'};
data.odes.res(4) = {'u(1)-0.5*y(4)'};
data.odes.res(5) = {'u(2)-0.5*y(5)'};
data.odes.res(6) = {'u(3)-0.5*y(6)'};
data.odes.res(7) = {'u(4)-0.5*y(7)'};
data.odes.res(8) = {'(1+y(4)+y(5)+y(6)+y(7))'};
data.odes.black_box = {'None','1','FunctionName'};
data.odes.ic = [0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0];
data.odes.NUMs = size(data.odes.res,2);
data.odes.t0 = 0.0;
data.odes.tf = 3.45;
data.odes.NonlinearSolver = 'Newton';

Anexo
48
data.odes.LinearSolver = 'Dense';
data.odes.LMM = 'Adams';
data.odes.MaxNumStep = 100;
data.odes.RelTol = 1*10^(-8);
data.odes.AbsTol = 1*10^(-8);
data.sens.SensAbsTol = 1*10^(-8);
data.sens.SensMethod = 'Simultaneous';
data.sens.SensErrorControl= 'on';
% --------------------------------------------------- %
% NLP definition:
% --------------------------------------------------- %
data.nlp.RHO = 7;
data.nlp.problem = 'min';
data.nlp.J0 = 'y(8)';
data.nlp.u0 = [0.01 0.01 0.01 0.01]
data.nlp.lb = [0.0 0.0 0.0 0.0];
data.nlp.ub = [1.0 1.0 1.0 1.0];
data.nlp.p0 = [];
data.nlp.lbp = [];
data.nlp.ubp = [];
data.nlp.solver = 'DE';
data.nlp.SolverSettings = 'None';
data.nlp.NLPtol = 1*10^(-6);
data.nlp.GradMethod = 'SensitivityEq';
data.nlp.MaxIter = 2000;
data.nlp.MaxCPUTime = 60*60*0.25;
data.nlp.approximation = 'PWC';
data.nlp.FreeTime = 'on';
data.nlp.t0Time = [data.odes.tf/data.nlp.RHO
data.nlp.lbTime = 0.01;
data.nlp.ubTime = data.odes.tf;
data.nlp.NUMc = size(data.nlp.u0,2);
data.nlp.NUMi = 0;
data.nlp.NUMp = size(data.nlp.p0,2);
% --------------------------------------------------- %
% Equality constraints (ECs):
% --------------------------------------------------- %
data.nlp.eq.status = 'on';
data.nlp.eq.NEC = 7;
data.nlp.eq.eq(1) = {'y(4)-0.24'};
data.nlp.eq.eq(2) = {'y(5)-0.26'};
data.nlp.eq.eq(3) = {'y(6)-0.20'};
data.nlp.eq.eq(4) = {'y(7)-0.29'};
data.nlp.eq.eq(5) = {'y(1)-0.65'};
data.nlp.eq.eq(6) = {'y(2)-0.32'};
data.nlp.eq.eq(7) = {'y(3)-0.29'};
data.nlp.eq.time(1) = data.nlp.RHO;
data.nlp.eq.time(2) = data.nlp.RHO;
data.nlp.eq.time(3) = data.nlp.RHO;
data.nlp.eq.time(4) = data.nlp.RHO;
data.nlp.eq.time(5) = data.nlp.RHO;
data.nlp.eq.time(6) = data.nlp.RHO;
data.nlp.eq.time(7) = data.nlp.RHO;
data.nlp.eq.PenaltyFun = 'on';
data.nlp.eq.PenaltyCoe = [10.0 10.0 10.0 10.0 10.0 10.0 10.0];
% --------------------------------------------------- %
% Inequality /path/ constraints (INECs):
% --------------------------------------------------- %
data.nlp.ineq.status = 'off';
data.nlp.ineq.NEC = 1;
data.nlp.ineq.InNUM = 0;
data.nlp.ineq.eq(1) = {'u(1)+u(2)+u(3)+u(4)-1.0'};
data.nlp.ineq.Tol = 0.0005;
data.nlp.ineq.PenaltyFun = 'off';
data.nlp.ineq.PenaltyCoe = [1000.0];
% --------------------------------------------------- %
% Options for setting of the final output:
% --------------------------------------------------- %
data.options.intermediate = 'on';
data.options.display = 'on';

Anexo
49
data.options.title = 'on';
data.options.state = 'on';
data.options.control = 'on';
data.options.ConvergCurve = 'on';
data.options.Pict_Format = 'eps';
data.options.report = 'on';
data.options.commands = {''};
data.options.trajectories = data.odes.NUMs;
data.options.profiler = 'off';
data.options.multistart = 1;
data.options.action = 'single-optimization';
% --------------------------------------------------- %
% Call of the main function (you do not change this!):
% --------------------------------------------------- %
[data]=dotcvp_main(data);
Código correspondiente a la implementación de Matlab del caso II con la matriz N1
clear mex; clear all; close all%
% --------------------------------------------------- %
% Initialization:
% --------------------------------------------------- %
data.name = 'Red_inspirada_glicolisis_N1';
data.compiler = 'None';
% --------------------------------------------------- %
% Settings for IVP (ODEs, sensitivities):
% --------------------------------------------------- %
data.odes.parameters ={'C=1','k1=1','k2=1','k3=1','k4=1','k5=1'};
data.odes.res(1) ={'-u(1)*(y(1)/(y(1)+1))'}; % S
data.odes.res(2) ={'u(1)*(y(1)/(y(1)+1))-u(2)*(y(2)/(y(2)+1))'}; %X1
