modelos avanzados de bases de datos base de datos … · base de datos distribuidas 9 la...
TRANSCRIPT

UNIVERSIDAD DE CASTILLA-LA MANCHA
ESCUELA SUPERIOR DE INFORMÁTICA
MODELOS AVANZADOS DE BASES DE DATOS
BASE DE DATOS DISTRIBUIDAS
Grupo: Distribución 1
Francisco Corbera Navas
Alejandro Delgado Gallego
Fecha : 01/04/2008

Base de Datos Distribuidas
2
Índice
Introducción ……………………………………………………………….………….. 3
Sistemas gestores de Bases de Datos Distribuidas (SGBDD) …………….………….. 5
Tipos de SGBDD ………………………………………………….……….…. 5
Los objetivos de un SGBDD …………………………………………….….... 6
Arquitectura cliente-servidor …………………………………………………………. 8
Diseño de Bases de Datos Distribuidas ………………………………………..………9
Estrategias de Diseño …………………………………………………………10
Fragmentación …………………………….……………………..……………12
Asignación ……………………………………………………….……………13
Transacciones en base de datos distribuidas ………………………….………………14
Control de concurrencia ………………………………………………..……………..15
Serialización distribuida ……………………………………..………………..16
Protocolo de bloqueo (locking protocol) ………………………...……………17
Protocolo de marcas de tiempo (timestamp protocol) ….……………………..17
Procesamiento de Consultas Distribuidas …………………….……………… ..……..17
Objetivos de la optimización de consultas …………………………………….19
Características de los procesadores de consultas …………………….………..20
Arquitectura del procesamiento de consultas ………….………………………20
Ventajas y desventajas de las Bases de datos Distribuidas ……………………………21
Conclusiones ……………………………………………………………..……………22
Bibliografía ……………………………….………………………………….………..22

Base de Datos Distribuidas
3
Introducción
Inicialmente podemos decir que las SBDD surgen como respuesta a la distribución que las
empresas ya tienen, al menos de manera lógica (divisiones, departamentos, etc…) y que en
ocasiones también tiene de manera física (plantas, fábricas, etc…). Todo esto nos lleva a que
posiblemente los datos también estén distribuidos, ya que cada unidad organizacional
mantendrá los datos con los que normalmente opere.
A cada uno de estas subdivisiones se les llama “islas de información” (sitios), y lo que hace
un sistema distribuido es establecer los “puentes” necesarios para conectar a esas islas entre si.
En definitiva lo que pretende es que la estructura de la base de datos refleje la estructura de
la empresa (principal beneficio de los sistemas distribuidos). Es en realidad una BD virtual
compuesta de varias BDs “reales” distintas que se encuentran en varios sitios distintos.
Otra de las principales motivaciones para el desarrollo de sistemas de bases de datos es el
deseo de integrar los datos operacionales de una organización y proporcionar un acceso
controlado a esos datos. Aunque la integración y el acceso controlado pueden implicar la
necesidad de utilizar mecanismos de centralización, el objetivo en realidad no es ese. De hecho,
el desarrollo de redes informáticas promueve el modo descentralizado de trabajo.
Los SGBD distribuidos deberían ayudarnos a resolver el problema de las islas de
información. Esto puede ser resultado de la separación geográfica, de la incompatibilidad de las
arquitecturas informáticas, de los protocolos de comunicaciones, etc. Si se consigue integrar las
bases de datos en un todo lógico coherente, podemos resolver el problema.
Con todo esto podemos dar una definición más formal de base de datos distribuida (BDD)
como una colección de múltiples bases de datos interrelacionadas lógicamente y distribuidas por
una red de computadores.
Base de Datos Distribuidas
4
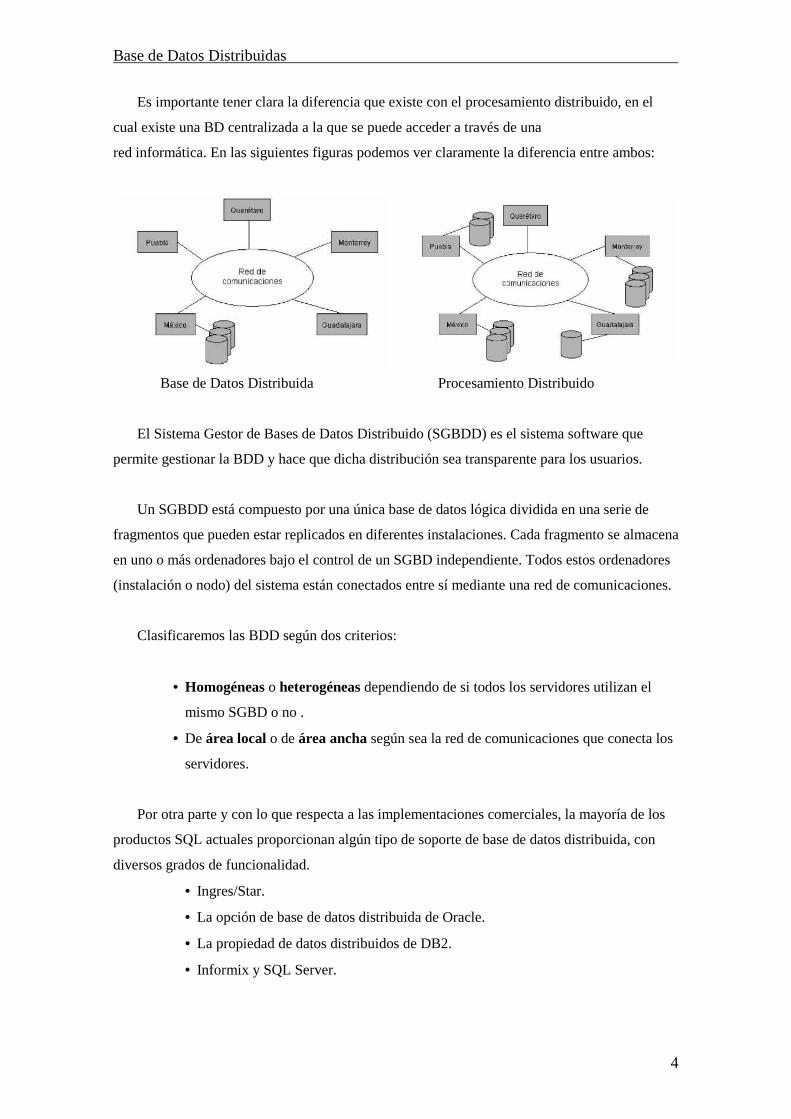
Es importante tener clara la diferencia que existe con el procesamiento distribuido, en el
cual existe una BD centralizada a la que se puede acceder a través de una
red informática. En las siguientes figuras podemos ver claramente la diferencia entre ambos:
Base de Datos Distribuida Procesamiento Distribuido
El Sistema Gestor de Bases de Datos Distribuido (SGBDD) es el sistema software que
permite gestionar la BDD y hace que dicha distribución sea transparente para los usuarios.
Un SGBDD está compuesto por una única base de datos lógica dividida en una serie de
fragmentos que pueden estar replicados en diferentes instalaciones. Cada fragmento se almacena
en uno o más ordenadores bajo el control de un SGBD independiente. Todos estos ordenadores
(instalación o nodo) del sistema están conectados entre sí mediante una red de comunicaciones.
Clasificaremos las BDD según dos criterios:
• Homogéneas o heterogéneas dependiendo de si todos los servidores utilizan el
mismo SGBD o no .
• De área local o de área ancha según sea la red de comunicaciones que conecta los
servidores.
Por otra parte y con lo que respecta a las implementaciones comerciales, la mayoría de los
productos SQL actuales proporcionan algún tipo de soporte de base de datos distribuida, con
diversos grados de funcionalidad.
• Ingres/Star.
• La opción de base de datos distribuida de Oracle.
• La propiedad de datos distribuidos de DB2.
• Informix y SQL Server.

