modelos de clasificaciÓn basados en mÁquinas de vectores...
TRANSCRIPT

1
UNIVERSIDAD NACIONAL DE EDUCACIÓN A DISTANCIA
UNED
FACULTAD DE CIENCIAS
MASTER EN MATEMÁTICAS AVANZADAS EEES
TRABAJO DE FIN DE MASTER
MODELOS DE CLASIFICACIÓN BASADOS EN MÁQUINAS DE VECTORES SOPORTE
Jorge Daniel Mello Román
Tutor: Dr. Eduardo Ramos Méndez
2012

2
ÍNDICE
- Introducción 3
Parte Teórica
- Clasificación en Minería de Datos 4
- Máquinas de Vectores Soporte 6
- Máquinas Lineales de Vectores Soporte 9
- Máquinas No Lineales de Vectores Soporte 16
Parte Práctica
- Construcción de un Modelo de Clasificación con 21
Máquinas de Vectores Soporte.
- Conclusión 29
- Bibliografía 30

3
INTRODUCCIÓN
Las Máquinas de Vectores Soporte (SVM – Support Vector Machines) son un conjunto de algoritmos de aprendizaje supervisado que construye un hiperplano en un espacio de dimensionalidad muy alta. Se utiliza en problemas de clasificación, para reconocimiento de patrones, inteligencia artificial, optimización, entre otros.
Este trabajo de investigación tiene como propósito estudiar las Máquinas de Vectores Soporte como herramienta de clasificación. En una primera parte teórica describiremos lo concerniente al problema de clasificación en Minería de datos y desarrollaremos los fundamentos teóricos de las Máquinas Lineales y No Lineales de Vectores Soporte para construir modelos de clasificación.
En una segunda parte práctica presentaremos algunos aspectos del mercado financiero paraguayo, y del scoring como herramienta de acceso a la información y sus beneficios a la economía.
Con base en la información proveída por una entidad financiera local, construiremos un modelo de aprendizaje basado en Máquinas de Vectores Soporte, utilizando el software GPL WEKA, a fin de discriminar a los clientes de la misma, de acuerdo a su propensión a utilizar los servicios o productos de ahorro que ofrece, finalizando con algunas breves conclusiones sobre el trabajo.

4
PARTE TEÓRICA
CLASIFICACIÓN EN MINERÍA DE DATOS
La clasificación es, fundamentalmente, la tarea de asignar objetos a una de varias categorías predefinidas.
En Minería de Datos es utilizada para detectar mensajes e-mail - spam, categorizar células como malignas o benignas, y clasificar las galaxias basado en sus formas, por citar algunos ejemplos.
En una tarea de clasificación, se ingresa una colección de registros (ejemplos), caracterizado por una tupla (x, y), donde la “x” es el conjunto de atributos y la “y” es un atributo especial designado como la “denominación de clase”, también conocida como categoría. La denominación de clase tiene que ser un atributo discreto, ésta es una característica clave que distingue la clasificación de la regresión (una tarea de modelo predictivo donde “y” es un atributo continuo).
MODELOS DE CLASIFICACIÓN
La clasificación es la tarea de aprendizaje de una función objetivo f , también conocida informalmente como Modelo de Clasificación , que aplica cada conjunto de atributos a una de las denominaciones de clase predefinidas “y”.
Un modelo de clasificación puede servir como una herramienta explicativa para distinguir entre objetos de clases diferentes (modelo descriptivo) y también puede ser usado para predecir la denominación de clases de registros desconocidos (modelo predictivo). Un modelo de clasificación puede ser tratado como una caja negra – como se muestra en la figura 1 -que automáticamente asigna una denominación de clase cuando se presenta el conjunto de atributos de un registro desconocido.
Figura 1
Las técnicas de clasificación son convenientes para predecir o describir conjuntos de datos con categorías binarias o nominales.
SOLUCIÓN DE PROBLEMAS DE CLASIFICACIÓN
Un clasificador o técnica de clasificación es un sistema que utiliza algoritmos de aprendizaje para construir un modelo de clasificación que represente adecuadamente la relación entre el conjunto de atributos y la denominación de clases de los datos ingresados. Entre los clasificadores más utilizados destacamos: Árboles de decisión, Clasificadores basados en Reglas, Redes Neuronales, Máquinas de Vectores Soporte y Clasificadores de Bayes.
ENTRADA SALIDA
MODELO DE
CLASIFICACIÓN
CONJUNTO DE
ATRIBUTOS (x) DENOMINACION DE
CLASE (y)

5
El modelo de clasificación generado por un algoritmo de aprendizaje debería además predecir correctamente las denominaciones de clase de los registros que no formaron parte de la construcción del modelo. Es decir, un objetivo clave del algoritmo de aprendizaje es construir modelos con buena capacidad de generalización.
La figura 2 muestra una aproximación general a la resolución de problemas de clasificación.
Conjunto de Entrenamiento N° Atrib1 Atrib2 Atrib3 Clase
1 Sí Grande 125K No 2 No Mediano 100K No 3 No Pequeño 70K Sí … … … … …
Conjunto de Prueba N° Atrib1 Atrib2 Atrib3 Clase
11 No Pequeño 55K ? 12 Sí Mediano 80K ? 13 Sí Pequeño 110K ?
Figura 2
Primeramente, un conjunto de datos de entrenamiento consistente en registros cuyas denominaciones de clase son conocidas es usado para construir un modelo de clasificación, el cual es posteriormente aplicado a un conjunto de prueba, consistente en registros con denominaciones de clase desconocidas.
La evaluación del desempeño de un modelo de clasificación está basada en los conteos de registros pronosticados correcta e incorrectamente por el modelo, los cuales son tabulados en una tabla conocida como matriz de confusión. La tabla 1 muestra una matriz de confusión para un problema de clasificación binario. Cada entrada ƒij en esta tabla denota el número de registros de la clase i pronosticados para ser de clase j.
Clase Prevista
Clase = 1 Clase = 0
Actual Class
Clase = 1 f11 f10
Clase = 0 f01 f00
Tabla 1
Para comparar el desempeño de diferentes modelos se puede resumir la información proporcionada por la matriz de confusión utilizando una representación métrica de la precisión o exactitud, o en términos de un índice de error:
e re icciones correctas
total e re icciones
(1.1)
e re icciones incorrectas
total e re icciones
(1.2)
Construir
Modelo
Aplicar
Modelo
MODELO
Algoritmo de
Aprendizaje
Inducción
Deducción