data.odes.res(3) ={'u(2)*(y(2)/(y(2)+1))-u(3)*(y(3)/(y(3)+1))'}; %X2
data.odes.res(4) ={'u(2)*(y(2)/(y(2)+1))+u(3)*(y(3)/(y(3)+1))-
u(4)*(y(4)/(y(4)+1))'}; %X3
data.odes.res(5) = {'u(4)*(y(4)/(y(4)+1))'}; %P
data.odes.res(6) = {'1'};
data.odes.ic = [1 0 0 0 0 0];
data.odes.NUMs = size(data.odes.res,2);
data.odes.tf = 10;
data.odes.MaxNumStep = 500;
data.odes.NonlinearSolver = 'Newton';
data.odes.LinearSolver = 'Dense';
data.odes.LMM = 'Adams';
data.odes.RelTol = 1*10^(-8);
data.odes.AbsTol = 1*10^(-8);
data.sens.SensAbsTol = 1*10^(-8);
data.sens.SensMethod = 'Simultaneous';
data.sens.SensErrorControl= 'on';
% --------------------------------------------------- %
% NLP definition:
% --------------------------------------------------- %
data.nlp.RHO = 4;
data.nlp.problem = 'min';
data.nlp.J0 = 'y(6)';
data.nlp.u0 = [0.01 0.01 0.01 0.01];
data.nlp.lb = [0 0 0 0];
data.nlp.ub = [1 1 1 1];
data.nlp.solver = 'FMINCON';
data.nlp.SolverSettings = 'None';
data.nlp.NLPtol = 1*10^(-6);
data.nlp.GradMethod = 'SensitivityEq';
data.nlp.MaxIter = 1000;
data.nlp.MaxCPUTime = 60*60*2.5;
data.nlp.FreeTime = 'on';
data.nlp.t0Time = [data.odes.tf/data.nlp.RHO];
data.nlp.lbTime = 0.01;
data.nlp.ubTime = data.odes.tf;
% --------------------------------------------------- %
% Equality constraints (ECs):
% --------------------------------------------------- %
data.nlp.eq.status = 'on';
data.nlp.eq.NEC = 1;
data.nlp.eq.eq(1) = {'y(5)-0.9'};

Anexo
50
data.nlp.eq.time(1) = data.nlp.RHO;
data.nlp.eq.PenaltyFun = 'on';
data.nlp.eq.PenaltyCoe = [100.0];
% --------------------------------------------------- %
% Inequality /path/ constraints (INECs):
% --------------------------------------------------- %
data.nlp.ineq.status = 'on';
data.nlp.ineq.NEC = 1;
data.nlp.ineq.InNUM = 0;
data.nlp.ineq.eq(1) = {'u(1)+u(2)+u(3)+u(4)-1'};
data.nlp.ineq.Tol = 0.000001;
data.nlp.ineq.PenaltyFun = 'on';
data.nlp.ineq.PenaltyCoe = [100];
% --------------------------------------------------- %
% Options for setting of the final output:
% --------------------------------------------------- %
data.options.intermediate = 'on';
data.options.display = 'on';
data.options.title = 'on';
data.options.state = 'on';
data.options.control = 'on';
data.options.ConvergCurve = 'on';
data.options.Pict_Format = 'eps';
data.options.report = 'on';
data.options.commands = {''};
data.options.trajectories = data.odes.NUMs;
data.options.profiler = 'off';
data.options.multistart = 1;
data.options.action = 'single-optimization';
% --------------------------------------------------- %
% Call of the main function (you do not change this!):
% --------------------------------------------------- %
[data]=dotcvp_main(data)
Código correspondiente a la implementación de Matlab del caso II con la matriz N2
clear mex; clear all; close all%
% --------------------------------------------------- %
% Initialization:
% --------------------------------------------------- %
data.name = 'Red_glicolisis_N2';
data.compiler = 'None'; %['None'|'FORTRAN']
% --------------------------------------------------- %
% Settings for IVP (ODEs, sensitivities):
% --------------------------------------------------- %
data.odes.parameters ={'C=1','k1=1','k2=1','k3=1','k4=1','k5=1'};
data.odes.res(1) ={'0'}; % S
data.odes.res(2) ={'u(1)*(y(1)/(y(1)+1))-u(2)*(y(2)/(y(2)+1))'}; %X1
data.odes.res(3) ={'u(2)*(y(2)/(y(2)+1))-u(3)*(y(3)/(y(3)+1))'}; %X2
data.odes.res(4) ={'u(2)*(y(2)/(y(2)+1))+u(3)*(y(3)/(y(3)+1))-
u(4)*(y(4)/(y(4)+1))'};
data.odes.res(5) = {'u(4)*(y(4)/(y(4)+1))'}; %P
data.odes.res(6) = {'1'};
data.odes.ic = [1 0 0 0 0 0];
data.odes.NUMs = size(data.odes.res,2); %number of state variables (y)
data.odes.tf = 10;
data.odes.MaxNumStep = 500;
data.odes.NonlinearSolver = 'Newton';
data.odes.LinearSolver = 'Dense';
data.odes.LMM = 'Adams';
data.odes.RelTol = 1*10^(-9);
data.odes.AbsTol = 1*10^(-9);
data.sens.SensAbsTol = 1*10^(-9);
data.sens.SensMethod = 'Simultaneous';
data.sens.SensErrorControl= 'on';
% --------------------------------------------------- %
% NLP definition:
% --------------------------------------------------- %
data.nlp.RHO = 4;
data.nlp.problem = 'min';
data.nlp.J0 = 'y(6)';

Anexo
51
data.nlp.u0 = [0.01 0.01 0.01 0.01];
data.nlp.lb = [0 0 0 0];
data.nlp.ub = [1 1 1 1];
data.nlp.solver = 'FMINCON';
data.nlp.SolverSettings = 'None';
data.nlp.NLPtol = 1*10^(-7);
data.nlp.GradMethod = 'SensitivityEq';
data.nlp.MaxIter = 1000;
data.nlp.MaxCPUTime = 60*60*0.5;
data.nlp.FreeTime = 'on';
data.nlp.t0Time = [data.odes.tf/data.nlp.RHO];
data.nlp.lbTime = 0.01;
data.nlp.ubTime = data.odes.tf;
% --------------------------------------------------- %
% Equality constraints (ECs):
% --------------------------------------------------- %
data.nlp.eq.status = 'on';
data.nlp.eq.NEC = 1;
data.nlp.eq.eq(1) = {'y(5)-0.75'};
data.nlp.eq.time(1) = data.nlp.RHO;
data.nlp.eq.PenaltyFun = 'on';
data.nlp.eq.PenaltyCoe = [100.0];
% --------------------------------------------------- %
% Inequality /path/ constraints (INECs):
% --------------------------------------------------- %
data.nlp.ineq.status = 'on';
data.nlp.ineq.NEC = 1;
data.nlp.ineq.InNUM = 0;
data.nlp.ineq.eq(1) = {'u(1)+u(2)+u(3)+u(4)-1'};
data.nlp.ineq.Tol = 0.000001;
data.nlp.ineq.PenaltyFun = 'on';
data.nlp.ineq.PenaltyCoe = [100];
% --------------------------------------------------- %
% Options for setting of the final output:
% --------------------------------------------------- %
data.options.intermediate = 'on';
data.options.display = 'on';
data.options.title = 'on';
data.options.state = 'on';
data.options.control = 'on';
data.options.ConvergCurve = 'on';
data.options.Pict_Format = 'eps';
data.options.report = 'on';
data.options.commands = {''};
data.options.trajectories = data.odes.NUMs;
data.options.profiler = 'off';
data.options.multistart = 1;
data.options.action = 'single-optimization';
% --------------------------------------------------- %
% Call of the main function (you do not change this!):
% --------------------------------------------------- %
[data]=dotcvp_main(data)
Código correspondiente a la implementación de Matlab del caso II con la matriz N1 y
dinámica de enzimas
clear mex; clear all; close all%
% --------------------------------------------------- %
% Initialization:
% --------------------------------------------------- %
data.name = 'Red_glicolisis_N1_dinamica';
data.compiler = 'None';
% --------------------------------------------------- %
% Settings for IVP (ODEs, sensitivities):
% --------------------------------------------------- %
data.odes.parameters ={'C=1','k1=1','k2=1','k3=1','k4=1','k5=1'};
data.odes.res(1) ={'-y(6)*(y(1)/(y(1)+1))'}; % S
data.odes.res(2) ={'y(6)*(y(1)/(y(1)+1))-y(7)*(y(2)/(y(2)+1))'}; %X1
data.odes.res(3) ={'y(7)*(y(2)/(y(2)+1))-y(8)*(y(3)/(y(3)+1))'}; %X2

Anexo
52
data.odes.res(4) ={'y(7)*(y(2)/(y(2)+1))+y(8)*(y(3)/(y(3)+1))-
y(9)*(y(4)/(y(4)+1))'}; %X3
data.odes.res(5) = {'y(9)*(y(4)/(y(4)+1))'}; %P
data.odes.res(6) = {'u(1)-0.5*y(6)'};
data.odes.res(7) = {'u(2)-0.5*y(7)'};
data.odes.res(8) = {'u(3)-0.5*y(8)'};
data.odes.res(9) = {'u(4)-0.5*y(9)'};
data.odes.res(10) = {'1'};
data.odes.ic = [1 0 0 0 0 0 0 0 0 0];
data.odes.NUMs = size(data.odes.res,2);
data.odes.tf = 10;
data.odes.MaxNumStep = 750;
data.odes.NonlinearSolver = 'Newton';
data.odes.LinearSolver = 'Dense';
data.odes.LMM = 'BDF';
data.odes.RelTol = 1*10^(-8);
data.odes.AbsTol = 1*10^(-8);
data.sens.SensAbsTol = 1*10^(-8);
data.sens.SensMethod = 'Simultaneous';
data.sens.SensErrorControl= 'on';
% --------------------------------------------------- %
% NLP definition:
% --------------------------------------------------- %
data.nlp.RHO = 4;
data.nlp.problem = 'min';
data.nlp.J0 = 'y(10)';
data.nlp.u0 = [0.01 0.01 0.01 0.01];
data.nlp.lb = [0 0 0 0];
data.nlp.ub = [1 1 1 1];
data.nlp.solver = 'DE';
data.nlp.SolverSettings = 'None';
data.nlp.NLPtol = 1*10^(-6);
data.nlp.GradMethod = 'SensitivityEq';
data.nlp.MaxCPUTime = 60*60*0.5;
data.nlp.FreeTime = 'on';
data.nlp.t0Time = [data.odes.tf/data.nlp.RHO];
data.nlp.lbTime = 0.01;
data.nlp.ubTime = data.odes.tf;
% --------------------------------------------------- %