Base de Datos Distribuidas
5
Vale la pena reseñar que todos estos sistemas son relacionales, además hay varias
razones que iremos descubriendo a lo largo de este tema, que aconsejan que para que un sistema
distribuido sea exitoso, debe ser relacional.
Sistemas gestores de Bases de Datos Distribuidas (SGBDD)
Software que hace transparente al usuario la gestión de una base de datos distribuida. En
adelante lo llamaremos SGBDD.
Entre sus funciones particulares destacan:
• Poder acceder a sitios remotos.
• Transmitir consultas y datos a través de redes de telecomunicaciones.
• Rastrear la pista de distribución y replicación de los datos.
• Capacidad de elaborar estrategias de ejecución.
• Control de concurrencia.
• Mantener la consistencia de las copias de un elemento de información.
• Capacidad de decidir qué versión de la copia de un elemento de información es la que
tiene que ser accedida en un momento determinado.
• Recuperación ante caídas.
• Control de la seguridad para mantener privilegios de acceso a los datos distribuidos.
Para ofrecer todas las funcionalidades vistas un SGBDD debe contar (al menos) con los
siguientes componentes:
• Componente de manejo de la base de datos.
• Componente de comunicación de datos.
• Diccionario de datos
• Componente de base de datos distribuida.
Tipos de SGBDD
Hay diferentes tipos de SGBDD. El factor para categorizarlos es su grado de homogeneidad.
Partiendo de él, tenemos dos tipos de SGBDD.
• Homogéneos: todos los nodos utilizan el mismo SGBD
• Heterogéneos: los nodos pueden utilizar distintos SGBD.