6
Toda técnica de clasificación busca construir modelos que logren la mayor exactitud, o equivalentemente, el menor índice de error cuando se aplican al conjunto de prueba.
MÁQUINAS DE VECTORES SOPORTE
La técnica de clasificación Máquinas de Vectores Soporte (SVM – Support Vector Machines) tiene sus raíces en la teoría del aprendizaje estadístico y ha demostrado resultados satisfactorios en muchas aplicaciones prácticas. Funciona muy bien con datos de grandes dimensiones, evitando las complicaciones que acarrea la denominada “mal ición e la imensión”. Otro aspecto único de esta técnica es que representa los límites de decisiones usando un subconjunto de ejemplos de entrenamiento, conocidos como vectores soporte.
MARGEN HIPERPLANO MÁXIMO
La figura 3 muestra la gráfica de un conjunto de ejemplos que pertenecen a dos diferentes clases, representados como cuadrados y círculos. Diremos que un conjunto de datos es linealmente separable, si podemos encontrar un hiperplano tal que todos los cuadrados residan en un lado del hiperplano y todos los círculos residan en otro lado.
Como se muestra en la figura 3 existen infinitos hiperplanos posibles. Aunque sus errores de entrenamiento fueran cero, no hay garantía de que los hiperplanos respondan igualmente bien en ejemplos no vistos previamente.
Por tanto para representar su límite de decisión, el clasificador debe elegir uno de estos hiperplanos, con la intención de que responda acertadamente con los ejemplos de prueba, es decir posea un error de generalización mínimo.
Figura 3
Para tener un panorama claro de cómo las elecciones posibles de hiperplanos diferentes afectan los errores de generalización, consideremos los dos límites de decisión, B1 y B2 mostrados en la figura 4.

7
b21 B2 b22
b11 B1 b12
Figura 4
Ambos límites de decisión pueden separar los ejemplos de entrenamiento en sus clases respectivas sin cometer ningún error de mala clasificación. Cada límite de decisión Bi está asociado con un par de hiperplanos, denotados como bi1 y bi2, respectivamente.
El hiperplano bi1 se obtiene moviendo un hiperplano paralelo lejos del límite de decisión hasta que toca el/los cuadrado/s más cercano/s mientras que bi2 se obtiene moviendo el hiperplano hasta que toca a el/los círculo/s más cercano/s.
La distancia entre estos dos hiperplanos es conocido como el margen del clasificador. Desde el diagrama mostrado en la figura 4, observe que el margen para B1 es considerablemente mayor que para B2. En este ejemplo B1, llega a ser el margen máximo del hiperplano para los ejemplos de entrenamiento.
RAZONES PARA UN MARGEN MAXIMO
Los límites de decisión con márgenes grandes tienden a tener menores errores de generalización que aquellos con márgenes pequeños. Intuitivamente, si el margen es pequeño, entonces cualquier leve perturbación del límite de decisión puede tener un impacto significativo en su clasificación. Los clasificadores que producen límites de decisión con pequeños márgenes son por lo tanto más susceptibles de modelar sobreajustadamente y tienden a una generalización pobre en ejemplos no vistos previamente.
Una explicación más formal relacionada con el margen de un clasificador lineal y el error de generalización, está dado por un principio de aprendizaje estadístico conocido como riesgo de minimización estructural (SRM). Este principio provee un límite superior al error de generalización de un clasificador (R) en términos de su error de entrenamiento (Re), el número de ejemplos de entrenamiento (N) y la complejidad del modelo, conocida también como su capacidad (h).
Más específicamente, con una probabilidad de 1 - n, el error de generalización del clasificador puede ser como máximo

8
(
( )
)
donde es una función creciente monótona de la capacidad h.
Con esta consideración, el riesgo de minimización estructural SRM expresa el error de generalización R en relación al error de entrenamiento y la capacidad del modelo .
La capacidad de un modelo lineal es inversamente proporcional a su margen. Los modelos con márgenes pequeños tienen capacidades mayores porque son más flexibles y pueden encajar con varios conjuntos de entrenamiento distinto a los modelos con márgenes grandes.
De acuerdo al principio SRM, si aumenta la capacidad, el límite de error de generalización también aumentará. Por lo tanto es deseable diseñar clasificadores lineales que maximicen los márgenes de sus límites de decisión, que a su vez minimizará la capacidad del modelo, asegurando que los errores de generalización también sean mínimos.
Un clasificador que cumple este requerimiento son las Máquinas de Vectores Soporte.

9
MÁQUINAS LINEALES DE VECTORES SOPORTE
CONJUNTO SEPARABLE LINEALMENTE
Las Máquinas Lineales de Vectores Soporte son una técnica de clasificación que busca un hiperplano separador con el mayor margen.
Consideremos el problema de clasificación binaria consistente en N ejemplos de entrenamiento. Cada ejemplo está indicado por una tupla (xi, yi) (i = 1,2,…,N); donde xi = (xi1, xi2, … xid)T corresponde al conjunto de atributos para el ejemplo i, y la denominación de clase esté indicada por yi ϵ {-1,1}.
El límite de decisión del clasificador lineal puede ser escrito de la siguiente forma
w · x + b = 0 (1.3)
donde w y b son parámetros del modelo.
La figura 5 muestra un conjunto de entrenamiento en dos dimensiones. Un límite de decisión que divide los ejemplos de entrenamiento en sus respectivas clases está ilustrado como una línea sólida.
Figura 5
Ningún ejemplo debe estar colocado a lo largo del límite de decisión, es decir, satisfacer la ecuación 1.3.
Sean xa y xb dos puntos ubicados en el límite de decisión; entonces {w · xa + b = 0; w · xb + b = 0}. Substrayendo las dos ecuaciones dará como resultado w · ( xa - xb ) = 0, donde xa - xb es un vector paralelo al límite de decisión y tiene dirección desde xa hacia xb. Puesto que el producto escalar es cero, la dirección de w debe ser perpendicular al límite de decisión, como se muestra en la figura 5. Para cualquier cuadrado xs ubicado por encima del límite de decisión, tenemos que
w · xs + b = k, (1.4)
w · x + b = 0
w · x + b = 1
w · x + b = - 1
x1 – x2
x2
x1 d
w

10
donde k > 0. Del mismo modo, para cualquier circulo xc ubicado por debajo del límite de decisión, podemos afirmar que
w · xc + b = k’, (1.5)
donde k’ < 0, Si denominamos a todos los cuadrados como clase +1 y a todos los círculos como clase –1 , entonces podemos predecir la denominación de clase y para cualquier ejemplo de prueba z de la siguiente manera:
{
(1.6)
Consideremos el cuadrado y el círculo más cercano al límite de decisión. Puesto que el cuadrado está ubicado por encima del límite de decisión, debe satisfacer a la ecuación 1.4, para algún valor positivo k, mientras que el círculo debe satisfacer la ecuación 1.5 para algún valor negativo k’.
Podemos obtener los parámetros w y b del límite de decisión de manera que los dos hiperplanos paralelos bi1 y bi2 puedan ser expresados como sigue
(1.7)
El margen del límite de decisión está dado por la distancia entre estos dos hiperplanos.
Para calcular el margen, sea x1 un punto colocado en y un punto colocado en como se muestra en la figura 5; al sustituir estos puntos en las ecuaciones 1.7 el margen d puede ser calculado sustrayendo la segunda ecuación de la primera ecuación:
( ) ‖ ‖
‖ ‖
(1.8)
APRENDIZAJE ESTADÍSTICO CON UN MODELO DE MÁQUINAS LINEALES DE VECTORES SOPORTE
La fase de aprendizaje de las SVM contempla la estimación de los parámetros w, b y del límite de decisión con los datos de entrenamiento.
Los parámetros deben ser elegidos de tal manera que sean cumplidas las siguientes condiciones
(1.9)
Estas condiciones imponen los requerimientos de que todos los ejemplos de entrenamientos de la clase y = 1 (ej.: los cuadrados) deben estar colocados en o por encima del hiperplano , mientras que los ejemplos de la clase y = – 1 (ej.: los círculos) deben estar ubicados en o por debajo del hiperplano