% Equality constraints (ECs):
% --------------------------------------------------- %
data.nlp.eq.status = 'on';
data.nlp.eq.NEC = 1;
data.nlp.eq.eq(1) = {'y(5)-0.75'};
data.nlp.eq.time(1) = data.nlp.RHO;
data.nlp.eq.PenaltyFun = 'on';
data.nlp.eq.PenaltyCoe = [100.0];
% --------------------------------------------------- %
% Inequality /path/ constraints (INECs):
% --------------------------------------------------- %
data.nlp.ineq.status = 'on';
data.nlp.ineq.NEC = 5;
data.nlp.ineq.InNUM = 4;
data.nlp.ineq.eq(1) = {'y(6)+0'};
data.nlp.ineq.eq(2) = {'y(7)+0'};
data.nlp.ineq.eq(3) = {'y(8)+0'};
data.nlp.ineq.eq(4) = {'y(9)+0'};
data.nlp.ineq.eq(5) = {'u(1)+u(2)+u(3)+u(4)-0.5'};
data.nlp.ineq.Tol = 0.000001;
data.nlp.ineq.PenaltyFun = 'on';
data.nlp.ineq.PenaltyCoe = [1 1 1 1 100];
% --------------------------------------------------- %
% Options for setting of the final output:
% --------------------------------------------------- %
data.options.intermediate = 'on';
data.options.display = 'on';
data.options.title = 'on';
data.options.state = 'on';
data.options.control = 'on';
data.options.ConvergCurve = 'on';

Anexo
53
data.options.Pict_Format = 'eps';
data.options.report = 'on';
data.options.commands = {''};
data.options.trajectories = data.odes.NUMs;
data.options.profiler = 'off';
data.options.multistart = 1;
data.options.action = 'single-optimization';
% --------------------------------------------------- %
% Call of the main function (you do not change this!):
% --------------------------------------------------- %
[data]=dotcvp_main(data)
Código correspondiente a la implementación de Matlab del caso II con la matriz N2 y
dinámica de enzimas
clear mex; clear all; close all%
% --------------------------------------------------- %
% Initialization:
% --------------------------------------------------- %
data.name = 'Red_glicolisis_N1_dinamica';
data.compiler = 'None';
% --------------------------------------------------- %
% Settings for IVP (ODEs, sensitivities):
% --------------------------------------------------- %
data.odes.parameters ={'C=1','k1=1','k2=1','k3=1','k4=1','k5=1'};
data.odes.res(1) ={'0'}; % S
data.odes.res(2) ={'y(6)*(y(1)/(y(1)+1))-y(7)*(y(2)/(y(2)+1))'}; %X1
data.odes.res(3) ={'y(7)*(y(2)/(y(2)+1))-y(8)*(y(3)/(y(3)+1))'}; %X2
data.odes.res(4) ={'y(7)*(y(2)/(y(2)+1))+y(8)*(y(3)/(y(3)+1))-
y(9)*(y(4)/(y(4)+1))'}; %X3
data.odes.res(5) = {'y(9)*(y(4)/(y(4)+1))'}; %P
data.odes.res(6) = {'u(1)-0.5*y(6)'};
data.odes.res(7) = {'u(2)-0.5*y(7)'};
data.odes.res(8) = {'u(3)-0.5*y(8)'};
data.odes.res(9) = {'u(4)-0.5*y(9)'};
data.odes.res(10) = {'1'};
data.odes.ic = [1 0 0 0 0 0 0 0 0 0];
data.odes.NUMs = size(data.odes.res,2);
data.odes.tf = 10;
data.odes.MaxNumStep = 750;
data.odes.NonlinearSolver = 'Newton';
data.odes.LinearSolver = 'Dense';
data.odes.LMM = 'BDF';
data.odes.RelTol = 1*10^(-8);
data.odes.AbsTol = 1*10^(-8);
data.sens.SensAbsTol = 1*10^(-8);
data.sens.SensMethod = 'Simultaneous';
data.sens.SensErrorControl= 'on';
% --------------------------------------------------- %
% NLP definition:
% --------------------------------------------------- %
data.nlp.RHO = 4;
data.nlp.problem = 'min';
data.nlp.J0 = 'y(10)';
data.nlp.u0 = [0.01 0.01 0.01 0.01];
data.nlp.lb = [0 0 0 0];
data.nlp.ub = [1 1 1 1];
data.nlp.solver = 'DE';
data.nlp.SolverSettings = 'None';
data.nlp.NLPtol = 1*10^(-6);
data.nlp.GradMethod = 'SensitivityEq';
data.nlp.MaxCPUTime = 60*60*0.5;
data.nlp.FreeTime = 'on';
data.nlp.t0Time = [data.odes.tf/data.nlp.RHO];
data.nlp.lbTime = 0.01;
data.nlp.ubTime = data.odes.tf;
% --------------------------------------------------- %
% Equality constraints (ECs):
% --------------------------------------------------- %
data.nlp.eq.status = 'on';
data.nlp.eq.NEC = 1;
data.nlp.eq.eq(1) = {'y(5)-0.75'};

Anexo
54
data.nlp.eq.time(1) = data.nlp.RHO;
data.nlp.eq.PenaltyFun = 'on';
data.nlp.eq.PenaltyCoe = [100.0];
% --------------------------------------------------- %
% Inequality /path/ constraints (INECs):
% --------------------------------------------------- %