Base de Datos Distribuidas
6
Los sistemas homogéneos son mucho más fáciles de diseñar y mantener. Esta técnica
permite el crecimiento incremental, haciendo que la adición de un nuevo nodo al SGBDD sea
sencilla, y también permite conseguir unas mayores prestaciones, al aprovechar las capacidades
de procesamiento paralelo de los múltiples nodos.
Los objetivos de un SGBDD
Una vez que nos hemos introducido en el mundo de las SBDD, estamos preparados para
establecer el principio fundamental de los sistemas distribuidos:
“Los usuarios deben actuar de la misma forma tanto si están ante un sistema distribuido como
si están ante uno centralizado”.
En 1987, uno de los más importantes y conocidos teóricos de las bases de datos
relacionales, C. J. Date, propuso 12 objetivos que debían alcanzar los diseñadores en sus BDD
junto con sus SGBDD basándose en este principio fundamental. Las 12 reglas son las
siguientes:
1. Autonomía local: Los sitios de un sistema distribuido deben ser autónomos en el mayor
grado posible, lo que permite una mayor seguridad, control de concurrencia y copias de
seguridad. Esto quiere decir que los datos deben ser gestionados localmente, las operaciones
son locales y todas las operaciones en un puesto son controladas por ese puesto.
2. Independencia de un sitio central: El anterior objetivo implica que todos los sitios
deben ser tratados como iguales, por lo tanto no debe existir ningún sitio maestro central del
cual dependan el resto. Esto es así por das razones fundamentales:
• Puede ser un cuello de botella.
• Puede ser vulnerable, si éste falla también fallará todo el sistema.
3. El sistema debe estar en continua operación: Un fallo en uno de los nodos no debe
afectar al sistema. Tampoco si se añaden nuevos nodos. Así, un SD deberá proporcionar las
siguientes características.
• Fiabilidad (o confiabilidad): probabilidad de que el sistema esté listo y
funcionando en cualquier momento dado.
• Disponibilidad: probabilidad de que el sistema esté listo y funcionando
continuamente a lo largo de un período especificado. Podemos decir que nunca

Base de Datos Distribuidas
7
debería ser necesario apagar el sistema para realizar tareas como: añadir un
sitio, creación dinámica de fragmentos, actualización de versiones, etc.
4. Transparencia de ubicación: Para el usuario la localización física de los datos debe ser
transparente. No necesita saber dónde está el dato para utilizarlo.
5. Transparencia de fragmentación: Los usuarios deben comportarse, como si los datos
en realidad no tuvieran fragmentación alguna, la cual es necesaria por razones de
rendimiento.
Este objetivo es deseable, como el anterior, porque simplifica los programas de los
usuarios y sus actividades en el sitio.
6. Transparencia en la replicación: Consiste en que el usuario no debe tener conciencia de
la replicación de los datos, así como de su destrucción
La replicación es necesaria por las siguientes razones:
• Un mayor rendimiento, puesto que disponemos de copias locales.
• Una mayor disponibilidad, puesto que los datos son accesibles siempre al tenerse
varias copias.
La principal desventaja, es que hay que mantener actualizadas todas las copias de ese
objeto o dato replicado. Esto nos lleva al problema de la “propagación de las
actualizaciones”.
7. Procesamiento de consultas distribuidas: El sistema debe ser capaz de procesar
consultas que afecten a datos de más de un sitio y hacerlo de forma optimizada. Este hecho
puede ser considerado como otra razón por la que los sistemas distribuidos siempre son
relacionales (las peticiones relacionales son optimizables, mientras que las no relacionales
no lo son).
8. Administración de transacciones distribuidas: El sistema distribuido debe disponer de
mecanismos (protocolos) adecuados para el control de concurrencia y la recuperación de
transacciones distribuidas. Una transacción puede acceder y modificar datos en diferentes
nodos sin que el usuario se entere de que múltiples sitios se están viendo afectados por la
transacción.
9. Independencia del hardware: Es necesario tener la posibilidad de ejecutar el mismo
SGBDD en diferentes plataformas de hardware (IBM, ICL, HP, PC, SUN) y, además, hacer
que esas máquinas diferentes participen de igual forma en un sistema distribuido.

Base de Datos Distribuidas
8
10. Independencia del sistema operativo: Un vez más, es necesario tener la posibilidad de
ejecutar el mismo SGBDD, en diferentes plataformas de sistema operativo (UNIX,
Windows XP …) bajo un mismo sistema distribuido.
11. Independencia de la red: El sistema debe tener la posibilidad de soportar también, una
variedad de redes de comunicación distintas.
12. Independencia del SGBD: Lo que en realidad se pretende es que todos los ejemplares
del SGBDD locales en sitios diferentes soporten la misma interfase, que en este caso sería
el estándar SQL oficial. Con esto conseguiremos que el sistema distribuido fuera
heterogéneo, al menos en cierta medida ya que en realidad los fabricantes solo cumplen
determinadas características de este estándar, que suelen ser distintas de unos a otros.
Debido a que estos cuatro últimos objetivos son ideales y no existen estándares
al respecto, solo cabe esperar un cumplimiento parcial de los mismos.
Arquitectura cliente-servidor
Las aplicaciones de bases de datos distribuidas se desarrollan en el contexto de la
arquitectura cliente-servidor.