11
Ambas inecuaciones pueden ser resumidas en una forma más compacta como sigue:
( ) (1.10)
Aunque las condiciones precedentes son también aplicables a cualquier clasificador lineal, las SVM imponen un requerimiento adicional de que el margen de su límite de decisión debe ser máximo. Maximizar los márgenes, es equivalente a minimizar la siguiente función objetivo:
( ) ‖ ‖
(1.11)
DEFINICIÓN. La tarea de aprendizaje con las SVM puede ser formalizada como el siguiente problema de optimización con restricciones:
‖ ‖
sujeto a ( )
Como la función objetivo es cuadrática y las restricciones son lineales en los parámetros w y b, puede ser resuelto usando el método de multiplicadores de Lagrange.
Primero debemos rescribir la función objetivo de forma que incluya las restricciones impuestas a la solución. La nueva función objetivo es conocida como Lagrangiano
‖ ‖ ∑
( ( ) ) (1.12)
Donde los parámetros λi son los multiplicadores de Lagrange. El primer término de la del Lagrangiano es el mismo que el de la función objetivo original, mientras el segundo término toma las restricciones.
Es fácil mostrar que la función objetivo original dada en la ecuación 1.11 es minimizada cuando w = 0, un vector nulo cuyos componentes son todos ceros. Esta solución, viola las restricciones dadas en la definición y las soluciones para w y b son imposibles de obtener, por ejemplo si ( ) .
El Lagragiano dado en la ecuación (1.12) incorpora la restricción substrayéndola de la función objetivo original. Asumiendo que λi ≥ 0, está claro que cualquier solución no factible puede solo aumentar el valor del Lagrangiano.
Para minimizar el Lagrangiano, tomamos la derivada de Lp con respecto a w y b, y las hacemos igual a 0.
∑
(1.13)
∑
(1.14)
Como los multiplicadores son desconocidos, todavía no podemos resolver para w y b. Usando las N restricciones transformadas a igualdades, junto con las ecuaciones 1.13 y 1.14 podremos encontrar soluciones factibles para w, b y λi.

12
Pero transformar las restricciones de desigualdades a igualdades, solo es posible si los multiplicadores Lagrange son limitados a ser no negativos.
Lo precedente nos conduce a las siguientes restricciones con multiplicadores de Lagrange, conocidas como condiciones Karush- Kuhn- Tucker (KKT):
λi ≥ 0 (1.15)
λi [( ( ) ] = 0 (1.16)
Muchos de los multiplicadores Lagrange se convertirán en cero después de aplicar la restricción dada en la ecuación 1.16. Esta restricción plantea que el multiplicador Lagrange λi debe ser cero a no ser que el caso de entrenamiento xi satisfaga la ecuación ( ) . Con λi > 0 el punto correspondiente a dicho caso estará ubicado a lo largo de los hiperplanos bi1 o bi2 y es conocido como Vector Soporte.
Los puntos de entrenamiento que no residen a lo largo de estos hiperplanos tienen λi = 0. Las ecuaciones 1.13 y 1.14 también sugieren que los parámetros w, b y λi definen el límite de decisión considerando únicamente los vectores soporte.
El problema puede ser simplificado transformando el Lagrangiano en una función de multiplicadores Lagrange solamente (esto es conocido como el problema dual o forma dual del problema). Para hacer esto, primero sustituimos las ecuaciones 1.13 y 1.14 en la ecuación 1.12. Esto conducirá a la siguiente formulación dual del problema de optimización
∑
∑ (1.17)
Las diferencias claves entre los Lagrangianos primal (original) y dual son las siguientes:
1- El Lagrangiano dual incluye solamente los multiplicadores Lagrange y los datos de entrenamiento, mientras que el Lagrangiano primal incluye tanto a los multiplicadores Lagrange como a los parámetros del límite de decisión. Sin embargo la optimización para ambos problemas de optimización son equivalentes
2- El termino cuadrático en la ecuación 1.17 tiene un signo negativo, lo cual significa que el problema de minimización original que incluye al Lagrangiano primal, Lp, se ha convertido en un problema de maximización incluyendo el Lagrangiano dual, LD
Para conjuntos de datos grandes el problema de optimización dual puede ser resuelto usando técnicas numéricas tales como programación no lineal. Una vez que las λi`s sean encontradas, podemos usar la ecuaciones 1.13 y 1.14 para obtener posibles soluciones para w y b. El límite de decisión puede ser expresado como sigue
(∑ ) (1.18)
El valor b se obtiene resolviendo la ecuación 1.16 para los vectores soporte. Puesto que las λi’s se calculan numéricamente y pueden tener errores numéricos, el valor computado para b puede no ser único, y depende del vector soporte usado en la

13
ecuación 1.16. En la práctica, el valor promedio para b es elegido para ser el parámetro del límite de decisión.
Una vez que los parámetros del límite de decisión sean encontrados, un caso de prueba z se clasifica como sigue:
( ) ( ) (∑
)
Si, ( ) entonces la caso de prueba es clasificada como una de clase positiva; de otro modo está clasificada como de clase negativa.
CONJUNTO NO SEPARABLE LINEALMENTE
La figura 7 muestra un conjunto de datos que es similar a la figura 4, excepto que tiene dos nuevos ejemplos, P y Q. Mientras que el límite de decisión B1 no clasifica a los nuevos ejemplos, B2 los clasifica correctamente, esto no significa que B2 es un límite de decisión mejor que B1 porque los nuevos ejemplos tal vez correspondan al ruido en los datos de entrenamiento. B1 todavía debería ser preferido por encima del B2 porque tiene un margen más ancho, y de este modo, es menos susceptible a sobreajustes.
b21 B2 b22
Q
P
b11 B1 b12
Figura 7
El método que presentamos en esta sección, conocido como el enfoque del margen suavizado (soft-margin), permite a las SVM construir un límite de decisión lineal en situaciones donde las clases no son linealmente separables, tolerando errores de entrenamiento menores. Para hacer esto, el algoritmo de aprendizaje de las SVM debe considerar la contrapartida entre el ancho del margen y el número de errores de entrenamiento cometidos por el límite de decisión lineal.
Aunque la función objetivo original dada en la ecuación 1.11 es todavía aplicable, el límite de decisión B1 ya no satisfará todas las restricciones dadas en la ecuación 1.10. Las desigualdades por lo tanto deben estar restringidas a acomodar datos separables no linealmente. Esto puede ser hecho introduciendo variables de holgura de valores positivos en las restricciones del problema de optimización, como se muestra en las siguientes ecuaciones:

14
(1.19)
donde
Para interpretar el significado de las variables ξi, consideremos el diagrama mostrado en la figura 8. El círculo P es uno de los casos que viola las restricciones dadas en la ecuación 1.9. Denotemos como una línea paralela al límite de decisión que pasa a través del punto P. Se puede demostrar que la distancia entre esta
línea y el hiperplano es
‖ ‖. Donde, rovee una estimación el error
del límite de decisión con respecto al ejemplo de entrenamiento P.
P
Figura 8
En principio podemos aplicar la misma función objetivo anterior imponiendo las condiciones dadas en la ecuación 1.19 para encontrar el límite de decisión.
Al no existir restricciones en el número de errores que puede cometer un límite de decisión, el algoritmo de aprendizaje puede encontrar un límite de decisión con un ancho margen que clasifique erróneamente muchos de los ejemplos de entrenamiento.
Para evitar este problema, la función objetivo debe ser modificada para penalizar el límite de decisión para grandes valores de sus variables de holgura. La función objetivo modificada está dada por la siguiente ecuación:
( ) ‖ ‖
(∑
)
Donde C y k son parámetros arbitrarios que representan la penalidad de la clasificación errónea de los casos de entrenamiento. Para simplificar el problema generalmente se asume k =1. El parámetro C puede ser elegido basado en el rendimiento del modelo en el conjunto de validación.
‖ ‖

15
El Lagrangiano para este problema de optimización incorporando las restricciones respectivas se escribe como sigue:
‖ ‖ (∑
)
∑ { ( ) } ∑
(1.20)
Donde los dos primeros términos corresponden a la función objetivo a ser minimizada, el tercer término representa las restricciones de desigualdades asociadas con las variables de holgura y el último termino resulta de los requerimientos de no negatividad para los valores de ξi`s.
Transformadas las restricciones de desigualdades en restricciones de igualdad, tenemos las siguientes condiciones KKT:
(1.21)
{ ( ) } (1.22)
= 0 (1.23)
Los multiplicadores de Lagrange λi dado en la ecuación 1.22 desaparecen únicamente si los casos de entrenamiento se encuentran a lo largo de las líneas ( ) o tienen ξi > 0. Por otro lado, los multiplicadores de Lagrange dados en la ecuación 1.23 son cero para todas los casos de entrenamiento mal clasificadas (es decir, tenien o i > 0).
Igualando las derivadas de primer orden de L con respecto a w, b y ξi a cero, resultan en las siguientes ecuaciones:
∑
∑
(1.24)
∑
∑
(1.25)
(1.26)
Sustituyendo las ecuaciones 1.24, 1.25 y 1.26 en el Lagrangiano primal, se obtendrá el siguiente Lagrangiano dual:
∑ ∑ ∑
{ (∑ ) }
∑ ( )
∑
∑ (1.27)
El mismo tiende a ser idéntico al Lagrangiano dual para casos linealmente separables (ver ecuación 1.17).
Sin embargo las restricciones impuestas a los multiplicadores de Lagrange λi`s son ligeramente diferentes que para los conjuntos separables linealmente. Los multiplicadores de Lagrange deben cumplir la condición de ser no negativos, . Y además la ecuación 1.26 indica que λi no debe exceder C (considerados no negativos). Por tanto, los multiplicadores de Lagrange para datos conjuntos no separables linealmente son restringidos a .

16
El problema dual puede entonces ser resuelto numéricamente usando técnicas de programación no lineal para obtener los multiplicadores de Lagrange λi. Estos multiplicadores pueden ser remplazados en la ecuación 1.24 y en las condiciones KKT para obtener los parámetros del límite de decisión.
MÁQUINAS NO LINEALES DE VECTORES SOPORTE
Seguidamente presentamos una metodología para aplicar las SVM a conjuntos de datos que tienen un límite de decisión no lineal. El truco aquí es transformar los datos de su espacio de coordenadas original x a un nuevo espacio Φ(x) de modo que el límite de decisión lineal pueda ser usado para separar los casos en el espacio transformado. Después de hacer la transformación, podemos aplicar las metodologías para Máquinas Lineales de Vectores Soporte.
Figura 10
Una transformación no lineal Φ es necesaria para transformar los datos de su espacio característico tradicional a un nuevo espacio donde el límite de decisión se haga lineal.
Por ejemplo, dada la siguiente transformación:
Φ ( ) ( √ )
En el espacio transformado, podemos encontrar los parámetros ( ) tal que:
√
Una dificultad potencial con este método es el que puede acarrear la denominada maldición de la dimensión, frecuente en el manejo de datos de grandes dimensiones. Las Máquinas No lineales de Vectores Soporte evitan este problema usando el método conocido como truco kernel.

17
APRENDIZAJE ESTADÍSTICO CON UN MODELO DE MÁQUINAS NO LINEALES DE VECTORES SOPORTE
A pesar que las aproximaciones de la función de transformación parecen prometedoras, su implementación suscita varias preguntas.
No está claro qué clase de función de transformación debería usarse para asegurar que el límite de decisión lineal pueda ser construido en el espacio transformado.
Aunque la función de transformación apropiada sea conocida, resolver el problema de optimización con restricciones en un espacio altamente dimensional es una tarea complicada en lo referente a los cálculos que deben realizarse.
Para ilustrar estos aspectos y examinar las maneras en que pueden ser abordados podemos asumir que existe una función apropiada, Φ (x), para transformar un conjunto de datos previstos.
Después de la transformación, necesitamos construir un límite de decisión lineal que separe los casos es sus respectivas clases. El límite de decisión lineal en el espacio transformado tiene la siguiente forma w.Φ(x) + b = 0.
La tarea de aprendizaje con Máquinas No Lineales de Vectores Soporte puede ser formalizada como el siguiente problema de optimización
‖ ‖
sujeto a ( ( ) )
La principal diferencia con las Máquinas Lineales de Vectores Soporte es, que en vez de usar los atributos originales x, se utilizan los atributos transformados Φ( ).
Siguiendo el enfoque utilizado para Máquinas Lineales, podemos obtener el siguiente Lagrangiano dual para el problema de optimización con restricciones:
∑
∑ Φ( ) Φ( ) (1.30)
Una vez obtenidas las usando técnicas de programación no lineal, los parámetros
w y b pueden ser encontrados usando las siguientes ecuaciones:
∑ Φ( ) (1.31)
{ (∑ Φ( ) Φ( ) ) } (1.32)
Las cuales son análogas a las ecuaciones 1.13 y 1.16 de las Máquinas Lineales de Vectores Soporte. Finalmente un caso de prueba z se puede clasificar utilizando la siguiente ecuación:
( ) ( Φ( ) ) (∑ Φ( ) Φ( ) ) (1.33)