data.nlp.ineq.status = 'on';
data.nlp.ineq.NEC = 5;
data.nlp.ineq.InNUM = 4;
data.nlp.ineq.eq(1) = {'y(6)+0'};
data.nlp.ineq.eq(2) = {'y(7)+0'};
data.nlp.ineq.eq(3) = {'y(8)+0'};
data.nlp.ineq.eq(4) = {'y(9)+0'};
data.nlp.ineq.eq(5) = {'u(1)+u(2)+u(3)+u(4)-0.5'};
data.nlp.ineq.Tol = 0.000001;
data.nlp.ineq.PenaltyFun = 'on';
data.nlp.ineq.PenaltyCoe = [1 1 1 1 100];
% --------------------------------------------------- %
% Options for setting of the final output:
% --------------------------------------------------- %
data.options.intermediate = 'on';
data.options.display = 'on';
data.options.title = 'on';
data.options.state = 'on';
data.options.control = 'on';
data.options.ConvergCurve = 'on';
data.options.Pict_Format = 'eps';
data.options.report = 'on';
data.options.commands = {''};
data.options.trajectories = data.odes.NUMs;
data.options.profiler = 'off';
data.options.multistart = 1;
data.options.action = 'single-optimization';
% --------------------------------------------------- %
% Call of the main function (you do not change this!):
% --------------------------------------------------- %
[data]=dotcvp_main(data)

Bibliografía
55
Bibliografía
Adiwijaka, B. S., Barton, P. I. y Tidor, B. Biological network design strategies: discovery
through dynamic optimization. Molecular biosystems, 2(12):650-659, 2006.
Alberts, B., Wilson, J., Johnson, A., Hunt, J., Ra, M. y Roberts, K. Molecular biology of the
cell, 5th ed. Garland Science, 2007.
Angira, R. y Santosh, A. Optimization of dynamic systems: A trigonometric differential
evolution approach. Comp. & Chem. Eng., 31(9):1055-1036, 2007.
Balsa-Canto, E., Banga, J. R. AMIGO: A model identification toolbox based on global
optimization. ICSB (11th International Conference in System Biology), Edinburgh, Escocia, 10-
16 October 2010.
Balsa-Canto, E., Vassiliadis, V. y Banga, J. R. Dynamic optimization of single- and multi-stage
systems using a hybrid stochastic-deterministic method. Ind. Eng. Chem. Res., 44:1514-1523,
2005.
Balsa-Canto, E., Banga, J. R., Alonso, A. A. y Vassiliadis, V. S. Dynamic optimization of
distributed parameter systems using second-order directional derivatives. Ind. Eng. Chem.
Res., 43:6756-6765, 2004.
Balsa-Canto, E. Algoritmos eficientes para la optimización dinámica de procesos distribuidos.
Tesis doctoral, Universidad de Vigo, España, 2001.
Balsa-Canto, E., Banga, J. R., Alonso, A. A. y Vassiliadis, V. S. Dynamic optimization of
chemical and biochemical processes using restricted second order information. Comp. &
Chem. Eng., 25(4-6):539-546, 2001.
Banga, J. R. Optimization in computational systems biology. BMC Systems Biology, 2(47)
2008.
Banga, J.R. and E. Balsa-Canto (2008) Parameter estimation and optimal experimental design.
Essays in Biochemistry, 45:195–210.
Banga, J. R., Balsa-Canto, E., Moles, C. G. y Alonso, A. A. Dynamic optimization of
bioprocesses: efficient and robust numerical strategies. J. Biotechnol., 117(4):407-419, 2005.
Banga, J. R., Moles, C. G. y Alonso, A. A. Global optimization of bioprocesses using stochastic
and hybrid methods. En “Frontiers in global optimization”, editado por Floudas, C. A. y
Pardalos, P. M., Nonconvex Optimization and Its Applications, Kluwer Academic Publishers,
74:45-70, 2003.
Banga, J. R. y Seider, W. D. Global optimization of chemical processes using stochastic
algorithms. En “State of the art in global optimization”, editado por Floudas, C. A. y
Pardalos, P. M., Kluwer Academic Pub., Dordrecht, Holanda, 563-583, 1996.
Banga, J. R., Alonso, A. A. y Singh, R. P. Stochastic optimal control of fed-batch bioreactors.
Presentado en “AIChE Annual Meeting”, San Francisco, Estados Unidos, 1994a.

Bibliografía
56
Banga, J. R., Alonso, A. A., Martin, R. I. P. y Singh, R. P. Optimal control of heat and mass
transfer in food and bioproducts processing. Comp. & Chem. Eng., 18:S699-S705, 1994b.
Bartl, M., Li, P. y Schuster, S. Modelling the optimal timing in metabolic pathway activation -
Use of Pontryagin's Maximum Principle and role of the Golden section. BioSystems, 101:67-77,
2010.