Base de Datos Distribuidas
9
La arquitectura cliente-servidor se creó para manejar los nuevos entornos de cómputo en los
que un gran número de PC, estaciones de trabajos, servidores de ficheros, impresoras,
servidores de bases de datos, servidores Web y otros equipos están interconectados a través de
una red.
En un sistema cliente-servidor tenemos dos partes fundamentales:
• Cliente. Se podría corresponder con una máquina usuario que proporciona capacidad de
interfaz al usuario y procesamiento local.
• Servidor. Es una máquina que puede proporcionar a las máquinas cliente servicios, tales
como impresión, acceso a ficheros, o acceso a la base de datos.
Aún no se ha establecido de forma exacta cómo dividir la funcionalidad del SGBD entre
el cliente y el servidor aunque existen varios enfoques.
En cuanto al software, en un sistema de gestión de bases de datos es normal dividir los
diferentes módulos software en tres niveles:
• El software de servidor que gestiona los datos locales en un sitio, al igual que el
software del SGBD centralizado.
• El software del cliente que soporta casi todas las tareas de distribución y maneja las
interfaces de usuario
• El software de comunicaciones (algunas veces junto con el sistema operativo
distribuido) proporciona las primitivas de comunicación que utiliza el cliente para
transmitir instrucciones y datos entre los sitios necesarios.
Diseño de Bases de Datos Distribuidas
El diseño de base de datos distribuidas se ocupa de tomar decisiones en la ubicación de
programas que accederán a la base de datos y sobre los propios datos que la constituyen, a lo
largo de los diferentes nodos que constituyen la red. Tenemos que distribuir pequeños
elementos entre diferentes computadores, es decir, distribuir la información.
La organización de los sistemas de bases de datos distribuidas se puede analizar desde tres
dimensiones:

Base de Datos Distribuidas
10
• El nivel de compartición. Esta característica posee tres alternativas dependiendo del
nivel de compartición:
o Inexistente. Cada aplicación y sus datos se ejecutan en una maquina sin
comunicación con otros programas o datos.
o Compartición de datos. Cada máquina posee sus propias aplicaciones locales
pero se comparte los datos.
o Compartición de datos y programas. Las aplicaciones locales en una
máquina pueden invocar servicios en otras y además comparten los datos.
• Características de acceso a los datos. Estas características pueden ser dos:
o Estático. El modelo de acceso a los datos no varía con el tiempo.
o Dinámico. El modelo de acceso a los datos varía con el tiempo.
• El nivel de conocimiento de la características de acceso:
o Sin información. Los diseñadores no tienen información de cómo acceden los
usuarios a los datos.
o Con información parcial. Los diseñadores no poseen toda la información de
cómo acceden los usuarios a los datos.
o Con información total. Los diseñadores poseen la información completa de
cómo los usuarios acceden a los datos.
Estrategias de Diseño
Estas estrategias son las utilizadas al diseñar una base de datos relacional, pero añadiendo
un paso de diseño de la distribución.
A la hora de abordar el diseño de una base de datos distribuida podremos optar
principalmente por dos tipos de estrategias: la estrategia ascendente y la estrategia descendente:
La estrategia ascendente (botton-up): En este caso se partiría de los esquemas
conceptuales locales y se trabajaría para llegar a conseguir el esquema conceptual
global. Después se pasaría al diseño de distribución. Esta estrategia suele ser utilizada para
integrar varias bases de datos centralizadas existentes.
En la estrategia descendente (top-down) se parte de cero y se avanza en el desarrollo del
trabajo. Los pasos a realizar mediante esta estrategia son los siguientes:

Base de Datos Distribuidas
11
1. Análisis de requisitos: En esta etapa se determinan los requisitos para obtener tanto los
datos como las necesidades de procesamientos de los usuarios. Igualmente se deberán fijar
los requisitos del sistema, los objetivos que debe cumplir en cuanto a rendimiento,
seguridad, disponibilidad y flexibilidad teniendo en cuenta aspectos económicos. Al
finalizar esta etapa debemos poseer unos objetivos que servirán como entrada para dos
actividades: Diseño conceptual y diseño de vistas.
2. Diseño de vistas: En esta etapa se definirán las interfaces del usuario con el sistema. Se
determinan las aplicaciones que usaran la base de datos así como datos estadísticos o
estimaciones de las mismas sobre frecuencia de acceso de cada aplicación a cada tabla, que
nos permitirá poseer información que nos ayudará a optimizar ciertas partes y crear un
diseño conceptual mas eficiente. Al finalizar esta etapa se debería poseer toda la
información de acceso y la definición de los esquemas externos.
3. Diseño conceptual: En esta etapa se suele realizar la integración de las vistas del usuario.
Como resultado de la ejecución de estas dos últimas etapas debemos tener un esquema
conceptual global, información de acceso y los esquemas externos que servirán de entrada
para la próxima etapa.
4. Diseño de la distribución. Esta etapa es representativa en el diseño de BBDD
distribuidas ya que es la etapa que la diferencia del diseño de bases de datos centralizadas.
Consiste obtener diferentes esquemas conceptuales locales a partir del esquema conceptual
global y la información de acceso. En este punto debemos considerar dos actividades
importantes:
• Fragmentación: consiste en decidir como dividimos la base de datos y en que partes.
• Asignación: consiste en ubicar los fragmentos que hemos obtenido en los distintos
nodos.
5. Diseño físico. A partir de los esquemas conceptuales locales y la información de acceso
obtenidos en las etapas anteriores se debe obtener el esquema físico.
6. Monitorización y ajustes. Este paso se realiza para llevar un control del proceso y e
intentar reparar lo errores o desviaciones que se produzcan en el proceso.