18
Salvo la ecuación 1.31, podemos notar que los demás cálculos (ecuaciones 1.32 y 1.33) requieren el cálculo de producto escalar de pares de vectores en el espacio transformado Φ( ) Φ( ). Tales cálculos pueden ser bastante engorrosos y acarrear dificultades propias de la alta dimensión de un problema.
Una solución a este problema es el método conocido como truco kernel o núcleo.
TRUCO KERNEL
El producto escalar es a menudo considerado como una medida de similitud entre dos vectores dados. Análogamente, el punto escalar Φ(xi)· Φ(xj), también puede ser considerado como una medida de similitud entre dos casos, xi y xj en el espacio transformado.
El truco kernel es un método para calcular similitud en el espacio transformado usando el conjunto de atributos original.
Consideremos la siguiente función Φ de transformación:
Φ ( ) ( √ √ )
El producto escalar entre dos vectores dados u y v en el espacio transformado sería como sigue:
Φ( ) Φ( ) ( √ √ ) (
√ √ )
=
( ) (1.34)
Este análisis muestra que el producto escalar en el espacio transformado puede ser expresado en términos de una función de similitud en el espacio original.
( ) Φ( ) Φ( ) ( ) (1.35)
La función de similitud, K, que puede ser calculada en el espacio de atributo original es conocida como la función kernel.
El truco kernel ayuda a aclarar algunos de los conceptos acerca de como implementamos las Máquinas No Lineales de Vectores Soporte.
1. No necesitamos saber exactamente el tipo de función de transformación porque las funciones kernel usadas en las Máquinas No Lineales de Vectores Soporte deben satisfacer un principio matemático conocido como Teorema de Mercer. El Teorema de Mercer demuestra que las funciones kernel pueden ser siempre expresadas como el producto escalar entre dos vectores dados en algún espacio altamente dimensional. El espacio transformado mediante funciones Kernel de Máquinas No Lineales de Vectores Soporte, es llamado “Reproducción Kernel del Espacio Hilbert” (RKHS).

19
2. Computar los productos escalares usando funciones kernel es considerablemente menos complicado que usar el conjunto de atributos transformado (x).
3. Como los cálculos se desarrollan en el espacio original, las dificultades asociadas a la dimensionalidad del problema pueden ser evitadas.
La figura 11 muestra un límite de decisión no lineal obtenido mediante las SVM, usando la función kernel polinomial dada en la ecuación 1.35. Un caso de prueba x es clasificada de acuerdo a la siguiente ecuación:
( ) (∑ Φ( ) Φ( ) )
(∑ ( ) )
(∑ ( )
) (1.36)
Donde b es el parámetro obtenido utilizando la ecuación 1.32.
1
0,8
0,6
0,4
0,2
0
0,2 0,4 0,6 0,8
Figura 11
El requisito principal para que la función kernel pueda ser usada con Máquinas No Lineales de Vectores Soporte, es que debe existir una transformación tal que la función kernel calculada para un par de vectores sea equivalente al producto escalar entre esos vectores en el espacio transformado y viceversa. Este requisito puede ser formalmente planteado mediante el teorema de Mercer.
Teorema de Mercer. Una función kernel K puede ser expresada como
( ) ( ) ( )
si y solo si, para cualquier función g(x) tal que ∫ ( ) es finita, entonces.
∫ ( ) ( ) ( )
Las funciones kernel que satisfacen el Teorema de Mercer son llamadas funciones kernel positivo definidas. Ejemplos de estas funciones se listan a continuación:

20
( ) ( ) …….. Función kernel polinomial (1.38)
( ) ‖ ‖ ( ) (1.39)
( ) ( ) (1.40)
ALGUNAS CARACTERÍSTICAS DE LAS MÁQUINAS DE VECTORES SOPORTE
1- Las Máquinas de Vectores Soporte al maximizar el margen del límite de decisión, determinan la tarea de aprendizaje, no obstante el usuario todavía debe proveer otros parámetros tales como el tipo de función kernel a usar y la penalidad asociada a la función C.
2- Las SVM pueden ser aplicadas a datos categóricos introduciendo variables ficticias (dummy). Por ejemplo si “Se o” toma dos valores; Masculino, Femenino, podemos introducir una variable binaria para cada valor del atributo “Sexo”.
3- La formulación de Máquinas de Vectores Soporte presentada en este trabajo, es realizada para problemas de Clasificación Binaria.