Bartl, M., Kötzing, M., Kaleta, C., Schuster, S., y Li, P. Just-in-Time Activation of a Glycolysis
Inspired Metabolic Network – Solution with a Dynamic Optimization Approach. In Proc. 55th
International Scientific Colloquium, Ilmenau, Alemania, 217-222, 2010.
Beard, D. A., Liang, S.D. y Qian, H., Energy balance for analysis of complex metabolic
networks, Biophys J. 83: 79-86, 2002.
Bellman, R. Dynamic Programming. Princeton University Press, Nueva Jersey, Estados Unidos
1957.
Bermudez, A. y Martínez, A. A state constrained optimal-control problem related to the
sterilization of canned foods. Automatica, 30(2):319-329, 1994.
Biegler, L. T. An overview of simultaneous strategies for dynamic optimization. Chem Eng. And
Procesing, 46: 1043-1053, 2007.
Biegler, L. T., Ghattas, O., Heinkenschloss, M. y van Bloemen Waanders, B. Large-scale PDE-
constrained optimization. Lecture Notes in Computer Science and Engineering, 30, Springer,
Nueva York, Estados Unidos, 2003.
Brown, A., J. Enzyme action. J. Chem. Soc., 81:373-386, 1902.
Bryson, A. E. Dynamic Optimization. Ed. Addison Wesley Longmann, Inc. Washington,
Estados Unidos, 1999.
Bryson, A. E. y Ho, Y. C. Applied optimal control. Hemisphere, Washington, Estados Unidos,
1988.
Bryson, A. E. y Ho, Y. C. Applied optimal control: optimization, estimation and control.
Editorial Taylor and Francis. Nueva York, Estados Unidos, 1975.
Chen, W. W., Niepel, M. y Sorger, P. K. Classic and contemporary approaches to modeling
biochemical reactions. Genes & Development, 24:1861-1875, 2010.
Cervantes, A. y Biegler, L. T. A stable elemental decomposition for dynamic process
optimization. J. Comput. Appl. Math., 120(1):41-57, 2000.
Chang, Y. J. y Sahidis, N.V. Optimization of metabolic pathways under stability considerations.
Comp. & Chem. Eng, 29(3):467-479, 2005.

Bibliografía
57
Chang, T. N. y Ma, Y. H. Application of optimal control strategy to hybrid microwave and
radiant heat freeze drying system. En “Drying ‘85”, editado por Toei, R. y Mujumdar, A. S.,
Hemisphere Pub., Nueva York, Estados Unidos, 249-253,1985.
Coleman, T., Branch, M. A. y Grace, A. Optimization Toolbox for use with MATLAB Unser’s
Guide Version 2, 1998.
Cornish-Bowden, A. The Pursuit of Perfection: Aspects of Biochemical Evolution. Oxford
University Press, USA, 2004.
Covert, M. W. y Palsson B., Transcriptional Regulation in Constraints-based Metabolic Models
of Escherichia coli. J. Biol. Chem 277: 28058-64. 2002
Dekel, E. y Alon U., Optimality and evolutionary tuning of the expresión level of a protein.
Nature, 436: 588-692, 2005.
Dorigo, M. y Stützle, T. The ant colony optimization metaheuristic: algorithms, applications
and advances. Capítulo 9 en “Handbook of metaheuristic”, 251-286. Kluwer Academic
Publishers, 2003.
Dorigo, M., Maniezzo, V. y Colorni, A. The ant system: optimization by a colony of
cooperationg agents. IEEE Trans.Syst.Man Cy. B, 26(1):1-13, 1996.
Dréo, J. y Siarry, P. An ant colony algorithm aimed at dynamic continuous optimization
Methods and Case Studies, Springer, 2006.
Eliceche, A. M., Corvalan, S. M., Roman, M. F. S. y Ortiz, I. Minimum membrane area of an
emulsion pertraction process for Cr, removal and recovery. Comput. Chem. Eng., 29(6):1483-
1490, 2005.
Exler, O. y Schittkowski, K. A trust region SQP algorithm for mixed-integer nonlinear
programming. Optimization letters, 1(3):269-280, 2007.
Exler, O., Antelo, L. T., Egea, J. A., Alonso, A. A. y Banga, J. R. A Tabu search-based
algorithm for mixed-integer nonlinear problems and its application to integrated process and
control system design. Comp. & Chem. Eng, 32(8):1877-1891, 2008.
Flores-Tlacuahuac, A., Biegler, L. T. y Saldivar-Guerra, E. Dynamic optimization of HIPS
open-loop unstable polymerization reactors. I&EC Res., 44(8):2659-2674, 2005.
Floudas, C. A., Recent advances in global optimization for process sysnthesis, desing and
control: Enclosure of all solutions. Comp. & Chem. Eng. S:963-973, 1999.
Furlonge, H. I., Pantelides, C. C. y Sorensen, E. Optimal operation of multivessel batch
distillation columns. Am. Inst. Chem. Eng. J., 45(4):781-800, 1999.
Gadkar, K. G., Doyle, F. J., Edwards, J. S. y Mahadevan, R. Estimating optimal profiles of
generic alterations using constraint-based models. Biothechnology and Bioengineering,
89(2):243-351, 2005.

Bibliografía
58
García, M.-S. G. Métodos numéricos y software para la optimización dinámica de bio-procesos
Tesis doctoral, Universidad de Vigo, España, 2007.