Base de Datos Distribuidas
12
Fragmentación
La fragmentación es el proceso encargado de dividir una relación en otras subrelaciones de
menor tamaño, y su objetivo es encontrar la unidad apropiada de distribución. Existe una serie
de razones por las que llevar a cabo la fragmentación:
• Utilización: En general, las aplicaciones funcionan con vistas que normalmente son
subconjuntos de relaciones. Por tanto, es lógico considerar como unidad de
distribución a esos subconjuntos de relaciones.
• Eficiencia: Los datos se almacenan cerca del lugar en el que son utilizados con mayor
frecuencia. Además, los datos que las aplicaciones locales no necesitan no se
almacenan en ese nodo.
• Paralelismo: La descomposición de una relación en fragmentos permite que una
transacción pueda ser dividida en subconsultas. Cada subconsulta operará sobre el
fragmento adecuado. En definitiva, se aumenta el grado de concurrencia.
• Seguridad: Los datos no requeridos por las aplicaciones locales no se almacenan en
ese nodo, por lo que no están disponibles para los usuarios no autorizados.
¿Qué unidad de fragmentación tomar?
El principal problema de la fragmentación consiste en encontrar una unidad de
fragmentación. Se podría considerar como unidad de fragmentación una relación completa pero
esto no es óptimo debido a cuestiones de eficiencia. Las siguientes afirmaciones nos dan
razones por las que la relación no es la unidad de fragmentación ideal:
• Las vistas son subconjuntos de varias relaciones, es decir, se forman a partir de trozos
de varias tablas. Ya que cada aplicación posee sus propias vistas lo mas adecuado será
conseguir que la mayoría de las vistas estén definidas sobre subtablas locales a cada
aplicación y así logramos un incremento del rendimiento. Luego la mejor unidad de
fragmentación seria subconjuntos de relaciones.
• Al descomponer una relación en fragmentos, se permite el procesamiento concurrente
de transacciones ya que no se bloquean tablas enteras sino subtablas, por lo que dos
consultas pueden acceder a la misma tabla en fragmentos distintos.
• Al descomponer una relación en fragmentos, se permite la paralelización de consultas al
poder descomponerlas en subconsultas, cada una de las cuales trabajará con un
fragmento distinto produciéndose un incremento del rendimiento.

Base de Datos Distribuidas
13
Inconvenientes de la fragmentación:
• Si las aplicaciones tienen requisitos que necesiten la descomposición de la relación en
fragmentos mutuamente exclusivos, estas aplicaciones cuyas vistas estén definidas
sobre más de un fragmento pueden poseer menor rendimiento.
• Si una vista de usuario no se puede definir sobre un solo fragmento necesitarán un
control semántico que dificulta y degrada el rendimiento debido a que la verificación de
las restricciones de integridad implican buscar fragmentos en múltiples localizaciones.
Tipos de fragmentación:
Fragmentación horizontal. Consiste en el particionamiento en tuplas de una relación
global en subconjuntos, donde cada subconjunto puede contener datos que cumplen una
condición y se puede definir expresando cada fragmento como una operación de selección
sobre la relación global.
Fragmentación vertical. En este tipo de fragmentación se dividen el conjunto de atributos en
grupos. Los fragmentos se obtienen proyectando la relación global sobre cada grupo. La
fragmentación es correcta si cada atributo se mapea en al menos un atributo del fragmento.
Fragmentación mixta. Este tipo de fragmentación consiste en la aplicación de
fragmentación vertical y después fragmentación horizontal o viceversa.
Asignación
Supongamos que tenemos un conjunto de fragmentos F={F1, F2, …, Fn} y una red que
consiste en este conjunto de sitios S={S1, S2, …, Sm}. El problema de asignación determina la
distribución óptima de F en S. La optimalidad puede ser definida de acuerdo a dos medidas:
1. Coste mínimo. Consiste en el coste de la comunicación de datos, coste del
almacenamiento y el coste de procesamiento. Nuestro objetivo es encontrar una función
que minimiza el coste.
2. Rendimiento. La estrategia de asignación se diseña para mantener una métrica de
rendimiento. Las dos métricas más utilizadas son el tiempo de respuesta y el
“throughput” (productividad).