21
PARTE PRÁCTICA
CONTRUCCIÓN DE UN MODELO DE CLASIFICACIÓN CON MÁQUINAS DE VECTORES SOPORTE:
Clasificación del Nivel de Propensión Individual al Ahorro como modelo de Scoring Financiero
CONTEXTO. LA INCLUSIÓN FINANCIERA EN PARAGUAY
El Paraguay se encuentra entre los países de la región que tienen la menor cantidad de cuentas de ahorro y crédito de adultos en bancos comerciales.
Utilizando datos de una publicación del CGAP (2.009), Grupo Consultivo del Banco Mundial para Asistir a los Pobres, que trató de medir cuál es el grado de acceso a servicios financieros de la población en general o de inclusión financiera, se observaron datos comparativos de países del mundo y la región.
¿Cómo está Paraguay en relación a ellos? Para citar algunas cifras, en la figura 12 se observa cuántas cuentas de ahorros hay por cada mil adultos. Por ejemplo, en Chile hay más de 700 cuentas de ahorro por cada 1.000 adultos, mientras que en Paraguay estamos en alrededor de 80.
Figura 12
En la figura 13 se observa el valor medio de esas cuentas de ahorro con relación a cuánto es el PIB per cápita. Se observa que en Paraguay el valor medio de los depósitos
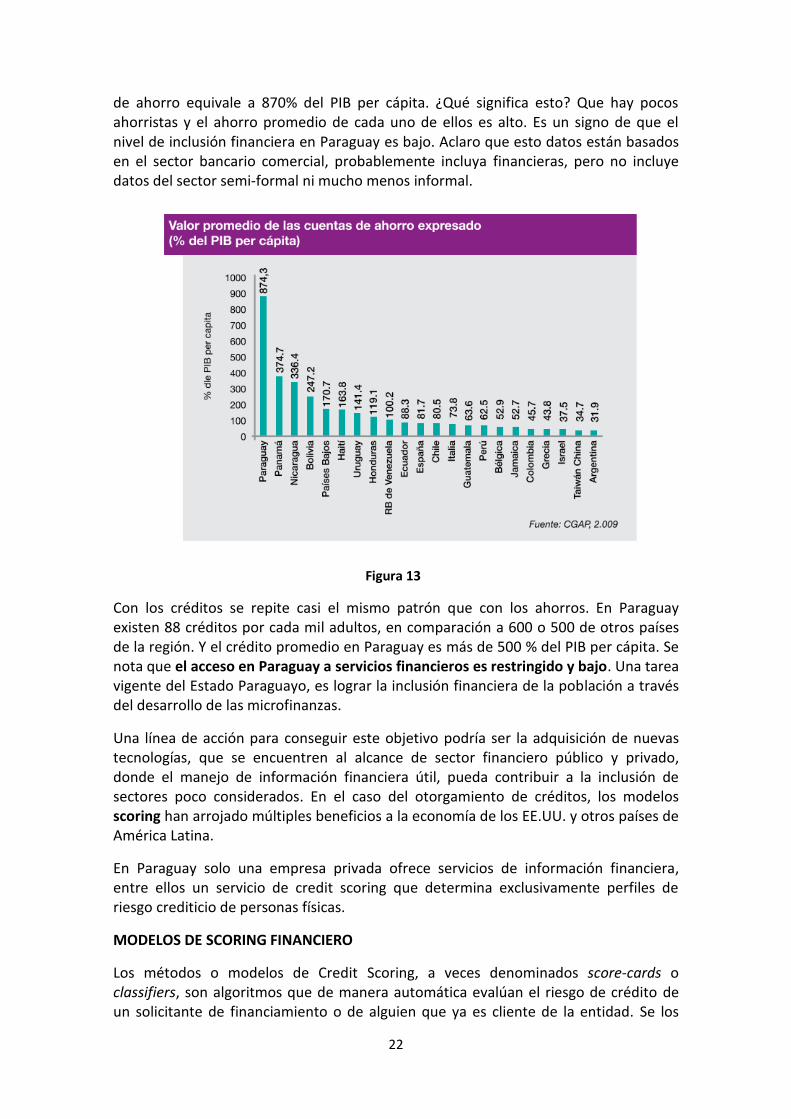
22
de ahorro equivale a 870% del PIB per cápita. ¿Qué significa esto? Que hay pocos ahorristas y el ahorro promedio de cada uno de ellos es alto. Es un signo de que el nivel de inclusión financiera en Paraguay es bajo. Aclaro que esto datos están basados en el sector bancario comercial, probablemente incluya financieras, pero no incluye datos del sector semi-formal ni mucho menos informal.
Figura 13
Con los créditos se repite casi el mismo patrón que con los ahorros. En Paraguay existen 88 créditos por cada mil adultos, en comparación a 600 o 500 de otros países de la región. Y el crédito promedio en Paraguay es más de 500 % del PIB per cápita. Se nota que el acceso en Paraguay a servicios financieros es restringido y bajo. Una tarea vigente del Estado Paraguayo, es lograr la inclusión financiera de la población a través del desarrollo de las microfinanzas.
Una línea de acción para conseguir este objetivo podría ser la adquisición de nuevas tecnologías, que se encuentren al alcance de sector financiero público y privado, donde el manejo de información financiera útil, pueda contribuir a la inclusión de sectores poco considerados. En el caso del otorgamiento de créditos, los modelos scoring han arrojado múltiples beneficios a la economía de los EE.UU. y otros países de América Latina.
En Paraguay solo una empresa privada ofrece servicios de información financiera, entre ellos un servicio de credit scoring que determina exclusivamente perfiles de riesgo crediticio de personas físicas.
MODELOS DE SCORING FINANCIERO
Los métodos o modelos de Credit Scoring, a veces denominados score-cards o classifiers, son algoritmos que de manera automática evalúan el riesgo de crédito de un solicitante de financiamiento o de alguien que ya es cliente de la entidad. Se los

23
ue e efinir como “méto os esta ísticos utilizados para clasificar a los solicitantes de crédito, o incluso a quienes ya son clientes de la entidad evaluadora, entre las clases e riesgo ‘bueno’ y ‘malo’ ”. Originalmente en los setenta se basaban en técnicas estadísticas, en particular el análisis discriminante, en la actualidad se han construido varios modelos utilizando Máquinas de Vectores Soporte y otras técnicas estadístico-matemáticas, econométricas, y de inteligencia artificial.
El objetivo de esta parte práctica es ensayar la identificación del nivel de propensión individual a ahorrar en clientes de entidades financieras, entendiendo que los modelos que evalúan el riesgo de crédito han sido ampliamente estudiados por la comunidad científica, y actualmente de uso masivo por las organizaciones financieras internacionales.
Y busca tener como impacto positivo, la propagación del uso de modelos de scoring financiero accesibles en el mercado financiero nacional, que abarquen los servicios y productos tanto de créditos como de ahorros, llegando a un sector más amplio de la población.
PLANTEAMIENTO DEL PROBLEMA
El ahorro total de una sociedad depende de factores de índole diversa, características individuales de la población como la edad, cantidad de dependientes económicos, la valoración individual del futuro en términos del presente, la valoración individual del ahorro, la magnitud del ingreso disponible y otros. Pero asimismo depende de características económicas generales de dicha sociedad, como la política fiscal, la política en materia de distribución de beneficios (jubilaciones, seguros, etc.), la solidez del mercado financiero, las tasas de interés, y el nivel de desarrollo económico de la sociedad.
Bajo esta consideración es posible identificar el nivel de propensión individual al ahorro a partir de datos básicos proporcionados a través de formularios, u otros medios de obtención de información. Pero indefectiblemente los resultados obtenidos deberán sumarse a los valores de indicadores económicos disponibles, ya sea para la toma de decisiones, o la construcción de modelos más complejos.
USO DEL PROGRAMA INFORMÁTICO “WEKA” PARA CONSTRUIR UN MODELO DE CLASIFICACIÓN CON MÁQUINAS DE VECTORES SOPORTE
El atributo “Nivel de Propensión Individual al Ahorro”, puede arrojar dos valores: Alta (Clase A) o Baja (Clase B).
El modelo de clasificación obtenido de las Máquinas de Vectores Soporte como modelo descriptivo, permitirá identificar las características individuales del sector de la población con mayor propensión al ahorro, y de esta manera posibles clientes de sus productos y servicios de ahorro, o inversiones de menor riesgo.
Como modelo predictivo permitirá la clasificación automática en “Alta” o “Baja” a la propensión individual al ahorro con solo disponer de información ingresada a la base de datos; sean clientes y/o usuarios de diferentes servicios de la entidad, así como aquellos que solicitan por primera vez algún producto o servicio financiero.