Gill, P. E., Murray, W. y Wright, M. H. Practical optimization. Academic Press, Nueva York,
Estados Unidos, 1981.
Goulcher, R. y Casares, J. J. The solution of steady-state chemical engineering optimisation
problems using a random-search algorithm. Comp. & Chem. Eng., 2:33-36, 1978.
Giuseppin, M. y van Riel, N. Metabolic modeling of Saccharomyces cerevisiae using the
optimal control of homeostasis: A cybernetic model definition. Metabolic Engineering, 2:14-33,
2000.
Guldberg, C. M. y Waage, P., Prakt, J. Chm., 127. 69. 1879.
Guntern, C., Keller, A. H. y Hungerbühler, K. Economic optimization of an industrial semi-bath
reactor applying dynamic programming. Ind. Eng. Chem. Res, 37(10):4017-4022, 1998.
Guss, C. E., Boender, E. y Romejin, H. E. Stochastic methods. En “Handbook of global
optimization”, editado por Horst, R. y Pardalos, P. M. Kluwer Academic Pub., Dordrecht,
Holanda, 1995.
Hatzimanikatis, V., Floudas, C. A. y Bailey, J. E. Analysis and design of metabolic reaction
network via mixed-integer linear optimization. Aiche Journal, 42(5):1277-1292, 1996.
Heinrich, R. y Schuster, S.The modelling of metabolic systems. structure, control and
optimality, BioSystems, 47:61-77, 1998.
Heinrich, R. y Schuster, S. The regulation of cellular systems. Chapman & Hall. 1996.
Heinrich, R., Schuster, S. y Holzhütter, H. G. Mathematical analysis of enzymic reaction
systems using optimization principles. Eur. J. Biochem., 201(1):1-21, 1991.
Hirmajer, T., Balsa-Canto, E. y Banga, J. R. DOTcvpSB, a software toolbox for dynamic
optimization in systems biology. BMC Bioinformatics, 10:199, 2009.
Horst, R. y Pardalos, P. M. Handbook of global optimization. Kluwer Academic, 1995.
Ishikawa, T., Natori, Y., Liberis, L. y Pantelides, C. C. Modelling and optimisation of an
industrial batch process for the production of dioctyl phthalate. Comp. & Chem. Eng.,
21:S1239-S1244, 1997.
Kameswaran, S. y Biegler, L. T. Simultaneous dynamic optimization strategies: recent
advances and challenges. Comp. & Chem. Eng, 30 (10-12):1560-1575, 2006.
Kennedy, J. y Eberhart, R. C. Swarn intelligence. Morgan Kaufmann Publishers, 2003.
Kennedy, J. y Eberhart, R. C. The particle swarn: social adaptation in information processing
system. Capítulo en “New ideas in optimization”, McGraw Hill, 379-387, 1999.
Kitano, H. Systems biology: a brief overview. Science, 295:1662–1664, 2002.

Bibliografía
59
Klipp, E., Liebermeister, W., Wierling, C., Kowald, A., Lehrach, H. y Herwing, R. Systems
biology: A textbook. Wiley-VCH, 2010.
Klipp, E., Herwig, R., Kowald, A., Wierling, C. y Lehrach, H. Systems Biology in Practice:
Concepts, Implementation and Application. Wiley-VCH, 2005.
Klipp, E., Heinch, H. y Holzhütter, H. G. Prediction of temporal gene expression. Metabolic
optimization by re-distribution of enzymes activites. Eur. J. Biochem., 269:5406-5413, 2002.
Kirkpatrick, S., Gelatt, J. C. D. y Vecchi, M. P. Optimization by simulated annealing.
Science, 220:671-680, 1983.
Laarhoven, P. J. M. y Aarts, E. H. L. Simulated Annealing: theory and applications. Reidel
Publishing Company, Dordrecht, Holanda, 1987.
Lang, Y-D., Cervantes, A. y Biegler, L.T. Dynamic optimization of a batch crystallization
process. I&EC Res, 38(4)1469, 1998.
Lebiedz, D. Exploiting optimal control for target-oriented manipulation of (bio)chemical
systems: a model-based approach to specific modification of self-organized dynamics. Int. J.
Mod. Phys. B, 19(25):3763-3798, 2005.
Lebiedz, D. y Maurer, H. External optimal control of self-organisation dynamics in a
chemotaxis reaction diffusion system. IEE Proc. Syst. Biol., 2:222-229, 2004.
Lee J. M., Gianchadani E. P., Papin J. A., Flux balance analysis in the era of metabolomics,
Briefings in Bioinformatics., 7:140-150, 2006
Lee, S., Phalakonkule, C., Domach, M. M. y Grossmann, I. E. Recursive MILP model for
finding all the alternate optima in LP models for metabolic networks. Comp. & Chem. Eng,
24(2-7):711-716, 2000.
Lehninger, A., Nelson, D. L., y Cox, M. M. Principles of Biochemistry, 5th ed. W. H. Freeman,
2008.
Leng, X. y Muller, H. G. Time ordering of gene coexpression. Biostatistics, 7(4):569-584, 2006.
Luus, R. On the application of dynamic iterative programming to singular optimal control
problems. IEEE Trans Autom. Control, 37(11):1802, 1992.
Luus, R. y Jaakola, T. H. I. Optimisation of non-linear functions subject to equality constraints.