Base de Datos Distribuidas
14
Cuando una serie de datos se asignan, estos pueden replicarse para mantener una copia o
varias idénticas. Por tanto, respecto a la replicación, en la asignación de fragmentos existen tres
estrategias:
No soportar replicación. Cada fragmento reside en un solo sitio.
Soportar replicación completa. Cada fragmento reside en cada uno de los sitios.
Soportar replicación parcial. Cada fragmento reside en alguno de los sitios.
Se considera de gran utilidad la replicación cuando el número de consultas de solo
lectura es bastante mayor que el número de consultas de actualizaciones.
Transacciones en base de datos distribuidas
La pregunta es qué pasa cuando dos consultas tratan de actualizar el mismo elemento de
datos o si el sistema falla durante la ejecución de una consulta. Intuitivamente se puede pensar
que el concepto principal que debe manejar la base de datos es la de ‘ejecución consistente’ de
consultas. Por eso es que se introduce el concepto de una transacción que es usado dentro del
dominio de la base de datos como una unidad básica de cómputo consistente y confiable.
Lo que se persigue con el manejo de transacciones es por un lado tener una
transparencia adecuada de las acciones concurrentes a una base de datos y por otro lado tener
una transparencia adecuada en el manejo de las fallas que se pueden presentar en una base de
datos. Las propiedades de una transacción son las siguientes:
1.-Atomicidad. Se refiere al hecho de que una transacción se trata como una unidad de
operación. Por lo tanto, o todas las acciones de la transacción se realizan o ninguna de ellas
se lleva a cabo.
2.-Consistencia. La consistencia de una transacción es simplemente su correctitud. En otras
palabras, una transacción es un programa correcto que lleva la base de datos de un estado
consistente a otro con la misma característica.
3.-Aislamiento. Una transacción en ejecución no puede revelar sus resultados a otras
transacciones concurrentes antes de su commit. Más aún, si varias transacciones se ejecutan
concurrentemente, los resultados deben ser los mismos que si ellas se hubieran ejecutado de
manera secuencial (seriabilidad).

Base de Datos Distribuidas
15
4.-Durabilidad. Es la propiedad de las transacciones que asegura que una vez que una
transacción hace su commit, sus resultados son permanentes y no pueden ser borrados de la
base de datos.
En resumen, las transacciones proporcionan una ejecución atómica y confiable en
presencia de fallas, una ejecución correcta en presencia de accesos de usuario múltiples y un
manejo correcto de réplicas (en el caso de que se soporten).
En un SBDD puede que participen varias localidades en la ejecución de una transacción
por lo que es más difícil garantizar la propiedad de atomicidad. El fallo de una de estas
localidades o el fallo de la línea de comunicación entre ellas pueden llevar a un resultado
erróneo. Es por esto que existe el gestor de transacciones cuya función es asegurar la ejecución
atómica de las transacciones gestionando la ejecución de aquellas transacciones(locales o
globales) que acceden a datos almacenados en su localidad y el coordinador de transacciones
que es el encargado de coordinar la ejecución de varias transacciones(locales o globales)
iniciadas en su localidad.
A más bajo nivel nos encontramos con la necesidad de transferir los datos entre el
almacenamiento en disco y la memoria principal. De esto se encarga el gestor de búferes.
En un SGBDD, todos estos módulos se encuentran tanto a nivel local en cada equipo como
a nivel de nodo. Estos últimos son los denominados gestores globales de transacciones.
El procedimiento a seguir cuando se ejecuta una transacción global en un nodo N1 es la
siguiente:
o El gestor global de transacciones del nodo N1, divide la transacción en una secuencia de
subtransacciones, siguiendo la información guardada en el catálogo global del sistema.
o El encargado de la comunicación de datos del nodo N1 envía dichas subtransacciones a
los nodos adecuados, por ejemplo N2 y N3.
o Los gestores globales de transacciones del los nodos que reciben los datos, se encargan
de gestionarlos y los resultados de las secuencias de instrucciones SQL se devuelven a
través del encargado de la comunicación de datos al primer nodo N1.

Base de Datos Distribuidas
16
Control de concurrencia
Todos los mecanismos de control de concurrencia deben asegurar la consistencia de los
objetos y cada transacción atómica será completada en un tiempo finito.
Un método de control de concurrencia es correcto si es serializable, es decir existe una
secuencia equivalente en que las operaciones de cada transacción aparecen antes o después de
otra transacción pero no entremezcladas. Una ejecución serial de transacciones es siempre
correcta.
Se debe sincronizar las transacciones concurrentes de los usuarios, extendiendo los
argumentos para la serializabilidad y los algoritmos de control de concurrencia para la ejecución
en ambientes distribuidos.
La finalidad del control de concurrencia es asegurar la consistencia de los datos al
ejecutar transacciones, y que cada acción atómica sea completada en un tiempo finito.
Uno de los problemas de concurrencia específicos de las bases de datos distribuidas es la
consistencia de copia múltiple (se produce cuando un mismo dato esta en varias
localizaciones). Además se siguen dando los mismos problemas para bases de datos
centralizadas (pérdida de actualizaciones, dependencia neutral (uncommitted dependency) y
análisis inconsistentes).
Serialización distribuida
Si cada planificador de ejecución local es serializable y las órdenes locales serializadas
son idénticas (es decir, respetan el orden de secuencia), entonces el planificador global es
serializable.
Hay dos soluciones para el control de concurrencia en un ambiente distribuido:
• El bloqueo (lock) garantiza la ejecución concurrente. En este caso hay que tener
cuidado de que no se produzcan interbloqueos.
• Las marcas de tiempo garantizan la ejecución concurrente según el orden fijado en
las marcas de tiempo. Este asegura la serialización global. Si solo hay una copia de
cada dato entre todos los nodos, se pueden usar mecanismos de control de
concurrencia para sistemas centralizados, aunque con modificaciones.