24
El modelo obtenido podrá ser incorporado a los programas informáticos de las compañías, para determinar de manera simultánea y automática, el nivel de propensión al ahorro de los clientes.
Existen muchos paquetes computacionales para construir modelos de clasificación con SVM, algunos de los más utilizados probablemente sean MATLAB y WEKA.
WEKA (Waikato Environment for Knowledge Analysis) Entorno para Análisis del Conocimiento de la Universidad de Waikato, es un conjunto de librerías JAVA para la extracción de conocimientos desde bases de datos. Es un software desarrollado bajo licencia GPL lo cual ha impulsado que sea una de las suites más utilizadas en el área en los últimos años.
Figura 14
En este trabajo vamos a centrarnos en el entorno Explorer, que permite el acceso a la mayoría de las funcionalidades integradas en Weka de una manera sencilla.
La base de datos está constituida por registros de una entidad financiera de la ciudad araguaya “Concepción” com uesta or unos 76.378 Habitantes al año 2008 (Fuente: Dirección General de Estadísticas y Censos, Paraguay). La entidad financiera es una naciente organización cuya principal operación hasta la fecha ha sido el otorgamiento de créditos como beneficio para sus asociados, y su cartera de clientes es un sector de la población económicamente activa dedicado a los servicios.
La base de datos proporcionada está constituida por 77 (setenta y siete) casos aleatoriamente seleccionados por la entidad y proporcionados de forma confidencial, recogidos a través de formularios completados por los clientes. Conforme a lo expuesto en el planteamiento de las preguntas, los atributos considerados más relevantes para estimar el Nivel de Propensión Individual al Ahorro han sido: Edad, Ingreso Mensual Aproximado, Principal Destino de Gastos (1 = Familia, 0 = Otros), Cantidad de Dependientes Económicos, Gasto Mensual Aproximado.
Del total de casos hemos escogido por muestreo aleatorio simple 65 (sesenta y cinco) como conjunto de entrenamiento, descriptos en la tabla 2, y que constituyen el 85% de los casos. Los 12 (doce) casos restantes, 15 % del total, figuran en la tabla 6 y serán utilizados como conjunto de prueba. Los resultados obtenidos para el atributo Nivel de

25
Propensión Individual al Ahorro (A = Alta, B = Baja), han sido obtenidos en consulta directa a los 77 (setenta y siete) clientes, quienes se han autoclasificado en el atributo mencionado. De esta forma es considerada la valoración individual que tiene el cliente sobre su posible comportamiento ante la oportunidad de usufructuar servicios o productos relacionados al ahorro.
Conjunto de Entrenamiento
Edad Ingreso Mensual
Aproximado
Principal Destino
de Gastos
Cantidad de Dependientes Económicos
Gasto Mensual
Aproximado
Nivel de Propensión Individual al Ahorro
21 1400500 1 1 1350000 A
36 3512130 1 2 2821000 B
27 2161000 1 4 2100000 B
26 1908353 0 0 1000000 A
26 4050000 1 1 1250000 A
24 2257000 1 3 2200000 B
18 3250000 0 0 600000 B
41 5950000 1 4 4500000 B
54 3256000 1 4 2300000 B
42 1853000 1 5 1400000 B
27 1853000 1 5 1370000 A
59 1200000 1 1 450000 B
23 2210000 1 1 1350000 B
23 1350000 1 2 1200000 A
26 2650000 1 1 1400000 B
40 2698000 1 4 1600000 A
18 600000 0 0 400000 B
29 1000000 1 3 630000 A
19 1400000 1 4 1200000 A
31 1500000 1 4 1000000 B
20 1250000 0 0 1070000 A
36 1750000 1 4 1650000 A
34 2600000 1 5 2500000 B
36 2200000 1 3 1080000 B
36 2200000 1 3 780000 B
47 3260000 1 5 2200000 B
28 1000000 0 0 850000 B
20 1500000 0 0 1400000 B
40 2700000 1 4 2200000 B
69 1400000 1 6 1300000 A
34 2600000 1 5 2500000 B
36 1500000 1 4 1400000 A
20 1250000 0 0 1000000 A
29 1000000 1 3 900000 A
21 1000000 1 2 900000 B
30 2000000 1 0 400000 A
18 1450000 0 0 700000 A
29 1538000 0 0 1350000 B
44 3250000 1 4 1500000 B
39 17000000 1 4 7400000 B
21 1400500 1 1 1350000 A
36 3512130 1 2 2821000 B
27 2161000 1 4 2100000 B

26
36 2762130 0 0 2250000 A
21 1500000 1 2 1200000 A
20 1680000 0 0 1300000 B
26 9000000 1 1 2020000 A
20 1750000 0 0 1500000 A
49 15250000 1 7 10000000 A
20 950000 0 1 750000 A
28 2100000 1 1 1800000 A
26 2300000 1 2 2250000 A
36 2000000 1 3 1600000 B
22 2500000 1 2 2350000 A
23 2500000 0 1 2200000 A
23 3000000 1 3 2500000 A
28 3300000 1 3 2800000 A
32 2000000 1 5 2000000 B
33 2500000 1 4 2450000 B
25 2500000 1 1 1200000 B
31 2500000 1 3 1840000 A
49 4750000 1 4 3000000 A
37 2800000 1 3 1550000 B
31 2038000 1 2 1600000 A
25 2500000 0 0 1100000 A
Tabla 2
Para construir el modelo de clasificación vamos a utilizar el algoritmo de las Máquinas de Vectores Soporte. La denominación que se le da en Weka es SMO.
Aplicamos a la base de datos las Máquinas No Lineales de Vectores Soporte con función Kernel Polinomial, dada en la ecuación 1.38 buscando la mejor configuración de los parámetros. Weka trae por defecto los parámetros C = 1, filtro de normalización del conjunto de datos y p = 1. Variando primeramente el tipo filtro obtenemos los siguientes niveles de precisión (C
= 1, p = 1).
Tipo de Filtro Exactitud
Normalización 66,2%
Estandarización 70,8%
Sin Filtro NC (no convergente)
Tabla 3
El resultado en la tabla 3 es explicado por la diferencia en los niveles de medida de los atributos involucrados. La estandarización unifica la escala de medición, sin perder la información contenida en el conjunto de datos.