IEC Process. Des. Dev, 12:380-383, 1973.
Mahadevan, R., Edwards, J.S. y Doyle, F. J. Dynamic Flux Balance Analysis of Diauxic Growth
in Escherichia coli. Biophysical Journal, 83:1331-1340, 2002.
Nielsen, J. Principles of optimal metabolic network operation. Molecular System Biology, 3:2,
2007.
Ou, J., Yamada, T., Nagahis, K., Hirasawa, T., Furusawa, C., Yomo, T., y Shimizu, H. Dynamic
change in promoter activation during lysine biosynthesis in Escherichia coli cells. Molecular
BioSystems, 4:128-134, 2008.

Bibliografía
60
Oyarzún, D. A., Ingalls, B.P., Middleton, R.H., Kalamatianos, D. Sequential activation of
metabolic pathways: a dynamic optimization approach. Bulletin of Mathematical Biology,
71:1851, 2009.
Oyarzún, D. A control-theoretic approach to dynamic optimization of metabolic networks. Tesis
Doctoral. Hamilton Institute, 2009.
Palsson B., Properties of Reconstructed Networks, Cambridge university press, 2006
Patil, K. R., Akesoon, M. y Nielsen, J. Use of genome-scale microbial models for metabolic
engineering. 2004.
Pollard, G. P. y Sargent, R. W. H. Off line computation of optimum controls for a plate
distillation column. Automatica, 6:59-76, 1970.
Raman, K. y Chandra, N. Flux balance analysis of biological systems: applications and
challenges. Briefings in Bioinformatics, 10:435–449, 2009.
Riascos, C. A. M. y Pinto, J. M. Optimal control of bioreactors: a simultaneous approach for
complex systems. Chem. Eng. J., 99(1):23-24, 2004.
Rechenberg, I. Evolutionsstrategie: Optimizierung Technischer Systeme nach. Prinzipiender
Biologischen Evolution. Frommann-Holzboog, Sttutgart, Alemania, 1973.
Runarsson, T. P. y Yao, X. Stochastic ranking for constrained evolutionary optimization. IEEE
Trans. Evol. Comp., 4:284-294, 2000.
Savageau, M. A. A theory of alternative designs for biochemical control systems. Biomedica
Biochimica Acta, 44(6):875-880, 1985.
Schlüter, M., Egea, J. A. y Banga, J. R. Extended ant colony optimization for non-convex mixed
integer nonlinear programming. Computers & Operations Research, 36(7)2217-2229, 2009.
Schwefel, H. P. Evolution and optimum seeking. Wiley, Nueva York, Estados Unidos, 1995.
Serban, R., S. Li y Petzold, L. R. Adaptive algorithms for optimal control of timedependent
partial differential-algebraic equation systems. Int. J. Numer. Eng., 57:1457-1469, 2003.
Srinivasan, B., Palanki, S. y Bonvin, D. Dynamic optimization of batch processes I.
Characterization of the nominal solution. Comp. & Chem. Eng., 27:1-26, 2003.
Storn, R. y Price, K. Differential Evolution - a simple and efficient heuristic for global
optimization over continuous spaces. J. Global Optim., 11:341-359, 1997.
Tholudur, A. y Ramirez, W. F. Obtaining smoother singular arc profiles using modified
Iterative Dynamic Programming algorithm. Int. J. Control, 68(5):115-1128, 1997.
Torres, N.y Voit, E. Pathway analysis and Optimization in Metabolic Engineering. Cambridge
University Press, 2002.

Bibliografía
61
Vassiliadis, V. S., Pantelides, C. C. y Sargent, R. W. H. Solution of a class of multistage
dynamic optimization problems. 1. Problems without path constraints. Ind. Eng. Chem. Res.,
33(9):2111-2122, 1994.
Vassiliadis, V. S. Computational solution of dynamic optimization problems with general
differential-algebraic constraints. Tesis doctoral, Imperial College, Universidad de Londres,
Reino Unido, 1993.
Varma, A. y Palsson, B. Metabolic fux balancing: Basic concepts, scientific and practical use.
Nature BioTechnology, 12:994-998, 1994.
Vital-López, F. G., Armaou, A., Nikolaev, E. V. y Maranas, C. D. A computational procedure
for optimal engineering interventions using kinetic models of metabolism. Biotechnology
progress, 22(6):1507-1517, 2006.
Wagner, N., Pross, A. y Tannenbaum, E. Selection advantage of metabolic over non-metabolic
replicators. BioSystems, 99:126-129, 2010.
Wang, F. S., Su, T. L. y Jang, H. J. Hybrid differential evolution for problems of kinetic
parameter estimation and dynamic optimization of an etanol fermentation process. Industrial
and Engineering Chemistry Research, 40(13):2876-2885, 2001.
Zaslaver, A., Mayo, A., Rosenberg, R., Bashkin, P., Sberro, H., Tsalyuk, M., Surette, M. y
Alon,V. Just-in-time transcription program in metabolic pathways. Nature Genetics, 36(5):486-
491, Mayo 2004.
van Riel, N., Giuseppin, M., y Verrips, C. Dynamic optimal control of homeostasis: an
integrative systems approach for modeling of the central nitrogen metabolism in
Saccharomyces cerevisiae. Metabolic Engineering, 2:14-33, 2000.