Base de Datos Distribuidas
17
Protocolo de bloqueo (locking protocol)
Nos fijaremos en el Protocolo de Bloqueo de Dos Fases distribuido (2PLP)
Se caracteriza por distribuir un gestor de bloqueo en cada nodo. Cada uno es
responsable de la gestión de bloqueos de los datos que contiene en ese nodo. El 2PLP
distribuido implementa una protocolo de control de replicas Read-One-Write-All. Cualquier
copia de un dato replicado puede ser usada para operaciones de lectura, pero todas las copias
deben ser bloqueadas para escritura antes que se puedan modificar.
Protocolo de marcas de tiempo (timestamp protocol)
Su objetivo es ordenar las transacciones globalmente de manera que transacciones con
una marca de tiempo menor, obtengan la prioridad en el caso de conflicto. El problema es que
los relojes de nodos diferentes podrían no estar sincronizados.
Procesamiento de Consultas Distribuidas
El procesamiento de consultas ha recibido una gran atención en las bases de datos
distribuidas, ya que es un aspecto crítico en el rendimiento de las mismas.
Sin embargo el procesamiento de consultas es mucho más difícil en ambientes distribuidos
que en centralizados, ya que en ambientes distribuidos existe un gran número de parámetro que
afectan el rendimiento de las consultas distribuidas, mientras que en sistemas centralizados los
lenguajes de base de datos relacionales permiten la expresión de consultas complejas en una
forma concisa y simple.
La función principal de un procesador de consultas relacionales es transformar una
consulta en una especificación de alto nivel, normalmente en cálculo relacional, a una consulta
equivalente en una especificación de bajo nivel, normalmente alguna variación del álgebra
relacional.

Base de Datos Distribuidas
18
La transformación es correcta si la consulta de bajo nivel tiene la misma semántica que la
consulta original, es decir, si ambas consultas producen el mismo resultado. Para verificar si es
correcta la transformación se hace un mapeo bien definido entre el cálculo relacional y el
álgebra relacional.
Otro aspecto importante es el consumo de recursos. Hay que elegir una buena estrategia de
ejecución que sea eficiente para que así minimicemos el consumo de recursos de nuestro
sistema.

Base de Datos Distribuidas
19
Ejemplo: Consideramos esta Base de Datos:
EMPRESA(ID_EMPRESA,NOMBRE_EMPRESA)
PROYECTO(ID_EMPRESA,NOMBRE_PROYECTO,FUNCION)
La consulta trata de encontrar “todos las empresas a las que les subvencionan un proyecto”.
Expresión SQL: SELECT NOMBRE_EMPRESA FROM EMPRESA E, PROYECTO P
WHERE E.ID_EMPRESA=P.ID_EMPRESA AND FUNCION = “BENEFICIARIO”
Dos consultas equivalentes el álgebra relacional serían:
1) Π EMPRESA (σFUNCION-“BENEFICIARIO” Λ E.ID-P.ID (E x P))
2) Π ENOMBRE (E>< ID (FUNCION=“BENEFICIARIO” (P))
La segunda estrategia es mejor, ya que evitamos calcular el producto cartesiano de E x P,
por lo que la eficiencia mejora (al disminuir el coste computacional).
Sin embargo, en los sistemas distribuidos (a diferencia de los sistemas centralizados) el
álgebra relacional no es suficiente para expresar la ejecución de estrategias, que debe ser
complementada con operaciones para el intercambio de información entre nodos. Entre estas
operaciones destacan las que hacen el procesador de consultas distribuidas para elegir el orden
de las operaciones del álgebra relacional, el mejor sitio para procesar datos y la forma en que los
mismos deben ser transformados.
Objetivos de la optimización de consultas
El objetivo PRINCIPAL de la optimización de consultas distribuidas es mejorar la
eficiencia de las mismas. Más detalladamente, podríamos decir que se trata de transformar una
consulta sobre una base de datos distribuidas en una especificación de alto nivel a una estrategia
de ejecución eficiente en un lenguaje de bajo nivel.
Tenemos que minimizar la siguiente función de coste:
En función el ambiente en que se trabaje cada uno de los factores de la expresión anterior
pueden llegar a tener pesos diferentes. Por ejemplo, en la redes WAN el coste de comunicación