27
Procediendo a estandarizar los datos de entrenamiento y utilizando todos los casos, variamos los parámetros p y C, contrastando los niveles de exactitud arrojados por las
respectivas matrices de confusión. (Tabla 4 – Figura 16).
p = 0,5 p = 1 p = 4 p = 7 p = 8 p = 9
C = 0,5 64,6 70,8 84,6 95,4 95,4 95,3 C = 1 64,6 70,8 89,2 58,5 95,4 NC C = 2 64,6 72,3 89,2 67,7 52,3 NC C = 3 64,6 70,8 89,2 96,9 96,9 NC C = 4 64,6 70,8 89,2 96,9 96,9 NC C = 5 64,6 72,3 92,3 96,9 96,9 96,9 C = 6 63,1 70,8 92,3 96,9 53,8 96,9
Tabla 4 - Figura 16
A fin de reducir la complejidad del modelo, escogemos como la mejor configuración de parámetros C = 3 y p = 7, cuyo modelo arroja para el conjunto de entrenamiento una exactitud del 96.9231 % y la siguiente matriz de confusión:
Clase Prevista
Clase =A Clase = B
Clase Actual
Clase = A 33 0
Clase = B 2 30
Tabla 5
Con la definición de los parámetros el modelo de clasificación con Máquinas de Vectores Soporte se halla construido.
Comprobemos la eficacia del mismo aplicándolo en los 12 (doce) casos que no fueron utilizados en la construcción, y que denominamos conjunto de prueba.
0
20
40
60
80
100
C = 0,5 C = 1C = 2
C = 3C = 4
C = 5
64.6 64.6 64.6 64.6 64.6 64.6
70.8 70.8 72.3 70.8 70.8 72.3
84.6 89.2 89.2 89.2 89.2 92.3
95.4
58.5 67.7
96.9 96.9 96.9
95.4 95.4
52.3
96.9 96.9 96.9
p = 0,5 p = 1 p = 4 p = 7 p = 8
28
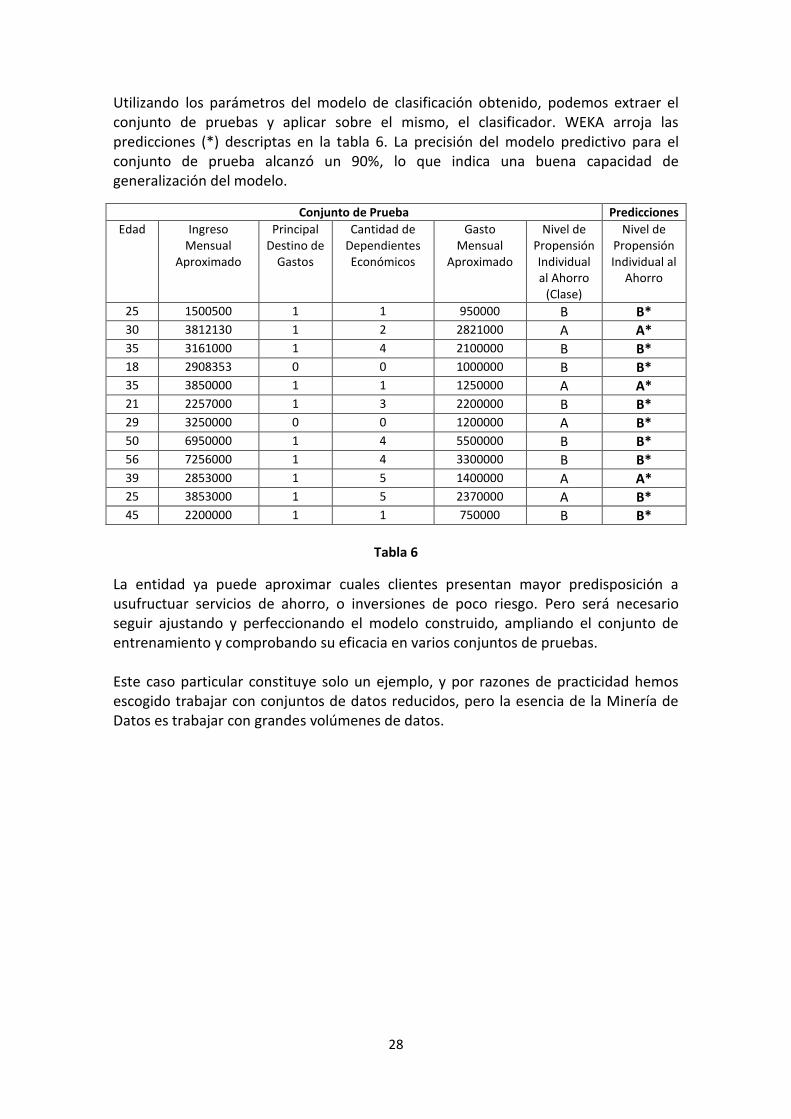
Utilizando los parámetros del modelo de clasificación obtenido, podemos extraer el conjunto de pruebas y aplicar sobre el mismo, el clasificador. WEKA arroja las predicciones (*) descriptas en la tabla 6. La precisión del modelo predictivo para el conjunto de prueba alcanzó un 90%, lo que indica una buena capacidad de generalización del modelo.
Conjunto de Prueba Predicciones
Edad Ingreso Mensual
Aproximado
Principal Destino de
Gastos
Cantidad de Dependientes Económicos
Gasto Mensual
Aproximado
Nivel de Propensión Individual al Ahorro
(Clase)
Nivel de Propensión Individual al
Ahorro
25 1500500 1 1 950000 B B* 30 3812130 1 2 2821000 A A* 35 3161000 1 4 2100000 B B* 18 2908353 0 0 1000000 B B* 35 3850000 1 1 1250000 A A* 21 2257000 1 3 2200000 B B* 29 3250000 0 0 1200000 A B* 50 6950000 1 4 5500000 B B* 56 7256000 1 4 3300000 B B* 39 2853000 1 5 1400000 A A* 25 3853000 1 5 2370000 A B* 45 2200000 1 1 750000 B B*
Tabla 6
La entidad ya puede aproximar cuales clientes presentan mayor predisposición a usufructuar servicios de ahorro, o inversiones de poco riesgo. Pero será necesario seguir ajustando y perfeccionando el modelo construido, ampliando el conjunto de entrenamiento y comprobando su eficacia en varios conjuntos de pruebas. Este caso particular constituye solo un ejemplo, y por razones de practicidad hemos escogido trabajar con conjuntos de datos reducidos, pero la esencia de la Minería de Datos es trabajar con grandes volúmenes de datos.

29
CONCLUSIÓN
Este trabajo de investigación tuvo como objetivo fundamental, realizar una revisión del aspecto teórico de las Máquinas de Vectores Soporte y aplicarlo a un caso particular de clasificación como tarea de inicio en la investigación de Matemáticas Avanzadas.
En la elaboración de la parte teórica, hemos podido advertir la falta de bibliografía específica traducida al idioma castellano, y esperamos que este material constituya un aporte para los académicos hispanos interesados en las Máquinas de Vectores Soporte y sus diversas aplicaciones.
En la parte práctica, como ejemplo se ha construido un modelo de clasificación basado en Máquinas de Vectores Soporte para scoring financiero, específicamente la identificación de la propensión individual al ahorro en los clientes de una entidad financiera.
Con este ejemplo, pretendo aportar al desarrollo de la innovación científica nacional, evidenciando la importancia de las técnicas estadísticas y de minería de datos para la toma de decisiones, así como la multiplicidad de tareas y funciones por explorar.
Tanto en lo concerniente al desarrollo teórico como a la aplicación práctica, dejamos muchas tareas de investigación pendientes, posibilidades de profundizar los conceptos de Minería de Datos y la construcción de modelos más complejos.

30
BIBLIOGRAFÍA
1. TAN PANG-NING, STEINBACH M., KUMAR V., Introduction to Data Mining, Edit. Pearson Addison Wesley, 2006
2. YANG XIN-SHE, Nature-Inspired Metaheuristic Algorithms. Edit. Luniver Press. 2010
3. RAMOS MENDEZ E., Modelos y Métodos de Investigación de Operaciones, Programación No Lineal. Edit. Uned. 2008
4. HERNÁNDEZ J., FERRI C., Práctica de Minería de Datos, España 2006, Curso de Doctorado Extracción Automática de Conocimiento en Bases de Datos e Ingeniería del Software, Universitat Politècnica de València.
5. Paraguay, Banca Pública de Desarrollo, Paraguay 2011, Informe publicado por el Ministerio de Hacienda, Editores, Rodríguez José C., Miranda E., Insfrán H.