Base de Datos Distribuidas
20
domina dado que hay una velocidad de comunicación relativamente baja. Es por esto que los
algoritmos diseñados para trabajar en entornos WAN suelen despreciar el coste de CPU y de
entrada/salida. En redes LAN el peso las comunicaciones no es tan dominante y los tres factores
se equiparan.
Otro factor importante a tener en cuenta a la hora de optimizar consultas en bases de datos
distribuidas es saber la complejidad computacional de los diferentes tipos de operaciones que se
pueden hacer. Antes hemos visto que ganábamos eficiencia al eliminar un producto cartesiano,
que como veremos ahora, es la operación más compleja.
Veamos un listado de las principales operaciones del álgebra relacional junto con su
complejidad:
• Selección y proyección sin eliminar duplicados: O(n)
• Proyección (con eliminación de duplicados) y agrupación: O(n*log n).
• Junta, semijunta, división, operaciones con conjuntos: O(n*log n).
• Producto cartesiano: O(n^2).
Características de los procesadores de consultas
Comparar un sistema centralizado con uno distribuido es una tarea complicada ya que
ambos difieren en una gran cantidad de aspectos, desde su arquitectura hasta la forma de tratar
una consulta. Vamos a enumerar las principales características de los procesadores de consultas
distribuidas y que los diferencias de los procesadores de los sistemas centralizados:
• Tipo de optimización.
• Granularidad de la optimización.
• Tiempo de optimización
• Estadísticas
• Nodos de decisión.
• Topología de la red.
Arquitectura del procesamiento de consultas
El procesamiento de consultas distribuidas podemos separarlo en cuatro fases o niveles,
desde que la consulta llega hasta que se optimiza al máximo posible:
• Descomposición de consultas.
• Localización de datos.

Base de Datos Distribuidas
21
• Optimización global de consultas.
• Optimización local de consultas.
Ventajas y desventajas de las Bases de datos Distribuidas
Ventajas:
• Favorecer la naturaleza distribuidora de muchas aplicaciones, no solamente a nivel local
sino incluso en diferentes lugares.
• Se consigue una compartición de los datos, sin perder un determinado control local.
• Crecimiento modular.
• El rendimiento se mejora. Cuando se distribuye una gran base de datos por múltiples
sitios, las consultas locales y las transacciones tienen mejor rendimiento porque las
bases de datos locales son más pequeñas. A parte de esta distribución, se puede
conseguir lo siguiente en estos sistemas:
o Reducir el número de transacciones ejecutándose por sitio.
o Un paralelismo entre las consultas ejecutando varias en sitios diferentes,
descomponiendo una de ellas en subconsultas que puedan ejecutarse en
paralelo.
• Aumento de la fiabilidad y la disponibilidad.
• Economía: es más barato construir un sistema con pequeñas computadoras que uno
grande si ambos dan el mismo rendimiento.
• Por último, la autonomía de estos sistemas es grande.
Desventajas:
• Hay una menor seguridad en cuanto al control de acceso a los datos: control de replicas
y errores que puedan producirse en la red.
• Mayor complejidad en el diseño e implementación del sistema. Además si la replicación
de datos no se hace de forma adecuada, las ventajas se pueden transformar en
desventajas.
• Excesivos costes en el intento de conseguir la transparencia mencionada anteriormente.
• Falta de estándares y de experiencia, una vez más en estos modelos avanzados de BD.
• No se puede garantizar al 100 % el rendimiento y la fiabilidad.

Base de Datos Distribuidas
22
Conclusiones
Las bases de datos distribuidas son cada vez más usadas por las empresas y suponen una
ventaja competitiva frente a los sistemas centralizados, siempre y cuando la empresa en cuestión
tenga necesidad de usar una base de datos de este tipo. Lo más habitual es disponer de varias
sedes y tener que manejar información común, para lo cual las bases de datos distribuidas son
especialmente útiles.
Es una tecnología que ya lleva años en rodaje por lo que tiene la madurez suficiente como
para ser usada con garantías, no obstante, debido a la gran dependencia que estas bases de datos
tienen de las telecomunicaciones, en España nos encontramos muchos problemas para conseguir
el rendimiento oportuno de las mismas.
Bibliografía
• Distributed Databases, School of Science & Technology, Bell College (Hamilton)
• Silberschatz, Korth, y Sudarshan, Fundamentos de Bases de Datos, 4ª ed. Mc Graw
Hill
• CONNOLLY, Thomas M. y BEGG, Carolyn E., Sistemas de bases de datos:
diseño, implementación y gestión. Pearson - Addison Wesley, 4ª edición.
• Armes A. Elmasri y Shamkant B. Navathe, Fundamentos de Sistemas de Bases de
Datos. 3ª ed. Addison Wesley.
• http://www.fing.edu.uy/inco/cursos/interop/interPresencial/transparencias/queries.pdf
• http://www.mitecnologico.com/Main/OptimizacionDeConsultasDistribuidas
• http://sistemas-distribuidos-unerg.blogspot.com/2007/12/bases-de-datos-
distribuidas.html
• http://catarina.udlap.mx/u_dl_a/tales/documentos/msp/alvarez_c_g/capitulo1.pdf